Some text
2023-09-22 09:12:00
If you’ve ever attempted to create responsive type that seamlessly adapts and scales between pre-determined sizes within a type scale based on viewport or container widths, you may have wrestled with JavaScript or wrangled with CSS calculators. But with the help of calc(), clamp(), and a somewhat wonky use of CSS vars, we can simplify this process and tap into the dynamism that modern CSS affords. We can create truly fluid type scales, with composable and responsive type utilities that let your type resize and adapt to the viewport or container width.
Here’s a demo of what we’ll set up (resize the browser window to preview the effect—it works in the latest version of all major browsers):
What follows is an in-depth exploration of how to achieve this effect. If you simply whish to drop this functionality into a project, I’ve collected a range of type scale CSS utilities—with breakpoint classes and other methods of achieveing higher granularity of type control—in a small type scale library called bendable.
Creating this calculation should, in theory, be reasonably straightforward, but the rigidity of CSS calc() can make the process feel like you’re navigating a semantic minefield. Unfortunately, CSS calc() does currently not allow for implicit conversions between unitless numbers and pixel values, so getting the syntax exactly right can be tricky. These restrictions have been relaxed in the css-values-4 spec, but until those changes are implemented and widely supported in browsers, we’ll have to work around the current limitations.
One method of bypassing the current limitations is to, whenever possible, pass around values as unitless numbers, not as pixel values, and then convert them to pixels when we need them as pixels (by multiplying them with 1px). With this strategy, we can achieve adaptive type that stays true to a pre-determined type scale. Here’s a breakdown of the calculation (line breaks and comments for clarity):
.container-adaptive {
--font-size: calc(
/* Minimum size in pixels -> the starting point */
var(--min-size) * 1px +
/* Diff between min and max -> how much should we add in total? */
((var(--max-size) - var(--min-size)) *
/* Container size minus starting point -> how far are we? */
(100cqw - var(--container-min) * 1px) /
/* Diff between min and max container width -> the range */
(var(--container-max) - var(--container-min))
);
/* Clamp between min and max, to avoid overshooting */
font-size: clamp(var(--min-size) * 1px, var(--font-size), var(--max-size) * 1px);
}
In plain English, the formula to calculate the font-size is minimum font size + diff between min and max font size * current container width relative to its min and max values. In its enterity, it reads calc(var(--min-size) * 1px + (var(--max-size) - var(--min-size)) * (100cqw - var(--container-min) * 1px) / (var(--container-max) - var(--container-min))). Again, the calculation is a bit tricky to get right with CSS calc(), and looks a bit wonky, because we:
calc(5px + 5) is invalid)calc(10px / 2px) is invalid)calc(5px * 2px) is invalid)In other words, when performing addition and subtraction, both values need to be of the same format. When conducting division and multiplication, at least one of the arguments must be a unitless number. To ensure the calculation works within these constraints, we initially set all values as unitless numbers and convert them to pixels when needed.
When it all comes together, our variable and calculation setup can then look like something like this (notice the variables’ lack of px units—pixels are implied in all of these variables):
:root {
--min-size: 12;
--max-size: 18;
--container-min: 320;
--container-max: 2400;
--viewport-min: 320;
--viewport-max: 2400;
}
.container-adaptive {
--font-size: calc(var(--min-size) * 1px + (var(--max-size) - var(--min-size)) * (100cqw - var(--container-min) * 1px) / (var(--container-max) - var(--container-min)));
font-size: clamp(var(--min-size) * 1px, var(--font-size), var(--max-size) * 1px);
}
.viewport-adaptive {
--font-size: calc(var(--min-size) * 1px + (var(--max-size) - var(--min-size)) * (100vw - var(--viewport-min) * 1px) / (var(--viewport-max) - var(--viewport-min)));
font-size: clamp(var(--min-size) * 1px, var(--font-size), var(--max-size) * 1px);
}
Finally, we use clamp() to avoid overshooting our min and max values. With this specific setup, the font size will be set to 12px when the container or viewport is 320px or smaller, scale linearly from 12px to 18px between a container/viewport size of 320px and 2400px, and then stop at 18px when the container or viewport width reaches 2400px. To set the size relative to the viewport size, we use the vw unit, and to set it relative to the container, we use the cqw unit.
With that as our starting point, we can set up a few utilities to independently set the maximum and minimum values, to easily scale between two points in a type scale:
:root {
--min-size: 12;
--max-size: 18;
--container-min: 320;
--container-max: 2400;
}
/* Setup size calculation for all max utilities */
.h1-max, .h2-max, .h3-max, .h4-max, .h5-max, .h6-max, .h7-max, .h8-max {
--font-size: calc(var(--min-size) * 1px + (var(--max-size) - var(--min-size)) * (100cqw - var(--container-min) * 1px) / (var(--container-max) - var(--container-min)));
font-size: clamp(var(--min-size) * 1px, var(--font-size), var(--max-size) * 1px);
}
.h1-max { --max-size: 128; }
.h2-max { --max-size: 96; }
.h3-max { --max-size: 64; }
.h4-max { --max-size: 48; }
.h5-max { --max-size: 32; }
.h6-max { --max-size: 24; }
.h7-max { --max-size: 16; }
.h8-max { --max-size: 12; }
.h1-min { --min-size: 128; }
.h2-min { --min-size: 96; }
.h3-min { --min-size: 64; }
.h4-min { --min-size: 48; }
.h5-min { --min-size: 32; }
.h6-min { --min-size: 24; }
.h7-min { --min-size: 16; }
.h8-min { --min-size: 12; }
With those utilities, this markup effectively reproduces the demo in the beginning of the post:
<!-- Mix and match as you wish -->
<h1 class="h5-min h1-max">...</h1>
<h2 class="h6-min h2-max">...</h2>
<h3 class="h7-min h3-max">...</h3>
<h4 class="h8-min h4-max">...</h4>
…but you can use any combination of max and min utilities to easily change the start and end sizes, and it’ll all smoothly scale between those two sizes.
The versatility of fluid and adaptive typography presents a range of exciting possibilities. I’ve explored this concept further in a small type scale library called bendable, which captures these techniques in the form of a responsive type scale, with some extra sugar on top.
An important and significant limitation of this technique, because of the existing CSS calc() restrictions, is that you currently can’t use rems to set your type. This limitation will be resolved as browsers add support for the relaxed calc() restrictions, but until then, this technique is limited to use px units.
2023-03-15 09:05:00
You might be used to adding and removing .open and .closed classes on divs and containers to control their state styles. What if we could just write CSS that reflected the state of the DOM, without having to additionally handle state by toggling classes? In this post, we’ll explore how to hide elements with the :empty pseudo-class if they have no children, and how to make the pattern more granular and practical when we combine it with :has() and :not().
The :empty matches any element that has no children. The pseudo-class is supported by all major browsers, and is safe to use even if you’re targeting Internet Explorer. We can use it in combination with the display property to hide an element if it’s empty:
.container:empty {
display: none;
}
In this example, the :empty pseudo-class is used to select elements with the class .container that have no children (including text nodes), and the display: none rule is used to hide them.
<!-- This will be visible -->
<div class="container">Some text</div>
<!-- This will be hidden -->
<div class="container"></div>
Assume that we have a some HTML markup that looks something like this, that we dynamically populate with suggestions inside of .results…
<div class="container">
<h4>Suggestions</h4>
<div class="results">
...
</div>
</div>
…and we want to hide the entire .container when the .results div is empty (since the container itself will never be empty). For scenarios like this, we can combine the the :empty pseudo-class with :has(), to hide any .container that has an empty .results div:
.container:has(.results:empty) {
display: none;
}
<!-- This will be visible -->
<div class="container">
<h4>Suggestions</h4>
<div class="results">
<div>Result 1</div>
<div>Result 2</div>
<div>...</div>
</div>
</div>
<!-- This will be hidden -->
<div class="container">
<h4>Suggestions</h4>
<div class="results"></div>
</div>
Here, .container selects all .containers, and then :has() filters them to only those that have an empty .results div. Note that .has() is only supported by 84.68% of all major browsers, and you may want to use a polyfill while awaiting broader support.
You can equally choose to hide a container based on if it doesn’t contain a certain child, say a .result. Imagine that our markup looks something like this, where we return a series of .result divs:
<div class="container">
<h4>Suggestions</h4>
<div class="result">...</div>
<div class="result">...</div>
<div class="result">...</div>
</div>
For a scenario like this, we can combine the :not() pseudo-class with :has() to hide the .container if it doesn’t contain any .result elements:
.container:not(.container:has(.result)) {
display: none;
}
<!-- This will be visible -->
<div class="container">
<h4>Suggestions</h4>
<div class="result">Result 1</div>
<div class="result">Result 2</div>
<div class="result">...</div>
</div>
<!-- This will be hidden -->
<div class="container">
<h4>Suggestions</h4>
</div>
Here, we start by selecting all .container elements, then we exclude elements from that list with :not(), and we exclude all .container elements that contain a .result. What remains is any .container that doens’t include a .result, and we use display: none to hide it. Note that unlike :has(), :not() is actually supported by all major browsers, and can safely be used without a polyfill.
We might not be able to avoid toggling classes completely to handle states, but with the help of these patterns we can to a larger extent let our styles be a function of the content that’s being displayed, and build more robust experiences.
2023-03-09 20:05:00
One of the more maddening limitations of CSS was for long its inability to select elements based on their children or preceding siblings. This made it impossible to construct CSS selectors that could target previous siblings of an element, but the has:() pseudo-class (along with :not(), :where(), and :is() from Selectors Level 4) has thrown out the old limitations and opened up a new world of possibilities when working with selectors.
As of this writing, :has() is supported by 84.68% of all major browsers (including Chrome and Safari), with Firefox being the notable exception. Experimental support for Firefox launched in July 2022 and can be enabled through the flag layout.css.has-selector.enabled—you can track the progress through this Bugzilla issue. Until that ships, you can use the :has() pseudo-class if you’re not targeting or supporting Firefox, or if you use a polyfill.
Imagine that we have a series of elements, like this:
<div class="box"></div>
<div class="box"></div>
<div class="box"></div>
<div class="circle"></div>
<div class="box"></div>
…and we want to select and style the element that comes before the circle. The adjacent sibling combinator (+) can select an element that immediately follows another element, and we can combine it with :has() that to select only the .box that’s immediately followed by a .circle (or from the circle’s perspective, its previous sibling):
.box:has(+ .circle) {
width: 40px;
height: 40px;
}
You can think of this selector as first 1) selecting all boxes, and then 2) filtering the elements to only those that match the pattern “box + circle”, which will only return the circle’s previous sibling.
It’s possible to use the adjacent sibling combinator to select any specific element that preceds another. We can select the 2nd previous sibling by using two adjacent sibling combinators:
.box:has(+ * + .circle) {
width: 40px;
height: 40px;
}
If you want to, you can equally scope the selector to a class (rather than the catch-all *). In this instance .box siblings:
.box:has(+ .box + .circle) {
width: 40px;
height: 40px;
}
This selector can be difficult to grok and parse. It might help to think of it as selecting all boxes (.box), and then filtering those elements so that the remaining .box is the one that matches the pattern “self + box + circle”, which will only be the 2nd previous sibling.
If you want to select the 3rd previous sibling, you can use three adjacent sibling combinators…
.box:has(+ * + * + .circle) {
width: 40px;
height: 40px;
}
…and so on and so forth. You can keep on adding adjacent sibling combinators (+) for as long as you want, to select any nth preceding element.
If you want to select all previous siblings, you can combine the :has() pseudo-class with the general sibling combinator (~), which matches the second element as long as it follows the first, regardless of its position:
.box:has(~ .circle) {
width: 40px;
height: 40px;
}
In other words, as long as the .box in this example is followed by a .circle at some point, the .box will be selected and styled.
Finally, we can combine the general sibling combinator (~) with the adjacent sibling combinator (+) and select all preceding elements except the most adjacent one:
.box:has(~ * + .circle) {
width: 40px;
height: 40px;
}
This selector selects any .box that matches the pattern “self followed by at any point a box + circle”.
2020-05-20 15:50:00
A/B-testing is a guiding compass for making product decisions. More technically, it’s a method for quantifying the impact of product variations. The process can’t tell us if one variation is unequivocally “better” than another, but it can tell us which of a set of variations is better at producing a certain effect, encouraging a behavior, or achieving a goal.
The basic method is similar to a clinical trial with a placebo group. By testing two or more variations of an experience (labeled A, B, C, etc.) and measuring how they cause similar groups of people to behave differently on average, we can assess a design’s impact. What we need at the minimum, then, is one control (A), one variant (B), and a random sample of users. The two versions could be our product in its current state, and a new idea that we want to compare it against:
At a surface level, A/B testing is as simple as that: build two variations of something and measure the difference in behavior.
Before we go into the details of running such a test, let’s take a step back and examine the underlying thought process. A philosophy that’s usually coupled with A/B-testing is incrementalism: the idea that we can build great products, make innovative leaps, and overcome daring obstacles by implementing gradual and measurable improvements. A vision can guide this iteration and experimentation, but rather than acting as a blueprint that gets fully built and realized in one humongous project—a risky and expensive endeavor—that vision typically serves as a north star. Small incremental improvements build up and inch us ever closer towards it, but experiments feedback into the vision and slowly transform it over time, placing the north star forever out of reach.
To embrace this philosophy and effectively accumulate insights and improvements through experimentation, we need to foster a culture and process that supports learning. If we don’t, we risk going in circles—running tests that have no impact, and that teach us nothing new. An important goal for a data-driven design organization is not just making an impact but learning as quickly as possible about a moving target. We need to allocate our resources based on how promising our different strategies seem at any given point. What’s worth focusing on will vary over time as your product and audience grows and transforms, and it’s something that you will have to learn and relearn continuously.
With learning as a core pillar of this philosophy, we can map experiment-driven design as a circular process of building, measuring, and learning:
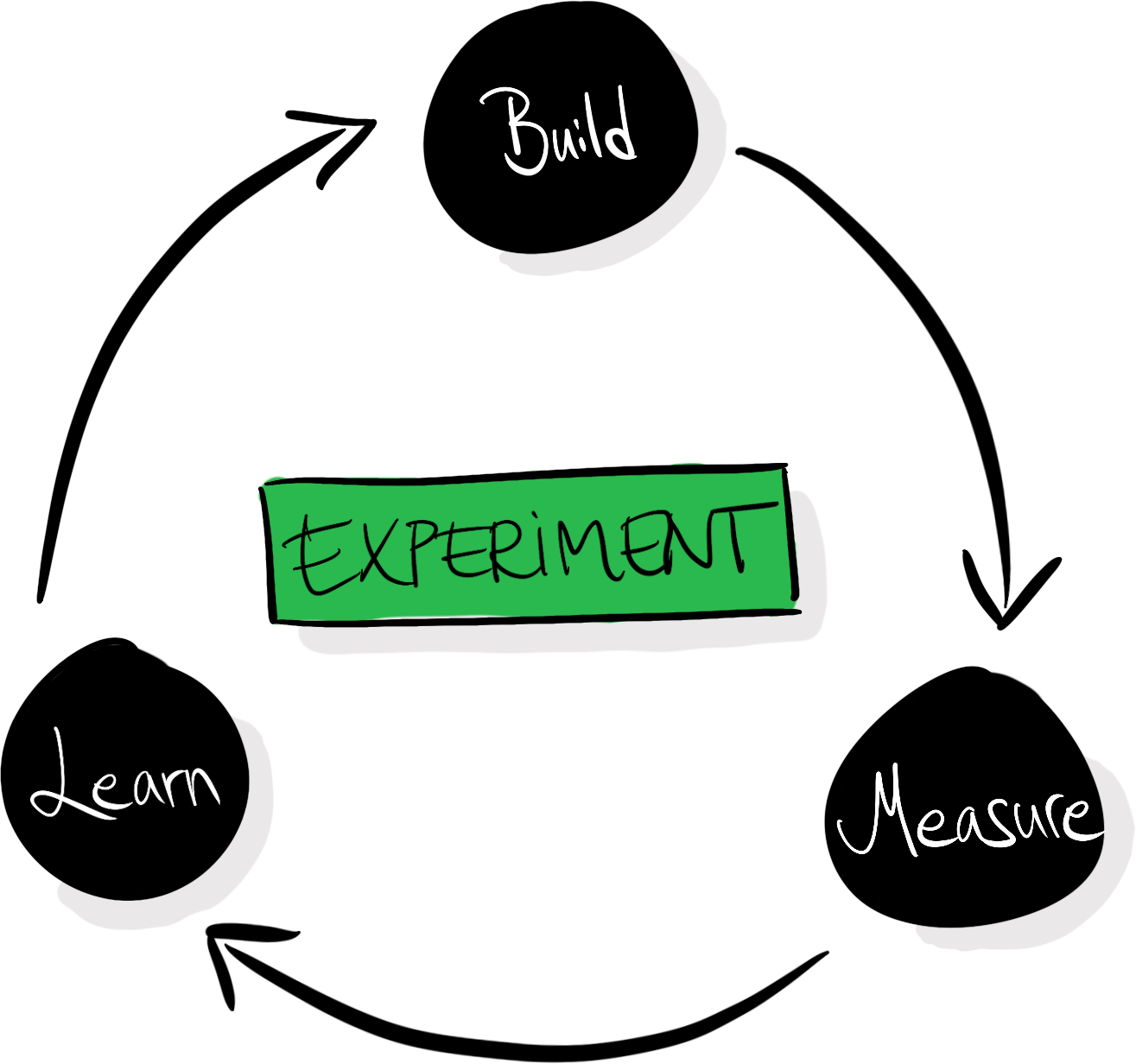
Every test doesn’t necessarily have to make your product better—but every test should teach you something. The A/B-testing process usually includes the articulation of hypotheses to facilitate that learning: we make sure that we capture our beliefs before running tests so that we can compare them with our new beliefs that we’ve acquired after seeing the results.
At a more granular level, an A/B-testing process can look something like this:
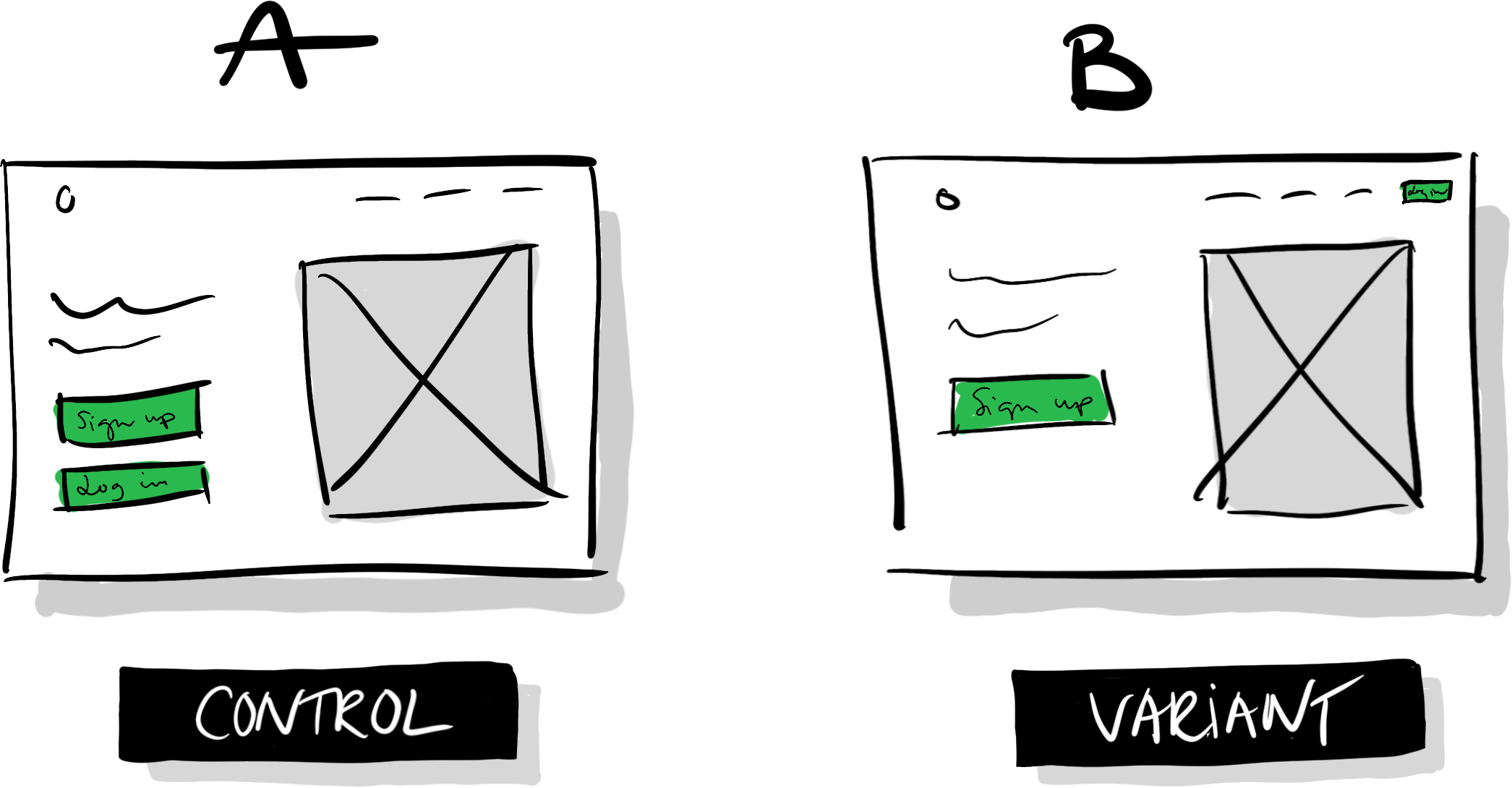
Say that we have a website that looks like illustration A (control) below: we have a logo in the top left, a menu in the top right, an image of our product, a header, and a short description. We then have two large buttons visible above the fold: “Sign up” and “Login.”
Someone in our organization has proposed that we should move the “Login” button to the menu in the top right, and keep the “Sign up” button as is (B). They hypothesize that making the “Sign up” button the most prominent call to action will cause more people to see it, which will lead more people to sign up.
To measure the impact of that change, we need to implement design B and expose a random subset of our users to it, alongside the default experience, which will act as a control. The exact proportion of our visitors (here 20%) that you enroll in a test will vary depending on the test and circumstances. The more users that get enrolled in an experiment the faster you’ll get the data that you need to analyze it, but make sure to not expose more users than necessary. After all, a variation might mistakenly make your product worse, and you want to mitigate any potential negative effects. In our hypothetical scenario, half of the visitors assigned to the test will see variation A, and half of them will see variation B.
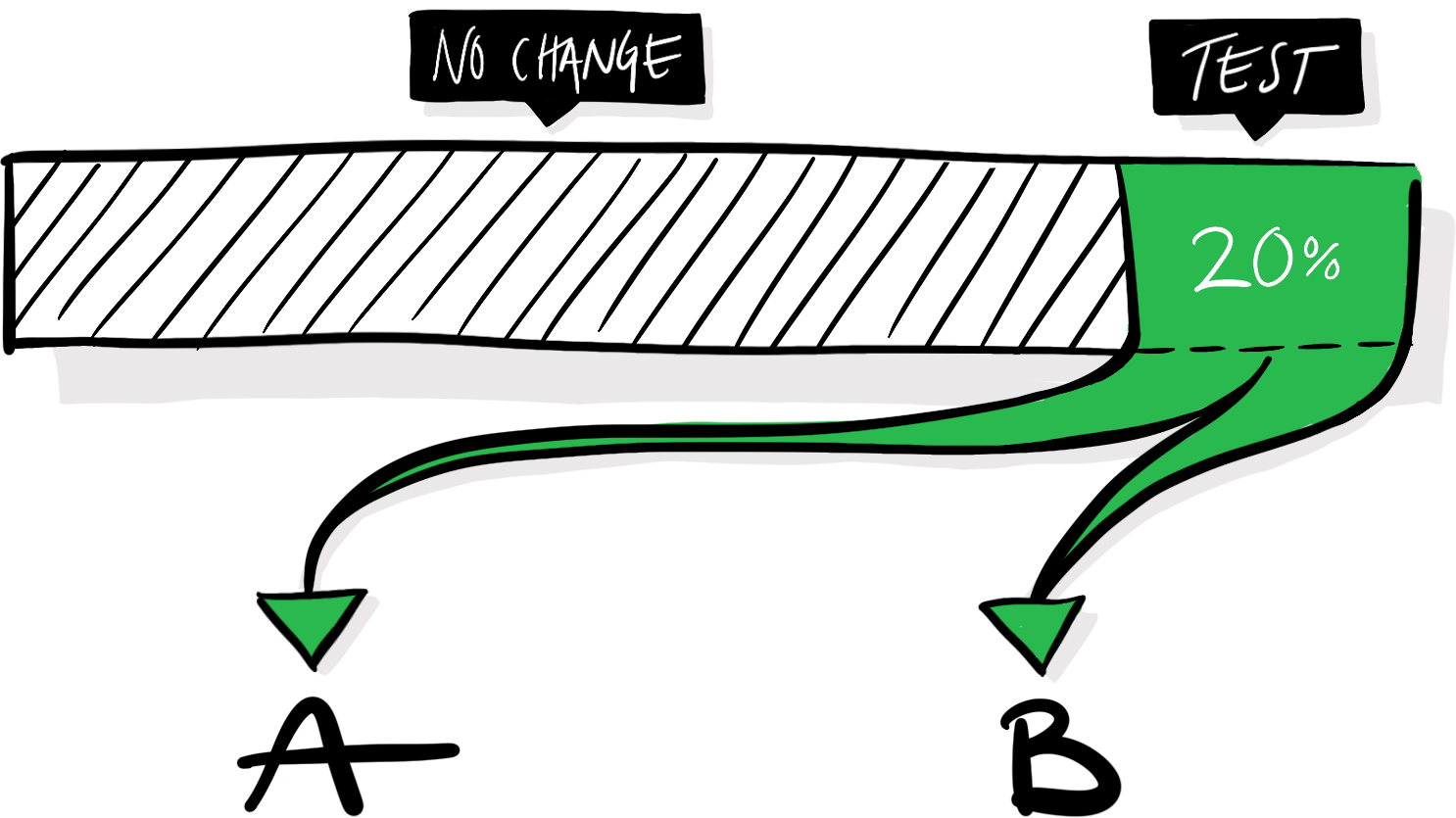
The experiences are identical in every single aspect except the moved “Login” button. If we see that people using the B-version of our website are more likely to sign up, we can conclude that the altered button causes that effect.
In other words, we can establish a causational relationship between design B and a behavioral change: an increase in sign-ups. Not just a correlation—this is why we need a control group to compare against. If we implement B, launch it to all our users, and then notice an increase in sign-ups, that increase would only correlate with the launch of the new design—it could as well be caused by a random tweet, a holiday, or a mention in a podcast. We wouldn’t know for sure, so we wouldn’t be able to draw any conclusions about the effects of the new design.
We also need the users to be randomly assigned to each cell to infer a causal relationship. If we select users for the cells by different criteria and end up with more engaged users in one of the groups, it might make that cell perform better regardless of the introduced change: the skewed selection of users is already more engaged on average. If we randomize the distribution of users, we can expect that all attributes (engagement, age, experience, etc.) are equally distributed between the groups, and won’t influence the outcome.
Presume that we run this test, and after analyzing it, we see a statistically significant four percentage-point increase in sign-ups for variation B:
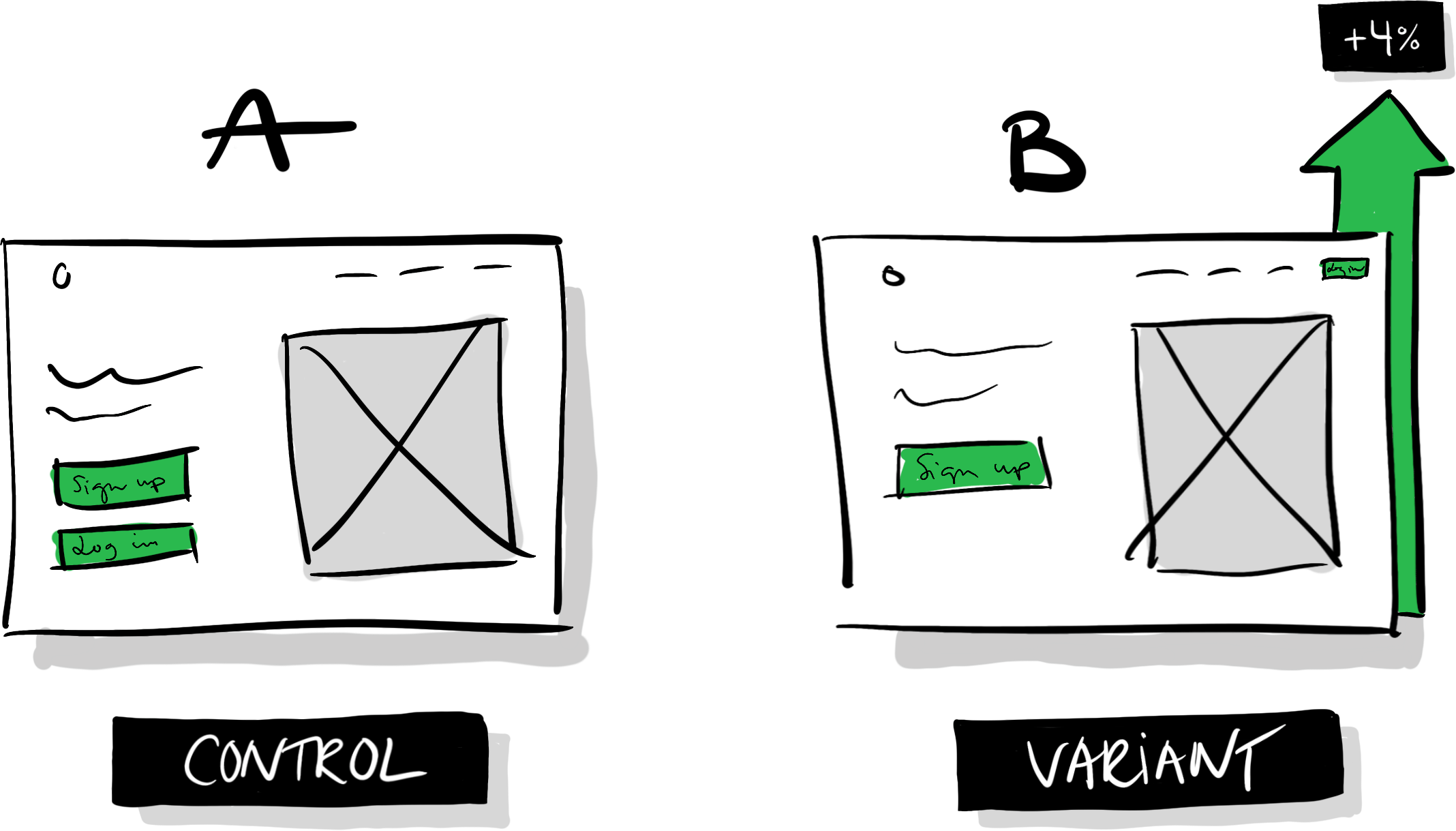
Variation B looks like a clear winner! Should we launch it? Here’s where we need to return to the notion that an A/B-test can’t tell us if B is unequivocally better than A. If our team’s goal is to increase sign-ups and we only measure sign-ups to assess if our tests are successful or not, we’ll likely run precisely these kinds of tests, where we promote the one feature connected to our goal while neglecting or diminishing other features. In this instance, the result can be a slow but steady accumulation of changes that taken together go against common sense: we’ll make it increasingly difficult for already signed up users to access the product.
If the only thing we measure is the metric that’s fundamental for our success, we have a destructive setup that will enforce skewed incentives to promote features connected to our goal while neglecting other parts of the experience. If other teams in the same organization have similarly skewed incentives, it’s a recipe for conflicts and counterproductive back-and-forths.
Unless we keep track of other key metrics and keep an eye out for accidental changes in different behaviors, we risk accumulating a myriad of unwanted side effects. When running the test outlined in this example, we might need to measure successful logins and retention (returning users over a certain period) in addition to sign-ups to understand if the change is introducing friction for already signed up users.
In other words, the goals you set up and the key metrics that you keep track of will undoubtedly influence your product decisions. They form the restrictions that you iterate within.
Why are we spending so much time on analyzing the effects of such a tiny difference? Wouldn’t it be more worthwhile to test more drastic changes? We could, without a doubt, introduce more ambitious and more significant changes. The challenge is that the more we change in one single test, the more difficult it can be to understand the results of that test—to pull it apart and learn precisely what variable caused which behavioral change.
On the flip side, if we don’t change enough, we might fail to produce any meaningful changes at all, or at least not impactful enough to be noticeable. If we focus on learning and incremental improvements, then, there’s a U-shaped relationship between how much we change in a test, and how much we can typically learn from it:
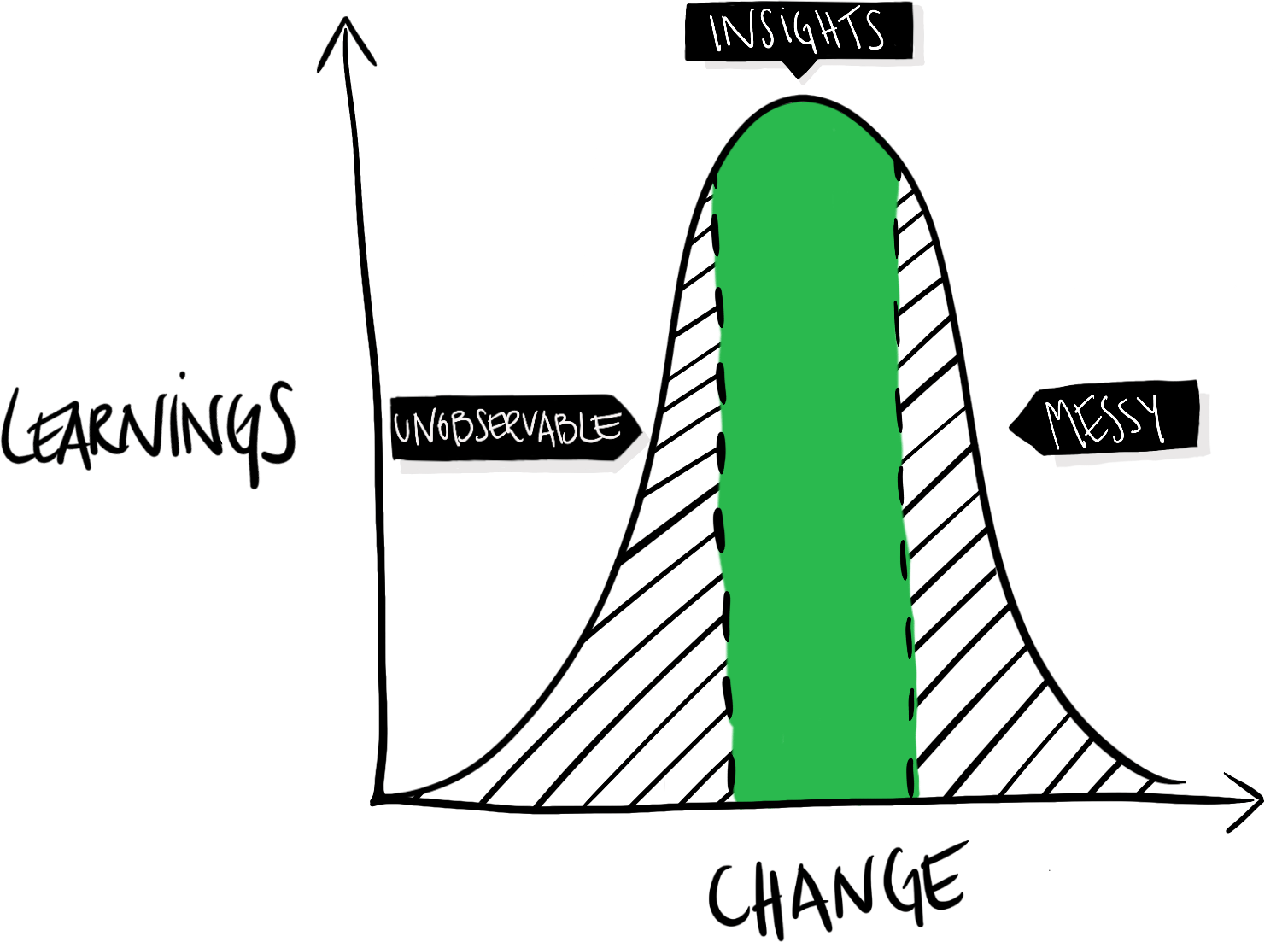
If we don’t change enough, the impact will be too small to be noticeable. The difference will be unobservable or negligible. If we change too much—e.g., completely redesign the entire product—the introduced changes and the produced outcomes can become a tangled mess. We’ve no idea what variable that caused what effect. Clear and valuable insights are somewhere in the middle. Developing a sense of how significant changes to test is part of learning how to utilize A/B-tests effectively. It’s different from product to product and depends on how well-optimized your product already is.
Importantly, this doesn’t mean that you shouldn’t test more significant and visionary changes or ideas—it just means that every test is a gamble, and the bigger the change, the higher the risk of blurring learnings. At the same time, an ambitious change might hit the jackpot and make a substantial and meaningful impact.
This process might seem to be a terribly expensive way of improving a product, and to be fair, it is. We’re spending a lot of time conducting tests that we could’ve spent building and shipping new features. So, why is it worth it? Or rather, when? As a rule of thumb, the more users you have, the more damage you can cause by shipping features that, despite your best intentions, happen to make the product worse for your average user.
The A/B-testing process really shines when it’s more expensive to make mistakes than to control for them. As your user base grows and your product matures, A/B-testing and data-driven design become an increasingly valuable tool not only to learn and iterate but to defend yourself against regressions. We can use it to gate the innovation process and only launch changes that we know make the product better—we introduce an objective selection process that only lets the fittest ideas survive. An overly zealous application of that selection process might shut out any change which’s effects aren’t quantifiable (which isn’t great—everything that matters isn’t quantifiable), but done right it can democratize the creative process and create an experimentation platform with clear goals and restrictions that we can iterate within.
2019-09-19 15:50:00
As light hits an object and a shadow is cast, the shadow can take on a myriad of unique characteristics. If you try to capture the subtleties of a real shadow with box-shadow then, well, you’re pretty much out of luck. The box-shadow CSS property isn’t exactly built to encourage expressiveness. It essentially produces a blurred silhouette of an object—you can change its offset, blur radius, spread, and color, but that’s it. We can’t get anywhere near to expressing the complexities and nuances of shadows in real life.
But with a simple CSS technique, we can expand our range of options. If we use layered box-shadows we can get more fine-grained control over how shadows are rendered:
Look at how square and clumsy the default box-shadow effect (first box) looks compared to the layered box-shadow (second box). We can achieve this effect by creating multiple box-shadows (separating each shadow with a comma), and increasing the offset and blur for every shadow (the box-shadow syntax is X-offset Y-offset blur color):
/* Default box-shadow */
.box {
box-shadow: 0 3px 3px rgba(0,0,0,0.2);
}
/* Create smoother box-shadows by layering multiple
* shadows with gradually increasing radius and offset */
.shadow-5 {
box-shadow: 0 1px 1px rgba(0,0,0,0.12),
0 2px 2px rgba(0,0,0,0.12),
0 4px 4px rgba(0,0,0,0.12),
0 8px 8px rgba(0,0,0,0.12),
0 16px 16px rgba(0,0,0,0.12);
}
This simple layering technique gives us more control over the rendering of shadows, and with it we can fine-tune sharpness, distance, and spread. You can for example increase or decrease the number of shadows to create a smaller or larger spread. (Note that if you increase the number of layers you’ll have to decrease the alpha value for each layer if you wish to keep the strength somewhat the same.)
.shadow-4 {
box-shadow: 0 1px 1px rgba(0,0,0,0.15),
0 2px 2px rgba(0,0,0,0.15),
0 4px 4px rgba(0,0,0,0.15),
0 8px 8px rgba(0,0,0,0.15);
}
.shadow-6 {
box-shadow: 0 1px 1px rgba(0,0,0,0.11),
0 2px 2px rgba(0,0,0,0.11),
0 4px 4px rgba(0,0,0,0.11),
0 8px 8px rgba(0,0,0,0.11),
0 16px 16px rgba(0,0,0,0.11),
0 32px 32px rgba(0,0,0,0.11);
}
Controlling sharpness is as easy as controlling spread, but we can use both the alpha value and the blur value of each layer to change the concentration of depth and the blur radius of the shadow respectively.
The examples above use the same alpha value for all layers, but we can let the alpha value decrease or increase with every layer to create more or less diffuse shadows. For the more concentrated shadow below, the innermost shadow (with the least offset and blur) has the highest alpha value, and it decreases with every layer. The opposite is true for the more diffuse shadow of the second box, where the innermost layer has the lowest alpha value:
.blog-shadow-sharp {
box-shadow: 0 1px 1px rgba(0,0,0,0.25),
0 2px 2px rgba(0,0,0,0.20),
0 4px 4px rgba(0,0,0,0.15),
0 8px 8px rgba(0,0,0,0.10),
0 16px 16px rgba(0,0,0,0.05);
}
.blog-shadow-diffuse {
box-shadow: 0 1px 1px rgba(0,0,0,0.08),
0 2px 2px rgba(0,0,0,0.12),
0 4px 4px rgba(0,0,0,0.16),
0 8px 8px rgba(0,0,0,0.20);
}
We can also increase the blur in higher incremenents, to increase the spread and create softer, almost dreamy, effects:
.blog-shadow-dreamy {
box-shadow: 0 1px 2px rgba(0,0,0,0.07),
0 2px 4px rgba(0,0,0,0.07),
0 4px 8px rgba(0,0,0,0.07),
0 8px 16px rgba(0,0,0,0.07),
0 16px 32px rgba(0,0,0,0.07),
0 32px 64px rgba(0,0,0,0.07);
}
Finally, we can control the distance by decoupling the blur radius and Y-offset, and increase the offset in bigger or smaller increments:
.shadow-shorter {
box-shadow: 0 1px 1px rgba(0,0,0,0.11),
0 2px 2px rgba(0,0,0,0.11),
0 4px 4px rgba(0,0,0,0.11),
0 6px 8px rgba(0,0,0,0.11),
0 8px 16px rgba(0,0,0,0.11);
}
.shadow-longer {
box-shadow: 0 2px 1px rgba(0,0,0,0.09),
0 4px 2px rgba(0,0,0,0.09),
0 8px 4px rgba(0,0,0,0.09),
0 16px 8px rgba(0,0,0,0.09),
0 32px 16px rgba(0,0,0,0.09);
}
Which combination of all of these techniques to use is of course highly dependent on the context that you’re working in, but with layered shadows we can at the very least gain some more control to help us achieve our desired look and feel.
2019-09-19 15:50:00
One of the delights of working with Ruby and jQuery is the ability to chain methods, enabling you to conveniently invoke multiple methods on the same target. In jQuery, for example, most methods return a jQuery object, so you can build a chain of methods where every new method operates on the previous target. This enables you to update some styles, run an animation, and update an attribute, all without querying for that element over and over again:
$(".menu")
.css("color", "#fff")
.data("mode", "light")
.fadeIn();
Short and sweet. If you’ve updated the styles of an object with vanilla JavaScript, you might’ve been annoyed about the fact that you can’t chain style changes, and so you have to do something like this:
let menu = document.querySelector(".menu");
menu.style.color = "#fff";
menu.style.backgroundColor = "#000";
menu.style.opacity = "1";
There are a few different ways of making this more convenient, but the other day I started thinking about if it would be possible to use a Proxy object (at the time of writing, global support is at 92.76%) to enable chaining of style changes. Turns out, it’s relatively easy. We’ll walk through how to create a light-weight Proxy handler that will enable us to shorten the code above to this:
style(".menu")
.color("#fff")
.backgroundColor("#000")
.opacity("1");
We’ll use roughly the same strategy as jQuery does: we’ll fetch the style object of an element and wrap it with a Proxy in order to intercept (trap) all get calls to that style object, take the accessed property and update its value if a value is passed, and then return the Proxy handler wrapping the style object again, enabling us to build an infinite chain of commands.
Since we’ll repurpose the get method to also act as a setter, we’ll retain the get functionality by returning the value of a property if you don’t pass any arguments to the function (i.e. you’ll get a value through style(".menu").color() rather than style(".menu").color). Here’s the gist of the technique:
let styleProxy = {
get: (object, property) => {
return (value) => {
if (value) {
object[property] = value;
return new Proxy(object, styleProxy);
}
return object[property];
}
}
}
let style = (selector) => {
let element = document.querySelector(selector);
return new Proxy(element.style, styleProxy);
}
Let’s break it down, and quickly walk through how a Proxy works.
The first aspects to understand about using a Proxy are handlers and traps. We can create a handler to trap a series of operations, e.g. get(), set(), and apply(). In essence, we’ll get a chance to intercept those operations on the object we’re wrapping and do with them whatever we want—we can return different values depending on some logic, or simply forward the operation to the original target.
As a simple example, we can always return the same value regardless of what property you try to access, even if no property has been set on the original object:
let handler = {
get: () => {
return "hodor";
}
}
let person = { name: "Wylis" }
let proxied = new Proxy(person, handler);
console.log(person.name); // "Wylis"
console.log(proxied.name); // "hodor"
console.log(proxied.age); // "hodor"
console.log(proxied.favoriteFood); // "hodor"
This enables us to completely change how an object works. To enable chaining for the style object, we’ll expand get to also work as set. We’ll still only trap get, but rather than returning the value of a property when it’s accessed we’ll return a function that returns the value of the property only if the function is invoked without any arguments. If an argument is passed, we’ll use it to update that property’s value.
Let’s start by just getting the basics into place. Let’s create a new handler called getProxy, and create a get trap, where we always return a function. Thus if we just log a property, we’ll get a function. But if we invoke that function, we’ll see what it returns (in this case “test”):
let getProxy = {
get: () => {
return () => {
return "test";
}
}
}
let proxied = new Proxy({}, getProxy);
console.log( proxied.name ); // Our function: (argument) => { return "test"; }
console.log( proxied.name() ); // The value: "test"
Inside our new function, we can check if an argument is being passed to it when it’s invoked. If something is passed, we can use that argument to update the property. If no arguments are passed we can simply return the value of that property, basically maintaining the original get functionality while expanding it with a set option.
Let’s create a new Proxy, this time called styleProxy. We’ll check if something is being passed to it, and get and set accordingly. Our proxy handler is also being passed an object (the object we’re wrapping and intercepting) and a property argument (the property we’re operating on), and we can use these two to operate on the original target.
let styleProxy = {
get: (object, property) => {
return (value) => {
if (value) {
// "object" is the object that we're wrapping
// "property" is the property of the object that we're accessing
// "value" is what we passed to the function
// Let's use these three to update the style object:
object[property] = value;
} else {
// If no arguments were passed, simply return the
// value of that property:
return object[property];
}
}
}
}
This enables our handler’s get method to act both as a setter and getter:
style(".menu").color("#fff"); // Gets a function which updates color to "#fff"
style(".menu").color(); // No arguments passed, just returns "#fff"
Note that since we’re not creating a trap for the set operation, we can still set a property’s value by assigning a value to it directly:
// Works like expected
style(".menu").color = "#fff";
Now that we’re in control of what’s being returned after we update a property, we can simply return the original style object wrapped in our Proxy handler if an argument is passed, completing our chaining method:
let styleProxy = {
get: (object, property) => {
return (value) => {
if (value) {
object[property] = value;
// Return the original target, wrapped in the same Proxy handler
return new Proxy(object, styleProxy);
}
return object[property];
}
}
}
When we use method chaining, then, this is what’s happening behind the scenes:
style(".menu") // Returns the style object in a Proxy
.color("#fff") // Updates color and returns a Proxy
.backgroundColor("#000") // Updates bgColor and returns a Proxy
.opacity("1"); // ... and so on so forth
Here’s the solution in full:
let styleProxy = {
get: (object, property) => {
return (value) => {
if (value) {
object[property] = value;
return new Proxy(object, styleProxy);
}
return object[property];
}
}
}
let style = (selector) => {
let element = document.querySelector(selector);
return new Proxy(element.style, styleProxy);
}
I can’t confidently say that I recommend this approach—and I won’t be using it on this site anytime soon due to the just-too-low browser support, but I find it fascinating how bendable JavaScript is, and how with the Proxy API we can go even further.