2026-07-15 22:12:22
今晚遇到了一个极其诡异的故障:每当我尝试访问 YouTube 时,页面总会被自动重定向到 Cookie 设置错误页面。
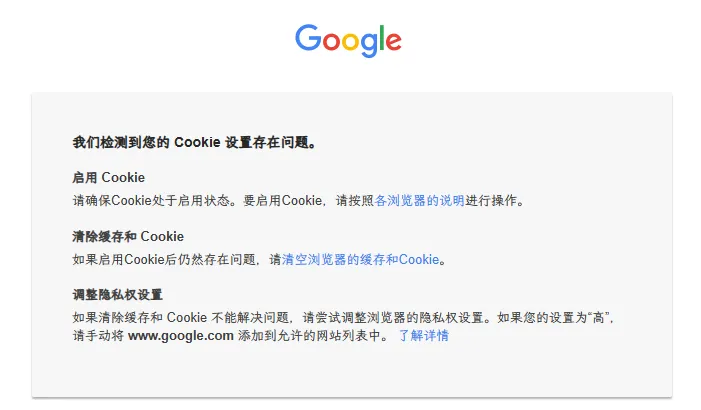
让我头疼的是,首先我的网络代理本身毫无问题,其次 Google 旗下的其他服务(比如 Gmail、Gemini)全都能正常使用。不过网站偶尔 Cookie 出错也算常见情况,不慌,于是我按照页面上的说明进行了排查:① 确认浏览器没有阻止任何 Cookie;② 清理了 youtube 和 google 网站的 Cookie;③ 确认了浏览器的隐私权设置。然而重新访问 youtube.com 时,结果还是无限跳转到这个报错页面。
不能看 YouTube 哪能行,这必须解决啊!在经过一番艰辛的折腾后,我终于解决了这个问题。以下是完整的排错记录。
省流太长不看版:浏览器访问
chrome://settings/content/all-> 搜索故障域名 -> 干掉域名主站的Cookie -> 如果显示有其他网站 -> 依次展开 -> 点垃圾桶干掉所有其他网站下的涉及故障域名的 「已分区 Cookie」
既然普通的清除 Cookie 没用,我开始由浅入深地尝试各种清理方案,结果只能说是屡战屡败:
Ctrl + Shift + N 进入无痕模式,访问youtube.com ,秒开!在里面登录也完全正常。google.com 的主 Cookie 也给扬了。打开 F12 开发者工具,在 应用(Application) -> 存储(Storage) 中勾选所有项目(取消注册 Service Workers、本地存储空间 LocalStorage、会话存储空间 SessionStorage、IndexedDB 等),执行 清除网站数据(Clear site data),包括第三方 Cookie。
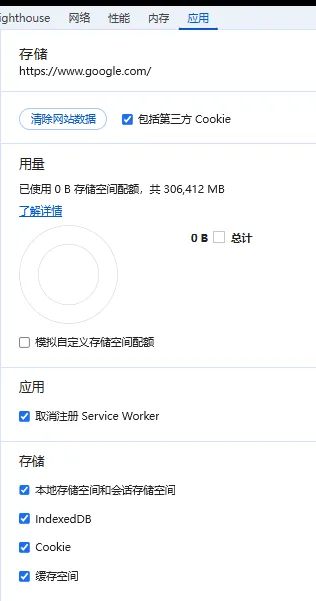
在报错页长按浏览器的刷新按钮(注意这时候需要开着 F12 开发者工具),选择“清空缓存并硬性重新加载”,防止浏览器强行记忆重定向指令。
判断:全部失败! 只要访问 YouTube 页面,那条倒霉的跳转提示就会雷打不动地出现。说明问题 cookie 还是没有被清理掉。
诶,我去,这是啥情况?按说我已经清理了 Google 的一切缓存,也清理了 YouTube 的一切缓存,浏览器内不应该有任何残留的 Cookie 了啊。既然无痕模式下可以正常访问,又排除了扩展导致的问题,那还能是因为啥呢?难道谷歌还有其他域名下藏着 Cookie,或者我刚才漏了某个地方没清理?
抱着试试看的态度,我重新进入了 Chrome 的网站存储管理页面:chrome://settings/content/all(所有网站设置),并在右上角搜索了 youtube.com。
这时,我突然发现了一个盲点:为什么搜索结果除了 YouTube 本身,还有很多其他和谷歌完全无关的网站被显示出来了?于是我点了一下小三角展开列表,居然发现在许多其他完全不相干的域名下,赫然挂着一堆被标记为【已分区】的 YouTube Cookie!(截图里是我已经恢复正常后截的,当时这里足足有 30 多个网站)
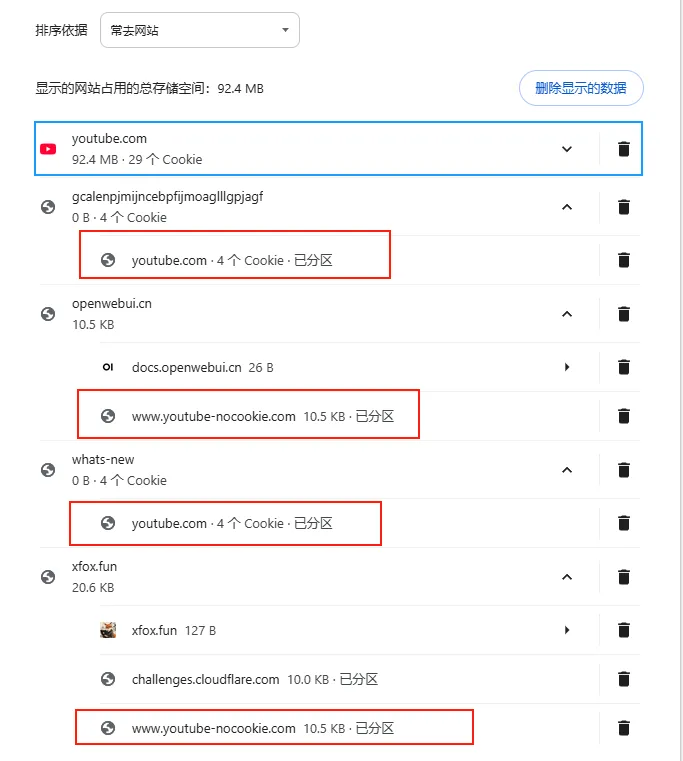
在这个列表里,主要有三类东西:
chrome://whats-new/),里面嵌入了 YouTube 视频做功能演示。gcalenpjmijnce...):这代表某个我安装的 Chrome 插件在后台静默调用或嵌入了 YouTube 的相关接口。死马当活马医吧,我把这些挂在其他网站名下的【已分区】Cookie 也全部挨个点击垃圾桶强制删除。
再次刷新 youtube.com —— 页面瞬间恢复正常,顺利进入 YouTube!
为了防止第三方广告商利用 Cookie 跨站追踪用户,Chrome 从 Chrome 114 开始推广所谓的 CHIPS (Cookies Having Independent Partitioned State) 技术,中文翻译就是已分区 Cookie。
whats-new 页面里加载的 YouTube Cookie,和直接访问 YouTube 主站加载的 YouTube Cookie 是完全隔离、互不相通的, whats-new 并不知道我实际的 YouTube 账号是什么。结合这次的故障表现,我做了一些推测:
CookieMismatch 强制重定向。F12 清空 Storage,Chrome 的分区 Cookie 保护机制都不会去动那些挂在其他域名下的“分区 Cookie”。于是,只要这个有问题的 Cookie 没被删除,每次访问 YouTube 时,谷歌的服务器都会重新读取到那个有问题的 Cookie,从而陷入无限重定向的死循环。哎,我最近也不知道咋了,和缓存故障杠上了。周一还遇到了小众软件论坛无法进入,换浏览器和隐私模式却能正常访问的问题,最后也是清理了 Service Worker 才恢复正常。感觉这都快成使用 Discourse 搭建论坛的常见问题了,经常 Service Worker 故障,导致部分用户访问该论坛。
这次排错也算涨知识了,原来还有个叫 CHIPS 的东西。如果你以后也遇到了某个网站“无痕模式正常访问,但普通模式下无论怎么清理主站 Cookie、清理 Service Worker、清理网站缓存都无限报错”的玄学 Bug,不妨试试去chrome://settings/content/all清理一下“已分区 Cookie”,说不定困扰你很久的问题立马就迎刃而解了呢!
本文 YouTube 无限重定向报错,谷歌账号身份验证无限失败,罪魁祸首居然是“已分区 cookie”?! 最初发表于 秋风于渭水。
2026-07-08 16:05:47
今天早上一上班,邮箱里突然躺进了一封来自 CloudCone 的邮件,标题写着:[Important Notice] Scheduled Collocation Migration Details。
幸亏点开时我没喝水,点进去一看,直接直接给我气笑了。
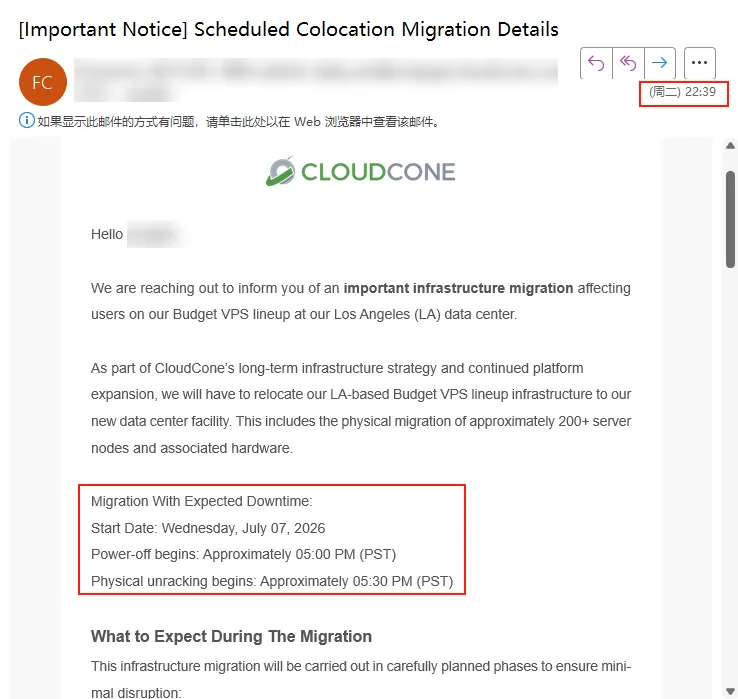
CloudCone 宣布要对洛杉矶机房的所有 VPS 进行物理机房迁移。注意,这可不是什么热迁移,也不是内网数据同步,而是“物理意义上的搬家”:邮件里说他们要把 200 多个服务器机架及相关硬件在物理意义上的拆走、打包、运输到新机房,然后重新上架、接线、通电、配置环境。
机房物理搬迁服务器没啥稀奇的,关键是他们给出的搬家时间和通知时间。
你们看啊
我收到邮件的时间是北京时间(UTC+8)7 月 7 日 22:39。
折算成机房所在的太平洋时间(PST/PDT),大概是 7 月 7 日上午 07:39。
那他们计划什么时候开始切断电源呢?
邮件里写着:05:00 PM PST 准时开始断电,05:30 PM 开始物理下架。
也就是说,从他们发出这封“重要通知”到正式拔掉服务器电源,中间一共只给我留了不到 10 个小时时间。对于他们来说是当天早上7点半上班时发通知邮件,当前5点下班就拔电源搬家。
对于身处东八区的我们来说,他们断电的时间(PST 17:00),是我们这边的次日(7月8日)早上 9点左右。合着我昨晚没有在深夜修仙,保持了健康作息的行为,导致在我完全不知情的情况下,在新一天要面对一个已经断电、正在被塞进卡车里运输的服务器。
更何况,这还不是一次短暂的服务中断。CloudCone 在邮件的 FAQ 里也说了:由于涉及 200 多个服务器的物理搬迁,整套流程走完,预计的宕机时间可能长达 24 小时。(以我对他们运维水平的了解,24小时肯定搞不定)
这可是动辄两百多个机柜的机房整体大搬迁啊!合同的谈判、新机房的准备、物流的对接,这些流程少说也得提前几周甚至几个月准备,绝对不可能是发通知的当天一拍脑门才谈好的。
既然早有搬迁计划,提前一周甚至三天发个通知,在流程上有任何难度吗?没有!
那我不禁要用最大的恶意揣测一下了:难道是因为害怕提前通知了,大家一听说要断电停机 24 小时,纷纷选择退款、关机、把业务迁到竞争对手那里,导致用户大面积流失吧?所以才故意拖到当天、只留 10 个小时,搞一场“闪电突袭式”搬家。这点时间,用户连找个新 VPS、把几十上百 G 的数据同步过去的时间都不够。用极限时间“绑架”用户的数据,不给用户备份数据的时间,从而堵死了任何迁移数据走人的可能性。
翻开他们在邮件里的 FAQ 第 5 条:
Q: What happens if I choose not to proceed with the migration?
Unfortunately, if you do not wish to continue with the migration, the user would have to cancel the service without a refund. Please note that this migration does not breach the service location promise, as your service will remain hosted within the city of Los Angeles, USA, within a brand new state-of-the-art data center facility.
大意是说:如果你不希望服务被迁移,那不好意思,你只能自己去后台取消服务,而且我们一分钱都不会退给你,因为我们进行服务器搬迁并没有违约,反倒是你提前终止服务违约了。
明明是 CloudCone 单方面无法履行原有的服务协议,结果用户不想受这窝囊气、想退款走人居然成了“用户主动取消”。这逻辑高低得是个商业鬼才才能写得出来:
反正不管怎样,CloudCone 横竖不亏。
作为一家主打高性价比的 VPS 服务商,大家平时对 CloudCone 的网络偶尔抽风啊、机器性能一般啊、工单回复极慢啊,也都有心理预期,毕竟价格摆在那里是不,要啥自行车。
但“便宜”不等于可以把运维和运营视作儿戏吧。如此巨大的基础设施的物理迁移行为,在业界,提前一周乃至一个月通知、并提供多次进度提醒是基本常识。像这样“早上上班发通知、下班就拔线、搬车拉走”的粗暴作风,真配得的上“鬼才运营”的称号。
自从上次他们被黑导致所有服务器都被格式化之后,我就把能搬走的服务都搬走了,自用的只剩下一台大盘鸡(还有两台是帮人代购代运维的),因为我实在找不到其他的,能给这么大硬盘和内存还1年只要我 20 多刀的 VPS 了。
哎,这次事件也算是再次提醒了我们这些独立开发者和站长:永远不要把鸡蛋放在同一个篮子里,更不要对高性价比主机的在线率抱有任何期待。 自动化的异地跨服务商备份是必须要搞的。毕竟你永远不知道,你的服务商会不会在某个夜黑风高夜,只留给你 9 个多小时,然后把你整台服务器抗在肩上连夜跑路搬家了。
PS:以后标题图是AI画的这件事,就不单独写AI辅助创作声明了,这些图一看也不可能是我自己画的
ip link set dev eth0 mtu 1400,这不是进入交换机,把 MSS 自动修改功能打开就好了吗?总不能是他们的垃圾交换机完全没提供这个功能吧。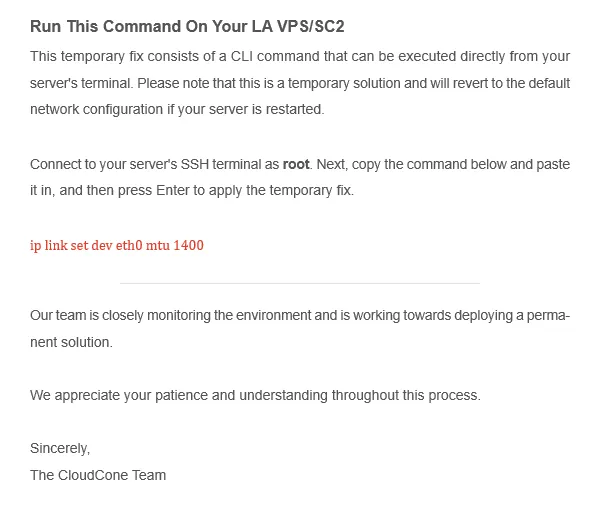
在终端输入ping -M do -s 1400 www.google.com,看下能不能ping通谷歌(也可以试试其他数字比如1420、1450、1470等稍大的数值,1400 是最保守的参数)
如果确定可以ping通的话
如果你使用的是 Ubuntu / Debian:打开 /etc/netplan/ 目录下的 .yaml 配置文件(名字通常叫 50-cloud-init.yaml 或 01-netcfg.yaml之类的,你就改那个数字最大的文件)在你的网卡(如 eth0)下面缩进加上 mtu: 1400,保存退出后执行:netplan apply类似这样:
network:
version: 2
ethernets:
eth0:
dhcp4: true # 这行只是示例,不要照抄
mtu: 1400 # <--- 加在这一行
如果你使用的是 CentOS / RHEL: 打开 /etc/sysconfig/network-scripts/ 目录下的 ifcfg-eth* 配置文件。在文件末尾新起一行,加上MTU="1400",保存退出后,重启网络:systemctl restart network。
2026-06-23 06:22:58
最近的独立博客圈可以说是热闹非凡,各路聚合平台的“大瓜”那是一个接着一个,直接把这个原本安静的小圈子炸成了火药味十足的江湖。
先是在 5 月底,主打生活类个人博客收录的“壹個博客(Oneblog)”被爆出在毫无预警、零告知、不留明确申诉通道的前提下,悄悄在后台对部分历史合规站点实行“静默封禁”。更有博主可能仅仅是因为注册邮箱同源,或者页面带有管理员认定的所谓“竞品链接”,就被不分青红皂白地进行了“株连式”的连带封禁。直到封禁事件闹大、舆论发酵之后,平台才赶紧修改收录和推送规则,打上了一个(并不算完善)的补丁:“(仅)收录兼具设计美感与日常生活长文的博客”。
而到了 6 月中旬,更大的瓜田来了,至今还陆续有新瓜爆出。“简笔记”系统被爆出评论区接口邮箱明文泄露 Bug,随后其开发者(同时也是“个站商店”的站长)在面对热心网友的 Bug 反馈时,不仅没有职业化地迅速复盘并修复问题,反而将群内“仅修复提及的文章还远远不够”的善意提醒,粗暴地回绝为“你这么关心这个干嘛?我比你知道”。后续,该站长又连续发表多篇文章,暗讽反馈者是“生活在底层、无所事事”的人。更有甚者,某个博主仅仅因为在 QQ 群里扮演和事佬“劝了几句”,其站点就在个站商店后台被悄悄静默删除。如果把视线再放宽到过去,诸如“积薪”、“川流”等聚合站点,也无一例外都在“三观不合”或“政治/观点交锋”后,在管理员与博主们的激烈争吵中走向了圈地自萌、淡出、停运的结局。
那,为什么这些独立的聚合站点,频频会在“审核标准”和“平台态度”这种最基本的运营层面上翻车呢?
很多人或许觉得,这些丑闻的爆出只是因为管理员的“素质问题”或者“技术硬伤”。但作为深度参与并管理过大大小小各类网络组织的人——从现实中母校历届的新生群/论坛/贴吧/频道管理,到母校公众号与迎新群的技术支持运营,再到百度贴吧、微博、知乎的审核志愿者,乃至 QQ 和 TG 上的万人社群管理——我感觉出现这种情况是个人主导的独立聚合站点在发展到一定阶段时,现实且必然的产物。
当一个社群还只是一套程序、一个域名的私人产物时,它只是一个“个人的自留地”。但当它戴上“平台”、“商店”、“聚合”、“社区”的帽子,吸引了大量独立博主主动入驻、提交 RSS 时,它在客观上就已经具备了公共属性。
那么,是不是只要摆脱了这种个人独裁的管理形式,改为多位成员共同维护的联合治理,或者开放式的公益组织,问题就能迎刃而解了?
答案是:不过是从“个人情绪的奴隶”这一大坑,跳进了新的“系统性结构缺陷”天坑里罢了。
随着团队的扩大,联合治理或开放式组织必然面临管理员素质水平鱼龙混杂的局面。这时候,组织者又不得不面对以下三个更为无解的现实困境:
这种松散的网络组织在建立初期之所以能高效运转,纯粹是靠初始成员间一种高度心照不宣的“气味相投”(隐性共识)。但这种单靠热情维持的共识是非常脆弱的。
营利性组织遇到内部观念冲突时,可以通过薪酬和组织架构强行消弭分歧——为了工资,大家可以“忍辱负重、求同存异”。
但一个松散的网络组织,既无薪酬利诱,又无强制权力。当组织规模扩大、各种带有不同价值观、不同利益诉求、不同立场的管理员涌入时,由于缺乏底层利益的捆绑,任何一次微小的技术切磋或观点交锋,都有可能会迅速上升为“路线之争”。
不管是否愿意承认,在一个没有经济收益的社群里,“话语权”和“认同感”就是衡量成功的唯一标准。正如公司以营业额和产值论成败,政府部门以组织规模和权力边界定高下。
当成员数量激增后,管理团队就不再是一个单纯的“热心网友集合体”,而是变成了一个微型的竞技擂台。由于网络社群的“退出壁垒”和“内耗成本”几乎为零(大不了退群、换个马甲、甚至直接拉走一拨人另立门户),这就导致了内部派系斗争的成本极低。
管理员们会本能地开始拉帮结派,代表各自背后的群体利益(例如技术激进派 VS 养老生活派)。此时,平台的管理权限(如封禁、置顶)不再是服务工具,而是变成了各派系在进行意识形态冲撞时、用来互相攻击和降维打击的资本。而很多时候,你作为最高管理者很难出面拍板,因为两边的选择可能都有其道理。你若和稀泥,搞不好两边都要得罪;你若选择站边,搞不好组织就面临分裂。
随着社群规模的扩大,日常维护的“脏活累活”(如处理垃圾评论、审核边缘违规、解决日常反馈、安抚巨婴用户)会呈指数级上升。
然而,志愿者从“用爱发电”中能获得的正向情绪反馈,却随着组织的臃肿在加速递减。这就导致核心干活的志愿者极易陷入严重的精神内耗与职业倦怠。在疲惫且没有任何物质补偿的情况下,有些管理者遇到其眼中的奇葩用户时,理智的弦就会崩断——“我凭什么在这里受你这个用户的气?”这种憋屈积累到顶峰,便会演变成一种“毁灭吧,赶紧的”的情绪暴政,随之而来的就是撕逼和开战。最糟糕的是,这位管理者的任性操作,往往最终并不会由其个人买单,而是需要整个组织为其背锅。
在管理了这么多年、这么多类型的社群组织后,我发现最幽默的情况莫过于:“组织者越是想要民主,反而越是容易遇到必须用不民主的方式去解决的事情。”
这倒不是说追求社群内民主是错误的,而是因为:作为一个一般水平的人类个体,想要把规则写到事无巨细、尽善尽美,是完全不可能的。
当组织还是小圈子、大家圈地自萌时,规则往往只是摆设,大家都乐呵呵的。但组织一旦做大破圈,林子大了什么鸟都有,你总会遇到你现有、不完美的规则里完全没有明确规定,但在现实中又不得不立刻做出处理的灰色案件或舆论危机。此时,微型社群根本不具备容纳复杂民主程序的成本空间。你既没有多余的精力去搞一场长达数天、数周乃至数月的大辩论,你为了体现民主风范也不会在争议刚露出苗头时就雷霆手段予以弹压。你等事情闹大了之后去搞民主意见收集,民主公投,结果往往不是看谁的说法更有理、更正确,而是变成看谁的粉丝多、谁更擅长拉帮结派带节奏。如果这个“节奏”恰好符合你内心的标准或者和多数人一致,那还能你好我好大家好,如果这个节奏恰好不符合你的内心标准呢?接受结果吧,你心里不舒服,不接受结果把,这时候再去搞弹压,那你的公信力可就彻底完蛋了。
更何况,我们聊的这种所谓社群民主,背后其实一直隐藏着一个所有人都在装傻的默认前提:“组织发起者的最高权威是神圣不可挑战的。”
大家可以扪心自问一个灵魂问题:如果你是一个聚合站点的发起者,你会在你设计的民主规则里,明确写上一条“成员有权通过公投罢免你”的机制吗?😂
你琢磨下,你有见过存在这种机制的聚合站吗?你肯定不会设置这种机制啊,因为随着你的聚合站点越做越大,你和外部的其他聚合组织、博主圈子之间,会不可避免地会产生摩擦、冲突和利益博弈(无论你在冲突中是对是错)。如果你的平台真有一套“可以罢免创始人”的民主机制,外部的敌对组织或看你不顺眼的群体,完全可以利用你的规则,通过恶意引流、拉帮结派、粉丝抱团渗透进你的管理层,然后堂而横之地“利用你的规则逼你下台”。
所以,这就把微型组织的民主逼入了一个死胡同:不给罢免最高领导人权力的民主,不过是一个披着民主外衣的“仁君独裁下的民主”,这层外衣什么时候被掀开,只需等到一个未来的必然;而给出了罢免权力的民主,在如今互联网上日益增长的派系斗争面前,对于体量如此小、颠覆成本如此低的组织而言,搞真民主就是纯粹的政治自杀。
如果把“独裁”或“民主”都否定掉,咱们选择走向彻底的“工具化”与“去中心化”——剥离一切人情和情感色彩,不设任何交流群,不搞精选推荐,只把平台当成一个“冷酷的、没有感情的 RSS 抓取脚本运行器”,是不是就能天下太平了?
听起来很美对吧?但这招看似美好,实则卵用都没。原因有二:
原本独立博客站长们就天然拥有极强的独立意识和表达欲(毕竟大家在众多可发言的平台中,选择了相对最独立的形式),而你又不可能将规则写的完美无缺,就比如现在的壹個博客(Oneblog)虽然他已经修改完善了多次收录标准去阐述他不想收录非生活博客,并且 RSS 里过滤(IT)技术类文章是交给 AI ,排除了人的干扰,但还是有较真的博主在怼他。而且互联网上还永远不缺“巨婴”和“杠精”。哪怕你把自己的聚合站做成了一个纯技术、纯客观的自动化爬虫工具,只要有一天因为某个博主的服务器配置兼容问题、RSS 兼容问题、合规性问题,或者存储盘爆满导致 RSS 抓取异常断开了——在“归因偏差”的作用下,有些人也绝不会从自己身上找原因。他们会立刻在心里完成一套受害者叙事,跳出来指着你的鼻子破口大骂:“你为什么悄悄删除我?你为什么要针对我?你是不是在搞阵营?你这个站长怎么这么傲慢?”巨婴和杠精总会觉得是你在故意搞他,然后写文章挂你、骂你。你再有理,多来几次,对你精力的消耗也是实打实的。
我以前也曾动过心思,想要自己折腾一个博客聚合站。但最终,我打消了这个念头。
一方面是因为上述治理中无法回避的现实问题;另一方面是因为工作、家庭、现实社交等各种琐碎事务已经彻底占满了我的精力。曾经加入的组织,还存在的那就继续管着,组织哪天消失了就不再加入重建的了。把精力留给真实的生活。不过,虽然我个人选择了退场,但花开两枝,各表一枝:
在这个很容易吃力不讨好的泥潭里,依然有些组织和个人在认真办事。比如大家提过的“笔墨迹”与“BlogsClub”。没有什么高大上的口号,他们只是把平台当成一个真正的服务工具,给草根站长留了一份最基础的知情权和尊重。在大家都容易情绪上头的当下,这种克制和规范,真的挺难得的。
说实话,这些站长能把一个聚合站、一套系统无偿维护几年甚至十年,背后付出的精力和成本是实打实的,这点大家都心里有数。大家都是凡人,做了贡献,想在这个小圈子里图个好名声、要点正向反馈和认同感,这完全合情合理,一点毛病没有。之前我在《独立博客如何在“纯粹记录”与“理直气壮恰饭”间找到平衡》一文中就表达过我的观点:只要能达成一种对反馈的可持续的自洽就挺好的。
但让人觉得可惜的是,有些站长的心态在后期没摆正。大概是无偿付出了太久,心态失衡了,渐渐把公共平台当成了自己的私产。一旦遇到技术质疑或者意见不合,就觉得对方是来“砸场子”的,第一反应是嘴硬和拉黑。
他们一边割舍不下作为“圈内领袖”的那点精神回报,一边又在现实的纠纷里任由情绪失控,用拉黑、踢群、甚至人身攻击去解决问题。结果呢?自己辛辛苦苦熬了多少年才攒下来的那点贡献和路人缘,在几场闹剧里直接被自己给作没了。原本是一个奔着大团圆结局的美好剧本,最终却因情绪失控沦为晚节不保的反面教材,着实令人扼腕叹息。
互联网是有记忆的,你怎么对待用户,生态就会怎么评价你。
最后,向那些至今还在用良心维护圈子、默默干脏活累活的聚合站站长们致敬。至于我,还是安安心心当个读者,偶尔看看八卦、吃吃瓜就挺好。
排序不代表时间线
1. “简笔记”的作者,一位行为艺术家
2. 博客 RSS 遭一个博客聚合平台连带封禁
3. “>个站商店悄悄的删除我的博客>
4. 简笔记这套付费系统,十年了老bug还在反复发作
5. 聚合博客与独立博主的自主选择
6. 深扒博客聚合与博主们的江湖恩怨
7. 壹個博客聚合平台无通知封禁我的博客RSS
8. 邮箱泄露只是开始,简笔记的问题不止这些
9. 个站商店、简笔记泄邮箱后,阶级哥在群里破防了
本文 乾纲独断还是民主治理?聊聊博客聚合平台的治理悖论与无解之痛 最初发表于 秋风于渭水。
2026-06-17 10:18:35

根据目前披露的安全公告,这个漏洞(CVE-2026-53519 路径穿越)的严重程度高达 9.1 分,属于致命级。
这个漏洞简单来说,攻击者只需要利用哪吒探针的“前缀混淆”逻辑 BUG,构造含有特殊字符的 URL(比如包含 /dashboard..),就能直接绕过权限验证,把面板服务器上的核心配置文件 config.yaml 给拉下来,从而导致内部密钥彻底泄露。
而且这次大面积被黑的重灾区,大都是开了 WebSSH 的 V1 版本。密钥一旦泄露,攻击者不需要你的 SSH 密码,直接顺藤摸瓜通过探针控制端就能拿到面板下所有小鸡、杜甫的最高控制权,直接一锅端。看群里一次性中招几台十几台小鸡的人大有人在,堪比痛饮哪吒仙饮了。
在这里我真的想狠狠吐槽一下:把服务器的最高权限托管在探针机上,是一个风险极高、极其不明智的选择!
不可否认,哪吒探针的一键 WebSSH 和批量下发命令功能确实是很方便,但这种“方便”在安全面前是不堪一击的。你一个探针,还是主打轻量化的探针,本质就应该是一个轻量化的监测工具,你老老实实收发数据、监控一下 CPU、内存和网络就足够了。
整一堆什么 WebSSH、远程终端、批量命令下发。这些功能本来就不该是一个轻量化探针该做的。很多站长为了图省事,给探针放开了太高的系统权限,一旦作为控制端的面板被攻破,就直接把手里所有服务器的“最高权限”拱手送给了黑客。
如果你的服务器也挂了哪吒探针,建议立刻执行以下操作:
用了哪吒探针的,赶紧去排查一下手里的小鸡吧,最后祝大家的服务器都能平平安安!毕竟服务器运维上,方便虽然也是追求之一,但安全永远是最重要的。
本文 哪吒探针爆致命漏洞(CVE-2026-53519)大批 MJJ 中招!探针就该老老实实做监测好不 最初发表于 秋风于渭水。
2026-06-11 18:01:29
在日常使用浏览器时,我习惯让浏览器自动固定标签页以保持特定页面常驻浏览器,比如用于获取资讯的 RSS 阅读器、监控网页变化的扩展程序,以及日常使用的 Gmail 和工作上必不可少的 OA 系统。然而,原生 Chrome 固定标签页的缺点极其明显:要么容易因快捷键误触导致标签页被“秒关”且无法自动恢复,要么在多窗口或浏览器崩溃重启时无脑重复打开,带来极其蛋疼的体验。
虽然可以把标签页缩小固定在左侧,但一不留神就会误关闭。如果是一般网页还好,浏览器会要求连按两次 Ctrl + W 才能关闭被固定的页面;但对于扩展程序的运行页,只需要按一次 Ctrl + W 就会被无情关闭。再加上我使用了 chrome++ 设置了“双击左键关闭标签页”,误触发关闭的几率直线飙升。此外,固定的标签页在浏览器界面中占用的面积非常小,经常让人无法及时察觉它已被误关。更糟糕的是,有时候浏览器一旦崩溃,所有的固定状态就会荡然无存,不得不手动重新一个个找回并重新固定。
如果设置了启动时自动打开一组网页,弊端同样明显:一旦开启多个新的浏览器窗口,或者在浏览器崩溃后重启时,经常会触发重复加载,导致左侧塞满了一堆一模一样的冗余标签页。我不得不手动一个个去关闭,非常影响日常的使用体验。
面对这些痛点,我的第一反应是寻找现有的解决方案。我一边自己搜索,一边向 AI 求助,在 Chrome 应用商店和 GitHub 上下载了多款扩展进行试用。
然而结果却让人大失所望:市面上的现有工具,要么功能残缺、无法完全满足需求;要么依然停留在即将被淘汰的 Manifest V2 协议,未来随时可能失效;要么就走向了另一个极端——功能繁杂、体积庞大。我其实仅仅需要一个“在后台定时检查并自动拉起被关闭标签页”的简单功能,如果为此去安装一个集成了广告、追踪代码、主题美化、甚至 AI 工作台等一堆捆绑功能的“巨无霸”扩展,严重违背了我的软件哲学:“一款工具最好只专注于做好一件事”。更让人难以接受的是,某些扩展体积臃肿也就罢了,居然还把如此基础的功能列为收费项目,甚至张口就要几十美刀。
既然现成的方案都不尽如人意,且核心逻辑并不算太复杂,那不如自己动手,写一个最纯净、最符合自己需求的工具。
这就是 Smart Tab Pinner 的由来。它是一款专注于浏览器标签页状态维护、100% 本地运行、无任何臃肿依赖的轻量级扩展程序。它原生支持 Manifest V3 协议,在可预见的未来里绝对不会因协议过期而“翻车”。
其实这款扩展我自己已经在日常使用了长达一年之久。经历了多个版本的迭代与打磨后,它现在已经变成了一个非常成熟且稳定的工具。前段时间,有了将那款主打“去 B 站首页推荐算法” 扩展 「TabulaBili-Plus」 成功上架的经验,我决定将「Smart Tab Pinner」也正式开源并提交到 Chrome 应用商店,分享给有同样困扰的朋友。
setInterval定时器在后台闲置时会自动失效。为此,「Smart Tab Pinner」在改为基于 MV3 Service Worker 的持久化设计,利用官方文档推荐的 chrome.alarms API 来替代传统的定时器,从而完美解决了轮询形式的扩展在后台容易休眠的陈年老疾,确保扩展能在后台默默无感且稳定地运行。
具体来说,扩展会在后台定期检查:如果发现用户设定的标签页根本没有被打开,则会自动创建;如果发现匹配的标签页已经打开、但因为误触丢失了固定状态(如果用户勾选了固定选项),扩展绝对不会无脑重复新建,而是会通过 chrome.tabs.update 智能识别最匹配表达式的那一个标签页,直接将其“Up”恢复为固定状态,尽可能解决标签页重复打开的问题。
支持模糊匹配与扩展协议
支持谷歌官方标准的 URL 匹配表达式(例如 https://mail.google.com/*),一个通配符即可完美匹配整个站点的所有子页面。同时,为了满足更极客的需求,它还完美兼容了 chrome-extension:// 协议。也就是说,它甚至可以用来守护其他本地扩展的运行页或设置页(就像前边提到的那样,有些还在用传统的 setInterval 定时器的扩展,需要至少保持打开一个自身页面,以防其内部定时任务失效)。
带沙盒特性的“立即检查”测试
秉承“先测试、后持久化”的原则,我设计了一个“立即检查”按钮。用户在输入框里写完新的配置后,不需要急着点击添加或保存,只需点击“立即检查”,前端就会把这条临时配置发送给后台进行沙盒试运行。只有当用户测试成功、符合预期后,再放心地点击保存,安全感拉满。
极简的交互逻辑
对于已经存在的配置项,点击「修改」按钮后,会自动将现有设置同步至输入区域。用户调整完毕后,只需点击高亮的「确认修改」即可一键保存,完全不需要繁琐地“先删除再重新配置”。
a. 在线安装
1. 「点击一键安装」 或者在 Chrome 应用商店搜索 Smart-Tab-Pinner。
2. 像安装普通扩展程序那样,点击“添加至 Chrome”即可。
b. 本地安装
1. 前往项目的 「GitHub 仓库」,在 Releases 中下载最新版的 smart-tab-pinner-v*.zip 压缩包。
2. 将下载好的压缩包解压到你喜欢的本地目录。
3. 打开 Chrome 浏览器,在地址栏输入 chrome://extensions/ 访问扩展程序管理页。
4. 开启页面右上角的 “开发者模式” 开关。
5. 点击左上角的 “加载已解压的扩展程序”,选择你刚刚解压的本地文件夹,即可完成安装。
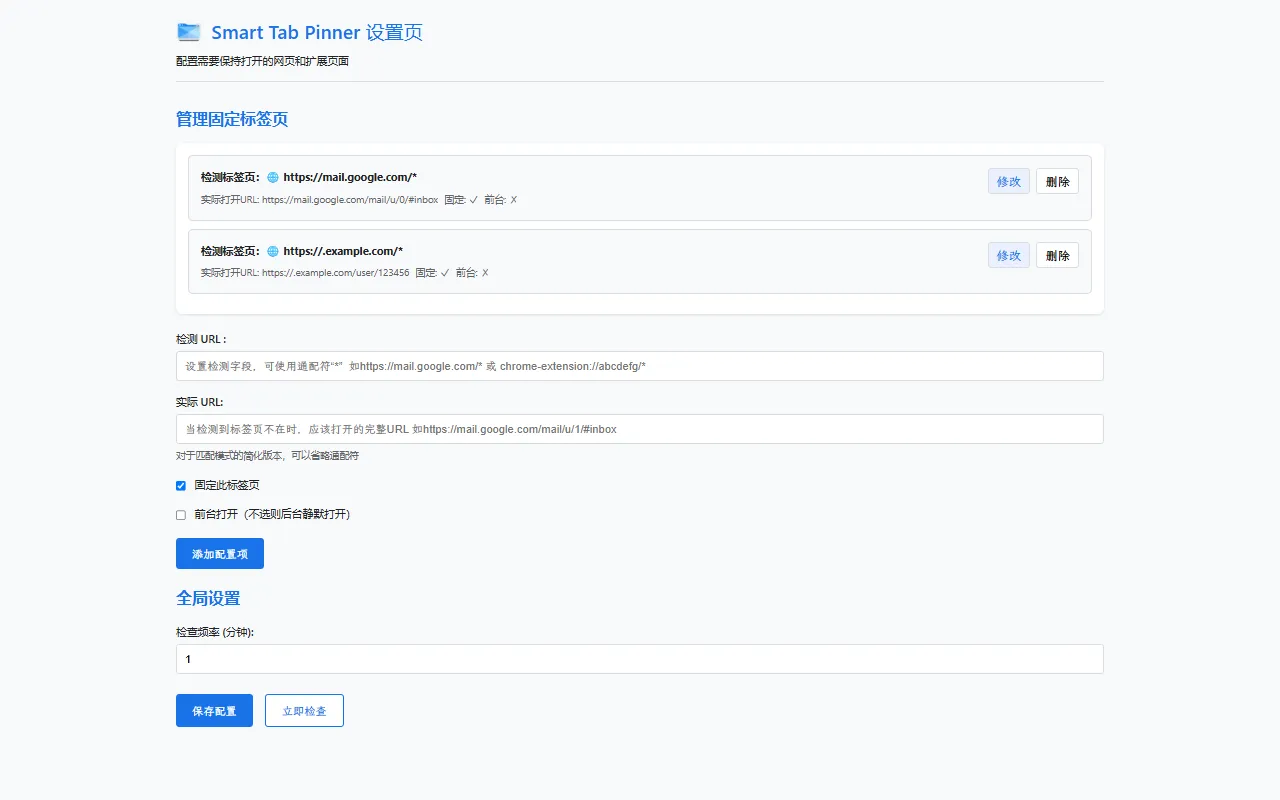
安装完成后,点击浏览器右上角的扩展图标,即可进入直观的设置页:
https://mail.google.com/* 或 chrome-extension://deomglgnplnflcbljmehpafdnhdklcep/*)。https://mail.google.com/mail/u/0/#inbox 或 chrome-extension://deomglgnplnflcbljmehpafdnhdklcep/index.html#/)。配置完成后,点击“保存配置”,扩展便会开始在后台默默监视标签页的打开状态。
如果你也和我一样,正在寻找一款纯净、克制、好用的 Chrome 标签页管理扩展,不妨去试试这款 Smart Tab Pinner。觉得好用的话,顺手在商店给个五星好评,或者在 GitHub 上给我点个 Star 鼓励一下,这也是我持续更新的最大动力!
本文 我写了个 Chrome 扩展「Smart Tab Pinner」解决标签页总被误关的问题 最初发表于 秋风于渭水。
2026-06-06 11:06:40
早上习惯性刷 RSS 订阅,看到了宗宗酱发的一篇提醒:你的RSS订阅源有跳菠菜的风险
心里一惊,赶紧翻开自己博客的 Feed 页面扫了一眼。果不其然,根标签里赫然躺着这一行:
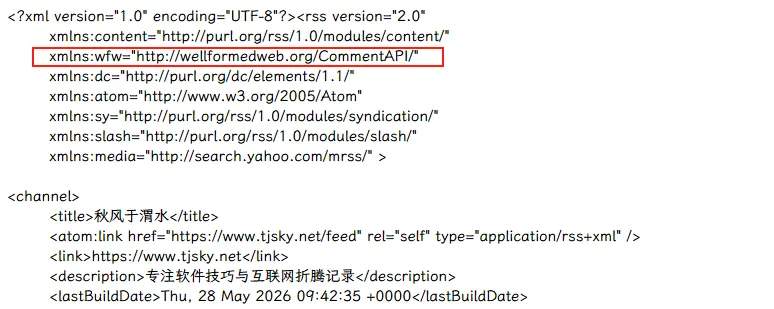
wellformedweb.org:黑产是如何盯上 WordPress Feed 的因为是个历史包袱,我就不细说了,你只要知道这个东西是上古时期用来“让读者在RSS阅读器里,能给博客发表评论”用的就行了,这是 RSS 规范的一部分,但这玩意对垃圾评论的防御力几乎是零,所以在十多年前就已经被时代无情淘汰,但没办法啊,为了绝对的向后兼容, WordPress 依然将这行代码原封不动地保留至今。。
最近 wellformedweb.org 域名过期了,就被黑产团伙抢注了。虽然 WordPress 只是把它写在“XML 命名空间”里,WordPress 本身在生成 Feed 时,绝对不会去这个网址下载任何代码。正常 RSS 阅读器也不会去访问这个网址,除非有人直接看你的 Feed 源码,然后手动去点这个网址(能不能点开都两说,毕竟正常情况下此处并不会被渲染为超链接)。
但是云服务商、网管部门、第三方安全插件会无差别提取页面内的所有 URL 链接(哪怕它只是个 xmlns 命名空间里的字符串),这一扫,就发现这个 URL 指向了一个博彩网站,搞不好就直接判定你的网站“包含低俗、赌博等违规内容”,进而触发自动化报警,轻则发邮件警告让你限期整改,重则直接判定违规封禁主域名或IP。
以及不排除未来这个 URL 会进入全球恶意欺诈黑名单,这会导致有些阅读器或者开启了严格安全保护的浏览器,因为探测到你的订阅源含有这个URL,直接给访客弹个“该网站包含危险欺诈内容”的红色标签页警告,这不是纯纯的无妄之灾嘛,所以这行代码最好还是尽早删掉。
看了看网上给出的普遍解法,都是让人“直接去修改 wp-includes/Feed-rss2.php 文件,删掉这一行”。
这就有点不够优雅了,动系统文件向来是慎之又慎的事情。一个不小心直接改炸了不说,而且一旦 WordPress 升级,修改搞不好就被直接覆盖了,属于治标不治本。
那既然不打算动核心文件,那就只能考虑动态移除。最显而易见的修改方案有两个:
所以我决定用 PHP 搞定问题。跑去问了下 AI 这个标签的钩子是啥。结果 AI 一摊手:硬编码,没钩子。
啊,这……行吧,既然你不给钩子,那就别怪我直接对输出缓冲区下手了。
在 Code Snippets 插件中新建一个代码段(选择在所有位置运行),或者写到你当前主题的 functions.php 文件中也行。利用 PHP 的 ob_start 在页面渲染完成、输出前的最后一刻,把这个 URL 给滤掉。
PS:更新,经评论区提醒,WordPress不仅会在 RSS 订阅源开头声明 wfw ,在后面每篇文章的结尾还有生成RSS评论区的代码:<wfw:commentRss>https://XXXXXX/feed</wfw:commentRss>。这部分也需要同步去除,不然只移除开头的命名空间,而不移除每篇文章的RSS评论区。 RSS 阅读器会一脸雾水,哪来的wfw啊,导致报错。
代码如下:
/**
* 移除 WordPress RSS2 中的 CommentAPI 命名空间及相关标签
*/
add_action('template_redirect', 'perfect_clean_rss2_buffer', 0);
function perfect_clean_rss2_buffer() {
// 仅对 RSS2 订阅源生效
if (is_feed('rss2')) {
ob_start('rss2_namespace_cleaner');
}
}
function rss2_namespace_cleaner($buffer) {
// 1. 匹配并移除开头的命名空间声明
$search_pattern = '/xmlns:wfw="http:\/\/wellformedweb\.org\/CommentAPI\/?"\s*/i';
$buffer = preg_replace($search_pattern, '', $buffer);
// 2. 匹配并移除每篇文章下的 <wfw:commentRss> 标签
$comment_pattern = '/<wfw:commentRss>.*?<\/wfw:commentRss>\s*/i';
$buffer = preg_replace($comment_pattern, '', $buffer);
return $buffer;
}
小提示:保存并启用代码后,如果刷新页面没变化,八成是有什么东西给你的Feed做了缓存,记得去后台刷新一下你的站点缓存
如果你不想动 PHP,且你的 Nginx 编译了 sub_filter 模块,也可以直接在 Nginx 配置文件中加入以下规则动态替换:(让AI写的,我没实际测试过)
location ~* /Feed/?$ {
sub_filter '' '';
sub_filter_once off;
sub_filter_types application/rss+xml text/xml;
try_files $uri $uri/ /index.php?$args;
}
不得不感叹一句,最近黑产真的越来越钟情于这种“历史遗留域名过期被恶意抢注(内容劫持)”的连带攻击方式了。
他们利用了对老域名的盲目信任,不需要入侵你的服务器,就能白嫖全球无数独立博客的连带流量和权重,不可谓不鸡贼。在 WordPress 官方正式移除这行代码之前,建议各位站长,赶紧去排查并手动移除自己的 /feed 隐患