2026-07-27 03:00:00
I spent last week at a summer music camp put on by WCAMS, the West Coast Amateur Musicians Society, pronounced “Wickams”. My goal in writing this is to influence a few readers in the direction of attending this sort of thing if there’s one near you. You might be a candidate if you partake of some subset of: Loving music, getting old, being female, worrying about mental fitness, and having time available to invest as you please rather than as you must.

250 attendees, a couple of dozen faculty (all professional musicians), a lovely waterfront venue at a swanky boarding school campus in an isolated small town. The picture above is the cover of the camp booklet.

On the way to the camp.

This space, while the camp is running,
usually contains at least one person
or group emitting
music.
Let me should expand on that list above.
If you love music, there are multiple concerts per day, some quickies by whoever wants to between sessions, some highly polished offerings from the faculty. They all offer pure sound; unamplified and in music-friendly spaces. The volume and balance and tone are achieved by the performers’ technique and love, nothing is digitized or amplified.
Then there are the concerts you’ll be practicing for and playing in.
The most common hair color was gray. I mean, there were kids and teens and thirtysomethings, but I’d say more than half the people were at least semi-retired. Not sure why, but it may have to do with retirees having spare time and no childcare duties, and music having been more widely taught back when us Olds were kids, and the price, $1300 Canadian (about a thousand US) per person, bed and board and music all-in. The venue was a private boarding school, thus “bed and board” was of a school-dorm standard, clean and complete but very basic.
There were attendees who were unsteady on their feet and needed a golf-cart to get around and help on the stairs, but they could still play the hell out of their fiddle or trombone or whatever.
The place was a matriarchy. My small string ensemble had three men and ten women, my cello seminar eight and two. Don’t have a glib explanation except that music teachers were plentiful, and women are over-represented in the teaching professions. So, it’s a space where (I’m guessing of course) women are less likely to feel crowded out or bossed around.
As for mental fitness while aging, the research is in and it’s not subtle. Music, both listening and performing, is good for your mind/brain generally, and specifically reduces the risk of dementia.

For privacy reasons, we were all asked not to share photos from the camp in public, but I think this one is safe.
I found the choice of tunes contrarian; did not hear a single Mozart chestnut. I think this works because everyone at the place is musically literate and many are erudite; they’ve heard enough Mozart classics. Let me sort the choices. One basket: Works written in the attendees’ lifetimes, including a lot of female composers and Canadian stuff. Another: Oddments from the back pages of the usual titans, for example Beethoven’s Septet (his first big hit, he came to hate it), and the graceful but weird second movement of Stravinsky’s Concerto in D. Another: Popular-music classics arranged for acoustic instruments. I heard (and will have more to say about) Bohemian Rhapsody for woodwind quintet, Cohen’s Hallelujah for seven violas, and the Cowboy Junkies’ Cold Tea Blues for four female voices and ukulele.
The big final choir-and-orchestra blowout, with 110 people on stage, was Brahms’ Schicksalslied, which I bet almost none of the people reading this have ever heard of (I hadn’t).
And also Bach. Because of course.
You join as many ensembles as you care to. Most people will find themselves in one chamber group or another, an orchestra or choir, and some sideline track like for instance, Early Music, Celtic, or Vocal Jazz. The organizers try to get the music mailed out a few weeks before the camp, but some lags and some only arrives when you hit the first session on Monday. You get five hours of rehearsal and then you perform it on Friday night or Saturday.
Obviously this calls for quite a bit of practice; there’s plenty of space for that. As you walk from wherever to wherever around the joint, you always hear the call of some instrument or voice, often running repeatedly through a tricky bit. Noobs join as many groups as they can fit in the schedule. Veterans have learned to dial it back a bit; I took their advice, signed up for only five tracks and performed only twice.
All this is a pretty fucking intense experience, let me tell you. And here’s what I’ll take away: The radiant and heartfelt smile on the face of nearly every musician when they finish their performance. And basically every piece gets thunderous applause, with hollering. Usually but not always deserved.
I am not particularly gifted at music. I’m old and have pursued the cello on and off since I was a kid, with much more off than on and multiple no-cello decades. What happened was, my wife Lauren is a gifted singer with a powerful soprano who enjoys participating in choral music. Her choir buddies have been encouraging her to come to WCAMS for years. I wanted to support her and it sounded like fun, so I ended a 25-year gap and started cello lessons again last October. It’s been painful clawing my way back toward my previous level of skill, which was never that great. But WCAMS makes it clear that beginners are welcome, will be encouraged and supported. So we signed up.
Anyhow, my cello skills were solidly in the bottom quartile of the couple of dozen cellists in attendance. Which was humbling but not a problem actually, because of that encouragement and support I just mentioned.
But during that 25-year cello gap I took up the study of West-African and Afro-Cuban drumming, with weekly lessons, and then for the last year or so, regular participation in a multi-hour by-invitation-only weekly drum jam. Judging one’s own talents is tough, but I seem to get musically further with less work on the drumming side. I even get the occasional spontaneous compliment that isn’t just politeness; something that has rarely-to-never happened in my cello career. So I see drums as my primary musical hobby.
But WCAMS doesn’t have an African-music group; thus my cello lessons. Then when we got the initial program I spotted the Celtic track, and I know that music comes with drums.

So, without asking anyone whether it was a good idea, the week before the camp I rented a bodhrán. It came with a “how to play” DVD that I watched all of, then I went and typed “bodhrán practice music” into YouTube and of course there’s plenty. After a few hours I was confident that I could keep up if they didn’t go too fast (they didn’t). It’s pretty easy to play even though the actual strike-the-drum motion is eccentric, unlike any other percussion instrument of my acquaintance.
I should mention that “bodhrán” is pronounced with the “dh” silent, “bo” as in “bother” and “rán” as in “roan”.
At the opening-night gathering, I tracked down Amy, the Celtic-track leader, and asked if it would be OK if I showed up with the drum. She was welcoming (everyone at WCAMS seems permanently welcoming). When we struck up the first tune at the beginning of our Monday gathering, she looked a little nervous but when I joined in she nodded emphatically; it turned out the last time a fresh face equipped with a bodhrán had turned up, they couldn’t actually find or stay with the beat.
Anyhow, I joined Amy’s Beginner and Advanced classes, learned a whole lot about Celtic music (starting from zero helps), and had more fun than ought to be legal. Got unsolicited compliments. Our performance was at the wind-up party after the big final Brahmstravaganza, and the crowd yelled and whistled, dancing broke out. I was full of joy — I think the whole band was. I’ll never forget it.
Here are the ones that I can still hear when I think back on them.
The woodwind quintet (who came to camp together as a group) played Bohemian Rhapsody on that little waterfront auditorium in the picture above. The arrangement was respectful and skilful and it highlighted what a wonderful, complex, piece of music that is. 100% by Freddy Mercury, who we all think of as Queen’s muscle, but this is a masterpiece by one of the last century’s top composers, any genre.
Arvo Pärt’s Spiegel in Spiegel by faculty cellist Marina Hasselberg and percussion pro Greg Samek, the latter on vibraphone. Exquisite, the notes suspended in space like rays of light.
Krunk, an Armenian folk song full of tragedy, on solo flute. Impossible to keep your eyes dry.
A Ukrainian song, lyrics by Shevchenko (there are lots, not sure which) delivered by Eric Hominick, a great singer and pianist who is about to retire from the West to East coast, and will be much missed.
Pride of Petravore is a hornpipe, the song that the awesome Amy Stephen used to launch the Celtic-music track. She projected the music on the whiteboard but wouldn’t make a print-out, insisting that we learn it so that when we opened our set we’d be focused on the music not the notes. It’s the song that Amy used to teach me I could get along on bodhrán.
I’ll be honest, I’ve always liked Irish-traditional music, have even been lucky enough to hear it in its natural habitat, a rundown pub in a remote corner of Ireland. But I’d never actually thought about it much. Now I have, and it’s deeper and stranger than I’d imagined. I’m pretty sure I’ll be investing time in it.
I really hope I get a chance to learn from Amy again, one way or another.
D.I.D. Choi is a young Canadian composer who, in his twenties, is off in LA, working on music for films and games and so on. His Remembrance, written in 2019, played by a wind ensemble, created a cloud of music magic in the air over the stage. I found my eyes closed, better to take it in. I’m going to suggest if you notice a concert anywhere near you with something by Choi, run don’t walk to the ticket booth.
I already mentioned the Cowboy Junkies’ Cold Tea Blues and it’s the one that hit me the hardest. The four singers had lovely light voices, the ukulele swung gracefully, and they did a bit of gentle choreography. The harmonies were fabulous. Anyone who’s heard this (and you can guess from the title) knows it’s not a happy song, but they shuffled that under the covers, casting a spell of light-hearted romance. Then when they planted the cruel razor sharp-hook at the end of the line of lyrics they’d been dangling so invitingly, there were audible gasps and cries of sorrow from the crowd. Never experienced anything like it.
I’m old, but this is the music my parents listened to. I’d always thought of it as boring fuddy-duddy stuff. That was, until I got in a theater with good acoustics and a live 20-piece brass band. This stuff is loud and aggressive at a level that approaches Rock&roll, the arrangements are better, and the tunes are strong.
The way it works is, the different horn sections hand the melody and chorus back and forth, never the same twice, then somebody stands up and plays a solo, a pre-assigned number of bars. There was this one solo by a young trombonist that pretty well melted my mind. I wonder if this stuff retains any commercial viability, as in, is there somewhere I can go out and see it?
Earlier today I bought the rental bodhrán, it’s a basic model and was pretty cheap. I think it’s full of happiness.
2026-07-11 03:00:00
This summer has been very sporting; in the course of a couple of weeks I attended a World Cup match and a minor-league baseball game. Took pictures and thought about enjoying this stuff.
I know that a whole lot of people, including not a few among my online audience, see neither joy nor virtue in fandom. That’s an attitude they’re entitled to have assuming they realize the absence of joy is a them thing.
After joy there’s virtue. Yes, organized professional sport raises serious ethical issues. That’s putting it politely. Many-to-most branches of commercial sport are rife with exploitation, oppression, and corruption. I’m not going to push back, and in fact I sometimes feel guilty about enjoying the spectacle as much as I do.
More to come on that.
I’m not going to re-tell the tales of galaxy-scale corruption, the ostentatious displays of wealth and privilege, and the cozying-up to dictators, both real and wannabe. Attending the 2026 World Cup gave me more reasons to hate; in particular the ticket-buying experience.
I have always loved fútbol generally and the World Cup in particular, as witness the plentiful digital ink I’ve spilled on the subject here on the blog. So when we learned that there were going to be games in Vancouver, I determined that I’d attend one. It was obvious they’d be popular so I decided to pounce on the first opportunity. Which is how I ended up buying (no, really) an NFT.
FIFA’s first round of sales wasn’t tickets, but NFTs, some of which came in packages that included a right to buy tickets for a game, participants unknown. Here — the first and I fervently hope the last time I link to an NFT — is part of the package. Can’t show you the right-to-buy NFT because I had to “burn it” to turn it into tickets.
Neither the NFT nor the tickets were cheap; my son and I attending that game cost well over a thousand (Canadian) bucks. (At this point, other attendees are scoffing at me for having paid so little.) For what it’s worth, the seats were good.
And let’s further enhance our basket of reasons to hate FIFA by noting that the ticket prices exclude everyone who’s not a member of a very privileged demographic.
It was Egypt vs New Zealand, played at Vancouver’s “BC Place” stadium on June 21st.

The march-in ceremonies.

New Zealand kicks off.
Confession: My son and I had a blast, can’t think of it without smiling. Most of downtown Vancouver had become a swirl of happiness, people dressed up in all sorts of fanciful outfits, singing, chanting, drinking, dancing, photographing. I particularly liked the pharaoh’s-headdress the Egypt fans were wearing.
The game was great fun — watch the highlights. NZ played better than their international rating would suggest and we got to watch Mo Salah carve his way into the defense and put away a lethal strike.
There were way more fans from Egypt than from NZ, but the Kiwis had better-organized cheering; they’ve figured out how to set the syllables of “Aotearoa” to the Seven Nation Army riff, and does it ever sound great.
And, while FIFA are assholes, those assholes really know how to run a tournament. They had sold out BC Place to the last seat, but never for a moment did I feel scarily crowded. I even managed to grab a decent beer and sandwich at half-time without feeling crushed or catching Covid; it helped that I masked up.
I’ve watched a lot of the tournament on TV and enjoyed it. The games, to be frank, have become less and less interesting as the idiosyncratic minor players (in particular the non-European ones) get eliminated by the better-funded Euros with their crushingly-precise and often-boring game. It would’ve been nice if the final four included an outsider.
And if you can set that FIFA issue aside, at some level it’s a beautiful thing; nations competing against each other in a framework built on raw aggression, physical virtuosity, disciplined teamwork, and kicking a ball around.
It could be done and it’d be politically popular. The nations of the world get together, dissolve FIFA on the evidence of its many sins, and run the tourney on some sort of co-op basis. They could slash most of the ticket prices and there’d still be buckets of money to go around to the national associations and some selected charities, based on the sponsorships and TV rights. Some of it would go to peacekeeping and Doctors Without Borders.
I can dream.
(One says “football match” and “baseball game”. Sounds wrong the other way around. Yay English.)
It was my son’s birthday so nine of us went off to watch the Vancouver Canadians host the Eugene Emeralds in what’s called the “High-A” minor league. Oh my goodness, you can actually watch video of the whole game. I don’t recommend it. The tickets for nine, decent seats, cost $276 all in.

It was an OK game. Vancouver leapt to an early lead, then the pitching collapsed and the Emeralds got 12 runs; the home team brought it back to within three by game’s end.
But, what a happy place! Kids everywhere, dressed in hot-dog condiments and pop stains. Snuggling couples. Beer vendors. Hollering hosers.
Since, in baseball, nothing is happening most of the time, the emphasis is on chit-chat and eating and drinking and people-watching. I noticed that when I wasn’t talking I was usually smiling.
This happened: My son’s partner, let’s call them “X”, is of East-Asian extraction — a Richmond kid, for the Vancouver-savvy. Born here, perfectly Canadian, but sports-oblivious and had never been to a ball game. When the seventh-inning stretch came along, I tapped X’s shoulder and said “time to get up and sing”. The crowd charged lustily into Take me out to the ball game, and X’s face got this absolutely hilarious I’m-on-an-alien-planet look. Later, X told me “That’s the whitest thing I’ve ever seen.”
After the game, fireworks. They were pretty minor-league.
I have a bit of back story. While working at Sun and then for AWS, I helped MLB evaluate and use various bits of Internet technology. Of all the world’s sports organizations, MLB is apparently the leader in using the Net to promote and deliver their product. Plus the people I worked with were nice and highly competent. It was one of the highlights of my career.
You will have noticed an absence of the sort of ranting that FIFA provoked above. Does this mean that the MLB organization is honorable and nice? Not at all. They are a gaggle of billionaires with an explicit grant of monopoly privileges in the USA.
The Vancouver Canadians are the only surviving minor-league team in Canada; MLB has shut down many minor-league teams because while they make people happy they don’t make much money. Baseball is a big business and, just like any other big business these days, often acts in ways that most people would consider unethical.
There’s what looks like a really good book about all this, Homestand: Small Town Baseball and the Fight for the Soul of America by Will Bardenwerper. I haven’t read it yet, but you can get the gist in this conversation between Bardenwerper and Chris Arnade.
…not baseball, nor fútbol, it’s late-stage capitalism, which reliably makes anything it gets its hands on worse. If we don’t like the way those guys behave, and in particular if we think some of it should be illegal (it should!) that’s a political problem that has to be addressed with politics. Feels like it would be a pretty popular party platform plank.
I’m not one who’ll preach “no ethical consumption under capitalism” at you, but I don’t have a good come-back when someone challenges me on sending money to the FIFA or MLB scum. Is there anyone reading this who is entirely comfortable with all the places and practices that bring them enjoyment?
The worlds of business and politics never contain a sentence that’s unscripted or incautious. The substrate of trust that a society needs to function is today weakened and still weakening. There’s a pervasive belief that what’s on our screen is at least in part self-interested untruth or, put another way, marketing. I often think of this as “The LinkedIn pathology”.
Not out on the field. When Mo Salah’s got the ball at his feet and charges at the NZ back line, nobody in the world knows what’s going to happen in the next few seconds. When the Canadians’ pitcher walks in the fifth run of the inning, nobody can tell which way his search for the strike zone will turn.
It’s unpackaged, unvarnished, and unedited. It’s physical truth, being created in real time.
Put another way: Live unscripted improvised drama. It’s not like anything else in most people’s lives; the only thing I can think of that comes close is an instrumental break in a jam, whether that’s in your basement on a stage before thousands.
It thrills and entertains me. I make no apologies for that. I’d sure like to improve the societal basis that poisons it, and increasingly more and more aspects of our lives, so I don’t have to feel bad about being a fan.
In the meantime, 🎵Take me out to the ball game…🎵
2026-07-06 03:00:00
Dear World: Now is a good time to get off social media that’s going downhill. Where by “downhill” I mean any combination of less useful, less safe, or less fun. It’s time for something better, and by “something better” I mean Mastodon. Which, I’m here to say, offers a better social-media experience than the alternatives. Furthermore, the alternatives are fatally flawed.
By “Mastodon” I mean the many servers, mostly (but not all) running the Mastodon software, that communicate using the ActivityPub protocol. Now I’ll try to convince you to start using one of them.
[I posted an earlier version of this essay called Time To Migrate last year, but enough things have changed that it’s worthwhile revising and reposting.]
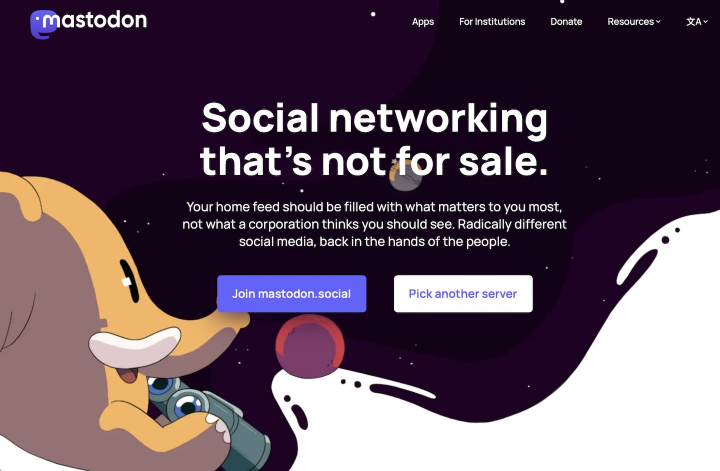
Start at joinmastodon.org
Have you noticed that social-media products, in the long term, seem inevitably to enshittify? I have. But there’s a major exception, a tool that’s been serving billions of us for decades, and works about as well as it ever did. I’m talking about email.
Why does email stay reasonably healthy? Because nobody owns it. Anyone on any server can communicate with anyone else on any other. Nobody can buy it and make it a vehicle for their politics. Nobody can crank up the ads or make things worse to improve their profit margin.
Mastodon’s like email that way. Plus it does all the Post and Repost and Quote and Follow and Reply and Like and Block stuff that you’re used to, and there are thousands of servers. Anyone can run one and nobody can own the whole thing. It doesn’t have ads and it won’t. It’s dead easy to use and it’s fun and you should give it a try.
The rest of this essay goes into detail about why Mastodon is generally great and why the alternatives have little future. But if the pitch sounds good so far, stop reading, go get an account, and climb on board.
Along with that “can’t be owned” and “no ads” stuff, the software is getting really good, particularly in the last couple of releases. It’s got cool features you won’t find elsewhere, and there’s very little cool stuff from elsewhere that’s not here.
There was a time when newly-arrived people had confusing or unfriendly experiences, or missed features that were important to them. It looks to me like those days are over.
Mastodon is many thousands of servers, and you can join the biggest, mastodon.social, or shop around for another. But here’s the magic thing: If you end up disliking the server you’re on, or find a better one, you can migrate and take your followers with you! You can’t ever get locked in.
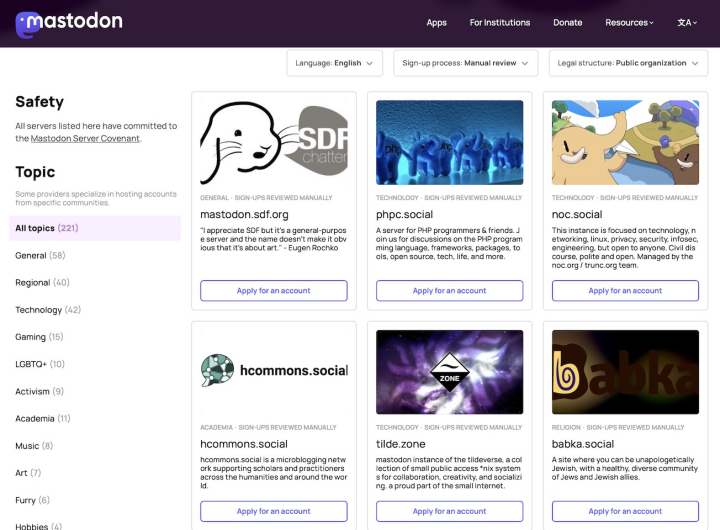
The server-selection menu has lots of options.
Migration is probably Mastodon’s most important feature. It’s why no billionaire can buy it and no corporation can enshittify it. As far as I know, Mastodon is the first widely-adopted social software ever to offer it.
You hear it over and over: “I had <a big number> of followers on Twitter and now I have <a less-big number> on Mastodon, but I get so much more conversation and interaction when I post here.”
One of the people you’ll hear that from is me. My follower count is a bit less than half the 45K I had on Twitter-that-was, but I get immensely more intelligent, friendly interaction than I ever got there. (And sometimes I get told firmly that I’m completely wrong, but hey.) It’s the best social-media experience I’ve ever had.
Dunno about you, but conversation and interaction seem like a big deal to me. One reason things are lively is…
Here’s an axiom: An ad-supported service can’t have sex-positive or explicit content. Advertisers simply won’t tolerate having their message appear beside NSFW images or Gay-Leatherman tales or exuberant trans-positivity. Mastodon has all that stuff.
Of course, you gotta be reasonable, posting anything actually illegal will get your ass perma-blocked and your account suspended. So will posting anything that’s NSFW etc without a “Content Warning”. That’s a built-in feature of Mastodon which puts a little warning (“#NSFW” and “#Lewd” are popular) above your post, which is tastefully blurred-out until whoever’s looking at it clicks on “Show content”. I use these all the time when I post about #baseball or #fútbol because a lot of the geeks and greens who follow me are pointedly uninterested in sports.
(Oh, typing that in reminds me that you can subscribe to hashtags on Mastodon: Let’s see, I currently subscribe to, among others, #Vancouver, #Murderbot, and #Fujifilm.)
The “Ivory for Mastodon” app for Apple platforms,
one of the many fine alternative clients.
Did I just mention, two paragraphs up, getting blocked? Mastodon isn’t free of griefers, but the tools to fight them are good and getting better.
The good news is that each server moderates its own members. There’s variation of the standards from server to server, but less than you’d think. Since there are thousands of servers, there are thousands of moderators, which is a lot.
If you act in a way that others find offensive, you’ll probably get blocked by the offended people and also reported; the report can come from any server and it’ll go to the moderators on yours. On a well-run server, those mods will have a look and if you’ve actually been bad, your post might get yanked and you might get warned, or in an extreme case, booted off.
(I’ve been reported for saying unkind things about Bibi Netanyahu and for posting too many photos of my cats (no, really) but that kind of thing is cheerfully ignored by good moderation teams.)
Then there’s Mastodon’s nuclear weapon: Defederation. Suppose you’re prone to nasty bigotry in public and you get reported a lot and your server’s moderators don’t rein you in. Eventually, word will get around, and if things aren’t cleaned up, most servers will defederate yours, so that nobody on their server can see posts from anyone on yours. Your site is no longer part of the “Fediverse”; this is a powerful incentive for server owners to take moderation seriously.
The effect is that the haters and scammers and Nazis who show up mostly get shuffled off-stage PDQ. Not always, unfortunately; a couple of years ago a wave of incoming Black people had bad experiences with racist abuse. Ouch. Is there anywhere in the world that a loud-voiced Black woman won’t provoke a chud eruption? [sigh]
But the good news is that recent Mastodon releases have been shutting prone-to-abuse channels down, so things are better than then and should continue to improve.
Corporate social-media services like to downrank posts with links. Which makes me want to scream, because my favorite thing to post is a link+reaction to something cool, and so are my favorite posts to read.
On Mastodon, when your post has a link, the software automatically fetches a preview of whatever you linked to and uses it to decorate the post. I mean, it’s the damn Internet, it only got interesting to non-geeks when we figured out how to turn millions of servers into a great big honking searchable hypertext.
Speaking of which, Mastodon search is pretty good these days. It’s become, just like this blog, part of my outboard memory, and I’m always typing things like “telephoto from:me has:media” into the search box. Fast enough, too.
Another good thing about Mastodon is that there is plenty of good client software to choose from, mostly open-source. The best ones are miles ahead of Xitter and Threads and Bluesky and, really, anything.
Anniversary post in the Android “Tusky” app.
There are official Web and mobile clients from the Mastodon team and they’re fine, especially for admin and moderation work. But iOS people should check out Ivory, Androiders should look at Tusky, and everyone should try Phanpy. I live in Phanpy on both my Mac and my Pixel — it’s a Web thing but installable as a PWA.
Commercial products, especially social-media services, have never been at peace with third-party clients. Twitter used to be, but then it stabbed those developers in the back. It’s easy to understand why; every product manager has it drilled into them that they must control the user experience. This ignores the ancient wisdom (I first heard it from Bill Joy) “Wherever you work, most of the smart people are somewhere else.”
Mastodon doesn’t have that kind of product manager, but it does have a fully-capable API, developed in the open and with no hidden or restricted features. Which means you’re going to get better clients.
The algorithms that commercial social-media services use to sort your feed have one goal only: Maximize engagement and thus revenue. They have no concern for quality or morality, and have been widely condemned by people who think about this stuff. So much so that there’s a feeling that Algorithms Are Bad.
Mastodon has an algorithm: Show the posts from the accounts you follow, latest first. It works pretty well. It also has “Trending” feeds of the most popular posts, hashtags, and links. I hit those once a day or so to get a feeling for what’s going on in the world.
The “Trending” display in Phanpy.
I do think there’s room for improvement here; Bluesky has shown off the idea of pluggable feed-ranking algorithms, with many to choose from, and I like it. No reason in principle we couldn’t have the same thing on Mastodon.
Every other social network has started with a big pot of money, whether from venture-capital investors (Twitter, Instagram, Bluesky) or from a Big Tech corporate parent (Google+, Threads). The people who provided that money want it back, plus a whole lot more. Thus, the manic drive for “engagement” and growth at all costs. They need to build huge data centers and employ an elite operations team plus an even more elite marketing group.
Mastodon, eh… a gaggle of nonprofits and co-ops and unincorporated affinity groups, financed by Patreon or low annual dues or Some Random Geek who likes running a server.
Since nobody owns it, nobody can extract a profit from it. Which means that from the big-money point of view, it’s entirely non-investable. The goal isn’t for anybody to make money, it’s to be instructive and intense and fun. It’s run on the cheap. You know what they call systems that are cheap and diversified? Resilient. Sustainable. Long-lived.
Last year I wrote: “Think of the Fediverse not as just one organism, but a population of mammals, scurrying around the ankles of the bigger and richer alternatives. And when those alternatives enshittify and fall, the Fediversians will still be there.” After “scurrying” I should have added “and evolving”.
I like the Bluesky people and their software and some of their ideas. But I don’t see it as a good long-term option, for two reasons. First, it’s not decentralized, in that it couldn’t survive if Bluesky Social PBC fell on bad times. Yes, I know about BlackSky (am a fan) and Eurosky (dunno enough yet) and they don’t change my opinion.
Second, I think it’s inevitable that Bluesky-the-company will indeed go sour. They have raised a total of $123M in venture-capital investments. The biggest chunk, $100M from Bain and friends, was signed in April 2025 but not disclosed until a year later. Why not, I wonder? Actually, I don’t wonder at all: Because they knew perfectly well that long-term survivors like me would be horrified.
You, see the people who coughed up all those millions didn’t do it out of pure love or idealism, they want Bluesky to become a money machine that emits a fountain of gold so they get a payback in the billions. Which, OK; that’s what Venture Capital is for. Except for, I see no evidence that Bluesky has anything resembling a business model. See the problem?
I see two possible outcomes: The company craters when the money runs out, or it builds a lucrative income stream, probably based on advertising. Which means we can expect to see the pathologies that make X and Facebook and friends so loathsome.
The only social-media option, I mean, that’s decentralized, not owned or controlled by anyone, and working well today as you read this. It’s intense and interactive and fun. Why settle for less?
(Disclosure: I have no formal connections with the Mastodon organization, aside from being a low-level supporter on Patreon.)
2026-06-15 03:00:00
It’s been a while. February was the last entry in this Quamina Diary; I never stopped working on it but there hasn’t been much blogworthy. This piece offers a progress update for those who’ve been entertained by Quamina, and also a pleasing (well, to me anyhow) dip into finite-automata theory and practice. With numbers and graphs and a bluesman!
Since it’s been so long, here’s what Quamina, a Go-language library, does: You can add “Patterns” to a Quamina instance, they match the values of fields in JSON objects, and then you show Quamina a JSON “Event” and it’ll tell you which Patterns matched it. It’s pleasingly fast and in many cases the speed is not strongly affected by the number of Patterns you’re trying to match.
The last release, V2.0.2 back in March, marked the arrival of a reasonably-full regular-expression dialect into Quamina’s
pattern language, so you can say, for example, that the Filename field has to match
map-[0-9]+.(png|pdf|jpe?g).
Regular expressions were a lot of work and a lot of fun.
Quamina works by compiling the Patterns into finite automata, then matching the Event fields by traversing them. To handle multiple Patterns, Quamina merges the automata together, a technique that’s been well-studied in Computer Science for decades. From a set-theoretic point of view it’s a union; an OR through Boolean lenses. There’s really no limit in theory for how many patterns you can merge, and Quamina has no problem at all with thousands.
There are two flavors of finite automata: Deterministic (DFAs) and Nondeterministic (NFAs). If you have a university degree in CS they probably made you study this at some point. Weirdly, many people find the subject boring.
I’m not going to explain the differences, if you want to know it’s easy to look up, and anyhow the story I want to tell doesn’t need it. Here’s what the story needs:
To implement wildcards and regular expressions, you need NFAs.
Matching data with DFAs is generally a whole lot faster than with NFAs.
There’s a well-known algorithm for transforming any NFA into a DFA that matches exactly the same data. It’s really a lovely algorithm, you want to tickle it under its adorable little chin.
In some cases, the algorithm can be brutally expensive, along the lines of O(2N).
I found a data file in the Wordle source code with 13K or so 5-letter words. I inserted a * at a random location
in each. To illustrate, here are the first five results: aah*ed, aalii*, *aargh,
aar*ti, and abaca*.
The benchmark is, you load these into a Quamina instance and measure how fast it is to load them, how much memory the merged NFA consumes, and how many Patterns per second you can match. Then you repeat the exercise, converting each NFA into a DFA.

I loaded 10K Patterns in NFA form, but the NFA-to-DFA conversion got so brutal my patience only allowed me to load and measure 300 in DFA form. (Which kind of gives away this article’s punchline but stick with me, the details are fun).
He was a famous bluesman and I need help from him to explain my APIs.
Quamina’s latest PR adds APIs
to turn the NFA-to-DFA conversion on and off; it’s off by default. There are two MatcherBuildMode values,
BuiltForComfort and BuiltForSpeed. Which are out-takes from Willie’s 1959 song Built For
Comfort, and the lyrics go like this:
Some people built like this, some people built like that,
The way I’m built, don’t you call me fat
Cause I’m built for comfort, I ain’t built for speed
…
Willie was a big guy, way over six feet and not exactly slender. I know this because I interviewed him once, but that’s another story. Lots of others have covered this tune, most of whom are, um, well-rounded.
Speaking of which… here is Quamina’s memory consumption in NFA mode.
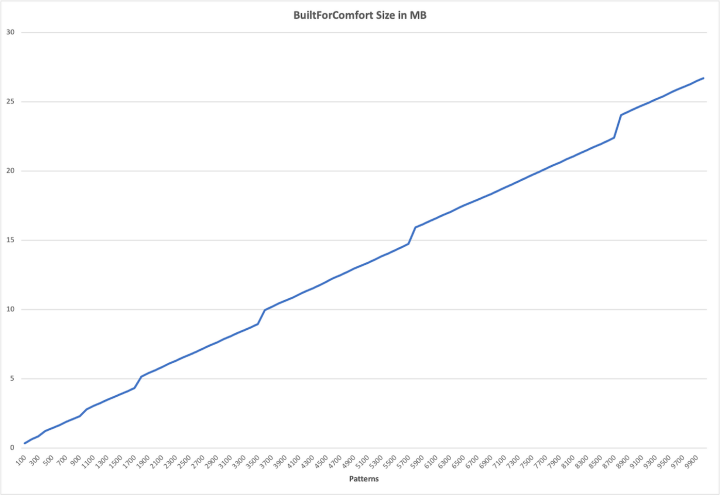
The memory cost is pretty well linear in the number of patterns. For 10K patterns Quamina uses something over 25M which feels kind of reasonable to me.
Here’s the story for DFAs.
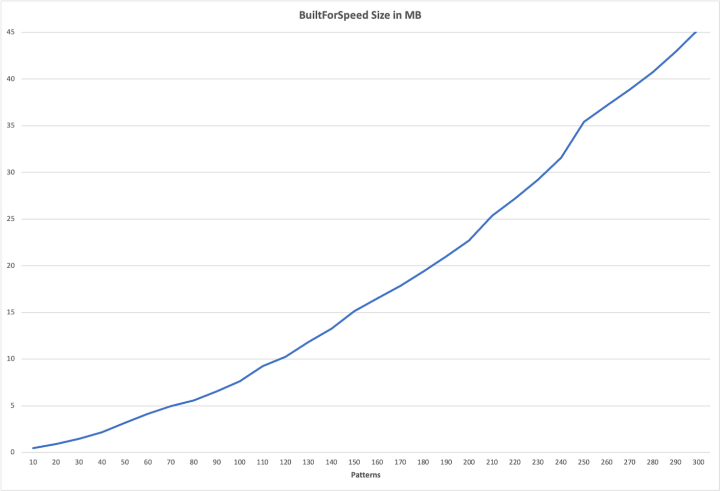
I haven’t run regressions or anything and I don’t think that’s actually O(2N), but the second
derivative is solidly positive, which in simple English means “doesn’t scale”.
Now let’s look at the Pattern-addition time for NFAs and then DFAs.
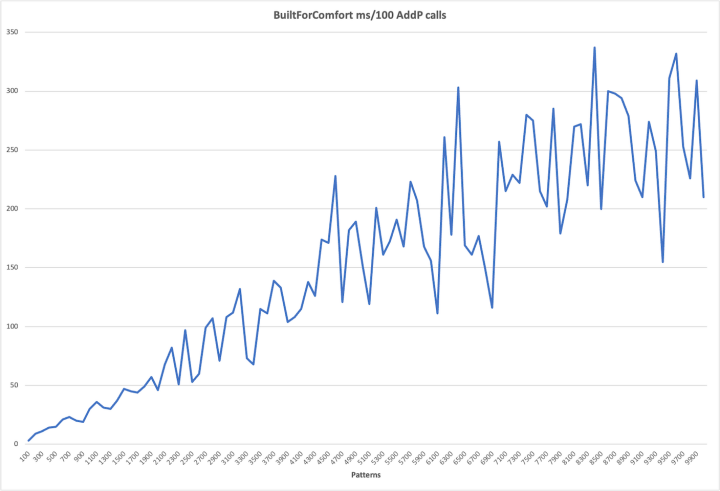
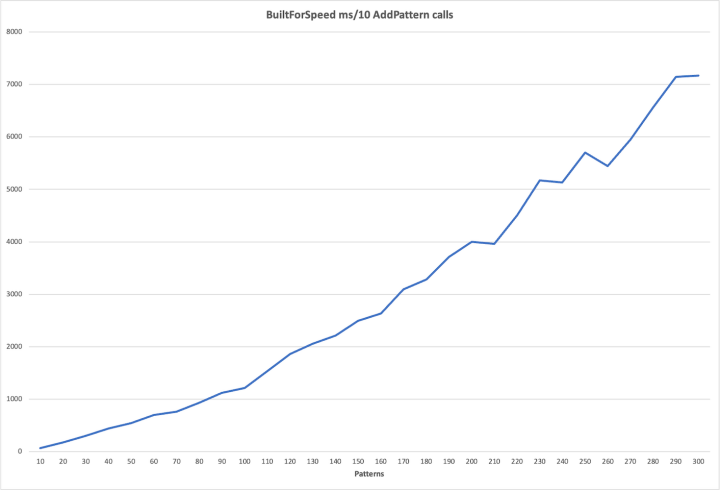
Once again, the NFA cost increases more or less linearly (albeit interestingly jagged), while for DFAs, look at that second derivative. This was what eventually made my patience give out and limit the DFA run to 300 Patterns.
Now let’s look at the payoff, the number of Event matches/second in NFA- and DFA-land.
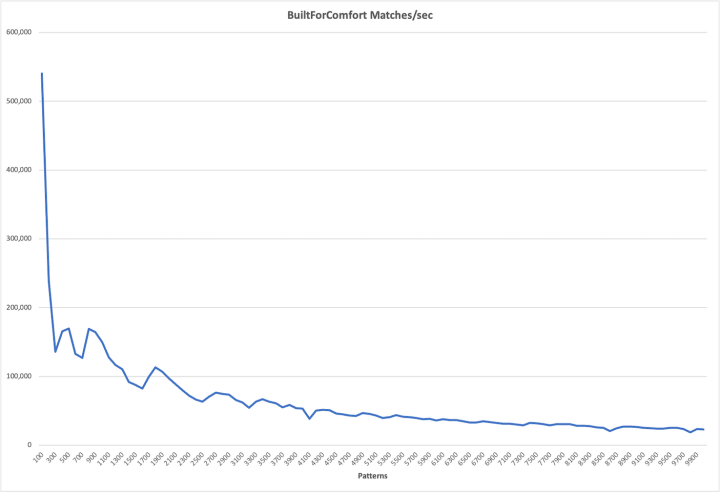
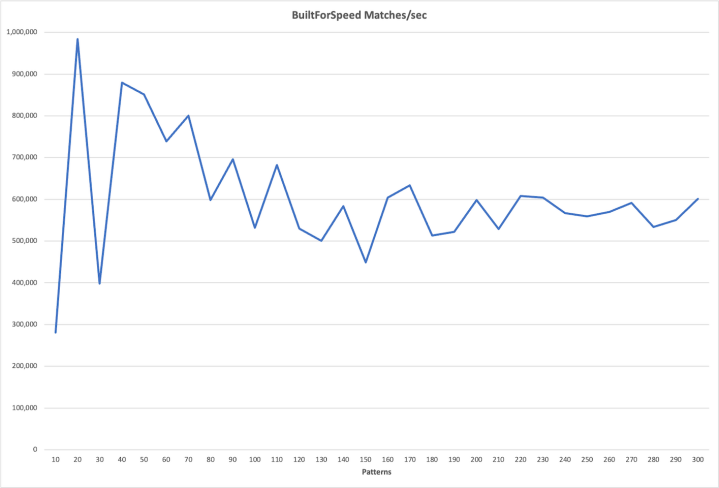
The NFA performance degrades at something like O(N-1), but DFAs just don’t care. After a few lurches
it rolls along at between 500 and 600K/second. Not bad, and based on experience with huge DFAs that were built from
exact string matches, my belief is that the matching speed would eventually drift down, but slowly, not remotely a linear
function of the number of Patterns.
It was maybe a little unfair to compare 10K NFAs against only 300 DFAs, so let’s focus in. (This is on a 2023 M2 MacBook Pro.)
| 300 Patterns | |||
|---|---|---|---|
| Memory | Add-Pattern time | Matches/sec | |
| NFAs | 860K | 0.1 ms | 222K |
| DFAs | 45M | 7.7 sec | 404K |
| 10K Patterns | |||
| NFAs | 27M | 2.3 ms | 21K |
That’s pretty shocking stuff. 10K NFAs occupy less memory than the DFAs equivalent to 300 NFAs. And the Add-Pattern time, which is totally dominated by the NFA-to-DFA logic, is getting into intractable territory. So why would anyone mess with the DFA conversion? Because it matches data twice as fast!
First, if you’re a normal human being and only matching a handful of patterns against a few Events/second, ignore all this and just take the defaults, Quamina latency will vanish in the static. If you’re matching lots of numeric and string values against many Events/second, don’t lose any sleep, keep on packing in the Patterns and Quamina probably won’t slow down enough for you to even notice.
In theory you’d eventually get into memory trouble but in my considerable experience with Quamina and its AWS-built predecessor Event Ruler, you have to be venturing into extreme-craziness territory for that to happen. (It did happen. An Amazon group added literally a million Patterns. It still ran way faster than anything else they could find.)
If you need to match wildcards or regexps, adding Patterns stops being free. The slowdown is roughly linear in the number of Patterns and isn’t actually terrible, see the data above. But if you’re using a relatively small number of regexp Patterns, go right ahead and turn on DFA conversion with “BuiltForSpeed” mode.
There’s one minor Quamina feature that’s disabled in BuiltForSpeed mode, so I’ll need to fix that and do a release.
I bet there are still low-hanging fruits that could speed up the Hell benchmark, but anyone looking for those should bear in mind that they’re fighting settled Computer Science, you’re never going to make NFA-to-DFA conversion reliably linear.
But to be honest, Quamina is starting to feel fairly feature-complete. I’d like to see a few adapters so you could use Quamina with Protobufs and Thrift and CBOR and other formats that aren’t JSON.
But in fact Quamina doesn’t have that many users; I’ve only heard from a handful. Who knows, maybe the problems you learn to solve when you’re working at AWS, and most of the groups think millions of events per seconds is an ordinary workload, aren’t widely applicable in the broader world of Open Source?
Which is to say, me working on Quamina isn’t helping that many people. At one level, I don’t care, because it’s been fun and instructive. I’d probably enjoy turning this “Quamina Diary” series into a monograph or small book if there were an interested publisher.
And thanks to everyone who’s been reading along.
2026-06-09 03:00:00
The piece you’re now looking at exists because my latest “Long Links” curation of interesting not-lightweight material included quite a few focused on our dominant malaise, namely you-know-what, I mean it’s in the title. Plenty of people have had more than enough of this discourse and I thought I’d spare them by moving these bits over here.
Let’s start with raw data: Is AI improving people’s lives? Christine Lemmer-Webber was kind enough to ask the world or at least the Mastodon part of it, and the results weren’t subtle or nuanced at all.
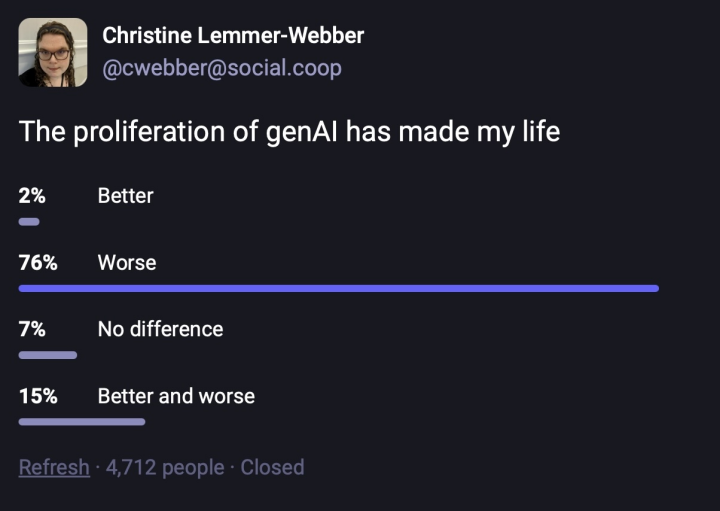
I encourage everyone to follow the link and read the conversation that broke out around that poll. It will not cheer you up.
And for my money that’s the most important take-away I’m offering today. Whether we’re using it or not, “AI” is not a thing that is making us happy.
Currently, I’m a contra. GenAI is being pushed by terrible people who are trafficking in lies and abusing the planet, and should their far-fetched dreams come true the consequences would be terrible for most people. Because they want to disempower knowledge workers, remove them from the economy, and cast them loose on the tender mercies of the market.
The reason for that “Currently” in the paragraph above is that we’re living in a liminal space where everybody I know who has any brains is convinced that there’s a bubble inflated by trillions of dollars of speculative and likely doomed investment. It’s very near popping, and the consequent miasma of fear and greed makes it absolutely impossible to have a reasonable discussion of what GenAI might be good for and might not.
The onrushing terrible trio of IPOs (SpaceX, OpenAI, Anthropic) feels to me like when there’s a 9.2 earthquake 50km offshore and so far no tsunami has been detected but everyone’s glancing nervously at the horizon.
So anyhow, for now I’m not going to use any GenAI tools myself. Post-pop, it may develop that there ways it can be ethical and useful, albeit at an immensely smaller scale than the LLM edgelords are pitching. We’ll see.
I have been accepting human-curated Claude-driven PRs on my Quamina hobby project. For which I’ve already been called a Nazi by someone whose views I take seriously. (But I really don’t think I am.) I do think that when the dust settles, there will be a role for LLMs in software development, but I also think we haven’t figured out yet what it is. I absolutely do not believe for a second the claims of 10x improvements in “productivity” (I do not think that word means what you think it means).
Having said all that, here are morsels of gold from the torrent of AI dross that wants to flood every fucking one of my input channels.
Bram Cohen says The Cult Of Vibe Coding Is Insane. Yup. Kyle Kingsbury writes a long sad series: The Future of Everything is Lies, I Guess. He seems to come out about where I do: Not going there for now.
Dr Bethan Tovey-Walsh offers us The Community is the Achievement; the Achievement is the Community, subtitled An ethical love-letter to distributed technology communities. It’s long and defies summarization, but light-hearted, a pleasant read. Its bottom line is, and I quote: “The right thing, in my view, for tech communities and projects to do is to reject contributions of LLM-generated content.” Recommended even if you disagree.
Wow, here’s one that hits hard, academic output from big-name universities: AI Assistance Reduces Persistence and Hurts Independent Performance. What’s shocking is that it doesn’t take that much AI exposure before the symptoms start appearing.
Corey Quinn’s day job is helping people lower their AWS bills, and he markets it (very successfully) by writing snark-heavy essays on more or less anything cloud-related generally and AWS-focused specifically. It seems he’s got a new AI-oriented platform called “Artificial Confidence”, whence Artificial Confidence: xAI, the Neocloud. Corey is a gifted polemicist and xAI is a soft target. It does not come off well. Since xAI is a major chunk of the looming SpaceX IPO, this piece is highly relevant, possibly to your retirement savings.
I know Appearing Productive in The Workplace was widely posted and quite likely you’ve seen it; if you haven’t, go read it and if you already have, another visit might be beneficial.
From the Linux-kernel world, there’s AI bug reports went from junk to legit overnight, says Linux kernel czar and Significant raise of reports, which says about the same thing with a couple of plausible and important conclusions. There was a report about Linus Torvalds criticizing the inflow, (see here) but it turns out he was after the practice of LLM-script kiddies reporting them to the “secret” mailing list. Which is a no-brainer because if an LLM that everyone can run finds a bug, then it’s obviously not a secret.
Anyhow, looks like GenAI can be put to good use finding vulnerabilities.
Assuming that post-bubble it becomes possible to use AI in coding without being called a Nazi, we have to face the fact that we really don’t have any consensus best practices for doing that. So I enjoy reading narratives of people who describe what they did, in detail (no architecture astronautics) what worked, and what didn’t.
Lalit Maganti’s Eight years of wanting, three months of building with AI which centers around building an SQL parser that exactly matches SQLite’s. That’s a freaking hard problem and I think Maganti’s narrative has pointers to a plausible future.
The redoubtable and loud-voiced Daniel Stenberg of Curl fame offers us A Human In Control, which says about what the title does, with feeling.
Nelson Minar posted First impressions of Jules, Google’s coding agent; this will probably be interesting to those living in the Claude or Copilot territory.
Rails is regarded as a good framework for building certain classes of Web site. Normally, it is considered as Ruby code and executed using the Ruby runtime. Sam Ruby (the surname is a coincidence) has been doing remarkable work arranging for Rails app specifications to be executed by other runtime platforms, notably including Typescript, Rust, and Elixir with no ruby (except for Sam) involved.
He relies heavily on GenAI and describes his findings in The Drucker Inversion. It’s deep, thoughtful stuff.
Joe Magerramov’s The Valley of Calm makes perfect sense to me because I spent some years inside AWS. His basic point is that if GenAI ends up increasing the number of commits, your CI/CD pipeline is likely to cave under pressure. Looks to me like he’s right, and his proposals for how to address the problem sound plausible. “Plausible” isn’t good enough, this is another area where we just don’t yet know what the best practices are, and there’s only one way to find out.
Hey, two AWS people in a row: Brooke Jamieson is a Developer Advocate, what I used to be at Google. Make Your Coding Agent Opinionated begins “I’ve been using coding agents daily for over a year across Kiro, Claude Code, Cursor, and Codex.” Here are her lessons.
We can argue with each other about how best (or if at all) to use this technology. Maybe it’s all irrelevant or (I think) at best a side-show until the AI-bubble greed and fear dissipates. Which can’t come too soon. Maybe it’s useful to work on the problem in standby mode while we wait for the bubble to collapse.
I’m pretty sure it will.
2026-06-06 03:00:00
Hey everyone, I know you’re overloaded because everything has become overly efficient. Long-form reading or writing or art or music, who’s got time for that? Fortunately there are those who still do and here’s some if it. I hope one or two of the link targets can chisel their way into your jammed schedule and bring with them joy or rage or another appropriate feeling. Today’s curation has a lot of books and music and way more humor than usual. Also, a good electric wok.
Now, let’s all take a couple of breaths and gingerly approach the A-word, namely “AI” (as understood in 2026). Which is occupying much more of my attention and cognition than I would like, and there are gems embedded in the flood; granted, sparsely but they still add up. I respect that many of you will have just fucking had it with that subject. So I shuffled that material off into Long Links (AI), which you can drop by (or not) as you please.
One of the weirdest and flawed but still good things I’ve read this year is The Luminaries, written by Eleanor Catton back in 2013, a pretty dark tale of murder and theft and love and oppression in a not-so-great corner of New Zealand during an 1866 gold rush. Really super intense and hard to put down; even though it’s 900+ pages I never got bored. But freakishly complicated and I was left puzzled by multiple plot elements. Fortunately (yay Internet!) there’s Deconstructing The Luminaries, an explainer.
Other recent books: Platform Decay, minor Murderbot, but still worth reading. The Incandescent by Emily Tesh, yet another highschool-for-magic book, only with the grownups in the foreground and the kids behind them. Way more fun than the last few instances of that genre. Also, sex. Finally worth mentioning: The Everlasting by Alix Harrow, which started slow but eventually got a real grip on me; recommended.
I was in the library today and I always cruise past the “featured” table, where I saw Nobody’s Girl by Epstein victim Virginia Giuffre (R.I.P.) and Empire of AI, Karen Hao’s huge takedown of OpenAI and Altman. But I just now do not have the spoons. Maybe later.
Hmm, they tell me men can write books too. Must look into some.
I and many others are deeply discontented with the current flavor of late-stage capitalism, that “late-stage” a conscious callout to terminal illness. So do we really want to do away with Capitalism as such, or retain it but try to regulate away inhumane behaviors and effects? Or what? Let’s not forget that there are still people out there proud to call themselves Socialists and their take is that Capitalism can’t be fixed and must be replaced. With what?
Anyhow, if you want to hear what these people are saying the place to go is Jacobin. I’m not a regular visitor but when I do drop by I’m starting to hear the phrase “market socialism”. Thus How Socialism in the 21st Century Could Work. The tone is kind of nonspecific and academic but it’s part of a conversation that I think the (large, growing) mad-at-Capitalism demographic needs to have.
Speaking of the pathologies of late-stage capitalsm, Paul Krugman’s Bezos, Backlash and Zombies describes a Bezos TV appearance in which Jeff said some really dumb things. Which is a bit surprising because while fewer and fewer people seem to like him, most people think he’s pretty smart. Krugman tears apart Bezos’s deep and broad misunderstanding of how taxation works. He attributes it to what he calls “Billionaire Brain”; the notion is plausible. The discussion goes on into popular perceptions of business in general, technology in particular. And (*sigh*) AI. Good stuff.
People like reading books on screens and most public libraries now support that. I believe a high proportion of such loans go through Libby, which is what I use. But the publishers don’t actually sell e-books to libraries, they rent them, a price for a fixed number of loans. And as you might expect, that price keeps going up, to the point that public libraries all over the world are hurting. So, Library Orgs Urge Big Five to Address Digital Pricing. Paper books are looking better and better.
It turns out that America’s capital is a good experimental platform for crime research. Check out Washington, D.C.’s crime decline and its lessons for American policing from the Niskanen Center. Guess what: There’s little correlation between the number of cops and the amount of crime. Also, when Trump sent in the National Guard to stand around with their thumbs up their asses being visible, the effect was tiny and only on “property crimes of opportunity”. Does that mean graffiti?
Staying in the political lanes, here’s an evening briefing from Talking Points Memo, my favorite US-Politics blog. It’s got two unintentional jokes. First of all, this little sequence on the subject of Trump wanting to print a $250 bill with his face on it.
… two political appointees at the Treasury Department … repeatedly urged staff at the agency’s Bureau of Engraving and Printing to prepare prototypes of the note, according to the employees, who said the move raised concerns because federal law currently allows only deceased people to appear on bills.
There’s more than one way to read that… I’m suddenly starting to see the advantages of printing that bill.
Then, a little further down, it turns out JD Vance gave a speech at the Air Force Academy, from which:
So as AI transforms the battlefield — in some ways positively, in some ways not — I ask that you be jealous and selfish about your role as a decision-maker in warfare,” he continued. “Use technology to make you better, but never submit to it. You are the masters of warfare…
Yeah well Bob wrote a whole song about Masters Of War and got the trade-offs about right. JD’s cluelessness is mountainous.
OK, here’s an organized-crime story that makes me smile because it’s just so hilariously blatant. It’s like this: Worldwide, cricket is a big-money sport. Any readers who come from India or English-speaking southern-hemisphere countries are nodding because well of course. Cricket in Canada is not a big deal; our South Asian and Caribbean immigrants may be seen playing in the park on weekends with nobody but spouses and kids are watching.
Nonetheless the International Cricket Council has been sending a few million dollars a year to Cricket Canada to develop the sport hereabouts. But no longer. It seems that Cricket Canada has been a comical hotbed of theft, fraud, extortion, and match-fixing. Recently gunshots were fired at its president’s house. The TV segments have been hilarious, with leaders of Canada’s cricket establishment sweatily denying everything while looking over their shoulders. Anyhow, if you like colorful true-crime drama, start with Cricket Canada surprised after “unexpected” suspension by governing body over breaches of membership.
I visit Petapixel more days than not; it’s got the goods in the world of cameras and photography. There are solid camera and lens reviews, and a lot of focus on individual photographers. Here’s The photographer who never stopped chasing the perfect shot (and, on the evidence, got plenty). Next, Jeff Austin has been shooting the same parts of Tokyo through vintage glass for decades; he contributed Twenty Years, One City: What Tokyo Taught Me About Patience and Glass and has a Web site, Tokyo Forgeries.
Not just metal and glass; here’s an interesting camera bag: The Pilot 88 Is a Limited Edition Wotancraft Messenger Designed by Chris Niccolls. Finally, the story of Edith Tudor-Hart, in The Hidden History of a British Female Photographer Turned Soviet Agent.
Now, I said I liked Petapixel, and I do. But there’s a dark side; one can’t help notice the many many stories about the terrible things that happen to photographers. Then there’s the sub-genre of terrible things that happen in the context of wedding photography, which seems a swamp of suffering and pain. Well… why not both? Wedding Photographer Seriously Injured After Being Stabbed by Guest. I mean, it goes on and on: Photographer Bitten by “Shark or Sea Lion” During Surf Competition and Woman Pleads Guilty to Manslaughter After Gun-Themed Polaroid Photo Shoot Ends with Photographer’s Death! Mommas, don’t let your babies grow up to be photogs.
In the world of Big Biz generally and Big Tech specifically, PR leaders are very near the center of everything. CxOs are basically never allowed to say anything that isn’t carefully scripted in advance; PR does the scripting. When somebody fucks up and things (including the share price) go off the rails, PR owns the problem.
During the years when I was a blogging in a relatively unsupervised way while employed in BigTech, I became pretty intimate with some of those PR folks. I remember not too long after I joined Amazon, my manager, a really good person who’d gone to lots of work to hire me, grabbed me in the hallway and said “PR is pissed about what you wrote about Microsoft” and I said “Don’t worry, talking PR people down off the ledge is one of my core competences.” He looked worried: “Well, good luck.” But it was OK.

Anyhow, Claire Stapleton was in PR at Google during the glory years, and was close to the center of things. She got laid off in 2023 and wrote game over - some thoughts on layoffs and life. A few things in there widened my eyes and I suspect they’ll do the same for anyone else who’s been in the Google ecosystem. Anyhow, recently she wrote a book which I have to say looks pretty promising.
JA Westenberg’s On wintering speaks to me. One of the nice things about being (mostly) retired is I get lots of time for this. It’s hard to see how the machineries of Late Capitalism could allow this kind of space though; another reason to find something better.
At least once a year I point excitedly at something by Paul Ford; this time it’s Canons. Beautiful stuff.
For the last few years, we’ve had induction stovetops, which I totally love: Responsive, hot, easy to clean, low carbon load. but, I like to stir-fry and you can’t really balance a wok on an induction top. So we picked up an Abangdun 1700W 100V~185V Induction Cooktop Concave Curved Surface 2026 New Electric Stove Wok. It’s great; I stir-fry a couple times a month and get good reviews. Its built-in fan is kinda noisy.
Recently I ran across The Sleeveens, Irish punks in Nashville. I said “punk” and I mean it, it’s nearly the pure stuff, somewhere on the Clash-to-Ramones axis, and like those bands, the tunes are good, and like the Clash, the lyrics are political and gonna make you sit up. Their recent outing National Anthem is just one banger after another. My favorites are If I Was A Casual and Cowboy Queen and then there’s the title track, which begins “Burn your fuckin’ country to the ground in the name of love…” oh yeah.

Now let’s lean into a fertile field of musicological scholarship: Guitar solos! Rolling Stone let their dimbulb flag fly with The 100 Greatest Guitar Solos Of All Time, which unforgivably omits Ry Cooder on Amandrai, Susan Tedeschi on Pity the Fool, David Lindley on Do Ya Wanna Dance, Neil Young on Love To Burn, Megan Lovell on Preachin’ Blues, also [Tim, enough -Ed.].
But wait, there’s more. Not to be outdone, Consequence (of which I know nothing) came up with 70 Best Guitar Riffs of the 21st Century (So Far), which is full of smiles. I have to confess that I’d heard less than 10% of these.
But anyhow Japanese metallistas Boris, about whom I’ve blogged not once, not twice, but thrice, are on both lists! #61 on the solos, #7 on the riffs. Which they noticed, and took a bow. Here’s Akuma no Uta and also a pretty hot live capture.
Finally, if you like Arvo Pärt and art that strains at the edges (what other kind is worth liking?) check out Robert Wilson’s “Adam’s Passion” (Music of Arvo Pärt). An hour and a half of fine music, well-played, and live human movement following Pärt’s slow pulse. Nakedness is involved.

I gather that Marcin Wichary is name to conjure with in design circles; he’s recently launched Unsung, my blog about software craft and quality and boy, it’s outstanding. A lot of it is simple celebrations of typographical or UI excellence, but what got my attention was a polite-but-savage takedown of a recent Photoshop release: Parts 1 and 2. You’ll learn a lot about how to think about UI construction by reading this.
Armin Ronacher, to whom it seems I’ve been linking a lot recently, offers Before GitHub, which to be fair contains equal parts of Current GitHub and After GitHub thinking, pretty well all of which seems good to me. Single points of failure are just bad, we should know that now, particularly when they start failing.
Finally, have a look at The Age of the Amplifier by Brian Potter at a Web site called “Construction Physics”. There are several different kinds of amplifiers, and most of the interesting ones were developed at Bell Labs during the 20th century. This is a history of that, based on the premise that “Amplifiers in general are important”. They are! The history is interesting, assuming you know what “voltage” and “current” are. It pleases me that people will still write long-winded pieces about narrow slices of history and apparently have fun doing it.
Well except for the companion aggregation of Long AI-related Links.
Until next time.