2026-07-05 08:00:00
终于解决了长久以来在 Obsidian 里的一个摩擦点──说大不大,但每次都让我禁不住地想:过程能再无痕、再顺滑一点就好了。
前提:
我的 Obsidian vault 和 Hugo site 共用一套 markdown 文件。
需求:
站内文章互相引用时,可通过文章标题而非 MD 文件名为关键词插入链接,并且链接显示文字也为标题,同时在两个系统内都可被识别并准确跳转。
以本文为例:
title: 一个更顺滑的 Obsidian 内链插入流程filename: obsidian-link-workflow.md
如果用 Obsidian 双链([[]])实现快速插入,必须用文件名中的关键词检索:
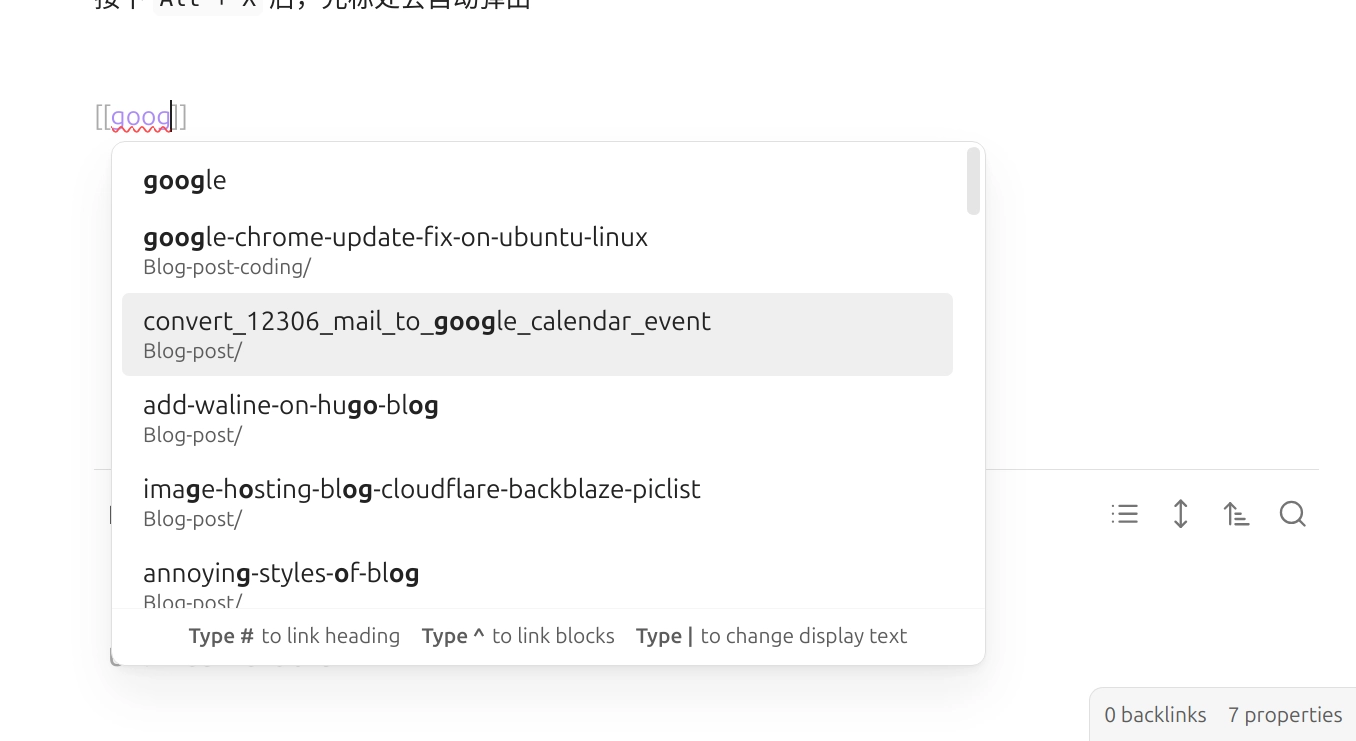
由于我关闭了 Obsidian 设置中的 wiki link,因此完成插入动作后 Obsidian 会自动将其转换成标准 MD 链接,输出结果就是:[obsidian-link-workflow](obsidian-link-workflow.md)。还得回头再编辑文本内容。
而理想状态是,键入对人脑记忆更友好的标题名(而非为了 slug 标准只使用字母、数字、下划线或连字符的文件 basename)来快速插入,同时输出结果也是易读的标题,即:[一个更顺滑的 Obsidian 内链插入流程](obsidian-link-workflow.md)。
用 QuickAdd 插件结合自定义脚本实现。
在 Obsidian vault 中新建 insert-title-link.js 文件,内容如下:
module.exports = async ({ quickAddApi, app }) => {
const files = app.vault
.getMarkdownFiles()
.sort((a, b) => b.stat.mtime - a.stat.mtime);
const choices = files.map(file => {
const title =
app.metadataCache.getCache(file.path)?.frontmatter?.title ??
file.basename;
return {
display: title,
title,
file
};
});
const selected = await quickAddApi.suggester(
choices.map(item => item.display),
choices
);
if (!selected) return;
app.workspace.activeEditor?.editor?.replaceSelection(
`[${selected.title}](${selected.file.name})`
);
};
安装 QuickAdd 插件,在 QuickAdd 设置中创建 Insert Link(可随意命名)
Macro
,为其绑定上面的 insert-title-link.js 并激活,具体步骤见
官方指引
,我懒得打字儿。
Insert Link,为其绑定一个不冲突的快捷键(我用的是 Alt + X)。按下 Alt + X 后,光标处会弹出以标题显示最近打开的文件列表,或是在搜索框内键入标题关键字查询对应文件,选定后即可快速插入。
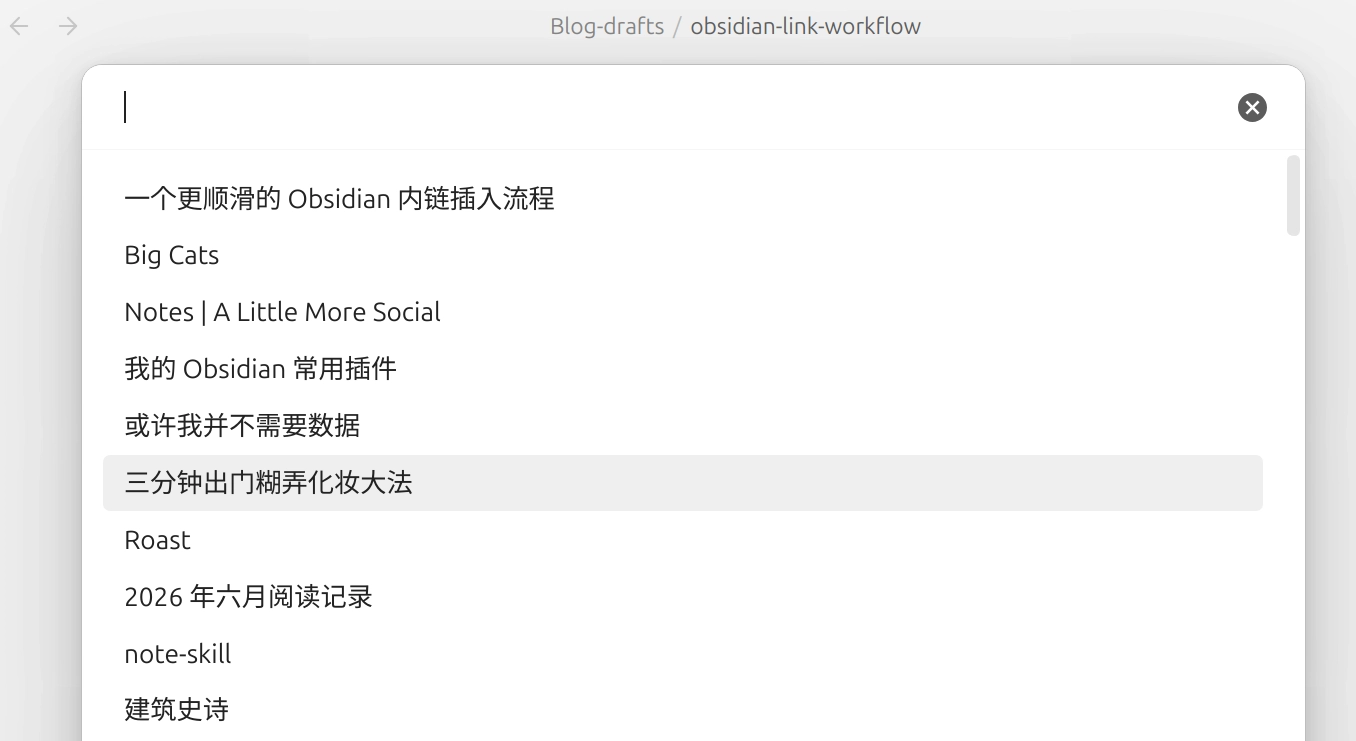
这样既保留了稳定的文件名作为链接目标,又避免了每次插入链接后再手动修改显示文字。Hugo 会在渲染阶段统一处理这些站内链接──依靠自定义 render hook 实现(layouts/_default/_markup/render-link.html 文件)。
2026-06-17 08:00:00
没想到这个系列居然还能继续。其实从外观看不出什么变化,不过我的「装修」一向是能不动 CSS 就不动 CSS,基本不会从视觉效果层面去做装饰。
这次的主要折腾就是它了,分开讲。
新增了一个 property abstract,目前的 markdown 文件 front matter 控制可见度的是如下属性:
---
rss_ignore: false
abstract: false
hide: false
---
分别对应的是:是否输出 RSS,是否输出 RSS 全文,是否在站点内隐藏(首页,archives,taxonomy 等集成页面)。
显示最近五篇 hide 与 rss_ignore 都不为 true 的文章。
通常首页对应的是 layouts/index.html,在里面加上下面的过滤条件。
{{ range first 5 (sort (where (where site.RegularPages "Params.rss_ignore" "ne" true) "Params.hide" "ne" true)"Date" "desc") }}
{{ end }}
在 archives.html 里:
移除 tag 集中展示,改为显示网站开启的 taxonomy 类别,即, Categories , Tags 和 Series 。
<div>
<p>
{{ range $key, $value := .Site.Taxonomies }}
{{ if gt (len $value) 0 }}
<span class="inline-block ml-2">
<a href="/{{ $key | urlize }}/">{{ $key | title }}</a>
</span>
{{ end }}
{{ end }}
</p>
</div>
显示所有 hide 不为 true 的文章。
<div>
{{ range (where site.RegularPages "Params.hide" "ne" true).GroupByDate "2006" -}}
{{ end }}
</div>
我用的这个主题过于简陋,根本没有给 Hugo 的 taxonomy 写模版,像 domain/categories/ 或是 domain/tags/ 都没有相应页面,导致访问时它们会变成遵守站点默认 list.html 规则,显示了整站所有文章。
新建 layouts/_default/terms.html 文件。
{{ define "main" }}
<div id="reading-progress-bar" role="presentation" class="fixed z-10 top-0 left-0 h-1 bg-gray-700"></div>
<article class="article">
<h1 class="artitle_title">{{ .Title }}</h1>
<div class="mt-8 text-xl leading-relaxed text-gray-700">
{{ range .Data.Terms.ByCount }}
<span class="inline-block mr-2"> · <a href="{{ .Page.RelPermalink }}" class="hover:underline">{{ .Page.Title }}</a><sup class="text-gray-500 ml-0.5">{{ .Count }}</sup>
</span>
{{ end }}
</div>
</article>
{{ end }}
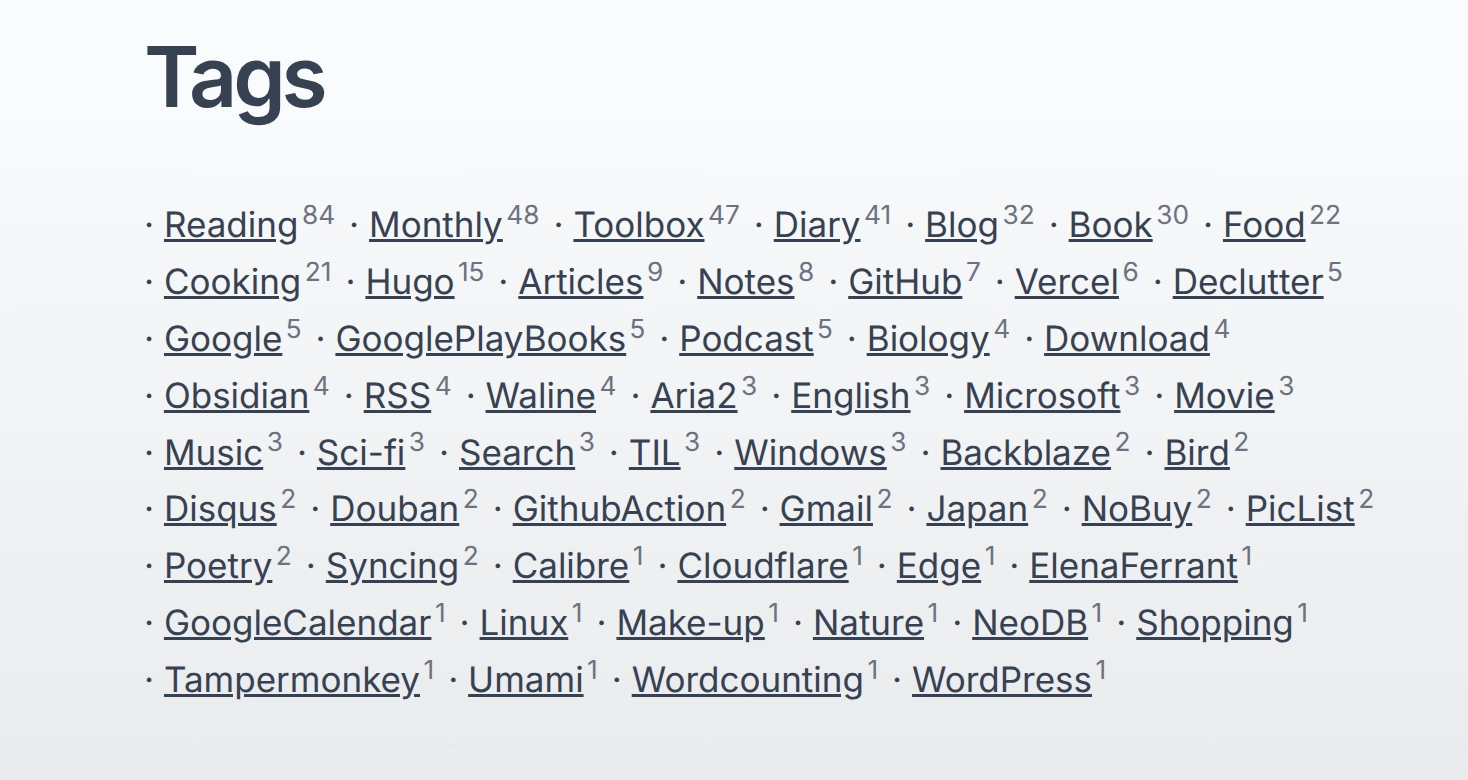
作用是为已开启的 Hugo 各 taxonomy 生成包含下属所有标签文章计数的聚合列表页。(怎么感觉这么不像人话呢,看截图吧。)
然后再分别新建 layouts/taxonomy/tag.html,layouts/taxonomy/category.html,layouts/taxonomy/series.html。
这是为各具体标签生成列表集成页,比如 domain/tags/toolbox。我的重点其实就是这一行语法,把属性是 hide 的文章筛出去,保证它们在任何一个聚合页面都不会出现。
{{ $filteredPages := where .Pages "Params.hide" "ne" true }}
上面都是给人看的页面,改完之后不管在站内任意聚合页都不会有 hide 属性的文章被收录。这里改的就是给机器看的页面了。
不放代码了,反正都是 AI 写的。
RSS 的过滤逻辑是,输出 rss_ignore 不为 true 的最近十篇文章,若文章 abstract 为 true 则显示摘要,否,则显示全文。这里为什么不过滤 hide 呢,因为秉持状态设计的 single responsibility principle 和 orthogonality 原则(?,我前阵子估计是看编程黑话走火入魔),hide 当然也可以输出到 RSS 嘛。这种类型的文章就是,仅能通过直链访问,而无法直接在站内找到。
然后是 sitemap 。这个东西通常是 Hugo 默认生成,包含站点内所有可访问链接,一般是给搜索引擎、各网络爬虫看的。那么,如果不想让历史文章尤其这些设置了 hide 的文章被挖坟,自然也要自定义了。改动的是 layouts/sitemap.xml 文件(没有就新建一个)。
我的设置是,仅收录一年内发布、且 rss_ignore 和 hide 都不为 true 的单篇文章。为什么这么搞,实在是最近被各个爬虫爬得快疯掉了。有些犄角旮旯的文章和链接一看就知道不可能是人翻出来的必然是爬虫直接从 sitemap 里挨个走了一遍。也幸好这是静态站,动态站的话流量账单全付给爬虫了。我虽然不用付账单,但限制之后至少访问统计里爬虫的数量能少点。
关于 Hugo 的页面生成规则有更多可讲的,这次把 Hugo 的官方文档相关内容从头到尾看了遍总算弄清楚了逻辑,下次或许可以写篇更详细的总结(或者让 AI 写)。
其实我也并没有那么真的在乎历史文章被爬虫或者是真人挖坟,但就是好奇对于静态站我能够控制到哪一个层面,所以忍不住一层层地研究下去了。
在每篇文章下加了个“请我喝咖啡”的链接。
好久之前和朋友互相打趣就会说快点在你的博客放上「请我喝咖啡」打赏链接走上网络 KOL 之路!其实我对这个没有排斥,凭劳动赚钱又不丢人!只是当时我严肃调研了各个平台,方便提现同时不暴露实名的方式实在太少。最后绕了一圈选择了 Patreon 的虚拟商品链接。至于它家主打的会员模式,感觉不大可能有人来订阅我这个互联网尾部博客吧……
给早期只有书名、没有书籍链接的月度阅读记录都补上了 NeoDB 卡片(幸好这活儿现在有 AI 干,让我手动我会疯掉)。
最后,最近突然勤快的原因:
补了近百本书籍 NeoDB 卡片后,站点 footer 里的字数统计突然飙升十万字,我这才意识到 shortcode 生成的文本内容也被计了进去。既然字数不准,并且想想挂在网站上其实也没什么意思,就索性移除了。
但我还是想知道到底写了多少,就在 Obsidian 里用 dataview 列了个统计,请看:

草稿 13 万,博客文章 31 万,可真有我的(拖延王者简直)。
所以,接下来的目标是,不要继续囤积草稿,该发的发,该删的删。
2026-06-13 08:00:00
别人建站的第一件事:买域名。
我:写了五年半,还在犹豫买不买。
2020 年底计划建个自己的博客时,考虑的第一件事就是想找个不需要买域名、不需要服务器且不依赖现成博客平台的方式,静态站点 + GitHub Pages / Vercel 这条路算是完美符合了我的需求。
最初不想买域名(以及服务器)的理由很简单:我不知道自己会不会长久写下去。而且我尤其不太喜欢做一件事的开头是消费(买装备)。倒是也能理解为什么这对有些人有效,那是一个很好的开始的心理暗示和关于沉没成本的默默提醒。只是我的默认模式是,一旦一件事被规则限定变成了「应该做」而非「想做」,即使这个「应该」并不由外界加诸,也会引起我的心理反弹而不去做哪怕我想做。非常拧巴对吧。
后面陆续写了两三年,确定我确实能写下去,这时买不买的犹豫就变成了,域名到底要买多久,以后会不会涨价,一次性买五年/十年是不是有点离谱,但要是买的短涨价了我是换地址还是交赎金,真的要换域名后续的变更通知又怎么办……尤其是这时见多了一两年就失效的不少个人网站(乃至好几个我的友链),搞得我对那些既不持续又无通知的个站怨气横生──还不如就一直挂个 github.io 起码稳定呢。
现在已经进入了第六个年头,更新不算稳定但也一直在写。怎么就又兴起了买域名的念头呢。
一是,从原来的 github.io 迁到 vercel.app 之后,站点在 Google 中的可见度就极速降低到几乎为无。github.io 在搜索引擎里的权重挺靠前,我有好几篇文章甚至在 Google / Bing / Duckduckgo 的搜索结果一二位。倒也不追求什么点击量,但至少我希望对别人可能有用的东西能够通过搜索引擎被触达──这不就是互联网存在的意义?
二是,从今年以来博客的访问统计完全不可靠了,来自新加坡的流量飙升到离谱,停留时间几乎为零,一两分钟一两百访客的情形都出现过。我给博客加了 robots.txt 禁止了 bot,但这纯属君子协议。没有域名,也就不能用 Cloudflare 里的很多免费服务,可倚赖的防护措施非常有限。
三是,一直我对 DNS 之类的有点好奇,同时看到别人扯 Nginx、TLS、CNAME 等等名词时感觉一种读加密文字的恼怒,有了域名亲身实践应该很快就能有具体感知。
只是去各家域名服务商上转了转,又挑剔又抠门的我很快被挑选困难搞得不耐烦。纯数字 + .xyz 最便宜,可这也太不像个正经站了!.com 倒是很正统,可感觉又有点严肃。
买全字母的,继续用我现在这个站名吗?其实当时名字取得有点随意。换一个?取名废的我已经开始头疼。同时我又不能接受真的随便搞一串无意义字母。怎么我这么难搞?
最后价格,.com 挺稳定,Spaceship 差不多 10 刀一年,但我觉得每年给网站倒贴一百块还是有点不爽。更便宜的吧,.vip 和 .top 三四刀,可又明显不符合我的审美……
果然买东西永远这么让人厌烦!
2026-06-13 08:00:00
本文属于 Articles 系列,前情提要或后续更新请见:
照旧,依然是跨度极长的网络文章阅读记录。文件名字里的日期改了又改,最后我放弃变更让它定格在了 20260303 上。
所有观鸟和试图观鸟的人都应该了解的信息。
提到的网站: AviList: The Global Avian Checklist 。
回答了我「反复造轮子」和自建服务是否有必要的部分疑问(和挣扎)。里面提及的许多开源/独立服务也很有用。我正是看了这篇文章终于决定搭一个自己的 Quartz 站点。(不过已经荒废了好几个月,此刻写这条倒是提醒我应该好好把它利用起来。)
之前在 博文 里写过的 Wisdom 又回来了。在至少 74 岁的年龄找了新伴侣(她前任伴侣 Akeakamai 已失踪岁余)并且产卵成功!野生黑背信天翁通常寿命只有 12-40 年,实行终身伴侣制,但 Wisdom 已经 70+,至少经历了三任伴侣,产下过 30 余枚蛋。真真的 live long and prosper。
用过 Python 的人都知道缩进是它语法表达的一部分,但我真不知道古籍里有种文书书写制度和它形式上颇为异曲同工。
探寻北京街头巷尾的神秘蘑菇造物。
在引用腾讯新闻还是丁香医生公众号原文章地址里天人交战了半天,最后决定还是选个起码是标准互联网链接的吧。非常标题党,不过内容挺实用,尤其 这张 长图总结,但直接插进博客实在是太影响阅读体验了。
或者, TL; DR:
只要同时做到戒烟、少酒、规律运动、健康饮食和保持体型这 5 个生活习惯,预期寿命最多能延长近 9 年。
先是在 YouTube 上刷到一个登山视频 Overnight in World’s Most Luxurious Shelter ,被这个仿若飞船太空舱一般的山间 shelter 吸引了,就去找了下具体介绍。

坐落在 Mont Blanc 山峰约 2835 米高的海拔处,这间首建于 1948 年名叫 Bivacco Gervasutti 的 shelter 经历了一次非常现代化的重建。整个项目采用模块化设计,在山谷中建造完毕最后由直升机运上山并固定。现在这间胶囊旅馆不仅风景绝佳,内部也是相当豪华,太阳能供电,还有网络、烹饪等设施。

2009 年耶路撒冷奖村上春树获奖致辞。这个墙和鸡蛋的比喻被反复引用,直到现在我才读到完整全文。写得不错──但这不妨碍我依然无法欣赏村上的书,无论小说还是随笔,我整个人都控制不住地想尖叫怎么这么黏黏糊糊腻腻歪歪!
Marc Andreessen recently described the moment as a “Mexican standoff:”
- Every engineer now thinks they can be a PM and a designer.
- Every PM thinks they can code and design.
- Every designer thinks they can do the other two.
主要是上面这个段落太好笑了。AI 给了太多人「我行我上」的幻觉。
何伟在 The New Yorker 上的最新文章。本来只是想开个头没想到根本停不下来一口气读完了,写得非常非常好,是一个看似缓慢、平静却黑暗的故事。有好多句子会让人忍不住拉回去反复体会。我觉得被没有波澜却深不见底的水面吞没了,充满了窒息感。
你拥有多少物品?你打算一一清点它们吗?有人真的这样做了。
我没有这样的耐心和毅力去记录我所有物品,但对某些耐用品确实有一份(几份)清单。而哪怕只是做这样很小部分的盘点也能够让我认识到我拥有多少我并不需要的东西。更清楚被显现的,是仅仅保持「拥有」这个状态也足以令人烦闷。