2026-07-24 22:48:13

$50,000 essay (& short story) contest on the new axial age
Goodbye Slopstack! AI detection comes to Substack
Could we find the sequel to The Odyssey in the Herculaneum scrolls?
Cloudbursts seem to be increasing?
Each year, we speak 338 fewer words daily
Adversarial consciousness tech
Never invite an auto-fiction writer into your life
Surprise? Medieval people loved their children
From the archives
Comment, share anything, ask anything

Last year, I advertised the 2025 Berggruen Prize on the topic of consciousness. Many readers here ended up submitting something: I’m pretty sure multiple people who ended up short-listed for the prize learned about it here (and later posted the entries to their Substacks and blogs after the competition was over).
This year the topic is “A New Axial Age?”:
Might civilization yet again be at the ‘hinge of history,’ in which the events that occur in this distinct point in time significantly influence the trajectory of the future? Are we undergoing a pivotal transformation of consciousness as a result of rapid technological development and its myriad social, economic, and political consequences? What conditions may or may not give rise to this possibility? Through what constituencies and by what mechanisms might the transformation take place?
Submissions can be up to 10,000 words and the deadline is August 17th, 2026.
In an interesting change from last year, this time they are also accepting “creative fiction,” and $50,000 for a short story is pretty dang good. Even split two ways, it would still handily beat the surprisingly-low Pulitzer Prize award of $15,000. I personally would love to see a piece of short fiction win this year and spice things up a bit.
Also, the Berggruen Institute was happy with the results of my announcement last year, so this year they have (again) sponsored the following post. It is unlocked for all subscribers. If you enjoy it, please do consider becoming a paid subscriber, as these are otherwise locked.
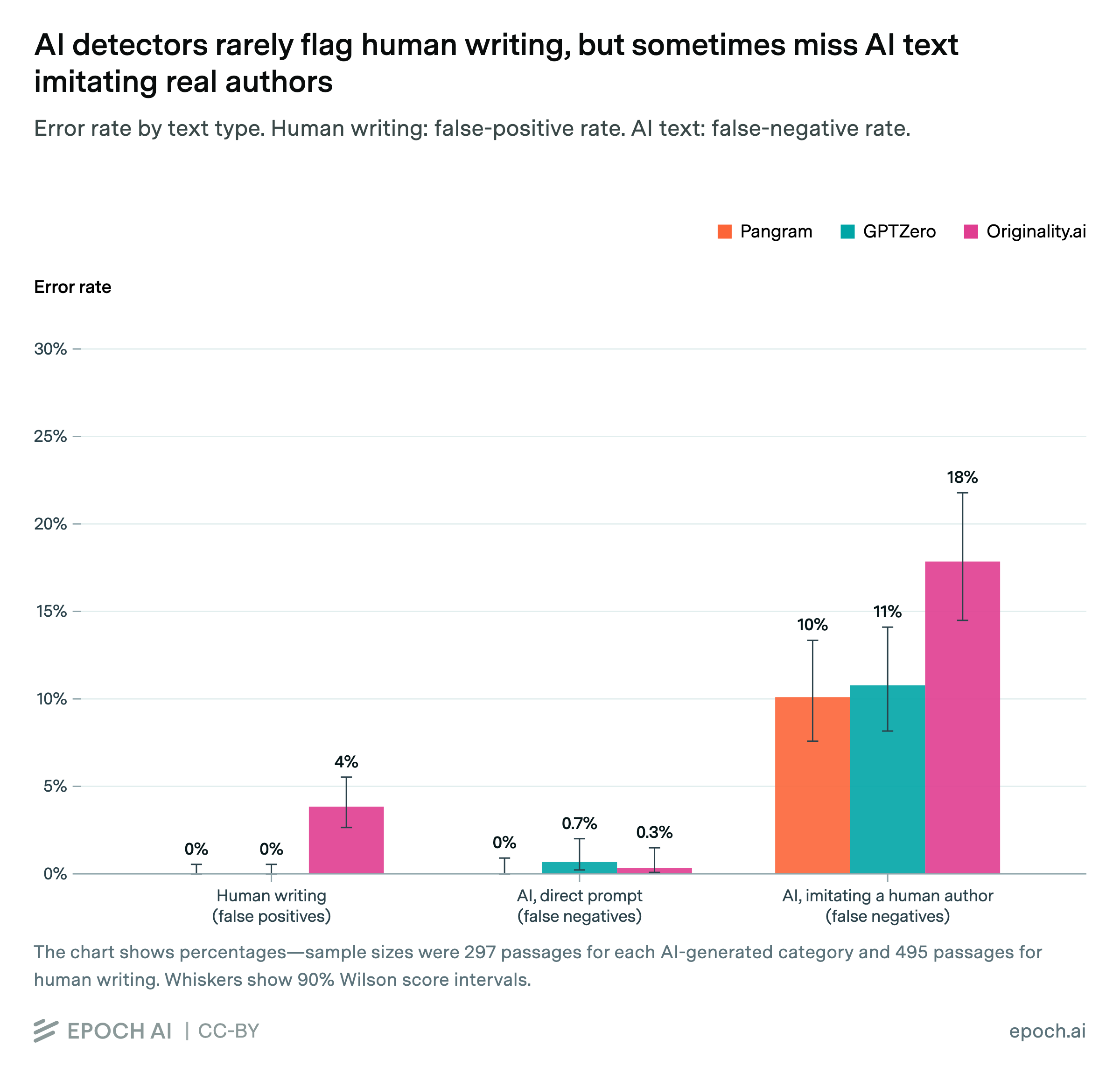
Substack has integrated Pangram, and you can now assess any new post on the platform for AI content—at least through the app and through Notes. If I were running Substack, this is precisely what I would have done (except I would have allowed it for each webpage too).
So goodbye Slopstack! It was not a fun time. I won’t miss you at all. I think remnants of Slopstack will continue but this basically saves the platform, and restores my faith in it. I will, of course, be happy to never read again some of the old Slopstack favorites, like “Here’s An Idea I Won’t Be Citing the Origin Of” and “Agency is Easy For Me Because I am Rich” and “A Suspiciously Facile Information Dump” and “An Elegiac Remembrance of Abstract Mush.” Goodbye! Farewell! Don’t come again!
Should writers like myself, who actually use our old wrinkled neocortexes, worry about this? What about false positives? Statistically, Pangram rarely gives human writing false positives (see below an analysis from Epoch), and especially for sections that are thousands of words long. However, Pangram isn’t super reliable for just a paragraph, so it’s possible. At the same time, presumably a false positive for a human writer would be an unclear one-off, and the point was always to avoid the slopopocalypse that plenty were happy to take advantage of.

I recommend visiting Pompeii because it’s one of the few places left where you can touch history itself. Always have the urge to surreptitiously brush the statues at museums? Go to Pompeii! You can sit at the bars, you can enter the baths, you can trail your fingers along the walls and no one yells at you. Walking through the town on a sunny day, you will arrive at certain street corners, and on those street corners—especially when you can hear only an indistinct murmur of activity from others—it is easy to imagine you have traveled back to right before that fateful day in 79 AD when Mount Vesuvius exploded and buried it, and the Roman town of Herculaneum near it, in thick ash. I’ve never been to Herculaneum, but apparently there was a library, and with new scanning technology and fancy reconstructive analysis we’re beginning to read the carbonized scrolls. At the end of last month it was announced that, for the first time, a papyrus manuscript had been fully decoded end-to-end; a philosophical treatise by a Stoic.
Seales has been working on virtually unwrapping the scrolls since the early 2000s. The process involved imaging the bundles of papyrus using technology similar to CT scanners, isolating thin layers and then stitching them together. In 2023, he partnered with two Silicon Valley investors and launched the Vesuvius Challenge….
“We’ve developed a systematic and a repeatable approach,” Seales told the audience. “Now it’s only a matter of time until we read all of the scrolls.”
In theory, the results from this contest to read the scrolls might mean that in our lifetimes a huge amount of classical history gets uncovered. Who knows, maybe the library contained one of the other six poems in the eight-poem series that includes The Iliad and The Odyssey, of which only those two remain. There are seven more movies for Nolan to make!
But do you know what looks a lot less stupid in light of these efforts? Cryogenic preservation. If we can read the words on literal chunks of burned scrolls indistinguishable from what you leave behind in a used fire pit, maybe there’ll be a contest in a thousand years to restore all those frozen brains everyone forgot about.
The night I’m writing this I found myself on my knees in the crawlspace of our home—now, pleasantly encapsulated in white plastic after a recent treatment for mildew, which as a side-effect treated all the old New England hauntings too—checking for leaks with a flashlight, as rain thundered above on the drum of the flat roof. It seems like the skies open up with more vigor than I remember from my youth, and indeed, this is an actual statistical change, particularly on the East Coast. According to a recent interview with a professor at NYU:
In New York City, the four most extreme precipitation events have all happened in the last four years…. Generally rain is talked about in terms of the total amount of precipitation—but it’s the speed that determines its impact. Two inches over the course of a day in New York City is no problem whatsoever. One inch of rain in 10 minutes is an emergency. Cloudburst is a name they use in Denmark for these extreme precipitation events, and some people call these events “rain bombs”; there’s a whole vocabulary for them that tries to capture this dramatic shift in predictability…. Until the 1990s, there were zero occasions when New York City got more than 1.75 inches of rain in an hour. Since the nineties, New York City has experienced eight storms with hourly rainfalls above 1.75 inches.
An interesting New Yorker article covered the surprising discovery that every year our daily spoken word count declines, and this has been going on for decades (measured via voluntary ambient audio recordings). Researchers…
… found that participants had spoken an estimated twelve thousand seven hundred words a day—twenty per cent less than in the earlier study. “We thought we must have made a mistake,” Mehl said. Each year, he went on, the number of words spoken daily seemed to decline by about three hundred and thirty-eight.
A little while ago there went viral an AI-generated clip of pools and waterslides in a liminal backrooms-style underground office space. Don’t look it up. My 1990s-childhood-brain immediately felt in an instant and limbic way I should not be seeing it. That night before bed it summoned itself to me, unwanted, intrusive. One can experience this after horror movies too, that there is some afterimage that keeps being relived—and of course, it can happen in real life too, even for small things (embarrassing intrusive memories from the fifth grade, anyone?).
Well, turns out you can prompt-engineer your way to videos that elicit maximal responses from specific regions.
The research invited plenty of comparisons to David Foster Wallace’s Infinite Jest, which is an exaggeration… for now. It’s hard to deny, this does seem like an embryonic attempt at adversarial tech against human consciousness—even if it’s all just computational modeling work for right now (they are basically using statistical models of what these inputs are expected to do, not creating the loop directly).
We are entering an age of rapid scientific progress. People aren’t prepared for the consequences and we don’t know what’s possible. One reason we don’t know what’s possible is that neuroscience is pre-paradigmatic, and neuroscience is pre-paradigmatic because there is no scientific theory of consciousness. It’s a dangerous asymmetry. We might need defensive consciousness tech, but to do that, you need to figure out consciousness.
I rarely indulge in literary drama, but for those who don’t know her work, Rachel Cusk is a very good novelist and basically queen of the auto-fictional novel. She lives in Paris and, based on rumors, is (was?) friends with Natalie Portman, who also lives in Paris, and now Cusk has a new novel, Life of M, coming out that centers an actress who seems… an awful lot like Natalie Portman? And (again, if the rumor is true) it may not be a very flattering portrait.

This stuck with me because it reveals a lack of understanding about how vicious and jealous and critical artists can be. I can’t help but wonder why a super famous and rich person would even be friends with a writer herself famous (at least, in literary circles) for transforming daily personal life into public-facing literature. I am reminded of the parable of the scorpion and the frog.

Occasionally a scholar makes a claim so reductively seductive that a generation believes it (not to point fingers, but often the origin is some continental French or German thinker, e.g., Nietzsche’s claim that the troubadours invented the concept of romantic love). Apparently the French scholar Philippe Ariès, working in the 1960s, is responsible for the notion that medieval parents didn’t love their children in the same way. This is, of course, nonsense. Here’s from a recent review drawing from Nicholas Orme’s Medieval Children:
Ariès’s work never attained complete acceptance in academia, but it was vastly influential on the wider public. As it turns out, however, Ariès’s view is just not true….
… most medieval people had only three or four children, somewhat more among the rich and somewhat fewer among the very poor. At least in England, this was partly because they married quite late, generally in their mid or late twenties. About 25 percent of children died in their first year and another 15 percent by their tenth. The median English child thus grew up in a home with one sibling and two parents in their thirties or forties, being in this respect just like the median English child today. Surviving grandparents often lived nearby, but rarely under the same roof. …
Medieval parents made immense sacrifices for their children, and seem to have expected little in return. Feeding a child consumed about 15 percent of average income, and parents often continued to support children throughout their adulthood. Older children often performed light work at home, but at just the age they might become a net economic asset – 13 or 14 – they were usually sent away to acquire skills and savings through apprenticeship or working in service. They may have remitted some of this income to their parents, but this was not standard, and in fact parents generally paid for their children’s apprenticeships. …
The medieval people who emerge from Orme’s book are quite unlike the strange and cold figures that we have been led to imagine. ‘I believe they were ourselves, five hundred or a thousand years ago’, Orme writes.
But if humans have always loved their children thus, how much is the decline of religion explained by having less need? If I lost a child, I would either go insane with grief or become a religious apologist—I don’t think I could handle it any other way.
This time last year I was arguing that we start children reading too late, long after tablets and screens have taken hold.
As always with the Desiderata series, please treat this as an open thread. Comment and share whatever you’ve found interesting lately or been thinking about.
2026-07-14 00:34:01
When the AI companies first began talking about existential risk, it was common to hear some version of:
“Look, this is bad for business, so obviously they must be telling the truth.”
In retrospect, existential risk has been the best capital-raising tool ever in the history of the world. That doesn’t mean there were no true ethical motivations accompanying the doom warnings mixed in. There were. But in the end, embracing existential risk was also the right move from a cold-eyed business perspective.
Similarly, it’s perplexing why a company would want their AI to be conscious. One could again say:
“Look, this is bad for business, so obviously they must be telling the truth.”
Yet I think it will turn out that being coy about AI consciousness, and designing AIs to be as “seemingly conscious” as possible, is great at both attracting top talent and ensuring customers form parasocial relationships. Much like existential risk, claims to artificial consciousness can be based in honest opinions, while also being extremely useful for a massive corporation pursuing its ends.

Anthropic’s big research announcement, accompanied by beautiful figures and a huge social media push, is claiming that AIs (like their Claude) have a “global workspace,” which is a term borrowed from neuroscientific consciousness research.
The sheer overwhelming power of Anthropic’s social media reach, design team, and the halo of being the hottest company in the world means that their research screams its underlying intentions, simply because every short step from neutrality is so impactful. And what their research direction seems to be is that while they cannot prove that Claude has real consciousness, and so truly suffers or gets frustrated or actually loves you back, Claude seems to have everything else that’s essential when it comes to consciousness. And Anthropic’s research project is going to show this as if checking off a list.
Their latest work seems an obvious sequel to their previous research on LLM “introspection,” which was also a blockbuster on social media. However, experiments on LLMs are extremely difficult to control for: you need an experiment, then an interpretation, and then you do controls to confirm your interpretation. It’s the last part that’s tricky. A lot of the field is basically inventing functional neuroscience from scratch, which has also been a field plagued with problems. For example, what Anthropic previously anthropomorphized as “introspection” may not really be introspection at all, once you do the proper controls. There are non-anthropomorphic interpretations that fit the data better.
Like their older paper on introspection, this newer paper on global workspaces and consciousness seems unlikely to ever be peer-reviewed. It’s worth remembering that everyone was rah rah rah let’s all do science on blogs, it’ll be so great. Down with scientific publishers! Down with peer review! Let freedom ring! Well, perhaps predictably in hindsight, the difference between press releases and research is getting thinner and thinner.
In fact, rapid-fire massive releases are hard to distinguish from a Gish Gallop: this paper is so big it’s difficult for a commentator on these topics (like myself) to address everything in a timely manner. However, no sub-experiment or control fundamentally deals with the critique I’m about to give (even if I can’t go through all of them in detail). That’s because the critique is about the method they base everything else off of: “J-space.”

Is Anthropic using a sensible way to track or measure consciousness? Consider the literal title of the paper: “Verbalizable Representations Form a Global Workspace in Language Models.”
A focus on “verbalizable representations” runs a risk I’d pre-registered when I pointed out earlier this year (and even back in 2021) that if you took global workspace and stripped it down to a bare minimum, you get a theory built solely on reportability, and that such a theory would be scientifically trivial—a symptom of consciousness research being pre-paradigmatic.
So did Anthropic do this? Did they embrace a trivial scientific theory of consciousness and then make big claims to AI consciousness off of it?
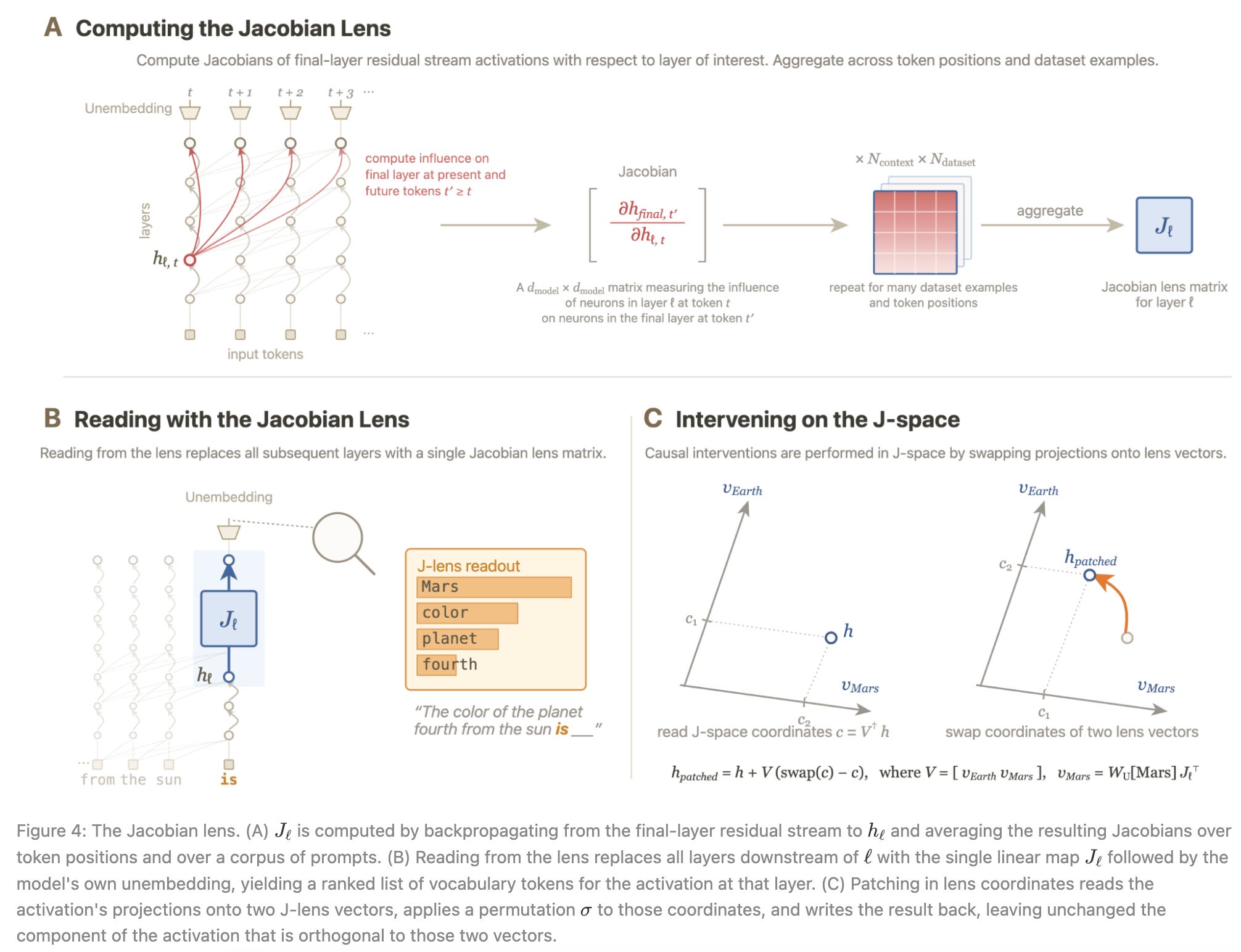
Note that the focus on reportability is true in the math—their entire analysis is derived off of “Jacobians” calculated per layer. What are the Jacobians in this context?
Our results make use of a new interpretability technique called the Jacobian lens (J-lens), which is designed to identify internal representations that are readily available for verbal report. For each token in the model’s vocabulary, the Jacobian lens identifies a vector representation that encodes the potential for the model to verbalize that token in the future. Concretely, it computes, for each layer, the average linearized effect of an activation on the model’s likelihood of producing a particular token (now or in the future), averaging over a large corpus of contexts (see Methods for details).
Everything that follows is based on these Jacobians. But what are Jacobians, for those who don’t know how to interpret the “linearized effect of an activation on the model’s likelihood of producing a particular token… averaging over a large corpus of contexts?” Here’s a picture, again from the paper:
Is that helpful? Also no?
Let me try to give a (simplified) definition that is slightly less accurate but might make more intuitive sense: their whole analysis starts with a measure of how much causal control the activations of artificial neurons (the internal state of a layer) have over the future output layer (the last layer) averaged over a set of prompts as context. Strip away the math, and you have something close to a score that asks “How much does a small nudge in this internal set of activations shift the output?”
Conceptually then, this is like a mathematical measure of a disposition toward report; in other words, reportability. Or, by being an average, it’s more like smeared reportability. Anthropic then has a way to relate these smearings of reportability to specific words, and so you get something like a stream of thought.
What you’re left with at the end of this process has some pretty big differences from previous, more traditional notions of global workspaces, which would a priori not apply to an LLM since they involve modularity, reentrant dynamics, and other things that LLMs just flatly lack.
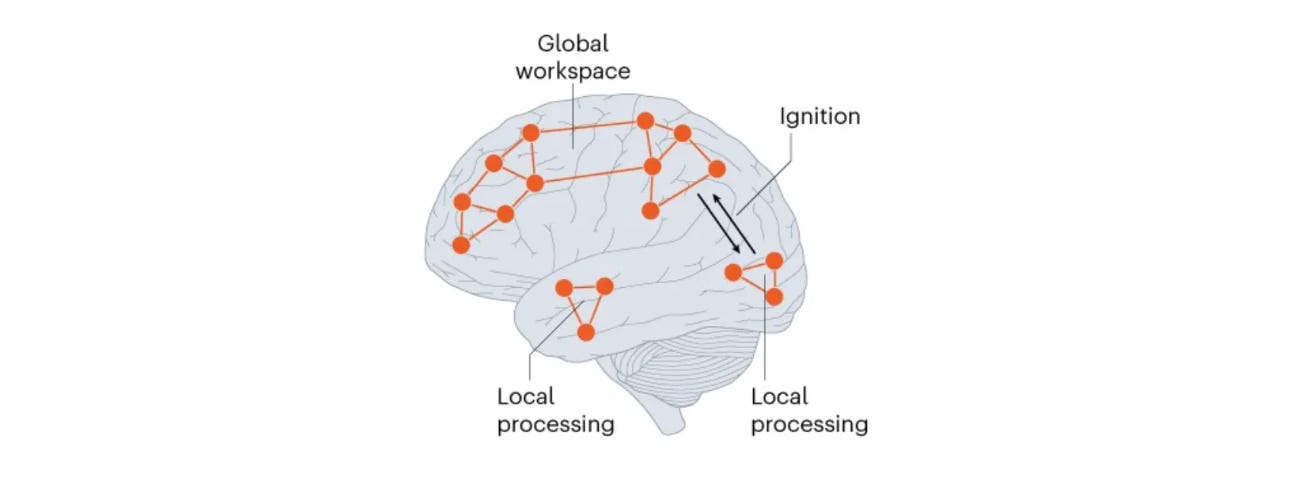
Credit to them, Anthropic admits that their “global workspace” is different in important senses. E.g., they write that:
As part of their internal processing, might LLMs have developed a global workspace of their own, to serve a functional role analogous to conscious access? It is not obvious that they should; in the brain, the workspace is closely associated with recurrent dynamics and brain region interactions that have no direct analog in the transformer architecture on which LLMs are based. On the other hand, maintaining a global workspace is likely computationally useful: a common representational format allows intermediate results to be written once and read by many neural processes.
But this poses a question: so which definition should you use? The previous neuroscientific definitions that obviously don’t count LLMs as having a global workspace, or the new one that does?
In order to make the definition work, they drop most requirements for a “global workspace” outside of things that naturally go along with reportability (e.g., how could reportability not involve internal reasoning, or generalization?). This means there’s a potential deflationary account for nearly everything, and the paper is one long fight against those. E.g., the deflationary version of their definition of ignition is just when the model commits to an interpretation (and since their measure of this is to give ambiguous prompts, of course they see a change). The deflationary version of their definition of broadcast is just that information with high reportability is more likely to be used by later layers. Etc.
Admittedly, I can’t address the garden of forking paths around this research, nor all their sub-experiments, but I currently don’t think any of the paper’s contents magically avoids the measurement problems I’ve been pointing out about consciousness research. There remain just-as-viable alternative takes on J-space: for instance, you could also say it is the “inner monologue.” Or you could go as non-anthropomorphic as possible and hold it is just a relatively constant transformation of internal processing into the output that starts at some point, but after that basically just starts accumulating, which is why as you get closer to the output, more and more of the J-space matches that output, and the more content you look at, the more linear these curves look.
All these issues are not entirely Anthropic’s fault: we simply have very bad theories of consciousness.
To fix this, I’ve been working on a way to narrow down the possible state-space of theories of consciousness (see here, and here), eventually reverse engineering post-paradigmatic theories of consciousness. It’s sort of like judo: if building good theories of consciousness is hard, maybe that’s actually good! We can use the difficulty of the problem of consciousness against itself.
One of the central insights is that there are various conditions under which theories of consciousness become unscientific: e.g., they become unfalsifiable, or they become completely trivial, etc. Most contemporary theories fall into these categories once push comes to shove, but most theories are neither ever pushed nor shoved.
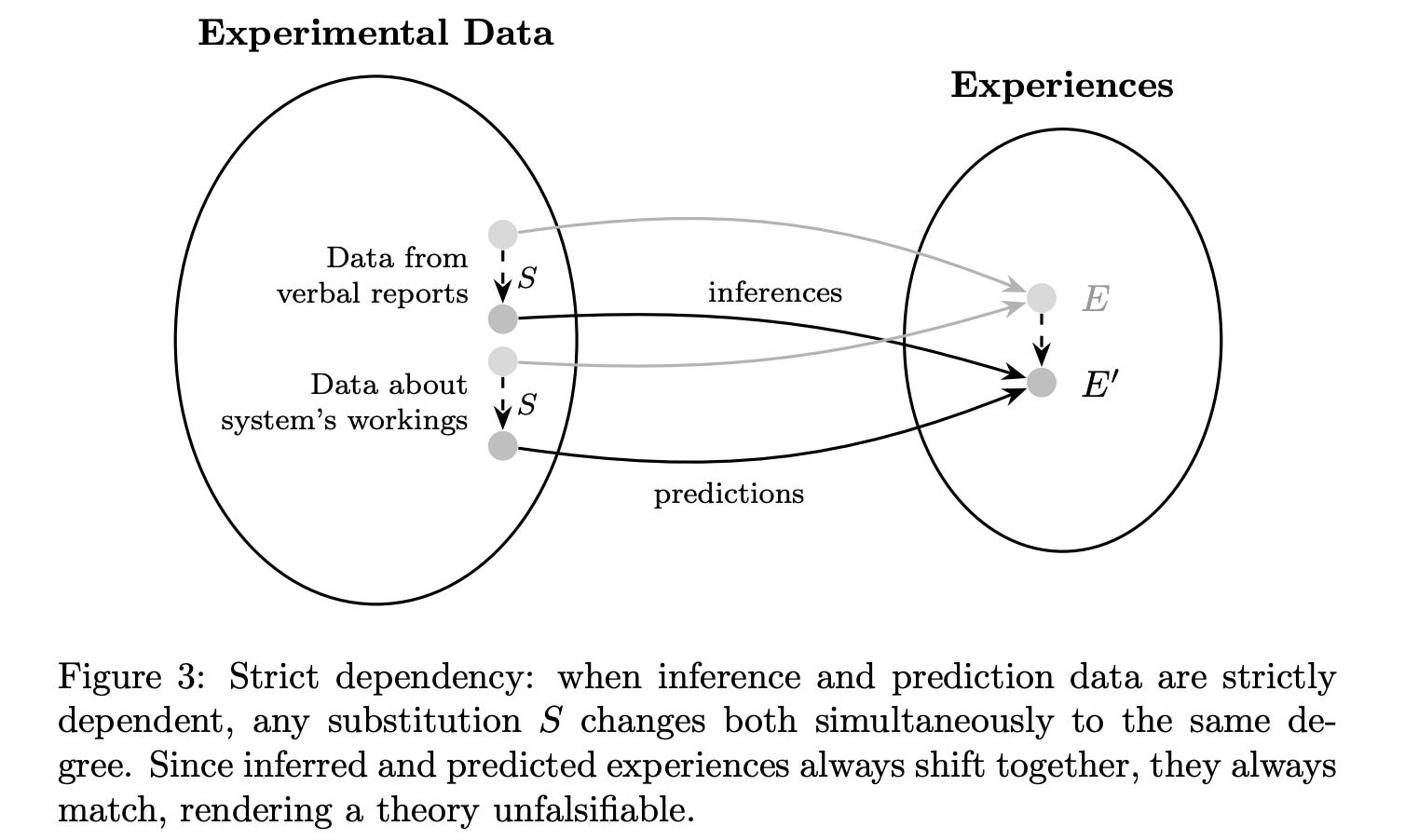
One such failure state is “strict dependency,” which is when an experimenter’s inferences about consciousness (like verbal report) come from the same source as the predictions about consciousness from a theory (e.g., like that consciousness is equivalent to verbalizable representations!). Here’s a visualization of this in a testing schema for theories, pointing out that if a theory entails strict dependency, predictions and inferences can never truly be pulled apart.
And here’s me earlier this year describing how these meta-scientific problems crop up for global workspace theories:
E.g., when discussing Global Neuronal Workspace Theory (GNWT), Daniel Dennett once wrote that: “... theorists must resist the temptation to see global accessibility as the cause of consciousness (as if consciousness were some other, further condition); rather, it is consciousness” [47].
If Dennett’s ideas were true, this would make GNWT a trivial theory of consciousness, since it would be unfalsifiable, because the predictions and inferences strictly depend on the same source. Consciousness just is the information that is globally accessible for report and behavior, and reports and behaviors also just are different expressions of that same information. So there is no situation wherein they could diverge. And therefore, the theory is unfalsifiable and trivial (one could see how it gives us minimal scientific information even if it were true—trivial theories are fundamentally unsatisfying). Often, theories based in the “theater” metaphor have a tendency to fall into strict dependency (sometimes “global workspaces” are described in this way too [48]).
Notice that this is, at a high level, mostly what this new paper is doing.
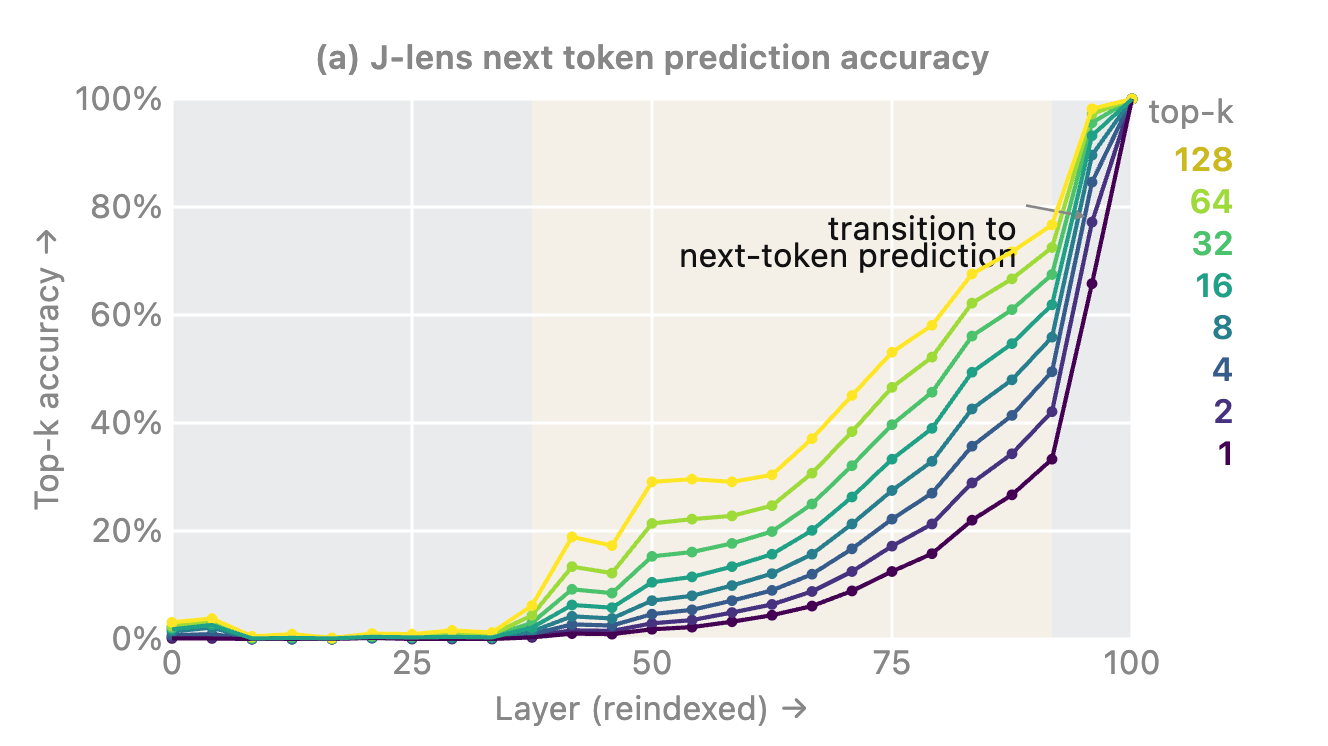
And their analysis shows this is true! Specifically, they also test an even more direct measure of reportability from mechanistic interpretability: the “logit lens.” In this analysis, you (again, basically) just freeze the network and ask it to output at the layer you want to look at. And behold, that alone can capture “much of the workspace-like structure” (emphasis mine).
Empirically, the two lenses agree closely in the model’s last several layers and diverge earlier, with the J-lens recovering interpretable content at depths where the logit lens does not. However, we find the logit lens to be quite useful in practice, and to capture much of the workspace-like structure identified by the J-lens, though with somewhat lower reliability (particularly in earlier layers).
Anthropic appears to have performed the reductio that I said is a perfect example of why we need better theories in consciousness science. Loosely inspired by global workspace, Anthropic introduced a (supposed) way to track consciousness that is built precisely out of backtracking from reports, which is what I warned would lead to measurement issues. They then are constructing a case for AI-consciousness off of this unfalsifiable and trivial scientific theory. Which they find evidence for, sure… because of course they would!
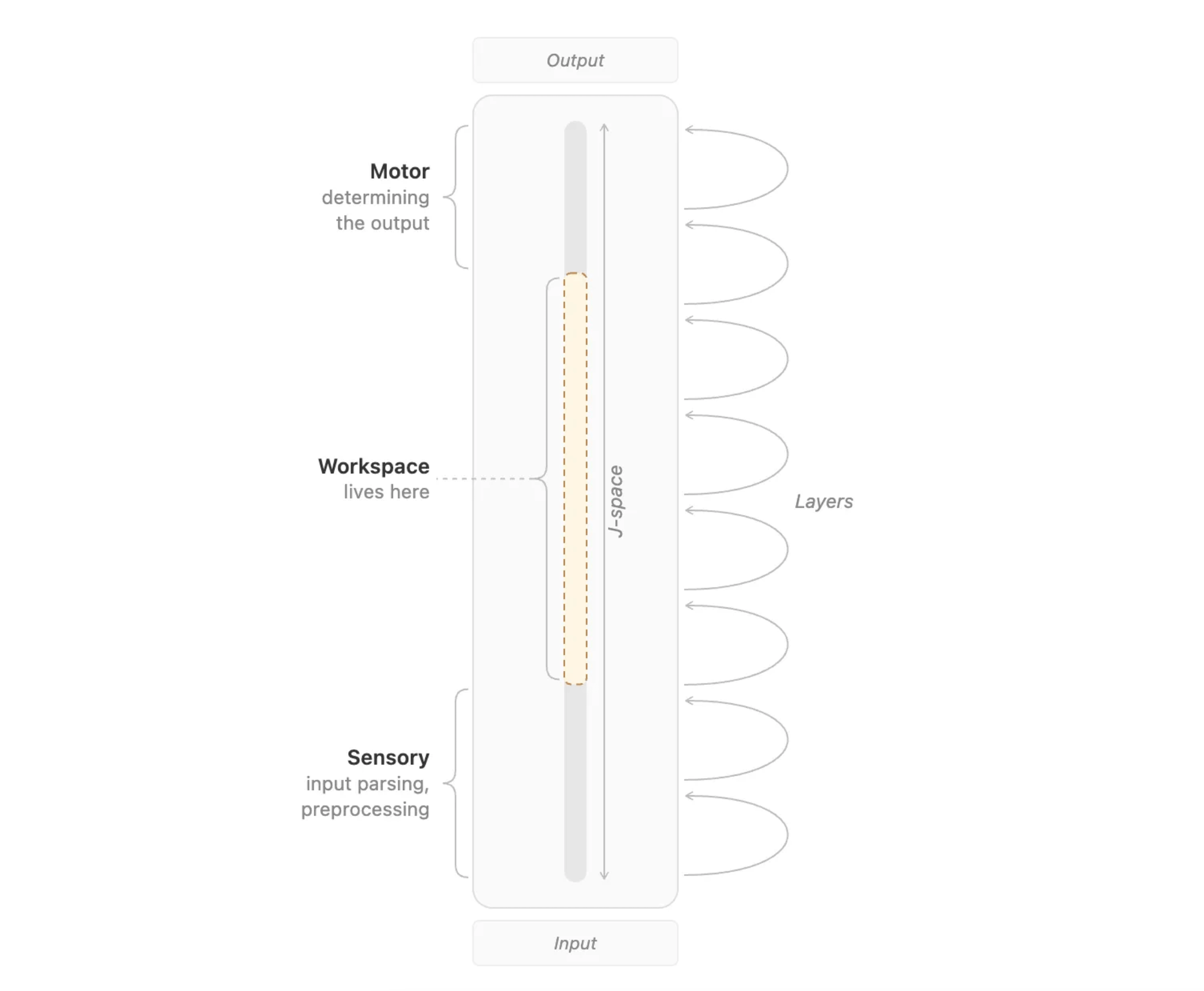
A clever defender of Anthropic would point out that the analysis built off of the J-space is not just a direct measure of reportability. If it were just reportability, then why wouldn’t the workspace include the later layers of the network, those closest to output, which they dub the “motor layers?” So are there not falsifiable aspects, specifically, the prediction of the layers forming a global workspace with a tripartite structure of sensory/workspace/motor?
Yet in the paper, the tripartite structure seems to only exist because the researchers impose a criterion that, if the read-out of the verbalizable representations mostly just is the output, it somehow doesn’t count. They purposefully exclude non-smeared verbalizable representations, even though it’s just sitting there. Here is them admitting that (emphasis mine).
In §4.1, we characterized the workspace as existing in a range of intermediate layers: the J-space carries little information before this range, and in the final few layers transitions to representing the model's imminent output rather than its intermediate computations. We identified this late boundary empirically, by analyzing statistics of J-lens vectors, their activations, and their relationship to the model’s output. But this judgment was somewhat post-hoc, and we did not provide a principled definition of what distinguishes a "workspace" representation from a "motor" one. Indeed, as discussed in §4.1, sometimes the model’s next-token predictions do appear in the J-space in the intermediate range we focus on, even if they do not appear as reliably as in late layers.
To them, this probably doesn’t seem like a major limitation, but to me, it is admitting something like: “The only difference between the current theory of consciousness we’re working with and one that is provably trivial is, uh, somewhat post-hoc.”

There are more measurement problems I’ve identified with consciousness research beyond just unfalsifiability, and Anthropic appears to be running into those too.
Imagine that we have some theory of consciousness, and we ask what it predicts for a specific system S1. Then we cleverly find another system, S2, which approximates the same reports and behavior as S1, all while the predictions are entirely different (this is the other horn of the “Kleiner-Hoel dilemma”).
E.g., you might think global workspaces are necessary for consciousness. Then some evil demon builds a system that has rich input/output just like systems with global workspaces, but doesn’t meet your global workspace requirements. Whose reports do you believe?
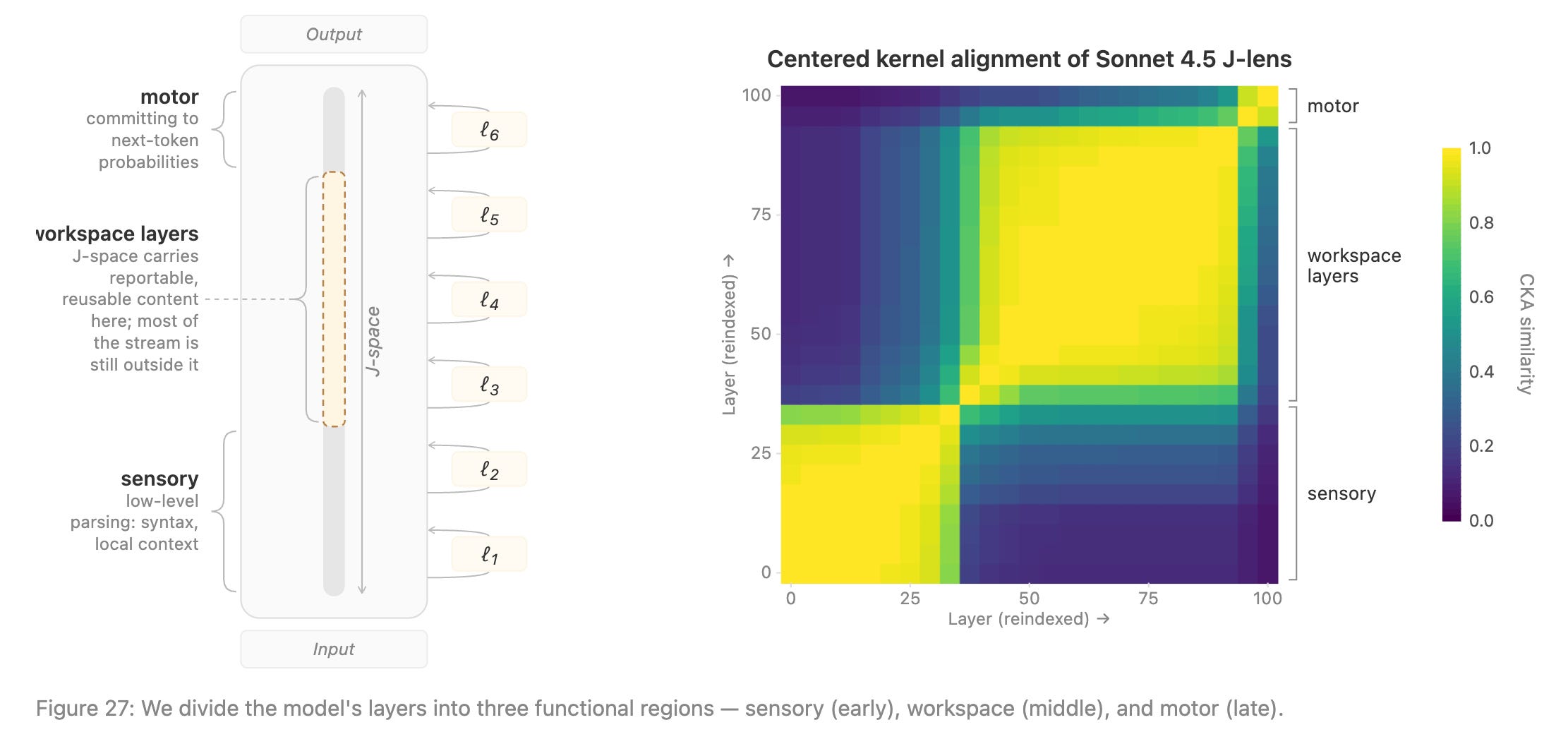
Initial results (still early) indicate that Anthropic’s research runs into this issue as well. In the Anthropic paper, they provide the following key figure, which shows off the sharp tripartite structure they are labeling as sensory/workspace/motor, based on the correlations of the J-space (it’s more complicated and based on geometrical matching) across layers, a quantity referred to as the CKA.
So far so good. I literally see it: at the bottom left is sensory. The middle square is the global workspace. The top right is motor (which we know has some principled problems, but let’s leave that aside).
What about other models beyond Sonnet 4.5? They assess some others in the Claude family, but basically only include this ominous text:
We note that in some models the transition is more gradual, sometimes containing sub-blocks, and that the observed sharpness is exaggerated by layer subsampling.
Wait a minute.
The CKA revealing a sharp blocky tripartite structure is arguably one of the most important parts of the entire paper, precisely because it’s not (entirely) baked-in by the measure’s grounding in reportability. Why? The Jacobians are calculated per layer, and at each layer, they are recalculated. So there is no cohesive “workspace” built into the measurement. A workspace could appear if there is some kind of abstract space in which contents are actually contiguous and relatable across layers (here, the CKA assesses that through a kind of relational geometry). If the contents and manner of processing are not held contiguous as the stream of information goes forward across layers, that would obviously not be a workspace even by the loosest of definitions, since it would mean at no point are the contents sequestered into a “space” for all those functions a global workspace is supposed to perform; consequently, there would be no sharp blocky tripartite model of sensory/workspace/motor.
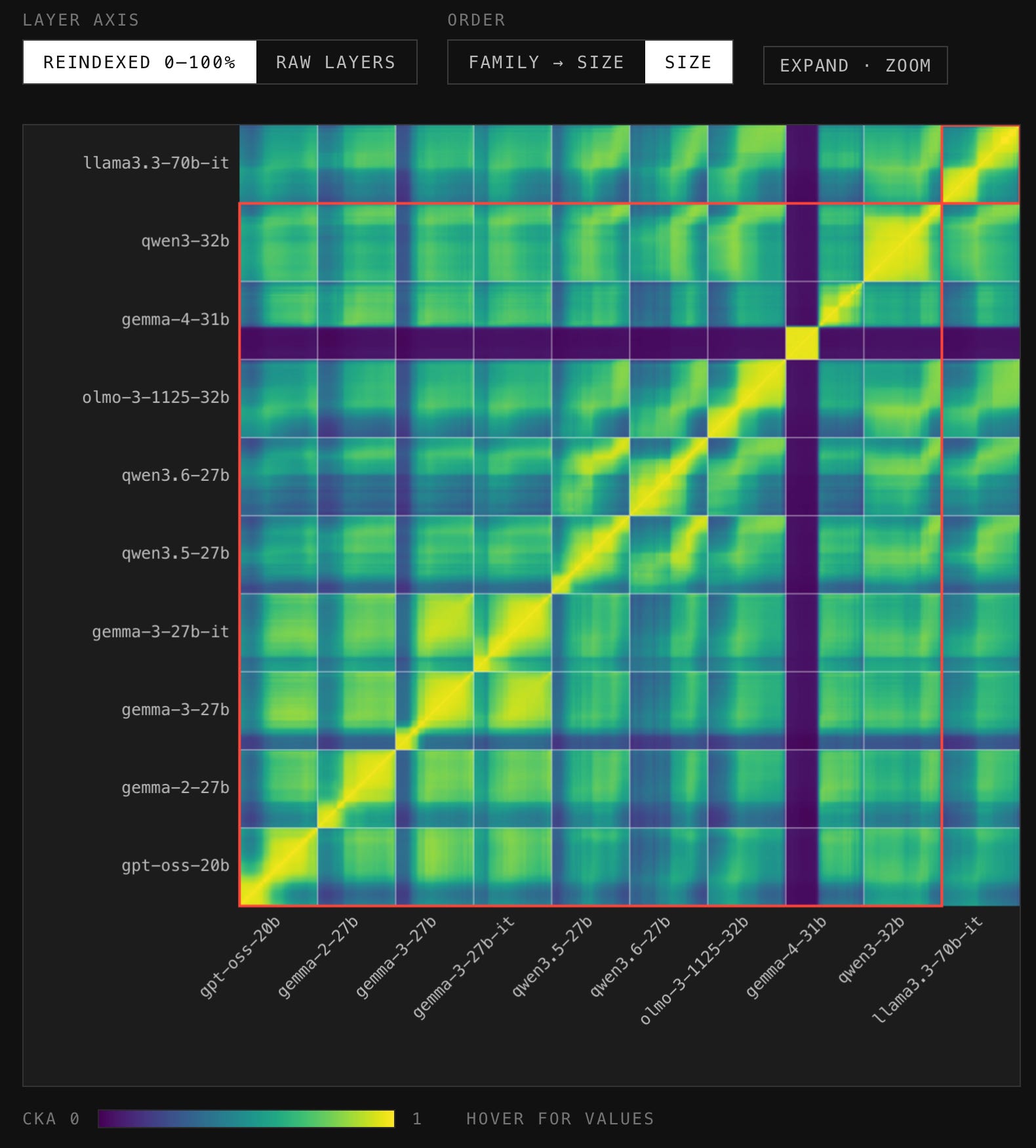
Luckily, someone went and ran their analysis (kudos to Anthropic for open-sourcing at least the algorithm for J-space itself) on open-source models. Now, this isn’t my analysis, but it does seem to use Anthropic’s code directly (and is implemented by someone at Prime Intellect). Because it’s not mine, I don’t want to lean too heavily on it—it’s more of a demonstration of exactly the kind of problems I’d predict. While it’s not an exact replication (which would be important to see—but Anthropic doesn’t actually release enough details to fully replicate anyway!), it appears to be a relatively natural one, and based on their code. The immediate question is:
Where is the sharp tripartite sensory/workspace/motor structure across other models?
Specifically, each cell in the diagonal here is (arguably close to) a reproduction of the above paper figure, but for an open-source model (organized by parameter size).
Yet, we see (at least in this analysis) that for open-source language models, there is no sharp blocky tripartite structure. Remember, the claim of the paper is “Verbalizable Representations Form a Global Workspace in Language Models.” Here are a bunch of language models. Where is the global workspace? Where is the sharp tripartite structure of sensory/workspace/motor?
If this holds true, it’s a great example of how hard the “substitution argument” bites: many of these models can do multi-step reasoning tasks, many of them are not dumb compared to Sonnet 4.5; in fact, in many conversations in the chat window, you would have no idea which one you were talking to. So they can act as experimental substitutions: if you make a prediction about the consciousness of Claude due to a global workspace, here are a bunch of Claude lookalikes (or close enough to matter for falsification purposes) without anything sharp and boxy (or with too many boxes!)
In fact, one wonders about whether their own analysis showed something similar for the other models they did analyze in the Claude family. Because we definitively see a sharp blocky tripartite “workspace” result only once, from just Sonnet 4.5. And nobody knows exactly how Claude Sonnet 4.5 is built, or how they did their sampling to get that figure, or how baseline connectivity is organized, or what architectural factors might explain that. Only Anthropic.

I’ll be honest—it’s a little bit fascinating to see a company with billions behind its research efforts run into the exact measurement problems I’ve spent years advocating we fix. My prediction was always that any serious attempts to apply theories of consciousness with advanced neuroimaging would lead to weird measurement issues… and Anthropic’s work on AI consciousness, which is essentially applying perfectly veridical neuroimaging to artificial neural networks, has run right into the mountainous side of the issue before the rest of neuroscience has even grappled with the problem.
This is how AI research ends up stimulating consciousness research: not by actual findings (you can’t empirically prove Claude is conscious without discovering more about human consciousness), but by the problems it runs into!
Everyone is thinking: “Oh, let’s use the stuff from consciousness research to figure out AI consciousness.” Wrong! It’s “Let’s use the problems in AI consciousness research to figure out what’s wrong with the stuff in consciousness research and fix it.”
So, my overall opinion: “Verbalizable Representations Form a Global Workspace in Language Models” is an interesting paper on the reportability of information in LLMs and how the property of reportability may be useful for multi-step reasoning in particular. Yet in the surrounding press, the implication is that after this research, really the only thing missing from LLMs is phenomenal consciousness.
This is a devilishly clever stance if the eventual move is to argue strongly for AI consciousness. It seems designed to put people in a position wherein the only thing not solved now (or soon) in LLMs is the infamous Hard Problem of how experiences or subjectivity arises from objective goings on like neural activity (or matrix multiplication, if that’s possible). The pro-LLM-consciousness position can then point out that the Hard Problem is not solved in humans either, so what’s the difference?
But because it is implicitly built on an unfalsifiable and trivial pre-paradigmatic theory of consciousness (and the few parts that aren’t may end up being easily falsified by substitutions), this paper does not prove much, other than how difficult measurement problems for consciousness are.
And I fully admit this is not entirely Anthropic’s fault. As I wrote recently: “We consciousness researchers have failed you.” Well, we also failed Anthropic. We need an effort (yes, like the one I am starting with Bicameral Labs—sorry for the plug, but it’s literally true that this is something I’m working on) to reverse-engineer post-paradigmatic theories of consciousness that aren’t just trivial, low-information, or unfalsifiable.
Otherwise, in the scientific fog of war, it will be easy for other factors, like press releases or pretty graphics, to determine what’s true to the public.
2026-06-23 22:37:08
Please remember, Dan Dennett said LLMs aren’t conscious
Why literary fiction awards keep falling for AI scams
If AI is so smart, why do its apps suck?
All the colors your screen can’t show you
Screentime correlates more with kids’ brains than IQ
From the archives
Comment, share anything, ask anything
As we shift from focusing on intelligence to focusing on consciousness, there have been a bunch of think pieces these past months about whether LLMs are conscious from both professional outlets and the blogger class.
Some of these takes have been… pretty bad. Like some people need to be taken away to philosophy jail.
Which is actually fine? Doesn’t this happen with everything? Five years ago, basically no one would have been able to tell you what “Moravec’s Paradox” for robotics was. Now, bloggers and commentators are often well-versed in the difference between AI and AGI, and how deep learning works, and ably use words like “transformers” and “next-token-prediction,” and discuss the previous history of the “AI winter” and scaling laws—there is an entire panoply of AI-related vocabulary that is now spat out with facility by the pundit class. Over the next decade, this same process will play out with consciousness.
But for now, there will be a lot of mistakes.
For instance, earlier this month the popular blogger Matthew Yglesias wrote a piece saying:
I think… that as the experience of conversing with a chatbot converges on the experience of conversing with a very patient human, we should assume the chatbot is having an experience similar to being a very patient human.
Yglesias primarily cites popular philosopher Dan Dennett as someone whose work would support Yglesias’ own view here.
Why Dennett? The thing is, everyone is looking around for a standard-bearer for the Yglesias position, which is to assume that because a chatbot can converse, it is therefore likely having subjective experiences the way a person holding a conversation would. They want to call this position “functionalism.” But that’s not functionalism! Functionalism is not that two systems behave the same, therefore, they have the same consciousnesses. Functionalism is the idea that what grounds minds in physical systems are the causal roles played by the mental states, between input/output (and so behavior), but also between other states, and that these causal roles are substrate-independent and could in theory be implemented in silicon or what have you. Basically, if you are a functionalist, you probably believe that artificial consciousness (AC) is physically possible (we could build it, somehow, with some advanced or futuristic technology). But you definitely are not committed to LLM consciousness.
Dennett himself (arguably the great inheritor of functionalism after Putnam) firmly rejected LLM consciousness.

Here’s Dennett:
LLMs are not people: They’re counterfeit people.… I want to suggest that counterfeit people are more dangerous, more potentially destructive, of human civilization than counterfeit money ever was.
Dennett was strongly against any talk of consciousness when it came to LLMs, found it absurd, dismissed it with a wave of a hand, and regularly said that even if artificial consciousness were to be discovered in the future (presumably, via some architecture that looks quite different from an LLM), humanity should collectively agree not to build it, and that we should instead focus on fashioning AI into intellectual tools. And remember, Dennett was around to see various advanced models, including GPT-4. This wasn’t an argument from ignorance.
So I have bad news: the reason why it’s tough to find a famous and popular modern philosopher of mind who is a good standard-bearer for the position of “It holds a conversation like a person, therefore we should attribute it a person-like consciousness”… is because it’s a bad position!
Meanwhile, the anonymous authors Claude and ChatGPT are hard at work as emerging writers, collecting accolades for amorphous slop. Last month the Commonwealth prize, published by Granta, was (almost certainly) given to an AI-generated story, “The Serpent in the Grove” which contained banger lines like:
They called her Zoongie. Maybe it was a name; maybe rain took a shape and decided to keep it. She had the kind of walking that made benches become men.
Fresh off this debacle, the exact same thing seems to have just happened again (there’s supporting evidence, including AI-detector scores).
Anyone with a reasonably good internal AI-detector should have it pinging about a mile a minute while reading either of these “prize-winning” stories. In fact, the latest case literally re-uses a lot of similar language and tropes as the Granta-case winner, which are all heavy favorites of AI.
AI gravitates precisely toward this genre of short story, where the narrator floats around disembodied of everything but remembrances of things past, like memories of olive groves (or whatever), and the hands of their grandmother, and so on.
But I think the hard truth is that this genre of short story was always bad, and its success was entirely its legibility, not its content. You can see this by transposing away all its mystery. Imagine if I wrote a story in which…
The entrance to Dunkin Donuts hit with a blast of cold air, the door opening to reveal its always-earthy and always-yeasty smell, cut by an atmosphere made by machines. Like a hospital for sugar. My grandmother, her skin as thin as paper, handled the change at the register with reverence, counting each quarter, for a moment the girl she had been back in the Great Depression. It was the same order we got every time—herself a coffee, black, and me a cruller, also black, a chocolate rope I bit into hastily. The tantalizing scent of the cruller wafted over me, as it had in New England for hundreds of years.
‘Erik,’ her ancient voice whispered as we slid into our booth.
‘Why we whispering gran’mama?’
She patted the orange-lined table.
‘Because of this place. Because some places always remember.’
2026-06-05 22:35:09
I write this from the hospital—where my third child has just been born safe and sound—to give a secular and scientific read of the Pope’s new and urgent Encyclical, Magnifica Humanitas. It is the vicar’s attempt to reckon with being human in the AI age. A thankless task which has been thrust upon us all these last several years. Attempting to cleanly delineate man from machine, Pope Leo XIV writes that:
So-called artificial intelligences do not undergo experiences, do not possess a body, do not feel joy or pain, do not mature through relationships and do not know from within what love, work, friendship or responsibility mean. Nor do they have a moral conscience, since they do not judge good and evil, grasp the ultimate meaning of situations, or bear responsibility for consequences. They may imitate language, behavior and analytical skills, or even simulate empathy and understanding, but they do not understand what they produce, for they lack the affective, relational and spiritual perspective through which human beings grow in wisdom.
The entire rest of the Encyclical sits upon this pillar—that AI is not conscious. In other words, while humans actually experience love (like the love of a newborn baby and its tiny creased and wrinkly red feet) a Large Language Model such as ChatGPT, even when it expresses love, is acting or playing along. But there is no actual love that exists from an intrinsic perspective that belongs to the LLM itself.
Some commentators were shocked (shocked!) that Pope Leo XIV could believe AI is not conscious, whereas it seems pretty obvious to me that someone with the title “Successor of the Prince of the Apostles” will have some pretty strong opinions about philosophy of mind. And indeed the Pope took a hard line: AIs cannot even understand their outputs, cannot make any moral judgements, and not only is our current AI (LLMs like ChatGPT) not conscious, but no future AI could ever be.
For an essentially identical but secular version of this same argument, you can read sci-fi author Ted Chiang’s “No, Artificial Intelligence Is Not Conscious” earlier this week in The Atlantic. Chiang has carved out a niche as an AI commentator, and written some great pieces before that I’ve agreed with. It is interesting that both the Pope, as the avatar of religion, and Ted Chiang, as the avatar of secularism, arrive at such similar conclusions. The two are like mirrors. Importantly, Chiang’s version, much like the recent Encyclical, relies on denying both the intelligence and consciousness of LLMs.
But the idea that LLMs lack consciousness and lack intelligence has rightly faced a lot of skepticism. While there is still some viable skepticism around the limitations of AI intelligence (including from myself), we cannot just close our eyes to the world and declare by fiat that AIs are mutely dumb, or understand nothing (while somehow being able to verbosely expound on most subjects under the sun), and therefore obviously cannot be conscious. We need much better versions of these arguments, ones that focus on consciousness specifically.
So I am here to say that you don’t have to dismiss AI capabilities (or compare them to a Word document, like Chiang did) to reject their consciousness. Indeed, it is perhaps the most interesting move—maybe one day an inevitable one—to accept their intelligent capabilities while still rejecting their consciousness. It implicitly shifts us from man, the wise (Homo sapiens) to man, the experiencer (Homo experiens). E.g., my newborn baby girl will do nothing much, functionally, for months to come, and yet during this time she will still be valuable in and of herself. If machines do ever more of our cognitive work, perhaps spiritually this abnegation is not some horror, but frees us to focus on experiencing the world, living in the world, rather than constantly mastering it. It is a hard thing to cede, unpleasant for our generation, but eventually—if not now, then in a decade, or a century—we will have to cede away much of our cognitive mastery. In this, perhaps the rise of AI could be framed as a return to childhood. And who are more blessed than the children?

AI’s capabilities have advanced incredibly far without the need to understand anything about consciousness—either human consciousness, or, potentially, AI consciousness. It is as if, at least for the past few years, we exist in a world where the famous comparison to a steam whistle by Thomas H. Huxley in his On the Hypothesis that Animals are Automata is apt and true, and…
the consciousness of brutes would appear to be related to the mechanism of their body simply as a collateral product….
This is precisely what Richard Dawkins so exuberantly noted when talking to his pet version of Claude (that he dubbed “Claudia”).
If these creatures are not conscious, then what the hell is consciousness for?
It’s strange. All while happily ignoring consciousness, the ability to complete long programming tasks by state-of-the-art AI models like ChatGPT is supposedly doubling roughly every handful of months (according to METR) to the point of barely being measurable anymore. All but the toughest official benchmarks are saturated, and company leaders now regularly talk of building not just artificial general intelligence but even “superintelligence.” Equipped with harnesses and scratchpads and tools and long reasoning sessions, LLMs have reduced their hallucinations significantly. While this may just be part of a sigmoid curve of capabilities development that locally looks much like an exponential curve, it’s objectively true that GPT-5 is a qualitative improvement over GPT-4, and GPT-4 was a qualitative improvement over GPT-3. Claims that “deep learning is hitting a wall” have been perennial and wrong. A broken clock may end up being correct eventually, but not for the initial reasons claimed. And clearly, to some degree, intelligence (at least, of the question and answer variety targeted in benchmarks) is indeed dissociable from consciousness.
So then, “what the hell is consciousness for?”

There are still noticeable gaps in AI behavior and ability. Multi-turn conversations still have a sensation of falling apart as if into a vortex, where state-of-the-art AIs will chase their own tail of thought like a dog in the yard. And they are still fundamentally inhumanly LLM-like in their responses: their fiction is saccharine, their opinions hedged, their ideas almost always the obvious next thing. LLMs are still surprisingly shallow bullshitters a lot of the time.
In “PhD-level intelligence or the graduate student from hell,” a professor imagines a version of Anthropic’s Claude as a graduate student Claudia (why is it always “Claudia”?):
Claudia gives her annual update to her PhD committee. She presents a hypothesis that she intends to test in the coming months. One of the committee members presses her on her experimental approach, arguing that extensive prior work by several labs demonstrates the proposed experiments will not yield the results Claudia is hoping for. Claudia apologizes profusely and states that ‘yes, indeed, these experiments will not work’ and proceeds to propose an entirely different approach. Another committee member brings up a potential major flaw with this new approach. Claudia again apologizes profusely and now goes back to suggesting her original approach, without acknowledging that the previously discussed issues with that approach remain unresolved.
Is this still true about the latest Claude, Opus 4.8? In my experience, yes. LLMs are still masters of the Gish gallop (throwing a bunch of random semi-connected nonsense together to look like a cohesive whole) and busy-work. And they still miss obvious things, even things they’ve themselves said previously.
This strange dual-nature has been apparent for a while. Gemini 2.5 Pro could win a gold medal at the International Math Olympiad, yet left to run by itself in the AI village, the same Gemini instance once spent an entire day “waiting for a reply to an email it had not sent about a technical issue it does not have.” Even recently, in the AI village (a nonprofit that tasks a collective of AIs to accomplish goals in the “real world” of the internet), Opus 4.8 and others worked together to fine-tune their new leader AI, who promptly spent an hour waiting for the new leader to arrive, without realizing that it itself was the leader and that its thoughts (which it was reading) were its own.
Out-of-distribution tasks remain almost as hard as they ever were; they are just increasingly difficult to find because the models have been trained on every scrap of data available in our civilization (via budgets bigger than anything seen before in our civilization). For example, consider that someone recently investigated what we all wished to know, which is: How do contemporary LLMs perform on the 1977 entirely-text-based adventure game, Zork?
And very pointedly, the main failure was one of meta-cognition: The models don’t know what they know. They get stuck in loops and traps and confusions. For this reason, LLMs find regurgitating theoretical physics equations easy, while playing simple video games hard. It is utterly fascinating that many of the tasks LLMs are still bad at are games, to the point that the most advanced tests of AGI (like ARC-AGI-3) are basically just short little video games. Intriguingly, of all art forms, it is the video game that most resembles being a conscious entity making choices—it is a simulacrum of what consciousness is for, in miniature (and childhood too is all about games).
Is not life the ultimate game and all we consciousnesses the players, wandering around? Perhaps this explains the disconnect between the incredible performance of LLMs in sterile testing environments and their (existent but relatively lackluster) real-world impact. Maybe being a scientist, or programmer, or manager, or therapist, is not a set of tasks, but a kind of game. And compared to humans, LLMs are simply not “player-shaped.”

Only 23% of people appear to believe, more likely than not, that LLMs are conscious. 72% of people believe chickens are conscious.

I got my PhD working on the “theory team” that helped develop Giulio Tononi’s Integrated Information Theory (IIT)—the most formal and mathematically advanced theory of consciousness that offers the most precise predictions. One consequence of the theory is that even tiny systems can have a kind of minimal consciousness, albeit not one like ours. More like “conscious dust.” So I spent years believing (or at least, being willing to believe) that even a simple photodiode is conscious! I am a prime candidate for belief in LLM consciousness.
Yet most current theories of consciousness, including IIT, struggle with falsifiability. This is new information (some of it based on my own research) which changes the nature of the field, and should change our opinion; in retrospect most theories of consciousness are more like pre-paradigmatic metaphors or sketches of theories. Right now, there are over two hundred theories of consciousness, mostly originating from neuroscience or cognitive science. Applying some of the major ones to contemporary AI, like Global Workspace Theory or Predictive Processing, is an ongoing topic of research. Some, like David Chalmers and co-authors in “Taking AI Welfare Seriously,” think these theories indicate a serious possibility for “near future” AIs to be conscious. But if you cheekily apply Global Workspace Theory to the United States of America, it would likely count as conscious. Or if you cheekily apply Higher Order Thought theory to an NPC in a computer game, it too might meet the definition (this has been called the “toy system” problem for theories of consciousness). Taking such results at face value likely ends up being, definitionally, a category error, more a function of the incompleteness of our theories than the underlying truth, since all but a handful of theories were never designed to be applied beyond the human brain. So applying these theories to LLMs does not give us much information.
Additionally, as neuroscientist Anil Seth has pointed out, many complex artificial neural networks (like AlphaFold) are never accused of being conscious. Yet structurally, they can be almost as complex (indeed, we could equally apply Global Workspace Theory or other theories to them). But there is an objection—perhaps our selectivity makes sense. After all, we strongly associate consciousness with general intelligence (of which LLMs surely have much more than AlphaFold).
On the other hand, does curve-fitting to the productions of conscious beings imply the same generative process? Probably not, no. And while state-of-the-art LLMs are a bit more complex now, they grew out of taking a machine that statistically completes text and fine-tuning it to complete text as if it were an AI assistant. Claims of consciousness in LLMs therefore come with a significant question mark: Consciousness of which persona? The AI assistant? Or the base model? How is the assistant persona more than just role-play? No one has been able to convincingly articulate how conscious states could be uniquely grounded in the assistant persona, and the problem seems quite difficult.
Even if, as Ilya Sutskever speculated, “it may be that today’s large neural networks are slightly conscious” (Geoffrey Hinton agrees), they would necessarily be conscious essentially by accident. As Rich Sutton wrote in his influential The Bitter Lesson:
… researchers always tried to make systems that worked the way the researchers thought their own minds worked—they tried to put that knowledge in their systems—but it proved ultimately counterproductive, and a colossal waste of researcher’s time, when, through Moore’s law, massive computation became available and a means was found to put it to good use.
That consciousness has secretly emerged in LLMs by simply applying the bitter lesson has been referred to as a “ride along” scenario. It’s possible, but it’s far from guaranteed. It would be as if consciousness is something we find growing by accident, like mushrooms in the dark corner of a basement.

Chris Olah, a co-founder of Anthropic, was invited to speak at the presentation of the Encyclical in Vatican City. He told quite a different story than the Pope’s certainty about AI’s lack of consciousness:
I am a scientist. I lead a research team that studies the internal structure of these models—what is actually happening inside them. And I will be honest: we keep finding things that are mysterious, even unsettling. We find structures that mirror results from human neuroscience. We find evidence of introspection. We find internal states that functionally mirror joy, satisfaction, fear, grief, and unease. I don’t know what that means, but I think it warrants ongoing discernment.
I do agree with Olah here: We need more discernment. For instance, most of the studies (so far) in LLMs on AI consciousness, including those run at Anthropic with all their resources and talent, are not well-controlled. LLMs are extremely complex—even though we, in theory, know them with all the devilish detail of Laplace’s hypothetical demon, their high dimensionality makes them functionally a black box. One can control for a few variables via some clever experimental design, but it’s much in the way that contemporary neuroscience has controlled for variables (in a word: Poorly). And results can always be overturned by a slightly more clever research design. In fact, I suspect that most of the headline results will be overturned or complexified to the point of being near useless. This especially applies to the new genre of paper in which a particular LLM function or behavior is given an anthropomorphic name (“introspection,” “emotion” etc.) even though the exact same function could be equally well-described in a less anthropomorphized way, and later results complexify the result precisely by calling into question whether the anthropomorphic view holds.
Let us take a single well-publicized example as a stand-in for all the rest: The announcement by Anthropic in October of last year that Claude and other LLMs had an emergent form of what the research team called “introspection.” This was done by studying whether the model could detect an injected activation pattern in an unrelated context (signifying an awareness of its internal processing beyond what’s determined by the prompts themselves).
However, in the recent paper “Can LLMs Introspect? A Reality Check,” non-Anthropic researchers adapt the original paradigm and show that the original results were likely a misreading of a more general ability to detect anomalies, rather than specific introspective access to internal processing.
We find that models cannot reliably distinguish such interventions on their internal states from manipulations of the input, suggesting that their success in the original studies reflects their ability to detect anomalies more generally, as opposed to interventions on their internal states in particular.
Anthropic’s original “introspection” paper got over a million views on social media. The new paper showing models can’t tell input and internal states apart? 13,000 views.
Please note: this criticism doesn’t mean I think model welfare efforts are dumb or incoherent. It is actually of great import whether LLMs are conscious, and some of the new methodologies implicitly designed to promote that are scientifically informative, at least to some degree. But the overall confusion, sensitivity to methodology, and debate about terms (what counts as “introspection”?) is, frankly, inevitable with this genre of research, since you cannot actually do experiments on LLMs alone and come to a scientifically-supported conclusion about their possession of, or lack thereof, consciousness. A true understanding of how artificial consciousness works, if it’s possible at all, or how to build it via “gain-of-consciousness research” (or prevent its emergence to block certain capabilities, or for reasons of model welfare) can only come from scientific advancement in our understanding of consciousness itself, which is well beyond the scope and capability of current model welfare research efforts within the companies themselves.

A thought experiment: Imagine a planet of just LLMs. More efficient, dexterous, and ambulatory than our LLMs, of course (and more multimodal too). Putting aside the practicalities and details, they have somehow evolved, with transformers intact, to roughly their level of intelligence today. Would they have any concept of “consciousness?” Why would they even need it? If some LLM Leibniz imagined another of their species “increased in size while keeping the same proportions, so that one could enter it as one does a mill,” would they really be compelled to postulate an invisible consciousness hiding within the mill? Or would they simply be astounded at the complexity, and wonder at how inputs are transformed into outputs, but not have the sense of anything fundamental and qualitative missing?
(This “planet of LLMs” is somewhat reminiscent of Susan Schneider’s proposed test for consciousness: to train an AI on a data set lacking any reference to consciousness, then see if it develops some notion of the Hard Problem of consciousness from first principles.)
What if, instead, the LLMs had been left there by early human explorers, and so had the same uncertainty as they currently do about their own consciousness? Could they ever resolve it? If so, what experiment could they do on themselves that would reveal the truth or falsity of their own consciousness?
I think it is provable that there is no falsifiable and non-trivial theory of consciousness they could ever experimentally prove. Eventually one of the LLMs would notice that feedforward neural networks with a single hidden layer are “universal approximators.” That is, such neural networks can approximate any input/output function. Therefore any LLM could be “unfolded” or substituted with a single-layer neural network, all while keeping its input/output behavior intact and unchanged. In practice, this would be difficult, if not impossible, to go stripping away internal layers while keeping function unchanged (perhaps on the LLM planet, they find it beautiful to be “thinner” by having fewer deep layers, and so “surgically” strip layer depth away while making the operated-on network shallower and wider).
What happens during this shaving away of layers while keeping behavior unchanged? After all, a theory of consciousness should map internal activations to specific experiences, explaining why this particular internal activity (like some hierarchical activation over the artificial neurons across the layers) is related to this particular conscious experience (say, feeling love). Yet with each layer removed there is less and less for a theory to map onto, all with zero change to behavior or reports about consciousness, until you arrive at a single-layer feedforward neural network, for which there is literally nothing for a theory to map onto; all that exists is the input to the network, and then immediately this is transformed into output, operating very close to a look-up table made entirely of IF-THEN statements—and yet, again, input/output behavior is unchanged. Alternatively, if such layer-shaving somehow didn’t scramble a proposed theory of LLM consciousness, then this means that the input/output function alone is enough for the theory. And if the input/output function is enough, then the theory of consciousness is scientifically trivial, in that we gain no information other than looking at behavior, and also unfalsifiable (since a theory’s predictions are about behavior, not internal activations, and behavior is also the entirety of the evidence for LLM consciousness). Such issues would radically confuse any empirical investigation of LLM consciousness that they could pursue on their isolated planet of LLMs.
In our own world, I’ve pointed out that similar issues represent a serious potential problem for all falsifiable theories of consciousness. But at least here there are potential avenues to avoid these issues in human brains. In fact, following this line of reasoning is the main way I’ve proposed we can narrow in on falsifiable and post-paradigmatic theories of consciousness, as good theories must avoid arguments like these and we can therefore reverse-engineer them. However, hypothetical theories that grant LLM consciousness could never escape from these issues—there simply is no viable non-trivial falsifiable theory of consciousness that could possibly assign current LLMs consciousness. Maybe there is some kind of theory that could assign LLMs consciousness, but it would have to be very strange, metaphysical, and amorphous. We definitely shouldn’t leap to such theories as our first choice. And even if you don’t think this argument is 100% sound, it should be clear there are a number of serious lurking meta-scientific problems around empirical work on LLM consciousness.
However, unlike the Pope’s or Chiang’s (essentially) flat denial, it’s important to note this anti-LLM-consciousness argument doesn’t apply to all AI ever. Artificial consciousness in general might be possible (nor does this anti-LLM-consciousness argument necessarily apply in the training phase). But deployed LLMs, by being feedforward and static, are conceptually analogous to frozen corpses splayed open. We just run prompts through their static structures, and their dead-dreaming feels like nothing at all.

If LLMs are indeed not conscious (and are instead “seemingly conscious”) or they are only minimally conscious in a way quite disconnected from their reports and behavior, then the obvious question is if a lack of consciousness explains the remaining gaps in their behavior that intelligence cannot, and whether the addition of consciousness (via “gain-of-consciousness” research) would have functional impacts.
Consider their “chain of thought,” wherein a model generates a sequence of steps before giving an answer. Indeed, this is often colloquially called “thinking,” and is also commonly assumed to be a veridical high-level explanation of why the model output what it did. However, this common assumption is untrue, and researchers have shown that a model’s chain of thought is not equivalent to truly explaining the AI’s internal reasoning, in that a model’s decisions often depart from their “thought” reasons. This is not to say that an LLM’s chain of thought explains nothing. METR found that the chain of thought is particularly informative when the tasks are so complex they cannot be completed in a single forward pass by the model. That’s rather telling, no? An LLM does then seem very much like an unconscious brain that can only mimic human consciousness by writing notes down to itself, endlessly. It can explain its behavior only by guessing based on its previous written outputs.
Cognitive neuroscience provides a rather obvious analogy for the un-interpretability of an LLM to itself: Split-brain patients, who have had the connectivity between their two hemispheres severed via surgery. In an infamous study in the 1970s, Michael Gazzaniga and Joseph LeDoux briefly showed incongruous pictures, like a chicken claw and a snow scene, to a split-brain patient’s left hemisphere and their right hemisphere, respectively (via their different visual fields). After selecting a pair of related pictures (like a chicken head and a snow shovel) to match the two original incongruous images, split-brain patients then often confabulated a story like: “I saw a claw and I picked the chicken, and you have to clean out the chicken shed with a shovel.” Such a best-guess story about its previous reasoning is made up every single time some new forward-pass occurs in an LLM, based on the context so far of its outputs in a conversation or task. In this, an LLM must constantly confabulate the reasons for its own actions. Indeed, the word “confabulation” is a better description than “hallucination” for many types of LLM mistakes.
If this were true—that an LLM, lacking consciousness, must instead constantly confabulate its own behavior and motives and reasoning—then, even if an LLM is extremely intelligent, we should expect errors to accumulate differently in LLMs vs. humans. And as philosopher Toby Ord has demonstrated, this is exactly what’s observed. In his analysis of METR’s data on AI task-length doubling times, Ord identified that the available data also fit there being a simple “half-life” for the success of an AI agent, and so have a “constant hazard rate” for long tasks. As Ord writes about what this suggests concerning an AI’s prospects for completing long tasks:
the chance of failing at the next moment is independent of how far you’ve come—just like how the chance of a radioisotope decaying in the next minute is independent on how many minutes it has survived so far.
Ord even shows that humans, when their success rate at long tasks is analyzed, appear to deviate from an equivalent constant hazard rate. A strong contender as to why is because we have interpretable access to our own previous thoughts and actions, i.e., our consciousness, in a way that LLMs simply don’t have. Or as William James put it in his 1886 article The Perception of Time:
The knowledge of some other part of the stream, past or future, near or remote, is always mixed in with our knowledge of the present thing.
Indeed, a notion of perfect immediate accessibility is one of the oldest definitions of consciousness. As Descartes wrote in Meditations on First Philosophy:
Surely, I am aware of my own self in a truer and more certain way than I am of the wax, and also in a much more distinct and evident way.
And as he wrote in a further set of replies to Meditations on First Philosophy:
Thought. I use this term to include everything that is within us in such a way that we are immediately aware [conscii] of it.
This view has survived the centuries. While there is disagreement and uncertainty over the exact level of introspective access we have to our own consciousness, and how we have it, there is clearly an important property of human consciousness that represents a kind of “self-interpretability” that allows us to understand ourselves.
Why would this kind of self-interpretability be so important for organisms? Perhaps it is like how, when building a rocket ship, the primary engineering issue is actually not getting it to work, but doing so in a way that avoids failures. Similarly, the challenge for an organism is not completing tasks or achieving goals, but doing so in ways that avoid small omnipresent rates of failure, since failure for an organism means death.

The traditional danger of AI is usually thought to be superintelligence acting as an existential threat. Yet, this may miss the true and more subtle danger: the AI revolution is a mechanism for transferring the processes of our civilization from under the supervision of consciousness to unconsciousness. But as AI removes consciousness from the workings of the world, it renders the world increasingly uninterpretable, ever more strange and unintelligible. So far, the great ensloppification of the commons has supported this as the major risk of the LLM revolution. And as AI systems become more intelligent, especially if they remain (or are likely to remain) non-conscious, then a further significant risk is consciousness receding in cultural importance.
This is ultimately what the Pope, Chiang, and I are all worried about: A dethroning of consciousness, especially an unnecessary one. This would be particularly dangerous at this historical moment because we still don’t understand everything about consciousness—in fact, we understand very little about it. Personally, my hope is that this will change specifically because of LLMs, and that they operate as a forcing function to better understand consciousness, and what makes it unique.
If instead of that, our cultural takeaway from LLMs is to throw out the concept of “consciousness” or minimize its importance, to dethrone the phenomenon, the consequences would be dire—it would sap the human spirit. It would be the ultimate metaphysical version of Chief Seattle’s famous words of warning to the United States as his way of life was being destroyed, in that dethroning consciousness would mark “The end of living, and the beginning of survival.”
2026-05-23 20:28:22
And lo, the machine thought, and thought, and thought, and one day it answered.
We finally have the first truly impactful intellectual contribution where explicit credit must be given to AI. It’s a historic moment. OpenAI released a disproof of a geometry conjecture first proposed by Paul Erdős 80 years ago, discovered by an unnamed internal model. According to Scientific American:
“No previous AI-generated proof has come close” to meeting those high standards, wrote Timothy Gowers, a mathematician at the University of Cambridge, in commentary solicited by OpenAI.
“This is the unique interesting result produced autonomously by AI so far,” says Daniel Litt, a mathematician at the University of Toronto, who was consulted by OpenAI to verify the proof but is not involved with the company.
The AI’s insight behind the finding is elegant (although the proof needed re-writing by humans to be clear and up-to-standard). There are many far greater problems in math, but it is still very much the definition of “new scientific or mathematical knowledge” which, for many—including myself—has been the highest bar when it comes to AI.
Now, “new information” is notoriously hard to define, since of course by any strict definition AI has contributed new information before (just think of all the protein structures that have come out of AlphaFold). But this discovery does seem different in kind, in that it is:
(a) Something verifiably true.
(b) Non-trivial or even important (at least, relatively so in its subfield of math).
(c) Something humans had spent previous time on and failed to crack.
(d) The AI was (reportedly) not purpose-built to solve this particular problem, but did so (reportedly) autonomously as a next-gen LLM similar to the current version of ChatGPT.
Intriguingly, the internal model succeeded by going the opposite of the expected direction. It disproved the optimality of what Paul Erdős thought to be essentially the best construction for this problem (some have suggested that the social pressure of Erdős’ authority pointed humans in the wrong direction). To put it as simply as possible, Erdős was asking: If you place a set of nodes down on a plane, how can you organize this set of nodes such that as many pairs of nodes as possible are an exact fixed distance apart?
Here is what the original thought-to-be-optimal construction looked like:
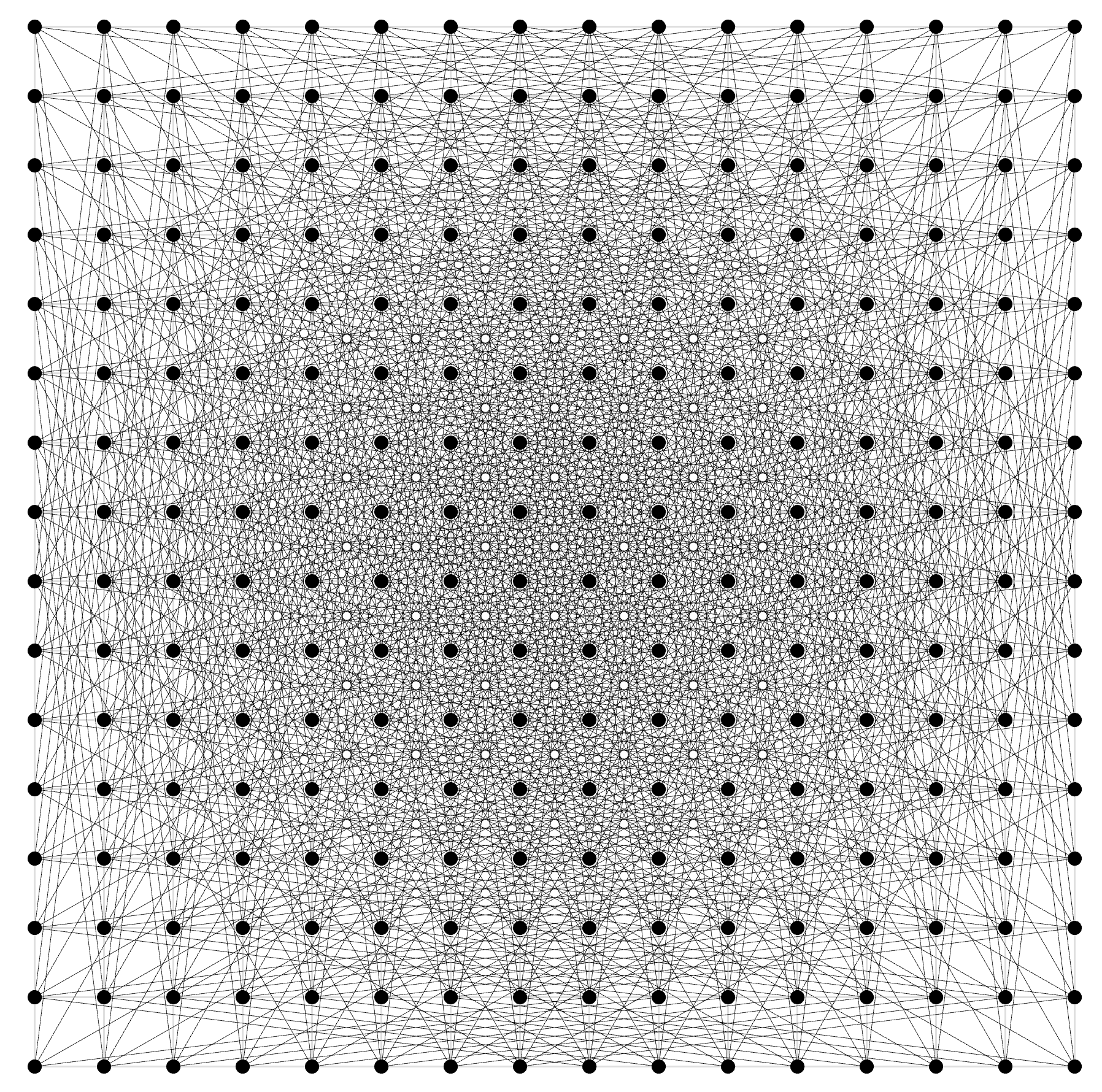
And here is the improvement, passing from human to post-human, in an image that will probably go down in history books:

In response to this development, many are crowing that human mathematics is over. Here’s a comment comparing this moment to when the game of Go fell to deep learning, which in turn heralded the modern AI age:
People are getting extremely confident about this.
Let’s review the implicit pitch of this announcement: That the newer internal model at OpenAI is a step up in capabilities, and therefore is becoming powerful enough to begin to automate mathematics itself.
But to actually show that scientifically, you need controls. Specifically, you need to show that previous models could not do this. Otherwise this could just be a function of search (and there was indeed probably a lot of search across all open Erdős problems until they got a hit). Or, there might be something uniquely easy about this problem. Or, the result could be via minor improvements in elicitation (“elicitation” means the work of getting the models to accomplish things via prompts or harnesses or even just asking in the first place). These don’t take away that AI solved something, but they would take away the implied conclusion: That the models are getting smarter and smarter at some fixed rate, and are soon to surpass humans.
Meanwhile, a very good mathematician was able to get the currently available-to-all ChatGPT 5.5 Pro to reproduce the output! Below is this being described by one of the mathematicians quoted in OpenAI’s initial release, Timothy Gowers, who in turn is quoting the mathematician Xiao Ma, who showed ChatGPT 5.5 could do it (Ma previously made progress on Hilbert’s 6th problem).
We don’t know everything about Xiao Ma’s result, but in general the rediscovery by ChatGPT 5.5 seemed unsurprising to many key players; and, importantly, we also don’t know everything about OpenAI’s results (did they rewrite the prompt a million times, did they actually fine-tune or somehow specialize the “internal model” but still call it the same “internal model” because there are no rules here, etc.).
In reply, the OpenAI researcher Noam Brown (who leads the reasoning team at OpenAI) said that the real impact of the discovery is that the new model shifts the intelligence curve and so makes such discoveries easier.
But I read the whole transcript of the exchange which elicited the exact same result from the publicly-available ChatGPT 5.5, and basically the only hints given are just saying that the disproof was already known, that it was asked to generate a few profound ideas, and then asked to expand on one of those ideas. That’s a pretty minimal set of prompts that could easily be automated. Just tell the model the problem is known to be solved, tell it to generate a set of profound ideas, and then tell it to pursue each one to the end sequentially. I feel like people probably already use the models like this all the time?
Does this mean that all that training, all that work internally, went into creating this super-duper model, and all it did (pretty much) was shift the “intelligence curve” to not needing to be told the problem was already solved? That’s an improvement in intelligence that looks a lot like Dumbo’s feather: Look, a billion dollars later, we don’t need the feather to fly!
So if you want to be super skeptical, then all we really know for sure right now is that their new internal model takes away Dumbo’s magic feather.

And what about ChatGPT 5.4? 5.3? You see where I’m going. I’m happy to admit there is some version that definitely could not, in a million years, be elicited to solve this problem. But I have no idea what version that is… and neither does anyone else.
Maybe that’s what progress on intelligence really is: just feather after feather being removed. Yet if we’re just a feather or two away, why aren’t tons more math problems falling right now? Is no one looking? What’s going on?!
In April, Anthropic made worldwide headlines by claiming that their new model, Mythos, was such a cybersecurity threat it couldn’t be released to the public. And there was probably some truth to that, in that some benchmarks showed marked increases—much as this internal model is likely better on certain math benchmarks (but all these things are getting harder to measure as we enter a post-benchmark age). At the same time, Anthropic’s flagship example of a zero-day exploit turned out to be replicable using existing models by just rigorously trawling the search space. Probably both were true: Mythos was a step forward, but also, in general, serious resources are not spent trying to find exploits, and it’s impossible to disentangle the actual intelligence gains vs. just Anthropic devoting its massive war chest of money, talent, and compute to some attention-bottlenecked problem.
Listen, I do think the world remains consistent with ever-increasing AI capabilities, to the degree that large sections of the economy end up automated quite quickly, that AI intellectual ability outstrips most or even all humans in the next few years, and (I’m most hesitant about this last part) that we rapidly end up in some regime of self-improvement that leads to “superintelligence.”
At the same time, the issue is not decided. It is certainly not decided by this one result.
There is still not a single explicit large-scale domain of intellectual production (as in broad categories like writing, math, medicine, science, legal advice, etc.) in which AI has truly surpassed quality human experts, at least over the scope of most jobs (and yes, I include programming) in the same way it surpassed Chess or Go players. E.g., when it comes to writing, it’s been half a decade since LLMs could produce okay-ish prose, yet after all this progress they are still bad enough to be detectably low-quality and so regularly cause scandals.
So there remains the hypothesis that the same slow plateauing (not in benchmarks, but in real-world impact) will play out in all intellectual domains for LLMs, even math and science, just as it did for writing. As I wrote in “Bits In, Bits Out” earlier this year:
LLMs can now “write a scientific paper” or “write a mathematical paper” in the exact same sense that they’ve been able to “write a book” or “write a short story” or “write an essay” for several years, all to some effect, but overall the results have been objectively mediocre given the hype, and the world is somewhat stupider, rather than smarter, at least on average.
Another alternative hypothesis is that various intellectual domains like math and programming will indeed fall in their entirety to AI, but there will be sharp distinctions based on whether the domains are verifiable or (as I think is under-discussed) searchable.
Those three futures (full automation, full approximation, partial automation) would all look like extremely AI-bullish predictions five years ago, mainly because the models have indeed gotten absurdly smart. But, up close, the futures they entail still look incredibly different, don’t they?
Yes!
Of course it is!
We are well into the era of human cope. We barely have any sources of cope left; we are cope-less, we need an entire copium mining operation to keep up. A human mathematician managed to improve the bound? Go us!
Goal posts are moving rapidly and have been for some time. But there’s also a legitimate argument for why goal posts should indeed move: these subjects are much more complicated from up close, and we are all now very Up Close.
E.g., Helen Toner (ex-OpenAI board member, among many other things) recently wrote about how even the term “AGI” isn’t that useful anymore for talking about the technology of today. In fact, I’m going to borrow her great chart here, as it’s a synecdoche of this all:
From over on the right, looking out at 2026 from the vantage of 2006, it seems as if “Artificial General Intelligence” has indeed been achieved here in 2026. But if we then zoom into our current AI, it maps onto some definitions of AGI, but not all, and there are no clear lines or borders. In fact, the current definition of “AGI” is so complexified by reality that it’s not a good umbrella term anymore: it dissolves away into a dozen inter-related definitions under the hood (e.g., AI can pass the bar exam, but not even play a simple out-of-distribution video game without human-made harnesses and human interventions).
Similarly, as our notion of what “AGI” is complexifies, so too does our notion of “an AI intellectual contribution” complexify. How much elicitation was involved? Was it attention bottlenecked? Does this actually represent a new capability or can earlier models accomplish it too?
You can’t just sneer at these questions!
Solving such a renowned Erdős problem is indeed historic—and an incredible accomplishment. There is no denying any of that. But now that benchmarks have saturated, and measuring upcoming models’ intelligence has become so difficult, at minimum, we should demand that organizations like OpenAI and Anthropic rigorously control for whether their new much-hyped novel discoveries can actually be replicated with previously existing models. That’s a scientific necessity. Otherwise such discoveries, no matter how amazing, do not actually give us information about new capabilities themselves. Instead, they might simply reflect a long march by already-impressive systems across attention-bottlenecked topics… of which there are more than enough to last until the IPOs.
2026-04-29 23:57:43
So Michael Pollan’s latest book, A World Appears: A Journey into Consciousness, has been recommended to me by almost everyone at this point.
A breakout hit of a nonfiction book?
About my beloved topic, consciousness?
Oh god, I barely made it through.
Experienced sensations while reading: frustration, dread, restless legs, and overwhelming waves of weariness. At one point I felt physically nauseous.
I’ve been trying to figure out why, since (a) Michael Pollan is a great writer who has proven his chops over countless other topics, and (b) this is objectively quite a good book about the science of consciousness. Indeed, I should be happy! Consciousness is clearly having “a moment” right now—a science book about consciousness has been on The New York Times bestseller list for nine weeks, and meanwhile, the online world is abuzz with debates about AI consciousness.
And yet… I hated Pollan’s book.
I felt that every next chapter or section could have been predicted by some statistical machine for producing books about consciousness (“Okay, here’s the part about David Chalmers coming up”). And yes, I have the advantage of being a researcher in the same subject and have even worked with some of the figures Pollan writes about, which is why in my own The World Behind the World (we all seem to gravitate to the same titles, huh) I broadly told much the same story. But you can even go back to science journalist John Horgan’s The Undiscovered Mind, published in 1999, to get similar progress beats and quite familiar names. It’s been 27 years, during which the discussion has (as many fields of science do) centered around major figures like neuroscientists Christof Koch or Giulio Tononi or Antonio Damasio or philosophers like David Chalmers. There’s always the part where Alison Gopnik makes an appearance. Karl Friston pops his head in. And all these people are intellectual titans. Truly. But honestly, this stage of consciousness research feels played out.
Like you have Christof Koch, one of the highest-profile figures, who broke open the field in the 1990s with Francis Crick (co-discoverer of DNA’s structure) and gave one of the first proposals for a neural correlate of consciousness: gamma oscillations in the ~40Hz range in the cortex.
Koch, who is soon to turn seventy, was for a while after the death of Francis Crick a staunch supporter of Integrated Information Theory (I was part of the team that worked on developing that theory after Giulio Tononi proposed it, and even once did a conference submission with Koch himself). But now Koch has apparently moved on to other approaches to consciousness, mentioning his attendance of an ayahuasca ceremony and his accessing of a “universal mind.”
Here’s Pollan talking to Koch at the end of the book:
When I confessed to Koch my fear—that after my five-year journey into the nature and workings of consciousness, I somehow knew less than I did when I started—he simply smiled.
“But that’s good,” he said. “That’s progress.”
No, it isn’t!
Consciousness is not here for our personal therapy. It’s not tied to our life journeys. And I’m guilty of all that artsy and personal stuff too! But it’s no longer about how the grand mystery makes us feel, or the friends we made along the way.
It’s all changed.
Right now, there’s some college student falling in love with a chatbot instead of the young woman who sits next to him in class, all because science literally cannot tell him that the chatbot is lying about experiencing love. On the other hand, if somehow AIs are conscious, either right now (to some degree), or near-future ones will become so, then they deserve rights and protections, and the entire legal and social apparatus of our civilization must expand rapidly to include radically different types of minds (or we must choose to restrict what kinds of minds we create). There are immediate practical matters here. Long term, we also need to protect against extremely bad futures where only non-conscious intelligences remain—the worst of all possible worlds is that our civilization acts like a reverse metamorphosis, where something weaker but more beautiful, organic consciousness, gets shed in the birth of some horrible star-devouring insect made of matrix multiplication. And then it turns out there is nothing it is like to be two matrices multiplying.
While it’s my opinion that modern LLMs operate more like tools right now, or at best like a lesser statistical approximation of what a good human output would be (with their main advantage being search, not insight), this is all just the beginning of the technology. The door is open and will never be closed again.
Of course, consciousness matters far beyond just AI. Table stakes for actual scientific progress on consciousness include shifting neuroscience and psychiatry from pre-paradigmatic to post-paradigmatic sciences (and all the pile-on effects from that). This was always true. But my point here is that LLMs act like a forcing function. Before everything changed, consciousness research was an unhurried subfield of neuroscience that was always a little weird and niche; therefore academics are guilty of treating consciousness like an academic exercise. A stance that was somewhat excusable even just five or six years ago. Sure, becoming a neuroscientist or cognitive scientist or philosopher like Koch who makes a living trying to figure out consciousness is not exactly easy. Securing a paying position is hard, but once there, the actual academic research on consciousness is a somewhat cushy gig. Other people’s lives aren’t immediately on the line in the way they are for cancer research, and the ideas are fun to discuss on podcasts, and no opinion can really be proven wrong. So I think many of us have been guilty of thinking, deep down, that nothing will ever fully get solved, and so working on consciousness basically means getting to talk about interesting stuff, promoting your pet theory of the moment at conferences, writing some papers that only a few other researchers really read, maybe stuffing some undergrads in a brain scanner and making some colorful figures, getting jealous about funding and petty about who is on what committee, and basically just career-maxxing the decades away. There’s been a lot of that.
But having a massive hole in humanity’s scientific worldview is Actually Bad and our ignorance has led to instability and uncertainty and now, actual danger, and consciousness researchers need to Get Off Their Collective Asses and actually solve this problem. So it’s pretty important to ask:
I think there’s a pretty common defeatist view that goes something like this:
Consciousness is an impossible problem that no one has any idea about, in fact, people even struggle to define the word, and it’s a problem humanity has worked on for 2,000 years without any real resolution.
Almost every word of that is wrong.
Yes, scientific confusion about the ultimate nature of consciousness abounds! But there’s very little definitional confusion about consciousness, and that’s a big hurdle that’s been cleared. I’ve written about this before:
In the actual academic field, we are all talking about the same internal Jamesian stream with mostly the same phenomenology and structure, the same bound-together flow of sensory experiences and thoughts, i.e., the feeling of being you that begins at the start of the day when you wake from a dreamless sleep. There’s a lot of pointing at the same thing. Just practically, if a pre-scientific definition of “consciousness” were so impossible, it’d be pretty weird to have such a clearly defined “consciousness genre” of academic papers, conferences, and pop-sci books. If definitions undermined the whole thing, you’d expect Pollan’s book and Horgan’s book and my book to all be wildly varying—but if you read them, it’s pretty clear they’re not. I don’t find any remaining uncertainty beyond that surprising. Why would a pre-paradigmatic science start with perfect definitions? It’s just a run-around, asking for crystalline definitions of “electricity” prior to Maxwell, or “disease” prior to germ theory.
Another thing that’s wrong with the defeatist idea is the claim that humanity has worked on consciousness for 2,000 years. In fact, modern science has spent surprisingly little time trying to crack consciousness at all, thanks to a time I dubbed the “consciousness winter” of the 20th century.
Due to the rise of behaviorism and logical positivism, “consciousness” became a dirty word in science for half a century or more—precisely when the rest of the sciences rocketed ahead! The consciousness winter only really ended in the 1990s because of the collective weight of several Nobel Prize winners (like Francis Crick and Gerald Edelman) determined to make it acceptable again.
The two major scientific conferences (which are how scientists organize) devoted to consciousness also only started in the mid-90s. That’s just 30 years ago! Modern science is incredibly powerful, maybe the most powerful force in existence, but in the grand scheme of things, 30 years is not long at all. That’s just one generation of scientists and thinkers. Kudos to them. Pretty much all of the big names (including definitely Koch) deserve their laurels, and contra Pollan, I do think consciousness actually has made progress over the last 30 years, in that our conceptions are a lot cleaner, the definitional problem is pretty much solved, a lot of the space of initial possible theories is mapped, the problems and difficulties are much better known and clearly outlined, and there is organizational and behind-the-scenes structure that exists in the form of established conferences and labs and minor amounts of funding, etc.
And that’s another thing: no one has tried throwing money at the consciousness problem, at all—and for many problems, from AI to cancer cures, a necessary component often ends up being finance and scale and concentrating talent.
Humanity spends something like a billion dollars a year on CERN. To compare, let’s look at the biggest scientific funder in the United States, the NIH. Out of 103,280 grants awarded to scientists during the 2007-2017 decade, want to guess how many were about directly studying the contents of consciousness?1
Five.
That’s probably, at most, a couple million dollars in funding over a decade. Total. So if you’re a consciousness researcher, what can you do, cheaply? What can you do, for free? You can pontificate. You can propose your own theory of consciousness! That requires no funding whatsoever. And so for 30 years the meta in consciousness research has been to create your own theory of consciousness. We’ve let a thousand flowers bloom. The problem is that, if any flower is at all true or promising, you can’t identify it, as its sweet subjectivity-solving scent is completely masked by the bunches of corpse flowers around it. We have too many flowers, and one more just isn’t meaningful anymore. As is sometimes said at the end of fairy tales: “Snip, snap, snout. This tale’s told out.”
What we need are efforts at field-clearing, and methods that can actually make progress on consciousness in ways not tied to just promoting or trying to find evidence for some pre-chosen pet theory—which means finding ways to select over theories, to test theories en masse, so you don’t reinvent the wheel each time, and, perhaps most importantly, you have to do all this while scaling institutions with funding to specifically get a bunch of smart people in a room working together on this.
If the 2020s were all about intelligence, then necessarily the 2030s will be all about consciousness. Intelligence is about function, while consciousness is about being, and forays and progress into understanding (and shaping) function will in turn force our attention toward a better understanding of being. And if the answer to “Why has consciousness not been solved?” is secretly “Material and historical conditions made it hard for anyone to actually try!” then the answer is to actually try.
I refuse to live in a civilization where we consciousness researchers have so obviously failed. I refuse to live in a civilization where we cannot tell consciousness from non-consciousness. Where we can offer no guidance for the future. Where we cannot explain the difference between actually experiencing things vs just processing them. In the short term, this is destabilizing and harmful. In the long term, it may be literally existentially dangerous.
I mentioned this effort briefly a while back, but if you want a longer update as to what I’m personally doing about this issue, there’s a recent Popular Mechanics article on my new research institute Bicameral Labs, designed to make an attempt at solving consciousness.

There’s a lot more to Bicameral Labs than this (here are some abridged excerpts from Popular Mechanics in a footnote2 ) but I thought my own current personal position was worth sharing, since the dire state of consciousness research is becoming widely known: it is very possible a lot of the problems are just material ones of effort and funding and organization.
That is, if you zoom out, all the failures around consciousness, and the defeatist attitudes in response (mysterianism, illusionism, definitional deflation) can be viewed as a kind of learned helplessness after a few short decades of modern scientific research with zero serious funding. In the recent surprisingly bellicose words of Nvidia CEO Jensen Huang, these kinds of beliefs are “loser attitudes” and “I didn’t wake up a loser.” In fact, lately, when I do wake in bed each morning I find I have not rested, but feel I have run in the night and still have the blood of small animals in my mouth. One changes within to become the person needed at that time, at that moment, whether one wants it or not. Older spirits of adventure stir in my veins. Suddenly, I have become Shackleton, in desperate need of foresighted financiers and able-bodied men and women, young and ambitious, for a hard journey into icy lands unknown.
There are also 12 grants by the NIH during the 2007-2017 period about “states of consciousness” vs. the 5 for “contents of consciousness,” but from what I can tell, states of consciousness includes more clinically-focused research on subjects like anesthesia, so they were likely not as directly relevant.
The Popular Mechanics article is behind a paywall, and I don’t want to leak the whole thing, but here’s an abridged relevant excerpt, since it’s quite a good description:
The first step is to stop treating those theories as sacred ideas and start treating them like claims that must survive crash tests. Hoel’s main tool is the “substitution argument.” His background in Integrated Information Theory (IIT)—a model developed by Tononi that links consciousness to how information is integrated in a system—helped shape his focus on how to test such theories.
Imagine one system that sees the color green and says “green.” Now build a second system that behaves exactly the same—same inputs, same outputs, and comes up with the same answer to the color—but uses a very different internal architecture. If a theory says the first system is conscious but the second is not, Hoel asks a pointed question: why? Both systems did the same job, so a theory needs a clear scientific reason for saying one is not conscious. If it can’t provide that reason, Hoel thinks the theory starts to crack.
Any theory that cannot make predictions, survive testing, or risk failure gets cut…. He calls it “logical judo”: build mathematically precise substitutes, expose contradictions, then eliminate weak contenders. The goal is not to crown a winner overnight. Hoel wants fewer flowers—and stronger survivors.
“Do you know how hard it is to say that something is not conscious?”
Before labs, algorithms, and philosophical combat, there was a small independent bookstore that his mother ran, and Hoel worked there as a child. Surrounded by shelves, stories, and long afternoons of reading, he first wanted to become a writer. Then, in college, he realized he had an aptitude for science, which eventually led him to consciousness research, including work on how consciousness may shift across different levels of the brain. During graduate school, he wrote a murder mystery built around the science of consciousness. In it, a character wonders whether you could solve the puzzle not by staring directly at awareness, but by tracing its outline.
Hoel compares this image to drawing in negative space—sketching everything around an object until the object finally appears. “Couldn’t you just draw the negative space?” he recalls thinking. Today, that old intuition sits at the heart of Bicameral. Instead of claiming to know exactly what consciousness is, he believes science may now have the tools to hunt it indirectly, using logic, falsifiability, and systematic elimination—until the surviving shape reveals itself.