2026-02-12 23:29:25
2025 年转瞬即逝。回望这一年的经历,许多事都是撰写 2024 年年终总结时未曾预料的,这份不确定性也让复盘过程更具意义。
首先依然是自我介绍环节:我叫谭新宇,清华本硕,是一名开源技术爱好者,主要关注分布式存储、共识算法、时序数据库、可观测性与性能优化等领域,过去六年也一直在这些方向做一些工作。今年开始,我把重心从偏存储扩展到计算调度与机器学习平台基础设施。尽管在新领域仍是新人,但也算正式以 AI Infra 工程师的视角开始做事了。
介绍完背景,下面按时间线回顾一下 2025。
一开年回来,同事告诉我:我们系统组 2024 年为 IoTDB 做的 TPCx-IoT 性能与性价比双登顶工作,榜单成绩被刷新了。这件事也让我很快进入状态。
TPCx-IoT 的核心指标是吞吐与性价比。吞吐可以通过横向扩展提升;性价比更依赖架构与工程细节——能否把资源利用率做到极致。我们 2024 年的上榜方案在集群多副本架构上已经做到相对 SOTA,且相关工作也在投稿路上,因此对于 “短期被赶超” 的结果确实有些意外。
我随后认真读了新榜一的公开报告。先说结论:其吞吐提升约 40%,其中相当一部分来自硬件资源增加约 7 倍(这条路我们也能走,甚至用 7 倍硬件资源的话吞吐还能更高);但奇怪的是,其性价比也提升约 15%。继续拆解后发现,差异点并不在软件方案本身,而在硬件计价口径:我们 2024 年是在云厂商环境测试,硬件报价相比其私有部署高出接近 10 倍。因此榜单上的“性价比优势”,更多来自硬件成本模型差异,而非软件层面的突破。
找到根因后,动作也很直接:我们将报价测试切换到线下部署。在软件方案不变、硬件成本下降一个数量级的前提下,相比新榜一,我们用更少硬件跑出了更高吞吐:吞吐提升约 50%,性价比进一步提升一倍。这次结果也再次确认了我们对软件方案本身的信心。
当时我一度得出“线下更便宜”的直觉结论。但谁能想到 2025 年年底,同款机器受内存条整体溢价影响,价格上涨接近 6 倍,几乎把这条结论拉平。站在 2026 年初再看,上云还是下云又变成一个需要随时间与供给波动不断重算的选择题。
上半年基于这些积累,我们也在继续积极推进论文投稿:一是“通用 Raft + LSM 的状态同步”。在强一致性前提下,尝试做一些类似 ECRaft 的工作,在特定场景里给出强一致性推导,并带来一定的实际性能收益。二是“异步复制 + LSM 的状态同步”。在几乎实时同步的前提下,实现三节点三副本集群性能接近单机三倍这一反直觉表现。我觉得这两个方向都很有价值。更幸运的是,其中一篇已被 SIGMOD 2026 接收,算是圆了我在 DB + Raft 领域的一个长期心愿。也期待后续能在这块有更多交流。
其实在春节期间那波 DeepSeek 带来的技术浪潮里,我就暗下决心:年后一定要去市场上拿一些“真实反馈”,验证自己过去两年的成长。由于年后工作依然很满,我的跳槽决心也没那么强;加上我也不太愿意把大量精力投入纯面试训练,所以准备和投递都相对克制:刷了二三十道 LeetCode,梳理了一遍简历与项目,然后就开面。前后两个月里,我断断续续面了六七家,主要是大厂、LLM 公司和量化,结果大致是一半挂一半过。
挂掉的那些机会,有的是薪资预期没对齐,沟通不久就结束;也有的是对 C++ 熟练度要求非常高,本质上是技术栈不匹配。刚开始因为 C++ 原因被挂时,确实会有挫败感:虽然我也能借助 Cursor 相对高效地写一些 C++ 项目,但毕竟写了 7 年 Java,缺少 C++ 系统开发经验;面试一旦深入到语言特性与工程细节,短期补课难免露出短板。
事后回想,这段经历让我更清楚地看到两类岗位的差异:一类岗位在面试中对某项具体技能要求较高,且不太接受转行。入职后通常希望你立刻产出,工作范围更聚焦,职责边界也更早确定。另一类团队更关注“你解决过什么问题、如何思考与协作”,对特定技能的硬性要求相对弱,但对综合能力要求更高。这类机会往往业务处于高速发展期,入职后更容易覆盖多个方向。这两种选择没有绝对好坏,但适配偏好和职业路径确实不同。对于跨行业跳槽的同学来说,显然后者更容易让你把既有能力迁移过去,拿到更合理的定价甚至溢价。
最后我通过的几个 offer,基本都是后者:要么需要跨语言,要么需要跨行业,但所有 offer 的薪资和发展方向都还不错。某种意义上,这也算是市场对我过去几年能力积累的一次确认——这份正反馈对我很重要,也让我踏实了不少。
到了 5 月,综合所有考虑后我选择离职,正式离开自己待了六年的环境,去探索学习 AI Infra 的挑战。在这里也想对同样在考虑跨行业跳槽但又担心面不过的朋友说一句:先准备起来面试看看,即使被拒几次也别太焦虑。面试本来就是双向选择,多尝试总会找到合适的。
回头看,这应该是我 2025 年最重要的决定。离开熟悉且擅长的领域需要勇气,但我最终还是倾向于在合适阶段主动拓宽技术与认知边界。比较幸运的是,目前入职 landing 比较顺利:新工作里既有技术挑战,也能产生业务价值;过往的技术积累和软素质依然派得上用场。方向上也不再只聚焦存储,而是更多接触计算调度、训练/推理平台等新领域,在新的问题域里从头补课并参与建设。
由于新工作不再维护开源产品,我的大部分精力投入在闭源产品上。但工作中依然深度使用了很多开源组件,因此我仍能在喜欢的开源社区里交流并贡献。比如我接着 Anyscale CTO Moritz 的遗留 issue,为 Ray 社区贡献了 K8s 下的 Ray Debug 方案,并被他合入成为 Ray 官方推荐的解决方案。同时,我业余时间持续贡献的 Ratis 社区也提名我成为 PMC,非常感谢社区的认可。
我认为工作中最理想的状态,是在一个节奏相对可持续但仍保持专注的环境里,自驱地做一些自己感兴趣、有技术挑战、对业务有价值且有成长空间的事情。这种状态可遇不可求,我也很庆幸目前正处于这样的状态。
以上是 2025 的主要经历。下面整理一些阶段性思考。
今年换了赛道之后,我对 Alpha 和 Beta 这两个词有了更切身的体会。借用投资语言:Beta 是跟着大盘走拿到的收益;Alpha 是你能跑赢大盘的那部分。
回想 2021 年,国内 AI 四小龙纷纷陷入困境,数据库赛道如日中天、深受资本宠爱;短短四年后,AI 浪潮已经被称为“第四次工业革命”。身边那些做出巨大 impact 的同龄 AI 大佬们,个人实力当然重要,但很多时候真正起决定作用的,是 Alpha 与 Beta 的共振:能力是一回事,时代把天花板抬高又是另一回事。
但本质上,Beta 终究是外部变量:你能感知、能选择,但很难完全掌控。换到一个全新领域后,我最大的感受反而是:过去积累的很多东西并没有“归零”。比如入职后做性能优化、迭代流程、分布式计算框架学习时,以前沉淀的定位瓶颈和迭代效率的方法论,几乎可以直接复用。
这让我逐渐明确:真正属于自己的 Alpha,未必是某个领域的具体知识点,而是端到端解决问题的方法论、工程直觉和协作能力——它们跨领域依然成立,不会因为行业冷热就失效,也不会因为一次跳槽就消失。尤其在如今有了 LLM 之后,很多特定领域知识更容易在一段时间的投入中补上来。
所以我对 Beta 的态度不是不追求,而是不把它当成唯一变量。Beta 天然风险与收益并存:红利来得快,退潮也快。在若干个“风险与收益都能接受”的 Beta 环境里,我更愿意选一个能持续积累自己 Alpha 的方向,跟公司和团队形成双赢——对我来说这更舒服。毕竟投资自己的 Alpha,更像一笔没有回撤的复利。
职业生涯里的很多选择,大概永远无法从全局视角判断是不是最优解。我们能做的,往往只是用当下的认知做局部最优,结果好坏还夹杂不少运气。刚毕业那会我问过一位在互联网摸爬滚打十余年的前辈,他说这十年最大的感悟:乐观点叫“选择大于努力”,悲观点叫“看命”。
既然全局最优不可得,那我现在做选择时,会更关注下限而不是上限。上限当然诱人,但它很大程度取决于 Beta 的走势,不完全可控;下限反而更容易想清楚:最差情况能不能接受?不满足预期时有没有退路?把下限想清楚之后,选择就会简单很多——选那条即使结果不如上限预期,自己也不会后悔的路。
今年经历社招,跟不少朋友和猎头深聊之后,我的一个感受越来越强:职业发展真的不是一条平滑曲线,更像爬台阶——平时看不出什么变化,但总会遇到一两个关键的坎。能不能迈过去,靠的往往不是临时抱佛脚,而是之前在做人做事上积累的那些“不起眼的复利”。
这次社招面到终面时,我能明显感觉到:老板们看的已经不只是技术能力了——更多是你做事的风格、你在意什么、你过去解决过什么问题、未来想解决什么问题。技术当然是入场券,但真正决定你能走多远的,可能是这些更贴近“人本身”的东西。
换了工作之后也更能体会到:从 junior 到 senior 的成长,不只是技术深度的精进,更重要的是视角的拓宽——从解决一个具体技术问题,到能把质量、效率、迭代这些维度串起来;再到能站在业务视角,找到技术的端到端生态位,形成闭环。这个过程其实不需要等到某个职级才开始。反过来讲,日常工作里多想一层,本身就是在练这件事。
今年换工作的过程中我也反复想过一个问题:职级、薪资和 impact 到底由什么决定?综合来看,它们大概率是对“一个人能解决问题的价值”的均值回归——短期可能有高估或低估,但拉长来看,市场总会给出相对公允的定价。想明白这一点之后,我反而没那么焦虑:与其盯着职级和薪资纠结,不如把注意力放在让自己能解决的问题越来越难、越来越有价值上。
以前在开源公司做开源产品时,我对开源的感受更多是“参与者”视角:怎么把自己负责的模块做好、怎么跟社区协作、怎么把 patch 合进去。今年换到一个以使用开源组件为主的环境后,我反而从“用户”视角重新理解了开源社区的价值。
大多数业务团队的目标很明确:用技术尽快创造业务价值。人力有限时,选对一个开源框架往往能较快做到 60–80 分;想做到 90 分以上,通常需要持续跟进社区动态,甚至参与共建。
从零到一把底层框架打磨到通用且可靠,成本极高。开源社区的价值在于:有一群人愿意长期专注,把通用能力持续打磨,并在大量不同场景中反复验证。
还记得刚毕业时,我跟好朋友苏总聊过:选工作时最好能选一个在 GitHub 上保持活跃的环境。当时我认为去开源公司做开源产品是最直接的路径。今年换了公司之后发现,即使不再全职做开源产品,只要工作中深度使用开源组件、需要跟社区交流甚至贡献 patch,再加上自己在社区承担的角色,GitHub 的活跃度依然可以保持。我对这种状态比较满意,也希望来年继续坚持。
以前我对技术价值的理解有点“理想主义”,总觉得只有在 SOTA 的基础上继续往前推,才算真正有价值。今年的感受让我意识到:SOTA 的诞生,和它真正落地之间,往往存在很大的鸿沟。
现实里,大多数团队对新技术的采用,确实会落后于 SOTA 很多。在这样的现状下,把 SOTA 结合具体业务场景真正落地,本身就能创造巨大的价值——你不一定非得站在最前沿把天花板再顶高一层;把前沿的东西用好、用对,本身也是一种稀缺能力。
比如现在 LLM 的能力已经很强,但如果每个人都能把其中哪怕一小部分能力真正用到自己的业务里,往往就会有意想不到的效果。
过去我更容易被“突破天花板”的工作吸引;但现在更能体会到,把好东西带到更多人面前并落地到真实场景里,同样很有价值。
今年用 AI Agent 越多,我越能感受到它能力进化的速度。印象很深的是:有些需求年初怎么描述都做不对;到了年末,同样的需求可能一句话就能搞定。
我观察到这个规律放到人身上也类似:能不能把事做到极致,本质上是一个 0/1 的信任问题(是否敢把这件事完全交给你);而在“已经做到极致”的前提下,如何进一步提升效率,更像一个可以稳步迭代的工程问题(如何更快、更省心、更可持续)。
回到自己身上也是一样:很多工作都希望尽可能做到最好,但资源有限时总会不断妥协,最后容易变成“每件事都做了,但每件事都差一口气”。这时候最让人不甘心的,往往不是没做,而是明明知道理想状态是什么,却没能把它做出来。
我经常会问自己一个问题:如果不考虑历史包袱,也不考虑眼前阻力,这件事的理想状态应该是什么样?如果真给我充足时间,我会怎么做?
这几年下来,我的一个体会是:如果一开始因为阻力没做到极致,后面即便阻力消失,也很容易因为惯性而不再补齐;但如果一开始就把它做到极致并且做成了,后续“怎么优化效率”往往是可解的——可以逐步拆解、逐步迭代,总能变快。这样单位时间里的成长也会更多,长期积累下来会形成更好的工作习惯与技术复利。
希望以后自己还能在更多事情上继续保持认真,把“先做到极致”尽量坚持住。
如果把过去二十年的数据基础设施按“主要瓶颈”粗暴分段,我大概会这么理解:Disk 时代,瓶颈更多在磁盘与跨节点 IO,很多系统走 shared-nothing 路线,Hadoop + MapReduce 先把分布式存储与分布式计算的基本盘搭起来;Memory 时代,内存更便宜、网络更快,Spark 把更多中间状态留在内存里,把分布式计算效率推到更高水平,瓶颈也更常从磁盘转移到网络与 CPU。
现在到了 GPU 时代,我观察到新一轮的数据架构都在围绕 GPU 去重新设计。原因也很直接:GPU 把单位时间内的可用算力抬得太高了,系统瓶颈更频繁地从“算不动”变成“喂不饱”——数据搬运、访存、落盘、网络、调度与资源切分都会变成主要矛盾。这个视角下,NVMe、RDMA 这些更像“算力的供给链路”;围绕 GPU 的数据布局、IO 路径、缓存策略、batch 组织、任务切分与调度,才是新的主战场。很多我最近接触到的技术栈(例如分布式计算框架、训练/推理引擎与 Kubernetes 生态),本质上也都在解决同一个问题:当计算形态变了,怎样把工程系统重新组织起来,让算力稳定、可控、可规模化地转化成业务价值。
每一段技术栈的更迭,往往会带来至少十年的技术周期。从这个尺度看,GPU 这波的 Beta 收益还有很长空间,所以我并不太担心“2025 年入场算不算晚”。种一棵树最好的时间是十年前,其次是现在。至少对我自己而言,既然决定往这个方向走,那现在开始做一些围绕 GPU 的基础设施工作从新人重新学起,长期依然值得期待。
今年我对 LLM 的感受越来越具体:它最有价值的地方,可能不是“直接写出一个完美答案”,而是帮助缩小很多原本需要靠人脉、经验和踩坑才能补齐的信息差。
比如换到新领域后,一些概念、术语和最佳实践,以前往往要在博客、论文、issue、内部文档里检索一两周,才能拼出一个大致轮廓。现在只要把问题描述清楚,让它先给出一个“地图”(有哪些选项、trade-off 是什么、该看哪些关键词/资料、怎么验证),进入状态会快很多。
当然,LLM 也不是万能的。我现在更倾向于把它当成“高级搜索 + 快速补课 + 帮你写第一版草稿”的工具,而不是最终裁判。真正关键的两件事仍然在自己手上:第一,提问要具体,最好带上下文、约束和你期望的输出形式;第二,永远要有验证意识——不管它给你的是代码、结论还是方案,都得用实验、数据或一手资料去过一遍。
总之,LLM 让我更确信一件事:在信息密度越来越高的时代,能否快速学习、快速定位关键矛盾、快速验证假设会越来越重要。而 LLM 恰好把“学习—验证—迭代”的闭环速度往上抬了一档。
2025 对我来说是认知变化很大的一年:从熟悉的方向出发,切换到新的赛道,也在这个过程中重新审视了许多过去的经历与积累。回头看,我很庆幸自己在合适的节点做了一次职业发展的改变——不是因为结果有多好,而是这段经历迫使我更认真地思考了几个长期问题:什么东西是真正属于自己的?自己的追求是什么?希望怎样去过完这一生?
这些问题也许没有标准答案,但至少现在的我比一年前更坚定,更坦然。我感谢上一段工作经历里一起并肩的人,也感谢 🍊 让我在工作之余更热爱这个世界并感受到生活的很多美好。
2026 年,希望自己能在新的领域继续扎根,继续把事情做到极致。
最后,感谢一路上帮助过我的领导、同事、朋友和家人。
预祝大家新年快乐,万事如意!
2025-12-06 14:47:04
Ray 官方提供了安装文档和编译文档,涵盖了多种预构建方案——从稳定的发行版本、到日常构建版本,甚至支持主分支上任意 commit 的构建版本。在多平台、多 Python 版本和多芯片架构的组合下,这些预构建方案在大多数情况下都能满足需求。
但当涉及到在生产环境中维护 HotFix 版本时,从源码编译就成了必不可少的技能。特别是在一些企业环境中,你可能面临的是在 CentOS 8 这样的老系统上,基于 Ray 2.40.0 这样的较早版本进行代码改动和编译。官方的编译文档看起来步骤清晰,但当版本和系统都比较旧的时候,往往会踩到文档没有提及的坑。这些坑有的是版本兼容性问题,有的是系统环境的特殊性导致的,网络上也很难找到现成的解决方案。
面对这些问题,我在 macOS 和 CentOS 8 上编译 Ray 2.40.0 的实践中逐个排查和解决了这些问题,本文记录了其中的关键坑点和解法,希望能给未来有类似编译需求且遇到坑的同学一些帮助。
我的开发环境是 MacBook M4 Pro。由于本地开发方便,因此我优先在 MacBook 上尝试编译了 Ray,优先探索老版本编译可能遇到的问题。
参考 Ray 官方的编译文档即可。
1 |
|
1 |
|
1 |
|
为保证可复现性,我选择基于当前最新正式版本 2.52.1 而非 master 分支的最新 commit 进行编译。
注意:如果仅修改了 Python 文件,可参考官方文档直接替换 pip 中的 Python 文件即可,无需进行以下复杂的 C++ 编译。
1 |
|
1 |
|
1 |
|
1 |
|
成功编译 2.52.1 后,下一步尝试编译 2.40.0 版本。
首先执行以下命令,预期编译能够顺利完成:
1 |
|
然而出现了以下报错:No module named pip。
1 |
|
遇到该报错后,我检查了 2.40.0 版本的官方编译文档,确认流程完全符合文档步骤。
按理说,当前 conda 环境应该能找到 python3 和 pip,但调用 pip install -e . 时却报错。查看相关代码后发现,Ray 是通过子进程来安装这些 pip 包的:
1 |
|
我尝试直接在命令行执行 /opt/anaconda3/envs/ray-compile/bin/python3.11 -m pip install -q --target=/Users/xytan/Desktop/study/ray/python/ray/thirdparty_files psutil setproctitle==1.2.2 colorama,发现可以成功。这说明问题出在子进程执行环境中,可能是子进程初始化时未包含完整的 conda 环境。带着这些上下文,我咨询了 ChatGPT、DeepSeek、Qwen 等大模型,给出的方案包括修改 ~/.bazelrc、将 python 和 pip 加入 /etc/profile 的 PATH 等,但均未能解决问题。
由于对 Ray 编译的复杂度有所顾虑,担心白盒分析耗时不可控,我转而去 Ray 的 issue 区寻找线索。幸运的是找到了一个相同报错的 issue,遗憾的是该 issue 自 2024 年初创建至今近两年仍未关闭,官方的回复也未给出直接的解决方案,看起来是个棘手的环境问题。
这个问题说来也有些离谱:按照 Ray 官方文档竟然无法从源码编译,这算是个挺严重的问题。不知道 Ray 官方当时构建 2.40.0 版本时是如何操作的,也许是在一个包含所有依赖的沙箱环境中进行,因而未发现此问题。
既然官方也没有提供解决方案,白盒分析又耗时不可控,那有没有高效的黑盒方法来定位问题呢?
我灵机一动:既然 2.52.1 版本可以编译,2.40.0 版本不行,虽然两者相隔近五千个 commit,但可以用 git bisect 二分查找第一个能编译的 commit。由于不可编译的版本只需执行 pip install -e . --verbose 十秒内就能复现错误,理论上最多 13 次、耗时不到 3 分钟即可定位。
按照这个思路,我先通过 git merge-base ray-2.52.1 ray-2.40.0 获取两个分支的公共祖先 02ac0cdc7adf5e611134840c73fa47dd7866140d。
经测试,ray-2.52.1 可以编译,公共祖先版本不可编译,满足二分条件。
执行 git bisect start ray-2.52.1 02ac0cdc7adf5e611134840c73fa47dd7866140d 开始二分查找。需要注意的是,bisect 默认假定新版本为 bad、旧版本为 good,用于寻找第一个引入 bad 的 commit。而我们的情况恰好相反——新版本可编译、旧版本不可编译,因此在判断 good/bad 时需反向操作。
以下是二分的详细过程,总耗时不超过 5 分钟即定位到第一个使编译成功的 commit:
1 |
|
出现结果如下:
1 |
|
分析该 commit 的代码,发现这是 AnyScale CTO 为 Ray 添加 Python 3.13 支持的改动,遗憾的是 PR 描述中并未提及任何编译问题的修复,应该是无意间修复了此问题。
因此只能深入代码寻找原因。幸运的是这个 PR 只修改了 9 个文件、不到 100 行代码,可以较直观地分析为何这个 commit 使编译得以成功。
经排查,发现该 commit 在 setup.py 中只修改了两行代码,其中关键的一行是为 setup_requires 增加了 pip 依赖。这个改动与之前的报错高度吻合:setup_requires 正是用于在子进程中初始化构建依赖的。
1 |
|
找到原因后,我立即切换到 ray-2.40.0 分支并在 setup.py 中添加 pip 依赖,改动如下:
1 |
|
执行 pip install -e python --verbose 后,之前的报错消失了,说明改动生效。但不幸的是又出现了新的报错:
1 |
|
通过搜索,找到了 Bazel 仓库中一个相同报错的 issue。原因是新版本 macOS SDK 与 Bazel 依赖的 zlib 1.3 不兼容,需升级到 zlib 1.3.1 版本。
于是我按照 issue 中的描述在 WORKSPACE 文件中添加了以下配置,遗憾的是仍然报错:
1 |
|
白盒分析暂时没有头绪。既然如此,只能继续用二分方案黑盒查找。这次由于需要编译数分钟才能复现,二分过程会稍慢一些,但仍可行。
经过 11 轮二分,定位到了使编译通过的 commit。从 PR 标题来看,该 commit 正是为了解决 macOS 编译问题:
1 |
|
切回 ray-2.40.0 版本,执行 git cherry-pick 65ae6076f25325528dabf1432d1ff1bedb1c70b3 将该 commit cherry-pick 过来(需处理小范围冲突,可参考我个人维护的 release/2.40.0 版本),再补充 setup.py 中的 pip 依赖,即可在新版本 macOS 上成功编译 ray-2.40.0。
1 |
|
在 macOS 上编译 ray-2.52.1 和 ray-2.40.0 的过程中,遇到了两个棘手问题:第一个是找不到 pip 的问题,官方 issue、PR 和网络资料均无解决方案;第二个是 zlib 版本兼容问题,虽然在 issue 中找到了疑似方案,但尝试后未能奏效。
在白盒分析无果的情况下,我决定使用 git bisect 黑盒定位。得益于 O(log n) 相比 O(n) 的效率优势,成功在近五千个 commit 中高效找到了使 ray-2.40.0 能够编译的两个关键 commit。
通过这次排查,我将基于 release/2.40.0 版本新增的两个修复 commit 推送到了 GitHub,同时也将本文的发现回复在了近两年未关闭的 issue 中并使得 issue 被 resolve 关闭,希望后来遇到这些坑的朋友能从中受益。
完成 MacBook 上的编译探索后,接下来在 CentOS 8 上编译 Ray。相比之前遇到的代码层面问题,这部分更多是环境配置的挑战。
由于 CentOS 8 已于 2021 年底停止维护,主流云厂商的官方镜像中已不再提供该版本,最低可选版本为 CentOS Stream 9: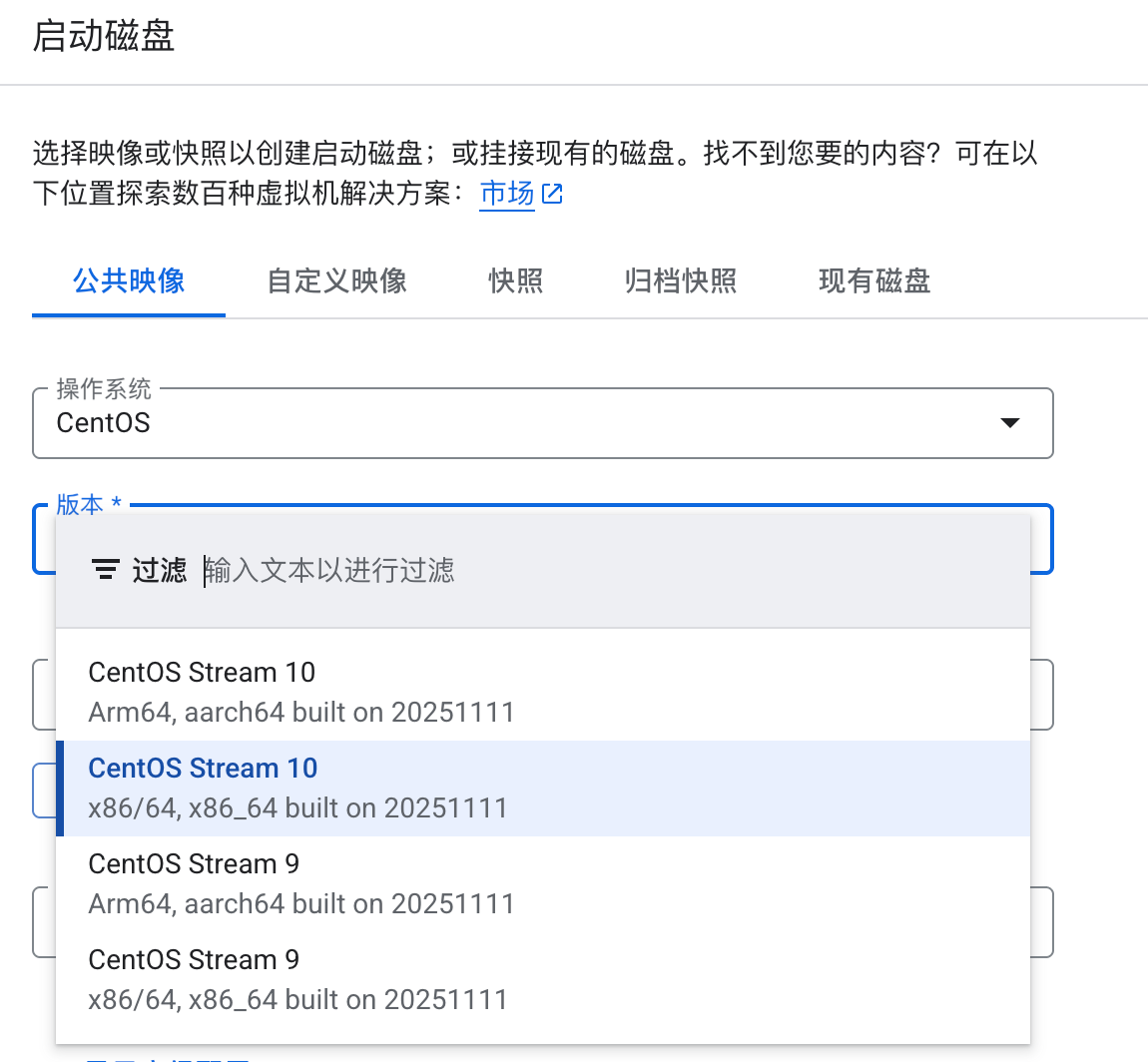
Ubuntu 同样如此,最低可选版本为 Ubuntu 22.04,无法直接获取 Ubuntu 16 等老版本镜像: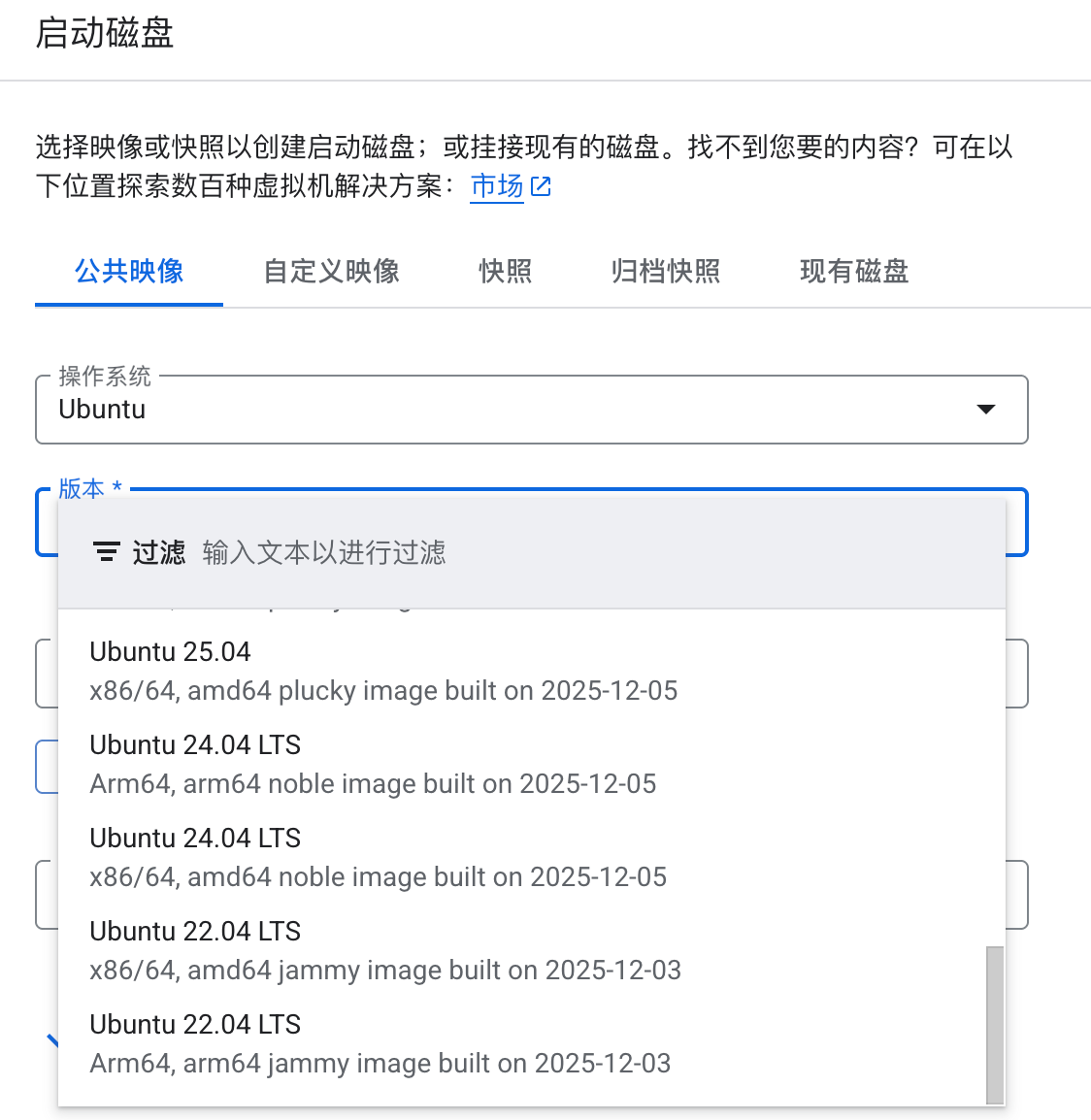
虽然基于这些新版本镜像也能编译 Ray,但由于其 glibc 等核心库版本较高,编译产物往往无法在老版本系统上运行。
因此,若需为老版本操作系统编译 HotFix,推荐的做法是:在云厂商处租用相同 CPU 架构的较新版本机器,然后通过 Docker 拉取 CentOS 或 Ubuntu 官方提供的老版本镜像进行编译,以此确保编译环境与生产环境的一致性。
基于以上分析,我在 Google Cloud 上租用了一台 x86 架构的 CentOS Stream 9 机器进行后续编译。
1 |
|
1 |
|
由于 CentOS 8 官方源已停止服务,需在容器内配置可用的 yum 源
1 |
|
安装 Node.js
1 |
|
克隆 Ray 仓库
1 |
|
安装 C++ 编译工具链
1 |
|
安装 Anaconda
1 |
|
创建并激活 Python 环境
1 |
|
1 |
|
1 |
|
1 |
|
这期间的若干尝试主要有以下三类报错:
GLIBC 安全检查与外部依赖冲突(Fortify 越界)
1 |
|
Bazel 配置文件强制执行 -Werror 导致的编译失败
即使我们通过 BAZEL_ARGS 传递了 -Wno-error,Ray 源码中的 Bazel 配置文件(.bazelrc)仍有更高级别的规则强制应用 -Werror,这导致了像 implicit-fallthrough 这样的 C++ 警告升级为错误。
报错日志片段(关键信息):
1 |
|
GCC 版本不兼容导致的 C++ 歧义错误
1 |
|
通过在 GitHub 和 Ray 问答社区中进行搜索,并结合 Gemini 和 ChatGPT 的多轮问答结果,在踩坑十余次、折腾许久后,最终一一解决。
解决方案有三:
1 |
|
-U_FORTIFY_SOURCE: 禁用 Fortify 检查,解决 upb/memcpy 越界问题。-Wno-error: 禁用将警告升级为错误,避免外部依赖因严格的警告而失败。--host_copt / --host_cxxopt: 确保这些豁免规则应用于 Bazel 编译工具链(即 Host 平台)。1 |
|
1 |
|
完成以上修改后,即可成功执行 pip install -e . --verbose 完成编译。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34...
...
...
Options like `package-data`, `include/exclude-package-data` or
`packages.find.exclude/include` may have no effect.
adding '__editable___ray_2_40_0_finder.py'
adding '__editable__.ray-2.40.0.pth'
creating '/tmp/pip-ephem-wheel-cache-rq0i6oso/wheels/3b/a3/3e/5871189f4113432e73b7e4659ab9a4d2edef3998a6dcfea06f/tmp5xknhp72/.tmp-_9ctuqe5/ray-2.40.0-0.editable-cp311-cp311-linux_x86_64.whl' and adding '/tmp/tmpr9lwou7pray-2.40.0-0.editable-cp311-cp311-linux_x86_64.whl' to it
adding 'ray-2.40.0.dist-info/METADATA'
adding 'ray-2.40.0.dist-info/WHEEL'
adding 'ray-2.40.0.dist-info/entry_points.txt'
adding 'ray-2.40.0.dist-info/top_level.txt'
adding 'ray-2.40.0.dist-info/RECORD'
/tmp/pip-build-env-mlv1uqa4/overlay/lib/python3.11/site-packages/setuptools/command/editable_wheel.py:351: InformationOnly: Editable installation.
!!
********************************************************************************
Please be careful with folders in your working directory with the same
name as your package as they may take precedence during imports.
********************************************************************************
!!
with strategy, WheelFile(wheel_path, "w") as wheel_obj:
Building editable for ray (pyproject.toml) ... done
Created wheel for ray: filename=ray-2.40.0-0.editable-cp311-cp311-linux_x86_64.whl size=7272 sha256=18b317c847a6088a316df5f5c98bda8e245fb62cd7acb720a374447e4b94646c
Stored in directory: /tmp/pip-ephem-wheel-cache-rq0i6oso/wheels/3b/a3/3e/5871189f4113432e73b7e4659ab9a4d2edef3998a6dcfea06f
Successfully built ray
Installing collected packages: ray
changing mode of /root/anaconda3/envs/ray-compile/bin/ray to 755
changing mode of /root/anaconda3/envs/ray-compile/bin/rllib to 755
changing mode of /root/anaconda3/envs/ray-compile/bin/serve to 755
changing mode of /root/anaconda3/envs/ray-compile/bin/tune to 755
Successfully installed ray-2.40.0
下一步也可以使用 pip wheel . --verbose 来打包成 wheel 供其它环境安装使用。
与 macOS 上的编译经历类似,CentOS 8 上的编译同样遇到了不少坑。除了需要通过 Docker 确保编译环境与生产环境一致外,还需解决三个编译问题:GCC 版本过低导致的 nullptr_t 歧义错误、GLIBC Fortify 安全检查与外部依赖冲突、以及 .bazelrc 强制启用 -Werror 导致的编译失败。最终通过升级 GCC 到 11.2.1、设置 BAZEL_ARGS 环境变量、以及注释 .bazelrc 中的 -Werror 配置,成功完成编译。
本文记录了在 macOS 和 CentOS 8 上编译 Ray 2.40.0 的完整踩坑过程,共解决了五个关键问题:
macOS 编译问题:
No module named pip,需在 setup.py 的 setup_requires 中添加 pip 依赖,详见 commit。CentOS 8 编译问题:
nullptr_t 歧义问题,需升级到 GCC 11.2.1。_FORTIFY_SOURCE 安全检查冲突,需通过 BAZEL_ARGS 禁用相关检查。.bazelrc 中的 -Werror 配置将警告升级为错误,需手动注释相关配置行。详见 commit。以上修复已合并到我维护的 release/2.40.0 分支,同时也已将解决方案回复到社区 issue 中并使得 issue 被 resolve 掉,希望能帮助后来者少走弯路。
至此,本文所有内容均已结束,感谢您的阅读和关注!
2025-08-17 00:39:26
在软件开发过程中,具备单步调试能力的 Debugger 是提升开发效率的关键工具。对于复杂的分布式系统而言,单步调试能力尤为重要,它能帮助开发者在纷繁复杂的同步/异步代码链路中快速定位问题,从而缩短问题诊断周期。
以分布式存储系统为例,2021 年我曾通过 IDEA 配置 Apache IoTDB 3C3D 集群的单步调试能力(可参考 博客)。在随后的几年里,这套方案帮助我解决了 IoTDB 分布式开发过程中的不少疑难问题,提升了开发效率。
最近,我开始学习并研究分布式计算框架 Ray,首先从其调试功能入手。Ray 官方目前支持两种 Debugger,具体使用方式可参考官方文档,这里简要介绍:
注意:Ray Cluster 启动时需配置相应的 Debugger 参数,且上述两种 Debugger 不支持同时使用。
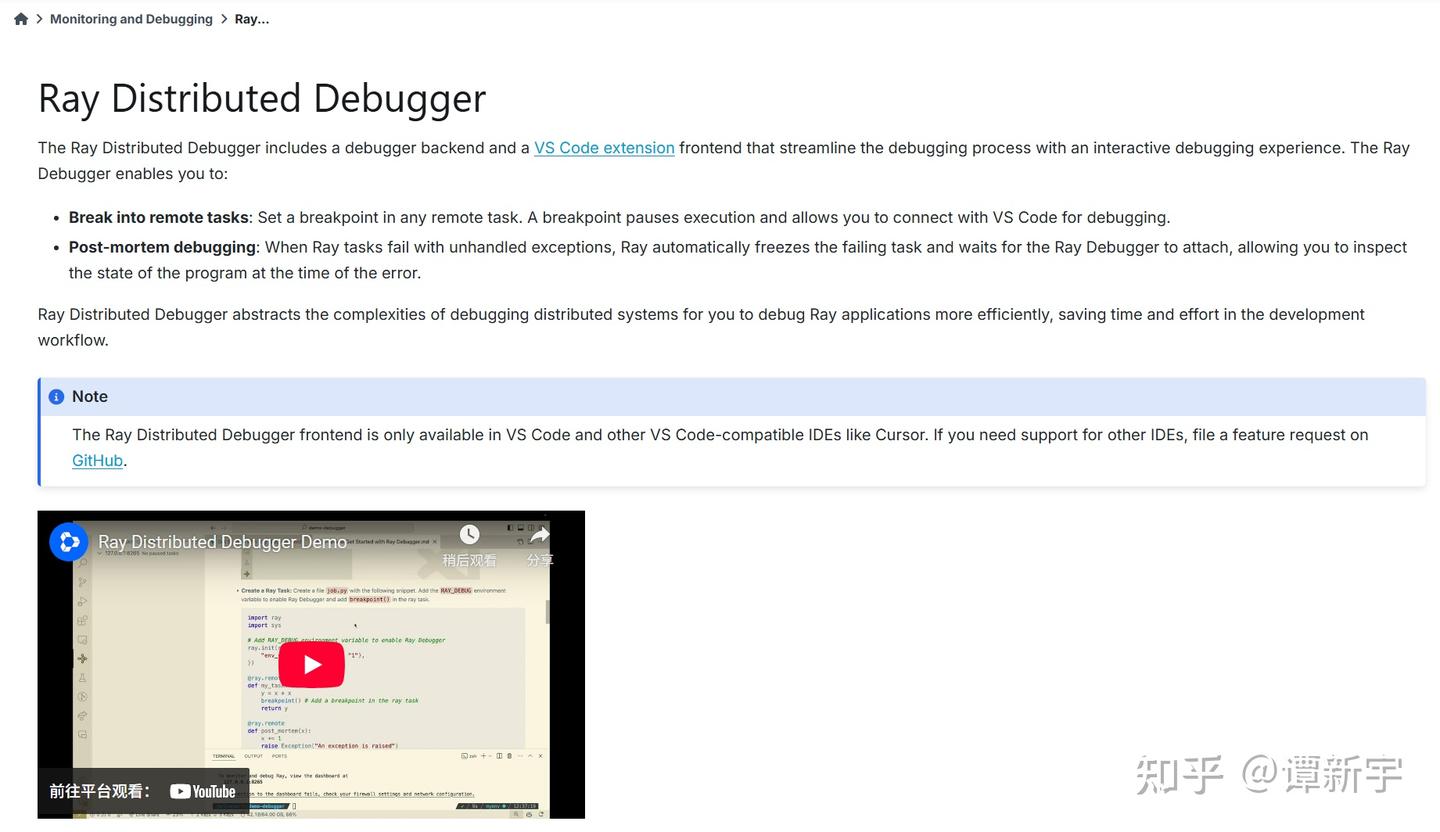
Ray Distributed Debugger 的核心原理是基于 Ray 内核中默认开启的 RAY_DEBUG 环境变量。当触发断点时,所有 Worker 会周期性地将断点信息汇总到 Head 节点。VSCode 插件通过连接 Ray Head 节点获取断点列表,用户可进一步点击 Start Debugging,attach 到对应 Worker 上进行单步调试。其官方文档大纲如下:
如上所述,Ray Distributed Debugger 需要能够网络连接到触发断点的 Worker,才能实现单步调试。在裸机部署场景下,只需配置好防火墙规则即可满足需求。然而,随着云原生技术的普及,目前大多数分布式计算框架都基于 Kubernetes(K8S)进行资源管理。此时,用户通常会选择安装 Kuberay,并通过 RayCluster/RayJob/RayServe 等自定义资源进行 Ray 集群的生命周期和资源控制。
在 K8S 环境下,由于其网络隔离机制,Ray 集群实际运行在集群内部的隔离网络空间中,外部默认无法直接访问 Ray Cluster 的各个组件。Ray Distributed Debugger 需要连接 Ray Head 节点的 dashboard 端口(8265)才能获取所有断点信息,此时我们可以将 Ray Head 的 8265 端口暴露出来,使 Ray Distributed Debugger 能够获取到集群中触发的断点列表。
以下是一个在 Kuberay 环境下测试 Ray Distributed Debugger 的例子:
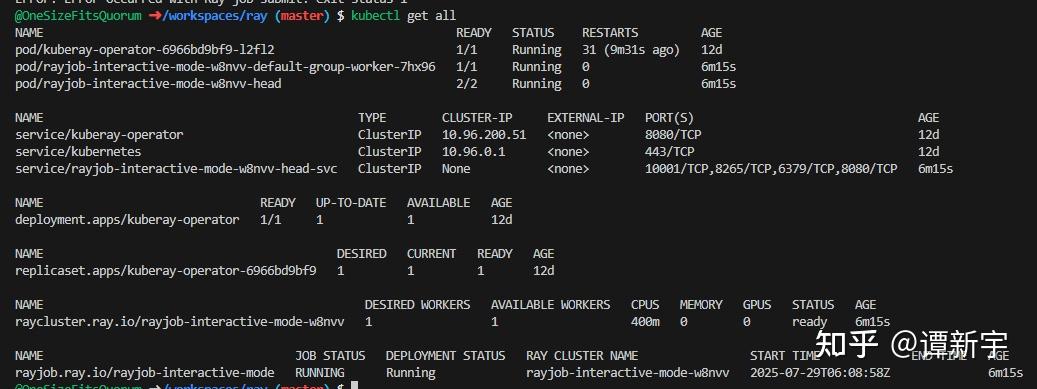

kubectl port-forward 命令将 Head 节点的 8265 端口转发到本地的 8265 端口,并通过 Ray Distributed Debugger 连接。此时可以看到集群中触发的所有断点: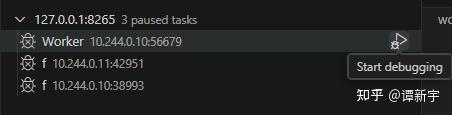
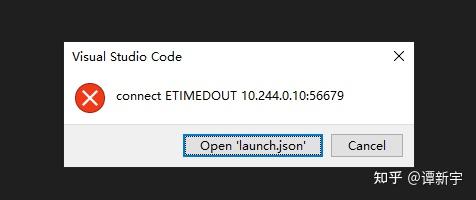
以上示例表明,在 Kuberay 环境下使用 Ray Distributed Debugger 存在实际困难。
值得一提的是,在官方文档中我们还发现一个 PR,提出了通过在 Ray Head 镜像中安装 SSH,并利用 VSCode Remote 进行连接的方案。虽然理论上可行,但这种方式操作较为复杂,涉及密钥管理、生命周期管理等问题,因此被用户诟病。
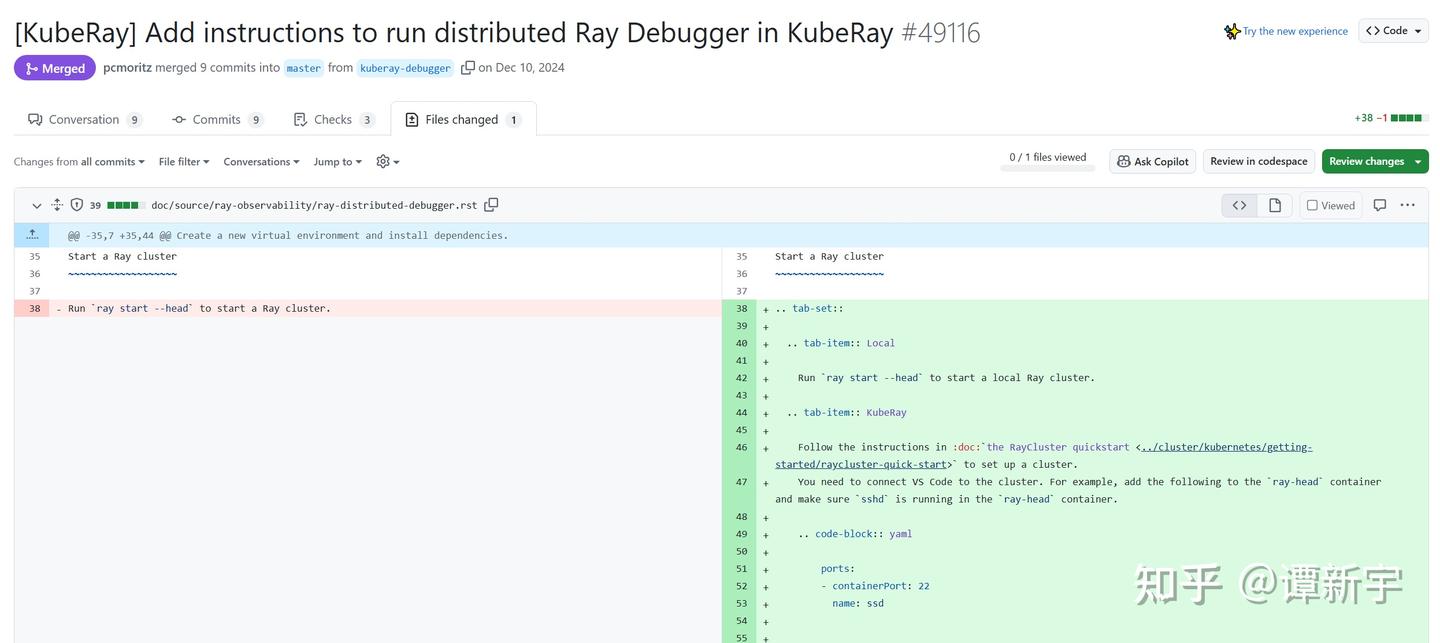
通过分析,我们发现 Ray 官方目前对于 Ray Distributed Debugger 在 Kuberay 环境下的支持不够完善,需要一个更便捷的解决方案。
在 Kubernetes 环境下,是否有办法方便地使用 Ray Distributed Debugger?带着这个问题,我进行了一些技术调研和尝试。
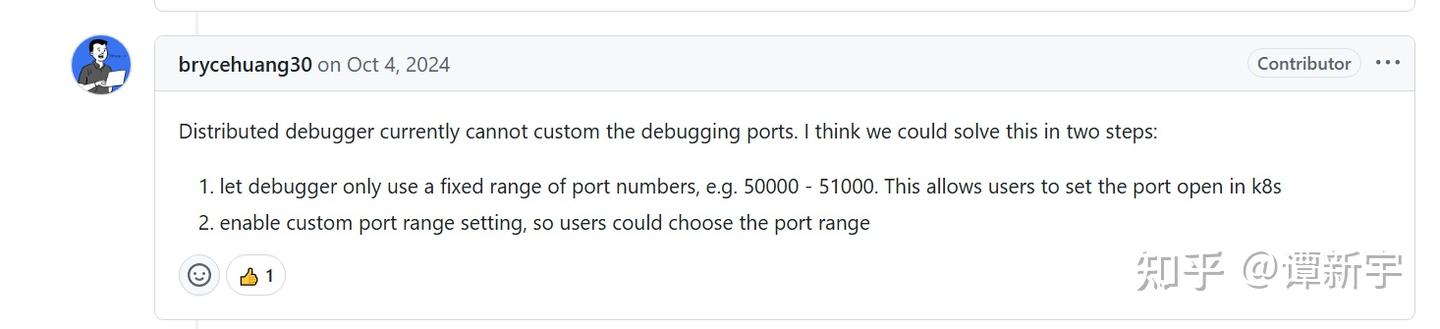
首先查阅了 Ray 官方 GitHub 仓库中的相关 issue:[Ray debugger] Unable to use debugger on Ray Cluster on k8s。从讨论中看出,Ray 官方最初的解决思路是让 Worker 在暴露等待 attach 的端口时使用固定的端口范围,这样用户就可以预先将这些端口暴露到外部进行 attach:
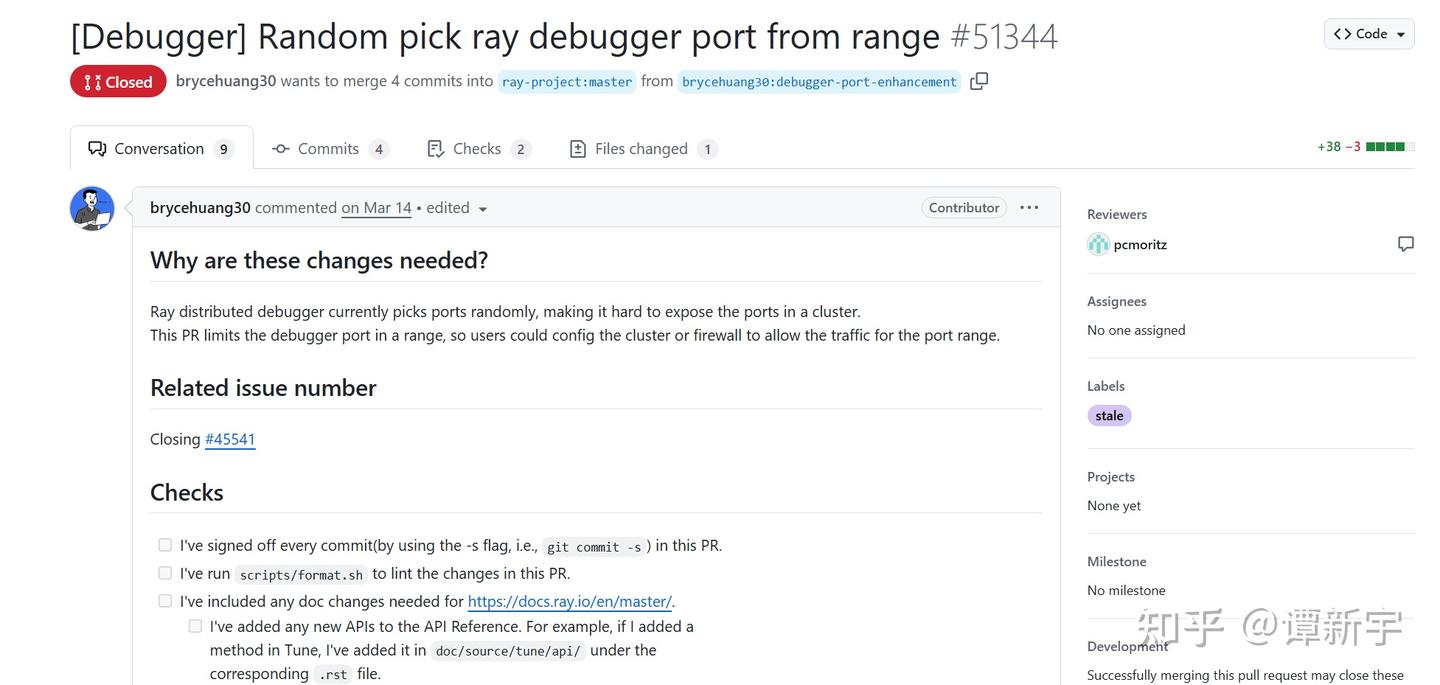
有开发者甚至提交了相关 PR 尝试将这一功能集成到 Ray 内核中,但该 PR 最终未被推进,被自动关闭:
推测这种方案未能推进主要是因为存在几个明显的问题:
端口范围设定难题:如何确定合适的端口范围?范围太小可能无法覆盖所有断点,范围太大可能占用过多集群资源,甚至与 Kubernetes API Server 等系统组件的端口冲突。
操作复杂度高:即使确定了端口范围,用户仍需手动暴露大量端口,操作繁琐且容易出错,不符合云原生环境下自动化的设计理念。
网络连接障碍:最关键的问题是,即使端口被成功暴露,Ray Distributed Debugger 的 VSCode 插件仍然会尝试连接 Kubernetes 集群内部的 IP 地址,而这些 IP 在集群外部不可达。由于 VSCode 插件已被 Anyscale 公司闭源管理,我们无法修改其连接逻辑。
理论上,可以通过为每个断点设置 kubectl port-forward,然后配合 iptables 规则将本地向 Kubernetes 内部 IP 发送的请求重定向到对应的本地端口,但这种方法操作繁琐、难以自动化,且需要较深的网络知识,在断点数量较多时几乎不可维护。
考虑到这些因素,特别是第三点的根本限制,我放弃了这条技术路径,转而寻找更简单的解决方案。
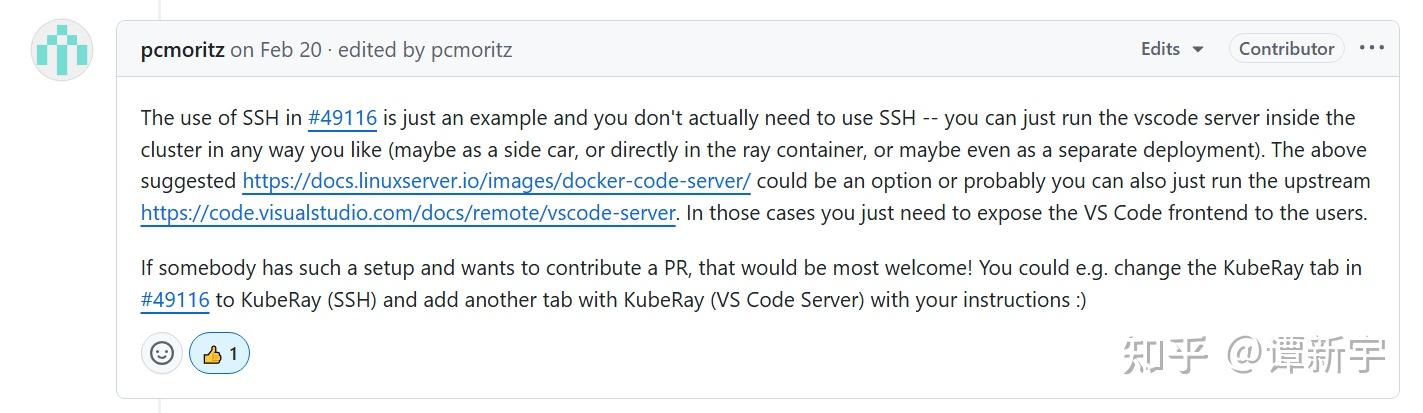
在前述 issue 的讨论末尾,有用户反馈他们在 Kubernetes 集群中部署 Code Server 后成功解决了该问题:

这一思路得到了 Ray 官方的认可,但由于缺乏具体实现细节和完整解决方案,该方案一直停留在概念阶段:
受此启发,我决定沿着这个思路进行探索。Code Server 是一个在浏览器中运行的 VSCode 服务,提供与桌面版 VSCode 几乎完全一致的开发体验:
这一特性为解决问题提供了思路:如果将 VSCode 部署在 Kubernetes 集群内部并通过浏览器访问,就可以规避网络隔离问题,使 VSCode 能够直接访问 Ray 集群内部网络。这种方案不需要管理 SSH 密钥或配置复杂的 VSCode Remote 连接,操作流程简单明了。
为了优化体验并解决不同 RayJob 之间的潜在冲突,我设计了将 Code Server 作为 Ray Head 的 Sidecar 容器部署的方案。这样不仅确保 Code Server 与 Ray 集群共享生命周期,还能直接访问 Ray 的工作目录,实现无缝集成。
基于这一思路,我开发了一个专用镜像并将其放到了 Dockerhub 上:onesizefitsquorum/code-server-with-ray-distributed-debugger。该镜像基于 linuxserver/code-server:4.101.2,预装了 Python、Ray、debugpy 等必要依赖,以及 VSCode 的 Python Run/Debug 和 Ray Distributed Debugger 插件。
以下是镜像的核心 Dockerfile:
1 |
|
接下来,配置 Code Server 作为 Ray Head 所在 Pod 的 Sidecar 容器,并确保它与 Ray 共享工作目录。注意 Code Server 需要使用前文上传至 DockerHub 的自定义镜像。关键的 Kubernetes 配置片段如下:
1 |
|
通过以上技术探索,我们成功让 Ray Distributed Debugger 在 Kuberay 环境下可用。下面给出一个结合本文工作在 Kuberay 集群中使用 Ray Distributed Debugger 的完整示例,所有相关代码和配置文件均已上传至 GitHub 仓库,方便读者参考和使用。
对于有特定业务需求的开发者,只需理解示例代码的核心逻辑,即可轻松扩展实现自定义的 Debugger 管理功能,无需重复开发基础组件和镜像。
在进行开发调试时,你可以选择本地环境或云端开发环境。对于云端开发,GitHub Codespaces 提供了一个便捷的选项:
这些资源足以运行本文中的示例代码和小型 Kubernetes 集群(如 kind、k3d 等),非常适合学习和测试 Ray 的调试功能。
具体步骤如下:
确保已安装 Kubernetes、Kuberay Operator 和 Kubectl ray 插件。如果使用 GitHub Codespaces,可以直接在终端中安装这些工具。
进入示例目录,执行以下命令启动一个包含 Ray Head、Code Server 和 Ray Worker 的集群:
1 |
|
集群启动后,会自动安装 debugpy 并将工作目录和模块文件传入 Ray Cluster。当代码执行到 breakpoint() 语句时,会等待调试器 attach。
使用以下命令转发 Code Server 端口:
1 |
|
打开浏览器访问 http://127.0.0.1:8443,进入 Code Server 界面。如果在 GitHub Codespaces 中运行,可以利用其端口转发功能,系统会自动创建可访问的 URL。
在 Code Server 中,使用 Ray Distributed Debugger 插件连接到 127.0.0.1:8265(Ray Head 的 Dashboard 地址),即可看到并连接所有断点。
部署成功后的界面如下:


通过这次探索,我们找到了一种在 Kuberay 环境下使用 Ray Distributed Debugger 的方法。这种方案通过 Code Server 作为中间层,解决了 Kubernetes 网络隔离导致的连接问题。主要有以下几点收获:
解决了实际问题:通过 Code Server 作为桥梁,成功解决了 Kubernetes 网络隔离机制导致的 Ray Distributed Debugger 连接障碍。
提供了实用方案:方案包括完整的镜像构建、配置模板和使用指南,可以直接应用于实际开发环境。
简化了操作流程:采用 Sidecar 容器模式,确保了与 Ray 集群共享生命周期,通过共享卷实现了资源无缝访问。
启发性思考:这种解决方案不仅适用于 Ray Distributed Debugger,也可能适用于其他在 Kubernetes 环境中进行开发调试的场景。
从更广的角度看,这次尝试也引发了一些思考:
云原生环境中的开发体验:随着云原生技术普及,如何在保持隔离性的同时提供良好的开发体验,是一个值得关注的问题。无论是本文提到的 Code Server,还是 GitHub Codespaces 这样的云端开发环境,都在朝着简化开发者体验的方向发展。
浏览器 IDE 的应用前景:基于浏览器的 VSCode 让开发者能够在不同设备上获得一致的开发体验,这种模式在云开发环境中很有潜力。Code Server 和 Codespaces 都采用了这种模式,降低了环境配置的门槛。
开源社区协作的价值:这个问题的解决思路源于社区讨论,也会回馈给社区,体现了开源协作的价值。
我计划将这个解决方案分享给 Ray 社区,希望能帮助到有类似需求的开发者。同时,也欢迎社区成员对方案进行改进和完善。
2025-05-14 15:14:35
过去五年半里,我在 Apache IoTDB 社区担任核心开发者,亲历了老分布式版本的迭代、新分布式架构的设计、盲测性能优化和系统可观测性搭建。这些年来,我在调试各种疑难杂症、修复线上事故以及优化系统架构的过程中,踩过无数坑,也积累了宝贵经验。
这篇文章记录了我在实战中总结出的 14 个重要教训,不是纸上谈兵,而是用血泪换来的经验。希望能帮助正在或即将从事数据库内核开发的朋友们少走弯路。
集群扩展性是确保系统长期可持续发展的关键。在设计初期,应尽量避免集群中的单点瓶颈,合理地将用户负载分配到集群中的所有节点上,并且要控制分片数量。
这样,不仅可以保证集群在负载增加时能够平稳扩展,还能避免在实际运行过程中出现性能瓶颈,从而提高系统的整体可用性。
共识算法是分布式存储系统核心中的核心,其设计决策直接影响系统性能上限和可靠性保障。如果确信系统只需使用一种共识算法,可以集中精力将其优化到极致;但如果预见到未来可能需要支持多种算法,就应当提前设计一个抽象的通用接口。
通用共识框架的设计不仅能支持当前的共识算法,还为未来算法的演进和优化创造了可能性。良好的抽象接口使新算法的引入变得简单,避免了整体架构的大规模重构,极大地减少了技术债务。
可观测性是系统设计中的核心部分之一。随着系统的迭代,良好的可观测性设计不仅能帮助你快速定位问题根源,避免因找不到问题所在而浪费大量时间,还能够在不同业务负载和硬件环境下,提供详细数据来量化评估各项优化工作的投入产出比。
投入构建完善的可观测性体系是极其有价值的工作,它不仅能够构建可扩展的工程服务体系,还能够支撑可持续的架构演进。
当系统出现不稳定性问题时,稳定性应始终作为首要解决目标。系统的不稳定性问题通常比性能问题更为紧急,只有系统足够稳定,才能进行进一步的性能优化。
因此,如果系统本身仍存在严重稳定性问题,可以考虑暂停性能优化工作,集中精力解决系统的稳定性问题。
代码量每增加一个数量级,维护的复杂度都会呈指数级增长。大型系统的可维护性直接影响到产品的长期生命力和演进能力。在系统不断扩展的过程中,良好的模块化设计是控制复杂度的关键武器。
通过清晰的责任边界、松耦合的接口设计和合理的抽象层次,可以将复杂系统分解为多个可独立理解和维护的模块。这种”分而治之”的策略不仅能够降低团队协作的成本,还能够使系统在面对不断变化的需求时保持足够的灵活性和可扩展性。
在功能迭代过程中,很容易为追求极致性能而向用户暴露底层实现细节或复杂概念。然而,这种”优化”往往会带来用户理解成本的急剧上升、使用门槛的提高以及后期维护的困难。
系统设计的艺术在于在保证性能的同时,尽可能对用户隐藏内部复杂性。一个优秀的系统应当既能提供强大的功能和性能,又能通过简洁直观的抽象概念让用户轻松上手。用户关心的是解决问题的简易程度,而非系统的内部构造。过早的性能优化和不必要的复杂性往往会得不偿失。
从项目一开始,就应该引入代码自动化规范检查工具,避免在后续迭代中频繁出现代码风格的变化,或者通过大型 PR 改变代码风格而破坏原有的 git blame 历史。通过自动化检查,不仅能够确保团队成员的代码风格一致,还能减少不必要的沟通和协调,提高团队的协作效率。
CI/CD 流程是高效开发的基石。它不仅能够帮助团队保持高效的开发节奏,还能确保系统的稳定性和可靠性。在设置 CI 时,建议将其拆分为 commit、daily 和 weekly 级别,分别执行不同优先级的测试用例,从而在开发效率和代码质量之间找到最佳平衡点。
性能和功能的持续检测是保持系统质量的关键。尤其在长期的迭代过程中,确保开发主分支持续接受充分检测,可以有效避免”问题积累”。随着时间推移,未及时发现的问题修复成本会大幅增加,因此及时发现并修复问题,才能确保系统质量持续得到保障。
随着 AI 技术的发展,像 Cursor 这样的 AI 工具可以大幅提高开发效率。尤其是在你已经具备扎实的开发能力时,借助 AI 工具生成代码并进行细致的 review 和微调,能够显著提升代码产出速度。
利用 AI 辅助编程,可以将每日有效代码产出从 100 行提升到 500 行,这不仅节省了时间,也能够提高团队的整体生产力。
在系统设计初期,选择成熟的 IDL 工具(例如 Protobuf 或 Thrift IDL)来管理网络接口的字段和持久化对象的非压缩磁盘存储(例如 WAL)是明智的选择。不要为了短期性能而放弃可演进性,否则日后很可能会产生难以消除的技术债。
在滚动升级集群时,或者在添加、删除持久化对象字段时,如果最初没考虑可演进性,往往会涉及非常复杂的处理过程和额外的维护成本。提前做出决策,选择合适的工具,可以为未来的扩展和维护打下坚实的基础。
开发初期,学习并掌握先进的线上调试工具是非常必要的。掌握高效的调试工具,能够极大提高问题解决效率。例如,Java 系统开发者至少应当熟悉 JDK 自带命令、JProfile 和 Arthas 等工具,它们可以帮助你快速诊断系统问题,特别是在复杂的线上环境中,能节省大量排查时间。
熟练掌握这些工具可以将复杂问题的解决时间从数天缩短到数小时甚至数分钟。
软件开发不仅仅是写代码,管理好软件的迭代流程同样至关重要。结合需求分析、功能设计、技术研究、开发、测试等环节,选择合适的工具来管理文档和迭代任务,能够显著降低团队沟通成本。
高效的流程管理工具能够提高团队的协作效率,确保信息透明和流畅,在团队规模扩大后尤其重要。在这方面,我强烈推荐飞书文档和飞书多维表格等协作工具。
定期发版的计划需要提前制定,避免将所有功能集中在大版本发布中,这样做会带来潜在的延期风险。通过定期发布小版本,不仅能够帮助团队及时应对问题,还能减轻技术负担,避免大版本发布时出现复杂情况。
建立每季度甚至每月定时发布功能版本的节奏,既能让用户及时获得新特性,也能有效降低每次发版的风险。
五年多的数据库内核开发之路,既有成功的喜悦,也有踩坑的痛苦。这些教训都是在实际项目中一点一滴积累的,希望能对你的工作有所启发。
在数据库这个相对成熟的领域,虽然具体实现会随着业务需求不断演进,但这些经过实践检验的工程智慧和方法论却是经得起时间考验的。即使技术栈更迭,底层架构变化,这些原则依然适用。从项目伊始就重视这些关键点,不仅能够减少技术债务,还将为你的系统打下坚实的基础,让团队能够持续、稳健地迭代和创新。
本文借助 Cursor IDE 和 Claude 3.7 辅助创作完成,AI 工具极大提高了内容的整理和润色效率,感谢 Anthropic 提供如此强大的技术支持。
2025-01-23 11:17:22
忙忙碌碌又是一年,2024 匆匆结束。回想这一年的成长和收获,除了个人能力的提升,在做人做事做选择等方面也有了更多的认识。可以说,自己并未虚度时光,过得十分充实。
临近除夕,总算抽出时间坚持自己之前的习惯来继续写年终总结。希望今年的总结不仅能继续鞭策自己寻找并实践摩尔定律的成长节奏,也能获得更多反馈来修正自己。
首先依然是自我介绍环节,我叫谭新宇,清华本硕,师从软件学院王建民/黄向东老师。目前在时序数据库 Apache IoTDB 的商业化公司天谋科技系统组担任内核开发工程师。我对分布式系统、性能优化等技术驱动的系统设计感兴趣,2024 年也一直致力于提升 Apache IoTDB 的集群易用性 & 鲁棒性、共识能力和写入性能等,并接手完成了若干具有挑战性的大项目。
接下来介绍一下我司:
天谋科技的物联网时序数据库 IoTDB 是一款低成本、高性能的时序数据库,技术原型发源于清华大学,自研完整的存储引擎、查询计算引擎、流处理引擎、智能分析引擎,并拓展集群管理、系统监控、可视化控制台等多项配套工具,可实现单平台采存算管用的横向一站式解决方案,与跨平台端边云协同的纵向一站式解决方案,可方便地满足用户在工业物联网场景多测点、多副本、多环境,达到灵活、高效的时序数据管理。
天谋科技由全球性开源项目、Apache Top-Level 项目 IoTDB 核心团队创立。公司围绕开源版持续进行产品性能打磨,提供更加全面的企业级服务与行业特色功能,并开发易用性工具,使得 IoTDB 的读写、压缩、处理速度、分布式高可用、部署运维等技术维度领先多家数据库厂商。目前,IoTDB 可达到单节点每秒千万级数据写入、10X 倍无损压缩、TB 数据毫秒级查询响应、两节点高可用、秒级扩容等性能表现,实现单设备万级点位、多设备亿级点位管理。
目前,IoTDB 能够为我国关键行业提供一个国产的、更加安全的、性能更加优异的选择。据不完全统计,IoTDB 已服务超 1000 家以上工业企业,在能源电力、钢铁冶炼、航空航天、石油石化、智慧工厂、车联网等行业均成功部署数十至数百套,并扩展至期货、基金等金融行业。目前已投入使用的企业包括华润电力、中核集团、国家电网、宝武钢铁、中冶赛迪、中航成飞、中国中车、长安汽车等。
值得一提的是,2024 年 IoTDB 的商业公司天谋科技营收同比增长近 300%,正式进入了指数增长的摩尔定律节奏。
介绍完背景后,在这里回顾下 2024 年我们系统组的主要工作,可分为 TPCx-IoT 双版本登顶、共识遥遥领先、性能优化摩尔定律新时代、集群易用性 & 鲁棒性显著提升、海量项目支持和海量技术沉淀 6 个方面。
在 TPCx-IoT 双版本登顶方面,国际事务处理性能委员会(TPC)是全球最权威的数据库性能测评基准组织之一。TPCx-IoT(TPC Express Benchmark IoT)是业界首个能直接对比物联网场景下不同软件和硬件性能的基准,涵盖了性能和性价比两个维度。今年,TimechoDB 1.3.2.2 版本在开启和关闭 WAL 测试的两种配置下,分别在 TPCx-IoT 的性能和性价比两个维度均登顶。值得一提的是,原本性能第一的系统是开启 WAL 的,而性价比第一的系统则关闭了 WAL。做数据库的人都知道,是否开启 WAL 对写入性能和资源消耗有着巨大的影响。尽管如此,IoTDB 最终实现了即使开启 WAL,仍能在性能和性价比两个维度同时登顶。如果关闭 WAL,性能和性价比还能够进一步提升约 20%,这充分彰显了 IoTDB 在应对物联网高吞吐场景中的极致性能。如今回想今年与新豪一起完成的这一工作,个人感触颇深,这对我来说也是四年磨一剑的过程。还记得 2020 年下半年研究生刚入学时,我就第一次尝试用 TPCx-IoT 测试过 0.12 版本的 IoTDB 老分布式集群。当时的分布式架构存在较大问题,性能始终难以提升,那年我的外号也成了 “tpc”,因为我一个学期几乎都在做 TPCx-IoT 测试,遗憾的是最终没有得到理想结果。经过四年的彻底重构与迭代,IoTDB 自 1.0 版本推出了全新的分布式架构,并在分区、共识和写入性能等方面做了诸多创新与改进。这些进展不仅使 IoTDB 能够支撑更多的用户场景,也最终帮助我们在 TPCx-IoT 榜单上登顶,性能达到了老版本的近 6 倍,充分证明了技术创新始终是第一生产力。此外,随着商业化公司成立,本次登顶过程中,我们不再是单打独斗,获得了许多同事的全力支持,特别是在与 TPC 委员会沟通、撰写报告等方面。这里特别感谢鹏程、Chris、昊男和苏总等同事对我们组的支持与帮助。没有团队的默默付出与协作,我们也不可能在今年完成这一目标,让这把磨了四年的剑最终得以出鞘。
在共识遥遥领先方面,IoTDB 的 1.x 分布式版本参照 2020 OSDI 最佳论文 Facebook Delos 的思路抽象了一个支持不同共识算法的统一共识框架,允许用户在一致性、可用性、性能和存储成本等若干维度进行权衡。今年我们不仅将现有共识算法迭代的几乎稳定,更是创新的提出了一个新的性能遥遥领先的共识算法
在性能优化摩尔定律新时代方面,今年我跟旭鑫、昊男、雨峰、湘鹏、荣钊、钰铭、江天学长,田原学长和振宇师兄等团队成员一起进行了多项盲测写入性能优化工作并取得了显著进展。我们不仅在很多特定场景下实现了性能提升数十倍的效果,还在通用场景下实现了写入性能翻倍的成就,这是 IoTDB 写入性能提升最大的一年。通过分布式架构、存储引擎和系统优化的组合拳,我们成功让 IoTDB 在通用场景下的盲测写入性能进入了摩尔定律的成长节奏(每 18 个月性能翻一倍或资源利用率减少一半)。以 2023 年为基准,2024 年我们已经实现了这一目标,2025 和 2026 年现有的技术储备也已经为继续沿着摩尔定律节奏提升奠定好了基础。在具体优化方面,我们做了很多关键工作,仅列举已做的开源部分如下:
在集群易用性 & 鲁棒性显著提升方面,我们也做了非常多的工作
在 IoT-Benchmark 方面,今年我们梳理了其项目结构和 README,使其逐步向更通用的时序基准测试工具演进。过去一年钰铭作为主力带领我们迭代了近 100+ commit,包括 50+ 稳定性修复和易用性提升、以及 10+ 性能优化。
在持续集成与迭代体系方面,今年在王老师的指引下,我们引入了对第三方库的 SBOM 管理,并开始使用 NVD 扫描并持续追踪开源项目中的 CVE 问题,从而逐步提升了对第三方依赖漏洞安全问题的重视。此外,我们还开始统计 IoTDB 的代码量,以评估代码复用效果和项目的复杂度。与此同时,我们也意识到,随着产品功能和复杂度的不断增加,测试用例的指数级增长与产品迭代效率之间存在一定的 trade-off。结合每天晚上和周末 CI 机器几乎都在空闲的现状——每周 168 个小时中,只有大约 1/3 的时间 CI 机器在工作,其余 2/3 的时间处于闲置状态——我与钰铭开始探索将 CI 拆分为不同级别的测试体系,包括 commit、daily 和 weekly 级别的测试。我们在 commit 级别保留最为关键的 CI 测试,在 daily 和 weekly 测试中充分利用闲置的机器资源,补充更多的测试用例。同时,我们也将引入智能化策略,自动识别并追踪有问题的 commit,从而在开发效率与质量保障之间找到更好的平衡点。
在海量项目支持这块,我则个人负责了若干探索性项目并参与了很多实际项目
在海量技术沉淀这块,则基本是我们出于技术 & 业务双驱动完成的很多探索
今年,我在 Apache IoTDB 社区提交并被合并了 84 个 PR(去年 119 个),Review 了 509 个 PR(去年 387 个)。相比去年,今年我的大部分精力都集中在贴近业务和技术管理上,也对个人和团队如何最大化产出有了更多思考和感悟。今年 8 月,我受邀成为 Ratis 社区的 Committer,并成功拥有了 1k Github Follower,这让我更加认可自己在开源领域的专注。回顾过去一年,我觉得我们成功将团队的许多工作通过各种方式沉淀下来,并影响了许多人。希望我们能始终在这段青春年华中保持对技术的热情,专注于我们的工作继续前行。在这里,我特别感谢我的女朋友🍊 始终支持我的工作并帮助我疏解情绪,让我感受到生活的美好与幸福。她还带我见识了许多新事物,让我对人生的很多方面有了新的认识和思考。
介绍完充实的 2024,回顾 2023 年终总结,可以发现今年我们在去年四个维度的展望上都取得了不错的成绩
下面分享一下我今年的很多成长感悟,欢迎大家批评指正。
对于一个稳定性打磨的功能,如何评估其完善时间?在打磨 Region 迁移的稳定性时,我今年思考了很久。如果考虑无数硬件环境(如 4C16G 和 192C768G)、测试负载(实时写入、读写混合),再加上注入各种异常(如节点重启、网络分区、断电等),以及多个模块功能的组合(如多级存储、存储引擎、共识层、流处理引擎等),可以看出它们的组合是指数级扩展的。即使研发进行了完善的设计与实现,但提测后仅测试完善的开销就几乎永无止境。但如果一开始就定下工作周期为半年或一年,也难以做出可靠的过程管理来向上汇报。
在这种困境下,我们必须意识到场景是无限的,在精力有限的情况下,我们的目标是用最小的研发和测试代价解决尽可能多的 bug。最初,我们按照研发视角将功能的稳定性迭代分为 V1、V2、V3,期望逐步打磨到稳定状态。然而在实际测试中,我们发现测试视角与研发视角并不同频,导致测出的 bug 比较分散,尽管测试与研发一同打磨很久,仍难以向上汇报阶段性成果,因为每个模块都有不少 bug 被修复。这使得这个工作看起来像是无底洞,且容易受到质疑。其实,问题的根本在于缺乏多方共识的客观评价标准。
回顾整体流程,我认为可以在以下两个方面做得更好
今年有件让我深受感触的事,那就是发现大家对 IoTV2 共识算法的价值产生了质疑。从纯研发的视角来看,IoTV2 显然在创新性和性能上都显著超越了 IoTV1,是我们组过去几年最具创新性的工作之一,其他共识算法也都花了好几年才稳定,IoTV2 毕竟才诞生一年。但如果想在开发团队中获得更广泛的认可,就需要考虑大家关注的不同方面,包括稳定性、创新性、问题收敛程度、潜在收益与投入的平衡等。可以看出,这些维度之间往往存在矛盾,而且很难得出绝对客观的结论,很多东西也完全看未来的事在人为,因此很难在所有人中达成共识。这让我意识到,当一个软件项目和团队发展到一定阶段后,是否落实创新工作,往往会面临保守和激进的分歧,二者需要不断博弈与制衡,才能走向一个可行的方向。完全激进或者完全保守都会带来不可预知的风险。
回到 IoTV2,我们能够平息质疑的一个重要原因是我们做了共识层的抽象,能在一套接口下支持不同的共识算法,从而使得各个共识算法可以单独迭代。如果没有这个统一的接口,不管 IoTV2 作为业界第一个多副本超越单副本的共识算法有多么创新,仍然会面临无数质疑,甚至可能导致无法迭代。而对于竞品来说,除非照抄 IoTDB 整体共识层的设计,否则也很难平息内部质疑,全力推进这项工作。这为我们未来的扩展性设计提供了指导——良好的接口抽象能够使得系统的关键迭代从“不可能”变为“可能”。当然,软件工程没有银弹,即使我们通过共识层的抽象让 IoTV2 的迭代得以顺利进行,但代价就是翻倍的测试和打磨开销。总体而言,抽象得越好,复杂度封装得越到位,测试和打磨的开销也就越低。
在今年参与更多技术管理工作后,我渐渐关注到个人管理成本 ROI 这一概念,其本质是消耗尽可能低的 +1 管理成本(包括时间和资源等)完成更复杂的工作,并在有风险时及时汇报并提供辅助决策的数据。
总体而言,不同的人有不同的管理风格,同一个人对于不同的事情也会采取不同的管理方式。有时像《大明王朝 1566》中的嘉靖一样,只关注结果,不拘过程;有时又像《大决战》中的 101 一样,会关注每一个细节。其实,不论是哪种管理风格,最终目标都是完成工作,并没有绝对的好坏之分。
对于我们个人而言,我们控制不了别人,唯一能够不断改善的就是提升自己的管理成本 ROI。通过这种方式,我发现能够使得自己与他人的合作变得更加高效和愉快。类似的例子包括但不限于
这些经验很多是在与我们组俊植一起进步的过程中学到的。希望自己能像俊植一样,不断提升自己的管理成本 ROI,进而锻炼出更好的职业素养。
今年年中,我读了润基哥哥的十倍程序员文章,受益良多。对于十倍程序员的成长,本质上有两个方面:
从纯个人能力上来看,可以按照上述思路进行纵向和横向扩展,但今年我也意识到人力始终有限,战略上选择一个正确的方向才是事半功倍的关键。所以今年除了个人业务能力的提升,我还积累了很多做人做事的经验。对于很多事情的可行性,我不用再依赖他人的意见,而是能够自己进行主观判断。希望自己能在这个方向上继续沉淀,用靠谱的战略指引自己不断成长。
其实这个感悟与战略类似,说一个应该做的事情只需要十秒钟,然而将这个事情具体落地可能需要十周甚至十个月的时间。人力始终有限,尤其对于一个软件团队来说,面对无数的输入和决策指引,客观上这些工作不可能面面俱到,必须进行战略性取舍。
决定做什么往往没有太多压力,因为人性中总有一种“即使失败了,没有功劳也有苦劳”的自我安慰。但如果要决定不做什么,则必须对自己的业务和竞争力有深刻理解,出于提高人效的角度思考且愿意承担政治责任,才能最终说服别人。这种决策十分困难且珍贵,但也正是许多高效团队能够成功的关键。
今年,我有幸在博士生组会中跟随王老师龙老师带领的实验室团队学习时序 AI 大模型的落地思路。虽然王老师龙老师一直强调我们现在已经做好了“存数”,接下来要把“用数”做好,但他们也明确通过案例分析告诉我们,哪些 AI 项目是靠谱的能够最终产生实际价值,哪些 AI 项目是不靠谱的做了也只是白白耗费精力不创造实际价值。这种战略定力和担当,让我深受触动。
尽管我一直对历史很感兴趣,很多大道理早已听过,但今年在工作中,我从切身实践中获得了一个深刻的感悟:任何事、任何人都会有正负面的影响和评价,不存在一个完人,也不存在一个能够得到所有人认可的方案。
人性大多数时候是非常真实的,大家常常根据结果来判断过程。如果事情没有做成,就会有人列举一堆负面评价来解释为什么失败;如果事情做成了,又会有人说一堆正面评价来证明“早就看他行”。但实际上,成与不成,除了人的因素,还很大程度上取决于天时地利,而这些天时地利,作为非人为因素,反而会深刻影响最终大家的评价。此外,尽管我们都在强调要客观理智,但根据我的观察,大多数人,包括我自己,也曾在情绪驱动下做出一些非预期的行为,并且不断强调自己并没有被情绪左右。
意识到这些后,我明白了很多事情,要么不做,要做就尽己所能做到最好,不必过多顾虑他人的评价。只有这样,才能避免不必要的内耗和沟通成本,将精力集中在更重要的事情上,这样反而更有可能将事情做成。
在今年的工作中,我逐渐有了一些中庸之道的感悟。每个人都有不同的特点,要凝聚一个多样化的团队,需要更多的包容性和开放性。过于从自己的视角偏重某一维度,反而可能导致适得其反,产生“过刚易折”的效果。在做人做事时,面对大的目标和原则性问题时,我们要坚持“刚”;而对于那些不影响最终目标的小细节,则可以选择“柔”。此外,在与许多跨行业朋友的沟通中,我逐渐意识到,尽管我们都在努力工作,但很多事情还是需要天时地利。有时候,顺势而为、蛰伏等待也许是成功的关键。
因此,保持良好的工作心态,营造融洽的工作氛围,在自驱保证自我成长的基础上,不必过于纠结于远方的目标,而应专注当下刚柔并济,才能实现可持续发展,并与团队一起走得更远。
今年对我个人的时间管理和抗压能力来说是极具挑战的一年。上半年临危受命接管存储组,scope 显著扩大,团队人数相比去年接近翻倍。由于一些原因,无法进一步进行分级管理,这对我个人精力提出了极大挑战。基本上,我每天都在不断地线程切换,盯着十几二十个事项。尽管我已经转变为“没有深入参与时间,只略微沟通过程便要结果”的最低投入策略,但由于我依然是单点瓶颈,很多进展缓慢的事情和无人处理的 bug 需要我来当“救火队员”。我的时间依然远远不够用,一旦我在个人处理的某个问题上阻塞了一两个小时,那基本上会造成四五个问题的连锁阻塞。高压状态下,这种情况对我个人的心态和情绪也产生了一定的影响。幸好,下半年江天学长挺身而出,接过了存储组的压力,帮助我们组的人数恢复到了一个相对合理的规模,让我有更多精力去探索和深度参与我们组的很多工作。
现在回想这段经历,我意识到一个人的合理管理半径不应超过 10 个人。在这个范围内,能够在个人输出和团队输出之间取得一个良好的平衡。此外,只有与团队一起成长、大家自驱地去做事,才能在不线性增加时间和精力投入的情况下,扩展管理半径。
即使是同一个人,在不同的年纪,对于金钱、工作氛围、健康和工作生活平衡等方面的追求都会有所不同。但一直以来,驱动我前进并屏蔽这些外部欲望的动力,始终是如何在单位时间内获得更多的成长。随着时间的推移,我逐渐意识到,能够承担越来越大的责任,并创造更多的价值,才是个人成长的核心所在。
固然我们可以在任何地方按照这个思路去追求自我成长,但只有在一个增量团队中,团队和个人的双指数增长才更容易实现。希望大家可以找到与自己 match 的指数增长团队。
通过这一年,我们为 IoTDB 在技术上构建了摩尔定律的成长节奏。幸运的是,这些技术积累也立即在影响力和营收上得到了体现。希望在新的一年,无论是我个人还是团队,都能继续保持这种摩尔定律般的成长节奏,推动更多的技术创新和业务突破。
最后,在除夕之际,预祝大家新年万事如意,心想事成!愿每个人在新的一年中都能够事业有成,收获满满!
2024-02-07 15:24:52
兜兜转转又是一年,不知不觉 2023 已经结束。回想自己过去一年的成长与感悟,依然觉得是收获满满。今年工作之后闲余时间相比学生时代少了许多,到了除夕才有时间来写今年的年终总结。好在自己还是下定决心将这个习惯坚持下去,希望这些年终总结不仅能够在未来的时光里鞭策自己,也能够获得更多大家的反馈来修正自己。
首先依然是自我介绍环节,我叫谭新宇,清华本硕,师从软件学院王建民/黄向东老师。目前在时序数据库 Apache IoTDB 的商业化公司天谋科技担任内核开发工程师。我对分布式系统、可观测性和性能优化都比较感兴趣,2023 年也一直致力于提升 Apache IoTDB 的分布式能力、可观测性和写入性能。
接下来介绍一下我司:
天谋科技的物联网时序数据库 IoTDB 是一款低成本、高性能的时序数据库,技术原型发源于清华大学,自研完整的存储引擎、查询计算引擎、流处理引擎、智能分析引擎,并拓展集群管理、系统监控、可视化控制台等多项配套工具,可实现单平台采存算管用的横向一站式解决方案,与跨平台端边云协同的纵向一站式解决方案,可方便地满足用户在工业物联网场景多测点、多副本、多环境,达到灵活、高效的时序数据管理。
天谋科技由全球性开源项目、Apache Top-Level 项目 IoTDB 核心团队创立。公司围绕开源版持续进行产品性能打磨,提供更加全面的企业级服务与行业特色功能,并开发易用性工具,使得 IoTDB 的读写、压缩、处理速度、分布式高可用、部署运维等技术维度领先多家数据库厂商。目前,IoTDB 可达到单节点每秒千万级数据写入、10X 倍无损压缩、TB 数据毫秒级查询响应、两节点高可用、秒级扩容等性能表现,实现单设备万级点位、多设备亿级点位管理。
目前,IoTDB 能够为我国关键行业提供一个国产的、更加安全的、性能更加优异的选择。据不完全统计,IoTDB 已服务超 1000 家以上工业企业,在能源电力、钢铁冶炼、航空航天、石油石化、智慧工厂、车联网等行业均成功部署数十至数百套,并扩展至期货、基金等金融行业。目前已投入使用的企业包括华润电力、中核集团、国家电网、宝武钢铁、中冶赛迪、中航成飞、中国中车、长安汽车等。
介绍完背景后,在这里回顾下 2023 年我们系统组的主要工作,可分为高扩展性、高可用性、可观测性、性能优化、技术支持和技术沉淀 6 个方面。
在高扩展性方面,我们主要做了以下工作:
在高可用性方面,我们主要做了以下工作:
在可观测性方面,我们主要做了以下工作:
在性能优化方案,我们主要做了以下工作:
在技术支持方面,我们主要做了以下工作:
在技术沉淀方面,我们主要做了以下工作:
今年我在 Apache IoTDB 社区提交并被合并了 119 个 PR, Review 了 387 个 PR。从 PR 数量上来说相比去年和前年有了显著提升,可能是由于更加专注于工作,并且 scope 也在不断扩大吧。此外我也于今年 9 月受邀成为了 Apache IoTDB 社区的 PMC 成员,感谢社区对我的认可。
因时间所限,我今年在知乎等社交平台的活跃度有所下降。但回顾这一年,我觉得我们团队完成了许多既有趣又深入的工作,并且几乎都有相应的文档沉淀下来。这些宝贵的积累完全可以与业界分享以交流学习。我期待在 2024 年,我们团队能够更频繁地分享我们的技术沉淀,并吸引更多对技术有兴趣的同学加入 IoTDB 社区或我们的实验室进行交流!
在深入研究和优化数据库系统在各种硬件环境及业务负载下的性能过程中,我越发认识到掌握体系结构和操作系统知识是进行性能优化的基础。今年,我在这两方面补充了许多知识,并阅读了《性能之巅》的部分章节。然而,令人感到有些沮丧的是,随着知识的增加,我反而越来越感觉到自己的无知。但我仍然希望,在 2024 年能够跨越这段充满挑战的绝望之谷,登上开悟之坡。
对于有意向学习 CMU 15-418 课程的朋友,我非常期待能够一同学习和进步!如果有经验丰富的大佬愿意指导,我将不胜感激!
今年,我们组深入研究了 JDK 的垃圾回收(GC)算法,包括但不限于 Parallel Scavenge(PS)、Concurrent Mark Sweep(CMS)、Garbage-First(G1)和 Z Garbage Collector(ZGC)。我们还对 IoTDB 在相同业务负载下采用不同 GC 算法的吞吐量和延迟性能进行了比较测试,结果表明在不同的负载条件下,各 GC 算法的性能表现排序也有所不同。
在 GC 算法的选择上,我们面临着内存占用(footprint)、吞吐量(throughput)和延迟(latency)三者之间的取舍,类似于 CAP 定理,这三者不可能同时被完全满足,最多只能满足其中的两项。通常情况下,高吞吐量的 GC 算法会伴随较长的单次 STW 时间;而 STW 时间较短的 GC 算法往往会频繁触发 GC,占用更多的线程资源,导致吞吐量下降。例如,PS GC 虽然只有一次 STW,但可能耗时较长;G1 的 Mixed GC 在三次 STW 中的 Copying 阶段可能造成几百毫秒的延迟;而 ZGC 的三次 STW 时间都与 GC Roots 数量有关,因此 STW 延迟可以控制在毫秒级别。
JDK GC 算法的发展趋势似乎是在尽量减少 GC 对业务延迟的影响,但这种优化的代价是消耗更多的 CPU 资源(JDK 21 引入的分代 ZGC 有望大幅降低 ZGC 的 CPU 开销)。在 CPU 资源本身成为瓶颈的场景下,使用 ZGC 和 G1 等 GC 算法的吞吐量可能会低于 PS。GC 算法目前的演进具有两面性,例如 Go 语言就由于其默认 GC 与 Java 相比 STW 时间较短而被赞扬,但其 CPU 资源消耗大也会被批评,我们需要根据不同的目标选择合适的 GC 算法。
然而,GC 算法朝低延迟方向的不断演进仍具有重要意义,因为吞吐问题可以通过增加机器进行横向扩展来解决,而延迟问题则只能依赖于 GC 算法的改进。因此,在调优时应该有针对性,分别针对吞吐和延迟进行优化,而不是同时追求两者。如果追求吞吐量,可以优先考虑使用 PS;如果追求低延迟,可以考虑使用 G1/ZGC,并为之准备额外的机器资源以支付低延迟的代价。
今年,我参与了许多问题修复和优先级排序的工作,同时深入思考了编程语言对软件开发总成本的影响。
在 PingCAP 实习期间的一次闲聊中,有些同事提出 TiDB 应该用 Rust 或 C++重写,理由是用 Go 语言编写的性能较差。然而,我的 mentor 徐总认为,采用 Go 语言后显著减少了大家的 OnCall 次数,从而节约了大量研发成本。
从纯技术的角度看,C/C++ 在极限优化下确实能比 Java 更好地发挥硬件特性。但工程开发,尤其是内核开发,不仅仅是技术问题,它更多涉及到软件工程的广泛议题。现实中,我们经常面临着无休止的问题修复和需求实现,性能优化往往未能充分利用硬件能力。我认为,尽管开发团队采用的编程语言可能影响理论上的性能上限,但在大多数工程实践中,项目成功的关键并不仅仅在于将性能优化到极致。更重要的是,在有限资源下如何优先追求满足用户需求的产品特性、如何持续保证产品的稳定性和可维护性、如何提升系统的横向扩展能力、以及如何在现有代码基础上持续进行性能优化。我相信,这些因素比起编程语言的选择所带来的潜在收益要重要得多。
因此,除了少数极特别的场景(例如追求超低延迟 or 边缘端等),选择一个团队熟悉且学习成本较低的编程语言就足够了。
今年,我们面对并快速解决了许多棘手的问题,但同时也遇到了一些难以快速找到原因的疑难杂症。这些问题涵盖了多个方面,例如 DataNode 进程在 OOM 后仍能响应心跳但无法处理新的读写请求(这是因为 JVM 在 OOM 后随机终止了一些线程,导致监听线程被终止无法响应新连接而心跳服务线程仍在运行),以及 Ratis consensusGroupID 编码错误导致的 GroupNotFound 错误(使用 Arthas 监控后问题消失,我们怀疑这是 JVM JIT 的 bug)等。
解决这些问题的过程加深了我们对于设计新功能时对各种异常场景的考虑,有效避免了许多未来可能发生的 Oncall 问题。
在面对问题和解决问题的过程中,我深刻体会到人的认知可以分为四个象限:已知的已知、已知的未知、未知的已知以及未知的未知。其中,最难以应对的是“未知的未知”。我一直在思考工程经验这四个字究竟意味着什么?现在我认为,工程经验的积累不仅意味着将更多的“已知的未知”转化为“已知的已知”,还需要将更多的“未知的未知”变成“已知的未知”,这样才能具有可持续性。
今年,我深刻体会到了流程体系在构建一个可持续发展的软件开发团队中的重要性。我认识到只有拥有一流的团队,才能够开发出一流的软件。
在王老师软件工程理念的统筹指导和 Apache 基金会的支持下,我认为我们的产品流程体系已经相对健全,包括但不限于以下几个方面:
通过在这样的团队中工作,我对如何打造一个可持续的软件工程体系有了更深地理解。
随着我们组负责的模块和同学数量的增加,我逐渐发现,仅仅通过飞书文档记录工作内容的做法,虽然实现了工作的“记录”,却缺乏了有效的“管理”。例如,我们组面临的任务琐碎而多样,大家都经常会忘记一些计划中的任务;同时,我们的业务需求变化迅速,虽然大家都在同时推进多项任务,但仍然跟不上需求的变化速度。这就要求我们能够及时调整任务的优先级,以便灵活应对并优先完成 ROI 最高的任务。此外,我们以前的月度总结并没有持续进行,我分析的原因是任务汇总本身就是一种成本,导致月度总结难以持续,从而失去了很多总结沟通的机会。
为了解决这些问题,我开始学习并使用飞书的多维表格来管理团队的任务。通过多维表格,我们不仅可以清晰地看到每位成员当前的工作任务,还可以在团队会议上根据业务需要灵活调整任务优先级,甚至能够一键生成甘特图来明确不同优先级任务的时间线。在进行每周和每月总结时,我们也能够通过筛选日期快速生成任务汇总。
一开始,多维表格似乎完美地解决了我们之前的问题。然而,随着时间的推移,我发现这种方式也存在缺陷。由于总结能够一键生成,我不再每周花费一小时来统计和规划我们的周报和下周计划,甚至我们的月度总结也鲜少举办。这反而导致我们的日常开发缺乏规划,显得有些随波逐流。在东哥的点拨下,我重新开始在飞书文档中记录周报,并且连续三个月组织了月度总结会。通过定时的每周和每月汇总与沟通,团队的工作变得更加有序和明确。现在如果让我去说上半年做了什么主要工作,我可能还需要看多维表格筛选半天,但如果问我后 3 个月做了什么,我只需要看每月的月度总结就可以了。
现在,我们通过多维表格来管理任务的优先级,同时利用飞书文档来汇总周报和月报。通过对我们组流程管理的持续迭代和优化,我意识到有时候追求速度反而会拖慢进度,而适当地放慢脚步思考反而能够使我们更加高效。
在技术方面,我最开始深入了解的就是分布式系统,我一直在学习如何实现系统的高扩展性和高可用性。随着时间的推移,我发现这些分布式系统的理念同样适用于团队协作中。
为了实现高扩展性,关键在于让所有团队成员并行工作,而不是仅依赖于“主节点”或关键个体,这要求每个成员都能独自完成任务并持续提高自己的工作效率,这样才能提升整个团队的整体性能。同时,团队还需要能够支持成员的动态调整,如新成员的加入和旧成员的离开,确保团队结构的灵活性和适应性。
为了满足高可用性,就需要在关键任务或数据上实施冗余策略,以防止暂时的不可用状态对团队工作造成影响。这可能意味着需要在某些区域投入额外的资源,确保信息、知识或工作负载能够在多个成员之间共享,保持一致性。
这一年来,我们团队负责的模块不断增加,但每个模块都至少有 3 位以上的成员熟悉,上半年我的感受是每天从早忙到晚,连半天假都请不了。但到后半年我感觉偶尔请一两天假也不会对外产生可感知的影响了,这代表了我们组的高可用性出现了显著提升。针对我们组负责的模块,我们维护了详尽的功能和技术设计文档,以及改进措施的追踪记录,这不仅加速了新成员的融入,也保持了团队知识的一致性。此外,我们通过引入自动化工具,如飞书激活解密机器人、各类测试脚本、木马清理脚本等,有效提升了团队的工作效率,体现了我们组在高扩展性方面的进步。
希望 24 年我们组能在高扩展性和高可用性方面继续取得显著进步,为实现更加高效和稳定的团队协作模式而不断努力。
今年我们组的主要工作之一便是打造 IoTDB 的可观测性,目前已经显著提升了问题排查和性能调优的效率,成为线上运维 IoTDB 的必备工具。回到时间管理上,我发现可观测性的很多理念也同样适用。
随着组内同学越来越多,scope 越来越大,沟通协调的成本已经不容忽视,我自己的时间越来越不够用,逐渐成为了单点瓶颈。在向东哥请教后,我开始按照半小时为单位记录自己每天的工作内容,并定期反思每半小时的工作是否满足了高效率。
通过整理自己工作日一天 24 小时的时间分配,我发现自己实际可用于工作的时间并不超过 11 小时,因为每天基本要包括睡眠 8 小时、起床和就寝的准备及洗漱时间 1 小时、通勤 1 小时、餐饮和午休 2 小时以及运动 1 小时(有时会被娱乐消遣取代)。11 月份的数据显示,我的平均工作时间约为 10 小时(没有摸鱼时间),已经接近饱和每天都十分充实。这促使我思考如何提升自己和团队单位时间的工作效率,比如在协调任务时明确目标和截止日期,实行更细致的分工以解决我作为单点瓶颈的问题等。通过这些措施,到了 12 月份,我的平均每日工作时间减少到了 9.5 小时,而感觉团队的整体产出反而有所提升。不过,到了 1 月份,由于一些新的工作安排尚未完全理顺,我的平均工作时间又回升到了 10 小时,这需要我持续进行优化。
总的来说,定期统计和评估自己的时间分配及其 ROI,我觉得对于提高工作效率具有重大意义。
在经历了半年学生生活和半年职场生活后,我对职业发展与生活的关系有了新的认识和感悟。之前我是那种职业动机极强以至于生活显得相对单调的人。对我来说,除了那些能带给我快乐的少数娱乐活动外,生活中的许多琐碎事务如做饭洗碗,都被视为时间的浪费,不如将这些时间用于创造更多的价值。在地铁和高铁上不学习,我也会感到是对时间的浪费。我认为既然职业发展对我而言十分重要且能从中获得快乐,那么我应该将所有可用的时间都投入其中。
然而今年我的心态发生了显著的变化。我逐渐意识到,即使职业发展很重要,即使我能从中获得快乐,它也只是生活的一部分。我开始挤出更多的时间来陪伴家人,也开始与各行各业的老朋友新朋友进行交流。我不再认为生活中的全部琐事是对时间的浪费。我更加注重如何在有限的工作时间内提升效率完成超出预期的工作,而不是简单地用更多的时间去完成这些工作。
这种心态的转变对个人来说不一定是坏事。如果我的心态没有这些变化,可能会投入全部可用的时间于职业发展中,但这样的状态不确定能够持续多久。如果我的心态发生了变化,那我可能会更加注重工作效率和生活体验感,也许能达到职业发展和生活的双赢。
总的来说,每个人在不同的年龄阶段对这种平衡的感悟都会有所不同。我目前的想法是,顺应我们不断成熟的心态,选择让我们感到最舒适的状态,这不仅能让我们的心理状态更加健康,也能更好地平衡职业发展和生活的关系。
马克思指出社会分工是生产力发展的结果和需要,这种分工具有历史的必然性。对于创业公司而言,追求指数型增长是生存和发展的关键,因为即使是线性增长,在激烈的市场竞争中也可能面临被淘汰的风险。如何实现这种增长,是一个复杂且多维的问题,我在这里只从任务分配的角度分享一些个人理解。
在创业团队中,自上而下的任务繁多,而自下而上每个成员的兴趣和专长也各不相同。如何最大化团队的价值?关键在于沟通和了解每个成员的兴趣点和擅长点,尽可能让他们大部分时间都在做自己感兴趣和擅长的工作。虽然总有一些额外的任务需要团队共同承担,但是优先保证成员大部分时间能够从事自己感兴趣且擅长的工作是非常重要的。只有这样,每个人才会带着兴趣和专长去挖掘提升效率的可能,从而可能产生指数级的复利效应,并最终影响整个团队的产出。在现有的权力结构体系下,无论是企业还是更广泛的社会,我觉得自上而下的人员任命也基本遵循这一原则。
基于这样的理解,我在分配我们组的任务时,尽可能根据我对团队成员的了解,分配给每个人感兴趣和擅长的任务,并与大家一起探索提升效率和价值的途径。这一年里,我一直在寻求任务分配的全局最优解,并坚信找到合适的人做他们感兴趣的工作,能够产生的复利远远超过随机或平均分配工作所能带来的效益。
在创业团队的初期阶段,各方面的需求和缺口(技术,市场,运行,销售等等)很多。从公司的角度看,这就非常需要大家能够主动承担额外的职责。从个人的角度看,我们不论是承担更多的职责还是在自己所做的工作上做得更突出,都是对公司的贡献,也都能收获成长。然而人的精力总是有限的,一个人不可能完美地做完所有事情,总是要把有限的精力投入到有限的事情上。面对这样的环境,每个人都面临着如何在工作的广度和深度之间做出选择的问题。
对于这个问题,我今年有了一番思考和探索。个人觉得对于职场新人来说,寻找一个自己擅长且能从中获得乐趣和成就感的领域至关重要,并且需要与领导进行积极的沟通,以获得相应的支持和资源。每个人的选择可能不同,领导的任务就是在团队成员之间找到一个平衡点,不仅能够完成所有任务,还要尽量让每个人能在其擅长的领域内发挥最大的复利效应。
就我个人而言,我目前更倾向于追求工作的深度,希望能够深入学习并掌握我目前尚不擅长但团队需要的技术知识。通过专注于深度,我希望能够在专业领域内取得更大的进步,并为团队带来更具影响力的贡献。当然,这也并不意味着就完全抛弃广度,随着时间不断推移,我在广度上投入的精力也会越来越多。
今年,通过阅读《跳出盒子——领导与自欺的管理寓言》和李玉琢老师的《办中国最出色企业:我的职业经理人生涯》,我对管理有了初步的理解和感悟。这两本书分别代表了不同的管理理念,一种强调以人为本,另一种则是以结果为导向的雷厉风行。对于我目前的心态而言,我认同后者的评价体系,但从个人性格上我自己的风格更像前者。
在日常的产品迭代和团队管理中,我始终认为把人放在第一位是非常重要的。通过团结所有可以团结的力量,关注每个成员的工作态度、能力、心理状态以及需求和期望,找到大家适合的方向,往往能比反复推动大家完成不情愿的工作更加高效。
当然,在工作过程中难免会遇到与某些人的争执和冲突。面对这些情况,我常采取的做法是换位思考。我会设身处地地想,如果我是对方,我是否也会做出同样的选择?如果答案是肯定的,那么这往往是角色之间的冲突,而非个人情感的问题,我就不会在情感层面上过多消耗精力。如果答案是否定的,我则会进一步探索解决分歧的方法。我是一个性格相对温和的人,我通常不倾向于与人争执,而是尽可能地通过和平的方式解决问题。今年,我几乎都是这样处理冲突的。
然而,我也逐渐意识到,过分的忍让并不会赢得他人的尊重和理解,反而会被得过且过。有些原则和理念是需要坚持的底线,绝不能妥协。希望在未来的一年里,我能够在保持真诚坦率的同时,也能够坚持自己的原则和底线。
今年在工作之余也读了《新程序员》杂志,深入了解了很多大佬的成长经历,也获得了不少启发。一个很深刻的感悟还是江同志的一句话:一个人的命运啊,当然要靠自我奋斗,但是也要考虑到历史的进程。
自从 ChatGPT 爆火以来,周围已经涌现出许多彻底成功的案例,这些故事不仅激励着我,也让我对未来充满了好奇和期待。尽管对于自己未来的方向,我目前还没有一个清晰的规划,甚至只能对未来 1 到 2 年内的工作做出一些预测,3 年后会做什么我还没有确切的答案。
但在这样的不确定性中,我坚信的一点是,只要相信自己当前的工作富有意义和前景,并且能够在其中找到快乐,那么就值得坚持下去,全力以赴。关于未来命运将我们带往何方,或许可以交给时间和命运去安排。在这个快速变化的时代,保持学习和成长的心态,积极面对每一次机遇和挑战,可能就是我们能做的最好的准备了。
经过一天多的思考,我终于完成了今年的年终总结。回顾这一年,我在技术和管理方面取得了一些进步,但同时也深刻意识到,在让企业成功的方方面面,我还有太多不了解不擅长需要学习的地方。
展望新的一年,我为自己和我们组设定了以下几点期望:
最后,感谢您的阅读。欢迎各位读者批评指正。
在新的一年里,祝愿大家身体健康、家庭幸福、梦想成真。希望我们都能在新的一年中取得更大的进步!