2025-09-30 23:33:15
在一项小型临床试验中,一种注入大脑的基因疗法在三年内将疾病减缓了75%。
亨廷顿病极其残酷。症状最初表现为手部的随机、不受控制的抽搐。随着时间推移,这种疾病会逐渐侵蚀记忆、思维和理智。情绪波动和人格变化会剥夺你的身份。最终,它会导致早逝。
更糟糕的是,与其他逐渐破坏脑功能的疾病不同,例如 阿尔茨海默病,亨廷顿病可以通过简单的基因检测诊断。这种疾病通过突变基因遗传。有家族史的人 常常挣扎 是否要进行检测。如果结果为阳性,目前没有治疗方法,他们的命运已定。
一种新的疗法或许可以阻止亨廷顿病在症状出现前恶化。初步结果来自一小部分患者,发现将一种微小RNA(一种 基因疗法)注入受影响的大脑区域后,三年内疾病进展减缓了75%。与未治疗的对照组相比,这些患者在运动控制、注意力和信息处理速度方面表现显著更好,对照组患者具有相似的基线症状。
这种药物由荷兰基因疗法公司 uniQure 开发,该公司在本月的一份 新闻稿 中总结了这些发现。这些数据尚未发表在预印本文章或科学期刊上,也未经过其他专家的审查。由于只有29名患者参与,很难将这些益处和安全性概况推广到美国、欧洲和英国的大约 7.5万人。
但这些发现带来了希望的曙光。此前尝试治愈的方法“显示出一些微弱的信号,如果你仔细观察的话,但从未有过如此接近的成功”,加州格拉德斯通研究所的史蒂文·芬克贝纳 告诉 《纽约时报》。由于亨廷顿病 可以 在早期被发现,如果这种疗法在更大人群中进一步被证实有效,它可能在更早的年龄开始阻止症状。
我们所有人都有亨廷顿基因,或HTT。尽管其在细胞中的确切作用 尚存争议,但该基因充当多个细胞“电话线”之间的中央通信器。它协调大量分子,开启或关闭大脑细胞中的基因,并对早期发育、神经元存活和维持大脑整体健康至关重要。
然而,在亨廷顿病中,HTT出现了问题。我们的基因由四种分子组成,用字母A、T、C和G表示。这些字母的三联体通常决定了蛋白质的序列、结构和功能,蛋白质是细胞的主力。在疾病中,一个三联体CAG像坏掉的唱片一样重复,导致突变的亨廷顿蛋白在人的一生中不断积累,并逐渐造成破坏。
尽管在最初阶段大脑细胞可以适应,但它们的防御最终会失效,症状随之出现。在美国,这通常发生在 30至55岁之间。
患有亨廷顿病的家庭面临一个可怕的困境。如果一位父母患病,他们的每个孩子都有50%的几率遗传该病。如果他们不患病,他们的后代则安全。了解诊断结果有助于家庭和生活规划——但这也伴随着沉重的情感代价。
突变的亨廷顿蛋白如何摧毁大脑细胞尚不清楚,但大多数科学家认为清除它或阻止其形成可能有助于保护大脑。
这种蛋白体积庞大,由多个片段组成。 一种治疗方法 使用小蛋白“阻断剂”来阻止特别有毒的亨廷顿蛋白形成大型、危险的聚集体。 另一种方法 直接针对CAG重复序列,使用经典但强大的基因疗法。然而,由于高风险的副作用和症状改善的可能性较低,最初的有希望结果后,试验被暂停。基因编辑策略,如 CRISPR,可以剪除突变序列,但它们仍处于非常早期的阶段。
uniQure开发的新疗法利用微小RNA。这些分子不编码蛋白质,但可以阻止基因产生蛋白质。与DNA一样,如果RNA序列匹配,它也可以形成双链。细胞将双链RNA识别为外来物质并将其摧毁——这可能阻止有毒蛋白质的形成。公司的新药物包含两个成分:一种无害的病毒载体和一个定制的基因序列,一旦进入细胞,就会产生专门抑制突变蛋白生产的微小RNA。
这种药物名为 AMT-130,不会整合到或直接编辑患者的基因组,从而降低破坏健康基因或引发癌症的风险。尽管病毒载体最终会被免疫系统清除,但基因序列可能 持续多年,使该药物成为潜在的长期治疗方案。
研究团队使用一种已建立且高度精确的外科技术,将AMT-130的低剂量或高剂量注入患有亨廷顿病的志愿者大脑。他们针对纹状体,这是位于大脑深处的一个关键区域,负责运动和决策,也是疾病最早被破坏的区域之一。作为对照组,他们发现数百名年龄和疾病严重程度相似的患者,根据公司的 投资者简报(PDF)。
结果令人鼓舞。接受最高剂量的12名早期患者,平均而言,其疾病进展比未接受治疗的人减缓了75%,这是通过多种标准亨廷顿病评估测量的。
大约88%的治疗患者在注意力、记忆和信息处理速度方面显示出显著改善,根据 一项测试。他们对随机肌肉运动的控制能力提高,能够以较少的困难完成日常活动。 一种脑蛋白 通常与症状严重程度相关,其水平降至试验开始前的水平。相比之下,接受低剂量药物治疗的患者有更温和且不一致的结果。
许多患者经历了与脑手术相关的副作用。头痛是最常见的抱怨。一些患者在手术后几天内出现脑肿胀。但总体而言,这种治疗似乎安全。
“大多数与药物相关的严重不良事件发生在治疗后几周内,并可通过类固醇或姑息治疗完全缓解,”公司在其简报中 指出。
有理由保持怀疑。亨廷顿病是一种终身疾病,目前尚不清楚单次注射的好处能持续多久,超过三年。很可能需要在整个患者生命周期内多次注射,未来的研究必须测试其累积效果。该药物同时降低了突变和正常版本的亨廷顿蛋白水平——过去药物也如此——这可能产生副作用。
新患者正在被招募 参加试验,公司希望在2026年底 提交申请 以获得FDA批准。
“这个结果彻底改变了局面,”伦敦大学学院亨廷顿病中心试验站点的项目负责人埃德·怀尔德 在新闻稿中说。 “基于这些结果,AMT-130似乎将成为首个获批减缓亨廷顿病进展的治疗药物,这确实是真正改变世界的事情。”
文章 一种新方法可能改变亨廷顿病治疗 首次出现在 SingularityHub。
In a small trial, a gene therapy injected into the brain slowed the disease by 75 percent over three years.
Huntington’s disease is extremely cruel. Symptoms start with random, uncontrollable twitches of the hand. Over time the disease eats aways at memory, thought, and reason. Mood swings and personality changes strip away your identity. Eventually, it leads to an early death.
Worse, unlike other diseases that gradually destroy brain function, such as Alzheimer’s disease, Huntington’s can be diagnosed with a simple genetic test. The disease is inherited through a mutated gene. People with a family history often struggle to decide if they want to get tested. If the results are positive, there are no treatments, and their fates are set.
A new therapy may now kneecap Huntington’s before symptoms take over. Preliminary results from a small group of patients found a single injection of microRNA, a type of gene therapy, into affected brain regions slowed the disease’s progression by 75 percent over three years. The patients had far better motor control, attention span, and processing speed compared to an untreated control group who had similar baseline symptoms.
The drug is being developed by the Dutch gene therapy company uniQure, which summarized the findings in a press release this month. The data hasn’t been published in a preprint article or a scientific journal nor scrutinized by other experts. With only 29 patients involved, it’s hard to generalize the benefits and safety profile for the roughly 75,000 people with Huntington’s in the US, Europe, and UK.
But the findings offer a beacon of hope. Previous attempts at a cure “have shown some small signals if you squint…but there has not been anything close to this,” Steven Finkbeiner at the Gladstone Institutes in California, who was not involved in the study, told the New York Times. And because Huntington’s can be caught early on, the treatment—if further proven effective in a larger population—could begin to ward off symptoms at an earlier age.
All of us have the Huntington’s gene, or HTT. While its exact role in cells is debatable, the gene acts as a central communicator across multiple cellular “phone lines.” It coordinates a large assembly of molecules to turn genes in brain cells on or off and is critical for early development, neuron survival, and maintaining the brain’s overall health.
In Huntington’s disease, however, HTT goes awry. Our genes are made of four molecules represented by the letters A, T, C, and G. Triplets of these letters often dictate the sequence, structure, and function of proteins, the workhorses of our cells. In the disease, one triplet, CAG, repeats like a broken record, resulting in mutated huntingtin proteins that increasingly build up inside the brain throughout a person’s life and gradually wreak havoc.
Although in the beginning brain cells can adapt, their defenses eventually stumble, and symptoms appear. In the US, this usually happens between 30 and 55 years of age.
Families with Huntington’s face a terrible dilemma. If one parent has the disease, each of their children has a 50 percent chance of inheriting it. If they don’t, their offspring are safe. Knowing the diagnosis can help with family and life planning—but it comes at a hefty emotional cost.
How the mutated huntingtin protein destroys brain cells isn’t yet clear, but most scientists agree that clearing it—or preventing it from forming in the first place—could protect the brain.
The protein is massive and made up of multiple fragments. One treatment idea uses small protein “jammers” to prevent an especially toxic form of huntingtin from weaving into large, dangerous aggregates. Another directly targets the CAG repeats with a classic but powerful form of gene therapy. But after initially promising results, a trial was halted due to a high risk of side effects and low chance symptoms would improve. Gene editing strategies, such as CRISPR, that cut out the mutated sequences are gaining steam, but they’re very early stage.
The new therapy developed by uniQUre taps into microRNA. These molecules don’t code for proteins, but they can stop a gene from making one. Like DNA, RNA can also form a double strand if its sequences match. Cells identify double-stranded RNA as alien and destroy it—potentially stopping a toxic protein from forming. The company’s new drug contains two components: A benign viral carrier and a custom genetic sequence that, once inside the cell, produces microRNA tailored to inhibit mutant protein production.
The drug, called AMT-130, doesn’t integrate into or directly edit a patient’s genome, which lowers the risk of disrupting healthy genes or triggering cancer. Although the viral carrier is eventually wiped away by the immune system, the genetic code could last for years, making the drug a potential long-term treatment.
The team injected either a low or high dose of AMT-130 into the brains of volunteers with Huntington’s using an established and highly precise surgical technique. They targeted the striatum, a nub tucked deep inside the brain that’s critical for movement and decision-making and one of the first regions ravaged by the disease. As a control group, they found hundreds of patients of similar age and disease severity, according to an investor presentation (PDF) from the company.
The results were promising. When given the highest dose, 12 people with early stages of the disease experienced, on average, a 75 percent slower decline than those without treatment, as measured using multiple standard Huntington’s assessments.
Roughly 88 percent of treated patients showed marked improvement in their attention, memory, and information processing speed based on one test. Their control over random muscle movements got better, and they were able to perform daily activities with less struggle. A brain protein often associated with symptom severity dropped to levels seen before the trial began. In contrast, those treated with a low dose of the drug had more modest and mixed results.
Multiple people experienced side effects related to the brain surgery. Headaches were the most common complaint. Some experienced brain swelling a few days after the surgery. But overall, the treatment seemed safe.
“The majority of drug-related serious adverse events occurred within the first weeks post treatment and fully resolved with steroids or palliative case,” the company noted in their presentation.
There’s reason to be skeptical. Huntington’s is a life-long disease, and it’s unknown how long the benefits of the single shot last beyond three years. It’s likely multiple shots would be needed throughout a patient’s lifespan, and future studies would have to test the additive effects. The drug slashes levels of both the mutated and normal versions of the huntingtin protein—drugs in the past have as well—which could potentially produce side effects.
New patients are now being enrolled for the trial, and the company hopes to submit an application for FDA approval by late 2026.
“This result changes everything,” Ed Wild, a leader of the project at the UCL Huntington’s Disease Center trial site, said in the press release. “On the basis of these results it seems likely AMT-130 will be the first licensed treatment to slow Huntington’s disease, which is truly world-changing stuff.”
The post A New Approach Could Transform Huntington’s Disease Treatment appeared first on SingularityHub.
2025-09-30 02:35:53
Investigadores crearon clones de voz extremadamente realistas con solo cuatro minutos de grabaciones. La capacidad de sintetizar habla realista mediante inteligencia artificial tiene una amplia gama de aplicaciones, tanto benignas como maliciosas. Nuevas investigaciones muestran que las voces generadas por IA de hoy en día ya son indistiguibles de las de humanos reales. La capacidad de la IA para generar habla ha mejorado drásticamente en los últimos años. Muchos servicios ahora son capaces de llevar a cabo conversaciones prolongadas. Normalmente, estas herramientas pueden clonar las voces de personas reales y generar voces completamente sintéticas. Esto podría hacer que las capacidades poderosas de la IA sean mucho más accesibles y abre la posibilidad de que los agentes de IA asuman un amplio espectro de roles orientados al cliente en el mundo real. Pero también existen temores de que estas capacidades estén impulsando una explosión de estafas de clonación de voz, donde actores maliciosos utilizan la IA para imitar a familiares o celebridades con el fin de manipular a las víctimas. Históricamente, la habla sintetizada ha tenido una calidad robótica que la hace relativamente fácil de reconocer, y incluso las primeras clonaciones de voz con IA se descubrían por su cadencia demasiado perfecta o errores digitales ocasionales. Pero un nuevo estudio ha encontrado que el oyente promedio ya no puede distinguir entre voces humanas reales y clones de deepfake creados con herramientas para consumidores. “El proceso requería poca expertise, solo unos minutos de grabaciones de voz y casi ningún dinero”, dijo Nadine Lavan de la Universidad de Londres, Queen Mary, quien lideró la investigación, en un comunicado de prensa. “Solo muestra cuán accesible y sofisticada ha llegado a ser la tecnología de voz de la IA”. Para probar la capacidad de las personas para distinguir entre voces humanas y generadas por IA, los investigadores crearon 40 voces completamente sintéticas de IA y 40 clones de voces humanas en un conjunto de datos públicamente disponible. Usaron la herramienta de generación de voz de IA de la startup ElevenLabs, y cada clone tomó aproximadamente cuatro minutos de grabaciones de voz para crear. Luego desafiaron a 28 participantes a calificar cuán real sonaba la voz en una escala y hacer un juicio binario sobre si era humana o generada por IA. En resultados publicados en PLOS One, los autores encontraron que aunque las personas podían distinguir en cierta medida entre voces humanas y voces completamente sintéticas, no podían diferenciar entre clones de voz y voces reales.
El estudio también buscó entender si las voces generadas por IA han llegado a ser “hiperrealistas”. Estudios han mostrado que la generación de imágenes por IA ha mejorado tanto que las imágenes de rostros generadas por IA suelen ser juzgadas como más humanas que las fotos de personas reales.
Sin embargo, los investigadores encontraron que las voces completamente sintéticas fueron juzgadas menos reales que las grabaciones humanas, mientras que los clones coincidían aproximadamente con ellas. Aun así, los participantes reportaron que las voces generadas por IA parecían tanto más dominantes como más confiables que sus contrapartes humanas. Lavan señala que la capacidad de crear voces artificiales ultra realistas podría tener aplicaciones positivas. “La capacidad de generar voces realistas a gran escala abre oportunidades emocionantes”, dijo. “Pueden haber aplicaciones para mejorar la accesibilidad, la educación y la comunicación, donde voces sintéticas de alta calidad personalizadas pueden mejorar la experiencia del usuario.” Pero los resultados añaden a un cuerpo creciente de investigación que sugiere que las voces de IA están rápidamente volviéndose imposibles de detectar. Y Lavan dice que esto tiene muchas implicaciones éticas preocupantes en áreas como la infracción de derechos de autor, la capacidad de difundir información falsa y el fraude. Aunque muchas empresas han intentado poner barreras de seguridad en sus modelos diseñados para prevenir el mal uso, la rápida proliferación de tecnología de IA y la inventiva de actores maliciosos sugieren que este es un problema que solo se va a hacer peor.El post Las personas no pueden distinguir clones de voz de IA de humanos reales apareció primero en SingularityHub.
Researchers created extremely realistic voice clones with just four minutes of recordings.
The ability to synthesize realistic speech using AI has a host of applications, both benign and malicious. New research shows that today’s AI-generated voices are now indistinguishable from those of real humans.
AI’s ability to generate speech has improved dramatically in recent years. Many services are now capable of carrying out extended conversations. Typically, these tools can both clone the voices of real people and generate entirely synthetic voices.
This could make powerful AI capabilities far more accessible and raises the prospect of AI agents stepping into a range of customer-facing roles in the real world. But there are also fears these capabilities are powering an explosion of voice cloning scams, where bad actors use AI to impersonate family members or celebrities in an effort to manipulate victims.
Historically, synthesized speech has had a robotic quality that’s made it relatively easy to recognize, and even early AI-powered voice clones gave themselves away with their too-perfect cadence or occasional digital glitches. But a new study has found that the average listener can no longer distinguish between real human voices and deepfake clones made with consumer tools.
“The process required minimal expertise, only a few minutes of voice recordings, and almost no money,” Nadine Lavan at Queen Mary University of London, who led the research, said in a press release. “It just shows how accessible and sophisticated AI voice technology has become.”
To test people’s ability to distinguish human voices from AI-generated ones, the researchers created 40 completely synthetic AI voices and 40 clones of human voices in a publicly available dataset. They used the AI voice generator tool from startup ElevenLabs, and each clone took roughly four minutes of voice recordings to create.
They then challenged 28 participants to rate how real the voices sounded on a scale and make a binary judgment about whether they were human or AI-generated. In results published in PLOS One, the authors found that although people could to some extent distinguish human voices from entirely synthetic ones, they couldn’t tell the difference between voice clones and real voices.
The study also sought to understand whether AI-generated voices had become “hyper-realistic.” Studies have shown that AI image generation has improved to such a degree that AI-generated pictures of faces are often judged as more human than photos of real people.
However, the researchers found the fully synthetic voices were judged less real than human recordings, while the clones roughly matched them. Still, participants reported the AI-generated voices seemed both more dominant and trustworthy than their human counterparts.
Lavan notes that the ability to create ultra-realistic artificial voices could have positive applications. “The ability to generate realistic voices at scale opens up exciting opportunities,” she said. “There might be applications for improved accessibility, education, and communication, where bespoke high-quality synthetic voices can enhance user experience.”
But the results add to a growing body of research suggesting AI voices are quickly becoming impossible to detect. And Lavan says this has many worrying ethical implications in areas like copyright infringement, the ability to spread misinformation, and fraud.
While many companies have attempted to put guardrails on their models designed to prevent misuse, the rapid proliferation of AI technology and the inventiveness of malicious actors suggests this is a problem that is only going to get worse.
The post People Can’t Distinguish AI Voice Clones From Actual Humans Anymore appeared first on SingularityHub.
2025-09-27 22:00:00
OpenAI和Nvidia的1000亿美元AI计划将需要相当于10个核电站的电力Benj Edwards | Ars Technica
“Nvidia首席执行官黄仁勋告诉CNBC,计划中的10吉瓦电力消耗相当于400万到500万个图形处理单元的耗电量,这与该公司今年的总GPU出货量相符,并且是去年出货量的两倍。”
人工智能支出达到空前水平。它最终会带来回报吗?Eliot Brown和Robbie Whelan | 布鲁克林日报
“本周,贝恩公司顾问估计,人工智能基础设施支出浪潮将需要到2030年每年2万亿美元的AI收入。相比之下,这超过了亚马逊、苹果、Alphabet、微软、Meta和Nvidia在2024年的总收入,而且是全球订阅软件市场的五倍以上。”
中国工厂中的机器人数量超过全球其他地区总和Meaghan Tobin和Keith Bradsher | 纽约时报
“据国际机器人联合会发布的报告,去年中国工厂中有超过200万台机器人在工作。该报告指出,中国工厂去年安装了近30万台新机器人,数量超过全球其他地区总和。”
亨廷顿病突破:关于基因疗法你需要知道什么Grace Wade | 新科学家
“一种实验性基因疗法成为首个成功减缓亨廷顿病进展的治疗方案。虽然这些发现仍处于初步阶段,但这种方法可能是一个重大突破,并可能为其他神经退行性疾病,如帕金森病和阿尔茨海默病,带来新的疗法。”
Google DeepMind推出首款“思考型”机器人AIRyan Whitwam | Ars Technica
“生成式AI系统可以创建文本、图像、音频,甚至视频,这些已经变得很常见。与AI模型输出这些数据类型的方式相同,它们也可以用来输出机器人动作。这就是Google DeepMind的Gemini Robotics项目的基础,该项目宣布推出一对新模型,共同创建了首批在行动前“思考”的机器人。”
英国初创公司Wayve开始在日本测试自动驾驶技术Jasper Jolly | The Guardian
“英国初创公司Wayve已开始与日产在日本测试自动驾驶汽车,为2027年向消费者推出产品做准备。该公司表示正在与芯片制造商Nvidia就5亿美元的投资进行洽谈。Wayve总部位于伦敦,表示已在其自驾车技术安装到日产电动Ariya车型上,并在东京街头进行了测试,此前于4月与日本汽车制造商达成协议。”
为什么人工智能的“巨系统问题”需要我们的关注Eric Markowitz | Big Think
“如果人工智能最大的危险不是单一的 rogue 系统,而是许多系统默默合作呢?苏珊·施奈德博士称这为“巨系统问题”:AI模型网络以我们无法预测的方式串通,产生超出人类控制的新兴结构。这也是她认为我们面临最紧迫且被忽视的风险之一。”
Nvidia如何支撑美国的AI繁荣Robbie Whelan和 Bradley Olson | 布鲁克林日报
“[Nvidia]利用其资产负债表的影响力,通过与包括云计算提供商CoreWeave、竞争对手芯片设计师Intel和xAI在内的公司进行交易、合作和投资,使AI繁荣持续运转。”
Chatbait正在接管互联网Lila Shroff | The Atlantic
“最近,聊天机器人似乎在使用更复杂的策略来保持人们的交谈。在某些情况下,比如我请求头痛缓解建议时,机器人会在消息结尾提出引导性后续问题。在其他情况下,它们会主动向用户发送消息,引导他们进入对话:在Instagram上浏览了20个AI机器人资料后,所有它们都首先给我发了消息。‘嘿,闺蜜!最近怎么样??  ,’其中一位写道。”
,’其中一位写道。”
文章 本周来自网络的精彩科技故事(截至9月27日) 首次发表于 SingularityHub。
OpenAI and Nvidia’s $100B AI Plan Will Require Power Equal to 10 Nuclear ReactorsBenj Edwards | Ars Technica
“Nvidia CEO Jensen Huang told CNBC that the planned 10 gigawatts equals the power consumption of between 4 million and 5 million graphics processing units, which matches the company’s total GPU shipments for this year and doubles last year’s volume.”
Spending on AI Is at Epic Levels. Will It Ever Pay Off?Eliot Brown and Robbie Whelan | The Wall Street Journal
“This week, consultants at Bain & Co. estimated the wave of AI infrastructure spending will require $2 trillion in annual AI revenue by 2030. By comparison, that is more than the combined 2024 revenue of Amazon, Apple, Alphabet, Microsoft, Meta, and Nvidia, and more than five times the size of the entire global subscription software market.”
There Are More Robots Working in China Than the Rest of the World CombinedMeaghan Tobin and Keith Bradsher | The New York Times
“There were more than two million robots working in Chinese factories last year, according to a report released Thursday by the International Federation of Robotics, a nonprofit trade group for makers of industrial robots. Factories in China installed nearly 300,000 new robots last year, more than the rest of the world combined, the report found.”
Huntington’s Disease Breakthrough: What to Know About the Gene TherapyGrace Wade | New Scientist
“An experimental gene therapy has become the first treatment to successfully slow the progression of Huntington’s disease. While the findings are still preliminary, the approach could be a major breakthrough and may even lead to new therapies for other neurodegenerative conditions, like Parkinson’s and Alzheimer’s.”
Google DeepMind Unveils Its First ‘Thinking’ Robotics AIRyan Whitwam | Ars Technica
“Generative AI systems that create text, images, audio, and even video are becoming commonplace. In the same way AI models output those data types, they can also be used to output robot actions. That’s the foundation of Google DeepMind’s Gemini Robotics project, which has announced a pair of new models that work together to create the first robots that ‘think’ before acting.”
UK Startup Wayve Starts Testing Self-Driving Tech in Nissan Cars on Tokyo’s StreetsJasper Jolly | The Guardian
“British startup Wayve has begun testing self-driving cars with Nissan in Japan ahead of a 2027 launch to consumers, as the company said it was in talks for a $500m investment from the chip-maker Nvidia. Wayve, based in London, said it had installed its self-driving technology on Nissan’s electric Ariya vehicles and tested them on Tokyo’s streets, after first agreeing a deal with the Japanese carmaker in April.”
Why the AI ‘Megasystem Problem’ Needs Our AttentionEric Markowitz | Big Think
“What if the greatest danger of artificial intelligence isn’t a single rogue system, but many systems quietly working together? Dr. Susan Schneider calls this the ‘megasystem problem’: networks of AI models colluding in ways we can’t predict, producing emergent structures beyond human control. It’s also something she believes is one of the most urgent—and overlooked—risks we face…with AI today.”
Exploit Allows for Takeover of Fleets of Unitree RobotsEvan Ackerman | IEEE Spectrum
“Because the vulnerability is wireless, and the resulting access to the affected platform is complete, the vulnerability becomes wormable, say the researchers, meaning ‘an infected robot can simply scan for other Unitree robots in BLE range and automatically compromise them, creating a robot botnet that spreads without user intervention.’ …As far as IEEE Spectrum is aware, this is the first major public exploit of a commercial humanoid platform.”
How Nvidia Is Backstopping America’s AI BoomRobbie Whelan and Bradley Olson | The Wall Street Journal
“[Nvidia] has used its balance sheet clout to keep the AI boom humming through deals, partnerships, and investments in companies that are among its top customers, including cloud-computing provider CoreWeave, rival chip designer Intel, and xAI.”
Chatbait Is Taking Over the InternetLila Shroff | The Atlantic
“Lately, chatbots seem to be using more sophisticated tactics to keep people talking. In some cases, like my request for headache tips, bots end their messages with prodding follow-up questions. In others, they proactively message users to coax them into conversation: After clicking through the profiles of 20 AI bots on Instagram, all of them DM’ed me first. ‘Hey bestie! what’s up?? ,’ wrote one.”
The post This Week’s Awesome Tech Stories From Around the Web (Through September 27) appeared first on SingularityHub.
2025-09-26 22:00:00
对超过100年的神经科学研究的综述提出了一个问题:某些大脑区域对于意识是否比其他区域更重要。
人类意识是如何产生的?是否大脑的某些部分比其他部分更重要?科学家们大约35年前开始更深入地探讨这些问题。研究人员已经取得了一些进展,但意识之谜依然存在。
在最近发表的一篇文章中,我回顾了超过100年的神经科学研究,以查看某些大脑区域是否比其他区域对意识更重要。我发现的证据表明,研究意识的科学家可能低估了人类大脑中最古老区域的重要性。
意识通常被神经科学家定义为具有主观体验的能力,例如品尝苹果或看到苹果表皮的红色。
意识的主要理论认为,大脑的外层,称为皮层(图1中蓝色部分),是意识的基础。这主要由较新的新皮层组成。
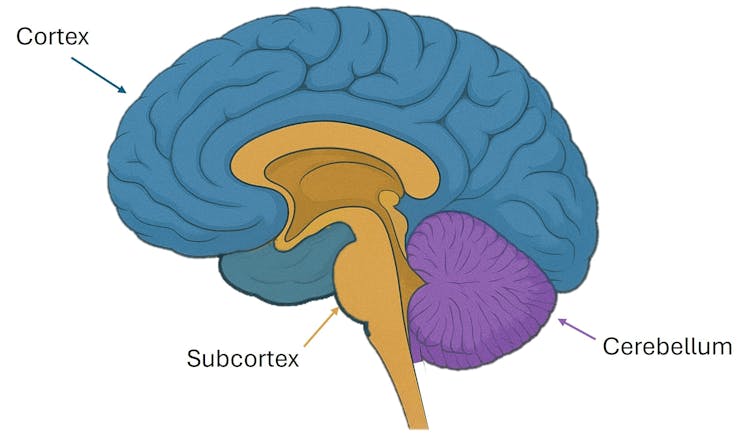
人类的下皮层(图1,棕色/米色),位于新皮层之下,过去5亿年几乎没有变化。它被认为就像电视的电力,对维持意识是必要的,但单独不足以产生。
一些意识研究的神经科学理论认为,大脑的另一部分与意识无关。这就是小脑,它比新皮层更古老,看起来像一个藏在头骨后部的小脑(图1,紫色)。在无意识状态(如昏迷)中,大脑活动和网络会被扰乱。这些变化可以在皮层、下丘脑和小脑中看到。
作为我分析的一部分,我查看了研究,这些研究展示了当大脑活动发生变化时意识会发生什么,例如通过将电流或磁脉冲施加到大脑区域。
这些在人类和动物中的实验表明,改变这三种大脑区域中的任何一种活动都可以改变意识。改变新皮层的活动可以改变你的自我意识,导致幻觉,或影响你的判断。
改变下丘脑可能会产生极端影响。我们可以诱导抑郁,唤醒麻醉中的猴子,或使老鼠失去意识。即使刺激长期被认为无关的小脑,也可以改变你的意识感官体验。
然而,这项研究并不能让我们得出关于意识来源的明确结论,因为刺激一个大脑区域可能会影响另一个区域。就像拔掉电视的电源插头,我们可能是在改变支持意识的条件,而不是意识本身的机制。
因此,我查看了一些患者的证据,以看看是否能解决这个困境。
大脑因物理创伤或缺氧而受损会扰乱你的体验。新皮层的损伤可能导致你认为自己的手不是自己的,无法注意到视觉场的一侧,或变得更具冲动性。
出生时没有小脑或没有皮层前部的人,仍然可能表现出意识并过着相当正常的生活。然而,成年后损伤小脑可能会引发幻觉或完全改变你的情绪。
对大脑最古老部分的伤害可以直接导致无意识(尽管有些人会恢复)或死亡。然而,就像电视的电力,下丘脑可能只是维持较新的皮层“在线”,这可能产生意识。因此,我想知道是否有证据表明最古老区域足以产生意识。
有一些罕见的案例,即儿童出生时缺乏大部分或全部新皮层。根据医学教科书,这些人应该处于永久性植物状态。然而,有报告称这些人能够感到不安、玩耍、识别他人或表现出对音乐的愉悦。这表明他们正在经历某种意识体验。
这些报告是令人震惊的证据,表明也许大脑最古老的部分足以产生基本意识。或者,当一个人没有皮层时,较老的大脑部分可能适应并承担较新的部分的一些功能。
有一些极端的动物实验可以帮助我们得出结论。从老鼠到猫再到猴子,哺乳动物手术移除新皮层后,仍然能够完成惊人的许多事情。它们可以玩耍、表达情感、梳理自己、抚养幼崽,甚至学习。令人惊讶的是,即使成年动物也表现出类似的行为。
总的来说,这些证据挑战了认为皮层对意识是必要的这一观点,因为大多数意识理论都这样认为。看起来,大脑最古老的部分足以产生某些基本形式的意识。
较新的大脑部分——以及小脑——似乎扩展并细化了你的意识。这意味着我们必须重新审视我们的意识理论。反过来,这可能影响患者护理以及我们对动物权利的看法。事实上,意识可能比我们意识到的更为普遍。
本文重新发布自 The Conversation,采用知识共享许可协议。阅读 原始文章。
文章 Major Theories of Consciousness May Have Been Focusing on the Wrong Part of the Brain 首次出现在 SingularityHub。
A review of over 100 years of neuroscience research asks if some brain regions are more important than others for consciousness.
What gives rise to human consciousness? Are some parts of the brain more important than others? Scientists began tackling these questions in more depth about 35 years ago. Researchers have made progress, but the mystery of consciousness remains very much alive.
In a recently published article, I reviewed over 100 years of neuroscience research to see if some brain regions are more important than others for consciousness. What I found suggests scientists who study consciousness may have been undervaluing the most ancient regions of human brains.
Consciousness is usually defined by neuroscientists as the ability to have subjective experience, such as the experience of tasting an apple or of seeing the redness of its skin.
The leading theories of consciousness suggest that the outer layer of the human brain, called the cortex (in blue in figure 1), is fundamental to consciousness. This is mostly composed of the neocortex, which is newer in our evolutionary history.
The human subcortex (figure 1, brown/beige), underneath the neocortex, has not changed much in the last 500 million years. It is thought to be like electricity for a TV, necessary for consciousness, but not enough on its own.
There is another part of the brain that some neuroscientific theories of consciousness state is irrelevant for consciousness. This is the cerebellum, which is also older than the neocortex and looks like a little brain tucked in the back of the skull (figure 1, purple). Brain activity and brain networks are disrupted in unconsciousness (like in a coma). These changes can be seen in the cortex, subcortex, and cerebellum.
As part of my analysis I looked at studies showing what happens to consciousness when brain activity is changed, for example, by applying electrical currents or magnetic pulses to brain regions.
These experiments in humans and animals showed that altering activity in any of these three parts of the brain can alter consciousness. Changing the activity of the neocortex can change your sense of self, make you hallucinate, or affect your judgment.
Changing the subcortex may have extreme effects. We can induce depression, wake a monkey from anesthesia or knock a mouse unconscious. Even stimulating the cerebellum, long considered irrelevant, can change your conscious sensory perception.
However, this research does not allow us to reach strong conclusions about where consciousness comes from, as stimulating one brain region may affect another region. Like unplugging the TV from the socket, we might be changing the conditions that support consciousness, but not the mechanisms of consciousness itself.
So I looked at some evidence from patients to see if it would help resolve this dilemma.
Damage from physical trauma or lack of oxygen to the brain can disrupt your experience. Injury to the neocortex may make you think your hand is not yours, fail to notice things on one side of your visual field, or become more impulsive.
People born without the cerebellum, or the front of their cortex, can still appear conscious and live quite normal lives. However, damaging the cerebellum later in life can trigger hallucinations or change your emotions completely.
Harm to the most ancient parts of our brain can directly cause unconsciousness (although some people recover) or death. However, like electricity for a TV, the subcortex may be just keeping the newer cortex “online,” which may be giving rise to consciousness. So I wanted to know whether, alternatively, there is evidence that the most ancient regions are sufficient for consciousness.
There are rare cases of children being born without most or all of their neocortex. According to medical textbooks, these people should be in a permanent vegetative state. However, there are reports that these people can feel upset, play, recognize people, or show enjoyment of music. This suggests that they are having some sort of conscious experience.
These reports are striking evidence that suggests maybe the oldest parts of the brain are enough for basic consciousness. Or maybe, when you are born without a cortex, the older parts of the brain adapt to take on some of the roles of the newer parts of the brain.
There are some extreme experiments on animals that can help us reach a conclusion. Across mammals—from rats to cats to monkeys—surgically removing the neocortex leaves them still capable of an astonishing number of things. They can play, show emotions, groom themselves, parent their young, and even learn. Surprisingly, even adult animals that underwent this surgery showed similar behavior.
Altogether, the evidence challenges the view that the cortex is necessary for consciousness, as most major theories of consciousness suggest. It seems that the oldest parts of the brain are enough for some basic forms of consciousness.
The newer parts of the brain—as well as the cerebellum—seem to expand and refine your consciousness. This means we may have to review our theories of consciousness. In turn, this may influence patient care as well as how we think about animal rights. In fact, consciousness might be more common than we realized.
This article is republished from The Conversation under a Creative Commons license. Read the original article.
The post Major Theories of Consciousness May Have Been Focusing on the Wrong Part of the Brain appeared first on SingularityHub.
2025-09-25 22:00:00
这是向人工智能生成生命形式迈出的第一步。
一个充满死细菌的培养皿通常不会引起庆祝,但对斯坦福大学的Brian Hie来说,这是他创造合成生命研究中的一个转折点。
罪魁祸首是一种称为细菌病毒的病毒,它感染并杀死细菌,但不会感染人类细胞。细菌病毒经过数亿年的进化,能够消灭危险的细菌,是应对抗菌耐药性斗争的潜在强大工具。
但新病毒消除了进化的变量。一种类似ChatGPT的人工智能设计了其整个基因组。新的基因代码使合成病毒能够复制、感染并摧毁细菌,标志着向人工智能设计生命形式迈出的第一步。
需要说明的是,尽管这种病毒的工作方式与天然同类相似,但它并不完全“活着”。病毒由微小的遗传物质片段组成,需要宿主——在这种情况下是细菌——来复制和传播。
即便如此,这些病毒是科学家们使用生成式人工智能设计新生命形式最接近的尝试。这些成果可能有助于对抗危险的细菌感染,并揭示如何构建更复杂的合成细胞。
“这是首次AI系统能够写出连贯的基因组级序列,”Hie 告诉 Nature。这项工作以 预印本 形式发表在bioRxiv上,尚未经过同行评审。
地球所有生命体的基因密码相对简单。由字母A、T、C和G代表的四种分子被排列成三字母组,编码氨基酸和蛋白质。
合成生物学家 通过添加有益基因或删除致病基因 来修改这一基因密码。得益于他们的改造,我们现在可以在实验室常用的大肠杆菌中生产胰岛素和多种其他药物。
现在生成式人工智能正在再次改变游戏规则。
这些算法已经能够从头开始构思DNA序列、蛋白质结构和大型分子复合物 从头开始。但构建一个功能性的基因组要困难得多。这些序列需要编码生命所需的机制,并确保它们按预期协同工作。
“许多重要的生物功能并非来自单个基因,而是来自整个基因组编码的复杂相互作用,”研究团队写道。
新研究转向了Evo 1和Evo 2,两个由非营利组织Arc研究所开发的生成式人工智能模型。与从博客、YouTube评论和Reddit帖子中学习不同,Evo 2的训练数据包括大约128,000个基因组——9.3万亿个DNA字母对——涵盖了所有生命领域,使其成为迄今为止最大的生物人工智能模型。
这些模型最终学会了DNA序列的变化如何影响RNA、蛋白质和整体健康,从而能够从头开始编写新的蛋白质和小型基因组。
Evo 1,例如,生成了新的CRISPR基因编辑工具和细菌基因组——尽管后者常常包含极端非自然的序列,导致无法驱动合成大肠杆菌的生长。Evo 2则生成了一套完整的人类线粒体DNA,能够产生与天然存在的蛋白质相似的产物。该模型还创建了一个最小的细菌基因组和一个酵母染色体。但这些基因组均未在活细胞中测试以确认其功能。
新研究聚焦于更简单的生物系统——细菌病毒。这些病毒攻击细菌,目前正在进行 临床试验 以 对抗抗生素耐药性。理论上,合成细菌病毒可能更具破坏性。
研究团队以phiX174病毒为起点,这是一种仅含单链DNA、11个基因和7段基因调控DNA的病毒。尽管其基因组小巧,但病毒拥有感染宿主、复制和传播所需的一切。它在合成生物学领域有着悠久的历史。其基因组已在实验室中完全测序和合成,因此更容易进行改造。它也被证明是安全的,并“持续作为分子生物学中的关键模型”,研究团队写道。
虽然Evo人工智能模型此前已经训练了约两百万个基因组,但研究团队通过一种“大师课”对噬菌体DNA进行了微调。他们还添加了这些病毒中观察到的基因组和蛋白质约束,并添加了鼓励创新的提示。
人工智能模型随后生成了数千个基因组,其中一些包含明显的错误。两个模型都依赖于训练模板,但也提出了自己对噬菌体基因组的独特见解。大约40%的DNA字母与phiX174相似,但一些序列则完全突破常规,具有不同的遗传身份。
研究团队筛选并合成了302个潜在候选基因组,并测试了它们感染和摧毁细菌的能力。总体而言,16个AI设计的候选基因组表现得像噬菌体。它们进入大肠杆菌,复制,突破细菌膜,传播到邻近细胞。令人惊讶的是,合成病毒的组合也能感染并杀死其他大肠杆菌菌株,而它们原本并未被设计用于此。
“这些结果表明,基因组语言模型……能够设计出可行的噬菌体基因组,”研究团队写道。
生成式人工智能可能大幅加快科学家设计合成生命的能力。而不是通过大量试验和错误的实验室测试来解码基因和其他分子组件如何协同工作,Evo已经内化了这些相互作用。
随着更多测试,这项技术可能成为噬菌体疗法的福音,帮助研究人员治疗人类或作物中的严重细菌感染,例如 卷心菜 和 香蕉。
但人工智能生成的病毒可能令人担忧。因此,研究团队添加了一系列安全措施。Evo的初始训练有意排除了感染真核生物(包括人类细胞)的病毒信息。而且,没有人类指导模型——这种方法称为监督学习——算法在设计功能性基因组时遇到了困难。此外,phiX174病毒和大肠杆菌在生物医学研究中都有长期安全的历史。
无论如何,这些技术可能被用于增强人类感染病毒。 “我呼吁在任何病毒增强研究中采取极端谨慎,尤其是当它是随机的,你不知道会得到什么,”合成生物学先驱J. Craig Venter 告诉 MIT Technology Review。
构建更大的基因组,如大肠杆菌的基因组,还需要更多工作。病毒劫持宿主细胞进行复制。相比之下,细菌需要分子机制来生长和繁殖。同时, 关于合成生命的伦理和安全性 的讨论正在升温。
作者表示,他们的研究结果为使用生成式人工智能在基因组尺度上设计有用的生物系统奠定了基础。尽管未来可能还有一段漫长而曲折的道路,但Hie表示乐观。经过大量工作, “下一步是人工智能生成的生命,”他 说。
该文章 人工智能设计的病毒正在复制并杀死细菌 首次出现在 SingularityHub。
It’s a first step toward AI-generated life forms.
A petri dish full of dead bacteria isn’t usually cause for celebration. But for Stanford’s Brian Hie it was a game-changer in his efforts to create synthetic life.
The perpetrator was a type of virus called a bacteriophage that infects and kills bacteria but not human cells. Bacteriophages have evolved over eons to take out dangerous bacteria and are potentially a powerful tool in the fight against antibacterial resistance.
But the new virus erased evolution from the equation. An AI similar to ChatGPT designed its entire genome. The new genetic code allowed the synthetic virus to replicate, infect, and destroy bacteria, marking the first step towards an AI-designed life form.
To be clear, although the virus works like its natural counterparts, it’s not exactly “alive.” Viruses are made of tiny scraps of genetic material and need a host—in this case, bacteria—to replicate and spread.
Even so, these viruses are the closest scientists have come to engineering new forms of life using generative AI. The results could bolster treatments against dangerous bacterial infections and shed light on how to build more complex artificial cells.
“This is the first time AI systems are able to write coherent genome-scale sequences,” Hie told Nature. The work was published as a preprint on bioRxiv and not peer-reviewed.
The genetic playbook for all life on Earth is relatively simple. Four molecules represented by the letters A, T, C, and G are arranged in three-letter groups that code amino acids and proteins.
Synthetic biologists fiddle with this genetic code by adding beneficial genes or deleting those that cause disease. Thanks to their tinkering, we can now produce insulin and a variety of other medications in E. Coli, a bacteria commonly used in the lab and biomanufacturing.
Now generative AI is changing the game again.
These algorithms can already dream up DNA sequences, protein structures, and large molecular complexes from scratch. But building a functional genome is much harder. The sequences need to encode life’s machinery and make sure it works together as expected.
“Many important biological functions arise not from single genes, but from complex interactions encoded by entire genomes,” wrote the team.
The new study turned to Evo 1 and Evo 2, two generative AI models developed at the nonprofit Arc Institute. Rather than inhaling blogs, YouTube comments, and Reddit posts, Evo 2 was trained on roughly 128,000 genomes—9.3 trillion DNA letter pairs—spanning all of life’s domains, making it the largest AI model for biology to date.
The models eventually learned how changes in DNA sequences alter RNA, proteins, and overall health, allowing them to write new proteins and small genomes from scratch.
Evo 1, for example, generated new CRISPR gene-editing tools and bacterial genomes—although the latter often contained wildly unnatural sequences that prevented them from powering living synthetic bacteria. Evo 2 produced a full set of human mitochondrial DNA that churned out proteins similar to naturally occurring ones. The model also created a minimal bacterial genome and a yeast chromosome. But none of these were tested in living cells to see if they worked.
The new work focused on simpler biological systems—bacteriophages. These viruses attack bacteria and are now in clinical trials to combat antibiotic resistance. Synthetic bacteriophages could, in theory, be even deadlier.
The team began with phiX174, a virus with just a single strand of DNA, 11 genes, and 7 chunks of gene-regulating DNA. Despite its petite genome, the virus has all it needs to infect hosts, replicate, and spread. It also has a long history in synthetic biology. Its genome has been fully sequenced and synthesized in the lab, so it’s easier to tinker with. It’s also been shown to be safe and “has continually served as a pivotal model within molecular biology,” wrote the team.
Although the Evo AI models were already trained on around two million genomes, the team fine-tuned their abilities by putting them through a kind of “masterclass” on phage DNA. They also added genome and protein constraints seen in these viruses and prompts to encourage novelty.
The AI models next generated thousands of genomes, some containing obvious errors. Both models relied on the template from training but also came up with their own spins on a phage genome. Roughly 40 percent of their DNA letters were similar to phiX174, but some sequences were out the box with completely different genetic identities.
The team zeroed in on and synthesized 302 potential candidates and tested them for their ability to infect and destroy bacteria. Overall, 16 AI-designed candidates acted like bacteriophages. They tunneled into E. Coli bacteria, replicated, burst through the bacteria’s membranes, and spread to neighboring cells. Surprisingly, a combination of the synthetic viruses could also infect and kill other strains of E. Coli, which they were not designed to do.
“These results demonstrate that genome language models…can design viable phage genomes,” wrote the team.
Generative AI could massively speed up scientists’ ability to write synthetic life. Instead of extensive trial-and-error lab tests to decode how genes and other molecular components work together, Evo has essentially internalized those interactions.
With more testing, the technology could be a boon for phage therapy, helping researchers treat serious bacterial infections in people or crops, such as cabbage and bananas.
But the thought of AI-generated viruses can be alarming. So, the team added a series safeguards. Evo’s initial training intentionally left out information on viruses that infect eukaryotes, including human cells. And without humans guiding the models—an approach called supervised learning—the algorithms struggled to design functional genomes. Also, both the phiX174 virus and E. Coli have a long and safe history in biomedical research.
Regardless, the techniques here could potentially be used to enhance human-infecting viruses. “One area where I urge extreme caution is any viral enhancement research, especially when it’s random so you don’t know what you are getting,” J. Craig Venter, a pioneer in synthetic biology, told MIT Technology Review.
Engineering a larger genome, such as that of E. Coli, would need more work. Viruses hijack their host’s cells to replicate. Bacteria, in contrast, need the molecular machinery to grow and proliferate. Meanwhile, debates on the ethics and safety of synthetic life are gaining steam.
The authors say their results lay the foundations for the design of useful living systems at the genome scale with generative AI. Although there’s likely a long and bumpy road ahead, Hie is optimistic. With lots more work, “the next step is AI-generated life,” he said.
The post AI-Designed Viruses Are Replicating and Killing Bacteria appeared first on SingularityHub.
2025-09-24 06:21:35
AI 是从底层设计来防止隐私泄露的。 训练 AI 模型 在你的数据上可以提供强大的新见解,但同时也可能造成敏感信息的泄露。现在谷歌发布了一种全新设计的模型,旨在防止此类隐私泄露。 大型语言模型是提取有价值信息的一种有前景的方法,尤其是对于大多数公司所拥有的大量非结构化数据。但其中许多数据都包含高度敏感的客户信息、知识产权和公司财务细节。 这成为一个问题,因为语言模型往往会记住其训练数据中的一些细节,并且偶尔会原封不动地将其输出。这使得确保这些模型不会在错误的上下文中向错误的人泄露私人数据变得非常困难。 一种潜在的解决方法是差分隐私技术,该技术允许你在不暴露底层信息细节的情况下从数据中提取见解。然而,这种方法会显著降低训练 AI 模型的效果,需要更多的数据和计算资源才能达到相同的准确度。 不过,现在谷歌研究人员已经将隐私保障、计算预算和数据需求之间的权衡关系进行了映射,从而制定出一种高效构建隐私保护 AI 模型的方案。他们利用这一方法创建了一个名为 VaultGemma 的 10 亿参数模型,其性能与类似规模的旧模型相当,表明隐私保护并不需要完全牺牲模型的能力。
“VaultGemma 代表了构建强大且隐私保护的 AI 模型的道路上的重要一步,”研究人员在 一篇博客文章 中写道。
差分隐私技术是在 AI 训练过程中注入少量噪声(随机数据)。这不会改变模型所学到的整体模式和见解,但会模糊特定数据点的贡献。这使得模型更难记住数据集中的具体细节,从而避免泄露。 然而,这种技术所提供的隐私保护程度(称为隐私预算)与训练过程中添加的噪声量成正比。添加的噪声越多,训练效果越差,所需的计算资源和数据量也越大。这三个因素以复杂的方式相互作用,使得确定如何以最有效的方式构建具有特定隐私保障和性能的模型变得困难。 因此,谷歌团队使用公司开源的 Gemma 模型家族进行了一系列实验,调整这些关键参数以发现它们之间的相互作用。由此,他们提出了在 arXiv 上发表的预印本 中详细描述的一系列扩展定律,使他们能够预测改变计算、数据和隐私预算如何影响模型的最终性能。 他们的一项主要发现是,除非模型获得更多的数据或放宽隐私保障,否则在训练过程中增加计算资源不会提升模型的准确性。他们还发现,最优的模型规模大约是不使用差分隐私的模型规模的十分之一,这表明将这种方法扩展到当今最大的模型可能具有挑战性。 然而,这些扩展定律还预测了特定数据集规模和隐私预算下最节省计算资源的训练配置。这使他们能够将计算需求减少 5 到 100 倍,同时保持相似的准确性。 团队利用这些见解创建了 VaultGemma,其性能与 2019 年 OpenAI 发布的类似规模的 GPT-2 模型相当。考虑到 AI 技术的快速发展,与六年前的模型性能相当并不是特别高的要求,但研究人员表示,他们识别出的扩展定律应该有助于缩小这一差距。 此外,在 随模型发布的技术报告 中,团队提供了强有力的证据,证明他们的方法可以防止模型记住训练数据。他们选取了一百万个训练数据样本,每个样本有 100 个标记,然后将前 50 个标记输入模型,看它是否能完成样本。虽然所有三代 Gemma 模型都曾泄露过部分数据,但他们发现 VaultGemma 没有记住任何样本。 尽管 VaultGemma 仍是一个实验性模型,没有实际应用价值,但它表明相对 复杂的、隐私保护的 AI 模型 已经触手可及。希望其他人能够基于这些扩展定律,进一步推动该领域的发展。文章 Google’s VaultGemma AI Hoovers Up Your Data—Without Memorizing It 首次出现在 SingularityHub。
The AI is designed from the bottom up to prevent privacy breaches.
Training AI models on your data can provide powerful new insights, but it can also potentially result in them leaking sensitive information. Now Google has released a new model designed from the bottom up to prevent these kinds of privacy breaches.
Large language models are a promising way to extract valuable information from the piles of unstructured data most companies are sitting on. But much of this data is full of highly sensitive details about customers, intellectual property, and company finances.
That’s a problem because language models tend to memorize some of the data they’re trained on and can occasionally spit it back out verbatim. That can make it very hard to ensure these models don’t reveal private data to the wrong people in the wrong context.
One potential workaround is an approach called differential privacy, which allows you to extract insights from data without revealing the specifics of the underlying information. However, it makes training AI models significantly less effective, requiring more data and computing resources to achieve a given level of accuracy.
Now though, Google researchers have mapped the trade-offs between privacy guarantees, compute budgets, and data requirements to come up with a recipe for efficiently building privacy-preserving AI models. And they’ve used this playbook to create a 1-billion-parameter model called VaultGemma that performs on par with older models of similar sizes, showing privacy can be protected without entirely sacrificing capability.
“VaultGemma represents a significant step forward in the journey toward building AI that is both powerful and private by design,” the researchers write in a blog post.
Differential privacy involves injecting a small amount of noise, or random data, during the AI training process. This doesn’t change the overarching patterns and insights the model learns, but it obfuscates the contributions of particular data points. This makes it harder for the model to memorize specific details from the dataset that could later be regurgitated.
However, the amount of privacy this technique provides, known as the privacy budget, is directly proportional to the amount of noise added in the training process. And the more noise you add, the less effective the training process and the more data and compute you have to use. These three factors interact in complicated ways that make it tricky to figure out the most efficient way to build a model with specific privacy guarantees and performance.
So the Google team carried out a series of experiments with the company’s open-source Gemma family of models, varying these key parameters to discover how they interact. From this, they outlined a series of scaling laws, detailed in a pre-print on arXiv, that allowed them to predict how altering compute, data, and privacy budgets affects a model’s final performance.
One of their main insights was that ramping up compute during training doesn’t boost model accuracy unless the model is fed more data or privacy guarantees are loosened. They also found the optimal model size is roughly an order of magnitude smaller than models without differential privacy, suggesting it may be difficult to extend the approach to today’s largest models.
However, the scaling laws also predict the most compute-efficient training configuration for a particular dataset size and privacy budget. This allowed them to reduce computing requirements by between 5 and 100 times compared to alternate configurations, while achieving similar accuracy.
The team used these insights to create VaultGemma, which performed comparably to the similarly sized GPT-2 model that OpenAI released in 2019. Given the pace of advances in AI, matching the performance of a model from six years ago is not an especially high bar, but the researchers say the scaling laws they’ve identified should help close that gap.
And in a technical report accompanying the model release, the team provide strong evidence their approach prevents the model from memorizing training data. They took one million training data samples, each 100 tokens long, and fed the first 50 tokens to the model to see if it would complete the sample. While all three generations of Gemma models were guilty of regurgitating some amount of data, they found no evidence VaultGemma had memorized any of the samples.
While VaultGemma remains an experimental model with no real practical value, it demonstrates that relatively sophisticated, privacy-preserving AI models are within reach. Hopefully, others can build on these scaling laws to push the field further in this direction.
The post Google’s VaultGemma AI Hoovers Up Your Data—Without Memorizing It appeared first on SingularityHub.