2026-07-19 04:38:44
A week ago, a philosopher named Amit Hagar put out a preprint entitled The NISQ Trap: Eight Years of Demonstrations the Hardware was Built to Lose. Here’s the abstract:
With a single clear exception, every NISQ-era flagship demonstration of ‘quantum advantage’ has, within eighteen months of its announcement, been classically reproduced, shown to rest on classically tractable structure, or closed by a simulability theorem. Six theoretical results from 2024 through April 2026 explain the pattern: the regions of circuit-space NISQ hardware can run with sufficient fidelity coincide with the regions classical algorithms compress efficiently, because the features that admit one (low effective depth, strong algebraic structure, geometric locality) are the features that admit the other. This reading dates the NISQ programme from its 2018 articulation as an interim retreat from the unmet conditions of the 1996 threshold theorems, characterises the eight years that followed as a closed loop in which the demonstrations the hardware could run were drawn from regions classical methods could already reach, and locates the exit from the loop where the threshold theorems originally located it: in fault tolerance. The empirical pattern could in principle break with a demonstration that escapes the current simulability results. After eight years and more than thirty advantage-class announcements, the burden of producing such a demonstration falls to the defenders of NISQ.
You can also read some debates about the paper on SciRate here. I think it’s fair to say that the paper is purely polemical, without new ideas, and Pangram agrees with my suspicion (and that of a SciRate commenter) that significant portions of it are AI-generated.
Nevertheless, the basic thesis—that quantum supremacy in the NISQ (Noisy Intermediate Scale Quantum computing) era has been a failure, or even an example of pathological science—seems surprisingly widely shared, along with the opposite thesis that quantum computing already gives oodles of useful advantages for optimization and finance.
So it seems worth stating for the record that I have an extremely different view. I would say:
Anyway, my son and I need to catch a plane to Utah now, for the next iteration of the wonderful Epsilon Camp, where I’ll again be teaching theoretical computer science to 11- and 12-year-olds. But feel free to discuss in the comments! Nothing about world affairs in this thread please, just quantum supremacy.
Update (July 19): Not unrelated to the subject of this post, here’s a podcast I did with Gill Eapen of “Scientific Sense” about the current situation in quantum computing including recent experimental victories.
2026-07-12 04:25:14
Here at the National Academy of Sciences, it seems that my first job is to serve on the selection committee for the prestigious Michael and Sheila Held Prize in combinatorial and discrete optimization and related areas. The committee chair, my former MIT colleague Madhu Sudan (now at Harvard), invited me to share the following message here on Shtetl-Optimized. (I’d add: put in the effort to nominate someone, and you can actually influence how things go!)
Dear Colleagues
I am writing to seek nominations for the 2027 Michael and Sheila Held Prize. The scope of the prize and nomination needs are described below. If you intend to nominate someone I would appreciate a heads up by email to [email protected] one month before the deadline (so email by Sept 8, 2026) to let me know your nomination is coming. (We may also reach out to you in response to coordinate multiple/overlapping nominations.)
The Held prize honors outstanding, innovative, creative, and influential research in the areas of combinatorial and discrete optimization, or related parts of computer science, such as the design and analysis of algorithms and complexity theory. This $100,000 prize is intended to recognize recent work (defined as published within the last eight years, i.e., on or after October 6, 2018).
All nominations must be submitted online by Monday, October 5, 2026 and include:
1. Nomination letter describing the candidate’s work and why he or she should be selected for the award. No more than three (3) pages.
2. Curriculum vitae. No more than two (2) pages.
3. Bibliography listing no more than twelve (12) of the nominee’s most significant publications.
4. Suggested citation. A 50-word summary stating why the nominee should be considered for this award.
5. Two letters of support. No more than one letter of support can be written by someone of the same primary work institution as the nominee.
The Held Prize is given to a person or a set of persons, as supported by a paper or a body of work. Unless otherwise stated, preference will be given to scientists who may be earlier in their careers or those whose work has not been recognized by other prizes or awards. Nomination restrictions can be found here. Joint nominations will only be considered when nominees have collaborated closely on the paper to be recognized by the award. If nominating multiple individuals for a paper with additional authors, please clearly explain the reason for nominating those chosen, as well as the reason for excluding other collaborators, if applicable.
Please feel free to circulate this call further within your department
Best
Madhu Sudan, on behalf of The Michael and Sheila Held Prize Selection Committee
And while I have your attention, a second CS theory announcement: David Soloveichik, my wonderful friend and colleague in UT Austin’s Electrical and Computer Engineering Department, has funding for a postdoc for 1-2 years, to work on the thermodynamics of computation here at UT. This is a topic that I’ve been trying to learn more about as well, so I might get involved too! David writes, “the big picture is to think of thermodynamics (energy dissipation / entropy production) as CS complexity measures like time and space usage.” If you’re on the postdoc market and this sounds potentially up your alley, email David to learn more.
2026-07-10 22:59:33
As I’ve written before, these past couple years I’ve often felt like the last remaining person in either quantum computing or AI who lacked a stake in some startup company whose valuation is right now shooting into interstellar space. My academic colleagues, including the ones who seemed the most singleminded about quantum oracle separations and other gloriously useless pursuits? One by one, like in a zombie movie, I learn that they too have now launched startups, and invariably raised tens of millions of dollars, for the sorts of ideas we might’ve idly traded at coffee breaks back in the day, before getting back to our real work.
So why didn’t I join this rollicking party? Partly because of a lifelong fear that, the instant my self-worth became tied to how much money I made, I’d need to humble myself before people who bluster and bully and lie and hype and conceal … yet who nevertheless succeed at becoming orders of magnitude richer than me. I’ve been terrified of even starting down that road, of whether I’d still be myself at the end of it.
It’s also partly that I can’t stand failure, or regret, or being wrong. Of course, as an academic researcher I also fail, and regret things, and am wrong constantly—but there it feels tolerable, because normally I can tell myself that it’s all just down to my inborn limitations. After all, if I could’ve solved the major open problem that someone else solved, or written the brilliant book that someone else wrote, then presumably I would’ve done it!
Clearly, though, I could’ve mined bitcoin in 2010. I could’ve gotten an early stake in Amazon or Google. It’s not even like those ideas never crossed my mind. I just … didn’t act on them, for some reason. (But even if I had, I’d probably just be full of regret that I hadn’t done even more.) Thus, my only way to avoid paralyzing regrets, has been to tell myself constantly that I’m not in the forecasting or money-making businesseses in the first place.
It helped that, insofar as I’m shallow or covetous, insofar as I’ve desired things of this world rather than insight or eternal truth, it’s never really been money that I cared about, but just being respected and liked. Elon Musk is the richest man on earth, but also one of the most despised—which isn’t a bargain that I could imagine ever appealing to me.
Plus, when I actually meet billionaires, I don’t find myself envious of their mansions or cars or anything else that they have; I don’t feel like such things would make my life any happier. Maybe I slightly envy their ability to fund the causes they care about, or their professional staffs who relieve them of drudgery, but mostly I envy the way their wealth announces, to whatever extent it does: “I was right when others weren’t.” Again, though, I’ve never trusted the world to cause me to be right about the future valuations of companies or anything similar, so I’ve settled for having been right about PostBQP and algebrization and BosonSampling.
The bottom line is that I made a choice decades ago to forgo trying to get rich, no matter how many of my friends did the same, and to strive instead to discover and tell the truth—to be a professor, a blogger, a jokester, and an “objective” arbiter and commentator. “Then, surely, everyone will like me!” my internal monologue went. “Then, surely, they’ll be grateful for all the free service I’ve rendered them—for decades of blogging, without once so much as asking for a donation or running an ad!”
HAHAHAHAHAHA.
As any regular reader will know, my attempts to be loved as a blogger backfired pretty spectacularly. Or rather: they did lead to thousands of strangers liking me (and I’m grateful for every last one of you), but they also led to probably an order of magnitude more strangers hating me, and congregating on Reddit and Twitter and elsewhere to discuss how badly I suck. And of course, trying to shift that balance by writing what people want to hear, rather than what I actually believe, was never within my realistic option set.
In the startup context, it didn’t matter how carefully I avoided taking a direct stake for or against any of the companies I blogged about. People on Twitter simply assumed that I had a stake—for example, that I must’ve shorted D-Wave or IonQ, or invested in their competitors, or had equity in AI companies. For why else would anyone write what I wrote?
Amusingly, my attackers here typically did have precisely the conflicts-of-interest that they falsely accused me of having, but that was never at issue; only my imaginary conflicts-of-interest were. Even as the Scott-haters greedily filled their pockets (or tried to), I alone needed to keep turning my pockets out to prove that they were still empty.
So then, screw it! In partnership with my brother David Aaronson, who’s long done investing professionally, and on David’s guidance and encouragement, I’m hereby embarking on a new policy.
Namely: when I hear about a brand-new startup that sounds relevant to my interests—in quantum, AI, or anything else—and I like and trust the founders (ideally, because of their previous academic research work), David and I will often make a small seed investment if the founders are open to it. Or, of course, we might become advisors or get involved in some other way.
In fact, David and I are launching BQP Partners—the link goes to our AngelList, where you can read about how to invest with us if you’re interested. (See also whether you can spot any differences between David’s writing style and preoccupations and mine!)
So far, David and I are investing in:
I have little doubt that more potential investments will come our way very soon (some, probably, as a direct result of this post).
Crucially, I can handle my burden of regret—the “why didn’t I do this much earlier, if I was going to do it at all?” question—by telling myself that friends of mine were not founding companies left and right until very recently. I can also tell myself that I’m doing this less as a bet about the future (in which case … what if I’m wrong?), than simply as a way to support brilliant colleagues doing things that I genuinely admire.
When I blog about a company, I’ll always disclose if I have a financial position that presents a clear conflict of interest, so you can judge for yourself whether to listen to me. (Although, if that’s the sort of thing you’d demand, then you probably weren’t listening to me in the first place, were you?)
Having reflected on it a lot these past few months, I’m happy with my new policy and with my and David’s new venture, and I’m curious to see where it goes. I’m at peace with the possibility that we’ll lose our shirts, but I’m even at peace with a more disturbing possibility—that we’ll make millions and then people will scream at me online for being a sellout, a hack, and a shill. Those people, as I’ve learned, were going to scream at me anyway.
2026-07-05 05:52:01

I’m at the New Jersey shore with family and friends, where we’ve spent this Fourth of July eating hot dogs, playing miniature golf, and wading into the ocean that my great-grandparents crossed to escape calamities they knew about and much greater calamities that they didn’t. Tonight we’ll see the fireworks, weather permitting.
And yes, on the crowded beach today you can find people sporting MAGA and “45-47” hats, and even a giant “Trump 2028” flag—a stark reminder of the millions who would redefine the meaning of our 250-year-old experiment to something dark and authoritarian, the opposite of what its founders intended. Of course, those forces find mirror images on the left end of the political spectrum, where one can find millions more who fully agree with MAGA about the failures of liberalism and the Enlightenment, differing only on the secondary question of which racist thugs should rule instead.
Despite everything, I don’t believe that both factions together constitute a majority. Even on the beach, the MAGA hats are vastly outnumbered by “250” banners and girls in stars-and-stripes bikinis, Americans who just want to celebrate.
Despite everything, I remain thoroughly American if I’ve ever been anything, and invested in the country’s future if I’ve ever been invested in anything.
JD Vance and his friends, who might rule the country after the predictable failure of “Trump 2028,” make a huge deal about “Heritage Americans.” Of course the point of such phrases is to exclude those like me, and recent immigrants, and even (incredibly) JD’s own wife. On reflection, though: could I, too, count as a Heritage American at this point? After all, my family has now been here for half the country’s history. My grandfather, who grew up in poverty, became a professional boxer in Philadelphia and Atlantic City during the Great Depression. He then joined the Army and ended up clearing German mines in North Africa and Italy in WWII. He was assigned to a company of Southerners, who had never met a Jew and were shocked that my grandfather didn’t have horns—but by the war’s end, my grandfather and the relatively few others in his company who remained alive had become best friends. My grandfather told me that he could understand the German POWs who they captured tolerably well, since German was similar enough to Yiddish, but who he could never understand was the British.
As for me, I grew up in the town of Washington Crossing, PA, maybe a mile’s walk from where this happened (and where it’s still reenacted every Christmas):

My earliest childhood hero (that I can remember) was Ben Franklin, whose institute in Philadelphia I visited often. I didn’t even recognize as unusual at the time how the founding of the country didn’t feel like a remote abstraction to me, but was all around me, as if it was yesterday.
That the founders of the United States created the model for all time of how to bend the arc of human history a little bit away from its usual horribleness, of how to overthrow a despotism without instituting an even worse despotism in its place, of how to found a new civilization on ideas and principles rather than raw power … is one of those things that seemed true to me as a child and that still seems true to me today.
May this greatest experiment continue for another 250 years. May it triumph against all those within and without who would see it destroyed.
2026-07-03 04:26:38

Scott’s foreword: Cynthia Dwork is Gordon McKay Professor of Computer Science at Harvard, and a pioneer in the fields of differential privacy and algorithmic fairness. On my recent travels to the SigmaWest science camp and then STOC, there was much talk about a recent Trump administration action that would ban not only differential privacy, but essentially all modern techniques for preserving privacy in large datasets, for example in the 2030 US Census. I realize that many of us have “outrage fatigue,” but this particular outrage hits extremely close to home for the CS theory community. So when Cynthia approached me at STOC to propose a guest post on the issue, of course I said yes. The post that she sent me, below, is cosigned by many other leaders in the field.
On June 4, 2026, the U.S. Secretary of Commerce issued a directive (DAO 216-26) relegating confidentiality protection in all Bureau of Economic Analysis (BEA) and U.S. Census Bureau publications to techniques dating back to the early 1970s, turning its back on over half a century of progress and protections for data subjects. Advances in confidentiality provision had enabled the Census Bureau to share increasing quantities of data at more granular detail. The order will result in less useful (or fewer available) statistics, weaker protection, or both. We write to illustrate the danger posed by the order and to mobilize the scientific community to speak out against it.
The acting force behind this order is political interest, not scientific merit. DAO 216-26 bypassed legally required administrative procedures. It fulfills a promise made by the architects of the Heritage Foundation’s Project 2025, and reflects both the rhetoric and misunderstandings of representatives of the Center for Renewing America (CRA), an organization founded by OMB Director Russell Vought. CRA’s explainer on the use of differential privacy in the 2020 Census is up-front about the stakes: “Even if the citizenship question is added to the Census, it will be impossible to ascertain the status of individuals so long as differential privacy is used.” But masking this sort of personal characteristics data is legally required by the Census Act (13 U.S. Code Section 9), which makes it a crime to “make any publication whereby the data furnished by any particular [individual] can be identified.” Confidentiality is also widely understood as critical to ensuring that people respond to the census.
DAO-216-26 bans differential privacy and other modern (and not so modern) techniques. It restricts disclosure avoidance techniques to “coarsening,” which it describes as “reducing the level of detail or specificity of published statistics, such as through rounding, aggregating (grouping), and/or the use of ranges.” “Suppression” (“expressly redacting certain values”) may also be used, but only as a “last resort.” DAO-216-26 forbids “noise infusion”, described as “methods that involve modifying a dataset by adding random values, or noise.”
Noise infusion was invented precisely to address the increasing demand for granular data in the face of confidentiality laws that forbid publishing reidentifiable data. Coarsening and suppression were satisfactory for most national, aggregate statistical series, like the Principal Federal Economic Indicators. However, these techniques failed when applied to business and demographic data at fine geographic or industrial detail. By forbidding noise infusion, the directive bans the disclosure avoidance techniques at the core of dozens of data releases over the last three decades. It bans input noise infusion, used in the Quarterly Workforce Indicators since 2002 and, until now, planned for the Bureau of Economic Analysis statistics [1]. It bans swapping, used for decennial census publications since 1990. It also bans differential privacy, the best currently known approach for obtaining the most data utility for any given level of privacy. Differential privacy was used for sharing data on commuting patterns (OnTheMap) since 2008 and for publications based on the 2020 Census. Until the recent directive, differential privacy was planned for the 2030 Census too. Many other products and procedures are implicated as well.
1. Illustrations
DAO-216-26 is incompatible with the Census Bureau’s dual mandate to provide confidentiality and fitness for use. To illustrate this, we recall and expand on an example due to Nathan Goldschlag, inspired by the County Business Patterns (CBP) data, which provides statistics on business activity broken down by industry and geography. Goldschlag describes three scenarios, illustrating the tension between providing useful information and maintaining confidentiality of responses as required by the Census Act.
· “There is only one brewery in a small county. If the CBP published the exact count of brewery employees in that county, it would be disclosing the information of one business (how many workers it employs), a clear violation of the law.2
· “There are two breweries in a small county, and the CBP again publishes the exact count of brewery employees. If I own one of those breweries, I could learn how many employees my competitor has, again violating the law.
· “There are more than two breweries in a small county, but the CBP chooses not to publish the total number of brewery employees out of concern that it might compromise the privacy of the businesses. If I’m a prospective brewery owner, I may deem the project too risky to pursue without information about the market I’m entering.”
In Goldschlag’s example, coarsening makes the published statistics useless. We now add a fourth scenario, showing that it also fails to maintain confidentiality. To keep things simple, assume none of us owns any of the businesses in the new example. The County has two towns with one brewery each, North Bend and South Bend. Furthermore, North Bend has a mobile bottling company and South Bend has a stationary bottling company. That’s a total of four beer-related business entities in the County. Two of these businesses, the North-Bend brewery and the South Bend bottling company, are publicly-owned.
We now have 5 equations in 4 unknowns. Using only 4 of these (A, B, C, and E), we can solve for the exact number of employees at each of the four companies with high school algebra.
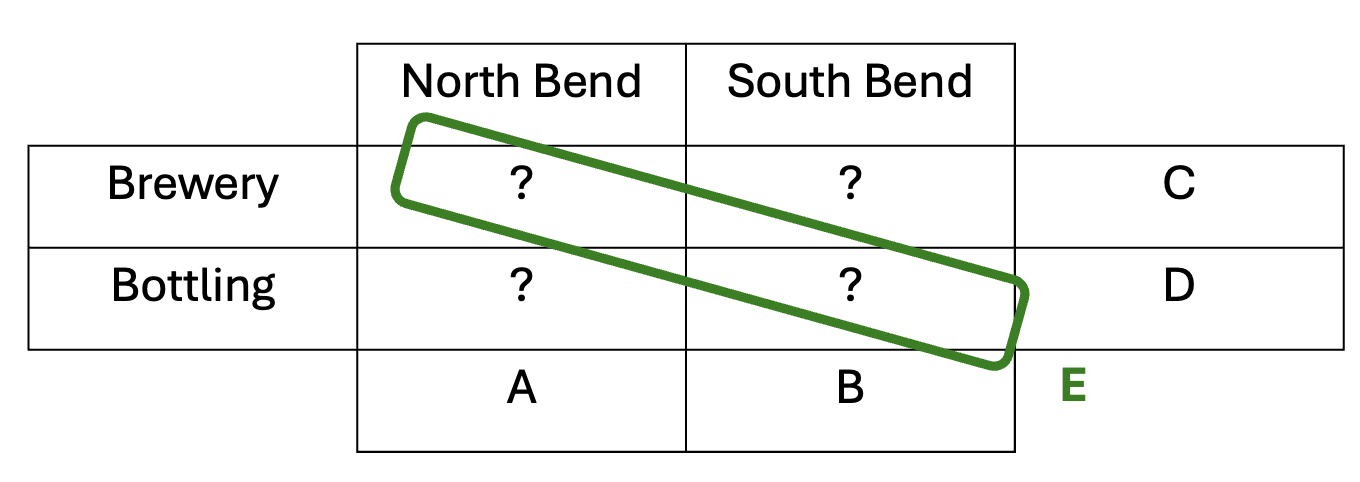
In the above (fictional but realistic) scenario, the County Business Patterns were released with good-faith coarsenings for the geographical, business, and ownership categories. Nonetheless, even without inside knowledge of one of the companies’ number of employees, we can completely reconstruct all four numbers. What happened? The coarsenings interacted poorly. Noise infusion perturbs that set of equations, preventing exact reconstruction.
2. Impediments to Implementation
The Commerce Department now claims the directive’s return to the outdated “tradstat” traditional statistical techniques of the 70s is good for data consumers: “This update to our disclosure limitation method protects respondents and provides the public with more essential economic information.” (Emphasis added.) As we saw from Goldschlag’s example, coarsening does just the opposite.
And it can’t be fixed. Coarsening by definition reduces access to fine-grained information. Our example of three poorly interacting coarsenings shows that this sacrifice is for naught: without noise infusion, confidentiality is destroyed by elementary calculations. For population surveys, this is precisely what formal noise infusion methods, like differential privacy, protect against; this is the “fancy math” that Goldschlag mentions in his post and that holds personal characteristics, like citizenship status, in confidence.
3. Confidentiality is Critical for Federal Statistics
The scientific community continues to debate the best techniques for protecting the confidentiality of respondents’ data, but DAO-216-26 is not driven by science. It is driven by political interests. Those issuing this order are willing to risk the public’s trust in the process. We think that this is wrong-headed and dangerous.
Civil servants will do their best to comply with this order while still following the laws that require them to protect the confidentiality of respondents’ data. To balance these competing mandates, they may seek to produce less data or coarsen data so much that it is unusable. Or they might be pushed by political actors to publish data that can be easily unmasked, like in the brewery examples above. Regardless of their choices, they will be hard-pressed to guarantee respondents’ confidentiality, which will prompt many businesses and individuals to simply not answer. This is devastating for an agency that delivers democracy’s data.
Rather than political actors overruling the government’s own statisticians, we need deep investment in our nation’s statistical agencies, ensuring that agencies have the staff and support to improve their methods using the best available tools. Regardless of how the scientific community feels about any specific privacy-enhancing technique, we must collectively reject this anti-scientific approach to governing federal statistics. Too much is at stake.
Share this post with others in your professional network and community.
Contact your Congressional representative and voice your concerns. Calling or writing to your representative is one of the most effective and easiest things a constituent can do that should only take a couple minutes of your time.
Volunteer to help preserve Census working papers and documentation. Pages explaining “noise infusion” and “differential privacy” are already going offline. Archive relevant methodology pages and technical documentation. You can also do this via the Internet Archive’s Wayback Machine (“Save Page Now”).
John Abowd
Aloni Cohen
Cynthia Dwork
Jae June Lee
Jayshree Sarathy
Adam Smith
Salil Vadhan
[1] BEA Working Paper WP2026-9, now purged by the Department of Commerce. As of 6/22 Google returns:
Bureau of Economic Analysis (BEA) (.gov)
https://bea.gov › files › papers › BEA-WP2026-9
2026-06-29 09:32:13


Spreading the Gospel of Theoretical Computer Science to an Ω(1) Fraction of Humanity (Or, How We Can Do Like the Physicists)
Scott Aaronson’s Trevisan Award Acceptance Speech
Salt Lake City, Utah, June 23, 2026
Thank you so much! It’s one of the highlights of my life, frankly, to accept the first-ever Luca Trevisan Award for Expository Work in Theoretical Computer Science—because of, firstly, what this entire STOC community means to me, but also what Luca Trevisan in particular meant to me. Luca was one of the main people who taught me complexity theory—first at an IAS summer school in 2000, then at UC Berkeley, where I took two of his courses and TA’ed for him. As a member of my dissertation committee, Luca once stood on a street corner in San Francisco to meet my friend to sign the signature page of my thesis, as I struggled to get the thing in by the deadline. Later, Luca’s theoretical computer science blog, In Theory, bounced off of my blog.
I wish Luca were here now. But knowing him as well as I did for a quarter century, I feel like I know what he’d say if he learned that I had received the inaugural prize that bears his name. I imagine he’d slap his forehead and say “Seriously, there was no other option??” But I’d like to think that he’d eventually reconcile himself to the choice!
By the way, I noticed that in the committee’s prize announcement, which I found so moving, they added a special paragraph at the end that basically said, “please don’t imagine that to win this prize in the future, you need to behave the way Aaronson behaves. You can just write beautiful textbooks or survey articles or whatnot, and be normal and sane.”
The foundation of my career is that I realized 25 years ago that there were better theoretical computer scientists than me—like many in this room, or like Ryan Williams or Andris Ambainis, both of whom I knew at the time. Certainly there were better quantum physicists than me. There were better writers, better expositors, better performers. On the other hand, if you looked specifically at the intersection of computational complexity and quantum physics and standup comedy, that was just this totally uncontested territory!
I’ll let you in on a secret: pretty much everything I’ve done for decades has just been drawing out one joke. That joke is, basically, “computer scientists they be like this, but physicists they be like that.” The physicists they be like [exaggerated doofus voice] “duhhhh, NP, what’s that stand for? Not Polynomial?” See, but then there’s also a Rodney Dangerfield aspect to it, because it’s like, how come we never get as much respect as the physicists get? (Though when we do get that respect, I confess that I complain all the more, because then I lose my shtick…)
It’s true that the physicists have certain built-in advantages. They had Einstein, Stephen Hawking, the atom bomb—and just the fact that they’re ultimately talking about, or trying to talk about, the world that we can see and touch. A black hole is an actual place that you could visit, even though I wouldn’t recommend it. But physicists also have much better names for things than we do. I mean, black hole? Big Bang? Quark? Gluon? Supersymmetry? Dark matter?
Meanwhile, what names have we got? TFNP. NC1. And worst of all, PP. These are names that you want to flush down the toilet. But also, the concept of a zero-knowledge protocol, or a two-source extractor, just inherently take longer to explain to people than the concept of a particle, or even a field—even though the latter also turn out to be extremely abstract and mathematical when you push on them. Ask a physicist what a particle is, they’ll tell you that it’s an irreducible representation of the Poincaré group. See, but people think they know what a particle is, it’s just a tiny little hard sphere that moves around, and that’s good enough for them.
So then, how can we win the grand popularity contest against the physicists? How can we, as I put it in my title, spread the gospel of CS theory to a constant fraction of the human race? In my view, the first step is to reframe who we are and what we’re about. We’re not this obscure little community off to the side, proving its little theorems about derandomization and catalytic space. No! What we are is the conceptual and mathematical core of computer science, the field that’s changing the face of civilization in obvious and undeniable ways.
This was even true a long time ago. The physicists had Galileo and Einstein? Well, we had Turing, a figure so heroic and so tragic that no one would’ve believed him as a fictional character. And while we’re at it, we’ll claim Gödel and Shannon and von Neumann, Leibniz and Babbage and Ada Lovelace—they’re all ours too.
That’s our proud history. But then when we turn to today, it’s like, holy crap! Even the densest ignoramus can now see how deep intellectual ideas originating in CS are changing the world.
Blockchains—some people might wish they’d never been invented, but they were invented, so we all need to think about how they change the world’s economy for better and worse. And of course, they’re fundamentally based on hardness assumptions; they couldn’t exist in a world where NP was easy.
Part of my outreach job these days is to explain to finance people, over and over, why a quantum computer could break the elliptic curve signature schemes used by Bitcoin and many other coins, but would have only a more modest effect on the proof-of-work part, the hash function. And it’s like, if you actually want to know, then we need to talk about BQP versus NP, Grover’s algorithm and its optimality, black-box problems with and without abelian group structure—and now we’re deep into TCS!
Speaking of quantum computing—even if we set aside the question of whether quantum computing is going to revolutionize materials science or chemistry or pharmaceuticals design—or whether it will revolutionize AI and machine learning and optimization [I shake my head, make a thumbs-down, and blow a raspberry]—even if we set aside those practical questions, quantum computing plausibly represents the most dramatic test of quantum mechanics itself that we’re ever going to see. And it now looks clear that we will see that test within the next decade or sooner. One way or the other, we’re going to learn the truth.
People sometimes ask me, why did it take until the 1980s for anyone to propose the idea of quantum computing? You know, Heisenberg and Schrödinger were in the 1920s, Turing was in the 1930s, so it seems like all the ingredients were in place a half-century earlier! In my Quantum Computing Since Democritus book, I reflected on this, and I think the deepest answer is that not quite all of the intellectual ingredients were in place. Quantum computing is something that it doesn’t make a great deal of sense even to ask about until you’ve established polynomial versus exponential, and even P and NP and NP-hard, as central concepts. And that’s what didn’t happen until the 1970s.
But of course, the biggest thing that our CS concepts have unleashed on humanity—the thing that the entire world now realizes holds even greater promise and greater peril than nuclear energy did in the last century—is [pause for effect] the Razborov-Smolensky lower bound method.
No, I’m kidding of course. It’s generative AI.
Twenty years ago, I remember people in our community—was it Fortnow? Impagliazzo? I’m not sure—saying, “you know the real reason why P vs. NP is such an important problem? Suppose P=NP, via an algorithm that was fast in practice. Then it’s not just that you could break all the encryption systems, or have your computer find a proof of the Riemann Hypothesis, or whatever. No, it’s that you could program your computer to find the shortest efficient compression of, for example, the full text of Wikipedia. For in order to create that compression, it seems plausible that your computer would need to create an AGI as a byproduct.”
I remember thinking to myself: “that’s an amusing thought experiment, I’ll need to steal it sometime, but still, what an utterly simplistic vision of the nature of intelligence! There has to be more to intelligence than sheer data compression!”
Fast forward to spring 2022, when I accepted an invitation to go on leave for a couple of years, to join what was then a relatively obscure little nonprofit foundation by the name of … err … OpenAI. When I flew to San Francisco to start my assignment, I had lunch with Ilya Sutskever, the cofounder of OpenAI and then its chief scientist. And Ilya said to me, “Scott, let me explain to you how we think about things here at OpenAI. For us, intelligence is fundamentally about prediction, and prediction is fundamentally about compressing your training data. As you know, Kolmogorov complexity is uncomputable, but one can get better and better computable upper bounds on it. We conjectured that, in order to get sufficiently good at predicting and compressing all the text on the Internet, you’d need to build a model of the entire world that had led to that text being written. And we made a gamble that large neural nets would do that well enough, despite the problem’s worst-case intractability.”
That conversation was when it hit me that, if only we in CS theory had taken our own concepts and thought experiments more seriously, one of us could’ve started OpenAI 15 or 20 years ago. So OK, we didn’t, and that’s why I flew coach to get here. But this is the kind of story that it seems to me we could be singing from the rooftops.
(Incidentally, the reason why OpenAI wanted me back in 2022, was to use theoretical computer science to figure out how to make AI safe for humanity. Alas, that problem is still open! But I’m thrilled that there are so many sessions about exactly this question at STOC this year, and I hope many of you will choose to get involved.)
In the rest of this talk, I’d like to offer some advice—such as I have—for any of you who’d like to try your hand at speaking or writing or blogging or podcasting about theoretical computer science for a broad audience. You see how my hair is starting to gray? Yeah, that’s what authorizes me to go into advice mode.
Let’s start with the obvious: meeting the audience where they are. This is something that I learned years ago from Steven Rudich, who along with Luca, was another irreplaceable figure who our community recently lost, and lost too soon. I remember 26 years ago, at that same IAS summer school where I learned from Luca, Rudich gave the students a talk about how to give talks. In it, he showed a cartoon of someone lecturing. And there were little thought bubbles that said:
What the speaker thinks the audience is thinking: MORE! HARDER! FASTER! Ah yes, QED, truth is beauty and beauty is truth!
What the audience is actually thinking: What the hell are they talking about? When is this over? Can I get a date with the person sitting next to me?
You know, this misconception that because something has become obvious to you, after thinking about it for years, therefore it should be equally obvious to your readers or listeners encountering it for the first time? This is what Steven Pinker dubbed “the Curse of Knowledge,” and calls the most fundamental problem of all exposition. (I could mention the related misconception that because something has become interesting to you, therefore it’s interesting to your audience. But you can make just about anything that’s interesting to you interesting to your audience, by telling a suitable story about it.)
What can you do about the Curse of Knowledge? Practice giving a buttload of talks to undergrads, high school clubs, even physicists, and listen to the feedback you get. If the same weird confusion shows up at least twice, it’s a safe bet that it’s going to keep showing up—which means, now you can anticipate and preempt it the next time you explain the same concept.
But it’s not just misconceptions that you should listen for. Listen for which of your metaphors and anecdotes actually land. Certainly listen for which of your jokes get a laugh. Use those more the next time. And if saying, for example, “hur hur, I’m in a quantum superposition of two different topics that I could talk about next”—if that fails to get a laugh, then DROP IT.
Eventually, you’ll build up what Carl Sagan once called “consumer-tested stepping stones”: that is, a library of jokes, anecdotes, and metaphors that can get you from wherever you see the audience is to wherever you need them to be. Here’s an intentionally tiny example of one of my stepping stones: “Why is P contained in NP? Because the verifier just says to the prover, dude, take a hike, you’re not needed here.” Or another stepping stone, for when we reach the question of the likelihood of P=NP: “look, if we were physicists, we would’ve declared P≠NP to be a law of nature. We would’ve given ourselves Nobel Prizes for the discovery of that law. And if it later turned out that P=NP? We’d just give ourselves more Nobel Prizes for the law’s overthrow!”
This brings me to a broader point. CS theory is unusually rich with facts that are true for silly or absurd or ironic reasons. Lean into that! Don’t hide it!
I mean, “if NP has small circuits then this theorem is true, but if NP doesn’t have small circuits, the theorem is again true, but now for a totally different reason”? That’s sidesplittingly hilarious! OK, maybe only to some of us.
Or why does IP=PSPACE? An alien lands and is like, “I COME TO EARTH TO TELL YOU THAT WHITE HAS THE WIN IN YOUR GAME CALLED CHESS.” And we’re like, “why should we believe that?” So the alien is like, “LET US PLAY A GAME. I’LL PLAY WHITE AND WILL WIN.” And we’re like, “oh, we assume you’re smarter than us! You came all the way here in a spaceship and all! But that still doesn’t prove it.” So the alien is like, “THEN LET US PLAY A DIFFERENT GAME, MATHEMATICALLY EQUIVALENT TO CHESS, INVOLVING SUMS OF POLYNOMIALS OVER A FINITE FIELD. IN THIS TRANSFORMED GAME, THE BEST YOU CAN DO IS TO MOVE RANDOMLY. SO IF I STILL WIN, YOU’RE STATISTICALLY CERTAIN I WOULD’VE WON REGARDLESS OF HOW YOU PLAYED.” It’s like, dude. Dude!
Of course, our founding irony, our founding absurdity, was self-reference and diagonalization. Like, “you can’t predict what any human brain will do 5 seconds from now, because if you could, you could predict what you yourself were going to do 5 seconds from now, and then do the opposite of that!” BOOM! Therefore the halting problem is undecidable and the Time Hierarchy Theorem is true, QED. But beyond that: “black-box program obfuscation is impossible, because one thing you can always do, if given the actual code of a program, is to run the program on its own code and see what happens.” Dude! Or: the reason why it’s so hard to prove P≠NP, is that it’s presumably true that P≠NP. That’s a wisecrack that, in the context of the Natural Proofs barrier, becomes so much more than a wisecrack.
One special case of leaning into absurdity concerns the central role in our field played by asymptotics. I’m always slightly at a loss when someone asks me, “so, how many times faster would a quantum computer be than a classical computer? A million times faster? A billion?”
Part of me wants to reply: “I must educate you about polynomial versus exponential scaling until you see the profound error of your question, and retract it.” But another part of me simply wants to say: “depending on the problem, a quantum computer could be anywhere from not faster at all to, let’s say, 1010000 times faster.”
The truth is, I think we need to do both. Anytime you’re talking about asymptotics to laypeople, if you can plug in some representative numbers, it will help them understand what you’re talking about. And then, if the asymptotics are what really control the real-world numbers, so much the better! If, on the other hand, the asymptotics are comically disconnected from the real-world numbers—if, for example, you’re trying to improve something from log*(n) to Ackermann-1(n) or whatever—well then, you can lean into that as an additional source of humor.
Alright, one last piece of advice. Tell true stories about how you came to understand or discover whatever it is that you’re talking about. Don’t be like the mathematicians who love to cover their tracks.
When people ask me how I proved the lower bound on the number of steps needed for a quantum computer to find collisions in a list—a centerpiece of my PhD thesis, and one of the two or three hardest technical things I’ve done in my career—I say, look, I was 20 years old and I had no social life. So I just pulled many all-nighters trying every possible approach. Eventually, I came across some complicated expression that had no right to be a polynomial. But somehow, every term in the denominator cancelled against a corresponding term in the numerator, and it was a polynomial! And that let me use the polynomial method to prove a lower bound. Why was it a polynomial? I still don’t really understand, a quarter-century later! My point is, people want the truth.
The secret of blogging is that, even if people despise what you’re saying, even if they think it’s wrong, offensive, problematic, cringe, you name it, they need to trust that you’re telling them the truth of what you know or believe or remember about the subject at hand, the same as you’d tell your closest friend.
In summary: we, the CS theory community, are sitting on top of one of the greatest conceptual and intellectual goldmines of our whole civilization. I exhort everyone here: please help tell the world about it! As you do so, think about how to honor Luca’s memory and make him proud. But also think about how to make me, and my silly little blog, superfluous and obsolete.
Thank you for this honor, thank you for the incredible privilege of being part of the CS theory community, and thank you for listening.