2025-08-29 08:00:00

《动机与人格》豆瓣链接:https://book.douban.com/subject/37168612/
作者:亚伯拉罕·马斯洛,“人本主义心理学之父”、当代最伟大的心理学家之一
1-2层需求属于匮乏性动机,依赖外在的缺失来推动,一旦得到满足,动机就会停止;
3-7层需求属于成长性动机,出自内在潜能的自发表达,是积极的、无限的
底层需求满足后,更高层的成长需求才会出现。
长期看,成长动机占比越高,人越不容易“空心病”,越容易得到可控的、持久的幸福。
人的内在天性中是具有潜在的善良、合作、友爱等积极品质的。
我们所看到的破坏性、攻击性、邪恶等,大多是源于爱、安全、尊重等基本需求被剥夺后的一种反应,是一种防御而非本性。
我们应该更宽容去看待自己和他人。
自我实现的需求为了实现个人的潜能、天赋和本性。它鼓励我们去寻找人生的使命和意义,而不仅仅是活着。
高峰体验是自我实现者经常经历的一种瞬间的、强烈的、沉浸式的幸福与成就感的爆发。在这种时刻,人感到更加整合、与世界和谐统一、充满创造力和意义感。
学会在日常生活中发现和创造高峰体验,能极大地提升我们的生命质量。
人不仅害怕失败,也害怕成功;不仅害怕自己的最坏可能,也害怕自己的最好可能……我们称之为‘约拿情结’——逃避自己的天赋与命运,因为随之而来的责任与目光会令我们恐惧。
提前拆解对成功的恐惧,把“成功后的麻烦”从潜意识拖到桌面,恐惧就减半。例如把“最坏的成功场景”写下来(如“真升职后同事会酸”),再一条条写对策。
2025-08-25 08:00:00
《我们为什么要睡觉》豆瓣链接: https://book.douban.com/subject/35858123/
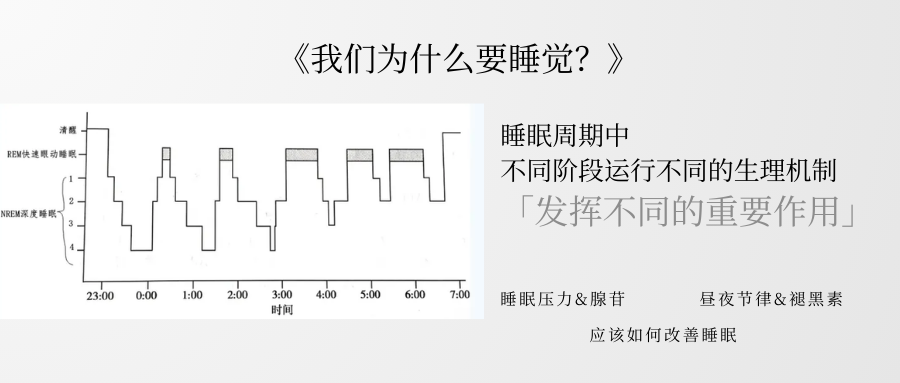
一、人的睡眠周期是由“睡眠压力”和“昼夜节律”两个生理机制调控的
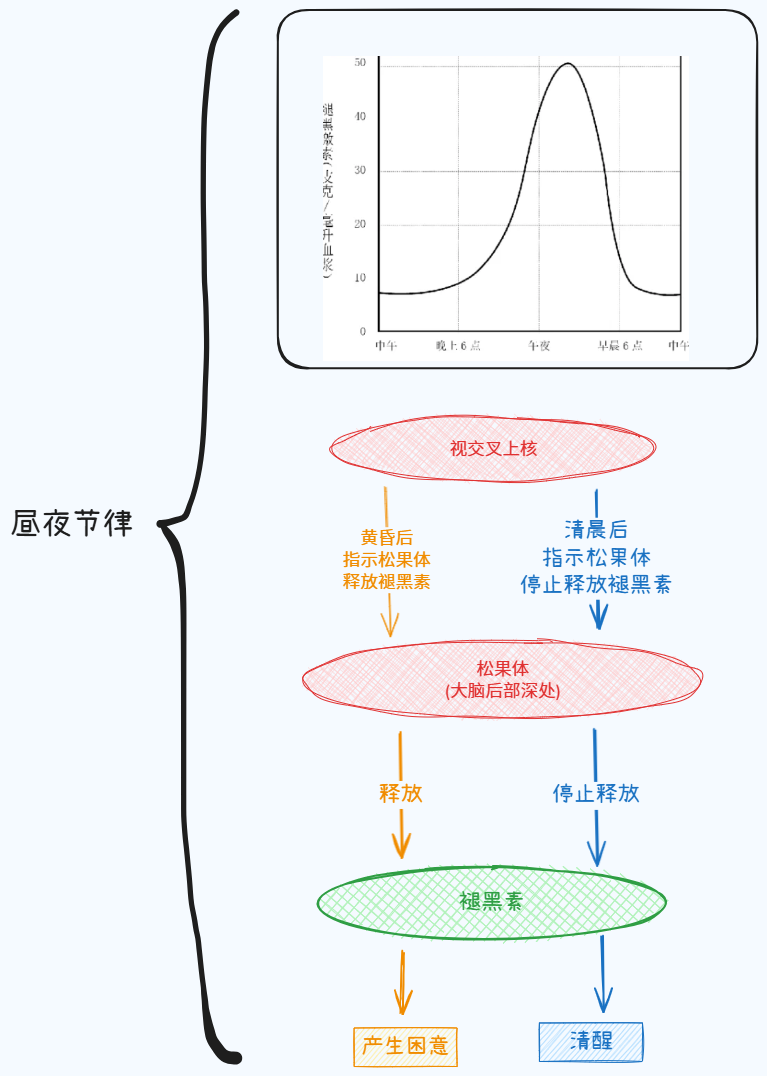
- 昼夜节律:由视交叉上核(SCN)驱动的“体内时钟”利用光暗信号通过褪黑素调节人体在24小时内的节律。
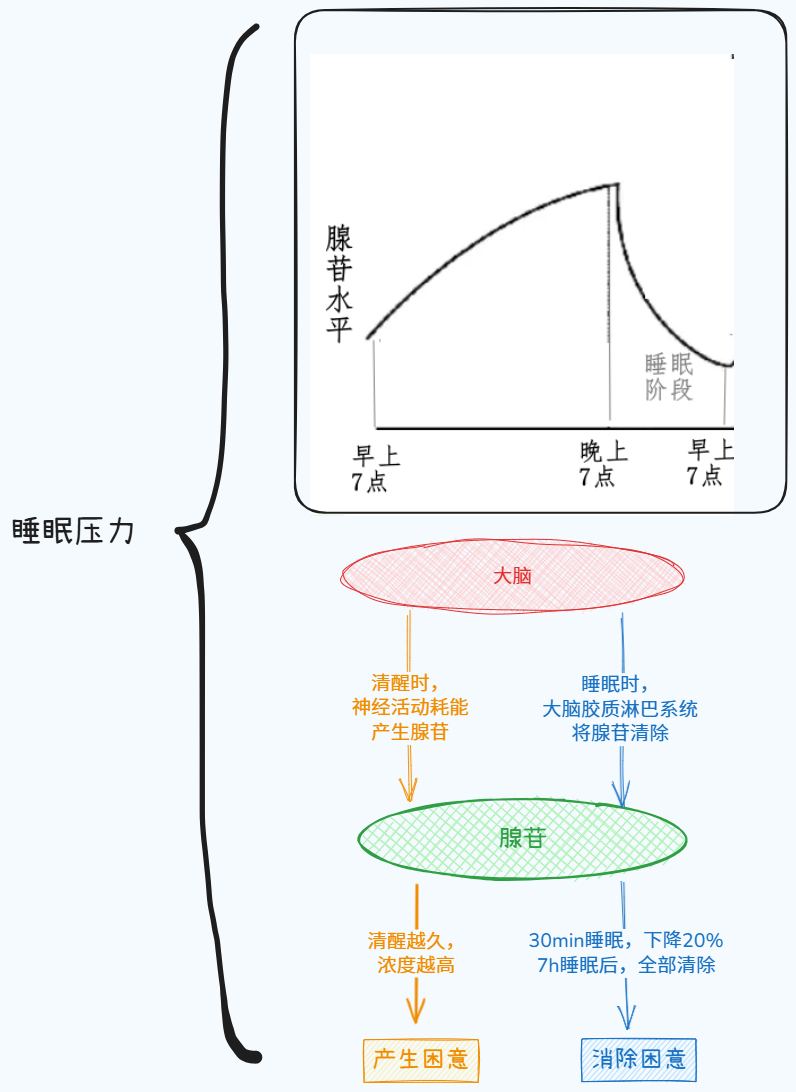
- 睡眠压力:清醒时大脑代谢副产物腺苷持续累积,浓度越高困倦越强;睡眠时腺苷被清除,压力归零。
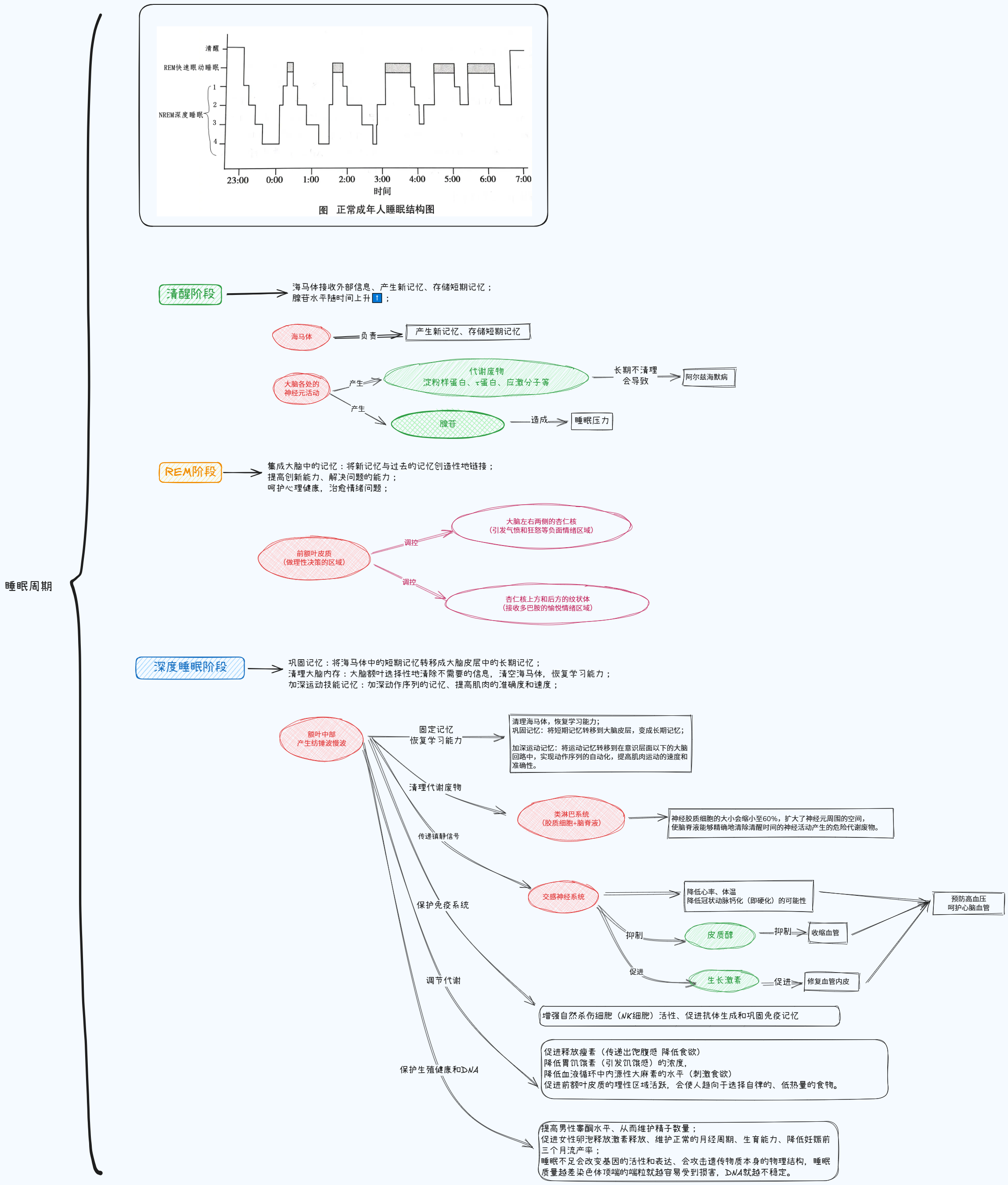
二、睡眠周期中不同阶段 人体会运行不同的生理机制、发挥不同的重要作用
REM睡眠阶段,会对大脑中的记忆相互链接、重整,激发创造力和解决问题的能力;
REM睡眠阶段,会调控正负面极端情绪、治愈情绪问题、保护心理健康;
NREM深度睡眠阶段,会加固对事实和技能的记忆、恢复学习能力;
NREM深度睡眠阶段,会清理大脑的代谢废物、降低精神疾病概率;
NREM深度睡眠阶段,会抑制交感神经系统的兴奋、降低血压、修复血管、保护心脑血管健康;
NREM深度睡眠阶段,会调节代谢、调节控制食欲的激素;
NREM深度睡眠阶段,会保护生殖健康、维护基因和DNA的稳定性;
不同年龄段采用不同的睡眠策略
了解自己睡眠是否充足、予以动态调节
改善睡眠的方法
不论工作日节假日,每天同一时间睡与醒;
白天坚持运动、避免咖啡因、酒精、避免高碳水饮食;
傍晚不要小睡、睡前2h避免运动;
睡前洗热水澡、降低体温、排除光线和噪音,保证完整8h夜间睡眠;
2025-07-25 08:00:00

胡适在《忍不住的新努力》中说,人生的意义是个人自己创造的,以我的理解,就是要找到自己想做的事。
我大学之前十数年学生生涯只关心成绩、上大学后只因为就业和工资产生焦虑;
毕业后搬砖之余,开始产生了迷茫之感,不知道是为了什么而“活着”。
以我个人之见解,
之所以焦虑,是能力及不上欲望。
之所以迷茫,是不满足于一成不变的状态、缺乏成长和进步的目标;
要解决焦虑,答案很简单,需要**提高能力,**1增加知识储备,多获取信息,多思考;2丰富实际体验和经验,大胆试错。
要解决迷茫,则需要探寻目标,需要进一步探究。
《心流》中说,在传统社会中,帝王、主教、政治等社会权威,给大众提供的人生目标是:宗教、道德、阶级习俗、爱国主义;
在现代社会中,以商人为代表的资本阶级,给大众提供的人生目标是:工作、用工作赚来的钱_消费_。
他们设置这些目标的动机,都是为了维护社会秩序,为了维护统治者和既得利益者自身的长久利益。
简而言之,提供目标的人都有其主观偏好和私利。
因此我们要从社会制约与本能冲动下,建立自我意识,不再以社会的奖赏为念,试着以自己所能控制的奖赏取而代之,自寻目标。
那么问题就变成了,如何探寻以自我为出发点的目标。
《心流》中提出,一个人身上真正有价值的,就是个人的体验。
我们的人生,就是由体验所组成的。
我们拥有很多体验来源:
因此,以自我为出发点,我们可以将人生的终极目标定为提高自己的人生体验,然后自上而下拆解,从各个方面做出努力。
《极简主义》中提出了人生中最重要的五个方面:健康、人际关系、热情、成长、奉献。
这五个方面,可以看作”提高人生体验”的一种拆解形式。
2025-07-22 08:00:00
《暗时间》豆瓣链接: https://book.douban.com/subject/35858123/

"暗时间"指的是生活中的碎片时间,作者刘未鹏通过这一概念,阐述了如何运用思维方式高效利用这些暗时间,从而强调了思维在个人成长和学习中的核心重要性。
2024-09-19 08:00:00
对于SPA,将更新DOM的方法updateDomTrigger作为参数传递给document.startViewTransition(updateDomTrigger)方法,浏览器会先截取当前页面DOM元素的快照(声明了 view-transition-name CSS属性的DOM元素,默认是:root),再执行updateDomTrigger方法,然后再执行过渡动效。
对于MPA,添加以下CSS规则,过渡效果会在导航到下一个同源页面的时候自动触发。
@view-transition {
navigaion: auto;
}
旧视图快照opacity从1 到 0,新视图快照opacity从0 到 1。
HTML会针对视图动效生成以下伪元素树:
::view-transition
└─ ::view-transition-group(root)
└─ ::view-transition-image-pair(root)
├─ ::view-transition-old(root)
└─ ::view-transition-new(root)
view-transition-name CSS属性,对不同的元素使用不同的自定义动效。因此,每一个 view-transition-name都对应一个view-transition-group(默认是root)view-transition-old指向动效前元素的静态快照view-transition-new指向动效后元素的实时快照具体的动画效果由CSS animation设置:
/* 只需要添加以下@view-transition规则,就会在切换页面时,触发默认的“淡化”动效 */
@view-transition {
navigation: auto;
}
/* 自定义默认的动画行为 */
::view-transition-group(root) {
animation-duration: 0.5s;
}
/* 创建自定义动画 */
@keyframes move-out {
from {
transform: translateY(0%);
}
to {
transform: translateY(-100%);
}
}
@keyframes move-in {
from {
transform: translateY(100%);
}
to {
transform: translateY(0%);
}
}
/* 将自定义动画应用到新旧元素 */
::view-transition-old(root) {
animation: 0.4s ease-in both move-out;
}
::view-transition-new(root) {
animation: 0.4s ease-in both move-in;
}
对于SPA,document.startViewTransition() 方法会返回一个 ViewTransition 对象实例,这个实例包含多个 promise:
ViewTransition.ready 在创建伪元素树且动画即将开始时执行。ViewTransition.finished 在动画完成后、且新的页面视图对用户可见且具有交互性时执行。对于MPA:
pageswap 事件,事件的event对象上的PageSwapEvent.viewTransition 属性包含了 ViewTransition 实例, PageSwapEvent.activation 包含当前切换页面的导航类型、当前文档和目标文档历史记录。pagereveal 事件,事件的event对象上的PageSwapEvent.viewTransition 属性包含了 ViewTransition 实例。pagereveal 事件的script脚本在渲染动效之前执行,需要给脚本添加 blocking=“render” 属性;<link rel="expect" href="#lead-content" blocking="render" />,其中#lead-content指向对应元素。
2024-09-04 08:00:00
通过z-index来控制层级是很常见的前端需求,
但是你是否遇到过,无论z-index设置多大,仍然无法将一个元素移到最上层的情况?
这是因为z-index依赖于一个抽象的概念:Stacking Context
stacking context是层叠上下文,决定了DOM元素上下层级关系
每个层叠上下文都由一个元素创建,这个元素被称为stacking context的根元素
z-index不是默认值auto的元素(z-index=0也会创建层叠上下文)isolation: isolate;:创建一个新的堆叠上下文,隔离混合效果DOM结构:
div1
div2
div3
-> div4
-> div5
-> div6
最终的层级顺序:


这个扩展在浏览器devtools中列出了网页上的stacking context。在遇到z-index和层级问题时,可以让我们更快的定位问题。