2025-09-28 17:54:18
看了一下 next.js ,感覺只是將原本 react 提供的 js 檔案先轉成 html 再輸出,還是獨立伺服器處理,不像 express-handlebars 可以跟 node.js 整合在一台伺服器內 [MozTW]
我不太喜歡把 Next.js 的渲染模式歸結成任何形式 (SSR or CSR or SSG),但想和你分享一下為什麼 Next.js 不是另一個 express-handlebars,以及 Next.js 團隊到底在渲染下做了多少事情。
express-handlebars 通常是純粹的 SSR,不考慮你在頁面中插入的 JavaScript,handlebars 不用往產物增加 JavaScript 恢復互動元素(也就是 Hydration)。
Hydration 是指 React 接管由伺服器產生的靜態 HTML、並為其附加事件監聽器與狀態,使其從無生命的骨架變成可互動應用的關鍵步驟。
純粹的 React,就以搭配 Vite 來說的話,是 CSR。因為背後不用有配合的伺服器,放在可以 host 靜態網站的 web server 上就可以(比如 NGINX、Caddy 這種)。
接下來回頭看 Next.js。如果只看 Pages Router,會相對簡單一點,可以分成 SSG、ISR、SSR、CSR 的部分:
如果頁面不用在伺服器端請求資訊,而且要產生的頁面是可以在編譯期推斷出來的,Next.js 會在編譯期 (build time) 產生好 HTML,使用者瀏覽時就會直接回傳,這叫 SSG (Static Site Generation)1。
2025-09-21 13:39:02
執行逾時了,Vercel 的免費方案 只給你 60 秒回應。假如你的 /upload 等待回應的時間超過 60 秒,那就會被 Vercel 殺掉哦。
有三種解法:
如果不想花錢,就想辦法把任務放到背景,如圖一。不過我翻了一下 Vercel 的文件,它沒給你機會建立一個超過 60 秒的任務,所以你大概得在 Cloudflare Workers 用 JavaScript 重寫你 Gemini 等待回應那段邏輯,用 waitUntil 把任務移到背景執行,接著將回應寫進資料庫,你的前端再不停呼叫 response 等回應。注意 Cloudflare Workers 的免費方案有 100,000 次的觸發限制,而一輪會至少觸發 2 次。
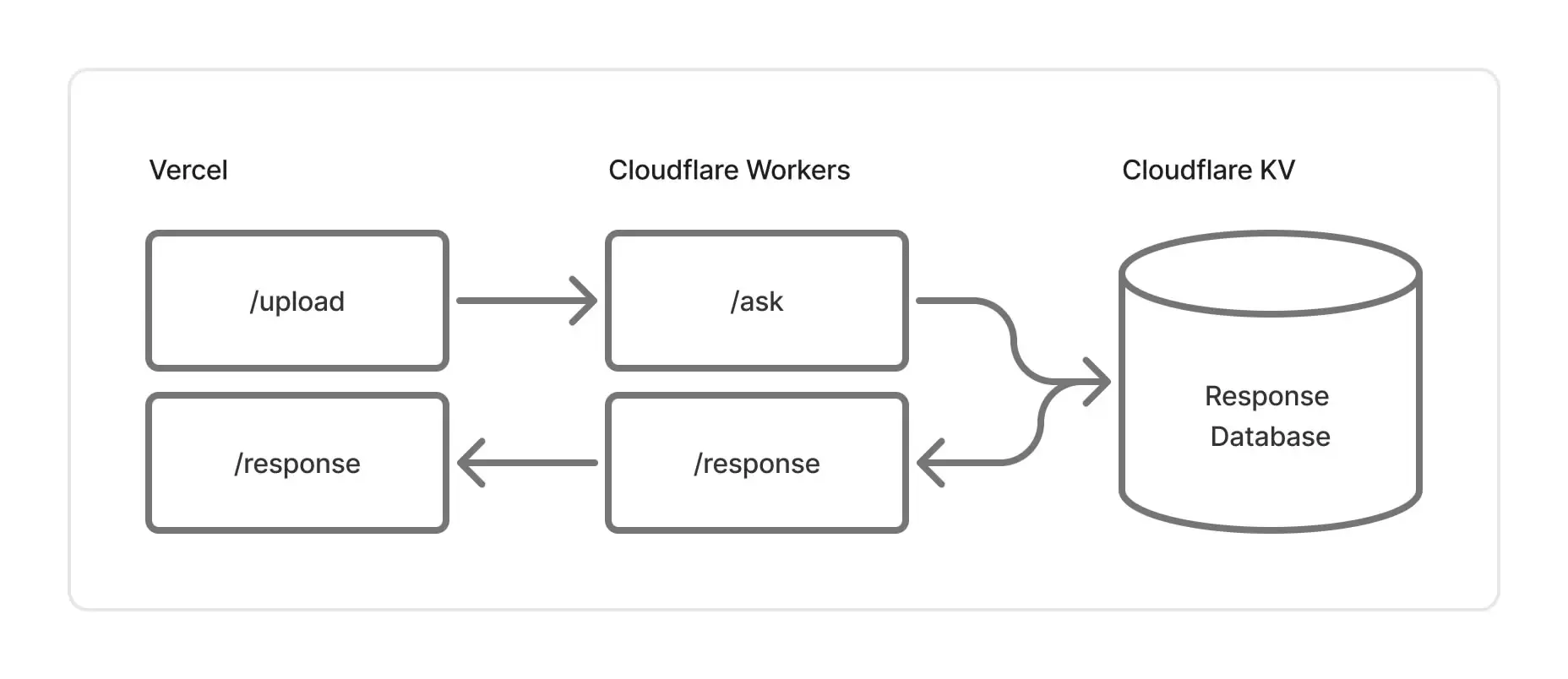
升級到 20 美元的 Vercel Pro,他會慷慨的多給你 12 分鐘回應。
試試看 5 美元的 Zeabur,不限制回應時間,你想處理多久就處理多久。
2025-09-21 13:33:35
今天吃飯聽到隔壁桌剛好在討論 vibe coding,然後就在講『跟 AI 說要建立「資料夾」但沒想到 AI 竟然說「目錄」???目錄不是支語嗎?』
嚇到我了,我以前也講目錄欸,目錄真的是支語嗎?當然後來都說是資料夾了 🤔
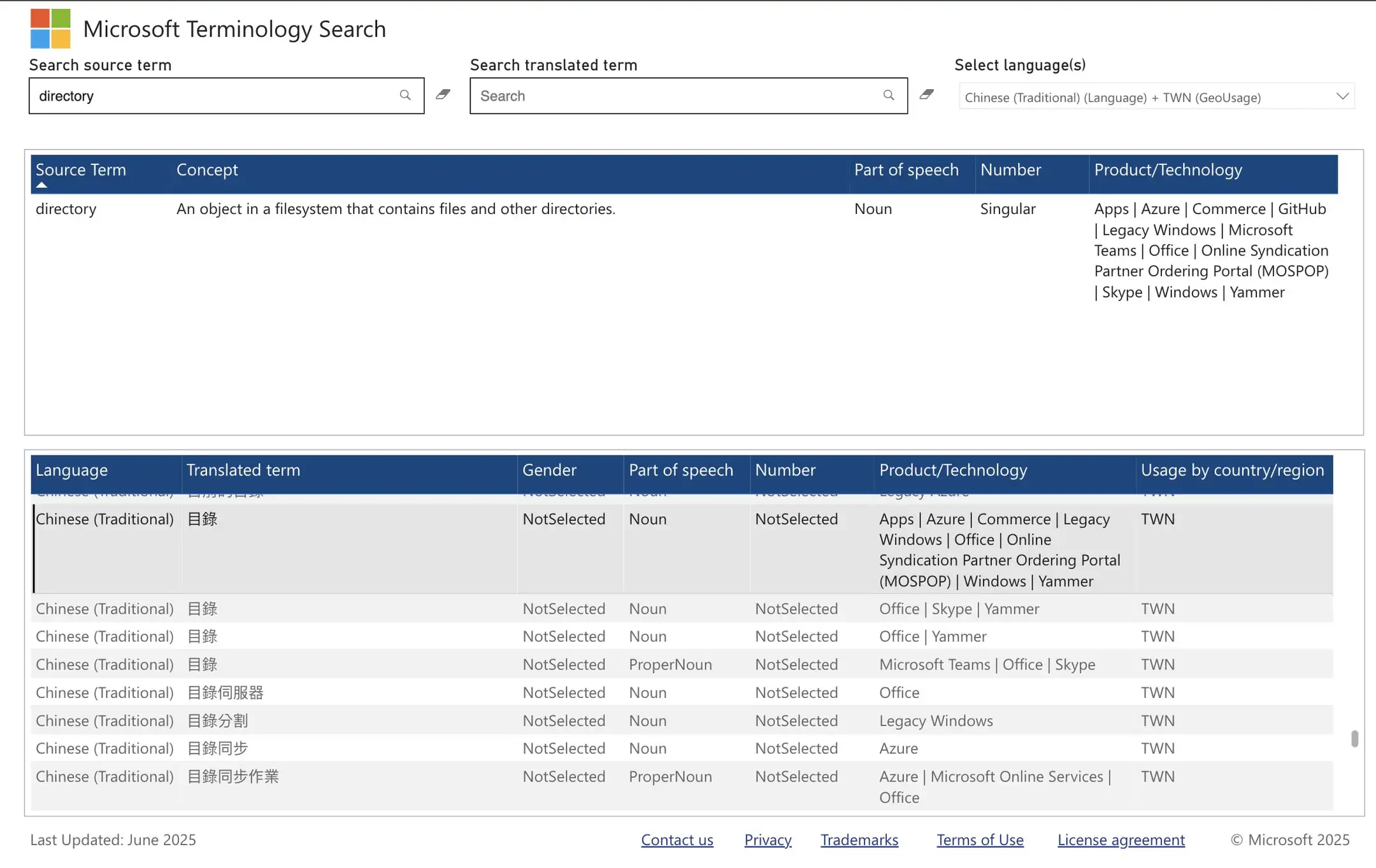
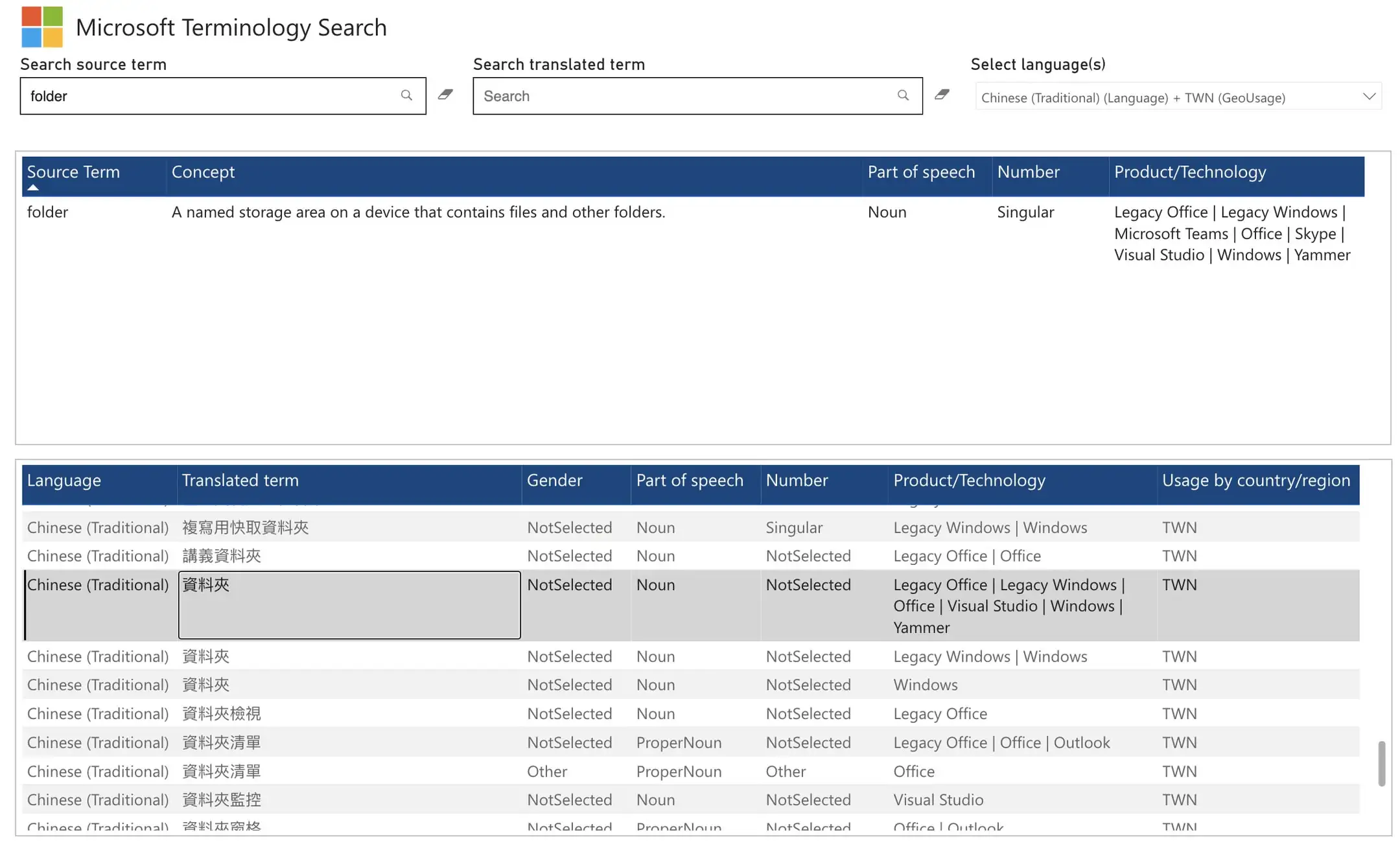
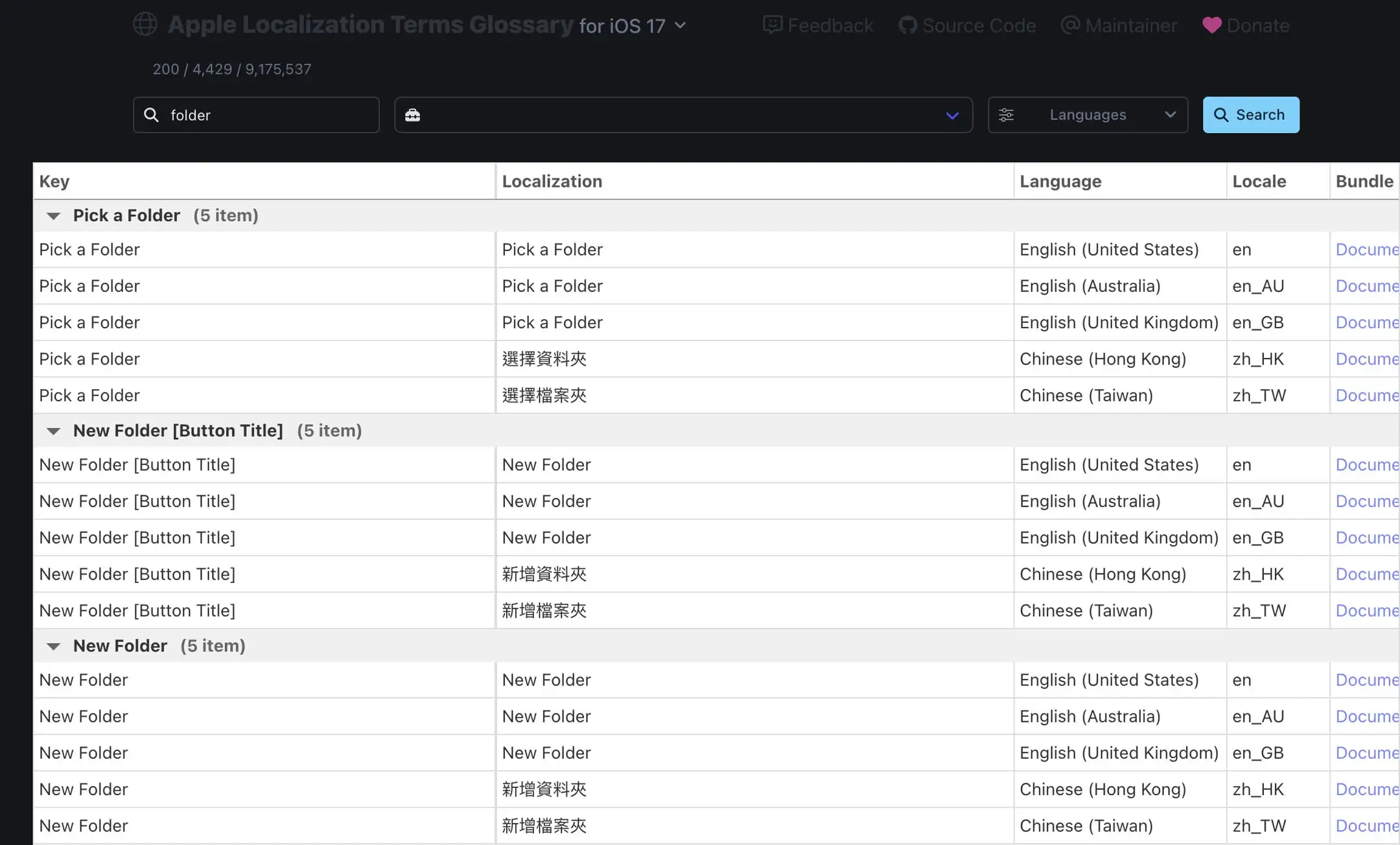
folder(面向使用者的用詞)和 directory(檔案系統概念)的不同。無論是「資料夾」還是「目錄」,這兩個都是老資訊用詞了,都不是支語 ⚠️
btw folder 在 macOS 上會翻譯成檔案夾,雖然和微軟系的「資料夾」差得有點多,但這真的不是支語 ⚠️⚠️
補上 Apple、Microsoft 和 GNU coreutils 對 folder / directory 的詞彙表。GNU coreutils 基本上就是常見 Linux 發行版內建指令列工具對應的翻譯。
其他公司和軟體的對應翻譯也可以自己找,但不要把不認識的詞當成支語 QQ
2025-09-21 13:30:40
我有看過一種做法是 api 直接在 server side 直接吐完整包列表資料,前端在自己做 pagination, 我不知道這樣做跟 api 做 pagination 比有沒有優勢
原則上,如果抓資料的開銷和筆數有關,我會設計 API 層級的分頁:API 比較不需要讓資料庫查太多東西 (SELECT all) 而造成資料庫壓力,也不會一次下載太多沒必要的資料回來。
如果資料量沒這麼大(比如一些 Tags),我會讓 client 分頁,純粹只是為了改善前端體驗。如果資料量大一點(比如 1K),我就會傾向在 API 設計基礎的分頁功能(即便對後端來說,取多少筆資料都不會影響速度),來減少需要回傳的內容。
By the way 後端分頁也有他的學問,傳統的 offset-based pagination 在資料筆數非常大的情況下,可能會有效能問題。可以看看比如 Cursor-based pagination 的知識,或許對以後設計超大資料的分頁 API 會有幫助。
2025-09-21 13:20:47
renderList ……?討論串很多人針對這篇評論給出很多不同建議了,我想給幾個我還沒看到的 point。
關於「元件最佳化」這點:React 背後有 Virtual DOM,所以你 render 100K 遍一樣的 list,相同 key、相同內容的 element 是不會在實體 DOM 層被重建的;useMemo 如果 list 的內容會一直變動,反而可能會造成 memory leak。如果是新專案,我通常推薦不手寫 useMemo/useCallback/memo 等等的記憶函式,直接讓 React Compiler 分析哪些東西該被 memorized。
既然 React 不會一直重建那 100K 個 DOM 元素,那為什麼在非常大的 list 下還是會卡?因為瀏覽器不擅長處理過多 DOM 元素。這種情況下應該要用 Virtual List 來只 render 可見元素,壞消息是他有 trade off——無法選取超出 viewport 的內容、瀏覽器內建搜尋不能搜尋全文。所以就算 GitHub 那種程式碼 view 很適合 Virtual List,但實際上都沒有實作。
2025-09-21 13:12:21
如果伺服器傳送
Etag: 1233,過了 CDN Client 收到Etag: W/"1233"那麼 Client 回送
If-Match應該傳送W/"1233"還是1233?
If-Match 的用意是在於防止「更新遺失」或「中途編輯衝突」(mid-air edit collision)。它的核心用途是在執行條件式請求時,確保用戶端操作的資源版本與伺服器上的目前版本完全一致1。
如果 CDN 傳送 Etag: W/"1233"(weak validator),因為 If-Match 標頭要求使用強比較函式1(即 E/1 ≠ E/12),因此用戶端無法使用這個值來建立 If-Match 條件式請求1。因此,如果伺服器傳送的是 Etag: W/"1233",則不應該在 If-Match 中傳送任何值來進行條件式更新。
如果要做快取的話,直接記錄 ETag,日後用 If-None-Match header 讓伺服器比較版本就行3。通常來說 If-Match 都是防止狀態改變的方法(POST 這些)1,CDN 通常不會去快取 POST 這類主要做 mutation 的方法,也就沒必要把 ETag 改成 weak representation,也就不太會遇到這個問題。
RFC 7232 – Hypertext Transfer Protocol (HTTP/1.1): Conditional Requests – If-Match: https://datatracker.ietf.org/doc/html/rfc7232#autoid-15 ↩︎ ↩︎ ↩︎ ↩︎
RFC 7232 – Hypertext Transfer Protocol (HTTP/1.1): Conditional Requests – ETag Comparsion: https://datatracker.ietf.org/doc/html/rfc7232#autoid-11 ↩︎