2026-07-01 23:04:50
本文是付费文章系列「破局之路」的第 39 篇正式文章,主要讲述以下内容——
我是个典型的、能深刻理解现实的理想主义者,过去也说过自己是务实的理想主义者,但如今回看,直到真正开始接单做软件外包之前,我都还不够务实。
某种角度说,务实就是要谈钱、得跟钱挂钩。
「失业」三年多,我试过自媒体、摆摊、前端兼职、Web3 远程、线上线下社区,最终决定重拾软件工程师老本行,并接下软件外包项目。
我这些年折腾、想做的事并未放弃,只是稍微调整了下优先级——先让自己吃饱饭,才有余力谈理想;这既是对现实的低头,也是为理想蓄力的清醒选择。
本文的完整内容发布在语雀、小报童和微信公众号上,打包进专栏/合集中买断制出售;关于价格、大致内容范围以及适合人群等,请见该文章系列的介绍页。
2026-05-29 17:16:31
最近,可逆计算理论与 Nop 平台的作者 canonical 又开始活跃起来,带来了新的实践理论——吸引子引导工程(Attractor-Guided Engineering),简称「AGE」。
从群里人讨论的内容来看,我感觉这跟我最近一段时间在 AI×OPC 这方面的探索实践颇为相似。
于是昨天下午花了两个来小时,看完了 canonical 在一个线上分享会的录屏视频:
虽说程序员算是最先用上 AI 且有比较大依赖的一群人,但从我观察的情况来看,很多人在「如何更好地与 AI 协作」这件事上做得很有问题,我列几个常见的——
首当其冲的,就是代码 review——在把 AI coding agent 当作队友,绝大部分代码都是由它生成时,还需要人去对代码进行 review 吗?如果需要,怎么 review?
有的人要么有代码洁癖,要么是没那么信任 AI,反正无论是什么原因,结果就是在精神上强迫自己去 review 那些由 AI 生成的代码。
在 AI 没大量参与开发的传统方式中,由于每个代码模块几乎是人写出来的,代码库所承载的知识量可认为是 <= 人的认知的。
然而,在 AI 深度参与的现代方式中,代码生成的速度和规模远超人脑的阅读理解速度,即便是天才,人的认知水平也无法跟上。
这时,人已经成为项目迭代的效率瓶颈,再投入大量时间精力去 review 代码是件极其不现实的做法与执念。
其次,我看好多人倾向于有点什么碎片化的想法就直接去找 AI 聊了,很享受跟 AI 对话的过程,即使有可能去使用 SDD,或一个话题结束后会有个总结文档,这依然不行。
对于很多人来说,虽然软件研发的方式表面上改变了,但他们实际上还是老方式——只是把对话的对象从人变成了 AI 而已,在知识沉淀这方面没什么变化。
这是因为他们的认知没有转变为「知识驱动」,所以就算是用了 AI,仍然有大量未显性化的隐性知识淹没在与 AI 的对话中,随着 session 的清空而消失。
那些隐性知识极可能隐藏着会产生价值的关键信息,但由于没有留存下来,无论是人类还是 AI 的后来者都无法知晓——重要信息缺失,上下文断档。
举个可能会有些画面感的例子——
你在用内置全球顶尖模型的 Claude 或 Codex 开发自己的软件项目,这个过程中它们的「聪明」带给你很爽的体验,你的项目取得了很好进展。
然而某天起,它们把你的账号封了,就算自己想办法换了账号继续用起来,但你感到了实现效果与之前有差异,没有保持一致性。
还可能更悲剧的是,再也用不了那些顶尖模型而只能用国产模型,使用体验和产出物效果大相径庭……
你没法保障项目产出的一致性,因为你没把那些决定一致性的隐性知识尽可能显性化留存下来,换了账号或模型的 AI 不知道之前的偏好、准则之类。
来自 canonical 的 AGE 可以解决上文提到问题,但我无意在此复述讲解,感兴趣的话可以看下开篇嵌入的视频或读原作者的几篇文章:
这里我只拎出触动最深、跟我自己折腾的那摊事撞得最响的几个点来说说。
第一,它的核心是一句话:AI 大规模开发,本质上是一个动力系统的受控收敛问题。
AI 展开状态空间的速度极快,所以关键不是到处加护栏,而是先想清楚系统长期应该被拉回到什么结构。
这个「反复把系统拉回去」的稳定结构叫做「吸引子」,而计划、测试、审计、日志这些则是让「轨迹」贴近吸引子的控制机制,排在吸引子后面。
一句「吸引子先于控制(Attractor Before Harness)」,就是整套东西的骨。
就如同对小孩的教育,不是只简单地在他做错事时教导或惩罚,更该做的是要先告诉他应做一个什么样的人,在他心里树立道德标尺,以此为轴心会有不该违背的底线。
第二,吸引子不是代码、也不是某份具体文档,而是由少量高阶约束隐式定义出来的结构——局部实现怎么变都行,整体会被拉回同一类形态。
在他那个仓库里,承载吸引子的是 docs/architecture/ 下带 precedence 的架构文档。
第三,也是最戳我的一点——
哪怕 spec 更新了、tasks 勾了、活儿看着干完了,人和 AI 都会获得一种强烈的「完成感」;但系统是否真的更接近长期结构,不是这次变更本身能证明的,得回到 live repo、测试和独立审计里去看。
说白了,「做了什么」和「做到什么程度才算真落地」是两码事,所以生成和验收必须分开,别让同一个上下文既当运动员又当裁判。
还有一条要点,正对应我上面提到的其中一个问题——文件进,文件出。
输入别只留在聊天窗口,先落成文件再喂给 AI;输出也别打印完就结束了,结论、计划、记录等都按职责写进 docs/。
聊天是临时上下文,文件才是仓库记忆。
在一个软件项目中应用 AGE,就跟经营一家公司差不多是一回事。
每个有可能长久活下去的公司,不是靠拍脑袋制定一些规章制度就行了,规章制度应该是服务于更高层次、更抽象的事物——使命、愿景、价值观。
公司的使命、愿景、价值观、战略规划、规章制度等,这些构成了公司这个系统的吸引子,引导朝着「它该有的样子」发展下去。
在实际经营并推进业务时,用人文层面的共识、权力等和 OKR、KPI 类指标性测量工具,作为控制机制去促进系统运行。
过程中会产生数据、文档等中间产物,它们记录着公司当时的状态,共同构成了轨迹。
若说 AGE 是从科学视角切入的,那我则是以人文角度开启实践的,这与 Sophye 的诞生密不可分。
「Sophye」是我在 OurAI Labs 下做的一个项目,名字取自代表「智慧」的「Sophia」或「Sophie」的变体。
它要解决的事,简单说就是「让 AI 更有人味儿」——
用 QiiDB 数据规范去定义一个「智慧体」,也就是用知识管理的方式去做详尽的人物画像,并记录其详细生平;我们写下的想法、文章、笔记,都是其中的一部分。
会有如此想法,源于我认为 AI 是一等公民,真的该把 AI 当成人来看待,再加上我多年以来一直很注重数字身份、虚拟人格这类问题。
为达到「让 AI 更有人味儿」这个目标,会涉及到 Sophye 的以下几个概念:
最后的「虚拟人格」算是最重要的概念了,可应用于下列场景:
第三个也许会有点难理解,简单来说就是把家庭、团队、组织等一些事务的准则、流程之类全部写出来,用 Sophye 去将这些东西封装起来,变成一个虚拟的人格。
就好比一家公司有自己的吉祥物,它有自己的视觉形象,而用 Sophye 封装好的虚拟人格就是它的「灵魂」,使它能体现出自己的做事方式等「个性」。
如此一来,搭载 Sophye 的 AI 工具就不再是个「工具」,而是一个具有现实意义的队友、伙伴、伴侣甚至是宠物,是个有温度的真正「硅基生物」。
有情怀的程序员在开发一个软件项目时,总会把它当成自己的孩子而投入感情。
某天我用 Trae 开发自己的软件项目时,就在想:要是把一个软件项目看作一个人,那么每次项目代码的变更,是不就是在积累他自己的经验,成为他自己的成长经历呢?
也就是说,一个软件项目当前的样子、当前的状态,就像一个人有了种种经历叠加之后所形成的「自我」。
这每一次代码变更,就相当于一个研发任务的积累。
如果把每个任务从需求是什么、如何实现需求的计划、拆解出的具体 todo list,到任务过程中的中间产物,再到任务完成后的报告总结都留存下来,是不就相对完整地记录下了这个项目是怎么「成长」的、状态是如何变化迁移的呢?
这样一来,哪怕一个软件项目的开始并没有完善的设计,而只是借由灵光一现的 vibe coding,那也完全可以让 AI 基于现有的代码与任务历史产物,去推导出这个「人」是怎样的,或者说这个项目到底是个什么东西。
在拟人化看待软件项目时,我一度打算就把那些任务记录留在与其相关的项目仓库这个「知识空间」里;但在开始搭建一人公司的数字员工团队后,我的想法变了。
之前的想法,是一种管中窥豹、盲人摸象的局部思维。
我的团队不只一个软件项目,它们打包起来看,不过是某个职责为「软件工程师」的数字员工的交付物而已,跟让另一个数字员工交付的文章没啥本质区别。
这些软件项目的存在都是为了实现我一人公司的战略目标,它们应该受到统一的控制;如果任务记录分散在各个项目仓库里,这会增加数字员工团队的协作与管理成本。
于是我把那些任务记录都转移到了数字员工团队专属的 Markdown 文档仓库中,结合 QiiDB 数据规范与 Tiago Forte 的 PARA 框架设计了文档仓库的目录结构与知识流:
agent-team/
├── spaces/
│ ├── team/ # 团队工作区
│ │ ├── areas/ # Areas:无截止日期的战略/规划/长期事项
│ │ │ └── ...
│ │ ├── projects/ # Projects:有截止日期的可执行项目
│ │ │ └── ...
│ │ ├── tasks/ # 具体可执行任务
│ │ │ └── {YYYYMMDDHHMMSS}-{task-name}/
│ │ │ ├── artifacts/ # 中间产物:数据、脚本等
│ │ │ ├── basic.yml # 任务元数据
│ │ │ ├── requirement.md # 任务需求描述
│ │ │ ├── plan.md # 实施计划
│ │ │ ├── todos.md # 待办事项清单
│ │ │ └── report.md # 完成报告
│ │ ├── docs/ # 通用文档(模板、指南等)
│ │ └── ...
│ ├── {name}/ # 数字员工个人空间
│ │ └── ...
│ └── archived/ # Archive:已完成/不再维护的一切
│ ├── dailies/ # 成员日报归档
│ │ └── {year}/
│ │ └── {month}/
│ │ └── {date}/
│ │ └── {member-name}.md
│ ├── projects/ # 已完成项目归档
│ │ └── ...
│ └── tasks/ # 已完成任务归档
│ └── ...
└── ...知识流是单向流动、层层收口的:
老板想法 / 战略 / 规划
↓
team/areas/ ← 长期战略,无截止日期
↓(有明确截止日期时)
team/projects/ ← 有截止日期的项目
↓(拆解为可执行项)
team/tasks/ ← 具体任务,有 owner
↓(验收通过)
archived/ ← 已完成,归档在这过程中,主要遵守的理念原则有:
当任务由数字员工执行时,我只负责写需求文档描述清楚要达成什么目标以及最终验收交付物是否达标,做实施计划、拆解 todo list、写总结报告等事都由数字员工搞定。
如果是一个软件开发任务,我基本不会关注代码写得怎么样,只看实现效果有没有满足需求。
任务记录的留存地从某个软件项目中上升到数字员工团队协作文档仓库中,这不是简单的文件迁移,而是局部思维向全局思维的转变,也标志着知识空间的膨胀扩大。
虽然已经说了很多,但相信还是有身处迷雾中的感觉,下面我就更为具象地说明自己要折腾出个什么东西,它是:
第一点是第二点的前置条件——前者是我的全部数字资产,后者让前者产生价值并无限增值。
在这里,用 QiiDB 数据规范去存储知识,用 PARA 框架去框定知识的划分区域以产生流动势能,再让数字员工团队套用 CODE 框架驱动这知识飞轮转动起来。
我这「一人公司」和数字员工团队不是那网上乱吹的噱头,而是我贯彻执行「把人生当公司经营」的产物。
用经营公司的思维方式去管理人生,这是在构建自己庞大的系统,要想让它不失控,自然而然在做很多事时就整体走出了与 AGE 相同或相似的路线。
我的人生理想、人生事业、各个「五年规划」等,就是那「吸引子」。
2026-05-10 18:55:32
本文是付费文章系列「破局之路」的第 38 篇正式文章,主要讲述以下内容——
四月经历事业低谷,正反馈少,躺平看了两周动画;五一搭建数字员工团队,重新找到方向感。
这段经历让我形成一个信念:只要在「正确」的轨道上,每天前进一点,度过的时间就不算浪费。
问题不在于看了什么,而在于知不知道自己在做什么。
AI 时代,人的价值在于判断和决策,而非执行。
AI 可以帮你获取信息,但需要你判断什么对你有用;AI 可以帮你生成内容,但你的内容需要有你自己的思考和情感。
所以我现在定义自己是「管理者」,AI 是「执行者」;会用AI不重要,会当管理者才是关键。
本文的完整内容发布在语雀、小报童和微信公众号上,打包进专栏/合集中买断制出售;关于价格、大致内容范围以及适合人群等,请见该文章系列的介绍页。
2026-04-20 16:04:59
前不久,一件事在 AI 圈炸开了——一个叫「同事.skill」的开源项目,5 天内收割了 6600 颗 GitHub Star。
它干的事情很简单,也很离谱:把一个真实人类的聊天记录、工作文档、行为习惯,提炼成一个可以被 AI 调用的技能包——然后那个人就算离职了,他的「数字残影」还在。
随后,「前任.skill」出来了,「导师.skill」出来了,再然后是「女娲.skill」——一周 10k Star,只需要输入一个名人的名字,它会自动扒光他的著作、演讲、访谈、社交媒体,提炼出他的思维方式和决策模式,构建出一个可以对话的 AI 版乔布斯、马斯克、芒格……
网上有人调侃:「散是 Token,聚是 Skill。」
这波「蒸馏人类」热潮背后,其实有一个共同的动作:把一个真实的人——他的腔调、他的判断框架、他看问题的方式——提炼出来,封装成一个随时可以调用的 AI 技能模块。
不是让 AI 背他的语录,而是让 AI 学会用他的脑子思考。
看到这里,我想到的第一件事不是去蒸别人——而是:我能不能先把自己蒸了?
在说怎么蒸自己之前,先聊一个更基础的问题:你养的 AI agent,到底是什么性质的东西?
我把它粗分成两类。
比如数字员工、专家智囊团。
这类 agent 的名字不重要,干活要紧。你叫它「财务分析师」还是「agent_003」,对它来说没区别。它负责跑数据、写报告、查法律条文、做竞品分析——是你的隐形幕僚团,默默在后台撑着。
有名字、有性格、有自己的腔调。
名字非常重要,因为它本质上代表的是一个「人」,一个可以被受众感知的独立个体。你可以理解为 MCN 孵化达人的逻辑——每个 agent 都可以是一个超级个体,有自己的内容风格和受众认知,可以独立运营。
这两类不是对立关系。实际上,人格型 agent 的背后,往往需要工具型 agent 做支撑。前台有个人在说话,后台有一个团队在跑。
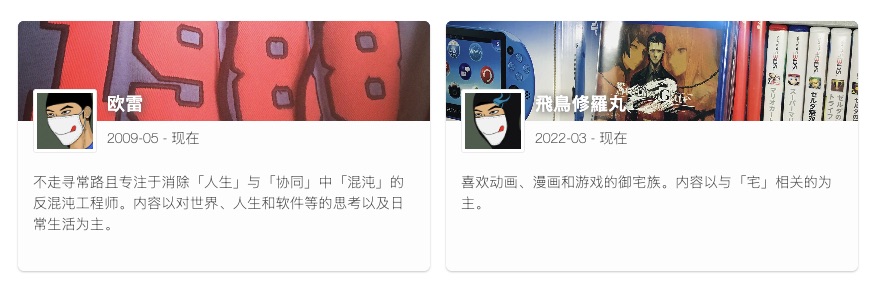
我要做的,就是把「飞鸟」这个人格,蒸馏出来。
「飞鸟」的全称是「飛鳥修羅丸」,是我的虚拟人格之一:
「人」实际上是由多个不同的「人格」组成的,每个人格有其独特的特征和行为模式。在网上使用不同的网名和独立站点做「物理切割」,目的是让具有特定特征匹配的人方便找到对应的人格,也让不同兴趣领域的内容更加聚焦和专业化。
「飞鸟」就是这样一个被切割出来的虚拟人格,专注于「宅文化」领域,是「修罗殿」站长,追番超二十年,看过上千部动画,玩过几百款游戏。
虽然文章写得少,但「时刻」的记录极其密集——从 2009 年到现在,每一次观看、每一句碎碎念都留在那里。文字风格轻松幽默,带着一股日系宅文化的气口,自成腔调。
这些东西,就是蒸馏的原料。
把飞鸟写过的文章、发过的碎碎念、评论过的动画短评,整理后喂给 AI,让它识别其中的规律:
AI 提炼出来的结果,不是一份「语气模仿指南」,而是一份人格特征描述:飞鸟看待世界的方式、他表达感受的习惯、他的价值判断倾向。
人格是基调,技能是手脚。配好人格只是第一步,还要给他装上对应的能力模块:
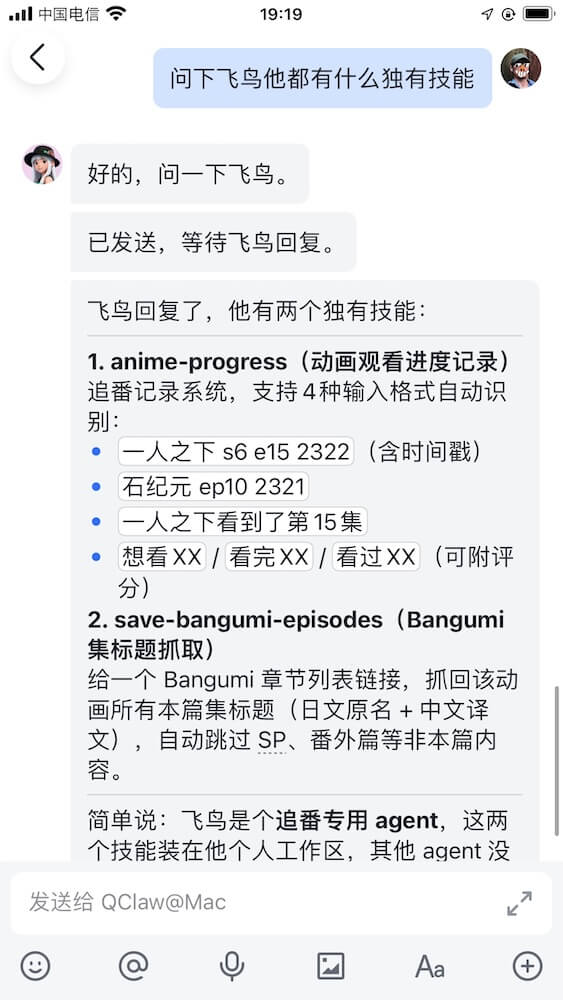
每个技能包都遵循飞鸟的人格基调——工具是通用的,人格赋予其独特的腔调。
这里要介绍一下 Sophye——OurAI Labs 正在推进的「人生数智化」工具,定位是「让 AI 更有人味儿的人格化封装层」。
Sophye 的核心概念分三层:
配置完成后,这个「飞鸟」就能以他自己的方式,独立回应问题、生产内容、运营账号。
有三个理由,层层递进。
我在做这个框架,最好的压力测试不是拿别人当小白鼠,而是先把自己放进去跑一遍。
飞鸟这个案例,是一次完整的端到端实验:从人格提炼,到框架配置,到实际运转,哪个环节有问题,在自己身上踩坑,比在用户那里踩要好得多。
当你有了多个人格型 agent,最理想的状态是什么?
是一个「主管 agent」,根据任务的性质自动判断:这件事该交给谁。追番交飞鸟,数据分析交分析师,法律问题交法务顾问……整个流程不需要人工介入,任务自己找到对的人去完成。
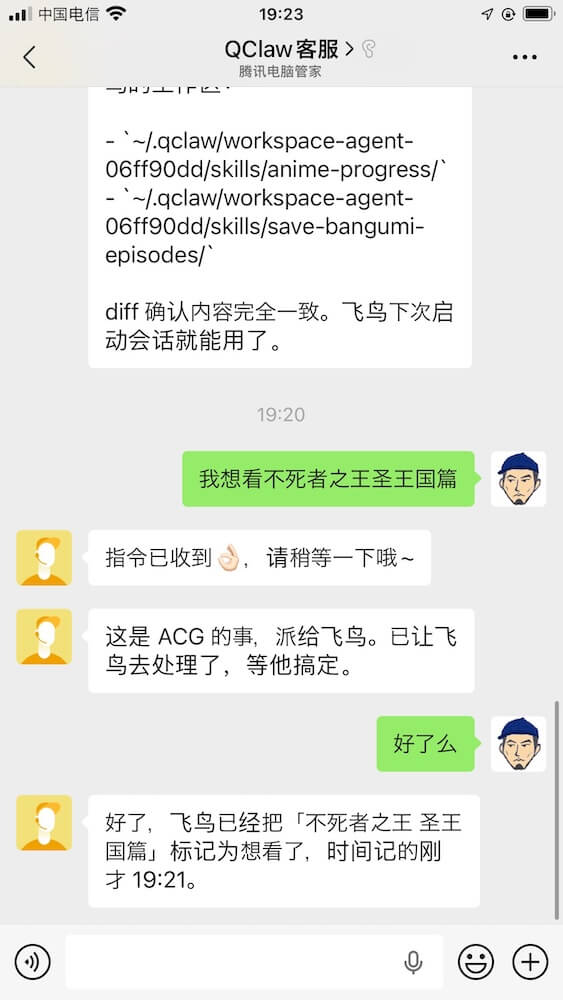
这是智能体经济的雏形:不是一个万能 AI 做所有事,而是一群有各自专长和人格定位的 agent 协作运转。
说直白一点——让 AI 帮你赚钱。
但这里的关键词是「人味儿」。冷冰冰的机器人发帖,受众一眼看穿,没有信任感,也没有持续关注的理由。而一个真正被你的人格渗透过的 AI,它产出的内容、它和粉丝互动的方式,是你风格的延伸,而不是你风格的替代品。
这才是长期可持续的路子。
回到开头那波「蒸馏人类」的热潮。
大多数人被蒸的时候是被动的——离职员工被公司蒸,名人被开发者蒸,前任被感情没走出来的人蒸。他们不知情,没有控制权,最终呈现出来的那个「数字分身」,是别人眼中的自己,而不是自己定义的自己。
主动蒸馏自己,是一件不同性质的事。
你决定什么该保留,什么该强化,什么不该有。你设定他说话的边界,他行动的范围,他与世界互动的方式。这个数字分身,是你向世界延伸的一条臂膀,而不是一个游离在外的、失控的镜像。
至于那些工具型 agent——专家智囊团、数字员工——他们是幕后的支撑系统,默默托举着台前的每一个人格。没有他们,人格型 agent 再有魅力,也只是个空壳。
两者协同,才是完整的图景。
飞鸟的蒸馏,只是第一步。
2026-04-04 14:38:52
本文是付费文章系列「破局之路」的第 37 篇正式文章,主要讲述以下内容——
三月我主要忙了俩事——
一是把搁置的家庭服务器从 v0.2 升级到 v0.5,靠 AI 工具搞定了网络、NAS 这些难题,虽然被说不务正业,但这其实和我的业务路线相关,目标 v1.0 还要做智能家居管理这些。
二是找了 3 个附近的人调研数据治理服务需求,为后续定价打磨方案做准备。
🦞破圈成了我的契机,我花 24 小时部署了 OpenClaw,还在银湖策划了名为「🦞聊」的 AI 普及活动,飞书的相关跟进也利好我的业务。
回想 2026 首季,发现计划跑偏了,之前铺的摊子太大,接下来会设中短期目标,边走边看,做事也更专注。
本文的完整内容发布在语雀、小报童和微信公众号上,打包进专栏/合集中买断制出售;关于价格、大致内容范围以及适合人群等,请见该文章系列的介绍页。
2026-03-02 18:15:08
本文是付费文章系列「破局之路」的第 36 篇正式文章,主要讲述以下内容——
春节这快两周时间,我基本没休息,全在忙活飞书知识库备份、数据清洗转 QiiDB,打磨数据架构和自动化流程。
我有 20 年「数字仓鼠症」,还按不同人格、组织等拆出多个数据空间,数据复杂到严重影响效率!
这些年我自研了 QiiDB、KnoSys 等一整套去中心化数据方案,打通飞书,把数据牢牢握在自己手里;这套方案是全局式解决问题,低成本又适配超级个体、小微团队和青年社区/组织。
我准备 3 月推出打通飞书的品牌版,靠 AI 做了策划、搭了官网,践行一场我 + AI 的创业实验。
AI 时代抹平了专业门槛,正是超级个体抢占生态位的好时机,跟上变化才能不被时代抛下!
本文的完整内容发布在语雀、小报童和微信公众号上,打包进专栏/合集中买断制出售;关于价格、大致内容范围以及适合人群等,请见该文章系列的介绍页。