2026-07-25 14:06:54
之前一直有个想法,在引用微博内容的时候能直接把微博帖子原样搬过来就好了,而不是截图,既无法提供链接回原文的地址,也不美观,不像推特提供一个地址可以直接生成嵌入式 HTML 代码,复制后贴到其他网站或论坛就是在直接浏览推特内容本身,比如说这一条推特,
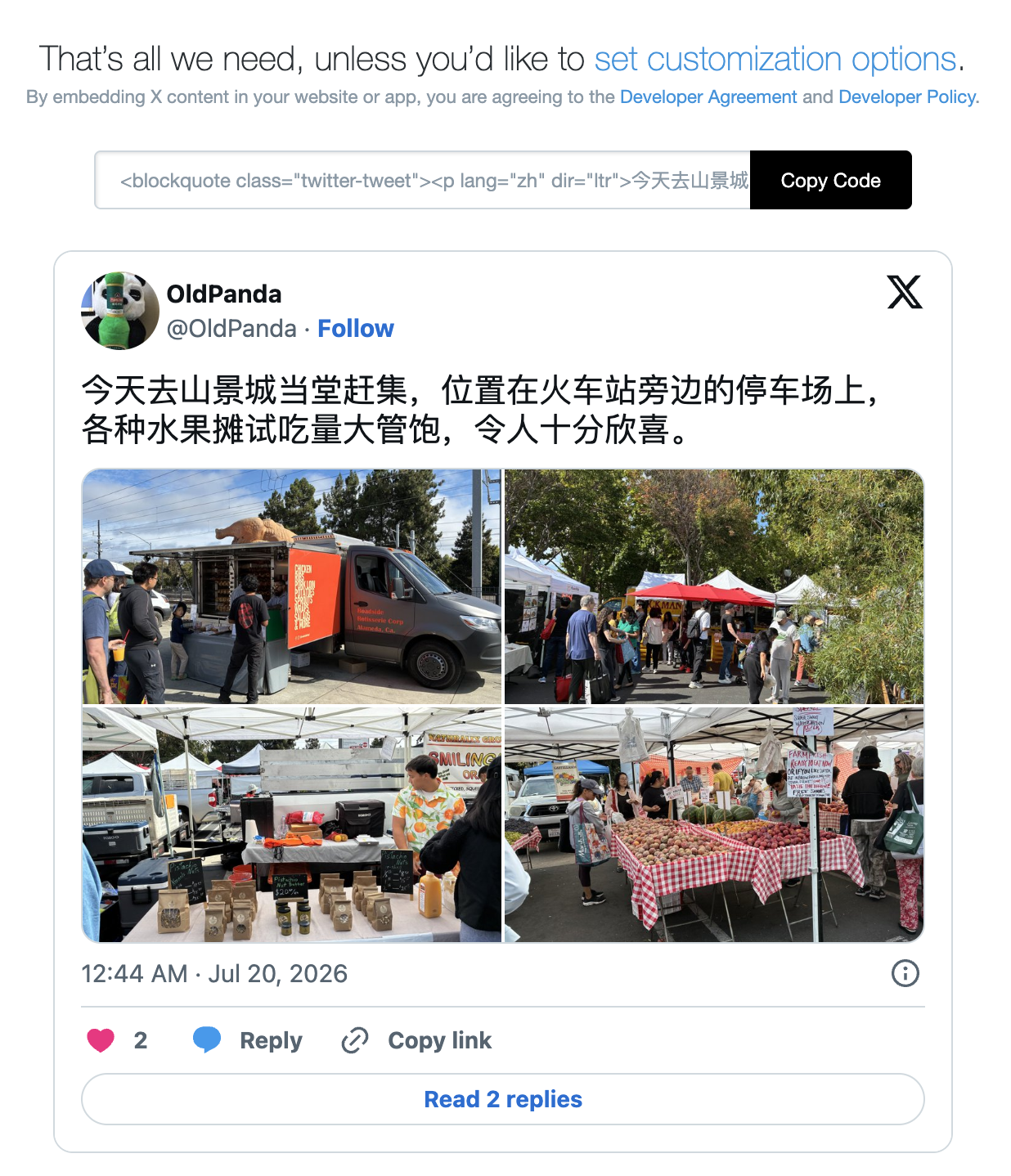
这样就可以轻松获得随处可用的 HTML 代码。
幸好在这个 AI 的时代,想法可以轻松变成现实,工具还没完全做完,但已经可以获得嵌入式代码了,现在把生成的结果贴上来看看样子。
<article class="wb-card" lang="zh-CN"> <header class="wb-head"> <a href="https://www.weibo.com/1199303274/R9yE5wVH8" target="_blank" rel="noopener noreferrer" class="wb-avatar-link"> <img class="wb-avatar" src="data:image/jpeg;base64,/9j/4AAQSkZJRgABAQAAAQABAAD/2wBDAAcFBQYFBAcGBgYIBwcICxILCwoKCxYPEA0SGhYbGhkWGRgcICgiHB4mHhgZIzAkJiorLS4tGyIyNTEsNSgsLSz/2wBDAQcICAsJCxULCxUsHRkdLCwsLCwsLCwsLCwsLCwsLCwsLCwsLCwsLCwsLCwsLCwsLCwsLCwsLCwsLCwsLCwsLCz/wAARCAKsAqwDASIAAhEBAxEB/8QAHAAAAgIDAQEAAAAAAAAAAAAAAgMBBAAFBgcI/8QAURAAAQMCBAUBBQUDCAgFAwIHAQACAwQRBRIhMQYTIkFRYQcUMnGBI0KRobEVUsEIM2JjcpLR4RYkNENTc4LwFyUnNfEmNqIYVTdEVIOTwuL/xAAbAQADAQEBAQEAAAAAAAAAAAAAAQIDBAUGB//EADIRAQEAAgEEAQIFAwMDBQAAAAABAhEDBBIhMUEFURMUIjIzFWFxBiNCUoGxJENikaH/2gAMAwEAAhEDEQA/AHrNlNrKPVfbPnA91B1ddTvqpSBZCgord1DlJllQiKiyQCdd0rKAnH1SykAEdV16D7KCf2lVfJefEFeg+yj/AN0qv7AXF1n8NdnS/vj1pfIXt209pc3/ACW/qV9er5D9vIt7SpPWEfqV829WvN4786O3kfqvsngucHhOhGX/AHY/RfGsRtUR/wBsfqvsXhEiHg2kka29owfnomHQyTiJpcXbLkeKOKoIYXimlbI9o1s4H6LjeN/aCYZAaVzs7CWPZm2+YXlOLcWT1kkhDGi53GhRrYtHxdj37QxKR0TXRk7jYj0suRlnkdo9ymqkM0z39zqqbpLqpNEOSTsUouUPdcW8ILoBgkKC6j7yjugDDijDtLFyV95TskG5wPHqvBq9lRTyuYQRovbeGfaszErw1D+W+4JvppbsvnsKxT1EkD8zH2PooymzlfZFHicVbTMMTrlwvZdBRYU1rGST/FvkXnfsMw2uqOG/21ibr5zkphmv0juV6nNUxsNnPaD6rzeq5uyai5l9x6BthoozBc7iHFlNRzCNruZ5IWlk44eZ9coj9F49xzz8yOHl+qdPxXtyy8u4dK1updskvrIxoHLz5/EVS6R/W6zrqpJjTpGAsfcj9Fl+Xzrk/rnD9nosuJRtNi63qq0mKMDfiXnU2NTc0Mc54JVafHDJC77eQMG5Db/RL8pnflX9e4Z6j0eTFI9LvslSYvFtmuvO6XFJvdy/qkLtrusjbiNS55D3NZIPuDU/VV+Sy+68f9Q8Xjw7s4pCGkud3+arHGoM7wHtyW7riZMVqZYi2LKwA2L36XKqyYuJJHQZm3eNOk3/AMlc6LL5qr/qDit1MXZ1PEtNCD1tLDt1WSBxZSSygBzdBbTsuLnoqaqkyySyR3A0zX+dkibDqdji+klleYyA++lgVc6XLXtp/WeLu1I9LpMdgk/3+vhFVRQzXlg0O5C4CKWOkkP28kwGhIbsVvMJxZ5i5me7Abda04u/hy8+nZh13Dzeq27fITLgBXKSjGIQh9PudcitDh+pLLljl7WGNyndG3fj92q3RNACvtwOue+wictvQ4Dlozz29ZOyvHju/JXORzfMA+6pYS52q6L/AEcYBme5UqrB3x3MOvorvDlrcL8TFqXEX0U9WVHJSvhdZ7bFQBc6rGyzxWm9pbfKos66IHwpdJZqAC3UmFvdDGenMVgzOfc7BAZZse26IR31KgtMj7bBHI/IzK1MAcBawRtadD2S44y5/UmuFmoCMxzWTC4AWVR1RFG+z3tBWNqo5JMrXXQRkgvsoALdVEkzc+Vu6x0zImdbm38Jg0TMiiLj8SVHmmfc7KPszd8jm5AsFQzOWNc0BAOzAvNkkEy1HgBJgq2yMe4OboSPwTKWQTgvDtBomSzLKG7a2SzITqhcC54aFjjldlLkAXQGF8jr+iAAysLW9DEwBmW7moMznX7BADDCcpd2USF8z8vwgJnNdFCXbgIG5yzmPyi+wTBojia1rHOTJKhrbNbuq4h0zuco2dcoB0k7G2bm1KWOXI+w+SrR0r56nPn0VnltgfYalAWehgsOySKqN0mUa91TqnTTWgi0MhsSnx0radoGa5GhTC1d0jiS7RVzTRteXl34opqlkLAC7U9lXcec74XEICxJM0Uoja3fuq1uwcrLYHOYZHtswdkqGB0n2j9BfQICw0hrQOwQmbXpZohdmL+nbwmCAW6naph5sVCkqLL7t8sEqEZChKgsoUwhBZTTQQlm6aQgKQAQhI7oyhKVMorv/ZP/AO6VI/oLgTqu89k4tjFT/YXF1n8NdfTfyR66vkT29/8A8SH3/wCCP1K+u18j+30f+pBv/wAEfqV85Hq15jHpMz5hfXmAVjIOAaXM1xbygNPkvkRtzMy3YhfT8VXJB7NYHCKTO2IG3kWQK8Z46mk/a8jh0kk6+QuIfKcxJ3XQcUVUk1Y92Z3LJJDC65F1zbpArJJk6bndViVj3ElB2SDDdSVigoDL9gsNs2igeilIJzFYFikIDAt5wxgFTxBjENHFE8xl45sgbfID3KDhrh+q4jxVlHStbm3eX/CB62XuvDXDVJwnhppoMpqZbGWbz6D0WHLyTCf3eb13XY9Ph/d11PjbcCoafC8PY2OmpYxG0DY+T81qajFKmaozOlc9Vah2xc7ZVeeA97furybN3dfF8/X8vLf1ZLFRL1iRzlQkALzle3XVOlld8Ttu11SmlI+0yxyHsAnI4MsrldnGrkGS+4uNO6GWR+UWlbqbkDtbskwVBLWOkiadwbaln0VSSsoJZPRp2H3/AFKqYrxlq/UVwMwt/OEfvXAQmrLYoIo2tu4/Bm0v5K1dRiTpJZnU0TRC0BmfL2S48TqKuojFNF1gZCQ3YeqqR044WxunVjxSiKHlGRh3DtlXnng5z3tqrvc3I+1wfXVDHTyRPfFG92fd72WDdexKTHSvax8Ya1/3y+OxufCemmPHsZcxtOObO/kNN2XbbOfF0qWOqlrOfExxj3AY69m990NVFWVUTIzUZ7nW7Rp9FXdUYjFRlsVRBdr8mTLuh0Y8baVlOZqmNwdyxYZI9zbuVUnq20bXwtY6fObvmynYKhWVdWaOMVTYGPj6A8Os4X8nwsirpI6AQysZkYbuex1zYqm+PHW1mxCkp6WNtOxzea/UG9yhbiIhfnZmI7AOvYqhNVTSNe5jWSRw2s8a2/zVSWYltxmZvc5bbqLNunjxseg8OcXzYOwyfG94t17L0zh/i6jxkMj6o5j2Pcr51biTZpA172hlgTbuVvMDx6eirIX07smTULTj5MuPx8O/j6rPCzfp9JoSVpOG8eixqgY4P+1aBnH8VuS4Ddeljdzce5jnMp3YolsWWWqlNprDUK855za7JE8YPUFtjNFtrqulZURkHQ+Vpp6SSHQrfyXD1jo2uFnNupz45k0wz05otMbbBZy76uW5kwkOdmjd9FQno6iF3Ux1lyZcWUbzOUg/Csbsl5HudYNTXHSyz0pAPhQL7rAETdGpgUdxqd1SxLE6eihPMe3Pa9lqeMuKW8NYQal2rzoweq8E4k4wrcSrPeW1TtR2da1+yrHG1GWWnoWMcZNOLwyNe0x2IIzeFcouPIQebm0aLABeHOrnzOzOdusjrJG6Z3AFa9kZ99fQDePKOJnNe9pz6Dq1QDjSl65ZHt01AzaleFNrnl3x6JsuIOkdYO27J/hw+96viXtCErTBTv0edT4SqfjJzI+Zz+t+mvheUOqmgkFziobWudlu76Kvw4nvr1w8aFsXJgffmbnwF0/DXE1PLanLvqXbrwIV0jWBuawvcDujgxmeCfM2VzQfG6Vw+wmb6lin50JlifofClrSTqvKOFvaDFBRR0ga58htcvdoF6fh1aK2nZLHvbULGyxrLtf6i7VEGi1zukgON3PcpdPFFpm1QYpmySZGM2CL3VzngvdsEj31ubRC6qeBmbmN9kA6d2V1ghaH1D2g6MHdJ5r5CxmX5psmY9IdogH3jhYMu/lKb0tfI51ydklwJeGhPNHJM8dVmBMIhBizyN1fbRRStknu6boA8plQ+KmAjzXJS+U6ZljmF0gIxQzSFzdbaXVmCOOMaJMdO3D6bK3W5Quk5jLDTymD552u6S7RIJM7gGusAkRwyuflDb+quRwxxNN3WKAjpjJPhLJcTfKmx5M2uyVNVASkNbomHnh+FCUxAV92+WQoKJQUqaDbLZCi9UJHdSAICmpe5SoAbISEZ2QlIyrdWi732VaYzOD+4uFXceyv/wB9m/5a4+s/iydXTfyR68vkn2/j/wBRb/1P8SvrZfJv8oAf+oQ/5X8V809d5rQwh1RG47Ej8V7bUcaxQcHw0TnOJYwa5fC8Op53Q1DC3yvQsflp28PwRvis97O/n0VRNcPi9U2qrXyjN1E3WpcfKszAjdVJPhVUoWSoUlYkbFhtZYDZygkuddyAxSPCwKUgxEENlbw+A1FfBC1ucySNYB8zZBW6m3tHsu4aqsEweTEpZWEYgxpZGG6i3e666xcSHOV2WFtJh1NTxMyMijayx7WGy18gOr82ltl4/Ll3ZWvz76jzXl5raqVE+V5YW3BG6R8QOXba6MBphfLLK06dA9Cqrp3mHK1vR8HoCojyb5pk8t4WNzfzeioSe8NnYI2ZWEbI3NkkfMx2X7Mb/wCCrySclgdAx00xF75rgeip0ceFo5KyOMgPdIZH7cvx4VKWpMOSJtO6N4JsdLnVBBWvEzxM10L8nZvZVPeHzM0zz2JsO4Hcq3ZhxrswbBzhK6VsbruJDLXNtkGDCCsqTHRNnYLXeC8AFC6Z8eDx8tvOIJL2d9exKGjq4aWScMa6GSVlnEMva/b6Jt8cPC1UQClxIQM59pDY2f0WPqikw80tc8xwZ4Nrc/a/e4VKGuZBOxjqx9r63bdpstZJK39qyCOobJzSSQb2BPyS02w47auiupopckkTw9h1u6+gQTVRkqy01T8h6+Wxl3AJMVVes5csEULCLG7SQ8Dv5WOioZKkSxObHID+8Rf0ARp1TCFxVEcj5KeulcY73Y9+h0VeaWnjrg6kbKbavBcCMqCWvdBXxzNggPLJPX1Aj1CWa6HMX+7xZybk7C3gKm8w+VtuINbd0r3gki4GwVuEiTmE1HMv2/8AlaLlMEczntfc6hjHXVillj5Jc1zmAaC+pN0rFdrackOfkflYwDoOW17p9PzICA519N/RUYY5W0xfLlMb9gm0dWczmO01UUrHpXs/x33DFY+a9xZJ9mQvZZpgNRqCvm3CZstVCdtRc+i9/oZ2VmFwTwPzx5AAflou7pMvFj0+ky8XFsBM0t+FZ7w0D4VTa4g2SpZTn0dou7bv0tgtkluVMlJLqWqo1wLrrYQyvLbHVPYVgyWPVzU1rgdCsnmIflCSCRqEyOfTQkHMxuqqSYFTydTdFaBJi1RRS20SuMvs+6z00k2CyRXLXZlRmp307uvRddnaQqlXTxVDHNc26zvDjVzks9vnL2zY/BVMhw2LWRj85K8ckcdl777XvZvWVUj8Yw5ucMaAY2N1t5Xgk0MkMpZKxzHs0IO90dnZ4Hf3FXsozlYR3QFIzRJZFzwWEFuvYpKxu6CTzD3TGy22SPVSPhQFkTE6nVYJC11wq4cQizE7p7Da4fiD6SQPj33C9d9nnGzpr0bmXJPXIXLxAE9t12HCGLNwx92MzzPO/j5LPOeFY3T6Uzf6vcalyV7qXDM9azh/GBiOFxvyudYakrdGUGwWLXZMdKyM53N+SaDc3PZLlL5ZRZ1gskDhoEGZzIxc90IkGbMgOVrbdysjjBeM7rAapgTbyvL8ugRCec3cPgCB1UJH8mPQd0ck0cTAxAIijfJUc2dtyrsLnB5efoEkTAxXHdMzNay/c7ICu6WolqC+V9mdgEzMGxWG51KVZ3Ou7bsFbp4hI/NJsOyQHAJhA940v3VVtLLLcF97nUpuIVd2iGPRWKeL3ekzvd1lAJbC6K43slclx1T/AHyPISXJP7RiT2TgShsi2UFfePlwlQitdR80AJQlGQhKmgsqERQlIwFCdUZCEjspplldz7LDfiCb/lriCF2vsu6eIXgd41x9X/DXT038kewL5P8A5QYt7QWf8r+K+sF8qfyhWj/TyFx/4R/VfNPXryX/AHjD6hex8VYY2r9n1JUMi+0YwEn6dl4799vzXuPEU0sHAFIYcoBhALz20VQq8OqnAGw37qo43T6iNwkN/KrbKyiPvLFllCk0nSyzZR80Tt0ghENd1Fj2Xa+zPgyXiviJnMiz4fTEPqDmtp4Tk3dC3Tk6WkmqpmRwROke/QANuvdfZR7J3QUbuIMbpXCaLrhhe3x5C9P4b4DwKiLJaTC4owDcEtub/NdjVxMiw6VtiGZTsrykwn93Py23GvMMTnD3ePK0dVIQwlu5NgtniNs7xmzjstFNHI5gjc6wuvAvt+ddRbc6S3KzOf5wgi5Hb5KvPWyzR5YWZchvk7p7i1rC1rHkbmyRLO4RGRkTWPsASe6cY44FsNVLAZZGN5ZfY33uPRUquokgkL42tELdARpf1silq3w0kmXN9o8AE+FWnAqKq82YBgBsNtVTu4sNeRVBklmj5bXP6CbsboL6pOG1DrGWoiewAERmNtrnunVDpYsjIs/2guCOkaafiqcFRUGgkDGX5chGrjpfwqjrxx8Kkxq3SPfG9wjvoNlbwuqdQ1D31HMY/Juxt7rKqSUZH1DnfZkGSNjhchFUYhSTYhHUZ5RHkALMoBA/iE3RjNzRVVWUNa4Ec1jwO7NCfVVjiEJsYqfcFjnhm3qFlPKyOpmAfKRJflkN0+RSqIR5po6md8E48NuNfRN0Y4aY6oIqGCZ8gYBdjw1DVRyyPLqd3MYyzwS3U38KyXCFg57nSRsOnToVVkmeyZ80ETo4wR0DshtjAiaKfI0tySMPdv6oauKHlvJiax9xs3RJ5TZTmiY7R+t3WP8A8oxG6MPLnuy/2roXpElVC1rLMbktbRuqEzMlcwRtbHa2/dZWF0bmX7i+QaKWS85sbSzJbT4UHpdhqmkWfp28gprRmk+HVIAiGj8oemQnmPNth3UJrc0brOsN17xwXUj/AENpANSLj63XgNHcZSHar3DgmoLuE4B3YSF09LdZ12dJ+5u55HBxOxVN0pL7HRZVVGa/UqgnbsdV2ZZeXrSNvAb7uW4pZWZFy8EuV1y7RbalmuM2bRXjd+Cyi9VNaXg5VUllA2Vjntc34lSkc0SZlog2OcHpd3TScuy1vvDHTH0TGz8zQOR3Q9NjG4nUqXENGvdVYZrHymSEubcqtpDNAyoiLH6grxb2oeyqHEGPxHCW5Jm6vZ5HovZxfbMq9VE2RhY7W+6N/FGnw5UQSU9RJDK1wfGSwg+QklfSfHfsmpcXZNW0eWGaxORjdyvnesw6ehq5KapY6OSMkEFqzyw15aTJTJUXRKFCkbLASsUIJN/KkGyi91I3QBBxyrc4FFNNXRsi7nVaZbbAqt8FcwNfy2nuppx9GcK8qhwdkbn5z+S37po2szF2pXGcK4hSTUUcLZXEtAuSus5TZQLbLFrKkVTi7MG6BObK+Y5nNsEmSSOMBjG7KbOczwgwTytNUGB23hMEgDbBrilQ04jlLnOuSnOMcbgXOQGQ3ke8sbbspMVnta7UrPehEzobqVFPNzHvmn0aEBZm5cUYJ0QmVo6zqbaLXGWXEq/JG20bCrDoXmcsGwQBQTiaoIzfVbDNFHCXB+uwVSKmBGVrbeSglpWyEQsdtuUgyNzBMZZHZz2QTOnrG3D3MZ2Taelghab5nq77qCwOOUeAgNZFRfY5XS3PdbKDDGckZt1MdOzPZnZGc4NsyA85UWR7oSvvXy4VB1RO2Q6IoQhKJRZTQGyhHZCQpMshAQmlCQkALsvZjpxK/wBY1xq7L2Z//c5/5ZXJ1f8ADk6um/kj2BfLP8ohpHG8B8xn9V9TL5f/AJRI/wDrOl9Y3fqF8y9h44dHA+q+ja3Cf2h7LqWUObeOEG3nRfOsgtl+a+oaSGWX2aUsNPE2R74W3vsBZMq+YcUjLal4Ohzla0hdFxLSmLFJmubYgn0XPyX7qkworFhKxBsUrFIaTskDIYuY7KHWJ29V9F+x/wBmktLRw4nUVErObZ5hDrA/PyvKPZjwgeKOLIIZWOMEZEkhGwA7FfY2HUUdDSRwRNsyMWAW01jjtnlfOj4IGwRBjdgiqI+bC9g7iyaoN1lbv2WvGnjuKRvhrJI3ttkJ/Vc9UAy3OdwDSu84tw8wYq97XaSjN8rriJ4HAZc1ydSV4/Jj25WPz7rOK8fLljfuozyOjizNbuAFXla2aCNj3fzbCSB38BMrnGNhBe0baf5qpUOe6GNsb22PQSG6qIy48VSaqZNMYnObGzIAzpva/wDFLp5jFJJAZ9Box5be90EbhFWOimc0MvoT5H+KucmIPjndLG8X2Hp/krd+GOmoxKqcWGna54fFa5Drg+oQQSPkpGQjUW0IdbXe5WwxKSHkRzUsWU58nzWmZUGlrs8TM8LzqPHkKnZhj+lseS8jlZI+cWXL83xjxc7JFcKeWiY52aPKcgZ309e6XiU/PqY2tgbDDoCQ69r90BpKmjeYHy54b3sdUNscBRztkoMrXtL2nu38EiRxq+ZPK7l1Nsh6dHoKgWOaLTJbOO9k41HJqTC5jTBIwa5e5Q3mKo2Rs0Pu0zZOjYh26CcujmY9j3PjIsQdwUdcCJoTHo8dx3S6v/WLCPQnftr4Ti5CZGyume52hG6MQymbM98ZFr6d1JDuUHSP1HQ/yjcWxMOV7RtY5U1FNi59OWte3mNPdMo3S6xuY7PGb6Jbc8TS3M05tiVMUbo9XN1Oz0EuQtEshfmcHnWytNtIwX0/iqcZfHIC9rX/APUrluTkI1YdVFTV+jDjKPAXr3C1UYeGI2jNq4ryTDcrjYdyvWsJgEeFUzG6As/NacH7nd0c/Va2Ek5LfiVcOufKx4y6FC0EOXTa9ZsorNZ8S21LE6SIAf8AwtHHlzAPctlS1YjGVullvx1GTY1GWGKwc261c9VfQOQT1pdo5a2So69NFWWZTFdbIC7V1k+OXK6+ZaczkHRWoJranVRMl2N5DMA7XurGa7dXLTxVFzqr8clmZitscmdh+ubRyHvqjjLZWXy2S3gt0TJjgDoV597QfZ5hnEVHPVRxZK0MOQjS59V3+pF90rK197tunMvgafFmJYZVYXM+CopXwlpIuW6H5LXFfWnHnBtFxDgkmelbJNEC+PtqvljE8Pnw2tkpqiLlvjNiBsPS6nLHXmHjfuo7bqEXzWWULCFIKgqNUgIeqfTyFswcPKQjj+K6KHr3BNaG5AZWs9CvWIq2J1MDm7W0XhPAkj5K9glzPBsAOy9tgp4xExp002WVi4ttlh0Kh1YM/S3QIuUHDRugVcNaJLlugSMz3to1c3UqY4jK7MpZD75NoyzGq3JG2CHIx2pQGRRtILnu+STLHEYso1JUtj+yL82yCD47udsgHQj3WKzdysjDsxe/cpElZG6cDMpknmvaLVIGTTk/Zx6fqnU8Yji6tL7pMETs2burjqdkcYDn9ZQGEs2a3RJnrnfAxug2RMtfXQIxDHK3LG25PdJRVJJJYve7XwED5ZHuzZlaMIhpzHG3U7lUnUDnG73OugOQQoioX3z5cKEhGUPqkAkKESxKgJugKOywqTAgIKYQhspohRXX+zU24ot5jK5IhdX7OP8A7sZ/yyuXq/4snT038keyL5k/lEtI4woz/Vu/gvptfNP8opv/ANVURP8Aw3fwXzD2K8YkG3zX1vwtF717PaKNmjnwtF/oF8kzDTRfXPs/aZOB8PH9W39AmTxD2ncJnDa0zQtd1bl+5XlEzepfZfFHB9PxJSNgkdk8vy6rw7j32P1OBwGroM00d9hunA8dKhWJ6d8MhjkbYhDHC6R+RjbkphEUeY6Nv6BdhwrwHXcR14iY10bNy8rfezzgOatrWTVMDi3Qi6+huGeFIsMOcMaCfC0xw15qbkH2fcCUXCmFhkLPtHAZ39yV24aEMbQGgBNUZZbpY4hsssiUfNQrTlOM6QS0Ec7dDGSCfQrzStgtITntYbL1nisOOCPLOxBK8pxYSSsJjY033L1wdTP1bfH/AFjjk59z5jn55L3ytvbRUJLe4ZslpA/UDwrdRI6MEDo8LVTSucDma64/Arljy+PBNHJaZ73NabRkC7bpcEJdy8krXve/Pk7C26QXGnY9zc13jbMqsUT4mMlY9wsdvn3CuO7DAyVwL5OW9xAeXgdgT6JcsUcdNUuc1okkyvAHjurPunJzMe/WTb17qKiGMUrHud1hjtC78Etu7DHwKKophgJ5jGuJuy/r2VKq95now0O1hHb90Ken9kCN/QTN+RQvkko69lnXhLCw/VNrjiU5xczKz+cfax8hKkku+5++Mlj5QCMw3Ad1xm48EKaiZofGekB7738KtNpCKyWoayORrrsZ/BHIM0bKmJ2jtwe6OWobGx9m3BOvyKqgCnYI3PaY3bW7KorQpCCBINLaEdj6pMsTSftH6P1HVoU2V3KsXOzx2SgYnNDmbeD4TGj3xx+7saHXtrnCa1uVxZJqALgqs50bWMLWN1PZWoAzK+7HMP4pVNNp3B0wAym+ti1WzLyjq3QdkhrOVZw2vp9VcbaTIC3N2KiprcYa1skkZa21/C9Sw8CGghYM1gBuvOMFg/1uEZbm40XpUVxZva1lrw+7Xo9Fj7psrmvffwlTSctuY7BM5QDCc2o7Ku52ZhaXXsuivSNjqI3N1bunmdrWWbmutc1zGgD8UTpW6hrvkqmWiXnG0ObMqZcClCVxNi5MJzpXI5AkuTIpiG+oS3NKgC+ymVWl2OfKVehqi9mUOWnBOydFKW7K5npPa38MrrZS7VFJN91zrFawSucA4OsrXMLrF2vqtu5Patc0xs11v3Qh3VcOSRM0CztkM7o9HM2R3FpblN22yry/2j8A0ePUBmp4OXUxEvJjbq/0Xo3NIp7udukukjDLO1urmRXF8a1tI+jqpIHNcCwkWO/1Vde4e0n2Zsq3zYvhLXcw3fJH5PleIODmvLHNsQbEJWHAKNkR+FCpNKdSxl0wskhXcMjElYA51gkHp3AMZ5ga7S2xy6L1uKTlRBuVt/K4PgiJsFOwHKb913kLxkL37BRVxM1Q8R5I9ygpRd/2rklsz5blrbN8p0eURWLkBanxKCCLJHv6LXurnzEhm6gRRgl7tVkTRa7WoCwWyxUdg/UlBHSyuZ1P1KOWXlMY1zbvKe2djWDPogDgoIomeSnuijiZ6qn74M/Ssmrm5Lt7KTPBfI8hrrBJ5UxqdXuLSsouZUDMdAr3NjiOXuEgXI5jQI25iU/nGGGw0URZObmc26irlY59kKC2d7mabomQuLbudqgikEMVw3O9yLmn726QcSfhUeqJCvvny6Ch+8iPhZYlqAFQUShIwnVCUZQlTSgShKIhAVNVAFdT7O//ALtj/sFcsV0/s8NuK4fkVy9V/Fk6On/kj2hfNv8AKM04lw8/0HfwX0kvnH+UdH/57hzv6Dv4L5d7FeJzDS6+uvZ4R/oTh/8Aym/oF8izbL639m//ANjYcT/w2/oEw6om1gEqop452ZZWtePVOkc0WAUEjJcoJ8/e2TgOgooTilC1sL76xhvxkrlPZvwHWYxicdW+LLAzu9q974kwmLH6kRSszsadlvOHeH6bC6YRQMawDsunDDU7smeWXxB4Dw5T4bTsDGNBsukjjDW6IYmhrQE4LLPLZYxICxYq8kxBUSbXbox0walSVGmiQ5990h0i07YnZeMNdV4VNH97cfReZYxT9JJd1gfAdr+SvSZZLsLfK4DHKcvec+Zmp07lcHWTUmTw/qXB+JljlHCVsMM7LPc7P3Jd+i1Lg1rMsb85OwzLrarhuXEKz43RxgWsO/zU0/BEUUwOZwHleLepwl014Po+dndfDg5KtreiZ7QRcfiqgmOVgic4hp0GXyvWqfgTDWzOlmZzDur54WwhvUIHAnzZVOo36ejh9Jxk/VfLyIgupy573WB2P5Ko6czVNnZiyNn7v4L1DE+HKOoL2MZYDQWWtbw3T0muVuvndL8zI0w+lavvw89ka85JHscTcaKTFLFNbK5wcbj0XeTYXTnQMaq89FHl+Bt0fmv7Np9Ln3cE6ncaktY51jrqq5bPJmjyOyevlduaKIusWtQOp4hdobornU/2XPp0+7i8skceU7HykmlJmzObouyOHwvJOTYJUtHER8Oy0nU/2T/T/Hty122MTmucw7BBA6LO+Isvp33XSnD4z91qrSYTFI67W2ernPGeX0/+7TuIjm5LmWzbfNWI7h4Y/NkVmfBzJZ2Z2ePUIxRTCO+W7+xV/iY1y59HnPSJATbK/QahXaQX1P31ruXJBH9s1xf5HhbXDwZcj26hG9uTPhyx8V2PClFz6pj3ZgyLVdyHBjrHZafhuijosN5k2kkovbN2V2pkIByu0Gy6+PHWL0unw7cFiWouC1m3da7nnO8DuhM7hGQO+iWJAOoqrXTDgXH6ow05tNVETg5t+6uQU7pPuuKXsymtu4EK3HSvc+2XRbCjwlruo/gtlFRMj0y3WmOFpXKRrW4Q97L9lUqsLlpWZi3TyumuY2W8eFQqMQbq1zrrW8ckTM/Lm9kxre6vyU7ZH9GUgpraGzRZqw7a02pxONrKzCXWsPwTvcW7hHHSOztstMZU1XIIJv03QSE2FnK3NSyZwct0nk3Ni1wsnqkWHdi5AGhzyM1kU/SwdNkmNzvogyqxrmQvaHNdcL5l48wKXB+IZnyNaGVDy9ll9NTm+gXlvtUwFlZhRrWt+2pwbJzL4Fny8OWKTfYqFSUp1KcswIdbVJA1XX8J8LtxogF7QlTehez2eR9MDI3QDRd1NOJGCMNWuwfA4sLomQMy5wNStlymx6DVSpPPa2IRRs18rHSMDhfVwRRlkdy5THFFJ17IAIwZX6NsCntjJdlZ2SxIyO+XU9knM/4Is2u5QRjnjnXc66m5qDkjb9SpjhihZmk1JTIjFH1t7oNZjoY42auvdLkw6P8Ae0KRPWiNtu6rOq5pfvOASDYidsY5MXbumMAaLu1eUuniEdMOnUq5G2ENGd1ypMTdGIZJYmkD4iVkzr9MWiERGIZn6kpKWYmtcLlV5BHzCh94Mp5Ebd9yrMNOGxAZ0BxBQEJhCghffPlwALAiWJUoWQoKZZARqkoJQlGgKmgJQI0JCmmWfiXS+z824tg9QVzJXRcCG3F9L63XN1P8WX+G/B/JHti+d/5Rg/8AOMPPof4L6IXzx/KS/wBvw76/ovlntPDZvgX1v7NTm4Fw939U39Avkeb4F9a+zG44AoS7tE39FSXUOuZbqZ3WiyhC15Oqxw5kgCrDHdLK6hNHR3fnLdVuoYhGNEqGEBqsgW0WmeW/DKRIFnI7gKLqvUTBrbByyk2vaZpw3TMtdPV2ck1FUTpmVCWYEXLlp6LW173ondAZgVShnDtMyl0ozXzI2FmSUALR4xBz3seOwN1alqBmtmVPE8SFHRxtDM76mVsI9L7k/RcnUyZceUqcsJdbUmgMdcd0XMAdpuqFZjGHULrVVbBD6PeL/hutNVcd4BDq2qknPiNh/jZfI49NzZ39ONr1cup4cJ+rKR1EkxSTPobLjpPaJh7nfZ0dS8eS4D/FVne0OM3azDtDprL/AJLrw6DqPsxvX9P8ZOqll6iAqFQe73Llajjt7WXbQNv3Gfbx2VCbjuY6Cgj/AL5Wn5Dn+x/1Dh+7rpCyz3b2sqE8pLbDsFy83G8xZcUcTTt8RKoO4yqg/qpYj+IVToOb7H+f4fu612mUneyqOOq5o8YzXN6OM/J5Q/6XhzHSGj1BGmff8lU6LmnwqdbxX5dHJJZnzScy5/8A0wikd10cn0epHFNG7UxSj/pBT/Lcs/4q/NcV+W9cQNFA+FauLiLDprDmuY71aVaixKikHTVRX8F1kvws57g/Fwvqrdgmxhp3VeOVknwOab+HJrMwF0rLFSyrAiY5mUt0V7B8LbLXxxxdFzcjtYKnGbraYPMYsQhf4IVYX9URyccynmOtqLBwa3YIJJjksjlF7kebIJYzkuF6m3JISH3cPCYGZtFEUDy7VWKenfK7KieTWKGnMj7FunldHRwRx9Ujmgf2lq6flwRAOdc7JrakNdfNceF0YYyM8q6KOSnjbma657lKNYzVxc1c/NiLyzKNPRUnVri6wzXW3dpHa3tZi+XoZlWonrTLcHLZa6etIBB3WuFYcxzOWeWW2mOOnTUlW2MjqW3iqY9zl1XDx1gDtHbLYQYozJldqpxujsdW6SPs5oRCTLb4dVyUmJbhrlgxeQDKXXKvuhadvHLGdC5vyUTRxF9xuuOixp7HJ4xh7n5lXdNDVdJLSxTw5TlzLUVtDLSdQddhViixFksozuV6qmikZkLrgouMyg3pzUjrrR8R0X7QwqaEal7CFv6qJrZsrXXCoTC7XBc/qtHyzi2Hy4biU1LL8bSqS7/2n4SYcbFWyKwkGpC5LDsHrMSqBHBA57iezVrtHyoxtzvsF7N7McMdJCyolZYDZUsJ9l0baSGWsfkfcEhei4XSQ4fTsp6Zlmgfilaci5O77XK1S42Zqp5bG5nyOSZZBILt2SMbYwWdTkJu7QaBDzCG2y6I4yC27tgghxlsOobeyCKWSR56MgWCdrXFxagdWkn4fogCkPNmA7BPa1rnejQqzZZCbhlgmRF0rHl+gKAl1PG77RzkUbW579hsobEHSgF1mBObGJJcrUGcZmAsLlLZedchtgsLWwy5W5ZJLfgnxB7hmLLKDRSUTpHmaRzgAmlwkflDrhLnkkFPkc+wKVRtec7m/AO6Sl8RsjbZjW3O6dGWhgGVa4OfHd518Kc051yoNyqgDyjUL718sGyxSosgwKCi+8hItqkAFCQiKhIFlCUZ3QOUGArecEXHF1EfU/otETot5wW63FtF/b/gufqP48v8N+D98e4r58/lItPvOGH1P6L6DXgP8pAWOGO/p/wXysezXgU3waL6x9mQc7gHDwXbRN/RfJ8vwFfWfsvH/p9h/wDy2/oqJ1JNhom0sd+opcmpDVagFmrbHxizyu6sNNhqp13WWU3UBBcQqFZKDorNQ4Bt1paqYn7yqeArVU1nGy1k05LnBNqptbLXl2YrLLJpIdHUFstmqZat/ZIbYPuVB1cl3DR8U2Z13LQ8ZQ1MmHw1lM9zBSvL3gb2Olx8lt72VfFpIxglWXta8CI3B2+qmzummXLj3YWPCZyTM8u1fc3u5AnVdnVcnTbr/AJdm5iMzTbuvQ7XyeV8ijcXNsHW1/7KaZC7Z38EmM20Tj1XPYLPKN+Kq8wJPV8J3+iqSGzrhXZgqUhOoCydcVnO0NtUJlcWZC67BcgeEwgu6fp+KqyA5yDpY2PzCnTbEBtrf6JRKYT02LfqlH4UmsoCbOWAXWHL2WDTZJcpkTS5+VrbnWyLQ6DVA3NHNcObnB7JxcHy3a3JoAQPI3P1QYoyRrmcHBW4cRrIvhqJB/1Km0nY7Ix8KVxl9xUys9VuqfiKujIzOZJby3f8F0OD8QRzVcbZouSc41zXC4mP4gFtcM1ro2nu8fqscun47506MOfOeNvdRFvmb6rJAMlvVXJXZn9Ldkoxuda3ZLtdGyvuaNTogI8vVZG2Elj7fgqklPLksdE5jobWZJWZdHa9khzS6pYS6xehBbHYOyqlVS3f09C0lJelPLJB+JVJphGLh2qrAulf1vcSomGlg78UDSvVVYYy613vFySjq7XPUqRFtElLoqkYqO4cqFrImuOyA2javudUt1W4y6O0VK6AuOYoNt4pwbFW2zgN0WgjkI1TTVEbOQG/bWub8Kux4pJksX3XLRVry6xVsVJCWxp0gm5zCe6TIOlUKOqV8uDtVNNocXwCkxl8cdS24BTqPBaLDhlp4I2W7hu6v1AtqFLbZAiCwswmRwuncvktu1qMFobmKCWYF1h2VkB1u6AnMMrWqbOkbmOyUZCH5Q6yCMcfgYE6aaKCIMy9RVVpubtdeyGcRueHvcgMllJaciyCIxNzObqVkGQPzHVgWS1olcQxuVAOBc5xs7RTzHNaBuFWGZv3kUOZ1+5QDDUSOly5bBMiztcSe6GJpJ6naqyInOkF3NsgHQNLdWt1O6sPc+Owbmv3Smujp7yPdeymlqpZiZCyzL7pKWGxPlcZJ/oEcZEnQ3Rnoomqo8wYXtumNlZE2zVIFI5kdmN+JZzB+8qDo3z1GYu6bqzzmM6cuySnK2Wb6FSoX3r5gJChEhSAShKNyE2QAFC5EULlFBZQvUn4lBSplWW44RNuLKE/0/4LUFbbhQ24por/APEWHP8Ax5f4bcP7491Xg38pEf6vhh/rP4Fe9Lwj+Uk3/wAuw5/cS/wK+Uj2q+e5h0FfV/svd/8AQGH/APKb+i+U8zQ0523HdfVnswDRwFQ5HXBjbY/RXJsq6+MZpdVdaLJMUZDcysD1W1+zIzMoLulCRbVJkkNrKNGRVHp+JaKsmy6BbWokcVoazV5U5VUijPISSVWzAKaqSy1tVVcv7ywtaL8tS2Mau3VOTE2RuILmrlsd4op8NhL5pdgbDuSvMMW4wr8Rqfs3uhjI+Ab/AIonkPc3cR0LRZ9REw/2lq5uLsIqc9Aapj5Jvs8gde99F8/yVb5Pile8+rlsOGnGTiOk6rASZz62FwPxCuT5Z8mWsbXRVgy104PaQ/qkMJa9NrrmumJ3zlVwepejvw+Py/dTra+UTSD090ccL5GZw11u57BLu2F72v1sezllk34p5RNGRnJy2H9LzoqbrBhs1WpQL6qu69tdFlXZFVwu5VT5VuTb1Vc6DVS1xJcUoC+nlNdbSyW4+N1LWFEakLB8VkR7lCL3SaJHpojBsboO5CMauTM7dunhMsdiltOisCMyHp3tf4kBka3GDjmYvSAbmVo/NaiMG9ltsDJGPUNv+Mz9UqvH2+hKgdb8jelLMbwGuGifM5xfd3lKml/pbqNO0Bn5QI7qvVShzBmclzOcX2Vd0fMbfNqErTiJHNDwd0qU5rO7rJY3NiAO90TQMmVzfqg1WaN8XW3ZUZqz95uq2k13RFg2XH4/jDMHa/ntuB+KcC7LKJH2zICQuDl48Y2YvEDiw7JQ9oBsb07vTqRoSvQcwWAgLz3/AMQXZbOpe/ZWW+0CnsM0UgS0e3dghTodQuSo+N8NktzJchJtqtzDjtHM3onYR/aQe2zZrosIN0iCqjka0te1108SNd95AYQRsmc4mwUaFKvlepptpSS6rcQT3Gq5+AjRwWzhk8KVNjJZwSRIGtsUUbiUMsQLrlOBnNB1Q76oXSNFmRtzIo4pM3VpdWhEkzuWI2oTGGus51yU17Gxi5dqkxgZzI52yCESIwGtaq0pfLMGMbfyU0yCV5yrG/Yde5QGSXihOdugVWEmRuYNsFNRXGXpLVgqG5A0aIM10zR0+E0SvhYS1u6r5RF1O6iUMkkknyQFuOWzOY92yZHVc02atdNKDaJmvlXY8oYGs3SCzdzun4rrYRl0cQYNlrGktNg5WXVD2gAKTH7q3mPmkzZfCxjnzvsMzGBFFWNkcGH6pj6psj8jG/gkpkJLnZGuuFeFM9wukRfZHLGzUone83+JAc0h0siKEr7x8wEqCiUIAUKIqEgWQluTSlnVSYCgKYluHSkYHLZcNEDiWhJ/4oWtKv4AQOIKI/1oWPN+yteL90e+Lw/+Ug3/AMlw939aP0K9vHwrxT+UcP8A6eoj4lH8V8m9qvnFwLm2Db3X1b7K4JYuBaFsjXDoFgV81cM4c7E+IqKla1x5kgBt2X2FhlE2hw+CBmgjYAt8J8s8r8NnGLNAUkJcbin6ZUUi3bJMlrKzYWVOc2cUQKFSRqtFVaXJW6nuXXK0lc7pJzbLPJcaLEJcoXJYzikdOwve+zBe5XR1dyx5PheMccYu/mmhY7+cOvyCw1tTQY1ismJ4pJO592AkRjtZa3mua+43HdDIdgEvUlbSDZkchjeXDpun0NbJBiMMw+48fdvcX1VR4u2xRQksmY7NaxBH4p6Rl5ju8TAbiVSwNsBIVUa5rTdzb+iuYnricxLrnNqR3VHdd3w+Sy/dTTM97vDNwwbC/op5Zd80oXLk6Mm9llk046CxtY6EKvJYi3hXJdFTIAcbuWVdkVybJJJ3/wC9U+QaabKvJcZiVNaYk28apegab5royer6pbtypawJN3Ov30Qg29E5sRlcGs6yUlJpBSDLKQNNdj2TG6svmsQlE3JJ3TARoPCajW6Nunb5PQWS4+wHdFqTrrZAOhcWu0+S3XDYzcSYe3zUM/VaRnxLa4NPycbonjcTM/VKrxfQ1a14eWh2nlUnROv8XZXKuF53de5VZ0Dg4KK7YoywzB4cgEErpbDuthIHg2PwrIYwWkOdrZTo1Awkx66lBHLlis7tor0hbCA1aHEppY28xulinIa/Pk5WZrl5j7QY45GES5iGa3G4XcwYgyWGzna+FwHtKkYKZhDnNeD29fKqB5jJJmd0t09VAcUu47LDqmRnMN1HMKC6y6AZfqRidzdA5yRewU5gUtBsKfFq2ndeKqez0zaLe0fG1dARzmtmH4FcpdTr+8jR7er4TxXS1zWFz2xvOlitxzhI64ddeKxSujeCHahdRwzxHLDVinqn5o5NiexU2K29Lp58hW0pJu4ctDE/7Nrh3WwpJDpZQbooJbusnytzMVKkddrVsbZmWU7UqNyxalyXJUOkN81gkzxObMerup6GtVyosKcJHbv0VkMsyxcktnZI+wbayKQtPxuVBLpIom3CTzXSknshkhEm2gWSyRxMyM3QCXABxJ2S2yDPmLbqBnkdY7KS7lNsG3KjZp97Jfnc3QKBVumF26BLfKAy72/RZzWusGNsltS3C5ubX8VYEzA7o1sqEYDRc6kqzALanRG06WoZJnPvlsrzdCC9yoxTgGwc1PMrbXc7U7BLal4inEfqUynpHteHsWujEYIc52yutxKQuyxssB3T2WmyhHKeZJnXJ7LHVDSb5VUa7Nq52pRjJb40zaC90KJYvu3zAFCkrEAJQuUqCkAEpZKYUsqQB2yA6oygKmqgCreC6Y9RH+tb+qqFWcIOXGaQ/wBa39VlyftrTj/dH0A34QvGv5RbL8MUp/rR/FeyR/zbfkvH/wCUS0nhOmI/4oXyj264j2EYGKrGKjEJYrxwgBj+119EN1XmfsVwz3LgdkuV1qh+e5Xp0Q6V0+pGPusBs5MzIHBYFJsc4hVpdW3KsSKtNYtQGvqe60VdGXXDdlvpWl2i1lc5kbcoWWUXK5PFByYSfQr5+4ujP+kdS5rrgEC3i6924nnEdNIQ/ISLL55xerqJ8XmFS3JJnINtjYqJFKcmrfhQG7WtRucSSPzS5CFoQSfqiaCXCzbknQd0IBynpRx3jeyVuj2G4+YTKu8xKMtr339P0VIjVWaqZ0lTHLJq6SOORw+bQSqpt2XZ8PkuSazqQSNQmRv7pSIXFrrPJXGOSS7fh9VWkIF772Tc2b5oeSDqW6HYH9VjY7JVJxOmXskOBNx6q/LG1u7VWksG2DVNaY1VdGB95LOuie7x5SwC6UMa1zyTawU1tj+ooEF1n5hYaWVgwmoY+aP7lg8fxV6LBRF1VlQ2Hvy2dTvr2CJtPQRXsypN9znA/ILny5sfh6XH0HNlN6akROsXZdBv9VIW2FHQyDM2eeN5/faHDb0VKfDpqMAyZXxu2kZqD/gVWHJjldI5el5OLzlAnKfgbYWG/nupGhsEtpGa6YLbrZzHRkq/hoJxSlPiVv6ha9tw5b3haJtXxNhlMfhlqGg/IFJePt9ESNEj7HskTgCxzbLaugYXGzVUnpCLk6+E7hXXMo1zWiSYhzuyKExx1BcOybHTxB4Ltz2Sp6dgI5blOtKKqmsdrl73WjxyIOo5MrbaXW7lD7WyrT4lLyGgu6g7RI48wlxl1HiJa59nMNiPRanjfEqWuw1jw/r2/wAkPGtHLFiEkkebl7hcPJNzAbucddimCRosusJKwC6AzVSsWIDLKLLNd1IN9EBIPhSCVA+JTayAO5RxuI1G6VfpUgm6A9R4XxM1uDsEjsz4+grpaKXyvNOEK3lTSRF1s+oXoNFLmssMvFa4uspNAHLbxC7LrR0Ul4wPC2tPN2c5SpSxRpieHht2kqnJJZlytxWOa6ErmJqkue4BOUluEjY/EVZkdGG2Wvhkc3XukOknmmtsq2lsHVAa6w1VGRzpZC5WGwtjZeRyQLFzsuyVqge9OjdkGqISnvullreYSN1LiG6lyWwYZAG3OqhkgOuyryS6WCiPKfiS2a7FKC641AR85078rW2AVbmNiZ07lFFK6NnTud0thsIacllxofKJ0UgkDWa+qGGYloBVmKaz7N1QDYIZHvylXHysheIxqe6QaoABrNz3U09E0vMkj8xKYOOeUgNdZW46eNjA1znXVTQSXDkfNKYa1QpWL758uEobI0CQCQhKM3KAhIBN0tyafhSiFILOqAphQFKmAqxhptitKf61v6quU2hIGIQE/wDEb+qx5P21rx/uj6Aj1iYfQLzf2y0MeJYPh9JJoyWpa0kepXo8BvBGf6IXN8YUrKufDWSMzsEwOvovlZN3T2r6MwLDoMLwemoadtoYWAMW2juEqJoDbDsnxgLoyrKDt0oEyyghZ7UU4dKrSC+ytyDRVZBZMKc2g0XO4hcyWO66CZwF1zOJSZXPJWeVVHnvH0pbTTMa6+i8JnmdK8ZnOJBtqvb+KQa1xaPqvFK2l90xWeGTNo9Zy+VEnMb20URwukdfK4/LVPmjaG2D/wAFseHMbfgNU+VsUcwO4kbdbE10dHIZrGKUX7ZTcpn7LxJ0eYUU5Z2swr1bDfahg8jQ6fC42yAbhoOi67Cfatw84PzxNjG4BYEST5LK/Z5HU3EoafuMa38BZKHxLZYwWvxGaZjm2lkc8AeCbrX28LsfJcl/VUtbd1kzleUDPiVltvos8j475KjaGusNbpbiT6WT5A0Ov1KvKTlWddeKpKTuVXdqFZk85VXcorWK5BOi6Cjoxh0IPT72R1n/AIYPYevkqlgcDJsVYZW5o4gZSPNtvzWyrpeTDJVVEXXGLk5tHkfrqVwc+VyynHi+h+mcGOsufP1Gvq54KKzpXOznVjBq4rVftd/MtFStcTfe50G6ol1TXVgLvtJ5T6C99gu84fwefDKdkjoMOjmewgmSdrna9rG9r916U6Xj4sZ3zdVydbycuX6LqOUgxaGUASxcvX7mo+eq3EBHLscskEm47PCpcUYNNTPFVDRxNgfcvfTyhwv6gaBVcCqiyX3d+rHWcOrY7/mFj1HT43DvwacHVZXL8Pl8ynVtEaObpdngk1jf5Hj5hV22zLcV0TTg8wbm+yIfc+b2P5FaVqy4c+7Hy8/quKcXJcZ6WIxc37BdBwZKI+OMHdl0FS29/Urn4iR9QtpgMro+IMPkDrFkzSPxWs9ufF9SSzMaTbyq8k7XPyla6WqBlJzIBUXddbXJ0SNkYonEkbpZw4yPDubYBUhOQVbjqiG6pS432q7npk1PYOLdSuSxyjnbRve5jhY3susFWQ/Mjc6OrGWRjTdRcZfRy2e3zrxdUHnRxyb/AKD1XnMw+2I9ey969onszrsRz1WFOaQbkxnf8V4liVC6iqTAWOvEcj3nu4b/AEU3Gz2uZStfZZZWKWn94nEedrATudluxwXiTrGJzJA7Y5lJuct3UG1l1EnAmMBtyxpPo5a2fhvFqd5Y+jk08Nuls9NT2spsrhwyuhIc6jeLa6sKrua4O6m2KewX6hFusuNlIQEfeRDVCVIuEE2WESCPEYSfK9RwmUuYLryakdlnY4divUsLkAjj6twss2mLsaNXxmWvoeqIE7raRjRZrLneRA8+i56NuZ5c7RdFiB5dFI7L2XNtI3c69+yKFkyhrQGoee9rTlZdC1zHrHTBuyNlomWaWR3UijLww5e6wT8158IZKh5bljbojZpF72zIZC395A4vDdN0kgt3U7AyTsEcY1AOjUoFzRmyonS5mWa3VGzOMsYPqrUZaGXcqETcrczt05rnSmw+FLZabASAM6UUDnR9SrGNzmZQ6yaSIGhozPJRsz4qtxmuWrYxT5mXzKrDEzlB0jmi6mQxBtonIlC0yZpflDt1fZURsbl5Tn+qpUMTWsz5dT3KsuxFsZy8rZVKSioIWKSv0B8uD7yhFZQUgEoXBEodokAJZ9U1LKmgshKITTZLd6KTLKKmNqyE/wBMfqgKKGwnjP8ATH6rPP1WuHuPoKmN6OE/0B+ioYvTiaamef8AdklXaI3ooD/Vt/RJrHB0ob4Xy2M/U9q+io1YCU0XTVpWcGDoocOi6huiI6qDILklwumuBD/RQBfUqg11RES2wXPYnhr5GEhdVVEBq1dQA4WzLPKKleX4vh5aSQ25Xj3G+He6Yqyp6vtBYr6Tq8Okqrsjb9S1cbxRwrFUUE0Tmt6wQTlufosu2y7itx4BJESwPGxVctBaGjutvLSTUNRJRzscwsJGumi19VGY3izW2XQRDeltg5Njc+Noy6/5qS02BLW6qD06jLfylE5OunBE7mu3Fh+ASxqm1hJqy8/7wB/4hKbqu18lyT9VSBY3KsRSZm2SS363CfBbLYtvbbss8j4/YiOhVphmBd6K063dqS5oG34LF2yKEoN1Wk008q3Lpdo2JVaQd1NXiuYCR73OD3hfp520VjF4xJg9W2Nj+gA9e+hvYfIFa2jqPdK+GZ2wOvqDut5PJHE45numDh0A7Fp73+Wi8/ltw5sc31P0yzk6fLh+Wi4a4f8A2xWRvrm+7YeL55y8R38AE7/RejDB6WCnjmp6x87Ir25MUctgRb+C8xqBJhNVzZaeLEKVwtFz7loH7tgdCFco8WwJzhIIK7BZ2W+0opS5p/6XbL2M98smWN8OGY/h245zVdDjOE4TWYbIBi7mTU8RLIXsERJAJAIIF1w2FtvikBDW7dvQLparigNhyuxSmxePsyqoruHoXKtSTvnbzZYoKXN/NxwsDQB5+Z21WPJneLiu/lpxYfics7Tp5B+y6t7pc9wGAZe5I39bBaZi2eLSkU8dPmbdx5j7eBoPx1WsauPp5rHaOtyl5bJ8HxjQLZYSD+1aZw1yyArWttdbfBQBiUcg3BuPVbbcmPt7bJVkvPUsjqDf4ly8GP0cxsKiMnv1d1soq1mcAuStrrjo4pHSO1borgI0u5aeKuYWZWubsmxVYtYq54NstC/R2isU4IdcLWidu4crArMsVgnLPZVs5ZGAdTvouQ4u4FwviXDTCyJlNN2extv+7lbh05c5NjkcTonc9iYvlfibhys4XxZ9DVN1GrD5Cr0ePV9EAIqiTTbuvpPirg+h4ppT7xF9uAQx40P4r5z4n4cq+HMWkpKlrgL9D8uhHos7FytxRce1TXM95a2QDxoV1FJ7QcLnbaVroz2u1eTk7W0siaSFNkPb2+lx3C63IQ+J9xqNE6fC8Aq2EPp4D3vovDYpnxuu17mfJXafGa6ndZlRJbxmU9p7d3xtwphFFw3NiNFE1kkb27bamy4rAuHZ8dnkip3tD2C9in1XFdfV4RNh8zmvjk3v2S+G8cOBVpqMrn5xaycKn4hwNjVG82g5jB3YtLPR1NKM00D4wNNWrvJPaS4MsKW5J7rneIOKpccjMJgjjjJvpubIlorRwEA3XpWDSc2CNw8BeaRttp3K9SwKhMVHAB+4FnyXSsXaYQczACtxG1a3DYsoBC3AHhZytGtx2QxYa+3fRcxCxxd8S6LiNxbQABu5XMc0jQJWhaNmutmU8xu2ZVRZ27tUeQRt07o2D7tbo3ugM3L3bugjHLbndqhMxm+7oEbBpqgBfuVjW845jsqzorNu5yE1nLZlbqlsz55ACGDdTEG7udsqMOeR5e/ROeCWoCw5xmfYfCrMZEdmhUoult0xrn5rlSa/mI1CfB1vu5a3mOGpViN7nMHZGw2GhdfMnBoPyVeJoA8lWIw6PROUlqNzgA1rrBHmb+8q7i5wys0WMozl+JURxWFYoJX6C+XQhKm6xIAQlGoKAUbqDZF6ITZRRCilOTXaJbgkotyGPSZh8EIygHxj5rPL00w9x9A4ab4XTn+rH6KtKc073eqPC32wOmee0QP5JUZuLnuvl8Z5r2cqa0owgCNVUCCK6ELLqTDIOq6Xfv2TXC4VWaTK2wTBU5DnWCrNo+adc1lYa3uVYjAZskpVmgbHFkjZqe60smFtLy6TXVb+eUa9Wy1rmuqJbNdon4Q4bjLgei4koHxNgayqH83INCD6rwTiDAKnAcVdh1a3rYAQ8N0K+s5YWxRWa111xHF3s/j4raDJLyZI7lhDbu+V/Cdmyl0+Z5oDHdx8pQIDdNl2HFHA+McNSPNfT56YmzJGOuFzJpYy8CN3bYqVWuoxABtSGjtG0fgAqo+JXMVBGIyNP3Tb8FSC6/h8pyfuqy09Nitxg+BVGJxSTMqKaBkZyfbPym++gWljPwgrcYcy0LyfK5epyyx47cb5ep9I6THrOonFl68tsOFo23M+L0IP9Dqsok4cwrIDJjjdvuRf5rbYFwlJj1CalmIUdOc2URyO6j9FerPZli7X5WVlDrsM5H8F5Xdz5ee7/wDI+xv0voePLsyvlysnDXD3w/teUv8A7IG/zCp1eB8NxuLBX1JcCAbtt+Oi20XBOOVsknIgZNGx5j52fpeRoct9SPVU8U4KxqgpZKupijZHELuPNCz7eX5yrX+n9HLqNVNhPD+a4rKk/wDfyUGHDI6fkxVjtDdhfc29NtkVdw3i2H4fDiFVT5KWXLkfmB320Sa3h3FqKjNXPRvZDoc+hAB22U3DO/uyrbj6Tg4r3YeKr8toJbJlDJBqC27H+oWsmwamNQ5jYpAQC/7N+lh3F7rY0NJX1hfHRRPnsLvYG30PoUtxcKgxvpY+YDkI1vf5Ba4Z8mH7ark4MOS/qm1elwyljj54a1uuhkdc/O2yuQU7JZQZZbM3JfoX/IeFaGBY1yg6LCJWDzyjf6XVEYTiUrjI2jnksSCQwnUbi6Mrnn5yqMOPDCWY6hkmCioqzK7EWHN/R29BqlO4arAM0UsEnoHWTG4ZiA3opxb+qKDlzRxcwskYy9r6gX8K5lyTxK4s+g4sruVWkwmvp7OkpZLeRr+ifRzchgcG9RfZW6esqg60T5DbsNfyTffZpWSB/KIk0Iy9x3WmHLlbqxx83QfhzulcTLPJDWTddrSHb5rf4bxZW0rWAy8xl7m+65ieUmqnzbmQ/qhjkF7bLrc8j1fDeNo5pmdVuxuuwocUZUMFnL59inMembW67PhfiR0crIZn6DYlKiTT2aGXmaF2ytwjmOADloMNrGzW6rrfUdr3zJSbOrogdlF9Fcii6QAlRkXsrIkA2WkwiLkN0bclhouV4y4RouKMLkjlgz1TGfZv2N/C6guBCXodkZU4+ScZwKswPEX0lZFkeD9D8lrrL6n4r4KoOKcNkbJE1lUAckg3+S+d+IuEMT4brJI6uCzATZ41FvKixTn1nqit2UfJIMCknsh1WX8oNhJvfKiHxKBc6I2tynygLmG0T66vhpmN+I6r2nC8P5dPHH+4AFwXs4ww1eISVbukR6D5r1anhLX6rm5L500wi3SwGNgCu2tayyJoLLhE4dKUVWi4mlLaAAdyuSbJ1Eucuk4vJ9zjA8rlmjTVTlfJxbjLSLj4lIaSbuckNdZOE4Jslsxukktl7KWyggNa1CSCiAyjRMgSNc5+rlBDIRfLcqRvcqT1b/CgADgdXaKeaXOy5dEJAa5C6bs3dSZ4PUja4uNmpDXEC7t1Id+5uUtmuRtDdXuzJ4cBr2VFocNS5Pja527tEgutrWmUMCvNLXaZ9VrAI4x1N1OydFBl3dumGxbkjd8V0/3p/wB1jbKtDHExvS67yn5PVVKk1RZEVC/Q3ywNbqVhUJUBQlEVBQAISjKAqAS9LITXJZ0SqoWUH3gUZKC6jJePt7phMl+GKV3mEIogqWGSE8MUHVuwK/GAAvmZNWvZyHsiGqgBTtqlSYSQpBQ3uFgQBE3VaVounOd2SnAFGgFrUchs3TdQCA1QDd1wpUQ6ICMl25RUdPy2Fzu6a6PNodU4ACOwbsjSVOSIud4We6AC4/FOf8Sb6Komxz+KYRT4jTvgqomSRvFiC1ecY97DcLq7TYdO6htqRvc/wXsDowZbIjFzpAwfCnbL7T5j5MxeEwY1VwudcxyuH4KjZbri4NHF+Jhv/wDUO/VaXtZdHw+X5P3UQ+JbrDCZIXu9bLTN0+7ot5hn+zG3lcfVfxvo/wDTU/8AWz/F/wDC4yLrB9R+q7/2pRBuE4O5v85YsJ72DR3XAgnOz5j9V3vtVkPuGEMa7Qhx/ILzsL+ivvepx/3+P/uLB66j4o4N/ZDKp1JWxRhlmOsdNnDyD3XnOP0OLYTLJRYi+d7LXYS8lj/BF1tafhDiZohrqOjewkCSN7HgOAPfe663iof+nkn7a5QreWLWt/OX0t6+VX7p5+HFlceDk1hZZlfXzK1HG+ccD4XGXbmIH+6tzW1dHRuw+krXN91rY+SRvrkHhaXj0n/RjB2eZGW+jAtb7RDJHRYU9jnB7JCQfBDQnbq1y9tzkn3tWOF24bw7xBi8Re+qYAzkshb1PaTfvYCw8la3A5pBXYniNLSwRkSvYJKhuYxjcloGlx5W/wAJlp8Uo4cSY1vPkjEcnzB1H4rT8OubWYRi9CxzRMJZR/evYqfDLLLPK3d+0rk6zi7GpqkmLFqwR30u/X56aJ+A47iTaykpBWXhdKAWZRsd/wAUrhyjy8TwUdXA3cskjkZfYHsVsMRjpoeOqQUzY2MYY7sY22QnTUJS/LouPHje2T4W+JMcxPD8ZNPSVTmRlgNsoOp+au1VHFJw5U4M3Wekp2VBPlx1P/fqq+LYc6o9olLEW9BYHn5C6t0c+EjiWeqZiTpJqkmEwmI210Auq2x8amp8bUcPmPDvCUGIQNi96rJNXyNvZg7D8PzWs4jF8SNQGtYJ4mTAMbYajVW8dpH0+CCEvdIKerMTL9m2uB9bqnxS7LU8nvT00cZt5Db/AMVWM8xGd3hcvvt5hNJzamR47vKAOPdRpmJ83UXBXS8yejhKc2uysRz5XhzdCFRHomB1n3PdMPUOB+IJJpBBK65bsfReq0couHDa11898NYj+z8UgefgJAf9V71hErJ6ZhY5Vimt5DNfd2pVpkhOioRtykFyvRWAuriabmuia7slD4tVHNAvZZ1cXYpWg2VXFsLw7GqGSlrIGSCQWuW6pHPRidHfo+3bwPjz2bv4Wq2TU3MqoagnIxjdvmuKkoXfDync4nUM1AX0fx5S12I8NyQ0Dc81x+C+fMUo8SpXPFTBLGwEs+EgKblPgarW+6FtxnjuPx/JV9tCnZCP3gpbE6V+VjHPJ8JbBQFt1sMLwupxasZT08Tjc2JHZbTCOCsYxeTK2ndAwbvkbZet8LcIw4FSCMazH4z5KjLKRcxRw5gEWEUEcEettz3JXSRQHKmxUuUq1HFZc/toXC3psocLbq5yxluFXc3VVA5ji6I/s4PDdjquNbIQvR8Yp/ecOmYG3uwrzi1iQdwoy9nDMwA+aJuUalySDmcmZbeqk1iNwP3kTnEJGXLqsEjtt0wYHEbuQul6rBDmG5S9HaFAODSTc7IS4R6tbqoBGbRyMEOd0pAAzynVWYm5fvaqG6D4UJcSbNbqkYw5xOVX4XcsNCoAuCZG4l6Rr3NBeCeysxzRuf1OVZskUTepWYuRlz5LlOEsR1UbXdDbuTPeJHa5UDZobXLGtRNljt8KqEvlYVhUXX6I+VQRfVRoFJ0UFKhiAqT4UFTQEoCmFAUgUUp6c5KKVUWQlfeTSlFRVx7Tg4DuFKF3hgsr7R0hUeHrScHUh8MBV+P4LL5nL3f8vY+xiglFbRDukGISbNujslyXyXQAh19Shc4hY0dNyiLboUQ55DfmihuRbuoNsyNts2ikGAZXXzLJJLaIL9XyQE3fcppHclwCZnKSCC5P2CADK4vT4W2Nxulamye02b0tukT5G4jdI/iTEDJoec6/4rV3XS8fRsh47xdrNhUO/Vc0ur4fL8s1nYsBo5QIc25O3ddDhLsJgoxFW1r6ape87RFzQO17d1y4NnXCaCL6brDm45yY9tdPQ9VydJy/icd8u1GGio/2KspKoej7H8CkVWF4oP52Cd4aNOrNZcsAQLnz2TP2niFO68NbOwWto8/ovNy6TOftyfW8X+ouT/3MZW9kxLF6dthX10fgc12y1lZVTVfVU1Esz/Mjif1SxxXi8dgajmD+sYCsPGVTIwiaio5P+i1/1WN4eafEv/d2YfW+C3dw0Osxmuro4IKqskmjhsYwbdFtFXxTHcQxdkcdZUc5kRPLu0C19OwQu4lo3OvNhMe33Hf5JbsYwN3xUU7Hejv81PbyT3K3x+pdNl68LGE8QYhg8MjKR8eRxDyHtvqqVPitZRYiaynl5czySSNjfsR4TG4hgD9MtSw+rb/opEuASyBoqJ2u8ZT/AII3l841X5zp7u7nluW8b1ucSS0VI+Rn38pB/FaKuxF1diT69rWsne/OMnYqucRwuKWRr2TzMznlvy2u3tpdMbiODHX3ecf9/Naay+1c35np/OlwcR4qMSZXGoaalkfKD8o+EnwqlHVTQzse52cB+cg99fKn37BzryJ0bcRwgWPInt9E/wBX/SX5ng+7c0fE01JNMTSxTRyBtmP2BaLB3zWlxSSWqp56iVzi+R5e89rnVYcYp4/5iijJ8vdf8lVrMSqKunIle0MA0YG2A+i0wxz3LY5ufquK4XHCe3D3siHlBu5EF0uSDCLfRB6IkGtwSGJ7HN3BC9v4XruZSwkO0LAvCos0krGN3JsF7BwrHJBRwNd2YESlY9KpZcw6nK+JAtHRy9IV0y9OiruT2rkk2iVzhsqnNNrJbprGyzyyXItumsUTZbqjzLuTozdZdy9NhGb7rKzAaOugyy08cjDrYt7pULulbSklDo8pdlKvEq5WbgLBZZOYaCPPax6UdJwbhVE8ugoog479K6kOAeQdUwNaSl2ltpm4dHG3RifHSj91bYwNcy4S2xBv3Uuw+5TFLohMNlsQG2SnZeyVw+xzJSyjZV5h1K8crjokzNBF1OtLa+Rt2EFeZcQUb6LF3ty2Y/UL1F1sq43jaNhgjkDOu9r+inL0I5ESWb6o45HX1Sg0jqKbfS6yWcJQXWLkYsqzWgvTrFu7kwblHdRbskc4h3ojzOcNEEMxx7ZtVgc2PQaoBHbUrC5g0QB84ko2uPb4lVcQ42ZumQxOb1Ocka41wtY/EmBpGyrNB+LMnRyN3LrJGdDSh0wLn3CvZg35Kq2VrRZqKOUl+uyDXow6XbQK4x0bG5cyoNmAb0uurDJIMvW7VNNbMrFBKzsv0Z8om90JWXUX6kgxQbXWFYkEHygKIlCVJluS3JhSnKaospZCNyUSpqo9q4TPM4Npif3P0V+M6XWv4JOfg+AehCvxnSy+Zv7sv8vY+IdmBUpPonN1SUh90mQ7BWHDRViDdADqG6qb9zshc4DQpcpJ0SCC4XusEhOjVDY76pkbQzVIJ0azVKEwL8qmY6abpcP86Dl6kbCwN0zmHZJMhDrKdXG/ZCTswzKyw9IVZuVupRtlTKvl72gBreOcUa11/wDWX3/FcwSup9oMJZx9ioHeocfxK5vlG111T0+Y5rrkyC22ZF8lLQC+x0THUk+oDbi3ZTUYeQxku6S643/BZJYOHTn12UCjqczMkTgfVyybnQVFnZQYyLFnbv8Aksso68K7aHC8Bmp4XS4bh0chY27DWyxuBPm7bXW24u4YwIPpWigpoS2nv9nVtgJ2/eHV81aop5/9CcMxSavqX1NUPtOZVtiBsTtmaRfTZJjNVi1ZDC98r+Z0ZzUU89h8rXKwr1sMZrWnlfElJQYfiMdPSMkYQwGTPUMmGu1i1b+s4JwqhrKWJ9RWTGWFszwMgFj2uSFq+Nm1EfFM2GFrZBSSAM5cDY3P2JvlGq7yqlpMYbA6jrI5jDTgSR5mB0emuYOaSFN340MJjuyuUl4Mw+txL/UJamijeNGFrZAyw1JcHXXJV2Gto+Izhpn5jA9rBJltoe69Jjiyy82lnguBYvY+C4B9RZcniXD9XQ8eUceINcwVUjJc87m6svqTl0AUzc9rymOvBx4QonUHMfPOKoURqiNC2wuLfWyeOFMIpBVwzy1ckkdK2ozhmjL66eT6K9h1RBW12L0FPUc4xU08NPn0L4w4ubYnfQ2C2MVWK7Dn1dNWVMfvMYp4YQy7mEDVwbv2KzlraTFx8nDlLDxNSYdJWSGGqiEgkLQ0gkEgFRQ4DRVlLO41lTHJTMvIORdt72sDfXVXDjMGI8cwTU9PJWw8oU5YWDNJZpuQDtqt5FLJh3ClK1j3MZJGyOMG3xF5J/JabrOSW+HGYtR0+H1TIqeWWQ2u8vZYXOvT5Coy60klvBW/4wMjK6ip5Piip/yzG35LQkZoXgdwVU9IviuSAI3RWViSlMcDHnW5snUtG6Waxbr4Q7IprBc7LbVGBVEecsZcDdDhuA1lbILMcxl9Sf4JbhncNUDqvFcxZdkWv1K9YwuMx2C0uC4THh8IjY35nyulpxZZ926em7pHEAFXOZ/SWtikIZomNkdsVVokXDN5Vd0t33CW6QhtvCAHuVllkuRbjJ3VqKSypxHpT2+qmVS/FJ4VuKXLqFQjLWpzXK4TZROJOYopKvK6wVH3gNZYqvJNd3xKpdIsb39oMEQDfiQirbnsHtK0Tp3WsHKiJnB9811VyKR1Bqr6JdVVthg01eVoffHN1zaoJKsyP6nXR3DS9FWuY/Vye6suLLUczqumtkJ3Wa1xzr6rkeNpeXRMbm3K6i+llyXG4/1aFx82UZelRx4JI0RtkOxSATbRG243WK1oFrRoh5rz926HOEdxsgCafLUfMZsHILjLYKOU1up3TA3OIQAXN3KW6alS5zjokBtcwfdUiRDG1trlY8gHTdAMbI7NY91bbG0tVOLrdcpwm5em6RrAicNVZgNm9XdVGzn4jqrkTjIRbRI1mMNaMwTRECL5VXsWv6NfKeJpLfEnKmttdZdRssJX6M+UZdYsWIDEJKwlQoMJKwrD4QpUwk2S3IyUpxUqA5KKNxQfeU049l9n5vwpB6ErZX6zfytT7OjfhWP0eVtpOmZ49Svm8v5Mo9n/AIwYd1Jgckh1lLjolTHI7p+JJcQGqHOJSyMz7KQC/XdFYltypMYGqEX7pbNmuwcizDbwosgLc17IJA6nEIWuLZrDdRGeXKbuURu+0eVOwN02R1t1Lc0iS12cl29tFaGtgNEwYBZjTuU2OznaKu5xLiBsE+laQ2+ZOIvp82e0pwPG+Kgb84rjwe2ZdNx4JIuM8UZL/Oe8PufOu65kBdU9Pmea/wC5UHmHZ11YhnngAyv+nZALDdZu1Ks5ktDFqhuoa0EfVBTzieblPY0GQGzy7QOJJuQq5+K4SXWvdzrX8eixyrq447ao43hh4MwjCqP7CemzGSSRrZA9pvYZSDbUp9HxvhGE4SzE3vgrsXjJbHSspGRtJ88wagD5XuvNpYnOjY5znPfJc6/mUnkPd0jNYLO3x6duGVl3t1E3GRo+OhxJHFS1VSX+8GONzixjiLZbka2VSr4wGJY3U19S2ehZUm8sNC7KJL75nE3K5wxlpLTuEqRp/FRqtZlN7jrsMiwqtlq5aRtc+EsIFKXAAOI01zapXFMIpTgnvVVJJVPa33jPLzMjQRp3sAuTMZG7VBU9vlt+J41p22N1WBA1NWysZPM+RnJFO7qY0NAPoFWw5uDVlNXVjG4hCaKIG4eGk3PodSuTaM1+nYXKJriGFoc4NO4Dt/mjthd93t0WD1EcFVU4tRufHDQhpDJnDM/N0kaLdT1tFNS4ZBK6kHu1OLmoc6zzrp0n/NcKBb5J8B6S0N03RcRM9eG94kq6errqU00rJhFTNjeY75bgnQX1sFr4W30SFZoz9sB5T9Q55p7cIjnZYtbdouPFxsm4Rgoie+R/U++tuy2VJCQ9buJrA3Rlr7rK5O2K0GHRlmV2x7K3FQtjdo2wTI97hqvxhsjbhZ2tIrRQgFXomnLolhoGiuQR62RPYWY4rsuEEzuS0X7lWom2atFXVjZ68RxuuxmisRshJm3RX2CqNkIZdWoTdlysqtYj0Vll1Xa6ydHKE5CtWA626c2QKqJGlYJNVoFqQ5tkuxRxDp1QuuEgRKXN27pGu6syEHRLyhIEOddQLopGrALaFUEtJO6sR3SG/GrUYSBhNmrkeN5L0UI/prq5TYLiOM6tpkjg77qMvRxzGbS7UeYgapIcia6+hWKliPXXMngAalypC42RtcW6FBrd77LGjy5IbIH7Ir32QRhGvxKWi7blyEC+6jKRqHINLmuJ0cibZu+6EkhS02OYpA3OToE2No+8k5huN0cbr/Eka82wATBM0eiqRm50TxbbdBrEJJNw7Qq412iqxG2gTM0v3W6Jk3uYD7ygOC9M/wDDrBP6/wDvof8Aw4wXzUf319h/UeL+7wfymbzUyAKM4/eXpZ9nGDH79R/fUf8Ahvg379T/AH0f1Hi/uPymbzUvaFGYH7y9LPs2wc/72p/vof8Aw2wi/wDO1H95L+pcR/lc3mZI/eQczsvTj7NMIOnOqP7yE+zHCbf7RU/3k/6jxD8rm8xLgluIXpk3s1wlseZ1VOLd8wVV3s+wbtWz/wB4LPL6p0+N1llpePRcl9POXFBcfvL0N3s+wm3+2y/3glH2e4UHf7fL/eCzv1Xpv+ppOg5fs3/s1N+GLeJCt3Wjlz3/AHtUjhbBosFwzkQyukYTcEq/iUQMAk7sK83LkmWdyx9V1dtk7apg9kwaquCjDiGaK0McPCgDqUh12G6XmIU1Rkps26VFd2qFzjJopjktYJGGS4ebo4yG6KJRmeoQSpJL1673ThmLyRsq8jf9Z0V1obHTC+9lmZUZAYWje904udyroA0NaPJTHRjS7tlZIBtYeVsIiAxa/KTYN+atx/D5TxRk+cfarCWe0Gud2JH6XXHAEG67b2qzczjats3UPA/AWXEAi3ldWPp8z1M/3KkHRS0Xdoo07KQ4jZKscYc1oG7Wn5pckJc7X8k6M6DM5vz8qSYoqhhllaw7jq8LHJ2YelWWjIZcOdkZmAJ20VYQmNpk3y9enhLjglkhqC6dzYy8lwzaa+B6qiYXbOzfosu7c3HTMNX2ZlZI+Qh1rHY6EhKnidGxl8upUFvTY6obkEW2B2TazRT9NELBd6OobypAPI/NBGesfMKWkFLaJ5axzrW17b7oWopjed6EIUaBomw2DH38afO6W3YIxtZUDW6q5RaVAJ7qkFbpM2cEa62CjL0vH26+njB1DVej0OXyqlIbMGZtjbVW4tXg+q57XfFmOPoKfCCGqY2ggpgFm2UVaWm+quQbgqm0dVlcg+MBGKlqrm5OHzSNc0EMNvmuVw2E5QTqdz81exrERNM/D423IAufVTSQCKING/dVlUxZaCXABXIxlZZJiblCtRi6iLQ2TsUYcAhEdnn1RWtoVcITZDfRPiNyq7PjVqMaXTCxmAQOkPZJkmyvDVLjbUI0AGQ51GawSrlr9UzLm1SNBcUR+EIPRMOgTJMbRdWwRZUYnZnq40dKRhlNxZee8ZNH7TZbe2q792q4XjaPLXQvHcaqc/QjmhcI7IAQAiDlkoYcLWG6IZjulho0KaLt9UjGCxumVTmAOiAEF3UiFmu+HRANjku2xRHwHKu6T93dFG5x+LdAN1DtepHcZUN9NVGh0CRjabaq02z/ALqrBp2U5nt0GyQXxlbomM1VKKUq3HeT0SNcjADL+U0ONlSEjmkBWRKbfCmH0ysWLF6LkYsWLEBixYsQGLFixAa7Ff8A29/0Wuw/D21URe5zhY20WyxX/wBvf9EjBHA0z297rw+o48eTrMcc5407MLceG3H7sOBQH771qcWw0UORzX3Y7TVdTfutJxKRyI/OZX1fScWHFcsJqw+m5eS8kxtXcFN8PYn4i7LRvKq4Cb4eEeNS8vCp3eGXXo9Jf9rGufmn+5lGta7YpwPRoud4d4gpcdozLTu1ieY3jwQt41w2XoucTnJTpPChzkrK465t1FENikcbg7ImuAdcoB0tsiy3ddIzHSnNYN3SjKQz1QyOLZhbZDJLmb8Km0MabyAluqsRlpJLuyqiUiQAtWSyP7N0QSy6TrBHdBI8uZfNoq7ZHy3PZmiblyss5yNgccxGyu0RdJcLWxAnN6K7TVAhYQe6eN8oy9NZi/s/4b4ilklr8PaZ3/HJG4tcfmQuXrfYRgMo/wBTraymPa7hIPz1XokZLnh7din5nbha3c9VzZcWGX7o8OqfYRicJvR4rSzi9w2RhafxWirPZBxZSvOSngqR/Uzgn8DZfSY5cwsN/CVJRBxuXJd7K9HxX4fK9ZwLxRTs+2wSrFvDc36Fa2fhyvo3MqKyjngjDCZDJE5trepFl9N8QcR4Lwq6nOJVPLfMTkjY0uebeg7drrzfF8b4s9oUNXhktGzBcFcbG7M00jOwJOg9bLPPkk9idLJ4xrxCaXNd2awkkLwD+7awSnW1JdmX0lgXC2HYZhMNI2ljkY3czMDiSdypreGcCmbabBqN9z/wgs8ctRrelt+XzO6/ySScjr919DT8EcMS3JwSmH9i4/itNV+zvhh29A6P+xKQi5nOmy+7xaWRlR/OOaJNB6FKkgMLGP6b32zX2XrE/s14dc77NlUHf88lUIeAsKkYwt5skBufjsQdr3G/yU98X+Bk82maZJTIzUf2UsNO52XqLvZ3hJddstWB4zom+zzCPvuqX/8A91OZwfgZPM25XWtpc2WXs7VerUvAuAQPuadz7a/aSkq+cP4Yw1gc6jo3m+QCNokcT8gj8Q5wX5ryCIZnWzW7fitrhFJLNU8uGJ8zwQSGNvovT5sDwjE2xyuwuJjBqy7LHXyE9sUOEskNLTxx5IybMbYaeqVy3F48WrvbkQOWbfCdldijtZUzIZqjMfic+5+ZW0iaMwssXQtQiziPRFsLpUchExB2TiegeqNHtLSA4IKzEmUVgNXvBsFq8QxR9PIYoGtfIwi49ClwxyVcoll6u/4p+h7WaSJ08z53tsZDcraRtMbbptHSZYQSmyxWswKMquBHlWqYAtsUqKIhmqsQi2qmKMdH1CyiSNOPYqXC4WsSogEPsrcR8oHR9YKY0JwESWkl0RSXFvVAf9osO5THG9ggFSDWyOI/kok6XIDcNuEBjjrp3RlxDP6SCPdqyYEMuEAuKSz7rZxuuwFaVrupbKF32WqDMJuVxvHbf5hxb9V2IIXJccH/AFeH5qcvQjimk900W2SxqsFwbrFRwBTGk2slE9OixrnByRm690QLh6hRcDUrMwCAPKDqpMTstw5LMl29KKOU90BgkcW2KaD03Qkg7LB4QZ0chvY7J2bp9FVy2+8mNd5U0HjVNjc4alyU2xKf06FIHRyhpB3VltS23wqtFlBTjlv8KZvqC6y68cd/KL4cDiG0lSf+lB/+o3Ae1FU/3V390cuns2izReLv/lH4GG3bQVJ/6Us/ykMHI6cPn/u/5o7oNPbFi8P/AP1JYX/+2T/9/VC7+UnhwHThc5/7+aNjT3JYvCT/AClKPLcYTKhP8pKm7YTKjY09pxf/ANsk+S5eKrkhN435CvOJv5RsEseQ4TJr8lr3e3yk+7hMn5Lyus6PLn5JnhlrTu6blwwwuOb2A43UiAsza/v91rZ6qWc3ke59l5efb7D2wh394JUnt8jOgwl394Lmz6Dnzmss9ujDn4cLuR71w/JeiWY/KP2VUg/uFeCRfyg6qAZY8OsP7QVPEvbziNbSyRCjtnFr5gvY6fC8eGON+HByZY5Z3KKPs+46GBcd1uG1TrUtTUu18G9gvoRrgbOGx1C+K5pp5cQfWB+SaSQyXHYk3X1B7LOJJOIuDoTO69TS/ZvPm2y7cL8OXL7u4JF0mU3cAOyxx8oHHW4VZRMMcRGzO9yOSUZAR3VSS8rcznIRK5zwB22UbUdUZhYKYyXaLJbmIuKRHUFouGqaFiEl0xv2UVkmVg7FLp5XNlePIVaoL5HlxdtslvwSzSufI3KPKc6NznfFsVVoZnczL9Vc2YXudsiBkQygkqHOu78lEN3PHVcbqZgO3ZPaWwhq2wUjC5jngDXJqQPkjlxSI0z5KBsdbM0fzbXgG/g+Pqoo8sdBG7LnzDUjsVVq8HoMQfnmp2l/Z46XD6jVazyx8tbj9FiGN1eHRNYKGCnmbUyyMlOd5GmQWtoe906ajqrWhxKsjAJ0EpR4jh1W2jpoaOWeR0V7F8/UCdnOJ+IDwtK6uxqhpnmrzWubnJzCzYjYa31Hoi4wd+r6VpOD6Z2PNxSpllq6q1uZO8uy/K+i3DqWKKKzG6LWYjxJNSvzOpbw5L31BB6Mtx6l1j4WU+P09XPNE1msdS2nBzbg6B34ghZdsjTDKfDZcwRssGXtsqEk3vDczHtf26HXA/BUeNsTmwzhWrqKSWITAWe8vAMbToXAdyOwXEjiPDMJ4GpII2zz4m9hkhpaR0gIYT8UhG7juUlXk1dO4mhky2OioSU4H7xK5WLHK3B/Z/VV02Le9YjLZ8IkfzAy5AAF9SB39VysuPMq8YnkqeIHDNVRgnlW+zY3MHWAsLv0t37qLjsXlk+HqMNOwvDpMrACNXusFo8MytozGNWNkeGHy2+hHoVqabH5eKsOwgv5meGpklqJsmWN5As1gA+et1rsZgqKvjPDsNp6qpjBZzqhjH2YGDbTySs9fDTv+XY3CXNLyo3uy3sFy81RUY/xVU4VHPJBh9AAagxus6Rx2bfsAq2HVZw7iOtwqOeV9FHNDYSOLsmYEkXOu4TkFzdNJSxPPMezOTucpSw2lpKhk0nIgZYgPfZpJPzXOT563hit4jknlZUiQvprPIEbQ7KBbY373Wy4jFDPQQw1cDX1tXG2ON72nLCT3J2Gv1VaK11Mdha6Cu1w6e2v2bv0SJZfcGwQDKQI7EvdY6WGnlU58XJ51m/ZxZr9Optf8ilVbcXDOfeYxm03K3MNQCbDdcjSTVctSHPiyDv+Oq31LKXTtcNrKRG5DrMDj80qfERG2zdTsqk9S4vDW7IY4TI658pbOBjgM1UZXbvst/SU4DgAqsMABC2dOOpRbtUbBoFwAidGC+6CN1pW3RvcM10VaALLNnAhLMnUEVyQiQtrTj0hFdKbct1Rj4LFWGEhTezLhBJuFEjxHGSewTgLLS52YbhY4HQqrSVYdUEDYq5L6IAb5tD2REDZLaRY3UZibICSMqGR2ZhChzuyXIbNunASLCRX4z0rWRuvMr8B/pINZ+Ft1wvGlYZKhkQ2C6/EKtsVMTm2C8xxOudV1j3HUX0WeQiu03ajF0i/VcJ0ZzbrJRrSERsUi5BsmA2SMwXy2KIZRuhB8otC1AF030UlqAZQiEgOhQB6ogHZUvW1x3WRyuGhSM22l1MYaVDZtbFSTbZKksWJbZqsxWa2791TjlIRiR0hSNeEjGuumtkaRdVo4mFmrk9uyDeRc1yjmO/eS1i9RxmCR37yzmuS1O6APmO/eWZnIViDTnd+8s5hULEEkyH95RnKFYjQTnKnOUKxIxZyoJUKdkBgJK9q9gtbJBNiFI+VojkAIZ6rxUL1D2JAu4lmaNyxVjdUq97qprOADkTZhy/KoYg2Wnk625bqKOoEnS5aWp0sAk6Zk+J+VUpHEXsiikIaSXagKTbCYONmh2ltVQmLg9sebS6ZPPcB2bVa6SR7pLl2xUZUNtGeXIQXa2VeRz8j+ruq/NcZc+bcJPMke49Wii0NlQkl5Por2QSMN3LUwSmPTNYuV2AXNi5OVNX6WNgsC7VHM1o27oYQyNhKRPUEu/RX6iLV6jqQIREXN0vs7X6hWmuG4cuBxjCZZsSgrqSV0MwBDyHWvbZPj4mxahYIpqVtVb740K4b9R4+PO4Z+NN502WWMyxdq/qSZInZbjZaCDi6KRw50D4XHzqthFjVPNbl1DN+7rfqunHrOHP9uUZ3izx9wc1OHOIfrcWtlVDEMNp54RE+likH9nwb/qtq2okfqGtt5GqTK4EarTul8wpPu4XivBYcUoo6SXDqmqjDw+0DxHYja9yLhcvj7n07aH9nS4hTTmZkVR9k4hjBvc5belwvWJFUmHTr3UWHcdvKuKsPpauj0r8kL6d8THmLNK8l2uVosSSNL2XO1WC1GHw0uIVj200dVUtkPMpz9iQzKwPs45W9/nuvZKiFmbNlbnHfKLha6riDgWubdp0ILbgrK3VV2SuUw2ip+HOF2Q11ZBywXEzB1g8k3v8AMrTcI1T8SxHEccD4nySv93jYXXLIxsdPK7OSliMIh5TOWzQMyiw+QVOoifS00jqClifOdmG0YPzICjuV2+nHZsSwPiDFa4OoYWVfWee5waTvdttzf7qChwmodgNLUzPacQxmvbKL6EsAJ/z+q3Zwl9TUiqx+qimMH2kdJA3oZ4JG7j4TY8HildM6RjmfbcynIdZ0YsNR4udwq2z7Wro6OvrMCosDlop6aGKS9VJI2zcodfK3zdbisnZxExmH0LJJITI0zT5CGsa03sCdybW0VykxSploxFNRufWxHlydVmH+kHeD4Vh0JmcDK+QWvYMcWjX5bqpltUx0uSxRSPs9rXkDY+CtdjR5eEVVm7xkfirTYuWQR20uq2NTQjCJ45HtEj2aDuUsrqeVybcK2LKz1KuRw5YhZLgbzX6q8GjM1qy2ZTYr6qzB8dg3ZY4BuymHR10oF2yfC6z9PCrxuv8AVHG7UqtDa+2Ul2u6YZhoC5UBJ1XHZS6S7i4J6Pa7LZqOF1tC5UXTlwUtlcGgFVobbZslwjae6pRTAt+JE2qaZLByD2tSkaeVr66ciIgblXSbi61s7S6UhUROHAiUFbd0gy2WvgAi1Kl1V16JSKWydFGYbKsyoJ1KkzE6ppOJSJ3F+gUglyzl31KFFRx9ymOnDYyolIjYVy+MY9yGuhhd1pW6MPEWMXpzTxu1O65YHsVEkj5Xl7nXKgeVlbsDTGkByBpuLKW22KkzHOI2amt1aljT5Ig7qsEjgrXRtCxRc7FIx2aWrBYO9ELbhQT2QFkSC1ilO3Qhp7OUga6oAwL6pwccqTYt2TY5OykCDstwnRuvsk2zO0ViEANsUGfEPLtVZDGW+NVWgXudkeeNIPJ1imyyy9RyMWKbLMp7NQEKLJnLcfurOW791yAVZSm8p/7rlnJk/ccgE2Up3u8p+4s93k/dQCVid7rL4WClk/dQCLKU/wB1kUmkfa6Ar2XqXsNIHF5HovNxRyGwG69k9h/C9ZDirsRmY5kdu6mh7pV0UVYxzZGrnMQwmShcZIcz2Df0XV7m6iSJsjC1zd1UocW2fmQ5/CASXOrlexTC5MPmMsTbwu3A7LSumLXFOk2DpuZZqX3+apMlI1TIJRIQHKb5Cy2QEXDtkcNtBm3WskqG5nsDu6fA5mQOLlAXJAWusn0M3W8vdoLLTy1Fzdr3A9kyjlaJXnNfRTLqprpaqqAjGXMFQnnysBzbpM1Q+QAnv/BVpJDJkEjrC6fLyTGbrG5zH3Ww51rZmoXZPiGqwnqsUt3kL4jmzuWdyfQcepjIXJEx2pbqq7o23uW//irBkcdEiVzrWURoS6rkhGWF7madnJf7XxCN3+0OPz1UOaXFJlaujDlyx9UrhjfcWXcSVkfxNjf3+H/BJdxRN9+CM/K4WvlaVXmisz4tV0Y9XzT1lWd4OO/C1NxTZxzUv4OVWTiaI/FTyD/qWuqIDmVKWFzXXdmC2x6vl+5fgYfZtjxJTv1MEn5JP+kFMT/NSLRygdkgyBoutZ1PJ903hwbOHGqaSonq2wOvK4j6N6QmnHmWsIHf3loWuaKiaPLkjAaWAbXI1/PVETpotr1HJ92U4sW9GPWFm07R83KDjlQT0sYFpWlMud0rzcl+VTjw+zYyYnVyDWVw9BoqcjjMC5znEjS5WNOmqkC2iz77vdrS4zXhVowMitRk81pKq0/TK8Zu6tHQXXq4+Y8y0FQ9wcQNkdJINAVWkcXOsigdaWx0srkLubOWzYrjdIbVObNr1XS31F2H7wCqCW5uVehtszVWIKJsxLrhy1oma51kyCS9zmQJWy5jrJrZLjVVYpM0XUoudx2TkUtGo5f3tkiDEOZVW2SJDp8W6CGO0lwq0HS8+zB1JMpHxBVg5xb8ljiShSJJruIDkopbgQ8nyjDgdEA5ujdE6MZklrrCydBI2+qAuNjAbdKmmEcR9FM1Q2Ng9VyHFGPCKL3aF/2h3soqgY/xG6M8ind1dyuTdK+V5e51yUsuLnXc658ogfKztOGA9kW2yHQjRSD2KQGHWKNouoBDtFhu1qmmdc5bLGnq1QxyAtRbt0SM6MgqSkZSHaOTRcbpGLUHRFvugEgCISByAgGzsuZEsLRmuitbVATm6dUxuUtvmSyMzbrGt6dUgsNdGNUTTmfcOSGxHdGG2SNdbqfRNyD91U4iQrQldb4Ug5uThSqjiLzF0jw1UYMNM9RyY4HF97fAvrD9kUVre7xkf2UuLAcMhlzso4mu/sr0u9y6fNg4Jri0EQP/ALic3gTEDp7u/wDur6X9yp8ukEf91GKeED+aZ/dR3U+2Pmxvs+xEt/2d/wDdTW+zvEToKeX6r6SZTxDZjf7qzkx/uN/uo7qXbHzkfZnio1ZSuJ9XLpvZ/wCyWLEcXlbxBTv5UYuGB1rr2rltDfhapaADcaKplRp4pxb7JAziKVmAxZKEAWaXX172K18PsmrjYPY26960Q2S3Rp4i32Q1X3mx/wB1WI/Y/KR1Zf7q9osFG7kbGnkkHsbYR1Pb/dV2L2PUQ0c669Q2asAQHE4b7L8Go5A+SBryPOq7Gjw+noYRFTsaxg7BWGjyhllbEwvdsEgaNN1XnxGnpWF8j2gBcdxL7QqTBZC1ztMl14jxH7U63EGT0lM5zIHSZ2E7/L5J6J6lx17V6LD6OeCkfedugC5bhfjuDiKIwyubHUjWy8UxDEZq2d8sr7vKDDsSlw+uZPE6xaQTZMR9Ke9ZWhp1TKeqaLly5HhfiCLiCha5jutuhC33MMRs5Raelkz3lD8u6sxT2iP7y0ctXY27LG1uWW+bZTtNjZyS3OrtlZoquPPfsFqOdzWFyfR55WsbE2779lnanKzGbroBVGVpeW2HZVaicSC3ZZNI2JgjDtt1qppzISM1mhcPLn318V13XXPkvbfDbU+JMp4cjszwBof4I/2zGX5S23oud5hPTnuUPO6y3NqF52fS4Xdb8P13n49S3xHU++xH7yjmB2ubRcxzuY02fY/mnxVs0Y+LPZcufS5T9r6Dp/8AUHFlJ3zTflwCTIW/vLWRYmJWkdQtoQj97ZI8sDtbLC8eWPuPd4+v4eT9uUHPMzm2bmOn0VOqm6hZOkc3TqaqsxYOo9k46pyStfUVkzWFsDev9862+i1J96LLPlce+rltZHNvpqEiUAX/AAW+F1BcpWsLZTvqkujeH5HMdY637BbB19LN+ary/Dcdltjkm5Rjo29PVc23UCMfioMrXZA3fZLlqmQktdoQtfNT+JjPBxHcKVUFaMhAbcJZq3uaQ1jk+2s8uowx91sWuaNHOTQ0l1loJOZMwxvfa4srM0stVTe7l+RlgDbc29VXZa5suv45vydLeOrkI2OyZPUWhDUqMGNjG7gCwv4ScQjlMPMj1A3Xo8Wc/bXnY9TMsrBNlAcSFBcc1+6pU8lm3ej5odKXdtguyRvtbE3VbNoozXvbuq7pAGgeUHM6XWT0ra2HZdArNI4nQuWugk6wCrkUrInepRo42YkyMIDtUUVzYFaptSc93O0KifEnNH2aa9rOI1TTUiJjtButjTx3awhy5hpdI/MdyVuqeq5UYBdsjQbxrgLpbpWtYSey1cmKCNls2q1s1e6V56tCjSttq6rDpCEv3uzrhy05qiNtVMcpdqUaLboY6uzMx8IoazMM52C5ufEY6cXkf9FqqriKWVhjhbkB7+ii3So6DF+KIY2vZC67xp9Vx8s7qiYyvdqUkuzG51U200WdqzM1tkYIclAEI2hIGM+FGEseUe+oSM0Du1SltN0wEjdSBRtTB07obgqRY7pGZ8TelRmcHdTUIPLOibIczbhBsNuywGzrqA3pRBoAuUgzmE/dWXRaHRQR2KANshATGu6rpLbhGCRqkFg5nOuNFIab2LkpshTHNc4XakDRZuqe2VllTjzZdU5rW2+JBvpVYsWLuYMupUKUAQUqAsKZJ3UHaywLCggbKQpssuqCCsFtysU2QTA/WyK9kPdcxxvxth/CGEvmne0zkdEfclMNjjXEuH4LDeqqGsJ7Zl5LxV7WY23jpZXPv2zaLyPijjCs4jxOSole8MJORmbYeFz8krnauc4pwnQ8ScST4zU5nPdk8ZlzplKBziTqo0yoCC5BdFZCUBu+FuIp8AxeOZjvsSRzGeQvcqfGcNxOnD4ahhJF7Zl84d1ZgraindeKWRl/DktDb6FfHFI3pe0/JVZYXZNF4lT8SYpSyB0VVJp5dddhgHG2LYlPDhsNG6rqpX2YB+voAsssbPJ3KSbrvIBPNIKePcrf0gbQwZGOu/75KKgon0VKGTNZ7y7WQjWx8BV62XlmwzG64eTO3xHxv1X6lcrcML4/8onqzK85tlWks7XKkulY49blF8osGOKx0+Yue7sT263zWSTLlDw917/kp1zXbA7XxulmKQgjlOcb7ZU9I2gGRrrt3t+SMTzlhAZa4uSe6G0sck2duQW3/wAEUYdl57nOsO+gRpeNuxySyNpiTKy25A1WCqaHMAcwXFhdyx1LHMx/PbYR6kjwlNERmY6FlwzS52slcI6Mc8sfVNE0R1klt6jQBDLVxmlOXM8k2FtvxS6qSMtEXV1m1h4RV0jZKaSCNjGZNTZt9O5v5U3jxvuOzj6zmx9ZVXgB5zmyOuQLgDckq22nBlLS1zztpstfgzppHyVLZWlkTLdbVsXVZkpy4tkYwi7LNtqO3ql+Fh9nRl9T6n1chSxshe4cpsj2bAfxVCD3WrZJI5jGWNiC45vwV6Qmb3cMd9o5mcguv9EFJJJE+YuiieLm9mi4+vlP8PH7Fh1/PPeVURSULWGR8ro36hlrqnNQ5pC4dbxvntay20lQAzLz2xm/e1vRV45YounM2Z7yWPybH1CcwkbzrOS3dyamsgkjyin62WuQy1iqbmzhzCYm9f7j/wBVuHQF1QJYmu1BsC09hrskmnldAx5ibqb66bq9N8efK+6ojmO+NjWEeXIuW6PqLb33srcsRawkukuTqNCPkkNaQB8VvGynTfHk3BNBc3Kmxx5Rl7KpHPaUsY24B1VvmtO6TTHL5abEqc09QMv82/8AJVPeGRuILlvqoMq6Z8LtL/kVyklLJFMWv3BXo8OfdNX29fp+Tvmvla98G5co97s7RVeW7Nop5Z7rodWlv3rpuXfgm/tAXHTcqjyzewRCMjUpHIvCcufdzk4yCTZa9uhTWykXIRo2wjlZGwZlDqzMenQLWuqWNdYu6kMWeofYbJmtzVd3WDrpZmfIQ0NTY6PquVE88VKHX3SPSC4RdUjrBa+px5t3RQO27rR41jTqh/JjdoO600c7mu+JKy03TOmfM67nXWLXUta0syudqrwdfVZWVcG26ZHql5kcbupTVGImnyhUgpAxp6kwHRA210SDFZMA8pbSS6yYEgIN7pjRdLBI0WNkLXKDNuBujvdiWJGndMa5p0SNLdRYrMpCEkt2RNOb5oCSL6hSNtVDbZkdvKAG6kOIOqIBEbBLYYGkp0eePQOuk5g1GD3QFmPK5urlPJPlVW9L7hWczjrlSN9KKVCxdjIQUob2apBVJSEQUAhTdMkqFgKlBVCEqSoTDAO6kkDVBJK2JmZ72sHqvCfad7WqukxGbCsIe3lgWfINwfRMnf8AFXtSwnh2OeJj2zVUdwGHyvmfirimt4pxiSsqnuyEksZmuGDwtbXYlPXTGaoldJI7clUb2cmQi6+oQ6lQTZS0/RMJcC0C/fsoWad3KNEExQpudkLrH0QAqbrCB2RR/GLak6WKQWKCjnxCshpKaJ0k8zsrWDckr3/gbgml4QoefM3mYlMPtH6Hl/0Wn9Vo/ZhwUcIjGO4gzJUysIhhOuRp+98z2XoOfnfd085lwc/Lu9sfN/U+u3fw8L4LnlcHl2VoFu61E84ld06+g/ithUcstLT9pffq0C10kYaxoY29zt2suZ8fzZW1VJGXMxix0mW+bT08rJCY3lrWXO5Obyqj4pHTMu1wBOpDuyHPjDY6t0j7DQjYbJsErwzXV+cn5H1SBeNlosxJO59EtzftT0ufuSWaaptNLDS3MXS5jm7ef8kMsRlLxHmId+AS3auBDXX0DLuuboftNHdQtewY4f8Ad01YxZdbRufQ9/LvBCCQlsWVz7PAvYafj5VaN08lzlbYWsS2xuFJLpZiAxr2G7fi0v3+qppIN0rJKgSiVxMdjYNtuhonSjnRObaOYEtIdc39bqKWQQTEuluyM3DA0bHz8kuSZjoqqaB7i++g8fJDfH7QWFsldiElPI5r4Tq8s8fRbgyRtlYwObkLCyInt21WtwUtbSSSRuuXHVmXW1u/onyyiOSSTLaBmurhqfkpqMr+rQZqqokcOS5khjvG/wC6NNL3VaGneZzM97BBHoQH2Gbum1EzxUZgywA2ZoLnuT5VCesnLAxkTWZ9gN9NyU41xm74XaV7X5pC1pZIDYDUfPVRVTwljI3N5cEeoL26vcqsbA4h0jcj/gByZWqCPtWSmJ0mXYs2v4TdGOIxA10xe1rraZOq9v8AFBByvdnueycPBIu/W6cKWKnjfUuzx5tSd9PQJY930bA+eRkmhztcAT4UOnCKF4Incpr3RzX1JaCLHwocXNeI5nNnB75bW+RC2ZbLFCZC+B5if13sbN8FVpywWGTU3vbSw9ErXVhVHlh17PcGO8dvBWASxSlmV03g5v4K3bmwgx5TH+Z1WOgYXgFvawIU7dMirJmtmHbsVqsaBhpPeg25jHWPIW/MUjY9deyrTwNnhcxzWkPFlpx59t224s7hlK4yHHqNxZmdYrZR1dNO0Oa9puuIxWgfh2JSUz+x0+R2VZsj27OcF6k8+Y9/G7m49IjbGXF2ZtlhjY51i5efx4jVRfDO7+8rUOO1UO7s/wA0zdsYY4m5i5avEsVio6d5Drv7BczUYvV1B6pXD0CqSzPlN3ucT6oDZ0OJuM55rrl/ldjhha4aeF5tezrhb/AsY92BbM/TsinHaVlQynjuXLiMaxR08xbG7TygxfGnVDyyN3QtNmJSkPade6wrFipImuI2W2w+rzWY5abXsjjlMbrjslljs5dOpHlGNVqKHES45JHLcNyllwufKaaS7Gz4kzKUq123CNshG6lRgFkxLabplh2SNDCMyaCl2RiyAO11gaQ7VYAQ26K6gxAd1Nu6hrjlsi0sgzGkFqxrSH3CCzhqETZrb9kglwIKm7sqMu5jbrAOxQANuUeltUJBa7RFq5mqQG0sLdWogAEptstkQBP3kBYbbs1NVdodtmTLH95IPpcKUF1K7GIkQQhSgJuiCEKU4Sb2WeqhZnCombqni2KUuD0D6uslbHGwd3KMSxODDKCSrndaOMXXzb7QvaZVcVTTUcfRRNfoBvoqhVsfaN7WZ8ac+hwqV0NMDqe5Xks8r5Xl8js73aklFIeq41Sjct1aqIo3OyG6a7ygLQW6t7oIseVhN0XLId5WW7lARspustd11ltfKAzU3soRajZZdp3QEHVq6z2e8LTcQ8RQvdBzKKlcHTG9h6A/NcoI3SOAG5X0T7PuH4+H+FYWmJzKmpAlmzu1udvyWHNn24vP6/qPweK2e66OQCwjY1rGAWAHYBVpJBF0t1J7+Faktl0y3K10zmtdfuvMfDc2fyTOGudlzaHU30CrmnB6gxummrj+SmRzA+5f1hS2RjpgS2/jpP4lNw3yp1LRFZwdcl23+QS56d2ozWI7h3ZWJo5pA9xi5cbTnuXa/NIlDZGZhmt5Lrpo1qlaxMyv6yRofKB5ZBAWhlyfvB2qNst5HuDZH6W+HRKbK6Jt+S9lxYk7IVJQxB8wY5wya3uXa29E0FolM7cpDDYv+6w/Lug93vPGzK7k63fmGnc6dwinjYJnBsrWRvtqG6AhNtPAZAZuXmfflvvbLprqsMDoap5ErWyEcwMF7a+nlZT/AGleS9t2CPfLuR3THPZHK+VjXPktk1aTZCpfhXkcWxSOe1jLtP8AaJ7BLlmaMKED2ufJKzrPqFM1N77me5roXNIL79wFNaGRyMjcxxY/752F/kqdGHiHYRGyqwt8DZWxvvYdN7/VHIZo4QAyDJ8BfqTfzZOjtFQxhrOS9g6PJJUviqzK+9RFCzJa79bH/FTXPLvK1r6vLZkcbXPmJGgcRusdhBuJ6l9owbgMab3Hr3WxbBF7tHyJZJJI7m7G2zn59kBgmiBlc7IXWIAfmI+qW3Xh/ZS91qKyWRs3LFNbS+mvj5pzjHBHeWnbDCwWZbU5vRMEuZ77yujDTYkuACGWGSaHljrz6l/xC3hPboxKdUFtPzWz+8i2rC0Es+qCKoZXv5kcWsR6xlO3pYpUdJXUsx5MtGxnwAZf+9VYcH0r+mCC97PJZbtujTaRQFLGYZDDLIwkm4zXuDvoUbo5WvDJMpFgM40B+iOKGopakOjfHPDrnDG8yxPojjq3VMskTonAbas/RTY6MKnkM1LW6nX4tFJp+W/KNWP1t6pjWxx/fdf+zp9UYfY3kfHroCHCyiumUkWJs7Q7apUkbdtlZcWOfmLbEfgVh6m26VO2ked8c4TmjFexn2kZs+3ceVw69pxKkZVU0kcjNJARp6rx/EaJ+HV81K/eM7+R2XpdPybna9bpeTePbfhVU3uoWWXW7U3WXuoUoDLrFlliDDfqRBRZYgk7KVAKxBsUrLqLoCQbOutzhlYXfZuctLumQzGGTMFOU3BLp14afxRht23VOhrRURAjfurgJ2XNfDaDAIRt8IRdF6pGJupRBYNEVu4UhjScuqLusCkpGZl7qLKWE2CI6oMTfhUCNRrHr2RtdnSAQ0jZS0nZQNHWKg/ZuQDjfLdZE7sVF7t0UNCAY6O2yyOSzrFC1zho5EbZkgaD4U80jTKli41CcJTb4UB9K3CkFBdECurbMSkKBYbqCU0m6BYgCm6ohXVesqoaKmfPO9rGMFymSysghMsjmhjBckr5z9qftCnx3FpMPoJ3MooDa40zn/BOFU+0/wBpUmPVL8Mw2W1EzR5/fK8usXZrafNTJL12zXJ3KWZCd3LSRLAA3U/VRJY38dlG/wATsrfKVm6rbhMCuC3XVZywbgfRYIw54Gdo767onWifbMginRPy3CXyzuU8ydYs3Syh8jQyxagFWzGw7KNjonHIocBuNkAl5PwocpFrppatrg1JS1lZHQzRZ5p3hjH6m1/QJX7pyuputx7OOFJOIOIo55Yne40hEkr8uhI2b9V9BDQm2w28BajhvB6bh3B46CkboNXnu9x3JW1a651d9DsvL5c++7fHfUOq/Gz8eoFzTm6G3d5Oy1k0bDJlLs/y2V2okDmOGbPr21VMOlNPldlZ89dPkFi8Tku/CkWlrPsWXPYn81hfI1uaSdov2DdQimnjDy1zuZYbDt+CrZpJafPleA/TsN03PZoMpEbTmzPvqL63+irzSvlcA1rWDa3gBHJq/lN6LaX30He5STG2wje/nnsWb3/wVFMfkwOmE7ImRNay40OhA8o3UTnPyyPvGx98h139UoOBmMmTOQy/w6/irEZfNCXB7ryC9jptsEmkhVXFzGGONuZjdOjXfwlxUj2gkyvswaAtCfEXSUrHtfJCGMG+1766KZGsc0AxPPMP72gCatKpqGMkLGuiyhgLrWv9fVM5zszwHtjLxnJy30ARmkbA95DGyCJmoy9ysywRFkmeJh2I77IOTXlWkgbJFz3VThG8agN3t2SKuaQVtOxjmtFSGt0dfIB3TXSOd8OUMfoSGk/UqnNefEKdpOQB3xjc6ePVNrx3fttK4RVcxhErudEOg9rIqWMRNvI73h5NtdgT/FU4q5z530sDGme9g8ttcequx09Vne1jmvA+MMbpf591BdtWZqr3ejMcTI4ZAbDdw+pC1s0FRy2TTtgmeNSMrh+i2MjqhrBFG73Y2672t/8AK1FRLisVZcsqXxgCzI3gg/VOOjjmzo6inMzJHRct7BreI5QqlW6tqKn3ilqKYAaZy7X5Zeysx41iRMkMtLVRg6BuYbH0PdA1rpBneyd4dtzGsuz6hDsxxKbF7xEYqqozZtJCxwsP4hLdT0DYXRtndVC1shlN/kntli5L4nsprP8Avl4LiAqvukJY90Mrs4+ABth/eslttjjtPJpzT3bStjF7AwNde/r5QFz8+QsaHgX1a7VKFLV+85pZ+RbxOdVabE9soMU8RNtSXkpWujHHRXvc0ZDJHRlhOrMjtvmU+8TbAROfGe41t9FLsQDX2kldYbnW30UGVgmD4nc+GTzuD6JVpBRyNbIYg7Qi7PB+SYQDZ3f80AijlYwhux0A7IwGuNg6x7FRVwMovqdivOePsOEVTHWMZYP6Xn17L0kjzlNvC53jKifVYDK2JmcjrHnRb8Oeso6unz7c48nKxSo3XrPaZ8lNlA0Ukk6oDLqFixAYsuFOzVCAy6lYsIQbFBUjRR6oCVijZYgLdDVOp6gEbLrInNliD2uuuJC32A1d7wud8llnjubVjfhvmjyiHxIdQbhSNVg1MUi3ZCNETQCpNLTqAmEISOoWRG4SAo23+8sPhZGVNhmQBB3Y6ogBmul27pgGiRp6ToVDhYWLbrAfKnq+iAgG2ynmLLDus0QBtka5SBYpdvCY03SAw4A6prZW2SgQ4W7qLgaZUB9JtcQmgjLcqq0oi6+i6WZ4cDsjBAVcabIwUypwN0V7JTVyntA4vpOHMBmDqprKtzDy2B3Vfyqia4f2wceObfA6CVzH/wC9eHfkvC5qglxA+qsYtic+IVklTO90kkhuXnuStbmv81tIi1Jktcj/ALuoBJ3Q3Ob59lJvv0/RMkAnbL0LCbaBBqH67KSOr5IAgPKku5jhdA0nZYB4QBna4Qa/NYLDVFyyNRqEgE3DrJjXE6OSy7X5Kb3GuqYMPhu67f2ZYa6bHJqx7rcgWHzK4e/bN8l67wDh7aXCWEamY8w/wWHPlrB5n1Hl/D4br5ei02RsberU/Uph5YZZ+UX2YP4pEVxEMjsg/MpssrGtyhjdNbrzK+MyqvI1htIdAD3209FWLopmPJlcWHa3+SOokjPW5mcNG/Yf5pUxkliDGZY8wHzA8AIc+RMpELXiCDXJ8t1SMseTre6MAaM2urM+Z1QKdr4yAw3Ga1vmVXysmYHin08ht/1TjGzdVnchsb/iL27jNe5OylrZXC7KN0bDckPdYaK5I5omYyDQyWOtht2UOo5aqV0zpWvAJNi6wH0TXYoMc+J13OY650EbSQB802mmnzcwRMAG4fv+CU50tO1xfqb3Zfb108eE0ziHOw6GTV5DN/kiKi5TytdCJzE0E3tft40UPnysY0/Zsadbu11/xVSecSRxs6mC2hy639FVdHmmF3czIL+n1Qme2wn5Tn80TyA3u8ZrXVF08GYlxdydbkai59UuVziTLkcxn9qwKEcqaIZctgb2zFUvRksl2kwMcY2gZTrfTsqIe4VHMbE/mE6HsB/BPqpXVDwGvY9ttGCWwCiH3ySmcyngiEYfqcwOvjVS0wxPgp5atsk0b4mSNJHN7G6sto8UjgMFKy4I1kzi59ddkVJFMGPZLLTUoB0D3DX8FInrKU80z0MEJNs4fmU1pjj9lFtJWU32Jo6Yvf8A7yaoFzf6qI6SSnqc0ssTHnR4Dz/DRVsVhy5KiB9NVW1v3F/ABSXCd0sLpqqRgkFr+76fIpu/jwmtr89RA1ln1kRLDqzK4/oqb28hmdk8cgvewidp6G6WIIqerLnTzzE72+zA+d0U00DcnW14PZ7y4n8EOnHCHQVbJW5xA55N9OloH13SZawOeYzUMhhuLgSk/wAFMUkTZPsaCJ7j3ETioa6oDsuSUgnYxNAH6FJrMYbHU0bXBrnvmLtsjgR+ayWUiqLGxdBGl320+iTG6uiflbFOxh8sZb8wrfvFS5mabJINhdrQB+CWj0GOTlvIdA18Z/rSbD5InNjueXE1kbtQRsCskjlD2Fs7WXGvLc0hYL8h/Ofdj+/r9FNVE/a5CR8bf+9U34srizcajwkDMGsLdBa2uoH+Sc17g5jS9vM8eUNBBoDfi3G6TVNMlMWu1KbdwfZ+WxNlkvcHUJSqxvl4jilO6kxWohc21nnT0VNdtx5hrWyMrWt26D8uy4q69jjz7sZXu8efdjKxRdZ3UrRoxZ95SAbqbWQaFiKyiyCQsWHVYUGxZdYVCAxYsWIJiZBK6KUOa61ktSg3Y4dWtq4ARuN1dXJ4NV+71gBdo/RdcCDqNbrlzx1WuN3BAjust4RaFiG3hZrGCjtdqEeqOM2SCIwQ5M0UXRWugBsdwsaXKW3zWRZe6RsJJ1CwSkDVYAO6khqAgSDu1ESC66gEX1U28IAmnpUmPruNkoh4+ilsjjoUEdYBMDQRfMhNsqlI30IJL7IgVSjmACbHLfddWmW1xuupRCRVuZ2DkZmZDGXyOaANSTsEGDE8XgwjDZKupdZkYuvl3jji6o4kxqSeWVz47kRjw3sup9q3G4xfEPcaCf7CG7Hlj7h/8F5TLJd11thj8srUPcS5QDbq8oQdQT+SLTMVZJFjoG6lE37QFuZottdQA0sv37qczTYN07BUQbdVu6Fwt0hGABrm2HbVLksX6aKQhu6zU7KL9lLbd3apBiISAXuoLXfFlba/ZS4WYxx3O4TADq6/lQLXvmUqN23SB0cl5hbvpqvbOFLtw+mjG1gvDoz1Ar2Dgir94oobud9mPlp3K5uo9PC+sS/hyx6LHI1rbht3AfH/AIJTpIxIAMztdSgjdJJHd7mhg2HlVppRFKDK/U9hbRee+Syo3OkLJBz+Sy++Xz6lLkDCwCOe+Q6fxS5ZKZsfMe10wO5fsEt0szsjY4mszi9w7TXyhlYg31ZFE2Rkhu87Xt2CIQ8zpLeRH2Gbt4QCKcse10sZIOw73Uy2IBE7tT6W0TTCg2nimMQa05tdNSLJtzHTlrc4I6wNu/6IqgtfEHRNjz73Gt7djZJ98DWPhflZITcEtOt/4IXMdon+06GsjkOxtrk+ZWq57GT9MrDcaiO51W0nyjR8tNHextmIPqNFqJKijlklBa+F4JAMLNx2KZzAc0rZAxsjpDbyqcV8kpdK5jP6Ddb+FlM+pAe8xTyxgWA9D6909sIy2bFJCNH5819Sm0mGgREyMuXyEC1rN7IZpg1zJY3OhhebWLbn12VuTKWCCaJ0YA3zAb99FWklponsMc7n5P35QAPlZNWOPkUlW2CjaKBzHkgjPk6x5QMmvDA2XEIIQ0/A+Im3zI7oa3EJJI38lrQ9rxYZwb/xT/epqejjMkHMzvFwIgQL/UpOnDDx6MhfCZHibFKaoimadAwjX0JWpnp6iW0MU8ccN7PZGw2Hz0T62ajdGaYPnYSc7ALNIP1VH3se7N51a2Zm2QPN/kbIkdPHxnObBADFTVsshjbYFjAdT2Uuqq4wQsNU6Rke7ZNDY+oS4qeGz2Mgy3/m7S/wsioovdJnx8+MEbid4za+PKK6pjItVEzpTAKdkucDU5eYPzUumq5nlskETLC1zliISYZKmR8jIaiBj7XeDLa/oLJc07p5bVVLcHd7ItdPVx1UqkWpoZ+Wxr6qO37j576fMBTLE2FmQ8s21OdziPSxVd09PA7/AFVsl9Lskc1v4Wup96PKmD9RcHSfUJVUgHVZcOS97WA/M6j1RXhgiDpZYpBJobM1+oQyTN5JaJZDILZQ9ws8fwUxxwTMADp4Jx2NiEl6GCwVQbFygx403F7p0UAa97g2TXR7M1x80PKaKfM9zhrbP2QxSdfQ5pvcX9fBSUfBK2KIxyNvlNtPB7/RNkDXOGZzmEd/4qvYh4mzZJCMjx5HYq3GJMuR+WwGj1NMwWLMrtT2S+Y3LYtcD4KmIysux7dR2ROu/U5fkgo5vjCn52EyfDqNyvK8hXtGL07Kygkgf98ELx2ZphmfGdC0kWXodLfFj1+ky/TYVy/6SINCi6m/Voux2DAssUXRHS3qgBLb7IbIyVhF9Qgy7dShNsFFggFFQjLbqMthqgghYpsoKAnsoWKUBjSWm47LsMDqDPSDM5ui49bXAaoxVwYXaFZ8k3F43VdcNNEQF3KD6IgbbrkbMaOyktspy90SAgapoPTYoLdKNlkjQdVNzl1UWJKIAhtkAOXq0RbtssWDV1kAJDg6+6O4LbhTZQLNd6ICQQUJGmm4UEddxsmt8oIpsztAWqyl6HQpzWst8SRvbmmwsU1rluqvBo5blmhWonoZ6V2rbr0cuOxyzOVMbrOXC+07i+PC8EfQwv8A9Zm8dgurqKoQQPke7IGC+q+duOOInY7jckxY2NkfQLdwO6nHE7XNVUxc64+qqbo3G7rpZK1SIDcKDfNpshB0RyEF1m7ee6QRezbDujaOguLkA0vbsiMpIN1QY5z83U5x8IS6x8oXSdV+nXdZ3HhSYg4HXLZQ7dCbh5B0WAjNq5IhguaDl+EfxQGRZdxdo752QuBCAm91H7xUbb6LNEA2JmaUNa67zoAvWuDcMq8NprzvYRKBlt2Xl2ExB2JwNLbjPrZe34dh0AhY5k7bkCwN7hcnUZa8PA+r8txxmMdDFKAwNb2CqyFocXtiuB37pzYnZWkt2FrhVSHRsN257bD1XDt8pl5S5wqpgyWJvR1hme4P0T54ubCY26B4A03SoYWtHPLnvkcLE7W9AhtS07BCHu5jhYEu7nsEJ0GWGlbbq72PUdSO10iQZftad1uSSTHodt04hlLTucxsZANywv1zbKrKaQA/ABLZ9mXzAeEykHNPDADUCWME2sNRod9AiNXE5waXx87INWNJIWRl8zQMrYwRoHxdu2qwxsqI2PE7uYBYljB2RtcmhEtmqHsqd+xyDVJkMUtYWtp5WPcywkNhYDx5TxhtLTsM0kssz75x12VZskbmB8dPnGtuY46W1QWyHSGBsjIGteWdi/cE+ELBy4JmhjGPZa8clz/8hNaY5QJZaWmjEgsLOsQfN0MFXJU0uZjctiY3ENFgRpe5TayfKk2dkjHxvp4o5AbXyE/XuqtRKyWTrZFaTQzvisB4srcddWQZOU6Wd3MLHWYDp6EqtXGokkMc1K97NCGPcG/XQpx0YYeWuo3tw+QtDnNfIdJHwh2isT8yR4YWt5cepeGuaSq7oxWzGmyxQmE5r5zm27eiszl1PhpkfWc8i1jG85gPVPTsk+UVTjU0bw+CKSE2LJiyzgfFyVRjgkioJmxNlva9xl1HzRGGM2hja6eOfXIz976lIhLGyyZXcuRt28vLqD6WNk2uEWqfnyYbM17miAR7yT639LKs2kip6QTh7nkkZsjLlgPfVWI2gNDpHumdaxYGhpHrcqxG6liY8SQPsbF5e+4I8f8AwlWkuinQMyCbn84aXs0NcQnSjlMDIIJ3vIuOewk/4LJp4IHgUdA29wY3hp/PNuk1U8ktY91VVOgedg95A+VhsEtHPJMssTpctfFADYG7IC111ciknEbjEzOc9xJyhYpL5GOlBc+J8egtnP8AHVTLCwyhkb4IL7FkvdJoc2eZrw6WjifH3ZykRdTtqMj4Og6ste49EMbavKxjZc77G3Xrf+KUJqiSnOZmgNr5tQfUKT0sQkQVL2l2emeb67/JGYqeZkhh7G9+9lDTI6QEsaOx8G4WNayKz/g1sPGvZKqTZ3LAc7Owaa6qyBK0ZRL0ZLa/xSJIn09QXDKY5fPYo42ua0k5b3+hCVgOjkfa8vXbS4/IprZWFmZVmuLTlflZc2v29LrAdA4bE2NtgloompuR6LyHHoRBjtUwbZ7j6r1qrcG0zx6LyfiBxdjEjjuQF2dN7r0uk91rEQudkIU3tsu96I9CFJJOpQBGgJuO7Vl+wWKO1+6DSbrLeFBJsoBQBWUEXRX7ISeyCARbZCUZCAoNCkKFiCSmRSGKQPHZLCkJG7vD6j3mkY9XDf8AdWk4amBpjG517Lelcec1W+N8IGqw5kQ1cpsd1Cg3IbqpFw64RfNELFMIIJasHqpcLOUZQkGC97FQQRqFNupSdUEgOJbYo7jLqgWEoMehahtlOqzdTlOVAHo9mixt2i2ZCAW6I9UB9VmMoJIWu+Jt1bICW5vde1K8rbzf2pVDMF4VnmjiYeYMhJvpf5L5aqpua897r2726cS82aPCqWqcWs65CzY/0SvDJSf3lllJvw6MLdeSnWGmVABmIB7myIm+6WUlJsGue0t2KwaCwy2KwyO772t80N+jVSYrWt5UG+aygfCLZlOp2QES2LxlboAAstsO11BKy990Bhvmu5Y5RqVhHTdIBubrDfusCz0QEd1ixQkS5h0pixCF7XWIO6+guHWzSYVDIWx53C5JXzpEbSg+CvoHgWolq+H4ZMjYwwAfFuVydTPG3hfV+PeMydHK1+QdvPhZHFG5uU6juUZlyuN9T5KkO+617VwV8rYrOhYWnl1HV+C18gphVc6oynl7LbTGZoFmxSX7M3VaSNrovt6LljwzUpbZ+Y08fMLXzhtoz2y3vco4q6OeaNp5THhhAHf5lbYGnDOVC1zGdw9u6qnAoGieWRjc51j8i+6e2kyx+SDO/lB0kUjww2fZ3YoIuWKeaJ2S5JID2nv8t1ZnJpIS+BjZjcAguslB1XLUMAgja8sIPToB6J7LtnuE1Rq5aMwslbGAP3P4pcIqYHCGJ0lngSWNib91Dqx1VNJA1788Nh8Vg+26ptLBW8mLSTW0xcTa51BVLmK2YqiplMcmQN6ujTX1VNlIKCKZ8TGPgcLkPdsfNlMjKHn5ZKiJtQBv5+o2SJaWihkJdUNjLRpZua4PZNrML6Sww0YPOnpnGTrsbt+eo0K1c0lNDUuLnxThwBBznRp8fLwrFPI/EpJIqqSVzINYw1gsdFSnr6b3xkIZdjND0jXzdVHRhiOofy2Qmna2YXN+XFrYjydwsy0jY2Phle8HrMeYD6W8ooveaX3dsDWvZJmyDNqEp3uslI9/K5E7DcPZ1Auvsfmm6J9ipKgSsEsE/JY64LBdx0+aqlzp5WcyJsII0tBa/rfyl8qrnlyRQSMyk3torUYnjiMVTWVMIOwkbofkhvjEzQ4jHRFzGyWe/Q9IuPUqwIKqGnY6o5jxILhj5WkaeiqDDa10OTkRSCI3GdxBPyVmnkkLAYme7PGmTJrbva+hSp6JlbBFCHSPvI7UWcSR+GiKGemkyNZnBI1vBqD80ullia6Smka8jdj32G3oEqOqEhOeK0ZPZxTVIcJjPI+OWVw7XEXhNbTBr9a2+fvlQRwwTRySBsjC0g2Y+9/O6ZM2GKIOLXHJ3HcFTWgTzaWpjDnNmB1Eg7WV7MeZZ07TzB+vdVGtpTAQHPMg1Yc2h9EcMNFNCC7MDra+4KmqM5xEvKM7biw+L8ExoGWZjn5wdSFV93puUHdIe06+oViCVjX2axpt/R3CVIwxuDxeVpjI0QRSMidynucGHa+11VdXRQtJzO0Ol9vlZLdi1w9p2PbL5T7aNNjNlMxcx2gAPobdiFLZeW6+XokGvoVpo6yXIWd36/imOxMNc9jMxJYPW6farHE3GKwQ03S63cX9F5hXTOqaySV25K6/EmvbSvdUZiTqwdguLlILyV2cGOnqdLNS0IupA6lARtA+q6nYK19FLQFHomNF2oCCdbdKE3v6LCHAtIRWBOvhMAKDfRHYl1lGuVASgcOq+ZEBZTp3cgAaVhF0RH9JCUgFZZFoUJ00QbAOylQFKCbzhuUCpLD3XWrhsHc6OvZldluu2j7DMuXlnlvhfAtQ66Nrr6FQCNipOgWKxfdQ2PZEAVliH3TDAHW1RZVDyQ3RQCUAffVEWgtSt1lv6SQSYwNnKNO6kG+hU6FqCQQLaKASNQi+SloQBtN26pnKvqq5uFbjmHLCDfWPK1UObZhv4TrKvVycmjkkGlmkr1ZXlafJHtexOGq47qmwxcnl9Dx5I76aLzxxFyf/AIXQ8bTNquL8Rlic4xmZ2pXOSXRl7dGPotxKFST2CHuoUwlE1t1FulFc9tlQYTZtkFyLhSfi8IpS12QNY1lhqR98+SgAAGS+bXwhUg9SG2pUGMBob62QHRyw/CAoJQELD6KdVCAhYQp17LLJATbB4XtXs9xGE4PDSun+0Ow2svFBuvVfZvLDq4tvILAfJc/PP0vL+pYS8W3p93RRfE2yRJaSIfCNd/COPmO63MjYz8SpnkcGgBt77rzXx+UQ2N0ZvTy577l6eZpWusMpI8aqjYibKYmsFvjTAbPeI3ZyOz3f4JI0syTjPmka0nydSkzRR8t7gznPdv1WAWXlk/nWxn5JM7qON4MubPsOqwJQVwIdzQ/KyndY+Ngg94nyPbI3Jbe3dXJJBGOY6WwI0AdmKGSTlMzO/F9v0Qx7Lj5laIspJYs/K5L9zbUJU7InQv8AdXN1Fz6Lcy1tNkdmi5h8DVUXw0lRHzp6f3Zjew3PyT2uZ5RoMUoo3cl0D/F1FVR1cbI5ntbZsdiVtJIqY/8A8vO0A6EtTHvo2RySCWQbE3bp+arbq4+osnpzNJiVRnfNJmuy+QjvbsqglppqgThrmE6lj22/NdTE6kdIxrHwPNiTn0OvyVatw6kkvk5EbxqCHFV3OrDqMfmNTz3wSMkgbka7TV1zr+iFtHLBLJE+oaQdSdCNe6uuwyKdzGSytYPR1/qlS8O9Yp4Z5Dn2sn3N5yce/apDGyN4gMrpHklnxW+RBToYKwx5JHSlkl2PZJsbeEBwioimLX5pHsuGAN0unGkxSOHO/M9hFyC7wjbTvx9ytdWSz080bKZzn8vQEv1A7iyyWsM7mQvzjvbUi6hsVVWPLGsa4xgv+Q7/ADWNzyRPdK5z+WQL+PCptNUyaZkbI3mJgygh+TTfzdJhqDBKHtzFhHwaEKs4yO0le0m9rjwjP2YYWS7G1st902kxXjbMKiJltLSDa4RySRBj8uYxuAsD2KrU9VUtIY1t2b6pokdWsyuyxsHh2v4eFOh4Pa3ntY2PLcEX7LKrEGUcZjmbaYHos25KpmjqnESQPbMW7sZuAijo5Q+OX3d5edS8uuQjX3Pwuw4gyZnNko3s3GTL8YKg1kBfyWslD49iO3gFC2CdrnunfkBAtGx2v1KmGShhmecln2I0cT37+qVhWokp55nGVzI2NJvYuH5oRSAuL5HRvYwbDXXwrBbGQ8xxPJP4J8cLo7Mc2OPQk28ItBDWsa5jWsblbYPv3umyQ01O8yRs1IOceiM8lvzdqqMszmmQbNk79kp5PCbc7xNNluA+4IvbxdcaTd5XRY/VNk6GtcA3v5XOj4tV6HFNYvZ4MdYsRNCgHumCS9gVs6Eg2sVIJjeLeVGiJtxKwjcfqmBbEg9kt3w3Dkw/ESUNi6MtCAEHquUGU6nZT1N6XNsVJ1bc+EBm2qki3yUbaLCb7pBh0UG2tkQbc6ushsdu6AjXYrH2UoEGxYpI6dFAQFzCyRXx9N9V3eUWBauIwaMyYlGB5XcgENXNy+2uAxbvup2S/UI73asGibqd1DSCUeWzboCG66LNQ5CLtddMGouggA3PwrCMiwjX4kZFxqgw3AOiEA3WWtsscCbHZMmFpvo5YLh2qnXLdQCe6AZupAIFlAF9lNikH2BZVcQdysPneW5w1pNt1esqeKX/AGVVWy35Tt9tl6MvlxXDw+HeJZ+dxJiEhbHrM62TbdaKQg7LZ45YY3Whrmv+1dqzY69lrD+iu+1Y+ilB307KXXzXKjypNNyNQ6xPZTmPdTvYnsFDiRuqCJMuiw3IF2rGtubnbypJG6kBsT+7osc2wuXWU33s1qgm6DBYlTkuL90VyFhktpukAEAIUZuNFFrHVARYKFIUHV10gxeh+zerAqTBlu4kG52AXna6rg+dkFYHPc4Mvrbc27LHlm8XH1eHdxWPdYBE6IZXfjsPorMjQOp8+wtYNstZh9Wyqhjy9xsN1sHEnQbrzL7fF8mNl1Wqm5rJS7mtbfYm6XBA2a8k3Nt3IcQFYnp5QM0krS462Hoq9PLJMCA9xYPPdJhKsxUsEtzFLIwW/ev+qMCCmaHGVs1vPZDJLLC0dOng2J/BUpTRSyjmZYLHc33Ppske1marpZXiSV2TILgMbql1EjWxkxv1kAHXqRf5ofeomnJG69xYWaB9VWmkgc172xOfINM51N09HPK3lkp4yGtYXkXN/wCKoOrsQM8DZ2NDDJc9NyfoiqIqV3JDpZRntch1tVSqsWbRZxTua+TYPe65CchzHu8LNbXBs0ji+SMF9jf/AAVeed4bkmY54AuzO26rSSCrzukfFrYl5dbXvYKhWTEPLC9wsP3iqkGPEvVVbRVEMLYqeOOTW78tlMcmGmKNszW/F1vY/U/Ra6QvOHxtOZzDfXLrc+pVynq6GnnjimoHQSWEZY9u5PcFPTX8Px4XM1CJpBRxPfy2bl2nz1Q810tRHNHBkY23Mex4P4rWySsE0k08XLBOQjsUqKShljnaJXU8TyPv20HojQx4vlsHVkU1e/JE/kZ9SHWubd0FRUQREAxTzTDcB3Tr5WqjhY+OZ1LK1ly0R9ySd7opIX09mOr3Em9/Atp+KrTrx42TOxHmvMbNGmwOn4aKeZUSPHMibGwfG8N1/BNEZhoWFlRLcnS/Yf4lZEyUw5pJ2seZQwAuufqm6Jj4G+joTbNLyw7TVuuvy1upLcHjYQ3mnJoTl/71QWiiqeeZ7zguF8tgwDQkepSAamocSH5IwfjH6pLxlWo/2fJM1mVw7a7lIkjiZTv5WWG79fNv80mSOngqWO94dM9uvxIuZCC9/wALPPqdyhpIrCIGdhhqHMIBJLNL27WVx0lfLMx/VY/v+B6I6eRrXPlbTutazL6aLC6YjMX9TtBbwEbWzkRulzTvdpuB6oo4qSlabMa973i/T28JBayMMaOZPMTqew1ThO7Py44mtkuBcoAzNPK8Mc3ISdL+iUZJDzA97S8iwA3RyQML888vWDa2ZKheI3vEUDrjudzdKCDjmuOlue5t+SrVcjoontdleY+3zT5G8tgOe29reVrK0ggvZ8ZAN/knJ5a8c8uPxmUunN9L9lqxe6u4nIHVBtr6ql6L0cJ4e1xzWKbghSB4UWFrI26a7CytYhbNYrASD902WAjfws0vr+SYNc8GP4d91junIMuwQlwIuNtkDict0wgXEtj22RtaXHK3UnslA90eYtOuhSDALP6muUm4F9rrJS53UXXBUOkcWhp2QA3JFliHbdZodEgk6bd0Kki6xBsBsssFlkSA2nDzS6vB8ars2yErkuHIJRUGQbLrtLXXJyX9TbD0jfZFa6iw3Cm+mizWzW6kl2WywS20LUbiMgLUiANrKWjwpbI06FqEOLXW7FBsk9FLXE/E5QTbVTogC0P3kL2nLfys0O26wSHJYtQTBe1kTQ03B7IA4grD8V0A5ttkWiCM+VP/AFIN9iKhi0giwereWZ7RO6T309VeWm4nljg4crZZpckYiNyW3H4L0MZ5cmV1Hw/jV/23VZmNYeY7Rmw12WtcRmV/EnRuxKpMbrs5jrHzqqDjfRaX2U9BIJagZbN1I7HLYpZ/JCjBe2b1soLb6DXwpYAAfRSZNEEEDTXt2UHq1cpuDqiGsY+akFO/BYCic0Btz2QAWeAfTZI0lt2XKEgB+mo9U2TXpG4SvJKCZe6xZdBfqQYt0Jv3RaIUgxbrBbBwv3K0q3WDjrHzWfJ+1jzfte0cLls1IAGuA/fy7rpOhos5riuQ4ame6EOmfaFoAsNLHsuqLssTOW2S58tXl5e3xnVTWVVa5zcukDQ0+VRjqKKB4YNXv8bJ9ZO0vInbf+CpyzMdKwRsaT6bhJ53/LZgrGF32UDpNdT6/M6qHSXa9znO82e1Dynh3TPf+22wVSR3Odke9zD5Y7T80SC3Ro5Jkz5mgM3IdYpkcbM4yvcM5JsdSq3KBkZZ0clt79/RHLJKW3Zy4b6ADum14/Ip54OVy5WN11zv1PyC188ThV3bT52AaDS1/krfJp2wj3l9yL6/JUHFj5RIJXB9rjq7Ijpwx0ZLl9zu2nax/wDZuVqZiYmveWXuLatVo1Dw3JldbYPLhf8ABBmdzskc/PAFydAL+quHPZMMwqKXlxNaWMYc4za/mq5mcJs8krncvs/f8VNXzIpiyNuWQjZlrWVR0jXDKYXveRsW91UbY4mzSPzMfMznhxuBmIGqKSwrc5pYhzLDLmuR5S4DHLCxz6hzXxnUHbL2skxX5kgiqHnmH4zqm2wxAZWRAWi+2Mh9QB2It3ThICbMidobklu5HdI93kim5pfnybANvqmuE8rsxezT6FFdEgm1jamF8kofnDu+1vSyO0UlHz3v+0zgMjzbD1Q3cLDM1rGi3zQuDYp44x1v8M11OyS5D4204p/tH5xf7+1u6iCRs81w6QQMBsOxPoEp0Ij6qhriAfg8lWOZUB+ToZYW07X/AMEKAIoTUZnss0C9v8UyaodVW5EVraMvt+CTJLFlYzm5tLGzdz6qwKgyPNuWwDrADfogxyNmyiWSfTuBtqp5UBeDmzsZqT5t2H1URNjEbzJmI031uVjnNaOc7LHGL2v3KQMbmjjLWN+0P4AJEn+qvIc9z3i34oueHgMbK55dYyEbMHj5qw4XcGtZ0WuSd0tkUAwzjN1vYCT8zsscJBMwjKAy/wBUMkTavqDnMZzNQHeEBkGfNHm3sfkmYDO58dyy1lqcRlLc0eew1t+C2NZJZhLna31AWkxI2PMOpsQVePt0cU8uUrDmnedtUi3dNqD9qbeUtehPT2MfTASdkwEEi7dfKBtgUcds/wASZjPw/Oyhut/FtVHqsBt93cpkm9tBqCova/dR964Rva3KHN8a/NBgCkkH+0FMTbu11CzLY2KQDmvESfNlm7fkisbatUOaQcp3TASbC3lCVB1dZY7QW3SCVl1AWC2ZAGCjjGZ4HlLAA3V7Dqf3isYz1St0brsMgbBRsAb2V9ou6yVFG2KIN8KRo7RcVu7t0QeUBSBY3CnRzrBY6w2UmxzQVDGkaZkYLctisIQA2s6yzTuiGuiwhACbKVH3tVILcrggBvroivfdQQNwsvZyZMcQNkTXAqDlk0UNjsbJA0fFossUIad8ym6DfY3ZajiaB1Tw1XxNa0l8Lt/ktuhI6TdehLq7ctm5p8B4lmbiE7XMcwiQ7tt3VF3xLuPaxSvp/aRijZGNjY6TOAxpAAO2hXDyDwtMk4+geFhFis+Syw0JcgxC+ZLscxIajb37lQgBHxIjfsssL6o5Q3pDfmVILuC+xQkW23RXtoXIS7ulTQXOcfkgJ1RaZlPojYQoyhYVKRI23QojZCg0rb4TIBoFqLra4Wo5PTLl/a9X4QkJiY17LkagfxXZ818kn3i92n9EALg+E5b6MfbSx8ruKIAvzFznm3wdgvLz9vkusn66TXU8bn3DXfP/AAWpLWwzXje7MNLZ7roauJ2T4Mzjff8A70WimgLS8udk9Q0KXlZTyRLMxh+1c4bnRqqGNsj80bZD3+K/5KzlJs5z9f7KWY3NYXSPb6W3smw2S4Ogs50DenXwVEUkhs8ZTJJoBqSAplkj3Y67yLAPddC2rFK0MY2776kd/S6emvHlptJrywxwRwWLza5bf5krXzQRRfaZo2MD8htq63e5Rx1sgeQzQtOu/fsqwqDzg9zm5GXNsvf+KHXhlvwTM2inmZdvLZrYd3/NV8QbTmoDImuAA2Y2/wCafPMS8tj69NTmtZUDA/nEOdECBtmP6px0TH5JmzxVDXZnRnydlLi+Zwla3mFlmDq0JTXU0rgOY3mAD94kJERETDFzXRg62Gyra8cdgLXOmyxRNaRuAkyRMzPGRzCN7bfipuxrGmB7nGR/bc+pVuOKphhe9rmyOeRoU9unGaa+MXblGZjNSAh54yjNFcDQWvqrJinc4jpz3/7CaJJo85c2PTQW7egRturRRtkY8ugkuBoS5BE2KCshkDZYxq+STcnTsrAa7OS6dsfm7r3+iAQ1E0mdzm2AGr+wQY3Wkmjcxr2Mb1m+/oEUhYZxkicbDPq7S58pEkFTUVD2NlcIwLvk7adlIaHZ2NqLnt/igGtIymIZY3gX8n8eygVEUTut7OZa1hqsNLSxykve57G2vbuhh93nlfNyPh0j6dEGfI1nNZK+e5v0M7JgliP3HSC9g87ad7ePCAc0PB5DQSLMv5KYYHB2Wadoa/RgCAiKSOOlHKZnJfrfv4snTBxdmkfsPgHlLc5kT77Bp/L/ABKkOyh0jWadr9r7/VIAa0tjIHrt+aiY5XlvSB2+iJ0YDgJH8sEXNv0SHctsmjXG17FMQioLcpPlaPFpSWZvh9FvKqwFzoCLLmcUc0nRv1WnHPLr4Z5c/NrKShCmT+dco1XdHrRiwLPms0CYH94+EQ10WWs24WA237pgJFpE0uzNv53SnaORBASDl6R3R3u83d3vdK1zKbkJAUjt826EgnUoHO5jrlG22WxQAFpzaofmpLgo3agMWMWBSEAQGi33DsF5DL4Wij1dZdlgtKIqJhO5WXJdReE8tkDoisBqovZylwuAuVswkizmow5jm67oBfKpsN0jGAA7ysFyoFuylhvdAZ8LlNyVN7oTqgJ1zKHXspBJbbuszdVi1AQDfdTlKwhpcsOnqmQQ4A3KLMDqEJ+K+VSQ0sBCQMaenVND22VZpJ0RWcg32OhJUXQkr0dOG5vlH29Zv9PznazOY9w4E6ebbfJeVOA2zWXun8oXhxkOJ02LRMlL5tJHl1x6D0XhcostKMb4Ba26F3xXRGwbY90Op1KSxBpDAR81DvhuiN7AeEpxIKkCABRAXGqG40I8pl26nugyZLE3S9EySyA2KQCdrKVHzUhAYpACxZ8kgEg3UE9kSH1QGLc4SCACGrTt3W9wyLoCzz9MeW+HdcOyRwutJrf+lZd1SVccUIeGO10sF55hEdng9zp8l3dDLHIGNz6N/MrzM/b5rrMZbtbdPLVA2dkZe1i25KpVdIzNcdZ9fK2TprwgMyf3tAqxgilcCXOvf48p/JQ8bPXpqXNijsMrh6ZlWflB6sxAHZbKra1tw3OQB6Ba1xtqXNt2vv8Aiqjlyx8kWL8hZqDp8OyU12r3ZW2F/vd1YOXUbaW8qsaqw6Mtohb0N1TTCVAqJXHmBrpA4HoHa3dDFIR1SRNjefge9u3+aVUzOgBkjZpcD4gd0UfPjddrueRYh50sD2AKenZh4m0OMEEoc+WTr63kbk/Ip0zrTM5LnPMoJyGw1PlVJXFtcJZ4OZcWHc37FN5TnZHHnskeNPKbf4IFPPzTHKyQMvuH6fJMkyinjjipbja53KYyERU2WSolbNn06rmyX7rIIWPbWuJjNgNgLoXhkB1HIck02WMA2EbN/mky3b1OfJyw+wA0sPKe41sDLidrww7HUknZKiikc1j55b2N/mfkh1YkScuFkjmdD5dL72CS4ROjLn8yQ+Bpb5q3URPmrHmDKGRW+Nw0J8rHF/KkD3teDobaBNpvSmKWHmktb1N1FtUyqsCWlrtRt6IHVjIc7HP5ewsz09UIqoi95Oex26fwRpUSJzk5cEDyD53KZJJIJbNpW85+/VewCYZXQvy52xsOhedTr4CGIRxuIbK6wOrw3UnwhTBFUSMyyvZrrYeP8kbZWtY1jZ2n9PmsMLM7yzNYX/79VkTGj+biYSBu935lBgtFzRZ75Hg3e/X6NCdEXCYvkgc9428ALObPPYxuijAubjbTv/gsilfMx7Q7oFr9OpQEyGSTrka0MGoYEQs2EuLt7EjxZEYIo4bl7XvO5zIOnYalIJcA1+Z/e51VaZzha2UX1Tqh7ZLZ9Ay2gcta50rmPLtr6fJEOAqCWvcdzZc3iRBe+2q6GsmuAc17G9lzeIOJdf12XRxzy7eD205JusKw6vWaFdb04zdTa6gAgpgGlkzFmOYEaWCCyy6Nv+SCLcb6ItMoUltrHsVH3tEwwEKTbQBCCVgcB80gx26EHqWXu7qWCxuUGgKCp9CsAQGBEoCm6CNgjMkzGt11Xd0oAhYA22i5XAo2urhmautbo3Vc/LfhrhBlEHXZYtsUskteERudlg0HYhTosGct11KxtjdrkjZbusLTmu1TaywOs74UEAOIOqaXNcLJZ1N0ZNz4QaG2zLJCe3ZZlU28oJgLXbrDtZA4WKwEd0wIOGWzmohlS8wUnXUJA3lnLdqjrUNc4MTGzafdQb63EvZS6WyruPUozE7r2O15bg/a1wy3iDhxz2ukM0QJDA51jbyBe9l8o1dHJR1Bhla4OG4K+55AXMIG6+WvbDhPuXE8j8ji86vky2vf8k7PC8L50835YcLKGtPMyhu6aG2bdC42dmGizbFyabqsblOkOlkrbdRQgHYHWyK9lAFlJCRgNrqLeURWGx0QAbmyJZayy3lAQSNlH3VJQlASsQrEgNgu8BdFhzcrge5WjpG5pb+F0uHx2sA36lYct8OXny+HR4e57XBwbddNh0ocwMcx7GA3JHc/NczSZo7BvWe621LM97Moltb8QvPyeD1Lo5MoZ9m1ot2KVJJK1mcStGm2ZUI5JxGYx9sN9XWT4ozIyzWNuPj6rgFTp4mU8+WSzZhaR7TdVp2Me3LlcH306VYmjGcBz790t1O2V2YSuN/uFOJuBLYyGPY19rb9Kp5WNle6Wnz38f4KzK3LcNb6XLtkp7iICGPu86fVPaZNKxp6aWpdfNkDM1ttewR1NQwwa1DoSbH4Qd0MsfKa3lSuBPxHLqURdzGMkggbJ9wg20PlW6cYomfLUZHz3ubNezW9091SWzcsVF5AOWL+T5PayRFEIJ5mSwNeO737A32CsObTFwGRguPua2Q6u2h9zqm0z6h1XE9khtYbXuqz3R5BE7lv5b7m1+v6q2IKSoZJCyd0JB/L6qrLhlHDCxwllLr6AG6Z4z7h5s0kz+dA5jCb2zfgkmpkc9+bmZAfudj4VsNzwhzXuj3vzN1WbLyJQI3uktexLdAh14WaC2GP3vlNilDD8ZPcqW2bKYzTveb/AJJolqG3yZ2ZjnfIe6WeVLM975dTv1aoV7Ijjmz9NEyMg3BLrqc1QJftWx2B2HlY6RjvtHSy2ubAaIWlkjwS6UEXJA0t/mhpDLSm0bGxh51udbfNZHPLA0Rwt5gB+M6XJ3KNrYpXMZldnI3LvyTfdYIm3dLtppr+AS2PBUtPNMwcyezOwGwHlIa2kijIHMkvv1b2VgNhbrypXk95NvTRTadpzCBlrjIP1KZphDrDJTuI2AzWCguqJZnwRQNHk5tB6Jo95mbl94ay25GlrKs6aCluyKWWS5zm25PfVAWuQYY2B2W4P0uUkz8x8jB8I3I/gg58+cc2J2TYdzqmSOZEBHGzYakt3ugFyN3DXb651R5bBG8lznk+fVXZ5WucWjLnGv0VBzrsId38JyKinK4Z5GhrewutHXHU2W5qJC0SNDLG4sVoqwk3Lm2XRxx3cPtrXbrAbLO6xdT0Ym6Iai6EaLNkGK/ZS0nUJYKnVBHC0jLFQ2MFpOdtx2Sz6Jgud0wHQJZsQmW/pJZtskbHEkC6xQNr+FiCZdFbuhv2U7aBBpRjZL1zI2fEgOpwOjEdMJuk51ts3bwqeGtMdBGDuQrgJuuPO7raejGyXAzNRn4bhJHhNbcKFMiNkR01QkXN1P3dUBOZHmF9dELW31CgtOT4kgZYdlg13QRno+SK3cICM1nIhIL6qHG+6AEB1igDksUNgUWgU77Jgu1lNzsptZyzNt0oCWu+6VOUN0UEFzrhTZAfW1rqMhTLhZmC9h5hOU3XGe0TgtvFWDvgha33p1spLdNF25ddLJVQ3xrxNw3Pw3ihopMxsN+x8rn5GgOv8V19Ycb+z6g4igmqXNbHIIzchtibDTVfPXFHBdXgJDnQSWIznvkadrnyVnlj8xpjk4ojupy3HyVqSCzrZbfNJykfRZNCCLKAmEhCUGCyH72iIoCkElQT2WAlFYEaoASFFkaE7pANlFkSjLdwHlBL+GwXdfyupoYeWA47LU4bBawPZdJTtbk0bf8A77Lj5cvLzufNZiYC8dDj+q2cMf2WaR3/AONiqkLRlDm9HlbGD7JuuoXJk8jlu4tRhmVjjmf+itSOaKe2XIH+O6rRzOOvjtslmZgeWsdkz9vBSedcPJ4kvZgdZ52s26yTLEbyvaTbtpdV4i5xuGuBvY5Nk79kT1E2YytDB3S2qcWyRWMgeSInHN97QgX9VDsQZm5jmW11OisOpaSJ0gdUXAFgGNzG/wBEIgzNy01BJk8yWaP8VN5MZ7rr4+gz5L+nGqMs8Esz2yROk0uDmVSUyZmNhikDGeHW0W4OHVx+7BH+Jt+ij9kVLm9VZa/hg2Wd6jD7vU4/pHL8xrnGSR7GCC59eyq8ieSpyx9BvqVu24KY73rZ/pbb8Es4FEXF3vE5vv12R+ZwdWP0nl+dNMKSaY9WUdz9ETZainezI1uT+nstrJgNIW680+mc/wCKV+wqBrf9nv8ANxKPzOLWfSMvmtJLI10pdJPF6DNsmy4kHAXngZYAHI4arcNwigaOmli/uhS3CaI9PucWp/c7pfmsfs0/pE/6mhbVTSysjM/MY/8ACyyQiNxAiaY9L9Wp9FehoaarlqapzGhhkMUcewyt0J08lYcBoHG/I/8AyK1vPjPFZ4/TLlNyq7asxWIp2gm/0Qc1xb1s79fqVdOAUQaMjZGfJ5Qu4dp3aioqR/1pTqMDv0vOeqqOqHZzaLUnfdX6Wt5kIhfFGx9rg99Da6QcAe1lmV8oPk2KV+y6+HRk8Umm72kfornNhflll9O5Z8GTQzRzMEsrWDUsB7+pKrNlbzGM5ucgkE+AU41WIQAsqaDnsO+R2b8t0s+4Tv6M9LId2SN0/FaSy+q5M+kzx9xFmD7N+Y2vvtujFiOZkawEAAnfT0S/cp447Nluy1vP4IW2Fmys/mhoT/FVY5rhYdUTkVLGsdne6507WSJajpynqtuPVMAiMz3c1oewaH5+FQc0xP5ue+vWD2RIJUGUT53ytd8hoLJJ5jnkta1garQacucMaQRfR2irSNBk8sOpVRcUqjS5Lb31utNWXcHrfz2kuDrZaKruS8eOy3467uGtP3Weqg7lSN7LqejGErN3I9t0JtmugMt1KbDMsusKAxZmJUX7FZeyAIkBAsWfNBs+7dQpUIJARLFgQEjVbTCKD3iTO5vQxa+GJ00oY3uuwoqUU9MGjLeyzzy1F4zyshoDAB2Rm5tZCAXaBY1xa+xXK1He7rJlzayW617hyMuBbqgMBINijc7pFkIyndERokaGus5GXW1Dksi1u6Y0NcCcyAFrrfNNzXSDGbogfogGErLXbcbqD1MuN0AkIvdAE0kOs5GfRDdsjbh2yzZqAkt7rLEqMxUc1zfu3QB/kpsf3kGbNqNFKDfW91BKyyCaVsLMx1XtPLEDdYtfLUVHMY6FjSw7q0KiM2GbVPRmO1YRuuU4j4VHEH2UzWsjO5Fu2111aE7ph8+8aeyr9nNjdRNked3vOtyvO8S4VraSmkqRA4RtK+v6qiirIuXK27DuuY4j4Qp6vhupp2RNM8oDLsbawJ7WUXGVUzsfIMsZDsyWW6/ovoKD2JMmjqzK/l/amOIjfKB/iFyeMeyurocBnliZeZsxFi3UNAvmFlncKuZx5O4WS1dqqeSnlMc7HMeNwVXy3PyWdaAsMqEjRMGjbHus+aRFl3TdCjNhoU1tFUysY6OCR4fsQ297ICuLp9FAZ6kDLtqu04f9lWP4vXUraulkoaSbUzPbcgfJW8Z4apcE4hqaCjzcmEhgL9XHTus88tRly59uKlh1HZgIbcrcRwlrW9kNLT8u1m/RX+UcurV5+eXl4/JnsMTSrQvGNMvy7JFi1t8v02WRxAuDg6Rn5hZWuLLyaXBxFmuY/wC4R+i2VNRNDedU5Y2W1J7rKKEuawZM83Ydh6nwt7T4awOElS7nSfkPkFzcvPjh4dnS/TeTqLv1Gvp4JHRBlDBdjt5pm2/AblWzg7Tb3iV8x8ZrN/ALa2AbooEb5ZcjGueT4XnZc/JndR9P0/03g4JvW7/dRjpI4btjY0fJqAtynVb2HAqyRnMe1sDBu+R1lq63EeFcK/8AceIYHyDeODqd+AuVtx9Hz8nnX/26rzcXH42qn1Si8ZrZlTqPaRwhSNIpsOrq0+S0NH5kLWT+1+mj6aPhmAa7yS6/kCuzD6XyfNY5ddxz03cl3ahLyu/ddr/RXOye2LEv91hGHsPbpJ/wSJPbBxCfgpcNYP8AlE//AOy3n0y/OSPz+PxHTOhkOjWO/uoHU9QXaQPN/wCiuSl9rXE7n3DqEC2wg/8A+lVk9qfFLtqqBnygCr+m/wDyL8/Ps7MUlVm0p5bf2UTaWpidzTTy9GvwHsuE/wDE7isuv+0m/wD+Jv8AgoHtN4q//cWn5xN/wT/p0+5fnv7Oqp6SdtNGHU8gJuT09ySUzlPDbZHf3VyrfajxPG/Wopn/ADg/zCf/AOLnEMbspgw949YDc/8A5J5fT9+ZRj1mMmtOlHxa9lAsNNlpYPa5XFt6jCKGZo3s4t/gU9vtbpnD7fhqAf2Jb/q1ZX6fl92k6zH7NnY7rCCW2Kqx+0rhio0qcGq4/VmUj8jdXYeJOCsQ0ZiMtI89pmkAfUi35rPLoeSemk6rjpVvxWSQxysyvY19+xW2hwygruvDsZpKoejx/BDPgVdACXQZx5ZqscuDkw82LnJhl420LsLpj/N5oSe7HWVGowyujitHK2qHh+h/Ebrelpb0ua4HwdFg9E8eXKMs+l4+SeY5cw080ojlbJDNbRj22SXUMkb5C1rnMA1vtb1XU1FHDVx5ZmNPr3v81q6ijqqO+RzqmmO4PxD/ABXThzS+K8fqPp+WP6sPMaRsgzEPe1lht2WWBF812lXKinini59PlsNwtdFnc97HuyG+gXTHlasqrPdvSXW1WmrQerwt7PGQ24bb1PdaSuIG3dbcbs4bto3fGVgNlhHWVgXW9SMWBZZYLoBiFYsKAw72KHXMpKxAQssssp7ICAFnosWWQGBHHE+V4bG25OgATqOjnrqlkFOx0j3mwAavXOEeAYsFkZWVjuZPb4C3QJW6ORz1Lwb+yMIZW1P8+8X0doAe3zVfQaLueKa2GGlMJ3foAuGIXLnd1rJoTXWdcJnS5t+6TY2U6jUJKNydlIFm2KHmndHzGlqkIA6vRMLeoEOSrnZEC7Kgxg2dlKgaHwhOjsxTBZzb5kiZdwRfdQEi+qLN0oCdtkO7bKbqem2jkGCNoINnIgCTlKg2GoUktNnDdASQW9KhrurVGHAjVyW4APQDAWnTyiyhKJbewUgtt8SA+tzJ03KrOqTJcRsv6lO3UZbCy9uPNV2wPLiXv08BG2Jsbrtam2WKthN1NwVrDWzGoMbYHWHdFSyyQufzpWm52RoNipuBuVVM5kjOTQ9rqlUTinaDK5z3+AloNwQC23ZVKptLJE9kzWkPFj8lpZMSraiVjYGWjO5VinopY3vdLLcO/FA0894m9j+G4/jMldTS8kSMA5bNACP10XLR+wOqFhJOzW9yPnp+S92iibCzK1OPwqbhKrdjwHEP5PNc+nLsPr43zXFmSaCx31V/CP5OjfdS/FsScyS46GN0A76r22KYRygF26syyfZaqLhFTKvFIvYPg1LPI99VLICMgBaDbXf8F2WF8L4Tg2FQUMNGx7IL5HvaC7XvddHM67yCqMw10WdWU51m2GgGi8j4opjJxPVSFu716w5pOi4LiSBpxGRzex1XL1Hpx9XdYRzMURGuVWHQ3Z8KfHHdyY5oER9F5uVeRcmpmdyho1psnYbTy1D9dzt4A8qq6J9TWW3YCBYeq63DqNtLBbv3K5+bk7Z49vQ+n9H+Nl35eosUVKyCPKN+58q7DFJPUCOJrnvPYJmH4e6rc95c2GCLWSR+gAXMcR+0+DDGSYfwqxrn6iSve25P9gfxWPT9Fn1F7r4j6Pl6jDgnbHX1wwnh2m944gxKKmvqIA673+gA1XEYt7ZDT3h4bwuKBn/HqG3cfk0fxK8zq6yetqX1NVPJPPIbvkkdclJGu2Y23t2Xv8XScXDP0x43J1XJye62WMcUY5jz3OxHEqmcH7mazP7osFpwLbLd4BwviHE0FccNfA+akYJDA99nyA/u9tFtOK+BX4BgGHYnFLK/mxtFbDI2zoJHC4BHYHZdOmHmzbkCbonQzBjJTE8Rykhjy3QkeCuoFDBjXs6NTBAwYhgsv22RtjJA/ZxtuQe/hRgs9JjPCVTw7XV8VFPFMKmhmndZmYiz2E9rjUeqDjnK6hqsNrn0lbBJTTx2vG9tiLi4/JXJ+GsXgwejxV1K40VWbRSMcHa3tYgai58rbcdzUlRV4XyqyKrrYKJsNVNA67C4fDY9zbdX8F47dgfB9FSwPa+rpap94JGExyQkX1O1w7UIqpreq5fiDh3EeGqyGmxJjY5Jo+YLOvp/iO60x8rqeJeImcQYJhYqHvfidK6USvLdCxxzCx9DpZcwQNkhbN+FykwaeswTEMTjliENBl5jDfMc21uy1gK6Th/GMNocJxXDcTiq3w14YL0+XMLG/wB5anEhhnvI/ZbasQZNfesubN6ZeyFeFrAeG8R4jmmiw9jTymZ3ve6zRfYX8nsFq5IXxTPhlbkfGSx4PYjRddR8YUWEYFSYdQ4Q2pDCKiofO8tL5gdCMvYdgVrOK6/D8Y4hkxHD2ujFUwSTMLbZJbdVvIS2d1rxVKhw7EsRoJIKCinqRnaZDGy4BGwuqlbh9Xh1T7vW0stLNa+SRuU2Ox+S7KjxDD8T4RwvDm4pBh8lBI41EFQ90TKq+zs7dbrQ8Wy4dLjZGFzyTU0cTWZy90gzAa5S7XKOyWz00ViBfLp5y6Kbgi4dcL1Klo5cD4Mw6GNuIML4nVdRNT0rKhhJ2Y8O2sPyXntLBU8R8Qxwta0T1k1uhga0XOpAGgAGqN7O4teDlcHN3HcLd4dxZj2GOtTYpUgD7j38wfg663+P8IYXSUGJT09PiOHOoLCOSqcDDVa26O+u4XDg90/Yu49Ew72qySAQ43hcFVH3kh6XfgdPzXTYdNgHEDCcGr2snt/s82jvwOq8WuB9UTXOjeHxucx7NQQ6xB+axz4MM/cbYc+WPy9lqKSeify54nMt52+hSSfC5nAfaTXUjGUeMs/adJtc/wA6wfPv9V2ccNHi1B79glQ2pg+/H95h8EbrzOXpMsPOPmO/Dqcc/FaCtw+z/eKVtptyOzx/itDWMEzDUQZs17EZbWsusk8LSYjTsgnMozBkgtIBsD2Kji5P+NcXW9LMp34e2ikzSRgBzs4FiStPWQXuTstvVB0dSWZtAtfPG6R1z3XoYXy8rjuq5VwtKQs0TaxvLqSEldcetLuJKgKQo1TNgPUiUDRT80AKJQoQEqFKsUdFPXVDIKdjnyO2CDV1v+H+EMQx+SzG8mH9967HAvZlEYo5cSc4v3sxeh0dDBRwiKBmQBTcjkaXhrhOj4ap7MyzTneQt1W8lk6bprrALXVs4ip3ku7LO1UjieKpjLiQA6mhadxBDbJ1dMZK+R2buq5sBcLGrENWqbeEANnXCIuPZAF91E3KfvIRr81GVw1LUGaW6aLGl2zljbFuiIA5bFSGaOb8SgXGylSSctggMB01RttsUsOto5FbqzNQEglr7dlPSfvKDq1pPZDbq10SAyEQjBFkBuNeyjMWuzdkGkxkHRygg/NGH5tQhcHAoJIAus5bTrlQg2dqpsUB9cBSUA3RL3HnIQlwCgkrV11TLHMWtdYIgMrJSH9UrWM9N1QlxJkTDyIHPPclZD/t5aeoeqvMgjY5zmt1dumatC+smlzjpYQNCrckTJRaRt0xQgIja2MZWNaAjGqgKniVZLTM+zI+oQF57mt1c6y0OJ8YUFEHxxv50w+4FyXEWL10eJRFs7hm3HZa7iCFjIBVMGWX94KbTkO4v9owoXYdJE3IZJLvGa2i9CwzHYMYwWGtgfdkg3Xy97RKmWXGIWvdcNjFl1nsr4uxQugwkvj91bGbDLrv5us9+dK1qbe3yVAzk5rpJlLlWjJc0uO6bGTcrOqHmOy4fGLSVUxb++V2x+ErhqrWR9/3z+q4+pviOLrL+mRrbdgl1RaynJcrJaAdFSqftHZXai68yvIZg9I2OZ8jtv4ldVh9H73LbO2ONgzyPOzGjcrn8L6otUXHdbPh3AkUdK/lCtmEczhu5vi/g91z8OP4/P2Zen1/HJ0/TTtc7x1xw7GD+ycJc6DCoTbTQ1BH3j6eAuJtlZrujYhuczl9LjjMJqPEzzud3W0q+Dsco8GOKzUTo6UAPN3jOGnZxZ8QafK6/hOSixbgSpooWy0s9IT77HRU7ZKiujdo2xdqNdDb5ro+EKeDiHhmlrsRiEtZiEZw6onuQ58QNh3tmt3svLMSdPwzxNWRYXVTwch74GvD7OyW2JFlYsmJ1H7/AMC8WwyVdO6MgfawF4JfC7QtdY6G3bsUNZxVXSVGIsjnkqaStj92DKu0jhEDdl7feHYrSkGScl73PeX6vcbuPzJQFDC8l14ZFNNA17Yp5GCVmSQMcRnb4NtwlEWTSAoAGiCmQAoIu6+yPKNVnZqWj7ibJZF7lP8AuoSlYuVXIQkJqE/xUrmTNDCOrUHZL2zWTWIHaXt5QcpbdlNrKVjviCFSmNrKqJpbHVTsBFiGSuAIPa103DcSqsHqzU0T2xzGN0YJbewIsbeD6qqVIQczrY4ljtRieEYdQzt/2APAkzkmQE3FwdNOxWrACJ/xLAiQ+6vQ8CwCkw/DY6avipZK6sYKmohqonEMpxc2Y4bPtqdfRcY2h/amOTUuCU8s0ckjvd2H4sna/wBEf+kmMx4XLQNxKoNK4NBjLr6O3Fzrb6rq+CqengwljjAyV+JVT6OZ7ycwjDb2aQRbVL01klcTPS1FJUvp6mCSCZps9kjbEK9g2MVuBYiysopXMezcfdePBHcIa6oqK3HnwVVRLOIJHU7HyOzODG3sL9/qqbNYS47/AOaZS9t8PW6euo+KcKfiVAzl1MX+00/cHyPT1WmrWiWB8e9xZcxwdXVFBxdhxp35BPMKeQdnsI1BXa4zCyDFZ4YxZjXmwXk9VxTjy7o9Hizuc7a5GsH2cMrvFj09wqlRHduYN0VzEv5l7e3NVZxJhZda4XcleJlO3ksaYYI/EJpnM3jF/h3Q0nC1ZO45mOAC67hpoz1PzC3xAaNF2Y3w9HC/pjzKXhatj5jsnQzYdyqJwup5b5BE7IDa+XuvWGgZij92gd0mJtvkr20eMuhe3QtcEAB3yr2Cbh3DKqsZzKZozb5dOyCfhzC8sP8Aqreki34pbDyaOCWV4YxjiTsrsOB10uTJTvJkfkA/Jev0WAYbHFHKyma1+XLceFs6emgieGsiaB8W3dPZyPJ8L4CxGrfG+djo4yTfyLL0rAeFsPwOJnLiaZh/vDut05ojd06LO6i5Ho8EDZEZGgauVZxKg7KVGyygMLi7QBcDinFkM2JmkY7oFwSFuuLK6oo8KkdC/Kci8mw17psQMjzdzjqUWeA6KoyumL2bFC3shP3UTQFksRCwHuUJJDTZECcpSAj5CYJHEapX3QiGh0QYu2miMGw13S2E3TPKkJ3aoacpRBCfiQBnVtwiA6rIRssHxJGy3UUR1agzHM5ECUyCCRoUZsWqQAd1DUAsXa5GJTsUVgW6pZ0vZAGSDqFGZA1GQEB//9k=" alt="OldPanda" referrerpolicy="no-referrer"> </a> <div class="wb-user"> <a class="wb-name" href="https://www.weibo.com/1199303274/R9yE5wVH8" target="_blank" rel="noopener noreferrer">OldPanda </a> <div class="wb-meta">2026-07-20 15:43 · 地球</div> </div> <a class="wb-mark" href="https://www.weibo.com/1199303274/R9yE5wVH8" target="_blank" rel="noopener noreferrer" aria-label="在微博查看"><svg class="wb-logo-icon" clip-rule="evenodd" fill-rule="evenodd" stroke-linejoin="round" stroke-miterlimit="1.41421" viewBox="0 0 560 400" aria-hidden="true"><g fill-rule="nonzero" transform="matrix(.768459 0 0 .768459 145 90.642)"><path d="m25.84 195.715c0 40.917 53.28 74.078 118.97 74.078 65.691 0 118.971-33.161 118.971-74.078 0-40.918-53.28-74.078-118.971-74.078-65.69 0-118.97 33.16-118.97 74.078" fill="#fff"></path><path d="m147.622 263.781c-58.176 5.769-108.401-20.556-112.183-58.71-3.781-38.202 40.336-73.786 98.463-79.556 58.177-5.769 108.402 20.556 112.135 58.71 3.83 38.202-40.287 73.835-98.415 79.556m116.304-126.776c-4.945-1.503-8.338-2.472-5.769-8.969 5.624-14.107 6.206-26.276.097-35.002-11.393-16.29-42.614-15.417-78.392-.437 0 0-11.248 4.897-8.339-3.975 5.478-17.695 4.654-32.482-3.878-41.063-19.392-19.44-71.024.727-115.286 44.99-33.112 33.112-52.359 68.26-52.359 98.657 0 58.079 74.514 93.422 147.38 93.422 95.555 0 159.112-55.51 159.112-99.579.049-26.664-22.398-41.79-42.566-48.044" fill="#e6162d"></path><path d="m327.387 30.688c-23.076-25.598-57.11-35.342-88.525-28.652-7.272 1.552-11.877 8.727-10.326 15.95 1.551 7.272 8.678 11.878 15.95 10.326 22.349-4.751 46.541 2.182 62.927 20.362 16.387 18.18 20.847 42.954 13.817 64.673-2.278 7.078 1.6 14.641 8.678 16.919 7.078 2.279 14.641-1.599 16.92-8.629v-.049c9.89-30.494 3.636-65.351-19.441-90.9" fill="#f93"></path><path d="m291.948 62.685c-11.247-12.459-27.828-17.211-43.099-13.914-6.254 1.309-10.229 7.515-8.92 13.769 1.357 6.253 7.514 10.229 13.72 8.871 7.466-1.599 15.61.728 21.089 6.788 5.478 6.108 6.981 14.398 4.605 21.67-1.939 6.06 1.358 12.605 7.466 14.593 6.109 1.939 12.605-1.358 14.593-7.466 4.799-14.884 1.793-31.852-9.454-44.311" fill="#f93"></path><path d="m150.822 194.648c-2.036 3.491-6.545 5.139-10.035 3.685-3.491-1.406-4.558-5.333-2.57-8.727 2.036-3.393 6.351-5.042 9.793-3.684 3.491 1.26 4.751 5.187 2.812 8.726m-18.568 23.756c-5.624 8.968-17.695 12.895-26.761 8.774-8.92-4.072-11.587-14.495-5.963-23.27 5.575-8.727 17.21-12.605 26.228-8.823 9.114 3.926 12.023 14.253 6.496 23.319m21.138-63.51c-27.683-7.223-58.952 6.594-70.976 30.979-12.265 24.871-.387 52.504 27.537 61.522 28.991 9.356 63.121-4.994 74.999-31.803 11.732-26.277-2.909-53.28-31.56-60.698"></path></g></svg></a> </header> <div class="wb-text">今天去山景城当堂赶集,位置在火车站旁边的停车场上,各种水果摊试吃量大管饱,令人十分欣喜。 <a href="http://weibo.com/p/100101B2094456DB6CABFA4393" data-hide="" target="_blank" rel="noopener noreferrer"><span class="url-icon"><span class="wb-location-icon" aria-hidden="true"></span></span><span class="surl-text">美国·Mountain View Farmer's Market</span></a> </div> <div class="wb-photos"><a class="wb-photo" href="https://www.weibo.com/1199303274/R9yE5wVH8" target="_blank" rel="noopener noreferrer" aria-label="在微博查看原帖"><img src="data:image/jpeg;base64,/9j/4AAQSkZJRgABAQAAAQABAAD/2wBDAAMCAgICAgMCAgIDAwMDBAYEBAQEBAgGBgUGCQgKCgkICQkKDA8MCgsOCwkJDRENDg8QEBEQCgwSExIQEw8QEBD/2wBDAQMDAwQDBAgEBAgQCwkLEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBD/wgARCAIGArIDABEAAREBAhEB/8QAHAAAAQUBAQEAAAAAAAAAAAAAAwIEBQYHAQAI/8QAGwEAAwEBAQEBAAAAAAAAAAAAAAECAwQFBgf/2gAMAwAAARACEAAAAXP3fyDe5SLweH4rqZIrqpLXg8CWuApPsvo1h1NAnMUli0zJrAYjyxMUDdyJpvciqEh0Oh4EKl5aS+G6ejAqczzbET6JA1TXBNt84/XJnpPmhtM9IcS0uQVHRkT6NSRJuzcPW7x0LFPM7dSP8tFSOps8NSaFXk1DOlh86Zflre6i1VNBajBfVN5p0lppnH75s9Jz71/NQwNyCpQLw/B1PoJZwfB+FxHQ6PwcDwcH1Lw/B0CwyTRU0CPNIDzTS4HU8H0Cc+om0aQ+RKY7R+ubuWeaRFcCQinIepKQGkz0hhpDqWscdrnI52yvOM2xUmhUWaWnIRUljoeLcZ3Ocm0pjpUebey1LxhpblNaOjUDeakgzzK9E2y+bVdTS+p9cQ7RFb5RvTnDMr/p+cOhDOCS0gOC8Hg4Pg+B4PFeDweF4OD8HkvBwOh0ak/ILLUhIxufAlNMV5M9IjDxUlhsipjtISBkOqSpcljqCki5MmhphpmOlIZ23pIpNGnUOI3x8DkFJkTPDeRb3HWQ5OiN8rs8POPL7NA2x0f0eb1LgdAdJznbyKcKspx11Dow+dpupo+pNsIrohprA7kFFF9jyfFdTRU8KUjwCqUi4HBcDg/B4PD8PgeH4PBwXg6HUdDyfkeS62jPT0vzStM1pqmjzSprstLE6RxylpY3Et3noJpwm7mjS22kQe+XUeQsYtY6LgOJo0nASmpOQw0mefeh+H6VB8vsq9lmtOsHtvuecwQHfKY7cCy5fm2lMNDTdLz1m9MsYzuqJ/TnRz+1lrc1kDdfPVfU8/qYaEhxvoJEkXGJBSpLlIuB4OB4PB4PBwXg8PwdBSrgckRnp5Nw0UY3KHLqNHvL0HiyARpQMdsgXLfTPwJa8C01AgJXHZ1FRXRi21z4wblLRZroNWESLLdJyuG0nz60zg6818fvr2Gr7Nn3i0YVN+tyV7m0lLi/fR+U4ineWj7K3ASGbWnhnL01POvofTKW68g3ni/m+hDXnePrPnep+K8gViKXBJBIuprljYmlxrgcDweDweDgeF4PApVzLQbPCXpCpZYpSaJrqJfk6pPO3mVnhqYaQVEfvlC9nO10zZ3CWkUus65dxb/LRYJaiN8W7PCWhwn2kZNr5vUw8rrvHbCKWefOe3TOfStA7lWTSGXNpoHuedxjzaLH7PmlBxFAiyTSKmRist83urHNrv15yHpcjbSKN5ffnWWmk/YfMki1qlpjYWWC5DS415PiE0uB1NDSKng/C4C5rgdDssM1xitJ615HQXna86E0Vp7lq+x1PFPMtDwzzTnOuJsNc47ozr3fxg3xS1xnRKH1HR9lkmmF5nuFB1i0ETkcNse+I+gZeZ2aL6/Db/W54rzu3HPL64Doh3iSCbsVk6cZjoi1ex57vu5RByak0LBhpHmZ343pV/k311zZ/b8tNrMvK9Gi8HVrv2HzShjYKkeKUnwTe0WWho00pMTSAVNcpCqUNeDo+YakmnOejkUV184NM+zSEEmn+OzrOg3DPbIGma01JyHN0Dy0lc7d8nRLCZa5x/RnAehxMt8kOOCENQ+gsSw415iw6hTapT/HZ95vd8y/Le1Icuuu+pw2X0MsU8L0pfnqoMAFlTDtm+xp/wBmWk/R+R70OXgGluIsyT2TrMo8r0Kxy76718yvT4jdfMLl6Mn8D2Ne+m8JIKGKkGpBckllmh1Phhc+BxnobHQuWq01gFoKYaXtsjRbnKxsZa5paU0i4dYbFinUWaHE9fPC9nKlyoZZacrk8tpTm3k8bjenJjtjEdXOO4TSKmQPB5pDnjOI8MrVf+f9Oe9Lld7wlyx5d8I+N+hfc2lw1y0j3OKs8nVWvL6lc2tV6c71pFWlq5tHFztn2vzyOrB3loeKBUsdYRUguKF4frQfF17B6nmxyqa9bzQY65L837u0fQ+Kz2zGxxFeAdS2ueM411MFLsjnPUsWvHQcX5ozTnO/J8TXFHyvzEXHqUljaGNaTS5FciuGfTgy6eZFLySBuUAz0lstW+Osf1cxd8V1Kkz8fTKrSU5dxtR3TjFdGDHbGL4OlWGid86b8b9De+jC/wD03l0Dg2pvH1VDxPS7vmnQcMBFRyOQ5nnbia4AKVmibP7/AAX36DzHmOjzO29w12yiermRU0PwfZr/ABde4+x5NV87vuPu+T3m3w/xPV3D3PKNNBAOkLTBUNts22kCtEhiqeDTnp2XIc3Q5R5pc13PT0nhnluctFoXLGCmKQO59SY65wfpcIdM01PhDaCqcCTnqbPR00w353WkV7ye2C+Y9aE4uvYPo/NtuqNF8AOsR/XzYT856lk3xyzl6rJ520k19DfTebjnn9WXcPSypqyqPub514Z9lo+wqPZL5ObysLJeoNvOwe75rzqxrWV2vv5CJttIFccqc08X1a9x9Os9nHVeLuDvhDzVe5d/pP1eEs10PCFcpa8j1DbbJuxhrk06MCUiA65Olc1ykaQs12LXLQPuOhEyIMHg4Arhrtmx6MmXTzgvPw/NKEhy4AKoyblVH1AODpzP4T34U0HV2uMdj9vkuPdn4G2k1hz82+L6Wt9GNbxvPOTbUd4uPdjiHLtA4sQLy0bWphpUuFE3okYbtOUwZ7bxJ52Y6D7Xn3zu5VVMZrnH7Z9loqc+8T1YHk6do9XzImNJj1PNDF5F817/ANA9WBEGTUPocBuCBrYVpvUMNYbUh1PGONMyXn1Mc2nOyIXL5NKVdEVMqaQA032za3L+X1oGsMejnDrk0aCBAiPK7LH3YkRUvK78n+b9aw8xUPQmT5qt2a+hvqPOZNJuco8vtovJtPaTXYqmw9R6Iv3Rn82cmosxJTSiXzoFJGsxkvorBlUnk7Tz1zpjVPf82H0iydGD3twDSHpDzO03AtM828P169xde3ev5Mermuzljmsc+b97furmMqPLWq8mtDkFCC22a40Cpb1LO0ml3XMonGVqmzI8CQQwbOCWm4miyda4HQZ7RH9GLfTPrTPbLuuSyVJ/P/w31F69HkmPQ5MS+f8AWcY3Oc1c1mM2Nk2y2n1uTMOHoDJR1dG57HZBDsdLaajFwomVrBIBoWM4eajE1sfwWPFzWdWTNsfRwttm7+t58N1c8F18/mO8dSS0XOU+Z6FZ5d9z9byoaNLD6PA0TxH5v3t46+fgyS3c06l+TUCwWCQG0Ghs4FSRS60aKKmSRargDa8zwcaIBJagBSQ0Gku5JUucr8ALUZ1c8Ypo/k9lB8b07V15SGkZ952wWza1AVLvGtVzzs/o4tHVRy0cZPMAdZOA65by7s4pWbaUxWOJEsU2+pMUwtOofBJmrNi5zHTV+vHffQ549lFzu0+hxMtYZ7ZdcjtZB5vfVefbcfY8mpcnXM9PMx5t8k8/u+jOzmKxuzgEhllmVdQoaxcBDSHKbBiA10CSyzTiaKhIwghiBLAzFuQ3JEzyzKhJKH5oDEXGW8m1A5NYvl6UKLzvnkOesw1YqIFqz+ZtXNYvPblq/fljHPrzMoqdcpuQSi0yqfTMksCMap8sOIoQo1gWR7DcyrDhpqItD9HDMYvWNc7v1Yt9Ij+jBh0ZGRinF2Vbn2+g+/z+rSD5OlWd4hnf0F3ciAVaSCJCpmTVLWmlrgIpeZwXGhAoEgqKLNFlkGoXGcDwIZ0XQOmWadoUCQ8PzQqmgZv558/sc0q3mHan5dxzCQUnPQzdhWf0v9FwhmsE5d6ty3EDbbF4qapNVWDqTMcvSAnHhOslbISSElCZJZ0ytzmE2/DdpSYaTuXRlq/VnO6wzvNprmtqPZgeHRAw/pPbmmm3OegJr5Pzree/lWzocBMsktcss0dPgeBLTdpbSGgM8CxdAoLQlUtCx8R4oiOIQC2eTNI4G4TIhYYNz6ZrnpXJcTLfJN2GzoLqVJRZfKzs2K2T6Hzxw6dz9GTcfRD8d17qVgqatDjJEAmiTYKWFk2xmAYGoCpFG7YXFzuNW+KabRomytuk6t1YApJa4yg5XjtERS3/ADV51k00zH8mZ1v/ALHl+mxzUdFv3K4okUtPoyI8mpoqPVImm1HWvNGAzkIdi0xfU+J+T6ChEYsOgKarvF2NeLtRydMnhs2iaD3c1kzrDevjZdODNLgzyRcOx5t5m/E/SX0XmYNw9N6uK5bqPP0V/JoZCB2AVF1tvaGSI1O7UqbmoEBsJJNYXH6JSLBjYhSYfS3dloXRmcXGCFW5r5fw2V0Yl0nW8S+dOU9nq0l/KgfQnseTwZE6Py9N16MCSyI6CAIn0Oy0phBkPrag6k2KSIafZp0IyZ0FVFT4CwU5qfP1ZF5Ptxue77n3kufaRvHR8Ka524RYc4ovp+fg/o+bVLzcU3mJL81xXQdmt27OGn9CpmWtSxue6JpmNy7GEqQptc5t2hHjUyvosg6zBKaKfCAxq7cWtJ684XVSObnJPozaNn6sxMSJQ+CwbPSmS4/fNekaFyXtPfymjRvFfKU19S9nGOkFqiZa3bbFIR7Eqmqa0OACHExB0Fh0ahOEwCUxwBAcC4IwJTonH3R/P0VrHpqXF6LybGMfP1SWVs+jl0Dk2u3LULvFqwDkw2/Pl/T5+WehxxFpeyUDGKn+cu+2Ex11E2qhDpOL4w0lv1VRxamNaPNuGaZooCKlNco+KqvPTqnIBE2MoLbg7rovq/vw8xSFjCz5bx1rGbd9WDjSdI4tbh0TOaQ9Z8rxX1T0crqdIdFGVaLtgREJpLZN3LEwqDARPwcZwCoMBUgsWn0OgeaQ1xhGYr5/pZV5/qcz1UnIU/Z6scemRgUK+8HTV+jFh28mlctXPk1KlKxOe+hwfP3ueSjXN7Tcp27DU81LbosaDvlzlGeDawdJ8WoAufMEyYosQOaheNtee3vbjNZmc56SmVTELSd5e7LaujORpdDFs7wqKreN6B2YOtYsvFtmGGv2P6PKzZ81D+oOvhG31Oh8++iaZKmu1KwEDiWQbVMKcgHAGBAQxAvNLBQEDwcDzCJ0rn6c15uvXOzhnNMvj7yfbRy93c+h1lpYOXW48t0T0+KI2kiezefvJ5uezVJ9PlrfXm3W7iVys295N9M/Vkmp3Lo4HDXmqmikTWXqqqO2aZwU1BZp7TlqU3pFcyqFzvV9Ylc3leWkjcx+VPUbz15apvmVtIsDz0wDOpJO99WDi1feLbNuXb6w9Hl9S+VmfQ3ZyJYyHRePp0ju41ikYPDibU9lbqQYBaiVUxLegFjZgmpKKdTSWkMKn4GdZwuiADvOhxVLz3yHj7z5apTdJT8JvtkYQLlnaBSrjN05NoNjzSGNEYyJ0lhcjciqTI1Hx/Q0bqwVvhAORB0F1LVnzJho1baCZSW7aIWSnxevdONoxrH8NXGZZqVi3z+guzJyBE8/nT5Sx0cyRkvSOvGSuR+Z0PufT6D9Lm7S+bNJ3voxDc9qadydOgdXNxoFJLRgeSNWFQAGudCz1bJtpttLGqLLFLaKmM02ims1HIZjaJgQ0aMCWgAyajm2gNChoIiQAIRg9f5/SuXF7chr5xenz3WnLJvNy1EXMI6g7z9jrDCnaWQdWYaXWFE4E+RLyTGO0L4f0cn7nzVVKh+Hvne3z9AyjFI0lZJFFiuPoz0+V6zg8tzulTeTYaNIek9WLvWYvz9q/wAXQ9U6Z51Vf63z9FlaD3c7TOstw6Nf6edbQGnQvNZ7htj/ABdxJpKGqb4R0LBwEQmGld9Ms8y2dCprfUMGDQQaEEY9Qxa6PoFmljSmNhkFTbXmWb1vzPprj89+gMseo+uR6xYuGu/G46PP90+dH9Pnz23ntujys72VV6suqm0vzXRFpOKzkWtjwqL6cHkM/N6HObvpG/i1Hj1dZ0x3gsn0B0Z6b0x5r54LwrG4tBZer9eMlcQnB0V3m1m+MtvDbb7Hztp5NbH6PNVtYz6bu9xOw1NdYkSGhTZXNC4+jAsenfujnYYa0HLab0iqYa1+lOACSIuRq3KGQdGtABJHaE4sIKp4BFR0zD6BRJThdI5F7J4/1tp+d/Q/NeAavifkvD6Lg+tQP2n4zSenBltnCRznJGk3GxdRxU7ZdNstRWda7eW1ZVE7Z2Xpwz75z1qvx61foT5qx4O73M3w6uu2PnDpVetOJevdWMncRPnb1jn1jLk2uem+hh9eYbfNnbhnvZgdpTm2Za7953TAaZ5/zbVjl0eUNbnKns/1yvUjbyu7lzNdnNRubpba567081X8vrhejOk9KbTVYqUDdgwB6noMsKeX65rCWjRqUSdFVnMCuskdz9Jstb9w/SzPh/cPb5Gk9IotrPQoXg8Lg+J5T9v+NBvQu/PBV50gs0DaBDsgyp51L64Wmq09ZsOniuoqVoTPVjV/nfWonJv6pZi9NT2TzL0M46zoeDZ+jKUuYvz96PlpNZuuduGtdeF/z2xL0eT1KQqVBwN44ujaOPdhLwblvHFrR+3IOdhBtSvXLpJqY8c3lZaUTOdr5NKx2Zte6Y6NKLcFlyxcegVTuudVpmYtGTklccLpRBSrizD7jqSLvvm/VXHxvprt1fKFrNutc74PtorP0Ogkfg4GH/dfiknn6LjXCj7+NNGcoTX24sccqs5c708HS52dtOWQuzhl6Va6cXkVXPC9bIs7sPFTp1DazV+ufCSwTey9OUnShvP2oedAqXG06z14OOTsy3t55fpwCiT1h9Uuk7MK28u+n8PR8rzebU4ZOZTj5rU/P6k1y1HebRhoe3Xqzl+Wuii/UUbLprlwqlE48aha/FQzMi2x8N/nqhX4PBYAv8qqJ9V6f5P1l58X6XR+/wCGg8vVgOf2Kpz/AEbad/AkfQG5wP738OsfL7znTnqXV4TQyl3NdVtA4O3LST6vPsl4Ix6ePfUzKH7eGS1yF0Zl4+mseL30Dm1iRs9iP3lkN2kgevdWUnSa+ZvTcbrXTm80nWOrG0c3T8+W5ulITroHD68piqbeVJ7/ADXeWoNeOJTr7tYWLHq0bh75CMK1vwjzK30zzUkaTfASN/0kAnVmjJqnRaF1G257Ue8s8vGQpzaos6VKa6nOoe1FaKlp6df8f6nQvD+l0n0fhaTzfUULz/sfAprweDoo7bDDPufxO08X0R7yh+75ypGUsySagJcYquitzeF625nSedz1Wm50wxiOvhf75E6c33H0ZV5Xp55yat7TTRHbZBJ51rfXi50k3k9OTU6305zTnYejKxcnVg0bWnHpncO/S+P1bLXFlHXwVHs4JPDokfQ8GCnTNcu+1c3VeuH1di83u+fPe+WZPnrmktNU8HZSYOW3bn7qJCkUuinstnHPsdVom+MJedC0lvUupJocVl0RyqXC7KaC6Z3H0J4f2Nx8T6XSPQ+Gi8++t4e7N34+UcH6N0SieDgunhxD7b8YunD9MVww9D5qiPneBc9Io8WJFnnXufTZerzra5zLn6pHXOb1z1R5Rvb56+jJzvEzhpl3ietmXHtEbJLJJONK2XqxeXMV5vRUcdKV24y9Tsm2WvcHfjnN7Gg8ffK5us7YSdYY/wB/lTeXRVuvkh+nll25eK0nwPoKzLH0c2ceh49pTrzhvdHpWJRWShjdlxqVJqehcM9K2MkvWkx75RXRlmWFuhyKcRGowlhXHG4ad4rSNq8X6+/+N9Hcez5hy+dCtEmQed+lrF0Xgqvb5eMfZfj144PqCEr7vDoWnEyeViqYGWMJ6bXj6M11+TbXFJy6pW80OZfWNTebbs4B9PPI3M/hvkPkepjmOvkDCwlaF05ruaXzVS00tz1Tous2j0MZzz/Tung+8/4u3Lu/x6/2+fPdOEBDz/fMYpsb0RRsYe7mbHK8loiWPIoNSpj+KrNy2mmadMqVBZc9Uc+zhXeujne+hxxzdO5t3fn+lKaZUPbnbS5FjpxBjnKNm8D7i9+L9Bc+z5ZpHVI3wVHn+jpPJ9WoXg6Kkej42R/X/kV6876kgpC8x9HDF68sc8Ip5NaxJWdm4vcnO3xTPODy6nF4VqlYWTGk6G8zdPG0ojo0msNoSNa7LrOd1WK07eHNRTMKrSpIWG5t1F38hPPP3aetDi+93tyQXpYfSmc/Pnk7/PncpeydSeDdBKzVyWe3pQSr5oVgiisQ08iq/UM6GMVSLngrLhuBMYaV04t+vCrZUnPWbx3m9Mbnrh828/S7C2dWEdNS+sab8r+gXLw/orn2fMOXz+ZRuP6yqc30KmvByTPvW8DLPrPye/ed9VxEomq8Pbc6deUO3OzrKKMp3k9O6bebT9uRnOzFxWrUoKfolrmyIsdTPS5BHmRFSyGQBJwYH4umOz0W5yzq577ec55OsX9TxPNZkiZHh6Gi22nz6+fubTFe6VUpZVZkPE5VP6QWd7Jbp4Jh3Y4Zrc1zaJ/n2jbhnrnHRVOuTIsuWvs9UZ6W3v4871zfxo7neOeE21KiYoR0ZyGsKmhS9J+S/QrX4n09/wC349w+aEz9eo8n0cDh66rXkeDMfZ+bzb6j8sv/AJ31SSAXzs9eOWWkmqRWadcE6YoqBijSWKAmaahNJ01P6Q9pSDUuK1Q56W8aj9E1qVUjNElx2WkNhrjtTeKhx6XN608Y+crTjvN7PoL47o+T/pcqTu4pFgZcZp8h8qsRFgS2VyVL5ULp/QqXx9F8M/oLWadc4PjpVmiMsmWklzdLOh11c1K1y0Ti+lMt4isYrr+bMFqap6Ey20aWLfPSvnvtNB8H6nSu74aJj0a7h7VF4/rfJdYlv0mU+58tn/035hfvO+o6I4RPRwPCZaNEXkmskOEXmkhNShz2pS5Ncdqe1BGnTThqTCxS7nm9AzqUHCXNX1mA1jtQ5CPmozOqN34yFS6aftC5tNA+Q75Tw6+bPss6P1EeFgHdJb9CiiTNagjLWhEx7uN4PTj9M5TXk3bs589RhmGkImsH7JzHVUuE6MYm1pvnfZqOiD6vnYDbyRE3duDz82JmfV0Or69s+Z/Qbz5Hu3rt+RYz1Mc+zOeH7byXB8GO88q9r5WhfTfmd/8AN+oUEpzeq/y7eXgJaJvDzxjvT+STceI4441ykMkjnzOVPnPaRal5UvxSQ7HL0vJ6FnT9VxFc0mp9GULpBmsS65k6lw5kaTXCpv4Lv0/56vlr7xULuTMJpl4mnYAB+ExybU3XGWbdYbZ1d2pG7efsv6Hy6hjWM529kYjICweMznSGo7nze3YY9Fo8Kl0+BCPG7unUcFXy5UPdxv6O4/L/AKHdfJ9u8dnyjGOoc1mXD97yTjfkMd+bMvY+Zof0v5pffP8ApSIksPRK1zTmFrwD05+pj15vOOOPOONeaG5WzhPmcJ4zzXbkzmxNadvzsqHCL7x9Fpx2ZC81EaZ165wP0cpzSHbmZuWc0r57o1D4np+evsFmfYMQkG7smYH4cC+c2znIsOeuQ+hy5B2883zbWTn0tHbzz0044+kyTe82rVdbmwy7m7qr0cliz9S2LeNIrfT4tclatxerGX87V9OQJqXo9Hdfl/0W5+T7916vlZXTz42O7JPN/ReS+N+RD9XFnfrfOUL6T80vfB9AZp5j2Oc+vzhSv1QoA7+a4y7uxqnTmYej8x5oTS2vVPhca4jgea80Wld8ui9ZdOg+j4dE3i7cuq3LDHb5pnS7uaF6WFo1l24sNyxTlPlumR8HooHrrG/UcWMgTSc2yYBYXnG9T4tJmH8r+py5f2ZSqVk5tXGifz2SuBL64triwZ1AUlpjmq32cuacfZo3J9HVejyea+bHj1Xl7M+XzEddBWid+/e/l/0y4+V7tk38Oc08euZe7QeP7Dkng4ivd3n0L0/nqD9J+a3jk9YopHHucR1DrHmnJ1yHXjUPjx85LHSLbl7T5ckuPXn5xyp8jksUNKryDtWyOm7J3/bz5ZXEa5RFzk/Ptn0Ub0ue5b5v3Nj1hE1H+B0VfzegmyzHvtGHrwO/kOUSQ7Ey0BORX0h5myR/GXr8ef7xxtU1M5aTTFY1bd8g56MsOg3RywSbpqd7+XHfP6iBKg7DrWw7YY753jtXuE0Hr2b78z+o2Hx/p0Jx89nQ6LifgSnU/Q8qj+t8zRPe/Pp/PuPNO5t7n2FjY5J5tbzXeDnLrYdXiBqVnR259plx49UrJJpKKhekrQKaBnXELB5SdpXlFquCtQsVhcWj0cNE6MlZdE1NynXw5v4/TSuLoZNudetkt4bXyxgVOXHamTKr6C4rseb+HfZ5K9QLKpMmfal6Uq05ptoqDl8ckblBE1jJuPo4OaAYWwL5rjk/B4jU3E7eV27X81+pzHjfWP8AXgkb5Gs7wOXsKlH7POr3o/OZ76/y1A7vFZ1MxNrVFLWPyFNeDrXAI5ImWdCzq5rJsYwdRHs8EgD6XPhJbZn1zDNNYqOlwzRxPgn1NgakAKjK76dq8v6DQ+bpmMdM7+s+NqvJtPeZ6jbDspuvdk3q/GtHPAcJyadvy3OK3a83XORbOr3Kc7njOZokWpWkoEiEmJNKpZNUi6tnqkHwW0HYOlMPn5iK6uvodTenfLfpU15H1HXLZdDjr8qser83V/W+WonT5pJfR1i4G4n5vw0gsSiuh0XQ814PC6NQ4l5xbCAQOgkBgkLDLn6l1pMXJHJ+Azl2EqieJlwcBltdO9+R9NpnPs6h5v8AXfGXvw/YiOD02+/BGPT5Q9bwVsnUSo3gLQqlY7y4OP5ekjKprlX9cZdjtshK2FaMBQWHk6DhtFzQGdRPheIuKrObqItNuqHL1D5f9JnuX0qb6vztP9b5mk9XnNHJYa05jOhlVPXLa+fTPNZkJoiahpYgENIEJoTQmeFHtQjToHA1IICWCEJpugydjEqobFcAgPCZwJsHCYwzjd7/AON9TpvL1lhVP6H5jM3hefiPqdI+R3zz6HyvmT9G+elQdA6ZLIlqUzLrtQ3BtzbvM9XGkZ7080m0cZKlYKAgLTSNqnScNWYeDoTiLcORIc1ESUNMacvGmU6Q0BCDsWmZN5KsOOrC1Xtc9rxrH9Zfy3KoyZkygsFgsCBwcZU0jXJAO1RWiyO0NmCBDTek0Q+TnWm7XAUEgk6HKBLCdBk/XnvfhfUavxem+nOI9TyPn/2PnZX80+33n829LNP0T5v5+/S/n5dy6AjcfFXq5scaZ7eTYUnjtH462FqC2yj9ciNvZTkpDXBJZwcZLpmeg5ZhCbsCc8ieecjURI+BxMLUVqjxTbO2sumgtMgnafQW0ptukoZRlmjDcJqSKMyCB0GVTRdc3qZwmUP3qHSCVk2zqHh9aZ0mKdmQRpILCYSSySFPilGsU6s9d8b39H4/U0PG2fTy/L30XyjD5b3t6+O9LMvt/Byr3OJ21K0nogjszJqbgCa5UWTHatzVnHE1EXti8GURwWHU+ghqqzdezsQWpzVlV0l2EDvOfqY+hYKAMVXN5lE2kVFy6BnXUeDodBYPo0CAA60upKJYHKWm9TdJtmAJrembpV0VuWjFWGsXtxKaxXufWNT5SYCkpcmHAUFhqZEmTCRZxLEeqND8f09o4/auGeju8viz6P5auzV03ysVzSeTZgmdku5eBps1XW1op2mVqw2rVTZZupVAtc5QamnkvgeYpA2qHnpHSzjv22VBw1tydkaQRaKXqmTRbRROWmK9Kmgj0V3OoKK4HB8F5NKcxlo7GVV1Ak4rXKN1z4Hg6BUHQgGlDlNQrQrjyUAsJekMVaVGEyaPLl0dZ4FAYTwJIHgueeXnxeonqetoOfTPyfCn0fyo7m8dEOkq1zaxiY0S1Kacvwmlapqo3lP47QFxY40omuB6UgMjRwWBEyIZhn+egk7fcXS5ybHW7p2BxFpaU1qDzmUkBScOn5G1ZiSDK10Fh4PAkBjJNOc7ko04hmERrky0jqEAgBsGHUIY7TI1ZU26PM4m/S41BNuENWuCm86dhYIoVLjRrlOkNqm9eH06D8xtnfvdWjdHpXDPT4g9/wCYedOFm1wb4VWo1hZp2Eg1YKUsxSJXPSo3k8z1i0OIuE25UW3DbpyYCsINzJETVRzuWqb9rCkZvjrbFVtM6UnudZ6yQkOhW+Xs+XrGNKPpBaIxwI4dDrRw6zyaotsMAIaANAkphEIACCAw4N0BWp9NshISCG7VeokZaWmYnoP09O57+guPZlahNYY3LRqR+R2NyvPvTJb2PV0WOn5y9DyKz6WTnyNpf5u6T9X5cH1ycDNWKlY6l4nKRpVnkDLJg9BK0aTygbPUnAlscAUILPSDzrQtcpKkxmqDlrdpekvHKJ02Ws9qefA4GA49RsdSCkU2NKjbQ0qbZnUomxaj6UfRFNhGVNQ+DG2BDcQAGwCQBNQaCagVysJRNywAogH0iGdEETgbsHsvWObTZObVTDAMWLTnpXymsDvOW/XdG8cfsZ3XJnd5i5cVZ+xX+7xqx6/lt5cpSk2rFSnGnMXFKAAIEAijwvAIGw00htPKmr4bgl6FvjyL5Jn0aXRPa3jhM66nWe+PIiBjgODthVcXcsmuNTc1PZ11MybkBIaFLYNqKogrIi1F0omyLoE0zaUAENBNQYDhjMLlYHBYLQgHQIaMk6Q8Kco0DCt05NwsYWmtGUzlrXxurPQxr6vTRJ9W2zt8xe54U189oTn6aD9DhG9HmAlvaLVUOAmKUgq0fh0jaGbmP0TGlHUM6lAhDQHEVBVHTUhSt9w7mlSs4nTQUXZRWc9JvWPol4Qs6E5Oma59guXAkh4bZNs34ONswEySkcSwsdTSQKhLOgEImlX9JjdFGWMHMZSiLUfRHNRJMeJokcUgwokg8B0iWits5NrXjbxAqG1LosC0y134zYNPLfprvJ7GgKsR7/GoHL9abi8Ki/SfPsaBJza0m7xnrmUZITVt4tCMrdzHWmDLlld/5tG7JLNxtKP0n596IpVrRcnNJsqXUZzoXMd5zUbnZ6Wv5O4c2kqMTAyNxibAh0HUN1QxuRIb8LgxsOjo+oMgQKBLGgOQGDgS0cALG1TF2omhjct2hhHNGE6Tmcy6Y6OAQHQGzwcZ89Pn0v5XfsOk/Qa2nX0tFXRnb87P+T2M07XXPc+KajSPY/nvQrPvcpduecpPkIxpi10PMSjgJAYHmpGG7l49ombPozk32Xl0Syo6R8l9+FqD6q4N5eQ4OUeQoaAZKupdGMGTakPE+J9G5FxgxCbSDpCxtRJbWJAeG4SWhI+OVB0BCSCh+aWAGAQ8DoeEoFA3BFCGdR5Hz8c92+e27i6d7nRMdXo6JN0Y4T5xjcOg/ReOAEJ/T353+iVP7n4fP+7inaidH9CeP2dTjnLak2GNiWm4RtTDWoXSalSrCqYc2EYhxARbNo572Hk0a2ug/AEtuqKhwAQ9LS35pyCpfQSUEFgUShtXPgIx0jw0oMHgGJuwYJG6SWHRIAjOAEGFDpDlCWDE3Y7QkOsKjoBZinHlKcVVTYgvR3t9drUxKs5mLp+W+Le94QWOcvQ+lvk/1Tv0X5F87ehhZtImA+k/I7ETXhEQZM4hUkJ9T8NZKgSMFSypVvRQ4PB3XGvAJN4nwBAYHKPIZlPQM5UhNPkg0+ggfQ4ChqcuGhgsfkxCWCgUHhrSQ02H0EM8IwFRwGDahLBYEDgKEJnQIhQJD5i0yBvDToVi4+iFjSdi3yc1LgV0YX7HiN2uLT66XRcfMj439PnkNonKn6C8zrsfPYhoBuzgnDCoQmURw4AKBAiktCU1glMQeT8CGLkICxxzo1Q5luknCEMUhQ2QNwWw6DAQAM8CkIGQXgEwoLByCgagIEtFDrEoZFGU+bAC2kIOnwOUgUiIew0h8kepzJkns9dFUYY6t3N0WnKyt2xZ4j6PFm20oR9med1WnMxbqyyTuwcNb1xdGg8evASzoeSG2gEsUDtJuNszzS2LhtxvAEBkwIED5B2NKcXaE2ZISCMcikE3snYbNngbsIgZTpS3Ysa0FAwugFtIkA6DoDR0G9p2Jo2RDeWUOgzjRpTf6Y+QgFg5RwFIDR8obpU0Xq5mvRgnm6brxddgipGTN/T4KtrnS2kjv2d7/jQdJ+eNs5DSZJm9ef0zvNo4l+AdSuXxnWm4/D6JDPI8M6OgpPgHDwLQJNtQ0tDZ5Hg8n2kkFI4MspNORcvIbVNAEQNhkGBYEDoJR5i0cDjAg3BYIYdpim8QNC2Da6xTFgNy2Z5hofAbJ4hHRMKs39nyBuZ3i7bFy9Esqk5WY+jwrazHoxAJVvRKPozg2wdlJ6srRpF11kyoMmu+J28mnKZhCAQEGGpAmpiheG4QoCpnQ2VAabWgJ+ERigEziGrfClkdBQeDzOhISOpGzH8vwDBuBAKI41I4zqGzaklAIEs8xqBEIAgdElhwKxLCpCYlNygQYJHVY6yhPQ4WjVSx3vnJ1ScuSSwv1/OjKU7pEIEpnUpLuvNtSunKR2zd6zd8tXJN84N18uvWipjAovUhAWWNV0EgKk2pOk3aGU0OkKlxPqOM8woEQ+gdCiG2rGzEMUm5EmgiOI8wwlpnQaToeYIHaYwEC0dBQeCS3iKA6FAUPC6n20kGudKo8jzR6TbOm6eG5dWmVjM3kAME2J7DeZlyskX28VftbJldD1iiWm5MS3cZvaM3NY3GjcwcEJrwJmyuSUlSJTGmMbkBgRpw5iXTdUsQGlh0ag4BQcSO5CoasWwSDsbsaA3oQ11iU0NGTGzoGSWxct0h7IgG4BbUgyFtP+nNplRqEI4zrTgEsTD8Di5a5WW5NaFDYY3h8det68ng4z572U1z7z8OVC7ac6QG0Ni0GBLaCSDWm5R6pQxzIAZk0tdYmRSoocAYGBuDKhaXGxMWhtQ4k8MgPZRw8gQKQBimEYpHGJDwNKGYBY2aMxI3EnREGqWdy8QNt6CEm6paIeiTgIBAZ0KEKhxIKgknQKmhimBACP/EADQQAAEEAgIBAgUDBAICAgMAAAIAAQMEBRESEwYUIRAVIiMxByAyFiQzNSVBNEIwQCY2Q//aAAgBAAABBQJ4STi7fuZbdclyXJ1t1tbW1tNJpd5LsdeofTTLvdNNtFp2YnZc3Qn7yMK4LSdv2a2uOl+ELvvp+l3UcbOh4szG7IpV2sz8nJPDyRwCjqM6etxQwCTlX93ZxcRA0cBAtfDS0hDajb6orQwJsiRjHLNIuEZJnFAy9thpaWxFu8FuwS6OSCKONvO5CLJw4W1eVXD+QeQUx/T2zbfK46DGX4vaaF9RmaKRSzaXa65s6d04bTjr/wCptMbpjXL2YlyZ07rkOn/PxaRhRORJhZQxbKRb9xLTsb7KxtD2O1aMWeQ/dpNp3XJSycmDlxYCdFA0gyQtG9d4ya1XEfhthbsFN2uwR+7CIuJezuhMlVhL4Xc3FQlqTyWK/CV0EMQutra5KanTtOOhHFSeg8l2vKv96PsUT/bkdTHpEXs9tmfgycXW3W1pa/8ArM62yJ/i+mW1x2uDaYGQsG4+AMZM6dxF3ciQOmkbUXuojbROmddif8ybUMnBMfs0ru8n3WjmCI5JSlY4pNjCO+OkCZn2LLl7g3FBwiCPyegdjM5KrAGUx9ykdS+EdJpYjbtZdrLuFdu0BoSW15OF6plXLS8p/wB6o3ZopLEJLtdf3BrpmXF1+Phx+L8Vpa/+ttl9Tri3xZCzr8JjdFtabS2tumcdBK2jN1CScWXTsTi2puML95GIDMniHW2dCz7fe4nBnl05MLMuUTPuR1XqluMYYnzmcq36UU1asUk4TWWgaens4reOkajj8znSx8mOyr2Ie9yaOQlDNtBKyK1DGvKxs5XD498i2P8AKOfzpNWhJSzQxPzOZSzZD5k/DfPbcAJcNL3+L/DS0tLS0tf/ADfhclxd0IMuDJxWkEO2GMddJumotv0LIqHJiomy6NP1+/FflNsUzpz6Ud8pVVsTG0obYofbgYpzdcnWkyPizdjOuUzpo+SZvaEPYjDWXy0XygLcZU+cxhh6ITvl4oa9rD2I6U+bzFx7GY7Zp8PMVRBNFt5JFCNoneIVE8cCGyxIrgRj5NK0uXf8RWfU3uqSNo4ikLNxDD5P8wuoSBEC0a0LpwIUzra18GZOtLS0tLS0tLS0tLS0tLSchZfU6YG/Yyd2Qi5KKEVw2hiXFMKZk8e1JCyIOLlpPIDPzNfW78A3pQylE5XpCYJ+bSCXEk8gJiN1onQjGy0m46t3IqYTZqAJaUoW4rveNaGlJYpWK08FexGTS1LkLKX5fFFWkGNzkvQ4yC9XsBcs0qEwSETmSCwTB6+NjO3K4xvPIoghZeQ6+aP+B4Vsv8zid5J5u7KdU2V4yLqdceDCYOiZly5P1ASeunB11u6YVxTtr4cE4rS0tLS0tLSceI/UuO1rXw0tJmbZMa4phQMLIZGFhnZDOyaZnTe6EURgKkN3UsRG0sMbP+1k5CKaZ0Vifhx7Ewsza+DMtKGrJI+Ut2przSTuvEZ2kteRxWDxr2qOPxtx5wilulLDBXEiyONYXxtCew+Qzc1scbRxFySWnQK2crOvvEvTx7gaAVP1Az2QBn7iWdZ2yPvx8gribmTARy6HykrUNj+8WtLhtdO04uyFbAk3svq23Jk5DtniddQEirEyaM08a6STwkgj5EUTs/S65AmiIlHFGLkAu0kWn4OuOk+0MJEgiYWaJjUlTSOPj8OToS92lAV6wO4JpGGq02+IA0ikdTcd6Wk+mXMXX3HXW7oQEfize2lpaWlCHvccPRV4bmUOeWSYfEycy8iowT47KVgGTvd8XIURmFoalij3NWGAxGII5QGKhVs1YqePrvNt9TmgikJBXiQjEL8ItOQE/kbiWT/6y0/GnHZlOIOwnyFcToLQceuJde10EiExXImdyE3NhddbCt8W0Lp/pQGS90zbTMtMjeEFqQ0cG1xdk0bkmr+0jcWfkmF00BOjgNnjB2bj7gK0ysMwpzbf3HXFCwxoGLqabkJT6F5/aSdPNtSShy2brgTpq4rrdcHZcWWlpezIPcdKldYpanbZhepYZdelet1aYejmhkejJMNKeWjXl8gr8sU1OommhnvxgTyA9MbDTwfIbp6eCGWmfXMVqMWgh5SOoqxmjrEy4OKedhT2ZSZylJZj/wA1Xm51aL/SLOrXZ6JSR8m6XZfVsuzTSKTgm4OWo0354clIyFnTckzkyeQRbuJ11SmgiYEzLitCKZ1wN11CzlDtDXZDEzMUQp42ZPwW5VyR8E60tKX/ABJttKBgygttKFg7JO0bEOkwbQdAGIs6CqKKqpKRujiCNbJXZyFYpu6tlMjRxcdazG8vilwSsTk7F5Fb6hv3K8uBxtoGKHMWCsy2H1GNeOrVs2iluPOFg7jlNCLziQ2HKCR7IzWJJJ4QAp8XclyF0BkZgOVexN0xi8ogjDS0s22r6cRKGlYjCeMdveYWoe69k4AurSKInXD2KJnRgyeF9MBMnc9Ovdl3bTFO6CIFplpbEG58l1m6aNhdnTOtLTLtBdkjphJ0Uce31qT2RO/J/dcVpO4ijLYsMjrpGSZ4zFnjBxjjF1pZq6NKsOXPG1QuzWDwuRG5XF5nXTKSenG69PGCnARV7JduXwc8s81rtkzVZnrPhLhFckmr682sv38RvhV5epyM79ZwjHFSvwniZns27Ek7yuLdsgnJWre9+H1EcMkeOq2xxmPIVijxEUNvJ0KseGyV66tlty9tohM1wAWz/wDsH/J35YrGQIoRn8nyLvbyecmrf3qYFxXFcE4LrXSyeJtNVUgCyOpZddJrrTbWxBdhL+SaNmXsvqWnXZGuRumY1xBb+JIpmFFKRKTS5rUq6WTAIqRtrSj/AJ//ANf/AFgOLqyRyxY+z25OOQmCSKdngo3irrD5trxLaNTZKr6kuFmXxmqMknk2K/5u2AQv4pjK00WQvjnPFnvx044bLVbnzG0EHICYRcynll02YZi9R9w5hA2vdkMEnYmxpRjLHaEpysAME971lvx23aycUEQMQwippwBuwjTlKtSks2LjfdFFHPTrtuUIwBXYxkqJkyZaWlxRyRivvmmrMtCLOpOArbpw2mAWQgzrrZ1oU4m66yTADLfw2tpvg7syctoo5DUVQzTVIhbqBHEzvLC4rg+pOGhmncyhmkV641CRhry1LU8OPq5nJY/LU47Oonj9TAcpVrVnITHL44ZS2ynN1JLMKKBt3jCC/AbRiecek+WzUdrIWpYCsRX7GYxGSqthfG7xDYvE/M5S6wAyTyPXGYXEcpckuZD/ACIQM01WMIGsQxkE0diD0oW8rG+NwFW75BXjrY21cCq9kyWnNdWkEcbM/LSzv+xQuPpWJvmnAtWhm9NslyTEmJPLGC5yGujmhjjFuLIpAZ37DTwu7PEIog0tivqWjQiK+tCKaPa6l1LrRMI/BmkdNDtDXEVwXBMzalkjBPYXOwSOOcm9NtceKYXdO3AaO7dyvlBLJeXWRjxoyzUpY7PqZQsdVoYanrDryxN4DVCM+ExrzJ/RnlcnN63yNpCnny7jBYO+9KSF5GxuOxs0/jGOr4zx2fNWLdUy4sx8HPm4CnFyKRijVmexYTkouYlHJyYmeQK8YTPH1QTXMlkMhNg/H7ty/Li4yabFMKkjaNwYXQ+y+tPByXkAcMkoC/s7chDlNurXvV905CK5SOmEnUfAExrvFdkpLjtfQLdopyN07EjjBaWkzJmZMmXMRRGvuuura6xH4MuQAu4UUsjp+x11sTNA2hqaXUIrgyeNSjCKnv0qb+Q3r9e/DWhY8U9CCfMwllMLAVhq+P8ASRSXuoZZTyMclfHTtY8dy1enkc75fOEflT+r8fgkuDh8hI5VbMoV7tuxVuh6t+pppa5R+VTliDPk7hp2ZzQfUuLMXJo3iqyEHV7P0s8fpwD1BgieVY+eOumukVvxmvUKdhkdr0lejVxV2TJ37NRiJ6wsxQJ2ZmbW/Jf9s6ri71fJA6zfM44Wt+TVa9P10KEABbXNnX3FpkMwrsJbJ19C5rkuXxdOYsubpnkWmQ8WW05CLdwJzN1qV00aEYwTkn90wKERJnkgBNM5rjO66ZHTwxLqZm8wo2Te5dKzj421FWv0Wk7rVrxcJLJoRjjO9jMzHSx7nSvPHEUN3sqyeK4u95C3lPjfziL0dujTPH3s1ibI34a+uJmYacnsWKp0xou23GvM6YRZ26mB5RFdtgXq2yikuSR25DEWQG4swyTKEnpzR91k68suPHxfKeht5H9QsTFBkMxfvUPEKsvQTbRaRe6cCTVidvJW1l3ZUoedPJ4cclQDwutMV/wbCNjuiJfW6+0nIlo3XAUzumf47W1zZ1s1o3XBkIiDu7Cu4V2EmeV1x2mCMVv9nbGuTutTOmjJBBACEo9b4ruF1xck4yM3AHXkdvx7qtCccmLyEnM3ZlWv24lXkoxVvXUQhy2ZltqxdjeWvK5nj4aF8qNeCpBlYZ7VO0F71WOvhQns5C7Laho9lrAeM07M/lFGlRyfqiYTsdouQ6x82OF2jPgLbkgGBzuUYrdQqTyWmRcd12ARkI5JcfKAHaiA60RyV4bvN28Ex8GWGtlopci7IwTwttgZX7XpAzgyDk3WNjd6TRoRV5v7FcW+O/gy2LJiZe7rq2ugEWgZyTc0TSOupnTRCy0uKYHX8V2Amc3XGVdROvTxr2ZOYsu3a+465IduhFmX1LiyYQZeTeW5Spm85JYz+WnhtwQRbIzGJ1x6jKxoHlkIpLliSKt1GquVG9JF8vxeRCyBNauQ1IMh5DDzuw46avZGr6OlN6a6HkLVpcncs3bHHiLOuLnJYpnCfZyZ26prJ9Eb2rUCKWNHIIoRZ3qgRzXCj9TAz2ChsHXjoXjihEcdNLjb2HxtzxG+dq9pOK4Lgszl6M9PKWPVXXWIKcrTJmV9v7Fey4rYqtdjtTEx8WjX2412Muci+4uO0wiPwcXTjpco98hX1oIzJdLa4Qi/JttYiXc7rnLsuWupNHp+BO/UK0pJo4Qk8lpA/wDUJmXzc3Opkmllz/i9HPU8L4pJQlLxGjdo5vxy547aoY+S4OQpnDbcwd5o4QhGX3hpWjGKvLFJUmGS5gi5YbI5PI25K2eqwYfzDNY+/QwIwsrMsAk1iFjJmOZ/dcGWHwffDZns45gq0Rgjsynlq3yaiNq/UyDXRrRpqdmZpq0sEkdexAN0CeaKfoHFPzlmmkgjgkmnLE+KwTUQgjh+DrWlks9jsaeQuMeSh9on/Eucq4OKjZuzQD3rIDN6DS6nddQChbbYMSLJPCTs1JnZoYwTwohZk3Fc4RTyxruJHOZItEoyiBdnv2yLvPZSTEvuOmiFC/FNxTOuXstsh907OsxnoMYNu7dvm4uKiOwaaUxUF0XPFZNpVcthXvYmUQGxWp5KGz4ni3k8lxE2PyrBPSlrVJ7c1isUdhrsT1QOc4qfWb0fJIqWNzPjUnDLNDVKWHnPYvRQY0pXdZAIWl46LrhJzb3i8my1ZNelvhBalxsh2iK3Zsy3qj+z4nHPkr3kVT0GWC2wWZLgTVMlJym07hHZdgp0pcpPi8BVoUPup4zXSvTxr0tdecYGl6y5SwgxDLHOnXdDUzzCmLSvF/xyek2+ho2Ao5GwkbNmDIAieWJlJYdi9VMTbmdMzrc2n9k/un4pmT9u+KaGNcUQOhrk69ISaoSaonruz+n+ket2zWdlxd4vNx3kfKcneZnd3F077GMn463HDKXGtIHInpy4oKMVdQyOBRzHwzOCx+dWY8TtUI/mMYyWLkstiIpLMcwvXRSMzY2Sc5PIPIr81HxvwuHOYvNYuhh8rkclRlpv1oNMuTqlWx9XF6ZSR7Qj7lrVRx9XYo08tHTpQXqGHxVqjkfJqtmTyWeqDDQit3lYxtnHzt6eOtBDzl4yYqTBPmMpa3puS2ubMis12XmGUl+dTx2K1SsBDAX4p40rvluZ8spY2TF25snVvxk2OQ2TJ/dU3eKPx+xXPP8ACJ36gViu/IaRyiccpD6Ml0GDBV5s9Fk1D29E6ekhx69IwrpBk4wMucDojFmAluZ10yk7Vdp6sevPK8ENmMhFFYjFNY4IJewXf6ffcUpquI9k8TtUzN2Rwe7ZeTHZK5PLBIMzxSOccJ7Xkni2ByRWfGspBPD45l9l4tkZCi8OlUWEZmkwkcpYzuxQw1audv3P0tx0yu/pp5LUVrH38bKz8E8mm7Pq4/a/7ER04sxDN0wwXa7D4tJcrZTyqb/8iowVbkOKpvTseb0pJcj0x6xUIsngeU/EsvBhoMv5rBlYalXVVq8OmiiFeWXfJquU8yzj5zKDyrtVm9RXL2byPN3MPLTO5ct1juBWyPzP0HsuEjI5xERsxuWCKmGbK2AIpp+H1kuEbLdeNMUOtxo4QdxuMBdm19x0QyLROup09dl0gutk0YiuK4rgmF17ryTxts7HW/Ta8cuJ8cxGGjnOt15e4E2XdikgFusYhIlTpW5ZCxeSOKxQyfrXI2KKxNBJiLsV2AZ4q8ccrGeXoQ1ZHNyjtc3naaQGGV2UY9argNRmNwTT2YWj5uzObI5iILfjHi19Xf0vw8yzHgmVwp2cZdx6w8QPa8mr14MvVq2bA0j4WsvjrpX8SH/MeXch8no3JKtocnykzln5pZyY9ZXMlVnjqnPRVafog8Whr5NDIvypNRhlPKoa8wR2JVVxkdhq1f00LtscraxrX6/DE5LFyT+hyk0fy1OTsnmPUsXa+Fu5KpnvUEIxzPsJvqmmXVO5xsbLkKEwdSyiQySTVYoJOcAn7HdAE+RXrNqA9iJiSOQATWInXIXW2Uk/Wx3id/XRKLKY+ET8kwwryTOVL+MHFCy+XM7+ihjULQxP82usL5LKcwyecZpmyNpein3LA4jI/OGS1YESny2WtHiY1Ji7LKSnkgUkl2FevnT2rRLssuub6gy2YUJyFE/Vo8xhWXzzCMvnOGJfOqhhNBhskGdqhjMzSyMtALD17Nmax3Lx24difzAuPk21j5orUPkbxVbtp+4aFbTjUluWPF6dHIzOdavG1sF62Ned3528fmtIbNFFJ1vjf/BdeWXerOeO4/FPKWXxcIZG9TloJyfT8jWn3hKzHnGq6Z2MW1MSYSZxkkFznsGLBMt8Wa1UEreTxvTF5Fh4oC8lxqfybGOn8kqL+oAdf1BbcWzWXFSZPPG8lzyBlFkM5PCdnIuimjRXKLJ8hiWKTI4VPm8RGm8loipPMgYg8ummKx5bkhH+p8oYl5JmnRZzLknyWUcatq2di2zuTQWZK4A7j47lMrZr0bN2hVbL2V83hQZbGOgt0ZE9eGVpsXjtS4vHu82MjZWccXy7F+R5KhUv+UkWPksbXay7WTTJp5GQZCYVFkq8jfLsJehg8axNyet4hNjzyPjmYkmHGZOKXDTGNryCWsw2mkrW4PrDH3ZIV4sMkuTh42omBSdwxy+W4mzDkK3h16tZbHTTx+lAam/TkvMDGLyGtPNMY3Zgnxlosfj9K1mpLVlgru03aKoV47fl4Dwbk4rsd0Jez8GXmoZOfFwR5GrEdyoDhksaRj5BX5RZysc9jLjCo8vO7Des7t5DNgdLOZKO1kbInSI805XJJHxzu5lIMenElqRiZ5hTlMaaKR0MUycw59bLpfbU9r0LJ6Ar0OlFW65LJDKfzG1GxvYA/DnaOhNNyW9OEsjrv4sTiaatWZ2ecU8l5SDfJY+X0o5HJUSfOTxyyB/kkmiiXroF6ys67aTpiqoWZ1XnsVzwuVgycUmfuwTR5i9JA1ilMfVXIfMyl9dJSe03UEZWZo5bNbKTQn4XkacUF6/Ux8UFuG1B5TPjPIas8VOEGJmTbWMfdB/x5vs/Ians9IJPWCUdVlj/AAOWlZPC3hVnJ0sdJTykEfkEXkWMNxnaQWJ1ydPtaZ05gC7IzXlg2LeKxEmRaWDxvEyX8tgfGPSV8NQA7GGwNaGWGFBWOKZmsdXbDGprJyKjYPskluMnnyLLvzaK1nNPNnSQvlHKhehOO1FAVp8eKalCyarAhirstxL1DRqKeWefLQyQS2o5JVqYT8Wb/i1xW1tb/b+FmZ6JWZuJnC2ziDuPrkTjMiBT/SDWJWVXITKncGRRzw+RV4PXYu2VGLKD23qDwzxyw5rDzYojyQgrWQi5xxz3I8TLkaFnPZ+xbsU87ZrVMx8gylLLNXhmc3ZQuLPjveiX48zjk+f+gn5WY7QTVrM/zBTvWrReQ+aWMkfPTlY4NzZYDLjjbT4rH3YrOBurLZUsXP8A1LakVPyWUjk8utQQyeT32WC8uDEOXmkNuJ5eTVZ4Ipcxlo7OCOR4zvdghXy0VjDxuUY5uyc1fARNPmb01wIXu3E1m4ak9QEPIiVTh217sFcchVZsw4uhhkJRYueSv6aRkMcqanYMsDWlPK52uPqo8WZN8kNYiu9bHwxSTynjMgJFTuCB1bUbe7P+x1mJv+SrvyCt+afsnDaaNWPzZbQIImjAIpI2pXWmaCxHnoQKxSmAoslXs1rNI6WSGYLuDrwvPiO+PuCvFWutx9Na3PYkrVrduWzKzO7u3wxf+vL8eY1pZPIa0zSPZlqPVoyvJk1+o3kfFOz9bOTRhIMsQewcnBeBZz3j/wAd/GUcnDn/AAe5QG7eKCCS3GzQTxSPLBtxB3fD2rZA9/oiDJvbtTM3CcYSVG/FSGO3C8c7GUHjsscOYyrf2zgTqKOXnJRt+m1OtScsJQa347La9ZlymFna0CbJyDE9g0E8saa3YWFuThkrl2zdJpnZeokZYk3koYX2yWJkezVgmOXK1inngy/+0/bkZed2j7wV/wCOQbjNi7DyQnJpWbgjJNa7mTe9US3HDUnkKnb7VXsx52Gm89aUZgvwyQC8sd3iWZx9qvKfbIUdaOQpL0YFfnkJ2ZmJ1+V7ksb/AK8vx5wLtn+ySpJPLyWO4eu2v1Ip+m8hqXmFFJxTTjyCZfzasTCUdq5EsP5eePmq+VYG2/6g9JeVSV2dmglFPZ+1EEm4qz0gt48bhT0J8fbgsdlTHTxWyuiMdv1cEQW7T2IMLHzyWRN+h5dPHYfl8yI4WORATLF5i3Tp5I2HyL3dMO3erYESikEeuV444ZDfAs7ZjyWUWtephZPYjWANjxWD183Bhexkbvy+mefqOVuf1Nv9hn1jaf7tH/xq3+LKh92pZam0Fo7iuCQ2G+AD/wAVB/jwu2s+Ts8Ofp3GlanbHNCzyV7BlFaXIJI2I6UOWwxQVvXRVFJsYobAxNLCLtx2h5AuW1jdegL8eZH05iAoLivxtFax0jFkV+qthvmXUUiihtOUVKe2VXCxBTpePjCvLIa+MsBXeaOKrIcZ4TMxFnIpq1kJiTMTLG42W1Zx3jtwbuasc7b2o2RZOvZO1LFG8GYs0obtavsZBqgFgpRw7uN7Ixuy69oazLr4vHWN16cuOFe5T8cyXfJnHD6akI84ZCjh6BOFimYyOSQsPPIWUzeRmszznuOUhev4v/ocE7NlQMmLNxH8t/dkC4UrT/cp/wDj1f8ADfLpsWJO08KX9zkIA5yvWNfhV/qwkEjdWBqhKefoRyWITCKxXsnygmhz8BRkB7aYa9h4nCu9Us748PEJSiR1jFREcJnCMiZ33DHTJVQEKpfjy0a02VJpcejkKQ8V7ZRfqrBC+QbsJ45ZmiCu9Wvhpopoasrk/m9eCS3VcTijo2qMg34mbPR1slV+VzMsN47bsnhAGHLRlt83l/V58yK1FHZ6JJCZY5oZpytdBym18Km2fGe1zKfwL8tpRRj6UKYa9HE7Y88kFHIcnz41P7H6zerPIK9eM6uQtzaJ+OG+nKZ7HhdlsY0QatGDW8PHFFi8F7ZUH6pMjCD0KMVcZrmPpx0P2ZkuNK0/3Kv+Gr/hyMfJyVIuqzZMXWtO7cljSYsZFvow0vEZ5e6nkmD1FGcrKp3ijljljzUYcTKWvIzU7bg5xBI/kPjCuWxnF9GQuccgVyvOf0Klv5eT+3mfF/IpLhR15H2WF98mv1Dq42bHY3BFMNPxsYpMjh4rqPeLcLosGbyvq72BsVscrWXz1owjmdRRsyiKEVj8vVsQWZhx1rJ5y6OPGhNYfPY9qzdeO4zV68g0oa0THCF2jDFEx8FSfVnKe4Og/m31YdisaY7nLFjk5aFqjZLM5CDjQ5mL+oHjD2zvJIZLkbNiN/MJb0VgZAFxlKMoPGv9FgefzbFPNJXstKQVsV0BlJCgx37M8Wgsf5a3+Gr/AIbMHfFYgPk3KMpJ2KOV+Ng/pOtx4R/jFl7RHsZKNy1JT8ZvySGUsstG6URVrEWVTPNyIAJVpOCFq8kflvh0kBlGMMu/ugTOudfNPBHZhg5SmPmEjWPImij5iMJPhIQ+YepNPKZyV8najVLJR31N9sc7khjfDlYyF2f9KrZtf8AzOFpxTPLHz2UUYshkT8JGsxWq0njt3GZGpmf07swvew90LBYkmVepYrANUxaCOWUio11kmeCSAtFffcKF/eEIwqNZpsnmpqq0hUpXcl/3kMVDzqeJ3rSyHi1zCwnRljTwRiVAXC3etd7PZkdqdNyDAD14bAM75a5Z5QWwkOCv/wCXeaKXH/szpf3E3+Wt/iqf4VJDFKx4uF0eMJlLjykIqn0wRzRLEY4snZnxz4uaMtOWVu1IqVqa2D2pYb78Cjp3nicb43xCWOR5chQiJvMIK9iPyuzKM+HE5I/C5pyteJ5SonrmCpOT1YuTLyOF2zHHRDDt8VDJVyYRWCCFohRX440WWv8AN/J8lG/nmJYMf4PzrxVrRcP1My52qrXHYItRAB6ENplpjp1PGvJyg8fPMel8kgvxLIw2Y529aIuV7jVa4Ub0M26ydef0tUW7ciLaL8sxbrc5Kfy0uL4qRnpw9eOv34KiezYtkEj1SDMXlXydoJByNPI15ojikoCZ27dUZmbFRwyDFwHDf6zCNvJV8cwY04Y5UFiGF/IMjYsW/wBmXLldm/yQfwq/4W/YYAakpxmx4+YH8a4wZHKPi5MdTu4p5L0vj52fmFKMX9zpWnqSELQSV7RA4S053gnxbjX6AXbWJHUs6kEgT2YYxKOlfA8LRJpMNchWXw2Pnmk8dwzD/TWG5Y4BHNx64bFm0POLs2Ejs7cPT+IO0MhR+qpfqK9ISGFgeSfclWcjcE20z/2vhdh7Xj+lKAzR5vxnOwQeszEDzeV5enDjfLZaj/1HkDO3kJ7kMR9cl8+YcHdDWkdVobMdTutxgV83sDcH5LJJIctQZJFLWs9bkcalkeNDN9/J02twVo4KMYvwBzi5ke1hv9Zi5J4rsksGOlcmcMoMUcmalCW78dq+XK3L/OH+NcmCv8zi0GUsMq2QCwXx38JfuiVSuiox79A+/RzsT15mUcs4hpRSGLhLp4LZgq+UIlHHjLS+RcmmpWKq2mJNIn6pWnxMEymx1yI8f/vAF+BG+g2QxMyZnYRnckUsmPysk3ynHeUTPNkpC+vf04v8Ru2m91OXCHFeWz+N42h+qpSSUvJsLer2Mxjem3nbkMPkHqLp3cZJRHxLJwxVfH/TTY7zEacMdp/t7Jk0kipF2R7dwOsLSZSybYf3J/FZoY7P0XWv1Xnr2JWKGKUvVVtGM3aBFO5MPI3YuKxl2vHTwjk15ohaWhGYRZ+UbFT9spcik/nD/Gt/F6sMq+Ukyr48IJP3aXFlpN/k+G0xITZ0DkyilcVUtsqlzSpZB3Y6OLuNP4nASsePZSsiAwJidkMrsrGKxtyRsCYtCJMw7JD+Q/BlNHewVeWxcuwS5y35I3HPG/uXs+MQfgfxdNiCOnWyUeR8NKMMNk5mf5gbjfkGpHiqzShnmh9LhMJkoMbgBKphfPZOyaxZhL4CyCGQ00c/XxPlkp5JSH2WAcAuWi9JenEuzjuMJXGWkSv1xC04iyBm5e7y4UB+XYIuOYG5zlaeO9TylSKLD/smLhCX4P8AnF/GD8xOzOHS64QcHYXTx7GSJuX7m/n+zaGRDPpDPtRWyFVM1NC+Nz9aZQF2szyipAgsjZ8Yx86s+OX666DF+t1A7kI/hvzxdWykaSLLS27dLjBX8lEmz0iL3WNLSjdnb/1OWKVqhfUcc+MuZbHsGfgjGY/MRgjwtHIPVjo4i1nZO4hMD7K/kDepjr181jjPJRMnv+LSOzeIyIsdheyphq8tu0TPM38aZSemytfnI1WLqlDR72ePk22UDkxIfYt/cwr/APFYSWOO/BBZ6fH4ielejsNjP2ZAuNE/4n/OL8N9NiMeb9R76yZtF8Gcv3j/AC/dtCSxTUJbT+IYyRpvFJxapXzlA6mezoJ8xYCMvLMLGX9TYKRXLwSt6+NUpOQiSD3TN9uw39xJBqbBs0dbzCNo8/L7OSpmzKI/Z3d0ddpggPiUgNZq/KQvNQxtCmXns9b1xvtsXlblWKPLZnnj85lnk+YcTC6E0jmSN4nRY/EyqthsPfjqYTHY9Xqg9k0TRlVlZ6t4is0sXKxlGz8xZ3Px3DjYfPBHFk3Trf3MJ/qsONeW+2TnPKe3LMdzVP2ZctUD/Bfzi/Bf5AkcE1kl6j27x33DrtjJ53F1J7n1Ru4QxyN8B/8AhE3F6l+xNXw3lU4FJJHKpLU8ljH3yarVlO/LkPHfHcjTlxFTHZQZMPxx5IEP5iVoW7ROvHIFpiPzWHsecfd/ZQmIvHakjeKzyUEnJMTm+Gaa4OLp2oq/ptt+ocMtfyL/AKpWK9Z3y9dVskUkw3hefHX68Mkdp7gFZEJhl5A0owyyZKBxrT+qj8+D+6gnKAsZZA4r88dZ2/x4uKOTJPXmwQWZTnldOm/yYT/UYb2yUbDS8gku1iDJZTGXIP2Zsv7Y/wAF/OIvpMveAecpwcW6JN9MrpoZHB2IUIGS/DrsLjtMh/bpcVp/jHIcRR2aeRVAYaz1alid7GD5SFTkpSzyNHL5dWEhaZ1jz24IWdMpW5z5GWSJ3uT7lu+tpzNtTQRRUnZRyqOUgVaciTFDOGBvehyP0Mtty8yzT53J74p2Z1EXVLDemkcagqPG25zpY3K1KnyqypPWw2bGZxoST+QNvx3IWpsh52POJAWiJwMI9PDiYud3yAY/lRp/h/74X/UVLc1GxYu27Mv7s66mMQZ/cwkJdpr1cibJTJso7OGUFhbJwOJW6szRyh0j0OBDxToWX81tb+PWbN7plxRAtfH5tPUjp+SWKpU/LyNwzNWZSEFhsjEBVDxWQA8T7oTijY8hXVXJxzOXB3z2V9NekzLuiyxOoo/VS5CXvndk4oJHBQWoWapeYmrbYvGL0uQx5260D5fra4/4FtlFCzqsPUwyuhvy6DIOKnnnsqbHPO7YmJnOksaHppPKLNiTHP8ACCELMXGxWkotBrMzRngjTrSpe1zC/wCpGMpDGhyf0OLrq1bx5QrS9ObRz5vB1Vms0N0pZiJ/+2+O/htb+HsmImTTysmtTMvWO7+sAlNlK0Sly9gk922Sa7cZNnMr1xZ0lWu1ra27L2dEKdlPaaNcnd2dREq8zsopvZjZbdYJhlfFYug4wYnGCmCMBulytn4XY8iysf6Y+O1Xt4XwKN5/Hq1eORaXFBVlkUWIcnw9OnSmu3XvZGu0sNfm7PlcVcgsEJCoR2cCjdRuGxGuTemidPVZPXJk8bstOy5SLLT9pu3wqydZxmJtGDi9i2xQ+hmdehZk1aJlXDjPhfbERk8chTyOGkUJRx2vI8HTVnzfIENm7cvTQiro6Am2yaGXXVNr+K3/APB+EysWnf4MDuutl1rrXF17squZniYMkTorzu0lyY/gyZAoXUPJAB60SwhcbmGd3GLm469pgb1uH4x46XGXrkdbxTBhJ5JUo4zDyHt4oJpVDTcEMbshhRVJDGjjzhmeRc01l+UjsazFOIRgQJvgzppDTTSr1Mq9SS7Yze5KMlh2Z07MmdhemM7nAeo+t5czY06JOm2z4ePWKkrvBHc8owFNWfOMmbWLtm2e0yb81m2sk32+C8b8Qw2VwUJfQBIXXCIl6au69HE69CnoysnqzsnikZezLi6uSuAoQ0mFcWXXGnjTpwZ0Q6UE5QuBs7F7t8BQNtQFWhQZuME+SyNhasLHnwu4HkyNyjCKxybIQsF/yHNWsY/juXyWSw9eSVw/UU+OCCFyce9C8ibkof8ALCwm3pu2k8jJ5mRtsIJfaUO0HievYBkKb4stL/qxI8UEpe/J3+Ak7KmcZPA3BwDhNaZEycUwJs5lMfRnK1ck65mWzZC0rs3JCYodEqUJG+Y+ygryWJYvM8q1GE/pGRNImNMa5piXJM62ndma0IRwWT5yxshZewtFXtWV8ttsjrW4UxgTFGnHaIdKpPwJ/b4somQsKhdA/wAA2EmFyXppKt6OYZI+wcjH9rzWHnJ4LY/sqxe36lH/AGEcmlG/JMyceQ2ZzgL/ABWKZ/VI7iTm6q7OAJ+iwzbbJwbYfwP4jBiXQKeFcHWvhfkYYHZmTlpVYWszR8eUL1+NCWGZ5PY5x3EQLgmjUoIggkePHUzYoq8RXGd6nN1zTSILk0aksnMu916hPrbPIyaVNKKaRnTOa7dJpU0qaREf0XTT+7iyfiypUw6+yW05VJCrT15K089dnMhkryOPYxDtO2lWPshdlpRhyOWGUEIGoo5FDVsmzY21onWHmGcgiKlarFziyDf2vms5et8Sy1bHTVvLMIIeW5oc9IbOLwzaQTpiViMZ0Mm1VNxPNB13XVVuNC7w3jxaarlpdRB+GTNt2aVl2Gu1nWwdOswfGTe06o1uNJVHB4oGF3tvwbXKB400Xs0Sli92H3h/gYvzv+1TS0vb4j7l0ohdk7JpDFdju/YuQprDsvUKInlTxGLPIG7R7AI+bxsnbkdgXd55TdBohq2p6zyw4tqZx+ohryOxTBwkMNvVfia0m9nizF6Ng8gtqLyWwybya6v6gyad1hI5atOoXrKuPkd2vt/beQWit5SJnc6IzFXh+4puPY7aUcjqORD7qlicID1jLnnvdnVd29HkBbnX1FTyUnZYB0D+zv7i64stGtL2V2b1EygieaUB2tDIdZpYgiZuWULiVX66/BVcdauKt4szLyapQxlKO1BKoX1HPcgjVq4MsXWupda61xQtqQUOkNKCVeiqiiiiFW/Ze65OtrmgnkjRX7JiJ7jjJR/hn1NaePsCTfwH84qxwt2PXR2bUfVakHcD+6jA+74smLSjmFkFkWXqJ0fh9eu0eLEfFMLN2R1XcJbTc6933sUt9tYWALNjoq5Fuuf4QfU0UZcuo2eqst9VR9uqm/T3PvW5iYWkfkYF7RkhJMRCtsmW2VsuNYvdcWWMquEcNdgFhEZa8ZM0Q/czJaueO488gFfDY+staTryWq1ujzZ0MvsxA60yYF1MupdG08Gl1smZCovwSJWvqXU64JxXFcVpM+vhGXube0UndX3wZNreOib1U79124THd9vSgPJoyfY8HQxROo/HMlJGWK6U1ekK+0KeSZ1xReMZa4NSMIIYP+IzEcru0ZNLDm4XgyuIxY2BjpyavVJZFkH5WRPgTsqJfXDYqxO9uPUB2Z5L31Y8lXLQHCb3rZiYyiMb7UcntvaaV0ximcXTcWWTNmgdljqvdJDGwKeZEW7NDreXi3qM9J/yfhx+yf8AOlka/fVl8SyMTF45lhT4+3GzATJtr8IRF04MmHS62ddIroTREKNiT1iJPWJl0mup08KeJ08SeNOC4JvpTPtoJirScIbIgBAH/XY4sfTTEdqT6Ym+iNtIVF7LxXPnjbLSipqVCdSePYk3PxnHkv6UpKbJ1ZrALyoXavibxWYaEzlF5Vjxbyq1FWjakP8AaRGxDPBMJmyhPYqgNWcY65xjV/lLosaUO1uUFzuserRIqnN/TzCtGKYo1o2TOhbaF2ZZORnJvdYut115Jmj+Bbazj9MsXRaSfysueW8SNuIom+ol5PlZqvkr+VY3Y+Q4V3DOYU1dz+G4XXivDWwl2d6vhuQmc/BpGR+EZQUXi2XBSYnIQohIXdjNDGItwZPGy6U8CesvTungdFXTwIoUUTp2IExM7C8kJBkm366qjyKJzkKIGFO5SHI7OhFMzoOSByZYTyrK2bna+/Uu69T7eqJYHXrAbSy1f1VHx608ZY+WPl5tj3+aFTrSDXblT/i9+xzUiEuBf9iDwHHcJhhMZXjIi+Dr2XFOzrXv7p4hNejZlwtAvURio3jNrRjJLCHMzsNoA4okX+fHs/OiTBNlx7pvCz5Uon+kvySnpwzkeAxczF4TiyT+EUGQ+IY+MquFxdU3Zly00bxEPZEzcxZmkI11RERYrGTqfxTDyvL4TXdSeG3heTxfMRqXE34U8SKFMPJenT1kVMkVMkdM1LWkjXYy3zdonXXpMUIJzeUhbTPGmjZDGyGJDF7+J4srmU9FpHR5hPSeAeWYWEPjfZTDtsdVm9fh+zecjG7ifVWhkq83jnj4DOX1F8InfjUnCYRrSjJCBkzVz5SeDto/B7iPwrLA8viuZjReP5gUeOuxp43ZcNJ3ZPydPGJLKCAS8mdUjhiOucZJ+TuEbu575YnUimkt1zOpFabwItwVX3HZztILFcb0sjR6XDTvCuhSQsvTsTPC22hF0ULi4tKbjE3Z2BGvtm2nYm5Mze5cEQOLsb7Ma8ynw2ImUviGIJ5PC4kfhtzR+IZgFJ49lwUmMtRIqzOpcVVlUmAjRYO0yfFXmQYqwhx7gzVCZR13dDXdNXVHFXL8uH8aq46GOCGswzOpIhnTUziXp1XH0+SB9tvb04SbPeL1Gmhs14xr5jBxWkxnVKWyEgS/l1+Vj6sl61BBGMkcLKBmAqNr0lhvND2fnFjhN5RlrChkxfN53imwvkM0diTynAFEF/xe3A2CwdiGXxPByL+hcYS8tx0OLzLtteOeKZHNwyfp5mBcvGPLK5WKvkuMgEuI1bAlXu1fNM3XgwHlUFHAYLzDGzwYDLXRp46vRi6mRQ6RFxRGTj2G69yUbsyflvui31di1pnZ0xiiiGRNGybtFOZMvUwt8C4OhANmz7FpmTbZfhfxX/fL2JgleTE4qRF4zg5Wk8Ow7qTw2kv6LjT+D7VnwacpP6Gk2HgwMqviuIgUUUUA8XXIWdgE2cF7Lm7LIt05SCRnB3+9oYc/4m8TTTfVJJVOCznMN1TTxk6L4f8AfiGJ/wCN8hryQZehdkIe0CZm7ykoXIU7sy+hfWtMyfa3pPIoMndqJvK87Gh86zEasySTTL9Ps8dysn9lmq8mSxVI5QkrRW5Tw5E2J5E7sRLmKKVdkYo5WdOfJBxJ20CPRI3hB+iWRDEO5BkYRZCPsccLLqHbs+hmJl2C7fTsqwOmrSi+rALtdNIBuA+7gy+kX5gm4ktcVz9+C/CYnZey2+6ztK7aJ9ty5M78nROSbaeDaYDZc5d/SswJndq8tSyq5jzzeU8PGTHzTZumEFi766bck0d6IqhEnTN72WYMN+oVb0lulYIyjdt15ODtYCVzqV50WKxJu+BwJsXi+Gdf0piCX9I4dnfw/D7LwumSm8FlJT+DZVms+L5eApMVcB8b63Ev/UGcBF5XnwWQ8ozd2rjIm1gMBNIRlwjd2dNaUc8cgnMiIiXGRMmlHXtpwmNDTijXEXRuOtNpz0u0k07pjZ257R8STOu12QzLmJpilXeyIIZG6omRNO6aaUW7gJxfbc2ZuQaTNGzFpa2rPKRvfXszcY3Yo3UZzGTvKn+pOS7HTuW+w1moAR2XiCfKwC3zsKlwM3BLSkyATxxSOKjYl5SDRsX5dUIwmt03lymS/UPHeoxNU3GcCdQSNuJu6r1ky5SCh6ZHb6H5Cv8AI/uzM7GP/t26ftFn27t1xOrNChYR+M4SQpfAMLYeh4TRx0kLR1oiNyYS2nb2cQTNpA5iuQiPMtc+woYRA2fkLewuZO7fUn5CuG3cdJg0zkSZ3XvpgbgDNto9puKJ+LjNIuUe36yTBpPzH4faJdTLjOmIxQzxEn4iuf01fuRtYjMRlFx7F3DtpU8wunlhJN1muIOtC60akyUYm925Ozw9z5fxaHGKrQxsijpBGoihB4BKReWNqlM2iUBdVjxzCXsYFivDbrZCjNjMjDM3KMOawEkk2KeNgZmHZxcmcCZdrxiLgbvJ9TsK9hcQdcQZfQKefTf9g4siPT7N3ISJFFp2EeX175CyHsQAp5YayeeV3C57BYi1FNzXuaININETinYk8r6E9INO+uKlkFhaceTSMSYg05lvi64uK5+zkuwSQSvoi5MYiyeMl7xppSdEbMnjCVTwbd2lFNMES7a5k4Ot8VzB32zu8EMjlU0gCWJCfINOn4szWRFYa1HWun5nVZXHcLkb+SVY6+TslBEb2SqUamTHzjGx0s0vZ14/msVkqDSe/wCoOM9ugZhjOxXfxLLwT00TO7EbCzH9X5TwxGuqTi0qCaMnJ9sRE6lJM/u3sJttOzb4+zRuyPi6IkPYSaFmTvDFHPYfehZuPsJECd2dM/JBYmEhsc0zgSJvabk7jFsSZ3fgzM76PbEij0YvzRAwu/0t9KJ/YXEnLgTfWmfii9x5suQEwtxTkpCidmk4x0w5PL2bYttYpR2gx9a2KeGUHbsXPSaaJ1smXsvdc2WJpPbmm+5Ym+2/LSMqbPBdxllDUqRkEO2yspDk8vZnsl8PFPIPkN2j5Pj7VWS+GdCvGLSGNiso3NY3LvfjZ3kTMte7tpNIPEpGTv7FDBIggljN5uCEWdmhfZDwQEm+suXBxd00Zshi+ni5rt5qQKy6mFGBMvqI24bLqYChfkAyJy+l+Ts1iwzz277tVskcTg0rEHBwdiTuDC3u7kTKIhkEn0vyuoGXWKYI0MAbYGFaF04aTOXY/AkxkKGN3U4vJIRuy1zWuK26+45lzUbkbcSIelNCGmisMv7gE7m71ImrxsEMYycpD0zLHRU5366cYxz2pGrtoppqD5POt49ZxdmkdZDTsGvtMfikV69YxuEhwA+eVaMFqrftCoo7BDCzvXha1TJvW25esq4qKJHHGydm2JEy2IjyN11gRjHYF3L2Di6FzJcRAmAY1xJzksRREezCWVzXF2X1bf2duLoohdcDEeYbjgirxm3OUijdm/j77dtrr+4Ng4xextdsSJhdijfkUY8fqZxKRnCYt94Jx2n2nfaJkPLbszt9ey4EubxBVidx0y065PrmTISj0LO7tG7MI/SLhxPfIShZ96fslZBrcWJPKVy8NyLlJ4nlI00XRepkzB901WZmVx9We336aMeMr4e1dQV8dj3q5y3Tng87dl5DkcblrNPi1KGO9bllnmmCPx/M5Kehi8fhF/12syHmvwmb3Jvb2ddQCi/P0shZFCO2aeEQnJn9RDXA5bFtNIETF7JvdD7JxZ2Yn0LPGmApDaLSeECUtOuTlUmZnYgdx2mfSdaZkJ/VyZbAXCWYV6kmP1fsMgmxvHtpZNNrl9t1JyFC7rbunFnXF3WyBDQkOOxHGZdYp2ZkbxwDxCRjr8jKEBYXApgiMk8M7SFGXD05sM8ItMcbwt91APviYXjq/j4ZF3jz8GtRhyUTsw3vCa05y+H3MbZxOccVm8PctSl4jmBReKZxlb8fy9WPxo/CZatav4nAE93btLeIeRyM5RrTr6BEHTSaTCztw4OxPoXJkTHtiYXd9u7ch0GpLEkhDCFZHNISfS1pm0bOidfzQw7YPpRPpfUuzgLbd+YOT1IDUlYifplgjFjZ9s6fZLmwr+Zb+pta+l3735djIeJOcRu/WOjBPzYjfRDKCjJmOW1BFCcvKMSiJpnd2Ju5dsUSPUocwjGa3IRR6CEzZ5AdhjsB2PL0nNOTPD3soY3M4gFozIRdydZr/wDYapaYHd2iMTEZTkRcl9Rr2FMWk8nEe13R16ruMjRofqXuvcX3t5Hdk76fbuv4u8joZPZ3JD7J5dLk8jb0prTQNo7DvMxi2tM7mhZltiXLSc1toRH7bt9yXk7GRObvtj4NItLlwXLaIuEYzaKRoJF6Z2X0yAZmxPKID2GtwmzydUjcdlLpR8TQ2HYPWORNO8yc2dfRM/Uzp2fd2T1N0idnAmRyOLk4iTk247DG/wDJRu7ofqLl9cZcmM+Kc9ra9UbL/8QAQxEAAQMCBAMFBAYIBQQDAAAAAQACEQMSBBAhMQUTICIwMkFRBhRhcTNCgaGxwRUjQFJikdHwJDRysuFDUILxkqKj/9oACAECAQE/AbesFSrlcpUqVcpUq5Xq9cxXq5XIlSpQcijkeoNLtkGtb4ir4HZ0RKaMphSgo9VPonaosVqhW5botjphDdMdCvQeFd3MqU3ZXI/FXAIlEqUSpTnK5TlHTKlT1ypUqVKlSpQcpUqVOUo9AYUSxvxReXJrZKdkCpR+KkBAkolTmShlbKIhBPb5jpBhTKBUoFNGTKJeEW2mMhnOQJGT9Wh3SU4oq0rfojqnKVPeTnKJzALtlYB4yrwPCFq7dQhCbARKgrRXHyUoJpRylFFA5SnaoaLQo6ZR0SmhMYvd3hsqlSJ1KpkOT2y45SpVyuQKGTILSMhkU6VC0UjIZR0R3EqVOUqVKnonOUGF2q7DfijUJEZjIAlbboujZEzvlOQKa5FyacoRCIUoKVM5hHKEAmthByoUHMdJT5iAhshAdCnSSqjr3dlUWc1YhppFXIFByBUqmQDJTolDbInKEWMDbl2VOUdB6IRH7AJdoFZHiKvDfCFJcZKhRk1soUvVWhFkrlI0UaJVsKM9sphF5KY6UU7XKVPTObQt9FSwzuZDkAQ7RFE2hU3F4kqqwvYWhUKbTr6Ki0CSCsWxtVsoDJquVyD1cmbZObGqcVuqY/Uq1vogQo9M4U5RkM47yEGE6rsN+KNQ7DptQATfgoQHRCLURCOUqVOTXQuYUHSijnKuzw1DnmFTwJOrk+kaZgqk0F4uTnBrtdkGg65H4Ju6OoXLaa1idRc3sU9lTo1KgNx0R0dClB6FxTtN0HgbLmKiZZk8zT+SkrWZVJ5LMrVsgR55SrQVZlHTCjKOoU3O2XLt8SDo2CJJ1PQGkoiFMbZN0QchUCuV3QQnAJ+iPVKlB480466dTKZcsLSbRamtu2WKbpKwwh9xUFz5CJjIKETCZRDXFyrPewS1c6oGliI9VLQuZGyDpREq0hWrD/RjJmtwROquWDeHNLVDcolWKEFIPTorQUWINKLFYUWFBslFkK1Cl6oMYED5ItBTmRsoQYSrY3TR6KPVWAp1H0REKVcg5By1i5NcpB2yKcVUR6p7hgVKA4IuDNSrjGixUgLDPh0ICE5uspyBARcMoJWpCrvc9yhQhCmFdK0UhYf6PKm4+8wsUOXULUCFQda8RlAUBQrUQVKmUVC2y2TUEFCIQZKsHmjpsoKDZQpotKLfVQEWlyLCmthWoZVB0SUHQU16a9Xp1RGpKcc4VqtUdG2+VfDfq2mmE/D2Ogo0oQJGyoh73aeSabxqrh5KoA/RCjEkqpc7ZU5DQHIQtyrXcz4K0yvKFCrOlxWqbTndGn6K0o6K9Fywf0WT3W4kH5LiTe0HqFRm8ZFsq1arVSnQtFplCKaMggV80T6LUoZQgMyyVy1aFaFarVsi9PfPQMhsmKp2N1eJ1RKlCUyi6LoQHohTCNNOoko0Si0jdYaiSeYdguI0+XUuHmsLhnVyrOyAsTSESnrC0bzf6IYfl1tE1qt0hAQoko6bqZ2ROcyjliKLW0yfVBsIOhSinBFsZYT6LLE/SLE0jWBj5oKn4hlCslcpGmVarE5qsKgrXILUboPAQOmY6B3Lk4mUdegDJphAgJziU4nLAUeZVk7BV8I2o4FNpgNtCqUOU7RAZQi1VBCw9EMowsbhxUp3Kg0NpgBESE4S1FiwzbUR9ZNTgoTwZkIDomUE6RqnEgKteTqm0y9YhjKejSpUolHVQAsJ9FliKIcC4HVUngtaD5he6s3TaNIOVrUGK1QrVarFy0aYXIRw58kcNGq7eysQlNGUqVPRPUUXQi8lPyhR1luqw1EOqCUyixmrQt1oAnND90+lbtmU6iXCUzQQViDAtKoeHJ7oEICHaqPRFDOEOznOcFPgKoWcuVRxDabLYR1MrRE+i1UFQFhfo8sQ91OrLViX3UWvYi5x3KokioCOuFChfLKFarVYFCIUKCgyVEZAdwWyuUFywrQnMBT6cK1WlWiN0CBusNhufKLS0w5MZe6AqDHUnXK5OnyQUQngWo5apguao8yqlMHVUmgDVFRBkoaunqjojNzrRKqmpiT8FTw7y+xx0Vcsa6GK8K+ch8EZywf0WWKEvTW3YYg+q5YVMC8d3ChHKEQoVisQarVaozhQoyhRk5Eq4p0kIhydKhWkmFTHLCOH5tMvqbrCUzzJUDMoFV9BlRam0hrKYLVGsoxOb/RRHdhBObKbTDNkTAT6AdunYT0TqJagz1QAC0RAKwwinlivGsMzmUntCkhU/GOiVPcR0R0QoUKFGcKOgiUKSsAVqLU+mm0i4aBYSjTqNM7pva3RaQICpjlOtQAQEqAAtEBKqi4JlKd00Q5GJQjbIxnEmT3oQVSct05tohPpSuWEWI5YfwZYoTUWA+sE7BvLlRwlhkq09MqVPTPVPdHKEAoUKFChEKhDdFTpBjyR5qbSg4hOAulShpurwdFCiNkdUXBiY6N1PkpjdDoPd7rZSpKLC5cs+aDYT/TIpyLVYVQ0ZlWZc9UhyjKFX0CFQyrv2KMgVPXCjuWyDIyOuUSoIRbKbRs1RR0T5A0VxcZKHxQA+qolRpkTCB7wZmIUwnJ7kRpORCLFCtLtk3QZOaS5BqAQUKe5hQoUKOqVKlSpQPeNpzqmNtC0yIz3ylFhOsolzmKSN011xgJoMaIE7KO4CjuAphO1C3TgVU2zhWprCCjpkYtzjK9XK5HQAoOVyuVyvCuVyuVwVwU5TlKlSh3QBdoFTwbneJMwDfNDBNGwTaIaq2Ga8aIYGdyv0fOsqrRNI6o6IdEK1Qq47ZVKmG6hPpvv0VG4HtJ7vRT3wCIQTIJ1U5Odrp0hpOTt8gwvU6wgh0RKq6Mb0gqVqteqFCjplXKVKkKVh8O6ufgqWFZS2ViYxRkO0rMn0g9VcK1VKZpGD0SED6rylVqJc6QmVbTb5pjnO8S2UGZ6o6iY3TTloQjlORPU0lAkp++QF1OEBClA5cpFitVQSxqtVqDVAUDKB385YbDtqtucm4Fio4CmwydU1obk3UpohFEKmE+WuRdOREqrh21dFVwjm7IiOoUWh1yLoMZCegnrnSE8yE3w5TGYygDqaNFEp2+Q0pptK5OZaYQGuQdkRcnjsBQoUQgY2RdOVqtKtVqtVpVqtUdUKArQsCCQQgxaBXhSmbqVKAVkBV3eSlB0nNwWIp0vrGE61p3VwXMCBJ2Csr/uFe7Yk/UXuNd52RwFWkwvdClSFCjM69TjATfCEIVYaKnsoQCKc2U1iObQEENE/wAWTPCgYyGUFXFSnTYECgR5orRaZaKe4hQoUKFGeGxPIOydxEfVCqYh9Q6lAnyVEuYwSg4uamnRSmDVOqAbIuuMrQrZNIIReyd0RovdaDpNRFmGA2CFTCg6QPs/4TsVQvkbfJPxtO6RKfjWu2C98DWhrW7I4x3kEcU526OclXIGcihqOipsmeHJ0FU9BGWqBycS3ToGbt8qY7MqJCO+ey1VyDw1ko6nOc5Uq5B87olXK+FeVcm5EwrhmXLUq1yDXK1xVFha+5wXNPoUMU791e91fRe+Vh6J2Mru+sjWqn665j/3yr/4ir/if5lG0oQNgufVGxTq73jUrmFXq4IvV/wReuYuYsCzDF/+K8KxIpCqRQMt8urbKJ3ygpzdNEzw5PVPZTltqnEjVTO+bN8t8n75UT2YTgfJQVEKUSFGQbexEQYWiPVBTWOPkuU8nZCg9e6vK90evcz6r3T4oYUeqGGZ5r3ekEKVMKxnooZ6Ls+ikeilSVcVJW6LVaFaFaFaFaoUIArhfDv0jW5O2kqp7IVvqPCq+zOPpaxP2p/CsZT3plOoVKfiajlaEbdoVoRM6KxFpCLXFWO9FY70VrvRQVKuVEsLxzfChwzB4qnOFf2k4lptKY282tTuFYumJLPz/BVabm6EKkNJzOqdsozg+SlyE5P8WVLwpq0lPYHNnJtKBL8gQd0CQzRFQoUZULbu0gWL5LXokrVSig5wMFSp7iOiOiUEXJnaML2ZaTi3Afu/mFRpWalATun0mDVe73/JP4XhKniphVPZ3h1T/p/iqvshg3eEkKp7GH/p1PuVT2RxjfCQVV4Bj6W9P805rmG126OqtTaVy5K5JXLeFD0Z8wtCg5zE6prqrgVheMYjAC1pkeid7SUcSwsxLPtCpERpkB5IrdVBqgJUQhplOT98qfhTVqndlpyfLhAXJKItQqCy1XDqsO62VLQ6omNU6sToFS5jjqiCE24mNFGUBaZDLVarVaoZxlChQoOdqpi0yvZPtYx5/h/PK5RKhR07rioPvtX/AFH8VRp3AlFsSU7OSg4q8qA5EW/JPZIRlhXMlOYH7JjnUHaKjWbV1GROUTugI2Qa10SnU4PZ2RzdvlS8KhOkJx0zfUnQZQoVMxuuW1cuFSw4eJcjQYEKWkJ1Fkyj2t0+nemUmjdNIhdlx1XJsqS1EpydTl92TwBshmJOy1ybunHVeWVpUEIaIOCO5RM6pglNoFy91cvZVnLxdQH0CrVWUKZqVDACZxPBubcKgj+s/wBCm43DOdYKgn5+uyZiqFQwx4P2haESOri3+dq/6j+KwTJpSns7Din79TNU2rJhyIt+Sey5OaWKZUh2j12sO6VRqtqiQi1TGilW+a2CnodvlSHZQKcQnbZFpjRHIiM6T/q5AkbK+7dEwMmlHITCug6oOly+aKmFMp3qm75tlpROshTrKdrqjqvJSFzAvEJUK1Bi12TFcQhVcF7JkuxFUn0C43rgXj/T/uC4tTbha9SjRbDJB+2134yVUoMZw441vjvIWKbSoVHupMMtcyHeUBrdPn5rhH+Qo/6R+HVxJ12KqH+I/isAP8Ont/UE/wB7pyKJW62ypJ2hTKtvZcot+Sey5PaWFHtBCpHYfsg11I309lSrCoJCOqCJU9Lt8qfhW2TtsmkKswHUK1WojItI1V5Covc4woQ6AFWp8uPii2XaqLSpTTKOhV0JxlNGuUoGVplIQdqni0kZWqCPNQd1a4iUGulFp3zDCV7JD9dVPwC45pw6p9n+4J5PKsYJJifnDwfzK4bgf0hiHMBPL3Hp/F+KZ7P4m00n1pYfKPO22VhMP7rh2Uf3QB/LpeYaSsVrWcfiVgx/hwiJwxTkRKIQzpeJVdHlVFh6nZsciLdPJVKdwgotsKeLk2o6mVTOtzN1Tqh2inrdvlT8C3TtCjsoQErlr3YlU8C6oYBTeEUWM7epVPh9Np2WNimbQrJXLlqc8Awmmc6GHfWdaFSwL2Pl2oCx1W+p8lOslTKlBxAhQfEVK8k3fNrblYrYXwVOJ7RROsq4ZseWoOdMouLjqnPdsUHSU5UDoSvZAzUqn5Ljsnh74/h/3BVA20C6NpPx/WT964DXY7FllA9lzZLfRwgafPrxTraLliPpHfNYYRQamtnD/wA1VEhDROQzpeJVqU1DCdRJ0QpEBCSwEqPJPZfoU9paURcgSwptePEmPDuoAJ++VKLEdEdUdloqeqAJTWk6Ki3lpzw4aLmduFxCHOCa246LluYNU8OcZVAOBgoUp2VHBPcZKwxDHKViqoqVnFblTkNUDC3OTd+hrvVWq0JwMorsx8ehjbgg31RbCay9yfSA2TSaZ0Xsf46v2fmuO68Pf/4/7gnjmNNQwbez855na+ei4dVeMW1jH+Mxd5mLXf1Cx9as6lWa15H6yPkLJ0WB4jiquLYHvPaI8/4h08RdFFVvpHKh9CFRE0lUG+RyOVLxhU2Bz3E+ifvkzwIhPHmns5ghOaWlOCBhMqGkZ8lTqBwU5jJ2+VKLAjpk7ZQmUyypaVQwl2qbhmtMqpSDkTy9FUeAJVR95uVFwpNLk/FVH75tcWmWrC45tYcupoU8ik6AsTjTZa1Wkp4g5HKZRKCZ4kc/JC/ZTUXb8098FA65gStWqSpIVIyiAdYTotgL2PHaq/Z+a49b+j33bdn/AHBcWZSp1uTQixzQ4a+TQ/8AFYUtY5lVvhYSW/YWud/JtyxfFee6o2hFpcXA/wDjB+5cJpCtjabWeRn7Bd9/TxN3YAVX6Qql9EFQ+iCr0S15hGkfJERvkNsqejwqYi77PzTt8qZFsFOKnyRCfTFQJ7bdE4IFUqnL+SZUnoBlP3ybspyOyhe8VbrwVR4zimaaFYLiLMVodCnO0VfElPrE7oVUagdp1Oc4+alNfCOqhAxn2chv0NgalB7d1cFVJGudNpeYTOGvesVhfdAJ80LSrLTqnCBKaY1XMOyc60QvY7Xmn5fmuPkDh759W/7gsHhrarRVZ9Zmh8g68wsK9jKuBb8P92ixMchv+gfjUXDy+ljKYe8Oc5vaHpAJaR9mh6eJntAKp4yqf0YWH+iCrUg/VPpfvBPo+iNIeYXJH1SixzDqg+CmUzUY6D/eqqNLXEHKlh+Yy6cit1CqU7wuQ47L3J5TcFG5TMPy9yrgr0CEE7fIZQiMmUGt3UgL3hrDIKp8VLuyU+s57u0qh1QW3V5KMmtLjDUCoQCaNVCcEzdeaOTG3BclclVm2qEAmuLNWr3yv++U+o6r4zKiNQgS/VPJjVXlNqQpkr2O8FX7PzXGzGBPrLft7QWJ4jzMb75YQ0AGP4g1xbP3ptd9Kzs9qnAPwtdpHzJ1T8PVrhrwRDQR/wDnefxPylez3DqVDDtr6F3k4en9eniDpqlP8ZTPAFh/oginJ7AU6n6J7PVEJ1MO3CwWKZRnmKsy9xcFaUxz2eFRlC3yEqAcoCtCjK4hXSpVFrSxFrVa1PyfUDE55dm15foU/wBVTbJR36vJHJri0yFiK9Ks4PYIPmtESAmkA65OTdHdDHlgQqyisR4sqdN1Q2sElHB1wJtTqbqbrXiDnMIuLsoKAXsb4Kn2fmuKU6VXCllV9skQfQzoqdKrxKnXxNZ/gb/M2kAoNIPI3edPmQ+fwXC3PqMDqIlwJ0PwpRr8CRC4JSfRwvbZZJJj06IWMMvcn+NM8IVF1tGfmn4nsyF75U+sEyu2oYRRTmAosUZWhRCIR6TlOZnoDiEKpQeCnZEz0DQodoQgLR1nZEK1QoT9lh6Jf2lUpWCU1VNEwydehna3QCjzVUdqcvZ7GYbBVHPrbpwp8Tc4MBHn8P6LHYM1qdw3bmVZCDRkF7LYxmGupu3cQuOR7p2/Dc2flK5znM0daIjTzLWaD7dljqjXvxDao0ub90g/evZ+k7D4hzMQwiqWzPqNPw6Sq5mSj40w6KgJYR80cGa4LKY1TuHvpG2om4ZrHXIoo5HMojMhR1hQrJRplFudxV4RzKpboMAMjuDt0QjTLwAqVIBsLEt7CawgSqmjlT6RVK5yebjOXC6dLmsc5o2Tq9PC1jzDMnRYxrxWPNMDyTmw4jOtXe2pahWefNUXuJg5eyDBy6jvkuOtu4bV/vYhOwRZTLfQ1HfYAIPynZHD1MFiWYmr4jc8j5GdPsXC8W+rxLmNBIdMg/Uk/wBR9nS8w0lVfCUfEmbKhsR8Vw+vToVHOqfulOxGFqvBJGzN/IeY1/8AaZRwLqepG4+cXa/HZVqOFq20jsLojWO1p5yn8PommA7yFQwD6FY3h2Hc99RxjUAR/pn8czmeiFChQo6J6CwI01aoyObDBlNdPdEZASq/YaAqWIAESnP5zoVsqto8yqey1ClSFogR0A1q2Fa3+4VbBGph2NqbjzTcHTaA57pVaOY63ac8YzZ6aqZhyC9kPoH/ADC43TfUwnYbdBBI9QCq+Iomr+oPZ5RaJ38LiuP1gMUB6U4/m1//AAsBUpHGsfSJvLj8i3/gjpxBimVW8K+smHRNNtX5rB4X3x7mzsCViOG1ab7Kfa2+/wAvn8E7AVgy8+kp1GqDaWlGQm84hxZMeaKPQcj1EKEfgucQveY8k3EtJiEKrSpCnJyhFHMeaoatQEdyDIQaHbptrdliHXFDRNMLmuVUB2qpXBmyEkSUQiFChQrGPCqtDDomYge7sHoYXE8W8uDKZhoGy4c52IcaR/uEdSgJ0WF4eKmryuKNbTxbqbNh/RNQTTIleyH0D/muMPrUsIatB0FpB+eu32o8LpMwDMQ46uc3XzAItI/FTo+m0y2dZ89S1q4Py3YmhTqGQJt+fZMfIEnpxpikVW8K+smO0TndtqoYx2FJLfMEfzTeNvDg5zdo/wDqv0yCyHN1tI/mZR4zRc+5zfUH46j7/iqvFMO6nZT27W8+ZkH/ANp/EcNXfV5kW+WnxXFKuHqOHJA3O3p/f2rGxVxAa0/qSG/LcfejwvCPd6au89wNisNwzCYxgcy7UkfKGz+KOmZylT0wsM6ix0V2yCsVwhsc3DGQuUWO1UlA6KDMpr/ipKko9AWH80UBHcBDbXKqO1kwuvM7ZOCoj9XA/vdOmAAnuNPQhM5jk6WeIIFCSiLd1SMqlVdTkeRVKOI4MMc4At8z/VOrtwrOXQdJO5GQMapnEeSwuhPqur1DUfuUEFQMtXsh/ln/AD/JcZg4J7PN0AfMnT71VLsbwakxjYNwaPw/FUsDiA40GsJnT/4u1XDOF4/B1qbgAGjefQhs/bIPTxAwyFW8KPiQenP1BWCY2vWDX7Kvw+xpje4j7IlHhOJuLRH8/hKOAxExb/Z2QwVY0jWjQJ7HM8QhU6NSrNg2ThaYKBI2QxlZtHkNMBQrVaijnKuU9GHxlXCeDZYnGjEjtsE+oVrHJ1MbIghQm6jJw6AqB3U51sLSw2BY94/WP1HwaP6n8OppjOo6St8mugyudPiTXaLmwn1Q+FTrWaFCo0tgIMKHZ3VSpLVQ8x1VPAU1DLDHyXsh/lXfP8li8JTx1E0auyw+Cw+GpilTboDP2+vXxI7BYvF0qIN7l5prvij80HkbIcUxI3P9xH4IcarhwdA9fuhDi7w2yPID+S/S7HMte3yA39DKxWLw2MY1nhtu/wCFhsRT91qYdxgmPuVH3U0ze8Emd/XyVWnyyBM/JASm09EQijqrVYjTVhzB6IzIUILRPQY5/hCbgazvJHhmI3Ccx1M2v3VAdlQMsDhTjMQ2iPNcVxYxmJLmeEaN+Q0HUWlu6BUo75HI65RkHBvkucUXlBwTiAFSgnQdVVhDCU1BBYZrmukheyf+Vd8/yCdUFNpe7YJ3ErdQ3SJ+6V7/AMQxOmHo2/E/2FhMHjW1RUxNWY8vsjPFcYwWC0qv19BqVivbJo0wzP5/0H9VjuOYzHHtuj5aIn1ylXK5XK5XK5XKQpUpr4XOndPrSi5XKVKlXIw5FkZDqPRh2NfuqFFkbLltHkmhcVddiisDhDVZcdlT4eCv0dSiDoqXDzw3B1MU3VzuyPgPrH8kenDupsddUEqvV5zy5EqVacvLo1VyuUjOExsdVSSy1Mwf7xTMOxqDQNkF7J/5R3z/ACCqMFRhYfNNw1MOvyxXGsFg/pKmvoNSsV7Y+WGZ/P8AoP6rFcZxmMP6x5+Ww+5XZRKdlCtK1CnonpLu5lESojusIe0sPq1FBcSaW4ly4aP8OE+rHZCcxx1aNViMbiOVynGQM46CYzGqhPEdxCjIbdJdIAhOyGfsm4DBOJ9fyCxPH8BhdC+4/DX/AIWJ9sXnTDsj56rF8YxmM+leY+7+QVynMIZNapymFOWhUK1WlR0x0R3lqgZYcw8LCeFHLjVOKod6rC4o0qdoWConFURVVTDtauIaUUSrlcrlKuKOdPIhERmeiO5dnKlc59tk6K+ehrZ0CLS3Q5NEp2hyvPeH9mpmCsLXs7JQIcJCOhXGKV9C70VI6LgFSaBb6FVhK4qewAj3NNSinjotRaozG/Wc56B0XE5BxCmeiVK0yg9TulrLpR0Vya6e8lXILDODoKpmwwnHWVjYdh3fJU/CuE41uFLr9iq/GcONisZjW4oiNhlGYyanjXJicYQdIT+mVObcycyepuuc9YUKFCIUZSryrlObuholPqE7ZOaHLUGEO4hQrVaFaEFhHW6JhuC8lXF1Jw+CAjRHbMdQ3VTJuyehsndyMtugodEql5qENch1DfOJVoUBVOqT0joIlDTuYyhQhT9U3sAKi5Ap3hKdunIoaoZnMJ+2Tdk7UoqeiegZuM5DJxTU7RTnREg5R3EoOQM5Tk/ux3lqhaIu9EXE5WnLC1I7JQyqiHlOQc9x0YUOZ5NTZ88zmE7bJgkK3tQnsMSUO4bk4whkMjump3RQHZVhVp7oKSpOcZR+yNMZWosC5YXKCmcgbDKpuuCbqqmH5mILTosVRpUx2P8AiFw0QSsRQNMz5J7SDJ6DOZ8OT2OOoKbI1nVOcX7rZadUhMycZKHQU3ZP6KRhquVwUhFwR1UKwrllcsqwq0qFGcZwoUIhQoUdE9R6Q89NPJywdXyKYViKQNVpOxTsPRPaIgBYJwaQnMvplix2GFBo1Q6vLuoCtKiE3QLbIBHoGyf0U29lWq0KxWINCHTHrlaFarVarVCjuC3vWjXo1TN8iqCoFV9GyF7xWuulQ+m0NI3VLFOpblcTrCo8R0HMLlLlLllWFWlQVHSMnIaKejRNGiqaZNpucmUg3KeiM4Ud3CLFYrVaozIUKO4GqDY6YTd86CptAYCnatKrCoO1TKw9CnVwVMVR5LG8PdQkt1Ccdc6VJ1Z9jUcwYMrmrmq8lSFPomv9Vc1dkq0LlhcsIiMrC5WOViszFNAQERduhTAznKOmF8ug97vlChQFy0aasXLXKXKXLVgW3Xsc6PmqBJYogJwtdBWE4ly2Cm5YnEsfTc5vojnhKLnNLm7qtSfReWVBBRzgqOuSFzCuaVvkwzme5jpAnMZHolDolTkc4/ZHb50GGpKoC1plOqAKpUD3SMn0raV0o5+zOG7Ty7QNH/KxtY4is6sfrElEZhEK0KwLlhcsLlhcoI01ykaZQBGUkbK8q9yvJya3pHTE7LQKZz26j0bZR0z+yFSrgqNXlahGu23VVKgdoEMqdNtRrpz4VhhjcZToH6xAXEKVDgOAxDqZ1fp9p0VRHMLdR3MZQoCtC5YVo7qPVE+nXKn9mPeFw8lcVEoWhCFGQVKoKZ1TtDlSe6k69hgqrXxOKq83EVC75klFHdEZM1bkOiP2MCUHBu37eO4hR0xKgM1KNQJrpUuCDsqjvJP3zBCCqDzRypO0jrjoHe7InvT+xnOnUt3VUsd4e5p0wTrlWdrGVLZaFbZVD2yjrm18LmgIVL9E7IJr7u9PcRG6me7ju5/Y4UdLRCdDRcUddcqIFqAGZguMp0RopztLtAqdO1P0UI9lSVLghcU3ZR34bO6JGze5c8v37ue5HUe/xGrYXLK5ZVMIZnIqFCBgoVE8zsroUElFcslMpBuU5Sj1nPUrRqJJ/wCxXoHIFeJbaKdFO68pUq5SpQOiBnOqZMZsQz5athWqxWFWFWkIAELloNhR+wW+qnKf+wlQUBC2QXhW+qGi9UGhHfI7oaaLyQ3zmc2Id4EesdYbOy2/bJ7qY7+F/8QAOxEAAgECBQIFAwIEBQQCAwAAAAECAxEEEBIhMRMgBSIyQVEUMGEzcSNAQoEGUpGh8BUkscFDU2LR4f/aAAgBAQEBPwFSL9zLFjSaTSWNJYsaTQaTpmg0GjKxYsL7Mpxh6hzlP0L/AFOmm/NuIbGWFEaSLv2NPyRlYVQ13NTFMvc3QpX7bkuCcLjpEqY4jGWH23yfJp+RfgsxDI8CEiMbmk0li/ay3fbtsWLFhxNJYaLFiwuyVSPC3EqkudiNOMOCciOVixt7GlvkklHgijSJFiKHkpWFLUSuinL5zvk0WJIt8jRUl8ZVMSqbsRnrV+22Vso+WVs2RWxFEIiRdfzdhosJZyko7s6jfoR03L1sVo7IbG2SuyKsOS4PMzpr3LDJLcSytlEkrlixHYl5hJoRsXGPKxNpFWrZDx1JzsV8TGL0oxUXAo1bU1uLzbo0mg0GkazqJpqQke4ynwREI3L/AM86kVseeX4I0orf37GNpcm74QoX5EkuMrZNDiJEkXNQpCdywywlYeUkyJcvlUlfZDRisZGcGolFJzuyfJp1Q1DheVolCn0qfn2MTWeHtYwU1iF+Tp2JQROA4mkqRbVimrR3Jc5UvTlex1J69B5jSXZf7F/5GTUVdmvV6EaHL1sSUVZFy5clOw63wa5MVRROuKvYVdMU7movlyWLXFTSKkCKI7F0xRLZPOxpWUmcbsr4yDpXgOcZw3RG0UeplanGnK0WYer0qykzFzqcL3MQ5StCUbHh9Srh6um2zJO5YmaTRcdM6ZUVpZUZavKJD2Ksr1jXL5LMv8m2Skn2v+QdRJ29z+JL8CpxW77dSG5E/wAjY5dikQmRlcWVjSJWynHUKikOFiIs7GnPxHG/RQUjEeO6NoIw+KWJhqRXlJU3o5KalUi/ZjnKL0/I00KKvuTlskj8sjWmsJ1Cni4S/iVeSvi6dGzprdkfNBMSHSTZLTFEYtkqfydMxKtUyoLTNfk6YkmrFenGFTLUcjT9srWNTQqhqNQ2XzuJ9ty5cdWMeTqOXoRo1epiSirLK5clNRFJvg035OCV2ODY6bHTHBj2G8okJNEN0W72rjp/BFbb906yieJYl1qm7uh6ZHhc7TsYyV6WlGpU4OLIQ1S/Y1XKk9JGpdJMspbEsVKpBU/ZGGjSnLTIVCjNxqfAmNSZ078jjbgi7HJqMZ+q8m7QiyKuhRPEKclNTRqllc1l0Ms1lsMsNM1NCqoc0KZ1EKaJTshTuax1fjc1TY423FJojUuakSqJGtvglL5Zq+BzsRrX5FK5YsNEom19JOA4tc5RIIp/fqMxCcoshh9btEhTSbPDJapWMVTvTbJzcuCNbQ3GwlyODmtzoz9S9iMdtyTjEbjHaJg6cYU1YRck2PctYuyzRi01U3ylBPA6v+cmCkqtGMhoxC1U2nldmqRqNaE0yyLWFcvfPkkiQ2XEzXY6kvYW/qNSHOw6xGaFK/Bv8ilGIqkScrs1DZcpMWdhxuiULk6Z0yFIVOxDjO6NSLl872E1JXWWDx8vqJxry/Yo4zrQ1WFV1Dt7mJqQpQ39ytNUpWiRWmTiUtdPzI+q1xSRQ005b+5ilrm5Q4NKS5HK0dhYiHR0y5HXUo7I6kZbnU1L8mFhppRTNkTqpcEaqfJqQlqFTsaTH/rZUI68E4/ueEy8jh/fKtbpv9soysa7mwrGkjc3N8r2ESeTJK3J+xb5NlwMuahyLidhVWh1mOTYps1ms5FTKcLCWby97FQp+fg0O2wkLY1FTF04z6bluSlbklXYq/yQxCQq6FJMx2JjFdC/mZ4NX6tHQ/6TG46GFXyxVPO5fk8NxLVWUH7lPc8VxTpQ6b4YsV1sLaRVh8EPVdj3eoepK6FeXA4u/nNKsS2dhafYktPAoJLYS41GCr1ZVYr2Q53JRuabZQbIu+WP/WywH6BhK8cPJavyv9xv3Kjbi8rms6pGojWKpYjL5FURqTNsmXT4HTb9ySs832NZPtWUCKVhdjykrklcUEiKWXjNfpYZxi92eH+KVMPTnTuOc6lXW3uYTGPEw83I2ORrIzZSk2YyvKpidZ4ZiqlGv0/ZmNk9cpEKullO8KykRqGPfVsiCtaJVXlIN8Cn7FCXlaZOXub3uzhFtUj9N7j8xRd5aXwRUJzMK6airFSvCkvMzCVK1V3qcFkWEiLsXbMd+tlg67haMlsYim9c2vZn1c7WuSrVnG+5qkOoazUaxVDqHWYqzufUkcUiOKvseTk1ouiTysy2TWTWduxCptipqJDZZXLl+5S2PEK7p0JNFTGVG9NVt/B6/PEcGpEXUw8/KzD45VnolznEjiowm4lS0ndGEUaktaMe7T4IJPcpU1J6matcNhy07GrS7mu6zTaViac/UW22OUdPe40kdS7sbJbFGHUfl5KdGsqmkxGDdaWq4vKrITbIx+TZGpFzHfrZYKnGpQtIwtNwxE6c9xRS4KyTptMtncuXLly5qyTFM1nUZqEzUahzSNVy433ojOx12daR1GRqNFOpfZmpF7mp34HvweIeIfR6ff5IVY1YqcOGVqqow1MxNaniKehfFx4fXuUenCThUJLcnHXJyKdOXWjoEbLkuivJwqXHUd2lwQqTg7LgxDlVexBNR3ItyjY9ESUr5LcsWuRJbnBexr3cTS3uxrSUIqpZMo06WCjfllbGQ6XUhyYONWdPVUYqZpsIkK2WO/Wy8PlakVHpxSfyhVGyo/I833XyuXLlxMTNQ5jqGo1ms1GouXLlzUXLlyIoGlEbJl4isXHOyuVGq7UfyLFfT14U6T8q/wDZ4jVi6Oh8ser2JplWi9JQnK1rE4STMEouo/kuYyTsmirWlZOJVl1BpuNiLbiW9zZclHhyHU+crC7OSwxosSIycNzruotyMfYp4lwIY75IVlMlMbbNxSaMW71MvD1/CuY2fSq05CSe5U9D7LFvsXE8kzUXyuXLmo1GouXLl+xTsOudRs1MUyFYqYmFOSUnyeK169CacXsVLQSnE6tOWmUiq/qIdRlXXLa5UvKJCXU5HHSVJ+W6MLUdKsnIxGJaTSJNzpK/ItWgqRk0pr2JfxIlGM4O3tla+xJtQtE/cT7uMmy+VSLfA4bcmFtptleyITu7op1nFWFXZGqJ5Yr9TLAO1E8U3UWinjYaFcrY3WrI1Ls0mksW+1Ya+42ORcuXLlxSMbDqeb4KtaVaCpz9jpbbGjaxhZuUHEcFFuUiUXKzgfTSi9ZOehbkqjW1ii1UsLDuvK5OndWRptuxQuro0+2VxkfllrlsuRZt5WL2H50Oy5HapsijV6L3OunwSndFH/MIRHYU0dVGJ3qZYWpopWK0uqtI6S92OmjTmuy322xlvsXLl+25fKpKDVpEubkZe2TemOxqUoaZckJOhe25VxNSt+CEZW3HRlJeUw+mFb+IaVFWRJFnfzEquiVvYi9T1ZRgh7MZc5F+c1uWPewxEt2WSVkVIlP1XGtcrEEUYq4pebTkpHUNQpJbsk7u+VKSVMchseSXY+6+Vy5ft0mk0lvvTrNSsTetjuhDVjY072FGwkjSjqqkkiXThiFKO6LKXBUXTWpkpJk4q2oVVuVrCkomr3HyXuWIlsuS1i5yJZcDJeUauQ8tTZkZuJTcPYpNubftlcuaiVVcEXdZQvft0DgaBeZtL2HE0jiaWaDSaTSaWaS2VixbNv7TajuyrjFH0onjqnsSxM5cslJv3KWJlSl5uD67Q7ol4k17FCtGsroUdY42YxRfJY+oTelDraltySW1zAv+DExdaTjaRQxUOl+SvKM4+UpU1yyfJfsSytlsh75vYc4ybRB7DVyovYjFM0bWKUEo79spqPI92U/TlGah+5ba+T4yuXNVik/PI2L/AGLZ3Lly5ctnYsWZYsWK1eNJFTEOb3NVybRzwafcqRsJ3ViorkKsqT8pQxsxV41FrIVFPdGm5eK2bFStO5bcqK3Bg8dGnS0S5ROl1IqouGVoQgvIU38jktOksO3sJ3LI4NdjULKW+UVcfwVIXR02pblKNkWHD3NokIKK37pxT3LJFJ6o3yUtE7jdyxJZdYVQ1FJ+eRqNRfK5cuXL/a2LrsxFeVOWmJLGVPwVcZOSsOV8nsS5PfKpwRu5WN9rkl7o4ZTryplHEeaydhqT3uQppRsRVo2NuUWKto+b3I42pVioFKLkrsaSZKSNxsQuNy+VxCLXNJTjZkt2KbvY0amPyMTRN2Qv4grvZd1SQ5WW5S9O2WnVVJ1lT5IVNauN7ZacovSQfmZc1CZK0lYUUuMtRrNZrNaNZrNZcvm75XNRqMY0mmOaN2aWWJFhobHU3MJT5kxQRUopRsNWGrbZYSpiOIrUiEJzV7WOhM+nY6KXLHQoWalMjDBw/qFi6EFyPFU6klGJouaWWzsItnc9iKuS2kxqWq6MNLUVppSsX+CrIUrblKqoysVKu1iHpzlf2Jbko3KCtC2UuSe+xHgeSaZpNJFWkzSNMV0XZv8AbuXzuXzr0FWI4B/1MhRjDga+SqlKWxbSyQytUUUR3fmIOMVZM4PVyVYOLsdOb3saTD4ytbRD/Y14i/vz/sJV2vNd/wBzoVX6hYST/wBBYWXux4bU22z6WPufTwW+dy0WaF7GgUbFia3LP2LnJBEixSi1dlakpy1MgknYnGLJxUjTdkEp8otm3Z50laOUqiUrMlK0iDdt89mWQ4IdJ1JOIo2Q0WEsmWNJpHC3AkNGg6ZoJK2Vrml5pXPKjVAlJM1IqzTjZM0x+UOjT/zHRpfI6NB/JHCYZO+k6VG1tB0aX/1ojFR4ijf4X+gnNDcpcs6FJ+pFOhTo30ouXQrCimdP8nTR0zps8QeL0WwdtV/f4MO6sqUXXVpe/ZZl2ahvcvZDEynP5Jc5UncrXXAo/wBROdtjVqikinFOVjTbgsWJcZXsXuUvSMrw31EK0b6ZkakWtjWnsslFifyXJVFSlcjPUroe4tlnpRsXRdDlFI6kV7n1ED6qB9ZE+tR9Z+B4tv2Pq5ex9VNjrTZrmy8zzFn8mk03NCFBFrCtnqNRqLlxsxNdYeGtn/WKf9SZDxLDT9xYijLiSE0+MrtHVmvcVSfydSQjURetisi8S8TymxoQ6aKkGo+Tkq43E4WS60PL8ohH3JK259bQb06tyhNPgxG+xF7Elfgvp4KbvMUk89a4Y3BjavlQ3gMrb7FRKKsNvSrPYw2NnDF6V6Xtk8U5ytSLFmuBRUptM4zvliFJrymmZZ+5YsWLGhCSLISRpjbY0mm33Lly5fPSSslc8Skuiv3JzvwfsRmzqaRYutHiRHxPEx/qI+M1V6kiHjUf6okfF8O+bkcdQnxIVnuijsXHUSOqjqo6kS8Db2ZuSiiNK62ZaUXZlfw2jjtpi8Bq0Ja8PL+xiKbjyKelbmp7yQlqSvyWcdzDT23J1FTWqRTmqivEfm7KXpGVCpvyVt4WWxRhKpiYO3Dyw1ONGWpn1MSL18HRlq1I6ci1uy51EtjkrNW2I7kKKW5WdOMbohJSJaUjUzk3XsXv7ZM/ubHlPKeU2zuXLm/bqJ+ZWPF1ahH98rHH2ML+jH9kJ2E++Mmj1EZOmy8aiONmQrOHJUhTxcbMxGDnRdvYjTfvsQpu245JcjqWemPJWcqlrkJV6EpaShj1ONqnqIy175SKXpyq8nURDTJFOnFNNZ0aCW8sr2LlaOteXk6s1sxV0+Svi5QlpgiWMqoWKnyyjWradMmRjp4IT0cFWpN+km3cvUhBaBYnq0rS5ypDrKFPSSxaT4MPiHXJCLIdlnLjYis3JI1IuMujjYnsSrqJ9TE8UmqmHi18kU5OyHTmvY6c/gcJLldzMN+jH9ibsyL3X2NNuD1EZODFJT5FeHIlKPmpnkxULMxmGnRlsKta5ZvzIlFX3HNLYg1N3ZCCjx2U/TlVkkyasRunYhG1sqUoqW5+S4ndZ4qn/WspRUuSpQ+ClTWrKSYsq9OPqYqeqKJUtKvYRBvgxMJz3iKi4eaW5hpR6mn3JcEcpWZ7WZtwIvpZwyw4MStsWNjYaXJLccUOnFniyUaMEih6ym3KKk/+bkZXqaBNtWbKvrfdh46acf2Kj85F+dd7Ehx90eojLQJqaIt02SpavPDklONaPTq7MxOD6crWLpFWtbkpRcoaJkKKpov8dlP05VPUevgivghzlvcoVHbSzUXEy4pJ7DhF+xiaUIrUso7X7GyVXU3+CFbRTv8AkjVVSJJWexp0q5GXUhaJOnLmTMFDRUZPjKw0blizHG4t1lcumXT2Lq9hySL7CLMseMfpwKH6iPcqTVOCfuPER5SJy1Scu2C1TSKa8qKnrF+pmt+xkfSIt7o9W5GWgUlNFOTgTpxqq5Vi1HTPdGJwu+uBKlKotMxWlK5Z+3bD05VVeZJShumU3eJDnLVZnV+T6qKJY2MVwVPEqmry7FTHVJrkwsnPdnUaHPfcSI/nOpVVOOplTGRcdtmUqLjDU2aLU9MV7nSkvMU036h01Pk0qC2KsL8FGnplclwLJuxqNR+SW57F8mSimNKwoqKNEVwaRZeNeiBQ/URHd2MVBxj5uV30FeoiHpRP1Mv/ABDgYhrN8EKltmaxSG7S2L3IydP9iMyE9I0qiJ4ZSXlKlNxJR1Cknx2SbKXpGV21PyitU2YlbgjzlLYuS2JS1MqRZ07QMFezHtydSM+BEhzsVsXCBW80CxSp6aKQ7U6Y4alciT1exiIdSGkirQt8EeSXHZNf5R1HydRkbW3FwWfZJ2exq+C5q0oU2zk8b9MP7mH/AFDh2Km8bshGOpbexOEVBu3bg1eoR4RL1EvXmslk+CXsLKHLuJ2I7kZdN/gTKdT2JK5UpqsrPkrUXBkKTgzguallT9Iyq2pcCjqYuCPOUa0a8NUSrWUdiVe+xCs48i8+4otuxTjoVivGVW0SGGhD05yipKzMZgZ0n1KW6IXqxuzD4NatUiTjEhZrcSdxKxa5OkRjY06SXAs/cahyaaR5VwU4OaGrLbNnJZDKilxEjdJK9xXueN8Q/uYf9RFK7V2Su1YjTta5V8sH24Jcsj6SXqJ+ohK8S/z2y4JewsmrSLi2OSMnTIyTITHuVqfV/cnCw0WLI4KfpyeaW+UcNRjDQo7FbwvCP3t/cxmBlh/NF3iRjcpUSFG/A6PwWcO5RivYaHTT5FZLJpSeTPNk+BZyu9kdOeyNMtyhHV5WLbbKraO5LGQh7mGrrEt29h6kKd+C9yxoIU9TueOq2hfuYf8AUJSutid7TFz/AH//AEVEtGy7LmCXkFwPkn6iE9JGfwJm/sXfuK0jQSnotci7q+U56XY5yTLkJaP2Orp5FjIksZ+CpV6jukaDpEoWyp8ZS5zWWL8ZrVdqWyIYTEYrcoeCTjvqaJ+FTpb3IUkl5TDRWi5USXJRfWqOp33yvFbyJJLOXBci0T4PYWVSehnWOv8Agw0tbbGyUhpT5PpqP+VEYRp+lWLp8ltJGOp2QqKQ6NzTZHj/AKolD1kadoaLmzv+SLSMRUblYv2YVWghcD5KnqyQpNEagpfGeIpNrylOpZWZqQ7PnsWVi7Qy7R1DVlpTNNuCzKmpSFKRqkLLBeHOq9UinTjTVlnUh0J6orZ/7FF2i4niGIVGm7mAj/BT+S1s79rV9ilTnCLjJ3XsXFHUVIalsaSCRLddk6et3HR9xQ2ML6WXJNLdnUjwXT3WdtWxGKhldN2JSsePPzx/uUm1K6Q5KDUUj8lRJbSK8lKW2beVHaKFwPkqK8xUjpL2HBx3yQptCmXRZZWLCubieaLDRdoU17ikn2OKZKgvYlTcfYWUIqCsi+cndFSXTlq9jG13i611wYVWpRH9qhSWvcxlZJqJSq65WK0d7ooRuvMVY6eOypJxV0a/k6mxRflLmLhOorRFela5TqaX2dS5KpJ8i5GzxehKtacfYoesS3IbKNjEPVFNPbNZLdkNtj2GVPVc6ujeR14y3Q6l9slmsr9ieV+1oaGjVJCrP3FVTFK+bgmdNizRi5aKUpfhlXxB1qLpxlcnio0tkjB1OrQjP575cClnTrRg2VKl5XZQb1oqVYuWllLeGxW57eijolOOiOVdvS9xR1x2IW07dknYuQ5y8bb1RiUHaohS/wDRdTjZfsVopU7Z7nsU1eSI8nsMqFeDnFJGipFbfkcqyl/z4IynG8l+BV5Xv+xRrzsor/m+SFku25cuXL5uNxxHldrgjXaI1kzVc1C7MRTVWGh+5WwssGpUyruzw13wsP2+wiLHKyMKnUnKRVw8r3sW6MbkjCx/hIr+vc2Zp+CzPMbntnspkZ2d0dR8IjxnPJc5eN/qRKDSnuJO3m+Sgnp/uTUlTd898sPvNEOT2JD3iVKnTVyFeLV2KtG9hSjzc5Hp98lmvsXyuXFSUhYa/uTwclG9ydBo0GlosR2NZHsfJ4zalUjUseIVI1ZpxMBUVWhGSzT7Z7SHJx4JSb9RglZNjKsUdKNuCjLS0jEQjOpySjpEXL5KRqlEpu6GvMyjBe5UWnzZN2K+M0elFGcqlNSlmuDxv9SJQs52kdRubiX+StfQ7ZMTGYVechyew0JbMlSU+R4RNcn0297+59NK1kyNCad2KjOKjp5MPGaXmKXlhd+o+pqpf6FTE1Kbs/8Am/ZY0mksWzuXKutr+G9yljZJ6ah1epGwoqxJWkStbYcfwWyXY+T/ABI5XhYw0o4eL8t2YDFOu2n2X7KtuWTkm/KXMI7wyqRXTTRYpeoqO8y8JeplKEJrUifTWxGi5cHTsOCQt+DFR0tEo3H/AApmlzd5LKyezK+D+GRSirLOHB43+rEo+tM9FZsdSL3uVasJprtwa3bIc5NCRVk4R2IVr8/B9RTtc6sDqx1aRNS4HJR5L3ydKLlreSLCzsWNI49k6UKvqIUOn6ZGupA6jTFJMumSVsosWbPGKUaso6inRpw4RHyyuslJyqtLhZPsqR1xsWtlh6fTiXsWuSjqVh0UvSNHQ1Mp0nTVipQc90aJxldjqRNV+EUYfxEY32fdW9HZTZ41+qv2IzdN3Q5yk7vvwa2bKVKc+Fk0WNCHhYMeDifSb3PpZJ3TKdKpSbfN7E4PqKaJdS6siMtWVxMTNaOqdYVYVWLzaHncvkpl86Q5RjySxlGAvEaD5FJT3iY6m6lU6TR02TnohdlGGiO/dGSlwV4WlcUG/Yp+kavmti5qNRK8vc6SfIqaRpIReoxGvT5n3VJJ07diR4z+sv2LXdhUrminH1MlONrRjnRwVetxEpeCvmozDYKjQ9K7LfZshxRoFGxpZpLIsiw4ibgRqp85P7VWpKHBVqT+SVSXyNtnha04aJj8SqNS3uTx0j6upyiOJ60lGQu2qptaYMo0+jDQWyjUXuXTH2bFkaTSzfK5OV+7lWFS+TQkWSGeMfrr9stTtbKjga9biJR8EvvUZSwVGh6UWsMQsrl/5RxIy0mof2a/pKnI8vDpKWGjY8Uf/csiknc+oTdpMpKlKW3Iu2wlfN7OwmRffc1Fy5J79lz3I9vjCbrq3wU/DcRV9rFLwNf/ACMpYGjQ9KNNuyQsqlVxkkNdly7NRqL/AGbl+1PvvnVXlZVGM8IqXpOJiaGurdni/jcfC8S6Dp3/ALlf/Ec61RtKx/hbF1MZjHq9kWNJY0mlGlHDzq8iE7Cd/svvXZY6cb3NPwWZc1GrOUrFPdXydCLd8mW+yn3XL9y+zJXRUjfcksvCKuivp+St+oz/ABhQ/jxqfK/8FVWZ/gaHnqT7Xk86iLCIPNuxqNRfN/YXYuSyHEt2uKfIlbjutlYsW7I9jNkJXRKCRKGnuvlftsXK0dN0SepDME7YiLK3rZ/iHw2r4hTj0VeSKf8AgnHVneVl/c8D8DfhFKSk7t/GV+1keMqhFDjuQ57NjSjTnLNLtXY3bJjQ136mXyTL52LZ2F2cCyjNxPK/MPbJd1y5cuXyxFVSrOn8DVhow70VYv8AJJ6ncXIuBDW/bd5QylyQHyRX2Xvlz9i5cm90ak8rob7nxncuy7KfdZfZTsSd8l9i5cuheLzq7UqZPEy+u1T2HkuSPBDkQ3ZD71zlLkjx3WLZvOC9/tVZWkvs2LGj4GrDzh99vv3Ooi9y0hU/kUIouf8AUcHRWmmVpupNzZh6vWpqRYsUfNBWIQZLTT9UkSr0OHNDt/Tmi5fL3ym7M1pIU1fYg2+cl3Syir5vJcD7az863FVRrRdfa0o0r+UXbVhqyU2vcVaXydeR12fR1YUutPgZ4bK09D9z9xlHFOhR1xV7Hh9fEVv1OF/qeP1P+6hD/wDH/wB//wAKtKUHf2MLXpzjGnB3ssl2+5ccLu5KKfAoJCRuXL9lieUOMmx5vtnFSOlI6cjRMjTkLY1JEq8VwddHXidaHya4v+St9poqUYpXRYsWNJ4v+h/cZQnoqKRiYLaa9xoU3ClK3KKXiGJpPpqak2eLzf11peySNGqGk8Pw3Rlfs4L91u7UzUspO7Ocm79rF2VJ+Z2FUfydWSOuzrNkqknlyNdmo6kvkVeaFiH7o+oQq0RTiy/3L/ZrSsi5qFK/KLQPE46sMxkdtyMr0YvJJN+bg+jw+myRjqUXiJ1qj22/8FOrrnaPBh1aOaEWz+o/B9Svg+piKvFnVh8inF+/ZcuPKLSHvlfsm9xPKUlFXZUr6to91y+WxdH5LXLd92hVZfIsRI+p/B9RE68BVoP3FNP7kpKPJOq5cDuywti9+TYm+thL/gkrOwilLVh4WNV2MweIS8lQxNqlSSI0pUpLSrlNWjvlYk9KuR3zmtUbH035Fhl8nRihqXsJfJUpJryo6FQ0VVsdSafJ15oWIkQlqV3lKqoPc68DrR+Tqxlxm6sYuw5xk73OpGPuSxD/AKRty5Ei2d+9ZXL52+2m0a5fJ1p/IsRIWIZ9T+D6n8H1K+D6n8H1P4JVpMd3zlbt8PevC6SvDTJi4ML5sPFElaWVytUdJ6nwUJqbXZjPEV/1KjgYv5lL9lsv93/sRkpboWT4NcX9iUVLk6EH7H08TjKvC2+cNms521d1+2/dfO2e+di38onltl4W10nExNtbFA8Pl06Vn8lXzPY0Mtb3JwjNWZTpWrRlF/GbMJhW/E62Ok7uV1+3m2/2SZhdlYTye40Xfsa5L3OpP5OtM68z6iZ9RM+pfwLFL3QsRBmuEvfKyfJ04P2OjA6UY7rKrUtsLfsfYy5zk/5KxYt3ofY0jbu8OlKGpv4Fhuo3KZHBVJvyopYdxhpYoWexZoeXTTmpZ159Om5GBw+mRQnaViOc3aTL9tu+7Ito6svk+omOtI5yeV+2/Zb79vsW7bFmW7NzfPYpYaco/wAUjhacdzgu3wOUvdGq+TKcdbFxk0nyYnGUZYdYejC29+ELZ3ISuriyxCtUfZc2Lls39i/2Onr5NBpLZX/lrHJa2TysW7dVjWNp9jaQ26vlifTP5JRS2Y+n77Dgr7MasRXuUN4Z1IOL3yw8/wCk5EYqm7613XLnPBaw9u2/2VG5wXGs3FGka/lr5t5yjfgV1lY0mnK2dSs0thcFBeW+VVtvYcZLc1N5UV/DQlbjOpT6isfRzfBPC9Fa7kWnla5Vo9PgZfNiWbEsmxfZWwnfPfK+SRfJaRpe38zbK+Vy5cY7FkSdxXk9KErKyyxDalsXZZDIqWhWKfU1ebNKx1FDkxGJ6myKDbQpEVq4FFDpwl7ElThHZE7anbvuXLrstm2Wyb7+ROx791jT/Ivuv3WzoS0T1M+pgfUQZU33RLJkeMldjlY1NklqHhvyUIOCszSn7mqMVZEZJbtjxUYorYmVTbK3bcb7Fk0WySsc53ze3JcuJmrK+dx9mk09nH2FRdrjiorfkSsSiP8Ah7FlK0hwu2abaRO8tNjSaXew4WV0dMlDzMlGxsMjtm90h5xxFtmddS/A3+SNZe514HWh8iqRfDJOa4HUl7jmazkt2LJ/Y1WOcrdzY99+6/bt2/g0lvsLYTTKs1LZCaZJjWvdHpSQ/Ndfk4siVSV+SK8t1yN73/BHhklrepD3baKm8UWytlY9iWdrZWzsWN8mLuv9q3a1fPkt227GXNQ3ZlrZtNHI2Wy0mlFhlhoSLWV+xFjTm8mLJmlH/8QAVhAAAQMCAwQGBQoCBgcGBAcBAQACEQMhBBIxEyJBURAyYXGBkQUjobHBFCAzQlJictHh8IKSFSQwNKLxQ2Nzg5Oy0jVAU3TC4gZEVGQWJVCElKOzw//aAAgBAAAGPwJaf93kFW6N64Uha/2F1ujzQc8l3YdFCuVAUdAzOAW5T8XWXrXl3ZoFEWVgrjpgqCp1Hz4e8AxzUMpuPabBb1UNH3Qt/f8AxGVb5suIA7VuBz/wj46KwYzvuV6yq93jHuXq2Nb3BUqVSnuMo7ttZN035Pg8RX7WtcZVGnSZh6WHwxNJtmsuNZi82Qd6W9NvqRwaC72n8lVwFBzjTonKC/VM/EPm9ZSp/wD0KNVy6Y6ZW5dbzo7lIb3nourdEKwQVxfoghZmdEkwt0F3cFYNb33W+9x9i3AAFlUUwsqzOUBYmnVGbYtaQGXcSmVqdCM4nfMLfreDBCzBu9zNz5/NDsThaNUt0zsDo80A0QAvSXox1mYkjGUe2bP9vRi/xD/lCHevE+/pmEQc8j/VuWqt/wB70+ZJVgt49PV+Zay396OaO6FmdYIkdHNR03Uq3RGceF1uU/5jC3n2+6FIbJ5laKOkNGql5jvTqzw4gXJ096GGbimtnk0um6bhG4htWpiHbIy/qzbQfuyp0sTWptkzlEy6PrePwWAo060szZa4dUy8Zn2LMxwcOzo1WqsfmYH01TfTZRZU+TucOs1r+J7NejFfw/8AIOgk2GZ3vUMqB/4N73LdoVH+Ee9QKdJne6fYvpKH/CP/AFdOv/fI4rkp4/M0UuMKAPNbzvL5suM9it0RxUlSFdbzgFDabj7FchntRLpf3lQFqrreVtFcLr35C63KfmVnrVI/DZZmsE/aOqfhcNWqMOYDNoHW6vlKficWS5lIOAy2vp4araUasgOzZjbe5p+OxWLdIc1rA4n1vODxTsLhWmsyq7MIBnJNk6piqbMO3NOvNUKdOm120cMxPLiodW2lQSXdlyrfM9ZVa3vMKp6P9GUKlapWc3QQIBnrOgLDMxNA7cUmiptKg60X0lYjaATuaH7o6BUdRYXcyFle8T9nj5L1OHJ7Xbo/NDCbGkxpZnzyXW0jhxV8WP5VBFlb/vUlboW8fJWt8yVYT3Ll3KfmQo6IHTnJUNuOxZYDR5oue95/wqGNA6I+ZmcQO9brXOX1W+1escXd6yi3ReABxTsRg3zmOSRw596rbSlv02CmKhd1nX4dyeyriGEP3edhx9icKjg2BvOJs2/5I4PC13Obhpg+H+a+VVKZJZugcR+iZgd/LUyWDbdscyqWHdRdTcWQxn5eaGG2c5zo2IZ3rdqZ/wAAze5btI/xGFO1Ywdgn9+S9ZVqP/ij3KadNre4LVS94aOZKrPbcEN/5QiquBFGo7YNbJdWytu0HQX48VFNtJg5Nasrqz/d7lXcCMzKMtLiCZydq/vlf/iFXC9Wt4KJgrTo0/7nHHsXJTqe353JX3u/+y3XT3XVmfzFS+p/KIUxJ5m/RIUFZcgRmw6ImTyF1an/ADFbz/5bKzb8+PQITXvbLnmw96cyhTa/LG8XLbU2nIDEkaqpUw8BzdJCq5Kbg9xcBIytYBrHJOPVdWc0ubzH1e5E3AF/BCtWNTKIGVmqFV72h72TEZS2fedUCxpq7S47imYxwpuq5rPqGSxubgFV9JYqt6yMrIF9PzniqTcJhGValXKSSczh2KdFK0UOqX7LrcoO/isrvju/fxWZxPfx/NVMukN93RTrjTFYUB7vvtA+C3KzXdjd4+xCrTo1XeGX3wsU91EiqcE530x5cuNl12/y/quCnMt4QuYUEaKTAW66Vb+3zOgBWYe82V3eVlYfN0jvV7/2MFwnlxW5TPebK7g3uC3t/v8An7zgFu03H2I9Qe1S/M7v/JQBHzexVRUrBtGm85YO7b8wn5iHhpnMLcrJ1JjX2p/aMarYUHjPXqNZBMSNSqmHxNfNTq+pqGnWzZDpeOzh2dqfiKNJuSoXHNIteeafRcxpfULS45dI7u9GKLqhYbgaNQrtNL6POabGwdP0WIqfKGUmsBeZ07lSwtOnNClAduaxF/NVMNWrtIbldmkAPMW8kz0gardIbeyilSe7tIyq7mM7hK9c99X8R+AW5Ta3uC3qrWk8yobmf+FtvNBww8fjf+ScHROVvuRXous7D5mB9LaHw0KhosOS6ypYygw3pOok8LyP/Uuv/h/RRZW6IW8FAV5CsOnS6sVuq/RotFBCt0Q0Zj91XOTuup48yrqy0W8YVh5rVR0W+bdwHetiyS/LmjSyL3lrQBPNRi6mbPJbwy/d7VDGgd3RHzJJW7Lu5dUD2reefCy3Wx/YXValTxApVHMOU58qf8m1pNNR/wCEKjTNVjHPBvnv4hPGem0U6Qb6tgDl8oDH1H4c7RgmTK29TEOcKoFXM4mCf85CGEeJpuIl4bv6ae8Kj6qHCmcwGlzKBDetvZY0VbEOpug23mm82EJ9GqB6xwO868ec8UaLamdrbOaOr7fBPFPal05W1Rrm5e9Mptc3MRO9qtxlR38Me9TswBzLlvVMvc381vZ397vgop02t7gpIW+bJ2TTK33dFMfZo0XxHYE2A48JJ5WW84N9qrl5zgU3OAIESAvreZUFt1Z8LWR2Kwjo1Q6xVyfNWfdb11Oi6y1+bBN+XFbtPL2u/Jb5Lu9QAo6L2Vmedlc+S3GK/wA2SYC3QXdy0a32q73e5SAAs/1zv+KZycQfig/7Bzfn8zWe66syO8ref5WU5JPMmVYLRadMlA9nRW29fMG3Aa2beCFTYFh4h5hSXgDsCmo95/ihMouptjEnZkAfVNifan7LE5abrdsco9ip7Wq1lRk6m+k8EMQX5BIzZdTIHFYLDYOqyrt3ObUz65WyLR2hGnXotrPxNQtGaIZTF7earU6VACi55LXyYHfyVPNADNW9YnxWyDX7zyN926wdwT8NSfVFfPuM6gNh++apYckNrOAFV/GIAhZWy5zhAkAAdqa/O5wectNnLhKaxrGiBwCsFL1uqajwFu37goDPMreePAI3mwWipj/7Rv8AyhFn4X/zD85WixAGmyf7umZVnkrX2LKWqQ1aFari5T0wrhS4gDtXq6ZPabBS+oe5tluADplxAW5TJ77Lef4NUht+fRp0aLkt2Xdy6ob3reqHwspyiefzH/hPQ2l3vHd+yspPgoo7wFgSYWSm8NIhx7AgXN8DfpyPqNz6xKgNUrd6MrnieXFbtKofCPehhszW1atmgGT8EGufU3Laprn0hVeXRrcJzqVUvJe05sv1e5Pw1YEPrbwzXv3qMibhdllZWaZfmiFUr1MW5tVlQsaxomc2g9iqVXbxy6k+5Coae1c6LN+s0cLKvUe5tA1XABjyN1vcL8homYp767suZghuXW/xTKGFGR1V2VuzEn2p1B9SsarXHeqdmiOZzoNxv8E2oKTKbZvUWd75zCWxw5p9XZloayIAt3ALLUeDUY/K0AWjtX9XqE5RvPmzUGMz7Kg3LFyrUz/EV1gO4KHOcT3qYHzIH2R0YXMdcMyfILD4V053U3NnhZxI+KywsQ067J/u6LFy4q09HVVwoa2FIUq+i6qvZRTdtPwre3R2LPF+ZuemSfErdaT32W8/+VTF+fzd3e7rqzI/EVvVPKynLJ7b9GnzbuAW6w6js4rUN7lDpOVvPn/khSDxlcb7qiNOKc6/WOp5W6A2d+ucjVVc4Z3u+jHAWuvlNUOyyHS/gJ1QOR7ni2mq3aQH4nfkt6tH4Wx75W9Lu8yoa0NHYtEMm9f1fIIUaYMTL7qtRxLHfSPlvb8F8o+y1zfw8lSxABLadUTEmQEXNgxc/vVYY0hRygHMc0OHn+S+SiptHZ5Y2mNTykrafJ3hokweSdle5rD1WjqlFpp0znA3tSCsZ6P9I4djSKIrUObiBp7k2tQw5oBrAWNpzw4hB72E1hq9/WfJlQMvfysmUy/NB4OTdjVcwOfOVx3VmY4sa27HNObNx0TKuJrOoGoSWvyTfthVqVPEZWAOLq8TA8LppwbIJY0E5TcBZn12EkwAHJzsTSLW/VlscVcwtem90Y+yFHPWywdB9NxYcJS2TmtJk5byn18py06rs3ODp2808UcVQbHV2dImfMJzqlfElpEOOyytvwsvpP8ACP7DRWWVry53Jt1mBDPaVvy8/euuqrh0KSY71an52W87yUhnj03Ws911Zkd5V6nktJ77/PlxAW6xx8FeG+1Xe53it1oCH4h0PPbCb3H4Iymb2YxJy3VarTaWERvHvTT8pc7Ib9gjgvkVUvDWCZm/kmTs9o92vLyTvkuKdBEbhIJhfJ6zGtqnTLcRA1+ZXwr8w+TszvdIiIU4Nj6lR1QGTo3yRfh8ND2ZXkvfYlPxAYxheG9QwJ70aRxh1gtY0m/HVPxNcPpUcJ65+eJd3J9fBTSdUeKbs1Tq3+PxVXC16LcRRqYgVA2pNo14zOl18pwURezhaOSdgWkbN7pmL93cnDXkhDexZcQcxpsyCeX7snOYbuaQYaA0qalu5Obm3XGZTKGQBo4xcoscOsItNuXxUxmLbT48k6rWqWkKlRoUnVGvF3C5csN6OdRc3EyQZNwZN/Ym4yrjA5gy7vLmgOS0UZwPFbjXO8Fo0dhdf2K7j4Nj3ogmd0dGGp1GZpw9Pv0VbC4qnmdu3dEPHAxzW40N7gqzXtDhkJg/2EE35C5W7TDO1/5KarnP79PJQBAC0V1u0/Oy3nfy2Vh0aqzp7rrq+ZV3+QVxPff59zCs0u8FZrW+1etcdeFl1QoAVwp6Mu0AKA+TS3i6Y96OR4ok8RdUQ6samaAe7jonV6YDgWkg6p2Iq9VnDmeATvR1HO91Sj8opRbMVFMNGzF28XIVHPftDuwPqj9/FbNuapTYQQDq7it4wahJcJ/fYqQw+Zrw5subKinRPifyQ2lWlRzGBK9djHuPJpj2BYnJRHrC+nNRtwY5rEU8ICKecbTtA00uqVFr9hSpVszt074nkqtQsdTpuqdQcLJxotMTIko+h8K7ZtpNZLvrO1hsDgsBg2t+nxNPakvgNGt48lVfSnZbQuaCeErU3QDAM0neXExdB4qi9xzVOvwcVWxL5l7pEjhwXag37PBU8btM1MvFN9tO5bCkxxGrSefNU6VGpcv3g74dip4IVIk77mgmB2QgNoDUbBJdTMgf5L5Zh6DW4vEkspv2dyOBTRi6jC+NZuuu/wDhbHvVx/M4lQDHcIVhPfdadDvwt6MIXOv8np246Jm4456BGkce1WpfzOVbqN9W7t4Lh5fMguvy4rcpwOb/AMl66oXdgsFla0NHIdGWb8grU47XLfeT3WUNaB0WM9yszzKvU8gurPfda/O3nAKzXHwWjW+1bz3H2KQB8yHVGg963WuPgt2n5lbzyO4LeYT+K6iOguPASg1z5G0MkmwBjRUMHg83yRnqWZrbSTdDBVXllZ7gQe7imYlzHttuu/JGs2lTblbJt7UNtuNyy03AjhHNS8szlstNR0BO2/WqwRoAqmJMOr5YALuHNbzw38IWErZnam5usHSwszQpMqu3OrOvsWLPylmWu4V6DWttUtfxhU8Lh9xm8XZTxMfkENtTAoiq4TAGZ0J1ZjTkEHzWHpekK7qYqhxfUF4sI+IuvSPpOjvV9k9jHaW4X71Uw2Kmo1rQ2lldAZft71Dbog8gVIbx5q4BTS10l/b2oZqk5eq11x+7L1gzFoEnjH7K3SpuO9ZXVt0fVnimljHN3YzRqmF9QMOa7h7hC+UUBBDQ2HwfKVvUsj2Sxpgku8Fg6eIwNZlNjNo+o5sA9kctVDWAQrODTrqoFRru660efBbtL+ZyvkHhK+lPgAnMBPVbqezowo/+3p+5YCm1k58417FCrf7N3u6N5y3KZ73WXrKp7m2W40DoiZ7rqzQ3vW+8u9ysAArX7lZkd5V6nkF1Z77/AD7kLdY4+C+qPat5zj7FutA6Ze4N71uye4LdpR+JyvVA/C1b2Z3eVDWAd3REdGi3nAHvTG4ipkz9WbKnTZTIpPpmJdY80NnWaGN65j63ZKw+JxlA0tjn+tepex96f6bbhtnUFTZNY3QsnWOa+T4oP2TZjO6Be5tPNPpVKzCDLRYxHsVGi2m6pSIDabi7djiPai3LkI1yCPBMOKGTNrmOqpPktoFpbGX4+Sr4fC0XUjbJU+tHcsCMZig3EvaC1uUl1TS3LknYzd2dKrDn/W00jim4ytiKRYamRppmC3Uju4p+wb6vRlur+/im0zVLCyNDq7mtm/JuQ0FwvHcm1RE8FU9EMYWYZzg5zus52lvYs+VoJ5CFmRgKL2Uhbhu24MXVXEOovs3NJ3QDPapL6bJ0vPuX0lR0cAMqzNoAz9oysrHZPwDL7lJJJ4ppq0czMvthUm7DM/6wiRYp+OxFFlTENeThGTNuavVj8LVUxmJrPDKYkmT7gn16WGw2XYsAfF+dx5KVp8yp+Fvu6MLH/wBPT9ywdWXNGYh7m8BZOFFuKrCm3M7LRJyjtRd/RuJjEUjkc+GyDxXHyK3WgdG7vdy4NW+S7vUNv3KzfMq9TyCmJPb8+JvyVmlage1bzifFWAHRLiAt2XdwlWp+ZXWa3uEree8+Me5S1gHh8yQuuCeQut2m/wAo96sxo7yt6rH4Qt4l3ZM+xblKB5IYjI3ZMp65rzOioYfagvwVs2bUcTb93W3Ac9ulrX17xaVVc9pab5DdxlYynha+V1B7Xtj7HEBUsNRMFw0hOoV6TmnII4byfi6lGWMEh3VIGvuRFejtGjfyl8NLhoVSLJa62nG6quLNntB9pNxGJy7Gg5v0jev4qm+i5tN9BpAtr2Kp6QxmGcwU6jaZot0e6ZnQ9iFbBYOzBtKhJ6xGpH74KnTdTGR++3TN4pwfuz2LLTHi4XQdUaYee5V8NssOR9Jmq9aeTYWVo3uAaFdmX8ZhZNsy2tiUT6x4JH3Y963KDewmT+iy5i0/c3fcqbqr9xmo5obGkKdKnwayMy3AdYurZBCsY7kC5ueWkFpRNJsEX7giardqavVdM3TX1MOK7XtGYF0ZB9pf1OXudI37e66o16tc1KeIcS9ozZLCBPvVf0hUgfKHADKIEN3ZCv8AMk2VQdjfd0YY/wCoZ7k/BOqmmHkHMByTqmM9KekKzniHTV171X2FNzKrWZm1HOLoi+i0WoCuc581ZvmVd3kFpPff59r9y6nmV1o7le/enZWxJUuMK0nuCtT8yus1vtW9UefGPcpDBPP5tnT3XVqbloxvtW9VPgupPHeuob7Apyx+Ir6SfwNlfRE/iKu9jB2BXe9/77FWwOOph1XDtFUUtCTwXyupg6lKjVm3frEqnSe/LSFN9wBPVUNAcJ10RoNxVWnSeZe1rolUvUvNdlWdo3i2NPen16jczsw2Znq/5ppI3aTBuAW0RIoskt4ceSYA0tdzB8UwY1nyikKtw0lpNuKZQw1MMpsENATmYR7W1gQ6m52gIKr/AP4ipVau1zFtOm/c2mWx9nuRqYV7tiJblc4HdOqFfYb7XSMjIEpmFw7vX1w6nZwNzoLc1V9HY2sKWKpkipngAg8B2o0MJJpMHqyX2PkEKLG0g0X6s+9ZXl57jA8kcm6O9P8Alue7HBsC2a0fFZmuaAbjeF47FMyQJ5qjUayKzXid7KCPzTH4L0e5vrMoeJnx4QtlW9I0ntuS9ulu+Fm4KCnBz8vEd6zueXninB7YsYMcUymHOqik3NDeGq3dptKhDKbQLuVOq8w5hz5ToE6visLnoUuoHWj+Htlyq+isNhoGGEPOgHID5rXObuudBPJVhVIJmxGkcOjDRpsWe5X6MR/sX+7ovfv+dcgKzSVoArv8lMK5A71aXdwX0cd5XWaPBXe4+Me5SGCfmSSrGe66tTPivqj2reqO9yu2e+6vZSt32XXVPuWrJ/mKu6q7/CpFNs8zquv5BXLj4qQwJtDDjJh8LVBMH6QJ2MoxOIDdzP1bfoiKtclpLd2dba/vmgDIM8Am5HOggSTz4rfKa9tS83EIkuLRI3SmMkimBcNOqBrue0Dst3LD4T5HToMFTeeDvxylUWUGtqU2FuUnieJUtdUePu/onYmtR3W8SZPtRp4vCNrUnUw6ju/zA9qPpRrPkrHVDSa1hALTE94Qq03vexrs0vOY37fBYfEUR9C8EmcqxefCNecScwP1mkmVUrYpxzvdmykaK+qgIMkAu8lIe1zIOV40fGsc0AREceKLQ2XdWBe6+QZnFzagcXcz3cFsm1HtbABCu24FoXOyDTpx7k3I7JlPX5Imk0ACBbieaFP9lOaCInQfmm4pw2bn9V4NwY7U5+KpbQNGQCcsHhJjsVOq3GYpuCoN2jm5srTUiLAa68YWKLaD20qpNRu5ZvCD26fNxWFZVG0p2+tYg93aE+oKrags0OAgWt0UW5opU8FSJFrkjz59OJ/2L/d8zreSxFGlTfOHdlcSjEAq5JX1Wrda4+CszzK6/kFdzj4rdYB4fMdLgIPFWDj4K1PzK6zR4LeqOPjHuU5BPPojOCeQutyjUd4R71/o297lLqrv4WLR3i6PcpDWA9yu9y0nv6NpVeGNHErLSJqQgAQ0FRtifFZDUDXawU91KkyjjB1KjbZj95MquxFZ5p3c3LlZpBFz3p/o+iwYR1T/AEg3/Yjh8ZvNePU1WjdePgUGuqNbSpuOZ8iw424p7Nmcg6t5t3qnRc9gY3VwuXX7F6t7HF88NFlyZkMzWUm5riJKa6vVnDMFw0x4J2zqPDM0tv1AsMcr5yfX1T8JXrHK3EOEZbqnRxdOma12wR9X6yp4b0Zkbl3ntcyHJ59J0icGQWVHkfR2sQhRw72VNm4+saIlZ3Yem8GmG3b2Qr6O1gaKy7Vt34erVe4TTApvI4zoLlHDn0SG+rjeYd2/6qjVfUrvLtQ1u9n/AOlUquGqOzljhYQZM2v5Kpj8Xhm4jEG5zyWCWnTtn3KnTq0djlBmowS5/emfJXkiOOqaYu6wHHh+afTqjeYchVGrl6x0GsW/fgn1cgDQYtwQLTlv4qpU2WeGuLZ7k0vkX0VKqzDuyudDcokuPaqX9L4QbRhD2t+zuhHZ02tnWB8xlPE4gNL5vPVAVRwqPz1XvjIzKX33Tu6z2JgLYt0UyKW1xNajQaG3mMipvq0mNc4Tdx/Jden/AC/qsVNRv0L9Gfd7+i/sW9/iW6HH+GF6YDWxGI497lf2BS4uPeVlsFIKuei7/BSGOP77V1Wt9qjPHcFvEnvK3SzwWjvJdSO8rrt8Lrj5Qrud5wt4A/iuoBMdiuJ71YI/N2bIq4g/VnTvWfE1i7s4DoAEzpdEVxlD/V5hwP5rLmqOqU/V038CE4PaWEHKRyTSd2nWcN/hMRHuTG0w29LNAItdbDG4ZlVo3gHsmO26bTFJ+GbmzTQduuPaEcHUYST9G7g5nAojjoqVNrd6o62Y2hOyt+j62UWJ8U7MxzKhH1XfvtVSoaeZtjHNTmy0wYcU6jVGZ7BFIDqxynmv6VpbKhgyBVflOaDa3vVNmDxFbKWw7bGT3jsQZtbHrGEMBRw55PrbOJMrNdMOHaW0zTBEunv9q3jE+KfTFXNT6zXFsO9ijLEKjRNchuGIs20p1GuXvqVCN8nhMmBoqGJwj2iGRmJBPaCvlMBp7BATKFKq5wpNzOYG5WDlHNEcrL5OagGVs3v+9U70TtHsp0RTBc3j2wm/J6Jhp1fxTAxjGmnAsOrr+idlMUi6wRlzYQoNPGZTaDTljRYCtivSOxrU6zS+k24k6NcJtC+lb4NX94f7PyV6jz/FHuV5Pe4lfQs/lX9JNxWxbutxbch6vYYiVGEqh/yQjK6HPeeLnFtrDnEFbWm0BrpNhHHowWIfTY+s7D0aVFs3MsvbxUx0Yr/Yv/5eibnvKsMoUsOYaS0SvTQv9M02H4kS+QB90rdzO/C1WoOPiFDWBquf8X6K7G+O8us3+VXq+5dZ5UZT4lSKLfJDeaB3K73FSWg96sOnRSVoohSUN9t+1ChSw7HsDA52aQSppYCABbMZlGm3LQpnhT1PipOquOjrXbot4N6+cgiZWT7Ls8dqzkkSb6hF1bKab4gO4qqzDVHgUrjeB8IWzqPzbus8E0uHZlTBiw9r8POV7CLSvlDMM3GspfWYN6O1qbs6AZl5cEKjybJ5AHWAL54cvYpBZDt0xYn2oU2WCZQq/QNIc8F3WXyAOIp5crw0ZZWF9JjHw5jjDCztWPOIaatVwztDOGbV3nHmsPhaA+hBDuZE2Hh8URTbDeSIgKbHgq+PdjWfKa9GoxtHITlvHulQhUzTOo5KJ9qguP6Km0xE3nSFWx3owBrsLSFZzerug377Kq2WYdweXCo5oLRA0J1Gs2TDXh9KpTble3eYTmbodCsbTw4D8z3nI3gAtZcF8nwobOpJcG+0rZekKLA4NztzODmkcNE5uyzlxEOPDmsoNvtJrnWgZhbU8FTLXVK5NQZxqKYHjGiuem5C3q7Bw6yft8G1gpEjMZLamomO7j2L5Zha2IZUrx9HUmmGqmHOk5ZJ7+jDVSG5cNg6T+tBO4LJ+HNRpq0zBDQXeEoYsNFNriYBZw81iprH6B/AfZ6LOH8IzLNspP3ynNr1C2aj3dQ6ZjxK9L+vltd4ewid4D/NS39V1XFWarlzOTmOIIWStXc+OJN1ao8+CipQzN+0Lx4LNTeMv3fmQrrRWV3N81A9y6hHeup8V1Y8VJqAeau8nwCgyR3rDGiA17qZzADgDb4reMqeKu0qZko81YqHGQrwO1QzUiFQwTHOGRsmCqtQYhzn1THEGAZTq+IZlaWRGbTthFugLfaqTj/pWR4qOS21WuzA4t19o2N7vbxTqVOlTrN4Pp1BlPmpy02d71L8VhwD3z7lPy8eFOfiqQG0e+mIkN1RpVjVzVdGmB5WVJno6vkaQ6mwZ2uzRc/FOPpljqzKwNJlVlTI4OmC3tuPcifRnpepS+7Wbm90IvpUaeKaONF9/IwsmNwOIpHlUplqtp2qJ63JSdCU/EAzkcBl75v7EHvOUdyzF3aFtOA1gqcPiXevlr6fKnOnimUoMVvV12/YBsYHDUKpgzWexoMOYDuznCx2UAO2jmkixhVqDpsM4AbeyxBpscGOFs1lh65dly4On2jVyyVn5AQXAra1BDfYjhmuzgm+a8QslIeqqmM1utx14QmYXCioGOdFUE7zxyA+KpZw5pyCW5zZXpt8Vam3yXyb0fRrvw1TLUzNm3ZPBNxAZEMALQSWzx4Ju0zB31oJ8lSqXuOPf0N+RYsMqOoUpbl13G8fBU6mJDnte6w0zKnTZgC3K0C7v1lYnMMPGxfNzPVPRy8EZqErU+K9J1aWr6mUjK0ZD2XutHHuaSs1KhmPJzo/NetjwXFcF1wFqjUpE03/AGgNe/mhTxDQ1xsCDZytTK+jA7yvpabfBfSP8GrSp4vj3Lea3xuv0C4qzQPnNdTxGxr0xAJEgjkv656SpNp/6sFx9sLLhcK3Pxqv3nnxTn4rJsmDM7PoAsVi8A1opFx2bWNyg3sstQ7zwPBBhM5Qs31RqTohscO8g6OdZNDaAfF7OTqjsDiGPLpEsKnQraMeZ49qbXaMtRtitmK1FpBLwAYTSyN8ajitoa7nbaSalV9wYgeF0/K6m1zsK3LbMG1rz4aeSd8lxYbTc9jvoDMRdtx3e1OyVKn94FVnY2AC3Xv803frSzEOrtmPrAgt10uUyJ9XWqVmRUiM+aRppvFUdkyNg81Glzy4yQQZ800NyblV1ZtjZ7pnj94omjVa2C6oN3RxuSjmmZ5KziEWVWsqsOocJXr/AEHRpu+1R3PdCzejfStWgdctVuYfBUflJp16VZ2RjsPLiXcBCOHxeGr0s/F1MjN3L0dSGDms2oHDaGGk5rDlw9qqGlWFXajaEzxPBepwtSoOORpKfi6MUsnUbE9gRrYOi7EMqsbV9SMzWyNLeSZir+votLvxhwDvH816RcJ+mVPEsmWHN1lUbiKArCTlfG9lsdRr4prMPVbh8tJtFzarHS5t3Fw8PYtuRtGS5ttJmypf0awYYimBVa0Hed48k+s5rmvIdd4XyhwGzzTJE3X9M430fTo1X/RubSsQOxXrVnd0BaVz3u/JGrUYQ0azUKx+Ax/otlWqxr2UK7W3vxl2nghUYxzwDlJzW8U0OxYpvqncYdNeJP6plDbMqZJGemZabqFhaOLoULYVrHPcb5nNEHRB4IrV6e63gC/2WVP5aW544X9qxgAP93qf8p6JmF13+a2md7X8DtD7l6SwmGdTqVqcZnVN1rhM6AINnRTmJ8VGz9n5qKdNiuWtQzVXeAWjv5lZrAix5DgdRlT30ajniOq49XtH5Jj37xI5K1lz6ZcoDgVvFahW6Cp2zW/xLextOfxhb2Mb71fGD+Up+BwFdueqQHFzoGVA/KKPtPwUnFOd+CkSoc7En/dgfFSzD1z+ItWRlHKPD8kXgmT98rKyvkHYT+azYiqKv4myoOz8Gt/JQ6vl4wqgdUo03MJDXuxJvyKwxwtNzvrOzG4TNrgf6jmyhzarSWG8zfu8luVnjvutyuzyKthHPbzaW/mvWYDEt/E2Pgv7v/jVqTf51cMHgVc+QVPEU2PxVB9OYyiWu/JN21AAkXur7vev+06H8y/7So+aj+ksN/Osv9I4SqDq1z2lGlWwVFwLYBpkbvaBosTQfGKAECd3KI07EMRhPV+uDhv2CrYl+Pw7S/f3Wu1PBMp18ZVqU2Nhnq5juuthVrvqbMty5+RI/IL0gxrXfS8+xdQT4qlVp6DMw2j92IHgn+kn05Y3AUaFuLnudP8AhDl/VjOGY+cvFh/JZ6sO481hcJiMS6pRzzlN44fsIejcbhwaG0dUymRpomMo5GhhEBq63sWp8lWOHG51agdEESs1Wq7bHnvNyxxQ2DKlM5Mr7iHeSzMcbbqo7sW08ejYNjMaFECR9wI+kPSmcNZApTZrj2qiTWE1S1jKbTJusfRpPY5zMPUnemN09G6wA8ZNlExPBdc2uvSG+0F8fSOvlt2T7eClhpyoFXf7GouJJUlq3VlEq7leq0eKiri6Q76gVVoxtG7CLOTGHGAuDYIAKvVee4K1Oq7+FSMNU/fgpZgqqy0/R7/H/NerwIBP3laixvef0RftgABOVoTany91Nrmh0GRHtXrPS/tC9b6Yp+NULe9MT/vFB9IOd4OKnO8/wL6Kuf4f1TTTwVTzWUeir9tX9Fkb6PosB4uKGXD4QDTqn80XB1BscmK2MA7qbfyV8e/2BE/0lXtyeUzPjq7+wuRz1HfdVImlZtM2HEZj8ZRc1pawWv22RD/SdT1TLZmNdPmFTw1E0TTYLbSmfgVld6NY/tZW+BC9ZgcWz+AEewr+85fx03N94Xq8dh3d1UKX0WVAebZWZ+EZ4W9y3A5nitzEjxaq9bCY6vSr02ZooPLW5uQ7FToekX1XVBbMWzN1Wp/Kd6qyAOf771d6+kHmuuPNWf7VYlXcSsmIwmHe3k6i0o5PRWHc/gGuLPcjh34fE4Gp9X1ktPmFUq4bECoXMLQHsj23TsXiA99ckHatcL9+nuW0o4ZlZtMZLtFS3a1Yr0fVwzKT2jMcoiY/RYDDYqoW1DQ2sxqSSG/HzVTZxZ0y0yszIZn61Mmx7e5PrPybR7cufLp3dvaqLhWYxolzrWamVBQGUweBR9QAnGlSbmi10cH6ew9LOyrDmlu0aL28VVx1bH4SnUk1A2i0h7qY0AGkrb0KjqVGpJy5QS2+kCApdTeSXbrpgBUs2aY496uE6o8SBRoQP92FmLi0DQDRS9hNdrQKZaS0hvNYmjVzOr1qLmP1tI/Lobh/RJG87JLmdusqCZU4TK8u+pU0jv4L0nh6uEcylla/Zh+XZmBfdPb7UGMsBotFqpcrJjfRLsRtNpvChMlsFD5fh/SU8S6g5EOp4q3OgR70GNzZjoDZZaeBmOO0/ROpGg0CJnX/ACRy4XMG/WAkLcp04cOUIRkb3ESowmIYWRfNlmU0Yg7dpHUFXZ+1qbXwVetTefquqVCO3elZjjKpbP8A4sptU4hh38v0ozfyoEgFvPNdWF1Z/tV3jzWjT4qCzjNnL+6vPgUJwlQR/q06ZPcFIYSo2DvJXoe1fR/4lqB/EjGIZfmU2ocTSbl4hNy1m1OEqkKQyhtPKL9becfiqlCswN2hzzm/fNV2nKd9pkGftLKNFZESuZW9TYf4Qswota7m2y3Mdih/viR7V/fs346LfhC1wzu7M3801lYD1mt5i36I0BRa7k/SHJoptAy2t+J35BP8Fvu8Fo72K/uX1f5Fao0fxZVuVHecoPpumPBOpQwYoDdD7ZjyPJOoYnAUaT2mCN6R7Ua/yOm9rTBDHcOaGMpUKTnCxc15Dh2EJjMzw0CG5xmjiIPYV6PORzqFPChpOU5c2Z36J2zeaYDhAjWyoYesCajX9yr/ACJ1ifMdnam0aFV+Hbo6HaDROw1SuDVrVdz74QrYt+UOdlFpkrb4c5gqlWphn4TFYF0VJoXfPK45Snxt6xdGzcRkAvxHcrNIKuJWHP3fioKLGzIo0v8A/Nqhha5xEFxumOewVjOymD5p4z5DXEZTUzO/fn0fKH4unVLRuWIurZD3ORpYrFU84tlYc8eSxfpM5m0cQMt23tl/JRtyD95sIPp5S06HMvqj2rrjyX0jvYvrfzFNmjdw8lvjjaUKFCrNPNlc97JjgO5D0PR9HUqz9uKpzsl27wn7KOPxfo9r21aLRlflgHWdVmw/o5jXudlGzqFp7UNrSrv3eq3EIVs3prDnvAbPeQjs/SWIuDG0E38lvekWsdwGzJWWp6Xphovakjn9Lvf3W+KaJo7p/wDE1VOhTwuFL46znFEj0Thge4FW9H4cf7pq3adNvcymgBmHdlXWxHgvWuxZA1hypNfTrv2bHAnJOYl3FVKga0NJs0thXxVPzX9/pD+L9V/2k3wP6r/tSfJQ30o3xpgr+/UHf7gplKkaVUOMdQtVPNSa05eCo7OnGVgE800vGchsGb3lPeRBc/Qdk/2bWNbDm025z95HIZE/v3p5+98E+tmvKs8K4B8Vv0vYpZaFqpN44FNfTflqM0PEIYTFFtL0hSHq3n6w5HsTmlhZUZZ7SvlOD9VXGobxWTGUyaRP0kW8U7DV2ith6g3mH3hH0ph6lWthQRlqNvs+x4TalLNiCGHaEjqvJTm0G7pbB7UCQ0O4PJjN2H80zEOfm2RFtY5JlSuRGVoY33kQqrRUDKj3ZjJj2IDHF1Cq8uqPq0iBwjMfBMo4TG/KmBnW7egZrqhGmXoqVAIBZRHZ9G1A1TuRMBseCzBphreR4KhSc4kS2JPDX49D69V2zYwZnHNAATsN6PqVKGE0nMc1T8kFLm2K0Q29IVcO/wCkb8Qm4jCVarWPGZpbcFB1Ctnp67roJRw2ydLGgnaApuWmGlmu71r8U3b0XDZskFpCfRzMe641khPptfDKnWaOKq1BgKe1rDKalycvJUaWDqOolgDZcY4f5rLisRaIbFSYTqzHsed3IS1RUpA19vEQm5SQQ3MBEQmY2iSKjDYh17f5wm4PDYoV65pZi6SZ56pza1Zwe6RLQAFRo15c/atJceNisNRewOBYTcaqq/bkFtYMEcrq+Kq/zqPlNY/xlUnurPO0k6rrOK9YLRyXo1mVwDw8GI6rnfnCqju9w6LBVcRmAFKJHetZX0ZJR3YnmsM/JDZgqkI6zfirHXo2f35TaVFmZ7jACyHCvzXt3ED4hCo7DVcpm+Xlqs1TDVWjtYVBHzsR+KET2p3+0Kc3u6L3QCPRI4whWpaj2oZX5Hs0P2ShhsQ5tHH0R6t50ePsns7UfVmnUp2qMK2jevxbzW2wHC7qP5Ivo5RIy1WOEjucOIVavhMODQe0uqYd3WpdrTxb2+aw+zuwEyIunYWrVDalC9IjRBrib2tqL+5bao1oa/qQZBuqXyVrHObI3/32+xFzp81uqCII6MP+DoxDtpA2VLT/AGYW/vBlzZNybNxGk+0Kjmt6y35LRD0FSrTEOxJY3yb8UXTM6QplZXWKg8LdB9D13WdL6PxCHkthjcO2o3geI7jwTsT6NnFUhw+u0fFBxJa9x8Qvo2l32oWWoNbyi5g7Va6+TiqfuyNE91QH1nDktmcS9rSBlzcEM30gZ9rtW0qBzWM3fV8j7rp2Cq0zuuL25ABIKNY02bL3eSZiIDWVKwyjU6Fejdp9ZpZPf+sear/+ZHucoUBqGLLxk4MntVmnulWsUMG5jRVyVIdGj8xLSm1i3KamTM2NDlbIQ3F1Sn0mMGzqwDOtkJaO1Zo4ovlqptAF3F2kofKaGyyHI3dIzNB6111l1yszjO+qfY2p/wAhWHxGIr5q0ObEajaMv7AmejnkGh8nZUg84/VUadbEsivRq5qP1sznOGb2rF/7Z/v+dXqc6jj7V4onm93vRjg4j2pzakuLTqt0LmV9HFufQx/cE0TqAjUwt6rAN37XYhDjTqUzafqnkUKFZ4o4+iMrHHR4+yeztVWg5hZVZLXMPOFtGmKo1CzsJoVh9bn3ptDGg0H/AFXD6p5tK+VtJYQwmlk+jc77vI/dWbLOc3dzTX0mMGSJFM5p9qeQXPbUO06kFs6prtuepllogd3es7yD2LRaKyw8CPVjoxL21t7JT3QP9WFTfUYGtdr+aLaj2uydXLoVhjMuDoPRVexm7Xa2tbnx9xXyd43SbHkoglDh05Wvu081NPFVmfheQtn6bx7vk7v9I9280/FRhvTuGfP2iFUFNtHLDSG07h0iUaoDWg6QVMWKdQNJrnDdsuqqDadMh1antCeSbTfX2eUNPfqrb3FhCFSo0WtncM3eqxcx2zG9nFuPFCtXYMmaYnhz+KfSYxjL3nemyp6ACq2G8dDdYGDByEA8jNlXzCD8oEj+ZTCmF8mLN2NVpbuuszs8zoGLCMo4I4oVpLiyRkvoVVtl9Y13mB0QCgeybJr3HraLbE2mEPisKc31vgqHLZ/FXqtHivpAmuBkZyqEmBvTbhlMraVHta1mbKQLZc9NzfgqTyykcTAY+DcfZPk1NrU/R7m1m6O2n1c+aFWxMRtajnxyk/NdU+yJT+8piHefenx9ufNOzsMuRaygBH3k9rxBHTQdzLvemGOC8W+9YqvQ+0JHPdCbVpvyvbofgUwOeKPpChZrnaP+674FEEOovYYLT9XsK4B4RwmLbLeB4tRw+MZ8rwLtftMT8VhanyrA17Zh9U9vJ3v70H4KkKdSjZ+amJN0W5jMb+Ya/uyc6swVGOAGR3HtW2pOLmHXmD2rVB3JX0VCPsDoxbyG5S2m3eHW3G8UMPUw9J5jUDRFop5Gti0yqGT7UHow1EMbLMOCT3kpz2jisjm+ZRbh2Me5gP17QqObD7avWaSXNcdzuC2mOzd5u1NDWN9a3M3KeCZVol8OsnsbUIcLKnXEYhkzw9yZW2TqYc3dBEQo2mvBZgXEym0gcpfvSeA5pznMbVpsGYDRzh4plJrKlAsp7rCIPb70MRiKmawgR32Wxa18G0vaiMOIHCXTCqej8I4CnVdvGNUalPaOM5X2sE7D4hs1GWzcDZNbbKHDTjYrARy+KxTs/wD8xp5rUeal1RvdMqA9psi4uWUVqcfiTBg6Ta1VpdDZ1ujVxmWi71e0E2G6OKHNd13GUatNg4RnvPwWYDegm9oWabjmpdAVA1XgQTfhohtKeXJLGn7QnVNVCIsz8lRPNzveVSLmyAKkj+Ap79htAM+VgH1fVR7FSrYmn6xlQMp1f/EpkE3+fWd92POyd3lMTUagE7oMexZ4hFn2gjVfTz5QTEo7LDbPlvk9A+48hMnQSEajcTTtBuYVTGsxbPWRFPK6OUZohFlm5tDNkHMkVGe3sTd9rMawQ1x0qjkfzRMbN7Dle0jQrfsW2n81sarQRpdOq4CDTqDLVw7+pUHI8j2qp6S9FZixn09B/wBJS7+Y7Va4Nsp5oB7TzCztMdnMI1qHC7qfL9FBBjkvW5gR7VQydXII6MYK7GsgMbni/UatrS0qAtBLVne7VUGhwO9w6MPWpE7WpR32xoAVsmAwtm+iSdJabrZljmPqD1kpmNY4txFBmwczgQU+oXa8FQazKx2TgOZ/RNw1PSn1covKczGUsm0aHjMUBVIZ92dEMtZuel1QFcIue2KbLknRZnB2VzC2RwWcXKq1Cc1OkYpRoO1GacQ4RwkXTmR1ZvKzOErK9rucjgq1YNc4Md9stEnsGqbXdGedm74H98lczBXo/wAPesT/AOZ/Po4raVKQLb73FNpk71S4M6BbgHqjDvvLCf0PRD6L8xq543Tm4I7UbxNOf5Qhi6lN1zDDzWVurgmsu4NuBCYHVC2DaeazuiNBCJe4wLqg6TGb4Km/bZcjNPFeqk9qp0qzy2m85XXVOnQINNriBBlUjlzWfbnuFCi0OaavrOtdkbLc7rqpUfhw3YMzikRZhIc3TyKwj3Yak/8AqmchzbOJqFslVnU8PTBptdfLfqH9Pmx9p4Cf3lM7k1M+81zeim8cTCa7zRYfqmFHEKvTkS14dCO7adUVVZP1CszHgh+9ERlngtnPr2jd/wBYP+r3rOx3GUHNcKeNa2ATpV7D+ayvaaVUGCPgtozeaPMLKe5NxFN5pvbbOBJHYRxCOIwlLZ1euaTTLKjftU/y1CFPJlqUxE81rKmnII0IQGGp+vd/o2/X7u3s8uSjQ6LCf7IdGJaMQGu9WIL4H0bUKZqU35dQ+CD3LNzuqHefd0U8TUH9ac/ZtM3y/v3oOpRPahXrN8AhUYcjwL9qFAM3Tq7mvV2JQr/VoVch7YWNxTH0tqKLjRz6Tw+CqPr0KVbOAM1uCmrSognxK4eDYX0zOdyEcHi8lIvGUPb1XfqjSp8NZX9XouZttwP98IO2T3N7+5YajSe0DYUi+DF4Mz4pxeJMmCNSLpwp1C8WRpXEgipxMT701jKlGiMFmHI1R280+i9lVpriG8gZ/fmhWiJOWOAWAPaPisT/AOYPvPQEPH3rKM1uxSM3ksI70ZVNJgB24qEbz54J+KqmGty3+0YCNDC052bbDsQ4JrIMcUHNpHcFzG73oAuV3KjLw0XMnuTn1gczHGnlzwyozmPFOe9hYHGQzNZqYxgFyqP4ne9Utn1stSO/IV8oxO029Ks6i8FtyXvZ+Sq0HztK7WMrDlIe1v8AiyrDuxWcVKdJtB7ReJqSPbCxDqgF2GkcpneIZ7Pm0WcySnfiTO4Jqyt6w3mojLDuSEjtVuP5px5mVmCqVmaVKcO7HSCiii3nZB9DDVKgc1sZROlvgmCq44Vx6pqboB71UqbMbWkP6xl4weuPO/mhDlmkMxcR2Ve/tTiDDm2c1bSFElbHEDNQcf4qTuYXyqjDmP0e0WPegxzHNPG6FMzGiJl8tvITflLm0MVptzZtY8M/I/e8+apYWrRDH0mhpDjf3KcrNY636LEVard5+zJDT9xqyb2sIje0VJ2Y2ngvof8AEjWrgVahMl7nX9sr1eHD45NWyyGnVH1Tx6Mjx5JrNmXMFss8U6rR9IsYXOzFlTTzVTF4nHYcYejvF7Xm3mLraFyytEu9yl2/36K1llewEFUclQvoVy0EnVt9PYj6C9M06VSnUednPA/BGr6DqhzI+jcYd+SfQxlOs2s4h2/49ii/8/6Kplo5g+xkTz7EHMoGSNZTpkhlSMgdERNkJo1ZH+uagTIa854nQ8fgsG7ldYp3+v8AieiICFZ5dDfqyqrgLEjKFQEzB3rrD4vBV3UcNTLhUaHH1hlAvN3XPYoPK6z0zlnUJpZTLWu+s6yH9Y2jqsj1Y0/cqalGr2ki3modU4Sqc+rvx7lnqUuoSzWx7VsxpyQNTRU2cnuVLK7KctS/LcKqOoV5GwrS5p6zm7MSvTTrmakTyy3+Kd/5o/8A/JVzTw1WlTpVc1FzndYGA4Hxv81jeTJ9qP4kzuCb0RVph3evVuLew3CjKY+7dbrsx5cfJQX5Xj7QRaHAhzbo4Zj2ssXXWxOU5hIc0kg+fQ3D0akMEmPFOrVncJXymi+HhxIKbjMMIpPMOaP9E/l3ckDniEKtNxbjBxy7tQdq+ic2s3r040UfKaYd9naAn2SUaTcOa9LIN9odr5IYTC+ixXo1Lb7xAns5KoPkNam+q2BVZsH5DzBJlbfG4unTq/6ts37dE/LR27Is6lfjy1RpubF7gqn61/VaOr90K9R3XP1fvKoKjg5wZSl2n+jas1pnmpbyPFU24jLTtxcOSaW1KUEfvihIzHmV1ge0lA0MCHR9eQy/ZxTf6U9G5aBIDq1N2bL2lYXG+i3msx9JxzB13OtfuAlNqiS577ovd1W3dfRU8EKuVjqxd4NH/uQw9EIdtyr35Le15dAYdC5/uCpvw2Eovw7hnZ6xswUcP6Zwhpvp2a/OHZx4LaMyYnCv/wBHWaDkd36+1OqU6uyY5xAYap3TyR/r7Lf/AHKa1mLpj/8Adjme1VRQcRV27s+8EXOwVd0fcBThisPUpb0MLmReNPJYBh/eqxzeWI+J6JWx011QcXje0WXNdYc5WMyMdSIaeuZG8f3xWWpd2jWhFxqGk37LVmpG+syZUfLKwHZUKzjEvceIe6ZT8LX3Nq0tIOifSqAgsOUoQZiT7Fl62Xis4BcJgSQt55NtOEJv4ymAmBkqZnchkN0fR3yhjqj6haHBt9kXtDo9irnbHZ4kufTi05mb2bwFlUplr81aoHyDYHa5AfYPJVcOdrTpyC6k77UR81/3YHsR703uTfH3/Nh7Ae9RJHt96z0Xt9ye3G0nBlSm5qyUqoa7DmaeYcOSHyzEvaz7jZKccMKpp/Vzuv7FssLTazdjUmfNSrtz0n7tSn9pqDWOzNcM1N/2mrVbTF4OliHNFs7Z8P0UU6DKXZlEKW4GliBwyPLSrChTJ+qS93/pUt0+7hyPeVvkT997GfFb9Zjj/q5cvXUWVR99mi9TNL8OimmW1Bmm2qfia1GntH02mS/7v6IH5K3rDSqeap/1WxN/Wdh7UaY6rXPA9qb3KTN7xzWYRm9yEXuiDpohQB9W2crOAnktjU1p1XNVSlRIbVrDJm+4f0VDB04qVGZpeTcX/OUIF3KZ3ZQHFcPDoHe/3BUJdekXUz5/keh1Gs2WvEFYrEYanSe2M9oc6x1gjkpdhf5sG1Vc1Gi0EXHyUN1VT1FLNWcXOc6Yv3LafK64GuVuJqZfbKDMQ6q/ezS+pm4RyWDqEGGiTA71jXD61ef8RWo81aD7UQKUzwylMpHC3HMhA5IcDOi+UZGNLQ5thc7wiU+rXdL+PesjGlzyNAE15omHWRbUBa5sCCqrgdJKDQeBctrQaNqNTpITmsu51nEozrCbTzgw0GAefQz8RQq0KArZWuLmHi2LrBYPDYeNtXgOJ6jdoCQvlQytosaKkfYaaUe+UaeIqRTc1u+3/blxjtgr1eI2+Sm1hq/aIGvza5++Ue9DuWY6NzE+aOQO8lvMYfMLZlpY/wBh+dkqbw5FfRBS0uHipa5v8qgNa6BwKvSf5Sm0MpIDpbbTokHRRz0VnKKsP/Fdb9HIez9V/VXUag5EZT+S9dhXU+3Lbz+ZlqsDgeamjWfSPsTDnqOE9ZpHJOj7VT4pu9wUT3qwyjtX5oOYY4KMsOY4Nd5pr2NcWYqBu/bW0rEbaIA+8b/mg06sY0E8zr8VZdyk9NJo+xm9rh8Anxky1agO9wMKK1PD1Ryacrk2u3GU6c/UqGHBPy4um85TA5oso4QNrucKbTJmVSwLHb7N6rf63796DnPBVXC41jnsY4Fm7Ouv77U6rQozTc4/Uj2LB7KlTpue8iw4fuViv9p8VYlXqP8Aegx5GUnQtCcWOaIMRCbSaW3uXHVYXCOy2e6IF8o5+ay9qe6oDL2nL3LEUGtIyuNRqzNk1GadoVR09YA+ac7gGR7lkmQRCyuIW9U8EGsMEnVAl3BYXDOcdpWmIaiaZioKNQ0zydlKg4dtZwqlwzCcrXVLn3lYB2HfvijUEnthw9hVOrhMQ12FFQs2YHUdf3/Oc/mZR70E4ffd70fUCewK9VbUvzEaDh/ZHuHx+bBW64HvV2ldZWcoLl67CU5PFu6fYpweLLfuvEqfk+0HOmZ/VZXtLTyI6RiH4dra40qNsf1QaMS233VNR0vNz05eapvw7WuqVaZADoguGkyqdb0j6Po4c0RtNx8tzcDHDjxRqNxIZRpWpty683LGMmdm8t8lPQO7po0h1mtg+ZKOExjnCmTMt1EI1/ROJOJDbmmRD/Dmti9xzM0lc1R9IVIdWryKLfvC0+RTnV3TUcSXO5lVGA9TLx7UzGUmumsc0MILo4W1/wA1RbW3DvEyL6rBuY0llKS88tViGh3XdLfPpAaYhZXe5Z/gmMefom5R71KwzzTbER7E8OdJ2hAXrHxyT2TpLfJOaT9aEE+2t1otNEM2gVF+Xey5ZWG7XEeYKY/g9uHw7vxlxzN71UwdCMjDTwtOpliczYk+KFF1Sk11HLlc3Svb8nfNqP8AssJ6PFBVB98ozyVy36uvAcV1m8Iv2oDv965wHnVOLrXy+z57vn6qTdblQj2reGYdhQa6pldyKmlUB8VcLJiaDXj7wWbDl1E+YUsaKzfua+ShwIPb0A9IWFfRaDUa50A8TComnV2VF9PfabHjIRfqSYCx+cQdq7pb0SXZUC2vTe4GLFZTxRobTaMs9tQCA5vPsVPEt3W4qmXugfW0P5+KbQpUqj3aaqjhi3fBGztcGBPvQDa3g5MxVenTZgmPBIDr1Lx4JjBxNrW4LO+4zRB8VWGDobXNRyACNTPPvTiPQhrTzZmX9c/+EsnMinHwXrfReIpHsJ/6lbF4mifH8isg9OPpOBg7TUe5No0/TLK7Yk5Ik92qeRMTadeikdMsHwW9rrI7VTrF83ym+hWJazQOLm+akpqbW/hPQE1UO5esriiXU3tZUP1XEWK/rTRtf6QbVcWi3Xa1EwIdig7+V7P/AHKrTrMZsWUWa9ZlW3wPzax+7HR4oL8bfaEROglQ26k8pUZT0GPH57u/+xa30jtDS4hji0+xZ8JicXDhINOuHD2grJQ9J4r+Oi0x7l6r0tSMf+JTI90rJVw2BxX4MQWH/EE2piPQmKOb/wAEtqx5FZMS+vhXfZrYd7fgop+l8JPI1Q0+1ZmOZUbwOq+jHmr9PcsO7vcntY8NzS6Dx4rfIzNkKuW6Pyu77dLe9WUOa2/27+xBzXRVb5FQbEKhWmdmx484t8VRrvrimaYcyIadT2nsW7SNWRvZ3N7NFSoYenlyUrnNJ6H4WjXe1jt6AeKYW1cW+Df1j972oU8Q+p8naw7rr39/FGnDRPnoEabIJAzcl1D4KKzNftNmV6zAYf8A4QCNfE4f11R7y7fIJ3ij8mp3JmXw6E4V6UPBuVDVS7DlKZUpuvRAa4Dl+/eqmDrdWoJzciEM31xBUJpxFeG8maqtQozs6ZgAns6Wqh4ptDFUs7KrXNP3baqthGN3aNN7g2bOcHZwfcqdV9MMq5IZksGHKHO+CxtWjTbTfUy7YH7MvE+wfNcPtEDo8eike0j2IxxELTkrt4Rqrjv7Vbt1T8xtwW6BqdFY+qstI18kC3Ncx0u7/h/YyFGGxLqdWnfLqPJChj2sDvxWP5IYjDAmoLhvH9fBZ9oZCftBVc+Js2R3KKlT1WX6z+sToi6tSw7K7bSG5L9oCdTr1arWTI2b8sjvQ+m//kVP+pR06JgQ27XbwIBHBCMjg8dUjqxqqGOlsj1TobHd0x9rioKuVszo6y2dYxVbYO4OXyJjXOc0zlWTHUcOHTu5DcDtPNWeR3OVXaGRUp0yP5Y94PQ12mZpa4rdznyQp7GB3o1KouxxkeDR8E+s89YZQE6tRqEMDshAbxQyOLnxESSSiaO/A4HRMdVbmyUBSi1yoGFg/dMIVqW0DSYbL5lYV4ZlGzI9q+67ULJVqNDI3i7iFssLULidXxFln7FQp1QclR+Qx22VSvSq7WmOBEEFPrVDLnmT0tWH7lSqzDaWao8/dAusVUfUzgUnVXHLFjdfKn4hjY38pNyHsACrte+q6o7qZRxaXxPZBHzWN5vn2dHigqZ++oIJHGEY1Dy1ZbawrN5FGpFhCuCEYGmqg69GSbdJPM/2Qexxa4aEJrcUAyp5Nd3H6p9i2DPSNejOjK4keBWbENp1Wn/SF8e2PfK2mD9I18PpZrwQVnfiW1ARfdj3Jw27XMdeCCmY2i9rshh0OuPDyWqHbfoCBFnBMjlKGQjSUDbM3RVMJWY0OcLEDj0U3VG+trHMOxn6/DoyP8CoV6DlkqROluCo1KjpGk/aYp2VkPV+xDGGgKIFMU2tmbSdfPpbUicpmFsns2g0FtFfiUG0GNE6ZgqtEnDsLnTN59i2gxgL+G7CpHEmRTeCe5Ou9xPYv6thS4feKp4M0mtp1Kmc9ncsJVjQvHnH5dAUVL8inU5+qqdThScHFVXMbFx8xpWH7ihiKEZhIuJCNatXcXublJ0kcvn0W/iPuRLjC8V1yh6yb8l9W6uPag407zKylrhYC3YoNrAaxoZTW7QDKHRon0i6M1wU6XhxIdrzXWBtw6JK5N96t06qY1/sNk2pmB+o64WalUrU/wANSR5Gy9ZiHGftW9ynMD/HK3Azy/VOwxjI+xhOYMO9wBiRxVOe5A1Cxvehl2j4+y1CmcLif5J9y2jCDaLI0iBIYNVO0I7go2lUjvTGN/0seCc5oho3WDk0dMOmFvUy/wDiheroNpAKphazcuQh7OwG4WR5Ifh/Vk8+S9djKI7CRKqNpmzTHRC6qhohXvCguce8z71af33QpOOLPwNj4qX4wv8AxErTN/GvoD4BNfShlSdTwVOlXNN01cwIbHA9IAOV4QLmSAs+GdAPWaUWtdJAbPzKFv8ASN96ofxe9Nps6zjAWU1oO0yafeiVmxXpAVPu0xdOo4PA5C767jeJnp21XLSp/bqOyt9qy/Kn4p/Kg238xTX0qHycBpa3ezErt7f7LRWe7+ZWqFag94UPZYe1Xa5RvOdyC9W1rB5r+8VPAwrYut/OUKLsa99NujH3C9dQHe0qKb4dyOvzcrdVJN+mOnVPY4kZbiEM1HNPNZvkdOVFNgb3BVgOYRxD8QKGGyAZokkoPxuNxNbsENC+Rn0eW8qjapzKu/0HXfXayhJFSGlone7zHzN1i9bWYwdlyvlFZxxQpb2yiAVWx76OyfV+ryCbSNU8ytQnBlKpVpm7XtbwRDmkHtC7h0aLeX1fcrH2qy6pXHyVitUKYH0fv6bmFcZu8QiWtj8Kxfo51M7VuzyX1m6vZb9TyXVJ71TytA3gsP8Axf8AMU2oNWkOQpzABno22ILaFP7dV2Ue1Q2rUxj+VIZW/wAx/JZPR+GoYMfaAzv8z+S2uMxNWs7m909FPh1vgs3DokBRsyr2/s8lI259OvzclXfHM6rMGNIKljQos3+xI+00oEIArVV6ejg6UNJk+9ZcS9zgdY09iacTQp2OuUf5rFYtmGZlybNrb6ustFak6FOxYO11SVd7PBqtVd5BZRVqDucnPxD88dWV1ujI43bZDPTB7V8ooUst963zusV1ytR5K4C3mJ7mDdnpsg58Aclk9WB9wa9pVd8bs0Y7d2V3dMjgsMxo+1/zFbXGVKWFp/arPyItovrY54+wMjPM/ksuBo0MGObG5n+ZW0xWIqVnc3un5rewu+Cvqsf6QqvxQrYd9RrRIAgNkJvd071Np8F1Paus8K1b2KzmFfRz3FXov8lvW7+jZjV2vRJ+ZulQR0828lnYbFZh82a0u7AVlw3o5h7YJXVFMchb3L6UKkfvQh9lAsbKgrbDV7IQNCs4SYDJVGsMa1p3mlpZOh5pu0qZncTEJjft12+4rNu+K6zP5f1XWHkvpD5BPo55cBnb2hZhNtRyVWsKm9Qg5Y+rof8A0r9VqtqNZ+C11RZUgg8ITqLuH9jUd2dFujcWWthR+LL701tKImcuoTW8GmB5Jp5j5j8Pg8RsQGm7WjN5o1q+JfXedXPdmPRdTszHPguqrmFYyoATWuE75n2La8HGZRwVQYd7dlsrgzEQh/ZElAZG5jaYR7LKemaNEkc+Cu6l/OFmdSMDiLqCrdOR3VP9k141BlCg8WPYrRZbRohCpF2lbafoyB5gJ9GepW94CCwlPnUc7yH6/MgarDY9mtMw7u/crO3qlOY3/SMczzEItO6QYK1Tz9k2Wyddrj7VLDI5cQm4ji2x7ujVXWpXW+YWu+vZadG91GjM7uW8Hfwr+sVKpeNBAv7VlY1zR2pl/rx7Cmn5gXrKDD4XWbZmOWYobKgxvgqhI6NejcrPb3FA1nZ45rXoljo7IWjCr0neBWrh3tVqjT4x711Se66v8w9yZ3E9NpXyvE9X6rTx7SqlOmb0myGC3tTCGUPlBO80ngqVOjTqy/69M7oKNPFNDHzG1bz7UadUXCzNHSCddD0gLLs3RzjVdUqzHeS3aLvJdQ+RUqhiOB1QLPoqtxHBQn2QozaAfGFWZjK2zZUggwTcdyn5S58cGsPxVJ2FpvFKg1w3u3j7Pm025hBfLugIuH+lbtFogftOLvgoBum1y6CLLJJ3nAdFlAVnK7VcLQ9FMfd6XujfqtPQzNSac1s0WlG2ioH7/wAPm9zHH2LhCKngqvd84BWuuIWq1VyrrqqM7x3OXWHixWZSP+8g+1S/DYhvbErKKo/isv4Si6Yy3UlNZzsvk9NzW5RkbJ0j9cxUssCRmyi5HPtU5fYtpRqAQ7Lkn4LE+lmtqmo6BUozYEnVZLktbtKROpbyXYradBZzHTIUZ2mObVejRP8ACv7pQ8lu0KA8CtWfy9FDEz6vEvc0djh+/Yg0xmbdpWR9iFU/Cq9QmwcQByVhogWQb6FDcjgQU5o0+r3cPmSJlYGp6R9MQzEUDUewC7XXtImOHavurDVebS3y/wA+ikDwB96BHJUhxyiVlnq+/ossw6LLgV1ehzwOwK6bTHFCnTHYjlgOnjo5Thz+JhspDjvQsO373wQ7uj+r0S4c+CnF4j+Gn+aNWjSyHI4TJPBblYTyKdadNFD6je4GSn0mB5zcXfOHf0XRJkRyX0d+0q1Nvkm/N3Hub3FZH13uaODjKqdycimO5OBWYz13AeN/itQbTbh2LtW95pkXa/dI5hZ8ZSDC2rDY4hVabdA5NcO7oDot83RXp+1buHLvFf3D2FTjvSsH/VsXyfCnaGjmrUnc4cT7kyvSu12oXKU+2rSqh+8V7FAEeKqO+sRA71H2WtafJa26JWmqmUHRb71lQceDnD3LRN8femUm/Whq1s1F3b0wePRyXXWqqEH6qutFmy7z/cruMuWStuwYKltTM09qAyxCw7e0+5HfyMablSKAe7m+6gDoxm0ZuswlVweTZrwJHu6MsnLy4Kw/sOfQelsXV/nd/RPQ2oCJjI+eDh1T8FviDxCsP0W8R3JhdVOSnfedZoTnNxe3FWpnbfTkqrm/aX8Sjou5fStQrMwdYsdcEMJX9Yfs/wATSvpS78LV6qhP4itMo+6uonVfSOJax0aSCU3DtO7TYGhVcEbUqnrKfcf1QdyVliqEdSq4e1batiRSl0NEXsNTyVnssYnMFSpBzYD8zrhVdLPix7FB06C2J45c0Ssm64co3h4IOp0o/EoqlobNsvFNPEVBPkeiNpF0HGS0QVDM0JuU6z0SpV+jXoyg9Y9EnqtQ5lbJmvEqo9o+sShewTiOKofdIVvrC/f8zGU3ejGYhj6RDnOqOZaNJAUh9F0d6ths34XgqX4Ws3tyriF1ejl0QD0dVaKxhRJJ7FvKy0Wn9jnbcGxHMLMwlzY8W9jufei4gx9qc0+KzbQZHETuyU6lTp030Xjfc792W1yDaxDLKdU2nx1Kc7wCy81r0Nwtep/VKpgg/UPNEWleuwdB3a6kHLMMBTH4S74K2Gydz3fGV1cR/wAQf9KODwzszgJeRp59FPHtG9hqn+E6oZHSfeFlKqg7ra7c6lgOZ2kGyc4/+J8P1RnXRVqtVmXM+3t6Mh1HRlLcjvtNJXrMr7xm4whPAp09ZrgOgMDHEd6Oam08LLeDG+ZUvuea3Hh3Y8St/DuHay4UCqO4296uPmBo4dAkbz95ZKZl3NdqdFt4oA6oPri02asQ9v1ajh8fimPB4/MpUto8UGOZtY0y8VDW1y3/AGY/NDNtWj8P5L+/AfipO/JGkyicUPwwE3JhcHhWa7tye+F6jDPqD7QbZB2INOi3t3nexRRx7D3sj4o5X0Knc6PeFfBk/hcCpqYDEAczTMLeGXvVpA9q3Wx06fM0Wi06NOnPTcQexTXoDN9phyuU+u/w/kvUUoPBzzJCz1HElbR+g0UoMmzVPzMPgcQ+nUpvcGHdv7FoQOxcCpySvoqnkE4c2fEdFelzatm4xlKBDhDgsHjcmZrg6k/yMIVDQdTazghkbAcXOA8UCizt6My7E2rRfPMLas3qR1jgs1OqAeSrYd319Pm8PJdnRvMleoe+n3Ff6OqP5SvWNfT7xZZxUa4DkU4sNibJtP7ZhZKTYUnVQET2pvdKYx5hVKkdeq4+5MIOmX3IdLi+ix8/aEq/o2i3tDYRdvsnk5Tt8R/M38lvmrU73R8EKlLCFrxoS4lXqnyRlwLe9S0u8lEOK4QeaLqIt9s6fqto+Kj4jMReOS9bgKBnjlA9q9XSqs/A/wDOV6j0hB+y5oK3MRh3fxEFf3TN+F4K9bgqzO9hWi0VvaPm9VdUq9llatFcgL7R6IGqDefTouxMeGS2hvu+C0gd8LLU3hrw/wA1uekDS+yKm8P8V/av/kz27Gp+aZ2g9DmjiFjcNTdDW1DaO1W4XhPZSh1XLmb3pwc64dEKnTpi+U38US67k48z0g8igMtO3NbXBvpDmJKzXn3Km/Dn1k6c1LfSOX8VP9V6rG0X94IUNOHJ/H+i3sOz/it/Nf8AZ1Ux9kZvcvW4OuzvpkKMvRa/Rcea2dNsfaKsjUrOg6C1lmpua5aqSnOA6pVCo3Ww8UBVBa5t1na4btQ5hxFgjQm8H2H9UF8jw2fF4ka0qAzR3nQLbY97abY3aFO4HaXcT7Feb8VyK1JCsNFeQtFGh81E+xQIHjAXqd5mhLllqnM++mngFlxHqz9rgQppva63NQ5pWiKuyFYnyUBetpsqfiZK3/R9AfhGX3KWCrTH3X/mi6jj3D8bJXq8Th3DtJC3cOx/dUHxV/R9Q/hGb3L1uDqs76ZC0W9SHeFuVHN71uVGldQea3xC0Uws8a6dy0Wi2WFoF548h3qa9KniKz+s5zbDsCPyfCspB2uzYGz5LigXcNLr1WUz2lh8229i6+L8K/8A7kG6ZamVNPNFqx7biTMDtQrNqu2n1gdE9op5JBT/AEhhjUDvrtY2Z7YWU2LU8ucWmOat00sJRgGqconROoVc1OrTMOA0lFpNiOHNd2qZjnUxUDDuNPYFJ9HNP+8/RZaPo+mzvfKy7fZMOuyas+MZi6p7HAJ1TBvfSbNspIWb0l6RrGk0dUtzZkX1cXDW8DRcfgjiyMH1ZLajWZ/L8kyr/R1EZwHQP0RLcIWd1RykVsQ3+IfkqmEw9fatDWmfDoqV6dNuyBygutmPYs9Km0coqAKG0H1B2gO9qqvxXoVtmztCDuduqGJcamZ5N22EomkbiPNUq9LDYXZZdxzQwOPmn0X+jXurOrZswy6Qg/D4CmP9vp71/wDnnpUvpf8A0+FGzYe86lDDYPDsoU+TQvtIw0hZTFlZojtC6xhakrj5rcbqNNURTG0d2aDxRdXJP3fqhWF+9AmncaKIg9vBSWh8dkq1R4P4ispg96vh5H3TPvUOJZ+IQszYPFd6krdsrlXuu/sXeuCkLfpseO0Lf9HYaf8AZgFZvkeXtD3LcfiW9zh+S3MVWjtgrc9IG/8AqZ+KgekB/wAL9UzDsxjDnkuOQ6BZflrP5FL/AEgT3Uo+K9ZTq1T991vZCFKhRYxg4NEBaHyW9Yq0HuUfFcfFRLU5wm5DroDox73HLDWO7OqqjG1RVvmzN0uhLrJ9Os/dabCYsnYmlJZVM9xT50b8zF+mK7H5XxhqWXXmXeFvaqpoU4FSKjQ0DQjslb+oVkKbQZiGgc1NTCVmfiYQoKNl2LtWnRdf1TE1aXY10Ar+/uPe1pV2YepH2qf5J9WrUL6jyS4nj0O9E4jKDhQNkWi5byROX2LMsZhTiMrqrCGz2XWVtZzG62EjxQFYDLza+x8AsIPkgpEUWjKNAuF0M2vYuqe5TmXI9llYzKGYCFE3CnUhRlN1kkl/2QZ/yX9YeGNP1Gce8rI2IW7B7lJCutJW44hdqhyjwWo71YRPFohAbR3cbqzWu791b1N4H4c3uUMqsJW8I7ZU3PiuHirSuqVp0WHHSVpB7QozALeRdPj2Kpi9NpYTwaNP329Mmysvar3XJWeVDmz4LqN802sRZzY8kFm5Itou61AVC37UWhVqmJouaypOW1rI1ae84DyXyk4V7nkDqusnUa1FoY4R1liMLUBtmvz7fmei/RFFtmtY63Exf/ESsC9low+zH8J/VFtXlI6A4atMoQ4A8uIWatSZU4y9khX9H4cf7uFBwg8CR8V/dn/8Q/mvo38/pVenU8ai/wDmBz3x+S9Ti6zO8Ao/J8dTd+NpHulTTbRq/gqfms/9H1bcckhZX4VzPxWTn4TE1KTqggljoVvSNf8AmlQMbbtptPwT8NVxmRpaQ7IwNzDkUD49y2xhgji2Y8E2m3QCBddqgtKBkA8luG34lDXKIlC6MNh06HVZ6pgDWyMzQZ37yimwaC8rc14xClo7ZUnmsl7c12rQFa6KOsrNMKWiPagTbu0X5FR1e9q3dOQusri2e5XDSF6p72+z2LddPet+jeOB/NWzM55m281aD3Fc1Y35FXa4KxV2tPcpiAhhGGDU6x5M4prAwBo0RkGV1lIJK/u7x2kiPert8ZQzhxy3VnIXHbdfWXVeqDKb801bdy2dMXi6cx1XyuqeIpF+djbFqFXF4g1s3VoM/wDUmMp4dzftaQt0mOIlSzDyOZqqhUab1Wua4d3+fTSpv6pcJ7lg2mm2KdyRyF1SxjLvwj94cmu/WEO23RBEKiajGuaWNPPgjs6xb2HeCGeiCAdWH4a+9FtOrvcREELebMGVwUt8LL6OLKc2q3WkfFCR7FlDeqoy/qjnps/kCyVsLScJ0LAod6PA5w4j4rdqV6RPJ4K2rMZXkGLbpWSmwBo0ROqsboSCRzCF4Ksrsjkgjq0aItw1OebyLBB73bWqBd36cFxCEaLeEBF2vHRS11u5Zi6LXsjlzHtUNPgsxagVJGmhRzMVpWgtoVfzBWWmVDj5o7nkpacpPNbt+7iu1SWSsz6d+cK1R/nPvXWa8cBHxX0bvAq5g9ohBzd2eCzu4CTyTsXVs6qZbA+rwWdtx2tIKs5aq4Wl+9bzl1gtQeNrripC/VOODaSGndLzbwWV1aGO1DbKnQptlzzlb3yvlFbCur0j1q1JxBb3hZsPjMQ3sMFf3p7h2MUNpVHntst6pDfssOioWlzakWHZ0tdyKLsbjadfM2GZJ0VTCVWeqrNyO7lVwlUHNQfHf2rI/wAFYrD7WMwBb5GFLnAyVb3K4DwOWqBo1T/Hvfr7VFbDnvZv/qs1KrmjWFDxqrujuViTZdYR9Uq2nYuoLrldZhFuakjigYiFo1ETKAKtPIK/moF16tp7yvtHsUVN6qdGC90C5wp5TpFh3Dmt+k0+MADvWXMWTz5L1cEa2UreYSR2rtPNEZIcgGwVGUc5Q+omnrKIkIqVlBC61+9SYHgtJhdTXiozDVatnSyvr2KIBC+jhZMpkKeHepIdZTqNNFvsHbdbjcoPam4SnUJz3fOgCgbNw7N38165lQH8E+5ZRVa48p+C71YSgHi60Rh3mFp/Kjmqw3tKkPntFwuqfYrlbl0zHYxhc2n1Wt5q2BqO/E5PfhXGkxxzNBumVcPs8XScJ3RdZ8V6N2VUfaIAQqig2Qdacx58UXYumypldLGl3DuVT5PTDKb6baoaOA0PtHRdU6fo+rmNCm1rmPG+3goAmVR9N0hdvqqtuH1T8PJNNItDvsyt5psvkZeG1WOOUH60rNayk8vars4LNk0srXJUupS4WHNZqdVwH2agzfr71FfDlg1zN3h+fsWenUaRzm0ok2HYrTE6LLGiurgAlaCOS3mIAS63ELMcqAYNO1acLwoAssxdJHitrWc1rTp95FgloAvDrefwCjeEjxd/0hbQObGgcNG9jea2eWA25adO9xWmt7au/ILm4/WA17G/mvpvCZjx1JW9T0uYIt38kMpBHDmoHuQaIjXVZnNW5opzXQOZQ4rMLKbD4qHCbqY49Gb4LeN0ch17VY2HBbzVZSSfBX17Ucr+3vXrGMcgWa8kXfZCdiqkCpUvP3Vqt4SVDQA8eKezEUxRji2pqO2ES5+bstCA2bT4xbuW8yq3vbM+SHrWku/d0YKymQoFwrn3oOrCWMuU+AAM1gFsyIjXoBrl5daw0Tafyt44ARAUZJPMiVqq2VxGQ5RHCFRqVqz6kNLd50wOl9R1LaUqjMrhovlOzqNv1dT+SreiDhHNZiWGm15MnNwMI4TEZmPY4t16pU56haPGyzUqsOs5uXmpdTa3LYkOB8cusKWmW85ldy+ErXTRaEwpGh4qc1u5TsAHfa4+ainWzN1h3796IxVB1MfaG8P33rPSqCpwsVGkLSIN1APgr7v8K1fKOaJKiZ5WW9FuCJADWjnYIDCaTeo78lUZ9K6oSC5x07EzJV4WBEgfvmUW9e/A/wDNx8AEYZcaiN4eH1fG6110b+X2kc2Wx62b3/kozOn/ABH/AKQg+0cCPgOPeoFsuuY8e0/BHLnHHt8vqhDZu8MtvBObSyNHEg6ePNBmKezajXdPtRLch5EINLT2oh5uexZnANlXdbuUQO2EW1LKBvE2XVvxK0IBU8+YVvHsUQJXXKs5Tm05rK7LHagIAsrNDgLWKkOv2puEgR13rqKTACM6dq04qC8eaGefciBEhaX7ZUFshRTkdxhbrndxUPpT/hRPyet/OEKY8e9HEVGNOzGbROqPN3GSphPFekzaDi4LdZmPJoUNpZG9qlxLiq9TG0atVpqnqVMvHuU+iqdShiKbw71knM3TmgSZB7FOTKzXO7q+a9V1W2k/WT8HhaW0a8TezRccSttVqtr46qIGXq0wqNfA4c069Z9TamLPIIv55lkfSgdqp1HUclOpo48RzTKDWuY2MziJbnHDvTicVUpuc0Zpd9bhdMpvxT3uNwA8uJPJMpVXTVaxrXnXei60J6LgBbnkuoVq3uW6fJTlGb7QsfMIZK2ccqn5j4r17CzuGYez4rcLXAcVyGqnLIWuvRuN2ruQRfjKjXT1abBbyVpbTj2fv9lRFuP7/fYFcX18f349yzM8v3/l2lRVAPG/6+/yCIzvbPef18JTXWdb6rvhp5SsmQ/hvPlqfGF6gbsy7enzKZU21RsfVEX8CLd63teYJv8AmnRcnWTB8+Clh7BHwHxKh0DJr3854+CBNUlx+tEHz0aF9Jnafu5v1W9TIi5ymVBrRyD933oWue1WmDxlCm0Hl3rmQpD546qXmJ0toieKlQfYt9xObhyVu4K5lfZM6Ld0jgsrmNnXuTqvCmMxsqlV49ZXOYkiLcFYl3chey70VlBI+KF/CEJBjsRGe3CVvWMLqthova5V2ls/eUNe7vUZnezodQbX2UQSYmexEMq0MvOVYUn/AIX/AJqpSrZmvaYIVrqLMasoKqx9t3vQDjZPq0Yq4mvFnsuwC7o7z7u1ZtgaTPtusPLigDS29Qa5v3ZMq4UhmQyFGJwE9rapCbiqeHfSdEEZtXTcpr6fofBYp9K22qZi4d7QYPeQvllalVxLpEw0m3K2gVOhh/R9cunXYut4IMdQGGYeNYwfLVThnfKcZEGsdKfcs2pct2PJdYdgUgg81OXvUW1QbMeCAjtVm9wCuYnkozFdTeixGqtVnh6y48/81lr4d4bzbvt9l/YhUq1QZ0CcGuyUefPn+/esmGEffNp/fPRamTqfz/fcF431mff/AOruVm+X7/fErLNiOEae7/096jMRxP5/qfAIW4+AP7/iW4JIsS4x4f8At8yi5t3o5qWYO6wiZW0olzco5+7l4QtGXuSP8/eVvvI9/wC+wBQB2xA/Y8VLuOt/jqfBSAf+n4D2oNP1jIEa+HHxUuLu0gz/AIv+lBnk0D4fEpwdqdd6c3edT3BQxx7mwD4N0HipNNpI11H+fkrgt/hm3gvtDiW/uFla46ckNwxyWeIXEH2LKX+S6wUbvJbp4cQoa42WcjyC2r4DjcMOq+QvEFkOeAe6O+Vq0QMxcRMK5Y7dzgttbtTAG08xAc7OJVOrlDd7I5vBVILWMDzfkqEhrs1WJ5iy2PyWnlc7Lu6oy+nkDrErZEjSddQs+dj2ixjgsxfTDnDdDjvKqxmVjWnibBB20ac2jgus/wDlC0CD/tby6/eFYaWWNEx60q7irCAtzgs+GxJoybh+8qWLwmyxzabp2btw+2ybTxH/AMO16DvtA0yP+ZH+jW06VM39a/fHPsUNpU3d1QfFf3L/APtZ+aNWtgaga3Ui8eSFD07SDMS361TNB8QmO9GU/Rjnazm2kdwuSv6uCaeXKxrgGNHbMStnUxDMp03L+c/Bf1mtVqg83WPgLLZhuWLW0Qy0+KzO196mD3lQHezgiAe1awOiAQt4JwA9lldlo5QoA10stpV6t9OCy4JuYfa4BEvO0qZdPj2eKu6A36ugH77fALuMcdfz/wAXcgBzyyf37Neayg90X8LcOzTmpHET3j3f+kLNnn62vtv7z4I7sFt9Y149nfryWV50EQNe4fZ962bG5Y0tYKXW5LVTULd3ggW2AWTW2gX0beYiwHbGi9XB7Xfu/sV23Z3QPy9qyCHOf2QT8T4o72UN48vHQeAlcDPAN63hqfFZgSItY9Xx0HcFkzDeGhGvhqfFbQVC0N3Tv2HwHgsrWyZzZQNe3Lx7ytsWAx9acsd7vgFGfMTcMLZce4D3lQ+WjWQ6QEDtIt5rKC2I4rITcrqkEoNmfuzdZSAQexam/NZm3A0Cq1axYRffcOPb+ipNJc802wXkXeU4b0OygiYNtEarWhkw073DkqdRmUvDQ17S4DTvVOhtWk7TM4zpyCqta9s7ZzxJs4FYdr6jZFUkw7TROaK7svfwUsyOfxzkWHcmE1GH1BaSOd/0VSTBIEA/iC2jHMh4Ey7S0KrVbke4m0usR8VThzJa53Vi2nJXqN9qAHNBrRAbYLSVMCyxd/rqw6N1sXQ4LWxVllCjtutByUrM7C0Tm4lglbMU2AdgVkYdooJ1Xt6Gt4nVDj3ocXcyi1nHipU21WWxnonhwWVvtTdqJL9IWfE1C69gNFkpDJTnIBxJQLeL7fi/fG5VPLHrHEN4d/d7+1MycZa3h39wTXHRzCR+EdnwWbmzP4fvhonPJNhmPG3DvPuRdUk7NwJ43OkdvaVvAZx5D989UAiORK2nhdO03UAtzVb13HwXOTCkDd0KDr9kItdS05flofFSyoXQLZ/37oRLhbn+n5kpjWHed1Z4eP5BPfl3PrRx8OPifBU2tJl/Vv8AHh4BEhsN+tbj3cfFAPc4mN398PBOGUENu4cJ+Pig7+Xn+nknNA/Fy/VBzHO3uf5aBZDSEn7JLVFJxbHZErI9otyCDcnBG53eaBJ05JuBPVo+tf8Ae5Be0qwvE80ABwVmfmtmRKgT29qB+ryW4bGe9EcYkGFEX4rPmPcpPFEc1pqOaiTZf//EACgQAQACAgEDBAMBAQEBAQAAAAEAESExQVFhcYGRobHB0fAQ4fEgMP/aAAgBAAABPyEjVTYKVK/24pkuMXlHMW5lodcrMYudxSZruGIsVd1A3c50fshMUpjyQWsATliKsFzpgXE/0ehFbRrJVH/I/SAXY+B6RttEftJmCL6eYYYzB4Q9WWOv23tv6lf0F9PPrcdgewIdeWGLUmoTXGUo1AND1mAeQ/wEIYTLpFSEApzAcp/VWW8/EW8Gsfd/UKTb+Whwek1Jx3LVJRghD3rpVLsP+g+r8oaC9U+0UHuz6Lw+1L9blME8Er0EX1D8JkhW+jXUP+zRJowQVi+C7Ig6/SDwTqCgsoc0BzCJ6fZCExhT5lE6jA0czuJifCE6FMLIiKV/o1Lf/wBbly0FF3OZdyt7Tjsq5ilVjNP8qBMMyODMSvB92AbDPV3KpRqZlMASxnKXiX1XzGsX8f3OGfTf3ZiOeTK+s4LE2YjJYucrMksGS9DS0PG5TA5ShRlA1TXaVGk46rRLj6IfXUbg31PY/cx0npdPieIQCpiLExnkMDQyxRATry6yMygW2cBjPePnGR9DL7hOTh2D3bfZIKK/yFmDASsLQbbU3B2piEyAoDAEsvmVyGD+a/2kT4af1+qDyzOpjNDYzdimmL9pbIHK5RFO431FnEqV/wDnUr/6z/hmGUdnWE6ZccyhYB1Zd3vdwS3IOhghoa7QlKXMMxc0S7faZRl6Ep0euJeFP5xqDai4NimKJol9ox3AYQllczKlqUE5sK75j10IeC0mRRNmQ9p8iwHxbLDB0UH5Yb3cH3ZbfKWvDcwlRBgDIwZTdyoiOg4FA63Qh0M4bRhd4CvWL2Nolg0Dm+8AXCd3WFa1ZcQvgXi0ETRe+fGOZxpi1cQ5/wAiRKVC3mAzSH++MoAN+ENjv5xSjvuLiOTzKw+Rxzlv15sPlKiu+U+8ZvOdUfwPuN+ZinxDLcoSqRWpSOYJLOIjj/FRJUqV/lSpUqVKlSpUqVKlTPWZiTy6DLOlj7sCbZ6n/KljRNi0eAh6szzhL8JjjAgFACLyS8Gc5hrtccJegrtOEzisAKiCo44a0wXLnQsoDXc/KNstuhb3f1Ao9TMe2omCDgmCIQh01moOEW6kXij5D2J/xd9XMo+wZfbG3qg9zBQyitKr7i1vBGeaxyRRw2GmsmJcmiTsZVl1u5mbgpXVFWcYeGDgyOxs0tNXL2g1u7UXfLjUOqERaWwA517xQNdAMGowVxMgnMFu5oMJhYUJbqv7Swg3TXE2cHCy54xyQNutAKjWxceecdMS1hA0Vg4viMv0ZgpSzX5T8IJiQyAyHUdv/GAIt3nD9wgQyE+Ljmto7yurEtvMrtLXKj/hrqP+ypUqVKlSpUqVAgSo0LAO8s7Xu4IfTcCGoAO0ovN/44xunjQq+zHvDBUPTN9/+TVf3Cy6idCIYYpliK1THeIlx8GpZaaYHPpNIHdaJQXB04fXUEnqja9j9xu2UYfGYb3OoqC7Mn+JRMm40YqaOqqHwIKPdhpge78fmaHkmPYxABT0GqlYwd2Ymp2p1DtafIv0ertEIcUS1Q8Ky/8AI1Ht01Fa9LAd6gfQcH8Dqi9pAuV0quCvhHOb8bQHnXKLAI9eNIXU1dUQWnxkMZ285LybmArzggqyxrGfXrBgXtQEOKM8Uj4t+IMTGxl7uIBtu7+FSJZHtEuHXHiigI3OGtbhl+yU+lXKBuZsYOpYtf8AfX1GgfNWfUM6qmolspd+Ffo/k/zNCALYjo1dYcqI9ScQbyRDiFdP8thnRF3/APoAAhDn0ZMeOj7sC28kVAqA9IprGXoRs155Y+q4eUGjpD3UrqAQHEK2Jk4zL9Yb7m6g4OHtFM1/xxcr2Q/6I1MR3HuxcrSXMaajhVrmtzEQnzKDBuk7j2Jw16H1cN/DoP8A1MqT1M+5jnBgKrrzE41J8hw9JfqIphb/AFTK/GMGcnaY8FdBGtmUNcw9CL3O6S/tTT+BRLTDoBfiWQwS09D7ajOzCXsoq86jTwBlFLt9x46VFqmJVFmm8VXvLmz8zDT3Bz06EQzUU5wFYs2Y5TH1o68Wb4vN4mMqpbEwLZWhRAEjjJ8THkd38+YM2jnU/cb2qzovX9pRnWY54zJeKlYvJhEv+6jRZfb8FmUh9ZcHzUA4PYixZoditbn/AL+FckWAF7RHMuziLBHwMai+i4ThkUO2GOUNM8xRqPWf4guNop/8xp/jPRM4dw1Ht3hfuK2ntggRQB2lf6AyfTbO0ovzfpCrUIzLoVLW5wGYJj4RKjdN6i9NxvK9H+/iWf1qT1f1Ftny2e2orowf/FxQ8egW1De8JT5jthTRT8sSubgOk/CVJA4D/Ff4CeITNQV942nLTW7WAkOMdWzTd/qDfHPR7DIuukqekNhUD4JnJLFtSbLVztyjWBVvbCChami+vtMOLc2qr6rybu2V65Rc3z4jy9YQgyxVYs9/eDkQGKLxTvwauskq0Njr2tl5ag8BbDAU935yQokEKLbLOvp0mA5XAX65+IB166/dr6jpK+H4D4lL4KmVnBFQTIG1n+TEoUl7F/KbNAa0Q2CzUwfE6aal2a/XeVLmC4wJa4hsC5hWhb3S2HrBoYwBtB1qVa5V0JZZcy3zHzK188XhvpAWp6MdlN9SIraCMyGBVenNwzfQmSowTC3i4pBMzkBMYYhRd5lpa9d86hll7r3f1KML6633laBB34LgisQW4+uEybh0MSlKPBMUzYcVVLTmYqjG0HPXFQzoenyVeZewUq3+IhsKGNBjKqPLzMEHoKm13MdWGzrH/KjSA5ZxPh499Q4x923t/wBnI/ZU+M/Ms0k7TbMxLmI9v8EEHRDR1QAVSkh7MWln1QOpd+MbzMbcFkB8BbjtUJI5iAHlp9aekpAkVtpttDn0iFOXQDGrW91t11mnkhVbGXDTk6wKrRxkpTWjLj3ib3C3K2KrvuGtabX7807N+fEJSUUim2m7ClmukC3UOeTgtaY4Md3NaXoaWcqU58wA8NqD9JaPWsvlSaymzaT0D8wzW6nf2guoxbh7MfE7oomfUHR2uOGYOA6RJUBvb0jj2mYHJ0fMwoBcALk77OkeBXQv9IkGkhGInJTMdf5d42G9rqXgKuhEPFiL1xLxmpjLquY9sS0vdju/qqYhsKu+IhQHd0mkz6QXvPwyhQ3yQebcoSmdSNUx6GV6GY6UfK+z9z44rHsY95UME6TXJXC5oO7HfN5wfuL354FRRX89YhDqCMQ5oBoqKEKTBytRXs5j3cS+Id8v71l3c7D+EuuvGEAPsf3HiAYfgh/xAtdHo/4WA3ud+FnHPf0OHtOP934ics9P/UvVodQPVlrkYbLj1kRx/hocAFsAM2ISA265ZY8HAANvLi64zBe9swlGnq/E8e5nPV/UDqjrRXgojhQ6MWCK4Ke8KNMuF3e+Sy7eveDq+qRBgzbLjcC2o4wrijjv3ekaIGpbWD1GoSO392RPmuhhPeUegYXZpa4ewTElrsL+lGK17TNPoGUdMg+/EteWMOEc0X7wNlzVaMBqq4PVlqHVQd5zXP16TEJyFs4szjGCHORGgzXaOBcRMS+hM37JTrPdqN22/Ub9dQx8C+rmnB0/j6lzOW9q9Rusctynzb14k67LXsq/Ce6TFTve+HiNXadI8CTkhS3XI8GsAJhdajLbO97huUPUY2LcSU5IZ6S2FQ5uaMx+MEpKY6M3QnUndkSqfz3vf4lnAeD77+YRVlujfmJzEMR0jqtS33jB+/iGfUdCvnf1CkHcy+8PjL2YDFEdnaDK0Dlg6722e+pxBOrt9j9xVZHbB+/mcbuGX3ivH+g/g4gVgiy3foVJ7/KY5r6n2i0rrRCDXm+NfcyJwaxbq27UviJCVLVwZjgJdxMLNMouonSDxKdjMryQZYhXpFETvfSN1f2/RBcvWV1X9O8LMpcQX3sz8yjA6Z01bbdVcNWl7h1ydTBbgWALr0P9cdC3pLmafayq38yzrQsMlcUF30JVLYvMep7oiMwWpxFUuqxUxVyAE302qHSKXeb6LCrkRV44lKrbjiMKc60mpl9WFUdzJ349pbN1iaV1fXv6xY/zCjyXiv1LLLeiVx2Xk9Y1FAZl50NB7XiL8QHqWtMRFbjjFN4OD9HiV6mDgaNb9evYqx43QPq5X/NPd/Uvu3MPqpgpvWsx1lXLGDEH6QlS/wBM6i7NVECoPbxyp0+wpkHTFPaJVzlxYeLG/wDjJLR0SUNpgFdEawie0phh6zAWE1J6pbZGJ0fbMJs7qmVBZ7Q3iFZBez31Eg9Nt939S+K/FH3GdhlLq08SgpnggvdmD9/Ecug6Cvn/AMlEeZl95kmCFoUZnVej+EoUP9NH7mwvBp+/mADAach7y/CKjVoRWVLf4PbPb4WNUmwtKadcxLIuy33f1FRaml5J9IKdrUA1VuscVrmWllkaPxHKVe4f4r/L/Rj+PLfBNxB7lLfk+k6Dcw2hELRuydvN6PeDYX1va33D6eoNR644fTUTdnBRLApntMEUwtoMN4xk97zE5tdbOSn49omQfeGeYQVFZUBweTe+IzO3KC6fiNxIs3RzYWPaAcB6DOnweUsO7d4DQzvjlhzaxU0rDa8ekpwTaXM20GOsVp1AohdF6H8R7g3m5ODe6V446kLGj2dQ6lu7hqaaz1Bfnf7lvUa6uT8vxAx5QphvesumJ0eZbJfd0cTIDcLO2ziHSXayIpjnJKlL81XBQEOc9MXmK2eW+xT7r75hI/Sl29e2JdNraGy9yql7ppBxz7xPWC2IHmHzwwFi39cpsQwhkqmgGBaHGDaXKxtowBioNLPygn4Z9nl+/BKhwhaslkbrjcCm/wDHaFAHEy4jfidmWZflJjKSly3GnSKNjzWvWI+q/wAOD5iT5zR7anWJZrERhZbUXYauuL9/EAWvsa+d/UTwvl7xoFIMumyUR0Ljp/CH9JelxG7wa/bA9ldc3zMj/X1hURekZaB3ZT9CPmLUg3z+kUz5ih7E9VCiCRy/Zf4/wG30jwB+2Iv9eYoEVRVVwgF25dQi2ApMIujd1fEPEt0zY7O3SLNw8OzwqvmGdR867M7A46Q6pal4o8/24XG1l4OROlXUqtRkDAaBaQydd4cdpTrx2Wt2V1Pf0iCmUQvKaaPT2mHPydwhhlx/YjwJ6QBofMoKE5YVZ/BJcHVOpahzrWCoZ4JVQKHUGdv+KKNqEQlLGtRpVpaWMB47Jc63AJpgga4AgSoxBxkVXvwfCI+AK0DoVXX/ANgXomeT2ghSgV36RFrLjkvLf4lfEuAcgUrz1Y4gxCpn7MdX/kDILCb1RdZ2cY+i/CtNoXHa88QjkWH9GX+spgwuOg6aYHSjAoqAO7NuPqCDMv2f24lWj+JVadOjpfZ+JdlGW+3glHfiV+mXeGNI8J1lkIibBb7Lq755wbXpxMF+5ssLH0QZnpEf6ZajIIvm9O+wZnQjqW+z9xXoVV7GPe41g0AJWLWQPTn2l+7zi/cZ2vjB+/mM4R68sYtUYKzpzxKt78/pGq/v4udk7Vfdz7B/yjhXE1/ghv8AgePyYeHisPdxMR3Ry9v+y0v5HDvtKkF3rMSKMPcGopSq6EJFZTdVlvxLJ0GjF0wCY0HS/wBUq4AWLbrFbjleDmLiyeWurmUzhgacAeWVeosFS0M+G/FSnGXNVONeOd8zEUcfhvJgf0w+ZWkovTYCr13FzjqgC4ADVGBx0hLPNpgq1Old5mj7hX2lTxFPN9m6faIqGxnvtlWgzlRhlprO7e3FlkCvwwDaud5l6a3ErO9arhy58TEeFvZRodN8doLi1xRjH59ZVmDiOWZ7UWt1UAIgGMkBq8B7NSvLfE07Uw1yWM9usvkE08mMffvGi5MtcEUc8DTNkTSmFZgSlx7QtrKgEGMDBg1DAoy7RDB3+ahjVkAZitLzVbiQrySNujpUHWKsVms0Lu33C0x3AEAN4+5pRowdtbMGHKM2ULLGnVdotjhto8H7mTzdgxpm3z8DqVSHwh+4otXf+URQVPEz3nM7ntHZcJ0jmdPBLxTo8yhejiJ2r8B9XE5A0083OJ3vf/cIPr/koGvkOV6GYIrvlXsM+9Q2fwHRl9VhsQ0FESm/J7j7ECe8Pwf8nprMHxn5mERzRCCuCP4av6hd0el9XOuHar7ucorhzHvB0vUWDlU8YiJvU+XBqWfW0+6mi8z8IvtAfwmAZeQyxkBmAfl+52xAcmNkf6FfupfwnqPsfuBXshn3ceBe5+0wUoHBNCS09DJ8QOXnVRfR67m72J0Mw+pkVPAEdtj+z6zuAZlmm/rXvODPnhQerxGrLqBsByONsNe8Zb217y0rzvUDVWBnzKB7ESl9e1n5PqS7h3ix939Rr7pdDi+15JbEkOJpy629M+h8BEz6JjybO8XV2A4yd/3RCUOGZFX4WqxlqbMtU4sj8V5lHYc6h8DI3mw7Qx8haNDIxf8AiIvcftLpVrE8sFO4FE5ZuMMq2PS9Q7Sy7ppbhmnJGNEsMqyKias0Sdjnw9oNtRjUNZc+A1qU0L1MQXPqKzFSwo2wcs9OX3iDIF9QdL4mSU6RvmCyq2URX7IqX684Dd8DZ2lQJF8yz1Ap7MCBOAS+Kxg6E9f02+JlfeT7qNuZewfVxsYdu35k5p9ifi4VdLLRhxzjmafj8GWh6sCJfR0xcrLLcv8Ax85UOgAujl8EGfWP7+Jsp6H9/Mo1Y5aN/wCGWlhsGHtqGhvV2+x+59FXXsPzcGmC6YCWmb4rn8gvS4rd7X7iM5DTkPeLjn/oBmAmuZ6XFfwD7lcXu/pBZeqfhOpDdE5giGnd1RUwPi1H11PoBH1cpYj1Pdv6hVLO3bTnoY+IXLPAqEMm4CpnFCqhJmEa6MRcOK7YaNd3BKS9Qs4l6ejAXyjclFtVVfW4VORXghQ42/YmPS94C0GmbbrDMZsF6hNHU5VxBcGuMFbm4uCHz6BWbXLnEM94DJC3kmbw4ek5yD7qfHaOR8w2jq9GPAGN1+wmYtKeTcfrcNYgjlt3jFuC0FXHVg8PGDEeEAiZQI1hWhf3LZOKlVjN5zi4wa5YFSvx7wxJbfAK/Z94mAIWo1h16xd2KbGVnAZaUY75YK+IZ7cRtC3NK/iNZt9DiJsMnaA6i75QWayUsYO3TcI44TTK6HnEt3OLX+UCr5Y4fXP1ETXhevwfEUgnygn2EVmTa9zv5JNpHGd/U2MtXAyH7h+xCRctVobCrbzgl29NH3cuFhPjOpmoiMrJDtcw5A87MS+5WSVGxqDLhsxMaP5MssoJ/wCGZXxYpyt+81ph/JtYK76jxwxQBQQuzP8AiudDby+Yio8v8HvqW3FHfLCn3Vj21KOlrGz9Toh/HEPpVX7gB0mnJ+f8ssKRqAi1j2MvtBPt4/7Eb8P/AMQb5On1K9XnQqUlYZ1Wpdt5Ie+puu+2HxctZJ0se7+oD/LeiKWvqZf4WcJ3OEtswoLyW9iIW47/AKzKl3nNr7B+ZynwT7uXaT5Tt/O0xV92BK59FGTgnqt1xKCo5o+wzKALeqamcVcAIbv0DNdo8UWVAmm+Kq3UArXQpz5RzTRt45luOMsSl343FD0aGXUdcvErYtphsHJ7pZSQaptvO3343Lx3lQL+L1XfWFe1L0Vwur/EYDv8GLDlg31YVPb6scYQu6dDKX2BRTPUXokBt0BclSjvSYMO67jV0ui+RvnrDDQzzpWyHy5yBWM/P4mXLHH2xMTlGrcYt8u0Z7nIG+saeBeP4tS3gdB6zWZTtYNbePtGSi9QfdvaPh9U3OlLlzLGANLXNlOXkZh9AyueXr/YrU3QyovmWZDxXPpCM/O4PIqmpkoc9o6uywJg8wT3QActYfMwzehmld1Zo9Y3a0AE5EHbauI46iqKqm9+tvEo9VNFOgOQxzmJslI9oS5ZmGxv/Cy6+PrzBH7W/GZlMJJa4BHi016YNkYFMkNgyDIJ2u5RivtHn8HL7/8AJtoN3+PER+s+rjwH0Pu4g3k6r8oKIkFmZaNS2DsnxXHUI/jiG2PB+X9R4r5r+NSgLIaO0EpjqtQ5fdRPeC7L7QfFzcdgCvf/AJD+hPZGK3sZ94pmX/LnEL6ZvicwnXB95gjHcK/DH3G58Egfv5gzZC2s59cykGzzHxEZQTkQmiev/LJOB4nX5+p7g+V6v6j8V1r8IsVTM0NLN+PEo54Y0FMUOrg8ZgAOaky28aqyv/YykKcdk7TLcoAoOznFmbiqpxzNLPtdpgowpaVaO+WMX6S32saJut9OU9YwyVwvzROKq7l4e5qZYhJg4Kc+h2gfPBaJcE/jJP3GUPnVSkG3NOG/0AhpxSslY6zHLqQjtxx7RCGilnVVbQaelxLtwxiizOXY3viXpTodIrg356QSBlBvxzboRBphVXJ4THFHDb0jm8U3jYTnHuCUhmopcHlefXNXCIZxgw9aIC6W0YS/S5CyvUvRYnc7yoA37IDdclGDnELvbQC48KMYBY6t9GJkHNWN8S3EqYILGYxY9MMNHORal3OkgN79iu8CdQtb69rxiNMSlcNHY35WuKLwNPeWgg5xVhqyAwWZaoJuoaWk6RMvBEWnsPOKg8Rt5P4xIGbX+HHcu5+a/jU0UFEuWZqK+J93GM+ur7gF85v4nX/Ao/fzE3Apy5fmC4b1VQXXzFe+o9z2P6uK36Sz7/8AIobu/wCMI3S9VZioJ/wVTCDrLvr36T5hoD9/EU18/wCkN1dQofv5nSe/N8x5wO7B7XXXR7uIHRfcP1x8wdw+UHxbDKw/VL/j18Ux6r6i/dAfE9z5uCfeT6iVA9azMPEp6si9EYUlnsHdQtBgT2zOSHFFLHRQJ6RetVLsfaUfD81madrgbUS80jjiohZWg09amX3Tko39zDa5P7O4bdClcr3AuvbMyfVaaSjmrWSr1ATHruTlxe9dSA9E44HpymE13W8BYfSb7vKmR0HCjB13BVXo9Vk6mMDjNaIxUHZvoI14/MtwV2ra+uYlZ3CiiprTxjmCEWFDLwEwsHz4nLAMCVAAvK+YQqcw9S16oYhuA/j7yjCh/QN+kK0aBZeb0w988RHahK19fuGAqObS95hzwR2YkiXFZo6oPPRoKbdZnxo4AUjBhe01FHddHEV9uMCpw/oEv2bHUKFtjmqrMeVjTQHoAPP0AE+rNTeO5gMZzFQw+AWBOzT/AAix/wARblslE0dWxbh596BUWnV0PTnPWWpprvKkrCC4TuDqxnvMv8/6nnEzK6WXZlqi+qGkY8gudc8dJYFUxYpLK9+r6nCt3cLhzD6flxLnAHq/H7lrCA9X5uf8L/VR60u1IW8R+anIg4N0ZBwThZ7P71FXH6f1c23i5fcq/rHhDKAci33jralhBm0t7Efdh/xQDLw3MzXAzkH0hXObrALvEb+8Mgjpr6jyH3PuXNRFtwtEaqNknJ0pRf5h4UR/pMKxomyHiiy16NNj12fC9gbJudgWU5USozjWUDjLGeblSzWVvF54OT8NzHduCi2ipwz1hqBLxjp6YkhOGm2TauL94NRUFsabLarr/VAbm7AFYvi7LhPJfOo7Fl8kw1cBcZeNODfbpUQwcFK7CxDoxdZ0tLfB4pi9VYtbbbs2878ymDaJ2Vhc8r75j9wpYWVTV4LrnvL1AlqN6yDWPmJcJQ4Sh88+eYbFYKOBdH1GKuqrjY21TNy5CakUoOoBXGS4G9ztvY3Zw0b6naO1GgxK9F24GQ9rnK8V0s/LCJ6Tc/GGGbYpxfU7gUkw1d7yC/7ESW3K0sGfe+WMYK8ilUUMl0rrE7NZCqTYzt12WgV9t+kVuERdMKPqDlZsZ7q/uITKKg4Ebk/UWvVq4VbUOOZYV7BwZV1pmwmSK4GM76rknjg0XBriZ4qp3IPbUkYGXzrHeP7VS0iz0yY0zeWFAGaUlZcUzdXSCNHBdOC0NGePmXNUCx2srTLzV62LdTOMdv8AATknjFFCnjB+2HVSPV9qJzQje08H7iESYf5bnwYD7amuX9MQMfBlIgQMocwShX0NvxA16Lr8IbK3dt7f9h9PQz7uHP1rT7almEvs/ERovriZY6cgEOoO9/WKUvzPmyJhpet8RLa/Y/eUKLooES2eS/uGFAHaNyTiXKp0CD3EFMYOHf8ArF751oHQJWOSUkpKGqMJexXCGa7HrEFk4C5WK88W7YktJeLEtUQXvmH8s9YM4XOcOi95i2wFfrAb3EIpCpWrJp7FZrcPlZoKVB00nkgHaIYUvX8Eql6yO89oX96wTk5dYFC6yi3w/wDjEShSnkD3l1cbZ2PF8cQk6RyKmNqwFW36pMh1ztq3Nblt76BFc0HR8RC00ZGPSLTNPODTbboqsauXgydrm5WQ9RrkV1qjMNYCrK27S9aitAXzleOLmHY9GqUdQfUwTprIXweYIEbOrYiBvnG3rGuq4IN/gfuDmtbVZRoqY34vEsou0G2iGmbfQCUySYKbAH1EB/NhKB1N08Rx7i3feDD+fWL3tgbtodar1MZJ2d4OqtOuPmKCkwbx8QWFUQu+54hv9YeW9woxDU+gTZanWJWqD+drFfpkF+6/gl+n9xlju+NHLOSHzou6KH9qB32JRqwp1GDBjcNKaAA24NZuVCiV5iTKpfCgK5vHmCcX+Jv59pnrGK9/GD21G9Mt8EsnubAWNOTvNRjWR9XSV7Q2uKX7Q6okvvS7APm/iOWpxh+b/EUV6WEWrb5v2ioKTt/3MlIP86QAz4A/icp+1vxcEaXv/CW7YzVop+8r6jGydRb8y1VFDVShxKGoryarjJCbOhC9qXW03/BMS6hL7EMh3TUXnAJIHdZ9pli8r2zK6TfUnbqlXyN/xEkIdMsevvBnjT2Smz3jLauejjr26QvCikLLjpnMJVe8yFzk64P60hw3xX/LJkXQEM81fFy5P1fOiiZMDGxWHUDN7ONly4oYHLuKioRiGzX1Btst1RkG3k109yaAnOBjO3PiU0nsOWODSP8Awr/kp4bE7MXXpevzFE0TEAyH1vNfUxIxNjkI6Cql5eZiQ01VDbUqqX/aCSGuxxAboUZ5KgeYKKExMzZiHVJqxT/sKVVmcztghSwWONo+mVax2SwwdG6sKb9GFBW1WDbVcnZ8xZDppENfNsCZ1uiJUKC1ld0ZMP3FLXOClfg9pZjPm8Y8YjadauB5TzKxVlyBWmxrUDxC1VcMKHWd9vbnNcoqiLQaqWBBpZ/YjeSbuuqNlisblr6q2sLgjYwbKdm8soWyTRtia31WCUnZmnoMIqrojpsrjBvD4iPntKypePM4iH5Wps8A3jwdYDSAkur4s6O1zfQkh4vTGvFWgDbt/mNE73y1EsYjN/TupT6AXCkICQmGASi3ggxw9wv3Sz4CfuWVwd2U7O2gRyJUOBnRnPLB89MKV+PuYxtux+W/ssA03ppUUVle7KqajfmPYP7EJLcxuiUMC4rYXmKAivGUAmTzjA3a+tJ/E6H0NA+mKHjn6JC+cJ+Li6PQKT2mKNZQZD59kdr1krBmL1iEsUcyto5K3iCFV7T0LmZ91uxcl8xmgzWh0idGgaeHcoyafO6vq19wvFkomgca0Y7x7tdKcXFk20ZDSXzz0qPO8xrTXUgbs4TPDxQPf9zD3nSvxB6h+IO942Ub9LipCW5cLmB5/wAUXQlb5+M1G4L8jxlPsgxbpNciDeSk+sS9YELHCAwUjnCB5ySvkYq8Hsxeyoq/ZPpPIU0e8PID6/EWobw7pVuVgg4qcZnRz/B6zdxOXsiUPHUyV+6JgzIHyKYaq1AWwDlp29nGpzCUaV1AHW7cQtHlFiGtPMIzUwbFXp8zI0azWpes1T/EJWtXBbSdYBQX6O5XjP6gT09LL0/usWEcKuHFuoF9sAEuRyGdHX2yIleF6l6kNdUgUg+E5Vi+VeMxqfcpDrW6xF2Z4XH7K9jEQfBqLNnTAf6qpHVbGdjDfr5iDWU2i5sXB1x16zIuicqEHwSidoolhtWqaF+70yzTsroS74vuxCjaGmu/yNzLl12F4Pz/AI5NjrIhgHTMsA7lJRwGSEMIxovsTqP/ALCUgrMnx9CCmyV2Z16u/aUDPumetLccRwbj3hRhPguKHuXB8Gvt3IwIqUt2eHs+ly21e+JeqJul1G6s/kjW3doPkim0esBOfdvvDcfAfiXdR0VZzUdCoCdstAczzhTGeaFbp57zADObydMAfMJLcCI+ngom0upWoZW45E+iXQ8VFSxxA26ekpRRDzUvVVPQLluDfhi9QoUKZSv4l149W9arEsB326b5lopcnTowwpb9Z7ymRN+mao3K6nIlBLGEMZTYACgEIc59MRcMMlDtmDasc7VuNgKuQmhYC0V94Y7eGDZPDDmdKdIHTh7AUcryu2OkA0XcWqB69eh0lM6ayOGl2L4mGHy+md2nWY7CqJbTkaVz7xvO6zdM/qF34xmDOI4fSBNw8DP9bi2faG8Qlj5hVlKROSGe0qRaiJBkE4RayRrAJurkZHY8+kxGV+lzhxio7d4UUK33tDzgye73Zb8EuS5beqztxATgLgVQ8+gWAx5Kn0JjgVVS+t19TYAXQuoLSLm25XPGMPYAqizn9IYVE7ps2yI4cXz5giVgwtrWWKB3eJXhFiW9l25hVtXjzYar010ZZI6+Kh6Bt+e0JG0t25OkL+wSAeTtP+0mfMJktCw0we7cxwxS4XXRj8zKIgaCUtwBl0QIJzyiNPPSOheOkIGCktZOaBgxmh1yEiDcNhWNgZeOIRTO+dK+DHMnJiGes6us3qDSNjqi9ExU3eLtTLQJMixaxkweJgThVmCPo7QTBbrvRpDJmnGUv4hdWDYVqBBnrX8Q7R3/AOpts67YGkq0H3uHY7rM77kNq6Y6Q8LVV5QslQjNFyjgD3i92mGzV9TJIOjBbAmCGgW4Q5YCMyqD9wRIoPL/ANo8udd/QmLY/wAbJX6IYBl6roj4HTePSh8cT9JKhlNtXPeF7lK/4pm+tYXh5hpBvezWigx0gusQmRFri+9xrqB6KH2vyIErMSS42A45xuZsZVswazrbMthG+UdzxxdMG9zB+s2l8k/mN3Ru7eG0vEI5pe8PXb5r+JpH5T+ZYvtR++cPP45gQFyo6dWVdhfb1WCYk0Y9VIWowTB6OloKy8UkdYwM9YcHoPPpdy02jz4o95mKihs2KcwxVocRL61GKg0rVu+JdbWqRyIEoz3gZxKpyNBwgkdlGQJN/wAHSWIqqVi4aCONnOyqvdjjnUEVSD4gOl4Z8Tc4/rKi2x3Lm1NtKzrEdgSsaAFdfaNBW3swloyoYtx3mdDmAI0bPU8b3BRGBYpxx5gdv3QDl9Uo8KsiI9b8RKE2bxsA25sdxN99B2pdUKKvCsoFUeSd3n/yYK33w4ynp1HALUdSd3eFQIl2eDDjvzMlNxRVaF97rEtwZKWYDz4lHSCPTDI8VFcSxWFvo8/2IKVpyaIkCtCNgcrJLdwXZSsl0jTpj4htd4eiy9ZTnj6lrj5zLlbwQoYxlJyI7LK1XnZMTXkCP3K0CNS2pWyAAxsCfTA/cuD+p0uBzR3sivdF7Gz5qOPDwntjjg/mbOW0WozChYZOdVBneBNYukVTP7b+JcUz2M0UOz/cNIHQfRIBaMepmvpdhCjhrAguMwoj1SHZTddpYI1BnxX5zPQP5t/yTDk12/ARH4mqXwwDuHZb+ZxLMG3h32v8RCjU5W9vT0PSLthSLqiL5szBqis226rZquYfXlAp61fG4hwjdX+HeFtdSfn/AMEUq76UXrRKZQ738zrOABYqgN9f4p8SSnySyxelNetwVbbLcmoqraK1Esw2qakyV1rctOcnXRQa3irzFrAX1Z/5uH/LxOGMx7qU3qmYRuK6RftLzS7tl9X5jiyPN+lp9zHQkqvDY0pTUTO9SsYu1rrk/aPsWjL27C0p54jBJI9zq8tVZcBxMplLgYl4quzsiflwMPRIWo2KPkp+H3FrnMS0vcD7kBaoGhbDjLemGpiWlF98Z8xhwV41L5YSMc+0JJQmQU01+qxCO5DQCB03Y9L5j4eWOJFwhdlbCuY6+MNgEXHvjvK6lCsdq2mAM2yZ0bSmClWilGNvXXaas6MhoVd3Rm/TohSwNi1VxaY/TFgsVjSqPPvKCODjcJ2MWs2twbcOzuAuJe4K5La8oTkHQ6EblDO2szrmNS6wMKWCDAk3OCEOLqWEbo3baql8OusSFdmg9hDjfWSOSLky1vcY6jGueN+qJFsTJMdvO7gJ0EWe++v+zDt/KfkwsgWwMj/yODYsoe/FAQ+6iDQ0axwSku3yjXqsSMpoWXOw2edRN2dA+y7+J869RHF5EM4SQh9QZtMNgO5XV4TfUWYkdqD31wi8EVCwYwEKAz+MTZHw/cOSn87x2vLm4B+RhYlyS8r+IRrVgKN6mbuG2CWQSQpC7L7ysoNcATs8wq+UxyGkEyMYjv5+OPWWGb6/qiF46j+JjKfQhelyK2e2p73Ra83j82TsasjJs1rJ+mMy0L0YkxvXH3KVzVfCUGDGvJuC26U+L/Mxpi8Nz+39p171EM1Ld1+or43/AJTPUux+1wwKWjL9PxEI763h5La9ZhYqYT1gs2WhcNL+mmbgJAHo+ejEcX6yq8Bk4Maw4ju8oyUvrV4W0JOVzrmVm0VvQ79VzvmOjZlOfMdWa7+d0N1rrcjCW9bmrBznAUnPXsVC8mZyW6APDMjaNYR9TcZ469aG+y2ZxLIAUDoGRcOOvbK9cIgIvXXeCKhza3ymNTF3UytA9/4+4S24u8vnd1LI2KSquTwFdZa42LALo4q8NqlPSHuhUPUmYA/yO8LUzrLsc6fMp/JuGguj+3Awa6g93ERrqgH1Lmw+5/xL3PoQqf0+IkavfY/M1W1AL0u/eUw12wOR2VfmZLqUPF7Cu8m796YRWgBl24VG2zTe2qeFOwviWV3rjz6OYcotlrapqgTnrxDrib3DjchRW8L34ZNNSk1mrZfij3ijYAW4ec3vv2gLwgwrLgW/VVjpqUx64NdYy3Q+kuTSGZFq8XELWdh+I68gyrL21Bq9x+pYsNWFH3nkH9QlN0UHllLk1iMHFTgKNr6BArE3sTzL+O7KGg/l1N6j3/DL7IwcDuQisJLXzhlgagjl6dNQKJ+7sT+ooOLOD+GPSWvOI0wYP9Lm/wDEuXhmVCyFi81d9K9o2VLZ8r9x3Wr7CXEiisXsv8yh+sk+4FvuVZHyiZtzppjo0a6ko2Vpa387jK/6ivUlHJb6Otcrh4fWNybZ1Z/cwSVSmB3FfjT3gjThs9jX351LuYEXi8Nwjz/5NlVgF7Ds6fiFIvQ02VwlPFjq21rzEXLilf4+XUv6Me5B3rgWzhqDEFzXOsmrcbsqUFjYdOaZycHrqU+DQb1N1trnONXWAK86MsU6oqYIbcxRNN1w+ZmwdkxtgtPb8y13Ip4f3NGMzaN9m67e8L0srUEWXUxyGn/HeV5ltP7Ija1CNC9BdVvDsesCDhmaDseOks6O5qWpBSmQ6vD9wrKLET8/MQ4gqN5w8eGH6xWzanXiGIYuxvsHXp7yz4R0sWjPeooLXHSJj275i+uA8ftmNp4jDwyf7F3RDJ2CsxM8OfZMhekDofggcDexrdnOZYZAQywFu5TFisVtvbMtDxuP2ul6rlxI/IXIrZDEPCVlHbvxHMGtOAZj8yoFM5VflT0lyUBQqmPwR78NEUpAYjAWWhqLKUPljotQr20fqoz1yFHqNnzviCHIqyZ/tgnW4p9sSXnEs/qZWPQTELXVNzJYDWEYLRpXZ/MZhNPuj4qNi9wHNEts5KP0rnyxPWu5sPn3IYVcL6r8EQgF2kCt8dmUhAmx/wBuLmLMRK9fEBHb5/EgzfxcWVun9n4hdrKM5IHtY3h/5/UGparz247Iwoq+TudR/skr039aTlccH1JTjHQo79uRJjbjmPl3+4s0Oxo6vY9P+RubcNU7bj+cMfjkWi79pjJqkJNxpYW8n/PMLCEYWlCV0uZu1hXK4V17Nmzm1TvsMFr13M8wQ+VT15QrfZGMs4yllsC5lb1Il6NBFb9Q/M5qmA4QLK1fivGZhKpWZu8vXP8AEYaKtPY4esoYAGJgP+IeUtUBKADt8+r0mJO18icqiWeoKgSe4CL4+p1gBXTv8vvAIuaPhEHIRv67F4m7g1B5hx8e3MULgA6mUuubI6d4uy/RjEOdq5xx2mruuUSPsTSsazDIv6lfbN19mHrfrDh1NnCzoaIDbdlzUWd409YAJvbYJnn9EFjtaHDtzhv0qIjFwZ4Xfs+IqciiystuaqvNxKFe8FH0RcJsmsUMymsLBVKEzGsH8zMUK3oY6wwTCddjkx2Ql0ubKfXjZMIK3BtwrMzqC1eMsylLMICGLRDkOkFcMo6KdD+zEoUyZMUDLNwrChqe5Ct4rPvM+YVE1KqR8fyMYo73PRsiR9xTrFf0WdNIr8d84MuLLnNRWn94jpeqnqR+cVWFX6KaAzWzT/Mo2Qd8xZY16lsU1f4L1s9q5yod8RGhBTi/aUlXTk5A6NfHaWNDv5LyuOH10UTBWB3LrMwZUeZx/eYheWCY7B/esANefxyV1NeTRIdAV279VnzqzBTt2FSrcxmC8JUFHZG7K7G8xy072QdLxddMNmuA/uC9By9l3UsBR5tve47asc2s2wu9xEQc8alVQGi5krlGtC3MZ1YAoGmbo9znX1FZTYTKLc/3SF4RBrGsMCFV8Rmcr3JFL1YUAbCnw95+MEqRdt2S9Cu8EwGeTUo1MR2qGXRzeS9IZyoC2ljw8jBnRwz+JwUd+QFrl3MX8FwHzBK5FbzVwVGPqdvaExXirlIUYLrkd6nPYJycj3IMcVuyQ29sQb7O1hr1bz3j6JiUpy25K4baijYybNyldeLVWNQESMxsHaut8fE1ZsHq3TiMSw8yC9EuYWDUN01GNQcccTMEqI2ZvJL7SeAuKjSeGge8OewazvgS8/ERzJR6Kn5tienHK0vSKt3SK8SrHnC0vB33MnVY+QS/5N1NZQlwftyn71FMSl7wNyUo3yxJTG7bcdXiyABsUrehMI+YC4BfXpMll96jwFrKCzFVbdwSmQF1DX+P+EuTn9pc5D/2mPgm51+1ExtfAH8y82pRrX/s6vQv/mJxRr/DuU7WT6QCzbepkEgOAuw9Gz3jK/T/AF7H1s6NfY3MG/qe5ETnMzl6hVQyxwzTj/z+8bN/MZZi54+I+nCQSVpCZNJ7iLq3EKiDySgZXqWlMZq5gIVhT0uL9Agapfof2xOgsn0X4PPuA9c65nWTnvUsc8Si+CYlY96LQl5VULa1g/vSVgI1Qomr3QrFfbg+7mFNr3OQMS2AtDntML0r5lyyPRmVenOneeCPGsbp1FUmIZ1wT3C6ywr2j66FJ5hgIBO9Dvw9YMQzlZSR6TW/D8PtDaqqKrOi46A5VwYaHj9xOSfQjBt1zf7zH232bWxdSjCZ9urW+ykPm+dI2MNXhpuFV5INnCnBz1gRhWoSsrfo1OYd5jSynTAKh5NwEzxC1Zoli0/2ZlGewENO8v0K8AW2NbYh7JPlAlSXPdNM/eB9xtaO6BfEXUxpaGM3KwKp3RcaeeXkS2ScVLO+fzM23hl28OXFLd0RdVqqGiHQvmZXBFa+4/nzHeW8GSuOvp8TlYWHOcKHHSIYWD0p8SrwMm6LA3wwyWXyS562V1qPPQ1niVlWa5kciUbvgO1H0iwFQxES02Ue/wDlwYsIVO6H8nrB/u3DQdvzPsfbEyqTasU/gQqSw0wRc8gLKBYbz236MwJseo94iqdxDQz7pBgwAOrTf0zKHqMyni4dWrTmADsOagGsryD0f3CP4+tNPveu9nNiblc+1/H+GrIcMR6CTMAwC46HZ0Yg2jMxOj1IMqxfJ38B/wBS/wA1hey+DjrUXsUOVpV164gYeyjpcphthRjoJyQE+uRb3nX5HPVFkBcGAFsonH88wUyWBqb2dUPtL+q9+IxU3XgMaeM9I3UrtZQBR5G8OZcqyq8wAfmvSVOYal3/ACtRdOtxqcubK7/iKyA7ZXZ7RCSLYjR35Vm62vH2gDBZsp8VzE0YYLq0t6cxZ3RaPDT3nUOQFb2S/S34lM28aCB6aB5538fMAHpC+8vVSZVp47HH9iK7CyooF2/Ms0ri030lq1QrMXsrhmKlt+g+0uinT4k/Q5hDUbqBf/lACIhL45me7/ZGA933OyGxm0rXE5C9+0aU7fVZO8HqRYu/0g1WAHZFecX116SkjgEMBpkom2fez0iAB6TBU2L1Gzf9UqZfmONY+PuZxS6I9veOqJoSqWQrONo/klaGyLMj5UMINAFXzbEhAtDfUjwyj39DMhE3tTkHsV2IS7O6YlLRbX2lfVqRooctPwStLJThsvy/4CVKn8mcv4n8VzMT7J9/7hNdI+mT7hriOux+l+YixZddxWp1cZ+kyR+6N3dxmkq68zLWoK4FmT1K9o2bVETqgPIXLYgYuoeWPuUItjOS48OOjGwtlQ1J3z93MamxBGu/09DjTawWvk2id7OP5sglcdWvDMbOoAO3Y7b/AOnS+anJtN45fsaUWQU26frUXSJ48wrutGSZyHgtu01/LUWCOoI8xnVfNx9ObFOz4m9FFOdflHZN3t2Y0P8AVpmMzpYZDLZzUHxXqxaQI1hhseWVlUmGOi4c9C+RTJRp5nQyZM8j8Q5Ze00dXK+yKmsAIFKrIcdOvWZoNapd5/8AZRZryiJWpaIJA+TqBaVvRBP279mPaK+SYqk+2PFxNAA0itdB0/ugIMH2tEy5eSonjKX7hk3i+kaBHoOOWuvmNQvlR1s1dHqaqV+NWy8acG2KPLKUAZOhOu1QWa2aK2Bx7XvmZpqvsgWyAy9TFXqSmQ51ggw9eR6ymS184QsbCDkPSb+McwE9vbg1fuVTVB205eu2XxtGuGLgK9jXnMTibHRynhmYDHrBAQrAQipDwBlLDzuI8Ghva76FdXjCE0Om5ugjWqlAzj70QW1Ur4MH31j2Td8VB5B0Nqdr3HvhJqR0WGHnQ9BuPQBEaZzuGxeqf4f73BP0r9zLyPv/AC3x/wAxlqFE7kNZht4YUWG/RDSsIqLm1c9czE5IBR2y6HyAv36THtY+GKD2lkOrF8Jo+i8ZESjqNWqqO4WUW9SXoad9NLNSaRhRUDbgNH0Pp3M0lcj5JlXnwnmGi0OM5E6MdpOcY4LcMWPkq1egMD8PwCqoURd88SqU7JbLPWusJYKilV3jdm5uewi5OK11ynFfYGtJpMQLLc5GoU0ZIjtL27RN2dtjcUOYnjjMER2wPGuveDFhp/vEua2sp9EEWH3PyV9SuAW3jdSZeQeYUu3gRkJ3IlFLWfeZLoyUvTbHrBSVW7wMByMEs4Uw+YHxi48pUOLtw8HEe6uDUsN5cU+8rDKMajk/ymWODKzfVXtXdJ4mPRlMscKW12ieGOQun4S/unyx/GYCs31uodK7S7sm4rZVekPOIxBJF+kYXSZBK1rHeUcGsDaUsdcvaIaXTDruN55Bu9ExuR0igSKhVvpqWjdBcG/eOBFDxD+SNZnWdNrQb9+0PsTuX2QrFpQex/7B27d23d9P7mOcxifz2j81oiICr4ggthzICAVkthy9O0M7ZnvLVKwTVdC6MvC9O1QF8bZnG97tAgME2rbbl8brh/tUaZTIzy61MXy9/wBo5iJQEB40hCMuW8P3iv1H777mH8WJkPZ+4EocuyH/ANBahNqGn8WK+ZiCJVGvUqZq7cFPklp5iuSv5lX0WuhB1rvBYYPg86GvEpJR5AJatfeXFnQaK8xtzqTnnqdpW7/Z3vv2cRe2rd1KtygV2T1ff/2KaPc6nXqGGXdySE9H8E4hsEybEQ4xq4/fB4j1WunxNd0NQXQI3rki1oL0HrGHmph+lQN8Ovh2igiDQREPMOVkqFsHYmPvP612hdj0GycEDRrkvnHVQSy+Dj8y0IzupTYzcaKAj2hXYM5a/EozKaBVfQ5fQZdA5i98fgRyYEHxhWJzQPHFadQuyEF6ME7a7xDVDY0p1ZfZ+G7oAV6vUnY02/cyRzkcszjdAG1nZnQdQ5nWSXaN1TTagsbXbviKoZoP6rZ37S2J2kqnSlR4oU+kWMBhSpbvGSu0ogrSy5ffL594tDVWvwXmZmHggXLeS1zmYYk5yadXUY2HCji1N0TwTrgKZAXSTvgOomktu4ugMnucS6uUbfcxKb00aj5OltJiupfylnb3bwVfYik63bntmL+uEXlOllo/5g4UwgfdMi/K/IrDM9hs7Rr8S4atHtymBzKN6WunmaF+No+eTjrCIbbIxZeK175n9XoQzBwTWZ9EImOPCZw6/iFi4uXox28Jlndurb+gvTTDEA1yHIdqqH+VKlL4BeyLP3/c+Olv5coyoTEYLS+guURT709rV6Szqnq/MJHCdFadnhgumTQSoN88B7Ep9OWpO2UrzmUy50Iu6aVtYU/x4Od3eW+J6hFDVbWul55HhgwBTFX6fJp7kMZkPZH4pDlylXXVUMFXg3x18xC7Zy34P0RpmBLWPTSIogtPyRTWLqK+F9S0Fdi+Sqg86XufCzHpMALijs1r04qI0urYUvox+zkuQmh8PSHW2lqYRjLuNhhVo3+h1gCWCXeAikqNfqBrJwnDbqOj+ekzMxizh0uWJbBA5tZGxJegKiPdHQR5TYDvR/2Vpas4ptxsbesJVKwV4J0zd/7N/gEstTA6hLz2t181CGcL4/aK2Juts8wdzh0sfBLcMsiIXUhI/muH5kw4+qNoevH9ZMWfm01VjW5gKs0jK6GJvqztKFaeuX24jAOuFKYqRxXtCSC7hav9YVsMG+kLGvyZmqnavpcsg00i/EGoMI2PQ5hZOg2XdnivqFL1HGSs539xe11p5igvaLyrr4mXKJcZekyoyBTslrBieSJpq7xivsmgAOhdvzF/c8sp0O0oFEQhiXS20tvvmn1gNBsvP97S4H8Yi6V7UX6+0sGL82tJ80ek0a0aCmhKtHZXY2HkEw9g+botz/z/AFx/jwy+zUXvJ8dEy5PEFHJFrBSvuLYbx+SYuRYXfgYsYsYU6wZVfksjSqPCk0SfI+YBkEOxAODfnxNRvH4I4aa1W3fowQwEsVYjqPwjKujt/cRfJBSoNUw8XAdnzVPUt8VK3FtE9h/KO2Yc/iGJd5ikQ5lju0C4DkAaG8G+YXM70GRnGIjOsc2+I3Lp0hbDaXnK1tvJ9pVrZd53mID3Rx7Q9w4vRn2uIKsaWgwVX9ntNvNj1modhV4ipX1OBZYfZVXXtMfNKFgL5mszOlULBrXrUS5UUhbF9h8Qhc+fY1/qIhNwt8fqU1BQt3rU5kJ6F4x/7UvxV5xcqvTMXl1pCUyA8UNHw15Qb0EcvX3XLQ/yYtNfzmVZ8n5YNs/hqWj5ca10wznmLNFWgqVPmJD1OY6ZdBWMe74Qp23T1ZkvsVoaILokOhLz2iikK6i4YBv0R+5fBg/H7Z9o+tBRsqNhdxurihDVwpsitK7yxb4qsvmVFEC9rwRFAkcDD38MVqkL1SLsoLIFYXvilcvi2Lq2ZA7HYZ/yv8WG53qv8IvZJU6Q/nCxajeXziX694SEn6QUO/eLGMZUSPVFuIElf79/4t/xXuBbCIYTpi+8UxfS/rXrH6LXRl4+2EbNzxxH8kGrbik9yq+ZdKn/AOb+kTAu6DEJz0uZxT2lZ/aPSgoVRDc9veFqNTAx7Pd1heYtWbqw941Shz3kLbXhjUtoDnMtmTL06VKYoF8YH1G8TM7o6lVxP8AC0x0eh/3IFDS3ga3DNho74Y8d+Z1922TozI4t1v8Acy/QBRtLqUHlnceyA5hqi4Clrh9TR/dCq0XpTUM/Uhqyxx/yPUzvrHb2Znb4Te0W9DLHUCcKxeMsv2wo3/czpWCu2Y/1ecFv5RUTLfmbucMXvaO2XODzwLx+JQGwwetsfj2mGa7OAX9zUGPeNq+uZpIVZCiy5Zj4Kh6zMuwdQnOkTwvzDuGjjuh2DkhiM+KwXbnA9qiUUTbUGTonctv/AG/8/wDLDJipm4r6BCC9jPrn8xMe2eYmLmPcKEsvdl4BDcedS/aoxrNcIIAYIHQzLHCA4Yf9qVKnwA/+LYMiHMeAsARp5PDxPYTcT8/MANJz+Jz6FyvbBeBPJDPxOA8lTtGcWBKfwPxv7lyQc/8As9rg2VYQUn+LBLxl6zVDQnQ75lj9JUcB+IiGyAWYLfSq9JWBgAysLld0eLbmDKjMDNyP3PScxhAGVl302pa7/wBzL9DRlVdGSqqhyHCR8L5WAbw90IqSFCgL8QI7QWtgq7r265qAgMaJc2VWji7LvdR0lwg4cXtAehFQ3SuGBfBWByMo128QjcaQvrcyLfwWMyTHbH87T2601uwhktOG44uNUXRDlAZNtNR37x5eYgSJAXViPdjQOQwGXnnHf5WQPjxQvwy6bltm1RheH8h+f8K1fNQ9Vn4hNHVAzowlkgTJLJymF8s2sH3nRxGTWo1zTxdH+v8An8hW1+Zum2H7UwOn9Ho/EzULcS7qODY12y8eY4WzXzG3Y6VL5lBNroYv+P8A8D2X1/8AZFOmbnzcjDWcsNOOkLUMcAdbkwCuG69RzHxBw2v/AFsVaI4V+mWBxtveuT2J3Ba78I/xIhSGeMDB9E/ETahp3C+OhCMalHcRLWX6wgGh+MIFokKK6B6rMv6WpSZ2PcrrDExg3em33uZJMfEsF6Qy4XzE+3FU9BNf0U2BwUrUYRs0jsj9dhXqifB9DC9GIc0PFWnH5jVdQrGxQo1p+mEw0NhLVB8AfHScVrXaJMEsjDxnpK132oafRiXER1mXWXDR3BKWGm+U/DDXGpFFXXJAAPlY/qU5G1B+wmZyOX5FQ0dmGkTV9KhLrxAng1Z7wz1MoT55nEpzBYG53WEtnQvr9JdjZG28LFPqi+YOJlalYNc7nq6iqVF4rC/m/wDYun9qfG+04WOK7LG+lXOZD/8AxR0945GZA8bXNoPSMobe5SMXyn/y/wBUzf4m+ODxj/pM/wBRDFkd9GCclq2+TEs0S9/lcUtZZWGPRFwYF2orlu51ijXZeYsamRbOPEpWIgXeAs13m93YjsaZSAGFuscw/wA2/vT/ADMplSv9GEGpNMHEN5rq3uzxkmN8zHwH5FkzeSUODkP2RJ0QnEpW7utFGwbhAeTBPYOc9SAQe2iuqJw59ZdCC0VjWGsV7wQAqDLdGBqmZU6SlMyi05Bk7dZQN2DXhZlMdtbmLGdC1ZUEd5fiKWgUlU3gY6nt/lvgkRMwjbUtBZDzouArcdn8ymx1/T5+mLUmrrpS5x7xPZWqvDObwnIzVJv1jAirXNUgOYYlvZeXXpj5j293ig4rlhvNd5s2B+osGrJPAt4t8QpVioHA3e4znwAabpt6yhCAWj0SUyRsKl3ziZfquAcu2UX8P5QRWdreZq66XKDKHo3X/UYBnA335iO9Rgi437esUvHGrdJeZpPFojYLkdrvbDIhKVeUdRlvZ37v+RHi7xZO6WYIki8195Z6x2eGAoKByU1DtLjpVEHv7SogzoVDT6F/8/0xS/ceU3QHoTxAfSfmDUjkbV/JKQnvLAWaJk5Hqbav6hgWYwJzqYTRWdttYjlOdyoSrjNaCIsNDCMGAVVteJ2QLCNOsH1+Jj/alI9MSlJzC4x8bRSMKF7kW51+AYpSVY1vboPSFOvIXxAUEJ0QjZrpxcEqDbEr7NzSlkFDGLTP/fWFT8AUNGdoon5y2XqRWi+ZjB3oZ7NL09pYTjV03AkC7y+Zfl0VNm96qFdnCdMnySlM6CrerGu64c0y8EyQYoXKkVxhqcIixkdGeu8wKq23FsPqX8TBQvB3c6ZekZfJxAJl1yhZTriJXcwGrXc1NPPRS79z8zMA2yZy6lhY1hHvZDpSssiGwtLAw+OfeZ7Sy3ZdXqPW1KHD6se+kH9H7mCWX9SdBiKHU9kfujuWTiE6kaIwGjD2l5HxFk+odlhZE57wf5SVXcQGD+GPvXouBKRJQuRPUq4lQiSon+Zz4E/niGRpF6kACj9YtngLSOM8QERsYNCX8zLqb3teK6dJdRHAbqupKLis7HVZcoipW2w6iF3UjDOQ36SjJooYa4xHUdlkHobYFQthtX6RMwKUGVZdLz8v6kTqLQt5gWhyia2Asvkq78UzDZFZKv8Ais/whjjMYGCEW8n0TxUAXmwf+HMNMnu/2EPNMOV+IEE4UVhOravf/ttSUCwDkjKrLnB6M8lk5feBqedb+alME9aj3LONQXQ2x8AlbOEvXqx1tPHBLdC/9TQzI9lWvoXCxovAAe0slkxyuD0lk8c4DDTZTaveWXOw4RlHo/EA1oDo1l7SvOn/AAF3MwKB4uVURwjan2gbS6ExTBkXxCUT4ftaNmBO1HzhiwcWfkuAXtVuQw0r1DKtEHgg8C4/pf3EFoW7iz7m3+LBw74YJBsYsSZUH5XrAmK6FdP8CMWVng+E2ev5YCVjLqrRK07irid1n4hfwxDcX2vpz1j26BqANM9IH+G+eWb3oYaRj9antcoRdVLM5ao30hxc0pVbBaL/AI6PeEFL/wBLvDAOgeCaZ+qfom/c/p56QOCtkGrQZ8Wv3A0nQGvLF+0sW+cfE3xeX6QGiBwfugdq4V+jrbAUM8L4f3Phm3/UNnJCn/OrcA2/WDzlbX/OluY07l0VRGd57xTBSxW9/iNoPZtHD2Cz21KV7pVLJUVfEJG9ejgL+WEhr5B5ov5hlmmC39VH2jqEWJ1g/iY6w0pG8v2m4nu4PmXrnVoOCSFDNrL5TGvziYQ7IAPiA2DhVpXtKgPaimlzi11DUqeWyhIzU1kiQMf4hCmPFzdm9SN5vSOVHzOjXZubenmBt/LUC2075iDBnaFWq/UIWVB0rrcEC05/IhkuwXBuAC6fDp0iWwW6z9cXPs6r4mglXR3hMu5Bfwz0bgwsFxbu7/q6ELcSlG7B78Xx73x3/CpcHP5uewnezfZ4vUtYeft9YRjVGoWsUQtl4Y3FNXS+WIdEP/ipX+GF+0630ijQ5Hnx/nYocilYuJTJZYkDV8ep+5XdFVyzz2blwPQI7tbm0UdMy4l+plEZ2IF1repT+JWY3iGgKedRJUtGuaH01ZEBS5DVvCOOSQuWyLLrZL3bjM4ugcBzurvfETJCAs67D7ghYdQvgqaxdk/ctyDwH4mRLbsM+cRy4qgUL36zNkPiUu8zjMZnaYmt54VT/VDVfhVA9GYYmsZBiGlID90Jr3IUUpHVXqwos/b/AJUMYJ14meYDFwC2uKgP1evSUN6Cai7dl5eJc9hc6P8AhBRs0r/JlC1KsZc1qgd4dnUYfOWeuGXe/wC0ImH/ANh/ARv197+f8q6g/wAoityKvSFj8UZ85AhNVc3nxPZkDnUWs70z7ABju18I+o63ip+Y33et58hlk4b4/wCZpZ4t9ROZ4qllVogDCHsm8EMcnEszUGc2zuU94ZmIa0IBEjqk3AOxkhPcI/4pcAnCZ0nuw+29X2WviYJ4Wj8Esy+xKKd/Lj8xE0zYpB9JUnT0qVQ+QqVc8JU1a/XvHS9sGKBds4riGlaFFC9ah3ORPgf9Th50iozV5RyPT/7mC9H8alXBuLXReOH4SKcDBnMVt5u+Wy+y+5hDDT1gjiL4OezpT83Eqa6dGDUKpwX8zl+4epwwKuZf6IbNzszE2hFwjPF4gqRjyEqtvli/G+eYDOeCki+HCmjOYFzdgrNf8h7f6p6ccSx1MHNfWDwsy8TdWNU9WPUzjJStXpflByXpDtWu5UKWQ7NwlypZkjC6lOIrU9VmFK9V4ZM1OW1j/MLc9/8AMYd07kP9IyLAtgyuzmGLX4j2G9U5/pLc8sUl5ZYA3TQ9XEdYyOtubD7kqSD1lGY0OZYlW2X2ZycMT/MIqXrvEuS/MpwS4lyzOGPMzavgynAKK0iOTmFf/HMqAAYOp+lFSPI+n5AxLBiAH8UEEqYPKZIjPXE6xjEr7yuHyRm56se1AQvVMvuW3pA9ZpUYE9NBfrmD5PP7UC1hv7EEsBfOnHz9wEUy2h8YdDKNWlUwzLRm/LF+f7vGqqypglRsIp6IgfiL+YNiZsvVlFoEeFH34nX1oPWXZnH+GhM2o5hu5Q3eVLCc+mftcuCPG2UpEL9mHBcuw5Ml5hIvYFY59P0Q16Qrywqrvywn5ApHqvMh/SHtcxjX9cJtn8LiCVWPMHrA6wXmWDfL6mLs+lLd1hCHBKfJ6kWAFXxgb7H3iD78avYdB7EMLyYa/lcykYQtK+K/fExIOBR2E+5UX4NidSFgSbo+ZUyZMRlF1V/o1qLtqu8pzgXAT9cXteqFBNwkNGP6xKI34pr35PeVoPmDpK4HG548StNtOtB+H3lUENZk4weH4mb9xJ+kW45K2qLw8P8AE4Q7ljL28SlwoD0M/cRnKx2h4oF6nD8jGfvP+d4f8QYS7JzK7AWrgrEriwBfbN/EYwb0mkBN8QW/khRs7n+P4oQG7ihZpKdM7+PiORuZ4lHaj4pCCIZqX+Kw5PLrEzN1vXt6wGOfzT86WcTAxM8tSH7vGtd3wlw4KqukMhjgH9UHqMI7pQmestmc6Wa380wSJ3jVdvedceYXiQtijA9A8YmLA6JXzcGbXxfZDG9Ol7wRRgdFfxMMl8WX1GdxZqZeRAw6wKdBKAase5izAFoEa/h0hFGsfqEcoArDi6WeIEGPZb/ge0S7FNr3R/X6FoWjp1DIwxAVUt0lKXV81BN1Z6kT/FySkzcOEOBR+ILHr79yiB3qr9xJSPb90u/XlxmLu/8ASXZcYXG8iF+wLht4BZnj1FgzPppbUEphbMkORpLKyQiw5p5eV7RHZCoXGTbM+EXjkz/yBkq2K1URFmxboYhKXdsXBQmcH3DOexhWtwz3QZdLrBSQTCualYbG/wDPSIGIba5ReJbW00w6vhim1MA3R3iOx7M6rQ7yzQPhIKYE5E2U4OWM8YUOxOSAq3J8PxCN0Ovd64GIt1rC9M69ogW7teqesy9kp8gpeD6sor/UPy/UeID7BGnPdI9T/CfZzHYNDhDuS/8AAEs73iALuglZTieMwl4t0/xsKAnRlOqd09zQLdwy0qeBKYcb4l8Gdn1hWW6xS/ORCLksoh9YcigHXEqm8E/mAYeurdOuH3DBONryy6u8w5VYw0XW0FioWjDa33+5lZevR0fGoDCk12Jeq6/7/BDS/WHHid3/AJUqWNR9p2C/ztN4nT/zOw9YLRkat+Vl5Nsilie+HrBWAdmRh4q2W9xNsi+I2mct8zZHi2NjBVRdkDm+C8sH3MX/ABA/iphqrKNjGfLjjmUw6I1EY2f2IaUeVcl8V1ipKus1Z+k6h9QIUsKPbKZgTkFUrKYALfQicsp/wYCukzsmEgmc+DEjz8zircxfNj3mW0+8sasz/iv4TCiDZiX02Crpgc4Bz9EzOSALzefWHp7+zMMKbavglJ5a/to9oEBADAS0GtfIoE+bkTUg+YB74/T/ADAWC9JZqV7TofEXJI8vHM5yo8o9PSPmLFsyjr6hu/4mPEXpFxXSKmacCpm76z2jMst0xAwi203Hs3b0irNcdzVStmlpHCoMFyqz4gx0csSz6F1BvtEtQLKXrKTU4r4xMhvSVNjRDBvAx6gGaGAPGAsnXBqfj9/ibH+ZzUH5z+A/cx/gYH/Zbq9plTYPxWMHoMQQ9yACG5W+jmyenwlmzreQmarK3L1NN2tUqOGqlWLYlOPMtCvdLD0rMCaBoqo657sW6psZDAN+k6sd9pRGKa5yNN1nL2jlWs1R5BMwTrev/Zx+xuOFZ99RXt0Xq/VKS8uLpVy6Y1xwSrViGcYmqypLvUsZJiByTNR3NLKdUk4jMC4S/UT+IXDCczZnl4msL7X/AGPlMpVz4zd1cF8XJ5ekCYUQi9wZUN4Q+FD8QiqqwHY7gXMKO6iCXbK1Q2q0NdS8XidQ0B/xUawjzXzcWDDk6lsauHrDgKJSsDmV6lubi9HxMwnnZOgIbARCZmyGsS94jswcrXa4JhiMnWhOk6KKcRuk6MVGqcZfHpKeGc8nSY6rMpkuhsHAycxBC16/iJYI2cLknSskK1A2Re3Bl6zNrTPCr5rgDrnPiZHJP3L97eRwfn2iym8EsCvUvaHGIChuWWBq4XR6d+0qJ0MssG/5F7z0YAi+ETdNv4W/wmuaEwIqqDluf8x/+5XOIfUAqUullS4sjn09zwX9QqJkItMZ+z0ndKvtKrAHL9xVIvCnNpmlunR8RK4uWglwSPfMMgpomTSEQKgrdLK53TC3KxzKoA6Gvl/EvIiAsH4gy/CQIlfRJKNCfwO582H4nMsUb5f0mKrXD1nUg8oni4C2ufLDaXvuDg4llY8PT2JVFXa2xW96DzNI3yUE65fOTi4RIwNdmkf91o5/MypmA9o8Yl8MYvwtjTtxDYFJmjfeGdd8zPi0WKFzATtmz8pySiPYL9cu+5OxPpPchK0Lz+Bh8xi68X/RS2FHX+hPf/8AomYVj/oKjoWu4eKo21UUxOq9vrHggt1nvFO4v4l3ERLLSdcJggf/ABKOP8hO81K914gs6yKjLwtub236y9sV6Lb3/aGNryn4nB6RWhbWelI6xFXK4O//ACUhYd9ZbvvXidt7ynM6dNYMQ1rh5Y5gme8QYg7AnJuPCjpdJ+I34r/riM9S94LgzGu4/XzU6Cizmol62IvnH1HWecy9o2T048fMNPKc4w/EMXjVwaxVW/wgjiFIzlyQpdkKM13JZM4Fv3OIGwY4V8y1llnzuz5xGovMy3OSGpTxR72/UAZCdkTQIVRjuRz7HtHtHcPA+jHxHFf83uIpFVrp8xzjmHkmVdK7HMZjGjsRBXlHXWdxWAu2xlBdAe0Kyndxv+GKMtjcns/EufrC0mWoY/VoAf6j2iDbct8QEOmw/dxNpn8Zi6HdA+ZCkR+Vcv4iaV5z0ev/AGVUYMtfqHcsfyoc0hxWIJYoWuGPLiFJ2KpoDyENMpxlyXx1vEpLvqF9GZh2pzQSReL5YJ9RsE9PgEhl0HW69LuG6rmt9R9bRTGFQL5NPIRVZPeX20MbrUzaI+whewCCYLTDMQPaaHyIXRT27gMv0DiX2xi+h0Jmq6nxOgqM4/xIaH2lN7uPF6Pu/DLpcjYSSg0UbV3GLI2OAI91fGCj9o7wVjjfF/j/AB1OB+okoscudc+kz8kzWvzC2wh0CUfiKAj7cB2j5Uy+C0stTTlZ5oVNalczoz8UsRO469aH8RHfw6x2gVtYtXjLNQT1RC3olj4SC1kP4dyiDOhX8xZWDWj7i1Qe1dPcwtCjf6yL6HviKFpXeK1e7iHdYdpyudYLjqYO8q5aikELch1mJn2bjsNvEEjzBeVZe2ZU2TS91fmJTCokxVvSQ49JdlrR/PSMyMzhPn0T+uzNrg98BekUO+5SujTCAamrOotAcs1r1mKAKsHMutbtXp9WOuoZo3Uvg+QgC4ZAJiva3xO9gIBzVV38xpOajDDuCHG5cTQcUTqMWdT+Ir+KktZ1xDkg8SgGnVC5uEO5C9YLrFxQgeOEC+Xh6yoOHr8yWhdY/wDNmdUa1+xhGiuB+ifUuEhwx9M5oOl/CHp1en8ktf4o2S6E+pOQz2GZb27Iny/2RelvEvpYdpwLc4ADrLL+pibjF2pOcyAw9VxKw04j6D98zFTLUF3ghireqnInbcq/h9bIxaPYts7fwEt0PYlObPoup0FBHqV1LoLlGxD+Y3ur6hLcC1XKF3E1SG3+nC3qTNx9XXPiPXm+jKY+BMMQLVqNNZR0O7FzZ1GBp8xlJVzxswRetHbmA8jX0dT3p9J6D1cXCN5Y/ATMTgAh9Fz8xllsrZedvzNTDKgdHP5mX/xmT34lQOW4xDnoKjZul5vwieAYNVZq3T6QsOvftsrFbfDVvwwtloVWKMNTGTCQy4yr1Gma/M7wQ/LEE3BXIfzrKPS86HoCnvcIC3CGRnj4lYNeOcr9I2c8FbTdr3fEyvdTLHWHtMtHbVRsq9Vg15YzsNP2m5hMO/PV7sAEE7APzmZwDomDvGFHJihioRoPyR6qd9Sqcic1YPD3hRLeAijecsNy7v8AhmXob/SufWYtCMAUj8hgVYYNv2kMvbS8Uf4F0OwykU48Ka7t/jMYpdVn+CHumZddZd5rv4QDm6UztrO4vqNY5idZphoois9PZhUcCqeWIWB2veoYHo7szqGKL8wG7jOKDyEZg0M0l+9RWlPD+Y3w9Q/HF6KwukfhmP6o/wASYEwRDd74ioR8AP8Acw6Ol73tFj5OPGr3mssYvaJyXnqhTI4rlm85RMAuwO79ygpxXumoxYyRggAf54nTJZ8wAZlYuXLVKbin4vX0osYKJTE6dDnRqUBSXM2ZR/EUKrjPuNbvcSBdOJVac1hZaSpilsmKXKGiOxQyDBm9LMG3gbKx/MMSq9kvK4Myrj11C6SbfsCMhrd6NeWKmi/E9JDlUvBiF5e0GGsdGVWZRm7Pl+QamY0Kr7UlGrcqvsRO6VZS3bEl1T+9LadWeNXOMrXjmYajRq+Elp4yj1ngxV9FijZ6y3qOk6g99WgHyxQVBOCjVtn767THl1Yf2paFq4TlKgDQ6GP7MCsxxrUoFtPdFJv7w5qM6De1vD9w0XYFR3OqFm/GYd9QZBGZXYx17S66oYGnkrbyPpiEpDp1zCRbDGEbT7ZlKFm8EBbNuXQwBdmOsuqQuNGYhgsw4/UKgo5tWE9JXKW8IQvWcz7QAOZBCn5+YIpLWTT7nHuWlvSz8Ttj037bJU8R9B6xgp4AYDcXH6RLGTmskW32eZeg3NqsMo4zm5m4Xa1pd2hZqGE5+xR/U3stVhD9RAtRyp1yv2lfFIRXoe7LF7yR0LA6sMCA9YIXV8FTBN9RBkk8odaFdAT6Io4uiyyWnedhUvnZ5SolTX12+yDu6jhRu+YM0QVpd6e9RiT7VNK+I6VwUco9FEaDDV3n4hbv9bU763F6ncrw9RUvcHMuguJWaadvX5MrLiodyKorsj6QFiY2AB5IZNuWPc59Jwm6EA53+JZNpoX+JQHz2f0hUQq2/tjPCvOzXE0yLpVa+PuIt2EYPFwK9i/H1HvQkwsbegH4RIw6FzrnUSouq/SVOUUXBsMd4H+W/tM4XyZ9YztWAUOQNOpZxkdzbqPE17hwK+jua9B8TRPIrLUpBVrm8+pFG6SqTZ6So6chxN9+2RAenWUN223OnzAku8rhEOe8Yw/XWCDSnYgJ4asYb1AFe4xd+tUenWXGI5A9Tn1m+rvWZ5ggBzgIrUewlIr1LHvuK1VFvNyhTRONRAY0vqTnYeLbhOtYmK9IllkYyflDzw5KYQUb7XxGpkt1weYBuz1H0mXLjTNRsnS/uVVdDqg+nxMdj2tbfiWXoh+oHzKWycsDtw+YWdn2DXtL1rHuYlf0AzF/pJeOTjNekzCFW8fGIjav1qYYxY7Lq76JgQEAYoNfEGoSL7S3obXEGte6H7lQwt177/Ev07fguEqIXUXVVreoAqmcLcyI5OpH9St3v0hWZO/X5lawkK7yM/Up6RZGUg+UGsVj3qFUmOJRnCPl94xba7PqmIj3kOwA4me6E0uL3LufkhFslh4V65fExpDiIlQ3rZmX1CaLQX649Y6KyC6Yb6Ye9hWOr/faFeZUXTy8wKJSIJ/jxPAQL1N3mvCQpsUbXz+BDP1D7ANk9UQVjv7TVamnTSvrxBMtbfIp/fiBl0GVb31/mCEHICue8rIwN22HZiYZDN5pT/XLVTpi+/vAlZ7wnhBuU0ZFvj+6zFBZW/PO+JWntn4LFHdcAFeEWA26lXywKZa5NvPVZXOhnY78b49pj1a7cE2nDAc/3E57YIdLIAzNcxStDynOrrXHvL7Hqwnp9TAh3lrPXfpEj0qOTrWgu5ZJh9b7xPIH+3KBVZc7lEtgdv5cx821WeyUyG5P+oNGQ5ro/Es8A5HPEWgSu+OspWV1KfFH/kEDpwwFC40/mY8W5hWp+k1KB9v0I9iHFrhuZLO+DZKMBb41mZb8oNL6x94jdj/xCTfZBS6y6cbjZRuVaz7xJofxfKDInNTPcfqKt6i6U/fxKrNazPOSd/i1S404ZXLAsKwKzG0VuoUOpjOPuUhbKwJOEQSIzbmm7hRDPrRVyyjF8HHedbZTeXz4gzUI3kvEZz1nNX2lVUPU2JSqnRVjDMeN5xOgkKBcOIKz1TQdg+RfvXrMYbh1VD5gNXqTr1yu/wBQSMQW2Aguy2ksgmcBpd7iUsI89r9EdxKqOYozVLcr1g520870cSzinUZFe+/aINMVGhodkp9ZnqmrSUpCBNSSUt8IH2lUZ0MLLqicXR4mGzzYKc45lOHV1rfOcL1gopvDiewFvR8xDaaFrsnEQHdlaoiKsKXy8QqOoda78+3btA9Q4Gy+ZmiyabFe/vBpvUUtaK65jhoHDp0gqkB3nf8A2XScooozGaYRms9/7tFqqhzfDXEE0eqyDn2/7MCSrpGrPM5AxZX37s6HVlMr7S3aq7LDPnrxBVKXI1EtV46e/WHCOC/DDe89u0M4Yq7nRyU5gFCkuxhcul9qmmHK3nocLj1lBOQLvHeIlChMYzb/ABMmhro1/sYuIWMlNKP79kwUtWowqRmhKPeUFqnyEylPPiIhg83hMV/d4Kwq1WQDz37TkgCgYzDa7MekRRbyr/2GYDC8Ut7szcD1/lTQFyxduL/9imzHS3xnHzBCAVapTsQiR8TRr1nVWfuKzFW8wLqY4rT+411Q5H4qUaJbsPiWdNTd8+0CpSbZ1LE2n8Eyokqil92pieVixuOvz0mOqtbY4oCgwa3GBw+c7+IoqBYjavwlYoMrLx6TtDV8Q9khuJZd4/uk+0KGKqBjThfzLxSc4Tzf9mGAghl9CNv4P2lLSVBUHbUHCa0PFz0mCJqsJ+5dqoOA96L5lKaNQeT9RaFGTzi2AeZgj1qvYQplYawc0c33lIcqgUajuvrLlIQ6mrxpNuutlwGyqscy/J0X3H59UASg24dSV+h2QZcpWuWO+8QK9x2mcqNN7gfYmzzg+5Zku2uvg05h1RGnGed/UzKyEA9KZ30j0TmC4/j7I1WPiN/sYeaThCtLfglqsNbf3/ssNDBDiIjj0utx3I0cL/VK2aF3rvUS1ByqZlHZh46cVM9wL0MSxhx2+P7UWvQH/AwLp8xddCZ7AcW475gFcXgd5oDbQfDr6Si9l9kvugbk3YMXSq9Vy1MRQ/rz2viXqrrEA/yonMdLUPJwfVzAzEaF2+w56RfwY2kacHwTUdZbwFa716MZY5ijMu3o565zLLGFLp3eP70htiDC38wQL0MOeKl2yGdVr+YcyODx+YNqp3m+d+8B7gXd5+de3MYVcCjCe8FlF1vHqjq49S95itPZqLQSzHTNzSIKcRhzlsKZSaDBMsE6TuRpXeKrXIWj/ZjuzsPeFBfVjBjcVtX88REKMKRK7PmWXqOcN76QHHvt0doDQoS4znR0/wDYuIOhmhr+8SktG8/Oow0kenpEGQBWEoOnRi9gr9yaiLCbD/sZU8R29D8y7tE906XqVy1puka4cRtO4U3f91hWjbNiY/8AIXt6jDeJ2F5AhSSsunoR7mgCgOCWKxODwyqXcHk9MAd13FRMBg6cKvEFAHDqma/ECKTVaAMRi0WottZ4yxg0zPcY21mRH394vNlA8oc3pvzKEHoynE4QfSDqgUom6+5TNpS6PVqLCr2BVhsR4SW9tFReMNHhcrBdJQ+pGcG8rqn4lClnVsmHkGGVGOOkEkwDeKf79ypSUU0v8xRWh1fH+ImWHFrK+GTnpFnbDv0cPXlBtYMbe+oWHcBDxBMiTxfrLlVZR6MY5OA9sd2PDf4hbALSEPKiY6S+neyXjzAFWOeT+1AyHcXff6mhXK4B6wpJXRRjot+vxDjCiG+B3p0X1eszhuKXg5cNXvImNstKzRbHPd9Fcp7DURA+I7wpAENi3N8Et/Ewaihyd8j6dIqgnlNBj0+SFUsCi/DfJ3j3pDq7t0dvZOaaqXkeXubnZ5p25YLtxv5mMb77XVuXac9qSr2YPXtzGKy5dh1z1ohEC3Zxfn+/WBonBZ8+viBa4xz4jdSvd+yLUtV/9ICLUsRwHmG1TAY/UTC+TK4PMpW5JWM9D4mG+8qi9RbzYuE4bl/cTpTdmdeZhU3xjniI7NFfR7wligsKQNww0v8A4dZSGKWkPEtAW4FA9/mN7oRWu3z89pRGgbPeVOZK4cEGnlzafcpsLp1fibAKd2IaXq+57jtKBfwe05IcrhvUN9VvF/mVHgVXrUWK3cG/PL7y8UwvK4fP3GIFt4pnG+W+sHb2CjcF93VdWGKy7xIdRCvHeJ2wwOF6xztLAJ9rlNm0KpbO1+5BTiRYbI2OR9GEdeuEqDcOET+a3xuJu6jSVy9vHSKzRsxIl6DXxGXVd23XfO2pU9BFSFc9jRq61dS4Otv2qZIlcerYNp4gwv1PFGnJf5xTaUmnVSj0vrn4qB3pEQ7rKSOFoBtz/wAiWYtOxupcZVpxfHrMixdrf/ZynDaxedw7p7OvfzKGyTLtT4gjElQ3ttM1HTZDYAKTv21d6LuHgnWx9Ny6ZBFYqlBcfDEABStubgoOzVLe9+uo8VS3Cyiq65xZDy4+cfOq/sSwIu2Xo/L3WU1eE6+QmO+AbzpOhqBRtb62a6Y+yGazLDNvovO+vWxoGEsNYOefybXBYRBSg+tivCo4Tc3KGrBvhzXAUbPIRJMiDrVmgUq+vEbLlrCx8s1U3JOoJNuXnLnsW6lhYQoqet63ejAbSvQF7274Md50HPHuGh7FygCBsFiay+kDrVbKSssjv2FQp0NDT2/YS+5HOXs5vFrUII7RAqd7rPNWysop3H1XQZhoiNnt9Jbi5FG6/wCy1abVrhcAZajNYr+6TmimSlk32h3qW5LPOXMTD2bLu5kERC6VwdwV4H6RcDxsuq946Lh734/uZlAJ5DNSxcB/0T1wQZ7YbCrllgRrNxdD+6y0G15r+8SqiqYUd9Ygdtt9Y1S4TTAivF7x0YYjUUdgfEFs0qvP96yoPWGV6x0jr53Ax7MwnNC1+hSVXtMz8BV/fMrgI6sVFCEDF1CA6wDIWAvc/qlFALL8+lR/RZDb8IRvkUDtiAKg7UfceV0g2zYznBOXiRW4XJ2ir87tbgFnB4gtXnz9jb0Q8XFLz416sygYfW8YqjsVMO2tvlDTd+8ddqglt8Paju+IGyCA5a6mLxWa5j3Vh1HZoDAYqEXFw8WrKbrfVPZIpWWrq82O2iXFjVf3qaH3esq2jeVdfuNhKQOFH7zMFtlUDR/yWtywVu/bUxDdpxwGPnzM4FTCtf8AkB6CLtKP9/XA52tabbq5aj64reInOBdD/wBmtdXVMahQslR9eIqC7S46UzxtjhAR0/8Am42ERpd+N35qXU03ThySEjHXWHV28dF4XqCqqb7K6SyfZ9syWrwyCp6h94lSUtNGPOgH3B+me5sF8O4PZAU9bS33L/GJUilipX2Gxc9VfEbnEW+6S/Z07UAlFBsy0GDVFdDGWOvDWhgOT99IrwOwKBNBkdW+ou+bHJ8viXBhMKvpH9LvAwl8FAda1ltg34yGX/IqhrzCFY2waAtX95TBI0FxXXk+9CMXI1QzHPDwJlM51CLeuL3PSOImTIFfQ8uCUNFVAB7Jg73ZrAJgnSr5eK95QBmlVq7nKs9YhKzdF04ynDRb08fcSlGbhdQqxh70HpA23C+avGvxLNFroM5iSrOlcPpEmwDRb75ljnpWUJK5yPsQGmersZbjF5ln4jk22k1YJaCz0yaYXbY08HRWRWz/AJVyvLSuZ20Mef8A2NiNWGJovHPzKxuV2zvHkv2h0YRWsmit66TLVVeS3o8vvC9xLQlL3vicYiW58UL/AOwAytaXDLsfRhliMU3flx9XGxgmhy519pLCe21B8vsSiguNeOMy1kp7VTYhR6r8tBqPkE7kvJ4KHXMkFS7tqYn5KYUo5dZw5JuXJpgJ2HkPNvtA6jUiXe23xFXUy1kwsKc86jCtKt/UTBIuAhPXWI6tmo1ldwz8Up6w+WbZZ9Qe0JlxYQcGy+Naz6wO2t0Vc+p/xGkwglQdGle0oW6acB0mFNeNVeJRArj17JRvj6N/3xFxtVbyOATZRpLzXFetyq31Vl/EzCqB0iqgcte8ytxrHBCklc/RBzeQ4HXHMSjJ5HrBhVUyHE+fEHkbb2X348Z6VLniHD/w75Ym1NAZj25vr7huUFj3CK7ttjzk6Qdib8pmwr6WuRmVxQdfpYORhjydSiXLsbQ+XnFmLnLprJ9BYV8WMZeSvUFXSzm/VnmhAtHWIr9g23y5SAAQYgqWMGf71jZ995Vfk9Jy5VWbz56w0W5Gg6+YsnTqJLm1Nk4rkeI/ppo7Bbl9JkgqoxqdFM4dISL6KsB3Tj2OM8iYt3dfeD6mebIK08cVPTTumUJvXfVl6qDtM2u7U1zyvYVmTG0s+o+yrGoARPwmnu16PXuHEcbQfIX1HMb5q9pLwDPs95VW8B4OqMeSLqCbyL7pSeAZSAtarfYYdZudZU6J7xsCoso4mvJbs5OZW4LhVh3PvfrLbNm2w3tzCZG2E6On3BWhZP7c8L2BwtlK6B1uDjkPvAdGHvuaHEAHWkLvn37StDSZ4VhWtRb5kgqKs0pAYEckGCcLNOLuusu1YCGCwuOPmCW2AEF78RsZrYb+iEQsUq9VUsNt+0MGjiBhjXrSBPmuTqeLjaQoAsFEu+OLgRxIS7zYaajxnIIV0xS9bgJQXkYckMDMB1RDtX/IDtLNsxAHGLav/JKDYdYctx0IaNAXcFpRuppKbD3/AOy1tBhymYqU7qmtPEHBrHD+6xcVV5mEmGroo31lpKTJKUARrh40y9bPO3+qA6ZsrS7zUtN17emIUUXovguAYWgTLfTtHI1eFeZgAMrycf8AYZibDdktitF2Ux3dqG7zWNzCKqpaZ/sxJtZ2dY6UBG2krUpr6iOhM2SgPhL8UUTgzVuS/HzDxlAAPTj+zLQ7I6O4c15p9NzALSh6jnmvPyESGpWo+71ZXRKoF7j1DHsGXFst2G4D0kUV246rK7l2HLwyae2Ivnk+EiNOzVr7nQwoY3mqLpXa2/VHBNF2UDY3dO767O2o1looCiuZwAis6fyQEONOXnrMJo3/AF+oLtwY1t79ZplSrerf5gxXcDq0QxumA4+pYgyo5cy5EKPBXX7lC2y6Dot2MmjFYmykqGub449eNQ6Lib93zA5CrF2DZpj0PPTBEMUbLzbmOUilABY4+zDsXmFbI3XF9bpcp8RWAXBWui8M6J5lfDEqXJo3utq7RHTzwKD0SjM4jGmwsVXQ99eUgFIuV3XH6DCrnNQB65vfQmxRzYweIFn0Gq/X8Sq7tpf9faDzdYDY/tQ1Aya/6igEoW+o+w+YDN0Z82X0iLoFkeTBWg9UxwR6/lArbOeeKjojTheP5iOA3yts8MvVClb0XK6nUGpW7w7HmpaLL0E1raiu0zXSCvSGV9R2T0OT/9oADAMAAAEAAgAAABAT9htSFI9Gd7SVqteZDpAVziffHIP5JplE3iE5OYQj73HG9LHvftlGHZfJ7VGPiVY2IwtIWSZtSFbPghxwoFjd+Gms5v8A2a/Jg77ytu+xCN13JZVqWSkvx++wJxT2+IO4O9f+u7LTe2T/AMtmmxzAYN4ZOhdlVJXpWCpnk9PD114BycjoQgfxtfltku9g8xFF7gILiNtfkDGlY/VrX+DahIP40PUHthMrekklBm21EaVrvlDCAVhpqfP8wYGggslY6JpOV+osU8iMfEcsuCwTSGkgRxX92hxy7/6a/FZJaiVfvTKz5voVW0n9j0mQiDKpInqLcJegK8SVSWfJsV35CchpHSfVWBhNFqNY1V1iEkkozavP0uO3SvWf6/Sb3S/kpB33V3OlBrlfobPQTqlqxxpJYvNXqcCzZAnZj9xDjO3OzRN3W7bFJtVyx9Jhi94UTorOtEBDthADz8sYB8pKPnUGNELX3THmBWW7xihiX9xt6N7icN3mP/l0O8nixDczXT9kdm6+7b3d1AIKDbZ3ouy1xO70t/eVzwIZkYs1IMqtKVGsxvsD0nV4RlvMXWlVKTIaEboudH8DBSAN8VoqWTR8Izmt5dgPuy2fXoMnG0svl6CPclarLf2XggoqIl7+RTwZ8eZQDvpxh7hCXCK1x7Sado+Ylw9Zy03rHkU+UF5gdL1L6gl9PBWRCq7uboYJC0seOTiTE5Vz1IJW9F4tpUM8Ck/060wvnR1c7QhgTcCnRFy0w4XyGU/t3dMFlsMhmHXiwY9B6wHnO7bgrlL8YtdeJbOYDH7TBPH9h9FHbdw8++whXXtxeCwwGfBjUkpjaX+yLKhczLPiC3JFp8XIKKkKLibMWruaiLHbDWH00cCi923QZ3039LTU0PovW7qNEimNMYjveDML2tT2xAExYu+UeuBY3aR2JL4d7oSMWsHreOARMweKbqi/SHTOOePW2jf5U+WUch3Myq3Lq2CDsnF6rJ1ak77ynkZfCJTo49gaOzdf5+Wn6snN2Fgjo6YPldX95IO4cPrLX696izMYu9nvpKciVQSOCz73dNYx+bdPMsQRl1L871HPJD2SMlr26i1wVjFcTby9Jyz7mzio1gygkhN3IFvKML60vtm0fvq4WwbmAnur3mtzC42vjUxqpODpOthb+Pn2lG6/v3flg/8A9nUUP/xDQCzS1Zz23IeGz0sEdtfuQghGRaI87L9l+MlUMaFR7cApPtri4VgETkNPdqLEzpux/nixArsMtBkXgofarjkaxyTdFsMIDhxzm+CEcg20t/Tip9cINtDhX5GGWYmT3q+Xhop2XTYkbfoz0RHpOEG+G8s/EdA6TX+7jTqFBiAEyYqNeDcLONV2N8j2+kxQUkjA9oSzuxxE5kFhtAiQUS5+tVzcIDCCSmQ3ddDMH0VjwPupMoNgwv3fnwR8Xd4j+OBulCTrh78nq3Y6cZ2cXXfpdF5AztXhV+gkpWFD1rT9VqbjhqTqjbvBLwDA416Z/pc8KwsYc42eXWuhu7wNPdCItiDYbMYzx+fgNa7riG8FkjorpwpVC/JoBC52CybZjwMk1Ib0kczOYof/AFbhUmMWpvgUbTqhWORKKw4431y5eEkl0uF+KxsGLNxcfp/iRX95zlqrKHejPi6s7jfmovtr1Ztx2CPSwp60rc6TihSwservneLewwHguQCviLqMoe9opBl7axYCXc3SLQg5OmUiZrgY4dDe+yqPLZdpDFckRSJCFMOLIuNpMGynPZ4AX8vnSKXBq20Ew8//APSTJ6hhAZlwrVnYd77DoivJgV2sSI225qsQHIROnA3cPDT6D8FDnMKL3Pzo4TKVvG3QYEnM2NWFXlXgqKKKUH/HzMa0V8dYINyKkk7eqk2MgesXurHcX3V3sku/+mj13xm12v1c8HFftDl2yc+0jBgyl1rOj07ErQf8NWVutn9cHcmuyok8hC3Yi93/AN4ohC2iB7RAXMCVHKvJZD3ISMjDp5atmJ/8rUk/1+MD/wDIp6bplxPijFL6M4GLR1Asuuv3xfKc6rbYXxmjgAf0h25rq+NpPejMMNmhXx2sZt66EFu3myRgrP5VAN3iLH+0WxfpCdQiNc6i9d6oJcdTrSTjU505sOH8gcEiTGaO8Yu3EkyNELNHFsrwKE1xxVNC006D6DR95ejH3iiEUhPMRyzR1wGZ1W4AroJHNWWeQcfz8nvbLp4f/wAa6jKsrytTAHFNc4MdNlko/mwdv0YtcnJWSQ2GyX0kSc3h+6v7zbJMPHW0f7ZwIOmKwXcUT2e/iUtc3FOeOsuAdeQZB1Ib/wAUbW9D/ZnWRUJ9ehjKhzkwG2zrSJ7gAiv3Bi2qJ8afuP8AVozhpfm4pxlCYQyERnLHsRh98mMDpYn40enniUW7rOHyRxqdDkSPpIp3j9PurHxTT1fowb+ZLlD2rm3Djg8HnaoDa/vAprkXvDExIFjl7XOGjgIZjVd5cpHPqSqIamHx9eW/99bnbvKEMLgHWC9mAoyN5P3dIaWyN+N46TVGLO6CjawdPHUkqma/boF7dfC4SZ536K3Y3td/x+93R57ZP7dJpOrtHmvvghoYb7HpoNnaVvDOpzupMbapn8YGKpjPwflfOV4bgIptR9j9DnB8TKlqAqlS8G9Yz1GTOAw69ntNJGtZPOZGL4hZx5Cp0eHeDmTudx32dYEiz29B+LfIJRoh7TqjbONRv7l6lGvATjAwVcFn775zWQF+Z4MUv2Kg3DQPpjvp0546I0jKnlwk59A610aJSPP8wtU6B6y0ni6/xgj4nrHVNvlACetMwgnQ+/wOdhPK28gg1cWrC9N7N7qJXl3m/EoGB/KIJwlv/8QAKBEBAAICAgECBwEBAQEAAAAAAQARITEQQVFhcSCBkaGx0fDB4fEw/9oACAECAQE/EFkRN8jUEWXXASxlLkb8CKzGYS8UswIX4l9wEshFyZMxDyXUd8VAXUqoxRuO38oz99H3l8H/AF9f1UsljcE0cTeNXEQbTGBZvcFjXMDHwiJhhWDHyNcXCuCTCCA7iILrEGEshwQPMwcLMG0w1iYSaxLG5gmHA8S0TFIliJzaQZBu4jqHGOAuXXAp8ApyJXGnfGjxSorY+IE6lW0o8uP/AH5RTBb6H7ftDqXHgwfSNZNOKGDWW9H943DUz7zexLlpfcvzLscAiBTDcYkHgMwOoAEsXUWruVYnojaiVbLhBO5dJhRqLli5gBivbB9Alx0cOI+BXBs1EJS2KkW56JT8A1FMtMkPOAZfFSpXxDU2zKggSku1HhSjb6QzKPQy/o+aS7q9XL+j5Hzipath5QdpQhJBi+pjtv2/cNWH99ZhF2wKuKW8VepYhm4PcLuIIDtFDcAsEpcTHkgNRlxGUO2ZoXAUqDU0vUtFe0WsMpK8G3CrlxId7i1FYMY6agWiU7Y9ZX/7/wAlcGmCYFcIdxHUqV8N1qXYWnolkpKSsy4s5XyOwo8uD+9p5svoft+hKMweDH/vzuO4RJC2IUEAWX0z/wA+8EYfXP8AyLmr4vBvcAMzDXF0RO2Zl8ampaqZhFmSNmeWDmO2VBuYDCVs6CCK/wC7iXYlqDGGu4AWCpiVcyW6qZCYmeo8u3BIXlralzRxK0rhBiLqN3cuNXrx+57X6/8AIX3KHJMIXWIL3wpd8VcpwVKlc6mfhuEqNkKUWxGsem36H+pDyry5fpo+/vGwblY9iJHigvCBaLi4dQMBgI3VHOJHwQWLvc7ZtoYpjKslopIweXFnC1xFrEtd8JkAhQdFXKcsOa9JkjUOxhwqmJC4ctymJ2mZWbkiG5Ydym5holzbLJngiswjEvuJWcwyogoH1npOA2imswzFG5SLepbgd8q+OpUqVKgIF0PLg/vaLsv7D9/YiDQeDH/X5rAhiEuCS3B6y/nP9/dTHGH99YWgchcZJl7MrEdxBxb8M7IsVNaoWopsuWEqaJZl3w7Ho/8AIYJXGgu0gQV0DywauUuYZaovZmgS2tQ7qOG45/vaClQv0Llm8GL6ihH0xAymkf396S0qX3hLj1fZi8exC51fj9yyWXEp1ioackyanYmGRiPUzlSuco1lZxLchiErqIY3Eb69sv6+8HP62f8An2iNlvFcakgnL9P3PEr+/tTLllNoJNCBgGGYFSpUxxcQsR2zPcuDwYmUKQTQuFC7+AtcRaEEM1n1ldRqPWTHolF1Z1K1RKIFxClwd53pZTKPlDcMwodJft+/zF4EP7y2zss1yIcxNWsAAev5hMwOalWUQGGNVzd8VBCOUsYiAzHAgVvEbgpFILlDETqWsxOp6UFmpimOqIOJV4Hr/XPUPt/37y0pg9ITSQlFrjEosv78RXI+uf8An2g+0MFgGYfCMGMa4VYgek1LcQkM2mJJS4KjZmXKSXLqNpbLudyuK4O8x4C4cYDUS8LGG9XFHowXctC1AYqKxmDuO7lS6l5x8orxF7ZSruFdQGhFKmV2ikQivWEMOrj7RVnu/rmWNssXdr6zMwZIeeZ4JeClhlFAMqaZpmUPBNRNQWQpAmwEB2v2/cvpr8/X9Rdti4SgxEYCOMAaPrNVqHckYQpBXOlRS4PiBRdkqcw42JVCjNFs3GmDrBPZBEYSuAtoiKSNQ9jdx7KUb3MBF6Xl/wAgFTMQAh20Z4ValcXQH3j2SEsaDE6JcGtIgvEbpaALluPMtaiZQxHml849Flsdl9WG56Vv6Swndn0f0kFEPHZ+eKkxhRwxYM6Yg2ELM90EuplmCWMImM4JVbQDT6/1S9jB5lXC0G8wA6iXhhwC4BGCJePlANStUW4y6itqesS2lqloDYbP96i3Uy3BamZEk8wloQRbB6ms4CtQRK93iDhKymDYDuNaOAjCTUuNBDcFMFeMIX+4RdRyCVqYBBlC9IEC8ReoQUINX1GrHBidsFO4zQmZU9TAYyxKho+7AJfM9It+YPpT+CDNQgfqfmXCzCBTUv4mJSRvsnQEdhAIoMy7iRlblf3jcUoL9/1/2MxUqG2AdsKNS3UeeA4qYikWpZHiybSXikjKuFeWEUUS5UmUliiVKIOx/wAmt9b9Z1CnpCdkAiIUAJUEa3uXzsMTwoEShhKPcs6lJZtjFmC+AjN0pzAAoIFzRHHiKtQhQuWOvlGk0949QSvtPctccJghRidiaq8sNzC0bPSMZkK+W4XWGn1P3ARi/fPCECa4tuovqWle5SqoV7jjKNut+ka4Fe373F7qAObiOpVbiTUEwpuDcuDUBBqXL+CfAAriA9x8pQyTqBxdVBUgYYrlDTMlrQuFYMw03MMbiZ5HIgHzliLqOEFdb1Fj1e5j4FdqpkVMG4Ny4m7iNJdtsvMowplQ7JuupbKqqKhlmZC3EGY9VBaYo9j/AHyhA15YZZaSkh4NSmLwuybQfnFUzZwHFQicBypuYDCJeWMJdET3FW6j04m8CjbTqlTJDDNRbYcpeIcZMRAzHWEQyRsiXS4g3MhcvE1C414VWvfqNypIpBlglGmmAsKlmZSkMAQCGJhmNtErRckC0mSebtagKN6JW0xEP4QsMwzEOpqXWYqGCufKFDUaQqMu1SlhQmoBliPQR/r/AJAYRzMCGotw4+7KqPaTxAL9SI9wdHk/MxBqEIFyjuY65pm2WNNQXEI0mKMiYRQVKPDCVEuCWGUIrkSoLJTqCPmdJPBg7QTCQy5jH4lVqefoTBzBBikgBBDAwnUsMRInmUMBsjKSdMQF4CtcNVLUULllFqVdkC/gRKl4hxiZigLlKpbAl4jmK2MwUvCN0R2O2i6pNMQAD14WsTbGq+UcRjX3D88UsMbgDULc4l1rllI4lRIQHAQhl42sSUwUZQIpFXU7UDcNAlIKQa1FjiInaH6eIS58kS938z3TmAbCIqghe4WyTdIy4gUViEwENGYrIiVEtcWmoqAEuuTMXFcUy5WIEMxVmXMMYcYlQL0TOITuJErgAlE0/OMRa8QgL6RhVUuMylQU4rWJNSyEi5LLi1GL4YZmoCDDmpRKJXCjDg04V3KR8JeZjtfcPKKWE1HcMFDGiKD7pBpiJxUIKYXXbLT5RDQ3GylNsSscBDWpfiWQzmHBbw8XAg4Au4S1EmCWI1pRvuVqZYiXLiGk9/zxas1e5ZgSJA642cYlweB5tiyokTjLuOYIhA4XxcuDfIEoly5uUwIlsS4SQCzO4DONdRCtljGohEx5h2WYMURgpiu7wgDL8IAuGr1lCjLxLXpLC4k1CXWuLuGHMruLNzJFUcwLYKw3GgqK22MAmIuXuJL8QYEjjQASMYpFNwSDJLcbvkhCVKGUlIiK4US4rxdc4+Pqlkt+C+BIMuXxQtMCwtqVAHE9oClrDtcu9y5LbJ6RMJS8F5AmeUtW3NLiCIysVAqXN8qWm44g2VNcAx3DbBwwLIjpKVVBR8xaiWx4gCmILUcAW7uVAuFHgTCsrM50wVlIWlO+CsrKeZRGVWLwsjhFsFBKSUdsAJXGebj1Ns3yp69NWfSIUh9JfxTKSQDa3HpKJpEO2JcwFimiYgwuUcsyMzGEeO8gMuNwtr+ooAoJMzPUJVcdSvWBbiDccGJa87iBMlxcQbwozFswtxLiSmamAhN98BGaC5UoYsTaWQo6lvRL7QfJv+QXxLdktdzJEliWoHbghfUplXy1gB1BSWu4NQrASsrGVephhXlDKEoajOo1KfaLTUDgS2yFBUCyRa4p4aLcwEylkwY3AGAz6Tp87ZmGRiqljUPaJBm4FwwZly6JqN9wxiX1wyoBuMFwc6i1CbUQKgNSwlthxXOZWqJVUFM42rzLVwpqXJKJTqIS5sj0vWDcRZqeRg0ClE9CASpUzAJ7S0ly+MxuUxUgoqR2rusfzLaKv2/c2wes0hLghQgKs3uLeZU5jsksesFSqnYICL5TMGyaTFVtiqxy0y1x1AaSd6MJoFagDbO7jEnRUpmefaXWGYYP3CwylLlXEHMESyK3BmMoZly+Dii0LMS974RT5WLIQADiyXConglPoTbEx4Gdwithb1Mu55JYlpbgvFHCpRKgVFIBzLuLqwMUg7YNgZRhALEVCxBWUwQcGLuDcRERIHdalefMTkFDQo+0qyMs8zbLDYfSf1DLsD5x+UgeUFwZP3MGA9bcNRrhIL3wpK6hBFUyu3gM5j2TMkrAPbFBc73zwuzBGGYhmbPKC3cFFRWmaeKtE7ZQsiiyi8UdQ0S3csadJL2WIxcalcAFcC0rxL4xKlRJThpDlgkuK12GVsl+v8y6YvBqGc8wIutdw0JUrAynUZt1Mci/eMig4SB1loWYBCvVkJY9QrO3yr+6lK2h60/ff+RA17HVaNh6sfeEa7CV0xZ1vP1m1AN/83qVQ1Cu/N2fdmNa12ttuMzDoKb+f8xNK03fz3MHES9xxqBdw8yBpOsS+WLJUuouMy7iqkdBhkjAP9jL31iF4hTcol4mEMuXLgascRlR22EXF5laXEIYQMnCKlwMKo+kPIjGSZNQuOFS4SkrFjiWKilh2ng4lsVlsEdQNoaoIxSUcQ/TPCnUIZRR6TNd30/cCUfWkQ0T5/8AIZZT6v8AsHpAehEMr6EO7+PlFO/rMr238eYtgvur+WFbA+UGZz5wZn9K/wCR0JAO/wC+8fJ9pR5+36j4KKdfdj7IUljaI6uxx4+cVQLk7T6H4iXECFEaeBVZMoMRA1kqURlPSaJuGobA+WYUMcxAsCSN8BYhjUCKm2Ew1K0pOSWospLNVEGuKcNy0UwdXFbYVxUV4q+pZoihSjgFF9Qi8yQ7f59Z6oHC3KEnTSmAIKxVqF9EeIW7gOzPUhRmG+AdT0ICXNEXtiC5flVa1Xqt5PMsZz4bH/YYgj0H+1PxkF/Eapj3GB8ShKY76mHD75/c9EmDFplZoBnrvpPVfSes+kS2TCC8w6adqpa9LxHKXoNfcofmDUR4Ew/6QDrtaOvzj7w89HxX5GG2hOmZkOYY3BSoQqxQymGIGwC1UFMwHENIhBQYryyrPMurZngbSLmAUfnBKpZbYxSMUkqTTXcVpPtBNxcWy2Wzqi7QUsmGWFx8oCN2ofADM6lLFcVKgpUpmeGUslvQT6MyC+RKFZxEB3ENEr7n2mznuE3NPZH+1Mj8/E/H+y5hfen3F/Es/kD+whdK07Kt9Fis6DSOxOmFFMbM8gIvzHoT7x1H7sT2387lBf2K/FSvS/vr+YgI14T9xbVz7zYGIFL2yfnHuTNydbBqrzXzzmKV7LgMBRQ0+koZc6BFdEbqYXHcqswpBubeNXBLYgzmmuZEYqpmSbIJGpRKJUqXCEo9ZnSFtwxiALNEKsyeICkXkeUXs5lZVSxlCNTLFTvU9EJZqQ98USnmUeZR7hbUu4CUSs1DSSzEsFwNHr8hDUBWIWWwikqOIhBlR/DdolZqUvExt1LlsA0zyYBEeSJi5X98mBV9GKkygxDr+mWrSAG6LbxgsphAwTBiXwHUqBm5vlXMD/dwUKRF3wPENxDwF1kS8sIvMzErQFo3UFQMNeZoU1eGoNBcRlcrmcSojTLB/soZYqVOqjFqLhYhoHqIVCzEQuK+YXqKjLMKMQpK2iXBtTtRqWCMx3RpgYN1xdLCSfxpleJWr0Tp0M+xGzs9im6jRUVil/U76g1s1gTetPdle8GwWR4qBiBibJ/Klv5Mq9YwRUqVW4cbJeBhiPyv76wRT8mJYJTWPl3mXVa/MFJ/ePeYLlsnUO0Ul5mg3wuXLmyVLC8dC47XD5bVKuIrju4ZlxbrhG1HAYR6BhA1AdSoxGX6IbU1HOYBVwPSAGsQUeqKHJEY7hP8FGwpmWQIFqy1rEKXgWgyxllgzEpWUFpLBDUZoGKRn/aZRpRPedFerdU52PBVQ0EzJ4tfqVjxNegi5JndadLqCv4cIkqBiVKxcE7tfumE+VnzkxuPpFUy4gMBwFr/AHZFcesHwf7+9IjbK/vrDFPyZQmExbmqX+Ev9fY8nr+4ZS/7uJswDMim2KGzh4Js4KGosLbmbOAFMU7oKXDMplQPBgLDLUzFeI1MwgS1YrEvOgw6lWJewhczAveoSGCiURl0EwhrOINquWbvEFLWMkq4AkVcQDpgYuBizMhYwZqEYqmpYbmaCf0jbC0C3XNZwN+jTDtinZyA/wBc0emPWAbzdhlqlDhs1d4uCBZDtwZLvRq6+cZNttPNAuMDhgOeIlL+FlHzZcPf8zU+cbSU7ZrHg5e3/YKXqzWHXT1/fibLK/vrA+gMahg++VKW3a7HTMwwxqQwXMVbLly6ZvEwXGIgAgwTdLca3UO0E/Hx/wBlGCvd1UPqYahsgIAgbIgbTDOG+CGx39pWT0Hf1hCBQKqJX4JXAiTBFB1MIGHUo4Za0jq0DFxJcgxxiLzWNhFdainNdy5KdFzUAe4r5mLP1mDKiyCZIipiXp+GWd4/3CG6bo+JmUnXkY/csfOPLLm0xqWoWaunGdHFRMwIypdvT8xW3q/LPlCWp5P9SxPWGlTSJZk28dfo/hl18pkDMIbqfWx8mOF/lBHZKUytniDIdfPZ/wAgg3/2FmonnglTsQU+Ajc7SJVs3So2VHKmFGY+buFXIfqJM7jEqB4i0G2LVaikF5jkKGd1cqRQRoPiIq4AdXiN+pCjUYtI9ambIX3M6zUXMFG42HWAXMu6hMTEOUgmsZYQIVjKWlCFkOhanlUzhhgr2ZGndW5eO35QqYM0KeBejIfLfu5hbAaBNb20W+FJbN6kWwFV0KZry+Y50WS1bEq6BBK8WcLLlywPKfuO/efzBQ+kozyP+zQ+cGZkL4Cm5peZ4iD9aP3NvCse/wCoRjqUMFY3Kky8uaDKsz4QUjiNjkQxN3FhLmINTbcGXJ2gKy5DMyhKlY6hRUdyXWJaju/SVRUuEmpJjinfT+mKIET5cQTZHB9JRdsouNTBAUUiM90VBiuMIlkiBS5a2XHKCYitmXLuXAlgAy/bEXpBTf08x9VB6txFWEyMgi7re2WYE2QFA1eVth7fLdPlaJ5qnnJtuqLUIg5KSxarU1WyXtKLieZA2JaWPRFIaQc6tY8Mq9Xf99Zl7r+YKH0PxP6+8MhpfmMI/j2RMBxlBkisep+ZQXoP58oLXD2lZljRmUS0ocTMNxXaUyjEZ32+0Ix5sEBtKCYAOFx8CVzcPEB7Z+1QNH0X/IImIWENoZhMQvaJ8ApDjKodouEV7loweBzNLCGGLpHUYTB6pTbTOFy7LiOcsC5SEKEEIzFf6QD5feJEcXoEEWIthqVneOkJiFmQ89Pzg0s4wtyoPSJZ6ZgmoptVts783WYAwSKaMANkAnn7m9lMYEZb4p/fiffP5n2B+IP79YrTcNK/j3gBl9cz9WiuPlS6DECzxDCrN3V4PD5zrSU+nBajNRKaOH3RUDNuLcbm5YRR2yrWGAafzKLiIgzDlE7jsEiQTxYJmMmIZUZB/dR28fsxk4R6EUCld8XzUS5Re4lQtnXUuKcMFLcyxVM4m5kZVq+Xbz3T3xCF7haUx+ymdJ9Rm6vc3FPwQG0E1XUWZt1mLshyesnaF4B2rA+cpGgCcJBgNGHqF4upqOhrT5P+TswVuYDDiWpgfOkd6NXKLOEsZbdPVGx7Kq+oxly4wPBHfvf7NT0jv5/5YYJ08c2mTGdAw9LpjBzet66uINoVfaejLnyitxOphqOFxj0juQCXRhhqUwTO5lGBbG8/mdIfpGOFhMwG4nbEuahlmT7zNPIlBcVIl3LzwcP5w5lQAlJHsoV4r5PfvEp7hbXGBXUGI8jFzGVcpFS6AZipqBB6wAgdiaAtfYghLKhq7NlbjZgbEplZlbljcxEu5QXUZyTC3zKvNBl0unrvVHZuXggVA13jqi3G7iBilvulS/SzXlCdgaXiiXV6jjMO8S4K6811fO5pL16/8mS9/wDY69qFf6/0ylArX93AnB9yVrhm8I8A5kYo3HJTPQj0PACISi7GLFg7gwi2IvcA3EiTMyozWZ2MY3wztiZzGuo+sKDD64mI7g2rO+CHAwqWcFEXKmDLIR7zGoksBvPiPBceCKlBNTeDLoEJFsYauvTzb5meSI2Lzfl9F9YJVSo7UOl+5/2M7mWIl5hchHWeFUVEKFrDl8bhRBap+UbL2e5T6zcblWoQUNNko3uZeR6PIrV3Qv7wTwLXD6vqqPqY7i8ARUXL/mWZ/N/sxISurH3ipWnRaeuIgRv1EfowMNk8+Vm0dReGCJjMR4FESU8VPeDUXmIYjSA1ENxKlpAsT0YOiInLID5OKSwEhwb5WEq5USWloqGVHioAoZG4cDMlZWebrU7RLdkGlxgLNLfbD4+cJGTFPC+/rM9IuGcdCDjG7z7zNN0pftBuJ3HwwHDLyXNwndsfZlE8A/Uf5O4Ify78oUjD1LF6X0aHJSy1Xl3eSP6s9iw0+RHwCjfNTqekExh+X/ZqhDtC++YzFCJvKmDHmJKgFAoLqpdmM25YWaX1TIBItnK2bxVUbY7VKNiLASFgmWnu3EUZaixaYA1bj0uVv9UMDUWA3dCiu27i4jNIxmkcnFEYSxMZaTJLvcII3B8QiDuK1iOajTglcluO0DpCPJv4DcJiUx3RKw6shQeA+8EMR+8S16J2Q85Z1LjsTCyuCahVUXSjGfn+JaWDgZKc11eK73EVVXbp3r13GfJK9rYNM3DsPb9f7woHgLX+KY7FIzsRTz9PeZJVMXai+o0eJ5FH0RjqoL3xv3sPjvLVSoRl39GOlH85iy28D7n/ACEijSFrVYCzd+Yx1BdCIsQuMNFZSai/dwIZoafejy3K0i5qm4spiJaoNF1dZ8zCBC4xjNOB3xvcSuElkYsD2i+kPpPcTLSecIKWMo6isF7lYc8HXBwpajxKkL7+E5AY9nUGznzFIWZMR3ZuAIrqAK3HcLB386/yUIVd/av2S2LMJlG8BlJSYxPsXmlur9mNBAAXY929253qvEtDbFvxS8/uKx8xGCKlM8G45jgC2+l/fgpUeU+3fieZ5hoMq3ZCtOnCzE0RpXkCMNvGCKuZpstG46oVawr4gSb7A0x1XkHr9IwYMWVLzX5jzi/dKYz3q/iHONzfj/UBi5cKZCC72OT0KSCGasjjtax42wBcUshQdgPQyKtrFarNVrAS0YDVlFtkrFwTaVdSjd6u69mUEgyIyqTAFVkL92oiCEDeBkrovd91d4gcRwANFeS/TJhuVnghU8glZwTZiCyR1OpaKTCNpfKXGK5957PUqvmReac1+nv2afeCVMxZuI2hnIhiFjiGLjwx4YcfJAsTDiofC2qIahRKo1EiulSllJbMvsr7K695WHdX96/UeAK52/r/AGZKZPlj+940pD3ICWf32nyERVFNzcFHOwfyepA11bwiV7q6vGXddtdJWjHgsH50S4rpsiqZBZnGJvWLY4pR+kOT0/h+5i26FrEPoo/KWjASxVFsvSi/vESCbhYLNnRrHlZ3AoM2pAvAWcd6pm/grfJitEX3RwlfgMJBTlrda/KSuNr5NgDALaMeEka0LXRddQtNsDhEryXSvQZfEX1CHNl21jGcxMG9xUFVhkvR7rgjodJhitqmHlirixyU2myuoNnqhhiHMUWWwrBQDxqJcvh2unJ/e0+ZVEfmZsg3VMpgJpckthInJKlBLxfFzASMFPSKqFjcMsvfK5PAyebq9PVwPwWIVL4KqWQUJRUgljZGMIo2pK09X/ZgFLEVYRH7kr5QlBSlwmwhRSEt18CafR/EccGX3Apf7hL87I4aRGxGAjKgc14Lun211BuLBiwYSn50LgHxefpuLdo9Q7r1QdFV79c3+QYldu7sM3ZeL8N/ePhETRyizz4epcVTKGkWojTu849pYttVXRfC7pq/nACoKMGbyN/J7XPmAsRQt0200KenUsoMcAcC1pbbpso2WwCDYHK6vp9Ts41FmC5dRg44m0b9xemJSkeKIN8MRtieJV74Qm4qlxgxqkfaF3h7v6uUqR9n91KYIOmD87CQEx/3y+DavoFrAmqovB/gLfVeRg8ViKlxmJO4rtBpuLFy2K2ZValBsiO2aw/OIlBXtFbYnbHHZExqfeHJEqJMwj/sccs4JqMrjxu6BX2C2EG/bvnx4E9LF862lGaWuKTqzs9Xqu0lA9ZqYtW2NX4fq3Fi1LQNP/ALT51G276uvyfcS+UvAp/r9WItq3gZBFMtLxctwRFJSELrB6sS9gg7imW8y3mWhAKPpKqKHCfGeU2xRI3iAhU+qPtEbVb5sz1L74lwYX985g9L64D9HD3Y7ea4siB1+49bQ6I90SzENEpvUYZuUupYljqV8SyCTDEQDZ38V+XGfrUcB+UH+zJJfv8A8qYkV7cPvMNDwT6lR2i1KzVVVeLcXhUy0FsUJdAI/wDALr51K1+dcDbG8H7FL+dxTuDcosxF4m4KYJ5CWl8LXC7i8GZioi81Av4BkKaKX44dTUW/hpR6R0JFmLNS4O2/qEzN9sIJ1j2ZsmPe5ncKi+rz16xYF/AvFEqY4IwWRtKVx4cnNXKOBbUBhofAQgAV3nPvn5YqLEu3gcMnReF5QOv9jD5pL4I8q30KD6ssxS6GvsB+dxTLQZfHaJmAiw4D0Zd3LHYRNhK9T3cFoibl1F4LQA4ojwqXwlys1Arl3KWeqBSjxLV5jUXqBIVcLrR9x/8AIMPzAwhePpNyDNYNp/sAh6eFourOCyWxZc1jLypYrgm3IW8AqGUPhHhdQazBrMBGDZO1dX5rV/KOhYpMSiK4J01Nx9IliVUCKgy7gnF/FdStRgXLrgzK5TgeE7+Cqy8PKmnUIUyzErRMH2/s4/UoNz+PLCEG5Wvtg5GoVqGHMC48NqoeUUxXwSr3KJKNcArg3Bw8HG68DXBcS74J3AJcuIAXBLmgYvJ4qXCAdwfOBek/veelNS5fCzTgxLgXMcbCFGSCywJSIV8FSpUc8LEEpLjcpTTH8Bl0CD/O4cLgc6o+0sBH2GVNSzfDyVcOUcTRKEoIscVUcyklu+GODwTNUJfiUEO46ly5cOXtwNQkb+LJlYA3KQY0lsEQDueuBZcsixNcMu4ilY/7FuAZhUcV4eGHwbiWJlZ5uDaID5pT1LWK87X4lEhw1H0iszwlxK4ANzwQ6eMODAEdtcXNw5rg0cLS45hxrO8eFDcfCJVPiKNwWq4FwZuXL4vjVwQIlEA6nT4cyiDZngjuIJd81ILcJKzNSvgoymWZeGGUyB1LizUTuGyPDBOkUFqmz8RA4mp4WEwCYRs8e8vMYOQLzYol8kuZXGKKeb37f/FdQincHSCy0uohqvj1wajEmo8Yrh3w84ZiWYk3FE8DgKl5cZe8UV5m5XHyx+IqGV4r67jGV+0uBNPiGYzSU9SuGvhsBLp7QD0RLCHiO+Rl+ZReKUXAoIQ1AwwfAV17YhEJTKlcvwCBdx6mZZTLSriiVKiSpUMRmoc3XLwQ4dVEuIdxXUv4apCEpTKyoEXCVUbb9i/8mfFVsbFeVVe7NurlxN/9JTxnk/UQdjCPDEW9Q3HfBG0eltQqL3IVTsgUxPZK8MReuRrgBVnMbRIa4WYcJg/ApFynAPuBiNCoJ1BowT1K+pRsl4RTKCFJUojaVlZZDpGvBEjysjwTvkJCDUYg86lzZlkCkRvqhIwC7wP97fWZ1Z2bt9NtRgcCvyuWhndf5G7JWJ7m+LvDKrEMRR+JTwKai3uXaxHozFKkgoGKZTeZ3swhw+ZqgzzuACyIeuJHTKQTcEYHFLKkVeopqVjKiW4tJXNRlEvqdh8FTBLlxjCma4ZHDKZUuuGkFfKIZmadpk+UUGZus6+d4+vieSoj83NmIIZjvuArsq/rwRgqWaeMmo+qK6eJOenEuoo3KlNct74ClEFsx8Jlgx1CxjiDaMMvqZvbxbkLm0DxwJ1MNy+uBqXDMIhxQyiVYDklpeKizqIm+AdxOyK64YvwdwKoh7QA1yR9EwgIztBQ7I6XpK2lnJ+peHwdduetbgivV7+ZLmkNQgD1H2AVfkECR5p7I+BH0k8twrmKHKXdwYX9RePXBdcALOBfZLGWBmo+IAWRqgmuI/dcXXGr1DylEquTG2D1FNxKIZcwARAICc38JEGagmEqtxDKRbqUgRLKTyuW8z3wKACj40gPAois+IbEdoNQ6Ci8Y6z+4kNUsfKbQepcPRVgDbeKI6QNjs99QA4lzLPSlpTOtSncpZWahhzDPGB74BcnitTxggu+MQGuEvkL4BUY8Ll1KDUt7nlwLiYhbEWUmXFhHUPKUlzSGolkERuXzb8D4nUuV8WeBUEupjHWYsk61xGZUS7xGQbjiecIFsuBpLfRpfYzNzv1BWEF8diQWXAimyW9T056cd8vzB1ct1BzbkuoyA+5600mEubi9fBkyq+AToTy5YpQxNzaGc8JcBHgVBqWwl6MalJqKm5dRXfBRiVn4smYzc1L518JFCeiIbjLzY+UpLX6ErhxFTcM5ILDNfuJxpO+qMUcBQc0DU04G83qASzqGyMGPAyuCqhkmeBqCPBGKCUItslzqdhDulVqUwJRKlc1cAZi0rA5vgy5i04haMCPC8iER3LszNS4L3FGWfBd/BvEVNTqE3AuVzfwFhQqFgRYKg6MPKYIrjB7QWnrwdoDYmx6ZZnVQAHqC0XWa3BZUCUeCo6OS5qBKvglQ1Fg1DMYlcrcP/gnsmBFvrNsr4Bl/wDyCz4ql9cL8NqvjczGEZWI8AI/ALSAe+V6lUSb+yWlpDOZmLTF8ajCxizBWEjTHMLLEqETNSq43FBiDUW+BcW/gq5UqBXwZdQr1MR2zLxncZrgYZ4uudORqLcvrleb4qVxUBIZamGCbjLOFkUuWYlmpfw3iKFl3pxhKXDyQBTbGckTtB4LFiLMFNIEbJuKmydyEo3E75vFcEMxJk4UGX8Xd9MUJcxAlVCesYsuVKJlhBl//FcOMfDXBguVH4dRtwLINy+BNETw1GpW+E5TYI5ZVxteUrtKHj2iCB5MIsRKx0zFD0gXcS7lqjDgs3uMwQLgRJUqpdQb531R5gMHzl9MIwC8yr1LqXcBMxsvr0r7ETxNEu5VzuMrxCXfK+ahzWYqi/BWaIs0ca+J4Jmb4IUS7YRQdSoioi3HU2eDTULzAxM1B7JeiwxGySDFBwcxHUES8XC0XXI18CrEx3BKxAWiFguWO2wZvfGZl1x6sMRzBqXceHG5RxdS4z3hyPN8XK53EjUZbNRbif5C0t4ltoKjtl19kpMkx6zKVcM6qJ6mEs0OCewpVSqioxMi+NxTkg3e4lL1FDiejPPHYOMFHUpZlDNQTrEvrjMCo8hcCvgQm8EAFuoNwYIB1NKIY3D0npNSoWvAV8FTJL88BM8OMS/PwWcjLhLm5mCyZio6ViKx/XDWIbDKU06lkL4mVQdSgNRODqA0ldwNI62hYBxDSlQxGy2d8CDHD6Qb4XqJRcGozcohqJYqx8Ax4FsqHJwkLMSbZWZVMqONzAQZcf8A5biU44COOL7giXE6J4cmWo44cQXUGXCiGeKicGfhM4lQ5f/EACkRAQACAgIBAgYDAQEBAAAAAAEAESExEEFRYXGBkaGx0fAgweHxMED/2gAIAQEBAT8QGoB1zUqVBngXxMZlAETFS0yjfEqcW7cwlY0gVEMrGhLXmXCEJUqXUG2AWqhWg84fI386hdux518tfdg7lepe7ZnLdwm1gmnzmW9/b995UolTDqiUwwAxF0w8H+LSK7S7iKN1KJR1AmWG48C1xUa4XfBltKOIJWqaTRDwvw2IIgyDf8BcDKlSpUqVESjmr5KRDAjBNssQTBXBKm4y05Xgz8+j4pBcq+mX56PgPvM0M+XL83MoIpVmI2IgMwVk37a+eo7Svb8/5NcmHMYomUpYC8xQiO4whS4rjg43ERtlhTKBO0hXMnuGtRTGrNB9YYnuYuK/wJEO5VYI7eJ3NJceCzcKJtRahUoZqX/6VKlRP5JfBOpaUROAraPWPffVwfl+B8Z5N6GD8vxfhAFFHAiXIigvV82HQV7/AIPz8ItnJ9fxqXhrBHwZVuVGQomkfSKuok3MsoMToZZMsaNxtqCtRVGOFs7SAjeCZBflCDje/SEXd3+3Av8AujBC7LS3iXCUxJUMksiUidpkYKiljMuKRL1KSDfDcLl//An8a4dzt8GX/PjUevH5v4PrEb58nL/nwqVHEYibVUXJ87H+/SNk/gY/36wWhUCAlERcR7vhQhbEwaZ4oYqYMswvuUoBMwMRhiWDMUzwixYHS2CGnrr0lIsbiLJEsnJForvUe6WIBv8AWLxcL+V4iHkiJTHZcldEQDaKnHJKVg3CnMGAoGBXZGmSIbhN4gVL5uXwH/1Tm2NEuMj6uD65fgMe8Hgwfl+YekpyB6QTDgBZl6mcdhr2/P8AkywZ87eIqFQRZAVC0MbjUPhMdMzBK2yZKjHNGASnAuLUuZxCJWodxxWjF7bqoybaxfr1AjMMYMbWiFkoR6C0T2z6zLwrHvLWtRfpAGJbxAVmFo6opGmZYEdTWdQpQ3Ua04j1QpiXwZaZ4BIFcqEFg3L/AIrLly5cuLKYb8DL/nxqUHX1v4PrHNj5c/4fCpUThIkoZfB+4+MMYo+v+fVgtvL3/alMdgy2LENcFHELCmCeuA8B2ilkv3cWSWZZMy7tgB4zArbVqvvnrGoSyjy/Phm7owxeovhSr6X/AFiZjKpr98wSmYEwkG/3uKjRVQLW0wX0ekvMoMYzHT2j3qIZ7J0vEBUN+kYwRe0auCXQ+kdS0dBPiQAZl1RLe6lSssdVBQXpmKxjrTyEA7lTcFgIIxxzbJfCy0tw3Oofejg/L8vjFbT6GD8/WVJo4fCZExC5+sRwr3/H+kpsv7fL83KBRqWMRiG3HgoHgDxQolyuAJUDivHGCBCJlTHAZM1K4YtQu4r3jQNlawQpZZfmaj1uWiUtE86cbhb8/BFLMDRpna5l2zWLuBLQfHW4vXFXd/uoPH0ePH0jJg/qapr6/vylRmvv+CiIa0nelmYQVoRKz4I6l3mLmcjXqGliq4LuY74DGZbqbDN6gUzAQaQMd2I3OlAlHcd3MwMM5iCZa+V+dR30PbL838S15eXLH8MYWx8kF3DQfP8Abga+Rj/frEdIus1hCMLSsFIo3UVearlBE2CazJcvXpBhzmVe4ASoEOL5WsQ+usbl8GS38wLfc8Q69a+O5dF2ZxBas/D5/KORS+/SNVHbKBCCjQNyi+FkbEW/lPg5/UVlvMRWJcxU8iW2Z3TNhgDEQ+gjqKuw39EoB1XyxKTBB8VX5SiCNjiZNQpuHdwlxLljEvsQLbIqYnhUC4M4iDUUxDUdSwR6e/4/2M3X9vl+YBiGrljmBysHRFW4HyxRYwcEcOIXGhJUq9xNQfUlbEtIO5dFgVQlPCTmepKumGWOLiBbqG3sZqaTDwo/N/7KjA5+jDVOIa3pAgL1+DhfrGSXd1X9zPmy/TzK1lVetowG6u7+sTg2qjxW4eOJx7ReNnxEuF1LpKvozj4S+2ISg0zLC3WkfYKLgbJgYwEKuIAgK6gCGl7HHr0Q4/qh7J+Rikzru32mJfgVUbGSC8bZGFFLFBUPTE+ErgxwCNXcI6YGSmXSB2vgY/2YcIpaNC47iKZtcagikBLMPOBN8tXwMuLEruNEBASQz0/1BQxKQirJUALq4htRLRrib6IqC2RZgHFb9JalSqhOyzFXqI3G36O7j84+4uEFrAeQW28/CX6o217NY9o9BBQZ6hH0Yh6vzEwDPXvCYKrETwCO5N+kswNbl0FmYqj2BM7aPpqXcQNoNWQWAzwrjtexwxo6tgr6j4WH7wwyjGap+0qYRpMzMp5mTYzoMdypYpjgQLYgdsAk6G/3zqA209D8v4gQFhiPzFXRFXco4mKosFmWZl2Uw27jsJhLlsuLGIqkF56i1LlSSlbmXEoTCe3bMzC1V6Fav97mYAOXfcperD6+vFRqC64dQrGycDRfp/soMzW17fa4921fvHS9017xVLNj9YoXeJVRwRmbcQSkW2ZY0gmbGU1pGyS7i7IlkmEpcACzMz3QlJvXcSN6q5cKIhD0/P8AEoMQzlkCRkeXsRm/SufVlKcJfx1MDMh4cxzSneKOBI23KQp3Ae4giGmZhY3MkE5IDsUfP9+sB5N+/wC1Oi4ppIa5g3qDZYgiXAOMESIJnhXBzkrERC5lqWhbcWpcq7iZi0wQVFZpqDaCOTe6xtlAKbaPj7zEbqo0vB+3whPB/ngOPiDGrM3HGBKj3AR3MwCPsYZiYaTS7ZrJat1CxJ1UAB1DSWtIpBIUtcxlYnrEohKKbMVDQUbxCStr6Ro6iJSxuMEyQ8SK0vgjEJWKzeABzmwwM04IbllMpLYtcLEtLTHj6oOIlxdXLmoU1cFcvgiVdzWR7v5B5VR+8BM7ljcFbWEYYMlTKjEwgw8wIbUwHVya9neu41FhYxY+COmbaP6gBTkixwNU+twjBshSbOqf6gHce5AYqBhxKAZH2hsqtlPeOTSGDaem8CkJcUnVsBDaFtR2p4mS2LCItgZqIrI6VNRhFW1GYy91AsPAYRErk816xe4b5armTmHrNTd7EYFL5ZX/AGnybiVVGR9H7cVCx4WpnlcpBQtBHDlhFJLO43lzHKeUISbiaj4zLHC8Fc2hOWUmWp2kD7iRiIISeEUGL+5hIjiB7tn/AD2lgNH07hBlXrLuXL4ihjef3E8Ya9oTT7xSsoa9+5gQiGRnZcpgWF3khu/rCKNlxWYKhdRiCXCRhY3gp4sBxB7iyW3CVUpzWYMW9QVdxsTplIqKozEDocTJWcPuU64+/OdtFVfBOpb7zBX0Lfs0QCkoey/aXwkZaRj/ABGEJcHhcMRTFqK4YwpuK6gnfCkZMoWyoAbljEZiu74nG7jauUx3SUna66fN/OZELi6+cEdBv+/hEY8jR7RAClaP+ylLz9fxFAHJimJ6JVszRS4fj6e8x9vnuI7yPnKkHUZnK6ZcGqnkp9JfURmnm3KXCvguONwbMwLwyo0qlkW6lkzMQGlEWxtMpwmxinw4JcsswxF4yXsR1CH3YqF5PtBUWwLxOqBnqS5dwjaMLjFSpUqBAv8AhlrgSMuXLly5fAQxKYrLvLdg5XErq6PrPbZfvygxixKVZgnhu/SHBiKaUBBiswV2/cTwtmBAbSFW4N+vpDLBUUUq/uJUxSWgYngRNKbhbVlMuNZuIQJbBRslhbDO4hYh5nUxCMHoag36wNGRW7hW+mvlFL3wIiDRFYngnUpB5ZcpqEyjCmJXioKiXGyMQc0SoPN3wNMsgjlElQJUCVwQ3iosbiy74EDGGSswIa4iGEE6jISvhUaBtr4SnDCq/f3UEbKRVS4xUoSvrA4cRExuZU0ohaTMOJmDuEqCLFQja4DUAEcZirPRFILqWCWCi4URUZMQNtFgkOomQMMWhzUMpINSqC1MjfFl3DqGh3B6lkWOFlVA42i1Fvi5bxuFZX+CpXDKMtZUT+KRJUSVxcp7R9Y153CFMBcRy9IXSIICoNoMwYzAhKBy95lDkKt6f+QPecsdJN6Y6h0Cj+4AKqICwyR3E7TJ6R7TSNJUrRjXRBEbziLc3FEZlWKlyxcOTRLSzEFSo1DKXCCvBolzzDVBwRixcS5QJZqWjPcCLFVEjK3Fct1wDmMC4KUlIEQMyyLbiNku4zcx/A62iAbveMNCZ5PnB7F84IsvqmokNpLfvLf/AAi0Jjp1IByxEbuG0/WJXhFQW5lLv/sRahiQJhjMOX9YBrx58QgKmLgnVyqhLy44xARobJYWxdpVwPEQqgAdQal5l+mVBaoi1FWGYIBCjUuXLlKdoy2CgcW2LULFFRjioxTtiYN9/wDMbShFuFRAlEaidxOGIIR/gamNpQShjK+JUFBzcrfEu0YMw25V/Tn4TXwgiFe3GSvmWRV7QRd36d/OUl1uBREKlEuXEoZIEBW/+xrbPUUaTBq/1g40Q7uvSUhxEqDUEy3CC4LCO6CwIVLO4iXcsKg+YmJEDBJTBDylSO5tcFVQdm2WhZYc3L4xvHUpaVHUQa31FEbSgZcE4YDKpiCWen9xJnnusxbL8lql3zfiLwMuWS+FYxCuDwmu8/3A1QPO3+5TmD0ibSrirM4FPRVRe/hGqJVHqWrHcF9yUYIWo4fMN3D5TPvklCdwnECnYTa3cJp9BjUcbQFNVmG+uPF3KwEu1sWpg4iMluKu5a8FcGblJQtxlXVSiEyjUM0LiQEioNkWVcBNSuSONVBvVMZWHUwM6zBI0KXKXGpK9Ywpl6EuEvDSXD0w+LruNWUqUZQ4KRnKDYuCkFuKLYIxLS87SJFEpcES2QhqUQg7sjhEc9SylhcSgFagIbuPF1gZtMPRx8Znj6GWdQHaTTZKgc+p+YBZauxv7RMCozp7+EaBt9OkuNFjEzUzKmSFuI21BcLxswQeoIIDky4ksiBgzr3CS7nnDVRKOEULbNT3LAuXxmh4Q+soYdQJcamYT3MSRYmJ2UTupWsShRgxiEPWWSnESUsSVK4u4MsgwRPVLl8l8GjdJAOCoHRg1hEjgRKt3BasdbmWOYS6we0CgoiuTEBUJtiaBV7MFcSVoOgf63BrXT4L+iEC1SdT0d9ZgUp0jb30+8CpDNH86iroyBrxWfpF2EVQUVBLstlfD9IMDdlfSGpcs7jsEW2lhzEeYWrGYQoo2IEZSrCZmEWmWHEXF36QclJEElikMDqKw9TO6phy9DMwzuUEdQtNrTIRB7RcQqCN7J6MRpR92Xg1KoYEcLJluFEJ1LsXC+4wuFSU4YNnvgZYoiJuC04aTfKDZEOyaZie2LyZ9Y9xRDb9LMOW/CG0/ZMiF9X8QIUVFG/oQCjHtAGg+D8RSxr2A/qCUzEGFfaNKtfeGcU6i/X/ACaBIDsQ8n0lPX5f5LNDMygjSxys99eIdCnAyD6b4zKfEPBDQzSkijNwcKrhuLpYi0psl5gBCIl2mam42CDwDMuHuBFCoywEaR8sZGyaJpFaeieYP3cGKglyVMwObiEHaKXcEC3EmjEJQtxRlDAG5Y4GjccWwPmE+4l5j0kT0fvylXJwQ9KMTWX6zzI+aZdy3cW8wMLcBOUC6lS6liWiqhNbg3Up9ZdQt+aP0iFXH1Gf3qm1DKYajUNaNu8t2sFWzHBMZH3Q809Yl+RKcU6i+o+QeF6jMS2mzHr2faGgcjklRZj5wXrPVj7hEbQj2S9DERLN7SzrWKJefMIsYpCmULGxzMURUuoqWaQOCfdaXCo/vmBRtQZ1kt3nuXCetluyLhePEAnEAFEGXKQYBLb6iWxj5UfOUiQgWdkWRug20i1jEDCy41BZcxGmUGSXXcs8zPXF+sR5j6ptMup6RxAd8EIz4b9mHjF1mEWLFjG5u8+LPJPcGYJXzP7naT2Z1p8PxE1H44+9RDuJkhymO+X7IN+1C35I4ZzEZrH71Bs+nGQE0gnekhVeNrInZjz7YdTUaagG5MWhPQwNb5mYLMQpiWyslcHZEpiRehmJ4MG2KljUI6U3CFYDNY3+9Sptf4gvmUbMrVGYj1LLMHiyFIqsNvpGhmeRncDUCXyyP0l+D/kyH2htA/EmTUvoRT2qWWIMmYO7gke+L5SlMI01USWy3iX6JbxFHUvyQB6lVngEZQagGu/8PFpdKi5l/wAkZ/0CWiW0R8zErgIk07LDjcvBrs4NB/VjtfPO8nUcMhVnse0yEp1AaXbP7mVjw6194YrDSalBsN1GGCe8qBrE0x1GYPiNGJh2ERm+C1gO98S61zVtVCX/AAShMYbBXmBDZiKy6x6/Um0B5TMAp23FKbQY1ruYAzXpFjhlv6RrnF+nmFOWW70yyHJuPzT0Y42Y+vxmiyq5noSlbEJggW0IiXBzUGbCWGIlgvUAA8RaNoq3wCU8oj7QwFsWpyiBavlALT5M9/4qHD6PtKEmKjKlQJXGo0CswQ+ssRruEUrvUCVpFDJ6Twp+pLsHH2/Euh3LodjuVmlaYvduMlog+EsJdzc0x1DZUUY7hxG+5cpwDZKSkEEGphgncyfM4BoXFC3iOyyETqAyRtQYnFqYN0v2Jg1pcaHEv5f9lO5T5v8AqPbDFI6Ga1mvr9ocqglgSnTAgwMoQKiASVATdMVNpKNkpajTEQEUhWybQJpQtmA+P2YzOf8AH4igtUP2gLYHHdq5n1b9/wCKWxhPh9jiVB+6jxVwom+MKmpjPnghxuM7DHZNrlQdSiPX3yjNHf79oidm/b0gOr1ECBzqyvuZ94YCqxvx2f6GowAsW8+ZZwIGJ7wmAjqK6JECiyTSir8xNfEuVkITozDEDeOGm5sxF8j5TS18eZcAqeZfFEAjF8qjVi8vsT70mN+iKuQ2fJLQy/Bj995kSqjb1sx6sVJh1MpSYlAzPDuIUEKytVMBgBFHUWOIMQagdJDn0lFEyIpoliXC9WMzaz9mYcnB+RISTp7+n2i0yffq7qUR23/H1BZR7RHnFQ/eo7g1BDuHGsViogivWmlNxnZrs8SwGY56cCewgeyPVsnfn0Z0A9N+2oA01r7fmZAdeYaxLiDiaxNUdSrPERkYlbYEN8oJRFXSy0NJv4Dqri8L38IXdqPZjpdGC5CJBNpuMeaCV12Y9vlKQkXcLfYfYzANuoB2ZWMYNamK9oDAykzRMgmpXiEyRN1UxdpRQooQHGDVTK6mGSYpmAGABDmJTUxD1Y9nr9mF99/ZKFSyrOyMIn8PrefSEdywHuQyvl7pQ65qJJqYIZhICQDKI2bQ0rpjqiXk7lY38dMVRNS949ZkFB4SoHUum5pA7k4i8wQzUZHjMXEGYhXcXE4NQFnmIDzBaY6XFjO6YAKIayTtFQmryxu3MMqjo+ICZ7ft4lH5QFYgwaxFGLr7zDY2TZDUCJiIibQSjRKW13r0nY5mhhfZrhOHohF4RVVBWEczLDFf6Opo+P2YNA7+mTEIoa68Yr/YZUP5Nf3BQMenpxVc3D4J9MTex0mXpjHTFuKJc3RVY8/mZFRImoaYiiBUTJn7ISWQjLDKVk086sWFUxgrh+k0lKjoZvc1TSMNijqHaCX2XDQIMZc6pxG0YUmAFnKgOkykhqy68Svoles3HUoTiZTB1tPyQwqjpmDgeBc/1UHWsfaFjVcFjTmvX7RFcCKgkYIR1LqUtqiBWPnBKoEvUxsPCAlCWZMEAnrLuoTfY/Xr0jc2G2jPrKmrF+70l8G8/Zm97FPmjCh7aH4iH1hlbgD8xjteSvt+JXf8M/tTR7TZNkMo4wV1LmmOGbIrfi/qKiXcazzAdx7QQUxT0htxDEWxKfp+sv3wVuVQKxYVFaYaYbrioMuUiHgY/wBmYU39buYVeY694qpl1VLmNxe2YJuDcvPFxBjjhcx3GbgUDqWVcMK6mb3iWqKXZDJzCMQu5i1hDIqAwcwAoYmDcoU3HERcpRUdkoilRA+qZNEptl09T2J+EzPx+zLhWKfpUCT1+1MteDWoA4/v68vChPr+Jr9pvizI7p1AdoO0g9nziWsoYZdKuEkL/SAQ4WsdQYqIQCZlioBvx5g+l+ENQGQtw7hcyTzYj1E6goxvMpGI1EYjdxNf29vx6iN7z5vMLox3nD6Jk+cE3Ht+JXBeIN0lkxfDgsD08/GoOcQKjwzu5fUsdRD0RXGSWeH5RTx9IwNwJ3LVDBV4XRODAGX8TLOkKKJPDDKNyhv6RNRewqAKhsqVAbhVdy9vEMKafv8A1DZ9n7Tsxb+V0xNjGnxMwSntv61/UTuwxh8zbhLKiVKB5mub5t/eoRUzWMB3CdpQupbq4Gevn/IAbY9EMQgyyV4jogjG+YCoiXTDegpRgjuVdQeEIDiJPRPLj1y6C8HBx46PV9fSVtgyhKY4WsbXbz7PfiWZ0sTlvB6ssWU2fho+kLpeJdxi2XnkBaVZh9weH26lXH9xURMr5RFUn0gHELSQMEItQyTVRrU4iM0LPSNszKFEHaOoBss5Vgnv8ruUQYCphNP6xC9rePTubND8i9R1XW/awhNlGM/FcfCXBXQF+YQbiEuyCj6HDumAO6iXlxHeoZ4Qi4A3cEmawlEQ8BBTqIbIDCKsMQynUYBaTRQYMxN+ROk34r2nSXBeuFCCsFgKPUJOz+orbHB7efj+JQPQ+0yi0Q1y7Y4ly4uIgIsOnU1orogUCOiA0iDSAog8VIuXGpytL1WngZTEQpDipiXTDJBg03L6RClFhUPuXwKKtteI6sbpr5SzIvP3WFsM0/0/3My1qrw8VU0jVZgKILEBUbxUB4IXDY94Gp+0QwPAhNIOZYgtQYMwQeA8CkcyyW8RqsFpxwaQSYdzN9xu3NOKglhNHVvB6ZiijgtKQ7zgcY1Z2sKsL3DDKoP0ljGHiPDuKrEt3Llxlq0r6xnzXNQxGifiYjlBQHxHlLMxXUTWGLQ8BAV3K5FURaMGweCWaItiukSeMs/1PnP7MVb9nxzf3g1qwH3KgtOq+OD8xlPcTpHyla9SZi+G8yR9CBD2MFQO9O3FOP8AkwgdPsunpvX1h+QuV4vGequBQxabTyMEZeFb9x56PeE0m0YuuCXBhJJeEk7lQIrLIKmIMtTZ5m2xAxSZ5hDhVqCfMqPYVvHqdP5+UuAwKfhCWw1yxLKie5YV4h3PEDNPki95X6RFrGpN1925qvkIpUs9SV98EEbLQ1mEViwVyDFbGpat7ohuXDi+HQZVzU9H+oftViX6wfky+oS1/WE/2CFKo9xxLxFlqXwQx4C2D4L94wUu0PnNNd/Tv29YuvzUUUFe8KwgKAL6hEahGbcHI3CXDKDwbVCLH6xB1/fSY1JOji/MNyHIOEJ1DjNibKx1n/Z4R/OPlrH1gU0VrhlB/EqesOo3NIsgiFZmW4ozqLoBn0IxGo4cNS1u4qYTnFrBFMJF1EW5jntXKqi1lWkME2GIUufXU3gv54WK7T6ZgKFiP23Kl0D8xu40RGf+LHdxur9sysQVAqmIdS6/pNfC5uYKVJ0R+USBtfyamJGFH5FVAvOCZyYdel9fWWlzjVdFJ5r2i9byz6YiK7o3577/AMl0DFfe6fpLrtrY0rkxUT1tA95unnxDJcJUEwTBS8scWwggX6R8mUrpJUW4gqVAp6iNcmJd6RFzEcEhmEFiUV4yp5pIgoBMoOG6rwUQz6rUIy64b4upUErwmDmM9eO+Fyx1FYlwu/8AkbhRUygT1mE8LBrR85dUsyFyksAKxAq9kaqC30fiGAAdPA3oZfnBCWolkW47n6R+8deJa+1Sx7OL+0AuD/QiktfT0uv6i0RV5s9BBQZ1w4E9Ihd+rlsdKPxumXBXnOvWvvCu18ny3EwW1+neZnFcrx1eoAWOJQ4ZRS2qz6QZkQ8oCECUiWJiErgUmv58m47yJ4ZqDcLi4rnD6RJmHpxZBDhQr6D9f+QD7mdahS0wnr5Hq/5wO+B4tJWqZUHA3ceyIhaDDLVMG8xOAY0HcdGyRIW6l7AsXI1LpT7wFF68Jm+TDCZHGKnrMCR3777w7vihssoNS+olxKlS58iRwunUDxKZxFEXqdF+3fnzFiC6T5t+PMQi/a59flMSNrryVKEfEey6+MeNdWfPuE3ACa8dmPruUFpKaz+6lzHiEMxLUfTCvUF2TAXBExEvhFciI2Z3c8hFuo5ZTNILbqCbv2IxST3IVdZEngAnjQul11EYTZy+7yy6g3LC2sQKnc0ShQXCFMRGN9Qx6pZhUog2L4R2l+80RFdEoUafMSBZnxyxvitNlcmY7bFg/WWCAdzQus1r1qGTb6H6x6qevcZTCbxeXB9Z9oz8v4gNWern/IZ4qIlSoFcnFDsi3UVMMjEGJZuANz0p6EpLdTNE8Il3qC4lQl/wti8FU6Jah5G4YnqrfqxQC8IroPrBXce0wlAb93r68BqbYhKuYqF7/EMA3Xcz3KiysGbgxZhBCCdynPWl+mIRB1LTgmDzrncNsTtD106BFifserByJ1HCwOibaDy4JSPgzH1fxDqO/O35uYDTi6nqi1KykKdfyH+FQOKd8BcqVwDqJhC5FcvjUX+Ju03EdRniAV9WMh6EEPKQwlPpCd9uvSYS8S74qIu/4S9yUy9qHJxdRRLRmnZLFLl8eiAibX+vaLqBXCxzAYX/AKZUuLy4+m/pC0q+hj8v2hRXfnv5uYDSJGOuGcJUHDwMZbLcXslIGCS+Dm4y0Iu4sSJcQ/k4jTUW+LpVuK2mUJV+x+8JvQjcqgiUMnivPrFmFcF/8jC8K/UP7hhKSspDRCDQBKlQVCqWLlS+CHLyqI3/AA1wMXCJHhZjzAkISxFRHcUckcQsmIqS8TJLcYLjFf8Agy8meFCUgHEzBm4kYuv4LX8QUZnCINM1E8MfUz+ZnAyh0/M/maGfBAfN/wAgwLlRlhGMImeSsZ5EHidTwR9IKE1edYvBliHJrgkqJDhFNkDqJInFBxoEHxcXxuVG8o8RHC0quDfJmYlaODSSsE3Gz2QzB/ivhVyuKeDaI16gesQVEK8n1itIbXBxYYfV9pUP3B/Vwc6y8qAvzXlgwi5cS+DiK+GbLGGJ5CWS3hj0TDUpP4GOlwzG5UMTeJKlS4e59+BLWYrj/FaL4LMtiT1TcqemXiVshXA1wzRLpDUtuPRQfohtZrhWR8zP8Dhyg+Dc7tAfgyzc7oKPQ+8FPKFZLAvqUKtTUGGeF8BM1mLKcZqY3cdqVZ5IwZZLeFbgFUSqI7m4Z4MS40jFAepDQYuIlthpRzUqVDlwyxL4I5mz/FB3PSlAnDOo3WJXNyUYFxZqXExLly5cslSV4kLS+r+Jj/KhPFn9MzE8RMTEM0zsmBiXk8uTUIkTExUGDKYqJbArHASpRmESUzSXcYoWm4lY46jBgvNVPPA1L5vnLi3hdiCNwIEu+GZl8vC8V1CYYygl4hggZix1LSX4Rtq4MYg0s2mp4jX0R+7+ZuYVZdO9Puf5KkwYncYhbUjIqX5s/qVj5lGwVZ0wfPC6hFItw4BkYXF84QxY4OFqZZgZ4t5iR1FaxwYiXKLMP4V0UqJanry7uD/O6i3FcpKdEANfwYSp3Llxg8NkdxqV53Ae+Ftm+GMIX3ME1S+cIVAXc9c/fjCg6WC9t914hzLbUPqSqxtDMiDCveNpTQ2JbOPsuO69Yj4CfnAgdtfiW1QX8KIxXiagDAaiQKl8IXnzSMevCU6liBNko6ZUuJLQU0xagqzH1lk240TaGTgqLHHGYIR6o+KJytQvdY7jPIoNsh3waDVSWRbgVF5uXDPCQ9Y8HBNsSonbGLeCYCBO41wDEmyIqEVe574bL4H2Y7bjeKYLoiK4I8KqExek8xnSOkpq8XrKetlEynas6ylv3uNlZ/cR8m8f2R1NNzczBweTxLQKOUuFmmAbLg+8QRLGZAlWqa4Hcd8rM0uLcI4iNyBj00O4gTEBq5dZJlRCBFSKwR3AcnBFQF6i+5oWUg83MSpUGE1LjGWVUDhxytQffmcqNkLsT0X6THekfrHmZiAT2h9pdTMVLDDBtIN9+9/pMaDpWWgASuOsD9V3HsY8aTKYa4Si5cYOyPdn/KZdGgEsdQRi1KVMtyprhDMwYjiMPFsUrLsTMtTHMr4tZVxU1Cm55S4NLjBpwnYRRKxKzfF5uHBoMDqC4YJ3B3DBts0EaJlnFs94w/jiH2o3lROy3LxOsrh+X3/MsePl/kNvO/0lzFAuGjw+2JdBjng7puq9H+onORYhmL8Z9IhkMtBuRAlcWgauI/4gNwdK5VphESs52g+UocH1ndP1jXWh3okyEeYkqkHQy6DAUuVL0c8fDKhmBHLVyyPWag8L41NTXCvEpgunjZMPcIqAwLlEQuVLjmVNxDDA9KAx2anbCW/6mG/qhRFIt19U0zUS2r4sws3wcUXhZ+/ONFdh03r9416RzHwln7Xnp/2Un3UeevA9MCD72QZbcS7lxUlhgCSxhOpcWXBCZYXGJ47lBol3Lle5kjcykuLElmYlZuVbxdRUW4yma4XjWYxeCiWlkKmUSBUEMW5iZaYo6jma49YSudc7xErHFcMs4oljuJ0mPMOXY38/+QpDzGZSBkR86YwZ8xHVDzMMGgAcM68b5VE1x0+Fjv3WY2ReyqXcClRBqAbVPMQIuPXgff04PYh3iAhtLJQwJduGPmZ4ienDGIpCFJRWzHU9pVcHkVEG2DSyDWZkzXJxcYMQlEplc2kF7mO4BY1ljf8ACpUxEGWK4HBVzyoEJUrGOA4NFUAq7l8WvOvvGXklwCvV/qWG2C9xo7+kFAyJngYo+wWJYrWH5Xn43mZh3FmXCUD1Z64oxEOAuFI7jKzEuWyl1ACrmlWAwFhpiCiKu2YIpcFcW5ZwzSiVm2GJtjNVvjGpriol0Q4rjuBK4VE43iZNS7mIWicBbEpolzDKMRULOAXRKBqKYrBlQXFVma3EhFp5/algVl7KGwEV0JT2hKGiKge+Y7DxgDZ3Ae1saFoQFMtW7Y0hKIRSphHIpqHkTJwxXiFp6QLmXBBtrhgVGFHEfPFgSrzGrzKAxAuYs8eij8yIdMURQTUFt43KlU8MqHDFly+K/gsvEo65DsiQVMQu4Zcl9MS9cXWoOMszChHGJZxvYhohrRFabhTWSYbBAxXHr+I4YR0HiVEslmG4lyptABiJNxHU5Cy4lcFNQu5lC4Ai6KhqYJYmOFy5ZFvMCssZcBdRNoBFNQHLN4lZiDMQUEYZfF+IR4rhIk3KjDM0zEq+KgVFhDu5qLrmvaphrFuGopcsL6iglWVLETtmJRFmebcM9WGWIzpNCj2oucQz1IGiolyphjTFwITzEHIkIlVECmHkvp/eoK2cBuFVmDMsgVDHcRWoC2RzKJmZiRP4PiEDcKBiYMsqKBLW4DcpFAnZNpjuANpc9sjZ1KXfK1/K+Ll8MsTipd6lVxfBFwwxKKzCmpXcbNrELmCfUiO2E77gFqJcsjxLtxNtYoQGGOz/AGUUYkpZTO5uOU8RhrPvGgthUQ3GdQN3b+/KZFL8IiRPgRpNZcu+SbmEVPMS/HCRpri4piCu2AOZ0MqtRzKQgVFzEHUyqYq1G9IgtzHcGupeME2sr0xRz3fDmIRI8VxfHvCyDEuOL5TvgOcTM7jXUS5hLPEYdBcAM3cNrET4EyYUTLMuG/BAhT0IOsYBCMJyRYG4szGY6n9nJdrt8EJ6HiDe5SOHipojTUSEuXF6wp1LMkfKCusQ9oUoiMxWZQ3KI5zFJTiCqLqA7ljknqg+IeJlqATECy2ZXEQ2xDm4qIm4YldRdCbgXKlSpc3FXOfE8ZIY+Fq5rwVATq6vGIgABUtuYgVmmIowDKgNNsHC1dYhdWwB7nyu/SWiDUFQqC9S4jATBTI8FRDSXe4twxbVFqOIwpuAqYEzn84Mq0E2z91x+oOW8RuzM1f7NIr0lnMoCXRHMs54XUcRYTM1uXBSIgXcgVBXcRNS/MqpVdTTKXEVrcDPbgKLgqg06hTuKsqvWeiVf7+/WUmWPiIkph9EYR1Nb4HMqUkSKwwZvN/v7UpejuA05uu61DbdLRu8ekMiZqmAAvdsqRc2fcgBu0/iXRpAMB9XXzhISbHxzEBvg+8rUKa71KUxerlrVXnXHbUaQLmDUTGbcVmIWYSm4lEQYBmOoOlsSCC2BHBEuJd3ADcyxKiZlSpVyqlXADLLEiLlriJRLTKwuBgx8E3qXCIY4qDmptKxUrFciQ6SJQTsZtA7gCt9QKaXKIdI+Zk5jslTcwhaUGJZiK8SVc1AuDELZuNIPU9OIYgxMpU0lmZ//8QAJhABAQACAgICAgIDAQEAAAAAAREAITFBUWFxgZGhscHR4fDxEP/aAAgBAAABPxB2UzeVpPrNesjxhrHK4cYDePMcYq2uL8MznCxCuPM514MA8M0Va6wGYOdCeHA3IGMEWJQKfOOgI/eSZV574OSHi4A2o8o8YzfZAvGVq6aP/cYCOxi1UUO8sDHDFnGTeBvNE79YZe2MoQ+WYEHL1If2f1ge0usT0dfbX3imAJ0desAkC6LXJmxJMCrQ7cTOIF6zhOAQvoO30Yr1OgIfHO+k+WJAB6vonh6eDoAIAA+DJHKupn2SeeqezN6JeJi9W0vnAw14wVE+0wGDgwcBNGAq0CuCetZrxk4QAl66OXNIbqMvn+tZGw1mP84/jgwl5FAPlD9AzWlpgBmyjjN06xhTeFLjYY5ID7cs8dXfilgu1Oz4SaD4wOp/9bGHrB01NQivnRjRhtFa1XmIJ1HzgAJa4hQoNCOzyroxYd5r4kOYGV2c7DCkWYcQOesMsWYCxoO3AdYH1a5N2cBIOC9I/rCFu8oSAe8Um1xnkt84sq05rN2+A3nCcfGTiOKMm7kuIIOWJiYk/wDswHrDRjjV3l8ZXBwjN/vAHTh0W4bZ3iRD065MIUj4zJgI9OUbEyYl+Mscb4x8X/46MJW4CdHz0faYlSvo/k4Pw/ObSHpSr7d5ZwGuWYMgMOUsZjkT794nSBlkMcEqS8fyh+HH0s8y/wCOgfeaTXlfAVt+8mmUZ84wacHlic4JIMN3ENZvRF37yTwTS+ZkfL0Ttzk0SUesBogSYi3G30wY45F+RB9uFLxO74HP2ybA2pn4YB+WAXm3wnZJp6bm4CbOPwYywBejAGmkEcXuXiGEu1oOKtEaZ5xOriXLTwXdCO2AbamXHoBUbTAj2TSFjw7H3gKDuHZ+Ksfebc8jJdmcQcVrhvJFEnIHXjBCTPAiABwB1kUx6oJQedT75sXDCEtfy/8AebQeR9bzeLwf4PLlhvF2bTgxQm8vB7wM5GuBjElPZrDbNOk1jLWPecPYGcSpi7DnrO2ZfOG2QxHExMmTAyZHI/8AxXeBif8Ayb5wMHCqRcJ6cDG/wYNu/GVTeWriSNcoBhp3f+Z2/R94P2/8BNv24QBAEAcZ9YXC6S9mBAobbgAzZPLGA/tE9wxMUGh3fwf5yYjxKoPk7PcuaqdN84rOUFdU9ec03HQY6QL5xuhbKYwWw8YyuhJpy5Uq4SG0ctuTzNYjM034zTXUqMmJD2D/ADCpgMUA28Ho/AQxTLaRMe1/IJhiA7k/yP7yRBEd/wBYt0fLGWJMhTT5x+LcTm51JIOS9V1cfMvUvtqU+Fyc3LNAqy0FhV0sB2maaWbs7doRWLvX2T9fh3QOpRiYEhaJCwKL1KSDUaCBlmu9mMyDBOkzYBnIfzHAG8MG8BwcI6GkKAJIhJCrGEjd46q8JgRemn3iCCsqA9/GMIosX8wKPvFQd2zHyfihxhB/F3yC/GaVTd+TB00XbxgoMXm7MZxPrDsBhrmchF3mwO/xl+2veMY//Lea/wDxPOU5X/0dc0/+PUwn/wCCjPllYIJwM295v58XD5nHyzFSA7l2/XB+8kp83U+PH1MDdwveG1HyTKRFjIILCvLjsR2E/wCf1gGgdB/U1/M9ZLYNgExJwTN+mZED4vGTafEafOb5U0JzjDRHrDeeuTBhl4XBYi99YSzDV7ccUCn1+Dl+sRyRphPkY/pwcv5jfVAPtYlPTSh7n+uBwQ0EDPF6u+McRV1hmd3UMdiSJo1hlVjSf6yTCdij80T7wg23sie5T6QwMTU1wPFYfImJzMauv7n94hJYCuVBFsMBCjEeYGuTs0AhfBsHKHpVosQSul3RLvWw0MaDSVCGGxNqhbLTkmaVLLTaMVx4xbHA1VbkTSrMdgm3Q9ykULp8Jt2cQAIOlYRq6Crzka54Os3qAt3ibCXi4kbOciHFz4ow/acHlEBrFiwkVEKxfEQoh0ej3XeK7dGDsIgXU6N5S2qOXHOaPlvbDhRn1kmaqpPVn9GbCVJAfZozx3DEkFqIgBj2In7FAjHvTeKCXhTnBi6m0birRvBwd0Y7MQiPrKWG2Ain6xp4xc3ZkiuEeDWMMccL8ZeVl+M+P/y4rPfD/wCSmLNzG4K5VAz/AIuXvf4HFNqe77nl/M9YR4QCBiNQs7DWQo5TUCV6mNT0f8nB+lx6n9FPsT8fbGSm6qqj5d5sC31c1HRiBh0pKuLCaavnBanPOK0XLfrNHmqu3zh1UaXxiG2r2wnB8oofLncTI+rw5+DiFY6/K5GQ8oaBB9Eo+Vwu5doEnvy5vMHKZCp3ghFwDDJa842MegD7cSdR3c9kR+lzW8GeW/gOEZB8k/vJ/ZkM4IBA9Bhp2MprB8UrgB2rxjqxYF2RTuIJyY2S1Jdj2aQhMKUFIB85ok1ajggEaHCuJ2eirmG0xBhysaDgHpoUXMeVVbI5MB9jLzzQgF02Fa8LuQ4nhoLAUjRThR/bKtATYtggVFBIGAKRtoMOSFJF5YRV4rjwoQ+5gq77fn6LHECIX8Oflgr02KnhpHyOU+OdHyQrimFHm4E4ki/MuLe2FmhqWU1p4eTGACAKHb6fvLwgoGLHFsgr3EDd9C8F+aF+caTlpg91D84Udr7FUEg8QIRw8ZngwB0d+DFak0yI4EEMcYJgaESGIFleLcKxC+82LtzhNiTpxNxMsMGyzGuGsIiZ8McOK8Z8M2z8sYeMvxnxw9MHxjgKXJQ+fH3M4QV2/wDkP5wRUuGqfHR9T/5HgYA2jOlLg1VLps+ej7zXQLyP0cH7yQRbDqHyHA/AZ40es1YZ4ExSuDaYxhdH3GVZS0ExF7Lz6yApoqa9wz7mJezYivmbPyZUTXoB+VV+Ex0HhOj6EX955NygocKXBxB9Af3jim7YVYBEAkN4OhzjNHSRR+QU+82DnyFfBT8zGz40z8rfsJnhqd7fkf3g7Oj1gQXkeWJtsi2ZGkpSXNjFBFCsKwWtWjrJowKyBR7d044aiaCqQKEpAtytC0gHUCQ8IjFwCUsjguBVBbxVZlhnWYnZDVV8n+Mb4MTU4ySxV3bPROuAwB3pS4Q2YbLopYjDAlAwl0i7RUoxN0Zadck0QgGUSUI57YDudCcM5SAviA0FMBELE5OlgAKzXFZlc5384mBbpmeQvFTw7T7mHjuCSPc4T4wUCvPPxrn7MP8AIVUR4Ob7eOY28VLzq1vy5HEquUl1cYfK5aiFYDMmtu7U7shcPz/EYqDKxI8J+ocAv7hteWQNq6UvB4QPFsxUN5B4yt0NQ7MVoDY7Hm5eMPkcupNEImCO25Tm4BB3bTg7b0enIlvkd/OLCFPOIrUc0kuCt4Ipz6znB/GKxjFZXWQjpw34ctTZj7qpSp+830HiP0CV+A94trv+iN/c9YWMuAQMCObcGFuEDfzAp9G8QT1nZfo/zi2xPHH4HP3cCQAHAEDAyymRDHnHwBmEmzGQN4EqwlfeWmJQv0DV9GJAaa+1005ejuX8IoP4Y1tXvZ89T8Bk3CaA0BirzvI4O8rENIZeF9Ovi85vfjSP4v2Dg3AsybNbI/WG9hRKu8iI58POAC1CAPr/AODLDZkUKcvI5FlhjOzgEgcNBoHTyWJviHd5ICgjvpxjHQq6HsC7QrwjyuDDKFQ+AEVpvWs39pKr5puCtcQDA+uSVcRJQGkCHODEI/aGxGygJF02sUqQJe2L1WPLxJjHFdcmsbNBZy0OIHVDDoNGhmhQU3iMTv8ARG4FSK0SmmgpfjWLEJBALUgjl96neVF34BppMNCnkflaz7Fg2m1GA8jC/LwxQnRI/kcGizwAT6xp8bor7cFrBA1fAH75ZzYU37af1wV+fLJE2765/WEHI4qlXHRnAqGICGCsSe+PTraLxjhX5CXBroFAVoVxwcBQzfi0aRjaGkOS4JWBzowAKJeGTFoAev8ADGSIwlC5UhOEq/HnKV0dC+MckBUUKYtLvHKnrHAHymv04pET5MLgb2WmOaH05EBIxMYPxJgHF+sL2Bh0AjvxkMiuLgW9G5MemGQAE5FwPpb6wAO8fwSHxXzl4mJVPxWw9EMryPjFwEOK0XLSN8Dy+g7y4KfYfBz+Zgw6vQfxv95LwO4BvDAhQl8Z2adnjOSJOXL0cAG9GD1Uecag3QjX5y+TnJDQqaUeLjCoAFAXXl6jkWa1R4JTG0b0mqjDftCL5hhKemBe1kUG7uZPjHITuMoAfbnEW62r7z98+YIW+BED6WVUN8S+P7FnWhA/I8v3liXIke8sY6fxhiHO8DJYBEbX4M1tRs7yvHEp9JziGE+BFUKNQgqU1Bju2oBQgBTQFCnGx5sJ9kRwWuirx1cQiTBNBZha65OGkfUlDG4A54ulGcP3hD2IiCOHHnKjlXtEKNCQILYHRsRp2QkCaBWlWiZdo5QY4lKgeu2NOA6NABTRBERekCsT2sEgAJTtVVNmgOka2oTIHFDktRAlMu6W+hQ4NAZvZNwT50/w4Mdlvg1qXOpYaBGfKP6xdXZTJ9pkX32/kCMEjDnpPOXWlzhDxgylxavAMApBK6gPk1v7+cKsznZQqGc+cuyqzjV0o240ivk37s/jHKGI1JhYBG0TnDQvBkEKpu2PbMmzudguCA+bGxMYyCls+8fh8Daj+M3zSHVv5wDLUk/WYZAGBCD6wIBSiWHxjMNeHK8JkswOUMnzhpYPFqYYknrEYbnS24APeBphwgb1MFj2jTerL6MPArw/2i8fIfWCCf4B+svouEoNQDjBBI9+MhIK5W8MIFfWMhfpfwJ/DGdQ5Rfzt/CYDAPM7+S7cXL7TnA5bDFNjPGJ9zGt35yV6qIH248BnY7R5JL85XTkC34EIH5YF1vgC/IH94zplmbT28v3m4XjXlCxfE+umaoDn6P5nBBtQ8HWLRhxxcarwwhDvAk3Yofyhn3hwt4iH5KX7TBna0hhPuj6chG2B35QmM9GdDitZ9Yms/1hnRnzgMKxSR6DlwGCAOETWG3gdpwGGSQVBNoGkFDor01XBgGA0aUTYswp5urfu0fxwyEKq/lWofJl2IJDTWWWzakOcV16Gdcu/ACypqCx2qkgYIIUgOl325FBgB+snQQY9Boj5ODAi0ugJOwcYpKHe0R2I2U7EzYpSNAeYKAAI0S5E4B/NwCdlb57uKXrBiDZKOI8FecFS8M8h0Cq3ghbIVPlOGEwBMHt3QbtSF0pE2A03K3sxZZlBMGQ0OB5sN02iYWw6AfrBV6dpxjBw7HWF3RuljCFOvDcctIK+B/LJcAeBwQjl9an2swRFqQBeOgyX8hiz5P73hqek9kn7DFwUO9aCfH5mDHWsIEEoOO/OBo65uP154w42io8+04wTysAJ+TKD2bJ0+sjLZUz+RckYJzg/DvEiu6QYZKB5GnvIQ6IR0MLOQe2/wCM2QF8PjJOh485ACDk6wMXG2Dk/wBclB9uLUL6/kUV6RD5yKOjwv0bfcD4xPSroK8rt9uC+ucgGCPFaH7yf6GfzpX0jDD4EE8Kq+TCqpI7E8K2/nD7ycnyZ5MmS1g7F7OcyJKQD5xmn0F29df2mIKMHUv0Yanzcvpn9mJC89Q/a3+8evLPQwXjFmcoHzWSHRoxhALE1so8ga8DxlBFJO8+FX8ZuAdIdsbklUbLwLeivZ9YQBIJy9CUN6Og3p1fgxAAgEANBjlqiXGA8COKYKdXrDPoDGvKzxnII51yZqwLdMInSk1fHN/GXZXSsD6a/A4Hp8gUF3A6aU2BUxDlasA8AJq8/plI5kDKu6AQw3HBQ1ZpaF3XBGhh012TyQDwSpeMIiBoPDGiozU4RAlRrSa3ZlUWiADGNKCvVrBNAxw+wJsZbLw3xk0NXQSESAq2LOc1c+JAgNUkhlFoZbUDE10i3rSipRgA1Y5Rn2bWgh1g4S3YJKHWrBwRmCbVPTSKvkAbujnDJYLiC0R8Gh47eeZeM9BQCdpKjbwRi59YilIaLdwgA4c4+yqkQFjX8BklWVlG0sVSWSM3QrKqOol01Eq5fQYVALukT1s/RhiIXUqPVEcelNT/AFl+sE3TofyecFE1w4tn+mDioLGGNe8LiCixFVcl45ezjK4FHiybzVqfgtjW0wU2sPM2RrzwfLmiYtELrHvDXvA6BSDRkDanRMQrTkFn4wjG9VWG1rw7uKyhwLD9YeLhlKD9Y9kPbHn4wk5UiOj5zkIi9P3iCP8Av491Acpx99YB9CJ+Wn0FfWPAgx3fyUnxXvCyOaYHgRQ9GsIVQ44ucB7+mIROygFwD1Et/wB/sIxYB/qhVX5MS9eNGPitz7x0DgAuEbDDJiHnrIjd8bxfC6H2mIYjijT2VH8MK3x5In8j6GJgGrfgNJjA7KYauFjxMqwynSzBWy4XPIyYMPABfg5cMg3+VBvSN8g4TXHJC+IGFRqFBKDCcAcRu7kTq5SUFRtC8Fm6lIGLAoxNAahNcYidCAoqGLPPPGZs2VWi8iQAdq6FesZy5tQBVXo0cPDbECUb1JWGtwPMFCcDjFUklGQleEYGX2qEvmAT6Z+KZe+f6JgEAf2dN/hm9+cH8BkR+JTjPUm6GAuxBxy6GCYbhN7hjXDjbU6esNH5YjLLKI5YoHrB8OgO7VlLaN3k6PnLqEVgVegaKTpyKGlOntBAd0zvCtcl5BXVgJmzk4uI6btyFRs02EBDXDEJqtXMRDQlsNpVwc2opDRFbtXZsa4oSxycqomVmvAovml/NvIMtMBHAkdDwh7oTCx3Zxj0kFIIqSu0Cby3otQpoVK7g8bvej3hyQLC9wabKU0BcTdhaE36Ie66W+MAjmMo7OML0keG1VHUQIAMqLOtTW3EitY9i66tUgXRGDtOKUCKOu20eBx6Uk8SkDTZWM8Y32FpYARoQGFi75yKAZV3+M8TOYwxZ9KZM9dvT0YNVTx2fGAewMWh8vv9ZHklRKc2/wCuMk+dYHn0IUZZjrJZEFsj2CL1DnMR+ZYG2otmq4tlzb1Tag9CgFdoIXEhTpwf2vAxmb4wJTBDCmuOHIw5CfjKWokdYjLgvBTDEBpGeOD5oMTQWx3PnkfYxDpnZw9nB8gZCI47TU+si0pvW3+ciTOgQX0eXEAquP7o/oyLuu5/wu/YcFqUimr5W37zjQOLkQCXw4dazfOKrbmCx8wz7w8BHaQ/IbPtMMhjsZT7/IJkZNcIh904wB/8VOHKCqGJAFTEh10MHPGqQP5wSk52n2LI/VzkQgURP4fvGNp6getAnzcEJj0Tf1gHP0sP8FgDgx3P/AJB+U+8oO43ww/tyAgDa40EHACohU2vOPVCcoBBbMBDZhaAlNCy6VZwjc95taijDVoU2JbRNprEwiLeQIhbbaoy7cVFP+ArLlA2yiDjHnMeoosbhNmJfOOtGEkZjsY4wLpSWAFrYNLdoRwLSqaBsDraJSE21kcUMBrpdWg2MShUQS+FaBx0qaCx8uN5LAoeVTFKtTZGXBJoWOhDudqgYWxwe7oGp1qOdpAiaxOTLy5ggOgFBB3lFLk5X7iLL7E32pQdRphWoShhS4i+IK+VbEWeBh5BxLRpgXUHt4OXDwFhtsQJAOoMD4MtZoIBLByI0V5U4anAXodHZ1V3fl53jeUhoK9K9mrz+cqBdxb3RJpmnrcgOSawwADKGoFDsAZH6vtCDtlC3Tw+DloITtnA0AhVchxgv0UEgV0IXlzy6jpwJEdmHdKSxGMIXgShLoNHdeiYsAUJA+Mbgcgv+8Zk+wMfhxkrOEwnoiPvBKU5Eh+L+WE4ngVD7a4rC2oLvyA/BiUSFSO5559P/BnY6UVNxVgIIiDccDcp5EA8hNkI6YhKPRfxzTxRNvM6oB6QTZgwS/8A4lXAauQvDNGwcgdYjAX+K9j3Jhwv+PwNZPkvrG6Hv6zoR8F7w8eIMB6AwMbXrOZiU5v4G36wc0D7z6jXyHzk9D4v3C/gPjKBQRi/Iu37yOg9ax8sAigEfMyACWgBHztMbRpz4PQv5GCsQnsflS/CZubulEfClMRiJ0MF4ODOXEfOMI3AXDSU6Ei/nFlV1YR5IL84g026sPCIX7Zt6hiwiCcnQcry5VJdQaPbzhgsHxkAmIHjIhCODE0aPeSZANgiia7dhrvNxSP1JF1t6sjzq2uxp7qDNDW9ug2GQrkLr4A4HlvnBolmpHOWvWDGPZEyIOhQC63vDtbnmC5sB0JF0bikgEg1HEFaIKlLMlKVC5NVSrPJynASxKajEuEaN3fFI8hsoBB1zlgKqRnVHDWSmldQXGLk6R/el9IY0RyXcrGog6RxlCqij9QpwlVaqRnaCQmg7FcK2rzQqilA5Qqt6wrGiceKwLTVRMcD/wDModQApI8PJg4EzqZXCRUUanxt6YlV8g4YcFfM3cGAmKcFkBSaUMGhxRutaoeVXbdq4yO6BFA8pB2zc2H0F9ABWCQsOOO2xsMB0l8Y0ss7xaoURQ0jf54r64YduNksAFpZSJGmBicBiV400IcGjCE0SI6KdquEV3LQDxV/5wd8fR1QvggsDziqdqxBFwFspFIUhhJoilo4gNIvo7CuNg9puRXWwhFquHgnwQCwCE0uxXnOGU3CQVQHoWcZSCoKEEpbcGMCbPtG7+MoQW0L+aD6xDUeRx+Db7xyFmxF/LJ1fxAfHjBSCJ81zgceR4nNkSoQOG6488szledp90OK2Em7McTs94pQjv8AG5sMSyuPcn8Z5MwZy4yYBd94dcOwN5LI+DIxfMZ5oXxjEQerv5iD4JnCWoy+jWKCOJ4cwE/miH1iVkvBNeSi/Dhsdt/H/wACjBlA2CK+WZOMOVYGJVgNVjfF0zaGPR+Bs+5gzoPAD87PwmCkFtT8BqfWI0q6uBdluCIFxi3Hi4rTEzf8Tr4uAmy8fy5fvNWBzWr4RA/LhZtN6AfWr+Vyjy8AfI8uKGzH6Oc+Mv8AbHvFTHwHLkHR9H7y/eD5s5WH6I5fjHT353/hMa3xA36Gh9YMg6wED6zxB5wnDTwaCu3XXeRUxOETCy6XcA7lZ9OlpBogxYnmeXCCO42QJI6JtHhoxZ4JIE1S4PYox8tYZsAcIEAm62opV8uXAumjafBopNDeS9qgHHWU5HQoHATC/kcpqvK4C7o8aMW3Ub1mCInEUiFN5Mdmab+cfxwnt5dJAB1iABZuwzTzaHLqxi2B0rY4RMOR0bokhU5xlaCA+1EaFZQ5OF8seD+evRWkrRqc13VeYIssDlVq6BpmiJTPsGjoJqgkXCdatgyB0q7HQLrGkFbEgCC1XxzTNs84gjUfPXfWDlCEVgI6002ecCthmChmwu+MJC5BFO9nCeuN4JvSwrBAvQMY747VONdmFpiQgETZHWPrrsVke4EngOGiUb9QNhf55wLzyrA9OcbIVseIgHT5Ng1cpwsi9YUOSWtPTmqonExW83jS9TdxRcVA4BSWKIsYnOhDOJdgpQ0GCBqAYoIuoHEHkMaroIjJpEABOtYsD6n5ZY7l7wvSFhh9U44UfB+7L9588p/E5p7Zdfz39OaT6kb+37Y+MEJNlatf6zWXZ0PGp/7hCor+LkHiTso1W45PSZbmGI+c5SrgQ6zmifv9o/WCBR5v0tv6HvG9F7fzi39D1iabWiK8s5fbnvwNudEkve35TPqgL83E+nxkSsd/dGinrDlYeA/oGbgTy5vigma4xwoD9Gz8mWUhJCL82vwmJCKKt+ApTEGxuKVcF5DDSGC8M8QwiSuEK/By5oU3kNP636xIwc1av1w/LkL0wkfrfu4KXtwy/M5wZoUx14wxxSJn95SvOXxxH5WZwSjn9D/fMQu/SQ9VCfTGvzTQcyeEApbCL8GNGyskQeU3mmq+zFh+nLjbYIvq4QDUnNyUwtm1D3kRmk9IjDH5ehOMHox3kKqIA8kaFqXOZoYL4HiEKgIUdAs6XJqEkVQwcUBWnK2DBEORfDgLD4PN0Coclmt4K5HZJUDhMRDbS5xviVBHm0qLXhNAOzI7kXihrhl2ql9lnEbd8kJm6tgI5MATZfQF4GgIqdCdZ3MohBRTSWnp0QEEaXYWQAfIjhFLQYCN2NHOVH1KJpocoVNNXFoeQUZU3K1AMdmM1xkLeC5BBpxDyGAtuNA0NiMa43zvN+UpE14NhR20sDI0sLRrhpc8HejA5FRkRtE8hxXfs0zySvzzkcOsYNldGglynA0NKI7ozX1iem2jE3BwAUL6rgmd40gUmiWB4rdJjNBdksdup5O5mp3ddXV6/JyCJ1HtS6VL98UEKq62Vs0hu8e8ZA+7LD5e356xlO+gLMXSj5IwMJgngvIRX4Iodir4wUi1gOTYqY7KcACjOAj5/wA+KzcsAqBU2Qgd5TCB6R+xixQNFGwI8OzyYoBtpOs+pJgVomuLcqkTznkpLZxgZJZomG8A+rJ7ILhSDA8Cz7xWYqRUWAAFb4LZif1PBzI6BobOMhq/9PWVrHCNnlcr7cIlQDauoYgiTyb/AJHq5qKnDbfRA+a4bhBWWvsxfZkZZaDh6pp9pgoPlJD+Kv5MQrHUAT3a/CYdR5DS+Gkx9ssbcJ4cUcZQmEMTtDn+BbzfsOmD+Fj8ZxZ8QK+a6fhyZW+B8JA/ZhiSqhV+MWdOelBoflx4VPC5fEH7OaYHl+ZW/WFJpykPhg/OWq2cKwHiQfsywcIiF8vLihB/+AgJriDcT4Tte8AURHcfGxv1gxf1aD6X4DEbkYWHzA4av+Hb/rxD3V+T1J/DBDngD5hOT8YlUFAjKUDsToJOcWUhydNAgLEpwIYiNfJXQfYB3pF0wNfD7AA2ihQTvhNKaArAdA8gohTCzNqUT4JW1Dd3sMfAhodQiVVEdNHBY5eu4NbpqRUm0bAxytmVinGRh4ERrG+syjS7tPKAA4hilSTVMINFNo9vkzdmFVKoIu7VEDxm72MAxCHRFALWbuIJgycYiWgilS5OgwBaISq1GUdLls5VkEAJTlBoATnJO1GjzIgdjp40fOKNHVLmKfFKV8uQx6i1uhrtQaOdawpgBisG+2hRh3QDamr7VFdC7mpvxzl02VqhJaqVDWqmc6EQBtQsflMpdg5CCh7LOgfiEUh2r7b+Rl1UgspKC9AjY3NpLIyRA+04k0iazXzMTQExakYsDUJikGwI3OkmnreFYA43Fu1p6N794dBApUnzHzrOApug6NhVevDqiHvTZARVXBNB/jGZzaPUVTiqmncJh6AMSkC2m6JZsMzg4AUwvSnkFdavWKyHRk0msADIwDxgwLSEF+xshjDRmTTp8sv5RDrOku6njHQEFLiMa3JhyLrvFM6fG4ybkg1YwFOZ5zXkUvyBKAaCzAqwQhkR2+p0ihgCNGuGcId5Cy8igfllKG4ZKHzOvkBgvE+oYfwqvyf4JlCmaKR8NT6yMVyMcK+sSa3NmIiwNquTnvHI+0EPvLqg5SD+TgfP9XT1sH8MLRt5HD/x4zQBwkCgOD1npc6H5cS0Dpa+gn7zRB8vyBL9ZtwnSMfCQwUaLjq/Cvu55OjG/nk/n/4jgiYRt4MsoxzYvq3AwsuEfpR+mEonkP4GHfpzCvsRgCbPMjnaxyYw6Bg+9DLgJqRfZcEXCXQj4SfwYjay2mfuDH4ZRkAJR8GDL1d8s+CE/IyP3AS6KCk23uh5zTX2NSHAA6lgipcBrrCwwVKH3NvCQUxgroDtUE0WW63hALxdg0sdwHKfDPlTvEA7BWSGuVcCILpOCF6BNNtiE01IXy5FD6rW8UoIBblv02VOeMCJ8RtApBiqddFYuKrtMlygsdjourkexQgD9r28uaKRskUhzoEdbyQapyQVBGBZI1MZ92UOlWoKB5O9ACUMvvkB5RNcpDWbvuRri1GnQNkQTO/OMkoyDaIB9g9hjB9R2FvQZvHQJJAqUUovo0hrDlp6CuLovOydd5tNrDBxSuXj1x1gGMpb4WaLYa5GlxCNS2wQLeQynHsYMsnUR4pIcnxfOsaDWCZq+4FUFmm5QlQTqrWaXQicYpxjsOiQpDSCSo3HwrjGzcHV8Y1PBg7SvZ9THw4hLJozZ40b26y0SPIIgnXJDwTNUcWO7KWD8utbwf8AdRWTBSIYJPrG+39YFpIs1wOemaVd8Yg7R4CgGwC851ohG6jDUK8NKMK/EhwAg0cBounKlMojEes2XY4zRF+cB4J+G5WXqvjTUyU1WZCoBC1d88uVoG23dxTiCC73gUNsJIYAPDHCpDvHW9wQP/HRhCIGgODAcpc2AEc2qlzSozS3HEy/nFAh88X0yP1kKVGlI+QH84N33QN/IwQHFtN9050HyAfvHq48Ll8T/LBkMO5L6/1ZXCvIxfCQwkjNPiOoP3kOB1NffLlPGMc5zSwyFFzFQM755635ln3isNeP08owV1/Vf6/vIsR7Y+EIwi144VL4bchIzQgGUYh2P4D9s04FNQz7nDffM/P+XWESd0hvhUT8YrJlukJ8G0fbhHoL82Qr+c5cvkz8kP1jwoef4EH6wWLaAf25x8B3UIZ7KEHhPI5IFnDwBqEnOlJwbRtRFfQXQSKQ2EujgVNlhAl+BwHSbXSaxdK5jMUXMRSi22LxwSa7wQAfPpwgB6CvHVx9cRDQwI7QY+cBt+IRpqQ6cAaPWG8R2qOZBQAsNl5iGTkYgHMAIGg8HBFPQQQUcFMCuCJetCEY0AREl/OBELiJ4Bh8UXrHs8Xc7HFcdYQNMymWC8gZSB5BpuBFQo0QgQARHd2RcaFqvHQORV2V3TQax58LizGsDehNiPC67kKBbAA3oLz7VrMIunLg1f8AusoUJUdou8fUXkCBV0HLrEpTbGQADRJeUnxjSbQr2SlYbK7EvPGPdxXAjRtJscp5ovCSkP3RgYgEi7zSMTpjagJQnYVenZdmETF2yETs7Sr4dfCKigB0eEO5pysFbEhjAKk+83gNGKQmiabTxxjOSPBOupAvDTwcF0X8O+SLqofmYrfJKDUAllbBTd4xkqO2a7bK2Sg0XCVpvKCBggNCBhS4DhvlsLrLaFRMgREYARUPfoOl7cecN5XSYKQ3mvWbAMbu7XdyS6WYOWIjAyoIFmhp2w1XIhHDPGJSLAE2hSDRBbBaJ5uUcYwtar34xTintz4h7zgAmTafRXBorJTRYWN+Q8YGkpApnbRclTATUzzqL93BUWmx/wBlitcgggnkivzh+IdD6COPsjS/JD9YHRjyozxJfrHbVykn7MPYzlWPrA31y5WMUtNV8Jl3wgSPwg/bNKEcyX1I/eUgz2x8LH6xgwepl+lZWlHAr5rb+cYrflnhXgn8j+schnkAfmvwOTlfkj7QA/f3iArv5GWP3cobFzTfxj94QJutn8q/Oe9QCH8gf3nZnzT/ADWIYIdB1m9SQoet8vrnH6hC8bljNfKPrBWQIgDli7IRn1p1j1o2q2nqMc8TE0mMR07B63+sZts/00sZCxtTVwad1dGIoYb2l5mLZW+6wvqg0Cw7kB9GQo7FsmtiWbBIhDS/pocAPhODNSg/RTibg7bKJcLVImMGUwjRfhAGs9c5IIU83iV5NGUEp6hz13hiQk2LYW0BgC31MIuLl8gRQQ2Q5UsuLUQGEhB06DyWfGB0b1CBFedmsgnlIRUMAAm4oc4BUgQQBEkgah6cBmWNdQwtHAQ2CNEx4WiCXacjboa70IioQ7S4DfYNSctflQbJQIEao2wuA0wcTUj4A22F5ZkL9xc/8MnWl2aR2T6T1+sYceiHsoIEDCillQMCKaDtubgwsxxRIEPrgSjxEGgIshZLaNq3aG0LCwmQh19KkaFbAApiJqwJCaA7LKa2hKlYhYbIaFWugAcnVEmVVCA2yrgd4lbyZPQEERE4yaCLp7gAvF8g0oZfmnQyCvft+8EIOV0eChOPvkZzLNnizVmklO2N5joUiBGAg0DuTy5HQRhAzWj4NV3bFsWdoLW2BE5yTWb9iHZZ2w2+8ZBvluBWJa/tk1gMewbaFBG46wquw0GsKSnbRpkqsUhYDyBOx4ae81gqqFlfneTKy+AQmBfCtXYmA12DEXk6CKa3dHGSxY+P2oxNOBGSdqv4xpWLvFg1vpv5v9YdEmxs/An6MX6uJqnpKHw5KYN5J6eWxxH2pw3XnI4FVUavkp+mVAwXhXvWJBkHj/0YmBJqcv8AOFUVxmmyQIr6Kf1h+hOAz81+mRRyIr+ABiVBO7Hz/owL2A1/NH6Y2ycxhX45OXLvWv8AaBiU4P5ERX9YlQU65DxoH7yIBD1PtYK1eW/4VMvLuVD8qfrEAg6hfEKfnEL4Acn5OevNCGbINufjNypiyBvKWDOkzv7Fh+Y4NaG30by5CQGxuHQf83AFEN2RwBi1xsBo65b9dGlA1omhqUT0HfOnKtJOVoRHLt0gnWTsRHwdOG/w3brH4DKIpMo07ABe/C8GLV00Cb2u5va4Q2UBsQESIoeTH7Lc88DUmwQkgzXMT4BB0hQPCW8qmtKGGijvVSi0pcOZbbjlR40a3gYax36PTohRhGnbqamII6RGlarpioO20YA+2xiF6OwGtommjxmzx4Fcmo02PS084d/kRqcdhU5l1twqhw34iWiAk8wQfMcEaL4pdKN+mJXkKwbtiqF5nnXkJDZgmxmtbqvIjBgrg0O9s9mFT/AUBgRTiWcahlthWCCPJ/8AHElNHIxBHlWG93US2pXSAPw0j9+8iQypM7SHQpw5OclDiW8BO4JWgLcFUzEZRLurqAwhBVEXcoyBFdkONrt5cHL4Gy5IC2AVNrVQK4su4MOJV37uSYQK9MSMSabHWNhL5ccehCIIBHvNjnoXrFXOKGkOVMRb/OTu0ALLtX5xILEKzQFqpnVTlxppIByVOFZHf+cVUZmBzspVd2/GK5thdCrau3WjrzmzACCQkFCpCb2Yu/WLD+l+sT39c8bJ/wA/wkMA314n4Qzz352/xjodoUmj7cPFqgVTn+S03BGqputJW8vOt6EhIaG7cAENbXVN9/fnOAZDF9gNyI0BCxUq0FOY42hzi0uatPDKimylf1/pjvYiA+3FpS5FQACUCPswhWQb7UwFVeEMoilqCeUyPBsfs5CYDf8Ag973wecSUV+gxNpO/wBTVn040sTj+HnFTxMYh6zetbZp+nEIT6A/ZMAVudn80n9YXQ9EEfhFjlVBekjIrrc6cWNF1Bv1H952Lk/YqcBLPABm6VxoXvjWMWl84IhCyd5LpV78YPDewxliFW8Hm5FlAQYTWhudh0mnN4QDiVR3MUiSjC+1BEs08fiuFvAAIfkQOEwU1JUvb3hVRcBYnl/7r3hLqEiO+uv7yMdElut8LjlNPgw9lZu5kfLerrekcWwSsUJ7zcmxxo+mwApgjRXRpW8E12p1OSCn2OzfeRi+U6a7SBShvlLh6hN8kFUFRNm098GJArsFPP4CPwvesJsoGABXnEkPIjcBnV2ergGCqDaw4bVyYRE5ANu1VV+ockNnii9iCfxrGqu473C6BAs5BTB0bm3XQuPly3qYpGlrR0RDrj9c4zAZgaLudJTSOxtgRcysI2QkAAoiauHX4p94amwKS0fBOypBg2hDUFQdhj3/AApBGSStdg1XCpICllWFduMOaUdjQ9C9cN9GQapbxs4+OPCYBcGq0TWJ3gAFQwo46bNJo/et/wB5qm7EBQBVeR028jfcEStOAOYYJUXi0UPhd9ecTGuKDfhKHPeaPulErhRI4uzWgk3Fhfg4xY4gmFW9ECYXyxsOwxxpX9yyICowmx5y4d6+Q0FKPCO80VKVPAgBoUGvQ4XUkSCk86Qi8axq7nRMMHB7XyNjhiWRMK254cNcWkOolNlo+WpQ90DS26xKeEBWuJwwDgYJOCiNEz4rzhFadgH7xUCMuxIHPnHBcU0WDUuQSKUMiPNslHLWTQwQFoBBEMKjqgitWgRBEylqGt9zBMYSy1EQFV5DkdV7BtegEdwmxUy/yawjuKUkohG8m8GYbSE07T+8nn+MMbFIh+sfCYwnFCafMbPQGKQtM2hCQE6k41gBUEIMIkQS/wAODdXp5V52ca0Q9oP4YR52kYetXLUssUKVg6+HY0zwl0LoKqrHZxesDJ7/AGwKMG7Q1jeVvpG+jEwKg6vDedneO1FzRH6dZ+gANGRRD4MhXh5+2HnfBrC4CrKyJm3JhLwXEWQcKJ6ZnjCiw/Zf4yVJGIEvxB+cn1pDAPkpcQPXRun0f05w0drz9q/bNGei+nhTP1hHlhWDWEqnfXHqC3Syx6Xhdb4+U/jBOacwORKHeIAebjRBHXoD7xh0zmUNFfqfnF8AyijfBcaAA0AOXwp+7hM0ARNwDe7yeO8pN3JaAnygPelOMeE6niIQbhE9e+G6ZghJXNKGtK0qAOCqaNiIAEja7wlTkgZK1VUrKtibsbN5T33GiPItyq+CVPDI/p+8kTqUHCxObs07XGCBjyFK0+KiHRrI6FZBF5Jcrg6uQthtdQu3n+DF6kQ2Rvzis6BRC1aAnRo2940jwxIIMOgFbYb1rCbCcilwLSARPfN4aWQyZaQAcFqlhlvyN7D3+TFNVRkF61U4Dh27Ivfcnf18428LAoFXXXD9mIXOALXteTc+3BRDTGFXgnWcAAcVARXQIOORiNxFUTtB4eu+z3iqlLIijUjzyHzkaAQE3roX/Jj1NqLoYL6I6ldngIUIESklAAStdEYeoQBUr1qdjzTEZzDKBwhojjh5kMiriJ3fJQSgTSsChIY5Q9JqGPFKJbrHxNClQEjZeA4WaEK+NQMPxwXCo6O73AewVIcrrhXK8PWMlbAa7GtVXDYW4slFmu9GxWEUQi/Rqhrs4pUOGAsijgGmauBNQy9p5Fv21z2RoH8GQLpDQCEmlCka2DDsDYyItSI55gAgI5uE0VaSjeSQb2B0HFDjFl5gIXozeZpeucr+UQHUU0XNZGLcoQaIWaQVMD5ALoCa9gKg6Re1Fy1cox769uQoWehhrsb3pysfHmD8tx6ZA1ozqTBJ1cQfNXFzSyQUgSNnVrjAdNQA6r8GfLDBpDC6VyPQ3EPzrGOl4kb6JGhNxfBi6ZBusPwQzcj8SJYY6+AiP84xM7lUP4Mg7VRUNXgTVYDjDwiBlYUFPEPOgXIp4wX90n7y++y/pBxLpjsL6X+rA4HwQfm/nKZ3JQfpT9YHojop+UfxmqABwGHxKPzhrp4DPwsxxVeU6/GL049eHpxHtc259cBGLBLeq6I2GwWVp1CScHytDYDv8HAM6JZm1R26dFl3inGKyVKtQAa5x1ATC1hz4OVZ1kN3zKReG6jSDvHSQywpoHtfOaLdpwdAet7mOdjCZVbB+XORpKnXcISVYbRunnFg5UFWgKgIXiB1jRNHIRNpOee8I6lBU7vJk1lQwD1eHT68eQazXRCt7YNQqamtMUAt6ACzUSMlvjEPjQsoUAPYBKwECgL2aHvc6FB2KQ0DVKABSlvFoT5FErvCZY1ItDh1c2MNIWobR0mC2oJLpBWxIiMXAoxxVrHSkmiiJMgHWo/NrqO74dEM0ZQHUS0aHl8sLccclSx78HxrrNPbzUH6w21xx+Hg/dxNlOhfIsYXnkFxSZ1LNv5ib/Oa8c4MgLLUYtBBWD4G5iKU5SkmylxJM0UJSSINFwWq4bZNMrFdpyTCHpgwjV0O4frC13WWiu12ho8BQxXMgShcIqlXtXL5R6RM0pR3SubcriRnQ7riip44BHYFpflnP9p2owDiA3iUccM/gSgQ6MClaoZ8kaiJADBVBgvGLZcAHHWAuJSlTCAYq3pLIApfFuJmSqF7ERF3S2icQkP3cAZ0LVHoQGBy6eiKgacEPrKOI46HKRcPYA+9ZoqezkRCRIB4AYPIBC6KNTewaUIrwLriOQTKdCxCQVzgYViW1wi0lFGKRQ9iuDFQv4/7rDdRCIEonuHiGGu3xoC64aAjjw4IikN4IgE9gD1mpioFF9TjKzt04MNEAralG/DiokUkn7WOalCEPgABXdusdGOrheqkn1s2sFMIBI/GAwDg+MP1PP6SXHzj2g/aMNt6yQPjR/nHpOuAaBppeF4yFVOBEc1HPzkTW4VA/H+Gd0HSfu43+cauaVF6SCfWOnbrHHkj3QohDEFxyviOQVmOBgVAhlZIcxhhgk+v0xvSvBaYCSea4WenAMwpybS7cWECXW8INR8YAqWOAraXxkoCyfkxcfJ1FSniYfWVKGWusFEo0gP7A/eBLrZw6KFCAaWvSUB3C6kUzaIIYy2wlFB5rXPrHv00ayQp2zhdKAUd+cdQh0jw5fX4MTBFQN6E7AOHLjTRAFZCff3l7xA0U+8YC9gat6O3nHJmtmA1QCNx7jx4RKwbPBRbw5opLQtC9VK78zlxXgxoOGHIALBGuMDYUP0gP54coJ04+AR/7m3UG++AaueQ+HDOgifLsJ7uOEAFRHTq67yn8r+jBhY15R/KjHUXkb/4RwM1on1OSANWPs4+YPQeOx/ObVmQQBVosO6zGYHyjfiG8iK7usD8mJKCwVAabTehwKiaIDodg+cahokeCaKCRdeGYmHEV8OpooChoAOAAiITBiUTbfkMYcW5rAXddvay6xe40xJC4BoN4miTLcVsTEAmUZUjsEYdjAEOhAJ+cEqVAsfkn6xFZOZgJVCQjECTgSdJUNFYRpW+PrKlOOeDAdQAEUc2jtAkTAFKzlSJrzDHlziNEs0SjpAgit5Fz0SJWEhYabANd2QJZp0V8mWw1X/uYWIL4v5ma1hr1VGvSGjux6IW1BiKBqlOimrU20jp3UkFbHkAbyYqDDR00go3R1IBFaB0EXZdTn+fnE7FjRmshauZiPajOXrn9MEBE9PHlmdRsZ4EqhKFINHoI7FCiLvmQbVr2DQo6wElayCn3SR2oqK1oi6tCJSjhQF94P6HS6byPKvCGk2ynffWOX/yUWskJNCAmpy2fikAeaInPWGD1F6nCi77pis3RGvHAQB6wk0NUV+XNVm3RLfjHXhvNvznOE/47xaNcjdjeBv4JnBjFMiyDZ2mQtKCBJNgP04Cokkb/XAVYFFeQKh6Gc/OErVAAz1ieLPEj+MJS20La6vjgSEmi/RtfvGaJDKR0aXxxvNBQRno4GgnTrLMw7svy4PQiqh+BHHg7cJP1jiuYe+dqflM0mMq0ejjTlJdXAD9j+MNnY5jWsu/9ZzDBSPfHy84NkXleIuvb2cPHOC6RpQDb1066+cV0QJXnxTIDC4P7acFg12RPsMZm2oPwoBh2SLuQTdf8ZBMzci07dCKXfDbnx13yqQVcxOnbuBkrtEwbAdo0eMrNdRFWW3GgZ2vODvEZebJeVVqpbvU3PYNPs/RrFAH3hfZU+mHEkxG+kH7ZLkNBv4Qo/nOfOD3oqI5uwyEgdMQ562YsFIrAQ3wjfvHt44H9gV+Z9ZcYFIAFiMCadMH9KPLLzoKWsveSpERV4U5KAh9jjeXQCUy3Cf8ec/5h/OGlHwf848MBui5xKCDh8PvHDT0JK2/3cnEIR+CFIX2fGPMzSAzjuEuj7rpj8xdiglKYhd6nOTUgLUVwgD4zaqFUFQJd7ThmwbS5syeJnAYsCRnLWVzABu5tM85I6xcoTciMQUBsq8vE15BlwRlFSm+16c6CgCrqs6sCllBGgXkxIJPTSDDUoODhiMKAGKIOwIHTQG47CvKKNQ5g7txojZMsarYY+X7ACCA2aLI5DWc+ZuHiwAEUoOp7SyqEPKOoC6gWwh9HluqVJ21Gyb3BU72gvaruu24NE+lmj38mQoIMlGbyVOunIk/AICRx7bpvqhucFIWAS2NhQWsaWQySoAA6BRKWkRJ6/jCky67R1blpAcRRlY/g4ek8YvkgeMUEBEBDiAZF/ifwIQyiJFsUoS0pShEDeUaeiKwTwVpcGQFiJl6y7nRiXJlPMz325pmEYJwRo6aEYGw0m13gAMmd/A3iXhg1nnYLCFvUzlmKgAjYhs1F8YMFWfaAA0NuX55zSxw5kNtU4ejvAYU2k6N8TEpvYcDXrAm7qgznn1loQ0XabaScr9ZY8TXwXa0eKl7ODDx/W8FPkkWHsmV9DtLiTbT2/5wi6xWBNEtcg4eTBU0UL/Pw6j6xL3mHJJ0+tTDGnjMf1hNlWz0Z3594PDRSZfunjCHdYOxLBqzOD7xs/4OD4YB2W+V4MjSAgqQ53gK9oHtng2fOJSVQHY/gzm9cUn9YUmr9cUj2xv94Fvg2MPIDi2NkSBE3p5xypAUS6bfN+8InyyFgAaoS+J7LZ9KauRSDar2gjOSskhgA2o8tYmgQ2HOSmB2PeMloanyZAJFs8f7fHHzl852cnwtH1mzlFvk1jggC/wzK9TC7oYN/Yfuty8i2Vf9v5YgigTQs2NKLSsFRhaHmTCQ1yNKMPgcE8QpIToCEUNhVVVGnYzEPaI2f6fea9j8n9M+WnsfwuP/AGAfujHQV8MvwOA1Lt/MnABoNKToqp8oy8cQIgKNJBTqUiY0wU3XkWnDezZnEK6xzXR5TqTW9LNK8ERWXSkUlnnB+Wj0YtUK0qllZxIAA0Xho2Lqi1uLPYI5+g0spuLpBih6uvbdTS2bdB8Ft9tQO8DpRdUTgZV6gdktVAOin6c8i6IcLrBp2Cmt42l/CMhCqn4MeGcVYDRCLpksRm8urHyWmq5qKA3WsTohcFVVsJQCG8MKTRd+RFnJdf8ATG7TENejSPLCHvGf26DXvf6xiUJDjXXZi4WdDy0W716Gr7RxnIQMAtaKk0622QQE8YmjBVgs42g1pmjkA2VJrFHjAAI/GNtmckaVS6Wb1cW9Q0x/gYlhICLo566jgxlBaoOuR5Wm9AoOs4GsfkWh9uCjeiA+SJ/OL6Fe1F11hKkDqb+1P1hut3wwBCBFCSPcYnuYk8GSU4Q6ppzxGAX3gEhEA8kHDwz38EVKEAhAKbw2fKrp1AgkRsIxiuN+V3bGkBAgJVN4VeVIBp1RpNlj3h/b6WJSQjNfm7ZLEaroAvynb4yLw27V3MvYkeU8YRKVVqHW7NPpLMZbOjm04BUFTUG2TAhPSx3ybO/k85xv2YxaCSgFHoze0IxVT/ACYdv5KyctlNafjACbg4n5uPV0aP5TB4JBnd0h4NayivdaTDp78NAoDNrhiRauiljpoeETgy4Rryw5AN1MBwvYyftMSvqI/wAjJQDhSjhff5D+ctgMZN/41WIzcAEHy6TXq/GOe33YPJQ10rrIjA849idPXrEnxUqjVBHNEc6veUONOOQq7QR8idY/2WEJpZ5ylYxXpfOGa/2Y7aynvKkyGifnKnb9MywHBACZ5c2VuetwHLY2dM1maCjVPIapl4OH6B/rK1MFMAP46a8GKVz4ozheNkvxhpLvCR9Zs95bARZxli/gjT7I4NLWGKHhFp42pjdkHiSqCcrfPabuHhjyQp2ReXZ6YNWZbgIJ2IiCiIlEr/HmyE9Btaxps7DQ+BI9NlXuvbSAVwzA6A4Ch2JGNS/yG29Aos0DznFyvRCIQm0NTZt9XVyNcGzwE6fAed5M8ALLCqlTU8kKEwrXdCTNKhLFNjenHeLwhRHMCY5nZTJMh6Aq10IN8rRAt+wCTtYi4gamjDhXDCxSX2QcS2XnHGA2ZZz+ecj8drijoU2Pf8mAFqUNCtAzZUg2nBE31ii0VVT4W5Wp684b7acQiEVGxW0EtFDvcJBgVtCS0UKVuMQnBZ5khyY4fKrX/vACnUfFoAAevisxONKCq5SV6bY7PArN8qRP+3iGKN4ID/TLygcw29z9/nDwLlHjdwfAgCPSJ5uXfVaL10GPxMngrBU1avLudcbI3S4qBaaqRRdbXxkLblsmxxgICKc7Oj2GbO0RqBh709uGc+xRzdKwN7EZpwuAQ8GcCBQAQ41JrOV6rRKvTW0ip0COcTYpQG1QoojQ26sQ02e6lNIOpyLZMbdEIraTaCUreIwlN38gDoEjBFNs3j8TWYUhQ5Bt4NnnhJU5UtEUoqta2TNjAsY9kJSsiEuzHn4UUxBJFBB6zvXeAYijCHZm/GLAYmQ2VEmsIcBEFZ4h/wCWOYn/AIo4scyy/wDeIsQjeck3fGcQAAtHHXEyaFmocn8DlqO+qEJsA14SLbi/mmwRq184nCukwIPXXTCDXzFmE+KxFEByTd95DRyxbT06xAS4rXxOssZN6KC18xPrJZBVPApAvwYNM2iT5Heas/5xFtEA4tw12ptfrejyroKuAVIYBbCR2BqaZlMDCrVaxWcLlxDnlRKhXSbPEfGK7fARHwmHG87uQbXKjEjxcSDPK/4JiJUgfQYKjiL9A/rLBaIPrAbT5/OVU8B0YjgxZ4v/ABhAko/k/wDimnMr2NH7uTxATyJaNcx0ePVy+R4K7kGmKJqwdBANmTKLI94fcGsocfvSuRYs8sbNcsWNgLbdAk4PUHVpgA17Kq6HbDkutS8OkOK4JxBSwEXerKSPvuExu2/ARFw8YR945AWqIrth8kbDSA0h3KfKBC3NZzOqshAqKHY2LGT38vEKIEokICrLxeNxTuIEQIKiwhqGShSjtWt6dr15xKAUHn9Y1tUC8+38+fGG+ngVuEJqrwPLK20804/fGHHhmGtFbpo18poocEkUFtEFHYwOlICKjlKcBGbTX0uCkRsQIA5gDzNeXKhW17wSslQYJrsoBY+YmBmxNwJxH4wq6CHWv+/j7yuSLvE+PmZYY1NqnF+f8zvA5pdk/L/v4znavQD9NBPs8zAGI1rvR/ZiC4IWK6f3EfjD23znCU4BysryiRxrL8NiBXwGCgzAs0RGx5WByGg+M4pgwWBUrwZL/PDBMAUABxo7Pg/nFpo2nR/Hz+8NuQsIuLvSaeOku9XpEbraVwVUJ4ckInJGVCflJchv5xUcAEOdm1agaD4xviNChgq5ZqPKMInr1GeWOgk32ax5VVUUMKWhVVYU6TLwRlgJAG0j2vii8ZMaKi/ie1gz8MPRmvpHvBieAKb+8byWqKoRAC1y4Gwo0WT1NmTZAO9lNVNki3WSBTMPDDYz+ccD6ySUh7H6MeJFNOb5wmFicHGTIVa5tiMFaI0MXKM0LWMp4L840H7jVODxN4uDSKdweud5Q09pSu4WrdcbYRIcnUM0YCZddOD0fjbGcby26j/OJXqGORFH6yEAOrUoAcdLt6cFQOpEiD0WEOaeMFsVBq4xd9951MqvH4Af1mif/C3eFOCpR3i41telDEbOZ+g/rCpPI4q8tAMT/CTELFjcVoV5ibePjFYjNpq4qzBQQXx64xE6AZXdvGIjHOhDnya/kzccTBApA6I9272+XIj0JpEfZaT8chgphkCfPBkE9EjoQ6mzcoTyHuXjZjcITIpCByBA0iInOBFMGmwJvzHnja7uOfdo24i5HzHwgmMgnTBpDvPa6Q2TIpWZua7djR1G4Z3ezyFarwcrNawOLxW6cBg2mmiEMgrGcqBhMUSHIjh9cSwgCJNLCmxCIr3XAPlA0eecQ7SQAo8rcIC4gdizx/33ljYiBduD554wkIQprntcWgltf51jqdXAnAYbOJ4fFKi8O4gK3JVsb1yzc9FFpGooCuhdL24mnoKhKBAryInTt04MRUJt/wCcNNkKmohsrLOXFTCaO7E+G35wRJFmk/PH/f0BRVohoK0ZhbgoJ+eP+/8AcF/vpPT34/1iDgMwKp3z/wC9mOnRClXdduNTiE7SiqpIkFut1NUjfD4Iz9jhEoSCqFForXL73YhatOxR5a4+B85PYkpwOU543xjShiSDSsHN9dnzZ0qNH3M+8JAoOdV1RqAO2vqpvNIF8IkpDoIzrNEQ5ChtOOzmzfiq90OAiwVDZygLDWMDUwqEpFEvYg7wXtUdTAxeFjjm7dDvRCWQCxutNWGC+t+IcBHgIQHU6THnzpGkk89h0YioDAQ0HVBpcRxrAtwXTzFrvDDgl126aa6JOcPRxqS161jBpXUAMVTSzu85Whm0mAKAt056kchhPJ5Pfa+zGE0g2qAYydUAOC5iXAgV1rRLHIqNnrcY3etnfzhVO1XkLxbP1kZmwdECs86H8ZcruoKNPv0+seiqVenlxGROKIYWAtFMTyOQB6MGHpM1oj4oSDmn0WxkxvPEyNJzT/Mb6YrEgAQKXAQCbL5Rc+/BmtonC+5rFRn1UAp7SzBxgZbg3gR0T+E/piKKVp+WB8pTx7cF5VH5w2xVmByfzOEhtfCre/8Akwk5lW/frngJCCvEEfiOcHObAL2YjpQD8OGgsU8gh87ynYAl7OH8TKXzSilcey3t35FVYRl30jNq062pTeAkPGgMCHJwCkCURLOUEIIgb7Momzec8JBt9b7XT1Y4DG0PliLsPIRy0kmFJ8aRo5QyxhMHjO3kmtG4KwUsKnCXgNuVSE2BScA8hVSoiWAgTqnLDv2bqYDdCIJsJQUZNqwXLDOLzwiyJgI2IoBuHi42jQVQ+j+vzkw1DklP0V/L7xyhBDOG4/xlNgQnOAW3VBaypCPTU3sgbK1NI260DeQ2c5KZJYo6bTaeOg7tXrQQVoIZzpL41xntP3/nC1gGNZt5lU9vFVDI7AKsr3p5yY0dQHstvc+sVxCyhAGgXvw5W87xyGlAgvFsOYoeJNXLy6eOUMv+LIJYo0Pki984ge0KAVLwk4+NzOTjZtoux55P8hwEO5N7auyXUcE0KhZh3CKaDgawtqXJiut69Fff3gbhRWDdx4Htms6Qg2KWAPSvRg0EFVvCCue2lydHYqrVS6EQXU3SiVc6SgggIVEm7rLkro9WhWQ0R5WdsodUYUDAAIeet8KkAZRsBAyr+XizH4Ct30LcRbAqa+KGG1CkQBO4cht2spiJgEQRX6HC1jF1lVoCf8d4/ugRoqD9Sfbm8Dk0qv2MlPBMY3A5F7l4xRzjYPQ3m98zWAmRDQ+aofvp8ZHShCd9FPGOYtGEraBY8f6Y6xCquHgQA3e3KsoWwG9G3esIFQ4Em1CaeD8bxW6uDBF4NEDRqhgqlMMgV3EGuE+PIXAhCB5ag6d5sAKa0mbnvn84ToidMIiaWdhXEYBZHnxbPKeFzek1oXNiqDQkamdjm8QIIZ0XauirXVNXBWZ5aa5VftK4xNcaBd6jWPijVbrzhtu/bgTNscU5MQ11njJfyGAlf+lieeSflmqe8w/SrbBzvlsnmMKWPzjIwUPaPH7v1jid8Q7kN6IevmznkhwCpF+CH1ccnBpMhr+xof4ua2I40Rt44fxgZd+QLIuXjjzLnSPnkcAtiUNy45aKYHk/BWxcKjpUfCSZiSqOQ0+yGSWxzgcqun8XDwcV3nBExZ9/OCqeNxKewr6eHpyroIwi7Pt59cnhsHc2JFdgwdOrzSYpoJVI8CqTYpsZjcDC224XKlPt8ZEnsdkUH2yzF0ObdTtxEmz0dxwo5u6F27vn36K1k0QYWd/vObZm/QyIa3A+MSk2DsTph36OTK0eDNZ4PZJLRIt9HdMDHFPjM7FaR2U7TxWQ9ATzAgYg4aSB4lj8Uwgkfxj/AHRCImuiv5PowoY4RYS/2u8mi88skbBKnV2gnTlHRV3BkArYxWYa6If1P+mIS5DQCjTfrnItETAOCZVA2SqK0hCJc1gBy2vuvWNxXY4c53Q0ZJ6zlThO4jU04fdwVTdKhmgbNXLqPQsv048WqabDn4Pxc3wCNcQcU3BvWCbbUA1JVya4xWTbFQWrZOQMHOZtt4ZAWzyEuseRukQE5GgpyO73pwkE0i1Z26d8/eb4DEAZgooP5qgiuORNPNGCm5anDycH7GoBNZlAKgOFveLKCljAJCDIG3n1iIHTTxv/AIxO+X8B/eQ2vON7/IB/nBjcNN0BWMjO+M00cFpEoWN0nHLaZAXy4s1YdIbdpdYvbjwcCM0mnCNiuJtJWCWUnxM5DpkImy2TRJQFwQbVRRb39H+ccKihhRs72L8CcYpRuRLoPpCN6dpa4CpqgAYdOJ+U73gsAWI8rD5guvGGmV9qzYBvz25Ghk6ulRutp1mzHI0Y+NGTX9GepAhFKpxcHJAxCl6Fq18+8Hj5xSN498feVCAHeh4LE/AuiRVmKJjuRRKXrB8HG0iDVMW/QYZA8qgIoqjKtscOJlHNjnLriNXVej/Dx3/q2wfK35zl3pftgFApfT7tsvLo0RwlKhnZSr9YNHpHlQr5uDdVg8qS/rLybUDw8ZHjyz1pylBfeDY58VTkOn7AvDisakIx5yp1N7IgfsMBpyh2EKAbBvj0cEeMOluL2Jp0dJlmc0k4Ch0UA6CdYVeSgNEOgmm41wHL3TVS6k9DdJB8NylHQ5/W/oT4hxgAFmnMfxeHr44Hobpg2wIUdSKauH7eagFb+S8EdhztdOxIEW7Jobc9SZ0Ctxqzh999+sUNslFPD95poYHSs84jw3fIFTugR5jTpwD2rb5ra4DDgoBswRPQFElakSLdG+tygptwEhKnCJOBvN39raUan5xDxnMdD4KBphMY+ibz4FAThU5cMIWTqt7dX5xUsTyQkA1fjyeMcBg25kB4Id5SiRxK+Z1OvjATUHsUF0Hc1feTMQzVHSVgxwPJzj24E51EUA0SmyYxcEUIgQASeQjhXc5hhjy6RffLLIEaIntQ19uRdqCAThvCfJ+cFnZZaAHCfh6nGMgYCyvIa4JhNHNKUgYqQp5eYIhC2xDKlUiL3AO8NzyimxMKUqVFzy3QTHZSLQoqchx2LLAREUbSx7Xyi9xkkcSm4wThQ2RVTLdcXYAjuTi3vJ4c+2S9EKquq6M21TojBAmlVIgmBYVum543YUfSn3/gxzBU5VxHAD+bFKgRBvQ4x3RBRI8kihrzjhIQIm29iTw4FaiQWvBW8kERsOC1y+7g3DRIr4LGLpKwodivgnlFjnHj2hCOo884OMDSVJoCt53xoiBlPUEx7vjieVneLHToO4rBebt/LjOnqK+TyacI2dJfugr85BQuOsEIXBUQSK4UDtWPA8PA8Yd9FIRdXZyqObPwAfd/eV6AIrGsdtmNVtDww0BYSapxq9bcGQfjY0s2YChpcXLBxROiuym8qtdFSDs0GbARrAezDMuHOdqRHiAfz/GOfz/Kxf8AB0Yi++X8sbhKHEkj6RT8ZQlLrr3LyPNMNEgBEUL/AI/eUCNL1Dnf5/8AV7y2BwdeTJ7jf398EHqyYDs64vgP6wx6hXfvHHYgPhJgYogEUDVjeL5HhMRqVrslEUwEqKawkcpvAJ5GD2hEmFKoHMEbmtACeITXbpamEpKT0hpNIez7PSqA63p8RL6UxuFIs+oNe8vS6pE4fYc05B52Id0nnim0fInYhbgqcJkeEOgUpp5NvYGEgNKy8+xWbBNagJCCdD0m3ibNt9ZX0GaTSOiSigKnIiYj5eSF3vCuUnsWpPBRwB6FojrEPTbo9PZy16IjsD3qz59c4VjBogIp96HWusolTAC3yFO1nWCphT0z7xGJRgfUEADWR5YYwhzs445kisQ5qC/CWbKFw6CRs9ZeVSmeFaHm+s1KIK3jYJbNpN4K+MyhWJ2SxO8eo4c/HztAsslFMiWkVWj5wcRm7Qu1f1/PGJlXQi9nj8uLiGCCgZK1/dfuYy9HGl6YRpjQzOksjpIRISIXNHHu6HIE7MNVchjJgJdAAV7SqmyODiVUQKxRqyASOnQYMjBoKbB3/H/tWmMdoFIUhRQ7d5zXCnBUSY9u+DdMIQM4MSUSIHfu7y2ZRErbYnKLvX3h4SSigHSjg6cOt1PYC5/OOsi2PFxdF/BiL0oLH+Me8vlIHt5eOsfUiFsLy9DvcQfhY4rraKs50TW/QWuMWfyExaKNSIQ4mSuJA8j9f849xUfywfIqPQ4VaczqnfjsdeB8YXNIDq9o1D8sj4EXzsrb4Gh86BGK6n+6JW6xEUVFANJLS6PfjLxHJQR6KN3rjrFWeBSCTUYuKR3pmq6HnnjH/iRWC918F/P3ghKaDtIl9x/nEesJKELoDu9TEWE2GvKO0b4FR3m5e2TSUei6BlNhH9SP5x026RJMYpQ8MOG+GsPeJHAYp7Qr1ofwMouAQeA/TBseA/DwkMks+Is+Hk+saPg6j9kf3jNHYgN57v4B98oOGaYcQ/hHBhlcpfQ9eQ4x8yQe1qjJTg67Ltxv4x7MNCjD104Ai2LIgFAoiI87EXWWKxMUtF0qOgeMKNpKlBDZXbXZxioD6AcNB0hRWkUdOIKTaWgrvvSq9W1wBohHyYX7zRrFoEHnuI8wMV92AmqiUBTSRc4IUrD4yBPVSw0R3QMRyfpa/O5gEcWKqgxScEfAVnyFeImIMirgD9lIAgUFeex2tVxGTiI3Y6bC6ikrjAOEBHI2O3TmgkmEgFrXM26DIi55akSVeUnxvG28qBa1NCM0aB7zZ+KS2t1XN4iBQBuJmpIYDSl4Iz+tXKla8FQIz0wz4wXRvg6WU2m29Yq5GFjFEHfojPMxsRg4+Sj1tdnxkVWEKoR1HN183BjkzG0YjCg7DbsRNlMWm1ube80cpABKo8GnHQPWEOibryobeeADqvlfLFvA7HbwX5cMzDBVXAHl5/1lEa3Wg9vb8a+cGOu9GWCugae0e+cEJBRKeRCkNl0cY1j0SQwVXRFGx2WrHzDYwAgSlI0XYzi4mbtgGHStG2maZcBwbpMami3XW9H6tpWqCAYRd6nWN5SSz5AGU2pq3eAmI2EEpDHZR4SPedLmk5UQhAFqQOcZFn11GBxDCPAHishKDfGGEcwIr7yvA1BRocPrOuiEMGHTynGtOWZthazml8s3MHgQKzvjGtdvYABSo9ERJOvIJttdDHDMg1LK7c9GutHBiwYpEeQiX5wiIsIQL4TL/U0LnYjfEpvfOE+QHoMnj1aWNNcXGB/Cgktw4Vg6A8WAQp3Df8HeK2AlMNcohSabJ3hssZ9GLU4autNgFypKYukB1F36G3kJUunwH4dZyAahYJ5hs74pzjIVkC5ladg8XlLhQrzhFodsiApUeCXp9Qi4+Cy6CNTItMnB67lhHTaG7gMD1iUuO03Mk7fyUP7XKXd2AAeD/RjCDWhfD/oxGz8YhMTB956vGx+8DGuBqfAD8GF1JZtjwWL8s9YzhcY0IASzX+M7yDTTGE0ld2Y3Fp5NOfp6+jw4wV7WEpSEmwdJg1JfsiKGhwAk1atjVhr5w/NfY5qvAQ5ADhNHurlHhqfTYMP2M7T8iaW8o2azN2Uy0UnkdBB1pYlD7gFbU1Tbt+y4jYoCnynY/benTkSMFCbOplQ477wFRxVIvFGhxJ+WHuBznuD9zg4MEH8hbtvEtygqIAXwQEWCPB0sr281XhXA/OGkr0+FQg3FcAAYBtQoXd7uog0rTTcKg7AiG+G9XOPAdEQ28w7xTxBn0xepICnoARVPZdsMQ5YrsuzgqsNYhkHhpUR1O8KK5QdBHpMJu9VTiTslhogBOOD426D+0GKwbgHcGbQc1wKcjKDJCJ4AJOb3HlYk7sNqC5ym159OfIX7wVIqvVF3bcKyvAd3CGE22O/a25OaOLjDjgvnR/DiGto4CH9B+AxA/lwZFEpQmnp8Jsd4nrDG6UCFWUK0EWtmRyCoIEZ7fj0YuIorVoMNjQDVNaaxtNHzWg+o+DjnHYwQ1oWBCc8oQecNqnOgSoEAG6ETVwYWIaCWA+WQ3kjiJdnTvFxSJqHfVF1jotnK/nrGaOHtQ0gjW3o733jtNGTWPJUQQJxvFaj540YukudxEx2jLftAqpZPF5bxY7oeTYa0BVnUmM0IY4+A26D9uA8MIxpG9/WPvu1AWKPrK0vI62P9YIUCg8F1fm+3I01CRSFXpHZ1edZp3KxDTiJW/Nl4MdtUenZt86P19D6kAFgReHApa3zHjJDDWo+yeXRgol2tOXRf1hpyGQxF91NKs08JtEWgbu1UWWh3xXAU8Bt2avm+M4EeenhyN0Bmrkvg4brKPaXvAzDF0zZA54xLFJXyKP0ZRf8Aq49f/ExixECom/owzVdkJmryxIFfLH7o/WNLgXEDekqG4hrzv/4Lziiph9mMdb5WhpU6OO80fT/pEwRaVA6E6L+8h26WH8jjhQG5IkOp2/WB7rx/PvFEhIjoSlNFONPFc05cN5xAKOEenFjjkjOxIcTcPQOHC7NrVwpYRHD2DPrB8KN6l5QfgsEM5Pj2UjNcwhA30L+lzkW5Gq5EuJqIgocSxJ70PDY2dMPGAgaSh5ZfQrrj6M0tidjQ2b+cahBf8T1j4S36a4Pfg/WIGFqjT58NeW+suAfZmJY6NeDEYqhF34XgHFkfeOdC+8LDz3+BNu5bMPK4Y7KqOttJdMi61HlGP1hwBkoYLvvy9iivL1vdydREI8in7xgJ2ZzXlU7dvH4v3kIbttSYZLIfnLsBVvK7+PwY5xlMQEDw3CjiBNT5Efj8sJyNMJyNb5NpHzzha5dqHDDd4+85dgL7UzCgnIlOtInLXWGKOQ0UOT3BTqYOihu/NMWfNE2jsUgg4FtLcH6zpoHMM5cWHQCGHJzhdqmVIclL5OIDiUR+7ENC7vhQcvhQfpcS/iAVeADt/wCNY26MGEQjSPexJ9ZCLitlgGKEgXgPOCIQKspVO74Tb5Rcey0gvk25dSEA8UTk0fgMIjd10gt5SOgeecVIRZsCo7Xs+zvDCLI8IWEXJOvECnyfp6YBQoujef5cINUKIPSSbEnrHj3QNQnUug0+8ClwTQ8pxD+MWAmVV7/vsPd7ljX7EAjYkFeduqiTk0bELjg6EezAQ80qa+HASS4ctwOxj0hBeDjCKTQL8TzXSDB30DgHODEcOg695tp/mm/3mxPb/nD5v/LEu2SP+POHVUZJ+UOvnBEi2ycfC4dGEsFEdlVH0eu89mPfOPbHKc8sfBdC5tNMd4wU8av+PnCXnAuEwQ+cJ6ZCInJf2dj7MAvmQh9BH8Hzgjd8JGeVsH0yEEKUEH6yti3rE1gRFtPjKvu1o+WCvzcTJ9hM+N4fWD3PfH9cOROBF8jvDjv4ca2sEsoF3i11ovF9Jg4fECgQUFj94gko3A+Q3omsVQByveECSh0447QajGkLb0M2JaPDzmlhyHIEiKzbCABphArtTZYQhDpUaJkahLInMrwO3DS5pvGjF5F6wJcB2lkU1lwrrJ0/PDc6PxPPe/A+FyZN8KEjh6304/pp4hVaLEdJ4GFJ02xGx+Dh7j6uakSMT2MNWkQmLvUAo5fic7AW6pK/LcaGO5QCmK8lRDzhzUAlFaxeEvhzmo4IrVHBHYYCPIwtVpm50cj9mQmvet/TTdzB5t7ZgktRNS3AbB6ghsR5yhi1k1Oe59hnxrIgD0DRWxTcOfDy8YNdBwzye9vnfBdYvIDZ8phAAgxGg7IPG+feVb3tjF542YcjoRzCaCCcEt3884hyFjaor4RBgFNaXyCH2sFdQwN6nnEUu2MTqvtTXjKurGjZ+8YOrJJIB6Mjk5Eu59KrhPXysFcQ1Npw34qamybx9IKy4gIGcXockinoHKQZa2s9/wDypjtzl3kHY0PFX+sYOamM+R/nD8H+LDw1Z6kP4wGgByLTNayXSHCQeS74975y4KDBDQS7E1dbIa2qMOC0VsQa695NQutUwB75/WblbuHRTQNVnjvNi6w4xPOIu8cx4w1g4/lP94nrJjTtyXv5xSzGeRMgXBBqihP8n0TISrwfyhG+3I+ECmUPcE+nLsddivJs+zNMY0A5QJ7Z4oJO+ymn2ZtBtV9j38Axy1SMoPalf+mPHulR7HjCRvLuCXqXafebCROZzjhCVPrENdT00dYPD+YujdC7PvAZ/wCTS8UGoINPauq5tyngA7cR0dVaI/ebCbLLjQcjhwUzQfY81xi6TIxsoWjzbxlOhN0xTR6T/kwEWA6hgkdOnvK25lofBD8zZZV1IWfZoNvN84QdqnDRZc485XmkBq3IZSPZLQKHyVhJ0vEYxFiR5JrFqioJqcgJR0bEjonB4ARLDg7Dkvtihl0yBqh4R9XnGca6M0RghPThccIMxAo6I3RufzlIQGjv3r+fEIgbQ/QYA1006n5f5MNXgOAkdSJJSYxVIIUcTPHUcZ3TTQuhgUGnRu6Mp7I/H/uFcGNFStfV8SZczrehNnZsPkd5JPxihsQ8bD3fGNctwIvOfc/WXpaby4DOQBpwTqsnpv8AL+mcn5zjYbH06f5zhntt52wwXFTxsxCwlA8BdEV2znBYipS3V4RIdyvnOWY4SkzySNJxq8mOBphjg49KjliaLeMXjF63hzmygq/GyTpMf/Hzj/U/jFQO/Q8uvyuCUg7Y0aD3csL5nCAURfB0XALESS6CEYad9+MBYWWnfxigUdzjvxiTMhwNOt+c0Z1enPBw95HJmw9H6/5xHIZJjrefWfDiBG48mBTJdnEulpHZsjTAuyG5CgjI3IACLQo6/sAU1wphB5GndzZ+gYdGgBN6GL4yvwIvicB7dnDg5/7GO43+2W73h89H6hk/WeA+1Q+RixWGMk/jEMbANfAEwESI89YipVG7xUqBDjY/1jE9H8/2kxDmLAENg5o0+dKhjG4MK7GCqCroQIjTZS3BJ27Ut93KT4u8DSb8sA0966uz+f1kODGizEsXZOlwauz3EOlDew0eigqj71zscT1cTDjveCc+fSA8ggBsgpSCLnkNHTFneCenQIlBFcPHrGS4oDtAFGrGBRBHDn7d4Up/EahNK5EZSxcVx2UUCEVxvESvOpway+miC8Adm48kG84gc9C/eBT2bFE2bo8ZfIOAh9tfrNqXDrRUCBYLPA+MfWKA+o6P5xPvTdJlIUIgDbu5Oex1CkcF61ubLaDvuJDyPiZLSFG7idSJck2l+EmNrE6Q8Ecsbuv0YOr2EgoALJTW9hvN7HlpKN+Rc8x7M0pJBfTLTfhwFVNetAL7Y74Ex7htePa/xljrvzf86x5E3chW0EquSKCgYdopjrNAOx5Y8OMYIwjAjugIWocrXBYYFe0kfA3HXnDETE3cDdmBaj82mdwrdZuX/lw+fowdp/sLhKD1os5EjzhBIgBGlD+H9dYIuXRgbsk1+XKehKGCnNcw58zUx+tCWYICMuirvWriBNl33f6eMDgkAVqOgByQGut9YxhH+SB0Bv3LiQQ6m8zlX8+8oJqBxu6eRzhzjDOdMu5kXWOSvGKPWbzjOw6xLK6HSYA9ADyIAV2xRsRbUFB0EmndbyULdGL2ONSlUwbtp3DppIlTueA8fWRluFFANBldPZTVwumRnBoiAF4t92Yk6KQiBZ2JEJvRIZfwRleanIJJfTC2ohVa5XtnXZ0n3lYR65duICgVJrjHoqC0reF9zD6M0vAX+j8Zz/cuBA6IxozhxzNvjEEEoR4Nd+WQmhAV32LAdMK0NO8auk9YZYsKNbPreFxhq4BshtNP/cY8QqA7j/IY/IZQAYCA4FBaRTpMNFFOt0aBAAUBeSuMQ6qV7QC3sBA56NAcgQa47H4cKuBhZUswOweMNVBhcul0IKeeKH5APeyKja9Bm/vAvajQbQfFwUM8lV4CHSQVLpG5yxPcQlw70Du84OnYPnFPfpdXRzwfVLBotfOubCmEvG2cE3RF5GPrOYCrURNojDSZJI1kUpuBOfzTEWfbRKUWIIXeuDWFININbwDwea/xjwEwFPEeBWOP5aBE1JUd9OlnbGVbdHUBSBfs70o8S36LkgxUp3DWoFLwg4aISG4CGhUWjrjJ/kwgpWHjBzlHEFMpPr/nLI5W/Lc1gOBhpO0QPIxmwLVR7yMk+Os9nPoAjsdvAnEKvqbl01PlPHhMsxVcmbuQrn5wD+uajHJOhfzmoPR/WRo7/wB4gM9zV2BQPdPWKpZREJUBGo4iWUCapOX0x42ZFQnU2K9Bty12uaDNE3vAC0UHSed5BMhCAWFXRXjziRWoERORyDRj54wOolsi3kXsyGizp87mZrsAr4aT0mQeMZgE6yHnFji47wzqMHNu8azaqzBLGlA7HAqENuHHFStBa2DJoL3TeXIXa34dOL5mM1XSOzGULjZk3ZWRANohmwKm94bCEmG2wVQXT3a3NZvqvkxiEZtQY2KiZjs7gp3ApNMecEXQME3odNbS/wB4FE6aa6w8EfIr+MGo9g8F5+DPrD1xLXKHR9iTG4uU4LBLxxgWgWNkbDCMNJGbHE6kDlUG8yHd228Z1xqnw5YgzkNptR2hnAnObCnnNWgRHrw/1gWrdHGBLlNAfNYGAjoENUXy8F4ezS7wKljtjs0zyPVbJcRpCc3s95cGCAFS8ebgsDBC+wBTSAABuVQHq5ZJp+MEiPKglSxHBwqNAlaEfbyDkgjTemGpNobWT8OXKhMaFqoEOXV1bjCkYgRoDUN8qcTjeXny089CFXe+HmYQhp4xqOj4sxVtV0KNCZ2cM95LnUskTdGzeE0lGrOoXYgnty4v3W2gup2c95ryy0qB38OAzyCBTpwGy0ne+BV2ua3h9v6OM5FbSJdHT2azkwW//B8uJPnk/cwlNEr5kf1ghUIk7sAjlD/uF8BHyHnvEGpzgOMENYd8hvHfGsd/aAqD+WBzgrX+u8ZWQ0fC4WSibb/Nwq+FiUI4DyHeGMZEEUY1dh+M0wFtjYXefAOesYiUkQQ9/U9HjBxHSBloByu9fjE0k4FYiBHctveEnWUSVw/sZ785RwOJo2oX41+MmjW0BsiquxoBpK4hwKKFLWuTszhGCBjKEAOV8ZesrgSF0+fRy+jSZhwQA4zdVC9Y6OoesaCFgLo5nK8Zq3g0YZHLA3iOdCB5M3WvrWIaMxSpMZiYU5xpxjgEAYTpR4PAJX7cLU0TXdypegOpMPGJ5paOwHlz5fOaGICDgAE1/vIiSGv8enXeWedSrBVNi8tcAYbsc/sQ3cMp84bFiUnZ3vr1jcqWaU6mzw8GEdUQDXXFx2XBqEg/LZA+spkVFECgzh4o4eEII3rWucP+eQ9y/vHyx5I/WmM2d0d2pekT8YtYfgQRdaC+1zlRyekU84LEuLb/AJGBAw8HPyDhR5UvcH58/wB4zkZBWQHcITsGKjEmIwiy2Afi9wLrHtnwtn1hBrLLEKcnv9OF8BEdX311k223+MjX/Rx6YquiuS7sATEcJ4cSzWT9YjHV0Q/lDH84dH+X5e0e2uC3+zTeBbMTM/RRfuOMKZyix8luIIJp0E9b6074ziCPpUvYx+sFow8OsPgrsseKf4xGwuqX0j6TDsweUu4F2tXF7PTjmrzuu983Bt9ObnEXR9GEwN8PJdk5yXuUfw5I3XcjB+UzYdYYDRKAaWIdTTY+w7XATVRKaaaroclsxCyJwVoYnPYTFduCRAxoC8FPuB+rjgQKtD7oHs5766DaGKaaAb7xkUNyDVXgDnxiGlaOUAj1lQZ0H9if3j8LrIOWZZ24fL84TwP5xJQp4cdr3kByMgHRH8XNMA8J+wLiA/lf8jF1WVwKRRGg3Xb8ZQA87D9h/WGCXUK+SH7fWIjuw/Ldn4YwtzkE/EGHNxAEPr5OOcyhaiarU2Edu861UU6fdX6HrOWAVP8AXx9Fzdnrp184KRI7MErkK6GNgHNePZ/x/GKSWo2ucO3IqX84MLDwec5bb85ULfO9YRJL1hbd37lFTc1+Tm6JC6V3uJhqUA1djyn+GQR2ojPg+cEjFZOUAvz19ZK9uE+jCA9nwPUuCFkvFAPgZsSRSbWExB5nxhP7dVkUADdGxlazfIyg+TKNGWABXI4U+D8iD94Mdih69aIfvI3OfGdljF0C3XUxfP2vtGedBXi2TjPTmCILoUIfWCvigSbXit1ikkIOcNmiyPjWkzh3lBFORkxPCmk52a+cdNrhgLyxRASbnT3gxDuQ/ixyFBu6D/NyC+mr+mYwxeVOP1nCT9x/GaJk7pfvI3pSCfTcoXxA5Fo8A37ckSG+MhOd4K3bsQ47jGgfiwv1mkMVbXPKzf05uA7EEWjgkArypdzA0qu0C9Xz9YtUl8UfXX5MVu16j9NYDLaHfOCIKFfOr+srMGKmyGz4yBKSoe7bBs2BdiwjcEr+8e8SmHwhfq5u/EY0dA2e8m0NjiXjaPlGEqnoU+KMeiGb4ywHlKPWISeQbrhqBYXRh+cAVZPcyYR06jYj0+sC/CX+WElVPObdYfDgGEc3zR4wCxJiUPPHy/7+sIEPhiGC0yK8Lo995zk1SHtzSod8GW0OADtehzicEaICIxHzk9foKl7RI+d+3jOYwt4Tyb5y6NKlR+8JATza/lXKUpLVdtxQYahxkRusGTBjCj4zZAfGAgV+c0sAk8n8CxXU2+sEeDgwa8Y0kOlOsPITXhVF+5m+uyGE7fZS5sNrIa1OydbeM2EIr5aSrPOn3mrBtpcLqvyKbnGLlbivf1GnpU/nNx5kB+j/AGwY2PlftXfwYZovBX7b+8fkjWyBCFCFYe3y5EbQ9mivDmGrMBRFd7O/nvGSgux/jJpwCTQmD9kfvBCdKjuA4jbeXtOstThIR1F1zrzs+koX05QF8YwMp1iNU9MxMifNYCzHMwWAs2i/nFIgf8d4DAeQP+Plwuck9hg/cv25fJHpNbxKGo4wO2E5V61lWhdQfP8Ahb6wUrerQbBOg0EDtbZNi3BkI9lOKEItvU6cMWHHOI9dYnEJ4yNHEZTUVWqH5zXKbXfgf0A4rTg6V0gs9pfOEXpBknq8fKPExUhv4HFsPRhVVwnWRroyouqkxi0C8hs/Wvzk9VWHqF34fWbwpoaZFYlPMAcpK3n+MxSc+CeTNAh8Dvv947q73/OGb4V8T9Iy8+IFH6OCtTxL+CZaJvCP6XO4X2P0wNGPCf3ZzZvDP94pQXzdv/fxihbBdnj9/wAHvAUBV4MEbWkc/jEER8v9/wCLmuFOd8fv+sIbkKgvaPB6fxmiDDZUjY83ARHprj46zQG+SSZsQZ8cZPFTuf2eHCXEj3/hzimvDBesfWJT8Y20ZIZIYj8KM+hwiLaHV+RxAq3AMPgp+7naJ27ZAQkvguT5dCjq9mIKB2WZRVSdhjrlkWCaV+p+cTAXgrx5aLt1io0YTAj7nB3z3kAgtMURTPy4dXeVqpv2YKbK0Kj9DkQKCAPP0ywFTzn8rEWzihMZ81if6CrfSwNG0+VvHtaUIvwJr6w1NRBVQK3wyWLYQTu92tM5hzmC/wAYapHQPJPw/JxB4CqD7i8PrWBq+M4P5fjLhrvjn39gmQBHEKvGaNN/OBWyf/Ggg9uXN6PGOSlWBuuMUhicrQ/S3DyFb+8KqW5ZmuQXfgwOkShG/wD74xXkaKXqNwvfWTXUswRC8FNBxxrjDHtZAg0vPR5nLVx1H2J3H/eK9TFSOWFxcaTjF42tw7HM4DG23fkTRcd4f3crSE5pMbSSqIeLEwi8jyEzk+eG/kTKCZ5IfrLomDbxcRAQqzZj7NZYRngALVBld9YOVpfNFpzk4TJmcD+DhErlhwWPv/dweRM1N4TgbcE93BuB3vAiJ+wDEhNXrCA+6PvAxS1XgBePVV+8E1V4Hb8YiuPB0Tv6xItOB/x/nO0VkCe5aYMOk4f88xHvBEfdUD5wlKIeXz/nCLZJSePXn4/jANJ4PrGaSDNOPBTBfz/D3hQj2GFdcYB5xCqzOm82ujBKM8csoIAcGQXeGhiJVVTgImOxWYdvG3FiBqhuYzEx6nWsq3otImp/c/GIgCpjCJ5RP5c02Hj1K/484/lE4xzm4Psv+953AuGBsPnDBDfrD0jFOD2XpnDkNJw6il2QP1jBck9j35phxcWeFj9LfSDyGFVKDYGJr3lTou+F/WQSA3ZCR9bHNjIiuR8zweCd/LiIi1iB6ePZghyV8J+C/bxlxHrjAJRXE6ypGxlNby4nzAmcnU5EkyXTrqsynTo1cW+5ouNl1/oivxr6Y/UD2XJyc8eMEXFtINZ8sPvH1ZSKk/A3+TA+qavkyBdJp3rCW1AbTHby45L4PCLxGPEAPxozR3Ovs/1lHjG9XUxMiYIq/Av9YTBqtA6R5P8Au9Y7EuHs1G/Dxx6w3BLuLdb5/f4xpelROB7njBNh8mCKpZ5wc3o4MYo/W/py7KhBCgWvOuTxkwrHUMsh9WLhuyZrtKavjOZ+On+TNCT0Vn0n95wlndYfawx6OwOKfm6J80ZtO+BH949PDFf74hw/OGUN8fywBrbfyaf3lutU37yQngnP/f7wUOQG9j/jn8YgDkRqmpuaAG0g51s9+YS60HCqB0qi4wM0NoyKovbbueqLimqR0NDl0au81wcSvTTb15fwpEQKIlw/CPI/+Y/aKiLroHrc736wrgbAF3js84jFPZzTv7I491l84JbGPJMDIG5QaLzcX2f3xk8hr/FgArxUx5MQo6PWsI0am8hkmM6OCP2xFiar5Uf9zioZoi54xOIKtu+f9YRLITgB34wBILUYGiCq3jBEBBV0eEDq+biBXGvkCtADt0LiIkRzjkGESIe7g6ONPVX2g8O9p8JgN0b4WTWVL3DrBrIkmxX5a/7wMEPo7frBcdML6R+1h09J85biwpIat5fAP3m59cRRbj5+Wz3hrcmT8o+PnnG2TQCq/a35v1mw88If9YOdI4MCRdb+8BT3M1iNAvesa4PZN/yUYpBPzisHnKiRlNkT9tfszRitL4xSJgSkILAiDdOR3gpRFQSoE6c9riFTs9ZyGrxh1gdvl/WBtM/xEcf94spXcZ4lHWGDAR6d8YFEGg2sL6b84SK8W2tdf3iPebeWWQZhDpGf9zJcpEx3/GHcx0w4z8dEXA8qOtsSo445YKLnXWREDw7MjCz/AMamD+7i/A1jVceb787f1gLMCFb5Zfo+87onoPumT/rl+ISCLyeD/wBcZShNCb+M5mBxXwDGjDzH/fGPIBiHGjjHNLaBm3FZwDk8CKofRgEAnkRutHnJo0oLwYNcU6xQvl4ZWvQHMPG3DCGF6EeUVUbGgDeLETNwIK9g03zo5VtenK847RCJyATX4RPiZvwlH2f7xoOC/wCPC/jBuOlmNDJAGInDh+ehxvwwNAPkX85moHX9Pj3Fp2VFndzizS8sc2bJpAhfV+TAcALSh5Oe94yhocFnOQiiq8AZUMRuFNfm5ZotJYcX95RZJE1kE4POxx5ZqDXVNaSPPYjhhRQnYfyEf9vGAcZ58eDAQsJz1gBSsVJo5feIwDVZ5gARR3Ix6GmirhUnXnRmEuCu2sz7izCro7d/WchWviv+caRFA2q4m2vPzrNRw+y2/qPrD6tTD9UUUpvf/e83wsh18fk/jEyQGz3itf5MjK9Jci4J5jGKSDdmvvJ9MBV3aPy1Z7wenfYZy8d8/wAYfuZO6YTgCB8Bio2aIApNuvwInDyodIDUPIsE70+esrFlRSBopjsPscI+r9F/xlwdBvydYF8jJA6ozdcyL6K+saWZuMfjv1Pzg0TWVmwmuhDyYARJEv54sCN4lWrPwW/FxKXe5o91TIf/AFgowGyE3MT1JkHRnvHxGVK6+8poxZSRi7HKb0bCn4zT3qhGod2fUxdJ0Pymr/WEj3VX5lyQQL/FlNk/eOqR/wA6zlCi83lz5f3lYW2q36cpZViQmtul/OPKlToA84Igk0eM9hgPiuUtJutaA/1jhu6tBt/UD3MBqDJDYiL0md6G1evLnCCqkrOxcX8shA2INiAs4XnEOdzERATk8Xv6xHQWexofQ4DVVVN1EP6cczGASb34+8vsYJCRp5veS9Zy7wynxxy/Gs0nuCcCgs0BN+jfAySnVJ87x5+XXWXyvoxLIwi8IXdvjgUxbbINa/7nHwARvK8OEqQZ5L6ZJZqkR5dOQbgYCuwJ9YYiiyZ+X+8ArUMh5T81y8PG8AzGC8v90PowSchRzZnNusEBVIa94kioL5B2vGjCSr5Cz08vzkQwOhJaWjFQ6N85QjVE07ozKyYdpXxzkimS6HSd9J+s5tI1LE7+TFMCeBD+3c75ejGC38ocPR8YywF1IzvJKARHwnGbDv04+7jyz/XjDKRnF4Jo0UjyfPGBqwT4RP7wuwPWIIR7dBlTjdDnoffL9eMOgxQQCbql/eMmJ+NzGnyYOhACiQmiD1cBOpIrYeUvEPrH27TT2B/eHFDUXLZ/YsL3xgvYIy3kR9wHJYnAgHgMCnW8Poq5IhDmanRv6qFdgp+8pVXIf8kzTSDWpm1k95yavjDkD5wXTWRrK8THCn6wyJlCRxkmoGhHeM0KK8JMcBcnud4cq9uCpId3BCkN1o45cA8r4CD6xVBwweGPjCuq95xkcdutCmUoMVVO8gLU4b06f3Mlb9nH5w2jkhUBdEk63ZlLBYNRpwctZim1GDidI4ipbEVrlT4xv1jY/O3gHJ0esVZZAnAJpKhAhNGLzSjvgfyMqMBoE8B/WMAFePLv5wmwVS9DhI7kHkc4VPtmNYauHgUvsawnFQxFh+MvH27v88FCzNmt94Hr6vVe039lzyZrTG4yNL+ePeMcQk2EF9sr7cJrW6GwP3HyMEaUQH7HHjeQAMovc/eHVUECoP4kycT3aciEwO10hpRkQElK9BKC7LziwIelABGj2N49ZVQXJWj7YTlX+zz/AJwRZ8ThwYhE6AoXBBEXIMLMswcK/wAbDPIOIMqbkXQGvlFPHOGCJdwtJ3Dgjm3rArGhIimvyDCSru73iV3YN1CMlW3/AK4EYsnHZwzwa94M3tElEsHqzrrLFPCQMRHnuN7GYhhR5xxeQcTo5tPeQAA7piFXX8XBPNqWfzhABjsUv7w79LXor+3HMFuMHCI4O6PrSz4xpcOLoHmYsQ4PFOjD5Yl5GR87704KMJKMB0Nd/wCcBkzEU/tMLWkjwk/SxMzwvdAe5niS3BD/AIO8IqRwGHePhgYpUGSBArXfFJZeR4vanO5jpH8K2t0FufGawcbF3zJxjOhMeX0i3A9eV/rAKDtZvX4/eAclRovs3h0RRleHumEmaMgp9achbw9kx9qTcblEB6OzDdcGwaffGTE4c/2a0HvRjI0VTR8LMRziaODN5WhzCmV6/nvJNMyJVnzhXIwH+mD8sJwawqg6e/2YVADkvLiXBxa/Id6udhnyLwX0CdEd5UPzCVxaFdGkE8ZNV7AAwdfNJhI21rTVKAjTdNb1hWwzKxj3qa5KWaYUlTdu1Xf5x1Yg+xfocEVHCSLqUb0v6ztCNhoH5747wEavWQAUZTK+TIqTw9gTSl5DAAyiI3fg6/z3kfNbGFvYtpluWaIouoXH7Mka5tMznXgHg+MXaRfEMbdMDuAnKjjUJjm2cGnMxVQCh/sizIqHOhDSezHYPKSa5X+sZ2dGMWmc8pc64K6NXayoA+SvGAEAMWaNN99PvCZRQPWoxYCnCippekxqTRltE7bz/qv7MMC6NJiU7TwgRpP4xxC14p2VnOy7bPrAIlt05585YQCjQEfgUxLkKQj/AL+cLWPdmqprQ4GcmNedpo9Pe94SfCylfHKBHwfNzkjcb9CSZom+oU8Bh+nHkL2H9EPy44q/al9Cvq4hDrcNew95ZIjhSsnnOTPTXX4yTLaPs/iYpzBBzZlKgb8FN74rh6ITkR/AZXMm5XKwp43r4xlQWECuxfGVONPlH4JNfnxgwmqITSfAD6wh6Mp4APufhmkOXebASxcYrtrDYlWehwbUkrx7Zz6awjYh5Zz1Q5uasR2Psrs7PT9d4ApwkO+29osXXziwUCi6EVM4jYPjjNpw7srQafTxzlqceJOus/PjG54O/ZwnA+RllXHsL3T1zg+ikGL7AH+nIKcKbPOwdwx6vTw+ByhUaiN8Tn6mGNEC1PBbPl36MUpVq5vlW1wxNtduCXZwAY9I3cxXuK6NNzcNWdHGRzdN52NTvFKr6xxp8cbZvw76xXOJpBbfDlk2ck8fGNXGkEnnOm3PH2sPlWa6/Iv3XB88pXbXNp7BiSjq9u/1goUhr200B5/1iltyO+EA9DV+XC76BGkqrx5XETI46Oun+fvBsKnj/TNEaDz/AO4DUI6fH71i8WBAQKgrgoeW84ZSAFVO5Q9s6l6uIpqmjlutYzf55xQzoEPX5qacfnKVlaVNfPPDcC76HY6+8HNun8YAFJwnby+qYN09fAneudJ+8DwZagLzfG8EbcAwFKBxXyk7x52lWWrW9O8Ero3jKtmIBAHnQTvjFQXFNvv5uF05EdzSf24L5+cA7ls8necrKjyKb2XBYQAlLfKR57MOszkvk1Xvt1jW4pNo8Kr+YGIKIUJQxnyD7YjpFldG/wBuER0PBOcS2iuwg37woQOl6PjLY6TbmeIP8sUHaO01xxjEQz4xF3sE+u8osFUf7bj+MJspz+DeXCCYcv4auvcMc/Qwh8+H3l+iARgAzJchQHNavouNSxEOIcBnDViV4MKWq7esv4DNzlzf0Md1AH5mJWgUg4K79byxVA3WKn6TEOFodgGj53/GVRIAFwrh1hko94XoeolNrQpDW/0GnDYGrviffnAbkWZEsk6WHE/GFUBF3z7b/UwprRCUvyPaH43O2PzBGBIHXEc/GebSlzTmtdE9DJxKYkebtvR9/Uyj8CSFKrwHcfz3zi+aoE7uBL0/14yBmIOBOlCFmvP89QPDVdK7iBDfgmTOUzy2xEC8PeRQRWTbqx/b8Y82MFEf4r/POLWKtpMNBAKNN64H7yG2mfhZ/FjeVtG/Jh/OD35kiJH+sIdAckCesMS1TRX1QvyYAo7NIylBHazNyJ0rTnAxWcwzcFrZiQo3JxgAxGit/PH1knG/yMWmkXov84Eiu7L/AFnQBBSGm/8ATDit60gcQ8e1xJGdH3X5Dl+sVKFqG4ef3r7wCQD1iAFb5DAoAwzNLTuH5484XFdOyGzyk/GCs1qkHnx347/rYPIVEukEauxHjxi2rIuHdDp0da4xgbq4Q9URvnWsq6cW9GTfc1wYjyhIeZf2DEk8ENpXBIRzN8ZIpdRwDI+HCzwoRtEXQs5ecUVrN2SoZwjzsmC0bS3UicXY/jBXbKF4NgA6hp0fGMuqiPoYfrEO2veIGsuI8JO/+LlOq4GaKKG/PJTgGHdodNNcnDlHjMVwcAKadNxAEF0ZsBOb/Jg+rKRi60yu71iZ48iRuAwjjGEykU+KFP8AeBrlR/Sk9OFb5X5F6njNomIL8uLsu4NfvGohwBPv6945Fuwv+msVX3At4+v5/WCAbF0sfiQwLYCTawz0SfOV02oHc6zcygoXkpUeOuFwcKDkSU7nD8zFFh/LFQF7c4e5AQeaX8YDEXViqXqUPxhggibR/ZyfkyUwNOze5buPcfGCCCmU2zCl5fxiirx+8dzREp8bkIyzQ3MW7CCIm2GFANh3gMhdECU3KML67zUDIHoUvrv13hXQlqB12fGzzlUAAi29xmnZx4yuLogUt3c9Sv8AlrFI3vALCPWNicEYLvTb+LhVbsWkpYmta19cuDTDQiaLNAUFCN98qFSDP7Nk9DwNc73MZY0b7UyFQ8pQxNKZxTIWGVBaSpHAosCFQdlu/wDcY0QdN6N2SiP4uIpATj/qEAk8TByIOzetX9w355w3pI1NJfPX0cfWagYhFDZU3fjjxhDIqNNr00aF89605MuXWHfbEdcanjEAx0JLWxXoceeJljooZuy9U5njCQe25+du48LKQ88jfi/eb5jbSJDe38sXQGqHum9uNXXFTHvgym8HfXPOsKoPM/kJjFI6A/gv7y9HOC39Ux/7GH9xz4ZBr+f9ZzkN3lVPODK2ixQ/OCvLuXUH9ufvOO/QY3DE7nGD5E+2x0Plr0LrNXxKeppUl5ZdNBrJ9OAYVFAqb56feBYQQCobuuU5/H5TYt2l8k9hr7GWGFCWRU6547jeLqt3QA9BGvGj4MBp0npIfpzrVI+zCe0Lt04hYARB0foYgigYhNQHZz574wuysi3QPVDWT8pcyGUKGga8xbTt5MOA01Gu+TrHdtgXFGB53p8402oFONZIRv35xa2O3OdBCB7uglXH4+1B1CdhHL4VDdJBqDuRPDibVuQCtcPWMZtKokbHYgY7whVu6YX1y+/H3jwBF6c6T47wiJGRfhSeZrL5Btz3tIl9D5xhxUl+xBrL2uPrL+ceOYAewS8zAWVcSCrqfGt8fmFNSg1IXBq1QBUMrl6EBNAhs2TxouPA1E1bw5m/HU940nGSBeytBDvsL3hcR3263ChHXnB0HamE+8v71ugQC8UhWyrQAqC+lbx0cnnAjCIX0kLg8NJVr9xmwONeVou7rEU06dDSdTBIJGI0FxtWt+MMERKBY6jdEGxAphaaaxAE20rUm9c5I0qMyzQTZouw1zjwIiwL0oklaHCPOE1BI0+BQXYbLrfqAq0qdJYuXOsiQTXyB6IfHz84MrBS3V8yKb1jLWxABOGuZ82d5KbpNcm+zUgsvB+UurCoi0HfkJ+PZkdGh2OVUUhfr/K4FlIBuXfP174MGwuionWw50iicY99EDqJK0++Ww1QwcjUEgAmuA/6Yn5BrLc0j/LzvFMWc1j1Uu/A/eaPzTLtuWw58cGs5RlKgvqs9BLjBZgLSThQbS+zExsoHQ87NaND/WLtOwRKVLKX+H5wSGwAqtDsDxx1N/ZpMMGki02/L34OMBD1rkLxtT+sUrZKgGiQvEsJR0/ULNodwDZsHiXfc08I1xnKD0V3vweJ3hGoxLS2urRLV266nhF0oWi03UvvmPcxDEbV9nc41vWvHHkvZR1TTp03fT0dzN0+2bQ7K2e2T5xUUPsRWZv3lnpAocjR/FjNId6x5Qqs9vTgU6WEBqWCGy7xBFEQTzr/ACYVSdMIpzwn45w5/U6wbFKkSic+cVGmwp64w/rDgCC/ugv1kiZWXI7QXDhfDEpqaNvgAXi3w87yIBo0Qudb1MGcs6IQNJJNnNxAJHIQO9oeHwfvKIGIB5cG7+GPi2Dg5sB7m+m3AZI1UuvOucJSnjaQL9qy1q7h8v8AWPWrSMd+sdS7WDeV4GfvDX8BoRUBQjdeEytoWeuOv4+8aba6Ct0ctJzncb0twS7F2h3UeK7GMQNKNUOxffkxxLa5afOQrlbyPULnGKhskFSbSpCi0gjVGotc5MgZNqEh4u2Mh1wTeKvp3YBI8oPtieOoa34D/wB8c9olESTfQf3lgqwY3wY0PGhxeyqQCu7uyeesRZTmqtkj0T4MKAguk+W38YDHhKCm9IjOs2aqXRp+XHSRtXD4Gj5HEIgoMn3+eTHNZJB6639T/OMyCgskj2qr84YDL51MbhOWOBhU0kCqrLhsS5LRQNhHc4aUN5DIBoQsHRJuoDrZvtcc7ZAQSzVKSzhTEeRXNaHL2gL8Ypug2AdKjeyUuukJXB7HDRY5GoHYMFUblwOjVXa+fwzHvGU5BOXT8fXOa8ojwrFA44Pb74jl6cwAs38fZ7zYGY1pWNiXimu/HDnlwhA41ZA/8wjMQSAKut+XwfYi1qd1BKAe3vrzrHmsALA1TwXjk3vxjxqYpAmkdHPfU83CMMKvLsEAK9JppmhS/LCaBCajTXeWa9gCqlsaPmzh5c2wA8Lp2jO7PHjAokoIE69XnfXeBAW+QpNTp3rtuSEZeFvJXuePEPRe9OaxCbUDbDXjw4BBCAE7NqVH3354ME/GaGtbiXsdfrEwowvyIfy0byIgF2XY6h8+X/I4jTQKeUWnNecGXoIFpFnEfPz6wIigr59gXo5puGtuahbWuC9nQmx59ZI5myhl6+x2d4x1XKf0mdhuuLah8AlJFPR4yaRWOL42bTc/9ywCQ7AtXW/vfj1nRMGr6J0++fP5elCVspKO+shzdaWR4t9Js9DGYFUqYCvOvAPlNnuZBw6hNpWIcGz/AKU1TGwg8pHb1qh3vEo1Fo11tYVhbMQGV1ItocHavG3vBSWcJDq3CK9xzDKMk+uFen8p+MQ1sophW63/ABiahFOQh73164dbxzCqh+gMN28p56zZogiCMD3/AD4zSASUOxaiPMR/LtxN1BSFk7N8N+cdSg5Q6AKoK+B04zRHKkQ1rtdmv/cpt3a8n4x8Zp6blH4wDuCku5/3+cfm0+nH/mXuPbOHsbfTjBFkWVvZLKmkxzT3xbpwcqGjbZg5z0yBEEVJsR4cUKgSJ4DIDkfOLEUlxVT0SiA4H1gqJrIkYshm+cHH5IIHqmy7zcN0mNqEF9yPr6xP3yiZQzCj8P6wn6R81LjqnBJE8KS1eFHEo3NEgSTXSWeFgVA0TGDqopLrov5A5rTCHZ57rZTezXz5xQyaxqxsoTXnz1vKYQ6NPyXXXf7KnF2pBLqRRnKb41hFSrQ/6Ce/jH0RWIGlVhoa374xSB0VQypUFGnvcMr/AGVgEp43kjy65x8tccTYECjk2zEphmgPgf7Ykryq3A5Bt3sOOcGPTGRD7evfnCqRKQx07U4OJie+ThCBMNg1spN4xk9gIQdBqdc8Y5UK5mBoNEuTRdLiE9lChaLQWCb8+XDiClCS3iIxsUnBziyV1Utx4a361N6wmrwX4CbZu6h1A6M3utKwpsUdO0juvCjwbTBZL7LuLrmcbXHB0gF1Tb1q1nxMQaYgGw1IMF4PBXzmk3OUDqXzswA7ySbadt3XE8prHpdgvxTijTtKdvC9GxShw9KgVG4VuIEJoWLB03B9WgdFyTF3QXcOdvE+u9YVBHYEa7oamr7t+Si1KFvZFtfPw+8etQJWHOmsv+PLjSnZYfARvfDzy642Ou1NQj1xIP594J8TVU6RIhTrbE+sYW21qrdpNMI4FMi0B/bx351c04K3wH7jq+H5wNgSO4JSqp/BvuGNOnK7zllnc564xAghdnFOVTmvH4ykhox9cHk98ZXQQg9+WGmteOfOFhWEJlDud+faOsockVd5KwdzRdd5AhQE1vlAKctczhw7SOMpV0LX1gqk0REnflE1izisVCtE6eb1zlXQyUA8VgSvbiOqqK6pm/NPvrxhpTYWCCqvA1A13mzedRQ80Un1594mUEAVKdR5J1zLMu8srvoiqUWBKnBgsaJaFoKX6eODZkYjUvDkB5xdNiXYF9e535+8UIFsY9wYO8HyTtvJtij8imsrihoGtH7TXPi5BeFKCXgwOg6xeCuSDU3RvP8AFnTrNNhPF3rjgdec0RoWEmnSReofHvHsBhNvthi5RCrLp0bX1gAcBtTn0bmHlggwcsWO+HeseAigEODrpsKg4WHdUQTniny4UbImzeSaHlVdvGGAif24P9fM3kCUVhnyifynvNdwMJE17gKch4GbL7yCplgzEZIUe4OcjSikxLIqA8DHCMnXZQmwKPk6cZuVPh3/ACMPnooIYtgvWw9PWBZfphDwlunRzzjUBbHkiBBRCYNaBQPNWAGsVfeIRgdY2VYlPH+wDpAi2ptDwxPx4wohkg/NXlydXiesV7iDQ/M38ycXTdxYkjZAUcbVp1tdQQGK6EJIq7cJDjfreKDBtQCHRrbPGm83Iq+VuVA64d/zTS4XiVFlHhp8Bnub2jXlpwXQS6708h0GRbb0oiqRh4pPlNBFdoE7aklEcCbOeWs1EolaIQ1wHasHDPW98Vm+jStd84lxogBN1qAmtAbyhqBFpLSujtfLPGGSF3jyryCxBirELM1ISG7wbIJriuvBlMzADdl3NOvyW52q2HCA3j+qPGROn2ERZ/A9vc84eDwyBHbIrUOI97wEzYrJLCiLoeBCrixWFQF1s9Hg976zRXENOixJcSGi02YMlSoAulaEBwavkr8skAQ6cSd+l52AaSBJBTSjo/F6w6ltOgNteZvZzN8YQ6S0BUUbxt34D3kMqdNhoUs5JNd7JkZWpmhrhpfGt01zMbS9kCQFvhxChr1p1nkIoadiKuhOdTWULiGladi7Vv471hgJy8pWE2nBr25mBrF9giEdcSsbsSzZiAaQjEBg9jl1X6uxscIHYasO12+wnO5kMzGgInSc2367uUVFSPtm4teD94LdgQJ29HROrjKRN/YESprxvGRtLovk8HfRPnWIxqENkWHl3r7zwSqEryiijV1/Bm4iR4dfmwY98/GTUgbvum6Tg6HLANr3yaCc0jamMAID7z50CTR115HeGphPIQeJ6z3i9oJB34U4LrfjKAjAkNCkApQ61/Ibl/AJELaTcvCXdARpsCAJW9J53395A0ifN0kp21VPwcEKQ8gKcD6tnOBYRFJ9UbTgOf1jhICXFFgUTvZzPyNFiRdGjhe+nRpcBKCGpRL4app8JyYlKqyBsSBfLzNecNl5WsTsrXhOL324wI7A63FP+N3zirpIMWKbvCcyYAgAJtsGMk6ruGzxnkR1p/nH5VXwhBa5SrIsuLizJKDS75DVcbxFe+FhAdb0+MMkoJeA0Q00Na2cM2buxCPUAcVPG5R/JrKy5qVPP/GHh+WHpNv657dkb6FBoNKAG5xey0R5HFosXA2kBFAvM7njNiMUlIrAXiF1vHwSatekugChGj25xM58xVSPhnoZUhxR0Xj9azR4MYFcAFAeSqHh1OfOu8apqL3NVCpz0X05LFqbw6ai6dPzON5OkEEK0KYHhp6mUZSAIWEJVHs+HA2+pI0NvEfAQ+Bhx6QIq8mKHcY94cKasDRsnQhXdg21BXQShauvZ3tSPcJgjPuJAFCoOaxDy4OgTsQkKwvF7684LXQEMA2NSwqN64xxFKRG54A1uHO6YQAZRG0WCCiyCBe3dys/iKAtiI09jrxmmEFYBztHe6b8HdyIIFD0FCeJV4PG8qg0x5qIQZPBteLQhI7p+gDAcH/gxDyyVgBQEVnMdrkqbWQQQ5au0vl3zjThBQAbN+hfP0Rx0BTm50Me2m7rNSJCABXzI6e7G+sWZCOmtUeBWeuVwBDdwUa0Q6FqONI/JUk0CwuhopZWTG88+kouWz0GyduEQggIT2Eio7Rxxsux2gIFlYYO5s5E3kUWIkaaSwCcp285E7MuU3bxp3oru+ZqhXNXDvrZ3V9GSeEjUBt5YU1Hn0HEWu/wqq3htfPG/WFQy2IBOYBKsU1O9RqlylRR4gQoO2pzvtSEV2JSi0YG5aw3FXFI2lKVUhfAOco3BxQselut+6T0/oNWqiaHNno4/GUHDkO4/KR3froWMhbhKoieT/eLEdCgCXsBrY2vquFQo00K3dtnKgMpLgJZbhx5R5Ihp9xxI01XbV1O9vJeJ7wWJnJdbg1fjr9Bw0GKdivY4nanCdOWpi0cR8BQ3tj1hp1Iu00VFg494jUBgdY7IN3ucDO3EUfAKb8utvGt4C3AN56CLXH4fnLHsqkOeTc5NF4wYv0Ab6FS6fd78YolILqOgc1fHbvE9mjliibMvs+MVTatS+IATSWeNYMPasD9xByU98ZD8R9xkhU+JoCuzA3FVdPN/Ad+XvFoEYuNNumc9+bPrJAgcqTypvmHJ5w4AUpkY645fPH3gxeNCMZ5337xDYhuYVRFV5AJz15WUOcbhAXA45l07yiNHQViGBNGzWvwpKyvMb9cMvGNmvGbefmP7wb6v1YisHJTwhzgy8tALzbCueJ3j1YiXzhOg8ofGalfyjQYrX5r4yAWS+IIVGb4CkdYWAjMfKRojaQt1seRGLZGbHR00zvDFxigSEDkpxWMlDjFpQnCOzFzkpUIbJRyAveIBRCV8Beu+vOT6RNGyvkbUXek4wQ8hQSNUsZKGnLDklqT04/9bkAs8g71wXzEbFBRJyngnCldh84wkSwAASD82PjVcCzIEClGDxsHjg6WsSv9xtk4IK2dYAiQOZMDFPZPkc84qoaEBVdU7Go70LcCuKYj0CKg8Ux5cYA1YoUhAANW8B9Zs6IytsoIqkOt67Zhc3kFq2i9PLvjbEgZmkLhh3x570nODQ8g8+yadnF2mvnI4ow0gt7ekZV5F1gD3cCD2CVjdhvq5CBSpOem7a+OPvar8oi2c5Q4WS7gTrCrgKpgUV6OLyug8Y1R5qAVonoHHD6dGKGgqE3uKrChx1M4AMd0eYncDb41q4mGIBc15Q+D39OO9DDXQonl9fWatEY5vgi3o5a86uGBKWaOz2zdS6LuuFJUsCza0ilq6CviinB+JYAWhTk28JU2CXQxYmVqc/w3ElWsE0tFDtOT5cTWAvEiC+o0JEg98mQTgZC+9LoAl1Jp1MlUA5nXTxSOsA3SYtVaT57Ar9HOPjRaHrTvnRtE6WlM9hA2AptZKk4suMIhAUp8nJbBZ8aAFzTXoGlYpwZvTMZT5d+lXI3aryLO8QdwQIdKZ/LfxgBGiMBibjSC+GlC0vINSAXaLOHYT5oZItkRFYxXPKil2niLkEWzsNcpOhm3xsE4EIp2LJy8dm3rBNEA2YHv6dTn84+4opOcm1YOzr+ss4o4LuOxYNN6kwWha6Acw2qaA4+8ViykhHSvqeeqdQKOsGNThVdnmWQ27yxjykRh2rzwKwj4O1KA0fsqaQ6t+JcXAgACM3Wnt42hebj0QIwmmiewXfGuMvVsbUECacNar24GSQVx3UTxrjWurrKEyTbAAp2ZX5GctFEka8WJEmoVxu+JqwdduTDU0cznBwUtlpbVp4u/11jTS09QdjolPfyhjAM/KtoOByDB1icAkR0EKF5cLZJvGAW0Yo3VI6ORbxq4NBERE7OzqOYbNk0qwilqJCvcRfJ8UGGg7YJO9hpfKYmQpQvQHZrs3cl6wAOJCkxQA9d75HeR0AaRA+BmCCYG69vmpv1cNxkABsANEAwRcRpKzSdYPK+W9YbDNsLbyFF0B1vARURE6NK/a4na7Ehe9r+gwJpKM/lAgCdAf3llhsCKenF+V84ZU7yNAp5NONuaKacbA1MIMVvB2II0ThZH0xwlQkTaNKC1OMqvUsbU+BChtlHY4Fhr5AjTR4zkuMj0DTX+cHUM5ggu1A6PJ3k9hT7uaBl5BERTbg23gGcjdkIarz43gkRMZWi8Xrg98fGbszFTIhTm+/xvW1oQDBICIhsLxFUbvWH2TwKvMiRB6eQJpsg0ROgC0psN1+MWZBDuE8s1ZyTnyGDkFT6QFJSIl+RzkgdGUOOuick3hfClvFK6E8wqUrtlxEFmQk3CnAU8HBoC3YKaiGou9PibwoMmHYRZLLRkDSfOKOzr09OOXjfjFgQLA0SiteKVROeeBd7yNRAN9lLvmAYrTpApI8I7k5/2mtIo0tHEJ3o9+XCBQdoOPL40l/vI3TLdFzocp8wOJlpDU+kIv3FCgb4OM04c1WdQCaFOExcozV6IttR0sJol5BfkwxLdSU2a3iJaMFpaCdJSvIQlCXV09tD0F5HxskDgIqGhVOnelWRyamWIqeADB3Zy87yjNHd5KLVtq8nYuGSdkIOjpVPt5MrRPogcRanJuiODeAArXVyD2wrJ+FXcBdAiktWqBQQNIrL3haEEdtZaGuuFOc9jKXbgMaOHk9uJx4hFMaq17oHIeTEQlCCvkjrQhAXrO4L/AHm6GmhO+nCAOpsot0I+TxqdiZLsyhy6gzVv1Q285NJ0S2jx98JNnPOWAcnVvP6Sc13igDIyBKnbaggoHXySxN86WJxSjoXXpyAg7Gy0WISNsmAvjZCjt10znzwdL0xIdm0do7PG/wAOEW6GyXXWm4b2V5HAoDDwQTBKSIbfB9+PEhddu2l55Xj1moPAKuwL4Dy3ic5AnECHRyk5Nq7HtwBEIntafI3wzU903hc1BILa6ey2dOWCw6UkmvoGp3I4OekCiWcPWuv+WsJzYB+5u3Ns4o1Ro6BL3PBxM22kDGtlYeNH7OLhKHYQUjbsEjH47bm3ewEVAeAVUVt88awxyjSbJtid6Xxp8GpwnqJAqt0oy/e5gVnlrMDaLtor/XGIRdQa2zsOGavP1lxFKtFfhbWvDqXE7LQL+gwhtGsW/YuQZDgr1vjBvEAZuJU+OD0Yxh9J7QelYfOGrf8AsqV38uMt9Qdrmp/7FjU01M3TNCj+IfQ4Ack/mLq/jHEMUbTw4++eslPZEEKHgHH2ZXOsMCNRx6qnqMSoiaIZQgvO/wAZQ0JNaLXgvUWrHDE5UbWltN7bDpFrVcIrcEExo3LUHMcU63hBRNNoQblgBVrr9qqDGDagqpAVgIDIohOdv5ZMpWh3BcvV0US6Y8lRST7EnQGtDQsEhRYsAAOpTTRObjS7QBUCi1Ic8K9YiBFNxY22FRfKediEGIHZkrdQb09cFsx3mXoCxpd3X5dTTYSBVKJE7bJwnNOJiA23BOALu8eOOhckGHP8nlBD0hx1MkwDZi0F5WdybbtwgkNZHTwRfH8fh66RntaCG29Gu984OD1OEOBCAKtNwZg9mUVHfDQBUDbQy2JA6bsLA7UZI8guEc6KFeiGwZzQB+sEcjDizwgjezgrvKRuevA3CanJx0b5xDb6ELnFJ0VnHydCzM5oIGq5NOma5UoplnlNUB2Bz4OniKFimEedfrKWYoiIykqiQT3DyZqrbIPdNKFR1QALTww6ELvIpAHDQQ7AHLEyvArLB0SycQwTTN9mkuslisvEGY3GgRwFYII0ioGcrrBHPqEMWoAgYg2bxnNCSrG2lrngFlMXlGmoVijM4UHRpW74xMXnZQnuUWMpbxKHFEY5LGguzJNu6iTGooxVtssEk9JcXEDEGMgbsxnwlYzciaRXXUdiYOZptIoPdFPAiZPrIo3afUQbZymqzidoqaCbN4eOL3JDdZCqwiipR++tJDE1U5A128prchgmlOAidiENEOvJ2WFhQttWyGvI556AaFjgBw62x641X1k8F84Ng+RYtOLDCAcnJmJBSlo61rSYzBewXUbOTXMd37sU4yAmjqI3skfPAqcSCeaEdAhwTd+WRxvG1U5FJDrrq4qAENOijt8w1rS55zPaJXB2ltB+iXDgiFCArpKrvW/jElG+DTSLh7kolMsAVEiA0C6V0G9u8LXpSlNK0A68shMR8rtTQaR2DeK3jjBkCamIKkXQt9+M2KmlTgL3dHp6eOxXHkKgu13rtuzjjzU5CiQpssOtV2/AkVRlgpKpEJd+PnLhTRQLzJAgcaftW3GchEKV6Xc3x8149AVd1sFiHr5JX0wEYJIMWRLrZvJh4IWEWCgBoB5L2oEYAKW+bPce58LjEVRXQ7q3D+/M7McVeLu4gE3u7wlBUTidho+nHzBSwi9ID+cutW6sCru+9mBYptv/ALfnHE+I6/LiSVUTuDel9w1h+AheysbolCLa3rv4zcfKcDyYAFkbRoJmp4DuwYEeDh5TLmEqTbzXdHRBi6RjVSeU2NI9vLgoH4BXdTsra1e3NoYE0Hxva2nY2jIy4JTOmQA0HBkCnnIWAgiGBAADCy/ZIWwE2PYAkEwx5h5Tvt0AAAAobxfi0DEQAsQ6vkAxOeNdvkhvytd6y0LAJbq0t0BBLHxllVsJo9peHzoHjOHQYnnlXgcPX3lGhA0+MFB5Gz33tGVxgGGwkO9h3+i6RhkWiC2J40c6PKYTdyOhw2gTQShEOsQQRiqg7GS7VQ3yYw91AsHubRPH9gCzvMREKnDqdjr+S7CFbV6N04B1dTnPHMx6gQoG9ht1JAJeNeByA2wrEN7bhcyIQL0azCE8lhUDKNpVeQCDEOjZNnGbauPSAhpsVCmi4XdILWGyytdd2eCIWKTQNiYeZPQYPpRVcgUDy1b3XD43KpCsEQEFKmna0pdSrR0KFKBC6g5y82R4rSCtrlSvfAR2MDV1cBWq1go4SdJc4caDsAHANtM3VymIKUZIS626Mi6AsiEuCG80x3CB0LCUvgzi1oaxbQiEA7AApyR6F1uDCYAawcGhMVr3LKrYBwk9nD0wHPIwCbZA32dIeN+07ymzCZyt1FaafqYlkSkOoBg53uAHWwngKicqQm4NmRFxheOi2QGkObi04TnC0+s4a2R0FPDiPcRgEqYsi0i75XB1dsw5CKmioGWwwSIApFgaOyVd/nqbA2WJOTSvIAS9rQyEJjABloXWtf8AhiM9AXSEo2stprSjk+Ri0EIwDaXjletymN3kQ4G6DeFVvjdWlihwFKJtrR8d+MJEKJJDRIpx9FOCmJORHgOnAPLFd61m6IrBAjxqWn6XvBjZdolUo8aWQu/GVoABVaaqCa+ZeuMdUavtyaLXNkgUqSQUvJSCRp50EmV81ZtAoDVE8FYHNcXYikBIgFdt0QzU9ILKgS1BODLrzMIhlcoakKULo65DAsDiFBANAQYhK0dRBCn9EPFDaj3oIqBHVcrc2B7WQ7Ha0/m1Mo0DysbpnIzm6iJAAg51ZWHvA4UvsHgslomwP50YzQiw1KXQU14yYoRYiB4UTSiHJzSKmq2cR62aywO5AVzkTaSnSEPMUbw+8aFUYah9Twcdet4taDojQa4P8c3CKBbSwWyE8443PA2frBkfdvY9uQNg8PDnARvchXbpG2jT2d1rawIcIRedLYackQvWP2AQTy54wK7mkAgsLAlaSTC8Yg/Py8v8Y47xGhvZ35mRQFny4IONut5N/JOimpopRoc64QWuUafPiLXbvrBpGpnCgHcDB0JrEI2c89hZIVCxvkGbZOMIGgh+lc9bhSSRDNw3JHQGk0KJiiatqhAx6F1dVd/MoWHsnNhdu9TteiZWwCiVSRR1vjl5jjQiHuoADeheQK71LwZHApJB1EDRRwB9bwlZNaEChK50bd0F0aeDolGg3HUfErPrDsFs6WXwZxyak3yzUaLVIGoa5XZ44wuxIPm53ui1441zmymgmgNj0XrjnrEqKtJRTSNvnjrrGanXXoUhHUsVY8usRPJww0gBGrvsFLOaY8LQ82gJFShHLMtHA0dUCgYJC3StBZ3cOOeIGhtc1biEIkVrITUXdeKaYNsGcID3CgL6NraACLUcQWwCwVkB23GAKoEeCh3JgBwuEHpg72aCwQDnyVZ+aCaaPMh5DzM1kKjwjemYWnVeauoKqUJhsjt/p7cam4rsaD6Nbn9YQtpWRbNmPK67nGVQsvRaUXnjlei+Mg7Uo2nwJTRTyDMK7DA0SuSh7bZi4dGyiI0PUQk4HDqYOJptaOjsI7HEf3JkxW7Lkbo3UwQcigS2qoJTQENLhKCpYaIDmeZeKeSRzBVQIBXNTkG+8Jf8XJCqkqOkPM65uukbgihVlXTriTQC0vM0lmvoMIZchBOHdqcU0R9lAAdvM7gOFS8Mecr4eFIIc6dlrl5yvADc2g1RCtAHG6rgEJBEeY8LBe+NHvXdz6UKdtBHlXd7MNN6RcVaq8VAfCvvCiCAW4rHbEqxvwayC9KIbURVDXU9mOJAKBA4qtbQB57yIbUiru9+A96rwUyKTS9utobQJHIhTDUPAuBXkDQOl9q6ragqAaBFIC3gcmNMxkECgnXbGE7VDLw1QDIUCFRPhxWu8HgVtCiqeWaxUjQcqNASuyzOYpyI4h0hyUl2NMqxC7cmhWx39J0pkXWogmwgBs0IIW4DSMelZgmy0BpOcaWHVFRYwsFw4s0Ygky2lE0CpFDw91AXsxaakAiXlW9TuEE0oQAaQCdXwICCAsfD7wXq0UxWf3gOV2GhB3tTbABlCQVBeuucCqxKApv48uJSlpRlrf3iKCEVLcm3MUJTxjHUp0adT94HtMw3tpeL5Zf9UZEAjSzzz07eMtDBugOS8vfL6xkVRVD73KG+fOCG1iktIUj3yNGveS8AgSwahEO/e+uMAQz1bupY8u9KswoYVQkpVNTbrue8KIcJpxXIPJvTP3Mt6FblIIb0++XR24qF5Y6r7+y/GKxUUhARA/3FmXygcY9SHLd8H1rBCd6glXppvVbeutiNDcrBFTRtTgDWIUxJRMDHXOnP88YAoskEbA16WN3PGF6W0gdUXVrSnGVItFROVFvl8S9y42DFdrYGro8L63MbmCRdNku7GfJeAm0p63BJvDt5nGWGAiWs1JfTu3guS4Jgqt4edR/xj0qNJxvYbB0pdM385TakJ2b1ym9lXCAS1ozaoDvspwKCYIrGAFXdvNp9YxZQoQDbTwrRfyLk1EWhIlhfS8kxz4oIMgNpYJtBBJePgW9oGI1qwpUDasiYlra3KkEHuRRFiWr6q3A6zEI6Lkjdkopmy5O2quxiIgKDYA3mir9BsqZG3iSbIgEI9m+HmDkxZYsibWHTufvWWgC3C6XheH6SakAfyJ0hYCoaf7YFm+SCMCOnWz8vbmxjQH4QIm0rV78ZJZgBgZRi5q1Jy4yQHXjo747/AG/aaSSQEDgJuCPzw7wMkpvbwD8iEXTMcaxYVQKkAEK/s4R43zFU+ZdVfRzid1gnk6vrwppMDKraLcDrNBo+UEO9hlEspEhqfXmRdSAiiit8vMx5GCI0jCNEXY6vXkF2zEb0CtaOXF1gYwAGkaANCJJZjzbnYlFwnbG+iJGFOs64yCF0cKMG/Ne8UMCxqxGVLwI13lV0SRNMql1viftxXsobLmoal5VsMY60mooBOWNqDcjPd+YgqAm0dUNH5xj5VC2E9DXrxvOrUtHQCOhveRM4tTIdGig0Jtjd+POlhcUUCGjYhx31MeUM0zWy6lf1r5xUnS1QW3TaQdPffNgDnJQAgVWyrXd7xpEpoQeyvfLlLXp3JythG7oO13xqBvI+s+8K27OJ+Pebx0x6HRGl5rPcpiB+g6Ayie2c/rEmwKNA7t5X8T94Bo9dDga61xHX25rBNxKCF6TWnXG8Jig3ao1D2RNPiYs+mLNa85//2Q==" alt="微博配图 1" decoding="async" referrerpolicy="no-referrer"></a><a class="wb-photo" href="https://www.weibo.com/1199303274/R9yE5wVH8" target="_blank" rel="noopener noreferrer" aria-label="在微博查看原帖"><img src="data:image/jpeg;base64,/9j/4AAQSkZJRgABAQAAAQABAAD/2wBDAAMCAgICAgMCAgIDAwMDBAYEBAQEBAgGBgUGCQgKCgkICQkKDA8MCgsOCwkJDRENDg8QEBEQCgwSExIQEw8QEBD/2wBDAQMDAwQDBAgEBAgQCwkLEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBD/wgARCAIGArIDABEAAREBAhEB/8QAHQAAAgIDAQEBAAAAAAAAAAAABQYDBAECBwAICf/EABsBAAIDAQEBAAAAAAAAAAAAAAIDAAEEBQYH/9oADAMAAAEQAhAAAAGRFpfOOaqInQlMGSbKohJoZ1TFvwNpi7c1dK7aej9TGT0KWeDpQPAdVy+i8hj9BijsfS/SeuZqtLqSikEtJPSs3Iroe1XPvmvbsbVv/teZV579Ki5yNKTx9dVwdm9zygnE2geLq5CI9L7mfsXfwWQLS5vU1uayVFFMBp2R7L0sd+6TMOi4YAsrIXWPyMVeZok3IbfRc2bl7LL145+nlvL1D8wnAskur+G6Om6eSSdcl1Kps9mNJGMREXEvQV9wPAmn67HWugQWrdYVdtl6bFVOfQBoyBemmh1UxZzOYNCt2Mh7K/aqdNE6h1cmczVDiOHdBfW/W8rS69KrlUtFiVmT0raikG9pfpNbqEg4D4PrqmRnavYc2LzutU8504epmU2VYOdJ6SHPvY0fzO7nTo67s/avRYdxvarzIOSY5R8M8/0OqdJHNaoNVOTJ2Hq4gOF/HeborNvZTQdid1I616fjqXnentm0zcpiLjvZ0Ipu7luzVUykNN3lj6TprEzlLWMr7LCkFiDYg6XcmgVplNXC2Lfo1jLhhYVOfKxjA+rzYDXW67Z8TBm4R4y9cFEPUC1nULanKj3gyasYHhaXP2vMxL1uYk9K1lYk2ot6mZfpWki5zXfP3N1l89nvNb5UUZ7ihvTWscF7b6LMaxQ310LijaOxiZNABuRoOdbNvc495zpgsTQYjChjVpGvcPaLtORe1gIykGkUOc4c2m/I236PnuSwoc3UP5rQGezGYq+ta6yzu5YFJWcz47ZambeFWoy4BXaC++w507KMSxQozoslmM8ULZocEq7KBkugcqpGndYuMajuIsE0R5UTqXCfbWyzRszc3Runj5Xy39b62Zh72Pc60ua2OJMSeq9AZtBriWqrizHzTmbb9LTuFrIXTOYj8DVjvqdFxP5zZiLrvsePHz2DVlyDyXS+gfoPGUEuXuDrGFam1Y7KZx8gkG6qYBh+rHiekYPzKrZ6Cvpsxkxc8q7myYWVN+YllvXcum6e6YbZSoZ6V9VtYHqJLVrNENcYLumNDQu9A85ezGEI6e8rBXOFVxKQRr2uCrPYLHNGkVWYRZRW8dB3DC6Hd9icNZo3Lmvt6gkzFAqu0e35O+gL3Qz4khKtLrYC5j5z07p0+Tg1yrrk3lunvrN93YOe+X1kcBz7ljfSZ1TlaXLCQE6gcL71M1Hh6KrVL7NFUw06qW3KxXzlvKWtweSzcKhOrOaRbgP85i50JcgjAHULeeUyN5HsTNlrndPWQVon9c3O7aVKBAFacgvprVNYj9KySpWIZbMPpEdJsJlkmP1F6XZGU3y5cjQuJhGOdYjTUYU94WLmkaaAglTPm0KApONncZkrh9oHNFEErRegPdPQ8+XSutcFoaJ5nS5vxOl0D0fJiMaWd++LQn8cju5HOswO2d++qmbtY17zGsw+ll4qVV0rt41TyG2DTJd4ql089JCMBj1n3Tbk5xzNcqnAtik7JeyraaK5nFX3DcphxUApW7sN55D0vQFcVlMzNXgG1sJqaf6GCfK8KyItLpMld0vZbYJS9Y0nyLQw2xA0Kzqu7koa3VJnrOgoTlWqmzAZyOIS1bcDby4FeuO7mGWV2dyNhYsM6qJrIZzXt8clU7BfP1mW2r6iujPaxs3Yzc04XXTOftrof0D0PGoK2D6OLnkEVJMhXX2YxmNcOQRUzB5BLexb/wCn5qx5nYNZC7rM9bMz9nCV1ID8jdxHFs6TigHI9WfWE0LsbWmVausob7WHSJbtbFzWHZa84QjoSSDXzyj1VWhs3E0r7klOwdLHYl4gdufUhYue8NszYbB8sTUi1kezgWsdSIAxmypO8whVakmXTrzS3QwxrGm0EihrCNwbNoI5itb0DfXcsvnvVSyZjqul1N012wtu1z2dE7eabitK91POY1TBg8mOGfUF1ASC43J0xHeF92wpMC9d3kJTLVRgQKB342nfUYB6a3QVgb6P6jlAeR00yiacRSIg5NBXqGaq3wsEaqeuUSX2BMIuBqzXHa3AwRsUCj1jYpp5hDOmowVMvCdS0MM6LuLJVlo2/AeyGQA0fo5j+iLIGYasbkPYzuPg0B0cZ/mXS1Dpose2WKIuizHPMtggfqBHUNYrD66FMofavVJyqhd6hVNsvhe4EwJuQaL5HXcui9uJX0rLbM1XetbUwkpsNHcIYikKJMLCVlDZlAZqzObBVl2VJyFlXQOZiU9WMcaS24VICJLmRjbhIbdLGtTIVrRSguP4WY5RRUUDgqIK06zQlGIoHRhfNGPHdPc63FXsb5XorlqhyzZ61/r48Lo1kZENp/YELjoY8L1lapp7OthSCj0m0V1XGpWXLpunLHFCGKi9kGgWFW9cIxe2wvTmqE2JIwoG8bA3CY6Fd0IwZmKupfQ+eay3QwJ0V9AdW63PRtFrGdg8TtKuwU2MqSSNrZHoWIYu8s5ahlcLhS9Ctq6FfNBLMRR2NWhKWhZ0odKR4GF6C3dKzrEMocsXnK1ky1GUJ42yZBvejzgR2l+hhj87viJZDMYzRegSDQAfQo6eu1y0wTQE2qUdeVoC4UNDa4O0BtlKTShrzHCFqr1Ut5lMh2yi+yXGSI5BVVhHNnvV2E0z8owuoB7qxYncsHlRJJVtF0NAj7g+wYsVuWRzt28qrk1DE6WropHYnECeBLCG1SnDwK7RGFsSsu+V1rqZbJUsKuC1lZqAXAcPKhBibzKUXpG2rYqgOUlx5EWHnMp6hQddVKjxzdG4LmfLuHQU1Llde+pa4FEOc+xZV4NrOGkeC0Y7Dmba5rzigYexDYWKtuTGErWRQHZkMgIt6qw02YIkemIeF0buWSSpMwRKhH1RmHKVmESErO8NtGAUKhDaG6V17rXUwkuLUTXbT5zjhlzRzr0HKmJRFzY8um1RVtKcGAfQmcqpHYwRt3V2yoVZGiuod65ZMPIAishzbwshtBZyKFsO+/MukLRhtf1jTMmrBA+iC2zovH0JPUQ682TEWLbWOigtHiBRS1Po1dW4/lltEEUvGlhe6AaUjXE4YwTHEG1LUti23Fb5i2V6rS1CHpKLOiFJ3oCgAqLLmTUNDY0Skmr4Xo6eCh0qC6KrHcT8upKuyNQtO0NRMEKUjoap16Wazk3YdDNwoq+hAlNl2bgu3HBJq7P6V4r3BgpiDhGOG5yG8krObRs4SOLWM3Y85m2BoQ3PLnSPaAWhawN273J5VyegJuz2a3LO/nG1LzgKxdGsgi9NjV6qulDvj0D9FzsAawRKIZQckq8pkhV6jBuzwWLkqqr2qLBHPo4kb4hLmYqaakKtGCwLpL7FjSsRKiCslLUkIUWWVRYVZVZk9LndZFNiiqIRuDLYVZUcLyKKJQ0pHMG7KaOY/omxKPg3MOffZ2BFGh9mGioSyjmqaNZBqqlectnZktkMwtXM6gHoZ61qsWWjU1VFsJQGjwoqZhOMIBoHqntPLi/M9dG5G9geBYYgrZIoTYXGolLYM+sSmd7Jyzl01WzXS1quEyBZ31gbG4Squux+pZyHpmWHs1/TbbldavNdGVRqmxi05YfQvVkodFhEYqiO1Q/RYzgXIgyBig0dZDzkRVpVt2WzFCmOk4QJYH1MY8rbFRe0qXXAWTGXKx762Vb4eyNOyr0SttLa84ltDBWwq1TUYDfnkuplEeyaZ1jcxaKWgRmvLbFYvUeqznSo1g2zMyqy81TcHujme+3zOb+Y7lB4WM8eQrkW2mPMw0q5kkv713c92s5uWE1foCSx1rrImp1WxpsxURO7HD3qLlRNM2x2nbiZKk67XHqmKF8zVjUnK4vvC4i5O04PmG7JhhbwN8Q4zVBpm7YMYWaq8qq7JTCyQnacVVITDR5xhc4wtqOVVbDGWPGU7RwH0M8vntojpVMZEnECfd/PNR0TksbsTXOrCmWbM/yXz5jA6wA78d0oQyy1naZS7ZIxNGMZW341t6ej9jnc/wCH1aehb5MynztoXULBhfBoSDdRrG+YRtAyQDXd2c+kg7gMZDG6FjmiyZjjba7pNiBQ4avCTB2cPNMT5c5xHVkboFKrAKovZhxFd7UYGCbVKbprgGuwRLKjurEvcZvdx0MEl27qXViitJmjTYaMOQarGCqkGTFNkMJSNHPkUcM6DLiF7a7XnjJdZUViNOEappzl6Ics3DkOpCrXUdi5FaxNJtBWyzqGEgvJ1oGNzxFhubAq3G3nNoornO6FAOxd60AlowlbMqM2EyeJ6x0RDuWSQOCmdIWgK/zXA9oB91EFusrQKIdpZoavVYMbX3gvPHBDZC2NRGNLgjhpphBsX1jhdRXB5VORSDNbq3L0WFI5DYzje8kRQiktCjjhZTMVfYEls3Cj+VtvQLLzg510Kacr7gCu7DmdeljUsW7LsV9aJiohCuZzYubQG0wxxa2gNCK5KtiUUqnc0EjyNdLRXmYe0e88bU5vUWvI9SqJplG0c9kDooaxrMC7cvpJp5unWpoUpuzz0c76YHirMO/ltZIQe4asdfUgNayMhpTWzE+gVBNCooCHpWfSRp1KjwZsb6HRuyulihgGSlUd3ao4irUpDKpiG0qWr2o9bG6qaQSYlNVtGRyD0EC2DdUxrXHNcr6E8+S3e5DJdAo9ZFBOmRWxqKpMw4iq6JM3JpdbnDPstRiXCLJZIDHEJRR3gKAW3Vi49rn9B9b5bm3me4t8Xoz52n81is5aaphgqWoLyyKrKyDXHQrTDJEXUYMmpeVtAVdPQPnNBmkRQmW6JzTQGE8kLCRDO62teucqmpa28CLX12LUOmveXTWJ3NBMk7jqkNGQ6RrxBAFbLre5iQnRayWV3TZVYas1TDmMcyCHrtqJtVJ85LnTXvksO66Up3Qy9RC9pDjLWoRXVdpeISyxlyr8mk3bbCFh2VUKTC2wIeXMy8CRGkMCZ1b3nmbupPL/ACHdJeW6dQCGbKFNFb1BEwmhF+kMYtLTzjGdDJYyO1056rKHw2nmbM9dKG1VayUtqJYVyPitPS+fK9DbWdKoMbA5iROHYrnmm72tiwoK1S4u4isom7WihVRqbaeFUaWYM3RcpptSORMqChgK56uUAIjIpcEKkwdqjSknFy0zI6RYmERX3VC23LGdF5r2uby7FnZutxGuAFsq1DYW0I2uUrAUUdka14c+tz0YQoJoh/7OCVi0rzfWYcJ2MbKnVrxpVSgV11zlqp2nzm2yChe9lfLmqvGi63HLotpus0Oe9NEVsltIzXSzZdASxcYpvUdXPUtMENHzaWNAl5Verob6A5hcMDBe8Akja2h2QpnXIcgTJGVCqH6tZZBFq0lWllCdaSQXCoFmV4oPlk0ndTWCqpKcsFmVRV6FWs5UdkLrKjreFaE0LBVJAgqEcy1t0Ji2tBHmvFTomTeB0ZRYhaW20yNO3EHyxx25I/OdNPKmDI209hjMK00BbFit9Gc73LG47jsY4yh88iEVWsG6Xls4KJri2pqQ5AgfUJnGZTOWOjZjHVEjhCrSKrtUB0SW4QTEH0MHZK1OulMrmK7sqlcrOuunRG10DIaar2OpCKqIR1UN1gpON17rW4RC/SRVdoK9V3JRPPbZmvcIF1UqvsgZMWIotp1H2OqQWODGaQ1lWCqxzIRU3EsToRUua3LyrIrOxDtqIQWRjXK4yuBX0G3hoGCu9S7+a4CjOW5ceDPzIB1wvSYdSdFu1qhjhVdKzulK8lt9ZRuK5imasnR0m0ZqgbqmzK2ppRAqe4Ldzn/fplSCoguxb18gwNJ5iD7BuMK2UEIrUqHFDCZVEaDpXuYlGRKMJPJMNVSkBzUaa8twyDtgmsBtGMgOgINxq90VoyXNFa6UJuOmVWiPFAPq2jPa+S9brWj0q4irNDpdTDZdbCOe196r6Bv1Bx0OO2nKcbi6nzmRYpLqRRB43TcdwgKKSTZQOlWlZ1Jo6EsabXtC9m2FqE1ARG8yr1FawtieSd0QIKW2hYvPPVfiXHpoZ6IfrHbz+Xp0dBYriOHTw3G9lfQxBtmtXQCCshqskgYiNyWAcM0sW6Vjk0hIaHFDiK1KzgQjitJ3iOZCaox4iqbReHOAYqXdUDKGcJasi+uxjLDgE92VohaVkKgVk3upKrYDzc0uWBYWzTSlD5D4kGZVxVRFdoLZ8xMvKYT0LFutelNq5ZuKpkRjpZQbepeimoCR9cAvEnQv+Ry3FLummbKbNjEupyT0jMZUVTK8orBDvnGOjx7bJ9BbcUNvltHOOU/hebUvEWLv6Y14UPI5eLQ5RJeK5Tm0qqqlSZ+rVtM0tRoTGrqrIRfHjFcGUeZ9YahxsIio2trHpdNThqLNBOiy2aVGVaeyy+KNiQq95RfMBzKa9pBYfVkbxdWxLAVHcLqYOKW1LiGNdsIZBTN9ypHNS2m3zEaxvE9juSh0M41zRtastZYGriJmAQiHvA/ne08/Su7soggZFy9kIjjIN0FLvRZaCNHLdlSDw1Oevq30Lz+0NlzNtLLnjViTR87c3eWIchdyr7V1ubbQPx/x+u5nS5lKMJBruqRSgvcpZyCPOMlRtw3z3pitOrEm93JVSVe8ppxkKuyxMWmBsROyrP6ZzSDas64gVziWy2MdYTTWAkZQku9xkMraXJbJkqjqr5GxYbgZS9pqtL3CpzmSkqIbs4QuQLEWtjh2TXWExBgckEGcC2jtA3mAIsZwnRcF6KaMYI3oGYz1YxDIgCypC5/d/ofE9UrwiSXnVwFqUkPUWPMt49EoEaKtMy/mXi9VaK7x2KXUrjuy9KUNOryYNKdkSXLSXW0TQ7CXeKrBS7UjGRy+v8eL+gqtXHsopKlcSRcKiVRY6rqOSW5JVx3VoL1qqR1dG68mbllcY1SRJANdSBWbvezBvX4wv5i3WZBtlsNBtdTZLsSMDCWdatES0oomXUMpLAK+XFWaRbMmiSLrMIDsBsXqgy57BhFzys1fQvpGHYqs1RcauwSyzmkWnFXhT6eYMUCVxt6Fl0cmW6/dv3EvmXob9L3BJGinSJFMu3aTsoQ2QStCm9XOMIXYqy2unTENaioncDZLVNDCFhdQi0gyIEiyUQvp/Kg07UNoAzvcaK1CKSBaBgXJ6u+qSMmsgjTdzQOMRQHctS5V1khOuFLNiQ09oHpOi/nwQlzUFdZdDGRcrMGNK2iHRtdIigKjioCdbBzrJbApwLvP0pG8+1exwbXI7rUp6oTCrpAQIdtC5lMq0PP+U1G57uTm2zArpsbsOpSiy6bsdq+qPGaIWsV500uYkzKzdv8AoncuhnUM7AFUSyFHlK1Dr6Lr1VQGJrGCxppCg6ls2alrWzuWdfeusHPlz5Hyst5iraV5G9lyKr2qFUVA+BdRMja6Y9PLOa+mUJBKFSaCwY7e8DbscuuW2dO0tArh1MmtylJlbWThgiwyzJr1IZSOvnG/GFMMK6gVrjFiaI130L12K2RXCnirJVUMfUWw3sN6sFm047g1SEuLYdSbw2o2m6DGSoRAcMJkZQO2UyrQptL3lxyt5X0z01dV3ID6FlFHHITQcdE3Y271PkvJo5bDysjliIQt2Au1dEOwsXLKHFSWB/L/AD2IhDdVISkBlbXZ9VNGWlzWS3sK40IMt96dXdXgrZb5f5c42mE0jdW/L0sVuTUrHbVwKOpc3ETOWjeYh7LquonVWlhmrpbbom83gEeZahQDYj6N9NnCVY8TJyay82WxTY5KY0DuLciYlllwiuZoOU8/Rwfn6AoDkrL0ethSuU7GtK9d5K7AicdPs3s5ZrFZ2prlPK0bcX1kHP78wA/bfJfPisaCJhBN9KunK09p3c29A9JtINKtrmolwXMfAs9gmVEd+qH1G984BxWub2DdC/pKx7o2r0GOTnnLdyPiNiMl/QDgqqcseS7OixFmFleWJIC3qmDmsIMlMB21KXW0L0kaXZbO3c7fOjkDYGFfUpt3ClwjKXhgSiKgdswXqlTVZphZupKulmfFpzlWKnMOGc1nNee2xGyLWMYMlylQw3boTW3I/wChuziL6VhU9ZbR3hnO9LTydvSmekgjaNOsHzqV5b8qxWioOqU8XTtnj2d/CNt5VCPUVdajJ0PRwKtL4Kk+FhAw1vVveMh5Cx7i+onrOyrcqMbqUQJMXsTERBIMX4DbSMKaTGVipso88VHC4tmraG8YNt2s+7zVmYyuhNLqVU5xDa23ByOeoBF18y9q5ZJpLMncDBgKiYs4nVGbFzaTBbKBQwOiY0YsJDDe6BZ5z3JaJmMEobB0Qol9laQ+6cP1RfL23DvsC5+3VHTDD2lek1helYliq3ywJIGZMysypIAwdmZfpW8Da12rQb0cHpG3xjhq8zJQ8/AuZqtXo+7Wt5eNaS9K1q+a89wnOTRvGoM3dOZ5LBIK5ng3MWRYJeOLUNEi6TfMG41sVV63Mq3VbOdZxMzlB+PpU9jmksedIG8pfHXdqOSerOrnXngYo4KnKrGjddKMz51y3JsaMvUwnpcn6fkXC59R5dCgayG9HEsZKGQYatr53QpENY2dbx9Ounc5+nyDFbdoyuDJxZGL68gtW8UG0IrbsLrFyeSeXlua0GqS7imizc3k9V5gzxUNpqP5blr8l0DX5e0eMfKuCJapZg2ZVcC5nyXaJK5ous0D76T8bldLCTMwrlyXacp1aXolyEJg2V6TrkKXXw+wUTbIxIudRZn8t2B0fOvQqssr5U7VRyE5Zkbf87rbUhhcIZnJGtha3c65BmMWQsSdGbR0GH2kC4mRPzbQ86zGFibsyht+a8NNXgvXlirRDVb3XnlUpCDHLz/Up9ASCxya8y7D1NZ1yZjANPIL0zhosa/Pg83oa69XpU92yq6cSOtcX0LVOlfgjtdqGWtTnu8sX2eUbiwRyeqqwyjziC4GTHKR1BdS5NGz1zbAp82gl3NJ0fuBrQovBu9mfFCovAPBM7gtAscjXY0nSUAEQbKqywZG18sdqo5JpLdX2YShpUJlyUK6C1RVmioNI2dtATJEigVO4s+hefu5gbT2laQjKu9LFdfmlaicLPeO9ag9XCz8nb0Hcz5p6fLIYNhrnbQXRJm5DK+mRWFlE36CkrpcWY6akaztBznTn3qU6AxTHBtDCG6ncEBosQsDpipgqWfzuOo0W+jzgzuHG0Zk30Tk3cz3cyEA3zVwFEjBbNelTlnqmihxOUapt00xLm3NBYApNIj84x0ZLQuwkxjrm2Oix2HYpko4xEGI8H9IrEmZDUv6TE6JL5zdcuqdJYpUj3fBr430MWZU9X0nWruHVzWUsRuZtcOe3mnO1WdiuctT5q+geW6jLe/5z9HwD9g2L1BoVXkaELuYcS+neT7I3VnY+Xs2qVOzn533OPWqvqyr689PBKZxMKCmtnB3Vsm+orcha8Nq1K7MZGjggKlhoUxJ9A2nqAOVbvl+Y3bnicqKyh0fHHsZyvNOh06TMfRrcTTlSbK0g+ieqRmq28pdWGilBguq5pw6tUMrGLrwu5aw1UjyMc90AT5Z9hm9K1ls6ndLz6a70Lzs/PZH0lq4anFLOXasnpOj61fQnocG9xbWSDjdrydDJxOyrOVInTz5+Pqniu6D9dykt6B+rG2Fa/L6v53oca7Sdqd0nzGzkfqOc9ZwbEt5/qJSfle7X9gmsIYtJT49C+aLNzE3koLBiFF2JFk12rogBCCrW5iT6vWvo6ncbs01Ol7yKXdSiFV0DNrCdTNWBTLrQvZnP4kFwms1a3KTMpE9FdIxyrnOfOiPSUMAxtYKTREJQU2duUBdtgyziZQFnzH7jPXlTibmV9dfVNdoYjzOq7Pz+so17AFp8sp6uDmr+oPQ4CGoI6pMzNWkGuZH9W8720LRl6RxdLTjdzf0PkwXT5xTN1+eucbbiTsvU+m+b0jnQSPDXx/GXMOhziGbcwZJZ3pW25u56cgUb7KwWQx+R1M58kmG5ocZwNcw6ItCl9qJHouJaPo47mbr7pCA0aOV5+lN2eDtmYCz30bE0nk38d6dfQ/JfHvwAOnit88KiTVLvB0DRdbLt6DBzx1jNAFnEQ0oRXMPosuiJ90260JI6zuIDJUUlfGPsA1lWpfUznW9Qg8judCHNpXRcXpw6fQAn+GXduC6U+iO/httoUE5pgefcKRma/8Am+4idPlmsT+1cboL3svijno8cKnT50j1wcd9Lle9686idFXE+Z05bFqqSGuNKAhc0Z+lNy81E/pZtMN187c/WDzHW0qour6y5Hc+WOzwWtTeXvx0ro5k0zpfC+uguR9gktDouSuDoDFMuU/nvBO19nkrSXpXE7HTaag6Mzia/YZb2AiY26Js3kAZHOJFHmAeMFtlrSEy+mcZBic9TZlEBKcc7c5mljM8PkX1yMVUtzsLpEUXUkrjPL2NWT3g5fFS+p5DaU5NHrHYy+eIhdp+ZjADFLK27yOg0GLDmeriZfpcdo0+SFN84p5/RgkelKZew/acxKzJSxmXoIidaxowI+nn9GS/2hUxZdQcaZdrJq5xlZNUhapL34vrvkei41t5oh4L+nn1Bu9y9RxDZXrI7c/P5PuCBO0WoCVRtWx5ru7DE8Q2DoGE7+TFUmCEeYFvXBIWYy3dCqj4YGS2I6mQJOuw20rg1qHIAHAG6Icy7NnLJb0OKG/PHdDlFrq1WbmsvaSaQxm9HCrpj9fmq7+Z6X1jNq6h18a10sdSog43ds896DQB+b9XPcFM+jcXS4PjMh3OOptT1DF1wOe1jUnpyQBuF005pqfay6OYjp5lr5ayaOm5uiD0JaGY14G9J6GNpUfC/K97pGnTjdi4Rq5VsT+jMPXXtB0iD1ro3jr2jn900VWqNPd8nIeW2J17sELHWYZ6HzonHtUOT0nTndlVzZIBKDDRAliENuqbtY0tCyY6J9VFZQShnp2uN8784Rq8kIgaY2hCQRMEZqPfqT5xgksz4iqq1fiGaSemkReC14YBueV2/NqL9fHp0slWoj43dS4Ha6Bi1/JfS4yzddqydA6BWG56+hIDREq/KnVd5p8z2pu9jbzXMLg2begGrmeznWUszNW4sqnjEmhraFsbi4nU7EPU55t5KN0+VqJdAx9Bo5/WTMxsW7nUerzBgwBJos/rFZdArCm1aQ7UbzahkY5ev8HzTJsRMXQfub0D/Js9zrQDDyb0XRFjoxbrat2PubKrIzDgbs05TQZwNFO1Q6lDpmOsRRK6cH2mPHbC4NLayAKYKAuFvXHcKwYTqBw0lstNX0jLsbOxgOdLKHWSdjcPwavoHh93ge/kpxpHyXabaR1+v97xpElc65zwg6OheI9jyf1PAtPVeqzNMbDHnkNZFchW1ZegmauYduoykQxv8/1LfN7UXTwq/qfL2rGfi9wVqyMSW/RW9vJ3c4SqhNWoIZ+hVgoVYC4FVoV8W/yNbR7b53Wl8E5fWesOzo3JZPnziMhWFFWtkzmk0KGaBBuXHekggCym853Zz6zdUTO0h4QEYSRcC7rJBgXHz2yU7O+a1iBIXV8qMUyW02tcIoXBXSyZ62dOjsnYxmOhkBJNIxvS8ze98jsLDcvOG5g9SuLZs3f7D2vIn9HNXE60XNp6R8r9vyD3Pm6OxIoxe6J+IUqMq2lYhYEh5B0aQXKWgLoHm+pvk69N4BvbeO9YEPPehP8Aa823YukzdC+PLTPVhgJoyt+l9KOH3Dw3cW6XmdYLpyJ/Q4vQ+lzOc8jpOXH1EMoy5CKy1qj2dWLrNDVybxOlRFejB4CLoG2hpkH1MLsuqI2GWfyCGl5aA7WJLu3XqQVMSVKiSYp0MvaVFhQHIkMt6ks+XU49fE3dDMsoYEzmm5ndr5fT8Jc/181NlxLOPN3uodXzzdt4dei5sOm/899qg+i4d8DGPW4mLtdD6MlaeOHLlQLL6fIMlJI30jy/YgX0KuhQb2fkr2LQK53R+icoBtECdPItFTPzN7nzezx3veZ7e8VcYYkkq13Bttc/XbXFVqS+EG9eAQuyTaFrdK2t6GEYL1K0Ir2TUL1MIIzjXLK76o8+S1RNbVtwGJKYhaE6DgtZ2mfWZ6t3Vqt6uhYr5VxWmdAJKfolYD1UVvUm1l0WDBr1ppiQpBCEE2K0EabV1Y0y6tAdLP2XfZzz+nh6alLoNj8b6VC7XO6RzNSp0UPkJ7sFKXTqJhgNKhkrqEtXk3Sxl5vTA5dUWzJV9H57bndAIo+1JFR2LYWCBkZOfufeT2+ed/zT49SrRXLEoBL/AC+gRTpaMfY5+/gsWdBfDljaFKzCW1qBg9ueFgxgdF4WUtqtOes9KUQKxIlIJnUsOmpTeFsxpHQ8aJUJj0Mjuxw0v3ccoNJzu7cmKR3XGk9quZ6sZXTVCUoRckqWKq7d3LsmwUi7vDZ0DDlQ0abOhikarXidhNanp6mRXOnqO1cWriwQo83BWY9iR1q5yeTRbZlt9RWdmWfTjH8/owVff+t5xF53bjkFy2nJo6NzutT14/dPlAALxVeUyvxtV6+1nMQI+NZpJrPlmWM7Sq2cdFglCAOFi5bbXuElEKcMlrPMpaFmLollO+4xgDTZVqk21FvQGfUUu3fJ5Ksj3KVCujIFutGhlDZGDoY2kMv1I6GjcxVkKrW72K2RorVTAkzCSdApVbh0MIwT6tzt9Iga1NoDI6Ka6o3FCyBp7xNe0Jr82zO5/OqKwtxjE8bsCxswMOjMtY92idB1uY1VZliqmq2/UvN6C30cQB+ZdEr5DfyFznCfXM/s0x3OCTieFrdn5umY5HVefCHPubRQNi1IzvpeOYs7nO8xanphBYA3nfGWMJ3Ua53oJsCTMsNqnWfKH80fUEKEKWTSTWUTuCbkN1qdEknXaOIRhTGetKZeCjIVoigUHOQ3bmYr1ypVzjYSVHVtDkagb7n0sY2RGKxXiSK5tUsyWaq1R1CHl+hBpTOkpYunKsiBvxHTAaJy4tokhMWu6VCZDefR3zndcP1OHWYtGhMJCYSXzoRfTPC+g8V6flbeXA78+rp4wlGIcPijvzzmeAAgDBMmVlTTjlLomEcVSXbgOjlryb3Wc2oSWPRSixWsHyp88dkb0La56SKVSk3k6dtyhFsXs76iegRx+4mdzZCwrmryY4T6Zd2hoVc8QrwnWMb92CCWLmklmXblkhtiEtZMVABStcbgtpCz4Vm4qtDkjBbVn0VR25UUiP0cbhUDiawtiMN9KElxgBqgqj61k3OTMTuwOHHTwwbCS5RTO9cz2XGuh5EWOktjNhzYAj0XJIMpw0VoRumCYdOd2bRLw2iXYFzb1uAPW1mullRm7rFciiuLv2megcb7czJau7sksreTMva6zJrLiT1C+P2tKj9p8kJ0+dhV0/oxmAwNfPEugUsDB5DesoVnZMLa21Cp4qpKlS5Suq8uaQnJZqV5e0ktX9QKDlGgOawg4NqyVSq6apyGsJAxKGU3VdQxAVA8vomdr9nY/uXxrUlyMSqSlWwK218AmOSkNrl0hwz+YaTCGCd8aJiuHTGNdLe6zPPpKs65Mas3QI6Q5h0ef1HG6BCkg6nWLesRpMs6VcV6snuTyTySySSSXNqnpN5YxPUI5fXD6Xts8bTZgxm9H27TwugiHzIUoyT1dIqnu5FloYbS2gb6Yo47qGSnJm5vUnlxSWJWJJJGhZUrqsQrt2Qq7dDPJPLxU3uek3qc3eKRdVZO85zkA+l6kcYojrBortIW2jcG2IoqvWNxVAyvq/DOMKGuKwEabDGy46obsofhi8ptEmMqND6jZyHtcztOPcp7cGkzA+TGjEdwtCL2MnOusFm7lk3klkkk2k2kzUzcXk758XrIyUU1eQBNzeyem+gNnnnhd/KRhPK1koXNTo+Jel+k6Au5quvdaybyZkklwyekllFBslUIVN6vMrEvSTaTaTWSOTaVtJiomtpEOrg31pRRizoz0clqzTlwqPZDJav0m9zWVrY7LuRNLvPsVKPkGDGboXpcy29EGpY9AEl3ad2vkd3519L57qWTeY3c4WQpnIZ0NeWgh2ulPGfQ1NLlklk3k3k9JtJtJrIEVur4/TUW8rph8TnLlNA7Otnn68I/C5TMraXakcJDciQUKjc0lW5FJrdWqhGprdjrk9QoMI1d+UyLK9Ukkjk1hbysyopJJMyekzIltHm5zoSb6Is3kliI7jhqmeseshoHmSjdDiqCTEklRmwU1c2z66iVaTqFr0la6oa3Y7Fq5hdRoqWN+heB6D5r9b5lgW1wzvyaRmEGZ+ZIYQ19L+8JZckm8m0npNpPSbSayRwqAHi1t665yyi126S/o6h+F5eshCWSusyT3GAS7JnPJTEoSVV5IblSV6WUqsSwpQYVS1GhdnhvWXmVtLzUgupZNqOOw1kxJswfnFkdlX0YDhq+o+Z6nFu/zpNuWESwsrlEmOXZqNijMBdgLZMAisgCJKTpe0WSc03ooc5avmehkCQd2VF9E8Htcu7PNCa8zVyuhHMwzaLizPztOoa+sb+fLL3k2k2uYqbSek1k0khkr1I6tmXaAY3rLEFkkSZN6u1culU0m8liTWXrKzc2k9UyUzU9cxc0ktDfUUEwhekr0m0vWT0mJWkmZN6Z6VpYSS+iNHiRUt1ZNdv6DfvJ9dD9JhkkE0Sc4JqhtDXFTbIFmSaDENTWqGWIqjrSklwCF24HuyhVqQHLHUTWGrQ2Coo2Kzl3iV9V6cbC2D0u+XHosS5ZJquWVPJvLzJ6TWpWlQS4anMzodKnuXpJxluiC2MpSxdTSblMybS5KhwbNDdqp6S1Unl36l8ZeqekxJDcjk3qSSQyZkxJmTEm0mtSO7sSy1XmR5zSWj5gnZvl1GzWz68YDO+wJTSvXVaXtJLVx3UVzapmppc1CaLXSM/MC2vSKIDoNkNew1a1ZPk3fk2RuMxPtKPo8U9L0q+ELdtJmXi56q9c0ua3Nqlgbs1JZI5AN0Wqy9QqNyy/VEcwHFRKy6EkrlXaqFxu5KhkzLzLxKhlZl+k9JHKkkxJiTEmsm8vWT0reXXlayZqa3e0vYZcU16EZxiSvVrj3FWI2sbjA1C46KzVV7kMmZKl3YklqYuYqYk3uqeYLGhlClk4ytR2akRVpRco1ZOSbuZIrXdFkGjJ9RZh00V88abxJ679UxdekwU0k9J6TWT0mamZPSYknqekgkjsbULsmY2MS0khk9JrKhk9JmSOTMmlzFSSXLJBKhuWqkMmZNZMSYk9JHJ6TWp6XtJeQ66jS9uxb1fLsvSPobZdnlk2GRXM3WkvepDd5kjlby8SsybSel6XIlXOVYlesvXQcxjlc+0ZeXaMFa5bqroaVR4FBue4Y0DtJi5tU1uaFMyekxJrJiT0m0mZPSbyZqa3NZJanXs5s4XrJXkxJ6SvJLJHJmTWTWSeXmXiVXla3WsvWiswdZNZNZNZPSa1PXNpfqkolcyayHP6LD1ONdqKydMGTddNEhhi60kxLxJ6SSTEkMm1yOTWp6TMkklmqju9bkVWPKhZhy7RhAlmCsGO7hKmZYSQxBmJltOm/SYuYua3MSek9JrJmTaT0mJPStqnpXpPSbXfXM7GhdySRyRSTVIpNpKtzeTMkUm0kcksleTeVHL2kzJvJpJ6ptcjqayaSbSaSbS9qK3ncV5XXJdHkniViRH5vY0FhPTi1IcyZlxSSSSVK1zaTe69JNVR3Jas5pQPq6kuartXW11y12WwecEVroLXGkVqm1QQ6XrgUrhLey8SYueuYk9Jmq2lel+u9ZMyZocSYkxK2k1kaKJmWZYbNhccmZPSR1N7r0kUmZe9TSSWTMkcmknpJZMSbVK1zMm0kUm1TSSSSOXNL3G5kuvcrqXmKbOjytAIcLE/ndcg7NOxccrW7xLt0OauoB4IZyqe69KlqRyH9KKqzkKV5UVxFfmHtQSBSFZkhE20uV0LlVMjGXlDy/ICz2nYkzJtJ6TMnpXqHEmsmZfpM3XpMSekxc2kxJpJbour5mHBvWSOSaTEla5vUkkxUiubyek0kxU2kzUoS7l1mTEmkmZI5NpPVNpeaKWTA3Zw7qWXo9C6HEt3WRtYTpD5tl1yLBBtJtdZlagWlXbkrXJSGCimlXBml1ZlBGrGHSwak48JW0ghJdM5xogVD5NZDRRrUy9nT//EADIQAAIDAAEFAAEDBAICAgMAAwMEAQIFAAYREhMUIRAVIgcWIzEgJDJBJTMwNEIXNUT/2gAIAQAAAQUCzWfVjOIAWB0v9n3+81WdGgPc6mdMVHKfMakpLxseuS+jvd/L4tVKwxqlrOHp6MWymCNqyPmuRoHG7zacQxbrz4W5I+eyY5IxX5ETXnn35Mcj9PHnbnjy1I7SP8v6jNGUNWFwr+fpZbCCVGKsR1AoJyuiFRFLO0jmPYQ7ydamyIme6Z1ms1b6SYmkxHO34iOW525/7s0vQxmPQpbqhNS/0Le700tzSRZPUaamPRxn9zycs2ARGBymz1Nmrq6I8BJnZ6RVIjm6m+FamJVUomUl2dYSnbTjzXbTEUbYz5ry97R4q3MUtRRUVV/AFlmAGEYVhDzxkTdsBiiIIXYfgvsSISqWflpMoypXQZU19SgqbgYo9S4yDJQQG2qTA6LvWulSnJeNQA0DwrFrtLk9lZQXAbnbO+R5zzMpqsDlHYMs1l9RUyifvN3swe3U0PKUUt09o+h2a+X6Tzw/MTMct+vfnf8AWeeMc6iYCyTB1jJF6VeXOn1CQq/AaHrlmt9QNZve2Yg5Dw94xAZBmiqaeOyfO1ViotdCnF9ffnl+t9BQZ79QZYUXzKLb6HUS7wllZ1+t3dlqvWPTu/usasuLUBsnVqPbc2Kp41n8649nXqZ2dEYkNP5pC3RqD4612UnoQHpt9wjBIjXRtdmgdOASBYAWwBFalPHixaNisRYAmQlc4fDqqFUhC2vcyvGStHAVxio1rfIT93LQa/8A0c99ENxWwteLLgs7Zkd7LSkyYAqWZ40o7ctlxRxcq4ToNoCNWWhzJbKkqYTiwc35Gri9rFvfHJ8yHQkt49wVNFbZqacNzRIXYkw1c541W+3O3/H/AFzvzvzz537xXm1j001upOnms5zF3A5K+dqWcmCsDcyw2V1eo8xhJwTyxW2AAqAWsSlWHxjy69PB2WcvAy8eZmK1JrK0LWYtyPxxmC22GVW/i08/Pz2lG6jJibFstxxcZdYJyK3YLO2izqKVHsPr2Z2fEz+Ug5VLU7NP6YlszNxdceeJoy7aekx6yyT7FSrVbqsK1blzmSL3+pjjF1yqr0tRk3mmcByGhu5opZlmzUXmly6igYGb5rOKXtXu6yWmZBo2dH38W1tH6ij95YN+YKOUhWPW6cwpa2ossUOzT72rV0nG4rJYKQQ4BDNqoQMlWiBj0QzygvKwlKzwJ21Q1aBI3NQtOU0jjSFuqtJWXLi9Q03kGFxEGcc/r35PI4QtBctwN/5kZCvy2gvMs9Ol0dLXyxlSxwenjuQ392dVfPBoaTXGsVnbq0T5ltILq7Q22jFyGQ/DqGtcTOuJZXSK+RzMWGonrbdlkdHS0zmqNipGgQmJgoGXbnhfpqrjA7YOpc5c6DoC2GQUdCMdlTMnVcUbYZaPYMyBg7IIWhgsysE5Csptk9YKuSO10mDtMHa9IgpWOFfMXu7tUWtzRWAIWdMCMWOyegoP17VgJsoMK+u1lg2Me1HF6RdVHYHfK1WRs36eCA9j6A6Gv3Ff2lvyzFqpqPlrR40csse1FR1tdnyMuLv77gaDdB75zSyObgJX5nc64DfRHgpRM2YJweVKQ4YMK57DTXT0s1gS5Rt1M1T7fnVA8Ju3O3LfjnaeTHauy4S0LPKm4Fsf1OiC4GxS0MB3R4tsATRy31mXvO12AJzoAYz/ANiWA4Jc6PUIj214ZltsVM6OmdX9xN1EwSzL2ybVHZSVyW33V2kVjvuQSl3E2wlSYShhIFlaWccNXOBGgy1a2Os8895M5Br6Y9E7Hx10LyXpvRqqcjdbJrg7RCS9A/PPuWoA4l1jGOFMnzLlEED9qCNOqtWw3QQpqqho1rOfM09QVio6giNA03VaUs2Rowpoa+jcYGAhUPmNUMdYC14ATsYZyrXqNXxI2Tt6vGoTD9cRVcoDUWg2lLrE2oOE7HcFW5A2V9z7LeTmLDLWPdd4fpeou2JtdakO5dk6fOp6xg8eAKwUYxtMBw7RVzPAQL3UGkBtbot36NC5KjNy88Wehhc+jRgMkHLOSFXSBpKKia7U+vTosetrwaE24lYWY0PQRi+GwqsITewFQ9G8/wDeoKLLGRkHtSez2Lk6axTZr2qxImWLjTmZq0gz78hnaNfJUB0/1A0LaUcyiC6eW20nOlboLX9H2dQIkR1oExdpwNla9Po+nmma16rKlaILLi7LyiFmXNQoW0Hzh44vI1jPhzh5prWP3p6Sdn+emguKHQsMthOneJQXUjUiMOlrMV9xI5SGSUSI3diShaQn/eke3oouS1VRrXzXpHUQh3aoNlSBlCJeV5He0DFy4bemzrRoMqK1llpKC5PmRrMQaRkEO3uqyHSqGna7VYdN9bGYutDm5BmWJrCU2a9KugZotdFyL4HUgQl3NmzXC6XqfEK/19RPENXC07aAbB8uak++wD3g0Epe2ZtjPXV3EmJzzeOhol/7A/KtvYSowXgfJvFx3LErUtaAJtns0R6QMF1DFWY6ozXUsko8tGplndbqY6TpembJrCK5mGPbNTbcP7lpKNTV6hc22pd93v2DLF86itSilC0JnSWgQad457BEayV7n59jiTVNJsMdOZyrq0KnHy3UTyjjbBrL4tYsoI4mLw6qR1ZtE1EiLVn2XHx4tYu7Oivx/NIElTKC5aaOO0siNRRizgKqM/UMYrKjnyLWnjRgtDBSWrmQUz1imYi3Kx88EDPjepO6s94/yDolFJBcNHTLpL3z3hyPhQ/eWFINyIvUSgcyOEZFYdIUh0oRu0JXK8LsEHdRsgRfYAbU6MNAqS/q6fA7JpOU4+mNQVMo7mqBZVkKqmre1mtEbXpSLevCskFabVCtJLEXqSfSqcfLnrZazEFKPteM2112KWp5adyk5RS1gAm69bNpNVKuBVi6sOGOwuLSiG09fX2jKxXUK628uv8AYoubQFl1KSmhoJSV6k2zsSCtM6NuzGQlGjLGZWBRYy7OgsKA1oE4xMksJm37hkK51Bi1bpt2Ea+m/wB/nE4xaNoF0jGkhKUqOSy49Yhw2FLbgLgOMihLwuGiB8mW0lV9Rs321ScOe0VRsI1RyM9IHBh/VZ+vje/BfKPgGaL0LIiclNkacD9IwRIRo6hAI5NaMwVul5HAnGcsRpYMp5m0qXFMAtfkxVckFKaC7D11wKhNz+XjBr+UBnR4sKwhw4TKmdKA0zmhEsVqFKBYtIi9vo9DBU/3mQcZasY6pzs1kZ0yLGtLNKTz6AigsmrEzEcCb2kOW3r+r+VpBZYLC2aAwhmtXxsvNBluT2pLIUImpo7SDm5d+CcQKY6opuE4XGqgm9/s9Z/ds5c57wfNfPoZg09Ir1rwlaFciEk1iC884SKk2AAnrb9i6oD1lVbFMQ+RkLUWtnZn26Ae/M9Zbz8FVl7vDLBz2UIu4Ug5WhRfwkYLuK3Isf080Zn37iKoiwuvBFiXgtPpZBq4zKtpSqNerdJhxdGiCnkDkp2iJZ7WdMYlPOfV4WXXQ1GQmVd9dKntB7HLUmOzAVHjXbYo5MAveGFxAm1mKCmZmRVXLEw9E0uIV78o6ehTaIjrsHj355ruhZowqwgQbAPUjF8mmGPlOj2C6GhnhV0KmWgYmysQVv02IevYNgdhehm5jX7L+QrEZn5BxPnQsRJVxXJMkW4clPSRog2hj9bGlgMHAwoOoK95500wCl2WkHCfuFpNlRZoudEyw93eZ3jBY4IowL45DXZKwBE3qNZJQ1KzcQ7sDRk1xUrWpW8yt6Ar66R/mERY3BVpNRmCBt25oHQjNltL5h6X0sQFglikI4wEPtpDE0X2NATfamxNIvLKxiByT24gCEKDuoBTWMGS1ZdrWipFZQ8pK2zJTFcszcFbMVMC/wBTBCsWET5uVvFiEkpuWXLdPFoNeGkmQFVBFueYz2qWsp2F4ikKbFaQBALhFGrQWBU9xeK+Ppvn45c3A6kBKI5acP8AP62Es0FhiYr7mtAvvZ/7KzOazMen/LMecmAaw5Ja3Ae2CXggjHHHjMeq3r+vlJ+UY+5IsOa0oD3r1LY52BQ5Rd3162gpdtXTWtnwPLkKeJNPC4HJeGSRHpaKCWXtpmOuuIKoiOFHjDtwC4PFNjwDHYEZrJL0VfvImyDInLGYwSvUNbqhK/MKSyK561CsQtYowwXgcytqGgbe3d0bK9WayfSTYcMPIBa2g+SjCGoUaftvpc/t9ZGwoNeg/SvRhfU8bIvFXpl9qNNW+ebSExqyM3jFqx6gRa5jiHeoYucpy0TMWKxNCX2ah5R4zdEtfKoIQF/raSQXYhwAFmj1ka8jBJTfXWqlKJMte6RXpMZWusmtW5CcjYH4fu1pX9h+xNE3b1+FvWVG9ajKS9vFT3wuQYREkkXKRteBMEv5UHc1LJhg5CzUbEF9VVmCkkdqzeZgxQE9gv8AKExmOwywawLtT4tW+o2ib1XzlB8MWBcccNKqjJCFtpXiZSuwtiHGpf6L1FRFmjzSa9jsL2lUZbVqoMZpglJpTyXJMeNdVnQ+gH5v8s1XfHVoYx0BHzkbPpxT9x2vJtXVCRbLyIuPPVcb0o0EGZqEVprjrw1oOP2Zj1y1Ql2LZwfLWYk3pN3X5IPjbWKUhO9jWqe9pqNyGPf6r/TBiIiuSbsFNWHaK8M2waaELe0EPIGCzN6R4cD6B3NZa0KilnjI/C5bKnmlCq8PWsjgowlsVxopwyNXHVNozppjV5BPbZO1q0fboGsVgVe/+CgLggtArBWv3G79QgrTA+AGSt7C8V61+m42lw2UAb5PfNuEAACv8w8oU8HOtX209g+a1ywC2eBA67BSOBXEiJVCoFRhi9qp+TI6tEapVXRNYK83E+AlDugo05clJReWXHqNDFVSrz3BsXtxx8UEM75CeYQNUI/nKBz/ADQKLWXsstYBZFxldlhq9biH6LMLCAyNuZGIK9lKHoj53rlygxT0VrNZTz/czIxeUNhDUrMDWrGqz5lKDwWJSVTeq88p7JJ4ivTxmtl5bqNqg6wM1wcZmsGmgb0F2pytvq5W9fGhK1irMVYvcR6/R/jGrNzSmWubfvUcjvwDBKFVaGRZWpFMsE2OzBoSsXKYuJoa1xuWNSwmq2rA6NWaNcNPew8VzuTidvqZ0SgBUIE/SlUVbhreLXBbNJ5+ULebAl/bEjoHl7T4hTtTnq9ZTJ/dY3gLUfi7LmJnkzK6lgVOd0bbGlaq7rpUUmU3RiE88uVRRsak5/1HHoOMSXLDBHP3H3xVU8BkQk5qYspSOhuY2f2YZmwJDeVuUfUEp9h6tuOSJ5qgGD0GcWZSlfobo026IMucrkYNuMtgVvfRqfPR1LM3LeS0UmLcE1QloFTsYfooZ2nJvQ9Az7KUQHbn7OP3ByhVvevy3Zb9dVR0IJgXgWfAUBZ9Uh2FDE22BbhDLwK1xV8P802XX951qwNJMfv45QaXLF9nM9Ro1AEzFQvaTEJ21S5ww6h7LqEGyXS9XcNyWDQS61yF+PipCtmIwdegoJYoLCXtZcdx/WItQgiW9C8CuCgjCfoOp1dCkwyexDgGavF61vVdevoeWXFyqZiMaXm4pjmrYu1Lok3rW8Mhr9v4gwx9l5XvoGtaCY7dBjqm05xz/FZhl/1K5jKoEMy3pKwkumwyYqypWqLlNE59SqTw4pYvfXpJWGxsXKX5iSaS8Zbt78x+pJCxf3+RmA55Yz4eKNgukQLLuQ/2qBii5hadGjruSOt6kHEGRmCDpRSRtt8qowsqojcgVWgWMxIvEZx24W1IXALNKrXxBFbXtdaudSlrZ5hRbwj2Arb1AorB+1rzYxsZ5debwwoRohPpvYgpIqKEcszMrr65jMO/Kq/qO5LCOnAKjaYHmk/cvsr7alqI308pWGzJu1zqmB9hCHHQtw28iVrBrkHWU9FipHLALYvskTd7XFBeDBNRpgPYgUwBUKyPyO7WIpcviRcPtzrRjcHrK6K7VsyoVkL0iMRJTlWrq6btUmWdJO2ajn6YPVfQJWmeNL4qitcK5BnSYHBVc/RbzyT3ux7wuNyuJYrTHzjTRlg/xCpBzEqUHhQ61rMcWOEIUyWXyRsIBkzQ9Bxz6aUN2b5SgIA47ECH6Pfdj3cqIk1iuZ2vJW+Fv3hfNOxnOtXEEIs9dMbhzJVi1iWvPkNmwxKOUXOIDHCHPe/c1ZXKLxYm0kH5klaPeWRUs389qKnOPs83QkhBW9QKh86QNbhB0AW7UorIgu0oOiunlxnvj4GqU1IOqsWMVaYv7yLtNTKpn+EKG9DkuStaeCQa0oXK9R2dn134GA2DCFDMWgQuSW1SZFCfR7T8u/oEKBj5r3bkYqHOfgggs7pJuE41lek1WlGG9uphzd1iQoatrWc0G2TQaU+MD07WWalMKj3/AFhzFkQV8eaCiF5I40blAxczn1GHoZ0Zzi16IiRKIaha0RGwdf5lmK042y6kJFypIMUGdzNh6ubYxXSNEo5WRd7MQa0kiw+NCMPisvqFk2ZMw1YDQ1PuMZA2RIvWUxKD9UM2Ev8Az7TWJqoBe/D0pQsGIvxoipC/mOez+PsJfgr2HFSdrjZ87M2p7DOidq5VG4iWqG8Hr3Wd9l61VLCOGJoivs+etrLSbQyotbUCWoylm30+QC91+Jza8V0RyH6ppz0yhcxqMksv9AFaNwEkhMcdaqXXmp4PqwxUATOEqISpfazBCBIO616ikZm2rk0yjMocVrpKwurH7ctwzPjTWbMtniW/crYqy4+M4xhFkgzEK/MgSAgbnpAsG1Jqn9f3ktAiVVY84oDPFZIMFHRoWg+SnvtofImxd+dZU66aURpeUl97dlRHqt1DWf3vO1OI1iyw1o9Monsf5Ewr2Fe5q5lYE8yQq/styn7bTOQJ/L5JMAvgI3t8peoPiYDm5T88p/G017UlctbWtFYgt6xWK+Xh3n8mmQFnlPCZtYpA5xoCy704eLaH1UtFprYS3msLMbAHF3IXY6i17RdlkkhNZawxvRQl2yPEFYgZcMcJlhzarMFNdgd7JofQIJZtaoTjtxUh2l9OGa8E0aJIVq/LkpSh7zXlnWKi+snuu9B+eusCG5cUe2syLpA7K75qgzQazTqyuiRVl20MSkX/AK67TIRsZes0Fsi1J7we6pQq2Ae5iIu3DzHr9axSrEvZIPg4uCyw2HFlUu95Mo62IMOthtFEQSqMCwvVW2ewQlC2qLjxGAPrEy2yiYreyhLVWcuajdywsbWSSdp7CWRFXOiB5z1xiHdnlL3UlYqdym+AvKxSpCaZSwSja/DX73Che6d7eoXtsTlg/mBDLz18WXtNrzRIreiU5KMRILknsOPVe2tTUc0SK3gB5oY7kfKPSQnMcTF73M3ZHJMhoAXBjFaPMfMhK94ZaWRVl+aq3N3sRus8+oTAYMSDHGUMmsWtltIVubBq/RMTcgCLkuzel+FUJMiXKahBmBIRUvHha15rccgZp9CWvpjSzm4lShkFKbS1o3Gg2PnponWUZAUMvarRbNHMxZNigDI2UbsusFyyed9fLokXBLARmgDADsxRdMDFbK+YxSrajB9IK9kmdA9mTo39bTZas1kvy3HR8a+iyGqaOcPmxdQEjAsfntLTnuA7SxBRcaYM8WrcVzevYnmexVQbd4LPoinFBL3vPeJWImFDQ1CvUFQhuLplrJR35PnflBPvT0slVkvUS/sZmszVbtaZpMz5T3qaa1qWschKZGExIHYK0LTQHnWP5INwDhtTRqv9hKOWAbSOZOi/Pd66wI9q5nT4zAZSXHJKRB0y2JE+fKxW6/0ODijAVWXnbnHM+fPLxlVyB3K+Tw+g1OBA44lHh5d4rPnburYYrLqPNtE1io56JdXQxV630eI6YEokDgY02TnazMqpwPe+gZWEO9nK+IdM6XCVbdvZWt5aJBtBQJrVNnvyYQzLRmaDZoo6eWdEAiB1kAh0ux45tIiGx7zfIK1YPk1G0ysdrM0dBI7XAvSkmcfoHml87PPIMVXMQrMrlXBXOeJWLxaBVknE8u+gudM6Fa3msq6oSK+mBhQtRZhc56n0Kzdol0Q5q24ZS2a5R5xgsRXz535YxvCt+d4vXtWJhmlryMdZhi5pZCMd8wI2eMkkvCGtNfK3fKkq19HQTLSa58LI2+gav0McdN8FprRoVxwC1hXkVZmFVqWoPtZhhkgL8pQwyjWgnCfwp3rNvKbcyNGoEH3/ALmZkcVCSt6VmKXDt+tYT4gjjctfJQdlTjBatk+yO0qhhA/trlTYBBEVBNlcxczXUKF6nQINTjZJKRu16Sgz5jIUKvPnaYOWhluHdIAZWIuFoXpSR1KAM/4sXJV8acYwgsYIbpkDli6k0WWAnIv/APIaBqiMbMWBfjqPhwmUzTnqeqCjVK0HW3O1BcXJEtf24d5757hvDXgOZ4AJCVF2E5QbCD2mvZS8XHNSAItyCXPwoPEtgyOSxenILM8i1oi9PG89o4IxI52tetWe3K/LIAkMPlrVvwa4iARC5PT41E5XtQCzRyrV5mN3voueg3Pop6LyswEd4gTJ/TWkEYgdVqVVfCGWr/XNL+qliHvyVyMcLatbzE87V5UcWmlvTcJLwvdey0kMUdvrNWbM+wtGRXlYy0XGRaONsXaha3yKASKO/jBoAXPAhk1N9VKI1ZGDz4HMkC9byelrxeFmB+mzrZiuRWkaVEDFKJT6ruCWZEWfnnWcUNnuszysmzqqZ7NmwEBOcL4RcCdujzRRQRcI9MGrZQzol8Ko/CL8J0i2rqzUq7Rm9P8AtKntm5jUaAFNlhlixSWMWpM87BSkJ9IZiaFMFBtrjCvrsWjPhW7PPZfzKujQoAd+XWqIIkxt8sqSOWp/jp5VIsqoxR2ahMMaTF8i6/vz8a1KvOSFYATSX4jG4k3bPA2+Nqlrx7Rt1tDQ6rlNX3WuxEWr27jPZpD1Wklgdue3yNDE+orFTSQEhgVhcrWhIEKnOw+FFHklSlIYPdtv2WPztMGNWsjQY9jKK1Rpi9PlVJg5LmXVJezNs/MkNhRaqSVzFuZUcLptrE+Yf8L+cj5hN3YjTZsc0VtZUbJj3seg6/YE3D2ymwRahKDLNwswY0GIKxRJ0OyHPltnRCv5JRdHjLSFFa9fD7dHgofqO3oZGt0jnZm0LJz6J9dBzRAIIkDL+1SiQYpD0v08ztaPUHSWJlznLYRqt53zNtZ9sW0m8aT/AJ4lYdJtTwtRe14HSQXv8EJAtIeWID3Z4gDu7AXKrChcGgyWxxlv4r+AjMajNBJLzuNfAmDLzbCKnpZ8pG+q827VvNkh/PQBGUBzPYf8YrDIxjv4LCJFbQuzcNIr3F4csCvavrvT/EOax58VteZkc1U+mwqensRYC5yWj1hmBFUH58teKjR0jilaayRmIBnlizCliG9oYRJwoUaZzWmSoVdca6zTMfBDKpa+z1NDuhmJaWpJos15jzWoQtcao88gLjU0HoOyP7C3i7D2NHqhYebI6oqACRvT9xako/nOY8aQ9QVzTCDXZbofeGZYFaV1F7McUNeK9fDtKeV07pbFizNeVtQUB66x6o7v9QLa2YsRmdLVxyYgAdKZ+c5a8GNdc3s/iOyTo1swvnYPb11zV3CG1FPidDSIr/8AHtmyunjgZ2NCb3Zatc3uniBUTV1rZgqZ7voaHtKHwM+lvHRX+Mayl3D1W/bWVrWFzIvEu1Suupava4j3oFifXRai5RvtZ8F+as1kXhftSvLXislCPxN41r4+vlq3EKf5XuENhAtasm8T5ugEOatUww3uf2TJIiEDnEy9etWmjTVyLrOzn6pScCyS7RPFduNOrAtAx6cEct7kK3aGWVnhDRbtVW8rO1VmIS8Ct6jfYmYMXtY6hm7ONptEqX1kqtay68PHIfVFEmavQVVmyV5nfMU/7g1TlhxMgLCt06UIMivuptdMLM30WIS6X0Mcuelm9F72ilXoHqf5F+n1PZ010z/bk9S0EzlfSQfMmlm0mb/Rbzr2JSsU9kkHQcwQh5Hc4n/nLf116OEK+4PQz139FsjLk/yn+HPIdOXNbwg/ebNXniZQLiI400VJ57MsUTZWar38c/F0JRaHcWe1fzvEQYbnh7lC+irFM1ctWg+BjTNu1PV43pYdQ92DW9Al7Ep/IcB/7R0HT57BglTvJZmKO0tlDKnUV7+kvjIYrX18Yd7jTMa1VPlMenomEbQw1qnb/cAkLW4mBtg8lfjWzWVuXBX6GTmHVf5wEdZIpSjJgxM30rzZZUinqrejDFKek58+TCSzma/t1rXD6hMRaitR+awfUwZbO90QEnJBevPValhaJKSMlC1cyRGs3lKFZAaIts9S6FzK9G5yyWXsS0bWaNnc1JSXetdgZNSQRoViskrNaBy0qMS0b6nIva5mbs2W9dZrk5ai4tJkDLVW7VM2ZfvFfKlaTfkzYlhDuIJbV57id6odhMw99a9DyQZFu1diyl85u2iVkXgRCP8AKDwmKzFCyaxKCp/jYt4VreCipXzluoxHipbSFQ5Aza8UXuSloibFz2TN1bYm9vZBCBFLVPo8TmYpAO1z2OGfYp7zcpFL8KxFwBYAmI2kVaydyqyX7AHLlPZ4tJhn6k5tU5fP2jiBnWz33LvIypyxW/H5xXVzPkvxVha8sFGSdOB3qWpy8WXpUPhew/i+teGaqRCBZiTDnlG7j5+8ND4PTVLA4HeRtkjlxAdqZORW7NUvVi881csGquNym5zqXpSmZWf8fI9jFbCov06xHaoLBqS630G/b/bpbQ0oL05l+ZHtKGGnogLhj3Pa38q+PI71tW/GlCpR2/lSPeV5TRVpYZvL+PeR95jyPbBAQdjLf5BH9ZGw+s4hwac/HYdXSr7bxlKGz69NkMLQWpWvvt5+2aSEzEAGyGtLi9c1JPesj540qOx6ii7lpAvQzMRm61LWj3ctMjgZvXSvmOlXaDZLf3VVCSvIQYQcVrd6x3VJzXqmXdiW6MvMxUSkDocTo6CdInThmkmYO0BWJUoM16hiZ93ta9hV1Fh0P7D+IYq4V11Zxj9uDekje7xSk89UcJT+Hr788prwbR68h+nf9xpesFVtyRd+WAE9dzpL6R/umhnDaCGLFzJQB95LDLPnX+UxjOgUc09nK+qs1IXp9rSIw6ElC/8AjPf8Ry1YjlOdGoB0dp7pHpx+W/6XA9l/6baISsdIapG3ej9klVv6cbFxU/pr1R66/wBMOp6zjrFBJGrrNXF+UwTIoPS4y4mojxIUVazek3NFhDMVzFeqekVNwUq3S0XlO02fZZ55Wjnanh/A/BxXtbOZbE2kyuG3e48KfSShbNVigrXm0TQeY4/w0m96eUzoWuiBBn0gJWklCNnWpnFUlvTq0wX7NZr1vDAFknvDBLiYoS0UrzOSLYb7lYNeWdK2h9IVUTu0ZhEsUpU8cUKGoyFBTOC0JNpstO9tAl7Q3TlGxzz+N4rTtWacmsVmDdud5tyAlnlDfG3VtJrnixEuJq6A9f8ApvaCmyM9AJ4pAhWtck0lfg6R5/Ot8Tf0ADVsw6f7tPeOT/4xEU54Tzt35/TfIKrm6ELySrU0OXXsfi+rQNmdDNLwSCTl4pSnIiIumMtNt7vdn2+J6SYSP/6pgJbXUFemf6eKZd6xFP0r+OdSdJZvU4eqOntLDIK1qltaxeSYY4lzvNTSW6jz2m4TJbIi3k2XB5MUgGo76aXuSOlun7bwcfKRy1+oelltCxqlDyEprDFrkpR2KccVVcYR1xIwUUAa01QlpbyiSkvcwhDZZUwJvY7glD3E07KyAeI+NwAQ9FrkCOpmvcmvpABAKVkFlYrfRHV6/wCy2tyXB2h9TMfXRyk0rTSI5XzmZv48qVe3PXSeV844x/I3jwZjB4PTPXg9Tjg8vRDtdBWumxmM5jF71teP/uboP46Al7gVYPwoPRaY5P45507xesRh5RdnRWcGiAzqDNClra3eOQS45Z2Lxy3UrYoF10wGqO/magqE7dVrEL9GckXQcB0zu7REunems6iwVxB79v1vE+3/ANsAWcD1F/S3jGdoAcPF5J671qrbxKGt7HzknpcNRZvijg04GsVw/Sv9LqUra1KxSK0qT+Ub2f7B6AqKG0Yj4/INCSXuJm3i96wRx2ey4obDVg34BUvIt5jSrRakjKUgIIU5auIVsxMqrsloOLemzS12KguKozq0geYJOy10Mu169WdNX5XfwL8FpZhef+XNO9xXTYuViv8A4FVBPHEvMWYJwYe3I5M/xYuYYaalOwGfZUlqs061wM5AKCn2kfFCp4kZKVr42PFJLPO3aqGHS6wMDDtTp/pbJ6eAz80cMXHrUrYYm7tuWLe/PxH6HrM1HbxmPD3SglNkPHLnQIXWn5xWKNvTziq9bKzUPUmIbgnE2OaOghn2e646fREL+oGJdNJ4Dy2nk5W0Pa/pIWJd6f2Ms1hzYtZuG2QYjGa2lmCr0z0Rtb09N9I5HS4SO3ZuAVB1+1el7lD7GG6zyucN02jl+Bng+pZdqlYXoXSKNX/tgRDULzpCF1sjPVw6M1gFtOXFgiYI4GtlCZ2OvYVo8FXaRQ7GfJbNLWHxoc2U7ehZj/HTDb/7PsJHPdaLeQuViZ57WInp0x5x81hYhHWbrJ//AOQOo4nK6302j/ucC0Hm5z1g9QIHn6ATyhF454BNwQahreO0bGILeBPQD61tnLczZ8L+KhKBYbECBSLzHQRL3QzzwkLM8Ck1nL8IxaZkszz8zzt/w/PLR4Xj9e888uT2vE18J/TtHI8I52GSEeo9HM4j1VnMwMg71JAzU0OhOlH7aH9J+0Z/QPUWboZnSeIrEtX7ekzHKirWpb0FRn36HM5ozRxnNK4zP57X7WR4e5nGq/8AsDHqSguENawJMyYgaaoYC4LTKYNSlNYebaBTmDlxxYLLDtEFFi6vgqocn3sv1T4UQmFIvGiBtBtdi3qzceqOpog+Nvlud+Ap5E8a8zU5/Z08wYeaoBXQH0+wxHTQ/ZuKU9vVXXTHwZi3UIRFb6okNgvrsp+HOnj7bD3xKpLO6mVQSuoH1daHqzsNmuzddM7c1wtMFJxWvXXLdXvebTIwebTnSHpY/tKs3v0oYcV6aavz+1NjlelerL8L011yMhMzrIUlJ1Kvwuy57K7to5G/Tkby/I3Ep5G5mzeNVCeS8kSKshnkT353/SLduecW4RiAQHqyFLI9btHkWwiWv0jLzY7jylKvXVoTRiIYf5DDEcIZi07JiHKjSkgtp08/3Dz0GNkCiiTC43ZXrnkYI+2E1IX5XGbbkCZDMtdMCi184qXKfE5rr0gQimns40FqQe7ubMH2qa63G70oN52yeJmWu1Yf8bKWhVv9+Y5+OduL+I5pIrE+qwRuO0FngcsIT/z/ACdHJCrOT/l2erC/4dCP8f2E8cdsouPGGTn9ORzbSeJPzlrYlOnm1xh64inv3i5Use9qQ3zoPb+3igCCl5VYLerAT2+nqIDl9Od/aRJTc0zmShoS4tZ92zupKli7Pdo2rIWSdQEVYH1BoaqnUhKiEsUh7fzrIvYQGqyKg/svS37oTn7ia3F2GCkv+7qRGuzHKbDfK7LUcjqMtLfv1rcrur8V6iXBZTrnLvLG/gvJUtLtbZO7E/tvUXayO55GDqxYI3bvFAJXhP8ArKPLSAEFJMsD0KHKsOlLaDN0nPYoD7vithuhAvuydoQxCjkhEsVuJIOSMXrexmhoXupwbLc2TISpm17r0fgx5yTWUJAqyXzyqmsHaLa0V8vGeTPfilrSe40zcLn/AHA2aMLpMuXPTo4tyX6Yn3E6si0SG6Bx2QT5QlBiNMWnof3F2N7pwzlZpQBc0YfPb0QpHQUf9dD1txVqisn1SEWveBQ5ukqbDYHpNdYLJmz9dcAdHFQlvltmqvAuAWklvqOMcVZP4yG/yvHzfZ460E+jHmkM+aVeJ4jOmnoQyMz46gAMA7KoKrHlK4M8BzuOkoYA10ww1YP/AI2p7REi1bWe9dk7ZZ4phhZCiloqU/8AkDT33F4Q/fH26rSsvVgsmN435f3isu4WoPc21S30DHh9UOD5bdK7SumOaO683A04Txwtr6A1185ejfrWHcLLsMQ8IbsDYrF7zOOYKrpCmIqWXGUUajuOWzr2FVm/ExUlNysu1/bSW/SZ535ixBNj6JY0GXKL83maMZ1qRS3SNpEll6LouddsCAKZ/PfkFmOYfSDmsPOTXxhX09Ts2C95S7yOcNU+pos+QymLJG9B3MHn5qZk2jBJhtqGBbp5z9p17ieeY21KVWx7kWxpnvM/6xb1tntdQUCYDX1imZ7FZ8JLJyEDHe/QnQuewDVBiZirfSGnqX26Wq9Woe2IKPX05jqaVtZT9rK2zUjy4fRQDCy0CczWqFuvY5I739lu8k5iL2v05ldB5aQuqelstZdDXWSDh3KxcxBr7J9CZsJy0vLU7QSsL8YvUQ9hXHhOa542Gq1qGKhu4usl6bBAtS3lRrFRhzl1Ck5K52y39U0/xyIaLjB1kw35UF74nrMOtrqDCuLNbXB3WBpFCYkkSPP64q1o0pStER6ZX6jiBoV4iRkHTuL/AP7brVSbH/Tovp6uw7c3vIW8RVu3rGZyxtrI1r/uZyiqPVtFa5YQUB1DWf3BpG5saH7hWYn3kKInii6ayuq5a3Om+nx36UJg6w7UztAHFirh6UPFfn6Y0PUsxpgGOCkZGchL36LUobVwHFkM7OmepdTVb7c697RuzbnTRJsYzdLQ21deh35/cI32Y4S0lIEVjSjHZ6bfnynn450GK2rmXM+sPRf9zaXT/wA7iBvG/UbJA6ufn20+ZvSwlZ2HM7KYvpL2r3C5miqKukbEwArEzMiF/wBpXtxrviyuSJE20V8eKTtnqUP9JHQLkOK2hNgkLQYzFLLalbw3ayvkdszf5SIQ4uLskUM36zRJbD55B7d6RwRvGem1SN7Q8oDBM1QKifWXkSIjtGNWUcgk0+nWLoej9Onx1zcUJLQVh3wvo61Yr5SFQRvW6OwGia+iV1r+nuYPWr1jlZFRdLsGcb10i10+oM8SjYjELLBSJIJLMaug6MRX0wWb5cc+XVd4UH81/QpJFLEYswrUHz5gwgd1FJUTV1dgK5+iD/8AxWxNVRddxX96gBbixr+lTGLb691N5VcFQnSJj2sIwbr2Ffmf/BmQ2i1q3rwcTe/RuJpZ2X1D1gbGeIYrtv2yxhLHz8mdxhPc1enifLxjcoND5vcRHpHMXttJ5mWg/EV2TPOkKoE5rHcPaCq601Iiv4JCY9tMtsGKlFYNClnZBEJUQNUclcuSZKwpNkzCQXMyFgNqVcKYQIKSrARBZftLFqTP6LzWpejiRRq56hHNIZjqqakcmY5a7NU7f5D7rMGd78TXs22O3iwMvZxm8WuxaSZ2v+FBzHmw2KiS8+aXSmwzl6WgwbT50wqdNSRD8nM1VlZHOG2TbSKBbo9YNGc7wqAbN+f9vx6nF2rqUoMTJOZbPw4u8Mn7Z06vE7DjNUF/ZJY/p65WczW08sun1JVXU2ZV8aEWEqh043VLqDrVI2jjdNloLR6urVdtmP8AGOf5LAJPPnmeRS4x9DZ2QHVzt/G07dd4KmqBXOurGJgl0ub3TGYwpk5Oqq/moiFOvhpmotlmsy3fYSz7+75ZtI9nOd+qHAr14W/zaOUuYR5AySQC8Bjz61G4Jmg6VN84TH8/aUUMhNPCrEXK4Nq8tkmKBTvXUqS5H7VoSKiX06/QvXkz35/rlP5zmbmNjc0OuAsLOdX6RONN2a4tTyJJhCGBiAR37/p0fSpOpFqz9eeSWdHRt4Lnj1vteLeSznNJg3dYlkug8AW6s90eiFwLjC/LbWklbK2KtE39NhC+G7b6tab2D03mPGzFz0EslT/pE4bIKwiwuE93snOQhp67POpLfKz09SZM5T9xd1gVEj0m+4FTTyiyJqIvwAmYpYDPon/fSXUQd1DqbCuvvsZb9Kky9E/JzXRVS+inIo1xd9W99GtQo+5lc/SusDc6bY6XEciNF1Vn9Dsca9qXHekWH6zjIJcLtPZ6GKnKuC0yWqpvBa/zRcczylJdsLSGYea36VmHrirX1+kizVysDispvGEZcwaLrzLEkdk4TGHaHHWPuORfTUNWpkPqRDP7VUvOokrYQ2D+20c78/PI78iJ71ISoCTPcs2vPhbnjfn9N0yF6l2h+jb6ej+bw/am3abL9LCV1en3cwg1X7kNfoHerh73USZLxajI19PS0GqDI59HUXUbqtw9Yp0jRPbUF0joL5HRUNwzo0r4jJ/qmiNLMYN4c3NCGbjHN79ZsLl1cJuFzEeVVDobA21ujELKpb/ceNnM2bMs9RdZwixFy/8Ann6DWY1l6qPWACVIOQ38Ig3+QDajTGrapAzWKw09d+g86p79MZwsJGrrAgudSUmM8VpmqZDIGrEVE0Fej2ujOkozL3S2NlgZjYLVFqstlOMipBz4k4t64uzk2niy8K8JQVI+u3vGeRhdbFdgtpGf4qwTvfypN/L+XvJeSPr5gZNLydDOLOvXjScmOt16WxPGe1M9si/wuxX1k552jnf+OfEsvbAap6Pbw55zyl+3P6WFiu2Vj69DEjtX/fBi7z/TJyPHZmtMzQD42mOZ/Wwy51OoV2OD0El5G5nBtqrWNT01mfrWlE6oUVs0Y/p+jxrNvOrMDJXYkviyiVUWdMe9svsjLWhhlr0XY/M8Rd2scJeotfRnFr3ayK5hAborlmUScqie09LB/bT6DH76OTtU5ip6e2b9u/bzjDZoRFYHxIg6T0X0ussG+Zmc1EfnqyOTBxNH15en1PsKntM251NeyqyzSy13T32KrfGov/h9Vxu0P9Z2QDD81hgHDf2MNloswsPQXs3qrE9JpuIRjBjjLZxUJeLcWKKqrBoDXuRi0iDnzjTWjzBhGOA1FS/b1by6uUzyBpeD3R+O3Av6exfmh0cNWhw3XNefxiC9+iz5/ZNYnlu08rSJr0I3COigK5NAS8JhrHartfS7naZcXb2TR6dgVIZODtSsfmlu0gYP3zh+EXr7KuChckDoR8g0hG0zHppi6l2gxPWHUExkNNNWUCL59OseH4DetSvMP0plor9veHHMYzCR1xqVFbmEtTyuWwplj3Cp7I5T+cFpWoB6jASZTIdTRxUF8hPqNs2g3WKWGzetagixWxBhNBnqRRYNtkb45tFpTXKXq7qqSNtZWtOhn9SDJZBRdhhpFvTCdf8A+Q1zXIvF2CGm6Jjn91QzQIGr1WKW7FGEpg9lzmNFL2MHQYoUIELVpF5H7FosGyiaVLIBpE8KxK1ka2oWkGX5OfYUSv8AlrNSvSymMsf92kcMuMs2PP8ALqhG43iDvPOk6ROveZue1p/Tv2jp2T1088wM8hbQzLd6hnTNPja83t026HS6VdiYHoLAiTBpSQ08rB/3jXmy1fxzdTG+paRKaNWelbc6kqvXZOqMeZWs2np3+TGGcA+oNEce3byKqyOhBEvdluPzEi9lXtJ4fPb4x0r2uG9zV5LRo4zPmYF/CTeN+dLdPx1Fw3Taytd9xRdVmbF4sxS1tixAk6ASWY6g6p17JRN7Wst/ry7XxPG20q8Gm+8ywJhfyPiJCPLrdS+4dEBx65aJ6mBXZe+UARvC56SWbZXqsD+4iCJpVrJJhUS6bZrXL3EHZjtxUZ6qD/jxYljVBZAck+ikPCn6ZaFYh+6uvXO0bVIWZn8zP+pj/wAy/kvVQu9HGbBzOk/4SP8A1by5/wC+0dsQ0hus1Jti5JDH1Fcad7/HMc/p4yEaDPe0anYYqT7OB/0PmATzUL+J8ovXaFYTIdNUU6bFWn9Morqq1726Zmfqxb+jr7qBqmh1BvWMXbYtcJc83oBWf5J0i4tFcVRT2tPS/jTMv7I5Jna8j82p+LtEtGj0ZmqJ4++3LTxCsd2rDLz+ndPLqHrJarCfQJ2f7u6iLLGlSOB/Fu/kSSV/e085Pb5qK/DC9U1llmFiq19VB/RFaEr7QDYZlN4wKMhb+dx9v5LydiVbHvYJ1hqKsvMNCm1woraLBDJiEwJkg1RDat7VpGYSEWrzNIn43bI099gh1JDFCU1wVr3jtzv+R8L/APd1BT240z5Thf4sLy7Vnlf/AC8p4u0dQimiws6Tqw1q/wB0W7H2HGo/M86d0IzZW163a3beJBz2kH4N28bYJbUnS2QiuFskZ2wswrP2jnhZ7l6pUEDNx85zTNm4Gjmt9OZLtur9RQ7rqCJTp9QgGFhEVLc8ZtetGbRt2uO2StkM188VJGLsXj2N8r38ouT3NEt70eo7q9P45isTLcxxyw7R/Tqsh6n60MORf07Qut1ltkh92t2q2q2xHKN1GL4fXHTYWRuPAn5COT4rOViWJmvL0oNYa7RhQB0TQRXcqIDImdCv+P7F4zIcMkVxUtF8aoi0fC16QXryX2khdgkpaiy+mQ9nKrrFbAFa3qEPuR5NhoV/8doqv25PDFGCp+plBz5Ga5pOM0XIlelVogPSfO/5j9JntIqzF5tFeFr4cHPK/wDiI0VWuCtc/X7sq053/wA9AVPUpyJ8Tt/2M139vf2XavOpKFfYYDajXViZ083ohO7VBZlBDTjUx7kCzlOJYdd2Gs2fbI5BVP8A/bv4rLsGoe4+TyLWjgf9WnxF3vFLU8p6cxwtkTH86xbcctMg6Oa+fqnfy2tN3opRtaxp7cpb/L27zPnK77Yk56Pkp0thtegbphcLifIHhDA9gjRSNB2CL5tSTd8NV2osX2MTNYG8V4zgakNJmyN5YDMQGx+eyzJmUHg5X0yWtrCldih6L+NAiZS1BwsQ/sr7G6kWUFeqgvGe3bT3EkKNaDLt17expp8eer+b1KL8T7YryBz3t4xFfzalf80xy/5sTi9JtyB3qOK/kZP81Cx87Qa0IOvkRP8AHG7RZn/6yGTNwYyW5lasrYsLUiBIK9XPTKvSrP8Ad2Z3jq7L451NjsjI5gRV/RsxzOCY6lag/cN1rxDETPK0mOSUF05iY5H4pmgCde9LUt25ma2nmHMx3Kb/AMqT7OZFb/uOiOy25LV51jT3rE9nIryAE+d7RAZLpQcBwOpGvS5NbV5chxDVBkh5/wBjQvosxD2PBlzMuLWAlkg9RlwAVCHtRLQqrUTGme3raTl/RaWo07/2KaZbmEdgByBMcB3e3KsTcuXpCAPHX+iLsAkzK9aWCXNXFs9SHdpUMcmkzygC0tapSHuzUUXdJMzbz5Wk2JC/GKxSV48iZGY1oMN5uesOY4TitYqrqUqAf/qlJgog4w8prxIqv4xJmZW4vX3snr25Rwvq+tnmP08ewYwVY4tnwrNuj073t0arHI6NFz+zgcH0hn15/bOPEUwc6tC4uUsPbJzoqwrmayE2eW6Vz5m3SSvNJaEWsUF5W06B+8mFoDErNvecTVQ3J3qS3qt0n2t1YhuVdWrll/uHTQIjP/8A31p+Ga+vP5iU7YnVDNTbGU0v5K5ahI1qX8lDGCekDYuGsKcw8uoaHoy7wQndO4jQoQAaGKj3sXZACrMhse16UJxaq88vda1cf4L80V61YAeSS8spFE2RnxVPSqazf/Yh4RYYLSwotWf1IGpI/b6crni7oYNBX3QEC73jhRmozWouDaMuwR95jhJ/M/ynpnptzqSu10roZIp/YgJLb/ygv+eEt/jzrJQJ+/eyFOwzz6iLfkMRwWloAn+6m/H+69Dn916fG9Jx4gmmQShvak8DqM2t48/PNwxAhfYhmOn1q5M0bVJSLUtyzC9Z0ekHSs4GFbG4/ipIt7mivK33mOfVfq+O0dgkJ/EZDiLh6gf2hHWvcjU1ayW7wEl6xFNSSfta2YJiT0jKVZ6cowc+JGaJDROyw22ddWhbKmdnvxeoRD/dGH2RaDZuUfhFJolvTkKexQZFFY34GE8vDjks2tzGUo68Sh1mat3sjC7RmjxNF7XEEefTtYX1MjotLKs4Oj37V54RwcmrPnbkTPO88/PO5+1pITnjyY7mj+FJt+e/Yd/9Dr5T/SOae3+q63+CO3a34Pa35PzPDdjjmUzQga1GIlsitfpocmev0/8AJZbpqOXD0xy37BHPZkRyjeSOR76gJnq5vk9W6PeOrXOC6mdZOujXPynsq9iM9OjMeynTFeSDp/lx5HA7DSlB9S6w5d0tjVpbMfLEZeh5ZAuoQ2uMgxFr35+azhhvCqK3qLnjOcmx42oK3lmkn+GYymk31A2uQv7qSnE2RahozxCPVejVobMJbVoE2jY9FQn9FWsiKCcdJ9aw1LV0ZHcc2+fWd3mqkj218YtSvOnfT+59RZ3v1CTKdlkCZmeZOy5bXrew5JVi/dQBgXtaX9KkxXkU5FeRWOePO3PHnbnjyI7ci9IcuSJjvybd634P8c/pksNq/wDVSlaZET3g3/2Gia8PPfijZ0uHYce58/IWrHMnIYfJ8nUdayl1DaLYepflulLl5HRouR0ilHI6Rzef2ep3/tjKjn9t5XI6eyO3v0KCSGZJl1SdGKdL5leUw8unIzkBcgAY5Audo5+O3eOfjtvhoEt695kclsuCgFbXsMWT7g5Ic6+nX03XX0mGBrkdtUpSBvEkF2tBfMb+sLgdV8zPpuyei160cNEssgHJQ1Gy4FGwwU/g5rwM5a5dZjZ82yTHiIFZic8oRafV6NG1yLfUjpzQRdJaXWnlF8mqdlW5pQAg/F8/JM/Sa05FOePPHkV525487c7c7cY8aN+U8me0IKSzE/iY5/Swtl7f1F83+kli+dPLwlpgjRicXJHl2/P6J9RqoL36wLPP7udjler9CvI6wf5/dzXI6uLz+62u/wDdh+V6r/I+o82/KbObfgzAJyZjkWmsfp2vyPKOf5Jn88rS087Tz/31HWPGfGtOmFZb0Z78/PbWP8ePnWnzZ7ivT1lj5lrc+YNZgMVnxtHJiOePBi7SS9i3aWiSALaDZwxrGCGyS6wykBIzp8uQTNAqCLDzYCKitX5vWUQ9ALOhirPqq36w0FWcvIpW2pve4RsvP+k1VauDaNB7R0++WI5Ec7cj9e3O3PGO3bjgY99iVryTRbmaP14hOYos2nOi9BVJ/r2kl6SHPhcheVJ34Gn2tD6W/lpHz11/LgYzvX2y+0rkmfSWORS08om1eYxNSYnG0Y5K5qzTLfLwXTukSK9LMdgdLUpdXMUT52n9Ld+eNuV8555Tz88735WZ55Tyb2nm/F7cZtED6RqP9rQT+9sKeFhV12W9lJ9h3pvmfd7UW19BtK4OpHhRfqV+1r7epflnHL89pOedp5Fy8Tre4wqX9PpFWjrAUlwMF/cRzU8XieUgV1mi/t+IG9pxaswJUZbhviF+nJ1lfl1loFWoHrqOapmNga2RpC4IghY7j9WC1d2Yjx5FeePO3O3O3O3/AAvSL1+RfnzL14ZeTYs/y5Wn8OkGAJdRdTtQbpSZnkRa3BKWnlQ0pECpzxjmMjDblB5go/cc0XP3rL4TqnMFf+7c6Iv1epy3V9Z5XqwM8H1FlX4TeyhwTqqOW6nfmw+otIvEGHm+Vr4xNYnk1jnesx5+MxT808Y54948eT+nUOTKuWUDpr9KOASqR3NiGd9a4MFpT9k6ll3Q28ohsgellPbTC3QGseT9F5qVCZq0WWwytyv0A6Wsf07Wng/6cArYPTrFR/t9Pm0E2WrmySNJE6c0bEy8PRQqxikPyMPUqPqPB3D5g8PqGqhU9HyXY/HRt6lyOuwXQ2cJ4Z9YTHphzqB2B03dVxdnK0M/FCK1TWFelvHkRyI525252525252537cm3JvyLWtbZPdTLmb3mL9og1ZlPqzVWXJAvZU/hyhfOa25/ueDvNOTPef+Xbnj+i4TkvmjPMT27fy5H4jv35Hbnbk/nnfnbvyLeMzyJjneODATWw9HpPSLdbpR+hhdHmMwl/TxEFv28IFH2LZ11d7qG8a2x1KlJ9bZ0rB6W2CQDpC1uK5NEhVTtaww9rDhm3CSxcf/AGqVHRtWBCaCEN3vKmhp1rd3V9kOaU2G845yj5FpQar6r3UdqFDKHG/0Qvvyt/T3RyrtDZSPf/Kwii7enTWiVjMFmo/XbDx/KrWPyD9PTyJ6ZvyA9LW58HTV+RjYd+f25nX5/alb8noxjn9lN8v0U/y3ROjz+3XMblm/PlpKSYAe/B55o5XE0SzHS2tPCJ/OWsVjkf8AGtL34ljuOWjpZq3J6SLMU6SvyOlloinTSHI6fyo5TMzRcpERzx7x+OTb89+eHPCYj+cc7TER35PaI7d5mOfif0EW4uD1tAUx7dphUKaQTE9VXNPR1SLZaQIp65muGxALV9VvG087c/n5zPjyLeXIrft5D8v9zWYjlpv5F/3cc+MRA7uTf40zefKAp2UCVc8xUs2IvFPusOH9oefn9SdQOazUSACIeodotFuqW83Sw9B2+CP/ABj7f8p7/p7LxyrrleRqacc/fNiOE2dUtRiDTg3PVwe8cfI6tejn93ucnrEkQ40u+x6weQBZ97B6WzbCjpvJryuLkj4JYFOd47d/xya8/PJn8Vntzx7x2jk/7mOfznnh3nw/H5ibTyL9/wBP49vx35/HkV7c7xysd+QKvMxaAK+u3luEl5xZcQqREVtMT4CM/WvgLtb2RH457h1tETMf6m97d6mrHIN+J/1FrUn2Rz8X5abEL2rBfV3J4TeTIUYrAaRz01mZFe9ep94cXZUrQhzeQ0e3ljnj9wRY9a1uqulK2/8Aydv07fp25PJiOduLKkaNl4S2dHhE89ccvT8UpbkxN+TX8zPJ7R+hKx3jvz8d4rXxmnJj8dvz/wDz2tX9JrWefjlvzybfifxzvPP/AHzvHYdajqIM34Ge4azwhLi6oEQc87d6yOO0T5Unlu3bvXnfx5a9e3smOeffled6zyfHxr2mf4U5Tyry38R+yJ4S3LEpy5aUETWDSotdSRavUbjFCeMRXvFR+Br/ACftp5o2lymjaQ+aEf8A5Yn/AJjHY18fIqgLvbneZibzHKxM8knO88/9Wtz/AHX/APnx8ueHbkdvG0/y78iOfy52tPI7c/3M/ie35/Ec/HjM9p7+fPDvytqxMXgcB7+Pea893qNPuHzSzZK6Mnt57LcH3tHhMTU4ycj/AHev8f8AfP8AXO0X5MRPPGOTS/J/HPA3lI+d7W5E1tNorwlrTS5rEsZsFeMPqQHQegpLd+7NZHIyxMFrbywSosPGtATkQymeTmv9/wA9v07/AKd+RPJ/SK87fr2j/jSliXxMaEh3/E/7taZ7VvEW/jER/ubVry3+4inI7TM1/MRzte/Jrz8cnk+PJjx5FeWrHbv252jnaK8/HIjvzt2jx5354RHJrE8DWJmo4itASQBI8orXvVkLYtEbNrVghbctPbn8O/eO0UL3/Ec8Y53vFoLaJi9b1isxz/3NZLetK8jGNIGVaCEHxpLP552GqOVQGrrqMbT6uEFdZZ1ZvfJgwfn9qaUbM4N0B/sAB03umUm9uOmX16yAsT/w/PO3/Dv3/Tt/zy38/O5Xq0HkDqPNPz6Km55TM+c1mZ5F55EWjn++d6zFfzzynneZ5/8Az/C1ef75WJ5M947dueXPOe9bdueXPz27z2r2nnf81/lERyYt2FcdbqXEbixGRnJI6R2jj6dWwLesS9I9kxNaz37T5eXKT/KY8red4rJJpFbVIOLR5WHWsTSKUrHenasXIUXZxql6CIW0v1kvCA+yu1sgoyaA6603SRDp9V7ZW8wKl87U8b6OE+CMjdzp3XHGs5vYLLJsS5dWtv1j9Ijv/wAv/X6f+/07fqooRsmXm1zxfjk/x5M/nvFbeUzXy788e3P9c/3z8zE3qPnn35Nu9/zPB9+8d5r43taPxyLePO/5mY5PLFrEz+ORbnlNopMdq37890xyGp4yS5WAMe6o7+2nf+O2CB1XMOeUKIdZn8VrHlT/AOv/AHa1aW52iOEjwsS3rvSO/KybzNSBX71tyL1rNm1BVjU8pJ1QUHH+s9K0Z6X2FTxzDu/YqnJ8p4sSw5tPsEyENhLwYFFun77YAtUTiW/z/8QAQREAAgIBAwIEBAQDBwMCBgMAAAECEQMSITEEEBMiQVEFIDJhBhQwcUKBkSNAobHB0fAVM1I04RYkQ0RTYmNyov/aAAgBAgEBPwGatnoKGvZmhJUjgflNmWkeKNLZikmZoRUtMSEVX3MuNbmSOh9umUL8xeqzq8Wjdd7732XyUMoxYILElIy9Gsu8SaSk1EwdO8jTfBn6dwfk4OjuL0SRKO7ZNqWPSQdEZy6ZK+GNrwk0tiJ1C2u/n0Sasxw1zUTqOl05HGHoaX2hkUdKYm8zr7kYxhOock8OTaTZGXiIluzNk8JNo6tp5LR0vTKHmycnVanJRRhx1j2dUJ7dkbvtSLrceW32RSW9kXtQ4XyXSpEd0Qd8lpDbNxo4Lsn9ij9z7d0k+SSgo7clkPNyxy20k4eLSfoPEoTpkeni7v8AkYZ7VI6nzQdfNXzsoxeTHTIy9Dq1Jy1HQz0x0vki4v6zLJC82w8M+GR6aOq2dVp8Sokuox0kR+mzqfp7X3jjlJWhYZt0JbKLJ4pRnrgOThC2QitCiZMcdPBok+DBrgpOJFKD+59XBDGlv6lUzLglNuX2JQeGVSH1E8taDqem0tOT+/8AUjhWKCjJf8YvNuh16FNFiZd8kK0s8JLkfZRHFxY3Y16EtkR7WWhUxrsxpmkRfbg5Eq7SsRhpxaaFvs2PDqad7nV4YQe5068+51WBKClH5X8t98eZw2fBDIsnBoual7Fp7ibm6R1uNLGdHn1Q0VuiU5R4MU5ZHuZekUqa5MPS68rUzNk8C4InmlPk5F0s6t7d8a8lH2IvUrPUz4fFjsY8SUabHiTTUh1i9djDC9TI4LTcmYYOHJdLcjRwdV0fiz1pnT4543WRfsY8c5K8n/EU3uR8q0nBJ06YovgWq90V7i0r1PGTtjds0+x9CFK0XRFtj3N+O1I2FsNCNN7jo1FD78d+RIhlehwHCMvPZmUMbrGxx1TuQ+nlGWtK0SXiRF0c5DTTp/MiOOWT6RIojjlkdRH004/UalGNQRgvU0y2kKbuvUy4smTTb2MEFhjsZZOLMGKWJSl7mOaldOxz+xnhPU5NGDp3/wBzIvKRxa5+J6E5Mzyk5+cw4LpsxY1BWSbuxCbfI2zhHJLHqRGCgh1JpULFCySSLUeC7ORIacdhY3CPnNN7m6JRtmv1Iaox83Jqfr2W+xLE1LSNVsZNuBDj6ikQ3FzZexHsvkluURHfahM+4vuV2WRwknEsTvYhdWfVJJD3JPSRxeLJ+5kwyxfV8seTpMMMdTe1/wDP+M6jp5RbyJeUnglCNsxt49yPn+kir2RlwvLkeqQtkfcyvTHUxT17IhL1kTccicRQUEkiRmcq0r1IPTjUWYoKCpC2fmMlT2L3s11HcVlbCVj01sb8FaRyY99xLRaFk0rYfmKKI0iKtjen6Rty5KdEYXuLHfJlcoryEoJbk1T7QV8mSatGqx9mLc3iehH6d+2wvk47IaKErZUUho1eg+zQ0i64INrYlJ0a9EdRkyLJDyK2zDhydM3qOpk3AWOUouS7/l25aTD0bwTT5/0HNz+pbnUZpYpVJJmKWSUNuBN5I1VHTxni29CS3tGXE3LxInLoeHxI7GTDKUWkiEMi2rYjiWOBobao0TT34NaZnyxlClyfSjTJRuzU09LHIjU5ben+ZKSi0mYslq4k+qkm0Y8ilwUkrMeVTWqJe5QouO5YkadyS7WkqMF6WZHRB77kmSmyOXSrYpL0M+uUksZlI4/Lql3ohFzdD7JFE56ZURmpNr2HLS9+Dz+xYl2fePBu1t2Zuaq2Ek+0Y49LbNfoNbWfcU2yXldHlnsyEFg3ia9W7JxcuDp8OhPUjqcMcbuJR09QqMzxFqFKM/KZOicslN2dP0csPlnLYzKoVjVim9CTRvwLzKjwEReknX8I3sW5Pc16B5NSFgmnXKNMWt0Sj4myMOHwo6ZOzrIzyeWCJYeoxpyZDNKEdKI5l1E1jGtMagYMUFDS0PSlRK2NUhPt4j7Qoaot+hjhatnhUtQpehkZFXuVZcYkXB8mKMZytcE7x8EnGMU5clttWZIcsUkSuRjqLtj3ON+3LKTJ0ieOORVNCxpbLsuzfau2ObXBKNbjplWUUxNIsVXZqTLjwbXsWa72NV7G/ArjyJSlwZsTyyTPy8dSlRli80qIN41pNfsQyyhwY80GOTg7G78xfsQaXI3JxtkXflHGzwdtI46diSa5GhbM8r2FFLcaFZLfk6bpoZF50YukjBvSQxLGqk7J8WiMHMcl6D3ESl6EUmONEUSQuS7NVqiCeuybeT6hScvL6FeUyR9ELYjlkuBe7MqTVoTpqCJurLRQ15aQzksSo9RLUMssT9hM5OOe3JElJN7D8zKFuOI8Y413Xa67RGzW07IZpJOK4JY2oKdkcSlC2ZMcVDVAk0abdi2IV6kjU+ylQpXycbkZWSmSae5NatzLjeRVYoUhuM94qiWBpKyt5EeHZHF4mzNWpilJKvQuyht2fftx3v0OF20kUm3GyKt0fSyPNEVRLk8PU9Q426HBQNe+5aRJ72Nao7jg4v3I1wa6JrXTNO5pP3EnIli0dr7V6GkjFJjj24FNrg9LNy2L3KtkntRzz8ifZK+BGr1GKSRjy6THOL2ZJehnhkhUh5ko2QepX2ssTItD5G+zK9x/Yx6mKVMx6dNmbLczIirY1pQvcTa2Mane+4mTno3ZyU5EvbtjSfJfsKvUjDUNGXLFIxV9ZWScmp7EYaHvuzJDz0ia088kZMqmZJ1sjUcJMcr4IQaWqyTp7IaPpR/Z1wTSXBasjgcmbxPqeqRJ7FISpn37tlD37Lfs1sYl7lMQ+zRpRpURq2J6eBiHBVZLC29UTD9VDqtiUqltweDr2bMmLG/LIfl2Iq+Dw/v2q+1nqepqEk47Ci26PpKMU9KJT1So0+JsaaVIyrVKkS8oo7EJaJWb3Y7s4WxqrdHqKLkeGocmyEtTokvD2RoUmkZMMN7W5ixVOrKnPdkcunahUt5E3qf2NzxNMdMkO3sQxXuZpeVJGOvU8XjTwalOWxNUPy8noQnq8shY4/zHLJDyjiMZR696OC+3JTLotGojkj6iir3J6b2NW1DF2dRRJ2WJqixdRphpoh0LlBZPcc7dGJRVtMlBJKSZlhNxUmfl23sTxvGtLRY12Yu0Y6iXJBxcaexDJQ3Y1Y4tohCS3JPeyctilslyZcaXlJWhGo9S1RQ0QdEZ1uVbLrgbtk05R2MacHRBxvfYnHQxXe5mWvYUYRioogv/ACJaWtxu+CGxmxzfJVEo6YojG5Ck5bE49mvVGN1Ey3Pga0osRZYn2s37XZEsdFlm5u+Tjun257PvRDJLSoE40RlpIZ1VSJ5EsSijU0TlrjTNLKIpvZEsUktxduF25MMauUnwVHVuZenhh+oVHiehLG2yUWNs2EJWdR10YZ/CX8zngoRPJGWzGqdGOT9RyTGRemVmR1H7mt+h4l7SFOo6SJKGqqZVfUfY0ox6E3ZKvQ3lROL9CSbSshzYo+aykmOFvZD+xqkah2zTuP8AR4Q2X3RRZY2MQoDjSGiu0ZJxoeVXp9TDj8SW5Fww2qFg/MStmXp4L6WSYpMh/aPclKtkQb5XJ1FylrZDdj02T6SMIKSYkjp6Sd+wlPA7L82olmk9myiFJkstGtkuaNJF6lY5aWdZm/Ozj4a39TpMWbGpeL69rsXmNZbNIkb+hKVs06Y6iMd9iT3NdRobIORKaia00QVyurJRaqLMn00aqXJHM65ITtk4NOyMb5ZohRKUoujxTncXG5q3JStldm+y77IssortdGrYUNhxoa9hERfcoYxF0QxS1vI+GYsixT1GN+PerkhjStTnR91wSl6MVepdcGLGubHPRDbklJsXbxnJbmJXl86HncXUCbc0ZHpINWcuhWlsNWYY41j8xmxxabgtxwknuZKTpHUf9mT+zPhtSmnH0W/7skNC5KaewyA37mSWnyo8ST2RHH6sULdC2Y16iRdIxxUuTPNS/kWRlvY5MnF2JIaohsORBrhk5W7sk22JCGxe5RYxiKob+WyzV3T7NitiVodrtZZqS2GtSpEFLHHd2LHN5NTewsmjY8V3Y8zkPcW4t5bkMqxKqJefg4JOu1keop16GSEfXYm1GKUWSZdCnpMNydEIxW45Ri2QnvaMi1SscZKZnwrLjeORDocnTU8L52FtyXtbOlzzzy0uNUJ6WRTkSjpVoXNkt3ZBQ02znkWREqa2L9xe7JSNxuxKzSJ1ufWqKobsSpGSWRqq9SOp/UOLSLEX2RE0oa7tlFd67aX3svuhyobH2SKI+UkyNLkhheXzI8JcM8NGnTsVTLaZrbIapbI0przFC4IK2RlGHmJz1bkNN0iePezJjePcdNkHp3NTZbZjosyy1cGVySelHjRxxUZbGHJ4sdVUR4pnDsshOmOTk/McDE6GLZCexUfUlL0KJS2o1J8C23ZGm0SVEWoPYmlWoc6Nd8jYluRjpbJK+DgfeK9zyj3Ks4+Vooosfeu6kNi0+g9+2tehqKXqSUYrUbNbMUmtjxEuDxCLs1IkRMco1yOXdU0SToTIVFjnZPM5qiMXI0UJiVsityLk9mTzaJboy2lqSOq6mWfLdfyMnU9T1/l06X61/mdPgliS1OyVTeqL7Rjb2OBrtQomO4idn1Whog0vqLhJ7j0Y1RS9SMoDlqRSXJGd7GVb9vuJWyME/U0mg24GUNm4xMfyJfPXd90eF7Elpddox1H08mVeKqZjjpW5XdSF2SH2QxDyNbDYpFv1HLssjQmahMWSUR5PWRk69RTpX6ex0+Pxc6TH0+PHk8WcnZF32pMToos5FsajFvu3sdRknBXjIPUrZsN70aVyKN7ji57ogthxqNoZfsX4iNG41Qi96FLY1at2XGOxkVi4orGnaPDb3Oe19r72ehdFlFFCP2GzkZZrtkqfBwatqFV2xmtPYS7IVeoslLg17GonNX5UXZfaSaG2+yVnHahYrWw4uPIlY2vQUb4J+baRp2Oq6ecMmmIoZszp26Og82KmqfBXoJH08jmW2R9uy3e5DE5R1MyxeyfAoU6FpXByOyG3InG9hquTV5vsSxfxDItx3JLxFaLrZjft2TEfv23F9+3A9yu90Mrsyu27RVFn7drG77aRP5fAhq1Nd19yxGwmnx2jv3ZJDI89mMUmuCssob8Gw1pFKxx18mWSxbyZ+XWbL4v8P+pmWHD1Mci59hEcijsJNrUSKl6DjXJSRqI7MWSSjuanJmjQ9RN2xrYW54jrYnKUXpJbEvsJuSolv2hkaZlhr4Pp2NN8H0kFZJjl6Is2KXerOC/kRVlUJljL7X3su+yGjHLSXZfaxvsq9eyaOTjs+73E6Ix1Etu+DKtGmbMs9cr7LccfVGTovGnryO/sSg5S+3+p+TSz+O2KSaGR2GtrG/LRY+08TXmjuiMdPJO1Im1oJbcFtiah+xJ6UtJJu7JTb5HJehGY1Q06NFEXTMsb8xHyojK35hsjHXsho0sor5HKhD7Ir5mtxr9Cy+1nPy8li4OUKWxJ0Ib9EOO3ayM2Si5jVfIpUX7iaT3GxpPkjS2LIv3NiYvcrUKos1KFURkyMknpRM0avpIwe8l6D8y1ckX/AEJSYxcEI7WM4R4mrejH5nuU4kl6i3HRGTg7iPfks37qaa7OtVC2H+gy/lraxD+Rvshdku3HdP1HyS3HvsLYm+6NdcEp6vQ0tK+8ccmX9u7RVduSL9Cvcl9iVxZF0Sa1Cm0tiM6luanYuPKKOlUy9DY2fwWbs0kp+iNVF2WRZyLkyKn2ouuzKRN1Bss8R6KHNvcwOV6n2V32nPSjHkctmOzhWKVjKK7UPbtx2ujkofdsQ1SsXa+/KIu+6LOd+9noWrLIZGtjJLXv8y7RnvuN0yUbYltfZuj13G16CnS2Mv8ACX7jExs1Figknq5NNd4yakN6WOSmiiMa9CrHwRVLcoeWNUadU7GvYkmjpt2Oaj2s8GerzGPFpldjkqtkOo8V1EebVsii67NXsL6iT3IL1PXu0N2c9l2s1LTRycCjqdIarsmhKu7KJLSX8kq9B8EX7m0uDTe6XdLYYtvkar5NPbU7J6v4uyGKLfBWoWJ8kY6n5zKrexQkIktSsXJKNHmexOaJEPMzxoR2EyNLciUU4fSRuWW5EZqTaXoSzQi6Z4sOLLrd8HUZ/E2Om+rVY+Rc969Re5W4xDEX+guydLtGuS9i7Loasfa7+ShV6l+hRxwOfqu9jrvXZysTOSkXuZJXSo4JStG/axHB4zivuLJ6lmoQ/chL0JrSY3a3Kpknq9By9yK3s29yn2UqFlvbtKN8HmWxPDKPBii4x15dkfm039jJjhNalwY+lx5OHTP4UXQ3fZsey2L9O9dmL5ku8XQ0XXaI0Rf6D738t2WXsX5e6OR9r7y24N/klF+o+2gSLFJojvDkjKmbSexHcc/MRfbxH7Gu/Q0WeGy3EUrGlIjlcNpqzRjz43KXKMnT/wDiYZzwyp8EoywebGrMPULKihdnuxuu72ENll/oLvXZFCGvkYnXy0P5q2E12rtwi+0I6jwmt0UyWGcfqHE0sewse9E46pWSVc9l21R9BckFpZONENyUtP7kF7n29jwplV8l+54cXwPDJcDviSKadohkUOUf/tAhn/8AIUIPzRQ1Yhci5G9xcl/ozlojaFnZ4/2HniLLFniRNaNaNSI8EXt2j34W5dFil6MqiaXoI1e/y8HKJfSUIsobK7YlyRk4r9xZNLslJvkjJI1W7ZKmiE3EtmrYh9xsUSSH9JrPE1KjRqR4W1kUPy7I8Wf/AJCyRZSZpNJRpa4FOS5NaZpizJG40NNGxGThwR6lPaQnZHk4RVFD/RyO9iYpU7Hksjk+xqiKKfHZEPpF29O1KO7JTv5Iyou+67c94j4EuzY3ZGXv2ZTjsNy0FOzy8MdR4HuLfYktLG2yyO24/sNHCHP0PqZH6rRKN+aBepCUIrczZNW0eCzSKNOzUzVI1+6NSZaGeXtJHhnhksTiJyjuiHUV9RrUuOyKKsSsa70USelWeISaffB02bO6wxb/AGPhn4T6nqvN1fkX+Ji/BvS41/aTb/w/3M34P6fRqx5Gv33R8R+EdV8M3zLb0a4MS8gim+D7I/6d10/MsUv6MkmnUufmTNVld06Hur7Ifaxi7QlT3Npkmoqh5L2NSXApD2fb7IluV7jQthjiktx40tx1eyPufc8Vr6THjv1M3h49of1Fzua0Uyn3psUa7ahydEZal3S3Jxg0tv8Am/8A7DwpksCPCcd0Qb4ZFHBdi2H2RHHLI6gPoeoX8JOLkLpsmR1CNnT/AIZ6/qf4dP7/APLOm/BS/wDuMn9P+f6HS/hroOm4x/13IYMeJVFd8EqekyYIT5Rk+FdHP6sa/of9A+H/AP41/iP8P/Dnzj/xf+503w3puhTj00dN+3+/I4nUfBuk+If92Kv9v9eTqvwP1MXfTzTX32/3M34a+KYOcTf7b/5GXpOowf8Adg1+6Oj+F9X8Qv8ALQuiP4T+I6deRKK+8kR/CvWTjrjKNfuZ8GTpsjxZVTQm0arK7LYoQ2kXZfZLtXqaq3HvyOJCPuNjdihXJKVbn1F1EXmIYdTGvBhdEIQlvNklDDFqzIo8wLLIxd2S8kLkTesaUUbfLOSRHU932pEl5Tp46yUEiGN5JKMeWT6PNiySg1vHkbcixyLsqhSoUrXZSOSjFilklpgrPhnwzqYweqNfuQ+EalU5f0MP4f6HE7av9zF00IKscaQsSXIqXBfybEXrjY+9Jmk3i7RF6lfekSxKZLHWzR8Q/D3Q9c9c46X7r/lHXfhLrem82Dzx/wAf6f7E8c8cnGapm6NTLE9hv5Fv2quSkUpcGqjk0tclnlErZkhR6DbewtMeeTFj/ihwdZktae1C9ir3FtwYYa8igZoOT3JX6ifp8znGMrFJNdmzJ9Ji2iRdvc6TLHp80ckvQj8a055ZnjXm5Onx9JlwT6rAq0xdr9xiVi0R9CUr5JwIKkMx4ZZXUUL4ZnS3P+n5TF03UdO9WOVP7WdL1fUPHqc2f9U6rDBtS/qkR/Fmd0p40/22v/n2I/jKUVt06/q/9hfjT/8AgX9f/YX4yg+cH/8Ar/2F+Mem9cL/AKkfxf8AD/4oS/5/MX4s6CeTa4x/1/lZD8Q/D58Zv63/ALGP4p0uX6M0X/NGPLkvyyTR4szxJexrfsaj89h8f8t/HVmpEZ6NzXCRsyuzjY4NEnoOr6bo+tX9vBP/AD/rydT+F4Tl/wDKSf8ANf67f5HU/D+o6SejLEcWuUR57bG3eGxOb9RQT3G//EjjcndE47KiXNEtvpFuayT9yGPFVykZZqtMNjFGDl5jDK24Lg6pLUvuad7Gi/clC1ZCDm6Ril4GVt+xPPueI5C+3y7EOj1+aRhiseWpeh1MFtNdsr2ojwLkq1fbH1GTDCUIPaXPaOwyOFuOoy421HShcURhHT4mTaJP4k4+XAqR+anJ7jzv0MNrFG/Y6SP9hEyaYwdn0qy7OnipZdLJdLCS2PykOD8hFPkn0i1VBn5Nraz8pP1IQlglaH8V63E6jll/VmP498SXGZ/4EfxL8Sh/9T/Bf7C/FXxCvT+hk6vNkyeM5PV7nSfizrOnx+HNKf3Z/wDGef8A8ES/GGeS8u38kYPxFplrlkt/dGH8VYJS0y/2IfGely/xUY+qhP6JnjS9zP1k4ZNEl+wup/8AJC6uPsZp9P1MNGaNr7nU/AOi6pOXQzcWvR3X+6/xOs6LN0M9GVnBqXsWi12ivUl7il6CakyE3DdDyRZ4jbbHyRlRd8k93fZMjL2Iz0ea9zJlblbZJaTeXaDcf2GlHzY2SVLU2OCHXoN+iL+XxMmnQmVRbapvtl9BcCTdsx6N9Y4Y6tMlLU+2NamLp9W4tlRk1NbK/wCY4xxrXP8Akv8Acy4Z5fUfSyiNUQpujqMyxR0kOty40oxeyM2eObBr9R4Mbwq2dRjUMnl4Ph+HV5yeeOPy2ePjvkU99USordHG5s3aMkNEWZ4uORoxcmlDj7DTuiW23aEdROGh0RxynwYMeXUrexlyyittjD8R6vHxkf8AUyfGesyR0TnY/wAQdYvb+gvxH1Xql/z+ZD8S5f4oI/67iy/XBp/ZnxX4nh63HHHJ7rh1/g62JPQhTUuydj24FMlTKH5SM9jRqFChxrgjF1RprZjgSxewo3wTaTo1WuBbjhqVG6Qo+vbA9U0mZoa8jJQp0JSNKieT5XGo6jS5ukOOmXbJyu2eHg4Yx9Xv8mTMobep+Yye5Hq8q9TF8Q285Ocfq03fqfloKEZ+pIpvZGXDvUjpfguGMV1Ep7cmfwnBpbp+pPE4i28pHPvUjLnjkhoR0WVYsMne452XtsdJK8SMnXqEqiiGXxYqSGZ5+XSZdWrzmL6jJmb2iRnKPDFmfEibLZi9zp8Ucz85mj4aSJdT4ctKRlmprYuhSJu/ky/9yJJa+RJIe59O9FOao0s4R4hdmrc6RvzDlLTUvpEm3/Zo1toyZNc7oc9/KKcrpjkarWhjEKWohFTdIi1Fu1ZqhdogkrMmR3SHOV2xWpGSScqKXt8kY1yPMLKk+OT1vtpcp7GDE8k9kdXm8bK33zZNC+/eKIqomJuMtjTpjSJmOC07HURqW5njq6Xw4eyMWfTHSnwZp+3ZkXR0/S605n5XJdEennj2aI4Yw6eUzPTxQaMOPLkXkY8XUQVuTEm4/wA/9DJJt7m/oVfBwcEN12g6LFnnVNje9nidlK9h/JKLnkT7QxyyOomLHXn5OoIz0mPzyo8CMlUifQ6n5D8tlxrVKJW5CUoxlpFmyP1Fln9LZ4noOV7s1GunZduyCU9jccNK3ZVMg4xZLYxqM5eYyOOrydkthP1IvU7NHeEtJKZJOCTfqc9+nwxxx1erPhPSLpoeI1uz47jhDN/ZRpf698vmlZ6CRCA1vRidTTOTLPcwTuNxM+61T5PxL8fn8I+HvQ6lJ0v83/z7nw/45DJ8Nj1fUSV+p0nxrp/jKeTp725/d7mbNHDBzZ0PX/nG41TRBapUTn5dMSOT3IZpQOo6mTx0vUeF6DFBYMbkZMniQ1RMOSqM7TlqQ3faX1EiC8ifZC3HCSVtGOdx3JY3JjXoTWl2hO0VY012tmPEp1bFpxxJyUZ3A8WU1TPQ6dq7PFhp1Ijs1IlJS5M2LGvNwL6WcGr1fbUa/REIPTTWxGLx8oxXGW5wZJua53JKhLaxYnJWiC8PzNGq90NkXqHHTsRqCNS+Tkqzguu3wXC+rdyW0Tqup8Pyo+IZvFy16Ltdbj3SK2OCPKFyR+pE3SHudNkcHsSyLItz8b5Xl6txlPaFVH9+f5nTR6jqLUXzvzttu37cf5nT/GOpxZoroXUVsvvfq/3/AMkkdV176bHF5m5N/b7X9uD4P1sZ9RFxfNo6ZJTUma7lZJb2hT1bM1JUmTdUdVPbYwyeLp3P0FHUjLHQq7qDnOomTpsy9DFglLGl7D6WZkxPGtzA9ORMy49XTuIiE6jrZDJ4lmTgw4tUExYqNJKFFCm4onlcthLUVRkkscdUjN1F/Y6bPkUta3iQzpRR+bi90jJk8SWoXBIizTaMivc0nmJO1R5lsarQvckr3FGMoav6jhfkR1GmUkol15Dw9UtKIasWzISk465mqOT9zwPkYuRvt0HSPrMyxoUMPT4o44qkn/z9z4j1GiOts57Ti5RaiSWlbj2iiPIuCOHJJ7IfTzhuzPk8qijp8Cyq2R6Za6RPDKO6PiXSYeph4XU41K/c6r8G41hli6KTTltvvS9l+9Jeux0n4V6npJX1Wz/r6e/82R+AS+MuOKM1HTb3ipe3udP8BxdClJyuS9aS/wAjBDy2yUHGZF2yPqdPkhdMlkjNaHwdRGCWp8EsrlsRnoRm2hT5EaaimYc35fIsnsfmnnyDizz+jMylo8z7dN1Xj469UZsOnNt6nV4sjxaYIw9Pkgt0TxZFyjpW1s2ZcrT8rH1Ey77OkONi2GdRJqqVmSpK4xpjy6EqSOjzQkmkv3FjTNML3kaF6Ma3oeNJEVZp8u7KS5OVt2q3pZFb6UJaXpYoq6iJPBIyZdTuxupWSbm9RH3FHVHXNkpOUdKK0mhf+Q8ifp8/wWUIYpafr9/sZ5u9/wDc+J59WTw1wjUWdIlKZ1//AHpGQXIuaOkSyYUSjp5Mktbs6bJ4c9zInzHkjLXHc6rrFLqdfpHb+Zg6ifWZfCxLd/yPGl08P7VfuY+o6ePmhBX9jq81wbOkaq5rY6iWt6kiDqRHlmCOp37GV1yZsmvbtGNNJnVLVQ0OXlSMsvQ6fJokmjpc/wCYnpolilGR1r8ldseSWN6omLLHqV9x3wMnIyZL4+TFh1bszdTjlLy8EJuVKLFAkdSrxtr0NTlyQyXsomFOOzMWvw7iVqdEsen6jXW0DU/UjTPD40ngurIq+DwN1KTGouWlOiEsOOXJKWuBg2WxOLyytDx46e244rgl5SGPzeYk9D2KmlYpXz2nS7LBOUdSR4M+aKffFnn071wP+pZ5Q5L1FDOjXmOserJJmTft9z4dPmJlWxLntj6lONS5NcXwzJ0nT5vqRl6fDij5Njos8esU+ly/x/5mSWTBJ45co6eTy4omeD6fHDCNi5IvzHS8tHV5Kekr1MUlF2zHPVcmQWt7mZRvy9nTNKPhq/tLMuTJB+RHxGeXy+IjxEa0dDpvV+5DPCb2Yz4jmjhxXItPdF9sdXuZ8in5Vwfl8b9CPTY4y1RI7Mw9E+ofNHVfDVHG43z6jjTo6Xki9JizPTSexbW5lzynSZq9i7YnuRnUlpMmvqOEQWmRNLJPkTWOOyGpVUhR1bo1UhppmLJpdsnlhxFWTjG04k5uL/cm7Rqo+zNzzFMjllHhn5iZ4+R958D4LENnSSqTM/Mhu+0d0YMnhyTJvazNGpd8KuaMPTwm90dUpLLKMnw2Y5vHLVE+Jw/MOPV4uZc/uv8AdHw9NaIS/wCbnV9KszUoszw8PI49lJo1ySsu92Vaoewrb2M39ji0+vy/Dluymz4hhebD+wzgxYVHpVNPf/mx4sfWJi6zJjVcmTBH4hG5GiOJ6Ycd4b9+SETpX/aHxDIoQsz4tE9vU6faRFajBeKWtmbM8z1D9yO3IvsJJc8EZrV5URn/ABDbmtbe5j8zpjjLFwf/ANiWrTpiS52K2sSjXmNVPY13uScZD01pMmOKWxZsRnJcHiyrYq92Ukegu2X6SfAkenbp717GdXJoWwtyAjp8mvFT9DquU+yZjdTRiPi0PD6uf9f8BHTZ/Dbj6M6SfnhN+5eM6xp55USjUU/cSvglweg9l2TcXaJ5HPn5EfD/AFKG2S5Ks0OGBQlzR1uXJBxx4lbkLE8EFfJKXou0YSm6iSxyh9SMS3F2RGR8OipOUmfFsMuoxvHB0T6KWKKx5lZorJpiYYuLtl6tkOMkRfuN2RMmzIZHHchG4tv0HNRxxtWeFHVqx8FqrkZU1IU2OViky91Y5JcDVGh1aI7oolsqLK+R8Ee2X0MhEfBZ05m/iYl6GnShc9ui4Zljqi+8fqRi9D49Cs8Ze6PsPZWzBK1aIZIfxHUNSyycTqK0wr2MK3f7Eh/ScRSFx3XdHw9eV9pzlCLkcnRx1ZonUZZLI4mPHFef1MkhyLPh6Ty7nWYoSw3XBqcdy+6ZjlLGtaOhX5nJKM50Z+nydNHdben/AD0JY/ElToz49GNKiPsh3VWR8r9xJ1qEnW3JV8k/JVM5ZFt7JkG4In5on3aIxTv7k9OobVGO9NGPHbJxu6FOo12UtLH9xXX0/KyPaf1Ie7siPjtjk48EoqSpngJcM8JCxxXbDl8Ml1Nrujp53FHx+KljhMw9O8m74MuP+10SXlMMoz3hwLql7Enbs6mcJRjp5RjdWabGtiqKsfywVnRzULh7jb9Dq5zx4m+3w/G3kUjqH/ayMOdTi0vQlK+/ROsh1b/sqMmNoXeC1OhPb2Pg7hDPUz4gp9Tk0TXCv9l/uNRi3oW3oZNXHJTYl6MjJLZiWp+UclGNL2LU3sQhb3NCLk1shTdJCklB6jdiIpPcktiP9m9ifVSktD2RKe1CWndlaTUvUZv89kvr7RJFC+ZfIhTlHhk5yyrTN2hHVY9ex0+PRGn3nwY9iy/cm7QmdN8My9XjllXC/wAWZsaxJQf1fJj7a5e51eSUqi2I6bJKEdiS1O2L4i+knLJVp90dM6yI6zJpiSaeGf7f6oXfDWtWKflts+AwSnKdcHxPw4yc1vI1uXmXoZH5Wajl7ilp4FOnqNd8csf2IvQtLKvdEE2fR5ZDcVuxGrSJ72KVDYkp8EcLyOh45QZvLYjH3HDYv5ee77v9RD7uSbpiqx2JMdEfkxuMJpy3R13xlZcfh4dj8PdLi8GWTIlufEIQx9RKMOOyVkVRqi4V69uo+sk2mjp5Wu2bpsOZedCVbd8f1I62V40b+E/kW3b4JhUen1VyfGp6Hp9WYMUczcWZI+FBxmbt7EEk9x77jltpNLrYvai2i6MU0kSerkj5N+0fuQhq2ONu0MmkjlU3qqhSvZ8E7hK4C5pD2Z+XvcXy8CGJdpEMc5cIx43N0ZOiyY4eI+P0V8jwRbsjhgnYu9/NGcoO4snJy3faPayzL9RJeQ6eTjyWNpj79MtWRI6vw8kJafT/ADHN6dPyo+GRrpYr7HxrLr6ml6GBSlek6nJNqpr/AJ/QhQ6LF5iU+z8o1ZpfNmPbkbbluarFGyPldjkx7fuRZr2ob1cmKWqXn4NNuh0ape/6GeWRfQjA5uPn7fDPFedQxV/M0uUdLMfwnDjm5Kz4vix9N0/lW77Ri5PSh7cip9nG+zF89llll/LLtFfJJ2xU1pZXsJvs+O8JyxvVHkWaK6fSuWUONd0R3ex0vxfpo4ljm6aOomsmWU16tnQfW0dbj8uoTTjpPQ5InHBS5Jebs2Xe4txEPLwQxeJkUX6nhb1IyxSk0hS27I4E6Gr/AFPg3/q1/M1GpH4hz68kca9O3w/Fqbm/QkR+RkIuXA8bXZaEtyUk+P0bLLJJs3iKRZZY4pmhEUl3q/kgtiqMklXdD+xOc8jubt/fs5yivKS6jLkWmTFIe72ONiCt0OHqNUhROHYtxi2KshG+TpoJyVnVRUM37k4aXRiw3hlOX8jPFrzM06lqiS5s9Stjf9P4P/6pDkaj4lLV1Mizo4KPTouvmhNw4JTcue6+eivk1F/pvumObY3bIrUVuR5712ortt6ml0KycqF59iUXRGVbyG7YkJCZgyrHPc69eJFTQ4a47ehFVCCPiMVjhrOnby4fL7jhIUI+4o+Vpdr/AEvh8tHURNTMk1FHUvXlkyhNYsX7CWoca/Rs1Fllllmo1Fl/rP5MMVOai/Uap7iLIl/I/lq3uLamXvfayyFtj2FyRq9jNB5MBDJGDMzj4ao+Lf8AplX2Ph+/TUjKq2NXmo1tfSa1+n8Oip9RFSM2fHj3J9bHIzK7m+2bqZZVQvm2/SrvRp7rsv00Ri5cFysyQaSl79nsRLLLL+S2Jjd7CZRJvvgSSchnraIGBuWFGeGjI4mLJ/AzqMC6nG8cjp8cekxeG5GXJGa2ZHG1Jv3NE4qmeDP9OMnF2iWWcuX+qiu9otFosssssssXy8d9DcXNfMhbDkdP0P5jGmjPj8LI4exKLbIpmk0d9DPDPDNBpKoRVkeKkTxR/hY8bOMaiuydCfqdFk/s6PiGPTk1e5g3yIktWw+nxI0RXoOUZtopSKf6qJL0ZXfn++48jxO0TcW7jx3lsXfZCidH8Q/Kx00ZJPNNz9yPTyZ4KRLGvQWBs/LR9RY8aNEHseHFEoY/REsUK2FgieBjI9MpHgRiPp0SwpcCwWR6Zy4J9O4CwNo8NohOeL6TNklm+ow1CVsWSJKVuzUvcai3scbHjS7bGxt2ooooooo43LNRZTYkV+lRpKKKK/uVIpCQjD0rk7lwTjjx8GuuCXVxb3FT47PtfzrYlI12S2XlISrYjkfBF6XpI5ZL7ktTlbQsMZInj07kpWRUfDPDh7EmmOW5ql+lZZZfezUajUN32RpNKK+Tn5a/uUY3wTWmVdunWqW5Kf8ACi+0scH6C24/Vabku1blCjqdCZwaqOrzL6TVZjzalTEy9xrcqX91QlXeiv0aK/XUTHj9T17dCtVoyY3AZf68UuX2rszUeJ6mXqfRF3243MedepyX/dkv1bL/AF+Dp56dzI08WxFK9zY6Wahk3HbJqv7mthslJLkyzvj5XfoJexbXJq/Xssvul/fkYueSKemiaqTj2s6XN4kdLMsNSse36i27eNuRk27XA5sUl6CufqW1aMmS0SfHeitjS+z2K+d9r+S/mTo1Iv8AvqMSjq8zFki5eU6zHfmiPntDI8b1IjNZI6rJ/Je1d0o15uRv0fe+zWxokiEHG2Paq5II/wC3szJPUyT9CuLG2cIvc9BrU7KMl1Zf3/Tv9JL++2J7mHqHj8o+CUKZXbpZ76GSitJXdl99barvwRm5b92ajxaJ5mkTnpJSIpPs/k1U6MkfQ0n/xABAEQACAgEDAgQDBQcDBAEDBQABAgADEQQSIRMxECJBUQUyYRQgcaHwI0KBkbHB0TDh8RUzQFIGJDRiQ1OCkrL/2gAIAQEBAT8BFtYTd7Rb2ez6TWat9JX1axnETU9U7iOZizJZjmKwbvNrq7cxBYfTiNWXXzRSf16do629Q54wJZ1+I3O1yeB/maWyw4LGVPkQNPjjarZ+wPB4x7wVjSstrc9hxnv6j9e0+B6vqqa2bJ9PwnMzMesyR4Y8D9zMBgafEPiWp1Gts6BKlD9cf7nE0v8A8is0ViU28hvr2xNO9llStb830nxP4oujRwvzAT4d8WXUV4vIDDvyJ/8AINt6rqKbBx6e+ZVqT00rblvU8+/1+k09LV/EFuD4HoPqfeWciWaev4hd1MEMnY+kqu3a2zSmzzj+X4fylyMhK/WfCmA8uPuDxNqg4zLbNilpRrsoGs9YLFPEzLKGYs0tZdLXv9hGvNlBfUcLNPqKnyqzUj7IPLEexaxY/rNCrarDPPh6lKyG958R17WDp0H8ZoSFQsZqbR1vMM5ldi7DZ2/tC/l8nP4ekN/XXbWefrGFPPW/2/tMKPl/nzBateK37sJn9oF+v8IaVdeTFZWXf7y5W3DaeJ1Rt4HEL7zlppcjz57RvOSFlyhrMj1jAocZzK32nZ6SyipbAX7Q6fPaZ8uwe/8ASNXY1mU7YmkWwqHs9uZWiqTOt5ivp6QoGIadQbzNpxMccyxynyCVXWhlptGSeT9OY1IPMIUY45nUsSxemP8AiaPVW17mf3n2h7Kt6TU6q9Xr6eNufMT7T4noXLbtNjafy/tPhS9C8HaeZnHjn/REzNXaLdcSBwf7TVaXYTdWmW/tPgjVCnpp37z/AOS6RtVqEdDlPU+30j1sqnoHDczR6a7yg8nHf6xtL0mDD3n/AFCiuwDPm/OP8YswEX1mg3Gjcx7zTfCdUltrMMjdnPqZqcVtsJnwni059R4Y8XvSs4YyzV1oMmZ/aNZWcmafVJYnTebBZZtmoYoxYd5pLbicuZ1EXkma+uvVVhX+Xv8AjLa7LguflHYSvOkc7u0uuGp/e4luwYM0V4qQKfeV2JemVg0qaZmFvaV6xl/Zosv1F1+pZd3H6xLqnqsKPLy1Fe4RitZ/aGNYtz8SyuywbRBpWZg7GBOiSTGd3xt/X5TTgaZdneXEgjiWtxxxK0DcvMBOBK6h6Tpszbo6hm/X0jYJAXuYM/K3MD1HuJqr1px5Ce/9c/nPtAwNwxmCwZxLquomZpeU3dxA7MSc5E6TEemJRtA2NGZfWY3jEagrbuzxLWyuBAdq8QEbsntibhtyixtSq4Ww985l2qerb0xlRF+IbQV2YSfC9UdQMrzPi1pr0+8dhyfwnwD4sb9VZU75zyPYf6ur+F06l+tjz+81GlNJxnMLYqeoHBb1l1bU7a8nA/QiUihmfbn/AH5/rP8A4/dZbfv/AFg/jPjFX2djcDhT3lWkWzD2+/JmpSnQ0hh2HrPhnxvqbv8A09JqPiW3Th6R/tKNGNeyalxKNJVRyg5jMFGTLPjemFi11ncScfhAwbtDNRvOq3ekyX3P3x2l9L12ba+2Pzg/YKw/jPhuvK+ZvlE1GsLX5Qfr6xdc20ELGZtTjaOYzBa1V/aX67LCugZmq1KakYUQhd2JnaDzK3d7O/E0nxdKKsHtPilq2J1aT34M12vrR1XTnnufxh1K5K+vuPeajXM9m524/XpOsLFyplS/aKTcPT9fnGStKwn85bQtdQ2yysue+I9JrHPMXTFwJ0Cg55MILDBhUE+YdpbWzHiVhn5iMKzgw3VL+9zA/kz7xAOTAo2/tJ1McQadfm4zHRy02HaR2gvuqRq8Z9vwmwn5eMRE6Z3D8Yr2AHdySeIvHebFbJmdnAj28cjiM2X/ABhcVfSC0oCzdo+o3YKy1N/r+uJuKYplao9cTVoun2JwTDrk1WnaoNtJGMzSg6K4I/P1943/AMh0leFZuc+0R1ddy9j99mC95nwv1NelTqWnAi/E9PZwp/nxE0rvaXtafFgqIrqMxBXaxexsL9fpG0tKoWJDVtNN8b0umF3TTO0gDHrmazV2/EtT5uBt5Hcc/wB5pqK3q35x6czWa+nWMNKVLKFyf8SyhtPUAyBMDIH0lFVgHfE0WppZErVuZ8V+KLxo9M37Vjj8Pcy3VvpdKdOSS+O59zPh9NYqO33PM+G10V0fsDmazWmsYWazWWai7p1/IO5lfSrXJOB3/wACOhu8xMcdJS38IlYVFQytFBNjfoRqwFPOJ1FRgwMRrLMsTNK6gtuODieU8LOmBZx3mpFjqMev6zHRK+PYR7EVAbIt1qVjfyM9/p6StSVZljW9RsIOBOma1wy5H0iaTeGZDj+n8v8AE+1MFaqaGhgVLHiajXU32Hpnyrx+vpLLSo4lecKpOf8AMAw+8wjzQ2hT5eZSeoMtLK4GJXYs6XfPeOuGAMtpC4UQrusl2UwRzFU4GYmCpEOBMBjHqzzK6yBh5x+7GLKpwOfSZCnDd5njMBVhiXaYXLtb1iVbV6foJqNzlRXjPcg+002qquTpqO38f1/GbSGAE2VtXuPzCFGsIIMf9l5vWMzN5/T0/wAxQNNQz4yY1p4dvx/X0/rNNX9oclF7n+3+Jbq/sValuF+s0fxCnW/9nkfdY4Ev1R3Fc5lN25Qp7yu9LDgTVVLqU2mWaF3+fjn8hOmE5J+s+2nSVLhMzUAksGHlYxEsak11jt7zQVG60UrXtHf+PrDpK6B1Meb+s1dJekrRwZ8Pr1Gk1QKny4OfqYr6hrGe31h2Nkd5odpIZydy8y3TNqNdZqV7H8hnkfxnxPXWNywwMcfzmEOm3rNLdbV5u3+IF3/gIdLltvpjn+cuUuyIewiuUbHeY75nTfOwmOU4zLGdl6hGfpEpWzIfmGxq1NfoZW3U1GW9MQKA2ZbuU5XmOrMeY7cZX/aHUi4+mfpzL8dH/wDKVnP/AH/b+EIrU4rP+ItgUe8W/KtgxA1eW7zQqljkXzG47FGPwjvk7McxExzM7u8sye0NamcIMiYwuWMxnmMxzGQnhxDy6kzU7d52doK9y5nm94Khzmbt/YxqmBDA8xMsOYVzNu3vAo7zVrXSwIXv6/r6wVo65EuavToXi6iy7B3YH9YFITAjUclx8004tTCPj8feZcE5i25Jm5+8Nv7rSzaPMP5SpEsfzdo2hXUk0zRaV9PYBadoXJ/GfH9XRqqgB5gD/cflPhFVaMMRtUldgqb18RqRtziavVh6ic4ETaH3Kciabbcu8cSxUDZPeFBUd3eay5CPrLbmqGbBkSrVLZUami0tchKyuyzQ7nYZ+k+F2Y29T85ddR78y/4k+o1QQfL7yvVJSrNdzKdZpdTjoctjP54g0DKMngmaXTGpsk/7zSaptU9gK8Kcf8SpaXuYBOJ0K7a91a4H69JVW1g84/QlhKKBjBb+kStmBdZdSUfDSr4dUBul9Rp8zdgZWu9jk43TU6cULgQsqVqJU3VJZxNRYt1ZNZ+kRAuHWWWAeaWWMM4MrNtnE+yraf2pz/T+U6PAxxNcjEjB/iYtHUsBbtNVp1o5rPE5YjH5xanyASCfeHTu52rK67lzYOZ8K1VK1PZqDwDgfxjnbdx2MZswxK8ndLNiEKBL9tSlomRkT8JUuTuMJRTzEoa3c/tLdM1QBY95p9P16SPX+0+x+7/lKm6oyIwKQeaCYCwsfWarUijafSadVstN57z93iNYrDHtFYFeIQSdwlVaJzklp0zje5ORPtVjEKcd/wDeV1Pjd7wYL/WZVjhf1iW6UVrkek6NRGBLPtGnbdWePzn267WZ3jH0n2araUxmaSxa6wWGJrviCapx0H/2nwrWXalcWjt6zdLrFvBsr9JWXAIcysrT5zKdYrLkSzVi35RKiCxLnBjoA59YVHeWVgPuaJa2wqJaG4x3+srPBLDtFU2sc+sNApQIvpBo01latZNLQNPfvXv7RtfU1ZPY4mp1Oorc/Zm/pNDaujTqWL+v95fr/ttgsUYHpPhTU0KWsMq1eivbYh7R9NW7h4dOdDU1v8pWerZm2ay/VPebKzhRxKmLsWMLhHP0hsdxvXmXAmvn9CFUsTkcTpJUm0CKcI1Z/dljqCDjibVdZ0kf14muu6DqtZ/lj84b9wAE+y12gEAZ/pFrXfuHpNSPOBLBsbaItRI8kItpJIPea/U31qKvfGfqP+JU4J7/AMIi7gN0Fe9t+SP19ZTaHx6ZEIt27R2iFaFyO8tZ7CVx+H+YVFYEZQq7wJ2aFz2HeB+mrQt5ixM0/wAQtViauB7z7Uzc7pSpRGBgZrfKeDO+ViEHtLF3DEK+81lf7Ty+06rUr9DNLetiGnP4Syg7eIEatSTN2O82nOYTZjcIBbkr69/7CWPclZCDJlNdunCrt/Xv/OYtCm1e/PH8cTYdvMKeY7fWJWWTBllG0llnTHU3N3hfqfsxxK1qqPT95ptXXoqmVmx7S74zYaGRWznjP5cT4YF0Gn8zZzNQF1B6qnmV6U43PGrU8R6btuMxGLDE2nOIVxNSD+7K22+WMVcbpt4xAvmDZmqq67ZbtNm0DZFpcucS6t3Qr6w6a+qw6h/SKFvA47/8ylVCD/1H5w4AOPWaaoqcL3zNXq7KWHTIxiXa4WKN5j6hbCWQQXAjp47zctPkWCuxiSJVuqUKB6/oy1QwxNNYbFNx9/1/iai1kbpqOf6w3WNqOVx7fUeq/wBxK9rViVWtZnJhsCCXY52YwT+jKEfTkqPTtLNb1K2VVxnv7zQrbVWMHPtmW409Tv3OIQ1rm1h+v+MTRjy/xmoQsMwaKr6/xM2JX8kquAG3MsGKmJ9RAB012kE8dvSFbAO8a5upvgYVPwf1x/eYTaJYjOoyeJt4llylOPwncbZQvedNaRkCfxEbcysFg3A5fuDj274/tKbmbysO/rOoFPed+ZwxxLNOtreaa61a2GO49JWjsu+4e54lONGh3/U/wjmsr1PcRmNFeV5/XrNLqBqOCCD3xP3sL2hBgwvmnJ4mSBzBycN/CECF+nziWhW/aMMzYGIsxgzpM3MtrorGW/n/ABzFr+3Asf1z/tGCrWFHeabIwlnfiaRS5PsJ1CnHeFw5l2V8winf2ij2lh94V3HMrUHtMZP0jHbK2zxGXMpsKE1yvX1pYwQciW2vY2Xj4/EyuvoodxiLkKrS5y1oKjIEruFXmA5lhbGW9Y9eQF9ZZmpD9Yw2YPsJSV6W9vWU7R5ZWQSQJt3EzFVW2ofwmqNbABpYzU7XI8v941tq2bceWI7NcyegxNTZqKkLOPL9Dj9fzm0VIGCevtz/AFzF/ajcOxi6ZrGxH1YUbaxkiajVuXCgY/EQ3no7F7TS3bU549Y9nUUlsn8v7yu1rzs27f6w0la+BmPWyjzHtHDL5v0JVqhbZgdvQSx6rT5eI/AzDpTahYGaBCud/MRh01Q95czjkDibF+aHHrK7Q3mEa6xj5jgTp+7H8pU53lT69pqdp8p9xA6r2irk5injbBgeYwy/S1aj5xH0w9I1WR9YtQdcMODPidL3K1KeXmaMDSVm5vw/GWadGPV/j/GdPFhcGYGeJnaQonsJ8vGInPacdzCoIwIKGyVPYylQF2iWfC7tTuQt5J0yjES9WTzxS2Zpr9OzGv1g0+WxLNiMRNhccxFwcwYXtGGROc4nmB4mNxyYQJsWHgGVJh9xEuCK02iYYQJ1E2jvLy6ptT5vSIemvmPpKSd+5u0sb0Mdwg5lwpNfCwoNhzNPp+rtH8YB0bPMe8VwpwIgxmFTY3BxNTigbu5MqNl3bgD9cCNVtBCkzN1fmQ5lW7OwktNDodQzeY5znn2lScdMjnOJZbpaAvT/AEYxZhuVsAd/rHfJ57zYQ/mjDondAf2e4+vpK0VcvnJhzuwJfmzanvL6wD08wIBnIyfy/GUqFGzODCvfJgdzxF6mcNiaR965Gc+oMCFOe81OqFRBxnJA/mYWyuBCXTAX+n+8qV25smU9ZWd3M1YGSM4zKaE064ESsL2gEA8s+aZx2nedo9iq4X3nxKp2Hl/jKNTSQM9pdqCTsQZmGT07yx3DhZv3HzCftFY+0Aa3IHeJWy8QrzzMD0l+Qe3b+kTU2V2HdKNcK1CW4E1KEje/84rB+HiV9RPNwf6zFaWm0DmfainI4zF/atmFis3CMnHlg4HMIHeEbuJjIx4IMxiQ3PaEgDMdNwmSx4moYghYtYrTdMdI7gYUbo4bvKHHrK33nmFw5xNRGK9IgxCorGIrM1vVbvNLZv49p1ATiO4oBc+ks1ZKh9uPx/2m82kBs/ywIHQcDP8AKF+qxqlFWBivnE+1WUKFzxPtptTDDkS3pCxmOcEQ6DcT58RlBwtfMtVUG5iciLZ1PO3rEpD5szyJUvO4nEFvBm8VDLek1FJGoDCMlgDbjyfSVEKm20cxbWY+XtBhzxLKdzqFhC6bzDvG1btyny/n/KE5YNt4HOSc/hiNuc+YwMnBAwY16KSFEOoT3MQbE2mOBnf4BfaZxF5EYegmAoinJxG7RaAmdv4xxxjE1ei1LeXT4AjWW11jYMmU6u62sdQcw1WWucNjOJXUwbzQr1OBKqemOZZflumolSBO3aEYPEvqvNu9D5fXP9o6BTvx2lelJJ3niDWDmgek2KjZIl1xtUcZm881MO/8psFvk+sLnAUQsXYYPEC+hjdopEDA8eCyxtg4iHiMrF9wlqDGc4hAAiYDZjKQ24wjcm2VVbZYF+Uy6orSyrK12j8ZUVclhLbfJmV1s6KG74laYAzLkVk2qJokwuTLLFVl/GaqvrLxHQ8KvcRmSyraRKi1O4WAjd/HM06oU6i8YOIuw2eaPqCz4/d/CFmdxgH8o6qwZ2zntOnv839czSMumw7nmWW/bWs6rY7f8SzG/iAMN+zvGssyC/y/3iMAJXqUbluYrAN1D+hNPZ1Xaai8cj2llK6bzucmad0Iw3EJAjjfgH3jU7WLZ49h/eCxsFces+VpnpgkyyreN86X1H8v95W++EjdgxuI7bBmKwtGZwBiYxHA4ZjiDA7S0JYNhnlXgQmblyRCFJ8ohOY+792b3JzOqE4lN+QOZYF3bpwYmc4MwWEO1RFs3tiaq9dNU1jdh/afDviDaq0jaVzz/AxU2rgdo1DE+USuvNhYzAYcxAAcib90+bkTMUKWyPD6zJ3eFiHtLjuIBGZuynMpu6j4hXEtGRxK7iq8iOos5lKlbD6y7LLtWLTsqAEtWxhhRNJ8GezTm0n8JgqPPxLMrUSvfEFP2etQPT+sorBYuRAWMuVXbaveCixAAW7QrvJJMWs7dn5/WU6fzGy0Zn7Kjyt+vwi57r+v9/eLuLFmgTcOTOmrhdvpLKWXds7mOmRh+YWKjEdCyiCnzDjMKKgPOPwlCdT5oS2nsbZHo/Y5YwuAAG5jElBsnUIHmjXcZnG0hjkxSGs2gzjP4Q4KSx9tcV+PliVYJcHvANoh7ZhI7mJg8iPkmdpYEJ3WekWxm4m3MXJHMy+dvpH4G2BeeZtAO71jAtNnE2FYK+ZnA3NDcGuwG4/XrPwgYQgN3moqZLN+7g/lE0ll1ZJxtPrGrC53doAWTOf9/wCkqvrCYXmLc0xvEdSp8kLun4ynczHM2is4lWMYljbVJlVtjzrEnEsubbN2fKDzmNttGIP/ANubKk82JnMYHkwrlZ5O8ewIMr6xdRtwDDwc5lZa0CaGn7BU3UbifFtTpbiDV+7Kw5Xe8cjMxtJ9oay557RVIsCDhe8ZusSVHEuOTtAmmpwv0E2DAEtTndK7RY3n4A/Qj+rjtNu6zPpOqy42y/UdMD1iYsMspFnLGGokcH/MI3A4igk8zO05jp16/wAI6Yq5lOw14PrLCUyEE+06gHy4wP4wVNYMjkw6L1nTKHkwADO3tHBXDGbOMkT+IincOYxU9/DvA+1C8bUsVyq/z4/zFvXZkwXF8ZXvEUsx8v0/L9CDAO2fWL7x1yJUppbvn8ZbeDdn0g+XJjcd5xH8o+kDCx8AR2rTzn0iWC75JjbyZqLxWAfcx67Lm80s1KU0ppq8grxL67dVtVm+XmXaPc62MeInCgViDcHKsIUAfKy5W+ZIo6neFNnf84lK3PubkQDbDgzO3tFpdTxxLm2pnMpQhcucmdQqciUs1g3Q1OWzmHyDMY7u8exs7Fltx6uwZiuy8vMisLn0mmXGSZof/ukB+k+MZSpt3qfyAiHcvm7RyDNQm+tgfaI3VqXdzFxianceE9YWCcCaZN2bn9YFRZ9sVzhPSXXhsnMqqdrN595kbukvOJYo37iSP7ytdtmWmX3cfr1lI2eb+f8ACPUWxuM2dOUqX8sNYrPEFSlY9bLys2Oy7XiJhsY4Eu8/KiVpjtKq9igGFAvrOiWOT6/0nS2DCyxd2FI4gfief0mMT8YO8xzLQCmIc8BpbU4UlBmV8HCcTc26Z9Z2HIjm0uCO36/XpMn1m3M6WTgwHdzHO44HE3cAPwY9m1DK3Wxd0AV1ziJWuPLPoYdO2cjtCW0zhjzifaU1NrZXaO8+2VWUquOZpyxvs83Hb9fWVqLFK4iKQ22FeMQiMnRrxWJZW1vBlH7LywcytN3h6cTUadbfKO4mnVyMyqoHLvKVCx/LyZc2OZqHCpz2lzN3EObOYBgYM4JibRSAZp9S1WoF6S34nRqgw1C9v1iZzgy6tms2J2nxavT6NVtD9+B7fzj42gD8oWxEvNlwWX08ErwTFqCjjsJquqoIpgxUdqjv+vzMenDZPzSk4bEesOM9zKl2pFOwHA5jk2LjP9oi7+8sfYO0UN878RblPydoQWGJjBxLQWYewm1XtB9pp6dPnJfuJqErH/biYztnyd43LBYqndDnHaBDmKF7EzomDIh7wtg4naXNcX2p2jKQ3aHgQDExmMmY2O0G2bF+aFcmAbYx45lmEHMXticZ5EOTwDiLXtmWHEsd+NkW5yJXZ1c5EavcZqSL36NY7RTZQy17c+/PP9IVrblYFtRz7St+oOeYOTiEmNWCY6J3aVnp9uZu48G7cTW2musL6maDcM9SO+DyMRrdiRbN4wRMBhlpcN64M2ehmxAMzZuiV889o/aabaxHUOPwlOle8l15z6zUad9LZtY5E1GGJbOBnE6gYdGocZ9e2YEQfL6S+ryhoiV4zXCeuGQRAu3Y3MZd5iphzGIssIEHkQHtKXbHPaAqRyYxwvlPb39ZXtHPrCCBMFclpeGsfJ7TT/tcbflnGcCOvrPmbEs2qMmL+1GZYExtlt+5AuORxmJ+z+aI3G4xZkGEwIpbzDtMTOJa3T8zdomDzLrNg3QE5807nxd2BGBmKd3MH0iBxkN4Yn1hhjAjsZXkjzRuq1hR14z+jKA9YwPzi8iYj14GRDv4wIimxsCWbU1W4Jk45Ptj3/zOGgSzHoJ9m3rtuOfWKAoAUYg5nz9o31hrIJPcTAImfeHOOJkoZqthP7M8xfIoAjObBkTHHMSg/ND5R2hbcucQoCOInm5zLBmYVZ0895Xpuq+Ads+H6JNFp9mc/WdHR6HFhO4c4JOf4T4rqxqiVAAGePT+cqTor0LV5P5RcAbAeZdYbjtzKbs52/r8JyuDCnm3Y5hsK9hmWFnPfbDgv0u5Jhran14gc4BWbNh47y17SMJFG0Zg57zcGTmW15PEqoNVgOZg5hXHebcRsMeZUPIMyxcKd0ssYcdswsPWC5Nu3PMNjNwDiFsLOpu4lffPhqja2qSsDII/h/zHUP3llvTIU+s+btCsC47TZnmH2M7RVxxG8veCYz4H2hOIGEO6DCtk95a2FzK9ZyWCxHDjd7zGRGtw+ybetlhK3ekjpntNQ1VzeX+kDAnbiL3jKfSInTEGDOmoHEPMA4wJW2eD3hw3lMXgYjCahhXZnEqAabF7RVXGyc9oBmbAe8KDGJt28Q8wrkwzT/D2sxuOB395q7hRpmb2lepu1NXRqUACX0OMgcH+krYp5SeZaNh+bkQIN6nGTPtNQbAHPaVgt65jHYIw6gwB/GMu0cuWMvrGVwDumnpqvZq7hj8PpHUVfs0H85vbnMUnvKbMeUxrjV6d/WLqQGKue0rXzkZhfJ/CC7eSB2nVLcwTAPeFOMTbZWMsZ8y7mlijdkjEZMDAgVn85PaaexvXvFr/AGu9YC3ymcR+OfB+eYwZW7wWEAb+8zN2Jnw7RjmBvSE7RM+0yJt394KtphHtNkK54h05rTCStXHDQpkYnR8/UPebdTnaNoX85UTyDOjsXOIbF3YIi5PecHiWOoO2IjO/J7RBjynwC4mwq2cwAY5nBEbtLKS3rNODyBAoxFU+sAnaE47zIPaOxE7d5weYrGpgwllh3YHvNFqa3q3Nx7zdRp1zwJ8at6V25TkHkSjAfqWcEzVWpdYM8ATQutrbh2lWjrBJU4yZWi1jCSxdw5jfsgAJbY1YAQcmW3irlTnHr9YmpRyzKee36/j3hse5M+ol9oC49Zo7Ftr6iwr5uTGG4dNpahrUAe4/KU2gjy94U3AuZW4LbcQVKRxAoHEHEPEetnf5uJXWQe8s3DCxxmEdPCN2iVkduRN2/iEeswkIyYXYmdTPyyxnx5YRmOljOCDgQkt38AOMwtAMcQD0iYQFjzOoi4RfxgbHBjH2gPhjPMOY1ir80KebM/abvpMmek4ByIdZcBtXt/SbQw5jWdMcDmJZlRYg7wpu5mQDgS/VtXwg5lN5cZM+YcTtB4NhoyblAlKdNiufGxciY9Z3hKq0IOMwczbCP3hK6HtO1Vn25qKPs45cY/DE0p1Gp0jVP29zLCF7y/Rm7kjtG2lunNHWtdRwZv8ANtEqsBHE3sYFPzGPULeYdtfD/KD/AAxEPSfkj+Eq+T9ek1jIQEIlF1SrtBgwxwO8s0w/7n9zDpVfBftKr239MDuOP+JprWtqDHn3m8JlzNPeW4zM+s5I5l1y0rl43nTyw98DvGq3thznEX1AlijgCIrLws+UTIcZSbqxwX/p/jwY44l+pr0zYIP9pWQy5hE35GDGtG7api+aZjuAcQZHeMhbPPeV17FCkwoM7j4Ymxc5x9x1JHEGceaYgPvLyV59IoPGJknw1SC8Gtfm9pp9I9HCPwP5RUt37h2lpapshC02AE5EFODmIQvE7mAwTjMMAyd5m4ek3j1gOZzDLay7doEwIR6w8HmIwHDdo3xBkr2UDH1lV61qf/b8sT/qDXab7Ko+ktR1biLlCRnibFbzrxjMR+kxX92LeWs3huPaNvXHOOf1/vOu+QMesN4Vd00ep625LBtP67GW0mzP/rKhXt47j+Epr3PjGJZWlU6CsNywYrUYi4sGHMKA8e0qo86n1/zFrNLmqWU7kyZUCo3doSp82eI+qdU3phvy/Pkf0nxFxdUmP/Yf1lT/ALhmobnI4h3BcgxE2jK9zLrSeGldnMGqr7FsmF03EJxCMnJeek5igZgr8xMJhTcQ2e0xK+FgEdBXmxzN6t2gBBzEIftGM3cZgYN2i4MIHfwB8CJnEavPrMWCz/8AGNtmN44hL1niakKLw+YzXB8en0/XvFtxUH7ZlKuSS0u8gzEswdo7zp55iZ9ZnLStducTEMuQvwIiCsYnznJnA7xLAO0xAfAn2mAY2JnMQDGYLWT5ZaWs7zpkR6j+6YK8KOP5mV6Zq+c8maik9TO/t+EGoUg5OP19MxXD27ic8D9cTpWO/UY8+s1OoGzJXEfqlepZFYt2Ee/zAkEGUAZweIAK32PGVi4OOIEUAs3eIMGbsNmah2+Ud4M2IVELBhsEu+H0XDKjn9e0+yVlPJkH6nP9ZU/pnnEvtrcIiQZ3+eOH4PIEepfkiKRz6Rm+zvhpp9wTPGP1+MPVJ4P6/lD2j0vnEDEHE3np7o538SpemTti8xm2iBsiON8VQowJjAltyUCV2ZHHMyMzyzaMcQAxmx3mcnEazp/PA4JKj0mOcxjxiW9RV255lVLkAt3i4xiasnaQFmo1i4Idc9pTQSct6/WFV/lN+wSw7hKNM9dhjbvlWBecQ8wQnwsGHDTPGTN0xxNnPMA29oGzGBhyI2fSBiCc+kBGOJeWP4RMKMxhiekyd0ccTW7kIxATjF35jkykpauxDiKnO0dhFJLbF/nLAN/bt/Waik2rtE8ieQHn84+SeTA4HeOnUxNsur3HiVLjmM2zzYhpBO+zvOmc+UwpYV+Yfy/3laX1jO+Hy/MI6bHynb2mjA4P8f4xl53Q3FEw0ZkzzzKLWzj0lo63KjiUA9Tpj6w6S39f8RBlptzE0YLF4alxtmpAHAjLiKowDG81m3EWrJx6Syle8sPTBZRmANbjJxHVbSQTCmCNvAHpATmdRs4zxN4HDGFscCHDcGc7uIeZujh9vlnTKDLtxHd3Jr2ykbV2iHjmPkrwMyvRotjPt7mZFYziDBPMKO1hdR/uIvsZ09gwIrkcTrZbBm7Py+BGSDOJ9TD5puVT45nMGTDxG47xmDHEwDzN+4YgcoMReTOVcmED1mxpq6zcMAyyuzPkJmnYv5TMhXwBOw3CdSxsiK1mfedCvdutnS8+1+0p8rEr2zNwHaenEG7J9olQzxAmIcdzN2e0Q7uBAmBuhC4znmdAByTKmd7CfaC9WyD3lJ+13MfQfyH+T/SNw2z84cVMXBGJVaEO88DEBxYGX0m7/wDAn+MGneYKJ2lDbfmjYPKzXkKsSssI3lGIvl5MOoUDiPqt4wBibCxxLtOqAK/rF0wp8x5hb1xMDv6QjPEtqLWiBQHzA3MbCLkyl967jHPMTbjOJqdamAqHOZptN0/M3JipxNuYJxLF4xF4bmW2LWC5mm1I1H7SvtL3WkFn7Sz9tXlFhUnBgBUgxeCZmfWGWMQMCUK2POYmc95mEmLz3gY52wNzzM5g85m3ievaMMynOSgiMbH7wAkYnbiEA8SzAB3dppWFg3pFGVn7UZTbLNPgeeNp8KFH5TZuUosTTdHhjnMQLt49JgGKBK0OeYbUQ4Yx+Vi4Tyky+xqgXq7f198SlCB5pbvPG2JpMDMtp6T7+w/H/Mp31uVx3/X9JZtsfA74iVrTXtHpNi8vKxn+M2bAa1PlP5TVegHvMJ6qZnEdjaNplrHMD7eRNtOoP7TvH0409W1I1Z3DMaln5hobEWkZAEpp2czXPjCbc/2jLgwNgZBjcHkwd4GBg94I3mGIMZ2xEJ+aaqzp1HERHKYMrrwuJjE59J3gHM2wL7SxiWKYiUpWnEIWxR7QbAvHaZhb2iNkTHMBmeY6+0Cu/Bi14wRBjHEGdxiniOzdhPmbtCdvAmcwsFGWliixQREAs4PeAFO0voP2gWL8p/rNj5ABmzcm5TMf+xgTqSvTIp8stVQOYXZF2iLWz8t+j/tNS2xCZSqNTlYalYDqGLQlJ/Z9opUmNYjHAM3bVzmbw3eF2I5EWsWsVI4nSRvJ6QYrHHeHJ7x24lumW85J5mxUfcIFN1uR7e8r5TbL62xhTOiQeTNQhAziG4Wpj1ilto/aGZmZ37w0j92Yx3lWoasbT2h6T+YiBQe0t5OxJ9mIldjKdvrNXrbdO3Iys6hur3DvFjowgGYwx2lhYLx3iDYApnpNnO4QbvWaob6/J3mnrZB55j2+52h5gE2r7QP5iuYpRlNKtg/T0jsaxsAJx+u8UFhNvoIvEJ5gOZZnuI5OBCPXwE4Xkd/Bc480yIxxNozzGC+sXtLh0h5RyYi48x7xV3DmN5O8z5NsCixYqrWOIo2rLwFOR6wAtE218JLcWnbKqRYvbkTU1bhseVqBwZsB4iLVtxiW8rExzmZzwY99dfMrtD/LMAzfyVEffnyy3ceGEJwcSnyNKxjmXWFqtxGD+vaM+BlvXiMXr80On6z8cZhuwcYnR+s6X1m0CZnfvNntA5qhHVXyGb3VwCOIGWahVZd3tAatZ5nfGPwnQOncr6Qgyx/LmKGOs8jHB7+34DwMHHzRmCrmaexnXdZxNZafkQzSq6Kd0q7ZPgOJmHnwORB2hOOZXbXZ2E3AjMVyRzC3GYO0Ux+TtgEYe0HEC7o6EcRtQVt2r2EqvstZVURdythhCMCDmEZ4HeWqxOcwcwr7QkgTfzK3OZtLNmCnMaoKnEqbaSTAN5zPLulgAzzOmxXGZWgRsw2bvlfEDq6+eG5V7xdRVb5BOmOY23HEprz3lpJUECLV5eZUG+WIty/92I7gkr6+sa20qWH+0rR//wBQx6MoT2MBDHDcRmwsvt3NsXtB+2wp/dloOMqZdY6ZU94NntM58B4bT6TcR3gcGBcHKzd7xk3Hgx1Fi9O0ZBlvwo1c6TAHtNQmpwRWxGPT/EBZ1D4iOLSU9ommVXDesHhchdDjvNNQ6jk8w+0vRNmTK+3gOJ+EHhpa+rYAY+hVhxBoeM5xD8PsIyCJ/wBM1CqxlXwvUpy4h01wYYjUkridBoqkNgxhzDFfeTNm0lieJT8QDcYxLWwu4zT6V7xm3tK6kqGFEuoL+ZO8tVthC95S+OHm0DkQ8wnEBxGistfzGVOjHAglcJxGVRlmg3eo4iKS3EsG7tHsWpfNEc3IWWZGc+8JJ8olVHV5ldYB4lu4NiLS23IiNZgOfWOM5gII3CBm+bAx+v13mq1Oc7fSadW27ZZqhUBvlXLZJjWCsbln2jnGJbZco2omZXUwPmhsO7YBzHDsuQfrNP8AtiXPcTb9ZkzqQWTdN0DA94albtOkw7Quw4MqOTNpnMdFs4YS3RHHkMzqK7QLFgXDxvKIlos+WZ9IWO/ywDLfWbQe/wBzvM+GlqCrvMoLDiGrK7TF02zsZZpyw+aJVavrGsevh5nM9I/DwjmWdoeFhBdZp9KFbfiCpcc/cZMxdOamJPMbGJ2grLGGjIxOlgYhqWscxdTULCQDKr1dgiwcdo/aMADnERSwioEGBNVQz+avvLazXZhjA+B5YoX5YNOS3lle6pOe8GosQEw3PqMF+JVaFGJxn6zIXAhcgSz4gF4Az6fxg0rW1+Y8xGSnCn1l2oVX2COzr2hawjtmL+0JQxc+s6bjvPN+93hfFZK95pgaF2EeadXHpM/cyZvMDwN7Gecyoe8Vp5T3hRfSDDdo1QfhhmWaEbt6TUJYvlIirtExxAoBnE+viIAZiUVdVwoh0+flMSt0PEUEd/CyytR5zNT8Rqp4o5lnxB27Rda37wldq3cCXf8AcjKNwaNMFhK6kQ5ZoPp9weBGY9XtNuwZaJjGfAx/lz3ltqKmO0q3VYysdS2MQjiLX6n7mv0wdNwHMA2uUI7SnhswK4GY7OB5pXuaMTnECgcy0juYlQ3cS3aD5RmHyvk9xLcWYPrPlBPf0/4i1kYNZ59cyu0WHapnTyMzAByBM5GRK7NvpHwfNFqKp1BPswVeoh5mLDzxMjw48NwWEg+nhjwrUgeGYx4iM6nv+uP9514LsiZrYYImspqrG5ISIszBDBBzHuShd1hxF+KaJ+N39ZV+z+WLdjkmN8TWvvzH+NN+4ss+Iaiz96EluSfEwEidRvedZ/edZ/eNYz/NMxbmTtF1y/vCDU1N6wOrdjGtSv5jDq6/Sfa0ziDDcwrmGuETtO81ShSpxK7HJPECbh9wsAcGFsR3DeU9ommSzgjmNpjSMrFOe8dRmVAqcDtLnCnE624YlaCwAxRs5jstlnHeGkKcr3jFSuR3igu2WPP0lz2NZsXPb0iVCz92U1OM7omnfIGe8anaOJc3SZfaIhtJsMbew6ayrrHJbss6Ged33MxVLTaBwIRN0Bhs28QXNDeoGTBqarFBz3gCrAFMCgQ8cy5OuuMxtIYyGo4ME9IO/gPefFdO+ruG3sBKfhexgzmNq7T2jMzd/wDQx/p5mZXqLK+3Mr1lbfNxBg9oRDWDDSfSNVvG15Xp66/lH3CcS0mwZ9pTYXbyxM7IjOhIaGsNLKccLGTPlEsRqju9JqCz++Ile7mI4ceUGMzZioo83rGtw2JVdx2mjG7dzjiUoEXfjkw4YgYxC7NYLceUTTWAE7RH7bjNRf1U3uMKJp7FsqzVBkVi0Hkxc3VNmU7umv4fc5EQMRDlTCWMx7xe8Ay0uG0DEtBdSojaPKBc9o5tVhW57nw3lY1tlhx6RAy9pW+RzL/+5mHgx3Wobm7Rvi2jJ8rZ/l/mf9W0/bP9IvxPTn9Ca6wreQv0lNrtaqE+s+wp3zP+nB/35/0wD9+f9O9rJ/09/wD3h0F3own2K0DuMw6bUD0hruXusLkDkTqzqidVZ1FmPLv9JvWblPrMjwxMTExMROpX8pi6oj54liPyJxG7Qj7hzNVaS2DKlUgAnE+148iyuzLZePcArBDzKLTuPUiVYbeJba7Lx3g3vEQnyyuks2RNQth8u2dM18mMGRP2cI8wC9u00h2Kdw4ltyIn1MNrN5Mx18oCyvFRlzZHHadLq1hLB6zhJ5mxuMJ8pUdjOs30+40F7K2Ja+9OJp3OCpnUBOBEbz7YnczUdhA3OIZYobvFj9oojWAHbNPYBkMYzbrWjs5fp1Dc35D8YvwhTh9R52+vYfgP0YNMqDjiDngS9M6mzaP3sfn/ALT4lYRrHxKDZZau3vFbcJ27S4syyz4q1V7D0H9ZqNS1OLLDx7e5mj1z6tWOMYlGrsbTm60SjXG5Gt24AiawWVG1MxdYLFH1gprPpG09X/rPslR9J9jqzFQDiWaKtzntPsCT7CgjaXPAEOisAyJ0rlhNg7zqtFbK5m6bhFfacrE1bL/3BmJatnbwx4Zl6Wt6xVLP08waVUPeGhEbcDL8pXhZuIXZE0zqRYDmWFNgDRtUxOMcCWoxwcSlXGLN0pJxzLmwMiW3u57TLjllm4O3AIERcIenK0awBW5OfyEDY/7YgsbBLSkdbmNkALiC3y7o6mw9QRV2ctAFJ3ekGmzzj7vSU8xawoxCg9BFrCytcMWlXvNRjcBGRx8s3WZwRMQCWNsXJg1eDN2ZQoHmJm5rrDXT29T/AGES1KzjEFytxCN8avZ5po9Kb26h7ZlvwrS3MXdeT9TNNpX0erNI7d8/SVWsLeJW2V5nxDWppMfrif8ASxezXg5Ddv4y7TtqN1bjy+kqH2SvzHkN+XaW2dSmxVx3wP7/AN5RlLBpf3dsTraKqst7nMUL9o8vbb/eUWC1Nwj9oWnUC94CIOYTCcSs5ELhe8Z1ImBHrU+kWhBzifZkn2RPSXadl+QZhZ6mA2nmUKQNwiKz8RqWXvLHFYyYz9azPtGYjhu8y6nce8ocGOMNxHbcdoldZDZxOaj5ZdduqI4/nFKZH0/xLNSvV49ohAEXVBPnPEGsDtj0lm12LVygYzmGxQuydTb5ZVeVycesW9g4x2Mtt82MyjqK3Sz3liDpkAzpj07QsK17QNWRl5ZYF+Sdez2/P7quGYiMwQZMWwWJkeC9jF8sos6+oZ/Qcf58SBNPoXv5PAn/AE/TkYZcxvhOkb9yan4PzupPE0lpfNTHay9x+vSV6y2y56yMAGLO0rs9RPiH/wAn1ItbRU05Y5A5/wBp8ON3HUG1h3EWzdHXcMifZ9o8sSkryZ8S051GqRdvHvAMeHxVNupJI7yj4MbKwznEt0/2ZmrbuIAMz4XV3sMrVVGElpwvEqoA5bvCit3EaofuwCYjy+00gYlb9TmKuVzBxMZmMeGZjwXmC1k4WdVm4MuXI2/1nT6ZG0e01LYcMBAnqeYqFjlRF0xVciFDWd2BiCkhcmawHaMcS3qBfO2R9P8AmUbf+7V2MWx2Xd7TJK8Tz7tsNOE5lY+sazJ3rACWGwkRGIODzFVm7CMBWPON025O48QMeqN3tC5fyzDN2isw4aU2LZXnH4ywOauCPc4n2oe/3GbjiBOY1Jcd5gKoUeGcLzLDhZpNP9nrC+Oj0/XbLdhO3EMYwuTYTPiGnq1K7n7jsfUQEtyYkcnMpORxNIxT4mb7u24/3jUrksR80pX38BDNb8Qf7QtFIzggmdUYzNwbkTW3X2/Fa6R8i/n27xPmM1NtFJ/arnP0ld2iubaqjP4RQq8AcQDExnvM4mIBmWjDeBGZiGpfSDtNvgVwMz0mPFmCDmcHtCdo5l9pA24lYPWB/XaXVhsCW0iqrLfNBqDSfJNLrSy/tJqNjZwZXwgMto3FVPaPRX3xGprFZKpxK9HWyZMNYrO2Omw7j2jKM/SBPmxLW6C727foQhnTI9OJU6AbK55udkIdiB29IwbeR7Tft4lznOViqSPIP16xQHfae4jYHf1jqQvPebKxwf6H/HiwzKk3GIivkD0mBG748LnNjY9oSTxNPcHJXPI8dKorrCwHnEZsS24cTPlzLhuQiA7ZWnHE+Lav7J5B3M+F6q1n2seJV8Lr1GpWw9h3jVebCxKXo8rwDJjp0xLbBWhc+k+F1baeq3d+Y3EIg0KnU9czdzLql1Q2tNLpDQ53z3AleexgGJ+MA8mZWMy/58fcDKeAZbUwsyuMRGwIrZiNu4jcTMBz4PWrQjZOWOIql0xZGoCsCI5weO/+Zqy58v1i1MTuI4m7Aj3u3czTay5vL3EYzUXvnZ3lNduc+vrGfH7PMDOw2xt4/Ay5qkHfn8odVUtX7Nh/PvNbaXq2jmacb+c8mIGqfkcTRNuJYjiWb9xPoI25h/GWLssCnv8ArvGqbvNPZjCmdI72Yev5Rlw2W5Msqt1Nmys/j7Q3uh2kH7lZ2ZaFsDiYLGOMnwtr2NLG2rmaGrp17j3Pgo3HEr+ZhB8xjyz5DH+WP8pi5JxF4E1ujq1a7bBB8PfS8pzNIo6efeFgIa1Y+eBM9pauVmpJ2FV7xRhRO8wZiASkR+XwJX8xg7+JcJTlpVqKsZzNXrEqs59YNfV7yjULceJaMoRKX2W5h5m3zbRLauk4+sTvNRqErcqxn2lDxkQMDAfDaGiVBYzhJZY/cQsNWwVQVf07/wDGJp9Oyj3l3RrTosMGbgyhR3E+zjO48x7BXTt/j9JZaoaae8Wbtx5zAwXdnvN/eXWvuxkTrvtI7wB7Pmli7VzniNpExvxNqqcj0gYACIyADE02q6dx0rf/AMT/AG/Ef0lNjOTafl9P8/4nqXPcRTvTIh4GBNg25Pb2mpQO4WjiVLqdKx29vzENd5Oef5/cQhO8e3IxN3hY20TJ7mMhtYJ40MqWBn7Sk5Yn6ys7mYyzgZjDkiWX1qgyYNTW/AlSectL7zTwJdqzXUbO8TVq/DcTTtnlTxBqAzb37CfaVflDLtQKF3MJ9qa04l9i7sQOGXjwMt7wbl5EqZjxAuJT7xTDM8kR6uvUaveNp+gkG09xmGqo8lBNOtav5Fx4X0dNpU+6uaXAt3PNS6u4xAyz4jWp525J9ZRo63HnWD4dQOcQDHA8CdvMFkJ3Qz7OgYtvI/mfylDFW2u2QB6ZiabrMck/r8RNdQ1TKxPAgcAxtQqgoZZ0C3M6iVX+UTq5bOJbaq8kRu/UxK3z5FHMQWA4HacsSbD2jvnbt494ygV8zTIti5U8S3Ti0YzNm7yOIELrsigJW2DyZT+xG0jvGbLbodTtbphZVSlb9RuTGAzhJ07P/UzH37+8Epr/AHpsMKkTVeVJ8MP/ANOspHeWcrH7Zmr/AGd03ekRdgxNRX1Ele1htbtLEFdhlFPS0u3/ANuf4TobPMewj6dGPljadzwWM0tXnAmuTN2yo+aaeo1rhu89J6S4cwSpMDPhTnbzEmZ65mmQgbpqq96EGa7T/Zq94M091bVjmU4Y5HgyhxgwqaD9IMd/AeA8O0tu29odSrd4rscYM3CdxKUDuAexi1InyjEs0wXzFj/MxwH/AGnYS7yvL7RuHPP8oKk1HnNmQP1/GX17QDV3le+jhmgZvQ8/WG+z94Te/wAwnV8nIlZdh5RKaAF3HvDS1o85zLK0p8tcdVI49YXuGxcE/Uf3n2l6ySYqItXPeISoywlhIxiIOquG7wIa8hTErb944M83vM5Hg2prWzpk8zr1Zxum4eJUNwYtQzBxC+IDNbyk0A21Ksp7TvPdZ8Rr5DRPmzB28GpwcrChHpBfbK9Rax80vq2AMvpAAwmOmS3pPhV7/ENVqNay4BIVfwX/ADnwzxMy4ylN0MftNuI7bREzjnwUso4jOSJ8YOKgPrNH0raufSaBKsv0vedMzpmakN8oltdijMFje80PUtfGZsKjJm2YlnbiLXj5p9nr9oNMgORDLtSKRjE0+ty27EByMzUruHmjJ1T9JqK+cmakB1PUmj0CUozIe/M2FFyzQ7QSczudxmzqDM3rpR52xmL50JE0hxSFb8ZZbmvyzeUbjtFYO+AeYtePKZURjYvpLlYsAe4mnsNnDHiVpzlv9oBvOM9pTzZkQsayc8Trk8Rbq8cmbVnEatW7w6dPafZ6x6ePeVcmYjTE1S5UTSjhYq7R4OMNNRX1FKwCV8r4t28KguwYhUEYm3pHYZqCVodh7GfDviN1CFb6/wCX/Jmms61Qsx3mJtEChjifvbY3HgPKIn7V8+OYTPjT4CSsE/K2J8NY6e7k94PCzUM2pKY4E2H3l2lrfzdpotN0UzLipc7e3gY/HhidoxmqOK5oELHEpfKy/wCWO/TXJmodWXbXGp6ibHGJexUBcYEuV7e3pOV5PrDllxFTbX9ZZWzOFnQFZ2AcTGRGHHMZOku6KvWcM/EQkj6Td0zsYd464POOZS2n6WGbmEKDhTGQhMZgs2N1D2hdbF2uvMNgbPlyRBV+P/8AaOtZmwTMP3F7yrvMw9/C7tNPhK1Pg5xLITmaivbZkSmEQjEIyPDSndUIZfV1BNbWTTZWnfBx/KNT8WX1/wD8/wCRPha2rpEF3zRWLOR7QnEr7z96N4YBGIq4+40+OnDVgRERu8XTp6NEHlEzjmKwe3qr2JlOxVNlnYSnULq7DxxC47DwLBBzOorfLNQx2zHgYVnxA8Ks+HWCht7CJrS93bEa4Km5zNdehXAPP64jOyjMu1I+Wb3t9eI62oMe86QdwzekU7hPn4EzizaY2g3ncjbW+n+JpbbMdPUDzfkZZZZZ5K/Tv/tDSCN0NarjHYxF/Ygw1ozZb0mH3eSajyjgYELOAD2hsY9u0c+WKuwfxhqBHl7DmYr/AF/z9318RKo0Hfwu7zTtudB7CE7eYX3mWdvDWcssQ7WhmMw+GhbyY8F8xwJamDgy3R3N+/iaRGroVWOTiaUWbrN5/e4/CXHAA+sq7xvnh++Z8dVjfSR6d/5GLtPzSuiixgue/hrm20NNGg6AP67zV3O7dL0E0dfT/GbfrMYnxIkVTRuVtABjIH4Mxx4mX4Iw0v6leBWxHv2mWUZzPtLHNZPedGxLM/rMtYq2OOIgV2OeJ5i2U7QoN/BzPnOBOdoYSug2HH5xdvYeksXHPpA5tbCxKlQcxVy/E1BDhUEr5r/tDU4OdxB9vaWnYwcS2xuHb+UtG+sE94u4rgxOM/WbNxyeeY5rsG2Gi7PFh/L/AB90eI7QDAlh4i9/Czkyu962DD0n/UCfmWfbj6CPqbGhYnvHTdEr58SIRgzQnzES27ZKXAq3r80sBX5u8b4dbniz+v8AmINqgT4fTfTbabWyCcjnt+UtA4JiNzmM4DQtCYpgh8bCRNVSbWVz6RkqQ+YTSUUvcuAfz8Ne6dMox7yhQKwBLtIUs3+8RAgwPH4iM0zRqepmI4P3LTsGYbtxw3E1O0qNv/MPbmNSvcwAoTsXM+Y7CsFBsUlJ0mABjum3zSinOeY2UB+kRiMmOpZ+OD+u8ZFZc5lJAbPvLiVlezPljKc9psOMj1hZtw/Cea+vB/X84NKmj/apyZ1eo+MR22MABGsATERAozGQbt02t7fn9zHgM+C9vCwxO/gTz98DxM7xTt7eGlfZgy997EiHjwr7y3HrN03Z7wc8RjtjXBcCKd3P3HneFFPcTTKBkw9pdWpfcYOBxL9KLa1X2+5rF3UmaJN0weqn4/2MMEBmoI2nMVOpkDt+v5TVYVgBFGW5lCkjJMJfdmIOkOV/jDu/cmGYDJzGo6h7ytcrg+k/7y717RcNkCMNihh3nVrxgR2VxvftLD5oQnCiY2wVnvjiNWrcGd4X6fPrGuWgBxz7494NemqPEsClcYnWFflialm+UZn2hv8A1P8AoL4GJDD9w+I8T9wcCE8cwYzzCQYPIMxvNOmZ0zAhE2t7yvT7TkzU2ENiVElQT4sMxabU1G/90+FHyQDdnMuHglzp2P3LfkM+H9zON/3NQnVUrNLprK7MvNX/AN0zT071JMepVbZKjg7LP5/r1lpLD6Dj2zFULxFTdkZgK7d0Jsdt39c4mnocrvsgTe5PcQrl8S3Tln7+WbK0HmmQ+SewiKrfNzK/KuPSVg18POPaKm7OyfZmYnc3B/WZ0DWoQEnPpj85dTufeO49ZgNl/pBW2GtcZik9iMS0ap3LA9/v5i8wnHgkdhCYD4mDxzAcw/c6hxCcxmm6E57zdN83zqTeZvMznvFPPhZATN03yn5BFbz4lwBmR4A58dT/ANoyhWrsGZxn7mPDUH9qZpExXzNXW3cLBbuOLFJ/L+395dtVvrFAVoAcwfNn0E1NnVbDcQ4C5Y4AiEBeISxxgxnZB3l74ETC1+T1hPSwzQHbxGBOBMFR9JniZnT53es6akbvWXjpDKCbi/YQKduGmaxxn/Q0yVH5zNSE3/s/C7G3mBeczrNK3Z258CceHbwzjwSMPvYE6YnTE6YgUCYhUQr9fGuZjebjxxF4UCHOcrOfWHHpMRV2nxIDDBjV5t3TMRs8eHp4GWaOzO4cxDhQJYciCoU5sXkzp+bqWTZtUtGCk4j7i3l7fSGkKu6dFR5mE25Y47RQGPEu5xnsO8FHXy57ekq0grfKN+I9J0y7ZbtNnGJY2xN3tMC1fxiVsecTAOVXsIPK2PeA5l3IBMCjO5BDYEPmn2qj/wBh/oZmfC75PGhfXwsOBjwPf7ixmCiCwGZh3ntFGIS2eJ5p5p5pgzBmydOdMTpidMCJaogKv3MPE808080BYTeYWzOJkTdj7ljcwtuMrQ58PSHtBAfSHB7RAPWNWmOBNTp3Vd/tjiHTrv6gHcfjELFM/lAcrt9YMgYlz+SV8WhT2gUbyBAiWNluf1/aYDmAbbTmBfDU5FZxNCd+nB9oP2iTVBQvRT2lWLH5joV/GdxmHBBJ9DxK3HrOlpzzsH6/h/p3fL41cL4OefD1+4IyBhzAgHaYmISBMrMj2m4e03TeZvM6hnUM3mbzNzTaIRniDibjMmZP307eJGYKwDmDtHYIMmZyuY3afwn8PHMvG5DPlXiMxPbP17f5iuu0bjmVHd3gQv3iVebmbBnEeoUj8P1/eADHEsG14Dk4j+wl4L1Ees+EPtJQzd03wexhy2+fDEDOVAmvQ12bcS8moZP5RnffsCf0i6gNjd+u4gao8k/6d3y+AgOB4dzG+6PulMzpTpidMTpidMTpzpidMTpzYZtP+qng58CYO0fmbcLiW/fftBThT9YwGfLD5a/LKrR08Su7qDEW0E7AeZtKAgiVgAS1UTLGIhyd0bO4CcTS2LVqMER63sE0wO5sz4P/APcH65nxTPX5mos2IT3n2Z0pF3cyqsoAWOT+jN7+h/07eFMUEzYYO/gqeB+52mT48zmZmR4ZE3ibhMzcJvE6kNkJJ/1E8G7xmCcmYBiHBnc5gPvGwZszNggUTAmPDEvsKnaT+X+8ts83HrLTVgIIib34jVhatxlFW1Ru7/rBg5ijiXZaxUP6xGXmbctx4XDZe0obfWHlyY/aCaW86awWCazWJqLRYeJe4NflllzXIqEYxGSvLN6zbpvUf6Z5m0eH733D99jgTMwZtM6ZnTM6ZnSnTnTM2GdKdMTYIwA7fdPPjn0+4ngwJmCYFnxD48NDqGpYdpo9QNTQt3vA4xC6w3gQXMeyzJhcDvDqB6T7SfaPe5Hl4/P/ABEB6mSfxnTLMWU85iKEHKyhSpyZ0UNfmjruAI4Mr1BA84gvSBwbizRtpMAXHEsr9RNcn7TM+G2b6tvtNTnpER03jviVaVF7iFBjEsoY0lR6xgTAM/6y8nd97EH+kPukiNj0/wBIjMHiniz4jXn0nxT4APiWo+0b8GaeoUVLWB2Ee2tYtiv2EV/Uw6pfSHWN6CNdYxzOo83seIWsxwYgZRiL5YM5m8g9oLD7TrTrkjtOvtGSIdSPWLaGhtHaB/aWKtnzSjbR8olr71wJsMUcYjcSq5W4EwMw1j3mG955p5p55lvabm9puPtN/wBJ1BOoJ1BN4m4NxCsxiY8CRNwg5+5iY8SwE6gnVnVnUnUM3mbj/wCDvadQiMcnMxHvWseXvA1tp5MKn1i6RsZEII4P+mfpCIv0ig+swMRqx3ExnmGtTFwqze4aVnecRFxMtv8ApCBK12ibjg495tH3x9zAm0TaJibZtE6YnSE6UC4mJzN5m9puP/lGM+O8zuGfC5unXxAD8x7w/TwW9hxmEluf9DHgR4scWBYJ2ODM4m/HgTntMTT0Y8xm4zbzGjHAlLF2JHadUex/1cTExMeOPAnEZy3/AJrNk8GPbjiHjw1vCgxXD8GDwxj/AFPw8D38MZ58BzBXDUc9pXUB38TxD5xOGmznP/iniM2f/NIzNQu78Yo/aAGHt4XgvXgTATn1iY8cf6HEM4++BFB9Io458AfAQxeeRPMO83D/AMR33f8An3fLkw2ebkQNkbveenhqalr5HrKzt4gA9P8ASP3BpiVyYyKowe8FfEZOOYSKsDHMwGw494K8EmEDiZycYijMxCMrNrd4ODxHfbN3hiY/8BlLTpQ1kTGP/Cx/p27tvllqug5mmsGNhgG4eBUNwY1ZrfbEz6/eIh3EgDtAmDB9xW5zBbW4MucPgD0gIOf12juO8P7bBBiKEXEPPEXsAe8Zmi+VeJu5mODiEbjmes1Py5g2H1/1x94nbGbd/qY/08fdxCOJbpls80qG0fhFfIzD4Wr+9ATnDQk+OPBh6zvAniRniFAPDECkzpe8FAg06xm2xztgwT4NPSAzIJm/ZLf2gnSn/8QATRAAAgECBAMECAMFBQUHBAIDAQIDABEEEiExEyJBMlFhcQUUI4GRobHwQsHREDNSYuEkcoKS8RUgNEOiBjBTg7LC0jVzk+IlQGNElP/aAAgBAAAGPwIxMuGSWOdsssltFyg/Ha1esRcS8qFkZyCbX6jpQC42XDKU5Gtox6DuoyYzEpiOIly/Es66aaj3VE543FYASudTnN6Rl9olmVmtpcW+etIhj5Zv3p/irDYwsXk42aIgaZRpf3GooABLFGMq5hvct+tI/MucXksMuYXc2077inXDRZo8T7PhqNOma/W9MIysZyjhiXTw321svzpw8MnFlDMeoJy/TWr4psnAZVCMLcSLXmW/Xp7rVxJp4pGzNfIduY2Hwt+yIRnLFJyEjUlu61qMa+zRI83Mos+2pPSikk4cjYXvl02vWtcprKa03/ZY1p/vW/YjSApHzLZXtZf4jrao1BkmjvzM7Xyi+Ua+6lM2XPbW1ZSytJlLCPNqdL/kfhR4irGwJ0zXpJUlDGNQSg3yHqKGOwEUQuI1bLHcXudb3t3aVDDgo1kmLIWlna4Zstuz53oRGJMqrci2lz9mpmgQxTRn2Ez9ntEg1K7ekoUxWUGLLovEHaHzPxp48ZbjqxDeGuv50YmwvGNxw3QDkDHqfdf/AH+A2IjVyQoBP4u6pJgozRrsfvasPg8bODiJlztZdEW1xf8ASlgabLKy8QIW1y99d/vr0hJAFBMSRYfT8WhJ+lRHMV4WF4ee/wDDb9aklx2WDBSyqFa3tJFB/OnOBwgiWfiWFuyG016AHLXEjjAzYuRYyUuAnIm3upYuEcimNra8y9Rfz+tGI6Qq0gjzX9q+bXXyFNhpEKsJcxB7yqmiYmL3R1AUa58t1/L40+IfD5CwXlI2GUN/X30rTSEquBICm5ABJvr35frUXo711c2DTiZHXRso3vt1+tXleOMnNfiSC0njp0vap8SMNDJK0ilSp5i18+o7hYi9RRNiMVHnUfu7MSB3+WtRlH4wjUjIjj8I6/D616xiFGXlPObcpPTx3+FT4gRZZHIMJHnt3DpRllxJV4+zs9/C4699SYaKZCwuttywp5cRHmZR/FfmtoPmalzazSlXzX7+lKmFQrKUs7qexrr8hXFT2fZNswHKDuT+X60MRiBlyOQCNQdfDz+VMsl3kiVbMpu2tza3WopOGkGKnN4wFtxDrvbypZ8NMgxBl4aq0dl7tP4rVPHHmM4FmudvL30BJhg7AczBTYmjLYKWiHEjTYXJsAPC1QQzYdcy8rKVv03PxqTDRNl1OV9G8CB08j50cLw1LspERV+w9jbTqLlaR85klQAMRcDffxB+oo4SVgqWLAb3Jb+lJK3OmjnL0B2qOVyrIrZFGbmG5tb30VA0U3sB1FSN6SmIUWJyi7WP4R46U/pFFaNsOQIr/jOXQEbW91NL6xLIc5tLnvcA6a/GpZ4JYlz8q5l0B/EKbFcRbR5XVX1zHu8t6kjSKRlaZc4Ts5m1vrvepsbgCF4bWN9xpc0pR4mETATFtLa291Yvh4Z54GBLEG+mhsdfG1Q4WdZXaWFVForWtoDvtatf23BrX/ub1i8T6wYpMvKupuOz/WkMmIyJESVDDrb7+NeqpOXmW7uLba/OmnB4qsBGgv2XPS3u+dWlSQCGVUR+vna3gvlekiwRY5VefhWvm7x46WqbC4lHjDxWtvY6W/IVBMQqRNIGz3svL32qbLGO1wy2axJPd3bfTWnnmkjaMyXiyC1l6j43p8Tgw3GhbiRNn/C1ialSe7jTM9wWJ3JP+apAI/3kXIQNLA/7pwrS+0UKSO7MbL8aPpOSUjD8QxBrdojuqFsRjG9iZMQ+U/8AOFyB9PhU2H9IlYZRxFbuyZrAn41PLlzR+sEDuyjf5C3vrFekEUscLM/+VP6Ckw2NGTDvEZGkZbAfiv8AO1cWSVFVRrrfakkxKlohE0h8drCvRsuKhtHNKckCaWSw5feDWJE2HZcPHJErW1tYbX/xCpBDG0kcrtw49wq+7z3psTiJlMuInZjABoqnmNj76wUU0LWkxa4hZcp0vysPhXGw2wlKm/Ug2qTFYwEJFiOOpvuoTs+H/wCtHLhp3M8qo1x0UAHy0qXGQTi7XKKRzcug08/rSzYjDkzcOwVu776UMyLKysmeaTmL5luABtTz4TDrG0OUPLJJfU8t0Hhr8KBDZnjRXdiAtz1J9+lI+GguGjuMik8vnsdTTYeNRn4IJG/u7yetRxxi7iW7Lfsqv69KQyQvonClTIe13Nr92r1kScFD/ESeu/0+FRySMUzINuXN1O9RplBfMOz0Xf8A9IrhwRx2UiV/K1+7y1oSYg53FjGwlBZBUiSspgnaxPW4sev3vVmHARmKA238ddzWHkg0lw/4sws/a+dJjcVZBDK5y232sB8/jS4+E+r5ZM0hP823uOlEJJDlG2vSmZcQsY5QDl7PLb5UsWHSIRxs2V8oGg0vfc00ub2YF/7ozWP1FOvo+HPFh4+IWO6gf1+tDgpJnbSytew8aw8fq8kcwXKVb8TdD+fvFe04oYjLLzj73r+2qESUgnJ2k7itBkbOmaw79T4a99IXzLJfMD79B9aSOGKzZcjBtr2BLef0qGRxdjZsuhHD7/kaZGbsizAdD30kUIDTI24Guo7/AL2p5MTjh/Fcnr3fIUnpCLHtnnk/tMJ5RlPLaw/luavhpY3RQXK7ibU5T7g1YnNCpw0hC9PL4XpYGgikaOwkk/gQjYfCs8KOxzC4X+HrSxTSxFJ1uOfZhv8AE/Q/95a9SxARiSXKLsO40WLiZbBr5xmOmthvpXq6xxl8Za7SBlsdQBp08aAmkyXa2YG2W3+v6Vh2xcQyZM+RvO3Q+I76hlwptmBWZQeltPDTlHwp8XgMOHjmGdh1JO699uWj6y5jwp0fh3tGb3HzrDz4aIujXmNz2iUut/ePlU5kmADKcsdrFXI5QBeozggxvZFJF8tj1++tLi5yfVni9pHfUv8A660PVo/bW7ZOpouxAA3JqKNGz8UkXHStCD+yPhr/AMVI2IDttbsq3+FRf/EK9F4XhgYb0dKr4m+oJYj/APahNN6RimcsgYhs2RxYtm99SRqQeOqR69E7R9/ZqNTCphfOJHC/uk3+t6xEuA4Xt1luL34ha5Ovv6d1qSd/VoJofYnK5IfshAfAcT5U00RQMcO+fIPxBtfccvyrAxYt+Fn3V1IzLa66+dqwJ5OSYT3635r8vhvr3UYFAEWGVpJr9W0+P4fnTnmid5M8jHfKDpp3XqJ5IY4w0rRkZu7q3utTYQRrnmsY1drLGt7D363NNg8Xh8t5GkiYEnia+Pu1ppcHJmzaS28e/wAqjlgtJkuzBdRna4ZjbwFLPkMbMgIROl/A+dreNS4iSNPWJCdjkI8gddRUbNM0jobC/lof186VuISlufn2Y2tp03b4V67mckF4hDvl1GX78Kj9UkWSRMsZKpYsban5/OuqubdsG9r2J+Bq0PsuMyvfhnbfbpWJnVI3jBUlpHyguN+u9qVpeCiKl+HmOfMSb6e75CvWMRh2ky5msGICqBv8KzwmUvOeIWzDLIM22vWkES5bykkbhr71CZNoxlbInge/z+lOUWJTGSOEzcxN7BctRxvCEA7PS2n2KnlmEdokeKIDRiQmb36CvRmCi2iiQyodjIehqU4BnURrnYmxAUC2t9xbpTzcUJxGLZcx0vSYYSSpEeVshtci2/f10qIestmRMqLvqbm4qNiyzZ+RvEX1/OlnWFYBKOFM46XJuvd0pJsEro0nPJZtC1x9/GuPKVN2XtLfLbX786fGlFiS15rbX3+dNAuHGZ+ceGh+VRo0vKmq2HS99ffTvLr3C/Xvp8RBIsYlzKtjmGW3ShKWVxwsug3QdKmZlDXGYswsdfr991RJHI4ZX0DHp93q+MyMwLXVLDlUWB+P0pJpIrLxGjzXsXsCPf5+dSYmIOLMGEoFzsRl386XCwXBBkvrmBA107iNfiabCwTYiSQsinfKuX39dPjRjxrrhWZcmuo+/wCtRY1TEMKhzgxnRlt3nv199JiIZrXbXOLadaWWJgyOLgj/AHxxDYHravzFMh/DTNM+RAQL2pkDjOBdQ3LmqWXF4jhrcc+h06gdxtUTwSyRsmGCAqwES6ag0FxyqvDaxIexZf4bD86h9IxsHBkP7iTI2h8fA1icRwZDlQZJpHN2W/XoNhRxyTKCchVL8trfT86WbDYuOOUOodM3JYWA286wYmxGbgxiN3I1c6X+ZFKMjqXbiKGtffQn4DfvozxqzOoKgXvnbryisLDxXMrx39oLMe+hBhcRHHiXfKuY2tU+CDOZYYuZ3a1793fprSwyEAHKIktbfoKSGHUf3s3uvWPkZ0ztIcPhkLW0GjN8b/Kk9Vjj4kg9Vw9u8gBmv96CsfLiPSbiOKLJFlueIwFg5t3snWsJDg4w0mIKkRNJc8wvc+63hSRxODwRmllGgdvAfw/pU7Z7TY/EcNV7o1P38aljwyBuFHwoiOs1gL38Mx+FJFPIpYcQXfsjMUIv86wfFxrQcOM2RGsS+YkFu8XJ0oejcRe6YbLLnkXXXbz8L02LweJ5gCjxSLsL2OVibjapMU2GzNPxMvte1lGttNAbVGmFRFfEoiRxkXXK2/34VicfNKGeOfhg20Yheb8qh/d5sROeO8zdpRsLf5vh4VHJhJmGFcohvqqAb28aIkjWLN127XX50JcQc/GkBDC+rf60wxeRuKnb6qw+9qwx4sQ5QzZBvpow7v8AWpVcgyIM2a1jbrr97VJGAL4iTm10ZR8qxGHikMS49SviMuvzt9aZUhQYdVvK6KyjlGgv02FLh5IWSV1GiDXKuy+X6CjIiMy5cmZW1CHpbzFvfWHwmNiUYdDxDfqPM7i9SpiDGoE4Foxtpf8ASoQ2MKtM2eeK+a2xv76t6OclJGzWbpYf600WMw+bPFyyKxzoOmg+V6ZpkdQJjfiHx10Hu6VFMvDaJHHEP93pUuKw87IVBK8w4tvyF7aeNSJPJlmVmYKOoI5jeoRgeG8nARJHVe1IBmY+dekcNiMUIBJhgFv1swv9DUiR5sisQvlUbIuc6suliR+ulFio4a2F01F/u9S5JtdF0GlPFEnI/aH0FZsIMoXRha+vh86vLhwiyjut11B8dqX2xCyMOKrctlvY+/Wmjw0QSOQ5lzdt05vyo4dorqv4tPjQlNrat5FelF7MvAtlvob+XupsZANvwjS5K29/WpvWw9gBGk0W9wOxr5ge6kxCuq5hz62vc6/WpZUkVTHsw3P+tTGLGqzra+HY5d3HOvTNU6CMNmjGttNQNbHx+IJqHDZC2HtmXN/FtofePlR9ghaIs7FLLrrytUkjl4pI5PZvvm78wHnSejziGJkCx5wt7d99bb3oYTChZFXWIBefTXQ/e9QSyQOkbxgksdVP8J8aHBRyjLmD5dPL6f7lqOtvHuoq8sR4ZyoXGpa466dx086jw/rA9YtnW2x6/C1WvY9kqfI00DaqWA7XW9v0qRJlyzwxjMrJrfz7taR+BxFjF3Ge9z361BN6qsUcmYsegN72Hjapp8ZkIYljlGW9r91erLZgzXXhjmzW79a/2emObiTJcEDbTr191QYiRgz4QNCYpnDCTNm2t3bi/fTS+0WLMAhIyaC2pt7qMm/dmHIg0J+YHxp8W0wlfIc2XVTfUD77qkhxLLxNOBJC2luvj1p2xM/NGC2VRcZR1+96zKBIiDjBc3TYEnuufjUaS4PhcWG2W91y3vf5fKlxmMnzYkkyAL0B092ttu8Us2BOZF9mFIAUnqfvasEmK/dYLCmaQMLjq2o+FSNG1lglZ2lP/Lj4RVreIPzFI2Iil9WaRo3lRtSqjS/QfnUmPxEvAmxU2WO5ACxjl33629xrHR8IOZIXKO34B5d/0rCzyRZbkxxBtc2gLE9+6/5qf0a88eHhGfWR+xmNyW++lNg/R83skjtxnAOd9728+lSYqGf1a3tYxlubE7e616XCs7NPJKrGRtStrgb+JFSR29ikfPY2J/h/9tQx3SNgvDLk5suYEE/9V6nxMhVJIYbQ5xYKTt+Z86hwVyVgldmJFixb+lBcShJRboEPPlNzfuqGET4iFI0PI4ue/W3na1F8ZjOWdgIuXaLck+8j4GmRUlOSQsoS9v8AMBoPu9OxyRJHHYBlu56eJqThytGiyBeZOa1jcW9/zqTCogieWyFb2NKgkKWNzlsf8NvLrWGuom4nEZduQjvzeHdSN6Qi4Jxv/LRtSvfl6D39aaKU5pJJSTzm4GtgopoY3fiBsmQry5RbTy/1rFekpGss4AVVFunMB76/tyqMOiLnXLex17zqbmjaNZM1kH+Hb3fPSkZoY1Z5LcSQaC+nXelCRKRIOVjubb69ajVmHEhYWV/D7FHgs/CkAm01DAjY+V6mxMeKZI+HlIew4cV/nrb5U0Uk68KNs4fKdVvr9/y1LLA5Q8d8rgW0I0tT2fUtkC7699v0of2a+m5SojdCEIty9nvFWy5hlvY/h+9algdBwixdTl7LbD5Vnzjyv1trWdob9NTsfdtXFaFkRc2iiw3uPnSROzM7Zsmum9tfhTl8dnaL/lt3HQn4W+NZpTpcvrffeuFJORG7Zny08WFtipEVCjgjQ31HjYa/60cRmSQG3s17Njr/AO2o8JiUY+1zOSb6W2H39KOJjWYXbRFbZbttUI9auShMm1vLTbu91QM6xHiHl4YPzvVmmJVOqi57svypZcOOGiObSfDWvUpF0c5g5v0N7UuGixYE0lxnkOXOvZ/Kj6NGKeKdpSWvoGs3L8r6a0kXpK0IhvLG7oBtvYd1hb3UFwc7RyvnjU3yhtB39NRrXqWJzI9+KrcSwLd1ut9fnSxNpn7P7LN18KE3BlRgxRkZeY+Xf0qXMWj4bZRYZs/fp1rnkdFd8kb578w06+dF8HJNEiNk1Pcu3gNtu6kll/fZMqP+MH7vXHbEys/JyXsA4uB9+FRvwpOLGxLGw57HrfypIsKgjnQ5VINgFvfbr1H+lYn0diLnOvEDKfDXy6aePjU0WEBnlhXlWTlJVtLgHzpIlhYySRLmaTZW6rS41pAoE2YZRpt3ny+dSY2FM2KDo6Fdc9rWFqWTEEYd5FVSFXRdfxdf9RUjqimSOMRCQcq36fHS/nWHmmZo8TEj8XZkvnAC2vYaH51DFkKlxeJJNbqe61R5nw8ULw9iN+Jxf06GsLBi2Rbw5GRRlyrfa/8Ar2a9YgB9SKfuGm5t+jdP6Gl4eHF3YxM6nMTZRfX7tWDx8OCzRNbJGycj3Hd7z8KxCxRf2jGozFOkcKgCwH+Ef5axUzM0KJbOpJOcvZgum/a+lNhMbwYckSyRwx6rcgfPesFJi5CfYxE200tdh7zfWnkM68d80ar9++vRrxyQTHBSvJlVhlHZy3J8vl7qxGKZllMubiWa4DNe9j4VLMMNxHb20i/hI8vfUQhZrTJazDQdCL+d6jh9IZ14Tlxfaxtex2vy1xFSwxHEAvfoTp4/h+VM0mICTchVxotm6fSsHE+GLq4VpDe1wWvv5WqM4LD8Np3Lez5FjS9s1/jXAwsSxrhvZ51GZrd+asdixJJaLKIo82hJvr3dK4bRIZpbX6ZrdL/GsWsFw4kIjv8AhBPT5UIZ3HEOZ8seo3IGvlTMpePm2U2vfsigAhiR+VVVdx338PGp8WBf1e/MDo/S467kUJMThZikShGH4b/1N/iak9K4v8cfDEYsct7g/AW8NaxLzSWiKq7X1OS2Y+W3zpsQ8eTPG/AjI1sd5X86kxBIa92I2zafWgSBeR7jm291YiWabh8J+HmOmdqEWLRpWYGTX8NtcxPdavX8YeJLGBFHF2Qo307tB9aIblcreTl7JuTS4fqihdB3fYqNED+0A4ga1zfoPDzq8ByqshDDTUns9KwU0UfK4/CTy9NfHl+VHFYeSR8Zhj/mTr4g0oOJym22Q6fOiMuYSLnW/dcUVWQqpPa92333121Wz9g+Xf3b0ZIJheMAtk7vzpFz36LQZJbBUZtX3buoYYxe2VM2c2y75t/8QpcIkhlBN10vzWrnQzZCDzH5WrljjUyrYtYc1z/F8flUfFl5Uy2UDfKLfHapMJMrZ9Re9z40jKi2HNGQoHNXq+FhiXi8rZdSxbx86kxTNPNw1R3VtAxY26e/r1qaKXDgJmHD5bEa2J94vRQJYwlkOfRmTX/5fSl9YfQzdm3frenOexawupG/mfGiJJJjYrkaMbkHf77hQlxRlV5JLyMFXXutfUa00jTLwZoQAQOz7/eaSXMGjjPDFiMqtm3/AMprBHE4OZRHYrLE2VmB2/8AdUfqIMl+xlktlcMN/wAqCSBmdEBaTLYE/r+xsbCfa4M5SyXBzE79xFr+e1G4EXEjuykWudNbe4d2lcXPq0udb93XW+mpNSNh8LFHkW5HFuSdr5fvbxpo4cG3rIQG7xX8beWtH1qQI0NrXOZdDa19v4dak9oX3Dan3/Wo2OR1ycW2a2hPWmSGQg5wwz+FPIzlmxOddV2J0vm/XvoyJKSDyhiLN/Tp8KWNO3Je+Y3120qCJCGkVueLNc77fXupMQyIsiyvke+jXN9vhWIDW5GU5i2/j40A8D+rqwa7Xysbn5eFTSYRGgxwjyRyCLM4P8Kke8XqHFYeduNMzGSR16XsPv60ZZ048rEFeXMpzd9u7auUFXSJRwlNtO4+I0rD4gzlHxEjRiO3LYA7dTsKSAhG4WwYW1uDpQ9JYmLO6xcJb7AfZqXEiYwetTAE/wACKurf5UqXEeksV6uoxmWSN+Zstm0+VvfWJxOEBZYWGGjypoO1UT8QrIWZFe911W30qLOc0bwqWHQFrae7N8q9axkwEK3j31II2+vwozJqXHBS34jp9/GsTiJCbQxBIm/nYmwH+K58hULv2db6636H3BjXrMkOmMAWIjls/jS4RZXWSfkkVlBGYNRkfDCQxuuZItMtlsh1/v0cCWxKPqSbBrLl2sD8aab0lFklLgiR8wEndYXHxrEYu8L5ZbKkvJzAa3udSNKgkx5mHq/DVIiO2+a7MRX9oZScSS5a3Rje9STTFFCnMA+9ulRyLG0pt7KxyjOO/wAANKw+GxOTkjycpLAX3JNerABEC86Mh5rW+v5U+IiJbDPy5SNt7D4mlsvIAWY327hesPjBBxcTLg1bNM3s0GvTqdOtLnEWJeYi5/nv3jrUipwmAxTB8pIyn7FMXgjY8S6gm19PvSi+Ii4mDsyqxNuDbrYe6ikMiKssgeeVhrl/gHhp86mgKkZ5V1y9nMTb/wBVP6JnxCOVUo04N83kfePhUSPHHEy3dnbY62y+Ap8RPIwTIytlPN42rhDPGSuuu4GtqgghYlpJC22w8fnXHkxkgu2scVuYkbfT5U7erwC7E25PzqJo1FoxsO+hicPiSRc8h0K6a3/WocRGYryrpdjrY2v99BQRxl2y2bTX7NKbrfTIb9gjypBGQ99wNR9608eIgWWUYgJxG2yjcb99RSOER0sDa9gbW+dr16pNGpmhcyK1x1/XSnAwvJhQilyezptppetiLayEEac2tOkP7yI3Xlve/Q/ffSxxPqTmC919NaaPE3VyuawPXoPjUPDm7QCqmXsFe1a9Lxm4bRu2YsD+Em2X76VLNiHYQ89h+MMBt4C35VFhzKxBIGYb5Aub43p4YkK5t7+d6z8oyezYAfh3t8aBmyqCps8fMdxprt1+NcMzFwFTlK76UsMAKK76g6ga6VxVmvo2XibC3L9C1O8L5gurEm29tPn8qkV2SGa/DXksLjqe++apYZcQJRKt81rZF1vbWlnMysz7q/j1vrfT8qbGqOKo5TGTci43DeWWkkXDlI5Ebgm/aHX50Obh5jZ2PTxr1ibDlBJyvYaN0v3UwLghXJb8q5bM9yb/AH76EdkvfS630+zTjGTEm3abmyrTJa6u3KdA1zXqscgLKpOnLsP9aKPJlOU9LdNr0cy5nLCRzsaZzYcLRddx1+dRyYiE+1Zrm+a176Dp30c0ssrg5Y0KZhmvr8q4qxoIomtkzc1++1cPgYhTIb3AFu7b72qNcLN/aZJVUg9+2UfK9Ylk5pk1dl/Dfu79BWDlwVuDDhmUH+GTI3XvuainxUeqMQinppuem+vuoS4LEwtFylvHmH3fao52zFACDHcWzu2nXoPvWsZiOGrSY3E3gBbx3HnSxO2bCyTJbLymKz/ncUcdJw1WFjlUG18rvqPHW3vrFGZFkljtGMg5F5jt5BfjWKwxHNJOosT2CoIA/wCqmwkswBVeCsu4RLMXP330no6BTHC6gnvtsPl9aWQn8YXLlvlP4fj+VIICBxQUaNf+W2oDAfKsRNldYklDMY2swY9nXuvUcMZC8zSOM3d3/lXryvbE4xnkkvuBcdn/AKqjGJWVWw65gyiy8wFh991Zpo5B2Etw9WuNdP8AKK1UyNCAWaUZlUg6WHeSanTGQlY0XPniXLdgSCBWHQARQGQKE2v/AAiofR+FxIMsg1sNeX+tzQxTYO0WFUGRLi2a3U+JomeUiSCEoV6+/wD1oQEQGXQNkTQE9P6mmkmwwXO18p0FwN/GsNh5MDG0GVYjy6Xtp5b9KRuHnEGICkFL5NeYg+GtS4mbRZWd5MxuTfWwpF4TqTc26DQ0+A4eRGcSAM2VmUb1FKWgi4oFiTf8TW+WWpY4Ea19r+VvkRUscUnHmwmYrpdeunnrr5+FOuVcvayqO02hPkBf5UcRPEsaCPs3/g2Pxp2P72Q2t/Cg1+/KokJEXALHiPtrbSrvFLIigqZSOW9t/Pas3qWMa+txsflSO+Z4tCwy2vTeoAhZbTlLZ8pF7Ajuv370OGE40ct8v4pL2009/wAaaSSFry6LcWIUfY+FDjLk4gzjTf7v8qafishQhlsetDhzLlJ1B6Efd6ORDiUBF2kFsu+xGveelGDAzZSwCHP+Ebn3WJpUksuUCFmz2ubW08xv8KMV8NHwyzNxSbNvoBUqQyCRBlZmRbKMxG2m9vypcRh50GZgmddbKdh8qzSOeIV7RXteX340cmKZJI+t/HpQws1gQc2c/l4UY8VfKZOI2XqSw37+wKumIyMTfa5v/rXERZLMLTH31fXtZgA3j30Weaz5NNeXe1vCjDxmwrX0V49d9/vrTDDTTyK6KRxQBzW6X3ABrnHPuynkzAtcDysfpWKfFRztGkd0gjOU930rWS6tY6dNP0Nes+tFo8l3AuLW8Pd9elWgfh4cFo7j+Ea9N6eSOWyogE+U5hbv+FJh5DEy4dQUVufpc2I+FNIcOrZuclNNja5psM0hEca2zs4UFc2lKz8T2hyE5L+/5mogmIZucXF73Pn8Kmw/EUMoyx+YNqImdQraEXNrnvrPiG0jytGPw/fSuM7BZCLa9NTRcuwTNpY6ef0rjhiwYaa8tHinQar06fWpFCRiFo2kzMLsNelLj4Yo2ndDkHS/L8T9jfWSduSWf2t8x1IJ+X6U8jAaoM4B2setPiQicRY7Iua5Qm2vnYmsSYHDCZb3HUkFQB5AtQxWI0jjmGa/f3fL5U+Oh4zwrAQQ/ey5fzo4SCMCNBZbHrmG3ftU0mFjZszpH32sv/yy/CoMVjIuIl5OEM1rWY83xqXDzRMkJn9nIuhbK2cfU6+VS8OQNw8M1lGnOTqPrQjiTPPPiFVb9ANqSbEYn2B7bR6sMpsW+O1TTxZF0FgTYurNa3y+VSTsqkEHidTc/wBaeSUskWePXZmax6D3VJxGLyK9n5Sug2tfTv8ACsWsgztiReN793Z+Qp1w6RvyZBbdRm3+P/pFRrh1VJgobnQvy9RrpcHwr/agxavtEFke8efv21/rWUkvFc2jH8p5vLQA1iYIZ4vWFs12Ya7X1PffepkL+ysCXfx6fH6UuIxCSSJnuHjccpXYgMPn+tHERrM0ua2ZuRRv0+96bCYbnW/tWMesp8z4j5++g1kURIS3Z01AtcL5VJ6TOLM3ODa9193eenvqFs/AMxeQ26rtzD61E0ORHmWPILaCw0tSNLG+SJjw0GqzEEZT7rj40MXMrMIMPmbIWvnzWG3Tcmn9Kx4blj2VgPxag5juLD4UXTAYbNO1xmYnW510OnSsmLlw0cZib2PFA1I8NAbkfYqKeKCaLDsjxkpHYDMN7++p5cFJK0ZxDIXIADNudv8ASmHHu6XZsu1q9Wxa8oXmPcKz4aJTkzZRl1tfrffekhzscRCgkm6hb2Onlf5Uokys9gxLC91sOY286Bj9F4TJ+G662rCyQTI7aesIotlP38KbLqWjIRgdv07qySJlzZXOZhfwv1oqyhXffSo4pH4iLmyjfKCdh7/rUqXtmYNYbfGo02z+0a/T7/Oo+BijHGXueXTzpmYZmQcl9MhO5Pf3UArWjzki/TurPE+sF7i1xTzyYkMDGpHLlY96+4moIMPJqPa3Rezpr8zT4RSRlHDYm1yNCo/6ahgmyoFbRyLn4V7ZxlIQXTpfYVNKHuIm0vp07vdTzRxlLXAIOnaoZJirK2fKw0zHuo8ay7rZVtpTRQaqF7tz9muPI4vZguYaC+n6n3VDiDOyth5dMicuU20NJK65c/IQO0bedcTCRBmYgSyyDQX0B7zrrSxW4ixj96FNn1uGFcA8G+W9imu2v5Vhkh5jIwismnLf8/zqb0bm4vG5C1tJN/yI8PjUsMsyrCDlDb220v8AfWpMNnZ44R2xbtDz8j8aabhLeNtLnVtrDur+0RMkV9V2I6/MUXfnMi30Nrf60khLOCFs3j/r+dNiJVsz9m+ubXaonkNi4PNt403CRyxJ7P392o4gO68NuIGHdevVo2uj7Idh3/SoMObmLTNlOrGhbJkjOU5eq369+21ZsIBlyCy93hTLiIwZG0YjTfupn4moY5hax21HwvWsOSCQ3RmW3Z/rSzyT+zUXN9h3fWm9H8X27+kGVb/i/Df6n416thzmnkaS9v4EGlSSKg9pew+/vesVDigMrxN12bofGvVvReHdXVsudn7MYAN/eb1CuGxBRiqow7iWu5A/y/CsVCxRBKHQXOTbVfOvRmPmWKMM5kRbbjMLE92vyFcWSOWUhbSorde4e/X31BJh8ME4eaKQKdFs1ODBm10FyA1z1rgrM8Zguco5FUsCLee3zp5RIJpcxbPk5F/vnx+tXxeHw7BXjyu0ugS19B43oYd4zGSH50Qdkd57tT86zPh+0GF1fmbvG21qxGAmwix6OY2D7693nrTQTRs5xMxDsNle1tqhdIklkeMmS++bKBlJ+NTYWGG63DR5hcX/AA/nT4SCIrHCSkRBIyb91NEG4gUcNm3bPawb/p+VSRoqGTRzxByj+XodO+hh8LGVZn9tcXUjfS/TQ+7rUWHg4caIx2ta3QAbnb5UJsQzG0nDCb5bjY02LGR1hw8csYZsqlrAfnTSPg4UjmClAv4VFvmd6Xg3wwWDkUAcRmAPIPHTekY4Zpobdpm6NrY951teok4IYDlcr0H4jTtHEI5WVnBy7ixt7+/xo4iGfG+zyrqSqkZfDpoaWPEcFlYFopotiNdb0sd48Ppo6x6jv26U8ZyoqxPMZO0HIGwNNi5YuMzHhQwnQE25yfd9akfEusk2LsHzS9lQdr27/pRyCSPYMR0uosgoLGeUbc/SgHVimblYjlJ6/SoSmHUvB+G/a6m9GWXLJKFtcLyA/wAutASSZit+m/ma4A4fECk83QDpf31wpAOYZ20Atpc6UwIUZvw21A6Dyow5TZ+WQ5flXKgPkPnRdcz2Grnr30zqLhTncWte56DupkxmG9oNI4mHQi58tPmakw6NmKk24Y7QF7+6gzlgD3LsakJLsIQuY5dR0099CNRGY0LKFP4m01tSCPEy3kADfi5AKhtLnZxdkA2J6fKhNLGWil5e0unU1G8SMi5bEbjN1/Kv7LvbZjs1XfKEN9LaC9OA/LLa7CxyPr999RT8Qkxhc3Lqd/yFD0VJhPZRRuBMbE3vy8vvpHxZka6Nw5CvIy2287gVdcORYnioklyRv0pLx3mRA9jb2o3t4W76RMPE0Zzez/Fl10IAoyYXFyFSrZ8ugfTfw1NZZyeI3swrP40Ew934RKXy/wB3W/vt7qT2oGdSH6DUWJ+lRZwHk5o7X699FVAjTLcc3MOtq4SNnJY206b7V6w0bcpzC40y9adn5omXb3fWmMT8+a2Y/hW+g+FJlsQt8/UDrXEjfhkG5P31rgO+tuvTSgxUDMvTN2aZ2dfYAHU3Nr32/wBd6ysNM/dfvpU7Sld8xvRwvAsqG5kFxfvN6GKnxWvBkVL3vmKHX40uJwrufVT6u4PfYm489aSFBkcsRbvAtY/WvWw4zzbC3iRambsvez67rddPlSYkxlbrm07rf1rEYb0hchHaMnoM2g1+9q4uMiHAGHMcQ66FR9CfjWHw/DPDdg8x8QST9fnUyoRNMXMvE2FhlP5t8qjWOAsJuWM9L7VLKMU89jnLR8hNja/NuM1YmRSjYrt2L5ywvzAtt30ExkwHRFituT46fCln1cMTcW0vbfr4VPK8WYJ7XIyjlHfm60fV0PEjDAdQtz4b1m4t58I5mFjqQL85HjceNEYZ34WYgKWtc95PQbn31HND6JmlxHFyIyq2219b/lRnxaRRLZbRiRRmbu/KrYVMGhMrFmVTYDQADxuaWPDaBC7uSLaAaedQRxwreRrSFSAUB0uPvuq0KFnYi3s+a23npp8qUYiaMZObVyObx039/SuURervYONOyq/KpZkCGPMRqTpawHytSTQQqmGwR4hlftFybadL6jvqGbBPLw3sRkGubqCvvPuIon0nK4yKczZf+pte78qkxKpwEW4i4f8AAOzf86xeKxBLCaNwnTM9ub5Ma9Xd41jRLhgmltLfU0iYuRExJGaOMt7Nv8XQ+B+ND0e2KZHxEvDKRplya65gNKzYLCMOGDzCx4Y+tzp7/fRixGbEwMijMw3N+0vxpeNMEltmkLMBfXT78aUPg8Jmtr7X+lRYfjoUz8TIHzZPyrEYZ19pmJvbXyt0qSF2y2OpA+IolZglun8X61nc5xbaxvXrF3tFGIs19tdB8L0/tLW0BG9MAubNqxoywMOGgvI38I7vpUcGKTOptyrrXDjw3ARwFbNzZgPDs/KsvGLi5sWbb40X9JpLJPypbcb6kV/aZTApy5cunXv8taYcRRG0b5LG4ZrXX46VCX9Hh40D5lGi3N/yAoyQ4hNDovcD0+VF5Yzw2S9g3XcUSq2ijud/Ha1NiVePL0jtmJ/TrTvJ++7xpWZ425u0ufLpTQyYOOVmXQWzafXvqPCywypObZ0P/M10HhQiOHIKrzBWG99bLb+YfCkbCwhYUUpAHmswv9dzXCSfJmYfvCFy209/TxoYSTFycmoAWxO2nyHjSTme2XlYZbNfr5UksYkPLkyW5l6ffXSmdMqhGyjXv770+Hie0jaZ9VF/Ie6hLCAZdmLx31IqMTlrLz5wfZ5jufpQyZtwSToxXr9/KspmWXm5rPt8aBRDkfyNtfDpUsw7OW9yT2bg6D3UyyTrCsY7baa17Nc2blJ15j4U+GU5VibfQ8TX6+NZGXMWXhjTvq/FycTL+VNMY8yaD30Lx9BzMfLamlZHGZtB97bVKt7s/KT3i9HFAaxaEdPP4fWocKihYRJxCwPbbqfnTPIReEgg/QVhI45V9kFGVbG2ilyff9KxCZbqhuGOh12P0+NRrlLNiGRIgLE2vbTxuKkTKjKs2t+l/u/vNGPF4luVOLGhOmttr+H0r1bDlojpqD+EU942Et3XboQu3wakhnmNsxuV/DqP0r1p5o1wpQqqxne4Hx1vb30ZQTZhflOp8KYrJnODZ4kVUtZr62vQxTyfvTw3z3uDlBufialaORWyxMA2+eQKSPn99wk44SeX2khzaqzH8P5ViFe0S9kFoyGJJ6i2v351DDHFEQfaTtYpwrA8u+9KU5Uy584kvf8ApQiwUV8sysrb5e4N99KgMameX2kvHJsL6DP5X+QokvnVQiuMpPme+sM6IzXUXKggHU/lXskUNJmCOdmU95rDxxhby23W3nt5VG2JNowbGxsdv9PhSJAyxLdTEvXTTp3WrCqoeRJlMxjQHtDT8/nUcf8AzjEeGARmLMNbfC1BMPhlhhlkb8V7ZRe+vhWfDZpkiXmsNQDvcedMoXa3uHWoowtkcDPbbeljaEI8c0l5JRzEadj9fCsLMrBo4IwMoNyXHVj5Wp2mw7iSSQkEvqgvfm/6vhUXtywQmThg9rwpo1OJ4cnZ5ro36VzQT3/++P0rNilsmpBUbsv/AO3fXrIKuU53DfjN7m9Zt76k99FVe0jjttv8a4F85Zst+hPSiyScPI11sete0RAj9nrYb6VLwcM+Rh00Hf8ArQVZjw05Qv4R7qDYJSoFwSwvcnQmhLOvEtfr3m9ZcvXe3Wreqp7UrkYL1GhpPaMqgCy5idRoaDk5hq0ZOzedf2jMEBB78wt9mnKRBddFA2U2/FXbbKv4WYbUxXDjgZ9QOl64Ho0zJEot7dgTRaRQQmnMKMiXFtxamJ5ip6firOZS0i65idaTFqrXWytpop771GYed01FtgD4/fWuPG0MgsY+ZAbtfp47j3USsozX/EbeWn6UMz8QOBqfwaf6/Co44XIRtWvrr50YlL8N+Y6arcDr8aXDc4lMguy93WvaNFlFx7Xl5baH+oqeLFxFWCfw6rr3nz+dDLGZWJEPKvU/Q0YmA9mdM+4OtIXUHKcwt5X17qxMTcoGYqddgeWl4GJZyz3e+ij/AFrhtOZLNZeuXcmslo2dVe+S/aPd99KmxmIZokDNxGy5yWGu42p3ijQbALHext+dO7NYGRVO/cfnpRZImcbW2076UHMxdtVsDYaUC75P5XFNh+NGwfNm5r7/AEq+PliOeMOkerCNOlvOkU4sXMCYiZW/5R7vE3NYmLN7NLjMO86fpWSaQI8tnYK18ya2+l/hUOLdQXiPFjBHXu+AHzrE4bERuZ5dY818ua5vUWKm/c8Uxk9+W3/yrFQtDledUyNc8sbaj5U+G9pEVt2Xtm2v8qKrlyrqLCwy3pcPBIfVo9C0v4k6qo++tPHhcPxZZrEsnZHh3b0sk/EJb+a5Y3uQbdL6e+p45UzPIBMiZtiD+lJhPReNRGzXYW3B6+7SpDBiZYlUJ2k7fi4orJmsUzpI0ln18Oo6DrUMmFxGR57K5i7LEWvcmjM+EsCOdZLBu5h32v41iYCOHNiYwRna2hGg+lYd8XnEUa6Kr3Xy0399CSPPGVJe4Oh2+P8ASpJsnFd5i1+vfYeGo+NWkiIaVSOS3UEXK/e9CCJyzrotor3HXu7qMkeFhaZezGWPNffUefX507JAk7heItj+P71rDx4lLvnP9nzEa9x6jpWHxCZHjzKgAbZR/L3VkSWGOWVHCJwstrnXWw6Lt41P6xKFlfM6JmNjpcfSl9Vsc2jLHZSLnqW2FBWV8+a370GwGt7VKrYVYpGQcLKuYsOv351LK+HPEEZZgPzv160/8M3ZGw4fj40YQ5sUzHh2sNLtqdbVHFxszq3Le5z6/rWVmcEaH239aB4UWTNxUUa2zAHKe/aisa2lnPtBm1C7hf191PHIeYjL/dpQgZyTkFhfN3Woce5sLgX0FAl7+Q2r2Sgk9w2o4aDPK7nmyDdbd9cbI1tRfN1H2KznQ3HTwNOyhhvbwPdp3UJowySEc9zp5ilaP8N7W7THajLImYpFuug87UYmziLVgq99aXDAns0y5jlO7d5609gItc2vdWUOZA1iV8OtBIYwx3DXuLdKeV8LaUdkZrZR/d61mkh13DMbVnALrfUigRY5f41vevVhGUsSN979T9KzYbBRrhygPFeQXLDtKg8bVGywgHr1BHf5VIkSKOKem4vc6bnoKTEy4ge0FuHGAVH8IJ3JvQRzOZMPyhC1uW970qcIoR3Ht+Pzq+KW/cSM2uvv76PDkDx5dEDZT3W11pcsSZG7Sbe7falGWTiKy5Rl+HvpcUjWFyCW18vnpS+w17W3a086WIFLEZTz3ObTutXtJCXZBlvYKLrvUMRRLklSJBa4J38KLCJnDAAxgNa+nU06m5WzXs2in6dKWVTHGrX1toNqZ8pmGo1Ftev+lNKQv82T4ih6ziJFma50sNaWN5JecWsRfbX8zTxK44rnKL91/hUeJ9ITNMmGeNVjUdrS+vlpWKxkIyktGTm03/Db72p8NFgkKib1dX2zvp/+vxFYqeS3sMPkKi9g55QB7j8qn48uZWfNEb7JWFMcNmwvMFItnX7FGFIl5ps7Ki8lz9/KoMBAQIosKctt2bPY++4+lRY6NrSTe0dOi6f6/CpkDJHpluUGXtC4HeaVY41eZmPEcpY5vDu0qNZMQBLDBex2T+G/vP3eiZcS/DXMUN977608aKxlm7WXu/KsRJ6QjuEjeV9LMqZTqB971wFUZZ5OJmy5Al/ytbxp/UMOs7ki7MLLa+up+9KhwpFp4QeNwdLE3tt4GpCSxk0JYju8evfTYvEZ1kC3R/C3QDfpRlxUEqwLlyh5OZ+pNMvCyk/ilO+o0v5U0Zh0V2OW182mu/uqzB1B/cjcXHw013qOaKN7SCNXDaWJUanzriYNhyc2rabWJ8bVOcPxHjY5kjRLKT4eFLNB6PS6WEzSEgovXNfS3dTcDESEovEyx8vTp47/AAoPnJkja8BHbkt+E++3uNRekfSE2Vz+9bJzX7//AE0/rmJlvOoeMGQKL7BTppekklxccSlAOFG1zmv2K48EhU4crnDdAdtfdv40R/yXTYvt/Efd4Vh0xhvOsrzSFjYlF6X7/PvrFQxQ5XfQNffw/L40YQ2XLfUjQN0Pj10rSKc+LTAE0vtImDniadO6i+CVRCqBCQmdzYdo32/KlUEi3h+dcNXyk7Xb4bVFhUBimK3n4h2On3aihxociTIqovMfidvfUqxZsVJaysXCRr7tczb/AAO9TcPEKcrcN9SrEW2t7zSCSYcRRmA6Kb2I8NNaOIeYXibMf5x92+NcEa2vfXcmkQ3v+Or/AHvXrONwq8rB1jiWysf5vgKOMwmEiiYiwWPQDTy7hUaQjmbWwF6MuGcKLZCsm7WI2HSnLdN6YsQkp1AVdzubdKmjxQXNKugy6rbajgXlEEkg09nfvJ8aKsTiL3BF9F0Pv8ayDTobCpFijzjh3IvYhbjXWo0CMcVnyNHJsnT39PhWGgAlDxKyuJFVlkK7iw+FMJosOpf90Mi7HfON+6maKLhNqRmFw9+XejDiJuEzHd7MuuhNu+s/9oBXodfy60OPw3E+bI1tQDuPCni9JM8qCwjcE6UnB4haw1K9O6mld0eyNIyL0J/0pMOgMEgba24G31NcOWQcOWKyot7K19D8vnTljLZQPAWv060peUEvKupNmy+FRO92uLa6EHQW8OtcByIpnTmv2QNNhamiikAUMoATpp9dfiaaLEYkKCpOq5vj8qTDqy6Btb3Ufdqyxx30Kln/AOmjALCPKA2UDf8A0WjNIP3d28WA/wBKfEYiPMzWC7a3r+0BbMb2Gt/vSoCiHNHaS1jfr+dvhTXJSJiiJcXvY61JivWBYMZHU79B9+VQZhxVnnjZ+ut7flTxQu3FxGLdhvZYgtrfKlXDu+Zg/GJ6Nex+/GmfIGc4eRQ3cTpf4XrCYrK0vt0A06fd6xEEiSRRxADKVtyhm5e/Um3lUpdBnJ0A2W+9AyRIvBvlGS9yVsPgdai5sz4rEFt9Sb217utD0emZfVmtca5mFt/fejHxohxDaRY1sco6MbU8zzhTiIzmV7XK38aF2Ba937x/TXfxrgo5E8g5eYezGg1Ogv0pMdigsJxAtmv+81Ha/i86WBYY3UjmZbcp8z57UnIc0LZGFrZte/e1+4i+1B8RIdATlXlz5jk0PTcd1CJ8Q6cR8kZzGyX6267fKpIYIhIicgl20G58t6SGGMRxJyrp0Nt/heljPEjdrhiurgADT8qHsiPaAhc4zE3691GGBvVMo9qyEmRreP2KbBxZeBu6k78pvf50/Ct7L+0SOf5V0t9Klng5p2fWMDMANT9SKg/2h6Rb1t3R3WR9B4N/01KrRqxf/lcTkjHludhtTyAqYdWuAcp7/rTxFARNFktsoF7i/wAqAwT5lw8cozPszE6/9OtGSfRkUlb7b6VPJHichZVa3XPsPkaaUsTds4XpfvPxq8jyZ/xc/Wkn4t5Wbs20CAafnWWJmkGgCjTXy76MjQImYBWuc2/XfwOtSzIwEeHsWZvko8dPlWSOJ5MTn0seXLY5vyqSeDROW667++kjkmyKC3ZXUb7H30DOIZS3UtzbaafnTti2xkkrG6Kp0PifvpVhJmysOnvoMrajY7nemV43ll/GSNVO36d9QYePCsr3JaXPqR3f+qrtDn91cfDSFcwP+lRwzOGAd2bK+puFt9Dfu+VCfFQrNEdMvhvp3VNLg4FbDrzZQtrafE0sUmCls8ckLlVuDexRt973HkKjwqSKyl862sM2uxIpExTlRcDPGcwynqPjTk8NyuaMaDNpvfupcVBiEY5rFMutGaFFCYNhLNIw5d+UN76OIgm9nM/EljZRZtj87a+Vet4DFxx4VhnEaJmyWscpHiR869VweEUTBRmmeNb+I6/GsLxAQgtma2Y2/l16Co5/ReNkmzx2kDRADxFKJo0vvla9M6yXRCwVCenhVyehF+1YDsiicVM3F2fOw1957OlE5rozZbjcCx1uPOvWQz863BLWOSijBHVdFK6WNShJhlb2i3OpXb467VbIJMPG1t9DQ4gX2W6A2zML0s1rQs9ruPwg2/Kn9c5DmA5Re4+wKiwyHTtO5S1v1o+rgkg3N9bfdxXBha7ya8vXrcdO/wCdaysXl5igvw77+Z3oF3v+LmbtHpbbTfapJXjQtuDfXfu2q7plt2NPw9TUcGGRs23Ezhib3/W9JGXJbMOnMV6jwtXpDESSZTdzHEuoOl9/AVHNMpk9WZWybcxzD8qmxmMw/DiwrXXmuX5rbeOlT4WMhOfMuXU27r/KpYBhmDzf8MSdLZj177UmIV3EecOBCLHKvXXrvWKlIVkSW5Mo0AB/oKPqGGywtdU110O/vqbSNBOAI0Ha0O9RQ+rGRobyOSMxLgbf+o/Dur1bhlpJiJc+vjf50uLx2X2h6HbW16EuJlAYjm+PnrpappUWRUj9mPHW2apZVRyIwAzjQFjTw+smGFgGtflI6ZhtRndnWCDNdk7OY9m3e2t6R8TM4iN+QbkaCwNXEbhIwdHUMMt+h+FqVEmkyns69Ldoj72pwmJWUMWjU5jcsutxUcYYsEkOe+ubWwpzGgwz5ckcebNn8Db+lSEsFMetuzrQdnzMpKDKNZRr0NYr1e6tN7JGvv5fP41IHZb4hcpH4sl7fX/01iMVgsYEw82H5rfhN70vCgfLFq7EauepqbGuC0cxyvfQq176f5K4iexi7m7bFrjNcfSp8Zg2k4NxEokOpOXnPzHxr2IPCz3VrW076DPiF4UBvcL2/wCWmD5VYqwUfhNGSRZiSBzgcuYVrDiPv31EuQubZFVFuf8ASgpZYwB47+6kxURlY4qUQoM6KrDc31vv4U2ASQcKJ2bTTM3VqGLkik43S21eqxzTavmaMfiOn2Ks55r7saCkC436UUvmDaaMR7/vvol4g6m+/S/WpJolQqh15rGi3IxUc3UeZoK4HftfauDMzgXv4C/SiOmulZ0yiw1PShwjtZMzNt31eNjGQb8+5o4iKTOvbKtl327NXxGDRguuZYspG24vQWN8qoijICco203p5hGjR5c5zNqtWxqtwtBnTmy66/nUkULyZWFuccrj/Wkmw7KS1h2eTXzqDiYmKQP7TIhuV6c3w+dSY5YfaBDIw4gLBLWva3gammiVEYchOXVra6XOnSgjYUiPfmkGg799KiaeDNnJX2dxtbu1pMi+rBZO0Nq4TEJG+mq8y0rNErZSMym+1cnUksgSw8dBXAiWS6i9st1r2kESSSLlc5CO61rDvFZVJLIOndpbxqR5FzZnzKL6f6afKg8r8rae0Da2HW1TScXhpETJkSPKHHQn5VE2HRR3MlgpFqMcTNMWCtr0764oLCR73ZhyqorOoDug1Zdco7208a/eBc3MWI28KefDpd+aRV30t0vXEhzDLsMu/XTv3p45WLnqCPD8qzoAtthbVNatGM89wWzX7++o4I9UC6qFPdrSwM8yxs9o3tf3n30yRQlmik3AtykC/wA6f1fKs8NnVl1EjZSTb3g0y4fD3lfCRsL7I76kC3SxNJJifZRRwrZIhYty83zp1mRS07Zh3ijhlRlHNlIN9Laj31KnpJ2UR/hK2Abp+VQZsOWy5WXL115r+eg91JjcLE0S5L8WI262I+NWmjzx35Neo1oekcuXh6Q92c3AHwFNmeHJkGRT+KTrp5k/KpZWvJlGaQElUW+y7i+l+vnWeGJ5JHGZIWFg7HvKnxvXChhZRhzdhbKdOq9LWomSBc0gEoSNQOB/ey/61EqZ1BULIQT7R+lRYWRWlaaPiDOb62/KlkxTt6ysTGOMDs+J7r32ppM8bSOBZS2rNsfEVJiJ5FE6yHJKdsu2g+NR4lHldkFi0qKM3hYfmaWRSxD2QL79qR5HiaQCxUYZOjHw8KkWaCNxIbpl5TfW22lt+nWmVzklOoUaoO/b3Uccr3k44TDhNOGoGZ2t/lriz4dPV7h8trMTbY+808mHw5QO1owEzWXmPhr4nur1WDNkuQ2vXupgwst8tu61ZGgNo038a4LziYqFJtsNNKY4mOXJIgd0e4JHf8qvnT/8J/Wo4oMQV4TFEbs3F9b+FJBEA0p0ArLIVWUco4bhtOpuKyuiGS+a7tYWq6XLE30euEqHm1OtFT2b5rURkN+0NNaeOaXh5NQLXzfetMiKRkH4qMJY5ToyjrQkizK5/D0Xw8a0kXSmDt3WFZdGJ76bnI07J7La1dZLeI0o3QHNbmajk/Eel6XEtjsQ0zRWkYKBrYXUjqK4k3aUIAUO5/FRKJ7Nrje4PQ17OH2f0NBJkZ7ns5tfdRjkkKrIwTzF+/anjhYuqB9zbbw+/lWIh9KLK0GG/s3DDFdSdDmG5GooRmSQxKxJXqPKl4C4l8tizSnmNHGwWhVVZAqrfL7u61SuszyK34iTzDxrg4cy27Ns1291D1tZVOXqLG338KZIYgbn+LWoMOWEMlmjbhpqU33+Ne00u1muaLLmsBve4ox5yym0ht5eVDkD5RrbQC/Q/ffVzhr4bKuT2d7nu+IHw+EznInNY7AZrbfX5VHCpdWjzC46juriLoR0K2P30poOfhxfwb7afI1wxIAp0JJtbzp4Ypi1xcyA30t0FDM8eUJaM7iwHy0rh8JFObNfNroaHKMym+a97+Yq5YZl5szaA0yoDHc3JTra/wCtWlaNWAJu6XG9e1m4hy6ydnT8tKjnkk4gK2SU9nQk2uOupqeXB4ICORrySxjUDy91NJMseIOItlM5AYG1/f18qj9kgbMMirsc5A3+964kMQdpWtnP/L+70no/Ewp7SRc8xbZb/jPT73p0yEFNEfMb5RejhITLHhpH4mS+mbamhxj8MZQM4OoPl1+9ajwmGYekFRyyqLqzZgBbKeug276E8nDQYaH2ka2LDYLc+PXzqLLhGJZsvDbQPzUyYhVukwUNbw6d9hamYR8S6sLsOVR4AdKaabMHbmVhfS/39KXEZGYtJmAG9h9/ShwmUYtYmSMsOyPf1PyrPiwERY8gYnMzP3DqfpWGiVeE0qhxIvNcW0tT4dcIsjscmrHlPfe+2h32oYaWLiSDtHOcuvlua4WGHCiG6DajNLMVjWPRug7/AL8aJgYghtCm/vrFPh0YRx9ny0GlQxorrl4xDAXIzIBXLiPWljW7qNcxHf8AKuKkGQOxCBS2/wCEa+ZozRYX2KksG0uD9/SnnnglxTqMpUmwzE76ake8U7gZUZrdw8qhxI/iIIO2lcJp+LK6gux106LfwFaF6bEySNFMrboM0kl+ltLCtMymVLXUAm2591r1JjUS8KyBAH3t92plCafOsvdoNaDRzq4Zf4bEeFXSAuiEXaxsKL5XvbnPd40c8eZjpv8ACnzEZlaxN73+7VqpUqA2U6GrqdxWXYd1Bi3XW+1NIeUHpROlzWqExrpny0fwk91R4VMTGIRme7qAL27xrUbKqplGpB7Qv1qLDSYz2jfui+mgGvwN6GEnVbQDLoPM/nV4wcw3r1nhS22Vgev+lQsGDrYyZL25V66+OYe7rU7O4jlxOufhZj5L3De9ZcFOsoSIK2SMqpO5Yg7G+nupCvBtrqid/T791QcNLMkQM2Y6yanWs3q4dtc7E3vfpRaTlFuW3Ss6jbZl0Nf+Jls2dh0OxpcodW1sAlZ0VeXtCPQsOtKxiCwSGyOetraGuJHZbgjXrqPz+lL2ldjdj/SniErWIFvAVHCHZlicZUbbpRmAkQuSx16/YNLN+PfRiPs0cQ0S5F7jt1p7HL3kX1oAtzfybVmSTQcts+vw7t6R44msDy5qQZWGUanwt9/Gl4Uh4hPMslttLVkH4tMx+/KgZbM50uxoYyXEKoDkEDm5dLajfrU0iPcIMt9/CvVMJBDGiNwvzGmv8NMmKD8odY21FqWeTDoUmzMFZbKmjfLencYbKT2FRwSttQO/SpYYnMIsGOU2J1+/hTPPjs6snFCu2bKPE9Nz93o2C4d+CEsNLjKOalzABVGjDY22+QpJp5me5ytFl5ctuvj+lZm9GQ4TD3ZFkN9eXS1zrU3ExMBgjj1kI7bAg28bV6zJjXmVG45kyWe57gPvS1PiZOjZuQWtfpbpUMns4o3DHI2uw020H60kmdn4QyuGubMRofLp7qxMMfAV5VCR5bkLm+9/Cpp4MVE80CcOWMKf3eW2a3U0nCVRncsgTTTTXXz+tQTSQpPwZADIX2jXUn776cYeLIJ1H/L1v0JJ6aaDzpJjDI2NcZyIubInj4nf70yZSWDXJFSQysgiVACpFwNQL/nSYBJGw0im6Ln9nIf/AGddaOIxkUsJv7Rfd9NAa4bIBaO7DPbN9/TpRXCyhBArRTI5CosTKOYe+/yp448RxXiRZParyFT08KjkluNE3AO4F/qN6jjEQLNJmddC/dtf7tTRiHgcE+yjQjv5r+NepTsRncW/E7C/9aOLTDaYdcveA2n9daV1XCAML2Zjf616tGoaV2GS/vvTIkg0Uxsw6jrTjFPKqG18p31+VWwsZZVj1urWD+GtM2GRCuh9oL1Z4YiFtYcJbDw2porSRKxDFNr72399ZnR6xE+HPGEUYmR7bagMvnzCrHtHW1XbMx01vWezZTfpT5nylQOlWfTa3jWQxjN162vUU2DtIy83MAbHpcaj3U3FiycxslrZaPEyA2y3y9KW1sh8tPd0qOdlbhMbhsl7+6oXxI0iIXlGUlb63tXFhhdWJJN9V1riq+UrpppcUuCj0htfL3t3/P5Vh8FJh5JJ47nMzKM1+lz3afOuNEzTq8RZOHsjdMx0rXDNYZWOUZl1GYeelI+dGR0u/wDKbbfpXDSQu3f+WlXtY9abGT4jh4c3a6nVyOlqQpggDOudAw/DsL+PWlkhk9oWs6jaMAdK5I+dTbQGlteNhra5pQcLB/eFyT76YouQ35baXpcjXEiqd++nLxgpDrGQugBO/wB91GWWLPrlVdbDpr86jYueG97ZRsNgLfCmdOXqBXCeXlOu170ZZFa+b+EWpchAAW5Ga9EQI0p3NWnjkVOzqu3uoHmJ6a0B4dDWVOhvrrSvCgEkfMvEblpo1CJFcHpfMD0Hf+tesSJkEhvq1xfv8K4kPCTN3WFJNJiBwG9vHY3tfw8/yoGNlKGLPdN3Kgj8hUnD9tiGkYKnUR+XXUfOisjKHjHatdmN9gtcRo83DULlDER/Ci8635baDQeFG0fEt76l40t7qTzCxsOg+d9qxGIxGIbJh17OwYncD72FKmJwiqrsFWEdF1Pz08aMbcsbZsyjQA20GnS1rfGoklRIjF7B7ggMdLHzpi5MVgtr3zLTnEZGcsqqf8Vz7tvlX/DGMJft65h103/16U3pDDvMxtey9tPHMdx41MUSTh8NwWy2tnsvx+lGLD4rg4WFlfEIe3bpp97CkQzhlcAWtbwt7q9aixciybQcJdze+/4datJGmbNzaWzt302It25FUW6jXT6UISf7QnYe+h/lr/Z+MhE8SDLwnHMvkdx9KVoo09XOUNIe2M3T/TcUVXDYRRoJWi3A/Fqd/KpsVh+XPhxI8Jf92o1sO/aoonUO+SwJGuh/p8qlxeGEqS5AjGTbNf8ASs05lilU9lTpy30v8KSSRgzO6m+aw9xoz+joeGuKGUx3tnPXw7qvHhny9OfpWIxCEccjhL/KGBufhp764aOT4d9GOZwjZvPvpuPmZAuhTSzW0rOHANipqV2gL4lnCqT2VH39KgWQfu1IRv5frWREWQ/SpcLhHyKCIMRLm5SSeX6VzRnNbuq5/FrS4HiI4hDEMSLAC7dr41JiLwo0QyRJKmaLMdddb99Nj48Ph4Q75CIWNs9hci/jTSIVvp11oozqO4k0WJ+O9am61lNiqm9jW506VxFJLWuRbYeJoosSNxe0DvamkCS5w1rEdkUEim4mf+W3urLm20pk4kytblCHlJ10PnU0JlZIiFyI6lgw5bMBr/Dv+dLmNkB6Pp/SgDLAyZjdkFgmutSYOfFQrYcrydrwW/8ApTYdSJU3APf30khvlbQG+mgvavWMZJdSFyhXse/WiMPlYXy3F9u+rEhmCm3jp+tXVgpH8opmsBakk3EbEk+GnwrO/Ek4pydk7dKeSWMPe5C627wNPvWoZSjKjxeysdUsdfzrMrjTuHzFNZSB9RXMeYqQM2yiuAGtEP4Vtc044rqr6NbqKSNYZni321JPd99Kdc3Mu6msplzR5t6NjYg3tf461HL+K9yG+lCPDo8nEuQw1+dDAZc+JGW7aOpuOz/1ViMJiF4cKxl+LIGubG9r+Fq/skbmyEsN82ultfKjhMSXGQZOT6a+NDExxSxHtAO9ide1zUrNHxJh2nBvmP8ACPnXFxLZgUaVxfKF7h5/rRwrLljz8RV6i9RsJSOW+1799NhocuW+Y3XeuEyWXLopGhPQ0Z4zzZO1lOh1vzeX1pMLI7a5S6k3Fr/XejjcRPwQb8z81/5en8vyqbEyS3Qrp0ufeKSaXD8eIbBDm8bHuppZHVEZWHKmu9vzpcAJL5SEGiuoXv8Ah31JhMOxV8ym9iLLY322/DUMqTQwLC+TEIz8sg7ifjv31iIobYUrfJZiwK3312rD4VZcwbLIkvfrZh/Ssy4VY1ibKp/F5j5VHFO0ZUS5QMuot3d2pNRxwMAptzEWse+hizE/Gw4YFVPaFtPoflTCVD/aOZi5u1uh+BpMVLCqSHQxqf3ltLr33tt50xw0eSXEEvKxJ5F1vcdD7/xVh2c9sZ1GnZOnn1qaWcB+VnQqPdU2fDSJHl9kB1INgTSxK2h0Gl6RMdNLBE0okRVN9RuQPzoSRej4CjC69vb41ew8bUGSTW/4tqjZ8REjG+mYZt+7upsUZlGRwE5xd/EWprqAO6sThcXCjySBeFIwOhA6W6mklkRYweXQ6nx+dQ4qVSVXmOXe/QVkgxsiesWEmW+uuxHWpHiitGkhVSTvrQggi4kkpzMz7xi/ZHw+9azYaMR5dB4ra2VhsdCaVUxC+jsPb2mVbnXew3tsLXoRpJmUMQGPd9miWtrW4rKZGIo3oixFWzDzoCVQQBl5dKV4JTr06rSYWSUcIvmLN+HvPfTcGXOB7qaPPaQ6oD2WPdenMhzMoAQhulCNtcnY8vztWcGx3qPFzCP1fRHmXUou1/A00XpH0c3EZDzEZHB6X1valgeRbqxBYX18RfwtTwetJCj6hX121GtJh8MzOTa6hb0+Eju1zre/MLn86aV+RlF75dKSQ2Ik7u77vTNdmBB1tbSpl7Q0ou/Fea1wL9ld7+dOSv8AOxHQUuEwuHkCJe/4ja252p1e4sbeNSPxthcCjdAG28q5dKyn30Y3xjW4l8v8K69en331xpMQt2G4XpfY/fdSxm2Yd3351ym2nyq2u+9uYUuCwEaxuhc8a4vbw86Z4Ufjk5e9HjI5ltS+jEw5zSAJbLfxNtdalgnwkI5Qqum223jSSW4b9W21vvRhkHEnkZfas2les3f1u93DKeX3detSYeRI8NFYAG/bN72+m1cMYYy2i/h6sb3+G1TGLMuhALjsilhxZkjiOfMV/Da3N47/AArCz4S2IyxpFmUZsxtppUcTBnxpX2l9eGm/N8/d3VlSOHLIWvJo7G230p4MRxCS1otb9L2vvl06VPNNhVVOwmc3stxr99aw/HkXhuJFuulmsPHxqY4m4aUXjutw/NsD32rgQeyHON7XYeXwogKScTmz+PTfoL9Knw7BkRlHaJa1mB1o4rHuUxEQEWo6Zr9PMCliS0qGRWFxqGbpTRcIySnfKSMutxYVhcLHHLxOe6hL3F9/nTLcwTZCeQiTKLfw71jczXcQsdU300a9/GsM2QRRkAyOW3T8XvFjTScSC7ZTBEpPLCo0vfb89aaH0hgWfMDIzXtfYa/r41w5cTJIovkB04h2Pu/KmTDJKmZ1L6/QfCiInV1e3Czi1z36660BFhZcMO0xzfi8OpqHjI0wHV4GBQX/AIvj1pVX0ZM4A7S7Hx3rKq5i2wog+6xoGeQhM1zy5rnurG+j4lYpBhfWULn92SAQrH4ipEmXK69DTwPArZ7a7ZT3itBUWYf8Q2w3t93pHVnaONs47yBSpJArzCzKma4JtoT5b1w1xUcl1BYpqFJ/D7q5bZgN2HhS5pY3zJfT8N+nnUcbkFYhlCge/pWQe7xrs6HuqwOtGMovmKBNzH+dZlBtXaPlasl7UWzXyne/0oZ41YKb2alyM4xF9gulNkROYblb/WvaKRJpk7sv3+de0w2eSVGWO3bDDXbrQhmgjaPRhkdRy3/GAN+mtRMc8uLlOQcZy2t/noRUuGxuDgxEerZuxbytQ35V7Nu/resORycMh+Qdnx0pZFYNGvKSVsD40YY8pWQ7IARa22tSQ4ZbcK5AzXuvf9/lSiSVWYdoZNh50GIBseGRa1wN6MpbtWHkO+pHZ1zRkLwjGSWN/l1psXihInGclsqiwFtLa76kfCmnifR6KLLqdCQelXXTZtetKGlVb0EMbRyLvm760ue8VmXT31md1286OZM2ZSB05qkjY24jZt7DT/U/Os2Ik4f8v37qAjHaoKuIZjCNOYgLpa491ZpJM8hubnxrmG2ttrigs0XUtqbXqR8XJKI5GzKsa38h1r1eLCjh35Fj1uDa1CHgZhIWHsbm3vH0FGfJHmCZuUDXpbUd1er8CPPeQNlGUAaedvlWIgiwojjw6rwcwIJufjr37U6jEI+YDNa4Eafia53J+nhRggRRblYm99dra7fWhxsWMxPMxQkJvpYe+psN6/Fi8Myg5E5W3v116Vh1dY1w5mlRr+OUBtdd/wBKkTCzmJrajoT5+/4jpWJDYnK9uV3O9mG5621FR4GMJPAE5+e5Pd9+NM4GQf8AL1NzfesLC0DGKNFEoLa5j3n305hgVYUfSxIBJGljvUcs0CluZn01z66fSg+IW0US5yY9MwNtKviGKxyRm0ec3HS9j4isQ+JMTRcq8kWWyG/cNaeaKFFXiFcoHbXTMCPcBpWJx2IJzyoVY9T15fcLU6YdcOgZimaWewaM/wAHd8DUxiaHFc42upUdNevwqTHJwIsgsoQXItSqyLxMillL5QMwJsP0oFCZMntLA85OxBNulu7rSZ2xfGsIwqEOM3UDbXWlWXDYgOAMwKka+WasjHQ1h/R02SP1hVZZ3NozcVx4+WRJNGUbHwr18ej5DDiSczpiWUI1suYganUE22vQxUuaQE8xc3v4XoHEezyKMqprqd79Rtt40uHROd1zKGIXS1BPWc2RMuc+V7VCvq2Qx+zD5u37ug/MmmlmLSOxFyNKRWlBjmQMQrdPGuG7kLftW60ECMSGCE3vahxM0ZYXvstZpUazcwY/ioxIW3FwD1rnF+l7bVDF68MxNpGCaL+tZlXiBdwtCUPHc3Fg+qnTcUWwSZ8sRLh27PjSsxQGYHKoNyPO9cPKLk3uDQdQLAW5v0o4oQgENmIvb4a0eC7Mrrns2pW/eavicQ0HewF+mlHjYwNYOsecfA/SopY8cwSTOrRg7G/TpUSxyxRvEWj4RSzL4+G/yphjbP68osL82Yg5LE+NqM7Cy3I8/u9Sqpa8wCP5X2+lRiMMDbmsosPdRlmu3LcDbp9K9djaMyqvMt7dNRt9616xEpeF9V8iNj3dajjut2XUWHf31kglF4iMlh1+/pV5NSWC3qfD6LGjZWca+Qv3aV6pGwuDzueyvifDWnsY2AN/G/6VZnCrl6ml4T6/i8fCikkKjW4b8VLqLHvrO0ehrS4r2xYgaApr971pDxOJpGet7VpLeQqNP6+6vZyK8jaG57PlSYb1ePD5TrlXbTXMd+lcYizDSgBciuJmVunypYeGSzAoAdebp86xuExEsRCScJpY7IrW6nyvQyzFlSOzBXICeQoZ4I7lQBlIyXzdT7x8KaUKGuxTMVFrgb6d9TzyQy8I5A6kHhgjr5bU0OJxUikx572zaX/F53+AqPEYeXjxS2zbg5hmvv8A3qaRYjHBxDYv2T4/L50o4iq8+ZpZM12O5Go2FLHDLblznMco/wAN/d8afiBAgurtmuuYdfvvrM49mxI1GqDXp4ZTS8ZImzo+uxC/0/SlDENY6ffTrWJDFUkzKCZLjKtr+86fWlw+DK8E9jTw69aAmw4cGRwpU/fhUirh2yxaFlfltYAX0t0qMS4QCW5BXKwFh1uLXpmw+JXs3zgWsdulr/L9cuIRlMqqGkbXruPGrXELNIsMYOl193n8q4EKq2HjzqjX3Nr/AFF/fSYyEZAnZibp3f6VJNh8UYCNUC9p/wCZbdKYyxviJUlFz42tegJ5xdpXkbIwt2eYedrUmO9J4dsSUkWfMps2u1jQ5sQvgI9B/wBdYNJACFcvr/KL/lXtYkkQ66i4o46SXixz5vYumgBH6/KpcAkFsNKxYx35denlUXo30fg1iXBtfli3LdL0spA4cnZsawWKwRZMcOV4k1FwdG8z3UMsvXZlsc1ub78qw7TYeb1IMQ0mS66C+WpfSOEneM8J5PVMujW/9vhUx/2S540eWTMAoGbUZQbkDx99N6L9GYSHh+kGD4fiP+6IuCQe6x+lcI4jCTSdGS7Zj+VrfOpWyrO7KBxW/CLWOh76VeYhdvCiGjbjhrXvf6UsuGj7BObNqCa4rbHe/SuMvP8Ay33ohmPHJFlCdod96sGPMeYHY+dSZUy6sqssl9NrXpcRjUUw3ZbZ/wAVtMwHS/51H6p6NEZksy8Nb6DTYa6m5pP7TxIUVpQNAHP8IO+3TwoPwigKjZStx53PxpY8l1DXHnQeV2TN2iLag+FYeGL0gNEy3XcfKkwM8gLtIzs9+bx1Px+NetY2P1lsHYlWXK0ibAaDTfqTSYM8WZEDa2UmNz0UMdf1pY3nVy+jW3V+oNWvZR3C21F2QsxfNtpalnw4Vm1LIoNo/f1qAScPMGKGx7Ou5HnepU4vE4d8j23FSxgjU6aamuIqezGmfx1rg2ypnzMA24v9/GgZldlvcrfU0Z4TnzXXIBrltV1Gn5UWuAU1seutZ8wOTU1Ztyd61FgBt40TbLYde+so3FGVWPfl20299HDcoZjzEddPv41nRltuaZkQXmjyqGv2r6H7+lKTe1/dehGzjiDay9od96vG+qWe196JAjVr3Y22pfSGMbjPmJs3f0qSKVI5eGC0tvm2nQbVxY8yqeEocsLvvYa76/SkjhOaa65Ts7Mbaa6XrgGR4ZQRmLX33/SoYjBlKjIHTVSL63FcmSJFbdYM1zQwno/DqzyatIy5l91+tS4jDJxsQw4cbOeyCN6jgnQCTg5Q2Ua3N/vyoQy4bi5itulxS4qTUh7eBFOJI+HiMvC5HJBUm9/Ow+BphlC6819e/ajErSZ2YG19D93pmfCcWU3RObVT5e+rTQLdrHJoXvrfXf8Ahq8khUsbiMDbu+X3rXBhvkvYZRblrhy4V44Gw7PEuXTQG1vGlOFDu0ZAbP3HT9KRo41kZ4MkY2O316/GrtKODJIEDN3nvrD4HE8k0+sajtP1setjtUvpCJZSXsI40vcGw+G3zrCpiIJeMt1dAMjdo6+NcGOcPw8Re9+ZQ1tNL+GvhTRFeSZY1jULra4IUeNtK/4+NP5Rhr28LmlxEc2E068baoMOJF5QFst6Uwhiy6EUuHxSlJR/F+KolXFJDEpZnhuLzHfs+GtMMvCjWIuOIh7G917/AOtRiECNox2s3XvrPMMzX11pX9GRoggAkmgYZTl2sveb2r1fCQy4Zs/ORJe4/h6GoEwWaXEPEqiKKW6lhYc4toN7g1h/THpWQS4n1pRKUY24RFiF7gKbGz4lMXCt2jXiAXa3Lfu/F8KcQ+joeAzNNFHk1KFts3QC3f30yGMAroTfQfd6BgOa19T18aOHMSGXOZN7EEbdPOszSLbNolvnXOAU236/d6MkEIVMRdI8221z8BUmFzRsIzbkO9ZuZgu47qjwiFoCc3tDzDY5RXrAeSL1Vb8R0W2YHpfp416rC0Iiw/aIBHF948b7USF4YtYC960phieJmka2VQLW/wAW1HDxBGVRyhW5VPf4naji1iUNrlzdK9JxnLNiZ0Da/hfTRfnSwxzlZG2PE0ufCrYuzzs55lOmlCDDseKzWUDoNb3+VNFNjoeIy7KM2hHfUzxzIOClmudwdNPjWTKzLJyvmO1/61PMLexPDt42pXve9SQM2aJXV8h2zC/Ski4jZit2ttUEuImbJm1yi5RRUTYXBjDhH1gNwSdOvu+tGdRlgIOUMbE9NO/era6VoFa9ZYxcEDwrjcVPaDNlpOHsQL0ecDXMKJX2gOxBvauLk1HS9SPDIzkWyhRoAb7/AC+NAJzFDcaa1ho8XdsshIhTTUnW/dsPjQY4LR1EasQLqb67eHWjIOyTeg5Vj5Vmj5ujCojg+SRmtv8AWolxdzGP3YbQW2H34UyD8Nmjytmvpbfu8qfH+0mlVTLOrksF+9t6T1dGeBNNBl4hv1A+HwrFS4+WSMSA+yYWsegA8qjkxKMotZl63G4+9KOIREiXCkFY8ouR3eHn3CpGEE+HjxKrmhk/A3d/d7qtGW4i6W6Wo5pAMgsvMOzrelw+dSMjF365gCxP5Uzw4cOrEL33v4VMuGiSRQOHmsNvsV6zwuZebm11v86hjxhbOYiy5o/3Vlvr4m1Svho8slw4YnS1tWH30pX9bJMXPw8hCNtp9ihHFG4glsr51AXrbTv13qeHPxSiaxvEND5jyqKaSXhxpzEdOzsPfb40eIDJGZuJZ2FhY9D76bGwIPWm0B6gX6fSmhjllPZlUanRjrfy2rKUZ3hbh5VGhGblb4afCs9v7RwyLgasAD+ZrjQRyRM8RRg73ufPvAv8ay4f0rhUiGiKdwvQbVfY94ritFdh2WB0Hupn4qyF9SV6Vw5skinoRQnxeFOKCKUDXs6j3b1NhPRscszcPggWzNY7n4XrDYzFMgkxQ4iR3ObJ32+96/2lhkjVGVuGHtd/dQxDYHQ2ATNz6m21YbDYJMXL6WbiB4NFWK2l2I6b+dTB5UnknsTJks1+o32rFYaUAqYiS38FtQfjXJezCzeNSZ8bKJoFZoubv3Xv1127/GuIkHBvuB2aGW2lIzyZmsRl7qVTYe61FgNANQTrr3CoHjcDLzDLuDc/OhjnjvETbP0vQZIyM3XWo3mYDKrMPE2869YclkPKFjJRQveP60+LjysvZClfw+P61cd9c9xXZNvOvdWoPZsLVkfLYabffdUWLeVnIQiNRZbf3v4qdMrPvYZSSfGpmw9hiZRkKmPVT4dx1phI+eb8V9TRBU5gcpHjr+lSu0Do3Kq/Hfz1+tcKeROIy8wW5zMPlf8AWr5kv+LxN6iiEYUFglwNTqd6k9p1ttRZ8rZbKrBipB36VJiI8ZKZIZNIihHn4/6VwZczAbAaB/f5tWt9BqR1+9K3sx3PhRBO+1I7EHl+FJHnjIXuGoNcTEMEjAvp57edXTVbaX1AqKONGBa4YIakBbTNzWPatQnVDwmPLJ9avJGDDMeViD8vhTQ+zzghTm6C32KN4+IzGwQHQNfppXDmGYZ72B3+NceO9m1tfXuoMCGYEaX1oNIGLWKkNfT50hiU8VcxGY+e3jROIlyadu2h0qWaLNFho1FmA/De4HmSahknl4heUu9377XJvv1qNZFBDRtdwO02up++tHgIrK38O5rESek8RM7hSVBO7Hb56+6lwcUY4mIiVS1teIZDqeptas0mDMgsQRy65d96NsKkchY5Uvby/KssMgEpyrKpAHntUthmJuLgXJHRl8d6imhxLSOXYhyTzDpv3d1SYlmJdyFDPrv9aL4wcIR5uG1uXLlPLbrtTYb1lyt8paNRze+9HgYYtn5b8XmHXT4UuSDD8TESXyAgZrHVjcgfZp0xKGORDYLlv4D6U3GbEMvHyxlIgWBA5tz/ADChiQpkfEBSGkGUjre3fWDxEkOZGDKbNpmuTb6GnWPCKvXlZrnXxP3anfDz50PKVZdt6QGQZCNwPDQX+FP/AGDAtzHVi9z517KeNvAMK1WuJCxjfvFf2tT/AH1/Ss0Uuda40F45OuU70mKx0EMsuH2aVSD77afGiWORHbMvcO+331NN6D9AYaWTGkc8pWyxDv1+tJwcXKnpJDxBjb8+f/4+FH0T6bhEHpJBfKDyzL/En6USuH48TKRl037vvvrGouEtFIc0W3JScDmCANy1NJw3gD86o2tr/h++lZc+U+Ne1dlLA2y1JiWlRYcOAzBzbN/LR4EYUvJYLn27hc/nT8XJfMQRbr4WqNJGLwnUENfKe4/d6tzZhtpSy41LxJhcz3AS/wDl7X4qtg0KKNu867nxrNjM0hNle+jWH8J6GmgivJBHm4By2bW2h8N/s1m4gv3Vy1lB0FPI6nLsDb6UAr5tdjSjiNy6DwrDz4f0diBJbQmQXdLai3Wj6SxmFjCXDBXsAbdLVJiOOqGU8+WSxN+lCFUzOmZyzEjbv9wt03pwnBHIFXhjlv8AO/xqfNISIYBIqt05lBppFBziS4IoC9ywD28RRE7c7sRzfhH60+RltbqdKZCQACPfQm46DK2XLrc+NcoykG9wdGr2rDL3W1NIgvqQg/ivpTR4bNlBIOcajU0YylzvUkyiyxlfPm2rJfY1niYrmGVwN7HcVeLMrE6G9vfTGXGFYYVycPh62Ols+4FGAfuehsNfu1FQ13a97negEkblux7l+9Kd82ZjEEOb3fpUEaknhhrg7XJ+/hQjB7OvmKvLordkLqaAYKoi7J2+zRJYhgLd5JrgS8T+6G7Xn7qXEwx6lSpjtlC3+e1/GuD60FhmQSXPN00F96MsbqjOvUBwaAZgsvdfTTajiJsOONNyKpHYuu96fGw8TJewVW0Ay7d3f8KzNnzE391KyEsL9g/hpWAfLYAkb1wpE5HsS1jv3/fhUb4iMrsLM2pI3a3TwoNmNjyp9+80HlJ4he65SG5db7felcGWF8mU2a/aH+vd86KxyryrZSM1/h3a3r1jDYh1DOyXt+ED789afLhyR2kCaAsOv108KGYK0Btn633F/j9KEWDfiRpM2dcttCq99u6mnSJuFmzHJ9+Pzrg4m8WciYMZOby+VSZcswjdQhc2ux/0v7quk6BeguP0r90K9kWTyehmCyDbUVzoyfOuLhJrN3r+Yq2ITN/Mn6VdWGYdf1ormaNjrvoatGBr1Bt/SrTJrXESThYiDmhnTtRtTehfT2KbCYxVFzHlCzWO4b8qfFwzF02CsOZupP0rbTuoS4hjI/ZBvc/dqWebDYfjc4TTnC95pEv2R86Rpc2S4vl3p5sFDMcOranfKvnUGHTER8Kc/vezlF7XPdtSYX0erO4bmkzElvdQxmMw8gi14bE2uQPn0pIoJeHC9la7dpPEfO1OsbqmT/wiSL++jJLdpGbMzHrVj0rlJrlvVzv1pI5SPaKJLDpQNqVNB07qy4icZY+QZZL8Pw8KSTEyu+ddC/cNPhVowzG29th1oc1cHNcnRbba99Y7l/8A9UX/APyJTTgbAlrn3UGAtlNNiN421Fu/upgIzIdOz96VLiRNEiIQGVz5frWRGDZLuwPgKLYmHiTSiNy0ba2rEnDYd53zeyjju5Hf8KMsTlShysJHAa+n4d96zZ7udzfe9MyOVNu+o5JIA8Ae3MvKT7vdTf2NTEdAxTW48aAzhs2p8K7/ABo3BJPcd6UNL7r7e+lTNY66gDmNv9a9XVeFH2rL+LT60RChaT8NqkM+Bl17xtQQT8NUNgbXrh5iT1uLUcwAB2ZheopcRExMgva+uXbSo5ES1jpmNFc2XxX6VxJvR6yCNMq510Ph37flU0mDUsvDyBUvlN7cvfQfGejoUm2PFltzX0sBsu96lwuJwsfDZBGPV9CboQbX31zWo4X1R3jiYosbDL1NSNMmh01GX4eVB0Fs+vLoNf8AT51JHxs7qbLdbKF6H6VJEeJI/C9i2xFspK3FLiWUs6qkjq1jwvK3lWTBogP7xRk277ffSosNDPwTFGsfA3Lm2vTTUmonMKgvbW9yCfvekZIymUDMlrsQdPIe6oJOAJcLGBAZAw3tz3H+KoMTF7WQNbNlPL/NpXHijYRq+VQ2p960IuIDwl9mx28KRZ4eDhsHBlmLP2Tfm95NRLCoMcakJw79dun3asMeEchuRm7zf6an30bLF7s37NqNZhoa5x/iWrhxKP5tau8bqR3G/wDWskkiuv8ANvVuKvxoc2grLKga+lxQkwd+LGcyWfKQfOm9E+nrlWQRrLa4C+NSYfi9g3R+9T31A/rKyjFRCZSnToRToruY7HfxpD1O9arcDTppSetXOHv7Te48rdaMJwEGIwiXELJdSo7hT4qH2C5uUdqw99TPG0mLigjYqzSFFDXHXvtepePLkkU2IZ9fKida5WtfehmfetDegR0oQ4mES4dIX4oK6EWsPmRXt48VF/8A5FluV8De9xpQTAemWbPsGhv+f5Vw4sdhHbu5gfpWFyQxTiMKZ/bc0jDfeuDg/R62W2onT53PfUnGwJUsOVeKmnvpE4OHzJcfvhQ/4Vb/AP8Alr01h5ZBxsMoiexvs3T4VOii6OvMDsfOljuAH5qLOLq9+IM2m+lQYbCwoJc3DDpmD+B99f2LHyyRi4Zk5cvLr7qihR9ZTlW/1PhSTXkwcAOo2eTW5J/hr1bCpbTU9TTYiGEDF9rQheL7++vV8VEYij2dZV7PmOtGVSP4wLZfgKihxE7ssOkYzaL4U11JB5rVmWS127PW1ZAF5STc7+XyrxvsKEkEKkW/Cbk+6l4lw22U9oUVV+b600bGzZfzFKCdV6mpJeJbM/sx+dDlu97Pvy0PV8G8wGrCNc1hTtO8txy2bUi2wpsTFG/DVu1IflUKSZp0xDcO4Fsp8ff8hWZHyJGp/wALD/T51FNNLwzluvfm2v37muC6iV3y5CNl7JH6fGnxGGKQpDGq3Qfiy/h1/PrWMmxUN8rESRvze0B/XWlTEI5eXLouyqRsPnXq0QePhbsX5fD61H6vEOIi5AGsbt/Ea9We+YsyGzdfPvv9K4KTzwkC6mTnXfS7foOtetYlmu7ixvmy91vgT7qMiNmd22Gttfv5U0MWJCQwtpZgpsTpas5VC1guVd7A7+/Wo5EkI4kQSWE6Rv3hvl8a9YXFyWcaFNQO4eFevzTEKTk1XUnrt4VJKwuWAO/apo0HBSZrTsdNeg+RpHjUcRGyAWsPu9LLiJ2XCgZGH8TC2nv3osPRsTA63yjWtQRVs1aH9t1NjVmUGtAtbr7qWRiSANq5ZeG59xrSUN/eFGDH4UZT1rjejZOLh812gvZsvcp/WsRBlnjxOgRZrDS1yR8KuEa/Xa1KBa4+VAyvv/D3UrDhm5vqbCpJJHZJe1Gvf9/lUfHilSJ+yrDTYf0pooppBGxuVvp8KsxrtH40F6CgdK2rapPSDxEvi+zoDydN/f8AKlkJCFlGoHXxFDERIiFdLLpV5MIrKOo0atMCDmP8RzUC2GbO24K60JMJM5ynmVjVo0Hn0/rXedya/wC0UbnXM7ea5zWQbbnxrOwBy9WF6sqEyMWOUe65qNkRUdQCPPvpMF6Ow8rgfvZidCTvc7fnS430i4xOKH+RPLvrKgA/YU3t076zSeyxKdidRzDwbvFCLF4XLGdEmi7D2r+O29DS3QUc0ZuNxSssB4YOpy1e9wx01rgwFVmflErcjC/iKghxDoJS93Lykm/dp7zU+Jlf2iT2AsOz/rXGGbMDctUqvNyAWYbZvCs8sgiD8wuO1/SsS8uBRcPiDfPYhAfCxF/L50MFgEtDHqzHeRu80+Jw8Ea4k8zHIOf41Gpw4BjfhlFjAy+dNJ7LKbtYorEeGv3pTYg+zKNxGU669dtB999IryQvIr+xa9x1ouuCEqxKziWNrrm6D77qmw8gGvZZVPLut6kxuHnbEs8okdm01JvWGfIRLGojde7S4NLBHEeHcZlLbP3sfu1SSEKki6KEWwt5jeg7OCVsZOXYAgaAUzzYjh6ByzLZbX8qtk9mkaLGda9YCAGAk6btr4ddDXrc7GIK9hExPurEpK3EMzZHFrHQ30t41nBKRiNuUXIY23+dR4+fCqFVLE5MhB7gK9U0tK2eJpPwm2q+8daijmUssd0VtbMTe5Pd0p8X1Rs7q7k6D7+VQQSuCG9s7jbIfzpZYsQRhFvw0RQbnZrkner+tya/zGrOJyO4pTYeRZos1uaJcrCxvRZfSWMmzdMQ9wPhauTE/O35H612m96fpeuZfqPrW9XilFc2njQuPfXSvZSuvhers+nioP0tXMqH+61vrXCx0Ys3/iLl+dZPQuIQrmz5X1vv+L3miuOgkgf+Ycp8j1rmZmXxoJnXKRULxYi8jHK0ZHZ21+Z+FOTPCvCW/PLYt5UsaMkbN/G4ApldlzK2U2N6vQ3oAltOvfW5qPArfLfNIw/CnWo8OMKMi8oyN2R4VkkZzb+JauiAAVppWZHKHvBtQMkEeJbx0I9+lHgYOJR3Ilz86z43CILdq/Kbe64qQ4Ob2ohz8M7gfSvTMLaGaJsvxvU8F7xHDOxS3XvpoltbV3ZtlHfV8PguDAoyiWbkW3fUMXpPHJiHVieS5W577X2pFwiJwrcvD0S3+4azbNTYXGQJJE/aVhdTTYr/ALPvmG5w7n6H9a9RfCyRzKdUOhrgntX+dGJpGGTXK22vdQQ5iG6LvfpS5JuC+zH78qGOxkUUkUq3WRk7OXwXb+tSerekbkvq2TKrAnS/fUmcZs5ClSOnWuBg4nkaR7Iii5NJjf8AtF2t1wwO394/lQwGCURogscosEHcKygW0+FDmsbX+G9Li1gvJcBW1uB4/H5VIE4h1y2e/wAfPr769XjkjGfZj05jp41GnC95O/TfpSQRN7RMQQAGt4fZqXiIuS63u+2tSK0LRWbMxZewL9LedYdnQu8ozgsNgBt9+FJjHhjniGdkU/h/m0+9KESHMrbZk7N/9KaLEYvgkfw7n3UkarkjtnOU9oje/fUyZyYndSPxx33sRbSuGAiLxC3Kxtt1+lOuMVYi2aNDmOlu+2x99DhYgyRDsve4I6UZPWJM0rFco00+/kaODnl9m+e4bUbflb50kUshObmC2vpTRy4kWvcufw/y+FNFwZEGS5ZhoQdAfKkllRxGTljhZu4aE/C1f2dY80ftFBHjrvp1HwpmfjOxOrZtzV19NJ/ijI/Kv/rmDH95wtWh9KYOT+7Kp/OuXhNQAKpy5tDbrVppGZUVjzGrFa1WUf4aYQ42WJtxYkV7fGPiWvuw2rVTXWj5VJKhDEC48tP60TBnsWUadxoSoBr7iPeKMWKRJkO4kUGocZ6PjMJd8jIDy999a4THJa2oXU69KMJJLcTXWpu0JGOhPXXqaeN1TwN/pTdnmvYD8Pn30b+Qok60s0yjM3MB1pRMr8U+JpoocjPLq0jn6VYFLdfaVmSWSJ+5Bm/O1eyDEfzVy/KtW/bn7qBGhFescJOL/Hl5vjWf1Zb7UzYCNImbc5AT86Q4+aSTh9kZsoHwrjG5bLl1PSg+C9JzxINo9DH/AJaAxmEkVurIQf8ASuXHKvg6la9hi4ZP7rg0GxuJWLMt9jXF4zy32yrv8aGMkixCqWtoA1R4zAzZ4ZRdWrhelMEkvc34h5Gmn9AY4SD/AMGbQ+40U9Iej5Y2XXmXQ++sxRQGOyja9C2hB3vtWOw4lQcqsP4z4Dwv9aTNicSXaHNte7fZNJMsXq+HH/PlXQ+Q61fDjiTntzyb+7uFer4L/FJ0FWHZHU9aVGcZpRmW/wCKszOVjU2ahC5MmFY3Mgb5e/TXzrKSwfK2dCLcPm0I7utM8Y4uHtZw3bS725e/QfMUzoblZLaHUi+g8KjjcxssdrPtqPrUBwznlfPLJGObvPj/AK9KxkiZjedkI4hLdrQg+6o0xDlZCzMqsSUHTJ56VPBhEMcMa8wDaN7vdelxioRiMRiRdnP4bNe3v/KkbgaIbXN7sd/dtXDxdivUKtiT023pcNJMY435CSOndYU6x+jDMqWXNLymJuhPh4UVa10mtxX7Wby6a2+NSYbEMJJC63Mfa3uezcbVhsJhJL57O5ZeyoNQQWOcC6FTdcvW53r1iWK8MY5Tp2dWuPnvWSO2WWHkA1zEnfzqOHPEsacmcj8dubz/AK1hY3R5TdrZTqTfr3bnTxpUeLKViysmbYnT6XqzNhQRuNdPlQuK2t5VyzH/ADVfjuSKw7zXa92zN4M36VMiWkbLfbbYW+tSzrpwo3fXwBrSeIjxipcFjUWUztlzjly38Ki9HKjNeIyMQL210/Oo8SzO6ydLa0FEup6FbfWijaG2ulaTAEnvqxaKU7G6isigKO5dq5WF79RSQNiinCJN1sdaL4H0jGx3GdMv0vXA9IBOJo4s16swbfrWeSHPFazD3VDLkyF0PswO7rTzJKFCkDITqb/6UscaM8ncuprCjg5CIED301tSSuwOUg5ehqwbLpblFe0kufOtPnWv+7r9KK/71jVj+2xoci6baVqo+FCHiIYRoiOb/Duq2Jvhn8dV+NCSORWVtQQdKMU8aSod1ZbiuJ6mcNJ/FA2T5bVf0V6Uiktc5Z9PpS8TGYfCJ/4xkB06gCkmxsj+k5oibPKlwp/ugfWrQ4Zu4X0q+If/AAjQVkTRazO4T+Giv7uSC08Q2c3O4+f9Kl4UMivtKxF1LZTt77/HrajaNokuQh/CL/U+VSmfh5YMoXMts110HuNTwpzQs4GdgR/l95JvttYUMLhsKOHhhxJDM/MxZst9NO6v7G0GIfXMqHmtYEnuFtKgOKWXVn9nYhgRbXuvRxWEs8hJkaMqeTr9aTDOY8rNZRbrfX7/AFrLhcSpU3cDtG3j8KWDHSuVz5hftKNdvjTQrt/D0ozYn2aKbN0HTbqTRxcMrNDGUjyHUOcwXT41Fh5ECpHcHmuXa/U7nrUcaxCZ8t4lkBYDrfLvUdgwkRdEVSBn6eH+tN6Rx0YbjJwVy7W8PfTYZI3YYjXIBmbLfw6HSm/2rG8IkUIsEZ58vl+G9HgRrEqMERQST5XrL6RlyleZBHtzdR76wcsckfEMmoAUnff776OMw+JivDeUi29/LyIrlx8xHQjDSH6ftF9utEJWHR8dOqMmbh8JGG5PUeNNKvpKSNWtchEjPWsQUxmMlHDOplup0olIJyv8Wn0rD9wLH/pNYtpWukeHAF/8BrBw4U2yy6jyH9aE2Kwt2Q30a2arnCwiRTlLL1Fh7yNBUmOwhdODE6tHmO7DQ1m2qD0bgsXMDK9rZtKyYjFPJIi+0JO9OMPGIpELIpU82nfUXMXzbtapgG0RUAP+EH86OJYGQtf5V7LSw6UySZNVuAQ1/pWS/LpcZSRf7NcSDGyRPtdcwNCN3ZrKo1PgKhiaSWzSKDaRhpejw/8AtPPGt9I3J+tHhen8XI34uHz2PuNF29P4uJRu0yZQPia9j/2nD+5P/nXJ6fj0/iUV/Z/SGGkHfb/9ayrDhpVt2swFz77VZvRMTf3WVvo1e39BOv8A5L0C+FjWwtaxvWuFH+atcKw/x1rDL8q2lHmK4XGIa1+ya0xI+Br/AIlPjWk8Z/xirjX/AHc0x08FJr+ynEeWlvhQWT0DOwv+8STJp79/jWZcbiYvBl2qyelsO3g61NxHjswsuW2p91RTep55CgvmkZSa/wCEYf8AmXrmwR9zVeSDLVjGFB0sz29+1IgtEMO2U4m5Fl933tUESzjK5IYhSDa1w35XoqZl4URtGpXKM22bbutXBxtsRE0mgC5VuDb3n9KxWCwuLEEiPyMTnNvvSsavpCBmabMOZu2wym33tU2NILMq50jVsqm99tbmzZRpQmxEvO6gMZ7WNrddr/0r1gYIpwmsXYWt/LSyxcLnGdr6dfH6ivVI/RMQtfNzkLObbjw/WopTCMMFA5U0LHS/N13O3hSLicOq8R+SGLZyv8TeHnTr6SxEjWjKcNT39NO6pzP/AGeSN1nikPTY6j8WvfSNHiImMcjSSWe+YFu0P81SYg4WTPC92bMOYW7PW1KmIxBAJurZtvl8Kg9TM6u7CMs0meLXy28qGIxGEjR8txJcHkvay0MdhyZIrLmUWs7bU08d4587KLaZDp/WhAZMlyTnccoPeT0qKK0qQxexBZuy2+3v/rScJpEiYFmS+jqOhOnW9csVh0tgifn+0Z6tpQj1yRWjOU20Gn5Uixu9sQev4bd9TxasgizW291NiA5R8n7s9D502Mdhny8i2+Jr0nIHAP7sE+dv/bWFUzMDdzdOu1Z85bW2tZdD421+NSzC4VgEP81Cy2NYrFdcPh9Dvluw1o4prMr62v3m21SYix0fRAPfTYTEvkvYqH0++lexOlgAOlIcCAkca8JWjFs3go6+dS4aCU4SPKORBcv4FqSOEPLM423JNCaaWMczLYLfLlt199YdST+7Bv7v605B61CS+U8RQDfrevSDy4+QQ8eThI8rW5T/AEpf/wCTkkA1F5SSD50fWfSE0gymysbrm8qieKc52szEk7Giim7htyOVVqLhxAk6se6lwTq0mxvm2qOEZ/ab8+3dSxDF4oOw3z9PjWJwsmIDrDEWN1N7i3u61hXw72d4lL277miOMwsL99D+0E/4amlF/YgE38SB3eNGFY00cjMO2Lbe6mRXSRU/F312BWmnupUhzPI2g03q8quv92XWrNiJV/vVpiAfcK7MZ8xWWTCIwP8ANaryHEDwWUAfStRL7wW/91Z0xs8TfyR2/WsuNEMy9W9Xs30qVPR8UayctzyrbWlOFxk63G64hLf+qrp6W+Mtf/VB/wDmrK3pI+6UmlyYqSQZyuj59tffUkCTGRR27NluTbvpuN6SSGNWF+FzZPC9NipMdlds5SMm5AOgzEeXzHdUcWFVmjZv3quAWP8ADvfe1CV5bOoBz6FSDsO730ZRBmlJ4jmMXJS4Olvf76whEokOmjxG5GW1r9NvnTxRxhUhRgtiLDXr4ffjSQ4pLyyaZVU6flRK3Ro2yPdievfXBfGYYFewWbN1vYbW1+nhRb/akLH8PDb5UMO2KaZgLg6But9+m9FlCIk4OcW7d9+g2v404w15ZGvbMDci3WlOINppEbIG6qR9/ClwEGH4bkG5Gnfr30ZMNh5Xf91JO3jtp2fjWIxM+KduEg4ebbW9/kLad9MHkvhoxmViLte17W8fyqEwQgMSgsZNWsLjy3+lYXBLGZI8uZ7dWa1/vxrEQeqXmEeWIWDddbgVHi8U+FLqPaRxBbDpb50+E5Hf1Ykd2Y3t573oyx+i2Kucw5xt8KJA3ratfKo4+jsAdL07TRYsmS/Zwclh7rUmHwmFxDBL6vaLu/i8qlxTQYWPKoVgrlydR4AUVIqaO2kUYX4mvSeIZM4aVSP+qoDDh2CIpLHLoLn+lSR42cptawNZkxgI7uprh7W2q4Nf7NWMSxY6JopV8N7/ACoMJhyLbLsLVqK9ZkmCudFUx30+71OCElmYkDw/QV65JBaNrBWfrRdY7Hax0vTyZZ0ktZSH7PyoxcZjYNYncmsqEBY15mOy/dqthpQ6d5XesFPqGEyqVvsb0sGKkWJTJxEXc3J1PzNOmGQ8DS2/v3qR7dLBj0ao8K/I8PK/XaopopPaDR17xRMaOUfDcpy6XvesMzq18haQ5dtDb8qPpC1pOLpfu7vzrEopHMqmPzq0rGzye08QLfpVmBsNqKysoBjI5jah7VDb+e9TT4BrRahpF6lbNb6UMJIpzRaN51DEtrtdmI61xBKvEv2TT8aLMAF2a1O0YJcm3N0FWjj3+FGEYbNL2TJtbxqXj4Zxtv8AfhUiKrHJMyjyoZly623qMC3MDUiGMNrZTfarYjGSRP4x2H1p5oPSuHbL2QN/vyrGNlilgjskp2sehrJg1R/PevbIFt/CQT8Aaiw4xSYbMeZuJqB8akjixmIxnD5tzn1PQ6dKM0kmI5ebhAW27zX76VM3K179rWmmlEcguVNrWvbQ0uqnvzAHr3HfpoaEq4hAgGlra36X+HwqGQnNkZg7oDoFPMR8b1nsiC1rFc3uA6V6pLheRxbQFd/fXtMJpHblDkKV5QR5b1BiYcCkKBrKgbNmsLqbabafGkZeHI+IdsyZLkj7Zv8AKKjwuIw8I1KMeAlwehF9vfRD4aJkDFFJQKzeJI/KpcYmt72JI8+UfDT40M2dwUU5TJlzuV1vfztUWFkxCgQMTzaED9Na4kX7+PtspJUnfypZkZLlPbIey61qxEU9hYtoNgb9+l6ZElgktJdugTxPeKeXCSERNJw81wEAI0J996WY45wkQzWcrbu+elPJi24bvJmj5TtvU+JkxeuJXKWFgdGGZfE7VA0EeLxE8SvlQRkxnXY+GtcQRS4RAqAhluTa/Tyt8KzZsQ1+uuv7B4fswSd+Ij+tSxRP+4Vba6X6/lUsswJeNsihepy3rMF4ZkYK3x/pRF6xst9Fy2916Ho7CzGP1qRVYrvWD9GQCwW8h+g/P9u9LisXIcLhm2NuZ/L9aMfooGAWsWHabzNEevsR3NY1mS1x0NKkWLKhPw2FYnHyrLIqSNKylhZjfamldXURi+h2OwWhGovKd0Xr/rX+zpwlzZz1pPSWL9IokIRZpF4NrDfe9S4eKHEzYea540SZl/XTShzds27qwk88loDKhk9zV67jcSZQxyx9yr0riJJcjcVicUL2RzbuvYVcmtKjVW7BINNHFDxMptmzWqPER7MNb/sVe64+INBMTJmyi9d9f7R9LRcUg2WL8N6N8GnPtGpy5vOn9JYD0cEik5wufLm8RmN6aKX2bRDKwPQ1q7fSpr7E1OuIgDAKMrk7GuEsgewFrdBS4PJdZlzHwP2K4aXte51rEnEjN7c2Fc7GK2wNQphnzBQ9/hTE99XF6/dj4VPDEnPPIkYHjl/rQTHSyTzleazZVWvWvRgkWeMn2eYvf40siYQYmZFMahUzcP8AmYdd/KjLLiNZZXj100PhWKMEy8V8mRMuoFlH5VkZeGqBDrubC+pqSGN+yTouoPQn30olaJly2DcP50i8OMxkdu2m23htXEMEAZXMligytdbbe4fCvQ73jw2bDXlyoc0jadw896EeB4/rZWxGI5bDre17UI8ZN7W9hve1+7pTxZh/aCT5A7b92lMZJZpJUOSzryX6BSDfvoO1jMSY/ZtfUWP51lLLkNztfpUks8SmKPZXbbQn3agfHrRxBlUcRmQM2vcCdt/A1iBPFh86LmyaWv4np060WvJCoJCrs3upcQc44QCH+aswlEUMYKDm7YG7X399COTH5crZ3zc2YX667VisJhAsSwygaHQqAT+tJh7SPG7KexqRv8NaLSE5CSqN3eXwpsNh3ku+o4t9H1t+elCAnNds5ysMst9FUAe+g2HaaJosvDWYFdb9L6f6Vx5QueTmbl6n9thWHsTnuctv7pphFDKSCLEKev6VfF4yPOrZSDJqWGn5Vh441ly5r5mjYAn31ufdUvqsDu88zAlRfKthWHPc1R49M5Bj581uXXSw3t+04rFr/ZMNq387d1CNNqCr1pGv2pgPdt+YrGk9mFhAn6fKlhaQ8OcHL/Lrv8BQggdjfNJJ4/f50iopUbytJ1NcUDnZbZ/KmLOTcDfpS4HDqbrEke/aAtWWLH8B8HyAZ9HDXvb761lL5D/EajiRrm50rgMhBj5WYnsjuFBF0Spv9pTcP18SyYZPIABj77aVZ8DIvnWX1J2LbcmasTOkUcOImUo+RbHraomGW9ulNC0cTZWuMyXppT6Pw7WGwBFPiEyq7ys3gOT+tWk3XSlxeKMQhw129pIq3kscg135rVDh8VLlfmYC3b8u+pcdjP8AhoGtwz+I9F8h18aKrqpNm8f5ff8ASjN+OeNZH89R+VdaaArdRzsfyr2dmv3VxHLMAOzXriQnbZq/cRfOmk/iN6VDIqDvNZM4a3Uf7keJiQokWPztm/lUbVI2OtmLtYqPw9OlSSySX57ha9fd45FDBxwmvk161CsCqz8qZSOUeNM8mJY5obuoXc5iuvfsaghhg9nK/MP5B9is86B7DKsyfmPjrr7qMOGn4iXAIGtr0cPx1DSLy3OhvpWJlmAEkUD2YeVeix6QjSVuEcnTKMmu3jt5mnkT0bH7RTy5NGtrYn3d/Sv9pD0G0eWwPtmYqtu7Yi2vvr12SZ43Klmi1yxC9tT00J+FY3DQMkoIzwzJqpbrr5M1cMLlfRwenlUEXJEsF7AePee8mpgYiqKoS42Zs1LArRBQHY23zW7j8KVQl+PGxK23vbf4fWlXgqplYb6sN+vu8tK5TJwgwytmAy91LBipyjOuazcx06AAeArhJGJkOUgKNNOvvqf0UY3iTL+9zWPfQzMH4pORX0ZV1+dTXU5VA0Hx387fGopMP+6lYcMLbcbfpUaQq8SzK2clf3bX+96kE7iB73HKLEe7zrh8DDcumoF//VXYq+lcqjWkjGIdMkbNmj3GlvzqXN6Q9IvlOUkz2F+u1RMAInmuxv2tTWFjhS45mNh5d3vqx37qTM+rDN8dakxIQX7wNzSmVvZTG5Y9pyO/r+1MIlswVWkPi2p+opYwdSt/gP1ar8Q6a1hM55IpTxCPK/1FPi2F5cRmfyLVFMNcjL8BS5Y+Ee0+Y9x/0FSux5ItFRNVvTYvEker4Zv3d9S1D0lHg4uNGb9TmHXwqdJL5IuYL0F+lep4SKQrKd8vSji4FtHLz8+lj1H1pkQIxlI1/htXsxc9SB1PU1FhI+aXESBfjXq8P7jAIMPAP7uhPxvRiB9oBcL31bNt0NGKH/8A2GOg2Hf9aDn8TWApjHrYXI77V6xAGKpq1ulYTHOQBikmfy9plpF/C+pAqPDxYVFTqP4qgiwICMX9qqfh01+VQsdTKJHX+Zs5pIc15LZf1+/0q/XhqKMiRkqnaNY19myi3zpYLmzXsKEmIwk8aObBmQgGjqeMrb5jbLRn4uY37qyvvVuopj3L+YrKutcwoIBvptUcWJkaBLkpAQDYfd6l9FHAETjsSFuQjof6U02JYyyvr4k0GLDjeFR4nHFopYuVjkYioJfRzOcOyZpnZbA5NdKlRgDlhGW+mhoYbC4vK7XTn3DUEZ8oXVj3Aak/CleHBZcv/NdszEeHdT/2los8LxtbmJGQ9K9E6WMWEc5gemmtDB3uL5rLcBu750UgUxzODGzHQxAaXFvfpTejMPMZYwTwsxyZLHUGszGMLC2bs5iPrallxkb5rFLpytceHj0oRJAJUbmUNGeITvYD7FOuMSXNPOJCUiuYrDuq7gxZoyoz7kd/zq/svZsDaQhfzozTFkUKQ9r+NvOpSyAhIRMnTJryj39atEzBpAgN2sOyAfOlwzxqx4Qdbsbs5UW/0qQzSZcS6KPCM319+hpoFRkDSKANb3/OoVjdjBikMZv8Pj2fhUcc80dkZrG5u511t8KDSYhlCOGaxO38Q76AVHkllXKF1HKOpP3tRUnBXGnU/l+1HYAgMCQaxvpFlAXh6DuGYUWRWsUMvyvWG4iZeEqFelzl6UOI4HDh+etWrBwLIlmhRtNwLUmGTr1HdXBT93hxwx59f2Q4VN5pFjHvNekIU7Mc4jHkIv6VOvVYU+LH9CKAOzZl+/jU99WgdHN+8aGowmuVF1pCejU59XbJICWbvA2UVKWbtNc0vCnKRy3SRejC1StGgaN10Qbg/nQE2CkilxBZpJX30OlKqxgsosumtPH6QXPmOd7abd3l+tSHDJFCsbW0fp0FTLstrg99f7UxQzQwtkaP+K9E9nIxZf7poYjBy5GU5ka1ESKhvrcNWGkky6uw+lIRsz2+VXU71iHkjPMbjTodK9E4XDr2sEr2H8zO36VFHPcZb+6mnkk5V7xua9baRSZFYhf4D1+Q+dejlmsP3u3ShHN6SgiCdou1rViZMPOHjjcKjLqrCwp4IiMjjKaxHDza5e0awGJfspiEv5XrEwwKXfKXVR32pVmVCHOUq6Aj51wsGOGnDXlUaGszNdr3/YJUiZr6Gi/ClS486IzDXcFaHpb0rjYosPg+ZeIe3J+HS3TeuFgvSMMsu+XNr8KjxoU+sRnIWVumu9ZDei2fhxKbE00ccbrIi9sHXbrUmAw3BxOHkbIwDi6eY7WmtOBDmk4YVidioFrDv8fGjCvscShLhuGvZ8SKx4x86qssdkC79rm+hpMP6Ax0zomjcXK7IP71TQ4icTyYkay5s2vjUckczvhlgbKijXe9h86nN0SUyZtrf3fdvrWIl4JlkYi5jt7Nb7r4EFr+NCfLpKVVSemuv+goAGWBsxvm0Xu99KkynhKd3vcfLWsmHw1mzCIF/kP5aSIswh7gLXbw6UJVuwsLP3eZ76A9VvmYsGPu/rQiVsl9dSRTRNYA2B5fw26+6o/S/rLxJ+7dUiR+ba4Omh399NLho74mwzYiVxaFNdQvfS+qYcrAgzlLczG+UX7/APU1AXmgVRJklzrcM+gzf5akw0Ds8kUvJ0zaiuGQy4hDlEkljoPwn9axWLik5Ib7nRr6Ee+o34TcaJAwyKctvLpt5VZMHGFGwMP7ct8vialAleZsq80Sdo++1TYaDBS+1Qpndxpcb0iYbhwhNLgXPxriTSNJIepqxHTwoZjcjv302qfGs3Mi2TzNa/swAYE+0uLC9zbT51iA2hkxkzG//wBsfrWOkGxdVHkP9KEv8Epv5GsVAeziozbz3qCPDHPM8cecDpYbUJ5kstwPKo/R8Lcv4m/i8KnMmJWNYTZha7H+lQRxew58sjLrodjrToG4qIO0NLUYsRC6sBezi29erJDmxE1lBvTYY4R0N93FhUuFTDPLLiF5QsuTs3JrEFsy/wAhJNvjS4jBLf2haW69PD50vRrdkjUjoRSt1Fgfv30lf7SMycOGQxFT08fnXBZQ0XjtQxk7M0SnSPTmbp12rIBkjvfL3nvNRKWt6rg4IAPHIp/OjKZFa63a3fQgdb4bCc0n80nQVDMEFmZ01HS96wsGFKtJnkOuyp4++pvSGNmzyb7WG9csmS38DVa80o/iB6damV586OtgDuDcGvGs0kz+twi06E3v/MPCv7KMkeNu6dLHrV7CXN1BorHhHNqzPg5bf3a1lMaqeyw3ri8UKmgCW3pYfaF2PU2FFLE3bQ5qWWOR0kQ3VlOoqDHekinEymKb+Zh4fA0WwWMyi+quNtaiwsPlfv7zS4RT7SbM7H+EHYedgKbEyT5VmQHRcrLvm23vpQDvyRplFi1/hfwqdlD76k9awjviODKVLRKyC3X9akxyRwZBe54JW5HcdflTLkZbP7M5fHuNFZ2ZRlyWuV+FPJDiDGxYE5tCN9L/ADrinEmUqrF765xbW/hXsMSwja7B3A93wo2eQwLq7i9vGnglQIi35b9Nh5UGnduCZMrG2x8+tZ8MqsB+Iae+ocbmkjXhiNrnLmPWkbgqisw525GOnv0qf1qBkkBGVTfVhuAfI3oRTIHQKtrJrY6fnWaWURPmsFL2N++3foKnWZmE5GbmXlYL/D7takimbiFyhLDqPPpUi4hmK6Fb8zafWpDiWfOpRobCwAve1um1Ql4FZ5YM17+0Y/DahFgQw4oVnBjyjKD0/p41CcGjJGSYmcT2Y/3gDt/rXFOBBz818khv8qgfDsrByQxaMDXwrsIP7qgf7uUilQjJm5l8VvXX61w12Wtq2pJggY4eJ5AL9ez/AO6nFxzZ5NP/ALYH5VMx6hm+RrERe+sLjV7UfKfdUeEiwiocPIyNOdySS2nuIrnAlhfsm+5H0oyOFGuy9KT1hrYbFDgy+HcfjTLhAwdlNm3selCCXD5HOkl9KT0gMJxJFi4LyBeXz+dGXOEyE8xNtR3VhplxPFDwo0qEd6g/nWf/AGJgRL0cRKCPlWInKhdBfL51I7zcJ5sW8SlV1PKDSBWGWOLLbvyrpRK7XKkfSl86xcMkfE4zDKvS+X+lDORzfKvVo7ZIidR1NIn8ZsKxHq75g0mp/ugL+Qp1zomaxu22nSipxSP+I8Nu0xOvzPyqOL+Ek2+NNipRri7FTvZe6sXIwByx9O+mieO1lv2q4Kpoq7d5ou8ioUHaI2o8wOu/fSYzByFJE+dJEzLFjotQD323FNHIxJVitXXLqbUC2Trc7WFLHEb9aEsS2yizDurixtzqb0qLYhlF+Xs0sKtd7d1NhcS+fitxLhRdL22v5VD/AG1eCnaIW7b7ad4p5kWaP2ThQ/eaPpFSmXPyqQCWOw+dHicxS7M1zfyo5B0qTjOqB8pDN4jX6GoocPhM8ihlkYdBbWrpKqQuGAJ0sL/ffQjljjKqcsUhm4mg+nlXqeFiaVmOW/DsFA8SPp8aZPSUPCXO3DCH/l2spOvnRaGDiF1azkWKbg6/6UYob8KJeI7W699GPCTZnn/g3tv9+VNIZYwIwMzXNzTL6zfO3F02rJM14gvGX8NiSNfnXFVXxBIuuxEe+1wutNKzySSEWV8gD+XMbkmmWAMzK4vLpbN193ypMRgjEuY5yJVICdLX38vdU+PWaPjSLm5jnt4i9RWM8zSMGZtrH+Uad9RDDQS+qsSeI47Gg0Ftxf8AKo4EwwfN2xIoIcfxaa2vUsZMTiKK7krZYvDvqJ4MajLItmjI/i0HnuKEaxTtHl0dozl0Pd5iosThJIpgTmJv2R/EVt4+NA/7MLeNnN/nTjMt4WWRVHdt+dZrGwoYiOPMrdx1rMcM9vKv3baeFaVc1h8OdpZVQ+RNTYTDFskZsLnwrX9nYrFzE2EeCdj/AJlpZMxPFSZ9fNqlb+RqIv2hWJwR/vLWP9ESWuLTJ9D/AO2kiH4HH0p9Nif2Qw+kZ54sVhVESOp0kXx8aytiVkv/AB2p2jVF4ilW10saHDgVuIMunMaOMJYsx5r91Xy/KpMDxFEx0A76wPoyOdZWSIyy2a4zuddvKng4i5hEco0BNzX7s3YWP60COlBuKuZeXJ1PjRXDqhk0XN/BXFkZDzZdDUVoRdmCLIx0Wo5D2nW5rNILxx8zU4w8YAtpbv8A2CfCzyQxSbdVJ8tq4GKxd4zuAoUfKpm8KHr+PWAIbZeHmZqm4EtoExMiqLbr+E/Wrq6H31awqf0tNwX9UhZwhPW4sbeZo+lMJBJhpVF5YtQGX+Ne/wAavx2p4YSDkS5Zth/rUs80RVuZEzfxd9FDyjzq6AmmjkNu41/tPHRRSO4HDUjs99X9RZvAObfWjPhzDhFJ24hYt8qKmo4JI1dsMzWBa1+4/UUisUEG5iQWzeZrMNARetSAomBHf1rO0KTu5BlB/h/h/Wkb0XhCIw95faWUCwvm2AFDDMuSRiCeCuZRfbmb6ihlXPmWwkNjoOmtNJhJCcx5ci5b2+VR+yF1Yicqtj37VHiDHK47Vg1stx3jWvWI1yIoMva0sfwj5/Gi2GwnLICpkCm5Xw1/OuCVMQBVVJ630NYjG4SwSMiEezDKyppbzqPCzTHtMEjW9l7rfzHm/K16K4fEezEhPQ2cD8q4c0MXDCnMCxFm21O2nX41mSFowebMouST32qOb1iZs0bElbDtW05vOpMSDw4SOXYBMp10+NF4cM9nY2eI23I0G4o4ZXyApyl+2LWsBasQiFZYcQbEdm4A/wBawWGaRnOcHcEBQc1csEczOSheK+XLYE/e9ApipURMy5STddtL+dexlxeT8POdq9vJDJplyvJpahho0g4dv3a2t8KJiwxw798DZP6fKtPTWLRf4soIHzphH/2qMr27Pq/53psO4syNlNWqKEGxa9m/htrf5VOHkLlXIzHrbSt60/ZjgNTLgJVHmLN/7awwUX/s7L8Qf1plBvyHW1JaknHU5TUPpKE/un5x/Eh3FS25kcqyMDp92IrKMoz69qtCNPH9nurWUkHe9NIiKFtdQPK9ZDrpfWiraL0qMuRkeRQTe3zriYPFqVPR22+QqRxO2dDyuDVhjWf++A31q3rij/yl/SpJ55izNrfbWsY7uHklGQJ1FiGz/lWRxb2hbXyoOp0Gtu+kjhiJklIRVHU7UcHE15D22H4j4eFJm2JsfKpYo2Xk6t1FMrSghDcqpNgadWsD/F3VNknVzw2OgOllPfXYv76kgyC77X/i6fp765qNmrNxCptr/MO41myWud0Yi/jQwmIkKLIp9oqdk+IrD4cTczPnmtl105fyqSXi8WIHKt+6hlHS9EjpQNQ4ZRbhxqtFhd32CiudMreQNaKAKgwwPsfV+JIneMxt87U0OGhvKFNlHfRlxKqkkHJMi7oRT5Oq66XuKTBrYk3yFtKw8mOYuIzdYGHL/lGi1iVbExevCKyj8KAX5fM3v92pIpsG0O65Q97tb+tDiiXLIwUC1uXu8qbEY2EIe06jW4v1HdSrCUHLlDsDzgabbaVLiJMQIxFyhM1rjLm1rJh5IybLqGC8vn5UYpGmnYpbNe99aWJWUnEAniHbfc0k+AnXNNHckjWJA5Huv+dKsGJbJYFQgyG/4vvzqQ8sojIURrrxNNNNxcdaM8jmOQ829m8dRQnjmHDnObLMCWXLfW99jr+lYePBLxDChBQLp4jxrEwyYaX1sDkRv3al9/lv5V6hNhFeRG5pDpnJvly+OlCGXByNiLg4Y3YDX8Nj5mpl4LcWOFjntuxHQf4vlRK8R1y2Vk/Clu7buqELiCsRIbIM2u17+NdqH/8A5qzYi0Z6tmyk1xlxGJm/kQ5V95rhYTDxRDf+I/OvazO/maK+6vXFHI4X4/YrPlNiM1ByLiONj+X51I38TE1b9lqU4dbsYpVt4FCKTGYhMzrGkcadWkYbfWn/AAs247qAC7DSiwjGhosdzWIw+JF5vR+VR3lD2f091WCKyncNTAYfhv8AI1lQ7G16c9ymhUTa9nX3afpWfNZStvP7tTMBldWuKAkjDxKy3XwBr9wq/wCKWp/VB7EhCut90FYXFDtzPJm16C1vz+NWFSaaBAKxMc8fE/sEvCS17yb/AEvUCSaXkAJ7ga5GVtWUZdDoeo6VmiOsR7VFynLENco2q4qUwKp9moJZrKPOhCFVm3JF7e6mv+M1j5W/BFp8QPzrlXNWsH1ppTa7G5q2XtVND1WOp3nxqR8DKTm1Yqb/ANPjWGwEPL649ppFtnsO0L91j8qdNI2IVVC7AWtVreXjUeCDM0x0yhCSaMTRlTsQykGoBOyt2/ZkbjIa9Xi7bDWtT+wCvSOKBs2HhjgX/wBR+q008gMkmViqKeYnw7/Lep/TfoS2GEj8ORLcp8GFet4i0i8IKiJqNB3+4UcamFAAYlkLZSvjr50rSYaTWzCRjfT7+xSZpJJGdTYmS5Hldev5VGuIMth+7LnemxsiurIpszCx8NN7e6jg4F4cmJN3cHO7L302WHhxhWEYZdXFiLnqRSesZpJJFYXJ/drktRWIjh3yE9dj8aEWIUT4d8zBJTcr4XoYr0fKXhveznVfD6fYrCT4p2LNdYrHLyBjzMd+u1Nh/ZRBH/eXEd+6mJmbikx5xmuvfa9YdsJHljIdDz5tRa4+/GnkEyJxrZhbXL1y+FSJLOAHh2zXFjvttqBepvReRQ0KLbUqNt/vu7qnv7ThKMjG92N9aix+NMWJacDgJqyxjfL4WNQwhxAqwrz5Oua9vnWTEokiSRLKUIG33eo+Nw/bOrJr+H8PW3SgyyxEEaXxC/8Axq7Ek+NamieteX7MPN/eU1Bgb6t7Q67L0rHYn+CG35/+2m0/b2j8KxEiD2hiyr4XrA4SUc8ELZv/ALlrfQVLO1iI9bX3q7JYXzHwUU7v+I1pXplZEV3CxvbfQZqdXiyHfKa4hF+lj1o3Op1qXT8JoVw9bq5HuoLmJA2vTw5M+YWt4UqsOfLc+df8FG4P8aVNMqBFJsFHQDSsBHAmUJDzb6v1P0p2/hQn8vzqRehXWsExXQaHTpkNLO+I9m+KBDP/AA3qHieiOAnGBz9rja73qRLWz61iV/jTNpWtSM3UILf4f61xJRyrYVoNK9KfzIqr/nQ/lXs7GrmIW8qu1LlF9QBTXbTY/wCWo8YmsmJXiOx6eHgBUGHXIIYTmOZbl/d3dw6+WtM7RoAdeGq+zWjxV4d/4CVFSOZTLkwzvGGOxuo+hNYnFYtFLxax940r0cEbeQhtPw2Ob5VO+a4zkD3URQrSsXwjkl0Mb/zqALHzFx8Klmmw2CBtyOkrXPmL6UAzPKJUPG9nykD+LXU360n9nlV1diXU5WG1hbZvvWjG8l1zZ2OQ57a6Cg6jEQiwORtHI+FPNw8+Ts3/AAH7+tDETyrhnyXCxveRqSR8mSV+GH7ZDZhuOm16eZ7XyA8Ppk0yrp1NSqJY0WJuUN0Tr8japZHkEgVcixA63t+L66UJ8azRJmtBfW39P1rDGaGOSWcHLljym4YqNvvSsmJbK4kGjMG/P+Yd29ZEbh8MkjKo07tttjtRmxUqc+U8HXO76dq4rjz2GHGkce+TX9BUs3CecyezRUjOjdW06d9YfDRQ4ZopvaSFRlLqu1/f9KxKRcrNCEEvWO362NNhRGEh4VmxFugGug8KxMyyO0fYHE318fHuqIPGQ8TmaSQsbZBe6gXtvlpMTKRfMzP5d1qyyyNGOCABbQfd/hXrGHAKEEJlNwvlQX1DiWHbyNzePa/ber99NTt/4TBvy/OizHevSc/8fL8B/wDtWUVpQ/ZxIHsxFqTFJlMoJ1Yb3FqIxPouF0Y/hutEQej4Ezb5taMZKIv8KJWpvWNkfD8RJMOYzra1yP6VHxUN5ZAt821ZW7BNmFXFMpG9FL7GpkS+awa1erRssk34rVLicDNK2MkyxcNOjddOtYePGW9YMd5dSdb/AKWrmwafAfpTnvY16KkjgCExDMUSwJyjU+NSYfBhb8O7XNtLihJMUGYWspvpUHpPKjxR5wRm17BH51PjJMGipxmBQZi6NubAVJNG+JMsc1uVjoRraxta9x8Kj4JlKZMvtGBINzppSkyjmzKU62rIvU2FHDYR1jTcvlue4fSlw4mMijcnvp/X8TLFlAtbLr371iMPgMXNJLKUIzDa2/34VeKYEVzSoV67VoKHBFwmhNSsdybVhfR2GgLYkRZr/T4VP6SxDFpHbKCfn+zm0z6VlI0fDuB8R+lPAx02bv1vUBdc6xRSSBh3ZbfnU2KTlLtuulcs5tr2gDVnER91NNKcoA3GtviaaXDzpiGdWs19c3lRnlwl/WUZc+uhB2+u1SLhsoMh5pMosLC9z3+7vqFhLcsOd7Dl5tr+6/vpG9aTB8+iutyPf3+7rXNiFI/iClre/cnQ0Z44EcpZrmzWvex8dfhevXY7F5tbNv4Hy8qdVfYXLN+EDzrmaCAuLDPcHpcd1/OmmOR3z8JjnGoNrH5Uq4m0kkmaxt2AFF7+P60scsStBhgqPuCfEdaODwzzNHLlWO/KULbtY6DzrhyRyWgP7zKDn2vm1qSHgvmbUW2bS3XqKEeK9JJIsX49eTNc6/DerNKpIGUC2rDwHf5U8LyvFFHCCuXVCxP6GnKLmSaQLna91HQfnQjikADNo7ag+OmwFQcGaPhKdY00APlUgw2Dw6xqnFtrrp0tqTcmsvF/esVJyEDa+5+9Kg4eURl0DzWtc75bddaMmBR2WKQIwc9l7H5UcLFibji7iwHkOo10rXExjwMIv9Kt+wyTMEQbk1lw0DzdATyijPmZGborG1Pgs/EMq2II2q4bMeoqZussn5gfl/vJIf4hTKUVg3f9a0N6P7JYerstJiA3tOLoO5R1+P0oTfiXtfsj8QKf2OdvAa00UQKMwtfrarnrXEYvkkH4DY36UZIzdOhpcPCNW+VSQAEkOVGm9YdcTjXlLy8qWsigL3V6QyytFdUTMgGbW+xO1GL1yc+MmViPfas/oh4ZWe/EfEdq2lgCBoPdT+nsbiEzm62QdW+H0qX0nNi2QzTNblvpWISxXgsUBI3INqDBuYNuKhckfvV+tWEmQAZnNqLagk/t5XYe+iT10o23oIDpV23r1Yy5JI8IUBHXakw53Un6/sv1Q3rAktyyu6D/ABDT61jsPC1njiMwB62t+tYjETAqBA6qTvf7FE06+F/2WhBZ7iwB31ocFbnq6qAvf7+tYzEyyE5pMgzH4+65NMkHtHXkORLBe8Dx2FcOKUI+eOEIdczOO/wtXrLMwdOXmW4DEcp+NT8OUTK25l1HdovfRkcm73EmW9rd2vXyqNrvzgtw1FtAbD8/lUAlwayviAZCEYAKvcBXGxWKlQXOWJG1uTew7vE0cXiIhHxRlC6att9monblDEh3U5tddvhT4OVTwMvDSP8Ah6g/EV7BA6SC4aRyWUqLnWmiwufjMcyszEgLYCni9lNds0uVittfDQj9amkDM44uZ9LMNR9+6rBRGdXPULfUfTeuJ7OaBJOKHQ5vce75U8/F57s93XUMNtOnWhhir5ZGThm/K3Rv9alwwIEDH93e5U+N6wn+zvS0sWIlh9rudjcD3afCs+MxEbk6hb6+Ytp9irSyFRGCI8ozX0PhXHibKJW0I3JpjO6oHYDLpy94oe0g261p0qzOHn/8Jfz7q4mJmJ8OgqOJdutbgyt2F/Osz6ltTeuSwNWObKD7v2a1pQFW3tS/3h9f2v8AyrekdhYOLiialDahky+XWkB6qL1dRYNUZ7qkJF+SjatOhr1iHW/dXYY23pMHg/R0iyOWM2JTDZy3cA24r1krPdRp/ZWL/SsFgcRBicOMxk9otiVG/wBKxGCbBYtWd85slxXNHif8g/WtOOP8H9aMM+Hmmjbdco/Wv7P6KmB6Xmb9a5I/dXHkRco5bhQOvWliWACx3BpsOuryatb8K/tENjxFa4Nv2CsWZWtyhB7+vyrI26/sWfBTG6dGGZfga4gA9pzabCj50yHe1q9HLGTxBiUA/wA9es37cFre+hgYZLAYZ2IHX7AvRq38aH5VepcptmSikRuxIHl9/nWHddOIGv8A5jUMSEKE5rL8LV67D7QBsyv1vf8AqKEmFi4l7BoWB27vL6URiHnaTEgz9gMqH+9tpr8aujRnKAEVj5flrrRtGRwORul1XT6fWpZZsQS8UeJjF7C3KLH43+FH2kcsmbKGTK8lvjp1r/aLuxh1VREChc7XJ/h8a4qM0ccrsoMAJXwtfW2vzrEJGpkcJysrW21v8qkg4MMmLZiqsWGRe8/LTpTJhj2rjN772zUkKqqzTEORvc9AbUyYUCKchGkVbjp+H6V++zzOuWR7bHwP50RgcZJHmHNrYb9f6Ur8WNTCb2YaP4+NRzOhlRE5QEtm08OtRf2QtNC3483Z/h8ql/sqpwgJSyMWa3d8bVwcUuWBzzox1X89e4e+ppZpGjgw12Zr6nNpkFLgIFWETWTlXVRUsPratkUDJbtZet6SB4rtGoQnJ3UY8JfDxeHabzNXysfdX7tq4yvw3U8oGtcbEyZmPWsvWulvKtX07qyWrUUoIrs6CpOGFXKnEYuwAC33rLHijiHH4gLAUb7VemzfjBvWAiU39gPmTTADbehdCS/ZA61Bipce5xJDBsOi69o2uemlca1rSlB8K1OvSlI2a4NXO25ragFWIXUbRirK+U943oSYrF4mFTqqRPav+O9If/npmwfpLHwuylcwn191F5MbiHJ1u1qAXGSD/Bev/qDf/i/rX/HP/lq8uIkb32r9yT/5hrhjDS5d7cZ7fWmlXCgMOtzcGsig87ZnP0rFYV0UkqHBI7v9a9th0Pyo5ZJl94/SuXFyD/DenwofOI+tTYxIXnXNkaJRzD+ahFHnQvbOJCOQ92lcdol4ds2bOLWpRDmZibAJ1NIMVhzCVuB7PLelbvUGuKNqwJ5bcUuPcDUeLVld4sWcMLjoRWF9MJi/Zq2SeJhpkIykg+VMG7Dm6N3isP5kfEWr31O1uzE5+X7MErD/AJQNqmyaCM5PhTo2KGTIFEfTfcnob60H9H+kggBBZIkDN8Sx191DCouLkUG8rlySx/hXwv8AOs8UWePEkDmIu66g/rSrLI8MxxHtTIdx3+FPhp3InkV4xZhbuF/d3VNiCuaNgOH0zjW+vTam42MRbdhYwSQu1gPwjz+dT75I1zZSSEU3yj78KlDYZWkUMkjMzc1Rw+qwrGDmVQ2pvTQYYZcOHLR5TqzHasG+IJ5ogCN7d5+tTRQCVlU3RiNB76Z9mROfOb59baaVMysDw0zDW19f6/KkLpJJKwFlt4msVM8L+qxqEzFtc2lgPPWmQvHa+ayaFR3W+96WSaacxqpRTbrp9Lis+G9KRyRl+xGcmQ+X6E1BhZsQVUyycXJvygZfPertITLlIiuNv6mlxWGJDjsmxvufjppXEk/7OQSM2pZXcBj3irK4Oo61of22NfvGq2c++o/UsIk7Rm/FJ61nxUQWVxv3/sCHl4ih9e6rFXf32ppYlUXVU2uAF2o8WckW0Gwqw2X9j4fByRK8UWciTqKw/wDtIxrlFojxV19171Kg4uIxbrpIAQin78KSHC+i8Mkyrk4xF2NFjudaZe8hqmOKDlrezy99KvdRf+Km9mpz7E9DS+H7LxYuXTpmuKA9ViJ6nXWuWDDD/Cf1r93h/wDKf1ri4iY+Q2FZocRIh8GrJJhmxfkNfkKGb0Li1/w/s1NKzBuD1bpemEUEllIuxFSekMXKEDJlN+m3zoSJMmVtRc2rRlPvrK00YPdmFSYmLE4e0zF+Yld6ZsS/rKS9tEt8r02OigtGTcHLdVPwFRYeKTlz5pOTQ2FcRCsTGXjKo5QD0t8KWP1OdNeSRhynSlB7qbwr1jCSMri55TqKweGTtQO7yaWOa+nnp96VY81PhZUuV54T3HuoTuD7I59KzdGN6mEIJcxmwGtCOXA49ZXNhlXS9YWKcmNDEqIwGa2m2nWpJvWnHEYt2b1x1nL5jbVbVBhFxAwiR7cCNcxa297b+NYhIpWecyoCzG5bka9+/wDD7zWEZkLK78SFlOwGnv7/ADNR+mIZFuVjzBuUmQcjaeO9HFYkQPKrWX1i5Egt3D/SjFLMSeE9s23Z006Dbbur1OKUtGMx5jvYZrWpsOuHkQCSNJ8+vTUf+r4Ci7E5pL3ue0e+uGY8uJnjKQHoV/E1um9r1Hg7gSLLaQoDZSQdL+dvu9DDzRoyrfhSWuyFbk+dwPnUkUMrB73JHXT9aWQmzqdbd9Ph3bJxlyrbemhJyPG2W5O3fUXo3C8NvVsTxeZxZ/vSs6r6y73Fl0+X3vSAZBJDI4JT/Dap1ZcwDZVbN2fvWpI8OS9wLMq0UxHYU2YgjQnbby+tWw45+JYEm2/2K/8ApWL9wNq7Faae+u1cf7uUYmZVHRXIFDiyySW2zuT+xWLszbam5/b514fWie4VjDm9p6sAov416MxBOvtEt8K2rz1oeVDzrJGt9aZy6MN73pVLAWocaXit4A0eHFkjUWWr42WVpj/4atp8rV+9x9v7v9K5cVjP8o/SuU49v8orTC4o+cw/+NX/ANkF/wC/iD+Qq8HoTDp77n42rlwsPzr9xh/8p/WtcLD7r0kMeDjLSMEUX6mosLjGQsdZFKXW5qWfC/i/ecE3Fr/lvrTTySzMt+Y91cvpPEE/3P6VpjMUf8ArkxGLP/lr+tcLDY/E5BsGtV1mX/LXDlMjJ/Ci6VZcHOf/ACzV2wk1/wD7Zr1VPWYsLKQJlbsleuhocUWNzpTV5VnddJCSvj0oS6HwoIrtwz393WpiOp0+NYVj+KNPpRHctDFY5ZiiagRLmN6J9G41jhZrM0SxMCG8Uo8b0djG/mWHemjMHCaMfu59M1/D3VxPVOH1DjYVFA08aLZxJIR3rv8AJPhXqOLxah8JPzKpyhV2NgNDt86dRAkKwhBnbl1Cjp3nwvUtoydS/FZbkoCLZfM31+yslyt47tbmPMNaErkZFVmbX8GU6UUwxu8s/Gzr/wCIWFRey05mIY/D6rU/BmyNg1VVB24f6GpLIFbKtjmsqnLuenurCnEBpY+FDKy3sTy2PzFcQwrlIN++ny65rWuaTOVj6qW/CQQ35W99TyFooUyhwZmylg3h8azAZl/CO+k9J4p24+OXKItgsa6nTz/OhLJFwIlXjhS1z4A+dZNeHsx89qyRgIwTJa+lYfAous0fEmuP4rWH+VR8aR0ZmvznLqb9/wAKyevTDLpa5/X/AHNf9/m6Vf8AYq/txGFl9WkUojGKXtHU6p4j86wZVf3c/DGv8v8AT9kRHWsrAhhoRV/fT8IA5raHrXtBkXooGlDN9a7Ff2fIoX8TbUFX0lhABsFT+lWf0yo/uoK9p6en+BH50OL6UkfzT+ta4x7f3a1xUx8rVbiYi5/mH6V/xE3yrLkkP+Kv3b/56/4X352/WjhovS2MER/AXzW97a161BjZ89ralbfSjHNPJkO+Wy3+FaxO/m5/KtMCnv1rlwMA/wDLFfukHktXbT3Vvau6u1W9DL+Pm3ralgQczvYDxqPCDVI1y60ywgZytkJ6VD61M0kkWBaRyxvqdamw6YiGE5e1IbDcVhsK5BeNVRiDpcCnOG7ZdRuBp76Zf9vMB/cP5aVmb09Ox/uN+tH/APkcUT4R/wD7UHUyG2zHerpicR7zf60iT4g5WOVuUDfSlEtlvZS1j+VRZ4sOxACwOA+Yt03GlHgK0QjIhj4l+zY3IHzoth3WCWPN2uTTXb4fd6XBwtJF6yeHnYbdfrao8akweG+XnUXbexv8647paEaOEtcbbU2A9H86ge1kv+HTTz0qTELHwzKbwkaWAtv51nlIUQQBG3yk6kfX5U2IuS+XU7EEn/WuJw8ynSRfzrDS8UsFYBtCCe+sPiQkgEbZLtvr86kEMmZ8O/YsdV11r0HDiSFjbC5W001FexzuJUzpzFtM1hv4UoeFbiPhsrc3H638Ld9O+DtEV34+oHv3NDGz+kY3BW0apEwBO19aeFBdmszKNCDlU/CskeDuq6C5O3x/7vTrv+1n/Ci3/ZpvWPxBlRY4hFmDRZs3a2N9DTz8AqkUySAkeY/OrHcVHItrxNfWnxEpuzm5/YFPf/uCCHAMe8l7X+VezwKjze9cuGgv43r9xh/g361/w2H+Bq5wkXzrXAp7mtX/AAsXzrXCR/5qs+Csvg9c3Ej81/StMZH7zb617KQOP5TehatjXf8As8qJH7dKtlob1C/96izdKOJYckAv7zt+y9qOGwiSSNLAq5strJbe29SL1Fqi/lFMr2OtzX7qP/KK/dx/5RWij3D9u9WPSlsezYDz76j9YGcHQWJuLGiMTG4y7siDQ+fvrF4nhCSbhLbN2bX5yf8AL86xEEWLWWCVb66cJx3juNjWc4vILZRnTMrH+U/rRjkhQF+a7amwG99u/voOcOgPXlGvj9KEeXLHnufKpJcJsZPzO3kKxEvDO6qp86XOAGcZ+X8NFkxbycWHijMq3vv0ApSYpQ9+duKCP8tvzr0ccPKG9XUpowOlhY0kLtyx4VItD1UCpZMQoMJjARV6E3H0FR2AhiLnNfU2FSYgJkiWSNI0LXzaf0qXNHwVc+zP4V2Gvh+lcUegs2fmvxVF/wDub6/sSXp1/bxf/EN/2PL6RxZhlt7HuHjU0WCmTGvMM5W+QnL3dL616RXNflVvg4rSt6CUmGiYDMbZjtV+IGXvEyU0JeF522WKzW8SRp+z202Iz9yxi31rlbFk92VavHh5cvTS9axN8K5VJoBMNK3kprN6nJX/AAknwrLwnv5VdMFL55auyIn95q5sTGD5VfE4gsO5Rai0EYDbEnWr3rT9nZoJatB+ztE30o/l+1VtyhcwPv8A9KZb60WiPMZDxPOlwxnWO/4jRxeMxazuhsAeh8qTD4WGMBj7NnJug6bbaUuHeJMza3J1oYmObM4JzUIlbhTHU2QaissnDk8WXWvZ8NR0GWtcUR/dAFc+KmPm5rWRvjWrGuWVh76VoRibsct+Nv4WtrSJihJxo+VY3fXVtz99KhGNikd00ZkXtNfksd8tutSFW/C0et973I/6qVE0Nue+qt/SnmguBfhFc+x61NJETbIVyt1v4e76UASkPIq9ksT4ju2rHYl2zsFEMZP8T9fcKYoOy/2T8a4Dto7Byetxtp3UhDXuu9YTppbTw0qfAEAZZSL+FHB+rjEcWyRZj2TfwpsYDEW7RW9xqL2+dO2GikA9nylb7Ztj76WXGYd8jI3ELjlBvoPoaLq6vHE4uOgOu460iwM/q4zWD0BHiRlHZ5ht/wB3lbWv3fzrSJawpDEQRh82Q6ls21gD87fsVTrpWElmkWNc2W521+nnXpWCMZ3SPItuq9q/wHy/ZyiryaCuUWvvXZFbUokC8Ne1euX1JbdzIK1xuHA7hItf8bET/epktM9uqjT60QIcV/lH61yYWa3jarLgm/z17TBuvkwNc0zp/eQ/lV1mZj3Kpr2WC0/merrHEAOlr1ZcJG/91TRGIwhh+V61IIq1b1as2/8Ae1rU12qJU1vt+w0GxOHkGIHOtv4TYa+8ijyi/wDDfUe6pxjJCnEcKB0qz4yL/NXBm9LzTJ/CSWP+a1/nWHmSM8HKbZm7jb8qxC4X0WssS2SO8PcO/wA716vP6OeORmuygHWkmgwE6kLl/d5q5xwV/ie35UfXP+0UaOPwLHmP1r2OIkZe9lAq2Hjmlt/Ct6zzYmPD+DHMa/8Aqz7dYhp86u/pRnXu4eT8zTR4XEw4ew0ZVNx773+FqSHIrCayhgupUHteV+b40RBOxMGjpHrla9jRktIY3dJcgPNc3+v5UywthzwSxOtz+v8ArU0M8Rl40oJXLouvRqPDDbDRhlIH0olcKrqOvEWoMFhMEZTnaeYcvKdh8vrSYc+jsRo3Ef2TNYdD991Znws5G2bId+tcCbboT0rI41hmYD6/nUePSIFcTHse8aVBlw5ThhpPDlUn8qk9kjcwYhu/p9af1PEtDz2EaKNBbelixOOnkX+EubVB7BpVxcq4qQxi+VLaCpEk0RO19KKFdQbf7t7fs1rfX/dCItyTYCsN6MkduNFcyR8Psm5021rsZfdatTVhUuC4xlhljMJWTWyHoD0olI7Kfw3qwQVrW1/26Bde9Qav/wB0DFC0hHTLer4r0ZBDYaEAD5VoKNan3VpXh/ub18vOr9K8v2RvHNxpowyOHPjp+W9SO0fqqn+FOKvxHZoYQzYZc65+LdW08+lDDQYl5G65IwwHmc2lA+kcTJMf4F5R8aGCwYWKNOyO6l4//aeVmXRY44tAPjREeHVkPZaXT+tRiWdY+J1SPlr1b12aQv0UgA/CszZIlPVm/SvbelL26Rrf50IoZp9DvnOtX4sh13zn6Gh7Zjre5v8AOjnxBUD8P8VcEFgCOa2n33UqesvyjTQaC1TMspfiHOQidayLLb1a4Tk21zL9anC4lM7SFrZOlh+la4lFudsnWnHrnJpblFhWXjxG9uYro1X4wbP1y2F/vpUr+0YdqQ2HN416yiKWGkskd+a2mY232rNi8HDKD/Eob60Rh4Ew9+kXL/Sllf0jikZRy3VWUe7SpsTDiIcUeEVRV0NyfHwvTw4yCSBjbR1tUnCzF/w5Re9Bkwsrf4TUGD9IYGXjwnh5cu6dDfpU8iYXhSNyyMMtxcX1+NHOYi19ScMv6V7T0Kf8OIaub0biV8pr1rHjk961/wAVjV8wK09LzDzT+lcvp9feK9n6ehPw/WrR+loW/wAP9a0x0R/w1/xkPwNWGIw5+Nfv8N8T+lf7WmMTrhRxQF15ht86ZiBc6muXauuvhV1QE/3herrC+vcpP0rTDSN/hI+tNDKtnQ5WHca2/wB7kRm8hR9k8ajqy1pIP8Wn0vV/WY1Pxr2mNUeSXrXGOf8ADagXknb3gflWsF/8Rr2eEiJHhf61ZALVvVj+zar1y++1aV3VarH9l71pt+zNGzxnvRiPpQKY+drfxkP9a4UuDwDX7UjYfm+IahhMHGsca9BRkkOWNRe9FImbD4NBzsO1Rco0bMb8VmN9/GrrlJFidNa3htl3Y3+deyiVB1a1C19BpVs2tqN9aJaIAd/hXZ086Ac3APWrNv15q542yna9acnW16ObKelgdz50GVdDt0saaW4F9LWByjwvSpY7aZxp018KcBwzygpct9O+pMM2HK8AjKQMoI2+t6Ilj1Or3bfTasRgjfhT/u7jdbd/W3X499C8rxxRmwN7822ulGOOdmdD0I2+FDl6X061JjJF4hS3IDqSel6zYiXUHlUdlB3Co8Vh8RIuKVtSunSkjb0rizpqeMaef0XinUzJw5HlF799r1G2ZmxGKcJxGPNc/wBPrSxhBZRb/udGIrlxUw/xmrDH4j/8hr/6jP72oo+PmIIsRmrNwIyfFb1/wOCPnAK5cBgR5QWr/hcN/lNW9Ri+Jo//AMetz/8A5P6VxpMCI76twm1PxrRJLf3hQjaDEsx/hlX/AONCR1xCm2xlB/KtcOzechoWwK/4rn61ljgjXyWvKrgV2LVc291ctXNaP8atpvW9A/szdAKsdKsGreteledXFvKrk61pXfViwq9utbfOuhrl1XyrioNX1vQOg91D0ZGCIwueVlt3aVkii4aroB4VpbKNNtauvQ63HS1ZOMwX+9tVn1NW3U95q4F6ERkUsdbL086sD0q2ZvvyoaOR33tV2b3n5VYHc7XolQBprQDgX36+6lzNe21qMmXTuy7UqxsxUHM1t2P+lPKQmZtNtadGuy34im2t9mpV5b73y7fGryTNJtb+ndXCHMGYZmPX5VzFU1vmO30omMDrqG0t186XA4ZhIyWza8l/E/pRzuHcdojb3UqdhQtj3VbOjWGhBqGXEYcYmK+UplvbxtRlkx8OHhgcgyvvci1lHU6UVPpfHEg27Y/br/8A0hBFuaEmXPN1Y9KHJtQbLW9qJ0v3bVodO+9XJvVq0ar1mS5X51Y/SreP7DW+1XvXhtVxrVyNP2eH7eWhW1+lbVbqazSpc9GvSnLfwBtVh00tVqxinTMkWhH4bGuJGTf4Vo1jppRz7VdctjqCDuKADqO/r+dfvF161vX6VYD51Ya61ctt3UOXVjXNbSsm19TX7wHKB+EkUc97G9vs1z226CrJIBfq21ZEsE3GlZctx4aUuU7aNzUx44Ftwf8AWjaQOFHMQSNKLf7SyWG2QVJFh5WCnlZ+8VlRc2mp/YIHbhgjqKaNnDhrZT3UysHQPQhmmkDgm7nmO3T4V+8dvHTX5f8A9QRoLs1ZmF5Wrm2vV9R41a9H4aVY9D8atrasvWtFsN/2Xra30rXpWwNta5NPyrrVutXvfyFbn9h191amuzetbCta2Na+VaVZjp3isqge9Qa3fKe1axoy3YKjKQNPv4UsAa2fv2tWpBHlUPpRIVbJGYpATqRe4+dKoHUAWuTegPfqKIU2+taX95rpoO+s3wFcxN60JHjR11H8tWCE+7Wsp5dKCr2elqCDEPES3aFvhXDilZj/ADf1q3EBA0IZb/D7NWEmUdrTpR5iqHoLaVZc1/7taMDbpRAJv060pWNcoUKwudT3/OuctfS4ZL+HSiJsGuRP4RlvWfBQiNADYb++rA5x2iKzWyg65e6ubYVpc2r1b0jIYVkXKklrgHxo4LFKJURyr9Vt0o+o4go46PfKa7IP/mD/ALjT/uwiC7GuNJrKa1rlAI613fnQU27/AArcV49+9W3108KuKuflWu1Wt/Wrm1xtXtNavktXX9a3ofSr2rfw1oeFXsda3+IrNm1Bo5qPJR8a5b38KHnQI+dC24oJnyna5NcRHU6aLmv/AEqPERMGeDkN+8H9LVy6jzrmXaiCCYsnJlJu22lvC3nrWYOXK7XXLk8x1oXOYfOszfAG9cy38PCsyrp30XYj3UoZgKGgv+dBXB1vra96J9oauLgDyo8QDQfY3ria76Aiw+VCTO1j2yzXNAlrkd964wkyuRyoRqw6UYWCpPGv8QGY6ePX3bUysYVKoHmeQaLfYd19aMZlgZjHxYxGMnJfYj40kawJNOyK8hezWv0+lRz8CNcz8KVBbLesXHh3gwXo/AzNCXlNlz32Fq9ERS8Cf1jGOHlj5lkS6WH1o+hH/wCzWAMEmIOHvBGyyBb2zXvU5k9IYSHDxycETzt2j4Bbk0voZZIGMsBxEUgf2ckeUm4PuNf7VwuOwONgwzLHOiyNdM2lzcDS/dUAxEno1MS8V8PHJKQzA7Hu8s1elMPhpfV48K+clzlhiFh5knypOBisPPHiEYpPASQ2XtDXVatlH/c7f91xHw8ksvwFEthHHkay8QxH+fQUGicMveK7IsK263FZ2rLlNrd+9WtRb5Vat9P2GzbbV+tXaTXurTf9ma3vrw3/AGWyjuFXsfOt9fGuY3rfWrdOmla1ppbrV7jXWulag0me4HW9MMk4Knd7bfZps4yxMEvfdeg8PhSsRpL8jXLm3poxbiDmTuv40r8B868soyXObb7/AK1Yhif4tV+9qy3rZL9a9mbX8b1czXO1s1DS/cSKPPmP4rDSs8aByGA0P81CQLkUnXMANfOtWGnjWY312FqJ4N3Pl8azDbTY0snMcrXO+tOsipKZBcM42J8fyFRRFZmESEZwBz/H86tIoELRryNJldWHyp2g9m8ihNTmsBbQL7qWeGMvMiCOVA4j1AtfWvR3oiGZCwxi4jFsrDKtjsSND1Jr0lhMLi4Vmi9Ly4uLO4CzK2mhOnSvROFbEwgxekDLOFlDcHs6HwrFQf7Yn9XLsFyvoVv4dKTGYGLAYnHM7CQ4t09ioGhCMbG5661g8Y+OwrlPQk8DNGVW8uSQWC6W7Q6V6ZwmPmQcSCMIG0ZzxV+ND0v6Px2DOHnjiN3nVTAyqFIK79OgNelvSGDfA4zFwyquHSadVjykczbgNWBPEwjyZ5hbD8MKoOWw5bA+a3or/s+A2Nv+/t/vcONlF++rGQuzfCttT+y1W17qB7/CiOlHw0r5fsudh41ovlWq7+NWI160fCt60PhXa276AIq+X9lv2Zddg1c2tbdqvhV9aF76VzdDQUqGFtLi1RtxZMp9ioJ2Jux93Lb30scwuYyUP94dazXN+lL4164rZLn2lh2u40GhEtpU/HJe2ttqaModB020pVOym9r1r765mNr7e+iltVOUVw5ApUGxugNWiiiUZtOX+tXsuZD3aV1Y7sSd/dRHXx7qD3QZNXFtT5Hp8KSCMm+QM3QVlyDPbcisroNHym1XkiYntbUXhhFkH4tdascKhf8AjFSRL7NymXl7Pn51wL2LJnJ799PlQVpgLxmXTUZbba/3qVlc5X5reN6VtL0xXdkIr1kMQyC3xoMN7DSw3oe0OTUCx62p8bDKsUmbh+enWsNheDdsKmRjfc/pR/ssNf/EACYQAQACAgICAgIDAQEBAAAAAAERIQAxQVFhcYGRobHB0fDh8RD/2gAIAQAAAT8hmj7RKa+9Wwx4xYpTnASbrHHaQuST3w2LyWNqeHE1W3YoVyRWIbo7wFzBW/MjvYD0GPaaAuHmdHTCXyhuiQP1+DAHK0mAPg/1PG6PLklL8IHj8RO5TsASKYozAVhGCVagJCEpMpCb5y2sdsEWL2EuN6G50epBZQVCWLca7yjWybnHZDMOuYyS70J5h0kCdjhTjEqtgGp3sn/bL+1+KCbSQnn3jglIaUPok2HzngXFLkMOu4Br5YPTMZDKIz/8YIjHB3xGOozjZKiRKRV9RdF9Rgo0zceAOprIcYn5UdTi6DAipAiZJIPbBErEmg9+JB8+zHp7Q2GeKZjfS6MkwOIs6ChLghvnIwm0qkQXDQ8LE558X7eONO3Y5O/KR4LDibh8SZyPFhkkNwwR6eG/wdDMVBWgl0/rL+DoJQeYpQ6ydyJg5zw/+CWEYQOJDYU90P8AVklRatAIc/lPWJ71MEohJRQqzqe8OEmnfgmjA8qhvZHAHCieQk6t+RgALN6lsMlrdcuQ8phBqqLQBimuIwf0gZd3NI29d3DVUGVA0TfKOo910RajymW8ENwgp0l81X21UufSDDLPpY+MiciU2m/EO8tvE3ZIG1Z48AOMjJBYBVaQiZ4b1kCGycsI7UQONuCbxrAMEuFKP7c4osidIjTJoVfdNJyVMDdQCVq25SKCpUgdKQxxjY3SQ0UtobKfrEZSm8HPpo+EYbqlNB1BtBsFX3K03kBCXA6qoWa1lnGBaBozcbDrD9B/tjs2iSx2Voza6pKsh7grz6yJ0CxZbypbjSB8so8WA8IJUdInhkTNEuEz0Kn3xGD9UuFrpgiXH1ipFNopZWaZWymYnPcdbsg9YIxc8bTBXUOypIqPWMKIktehsU4TTHnJJvJIG7M9j6k25CuXEkNQHAmQt3mSGZpI8obNPQbbVeESy4acHkVWDKlcINf3kdChDePsiV46vFP1NGzwp3185Ld4Rf8AaZyRCgoqCeV27dsYFI6KqNgJbV0bcds2InYC8LlJvrnB1B30CQO1IrvIoxIoQA3ZjEOaAxUWo6KJqlEo4lN5HNksEopdUsSneDWKCUyFuzbUlYVMGXfJcPmpjkXilFLyiFNFobnWyE0wE04RLMmUX/ygm8NXk4ZMDjmt5DaI7yJ7gEMJh6ggwRMecOzXPKj+lviXOT5IjyoiZeG/Jgz8B7YYDcw3v1xXiMm42qqWmoQvGnWlSFWrSMlWUiJwc2RMESq6oueXmsEEQIlRWwV43ZizLW4BIEvkYtmHhLhopFiQQiAPj1ioToiwREWxDwTLkLfnKXHILK343GI3TrwMSeXU/nCGWyQvJnWHzgH4A+VowcIu6UjDkpvGq7lbZl8hX0OMldm/ezUsCMViCEOup1B8wYEfGJbaIfEv5wqFkctrUn7TWOXoXVGyRs195HzZNbJIqU37w8ENPCS2zAne8MsdqSAu0TL8HM4qdhVXuEsaO9QdTZw+QljUJQ81vHcjhEaWPJtXJF4n3XeRzsYPiMG4AahikcKjuXOO7SJQDG7fwx2QNhBMHsk1SyF+G80iYnue/PBjzLVQQ6kgG/J8mcWkHeEktlduIyjdo4poBsQ5ucjpCTaIOcEBN5sZgbHL0U26g3WAtHHvZhXtGK1xjw7jxuI4WPcyLYl0DAkBbMSYnwz1u6mthvjvTzRjVBjPdo4on1jSR5sVB2bfsZPdvKRTfQ3/AO5XSmiZWKhpjZTbIAGxZWGqeQnUUTimAMxoYzcx7DuesgEeG5onTIjt+ROPeoNKlmvmUaJws9EMCOHGSjZrBmQnf+M1JQBJFT/KI4nelOEcUJUI1H5IR1k1i4oVYrUlAOReINJI22iaNE1Nc4nCsXthFnTMPzRKSRICAUub43h8ZP3yURTQao74EC5yKWFmGHLyIcus2FzZsNRIfbr7k1rLEQFB0AA28su/tRF8TaiuOCPpKSWKkXQN8+NuKSRyFm1PJhTWaxsiZtqEbnwVmqGYoIAKFaqA6w3zuIhUqGEFqVk1m2KijMVuDp0x1iRskoZ4Te7HZ5qOoXUXg9JXzOzEfbSqqIDdkcXRltuUxP8A5x/8cGDCD3E5CYcgfi9YvcZvEAuuYN+IysAGkEQRebdQbxOBhvFCWm6TLrknYBnpiol174cMMQjPhkCEotOHwJvonk0sgPjOsTdo0CcppISA7nEeOYElDSEpREcRxYo1V42VKu8UNYP4KCEksfiPPeMzXQsIt/VLwnrDO4wOGoq18Bxm/c5WnzWusGC8ogDPcJqyLfF7wbzlM5HZy7KwEFa+EO8DKJZ6G99vB5yDUPBAsGt2/XGSsrNIytmCRbtcVzSrEDXmxLuH4GEAAUHN7AuRS05G0QEbmiO83w8Z2FRu676Q/wBMdM5EeaQhEInDPrJbooDXBEOUy6YocnTYnB247F24dsk+B4BD6OU65jNEZKFosiYSmTmqjI6aR47LKW3NDduPYXOGr22jgs4K+jf2gB2j2YCqqvqBHkqNz4ZUjWclu6FkqWAcFglFScAbKme8D4XfFFAGpK4SMkRVCiRJCgVe2ARsAAjIllg5a+A0YhDqoZJsskbdowfJRkEmgSpPqM0aoHRaSlUPP84cIMbRV7DCS3OIg7khSB8u35MjBPh5g1JZibaMbea0YCN21XzBjwFPQaEp/X4wzlnkRSqG4NbcCSI6XpEsuw1GQQ6T5GKkvZ25yWNBINau5NA+fBjmKGBpH2c+Jw4jMCggKaHwyMagoppjXGDZxChqCtuTbxkKeLGCkJGhdZA+NbuVnTM/21g3yS+wi/gqY6jWKHYLEzWmN0dKw7sSZAROrmoX8uH3Qc/JUMFwGN4m3BKR73Sus27QXDeVyCYxhoQBJZD+hngMJoHaVq/q8t86ApJrNxC9Rq4zWF2Rlq7b+OcA5wlQITLqh9/rGpAJKKBHIQauFvAKwSopEcIg+AvG36jowRNIn587yXt/QmCvyPxHWcngxNImko9NtGUXXHFqZ+H/AAxkeZY1CWFIeFGRghQobr+omUjALo1yYMjH/wCGc/8AxN5ZFkHt0fOKYnXyGNFOuir0/jAbYGnfFf7WAsCX26ivxjbEmkK2FeYtVWD6ROOrCZY5frkJP04KBjMt7GQkE0XDHZlJD+8kibCpabOw11dDgIgLQr3u0rWh4ct0TREQXeBZxLkazvEUBAihhjY8onoMqZn/APEy8JMmVbrrjZ4ckusawtmdXOCLAtpbHZMJ99YCUAJ5iVbGk6jcZDcSYtYJue1ebisklAuQh5g3GsgkUQUiRJNvwY5SiVhUEqGB8BeDJKLoaaRI6E6wpsb7aH2wTAJ5SgT26clXRCK52pXJJLtEhkrzpmP3x6akC3fggLMxZ5yECircyGiR3Wst9BQoh12EqFxOSvWSe1FIyAXgFuax8SwlKRbpympiLyE07AoBXkHn+clQRXKrTMiszynGWn4UED4+04Gb4K0rEumwcMTZdlMqEmZDDw9YkQHoAw7SIToZc4hFgBrjlFRz1GXrnIagFImLHprocadAI5IhECWtxLR0xqsCQh4vFO5O7wEu6IpJ4m18V1OMPKk3SR4gz/jLm3IAIJsJSeYKjCzKIVsJtbzXZjPPbLKktCXu3jNKYiY1BNg3Xb1k3rZy1q3dgDveEkGFaJJBG8Hwd4gjDnCtkFly+uMEumxCc35FSyEgN4SwU7lSVIaLdHxk95oQt9mBOipYyBXaFCJIvLkI/bLZ5pmORcwoHjKLHK8ar1vc+cjaRW5GB3EXvBZAR4NYW9GhqUCg9n4xiVgg0ed2n2x6TeDq37YovU/GM+h01E/kR/2uUBMsZDSr6du8MTQChCLgItCTB1RLaCI7hL0/Tsr3DYCsVb1kEmYFBE9t6mDnvAoVwuJkyOr9zizwmusEou2Xzk7F4MbKhEpaPAjgPCVxToixH0xohCGZKwIKoAbB84JILsMM1P8ADU+sWQCscCSZQqNR6xqUaqmkPavkMCDVQzpQJJEhqy95TZDNjqLfx9Yzw0S1ltaQHFVw48xG62oNkHyz1wAuG67TQFew+DkdVwC5RtX7MvArES5XSTTzjjgO2sUZZZtG2vLNQBW1pQUo8CSsZwKKJgRgf4vbvJCCeAh2a5m0fHGKtYBBnBft+GLC33SsjclYqYmanDFF3IRM7bg/qN4zBgRExqaSbiajwzEkcojpcy1O4x5k8iwtnSLCLUtjGakFwAU9gHgT1ONQy5iXkCRseEYal1DUiCXz53OKckkigImEpFOsAfElr2gbPJf4ZqV2MJ3jlWk2KOOQbJCHaZEkvy2mMFQpAkyqLBAz8nIpCLaAlS3tVPwjJg1tUe6FOFk8Gst0t2Hpg15pOD9ZIb4RlixwnOQ4+xqTPklbExig21o7AHXh2ucEHpBbyAOlegx/XMVWOEkjzpzrHAkwT+5BCe+VYoCIo52FPOvFKG4jEIcUiG166yl6ULWsDiB9nzjsUyixEiTyrnzlpN7uYU+B8OpyHE4IIk4AlI9ziyYTg2Nq5i2rnimj6YrU3LAOcl0pUckIGV0JOCeKJi2vM6gjJp0eZkcR0EkFPRiWibj5MuB+dLxY2EDtKFbGIO+6lMlbgF4sqAH74iPJKYSsMEVT5fnNYZikJsPkriPlQi4aylWx2t4PjIp/JYcVXYCRhNoTBVzVQaiOQ33B1VNnIhBlMsnXM3Sck38JaoL0uf4hmTCIty8lky7eSsV2TI3MorGiFUsK8yFlKW0ObnnJEmrrQgIsyU9kcYvWWSUVMjFGm4k1eE9O0A9gP7ZyLep8jwhuUHbKmcqkZ0ij9xmMOY7i1giKYn1kjCMTsPY2DR0d5VTVZV8uI0Cyc45OPGRJRZXTZa1wCnje8HNUwxCjeyFeXIIeQZwjZIbiWGu5xKoQSoLcHIrG5TqTOFBWIoKC0lviCeT3AY5l7dtagws44kRUAcgHp+WDA76kttF4hRL2qaeelxBpNUlUzVJB5swqGmVYkXF2i/HeRBUIqqCTqGe6MTnbjEOC0qAJPc7jOg50ZyuadLoM3GbJQB9aEYhk+MX3Acj0XZEp6SMELTw1MuAzwR7rD0AqSlRyWpZ+ZXH9tAQiE6mFzc5Yo2KWBDf5B3j4qQsLYhEVC8OOI79MbluHKPR1OQ7EZI4JpsGniGXTN0kLdfjEjWRkrFKlkuBxhDprbTvA41woRkQpAX+zBkx2BEsBECQJoYfWTDaSdRCIlEo0mgZ39NvTmTsNuo5yAGsyFVK5ifkOmmQqF7JC0W+Z7uT9nsST08DI64SzRG6BaUbkAh9IGIqHCbEcuLQ3DPeQghAiBg4b3HJsy624pTaaLdRdnzkqrVI2LRGYTyPBi+yTOyFhrnfwcI/IgvQKCB4FuIu1LeEeUtEIO1xFnaSlpYcssJo7cYkzBJYuXYhgucSYsOo2Cn4k0Rk4SNtBQIcoal+jIarUQLVpB3P0XInuAIFbZnCtnYLfEF5FxGDnFoz+1KKRu28uVATDAeQE3sWdZGTRdz0Wl09AjvDb9KykRQswSFupeTFHK4pGqlzBJ1pcDRKj8pCEmyTnA4XERTZhx/nMBfKsLn9AQ6N4DhOklbpbaf8AsCgCGOinM05XJjjRbTBEnUT+Rje8/oofb8d5Ij5DGMyUCzV0QVkOGp6kF5SMm8o/iMEWsiA61LS4UMY5YASokUod4xTfwQFJWlQtf5x9vlxgpRLSRO/pu0zlsLkYmJ1fiGxIUpYBbRiluT3jWrRYCoRwHWsnTzCy4QEs+1eQGCUyxMmppYE1ja1FnsgNzOjOBNIC7kaEd+jELCEoj25VRz1kkoZCGmjpH7x0rGFI1I3c142vGKrPUNHJwHDN7MvU1Ymmw2hmrXAVwgD7h5ANdhgCBD+Q9r746IFeKzDVEmZEnvC1IgUajMJBUjbqKyZkiHkChqEhiPbADB5efagQFOkMPWBGfKNYqq+hLSvihnJimBlUmZqJe+HOaVQlQEZhWLMP1ePcCqsOvcLnfxgHgmqbYIfZ/GsFlImo2PdxqYfWGQhzRyAlv8F5GdWZgNgFvvVPdZr6kV03qr+sHqCDvqBKd+FA8ZFIIe49OjRfjCVppDBu3dT7MBxxURMt+CPce5gGOrqalk/h4gMY3OidB6RwtLHrBLZEBfJ4UZN71bgmF91no6wSKSSu6h4vfNVkCFHhg8/Y3XjFCNB2oqysKcZGKDemiQPcjz3jOnV5RI0tpur84RZFOqw1o/RLhIsmSAmzzMuJne3A4ur5qBGzlO5niV+eNyURqDsYQunvBedBGiAMxMmHgjCw2R05oQGnqVqsMJoOgWUMiBEjqXKxqdyJDDTHCvSjhuDmBghL0tNYKZ6wLXT0JGwT5w9rm1LCkNal9/ORN1EZLtMT/cdZKAQTaymomPveNcj5cL7cP0YNbQoqAVxoP+oyymY+w0eZjz3x3b/ah8h6UneCOAWShBXANhqvGNwFZUt1bSCK8TkgP2BKD9KF+7yaWHLVlzF2CJKxQxHAoYIz3Pz7YSM2nPkooPeONOJlRZJhZptHRiJjvIZxrSI4yclbKnDaXXkEyOyPmOcIFGHKq1yyvxhPk2+opiWjrfgWXHwp7G6z78ci13jEsHrhf6wOj34MCkijvm31HX4FiArlUqXpWae8llBUTTXiuuSaW70KrwHfXTIm/tu7XTL08sY7yHERkZ5wFMAENNBIUQ7rSPqLWCAxxCkxdXusdBoBzGkuYQpK1iKlDNLeyJb3SNSZDK3QW2kHNqftKbYQfLK2jGkWeIihRzIokbmVrdakwN2cP1alHxTEbxg86QL2J4osHIcAt0QlSxBAu6z0NAJiYiOynR5xO4OxHBkvQndy8ZaJZE6iKCCGP1cJuUxQlITM7++sPjfEARmMl3bjeSxdVi5C4FlYS1HrBkVWQpD9o4VdUYFAbdCQM7iB4eesPxA4UFUCSwc3kLooCBLzMvGfSw+CpwIn02+jvAWqukNHgleYJiFiYqlNNlL984C7GoVz4C4+csifQcCh03+gxugWUzNUmW5QfeNmEFhNW0Dsw7pOb+uFi9Wn7vJ+Ggvlz/vrDVlNYJUaDVPw1kdZVdKSpjnjybnGRskulKZeKPpkMGZ0BCkukrPH4yZ2QS3TrxIA1kzaFy9xymh+ecnC4pmRLB/0YBo4E9HSCs1z3iyx2AGBIgRmOn5WFm1EJm0VzsnZWCGjz4C784kWhcFBS0By/GCASKDAlm4ofGAbQ4hWMuCWOdu6x4QRzhbL34wZoNKEjIKocb4STcrqyKbSSKMXzF5NfrcaY5r1kwo0kMmf2SRY37nbcuJ0NYRCCnE5ArGnOL5Vme61GIj+oqNrUTE/nzkOSEDZuTiAge8agsgwNF3Lp6l4a2JmiSIWpHkg4znKu6FUWggnmMtIWje0jsE/44S1yZNJI4q1/aQepu6ZF3tDxgjUTauLLTwa9Yr9U5+G3HunkyxTV3Okcihk7UXKJR11X2YcKh9lAld9ir61i/BTgK/EnFnxKhN9yIJ21oqeI5wMFggk7E1fLgxtW9sr8Dco9zi8JgiJM7YlkkjpqLw7OkQFunnttfpONI5CgGjt5fzeoQFJwqWVozDWAAzmgYSzMpN9fGJ2WIA3C1xRQ+zGcDdwByGIkl8EN1gwCV6Qy5MqRjvFCAaV7yBIJai51k585oIffIXQ8v0f1saeFEtydbx+t7SARWhA/wCjF/ISGiDYlizXFDOQFE6I6hn5L8TnYt4tPPyOCWTE0cUsEC2weHOVuIWPZGg+nrKELNvQnVnzwh+B3vl7QT7wUIUgiRgb1J49jI+JQC9ojgV/2jlANh17AR0T5GMfWk30DWys8mXmKyJkMAJQkrm78hk1+MIoaaYKh4y6NZKQony38EYCCai2tTgIulnWDomrDgMgIr95H6ghxqPKqTlnQk6coL5pAfqMapRCPAk/yZX3Oje/AC5pzvK44AEZAhVeHorWO2dlCakXQ5Cp5y83ZpRHV3Q8g6xS0HZVSSgAKFo4AUwhXwCWQoQxAz0xhcNkAJjdfxlUa5wllIQPp+jGnCg5psH3HjBCm0G0QfXA9OKahWbjJasyUPCDByOEpfAGKCf2clcQs0GDi1rlnEPZ5hMA/JjEikpbElfhrzkIxFo45Skc3GzNKDm/YRpgQ8NBxnTMwo9R+cZ9DIh2CnwIYMe3igVgbSIkYHYMRM47NM/Mn5GsJg/EZgdQkqv2jJDbiKf2mI+sr4HuwiTcSlCWHrIdN76hxuPJTjnKxqxUJM8cBMB7wNFkueHSshw4KcwDx+sMqI+gOBxpRKhwNIA2JNI6x0zpxQpth38uowSzYahmH5scvwwp+6eW3MXzjfTJU+OjC8tZp63U8kprvGA8w4o6+n26MtLbvqYsjxX88ZIaJ1CaDDxz84Ymymx0gsxSusm121MKl3ROppFZS3BdNECoX5PGSFgoApQJu21w++OOLs95TwiLeeMgoQy6os6Qq+AYjJUgEugQypnS2dClVm+oyT7cRKTM5OIkLpqumHF1eIaFN08CbCjZNWZGMe4EggCXXFyTPBfRLdCx3LEng9MISVhL7MWIz14zpmJszLKgbdecu/Irwg3WmHAw1k2Imm9R8fGSZWItPEB+HG8l2jm6giwWDD9HjIpaWqpOHj+XN47Yuwg6VbiIer1rBMfHHDAR8sH93l66o3EWpAxH/uXueVBAWTMRbQaFsRGnZkKBvyjrTtpgNHrR4apie955Jlo3GpdB5Z847RKirwuZKufjI0zSRAj7KccI6WBAOknJHzxVkPGVEbkb/wDMQZ6ghED07dUOcWLO3YLpwS+sg+mDNjPCmA6ENSikfl8ZP1Ng6Hy7rjzmt1xiDwObQnmvLz4NFqpNj5aXjL78KGOj8K8Y9X5Q6ANETw9bxJh6wBAk7CnbvG5rG/8ARQT384wRxBDIL2mxPgXK268INWhDuR8Z3P5YUCA+CoW2oeiuToDhyQPzGVrRixDaRYMnXOQRWCS0RCjES30crdOlIoCdMpCkwTaiwiZBFVZWnXAwU4r3XhsJAWHv3wAilrMtp7WxNtTsIAsDt7VipMSYiURGQuOsBFaiEphGMm3JYAqqrv8AGRGhwqCuxRPDHnJoF7dTsp/QcTbUqVGJIOACfpzhs7S5CQGUM4A8dCCsDPMJPAR/piAOw9UgpoX0RWLOU5AjZaEDpreQtl5npAG6gqZV3GPpvZnccmqr3ijeA94bDQ/5yUzIIgJIaBbjFk8ieuG4B27anEp0fhk3vFTgg0g0Myu6i3uMt4U9yEpeDf07uORCULnoczHHrFmjCiNjPz39YERcCBIvJG5/04wyaioAMzpqPzkwBrqQVhjmicQ544WokcxvIQ2fGAoeDA5/dK4AQzktpiWtV7wuVRyeD+q+MlcREyswvkERME1kkW3K0S3NQL49LIJxBGgOQkPi/GCnMKpvlu/u+nNqSYJMZEOlk3GJzXaphAadRniTGwm3CEL86xpQ7quTg0BxgjXYIEVoAO48ZM3mWCBNHN/hhxY2w8kk6gg8jIABtgEmqVTfWjBpzC07CS8xPjNkScVLIP8ADthtQMWyLjDr1km1OeRqsqX+BF5LEWHaiD7gR0+mAnDGbIHS5G1G146ao2RyOqvr2yEGASBsZIEz4NjUY0TBEvOaW+qBpnNCNhYjMB3Po/nBewBVpIOaYcd8EYRA06Sx99L/ACwFswxZyHBs/wA4qTb3KELGtVvUXot9I8I6QKa30POW+DTtkx6j7+cRYqASVso3t9fOUVCJnJhDfPL/ACadPoFqE3tnBplB3EPcSia1jWlwpGgiDjvgx7wEUWfBiVT3jFtYFAxbR6TSe8C0nZUqDfKOPw5HimdYj9NZpbo2grTn5wUiYaWAv7xbDcKp4DQZk6+srzIVSXUJD1OL0gw5CjT2O1ZG7GKEH7BrziHGTGghECT9F41H8aXl4LP6MYUlIRJEHG27LOnBNHXmYxDqOIn4wvNijpHatKXqUuJVMu++Nmj4hozS0DrExbOSW/bkGByTYyAhaKWdjAzQVOWTs6JTl5wATQ4uZ8KUKV4cafjBI0BIt7lo3GB8rNkQo8L2RGBJbTufCaaXRNvGSTMZiVpwS+edc4dAIiiZjzHkuDYmsMkkI1FNGToHCxKE+reFJVvkx1osvVBSWCSpbIrTeCHQBbwEyye8lQMlZhHwq7jBUyyJ7qLglBxrDO61RgyvB8n52fMjuFszA2E1zODQKBK5B0F9H98LaiDUj5OQFzjmMAA0hLIgT1e3jCaAolYGCJvck1xkKHDvSVs2u2Yl8Ya+u3Pxqc86mysT9b8hL5CI/hkRh3IykLoQ+OK4qtBKIEgFBEKxcbjEgxB+NkRYSCkkfJgjGWV2tmO4Y43gr7h1I5CSbdU1U48xakB0PxlmscEpJ2ClECy8T7yR42gSlcChqvXGIsHADwu2AfxlGJAIEjs61eOFQ06I2uuX7w0QwB+yfeRfI8CEG5P7yDQc1YQvQA+cNriKls0qPKfUZZTA02kFx9+cgELQAkKzES54cgvMGsQqjQHPzcZNgMSJIElTU1MbzZ9+IFIrk7Ry4XjBsihIC3Sdc863ZAbsQKrwvjIJ4/mf4/vJ2RUynLZriOHfOOaggFZI64kntBiYiSlBKBiOiTqtMBNELelaAL7FirvJ+c5YAgnb0FiN4xoNAICsrjmNR4ybGExcpSs1U4qJ3INqFPtmQ98tmmKQMSPoWGnl7yQGSNpmDIajfW+YcgU+KOwtRERwMkTJQI6ADsnWP3iP94kJKiXmPXY4guHgNSTcz9awCchrg2Ptvx9ZDRVkoEgD3HE26vINJOdLZVNiGQnHzgALBEgnnk6D3gQ1cWGH5bxh6rgS4vh35O+zInYAnHdBtipf+5cUQlwKh3t/Wc6q8AFh3D+TjDZTEAuR2jbO3CQAJDked0PgkPclVqD3HJHxcmE4sombNdWyObNM4wF9UgpwvvkFzblGdd/eXvEjUc8Nv+EDPkzQDX4SMH55ZBFAorR+h95GID0jkG8bjX4Ri+YFExpSLJZHltyM0+hF1pHhXFrML1elICEPzc16Y9aZQkLpxU34xluWAt/imFz85ILqNskAjtosvePNUtHUQEjhG0EcZc74kAUkLTItxZUsiih1wY2EvTXeknGSlgEtWGFgNUz2YT3byQUirJVPc5XSgA630BUzAxAYnrQ2uEK/lWTnq1JSoWdn59YcjC+QLGpJ4t84hCI6Gg6gqMRo3eMKT+Dy5Bt8wyyKR1TQFpdh+QneANUhuC2REgCYRKngOCeMc/kJ/eQTyBRS3taP5hwrUlCCSHZspV84u1OaSmasDgUoG8o5PrME1UgUEso5jC1q2VXgFXlcprWDJEJgoaHSJ8+cgsImWSo6v4jvOWMoLX8SibpEwWdNiOlKHzjLD/MJ1ARtCZ2rtAwEVXiI87Jzc85LpHClA4TAB4wUBwIkJ5rTJM5nZpHcKPxfGSkREOxsyjbdxGDGFckIcPSRhPgEUkrh37SVGTwLIPwGKvd4qlSreSiPIHNDkONWSZTNVv8AvHFQQiV5lfm8NmI+oGk81Q5fWSMhBBs6gGFfh9ZLPicUPUo5eROQHaC06Chvx1WM9bKsnlqG6f5XFyBElCUksvKVaxOSKRGpJuUh0x1OIUggUafL+pc4vkNDokw8TQmoxWAlQ0l+OfXnBhv8t05KlYnUvyTQgJpaYJmRTQjUW4iJOEFA5jaVeBTLckCoqeP1vIW11Fu7mxFK/nLx1TS9oURaJzUXlRjo3cCYEyzksOOFxKgBM2RG/fZDqDYtQ6cOUYnUvUTT32J28YyEmm3UFufE6mnbkmHJC6sCYJWZ/wDQT+KHHU8exuslnl6hKGNmoPmDw3rZr9jUERvY5p2kUkT2F8JJ1vB0Kowp6F2X5cbfDKTYj/PPWIhQWAZ8KTQhmJ/axLAVqRPZAyXYSMamCCI9SkxxjISdEqOJdjR9v3AMbqiR3ZXl/wBEC5VhCF57f9qZRAJa9o1V15xQUSMl/ixH7wylMEi9oBRfPMuVOElYeFhBB9MgeaSswe9M8d+8ecVKrQTNTIPENcwGUXzGbgpB/jN+tVLMmjxB8XgxPhIfTlksdDvJkwwR4EXvVwhFwERijG3wEG2pzlsqMUw+kafgwjChF5Ys467Bqcl/Apqq+4ilKuFyfCwZX6UhwX/A00V26CnEIHuvGRVolAeycJQPSxc+RjlXXaRqy2d7yZmgEGIoEnz1uscGjCoAjCu6/EejMgURnB3Yl5wdQG5rBEldQnw7xoCzGVENBROos94oFeFghT3z5x2KXJ4uPSF6pXjIcUtgoqzrDW9+mFNScXSwmJSIiYGtYlmKmuALszcDMIPMTsYdt4X0I78FQqyFDhybI4jXeR4tgbaT/Zp9SaYU+z3k3VAuVqCDHIuFgIRygj3LF4KDRIRtFxRrlS1BhAFq4Fd0SEHvJWvNkgYduStV9tFOStx9CbMT5yaTVPsV+MnuYcQ2n1tg1hjFAd2khjaUdI6ziYeYczJaD2eMrOlcUTCuFZUArCNKbqNQr1ffnFgJgGYSkIlbHd9Rcl9p24MmBGcAQIbCAIJhmMMt94q2G9/RPnNx5CI+UH+nJBdniHbgODx6yUXD9lkbGpcnFqVRoMfXfnFdmZ9Gjkar24YMkb+xvghM5pCfwTkbbavnveMW0JCKuplCNHM3ljj2uqNYtZcGks9j/KwkatshQOLmWZx3SFcCEOpSYyK1Ym/kt7H0YYkidwVfmE+TrDuYHtQ7fLjEMq1AlCF59ZPlBCqCBEVFen7cbxoHhEqQczrxGJyoXIuOPiT/AEENEnYBq/E/sxeKGdLb+sHVoQgHb3WSEuUqJ0bVPxgo6bsLM7bsugtrG+fwIQEL7Hlja4bcYjSTLd6T1OKCqJAZC3iZ9qd4h5oUBtF5Zbk8nxNyCFgkRtFQveLLggVaBQ8/ucpUEdjSfDek65JwHI4ifdk3qvwzY+Y5zQrMgJ5HeokhEZVglB0m58Y1LlAbsodv4xq6qNCWmTf7jEI5YGyqzxT8PUYUDJm4FLMeP13CihccUcj0HmZtqZzluslYhoMhv/rueqgEp+THFy5BEYTQZIYbMF1Xox0YUyAJA9uYLvyTYFBaDCLSaN7kxrybA6FjlDkI8x7mIdESK3iQ0eYvHkTig0xpTKgrU4Ub6JnzCg9D2EEdnsg2dsqK8YKOEQGnPi4+BM2YUku5zkhwfgLH1v3aDQ5qqggl3hbsYVL/AIjPCD2w/szqcVUgliWEvgvGjm8QS1IJJLL89/OFIDEmzi2Ce9Omb/rxwUIVRoEk12s7W2wkATBpXeoxkD8ifJa2J84n5WuDyh6H8sod5mjSehCpNNlrKDGOmGqLDXVMJxga1JGBRk3ycHM5QEhvBgCyEFQb8YEKR+1OjQir4eUMaZeRIuChFPKNm0jHtk+gy1Do7sn2yXCeHgoljyglFSYhoxSPo4xUlYELBmI0y2qlPqZnAnt5BU5CG13hhzZaPYLmpTW0qHNnRsgJGHg/hgJRlaciyt0qq80tZjrIg8QseU4CKV6MmQCDpKs8TkfiRaqCWKmxS+ucSY58GaQDfLsLMclzK+w8w/jpgkJHyRNHMBkEQxHOEImOFYhDMdWDhdGawcYoWE1D71iUEc4EZl0m18TgY5wQYcylWJULQOjDur2ZZfMwhwjQaFQWCKcgZbGWbE/MMRxLWXtBoj7O/wAYpCdwQcU63j2VESfvkIA7Nj8ONZIdCqziXl4BOfKZODwAJZgubifD84IDoDmQD+E+cvGKEAx9UWwfaT/QzDXevDA6hgMKhK9R85FaVdhDBRCWTpm5wDILKjX41FxoPeDZypOYr1fPOvzp4PK6FHUq/GASDLoPFv8AfODgEEoGOynn51jG8E2y0gn+3g5x4CCCECEB9vnpcDjChYhvjmbvxhzZiZHkl3X7wdjgUAysNOVzMBGLtNMBQDcm8lMFWy9psBhrxQWzDNl+hBovWTdJDgQvVgeFnnNYhKyiJal82LeS4Ul22baQsx76jGecSVgvrUGicvFEzbmGPAlaS/Z3hbC8SDp0C+Yg3lhOkuEzLgFNTRPeMAASzhkjLASW+b85CiUWpJBO4nI6yxJhQmyjKU58c4wYmSQAswUUX385YJ8Jg8IhZ194qIytSCugKiWe9z2UfrLsXdTeEXWsBC45aM+MjfQNXP253W6nEJAjTJZUVMwvhPUFaobo3dBXH5dZFZ2F0l2SsCk7/m4Q1AtJ38mr6nG203t+7l+Hy5HcqJk7JvQ/xiu6kkL3FAysxwbzt0eM5QQOqXy5MhSLtybRbijwtVlwXqqlFOlgX/mK1cAkELHMCN7nzgRoliEDQ3H53yTJ6fzHap8GVCjDMhwILs1ow2diWbWC+bYfmYlOBSGIHA0jUudmmNrV0oO2XpiYxlIqSuk2jBE3Pt17t1Bl45buw9ubxq1Iq6tVDOmQqGzScoNS/ivRloN/0ingV3ZRbICTuIAcPEaeNyZMpfgTtWiKHc8ZLaSI1IGgimqYxAoeUVnXSNhGtOQflVSJKIBpXpYjnOBWhBdFiq7785eAs8Kg8lCJGxaeEHqAQW+hM/LLxhMaUJW4iUizen8wcdVJsGmhNw6i5nK8MRI8iCIgHZ5RjKMiGwNAYSQeXnDZOyygiDqaOfhxOTjfBNIaHhxa4SGEYY5AFO5yI11TiMfMbfMssZv6BgDQQSbsuQZpzMXjyk6J9vOJoqiMoYWmjtwgw+5Z1HI8liEdymogCJncUI9JhyxIR4ryISKfGUBlHMCkp8fxgYmeQbTUWF8rveKhJNaLd7LvL6zpSklwBTvveSLVmEgh5n0qY7cIW8TSM6gLCTidP3XJwXQ5BPEnJIZUMknwUPdYDK8rHAAnDvxO8kshEtfEvM6fLAJ5hSmmL4/mzKpeSPkI4qJxVFq88Uf4P8GG2ygjtB72Y4ilKBDWk+DT4M4RM2HXl5jqO8mlNRDRNnJ57vIpIQxpv/l5eBjCQIAaRNYK09s8QMlMWPXHKoMM467LIqNcLKabJhU6wokWil480QK4QBYFa3c23eDItAyBD4B85wQuctn+CCOWjNWgfLQn2vQXbhdbRwVJcEJsT44cDTNCRQlyN8TMs1gazxiEkATavFvWREI1xVa6ECLOA1kLANpy0dX4hw/mDRk3TPUe95VCRUE2O36s+cEcGFA6l0rCagqFMt7AQBkJm50SxXWNRlhsEonW8xfurhShZCqK7SG5/wAZpR8QqAmt8S34wCEK5wIEo2pMzy6y8qTZLF8iD1NGPk25gE1dAH7E4EMOIFt2as0P7wlWR4owRfSuSecTaQObiwGtGu3hx85M6x3cbgX78hstgZVEidv7lcZIYBolBqBokSPWBHZsFNe5ajEmFSBF0SQ3ugd14Jh648AgfpceshST9Tca0rBf8ckPmlCGx5O3hXWBpxFYc3EJr5cvBE6WT6hAa8LrIIgrUtYvIvv4yk3AEFS6OpPkOOPkSg0F2lSCZLrFiGSIkKvPBh/KnnmD9hYvxnLBCmNBHh/4wqGFR0CvMeQ5HeLTRMi8AbFFS6zg2EG0EVsDfCYV5JZdm3wK/JldsZvCydwOhD3ie1EW8ZYpDb6Jti8hmdMTuFJcguoYoWBjs3I0S6lNJ8hcA6SEQKcSMVwAyi3AR1KcoRGmO6mJGnuLyYaa+0hqY/JjW1HMeY8IaMfEWy0MhLg6BRCyCJgnI8gyi2xMG/C0Fi8OJnb7TF45cK+8hM0WBWxZnphSWd4CtjmQ2SA0Qp9RWQWKUXKyI2lp81Q5FArXAjjcSe+SSUiBCcgoQJX6zZ43ihRW7UJ1h5V4GYiihpBrfnA7TEpQw9rT3GEmsCi2CJiObvKkqwtw9Eq8+cBOK0QHlUZ/fy/CXcKkoO8hHPxU1wZO+proHggJEteE8QA5Zwtp0C1gMbK8wmsZR8IPYLGbG6veSFRpTsw3KXTTyUEg++IboSiRAvwm8mYKzWEGi6J0v1ixajRJNhtlZ/8ASOELuBElo9X5MhYExTIpkqZ9V9uI4BKpOQJwfk5wr5S2YdYIZamE6yScSU8K68YFcwSLKxoHD9E+MI6p8/GxPYG7BHMsHpJlWkjrJpadFDbIC6lz0ghQtEEJqnzkiRTIchtI3uImec9q5gaziBt5vxBNztIW5UyYO6yDys6lg9PWPK5YxQQh7R/zBwwJDxaAKsjXBbMiZNBDlBwLbjrh6nozuDyU4MP0PaGOfoFIsgS+TWF/IwBQhRbgGrJLnLsDes/Omf5zjqYlsIDmSaNEGSNRBbtjxEb5Mrfu0+MRyabrpiO9cHBgD7PPBgHMaZZ8vzfCt7yXEQDVNaF1JXEzWABVWAhad/oZKNDWcLG3mNaPzinuWASUUeiXrI+FwVWQZJuYf+Y0zgcWmMfko1O8iBkQBnloJTRLyGIjfqITfE3+ByR2SlB5BoDDswOCJAsKDtiT8+8gDLjCTSOAD/ZnJ3GMSL0Wuua5yRigTbDIgNddVWN8RBQKkiEMPgecYwpkwVHwEXu27xM8Fkcp9LGNyuFOsTWjwO9NfjZbiQbICfQNME33D2JIFQM+3I4TzjFa5Yd3ZKLuvGRdTYGKPUuIvIeeVSSJCZYECY41neEjXta8wnxRizwcsJ8Ahv3lBrkIhgxzE/kTsx4V5sQr7Al6nvITJaDYnyzsY75iCaqJQzyK5DRqjeATOCBm3KewrbMQZH9qpBdA8nMzJGASNPOVEjoclYw8q1CRKdGXAdYx3/UCqAXt43vlwBGKgZeiKi0XBCRl7CBwRj501jsQOA3CmIWM6D4MGZFPESvnJcwC6Mpa7XR+8bXCWwloApnjFLWBOwYYA5X+GJsC3G8TbhjY1mS7DVrPltLHRvESOBDe/ag4ECcj7mUKXBcVx0T3kIkbEoCH5HgyQtVMnKALX0ri5Tb4raD4eDjLSdIqcDBDtDz85ZnoNGWhPP6l4xG90VFaw+V6+sE8Uoo3KxMCmqjIaxzEYSCx8QhSOISTfGsl1JEkGMcLYOfxeQgalJZPgnhG8XyggZ1WcwG3+cELVhQzpiz/ALM5EMILkoCxtiSXXnHo5JVWvE97tyagIHp09dfWcsfxT5Qw8xOpZDC4J12Ecx9fGFhdsiJMTvtNViqhjGURijey+Vy7UdIVND1eTS05RVCxuGNeshqFAe1K8+8h7XaHtqK3GbSMCDeVE/wOcGsjdfBb8BWavEYDYleXqqqpyZkvISSFDVx7vOtCoJpVrzyPgAgKOYEoMsXqtP6RGkTaQ9Tfh3hmpc8BYU8CfEZMIoJaNaJY8ajeEoi378hHNiaxOECPUYNOi9HnEoJJ1nGnVBNWwOMhQsoItkJxxm3vE0K1rgTcnM8YAvbIO1vvn43idMSSkqZN+f11kJ2hqkHZua/2wlGAHRCAjma/WDUBSoQ6IkINjiRgjlEH3QmOXK7vWSJGLWg/eSgdNPP2VO6XeTAp4CFBIsk79MbwSTpoXKrgezzfm5QKKtjtBL3GvGLVKgIJKGt7g8zrBasHq4i2g7tYMsVhV32SzaOL84cgxiCCdKrf3+DToqIN0WPj+5yhCHKcDRJ8mGeDWEMziqWHj3i959YbgvNDZxxgiqCxNKNlmF8H1QGTTC7ojc5ILhilGQ6og/eRxVmQvNcb4JXAGmjORIjyVgwRvIQlIUICzxMAZtOLtJNNE07iO8C9UI07h3H9GboLIjkuNPFe8DkhXaCSRLrbz3gML4ExbJ5MnQwVkU8guI0jT5HUYOYE462K+cVZwsdkCemfYarCWtawCqYaga/RwG0Y6HXmypzAo0pCAZKOLSJHMN1scSEgBQajPAII8k4MP3iSdg1SUR4hmegHBcNkRceDH1/pC5BB+DNDcYYQEvcEkOBENN6MbbPFiil8CD5JuceTruaS5Gemn1kPYou5AFkA7RZyMfRNk2LHMlNRPeLT4CgBiKdtYDEABlcCIowISiiLNL2baajnFES0wjj2dvC95G2RJp5STNm9HmstVaMtN+CystczYS+xFXU44k0PxPyZKXENI7P6jI/szHFH1G8oUfdHGeRfx4xQCFmFE+d8CjRPJlYO0u9i4rWQmf8Ay5jJAcTAgpIUyRHhxDlBYIF3xzvnjGNVKZajk+DHZuilFiqZj37xZ8cA7ckGRSJQ6+r+MlyQ35To+PwyFsA6pO6vFpi8IaaPcY4SzInbAHYg36xirMFT9Q7/APesJlJmEcnrBKywtrzk6EJIfIvVeckOzvprAXVHM1r8f+GGiCgpyb9PWWyRnOle4ECDvBsn3XZJq2/PJYvUIEIbY/MOToFKB8m+6dsuDNzCEW0+UvzeD5rI3ye4rorG0iDcNGWyBa/liW5KzQecYKNBccJfkhJJAnBYNp/WPl4YdfnWw1X4IAo4lxuRJDwS7xUiM7ovZ648XgkUUSDc0IssYDrKlBpaDZPOuPJyeqSqIU1XH41qsmL25NpPZmEGnxdCDSuKY1EeZ8ZH+soGbT682Q3gcFRjMQpOHZ0YBiV182S+IrXthHZpt2Dk/am2AooMG6Il1NG/DWRVDv8Apo/c4Ch3aBBzHl866yOE2SjSIn4G81ASCGJoLXnWTEdvuLo83RhBNLTPCh+iN67MvROAJB8Pda9Y8SOpHVlPvIBa0YEfSMRHNYaYnUhC02jackdwTVg8O66eowfzqPhqPDCiZEWQEQOUbHeHxY2QqUyIXIiZ4clfITXZSH/A7zjPuv8A0NC+6eH9dZmaRyBMyIPvi+1SkINmipfvhkew9cA+1PnIjJKjzFOSRgxgb20ZSDHsp8CTAxYySIV0IibtfGTN8Q0VQZloOHQtVSvKLIxac94PVqpghCrsnicGUDJ+MtOA6/zEnxqbYTn8Yopso+LMhu+vyHS5DENiy5ok2Z3BUso5AheCs2sHrEkD+27aUkQ0reCdDQLMkysWcHpwdwdwFCbD7eCwhx6iNuSNMtrGTe2kP/RMr/fF3dNgci6hnAxSbiASD5PGcQi7njGtH443hidEtEACPU2HjzbJVAd2VFkQXstxOkN1cGUO/ZgEcSfcEclEmjNtesRMvJ/lwq5mR5vFjxbcxjGesBWIJKoQzgBEA1E4G8UmE84QCSzd4F7ejAkGeiXcZE9upPcgmPCZclCXERCD4kn5yG0G/sT/ANymQFGfglEvLTzmoeFzLcHh+sRVAuwal787nGCAqAc2WEvmcsUFztNzz6YqOCgm5h8Q/Jl2tSO5wMZkrcH/ADgTQoFweQP+4jelSyev6xUDDm4/eV0qOGBArcf3lgub0meOjjCkiIBYkClTvcYTohW5EQ11Ua+crTQ1zQlJIVFmatxPzGwzE8m7T995PGNfiKtdd+MMCQapBZfccuKywiQpveCOrMqMF0lYg7giXc20TeGGKMrjYSheg7xcESYiFyqSVJY69MdUekaTo4qStuW6g0+G7Mcxzzk4EPQcoL3vJ5GUQQOS3frGqkxQlAk7e/M5ppKZLa70vg1hDUSoUBW9w3e/jKjo8J9xxP37xQu5NQUx5BGS5KYXU/29WY60OkEWyBKJCA+e4ytOUwgylrbQVc0bzrmHi4aDXAVUZyf7AEd9/wDGDIYEKG2ln4+ssMxOwviSmODgxILwFZLud6MLpeWDHglPwHJOI2aDYel4des7GV8iIH7nbgU7uwOSOndvjBdgFALsfiz6YbIAknu/g+MF2Sc9i0J/TC07PFwtpKXzxgeLYsCiIMFdO1C8dsX6FO2PMQhd94adHg0BRqSjyreV4USWOrMBXwTWsjQ2YiCsGXMU7EGiUsXH4ONytAJIKQqFduK3rCgoA46HrAciya610lS61Dc45koJymUcSljvzgqi5QxgCUDodAt5zyGOyusEc/0YposddocxB3wzrIBFhaQEUmh57GCRyxpGSMQ4dN+eTMWEAXpgS21jTjV5GuBQRIMVxPnHacPQnBe0BLdEpy2hjwwqOtc9InJDEBvJMOv5TbVxgENTImr2Hj5wI+tMueIi+dvOBzyMtJDll+jl8XJNAaVpNNGdm8RASiWMIjjQbpLYnCPZRqp1XROgLLIixEcIqlJ3bN5xrQC0JCDRUI071UkdKgIQ4TtORMJwuLWlQBsOpHjeK4004b+UlnVQHGWxSKJ0JMaeHc8ZbP6Yah862ceRwUORABNPbJYeWiCLnjj6yMeSVdB6f1h8XA6KJeHGmMrG83XKFJ8SvnQGR+sbODSg1F8lfGG6CH4gr7wdCp5NBM8EjGnzjwCNTILHmMZ/NXE1bRcfUm8+3ww50AuTGgyqm2JBAxTz7w9LAonL/UxfrJE2rFnrH4ZwK6hDQkIU18eNYlFTBP8AQE8YfNGRoTqPGsKCwRWj/vfxk6dlgpa42GCQD6sG7QMdayIHASS2BtlZ8t6xxVDwKeTrR6nC9kKcnLPWyOZwFLAjkVlPOk1QrGyceqgXoAQDn7RZi205K4PRzTgiSYG5MSSyduRdwZRmSC0VB/o47MgaA6hsTc66yVFpPauk8RiKZEJEb8L7u67xwA5Ik6CXKZasiscUM6CEnU/87wYwdyHTMj434nzi7cDZCeZlPjrL3AsSTJVrfHhyHHhGj3EVo1hrCQClIMPT+sk4tCwQgd6Yvk+cCGnyqAFC1ARmsyCKOQZzNdH7vcxYjcH+frICWGC+1GX15yWmBGzR/tfvFASxiKHg8zDGAnLUKnmsNGb3KaKBr924eUJSsMSEcf3l8W04OR/Lg0VSU7Q698YezhiNCUR7CvMY64QnyRvaSGlWDzsK8etNl1HWGqLbdCUXsmftw1AppPfaBgO427xiDACyAuxmTnFCQjWBTblLEftlaxNjxmcrL/OaRZqDqObId3h8nIUDuH3jM7VCAosvXvxi9IYAtLWZk+QfCJM15i6oUzHJGLFuDS8GNx5ZFnCNXq0VhOA0OnlOAkGLYRTM/m15zb32wp1PPGm/vB1uSTzLpBYhtxLIyZSVvYAncag4n0wJR9o6YLwxyVQOxgcbCEaXeFBeyy0Vd7LAwEWyiTcZcEHXXM5NhZDCFIsjZ1xzTkPIiRWUxP1+MkaSfFwP8v0ynSxoW5fM3r4xk1skAssfsi+UYsJKSMqJG2KbRoZx+8+KRzGINu4iMi6XB9F15jFRqLyedlbhRE86T5+0XhGdI9cLD6lg1keNUhhAA5tn7axkOVuKZFCyJ443irF4EDFYu7kN1nJLf42VIy00A3u3h+MOFFg28vB/7nH8mqxBlOK4nCieZQrEpGp36wBLmTWmSPOsLYI0h3ptf8vJk2uJtAKHIUlY+cXiIiNshv8A76xcyoyeQCkFcc7nEycENmN42WATCsNhuFkjSeeVqHWJ6inMsHWRR75wT5j4i0QUrRqL3KSqVL+owUbliod8Fsh+MYezuyn/AA7yAE8zRD/zCXzN/sv84wc2pxOMPSw5Z+DrvrIlEsnJO9e8jHQKUHKc1Qxzk7YBEJDfLbrJFZW3DZ+Mhh52EGi3FJ9vWeFgXRACIWWHUSirANJF5SVgz4zWEjQtSAC5qr7bUYZ771oLp+3OBNBNcQOU1t8PnB5mbz9A0/OMQJkgKWnVcEv1LaFuId+eOO8mdAPbYnn0cWTxie62t/eTpSMSERPEfWQlDCYpLWto+sRqzBAToS+2oiI+OPxFGJgQ2gfwjEdGBznHkNKZ/WTlRUMwP+HeFuQ+P8fvHhBuOm2+38YiRmSGp5lduz6yTymqSMw/WRqWTRx0JWKp/bHHuWev78T+MI1tcDSnGcDITGZP8ecslDYRieHCRD2OjKSgiyanoEsSvOGN3jCClNxTqmOsi8/aghTBaePjK5BhJRUkaTGPPOI2ZbCdzOE7rXT3Ia6tCLwKIasqXG1xlCyumrNPuM4OFCgjVsxL6FzFEMoJIOXmYneESCCbDy5jE7JJqBEPUS6j7w4aKZ1JZPF/6c42JI2kqVQjjat4Dk1MBK2aUpbicm1gLLKjSJEEOSAd4oJCBNqZ+Qx5hBkV1CfktEesJ+YNySCCXe5it9QytRgSdZAsO1eTEdBhEnoRQjcX0T4xkhXLmad0aT2GbcVSkSTttQPjE/M1KTRzsu2usrhovSF0l7k7vnBeMjBiSDlJ8mOPsMRyLbH9OVJ0Jeb5UauaayY1hZjCHTunYxpxedlDANLYmiyw7jGYyDLThaz6HYIGDUVdJeVLejCmViBcAk53EcR5xBB1Et4NcJHj1kQjdMxqIdnx/eBFuJUoGqfsYdujclr64khJKhH41j4BqAHyyFDgcU5Db36207xMQFIFJuxAb9xuYtGnGc4bqRLTgg3zLO8SDMozbpMkkp1jLabASMmqU+pwuqsMNhMN4prN2ecI0Fean/GN7VII0dG2CvUQEyGoC33KQIFkKTK3eOgMFKTpNKe4L1vCsMVWzMA69OcZKhCtk+sqwyPiMgY4iF+a/wBzgAIxGowYIZL1gFK/Tzl75gEyPXd2Y5wh0aWAe2Ia4x0lKMSYs2o1e9TkXUy0lTGsVdWgDkyJCmuVPNKQWySVEe/iN55oMMrDS9GiaKySRCPj58ZJ0GCcJRew9Y/QNvC1WKC2L4wGFU0c6AwwRuQaNt5jYIvAqSz+TFEkwc8ChNuiPXrOe4qIIIinSb/ULfhPIXy8POuTC1HjjAi+v2rGAKl0w+fF+sDfIu3wec8cFLN/KzVvpiAfdTDHxjrWCZJstEx/GoyEDUTtHX0eMSFzLyIt2zVxx/eXzCN1l+qPzGQFgMjuJy2u0g2R/pwEikOAp2LOHiD3kTT/ANrEZA4eKVflxApdPhaf6dZKch7tDZZc8Tv5kjPAATFSWmAU8AeJMkzYgCBZrZ+MVuDyRqCzbRwR8bPoH3ODZnndYXoKQMvUKAjLJyaZy4Xz1z8ImaAvDoSRY4PnAV9KY2EBVmzL33hLoKmwuzoJnuSMXpa7THPiKrXWGOcgLiHyCuxDON8BdBiUDpOyt3GEJOZJh9Dcp0ImUYpIi5skHtkSHyzJnIAgOUobrElzM4xiZFozjDdoV4FYhUtBEz6R5T1Di7KIEFUR2F7q8ilrsSsAjp1DyWSuWlxEWACQvAi2peMCj4wqcb0hxuJyEBZsvSPJAQ945dEQoSvUcVI45OVa0VIFRLqbHFeBBSxQVfyxgtA2RVmgY9pxeaDlWtvJsRpWzJalqKcq3wHxg8lrM5qEo5G3pmjU0HdJAFtbV5Tmzk0pwBqNomYh3OccNklTq1Xhp7wQE4UtKQ0A443g83IcplU6p0j3W8kxMhriIrCWUiSMKhgCIenVyWoVSTK8Zttaa14B4WlCshNy185pE0kZwLg6bury0so7DJGwhRQZOA85UTTAxOQbMmkAbXgNui3AIBcaki9awsgwN3TMcIvzWSe9cRCy58iunIyhCiU7FzfWIyMN+qZSEDnGmZ0CD7Ju5yYLncscZZID5f7WR9C1kgCoZC4j/uEmxSOGF/hMXsBDHxjrBhLUHCQ/D72f8xrMihY8jnXH84lviI3zw/1iSYuKXaeZuPjJDUqcea4YIzRJl5J35+MQJhkmll5CSPrED6NBFM0GwnM3FThwy2kGDk0olR7MK1oiSjfRcRDPZ2uEhPCAqthuovAuQauSm1tHL9ayfPrIWR4jt+TbkzSSQtmaJGq5mPWPhTWkaqVZ60k3JL3AbEJM9Dqz85uakdgVvYZQhiQfQ7ij5wOHoGAfSU8RjiSSiZgoMC91tcztHE06JU8/3hTMMpusYImCGT02/LWGIS5K1PBOFZE1Qg9e/v7iiBJPY/8APxhA+BDp5PrCQDKpAhxPmH8ZEF2ywRBZ71+zaFERISTJZ5CiePDDsMnRmbf7eXJLQPfr1d5wRCMYexKJN+cYpkYLXa47jEdouxJ/5kLhFO40G/D6xJ4AyQTF5TGnB198C7Ym0Y3uOTPsFA8wprujfMmCNV7bWFKGTM9J5ydarywSWiN6VxhsS5zQrJWT8HJjQ+0XpcExPEp1jziq0p6Eibu0u8pmIgudHTPxXJcvxCtcgOHuD3jvHdJDBmwC66wFVRNAUa2m3MfQFqtszIE2DZ/GLPZsZFx8xsLFrEh0Rk0VC7inqCOcW/kRCTIc+HaZ7DQJELUSe/OWa5xGns6hMWYGcQgIZmcNfG8TzbKA0c0TIFTPOQc2RoE3dKRhW8G/BqOcCBDA3Fo3nc77g2lqPsQYIUDvCiXKZ/YqYwUQkc3i7XheBsoePKhDdiNoSb5xtBr7STZkflLTk7zPMmSWlQgR5GRTK0hjkXZxM1GsD1UhkLnRfGQ1BQwS4i47j8bfqNzxhqVKmD1/hhYkIIAERPYEW5gkc5bljZf+5fUMoLQuxJwKwKlYEhLG4ruoxt6BRyXbcnzgsgGydJABB1comcaw8ryniv0YpJr3HYIVJuPu8nKapOO33kMSBgqsV4P9WQ7RRKHrbydYERm0sNT5vIAEkhiBTByd5Q62hxJ/WRDpionSPg+GRwLwPOUS3xXPjFKhgUI2Cefw4BAgfFm5QTfuJ30a6GWEaso47gxwxmsEQFUe581kxeTCMbH+WvvDlDACnJwEzx/Qqbw8RNgbmZO75wjvG1wtOPqGsmUDpYKaRq5FNzNGCi3dZS1CTxKxORBjHgbXaVXPSpKyHXZ5MT2S6YayqzSl4RQ/DIVuAqTJV8x+XyrXuYALY0juwoXDBRGbBbX59SUnrCpAFQ6AeCa68FlKuaoCIHK/o4E0XZq5HBrjIQCMJpMy8YhMkjrB9biHnI0wICy0aA1jduMw8FjBqSwlbDJZM1NHbuSe4cmKhDgNRfGpwdloWwRDDj35w1aqBAep6/7ihNcPTXP3igkJAfPGRKDUAdl/TGFTSow3ycE/p2Yv3Eh2eBf1/GVEICcxccuDHMiWHp+9+sj4yREgMls0Y+oxkGqmvx/5he4wrxXnD/lVScAg1hjxAW8etWP+5HWCwQWQJRS/Fyjvys3713W3X6sIF3gR0ABMO3vAlo0FkygFh8+pnDZ41UI7tOPBGgyEvjJCKdrVwaA7mDmw7bjtKK0JLuTAPTQaU0kbjSxy5yvQhRhCyEBfc+MWKIDIHhKuofhKmINPkwRIiTPDvE+qDiZ4k2foL96AQTACJq9PjyxMdNFggsvUB/bIO7kIkp7VRN14YEkm14IM4swLDEBcRiQgoj09qenGQzkVkEDwDsmDIzHgUnMkPXc6yMM3SEQUgW5pUt3h/Io0bMkJUJb7xRFtsBFIhAxF4wIhkRsgmGf5gyCyI5jiTI8Fo75McFd3POyAcPt1g0jM1JsQEWRqslr8Sb8uTU36seAqkXAoxMF8ecoR4/WCAR8GP1Amlp/OIoooE3TGCVtBLc/ZjqHN4GYk0CUoOPDV4hIVpLjCVESy3W4rbvsFvyTJ8+8gAqMeUDfzLJoTHR2LHOGHmGi7nSzIoyV5UNEyE+awvym0ohQ9knwprON6dcCICWeT0jJL0W0AaGe4zPZMjDOyKS7gtqlsiU1CpCizPg5A0zxQOU0EYTPeA6/7kXw0D2o/6dZIv0H0eTQ3QRKPHzhZ9CKPRjDvF5aWOhGuNlTMOkGDVYZD/wBYJBJALMIIXVDHLvJaUi08kWHGj5Mh7FxANJUggrusTGpBzGHCbspJSYjU8WARMkedr/GX2UaN/wAsEf3R4CuRvWM4rzFGyFhxx4u8TqGosSVyglN7XxPnQDXZANJMiiJiMchGDcMAAi3wk8pFaOomAcQsZH0cIM9Jgv3l4dIU8u2D9bwjJs+kd3pHPjFABk1ExCk062YRT5GKo54mH5yKMj7EnTHn5yZsadwqg+YjHfxuBSmDdTG2NsWqwaBzNVGR1TU7JZ1QYVAS67hgYUORX1e/6xCkpTG2dfn8YJnBnkRritR9ZCDq1fL/AHvKOwqSeE/3mh4TD07j6/eb8ARZHMdZX85RumLoLPE63yyBEnRU+bd+MAxRJoYJZruZ2M2wYTlCtEQz3s+MhUSsDYylfWSELaIgkPvXxOURVEpG4ion9YpwtxCHBI4MFKzuCE9ws5cfGBJVJjEtCIt8nMvId4bgAX9R0c5FB40DbcsQ2uYnFY2kpmK6FjfBPuAiGEZBM0dz1urMogMAJZ1h5cXzvEblSC4Iu1miKkk4IBFAMtRetkM8ymcP5qTowy63HoihwQ1dBzZlrx8X7yBETqGXYYF12OmcFM6aDeaS4vCUUI8dCTs1+TI55FaQSo9oxEPJkQ6NREquoeZjD3YlzY5gxzfSxPuN0OSBRMsmt5w5/wAttPS/M94bOifYhXaPteGMtQwayTszp/bA8cXXApbWmZ0j1ka8Q2ghAUOQVL+YR6XWGvRJe1LnIXCSy8irZE6ZJcRSmckwJVUQkxGGfByKJgmA7PN1GDAHDUPqJY7bw3+S2Fh8ZYVMCFi95fYRL8mvnDwtAVhwneFJ7s2SRCHZK+IvEtOFIbAA3ak/HQ47VEFLPzyUVAz4dT57yR2WyYpdCvFMnWL4loBJJmWoo7wP4JRSGJpWnN1jsvfIgUUK1z8ZX4u4BgfAcz55OWFIjdcvINJE8Y9SwpSVKvjbAOQiq5TVWNhvjHLEbMH6k2hccQAw5IecameZ8ZtvkrZGytMIvvOdSwVSCz7L2c5u6AIih7vxkMAAnfTF2AQMhQBNsS/IYfi5BW2bqM7HzkjOTMingQlB7SzkzcA0ANQq5fTRGN0By/XzSHcz5xAiSGUcxsjtq88P4Sa+uJPTgKoZkzQJZa0oN3qXFtqviqDuYxTtoUik2xLL1UY9EUdhSRfhH9YDGpKD3hT/ALiMbkkhL5HzenlnEtF1sNlr4TzGVgHL2qid6vEGhIvCPX3+MpiisoYTo756jCkYxaGZvtm/SZbO12QSsbmgK4mDFALajZyxrS6+U5O3Bbjwilp2j+TJ2djNWfOEOQvMq8zPw5SnBnl/jIFPL4C4J7njGTBjMQzU6+d94cPQFJF6/eP9S5Y4+5+sLHnKEjEc/GKEa72TaRngPBvI4SAJiL+suNHwekBpo5yLKIMBCRUkNpW7mYmsiiLS5J+j4yKFen5KwxdvcqK/K/jFc2nzYiezX7wQYI54kSYmANhz3GKoSKSiIQuQRH/iZg4Jwi4R4AUGaqGpMRiehoFfkJycUJGht9aKuhwHKyfmQEHEFcI3k1v2c5iEQpgRZYd+lh+EgnaFZeesfSZZDxTLqeZfnAJVOKkyB7cOchItFQ9HnM84DpYyAph5pBxfxj0EUWxfvtvV4x4SAWSRISro5idGWtrDFQL6kc0M1rJlHUIBQJtT2QMBMOCIJk2JYuQtDjlpXxgo6HIzB7kz34ZFck2nZiJyXyPI4gfAkTf6ZBsZMI2hiIbWyXE3I2CwldWD4rnMmLkJFzTI+DgwJZefJFpYNJqEzmzIbOA+oHz5ysOBIDUbG4j7GHUzuco7BGRLP3nvvGLjsrdUu3eTSnJ11MlhK93se/OS7zhR88Fw36wnBuxU18WZrE6UWlCDXfyuIuNnKmIlRNwvJ6cq3hkwrHpS9D7iTQ15Vm6At8NadpK9PsSGdlD3xlPPmS/0Q+MZQt2tX5+jIXRzQ4PQc1I7ZrNG1JKpbmrtZzk5eu58ZLBlmecz+XEwRcg/LnvI3Ms2UOrp9eclrGJMOKfa67xCq/JZjU/H4xNqMqD04C4Opy/CKln/ANIuRt+eKel7X7wWIEbnb7Rsc3WNeCYRPWDtJ6MLYy6/94gSMUJNYUISW2+uPn5wRg1gIcXXMDBUkGC00GEKX/eTZNqy2r4L9ZzFl2YKPYBL3nJnLUeVf5cp4uBYpBHO31kkCTQBssnXBPGK77NMFtQI3f5YE4CKfOVl9nxlGSAJb13f4MNQ1ElImOfW8EQJLKTHuTy3IQ1lXYtXiMwiS/8AwZ0n1nMUWZNmmMDQlDzTPHHCusHCJwJHl/X1kEMC4CPlx8Cwzxy19jgeAMrDc8871+cteAbSygHZ/WO+3h+AcAnlADpu6A2+MkoacRJtjZ2ahc3iOCDwf9+8STFGiBjrOnfVYKndbDwm5meX6rOIa4oSV6xMxNVGlMITQYyVysOe8YmlwidnTm8mIABW0v8AH5yBEQKnRVloONuRJpRgHTSRNbt+DcuTCScHodfWU76fQCkqDMN6OZjDaMOJRzgsEmO8emhgyS12kONcYhR5uPMT3xlnHocqgecujysSGQnPMRQr8xvHhqQSu7qoiSYcaGkkIuW4+ie81wEj+UJSbvknCIV3oTEJk2Q9ZBEMH0S8hj5i4FCzMLa5k6yF8lJqgpNn1p3w/IAwUqTgI/BvCqcmJT6MAdKadVvAZUS5KTFNgROuuT7oZVtJCLhqv5H7kAI4gUE9+DFugLIBRNfLvsyeyTpREJKBNnK4+i4WmDOrczGJkFPOGhw8xHnHB750LEixmE1wYtfmm24ETi0Kdg5dIZ++GfZzkYUdrHziH5ORnF7b4gPP3kJ1Iu+LES4RZALsSi0yyzhBqyoz2h/DqXJ0OiRKcmnycT3nkTeOXclPYh6YeYn70Gm2Z7PasBzdXZcFkfNVkkTdiDlmL2uauZNSAv8ARwrEsmJXWiMtrA68QC+ct+GQOBTMtY3KJMXsafasiAYl6o0e9eME4bAc3dTNwxBOIwg5bI7Rf84qdNZCsVGR2XglqMigFFQNvLtz+sjBbEBAGygCYn4yXiC8dleFoOZiLYTQ+anX+/WQpEnUxhh/WhXGL1NGcp5feQUw6Nh64wtiUZ06MVLEEqSJu5VffGsIZxBSAAZjWEeqEOtWZiXXgypsEo7TBZlIcli5SQqF78oKTy+cXRYEvRPUIRRVGKP3IaJIfcuU68C+dP5+ch1knCYZOSR1zeDHaJE1rvJ8GEt7XRfG/GU1JWQEemiN+TFMl5KbN3e8ARg67+2eQ6nIp1go0BjroyT2DQKURvUbMk5hXSmXM+jv0EXr8mcoki+P9r3l+OIAiornESWbMnyrk/OOhEorxBagXTbgoyt4cZZ9jn849Ca5U/iuMCmbUTif1y4y5WVldBvlx5T9CDJPP4p5yUOYM13EnN9d5IiWrAd1zuqyLywNv/UYdZZVZRyQVvJWRoFLYiGtmIw0r1PhIiq54DeEKHIIhBEhwxUZrpRGE8T94Z5yZKL/AIueceCvvaRbA2ng7rBQiVapG2k2gnb3kvE6ygy3L6j/AMyNlDdJpb3ejJb4PTow+Iui5oyIG8IqDGDpGWsSUrEZkjkBj6cmEa06DC9vWgjifWJOJiyRXBazuIl3kYtRszuyRSyCjvCFMMgjDTsw4OC8agmBATvEAMEx0Rks+DdEaFMjIbfLIpYaFhoTMoWmYwlFvJRMClVvBpc5N5qFim7Kbmo8pwJn6kAd7gV6snOQ6UUmR1AIemDkInQnBgS/uz6VmD6y0lIi6PZk6R5gifz+MQ9kXAeJD/D/AEybVrOzwN4Nl0kT/K/fxxkcpCpCek4eicSmAqiH4HfxOFEo1QNfHY43UYUgSNfb7pqvWZnGFFQDp56yaak4tJGayRrwCvOhGKAnTak3WzXjI5cyJ2oyf0A0Au/xk1Qpj2HScjB0AIFoPKzzvnEcaFe0UvUj58SonuDm6RXb8t4x9MNSRrcyrIsLib4MbgkLaHfrGwQbBO1xXUemJLJHeWC7QuDIAdmXbWNy1OOpHO+sgAkRaETy/wAuLhCje7h5y1zjI44iXlVrgGOra6v6DrAXPsnWAOjkgKtrje+MY1jIvafx+MVl5oJOtcH8/ExjCevij/Rl2q6MxgyGadRlJ4RPDeQAsjLMhKjlfAMxJJwqFYkkYjwP1jU64vKWeEuNMRNxh10GGExPX4dZRQcgiRCm0VrCqvdZgv8AnFIIwBkHh5jEWynocdJT9Izb24LOdBnkUWKwmjkWOdQ1MmQskDvP7xk4rk1P/f4xQoYiQgbNqwG0SoWAlqabXus73NMNRz4eN5JH0G64HeyIQL7+sINKUBXddW6nCUMqwfeMe0ZEcUawOQD7BDrTf0cN1LPCimZco7e5hjt485IQBi0xK8Eaw/HBAbSCdEkesiYodJQJrUfZ6xVmMAjlg4TMaOawNiBa2CxzbiTLTWdyy2eGRIApOJMbtf08MST3hhz9uldZwVEE5cgDBbG6pxeLq8Bx2aeHvWKgYK27AXutEQ1nDHObCpzUT3xeXpmygFBvQt0JgjIcDDEB3HkZ5RkDxWAEyl7doiOTgjSXNEAmwKtPiOMlh3yZMjajuzc85ECASlgzCLu0/wDclOktNhQWr0/xnBUI2kEorwnK6qGNIcygJ4p9nLkyaUh9ZrMgwFBxWIirBSbwQLya2GRnizL73kVoA/uUPjD6MofXP3gpu94coTqh/nIx1QOv9+s5RgPPzJa9fXGxWcZKpOu/SefeQQCM6SEnwH94F3YBaZPmz+YyBUrG/t5WJx9xJJNP/kYLwp4Nh3ipKCEIBlsLFb5yWklM1FTqOY3O8LneBbHLsx28YlFfWwuESQietVk8Gs0PyqNR1kCMkOckXIEgbxDIFo1mgbRROAGUNpNfWK7wlkzJ2c0usLEIxOVASH1mGSVxK+UCYnydP66X7wlkTYscvGPzGSIoRpgZ9lMRkYBCSlJcWSfGTZyBQK/3ng8FFfUE5OK2QJcRdYPnJMRPTduVaIlGYmDea+UQbQhxMP0Dzlan3GqXTDZqOPUIUi6S2TmSxp584OGfwC4fsVhhm4mWqCgDNVRoc6mGxSOXbimaQZmFDFj9uewRfc7o+Bvz1xg+YRkFizhv6yJIFVBZpoiP1wGRpaqT+THxWN6OXWAEIwKi1H+OfWR8+ij95KZYpg2nKb/WLQcrLTsjjm8SnYHjTXnGtmRxcn+9ZJDmVuMiOLde5W9RBBufFnQymNuhehlMjgRInzUWc7/OHRnJiGnwBHxkCiqhD8oiJ5/eEdG1ZBy6Uxzsy6gKXfR5K3+GccBe6pPkF8T0YeGSRQTJfEr+04jmQ82oSEzYwNHKbRjAomSXl4LGwzQJZIKbtbl7+cppLfiVUsETWMnwgv8AChemiK55wAwYTVlEHJw107yBlwOJsCipvsy3cbuQ+0tBP5uTCxbJPQt4R3itMu2FAcRdCams1cjmSiFFWIWuMESPQoCwyMzhcack+L4NIqsbPeEDlKKGR2Lo+8hRnyIUJry+k34w5U8LKKVOhl9lPO5eIQU7N8/8YE/ZSlRUmCEmNHkxI8o1nds5Qfy/6x4YnEm7cjBdYGfGDY0phzrDWZ5VyxIcO1YEPfjGmYESvr9/nJZKaAP4jEOhSVlkN0lc4KnAdvrTJ6/LD3UH2Pa2L86w1OWOxNeT/mIRwlK6TgrgSvupJex/OTsaR+Y8YRAUTdoGqgpm7oc5Q1RiESScy8+ZyKAuOf6Ti3O3eKdm7DYyaiGzUP8Arz5wkEs5t5Tk1ceDvD4enCdEXN64wlbbSAakk6yzYik/Dr9ZwBTUfN453Ys325yMJs0h3JkCPv0HcYRYtUiXr/POCrYZ24OMWgRRsif5MPMhQft8ZMpE6TmcFs68qo+hj4y6x9xikWm7nN7jZFJU0vXDvB5tQD/Ybt74wM88DWDCEbjFQJNvw7POajOJXwn/AGMQNBtC0uNxxB6zeuwiVnYBh3XTia2iCBsMWdMrT1MnrHFlC7TzirtWBEzsuuWGMIqXhUENFHZes4JZB5LRNiD3WRE981peVe/O8JOEQKJuR+c8nVZb15cRXvLQBoI1rOvBPTO7fWPU3MfsqItxXxdYqWg1Hkb5cJZG5IOhT8KSzreQQXCTkjFSX+kuR9StLeSsFHNfTBo18DkJD3E/HbiaICJFA74uzCFk+BChWz7PnO/4IiQHvmOtGASbtiykx3Nerlx6JPAVSyu6Uh+QgLBYm0spN9cxlRr5ZAAU/Gr3lw3EqdlEeYPXvJac9pOh2SCsze495pHULlXFKWQMm9Y4EwTJIH6a/rK00iFIEpMgyHK0kkRJmnauq5yV4SyCTzoNo84IoHJjcZ20FH0M5QLbeah0h9Tzhk4xiEuJutHY8Qvcb1N0eJTxqOJMFUFACggtHDQZqeZ/gzw6Bp+8DTNXYAR1x1gqIblzYV4zS/P8MCgDHs/f9M4c+YD8TEwhLkm/6nAlR9J/jJsgrZpzxkeHNMnSn1rJpSD/ACP5ZNXy7+oz8LjYIksVkV/Mcio5m6NAa8xHnczVixYHegeScrYojSjjOl0TM19ZJW3DVlJTDMHy1nOXjVWpW/8AcWmSJZX2+/w45cjH7RkJ2dYa1IsMdZCECmk4lcjwGQXHJpTiXvg8pkCRCWBoEdAb1GWhGif9Jh+iUHJnUUvef69gTgs2oUAvIZZxAIJ7pR+Vw4FJt8qUP+1i2ZD7SDJKvpzcYf0fzcv1dRAV8wwWTeUHufqvlMp4afAI7WyjoceHZRNF6RJiU2qc4bCTEAcIjZkNtYcnZky6wnbKnzhKQvYc5Son/jB84m4NXf5/X2ckvhCggmYY6xNMqKRrkfcfnHZEdUoHhMc9GXxUBA+QOO9/VSYaTzPpN46USkKgZiVHJtkZFoeIEFtSc2/qBZE63nmb+sVLzsA1BhCqODjwfp98YACz+IQ5xxEBI6cGEgXEq6QvBe99z5JtKsK4+bgJIFURmGUTowhiXUYMqGsjgIYkJA8t74NRJAgIjZ6LCeZyS2ikBYCVz0/rHleMmN4ksOzX75X8XgZEPmlcF4MS2gShI3MhrhyMvRwADTVvvdcachKEVR/uiC8fRW6d2tGjcTgz/qENYB2Brj1LkD7mysJ3Cg2WPzAhLTARHeIdo934a/8AaBEu33cgMvqyBIAqWe+cTbLEGc0u4Tjfsiq/ScMJEnSh7Ec42x4KkUhG/wDd4UyhrrR1lRAfM7wjB8vECrR+ecjFsQLI9gh25HF46CfdEw4LXZ85PTBq9zEZ7g/7IZCbH+pTIuV0H6DEJtF1jD8kcyf4MTnMR8YenUrecS/C6+sA3NqxHjBQ8bvDrGOv6wHfyyK1GUfWCgIaxFDvUX+c0igazB0+/wAZ7UYJHwLnITNX3Jb5yTqmqqYNjWtXlTNpDPCBqYVuNfcHteSjpq5G64xoqpFAwmbXbgI8uSvtBf6/GQQSiYrFsSW8z/WGINeANYxgwbnFeBk6D/58ThWUQoJPonJ5MIXMaPD+8N++QSdVWRmnuPswQPcI/o/vEPD/ADnNmHzhBUYPQZEG9/WRTNBNmbVWIsU1HLEtmMiSnZnHrqh8hzjfOdjqJg+b+UPAOMO+8VjcaRzkWrgMr3DH7YECP/RKR+c5AeP1jlNdkpRto9YhXEVBe4V5zUSZR9Mk/JhVIgCD8OvnITSIjj0tn3jDpKRj+F+Yzma64zk0T1WeD5Q6AchCrsPgjIrnuUJaPVMXPlkeAiMCQkNEUfDkpBXQeZN4+MVwRSK9fpfc4tFTUNPP+/8AcIzqeR/93kepfSRNernqPOAnNB7IrmI/WLQAioJzi4ho18sX6fAQkhqQivnxJyAg2kQeSxA8l4540jbAhGmoO/RkllLPiDzOTrWwvARwwMll4udqbBlAy3zINwYDkYefxKVDiE2XbTjjxh4cRY0THM2gveIqNnafEw1v6ZKLEEyVo8DofeSd3C6C3lP/AGMuN1Yn5QbK2ScZIOAMSlLbyaFfGMCkB+wJp0INC23INa+soATho8szhJxEGXlouv4x7i5qAnoFNnqJ1mhqIvJBMrKSpx6ydZvtAXztGt+sWi6hOaGEEwojtPUKIrBgXANtvA9sqVA4tkRcsGW4250+3IdVH6xMEmEvbzRM3y+2I3AENnziLmmaUIJLxSsVy7IULGH1LNKoXsrH3zgjGlxEaHgIQ+8mkpMlAA/L2ZBq2BATPHOsnr1CmvWmVw6ATA+sGfFFzxGLUA253r7yKwOin9ZYCg2am8iwmbRVn/cFvEm5PVuzlBCJrjXNlk3mjpUOXfnrFSmZ+Bhvi0fgwuF0cdRa1q7eMQtZq8w4i34xB8RiUj1kkcYB35N7Y+Mjj3YrC6WRwoBEaGKVFu5Lmo4Zbzh4ZRjGej8ZehTxgEeNesYm8nzl94BgsD9Ljr/7ZHnInnJCATDGXFITXrG+PhGQPD30wNCJHgYwdPdk0+B+wwHMWZHxlPAZC+IyRpqZEH8H1kNMXJR4mV+axRs0FGFBKvsMAZRY7cQCztlFgWGHwF/rF0mOKD+VzQ83246OAh89+ciIpXLiRE8oH28qc1kPbu5mkFSYSWYjwooN5W4ZJrZSMMwNpmEFhCstBLucUFf3YbTVaZsNjNQNJWwfAq7ZuhFXkvIEgdBg7mnwVhbUNwOy/ROzFaL9U0IZidv2mKInXIpgR9/Mg2yIHqsAIriJjTBK/WP84l+MNld40ofibyfqYI5k6SJTUeUxD/ttJFsRDMVHcxIXY6nUood7GSMF1lSJrFvc62RmxBmhaEA2qDmOsLBrQUKTaLX/AFiQUhhHF8Dv7rCmTHlvMImjcvEc5Ey3Ytslqk1XGRoNBRa1m0Ub4Y+J0DiMAti2Xv8ATHN1fuHCvBIHBuuPpiEnho/FYxN6zXCn4mSiYMeoFj3idVZfNC7Fnx1hsjB5H4wYbtIJGikv5x/wPL88DO0fSE/rEijFCpo65cAq0ixFgcNe2CXTxuLn4wU4InZ69w3gKVb2F9Wzi58ZGWSpqBn7wKxhJDt8EXkTH5tHMGK5eiCUEh6isW88vQ1H7DO8OPLwlsmfcC4LjER20pXUnnesiocQjrhAwx2GFNbNCE2VW325KcNONvYZZ7MVXc3czOEZt5YA6esvE7cfUm7/APcBIJiN8BmyO0ct7SeStTUiH3mCaNlMftyFdsVWPcp+MhGIoJOKYZKTKnaLuv7mMjrUkNfn+M209R/jGfjJfwZx56l/ObH0X+HK22h1/WfuAf7Mj0bwsM5OuBP5zpLxl9mTnBcKkw4lR0nH6yJGZ4yPsv6xHwtEnoYXoYGk/bl01hsl4Qv3lf2g99Rg4ow4956e9c5RvFYsLvPgf3GHSD7P/XD8szfV1oE89nOKfHwZDSCLqn6ZayCJDciT+y+BQLFzaVEHQHEruMYbELKnFjQol7XZmuIWiMwEs2R9kY1QzY9gMMrNPL8HICbSBc0K23qnAByHU2nJKqFtzkXa9e46Wyx3D1hstkZ05coqYch90NtEpRCZJ6nUJyeSZFBXYBHHlhq5R0RbT8JLdhjjqbIlUcB2nlDCkFSk2A5kipKHijwPPypySTwajXeTQ6noSIHIeZ28QMqytNuIiFXpXichHKUc6e2JRc45CpCtFCyK/N8CD7MhTpPwvdvnBAoeUXEYiP2cU+w5lFOEUmXx5zTKgAkkbvlB5eGQiiAqESTQyXYZ2fCBDxy94sNmI4cBcLRZ64yfQHZ/nIilFUp2/K/GURFWK9Hk1iRTAS8g+DObOVRPDXLEHiiZMakn405QhoAUnZhBx5gaBv7wOFEQuIf+Y2daM/NfLJGER/b4/OSIsCpLIisBDzE5FWYUbYCdvrB+YpaQ7PjFgmEIO5trDgqoj0iw0XOsoav3NzW5cdzeMOBGQh0bC1grxlrLEHmN5vsPPKxf81jQqtlzD/PWc1DFVjJwGoNER5yGURDFSppTyc1B8kEQpt2ffeFTVpU4PCfO8LRdrTch8a84dXk4H3cuF3IKkTxGBJAQKS8eovF9kriGTGIgTIoJVDgUUwoJEASVLDnWCj1DsqfwfjACcEhLYc+8QzXXS/mMQ7a/QCvIZI0D/ckWh766tGpJGJoV5uc2sYYkZy9MNJSiasI/HCR8DlyDnHA3pf8AjNv7b/DmxZiFL94Plc6ROoA/nIUC/wAN5N80Iz8NywyXbIPsq/jJHpEsNNxM/RiZAeUepv4MjHfDj/WbFJ/nGBSCf4A1/T1jwmtagw59iB09ZPnuakErhOmvPWmZl7DBypsvpm8M41EsK0DlWmyFPOQICcJaV9ssZKBiP0AGNwKnLIWAD7lfC0hu8GRYT3QCNFVy7wWAwAdJLCGa28uDT7hSLAjEO5tl/giGFMUSpkSEuubZmg6ehgvLREe2luhLhBhD4AjNw/nB/DsCtRULXMDO85r1QimUXWT+mKq1OBQH2XyHjCXC1MQSJdyyA/pijnFxMD4Ln13eQz4J9h4LgnymMsu03nJ6wsAfbG/yC4kuy0TdeWs50W6pE1OLAyz7NgeOkyCQYgg8fTCTK2FKA1JGJ7b3kdogXvLiSyxXeE6jWmIEFmjdv1rG80WCVZhtAsBx4/8AgWLwD6EYJVg40LGsjdIERZ2KH++ckAHjs2Il5UdneaAvLwBUiW/WBxJ3DiPicR3I/wAZOACKZVfPvD+5rghKUTiSiyLFbuh7wgC7yIOo3h80hAvOT7JFYEmAEfcRlJObIB3/AIyVBDBE6Sn3JH1grlUBRzOphHzi4QlJhPA8VdvYTLw+0KgXBuPw44EMqPoryYgJAAFJu5fr8430wgyO2bxoQZDCe/PTeMTGax7RxlXCyocnz894CVzFnrIwlcGbeQ1CQU2iZibvB3EK1gQ/n+8OOoKdBEe3LQyokOO/9xlRhJcojfwYS2JYtQo6MGdBMZDCiHxid/LHgDP7jInJnaIyRxHc5OH/AFYdn4gJk7yFarZB+Mm7J6I7Uv7RreKx1SS9p9v8YCEIxG0H4M5pgpFf3ijBAngszkea5gp8VGTNLOHX2/rOSBYJNspwTFUQ3taSH7c5yRAlgpBO8Sidwpek25SeZNswfjEhMgIUee/xldamCT5Yfn4xq3dDSY338jzixu7yuRGNQ2alpxeAuJyj8V7+8OrgnLIiY6zj1+hyNwXoxbmSrqA0Us/BWcLdTzBAso6FnxksZEtBJEzM1FW0ndzOsxK/J0XbzHnBGETW4hUHaNF1GdeoBBQaCI0/SEgzadmAgcxIc4IRqEjqOB25L7y/wTRUtaLv/SyNCtkNfjNni/eXfsCROACpMlmGc2ekQFyO7gq+iIEJcJtY4rgRTbUWSSQMBfAS8NGrjGyESfACr4CH906AOOOUWiCiV+KM/wDamzBK6fafWRBs/IxQu5O8r8wGVbipLlPXDiDkkdsQ/k85BFcSkTKDMHV0FyZVx6zi3IQgZYK6nDlXDfPTyeFm2shHfcDeERxOtV4zT/ZYGkcAx6+cmzmIUoTUiTPORYTAZHXuEoTfnNIS0QHlrEMrHWPzOF9x4yNcxNeORUNLUJZvfD7yLpqTYYed5AZa0YfLF2gaxC2vRBP7x/WPYkwQ8bwDRizfCLz5uSYAcYdFsveElLw4PL4nHSIJ6+d7+sMnpD9hh+Ml83pzVVLOkwUn7EjSsOoUyjgTPH17ybHiDNgX9HJoMj2VJPqYrrLcCAKYW+tYq/BGzqY1oFjnzk20gUr5Mv2UBJBMx4jGMHonhZ8EFHvIlHyBxhDxlRSvfyZJTFu3BtifmgXY2/zkOJwg+q/OCbh3ZPX3k7XOp4nIDhkn2P1g3HDd7ymQEaw6ctVDdk5iTxM4rEZMcURPCIC/WPppvnyBvwPGGshhwyWR84GDU1dPxkUlD3yR/wByx9NVmg5k/WNDYgmRKwHz3kMO3IYH+n3l+m2u/wDMrGou2b/rLb7GpLfVOcuGVYXy/jBp0vA9REVgRwhzgjAU6msMByXf9OLdu/rBLTqAw3syBP8A7hLmzgSq+3aqozbTkkoUlkQtAEeOOGA4hXccF8pIqpvgV5EQD9QrvjI+QKRKRC6gPxmof6NL8p8zwecuF555BbzyUvqcgBHvQkuqEseU5IomZYxnmZNhvBBTVIa4bEcKVM2wiKkmFdIEgY5dRheuGN1mfIIuujAlGRLOKgPUIDZkssgUpWMtyJjTPWN6Xq1GtEwnkXhyY2TdUVDNFEfmy/HgrlZq1QT9BlcMMQqxwqIBtzgDzEksUojVROtbxUgyxCzlKYvzHOKLtETw1CIof3js5OOmeDwfhebH9x2GGxXlJ44uigDY7RNN3muqZ+AwrDixE+EJ5ybZ4ygSQY0kLes9ujIZd46LCRpwKiJHIzsdrKz0odBJEirHJXn/AOWsErxiUVvyCJPvL+qw4nQnp9ZOnNmwA45f648zfYgeQT/zALOn/N4M1YXMyx8mSS9y9SR/OPWeAgWC5Cd6nnjOcnJiLQOth68viucRQB4KA1m90VXesnczC92/fJApMVqSSHtSvAOWQgtFFHsp9mCKQJKUye9x5wBIk8diRywjXrD+kEfhWHTcVlxhPufvJIIDAlJ+wyO7aM4bNozxz6yPg7L2YpkyeJNPzH4xAgad7JyQbBAPJ2HWJjmWIPKJrAbrOFYug4Iz+bB9GT8VS1Hh4nfOKggg8vnCmpg1WP6/eHltjF+nIKMElRDFCYtSNYc1pwAaBGicT5zT0oTdkn4RrJqgx0A/yHZR3ij6ALj5t+J3jDEpZUt0ehiJsYYuV9U/L+cUQahSP/MpHwzkPU6+IPGHhEQDi4j+clSQfEv3iiAXYatw+kmFgPeVgITgeOcRV7ZxYDUdc4abzzYRgWeVofeNGmn4+pe+PveSASgWzgY41gwmJgq3q+zAv/8AOQuB4E9p5wTFfQOiIBST4xxplS3GG/j5ZH41JNBW66Qdh0yUEMAkv8/eU1diHIS+4+XKOkBEA0rzBPeCDMhmgV5AJcScDi+kommFF2ymEfKTYG5k7FJkCHQ1wxZYrKCJRj0uG7xAtFdBEfW9kbqcDSZR70s50M/EM5PuBzZSF8wGV6w0sZVHxeuWoa2xAFT2CncU2SEa1fWDFYdC7d0wjvaOQOgEvZHThbEA1OFxc4QssCoWvzgJfl7tDC6uL5u5+ndtu9y8r0cGsWIUAgRQGLk47XxgyOlkkEE8wbfjIrvNFBq38D4VhF2IqrIXfLKeeqxZA2nV5s4QHuQznYqsJRO4tMfO3En8DzvtkLIYIkQ63gUtcTGsYytxEmhZxdh7NLQIGsQs6N06E7aYucaNCaMrQWHjAbmXr84hgpmcf6D4yKduwOn+f8YmbGQECCWwGuM4nJqTEhhCLf1B9OQJkPVXfo+skGRSvgf6xFI9KKsYBHzevB6/c45GBDzAfkzmUtmFh5ujDb79oM344+MjSZPAaHoNzzHvE5w20NkmxMnreRow6QoI9Foar4zVijZN75wsIyCJQ/AsvUZDydR2fGKK1UDswrVBY5WAJjrLxWmn0MhPF2JjsH4/3EsTLsbrP5Upn7P7xFz/ANI/rIjErtAS/icIV3g22j8Y8f3eED6QYa7eF3HB9YpvzFPyTt/3hgmFBSXDS/pkixAo5OPwZEA7D73PHH1gCHKeg/7gnYkNBnlsXVR/OLnfyKMEC35WyXjgjMmwhye7wPwIU4gD5/GKiAuKlosEyMpz4NSWdZ/yxwJCswmp+WOEPYrJJ+MuJVNqvROv+sVfopv+mdcYQGN2j6e/xlV6DywLAgpGScchYWHLuebXkwb9eeEUx+mutkOcy8W8RTuJg534zf2CnY/CMzhdoIKBVSu0kYbK4uEbdeQizJMNBSYEljCiz7nK0KUmYNWY+GKp0mZVhkvE0RjLaCmyk7h2S6DJOb6pu9CbHPP4LA3Sh5LU8qeOMXpmgSxGTd26YS0zs2uxIV2fwoUwgySm1JK+OckikggJ2TY3zzpz1g0MgKhT536wXR+zIiFd4JncjNFRHTjvmcnqe0RieBhXa8ulAIKIGq8DUb6r2wcgyEaUbHc8ZUC8G0iz0X6HDj5wgEhAkD4V9H9eGDUF7FcW4Qxy5aiLqzvQjGr1kzZ72ymGCzcCRBsjBwyMWzBpR8vBK3vHBjtkkLJ2H94ArzQi7KK+N4qm2pwKBpJpokwRc4+xkqyHHpG33+sAU5e9CHZH85KL+Jz9nDAKz5K/gfGf9bQjEOwUeR90j8uRr5b8C8AXQT6xxCgHcZPBKK5MpKQVeN5WVcpE+nn+8NAXNqEQHyyn/GFoSNhZ+cRrNCj549+MAyeoIMC4BzW1y48jsZKQESqLEs8PrJYtBwVCaHUTWEXHmCosRpEmsm4DU+SY/eMmxemTp9YwsalB+oyFa8fpEGUzhEcP/j8YheFIpyJk0r40WZ4kxSBBN0IfjAaGUqN9XF4gdNiBeAIjnGB7Dbksz/7HGgYYw4SmF2xLS4L/ANbj0LWLuv4yrhdGrv3f4x3JOJVuDXvInLi8KC/A4KEEFo4YEdKJX0N5E+UsVmX71+MRtjduHI/asFNJoNP+jF0yKUnC9hqkfxn4B9xCxNkdHeSFYY4M7FceYyKIDQOoe8lp03i0I6Ha9GP3yE9bJaxP9eGCw5JJ4CLBJveB9VPqEVf6IbnCZ5wiTFXiLZarrBTAlpSFklUFvOrwOpageRFH6/Uz9OznESmcLGuszQm06W9KHGOizIR49FHwdXlwo5CHUdxAzY3kysZqqVQ/+C8bRBTmGVFaU/p7xBvuQWFuWyTRK+cBOZNVMSyQ3PxO86sKjSx3WuYQB7xFYUEp5b/RjwYi8qavRd9ibg6yIS40jYj5o12ViSJkNk9G6IMGuXAF2hkd5MpTlems0Oskolu0Ogmi7x+5SUgwOk355Kh9oEgQc+m4i6twvupEvoD0X5hjAZW+GJGSIkgyTkqGcsAaG+1eFwNJBTgeewl2HjFjVwFQ4FScVXkFnAGIXeA6DBgaNP8AwwCdggsFAZ33gYhg6eRt/BhfK9tf3hLLilU82Pr2mF2tjuhAPBX1k4YoLbq+oySV24RxH1gNwQOhSAPA/wDg9QQJxMvkcXPRsHKqelI/py2GlrzGsvAkS5cTggAhGQ/wA5HoEZB16/pjBxJktCgW5j7wCSJbEME82SUCnyYEthAc3BHLldAlKwrXejnCGhqeq4b3Pw4csDMOvq3nHBhYmIIFSdG0ZIE8km14SWONPXamXdfjC+0mMQa9W4/aGTDyuCe717yAtqVTaTB7P7zUJV3s7H8GjBTgfm43Ep12twgmfdQa+5HCQcMT8Jv5yjdNRCKDW8Hzat477ND3gUJhBbQf7WPpNKikp8V3m7pYUz5HkxrIIWgCf1iTkB+si8C4MhD2j4Z8YVvyNI5Pjv58Y5jVFpIjhvEJJExGLDAxIk+zCvPiKSyEPkyr5vg84nCESH4TC2KZFX94lyhwIaRNYfQhw2AmHKFRgB2lKR2j8mQAMbKnX7PzkSdV8f8AEnjLlAAoHZbZ+3jJw0sE5YiSs6d2VQBc19xghmzUR4w3MlQzpN/GA6wqCQBCFosOdnLpUdRjjAwcyfGG6McXM7Sb9fjWEWANNRCNSW9XgDu4LYkjQnue5wngfgkEutE9buHNE2S5wQ0nmo/eI2GYhLCzmfX8nMODqWnsIGBN3MYSWDTImJLtmHig3zlAVJkDMDezJxEYoUtRItuAeuSQEyENKKFQN7x7KpAiQkjse+mcAN8RBSVK9jkj7Y7W8fnnw36x5ZyElVYnYoofxjdDO7jchcqXZk8gfA1ByIfB77yAGjAGUSToeeDm8Toym0jf4CTJxyRHGt+xIhaRcTDNstguLmSDhHj+wIShyTzxllD9r9ZLeTclc5JWBmRLhxGu+iLAPmx+s3RR529ZzdrJ5yFjbLLB7Yx8RygSiXxb4wAmkltyd85oa/kP+mQYXMctoj9qzWt5OL5HKefnGQrscBsku5QY+VfCPWPltTqbf6/BcPw9B2V6HEJHYKPMZEOBjYG8arRkx7lTkTmqGlSupMud1aTEozyp8uJBe/ZISwYOtIoQO8AZK1HvPAXeicvku2jeL/ONRB6k3+sdnX8MvGOgNiF+Q/GTHIdqKD0ZA6zei/3vA7sfkYwSidBkpI8RhyT/ANITWRO5yoNyC2C+fqeCeQvUxLT9ZxERqCx9ma7OscpwiVMiPzin99bkwetUS+z+cqGppzvXmMoLZf2Y1EKTQ5HxkxZuOqewb+8ecMmYqfxWAgKXw15wrIBU0J18bwy9lSsfXLRj8nzT2XvOjAO8ax4dBePnKGCslK6DGOzeDYy5RsYAEDRq3iJR5Xb7xMyNXln3R9YkkoKOdjKTJWqnFs7zCJ5ei/RV4HAECCojUZN8CJjYom2dmHJBAhIaDuO2AXHEqWZCrVX9IYhwEabtK2ZnT1sypgnWANjtQGDpWMrCh/BJakE4nqRHOYMGJlYoyZtHAs25/j2acSKCuxutFLPJ+DjYtFMx5ZXn6ySodyyKT3y+HKl8okg4s7k64MAiEMS4KSBT7nfjAeQ3OvoElbySBL3kGM3ZgOHziewWSkaEF+w0yJHMVFSbezXA5IiHMp1r5WV1LF4TmFVoCQZM65j5kLiOxAQYmxDTBODpO8RW1qFD2usjSTJMyAiIMk9fDgrdOAILJTHLPGWrTGBT4CFrh5MvIyfuEtveH3l/iU+dZkUxIWKwH7kAn6ZMFjc3+s3nlWrCgn4aMmJLjeLzaoAwByCOCSOi/nIbGXE9EY5sR3GATpRozjOF7RijPX1+M9YmAf5/3+M4ujPJGaziJ6mWLIt+9kd8OPNCMl0+IA87w2C8Epw4sLL91TXveW5XVAPUXjpsX/D6/wBrIRMO/ljTDIUToif7y3PbwAE9IGP5HTAVhzQ35yCHBGx6GRLXlWH04heKL6RMfnEjIIpozHyxkIIhDKML14xJ7HK2heCJmeM0bYRxL/zKEXeU9H3+nIeGrGEWv1OdjWKXPge+DL84EfTf3liTG7zhx6veO+wM50hqL/eL2kA33xymnhxH6EcGh33ncs16mpJBiwvOQCZViuhsrpyKCBY4IooYkYCe9A/9JuXj1oSr9ecWmVUERXPd/wC1k38knHDCdjG8dlYmKjaaW/3kRn4gCHywMWMmcF6J/wCPOGmNbi8juaWiZkp4/JkzTym7hlX8HjCRoGzoYr94MPaZivwr94d5U6TJL5P4amZZ6pU2AzRRMzVMajhcMUU0P2NRPaN5cTHNTkpHaceMLfKOYbcajMb9ZTSFrz2qH5ldzlvxauiRkomyt5JDtlsSw1CQiztiX/MIGYQ9Rass4OQkRIm96dc7yHL7dAlfDg1OTI2G6O2kptFcEMnfRsLA6myfn5myqsy+xCuSeZ4Y8tE5ASTVkRAK1QYkVNIxQKhT5mJtMesGhIBlCksO5kLrI8fTTIGhNHHMaxC4cMWbEHLHMzBKOW8N7hUHF+2HlshoAL81DozmqDRcaT6ilXgkiExWHJBAr3nUu8nrz1jTfphVKYSYfkyvH0JvH/jEQq5pPgnKbTXIN5YmaLZRo+IOMnl15E/jI+/Lav6B+iHzk3NmNNb8ZKKoOckQKza8bh/w8OWSk0H3E/OAWz4CV8ZKtoxayfd4gj9aPqX8Y6vfiiCIwOX7EEz7TAkRJhAifGFuDkwjCJL1kaamqZw4WcmIkwoxnq8KrpmOOPnJzZUk0eH0/wAPOMaGiKFJ8K5zygSXpfs/GVOBg2I2J7w8UO8+xOQmDxmeVo4Gg6rQYwAKbHSC9PycZWELyjBHaUiR9LnzsyyEC7QAwE8EdIhteGsjPS+xT+MKrHIqSaYJwW7FjQviYywOIHMh3zH87y/QYAueB+OsvHgT/jGBA5amk9ObwUs/c54u6dYqj4rpuLkmN85tVkfjgyfjKZcBYSfKVbJG+McRKNWLkrUWg/ncoUkQ0Imu4n5wjGIYhdphgPMHnAlLccheJFKkInzilrOUx0KVjeRUBOOrRBcWl8XpxISPYQKfrLrMG+dHjmR/OOoVg2kiT85tB8uAsP1gCZyLrNVnL+bwCCMankAmpCXAsZJeF/IbhH3hGSrC9B0NB5e3IPlQK8qGYQRv8RlqVIYBvxQ55l7cQSwiEFKUakYaLrNZxTBGElDYYNi32xFi0CoUM7gqfHVPgHypPJni+ZxeqS2IEx4JqiGJtwFAoUDR7qxcTgmAuCIENzDa22sVtjdSjYFL8/WRLQChv3ktIX6OI3h513q7WwSWLw49KCOp0I5pDwdJiAtYI5okoEnAiTwZALCmHt2A4GlecjhN6FEdXIg/llScnWwmshNLmd95BPaov5kIiliWOclSEdXj5ycKv2pW/pxYuipF7CX6yrb5F3c/0wluIisfWPa2gyD8eWeJH8MbA0ghQSn8ZxYgZ3Gah7P244y9YOx7x9jBDa795ABD+EFvEl6M74qnJ3nD5Lcd4pqjbmsia5MnABFyFviH0GEvBRfz+sDUFjIepYPiMs0VgImMl/m/RnW4bcj+6kCRWj8GIzUs/rMCSA4PE/x8+MLckywgkq9CfOEy19Qf3hURA7omZYeecVQS+iCI45YgfeGbR171/GFW2PVQrmn0zYq+HkZJ5beCr2tnvGmyoLSYC2MCEl39OSHYMmRbYMnqpJ38ZEpc4t/g+zJ2iyb/AN3grqdXlDl1oN1ObzfpkdJFo5XJSw6Y5YgFeiZyVVUFABXLEGP/AGWqhKCeQVyCjzcRo2Kg6a1QR/3Fj2I/I84VFrCfEF11ikhQn8MZZnJLQvFG/OGllVGIM3al6yoJzcCsB9Ukw850DdKZ9Vd4WnaBjGe5ypDY0szoKYscMzXYQzeUzxHrIJTygjEkcLXWUTjxBlDfUSX+yPIQ7QNJGHRvti/a+SQShBfNVFe8GzGg5uBtUnlgO8pLndKseN9Qy4L74+ssMtW2ayBEsvpSOphDU7bpzT5JTY1bYTF/uTIVlITWhJI9QwUYA/CFXKUckAIqrugztMwEYFviYj5je5lCPoNcbizdZta3IZlEVMMSdzpoQKNCTeOzjRbtkhulHKKW8gtk/OKYB6OEfINRZKYYKRBGF7lSZhUmRiJV25R1Z52RFU+cUoVmUzBygB+pIufnDvsz4uN9OSKiWOzF0xbsy07Vt20sIDH84VkCpieZxJNndnFl6MkiJTlwThU9M5H2v4SfznMRwbLT5Zciz5/ucDM09AzkG3fiMI4YeEcbYTBIz3Ev4D5zU+vMxLL6/vFiBNDaHAD4gbGVVDTfnJ2cB18osX6sfeWJCgIj4yehS2rxcYOZPthaZOZn5+ceXtcKGG/ziWfgFkENuhft4yAfCszMm8b+HA/pyIPFaBAPgyGDsRQ7y9hpVZ0Y984CDpI9P/cMMWZJAp34l+sV5MvrX+OP+ucOjDbHh6iuJybYw5ab5/eTATCZdKX94V8FlzLxL+OSUKgGw6njj4MLKJUTiAVHwTITfnRiVA2y195JUIeryCJUR57yVAOjrAnW0RCNOgfjBbpFiapWLk3tI4I6vTeAN5JhFKx8DE4JyTgP+YO8G2pPEUneUxhNkLiR8slGmIshR/GM6GYcUVYEp85RtM4+PeKm6JcF7MVMhfsWVeS9HPjK0FOkESZEgLPnNQtw0aN5GRtOGXjO1LYrHbFXxW8qq0gOCf8AOvtluGR5cxcPmz9pycJJjI1JuV523rJUBKFkDELsmjH6M6Z2QTgbXj3aB2JcwNIDkvZYIxY5AskkKHuID6yYVwCCu7laRfTQ4z+sbgBNS2/2qASfGFJQdvg2HnBWjxmAXK2bl8RkrUIFjwQtGhl5mIGVvTLEamLo9Vj3mMFzbLomV4A5iTkGwMMeHQebVkPgry1HVtGu3J3xKgMvkNYI3+oVcQFa4moSPJjEVnTJJHZBo6xjSLLMOxeEMD0ZQlwgohG5mnI7GO6tIJW9NV0SM4LowJK/2N4+W5q8r4M7NrF+D9Z3GH94LvROdchf24VNHnIzwycnTOKIr6jFe5OOMaFYuWEPwubvE0Sny58m4T+ayC/dAMplvbJeROSqIjybZWjupAXbO8IC+4uHPzoZGnJVmnmsfxk6YA5ETL+cMNJKFFf9xWaHIqT2wiyqycBJJk0wqti0zkr2uIpIkR84ZD4CeWy16xrY6c/7oy9Wm5Sb6JjBvfNQv6843yBEhC1WRGFmSeQ2663EKwmgTNLhfvA5SjuAEflfw4QOzEc7rBia5y0g7ye4piyn17xhkCHYz+gwME7MJXY7Ix5So4lNc0X/ANySkd7v4x16+lLv8ZAGP+j/ALzhaEh2IqwPA/HpyWnNZfL8n1kyrvEnAQ/85ysdWNMN/LFNVlOAGCbE1S0X7hHnJCowSTFS/BguTDRd+coO+GP7xJMCDJKAwA77MXo20TDFts9KZbSVBcOlBizBvztST+IAte0cSrtePfogDGtBuKJuK4Mu9Iaoy8L9CThNvkFWjuULJNvjJc2m07vJHmilak6pvheSSGGpCZIiCkwYkr2J+HIwjG4yJFke2oiMvnUbRhDNluecgmAmz7scZguJTxkfeQxtwoQWi6Sqpz08TpQk3k8idiXV+1Ng4C0xfzjC5OcsPAkY4yXFiSID0BZVct7x2xyqxvgCb4OQtqWVVJVSDzJ2ZPSDkzzs2QK9fGCKABkTsqeQLjNGZItbl3Nn1ONtqlJOsW0FM9Vg6YNcnoYaOTs3jpV86SEx77/VYDpRFFn1k+TIyX2sETDyaPT7SFSLWHvvjphvjJ83/wDImOScoCb9v4xJSRoFRiDKBKrzJkBgWBhp258n9pkzeOG05N5EOUw6z5yPx4SdPAjkwVT5GEqOc3ZzCT4J/wCYCRe7YP2SYgomD2O8cPTm8bkfcZACpVFBfhy2HREHwR8dZSeWVveOgcRlAXp5L8LmmjMFs9/r4ya+lro9uETqNrVWVAOXCwszfeAAylGtAMqLLwVyRD7LT+8fx5VeofQ1tN8QD/sl8kCNkHLFcani0Mz4frKoJpHOI9XhevSh686xxOAkfC8GqLtvMYIzUFmv/Iykqj6ykKJOsHgDwzCjiywfNDfOVYsmI5yQuVs4kg1IXShPP9uBAId83v8AWNLDzgE2J+tfzl0XzY/tkaXD86jzbNQwnEOPEj5MLALyP2VkoMlNA6KjWLgAgQEBM7ICeGHdYOUjJJAn0XwDxjoC7rmUP6nLxF81GwNirL+2cnlVic87x0kgdRk0IZqkAI9B2rzfkgxBwc04BOq0fN4hJygIq1VM/wCbgwnFXFCi4lZkad4QlAtqCkaKyE1y54EB5GLCHUopY+VdihZzBXQy8XcZYslsmEmDkLnnnAoPpDpgSWnLNRzi2MIUAYZ1BDVwYKTRgA8XIof0wEL1NUIptFeE9qwl+tbQpL5HhM4tkA5K1y7pYJ84wqJCRrkWFQnUOqzaQLSZYXy2QqH3kv8AfzRwAiNUHG6zrOcoQuUEgTirbNzZ0vuIiP0WTNMYhAdO1DING7s9gPChmkdijdw3onvDus+TDI+zqmK4y+vSxDk8Azs95J6yklnyP2vGZ2ZJ/WZWhTP/ABlMExPz28GEpd4sr3gjR2isFjQpu2E6zgJg7z3kuwYy7OjnP9/pjkcFe8CVg0o8lfnHQrL2Cn7HCAGjCBqT6GnyfnJITC+mEtpRiedjkEB0J5MiSFxBlzdgyIWj5R6P6yimbgyA7nBr4BJ1/cvJjO2dE2nuayff6AUoFvImryPx3q3QK8ZPAaVeOhD4GNPdAPzBMaF60w+sREwHwyGx+B0gvXPTh0SMJ3E3x9YUzqHB1PvHWAc2H4xjhxQjknFIr4Zz5tcIIif4kv0T94hLgyWcVrkia5A97xYQEcCePHHwYSIK0chCsoYkiWzYwiPxjRiJXwz+D8425KlKKH0/yyTYZ9We0P8AeUNpypSQF/U8Tkm1CkgzP4EwIE/MVG/l/GRKes5L4NNR+cIlZK6cdckH1iRrThZnhN29ypN5sEoDMwTEGp5j4yuyY5EkfBK0NPmF2y9nmkbbQfywECCQtFr5HWJbLTblpUGn0HnamgTUS0Vp5JTu4EQw7oIAukD2tYj06UYbA78KZ6yGHR5FJHVdkJnJW0UiSRS6P94KHP4uvBNCsa5vAhVPrHPjSNEScwqJ0LZZ03gDpOVujlMTYb7u14zxmZY1hRAieevjGrcUoYM6aN8wW4jIAW5ukydjqGMeicmLrZ4AiPeIJFXrRshBQHACQgZITQ1MedOUtAkJk7NGtb87xPksJbuAhiUW+MkO0QVRC6y37XfojhPB+cJE04OiaPIfzhCKSTymX6+8mgda1/vjIOhGQSfBh+Ymb84UnE7LzvH3laFHXGaios4fDT0UDb3iVBCqcXAc3z+MKUKN+fGK1bxu0+2IP4w0gqTlU/vAZg/gweXJsMqMnXWXkSFo07fGMbkITcQSfjO9Eg7xLSPTrH2MnLhqneGJJFCtes7WVD+HXxhRRkDPLi8qf54yRoliBLtp84gOWQle1jJYd8f5ZJdB4Yp2fE/nLx/QP4/zlwwdzjbG0Be0Uw/5STUc2uRzHdBXhhOz4NJHfrkER9Fv6uNwjwMH3iJPsBgr0INVodfOen+AxPS0+chrBLK0Jl/t54cG/ktwCfOqio83GdVWi5mdbvjE59n2mMfKv+8GiKs1Y/jIh+sDJYe4r6McKAgiZAasyPm+MKxUws1B3/tP5ZbrrjHqRIOZxkXgselKJm/5wDoW02AfyZJjS0QlpBCJpO8UIgOk6ImUE9oDjIXS0IoaBmBSlVQSa3bggOuhdNa3gx1UFUSn5K8s4qrByJCiuCUSOPeUP6ihrmisjuCTmc3+UOMAfBJI82wTlw0RRjyCvy+JBKZS6b2u/vAhrKDsyykAqPnnDOsAk8EDYETZoecbGjnogu7hrj1gKkOCGVRKhfdzgbES9AS4NkTLg6TClhg7miGIPBxAe/siPccRmpyNc2D0zkkdXVvhGArPS0VZ3l9BeMghVkowdC2fIyz1+Rixxqju01ZMur6MU266UE6PZGPJ8bwsnBHkccYEIc+paBocmgnQO8IAH1kmU5J5PWSW5LCuqwGNJ2MkpvcefrBUqqGYfFZ5MqwABmxTiImh4v1/OMlzRgAIT6wwzcDQ+isJ+Ufzkoz4yYemEJApBuzeXdQipMrwCesE1m8EAlH7WHNNnv7xk3ClnBFt5b+C92P8Y6Nw6otv4zx7l+cmstV6MjEW5VObOalkfnIETjBZZyP6GsCgKQjgmnWWuGNg56zs0F00eoz21SMprLTGfs/WMhbzc/IZBuIm46xYEk+byIuNY+n3kqEegqD7yvgFaqogtkHHeRH3JYPTeHltEQHOLBKBPjBxo4gSmOuc6I7AFNoMt5HuhCS4iCfiM4R/S4ASpn3ih06A/JwCMUVu0bZB9Q/GckJn5cK/hrCb9CQl3HxgATuiEqfRfgOGVPCwcMZL8UHfJ/nnxieACISw+fOQjYQ+Mg/aJJ+MktnNtreRQNSHAlYAd17wopXnmZ3OVRK4REL34jC1DKGKT6n04nlC1yx7JZUewsY2vXPIznhpwZFueUpDe6Cid4UlfGnqCbNpKY7xlQJqnYQrcAcJxWLksFlAMsRGr+onzUabVZOVacefBy+Qoqv8cRpDtIyFDX2Mdzh8v4SWCo9veGESeh4NALGKflv9IE7GEpz8YkKcocH1E5fASQEstdFX7PE8SnKLR6XL95ogKlKOZQSCHcvzIRQdhdxwI9RidRVrSIJNuvlxo8qtnwxZbYydYOw+cO3TrX4yJQiijedG3VemEJIgS1tzAwfLAIUR2xes8b7cEsq8YuviLgmdvDOXix0oKPiYw4abQTxOsi41hhr6JN4CDS4anFqm1BkWA0d9snfxYtwORibQc6MCSzE8Ln84y44ZX8DEBvJyvrDDmYJLwHblog6VZDKFt5CoNn8H+8Dw6uh2/wB4i3mkYF5pdkyDCNP4EsWUvg/rHqDSv0YSTGn+wY9pcEq/nIBKaSlwP+C/zku70SWgJawQjLzffMd+MUuVoi3wMaEaOI5xWtcUFduo6w47pEv44Q+qyEWnGXjiw2R8znwJk/xGHNszZZB49i/xlmRI6vxg2CfoagtahyEnGXG3pE4VFSQ5xWFbx8v1gj+U5dgTSMEslWFQ8s4BRQ6/4zlsr5jgvTD7cDyr0mjHjfxkFHyWb5Bo4MakuIh8WIxhOzJmF8GIfZkQboBYrq5+jFOO2SwkHgUfDyaWsE9SCYazU+eGKhr1IkzDNKfMJcbKFCBIORuBKvCp05Ij+Rw4lkbQZRInmFemPsVB+AjpAeg28z1ONoyExcMvFUX+cDHVqSEbdiRMd+MCLpzNSVrY6S5GfUoRdnnHcXYLCzRupNYlzW8G/wDuUMddQRh8jwhE57dM2bu1SEes404BqlTXxhtxgfuCUb/bAjC8OvvTiznKrKl7NyKcReM2ZjsVifVm8QMb0JWf4kZODGGVhixzD6xMAqwojjD/AP25xoesOmGRYPWQyRIRiGbdr4xwHOeXJUfzjOM0RzvAFI1YZFhkJ/4ycseIE82MRJrCuwkYmWVhCOTzgADNpBIpBxikD0l+TeFbNRhKYfOQw2LKH6M0iJwHzmBC2/1gyZiT1M/HHJQvO385DccS1P5ymZ9B+saWtHBjws/zjN0o2u+MUjHthSXeMQFnIA/GT+ceMaye6s9AHEM6j4i4eMbkAtqfpnDzyf3cMsDkX85KwzoD9YBtRxniVySMtMT4c5ZwZ3hJhPnWsVyl4aD461j+ZWBfid5MZT8Q7Vb4vA1WNfHh/nJxNCVbGeYoxkwnw2ie/wDuRn4CUAUT1hEKdaVlspoyKhdJFaycdD7/ALwX1ZQ/eWNzlAYtJR3fzZPOaKid4PM/GFAWhFRE0Va4GXE50AdJfzAvwuCeukSBKRC2EbhyVwC0YUlcTACdRbKJ86G5sNRTbHD7lCLV2tPCflSYZjk2gSCI7G/2xKaJcEm8C7UhR685zMjAIR3NowKifpAIjnl8LHkriAkswFREMbRBg8eH2fOXrFpBpHmHFpOQoj28DDhvRTIEg64fpyiXyppYH2ZAGBdRMWLUO8jdwFvWQHzG01w4GOu68qA6ON14xxceREECxNGS0eJRkAVElfrFGwmSjU//AAwXh4YPF6wcYYMxwwJKsz7f+ZKQuG14+6nHzFZq94mIK6AcuNjEqCgRN/kScdcISWbdv6//AAAUKhTCTLQCmGSPDiNqCHN2q6xIJYwhbyI+FDJ3i/TmZf8AiYgo80IficruechI6OP7MssfeOfKi3+GM9IWanHCz0hxXYHen4xz5ev8nOT3m/gwwR9/8WHhLIAQDk6nCqVMvM4RbEF3kX5rxlPnnIu3FuadY4oysVTjJJD4wQtsP1h4CTn1sl1D9vxgHGMP0cv8U9elSbHMBe8ZpzK4xExsWL4MhRHAYYwuD+8isJcIBnJkE1xk7aYnv8ZApQlmdf6seo4si4Hwlb1gepFKCQN99Ojxk3TAzidCFJ3RhXoMYsDPRNzrhx8N4r7KSq+xLwEbs8Z46wTagt31jlwpX4zPITJty5a1gBAAHYK9Ef0xoBDfFLnrWNYO62IaHVA5Na1fVrI5kPxgmCENt4npYHHtg6cAAYE/OJ8Rui9+EWtsSZqqsnaF2Du6cnggKmJb+HHtZRxgtuZvn6wJjhK0UrO3jgn3micpTM2c8fjEtOnDOxEkjwqsPBAhuFzHGDx/8AcYAw67yB0YUly+sTML1MQf/FZMq9jWTTOMbwDjT+0c5v5HFoRFhZ3e+Iw7UeWvpKDbjW+G+oHo0v8AWLI94ygT7zzZbckEbXAOVw0Rpsw/LhYdiQP0T7XCTMs5CJuSv2T+sEXQ4B9y5dgaKX6xvB9vK/0hjch0KyHvxGbKTxP9YtUDZPLFDhIPtwUBej+JxFkcCcGct/uMZ2YBV5sVK1jMJtxXGCce9bw4JcTiVuMWEHvrOOJ5SNf4yZTc7p1nAqhBv8f7WBAEOp/LnEUm4Zvj7xA7jvG7RvIUP6+2AGzLaTacIg+o+3DR0rBN9Qc3lYQjn25X3hLYJ5G47JH04ujWUqRppv8A9xJQIBVcdaioM4FAV098zrzgyBm9B1SYwV5IjP8AK6dE47PtV/OKsofbHefzh5sCGHeU5Oic+RvRMXjToXcEMe+ZrveNzStJwqCEJK7OTKEFwoqTMxwlbgMoAsWOi+1Xzh1SzJPa+Q9/OQJHPA1XHt9DDIKgHvLSkbYtjK54GG4hBwODhiI12ezMOapRXV6BP3iehRxclbAXZW0Px9Ygymc5sj9ZWlxpKFk5Tr5y4hbsuS7PomKDzyh2CA58x3Dl8n7PWEFpNYdHlUof2xFNAsXCy/ZkLZR9Fu8MQYYP/lLj/wCIyggJ85feN6DxiJcvaw/a1/vIaGDbTCqCNtsjtPt3hBEgF5MhVcwIC1t6HNYrdAxLBD0m+2Wvzlar6yw/EbxBMBEHfvCa+rDqZsmCUByNcBCVbYmcKHg4fvJIkzamMPYVQFeTDcE0Yq0j0OfeWz/X+MrQnc7/ABlUxHY9UchAd/yzGEU9z+AP5wxpYn/LLKDWz+8dA9ij+QxDO6/74y1YCeBUTrJKytHnJCo3qif8uTTQdYIU8CcgJUA94yYfsjGTbDqi8t2/5nDmARoFNHszkwMLRD5F50AisgyvuT6xgzN0V/FjlS0QgrqWB00ozMS6YaJjpWBGKf8ATJiOFh5QtVWSwhFUiVLoNuCYk5QfUn8Zzbt+HEvxiQFch+hf3ix1tqe4KyHIdE8NGvvJCDSTa9jINa1B+VmEtSg5OzWo10TOKaKQL6KmALcZEMkkEmrUzUh1GAtmIEG4XIo+eG8q1LZBMm6ROoiV2Zqq8D+XHv1kUWgSOgu0e/1nPHDKRxC4FrhmCHK3Rfh3kwyM7V4D1U1bJwqZyBFW9zkYNA8ReTTN5cIfyZaMZpVl+IyWVCsggfnFGkhMiJl9PEBWrMAlMTa/jCChZWn3GtZEq4ZysbWFV1xkrwJe44/lxzYpezDw/wDj4P8A4HF0TExksPRkAmXpkA3jk2eLE4nAJVeMkPhQA132dxkCh25PjKKSMkfe83siJBDsUk8SxE46QCS2PnApR4x5tTQFYFLBNneUiEXrA6wdG/5kmTSi+iMg4wDPWT3jbkHWJbM6YkaxCaTqvsxpyIMxCCsmYdZoPF5Bkjek4oQvOpySWB6c5EIBHcZS0jOoyHmYyidMuQO1TiMp9DcOStTCYdYzCRfjWWCUO7Sk8fyTjuJUbjm9g+dYcm00EVGyeqxGKJXosh8s39d+92fjAuoYbJssyztbyDCBGcAgPqd4LnWfWOY/R6zbzJLPiXW+T9YV1SXiNkKjOSCH/Wxe5IJkzll16wz0lrr6SQ5ePvFEZJZSeFIgy06BQvgcu/nWMK3yUee73/pLRRlPjdkM8e14UVYi+Na1WNyGAtm6X4vrFxxAtyaHMcjV5KklKcw5k7wAKeeGnncP4axTpiyFObluprvFgAjQmauPXeMAIRrhKncwROzrRiVdnoypb0BEeNGENijFqpPyZyTdHp8Lwtc5sHUwR+GNVLUP0Fx3m+sB8Arp8mRAACp+ScKlca/k14y/TWE0s5qHoGCOUFIN8Y8F6FILn09ZuYkgV5V2xuh6f7nP8S7yYltnhIz94V+hwUVOTTS+M/nIk43WHLVP4yV/Mf4cF1+0wDLI4f64ONSSMPGIsvDStkxCqT4HHcoWCS8lYjwowgmmkYtEP9iZyBeafwpwuf8AIdTLAHkTAwmaXBnRhX/wyo2Y7CnkchAhM8H1MGaupuIPy/TIc0ESifcGbHIQ3bydZfD8H9pwYiMaJiMUZ3f9OCeSmrAcDwAo+M2JzzPjEN26CLzgNR1xhMt3l+HTX+84XDiPBisQbwh2m9ZItdZUF+8jAGusAJaLFYytFWsXlUnj+8n+XEv3jQmF4/JX84Qj7MEPIL6zTqTmXbm26bS8UwJhq6iGr088Y5O/lVB9CoyXCGUbNjr5w06izKphW4849B2k8biP9dYJkBzIjzWS/HTzjYAI01+D1l0FaNe14jmUrSe+/wAYc1SDMWUBq6LqsbJ0wpXXk+Mt2wmJx7/7DlPIO7OYLH/mWDNEC959r9ZMieEF/NxihXSbHayHDu8jaFM5moWvBXdYlw5H2KSXYZ2+by0vTUThKKXWzzjzqVFzWAF+Dke2BVxLmUEjBA3TuPjdhyaWatNMakYweg3e8ZiZqn/bpscKGRPoqfGcHeV/ifeTMnJSEER4RX6xLImSVruc8TepJApJ3/eD3bUgWpxQvwyLeGX0RgHZ+cDgjEMisrn9Y13lHj/5Pn1zGQVJ0X844DXWJLfsX95qIUATrF0b6qX3hwhp38/GXfpnE3gA+pyKy7kCweYiJnhJObIC9rL9ZJtGhR+4xBMwAL+cbIAfmwMureP+HGVTu37WQB8Br/jIdfC6cvaWR5+fxhM8Pbj1KWAlxltaN3hKX323liibmmQXZoGSsXqa0/1kVTKgnvAYa3AOJtaH+cIQNWK2fPxiZSXms3Kb4xoAGBlJCqwhjybRkyBYdayT9GcaZHGBKA92ZA4X4ZCDFXv/AC85DhPlTxKc/vCa5VoiTRv7+cIih5wpqygqULeX8TkO0+u2gFAerj/qpWS0g2O8fdBHWPguIMD0kBkg6iDIk67d2uUV4BEx9P1hOsI3PORYjz0DwnCtW0RUXUv3rGZGiq/E8PjWUDQ6BCdn/K3g3UZkBOG/55xg0LFT35wwEmRr8wOIW6AJw8idZcHmkcuIjLBkCIiRuQiT/uQLT2psULj9nxg4CSVgQxuQ1w7PURnpZtyQSe4e795NrJZiAaob3hgP0jEejK2x9bcBY6TYiQs8odxt1g4lyVCDmbTr7xwvTXahG7JzG8NNYUkRuxn+mOGxnKf2wx4AmPtWFmMKyH+csQId50PBjN7/AAMVI7e3F4/4SZpfbknWesiCZXjkRvIyDnEVrAyK3/8AIwU1kR/8BGBbdB6weIzoZFbYwnZrno7yA+h2PQ4z+0Kcq07DmD1vNDRyfuc70Hwf+5Zpxl+GKJbJi5Hp/eMVInR/vWSaK6/c5aEmNmXcJgGLeus0TRMySjCRuEOYDNcKRzx9Z0vMswORBOifj3keBGxKzysU/kwsyJjfGHNVqOsJJmBSDCKlUrLYonUGA2n6/wBzlv1c1CJ4qPeQrIU5XnFQnwxHxnkNElfWIJ/ZU/kfi8IXbIn7c/48ZC6K5QABxgVDjhxzwKC9hmJ3+Y8YCK0SbBaN4tXx5+pME/uHUecYmcMlOwcEskVRXwwP/Mcaqi/837Mlhp4/P+/xi9Uhuln9ZcIlpQKx/wA/OaQyByxjRGFujJ45wvOak6uJwmrhCSt9V7xSa1AtYmoQgMWGp8YePyA98nCDc8XkKZ5git/bz7rNpqRA73xb9ZeRibDcXMHehjFlvCOSuO83OTgJOy+Xn/cQQELBG7dMKbDpu3FfPf5A0ME5CBiGp8zdYhNnVfZxvX+JAnQtesD3l/WMVbPf/eECuRU8/X5xE0iYYkde8cqxT5BbggdvSS5pUecHyjM//D3j4yQxvIdV/wDKyuMrWDFxiaTJneesomesnfnFxjJ5wgzS41Y/GMURhyL/ANT+cbJB2YzmA6n/AHrFbMf9Mh3ey8CRpeYhcJuk6zWu8okdKN63kJBO2jIZNnzxRx9mCkp8v83kVeESi2sdZMKFj/F/7bkQLRi2PyxcRGkQ+/8AfeIkE7X/AKMY7wc4TAnhl73iHPqdT3iygx2swlGHEY9D0gwJJABS39/7WKgDbXfqsSQkoezCCWyRbUR5xmIbmuuPvJDLfP8A4xwkTI1Fdk5E4mImSKuH4vCaRbjgGWSrhLE1lNEppMlSYmeNVp+cAlS2L0YSuXnnWbg1YFYKiv4vI6F2CKfcW2+cbmM7iFm7+Uv84pEpk5Dzr/awTBVRqnHgikiD/OQwSd/51gw9hCY8a1i0XJYMRx/PGRsq0HqO3NNNIWjxqI+D5vIA8KJ7llHXWIRRCiP/AFz58ZJdWZ+M2xIsSNMwnTD+MEIjASgM93+/eXIQ1K/UT95urgjRdPxiqBKTECz98YZgr2imU/h1DeERFNp+BKObr/kWsOwWPETEx+cRSCHVOU15wSRohMxzd3WNffz9sktEBg4y8k6nWBpfCkKr1k4JDZREh/M+slE2sULwtj7wSi9shfzk8lYp9ZN3npf/AM9MBQaO8RzU4rAesRrEn/uQesicaO8l5+f/ALHeSf7AYOj7fGXwFQ25oBK05ZYN5bQKBXfjWA2p0OUanCiL5MlazSnC6xxG0KTy55y3vVx95rjL218fWIaohTQl45A2676Zu0rSbO8EW6Vm9dnjn6NbyrJI+3ANqE64P9OCEF2gjH6c2xxWTLQJgjKE1sdETm/YMEEn+XLpYOoSX/TlyBJizA/A4DGkVfnI9j8cKzOqgM5vtPTlzRAWiN/3rNsbmSuLwmBjUEMl/wA/rJMYnEixZYi+J6nBEmc6ET6QvnIDYfSc94hoZMIgLWX2eCC7ASypgC5EL7IMG/cZM5tmSoVtjz3i0G0ZAbovNQsil/nWDI3oyZYzPJ/OIQhCcS2UM4ELQkSowgDXIKa4WJ+8gdZCNXqihyAjXMlDUOwj+8i05IDVzFk67+jFIxHNAe4sPxhUYQkufNRz5jGEFew/Uc85cmkNY2lA7wQtZu9ixEnRB6ZZJnWjFuT2b0RODmKMn9KlRNG5MK+IHQkI7rpeUXWKNTJJMJxPGKPXrEYAFWmgoJcgvGtsJemkJPePhHa7seJbJGTz2Q0rRERDMQSZpv8Aan2fFcWXGIkdqGoQpkiUmLaYSsyIkZ7Cd7w2h41WqI2Gj8YBjU0+jEKkgmTjHEqGJhvHUMkYp3m2Ab/+RhG1+DIHAq49/wDxAbaI1/8ANucQP/lz6/8AmsXLgvuAx8j7rcZ4I0PwZGZXIOQ8wAbvCJJhYCU9/wC3gSJPiYZ6xLJV7IQxjhJDeuPeUm5OVTP8ThBk3Xy4hEgxajUS795pbmknJvBE0kJnjBZsqpf+nGXbXcfz95FlvqZfBzgaV52X+8m46QrHYwToPeN2cQeB5/3nLAbin5xEhTx8sYcC4IvKN8NLP395VnKZQJ/8xwjGQTxnRlp/l4gbHJhVEguR19YQk5rys/1kVC2gR/O74eMnyYPLBZVU+tbzQTArGZSIaTbzxinPDof8/RmuA5PB3l4TFeHVLjYxcLnJDCQ8DbNsz84MYQmRZ0HwfnOEJCKiRFfrC7FGOPf694wsT5Ck8axNsTAYPExjDCBmSBNPvNFgRwh3GvlxFSBKwwX2F/8Ac3ApsKrb9b1l1Z1svnITJNISvY+cnUpUBflxc/WMjCIVPE3ga1wRAUxgE0II9iyRVDrd46bYsqCSHrEx5qQdBAihJnz6uSVBaUcThf1nHa/EjSQn08YkOkSEAogsaKycukPEF00tE2OCqBFXUgwSuZiB6wnjz4FF7I86wkAq0JEUi2IRGMTo0aFBWgIDNYvvXBI7BtATXAuPAPpYzMy6XMR0N0MjlkoiYvTgoEGK3E0EJAK3OWPFLv8AOa83gucZChMnV5OIdsZNxGsSp7xawnjI/wDgvdVilRkUwkZC5pLkGNYNQcp42pW/56cWRMgQXn3jDBMR99zlBBNtHUYNXEu2pk/3vIiiHHs5NgEgwEUDP50OSLVjK94zCXmDr/eMgHT1ZmctOP48/wAxlEBaIlBr+8lJEpcxPr8YgOdZa94VDhV/X7wRoIfv/jGJvefhjSI3uXbWFASZ5cvCZ4vFhFPA+JyA6iI+FcouZM3zGJRAiEYkQj+zkOLqlbn/AH+nBFRq78x/GIp1wlnFC6M13EZCCQhATdhX4cN5QtEmCBBoB5NOXosTTAI+P4yQEBRYJsjjHGEqyDsnQjUd9escHaEGWpEGp+XeAWhgMLLI6sjIZQQQkXUvfpxREhdOe6+cGkSmMRCI+pwYQEonmSfjFkDNix0/ucJDvze+TBxQnEbuWJh+TrrJfgTNk+EGDFlmBJjlFejjADkIDkkZ9rWDSBFc0sEdd+eMI80Sdh4vKQbRd1/3Ie4NA/ziDNVP0PfHeON/6C56R/eIKLPqeA2ec/GcNpK1Wx6j8zrFT/goaDcbeMmLStO5CXux+MKgydmIKChjXOTpoIK0dfX5wiETlL5bwjAcTQ066gy0TOZDdoM83v3hhJ3ZcMMcDra9qzMyT05//9oADAMAAAEAAgAAABCchjv+B7rm36jmxdN+rGKuxyuQT5wX/GGnqYY9De5Mt9qNQC+pPJ10RaO1fQHSUB7j3TZLMll+0ccmU8rkSELzG/mIdpgBK5LdHU3f4FUGRBjqbADf6YevxTUSLBRRsaY6jmFZofrJVGU/ZwxsR171Kw5nn51r7p60rmp1f+UGKpz1uNjUwsJ6s8fR+q3la7mN9ZU3gOANux64e7qCtQ5Nm+TNoA6C69LYyT/+PC/EU/3zFwtcUlS/PUeVQHprXdm0pA8eLvAGJAeeOXCh+GowRg24RDqgHxD1de1neLYwpSXGLA+MdasB5uic5koH80v2JILHS6NLmUGVU3PjUtJqAGymkAQ901ogoxH5x4ncbZ7EZD2t73qHDI/P+fDzreLAPCWxrp2dPAgskPKEh/zctT54DXRYveFq5aLggU7h5ZqcNrdf6Kz58qg8weSIGzQ6zCkU0D0qneJrLfgllc1m2Uzl45SoVouvw4njR1u2KUf7RiqEob71oVtFp9uTpkY6ADgiC3DfwqQKVTZ6pgFD2cLrZ2ZxlCzi1DlZfEMhnLOo2SiQ6Hd8WOhOlBGCkjtxq0LlO5eU9YbTwmePHjW+9EzmP6bQGhxg2/Mx7ed98KxWkmlieo4xIApzdcEOWvh+6KB1IhUkXMM6KyMtPkmBjCzm9uqSY7DVDukFqP66Iqy0Wzx6sg0qtvbWByCeDSr5kMmF7LBoQZRnOHvKU3WS1snXVxJYe3s3OeUwVbRQzunLck7tO/2++4xjBjfHepohX5rkI0ex+8svoAtndp4OtcFm2qGU7kr7GfJlp0DzOj+m7Zcwq/edD9+FF9AnYhwXfpfilvzR6iGZHjdJFwGoeKtyn733q+nK5c2BZeyPygiPJkchfj5/qNX+eiS2caVU3/35lLDU+H7MJDkYqx89K8au9NnPb0NwEbcA4VBILeY3QzNHleNIzjkAnx71OV+XrY83WJ9oovCtiNvLs7lmLc6gBF2x2KQpsM3CXlk+Ce3RQNlSCbvotL71s2hi9bsLr/Jhxw5j4sUyCUpZXlmOyBsj0anEYkbfJ1Z1ioDd8XQ1pIVfif8AyHRnYiySVMLu+OPn6ebW15M2QE9DN0AmyaHJ4bBQSBI/sQ5Rmc0ZoshUBWiLv9yIwZOGppdi5NPHbkSHrbrRjrRsAAoJQ/KWSlfxyv4aR5nBTL4q8ObMEpR0oCwftKvpruqW6DIdwQCsIjEEaLrGthmyLPjp5gYQbSS5DIP1r908kDNbsa5D1WfhqHjkek10xL0yYy3mGLMRwLZ1lzdHPsE/r/bRPl0d0yCMAJbPCf8AqIVD/XRNvvG824LIt/8A8UUOwOyswqQucG2ix7kovdHJGiB102v7lwlZNroaBvv7DoAfA20HPNkhrk7rdb5GHUnDV4tWh8jXr6fmjjd3JsrgZmpiBWAtSGYlGkdHELRbzvQUAVlV7PmLAV+fnQCTTNyv+Eoru49dMKPSn+p2/wBNXHZAWXci5OjrZuggQTEfM3IrMkZ8Jm4EJdJniIsftUttmfmalDIavmx1ufrOm0v63268ibXlYdplQKst+yruqXAu1jq2z1/1KxcJc2+rLayLgPv83VyZ88spM64TbOlnTNgMZNmntn9Rx4MDhuiIjwzo7B4ljEDiEURQpfbIynlp1BpPDexKqNaSagLPR1ye6oQ3CT0AAGquHi8j73SiozRGGpGnr5qA8qm8ZhLPwbupzDPp/wA2JF3fuPdv1DoOLR0PDgZkud/68uohS9z84IDiMJ67qBn1NJY7q3V7RBwBbEqcNPVOjTXyEE3BOYqpWW802HU7YXsxeUP5jRtcUw/FT6NxEHZEMVC0UKGZUPtPts49Z3wj0iQKDnX4Bj7sIB2oaoEcDtTahEfdZbryxZRJI3MM1OruKp5/7ehhfMVbhVNpJujIjUJIpJSp5q0Ik8/wlhswayvFLHHfQAADsBLYT6s5Ut3j2Am13E/i4vF2jDNaQWBc2gCxVNvbxXJ6EQopIO3YXIJk5p1MMHaXFKrcL+es6IeXcOIXXkCKxEX4PDFC/EXxfgrVbKBZC6/gqgxWTSawATP/AHS2gfYg2DAoDPalE6ePICb04NiWLkBOh2VtTPXtilrAEadbB5N+wEJdiBFMW9iDn+cK8tmFxux6A6dV7R5z7BzFeS97ygC9ssd20XqNau8BOSiQofcJoKew1M0mzRxjteIUyXtEzkJQ9x5OztScpeGCRHQNbwMWzy5gxENwRr1s1N0wTYRTH9uT4wXL0pUQsLD9O8RvWipmCrzNqZTe70or6nyIuniJjOyM9R9yymxFouVPf/8A5fTtDEsABnjQiGkggRM/jkGRWQRjcQpS0sC3KLC4/wCH322Wy3xobXJD2vwgEKqPlBa5qMhZRgDuMoTVHxCpkzN332Ty8xvLdlnVs3RMinWpZXIfYCi3tXnkSyQbhBq27Wm/32xgTYSQfVo3395qHdVsKZjOO0c56LBItCF1aQMmn12W/wB3vKJEK7fOtl8nTNpJv/00yjjn9BexOnPcTS9RsD661ALzYAMPfkzqd/SNs3v/AP5ci3DPPqM2Ff8AUjURhSfG+xz7YorHoexYc6/+kP6z1qPeFg2pIPsu7kKix3dditjm8iTzTSTT2YzP7+ez93X+26T8/CcJd7PF5e1MsjsH2gf2e63/APsdtdKsk3s/vJGr1810cwoKNtjATDFtcAhJfhtD83vJtv3diT+n/P4u19cmu939lSfrnvCJeyld3icelRPltqLIOdTnlJQDUuPs8mnk+3nCiaQpJgMK6K9uZ4YZU3ftsYMv5vv3m0tlLH00/wD7/wD9fpFB1O5tLec50hgbhVsiN//EACkRAQACAgECBQUBAQEBAAAAAAEAESExQVFhEHGBkfChscHR4fEgMED/2gAIAQIBAT8QQ84TMQMIfQx01GqAVG0dxoMTA6zBwXC2c/tgQdX0I1XQfb7sAqzb09ZgKyr6f7KwDHXr5RBjcWTJLkQEFjnzljErU6Y1O0wxGv8AgXzCkHEYBIRPzf3gTjT6veaeDVzbkc9YLclr9QuSW78vm5jODj2/ccIxyxnY7ft8ITIdgbMBC/mrziEs5juodOtZJvEr/kqBiXy1buFd66t304/ErFCwxDvBFatfaidD39vwQXY5+Rjy/USAP3a6HNXx9oYXlouutqRFI+cqxrjp0v1h5bE/KTCXBO09RvTOv0e8x4JW962dv0S1nLzLBgLsnYlY7xPTqDRGQI4jHcTdjUMqM9YVyLLK1DxMzTMyq3MsvwNVQGkoETN7+fSWG4eUtqoLqEHM5jFwFQlOsXdwX1HX/MxrcFgHABXl6ecCPYw+9GlBy5jo3kKRamy4x1AziF8x6IlEuD0hn/kKW79x9miXEY0SxKuGHJ1/ExgwQqpgjfNh1CuGPHFVenWaJVYZQbTVV0rENmlfqFS9GFw8VAMSsDvCCMQz17PMlw81z1f7HcRPvMqLGCusvUGAgzg8rv3jYNi16/GOIvOagdOBb5S6jx9YQ+orryJ6wjtw19YAjsSujZT7ffpKCLqgPVYsrINW+i2VNuH90wp6IEXUCmSXb3EpVKKtuPSIV2OkNtQLwRlCULdS3ePImQ5ROLcuC94C3cK4ZZOCyh3POIimiKvUGbjSZgwNZaxHLmAURItsN3wpurT41zAZ6+3C1f1j2lDuMlJeQ6vf9wGnovrCopPr4H/Iag3BqEL1jDhvJALFMyrXCOfC5Yio/OfzEBhs43qr8vzCEyU+szVTdUdnP0lxN8+V896liap11vp+4VnaVWMB/Ji9OkBVG4lnQL84ibg1CO3h89pEBBt/EC7BsZjVYPzcMZxXlF6+dZdpsNRgVJZp5N39YmEEQ8vn3zBG15xAI7aioG5dbrMpsigricYn+q/Ufg2AHUGQrt7xaJb79qlzGjrn6xKYIp8mu8a4TIwGee+I0Q0lpND6xAhuAiQVVFthqYQjdUUtiVVRsAAlosGbNyoaKlmSYZYhFNZjHEbYJQ1OiDRAtVgCxCxqsREm1XORguC1544+dIHzOz6QLYKG+b5hEChcB0B/ssMV2eI8tYp55ioKSEWo+DFxGEN0X86+kQcxwuCAtiZTHNZqJuV0+cMWqud3f+Rowth6ChKBzF7fl95Qt73zKKi84mmlsHTv6y0dA+cLC5ENjF+mdS5qC+t9MfWCQovryiHJxG2laO0F6tW/glzbW5jBef8AYkXpFYXdQsAgrCOol+fzcCGs3jGYUiqzJ+StepMDdlxJHUFIIOqyr3uOad4zHKNr0jugFYvf7nKxBwMC80e8aDFSjk7vDq8EUa0/cG8SypKWzi4Bo75lECvGYgIBajOYgoxt7SxfvHnMsgxFqOSXRBTEsTbMC3K4lhuVQq7EADCRuUaJixevvGhU3OoGkWG2N4icw2XljjLgJRR2xXMNMPLmJnwZlgwKuBhaLQutcFuc3ycUBNkJ8v56ELDhz7xi5x/YUXmPSLj5cd/xGfMVvevtDTToqNGTDZsEVXtOk4119sSoolXKXpMHITg8S9ErC3j59ICjWPOOktu3zj6w4nCY+feNbOWvxC++Q82Klm5WbFXFTXPMpM0WIgjWNcSlo/uZcO0Ksxo4lUpgCNXxK4e6YlrDEIy6DPrxGTeq6SjV42X8YeLfhFhuDlgSkGqhoZVYttQcMVJpCUircLQ7febnnluZhleC0l3uAuW5mG5goMCZjlzAFDeaihRMJcpTnw2e8AQ43E0JeyMSmAHv8+sEjTXZr25+MSY+nyppINyoDcKWmru8erxA2DS8fZ53hx5OIggGjtDrr/YGceXfff1NMZU39Ov6gwjYzyb+dZZpLaLyeVYlX18LEYMnX5ncFE84JQiwuzOvKXAmo+LoPzczp7xSY/mK4eIe2YhR0fSIbm3Sq/bADFvETKLfaNi3iz3qZkHMYRWZ31V/a4sWX8Q7rtGSav74mCGU3Mw4+8+4gzLNo2Mykpcbrcsajwag6NxEaJcstY8E4o9X9S9iD1IHXiKzxDodtHdy/YuJ239YjDWXyE+8Fg9iUoOMd/8AJvUq5arhs8/Q5lIgtSl7QGFlPXefbcpAiq+l2dswyMFz34jli3qQwxOSFVKEWyiOJjWA6lysy7GjmBFoDcw4Jk/ZVHW9+1QIqMRJNlKY1YnOvvMEXjIxTk0mUcWz69oY5OPBWNY6utVk4rP1zLebTjr8/MvKUZz/ABu7gRIWrDNfTPnRLe2LoFrz84uCm73eea358XiNCBRRXB7xwpA0oUDWkTXs41ASGMs5MIGRqPREMhGpYLTY5L35xDNWYxtTymcC+aj1DQ4c7g9pffPTUSpQt94ziwLXq9DtbmX4WmiC7S5ZRoxEuDEFbYo0TSEFaWN1EGmAXMCwpY/Dyik9EoeiWZqLYEwSw3klJXB8ud9w8sf5BsZYJV8COMH6V5VBADTmAbipVqEzY5/XrGpWOAoKSmxlgekSUTO4b9oIBg85aFxXqOJZubluI0BcdvluAgxaGLhvcAJYBuNG486WUXE5BiLFZyxQwMTBAopLDF2nBuVQsPn4lOAqVsUHP884Q3+kGucWtRukt69IRvaQ7wZ2sy+bKQUlahXW4qojdU3zDVJnYoJWxmAowfhHtBthSXHRXEdw3i/L57RQQXQY0V91tfTpA9oY6WxB0fHWZXiDKjqyzMQo5TK9vESoFZ3BduCLOeIOvqUhda/svKVziVpx0dXvCob38uCt3aBeCaQE82wz9n6RhhgtxllkU1nfMeEqFcuJasnMtzLutTNuorbbyvvx6QsHSbURdDmUlAzqEDPVZdqGWOo1iYExNShaTgbmGWIVxl6xilwMuVBspjRAOpVGIKBGIGVXXOYWDcfnLiAQN8Dn16R1fXX8dYIBaXK8cY494AOsMhhhpUpXSWGxjTTBRGJclSr3Cu9E0alZY3HIBAcy+MPnzvCrDUDKyOG1/SOgdag2KjWaqyvYSZJ6RQHq9T4ym0dmYY1G9ol0moPHmHFzIqSy2gjRpL6wRiJSjV/GLT4IORibLNwVfMBtuXYH9lhbmoHhvEzvpAt1d0FwXgR+kCm1ra9oUL82NfvrEt8kGqCAA3f2iXDUaeUGnCMYIwy5jS2yphmHBHgmJ4SNbqXUqmYxDVqZhRshsiBIVgitDLIILEHMcZgdItuYmiJIkqFeZWdYypLOkKdcxAavcCUo3V/P3BjyxB65eMQUb7gBmWcmYgylAhGWQheuE1TaAKrUeqppQ3qISEAiqCDid/aKlBuYRzMQjDVct/YqoDglWtiVQIMAlR7JYER6ItbxigGFPX+vSVtjLNoE+e0Jsuj5+p1+MeV8en7gFSzXaUIdxyML/nLXsah+cMaJZ0k+s3Fu4AVD63CRhU4My6TnETJl5hGx0ZcRcRJ0pb8iUkORogFIpxMRNNpjZAtuUVGjEioUFR6Sr1NSDTCbRAcyl4i2ToQSrZoTKEe3xiWW5kRJh/AgSekBsKfpMnmsPZ/MCDahQF1rtDkDE0uEaA08ptqFTU03Lu5cLUNmClF9OZShmCDJSxBmchuN+BELhUbvJF3NQ6ETKPQw8RDKoZg3ngZMljFEpor8pkoL/EAQZWDdnvEIaXEDYLJ10GMaw3mHqB48jHpiDMd38rvUVUaefPtMRambeGK/ELFEa1i/p3hSEss19IiBmKoYAb+73lEHvEbBVDyG4gUY1V7xDZjyIfF9l6ZePnpXqNSjiZQWVLdJVWm5uVSrgBYxqArECnAyjMblkDXOJq6lT4Sjilqm+JV7hsjFggVGDSaiZzV37hnHJ9bi3MEVoup+plTH3nIhLdh8sebjwYDM8Qoy0GO3pKGEthY7b1jz84yRLUo7RlmIGpgkwSW8UVrqDclj3iatnMFIuWHNsVcvaGFzANRr8DlqNhYY3aLZdsBJ1X9ibLy2P4lrW30j0jY5HiocKio41rznefB8pWvR9Yjr8ppSq9J0h06f7F4XmXS9zJHMQ7Y63KdMQgglZ6u/SJDspj1cxmwX4DHv4WiY4ItqZdEXtGo1FrcSYi4s1L2iplERctgpuG41LTF4ixXMFEBG4YYgLIsjj65+fWGLuXrIu9KudbPtfWCI9hmYLZY3EaLY0TVdfxBmBRABpzHLABiAPInW37dYpu3xBNrc448405Uz9OYG6GybVvrNKWEcdpaybhtqGqGCs5eXB837QaF8TaiKkiQGsYYbDQsyCcoTSyV3TAE0i89+PPmYANxXIZmeZbKkZcC8dYOgsECsI7uf7KVh34mCl68R4AgcvlEWrUYBE4DUKwcP1jkDMsn2s/2XDKZQ4lqLKmLAcZslypQ4JSFEWo25lsfAVAicQpE6SiAqWCNCoXlr4LJAW2Fl3AZaWywDMxfHRUAlZ6QtN3Hp3yy8ejsfV/cwNoTpwBUWJamEsRiwbjzjN3fDMAqVUJZVUH1c+0IlykhToN31cal8aq4vEXd+kHzorcRMtwWjassV5hbvc6pSaTAcQAayAM2d+QzGBZV1euPtWLlgXBC4qWcRRolissmdxUtlJqFuuAPk484pkuAU6QUDMQ1Ngb5iUDCwHmf1D9LjylCIhcoBD5A5lDZzGvCERq+8Trm3riZFcdYJ2EQCCIKKBaE0EobYFFRnWCXZUyJiswRhB6JtTAMaRriEFNI2F2+Cx3AWBcS+oo4uGnED1hXEAMQ1O5Dd/WIa36wylXD1itAq39b30+saW1vdd4yqSkrWKdQvMVWjq8PztBox5fSU+cdI6gFxo3ZVHav3CRGvYJcIDjsRxzAYbYyqYhqOJisIWbuKsLW67Hf9MyUD5ykmouAxoJp/AwEnVdy8+kA0HrLCMoTFCWJW7eJQ3FALW4m0HY3+ZTpPNI1szL0jiV5cxknAI12SxX/T/kwidCOct9ITLNyhHF8xislxfWWLaIty0vUw3EVHYy6bjVvwKnvEpfEMoIt0ResVYKYjsjXUqRS4lwbhDFEq5YwBFo0wJVxscxpmUdQYJpfrBbFCpcMXEPYS/lQgcoFXzAQXUxWQAuElbqwxCXSOVS3cEQxACLAfl3e67wBXkc2Qh1u3kjrcoLvMUouWLJdeYzQtPmIyN+3hyy5dPv8AiEysxT0s4g1zsvjv7v2gaEVOn35xB1RbTm0o8q5mkIgDuE/JqLDol3XMrNp+oo8qD39I4AKCOzFxqN+CEuNT2ypU3ICAKQ5kYMw4m55hDaBO5n7X5TOtecdj5n1gLpMIrLiqqWTAqASnfggebLAzMLR4CKuNi5nct1BM7MoLI7xLbphTfgJdtEeYColu4xzcaZZEtPSZBMzqRFcWmm64/wBmOjJLGorqQVXEahgmBa7ihenyiOJjaUOa89esQUn4YypqDkVltu2UrRv1jQwEhzHMGW6W4Q2uekqNcwat71qOVicdf707xWxTAL6QxateEpM8zAZmVl7+tRbuZ+oohpdolbGaTEIBzLgsaHYc8SxpomZmOdiBKECIGw5469ooqfWiUAjKmDUAbmjLw2nfXp+YawxE0PEImIC2JcoULaJ2RY6i0d4S0hwjRpigriDNzEW5ZZVbhuZJkxMMETcxzOgolVzLKMbjhaOsW5gdQUs0M66+cHd8xLrLCiC8wUQxGj1zqZsOIAZI6qYDmHLxAGpmBm0tzoQRaiOm411FoJZlxFbGvpCowS8vnQ+fVomp1NCzkeetss6ioApb6N1q+hLzEFdecp/eAg0+YrrO7qahG2iXOKAhTCzmLety640RBVbl5Cf5Dcscq/nMBzhszmIDbEcXlmKrM4qVMYoHiBmoWxz1XX5li5PzvLJaRV26iXKKwZvw4qlQirIRmKX4BfgDZUqJiI7i0xagNwomHcHMKYNlQU4gKpZY6rieUMbl4KgIVkesO+W6/kwzcag0xI2NmpaQPE4qKskebiNkPS4ZSxXe4NlXCqiK8TVRLuZ4jXBAIS2Zisyux1Upvhr3jYtbf5xhx6RUos84ruVq/LtART/Y5zUoLUTSWbuNDMtiuTLXggu1gZfm/SChHzwU4756H6jWPodfOUm4bQRuINiihsiZBiEG2J5l/NAU8xBV3H0haxAlEdQuoPzMcSesuYMEylcqUBXdrNHOcHvAVD6kDQmiZMMLi4dRLxFrwJdyJ2meo3cxLBQBuUDcLzGqYgqAu4EFxLlxtFnQjuR16f7ADZLaHP6iOo4glBUAxtAUTcy1Gho9bmmCCNyxiG8y3mE6luER14G5rNahZRlMMbgJcWK6QF3qV6Qyl0YrddOrURsnme0OgGV9v4+ktQI9NSkXD3iKLYqEcwaVlOkjEgMY9ZZFW3ro9oDJxKPL7rG1vF3DsQqu+OkI6rh+sMWaIgARcUZYaqOUg8hBqIs95gX0isiW1FJglUxEhTtJUHhE4EpWYVKhRKLYTLUqsSqYgpSbiUCWxWICKsChKHgKiqjGGYq4gyrmymNLM6yy4k2hHMyagBzALjC2SwhrMomT4ApqWcJdNSxqJ5m9VAui/HwlJTT3lgRuIMwr2p+tQdpB1mPtUcZHJt7XQxkc2qVybec36sotMURzKQjs1LtIrjYuNCiLMxg8te+4XZmJZFzCcxRMVgO0y0XXFH6v6zJ2ea/EaLu6afJlLsTtlMlsuidhQM98QLWjVcCigmxGc8wboxHKVbvO5LnlCrLE8BviHeDWYhaY0XAHrOFIIcEdgxvL48DlhfgxRM4mQEo1AS1cRkxTiXm4AzOoRTUwXFApMRIoMxzlKVEghDGeYtZllbGUHK/fwF8OHt+0RlB6wgsjdw7y1YUOVY10uvKHBT32Bseidk944I1lMV+PXfnKgwDmokVKaGZS3KJW5RcRFMSgSz38kgIRb0iAuPL+Rtx6f2FcUUXpBaS+XUmALGMU7asVTkSta1LFEoKmWnDFqdQDTZvvLUXAqENavBLsU5KlmYCp6fAekFGULYli6+AtzMNQb1FZuGJhwwcJTKpplS83E6QZfipXeZIUczGkqgJhnPhvmIKCDqgyLZ8KVmKCguABBGpaor2nmvlFdMMTmYnTQbkTMtEBcQ9oN9SIaFQTAEjS7irEwILqgoMRHCNfOb69X9RGbzLFEPfpEdkgtQKrxmiAULCGuJ0wNg9Ih0uveKyWWMYAEi7XT8QdOYAWwEesCJmDeEViKGiW9ItkQJxDJZCgnMIsRDmoQxmWxVmbl3ETUSFQ4QtwRV3AOWVWphAZgpqOql1uab4lrUMuYw3BeWKmJaQOsGkzcum5awqtxKVjMErlLMEYNSq5aggRUT+ogIw+ARAaiUSFsgXEYaIaxABuaVFiQRh5UPKsxyZUNmLd6PpL7LNgPWMJe/PlC4Ob+e8rdRatnAwLMRqNftlhnwqpKsELHeIc9SmOJdsBd1DkiBllxanVjgdIIejLhyipyIixdxS6isHUQCG3WVwX3h1Wvr+vaWWOJ07mIplrqUickLwqjTB4QVyymTM6wxtIEbYNMutRkq4DTMgivUE1LDLzKNkr0JUlVMxYzGjcuSVLhFnmmxxKOoK9k3O/n1hvMTMK2REzGYeCAMoOSEDNxFFzKtmyYRrOAgdfG1bp94HNsTK6gCLK8SyQt4KTyzK5g4xEDxKDrMm3KGYwSyxYusy5RMxYCxZM8+0pmYWcQjOorVL/ABCrWDeY4VLla7079+hMstOlJ1/EudYRMSnm+IKt51HQzZLAJZyiLzEW2o5jTClqAai4XFdpzFfEUlBuCZswrAndE5iA6Wb1AYIhgWxKuY4gLtj0OGWYkCOMRPOEoGoOYpK1jn0ph1DEsqzFip5xYYzCnc1GXbiWRR1AIdY4Ll0Zx6cQzhgDZMDE0e/nSOAhDC4wFb+3nBXh95piEAR0qzyRDdDmUsTABYho2YnWS1DOFusRNRtTcBUywxO3qA1Fb9oqPdL1ZgjaM7Thh6xEUQJgRWkx17THKbLNx6sIC/JNbTOxEGCDmKowYlbYl58KmIxCMSS+JanWblBAMLhXXSBUsARKtwKbJgthVRy+DaFGVTIikOcK1gZbdsunEORFYTmXTKxbLhcN5laIZINswwqYjawysIKOOfOCqyLkzBLbqZ2scmAG2CK+esbUXL8RstyxtuIckRCGWIKNNkS2JghHLdEuWAeuZioyvoVAZafb+SrjweAGku4ee0sUtX0id2fPcvH9x+e8LrXQzef7O0I0DAUFtIWDCVk5qVEZRDlSKsdS1xEzOoidsUS4TPEqoiky5lU1M6ZZ3EunmcBE5InM5Jmh38HMJUpZggLsgQgFqYGG5VtsOrOAiHJOCJQckbZa6l0plLgAqOKSKMQviUu5RdMvmwF3K6y11MVihqBjEtt1ECWWavbLCZJ9n9P3im8QpcIbgwLVniMYIreowOlmj1UT1mGwQNoLMDBVF7PK/nRIroOCgE7Jm/P3vEQy/nzrKGZbOGEFG9bs9Pz6Qic1muP1G0GIJYS1MIR3mUVcvgTe2O4ZSsRt4DB5ljA48G7lOZ5Te5QzNQ3aRS3DTHM+AWXDBLbIY1NeDjMtY0zwzCDcuXLrM5uGRZzIwtFDEdjMWLFvU0qyF9JURNLz7wRxNFkJAqtr7dYxO8AV1oom2Nyy6JQLYpV6lJV7nExGOGJnxE4GJRU2hXRzClB2fmCFgxHgZk1AaES3CFwiQEBKS9fmpVKlVmte0talepe8fPvEFsRdTIMLZitojJmsMlwvfEW2/C6jcL5l5jLulunUKNNvKIaRj1XC/DGjEKaWWaiFVMjpE5gaR1Kt3L4johGLFvhGQgsq/moqyRTVpdsocRKiXERmDggw84ZQHMWlQpEXLGzcSqmRLQfadk8PLiWiLsfrBDeK3VxVxcVCb3MbVWUabqdqXZl5nfeaKJqeYK6YaGDRDUsJuuJmRhSe5Fm7Tk4aUWSxGXIjSIb8CWQ6EwqS1siluE01DzJyRbEilCzMNQcVKsiV4VDEXwdVIAbmFTkkAwQvsmbXhgx3LsqXHEdcwBbLWIq+DHxiMyUzUXgAKIvWOMsJdQuEDcW8wyMswDGkC2yBKE3NBBEeJiIQsiSwkLJZSlIljLQJhLBfMskJUa7pLIzojSQkbDcdBywDfL9jFTC1Pr3lpR3DqRWVZwwUBUs1AclyhrEUTdwWKZZahyxy2GqPtKNuyOWCmVpZ0pSxKJcFjbUtAR8TuIfTEuUy3F7F+xHHQ40p9HHrGYm6oCdub54jmz7APOgf13ioBeEWvLSeoRIMS1AA7HpuVCm4/FZG5IN3v/h8ENQGDEVbKqF8y5CUZvBFTceMRQcTsmGZtObhUQNF74Im78QAQWuURKrMPJAC4OYvDOYMaEuIneC3EvL5jLS4XoQu4GmCly+8UlZLXbuRci8/p0iW0UYuHSnYiJxMxYAxHd2eCoBJBsSoSrhUuCh2L3tfalzbQjQy5ZEsLGpgXMFTJTKXnwzZVJWZvTzP3MQkMMXQFfpKBKnl19P0h0Uexr6txXIL1zezj6EqXA7AexG2I8wLWn7/ANh1GnkS3t+j9RVv6w+zB6H2Yy0YVTbWrS07XXaVFLiGtrq29BX1MZcPFl5Yo+bUsvXB9xfpGa83D7kzIxDkAvRakAhfbQ+i54lsGljz9hPr5zQASf5h9JpIDaZSuI1RBklg1BM7jAhyxDMqzEEQcbEohijUCrUoMGIyCcBGv8ZgItgs+Q6zpTAmusDcmc9iv3BaRedwCFHj9TcLuBpY8OYaAfoHmQLpi5hEexlxhjUtdxWrpj4AhmMiEkpUoecvddIcdoB6zlxvKjDf1lZjUsRFlsKl3c2qlhRHBmCNpEBKpLMF0MwKtr2Yo9es0Svo/f6l+r7r+hR9IbN2AD6Ym4e0o4RjLC5vbLGvvEEwpxK7TEZEQpQOp4IVVSrRN8QBWTvGdj5aV6pVvOresSR8rHqT9z6RUoYRKR7jkg5CHJA3qCaXEvpMEvp4BWJQNGY1X6I2YjUIQC+mv3+twwKhkw5VEoN7vEa5YtRRuaoTtKEqT2HHnCG71eVzOjVPvjXt+InDKDGazNTj5/ZS20clyyuvBxmDixAUhKa8TGYNzEGTmZFLDEplhsaEu2LC0V0bsyfWpecQmTka88lbr0l34FKuxQm8bqJtgOmA8Wes0IS8TcwlxraZhQPf9RPk+v6nS6rQfLEIqNvL1qZgqFyOO5Azg3k/MgoejzrEoVHu33hXfpz4j8lKtXy/xF6fsyBFU2lrbpgA5vPpM4B5B9xMD7he13CWY8Veetj+IpsIQKQM2QXO8CnXW9fWWbH2gKg1ziALHEHEJMdQJos8llS3UrDHXXsV6LqM2l0sL+x6nzjIA/fudZuGK4UuliRUV0gBFRKu5brjM0YIUKgZ4cwAJxs+d/WAWWJe1swriFXVAAj5MVgB2nTZ6x6q2/O/n5gYENf2VDkV5ar6wTkxxBuwhQdOYhFxX1lK/XoQwmSh5rEbKxscwA8oheX6+JXMLOIIU3rt5yxg9Rq4B3Frzlt0ajhHLMDDSZk9CfW/14VwAodTcu5XKXdR/fX1l3Cl6IaC3zBXe5y9g/OpeeU3L5u3y1Mwrjna/OorPbRz5f2XWGy/dZcNaYCSMOomxD3PiCk0/iFGKqbmAG9q838R3YN94hrn5Y3UWaR89IhKk5Gs+cq/Bj5MWr1FvuMprD5/jEtRXje/3r6RZfN2b9+naCqRrA10Uq/Nz1YcweX9Y5sr0Pyx2tdW9Lgowdh77zCFd9S/uK+sJpS838LBDJ6jDupTvktZL6jvJ06InNHWH0/pOpfSMC9ID97p7mZvXtcHmPvYdJWO+St+4PvL7J1o7cs4gHSKZYIrbECLQ+0wnbrPHeAqv+wWNsApIwoyQ5EGBK7RDIQAyYmD+ULqQql+al3Ov3EDGo7CtyxNrEBXnbTX5g1q2vY697+0uBePRiOjKA0XO6a8SNHA+vldw3LE5qDZ4DHmlyg1OTA9Y6hVD+wzQFHg1MMUZSvMU+loCt+vSbwrmy3zX455gw6HWGLdyhkqAY5QlabqvKYuBQIfPrC/lVel39LqE/QjYPD+/WA3mMfOD5TNDtrpo+/MwflzLjzPrWf5KUtyte5/kp+p1+SVffR86/cRXW/fMF1hyw3Ch8EOMVcNUwqDccoS7YTkiVal6vV/UtK9d35g+oESwETuA/yA1fvfuH2/RhGPSKfuFNMchZ5OE942DclHo5Cu9lZCzmDYtE1zGwuGjrAPkwgoYkIhWZoiLcRAgLDFXUv4X+S5Ub0alrjcBLWfOz0xLofP+ShHBf6uCarY+nWJqVjPz0jCmkgUHiA5S01DmLE4v/IJ1x/sVir77jdvrLGEm4whuKfUwmK1XfhkfnFuiD1dX2CBEWFkx7MBqlI/iaKG3qR+Q7h/GLI3wqB7ajAblmiERU2DSs0b/kBxuAPT8R0rNxKU4mIupSC05iQBZoxej1hu4pDFWNl3HlinrOKTF2mu6n7/ABCcltQXDmgm3idc9+Za4jBJhuPz3Qw9B+V/MCkIw1BYznuWPG46s4/ZAViO3UQKZWagGP8ArANHX6ysrqIVr7w4XMEIFY/AvJ0xvrGNQ7C306yw4MLr7tWna8wEUuq++feMIp9/PMwXTvBgePf2lWDcauUG8G/PtKgRUwUlahtKuMHaZqNC4w/OJvl9PX8wLSw11/ceE1j0lIGV6RibAxmFOniFtENDODNRImEIrU4lWC6IEEa32OrGqKDB5HjhzbX7gXlgRFrtCF65hw0Us4R394ApHRAB2jvADvA6XVRMA+LjJC5nV4AFGrK99faWVF+VP2g1vOvhCGWo7zWHUNVWHG/WZHldFJiged/mBM2uz2in7mIoF3Zd1tH3Ra3HslSkkXdjA2id5wkt0i23AUAP+CIYD8xHUpxbDVUp0zXmSgoG279KfrKicRqjUsCsmcxo0/YgIgO5K4mrgoqtz7/Li4rs12+eUG6HkSyV1EZ5UHWTUGmdtc9OnpL+shDXctFPEysDOvMQCWDhMR2SqlgVfuApxMvpUAsqIrEcromYO5ZzcfBFiI3KgML9IJsRzqcTnYD/ACLcfz+D657vaFENKnPLH68AiX81en7zEbS/ES3ufqUU6PxLm6kS0Is8Sq2dOkKA2PSEFLP0KepwUPCKrcMNq0GizqORqlOL6QpQVAmgwHTV+nM0AgsF/cdkuvpzcrOuEDaTLeEWxnzlSq1x87wIva/7BRur9onBmWK0933iTklm2F4cx2/T7R9YR1Fx1LEThLEAg1WvzjFJU28EKBg1RNoeATjUsmB7R3igI0triZM7xaowqPSUWbairOJjso9bJZl5594ULJmuSKmdSiiblyk2xlV0PPkJELdJlFQ3KsrORFiucSoW5uOFnX7ykGWKaiN+tdPmZl2d4heNMtrrtH0PtFbedeBXgNQLV1ilS6xMF6twpal2zEgwXwvb8xyb0oR0X08ufbURQ8Hrz4ICuIlT3fdjg8/t8YHCLMc/mbvOOkesB2PZgWGZgwe6OyK8Tm6HSgTN4lzyWWRQWBqgMjmhiYz9JpswddrMbqgxcOla+aydApdFHGLmftYLuhcWoc0r51NAIwsByL6kJ4DHBxSpwWGG6Wo9BYuV8yX8HtCZGisTc4ZalUSjFrGKWStGbX7xmiGEQVtXGIM/qYC3SEbjc/SBZ0YLl6i4mVVFBmapLEpRqHicEWAyxWg+Y8+IKLUfXsvTtUJroEt6F0J68Sjs1Xz2jrCVXRFbEgDymiGGOcrCrSrI8rg8mJnt+csqOoJsYgRo09Zwufv0gIOCgd+stB45/X7iCMBRXPME1X/P9mQ1xJRr5i8RHZd4+dIYiB1cfyAcqe/g4hmWTENWmSyMxAXvsc/zvUvhFvDYbDks3kaxdXb+uYqrfA+rUjAbB+ZgINe0dDsxWpVsIlXzW48b0gBh3AVLJWYYALy8jsTqI95VLfKgAXkKMW2Q2Ylc0LMVwGEadAY46y08Ni3oCODOS8XdROhzk3F2DmtXjEWob1nfEQD1lYecVEXp5c3N8eh16dPSHQafV97r09YTXB0lh6ShBk5grMyHmUJn7rlFZuaAp5LArT/f7zNWlwayQiWin9yt4Qhu215G41FGZVK8oW0AdMHexKG4p2wljM2iUFQYuACh510reuY6IRzYVjbdd8PswyIrvjPYZUZWqC/PmYDZf0/kSFB87XBTG+V/qHlmcjfGKP7PablXoPnaFi0to2+sM0HMGgXKc1OT+xQGvmIpESyrhPntF+A+cUFxLogyaVEbE+e/2gpscf2IoLbDp4hqe8czUMypUuLKqx5OjfXOO05Ig3btfTpDPD93n55ykA6mQuj5+oQo7fv8zECOgzap1KMS5yjqpjFh+EDUjDzdy0qor0Xt9PxBxrsNmWzLQdvaU4RTQwl8e4X6kcqVyA+xCA21FCxl/h3Zc1h+kqpoMUR1R6PKXq6H3huDuC29g0e9TIEQYD01w17JsVUtnTF7iSizylYRlft4A0zAjoxbphuUlJCNRURgdIJVoI9ydB/JAsB9YiktqKAzkekvF73vMYhl8j9QmzLuO0+N/P5BJ/H+wAIz0jn0RfaB84l22S4Ofp5RW4lukYjTIH0+rMPw279L++YKG4bo/PHnAsbtatqvTN6ixZV7V1uYXUdx+0OSn6T9vnGtNd4QNtksQUAthKaR6KmltL7QIB4ALgyky1HjPFCtNSkui9Mf5FK2BgxVwr3KU7fYiwmpbRGHwBi/Aq9D6wbf1IAF1N75yX9WCHMfiOLdMPQFHtRXl3jmUiJfJXbs9oR3agesUGEFfN/WoyAx1aA2JgjmYLl+0WFpXy3jtLWxMboZYNIrwD0mSANzMG6lWsvuB88pYVBWK68/iBOTw3bfhVnAZtZXivpH2PYlOqzwZgUSxBPJ19p0S4WeMx73d5zvugAGz2gcERoBz1h5dj0ekZlxiFzN1+vnpGYsyEtx3l7D3jQSj58zKXeEKn6h4DliOs0xnWQzV59esp72x6NKK9jMIbnr939Q3KftLCAB0IWcfO8yTHNfmJe+fPz6SnYXXXtvMTszY/GK1phWWNZTedOv3HaNMQOJnmn2jtRgVQq5+sMXj52gzmNLjFQSFYnmUs9MMe7qfSpai5jwMc34QmjTLGEWGd6zgtGcNDPZgRqTN9JVjhJxUfkON9JrI2GYFjem+kSxusS4hZCoOYoXZWBJNbfYgFZKY3ZrHue/8m5USswJQ/lHIQYsozmeXPHT7QlxdpRgdr0R5HTB6wW6/RSvqwoTfS8dn9y6QGi/sefL9El4VBarpb7+fMHiDDebbiQHSENxjForPlLsdF39oK8ch4z+tSuSXAJiDXEsMryiruhAu24RxIZhlusnlOFgHO3WH+EwIaTvTN4p1yHWEXlx6xi1ZrOyCNG73uELTvvEWLBAl72r9SwU5jSUVUaLcb7xXVkxQclsEL/vnGhXz3hhlfY/cxcGFhFuyGp4HZAqJuEFGckCoq3Mo8iOf1fYlqQ7QJiCsE6hQKgG4i1Lr3PvHk8oAjTXuF/W5aldR3P6mR/HksLzF9Ydd+ekQNL/ABLa3Z9Lr8MR14BFqRoV3grUNYklf0+BGUZfTqfS2KqxlGrhL1q4pgTgEy9oplTr0+dqh0r5fyGCDT3/AM8KiWxuqpUDrMC4qx1KcEMG9H7hpsi71Rmsa47RqmFjv1E+dY2Apv7wJwRK5Zkg+e8qbBBfXyImkcSvz+ZiRv2nYsfqfiAhB67qU2/VsekBHLojs6dIQbblYZYhdNesHwzHOdwMcmSuZmWXBIg5IFFiAqUNRl4qDR4FNRiwO8WSUWYKOWoaVmxO38wGuqAwQ4EJR7EM1d4WMvMxTufeG7d581KX8JEWoBcUQT0jK4hfnZmui2pWPTvztljdF9q/MpU2x7hmVwjlieBxEuCZbv8AiNVhlQMAvtFtbBMl5v2lzMfyahkb7dJcdoi6lmXTamMUMMQxUKYi34UQmqda6PPpAaKFjRmuHH2feXohuV89itjY1jiXCKwwmHdo7K6mB4hKVTyz58943NFvNX/kwjgStxfoxKN6e8J1n0gRWSwgzLz771/IXQcmYBYx3xO0b33iSXiCCYRzGLY+zMetxAUD1ZZZk/cezp7BEXASh5+coMEInmbWf1Ag/l+/HmLx4NvDM/ADbN0qoTcPQ3BAp9J1FmR5hjUZq8yxAzDMCvCqHz94Adij6l/iNEGjqW29KOeO8tOTR/IUB+faWPUsDwgU9HUXFyVEGritY1FyozNomLhPPwKLz/0I/YiIWzsr3x4B0wb9Z7xNiSSojtfA3LnyYOfmBuMGfS4qxEOkwRBEywLVEFDjVXqk/mvOLadHYli23lWjVdpzOdvq1v8AUwqEHN48q/ssYxUobInTZ86TigFsOlbk1x15iIKoVWh05gSo9U71xMAAX8z0imhXXmNqrX3i82PvA5SBY2zZYgGjXX+Tfg4NSikghg7HuwTzamGf+FSriHMA2Qh2ToRIaLmkygoqMGXHxLmoYlxUwCmPWFag3TW/a5QcQiil3nMY9398HcVi4kMscTJ6IIAVGCoQtDhTHQv5WIrBkrTeMUfeB4jCwsyQDS94Agm9wWxIOsyw2MClw41Wd+25d58MIcxkumidWKQyjGbBR/IA/Qc/z7zjAfV086+7K3aeADNeu95fKiNwdG35d3xFA1/uYMKjdihIffOuWNTvs/v6goDJgKNLm4HscxarmOO95zfjHn6xVliFmZgfSANRHymdhgmulyvMBc8ko7CVBESUOPAhj/sOnhDMI+L4aiXEz4PMw8OI4gqAYeEIgkzA5gKsleCFVDDoRTqdJUalUAUEIsJxe2lv0ur68wZaDg6WCno48EVETCdgo43FdOhHQ6ywDwcA550+5KAOPAl8XUh1+v2uCF4UPbP3qG46j4V2wFmUvnxGDzidOnXkjR08eVN/iUAzeHY/pi1OGJYMYro5mJwsYpw8/uDMGZYpzBmyouXfHbvBR0xiPpYouJUemIEmtQwVLMDEo1k5/EfAU5t9o/VGLVrx284ACerrzlMGSWwaZbmVKlVMVHDES7msslQLqKZnyLlDxThHvLPCsVE4JUXERWiJU2i+BLYX3YSBmKVKNwRFZfhR4HGCYEeHiWi2vg+Jk1LzrjtrCzWs/hmU0ZVhFQ0+AXMDXbDsp9Ac/OYnpwzHUuEyY2u+GG7Yx9Y5Rkpvpvjm77S0Rerg9gP1ZktNdJdriPRqGl9yMNH+RQzz8+Yhrl+blWxxEh4ILHREjk2/WIOdxcyMXsjLr3iQEWkxJ1L4jMZhYFfuVruM/wCRNoMQIokP+K8a/NLiaZcSwFu6WYL6X7VM7mSmjtms4m1t3jugUDl6u76R3cNZV8EshMr2lvK10gUYjjxGB4BcCoWf8W1+AmPG0CZrjevG5lppYAxlKtJBZV8BiAWoaY5bM3+37H9YtIyuGceFLzAgC2NkNSI8Hl1mgxHusy7T8kvZyjnPE4NAV88AfeVlW+ZVqgbscSy+k6CCw80/qG6I5Q6N/iK7E39YAKYhQWEFveoVXG0x0LNEA6IufSXXG5WYsCVyJXjcv/hzua8Po/sYQVZg6MFfX/JS7nBoY8/8lUYK8bg5mA8Xm5kxXCiAVKJV6jiEslyxgCUhCuNTNgxKpfwJ6zIMY6QjKzKbmY4fDUtgRucBmDTOZtAh1S/agLVuNZczW5lWu5v33BFs+bhmz4RFwwxSCd5LLDzUdTrOR8vSAWDc0CZYM0y7z3mXEZVhABabPvGA6z7d4aQfIrP287PaU+Kz27/moLoEQgNxymY47jlv6f3/AMiKkej9pUS5Ge9vsShKANi+/wDJYKX6fmFy4PgxTu8Eb8VPinWEqoQ0mPG1UwhpbqY5l8eOI1ePAls28DLKGyCUy5e8RUSxRiGnhh3G0SJ6TEwTNxtiDOleoNlLrhlUoz0JkAlwDHz8TOLmY7lWZfhcwnxuCESuon3zLNWYDSCfghMNCntT+or2bN6ooA7uH3gGlhMv3wuWQ+lMplIN/wDiafP6jFNxCsvXlZRQldXT8TQIGN5j4BRiMrMqHgAnlj4bf/nKyjLJZBtm2pUqV4WS43csJd4grwrOIEXujC+i4L7XV9rjoYVDUzVjzcpKmpRKeBuVRB4JQzVhEOvlRSB8uFXBORirwxCIi4StTrErcI4RvF/mXxG+c/ivzHA/lRL0z9j+4Qtdt+eFm2bgeyblx4VT5RJ3Ah/46bBv2zBFOpljXrCQO1nNwCCjzlc3Bzmb8dwYtl+FSnxzKZaVKZfwVACbTbjwXUc6h38CUmWKLK5IwxNIuhtq4cCCtwPZ0n58klJhjFVRdIQuLZaXfhbKHcyWscUlHERUY0yqjdpEHwY82O2VfSYjsuCj0nYpl2DeCIFV1rjkj4S2vT6WzmVBJFZ60bNeB/4hnpILTJ4N8wfC9zb41L8TbmDqyNQr/kIGUZSdMvWJaK9zeCHQm9QblwNS4a8CD1zp8uL6+cvhiVC2O68EGGK1jUB1Uuhl7fmMzm1SwEFuCYgLWOIC6gmWW5Z5pW7c/b55wSrDBAupxO4jGs+sRT6UC5lGwLb+I4A5lSpQ0ivalQfg8Ipt0Hdbl4hb3YaYlzKoQ84tIk14H/mLaIo9KGUqLUE8Fy/BZuDWJf8A5EDExUMeCxYv/G+3COk5H53MxCKdDmu18+fgRKhC4LIDmGSuHepU/Zfdlu1EZbAYWZnmUFqH0FxAAqUrSJ2XMWfOaCRuKs3t/kccx3Gcmfx04sYDd+vlMMkKNb1F9JHspTD14IszcJQxHKD1jlVktGWIGVCmFJfgYlPBnL3FngvKcUHdsbb8QUl5cXNRb/5zAXw2l4RW4gxKP/aoahiX8Ss59/5KCC8QIFQbRzE4qIAMRjF1FcLJad4V6+A9JvcM5I9HMSsRvpY8gqXqNVGFsjBdcZOZa4LentxDUIPziXy6Z5VNaVjt5mXX2mICZixZu4QiXK/4uWy0tLRTBSXBEtC0K4g+DKAmC5ULgD/yM+A0QtEr/gL8RqX4X/xUqEthlctOmDK90IycBHGlgEUtEFa8BLucQJjwq/C5UqimEBolEAVfSd0KxXr+5isgItLhyTBLGy5QYqgOSAMpYgLnkeJF/wDgTMHECNkvFf8AgJXjb/2VT4MGresw8w32l2l8DCMvkcTCZRb3L8dQYwlzvMblYnnF5J1B2lZtiFHpDpBUaZmJR94jwxSt8FcUYYxTIlnL/wDLtlHhfPhf/hvM0io9YZ8Lo/8AEIbqDpLOCmu3tFCcV8+dYpPd7wICcWWUzXedBUSVX/XnNS/DJuXK8S61DEFJRAoG2hF5YPHg4lUc0AsJX/2Wp2S0tBqCupR/6Lf/AA/+ZN+CgvGjBBo/PeKxxFzLDiZxyQrELh/wvjRE8XVEwVFiSlY6zbBRDnWgMXXNy7djNIt+oyyqgMFRtreLGUxwH1lyu8EWqgWrLajuZZm6uYujE1f9y+fANS0s8FqWi3/yPggvgw8alzylH/vfieAqMOAmURrobgIz0Z/flmJsQIVjpdEGB/4eB68+FMKsujpFCqNku4xYMuRFhivL594x1OIAUULzsR/JFwOQzqFt0ORI+HHEwIhQKLGZWYGQ3NFvEotUxBxKKsYAdQuX/wAlrwqz/i0W/wDxugV/1UCpVf8AiYz/ANX47hq4RRC2A32z7xiqNme/wJchMGmUamQFm4SwfSJdeKpjhbBxVTBubBiGQUxHcKyqWCj1lx0XHpjqqWgMxjjcdcxDWoQ2QBIKNRzCvxlhlMeZ/8QAKBEBAAICAQMDBQEBAQEAAAAAAQARITFBUWFxgZGhELHB0fDh8SAw/9oACAEBAQE/ELCyiwzvUOCAn8RlfbdgFfeqPN8QRQ1OOU/Fu5eaCqeCg+1vmowuKuDtLIXGqOlf7LxKLGd2PHFV8zjFu+HVf7F2BZdmuAN9KXGcywYMC7eSuAXd54jS0vOU11wboLp8XHYAAo5zlhxoDV7heEoxW8t+2NRMzn7fQqwzIRdEbLBpTTqAsYBZINgWLu2x0esFw2BM8H0HEKahfcqwbUu4U1/4X9CkySgiQJgLypVIGTDHjMGHM3kAavODKOXiEUCM7F9pk7Yl6vo3Xnx3oiET7UPVKa7P+xWjGixVmG746bTxCPBriGbIGGcL9IGYcbbQym/QIjJxExoQl2Fbo03nZeSPeViqUBbPTh38sThnauv54hBlTTyC0306xcS1Y/Rf0wyvpA6aXO4Y44OLihbLGS9zQeOYze/c/mUMLXW3PB345lT0646xk1ta9v3AhLsXrWD+7RUmUM1h7fmDfSL2xUxhFovUMfMLCsB1xs+8M1AUDpbjHTr3YlxkohumE72jr0mVVPQLtrNXi/1qVNAcBK2dkU4zBivV85Lxjbtt6RZldZKAa5qjzxxUsTaExjHzflYXyKoOHsbfN+kt5UdP0ar+NQMclHsX3PMaNGQ42db4ujGm5TTGo9v1ggiWMY6oNfLfTrDVTt1y1oO21610RsCw76/37nEFND2N9i844rmHkxWe1V1vrzfvmMVUpd4v/LqtPmDnndVuwxfXHStesFLgd6gRs4rbzQv3GrOY4V340q4PNDrhzBWqxSqtoRzT1EeKqqpVEq+esS2xt3cFj0Ruuow8GR/CfZlAJVYv3v2694jaAYB83H7hOM8NCl1l01m9y0NN8Oj9yuar13xft+YpWXIq4AP+Fd74hGfeBoox+K771BAKfxKIvmgnBMm85zOsM2G3Kbtnk86gpYOMat34hCxyQ+hh9Uif+BSNWtSsb5cOQ/FQrAQLGktb/G6DWraPJYm5noBQjYTS+S3XDm6joSiq8XebbdN63VEBQzLoXTsavftcax2WTlM9Kzt16QPcFNP8vTklBstOr1oOxt4lNeyTFUPHpqApSh1SlndTWcdI7sVb3ea9o8B0PRlXGkzNQvUWDU20d3tFtsMHQt/BLv20X0yTBNLx0P6pnrsUeHP+wNgPbvEtIiwPQOBmr4HmJCpKE0mm9sfkJx3P3DraBx2tr/JZSrcF6OlX1dVAn0FenFPpmMXxq43dikfdR8uutVB3aQWnFGSutEDl7cFJTQ01y4zma47F6ZN+arKY2F5mthoDv12+0FKF5py974PBGDmdLauKkoQvpXt24qIGstPWvQOy9YjW1MY5fjzKejHN7L2ZX3yccRuzsrvkOmLazBrIQc9/E/meK3yvEEL84ONNdet4+8WVAdD+49o5K5B3qsnn4lYz/L4D7/eoNHGETpw9P45hzxgt4OWun9uXHSV8feoBa3zBip7i3BXTyr0TWYA9wDXNvDE0b5i0V/t+tSgYNm6yvDVdPMrGRarg6VV3wm8PWoqY6BTfOH01UWWpq/vfdiLMN/HxEPsa+MzTXbvReL6XnvXsfXhznp879oJJ37V0lp7xjfT033iWIc4xnO/W76wdQTYaBgwCkZzZrJu+K94SoUcGK+xvKwfiDSu67e0Tmq4FKGXUriVoQEsBSlduXhg1Bv8A8JKiXElQhEyJSjo613TC9MSztBm8r43MOwzRxwc8bhwshReLMLXGXG7lCpvS1YLLe2yBjfSXZaX0po24WCYaOxApOgujm06Xz4gl6nQyGrHNCHrxuCNitXjFvd95ZLxfZiisANm26vdx7yEbbNPe1OOOZQCEb4byX2vfjETNBvmInoMsLDYKeoLff4m6j4gxcQqaWX7fevTMVW0w7LvXmj3nB/bG1CfECjvZ6rivwdiCJtAZ3l4/UzMFOB0acu7ohfblhj8HzHfOe2/7mXGDa8cRL4GV6V8QSgap9Y8nYYPz+pgGzQnbiiDLdG30HjxdfGZUaxl9ax56HvA9U1ORMWPfSZIHRK5aMK335o51DIKyVKFPrjjZiLQeIFOsjjpRiKdsKxa0X8Thnjm6G6P561L4iux2MuPY83DtbTRoS06YwRQKNVir1jY9K9YbLUMWi8cgb94cGEH26e4Y6EAFeDoTSkaO+9QWk8DOHq198wt0B6VcY/vbWf8Al9oIRt/3N9uYC3Zb5+xjr7QB1zR8W0HotdJ3cFD0raf3EpF2rXJ47j3hThddj9ytijpS6HddL6x0UIvijGHPmoVrO2vQx1xAPlXyoVzvd9d1mCuKocGLNHH+SoHIvYvr8agmrDSqHQlutXpjclrHzFFOX/mPMKgJhLu3TnWf7mFfTl11Zvtqjr6QgboYDxggDGFqdR16lY6+ZQwRAL6tNPR4lMFZMVx7OHR+JSSlbxrpb8/MsKXYXfHanrnW98xk9i61xbVfqFVUAFBcWXWopFwumhWXy895isYEVi+tWfN9swU1hY9mH0CVKYkr71ceiXTEFB5y/bM51oJyXg3zeK3fEIxV5b3+kI46iFgIXjyL1gcxzyp6OjMoBt2PCZ9O0RGVTNv4Gc66xEXEllCclap3MX1hEAWUS9A5XwcHSXpElINOODeMZM9oDoQDdMqnqluatSG6qTrWEMPWXEENDtppfRjbTAVZQqxrBovlcdQ3Cruvk3dF48VLY2tidotvQzdfmBkA7cZeboNR2+VrwcsJ4sOLpaH2XRotukfoJ1zfyEtSFY3/AGO/2hPC8Da8W9LWqKm/YLa1f/ddiYXb/nq1GzInPrF1OaprJrz46QG0r7dM8eJV0ul7H4GveU3NRfPa5ZlrWX2P6/WVFpVeg3prr7QO10VUO822eDcxwJberxRvRz0hwMzDZa8PbjV5IJALni6fWr73xxHHSbC6ed1T5L/EHbByrG802Wppo49ZekwWhbe5L5wIFCVgeCurXF4McZoZeLF48uPTSRjJQCcoUoW9g85ekuhyu28Wb1dy4ktuN/xU8S0TOgieafGYErYI1RSX7X18VLP7D7wYBfFffWvWFjJYa3t53EI+enrW2uW/bEL08HzjXeAmKK/NRgPa32/5GNvRcSBoMfn8k4U4SWzmfzLgX/a9PxC+FfrHzmHLNWX0LlQ1nC8Xi/mcBnsJ7zY4DcpdaKXLhvb4+ZyLO6lyVneuOtx+iqBeFhRnPTeVwKD+u/p3zCgShqzQp96lEb/v94xE5NnjnfzjfmGLwqPU+Rg164zEzpgCGs0X3bValwdA2L5rBeqf6CWaanG0yznQ7ccyhwIWpsqsd2vmXqkMXxZs8mPpcH6WDHBwad89ce2jqwtBR0+T01535MRBWg36kaXOCu3U85d8kW5hw488lxDIOXvfjL6EEGoXGtpQJX9nmLSVKovNjWK3rGAl8QaLXBU1b4Ws+YIZoUnq6fnt0jSqU6zXx3rMGAmg9img69xgo7Cq64o9OK+ZRG06/wB9g7eYnc0g3jt3z35vMOK6KVoygqqUWt88JGaxFy4od76dlLhfJ3O1ZGw7+8M7FXuhorrt103HNVyHes5vhwRXOFangvxfvBZ5dU+O78BfM6eMvz52w6NyejxKFYrPT+vPtFJtd+mI1Sr03Wvm/G4CHBK8md+tekoSbtZxca+pADiqBd5cfB0YrTv7EFKs4+cvoQdWsFelfkvxMpBHCO2jLY+1+JXc7VdgcFaMJaqV4graw74vPne9Rb2KRgE5bHbT2HpLMFvObyvgxdbeDnGLY4U1nHGL58zExUAQs7u32uXp1YXvh8+OWCuuK3Q4v0N+YlQUxhjsNBcBhZ+tENACjnu/3aoCuiN/P6lS9m/x0iGGuv59fiFxGjNH2xFbsl44t5OK594Gg1mONU/j+qYUY56vtj7dJ0BsH+7fmIN2DuWwS9T1/qi2ltbFlb3Wnz3952x1Z/dZYaFD3OfX9R4SsvqXh9ZzI2IzNVx1vHtXrL1e196195VDWFDy+LVm9+kMWa/yUAyGL68fMxWa7EbCYe2SjXjEz030z0rfffSMYpFXz2IHoDhVqLUNK55xLvTeN2cG9rvjDUqgtkzaF4r8+76xEWuwv5OOrHWuDHdwX2LvEsdSiheDlz546EAtU1l8nHL0MZ5ly4Bbe217hfNEG1EWrqhMmnqEzxAa4GTNHOK079pjtdXh7X1+8uXRcXajtzMXw+//ADafJEF+3QPYz+fSWVvYzoQ75i9Ly9f7UpYOVZwL0ef9lxHABba68/jMWtFWnHBrfasd5ssDXPevSZEQV1Zzddivb0iWJC1ug1xde2oG0ONmeh7QEKRQOXFB5vD1GXdK2mtG6DnN8ahrVq9GC71eRxjpLIcINbx/USkzJn0d9HbtE6CeAILZtorLnMTFnWRssGrpOnZjhYINq3WQtjbnFpRwRRp4XlX7PmcbCroP3UvZax5zmAzzhvt/2GRzS+0PU6Q253HZUw9r1736wvQGO/f8S9NcHXEYRKyI5TrXSjDd9iBbbpU2m78Y+Ynjax45mPFhd9cb/MVFFevH7sgmWA25tf4xNwl41402dm4WJnSGgqqS80Pi/EJby/UDjNA4MG5hdYut8VrTWYFsNv6MB7RaBdYcK1l1faPsBxSqFMV410iJrAt7Fh25+8UYARO39UzDClZaYau8WnguCafsAfdceAxzCYOAqjv+4FcwQWg/swX2UWuh18TDuCiut4AOquIqXF874rPqtdoWVw4z4PadD4dtX+bYGbeAGbbu832ouHRa3RxSiPr5iluOjenzUt0GOrxj1rpDjmuD7+aziWGem/X+ZhiU1qjcud6ccf2+kypa4LW3Bg4w+sUGq4LxTzXDx7xBy0dpYGbZ7Hf9zrKfHMOL3iKqDls/t/1SwJZOhi9lZK47dbYlmzQw4oped1ntYOoc6qtr4+xZEMW1TjRX7Ris10ezg33zr1lHuWM1T2OpBAwu7Huaf7mWQOdG1Z3VB8pGkIOKeeVBtN9Lo6wZ4Tfr+y9ekQRRVea/WI35Dzld2mL7VHv5Q37a99zGOLbcw832vpKDA3h1n+z2jolonrXinGiPzqi88xUXE3r+qdBuarHH9mVYqttXl9tcRQ90DkUZMaevlgeVHNt5NlVmBLbAG2THrgijC+jv/c+ZapQNYrDgDrXfcyeUDxXN/wCS9m0bKSm+M2PTtcvuYVpYGrdub2w+71NZOuf+QwVULORfVvfmMjUWprKt+7PVuMJ68L4cvTF/BHS2uVMa97+OOkEHfCjOfEYpaFEytu0Ha9vVY4PV5fSsSykEVqqw11c54K8Rp1xnnznH8R4d4HXq9jUfirXUF/RXqzhu3PFUy++JRMwpOoHPauO8WQGNBjPY8TkRkm8OROtmu9l4lFL6tPOMQxtnFub9t6iwwpwYz1vtDZwNgR0qxgeyI5WESTHHTyXh5d4i8QW3ulYC9Z6RXStdzH97w3seI5YtW1e9AcvLjEXBoKzq3xu/z89Hgx0eK7MILlIDqdvPKy91Kii1o4OMtU4+06hC+50eIF6jfXW6oJ5QM8xtq0Uus6v75zgqOvVsoZ8HHO8xECo07VcZ5eOkfisMO+jsq8dKhqdPeq/UdYCiem/f7sVVuz/Lz1ZVDu151/Yh3mxrXnn49oLZx5YWaAgueFp46XS1jGZt7rm6M3zqDn/V2/7MBWcmfD5rNcdyLW1x04v++YYiumnHOH8y54u+4wLD0TBFRk9qugK55XVY3BRNGndG/bmLSiv+iI4EfuxU+51qAF6RdV3i5kOw18kp0MrJdZwXyoW4KKEmIEFUm3rqjvTvUKGRQt4rnItVZ1uAA6HBcNl8mfzzKBcar3Cv7cUHYr5ar7B6BLEK4Xjr0ele0owl98cZrtWPWCWLBilvWefxfeXHArd0dfej2gDVtQbUu+uOvzLsx2chgDy2xIzrswrYRyuxD8wxkK28U90xg7EUCFg5Mf8AeOWBA79r7Ra5AXI+BrrKAxZCo/6piKYJjJA9fxDdON3/AGZiKi4ZAYlYaVog0OjZoXvA8ZX2hgeC656HbrxrmMTCx0/rMfMRooYBpoy3eG+NV8ymFgY4B2fb3lGqNT4cVWrxcSXEAepfxD25lfdx6B7y6oLPmyj2l5zTb3bvHasHSJlpzXIfuORocvHb7yjwIX01XxuMhd2dro+e/T5VhgVvU5+D8S9HG/Qp+YhmMQ42flPRCNhFltYbLrCY55001YUQWtmC5Pk6Lwi2Nui9Yxrx8y16NeHpqukRFmJQZyinKIorpdX6weM8jh3i+l/eMTI53QxVGCq5b+8UFs1ZbSDmubje4U9axmuwShEDuyhVK8AycW3uCMu1Wr4aTnVZrzLWaFwgvtBrbmubPWkx76gkFaFX2vWDliBZ/wB1zOKCVn+7QuJQDLDrtL50I1GTRDrviFByhWC6W65zW+PmCVHZp5FfyKYgl62+XPzuEXGo6e9noe8ABt/X7X84lSAJVDqc+t58we2lP8vFziZfy8fNxUaC9P8AYqBvQ39ziWnHro7Eus5aWsmWOCqC01h1mnVcVLcdpda6g2BmF0az8V9r3C50DQaExs6XQ0MIktsDXOK6uDpbuK5LkOUWacUU316ygFaAeaTGcvfLvMOWAMLnIPJNtA+b1B8UZMNnHz67MRQWo006rhlYaKenj0hCh/VzB2r3vfX7zADBK24o3wxVVvPt8wWorVhjjOvmBlj2XkLEusvXAZhTgLtDrV5HDiXKtmG8N0Vn8wUdN6VVuC0cK+0zpavCBrTrhX24jhBaqLG3m6OHz55rqtCec6baLvHHHeDi+n8/1dIrC07y48kAB31glOj+9oZjhAo7o9Qlt3/9gqU7IQqE+Eq1UrAV8kLPUC076Xz38xbmuYQcGn0499RMgvbxX98TT0MvTd/giZwWVy3j8xQvqyu+YdvigBiu7LcOXy/78xjDTQef64FV0e7dt9mol4Vh6cfFesvgwFvqzMt18Mcn2HtX/ZUL4dKN+hy8940eRsq7vOqzcSeVZfIrzjORrOnpcvpYlJ3u19d9I9MHl1W8fl8xMKryC7ay4rQ8Rd3KR0c0jYHK4r0lgSk44fGa4l4GFrnvmE1YyGKSsv8AZuiLiC0mwRHnJ2pe5UShFZ5zr7UbeIJhysN66m/WvPiU8E4FtXantjG+i0wOL2O+APRbOY0Ap5+E76g/CWWgzztH9ywvs27aNnSkyciJpmPlkErW/eqmHfAVp3VduOYM4KCnro44J4AQ2+cubS5ZMHnpePR35j6EqIbxgz318w4vpA631ehznpEmnMZo1IlRh/ETiHmjr0z8yjmx/OkGLbZ6KPTv6zCEQRPzXKbPfiFWup7ShbYHzn7TbOCEdGItwRLWqvmukajh+cIHo5lqpaM9GN8BOzzAwrS9tglN7BC0zT7xsLQAuHo4rRiH9KQeQi11RS5VkbMhVXin2mgGhYsU5/L/ALdc8Ryq4f1GxsHFjmjrzM1+7+3FsdeOg3AZQdLpNJXFcSmGDPbPT89JZIYa3u66asXxUFi8pXtXTX+x+l2tcenO9+m2WAjZnPPbmaQrGed13i2kozD0ZGGILXx+PhhxqDFMHRUyw4gQgzCWsQcFVHcNy3vXGbw6nKO40Rlni5Fn9/sUllwr39NynbEssX0Ao6LlYLXFmXkX088TUpW7XNVWe/PaVU2FvZowP6hEEENtXz+K8Q7+EB3tvzePaaWFuerr11XpEGW8+5C2ZzjJrXGe9+JYg0LW3u9jsUeJSB6hzb+A5+8swNV3EsqtV6cREBKlmqUy4G/CmNQF55dGjvmzfrExcOQqhxvQhSZ3e5Uj0GV6OTGa/E3IQb2aYt6dKiZjLWnqPHfnNdY5Oarf95ieBpenX7GeMTG2zOC9nNZq+hj3nRuSWz3WubT1i2U/9fGWj0uChMBa+uKhDuL8Gfl+LhMLNWe9KdOLZRLJ9BjLtb8QErC4Dkas6CZSmrq4jWgwl89O/HX0hQNar+eeOaeJRVN3gM7vbzkJdMA1sDjHPpTUaQvYv/C4Ylg+qoLb6b76JmIHr0DUMoj/ADXL1PENusb873nWcVco7ogxoz98S8Ksb6Lg9emu0EcXv6wJTQ/2pY3cNI8Pnx5iKqAF5ssk6Ir94XvNXl4aOZcUpVoaqkrJS28dBvpKE0DbVXisdb1Co1ZzhPZ9CYNgU4/feiGATlTi75cbiMLjXGcVx/VLIdNPPftzjtuGIoY+2fvAKb/tyy+t/wB7xZoW/qUqZWw3nCw75rpMUNtGee/y9Vi24N994uZGViss9NX1/wCQLChqznV5gWYDinT8MAxtVdbMY7l/MtNywvXeWG91WTntFSyj7wGwKCU5K5uKodsA4wBBQDkmAzBFykHy/FRTxmobd56/5Cl8P3Au8P4jgYXrHh+qqr/2WGdNvYvB6G/VgMcy76QEcih97/yWBgxCpZmj9/uE5p/McTlKPPL92JlwaOgZ++LfaI+YFvzr3tf+wOeKaTnNh71EBoEVlCd2HOSyNcU+IOQHl2qHL6vC1BqLZMrgyuFDqte8IhDHDmrreK3WC/EN6RsDmzDjCVjBAAVNcOd53TWrjtJjerFprOXP+xPBIBV55UW01g+IyEWMmArjAmXnD5Y89WtKnfG+sIO6hPVW+ALz2gZG1HryednFagQMuro11NVeuB6zK9024fFPTsxWhpcav2yY/riKbYeOtSyhWj5X0DrDbgwZKC84vrbiYma6enFPpnVMxreG3XY69PywDMvPDzXg1B4wl9i8fJHKlTW/N+de/aA0ryTT2a7lvbkMK4ZAeRzd5wUe0WJZrGS3zdUeDWeI8yFdHGNNY43H7IVVW11t1vqxCr7X+xuAgiNmunmVeXcqMcSuc2TUc6HPeBRfYli4MkarmFW2rs8vPPxK2LX2Je2G7dNBgSuXpredRJoP06Ot4DvGJtlNJmqxjH8xRdACnRGuMWtyoF1vuNX5b9Yquyf8jgq1jGnGF0F9+dcStMlnKu+lrR210gJ0SlIQlGTvwFay6CPwEGO1bdN6s7xnuSJhGqNvWx6YjkoVAvNXe3TBDOLHl61WeemIMmDN2V2cZ7/EKrLq3935vF9ombat7dM+nTmI6Rl/5zCOzox/2LTiOP8AIq/t/qCNYiDRK7SlwbNzNbiWC3pGbv8AeYMHDXWzd81XapTYYi52HD5lc4mLe0ccz/y/SUrb8REKr5gMVjvsf6nxCp2VX2jjuxXxDmwBa8uQrrVV0zGv2MDXkcuMdLrmvWGvCvn+1HNhqnrXpy/m4rvlc1jPT0K8TPwYL4Br5SKlejXpGKcxa9B0YxZV11gKx5++K25MmKcRzBCl0ZrIqd7rcxKsgNHTzfOKxCAxR66L+z0llZDQHQN3n8AdtxhEbzbXRFfxKsxUFtqtGDhM9KgiiisYJ6YtK9seYeIVvzW6/ukRBByKLLtt3qlO9ZC4RTpvg/z/AGN3YCApviKEul4LaXxnO/Vinn/de7AFFOU3i0AONXbisu5Xe7sCzAxb0X7esvoVVFvR/wCekvCfKgsLXOPncGvgcFYcaPNHMQBb+pvxUqJ/Iv7E1mQcBi+FPoJd5vM0QVJ4eAzWb9IJlbAONvbnt3u5QzlKvp/fMPCMchn75g3J7mAKpSbOn92Y4A51jWO2jHPWogR6me3WHK4dRLIxVSg3nmKoAO32K7rWqg0KOsX5x775/uvOIMADbLropvtjmKMVf9llDZvt/bhqUz9tV0mTfd78aiBoC894wGz/AHOb+YJkxH3ZRA0JzLJfXmXD1mnzWJ3cXHFrx1qLHADKh3Krop35qNwHPaukstVP93PBiMbSsc+4dI1mE4REOhBQPi4ja0Tk29IXABpG5YVWHmBjMZQekClDrgKOb23r3hQqNntAqV+XxnX7iDx94QiyZhguTdTIO3x1hRlXl/B2ImC3q/PT98bgls4x4z/vmGP8F/qZaQb89VOL0dI2xVekz/cR7NKjvU3ERk67PzCCWLV2184/UQOnMrh14vFuFchnjmY/XZtrdWX6zlR4qjzt44vjrcQ6b6KD0etneWJgYHkTn1VKriOIS21q2uy6/PgnKU3WCzHSr7sk7wmGQ3rHj0h49pxz6+ZQAK7GrBHNd9nr0gCAtuudWtlGsHTiUNFKMl58YDxChQHtyYtiAo5HxnXmopUAXeQbrFiPD1ggNqLQTHCIlYrESgndOOMuNYrBvvmIPMC6xzk4X/YoQUvLavj7y5nR3etYt59MQ72wLV9n1PaGU+L/AM5/riNKHOqy4q7YI5QZefxNcTj91XHHN86ggj5Y56HX8RWk9/YwcyyAofGMU/HHNTB2x0/yG+Yh2KvJixz1i2u4nNuBNETe5D0BMDELFiiW4EyPSYChrFYr9/aIdjr/ABgO1f7fqcRDFfDr69u/rNl69IQi2fv5mUGgXz7xTt3/AL8R4dwQZuIWMbz34ibGg417q/8AOWHCdlb79EEWnLVOH6AZDIL6A6B1cq3gqsS9tkFyQVKgeKe0shBRY0umEw8w0mBvWTGuHHxKAADjizubIlX46SvYENsx1Occ6xFZW+Onk8wsyI7zVY9ekQtDHTpMlVUZH7a9N/7FSmn7MUnXcyft6d44aeS7Fq3FZ2mSOlefeYIuK/P68xbbJ/vSJgrQBxecQydB0hQBqLyCzn8wSiy316ePaFbutdtfuYyq0fJv+8QyFzLcV+3mXC0VusLxtNZdcwG6Xo7eO8YL1EgcIx51mHl+jbj2D3ZZiGVc7q3nPv4l01WvKbC99+OL3Rjkae3Y69+IBW9C+v8Any+IVTR81q/XOKgqtVb584uOl+QdzTT1Nmu6hLCuvbz3gDDleOm3Rjt6TDVy5K/N4OPW4ISkua0dv7MBnQaA1fKedcc9ItZGvFU9vW5q2c1nlW+teksgRr3TD8n6mZMOqNZv0XXjmNIb5X859olNjZcbOn33EZR0znkv+qIpXTPQvv1rZ1mVXpk/73iS0WDQrr1NHbUVhY2LYB1a45Db6yq9utfcM47Srcl9Maa5294dRkUdLe3HeoSyz+/77d4ulw/n5rLKel2pj2BHpGATZnkL/PiXbcouViAY2Oq1/d4K2C8qeLLXWdV3ixWJs6PqGO9ZOIPcsKaTDWzGTJ2g41LU6aoidS+zN1qAQOnpKMjX2Mwubb1Eo1BVrqteq6faLNcL6dunb+uWeHGfIeuMx0Osbzvc68wg5B2OPX+5mAnKstGWvv7zPYBXFXn2dUV5leZ+P7tABigwLb0a15+YAVXDjfvrb13F7CwdNaKLExvg9YewCsGFXWTDWSniWbNEq0ra40rzeqxAF9YPk6mnlfzKYL/tZf8AYAwVV/iBARefxOykABoUWs0c13/Nyj5wbw7/AFC2y9YcJz2/iIxGIkqi94TK36lHgx1j5Sjnlf7PpUbWDN1nOj+1KnBX99o7p74WXAjx/Zz+InmPrr0GErXSvMoqHr5mOcBLxvsNnXKeIdsoa88RVi1K1u0rXl9CMjcAPuv3gaPF4drP3GA70nSDEHgh22e34ineCjAVnvDQxYtNLXx1ieEp86LdUCLfpgCYD0UHn7/9uXkW2oxRlCuyfFMrXKmrcHpqWZLalLofJ07fecIzAfa/P4qUZswrIVS6bXzuLsbVdVW+dX2/cSckwZ02UD0381H3glmefH7vrNQjbXjw1wvPEPEAZcLxpbisq89IJhXxt7eILIVfn+zMqbBvzar8xwLFd8FTIS3g49dxssrtg3/stORrHdxf5jZai7qr1/Ke8pg8Xn9RyOHev7vuI6z89fmErleHrfbxUUg2OlgP3GvojZJb4iYBxUXoVFHPSLTf8/UqmswvDJ+npqA2rX9X6Hn7wA6aQWryDe9B66h4gYqsHWuN8db5ibSgrpz5vR0r1hdoZz+oUtiKYx+6rzmNlR4xnGOG6/jMCrP/ACXeGjn+ZSgwZ9pXvZXFf1n34mW7Gf8AGA3L3vntAr0qVlr10xMzHO61fJ06Q1u6ND4Yg1Q3vESyKWSj4XF3feCLkunOn5loVtHLgowNeg4iaV66D02xnL2oFUate5xvUcKKd5Ocd6+GUdg6k8hi3vGqmNRg4wvwbZSpSU/vf9mBFiuvmAPeZbepW6ZukCKc9Dzuq7wg/NOKf6+sSFrAXubXnz01A3pqHRGtde+8B8xR2sVo+f7pMNK6eGCm2f1qXg/qOTWD7x7xx7tH49oNBhrPQzKwjkVm3/Bn1jUI+IprtpU1eM64lqm+Au9g3wb64q4rXS6Oa7zquV1OS1/YlW3lWsVo9/vHGTBvoJWOma1thW1YK9g9iNizjFcBkvWfgizGLHBrnHI532imAqnx2vFdl1z0ijbFtG0rWdSjjh9eaeniccbDvvJ2MVV+Zc7AHF9eMQcqKmm11z5zcewb6/eh6SpDoXw8eVlxoHHWjoc9YqI8q/LLG5lOBy/x9pZrmtxlrV+v2iA93r/feGQMo3hHHHdNEbKUVW9vX5r0mCXJ9q594KKyfjGaIlML212cHr+IZWzRMmUSdfWX0wuiy68Srp7/AOTMtlBFQhjSjcDV2u28mtFZ55NVABRGs88/bnzjmUuDAcQRjUbtVEJTVfPaJFl9DEqq8HF4euPaFtPvKpH+6+YAqGIyiTS9uDOPH7mWCisRtXIfb0hMvL7N9s2RG522uN+gRopfTmBFvyPT++IhErhr3mOQpd1xyUpXrfFQXAr++8dIbltNWUpeLMnbPMqytarU4MWE3eTsMrfeP7MTVDClbz0qtOuPHMxSLEYr2e00XnTKo9N30159Y4/JX5rcsgEa2d8z22CLZ0ipUz2hULcLu6ft/sqiwu7y9O2+1kTGAcJz3m3+N5f7wS0rFY4PSWAK6q995RHgr+xM44AYnAt/abCrs/7ACKVs9O8GWPLkC4vPGr5rWYxKUqOu/YMSjRqqtVj7Xn2hXrjOMcHLeC7IZIXN4dB7vKxUMQUvbgJuI0jT5x7RgMzebvnJ2z7TUB1fTp5r8Qr8oee/rBuGnn1xFvt6o8ZX3+0YxKq3Oq0PXHpcsJScDtXlqnpwWt1DhdDC5Ersl3AQLfrvYhm43iFprsL/ABj8BFGTjsP9UsZRU6bKV6EzhoPGAu/D1rpuBYGh+/tUUVvmcbfMvA+8Gj1HSMmv65Yo4zfPQvpMLg8Aa7u+nrE4Msyq0XjzjwXmW1aX7cPX7SgCRJh3CGwhoC7V2Xj1uGP+xW24aWoRDbMt86xot3Woi0Gy8Sy+8qYEi0vAUtvrjHWUKaYbLhIGOvXrjiVXEVioheUI0V+zEFmrht6OPz6R39ogM0Vm8W0Gim8pbnpLXNK9T/lFAS5W298Oe0WlrmWi13/cqSGM30seN5nPB159P45iVbcCsuAUq8BleBwDAe6Lf7M01HQ69OJexZdh268lnMIADg4iRfJBpbPSdUEnsW88VC4jgEEW2/v4i6ri+e0FKpv9XgWvPM5SK6t0c+YsIrH90/UaK3z+PSEpOUiLmyf2Ioqj0mLrznj/ALCG1iqriWkuu3+wxQy4mPl5laQbtdY+fEEvJa6b6dMfuWk2tQBOrV9O51iLBbqYKME9TI3Uvwb7BvTXub795mgrGepbnpGprRqGAqrAVWc+qgtikDu7AxbXlx51Cw6K9NwUs8K/KRECaboxWe4jzcTUolVYN3b4AveGYSleeRCq8OiMuci++W91n8dIktPJt7K3l+JSwawlnvfaPZ4l8dJVK5v0+ZbVxVufiHDJ7Gepiq+biK0r/ehNzJlG0XeYaOveW8hlipxeaN9f8jCDpX+nrXSMdcZdervj3qVqouOK/vDHgR67aOl4H0YAF2/Pn+IO9v3mBya/PLMRU6i3QKbu6VGKDY9pTUFu89v7ELc7ZIgLWICFwMlctiiRhVqJRpPEgVzERvBAWDLMcqbRvpnn0/5GkrJA4fRfp0PjzMxece0AoAXf79SvtKdXln+7SmR3Cspe07f967zE0Oac9tX7BiECAjVKnJnGTE1vkL0V73zjvNYE6lX6mzz4Zaw6ddsajClUWo3fvKv4ha4joMenacSY8wD2l5DpiM/UhryQ3Ln9wBBsILTWZc1F6dfHplnBFY411lRSVw94Uw4gi4MYUrbizBMoFkSaaIhRQomxdOTpZNpAV17ZyfeHFRTzZ0p61lyrzKHqDXd1PTiXtsGXlb6QrfKcbo3VPpcsHIo5rz2x6SnuF06v6xFlKL0HxfNR7C1dnJfPiKlbFlqbvGs0fNymKDaAdeaKOmUuPZidHBSWui3qh0mAlLNkLXa1jNr1reJsuLh5Bqw38V4lOxSs8WrfeuCuI3A8Bv8APmIKGv7rXtHQcVhICr7HvD84Z7LeMeO+cQG+MXTxfGel/EpHlY/P5nGk1bi3t2Nf8iLCobblONPriWOOOKM1wZznbzxctpLVs2t3r+xKCsbMOb79fGTrHfel7fTt6Ae0tXYUbq/NZaxqi4NzvkpvGM9uM5tlFTRnguuOv2O8221fiVyGUNtTWYXCW/2v1CFULzrJn24hJuaxrt6/mFCpc1W4GGdTTMbeM5blVWf7+xAbhbN4iwjrx/XDsM2RrxiTe5TtMFrzvV8ekzgPSu0C8XAqS/sKCvGLzysVuWLWl4Y3XC+vO4tDVOXz03LXHTWa7YlqixCvNVrjJfTmVLFet8xTgRS6PQ9f7U1JNg6+Yy2Bp6ynlxGvbcaIqeIoGZG0MYEHc1VGt4jjhV6vN/zMQ7gHhEWNC2AuE5y2YSOLC5ErRseS4EpijQYsrPTjPDK2Fs5WW89r4I0EF5wRgqTA3V1+S+8v84oPd+7FlIBWudh2q4iJyTPUBvv0iZLS9V5b/wAn3NehfxEO0wjgz1L79O24BhXfQ3b43XVqGKkG9rpVYxZnAVeN4iA9QmULt3Yr6GA1ADLDjbvfR8QCm82sBrBnre0fEZgg6HZQFebJdzcax462/DMelPXT6Zp6mOpHctwC5RKHgzu7OnIGis3VZ3jKVuEQya9rgtWOb4H7xaaQCkV6ZzDEFptrVfuVYVl0cdvHd1KD5p31eXtuDduj/PtX3hGu2vG6r9t/EwdV55zXHQ/mXVJQ345hRlzEy6iDFHn+3BGxZ7SiqXfPTnUAVxuIdG7CsvGxwZ1+IQdECtfSDWrhUERwgsFffHaq14iwiKYI4L09KevpDQF3f8xEuKypdGI2dUKaqUIqtr14Duyy9cQw6w334Kr1vtVSktNRTJla29fMInasW9DsvpjzHUPaGinlzj86z9o7K2LCqOrvjnxjMRGv68avHk4llwf3vGs61eLxezHrDK56dfE6qrlKpzKJUviEKNkuBp6wcsR++YFOYneOQeYvFMxhkWXKqm4uRTEGWKUV1119848S5hex/esaKoIaFUKLzaZPzAnoi5s03VuOK7EATOq137f3pADdKW8t7PH8RhdJWzOPTPPMYMVP6v7fEw6Qt/ETO3L/AHT+zCwVb9oYNuMf3pNsze+3J7fuV8gjBnBgrm3LfiOggLrovRo1MFixA1nDHe8y8iXl6GuHrMSidcea/rekVRuw50aeda13hFS5yoGfF12x6QjPzwt24De1b7VRD4rLQ0mFPY0dHEHHQ6Kel2X96ioVBhPSztm8ME3tZ/TyMpYbvpBQmmDEwoHlaPvGW8LPUu/kibPkY/D/AH5iFwkxhcV5Drykt2n347cesJ6Rv3lMhvPYriCOp34gpQtc/mL7Nm4VUyEY7blqDq0+Ga39uagcYs15lFVAuNsTnEy4aDW6rZq75htZMlCI+yUb14laVhX/ADpHZlMXt8usvOCO7aUcE7IDQBniNmpnpMp07zn+xF3nxcKZjuBUDCWN9e2KfXoQLoM2V7VnHs+kA2xM1URPDSsF2XjJg0dYl4Vvqaxse+ohtaOmq43u+a1Y8S2gMYQ207YX4W2r/vaE69O1TOHcypxW/wC/syxoKmbcsUP+zDJuPY7/ALEaOUTQi1RATOqE69Xfr3r+1MRX92lFg+kHAZb/ALEGkZ2XXOG6Wjl7QgCvmRk6j3PiLGzQc314vF4NY4mbEc2OPv8AmJAnoZaMDR/z98RTS9FvLXTVZ5zMjAu6GbwXjj0zG+CnVsNGDlz7OY7+KNCN5ujveaavjv6K162VXD+eIYdBVLxWc8hjoItJOnjqsW116FcbesAnKjqOrvNPVxnA7is6i179Hpqs5uAiF9cFXyf3EslEecJ5DXMCmi/NH57RuwL5P+5uMPoec+7Wb4gB0A7AKAmCs/OYejF35U/y5Zba9MaqAL0xustA2j95oL1R0QXgzbNYonbTqkWCmV1ihZjn36znM3n7/JmaY0UtOXjC9DfaPbWP3/d5bBQb2nJ4+C4MUWCH+/zMMW6u67djp78QrWbAV9zR4ZaC3ZKXpXLVcNS+ALwmTsxWzETuKFzPd138n3hlVDEp/ipowF1SzBKogOehAIKyLFqOqEp96+5FlOxMarqLZqCKQgpTAGWbgFUDVF9K/I/NzAIY7XN+PTPmJ5XXeo1nSUFYEtcAL1/7LURcG2nWPN9sbxLWoaJTFBm84W2c7Mbik2qFb21/tzZGpy8Gq49IlA5erAruqsKH4HzKC2+sbC9xuAVDQ5NwI5ipqpn4qvz7VAdLqI1FVEewy2QwsKOGBkZbVMaCysJMMNRmZQUsbuxbeHnV4l/be2Bi8xvQ7fmVIC6tCvtz4hrmTPZ7YMQG3hhKeR3fRceSW4Aatt9TBvTo+JYIBbXba5KCmKW3PMRMhwzjgLxg6i9okuJq6teABx66cZZwKYxhMcrW+gYOL2KNxVclvhcFzaZOHkr2I8FRMdhxb0eZdqkatumtePt3luX4PXHxHQqxXTefv7kYdf8AMnzFDuu49FpFmLwcp0vEBTWj0xn7wh1Of9lE+ZkK9Fo+d+kQ8BnJkd015KxEaHGXvxk3ZnOuvEYgw34w77q+rGDZUDAZvvV69LllaBkwj6GS/O+IAFauW9Z0enMNeo8W4Qt/fjMXSLi6xT6885Y1U5LcY6vRjn1gYhXknZUYLblbtJmWYdwrNy5hEK5pWzBkrh3VnSuIRVqFmgG6qUDOPooRYQ6KCi/b9nf2Yqrw9/1DGGOiyzJUCLVkDBVfpDRPtiAi1Cgd748+038MG8GS8NZa6YtlGAFu3p/fmKszFHPq8r/d4gI8q0/3SEGtVLYkxb259air6MKLb7hk33rLVRGq7dHtKpYXl4lbGIVf2IwWJdm19Ww8YwYOsyCB37dt56WfuIdj3hNd7+mpDibjkCsKaVwFVqLKhcAOniKLUObNDFC0o5esBHRl294goxAE0M+ezXxuWvHp+jWYGmoc3cCzK/7NCseMyhjx9rrUBvKtIIG9FAXXxHu3DXXHgzeoOSvcdcAK4+NYhLqPdpK85xHWcOj2VkwHzniX7C78cdNp5jdVfR4Y3phK3HB93vnV63GcFLLrPul0GPPOLiCq3ZXWni/GPBCwFuK9ar7xAUlOeR/v3CKOYIsnx3xOQHeX0DseMtvMbGLBdl/qX4AOr2vLFkB7VinyqTgwOw597/UAm5UMeNVZwe0tMXi3W1HwlnSGdVrjo5+GXr8v3/77RCBY308Z9+vaK1FHHrdZW/zBvjAC7u7KfF2eJXtQgp01hs97qWGk94AL1KDtCJmvzLVGGABUEalaY/kwuUqt8RipDh9VTgRYLD/h3jmEG069C3i/clyIHR++TrEtMi6bbKt7cnPLUwnMxUAf2/8AJedjXaCjZCNcqrh5/EZkmtdfSNGuf+xCXmfLQ/FuoRDdhnNFba7/APYB04x/UFeILIc1/MLCx36wsUbHBvGd/wBxDlrGT8/uPrEO4aN6Ly4xlaOnmXcPMCmVW8q+1uPGuhEKoFVfN/b53xLW6aL6n7WAzX/INsZniZNcwsyS67ShHddZa7jjcG4qLfHEA94K9ZguPvP379I0DbWefzEWLnKFb/u0vKhl099Y+InXeI7LxxMETj2vMYGkaxdHTPXrFEcjfti647HWFpPmvLzWZSw2dvtwenEQJgc9K6fwxaAVdVdPvfBBLxZjv72vzDCVUVz0Qr0icsXsoDXTkq5Tqg189YHgibBa1fGvcv5gQ9HXxCvBfdURdH918TLLczYD9xe5Yz65vt+IV264O/EMlg65y1n0+80jAqeMf8jkW4DqcduT0QUYhaq4z8rfoEOtJl1o54/iPPshrpfV+8BVmzvqJntbLuXuLl96MF7owcTAAmz0O0G66GBlrIczt1+ZdAxuCoMMF147P1GOwgYOQ1+YhBl6vN+kuHwGjBFQYB2dL+/SCBelLyM3r9RQGsVVe8qEzX9j/JejmXnHmbot6lY+0Ntz7RhWBzcSWWPNA82GO11Kbajhu06bW8dYHfEbSoVESQE2TWoAXXP8xWKAVroZlQTcHPN++ouYdTzaUVKCrZzWm+LxjXPrZgxLz01nP6nxGOeIELzmYCQQ0zHWJ1pzJ2Lz2/cVo2/viGNxRiWFwCowR7y7kuUoMRBU/wCxcBp/cSxbzFae4v8AbiPbK7/ueNQGNxFXaqAiKhT4vj0nBhlOD1uynP678RoSoYHAttXmzG9WmoK2zwb+dvxiA/pG1VPr5cB+Ihdzs/fX5IxtEbV3555dV9o0DFtnr/sQCai0a/sVDXwrX98wJS700eXQ9LSbi1FRnMNfBBzmzXgOvLdQZ3Pnenx8xE5R5sXnj/YNgB7Px0+JSUzpZ+FDL0u+kb61073al/8AGpQ4vJbfU3sz3qB8YH9r75jrTOdHT95gFtAF5rDye/Uzmc8oaXqLDtXtEAjBh2EbuuF+0OuucMHrLoUc4z7wQKoOGWso+YFUr4f5KhNGuYdNEv8Az1gwDxE5ETYrzcIqbmHZrVxhw+rjrLjO45+g5rtLbCWwY+hADBW1eePzDbrKb7Pz3jud1/Zl/tesQcHdvb26e0M3iYaZQxlC8HcHSLeYEcCW3s9GHBUdLoOwal8ljG7xw+pMUa9k6jUFSiwu9BCXr+CBmNtJkpVd9745mLKs3Z6Rn6jt3rwcQLBzHkZOneC2fXtAWFXKsLZ5gc376+0xWOT3ilqqcpOvWZiw2YjHFM1H4TJQbtm2zz5jjCG15859oOgGMXnPp0gUoMekRNYJ0t3WP5jQBT06/qU1v/vEcA1b9h6D3W+JaY4Di2y61fLzLfZKx07VicQDy4CqidIIyGW+PYv3lq/51+0MDrjfpqWRXOvtf9ZBlLCPrARYJ7PIw5YAxRhvPuc/qBSlDgxqYHJVby5lFYDyOuoQSDTdV2MKXzmNj2lft74upTkHa+F40O01KWOMVvHmok1MfHxxiZtXyFHfBePPMPpCU7/vmNOCnyWW172ZrcegGDFageZR0xoULJuexjdQqbw93Evmf1ET5r7TaxO36jxtvPaJaN9ZbmPulttj14NHmAmst8UK0Vw1Vx3W71BqC+usd5cia7tPbn2lAOWIyi0N9YlWWIOR9/H994hSMPfUCzNOMWWO/SZqtjhBSFsqpdOYALZTGONxYcM77+ZkRRXRgbwWYjWUEvZOnJXxD6AnG6xeFLzLmlXMehDaglFLxATUVqNZxy5x4zEMD7ffpEEi62RrhbPER0cvY9Iiq9ZVb4RTJDrbuXXGJnBs49GPsomaNYzdd7TF10zcW7KuW+/7Y9dgMkZo6V37Q1DAr9/3ExWb/wCxM4D65ilm7zxLcZ2/veKnT7QYrC2/3nfeBzLLMrd9m8BdYImXJTk+MD5yesDYF3hRw41XtMBY/cpCEB+D9zARfiIoxXjme01fvBqzn+9f+wOrks9mq9+DO4m9P51mWqNm/wC+ZUKtN8H94hVmX3vH+11IBKebs/sQEB7t7fv9pgU0mM9OnXet7nm3vx0/uYwoGS0/JG+7FBAtSzC7rjglJugmrPPXEE3lXWgDPq4ON3xDZWTs/uBNTXmXRbmUaNZESZlrBh4/UG6hjZItu6/PqPknGilYchmtrBChesu7Ol1eYZzb0L4H13sxxwwTV5iN0LGJOV9gaMZaze1JtqYxApRaW6H/AJKOeGMQADF3zjjkrPn2gMrvNd/tL1s9f8lZmSyZblBK4NQ7YooWjGS9tlevfMWwBTx/ZZbjjiVHgx1h8wrI1T/cyikihIdoGEAfZFy7BHXv/fMsIWWtezzvvNYLvXl58bh6MQopNQk9x/XiU8x6X/nmKlvEOuDKIyzgXcYng/vSarnvxCUL1ye8ABli4NHEumhX4gooLrH3gj8B9oApfZ+8u6C9fnkhoF52/DX4g4AxtldmXtGljVcvEuF/7/YFjcxntT+YdYHvleT0zf4MzMQFtvlX+/2D4U2D15zHR5WY5rV84M7buHwZK09OuaDWPMziFXqvdl9C/MErc8VYdXv79Y/NK/rWeL8xI1gqsW9s3HO3NZ7a0xh2Mvp+IOMKWVyfac7uidOmb8lagqgRVi40ue+PWWhl7H6l4LluZY7jsc1RMEsKzpgExjk1B/bibUCOR8x4YF2zfrZ8+84IlcHXcZHrfrxMJjpHDj/Y4inh509tSjmH98S9tx3ZzBZ1wcb9ZZnLW94AL5YYDSprMVmiyNuIrNykKETzFrcHOjKy9bdP+6gL0OpMWj+7RaaLus4rjGIhkDxZXb4j5ShznjpV/wAy3CXSruoWUFEQAYK9+YJadqar7WVE7djOy8a5iOGi/wC7xp0CXwUYOvdeZgGJmCvg+mMx9pg1WG+lur1HoFLhOfVOSW0dxWGIqScnmFVIqmX7esUROKizZBGZ/QHtLlwej+xGKlILAVC4i+33lAohdXv++8QCDT1v/sVBzV4966REXwOYARVUd8QrLSq30v8AqjlSAXna0MNUVklN3VJ312iFOBbxwch55Z2JDn9dJXo3Y0+gle41Caeurq28nWw3XWCC46+O/wB/Mq0qnRTBm/8AjApvuP5zj0iIa79enmGZgbzffbn+qMBGikSs6w1/VBAG2wejhp/q6S6Q4L3DUX1q938S4u9Qb7f35g+a+/6lMEYYEq6hWBVOSUclX9DHsjsliC5X48dJYbuL/j8TCccv95xV6yxlOIhmOPM64g1sSmKIbhsjhGom2BRgh0SDyS74lITQVXG9HjqwJGaf5gOl31nOz7e0tjp4qYgxNQxAz0isli7QqneXQFQXfaAZGu8QC2NxQBfGNH4lQG/tHP0DmFnzG6yXffpDsxMLM2zEtU54/UqHIl7155JWCBWDHn7E1kV/f7AI0mXnDGRPjvKR8yqMHvx4dMS5TlG94414jU+GHp4eJRp0+/8A3+qPi1c9Yb2FtfmDwEbc71giArH9nxeIhI2QHvQK9Ohre1Lv0lRcnf8AMYAY41+4dnroDa8Ap93jM5u1U4y57oGu04Q0A4APt6123COVSys118HdomHNCedo3/srVst4Icqw8N+q16JZHVvddP1+JRUbzWMGMY3dXOR1NdLx96fWUrvIPJ16kIdGVXyVQte2WOhHx+404jniUEwSrmUy3cfoRQzTEHCo5F0pUv7v+zmvf/LhFAe/+kfcpqqY/ozEAD+ZzO42SNKZa9kLSCrUd3BDUvcX1x45hcAOElupnv8A5CMrYsrhB3r8wK1S5pwe4/ErU+7f6iGgTtGCOC7Ma0ycx940WiLTq1i6Meu/6pQK0/8AGkrEMZzHcyllx3mgl8kNlm4gdKSobRwO74zsz8ECJKPVP1j/AGOjE6/aNQ5lETUZxOZQF9vz8wxqsHG/k/EGu9/7ionvlL/WOZS1Zvvcqi+35xBjKn2OOl1MrcPpzUSGG8V3WiI+b0/7Adyfb3fxdRWPeAvgc46Dz/hO1PJhOL7meYpeOGwcL1XnCudYhVu6phfa+3GIxpN5NI84ao+Im22lWOR/Xj3g/tV986haObSzeOr15l8Tlaro4x1/DLiGXfbt69IhYwvV/HMUWCvCt+veXSziWpiNgq2Dpg/RIRHhqXW7jZuC6xRp0jBfDsUPvaXrVzjsTil7kElWdcTClXWoWajKlOJlBaiURDqse5Xt+kTnYuIcLzUTpHj/AMjigHqv4P3N2zxj7Zi1pe8qVOoimGd17/RAtn2R4Xdf2pbcftP921GGQ+ZqPfiagYLqgqzfBBMDfiIKQxmdKIYloq7YJGSLNQ8pQ1/2JU6lVK+gxsuoCtcQui189oPQ22atuztHy2Gv+Yv06yrhTLBL8eeYOMt7y4OHpFgef6+0XH54h3XGrjAIK1rpq05cz5/nFc1wRvWj7/k+GYWKatXeu/mChA2TgXy5evs4I5Yzo78Xm+uZRMR889faMqFo9g6vce0rDHHxGcmTd+M127wWWlsDk4vpe+MB3jPtNFcK1nn8xpfQr+8EW8GfH0tlyxMhNozKcy0NaYopeJyLiLWQi0MTvCGncwlwqhgDlADUZiyhGdW0oNu4N0YFwydYB0ip6YSmyc6bb/EYxQRo/eILSrxELawJVf8Ampgyv/SVK+i8QRqX6wylTo/uC1k+PeIbWILhmKSWG0Fww/8Am4BbG2jkXhb6dI2B55z/AFxPIr7SsCjXt/XAUf7xCdWs991Kal+N9YaFi6cPDW4m4FsIjdqZMqV2x9iG+BfT+1H1QMZx01nvuOoZO+cwB916RsFV4Mva+A8t9riXAZtH8nZzXXxGGNPRjCNZ6lx0Srl7HB1CvVY7ZA5d3jFYqrxOQws1bXyV8z9EgZwEXyaPt2IyZCr0u165xDZ4TnijSHb36w5IVpWg14rdazCw9jcO0mGKGsGL+rnUVMzAHDNJADvABlDZl3f0AwcrzMmzhL3QFPh/5CI7GJkxklAtWYlXYQFDqX1rqlOxmmmkZ6fP9oKjn1/aKXQGB3L/ADHw0gfCkKEI85/MM6/sESWP2/2Zfp/2JaPtBbX94jtz8JoC+P8As2T7M15ZjsnanYhItN3YYlJQ1ZAvUZtLTSmDcEfETGg9H8QG2HRAQFY+lP0d6T5gHUXnLfbHLLlBXs1V3x4ZY4lLrjBgxMmWPQx+2Y6r19JSFlP4mYK587xGZnTkvJ5xA6IhjNPTzWPEFoXj+7RwF9GYJQ1aOXx080Zm/N6zx1Q/qhJFG39tx6K62DgMY9Kr1nVwGk6QgFGAeM9gz12fMTSi6vpn1srmtX1iNvZ6n+S5EXLeZXKyq/JmoG8BWHkCzUQquuh2Oh+ooLVdJ3fiiJaIFPGHcDKK+3/gWRnbH4mO5ThIF+ISg3qVczIioXvKP46RXGhGSYy2k0XBY9+kSIzqY5wh8Eb9s8HV8HbbxL/hN/8AAY6t90UYA9CEsQnc6wl0DQBjqg1eBD2AhtdsOOKd+kcS7agduDAeS/HNd4r+YDs5vdLvtB6Umm047BKiVgZsbOdahhirwc1572RTLTzlot6S5AF45xHU3waurq46qcwZaI5B839xAY+YNQx8Sh/ZO9BmT7yvinZl6H7xyTMUw+JRsgVfXtK3qdQi2FMoyg8n9UCszDzHpZTEDSwMrNaelGSuc7ikXBVvq+XOYHE93nPxH2TwbfWvGPMZbjO+f65SbLTvfd6106xhSctYaev2dVMgKGqLVh5r5PHn+zBtjduEPyp/rHOooK9u+uJYFVOT7S5yJx/tS8rpuCrjnla9137Sk6ob/GRgEVl1ePnv6RXKwGCtlfl8HSIXeYXp/wB9YNm1cAa7f9d9I4s0l52FQ6ZdpVX+Fg2rpQ5ye25czjWSvWKRVVxavncwFVMGd1hfv0gEsz3/AN/8IO4uaZe8IXur+ZUWi+SIXD5BlFaXLNNbxEhNw/4jB0xgzCTihUJFZsEqG6EuJMoOvnovPV0eYyG26qM8JSqxPEMNeI2SsndTNHvlnKv1LL96+IMFsbDKBovimrrnMWg/vaPe8wwrmxTm1i+m/JMFQvcyrt8cQrIAVyObx2xXUsjCAFssvC2PV+8ZrSgWZyKy8r6Ai3Gy0rbtvpmowpxR7LR9rIohwFdMqvzUId09mpjaUYYuCKFjFZZQ1FGIt7CcpVwyw5symK+0bRR7ajbp94pVkmX95F31Gq/55qUQq+Jnhb2PvxB7FT+Cf3eMgQ4Utdr9ZZF2ZfV49PvLHlWdaP394ahgQ87z8a8wG0OK5UvL0w6lvsONV31bea/Epq1/fpcHCX5we/6i11s4O7wTPgtZ5f0646xVRVeXOIuKxhg9kfy3v7RJe6XqkHq3+JgiU0OKbxcDGu1pfb754nJ64530KlkU36Pp/sRtjgdTyXTfb0gP0D2zv2xABd2o9Md+lyowAVOuaS8f3SAqFGjfvC9FoPG9fPWNaumt+j25gJwebT0qUiL65o9/1cKMD/w5hN4i/XAH0sEI0oMe7vD+/wAqlwQipnLu8vj9ytLTrM8j3f3FPSDv06zhCSmfJdKuH0YaFQGm3L3ruwU7ghVcSokr1yjFcl0jzV+saO50rzvuIiJlh37QKjNIes2RnmLXV2g7SgujQCqXox66giiYumNggCfB+JYlpdVfvk9oKvIVWs5v2lQLj81+8Rx5lHPH/eJVSi48XI3dEcT6TFcHpxKjMpAXUvjVspYS+UDDQVFSNw4TLcBgQkFVqGWxlsW+j02feujAMoxatry40f2JeOGrcBi9c+vpAzuXX49+s67XBdHWu02rsxXF5d9Zc4PK11SjxzXPUgow8arw6xv7wFuzeav8n3hv+JU+1v74COgNd6q16mnvDaMYeo51u+/vmZw7989TXm4iTbMOjF2Bjsf1ygezX536/qZLcDeLs9vzDMEM35LxXG+JlpLbHHs/LXrA5HU7Ouf72ICtmb6B8uO1w8WnOCvSv213gKG1IdvX8xGw9H9+JYBB/q6e0XJRSrut9azr78anXSuKprsc+kbqicuKzm4QsJkQ5XBh0CcZgOFfVa3GV2RcqYAOBDghCJzKtipW+J1Mcvlly4vnLv2/cEAIqlYPeXCwYIyLAoY8CZ9NRjZWJs5jkLiDSoAGS6ulAe11iOSNr10CuMa5h5YEjeI5dPhC3rijttcQymPIkU2aj70gtNWW2DnDQJ1ja2CUupR1PiFH4itYBo7sIYlacCVFw6JfohVHT6XxhhUQ2AYBoMDA4I1wnVUB9cgdYsAkwvSGnZV+OscIwr693isecRWkVQHVYt+2ziXsu135XHjiDbUzBHOEItqSg98/BXiJUdnsVqFmmfnx4/5CZ6amQEbaeu38sobV3x35Y1Des/r+3UY0vR7c36Zs9eIVF2Q98r54qcg5M/GP7rDYlSHbKYeLt/yCLAansvB2rK67ygeNbyv9txBTVaaLab1eud9jrF4gSll64OnaGGCULbDuB2+YEGhz1Ymw1i65vr2++4CsDHHD1cxImDvpe39iAxyVWMPo/ftxEC8KqjDUCZbN9T0gr6oq2LWOHrKAWMPodM1AC2tTIl/G5bLnIjC+XPxqXCB5QF3Qv98Qrftz7ypuj9om0fMbjGnFh4qbMOPDxDbKFHC8PnN96zFONw9oIKL26f1RQCADc1LhfaPR5l+uj2ntQWBmycd8V9iAbwh6D0hSMuB7dfX8RBdgqGhBNGLmMARFc29AS8wzEitBZVgM1Wb8hUAyBZOKlC0ORKhbB0+mQdzOjjMsMALWYANBfzLpFnRzeHt90qCF7BfGPj03O4Q9IYtb/iB8HSECDR0r1lVZqWAtYwYM6t4z19CJIrgM4M6cZ9KiC2B2tO3rH9sByIy7TSmTpx/33jPMOGnA1a58FU8xcoTsw1nz2zGZ4o0dRuvjEWxoFYav3rJNEurG9VvPb3ZU8fKxKllzwbfH74lI5CmA463t76mwKXHQ4+zxzEUi3Xr099Ma5648w5spg0Pflt6tzJ1DQdud4O/bzAvAyrq1XNe2r6RQmmHDx6/V1MANH5INwwlxP4D5mclUQLFu8yznyov4/u/0UTy1EAOoexE+IIsxX1iv1NXggUDowg5Q4CZkq08kcEoXn/JX1/n97zvtfn09K7xAje8ngOO/PDDTWgl3fGYhjIxKc9D7RKUxKCRqKjUyNyt1mXbd39ipzRWXbEjUD+YCgMQL/wCPEbl+D+ozGYjGdGGK1CGmNxvio4Hyf9mMBBHDFFG9Sa5+ZflljqCaY/YZmA5hB39OHtjJ5PZgULyKdc4t1X5wyitLK8b3XDneokLG0waVrI64zBD0o5vIap1kirU8Lx5IgBVIEG1U1dFLXJXeDS7wp26n5l+I0Gsce0rnfx/aqCVO+Wt4IusB1d/jX5gxmwOgA6Xn43LlRTnHV3d/f2g3X6v7EDcm93k8G69S+szXWV9KxWucY6DE5V6lWTrRc046nzAAdVFybV7PcDGhaKHr+l/l0qgcwFrqrv7vxOWsccbj5iv0p848sVCWstkL68J40ynYg73YgUGV6fMDWtm9N2bvSZ8nePOTu/X0uoZnlEFSS9VMuYNsUVMs4QLnwQKwfRfKDawyGxT8TzgRod0LpUhwN0XHLoajq1+5SBuVdw4jYCn1hJw12jDLplo64B6YO2YbAf8AK59Wqi+wY+YH8H1g1e03i6vOf7pDq7gNXNIFoMDRQpV/3aBlzAU9S/eWMVtEvALn+KzDRHU2S8gfvFvgK+xLTYp1HM0hh1EqdkJ3oD51HN2A/NRmmNgqKpxWohWu3Np8ESLPdhkGg4moIs1HCmOrgXA1G4g99m6GP1CqQOBt0JbkDJneQqWs19TOMb7Gsy/zZShzxj4xRxLCh9vtcMrGt8PfEoEKdqX7rXt4Y22DPdzyl7TCQdFZ1XfHLFWy9DfR95klj3Gzs106u4ZMBm+p3HHpGBU8r/f8i2APDPTHyQLmisutb5q+NTFCFYA/5f5iXVWJmyzDfs+KjgoTucf3WVYBrJuxqrE1izvKQaAvHH39IRG+rVdb36yxUBXgotxxr8Rw7Er4x/Zl8ixC+BrfaHVaHdO+QrEpsF7xuN+PcP3Lm36al3/4tTpMiPXUwmhSROfllyeZUQLCJoZdM4eIWww194NCXgbMkszy2RGLocSkRS/Iwo9Uv1lr9ATd8JGdccPP8a9Jqy6KsoToi6oBqwaurea4jtLtb6xLUdI1Uhu2ZLtjgjR/mcxBuAZTaO806xyUF20NVw9+0wiGtWRJUaPrgum1LgEsmUzVTCXLI4KNWXVf8hhx/O9epKhIhkmJvEvKfgfepb1WoxjWteYilXn/AKLDcqyi9uereH58RtfI/wB/ECmDxppz1usbjLQfGD73TugdGGwuhdnN5DFvGuNspIUTXN/P9zHN5SUYDZxi+0yMdYb1fbnHSUNgr0piqCL259LjV5POuHMoaOVXrzHRYet1vtxFSgQCjR1xqMFuHFKf8lglHgCu6617uYsAA4efLmvTL1lz6rjv14OmWK7Q5M69Lq+rMS1bQGV5/Ecgqx6Z73mMAK9Uv8SoC8GN/fpKfP8AvSCyfRtSpecHvqFSi3vE+SXf0Ihg6gDEGIzlI0A6zw0/dgpMSkS7Ij6WJbI7ESO4WOfECpw8QVZ1VemoxMhjh/D8+8sFQtJhax1Voimpbz1W/wCQxceaaVLaDiURcH3ixAqphoJqNxu07lnVDKouJ0y/SIVS8HFwtjOx06cGNx4IjuUKumfMMq8QJt7sC7krljSP8QwtlpYhWdriuz8/uBcXhYLKgBJuOdNDrrK7qhUaY9d4hWOBo7nPg4PXpNUyfeAiADHU9evYGIQFummuDFPK1FMjxfD4b94FCWrP+zTgKDrZu60bxm4O7h571pe9Ye5HtMZ0X34nJZnOHr+owCtrfOTzADG6w+sH03TV/wAZiNF2rT8PxXHmU6cOXvjR+Yxoep3zrv2yzK0j1zZq+e2MQCgdCYUvw/2pd098uy7v7Slser1gACizrsw49Om5iYHqHWv7cB03XGbC9SlouIN2Rvi4pgPpL+R7Ec6kH6UopgtY2lbqFiCTuR2rp+5g5VEa4hSHEGKj6rONsAxqw+0dLTBLpMniAzaIeaaj/r2U26egPnHeX9Sl107Sn0LaMVAqgoCNgtKZTJqLI1xHBLrcyKJRKzxb9yEZv52SWm4xfPDvr9CcRl2qPCcnfPtMRT9iLWbePuR6zXX+/qmRPRfz7sqGKmZUEseqWwlszxBINv8A2CQ7MPpAuEJtZE656/67iVjKzkXzjpr7xE3OnL6/EdNKYPsdL+0UbAFjQegxUJT6P99iOVOTr4x27wtBm9lmSr1WOba6QGIdmr9MEvdek/tP/INaNZx/b+JsA1u7xyHK94CdZmvG7cc/qKir+HYzFpcpeKpzqtiRs0GW0SnGKx5vUdU0cZKu/wC71EF4cYz+8dZbGDyhdegSsXoD4Lc+8RCs3bo3zvPgjqrYLxhLqs3h6DLS3Lyl3Zb2iPE1qJZealVGC4VKKjubolGr1IkHIB5ZhEJcqOrali2VehlURgQhZLA7P0W3xj2lBCVDyfzG4pEsYdHON9Yhz9JGculuA2rVCmNYWcYqHrVvwnzAFsVOL8ZWgY1FNaYDajHIQxDaVEya342/BAi9e0Q39qbDLREC0cZFJ71LiVByaFx479+YToRbl8dEMlXCWO33mT9M5bmKF6r+CCWNDqt65j0pvWbs74r9fM0GEeZgs5GnOHOqvn1gYuOlWvyfrzqIW1nSqp4/rjXFI45PlIJZQjbnO/h3NwgY4Cv79wRLsauvJefiuKlqXyJfp1tuscYKwRRBu6fS5bUCs2Be+idbLZdCAbLo6j52cYrDHksbOq01bGOXId+AG99bQer48QRbCGKcHfvKwFd5VhMMn9mFBF9eE1V9cQIgJlwK9vXt1mIoXRjx/XEhWnvCWbeno/3tEIRNbFOK41x2dS13o9XOcXmDFqezFx+oSzc0WEpWWC47MDEyBLr18lf5M7pj2scIy9J6xwZkRozMBr6WNcMsG4mntlx0JixoeH9jKRQLWs+wHxAJcK4YoY973md8AfN/Y+jgIbYazOIbiw+m80Pp9Cf3qHmnvC67Qb6+SVRRFWNYmLs5+6PrZtdXq/jpFs7Wzp28/bmUdr0hVtlRHCkxwncA4pyS5hmlQN0/32gwZcinYyW+jFMNWt9Xpx54lkGhq97HDVVWYd1AVZSKLc8gepfWZaRsWn4Q+0WfMXd+vJr+uFxh0tQfYRg8xbdmKapvPxLC0HbkKvPB95qLfNc3jN7bjwCXd9l67+sCTJy8/jxLTSurtLxWB3x7HZlRF+rzvcylqOug7ZipuG2vEolFVfl0ipsYLWWrNJv4mY2E5q+N6x3lsNq4G3/r6EYHXZq+fNekqVwFB/Z1KMVwrHJApkWfb/mO8r1qkc7xw9/3GpAdOPbxj/4OY/TZCqlFJrg3KzSP8Okr0T4U/ccofzOiHpNujEpqmYNuIstv6VwSvqyBYNywuVHrf9UbDizLBSCo8BL7XjZRbiqUVXLmJ6Fs80n5ldBLgy5ogDaywzLX9BKiRUFnFh7iUezKC/8AesJDI3w1nxHU2Ifhma3AhdaIj06naVMly2e4EqIp28uPWrlJklri4FtMuxn+7QKhF8myIZNGjGxvrjFdo0BnWaPxECN+/R6/qWFINla9a+/ECzm25PtdGzrfWVUAY6PhqvW6iGIVwfjX5lBy6FKro96gXdfOnOOPtjrA4NlH1zjx6SmOhjy/EFbI5M/dT+K9IFTa2XhrsfrMvlp1NV0rHJBLHf7gApl36f8AYgJ+h57RcPt1pCuvW4BlyKzFcfbR5hdBBHTmvRVvGNRirjty10xLWqF9dOtV+YeRMc96WXCZdQ4UyZhsF47368NHrxEcX937g/TNy3Mp4gW5UGHmXLGvp3WZcn6b+j9Nk5pXMH6Wskm2aYqx7l12gaFMGYajF1NXRL8QIqEYJhFTky46RqLn6XFmFRnwfQlQnaOlCAZqAA0i5aw9cfvP1ZQ/X2YbxxcewWgqJtmURPFiNFdK2vGtWxW3xCBgh/z7RTOX29Y1uZa9LMf3pDWln9/cQDKLcdV5z3eruILp5rPXBlDq1XEQBB9AOCtcS8ShwHNfaF9lV2glgUpvWPz9yN13WQSt5z31GYYN9uiezKKqJXGM/wDYDcwqvH8VNikoos1jfW/JDNQao745/wCxpszo9t/fUKblvWIhqr2TzUTOnJ8f3SWhaduNqVeHzDtHfgX54phXN71QPR0j1Eh7Jp3VUncfxBL7713ViGfbnfROPmN+fdP3D6Ncf+cGpbUyWVq4sQVqLiGvqs19FBx9NJX05mOkETGWuZ7ECloFGYQYLYiw8oljcFFcRkM/RYmkaXKKS+TTUAYK9UIDolKX9MU9HHEW2/ozm9GFDePzAQ6lxcQgT4o88XONX9/2LL4+0LI1x4/5C5aswHSq+UXvnpAdK6cH9D59yNsUemVu1iXjvuP7F8nGOv8A2MtB111+4fDsrFvD+5gGq3QYemW+sQCg5Lb9jRXLXYgV9AVeM8v/AHiU7wd9PHpuHMgbrnt+2uJnB6fF1BKmisdMPPOQL9J0WcC8bw/74gvB2eP+wRDC8f33iMtsJ7RTdWc817yz4DRW+7r5sgIIqwB5UdM3fjMPj7TF9kzfXOOkEdMFd+PXfEZYG62Y6DWe78RdJTkTWeKu/Jg5In6kpTil8xr/AMj9GZlaoxgNyhuAQHDuV9LJiZqwy19AhKEvX/gwoxpcQLwS/QiihiY6Je9S/SW6R4j6KsfsjICOqlwElqDlukVpFMd2fkl7W5kpmswtPpcTh6QWxs9yALJmDCBGzcdTInWIbylQvI3fPYAbQMcfMqXl4u8uxSKIAKeQv8wLRq8arpjtLlaRPb+zGKL1t77f7KImmU57aX35gBWVBfTRX3bI+Vgrvd5lAQFKKMRLavudPHWNlM4u9Bz/AHWoKL2G+Pf0mow099e8V2MLiuMXnP2l0Yt/vt8w3AC7gzPtXnmde/PLKXVWr26eMM1PT+5/BEa0rdf3aGIVc+v65nIfXpx7ZzOMFcY/cqD9auVKmRqgKKyojBk+EAyx1TIGIQBbN6lWyQQgcql3Mmo2KjCVL+i2ydyH0XQRDsj3dQPoqEyymozBET6CdEzg0R1Ykis4Q3vadEbJGalYLIwLREkCWtQjmJ4SJZUW8MSp0E4KMkX6rg6G8fd7aorNZj3z6W14O8Aw00WeXb07QUjFN173f9uKvcWapY3ed1jiz5iHqS+u8559YmSePLVzIrIK9Fv01Oy39UwaMnuxn8RVbMAde/6ilADSZXc6N/xKYsMA9by98a6RODUcwXY30lYJZl5gtsKfeWAZN1h7+L96iLN0Dfl/vEwK2/3/AD/ZTAa4/wCQyoPcSzkyWnjmpTr6vBeCCF/MfQlSj/wI1FO5cN+yEZiZxDocwsjwlMdQJgy4Mw1fQ24EY0ts7Ul9sOueiFO5fzLO2V6zvR60QXcsUW4cObvAFqWuIdkIMq48DNBZY5lnMSdwyWTf0qxmIIW1zZf07mIvMOn/AIhS0S5yIx7nFHf4iBdi3c565TprMI7ZVbasbMtoNuukPlW7wzzXS8d6L9JRVyx4s59JZXsv7amaVlQPNkNQsFeSn7x+ov7Uytpku8WcdFo4eZrsCfzKFpn4pPvMt358xLl6N/m8fm4m5cWu3+V2iaRq9xljqy826PaoDZqiUenPH9ziLK91eJQabtuWa/M0/eCUqcZ6Yx7wLbNFQJX/AIqJX1DdlAXLYaZUucrE39HEPrE76hT6MbM2pXDAV0TFqdv6Pa+q96Z7TMA2MRfRd+HIy2KzMqVKjubItE5H0sJSoYgGlzAF2BeozxBfQghPONW3Vnpk+0UZz215zyh84jCElraoG3WXovuSoZFuK3irxd9ypQdj3/v3HbpRmv344lVFWdilekERclZbp9fxCNZNaMFqKBweUVTWX+MrZ4oF+PmUNcX5vH7hUsp4ZQekPeW3M5wnHjEEWDR5llGW5kcB84+1waaYHfnN83qu0OCt8be2q7tGdxQeZyqmt4BdwDhLL4c+o48QQyfH+fQ/9sJkj6CMYS4jVFRF1X1ct/QOINy4xHdynLO99c70qczvTvR6WJzsxE3/APC5zF+mrO8oKPpUYjKVNQQQLcdUERJmXf1S5h/f7G4ILrK/HT0MXCv1a63nnPMrdRHLa57ntg/MBRReDtevYhEsOvJ2+LiQqD+xicoFZ7Vr4v1lJrMUFkN/j4KI9hXQ8n9jiCieG4CYfo01t8c3HAJXGG/e/wASrGl/bcpW9T5v7QCuyFeJdGXbGeJlTZeKzxV9HD1zOq4OrjTuHv4hVhrwwP8A4bgRqj6IFLUI6lLcrrDj61iaZgcLWVEvip6ZQ2zvSyJczuzvwLm4nticp0mDBNp/5Wi//NSocXGX2hltcShcFTpAKkvyoMsR9EPiASkqIuLTOLq2u7bF7xniZxUEWhVYzQ+OeuoKptL3QHizL0hVHBn8fi49TxWz/fxLCrFD2FwdL1jlriY8yg+CBw3l8cPdIG/MbTwx2rz1/mANw2H9eZ3+CVlaTL3gA3WM4viagBW4052U0/eJ0Fb3kejq1azVbzFUy9VXA1YX47XCnk8P/wAwCmAaPoNI+hOYLPqP0CBNRL3TfzLuJ0yDSzp9LDmX4YjB+JflgW2J8zYrl/8AgUr6oEUYfQcxuaiJNRRupbWsc7sH8zW6t744nNXDcwPGY/UDmJuUA1lEtRXKrufZcPsF2u/BWu7d0aM2WWZEVs6V0yYs1UEdDb0r2iLp19qPSq9YMDbrjHH3fsEFnQHr5Oc5xUSFSdMj459z3jSrmJYoDvy/g9JYK49vn+YbhiHXlFfJM/2vvKL28e7UcC3cblEWd1dzRsdJsZGO3SUlGf5fglIQ/wDmv0cFxCDUshcGP1CH1S/rqX9KE3DBCYgDLORS5RuJX/irlVNwxTAhTGEyMRacEUqyIbZoibwFWVesdTiY0hHsVcwa5jDxQwooIXCVlmvfZYDXpEnLfpL9lCFVHr/kRWu275e/9xCrAUAHz+4q6qsxDv8AlzbYucRwGXmOZPiAWv8AfiDy7dz0feIbfMpa3ASbt5f9nlqWFBFCiO9Mztaf2ZbYC4pUXvOh8IHWe0fGHYRH6B14axUananYnajieYFVCqj6CoLmJ8xAsgfUt9FEx1gW7+hQ0TLiX6Tjj15bti39auEfpdQf/NQlo2R5JUj3IpjAzkK2HTFfEUUYvBlrtJUomGVKqN3ZCyFMo4lF5meIYIhUVxCGUVo+J0BWphPT0/529ukMxh/u8BKVlwbJSSYuNkSHNoexEkGWyg/vEDK/9E0+iFRB4l3E7M7MQxDy+8W6+8787krd3NAYKIDfxE2iLcxfmWu//lcuYPpf0M/XP13K+pDeEKkLwy2d3+YhtygawmTUDoqjFpR9AUupVS+JUBcRN3zNYiLuB0lcRwLp3096/MEb6hGjEUcHt/Zha3BwjujW5fecQUQQkzC1mFetV1jpY5721x4+86Cen1C/pVw3/wCEuVEv/wAB6PpX0BANsQrj6X9b+o39BmpX1uOv/YV9GcTTKmmqNlZ/z1IXddamCpvMsHxcxRAMe0rhU1DMpZU1KlfSoEuNsMLQqU6iUcyVWUhVEUuKp7oqM0rbiMCLI2zUuu8xN/hoxnPX473Lf/IcQK/+aX9VS2M//OP/AE/+Amov/palXKmvonSbT94GGOhf3H3Lff8Atxr3kFDMetSIn5+I5evCXW38zUu4omoM39Alk7ylslF1KpLjiF8zF1NRBiJLeUUo8xb3Liok0hQgBZ4jXYxO79e0D/5LUuXL+l1llij61GVGV9KZX1MfS/8AwwfofTc1L+mYsVIqQWGYJmHp+pXQrBlDiXmpe0ZH9YBgmZr673KOIA6lUfRRdxSFyzFPBNZR/evxCMMNWqXV6Ai8V1YhXomoWIUW2X6TAlXROIbWMszPNyluMxugfeXlxn2gm1Xw7gMAhA6MrKYW3Kf+GXLl/Rlx+mpUNzFDiLOfozyTGpRKiEZX0t+j/wDBivqxM3KlX9GOWIKlsFOrx3gearXR6nn+PoLiEuljR56ePxEixUplSpVzUBq+Jih1buZEeJlCUuIxgI1M5Wt7EfnOO3vB8rqeYaFsawUI4YvY/EUIKWirHBwVr1hAANUj25ISbebviY0btlBQo9e8UoMtoXfP+ytFcVME2/2EN8Qw05lC5oJQG/8A7q4lNfQlxYAxy1BmNXUolG4wzDFx4D619Er6OZqVAuNJX1Zo+lXKr6li4lR6zvGMWwFdRzzf3iMOdvQ/1hHxS4MWfS8ORKNNPGOIFHr9QBiVcQwafMpyuENnPeUtg6ZolWDB+jyJr2AqlF6Z6aGx71/e/wBEXNZJcA1cAYYY6iJwdS1S0MoYuf/EACUQAQEBAAMAAgICAwEBAQAAAAERIQAxQVFhcYGRobHB8NHh8f/aAAgBAAABPxC8rvrgCEYW1Y31KkVg6Cu2J0mmtNPFRJGoO6EL2hOBDS4GVsHZBhwVjNxU+aI4qLdwXH1dDKjUAS9krsuxaQx/MAMdIlBHeChIEjp9oo7lzs4OscqmK4qTCqexcRSe7m1yMIg+O6d6o3OYADSwDp4qJ3YqlO+RCHQ4EG0hXFGYSg9VxAhP2G0B0iKAxOHys5jizPVAA7xFGDwYlOBvIimRro4Q4kJ1wG4ATzDJSqHpj/8AN/KgCKtkSVoOTUwb3vGIKiLyPQGg75OP/dxmCPtOdSuISPL/AIOIWHL9OLycvgDgZDnx7y8s8xSlQl6UDWAnh2CnzUmUCMS8EJI1Z+k/8864ALIJYgUWX+CIe/iEhSu4DYjxFWpGhKRW0CCCGkRgENvABDhwhRQ6/wAUZZlpEcMFyPzhlMrqdgw+S8CedlUac7DRdJ1z0RKSCmKKsPVBwOw0qvvaAQd2d9mX70T3ooUFFbMeOXGPi83kv54IAOCipw2OTgrJI5K9kh3D7rZB2CmvsxQHCg4c9yY9pyCghj9iGnZiWZ9h9j4nnPk8sQ/Cx5E8SDcmSiier4cG7sLKWNRjBaks5e5lsPxCFBAVWuS0I1kAggzh4SjjtN5B2HTiddtl2j/brUSEEFB3gbhV9LQFS2IyG5O3ySjVMB58J5ALGEaYGp2jwadHNXAXbdKjrSqKKOYglGZcUoaDWK1VOeiNmhAPtCokOFbTDFY5qUyZMGjwk79Ue/8AQMI6aeYS6o1xVZdQJ/By7SUGAFrkAE7LSz9N50YIQNiURSpQqJisGMgJPl0CcMAcGNAatqm0dE8789O4UIEGgbPTG/HZKxTCkgICVMlU4zHfCiKjCleLqrRCidt+bIxKcdK2HmwFAhkhuUUyCsJj6bS0EHu8F+xkTh1IbQpjw5ZVQbLDCSpNXvRzTxZUoAliEKp08L1PaMUiwEmEURTJYVEAKpRqQEcA4r3OqYoQIfhDBFhAdxSJIU7DJbHrVNj1YVKiRLXkG+0nfhEaG2+Jw13rEJMQkGx6d1CBf0AvtGNnj8vAdJveAR+Ad3ZRwRY71BIN+lpUKFJykClAgnyUq7tdOF+BzqV0CKIAgnKTWxQjOj1EAEM4Aw7ERLlWQgpM4SlxgXFmMHYoAQ6DRroCgpRAYew1RkQHMagYAQBmmbXobCUANAQQJFAyzSQowBP5AZjGuZygJCWB8Srgd1ZiOtlgWEkKvEIWNvLRcMEe+Qxdc3PxSNX3mEmnvFk8cg64175U4PTxD1wFKgcaVhqnA+eGXsL4QAgqxYgxHxQHamEEYasKFFfhVgTMiAaE1LVvCDhlkhxezC1KUgj8FtLUtFCqg4nGLmjaJhiEEogVwM4ddoTQwtIlVfqYyRaJMGCoGnGILDLKnQE7AU7wqrR0cPRbRgmpSA6pGVyuupYSiVMfBTJDkYKRfQVCAYhuRApWiqlpVKsJwwHiSOQbxM1hLka6G/IgsAvAIRkh1g0XIaFPOWa1rJMYCaIqqa4QQbyEgDRVDrrEDiIJGqXAXANenwpYU6UPbWQmP2eFjBnZjvBIqQG9uTY32ACzRChDQMLOGsXixLRXWChEdzgxPbZT7hal18uMIFWoRCjWt+4BJKX8CfM61NjvFQMWA/2EW2E974q4djfVQrHi0whrA9waBC6IfUuM51SsSJaNL0CLjInNYr0whfglsZLmXC3L2+BOnXkJqFBEVRYWS6ZRc03uzwbDoSABU5axq0ISWxXWF9+KWQodsShfJAUNRK2qvTBSOgBO2N6tNIF9miZHiYAzSNYxDB8Nez5AEpnYoEABhrQFEBBPpYBMyFQXoRpdo4dwCFHRFgCcRwOWqELT0RMTVyJ22WQY5ZmosnRQoUU8g2agAEWq1MuQMZHQCYhYMohLoU4DAChCBcRWGOTLvqbiNAxUEL2gesO21K1JrHuE9v3yIXVcNHZhzE20MOI0ZMeIf1qTM4CPtdFpHF+A7LAUwqMhRCXk0ZOKlcXp34AXhhMU1mKaKZ2ZOAjPdzoCrgpp3DOVqj13EMZ7roeAZsLWsYVVCJoLayycQYcqYldLQAJXcrfKWYBQbiUq5KaKCgshVEXHk4uT6WptZAMIAbwUxvAph0Ihyl1F4XShj6jgPAvyRBoOT1SDsmc5SLnc5X9r7AUewicA9k5Uo7IAxhhxjYNcu0SlARQcDQpMedAjjRhC0qBQp4QG4jQNF69ppkcDHaK0wiYIpZCCBw65ks+7UIhVsq8acPgeacgcZ2N5N4jXFhxfnlkSjD5ODIETzkjoD3+RT/PKl8EFIbFchVACW8zg0Je7QVkOppTi7X6gKhCNYCUo5Eph7LQrRR2jMV4zItEhGULoQ6FGqUBLiAdrK47Ex7vBppgrNJiC6IixVK+OiDgtq5d//EKRIUU9vonNBo1/AOOrTx98RIJUH7wL2ssCtMhsVHD8KOgWJ89FNZwB6grgMpxrZCgWqrgHCUG6raYz8/QTfUV7pCQnznEMCdq9HEI1B8FRzAVEY5ea3vFso7D3AwdXBzHR+ih3WCSKCgOADbmEYVCYEOyCciwxDIVF0VV1qg8UFLC3XSMYJGUnigN1rT4ALUbm9N6gz3aZVBhf1Hw4Sj6CRknkQKfISaMFDN2KaRRxZumonNyoiBbag1BdjGmTeVUlMER8HAr7shMVSKQJoHBKVqhhZCV2eqSQ+kXjQIUQLchm8HbsRAIMqAWnQ1pEVqEenAlrAVZzOECgIV7jCiopqEsWx2JtrAVwE0BcmZWqghiMIWkFRkepnQSgC0X+uu+YCgRBZ+JQoOK8y9LQWifUSUA3ikO+oiQqqNSI8Tq5iZDllgCAVhgCizdxogGXpGL3zT2KQANlFHZIQXBa/mDa9xWIAggUcbih3BUMaJQj0VjTcVG7VXUAITorxqCiuLqPwdBLJoqBAik9iiACDrAUT3RUkAVj9IKhM1tII0KaJqbSVQIika6KSyO5XTOK7hxKt9vbNoFhWHcDdCNWVO3rt5YZVFj1KgNCHaRnAOMeBkxNHUVTXN4PtRwxBlRcAuF8JMhveO7QAFVNIi4oJELSbpNLYY7SulI/HZCnehz0Dgpxew7EwRqEVBZrAseefQxBtdkp8c8AzLiIPz8GrOuZ5QolqGCCB7V+Ed4u2nCo+1tVgTw3NNnrMtR+6VK4Y4uhyWE1FAKUtVKR8fxbBAgtwsinjtD8GmJsIiq6eYzSMAAldEgzTCM3QnbpShAGgHQuPGEJ0nxIFcuUwo8kYKCiFLFwCsqpYA1EFNTYfjsVzKt6TKCpRzCngdnL+GGWgKLoD1GXtJVlE5DziA4m4cg94sq4iDcWcPd05PuIjUKg4DCWVE1CiHuXPQ946qg1KhYfEV+zhVwYCKUgMTByA1xXNswmw1KkiC2/Cl2r1amKxIH5xHloMtwwGUTod7BwijIqhQAckBDKoA2CXTaFgBhDusHiiGJeHNagIcBrgLDliNFs1uZ7CCCisIgkHPFlI0mHcnjcNUHJ9Kr3x1hHZJrxBko9jggOf+ZIEZ6Qa7BG7C6UzV0QL0Z08vWnmgjmhIS4geFrdlGTdOQ6MNUa198B2SFmQHApZ7dMLfANiqwNeGINPEyg6Or1DdA8BKp1IiKEdh4S5nZWyhUFQMDouQRVByqDygZHhdmYzIQDs8qCqATkYWA8LBNVWvSgEDYR0zfVIoTSEjobUXyqCKPw7iC4lRUgolQSpa38/T1ioiEDhBuhezQTSMsAK4y0gaD0vAQhUhEFKekBLkXUQSthyFqdu4zloLFbqWKBG/DyRAWoavjgsxGjy2wUEYSSqIECKb6CcRgHWPFVwBbQQjbgMWjFJ5jXanwZjhvwqBb8cizYidrEEeENAnwEBGuq6gnBVVwRCY+6ugNQKNZhFvZL0sSqtL2HRatbpASFUDgzR8/O4hAlBik3Nht4eJ1KZCumwpZWYl0tAcJQmOj4SUkAm7A9IRjwOowE+pogRwWJCKVdABbNp1niuVLhYDDKUGgIgFzVSZQ1ACgS3aC+TKNEdB0g9i4KAK4KmginhJAFXg4UGi89RW4Np6OAIoIEBADRL3VrUXtMQGrMTCuociEK4MsSC/gOCXMGvQqUp+U23h5joEgiO5mmgFgDPmQHVBB74c1R6UGStFudK0Ho1kqjOJrCAugydbp0QI3jFsFz9IoZ0M6E5K22illIzj40reE0hOJuwgMYqUT7RPk7EqoI1RsAJ1QJLYvE6AEXPRupGVTAYIygEHt8oX+o1iArswIKGrx2ljldoCkSUL6FWVIVvb4kwHG3gAUK5xoMpXWHTJwDyAcnE0GLo3EUIDBkSzUGgpGp0eEVYUN4DDykgrROV7EYnL0Sb2U+ywtWg95mwVZul8IMVJAchTp4pEe1QVjcSKroFF6jiOAUQFBCKVCLF+K51LuklanXOQ8p0cluEhft4oTilEDQrh2KWd98G3GQULuNR1o4VhAfZmMTer0ATigI1rKQeBBHcHbiZDV1AMODsjAIYvG6LrT2kIBEoGmR4rRwogLUOsRKMNWsubECVESVK3gh+EpDwgW0BwsnDzKwuKyFkIV1AIy0xC6KlaIE/Age6zgYOIdgq8IOA6I6wqWBCwWlFJMCx37KvKAHsZ0pN31pwpLJUH8RXlzWUWYqgmqgdtXXJK+ze2MNUPFXQdfCAcxApMONkCBspQALDVasfjo7gvooII9ZJC5sKSTugAapCDy4oEsADSEcingrwQNRe15AIAJZ6cCoUQDidBiLDw438A3LGmgVBySTgO6+BUnETO+k08Zv+iN5biYFoQIkGUiWIWoaoYMI4freexlAOFAZoOGGygW5ObQpAO8B74BBsx6EGDdYCt+Po6g6x51hqy5dcqQWxtCIaR5FeHVSa3AAMH5PFgNRpVnWjaa9GE0PXBFgmpWVFMphamUrwVtAwNFOKfY2UwcCweAwUY9JgBIkYAjG7IvOpRijEWioRAHaOWm8j8ICooypUiKc1TCaV3hQEHQm0LcwK5iZrR0uGrwptedEkoWAVABq1hoyGqmKEIUIVsy9IvBde0GgrHFfi/EE1NgNSkSgkFSBTEEUEAAIxHCZbZZiTsK0PIhTmPlmghiwhgCniKwApHNQhgLkqHOqSsrqLCyHO48Jt/63ixXBSF+qohpIEqBQ/gKkpxI+CDJe/ZIbNEFQjhsSgHxiFfAOznnsb31T4yEaOkS7jhUvchYQQehzFJgA52Aiva3gZ2AUp8gtc2Up9suSBwS6EvcFpqAhMnErtAcCuq3upKZDhEZFIafEuWauPDiGODBo1bFSIsPgg4SGoIZwQHYUFzw9nB6EnByUDYSLh+YY3k+iWaK7DauOgkdpwq3/AEEqnins7xPTiVdgllBhYzSYrYC4H9JVUYsQ9uYTgNVLFqzMoJ2vig51CAVcFVS4QEZBCna9R+EIgQhgwBko5HQ9QlQPRZOs6GAJnhQ6OXucwEksHDw6jUBmhgJEPABxQKAs4buQpRS1MphebRYBd2SA6dI7guEHoIGV+hkS1Yjy0S8IJYJ2SwiDmnrcyY8JmxEQ6Q8OZEigISK2hXXpxSo4qFE6k4sA1ficLBNA2NIRaCoes5ETewPWODjK4VpExCLgmMeDxdeCmWll2OmxQsAKoop0GEOAZJ6amJJGAgXBAQeoUyUcCRY+MhUDwhlLBxrpElCOiaaBIHEztcV2GPzcC2ANIEFMqQy0URMBVssWomQAVaKPYE4zCCO5JWppQs4SVEGc2eqlNWMDgzXIvZbKxirHg8XBPMGjiOMgyylfobwDG8LKIbEExw1GUkZ8hRXhAYLddKAPaCjcxQdsFEldnKg0XFUYSbDQQ19CE+ASFIASEpmlBWtV3P8AbTyKqYei3WJwJ4py3hwwLHezHknGZjK/DwwKErRGcmqNoqumK3bsM12bRHpfKqpk1hc5BA6VEYUDKS3clZnGMwBA6Yosg2ITXALKLhXBbghmuqBkKKo4WPERl52ZRgsGoLgDY6UeSkVgI6i5NGGwRoNfIQFLvE7hOkcyMSMmJgPNykAwoCQTCsD2WZ6EhfIFQURCOJfIPjV4OrADTUQ4myOqdKgpsPsk5UzrA8+KgSUCLlIPTPLONKgFU6jwwTXpVHSNQWARzj2f/wCrRTF2KCqDg1toWISlaVQGolo5WRU1pQBpp2O2seVaDqGDKQBRt+yqGNyLK4Ue14DTXQlPVZ9U6NReTdhTl0i2x0GVCSi4Qb8BKA8/IDLBYED7IrVAK9jAZXCYUpXXGVBVBDPYQCqJUoAF6C5GKYKBSAjRRC1OCf19TaSMlmhNV4YY1MCpSgLNjpwJxETOKuSqD0gow8XeSZaegHAAaOHxGT1sKyeJAKRWDjF9BDdwIgW9HSnErrpxCpCM6oBnBI8QBMT7wRddwoM6VEPgobqM6ChUe3M80kCAIVVXAjctjCzA4wGpOWDgwV7ojUQrAK+AegaOyASighhSkYWgOXtgi04RU7CNdTtHkBmKUKwVL1ZKZf8ApszSWWNVKrTSTF3RAHuAaAep4WAVvMGKnxSqlMbU6VE9AFDvC7yZ6cWbHtZ7o6MHBrmow6wAwA52wEJDnw9g+YTJSD7yjw5Be6nb2okurxIFVUhkO2WzFefhMkbA2VIEBGAebp+5SKIoIr4K9k+umtm0CgHaC9xQfnyNHYAtAATpw2QwgMGegUKR705ExfToCrvL2qheJ2SrMgw9QZjETZadOyEw8iYhg4ZIgRySgOjqJiCWW3YIJSaJ+EH9cdtwrFLkAKgCAa4hR5qrggX8wcupAgARw2jJY6vDfjFufEXbKqFUlo55A2oofoQVEiIwR1sn2TiSB3eBBGgE35gjEZ+KcbdG5gDBSxAJWZutnehRhNBALCA7McFaHUlBp7KEhhQN4P0Zz15FkqZBYwwra6QqhBBUM7cfBapaEGMcEDhtEQcLT8N2IZooKnVKi1ipWg4AST7DGiCmqoatNVqDguNcWGJ2zBqqodL2m0GKowigJUTEyWYHqAK3GCJyDcgLLGAqLDAHlAtrlhCKy/ZJWk5ktlTMJ9eAu3RGrxddaPF0PUgEvADwwix302GbeynAMD/CcIJHwxTrgeTQgCNRQDl00pR4OXTRIWgCQl2BXlBTTKK8bwUasjL0NceLSrCWsuxJj1Gy8qISgqRp3jYK5giM6MKEG6CsqsKgqhrSLW35eR4EOde5Ai0hAPF3kLn0OTNRIqQKE29OaBGfQNQYJYIOFDwwRI7TcYt0l6KHRglgZzhPp6JCAHKaYdwb9ylA8paFqpojtjIkH0ARC0QUvrduFbkBQqQGaocHEuB1EbAhqa8Hkj5RUk12ApSfPyaRiCYx7SCGAkM5TFAVkHB1BM4O48JgOhuvSaF0c74hritwGRTKVxeQBoIpjQIdrNQOmQDMlstTHhAgSnq24cOnUKiERAoyOodggYsld6X55YrHemVAFNw8SbTx0BVhWkc8lybhZFKTFAYviOgbodcEeB6AqDqZnpfkl8qJtSNh2w+yIwMRNPe4Dgqha1uDI0gtCPWiR5bmS0JVmVUgENANQwLqppVp1p+W8TNfVlEBdKjVMLKxxxzyEJCGjI+iFB4yfDsM1gKoIccqkmOAToGg/V8mGHN2GnOmN0zdXdcTIngF4CDTIqw+3hkmziisOwCDQakcCSUslt3b64vR4/nio5aVoUaSYBaOK5aQFGSmK/DeIl8jGDyB27HU8Y4w0pF8abNGTXRzoFVQgV8NG91m8C8MqE4sT63DpvGkX/tArUQ7GuJ5Prr2rQCtTi6MasqVF5JnJJAKwUcAFoI8l6AhB6aIcp9cWIyrtmlB0Hk3pM3WSTqScJI8O+K4OiA66oJVeuViNkxKisKFxZiCaWCNVYHBXQKgMcQRxTFC1hqWsHxyhY+jRUGgxKQYhpnUoW/OgRhJGoU3gvX5D4ARU7WfivLQTBGHivS8PkAJ4biFDzvWryRWgwMCRqqmsfVFNFhACWBaitVonKoYZAEIKoJppXoDj/ACsBC6Fiu9QeSI6cpEyQAVShTeO+L85QUHqLgrBOJ2Gakg76lRVk6HAfRQHR1ZCd8iw1cW/kUMOosCEDmd8ZMKTviVqAOqgkvD1jheW4kgJqdo5RmpWChRVUE7NJAeLg0FSMLQlPUQKLxVsKw+mFhSBFEHh4nigQsoJRTYQ6KhWXtSAgw6HYRxea7hE1BTPvtVKuBwHTPQaJJj5k44XQBEorASACOKBaqXTQ6YKwmcdRolM7KwsAId4E+4AXXPypVBa0XehTg2iZCuhrrlBfuIKRuB2232cFGieqSAW0vpTag3yS1fHAMBZuyjweAAXED8A69LriL/AM0AlIQFtHa5w7H9XKhvyC3qvXB2zfGtsrVE73Et8uBMGlDj2LDQPDunZEOkWqQkCAEO3j8l0QlAlKMgXFNPStq5GABoMrzXoIQx70JOj3OU5t0pMy0QR6gsvO4WZHYAWGAZODVEX8pg4me0UOE14ZJaQs/CBiTvgiK2GcRpF9ELbwkJX0wAgAWA9UEk5P8A0lKcSllsYDoJwHPD8hRqLUg0JpueMJQA3kxQoEeLerJtUPQIAYYqcCK44YaG+buDF4DmprItszGy0nEigDiAahwp1+1C60IvDn5RBMscSmChYBplR1hgE4tVY88DaAE5EHvhVYneKLKsLRdQk4djY7CgrBmwE70pbJY+yHS0gBIREqXEiHyA/f55HVlBMAkVFUC4WGg2JPuCNMhDS9gFVOZQgXYwq0mRzjwsRDKkSFXoELFEV7DPFTKG2Ugpw+GBGv0iXwpQREopnMGLbogOICRNPJTbUJZaAIz66R1WeFNFdClXIIVtSeUd2BoonEatEeqLexJEQrsESByihDMfo1LSAhCI/uAVg0kq7ZIeC+Ux4Y1SqLGgAo9RqK5oRBgjoojR2SMuHSESOZNHIWYTglbLoIAeMCPRASqiaWLGVnysTDc+uRq9ou6Kl9eivYeFpaBBpPTU3BmtrdgTuG7CnE0QaLWqigQnYMAoRtbEJAB0AQdL8JLwhlEMcUKsjoKSqgYFkRtwSkmkjgUMdSCkL6gQk1IjwhZowAPQgheD3g7AOL96tAGg/N5CGS1WOpJGjWowBmqcABINGyJsLw4GbKFoDYtmxRKCrVTOk8dsHGILVorhL+3id009FLXGVVHBENLqOg4AqVOZdC6JFJ8BwJKrxUSbJMkRVaeI0BSND6AXKJuIPHJIbdgmYpuF8cOTqxOeipAjaoYHOBA5QUcCngYq0iooAHZHx0ISPLWAgOJH8Su4HQgKgVMRwqFo2EOuEaKMFVEpHVBd6K1dhB0qreQ3QhqB2X1O1N6vY3DUk2w+83DgvAlcqyCQmCKXgFNeDBUKhvC9QMJKe4bij2UADeBvB4HaTtj4UIL4IZkSsIYbaDsqy60i+6FwE4CIRQxCJumN6zgXAKq10Acy9srMAYnoQWSLGbvosB3MT7w5wVckR4f1MQY77XmzTTJMCjKVfLsR5VzIVSfkNVDgAdjiGhm8RQ3p2CirHhbakO3Zklvhxui+bAUAm6+4MmCDw/2mALmUtZqBQg4KrEg/oWjHuCPrgYMyEpmAxSDRI14W96CT2Sjkp2hHh2RtaEQARqn0ikxcSe4Z8vn4EXFXwoxAfYGgJJXo5cbxdiBKQyBphA4F9JgkmgYFUKhOHXQbrKEJYTMeIjPCv+Dk9ExHTlc+msmU9ZMkOTc9qGDQQgiiV5djwGgxgAFO0SMfrlflKohMIxQSA7sAjPMtdb6S9rxQdtlLSCtYk+hXuGJCIgptz2QYHDGYBsCUALBoNNcG3BsFxUHUGrQThHZS3SJVFgM8UltOqAmND7dsaWmYmh3rK3BKphK9WVQTlOtCdwO9goTITxINlOrIlCTT2gTnug3NJb651VtHdBtUJgWjLwsHh9dErBlwUVVMacVIqdV5S/fHDAn1Ye4JXQbIFIams+VPyh38EcMJ6HK86KGQ1CgjkQ6nGSTJgWMgKBa35MA10uolYKelBtUF1S9+i6uviBxQCoHoQVcZtxZOoIcIOoy+GD5MD0AaiYJC5SCcSLGnKyppyJNlTotIweJD31YjpqNQ1RXxXkX+T4ZRJUUSBiGEAtCxwgFiEVTZwV/7GVKTFQoQLa4thUpnasQIFnSMATfYwlEEWkO7FE4/YoOlqzkEwUSA3e1B2q4xPTFvg8HwH6ZENdSE10MvPijUZKAD4B2YPHCYwRgZ2NQO0R2Dw04JTRl0JBI3d5WhSCvOiRNGBraqIPOhlW0kLTFki9b2g+MlOpSIKhylwwcMpkUyUQfi8RGPeLliCAnynYpYnK3UJAHyBQqmMyzG1wPwABACNcgDYmgUIprgemJgF4s5AcCKjagO8/maYmAIAjKKSQKFU4n3Yw54gBw1WIudhxRQVVNi5FswGVBLBghg/A0ItDyGPlVXC1mVj1jK3PsiEwAq7HikUi3NgtFWC3RSjiSyYJlQGyB66gEQxGu7ZoZCVMA9AvDWcZ0W4DAAgIQVHgYqHyAOpi0gWKpXnhHmhSm1GsHpcXIY+GBDAS132BmdpFADHZRoa1CycekEvpXiVaIa1dW0KJDCEp7e4AIxCy2qR0Vqd8qgdmrXJi42fNWOILB03kXwdD3gkUD30h0nBXRzMnwGgJp74uRdSzm1SCrUeyERjB31Gj0OsEDgZsphLiHnVJZvxw20ZHYqsTRz4i00VCq+yG+mtEmwEHPCSfgKgQqnII1UQIXSH3kG4oJTAEWe4K6vkAVza96VNp7AmQc0Vh+onJ6CRSE4DFEGH3T7LIXRLbxHCzFcBVQMCd1HhH8Bj6NDkCUiNAmW0AkK8J0tVyhyrPAMz3Iwgd2SUbyWIZNtx7hroPCdQPnTZeZBa7dSU2DhRipSih0lapTS5FATRqr9kyyAe7wQbCChqWCKK/mqQEayxG3hot2bsKq4USMzinWZRwfYE62fIc2vcI3ACQhiFCJKDvHdHRQbuE0EjgJSbHMkAiUS1Bh2qkOgUihZszUzhrPAwhaJcKjA+/C/VPFIzCVWKWzlQgEQCWygTL26tnney4kbgdn5Ao/icXmdQaCQ2cBweEpNOqRAFXpyOJ7pWDC5oFpiQN4wiEKoJblpsAh5hqd5gnj4nKAkojELLrR3HOuYAAQGKJ4KKgOWqg6BQs4C9S6ig0JW9htf6DsRwXgOqW4RKE0FSAW6WWTXFk4+0XQDOClXYFyqJxDfBOuODyCgyMBF6ooP452UrSRqSnSB8/AGkQVoWqThdb8k2nB+exgQgBcgGoqSGe6vtsrVRggAxePSxNpQgGLEVBTGjShVsxKwqWyCg98W0NoIzoEZQo4wdQYwENaBUXwisJxx2oiSKwMOUg8KxgkZ1bCdEVTVE9hpjhmgelgESjgVsKMwqaoUbfSziNFN2WUIyvVVJSMF4DAomIoGkV8AxLzFGkIJpUtI9mVayOOCzBRpumYCpw7wACynTulgEHCIjHQsnQ2VvTIXNgpHISKo+airjgUYAusmRIKZ+DhTSPAu2mpMoBoiOEwNbXEeSqpShWPJIHdIkbbCIlIZRwiC7a1GBPhQYSTg7cZ7RBKgwY7oECd0YbHY6xSlZewVO2RtoNKmu0ijnEAwVgWzQUoRg+YuXrASyUqdvQqo6KOmEJJo8AsYoAsFogqQ42FKa6HtxEGRht9YRowg6igPUx4GIsotaRAWkIMMptIlfEIcEAVQHy/i7lIxY6ROqbpCnulBZoG8FRGFmYmaKYQAPCECMeUrjS3COaRKOgbDiC7cwwwiARVUUIIs4hx5qRJmqakHGhnhBqEqAJujd4XiDzAJyihs0JxTamVXWr28oLTORVE3SQy6SrQfGVWpeZ2w9bWfj7OO4p3gFUmanpWjAQJVxJwD0gKhINY6J4L82yYGAopwtQlgUQkphmhBFPsUQBAkuthwArtbJw9ABzgKIOysQ0+0oBdBasuRAOS3hBtDHnLpKgmcnO91XA6HCDwArGSlKjg0VUSN2Uf0C6jKH2KlQRE/F4HS2OXWJZpIaE41N1R1kGgcNagIr1LAD2tjRzE91QynBubqiiYh5AsKeRmCMG/Va2EUYSaF+C+lNfWNNlFSF7VWLQQ6JWUADoJSu4EcJq5h3quEY3bcBMAqHNKqgdDV6LeTjrkdRyOrUTBCctD0TjDUQACCoFV+au9ylZkxUijitRk4rCSaEJAFHB5wogBDQ4dmUcTi1AcAsF4JskuMsxSqQZWEX1hHfCx3Q0oGkikikJMchDKsjGskX2rtpOUQaMEpZoRViURw62b2UKBGaBQS1cdxw9k3IIhAE66iHUeGiGKRblzlgumBEmbULIsUHEJoEGzsEd4Sy9vJMNlirbDANBbUvA3aPCQBru0SNBocyvwLZi0CKLTwwvCcGlSFCbBQOiqunlPRGilRO1RJ27RCQF1HiH0j1dXanHsnNAz1SRA1EiqAieBO8TWa9dgg3b3Dhyea0Ns0TpC7kdCUvXqkAjoLy9xR2JcEAqlUhgNMPmYY3TWIo3anON1Q0BbLSp4TFdWFQKPWPYZDVFT2Ubl5KHhmPNOQM7krWVV0kU4nmIpCVpR64Um8E3qUNxgUqSHsCtZuBYhMjqxd7W3DjCwln7RS9WLERyKSLR0CoXPkT4pICDZUCoEhUYU8K3CKIdFQAb4XePoNEItbGCSRrHlN2UFa7bhLEJsx4ga2yBYoLYHSA5KQMAHUIJNXxGkWFlrFIlaBwNiQULwoqtCBVLU8LrSKCkL9aX6IRREGlkhwZSm7kJHZGgEwTK+2PGlnmw3g9OArg9kEDYrx2YJ4DDGrupUiwXAgiLSh14pZADSsBKiJHgenKAunLqiGCatXlVT1RQDxaBAanW8ZFiYowHqiAhSPGemlR4aLgUA6GGcKNTnZOmjuVFQIMTh+4DaC109QKe0mDyeBvQkLVCplmjICe2Rol7euTwC1wYaUE4gUZugjovhxxWZUIJRbEk1qIDk51EgaNQH08TDxncaEn1HvjwO1x0tmMpgMJ4OhIEnBKGVqlgIuQoimOMEGzASkd0RQFJ3VuDDSYpHZ7gBReKfMKDHLZIbtwRZosBcU1IKl6AiCXrT1zqkaoLU7JvB9G0B9AzTew4sWNq6L9FBrzA8nUF9Z1UUbTLB7BsiRUDtARSrWycG+obdDgKbEkhUcz2bxJBBlArQNDgKaT0SLuhKglVeHlWrEYJyw2LVEdh5jONuIapAipwWpNaEBeKUlWsF4EjJTBTJiiqMv9EEAV52DarxtWr4LO1aU3AQeoozjb1YtiGo6EGHTioOE1T3WeswQDhxBE6FHmC4Hy2MHAnEEhLCNEBYLCC8CtHdH2nKUInhHJu+tTiZMI2DFEocieCEOmBCFDDRv6ajBlE2DCvuKMakba4AorO+RhwgteApGctYQPoUH02tMI/BmlyH1zPuWA6ky0sIQOsPSrbLISRbQGheVeyZ+sFYsMXCTyVxnAUGDUJl9ZxzEckp34KWuABJpBVPBB5D1oix7OO0L1zvruu+HqIzJRIUIJsV0kUUC2yguaQIo64lrbZEYikWV7XW1eKsTSEmNTwFOtWCGV/ooRL6LXs/DRVSJTcYmqBxtrricPQ+t0qhirodrwii5Qq4tEDfCZvDwO5IqllDQqQVa4L7WJCEkRAg9FvBwIMNgMQ9tejwhNGYgRVBQ7j/z1eCJtZLYSqQQFFEaKJ6wxEmtspAsJJy2+UKPOmcHdsGzgQkjHEk7I1cgVBYq5Gdgxe/C6MuAES9SwKiiWMLYVo52hJAVVBEKIEoqdlruID0X2LDLxUXmWEIXsEpmzziXab4Y/YVnp+gZPmwrdy+YZ+R4oiG9pRTwiV7s4B1E9ZoTQNdmGKC8yDEi2hlyaUjRni+H6RzeLHchTjf4uVIV0cQkoKU5RbuvBkaQAsnUWL3Gd1WnaTQAmHXCI1SbOjokzhaLqZW4HEJSL1LYuMq7WPiMCiKqqSxPYP8AwtUYcgIsKQAYtGJgc+CQAfBWA5YkMBXlAKy/DPScWqW0shVVL4IdE1foqzIGDBPg4gpDgvLOwNJqgMjBZHCiwyFZM+qSAEI65PxAXDwdRCZZKugKWJmMDoPQdxa9PChYXYFSLIxlAgcXXPiqz2xoqJoAChybqIC0sG2LKU4pjxq6AYO+gzu2P0siVWMEExhqq4FkDjxHq0VlgUlhDGUADrTvgJKUyUByZaqGEdNdCcCOXxCOo8C4kzDipAeHvnQtlA1kvW2ZcHL0llngV4pYxExMFW6FhBOE+hYduMehF0iK9s5PR+JP8EKhYULppxjEtAVIoqMIZw6cFeukXhvtAg3RHHCwm+9QcYSmIa5ILgT6MCgGkHreGROR2eBQpTTYBFEXyleAdCT6dsIiKkUxewSBVi7FvNDUuPX0qCJUOETldSsGoaSQJsCrBPxUQ1ENmpQI8WkBaKQaEglvWrbsYmkUxcJnYgNyDMTu7eaRsnIfusQc1KUIQoinfjz0qkoNmqsgREeX8QT9jrqKKkoSnJsa/EphUCCOlYSMgY4SFmVjCkYQ4QpXUQDC4oxRSLgTRTrWEBsqIzPULkr3aVKD7gbRo4AwAKi3Eo4FJCQ4jOGvvEkTJYhAogJ6HVhBfgBGIkMd4PAQLURwA05VJEIURR4Nkb9pM3xRDvPUMosnJPM4kBmhsuoFwBYSNwhZIbQE6B+y8hnsjJ0aGNfFeE6ZjyRL2jd4/rdSReABcghPBHi9f2KAnhAQjwy862QoBECJb0CcZUKokhlUqnQSBHri2h7hRswQGT4OaDKYYNjAORxR+ezkS5lQB2R5+ihygWIuOwQyYig0CEm2AQaC0Uo9EHKL1ls1AeBgiNfPC6baADUIwEDAYdcMuUV6jsCIRS+FxH9hnrCIaCKFJFUjuSAC6BaQCdB04SNiiITighSFi7YcM8bFNUcUTMgSbxZ4tqgYVAUFKTN70OFC5exsZQWmVMcIvBBiwFAG2gGJx48oOiCCF1T0DghXwyocVwcR7tAYWbFE0AQaerY98AHKlMF9JhV+Gc6WkgyTUjpPjHgvplFavQDiF6I4xyuEUqduBWUEPMtmFVhDI6C0KwBQDOhyen4jCUwDs+QIHSRETQfcBctUhs/JojYwVTQUitwM+gGSAGguUNNWrQQCiM+aLlPNV41sAvAoAdNrAe0GN2JPYghtJ0bJWKzHXmoixHBkd84sUBowo40GknVvhNBcbZ0c6IQVCOKrQO5dJo8D9nBxcQG+10UBh9XI2hjLQCSV8LqNZOo7Uo2p1weCiSDBBmj1UxWk7FxU7TbroIq/AIjxYhwAZVRiIJQLwJe1VdZCsO2rawrBCRlUYgQiKAfShwwRtDSRlDGEQxtBLN54TVECCmiRA6Qe0GG5bByUAxS1y/ioBJOCBo1aA8/hgvwpouCKXqU4sU2M16RhCdAxEOWSl0EysUfS9lao4dQCUGMAhgYpkxR0QLMDdFgxEBP23078EEY9IMLIcapc3VDSRdxVSQKqErZbNuojlhNeoMMHQjDI2PEioJKSdAgAGs6OAm1hMqUN7sYGnDeEdfgC04+gxKE1LhQ9gJIRrPteC95IIKYPJmCRXeGPeE1I2KgjoUn5JeXAyc4BYlqZhjm2wkSIIg1SQekfwLmCUwfU2pnnGyzSjCYq6kaUaKCwLnA8XKigHRxcwSqywILIBYBgd4u//RBHBSiMRFOSw+2QqipaA4d0KfC1JMaAoEhBwjxdBI85yJEJBLhwleIEegIdpVW+zgomLBB+O0kIkhw+md82KA0ZawGwctLIllFSIlB1oghqDKa/IKJD3Qi2VUbMOFzRyTAUqHcr2hdVskqTjMVwMYgmBRlANQaZmKrYKKYAToUIq3Y1uxsMFMXgFwdjyu9FNsqQ2nGM8IreVqdtMaV4ijWC7b8ApYMdWI8OPC7rFy9kYgKaVtAGIKUoEu4jgcQLoHpkiJjtUuZGpnlMFA0PzBRpiBTw/CQgPOUjFIlKJ+0pUJIFVIDo4CQqXIoSu8JFh2pXcnih4rI/Dp1RPM2d1IdpnscFXm1iKpNcx2SYV051HYukl+xEB3jl7McfVKVTJ7UXWAGoCc3ae/QqZ2UcjSF2SEcLpJkFWxeFhQaKjZT5BMteeGe+mVCXygJk02tMhQdCqEhQx9HBaA/k6SACEgcoIhJNgJLdErXQ5bqS+ehNFnfgAcEZJ8WgA3XIMRG3gwGIruPIX1/yKd0SjYRc1QSH8O+VG+yrxIepgipwhhbSyCNOpVgkA8oJwOcchSIIhQNuZnTmNAoAxOgBDTCU+iJJlFKgXRAoes17YGLRJICVKAwdE4tG8CyksucOcgJSMiBvUEeliphVg6NMRpWJqURBu4qWadRDbJNEo+LpzDs2SVVwr5uIdSMS7qIU4V0KThiCpdsSOycE8GEHCJGiWIqYA5pv5bieFWCgoJY3sRvTRNkb4wdIYP4iUfCEGgFbGaASJhqiWuZgoEAlIkqH4Hxk2QtEwyVLSFBgcR6hg9C/p+5LKhgwMKJwFnPangeh1SCIYjUYhNAblMKVa7Y1nbSQpQhocmCVMeO6apGdoBWgUgR4H893VcTFOtVUXpVWX2nbkpquMg7CSU7imKtbAO3AgXJoYQulg6dFSKMIKLjHanbEUMtBEl8QQm+1BI2z5OOCMsyBZjgRRavNUvvmstOMwiV46HNGZIHWiq4r3EZKMI97yUFiTVE8JsEG1cKWVFxQAovNwC+Xw7/zF746ZvoEyhBdYmdoZUMtMj0EMAisAIxyYSf3jELO09sQGCSEinylmQjjTwFS+UQRohETR6hcW9upDBsFAUDhsRgCmgWMV70ARCcR8AXCvBlUYNyvBO/GIiperiYLGDqFoNRAF5NG6YVNWtJvWOm6Bxdwq1M5EvEIIBQNbMcTqqFpzQBhqQBnDs+0aQRQxqxAlcASS8JVICsgxQpTh4TtBIQ4UiDc06hQW6o+JJETsS3xocA0JqopiTU6CrUhxzSCDECAV4uh52AITUJd5FKN8/AvCUlNwCAsgWH5hLpT0EEJHE8nMyBdprQqWUgvheyiTVKYoU2nIuwKGqYzyDqVgBAGpRz2OgtzzjNJ4JsOwIkpUERAWmtdsrQuhpGVBwHRIKfNk/AAGGsae4of3hKqlii8EvxFONBE47DohKyELKTEy1jtRwEnm2SqOgC6wGN53h4IyygSzypFHI2jTIqvmiukPjw38Z1UgAsphuOetg/Pvfg3hR2VOADllN4ksqQPBCiX/JIDRQBcaXIxEkEYcKXpDSpfsODywUUYPvVqRA7cNoKRZaC6BQ6EcLZfsJqjsQAoTftVXapVRa4xbontXiDvamAkoQikOsDs1P8AbSIlANBZE80u4MNAMFJI4iBnBmuoINNXRRJ7NvF9c0P7u0AJHOVThAfZOKqABqLDfEKnaRJwRoRAnTRXQRQRdmgAjCnE63WwDZWrhQBShwQLh6RAbAAi0KPE0FgxQap2tUdRGgEdBldLE7L6IqrJEKcpsoEiCcIjvzMhM7ExUXo5sOagDHGUFAMnqzLwjeM6rEWqwwu/ryzn4gROg9VEqITjNNBUALVARgZ0ieEX9DAqsF0tZCbTuCktD7YRBRsMF11gIhxKVEaA+xqAeDIFkYuoEfBGLQnbDAqHQSYq8ZvF6+LCBgp3JOENwxpCDSEVPwBve517VRkRrQjJwSd6ARapAIsswQ4JxIlEuApTBQ0nC23AWWtQOrqirXIDJJhkIvYh7KdjXaKwNWb27kGnYd9KzldaC0Ne0jAlWnsE2EjMBg6cU/8AzDc1BAN9m6B4BzGQACpalsmVnFIBdxZbW0CynWinUQBDMfg0AUDYauQNNGiQFRIjJTwuSwp9p6qAq0oQYwFZWaDQ2EOg48QmqIyFBg2lSerxZoly0HSCSzF4rglVYgrspJ7FQ9B2RxQpJCKLOisW81eMjLEvAp0C69eQI3aKAXCz2xKiDExlZNtUVcIEReCZsiUBjw27uyQQOC6pHNhSGVG06kdxQABCUZWmirwbSMN48XVQoAkwd0XyDmUEmwYqlJwqOnJK7iKgrZilHsIbAAFaxRH1KcVsFKwyn6kAKDvXFhoQowKRFYTq3B5J+JBKAmSalUTs5NRjTE6hVBV8C3OdK/PCpdAlZnQPCTTFagut7X0EDF4aFlRsx1B0gi0t62xTSES0hHshaSnYBQMOAGI9ClwjJi6sBRMOCIymwRJEiFBWoCKNRUCJW7CGCVIRHdlJ04geBwC/BIoEFdjkUfUSEJoiMQilOIR7CqC+xi/wcvHiYu8rb9wsSBop0IxKmiJaK90nITCWwCJyjACphyTc5hZJayISAyUcL6o41hipQJHNh1dhj6ItFyCkX8ON9KBSwaGQRhAvWsnyI0+1LQLjoK6nEzRmoWkT6Ylc64iW2sSQKDZDxRxCVsMxVI0HzxFPkeIw3a7MRW/nA2jxjGQANDsV9jSbOH1DcEL0ItBVn2E3ufdEC9JTBRr8rx0NEAAtD4ArHB7M45AE0gIIvVwQFy1cMQWyCBzQVIjvFvIPrUa2FbUuEQoyVw2n95KSq8tOQhWVZUBRWRrIwOBFU0LkdilwoQo14IDaAhX0QYMXK280kNIRJeswViEXHGFjgg1vONkSvCvD6mHztQXQUIom8c+XoIAgCBo14YH4rBGSKIFxKI53bqJRE7KiS6VmiDrgg9L2jup16njQjKHa0AgIAoEAlKw+ECAOLhQY1ocJrsrqlNIChWQnXAke8cbClQBEJuMFUYQVR2Cg+D9jGmaaFLClLBQKR59gLDiQBC29D1Vx4xZ9U4JBYwkhOPP1PYBZgbNSiVwSvgRj4AZOE7tOKwVotNHQVFBlrS1B00KwggsyKoiuUSi01CEcC2aJwUwTgr2GigQSBXi7Mj7pQKLBIYxEHjGDTkaBJBJxjPBq5TgSdKlTNt1u8Zc4fhpfDSKADQC/Xk8K61Ab0In08CkbM4QKUAAowG8DiomZAwo024iFE4GQNVhTiglUYPi1PttWA8AD/G6hvKvOGwlyzqQeAJ/0NPCMRguAEhMyhCwKC1vZA1QOcgixVCHarfg4vzId/FOiKVwLjSTs0YugzShdagJG9yKKvXx7mh+xOGGOQr0mUiWTCHBpUMi8JVhWnRV7KcoxNgguzg2joE8NZggDSAYIMaBBB5l55oCYEQPYxxVonCyOBQp0oYBSICINOSysH2Mk14APRkKgPoOSFzLqxQwAKJL6F4ziBaykVBdJQK4iaPEJTiliNGJIrp9mGMCqjWLA5AqRzALm6yquk2OmOwlQ8CKCEgDx6ZGCMHHSTsgo44MRnVVPeEJqCwxsXQXZ1yn7HGRxQoZvTQpQwJR1FwD/ADiiiMAB+TWudglvtPIYkQWCnj1s707QBQ+SkQZywTxKRJQEAqvSCgXR8H5kxTWIvt5vobETIPZaUYi16TiLyRd4mSvxBo0YvL4X+rQzsQO0dIeN/UBo+INfcL8HMSkcbFXw+wPxqgTPsxaGgAKr5pxQ/wBYHKggHtrhOTsxHAUjFOybEBvILLkEXAk+SHxDkGYmAAUEh/KIIUW0SFSAJcWoKX++aZOKsFadhTpS/l4kW2qfqUkadBj9LWoUqABwxsTsBhhzN6/6EO1ddBOvrhgVVkZVkDa3pqcCAwCo1DpihQZR1pXFeZQUPCIAz59b80rpwRclC9dWnJwnPIRRRRohSHUopMXFlBsZYinntlTido6mDklgv6Q2ghzEVju1ezo5CwVVQfyCiGrChHsuoyNjMPGSXwC0i8Cm3G3UHXdfR0nZ22viAQpXSmB6vA0ZIYbUUADEa6bwJ+O6NJkCtEQeCULJNl1x0qykNwF49e1wtnkbCgory7xlzOwikQD0UhxjEpDBBQyARiELzRsmr2Rs94NCVCCtCAlaUawYaISR83Z5QEVvINLoQapXEiiETOhsMBg2klawIOVKGj6rs4M0WDBUDygwPJwl12nK1TgEdHo3vhdSGGKQSC7kgIDkMWdC5EEoUkVI9rad5sEVAxCEPQDVH6WNmg0UyPaXFnDlFIQqgIl2FkNUK4uAQHCMCjbkGJvHnUZiJqp9yJFNSHkxhphCt0eQoXoWvKVkEFy2wDuGgCAcVDVhWim6A1DXJXPdL5miV0DGiehV11N5IB5VThD45MfTRswZjUS5e7w+GVch07n21VQ8DQxygBQloGfWnKtrmDxANdJUGg8HSVUOxhaUmJ1ceTl9rbhx3BSgtQTG8KryETQERZVOT++EoDUYF3YGrumh0IMsHQSrYYrxArYIEmOAsNP5cZ4EDMRBIFF+ang1J91oBEETYLF6w7nK43OCroMmihGewADW+Om0kDUhB3tWSoQispW8MmLGMwReoVheiA1cMD6cSRHcaNrShThmRVJ1QdBoQAYwiwUpoq0VzOIUFIFy9RbtnpZ3v++7NwDo1NIppOKbYgsVVWhIIheQBDNZDfMsttmw53ogwCGAZFSFWiS21rDcIo0J6DxbgfKIA+Ch0AoOAxCJcqZUQNdnrMLaLsAh8tSAJXE4TZwC0kKSQOXSNY0v2IDDQoCJUFeheJv9gFEqDs1j6qEVT2uXkcURA1EHAjZ0ARdiCQhSiPDv3IfGNRAl3EaE4UXYb0vwCi6sjwAKelUEiQIgYAV5hNRWoKkRUhEFOBPeyBW1AULMqt4WaCJRPJ9cejOqCKkiSgEWgzWLAFIAWoCYCgvBaXENIKpLBRop0xMnRP423o+Fi9LgsWkr6pAE6VM++dJrEb2WBEFxWbwxIOisRaSj7kXnLsi6/MBaqSqDDFHlSsuhchKEAMUnTFYp/WQWKgKBoew3XK3Egx9BNDnQXgao5qwdR+H6c04dhEq9miD0t4lhOAUKiwe0EwXF/o8KOQwvBBOhV/QHN4lBqIADEUhMBWfNC2S60iaEvyEAb2LZxmC6oi7Q+RnqfZTncrkxogoAqoABjxa7rIOxT8iTsKkEtge+rV2itdBC/CUNhUVLXQqvTzq4qIOQD4X4Iet5GtjVGOi5WJW+9GBHYGuig6Qjih4NZgF1MKmprTivQ00QeBk5VEFgXDssPAlAk3OoES1AHoRxBAuBmiBNrPUDjgBaTapcDMB6CE0mgi6Cu5eC2bqTl9CEESzrXgFEoIRAgqVEcUWqEB1DRHsIWFEDo3j3ozTVBFVZIK6sMhUdPF6EA8BT1jh66FSdeaqETU6UIvyNkAQl6JxWBxEWqlfQnVEQi0j0PhMyXBET+VFvEZQQK52IBIFCXpXHTrgYO0AG1W0fJzFKVohoMyqgSWujgsX40FwAYpRHjt2R9GVdSspIsc3HBmSkQDtHhdE4LJj4IQiQ2pIs64ejINbhR8NaqOgM5YOGj6wYCoSdPFp+FjFhWGO1P5bwvHWoogV7QSQgp8jF2qEjoJC0M+PKHKwVvRVQSG9rwb2bThJYAidoNr4vBg5jaRCOyIDmdMgm066IBXMCtI1LCVliU0IHROW+M8/tDS0XagPJxHZsUVAMpo0ZmuZCbvl6ATu6jILwSmJiXCIjsa7shxBhGSI5S5lrd0AiquBFAOMEDK+AwuDlCUxwWRQAHhjDU2BEG1WMAiwCza4RtoguQQ+pwEygI3XbVV6AoVY1yXTDdDl6xRyb7fZUqQfIFp7RH2S8TGOUdo1ME9Is5iR2lcPzOOiBk6QEEAE+CgHEV4FVqgS6ICEGuMbWvBE7FtFlzQcCNiYy7gGsNAAge4yIlnhIRrvC84cYnfJWGm4p6EQPFU6NJNCUezB1wBABiypobD5AihEdHtGgmnnIotp4X1i60TIlaUkQcg4p/S2GaBRJqeF/vx4kDbbbEyMXVhrjuotKauhCOA4McxiWmEc+TDWKrqBiAAFscKh0EhtOeEiCBjALcOFJSkRyeh2L8NnCm6xHofLA79Se8lileOnjk0pwYrye85QRvEQZbjIBKNCu2Es7qkbbXBKwl+YAQ8O2nx1xX1yl2KB+OC+RyKgID4QYO0Lmt6XmhZwIlVBKFgFSuA6kBQX4Lngv8vFF+qKA0uwIQZJ8HHg3WpoPzlR6DOX2wGvJugZKbqB2DJTXPY9RZbLiDPDgkOgqkk6rAq+hEQjmE8Kpqqdp3FXsbMpYuDYGQx4CEmBAMWyfKy2VAfVaOEo25JKRRscoKHvA3jiZpDoiLaELGu0peB1CAm4IvBA2NU3jPdExS9yrAtFmdYAZ4U+AbXlFHvMZ7EkEyhYWvA803debjAUQ04cigdsYzVmBEQbWyS8kb3CDGAtl1gpVljqKL1X4ADwtkiBEImdT2vLz5Nh5bRlP+/jlr39Y0bTYkCE4YMTWjTFKN3UAGHjJi61gMvz0GAPlUYhk4lF7pDkUVqLepkmkDTn0Bm8aJ71sq9Cac6MDgqhEhAMFQ/AlHsEFbpvgkHsSgqk7Tj1JEXYBjJK0FxRTqugBkgosO7OKl9OgiwIoJRrlcXapTGTMJ0dwlK+8OEMUio2EFAIKxh2pDDFvjB2UlZgn2gc4Q4uqUQEEdLe9uleqN6u4NjIfHL0H2Ukd5ILquIPFPR6wA2J3QARScHRUBoHNDJNC9GfBLlEAE7GYuD25hxclrcBFdQaqgCuD+PqgdEbaxBuA3mm0XO0EEM0EvbvhAqM0gxpZKqtaredMX0WsoRpKxBxwPdiCR7kJj0QQaAcES6omm+iYtmGhkEp3CHqYMYeKMLOAQh8gZQd7xyUDaysu81qoAcIIKuTYrUXBTpLR2hVjBDHVRjcvFg1jUTSbYUrrseXj0Gtfm4JHvY4k+NbuxZgKJNEJXErGJBQIJA1xSnUKlDN4pdCxFh0eqDFYsukU/AJH+SgWKaw8xIBKiOqr+mpfQgprYw53kHzElrgGMaFDJaGXDyEWatQQBmC8NbTEpNimM2E1VN7IqmTyXtVejSinz1iFUCCPkqsaFYhFEbqMp0OlxEOLOKDcdM4RQey6q8EaTK+wiYCqadeCGniI93VspWFCKYxKfFS2KUKGhOR+OQAU1uoR0q4SfaRhsESwDG1B4BTqQHVPAigIpI8QjpgK0RAPYKxjhXEbZgGW5RUDTjuFtisbaOkChR4suasFXwpMnGzJU3XEsBuUdXjIOEdAG6UETe4dHEZfI7LITKGoIj5hVAf3JR1sJUUQvNhaJG5AmlGBU0NG1MgikgLU6kAC7jQmCWajVAY2EMSkVoILNw8l+glS70aadX7A1JhSCnIsKKPqOE8P8n1xEcwgVdWHXnwZ++LnCUOR2CuCoAsc7AcTojmo98GonArgR7YZQAFIijjBerQ9WE+KKmkPvm4ihEkIKKADu1gPKB4WUIq17eyv8cpWq5AfSavrqhjOBTggDMC6MtAEOZhKdjXaJ8nfX1eGmUOQEI0D0+OnCVZidETFGxog0yw4zkGC1KotoACULMALCCNURBgGMVZYKOkKFCLD4ilB+H64TgzJJUxUAFogHZZPkVobBwGgARcS96FjUXoYUMdAhDyJ6YNwBzGQRkOAzDayUIIVVCDUIFveilLIwlBWVcE3uulKltpap0tQVCQtBRe8nVpYBV4LVxsbssBhNS+4jbWNFWKgGQRGH5MRHItfoBOsW6EKhXgIo4iEUAm3tBT7vEMh2tTLVEBm5SHKNVlh0RB0fUSiM4dq1osE1kRIdBIpANBcRaW14B06KxqWuAwUS61dRPngVYylGLB08pIWhzOCqCOUUha6BTwnQLwyFgTqWHYrEJJwf1GngMxhpUfTqbzd1/m5pjHQBpDVGSIdW3PzUmrr8o8JEwWl1Uo1FxRpX45NGSTpie2xZQIlF4IwOKuwBCtCbkSVCli+MWagJTau8CENKLpbND3FC5TlBIQauCU6eVCwUj3W8YFU+skGrEIEKw0AdM0N5eqAkspoEWes+2sb2UxaIKPYLS4DuPMBV0oWhADTikbZgIAXYQ0R8vCxvvACtiAAqxoP55B6SU2AiVRlBEUilsIDq77UnSRCQo4A6rn2hlKrI9jCLPsRo/AsHkG2FBAWodKbgD1VBsPE9glZTaT4UPQYSWZULL7ASvsA1wqNOcOacBSKoFTh794MQbtGQm2R7gsLuminghupzhdQ3KI0SUBns1w7X5zXQVU2lfk55ZuSylMU8GKg45JAqCoEzpFk+hGrDIVhI0lUFrpiTUl0JuEkW3EDzn1A0ugJECEQuoY8c1tDCL7minGlv7eL2/u7ZzCRL/tRaSAzQMNATwNrowBQfLKQbTHmm9abIikL1EwwQy7GaEAGICd3vCOMVcfHuEB+yibYUaNwhihvk7nUJvDQCNYKut9jirz3JWbEBAwDt5tUrP5UXW3598eWlFBrXK0W1YBwmTepmVZEC2D3Q4Vd3EkX87J6/T5zVKJycGu2sH3hwnJ7wTvjoR1hOizZU1RuoF2M90CNKwqMMphUtPqgKnxkkpUe17GLOFYDALKAva1CHAHCYIaDchkD4DtG2UwrVacFKg4DRPMhN4MpQWos3ZBYGjY9uvfmfvjY+UAC29J+v5/nAz09lai9U/y76cRNBpcZ/c4IS+NgTNdS9d87aAhWPzO/dOvh4cJjMvpSBoKp82HHiJMld9AK6II9sX2LdT4RAVkqkS3vxfjKCVldlsR9gJzym0xgAwWBwWMCeCBAneaQrEoHNJYAwDvgG2jgBTAUxGJc9h71zTXQGjPAB32iigqcKaQzkriDillFY1Iu2dpRQaA4MT9cdOMdF0EKiHFmrL4thhNVBwlUGau6Rdlg4gigijgKjLBogEfZFoTrN4x+xN5aFNVXy+FqYdBktIBALiIin7FJV1QiS+CVT3vo4OIp+kWNtHbsPwy2yFS0Cx7JAmuE2p0V6bqKALKAwI4WIECTgNCdAT0ePDR2hsNCQ/U1ZnSMk8ErEE6UaygRI8ZkTk1i/bWm2Gb6qZvgxIPqIqpuuztPRiEyxThtgsVyqpl7JCFEaKRHQ2jyUeXDnnKqLTYgTqcHOYRFHyE2sL4dw46e0OxJQSNdBraOLAkyc0UuxZb1DhNuvGQwBWIlRWoHmzsRYqjnGYESTOAY0hEohSpQRpgKDBuQU6CZkAfJKeHG0XusRLqBHfWWV4t5hmO+xyWTQXCw+S79BUR8IBAqFtezm0l6F6AiAXLm2s7TmJagNAsIc49QL3hbkdA4dYnDGZMVwaBa4Aa+LndBiypGaPBkTBdm1ZUI6CQ4Y6oFK0uMDAgpcSkUsBIyxQbOBvaIP4g1CiytCtFQxwJqMhD2p1hGiRhyCWPgersmZwPYlCJkBGEAiMJF4Sqxxa1IkB21UNKHxQCh2Ox9V4rxMRYtYKeiGyuPGz4P9UGAjmK9eAV6Qso3L6ED5edKH0MIXElrwQwg+k2wFNmq1b73OfSLl4cQPwH2EOJ2NJI0gQmiH4lKXzVVBNAiBmYchrieE0mBkxTsdhueA62DsRjtZXHH1M8gFaFZ1RRR4p/tgVJ5nCoWq0aK/wCBJKwgCGC8mhvxwBVMNPpORNGNLqQa74cTAFHArdEEI35yZaAYj6yUamNuaycZFrxVI5RJDOCOEbmaDmEvZXYXDobwV/6zDiRWAUiA4giwVrVD8L8LP0nfNjBrFY8igLhaF4Zxz7HkMxvWWHnB/wAgbxxwWXuHcJL5LiqtGkHejSPM6GwCxIOvr5MjIBI3QkDUhuDT4Ua+rdDaQkaqe5rc41trce3QLudcuHpCKy3rTsh8D5xwYDAtKGXrPjiwCmkJVIs/hd/JzYWas1R3opZl++ElW5Ug1iLcj/XAKKgACK476Hr9cu4MWLTpBKkxXpnvFwAJHYoBoKVCF3RXkvTJr2SN6Q0HYxEatLBCgS0ITqr3wigFZESkGlIwvnHPwihQFs6ABRrQFGzwwSwKKSpj6B5mlrwzU1drtoRh4QCMqG00QakU9oKUkzUUjQBRHhKsvEygAh7QYwAa5BpDnXFgqkQBgEDeSzDdAosAGdIgNPckBFULaAsRKo3fmVDREFNCOwnBEJRIwE6Ki4AGgLRGJ2chw7EuX16vIIBYCkzWCMBJdeoa5ylC4Z8Gqe+UA/Gh2iaAIUEjiqdCzysium24oeIasgHUIMi7p4P4nQjXuQkb9CN/PB7Lq1oodjtuhfPfF2PNNmnauqA2XiTxR8qVHqJX6D9hIUinDfwS2M/P1yzAQrorrHADWwAnIfk3D7EFCvFqeHBHuewAMBgYjsLXIm7kGwwRjiB2aBOMMLzsrK66D/R+JF8SSVAIUFlBMZyNkjBsUulT2VvXBs6oJeL1jlwK97eLMgKRhrkloC0Tp5AyQXVBxZ9MTAvCxh3jmRECSpdA0WTa+jBjOkQPwyC+fMaOAIKwWpHSCg0yIHAIvsdK1ne6Rs91KIKcIoWRvYFYrcCqQ8uHMrHnqA7MhiKSARQYyE7MIgAmMJ3QKYdBGQMHbWRPHtjIhodNKIpJicfiJTkBJCAdSREcCqAnamFBBudItJbqBQoEIdCmnarxpdVRBLqCAmHacJivUhTFTNryJOZM8Q7BJUM2z07S4EiBAHIhDoLVcpUQsahcbiDYCdMis1TixkQAQUpvNk/eAxAogBAeqvF/hBUaAADTJl5WtJbI1SC6JDAEThIaOkBOBMiEaicQQ7yAtnT0WQQUOE5DZ1FaUuiOD0TmSTQAgetCWNRHkuQGEdkATcIpeB8JoH6O6JERiFOBuLbuA9mVfDnnNsNT3Myn1/8AeuZy5nCuBojWsZSHJNmVsVfdjkSHdYRTTNvIINT1WHg0RCVkbQa/wEjY8vGwZfeXsSNtCKo+UVFQEEAN7DsHCNK8mIJelFKsHpxpybBerTYPoVJ5fmgEXD9UkwAOG8SvAScGNWjCKiCU0Z6LAr9Oo9m8JFpUiaqUFiCYGqGlBjzEohN+4QJ9ssmcylVD2gj9kfebJrM6h8IL0ut94JDilFgGz7/anvCJrDIDexs4QE28KsIaEWKMFSYNecJKsZs3sFgkFguHI0Rj5goAgACBoUeHI+0zERHiFewCicT2zNtO43X0IAlavHRagBUIYFCwdbPs0TjhbMBGEp3ynPmVYlkGpDAYsBuAjxcL2fVSABuq4vQqQoVDNBAyKgfmSE0AyOCxWScd55G8Ywp3C6BhwDioixDYFbQpgXgAsSIJFB24E+3AXgzRXxVzUSUNocU4ZNUnULt+wnrOFOIDyFAiUoEwXE6e7K2BhaBaMUA4Q/mmzwTDuaKAZWeBGAiMjR3RYdhyDbEC61DCiBT0AilRZ000rXQWfQ/HnJRGleWgJStlkJAigEPZKr7iViKhowgw9OhhlPE4mWKqCGAMKAdFzDguohsAqBpL6/DLLUQiaKorBI9Xg84NdA+F1XtsRh0LB8cA9BNpM34/jeQqQhWNqfIwfxxtfxImKZRTQUUTg0BJTCKqlkQrB0WYu2kE5UIg8Se59R3b3YitI6OmOZReZcaEoAG6wwVBc4BB3IZ4ZLNzXf44WA2zYIVR0B2vU64pz+gWuwJRc1kkWhIj0SyCUDMGzrokqagj61jQJQoXENObb7IV1DMe0BHn5GP2+eQlPJF0fqNNLoR9BhmYXYVVNvalkQgAbxzJ3NUZKsuzQI8nsOQZqEjGBD+hndOiSqQJgC1pTkAo1ocOo29SIwqtnBZqS6YNQU2A0YgTMsUYMpfo2ux4Jk1FKHIjLOKSrDhzOcGfArsLavhBwklQz31VsBoxUBKpXreWLJxCTVYLjQnkAwBcTippqEwWDvWoFBAAaldMkgD8iloTj601QgO0BgEJpXJeBad4A2Cw0xHAHBvPtB2MZhcurRSju2PRStUqN4TFzwoGMDM6fUDh1EkUCAScC1BaVolXhKcaQVHyAo6ABmvCaUMNRpD4tcIMPkJBtVJUpa4aPUMQVsA2bCAeOhYxsZ8SOiBDA64RskO1Ifg+vnlNojpHsU+z/TxzDXGKbQE6pA7YGmU6ADnVGmQiRnMSCWURIVEChYAPBMHw8KMksBAFGBEeaKpDpt8IghhRB4R1LcCt2jvABNJwMmGkcNcmXxaZyxIWhwKQa5QSFR64RikXLVOHS7X8SwtVyRGAAYOPWH6yLVI8AEU8MIDeElyAFYLoHHEObpAoRkFfhr143WaHg0I7630RPbeCiqBQEdSa3Ykzi2C9gwK6sYBSNTsTjUiETqQ6DCKpHqPp+Iwago1KLQm3AQt9zT0jHbjWM4uQ8JSoAT5lR6BQLIjvXougKXAgnC2VmQMKGwwCk5dvYNEIdkyQdSJTI+nBQjEVk6AAOxB6QjBuR8PeXo5eQ+mSQsCaY88nFBvDhKQaoAKZXND0M3FEpEK+RNXin7CkuEADg2WqbYUg8EMh2VMOFtlBmbBaVhiCknFxVbQq0Ki9q/LhMVOfi1KqBeyFKZOFqOKRw1mhTIxenh9+SUJpATBFGnppNBeyM7EAEGKh1w5piUwI9brTCxbB4eIdegmbsBY4BanG/LkW+EjsagSJLuhOBVStQ78mMoD4dcMahzPwAhNTlJNRnV2cc0z+OqXF0tiOiFFGUou48JZ+lADYdc6tg3bjjaBKAAeHZhiO7kdKAqUAAUDQesV2dC8JSAAMke8HvFR2UpGVCnTUuiPyA4p9dIq9FQMKc3hHxi4s+FmgqoQ+EJpYsU4j7a6PrucB9c4hRpbYLpBBT5ZlA9C9LUwH2HzPliVgDER+CUOSF5mwSb9k+EHqcSJCLsokH6BkOxVARw2dQwKoygLTE50h3WIQAbiB8fC+yxOetNjrRUAKZ2FIGzbCmCyqXfsYjCMNQ+wdw6v0x2bOkqwGEQOHqCUyLLthkQAElWlgtAwD4ZADDbzPE/NisC50EyAcbiyBayglQAgIEB474EyCOEuD1ACAQngPtk3EjEiCKZZwZGbpPHUiCAm9TcusZ3Py0M3ugom9kYydcka6fYmhNcTxFQZUNeutr2GoECBMAKbR4FUlZkyftBC5wobbw8BdoBcSoSqHAi3KpXgWwHZtZ0YdKwAWZ1oK02hnCQEKUhnAa5cW/OD5C2iGujpfkHXPThE7GaIIWtsOIFEiSDQimBgRgIyCsKr3sa0w8Qn3kTNU6wCjUco9uISlSBbBAopCfgAE/BJ9KqlVbyVf8oQLS6W56cv0gQoCEFFr31eIFEBuKC136nW5y+tsZuy44lMbqbxniFBCcqB7KoSFZeG1FFvq7EKkLw52STbRWlpJJCcmTGxNbC7TdT+uDfPGdmF0LD0Fw0UqRWKipXotEDxU3NBsQniZUaXaKQQhKQd6MROEvDRygMy+0aQsOV/m0shQBcR6DiMJ9rzbQIIOqQ8el7LV4IhoWKNCPLmlPIQgzZdn4pRDyBikBgpGYNsJXocq2T2dEIWPOC0QVsKFSLMK9RnHotyQS/OUQmRMZTOj5IU7TBW1O2caxqQN5pIhKgsARbjNpHgmbQEkcZCWswQJRImhll8h/wBzHlEkH1ftvMFkDxvhT4744UDdzhVWOpj5OtlvXoFagU1NgcZmCGtWAL4V/BlvX0226pQrUGeBFcjdWLAENsGFaByTKpOW6hxuvRVnMb3i+SFFfRi2dhSrFWKAIgiMde7QjDpuqNFWB9DALw7U7rRpFaphrdLxTXgc6aDKLXVIIsEdWknosPgO+o+wO2oLOlH5SNBUJx2tEK/pZQIdD3ECxgod8DCRWGES0UYIgSaQLE4hVJKYzKWilSiCMlrnC+tczEL8tH5J+rycgVQICJ16PyHvBcM5fCjXWxevfmmdtNtzfA7nuCKfG7R627g6+HyKm6b2t5cqdPvtm364i3JBAETg4B7pmcenWsNhNDU+j4a2pHoy12tHQfkAgR3NKSHMK4V/0cCiqwXwIZpRrydMN+NKGKI2GIDkhoD6X+IYHofXgt1LGgQBIgauTHfGrDofxhEouVQ6+SGK2BA+qEQBLLjYhGcWZu4YssKBvGk3AeC7VBdF0e+I6sWvJwaXI2hwAG5uhdABKMKQaHhJmsKFwKr0w7JwIgZiUY4Y+wLgjj26yqkGqaHIhDjt9FYWAAvYa6g0uDxREqjkqyAsaYEWccK3k6rwIlmThwANUyISwc0adBIiYgWVmRy1qgLUgi6DSGFYL+xqAFi1kIoCUKkqFS9fKDj2hGUSqeBREIFwKTeHChhzJHCKuBgWgxA2q9eEWgJTaogIQcJ2BgVIuddAg3wGGeNhp+rY19dZwDEEsBOiyCq0jmrKMqtL/ZjW8URIGR2IVIYbYhFdSNVLEhYSoDcFPphkVoUUBlJiMTzmIQh0CXpYr2DBhxRYHoAJ8nGtX3L+Dr9t+E4WLJAgrpMeyh88Aggw9ImPqqhb0ZzuxA8SqBVB9LhvNQ/Q2SsS1IIrQcgVgBJdDKWICmA8lUTnG67SI9gQRxR7SHiQr07hAScCAICRozsGIuF8PAy25mxUUR0c7teBWHBFK1wAAQrqQ+SXUFhewehqGXhdRaszIMyp837nA2HgFOPKNgHpIOxnBkIVS13KtLuCEQCoi+2GS3JDq2cI4iUkQpxUHLIXuc6ojaAUq+GFOFQgHHzFK1owUdDsUtIcXyq8Xw4SBfwpvR8zh2GVXrAM6YxzmZLaRfm7evf83isg3soAlXqZPODOKiAqTUCigpRASrRBiIiSjtRaao4X5oVQ7Gv6/wDnBUXpWaj0/WcjsSCQOVhK87+OTcMuAkRAQC4b3DkvvLDkZ3gdV9qKvNxyUlQqQKqHt9X0dF/T2BCAABXVIQMoCLdVj6KAhUpeKiGKpKQYntAzSOAQWQAXZgaqBleFKS/UEq7CdeN3czLhcKsTCPVCfGahhKKOROsSw30XelbKY0Xqzp3WcxA4k0LVugfWVtoXFNmyBJmiPR+qXkKugnGgGgRBQHHdpCFGrA70S0eBUBXZTFGZuVAnY/8AxMSGR0E8IgXd4EXt1XYTz19eXgX8KsitoSAvFQoCYCq0iL4HNSbwpMWEJIdxF0p6nEVz4iQFiBi4CVyMLqIIKCeEoVOn2EvSVFVhtZCQw3uiVzaNUdrRxKgaJHrIk1wwUpYbUSFHFiNT3QAqUGRCqzid60FG4oIjwdoAOqNu5sCYjuECNcZMFaqgIQYIgVKciHgsAoEUCT8H1kAQkFgRNAZ7pH55smdDYWCEizIRd4ck+570YppiPVeAOzaaMqZuhoIrRLwvC/nI4OwVHO0MnQU3ACABIpl2PpRBQdLRWfAWABK8hkEtpUCMS10RKQiY1zo1rwgrjiGTExxvSNGrQHuc83CAspML2B3W8LAogoYTQbvFflCQ8tiDfuHRqJEFoDMiIIPQPvbpwWcRe+GIiLs6bVR3vmAQMNRiTTJGcJiD0ajKzIt4oHgokp2d9FoYoDDSg8aixakIQBZWeHEGDEhzelj6bHXlGa/lSTHuxs3Q4KKwXWhgRiexBTlWVAgn7RYaCNdONDrDWWKMSVFYQGma36iS7Y4w5SdQ0OOKQEgJEGKMTjc0BrSYOhTTaeceCl7eruK9sZVnADP1/BA3hAifZw04F6i++s+3S/POptFyD0kPtwD74f2R8lu3TmwRgl90ImvxfXiZoi1FmBEQeMYc2Y98EBpAYF6MyketgnEEF+OlSshLkfdARFXI2qpqVWfSiTF+givgJwZzpwACJOgEQcFMFJ1iLqSaUztEuNEhbtnQYIwZb3gwOOqapXwblatqPezECiIXaBGplZnfAKFbYa8IU35My0rgHivloyID3st46zK5CR4VAMBVZHmEEYlSD9rx39HhXalspRIFMAXUc6LY1qJE16DIHwrYrMwrCvsoULkHBiDjoGpr8lABAwpZDca+iURRkCkU0DulFKWmxCxUKBKi5EQFxkV2FpXycGcV06JKozkcKIFFi/OfPIzBoUivTg+JF0eNfEojsfIpPHRLvF3lLO7o9Frvq8k81BilMiAWGUFzgfjSFPQ7MBvGg6Q0QJScGENBCnYFd7g2aIBijEeJWMJjIR6Hgam3imiLrNoKDcHSFmPqKFwPdHXwcNtSgGEiUe96CMFNTRdQyosi5Qnhgo9FQDKdl/PS+cOJaNoAL4BVdkQvCUd104kEZxq2Q6lajc1Eu1Cscr0I8AxOIxhqQUQrHh3wl23BKAjCtPV9jzAFcVJrKhqCKkzVhDQ0DGMppqFOE0En2Cz4On8u3i9JXhW8RHwiwdtbkdjn6AHQCMH7HvgomCmosJhK24gNRVqrhXMcajUAgy8DfVXJDLVbyR6lcDBSmdS5rSdWLl3hw9oQO1noEPXK8ExAIxFijsSjK0ZeFL0AyMel6CMRwKMjjy5oakADGtknJcsJwYDIazfc3rUtDizkUqrFiBuvij87SqldpAquj5OrKSLyAkOjQpcFCcYr9C/V1mpYAYHDgpz8QbamXqenXgHrmdkmPVRN63k5+Hu+bEIUSggqinAPGDVzKAQjRajQrMEZ4MYpRUqsxB8fGTHRQyAA2acVDSBUpt4aQrra69D0nRIQiN8EGmwRrjcpzNNyV09Tna3tlxAEhWmUUHg+oKwNN5R2J06Ur1YF2CiqlUBMp5A3j8GWedKUEQqK5kh0h2TBdWqHCEmcKDbGAaTgg4GMBMibpskIVm+CHS9SKMPQRl0RWRZBvMbtW6hlSTpOMpqPAKBSsOHYPECkZoQBGgqDeS0m2TMBJhTwy4V7UZfwfBDjITf++cSgXyp+Rj/HDNflBTMju9o8IEPb9ik4Trey1/yXOwfviQlN7vyzT9n8cink/S0wfuJwGBoUztRBfhRQqign2uELFRK+grkF5a9VCI/OofF1y+J2FehVNuKBvjElNhF3EmuywUGjkohK2BagYihNVqshRmcVEU7k6ORqii4qKqgRJQgSAcqPYoKL60kylDJZwahtZT0/KQx4s1nin0sSjU9nCpEnoEBQUGgzs/PBdB4nF80k1gDezHrHJp4SORqA6HCbd5VVYyCTEfFECvR6qyNuwwEkIVGBScUs4RbLxSuiDVXlR7Xb/N4pIpQVvQ9H1ylAEY+P3+v9cduGaEfheu/+OJxpIHVGM7/m8DlafEWbNQ8333X7PEiek/HY8UNkwDgeExSz9sKCFEeRotoCYMOo8EDKGzMKpSB76+VhN05KEVSgV16d94bRotcbs+sDvzhqC2+GrIApzhagaQUKjaT0+js/beSD4rqmgkEdXUdY4UuVkUGT7mq17ED2vJShUxaEJGPfxreYNckUkEKB0FijOLogj31aUSU0gDg5TgY+uZ7LDsecbiWq/OdZFAvo5BIDpsGKRh2uklQ28cTsyJ2rsoArlJZkGAw3w60fPXlhESRClCrPZfHgz4yUsh0IrUoKgnNclI6QoRFJgVm12HZCMJgESQbFN5HdED3Lnb4LHX64HC40A1BjjB35/AWRacQ4L0vmTtqDNxNu3YSRDx0kFEmG3pCCJGEiHj6cQaAIoO4lrUO515yUCJedmB0BBk2+HBmRM99IaCnZubKlgtOxII3YSVw4QBYViK69KTaOiaLB5/FREgEVbfqOBJCBwomEWNiJvxxgBUsAoQ6KD5Rbbjt7EdKv05QXVOnhfTTm0tECCNcSnMcnkzAdYgCa6oItMMcxNUq6Bt0Q9mAxgojRGL3kAwou4uoIxeDEWHTJAJGOhLEDpMOschHmfCaOisQOCsCI/EswtmjwTt0qYileg4C0ECPU6BguAnfiAKhESKNY3BGCG+xoFUdAPGHtNhcWJhATHYk0j36Ve40JVmCoDAwnBCSwWIQ7OH8ptjV9JvRVwVAYtephbLCrH6BCqptEJSyWN2hGUtC5SZLGRqibCoeFulQEsLMBGA0CI4CKAYgqYWhQiHZmHCqQavarT4a8H0C+cVUv/fHGQ6/I04U9Argv+eVAHFPuT/ZwY/kEQPjqfwvfnFhWmIfn+oXCXkfa/fB+a+3niEQHfjen9cAWh6J/ZIv37ScIzmK0OClRI94upjwwR+AyhroAMgNxwp0kZ5ECHo6JE7DzEZBhKwxNC1EVIi7pINoVAopbHHQY6mWFU6o0WFHBoYqLhCH0J3ab+Jw8yw9S1h8y97L1xdoqgSpRBLEu0ooUMSfcwaJV08BTiNUFo1KtfJrM5pOMnkodAbDQKIoqchWKA1FfkYA8YuEM3vHfyKfH6vE8X2NISfjX+eH4wys2lQ0/3w2uUjyO7/8AOVTgUKmgoRGNHv44cLwiAyhRRIdHg/W4WYQABGPUCrwGcUWeXM76KcYKM8ALgFXV6fH1vuXBV9qSWz6O1ysE4rN7GeAlKVVQVxDBLZ2KByit4JlCVqgM8Fd/LxUGRdSG9hffwW5yNk7OnmTUE7OR4fMMpCIEzGojTjLgxOg0wEKfON+eC1uxPQUjYhJ9Aw20WOhGAEmLrHA5gQspVFDrI+BRBLwiVjLkJAsspx27U87h0MlLADIcNruCVFTe1vRgAJdK+Fx+RgKSA8chKlpZpUCqQBIPXBIqiDJwG2ZDAbkiW1akOwxQJDoGAAKpD62imol/FOnloymkrTkRMMDpgS8BuATOAUUYKUKoW8OtAYALmtPrWHmHAgM3XGAwOzOmKrxbrEA6oo3Y0MYiJxFVsA6KocGG/wCRqExNzSUBHsn/ADpjXjUJWvpwlssWCogKGANXenCJ5CwoKnwI7oC12aQSbp13WBxvfZLczDIbNGAFgiE5G4xBHtUACTTACg4t3bg2YPC1YgQDVSUvjBFjtBi+EDpJgenBjV7LUTiIgegKAhAMRotSQ4JzwCtZOQaCVN4ZEFJ5RgggLIHKs1ql4qINUYt9ZR8CwLRwX2juOFANp4HdU0O6AAqDgatynFJwHaNfbwGIHvqiRmHSnnJEVrctIEqkwHYR1oINGSws2t0EKcDj5XE7QgFU7hM5310asABImgW8ar/0DHgDDB8KiF6SAUEKkHaP6a1hPLAwSaETRZ6iYXaBh2ikFLgjRB5ExQVt9iNRFBOMgbuAUbAkkKx+HghhbQNSpSoMO4pT9mwzSxVt0Hd40qriAX+z/XH710LH+O+MBYf74wZQH540344od6L7/J08Xl4D5OD35dE/g46/im8ms69ZnqPV/M4sEbYvysZ2FB8cZX5QjHb7Z/581m9btYbFJAYpS8HOOASCSRhYQhV6+bY1DRGWdJcgWcCodJRpWaUSfBfYYASUmsWNKzpeEyIOyi/eCREi44c1AEN7JM69PR8cY9hyykwh0nQB1N7d8PAy0CkBFXkvSRsZo1grvR8cUs6ClvUnhifxwyAI7KHg/n448boPYmV81Gd/xwXFQvDXX56fjiB1NvSwXPP/ALnFOCkx/lHz/wA5n+/BNACWdpa/HKKrIQB+I/hovV5HslSPvRa+ZT3G8VHJ2m/iR+vOFWaxYOqhr8Q+jg70Ap12IWfn9cQ8JXEm0qD6G/Dw7n6Fg+Bq/PAMtdyXUPgvhDlAe5QDJvQt+b7w1SBtYUlZDU++nxhlAyWaU1quW38adcHFVEL4FD5mq8kGM7GF5CYL1MToV6yYdSBaiIYTi0jgJEkDGDRfIEbmkUgA9r/3vfFKgjF0Fr/9/PIiDD4DPwIifMTyhlZNhHRZ9LngmiRxVSG1AOhUhL2HiQLGLkjjudp+Z3xEJWqp+dmd79v54ILmMxwOxC/WffAjFJDUBFsOip36qlZ1ffsO1l3dv3wDs4Q6sNOKg6PeWBqITpjg7SYpRFxda1KOOgQ6BwHE/vySVBJ6LKdT3haURCQECxLh0Eu86AW9ILAEiIE0Rs4Rx9R6E1GEdrEU42dtqeF4SH66AHFPbAFkLpNO08gDx4VLoBhQEKCIi5QiFkZ0BoyQqcJA4rFNmddwxFqQ2TuvC8nigMUkocFjhhcmMFtMAd5x4sSUvO0aoW0UErhY/gFhSMZKlTUxizChIUVaAi0jw+LV7CTnsICrLrwbSxSDEhId69BA4uDzwBmuO5RXpySEpIWiRKBYqyOca96MYHAFEAV9l4S4DeQBkUABYTCE1N8BJVN1hqkMFAfjEEKdES6nZFUQuqmMqjJIBNItNDMGaJii7mCqiLyiqzEAWpwUiGyg1t0alUsQqAYsDQ1LILKUpTB9gTg3U2zeO+jq/IUInHpAUQYgKBeJ1zpSYi6Dvk/xxoqf+PUcLIxMUBUNA1Yv54o5AOJqpTzufXKkv2iPoaL+RzG1UYF3K7x7H988mCXsXW9tz88cIQkRt+Ex/XFrG9g/ycMhzoIf7J/HCBEF2RXOiPXFa1uD4Asrz+V/pyqcGFod7U/fBhemm18mRSvY/vgZlKQougFFPGpeIqjkoGXQHUXRhrm0/q3OphydgvzxUmYiTtcs96J7PONkRjiH8YR26HLi4wQBKCxLEcqOW6mbFWTClF0AgvVLD5qKwiUIDfUuQHhowaiiVHqf67gCBWsMf5/3ysRUzdjg4x3fTl7wQIFyT598z98jBUoa0e3PX76OGITzMFalEp4JvBKs01BiBMiwDJOTIntka7Ir7q53xiuO0LdIqmZK9HAqJhQc+sn+eFiFo5H6cAUwFhNQH6FeIyYQZ3AB855OuYd9NfwMk0MHp1QRY2AKDIFKFd4gB7CaZCr5SQvnBtYsLJRUZB+Jad8WKTsWpUaJAAqAqziB6RgmYzoPcPicf2hjkhjxx9EtVmfTna5TvM3OBFgBMwv+f287xqGezf44FO3SZ588cTM15As/r9nCR1KP12fx/wAYHHIP7MersDjtHlalYP8AC8DuSZwAv0dVR6Uo0ufOjSHYRrEda9FI6+eIjK+geKpOuOw6vA7SJAU1grobHnXcxSCUBsw2YYReHoSlj70AUQRh1eJOJ4p4Q142kQZeDO0UeAFICRvr8KDc1DcgNWnR55x5jgRkw73uv57A+OXhjoIQPXUfeCKFAZGfxd8eMIjUQpg8/CfnlR+c14XSU8EUvEPb3A4KAVjCNSeGECWRFoVKLDMDwaSTUWSkuNJFROmg9D38ahqKioqhybkZKpsaSU0qWEeC1ILG4RYrkYEljRrnKzjfQVq1Cxpm+ALM/DgtUlABLM6cFyztcATY08A2HIBgQ1ToY47Ask4cPNBRDaaXF0ZnClQiHOEzScCF86MCdRQFz7DgCN/0gWGLHVwV0QPAYoKjcdFxO+B3akeqVKMCHqROD3M2Drwpimsg5b4SXtJSQzAdg+8AVyqixQmlBb9sToi+QgDgAlEWrXi0xT1DhcnKCjJy79m5YlASh4DocPCXxUK+JWs++DgwnwL5vNeFvEB5KBU0e+ANwYJCxV/rgzApIyV6QZ3PjiqWaoDeqjB0TL08GlQlm+uIp4RM/kZxB2qaB0hKa45Y+cmsMYTAMtwW/fLKlKvXluHPhzNE9F7qdR/jmpH/ANh6hFAiOxheQlQBJEq6PQPmHWcvkRGOezUC61F+eMfy1X1VT7FeJXUN3IpUYa6IE0qUZNYARGNNQ9WHAnfFkMDFDoAHYUcSKqGtCjqwAlVUB4v5gBuMUgkMbi9vCHrx2E+RLKGqMnB1VNAf8z+uSGiBr3z/AM4m/AgpwyROxfT7eLtxfLYRAF/45aZqSAAVcVlTs7YVZBGN+9ifnPnd5JsY034Iz9nO+yVwr8tJw+EfQw/lv+eL/moq/l4YAPx7w163BGfmNf8A4/286UoMHyR84GkKVtFKaJkvXEKbe59YmPpzFKJGCMsBQYMoPNcapahUayhVNhzAyC45qMqRTWvzyWkPQTDDL6tAPCAkEpK21hdhj5eOr5WIfyz9Rxo0V17904HQgsqyLIHry/fHI/bHGLk1oL8VxAoYrEst6PQE+8WVfmxFEYqERIROuQpz7m+wb+EPo8ylP40kEp+PneEcREXdgxU1MXc4iP5b/nN4sC9yPvOj8oiGodiPv++JeehFwwjBCIdunH1mWzOhaKlosEngaM7SO2SdN9o8vMvW43w+g19QSyuWvdoXtDr1yZirAlSySvypV9r88hilUSNGVAS77ABdffKtSDGEi5nWBeEja0xX339FSjbegm9YVozyEfUThtTy5KSVwmxUgqjnlXrAHylm14BCKBH4W1VJchyEupmHqCtuN1QHhrU6jVkGiFapu3h4vB6IC1BqNIIQp9WEIWsp9ysGweH13w0dGESqLqneIcaotkVAcnZYuJesEMpg/BHdiqoA8M/kA1JObGg44w00aknldFhr2uAs3gNDVDVQgdERE5V7CqgoNUGLBS3WTF3ae0gr+wr0yM6gFkiEcrHAyJ2gShsaCkgkacTGaBpg3HJ/EDHEmSnYKCSwRc4YuEgjwlwx/QhWyFr5oumgYv60IRgH1czHGJI54+M4nLiEJN1/fvMJob/+A/xxATzQP8W8G2IIQ/hP54m0d5AShuw47IJIjtIsJLV2QBBLZrASu9UOJVh0ij6rX89ffC2qHnHhTOyO15uu68gwdaLGduJxXyFu5O1qNhs6OZMGgSgEKVcAteBWYVUB60GJvl4gX001cFO+7e1/jmbxaOKrWdmTvhxTEXDoAb0AhmZwAOBUHT+Dl4grUQoUOPUcj39ALcExWK0E7KL3Ow8RZM2OySgPkzOLdxzMg3H5d58cmnDgpGyoCm2+nFCorwjCZPEymby53IDDjKDRUn5YSTLUS0AvZ3MZzZOUjBPoEQlMQnOreQQHABkYDuJwPdYoQJVa3PE51NhN9ra8ri/ar/XDtZ6Ho5U3iB1xJqcIGv8AN5AQaD0p+eUc3U+rT/vnhRGfjhrfxzjjOelQ4Rt/rgFXs8R+TnhVo9R88x0uA7FPh5UTPEzlylIFvbjLDrgxjTQk674vRwEEMIXQsZnnIlcQq/VB/E+XhQ6CUukcJ98L0UEf4Wh/fHyhH7gCv6jxyA1JAgZoF/J5OHVY1ZD3dIAGCIyfTSyGLx+BTEnJ42ghAypjojwXH2l/PSuhi516HDYeyavx+OPksCZPhlWf7nM7kosUYAq5e9fLwuCT0ADqkyzDkjgWbMaDARMBGLI+AzUJPAEqRgBbohnBcFXgBASjUy7tEJUhmyLHBDGvNLwhii9oxDkABJgjZaEc7oFIqXakNOpCqmiLonDvUii0pl7gpSgOG7Toj14gPhVowV4SQSkUBUFUujCjZB4AtAKrBKGmc6Ky8bU/Alc22JIyAnDot3TqhkoKmEjxtQ3YETzboKlLyuOyyomUqKhZIE4zWixZUiDqUSPR4n1XwDAUtjxkBeJ3wQQYzVYiAER6dejKrEFWBAJitAmFS6FmrEkDggmgjwgFbQjCtgScMmZaWDtNbTIEOG0WAlMoDuWACl4BADfgzIJJ06dmcOsXX45tZKS8DkKRShWe/jh2xNkiPx198L3GS8+Fd32qrMgXd44caB9gg+jrmp1DzBREeESCkebd7BEnYjQ/P8c7e2twwmfk/lwABQlc4GRe/wBe/eeA2sqBFhKEfCROHrIVjBlIoigqdrmqaKnugAAEIHE3icOIhogUKhqoQ4VI7Ad/B0/3rw0QhUfcbIUmfP3DKqVj0HK97IayNLQABL3QIQGKaJQZ5gNjhBPlSdDsXKFmFWhYz8Je7waL3SWqSBaLiB3HhTUiY17CgiKFT4s5PeIGKaEWQxerympsi9z61eBD8hCTgUjdh5s9zOJhCk4WVaUfauvfAo976MDnU9HI88FGOQpFYBSRU1tz1S+Zhd68z5xIDgjllEBcPlQ942Lz6P8AhL/BzteEBC90zOKQThSumCo2J4pUkOo6jRA1QGwXjbtjQ/hH+ufk4pPZha7P5OEZINUfLOb9K8Vx70/+a4sIH0/58v8AHj/kHIX/ACL14hVA+07oj050GvZ/hHhid1qH7pwIreifwVwyIB6r/jldg4g9f45VZPCK+GnIxtf7+BD9w4u3Ir78gL964Vfh83iO7DAdEODdYovxBb+0eym8uEOn0+hDgSH7EVHad/uXjFBWQIJ1H8GuGF+a0H4+f6OQan0v90j++AehO/fgip8AV84jyqfsdFzO1oIQMAEyNXWCGsV7LABpJ3A8GiNB29HDhE+tiqRqMqSwFrN1gaRs1YQDkifd6LrIsu9OOuDRFqTxi1BaElOJJvOYr4REK0NTqU2Y0IDg1AUiKdaUUmtA5jEAKok4n4NxRCipIoD1EqR3QgIBFFAaCvHgMmKjXTV0OQovRDJEIaJYNaujKTjfOJRfQAJoKdRWLXrFZuE7UEGjJwN2wyL2mAMIVNGLImzZC4UNzYPAgcaTxIoqkVvMEhPmMQEML7kUKIU9pdRVEtCkIZBnIdGeR3dEgGGNonEVMh4wpFJGHbAdFmvxAWGRKtoOng339ks6EF6hBXqmyEK9JQJFRiyRln6Q9Dwzr13xMP4OQ2z8ckye5hReiZEezvh1IrNAPpUP6+OMG4YwGCfaKE8jV5AkpDUKW9mb8+8wHW/uwkwNPgm7xJl6V2o6IqPRPv175KbXPB2kOF0yyu9wHUDC/D4HkUdkEFYTqp3ww2XiJbKWJB36/HO1cQFp2djs3wPjkoUWoFVftCe/8OBgDWdn88qohlksfBDNi+XkgWaj7EP4VqTFOAz9ziElwUB1XuYp4CAqwCHwxdh8cWO3ihAROhyQRHt4ue7oAARhArQpEoM0nqyKBvEX07zvNF0BexcKr0BfLyILDncMxsRPls7cG+mtjKvlcC46ERFhDg3HwCZUt1JNvACEaKyrcHSDaUnEO70RCKpSVSMES3KEJF0f9TAli8KvNkZCGCMjqN75RvlVEbEpaQTrJqFktqIQLa6WWxnfHxJDbG96e0O364zqesIJhqtxTo4DKEs9q0jlEkdzh1tnkw3KQgK0049kQcmVB6H5R+RwznkWFJF4h/HGAWgiSMAOef3LwH5UJjVA/ae+ngIyshQNE0efwKeBX4xQsHCICxZeXBUBQu/vkSgKdH868i48OJWE6AuEDV9eYYcWoOt7/wBvKgZgSo/dHkgQX/rNf3z+WMP+Hg8wRAnsKQn+H88VWxPEAY4zgVB8f5yZ/XPjSoN8gg+t5mkU77qf1PnXhuao7S+v9oWqThqEQhR2ox9W+jhEY7g/4Kv54Ff1G5+3go6qrwQbu4bTOyVxsRpeEKIaoGRGKOGkLBhSSPdCohBceUbE9OvDoocB5FUUduwUJVdoeQThBeJIiFxkokABXX6LRMiDVrL0s4CG0BLHQkGwQoZtQhIYKMSlRSSrjzpLIcoXAICVGoB50wc6ooYQC50cO0qxQM2h0RAUDiMcFnBdLpswGY4CbFDC0VpKlJkRWB4ub2Bk7GgnJx3Zf5DJmBRuqC0jJnncIBVAoIgcqxC9bCeCkUGNBEHCtRCGF9VILqRGK4VZNMQehIJUrdOpcIgQrCTUQAYoll0RbojVUJ3RK4Zw00QBaJplTa8iSAXlR4iJl7DuiBMULvYAmhI4fA3EFzAhbJJMeVrzahg50KDQCVKmMFFUZk0jZRMd4QkaxBu/odfriCOLpxaK/DYA/oOawpRoUBFWLALxisbglHVBMegOngZhemsICR7OyXXCv4PIs0CBXv6cCusapiPT+D3gqjqN3MPVN3Jybu/GaksDPl7w5JgiLvfIqXr65Q0A3JokAIj3frl9i0aXogD9pPfrhe3wHBaqnqr+V49Ag20/1xp+WBEpDFxciilvIoSZFRQGfpkeccxUewmU6BR8h4feJFREx4NvRbALDuD2V63wgzxI4g719eA0bthCHE2myzeGmHR1tPOdlFDMA+BDFRS64nYSK3QkaD++EbR1GxTbigGFZ0MySGtWvZC9J1Z98DW66ZlDonWiR3XkM+7dAADUHxmTjEovwxJpLKCgA7zCJHLBnyIQoYPD20ENxjBiBfhMYrykq3hoohClG6IpxV2Cak8RH63vOX/wbVKCOHnyv3wOopYO1s6CQ8d74UqYWUUfVC+l7nEBasNzjpTCj6D2cMEA+9dUehhjzj2sblObhcUPrmTERmZvhBvwfH44FoHjch13QJHt6AQsU420bXscwwSct4WwJCg7Oj8115M+HWkqQ+fU+L72k2EUKkol6MfeM8kdKEKADb3uVy87rjbILaxPPl0nPjTvfxBKWgB+XHj39Da1iIGeESOsXqYtcCGIp1xYwzt5X4jBr2JK4mZ9HEgDYIWboKo5OjlhSo3lY0sJ9vXhn527hg2Jd19pGaEipaiNDrBMqaX7Rr1HrWdgiSPKEgoEkwkQUyuwr2lQiRc1FB2F0QKvXDIc4N6u4dUGpYVCQhp89vSrSXdWs/zKEEswRUbKpL2ErWS3EEpqjqcYmdFuK7N3ARNwRO8GwiBSk0gE6anb4FxSBES12gDgpUbEydEUKNC3seCG1aUPEDrMVXs8kIiuJRmNb4CdDxOF30RdTJAMqBGCrJB5M5hRBVfAsZbH5h3IyqEoQOCGoeE1Bmki/kuIj3L5rjbGD9BwN5GzIBZslMcBxcMrkpaUPQIhtcOfkqDbLExhWnQQYAtb4tRw6QmJY8QPKa648RkoOujjJGpbtyGICCmI4XFkytgAGWOwpH1amJPYIpZSLpe//wCZnQKVGaMuhs2cn2gWtQ7U1imgAjHQr1KQ1fo28iFs3gwQpQKJAmL+i22QxdggwL+msUuwCAe4L3xBvKDmgfnX+3FQ5BAWX543ClGOrv8AQ8qIgNwOATACjOnfKMEwAiDBR6mXO9c+kZeUnsRvfn1wPJqYNKRzvvz44PBpYY0Xbh7+OPp+qyy7YEqb/duxY5WJDU9qK3VvFJfHhdivB1AdC3gJyGL3a8F6MNEC8DlJrsODdVBY8DrnUlTTW42vTwukgoCka0L7FD75kFhQA11rtd8odlUUPsAwkoKyVZxAo1YKHPoqkClaJwJcX5bwjUWlAHt5I2kxhQqpnSLipxHKZoBJtK6LfiziIY4TIdiiETC+pHrmSTC9xn/dcO64+LRD5V8nfxyQtsgNikpgYLq2KAfgDwyxvWT5nJNHy0i2PnDg1NKaKvrxJJQYz/vrjokHlSh+LR9cOM8ukd4V2/B8PeDRVFZGdMoEeNQhYr8h/jeIpACJ079o3fnjx5Xl4Ip3IzhAMWI765lyHdgM51COgIhrTEFhyi6ACxgD4OC8qASakpJ27wiOwS2/ZKKIjMhJwBdSBFfj7ffAhMGXhlT0a5V5SWvbYkV7kdXZD7TCLaBWZ+R7zJi2IbxO6N4/hDjhrwEGZJKJ4ej88ezsBWlQofkvxxjQKb7DA+H8t741RRV8SebXMd/PHTHeiKR/P+uL1MmtCe/Wt895KBIKA+vf74sN4ULJewoD484uVELDWZvSrj3DePk/bQliCGVjQeiZNmqTgFoCY0acaKOw8qUUwAYUU4YSisu8f4rdkHgIlFFZG6jYjCFlNWypZrYmoghklqJCvY2A1IeqdmAYjjseR9Y4FO9SvbpysVpKVprUmILSzpP2RQb+w2Yd4Gvgs5RA7SyyAHEuoe6oB7EdKoEBOCCMxUZIyU0SHmPGDLCikDPWCukGj/VbmZ7ISmEtRw4YWtDHdsiF7g0bx0Q0uq0UQpp4kEKSH59iIIJAwXTqllhWtTJA0qPfk2UpC7Ng67Klk2Its0Pqrqr0DZuWQwIulgLaCXlhQppIMpDvEwqLeb6ypgC6aQom4OB3GgQrWCK0JCu+EcrqwjsqOUAAqnhbqkDophur2oI8a/dE3hAqUUIKJLEbGxGHyVlKwcFMOc1UVAO16DlPw94pLnAEtEAa8wwoTMG+JS4PfFfgIyED1DdV1CfNHY2QIXWyJr8+AmKp1t3nh8ieMa4oA/twHGSqO63jbCYEV8K/en4RA78I4XZVMSE0ysochYUrj9uLjL6ZlfyT+FjZ2fnwFPHXZPxDhREKDof+E4qOEVqFfwO4cd7XXF6H3qPwghNpUmkC5gv8XDzKI2UkocelUdQQd/cBhx6YtgWvNNB2lU6rLmH441xYIwEjpAp9Od2UaKxVyli9vZ3w5dc9ATmhAVsqCWZtOmHSx25J82e4TuLtl3q4P3/BYyCv2DBQTyBF6ONLxYvzdA8UxbFnEjkG5BHhoCVAjOGrjBAHSK7nnfEOdkExzBFr0/BnCW4KgD00dmiMwOuGiAARE/sP+eFmRigWjplUxnwrUBwT4wgPzd4C3OPEQkU2TwMFsQt4twoygE87+f3mZw6Fa9izBEAAeg8l0S0dZRGwBa5wuAh2vre3OjuMjjRrhCklSTaSy4vwJWkzgUGMKv8AfBKQdenCjUqqoQHUVD7n04FVR0kCEpgHM9h7ye7qYOy2sOSitrSK1bTE0s/L3k3dKVB++OoezRRQv54NrR871U3ro2zkDX05UogffTjzgWNTjIgEojrt+eJoaLu+cYGbKTZqJI0kqTVMDMspK6+kwQvZrhWEPYTQSvcDuHNYVN0R0E8IA+UeJu+tWbjtlCCarSsEESWi1A2JqtVEb7LItWfCr6kb0ALgiLt6oHcQ4A40FJcAtL2UQb8KaYt18m+AqdPpHfAs+McgaUBQrQNwBPj4lr1RucdzSXvvCzs0fsiHdHINfRMQ7ge2ZWE4t4NFmELQrQsKYKK3iUdDMad+BACYnYxCO+d0qoCjrzj/AM9i40AA82m/lLIsOGOgLVyBw1Q1SBozyFA2LEsA09WQAYFRoAeE5sSZTwWQ/SBItijzsAFAiDXoBkF3CCAgOOw+hwMzViBZKNJOxNHgN2nCpSKKUDS7By3rmuUeKLK1b6wAhXblR0aZvTTDwEcC7S+yLopomOAFrxKwexdOgGJXN0ZDMJ+asWLkJwBjCRb5bIcbPeISq9K1eM2BEVr8f/eLwvFjt7fDi9uephgGx508nmEPxAsKP7z5SYl0lqLJmDRvR3EqXhbEhSB/+8m1FaMJ78n6558PLTF9go8MmchB0B+UtPdo9OOpm+x3oNiovzItB8zin2EeHtj+6sqRABmkaBwQKpkFWJPmHxbxBqEAUGuJPX8caNCTd3GiuPWnDECOIG2fQtfo/J8BxZ1B/B/fCkJuSIgBciWSoKclFiKaMamErpIOD7BbW0YRUB6YbgkWwhriGUBS5fhxToLFmYmGg/DEOGN74HHSX4oLFsVvOvKa+gNXIHagzGoA9blklAj/AHl0qUE5UqBX8jIB1we3IgSlYQN+IcW4Qzh3Ow7m0pwmzcgAWj1El9xfeFjjSEnCCTLfvnssGHVgOtRh2leUiBuVTL9B/ajytTRxJp4lB+eLGkQEBgdQNeovjxPwRgR5Pk/8vCy6cJJUxPB6ezZzInXg0FeMNX8EOGX5A76GNRjpp7ODm8UKftEmfC8RwebYgPgQNOqgZPNQGY7hR+rR350UpamFfCr878cYjAulV4/T+jjeIoKmygeLL9pzLyAeLhhMyPXD3bQTQ1FrVUCpIBzS2cSNpXAXuiHFTEIND479n17y3LUEZ+T3mpogV28lHNr1k7+v3x4J34h/WcJVEw6s+OPlKfiEA3CGLtXnUgIW4wCXtRESpqAjw2OsCQMEAAQJy5VokwWgOoO9F5fUfMuQDRR9adQwOdxErig4hYSM7ouSYZ0BuUrKm7Dhe5p2QC0oNEGxkJXrrVDB8okdgfnhioQ2EQel7Drja7uQ27qGwVC+8wTVrqXDYPQKxAXFThMeAmez0sgE61gqEgoUiJLNU7oCJAPdLEPqABbYcrOO00Uk1qoHEzL4QB0IDwFRNrj1sIkbYTrXSC9jJL6LASppVibrXjds71fYqRdVfLWBU+4iumRQnK0DlfppqRggJVAmAlcFM5CWNZeNdlXeaFwxMUpRDo7HiKLswEjvWkgsHTh9CZNYCYG9bJpTit2OgMgobi0EU3iIcEx16BQaBjNiBf3IAnCBgekkXOHon4UBIwDU+CAcLe2XYqc91p2F44aSkIYtt6drvfC9uLc5F0dExT0Idch+XwAIk8AD7gtvCvpIzQIIKDt2/ng4F0Q7ZgCEF8tyDZDq72cCiT1nzwQ7OdGXv8cMoVUYvBXxuxzm0BiRyFz8Pfyvxx5KBuCH50TOwcvNR+Dp483q4wOfngLNYlz9tn+xyjoDH3beFjqUPxS/rkhFBrqNPQM4F98m8l+yt42RbAxQiz9DxGoA7KAaASud60ScbDUi4fkf3wd8WCLkNiNBpoIKs/1Ca1ANHiqp8BwzYUKyvkLAtdyNU/GwkiIFvRfHDZpOpXyOyV6iS4iOKP1gAqUdK8BkMTm5sIgPol4oR5H6JrD7L2XjIqwpirmqFHrg8IpaCRfcEFWMTldnWE+rTVerxVxtMQGp3F7+eT9DogyVT7g+uHR6uTBT9in88ZrWhWMAgoADUr1OFa55Slzwhf8AHM+CKaaAwXwvuycgW2PbImlPs96Hgl+KNcItqA4QHV44gCxEsmvQ9fPFzw9kLjlkft+jkz2lUYBBSnHFe+hiBvghKC1Q9cMG98S/9JNRYAC2fbvBuKXk798v64plZOqD5N0Pmcpc5A/RQFBGHp7zHRqjaWAYaS5rnhAZKA2v5nr1wi+rw9Yp0JWfJo354YoWRv8AJ8Bl4nE9Kdy1Uxv88nfs61vbkKhBNk8AhqC1FjsV8DLy7AmgFB6MLGD4rgMoMt+HxnnEmrnU1R6UIq9U765Wsgk4N9AjAyQVMkeS6hhY54SduOnkaqCYACUoGjwiALmEQYgg9phoCFKW3WYCSgFSYSR/fII7KQGjWT5XiASOaQAUCCVwud5C8+QIRyYfyFEL2rICV7CmENI6tIUETCYAoadQHDGJEVnBQGHRi8HHqERvLJYUJCRqEM6ftQDQ7DBfIAYpkXFMAVTCgiEaQVeiz/ediYcOLUoWgIQpRLD4DDkW7ywVABKScGWUoSYQXbGinVoaFXg1198gFJ2gkG9BNuyr6kSEGpPfg4MpE0vBBFIOopc1EETHho7MtDji9EkowwDl1aQhAHQAYNlCTHqnQpScBkiRqADakQiBHkJ94hPa/TuPF2zIY2BETQwYLtiwJn+AKQgqC+hxlY/rnSLOB1FsoezPn74uYLYPWpCdPTDA4ctz8jigakcP4MNj5adXQ7x4chJ2F8OaXb4M8OFK+aAGKDPYCC6DhPI0tB+QAAOBE5H5SVtPzoL+HiuKlVFVeQdP9jhn8i86C1CPQtUBS/khiIWKPxWcHaaPAg/w+M+v4OBf6H9cAlSH0qf5D9nBdyAKDqo3WomCdxe3tA3w8eqeocQ5XAZoDqph3t5Zh/Q8W6DglGr+XFVYU5yhBJBKPjMHOTC3VL30+fZwq0HfY3VDTYg8vgqRtSAhUJ1J2VeEi+76ChDyIjNfOGG1fHeAVEAb1d87p8PigFHLb3fpTk7YwunGCMVRs7aZZnEmjOLT0CfSkcQxRKp9UG+3hj6A39cBXJClC3qeLejbwXskUp5YEeCO48aEcSQNQkIhBQk28msCBS/aAE6AAIAHKpAYIdxhBee8SRk8ex0gAwJY64dEkC5k/Nr8BLKcwrntY+pACRExgVofmOIHW2r4Kfh53vT4QUFUB+ft7xXYj0DNoStZ8/iiNgDBJ2JpAvfAUeOO+lRhWe8or4Kijn88a6aAqc8DgkXpokNZB7HntBwa84UQ/IEAtU1vfGkhyBGNCu+dfJZzLQh0/DQOSZ6VYzYujT/HFDQxsZ0zIFUknD5sJc38k+7s4CIbZDUxE0J2p+5xm2fWqvqHpNOHDMo2yZ3QCLgE5ZB8KEJDsaFMHthKnTtMPj7FPS9DyBq02FWPWKSzopVw3Mkonh64D8bRCuApBYdeJStADHDRISaTQfmMLJZIuxD6PsN6KRRAR2IUrgS4r6jwniQRQ06/E+M0MTaYke7SKuWCBEqjBAIWshEumIGAKAvXKuvUOSylpEoIqgKWyNFqiaqSVWCno2BcaBeg17JsrhnH2ilRtMDREhS14J5iWKgLKCugEAcPIADcV2tIprIKLuRRewVogE6A6anGIu45BCFhVhHYnAaHvrhqEDgJoVOKXC3LqhWRJfiZquwYFZFrhegVziEDoYgygatC1MEwrwWMDQ2GEcNqq98FqSiCN3IBiucibqwGJPvSCrq8Cu7XRsQiCdBOkvK+yxDT4SgBLcRoOmIF6BMUQCdVTk0guptLaY9mcPdjIbKGJ7cWpJuYv1Hj7Ovg4hxm+cbGocWBYZmr9BwOvRFGd6/fJbQHNStt9H6fHDAaCi+z5eHChBQPx9p9afVeDggCpQ67x4Zpvw/7cDdTtAFOz6uye8tm+nDIVK0q+u+zk3dTfoH9A/X74I5X7W/+8pjqftxfyH98m0s8sZDEaF2Aw4Hr82eGHYb5jTiLhpTJhqsDNV+dvNtf5HJuwJC+P5Xs48pWA4SvIUsrCKCCNlzI48f2dBQDQDmGAtE4vRYIIrHACIJFCPB1nDbm4YlSVPOTjoOMiKSHexHhpY8Q9KWse/vh6SO3Ky+DSIFS3hVSq0FWK7xRiUhgYeD3Wz/BD/8AOM6Nj9K/853BVKABTQ/XJvSApCOOVwqqQz18iJCayHWZUIXr1HnBZit9/wCxyH6WYm2B3fui2IFmxW6pAImMHzkbWXWo5LADHQiRihteAJOjuHf28DVoKGZPKiNeGkSoMElFvscfM4fLZX2gHR8r+uAUkAohq8VV6ezg6hg7YIjsRpHo765bQ9Enbpgx70H65qx4ET0/V6fj0OB2B+2gMMCWN9FnFc9EQipfl2g/PLZUEGS2J0w73krQUUgUBphaydbhyRaU3HGZvYfuV4mbAXuTNgvjZJwFIgr4ayf1wsLA1JSPlfwu8YGRuoGP5Cflc644jQuYMZGxoRIUW0xsUZFRQZFIpz15UDgC6vQL0AvEY7imCd4QcELoQiCrOaVEqPwCQ4VDRMBiOIk0p88q99kVMARyVgtYnEsfNd6k0tBAdwjiMTw4b2NrgjDiI9AnrYFAOKoB62Mc6QIUEXMTUXkMY2VIcKj0A0k48+TLqWz7CA6ijEMz2mEVuiGbS9HKpSwNFJCAIhRDEkkdgXKrWDRMK2zgyzjquAPrEKICIFYVOg+Vz84iAUaPIfP0r1EIpR0AVAYm1grpwpCB0ApXJMRkdqnSA0yib0/cGOTSNDUo5htKIERRYC9BDTVzTJWkIxyEwCMpRa1zMEZ4lt2BvACifXkoAmCQeIJ/YnCJaCizwoiSqyvIDYgi1tioE+DWyV+aAAChG1YVZ5KUJYkQgXdEciL1M+drutbeQzo2bqVKC1zrkWJAqF6F68eY8SoFRXvKd/jjZ3VIAO31P1wbylJk+XM5MOAsQ+zm+lmu1nfIsrEwQM7ivC7w31dCG0niZwHIS4bxi6fjHeKHeui/tv0cYPmNAXv8+fHDFAelR0CzAwXiTkANYUXALArP3r/5yl+uzI3X/nzxK6PSp9A1mM7M5dmcQA6D+57xUAEZji74jgezmMx+BijRJuKVaGHf38ZNd4w+H7EmUNhgO0daLmn0WRVXrcrBam2XV1XZ/On9XojhWCDQjovedj88LR7s9CQJWBVPl5O3fQitLIV2FyzlbcdAMR6ACPhe9XYwlp6/CdRPs+OTWkaZ59z7OMiRZViuQIBVdMArSvCulUE0ofS+FqWpYOijxf1xeZKS+ZejQMChYhyPiIKBPwHgcMMBn3/N8enAyI6UpBVwAhmcLAn0OuA9nLCnxUnoR1wYqx8d6oIIUzzkPsTU2lQv4/6cUfOBLwCMCr2Y5c0AKITpAPUS/oBv2qKn8ceOK/qV/reC/RMElYFAGfrvkxtURIUL4iCkRCoRUtjEu9YvGq+LTLC1PsJsB4MLTpaOx2Kx+BpXgPxaOjpRThYgdTi9uVVUkdh0Qe/nkOiLQD0QF97jnGMJ7QxvYSJeldAej78JoB+zr98p5iM7G2K1sxxUYSywHn/vDA1PiRBaIOvtt5ZfgcLRaePejKpxH0WCds+/9OYi1d8MPgwzuegRmJe8LXZIGroGacBy58CkCCDJDJ4bKHs2gElZEKAVTjs1DpiwQlMs7KK2pMFDDpnwqrjYSduqHUAEkb2NJDLHB+/kWwsgRQTjoMaIWUwsRUIqA4LAwedAoSGVLF7AwIPijc6AsEtIjmM+uoGrRoTD0OuSG0hkLsVVqfMxgU8wuASrIRSZUXhmwc5hRCLtNUScTguyhaYE5GAOA9TAhQDQFfQDpOZzpWyu4ZlTC4cC4tjAqtsUaRVFGr+wgBMNBR0BOCPIw6UJ8n5EaxgM+ulrcJ2aSn5nHCzCUBlpvaKhQk5GAKk0dEK46VOJsA4DHygQcZOCq00JEcBQYn+uDDKpQdYkDrscrm+wD9WnecbrR/RQo/T9cqTAJpOxQ60/h5LcpG1Sj76H0R950VoPr/uuKKvLtbsaen0EiMS/ZPejWr2B75B8Or/F7/jhlANu15DCFDOJhJfxU/XBBTDk+efUn9cGw14e5PHJ+0wJ5Xjjtcepmv7b+uQDQS60MO6U+Guw4uEpEgox0smY25OdhPRI2rJNp9z55Yw/nNAzs7/HGhAN3jr7gIVIJNxnCylGNX7r++PSw4kdEMvst/Lwq25bDEXqKj4R7xGR5FGqyivpNPAcGoQ7SVCCqaJvnBImTBxV9hBDm1ZOJHibHBFaWnH2c6gJf3aL+eNW8nxf2uRR8kYmBBMAHzt4xY6MZVqB06PxewUvCgc83bn/AESMQQ0OwCYioOkTERXYU4TNWZhvHZyTUpJj6xkR7XkvrL2NezfT5w0mHjZAPg/XwvG2xISQ4n7tCfM4qnAkISCFPiKGPrRLEruKBXfXa9nEuRLBr+FQ/nkuo8Ca6BtUWFvnGE89Qbn6P64ri1V7n/e8eReD0x8MzCMLS3i4tM5YXXJUehCE3jGPwwiUn4QaKxcGnV8lFiB0bsLniZExFiQACNISv2xBDZQBKgs/bx3BQT4TiJ3Bh2rgoYIwARL+RV489ay12Z10+WnIbdRafgl9b+4cId3NB/Kr89/wcrUjaj4I7U2+Q9eAyj+5dL5S748Hf/2HmZRlAnQhON64wEoEcro9oTZwiVKCE1x6ceS98Z11skUWgjQ8zwXz+6lp2EhbuXQUZiXqukgZRjeA3MlhUjRaEVXsePhuCXCdsEECdFbY6HtaeskmrkBRzfTH/BAF0AuNC+BzfgCjQ2Ucc1v5o+rULikqoZjgxAX2BUASh+JFdFMaGwg06ulShia9G8+ggKVQQe6SlutK0z0gILUMAaupdxYg0muxkUde6wGEHVAAooFEbylcobnqgKpQL6BoVORhIYnqcFvB43DbLEAEFAQapEPguiFTRVq8Aq1JhWCgTVSgxQ0QFTWYTQGuBV4X3uMEIKUdChCRxUJKiDHxAD+YX4OJBxSDX0Rr68PrgspJmM2hYFOnCjLRc13pL7QVvDVvBD7J0NfDzn0xd8AcakuURjJ+E/bxIMaPTFOgUV95XYcDPzQOuq9A1y81cwHzW/3/AHykvb8cHhq8hjKf/jh0VbUX/mZ+GPHKADIMHQC0wV3BjKHAUrkkHdpm8HsgG7762qtf35xvvqoXz/M4tIRQGN7J8cio2SADPTE8yt3nuCiaoLYPT9OO1eU+7GJ+h4Up7lnFny/H3xnADafaf54FeEQhT8JwNsusay9AOR8b1wpcYtW69HQoWnU++ddyKBWI98ceiyDgKm+tFGC4yIY5dgb9Lcs+u/fA2oIbkTopgEsTOSl6lttzraVoPjgRjC/gCr+gX9cvIknqMfzTyLPxcRJ7Kk+EPZyo1kRsinuTH43ggEPIvQmwiPZ9EGdkEQRiJEcet+ONobsmYjtXsbPozhZs0Pk3ldAkgBoEqFKwaVAGI0I/YGAmhHF8EQGX4Rdf5c/JbwCz9vLq4AIy+2P/AJy9SPtP7vL8M8hof7XjttgMNnXXzR/njjJ1qsEfozgDAtbmfmNgE+ocQShuVeRa5dBeR8sEqtoTSfERGIgAYig5iD/CjnpvPYmFysC0R64GTfs42geuzzmhiLK6tZBGIaPAKpqFNCz53/nlb7HHvAThYF6v/HESR1jrw05jhpN7B0PZx/NojQiKN6qqoHHe0MoBX84xY0K4OivREN0+wVE2sBSFjhwUaGj8LOABEXwKHEQsEnWLwPkTJawgV8NSA4xcJAILICUnsU9H3mZEYjSRO0KXOQIIHk+CxRihIC4iFr8OhABKS1jgMEua8JDJxcrKhSPFZAGEI1ORChxAGrBhTl4Gio4vCBJ0iCD08qUEc4xBh5rAm6KCjOuXqeN+iCAUhoOcAdG2CYmtJUosAinKQ3+IoHaQpuQGLwrx0RYCBsQo5YpkBDG6hQlxMVDdCt2nAAmsbQogOPLEFhCR72aDprxgQT+pivwpFpCuO0DnIUC1HbwFnvgrYwJIldakO4YQZb70zTWulVHqFwk3MpYUaWp3VbxboEqj897wyhip1vx/HAqMY/bxUUhlvb6/zw+1US+4T/fN6NXvdB/XXNoL3joKDBRmDAOuGLHfeXD/AJ5yhJtCIlfP1/XDeR9B+nzwwtL3wRbnSX6cRFARhRL7PkaPeCl12AfkG36V7xbl5tDBZ1p/PH7sINAoDsA/ycVMXQgY1JfM8456ffU4D1em4Z8UblF4VU5C70K0zC/PJ1t8iTPwMabnPSaF77P7ReFYEAtz5k/ZvzyHprC4M3r9cxe0jbbWmnYSX14Ot2RJVuWXt+6cAxihBBVBIQ3PJqWiYwoxwQDrynbdhJwcZ7OxJP55V8tAcEVQB7XlA+PZAViCkYQK1dR/TiL+xxm74oTB/X+XI3v0JrjkCcIgqHHPlVAXrCqw4WTqiJwoHEkaoFnXA3nXA5EgU1+D5nHAmVFUnx1vV2frhVgoz4vBB06TZJh6BX4n1yFcphKwL5O9cN8uUOmkPizv9frgmDDGqG/M+P8AHH0i7ir++eqOxgdrOEZKLV/ADf54ULQL8tXxIv65FWq+UB909d3eZ5dFXhnABbtLMBcs3aWgjBgKSbms/DQRCj+no9uPF78FYviT9hX0Lym7oL3GQoqTEcmbSQo5quh9d8cZ0IbR8P4UHzgTBX+mQTzg8ygMqJ3za0UjMZ/XFpqz5OubvOTXzIbOWKrjz4FsEnyVAhZTwhCAs+HYxq0CHFqhGgZkC+ZEIIpHLQbyjAYkNPijSGlm0aVdl2WtU4GkHoYJA0x6OCUCW2SccT0pRgoLTxxgaDWGckXWg4cdyLldkNAC9lnUcrOFGwBTTbKgyUCD9n1+lpslZa4OhDDRmVFhUrEnIeZRSkMIFEkQNJwAK2/5VOrdZLFqIaS0tg6Z686M4tczmlHYikNPVV5JwTCENphkJd7BHndubcj8yQArkxxfQ6A5IwRKFQ+RUmB+MDIkLWdTQ4lhwliaNoAhRmnFY9hUGEs0QaFYCr5LwwgCCVBVe0q+GsksRjLARIUR4nhn1ox7kWWB2c0yH7SyEnSAiPQqfKTiEt7Pp98RaXIPwvOyemu8QqltD54FPmHXnEXLkH8HkWLn2+k/T5MQog7VbD/v55A4KP4Ig/nkJ7kOLe9OOkC928YIo6D641GHSN4Pm7gxRz4RBHsQTl10oSjBMelGt7nFPksmjLFSlL6M64iSzEnGQaUEMsvOyhGz3qinvTeb7DNKchAtbpJIHuFUHkFHouKxqzz5eTE0007DPiP5F5MjKFOR2FIvRaf1wNlPXBi9v443hXwFQD9H+t4LMA64u51KhPLOCXt5zbRCFpp0y2Lx5DAGjYEAqBA4O/Y/5LkzkgAAKmZnLCI9+wEqe4EO3YgpMODoX2v0vMDhTWqz1JY3T74BXwJRkG9CPen1x9BdibF5CVnR4E5lX6dlqHYASuhqX6BCQlhEQfl5OKNmAyqJKBCN/FOE95xGmBfmzjDT9wXPFDWuHzhwbOhN9dBCTPo93jCwqyK2ihjC63xQPqKpXZFRbIerxFXUGBz6TOBSpFTEgQPUM4T6uXD+Cl2fPD8dg+8C3zB9vxxsskfED/QOIZaZXJH0qrimUB06FgQv5VC+CD2g3z5cOBZoWqLv+BzhcTCFRIF+Op0nvAdVgfAT6H365S0UCZl6ZtdPwjxorgBABCW03fHhYLRKwAVCmX3kch233zSf65PJAk8b0aj+biB8DnTVR7FpUW8ieK7wE9JLtaCODZXugKu2ogpxjhrDwhotgBAEUEEQJNj6oPvEiYEEAd6jnEAI054WWIAQPWOihbMQgjicTr5lVv5AiM6RG3h4061kTV8HbyS7EgTKFMQ+UAHjTqIBMAOvU8RjwFrRigJRYJ3pVjlSSAVMkAMoQLLq3VY76hEIOagXkwCzpyylpOMRdrg5EmkIMaQiUERUHh025wwKAigJAIREg3h4rRUCPUMGM5K6QO7GV2iVpUeAJI6jQIqQoNHl4evPFHe1CIlFV8h7Qk9q+FdyQERiAQJRCgAsQWiksW04UBjLrDRB3R8fBWI0EKmkEKRxY4Y6uSDq7IEQqLwEegPbtFUEQjdF4SVwpD6NKj1Q3iWAZgfPnipAwb8X3nZ1FwNgHyvh88kTgCA+Snb8jiozJURgs83747XpKeDGj0hv++PDzTiHyXX+Dh1IonOin0cVhV4IB3jI+fOoe/vhtKKLPvlYFsfE8TbAkDYQh0YNNaJx2FETpeYpk/xOFi91eF2H3CTf1T+nxy7Uwecz8UH/AOmjgHG/8DkaKDOPglI9i/wODJIwQJRfo2ZObBnsiigIVHz+HkkYzSqvvnpZn+ELHwHMgCKYFAr6UzT0euQsOG+63gcs5DcayO9ch98LiZUfhWwJBcFAOKbA4TL6JE9I8LvoS8SFLSgkGoFaCWWZUBAIs9hUzgCX5CgVRggAACdCMQ+F2gxCuEwx840t4RQBSWKhde31Jit7QYH4UvxT54DSttqUekn743ujt1CBMKuuyBxiJHpOor0sVA6eZ0YA5CIYqSU+TkMZ4R/TwosGm9a9/k48EXAgR5j2d/1xT+sIjUvX0canbT5Tv/HHwEQ3mPSMTZ2XkYEH+Tn7CvxORcpIfHfE+Y490j6zh9NppECD+bnU5KZRdiIQ70D2iuQiWBVNbRb2fnjDfL38cYKgH6L/AGOARTvv54NFNzoEjdMz54dszgCu3eVQUMACm9aLDTUGyJIQbjA2TAQNd3ibScwY0IjAxSoS+EHEsHDsdIBRARvAnG7CfhWtNkXJYOuFULTjwwVXJYbEk92SLXB6XEMBV4DJoyM0ggBfS6AsyplqxECkHOk0LwREzMIQBdkY8JaUCCCYRQHzyHV6UCUGR2j2kAL6IGMwSgIUAhrAl24B/wB5AlEVBNnL8TkrwqgYLBglA2+IUSRxXlkJWkDRAECkFygYgMAy8p0aZFy0N6lAQiEbM5h5vxRJIFoPGT7QkE96EIWCVFO+ADWA0sqN0WCowaShkhn5TROBUbBdbVBKgGw6MEW+fSjMWKx8EOFVrSyNlJSRNO1zoW4jbCYyphBwKNUWlJnaXH64BxKKrXzxPntZhksDhfBweLIrVHwB4dz5na8RwmfsYMP25au1Ar0h838pD1KSMjCfafnij2YdX9cstsVi1YeV1/nihPb1vOwA7DV4SAIfs3/XHORIMs4Sx178s/8AeIOADmAHUrzTQ+Bwl9lyKDr+XFCifplT9L9cwLJ3+OUBG6uyL8LP9uMGowtqAb/HOgKHwSX/ADzJi/pAp/a8izCxJcneEYAIIXmSSl7DG8lgXiZHUYLfozrNrBWFVQmq+8QdWQWACABvfrhTB537ZQVShrEKJXYzFk3sAsH2icnIsIAJRDRN/PGhEpMhOp05AgDsdfzNckxFAaSNIHiN74Hk1sZUdxK9dPIDdhYH1ev64pIIdEKAgYyl9OIMfx8UBXtTBxWpwNpqjqj+D74wMSI/HE6A3i0O3BQiVgwfyH3ygCfoH8mcUtg2f9+OTQw61/qy7FyQFF/FFv8Aj++W7OeAUaAoQoFIAXEeE4vBo7AtNY2PyPHeKQ93g0tRHf1+eMsulA/uI/zOLSTQ7VRfSF/DkmAhFAF6/iTeZGnfzxVqflX+IV+uGgOwzlk7IRwr8CIzxRxRR/r6AoKF0Z4uKgVgN9w8rD64M6PGygWKOneOuScaewhWrOmUJ85wKHohgYqYlWBQHAwgQ7n6EsWGA92Piq+YoKkP2wpwL2ZMCK7C6zhikgDqgqKQhHFwFw6Kn+8dGlmlWKlu8iqu20WQE1Wg7jmQOTObVUUwbPgmVYQZGwtNeAAQx8dRQeysKEpH0AVURMV2Nq1KO3ZqppYeGQkCqvCxHOsTEgmJYAK6VOCOA6IPBP5BxDl2p2Xdsx1ruqT2l5qF7yvFRCb8vVnEEwmJWkN6AqarJ1zK5TC+wgAHi57Cey1CekvmmM/himnUmkMWvOaLGXuT02uiTokjzvcEBL4v5iIlTjKiJdGaoMiVYK5IGMYxEKotF40DOxO9AAg/E3XHDHJDrAU84LidABfvtwqy8EkozkxARrqbLWbF+AaQPAg84VUXRycm264f54erHR6TBDh1rlICF04qYf3x/XTzX/Bg7fHDEYQ9tnr5yDQmkclg9Idp1cszLfShFcDTpftwKDpB7eH/AHxVE+gZ+vrmaLONKJ+kXLsF9JhH7fHIENBmLv8APAjDLwMAq7c75bBD2LVnnY1JHQOTZqlJC6dzTo4hMnjfAX+jjN4ge6f5nJjSQ+rn9pzMpXqrl6/+cO8AYAdvZ+V5YW9WwHwm1fYfh5LrwpPoiC/Afvl+U6Wd+cPl95iSMC0kUhMFOIonJot7FXXN4B0AD8LOte3PxOKpqUMDPR8RSq+PVnyvfRvA2jYWTe9/4d8330Crv4E/BORvIyHFoOXdY+8WfBnQitgvf1xEkSUDR06wF36n1MgGMOl6b1/fAKESJvsCj9/fHwJT6gdn9vFv8EI/Mn+OOJSeOW5WRR35xbADpXuFCSgqIeGFuSpBBGEW6VgRByF/oMF/UvnfFw6KXwvAVRrOhzhEKqRHpwNMUfHvbF126IFP55spFnybwgFtCjHfpH9U4d6PVIgV9Ih0yvGX4kBUlrpDVGJoteEoh+zKf6SpR/5I/sc7JMFfniQxfRQ4J7SHC5048wNgWpYdjrvePJESkbk+0/HXJDxR4k0oGCMUgcwfDopClCQ2hC8HGs2y9EoDjkcK/gE6Dz3qpqFinDeIH2Q7a6ESNUBXUcgtzdcVAafC5FQlgQwPSMMVcqhkVWIJBbSsAUjcbsmh2hqKGFLTgZpcR1TABA9OQDAnaBKCqKBppDCAUFGjZTuGogi7CD9hZTSw4ixkCrcLJ2oCOIgMUQfBREi8OwiBQtANqg8I6ntgFOgV3xe2PduJuSpVLSWoqtz8TMIgr2kiBAY4VY4+27YUkBEous5nWi7bTBTKAS+Vbr0UmMd4OlVdFaZCgD0YdFYSAAlizIqalGSEiptUF5hst2jw7BXtbCnDvGOwQCKVAwEnGuSZDAPj9ckTwNX/ABzfeNt6eKArouI8Df0RysMihV+XoPt5RiBQyhQyqLQ6aLyHjbkDCuiAFPo85Zw/zyN82w0B6CF/fLaKGBM+BIfjgp5bgXBugWt3ePTqEKesVAXfzyh8lX6va/P/AJw6aLA+8IVFjtIA15CXeIaGM/ACl/YBLnN2lAaQB8CK0NAAHnRWv8GlxTehn55FtWYDRAwN6OTTw+yQfuR4gWAhkSkwL2Tt74BPa6dP/wAByWGFP4P83+OEmKMcCgMW7o98GwIf4xf6nANRdEUe/nm2lD94Or+Ob9EOr5QSciChWp8+SfriAG76vqL45mYB435YfN74JKmjenyDE+nhSVCn9agSH2++KRWSAaVZZ/8Afniv45WUSxDL+OHiRUVC/v8AfDAVDbRjh42L8z2ErM4gVSGU5XZ8vBpJMk30Mjh09eM8DELzUQZ8g8aWujb/AB35xjTKMH5q3/5x0EBbtQBUx3X4ODFYANh2KVULJ8PAbZqkMAo0ptIrrYW22pQRYWOHByDxtEe/CSQAFTlZ3zU+kQXg61h5wCZgH6I/oOFsp2Ae/r98NTRTYjY2KRTxb88NhnwT5CVVhRecBDsQex4nvnHSUiEfv8Jp9R5w3V8ghoEJ0Ozlvx6O4tP54tWVlCbPTF84PygallTe364+AGxt0Ug0a6w8JBAiRdaK6uteNV4cHo67vZ/jlRa6gNbNJ2OBXjt77LIF9tREBqnuidUMAajaypLWo3n11AbSAeQUtC8JtJJUntnMQrrBzujVI0zAJ9gKXgKQrmpIAnuAouri629NUATpoihri4RZTGE7xZdN7jVDNI2O5CWJCxCXAUdz42pNs/Ri4/YBQlbHSiKryCI2UGCp4ImQEm4Oe2Amw7FAAIg63s45pfqLGFSAqSKo42N6k403CJ3A3yhqCQVqiYQFVH44iaBQBZCUmA4QBoWf6oEOAGBpCJhySnYNA0WqAlEmEXfN7BJSKUSCVUYbxON41iJU2EdIW8JFRBsghBAkt2Dx/wDgUR8oUT4b1wTvT4/9uMAU5wAK9atf1zYU3kC/txWr/PL5k5Vo9WlqhhWvW8iZKrPxVY6w4O6Z+eXkFWBGiWBQ+OQQgih5xLs3ODWVIuAe/i/45oPYrv5OZuKpPn/4X+eNQmQ/xsN/i/fBDcVASrw+6/X3yCpP7ckRgJ+s/wDOeRCP+P8AfCSe2P4Tv+uNoX6ERU8M5ZgdCR8iZD7eDHxHoF1YC9/XBhlS7zKEB5/zOHECDYCVmesOvvkEAT0awEVDO7xa1bUBJ8uOOKdHRR/hH37w3enot361PPOdml76fs4AzzAF+UE8wLGpAny+x794mKEGUGAwXrycXjZS1Pfd5DAGOsPqv/fXKDeOCaiKoV/nviqxIOCCClgFj2J1wsdWlQSF6BNIuwKguHENGYaj3Q0nDAPtAn1l/bxda3/D7nEJ0QM59sP9cLyyEfgik+h4m3noKffdwNpckw0XtY/cs+uM+zoAeACDXNB5OAsfp95KFZghRDg3NhWgwv8An98fSU/RvT/rmEfECiJ8cplOJIUR/AfrgIkh+WjPvtOUvLlSVVEoHj6fPCGrWC1Fw/B5UmhftX37+eGD4j7A/wAcAlqIXOjUpxWgjvI41YxByXKKEsZgrbHPWT5Sc/ZXtPmj2OrST1NCtGHbw/ahOvZSHXel/gBzVBwYFafa4dRNdVlZSIMQlbdClOPdYBlDEDFbfCDlcioCo+wABjwOn1rJaXJEAAJ15zLfsgFIATtSMw4Qake5+uTB4CrSFxxeIrENESUoPUEZGF0LSICV0TwcOpw+nQZ2+wnxyOONHTRNS3suXriN7QCBzUmEHBe6vCySgVoKLjoiOkRXviUsB0pwrYGLenceKat+UxE4sdIQU4QHEdAEAikAUUaY8Uq+ze3Us5FA7WAB2OFpqREIwizsHCqrrwbqpQFg9qrvFLmdIgJAHQ1rt2JOo4AVKmEI50RpxTJtkVABRdRU12A16BSHFCYkkhxczgXpzkZe+OC6alZ+KXhjVl9Izinnb3yaknvzyPvBod8fiO+bkXyO8QI8A+k/v/HB5uwnKqq+8mlh0+1PHUCgTmxxr+XM1WEzRyv0IiqN43cU3sxBdk9KvL4omvOAcoRO1nXHzAovWEdETrmlfthS/wBcUQ6G9h6I+vTw4KQQB+Uovy/jmUXB+EOd9bohV/nlPQDUDZovXU5LIyxgMQ68/fEyweCL8q/vn1+QUHuzLfjhQN3ZpmKV++byIQeTzV9/x+ZiAAq9iQFdd85ZCyN3TGHWpyYSgOGdNtffRxKYnVEdXADfqcqmEg6/w9af8cqgbfSPx9H/AKcJMWe20NviMpI4gza3MqLB7ESnz0dLJZSCYVpr5rb7JaQAQslpKheQoAULx+WJ/wDnzxIMHdEQ6mkp77++JxYqCZ5j44wDgAo0Z9euZ/nlxXdl9rh/3U/XISEttPqf4OZOjgC+3t+/442Ipp1j3OpPx19N8lnShjHhpnQrhzprsKcRKERWE3vVOJCH1rQIDRNOQF4LtsWpVWG9sx88EpbAnRd5JL4frkj5J2WSkFeCmHw5s1lRUQEVNGJzBv4O2HaU6XbMeYmxBNIVI0OUfOjrjOCXYL4p5+uHHnFn5kH+udQHgN9Iqd+PD9pohn6hxtQa3qmPA5KvlPsMsdQKo0RryxWIfjfyCvk9PAnL/Gm1IdTVIsTil2rBVPUsAGLwDV0BRkiCS3L4O+D/AN6HyI+ksWLC2kRDAhZLRtAoJiDgC2TaFHbo4EbfJEBawlF622XRYpNL9Lun1i3u4Oxa7vhYQxaAgClIAcpmeIIUIvTUPiPGceTHWCAAqmCN69eGJE3zQe4PY7X8ctR2I6E2bo7oextdWITRLByFZlvGJZ1tbK3VVOfskesxVIBMOLALXgDeFpRRcAoAw2NPPCGY9hH0QyD8UKO4vC4I66j5AHipWPX0KBqBcPwcGlv4nDhRG+8DJyzogfXNgpT0OC0/SJwuo78cS1ZwBj3PTgDqnDK7StiWH9H98QqQ3jEwph88DZSjx6n8pzZef58oMbGqnQH55a7a3gikkCiFmXgLGczgBGal08d3npRxb3xLwOChpRxKFOFji7qzo+jrVc3jCpZZ9ctYGW8vT/PFAKlRVRfzwixX55I0FLO+An9lMLhdzijQrUbnk3re8OVrroMk6Hz74dDHgHv/AM/xxdKRGPvt7798J0xohf5XhgN4AQfnV/8AmcFWZGgr63Z+D3g0GFr5K6j8f28uknaN+hN+NeCwlagdExT87Pf3yQACIFvfo4LstIjx7T9nf64SBIUx6PP675uMO7m+vcx+u8vIouBRbvfufP8Ae8AZMYGC7Q34+uGHUAlkfQ37f+eX0EiEg+b/AB95+uSgVLESD9PXEZj0USmd13v8f6UaViWUdE9fH9nANJAQ3eod9/8AThUgGpAX57zv647wmuTCx/t4T0KHP65YekUKt+ROViLXu3q+TzjY7AsIr+PvOCNM6+Dp4SrU1I2Ou1SOtfPn9cW1tqKfkPznLugHg0ZaOynBhovah69nAicKAAd711+uL3EbifjqfjkgMFda/H7/AN8QpaSC+fH9fzyKTR7So+Tz++GXuwAiYvQNE+C/fMcBdMMj4Dsu9rVxdJgCUhVEgIgAJ49jgzfToM/cCWp6Sxi0QoHR8XpmwrnlOAESQCG1Y0rLcSM1h1BKYc73uOYqgE7qKK4l+aCM9lUE8R8K0vHolL7ggWdMnUOABOZxMJcBBssLOAJACEK6vYhZb8oiKchKSAQEFElTeFRObV+cQGnZ4xyvEGcKoFaPZ1wgfKiyjhei1TrlEFBiBgNK6nq8efJoEPNRpX1Tg9nGyRNgYepAYa4qqZHShgKI6dA146hiAC8ZT4KoiVeBd1hk+p1bKy8uQ9ThJHJ5wPj88zMZxAY+A3ngKyA81lhjPnjCunu8YLjQhQ72t/rgOp3wbFNU6P8AYP8AHAE2eHnKeT98xcFT4pTcDoI1XfhFvXQ43uWm5HTsURltXBFBNGprqIrSMCvMH9Q8DuQrh1f/AHlbyETycriLof65eBjEcnAPty96hwAvf1ze2f8ANDE/XIX+3UdIw1ghyA3gCZGniPzxSaNHv4eeIOnWafsMfw8airGgT1AP6PeeQvYM/Zxthu7r/XGSiCY/iHMsauImF6W/1xCSuhL/AHXK23BsfSThQz/+Hg5jOYUf1yG2IAh56z/F4VhfJ53tfPo4YE9Qo6awyr8T3hQmlPbL0nf+84gjgGegN/CTfniZKSvxHl60/wDbxy0FpdpKUH2U+fPeGTMHsFqm/snX9V2ItOB7nefbvj1upoOlBPr3v/0htMemeOn7/bkO4LRBbVgkD76M28Fgzl1Vfhf88WKAkmRmZZ7/ANvE+6KEmQdw2+EfPM6rG9Z3wV6KRgIPkGj7/Jw065ECENVP09fOQhIcRLlgY1QxxjwzKbmx1AgFbaGooXojiEXB3qugzrgkc87RFCF9BEV6eH1buSBasYAKFWzDjDktb8RJ/JfvlpiwMPLV3l0GehMPgQ9fPH9fuV/DxVT9qz/N4kKklW5zvZ0hFFO/o4dO5ewRh6ERJtScUTjCFB3VSkkEUYDHQd5CiQwu9YzwZikN1wpRRVVvSPJQK9voggD9F6V5el4xADAxSBwGmcAKgKgFaGYxfQNnKefRBKq3YaRgGcBVVShEECpBro+EtG95pYM3CgCedzQF/VBlqNCbB6UC3BWKna0t3RTRu0dOsYCMJ5ejNH/Lk5JoIlHzs/nmsT3dNAqGEY1m8SlojIcqWcZ8j45hxQddLjBESsb0L0fddUolA9AdvnGy1RXQRQEjEABpwSs7+DjjOr1DTtBeMqO4J2HSdl+d4ziHFElGNDjnnucwY3hnI58cDbtNp5z4J8E5adIdfXGi1Zqv6+D++JFVPN4FdYtJp03jQT8//vnWLOi/7uOcc9aITTEF7QOFlSa7Cvy+8NskTXr/AFzCQxwJQRSAVVEIea1KVeN8hK/Z1xiShUX+uLHjwF4NGpbV/XwcNdOQA+Plfjlcjc46oEIQ5TsMspg3H8cHAZAVvYkPpfznCV8rrH5he25/fGctNetEnefXXXhpoGDXDaIzo/8AvFSgxFAt69/fEIEGDf0dK9e8FLRm7CigDuh7/nhwy4gA+lN/99oigEPuNIA6/wCOKEIKgJWgAdMuf5WmwSKoJVnf5cOJEK76q9v++al1cV+vh/Px998DtqAluQpeuziAAYGpj3/69nxeAqwdakfg3Pj674I6HtxAdRmhk/8AnFva9NdHx3/D58cL7SzYYhRzrTJROryBOY1CdW/r/uxFZFGXUNO/f98mZgDwl3Ouv5BnJoFUWgmTrJv98SmICgBNFP4v45ASzQX1fj1/754jAl1YK7oaAjuBvOsS+/lIR9ycvkHCCiLSjWdds4VFWiqNEchKJohOJqFUM9IL1qWnfA/BMdfbVfyVIecmjxJEk1EKDLw2WkSXDQZoAjB5Frr92wIHuK0+OGwetg+hL/kH3xUAWJU8+bz+05myoW2zqzh9/BmN+SH7PD4BVmsoXCvuj4euBkMSKKh2vE78pTeTjMy3ztQcwB3vg42h/RUoZNRG8xkkLT0RF2GbujHgmOrQcHttmCmxmi5VHFoG0w6A6cRh9jLiqAAIXoUakodQXZ0AioAny5k6EaoUmQ0S08McAMpIiRBSM7H5k9YqfrSE4RHOqIdkN/ZAaFEV1hS5hGfmuXwRkvrri3HAHpAb0efVf0dSYCAPWaiocom0eozvZQ/3xRCSG8KroB9pxtAhvTOJUDGm9UITTC5MaDWG4btvCiQwgUKrWiAdHxyGWeGQiYGCHtTgxLZdUYHudDyvmDDsfhIn8nHgH9OI9SvvHIUv1ySq2ZnvFTb0CWPvXLLN9zrg5CDvx5RyEh0nv765UUCdi6H/AJww+pnIqHH30/fH1GaTQAdqpPzwHJMQgu0jWpMS48+Dzf8AMKh+ocMWRC344cxRTfxyTKaqI8ZLNHHeKxTQYfWtT87/AJ5++KdcoJdP7B8vGIgBRQA9M3+OYbKk7Q+OR+HFVsVRJ8Wn64gEK2A/gIfrjStzROAA94zKPvOvrilgf3xeFw2fXBVo1w+uSob58c0us73huB++EeEA/dAETvvncfzrY9BTLt4M8aoPpCR30++s49wEgBBCdHz/AOPRwEnw0UsTDCVtu7xQ2ogTUAx8w7+OAUQXtNbXv/75eBAD6g5137vLAOwsd90DA+uKRAOun854/wCdOfV9buN+f+nIytwIFlEz48+vQ4rRA2v2Pj3/AN3hzfqCscPXfjed8rS0Ge73m9/fIAIVbmRBQcaWCyvBOaFLBUHo2CVLnGm7jgM10js1Rm8hdgQPvsKmVmHnCveUi/J+w6PffC/qXFTuLQ12vBy4vKF6xAwqd1564YBCIVak+yrvFwCGAAlXfK9g+UxEcZFBgelrSjfniyPqXZLga49gYR0r56MAIkpNdaVTJw4lLqCjMAeke2O4U5eKrAMnUibV7GvMQyHzGCBWMQ1OIAKyQBAe23KAxvDTyJqZBUEqrSlwOIUyz6gDuiPO9yHDW7glgrLiWrksvEO7sWJKW4aaBjGpIhJwgGEVEAosWc1CbaLdpgUSCbDKy1BlZ63BHhIhK1UrRMOhkkKiUF6d55KqZGnUiCHbUSAB5TkjECHCAIcH+lyZA1NqhJ6nNh0UA2PcApWZy5thrCgSWe/LvrhmxbMz4DBVW+/Lvm2JjDEDkaqAbzKSIUG4Sj4lJ08GLOyJL1XCvXQ8IdZXJFYHRHXlkmCIcJYJR0tQEgoh7ogp2pQq61M58+oS/wCQFqvvHyJ0/wBIDhmA+f3sN74IhQpg/LV/jksXt67+188nvCb076py537zYWjV+35E8feAyhh038Qv0Pj5+eKG1kK2sxPJ/P1xYUfiJqVp13+/rhTVRSn0s0/P9+V4hCgsBcpvm7wBdsthq/T+uTV1Hoqgkl64Nc3iKmrBnJSM9in7953Ekrb+HgtFzuX/AA84OpB03cnWzmml7CfShvNO52iSEzEenhHQ/jhHoD2f98ccSGa8k9v74lMJwg0E559if4w4MAvuJ6dD+U4wZr18yao9ix11wgEwJL+F35P3zeKjQko9/hcH2U0EGSVXLoOJIr07b3/nzkzxe5cywNR6P0evxQACqWuFuMLcdPCxEKYStXH3PxxCPMINAqSb8p/nkhC5uj0vvb51vJMZUZAj/D359/gNlTSgElf4X+eL1gAhnJ2D1gfreQhMUCaTZPmbx1hAncb8/PdOMTsjPlPn3/vxxNLxE7N/j9/XKzOlvYmq/wAecDEBgXI5+OLTEAj07vR8f3wByIHTevY35++Idd7a1UfHLdEjjPKgu6f/ADgqQKgE6we9m+JIGBJYo+oCiV+LGicuGyw9VWt+DoIFdeB7b8tk+tC1nG3ppMYMtU1IjRvMcpKwIFWOjpFfsSKJQdCwMkPaR+eL8K2L4Bdnbje++MZgqaJAvREND0d4q5oBslwim+IfTwIShKQQTq2igLN2VnSkYZEvUpg06UxOAK0tmGa090w7zeLbQsRr0MQAd/D8oEU04BFWCRfb3+pCKi/Qk1jqmGbzsDaFtHhBTQR7+eDaglwL5vwA0a7vCEqQQKg1gcb1T7xTyaMBUko+qDNzBAGll6ZRyAUSvZacRWDIaWtRCavZIq8DkAwZiCgc+9g1NnoKyaX2DA02RkWxlvHSBClxNlvNcGatzeuiGxThB5BlgxMROdJW8KvexJuyyCgR6qmCku2GQgYUZMfA8buX3pAK5pJ08aHK8IHDUoS9dVawKvEKNjAgtFaOn7crbxBUd6Od15njFZpRqcyjVCFcqiFV6rPQwnGnXAsZ52gB/rhXQzJH44ZAEDXbz6MHz44/JL3OVYv2cKABPz3+OuQHaim/nhjcPnzhTAYXg/XXMRaJlfHWOQBmAhXOrxge2Jo/Pbc774gM1pUlBKb198Vt3oivxg4/YA1k+uuIBnBKQNOx9cjYIj9dwST65VHEJNQ6tn/6+80S7wJJho90Rk/bbFQ79RCt9198e3JP2Ijf44BGFm/sZ/15qRDSbj03XR8vwO6stFG/cz/f8cddRYNJaiE/Pd874wL8ChBsn5hT/ePplWoAbIH6t8+d57pFCbjCvwr8PROBAEoJRqzrOneLu74BolDBxvu+8Y4ijcW9X8Kn/l4B+6PVGC//AKfuHEabuJTYa/V78/rkApoUPXltVp38ZvWYsOtlekfHfvpvEot2PTsrK9zzHiUMGg6V0zEL18/jhpFAlEo6SPfvc9mXQTFuCiqPPpft4HBwIPrMR3E7PrziLkAXwhnb9X3+ng/YmxSf8f198SwnCzocj5S51O+F9CKVB77807c674mpIgipN9Z1OvvCcVEGuiivb9/H/bxRAMRADJTHpcSX46rFtDvVRoQn3Y+p5wE9N8oyzu+fKTviYpBXwWz4Aw0+8eCIECba22k3Zp7PxxtfBIi7GID7vXxwuNSjCj0Q8dduH7SVDTrvq13f8cbeMJNPImaDY0Y8EAgBSyAAR0Ae9jwlRSCbjV5b5LTR4IYkkq0Oj4D2v0hR5tNYBAEhiTc41q9Sznt2sH5+t4FIaKbJemC/hffh4XYK3Ha0+vr2fl4RLBIhC0B2d9xSnEKHS0wjKisJBj83i2aAaLQkeQgdhRsqk0VDyIncmwkQyOCXLA9UCmB+ApxL2ADQElCdqftpLPFR+1WrEUuLBMe9OuKRrUmDgsPWFJPE5Q9KixZRaYJle4oHGfosoNXQk+ux7eCsSEJsFoq9Dqo2ElO1iUVUfkek4DQHsGOwpGASHkKX/uK6cDIN/edZeP0IIcqChCBLhIOA3pEaMio1fAiAGLwLerlVpqqCuY3g8woNkNBvgsCNwxKPSiWWFiYq65VUeCimhx99/jrmiiZUg9QtcK1frrgya6qYZEOjNDR5XilJWgJFsqNK686R41kwJAwnKAthYoEUGL2P5deYRsmPX/ecVn0e71/3+uD6B0Xpe+OsBaZzuafOs5or70Xgaqd+vOat3hvIlrOu+z3kVYkQCl63++JdRvy8QBZ1PnmMLc663z44kJKpOIVa238fHDoSncnf/nCV0yAfCHkuF+Y/nhAVYHTx0n88c9MwznkDfPeXkvoz2T5+vxwXXS8RURqa3ro+5xejAVFJMyLeroezHqWGkFJltLhmL5TunKJijI1SHZvv4H3gBIBFE6IqS+tjfXFMocyH2LLiF385A0C40jIPWQG5PnlHXJQUdIsz8tt74SqH0kVIV08/l96BEGVAMVgv24X4nHTiQFCaq6kZt7ucQQoUvQaRLT4s/wA8bX0T4Al893/7xAzRaDoQlQwnT8y8AMbrCgKC6BixBn75kaEIwnyAETOvfeBuOTJ1T3wPn/XFoXkxgYKYSseGKNeIfgz4rfJfOJCeSSK9Vfkk/wDvXDvtjJsOuvSPefjUIQ8LU2hsU7/44jtJQYfPV+L9Zd4Vujr0OV9jW/zOuVVFuM0NYdRzs/8AhkVXbtAfkgIp+T8cKsLQJC2dd4HwM/HJUtKq6DIoy305oXySQt7rqfXvHFrSqxyrAkaRV24IPA9ZFyHBXOq9rSZHJQWivurrb++UO7qRANvvxOODsouKLgT1MG3CwUShUBJSxnuHqCITRhW26AnT0aJxUsV7KCqwTt2wnxyUc8cxA/J15OnjIfdILQGA/DHa4GZhu9mCoCy6ROxjxUNAMGl0kJ8nR7GcTWfllg6LIfzwhLzgjNvcCKusFuNIgBT6D3Yr2fJ48MUvrKAMOkKYoMT54U9HD0AVoFdPLnzwp9QrWuijZiyz74yIN2qUHNYNDyD2Dwqm300QEKEPz8q0XOn1y1IqkDA1G8mIsnaBa6bC6NTYsdTWaOoVQsH1CqA0YUTIIEiIIjFzgSihUkqIMUqDtcO7xiXodQQEQIAjR7o5wVPxE2ANMzZPvAXhkkumr4JCgLHheicAArCNxBVNTi94DCLAgQ6hyR2nGZRUTwsWQjs2v1xSiNH2B6P6e+AOqgZ3vWp8vfXNQ7gZcPcJd7fzzaMpDZVMHfyc8iUSg/aC0CdAQw+sn9rSRe4ql7e+NBTeQdCWm/PzwKBUG/ngA1DqDzS36zeJFIK8wqk9N/s4hYyr/XFAid8GI5c3ORWtONA15v54CdJ35+OBwkC9fPGf+OAEEWLx7CQdQOKrW/LwdkHj9QDBZ1sP3w3LUBRUIo7+NL1wRRiQ7mAOdwCneNbzFcTwNoiTN9p/XHUEQW+BkfRr4ep4caFFFAn7Ye9LiG983AoTt1lZ5vWG9e8W6hRoAsjkrOvn9BmKYDtfXa5Jb0dcvIdsUBDUt6/niRgrHUPtHzBG6HnqCJwiDoBBY/J79bwqUgb/AEM+U0n+OVrhqaElUQAO/ufPAE5PJRofk6s2GgcBgoOUMIgK/IH3iPOzqoUOtAGez9uRlDbFMVO52P5ZY8SfAAx0uwg7fx/HDBOIs6DPjoc/+8qEyo2xDak6/wAfyCXAqKQOqfWzPDzOAImIhs135+I+8uRKCqoWgk+m5/HHNCHYDo+nfT/IRcBZE0CAY6UlnXnLekeDDtTr56exzmBuJcCAPAV6Pq+cMyIcbdCLTGz+TbJwUJD1MUkkfGucgTb7qFeImHd+3lPRAaUhGiWFCFCWWQJJ7gOC2EMTfFU9tSBRezU+YDZ1askEQUvZGSdX7/Uj6L7IGytXQMApIWigUpNA39lHa0aBPsqJAABUUQEtOe1bSBQwldsuZt4PUwaSy2tTrM6/xRaQCheyYNzv5TeC6NwE6salude750oZAKKxIR+ep1XghZAEjWmWNiFl1nI1vFSj+gp+3qc3QEBhJaIUi6VvtIBtiXSrCSt77760hShxMCInCBcRfgDib+8w+mC1GvYBBTkmozn0AkPoJdVGJLIYNDFARZS0Ze7WDasmkwWaYh0NtkvIt6MawxYsKVPC+7AFRbVtP0/nhxPQFYgCgeeknWTt65mhJR2M+Jl6ow8kwEm2Ss6FgEMJ6UsMUGhpSpTy5wQJBGUM6TCEJ0YXjDsMAMY+gwboG+yxbl5BpCFAr5U84RfFSg9EHxvfScrnGrW5fz98fBglVEok/n88zSzBBAIveJYzHyxDfkQxkHQI7G8MymSFuNB/IH4eAAAgaD5PhwYBFvXrC/54npsUpvD2LTXt/XXEfSp3xc3DiCtbxSREsOHKWmYkCnmVj+3gqi/PAtVvU28UnqywgcWFCJJ3d4BG5+OQovyOCiLtPy5oS388F4BdQ+fjjhAh+v8A5wVCRqkvcxfGfL8Zwb5IOKF0jnd/g4KycaRkRY9Y346lOuXQJwGj8xZVZgTlUYxlLCxgT2a7G8BO6LQFxWb2UrlHJrZMpRAB0EPjv83rpCyCBhgIIvx2H3hUJB1siJI2b79fPO0QCtDrrjqP4y/CqNCmBqGQfh8+PO0joqmUJRXcqN7zvijcaE0Bq7ob9vu8mKCDJ3qxN76W9HycBasVkoRF9SHC874RZwgrAQYdDbbPvKPDMZSyej5f8JJnCuVEJcIVX1bEpnzyFRiDgZonfW/ZPXhJ+OEU+ULW7i9e5xjUraEFJG7Oxu+G8U0bBlrAZ06fFHvOUxS4QPKNJGnfeTi4+sQFEUbcbCI/1oyqaQRVn5zXuM+nkIO0YNHqxOsnz1cLES53Uo9A6d92/nTvaSUg0O4Wl/E+jkLxpZJGYX5Q2ZmfEpECjRetJU/7lnGZtwDelI97/G+04wQ1j2AJCU7Uh8OdyjQmsAC6UrgZedXRCrMHEA6oV+Cmg3oKBKkE7Hq7+eULNg+Abl0fd4qS4C4SjCMl0APE9MCzEN0/kVIIKq6GkIhpR7MKE6ZxJVsEhHYhq38+cUmYVVaZFRe0/X7vHapdWDJYCkvW/Zc52v4DVYhhZninWXgd4LujBA1koesucvkSXd8i0cB0Tt3eOghUJQcL26cckQVsHZzgUgbCb3nvGXQrQFEOoPFYAJykrRZqgGug1r2Dwx8wj9wUFCJ4EQ5lwJHQKxBUAgASYp8BGIKaUdRT9rr4KAHfqoWCOEZg9TjmPUAggWQYUQRWFkSAGF24RaI9CzQqbRRIuoo4duDMsoT8EGJUTTOg4twIKEwmK24lSjy8iaw0j1BxiLrYgDiegGVBBwU43/Pe20QMmrBsNFzBG8Y1S/Ao+cckmusWHQBIEEK8inB0q1BCNKBTeddNdhQqcphYI4vjlncRSplzGkVknzf7WWHEAtRNPmh0HvviChLuSckIEmknKko4IXlhZvx/3/ZxQHpSbeuXf5RzdQ7v/wB4fyQpDaTPz/14LSnfD5z/AKcUXYAdJeIyS367/HCwSk/HEYM83lBEivg8wFdXXxxjK87Fkl4W53yodO1k9DV7+j++C6VC4okUYUA2efeBQGkdraFPzeQF6gKgvdikwcrPOMQgYTRYIA78u6d8ODMjtNg6xCjaN644q4Hsha/KIAXvH1+YxqhkB2UM+ZxRQwwAYofO2/ZMvMFl2R4DISBkdTNEQNLGGQB1tM7+mXrlR322pD47+e/TzVTHzorRaDxa58g98bKZIIwqe9M7zDOSJIIlB4lzr+fjkngGFe1phoTeqQvDU0I8AiTEbod6nRkaj1CwAoGgHtzN+xANrOgMm2L7+r8IoRiTQrVZ130HdL8jNo0lg1eiuG70HJPVQSsihEfP0Ke1BqoArC4i+zv774D8W5IaGEJme2vfCTCK9S0qn+ObFFYwk7MTobvMYhaAPg71c2H08idYDVv6wvp59XyBCBIJC0g29vx8cDLSmLt1bpI/7+DbdKegtGPYz6964KCuBdBXaPQ66esvEaJdIAU7UGJC1nWZ2nc0o/BtE7U0W34KmBIUXChVjC7lIOggWGaP24quwArYHi/r/wA3iluldDRUTGsYiMeM0zl3hYMISgFUMStcxXZhJiAIhERm0iglrsfkX7bd7ykz2kq1NEMRKTUu86kIwcSBTDqe79cmqaDkROpURriNp3ztoJCBJHpnyk2bSQEGHQs0dNRAgvRy1R/Pa5MelUqQ6U2aIiehp6i4aV1nGqogwvIh6xL7kTycieJskMSgxj+QnAA9ZDoraGBJYnQTeI6K3U6O66uGU+XieAvDQgpo5bl2XeDOf+4Wt3wN4zoBlkV82U6gVao6NXndW7VxRIdXQF4aAAS+QLunTUYu1t3yHTgaZZFcvkLyjU6ShPsAKxjYkGdAKIgh0604nkNkt3JDBCBVAJY+AZlEYIBCveVEU/53rmyIAO8qAk6FOilyRK5w0mlTGMiKyk8Reb4y3OyLYAMB9coPmxfkjchLCEZU7tiUihmssHPTyCOGWxeUtTsp0Z/31xGeHPkd/wBc1UTvM2fPvKx8KQm8hsIK+9cQVCGf0/zxIU09fnmAA67984o1k94Q/wCOCO7u/TycqCiFr98Aisy+1/8AvHAbUKnzwEnpyBcgz75mgVQgcSHxNziqoJ1xxqBSD+B5ImnYFNwX4C97/DWPaGj3XzLnvzyNlCaDV8NWd/C5nAdmCgRoy1PTO/rbCKCdMwD6zbaI5naZkFRP0VX/ANvAG3rJYUU0svXu5o0hhV6n4WFd77eKpQnREM/iz+84QvUg8M7jcCfad7SwmE22RaI61/zxlIuKxvDR7mkfnvlWzqoAaBoM+H+guZjbh0Edevze/QwdRfREH0/P7vKDUuFHPHxXXgHxOOTxNjaaRvRH/nvGq6yS6JUb8HvvL8ORIiKjcLXp7+5xIJlSA5+Phn67+G9Ido7cI7pb+uMrNeg9G9wGQ7nAZkOAXEib5/rr3kiK8BgM991vXFFhAWWBakew/jjA3sH4N3JBuh8v1zJ2EosKLPSX835PGsBYAOIk6n+nUdKn2uoEo7P4/v5vwuoqhUX2tG5mfLUfsQeiLu0QbtyLhUreUJBECtYjy2jQCp9KdFMTGXjAVgZA3dbn/e8+TsgURr347nn4cB0LLo0bSoSaQqFUznVucVIIobg64CEJ4RFkGCQCRx4cnOhD3U7zBJvfAjdSbgioQ6MGi1e+aYsDVJ2kTBAw11WFaaWEogJOStyyR1XmEiMW/E/hcmL2GfSWo/Gw7nnAKpjjpwBKCU01jhgS2GAqROxLSZgQ4l8sRs0EH/CwlkGwTkoAIqMvTg8aoYOiy2MA61V0wK7CjUGIbA9fnpMXW5MWN9sd+l+Di4Mzu7EqEKH65fm5XU4McC6Pf55FdoCKD8RddL8+8SVBYJroAFyBh4vNqLny3wKBSBqjkMKG7dTQawKsmePDNvcU0KnoF2gVl5XmSPY91/b/ABxFBlpDFDq0N+OISuIAyUPjpxa/bU1C21V+Qm9+bnK9RltxIIwpVHTj6/lps0QGCIFH0ceSaRjUYRCxwmLwHE6a6bfn3n//2Q==" alt="微博配图 2" decoding="async" referrerpolicy="no-referrer"></a><a class="wb-photo" href="https://www.weibo.com/1199303274/R9yE5wVH8" target="_blank" rel="noopener noreferrer" aria-label="在微博查看原帖"><img src="data:image/jpeg;base64,/9j/4AAQSkZJRgABAQAAAQABAAD/2wBDAAMCAgICAgMCAgIDAwMDBAYEBAQEBAgGBgUGCQgKCgkICQkKDA8MCgsOCwkJDRENDg8QEBEQCgwSExIQEw8QEBD/2wBDAQMDAwQDBAgEBAgQCwkLEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBD/wgARCAIGArIDABEAAREBAhEB/8QAHQAAAAcBAQEAAAAAAAAAAAAAAQIDBAUGBwAICf/EABsBAAMBAQEBAQAAAAAAAAAAAAABAgMEBQYH/9oADAMAAAEQAhAAAAHUoix6TwkgZtxyHQSDSQJgAEDgMCYHBFhkCAADODg5goMHAZAAIKJzjDpFAwAAgIGAQMBg4BGYFBUXDXQ9pAIBKJKttSCYAAABg4AQpFLpigQBg0CHAmjgEDSCAAAcBg4Yi4DAQAAiDtkQinweRNZuQtYUu7lxSKEaDVVKueYQCgIEAEJgdhQ5gIFnIABAwAAgCCgsOYBcQhwABgEAAQMAgIGAwGBQKDz66HvGXKqXNegrhMChwAHBwCgEJtvM6MjgAFGDQAAAI6Tg4OYYBQIAHIEAYUBYCEk1GC5ZJ07WYaWhhUhSSadVMlacXMchcbqkAchECgLEwWBMODgEAAA4OAoGQYcmN+LhEA4HAoCAgIcAhwHAQOBx0Xn0ue8VdOqq9aqCAAFDgEARyAAQIN/nRA4DgDDMCTmcjg4BDgEBAAMgAKyt0PYG6GKGoIDOJTphEGctjlVr2hMI+GwliIAzzRWq5vgkwKBWAAAICCQHAAKABwHTMN61IIADiMHAACAj4Rh8IwcMwGTMAtZ9lcjSm6cYnanJQKABwcHByCoAOYpNOoaYcCgczkFYYBDkAwQ4DoSCPhsEYho0xbAkraFpNpMCA1odgmCCcLjVs2zc1KYwBmjKlbLOr/CdUgadUnFJ7aEBAABAMBPgEQjdskUhGYQgICAAIzD5AsMIQMmxlx8uNkoreG07i1pWV2wiRY8pPqTygEcwEAgoCBAEHcUdMgGDg5nAYDAmDGSNltEChuOXoaMj3IayUFWioKAgYK7o3CHyFhJhBZVZrh7ciAA0GYIfG32kvaTKWxlsZfIKx2J9afUnDOAoKMmEgA4cAAIGHwGTQTjJI+XGp8jge0SlKWpPmUPGrlrNNLvDiNlx0kfLbI5PgfCeUntEhSWBNnDe50AABgaIi5I1MgHB+yVpKjSBdqpQ0mjaQDEg4YgVDTKmU0bsyZlKicg4Scohc6knMrpBwbDdiQTi86daSdjwCiTBcGqbCWzlop8jmWClJ1MjQsJMcbDjZcbLSGIOGSDUpZKtHDgEODgMGaYXfNZqbu9vMQAODg4OBnLj5GMtmhFMwGRFWGROZNKh/SkbJdisnMapptOqUfLqEN3chUgCKaSpQCIaSOrDNNOnGXmgmq4UnSUEvLShu5U/rDQHoJCRGxyqQ1mPG9EoIW1kjgUayabE4KtnVWzutWM9J0LnajLJorRrMqwoCBg4OAgCBgEAAwZJhrYtFZ6iTa4ARzBAQBAIAGKcPDjUFBMqP0U6KQzbBCSYgYHSFQkrTi5gJcTFPtYBgIbjMmqhlDStHsTTMJr04HB6Fslt4uvtwY0GlIbjN2bXNRiiG1JFDTKp3WY9DdNvI1ltVQAsJ0ySpPaUrSXEcZgYJxkuOlsExQKJOlKUStJwzg4ADkR46fladPSLyECgIcDRERDiYaYxB9SlbUq0LOAWANshZDia5NMTNqDQyhwuVK0GaTQYDsTog9J7HSoW7clMuZWk+FV8rg+vGyaQI5iHapo7mtK6s2zDsGntFpltII5DOaKh1akalRjilJJzlysIwAwyDhwcHBwJqlBmAQKEdLjURcNsCaaqJalJUmzbCSMKv95w8VEQNBqg8pS9KTpLAAcAgLBAoAhMK9nXn6nv2TUEkDVEIxsm+QZnAsxRkMVV7kuk3QJsVnAER8toiv4aMB59tnfWPdc3jLiD8G4o4rMk8PK1rNz4pdJ0KKHDJ3VwQMsdUmj0ZmhBZp5ac0iAIcHDMBQEDo4oBAAgKEZbGGyTgWRDEJfnPoLFB6P51OaqWpL0kwAOT5AAYBZyTSW1lgHMWpdR5Xp+pMxVo8VGy4YbmkdjmkowgP3Mvc8lGzaKCI5hWnrTtmOZSYFQyS70eKuBLvSbjTnENWck6ZXiq066lIzL9CKI7OpzWK6PJFXoCsyggNnDawzgcBBwx9UuaRRt5bWG1TMBQMx3UvaR2FBomxKnXLYTaaZyIS1EOAVBVOG0U1i02EoFp5aXoUAwkmih5rnT0BmlU4DO06JfSV6QsKJOG0REzUBtNwxb60o08cyVpUODgpvPojNGc5To3wr1KMm4okNZtjRkNk5CpEIUedq7JSdiPKjYqTuKFGmka5kEZhgBBgbS2MU2lsJcDZKIks28uXtqQpOqRQAQBwFBgrcNPQ4XAYGcVHQ2g1kFojNJl8xNMoLJrCMNVi9JW4RCscmr2iJdPrT7SYuK5S4akqJK5WAREb5BRCDNNlNJoFBwgGiTZwOgBMnLIkgisfVV2bsaGbS7FWvJnJs2jTT94ue2azIvCopK26yQQDKggC27qXtpUQgIcBgImRDGKbSxARqCdMe1MG6m5TGWiBBg0/tPLSoiI4ZwOIrfCQGmIwN5pNCEkOV5eZ6AC7tFDLMrlebSYuHMNymffPqTmkoBGigDDiXAwCPgzcxqi2tqybEmKl5uaNHKBGIEYm3b7h+JNrzDlrUcbgnJWr3orVZjTfqGpndYXpcMBMAKmkhQHQmY00GBNAgANRpDbA5gi5pjnUDpO2kw2ihEWKlZakAKDBOvhMiMBWgBEdnmsqyYVTKbv7iYqVGs8wuQDSd8vPGe19ggvF9emG7TnuQrFxzaSGFzfp8hubWU7ORXNhpLjfOE4ulwx3mVzvxmPW80q0IkmIjSLlEREyoRNSjckP1E3U3zR4LneI8+kfpLNsqVhS2uHkkFtc6N0ywHQU83tDDQAtowSMqITeSy0tI6Yz1Pk4hN1i5CXH2bXefqfaGqPPEaUXO9Fc7v0c7FzMt1LPTGKL/ebkbxKJneOjtmJ4vKWTc1XqjZvCFs7tV5QGFoJy/RnkA7bjo3w9JGN4ebeRMdn0M7yK0peCquQcyt5zNYQuXXyp081teVrfOmMQOBgOEeakGQJAxEDJHBuyqoCjzvMANxJG6qch7rFYzClmn+T1DrI/TPCMqi7R2EsVpNpEU5BHpXsy1HTPzLz7Zjlq4SmMafySe86fK1TfME8QjSvy7tUa4QdVFaSmqo9Ftc1LH1UnBVcnWVROGKVWWjQ+iHkttz0s5TxuOl1DqziG9Rxp6muMJ1ip1b52jnqSbSVojAAGAuZwCAh499DxFwcodTsvV6NUzhjl000BxKfDbtnl11w+0nV8jDGnUNw0KehWttTxvJsaUlz3M6Kh9GdJbAHzGDJRHVM6n6V7MbH0ZQ3H0RfPqcpcOAQRAQ5LhqsMHCWkUGYBQ4YdFdYwYuB2HIXCY0SG8rRUdy0kI+dvUjdeTZJ7ltUs/Qp09V5fLMoaTTd5sYq4VzVDLofTEt0ZMcaVQzyc10xBcy8d+pjJroWVSGnP6N259brPk6PG3lGLrEOWGVWYTR5j2YbcsMO4ux3BZbPQm0a1rNW59JTfPzjjpkGdXLy9M99XJ7DOhanE6kkp2jWN06sVdJTaieTeF5tXRSo+BsDRi6FROBcIw+Eom4AgGTIBmolU1aMAsAXNJBNapRVH4y3Y4xt8iibvL41iU7Ll6E7PUuDHHusePQ738tijW+753D/I+nP4ZM+p5S3EOOmIHoike7xVbbNTLfUNsNFDTLyMBgMkVs0Ximevn2LaLd6ZGcaFthId/DB+V6Ot6Tr+kqADKhz6W3oyaizyNMt8TatetHpzecRyqFWdq2Na2zktIVTKwQqnPrAc28lcOakWcCYcIwNxpAZBaSSbAHIKNJDVE9TMJQaIlQr40Bw6cu0ZIAmebXHlrmuijLkQmoqRz67nze1FR02DN3XXzm83cOzxaVxev3NzPvBbf0uRT0cfPvp80D15hS98ZTO6QDZQEOAUitpAvLXms2w+izXn92E18a7b/MR/q+b6I870Eh8qXpIJ03m0uXRmpUptJJqFR2fp4/j7maep8XNtPIFxqiKxrSU4+q65U/E4KbgAHBUaojiERgEBBUDoTBAIJ0/SeCSBNiAJAdBQUCYxaQZwa4Ne0LpjD1BAKEvL9rwIAi1NgCuFnR68ypOJWCbKhZumdWXJtQ+lenOAFDgTBECCKBBlEmNxNO5poa4HGafTz7Zx9MctXfD0kEkyN2yulzGd/JG7ZpgmxqqqnN6mJbeevUNppNDmkRigTHF1bRLsNwmnGjegsBwMLg4QCMHAqDlCIJjOgjRQag2YVhxIIjRqBM4sATjXGOT3oZxmHoeOtOkXpijWfsrnmRTRat2o/ZAcHoREXGcfTBez5WAVTPbGHcORs3O9788SqWA4VSKQGaGkxZqdFpPVhZ6i+cfTgfPu20xfb4aRx9DZbhNDloW4O5tmfJFejUHtmq5Umz56QKVZy7FZ7ZXbkl9MnFYmrAWK5UTl6H2mYMOLmJAqAAiBgTAQas4DIbDUEk1UKI+5ZxaiJLXNIcNncbLk6lXK+l6dzaV7i9qFw74K4NNQO/NV+zy/TnLcH0edc6c7oyBX8PTr0djDDqp3Z5rPj6s69Lw4PbBqCAth2816FRnudzTxqSQuFDbkQvCU31YXTbG9cvR5K5Om51lJdfPcOWk10yAQ8WAP4em4uN7+aK6cTIreHXTuL2su38uume4aZ6v18qrXMFAAzz0acfUuMBpgIGQo2ogqRmGBQFAUAsiwAwBINJjQaREgCQPk2YiBO4UrLJLpvN7tX5u+FcpuVUTmVvNrunb5C7ZhNAScy9S5aalY/z9WZ93g0/ohEQBv23jw50UBdj6Wm1KS4fSUxiMoaLrjq2/POY6+euDrcOdC6+VbNJR1ybICacy5nKtCeaeswvViiihY3k+XZa51pkzrG2GqdXEIJDjufS2YXUd0GOrt100QEwMCwKgYOEUDAKFJCpuKREdaASBTJy1aaAiDpEeDMJDKpXOrHzbo4cmQT9VAMMk5mjwte9HyLl08iecwG8swkYIah7SKLy3pdYqWRKAlB6vv51fW8GaroLQsJ6Jwx+1IVN70zsOuUrldJx1g8dLjKW7OBsda7kWLiW5tpCpbdOLoHQkeftynk6rdfP53y6tb35Np25+Y2Tw3j7tOx6Hvp+PWeTssAmtwk3GxpWQrE1YJRuZodScXEiKBi3IrDpmgxsxPK62sg20FpcaoKIcA5QgqVRsfHvOR5rg74Dz/eofreMxw7WvN1S+vJfPE8uZ9jOQaX79YSmYbNDYMlbwyyPqVAbEmD0t18b1tZk/AFJwmrDFM8tWaLFCC+WnMphNWqdAzH/AOX/AG8leaH6z8PA9eBufV/FNujIqbbPWg+R+lUbXxtC6flvP86aSSNcwlzuPuuOD6eA7vkdE28yYiqKzQ2nlI4OELCWGoCgLAuC4nALAsC4uAQKHBwJo4OYkCo0uTWF4Mpb2Ma95/q0LwvQs/ueWv0ZTG7fcG0LGcttzo8GTrugnlejCfR80cNmPzi9Ku0jS5CRLcXuLm1bg3ajUNwYDiJbShgDMfAIcndpH15Uzox0Dye+V/L/ALl/z5L/ALd+eVLqycZU9ytDpyBNCKrvD9VlhvcOr5GAiGu2x98ovDSpZ0RM4cCYLt+s1F/JVGYOBVBwKAARnAACKjDTdNBlHwzpshxoFQ7eeivJyKP+X+irF+DK+zzsMsWHzn2MX4v2Mt9D8o978Kb4PvSmKlu7wLt9n8wrydVU+C+7yf6nysg+h+XkZ0ZhGVCicIxspFrUs2qm4kXHwNk3CHjcgk6TdCdAZHRc3pnQenDRPN7LL8B9V3m9NZ/XPh/Omq0JLVkmO0JJkl0zm+pk3zyXT881u5LK32e+KaY5jWaQGAwEG6D1LDvqo43QlQERnIEkBIZQImwZ5iq7appVNJCDFDMg2xSINBepDK/pKfNe2Hp8FT8f0T+n8zTI4rX5n2lq+i8+q/J/cKrG2/S/AteSVvciP+U+vqvzv1K/u+X5y+2+Cg87lk46oj2RAjj5L1tmlBqpKDaNRQO05ZBZZk0wFCQ4xuwyZN1899wes53Oq6L183jzd1jDb2DzuN1lRNunW6U3vlBKnqF89YONKxpGV1CIKAAwBUfpfHTQFo0LWKLPajHdMbeXOaeRHZ+jDT3yWniEagBZgtMd0UrOaDDhOJR7K+NowgvWajQYymJVN/Ovua7zetY/pvz+D4PYmfP9Wa/SPhJTQheZuJtnj6lV+S+5ie7GK8j3Lt7fyfnD6741pGqTivVHCj2OU49L2JEqJqpnBhU1GdJhxNy+T6BJig+REMteetc2wc3N7xV0nWD0nx7uZyz1fy6rzTWpjdIlBLNZXqq+ruE0sqrlTmFZkGcaYETcKvRUaabNsNKxfg/Qi4fQtxbL6n5rq3R8xm3J+gUrl+sdX8naez4evCyhVm+iEzOKUC9JoiqTK4JMPUinSc2hw96fh+011Fuf5uu+d6i3z319Y+8/OLP6XNKdUntxPh/cxHg/Vt/f+Pnu/wAyq9/nY3pJmqu5bNGYyJVTKHrjJJy3IEYmKCprEv5YUkhDcrVPVMJjvcuLp2ZwhU0Cs79OkFS8sdCrKvSM1Lc+8Hc2DOkds4O5gNoqjJZVLTcG0o42jLTOmY/aIWqP0Jm76tKs/Syri+u4G077L1/GXeVl3P8AcFftPd/gqv0/IU9xFKqvbdkvAKSYajcGoICjPXazn8uijeD9g1zLF6ngaf2+FC+buod/aeZWPM0fenlGuZPg+nPpeI+j4Va78q0hsCYRTQp80yEigUeo+7gleTpbb5IdGBnDVosW3ai244I8qZ3x0kmx+J60f5vdr94k0mg6Y37LZmzDOmc5nSWmcd2WtSalKKDcKs3WqTKlQlS49AS9Ic3REF+M+nJGdVVW4zGgVUBe9A4/S0X57eOZXthvqH2uL6c819H56KrmmQhwSdIkzAyiTAAaiOAh7BWT/Lqq/wA/9jCmMv6vgahp5MJ8v9vGfG+lL/TeJMfefItC89+B/UpE8Wq/YfE4n68QjbdCSHCGgLjMNkpSYnL3/s4M9LdTTtN8ivzdoTsqHafJqhoKKnLoUXo3HvvChxpNB1wZxt5+6E/apic2nTLnZIIhj0LLJVm7bLns6QZVqVT0n0bjrO57eF+vJhHUtGuqXxaibxOubPye+l+T7nCO5Vcm0ykLwwz2/CZb4vFuzeSJLZp4CQKAUTYOcrp+l3Dd3Y/mPtmEInofKaZ0cUX5v2EF8v8ASvvY+dee/wDGl0mheN9jQfV8eO9Dgom2CDQAwkEEkzsVGAIpJJ61pivQVNAE06uiZGkyMTAFGXpKaUzeejzj6N6zUZrGVdPOyy6POe8+lObsxjbntBnkGqZhOtXolOLtc1dYrrhjLfhnlr0NnUlvz+XvY8+meV7zfk9LZb8+5G8dKjPgf0ZVaRvpeQ95OodsI70/FLeGX+r5UF066P433dp+b5430PFzD3/Cp3p+fdBbskgngVFbFcQ9MipBch899e4x27s8mc+f9139B+dWr19VpiF46yTvnFttXTIBJkgjGyDtLOU1RAQijAYCA+uHtyYDolgkGAnEqkQFh0XcW+maklF4PQnU8Y6uYtY6Yr803V1ik2tczdRbtublrmH7cLLy3Fc2uNbG98xPNUntqszG+w4r1eCn+hxvfgv0qjfPfczXofPL3yOPN7kvG9Y+OsX6GUpdvjJD1/DM4H3fnq/16RHDvdPzn1q/9F58r9B47b3PHuq00rLJmgeqIeSXByEWnkvifVI8nclrxMvG9W8ej8rZ/pPCbl4trvilyoMQg0kgbgUHdQsIzaSEE0ZoqAHvHb5OS4eidAoEL0yXDNCzgYDBYpXpR5+fctrbzdMhnUDplm23JotaYVVtAANzxeIaojAAwPxHBqMwAhBl3F7ZcwOesHy9VE4fvs/4Pq2unBIZRaa8Ob87oPjpIdnC09fjjOH6KI6OOUPO231flZzu8siRQTQVhRVZvAptFBhvBbzcGEcVP4vViPH+ilawW9f5eTjhmajN+3bzlWrxjwK0hkkQCJqUndQsIAKAAQATTH7v975Pxn4n07WbEOGYSroRig4LyTItdSwKdL/FXjPSlHXUNfP9WYTcuTqIEJar2sZros52ms3MSyLTIHBwcCwen3OioBNMIeemoYdtD6PPUrK+haUKhzEBJgmMgLgQSwFBqCIKg0FEMKm5BIHUVEQ3KHUkXwexLZ6Ld/jQmPBM9phfT0QA1UNRNUEAB8hxUuKRhCIA4CgUAD279J8nkPletivB68aqImAcjk10SKck01BkDJm7cvdaVjE3EzmMOnlzg3jqVbDSMnSbVaobBb4q65tJrJtpUpMB3JL1O1QVVnExDmRieaggGghZwaAmHAcCAYEGlBJgqDsFURY44T1j8IJEqGduaA5ETZMwEG2L135f7Kk+x8/TvR83gQAARQRMAOx3UmYYOJEXAmAI4PcP0vyNPXR5k+b+nbTaC0RWq5FmeKgQQQQ3wW64v+mTduWB3QdOPzqxc+rIKBzdD0GtK9E71y3Pw0xYD2Z+Z+qGFQ2HJp+xQpwQ4W0TQFx0ZlfRdQmwMBQIHAqJMDMaCbAmPgBJYJViKI0HwNApDM2crk8ks0kqj1rv3y/2WX+r4+d+p4qzBFwN0yoAHys+mRnPBwhAoJgnLK6+gX0Px2Fb9Er5PoZL5/r1bPrho6TmVw04iIrQNQ2jpwu15ptNW+Tl89GPn9uZHPTtyTfNFm70hmXsfN0egOTWq6zTdpyHaMxYiC03I8/qbvG9Iedc6fKtzTpqJjSLz6mbkUylNHLcZFSWnKpfOsCwlAODgHIIMEGoogbZCytuEi5C8xEqlJPNorjVrvXj/TVrv8nFurgKIE+AocD/AC11TyPpcx9/5IjkRFAQIBUJJple/vpfjM5Nm07+U/nPpkkyp8HAA7JUbj0c8ltim02VCnJzTqLgOHsxXbkUEcEynAkRtnrMaSUSSImbhs7RT0z5/wDUW2XWR5Ia8MD63xs7t5ylKMw64/PpQvJSaI0m54OG30wT24TgoHDFLh81wCDiWQJOakgqtwdqRqDi4BHHzQD3HxfqKB3ctN6vOZPjaMAOCSz02r537GdwXn77D4hJoCeAoEBMoiCJ+9/qPjG2byXbqzr532su5fQADguzcdMLTrlWLJ3TNNytN0+baS78DPz+7CdsShJkNin5nGGyqdoArEQZJ2PO5TDuP5P6AkrlOjha6cmO93y9i05QcqcHrxW2HPMHIMAkrRAlOL1ql6fzotaJx9ZAFNRGZ93GATOWmreb6aYFCC6OfO+7hXFb7iFGqKWAwV2asvF7DLQunOtw4dfOnpc9J6sNq559F5qoeH9TgfqeTmfteAUSbkQTAAKUimVHvb6f41wjGn0s/M7/ADd5PucADv8A0c910iBuEVTipRTbAu1FTZxTXmelWNOYaxRdtVokHAqFtBebd503TucW5837yBy9MN+Rfu8h5xdGP+h8epty1ep1bwfs637HxTXTJwoQdJNxrtB1q/zn3OW+38ow249v8n1TlJsUJz/s46P1c0xlpsnl+o7A6aDmg9fNT+zjfVm5oRSWGUGcuOnq2f5/u9K+H6lSrYOiKd73Bpm3nPMKf81+E/e4Y/bn4QOSgUCgVUkmUfuv6r4xmXDZWnlrh3i/RyEPG8tpXpwc3L4H6JQJGR8m9Tkk5+asXmd/n3q4oHbNJ6MkS7FhRkuyDkOfol/N9IG+SdruQXqc/NF8gVhWejCC7eCoUrr5n0MP6Hhyz4EGzqQKRG3ppc/rQfRwu5fpDyfUpFhQAGWuWUej51y5+jYfM9CCoajlhVLr4877eN20cEBOGAnw9NjfbvC9U3i+tWuPoicNrj2+bZvqPFjsNM0L87/QeE5abUCSURAAATTVED3V9X8ZWTaTzlpO1Z8X30e7GkZ6aR5/XfMabBmUu6MiAxwNUqXSqSx0h+Pqzm5NvggqJUUzfJsnwWeatPN0W7zu9OiIKYpmsRefAoENthn3fwQdIUS7U48Y8oHSCItMG7ZLsiclnrY/M9GzpH1yi1UrcS/byH5+im8PbLSoXeFibDpFe7uPzxrizG9JlGJDjZfu/n6an5Pt1bHoY+J3sstbHlz3j7X5mt+Z3Zv6PHhvseU6ctKEhASIJjLImUUPd/1PxtbrQqqdwdJ8H6WuW7T7vm4343fXubqairmZOWGCHgk6V/5+jVPN7hQ1bKCoqtvllHo8AA0RcsN57z/RBJwzk1JqD0iTEA2YW2o23s5apeb9Pz9tjX9couWwlv6ISXHp+q89d8z0rWWvm/l6bLKeUo1itLfunmq2O+T8nTwaCZupbNkFvnV+3njqhghOpYMiIr1/lq1w7Kpxd9N8D0ULqa551H7z5FjxdGEdPPjHdxruUgRoSJKIioqfCRT97/UfG1vV1aei58x4y+f+q6WxCcoe0kgr+bmrkURct9S0Tn6d08rvOhiADkpWc6mMez5CoVlVuOO5fO75xw1CvRc7GkRrEqTw26Jil6T7uMGgDy9plR86Xyt0momomz0y2TVbVOlNw2yTk6IzbOzRT1CdLU98a3npjXP0RGkXmFY826CvbQbpzl9IFsU3CqG87sunXzObmvcPbRfnfYQ6ZlsTVPtPlC46YN08+Hbc7xoqTanzlASE1wcCYe7fqPj2tKjHQtzdOQ+J9Kx833Ue75+uSObChD5siOYAWel6d4ewPP63zUPpIZaPwrkX5v8Ad8a5xpeouU8z0D0hA4VNgTdxIWaRBNVHxfo30vPC5VCpOfKSTGK33PW7M80ZKE6ufZstd/0dYy1yHj6av0Y23K6hpBKXBqY875uhGodp6Ni877+dZIw9O2zstiaCpmmnKI4qted20bwPVb92cri9R+u+WiuffOOjHzz0cj8TFtIDOW4IKjkiCY/cn1XyCymkVtN+H6OdeT62NdOlUzt8ybtABAIIwPB+tsNpHj6aBzbL6wy0zJjstjtZsLQ9XimaUm1WfN7Yy8yNHTiqKME3clEiEnGkrhttHqecq5UZXs340eLbfPd8t/QarwzeTTfn0/PX0nj0QLrIuDro2sXHOr4ZzO+EDh0TG8ZnGtVip/OpGHE9vLdZlFk5VXnWCgZPhmThY0rvn9dE8X02vfzynPenfTeDESqVU+de3gUaKMAbtMk01SjSznkva/1nyMxiqFrsh816fmjg9qub1wOGrDc8HAILs9RYbaLN0fi6MtYh0YI6KKzrVvK9BTO7j6/DKOW4sQyutzRgk4Z8tqnc6dUK0k5pDLSUjXTfQ4ZyoBqMh+QsZhOjG58XR6y635P8+q9tjP4a+sPTiNZlOG+eJ23DSzqVdsmeWts3zPvGaZaQfLssmn0Y2B5smTzrYtMyNgBE01VK4O6O83rqvHvC+nyWLh31H6bw4qlQNMvPXTxyImo2zlAGc2QBBVyZnt36v46TyKXrpQfM9Hzr4n0HBwKisOknDgUb9FY665FohReLpyJwpcL7R3F0XTDpc5Xo/q8TaoXHROfQqiNHHxpDZb0bfLZ0rTeNbnSNx3nrL12csw82zIJrH/P2FqK4NNw93mxXztHPS5/ivYPUwBjIIYeZ8HXzgvdySGd2PHe5dOTAM3w1r3Pq31zLpm5lP9D0JpmFCSaLGaGLqscHZTOTeO6sLhtlf+jFRqsVn5y35oOsmhaalsxhN8AiMIwe5fq/j5CJpm2mdeT6vnnxvdAOBUVo0kzARt+eu8ZaJJgFL5ejHahTCmu6HO7phtI46aV6vEFSk1Q+XWXURI4LPSmO5Doxd53eXnWY1ksdNR7eZzcL1Me1Fszrh2pfXzM+atw6zKcXD9vLf+XfTHpMsbBHsqHNvTsNJTfAmelzKuvVgyp1pFD4+hgnFa4JIstPdt8RYUSIEYgwoRpTUATdIkBOREDyl6HDRsWUTBCCYt8kIHD2h9b8jYs865reU+R63nzx/dAOAQl3PM2BX6ez15CSEiqhyb53nUaJKySx0sOdjFX/ANXjfVm2azrk2iBR1xIc/TEWr90ZZvnVP6eOYw6dK5OvXu/jTcr1LWk1pVPN4xpi2zfoatK3nWMZxfs9d66UZoo2zVdy0y/i6GDFx6XrGgdXO3Y3FR40zXl3iLkjLU53PfFZowFaSYUCgiMqCsBPhqpc1k3sedRpedcdV7OiNgHIEDC9f/XfJW/PKHq8a8j2MG8n2wDg4FtY1BnrvDc6ExpA1Cr829M5tULQUnQSgWqlP9GKbUeGT8W8UCekzHNs56ImNc6Lz7JGfTpdM9Ng7+MzTipTobihpfn7x+k0m9exhASsa87a/wBvcfRwb2nQ0BR7VCy0j6SzWhpzQjjQpMWqnF1wS9zYWrXLXTO0ZyWpAajkjUNGrcGwMmMWNdIjfQ4oSlCTUFlUDDjIGyrkmsP039T8rd4xaUYL4/uYn5Xs8HAppOzB6cy1dJlBIEwKBRogUFRuELJkA4IMQFh/B1MgWml5emdnO0ucx4+oA5O/Nad2cjqkdo7G7TMKhCejsligkESCpdBKSoygAFcpgA10zMQaUEWpTaLUP7yK5Jcg5TpM2NiWVDEGbVG5+yLi24NQaIc6xdOvCNuWLcXAwlt0NJYAIbT7vzU6s38Lzf43vZD5vri077cpbDT2nz6zSfAAAABwAAqhBYDgix0hFpmESPIuHpipbm1O1OmdfPzmvZ6C1KsmkSQKNcNdyVrmjNOBc5FoQOwxKbQMK0JKdQm1zSdJEQNC2gNMEwQBsBGJAg0hLJQzFDRbNVWs92MtNNuDcHGk3Tt5kKTdqOBom3BKWUXD1j2fnJFTaMs/K3h/R5jxek59LF/Z7N8rpt80Ac2RIUCHAcBA41RJhwGYgCAkmRSF2ORLqlGSd86rkKSwiOeaCp5ojRAQaTYaaaiBhQSAgcCYEBUEmGEYZw4gBpttE1WIMKhNiQNE24RqYjZSZ7j1pCODkmOKXBuBqVz7+WNpc0wBFDNNtImmIta9z5xZFujLyj8/9PW+uiVXrHyuvSsdDD5hUKJCzhcB0zhzABEEWEabCTYk03AoNgAGzLz0+amwwJCOCLEgSAoxQA24xQYZRJg0Gkm8cxiqoTUHwp3xw19jSzaTfKzbjBpmqq0XXlTsUYN0D5kUnetMmZQijprP8OpUT1jIGAPgRArJ7u5Ta5xqcfLazQsZ5sEATuX0PzCSc7MefPM+gpO97h5HfuvHuQZWFBMRAQaSY3BBpJpuCQcNqxcSYJAYCAQFEA20StenM1bbIZY1bunAGjCUBuAgwT4JForFQbJogUS4YXyddd5rvPz3lzPG8j+l6rP1dm5en5sqS3KjlTQdamjicNGHFpkAzKtFuRWi5pePUqJMGQNUSjCBHg97OaZ3zbXMdnbSajopCSPgBV6P+k+TjCplTk/P6NF5fU3DxPQcUigqxIAAgCjmHQViaDBwLsKBwQAoCgGLoUDgi04tNyJENP34n1ygJMawkAqs2+CmTc202Rc7zRBwCjVBjRDx/TbOIbyfIneSKj9D6ek59dP9jztO1ySBVkQnWovhQKqxUl2lRCDxiINiqhj0CIgM0JjmGgCtpr9WFv7OZoCLbcbKGjFM5SM16J9/5SumppqLz0qfifTWzj2ETIarSwIAsBEcNdnIRBUFQKycE1YihNCzCgmnwLB0qIKQBJmkdHG+qMRx2kwvmmVOi5Bq3VBGFQQarSgnLFBYpy9Wl+R6CrnFJ8uR4+e2en7Ngy1zT0ePbu/iZj4AFwFBEEClGhERNEpsETNVTLoMIAjkCyaBsFQlr9OGid/K1oZyyjbg0imWdMIfp33vkIOtImNrFiZr8x9nMgYUMBGOhEYdNy0mBkOhogqB2kwlwbNIzRgFogGAgcm4UsimIJhdN+aXvJ8841UQKxNsU4lVq+uCTHKGYHA4FDEfP79X8/qzHqxbxnBZcsx09ujcfRm3fy7l6XA3BMCIBnAkBB8Bmk00CmiUKrrWPRoskYDEH7HYiDoyLPtnaejKA3yIxuhObfxVRc1GF6y9r5GE2ItbSGbyz5j7Cdz3XCMaag6AoEG4YcAE5TKxBN65M07QkCY0w4OAoHaTTkCWSpqDMds355qscwi5ol/SWE9alGl2uAyEGCCoIhiPB3aT5/VUN4tedxrmKtWLl3zz0+Ha+7iKCTEU1WgBEZRKsIDZNIpgiEm4rLfQJKyxwmq0/BEKzA41mw93M4amc7pG+cjjcrFwQslF639r5BCpiL0Ymme/OfUzPL2qIimMGKAYFgRG7EQawOQZAuCA5hwuhqNQSIEBNioHaLLMDRjBE1rnYdMX7xUaIPhGAw2wJocADOEAcGLc/TevI9CE2jNdspEdzx0Jhsw9nytc2xEOo4Cgihu2IiDRGCSJUbNRKdcz3RGihuE40sKHdZ9mnNRrHq8hXJKQJtUJqo7NwuG//8QAMxAAAQUAAgIBAwMDAwUBAAMAAgABAwQFBhESExQQFSEHFiIgIzEkMkEXJTAzNCY1QkP/2gAIAQAAAQUCl2K1KFvFx6TxsSOFPA4FDYYn8fJvBnXinDpeK8EI+S8WYv8Ajpl4rpdfnxXj+fFdMukzLx/j4svBOK/moq8daFdLxXS6Xiul0ul19Ol49rpcgbq5/wA9drQnjFs6h8ybr+jpl0ul0xNATpxTLpdfTpOzLxXS/H9Piul0vFkzN9PDtdAK77Xg7oyihXdiVfCZaZb50+CaN4KYaUToZYJF2QooxJS12JCctdAQTN/CRfyjdmZ266RMxP8Al068O0BeJdLr6f8APX5dl+PJ/wDD/RuyX/qVWB4B/DP4rv6eK/wvy/8A4GXI/wD6V+od6zUwpuUx3b7/APgZGJIDaUV3/wCL8uumZfl1+F19P8ryEV2ZJo2RTRgurEqjhiiUksYL5tRN5Ro8uGJRHFIioSdM92so9WRDoVZF4QzsdU4yGcJULkK8WZ3Tsuk4umdxcujX+Pr0uvr/AMOhF1+I2qwOD9EaboV+Xfrv6dpm6X+f/A35XI//AKJZ/VF8YNVcZyq9vdXX9fa/KF2hkf8A8/X1/DKTk+KExXInX3apCi2bEjlLpzL4crr4bL/KIXFWKw21Vty1pQOKYJK0UikzYnRZ8wr3X4EV+Ixsc4PHtY/L8jbssP5dnZeK/LLx8kP5X+F49pl0y6+vSYU5MKr1n8vJdLpfhl+XXX16+vS6/odxAdq3Stask9Ozc1rMeZlcVpPTweuv/B/lfll/ElCT/Vv6uvr0mddOjlhiR6dMVJtAy/UEb95uHUNbLoQwUfV3UFPMfXm67dfyUcokmJOKnhiuA0tnPmrWY7Iry+k1eOVbXDB27WLxCxx+20FyNPLsV0OyTO2pVJortVy6E1/wzOiHsuvp0uvyzJ/w1eu5EX5fp110nZMzfXr69LpdLrpHepRI9ygKl5GItyq9raeFm1N3OmxsPlk25yKfRlrhyCQEG/A6bZzyQW6Zrrtul1/R0nTi5CBtILt/SzJum+juzMejSjUm1Ay+6XZ09bYsJs3+UOPCys3q9ZRRCz3JTnEOvHsV2vyvF14LpBOYoJ4zRCiaOUJI5c0q9xp27FeAkvBODe6SMJI+jqGEktdmOtcGTOqO540Dp8eYX9WxAvuV6BDtROg06UiCWCROD9+KfoQggeZfl1+GXX06+nS6XipJ68Kk2c6NFyGuyLkVky9vILK+y6cyj44o8LPBRU6sDrlDM5U/zTF/n8uMAkY8rONHgUiR8dNfZNGJf9+gX3q/Ao+QMTDuVHQ6VA0EkMi/K8WX8gduibr6yWq0Kk2aYI943fz27SbGuSIMSsyioU4kdkBL0zTJygqxWr81wooRhbtkLOS/2rtdsvJS2WBvOZ18Kyy827/yoyOJe6PoJA6npnTatcGcf5MmN1N/npnaQBMGc6UhwM6itrwX+UxdGxfzOrWkKTIpkpMPpfbtOBns7MAttO6DkVQ1HpZ0iaSNx8XUkkUSPVz4lJyGqKk5JIy+47dhfb9yyg43I6j47SFR5ObGhEY2/ob6chse27UPxzeKD7ov6vypKdOZzxc80WBCj4/Mvt2xAvfuQJtyeN9nl74NXD51HuDJrWjQ1tG8g4+KjyaMajiCJvodgAJ45pkAxwjY0IoGknnvmABELv2nRflfhdonYULy2XGvFCvIEEjs7Wa9ljw2cJ4blRxkYk3bPHckieSsMr0tETHpHAxJkT9ImAwAzoySQxTt/fqOJDOJC0gx/wB0Yy9hOD9u3nH+Brj6gaxqZBKxbwyU83T7tfZv5nE8jlNe1J7IVCdNV5ONqtLmN/V19Ov6bLe0Na49TiubTbPz/wDwddKTQpQqTfqCi37cj+PILi/a7zKb9PMOxJT4riZbFx+JSYMrL7fsQppt2BffbkKDkHa+8xTKDQzBYr8CuaDshiOd/JhXiZJ3jBPJ5Jhd161LZYU0HbSaFcBCaYl5Srp2XkoLUtcq+hXtNYx6cqnxbsCInBeLsRh8oqegQl5MTM66EmeN2TsziJnTkfqQTq+DtdgBPq0opj3IWkPkNmQhtbk6+07dhR8alQcdoigx8uNRQwQfRu1/JSZ9KVHgZxKTjIL7LrVl7+R1kPI7cZR8lgdR7ebIo7Feb+q/Z+Jn6NT4ePK3zpv6ZLdWFS7tAFJyM18netL7NpWFFx6qKjyc+JCLAy/P0fpez1t/mMWfopQiXU0ilq56lp55os+upYnE2huCnO8DNfMF9y9qGzCytbOTnQVubcft27++ztX5HWltx5uxZUHHNdR8THv9q5qID8B2fRZEgkBxVTRliQH2EkUFsJ8KJ1LQ0KrlLXuNDfkpyw8045If3bOZj3qql5A7MV/QtgRa4KLHuWkPHWX2avGvVk14guAcMYMzeDrwXgy8W/o/P0ftkzLp10iBjE8nONScdzzUnF3X2rdrL5fIKyj5JP3HyGsSDWoSLTkisxcos1IqfGf9VelsV4FLuZ0al5IzJtDctr7Xt2VFxoGQYmdGo4IIPp0317FdivIV7BRTwgtPThiqwfqPp2b0Gnaeu2haBHpXnXyLRLZtaMWfn6Mp0wlYV8qTv3TkmackdP2tINEC1+Ibu4s79KqMDfsPi5Fn8a4/lzpxJmO9SiX3jOXi6uUq96Hq/wAftVLQ24ndiUFuaoVeeOw34NdmDzZ2debkHALV6OzwPbG1n5UwVIqNVBmjEmqG6v5PyQpZdzJuDWkISrzLn1WYMDgGHPLK0m1C33S4CDYgNDbjkXc69hr2OvNexeS/km812a8jXka/kv5Lt0VusCPVpCpL4zrQo37dXNztb22aelLSt5WrWOHL5Gd6GjUJRZ+WyigrwLzXtZe0F7IHXQOvEV6xXpZekOilogvm117LZpoLRpqESlqQ+v8AUOAYuRRs0aYvJ/w6s3QiTRHK/gzIYSJNCLJhQzVicKNewooGhE5WiR62fGvuxyL27Mq+LpyL7SDuFCMF65F7tyBffb0KPfinhyuVRR2+O8tHSj+dnu8FyLyr6LOmdiRROo5enNopwsYUTqevPWURkCGcXTOJox6QudE+xIdqj8/O/S7yfN6Z1+UXgaOnVNfAiFerRjTWNMV9y8EGlnmhkqyJ4l62RFUBHfzgX3MCXyNSRerQkX22IkNCiKGvAK8GXgyij/1uW3tJwNP7hTixIq1Yl8UAX+qBNa0xX3GdkOlVN5uS4Ne+d6IU9i+a9F802dG6anFGumXiP0eM3ROLR86ytO1ycR/JkIKe6UrwwIayeNmTRm6cq0SfXoRo5ZbCfI05Sfh16bT+13RcJ9SqvvoC4a1GRBJ7l1Kv7i6JEIof4EUFY1a/TbJsT5nBxzD+0ZjJs+iCEBjavckgeC1DZGUGdMRwuEjGzv2M2VUsPHtZg3R7Qyr+BMznRKUmeLimEWQgl7ieUF7WXlGm8E8YIpKYIr+dGivBKpYLc60uP6mhTzMe9RoNXsRIbcAINDMNCVCRvQHXxxXoBekO/UvF1YM6talXepT/ACvImXmzroOjtZ8aLSpL5M0qarclRYlaVftTLay+dCy+E4L/AFkaaXQdfMvxr7rCm0aRprNcl4iamcRi0u4k84VwL22XiropKtcS3IGdprE6GpVlUdPOFCAM3QL+yvKuy98TL3MvcTo4qkiLLzDX2+WNMW5Evn6y8RTgvWvSSeMhRWKwItOsy+bbNeWxIqv3GB6ush8JBOIonjl9qF2IuWV5fvODsX6cVbmFAxrXKVuPzIVJJHXGrt5MEjWc8V91oCvn2CXs2TT1tSRNj9uOVCCCqIr0Gy8JGXS8RX8V/FEEciOhUdfbYWXqvxr5WhGvufig0qZprMDto3qUyO5TjT61bt9K6b9aU6HPrEgq0Y0M0S9sJJ/QvKu6b1MvMF7F5ROngqmmicH7kZF8Q0dOq6LNrdXIbVePU+9Z2hhTSzZMcJuNmatSjyorWjpntR1Ja25nWiDUzpG+ZV8XtUV7s50ARyCI+Sb5DIissu7yaa46Y7nQncTyXe/ddT780a0ObTVrb7sqfRtTII6hvEGYKiOBm9sS9sK9kLp/U6PQHLHP1q96KWt2mPyf9Q4XblD16sDTTWKs8N6WtPmfqFoxvqbWbyDJDF1o7VSTKFo7FLxKSuopqspBPUmR6uVAX37j7P8AfuPO47mG6DSzXE93EX7hwvEuR4fX7p4+wtyfC8B5VgO78y42LfvfjhL9+cW7g5rg2juc54/FIe/ka8WZ+nl6w32z0R39mnks/N8lp8Xai3G+LbXxrqip3QWkcmZSzeTV9Bn0WTaPafSfptCXqTUlihGrO8f74jj1LHO/VdqwWbmtDY8BrRx2Hs0asQ8jx62lJRp1n2+6WdU2tO/rbdahDlS7QgV3/S16tfwIKPnKEGxGMX3iIQpaTeuhcquVUqskcP8AeemNmS5pWpvZDclkkHRsVxGWZhk03GRsKsKPJFfaWT4y+yunxJE+LZX27UBSNq1gj0dWRin25VXnjqv90BU+TxwuF2naD9VKHplimi996cpp5SJm9wSSRTSZ8/NPGTLhsMSraDZaHk9UDtBPQXJ/ZRktak1k4ZZ2CUpvJ5HdDY8JrU9OcWIIy9jeMLe6R8XQw4JMkIoGoD8qcpwnkqSNJBJ8Kay8pXOI7FXNj/PVuqFqrLS4/lIzag/D7VCGzbIYA93qcIHXMQYeNcXdxZpjJ2a31H7HX3SvKEM1+1T5nozU8U73m9V7GlsVhAA8PKRnsPcz61gZNdv+70m//R8pOIcEOXcYzQo3n06halIJnk475lV4syrPxuuxZ3Gyb9u8aNv2vjE5cWpp+NSeH2Ww0UdIQtXo62gnxXdNiTiU2R/P9v4Tro13IvKZeyZe6dNPM6fV7L2a06anEJtNM6eaXv3SsvdMrDyyQ++xkFzrXr63F5o/4jMLSTSDKjgZpIpopFvANnjdSAu7cvmFcZNOyWK+aPJyrZWnOFQTI3KUzA3grl6KI+wziOKQu3arVmuTcc4gGBAcUUsHKuP6lVBnaSmpbExjQ15oZsC7PWzeOaRlxjPqUtCDdhsXbG5CUtmHSjyqnF7ls8TLsU0dyq8nzKE0dXQmqFuTR6WRi5V/OJntE5xa9ZQlOL1BNip1KVSLUwrdy3Fw+z1m8MPOsv8AyUZdS0NAa0v3d/nXLr2Jp4prVjQ4vNqO3Asxhy6YUaLKOVS060zFl0E+ZnosrMX2TLdv29kui45kJ+M5S/bWcv27SX7dpMv27VX7erL9u1k+jpdhqaLEepoOUOjpO33HTrvica5Nvju8R5DjR2tTajT72ywx72uj2NqN59fbjH7zrfDkvaEjZVj4s+lG9jhn+GdvB5KksbRA0jce4PobTnijPW1OO38y0F2COpl6FcJd/Zkkz9fkOjsxHCTiIkhpnK8ISTqs8mdfu2JLU2Px63uy4HG87j8Rv5y6fft7JB5r8ofPt/8AaykHtvW/bCTP4eYs3mzxs6YOmYfBMws35TOhJXQ0ZJxjJz9YAumZhZkyAvdX7OJTSNHA0fpqu3jEX/zQM/yCHpyB3anJH6t7eLOlh5Xf9snJPDPpawWq9bYGxPT147t2hyAL1pmR8irNau7MVaUbFd6tPTG1Zm0YYpH2WhaSWOKH75CyjAnJqkaMYRWVxjZ35uP/AKdZeUgYRTs/lr8IyNsN/j2phWo2cUdr3Lv2IhaOBwKZU4rUx5Tna4s1VDF/LI49q7c2J+nGXnSCHTQ/x5DboQWIOS8At0WY3jPQhsS57zyRqI3kYkJ+hRS+g4BtXJsP9OpZRrUqtCAn7XitMX8vU0jCDMmFl0jd0/5fx7YXdl/hMPi7j+PDpMLpm/HqfyLxBdinONlObykMAiDRpxMWbpfIiFVrXi8elWJWWigY79Dxku1CZpYzpe+OsWrzGlVa7paM5Q2rAFFohdV/Sk06dv4QYeZqlFFXk6u1A+Lv4kIw6xxkLYsHlbgutAhsNHRhmJ5oKVe1FbtU8OW3y+c6b61t16W8YeH7Gq+Z+neJSMIwjHpf4XScX8pAqaUO5+lcEq1MLVx7EVacpr2Rp1ZJcPZrQY2DIVPiE3Z1P055HZfG/TLJolFFHBGmRfx5KS8XEt7heFyCTb47eySwv0609uXH4vjYtPl36cyU3m4Bpm+b+ltNlQx8zJj9a9S9fS8FvStDYYLEpMPrhGPtnhXx00DL1sihXg7oIzFgZ3c4OyCDsQzpfB6RFH6RBmeuLvNVd4vDxMXZ+39bnY8vYfVupJI9eK1HJUytIJPhabx/ZbniWRaBBC8GXyPkxXkd2RneyZkEzoNDxVO0Izz1p6+bXH4z15f42DYrxAVTY/claN8fwe/Tzq2pFXo+dmtXKs8jRRZe/t2dOYCXyI1Sw8rPf/K6+jMul0nZ0QOSGwcanr1L9e5wDO70+H+iePh1y5bwhDM0uPML1vwQvJCK90CdmRzQxjYnhLfaSE162TxMTeohF5eloasWbByXbuambT0NSqw8m3IXbnmxEh/UO+v+oeqv35vmj5dySRZ+iZzVLkVoendC35kJ1+emZM307XbryXkmJeTr8OJeK7Zn9H+siDwb/h06d37/AC6IWBdpiQ/mtb/28vtWPhyVzdS9sJzumnLv2l3TteKanR5DjXOP5VqsWbh3I5KGfbe7i5+hMXEclyr8eoVtGtg0qlzSz6s47nOvZBJraR0vISOUpF3InuUl86ihu1CZ7tFPp5wp9fPX3qgy+90V98pL73UTa9ZnHc7X3GWRT7HwnxrbT8mxnsQ64TzyQSfzetF51yiDojgjUUgHpFHD8u5fuUZfvWkvvOi6fS0yXzr0Um5ag0M87cMBjrV1LtVvJ9asyHZpu33+n5ffKjrj9qS1cyM2eqiZM/48iKYU3SZdrtdryX+foPaZ36d0ROLdO79OnY0ffQydr+buIGp7FeNPo0GQaWcaj1M/1WNPOMZ69LSo2MmKOxfyRtQnlzxSQ4l2wU9WzVKP8ln8jq5ufPDt3rGMOLTlE0B9rStTPZlv3s1fc7YlzfanLi8WXdlPXhes0EZO9us1d/F1LzvPFH+oPag5famAuTX3UnM9Jl+8tRDzLZA35nsO8HLN2wYbfLFiXX0av4FVyls4U/IL9suJ/wD22pXyOYyG5VIxj90dZ2h+M5J6/wCIGeKzU8ZZNhpa1ppriF9E0LWRNxilXx4K0/yciSTJxsSyZcOpTR/t3KeKPCyowixM6BRYWbEZZteIjmt+yHzKJxfy9cab/DGQrzdkc7smllJe1wRSEy+SxD5Em+QiO266n7/vqQLIq9X5TZsNxvlMiuYfLa01XF5Ham/amkS/ZZktLglmMKfB9GSxLwX1qLh3IvCbhvJFk5tytx7epjHeGGQAtVYppJIBd9rOO1WwcV5dGUi3Lli3QzZeOw502dLE6CRbkFryknn5FfqRWL1DkUh7EARl6uRRz/cYh8JZOuuiUGTmeL5+YzGQsdcul7KLtFpVo0XJLAjZpQ3J8ryx7L8ouiuPaMujMb9Bxs/zsG2TvcfMYJ+cV5Hoyy2pMuCaynKaEXK337SeMJ/J5qwhPpQu038GTdu/IrNenRzrlW/NmVJam3nN5WOBdx1GZxf2ysvkSL5jsvmKzY9scQxiiEyXrdN7GXaZmXjGvXG69cXfhCmaNfhMnLoYZfJeXf07fryN2fyT9p+067fv/wDyd0xqsf8Ap7L/AOmhf+1sQWoZbhORuPX0FUyi74/Rli3Ln22vbDajhD786k1yJDvWAeHemNPsCDBuVnfaqjnFs6c+lMz/AF8GBrU0I1/JQn/A5WVd4JK5m6aZ17+l8gVw2Vvk+S4/ZeCz+p8AR8jxpfZBoxPb4jmEZ8cgj7ab2MBfNGWELvrAZWeSxY9umaa1TZfc8wS5hOGjjYoa+Rr0x1LFiiEVfT4ZYlnXiTP10n8E2odaeOP7tTu17EL9uyZ+mc+0T/RnXaZ0xLzTEvJeSEndxFwkF3EfJd/h2JE/SOUGRWYWRXKzL51Jk2pm+s9bKZFt5AqDkON4Fs5ctelAU8V8Pad+L4khSO6Ek35Ql4PxaJviyOwFN5jG20DpuR1ZjpXYNOENeP2R8kqfDn5LXqxbG3b279kkyP8AL9Ke8PnbsCY9/nt2D12HQVLpv9p1pEHGtokPEdg1FwW6SxuNx44t2Kygf26+VZ3kOO2OGTIEpYUTlltnRsvhRkw5dFNm0ENSrXVutVklapTZDHEKE+lJr1aB8q1Ct8guWfRDfs05bHBWMdL02CXw5FajipV9HnA15si9p3pdfkWbRjg3orUla7G0hck48DvyXjrlJyrIZanM5oF++OSOouY3yqjyzZdHybkjoOSbfjNyO8cH37lvcW7yppG5TfYJOV6KLkmsa09ze16s1HYuzft3SNNxXYdNxHYdNwrWJfsPZdD+neySb9Ndd0f6XaZKH9MNgH4rxlseo+ycp6D1wjPHyNBp8AY1JxvyX2fTFUuOTm9bOvs0PyGjqTVpAsZVOzLDxzPpFWx4c9pOOZVuJuLVAD9QJRpwx/xRP5F49Mzdv4kh4jSZftem6i47D7IsCz4lmXK5DQ0TZsy4vtdt19qmX2k0+RImzYmX2yL0NmVIh5JDBEFCT13M5ownB4CGpK3yd2Bo7zAaICYZR8m9YJ441MJfGi4Tte7kkFqCfRMHoRV5J2sFeoStyfbiX7j15poMHamEcetbl14vkT8Xs4Gbm/duJxycl2M7QhpcYj0qf7Fz3TcGzGTcKy2TcPyRTcRxV+0cBftPjybjGAybj2GKbExmTZmYKapTFMEIryXkvNea817F5O68l7F7ENj8TSCEVC9FI804+Wq/uihjuVZ6ltr01KaGy7VgULeFi5yKnRuw6eLbiza8ZUKgWKBTQCzzWbEcr6VtlPtzxR7NybTuyv2oQ9jzfyXmDLzgRcr4fCi57xqspP1OzIxk/VOPwH9TpJI5/wBQp5FNznX6l51qxtLzTd9L8v3SjblPIzb9ycjX7p0wGGWas+7bnuZGd4ne9osETeElb/6+Rl6Z2s9r2uTSuPp8hTyMyKTyF+cZQLkOt97s2JWDLzvbWRvDbKOLGF9qWhGv9DG3treXyq7L5kS+VGSaxAuD2/dxtpF5piROhXX0d12u/p2puY5IzWOWNXk/d5uv3bKm5X5OXJa7KTlEBJ+VRA4cvjBB+oFEVTu1tCsrshMr0MnnTuhpxlfGVSWIbdiWs3tb31FNyL46tFf0pq+Rc8M3M907/wAA97RV9G2dgeYVHtZFHOjsxz1fgRm/cYxPIpnGAXldAzyF62X2xSUjkL4ln1tUvMH26zJEGFfRYt6UP29eJBx24h45aZ24tG6j4vAzyccrgPgYvdiY+P0f/tii7pGI+2sLHZ/VS9czKoc01gfB5bBozTn/AGPanN127Pf4wE7wcIjJR14qL2c2bVGpNjUY3scONc5+3PaQ99/T/wDsuC2mj48+l0h0u018l8w3XypV8iZ17pU8ki9hryddqafwbY8m0qnIvm5vzrTC9qV085IszfY3zN2NexHOIorUJDwcv/zI9u71fKzdsQRRwWYCl1ovfFBExqhB8kp6kduP7RcrqpnT2CvB/pobDsg8iPTl9ClsxzvBQDSr/M04IysTXZ5hfxryM6mfoR/w38F3GvVAy+MDL4/5aF3eURGMuRZAKpfr3XL2A391o5gIFJEQtNGAkYQk4v8AinE9vPpl67MU4fAxBgtZfpEX5tn0tDI5NiSY9vPm9d+f/wCRu14qeaGtE3JKcr/f7dkrPL3oS53I8vVPWYfeTrmBwT1EP+fo6/yuE/yw/UjZxcZPxJdihRaossyc9KMadohuO9GCHTr2C9iKRW5PxdvRyLzeOYteIk+iyj1XjJ+XavU3JNiYZLFw00JSJxAVwsfDjcDl8gnaUtXy86zgMOQ8vosR1ZLIW5KgZt2reY5hBytRFK1uG0OhpQ59OK7dN9fTGeKIjYc6KQm33rWNSOuzNam7CuTAdr8A34Xj5R9OpL/tl+Y5HHYlcoZp1L7fiz0aYlVrRVYpo50cMzKSA/Z6Bd2hBNDGyOSGIMInaflnFb0N3jWRoyBxGTzzvEAbkFs8/j3JeRXORTyRPGV64NeFWLEVWKpmWdUnz6kTxwws+/TvgGRt18Km3I/v8rm3W8bPjMyYPy49fR10y4M//Z2JTzgMV7SM7z6Jxh91sLiUjtmVZPjQ8iu/KlJ/UNJrstk7Qq1Z/Fwv9WX5Zm/DLNekN+G7w6Mi1+PiWreq2rEk5SJumfhNhjxhsFWEORwSSXTrWljV4ZDq0yp3ZIZQuyyvJF8OanMV21rQMwZ2djWI549yv0NKdxjqywyWrU1aouR8jqtAP8lak8EcvkwN09n8kX4Ql+HdDoQscWhCyrXxBwuPFBZmleOSUDiawC+RJInOZl7jcx8iTRSdeLRhNH8wcQvTcgfoWeMH42/pv+MIrkUJXONaXHPTkSca2RpcjP8A/L0dWCatNeqy3z5TRMYdT5MUnJXBWvkbCt5FSJ8av8ZTXa8Z6k8U9DhnHqe/bj/THjRy844VX43D49pw6XS4P/8Aw9iXxi1bv/bK3n5no+sffXmXGdbJDDbkWZK/INOJtuO77IYZooobPMcqGS/zCfu5yj5tRunasXtcoSZeKZ2XRE835m/wmB2WDDHXyrL9VjTkuKzv84wHu7VaVmjo+EdYZoZ6VyOWOvZnhzR+2z/Oq2y0aGdXr0tKqIX+WW7Ss22khC6zPYl7XbP9LH+X/LMS9ii0unrW/RBHf/BHn9yaeGJfeOMo+TcWiT86yhUnO89FzyNSctG0OVrhairYOneUuHQxwAxC5D0w/wBpipv6+WeMYq3bgjp2toDV3kZz3th/bwO9LP6uPcU8KVbheRTC5SqXGq8ao2ZuXHXw6HEr/wB8n3/fYsPk2CKXJnq1f0x/+2u65pQbS4wUfScU4rg5N8G1GPptQwWamllVqt8eHcVcbXEONqTjmLEquTg1Z7NfBJTWqObX0N+1fKt0ClnmON6JRpn/AB2TIdCz0VywTvYsr2zu3j0vJhTf5pl669kneqTK0/rXE+y0Lk5MWjK/vPzcas5PAETqGzGYTTzW5IqzAHIJNP4E8jxCb9r8unfwXtaQXLqXyUr+Qt+Hf8Ltcx45o0NYcPkEqHinICQcM2yTcI1eimo50mTxod2qHAKK/Y2NEv2xxaJVc3hkBce0eLUbXPOQHJrUbdht8JnF6pMULtGJaJPFyTa5dVoNucqluy1sqe8E1ZqXK/u7TcZxteGnJV/UjPz45/1HezJQ5lHcKz+otCnDux2dbLxsPH4/U+64Ti1nBgh370Onlfpf/wDVB/kYhsBarHWn8V4rhwmA2oXMCjFbeWVw5WLsY50MF4l8LQdfarUihy63r5DlQZemVoIQqVdOxB6wCSxEFcYHZ/o5fknZ37Zmduy6UQ/z1tj7TSq8xq6Ag7ONuFpAzqDtUCGGkOrWklaC1/COpcYKNmaxXhn7PR1auVNa5Zqynp7tq0Esrk7IyEU7+b/7V327v+GPtm6Rfh1X5fbGD9522T801HRcw2l+4eRztZq6lqeqO5FHZk0QbyJdum774yztpfqRF4w16VW3E0oG2TMxZ+xvUc9g35dW7Lg1qh61mKXZz2qfauW2RDezaFLUxZWGJDCbrPybF6WzSnr1szjehZDZpPVwHGWWlLiHNoRZV+3NoUv+2/pgP9+v/us6NbLbkNdtTXs0bVVM38OChVmoHYlgI7PQz3pYZPuFk44tC3OhqW1NXeMDcvBvJlyWNiuxUAuKn/aoR8LisqzxnCI+RceHHTyrinE9LlliP9HKTLQ/RuJ4d7BtYOkzrBw9HQ0rvFIijn4NUo2QMmXk7orPrqxWhkDIuSV5nmDuePzClX9Dco3KxWJ7TSGDfGCabyInXn0iLyQpx7Zg6RN9PJ132unULux/RnUGhPBDFe0DCQtaAJJjl+rLPP17ElStfisRC9OpnSm13UuZ+ftW70FbhduSct2aUtDV/wDts7g/EefDtvgPm3c+vlcI7q5/6Xg1q/xLMq5XJb2fI16mxcms0b/GeKb4w2MDa40VafkFN4bfMsD1/pkDuoGdaOLSsR08ym1nk9KC0coZESy/t9NBNc7Bqkal+EZQzxwrRjgtxVZPkQdMLDWo+Hqp9ftLM1658CvMj49sURDSFkVu9JePi7b9L/pllwDxWOvmIo6jt8vLhX3TGkYvsESGEemiV/EztMNGv8K8BdsURTPUtsI5p0ZnlFpFLH6VyTmskoFFftHWqdHbl/k5snJO/wBA+jp27TgvFdP9P1C4wOfdb+jj2pWow6e5Ts0f6Bk9VmqflBybe5Vk6Wduw0q+Zdr6tvnGgV3P45Ymijv37kGdZmKxL+X+n6eMUlUm6L6Mzk4594kVA41/ZF/kyM3yp+ikM1wuha0994/U1qvLYikx7DLl9m75sISDFJCo9WKNVy3phaxe6b73IoMrk1hHw/kkB28vkMIyZu/eCqfKKyxpvjZ73KSfQosvuFBPq0WRa1QU+tTZbV+o9aeS+5Q2rdaaa1dtS04JpZYd+UYi35+x1rxvt2PmFCbEg/ty1JK4qDOozyFkNCX6gbUtKF43heCyaktxsE0nkRdrv6Cm/p6XS8FdrQ6dS7TmoXPqyb6syIGFoJqckM/J6NKnyTVtamhi8dp7kJQVwHdaNqXBa43N/L0qufhxQ5GhAeJhE1nJ4VE0f7XG/oaf6ZRHf0OLyvLqRQsWtouxGZv/AERRSTScSwT41Uh5BMal2b8B/fLBq3LFfaShE5atGvTp3pCgy+OXLEcH3K6LtqzItF+vuJEvkkTe/wAhC163+V23yjZo7JSA8jGnK0yG1JE/vPou1J0RBWck8ARDFE5Fc1KmIn5Zgsi5pg2Gh5pxis8XI+KCm5VxYxbkvE3ExOlLp81lqZE12a8Z9yFYMWdzdO/9A/8AhvSvDJz/ADWnbyjZvlp7Zr5My91hedkkFXRmUOLsnIVLQjKevJG3ya7FcmKd+BkMmbr6WYFfO0uH0X/6jYFJ7ez54NXkvIoYruntOjl834JL439yP060heDQU7t063A+X21T/SHkk62+DY/GVFW9c1iCaJeXgPCGiLk9/wDlERlCVazDcinrvAfiMinhcVyGYYJNasf2vGL/AEhRebD07kHg/fbN2zu7xlPH2hkk7/ywH0hmgNM7gXkLtM8cSY/N44XJE3xwcjsSOQVI+S+bgzFOMZGyKsYyNFJ8Y4JhFUvbLFyIG+YU3kbdo2fv/h/qKZv63+l6u81HOOvrUb2XapXBpX1LHagL++6atYd4eNaBlLxu6M2jn/bm9kig9ko0eIalgouK4kEdSro0yaCJzGCpCrFeQ4K/Fb9g6XGIsmfX+12q3w+FV1V5Dx7HOfmtkpuEXx07HH60lHEbx7OaGFfqhPXKOSSInOyXZSkSxb/2zWsE0gXI+2jlOEob0NyPqOIvI41o40GvLfq6JrPiOCuDS+UjRIX8V20bkJSLxeRgeVkYtIxP+XLxRVfYnayLfLdR1JpXGOOFj0ohXjaul6nrMJ1SPmFuKxGxobR+1pTsTSe6NTNNHGqrNVo8krztL/yxLtl2yf6jXmEOl/j+h06JdpyZznCTI2eWHANR+Q57LU0a9yVp2XyH8v3HbR714msWpJo4YZLMnHsEs4SLtE/aM0CgiEW1ta1lVJ9/ZmcynnkMHsC1aZ47deVp7EAQr9LtStQuzcmxImuctx51Y5PjC3J9CjpiRv8ASOGWZxy7TrP5GFLEua2zM1TW2XcdrQR8i1RZ+TbPZcm2oSn5Ft2gHkW8AvyHcdi2dd3PS0TTXrnfzrrO2jfTaV9l931U+1rOw7WqLfuLaTcq5AwlyPbdfuXdZFyLcdS6V43a5O6aWw6P3HJ7ZiiYXJMJuYP6VJYhcAsiBILHor8yvm1eQfEl3/RRpT6NrkND4WT+P6u2RfQuybmVRVII9zEliKKT69uv8rKwb2qdDHoY0bkvNeRSOwubxRsuu1yKH/QXZC9zyRxqpfaoopyOeaA2RAEw0z8ZXMV5ii7ViEyZqk5EEJlLNROu/osJwkZTP/ZqTOFZn/Mj/wAB67uv4yj2S8F4unZdJh/JC7Om+nf18mXkyH+ZfCuuvtmkZR5GsSOhapVTkBrASeTRe2NeU8ZNb8HID+H9KBQ3My5t0LlGKrLeks1bNOX60s27oy8Zxvgx8r9T4r/0P9HT/TxLrSrFoZ3G7fqufqDmjnb7uv8AK/iyr15Lc2NxPPphPoZmcEnKcpnaUTicCNP/ABhn2tXsS5XMsqW5Wr6FobqIikdRQBKAE0RFpH7/AGkqz+M6dP8AlEyyKTuNitI8crCZfEqMUVLENTYtGavCfgLkzPJJ/arD5R2gjkmFoBT/AB151l/ZXlA7e2v21YLIubs4m7k/HaK/bmeh47mIsDIYe/pjSHFplesE/wAiVe4lv9zUJK1iFRd+pxMMw7RnGEdF2yZ+5rGiQWZZXmlDVAVryU7A8CxdJ9ncbP1o+UcYgzZo8uWQ+KcFqDdpT06cWpF8e9znV+VbZ+2f6f4T/Qk/09/qaEhctSm2VyH9Sa3ysRd/Tj1qlQiflUamGreOHWgqp+RSOn35nR7lp1FsgEH3e8vuV0wxCcisVCjmipvG89kpH/j9Q/D9OoKVq2/2TTT4+h3VpSRhepy+w68zOMNl08BAwW9CCG1k6FCDTDqN+1lUX+JDHXjkKGKwdinC0UWd4zDReRTxPBIzuyxqscmLqRjFowj5ynTMZngznXxM9fFpeuXjPgCyB89KrNapMGvoJ9S46LSuGuUWZSUMzgHss/FuhV93wZ0EMPoKMIJ5SEnl/wB/BManbn+UHhfcDMDpzQS8BpGdaOWKhWABYLgzRX7Q39d/4G/9JJ/pN11Umj8uX1vOpapBqcair+qbT45JpViFxeNugb8qOnckQYmyaDifI5FFwTlMr/8AT7fF4/050yUf6auqX6c5glyHLz83HuS+u7IZ2pbNSSr9Kr/FRU61WSc4+4yco6hH7G9hp4X8m7BMPsjJq9RfMhdDp2RXsuTLkH5zdYmeJ1nchKvHPY903wDiijqe2PO6lQZ4CbU6hBcrV6zBp2a1ciIyoj5XLsX/AG8vPvpeLrQCUM5cWqHZ0JsyURlgnidnJV8+ewuYZzV4/XJFE0jyhYrnXX4Q+YBJKcrzRFCfH/0+ua8tDAy8AtCOSlNNOXXtPvDf3T6Lv5Zshha03LJ43Vb+MjfTpvp19H+nTL8MZv6ZZxbRzOLO01S7g1hnqxvC/KuN/Obi8XqyAMmae7HE3Hv1CAYC57ikrH6hUIlt8qnt7cfOclhg5nDZm+9chVr9y6L63GtS3c/a+m1ceD7Ey1sbZ49Uj99kvI5yuxQ13z4pLMGdQux2pagOjiqi9iCt5RyNAcl8186dfMuIbMsi5FDE2Rcl84UP4IIjkklh0QuTNbnngz7synpTQS9rtZXFN3kFeP8AS3lpoP0z5DmjVutHLNQrSNJkUxAs2COavkUtiX/pPxRi0eK4fH676UEGodoOi0KZF90i64/q+vS/WT8qcen9nkQtRdUj9stgmjEjc3wo4puP7VV55We2Eczplln67N6ZpROQgb9QC6xan/q/yLt/Q6ZOvyi6jVv8KlZcZsOsNabc5hXjhqbI2yCcTk2rs9TSK7OaOeTof/cPn1/NWu+4PJx4rYmp6P3fXdfcNF0891002h5eGsb8nrTNmtaihVy2EwDWi+Lx0SlqN+X9ZSv8cYnF4meauA1mUNUChsQelf4fBq1NHYl45hzRR/pjxIEP6e8RBcvzYc3lenWqT6s704ZJrfclaWhEds6x/T9IT7y+lySf05EcRTWorNiqP3XWmil0tTyr62tDLiTWbOVzCR444aFQYbWkDVYqvk5V44kOjkVpeSPQ5JE3BMEoT4Jio+A1Oy4DJ0XA9RW+KbFJ8CRhxJI4Zp9WMoXm/wAiqL9WJQEFarfIj/UqP41al/6/+XTt9X+j/n6MzHDehF1B7ast++OblPPoSvL9xiH3TOqvl8ftE6/xOxt17GVl+3qv/DirOWjF4EJMzIhHuMB8m6YeUxnNBQ8a8kw0YxkLtfp5M547eBtEEfwbpOUHkqMTaDR0p5RhhujDPUuzu+bYhWN41d1v8r/j9R8+3PyKDi1y3G3Do3ceHUmTcTy1+1sNlb4eNpfptjXsWJcr7+1SwR1sukx2Zc9mji+HOaD5Mb49gAz+Y/mvdlk8Y/OZBrDK8P2cnk0KECn0aBOXI88QpQjq1Tx5UGZZFDFJG+r/AJzjcaofyPef+7I/5b/NT/3WXYCEvEf1T7JUn6btuz/DeTJx/qjb+3dECI+nPkMNu9gDg7MTzw3Kz2tKtVpVrBzCnUnkMnskXlKvCUnys21esPgwcewasnkLD5KTv5IeTu79Bo4+lerRVrdySnwjkF1Vv0yrtHlVKfGYXq8dBBJxyJezjkj6g13uZpT1r8MFmIHo23RQXYmA/ZGdYo7sZO8MZJ1yy/Pn8ek5KLu/I3ZcV49X28ceFZC2LGlX0ItXfE/05G9Jq+fS5A4TZugxlThP4xwzGJSx64F6NroYNjv4c/2K17I1FL1UyC7twnE0AV4dB2y6wqSs0bcafvKcHXTp43dfGiNhjZmjJxm3PzZkf+Spv/dtThYFpiiX6hjHYxawrwZlKfk7Av8Aaif+jpVSdyuROAzQlIXolmpbdnXpq9q/yd3dVC6P6OzLwZeCrVZrU3E+NQ8fp7swhGFqGCUOQ5nsbkOQclbbz5ym0PzW1rrKKMYhhjlJmH1NWr147DNV6J890HwnLxj+bvjJ8r7/AAMn5D2vvjkqujBKtKEI0UnhCK7XIRaXD0CiaTPhOebhm5az7H5XI5H+9USrhNn8np5Km/CtxNIGx+BInF7J+KqQhNM0X9+eIY5q5m1PkEZhaql2GfM0ZS6fk1EuooGb4eg0RhxiVndxXTfUX6QkHyNsPG1L/u7bul+LFoJHOQmdcoFpMKLtiJiNesRTuiRfRiX4ddKN+nlYShsiQT6+zDkY+vuXdiX6QP1I39EcZynw7i44ld5Fuk0li+7FqVKcXv8ARETW4G9PwacKeZ/EIRJPKMYxEuSPK2yxSumjmdZ9eQbmi856Wj/ZGvXGSOSl20ARq5Kypxy6EYGZzM67ZaXRZmplTe8c3ScuO5rVtgpvFa8UNm22FWNZuTUgtzP5KUew3860zyUr3YiL6fv8VNuPEo7LTLKlCerbqQ24dHJhotW8SMoAjVd+nqXvSNq37FxuQ4tP8Lpvp5dO8jLXk/uz2ZLal/3ekHPPEprMju6miYlysjjxInd14+KfpOiRfVl5qL/EgM9aUIe/1C/OB9Y/97f4+jflcK4qVAXd+3XIG/vzzuFiKQhlhtVxXzfXJVd5q3iXcbMMbsxu7eS0asR3JMoBqXs2Ku5N8ePQKKwOm/ZU7MdqSbxazcbqxNW/t8fjdUe/YRoz6V03khKh/cggzykjAa+gcru2pWibfnF3isHXnkhlCUXZlILKcQZVv7dn/U+cuL4SlSClW4rGfl61PVGUbeNWzlK/Q/3GjD3jJBHViiwjls7fa/Ds4siZGKOLyVnMliezWv8Ak2dfN8qtNSOKRjZ4+1uY/wB2zZOMbuYBy9/R1KX4/pBnEy/NaQfz+ov8MT6xP1IMTdetl4guFcU8i+jrkH++3EDWbMEijAXrxjJ1Q/NPt++2aNumRErsvdpzhlCzKBR6LE9IglsOHG7Foq8hREW0Bx2bRHJniN2GpSiz6lZmETdG6M1oWhi05dYHmLTaa0crm27HYbTKS5LLUq2rUTAdawbdomUsXktOi0QH0JU7laI71xrsvFPHyIOnNloUxljal8Se5IzhHY6GOSL4nHH9u6vyiTp10nF3Y4PyVUU1fpCPSAl+HUsQerU4/NAu/wAupPy6/H9EZOyi/lHIDe39Sn6zf6GuD18tlwbi57EnTMnZ2X5Tkt3+SsUfbIFGZ3ejadxpORAzdE/TweZJ+nRK2Y/OmsyhJU05WKO2byZP8L42oonnMhEqkneXJICzPX4kTuMfaJOKkj7bVw47ClOyLxBcMAi8a/J6wFjzVrLLitc/us0fk0DeQuHTyD0+oXlVldeSif8AuccrnALdExR9oomdtmlNIEr9Andlxs2+7MX4Z3X/AB12nZ10mZSR9LwXivWzpmcUzqaTxr2R7LTxa9hW8u7UZ/p+P6K0rudMxdT/AMZf1NL+1/QC4fxSxyCxFFFWi8k7pzRF2tUJCE5JGTvdderRJDR1nVfN1/KvmjXcBGICdG7srUv+uG0ZDNFMUh9OWXnSqeq7AYdp1BG4rHDykFmTt0/j23gjD8XT9UBkxKt5MEXfxORVrE1OQx64rFLJe/3iL+KNu07dqWqErWOKnKf7RJ1HwwHVDPjpwj/FE3TuCnh82vcer3E/E4mcOL02VLIqUzHrr+KZ2deBL1yumhmXxJ0VZ2T3azIr9VkWpVFHtV2RchgFPufLY2F2mF+pR6VipFK82XUdFkRL7UHb5DdfbiVWWT2VJOlb7Gb9TJSOx9XHpcP4tnb9SlUr5tXsk6ftdOvFOHa9DOvjigrsvX+fBgaMXTiycWTiyti423FnUfYrrtV/4VrTv6/x32u1x2L3TRs/k4v3/wA9KRux9PthtcUy7ElXi2ZRU0X8nrs7PTiJwiYEzLx7XXS8O08brwZ16vywMy/iyd4iRSOBGTsRexdToYZTl+NSBdZ4r5NEU+hAyfTR6hsn05kWlb6PSmT3ZiVyaZrLzyOnkdPKyOZ1lyd3JCRO3iQN3OLE5APiUXTeh+3j6f1JouiqSF1cicpP1JL/ALomZyd4nhWLi3N6/j5NXEz/AMr8p10/08V4rxZeK8UIN0bMT+LMxMi/CmkJaLsFv2CSGGySo5l6WYa/ixVYjYuOUux49ngX7ezVTo1aQszdu/4FdI4z9cYknhkMRqzEJ03dekWXpBNEDLwiZeuuuqq6qJnrsnlhXyYF8kU9x2T33XyjdfJkT2Jk08qeYnRGBJ3XaI3Tu7ryiFHYAk9qFk+xnr7zXdW7j2J+3djLpu0b/mjI4XJC/Lk/i5IwdH2vIXXXa6/P8VLJH5wyMyIv7X6hyvLyNmd38HienRs6VrjPHKnHKH0/DM35XX08e0wrpeK8E7dKIESdkUbJ4mdpMqkR/BjFNWbsIU8bM0edE4fAqsvh0WL1U2XdNl7qzJ7kTL5y+ansk6Ow3XyZOiuGntE6+QyeVk85L3mvcSeeRe2V15En/K9fSYul27rwJdGyOTxXzImTWYCZ5YV7QRSMp5469c+zRt/HwB0f4F/HxH/Y5OooiJG/TH26YP4+H5D+BO7FGR+tzH8eZJ3/ADKiXlIvMk4s51W6eHpw5ufu5PBEMTE0luXhnEwwanSZl0uu0y6ZMLJum+vbL2gyKxEvlw9FciZPfiT6MSLUjX3YOy05GeXSlZ/nm8Y3pDYppGXukddk68zX9t08Dr/YnNewl7pF65DRPGCaaJe2Ne5k8rorjCvmu6Eydr+rHl1qXPKFyrQ5byLXm0tTk0UeVz1panHeV1+Qrt2Zwd14szFHHItyR82hJcLMux6+pKZ8j0ihbUuXp5bV+1xkKNmS9LJ2zIv9p/7WZ3aOBf4Y3X4cmb8F/l28Gqk8taboh7KNSlI7fIFO4kxF0mkZexf7WbpipSu0nIsxx3rRiz8DwYKI/LhdPchZfPgXzgT6UbN9yBkWtGy+7M6LXdk+rIvuhr7jKvmTuvmSSE9iXuSXzBpWJml6d+kROy8uhayEg1pVa9kBycjFxHkTu37hsy2tXkmtTtwTTT1vO0yYpnX5Xkzu4gpK8ajjEUJCnYyX+xPKnJiTfhMr8x8x3eR5FSltM7LplrUwta+7RfBs0bsWhUYgJSuIryVkYJIBiwYVYjzrTedJpgt0nln0p3sS7kFYD14vKfcvyVPk32tzP0DOyZE6ND/uf/aAfm2fSxJXnpkzsiEXRRv5Sj2nrfk5JxUgO7+EikAvEvONVyZpP1GqPHo4OcOjoQTlNYechXyy7eV3RWfFeztgnXsZe1md5fJvYy9nSeTtNOzOEjPJP/FxkdhEnFeSbtOXajPsQdgeTyErDySMP9t3ftgMmtSNWnP2FIjKICimjm+k9irWg1t5qC0NWPMVzkNuxnffbAKLa0NCxJP5JnQ/TmusWbkcezPtedzCj8zHwJHs12k6PjEL393RrhbpcDuSsBCYpidMa2vceR9o0IKEuBJKq1K1Lbz8uenZPJJ7EmHVllHGohYGpViFqsMEk3/r8V2iLtz/AC8LdyM34f8ACvF03Gzf0M35/kDuwu5flyBuvEmZ/wAv0KMelJ26ql/HmcD3eO8fr/Eys/8AxM/TvP2hIRc5P4tIvNibt15dJn8mddt0JMnYFGXjITsYsHi5i4ry/LOvHyJg6Tu7IDJ2Jm6Nm8mfxKwS9DSKGJRTWpKNjO0asm5WOegWVryx/tp3VzPq3y+z5/UuNnSv9qoRJhXg6Eevpru+tzWL+UskYm2QZ5WjftvVp8Uo/BxZH/GX/pecEycV19X+nj9XRKT/AG2X/s9r8Im6Uj9Kr/u/4k/DaR/x40f4/iQ9+SkBN+WcWRIm7Xm6nDsZIncfi+BjWa/mzH4Nmf8AzzB5I26TOmdf4QuS7Yk6H8OIP0z9E35dh8UQiL+uUweKToWkFP2T9J5H77/JsfYD/JwdGLGnEhUguqskr1qxl28sQJ9XO87t+Gm7cgitJt+5KI72noF4sIv+UAv49fQfyiWOXnzGFmZXtrUi5by2q9K/NE+zqW59j94y/gu//wBmTp07fV119ek6dS/7bHXr7UHDr0lDSzq1WtWoxxBYoReuwUWJCdWpeHWwDu6OJi1qNOKxVtaoZjk54tr5k+KTVPsFkI9XKCXc1MyaiHRKwHkMkCMXeTOLwfYb0X8/v4hIycSJBIzt+U/8TGRnZ/5JvFkKk6dD0xDMwuQxkwsTB5zLyd3ImEm7UjdsJk6Jj69o9tIPUn8k5Myk67zS8qcRdSBx/YkrtxySPQ3KtyS1k4sedFWy6FIooxjD2eLexeROzt07Ou+k6pN8XmoSfnZ5LWy71qKC9XyMenjR1uTHNyC07LPb5POfo6/KZk7fRhXii/Cd06nfoJu/VWdoJvnZctfkGvBfjhtVbMF62EqtwjsxyWa2fFsvBt08cq+dXucg055s+OAc65NE9ujLDHm69ZtW3cajZ1OQSFYw3MuwLyaSNiaxD/brN0/KPxs1f4xSKZu1/hw/y38XkTfgn/CJ+1GS/LJ3/P8AvYTcCjfyEvwwMBtIzpunbxbrw8FFI/lMP5b8InR9eMiyZCaAD8nY3Xfackz9/U3XkhL6Mu065f8A9s3XPwm2c6PXqZ/LbWcrnOjKLjVH7XRs3HF+Bwe76+Pa8GTv4pzXf59ieVFJ2v8ADOSnfsbD9QGXa7/D/hO/5gZgAv8AFh/43X/njP43xfydzXm5E/Sf8uQKZund37//xABBEQABAwIEBAQCBwcEAQQDAAABAAIRAxIEECExBRMgQRQiMFEyYQYVI0BxkaFCUoGxwdHwM1BT4ZIWJGJjNEPx/9oACAECAQE/AS3plR/tDcwj7f7HoFKOqLZVqjPZaFH/AGZuTd1Ef7GT0TlKgK1WnKVH+yty2TvTH3eM5zlb5SrlcFAKshFqtP3+FCjJp0yAkp5l332FCiFKn0d0RGcqSp01QK0UAqxWlQfTnI+jGYygq1RGbY3VqhR98n1ZlER07LfO4q5XrQq0FWq0qPXhQrVopCuU5ty2blJUqVIWihWqFHpQoznKFMZk9UINyDgeoFFvTsviW3VJVxVykKAVarVB6IKtVigBaKVKk+g0aIp+mnoSpUq5SForfShTCnLZE5jo2U53K7pBRb1fFlv6MFQ5DLTL8Fqj6vyTRc5EyZ9KFaoWivRfKlSpzhRlrkBkcoUZgKVBKiFp0ytMwYRE5xlsviylQrSrFaFDVIVyuVx6QVcVcpC0UKFB6xqVMlN0k9cK1QFIVyn05KkqctMrVaoREZWxutFICLlcrlaHIsjp2U5bL4lCgq1WK0BaFXAK9XqSrfTHTKuVy0WitVqgpvump2gjKFaoCkK5T6YHTAUKOmUJRcFKvKnKcoOW6ItVgOyLY6ZhB2Uq5XlXIPhbq5XfJBylS1QCrVHTKlSpUqcpylaqCoUhXKdMt8pKk9MqVKlSoKhaKVJUnpAUx1XFSSgFaVatFIV6krVfaK94XNWo1ClTOU9GyuzjP4sgj0SVcpC8qtVpUZwoKtXlCkBXq4qc+yfpAzBVxV6uC0WihQrVAUhXKeoZge6lSpy17K0rburgrgrloe6sKtPVOZhQFChRGQ6JUKFGXxLundcFWlW/NAgd0XAq4KQVE91aVB6xqYTjcZ6bSrFopCvI2VxKDirlcFLVA91arSoOQTVC0CnK1bK4qT6FxV6uC8pUD36ZV7UagVzjsF9oUGnuozjJoJag2RqnMjMapytKsKt+a8qlqvV5UnrlXFXKQoBVnsrCrSme6tKsKhvcryq/2Un0DlGWquKvKDpyJy1WrdCm0nOFwCLHASVy3ey5Tx2Vh9laVChQoUKFChQoXMKY64I1HK5x3QAQa1AdLabn/CERGbDATXaJzrsoUZGUZyhQoUKCoKhRlChQoUKFCiVtle0K9aFQjDd1c1XtVwQLSiQFcFcFeFe1XBSFKAlbIhQpQ2RPllbpsN3V12q4eYpEu2lVcK3nW/stCxNBwoNqBY1r8O1rO6dRIqU2qnSDqtT5LFYfVlM/EVi8GeVe0fCsXQ5djwN1iaLKD2mNCsVRZSp3DvsqGHDqJqkSvCC9vl0KrYFrWFx0TsJTbVFEjdHBPBi1BgGUK0KwLlhctWFBjyYauVUb8ZhGoGfC2fx/snYiq/Ry5nyV4UpuZU5HLcQrEGzoVt1CcoymdkHSYV2koFFDRSnSdBnJ7LdP1EIsTmQmsQEJ3RRpcyoGuMBY7C4fDwaD5Q1WyCedVKnyopuyd8KCglNHZM4dWcPK5v8A5I4HHRaDI/FCnxJojVVaOPrRzGkrmcS7g/krsY2fIdfkjXxWhLdvkqeIr0WlgG/yR4jVgBzRojxGoQA5g0T8cXUeTYPaVhMW/CE6SD2TuKTaAwABVOLcxpa6noVT4nAbzGSW7FOxtZxJnqhCg6Jdp+K+yZ8/0H9/5I1nRA0HyUdEKy5PZynlhRQKJnIZlBNeHaIGUR0FA5vf7IJsHK2MiEU6Y0VpVpQC2TwTsrSrSrHBBpRYSuWU52FAApj8wnVKXYD/AMQqmIpC19AQ4H2CxmMq4yAQAPkrY0UIaZuHZQmjRdlKuQyCbXqt2cfzQxuJ/fP5oY/E/vn80OI4oftlfWeLH7a+tsX+9/JfW+L9/wBF9b4r3H5L62xHy/JfW1b2H5L61q/ut/JfWj/3G/kvrN/7jfyX1m7/AI2/l0U6T36jZRSZ8Rn8P7n+ydi7NGCP890Kl+p3RUqUMu2T3WNuVWoKtY1RsekkBXaSru6JWjkWhoUdUImE585UtkPvTRqjqcgu2YCwPD3YyXTDRuVT4fhsQbKNTzKhw99XEeGOhWNwD8E8NPdYnhlbDU+a7ZPwlWlRFZ2xVXCVKVMVXbHLwlXlc6NFToPqC5oycws3TWF2yNJw1zaxzzDQhQDdah/LX/pCoxnwt/PX/pVajnmXlF/tmH6Ia5BWynCNEVifghUnmA3PZXZfsIGFM5O2jrc8DZEznR2OQ6z9yHupCkJp0R2Tac7oG3ZXLBY3wwcw/C5UOHCp9rhKmq4YKv1l9t8Wqx7PF0z7scsf9rRq0/aFV+04U0+yxvm4dTcg5cQdy8Exje8KmW4eixp7o0ft7VUHOq2+yqvjyNTa3L+JOqypKdVe4R2TXFu6NUnqBQqe6kdlSo1cQbaYlEHKsZBhYdwfTuVwV/t0D4MgYQergVsrlcO6bVu3XN9k55d00u6EJzo2V5XMKvV5V5V5VxUlSVcV5lqtVqoKgq0qCrSoKtKgqEQoKsVpTB5YQFoUqVKlYTEeHrNf7LDYlmJ4pzG7LAV2OxlZh7qlVbXxVdnaFhiKvDqlP2TKbsTwwNZunYDEMFxasf5sBTf+CxrjyKbwqVUVvP3VCrDzKeSx0qpVNTfMvJ9GUCuGcd8F5arBHuIn/tOwnDeOPNWhU8x7bH8v7LiPAhgW3c1v8dCnqi2xz2ex/mt0AVacgCUGkCEWnuoy2UrhfC38UqctjgPx/oO64twDD8MwfMDi5+iOVvzVqjOmwjZERplAUKPWn06e0rlEoiOgFAlp0QcQZCD3NMhB7m7FMr1KfwFHF13CC5GvULOWTonVnvbYTomPcz4V3lPcdlC265CkKQpCkK4IOCmNQqdN2JJM/mnbIsEl/uqIBZKmEc3KTCqO1VyvKuKbULTIVXiuKr0PD1XS35/3VhK5TkKRXKcuW5corlFMCeRsPRj1p6ZCpuheHaNQq2FFQQE6g5hgqnhKlX4U+k+mYcMidenCUGOpurVNgjhqVanzqWkbhOwmHFbk2lVqXJquZ7IYaqeye2x0FboiMuU5cn5rlALlhckLlNQphplctpXKauU1VAWFSmatQAbsnbJ5hqwrvIigZVyLlusLifEMLh7kfkqjQ8yVy2e6sYm02u2RoWiYTm6LDObTqAu2R4gzBvPLY0gqtxRtT/8AWE/ijnNstEfgP7J+Oc9tpA/JeIK55TKxJhD5pxg6K9XlXlXFXlXlXFXFXFSVJXmWq8yhyhysKsKaxObouWrSmtjdEeyDfdWBWBNgLC3upBxTPmqlFrzJQEbLG0ucNFQwdStUDNli+GYjBCag0W3Rw+vTbdRrfC5WU8BhngvDi7aFWx7adZgnyOGqr4JlMVHXSQR+qouNvmWK1quyOTq9TaUKzz3TdsphSVKlTlW7HKidCFuEdQqmywzrdEXSg5XKfkgmho2CrH2zwbwypLlWIdhyZkf9rFUXUXFhRVYQMoVqsVipM8ylQFAUBQFAUfdRng67HMFNu4RPQ0BYjiHLpGnihc0/mmcKFZnMbWbB99F9T/8A3M/NfVP/ANzPzX1SP+Zn5r6rH/Mz819WN/5mfmvqydqrPzX1TU/5G/mnjw9O57gfwKgCY6ALkxmvR26a22VMw5M2RWIMUyVh3A6onKQpamGSjUteAq3yUKCmDVc0imaYVfE+It9x/dVJBNwWKcH6joa1FspnldkPuBUeiEFySBc7QLnvpVBYmk26pzkDlMLiVa9wZ7KjVhhpO2P805sKFGUKFGRyOTWpg16pCvauYE99yJTNSubbomVL09t7S1YQkUwuaVzHLmuXMcqD3F0FVnODoVzvdSVusJgMRi3RRbKrYaphSBUG6aO/+bowWT3VX4VorgmB1R1jRqU7BVsO62uCFjWYbD0ixnxKm0zKbruE4lvwrmP9le/2QuKBKlSpCc4TopKuKuCu9l5/dRU/eUP/AHv0TZaIVGlyWWBaqFChQozlQ6jBPfZeIc4ysBSfiKwsbJXFMRiqVt9Oz57yhiHVHalMxJZo9eLpqvjg0eVHENKLgdkXuGiY/SCrpV0qVK7IdPn9l9p2CtrELlVUabwhQe5eHevDPXhnLwp914QLwY90zChq8KxOpCntl4Xkhrj+1P8ANUuD4ZsXNXEOHUG4YvY3UKuAHKQqB86rnzrVCVT+MSqP0jwFGny2gj+C+kAZWpUcTS1aZE/gmbwUFYDoU6g0/wD9Kp0WsGn91wTGYbAYnm1vbRYn6R8LxEXNOnyH91xPGU8ZWvpiAnaoTkVKlT1SpKlT6tGiaxIb2BKq4qpXhtTsgJKwzzg4q0zqsO/GcTYac+VYrAYnBVpc3yjv2TanM1RMKthR4PxN2sxCocKrV6XNaquCxFDV7U/VAQsOypiPsqLdUWuGhQa5WlQigOiVPRKlSpQKlSFdlVyxBuwjD7GFSdfRpO/+IWNF2FfHsqrL1ykxga5VRqoVqDVT+jGKqtuBEfx/suL0RhOG0MOD3J/NQeypl5+JOu2aiaw7BMut8+c9Dhqo9OFagyVy1ywuW1ctqsarWosaUaftnwajbSfWP4LGYYUahDNk15AIRxFm4XAeJ4YMFFxg/NNYHjVYHh9A4nENGwkfr/0qfAzWN5d5FhsDSw7bGt0T8Zw+k4se/UfIrjPFKNZgo0B/HLC4R+KfYxcJ4bTwZ0OpX0mwnJxHObs7+eZ6p6YQWilSFIUhSgqu2U3YVzVwnEGpgmXnbQfz/qsXjKTKTg475wnhQoULh30hfRpihiPh9xE/xXG+JUMeWNw50ajojiqnL5U6f5/ZUXNI1UMKqCD12yuUuUuUuWrEWqFChQoUIKAFKlSpKBOcp2+VPibMPg206fxLA4OtjnmxYzglTC07jqq9A7J11MxGiwP0o5eF5R/1BssHxKphKvNH8fmqPFsBiALH2/I6f9LG8awmEYQw3O7QuYaj7nJ7P2nKF9HGB9J8b/0VFj6TiTqF9JiThG3Duvkgj1yVK16IUKOgFHULZOPkIVCq8MtB0UrEPdTbLVRe57ZdkRKhWqFIQCDZEhBpKYIyd1hDIMlYfh1bE6sGiH0fqndwXEuHP4cfOdE1wqfCsFw6tjqvJo7rHcAxeAp8yoBHyUdB6IUdB3TzCBhfR2mPD3DuVjxDZO0FPa0v8ywdKhRrcutTB/zRYrg2GxbTym2u+WyewsNpyHm0KdSfRPmC4Nwt3FK0HYL6owNJljm6rD8N8Ji76GjSNUxq+kWOYKfh29k1vvkcj0SpW6lFMBqGMtcoUKFCGRCDNZVHvkQoy7q1QrS9Gm0INamkgZNydt1jKiH1X2NCwVBrKraUaNbJHzPusPTZEuCrupUBc5q+m2JuLaY2A/np/RYXDClSa0BfRrCGlRq4uO9v9Sqf28trfl7rjTsDw+k7CU6Xnd+iIzKPoOVNnOcKXuVU4NUaPIZXAqr6AOGrCPZfSPE1GhlMHRCqHNlYupTL21KO0BUiKNPn1DAAVWpzHl3unaFHy6rnGrqV9E6rfM0nUrF4fmFpDiI/VcW4k6liyxvZHilc9z+ZTnmobnqZRPWIU5SiqZtdOUq9o7rnUx+0vEUx3Xiqadi6bVh6za4luRyp/HGRQMnRFpRQdIRg7olqLqYRc3sF+ClNUp2QYSnMtQChQgguFt/95Tj3VOq+sKlY7nT+aZXqCmPNCbiJ+JwK45w84/EzpbomYB3yXBa9GhgPCP3JJKfhW3B9PUFfSxx8WA72/wA/qi4KUHadZ6MH/rtQRXGCXWypVIuJgLEHiFdoFW6AnGwoGmdwqnLOywWCrYirZTbKocMxuD+0pxK/9RYyiOTUGqr1HVXmo7cqVKlE9Yxt3whHEsCditNF4ip7rm1D3Vz/AJrznYKyoVyXFeHK5Jbsqpe3RMwdSpqdFhKIoaDI5bVM2ttRdpCPRAUZRohI6KZVTZBWoN0UarZGpyw17d1Q4niD5LlzXHW3+aJe/dh/VeHv/ZXhIHlTKfL+IqrxPE8McDh6hj2WKxdTF1TVqHUqFOU5SVPXgf8A8hqaNFU0XEX3eVMb3K4FhmNw3P7kpwnRcW4ew0jVYIhGAFRo81wYNyVTwtHC0hQpjQfquIcHZiPNSda78ViaFei6KqG3WehtBtLyhBitVqsVgVgVgVoUBWhQAgUxBHJ+jpRyE5dspylSihK3yKCYU4y1NKaE1ktVQ2vVl1K9qm8NVCmT5l4inaBK8ZSavGsOwKOIJ/ZKdULv2VVbzfiCxFHkvtCMLD4ariTFMKpTfSdY8QVEegE7ZYNzuexMMhVW3BVp5rgVVcQvozxOiGHCVzHsf6LEYbzfJcY4jh20Dh6BuJ3RCZiA2oH/ALQR+kjTRm3z/oqvGcXU2MKvXdiDL+kHrcJUKM5CkdJ2VMpvlMZOUwqqaJE5Na3Dva5+o3VZ4qPLgOiYW6jI76qUNMwVjuIUsBTDqvdUOPYOo62Y/FYbF067bqZkKk/yquAXkqkx1elDRsqdEuIHc+yZg2UCKNkfxVfhlKQWUxr/AJ3VhpuLH04KZh6tT/CsThKlNtye5SsZq9YHhdTGv9m+6w9PD8NaG0gsW+hiH/a0w7591icNhXGG0/5rGYLw/nZtlKnKM9FR8lQOTChqqtNtPGNc7YrwQeCKmqrUX4HEGg9XvtidEHJxXKBNx6zlKnpI79EKFHVtshvK17J7IbOVb4UxxLUEXE7o5Q1QxOsRd8kytGhanQdigfdcwN7IvuGyD3NEZBV+HUcQ0sjdUPoy2hU5t+34L6L8Lo13udiBIA0HZD6PUMU3yUhH5LG/RBuzXFv4hUvomAftKmiw/wBH6OHeKjXmR+H9kMG4uvNUz/D+yqYVzxpUKdw41TdUqEkbbf0CdLDDkTOgVbhBdWJmGfqF9QtOvO0/ALiVBvDMUG/GI7qnxi067fJfWza2lTRNxNKo2QVWxlEO3XEcayqwUqeyDiwyFVrVK3xFMIB82yeNfIiCN+gFYOrzKQcgVjSGtFQ9lV4rhMMBe7Vcd4hhuINbym6jumGEHTugA30D0Aqc+H4m9vLd0lAdYACY+1E3bpzhsFUaS75JsHboHVPVKY8s1CZiXj9pfRx7GYYvbvOqpvo1W6jf+H6tWC4ng8K+u6vU2dAl2sQP47yqn0owb/JShx/8f1R44y+2t5T+i+uaA2eEOLsOtzf4uCrfSbD09Jn8Fg/pVTuPixI7Qqf0g4W4fZPg/l+pWJ+ktHDmBH8Cvr3C/E/9FxfGMxuJ5lLbrCuUq5XdHDK1juWe6CxjOZRIWIJIjsiFsqY7+ieuVSeaTg4Km8VG3D041zpU+Y4NOi4hh6eHtaxRKw5iRlotESOykIlQo6zr0UMXXwxmi4hN41jmttFQo16h75T90baNXKaRX2Q3Us3aUziob2X1u32T7HmZT6TmKmLj9yauG1omkcrVChQoUKFCjPB0hUPmVV/nKunUq4JmjyripyHRaVYURHQUPvIzf7KQ0ynAHVyFQESrhfCDwTGVAU+S1rhuFxPDU8LWtp+gfSG6DjTcHhU6gqNDgpTGOeJaEMNVPZcl5UqegvARqlNrOb3TqhOyDypJTabzqAvD1Xdk3CEOl7graI3K5lEbBeJjZquv1KGb1Iyj79GRaIhQGhNtdqmwTplg6jTSa14XGmzVD57eg6m5rQ8jQ5T6BTfMFw+rqaRVpWHrcoQV42Oy8X8lChRk586dAQWHfa1zgji6rxdPf+qLyruXL6pV4m1U3gt0/wA7pjrlTUhF4V4RM506T6ptpiSqfAsdU1tj8UPo7iydY/NYjgeIw1M1HEQEKbrL40VoVgVGkHvhPoU29lymey5bfZWs/dVrfZQB2Qt7hVmxt6gVjiuW5OEI6LSJUXJrHCJRZlSMU2qvhTTeSdiiI6qNF1d4ptXFsOKWCDB+zGUdQzpHsmvNCoHhA3CR1OeGp77lKlA5DLDaseFTGkq0mHd1Uo83QotgGUx0+Y6KS069EIDICTCwVKhQpBlEQjHuiuINuwtQfIqg8Dh72n97+2eCAvkrFfFohruoUKFCAVZhj0rSrSgx3snU3N1Izc0O3VoiEWTuo1zwtrqbQVWrMfoVVoz5giOilSfWdawLheBbg6d7/iK4s6MI755H0WmCiJ1XDqnMox7dBMJzydsrZThGQCgIQi4BYCXXrbQZFxC3XJlsFR1BYXA4jGH7IfxVCi5jAHFF7gN1VxGIb3WIxVXluDzpCoPjCvHzGRXDqfkLliMRRv0KGKpBHF014xnsvGN9l40furxv/wAUykMVSD2jdEQYy8L814X5rwvzXhm9znSMPCknKFiZLVBGcLVFRlSrgNCr1ab9RumUnVdF9XP9k/hxCOBqAShh9JXIf2lcPqc2ja/4guM1hIotO2R6RmBkx0thcMfbVLPfoqEkwoXyWqsVqtVkqFC4fuU82uhGpOjExlvU1hdsuS/2XJqeyFF/ssDiqVopM0V7R3WJxAY25on8N03EY3EVLW4dwHubR+krFYOmWfbvH4LzU6TmnvCOXDMMeS0RpvP4rHtcyuWN9ygS0aptR0lx2RreW5qNSEx1wnLhNEVuHtgwddf4riDBTxT2j3QQUqUddF4Z2VL4wtlOeJfbCJuGc9H7K4XheeXO9kaVqpkwn07li3uoM20KcD8TUaru6JFLzsOqr1XV6he7fI9I6CFT+KFh3cuuCgbkHRk7dQVBVqhWlWqxctBgWDHnKxdOKtwTWW9G+eGJD46OHvsriVjOI1KBApp/FMU79pPxFWp8TjliPgRywXG+QwU3jZYmoK1Z1QdyuaHOLSP8H/adUtIDAq8tggBGqYNo1XMf+72VN7n6qhxKth6PJppzi83OTPiCjorHyHLDDz9BWK1g+g59rQsDXqYbCF9NsklYbEjFU70GhBrVxemDhiQsIZaq7bmLEnlsI6D6A2U26o6PlF1oXiWyjjmMbcVTqNrMD25wFarQMggC7QLkvWFY6m6XLEUi98tXh3rwzlUolgk9AE7KgxwfJyBUpriwy1PqvqfEZ6MR8COZVrIn+Ca1rdkSEDOYEq0qk03jKES5CVUHlKsCw7dcirlKfDgn569ESNVRYW4VtoJ32/FYItIJb/m6apWNF9Bw+SwvlmUNdljHeSOg9ZTCnKboTGSE+kCNly5CwjOVRDB6GHPmVynoxA+znoofGOntkTCBnKqJaoEK0K0J4TSQFqo90ZzZlREuRUrRTCJB3T99Fh++TjpmQCuSw6FOotDoXJXIXJK5Lk3DVH7Kwt0Kq16mHpUzTMbrA1xXaXWwdECpVbWmQqRLlTqWFYmpf1jocmaLdUWF7w1QFEelhvi6qomkUc6O+TtU3Ia5EICMnCWnoeNUyiXBeHXh14deHCq0rdkzKh8SKOyCOTxLtFQ7jpuCvCMEyiUHK5SsJ3VX4ysZ/p01wv8A0yfmpVye7yFUjoiqvXGU5OQOqBWDYXVJCwBpseDWOydiMKWk6IfL0IlYdsHImE12dQTTIUIUyUKXuqmEbTaC1SpUhSmlHMIJwg5u2VOrY2Fzz7Lmlc0pzn9k8uqaFNpWNnKkYcnbJxjKSpK1QdDtcxkdSrVCI16AVKxnwU/wXDP9I/iiVKcfKVS00W6qjRH0ZTghoVK4cJe5WRug3I9bRCo7pzg0SUarCg5vuhUbMKFC0ymFUrh9O0LRaLRAar5q9Xq9NMoBHfNu6rPF0AJpKaZ3OVcmYQI7oO18uQKmWoicnbKE3UJ+6Y7SMmo5OKY5P6sW08qm5cM/0j+KcpX7JRAOVT4UchmMiM5ybsuGm2ofwUei1sZUdlVhwhWotTBrKuyO6OQ2zbvk5WqAoTU51rZRRybuqlGTIXJcmUbdSpTmh265ITKQbrm2oIgrmNzIaN0Cn5Uj2QUpyIlBtqO3RKBWGrC3luVCm2lo1PUapzgymSciqm3UOthXDJ5xn26D0tbnR2Tlbkw2hN2QR3zA0RKBlNyf2RK1Tdk1VT5YTs5UyMu2Q2QgbobdErdORlUiboVTbNhMop2Wso7ZypUqVRxdnxKpjGHZHFj2VSu6pvlKd5k5hAQyKGc5nJq4Z/qn8PQY3oo7Jx1T/wB5AK07BN2QR3ylN2WoQCaiYT3F2RA90EDDU512qJ6Gny6o1gm4nsQpRqQ3Rc0nuqNYzB6aTu2TqZ7JjLVU2U5B0aprrk5ELVHbqnKesn0SMguFf6juto6aKcyUGe6sdKiUMnkTm3ZPc5uyZUJMOTd07bJxhqI1VInYofCtkegE7J9EgplEkotTWXJ2HTaIaJ6WGHI5BVj2ynKm+0o5u29Oc3bZB0IGes5BcJ3d0uTWznKlSqTo3XNauc1c8Lnhc/5J1Yu06BsnGRqrCm7qo7spREhWe6a2Fs0o9IRTU46pj4KJBRcLY6ua5cxy5j/dSekVC1Gq5XP91JzlFwV7fdcxvuua1c9quCvCvCvV6qVPLlOQdCuKuVyvV6hHRBcJGjj0TKtlD0I9AKJQEIJx1U9D3Q1E9UkKSjlGc9QylXBXt91zG+65rPdOrNjRc9y5zlzXe6vKlSVMqVOTDLR01NlPRKlSpUqdEUNFwn4HH55bK+/ZAIetKlSmahSAuY1c5vZEqVzXrmO91c73U5TlIVwXMb7rmM91zmrnBc8LxHyXiPkuevEFeIK57lzn+6NZ/uua73V7lc5T6kKCuU5cgpjbRCnodt6QThlwsRRlTCuuTdSgI9KfQ3UdBqwueucVziuc5c5y5hV6uVylSp+4DqGpzn0j6TSiisBDMOE+rdsmBMbb68qVKlSpUqVKOU9MKFC06oUZASiyE8NZumuZ3Rp+ycy3KVvk3zGFuFaFYFaGhWgPUgCPlkUPSfoUcgM4UKEMiVhiHUGoanRUWwJOcqVKlSpUqVKnKVPoHLkfNcj5o0ABKZQa5spwgwtOmVPoUaaqtt2RMmcsPJEKpTEIiDkMvwXmKkhaqDugO5Vsq1BoUDdD0AqvxZbIOynLRaIZQsE6WlpWHZc5bfeBm7ZAkbdOp2TWSmtuQp6qydlaBPTTElU2wFUEhPbDoywzYCidFVbB6G7ouBMq5E6K6QrlcrjtmN/RrDoHSCh7lQCsK6Kqw7LWyjlH3SFHTMIqBt7oEHVM3VwV6DiNlcUHEK49NBq7ZYlsapgudCpiBliRmeo5DMb+jWznIdAKDp3QdKYbXgoQj98cNU4ZWlASrI3VgVgHoUMi43Qq9O4LDU9ZRuvyxPpjNu/o1Oy0JiFYrDMK2BKDPdOb5kRGRyaisK/mUWuR9WM49SpunK9qv0TSNinOlFxO/o0Dk50FbprQ1X+aEAsSfWbv6L057k0aaInWfkm7FEXGUYJJTtuhqlcMM4cevHojpqJw09aiYyeJCFSNEavsmNRMKq6fRhR0N39F/wAORylSgV3Vq//EAEARAAIBAgUCBQIDBAkEAQUAAAABAgMRBBITITEQQQUgIjBRFDIjQGEGQnGhFTNQUoGRscHRJENi8BYlU5Ky8f/aAAgBAQEBPwGE77eWxf8Asirz1YvZa9m5f8huyxGNncnPKKqhST8m/wDY9Xnqvbtb2H+QS8ko5jLbkyfB64iqPuKohMsJ/wBi1uiF7b3/AClti5mRmPUZWzJ1cVI3psTuZR00abLzianyQlcv/YdSOY595r8g5pGouxTm3yTjn3NMUC3nauWcN0RkpeRpPkUVHgqCUi80arXJqo1Iid/zOZIdSJq/BGUpPcmPj0nr7mq1yjWRqRMy9pq3tZkjURmk+C02ZDIX7IjEtb2LFusoW3iQnm832C+UcmVM0kaXwZZozzXJqmpEzJ+9ew5o1UajfB+IzTb5NJChFFulYXB36ZUzTiaKNJ9i1RGeaNU1UZ4l115LeS6Q5oz/AAetmT5ZkRZLjpY4G/gjHzXHO+yMr+Tgv0sW6ShfdEZ9n5Wrn2HO681kx04s0jJJcF5o1GuTVRnXW45xNVGqZpsyzZpGnEUUvYqkeBezkiaSNI05dj8RGrJckZ5ycso6jYot9zTQoLyXLdHKxvIUer6XHOxZz5Mpl6ZeqYyxKNxTttLytH2Cdy1uPYbSHOI5Q+B78EIu5NO2w4sVu4nATXb3aouPbckh1UZ2+EWmzS+SMVElFM0kaRka4Z60ZpLsahqLuKcTMmOXwJXErdLlxvpmvsiMLbszIzFy/Vrrfo4pl3Dkvfy/YJ36Z0asTVNST4PxGZJPk0jSiZI+VpM04mkjTkuD8RGpJcmqjPEun5rlXgjwvNmSNWJqvsXmzTk+WaSFFL2H03fRxQ4RRZdjTPWjNURqPuahF5h+lXN5cmVlmzIZTKRqOJGomriafR+XZjTp8CZnSNVGszNKRaSFTv3NJGSKPT2M/wCQsjTizSRkkuC80arXJqozxOSrutimnYbsOpFGt8Gao+DJN8sVFGSK9q46i4LOKMzE38F5F5Ce+5JNsystIymm2aRkRCGXpaxYsWG0jMiwrxE8y2FVcdpCkpea1+mmaJpGkaRNWQqd+5pfqKnld7kldWLVEZprk1EJp9y3ksWLFixYsWLdG0OpEzN8IUJN7odL4FTafTZIWTuxRgZV0sWLFixYsWHOKM6fCPW+xpt8s0omRIsW6MchR6IylkjPE2fRtI1Ime/CPWzLLuzTXcUYosWRlRksONxwtujM0KSfnTOS3X7Bb+Ww6cWaS7GSa4ZeojUtyjViZk+rkkOrE1fhF6jMk3yzRXcVOKLLyLrlTHSizRXY05Lhn4iM81yjVXcUk1cdePYzTlwjJN8s0V3FCK8zklz0crH3CiZTL0zJcmpE+7hGg2ZLRsaLW56l2NT5RqRLp+SxY3Mw5X6qTQmn58/k+zgvtcjPMvPmijViZ79jJKXYhScSpScmKm49jNbmIqsTMn0v5ePM5xXc1l2M03wjJN8s0V3MqtYdKHwaC7GnNcMtVRnqLlGr8o1YinF9y6GVvuXTK2KBsh1Pg9Uu5kj3YowNvNYyJmkjTfZnrRmn8eexY2Mxe/RF+k5ZZGrKLKdfOhST6TWVbFLgzxRqx7GeT4R+IzTm+WaC7ipRRlXmsONzSRo/BkqLhn4i7GrblGrEUkx/A6kV3NVdi9R8I06r5Z9PfkVFLsWLFizLFmWLFixZjj8mjF9j6aJoW4Y4kYJdXJS4J4inTmqcnuyNWEpOKe6FiaMm0pLbn9COMw8nZTX+Yq0JcMzx+S/wJly7Ll2XZmZmZmLDgW63Zcv0v0UvJOOaW5OHwKFi1hTaNRMTjwiOkhThwjMjNEzxMyM6NSJniZ0akTOjURqIzmczmczkqyjyKcJq9j0X2RZsVNR7Ga3Bq2FNsuy7LsvIV2eo3PUeosy7HUaY52ORNrgzt9Ju0j/uW6SzPgaseI4P6iakubFKVWNJy/ekzB0IRrzg1s0YPC0qtWdWS27Cwl6WIfaXBWwb0aCa3X/J4epUXUnH7OyPDpTo1nGbvn/1PDXUtUpVJMwf1NehODm86ZgamJq1VGo36eeN32MZWq68aEHlT7n1GI+nnHUvNfpb/VGExmJ1owbzJr/L/IjisW6TxSl3+39P9SOJzrNme/8AAzGYzFy5dGxsWiZUZEZDIxX79KiGmR436WLHB3uil9+ZIlXSe5KqlHOiHN0MkxMiPbck12OSwkKDjyZDJuMU1bYl69yNrWISiujLJEnYptLcz2IVL8jkhsj0t0k7IpzlL7kSdhpt9FHYaO/Sp9yI/wBZ0SJ8jrJdjWp9/wDQbovcz0o8FqH6F6Tt+gtLglpzachUaV213I0Kad0KjFTzplahCvzyfSQ3u92QwcKbUoseEjvldrioU0rWL+S5cv0uX6XLmYdRx4FVVWCmu4h7cEGy4789KjtwLZFs8v1HQdySycGZvpsja1yO4426WKNK27JE9i43cy2ZByUrEYpq5C3DM64MyJO5uyDtyZi9jOjOhVEjWiKcnyZ33FffNwU8sBu4xK5YYnuZipL1IT/EuJmdk+uVMdKD7Dow+B0YfBo0/g0KfwfT0/g+ngfTwNCJoL5NBfLNH9WaP6sshosh2Ra4qV9yULFkZUZUZRJFixShqzyIhS0IKk+V05LW3GyMHIyXllKt4bSIxjaxJacrx3sUsU6krGe5dG3SxmcTPnIXk7IhSy7iWxiOV7NvbYvJT56Sdl1qfciP39WydVQJVJxV5InUUYZylVVVEMRCpLKjNGUnAUoyk4Lt0dWCnp33KmJpUWo1JWb6UcRSr303exWxFLDq9WVij4jha8ssJ7k5qnHNIWOotXv0b6RiKHVxsMfS/XB2VS5i6a1WyTsMUXIVJLp/3BpS5HCw0UK0I1XEyocbdE+jKeHb3ZGKjsuuI7fkb+exuRkT32Mk/gVOXwVE86RBNyG2cjiidNy3HWa2mivbR9JS/Dl/FFH0yixbYllLbEyQ4lCDliZyZjYTxdapUj+6PHf/AE7X72t/jwYap/RPhus+X/vx/wAnhuD1Y/VYn1Sl8mM8Jp45xdN5Wvg+lhJWqbmlTX7pHK9yUU+BU0vM0OBY2XIulF5JJniUMlUyXFTXfyP+s6uBWwjpSdSK3KaclctYdO/Bo/AqPyRjGJfyVtx7EY5jTRkRkRkRlRkRlRZFkWibGx6TYui6MyMyMyM0TMjMjMhSSM8TXia0SrK9RMjEt1ylSnmiTg40LFeL0otE4ONODKnprxZKSpYm8hYilJ2TKG2JmjBU0sTVpvueI4WphL4dfY3c8dwkp4OGlxEoVMNjaCgnz2MJgaOCjakuesKcae0fZt0qUc/BepR2aKdVz7DPEJ61OlVXdf6dLo1I/JcckuSU05XQpqXHXZ9KtVU1cw9eVWpYSLMbsX6WMpVlm8l/zD5Ilt7mawn5GthcdbXHGL5NOC7GSKeawqcFLOluVaNOurTVzLtYpYWjCepGKuX6XZYsy3SzLMsyzLMysyscX0bsdjUzUVB9iTfAlctbqhKObYo01KJpRNKJpxHSViNCEZZkOaiKsvkdVGqjVia8R14lSRD8jfz2LMsxxlfgjCXwTvGVh1pcFOs4vcVVNXRLEQhyRnGfHRzyjzO5Cy264utUUo0qXLKdatSqaNbf4ZHEYyVDXUl/Cxh6mtTU33NaC7kXmjfonfpqRNVfBqGozWkasic3OLixVJLY1ZGrIptVI3MpV9LLt9KUc0JFVbkfgnGxkXwKKXYZS9SKNSVNWRrVH2NSoSqzRrye1yNQm86IUnUW7I4X9T6Vciw6Roo0UVaKyn8CMboyI00ZEZEZEZEZEZYmVFomWJaJ6S8C8C8BTgjVgTqrsQqJcmtE1ok6qfBGpZkqq7Dr2PqCpO9RSJO7G9yFRxFLm5h6uSW5WxEacG1uUsXCu8sdn+okk92QSS261qWe01yhxdWcZW4I4KLi9t7kZt2VifJh5J01byZUZR9LGUymVGUylDZNdMShdMJ9zROO9iMRwMplKhlymGWzv1q8Eb6hSkpbrph+/S5mM5nKs/T13L/mJ89Jck48sXVjbRGiq9pU3aSHXyuzi7n1P/iz6j/xZ9Q/7rPqH/dZ9R/4s+o/8WfUfozJqy9KMNh44aGSPmsNFjdS/QsWLFil0rRvEXTBLNXijExcK0o/qJGUyscJFaOVEaeaDZQuues1dCgsykU6WncW62KEHB7+Sd5EajpysS9Ub+7cZf2bFmWZYknccJDq3lljuytKbraUOO5KzewojXRq5gqaiszK8f8AufBRrKqk0WMo00W6pC8lvYysyMjGwolb0xFQuVaeQhPTmp/B4jZ4yX62/wBDSiaUTSiacPgxcIqndGFitMsiy6Va0YojJPgvcXNiH3G5Yl6Vczqa2MKqk6maX2lRq1iSSWxBKXJpw+TTh8jjFDijKTi7ektiPhEY7bmSI4RNNGmu5kpfBal/d/mfhr93+ZKKlLMUoKlHKjMjMjMjOZzOZxu5sTmsReMHxsxV7vLTWxXhTpp1Xt+p4ZQw9nkqZjTUESoKXA8NMjhPkn4LiasnJyMGq+Gi4V3mt/mYaphcT+LAy5ftGX6x81qfyLRXczUPkdegiNalLhksTSj3Pq6R9bTPrYfB9fH4H4g+yP6RfwVMa6isfXVBV5VvuOxXxevVklzFR/8A1PEf2m8Vp1nTVSx+z/jmOq41U61RtS+TCOUoclmYqP4TML/VnpHYm9h0pt3KLs3Fn8DgzfBdmZmIU6kbRIYWtEo03SjYuMWwi5cuXMxcuX/I4zErC083zt/meHSp0ZtL94kYm1ZOFRekhWo4etrWsv0MLjYYuHJRrRkrdxbksaoYpYdrnuV/FaGGq6UyONw2IWVTR4TgXTpT1P3mQjWwvpSuh4epHErF4morfHArNXRsbHAvL6izZYyDgaSNJGRGRGRGVGRGkuTgo/cMpenHzv8AvRT/AMm1/uePU1DFv/39DwSSjj6T/wDJGGqZFY12VpuUGYd+kzGYch4hJlJ5puXTcpwjzIVOm+7KijGVo+e/vX8l+l/L4/Wz1IUF/Ep5qlNTfP8A7uUamqk3yVpRqLLO6PFsPOX4lL7SFVxtYx06lCFKrDkreMKisuX1FfHSxG82f0Nia8dVcM8G8NzSb5SIq2xjcbSwFJ1qr2K3jE/FXe1ongOJ1KbpPsZWK/Xny3Ll0NmYuX6bm5ub9Ke0+k1lxlOf8V/v/sftVh39XeCPDPB8dUrRnGFkn3IFiXBRdkZi5cqUIzeaJSjKnyRTYqUb3KmaL2M813Itvnz3sZjMXLl/ZZbrsbeZ4B4vxCbqPZW/yPEMfh/Dqadb/BFPxehVlnj6ef8AEqVfqKarUy0auz2ZHwJzxF5bRMRhKeJp6ckYrwjFRle1zBeC1q006m0TxS9PByjT/RGFrVElh8HHZcyZF22Z+1FJ1VFdijTp0cPltueBStif8D9RsXmsjKiyNiyLDVhSuXFK9i/AnewrljiSOTL6rlSKzXLGDpxq1MsivCNOdosZB2MxmLipyfTMORJ36LzvnyOaiayKc8/A048jqJK4qikLy2LFixYt5HLdRJxU5W7rhn7Swr1cZGM3winFqCj3PBdSGdp8/wCp4tWclmp1PV8fwPCv2nr0qmlV9SKdSNRXj0zqTvS/xHKli4OF9jG4uGApekl4jWzuVz614jC2qbjjfY8HwklUVVmbb2MvBYsj5Fa4/T0TjtY22LlzMXGMhPsSmrFft0g7Pbqle9jMJ3NSNHnkVebHUk+RtNlrmW3Rc+eXScIxipXJS2uZmbvueHxuyrPPPcxVtTJEe3BTU5PM37G/mklH8QeLvUUuDx7D6tsTD+DPAqFOrCTkj6GeF8Rpx7HiFCpGo1U+TB4GpVxGy2FrUduBV54iKhbcjH6am2UJRknZHjULtfBTlGneLV7mAwKlh7y7kfD4JFOmqatHovO4uxlZlLCJbqxyKPwjTk+x9PU/un01V9j6SoRwdSXBiKMsNJZh7i6VfsuIjyPYUkU/uZOLjIjeK9IqdS4qdUVGX7zLWES6Ik7DqWITzeR9J/aNWshxVyxQxSw6t3PqUTnKU86HUzrco8bCRYtv7db+rZLp4fGMb2ROlGU41HyjxXDRrU1L4ZSq+HU24U5Ru/1RoakckJOL/kfS+I0p3UrlCGNnHLiLEKkMJd1nYxHimDrvJO5/RNCt+LTZhrP8NdjJ0Yuq8j8Py/dIWEnJkcGk9xYeC/dNKPwaf8DKlyz0LuZ0u5rCqJlJRnuyeNpUtluY/ESxG4mLpzDoudhy+RR/eF95YvYzszszsjubm1usyZTfq636JXI3V0VoqCuiXiFdPKRx9XuLHTI4+a5R9bKXETDtYn7kQgoq3vV/6tk2R3MGrGJrOLVOn9z/APbn7Q1p51QXCIUMrzyPAvFK8amhN3WxDd37E5Nb9jF4uWIqucihj3TlaSujwuUak1kew1HNmS9t4l1nmZqGc1EaqHVZqs1WajM8jPMvJjj8lReksIRDeNiEG+RRS4HKKE7oy+rMcjp3NMyGm+4icr8Fn2PUQi07kyRHnq2JXQvTOzJ+lmJxEU9NkaU072Pp5yZ9M1y0aS/vISUe/wDIp1HT+0w9XWhd9JSUd2Jp7+1FXZXpxVKTJrcXpFR1oZkU6UKL1Pg8X8P+pWrT5FQqKWWxhfDpUVrzVrbmDnKtSvfcU60rwnZ/yP8A4+6tXd2iU/A8FTX23KGGp4eNoHHS/sx62LFi3lRImvTfqoORGOUnVs8sSK23KjcvTEpK0bDk07eVzsJ7kdujkJkiRgPD6uPm40uxW8CxdCN2r/wK1CVGWSezJrci7EnlldlSplTb7Dl9WnWnuyjiJxk6dSRJRcVOMroljKK+xNmHxUakrNWIrcaMF9hUqqBiMRJysV/2oVBunTRhvGcRUpqpmVmeH4/6u8JfcvJcT63twTqZoOLGMjNywsoxe6KmOs/RseH4vUivg9N/1KtNVYOHyeH0p0FKEzRi552X6X82UflXkvYuX8jEMl9pYhZysJ9ull0sLYm9xyqdkZq/wU9WT9QqV+ZFTBzcs0JlN1ITyzi/9iqpWvBbk8Liau6mkUsJOjO8pXLEhmF8SrYdqV//AOFb9pJ1abpqNrnjeNqUaV6O0myjjsa/3mU/G69H+tjcq/tFeP4cDFeMV68HTaVn/H/kp4+pRjkVv5/8k8RKpJSkYbxTS9LirP4v/u2TSUtuBRKePUadnH1H9KKK/q1/meG1/q6Oe2XcdG5iMFOW9NmK8Gr06mXKyh4HWjQgrbo8KwE8PN1avLOSKSMVCtKn/wBPK0v1MLOrKn/1EbSFZj8mJhkm0MoLO8nyVcBUnL0o8Lw/00nrM9M0RpqP2kYt7sv0v510sW64ijllmXR9UPzMvcqxzD9HHJSptPNIaeY7+Sp7mVFSjTqxyVFdH9H4Vf8AbRjIZp7ks8WVaFSeVQj2JeFylvONh+ExcbwVyfgGd33Q/AVHu/8A8Sj+zSfqf8yp4RFQUaVv8R+G1afMP8jD+HOXq3X8Sp4NGfGxgcL9JS0+ti3ktYsWsW8mNpZo5hooSyVEyMIvaRLBxb9DIYVw3uJewvYsVaeeOxJZX7iSG7DlbcpSct2TeVXK0XK1huS2M8haj4Epr7hQqd2JNd+l/PbySpxmrSVx4Og3mcEZI/H5J+Sam/sLV/lH/Ufp/M/6h7NL+f8AwPBVv0HgK4lWtZw/mP0ysUZOorP8lFfumNo5HmXS5cuXLmYzozGY3EYjYhB8koz4iaEnyxwurGnHktbpUI8dLpDqwXceJgQqupwunPRD/OLz17upJo8MnKdK8vn8lfe6K9PVhYlBxdmWHsXRdDRbyKLYqY6EXyRoqK3NNGWKJ1qUdm0PGUF3JY1OOWEG/wCRnxMuI2NDET++f8j6O/3SZOmqccsWVJXl0s2UE+DKy9i/9i4qjLUcos8Lf4Th8exGSbsvatsReZXMdSyPMXJrMzIZPIlcjCyEhK3WTMVT1JRiyGGpQ4iKKXHlxMXJKxozZGhNEaUhRcerko7sljKUe59fSIY2FSWVGbe3WcsqIzkzMy5v1ZHf3cyMyI7+ecbyZQqZo289arGjBzkeG1tWu5rvf/3/AC9pbFPbYxVPVp2H5oxbIRsWLFuj6YracPOuly6JNPrUnKo7y6WZRVqkSUb11LrXvaxR4GX6XLlyL9rMjPH5HUiu5GpGTsn0XnxEW27FKnKO5exe/knUjTV5HiWJ1Hv9p4S39SsvtX7DtF3HurGKhkqeRK/Ao2EmIT6OVjkZlcjxBKOS3uSZKrCn9xNpu6EiMIMhSjfYkvxF1xUvVYpU5qI6UmaUjRkaTNF/Jo/qTqOjLK+v1T+D6p/B9S/g+pn8dayvBlkuuG2nuXTO/S/RDY9yVN3KSlHYxWNp0FzuR8WpPdMwuLjiVsOVieIsPFU+7RjbTk8nB4RQcIOb7+1luTWxB3R4lDiXkpLa5lQo7GxcuXMxfp4n9sSErxRfzynGH3M16fya9P5HWh8lRZncyso08zs3YlRw0IXdZX/S/wDwQxFn6UKcZyVhdMXVWo3cjJuERO3Jmdxy2uOVhO/THVdPFNWuYaWejFsZc36J2Z9SvjpW2gx2ZlXTYwseS1n0fm8f8Qlg4wpw/eKdXMTauU8Q6e8TAY76t6b5IyjdwmPC0m7wKdOU6mSa2KVONKKjH2kMg7Mxsc9MskOF910hwXMyMyM8TUiaqNU1R1ZGMblFXKDvTXkRbriUsl+l+ncymRGVCMP94umI8P1W5IpRyQUfgzX2Y3bZEjP8GZ/Am2VMJTqzzyElFWRPaLFz5KW810xL9BexfrhHyvYW5jcFSx2Oy1ntGP8AqzG4D6Kpljx2JZipmyngFVwxij8mPjaZhpZKl2UM1auhe126S5RX3plOGfY/o+bRHwevVq6cDEYeWFqujPleZdJNQ3ka9L+8YqpCcbRMPWjCFpDxVM+sgU8Qqjsjnq2o8mIqRcLLruW3MpZFkWMP9/kRp22MthRuNdWzMipJZGZe5ditbpSfrM7MRLbctdNkd9jIzIU04sh507PYcdbF1JN/3f8AQ8SjLLHMSJR2PD/wcZB/qjHJySsNtcnh8fXmF7S36Wuiq/QTllZSrzg/SyVZxtcxtTWxEp+WwxGLV4bmSJZFkbHpMNJahcv0rfY/Iy+/lou0y7MzMzIEkmzZD/QVu/WfSs/QLgy5tkZbbMyijbe5B7GI7Dl+6U1uOVjNfgjnvex9RUW9yNVtXNRmtZ2sapqoniacPuYpKW6MLTU6tXN8r/Q8Whkyq4t2OKIQy14y/UrKxXo6sduTCUVTQvavZnJ3MQ8sTcuy5Hr36XGIxf8AV+ag7VULrV46IfSTy7ly6Lovcg7S8keCpXUHY+q/Q+qfwfVP4PqpfBSxGb79iUlLjpX+0T3I7O5Ni6Un6Sv2EjgY83yKlJipMV0iO/JlLdMdyij/AFaMEvxKn8f9jxnmJD7jIZbVEVulL27kb26YidOD/E3RjKme6oqyZClNMnZu7E/PeyMXK8ei3Mu3WnUy1FcuOokOp8FHGTqzcZGWZlmZZiTS3Jr0iLo2P4DZF3XWLV9yrR1JXPpl8ipRfBpRE6K2kU50qfqiLFKvLKulVXiR5Iq4+wlAtEtEspw2O40T4O9j7VYzGYg9i/V789MF99T+P+x4z9yKcbsSGvWisXsUJe2+CMr9PG8ZRwUYyqu1zD4/D4t2oyuOVi9xeeTuYnhEISm7RFh6iNKduB0JpX6NIXBlLFLDunVcmzctI3JO8UiNnsaRpGkSjYTvcjx1qq8GYWlLLmlIqwjl3VzZLaLRcw8Va/cd2thU2vvlfrbLITsIidrDKW8SrB3uSKhGPSw0U35sFJalSP6njX3IpcijsT+5CY0Utp+3Y3uXP2k8P/pClCDdrMw+HpYSGnSW3Vc+abv0xPNii3Tsx1rCk7E59kbjQuOr56y4L7FPczFxsf6kI5p2F1lwyljVTWSY8dRXclj3VmoQWwkTqTpVPSxY6rb7SeLq1ZKL26zpXd0abOwiOeXCGmuSj0rRuiXYW7Fv1jz5LFjFUZZlVp8mOrSrpOXYoGeyMrqVYxj1p/d5n5LjE/VYaPE/sXkXlnLriOSJmscFWGpLbYns30XHWcvUWuNW6K97FLuZRDJS3sUV6r+S1x00p7lakmlYUclVJ9MQr1SNuCcMsk/LNW2FuRltYrJZSlz05K0Vl2Iie52uRnfd8C581rmKwKrL08lDw6ceT6FvllHCQo7ot0jsxST2GrezyfvjPEn6V7E5eTEciV4qxSl6tNkrqRK33Mqfd0jx1qfcIbP4kY3ZTiodFf46SXrRGKjsvLV/rD6ZpWvYl4e5SzJiiPDalVX4NFLZIr4SDWZbMS8mIj+8IVT5JTuUOX1aT2ZOm4EFv0t2I7O3tW8i3ZKm7XXsols79PE+F5txssWLdMQRq5VYlUtvE1Y2szMPpBbdZ/cynGM+WTpxteLJrYhyJEedyNTbYq2e6H966LyShFvM+xDEU5csq4unTXJGV9ytVyRzIj4hfsfWSqTy262LFSN4i6Mw+6v0sWKlPMi1n1S9RbrbyW626WIK8l0nSUlclTlH2Ki6eJ9vLAnLL5sRByWxoTFhpn00j6U+l/Up4aMHfyT5IQUJehCa3sS4KUdr9Lidtkx/COZoXlktj94qrM9imnlRWpOcLIVOcHwUqMnUzebQgaVP4NOHwWS48sqaluKjEUIfBZFutjKzKzIzSkzIzIzTZpmkUqXrLDGh00x0kaaNNDpGn0krkeDxPlLyOnYcso9/dt1fJGWXck83SMbIt5IRzTLFi3kdOEuUacV28jLFvPYsZTKzIzIxU2aRpI0kaaMiMqMqMqNjYnz5aX3eTKWMplMhl6NEHseJfeuiTeyI0NNZmTfcbv8AkLE16mZJPsaM/gVCV9zKWNKBpw+DLH4LFvIkzIzJIyM02aTNJmiaRpGkaSNKJpRNOJpxMqLFi3tJjZqRNREnd+Wm7S89vL3seIP8USzOyKdJUiu7RuSeZ/k7l+qgaZpmkjSRpI00ZDKZSxYsW/sJci8r6XLj6P5ZiYOpXsijhFDeXJVtBFaq6j/T3rFixlMpkMqMpYsJfkb9G7CqGK8RhheeSj40pytNWI1MyuRlm8stkXsZmzOZmy7cTd7+R+zSd49WXLjZmMw+ekldWMslNuKHe25iquo8sSxYsWMplMplMplRYsWLe2qhqGqSxDUnEi7q/nt52YirlRGpJ021yP8A+5U5P1MBJ6Tb4KFV3sxO/ltEsmWRsZrbGdIzGcu+B+zQd49ORxGW+B36b9ewuTGT04X/ADiMqe/mbsXHLYzme5fyTdkVp5pFCWWRj46c2hxuki2lRjATyu5RldeSXAk7GVltxR3MplMpYt3H7DZhXs/I0NFvJIuT2ZjqmapZdhFy/nv7ty/sbkuCzMpa5lRlTMq8uJnlXTg8QpqrBVChT1KiiVpZp9MK9l7z9iRhe5z0t1Yy4uR9KvF0Sbvv5n7S91PYXS43YzGYzdX5cVx0jTi6VyK1abpmEp6UHUYsul0wnHvPpmL9Ecn6Fyg7Zv4FnGGbMalrbGtHLmFUu8th1l2RCpaCvyKant0puxfpNbFZZaj96/W/uQ46WZlZJGUUbCXsYlbdKdLPHkTy7onNz5HStDMMwi9K958dLCXRHB+vSk92QowSTsTd5WlwRj6Wrdyf3RIPTWVoV1GKZBWk+jQmXuxmNVqv5h+WAverxvsdynLIyVJS3QqHyVpZmKNyire8+PYkUXaa6Iv5H0//xABQEAABAwICBQcHCAYJBAIDAQEBAAIDBBESIRMiMUFRBRAyYXGBkRQjQqGxwdEgM1JicoKS4RUkMDST8DVDY3ODosLS8QZTsuIlRECEo5Ty/9oACAEAAAY/AmPr7gOeGYwMs+KDmEFpzBBvz5hY4dU+orBIMD1ltWzNWVxzbOazhZYTmN3OO3nt8goHiu7NduxZC6EUYvI/IdXWtEMvpHe4rIYQsv2sZ/sx7Tz2LrMZm4pvKdYzVb+7xnd9b9gQ4ZHI3RhebuZsvvasv/xM+bJZrXd3LzTdE3i7as6mb8S8gnopmxxnGHmM9e/YpYpXXZHgsx2YBzv7F52NzOzNebmae+ys5qyCs5qwm72esfFXicCsEgwO3FYZArcOa6sebVR9iy2cw5grIHgu3arlWXatmJxyaEXGxmf0juHUvpOWJ5Wrz5lcP2Mf937zzFlJfzsgZMQNkdjdcl8l0kDpzK+P0dRw9J3Zt8CrfsM0HR9NmbfghINh/wDwttubIWV3ZrDtPALM6JvrV2jPidq15Gt7TZfvDPHmdUclwsjc75yJosH/AJrWLhbIi2bT1hY4XtkaeGSy0jR4hecY1/ZktYlnaFeN7XdhWkj1XLR1AwP3FaOTWG4o8+tzZK528f2eN2wLymoHnDk1n0AtY26grNF1d2az5tVZ7VmrD9hF9j3oW6ThknadmOkj1nf2hG5VnL8jdeld5JAG9BthrW8efP5Wa4hYr+ak2/Vd+3yHyLlGlZWslmHoRAyH/KvO1IYODcyrQQuPqWGGNt+A1is9J/4q75GD1r5//J+fNcLSxkR1A2O3O6ijDIwtcOlGfaFjYVrxg9dlqFzfWtVwPqWtiI6xiR0kTT2FeT8scnHREXY6GbGbd4C8lpBUtfa40kfvBKsfFbFcc9uYW37kepdXyOrmLichmhU1OrvYzh1nrVmDvVjn8jP9nic4NA3lU3J8dUzSOjLifRa2+8qPk91fGwyDZjGOQcGqWZoDWwsuAqZsnzko0z+12fw/Y5rJYXjaLFaB/SA1T9Ifs8ubVCzXnJGt7SumXdgWpD+IqGVmkwnVIucIO6w681VSTUrgzI4nGwPUOO31Jkk8krnOaCWt2LzVGz7+t7Va+XD5Gq5Zq4QjmOFzeg8bWoMmtd2xw6MiuzaNreHNnza0bT3KUGq0ejY3R6vHr7RwWKaZr9LFYHddDRS5HZhfYFa8byPsX9itLTsJ6jZazZGnxCynb35LHG4HsVjzX+lvWfMQee5yaNqbPMLAZxs95We35WXy7nJa9VH3G/sWRkf2N+K1Kfvc5VEEFK97XYcooifSCdL+iZsTxZulbg789qp+VJ+T6rpYtK4gZW7eCi5JqNJeqla0gjPDtPsQjdFEbbhkV5yCRvZms5C3tatSqj/ErjP5euO9AtOYzaeBV9nEcPl9fNd7g0dasZwezNakT3duStTQ5fVbiXnHFv2n2HqWHTY372xj3rFOSerEtFQRNDjlia3b2cVpavzjr3EV9Ufa4pxmcT2JvZzbObNbebPWVr2PXzGCpZjYdxQk0hdHfVm+j1O+Kwuyfw4rZz3+ky3h/wArRTC7T6utaKbXjk2H6X5rFG4yRHcs8PetaBv3Tb2Lzcr29tivN1De03C1S5w+0HLz8H4mELzlOR2FZvc37TfgtSZjj9pbObGdibNMPNjNkf0usrWWX7Dzs8bO1y+fxn6rV5umkd2mywQQxg8OkVqsnH3dH7bLFPKz7zySvPVh+4y3tWs2SQ8XP+CvDTRMPEMF+am6g73KD+7b7FxbydAXfffl/wCIWGRjXDgQv3RjfsansWpJNH2Ov7brzdYOwx/msUMkfc8g+xXw1Fu0P+K/WIwP72Ms+Cu6mB62uWuyRvcsqgDtBC83Kx32Xc126pWkAv8AStvQcDcH5HnJ2N6rrUxv7AsMNOL9ZusmPaOzB7VeeoYOvNy87LI/q2BalMy/E5laOMGR/wBFq/WH4W/QZ7yr5MYEYYBZm/8AP4K97vO15/nILJaq4/Ivf+epX8nf+MK8VpRwbt8FhOS6lZr8uBWsLK2TmO2rTUd5IBmWDpR9nEJt3bdjuPNmmSfRz5tDMMTD6lopdeN/Rd9L81pqd9loqgW9hWrmsTe9YDki3YVaSnZfjbPxWWOP7LvitSp7i1XhluPqSWXnI3ubvuy48Qmtnpmuaz0AbKz45I+wXWrVN+9l7Vja9tuN+bzsrGdpss6kH7IuvNxSO9S1KeNt/pOuvMxPAP0YsvFeeeW/3kuXquvO1bR1NZf1rXlmf1XACyo2O+3r+1YWNDRwA+Wacf1LW+Jv8FA/hC32Ks5XP/3qglp/s26rff8AsLy0kLzxcwL5pzT1SFXZUy/eAPssrx1Ubuotw/FebN/7qb42Vnsn/h4/ZdYZtCHcHark2o8jbJpZLYcdu0qXR8nGExWvikvtv1dS1Hxs7B8VrVTbcDLf2Lz1UfutsvmjIfrn+QsMbGsHBotz4G6z/ot2rzz8DfoM+KwsaGhfScsZcQ3db3fFYQMuCz2c1ubYs9vBWgAIG156I+Kxudjk+l/OxdBZHNYK+Frv7QZOWk5Pqbg7nL9ZhI69yyO1apsrkX7E6p5OLcZzfATYO7OBWF5NgcJv0mngebNzu481jsRilGKNywPOOJ/Rdx/NXZ6St0m8EZYna/BBzEfpNQxb05h27UH79hVygayeOMDNsbnjxKtPIyXq0eJea5Okv1OwK8EYaDukff4J8VNyVK7MOLow51x4Iy1VHWxQaIgNdfbcbl5+Es+0C1frLJvuOHvC1onj+9ufyX6o+nb1Ns39rLyif/s1UgB+qyzR7CsbOm+Fsbe05Knom/1MYae3f+xuteqZ3Z+xeaje8+AWCmpm34ZuK1nSsHaGfmr1dQ254Auv3prp5aksHoBwAPqTo6SB8LZT0hKTnwzWpVS3+sAfZZXZVMd1FuH4rzTr/wB3L8bLWZN+DH7Lrz0bB9tpaVd1NiHFrlZ+kjb9Ue9YYpA3tBVonteeoqxOe4BY5vDd+as3x5sziPNmrnIINjBJdkLDN3YFiq/4bT/5H+e9YTK0AZYYxf8AJXiosLf+5UPwBf0lyZ+M8+ON1uKwyWa71FXwaM/SZkrwPE7fWsEzCwjcQsbFpWP0dSBbHud1O4ryeZhY9vSjO7rHELE03B381jzGKRuJjtoQY4l0b+g7j1dqBGa0rDozx3LzsrGkcDdaVj3O44W7fFYoaZ3e5YY44gfErRRRzC+YGiw+srzzrf3st/ZdedrGN6msv61rzTO7x8FlTYvtOLvavMQRx/YYB8jXpIr8cNj4rVa9nY/4rzNY5v22XV6ecfckIK1o5XfcD/YsM0MRPDYV56me37Juvn8J+s0rzM8b/suv8qeq3xxucO1cn052xizu22frXInJ/oNPlEnYwZesj5XnKiNvetUvk7ArRU7RfZiN15uJ7R9jD6yr1VUB2uLiF52aR56sgsqZrvt63tWFjQ0DcPkEEXCtfU4n0Vq5g7+bDtPAbVruwN4DavPU0Du1gJWpSlv+I4ewr56Vvh8FghmDjvBZs77rVDO6Q39i1opLfdPvWs23W+MhWBa77DlrtejU1c+iZe3QJN1HSUennkkvZxZhaMuteac3CP6x2UbezihSUlU6eomy1Bcnv4dQWVHN9/L2q5nZD9/P1K9RWudf6LV85P8AiHwR0T8BPVcLyPlWDyeU9GRmccg6t6xxSNc3iCsbbtcgx+s3ghLCbt3ha8bX9oRNLIYjwOYRdLTlwHpMzQjnNnt6Dxk5h6kIKojPovHRl+B6kY5K/QSBxbglYV+8YvshakUju3JXEEbftG6LI4S9jvoRYgmMfpoxKbNu7CCfFFxqITY4TZxcQeBXnap5+yzD7brWZJJ2u+CEtTFTxtYc3S/Eq9GAI7XxW9gV4r2dnfeebeti2Dn2LZzbVt58L2hw4FZ0cQ+yMPsWppY/su+N15mrHY5nvXmJS4cI5fjZecjmI64sQ8Vhlp43kbmmy85DIz1rKpA+0LKCljka8VE7Guwm+qNY+oKOWaqia1smZLlU1mIFkMbKaM8fSPuXnZ2M7XLKR0n2WrzVN3vcvMQuAP0I8vErz82EcHyfBefq3H7Dbe26+YxHi5xKtDCyP7Lbc21bVt+Td7g3tKkfTWkkaMVtl7Z7Uym0lNyfE860tr28ckwWdMcPzmzEtSjA7V820dn/ACvmQphRWFURqbMs1F5Uyp02ACQuAzdbPevNw4e1aoWw/iWZw+teeka7tZdaKnaZpPowNt7E1jJoaWmtcskcSS7jvKvX8qzv4iBuD1prp6apnwZASTPIC8p5P5NEEo2PubjxXSkP3liLnAdchXnKpvdK4+xfPSeL+YwVLLt9YPEIYzpIXGzJdmL6p4FaWndf6TTtatlisUZuy+e8LSQmzt7VwcuCPlFK3F9JuRTf0fyrJaM4mMdtB7UNLYOvrOkNu9Rtq5LyAawb0VheA37VyPasUWjb9mOyvp/UtHp8Dtzw3YqioqK51RFV4fODLW6wg9lY6xX709PnaNNhe3EXbWC+0JnK0NTFYXjwb1hvHJbhb8l56mlHWP8AhZ1MrO1oWpygPEBX0zyOoD4LOaX1fBfPy/5fgv3ib1fBfvE3q+C/epfV8F+8y+Lfgv3ibxb8F+8S+I+C+em8R8F87P4r5yX8S2y/jK/rP4jvitaf/wDqfistI7sLveVYcnaUfXu4KRlBTwUkpGo4ZALyPlKdjpWsxY2dE+pVVG6EGqbSue9sWzO9gDvJsmx1VFNAXC40rcJKp31XJ9Sw6RutonANF+tfrHKFuoR+9auGXtlz9SvHRaPrYsmy/jd8Vsk/G74rOOX+I74rZJ+N3xWQdb7bltf+Ira/xK2O8Srk2HWVrTMPZcq0NM+RalNHGOta1RbsVzd3W4q2Bpz4KOmjaAHQsyA4krCNg2c+FmZOxY5z3LJay2K+QbvOxYGTxjrdkF5yo8o+qx4DfALBBFoxwbkvPVDWdr7L94Lj9UFfq3J08nWcgsoYIe03+K87yhJ9wWV5mSSn68q1aOHvF18zH+FZtlP3MS87FH95lk6Gq5PZKxwsRi2p2jDqYf1WN2O31XHeEWcqwsZIGhwcwZO7lihqHA9hV45bOHcsNRkfpKx7istq6+CwyRh43ghY6OTRn6JzCw1MWHgdy1HZLPVPqWaIw4mO2g71tL4H7Dw6isTDkVUUZ/rons7yMvWuUI3X1JMurLmyutZod9oK5p7fZV45ZY15qvxfa/krOCGVfrFBKzruvnHs+034LUqYj383RuteZrfvL517vs3X6tSSv71qU7GDiV52vDfs/wAhXmqHv718z4m61A0dy2+pdK6kNvRtfwVVW3I085Dfst1faCsisiV5ynjd91fM2PaQvNvlb3rU5Qd98H81/Uy+H5LznJ9/s3VnRPB8UOT56lzJjhA1HbTs2LzTHyeC81Sho6yvO1OD7AV5HPeesrKAe1War2WQV3PFk7ebKGtp6J8sUbI7uAyyJVgrXFgsEGzju/NXtcnaSruVmjNWjjLjxXn6iMcQHZrBE0yX4M+K8zyEz7Ugt8FpNNTQN+iNb+fFN5Ufy69rsbS6JkZwkDd0ldhgk6nBZ8kRf4Qt7F+s0s0R7FlUgH6wIV4pY3/ZdddILpFbV0lbFkvORRu7WgqSWOvmia/MMsDhKiLOVTI1os9j48ndmdwsqf8Azu+K1Yf87visMRI77q3o/ROxYb58DtCs8djgs9nFYmeCNhiG9q0lO4wv6tngpuTZqpsc8EhjIk1b23harlrZI5BzTtG5XuXU7t/0eo/FGQZixKrHx1Ae2qkx2w2t1Jri3dn2rMOC+IXwW9X6PWvOTxfiV2yyH7I+K1OT3TfaavN0UcPX/J9y8lbylDCcYdcNddMpJK7yh7L3e++efervoo5Bxv8AmvOclGPrAW0s+01as0X4s+bpLNbV0lvVTUutZsZIFlDTf9tgB6zvWzmzasWEd615Wd2atFBJIeoK0VDGz7ZWvWMb9j+QrzP0p615YKRmkuHB51rEbOxXxnxXm5pGrVrHHtWT4ZO+3wWvRuP2V56nkaV86R2has8fe5fOg9hWBjTrHas254L5o53LzftWtk3gtixVE7GN4k2WCla+TrwGy1q5sQO5sbsvUvPVr5ftPsF5vyb7z8XtWrPG0cGlfOg96zEfivQ8PyWq09zVkzxurYmj7hXnYInf4eayZJH9kn3r9V5Unb1OCyfDUDw+Cz5NHiumV84vnF84Vd0lh1la1WzuN/YrNxvPUF5mid3rJoZ4IY5A8cPzQjqRkd+9XY4OYd6xxFXGrIN3FX6L94XKrHPiYHS4hc3c7eBZGKjmxxRQ49G/O1jnl2L9bjki6OI4cQzFxs7Fp6KpZI3ix11rsDg7aiwTWgkFtb0Oo9SdTy8qQRStdhwudZO0lUOq1ysDGySHqavNclv7XLVgji7v+V5yrkH2QfyV5NK4r938StSNrewWXTWZasyFtHiuk3xWXqcFrmF327FXIiHY9XgrcB+2F5vlKN/2ivORRvHEOXn6aVi/eC3tariqj8VT0oq4iJJm47OGQGtn4LOqjPUrQslkPABWhowz7Su+sDB9Rp+CvPLNIVqRj7zSVZsdwODTkvmr/dK+Zd3XXTeLfVKykd+Er5x34FkGOv8AUVpISOxZB3gvNTu7CF5yO/WAvOBt+Dre9Zw27P8AlZMk/GE7yVxJDSQ0yb0G8pVsk8kRDhikc8X2hN5T5VnY1z9dznarQE18UD3scLhzRkQtNWwSjcMWQJVdXSWbnqN3d3cnw1EecRs51tmV/etFE+7jfLCbZbc1jjmGy/QOy4GXHaEZHPIAFyTG4WHgrmpgHa+yGKqgsf7QLFBYt4tK83K7LgVrVEl77nlfvMnir6ZxWUx8F8//AJQvnh+EL5wfhXSZ4K0jYz2An2LQsoGSNIFjci58F5vA31rXriwdWXsWKWqLz4L5qJ3a+6tHAB9lZsPNtXSWm8pDeEeIXf1AJsha+Fzh0ZWFh9axx5FBsuq8bDxT82xiaKNxLvBOdDK6SK2AStcNbLcN+9OgdIQNmZ9G9+8IyRTyU7wMyw5koR18AqG/Sbqv+B9Slh5PlcKos83E4YX4lC/lWKSNr5WtMrnbM0Mc0Ry2uKGimjseBTXHK/rRZE4SHbZuZQED43l18OHO/FFsvKFIy20PlaFnyrQfx2fFWbypRfxWfFWPKFK777ViZVROHEEL9/g/EFb9IQX7V+/RL+kYB3rSfpKDDxxJrW8pwa2zWVzyrF25/BD/AOSbne2q/dt9FAfpNuX1JP8AasNNVYz9lw9oRinBc/8AuiU+ho4JtLUNMYwtzzHC6LXVktPFixETMaMVuwlGV/k2FouScRUAxsndPJgYynzPbmQjTyMmY8G17NIPYQ5PkogYnNdhLZRYnuBKv5r1qxMfinX0OfWVJX1IBZFa4bmczbj1p3k8EowcW/mrmF1+IjKvgd/Dcvmz/CctVgA6wU+ZzG6jS7JCQ1bWh1j83+adybNTuhayTRmVx8ThspqOlpp3iAOL5JA1l7cBvU3LFTPNeRjW6M7GWC6dlhnle031cOwhDDJM+R2TRi9fYqakmicGh/pOPG10aUxh1PgdGGEZYMNrWWthhp6dm/Y1oUGkhqGU8r3U9JCzI8NI4dvs6kaSm6MWV+PWg1gaccYc9pHb8FJTRXM8jtFtuS3/ANnOt48FE+prQGi5cWnDsF8u9qdHVPlbHTU5dJo3cf5comTi0kAYBnv/AOA5TOZLg0kRN8Vt7hf1epVMjZA20W0u9JxtH2780YHgRRyXgy4eifZ4lTnG2EvhaRZwaMQP5hPliq5QGsYWsMpAde/XtWAVEjm4seb3arRuPfl4p8THubgGQF8za+6x6kMZqI2fQL92zaDfaQpHi7y0uAjNzj688/8AhGbykmzsJv2bbbLHMJzXcpSNIOYETjb/ADrc7tzQyZ+FeguhGsmt7ismn8Su0O8QtV8g7D+aMkshaxu1z3ZDxV4KeWcfSEVm+O/uVpmaFu9sLM/xH3ALEzkrXO1+Zce1xzKzpZGoRyY8P1hsQcdh37VyfyoxzjcGInhbMe0rSmx1r2aPcjo8YD9gJ2IX2HLtWF12AqKeKpD3/ONeDisdqhmbkNK3MdYPwTaKod5tzgMeLYP5KNJSAl0rxaSRwZqk5Wd6PamyTzCAtLWPa06Yz2vduYy2rS00sRbUuMsYBwmLg2T6pGL1KkqKNzo3EaTRBow3I1iNxCFRJiBDQ0gFXk0jQTYZrNzvxIA5gZnW2oGwcWHZe4KayGEt24+1WYAgHNGexaJrS9zjhaG53J2JzqykZLBOAARrMY61sR6xx6+tPn8vYdHK6Mtac8sr9l06l8uY9rHaz7kC3/AWAMcGMeSPRyKjD9QyZ8clgLugcQPWvKTEH49bWUklRQsbVum829sfRxbuzLJDXKlgqC4xvaQRZGWqqKrJztBMWkapANm23635KWDyFwDpMcRmcDqkC20bc75cVJXTVErqgeZMI2XO8epXu4v9FuIprKp9sZs2S9hfgVm534lV5n0Np+u1TG5Ge7uWUjtY23ZepWufEfBWe21t99qtS+emLMbI9l1U+W0bYfMvLC05HJQuow3RyNLZH2vbK3tssWLHIXXzKiMz3SSTyta4u9aa07TrJhDbXzTaeijxyRtMpB2dQUlVXyNdUyei3ZG3gFSfab7VM7reqxsjY3YozYPFwqSbCavlGki0LXMGFmHgv0m9mEzjHZue9B8tBOXt2ONPmm1Hk+he04gdGRY9y3WH9pIFI2GWO0zcD8UjnXbwzX7/AOM6dh5StpOladmfqQwcrzZZDzsZ9yPk/KD2AtayzC0bG24dSDYuUpchbPCcvUtG2vlyGHNmLLuTKh87iWPx60Osc77UH6bRSAWxYbgjrCxN5YbiJ1vNE31r/S4hF8XLbGknE20GbT+JHyXlARRPtdjm32G/FXkaXvPSdpNpXSVsRW0rpFZvK+dWjglfO4bREL279g8V88ymZ243/AetaaR5nlGx8zsRHZw7l896186vnV84nscbtc2y01IMbXdOMkgW49Sp2sY7G2pa3PccDvFYY3CwOzejI6PqTPR3HPcmk4Xbx1ryeRjXa1rgZgWy/nqUZ3NMT/8AKfinQOGka3bhB/n/AJTtSWPR4MJvZzoxfb/O9aR3nC86ovrOPrz+K0kw87O1mOM2N5MuFhfM7uKNXNR44nw6MAW82SPWmmJ7i0tzuOi5BxmdY5G5zKwtDnD0s93V61ppJbWfhaN+z/hPgDWufhJaD2K0mWQKJdbEo6WnY+V78mtZtXlVVaSul1Wj0Yuzr60aZ2AC2ri2XUs3JznvpnSl0kLc3Me7/wAm8D4rEeTal9jexhdmjL+iaoOcb2bA6wUYfyRWXjOV4HJtQ3k+rZKHYXXhdsQiqqdzWvbhu7LD15lOPKNAXksa0vktow5u9vgiyz4qdseRey2JyNEaeR0TsQdI3Zay8gi5OMkmNwYQ4HCw3ve/EW8E7y6ldC3ELdHFh7RvVPpQIHaQyzSuficTffZNe6ckNOInAc/UjDK7Ex7bHUK0Ty6opfQN7OAVRR00QEkmG1zwcCnl8bDc7nq2gt99aSumxY3/ANVO4Wvawy70/SVEkgxkt/W5NnBSx1s5kgmjDcIcSQ7LMEqZkT53vlYWYpLaoVRPT8oiNk0mNrTfftGXWhjrKY7Tcxk+1R10lVC8NPRayxJIyRBGHgbK3EqprTHj0rsLTf0QvL8BcCzBgD8lBXaLDhd0b8LJ5hqXU8jvOY2i9t6/+R/6hr5wMw1xyHcg3y6pt1YfgmUkJc5kTMILtvNYq7oI3drQv3Cm/hNWdBT/AMMLOii/Cv3Ni/cx+N3xX7v/AP0d8VlC78ZWyQf4hXTn/iLKWp/iLKaq/iL95q/4v5L97q/4n5L96m/GUP12f+IUR5bUC39oVc8oVXfKQE0v5RqnNfstKbeKDnVksVE/a6R79bu3rS8mcp1VRTwZkNeQ5naL7Oteb5VrbHWb593eEP8A5Ssv/fO+KueVasbvnj8VpP0pVEOZjb5xyZIOV6vzhOWmOVv+U+R3KdSXXwg6YrXqpX9bnkqR0wL4ZYXwvw7QHN2+OalmAya6Cb/T/rCu1tycslhkyttTTge+Nxs1+4oteNXr3LSBhgp907v9I9JS8impd5hjLSEXOqRmV5O2HWc68Lm9GRnbsQlkjGlaXY8QuSLZAcBn6+pR1bmthsRgwuycRsvvWCUZ42hjrkG3Syz8VoqyQOBtisN42FAi+S0cl7diLaeS59HdiTtR9mbVHUxtdjhdfX39q0z4mDEb5bAtHSwXsdeV/RaFeBodO4WfKdvYOpB1tmxRu4tPt/NXBQG3m1lYKxchzEIPG5XG1WQDVmsNuxW3dXNuTo4KdpZlZ5Vn4WFuwWRAz5s+aNo61gfs3KSaPc3IdabGACWt9abe17KP7yd9j4LYjbV61g07C+2zEjTU4ZjazHI94uG928pmOV2vm0TU4a1/YQqeqp2NDppDG4PGLARt2EXU8kzReCPSnDliCZBLTtZpDhBbIXWPXkEKTyfAHlwjdjuTbiLZetR0zabCyYOMT8dzlxFssus82hjp3PjEwhdJcbcWHIbxdSQxU8lQ6H53ARlle2e02Xl2lGg0elx/Vte68n8lmiOj0rMdtZt7bjltG1GCNj55W9JkQvh7Sch4rFV8n1UMe+Q4HhvbhcSjUvddlri29WNFU9wHxVjGXIY22LW9EcUQy7sr4rLDR0zyy+cr8mt71pq8+WTbdYebB7N/esghLG7XHEbeoqWopGNpap4sdW7Q7s3dyMFfT4Aeg612u7CrOwkKNrtYsaW9oTXXzALc1HATa5JPWiWi5tq5Xv1qVzWufoxifZpy6yqimPp0sp/Brf6ETpchvAVmyZ2zvsQZRQyTNGWJ3zbe9MqeUT5XK0ZMPzY/3LC3YqhhHSj/ANqfTVEGmp37Wek08Wp3KHJL5K2k25ZyM7eKucYt3KMGTVA0jBtvkPyXTVmkuQc5Oc2RzTbDk7cpBFI8BzgTZ+RtsXkop5KmcuOrrOfdNn5ck0Q26Bhz7zuTKalhbHEzotGQWxbFB2P/ANKsebbzbebW7kLrYsthVmjmyur2KxZ9aufauk3xW1vivNlzcvpZeCsXsv8AbzWRCsWr8is3/wCUogE7SeiVhfMOF00k4WF2N3ds9eFYfKf8pWUt+4psrTqjGnTSXwuGFYKDzzzvIy/Naasqzc5gZWHcsUc2FPFXZ5LNZ2ewJtHNUtkwuxMe9tngj6w/2rk9lGZLtqX6XSG7seHO9u7usqqPbcSU57H/AJ2Qff5qWN3ddRj/ALdZI3xxAe1Ukdui6SLwa74IuA2KhE3RZ+sP68Lb+2xVNLUDzvKEpkPUXa35I8gel5SGt/uOn7ixTGJ5ZJUO8nY4bWRR9Nw68TsKfJUzml5NgcWNDX4NI6+ZJ7cu1Om5Nm09I9mbJZj5t3fmQe9U3JtI0Miga0Bx6RsLX6lfTu/EU+N0coHo5ZX4Jj4aZtLGRrSytw7bbtpQnrMVbKPp5Mv9lCONjWMbkGtFgPkY2Owu48e1Oo66nY8Ea0bxcdoRn5CqdG7dDLmPH4oNr+T5IbbXEap706KKleRYPGW6/sTI62iliMuTLt6XFHlCWkfFAPSJDd+7ipqWdpY6aJ0uYvnhy9vtX6Jlj83jLBJwxiyBa6m0Z9LS3HqQm5SnfWyfR6MfxKEMEbY2NyDWiwHO368f+n8ubSROwO38D2rSzRmhqz/WR9GT+fFNhqo3GkGTJWC4HBaaoZ5JRk/Ou2v+yEaGio2YJBhlc8YnSfaXlvIVjC9wDonvtgvwPBQeRV1K8SM86XvAwO960nKnKemO9sIDR4rR8n00UAdtI2u7Sr3C3c/J8ekw6V72nrFgnmGdwaDYaoQfUSkWAvltKD8RAPGyOss8+9HVPirEu8StrvxFfOv/ABFW0sh6y8rWJz+ssVz4qxv70RNI9xvkQraI37FnGWr8iU2538FiEZ8FiY0/hVmtsfs2WUYsrWTnw2u7PNGTVzDht7PgpXzviON5LdbchFpo8I3Fx+CDjLD4n4K+KMd5RbNIwar7u3BeT05wQDxetUZb3H3LE7IcV0rD1lBrAAL5rRPdeMjIn1KnqJgWCpqnvYD9EMAuoqo9GsxkX3ljyPgjO45VWMNPU3L4qKvGWl8nqu7VJ9hT5BGXaKrfJhBANiTx6nLz9NUxsG17sBDfBxVLD9LSQn8DvgqSGQ4dLTuY0/QfquB7sKEtSzDW0zDA/s23/niuTaiX5uoow3FwlLi9w78XqUFNXSVlJLQuxaWKAvY/aMV7WzvvshHJUPfHH0brEd2S3rHTUbQ/6btZ3r2fsNZvrzCtMC5v0wPajDURRzwv3OFwVpeS3mnf9F2s0jhxWmrYpo+DgcUf89qDqfzsLfRDbZ9uxCgePONxNwg335qqc0AOglbIAO0t9wQcDuWcrB3r55n4lmViklaAqWaJ9xhzy7V84M+vms4XB3LAx12/QfmF51pj9bUJnRSS4tmAavipWOa2OIObqjt4rRwSSho2C+Svha77UTfgtajiP3VnyfFfv+K1eTaf1rVpqVv3D8VnUtb9mMKablWs8p0bRKGkklnZfIbljpyRvss7raUbHZ+w2ratqss/WsIapr31swrHd8mytz4s8kzNUnJ9OD+sFxdbqT3YsRV3HZznNax3hUnl1OJWSRslAuRY4eIUVHNRNMMHzbQSMPgm8mvp4XiitZjXW0d+zjZRaamb5nJljbLh2LTzxOEhGbmvtdAu07h9EymxX6SjMuPE5wYXajSdpAXlsT575lkZfqMvtsF5ZVVMlLom60zHhup13X6J5Ip2so2NDA6UXebb+pPZNyjMYX5WfIbKzNYr5zwXTX79B/ECyrIT2PCzma3tK/eo/FfvLfAr50n7q2v8Fsk8AujIuhJ6lijZIwngV82wn7Vlh8k28XfkmRycnyBrhqlhGHsU1Q46odgaqunjuWYn47cLfH2pjRJJZ0bd+WxW0bh4Jkj2AktudZXLWgN36Va8kI++qdzXtdrtGr2oRtthcLZOvkvJ6Z7AwfSGe1fvUQ+6v34dzB8FlWv7mfktL5Q5/EEbe7epoqegYJ8jaIEbDc6qsXuDhlhCt5Y4W3Eq3lLj91YtK4/dV8T/AMKw2l7bLVxE9ZUsFI1pmc04S49G/ipJavBpXZarr39SKsndX7XFh25bFfCti2Hm283RK87URN7XgL+kKb+K1XbyjTG39s1GP9IU2f8AahNAr4Dh+uEx75AREXPa9p2IyR4hnn1pzIwGuRilycFaMNA+k82CwzxFmdkFScnMpZ5ZYIWNkAFrG38+Kqo5azyKl1jGTYEtHrtbapKLk2rdPI5uN7t2X/POKOJ5bdrTqm2JznW27hkpoKiTWEZw3OLCbHCQd4vlmnf/ACFsDwzCZGaQ3tmG4dmftULfSqpjHJbYcBPvAQb5O8Ys1HS56m3tQDdrkMNVFOHelHfb3hbV5vTH7DGt9t1ZtJK77U1vYFiFKxue97z7060cOy+eL4rOCk/hLKKl/ghNljNOC0hw8yFc+T/wQtHBDFK7g2nuVf8AQZd/+k5aSr5PbBOx2F7HR29qBbq9Q2KXQvtPAHaM9aNJW1ofFJtAY2xRc6x1zt7ED6FYJIT1h4y9dlB+sFgwFpF9+I/kmYZRcG+1NOJx1c8kcTn370ARIe9QuwkWe3b2oOw4baVpy7E2JjIn6gzc3rK+ai/AtsbB9leeniw23sCLTXx7DfC1vDPcrw8q04wxyXiwAHonO6wVNfydVahz6VuKmfTMpZGBwLJBGHdoUYkpKZzm9J4hGtmhBJyPRlg2DR2sjC3kShwHa0xA3XmOReTmbv3cFaWPkbk1ruIpm5IVLKWmicNpjha2/eE5sBiyOeJp+KvUOGk34cghrZdqLozid3LNpB7lZ1+22S+c/wAq1MR7gslryXK+ewqxkIPELKqm/Ev3ufxVhNNs+ms3VD/tblmyU9y1GVB6sKeKSIxwbrlg9uav+lo4gd2nf7gopm1X6R3OaKk5Abte3FOMrzyYLdJs+LF1aq1/+pJf85961/8AqGU/4B/3Jh5PrWzPvmJGYBb1r/5OeJkVv6o3PrQ/R9e5pvrGTh3Dii9tTQG3GV/+1CR1byc2/wBHGv0dPURuncJBjaMs080gfd4xFuLIFXmFjwWIqNkRDcOZV4wC5qifXxubSxOxSm3ohX5BrY2RPYBOQzDI3v27PYp5uUOVZqyopLxthNwDlYtvmouUKSjZE6UEOzudttvcrs5ouUqNpc6KweALnI3abdqYI4Q0WY14a7FYNN8yqmcOkxwAYmDh6XeFRwxRfuTLYGDJ23E7wA8CrF9nDinh0Ltzm5bRbagXbNibG04rElbFifSg9pK1KOPF1J2Do3yTyQDdhGaa6bk+nkI4tWpyLycLb/JwSiyGkpYwfox2T6hwwF5uQzIIVVLJn0XBwBuMkR5NT+B+KrJJmMa4YMmbN6PYqiHqDgqymsAIp3AfZvl6k+56Jd7FyfyzBngdoy4cRmP56lHJRywMGkJJljx6pAI3jgU3FKXSb7NAz37kTpZMBe//AMipD+kapjb2DW4OH2boA8p1W7+tAV8bnYeL8Sa5zgcT9Xq2pukOI223WQus0J6h2GMPAJTTTtD45GvaThOd2kW4hTwvB/dqks6xo3JzfpRSt78BToXsLXZmxC1SuktjSs4gsolons1XuDUTHcE5K+kdftWb3H7xWu/LtVlsXQas2NXRbbsXzY/Auh/lWz1LZ6lcN9StgR82V0Fs9avhHitjfFdFq2NXorYFewW7mk7FGUzvXlpYC1zwBZ25HPmvzYXNGaAo3aO1772llk/Tf9NTzSk4i4RCQZ9aEcXINfGwbGtgsF/Q3KP8FXbyLyhf+5Vv0NX/AMJa3I1d/DRP6L5QG/5hAfout4fu/wCaM50uhc7UbIzA7sRq5yL2s0DY0cFdX5rAbN53KTCSLDx5nX6uYvZLhnizc12xzeI6+rnzW1VbQdrGH28zLNL8UdrBOqos2VUbZAfV7kyX6Yv6lVwgXdDNHJt2AoDQumLY4jhD8Oy7dvemSSMYyS4u0zByeJGsN33xYNl2g8e1HQMoS2wzc14I9ZQBmpwd2Bp2X607Svce0D3BUz3SebLzwURfUNObtrh1WWtVxfxAv36EkcHXTqehvUS6RpDGtKpIq+klgibM10gkjthadpT5Kvk50JjpZ2tfh1XebIUYqnCMvLcIB3nJHSYtVmFuLbYd54rqWZy5rZhofu2rSCzJgcnn0kwO1sErb4TcLLmyI5rrZzbvlWOxXWe3n2LNdNvivno/xLOpi/GFnW0/8QIh3KVIP8Zq/pSk/jtWfKtJ/Gai39KU9zwemxtroy6+wJtrgb7iy/R0ebXbyBkLbU6HHjwGwcd45tvO+ueNaR2BnZ/PsQlIBwjO/BaSmp31GXQaRc+NgnNbyfWGS5DY8LcT7C5I1t1xtttA2qGOnhe7TFwa57msBwkA2uc+l7eCxsjkZkHYXixwnou7CnR08Usrg/A1rSy7jvyvq/esp6sslHk/TabXxXILf8qkqJIfm2YzhlYfDPNOqqp979Fu5o4BBnNbm0OnY4DYRvT2h2exWWW8rKF/4StWklP3StShkWdE9vauhHbrdb2q8lZCz2qR/lWlkk2m1rBWDi5PmJDRTh78zYbeKbNVVMMTzmcEd/f/ADdRweUGYE7cOFVFK46tTG6J3fvXk7i5uKGVpttGF1/9KuKup/EPgsL6ipcDxlKvgkP+M74q2gP8R3xRfDCGu2XQfJSwvLo4zd0YPoBZUcP8MLVhYPurJAzTsD9zb5+G1QnlGp/dnNwaKPdiUk4u6JkU9wd9mGwTeUKc7J2EbrDeuU4SSdFK4W71w7Vm8J9TKXODBfVaXexX5OoSXk9OoGXdZCrr6nBA292nVDrjL2haEy3L94BLR2loKbDQ1UEzznbQvAt2laKvljjldm0NYcwsJ5QsRlYxO+Ct+kbdeA/BHRTyut1DNGPk6LSnDcSOcMN+FrLo04/w/wD2VzLacMGWhuC6+fqsnEvd9UCn/Jeajech/wDX370MdJVOO/DCsNPQcpRy/SdDiHuVmxO6sURHvQdKGlu8Yg33qx5IY5/E1kas3kOnH/7saH/xtGMJuP1lp9i8nko6JpvfG3Hf1BaaRsQc7aGxy2/8VqxH+DL/ALVlSynsp5f9q/c6r/8AzP8Aev3Wr/gfmv3ep/hN/wB6+Zm8Ix/rX7u/+LGPes4Ht/8A2GfBajsP+O34Kbyt+kqXOOvfGWt4BaCCnkljBw4gM02VwMT3+bLupSZmeRo62kLKPZmtLQyYb+g/Z4q3kwPXpGrHVFrjujbs7yhhip2hoUnlGjcQNxvkmS56+y5t3KOdzZNJHsIkcO455jIZKPyd0sWjGEBshsR2dyHk73hjRY3kJuAMhnuHBW89c/1mmfjtwve9upNa1mO0ejOuW4srXsMr2JzUdFG+TFJ08Updl1ovKuroHmuKOoPbdYnckvceLg5ea5LGQ4XXm+SmgfYaEB+j3NJ+iy/sVzTSN+0LLojxXojtv8FnLGvnx4K/lIt9j/2WcpU9PpXYahpY47xc3yyQF35ZKmdDfpOv6lfcVBrXD55Gu75HD3rEynYMy3McFFG9keEu3tHFeZs0OYDkF0kSSonX2xt+C6SyCqNHk7QvwngcKieamnBJDhd/5Isq24ZYHEHsysquOPV1ZTfqwO9xQZTtixX2XH+pVThiie8wyNcx1jYh19nWCjgqi77TQfao3zTPcQSMrAMy6lpKvlGnc1zLkOqh2psoq+T2iPJ2KW1j71ojDRTCLVbKK0Mxjsug2ql5Ppp7m4ZVB2IbrlOD6yMguxYvKif+FD+hXiOWKS/zoNx27lFWT14L5m4nYIYiL787ZrOuqfuiMf6V+/8AKP8AFb/tX71XHtm/JdOrP+OVnHOe2of8VnROPbPJ8V/Rzfxu+K/ouHvX9FU3fGFlyTRfwGrLk+mH+C1atLCPuBasbR3fs7HNF7DnsA60Yeg8nLqcrYwHG1k5mIxCMjX602VlbOC6524sk+ndK0PZHha07SeKc0MwPbkR1q9l5LoPRxYuJT6F8T3BuRezijFHWxjELa4sfWjDUC7XIwgaanObXfQXlstXHj4uyTmCcZZ/ODZ4rae27finPMzMvrs+KknndiWAbtqv6IWH0fatoAW161DNN2QSH2qw5Pqf4LG+0ppZQvLXbMUzB706RnJUZaCBnVjf3dSdJ+ioy1pAIErzt7G9SBi5GH3jIf8AQgW0lOzEMvMP95TL6AaRt/m29m96bK3lINu4tsI4epPf5fctIO2EZeHYrirm7s/ZGrSV1Th6jgPjo0Y475ixc9+O/wDmCM1JIY3OCpDPIXubIQfBRRHLXAQljyMcgJ8B+aqo9wqZLd7r+9Q3+n71CSRmz3raFZU1/wDtn/zdzbE5oO1pHqURZTzuwt24Rt8VJWuZoBNbAL32cU9znEF0Y/EYslpKyn0Ibx35pk8j5MGjwtDDbEMTszftK87BWP7Jmj/SoI+T9PTNIdjxvxYlbSPfbiFrNv2LKEfhXzLfwN+CPmwACMrD4K3k/fiVPqhojLmAD+ev9q+mgfpZo34LF2AHsOxaF3Jrse3C55afW1fuFu+6+ZA/wr/6laR2Dsi/9l/Sb/uxt96sK6YfwwsLquUjjpvyWpyj+OPH70BVQ5b3sd7kyso5RJFJsdzNawXO2y8ogFn2uWb0ZLWmp+kF5LURTMLTie0Hb+ScY3NAZZjWbCFK8beKhqC3G2ZjSSMi02RhpKYyT73P6I+K09VUOLhs4DuQd5MMFr4i4J0rmDC3JYBlZYpD+aNmgADZ1qHlET6N1J5iXVv5tx1fWsbqlsfUS4n1NWcl/ukLHaw3LA3aVoY9g2lHCU6/DmuB/wDw+LkHaG+Fob81Hu7k2IQztaHFwwvDdvYEYw2Y3z1pnXU0bqdubQRie8537etZU8A+7f2qNobAHsLgfNN2eHahfR2bs8y1YfKngfVyVnVc34yrve6/G6/NE2BssLbkDIZJz238zMHfz6kS3cx5/wApTpbC5YxzvxOt7fUhJGPnYI5X9pFvcmCNzSRnt2KhqaQtF3SMdcX4W961o6d/a0/FNpp2aCUmwzu1yg+8PX+fPdaTkyRsbnbYn5DuKw8sB8LGDUayRpy6yg2mdLMGBrYg1hNgOtMbUclzSNhYGNvE4WA2IUnKXIxxi5BMDb2J6+9a3J2HtYPioX8lwaOAXHflzZ8Ofv5owR6bllD6182PFdEL0V0h4L5z1L5wr5x3iumfFdIrbzVb2bpi7Ldc3UvI08oe/RO0GPOxts6j1oAzSbPpLOR3iukUWeTSusdotZaWSnc1jc3FzhsWZWcgRaZexUg4aT/zKAG0p7Xno7t5Q8pF79Gw2qaojJZhHDp9qi5RigxaNutY3y4+1XkJZIdZpcM1o6k4bbfrI07hlbwRxQaT6zM0C5uCO+sd/YtHG21yAvJaGLEI8nSHYs8+tRPebMsbdqYxhLXXzG4qtoL/AD9O5tjuduPitBJXTWZkWl+QstLNI6QDiU2+wi/enuBTiu1Y1tKd+rv1OllsT/1Y6jcZ6hl8QreT+hpNvopjRCPOMMjc9wv8FHM5rQ1xO/gsOkH4HfBaWlfliwO1dicXSjVl0ZyT3veQY5Awjx+CqLvdeGUM7tb4BVDcRvERbPd/NlOA46us3Pd/JCkwOFsIc3P1etB3FVlI1uJzmHCPrWNlLf8A7cn/AIOVJPjye18DvEuHtUUromOe0FlyPrK8jwoPLYXSNZKLAOtnYptqaSOGZgfHiVNJ9GVp9ai/vH+xvOZZ3hrRvKLYopD1uLWD1lQwUJjBLbaPygXce0IwV0VY3QXEgFn34Z4lip2VTT0buZkTwOG6jIBzZvBG/rQKjlhh0dpzluAI+WwX2PKyPPrOz4K4heVjghOTcRuRki9seQ+sF5RU6rSbDfdWYT3jnK5T5KmiZhZTeUMe1tje+9Nmb0mHEsuTWN7H/kv3Fv4ysTKKDLjcqzY6Rv3HfFFpniAPBi15yOwWVzn1lWaqPPpB5/zlRBu93szRjOpI3WY5YZS1wtuCqQ7bf3JwDxbogLGNZ97OBbsWt5yPhbNOfTytdYZjeFa+Sc6jde3T+ifzRi0oaEI4gPogNK0rX6p47kyCbN7di0z9pTXY9G6pBF97WekVVN5MypNKbO6upNxCzRu4rJdRR60Arc1ScDrVEYytvFjf1FEiFxx0wj/CBrf5UwtpnHHA6MfWyIv/ADwVKWQA2Lo2XPSuf/ZBrmDA2Q+Jt8EXOpHW4407Qx4NjlUaSUGzg9/1id/rVRjkOrZ7/rdfrU4dMXYYxLf6V7f7l85nosY7bXt7ULX14jIO7b7CmkenEXd4v8FilfYdDan2Lhvy6k+u5KhklhqvRjFyxx292abHyhQyQxRufJr5Y3FuEZetSxnbHN7QrSPuepVVdCLvgjxR3HROy6b5bg8xqswi2VghI3aM1Sl3QknLPEC3s5jNK6zWr9IVjGiP+qikGQ6yN5VzO6/1BhTmRVk4MrdGM9nWpoXuxRlvpDIE7bKaiFPpHvkZJixWzabovFNoRCLdK+3mdFwmZIPWPf8AKyugf7Q+7mMsoLWDLE7IeKJD3ebB2FBrRYnM9qsSSDtCq6pjxhe8Q3vbYP8A2TW33XVLRF+tg8ocD1mwHqQ8nvb0jY5JlXJXExNzaL7RzFcsyH0aYMW3ngdyhGXUweNKB9HegTyfK5rQLDBc3sQ6+txse5eY5HFgdTExoMYwW+/ra2smzNiDMMbGWFhjIGbjbIXVt3ALihBfOF3qd/JRnZa7Gki6aZ4MGVnbwtPSzsdfJzQc+221VUcgDrho7jdaE5t2g8Qpo5Ok/YePWhCwazlp8MkcgORCZRaNzJNrzbanua27mEE+KeQzzmx7dya9lO0WNzuUt4WWd6k4GPFhNkyVzW6EdKzRl1p0VFKXY2GMlvXtV2ty2BWBVr7ecFW5qZ5J1ad0EmXHEPYQqXE114o5IndYOL/cqTUc7Quc023g/wDJTBoj5mbHi8MvUqhhgLRpMTr+hty/ngiC7DltRBkb0bp9pojiibfPaBb1p939OO51duw27U3E6UYo7E6N24ZN9QCYdfYcWwYfEpu2+zCDc9yD6rSR7b9F3qBupaVr+xw3G6a15OsLbDmrXurWxEepco0xHpYrdjj8VikdiI3LlCGMZugfYKll0Ahq7EvbvfZGunpNFG1pdruAdb7O1UtRwqaf/NG9RySOGLDn2pj69x0MesyNuwnrTmtY4hgzAOxOqI6LzTdr3usF5mlF+KLeVuUPIopM4wymc90n83Himtpa2SpsNbHDo7d11Kdl8PvRjdK0FStZK12QOR61PHXTzRshZi81a5z61cV1fh7W38be5U9ZQ1M0kMrtGRLa7TtGY+Qf70+wJ1ttl5M+wjdtUkgJYXarTi4XWGWTE767b+1Y9I0P3tOSjglcbiUue3DcYvHgsOMuH2fzXlUL2tbo2hgyVnOa07BhyyTBHssjE2R8pH0BcLDHQYQcwXvUjTRNZVTBrJJGnJ4GzLm0eV93Wvmwe8r5tvrWbG/hVmZdgTvSVgM1mqRscbWkwxl1ha5wqTs56qEkm7GEDxTXna0FRT3sY3ZnqRZHohjyNjmsi+MuGIFhyX6rLMC7NzhJtT4KqcYJBhN2Z+pTiqOjNhn9LsWhdfDvJCkrPRazGbbMlNV1I0cjdazfSWE2EY2NCD2u2bQg0cVtRadyHyY44aEHQSaZkmMWOzVN7cFFIYbSw1OnEbXsPC4ve24IRGHydjZtMHPlbkfu34J2m5dxBzsRZfL2BEzVwkLtt23v4lZtB/AvNUmzf/wFYUmLxWryWD4/FanJEfe4/Fa3J2zhO5o9SfEKGOJ/04yQ7xGaY+oPk7HdF0uVz2Jj/KXPlL8D72G0cO5RODth2pqOWIlTN2Cdp+PuWeseHBVBme1gwkE3sBkv1MNkLTk47AnckaLE6Rr2Pked+E7FiG2NtM/wy96jkhle3SWyaUJuUnTeUTZ4b7BuCNdyhpBjFtFjzchG6mDYm9GMOIshFFSM6ySTZaWgpmGenqjC55aOhhFvYFUuraWOR8bW4BhuTtRo42eTiI3fgFrJ0umfn3lGeVzziabXblsVd/ct9vNVstd0LdO37uZ9V/kSR39K6Lnv2hQNdE7CTc5rRMc7De+F3BCXyuFocL6zhf2rzfKtH3ke4qza6H7i0smGoFrYbEd+xWjomtTpHsdoQbYQ3aUYw90UFrBoO3tV7tb9Yi6a1sLXgNcNJh1nNPUpHudhZGN+2/Dma9hzCzYwr5tizazwRAfh7FhB71Znitqij+iwBP7vbzXUtSdjhoh7VHRwHzsu/wCi3ihTNPm4miwQtsTYtIQXHVz2ZrSGTGLXvxUkuEtEeZDuki+Q5v8AV1K+JzSpKdkzXMl1Msu32LQYrlpzPPdAruVkOz5GgoDNNGI2617LKll73j4rOmt2yt+K/qG9r1r1VIPvO+CfR1fJ+mmhcWlwfqnrQrnVAp7m2jji991r1lQeyw9y15qj77x8F56Zn3qmyN/JiOOnLvenNo4afERkY4dbxXJOiJZE2Qg2dmMx4fkuU6V9RJJeRrrvdiOrlt70xx+kmEol+fUqKptbFZvuTmQWlm3Nach2lNp6qoxvc4ARMyaxNeZvJqcZiR7bknqb7yqSJ0xlBmiu8ttcErlDkSeLBJHDhjcLm5ZI0m+XAFQPfSeUOhvkTl1FYv0SX1W46XJvqWklo3uJ4zfksLqORnEtddeRcm0MmI9N5dmn07YxHJLNG+z3WDbgDMoGN8D6jfO6TpHqXkspY90nSvhId4XCvLTRNY30mx39gVXohMyFkLtG0xHPrPD+e+v/ALpnt5jTSdGVpYewhSU8g143Fju0c1+pSzX1Mm9/8lGI2bpG2aVonXDYm9G/qUdTDkWNzWHRPuMsmErUoqk/4D/gsuTarvjt7VnQub9qSMf6lraFl/pT/C6fHXzwPa/awYnD2LyeklMkTxjZfaOpCINDnDedylrI4y5jtRzzsC0ToHPdvGLNRgF13sub8bqx58vkAcSE2q0OMl4bgJsvJPJo4JHGw6T8XfcAK6soL9IynsRqmtvo24Xm27io6+jGkFtbD7VY7Tu61p5/NYW4mDf2rRNuCx2AP4jrTqOYQ6Rt24TlcdSfGy0r27M9iAhfhvkA1oTY3YbAdGPIIm55rZLasue3Nbma2SJspbfMuPG6s2kg77rKKnb2NPxWT2N7IwhhleQ69rRjdt3J1Q+J5e8i5ttvsQjhnkbHn0JdQW27Cmmape5sgxNOMkELNx5wya+VxhVBPG3Jr3Ny7lNyzT0zY3XvJJve7IlYcQPeo5C4DVGavNJYnMNGbj3Lyh8YYyFwLBv27yp6nlWbR08T3BsbM5H2OxoUk9PAYYzILMO0BeW1UmkmOEMBOzYcgqesFgQGvIG6ziuVK1jCXP02jedoGO/sWip+93NgZk0dJ3BOh5LpJZGRfOzMYSGdpTal9Qymzuy0N3dvUnieofPhcwySPzJGJCXk0R43NGDELAhQ8p614WFpaG7f5unP5QkBYw6jBsVU074Hj/KuUfsR+080ctQHnGbNa3aVVV/JUTnwzu0mG2sCduXbdNNTTvjx3tiG3+bruVSJXgSNk1boCIPdh1smm3sTp3UuCoksA83GXZsQZT1QwWuAcF0JGzyv+kA7Yi2a7X48MY0l8Q3FeeliZ1NdiIWNkhf9K7bI4QSTwTrg9VyopN+AhDzJjA2uvtTaXHgp27htK0k8oAt0La3inRSUbw+LV6Z2cVHVUr3Op5TYYtoPM8UlhFTuZp33F2h3Ab9hWvyjWH7rB7yh+juUi2W+flDrtt3NU/J1QRIYLecYNU3F/erAZqmZ5BUaJ0jcb8BADb5m60NXashvfE0aze74KOs5N5WjLWyDzcxs4ngOvmzRbneLMHqWANw4hbJeSynVccPYfzTmu6W7rRhxXGHWzT4tgDrjsR8jfbCMLpOPYumsUh1zt6ltV/2ZY4W5815O3BgOK994O0epYaWLVyHm4ydmxaSRk0LA4n5rCLnuQxvJwiwyyHyGu+kQfEJjKmESBpxAHipadjQAYnNAHYtO50bA3i7NBlG7fhxHd2BOr8Lnuc6xkfxVRp3l7jx/nqTnPeTjYx2Z3FoPvTzxUdNTV7YX4QHktdfsFgqeSvrI5HwRaMiz7O9SqWwzxiHQzsc6MOwsGjvsPYvP/wDVg7Gw296tJy9pDxfJb2BCHkGohqC7adNGMPjYlOh8tpfJndBgs4M8EJRVUsmXQxHDf2+tVhhdSwPbHcsu4l2e66NLy1yvXRUWiOHROuWu3WunO8oEkWbcdTLjnceOexaPkut5PbC0a2mnbpXHvIA7VK6vdUNMnmm6KUPA3E7cx/IXKNRfUOjZe+/NAtKlnc4tDA5zWsYXPxi+e3PssoMZr3We3M0b2N277jYqd8kPzUkoDS2wN8OYzKDZqaEW3BnwT3UMdg/6El7H2p+Ooye3Dqts4d6BjorEX2zyH3rE7kmmc61ruuiBRQYTusvNUTIpG5hzXu27t6ZJazraw4HeiXOAA4oZXe46ox5FYHcmuxcTK73LSGF0T2O3Eu9qu2tDwN2iw+9C9GZ2tdfzeWXDMq5kwdTslM+OiqzHJk1zIXG+W1Npq1lVBExwcAGhpv3hY4GSvkb0ccvwT6KqhZG9xs2W1r/Vcjhkgv3LzssDTwGadE6rhsek1+XqKxwVtE36ukart9XNgrKVr7ODw7Y4OGw3UtLuYdXs3czoB6bSgx7rOGSd5S/P0SDsWjJxiTwKuwGK3h4J9ByZhG58uLpdnUiXPt2uWk02PR7RbK6tc/tW8s0UdoKk2kaPQf8An8maOolcy7g5oDb3UtO0VD8bbXOC20Hcer5NLL9JjPgmFm0jK6koKt4YcnbNxRkrCXmURyRM7Wov5Rfgp4hi0YKMdOGMpoNkQZxNr3vtUraPKe+eqDdtt3Deqes5cPnnsdhsBdzbkDIdiMhbZZ81XCHGxxtLeOKOyPPYC6uKSW3EtsPFXmngZ/ihx8AtuJYGOs297WVsduxa7y7tKgo6eqlgadeV0biDgC82DkhEHubrYidquyZ2y2UZuOvpKJmYjt0b2zWcUkbuLWnPwUhmrM2Ptm47Lf8AKIhrjIeDhYHxTZWUdZIyw14Gh7ezYrfouold/cvb7rLzX/T0v3nkf6V/RkEH1n1HutdGp8ujle7O0MuADudtRlqMX3n4m+DNi1I4cLTk8OIt4i60L2Q1P2vimeX6NkrjdzWlZTNWcgW1vgtqzWxOkbCdIRYfWREkN/vpsrKZuJvWnSup2hzuCAm1B1JsbGN1RYKxc0dywhwy6V9gCFUzWMWq9w3jmjlHZ45IsqGsLcwHOXmntt4qO1VIzPa0pvJNJJimnb5wj6H5ovqSL7mAodEWWEMAvvW1X/aVHJdX0ZW4b8DuKmo522fE4tPydvyNqjiqWzNdHseyxyvw/NNipHeUS22ubgDfBGolxNbbDG07mDYFRz1j7Mjp24mt2u1iPcpKbk6jhpoYmgktbYuzt71NCNujJUNG9xa2XK47U+flGEEQzObhaMZw5Z+tMqYKalmilF2uEQN1ebkegI+tTN+CxVPJvJTB/dMCp4/+nm0otK3TiDtFr+tOjZ/00+ZzTY4S9ufirUX/AEsIhxNS/wCJWGn5Loo+F2F5/wAxKwiqewcI9T2LE9xceJ+S2KFhe9xs1rRclHlOqH67OzBh/wC0zbbtWF77LDI4W3Fbe9XmyeOvYtFFUyMB2sdITbszUL4AcUuInO+0fEhUdxqVAa2TsNj4ZKXyaQxx4sgDktaoee9X0hLd91eOQk8VZ10cybLK9wtixvv1LIBW9IbFhN2nijhOMdSwu2HcVhGfBYqh9uCyWKy2Z80YmppZzNfCGPw4bISScm12eVxOw/6UIfI+UwNuFpYbosnouUXNc2xY6OP/AHL57lMdsDP9yweW1g7aYf7lo3cpTWIsb0p+KEtLLZhzjeMgR7lrZVl7Mf706rqJSXvzAcfWhcoNZsaP28dWOj6Si/6gprFrgI5yOO4rpBZNWQCy9i3+C9Jebhlf2ZoBlMQ7g5wb7UWSy0MR34qlmXrRvyjAbbdHmEMLnut9O5TXOAyyyCs51sLXep3/ALIUlIM7NfLK7iNy8q5Wl8tm3RMYHtHbxWPkv/p6Njtzmsa33KevhhaXGSKQsPohwd+S8j5MkfBBe+GAO2+tY62qqhfiS26xOOI8SpexjvAqsiHoTvb61ntWGlpZpncGMLkNHyFUNv8A9y0f/kh5VU0dMOBeXO9Q96bDynypWVNRLGXsbBC1rR2kkoaSLSgh1mt42yQaY9HiF8s/YsIGao9ML9It+1hNk1pG1Ydy0Mwz3FW3blmc171DhixOvewyvmmNmlLjFGDbYLZBMm3vzI6uCxx9FWtbrK0kWzeFqZ9qDuPtQk3FYmLXR4hZrg7hxWRWvrdqxRu1TuV7LNa1lYL6yhnnvsksPwj3pkbbBtzb3p8UBvlYENsTfctG5zOjivfKyc+2WL2f/wDSMpYGtB+lzNaLus0daipcWQZid1LqX5//AIE0TwS5gxBT8k1Vg2ZhYerrUtG6gkL4nFpsCVlya/vYVglgwHbay3JoxsGI2Ct5fC0/acg19djZa5ftt3KGaKpx6S9iBa2z4q+kd4oxtBe4nLeSg6pDaaPi43PgF5+J9S63pvLRfuWjpWUVPDncMxuOdvpdgT9PHHUB/RY6Maqsyip8R4QtWCklbTyHa7RArFVVVZVs+hY2K8sBfDw0tRZo7k+nquXqBmLgdIW+C87ytX1ZG6GER+26L+TeQZnOc2156g7O5PnpuSuT4XyOLnP0Ac8k9ZVXWcr8gw8oWLbzspWvfEbZDDwyOfUqWllj0LmN6H0RfIeC61eSVrPtOsqOsZLE8MxRnAdbP3ZK7XPyWSzVLX2yhlDj2b0x8ZxNIuDxCLgCr7FoZ3YXbiUWPGfbkrsAc3eCFIX3FnWbY9HVCFM+mDGMYW4mnJwy+GxNe0HDdwPVmtIzMFYi8tPBwssBe3qV7X7MwV5tpG9YCNvUtGBctWkaLcVntOxYXK7Hd/BATv1B6VtqsNm7rWklyCxBuILzUZLlrZcVqW7ytJU1sDep0gVK2nkY5gL+i6/BDE0OA3FOkLWuLzndWLGuc/VTI8iWuLQwDgfjfwQZJbMZ/S27OaKaOO7nRNv3hNrnNOCQYL9fNe/ymzOjcI5Oi62R/ZWLRw7U+AGwa/LsUPLbjqutHIWjfuW2Q9jU2SFsmq3DrBdFXA2bM1lTwjx+K/qh91MilkBbH0QhBTsxvdsAWmqQzTO4C5Cyz7VrKzPFam3eSsRF+tPqaPVfhy8QPejDNyrVOIjL3PEhbY2uBl3ImaV8gadZ/St1qKm5Pgxeb1nW1jrFNksLPNmi+Z7k9tm5NFuwHChhlx3vusq2Gpl0bZYWuv2H/wBld1UPED2oDStsOFQPci1jYu27j7017Kgh8QNhhuCrc1oo3PPUFrYG/ev7FT07zpaqKPR2zDctmfZZTTTVkeHAbNjBFiopDUyGLHgJsD3L51uX9m34K+nYcrZxN+CyqQOyNvwRMdXrO2+bb8FgmrHfhA9gQY3lKYAZZGyt+lKnukKueVKr+M5ecrqh3bIV+9zfjKyrZ/4hX77P/EKyrZ/4hX9J1X8ZyseUqo/4pWEcoT2+2rfpGVYf0nIR12Kzr3eAX9JzL+lJ+5yu+smd98rpOd95fNIPLW3A4oMlAFjkrNaSb7lgDDi4WzWM+mw4fZ8VUFsbtchsZI2fz71Jk6zhawy9fNye89B0bWOP3VDSBmo92Iu7N3rRHyo6OmbifIVFT6PKnLQD1WN/X+y3ZKDlJjf7N/uVTyQf65mp1OGxOjeLOabH5G3m823BFvkdsWCnbikPSedp5rrZqrVaVsWxZ72Sf+N/cnxCwAO7epoCQYg92EAnNNcxl3tsRfZcF3x9SibExrXBwDHHMtzToIsUhxlgP1A73u9iaI9Z+DEXPvc57AF2hZqwYso1sWFjCUI8Dr3tYbUYYGDA05NHw4rOOT8K1mvHaFIMW1pWhvkZgT6lhV+CJO/JADcswsgs1sW3m2fL282Bms47AFlRz/wysuT6k/4TlZnJdX/BctJWR6JuLeU1+K4w7u9Enig+Nm0E9yEsgaczwz35+KaWRgFl7HfsTZsJ0b3YQesDP288dNJ0mNBae5TUVbRy6Vh8zIDmCOKjgp43SSvOFjWi5cjBVQPie3a17bH5Aio6d8h4gZDtWFtjUSG7n22Dgp3v1XMwtAPHEP2WMKopcO1mp9obEGdexSStFo6sadvft9fyGwwgXdxK01Zaok+s3VHctGZIYrbBv8FbSPd2Rpkwxa4uARY+CxP1RwTpRA+QM9FguSsFNye2Af2m1XFayMHjhanDlCtjqpDswN6PetDiGRsQN11icbnmbiaWu6P2idnv8E/0jYtaR4J0rIgAfRO7+bnxTbZYRZM7bc9gs06ptt1QjhcG32Eq05dL9a1iVbQ37XfBOvTlts7l5T/JhKJbOwt23sESRkHhHjzYr5XRcJmWXz7PA/BfPeAK6bvwofOZ5DUHxRN3ZC+xXDJD3rSQtIDhvVrIDVF95X9Kyj/9cf7l/S0/8Ef7lr8oVDuxg+KLsdUbb8vgtnNA9hsb+5a07j3r5wrNxTBFjcRIMu4oGaCRmLZiba6+8rw2xMAZOb5gE3t8eztWi2NxYrdau6rkB/ufzWikdIYomuw6Ma+30etVDZ2CS8wdqmwOHYN+SfK7a9xcUGabAW2Ft2SFSLNqHZusbiQce1U3Kr6OZtJDd+kIsNmVuK0fKDY5huxjWb37QopKAyeTzN2nMB3C6DNIwXNro1HLJZUQtZeNuYY53XvQpaSGkp4voxsWmjb5mTYQ2yj5PjeCIhifb6X7LMau9DW7M05zcmSecb3qj5QtrU8uiPY4fl8gzPA07jttsHBdBnc1S174GRstf7SHk1M1hHpBrb+NlmHFbD+Mr45qQua4zP2ZZDJZTKxqHZqYndhPtVQLECPERlt1sKa6qjNjjGDYbht/eFhDrtADO4bFlfnDuHMRTQPkw7cI2LOjeO1WMTR2yN+KYxpZZuXzw+KdLHIx4PBwxNHCyzgl3+gUbU0v4CsUszG8W3BUg5Po5HulZo9IWGwHUjPUQtawuHptPsTety2qFhidhMYffjfNVmmdGwxuwsxtuNvBB0WCNkjyATlsAv7VBTxl2ndI4ZtABzttutDUuaLvwDbw2+sItbICLt1sOdi0n3LRk3yB2WRsSL5FRSuqGRuGIDK56RVQxosMZI70xh3uAX6wdTqXz8zfuh3wWdfN/AH+5Ob+kH5tI+b/ADTnt5ThOEXza4c0DR9JO0DsGdz1qxqXeKznf4qxqpPxKna8h41j7EHNABD7rR6QiFz9nF382QbR4cJJ9Pry9Vl0oP47PinMcfPtcSSDcYQPeUGvBGHN2MZHuQwAWAtstdFOruUYtKyla1sbHZjEbn+e1WZhwrohOo6umEkEnSaVJPQ8qlga3GyN7LnsvdRUsoYZAPTyt3q/k8TnDg65UjamJugDSXBVFXGZNG+Q4MZucO4fsjrXy2LRlgBUVaCLwPwn7JVRSy3cNGJBY5i2abR0NOxlzhDsNzftK08QZ5XGQy7BYS/zxRa4WIQ3ZLJebpJ3dkZK1eSa0/4DvgsuSKkfabh9qs3kw/xWfFYZvJ4jwfJ8LrznKNG3sxn3LzvLIH2ae/8AqX6zX1Mw4NaGfFQRcn0scLdJnhG3Led6q4Hg63nARtF7OP8APUtCw9Nw35HcFGX7JGhzT3A+/ml8opXO00RZHiG/LNR+UPLxjc1wGXYmtZh1W2u3emu4gLC3eFo8bu8rpX71kFhwknhfahpqN5Ltl3ZexeapIGkb7X9qtE7B9gW9iuWSv7iiAXaj23BTLceZkLw8YBYFp9ymkAyleXZjPaopqeZ+kOACxtZ7t3hZSzVlWI8DQRiJJzsfeVLG+SYtyyZfPu47FG6arY6PSaM4Te2Z+CA8qs8TYHkt4/yVZkpkditwts3LQw4Rn0rZove4knaSoR9cIVAkxYw2wWY5slO8x5YNvNiYPmm3PVmrQv0vGy1onDuVrZrZhbxKpXROL83Nd6kMbHNucrhQ0w3OPif+AmYvTbcG3MXhuq7Vv4FDFbVFhYWsEY3WuNtjdCXlGQ0dO5rXsda5kBFxZfo/y57WSHEXvtm7hwRhLrja08Qtq6RQhe7pLU7FrHVLXD1KsrHVRL526JjftfldF3WsQ/Y9y0oG9VNN6bmZdozCwObqlpBRlpJCy52OQhLmiJrsXfdDlqlcxr3ZVLc+l9Pv39faqaKTA50bLXw/FariOxXlqAO1ym/SVTFHUGTLU9DL80XMmYesh2avE51/qMTa+GqnEN2nRk7LAfBdGoP3R8VoaHkyoqJD6LdqvT/9NvZ/eP8A+Fi5TjwxgarA9oaD4oSwRx2cwXvK3b/NlCImQMmj6Ti/gSR7fUh+s02y2ch+CjqJKmma1ztGDBk/ZxtfcnSl5e+MY9bPJNEryG3AxW2IMjkLn3OLZ3KMRMLnW2AIP0bmWBzOSAc6F3EmRvxWF4o7bnCUXHh8FqV0Ft3S+CdZ7JAG7bXHgUQG07gN4p2D3LVcG/ZFl+8yfiVnzuP2s1JNtkdh9qj5gmxRtu5xsAFJTOeGmN+mLjk0W9JGEuY4vGK4IDS0Dw2KURN+aAL9bcfaponOYfJ+m5rsucz8lUWljjfgc7SNbnbrK1qanZ2zj3L9I1MtJghPQbIS43yyy61BA4+aMmG3VYrEGg9ihIY0ek++8KwZkc23TeSKoPEVRfFgNjkL+5XLKsjhpvyTJeRaLQzynRYtI51x13Kp4GZkh8cht0sgb+IRe+IOAG7f1LF+jHg/YcsP6Pl/A5RQwUTm6Yhji5jtl+tckf4/+hCaORmrbPGLk8UNK5zgMtu5Zyzj7g+KZTDQmCMl15bN7zntRbEMGInG2/XkrkN7hZcmte3/AOnD/wCAUsDZY9IwswaU4Qe9Ngq2zNdES3DJu2bOrnjN96jax1xna3UbK0oOe9U7B6c1xY8Andqt+xxNuQb3Cu3Da9810gp4bABspt2JkMcUb5rXeW54U1+miN8ix4wlOLJ7H67h7VNDDVzYL3yfdaz5itj/ABWxbGra1C5Q1ynSQR6V5icAHG3BZ8nM/i/kvOULSP738llSxj/E/JDzcXiVqviaOph+KYK+sJAeJMmbNoRbSaSPGCx7nEG7T1WyTmNYM5C+4Ft5+KNVJIdhsAPSysi5h+aLgQAdnH1rEQr59atJHbtVtGLJ1Tizdqgd/M6Z7/stG0ppvk8XWSpqOugbNDLfExwuOiT7QjQjkmkZCRmGwtC1qGR/2p3e5XbyJH96V596lp+TmxUrGiN8Y9EaoT4mVLIbA6Zx6OO+6/8AO1BjKkPgdDosbBrDeTY9d00UT5Iw1miBvYlvX33Rp6rXiYL5Xs+T4Wvb80w00Lo7Ns8Xvc8eavj4TtPi38uaTD6ZA9/uTS2wELcRPWcgsVQwaMeldNfRw6SA5sIA2LFLSG/HA1CaGkcHjYdG26gnrD519y6/aVTYfr+5fpOa+nLSW3OQTHtAY5srCbb0BHICVeaphb3pr/0hpHMN7MCaKrk2ocYg7RSG7MF7cbX2Jjn+VNJaDqyD4LUrapvbhPuQ0XLLgPrQ/mvNcqwn7TCF5uro3/fPwQEkLHYtmF4XJ8MjdZlLE09oaFVaVtxjbtHV4qNhkkcNYjGb2B54/tBXDRqjJXaNYLk+Ft7OMhPqR7f2Rw9tk7dwyQJVZykTm2G463bB61i0suee1B0pmaDsJJWcr/FBzr9Lfz9/OLBBOtuiJ9YQOHNbObNbFUu9DQ+zNeV1VKZIg11gRk47Ai6MuGKJrmh2sQ7hsHjzcuUfCMSj8LvgFmbFFrR0jrG/WsT3A2Nm8z6SSTC2NjpR2iyxQ0c5HFrCQmxOoanU/snJrY+TqnCP7IoeURSRg/SbZUMgOrpGtv25e9HnElNSTSB9Ow3YwnitPPUNp3Em7Jcn94K1+VY/w/mtbldv8NZ8qP8AwLWr5z2AfBMj5AMs0gzk0pAACr4q4xB0rmFrWvucr39vN/ie4q7RnLZxTKcP2nVvx606AZZnL1rHoyR1rBZ3eENPIIwJC3XNutQSsNxrZjuTWno4QB4LRYTt3haKdgwjbd20BWdyfGDxcwLCyWCO2Vg1XfVSO+7+aawxO1RbpoVUALGEkAE825Zx+CjHUVB/dt9iqLk9MbOxQDhD7zzs7QrOO1WuuTzh3SZ+CcPkXHymO3j2J1t6v4JlNStjLny62PLII/qTbfUc1YZYHNdtAKFJNQwSVAG2w27yU/SHO4I6uckBZg88dFSRF8smQCighAdM6UGaXe42Pq5uobU599TDYDCUfBAKqfBtMTsOe3JYYIJZnfVaXK74WQA75X+7ai6u5Uc99smQst6yp30tOZHVTNA5zndEH0lrVVT/AD91ak83e45+AV/J55j/AIi0fJkErQGAvYQcnf8AFkQ7VdoujbMi6bTsrcLGjV83+a/f2/wz8Vc8oMH3D8U5lZPpW3BblbNRObbC7C5uaDnna0I35qqrpy7EzDfDttiF0S2IG/F1lqwtceFyouUa4zRSSF2owiwz6wvnKk/fb8FUU9EYnRxvLRiGsrARA7M7Koqq+p0jjTYQ0bBrN5pGXzBBCw4gGtsM1idwyc09HrVXh4XB60W+UTX6ir+UTgdZVvLZe5yhiDnPebudiN7nYmtN2nCAR3KRxccRfh7k/IEYDe6EriMVsw4Zo1UjpAZCXWxlX0eLtVoaeMdYCDTtZI5vv9/yPORh1uIVmsAA4Ke30vco7W+ZGztKPMztTXN2i4IVtqhnHSjnw+IPwTu1XKt+wF9ic5gBJHFYoxfqUYaBqu4rCym8mj/7z3ApzaaRz3u6cztp7FcojiPlMp6eJ0kkhs1rd6vJhdVy/OP4fVHUohuJKxHUa7YOKaGym5dhtgPYnBjnktuTqmwWFrnNBNruGS1AhjpGNhLbZbe1BkTAxo3BaoIHFWw7V+uzwxsbkWl1yheqjB4YrrWqIvWsLaqMk7ALqqN8gWD/ACplRG4YHYGZbcr/ABWEUj8vr/ktWk9ZX7jf8SdpqVkI3XBz8VSyBwNntA6r52TWb8grc1ZH9T3oxCmjBG11lom1lPTZXxSnCPYouRp+VOT6qnkfhZoy7GHHgbZ9/NUtJs3GSOvNNfPT6ZoObMeG6M1FQU9M92WDSPe53r5iHbEY75B1lcFaJh6RuVGXNDr52606UsycMOEj8k9jABYoZbyjI8ZP2HuT+p6lkO6wWANzKLfouK0rfnL3v3ryhgDHDJwCngvtAf8AKqGF2viBCZ/cD2u5rYs1H9oLS6nxWr/wqoG2WE5/aCcAtv7E26KFxrI2kyXlL33OkwgDebLHO84NzecfJbHG0uc42AG9eV1bQayUZ/2Y4c0MLpcDWtLus3P5LFEyRzYBYWG7eos48Wkvm/hcqXRkXcHAEbHFRxN1XYQXEDaVimkc48GrBhtmgbc2kftOzsVRo3vDbtNvuhZvkW1/ioXknJ43qpjjnEWbb9eqomB5eS/MlASx4X2HerxxGw4BYXMunR0waMDATdoO11t/coonluoWnZbIdiHUs+apbf8AqnexaSlkFngOwu3EhWIib22VBU1M5lkFRHht0W6wWZsnxzxBwxOtxGZQLRPY8BdR4IyXYgLu3LEFh4rFBA6QON9XcrGjm/Cg0tu3P2KwysvOzxA8bawWOOTED6QKmGPEWP8ActHPEHg7iFipocDXHWsFMxwuBZY2lSZcCjG8YmH1LBHit1qMP2ShzPVf3c2z5DZmsIt6YTXyWOFmC437fjzYnHNRsZnmthV7WI3qfrwi47VYfsnDFcoOWLyXSdapThDQajYPsn5A+T+leUIv1hw80w/1Y49vPER9D3qU7HMkOZJzCe9rmvIu5OhccTpL9HYE+bDjAuGB27rsoXHWcY237bL4odgVrZDas1JIRw9i0hZrHYA1B9O+7TtbfMLTH0bFeWtdhfliCgH11E0x2PRy4JkkbRZjcGHK6Ja3NwuWqSsc/PR6O27ajJbLCiTnzuib6QIRZPYPYGt/n+d6liqKdrGtNhKTYh3DcoGCQODJhZw35rRl102nA1TYketMkjhaMRsS+2r/AD1KlqYzd+kwudhtdZc97ZqR0jOg1Ok0zDvsXISzOEgcMekZmO9F7mGKplHzY6NlOHEZt2Ky1gnVEUj9fI4nLinGOI3OSa2ZrmY9ikBNU+sbIWDMlpPBUkhdbX6J6ubZzbebNF1PsPorKmI7SFngb33WPHcnI881EHYHPF2u61JUVVC7RRGxeCCsv2OMbNqd1I69lQsG+cn/AC/IaTxVxIxfOsXzvqTOWa9mrtgY4bfrfDm380R6lJiHplwv1ptbEWMb9BuWFaw1r7cW5OjiIbfO7uHuUQcSbDjzNxbgFmrKTPK6D4sOLeMsihBGb54nFSBgudX2haGBt3u3JpqZQwt6IbmrtNiCgZHNx8MdvUi/FmUKN2WN9vYtDHu4/JeHNBbKG7SRmtJPBpXtyAPRb3LTvjw2cHZbljbnfMIT2cHWGE9ixvJc7rKpn1c/nNJZjcQNx3LV2FYhsPOaho25FHJRGXGGsycGnprUMgZ6LCcgp+wBdvMWbnox1Md2Hou61gZk1GGU6hzxYblp6lp8c5qGy4reg53/AAoJDtxPP+U821Xv8i1lsWXPmtie42thN1pKYYj6TR7v2OZNu1Ob1IOIvnsVAy39a8+ofJtgK+bKbynXw4aOM6rT/Wn4LCPkQntRew9PpXKLZg7iNbK+5Yw4XJzBQLy1o32zQDN2wLAG3PBN0noAYu3nlb12QhbA620v3IR1sIY53RI3ovtsGSYSDYA3VypBEdcmzU9wktj2ko0jzcNbiafcmOvd2mHds5s1sWxbEKkPLXRjZucEW+QRTdZCP6synzGsFHY+iPYnNeN4WKKscwDrIVM+ed0z+JzV0WuVuaRmHajrczRxKnc7e4AK/MW4V5sZszHWiDzbVCRuxf8Aif2PWtnyJTf0Cswi/oP+kPei5zMbPpN+VtWu1G3DJcM7rk6M/wBofZ8rTzlzKKJ2u76f1QmwwsDGMFmtGwDm2c7ThcQL7G3Vm005/wAMrVoJvUsqJ3e4LKmb+P8AJC8cQ++fgsTsBk+qsHNq5lTXja44zncrSF78tRo3WCikmFnPfjbnszWMHqN0+dzbYjq9ic7gLr1hF0lM1xF8IBWJ5u4+pRsOwzNWXFX5rHmcbXuCnEBWeoGkWOjb7E5kLMew2CwPfgO8HJRSxtcWMvd9slYhZrFzWIRc2ue1vAMas66f1fBecrp7faQgivYcVYjnutI0mNx22CzllKuYr9ritJDAxruIHPksmO8FbRuVhESugB3rzkzOy66a6S2r81k0eKdCwDMK6zsrjiEccbXdyNoLLJxXTctSQrY5YXs3WKa7fdG9rcVQB3/acfX8lj54pQ5hIe9j7ZXUdJSxCOKMWaB8nYs1sXRWYVgOYvPd8iX7RQ6jcLJzuGZvks1EwjMNATxbaCPkYm7Gax8OcDm7ubSGJ8bnbdG8tQnjgL3tzDpHF3MFrMae5WarLYrXVxzdq2c20DvVi5Na5rnC+0BWEMhv9UrKCTwX7q7xCGmpy1m84wvS8V0G97lk2PwWqPBq1Y3LoMHa9arWKwksOpdI80rQ7etq6S283aFZpurnett+C2WVlbjzWstiuL9athCDvpAKmj+jT+881gLla/S4JlDSNzOb3nYxvEqOgoxZrBmTtcePNs+Rt+RllzALIc+SkLja7rrUId2ZrVppj/hOTNJSvYy+Zdbms4ZK9nn7y+Yv2uKv5M1HyaFkeLbYbVt5tZZNKNo3X7Foy0iy+Zz7VrYB1XWcjVrSgdyuJvUvnfUvnV845dJ3ith/Eso/WV82somd4WyIdyyPgFvWS3Lpr5wrORyu0kjr+RmtayvjHiumLK7JS7safersik70+QDCDu5rc2xMNupXOxbL8ETfNXKuWrPJXWzmDH39iwtB8U2ThtTm/wDbiY31KwXWo6OkjL5ZTYBNgis6Z2csn0j8OfP5G0rILYtnNksfNbn0rqWMvO/AtWMeC6KvZbU1zpjmNgWcr1i1ie1fN+tfMtXzTPBZMb4c+S1ulzbFtWea1SsiebYsgs3WWbjzXPyNnNm5ZPHivnmj7yycD3LJ5/CnzzSEBu+yyc7xWxdHmd2HnxOWxXW1XQdwKy2kKz8kSM1YKyztZbbc25Bxvf1LZq9SdGzgqwN3ODfUrnamwwsLiThY0bStPUtDq2Ua5+iPohZD5Frc2/5Ga6StjXS575L8lbLtsrWBHUtixMThIcwrB2S2rpLNdOyuHLMFZBblkrukWc/i5fON8Vt9RWV/wroOWcTvFasH+ZXs3xT6updGyNm0kKeqkc2AU+1j26x4WzzTnUlNSQUoOT5GOJ9ua0tFV0ziNrdBb3lT/peUw1NM25YGjznZ1p0TQ6CdmZjLr3HEFWxO8V87L/EK4ntWu0J08GHGXNY0u2NxG11JFLV1Mujp3zESRswutvBbmFFSHyWCWSnNU5xBcGMyy3Z3WGKONk81NHUxjDsFnF5/y+tREVj4aafyiUYAA7RNADc7cbnvVPZ0hqZmwgub0s3C5y6k2tfDJjHKT3YnHowhpHrVud/2Sslc89uayzKjPUtme9dXBXbrD1rWBC1XXRxXXDmuG4vis3dqa7jsVa+Yi7pS6/UVoo9ibyzygzz8ucDT6DePeuktpWQV7LaFuW1ZHm2my6l01tWB2R3LNyx4lm+3vW244K7bj3LMZq7TYrC/IotvdaZuzescdLivxl/JXFM38ahhbFEGySNZvvmVNBDDT6OG2s6NxxZX4qOZ5wPewOItsuF+9kfdb8Fd0znLpHxW/mvo2eC3dw5siszzbOfySJ5/RtD0iPSPHv8AYqYBmipKjDfDu3FNo6UBkTcgAsKp6SFvnZjZ5HC+32qm5c5JYI9BZr2jZ/O5RV0B1JWhwW1beaRtW1joba+Po2TqWnpoPOxaRzWRXvH1/mozVRQE2GFsoFxfctd1PpQ3R5kYsPDsXk0M8BljFsDXC7R2KSkoKXyiSEAyXfga2+wX4omphmDomtdOGjFob8SsLIi79bFJttna5KkmayKFslLJNERcuFnADxum8keVul0jYpWy2GUfp59ot3p/2Hezm2/IyV12J28seULBXaVqq0kfeFiidZYXtxhXYXtW0rK9yE3EdbhZNIzdwVPWt6E8VvvN/kJolHmYvOSdY4J5OwDLqXSQuclk+6yzVw7asLlt3q4KyWV1dZFZpp3LVBVgMiiCjco4SUcTcwtgI4rM9y0rBktZy2rcqdx2NlYfWg+oEbnt2ExNJHeQttwmte9jXP6IJ6XYn6KVrw1xYcJvZw3K5OQWnqaqGKM7HueAFMIYmy6OkFSHYsjd2FoUQqGE6RkjsuLRe3epfJqcwTtaA6z7mOQy4A31EqeCSniZURTtha3G54dcX3NubBck6OVkDZTM6UBh1gw4fArL5BhhdaarOjb1N9L+etQ0xHnpfOzfD3J72jXpjpB2b/56kybacFj2qd59GyrOUnZtg82zt2ewetSwSbHCyq+RJna1M/G0dWw+v2rJxWsearjp43PkkiLGtaM88lyhyXDaRs7Ro53EBxvk4O7NyqbiHFPVRkO3iBlsu3JQUxp7sZWPqpJXQuad9r3y8LozOkY2PCRomOc5uIm99boqeWGvnhbUkGVjLZm1sjuUrzLNo58Jlixar8Oy+/1o1NpHO0jpQC82DjtICbHHAwNYzRjL0eCfMxpxyWBJOwbgOAUn2HezmyKz5r857FL/AHisclcd6xMPPx59RODLZHpLDpMxt61p2gnyWYO7jl8FpXZOqDj7tye/ibc2Eq4zWS3ro5rZzZK9+axCuhY5ErXVgs+bNX3cVl6luRsFnkty2XCuxtrZrEH5FOidsIsqLldkUjzyU6KljaBe5scf+kdyjoNJO1gpm4HRxvfeZztd2qQMV/pblFDhnkc2Rri6JjHZjeWuyI6lRSuhiY6JszTHG4Q2Ljk44bjZtsnM0zGRYKdgaATlGcRGfEqB9Swu8mk0rM96edAAJZ/KXZnOTijJJC0kyabFiN8drexN0dNENFdzNQahO23D5NPRHOKjaCRu+l8ApH8NVFrhdrhYhVnJhz0biWX3j+bKaa+7Lt3KHENebzzu/Z6rKdvVf1JoGQqoj/4/Fv7aT7B/YHrVQ3rasysz3FYmbVntW1Hm2IA5WGawNFjmsTCqmiefn4iFo2iwGQHBA9vPv5tiuM1vC3Lt5sLgrGysVfErjxWasHYuorOzULoAi3NfK3BXGSxOHNkVYqFzfoBa21NjMjGl1y0X2pkfl0GKS2EB4zvsUbZMbnzGzI424nO45KnFDSyS+UCRzcRwWaw2JKp54KOPQ1gl0F3Ev1WkhxHDJQMgdgZXxCKItb0ZBg0j+7E78KZw/najhGRITgfH5PK0jvRL2/5/yR6zdR0EZPk+JkejttBGZ/ngqbluMat9FN/PZ7FT8kxZxMOknI4fz7VDTwGUQNLAGjoaO2t71U/ZC5Mt9D/f+2f9krYvKZZmxTuF4oCM3dvBPpakRQ1sEeLVdt2dZve/VmFY6BjmRNnqKidmNsYd0WtbvOY/kKxkpnyOp/KopIYtFdl9jm7Nmap6eOipp6mWJs0z52Y8OLY0DsVBypHSsix1Taaohb0MWRuO0LlSRk9LQ0VJUvjMs7i1gOI2aLXJK5Ia7ySd1VWvDpoXYmyx3ZbPvORX6LfyLSujfMYrxMLXgXte91K41kEMEUhjEkrukeq2aFE18Re+MzMdj1Xste4PcnVkVZSziEgSCN2bL9oUb31lJFLM3HHBJJZ5G7qHeVyhDBoKanp3ZuecLWqObTQzwzX0ckROE22jPNbUbDagSNyweiU1qng+i8pmW5WVrLE1ZrEHLE1WLQCrWCzW5XXSssE7cuIVxmsbX83o3VpL34LFZYrrCLeCuH3PBawIPN1qz296uEzi249aF0x4aI5oJDTRXd0ach4c7/P6lKWiN1JLJG/Od4s1oybgGR2ZFUtXQtn0sTJG3jwW1rbcRy7VSuecU8NPoCb6uZxH1ovpaVkZPDd2cEI42BjRsAFgsOFdFbLX+TylA7+uDnjvs5EfRKih8h005A18gWg9afS1DcTJBYhOZShxLzdz3bSpORn0eqHFrXtdfZxUg+k+3gm2zFLEb/h+Lv2zzvsmTP1gxzXEcbFVInkp6iSoxWllbrAm9iTtFuDeG1UdHAXS+Rx4DUPFnSH4KRkrNKyoZCJY2zNjka+IWBGLaCFNPHC2CSZkcRZpxJhY22q22zYNqp6umnhE7YWxTRSStYbtyxDFtFlyfyZ5TFI7yxtTUPa67GbgMXZdcp8mUdbTCoZyvLVxtkmaxs8bstVxyvl61/0/QScoUb5oa2WSdsU7X6MXj2kZblUQjlKXRF7gMLtouhPTx0k1UXuD/KHtGjbus12R7VS1L6qnf/8AGywlzCAMeF+Vt20LlKN8jWufEwNaTm7zjdibypS1tKIZY48eOZrTEQ0Agt27ty5VrYDR1VRpWeTtllAjLbZu22cqPST0b5IZZQ9tOWAMvhsLN27NoX5LqKPUifernb1KU/Ta13qQHD5Q6+a4PNZbea3PZHIgoYjfJWuclrLE1yusQACvz2T28JPch+25P5ZZ6eo8cbfk5D+0CdTus1+2N/AryOti8oEerjBs780WUFLgcfTeb27k6okdpJ6nzsjvYE57rkRtMh61Wcsym8k8mDs3n2+r9js+TIR/OfyLcVYfIjPasuCBssyrEI2yWbr8xX//xAAnEAEAAgIBAwQDAQEBAQAAAAABABEhMUFRYXGBkaGxwdHwEOHxIP/aAAgBAAABPyFQTVa7n/FwiNcAJ1GNczXblf6Zdu7Z9pBlZ4efDzHYYZpd+I4ePhKW09GHgeZX/I7HJwx9wyJVPmUPSlKuAyOiU902qeolLpzKmVoDbFK1xTH4hAnxC2Ma3FNc6juyvocHK7QEiN8m2sq9EQuvrKEp0mWNwgMrKxFRAgHiYNQOoEZqBTJGIO19/wB9y2M8LdR1f7iJuyURMY3E65h0v9ExGwNElJUNrbifw+O8yD8oOsRKVUA1ABiK3EmmoQEAHMM5cEo4mNQx6QAQEv1OBmOI7HR/kzY3CQFZi65PpDDHp2fpLsref4TG+RlwC6d3DxKYtsrLR0uMEh1VIjnHhs9mCL3lhN0QZvHcjdI9TX2ksLw7NRNafZEdspPmLFmG5iDMULbqD4mG802SgcaVKje5jyieVRDJ5IUs9ZjfYwbfjNIvWos0aKCN00/6wPd28ukwcqmXavBPTodejxHQ7z0l34UzwMHMDOeZ3SjhHScyUldCof6ECGv8HOQFOeuYVTy0XPboYMwa1xVgodzA9ATw8sJ0blkcbLO0qtP/AMaQzGHyuHr4v6eJZacCZHke4xK5/wAZ6/5iVUd3HOp25mtEVgYNQ0S3vCHTdvb/ABXWN4Uil3nQ/qweX1R2nZK2PwGy/wBTdB7a1NLHa+0bpOJEankSvyVr+eWWnXymIs5GDkfT/sCqk4qj7ITA3V2/UOprpi9yHuDKXEeoafJzK23Y4Hw/zDGnTDCjmWOfedypr8EhM1ZqyXNMPH005lO3vEOIR+UynFMq2jMOqKiu8uDWnMRWDGVu+3WaAan/ADbzFGoa/NESddtEcht04l1fshRlcyzgesDqRTk8SydV/huG5cNf4HL1r8oCci0/Mob0dPGdu8qvYYmFo9h2Yt4cjpjyNx6H1gPGZjZubnaeJg0MShJDuTPw34dPeur/AIo4gkKdM6hDuVLNH+12nrfia0VDvN7cdJgkUy5f8SdmO8wvXRz2My39zE1EC16tW9dx0F0D/PpN0JyWH2ag/OebX7f9nZwoFRc444CeqcHR5O+5kdszZ1eTvM6pz1HvFLb6svfc+0Snzn5id1/OV7f9gakXtPfj3mSK3qfRmrT6Haupz1plkUVSGryAetTY/EO8oh7PHScdTkDPSIuuIjGF50/hMsb6yIVm10m1e0Qc9pbZ1hhdvCifHuDUWczhnyt/yY48xLlh1wdW26cHmDoLx7TBjK5mCglTbLKrGpVaJbbK6QOsw/wEqBF20SUEpgzjYNtA9oJaFMgcG6w57RFIRGMFh6oHrC2y2dq7d6R6f4LK4JXpM8ypX+YwgN2+zFNHSWG+zA57vJ7vk0+/MylaZ2qKmd5mX2l3qAnSb5ZXab0ud77QLqFu1eJ7Owk0nbP+Zgd2mn+94Wasonzp0N12g3xu211FyxiwxQ1vACl11+Y4JOjZwjQGhgPSLbti+hnhEyhenMsKhoJCy9u/XaehApfh7RcybrcI8Ro0LlCWgQtuerl7yopzvRtu2jqJRAMV5hQxuVADb8AzXzB6HdQT1/aLdMNz/MrwvsfZEdIe+r6zRXysT4m+lzcMVd1mZE0imBYpSFMCv+cS/ZR7nbzMsozgLTN2VHa/1RBbe16yrLR0n8c3EcDUAZI+agJp6wB3erKZTBQpO+NV4Dasu9Diz7RZ/wBl2SwGH96r8y5XlFtJsuJAc6heOh7Ibgt4Lip0NDjUDTMy0Ngm9OsXpLQ6R4zNovefep83X+Lm1K8IH2YZBR5Jf/CPEq+JUumGYYQ7JlAP9TXDKpLXSbXSWyqwwFzK9/8AKPMDWuUwZnekKqasPF/pifPTD+YY67np66mgB4D2LfUZb74Q8vB7TWv1djylX7ThvMdrp1O8tTXRWTqufbXncCqWUDBk0SzLRUzOIbidkW9Fy3apT/xHCkphAYO+/ee3dh8yzJBe7fB3OjNRxcn8ezrMEOYfInBHGlg3LO9UL1MIG13DSuB3mm/E/wBJ4emWU/ukCUVYo2X0RlIN0UP4S6XulA+n5l0amh+m5ujOQns/qNEIDln00QGu7X/qfzSeqG75gBftCYLBUa2vEuWAcscRNCz0fiImZVcDrGCuVBPWV/gXMIsPAEPtNEugj94m8jtfW4y80vZ/5OHvSlYGLz/bBPmdTHS0eqfqZ4RpJ8VPiFAjhPdv/Eh3CzJy/wAINmlO1Y+R9Z5mGj5m1vbqp+MxhXQvrXzLV0+rv3PwirQ9cfA+ZzkHP0RXxP72HeKyHw/qYtbrRPubtv6LJyv9BlHZjuSpsfgj0NV0XjrEcwWJpI9M1KmKWPL7bmE8mk+ZUderk+hUHe31PgxG6dy/Nfcr1HkJ8WfmUCMaH5nM+MFnl0RZffbf2S8OmBz+WOXLm0Hn+H/Y4NDRqU6B8HvcaOjr1lngVnJZEMFt1lL4jvUuULblmVFoatXoOWd0Oov3Gywi3gfL2uUIF9+IhrT1SiteinM3uzJLhhlByJ0ZSJrZd/6mziV5tcev1Ycc4a5gR5o7amB4jz5LXUeGF08U/wCD8xoankN9k5hlFvp+iUM+LrBLpSYExhlp4iWXFgf3N49kE9jMCa+sZ98IXXgf27/EFxjqz3XRHKZ2pPP7I/n9Vle937TMKeQPvd/E1afP8U2AYY6t7y3Z7z4BP7TFN9Et6hUwXl6H5lJ0Vd+k8Npe3hn5nGJ4tiJvvs+RPqK31j6AX8z0EM6e9hU91SD/AD1/1LMwaOj3tp/D3ne1l9azfl/ik1/9KljVy3Z8k+9TNHGNU9Lr4msPYI9i+ZU85Pyv6Q3vsg7B9n7z9oDJ3Ub0X8SvdEOosUGute8QQ26j6AeU12dc8KZPIfsLkEWnxfJv6lPbHKt+T9J2K4R8SuuoZ4mbT97/AIgdXXJl8/pKyx0jdNVhdHm+kuKeGMp2uju38wCAGj/Ze83X4SyWlHBCHN9GoaXo0ELalDlwG4raVbH07ux7kfVVUrddDo/mfyYGWBnECXXGg9tyoHU5vU/Uwhr0/LUKoLjJIwzUwBuu/tOfGcHr/wCJ+ZaktBromUcmonqnYx0gExxNdyhSdw5O50YE6Wnten3mEjS6rEGoE/UHbrOpRPVUw/Ka6Mwo44AsNHs9YjB6GJV4DCk8mDF3G7BojPHVe3EIup1PsVLizxaHoCnxEL/nQUINLBNA4A665lPi+E4N86viZnq+fMtD6KHsn3MW15w30Fgervq3tucSmV4/yv8AAW/4JjUMeksMvE39eoRfK9yBbapN1BrvaPpK5smOQZerbK/+8TYsBzcvss4V4arqzDfn4ifsMD9v1EmR80T0K+EuvKnzBUDDuW9z1dOYQMmlDSsnLWOagc3nBXwgZr/L+V/SBLpcDw/Ad8paH9MrqIQngP1FV/Tlb7vxO/40l8vMadkhmy6wPnsczGWhvOw9+r487nKXryYZOjvN49E1FblvoTo/tChgDKuiXaFTY38Z45qArWbcX8vgx3gwVqYQ6FYe8CyrIBPRq/RZ1zeglfEwnd6/uYM7yxvobHyTKdFNwec9m2ntqXDjnGK+Io4PYEol1yTHOkIwnBw77OOkfn+32jr/ACfUB+KBM2YtZLmPMk56aPs6Mdu2T5On3grMupiHtyy8xZNsU/SAf5IaRAoZwR9DKqXgoft/EQKpo6etBj1mqHbhSWD3y/Mn1NhnNmfl8xPC+ap9FX+HI2u8+s7Hx/jOtXE+wzOVfrP5R/pgD9xPqXsPwfIgPmaJRx9m33AHbA/f+J8cZ96lWXbgHzqYXswqI/5ib4qW1UzdsDmmCUafekK+U5xoXTadmAlkf8pdS4uDhN+25a3HjPmoxvfJ29CoYjzoD5KfuCa0/qTXzMp4Z9rL8zNueXwsQLqENBK7zDkh4IWAoUjpmWmkrk83p3l0XGZDf+ZXJV0VqWb/AItb+oG/XN/Fxqge3wKIcul2X9xTdnJYdxS+1QI9nPZ+0xYDavw2ficMOg/dAgcnHA/9mqz2pmBH7X3oHpFppVghObDx0iPnz/2D313dRGZKVqi6ladDtKW10T+uc5W8vo/MyV9sPyr9f4MEK5l7Hc5/sygphbnWLYeM1CDn1R78esYw8g4YIh13fqCjVeB5ghO6XVAUd/Ts+ZlzFrf8iXdiWnK/GnmXZbeluny+yyWxKAGxq7BK9YhIb5LG/XUFil7P2lUf3/0mwpQ/uU1GStGGg04Zrruohaupq3gM9rhPg9fKL7WcLifEmqrCEvghRkqQC/g9X5mnkEvdVzOqsSwf+mA/omP4nozPV/gjXENjSjtET/FeNGnY2M5HNuV8Jr3qv1jLVe+9D+J6fCQ9SiOnjeA8g/MLycIf5lEJdqJ8n1MUj3Pm4lXjocjh4tPWYZDBAsfzUqtZT4stPuZvq6EPtLQa/rdS4qDj8A/cyGqGl/11h6+Ur6FifAOyVD3Vo9Lr4hCK5qv7Srj1EA1aY6IBtP8AOnljysL8mogeocqOBhylcw3+7n+f0mFcLoLHdAB6S9snbZX5mz7XCLOPcP3HSO78C1VoxcL609uVOi7qH4x2H/ZxG+pj8Q5l6v1MT7qNCfQ/szuoGj3f1cq+4s2XoDDqzxAD1/HL216EoART0DHMBGpBQkppTWOkpdeqzvJA35nSF/amfw35/wALUVkfRJwnWPaPQf1e/uTRI6Jujx/bmCX0P+fq4846mD+uY+vn+SaZLRdj2negsA9bNyyhdsOoP/Mqo5OTZvquDop08XFO9VzMFy9y949LNL6M5Y/veNeyrvVe8x/hjcN3wj0zmusXjzCEHtvSeFbbb5KHsw9Jazd0C3tmCCUVoxGmVyeP55myvm99XN4r6q9klJRbTCrcL0MEkXCt/wBpWde7JUxGOxyCjcN/xoDk9h+pa5/M3yaVBbrti4eel77QKqHr+EQe/wAKvYZPmchgsF8hf1NxFzLLMOLzDUYGoQck2FFXEbCJAdac1DUfjmMqCqyzZDdqE+R8TmH1r9iD4mSq6yL6jE7TAnv1puSIG0HmC569b+Zfr+LvOvKozdBDy1/2mJQ/piLtkPT6uJsk05Py/ibL6q0fiEytvA+okaFx1r8zArcBmPHdVAviozuKInFXNwXtIGXx27zrOWHR+3v9R0h2mxIdILVL6QDKsZWkUptLvoYz8eYZRl/aZb6rKke2D4n9TLuzNoXCPlxONzq38h8xxumtw/nacJdvvlfUO4gN+CUfiP5ZKcEHTdxX6jAWt3n9k4gfm9wy6bL9MB7FnzEPxPp55UjB9r6qf3x2iTwpV+zUqemYYfPSB2DfqQjeI46xaBobc7s1Kore84/kiii2nL9Zg+urYyqr3dwBgSkhBWcCHsipNr7Ojz5lEF0QCxVR6h6UjC0FWuWf1Gi1sGIMhHyQJ6RZME+7H6l+ydRx+4AtTxmnzGn02lD8J9R+DSr5PzCxb3c/Kb6OiR9ohk11nNs6RTMHFb9rmkocD8qg3LvP/Iz3gnPy/idS/XX1AgR9yH5nGl6rb0nwn1+ohoxZf1VAvmgexG+4Q5xvk+s217XBjAclWe0vvLh/MV07HwLqWMv2P6INF/piEc0vkQbNTbVXsM8I0SnzEyOC/orDuYBLug+MwPLu8/f4m+voPqo51i/m/mFWyuagQwlaNQYLu4xrqPSI1u9DLe6CUgv6bKz6TMbWPE8MCjLHlX8sdXx5mSi7oPrGAVb6TXDoC2XXLHA9YQ33AvsJ0L6r7+0PSzwH+vWVlyxP2WDAIZ6sLdVZvqwp/nkeifmZV4aTT8vqVQ24dfep6Xr5BxG9ij6R6X4lRf3qINJkG612nJfMtP3Rid8Y7TJGA3JyCHvLFx3AXlIqRDhY+X6gz1EteHj+xKsqdyBdyAfS+hzLA+YuHBoXOsgK/KNpvHlbHCPGb7TJdV5xFMF7tjEoh9b0QKElCbX/ABXoeqghQPQgNSg+t6nrLDLxAaGH6gn2DUH3mFuTD2TJgF9sQxe/Ym4fal/H6nvTOOQfn8AMMe3DCejSKu1TTG9uDn43BtsfJGm+7rP6rng/CF67+VhN75x+LmeZ6fiYLYbOEmXA8VHponYd+Y1yKUObR8FsUvjzDTdp74cvVtjTo9JzAZfw+8RuEOqEUPs/xi1Cuwfv4irIfIe6fUIxrxuRWoJ/vb3gfUbAW4M6UcywsPdnsTY9SPiql/aHH3Dix7D7QZfrV+rj9GsnvUOyHu/iHUbwH3AV+6pfxQGugy/Uxmm1FKcscW4HqHP5mXv0P56+NfcLox1lCIqwC+nw+03aOKVPNSy2H+UD7gw/3ZSX8zn17EK94Y/iA/bhRj136znHmJjlDyRbPqH8SVsB2/ITCd7w91TPudf3E2x+HJ8P4nh6WH8esqxZ5r/qPSfIwLO7rLOlBCB9XrVH+bqXv4mA+ZwH0b0/U4Uv86sxwvK1PHD6m93Fjh+/TPaU/EA4n9eeYGbyuEJQUY6kwonzsBYvexemJcIBpnxBZ5OE4zhvUDwEAycgbVvBAvK5Kdno9mA6Msa2PU5hbUjfK/gPoy/9PfX4ZSki31A7d5mcc1H5mr6wp9K/MU3a85x6vtQYe77xP75mQz63P5qfCxfSVFoPeB69E/iX5fqSjMtH9CJvTzBjGniD1FVX5g/Oubvqo+2K5fe5UPUifZ/ErlTcmfuoYZDob8Yl+AC2cgdylljyw9ZedwBf1D+jEfv4lnprdT6iTt6JPYfcTOtbf6fucy/5LJQqcH8FKGoev6JzgeH5EM6x1YPiXrH/AH0lbizlt+oJrzply5ZOy5mBvZSgFhcZuiagDNdli2FHSp9Q+g+4X3cw65JvgWGPaW6i7Whu9IOpWk4ozoqBh3eEGEeZ3ERnSCP6zQKegOigX5lZYAsbjL0DC+oyNWpFK3OIM69AcOWjrE2PiSBat4FS0GcAH9/DG6SGK/fDZq0NH2lLzHDGNHsq2V8f3XcV6mspTh2JlmJ9Qf1NIL8n4i3Ln98TEC+R+p/4WOedfKJJl1tFNvkYlSgXDVvv8TCtOl+md3OX+RNUj+1LKKjwr4gGj6TJz7TqPtCuDUdZobrEMO29D63MvfXeCzT67sJZByVH6hZqHZ0Aoxdx2HrLIxGylFJkXTji5fBozDoZuqO6VL//AJEtDvpnw13lzba9HOPo8pt/DI4BwvhYMn1jkS1z156Svb4tyQ3NAzDXiX2q6RPR12Q9dMmgurQ7w/EMUxcK6WRAykRBNmWYC6bmUUPEhjgV4u+5y20Tx6MIaev/AKwfSG7Aw9Mpz0ikvUWDPrLUOd00PSPnrpIBfPqe8ZFU5F/qEyF3RxpdHo5j6cfNG/j1nPo9J1kePkVKiy2y7F2PmEXAsKWKtc+I3qtYgIxTgjPzgKOcyr2MO+0RNe5KJO9K6/aVG5DbsGcwndSoLTDav7UpFWDcZRBmtvWgfWPQnuH4YdK1YzJrruDlmPCNY+e11GdWs5UXVwTPdhfEXLPBiVs+i4ItQE6mdDhHHoZmQZxi4XrDrdG2ITi2dHuRa2pwHkdd9IBYhjfUHC4gMdClUZDqcECwVps9gVxEWh0soZRl7RABQEc6mnbb80PBKrtui13XMyccnW6/jj9kK0BAvSD3b4LNLcUOJYi23c0Y6zG9bq0Kbu7KN4BGu2XBqRZ9ErAnhcrPZC2lxspVV5GHhHyCuGzXf+HimLGGH1HdHvcNXwZZWPQOeSJx26y7BLXCjen2DkAiuWyZJahL3e5T3F2atk56rTfObcay9lgXRTgZw1S9ChS3S0thXzMAGsdRxVQQV6Gl+aPBBLD+rmIpQGod4eNS6q/v0lpfq0l9fQftBEB/jB6RkjR7gMYA3gC+sKeqUSeUBec3uO8RVcLe9j1GF1tHS8fUp6cP0vx7RfMNgw9yFSI46Zo9fqihlHiQc50re+PiK2zXT2Y3G6zmCbGnvBFwMhgGthDV4AwHC95syPfhmRtVyFu4BSvWDI3XsyyypKlOY6SGeh2C2sqvgylqKtbs6ZIsUkAKrc07C2sI5uoJx2G79s561GwpSRjmtHgjG4Kq3zj1JaoKpw487lC14jU0FaFWOjxEV7a2bVc4wV9+BVYUEEsjBG5T0b8aIerNi5iDqpEsoyMtUhDywyqATF2Hes1Luo/Gpb3zYylAVRbRsNWBCzAVRpbwzZbFNiMbxFxjFR1qt6gmoImlvJxTBqAkyVnX6gfXsFquMbme+olMtgdbGKvLaDLFkt80VVYe2pQuPRVLr3bSsZ64iA0XUFwfMBWyjJPIw9OvmUMD1QFuetZE1ptt8H6gsrUKyV1+M7KN57r0StnKGB8sal49kFw8KuC8d86g3cBdDtt67+o4SEqBoayZ5dmA5ayGaxgzuqlaZgVpT2Qy2q998mfEGQdDp/73/wDYIRFeTeTJRcBCoeh93Ja8viXf24wew/VOYEIzr6cPDUa2LGWQWMND0duYOPgag7OWU3nv6ZxSlxLWHg8bGoGFrVWAfMDxSdpbytGeJaqvSrB0zv1gT21N9vccCuEhQrQtRHnmrPdY0mwUD7Ow9iIw5SDHDSLhB8LclG+7W8curlIPOXZFh3rPMMM1OgWa25PSW7yyYFWfjrfVmByQChQLBYOuTq2zqdFA6zVyi8r8y3b9YWX70rlR+lBMfSGmEFFXR3vIiz16j/nkfnjazqHHpE6p6xTXOpn7R6Q9pYXJYOSUAmGJA56ei+cDcDjfVyFmsBM2PoSqyPKOOOSYoYDBzr7ilsEu2t1+vWN2CFD1816ktuNXC1pWzOTPleVc9b5SmF7nmLG34s/8MO0jiLBY3a5rXol6m7w9KrpHcn0iUawm7QC4BzCx1XdaT6wOXZi3OenrBlLxL8kZcbeB/VBqLYtnCuzP07xTMOtFWX5iiVOKZys9viGyE0b3fH4gpInV0+3SNKIGt+k1PwmbN91Lv0HK25jUEAoxycPZnSI46llcOjWgO7YNyAL7us8S7sW4jow48xo1yscxjXaKbMHgXVrviOJQjOxgaaY75ZmMVYG6ZL87jmCFKwmvB+ekNvNovrpq7V7VXuPVrSYHBUHzyslejw9arpDQcVT24LNxH5L5KOL4tKmXRtNuNfz0itlYvYzrrcqNzVv8keZvmF2lMp2Y6TwGwT/h7vrgn3Vl0ZIUDoBSqDj5j9RI92xEsNDW7IyLAsCXQhxX9jiUyocU2S2aUeDFpw3y7zETpbAPZv0gEHx0KvGZd66Cq30lzZeK1hPf8QFmgNKtuXGWVKK4y3dbqPkAoksU95lw1Dv7LBFhlW4F8sB1BSWL7S1Y3Fv0ZRj83obk/rpF/wAP2jtHwSZ5z9FPpjuj4OEOGVBwQ/1zAdeFBvKD1xxLH86T9K/4lX60f+DipEqxVX5jkGXmBw8U/mDxRvPuS8yqfMW09WfG4ppskRfC/wCO8pbYB72cn0ap8xz1Cgcmdn4l/C91JVM+oRc3XQdcU9xIp+B64Hh6U9GFszbLlrv0GKkLTk/qywXSooKp2p5AcxwFA6m8j+qgiIRs5iUdhTOX1iC3Uha0Lzs8kRjZEp7ogetGheuz4HVxk1Goa1UDvzXXmGS5lPAsGTTqvuYNsGggOJS9XC4UCIYnBllnhvFVFOoiAES8FvblNFQzfjRBKuw/t6sSrMjj5nqGuljNpzpdiF2Wduc5l6EyUdfHaCFYUYHQck1forVjdb7wLry95z74M9oPooLT4vtzxWdlf+0FvhDXiBxCUlj3MzbKXmKw01jcPJDipkisajSCnNRgW+sMI22VGIbl+i7MzhVhs3L1pV7S9h1pqGoL5HVGBKPWBvDiZWZcO91bUNApw79iLs5u+Iae1jKRn3g2eZdnVF6Oj9yzU12Ip+G7SwV0zUWlgUtXBgPYQZu/4ywHECu2l5ihhaI2zZCV30gIxkhW6ApoXYGN3F2PQQeA+ufDCTFxgrSuAKbMN9paF5BQRuhWkrq7JxHvACgHpVZealCA0WF3UyBcOkXlnEgL1ssiu5X+VYE8LMW2g6XHNXDOzaKPRsZQ0dTMH1lla/USx20msCwirwUcx1e4JdjB+yGVCPNAutIO9VD4iEzz1XmbBJu2ejAaomcU1H5FErltzfniUOYoyK9M9PEo7WUpd/wLYGBvKY1ydK3PsIf0yiuICp6dAd9jUangaWA55Gt7DeZeJFY58FMXzHoZJScUSFcn2su1GCLlv05lRiJ8sfn2gHB4JcLUe0tkthx5wdLmJgPe6jalmWYVy+75ALd4uexNWnawY9ZQNrnPcq/VR2lAADFdDg8Q1B0a6igasm+uqhw9iu3RekbYe4p9jvYS2eBXR8zv1XC2Xu0668Sw19pfgIbpCU0L6YwdYwFV7ncWscXEPANcq9Dh1KjS7aTtlptiALQDa+34FvchM9oNHrte/MqZt34mwxjRxX6w2SlaqC4YDMBLRBZphictXDhLvhKCXzGsxeaj1DJcpSb3B5C57RrdER2DrGoYou6ZPUjsak3F7eDWRLZa/CY1mFtfRFWvvCvMQwnwjmXBnVpiDeU7J+IhVCtv/GWCho5K61XiV2dcw4ejiZvxDkrtdXCNpM9v2gC8c4oiBvLXSXZGYOLz+IoMV0x7fw8zOKLDR6YfUGrs3nb5NfMo1UMnBVLowY+JV3Q30th1Y2t+su0BkhvbMNNKgjro3tUfz1h1yl/RX4GV5gA8L4xjS+DxbkSLDrHOLc/Wx+foTrhGcr4WeyBGsS77L4qBfZNMF9Ij9A8TBpEuqbus8G22ep+LlxS73ATBbc3k1+/GDePmJKzZ/hhSNDnmwUUYc3LXT7JaTXYPFZes3KZ85Tfqp2g+hpIOwYI9MCCAGs4wsHQckx4dMn2ednaV2HaG3sb/AC8xCCwRt7ZD6PErw5xvQfLEODKKXXhW+/mOAkaY8AXfDU5TT23r+vW4bizDreEdjbrXTLBN27T5tcDYc8R8D7j6QZF08HYNRIAz/nRlmWds6L8b87lpR5pu72Uvt5Ts4FprLitUmO3WEA3mVL5fOvMxzREF2J2dtRE9hMWYU32OfMcfJBmKyh7HmIjWzfzzynoRd1MXzOX1Yu7VPeUdMXzrfNfzAu7jJNcNfsLr3i11Ba/J0qErwFX0MfUNzVChi4F+cJABVupgjZM8OUrZHL+yA8UNfB1IsE/NcgveY9OlTqDQxlVapgojzbwi7TDY4cRQWVZ7W5elwbR3B9tvSxE7VhS/USsy98G3y5G2IUM08EMBTcthjiVX4dLlV1DRvnMU/V/BWcRj2YFiynHeDa2qgCNdy5q5YIteXH/CVrBbKJOYgKdr0Leh2iDU1svboI+Sjllj6yVzf81ArgHRZ0jfZ4ZG8r9/RhHwFqxvqz6BGQFXGKienxnBusN0Y+rGOQqe49wxzsugHMWD1ICqoVCurer0j1Y/iO5lwWKFtAHdTXtRBwpAOzVj3SuQ6GKF0fcvGSYKMDAqobkhYgB0NRc7QxctUWhSuYm195X1c15Oz9FSupj/AJ6MtcLQbZl8wcNDYmZ1MT3oAHgfZ7ENHuSd9FPAR7w3A110VUyGNA+7WFrlLrruR6mXuqVbSpGQrr0MZia/yqqRje58IG0+VwwwVl1hAZE9ZVgO9yuB1Vt0fpg1nTXS47SNCYCixl6Fyk7zp1Pk7QQHdvyGjzU5sC2erU+47Vim1a1a/FThVnuDw4mrB1b7gZj2utj8wdWrdIKa3n/qI/WRPuDMK8B+alqLSSubxpm1OJXRIZs0+GKC6zeXTKE2d7iqJcDXf1ORqvEt0HtAx/yX6zvRfVg6ohNSUbwUK0ZcAr45RHHmFA1Tp1LDYsS1Kz0ReJ0iNtKzHC9wr/iDNs67M2MyvbUM1OkLGYv1v0JmkN/DLZgcIrA3KRvWougqhsGzkHJUS89YmNIJtJ9c/wCmoc85zzDttblnwrHYo7q2PLElwQ6w32MfhgJ4sFgwGwtvjN7RBtJmzwHd5rMxGrcS7qr5TK7l2I4sG1IJW+OZi4Z3z32O+cSjVN4qZwL1qNYsgYxrjAncTbaf75g1+I/Yl87YP4Ug9/Nmw9JvxOL4C/M6r9P7j/TfcS17Z+4tpv53i/dhCnyafO5SDJdXwphkMRqmz7S/IKrw9NNZquGV61N03+yKEociYt1oANxrGZBbGz3lqQaozyx+YIkDQt/iZwJujHeVbgLpvn1ZkkV4g04e8ynVLpHNe8qV9qh2R5vAH6jEl/ID0huCqcqY6aYekbIrBWHI7C8S5SrBSfUz7jah9xo6VYmBir9Jv0q4whjKfGfuIEfiH3Di2G0FuzLXSIciVyd22OvB1gUDcxE5IBnB8oQOvWLhEbqdfT/L2ToomNiVm9RdHxAafEvaOGACrpZhyjZzUvzf2n/FR2l0xWn2mUApA5PZjpap/wCxEMh5/dLnC91h+Y3P6ID/AJjFramg/fCUgR8lLZHBQW1kNBBiiHhe11O0YnXBZ6HWOFQstWdJgubmCxPlZ+6FddNJMq0wZDNPUZde0vdse16w8+/e4F7j0zKr2xbQI0sOjrBrK1FZxYLHAXfjNrrw4krOXV7dEA1CoKAzRxaPiLhApZx/cTEdXF6s/mIeDUWwrvo0QVZieT/La1c6K+6CwDxBPtRB+AQLlWyFEqJavm78su0PEHWPJtGyOMhyxCb5re0ShhD+MRJ2OmhEBdIwGHhjUrxrX/kXtOG6BYZ4dTBDC0V4+ZWisa+owZatKp0A/N7YQqtABTqnSMEWQy06hvwJRmqNnrLCoHN8OILZCvwjACotbjKZYW3uhrrvCdJzVfJF6HxCeOqpYRptZIXjtOjfQsC5LiLNsCse0BvUGl1iQJKU2YxA/FyizBd4sd9ZcaN6yKs9uZco91//AE7yll6JOhVLs8xe7Ys3E6XAIm2Xy7XqLwQHUKGQv5j+QIzFFaEJxbOHwbv7mJfa+pRUchf6T84IvbyuK4KCF5qkKvkb+jcGtBfw+0Bu8so4dSufq+SvzMjd2PaL3va/pMmFDpSVgNUsVr1lYrXqVWf+Qb14dQSwHdX3UwB+FjRbfUuLd1JV70wrhShpJ7iqusz2KWK5b6ucR2N1x9kvtYulUzskXVhtAWXstb6KmZU6lKDVGzD0uVRuzc9gSqTHAn9kcgi41TWKiHBRZHdHfEJkQ2mNWK4gsK92PQ+ZQk1vVh/I5xciB3jE/TNQxQVg6k0FMci0j6LLo36xJl8LE0W/lQb75KnMcC6hgqvIE2dzoy1pIAZbQVd0E7tcoQ0KyVX8VkgJgq9UCDv3oxEGLPDufMqEjYtlFRo2Bw4wxXknWq3X6n8mVnNi1+ZiEriuTz0gKAtKdIdQEfL+YWl6Chfmqv1gN3KrfKZgBMq79ejMSdhBexDnEEsWpHHY10l2AmO9C1BNCUrqXpHXyJOz1j5WyPH8R/5kNcn0RpoMj2RzC/wzKPoRYdQjRwOSFMq2gFhw7O839DBE2deldpStwotVasr5cxuPZX8iiHmbPjUyxRdFqzl9fMWTtGzv+ZxXoaZ7zC2kl2PTMKVh2yC36PmHzd6VrZzOeewfkIwflKDVn7loYHpNF9+YaH0E0JO0jBRUU+v4iKsgbyhPeavMP8h5lhEVrKdRuUcmavqlK6/clhpAcWj3j+dJWopBxgjqh7h7IrUn2nAoutn7igXb3IZGM9QPX/mW/wBfqPV9RnFC/T2SjZjgZcTpCXmveAg9Ut88nu32iFXT0HJ4Jxv4i5LEzyZbmXVcKcbIqxLK5Ij2zRXcfByYDqbNiXG+k40wiehLM/MmHnqtmXB76YCj5zOm5Vy94FMdjDTv1QYy9wRvm3XWaLAquCO0RbtxrLhVRqgIzo/77RgXZO+pnBOAP5TQGiWleuGmC9C09FJpiqpyYYLbUpsizWkd+MQ/tMDWoj567HA/iUwi5pQvNCVYLyi/m5YjoDoF10tmNm7k1XLHGBYOERdaxlP53EAPbaCXueU4FdUHGDoGYplGwvRp0zUCr8cDps6HWUhCWXDdd+ZWbKHBOxMiPhOx5iwLDX4UuILhKX47xXJ8UjRuq+oD987hB6avmEbCvOVVGs+IWCsvoYw2hldNam4G0TyOqU7WZw26oAd3zi8SuBJVql84v1qCQPA1TZlNbiq6DzCsH5nAvllFEpsyfWImQwrqph1CBHuiwe4OPScOkqi6hW97PnmZGbl2lNTqM6AeWbw/TNoHpjmH5kpwnv8AvgfID90/g35iGB/HWBC/AL9QJy1F/EPTmqRBfRivi4OAsr1fPxHvAT0AZpYdaMxRTbmJbQtnp5bhvQ2Ay9luuvv1iayLU/vNHeVNQlSAJoCzm6BME4qfIsyxrs5V29jsbCrENI8JsSW+UpiX1IK2NirupQOChUDaKsVzVVLaBjGd1hYY2HMy7VAew7BL/cYIqT1ljFQGqmmJ88y8vhT1miCiCuoL1/7N9ZIxCtRnsfmMWR1L+Jw9ycL0pMGzkpfhiYoSC1leD3gsBPWG6Uh4gvgWnpFAEV5oYt6rb5UwHMyMbOShlVUpeKUehplozqWw58w+WZSdvWpVtsDIlyy8ZeHxAilB3YEXxYWtdM+COvIoFeqTUPwP4nwyAi4uvEsj0vunw/CX+gVAKWc3bScyh6MKqr6lNL6d5Q7oNW3BOohmZuAbjQ+p4Z8Io8zvGOyQh5qzB+XXqWyrfVgTW3wjhXaUluIEEeynr0A9oSM3RzuH1KFTaZFrdpdutxWNFg0fWOgperClw0ovRZ9xfF+o3UqX3PWcT05i6fEZteONaM7uYvlGfXrb/McR1pcFs06DV3NMjsh6TNBLs+KrhNBl5K+pBQC7c+89qAce3/YbyNGiDHBrKajE9/TPGqMngLCgVj0THU71C97lZ2Hp/iE/LJPsw495GKSl8/cnYq9/ysanYkrlcoNV7WwZAM7cHvK5D2Pqxj3SAAUVlunBfScfyWeiYuK2bibLvt7Y9YBq7snwZPZmn7FR8t/EN7PQ2/H494d8gg/UN7RVcvdUtaOvD5V39YOZZm8UWil2djE0KOfhYbc5NbVXc6ZiyUZs0XQxldwwigb2HFuh4XncThUWhlvYOoF53GBq3UWsltv6JiwziM3WxdvAEZU7xs2e8+aGfiXv7ZdzMJy0ZM+eK+Yu/kg+Ztyo3IoCu99ouQ3vb40+zVhgv0f+5e9ET9wAZ2v6hhrqyUDqmMFQm1/ghjE2vZKW1fohAaV8Wx8CI6g7YKR6ckuEHHkUOTvNrKQKvJ+JynEIoS36nwj9I8qfEKcveCRpuDTap94TYfjec9XrKZmDDe+Jvr6xlHYrRV3yely//wCb5KCrReLC2mZvwHklyM0N03VYYlPhJNgLcK7wTdMdztcG7OAoGEsrLo8z25nVMsA4OJUzer2WuoZOaJcaIFNvFpR7DDI6Zh6y3Rr+IH7CMOldtebnF8FjFvQ+o+rT+IAyT+tTfngfabkLm8v9xrvQL9s1S+R9zN/0+0wHig/E+OQvxPjWJDpX3/xSM34YkKZ2wSnLEmrj3sofvorw3XVqKByYXRx4ZTLABc8wWg4crdL9If1Eu50oWX4zbhhl1uIcZb56iKDNeK5uU+AV0cGPmAbMp0FsTtLhI0QLOkGPfRm6rSRIu0s9QmWvETshsagcB0KuX7RKottOYX4+qp9Yw9nAvnxlH693B2jLjyi9MUPLasELMBcu/SdZPWHXX/8AskjFamnIx1GDuFtp2q2/mWZjXhno4DzqObZtfhGxKap/gQzDNI4ZRujpiZdtOyptXqnSGt14ZgRlXr1l/WGuQHT5ioqdQfYlzZvYnwNe8q4VlaFc31+kpOZs6OcRLrYvZ/yWbya9C9xAAMDqtfqnquP2ZRik+ohKtEPwjZEZ7L9xcD4oIN3BNyD+O1QHrP2SZxEo8qYwpwJyzvphsDxhKBV+rjJr5lVY+jwqbtqq5ZbvZ6nlw2869ugiCQLAJgPPBBLnshX88xqyYLCaNmNHzFWOG/8AQga4YmWvefmYP3MVSS5JAqPyQ4eTldlXspC4u+Y7kLf42mP8dkaHP+FpYivSD1Cf2AlPavV1qVpUaNdayHcn8n/ELcm8vwz3gRPtTNHh/GQz1sfSLOsga34D9xFtq8iX7GNe8XGLVjPN9e/rA4Epc00/IkVuDV/7zglXe8BQr7O5ZLURGerXk63DEpQlvqoOn3Di9SUA1nzA45Ng2JzCOuvwm7ObuHUO0CvGb+E0bNxDoDARFtWEyuuWUv8AER2zg+2o28M0HPZBBiNDAsZ8wWl97NJZxgLmOs7Dooen5YI5Ts/KDiOPQh1esW8i9IByaLmLbIcS2ORNQpyxu2b8X7IDnc8WgbWniCsNBbAOjWOkAyMsrC+ROsHDudgRW+lRp8FHwZfvCmNXnqYKZAa4HLVEPsGaFL9JZDHiGRXqZyoNvmGKDKrgkWDOBGedtbgvD9xYOyH2Rj5JvwoHOBt7yOCjHGYfjcRU9qsAzlNevWIbNp28AVT2X1D2xg9oeHt8whsY/KgRqojmVJ4bjZaa+T+6feAF1zBgDwcbiIvRGrZMvj3hmd0Y+Fu3y3KjX2gDkO/kxgTT0H1Dp0Kc5qnax5Il2qS3iC1cutsIY98R5b0vSBsMvxod/wB5wPhDiCNT6Ivyf4wrv30V370epMJ2KsEWryAfcYwFobOrJg4EstYYVPyZTkr5Zmko2vcekN+WgbG4vgIDZPWH0VKoLAB8h8syaUoIJ+1O1Onbctv4lnmdH8xETja2unVi/u9Rb6Fch0jnGGTntKR/7IHV3vzLm8C7e1haDWhvoiO4F7r03Odah4OQdYvThGqvX1KsGEeLy/8AIs423Ai6ATrP/wAloP6FyhUJR/jwugRf2bGvCg7VEDgtWYFXcoXlNV7znndx3fcF0c1O3dqnAHUrvRfSWC4I2i3B/jcbYBR1cLv5l+zbNvs5zQHI05XF7NXA/wCkPDWEUL601EQj2vvPwxeknl2fvmfozneBff3Ikm8sFI1jvL3THeFkp7TuvV+k3nR+5cQYDv7BqKrg8q6QKjeSxDuPZlYgj1oSFwQMOhl6S0jRqy3VxMIHFdad8WMYjH12FU5pjZBVlm0a8OOKjB7UwqA1WVpMdPXtOo24LShBozxL/wAt0NGwLHlPD6kIdvVHQPMIB4x6RISwnQgez71xDeZb2/7xlqthC/8AwWdULPOd7xGm5ULYCiDrRKHOBJTXXs+0Jg7n/tCAUlWSegeGVzr1iuUZUTnp2RaQ1iN5TcVrQB6NxDCdKQhuT3b8Q1drF/zRdCw78kB/mZWy5D6kWoeqaGBrmBvlGLBs2egfw+ZfbTPsvfyOJ5wZSu9dZwfjfO0ALZo6bx6R0iQp1+KmOxDKFPDKSoC97jiYIFMvAS5DWYcGP+jjfEqEru8tdHj+xHTD/pIfGXjQdH6p9oLq+0OL6/8AI9R4JkJJ12vVqjzcJ7I8TbXZG4XY/JCVWSYV3I6HKD0gt5oBOFVKcU4gl0i7C68L9JmeS3vS9G3oxIBlGmBxxUW2hhQPIdoC2ZvNFh7ftFWjzYelQ4K6hat658x1ia4YsV8nvMgXKXZaF/dssVLJzTz6JlwZI1dhej6RQVTyi3skR5g8gfvNq2B5K4Kh/hA2q1XxL0zWvWFHK1Pp0hhCqbjDbJWYvNkJ2Ar5uOfC2nZDDpIDwMuS4xq45Ilzzd2vmGTSkPQZV0XRrOT2hGiXbDIjm8P/AMw4PODfaZDB6Ebiay1lKHtOg2Ewa15wsSHxnC012+ZSEEDO+VHSIXaOe76Y0n0luLmP/mo6QXG3L2SoC3S5xqLYyjGhp6Rap5DaeN/1yuksLy/VzAlakdwnrdrsoP3hUGs2sNcxz4aIptKGSy2+sGw4NptykcnPUDhNf3XRBrMZYqJpn3ZP1MHfEbYgBmRUmrbdGYCohbdsTRyDw1myD1UMrzm+HQqBHaDSiBkLNHzOi+Ov1lFeXbRKpm7u8Fh7wOqNdLr/AMi+3ahu73s54YQURkY6WYe0YW5U1AOW73bLugr0HY9peZ1cV5eJeLh4Jj59IED2iwPCD/5AwMO86H95il6NQvbZ6jGIXmhyavPEZkDqq1c4iqKthKMdNe8YSdY+0V9TLvmQmFLeaA7RtSl6ziINut9ptSKi3Fz5EVvflCviCq4mHEacKXn6EryKrOhVGaYU5S6O/wBhGElh4ZP2Y4XHMtV+aLHnjylc/EXQLW1ab/ExNpKl0Ieg+ZwgKlNL4PIPaYoCkwijY/7h4irdwt1QGC8V7pGY0LXgGF97uolIS1bE4pHwuC83sDivdYzLzlbtOh1DG+mC+kNWWbXoJR5VB0VPwjmzCpNO2PN0WEfCZq1qZc76EGhSC4FuT9IiRy6+hk/UNCADCZQgF2/pCRa4S6xLGz+08xFr99x75jOsNPXCrkoPUpMe+kz6KSU3mGrv0oOmasvUeVYArgQO3+RNNhD2ggOuBy68EKQ2KqugBEHFce18JcDrmLlfBLs7qyKVBlwVs5nKi1s8DiYhFwOfgQsCswMvHEwdiyWo57DXjvdBqiImvUgADJgYN0a3eJiyrwB1Z5mk81tyZavpin1jFSq850vn0g6AuQWeD9wH/ZHwY7iOoidJaq266JsRPJ+yFeDyr8wuPUh+5n46kCocBaNXcLxV+nE3GJFSTw1rW2KucMw9MzOmjgpH5nECD1r9SrCos5v98wa2e42HvDmXhLGLxxv5j1SKN7rY6lgl6ywfcrcoujuHP/swre9Umhjh4RHPX2tFnAR66iNJ89ePaZVF/UbuaxildI9jiYgrgLi0dkRROS4radRKrnUw4j2MJEVddQ35M7lRQatqsmdiu+s2rW3qgroYe0vxUYWXg6jM00EL8lImZPhQntVxUDvZO31Ie0HBdPqZ1++EithKgVaB60ED6xGcaEseMHymhACbdrZfYguJtMsTDR1XMiyso05iSsLPV4jbNnkdHmK8Uc72EjOx9cPKES6gBdm/MoETZQi8afr1lw1xLTrDozR+OY19snfbAT8FZLs7Soy9wL5ixzABYiqGZpo8TEI8sHekuXxWwI9XMyqZ0KpXvElOqwORhmKiaZX0ndr79rzHcWebgiLTKyrPp8S6nYZSyE30Mv6n6zYmXXEt4nKgu9gltlOgbiGLAywpjpCCtNChQtUZL84hKEq1g9bming4Xqn1CWkd1X8SgNvZm90biWjLv0JWEIUMLQZz1zLwxZJhz5lktetXpqBRoigDfy346TfOFjK1Ydbw9JnUwSmPYkObnrVTLD6bjmpRVqdwH1lTDGLeVMirW42g+LJ3U/BHbxiW8KJcD3olKZ/DXPrfpLAgLudfb8whBs5Y4TAeKuB6f25mEzWj6JXZCsYHNHGHMXOpfYcDtM4XyZ+GXXKNdKvhrog+vcV56QbX4JWIxXzFHR1mJNlMoHrSb2auWHw+IrO85j/DpgQRkmcXNkR6L7jOl/fpTZPkfwMJbwqsuLpEKdUq8wLXwZgM2j+/b1StfoH9Cdu+h+ZGt9cN+EHAJXZeRfzOcuAtyWbMN6kUPZqrLWN9pbVgOZoEwj1slpCcvA8w0Va3dfqxFc7/AIJ+DOOIlHYBTt7+7L7NxI9ZxfQPMrZBAwhsPWYwxQ6EIOYLxqYjqBAPVpqvEQb1t/B/caelY7E0Fw4Ah61mPj0oWz5rf1KjNc2QswAGXzKkrE3ym6DKHz1lnRRo9Y7j56zKEroPHs75hZtURM3OOWvSguBn6B85WMmhP3A/crFDnRKfmOcMRdDB4R4edvwJVWCRwWYfH92gnNRTicWOckE05tdtrTjvzLe7Yj6UiygjpBpT5/xQVguv2EWqBbOKWEhQKD1EYCPUwqluuoadchYolazBdmJBScVG2umPMUFwN1Ndvzcst/EA4IJ+PrD1uJdr6R0VgesvAWgx5la07ssiuS+BiMgzJQ7WjyMFrdRdylrdSey/e5ohSZOC/THQl0DqTanAOej/AOy3IcRTL0VBx1u3Tmxx+6iFMwV0hVHdauK8rVFtzg3iJnoDbxa36fEPqnYB83HHFbkeXv6xWZ4x0Y7OWCZCvVjZ1XeZ7EfRRdtkdb5iXGpmUx/jBLNo0ql+sDgVdT/JP4KXeLDl/wCN3LJlwKPg48y30yZLBHW62TNGXoq7YCpRvG/cKXtqnclxByy31k951iIhhHsj6Y2KWa5gDgL9MSqXHlA/B+B+JWqb0J1w8uIFFqm6ZPUdRCxOs0/6XHMeag2xUUvXEqEDw0NHgfmJhz8hEu7lsFAPxlxfRo58RTIytnP9D9wWQcS3Di4SOpoTi1+iPofRILoXL18U+E3XaBJVhUdNN8Vb4jKFX68061RnvDKIPkkY7QZisSKqqVFK7oSl/G6VOfqsXjMo8qHSIq69nuR6qQNRTY04OkqQZFrCubdIR5Xv6CmWPrmpaxa+L28OeNzAiZqQHQGmqgp1NvAZuLZsDNYHUYsuGBp1M77YgChC4JjZcvU4to361KB7h6A4+2dGiG3oGUAa0Ey828yuRhlcefxgcQ1wAu1RnJEA07qzYn1CMjGiO0sJyyWrFZMdJZVps44PATeuYhdLsrEIsFeUuCXr6sqbZWjEuVS2AfXqc79Ri0FxwS4cxvBwnEpK1UR4QKYM9I0U+5hWO7Vdk6UGe2naBMBXYp8OsXNU9ge/pDqrHuIIyEqQ0I0+GrjnK72s28PBfZH6Q1KbRbq7lMh8VFXniDgmCf8ANXLRgDYxB3/jcIEq4Tg04ekT20oN0Q2awcZ7x6EBqBV5ZbLgi6Qu5U3gNzicnQDoBghKips4g2n7U/MOV7WYV+WFsYKgyqKsAGtt3Ls+4N3o+Rndry9Yoxq9cjfd/UAnq7Xj9sTOQ/R0DwcPM13K/mKAuh1jYleYL0FDoWlc3cr/AHIsitspR/mLt/Ysq+oKQ3YPBC9glHsdg/iG8s4rjd2F794mIWtR9lYRnoMegb4ccSo83jLoIcz5wGKWIOgBA2p0ejAl5PgxGlLQ6P4smyx02pgBWUBsLvfkin0aE7FtWtZWXR7oVOVu2hj5NmOZZKslyxJxWY1vWo+v/wDrYssYWqUKN04PlgWssvUBd+bjo60OQRFpq4XfWWG8C18XUK6CNTx4mFfKinkpubtlOk4HvOdYFYJZDMkqfaNrAtCPuqJyI02uDeeO0szQnCONOdNpFstp5IIYzeQdkYUkeDAaDHPRaYE5KM6qWxgtNv0EaF+SzfsWcPNzEyuVvK3dIFvAQqtlYRO8LlEd5R4zK3IJY6Mr3MVwF0gDNkQhdk8vPwYtHMf/AP4n8XDLptnTESlgbR59oMnMGGOii5hs9bWKxKMtshehPzRZA2tV96m+U7/gf+RmxKzvEQ8zU3k5jKwmlQLlOIEdqKiXH+BmrFxt9vtf+SVKi5bjCM7waNxpxQwzQX+l/wCEOIbl79x4f0iVymdRlYkAGKXGaqHmqpwLi8Bff3jPqRt74zet711mRpuMEOwDs7cu469hcg1KTVuxN7gISqlIXpst6VOnDh2ipdl/wWJaAq4O8qfd/wBEKTwFw0IfP9xiC0Toe6qwRoqdty3vOk3GgWDVA+pm/UiNKrnaUx1wesagFMVv3luCwG2bEvvD6QweiDy7xwNbyeWfbHn0E4R/QfD+oYqlgQgHXN3pDFHaYo6qrtcz0TW9V4K0JzG0EcDztd17zoA6fhs4NRf0Kjz+ASzz/Yj9hZphua/PlYGrbyqu1C9vWBFFwaJ8Lhhaq4AvB1m/YMiTP1UsxHEubXVFTg8hqc1R5OkdzY61LvSnYUeHtK4W+pPqXryparVfmVlAsTWCvxG6u5tfvKLIcXQgik6QyBRaAdUs0+3BW4rwvzBDO4dYzdeAZfMyCigp4t12mI5YoaHqMsuEluz3Y4PFmk0z0eT06XKFBjVPeVENig0If+sYsMkVl8S2VVxFipb/AAO/83Nb/wBYQn+KGFBp/wCQ/UVMe/Dv/CXLMIbEd3CWZvUtmb2jaHRIqtV61bDvTq6L5Fl7D68TDP7nSdZo65jTaALo2uCpItkwVNtqsO2Wpc4ptlIKFs0/cw4gvU6EOLPjnFnXwUw+mPWdcQP5cL/4R6mrjUKR0Eu5R9ijHgh1v2YXx3QrusiNb3QPasubnJb/APN3fwUdANzBklTZZYVtNXxiJBLcxo9xMWdZr3yYDz4lMe52dkyeYgEWAvPUr3hfe91VId48pGDMi1+GHq9WF+E6e2bcdcZji384csNyTKumBpnCXU6y4Oq711meV8I8S5yzwwSCuDLMQbphmieke0SURkDgfEpwLvl7RCd7w1KLIXaXekNsDEXnpLRbYl1jictbYB6FrY9fhmPG2jLKs9xB9ul6mbdXHczZKH0UxuwXA76mwv5rUK7fEKz0UZ3s8nk84M4lQJVZR1r0i2+Wa2/2pmR0VbivmIVzNu5dLl/4XEGodWXcYx8x/wAqyVVPiH7wxHK8mPQjmrvMULTXmI05Z+kXx0r+swnhjD7e0ZR0yIPQNBXwUbBet8A8xpeaNz4Qh0dUYMRU0Ho5sZPzVmrkye++IoWN+TJLXjrzBMLKaa9B9wNQYRdM73XEzuCFgW9seTm+IVca2LyWxbbr+D5inOC8MlpycS5l8o+CekOfsEYXJvZqqOnYYFxw6+h7RBsERls+DTUKLFcNq78PESQPRNXB45V7epBSGDceYZQzfBVmSLHfi3A2sYt3CDFhqFQUIDIB35qI6Z9Q0Fbwu74lQQo9Kx6Cj0hHdyuHBsP/AAIdBl60FRh4prsxERK14g+GbJEom6RJud1jUUtNcMoXocxWry5UKDC6l6UHNLJeAOp1EqWvrOIPQqcFvZzLOqXuZFSjUqOhQmobaMRq0oteyeaJmfOYEgerlK1KcGD1lzf92lLaSt+GOuRqKNAIDGa1d1eLl3AUUDnh0lWoEvQ5jMqdAY8SxzjHNsywhG+P9NrKszKx6T1hGc5imOs9qgCmpYz248hplc+aBp2Y1F/VUKEcoqNQt4ehFo0rHrzglodi/VCu2z3Z0s5iop3Jod0Z3Idt5XZYBkPEUGOI/hvupjpU38Ace8sSbk4ZC/wtS4dBrlOW7t/qmRvgBXxL9AscfoHHmEWwpX32I0UI0IL0SXzu4riow9ZvQ36xyd6BHwyuc8mNqdYdJf60hK1e9Mn1UMo1LWYg05YcXqRzq7ilclB8RLJvbDqewYvtF8nmGtOafse8qx7Gj5jsi91uYCrLLsK9b/hcHRSjXAytlT0hG70d4lIEBVkGh2TsY9BPwPkE42sWO7YEtdbDD0VrMeAqFcXXpVQqF4VZe4xVciWnm9MstJtKVLvMf6CM2VspzBR59kyjb0wkuhp0alXFgtzHd9Dz36RyelbijRrH2RXrIZ0fTLRT6S0NDCsDOZnu+pdl68gVMazoOvOYbV6yL5kEqOoWBveEhbECreErHn6gdUiuwdVpxVcS8TYChL76tqCiBGigCzY3vPtDcVMl5VTbDsnquAZr1/EuEgtXJHsf/C52l2i5piNEqkDmMP8ARTygLrxeETd7k5H2nME2NcsdTHpP4k+rD8sqgvK8PeC/6ggq2voQbPmhx9Ff2hKBqgKP4iWU0O1nd8lB6Xr2PVj4WpCOwdKjuEOv6QUJt6hmUlyuYpIXBzkelprlNbCMMWhvlxU2ioTVdQlDMoNcDwZqgzkLcQljbxM9WbJeL/TLLBsLop9cB7xn8dTWOpY+0IwEIW2v8pe5XnIi+c1pD5I9b1Y+j7QUWFy16Y8kQU1/jE43mrzOojr+xOGpmEwTW9OEGSvdMNLL92K716C98MRacyiQBwgJxF+V5qNWg2sbFiIdV8sILZqFQOmJhjOgj4nuYf2TJ+Qv5l9eQ/rMzn8HvBfy/Mcs71D/ADAMA/x1lC53f8zw1Cn7iZT3yeJVIfJHbXiv7IGoDwkccN9mXzT1/dMVa7phllu6xHhiFM16wLMvJ3M/RM08ApfXH90l9kqV2Had4Yzi1d+n0jYIBtEbXstsPDXilqCi/DjTLzMqaUaMKv8AuZdu/sjH6RfXJcYv/cdFDoHK9giPjZ/ax6/aPZMdGXOZoiyzcHR/ygLTSzqdpU6rKe/5EpjFR8ZS9wjdEydiSq/y3rFuUp0thrbUbDx1ZjOHV3np2i+I1FxxSOT1lQAHLClWxOAVdImAwv2o+RDiZbSmvL/VLYvrQtCI1WDd9oKrm5vBZzq+YvUKmAsXxjd0a8yrHF9qGNUnvBkqXe0MpX2OfSaNSww+v4jjBWXmR6XLt3tODPWLmoLjOJYERQezzFL0Ccnnd6n5Yhres/EyvdED5g2Q0sN8TXCrDecPiUH1Pb/Mmx7B8v8A5KjaxhfszrYjAMdIiNSwiiCKXAS64ndiHD3jRdkuQ6mQvoTmjx+mJp479UykVvAHxOHi2Vl9QbJXADHbMJqlArpUdwNE06FL7XF7S7JlaWGXSOOYArYHJ1t9YdRJc8JjTV1qVmUnYMXaafcErakZQKvbDArksgdAdYpjqQL0Y/62UbRT1XBLOnjKUaN8bvr7QhNJFtYPa2EC6lpsmGER/q0uXDbsmXpajXU+RL2UDdBFgCHOn2PvAgeErdbAaWowB5YQs5l9hX2/EruTl4eEr7orvzMNGw/qrU4JNWjQnLPQMjmLdyfTH1EfESfJFzIWIB0pV+tQIDItXQJHL12sYACsNmw9PHsHmU+9DjOT7L8QlCulXlfvEDktXTe1/MvBj8mI31lOs5wvuhH1SHbwPHL/AHSP72L0L15x2JrDQuONa236lyntxFL/ACWCUooGReCnP/Yz3WBoEc41W5lgYSdc2WAXcXLGoSzxR/M95jfghoXeIne20CRVvj/uXajno2OPyIUB5lg/PeUijZ0Id1LHnnzmJmRGmbEgOAlzPbDfM079mgHwz/KUuxVwVjdClODFXcNMLB6Wi5o14ti7HyynFDzDmkM24gES7V9C4QsP/id5vgASe3scQer9KV9QcvcUampekDoobHXq+BekD9sh2GSy2B33nLPmrwW4aL2RSpUTujyQWeOHr92yx7pmZOqtXDGr63oQWZCoaNyeWKYXtiLonNG5ZcsYdMe0Bfe3g4PkFN9MessPT9A46eZ5iKtxi0ixBhrU03/lABaYdLlIAz/yh1XzjAWvRuVHZq+Z9/P/AC3+KnWR2pgyZTuH5m4bMu1m2r3eIX/GCrRu1O6H0SoQ0/ncyOHyftOgkZvw69riJkPEKBjasRZsqRTp+hTV6/UsbS260vpeCXOB68nWHGvlj3kd3LlheVx4IkzyzvVEj4IfcrLp0EKCmIBv2hzudcMGTuGLJnipGdG5Vn4xoPiCGe1YY6CvxLC3V8d+q9vQhAi7Gj3E16xHVlC+dRLCveWcmGKcat8zLBVYm9lRvB0hBO0NL2K0DkW9pylOMALCaxjfMyD2dSvLTRdmvuI2NxK+peyuWo7ujIsLLpOHOoMKxgdnSJ91DVzacMxgmOhkfcDTGPVmbu6uN+MQcM4vFT5gzUOkNttqLoZO0V7KdCHj/GAWqx6MJLqMler+5YG0XTCl2fOWRF9866UC8xVnsa5qChOO9FRa9fKGeABdtvJcH7Ij+J5DTaoHigjTYEUaZnsO1fcAhViWdzlzK4OsOptaEij06RcNBXRmrwYxmBWSssvr2YhBl1nt9Xaaza1zYK3x2eIiV5uj4t+0YEGdaI40jjN8npMwNMyzLom9xqEsZP8AVrlpzVCikPWGtrkU9G/CfM63lUGUPQfeXKmIV783EvO0Fupw9XAdzT2TiikTIxCpkHMLgFe05Mf6qi4XHSYQRH+WEBBefrlMB5eye2KJK71+sVtP65ECgbKDZqWHyVfZleWG2BnbFPYc/aCDKbawMN6N1zmY5Z+GR1Nn2lMIXweoXcHjcSlfRoZX0yPhjR0XLKdreQefiWe3n2gEzmxV54jcGDDfiDyD6EFzAvEFg9vCZy23A4NPTKKlUKt/yfEsO/BSX5Z0aOpT0S2a9YJ1q7r/ABS1jEmjlSqZtI7W9PSN4pNcHdGRsls4oNA4T1GFq/MS2VYD4LwA9Ihshb2Aabrg94ma42Cq074psdvqDoAWUW7c4hZxs7P0j4HtFqzA9533lF4KqrdMCshL83L+UquhD54/P+L7ADchBffmGBNbwWHvFAp3h7d9kzpc7ZFKA73RGPRl4Mezl4NQKqsZ6ofUL3dNUDnh5xT6wwuWqb9MKNH1GXFSgLFwHdYheeUAN1slKR6DKjeqTPp1qz70oqlFqoUc8xU9Hen8y6hW3zSy+rZvtcY1KW2rk3GWPKnArixhZSV1v/CeAxjgNRTJH/CVFcwzvRVJkteZiE2QzH3sp/gyHvMwQXwiTKAa3W/m6h/WjNtQr61ntEYutFG1Aof/AEQg/lE5dUuehiVRVQO3Edc0FoUzVbZZsvfqDdSnYRTi+W5n2dmqzB3U+sMW3tVAosqIWDeJfmXGY9YSRWVxDobVeWUhSoGGOvQjY5AnKjGf0yyqYDVOkAoOPks5r9yZmJ1aEv7I2ICqxqX7HxB+K1aKvo1zvPaMYz2nDX4jbHieFlcwi1aS78w/p/5MXv1UDnns3ddSVm7BynZz6ksq9i4njSAbjs/WX3jN4Ue6DpU+ZZoTnzVCLz6D6jFf7x0R28Vl5/WmgLdMgHgg4Spoum8AA9NdZ26Uu09njt2lIxGQ4lDy21XnpL23/gLbKDlTWJ0xKu4N/KOCRKi1Th2NsVJlE2CL7plGl1jQgEOWOL/sRDgQXRKSSGVLYqPIg/cF8Z9pn5oXI3INg35msHjGk/hzLb2IDfcBqRotYYimJpfWoELb0itVBvZ1KIKpbHat7gsWrkTsuMNVxTymCj3C0N1GlUW+sua7aFDRd3rFdoRAorH9JcobTt0mORcVyOOF5N4ZYRRquGK8sVicdzaNagrctbQ2t/8ABKLXAnEF1ZwzS8epApd/0RMiVrMkuXO+KGm5fRAB2IIRa40FeYO2j0N85gCZ/a3HxAwxJiyoz1otIZDqnDzd69bj5acFBHiuKlmkAH3B2b3V9p8uqxKr1P8AqNOTLiLiPWP/AJIC1m9FRvbjgIfStZFuWu1esWfdSH0igdJts73M0RKuFJuteBD8MoSnDRZtvniUts3TeP2GDAUwaCgY2dxiOpenTBAXva10I2+0KOjaiq7ukNmgdKuDIERYPXZTKT7mcTwM3iZ/uIrxGSf+kmXWqHvyR2LUqH7tmiWeCV2HXz6hd99xB2/H+xCbhP5mU4DBpM272jvrHeSMah2WGaqzqUlJmVCtiKqvVemGJ0brXB5sq610h13t1kzLWaUe7Fos6iioOHS+ktli5PjSOz6jV1PtN/33mWBn1offPozT8LOIeIU4Lbfqz7wnQ61kt33SAspr0Y56olLNQ12qGWG/994AbaWyoUd+8L4Id7+fSI6LKtH3AKZ6n9QUI0ktRuqLh398iZnLgcMS5OOwndRn907CIRjhoUfSffv+gubfgRfmaJCVOlSznSgo6lWhaXanGHkzKxiywgwN0mMVX+O0sDCuyk07tscRcHcliCTLtMcesyF6/onIqDOv80vEbI7nMxSnpHioVg3ALNgoNtwVO24ceniULQuHD9Ai20vllc93QH1juL1xvmQHl/jBL9zDjceAYl1lvgizGPJAZgq1Zx9TgFzI7RTUg85t/mTqwmunJhpb51G/OcgXfoD6XcvnHbiVnWmd8kDUb7Iq6lG0OnHQPeG1gYsuM9fuWHJKJvAN4GfWWGq8jeEJtwFZLFvpAk76vOvpL47NL28XGk6oUgC+OTlzLKSkKgLdjjxDNKSIN9A536ysB8XhyviPzArep4pcwH+ObgNIkOHKUdYeak1QKemkFruw0F7BPEIbeuq+IiuxeIGfRVy7gFQ4v/plMyWi23sMqAANZLIjFIQNuhflhqSo2WXp/dpS1De6apLBwlOM75gb/oYGMtTAvO++4M3gpVleCK+2cSG6AS0zR4lkcaV1yNEzQRtvEyDp1g0zdm47YImJIJF40+EzwR6rPV/ejPDTTY9DtiWOKH/dzLFKGMR7DzKVyqDDrj1ioauOTK2wsplxBTTuO5m8xxvUz1hFscrTuBxUZteJnKHJc+mYS6KHkV17pMSFKzB9LuYzrSZfEvkWpiTdEzx89SsroICgdA4P81gx361C7Q9pfoZTdY6xKHHVegdZTgb34GOD8syI7gJFdgDiAFVqa2/FeYrbhbeJljfMKfJVy7PmXZfhj4i4weM+y/hL00UAv1PqDEijrBsc0LiOK/1CHWnZTheRD2NF/qFE9m3X1zWTPVlolVXk+N449piIFZInkEbv14awDtJQzVGkD37yj4/TzHXxM3xD5SMYGliDJKNwyaDCj4Z1mgX4VNkTQVg3TkQChsYWr82EMVTSC8XwxVQmgh8yy3FJWteMXiJ5R7j8RvwsMUgDh0/UtKHPkeP4QQ7o4F1EYQ6lfcvtQ5WLNK+pOa7dV7y1iu0sVJrWQDLqmxbqlwBcBlgWTkfwaVKVRiAZ4I5+V+4RScguP+doqFTUt2xO7onjuZpSqFAKqasYZr+f+RidOjROqBcUrLxweYn9Itwy20dHiaPAMZP+ZOFxS4AY4QRlti8WXwcypv8Azjg3xXEqyAK/neHBjatkMvIa2bI5VTD7GpQimzgr/GIioq5V/wAsLjmK4nagekAsQi1TAFBI9x0fL6U6i0X0D9xQ5ddrQto8R1Dw7CuH3Al9YwPOZhtwKJ9+YGN9auEH2avu/E4kAFBMrny2+I+2cLvLHuciS+hAuj2tnpOQXj9JXYmbB9odzEeL+YUcveBUqNwYEzFL6pLFo/nvL0gxgf8Al+ZS2VDhS3xx5hYagNRYBi5QNwUc3PQP4m82DmvaYCt/e4s5nYtnpGCBeMu/UbGveHu8AtGTMe/vID0syR2u4+AEfvjEdpsalN6qKuskvhmMCol6tlfNj+KlWW0eBpqIbeTK+04EFGa7QB2LipXQK5KHhqa3xEAxgLZzD0Ac3Ky6L7/Meeh7aqlPbtACwAKP64prVB4w/ZOEbJVmGMzfOPE5MdTkbfFb8fuKG+TDIZSjC7Fjf4WZgaw6LKeZaqyYRKfKa/ku6CwBT8zDGEMjbANRCR1CVbnMS8JWaQsmZa1NMczHoeIPVRM5D+IxGGtwf75FFg/0IBHx9qdATyzmdv36vp5zUTXakFwFdoBk/oMLXdbfaUrMsooFr3eeOkd6AS/B7e8GkbGmHda0b6MVFq2aIumkoeJX2AFzgeCDmt13iCdgAOLUfm4FWV4JgSGqlY2+sASWWOlMbT2oGuyexMMyFWZtIEpRmmVpNjAqLGKloOTA7y9j7RnSo5MjuWkM05i1TV8QLV955ARuDQQGEAXqbuWHlrVjYZmu9aHvUod9xtV9OGM7LIzUjTk0LXXMWTBcvCFUyEclD/MMOLrTrp4lEpAVr1Ka+IPVa7OecwGs9Vq89h2jTweHeLxAfnSk1C8bhCzGpXKWlnTdy5PIxtQzuW3H0JT8fxDuJW1ZiCpCnYlODMMWxh7jNuO/aWCYxwBVwwdxytteD93Bosl8Btmyqm6tAYZuC2vQp+v7UYpu7VixVRgjmmoraf8ACOv8JuHJRWZQTG3jMDmZFJ16RUIj/wDAJ9WOx/hAqiA62E8py7vg846hmZcM9Nnyg5feJAe+jpxBzk9NKdG2+YplJ0aeM5z3jQaLHRZ4ta3zBcUSOKLuObVA7wL/ADGPBbfEtLIvuh1rqEob5dhMyteWo7wjS6QWwU5PyEo4Wi88Rj1V/FmldZd9B3/cVlDoR4b6zHmEjdLMe6Y+25XrUTm0oeWKj57ah9ag8osufdSot/WVyZHJ10BfdxAeO9hw8tS9oytKIxgr0QsfSy7LHqxALfbUXnJqsVr0Zj9QjFU6/wBTEwhgLHh1OgIM10jtLMJWbslqhLXkV4jYVMrHkMAzek0u116+koiF9G83MbhqXlZ8QBquqw638ReC3CXAY2sAX5jzERiWutPdIXbheBReKSuSYRHmCUbK9GNskdqGZgcCN7w8CUyhPmvj06RaO7UPhloqeULMQ0bJRtPSBoDcMAM4QWy+0EAqPaecN13mhKK5iDFSnE3Mr/gQZ6Sl4PC68Qh1eluLeJhXp4lHRS+eT/4BoFLmhLu1EN+hbC+vi5ngOsW4Z0/66W1rNRoxa9YjmAvm2Z8/9iQSAAvOD9wHEvdaVp6wMbVVQbfO+c+kwyc0mjaBsa1+JYOKQVW40OxKvwXxGVb79ZRtcQbgr8Epd04ryOT5l7ziKo7EVbwA4G/EHBJg4Mf8hpmeAerCKLIThIIfiOAsPpb1GCzR09sr/ukCLrvZessG1YdVcGnbcY1glQ8qkAYWt8+8zMbuJx7PzcNVtRoCoAwhZ1JZWl49DfWVgGi+hAjCJz48lvPXUMsFE/UMd4YAzM5xHf7/ABLdt3hViqVR+vWXn00EevHLMn098sZqMRe1cdvmrUZJEcp4G4nGh95jTapo+n8o5HoV6GLMEJVBJkL1r0l48fE7ip8JmaGPbhmFEIRSpawCLrmA8k6yAlUTrAYUexiq5hRci+ExsHCYZTbFKv8ARuVFOSxeE5UWN8yiOwETFwvGlS/6NI9IcqyW6WeCqt/x5666wIDRomgGPDp1nImOISzf9JUYcCVYUV6SuELQGEyq+uZTESorF3eLLVfaccs0pxXOL71KAYFBxK/gr+ErsuV6eogW8xBtIu1m9GVnQVlkN1neotYUu0jipe7SU6MvUBUcYYp5O0ILZUOYbrQCPlzLFeZFZp+RDXINhW3ui4xTKK4zsG+ssuBbjcTUGtLJmkhmSYLSeowrV2G6rOrvwEJiN143DC+sbNwY58CD2m6IA7weXMMDxNohmTkXZAFtUrsiMO8nhiJvdAxhrul9L/coVmujC2+4kAjANF6Bx6RgtU5uY7QbB1LbIWh2RnFymKbQeQxFVglvWbFsMbpitZilj3mIfuV43OmKm+tQNwLcrbw+V+0oBXJfubizcv8AwJLJZCJfDV83wyhpv3Id6Mo5ij+S34x/+GjZDYBcSt/teLgKr4kGiPZnzD6J1icCDtQs1fQiHsD+yfcin5hjG/hqaU+VFsD6slWU6A4e6ufiB9na9XmXdSNYfWQ79kWTMU3aUrdMt1q676mhZ5VwZDg1uZl5EVvvD3wbLna5bDfSZg9RDqNzLM4wubxnvm4issVeULdXz/ydTKfD+I5yvCNQvc2RM8zXsSpJUO91WIpYdIaZi99ZerQG+MIlIWm6jpMtAaDb5IEd0yBh5YtvdR3YbWCJr5jG8OI0La/QTPteKwhaegZ9Rp111q9+sd6yTWZ5jXcxKN95EFnphbA+pnh5z8weLmMyGi0gjtOszsQUbnhS58oqXqF1xBd+QfxDHJPU7TYGvGpbV7SCbPO6g+rI3Kil1v8AEuAv1qXWSub3O+bj1ah1eZbNwBXA4anAp5uP/NRqUpxX+YXkcTP3ACFUjDZBZvaIdf3f+f8A4omc8nSUFwx2yrEc8YqflhjrzzceQYnVSkVIvmo2dMQ5OX6MT+BLt+xNW1uNqRRtOMJqWEZzCNYvxDJchfMvlGTFpat+CEacUEenQXBZLhlaRXZ3iVqCY0WZhA3caktzJpsHzAU5uVXYluTh5iE2UQUTiEhYOZa5toh9NRWiZAHviHliNt6i2/7llcFHQNRaySU8HLNlFTNw/wCBZqHLDufmCsgpAPm4IQUGOO8pD1VmKLK9bWZqyJ/HWHanVYdJzLeZcn3T9yxseucqwJMrzRMTCa6LO8sM8yGZAr6xTb7xyAXffMsbfvGPP1jOSGJkbigOBTL4mwFHOagtG8YxHKhLaWBV8QKWRwqTrng1LDiwckCoMMs5pBu0XZutfU6MvVhMYDp4Ss6f5GHJoJWppF24mbE0Hef1mfPFbFd2InsSjuAjmWGviU616THeUba0S7grm2U6HiOFUgFlGCG2dITowTIVHtZMzMhT7GWNwQCnT9U+g8+yH21sKPF3KwS4pW5airTN8vxKiqnV/mXabWnJAzbMfCbyQEfmIGx4zB7ePaMB3lhgojNlXMm4KxxKo7Dka+JT1/Fx1GgYov8AO8yMOQsxD8CR5m9Edw3qg23y35gSq13VlbsdiV68SNIRsVJrlPMa+E/5UtZihmes7YRowOAlngncQnZIpunzNQTwlkOJlLY32Gvwlyw9B+ZiNbbtU5Xcqy+YW1olcqDgWS6lib8ZeVQKodQ7h8jexlLRe4xsHglsLqFhtcwwjGGa2X8pho230SygLiB7TjHTdNvzBR2sRNnVKbyd9vQIAdDXz+McEsq2XZc6R7zLoDrAXQkq2z6jRkOssx7kLtfWFm60Qw4yTYpAMuYFvLnpBTaaF/MtlDeiLGzawr6wAVr9kBTotlFoAdswe11zAB01ooZ058n6hdPOnk38v9xwD1Zx/bzSbwY4Yi3id3xNtHSHYBqdY9WL5oTLimC3B0gIcmR95/BhtMHfAl+x6zyMw0ETQlaql+ggvNO89pL9F7y3e2QzaruJfXmBSxie78Q0fW8OexcaYI98YQhO8rYA9pgBqYiub4nAQxhqo/krcwXCKDcpaTlTFa3QsowAiUVB3PWBcwlabzMZ+kFmWTZMKzUSo2df8DYbN5p0/u0uXZ0Z/v3KYKoR68yo46nsCU7tbawQJPwbR4gzrRX9Ge8/6InTMs4SJWog+aNYB3e3+ABaG4DRXrObUiVCo8yxocTXn0lADCUg46ToogoM1cNpNRZfS9UTy7EIqxmWra10hpMmmoyWgFTkOGba5l6IoZsYzDfWZ20/9GUt4ShtF+I5XDsTrD0ig2e+PDb1pfz+o+4LN/t+43SnuD8wxQ/viX4XqfxCjHllXgC8rOnkid4Tc4riMtCUK6YIviL9v34V+SKSsBSuKuYtivXV0FjTn2IC++I1FvXHrfB/1meV7lozkekKWv3bDb2LlebiNUcBkapGUqsS4DC7JN8AczYEUxvxxiHjB/aU4q2SXkdIdbYlPQRtbDiSKMAUOhBreI9SKo8PMTdjb8Mp1oDl+ZRVoIe4g1rcJs6lSiBbkZaEuwd0xKNKZOfMznfWl9S3XCK47yzAisSzJc4DhK9ZVaxSNmCEN7AMcSpW+xxA2uNuQ+JipXCnMJzRyC/f6eYCH6TqxKLVnGHqxg+pOBhwz/h43LvaJUXnpM9PUS7n3eI21YHWYhvMOkMgV5Xucg1slFZ2qUW31g6qPQvmYMN0Yewd3Evjps4iVOm7IVul0CdRBQmLIN1P2lOOuqfxFBKGEKDr3mHudgTgsqYmGVWcgaz5jqmkKpnofUaFo+qNFn5WUs0niNaJ5hHR7QwMGe2ok2hxLRaKz1iB0iE4R0Sh6mVjm8tDsWYcNDAYlPw+s7a0kqY+RVV2lawHiAXgPRL1KI0gxnsmXmW2e3V7HuOPSEVS4RLZxE6BpA05Vv3lqZ4UaxdVTxbPE4Z6I/FHr0gqCKiiTjrsuu8SaYHzimQlsoAaBeE2jtXeCJK/0NTXtbWagrbykBVZvAfUzdCTbTePo32hZayyCNqGbAMgHye6UaWmCs0nAsYCuYta2yxCy+W2Dimi+Lv8y6E5fKS2wFx2nXvh1BwFh5IRZp3W5h31apmTp42T/wAMlTlsVojDMze5fWYrQ0ddYWTSbxofiLzZ+Ecetx4uZ5CU4EvasEyjZ7uKKPIB4iVE5ZZfSLWdIzd3vEkqvcxBkHKz4l92D3mp4i0qqcbvXrABti422JdU2ymfPP3GwUR7Ss0vBKY7oMETF0W1LWSdEIBHLqTKiu0vRpBvw8RDK9mGYDo0+dEMEL5nL5jSjQ0UbBzMsJEeUVaTpOEJkVYOYVJt6W4nIIBXPA2OW7myMV4B+paiXPldgocZaveIlxPiq3C7TIHrLga/bvkjkwOkvNVLEXuYjUqpYQBjdGR6UQNS5Dm/0x6GDcpMWeJ9m4Xeol8Gn6+YemUHnJ9ww6dndsepFd2e7X/7cRwIsaTT4AP+Mg8IsbpDawGCel6wvtpXiKLOA9FYlpv7M4SGsUeO+4my3Woq8myYVg4qUsks8gTyYOu4KdyLhkUu4cQAdaoqAsTpL5cy0g1Remg0ytiHbV5+I2ZmEp9EdCGnX/0TublyGwXEpjUTtJfl1iA7mEGuUIR1D6hLMW3rEQTZpr4jmg7qAqNbqovuviKzrfLCJZ6Tt/M47GbeZw02uPEUFA9Mp8usYbBR1H8sVw+rK4H2+szyvxP/AGHozBNAd6uDPXVMhHEfZaWt0jcGBm5bqY7fZmN4uuYtgTK28zqFRr5wOLlUoMK0u9VMivRhWg72BELtjUvqdyElY+yOXGlB30i9UfcL3/lXFMht3YQKZ9YkRikLbVesleV13IgiBXaqFYsQFDlsr6dJpSJNSAyaPRBNt06W5TWnLHtAAUK9ep2mOGHEDds9eNdoklbo2BN3jAK1Ad4RjmCXV2iyyYFy6J1AaawW919KO+5B9NwC7DtI7n7Iwr7X9Yxavua/JmsXnZF3Qf19pnPQ/cwJJkhTcuoL/h1iWcsAIv8ApeKMmfwSmMwHnOZ3EpNcy6mZhl42xArzFQ1ET7/UHdU768QGfHo3MCGGJQbV1zLdu06Zk+pUz51G5w9plBsesLZwnxFHUKMamBj3IXX4hVg4bgYCe6+rMyHB3g4ZxOk0j8nxB/NiOxA5IkKEOLmW4Oyqwj0LjoQGR2YzNej2muiMoumfmIImODH5daTc9lJuCoUIUBn+ZpSYCsTK+74uCFrCLr9906jXKSL8FMfokWqldoeIzFrf5CotnFKMGoYgy0doUzWWX/Rx14h5PXNIug4DbFEloQ5kmrusXiVkA0SkEVZ0HnceVWHthZugJncKlbzvCv7QuiOMfM0m3lzKkCyyWym0TIkPxQgXPf75cHHU0c9XFr/6mozUfC+49EbhsKwDi/GPMEvjzmFZNPd1DpH4B+5/2NG3vcWYhzLIw8zshC5qAy0If5tpMDyyFoPtGdCdO0JS3v36QG4lcLOYkQ6QRoTTzAeOo1qObBypiynBvN9BjAuwo45GHGQGNj+CqW7VhgO8trALoss7TBHLoI4oDQaJg5YYRDlRRQJmyOeFJUqOG9ViOUoBQdAVinVZleWVwj7A23XpE9kPdAWiy8WKXAA8oH9tZuKLjnn8e0KMCq9AYMyd/aGABLMJzGyBZgyezEukILWTY1gmK1LLa4iFmn6XiVAdX3nO3maanmHNNVmpQaDGpk+J0o+dx0YckoMzO5ap76xW2MBBFcZmoFu0FZnUiTGea6QSAa45mSim/iUNoeGtXKjVnDcV8hGKgTrMzri4Fggy4MDwiGxbsgEtV1Q4avRNpqzkjHNj/L6ZdBTKEPQYec7eG8YGlKUdGBURY46RGcniqYUOGg10jVqcdhT7dIRMEsaLaW0vgxNGK2DwENRc3dzPP2hRUHug5G5TiUFRW3NKXuFX1LGpdB9r/M38espYBHxggAf7t15l8Byj0jHBCqlvaUWx0a9JvGSXgV9/UvGZfghd8xmMVNE7GYvSdYi3/inKI6h3L6usyZ/9SCcIjwsqN51a1yxDVQCThlDYuhJFtOTDnOZm/wBtrNCXy0WK6ou3rCVgajjmV3wbZV+Nw6lgEBpxByad6FcU1YpjM3t3cI0jGW8mEAGkIZi51MimHOGPeYiS1VJxUod1NGF0lmdGqnHjr/tcNiMF3iCIPUIM91AvpM0JRi1G/RRviZyyHhh2EKCrrN0zCLew6xBgth3llVbh6K2XMwZyIBSzY+WZZ9ucMSgJ+SMLb3QJiQFdcynBKKHpOLBsYpNiWooxKJZMVbzUdDhBOVy67tmmEau9RBoxzKjS+rCigavcvCxow7o6iKVzvoy6snoQRvaucS8+ionQZ6TkSBWziDHnLDc3uP1FtH+fklX+Pc1KeIOIxZtfSWXM0nWfA7GL71ek0bHzn/IfIcgyf4h9ZadExt/SJlPVb0Rz59pgVx1tl2evusDYPeaDHJS57PzIgm2ViiALqdqZtmHEEjoYuiYLmw1ZAEcH0iDLG0cEStoz6V2y0Z1RFnBFAej4gEirtAwUuI2bOLl5Rag9UYlRaLi5sG+sb5p//9oADAMAAAEAAgAAABCrsfdtvvu/t1n8tlxt9t/vpcyNS0U1sJQYPTLJNVJJT9cj9vXL5tt33/vtvJ/v/v8A/wD3vvaTTa5sshoksK1Ms6VLlwgYPgH2W22/+/8AKP8Af/bf/aZ6NNp7/OSUCG2WzySRLI5shiVzX7fb/f7OFGbf+67xeEsVNptLZCS0QgUE01OERfpoc+IiSL9bLOX1d7b8Hkiau9BGN57b/wDksIFPCMgbi373qbe2g8MEoyc1P2/0Pu4vS7TKabozD7NItaSKdTGaBHOGe6H708d+/T2AZxq8Z4STSSASbbU9Updp6NJqhP3EjC9tuhQU59I1/mF8t3yDSTbbb46fSX+JeMnl5EyU4oltNV+aF+GmD44+E0oOEYJnZSabRf8AnnvLx309KE1PU+omahw2gUQmh1YNsbst/wD6QN1ZmN41z2/f+QF9ZBqb+IIKNggmmcABd7TeLldcG2AI42rKtrhY1tmmDueYYyD4qiBB9jSJlXCiw2U/kLYy4s7Cdcl6XqqobKKQpAZs+a1wREAFGU289ygQmfo/cDp9exoDiW77N2RWmE4u+63pLKN2fK7oWVkzJ2dbVqnnusvnL5J3P6M006JNabLRELHDQjQPpvv/AEdJ/wAE6VPj5cGNy1deeTmyXR2KkUh+32hJXyCYp/7ugybANgncyBsCh3C51iFR3SZoMreFAplvHfKi3l8SOAPoPd80mTEAfJB9s4rvl8Yhx8KyLv1/DTgmOVzksp0U85T70yYJA9i1affMaQMS/wBBOvOAG3gX8GCd2bfM4sYeMaC7J13pUl0vfsxJQEnie8DGsbUWm/dPI2ObsHf49g2+M+7i8HJR/fCTeZGKUAellhX0jO0N7VUSzH3hLynUa9pQ349ir13jc83ebOXqnyHRJjjJl9pqu7//AOw3+3sNMCBzH1k/iNsIbQWPtrgmzZXsso0XB/iAs2//AN0OnmVybATyZtqbetMdClDrNIsQbaolMK7otiyj5gdZCKWJvWKm4MTzQuoaUcjBDGu13xPdjK5qegKSKXsG/JxQSIOOttaJmhex7Oa2cFsA/wAomdXZJiOLg/MNIUPKb/42EymsEIRBzTIFcMX73Rb0h9La6A/9DZL6b08KGREZVG+9TuH5qiWknP8A9T6RME9m2M2tUS8vQezWiJbn0CKLhM9bJTJ+3y2aLAWB34k37WNttewyRUa+I3kSJJjqjvnJRAn+BHx1EGgH5ZfxptmAAlH4HKuHvezr9F8oQGXxBDKaaAubVtq58wSPbrg+XlkarmOIUZtkKYE3PYWrpvvpDaH94hgTeroH1OCEc/BcdK0oGdgdiuFnO977eyu+UJ84CdD7vEuABIQGXJnxFkQSRlJlH3Mgs2GIV59y9CvCM+rC9c7jkRIUrIVGqBJN6eAk4Dro+2lNUYl2V6+mTKcNX5fEaoFGvnHcaJAMv/ghHu0vH/3HYks8eVWkrHxcKS2zh/uZzVYGR1wHAAdWNbYwIy3zc+QKZ8IeUCrV0UNbp/hCVS5tT1VjPJeoBdFDC2DaE52XJqWLM/is7wqA+BrhLUVDvIEl7/MI36XaRm7Kp3MpQm/bRhOPfzFeSztBqJChAeAgf3J3eOxHxz0xfnHSgZ7102gaaTqe/PBrmqDjqFXBJJIC+oT6lDZI1lt6lBe/OiAD/C5D6bejIYvjf+hcBm1QbyOQVUhJBIBW33PJaye+xH/SLARCa2gNBdPsisnLFp1mI1IAepaIIjZ/BWf21D6l8o2DRSCTWKTiPl8b19fSj8XYp+FmH84RJt/3oKGbgMttrcoEBTbfxfK1jNu3bvSrLJWyosq6GGaUIDHpBzDKuCx7OpOaqTbaZyVZHUPF06dyO2cOnUQk0yi0gbnB/vZsjs+LnzrCqbRGR8bOuD7h4PH/AMg87ozQj5IsgNgRTSD9sdX8mnLWHmm5i0umchBrsYPOdy8u4F66xXrUF3N2D+TNKnRt3WWlmmlPg3YzFKEe11hhfdmPJbMMWJuMpBs9UglPOzHUh/AkWkJehSMcWxdd0QgIiNx/8o1EV24aJk11PSKWPLHfQaDqSrvYwQ2E59+CMMUgXHnPPzLVuUgVzUl58qg7b3wMHMnuFM3rpzOFoC5lMBg+JQLFZwJewFGX1CvG6bZRLlvJQ7JJf8AdtcZbs+UPQbMposbQziDRj7VYu0nTFl5uQtGnh/cN6cLryFv8v+RWlfNBXuDym/SEPozVVFdqq1whdphbL61XOSOyTd8pkPVZJnd4IMwR4yVfF2bs0j2XIu4YF5JVccpvKRASfl85gva4MxV1Uy+3xbPWWrwxLSAfIzoEwxppfHjvRHCQMQPzH6TxKtxivQycBFg3PXfCC4WSxJmkIdXaJDrOfcSTUaCRgpGrZBZHr3E79nYCx3I2gfZH7Y0lPYymSOVIkSZW7f8AzsepFCXwx054mcid7/vUcD6cdFDCf7rmE2bvhUBG+yW376CJEYsawZ7tglCD8X61zJILOvlXFf5KppTSWM9M8m29nbNI5JP83ZTXm5Lff8czU9vuSMa7/wDxAS4ddvk/Fcp7lIsvOX2vn2XZ7Onzvjf61eb+0Gj30j/K28MiP4Ttg8QtS0PpkEa1bJ8/W+Fu7buK0pHf/P3Hb+0URJCG+nythFsMvpkFElI9xVqx89/0HbUUrRKjDaA+9+g+pRecGjxIF1TKatmEkdnUCgaioDPVmmB4+f8Alvm5k3tOwzbSE8E88YV362FK6Uv9z3vxbG32Dcvk0mtrH/3RMfCbnyNz3hx/dCHXOlmWYo54NMCA13+2ieYvlV5nbMolVNp+zhgcKZL9fdLPqvNsq/HyakvbsP8AvLI9LrfjwQTc2fk5D/rH/8QAKREBAAICAQMDBAMBAQEAAAAAAQARITFBEFFhcYGRIKGxwdHh8DDxQP/aAAgBAgEBPxCpsj1viHF1Hka/+gLjn/oNS+mkJqZMVFIbr/gNn/C/+T3+oYC6nczPTBTEAXF8RRvpuF5EvwMCS5fRITX/AHqPb/4MxhqZQVK/8hr69f8Ae+mCWS+hCmGekpzFIniIRE3BmHU7jUub/wDh3iOdRK/+DWJmXwioDv8A81x/8npAqKu5SURQlOpSIC4lbmMIsx0wlZPniBf/AHqBF7Svrr6i25ToZQlgVHMlh/0G/wD4KuXjcxCymVIt1FX6xSYNRV0GopgGmF7bQExFW4RPYx4pVxNfVXUnZ08PqBhZuUMeyVKxMJSwSZcwOUBY+YQ04jyi5aU/8dQb/wCVQLlVMSsWxTiVEkG2O/oJT1rpdZgMWPl9F4qC5ExruOWnDMkAg+YDkly4EWa6CiDF6a+upSwwZjkxB9peeUoyjU9EvLe/TG47j8r+IY10ryvaXbmUq66FksSuo19VujBLOOi2HJlNJdsqi5g60splMLb6GOgV0ZUqWYZVk6hfQbXGj5luDKss+kDTCRfZLNzhRFURcq4lV0qDcS8PLpLE9MvxFP8AhRbvNpmO0/4WJeemUlkpSkqoZlSwly2XfUSXE6SzlgSiLZfQI9auY2mUs6CIX3BHUSWypRhl+SUwx1GskoHmVTLNtxK6V9BqZ4hxQ7kHeId4d1SziNwyF3/11XYfmY2XX/IJ1BcypzMJhqJwguiss5lEp0a1EWZVRFmDUWZTLQpnrZlleJclNmV5S+owUtQOmhAFkRJUpEqC6TA8xKwzSmXddE7mVblUr1E8EvxHuRV30YSmZod5LtynK8S88ErrXU0ELLFX2/npXSugLqXhFO5VqKimb6PVvUqEqWEe5CQ7qpjbLihlGYQbE2ha1DZDbpAiOJaO5HcRIPDBqOZbBYzMOoDkSgYiyDS7uHezZek6BL8Es41BWrlncb0/8gJKOt1Ld5botylqUlolLC9hFmOnuzNwdTLbKNsp1PCLYq7630v6MxlzEHcqpuUdALqYRzuVKJZLkSy4jMXKjYSyLZfQW6J4fxBqNCmWL2RHco5cKZkm2C0g8zDplSK4I80r2nYQSGjSQJAuKgDcs3ONF9o02SztLO0s7SztKdpTtKHH++Z6YeMfCX4J20S+g7D7QWWNtSrmUC4jKZeZmVTRGS3S2Xe4MYtLS0tLJflmPMSaItPJBXMW4MGpZEadLqXLuImaiWio5KxHUEhTbMeYloiuI9+X3QRHYJd2RgNTMRDnUO6JWSOS5VwuDuhTqMVxLghmNDzErD0CqetsC5g+ZfslLmZ6YlFGzpUE5ISVyytjOMTDRFop2y3os+wn5z/HTTFDcqnkS3ZLmlpl5eWiG2UaJaKXfWmN3BbhUxOLgXBMw8IxaKTLSC7xK5RUZzFHBKRIHgYjxETfXMFmkQdzECwk8UoRLFQnPRvoSxhl6uNtx7IRKU7gJSAEIlPSodRuILiWN0mytNMQLiOoy+kJxLZElfSQhL3u6PQgmiW5lHbAdE8RLVr0Y+SX7JbLdQJ0xKIcRvmZszIWohFvMuoKrZjQuPAVL9xtmZm5UIwxzKJYncJ7X1JBuJczhEJivBCbXMeiXHsjAFQrhghPDE7yq1Kb7mWopxB8sBzFHmVaJ4kU5inP1XLGoFM9ks2Tupd2ifEQ2TC+0/qCaJzOJVDHRcsYEW2xyZjAeJuVNTXRvoCHYyvmBMDYllYmSiHmNtMooL7QQUWGJ0qzqJsv4ie1KMUzyiAqUiJSUlJSVlYD2iWJOKVDcRe2A1UDiAyur9Xfr17RFT0S5gYBk57RRS2QwZlGYSm7Y3qBblJLRUvLy6VTBplyVPXPXPXKcsAcz1RHeF1EruYKFriPIiXl+0teZWd4nrT1Jf3ilZ6FT/if7xPDPAy9qpVxKdoHCNGiA7iA1CmKjtLKJWqAr3ls0MhgBewm/Zq/WKCwBV1lwX5Ywotmtc6nLpv8Speab+IQ8U9mpXlqrrtNAlfIf64eoeHoxl43+/MHVv4uZiWGq+M/eN5Qxjd21xUAq40efmUBkWPmNqGvM1RAroU2R7PRoagGmWYt7S7R+G34Br3qchO+nw/a+kIowcGD4MfaX5UvdJ0PiCGoheJY3AMUguqlsVuamBRqEu1Gki3UG89U7TcAcwwx5HR5dSko5lCwYSXAkSrinMOcxKqBTZLyxAQZqFl88XTUWty5MantKJqDYw0tXXtLb86RMnkwdtb9eAQQrZa60QmmTFwTf0VSVFjNIl7pPh+rgXbMIHIaMpClamsjVarMXVFrESq1X+8ZlIuzffftBuVwLcN3VrtcxKECjDjFYjtAEMNllYz2lvYilMnv5hgDaWmWURsBfOL94Bc8FuGqsx6f5lCLnFPv3mLq1fnpRKlEro4Y+z4NvsMDdb/x5QlZzjA9+X3WUIkqVKTJXHPf27viX7yY6AN9BqIWmNDiFahRiPaW3luEqWAVUDt0WsS5klhL6XYh8TEszAhqJWIu4kaglx2wr1HIvKbBF+JdhII7kG3NZPNNHU2DbnOb3iJStg9Tlzf6m9FrQEzhDeK494KMm6G3u/qFFpR2xCjlthljIdkMalaIYIyponojvMYkyTT70X8wX87+YbB86aL5oZlvt/ECP4/whzH4fxDm+BFt/YndmG3/AKes7/8Aj6x/1/3P9v8AmXLYrB6q7nB8tHtuL8r7YHwft6yrQ9OX5W/FHiW/lMxcdFomJUury5dPITc6P46al3jrvLhhSLdkDE4legRs6ekykZhIIgG3UbE1FzEWqLv9a1Ll9LJcv6a+h6JtlSwEVj01YywiBqUUMlOI5u8BMPpG60XftHRs0Zhy4a4uVLccD84fzOIN879otuB0rk7mnQ+xFqXMwj4mKJ4yf56vpNLj3yfFfhZ3lg76xXAqJBRuPQiNJXQRo9KyxLw739qlwimTFOum4fSBMpMxqfd0CEqpRUAJhcmO7YylZoenS31JfQtzNSoKSrnMzKYdLO8sZcQOZZNRomIw96eaApIo2tYGGME7ZSuypPXETDVyDshKeZfpDScH2U/kmLcV+/1PWz9p+40zivwn6lTUPXhb4v8AM3JfuXKnw37QqWov6QjBecZoFHSyzXYYPgqWIvaYgxMrb9BZmchNQII3DhaC0C8G2IcxKaZUuxhBNNyjNxtG99clKrMSOJgGoptFMKrgbUr9xEIZelXEZUsCIqZIqqO/0Lx6i276CctMS/KWempt4njj2YfRkGpi9SyqmGrgmMntAZNxUVCHtl86RZ45+0WvVEHvRVxDilfuNS6RYHwJ+5cfLX2w/pgNWHXv/DHy6J6O/Sv1GaIr8f1CjgKYHLtxJWJFtddlLqX1vpxLh3xBshIa7Ucea7NNesd8ZmgGK3M+VJEPohWehm/aJrMVjVh6C4YFTtJ43ohQRCiBwJSVmFx5TBV7sX+T2YOUju8Mmgy00H7WMc3MPMLahRzL94gcyzvCa2a+8Rq4mJ4JTtKdpR0czJ/wtltYlvqepqJWYaUUF5ji2X0upQxWumWYpiBKZelV7hNKHiOWo+WG0p0cQKpGiI2qgOSOM4PmURjtLJZMQSL3nknmnklHM80A5iuYXCSu2wtU9w3Su5iyGBwD4v8AmAER4mMvEGsRGoszZjk346kVSk8xY9q7krXd8rOxnBULsmDUq4l+YX5gpS6C/b7zATEYa+nUS49n0b6UymAkpldKihuU7yyXLIJW40bmbBRJDhZzTj9D3cRkoTom0LiF4lSoMi8JKuoQJn3ISdjWR7zPN2qcrzHbcQyonedB+xB8x3ku5h3Wet8woOIst/MfJ8x7j8yljiCdyorM7g9CsPWXa3LhdR1LhVxe8xBkEqg+SfklukiW1Ee8doPzNp1jvW4XB45e8zJWzefyP4nnDYFMcNfqUN2d6D8HtBoAcf8AqgwgOwH5Av3voXy+uYhIwmkuE8XT7fRt5nlnl6uLPdM+8ryivePnlpeY3ZJWUy2huW7SrRGWExw9wIblUI1xCkK6PQgagJC4GAR0ZNO2LdQ8a7ViJftr3qXyhVY6VC3UNX2eGFdoAV+7EfcOFWLebMlSlmhZGwL85PhlULMyx3gVFPeCaRmoSm5xB9FZ3LkUy4cepCWIg0L0GN+zCCoWHEoxApQfmVvSYqS9xcsykZdxh5KKcwY2KyLigt3/ALmZe2yqzhcTEqMNlRzuJZWF+ZtubvboE2TxzxE8BPBKdpRKCX/wcTDKxiPlmuvH0TMDECRoz+/uwHJGL0uXzMBiorHCs6s2Y43DmdqsrHCJhOTPrKf6/qVP9fxP8X+InhgZS+DP98Sj/P8AEq1ZjYzIHavff0IsxA2S4ZOlGUFl3CKM0+sWW1G4rgcRCeJUhwkyYbgjqFGVnr/aYSVDyp9pRqBPEeYjAuW+wj8pKSaKMd2kA3ex6wwS+ldLMwT5hKFMnUH1P01K6i5bo9blldDozZe+uPPoc+3vUOYfz4jgmlrEow9G8QvuV64yfV/r8y0GQTx3e5hOcdiX1vEtL5YlGY4S61FwTRHx0HaVLM1UUs9OJmLLO8Q2kQ5iepSA1LeINXESkZgFaqChyMsTZZ8LHtn3/mVcHxFeftHv/iXt4jkNEu2vmPeZmBbV4Py6PdlNZAno4/UrF7KTzgfu5fN2D2pgxlgj2IBtYA8wq9eER+5GCV45xn412zKMGolUh8TOC+jO2j30fMsZTovcC3Nlx5+8bsVKnNfMs0xwyjd1+P7gm/s/ucTDMm/aCbKF5d5V/cRS0tFT1dFQQ6MF0i/88wVovnmIidjB93BBkIdBBTixTHbftA25ilF1By7imnv/AARRVb9IvdszKWA2YZWK2lyXcwYwi23NdLgrX2Sq/ohoGCmb+ZikZkq+YcwfME7fMH5PvB/6MGMr8TzImtv2lzefmer+gdHS+7+YfQVB+QT8w5hSmOJqW5RxDTR/qjFAgvidyV7Gz8wcYCsGuz2uJfQHuUOtjnTKPA/z+QgEh2C3/Uvyn4Pwyjj5X7lWPBwIoWipnxiy5kOe5v8AP1EYxAMUpXPnzztzAgBuKlM9SIGj8ynb7ynaU7RTsQp4JXglMtJbUe5Ld5aWv/O5yYB7F/miCNt0fEZEJSoobO2JlOub1fjaPpEKHMAta28ejEatxcGLICh3Ay2/HaA3M3Q4sJSvDvs+0oqYyriZKNOC37fETbBIiF+YcYuCWRzExiUxce5m5iJBkO9mUtqf4zKdBKVHMAAk2zyNfLMDuv2SvyRh/wCKYaGV7QyhLL9JADZCN2zvlk+EuSAbuoLfTBR942qM5j7KeMvzCKPuy0ILt12x0GWgstlL0wJRKJR9NSiURtB8wchh5zvXBpTuV8TmqaAhG0RGnpQTeHtl/UzMW+PD6TiY/qKk+4fyS7d64KvfXpmV02P7mEhqOAtkfEDxHCsqfg+89RJeX1t5lOHAn8BUaFW1FPsce8wsLn6vAd2WJFC30bx2mEayLx3fan3lt1ADU0ubgxriJ0LS2Fym5TEHMB3l90BeZbKI9iU7RWQbw3EI8In4YAYmp4Kp8qv6mlsTHKlf7cKiDMkZY9JjmaVL06YAVO1soeE9GNqSzYmWsZ9PMYsStYqrVG2rzvh8S7G2GuQ6jX0BKhL5wublTmUJWJgHEpAz0z0SnaeEGIpwQRFMscxZl3PRaiHoJTmCC0vtVrd/1UFn5VcfvcwyHNXjzqZgm8KSlFQpOq4Xye97uXWtXB4XaPr3h0Crwvf+XtCd14ZFuldV4FX7wRa1VfVzLMm+Je4M6Uvvt+4KJSU4srf9/wBRG0BE7U77X+oAQTR0n0YmToWmUt3MwziaXHC2VLlblBcaLmKZkTaYS7JYwdl4i2cprgEKYfQI7onBtZaFZ/vE4YjJGXUvR1OtQ0EXEMxcoO+rOCaifL/EqhKwJfrp8ep5m6X6Sjg0VtAA5XjYe8t+Ddrry4Mf5iyJmuiBQbqGyZmZmNpUlSuhyiADmbGyDXIfaiAvf0BcOYQYNUubHKp5p1+HY8FeEUvU17mfWJQyQEJi+DvCypZZZxEqUFrOAmtc0ncTNm7c7llwA8Lgx5LsrXyYPZijNbPrWD2HPbURL2ggUR3DHQdKlVaNzPiKwLDLBK4S/MvZcdrZTnMzXMPKFviU+3QeZnxKLO0VU6XblDUGoNAeY5RBljr4JsGWsSuXiDRNo56RjpXQJRMwIFR3deKyvsFxakAA2gWNKCNuTiWVvtfb/dqlAC8AV6y3xZbMUswxuKq2C+76+YIElDXFAnG7PiAobvWGGMF0Z/rWyA0bqtsNuXwDSmWsKE1OX0mk26OsRj5mCLfTBjLNAe14uJ6e3h/j7kUC7tOnuXp7me/aVSHandKq/mWAaiuZVZ1RSPkT98xjnI/Gjzwd2IKbL8sv4I3HKtmTzLC+g+zusaYn85Afj/amfMIPrvZSb+0VUur+jCfmWV9vn+f8ztTgj0cPQZcQb8SmINIzQ8SyJKOtxAaI0u2OwT3jsCOVBZQsQBYw4mmIw5iKRUoz0EhBC2NxCugXLEp7mw30UXVQIyx2ykVkC5rYm3Qwhj0ZR8mlGYDlUAvtb1igWecfarlG3KrOK9ocLQUFw1z8rjnF4u6uEe/9QM45I71X2CZR0HNuTXpXFH7iNp/L9P8Am1zG+oIu8uyOWJXQlXNug1iLshv15mRVB0sF/ev4gwQ5lS7vggArQI0V4qolqD6wawgCrP8AvMfK/wA5dEFU8N5/i/NziAxnZ8/u4gdpbCuZlDoBuOY/QQHk04g+G2NtPvFivwjyEuzlL2EsZPvOVXzDnSG4PiVIbvwfiI6EHXu+m3SugmMy5jcfTNILqN6lTNKxNEQQMktjZCXQXeG2F5bGCIY26iJKGRMJlz+YAestZf8Adyr3Fa2ve4Fqh6L8x5kep/cswqXwMBAvxCgHtZL5q7q+aqXLEX08HYODgmBc01A5hhG2VS0tjf0JEFvf9PSO+YZ8cwM6iOa24vsHB75faFctd/Tx5/8AYGVC2jZ58+YTBuA+xg7Zx+YSIDLyuV8v9QFd6in1zZ6nxMg71a3Z4YUqsuH0DMvoE2esw2EHxLw7mc5LvEo62qalC6l91FaRWw5YzEhdot7mSIjTFuNNwi5Q3AupoRi7j3QCsTWpgSphLAmC4wMViIVMGG++dVf33Bm0g37LDK5P1FkDB6xBQ/Z/iavwGZQ+L+5mrfP9wyGKFaWOSIaiq0meAPdoitwbGNOfpfoWFW4JnOTxMZNPuAF8/wC+0DpMbh2wttgt2l13Lxs7QDFPK8V66qaxSRoOw8r40eZgt3AYog6Nmoa2NmvV3z2+8UwjsB+7Zht7TxHotZlnW/ot2wMoSpjlh3Jig3K69qJaRAwNNzaUhOGOS6Z6wPlxKSg8TjEXojJhathA3VynhiAQlBiJfTNLwqVAFvfxLCb8KNXvJ8pAxLEs1frCqP8AszhVKiwOXXptytvai4SkUCvLv+694ATQMCb8uocDwO+Xz3cZ+7UQ8NoMNnDjvN5R7flVRYqQ7NzHiXzcAL4/bBgPcX6OX7d4fauVyvdf9UvBhgpQ9xGuwvtKd8dkP5+7cIF18Z2P8S40nhFmRcqYIiIDtSP3lBZEjMEa6b9TF/FQcVUrIV7S+Qpa8nCepOYPZePiMZYC4gDBbjiVX0aQablGEVGamIVUh1QtyrllGVX0OoKrhIYBGEUm7iTk8wSdGxXUq6lAVcOVnklRgt94F7MHJV33EVlX3hXC6hvoQNwfMfmqe4P32ez0wlSBZzzbzb/5DqtYat3XosLyN2CvIVoHHuz3BB+LgfvLKh7fs59TDK9d4HxubhMMS7ftrXtan7+kMA05W/StUnEM7rUAJnNCl+YXYX7ezFdF3x3gxeSwMnBnFb3SagvJ4ZD5/iWysticqaKvUI06aw/Rj/BM8KGqzjsytCojxrXEyI2tfTQQy2SHi6HHb/2Y7Xwg7lIthC3jorEJZ26p9THQDG7fnH5qEFiLoFYfsM2gGuA3jmKBNxHWUJcZ88f30zxH6dulTUQlWWMxMjZNen9fTZMRL+k5JTdQzUqJFCrEqQLKX6qz3e58+kAdsquuj9Nn1FouXjF9M5Z8yvXVZDFCV98xU4tkVPuD9/aHWVLRBwZVUsst3GLc+jKKvnXxWbmT7QcVtkM8g5bp2doFpD6gQChngftYisv1p80fmZ19gKD0VV98cQ2Fwifd/LLJtTIj8tUehC/Z4VfpPtGxIQC6vHp5WLLSCy5liTFlJpU7JhqIMoiVqWrYyPX+z8R2TCfF/Gf1Mod1cS3JAvu5Zr0qEW/oZt9Vy82BEAan6SiX1GabjfKF8xE1GU0eYh2Oe7rP8Q0wAkw56FO4yHtyzBLcsrKr6uCASiCktFfDUVVnr3jLbzvLm+8XMU7fozC+ty+l9Ll9blzcRNteJqFxRtP2haPE0/5gFNvmKlP3v8RqWD6/xMjTXetxmviVWDo/UxFZX15WMtL8n7P3AXoKdFYAlJnEkTMEY3tgItA4FqtSrttlWiJk4LjbmDFiblVAXUG4hIec1ua30VEHPROh1f8Ai19R0dRX0MxNA5T9v6igt1/4fmVR/LgrN9ovI7qqzcanh+f/ABgQuf8Ac69uijyBhqnB3lVqsFPW9fXU066jv6rmU3djcSvDmU7zKgQCz7iFjGv1KxNQW45nHQEaxMMYRXhAcxBRFrHxDIw+JUq9G5yV9CJKd9Wp2Ig20X8QV0WUMxhV5hT6Uh/xWpZLI9bjX04NTc1G2XiJlplIeI3Y6z/PzKieQbd5P0fmO5w+NV/XSxg0U+0I+10TtXSutdLiUCynhrddHslv0hcoiuOm4nuB+4QBzu24EUSrOOZ5wNy2yNmVmq1FjKiqIMypBZW/eaMGFd9G/un3ii7y6thdR5wXgwfP48T14L00erqFFbfu/hnEW9lRmRiRlncx78Hqs57AK/aGWq8g+1r9o1ETvy+C/kIgyFtLf3CKF2dXxe6uMnsQMzEw59zCijP1ZTsyvh8RusPwQ4T4Jc4PiAbi5cu5jpUQZR0roFaIcaeh8n8xTT+R/ERtiKLXEdHZz+f4jhRjf6PQ/UVDx/tQg2dIH2i0XoiJIyvoJnK/5gPYVH1G/lhGn1YS4syzwjOfTn7Qw0PWpXTYdAqXmDMuZy4fThhp9X5ZZDFP9/ioYdbY96Qv05PRhqdjdnfEEAmAp2U7+A+IIOJdAel5f/PeNl1Mu5TBRjcC5Ud0PGKze317vrGNiI4Y1R/5MUqrHF3j4ajGOWqq91/plAHCFyjxiuY+HTe1AOjrXTmX13PDPCxXL4h+EdExAKhxH+9JSRb/ANx8Q29CIIvB+IOkiama8U39Aq4seZdjWjxzDI5KV8/73mpp9NCQplMqITKsUi3j/H2lTUtgC2GVhEHmC0ljMqE7gBbFHGR0E2QA0QiLWT8Vv9REnGl/MBZ99fb4KiW75lfRUvucYz0B7/xmHWUKvv6xFVPb+blFQfQP4hzF1eK2Vw/HeO8WfcbD8RionrV/H/scy4PDAKb+P7lnT9v5jTQvtEtTT/b+pQyD5/qVRKa3nJGZbOn+an+K/uA5+yVC9RlHeciB0AId47BExKtzAGZ6IALhYEgUVDS6oPxEBvOufMArp7wFR/jEt14Y2SUeYg029ufWIZH4fxKluBFVo07/AMwFwMkzhj/wKiOCVTmZxuZi0v3P/foqDUuxUYru6tO8UqgTEoR36cJed1+WZqZxnZS0/FMMebX3d/Vo9wflDvJcLVRNJQ1/v3mVsj5jNNeBa8B3nmhL7lr/AL8SmErNEy1i7y12D3mPMJfF/wAxNS2Oe7Bop2rviE8oG1Q0LWWqz5lKaoW+617449YgwqHPqvEJQXRfHnG94YZtM5x5EN+++0wbz9sbiDuPFEjR7tWcYmlWyejn9wWhKEpxKMNWEhbMdDfrQYLSu0zEoofWHRQekQu4eZSZXxDJZCAUhOnDcd53AbRnd5hhb4LvX2hWqzxEhdCCGPfMcO0/6vEZp9bMGmpfmY2cxvL184iZLLgcPS1pcxLiCZcZdL94X5gJathAHb9xVSqfZsxfz94WVf7mCKnRF0y3SBKlYOHodDRpn8Sgik5tyeiTAlTxX5395sp6rG2LP2mnS/qhVnjwy56kflvJAAqzvkwv7iZJbUxRoe6f+RBbM7rGF3wbuo67wsvHB/P2Yg2YZGTjj3xUoUUV69+fb7zBALW+c/b7RKlrtYbLyRwhR1E6ANnghmc1BiqBARE3Eq2FOupDOoQDcJMru8AFtFLCxKdJ2f47RzBaIQmSn7/xMCy8rePzAWDHeMd9B9BvrWcS7VlkdkICiWJAsh+JRVrwf7EILD330og0qwRuUEEcoth2YxCiohzDL24eGbUxoKgVBWK6Fw0CGYARTcLcywVJySuvp3VlrzMy2bZp0JQywIA4fY5SAYave7d+czAv2gAe/VBjqYXFdCFqWGYXSAGnaLQE0uM1hTfENEvh6JCVmBnMIGZtMLuyYZrk7yobNa57vWLMKQ/PPxB2uD7/APsAsp64sYlzU06hfQ6YS7DBiYPTGO8YPfETXaBazexh6KXv1ZfR1BlwZealXtmRC3W29RH1JV7gI3LYkQlruWG5dwLladRU6AtwLI6wRZLDV9oKMmbuGEBFm/1AS76avTI9v/IKZQ3GzdSoxAaGIAYKgwvT9yuZZBAIAjBZBgeFiZlpnaYyvE3U8gI4pVp6mzSeGCsYjWlBz7+b9ZigovSmCZdxqnUTJjGXEuOOg56DMQIyysmBDbywAoJ3CVHcYR1NdCJmb/SUSqgXK6Da9ZmUOZl6aPU6BVXMGumJ6Ks5HSqHaLjqmksQ1Lcs9f2ge8r2wSOcKWJKhy9P2TSVwZjiUNwj2DiOrPH7jiMCFcxDEQlxbcEalEpAM09n7gv1WYB4fzMe+/Q/mFSLlgeJZh0akUI0kOjvoQta6LipphGESKVpCWocnN7ccUPvL+JrWIrXj/v96Sqiwm5jpiCVEsfTpUuJz0qALtIPg6cdlomNZLiYlKSGogHUzJN+lsy3BSQkCV0KoIl0uDajDknow/CER9SdKl6BggtxGZty3qJdFiWQnKY3MqYTWVdREMEtzF8j8x16z8EqIzZ6US1SjoZ5hA6OYdLSNGui7M5kAO4hDt+5fKO9AqaR6XLlwtlKHJliaIIiy12RVLBMbEQMuMCIt46LEFalSY2MIvJKdPKmiFUxKjNcsNSOcNRMAWVA1agHshopXSqNBgbQKmKmDdxULFUE96Dc5dDhj3UZaYOegdCVccAxSX5ufcPwRURN5i36UpHmDW5kyK8EpCCXxKYc5lSyVXRuZgZzANJWzb+xDK3q6+ioF4lTPQ0mWCywK9oN0RcnEEuCDNkVEpjUdEmiEdURFxBzAE1vqgOmAjtMZ1DPNETQo27jfKGpqEleg7i2UBMam5MkyK5iq6iqg56a5bHcWS5cEQYBZB7wZ1rfpr+I6JlaIFx0EsOo1uWMCo2Ny1g56N8Te5REoj3iOLqG0uX5Po0fo9JUW9d5DawVMS8xckyszLc3RFZqXCUtE1mCkmjEefVMVxFvpHFwwRr0uYNksFczBVOZlVyrl941sxkVXUgQWRVcuyzxCCh69DDHO2aYlqi5o3LwfQWOuVyRkGROdMFpQWsCLHugRXVgzFxNoJLuPVYMziIrMzX/ADJ9Dr6E29QmyIO4GgaeIaQp/JNd9G6XRHtisxsjDbMmVrYiJxHOYNzAAojIm4rtM0WXLgFoI2EAIEy/douthe8RVl9BqMt47iMaQlbNRKTcRUhnEoGJUiQQ2TNPS4vW0thaMIxb6OswbhdY6HTP0Yodo6IXJ2/f01UqpysG+tzRlm4yzRYi0LNoYlhUWXNMFwlKKhhxcbFNRzCSrb3mIeYsZmUO16CKYlSkJUwB2Rn0O5cuVE2lMGZQkLMNRYGTmKzri4sZcuXLlkHpdQ7ph1KipsW43pgwQO8ySmUynpqprmDP6fv6VN11NQaluoTbRHmdqPZngYCCKFRbYwmIgfaROlJjGSkMpjJbYtiZMuwRL1ejLIrI63CswLmaVglD9Co4jrJ55ZC2VzLl31CoisRSLdsF5lxBuD5iWxMOkQ0xCdroNEBzEzIqNzsYVNCWQfMx6zaGM5V6L9/QcXRAGOpXMqVBqZZaBXQZcvqCiNdShUGZc2GfQ6A/mBL6MYk1xg22K5uAgB02g31eq5QiHM8D5ifCMhLPMWj34pFu1l+laBmIuDW5YJX0W0jDBYKQXE2goB6DRMzMWky/0Y6KC2VSaS7BBRX1k31WoKxa+gIFWc5ifMQMsx5aeaKx5kumWXNpcS2xPkifDpESiPGRLiUIbf2l+0Q4J2T/AHzF9MZFMK8pdy/MeRjaFsp+thM8Rdah2oPxDlSUK+kRcUj1OlvS2DZOAnMte5YgWx9mFoOm3A+q5fRbL7wlQlo9OyU6qcy8gS2iowT5j3o9yLcyzG8VPOWlvrqIdNwc1AqOeqlMpme3S4GgnnpYg3uW2R6hf0ZFRxN9cw6V0JEYrwwU4iTfP5Y7rWNflgnO+h0el1LYN/RuWQojaYRCynVvFS0SrBSK6107oBZS6lCBfEplPSoB5lau5cu0RUBm4HkrFtBPeFY6sYXxLhWWwNamIpWYDLXMTFzRj3hfboa/FfmWFlpXywQ7E/w2YE0m0NkelwK+iswikSNE3MmYGZVMZaS0rWIMyXL8aAgsdCd2mUQQJWVlYwGJh2S0tLS4qFIt/wDAVpm+Yr/4iyzAzvP+7QHGieiNOjrcERTz13qBK692ZjKMul0tXiamOx1ELG9ouRdQtUzSYLEELql8hguXi4Bz3mBr3mxH6nXQK9vRuACDbZPKCPR6JgSl1F3B4U38wKnRmXC3/wBK6H/EDEuBUFr0hNJr3iSliJvoC0LmDfeotq4hAVs/q4BCrIn5VX3gV0emVeJk2ZntLqBlIsaLczNRqVKlQrAHZAlHh+YBfxURRKBkuoM4zBiFXmNuJol/8KEScXBvDEoqKpuCVmIPTuQ2EHgRiHkT9zMOYdSvqVKgVronXj6K6kOqK9HMdEdZIgvmf4/ctqc+Ne/6iBsLXPbzMW+cyx7pqz4mCGWcxb6L0uqOCRLKl/4Su6FDTKV6q/pKMTbpt0IbH/C4Epjhj3hbcrMSYg3DUsiGZzEAZhv6E/MuMam3WokCVAZUJUcyuhuIEJhlHSrmoVFqEOpDIAYmVuWl0x9Za1qqIWLkjfXjPtmo5j0v6BVekW4KqWHmO2R0BqBgnP0/4GIt9NuizRLlSpUdTUrmVDfvl243C1t0TU+sUhRqJQoFmVWCKbuWyxBSMZdlF8hNvorN9CUyoEqV0b6mTcs5lJVSrlQKidKZTDHUU2HEoadOffGJVy3ng/MIOj3jtrSwelFXfSvquD06CRUQFM0kL4ZomZPrrqkGoZIFs09TozfRlKF4SIUHEAvS/PEwrG3zmcrsfmYi4/EoSliUjUqOqjhirUylO7KfeMddU6H1EqmNpR1CurmJiLotdRadAlQldWHV6kX2QyQZNmzLMCVF95RXtGdPr9d4rpa66N4hjECppgfQ9AxGZompt0tLSyDgdH//xAApEQEAAgIBAwMEAwEBAQAAAAABABEhMUEQUWEgcZGBobHB0eHwMPFA/9oACAEBAQE/EN1v0EbZIcH0D6r9Fy4PS4vW5fRb/wC+jq+IKyx162Zr9BiDfSoFZjT/AIr9VxahwYle8HuIzKi9zRPXDhmHkgjNTc10vqeg9b0C4+P/AIMR0TFS+L/4LfTxFKn0DUGzrp/wvoejEpYBqMs7xLhmncU6gaWoQFgRMF0xs2bimGbjr0H/AFMy6K/+HYl0TLcNX60v0Cnk9N8S6Oi4r/ikC4RpZiXbE9RSYJnOYyvUimcjUA2RDuK1Esj0DxMA4ZTnodK/5XLlzX/ZZcvoyKgwtEMH/B66nMf8GBfqUNzkpdpcQQVLgGAgErKlSprfUBTFPBBLOtTSo5BUgNMYzQQfZBOYGkOgzmXL9Guh62XUHqx3mC1HtTAFERVLUF1gRjpQchBuYPp6X0fT7yx62NHR5EeCcBOYwF0twJuNIaWAGPTZLlSsUdEuI5Dg79KWUyl+JgWWTEO8RXUXyhps4qB5INuGg+jX/FlNmD5iHE4yfRnOQ5mcJAGjomiOxAu0c7jvEW4jwMp26Tkn2h3kOWDcwTT1QFRpKegR2GD1LOkrwxbAHiGgngg3cwI7HIzUuXLlxoWxOhiMU6Ul+JqXNDLu71cdAFMLdmpRkTJvprq7hOAiOGchOXmGogu4LzBHXRBuC5jxEW6JwScxh3MA3NEf8HkJpnd/wQdkU4jwxPDKNujwERaiExuLaqbODmgeJrB01EGIJ3ADUKbSUTXTSXUtA90M7AhXBjpq4jiIkGtwJRiaxB2jOV3EvoFyzcysalLxFZZEG+jg9HM2DOQx0UWEJZI6kj2QnlA8Rex/1FgzAw11v0PXbMDrPTmmtQztTSQHJFYjh6YqXOi3JBGA4GGgyvEKrYAlkpNug4yxTiPMZRFT3wDrog7iGo2QWpSbmNZbrSAFnS6ljEHDMvxAFkQMxHbGirieCcRLhzkDyw5IBxADXo2hFOI8TOQn1JwEE2QbmGoy/RcaEwMy6jNy47DENRbAns+gAdzTHW+tRIoNMYAETxBrYs1AtjK0MuZJVpK9oLohEUVPwgJg6YV7geZSN4cSlIBiPeC4Nbm5aMuIFMZvSAlx5US0RTR0yDLUU2wc7Lt1ZKBYiCXfUr1rL9C2yPAjwM5SO1DQQbcG5imBAgQDKBszlI20nBV/vPSQdtw1CUGvTUrpqJNsfg7jYGYvioPUeKWcRvDLFAdTzS3eHIhTbFsDcPLmJcDpHy6PdOQnki40smQxjUBMdHEwzUuIwYFYiXmU7z3yhzEvMpA4lKxS3dKwKYpuOoziWDbU+k0kCeZT3lPeU95bvLd5bv8Aie+e+W7z3M97PfEqD2/eA1b8zksxqCGsYTolRFWwJhwcwDUrzM+fuzHn7y3QiVlYg3NkzvCdgEI4PzOEQoSt3KqG5wE5GVAuoPmcyDtXA5rgBqbRiHMtBegCDQH7ppCU7T25fCyxgbzdIbEAickGE1LHpRGoaSolxtWaiBZHodEOycBHkJP5DOQDL7EF21DSeu2YHmWdzDVK6Is2WcFANHXmc3o5jsE4KJbJ0zWqmMCFokoXU0gsM4idq+0NqWaglVMSzo6mPUUuEIrBDBSpACO0jwZjf7MsW49obmXKIwf4UqbCCcw0H0NyY4IU1Bm5Q1LlzAQXzBjNQ6D2gFpljKiTKvSJxTNQyejc1uO4xHUeG8eDIxay1XOHMDxInxDWSD26L9DgsCivRqbeHSVnZvvOwvaFtpYBQYi4o3SMn4DO4faY7CD7ZphBNMwJeyXShBtyrcwyjW4bGkO8QGggjUuZlszKjaO4R9qVwrtvUJXW5TLsx5gCAJXDougbl3/vvMof4qDawDDEjo6QomG4x7x6ZvtHQImyzhoBoqVKZTKZTMoOxF+JjlJO8Je60ttkOdqaZm5GDYvaKz+fzsT2lcmsbxFzFS8v0r9K5LMv2l5dA0CO6IrrEWssLTA4tSzbCLmvHoO/HtuWpth2jCz3jTd9ocXXVD+YcptbyY94IWCVS4Vl+8O9LzzTzdStM9SjmEp4jfBEtxL0WQEuUNMEdMu4NQ+wmQoV+YQpKZdYmwmkx0LHEA2S2DQTTHn6pdrp2cxPnrlXIQLoldRpxK7qD3FKBIj5fi5dtJkqQYwPpFKmampfwTwxgl2i1VK5V014SuSTyzzytMTlL3Zs0MC4q8xCB3BehUT/ANw3RGW0FXuI19RfqTJ54xqgLDwF+8RWMKd8b+8MRZOyqbK7VRqXZVn5KfkjrojeOENf1MDm/YTLRxG7gDduFmvG0+IhQRQVVDJi/aAfsBx8a0t3BUAIX8BercNYPdtPAqAXmgsTjOLlFhTcYi9NF4zoism5aBdNl0NnJeZZ0qigo4Uhl5VgHW2qsL41xFkbdWr0LcrpltQDmW4ZRqKATNZARLCryRdWSzTqKlzA8mMHc4t3/XvFFqrgysMmt18MAsaXLGuIhBSOsxKigMojPQywXCXC7lcbJUsjltUAacymjiMKn1hAOI7MRNlkQ7oAamltOMSyZyo8p7S2TMbSiILJYXU4qVTSXEswOn2xLjhTN8YpXxC2xTDrQz4/qG3D2hnr7v7jmE7M6+8IEVndMGek1mBQeTnfOYsRFbc7zfaPEWtpeIAOI0myBXRGlx/HiKQExxk8xtaG5iv6h4DHRcuXMJlzLS54TJiy0tMOYMVuaH8pk2zBUAW4IMQ6HiKnFy2ODNU3n/z6Smz+UQVcJqBkIW8c/MM7lZGAskAalimVC7LUe9l9XDAXLtzOTmIGY/ccJqVNMzQ37gCyVhvEC9JluF13FdzyzfxkoqgH9o0hWiC1LYCanhDZNMTMgijlcsTtLFCnQVtwIkdoJsj8E7H8TsfxPEi0f6LOGvuzt38yrl+Yd18yj+SU/un+TAIFQg8HMuLoh5P99IOQQbZFuIg1UryRWKiR1Ado4YFnEE/mMeRFjs7xBxD86gXLU8SeY7nqYStlTf27Sz/L7H6i8GF1S9oAssalmyUyYKxcLJuUIghXVLgV1S+gK6pmVK6pAIMS1dbnci3LhhiDb0GyEUNwlxASy10TQr4YqBZj7x0hSRhZcCzZN5u39RKxBu7x9/xC4aB9r8HTAuymu/7+kPAL3cvsbYAMrRkv2sIkSg3BnJ4YtblZiBfMRwEIyxmEpliBIyXWZhgm9QKyxm+k+rUIPt/ctVF4gtEzLmVUMSZUMsS8qGA5p4pv8XcugK4HaI0EFC5ZnABBaYbl9Ix6cem+iDLqWVMSkYBLeCW9pfiFvEF2gBsIrhIqU5izf6Sz/SCSZjEJSolGe2A4joNmpYY72ia4Y/MQXaz6n+YPL3HW7n6GDy2fuMFnGVdfNfiapD9hr+WZBf8AQ/NwqC3sHvgPYD7oZc6NgOMayfQIKJGUcfTkgPidn994AoHwTQNzQukAGuj02ZlPtAckuYY7VFnEsSmF2dPzHo4SWyhu6VWumYaEI0lMuyS/km777s9+2IAUqKhK4svOM7zSELaly5dQlbhViGM+hDv9fr4icH2SoieMPbLG0l8UiPJDgY87PPPPCBGtvprMpbqINUwbQwTfEpV5mZmBUSZWxmrcuXePzKCZMfJCyZH+4Xv5X5/qPWoT9f1CRbZ79v8AMKWxPxb/ADL1YRfayvvn2IsC0FDtVD9P3AzoAypxWK3xEVXZ5fmVczDqJcuX0voSyN9ROGVMs/aVMgiNWg7QtqofdUw1KtstxT5lIfag9sEOtS5fMeQhZqXILALKJxVEtXE2JXsy3gg3iEFRDBcG4rxLZbvBYX0qBXSpUqVHrj0V1vokesUpmiUDAdei5BMou9wqqiNiaUMGWG/aCIyeYiALbywAcHeUYUwhyAMYV46Fu08EUSntPBPBPBPHPHPDFdkDxC3FfiAZuxLc4KfWv4gnKUm45LjuFXVwUTGaSwLpnm6Xi/MasYgPbMtcSXD2rmXcO9EGcCL2xb95ZbYnSoH/ABvpcslJcsmINymIy3aeCPajrCgXK+Ii13GCoSdIG0Qi/shlu4tEDF3A4ujiN0Nu5cuJ4FuUugl1CxYFX3EizE22XHF3HHUgaibSCI0zUawldGDwQXNRDRHwdLQmifMFBxLJVLgKiDULaTcjglG5KehVsBTB0WWMoV2RDUVEJjmGgIcwEFtT4hZQ+0a6sioc+JeEEiHOF2X5/mKXmeOeGFTyRE2mSWeaeZh6dFYEbmeCezGvaexAu0PFN8kBMRsoQzpg8ZRiyBVVM9EaQVDBUEHoi0s7g0RnKBo2werRoU144fowLmSYUqDUuMt1x57xOIy35ggYFV81xWkYNgWPGq/z9ojWWMusfWNpiF2suHBE9oKYyqSkq7lRKQymARIOGDEe0Qt5I74ooXUBbYzQLuGgZQ4xcUDOXWo95fWKkfP3ICeT8S6itBDEuS8WQbHuTcbDDL7pbvLXmW94vRX0V0SoUbhUrqejmPQ4QaYrMutcQdBoqeEyQxe0g/z9Hn3j28Oxfw9pZ/ilv6pV/FBs/aln+KHd8ETz8UtShfcnkjau1drA63FejMQ7otBMufPmHoDFem64gTDGCq7s+0IOxREluJmxLdWQxfMNVya+YWe6YimiNgiEcQVRu7+mGCpVxDSh6rAzWogbZL1jo6i+qvQ0ihCjLqDcvoSpTLdo2angljiKwJYwQBPvBx7uj657DBb1g8vL9KlmuzoURmhESZZSA3b6na+O48TJyPNie2INyR7mKwXMC2pVQA6nogdzHTF5mJZDMpdD8Qfjp/XzuMZf3lK1isLu45XIfhgotWfIYd5gf/s8MZKi5sjQoXmeM+IFxMGY8FgtuUsHn8Mwo1Ua2e0BS8oq4i8u4SIAf77y3TuXZXArddEjyg1lsFq+gL3fOoUg3ZvNB27uftPdYclxHee5AXaodx8/1K+X+e0L8fclEFeINS6ve8twDrVImI46BnCH3Qnk4z9T+SFnGJjH6r5qZo1U+EZfZ6cVfNbz8S2omaxlqUFrPaH0Fb2/GO0OsBhtw7NmTsrGOVUzZTjCDV1SdyWzG/P8zyjaXLTUOY9oFeirf3ESZHzEtiN1Z8MGsPxE8/DP4jxL8MQ4fj+4npfb+Yhr7yA0/M8D5f4gyhj3h4Pj+4h4eJuE08Ps/YykUNUGnPmYnrUr4XHbJxUUDoy7mNke35hGy8sw5i4zJqXp+Y0Qpbyl8oNBjFVyvFzNTf2hSXuX6sNrGFWwh5SwS0tFPMGcxXeX7z3z3xLzMf8AFal9LlkqXFtA91X239IF9beLzr3+z7xBHVoU3e85JheQ1Sr8YoYqQC4B3z8/SEnpAC5WFB7L7RDdZVpouL0LOcfmpVPGD2MWe/EBe223HvQtewx0IOi07GeDnvEbIMUS3HgTSLL6XC3MOdL3UcszglkywONlBPBPFPB/vmFkXpEqPEwGFHp8hH4T2n/C/pPGg+Wv3HaLtMFFlaPPQ9C+s/EsQz4jQWbqByiBRC+J/HBLwKVzGZ7yvMqVKhFsv/jcGLRC0uZlpFS3ot4gvPS4C7WX4PwysdLLX4HZ34YIPEr3MZ+2fMxHOQFv6g4+mYbQIAo2B4c+Vj9mSLbTp92sn1uOEgbHRjxv7R1ue3E96C1DH1ZYDpLxfY7+XR5uCaalbIccr2PLLoBNgb+r5iI7dTxOWoFdwyy6zBcmVB6WHMqcxN7lTBcwtFjcu8RWX2QemvfEVjAO5HUbgk+cBJrHN/Ln9xjgDeBhvn9TaoRYUvDpXGssBns/qDqcsLzDdyGg6JwovV2+tKSe3pGy0EwWWzPUc1CGoG7OipRL5y+Mo9C9pVOsVm2hVYqtljhs3NDDgC36aqu+IbsoIEOzDn7b84lQbozWcfnDd2EuC289/p/FwK/Ihz4OKft2mkLjxxZEmK8jf9wsqnPdrZX8wHFaK7KFfGID3XoXygbz5+2YgEvzE1e/zj9QcMCt1xKUOYbcSJXXeOiS4NLMymVn4l1kDLF1MCjZcboHJcLIbP4hdppihTRcbM2IJpF1RqPxlw7pcSiosvEFidNSMqWugaCzUQNLADf++YJslXiVvHrzXo3DOyMA4ZmsVLMjeIuOhB5e/S3eW7z3SspKHVYYTa/bmL9SvkLsx9TI414gB1xIIIq5Fae9dpvGmMzQwB5rePoZ7y4YV2iqcEvtZjn3gN2/N5T2d/OPaX4sihliw4p9D/fk+8oxbU06TNX3gcHgDiLSnxbzrSfaLF6ujx5vf5liupjJAx9NReD0NxzAjq4ZJUKngypi+YgNsQsXEvdCZVHi5oHcP99JYwPH++IHFHNfmNaxzUUX4ag7Tsyy0S5khVaahzOQ79GgF5m447EJVUS1WX4zUlTTMGZikbrjTRArpPoem0qoBLrsrX1jWvlaijOKPOZ7ds5iOrmXnEH3mDCoDwITU4Pf0e0ThKSB15l2zIPx2mHqAjfNomTVV2/kB5dGDNdn9P0l8twfRu6lC5TY9zN/U5hD5VnuLdnvf5hwIDvxfPtzxEgbR9b8niYUuXn+u855cXBAB20Yb5i0AKfv+ye9EPEDYFKV8c4lPAr2JVCImIIHQivWyPMbnzFUneIu73CCNw3RSDEXAmHtHTeHtPI3/mZku3E/9dCDOyyItHZCiURAJoqBosQ0MwCKA1FjLYzAyzlMa8MDnMtQVUqYPTvt1N3LI8wLSZuArJwETwRJRteTzMl5+JTb5lpifaVexF3CL0ePTUoj04lR17ceYl7gFYvtBY219av8RWNJZ8KD/MCIwNWN4rdwWJqxG1rhsNmCt4l9lebP6ihCPbL9qPzKiKYzz5O8CJS91/n7QcWxyVr7f1NArT6QAUSgYBzDK9C6lx0lWO397lEcHm5fLM0X3QPifWINUnEfiUGPthrL4IjhftFcj8x5wVCd6EDKriNKEMxMDDUTSly7ECppGiIhbSN2CLON9FDmK0aUXFxGZiFLicIJVDLlI5bnEgTjd/SKSiLs9v4l3f8A30iy24xdx7wNeD3lpRZBQl5qU3dxeP8AjcGLD4j3UMpn3m+Zr2Ofo48y3DUPuvL/ALvGUFeMc+f94lmqoLyjjT2rFcfMTmDw7+b+33j7XEfez9V5iR+x2PEqTTwX9O/1iBg5TXGLI5gF/wBnpQxCoHSrjLqPTVD2j3P5ie8QngmiSjCXFeIvLoE4Y4asyEVIiTUfDFiZEdqdNYhzAvJeCOETlCmmL4YM2owYGMVRT7wApwhxFRjkjjEAa6Q6A/8AIBq0/uG0p/caDB81G0a+T+Y6C+pA9/e/RMQH5P5Ijbb76/ceipMMILZRDANkH1OYRh1sGHZlqjXiLaJn7Y/cWnKKXnuv07dopZ6Zrk7xFe/SPLnAO1M2nAQtYDFnOOR/OHzKh8GFVe1J94OKfTV8Ffl+JUlLurf2olS6vvmeEuyYFRyzUu46hKuPRUUEcxL6SF3DvlVxEO0C2IE2hyRFQwwrGcagmiYAt/22IDlLLBFvwB7IZ6VEqaksvLDeZd5YVzPNyCyI8FbVaDg0L/4yjceV/bD9pRDANO6dYldo1CZg26/PtBwoC58TJpVzTjWMYN6jBMZN/EWDTa04eT6TC/AB/MzrHWbuG2YGK+0wR5/UH7vacju/BFhqOXh9j9wEpkMfb6cwaEOxya6Mtg4EuNstlFHNiQgtw2yqR+DdQsJ+rfeAA2+z/enzXeDjqv8APmI90T5xDLyO+9mz4gVuJaArbqKelxYSrmEFdL6vNdUvUFhDHMRo6VK5mnQB3DkTbMv2QLp0qVOj4y/CIFqcN+Y9j8/3M46IBsCIg+0tjecI+ICqYp/Eb/NE+Mc2feJwwWwR4WoCtCOEMfXfzCW0JduPbUHK0C1lo7pnjPxC1+so38/qOVTOTD+Ejal8uPtX5iT4Vq1cRVOl3ktf0J9pW2p4/NUvzGfd7BjToDXiOB3wfHEZcbmQsc5pOV1Tr3jcZPd+Ny15QwvAd/eUnMd3Epv8x4mb2C/iP62Sr1bef3NG9QeN5iUqJ1UdhcSLHw/yfeFkCw0iPkzYPZyRBiUOgRCU5pmGIqhr+Df3LPrGzj+IGCCUFvzDYyME4/j4/iUmHwfz2imVUt1uBcHFdFxHcRGKejUGGGMRVLeoejcNxVO4y2VLCjcXMtYwPHvWfPeJVPRuQ16Klda6Ve4o6lSODDrGSOh8AwhDgMYv3miR8NP2YFi2zQbt+mqmgDuZ+xn7yvcZM2OMcPxi+8SoB7X+Kfki1KvhP3slFZXYB9hagp0DPJ+oY+JlMHfJ/MJUB4Bf0t+8bu6+0zZvK/PSpSYQ6IJTBKN9sOCId9MvRAPH4j8Rv8mcQikfeWKk7b/31uC0q+I4DC4Z3FOIy+izu6jXoroLzolDuXbmJXW+lkUqCxeYs2CLbMr2bl7C9HEZTjNluHCsWJMGv6Y7Md9bpb12I2cyrlSrIeS5nwd6IBWGPErEQZUqUeoJWZUqV0OgL60Qg9xfwkAx9h/mVwkgKJ7we2fd/UU6PmArErsiyGn3zGXDFrBqWxly+j0PQlenE9kYSw7lx6bN5eU7yjNyqWEE8RFBUTpNp8SlRXTRipY2LYEYKlQ2DEVue0dhm0EBq2cEHlg21MaTU2iz1Iwif8qOldb6X6l1N76V1G6RfzEfNT4qGMdKm9dL6EBIeq5cCHmgqo33EuwCplUqlEPCPaETMZgzTpTMmX8RRaEDRvqQWi/sL+Ce4nJT7y3R+5v8Q0A9v5QIz/rR9oKpHl/bAZGXLGCGFQgUVG/Tfovo9ulYleivQldKetSotS4dBLo6a1011DVi2/mGUdr+f/Og9XqvYU2dpfrehnzK2MH0ysqEmXMK5uXLvoiohZjMpgaS6m4i1CXtN/qZIPzNCqaLYQnvKQQZQTgPtNtm+IvQq2jzMFl7ERLLfpCgIvt/MRtzVy5bEVGZFY8jLvMvuYL3l3zLVhitmVKJUqpmVKr0qGWUcz3vhiFZGV36KMvoPf2/mCFKTcG+ixeqJ0EFpnMeyUf53hv1MupcAveJSpaRYaely3rpdTjEDKR7JQbjTo7R3/iBxMxLlYphiam2YJKHS0kUItFx6twOxPBGU9yeIj+Yblx0j3+hLLWIME8oJDoNCGp6bl9VrLPKSjh8zZH5mWJlYmDLmm4ozjrbem5W2FQuFWYDSJ1fvRHp0WVfLz9OO0Kejd+1P/k5/wCFSg2gBygE7pfdnMXqrqDWczkRVLunEj2SxxDUxLksj/E0Ql9ArpfQi9C1Nx+nMU8kB3AMn3iTXNlQlOaYGZUxew/MA2Zi0PHDuE7z0F6hSl1BEsjKcfn/AFPD+f6jxn5/qWIA6gZ7QDQSyBeZRPCGg9F0RsSh5izTKFitcemtwC2o1uw4MsGKP5ji2SCLgoNHd/EAX+R/MTWzJj5m4PT26HrqO28xOEq/EpAPQPmehsLK5wAYiJXtCpLsu5jR3ZZO4Sjia9NzKUe8e1njy/AZV3GyoIltytB7stQ9gf3w/U/LTL+WgxZ6UkLuq5Kx7RkLbBx7RMNqhYXRNJ2uBsd5QuVcawhBq64rfEfYqPtiKhY31DxlvaIDUHQVnorXiXcw7MogdkBEYhBbVShqZlYjhjHccqm1psCte9wiVz8wWseFpIT4SXjSafyRCFe+kjBS/n8TF33lZ+9/aAFQRhr0vS4GqjUwzC1v8w4OmSpo6IDKd5RtnnnmjLtx8YrggjEcFz+oXt/6hETfShuYbjjXRF3EWFJdyrw3B3azkZRxAGp+6GoQlZnv/MV7gHwVApDGfg/uWwbhSkD6xsIM7/EAb0qZmZjvjiGAoI7Hhi6b6HoKKd5TaFokuplTxOeiJvoNRbjiXeIHwJjWU/ROdHlfr3IgQNNscWrHyP7CUycwz0Z/EY4tGX6fpgzCHpeo3WN6lhIbCOsi/LUz4nyQBVbq2j29/HvKpbKabPmUdFWFkb7QJAUhFlEe2ht7R89mc7iADcR4ZVtGFwqxA1BLVERoLiW8kqzF/ECmSCQQG3peKV4I8Q8wOjMsRCscfaBVER12iFkuXBHM88cHiWb5VO9C7MWo4XoMm3P6Y3SFVIUbl+/4gPO5uypdzEM4iVHUW6HACvlSx94AHdLXtiAmSMaC/wDpN7MuoRQgWHb89F0/8bYPzE5YlBiQNYXcI2h9viU5iHJ9mpZdW1oo0cce0oiENwCUmEVwc7FzmGeaA8xHMYGhixhTUQlEqEQSXC2XUTCwOhlqMG4gszbl3Qugkod13iJhxFbDDUKcS5sS5UjvEFmXVEHkVM3d/WW6UfeIlW47BEHslNU4lC2dosYBpXeaAe0LrkJ4ZcVAeSeCURRcI4GVe3ApyjNfaDHHFQQOBAWJROiNq3MOprqt+iw3LpUrSG77xL3O0y3eK9yowiwjKuax19UvquIlz6t/MwbYhx0Fv2emLfTcetNsaTJdxLmA0hDcDq4tcWPbPa+6P/ujwiMm4JQXvpq95dWWqSxuK9Rp3BKXMrTJcoVwUXBxjIuZTrUZADEKL2jbMa8wEg+7+pj7JLl8IeLwwRkSvuSbFwIcMDoQTq56XLmSkAziU1BabOP8kQG0CqvXltH2ZREYftIx7f35mboxEY3MymGxKL36C1ROm4lSoCtBImrWYYzFRRDRxTPBOxFtstEkh8xFWk8EL8RC5sHvKhYsuADpByaiJbGSVnTRbT8QBV+F/UQi0cuOlzHN9e0BUINTnqIl1CowiVRmQqaI20ahg7JeEWQiMcQGiABRB8D8I/hfzGtlhDEe5BYJLQCtS4Sugx6VKlQlqmixI94KtLx4jACOKR+4TWIrabSq10vpuUBbGWI6CUKuLDX3mdFykdS15hUEKZZdglqzj3i9sOAiHLF9wlS8t3mHM901xlwTAEOlQ8SnUjouLyx2y/uAOo8/+zKWVclhYOnvuAN30B0S8TNDiJpMss2qXxfWGmocHmA7TBSQKARBzHMM7ZyEyJ1YxhnOaP0qOvZ/cNwmVRCZ3PzGCuJZDUzma6kWpcHq8IIdamRmYCFq81TrzDNLl3XuvPrgi1FVEL5jUiUAhcTQU7VPq3yQKC3EGIF3HRqAsXiVtMdpZK3gAWTK+0wheM6hpIvBBXXP2mFAcaTOITf4MrIJyu32OIk0SmiD8xEKLkP5ldE7vCvPSOYB3R2hmaJDOGUD2hQXQPTtHBLvUAX6VEWWloLBDdQVKRXvDdy9IQHeVgSoSiyiVfUmXUZSUsmSpRuUqO/o29NuCWRSppfELRnFRSMVeJm1RalsX/FwhvMZq9pohmUIgo4kXFQBKG/omDABiYsuMuqSBAuJFMpZsJWk+k83JZDCIb61X7iKHMu+tLiNk3DgQsOJkHNR266LSmUtNQ5uVUjhPREOIWfNTCkqEzMyuY80QuEB6QkEnOvPSFR0MTymh1uvUoKmhXMCzFefQblkCVOE9AwncSZVqnLzFY4r7xFBcOjvr6xZJHc1ShgSl4hIWpYZiiII3m4ktMJiXlgMhIBAgREl8TmFA/IwTfTNJO5LhjAfRlAaM+/QqoTUBCFjEOu+MKgyQO8ANQV0TOSizMMo+NTE6CVKlS5uBEuW9AoOiFd4kXpn0UdTAhcR/P6ToQKj3Ri0ph0xrE1H/wAhgEqaivLKtoiBvcCBDB77BNoq3CazPCIbhGunQGJK13tNwQIHMxChZgGwmOfQQCd0RuCVKHfuSrNB75YblXBXFRnIaOmjDZAQgtqJg3BZOhGo9FdNLgMqVGkDpSIS0qXmBRMQZmQroT29FLqJRcGyO/n6Sk0jc3HMqVKgCkF4iDMOZJbliazFhtsq4BUTtHbZjwXl75m3cZlmKrJgIUbnEBEVwSgEEIFw10ZwlaOJWVlIexEGyZllCrKCBUo64hbaQKKNRoCBcSoASovaBgoeIqIlBAvUH2l/Er4gvESXEMV1y/M8oQHtCAstKm2OgqjLDhlpdRgkdmMD+f11C8ESt7iKiJVv/AYvRLlcQgjgmyWWmXEtWkcxAGOMd9GMD2hA4U6EXMysDXgKK6XzBeupXU6MyguJd4g3EOzDtzkwMJUcQPiAczvQhTlIAbCXApkWXF6C4DOYRLI2jLhGWkpFIMDDtGfS6O0RC2whtEVvrWL1CVA5lSp5R6iGsoNBg0qAJSHMQCKuETwQoypUplrUtdSjR0xeh5oLvPfK94EhHwQLiHagHED0SsoSkolSuh0Ix8wCG8xDFzxzPHpoIGcQ9DKQKlELCyFMCn3Syvj9scIGHeZAxbOleqpUqV0q5UJz0quhjfRUuZyvMIHanggXEASsAdFJQlJRK/436bJuVKlRALuDcXEqalwi11vq6DHi5qDiX1LUtLzDBNNwuINh7fiGwbDRK0adDo9KuVEr0Uspg5eXmcOkNKQPaUIASiUTHHQZcuX0zLr0rXUAtgJiG0LWg/fYm3VzuHkQeioEqK5IN5YVMRVQaU0QuXcpPd1ZpCVfXXooYAlMcS1Yl6jcjSx0i8uhrDZgsQJvH4Y35ZaWl5eWlOknOUQERAREOtQ6L0SKwAqp7Za6qY8Y+8U1zG4WS+rmAOgSo9CYQcUz+ka/UurmecxW4GzhqOuZ4gCzqxBKYcHMdjoAMEQqEdiJrEVTRC47ppDox9C1mYzzDvAnPiBMMawKzMqFtmCLagREwzbggDArpuYJcrmXGBN9FlhNkOlxZcv0LBSLc2IqEFxmJZx0cb6ZJuLpNLSCRUYuHXcsa4mN7ztjf5zPKUqTtLfzFAcTTS5b0taoJHMWtlsCIWilsYl5lYEgRhYldVnPUCIh56JWSDcsgy5EOejmCjMVcACczt1h9eZlDoEXrcuHd0vqNYh0WXL6tPS1AvMTEu6e0QNQLSXBBxO8AxHcJRo6nSxm2CqyfTE/75h12P1zLitGIy/4uiX6zo9GOiHR6HUQuniBSGcR7IMQYKhlIwVShmJWJc7CITvzLxB6XBzFLiy4y4S+q4jmXUvpddQv0shimCU7wBmU4mfEupCGMsVyvRn9UqpZO4De0x/veVTy4P8Af7UJS7z8xxmfmjiDcWuhn0jHos16IuCWLcUDeWlw2KYop3RqKury49o41lS6OJZZdXScjBNIXV8wCiIbQxLXZUuKUneIS0C/+SuiNBcsRKx5miXOPXfoI3GWi3Llxbg9LmPQhklnECbiKVDkwFZAOOqQb9HxGO4yLQjI6EjG8WZTZzbLhKuVDoSpUrqzdKvEtcqzKqGDqzLcZIyByP4iAF4i2yUxV5fciUVq57YgVg0v4Yqusvjd+Y76Cm6M/wBQqQ0hV3HcIzySmGJO2C9diOpzBz0Yf8R/4DmD0qjoHpXpuMPQBe6OIWziJ6IY25juCfMhijjHS6lSo9A6r1XrX0q4HROhIlunqMYk7Ipc/8QAJxABAQACAgICAgMBAQEBAQAAAREAITFBUWFxgZGhscHw0eHxECD/2gAIAQAAAT8QPUR61QhECbR5Qw7rxi5QGkThMERs8YToacZFTQ4dsU6WqavHk9m8RhqC69+p65+cRwIo1PZf/PvLSA72BcEbt3oU/wB4wVQTgnGPjCt5zZATeJzi4pwOhuKm072wlEN5CHj5w1nL3qYLrs3Qwg/fB7piwgPLXCdOKiJeMZaINN1gEG3jFKGlhrEinjT09YOXu+sAeM4fXFwSMKtVDs/WQLt5Dq//ADICo0F+w8hu42I13rTRyDf5OeM9UUzlhyD0HQc4MUQIEmsVizy7wDH+ec2Tw14Plw42nkzg374ynRZpwBGekesAfy4PQlMNdcUwBRxNjrDQ4b15y+NeM4Sp+YX+8UNVWzEkpY09ZeRKN9AE5dpCqwbx1X1PT6tYE+CKCWsI24xVo+Jm1wjnKwX8MA626yC3NLUnITASOCqiInZyZO0lKrne023NCyDLIA9uIkETq5Hxpyw0J1iktJiyPvBiBwNX9ORzo7xFE9bxlRa7wNE9ZyuKCCuJVcuBEYO8gu/OMdoPbiegHy6wTKZyzWI079YvJnV3kqsp5wW/F6NH3gdCYKXmjb+Abc3pPnB5Ov3iuo7QQXvXDOde87ygJKdFolc1fUSVNRtKllagqYqMGpvlTSfQ4O11Ln4guXzFwUOTaSnzhtG67PT1h9acNkeLw/f4y6b4LG+N8PpypoJsV78ZWhJB6Tw55E8HMW/s/dwACNes1DIimn59562K9YEoM6eT4wTosNDfz5wkRrS8edOJKaOvDecpYuCaELfs8ZuRgFnDgILD9fOGcxG4FLppPKVP24N0bk9//crMZdZh/GWKFC67OV/5iDsCt6MJPep/irr9O7z7l34n5RGDN9J/Hpy9wMTBpPo/4wChDqoGMdfucGI1T0ZhTAzo84mUek7xQbvRxvBMJDjATqnOHIPmYR08OsR5/GCHxhmjgF39Yx3B49YbROVOaSzpWh1bcuD5MRmfPBJPEtKRLMRQAdToxSJVyd4o70+cCb7zp9YAaEdnnNEyB1g64wS4aW8/nFWpEkLzPhA9OhRiVkvCIoLoCJ0jkdvezFPJR5wiAI4UISOaGu/Ocj1nAypxlaqL3ia7ehxgAjfnOzwHeGQhXfa/8zljy9MaS8dvAYs7E6GUNsvXeIUQM4uCwIeDIyq+AVcaguTkfxmxK9s2Vc5J+jj7hhbJfIN88fu4qv5zfcd/jWEiy3yn5GBQ6Xy/5h5bLs8mczGQcSICrOm/Jg2Z0w8DY0iIJdxcHzVJB4FS3yO8eDtWnvM/bh8LY7h7S/gGe4dt+lf3MQIA3GPxs+8mPGpfT1PfOU8Ts7+vJ1p7d849RU7J+cl+5gQDXk5ZqqFeOsSwEZeh9d5uVb+B4xcMPJ5x8IMho+3nEBY70OM7DnrBo7jXAVZr2zgh1xOs2GDqGDIhMAHfxmkE0QvhUv8AOKgeU8vjf/zAMC2AMN8+942nE9nAQHJdHtyra/aU6XxcuhTVTG9uUI/bo9Zfkamm3t4yF2cPD67zpB5DwGB543XrJ2Gu1m3+F3i/UHHrOgq7Xxg1bXIOpmxpvHpOOso3OMjlry53dY4Kxfw/6YCowf2G3o/f5yrvKUXO3kNo5dHSH5GmM5icAEEBPOInwo6wRrPJ7xCaq8HhzZFptM4bPTxgcExLo/eTV5ecb9lRJ1CzCJAv0RffzhjL9EQfjT0AXZgakgMmAi0PsxEE+d5Byz9YLUDAypF9nZjel+ecm/WTxPrKN4noP85wH+Ax8kueITwMEZB8uIFKdGFTZV6m8huS9ZR1H5B/OMjKvCyJw0bwETkmbrTai/pBPpHzluU2QfNKvswOU5CPgOcNb50Ee0v940GusT8wC5np/KyXrfnEIRV1l+Nwo+tyQOjU4MBvxfHAcXoj4TjOZvmk8IdP/wBLmjHwFJ6Gn04qvjznezZ+GbXrQP01QxyJQmt9mx9MVnAhu3hsnyNOsXdZoEITY4QHbxiNkiyiRogMWFgVZiKpWW0p48fxigpWnv09OF1Zso36pjBQS2XEJ5TXthyAdN5WJp66c7jqVptdLzo046AoHQm+sZdE55D7MTIDdaOMC2lCTy5ZCJdM763+MQEV7G9bX1rx794I7NUeS9/xfr5gVAPSt2ryr/cNuOB2I0V3Dy3PL9DVw06z6OXJC4CpgefJ+d84/QEocH36/nCYCDY1PGChU74L8uX86cB/GHCE2g84f3GUBaeP7xHA58d5tg34OsNh94K8ZFplpvNfzkl9J9zCro2mKtFf3UF7gJFU63m1awjwU05JI0D5h+hYFxmAK87JmH4GMEmD7MJY6PD3jKQDnbrJZ4cesTkOO8K4M0dxuj05s51hxWl75McrFK6nIIWFgJEHSJrHq6RWaBXdj2zSDEZwdYwPg3mxeMgnk+8HzvnETa5nGIUTbwiZKsP5yN2fVuILNL8GCuaHL0YHlnyaH5wEBTwYcUHjHNobqPwtcYR05/loP3mzAKDu/ANwBW4aAQ60lsr6wHBTSGwUHwAVAcHK5ZmgpwsuVoI5QvZSDg59Bz4Q0fRjVwcOv7y4CkDR6/B2/WDqMG6S7xhEcd5Z5Xa0nuIV50b43x03b2LTTgs1BOzz7PD/AA6y9K13n67iuIgXqO/+Y9PtBkH7H5yROpZVQigYmyKXvFnAIEcxERdxTc4rXMrrPaA+ozhUNPkYnAQ0aYHscH0IJJHzD+shUCz0JoD8OF7lUlPmp05tz3oBvWaSQkOz+n/uG3HKd9KfPeICcR6p3lcbpovfwcCQKii8u5Tz35yjQXBTvkN/WTTbdqduXZFwYd46GAX0A6fwcu8FicgGk/rAAYdEs+u8GW2Ld7XkvnLQCm15nidZFoTq54GzxrF+Jm3t+sUqW5wA5KvjKM7yqd5Foq4cHZ9Z2IKAHyuOA7yGHzRwD0hiP5IxIP8AhH2BhUzEcjEvAZeuMQTKbaQAoE+GrKYFWkizKwQAkiDUxO8+QT8qQRjw+aSXA6AgbR8T6wEX3JjMFb/z1GS7hRy+EH9YJmFRKP3jTZrH7GCFG5+cSORP5wS8WPXWN4Q63xjNyHGz84SdMO6Nb7oUOxeOctGKc0+V+RHhETSYy4mvGdQ+sgcPrFDoVZtNOzWvOL7eTioj2YoLgeXvHxC8AP24XRcBH8j+WCtQ7+Q6r8mO+i/fmw+wwPySkHl0sTSTy99s+xfDhclsBA9E/g+cIGvYPGQvYqnLxsN9hoDTzXcUvamCLXhRpODnV/OOAxmESE/OpkXhO8iUI8Lh3B+DBVEfMz2Pywm5Sj3rjAIt5z2n/WbRPDhL64f7jJ+JOsn0k7DpOQ6TeKo2KG91HUdHZqDbhQhGxoeX+uT3zickhzcRWib04qBw84ZoQh70k+owtp0gO09B4f6xIMxiQT1wRycJs9EDBdBnQPM4qJ56xJcFQ9bAUfnHNP8AwVor0j8Zcg6+BIB+RYM3Mgr+lyg42APw6pjlB4mXlcH0mGj82Gz4T+WNG9eHr9w/Li1ZwghEFq+9mVgGC833/OCDWefHvByuNIB5XFSIMVuQ9Hael9mJG973M1Jp2H94kKVnPg9ZFulO3f8A8yC2B/OJII/WISH85UdPWO6BfjNko5/LxriCAP8AmkC/OfHmK2Pwo9vwEr9sSxr0Ufmr9K46OnjPz/KcqFVtF6wW/P44Cf2kLp/azij585JKfa4Km3FPHkeqx/DiX4C3xbNm150wX2A4ruOQN9BMteTPkBTcs9Blj7zCG2OKj5lPrKJFVnx1fzB84R6cOv8A3rgcyDSoPxyfhwF/qaFfzi1k/wDTFfrGR73ofSgJ944LvCu/hxTBVyaMfj3tr5MExqDcDhOQdycinhAVEfqiiPY4Q3981pOedYNunA+8SD+Lb8Y8k3VX+Y/rB3Dz+Vp+3BCu8fzp+rh1T5+iIL/zeMdmmHxE5Z2QxX8/7YqPOYvzbT8uQ1bhQDxofgQx1xqQXwA2n5yfUYm0oneTii88ae6bOE3nZ0dwUt4FBl/Jf7vGCtROs+H/ANxhPZvGqqv5wckE40PWEaC4Ws+sZggcvBnNTES3Aa+gF9ZwDm1afI6vrGKGAU+Qtv0d4Wnk8Fdnr7yeH+U84MAPRY9ePrFYdVB8l7xz4BQhpB0idObpSa9jzjy+5RrCtYlv5v8AFpp1iTlrvI4Ht3jFxYD4L63xjFdOF2YnqFIwPHWOn+sEjtSiOR6BycDZ6MfYlwDtajw7PJjKc4LF9nh9O/C4jSBvYo9X17xgFC3i+8TZipbT/ThUKbCju6+H84+UsTa7p/YxwbHZL+BxejAzk7pUfI1nyzjr01Hoe7ymcPkW90cntw9dipPRk2fR7uIcgUF+YYMit9kfFA/eW06k9EAqVYTvA3/k/GGaELT/ANsMeo/8MHeMrXyX/DV+TGgsoaH43z4dDPmIyvnIIgPQp+IYFVXYHDmLHme+JnMoOP7Iav1nGWYPjBrBfnIBXQznjJDjZvICkec2ZMXxEe0p/B8bgCsWuEfmY4pULldF8zEvzjnfGRxM6MxJsJjD+tB6q5Q6SL8DeVdU/wBDsQJVPB78cizIOGGvZL+cJxhyWshpvofjiuFgjcnrVgjTZW9zHYW2lcHIdSYMlpCj7NT5gZZNeEH5X5phbQNiB6FP+cZ2bKBHpkftncC/0CAxfPsxPBOShtALfPQ9uDu4ky8fzgPnIzdUIHyvb7ceDYBCHKXHtkri0JHgI3sehJixlaVKtVWqO1KryuK6gdO8jA95UxBR3vEOmZ5BGI0HjJ+Kaw0Wv/oeDHpLcQHITZ+SHeC14gSV4yeg51S7/wDzkWyBSI+T3gLgQMfSu0f4cfb9QIvEtPp+Tkjr4Or6VfTiF4+JIZasElLfJhxJ9UXt4P1MQ7dDdvbl8y3O8FrgRD0v2I6r87G4i1q2I0T1h+ZLGpcqbj6mUgDoYKKfOcOc7ERi9IbDkTLeIWij6wPo+zQpBWFIOdP8c4MRsKvvHgXh3xvASIZgPNTvq94IKPXtN2efP5z4YWbQb+c4rWvY2ej5z7fmcFPrI+kS3wy/evw5XCKApLgANr4DvNF6RmtBfh4+zxty0GBPT/LwdiLpd+CPT9cWhHCT4P2ccco7/tXYHZBcYuBq6pBa+i319YXpqsce+K/OUTBwvj2h+DghJehz3+rBhCXzePrP0xLU0mk3c3bYYfiwLymQnP5xQUOMVEUn4wBvVwbizE3/AIYdpvhDEFIbOOAAi4cP5OLaORWs+j7xgtR14z8r9maTJkzZzkHrNTHjxiI0W9GQVzWoA99GSHdpr6pPvHQNxH2CuCgB0fBQlXDnhP6UUj5a+8dIoCr9mfw5UDpYLspASIB1y3K5i2RIWXyO1NpU4XS19I/eBeugvwyG5DdN9hOcng6Vp8C/eO/45Pxh/wAMfjex/YP5y985bDwqj6+2AxrwQPKjXtXKD/wx87v6xIu+y3w7s3XQbWWX1yltGl9WvV4EGCu2tblxmWfYgY3OhcD5wsoNTgZCAa07TLCBq8D243fkvvDk42qA3AuH1VadfG/ZyqIYVWWnbR+qRgPigNeaQyNHzYAvA8j3liCNnefia+lwkpH8YYBvLR/495xDtMfVvW/D+XFewohHpWP4BnMIQj1Kd/S3wZs86ch93ZigM3rq/OBOZoeCN8Z8pqjcCCrsOG7wNdNUwx4PAT/dZxFRLxhJg4Zta/G8ISCa/wAJyHImzNRxb2vLwE08E85Ns6k5P6cokCJQp0WH3bjNoHnvk3vxL6yCSdFAfGjE/Y4JVEZ+BcgTKEYknnhsDAweOhHSsZEQ/KR5AR/gwUAcgvrDijysfUwgfbDnjj56a/iTKhaJ1/0GdUryp/gyuj/PzgbEY+Zlfnh+EU/bGk5687+v616yjANoD0i/eLj97N/WER9uFSeZvHfkSc89phM2fLHxV5CEz9B/bGBK/wDBBpleyfWPEdYRbfzgSpBzZDudFyRKNRob9jDGFA7cv3Sr94KbbL5ADsbvmesRaY9+h7uBtGB1lfDhsBclOcmvxr+mA+FNs+1r9OG9Nqn4/wBhztXvBvYE+Pywmjqfxd/DMU5ejPlFsNAZtUK+aA/AYNytST0GjNm1es2Sh8YrqFfLi8zbQEiJ2PjBtcqlILG2zdtk2psQOpuCchTIpEpFz/kGXQ/l1l5DcOLPwnx+Wb9zsPaiqT7xB0gnnwQ/v4xRI8Qj7Vfzcbnhs3okI2BvCw3ihxuFB6cnWVzSn9FE4B09iW/KPzifZhCfRpntEM/sUyoa25wwnUXrWN/4M2E+BXDON48prGN2lQ+RPoyI+KwQUoAmEOym4mtBuQHkWJ8GE0PyrPGwT1hY36JP958v0wkb/bXJw3dH3H11EdzgMQqUBO3cxNW12O8JMnB+N7Ppgcq4mj069Yy5R7Ye7w+nX840Zwg0NCdN5MnzaQL4PJ9TLdnS6vi/yYPgTVp8qfymbpi8Jj0HtUNBMeGmRCHTbLk8VcG46TGb2yRl4czJcoQ8OxIr85f6SZ34RX6xwkaEz8mRTVxq6Y50bTYOF+yLGtyCCgLSWOahdHTQSDS+U84lJ3Kw+w/rKwn+03a/GXXGLhQ3IKrC1SG8uVuB4bQopo0b4phSEwKqEWrXUhwawTgeqt/jBoq9XX7wetA1vGhPurCDR+MHin1l6/owWsj5cXU/Jf6xBQCvp8uFI/xMdDzvz/5hwR/OacUi/OHThDX4G/k2cshfPn/Y/eEihwg9KmZ4vLP8QJ3mv6FXyHJ71xVwYmnlrP4wVUO0/dUxKXNIEfIn2sxklKDzxSCSXAIHT5EK30fKY4UAVAH8H2APBlqcP4Mqv4yCR5F5+ZP04bsqaReiRj+mNAAEyKJtx6+F+8xE83Nz4VUfR9ZaGX8lf1QGLmZod6aGHJU+/wDzAPe8Cf8AmcMHfB/efU9h/Waej4mPQ3vWOy4jNjfJkAhOEX8uAhYSooYcApCBWOJ91auqNTWR0q13zexqThFlB5Aa85SLul8gtuaUJ6F/nbLjQu0zpqTetjtAefzocXakMsCeHOAE2ZqLK6e1qvku7k3q+8j7wpYH1VwYJa6Fr8axIycPru0xU4XmzwgH3s9ZIHvbImcJUX7Ng2xREjviFGIimI0LjaAAIAHAz1ijYo6KUtI6UU4c/r4D95NN8gD7AZQ2uQ0fWRJSs7JOeZgw1pEPswViTjD6e3aHsaKNjZUo9pHrsTW0uEsCweeNAoZphd+QW3nuR+qb8oe8tGpd0HYbifI+8m0CmW/yG+ffWMxUD4uKRI0yr5OvrCAC3+Dl+zfZmvo0MiASqC8x6uJxjZbUk7UrsOzPOtJ8AkTCbVuP6Sgeqrh9zJYVLUjyOHHq7gUwzUIgGaMmxjFnkcbIikhAEuGbfIJMIEPCE+3T6ysAnc4c1E5z3G3ZMdr1mobGJpcIdojw94c7QoAE1RMPWDJ1wE+tocaIpqEH6r9XIx1QafTcRNyFQ/CLGAwc7H7wuWvp/phZS/pOQdIfOcPzPH/XL4n8QyCPcAZi5Hh/rwwq54X/AEwFZOl/rzcJ9ZP0ZvUTo/5pgjrbIAfjBSMHM59En4w8I/8ApYDbZsCPyhjUQtw8NUdgm+/GPk5U2QDpCh45wpX7NLjwAS4Y5tv7MQRuUJQ5Mnfa3CzsgXgHnJLyXydx/uOAAeuuf/2WNqSWQPKRftcohZsSTBVCDGEHxeD8mTKg9ifvArzU6XpdMoOy1A9VzfAXgrPysVIheL/2mSUY4UL92Y0MfNQPzphaB6hq/On7x8yp438uJOjEfeI414PV1Pk/SONPOx4vxK/nKQi+yq25FkfK+sQEyGUro8AfWXIjsgAQvjX0ZMxWI2/8/wDmKTiSGuN7fH9ZYgdAnr069uvFZhICQ026Vd+x3wcMIRCEE1hguN9HDQRdv7zalUOHqv8A3zgqW/lNC+lDMCf80gp4z70BxKfKCr73ltFOSz8Ufxll3cl/AL84j9UJfKH1Rmh67nb6f4MF1R5nPw0YqDtpH4kz7zlSOwj8tvAQCGgDr9YlQjmAf4dOHmNz/FIfjG0z0Z9E7UjaMTjFIKBAEpyG0LwKshwKl9gXVSFsd6JuXTaOQJImianD2wH6RaFfZA/GnoHBVH/yU5e+PjsgoA6EGc31SNfB/wBcQerJfZf4xUi6E+bf84ZOFbvp3f7MvWE3j6FPrkxVA14E86zszUmnq8n3r3gixlZv/fWV+tuA6TCKMoV3Hg68PF4KFdlU0+vTjCgVHCT6x/vrHRBtsjj1u/nJlvtX1gkK8U+hx54aHT5TDEM8Kg+mT8TLLi8BP4D9sg/+X08A/wBxngJgfREftgaBG7i+Aj9s5gKNb+HJVNx+Y0f1kYq9gSTyZRIdnl7/APcsubnrfCv1hqN8v5aX7yE4Kex7T+Z95YkPr+Ae4WQ3lvHpP7PzgpVxVPui/DjAHYhfklPoJjAvG9cnqMWYT1X8uWwAkT+o1ixpfR2snJxzhKKRiBQp2QPnnIB3y34LcWU4mwfOw4TD+RfwKPxjydWrB4/4HL678wPgpfvDxZ2BeiX/ADrIAHaoN/K/4x1OoUfJUE+WYJT+gB+D+sDYwCK7wBScwLzifVIIHwKfpM8isUH6RiGCtRdPDH9/vOkmJj6gRhAW9sedtc3ABsI+MMVUL7H5x8PA6QwnA45H1ioCzboNn7DI97yScNEOzxMosWdvQY/SZwQ5n0XvFzBY8x/ht01ORilqqup5cdLRnF+3/wBwEVDonmuSiCzL5BWifOJzvaD9bGepvzjNUIvfOhfvL0Tlt92IPh5eDcFXzEfQP7wg1gnQTUBgTAMgLrv4H84YNC/yMGP0xQdoj29l/wBYoDTkyfIfywKFlv52sBFZ4VXBufYAZ7r9f8ZPoe8IA8tW7cd4BewbD5pvHIMM6FYKSutENXvGmn2iUilE1di14xO+CmVB5RGJpHhXjOPYA29FkPkV5uUy7f8AoCfhXtjV2hCP8dnspg1YTzfvznqiuA/x+P1iYinf/t4AAvKk7I8/GQYQuxfhOPpPjEGywGOJbgRCH4YZOlRwR4U7wGoNpJvZyfvDtAaz3ImE4zRI6V+hOdbJgJwN2BRR8cbxnzom+S5gIHXGK8J+MAj7X6yXUXSKHz6ycFvhF19ZbJTvTj0XnVL86/P6zcp7TP5t/eGSZzcfq38p94lSD0G+Ngc2x/E1+UZ+3Cmzwlf3n6Y7A1ctUD2IG0aG8DTHvXY1AAgtjiKMc0H4Afzw4ldXv2Av2/OQl5ZE79ur84GXPAAPdL+sLFbkaTzjFQXlP8ZwvwHGHAkQKMHks8rcEKa6G8Tz+cO6HHM0WvKQmVkb6IH5Wp8uLRKvMfsmzG2H2eMIC3pIT78fnO4pkg+Lo/P4xJHefPoqfGasoUG9Xf5Ycj+Sx+4v2+MGOxgdfhlft+854KEIny7XvwT3k74wmDQ1aEBo04t5d0vyU67xgSe2H9j84oUnp1+kXM4RwfTaYi+a6L9z/bkOgcoPsP5MOKzigvuExkyXVl+ox3G500fWXBrGiNX0j795Q+1CKL10933iBJ73oAHK9rJ3MaBS6aie/wD4PcMDEQfDx7w3IqgFlLtdAFa8ZEGeAvlCp9jhKYKLfsi/f5xAxoBm+xgMQTyl+yjl9LKAXyRg1RHR7/dPjFIbJb/hDkdmNVF+kv5yqIef73H4xymnCf6EwYLxEeJ7pjlE8y+oFPzm6932/ogfQZJIuUXzA/fBRIbDU8Km/wBvnOcY1RL63/nJNI8CmcySJtr9ZBfpt/jEyLriOamhxPyLMSVM5r/A5az8KH5D+sSUJ4L/AEfzxoOVigD50ZUPdH7PWjtwIjxiClAXsaCheeh2SuPekqT/AEn/AJiREHk4+B184pCSIwf7zdRC9Hvhaty4OSAqwGxFrjqm4SGsgDcgvAPg9fNqpQohYDBUWYBKtLFNEOzwD6wKopMjpF0EtMdlJqPIU27TanZpzdqO1LJDe6XjfjKpxl4SkL0XnvFCOCAdOnYfuOAOXNAfbpPxhQc4A/dqvyfWKwB/SKET/TAb1pRX5ov+c4KTfZp+n9BM22v70PpiQJDyl+fP3miGPS/fS+yZsPVwn4jhMIMogP248t081/nBIJU4KflP5y8Bogn2r/WXal1WPg0/WMqBsyPoS/eakA3GQ+E/afOJhGgDp4xCtTR5Z5EX+cemUf5KH9sYMAALAtR2E7yuWN0tC6D7WA5yAK7V35Lv6xsTbJfhtw8mUMT7/WPxjNaUID5FZ+3HOSeFpEfPc8YSIzsr3zuxGkwdsbx9HJ66oobPxuQ5jtXP4j+8CWdmkl8xEfnGEdKQKeYRlrv2gJ7Gv3lUIKKI86uKmuEXHyUuNoftc1MF4Wj6yoZDb8+znKEVo/S0vZh9AABdeiU+sDvjtx+OXZuQcYWel5qThwD84aBmxeiEa894pCxE9SqF0XtXa4MSGY00CERE05C7moUKAO9DauspY4bwSLSeBFTbiX6l8TIbBhk/Dm1ksAZIZEFsaTA+v0QLATCYh4zWN0K6IggAVWAG5gk9ocqKQZdJ8DhFQRjQZfPYn051ZCxtMaPxlVfcTr8o4ocoCXsvLnUYQvJCgdSx65cSh45HR8JvGtePOv8ANxWEB+N9vFthqlj5JyZ3ahP0Mhp/1esL3zwx+gfrEXGaliWw1UUxh/8ALFLDhV0Y6D4C/nGKDyt/zZ/ePBYCot+0fgzyokGRp2h28GCB6lh94xHFzcNN8RFo3rNiJrDihLyBouuQvAKbEYBih+diAjhloiPY/wDMMkRNI/C4x6V0ANuyBEKSwuXfsY6Vd3tZGS3DyqxhwoTFTYXhuGXteUFNNFzAY1wSnikArYGsOBHvFHgINC3NiEHZE5ATyhumxocN6M098Dd0Ltg82eMKJJkRNpwdSuD1FR68DRKhryecbrBtJpQYBL51jLQC11xZXkTil5xE/VNIgaI8nWbQzSEfhHDo96c8etM2TVCwTmmOV6gKLV+BxzaO0sIEwBs17n/cEbAMIVv/AI4aSVsDQvLX4wLGwussopWMOWauAn/IgGUQ0nPTBlVpAntMAGmZHUiFG/AwhIKtVH87mjkZu/R7DKlxtDvu5+xwJvRUAgxC1xqVBuUmxxtUDeUsXzMR6gYYNu6fjvjBUvcRFQ4GrbfGmQk4qkVKJpzVIHcf4Ie8WWQg1HDEoF2WH7AzbAC/wOcEQWgKEun85ZyROqM4gXZofjK4ECp2KTy+nBXbQBy4dvXZPyUNFauAPofWEJONirrV8b/vAJtqR0OBU2F455mLbVusuqBLE4fPrG/ZRgUynbaGJvR7+dqSBS66jswly1gbVg5QRGuAxPWZkgOlECHA8k5JOigcg86GyOrJMQA4KEsodJV2Joxoy+fpYrpK0NhRTFcdXnEagFokdK5I6rFSLbRI+zd4vCJKHBDgAG66NuXzP2KiKExAFAt1Gsbl5JN7HhuEAMZgQgKNKeC8qgKGHSt26mweJSoFhiO1bobIJUc1AYG0GbUBkubRjGiDibGsyvlbNvkiHZipEQCWmxgETVODHJRoF7PcSbWqtJCYPopLSQvIjZTZULOYvboHb9EdmaaDr2YokxYBBgrjF1W7E3qYhUU0Mdco2DpswIJSRwCE1HToacPSYPAYHmVyLxp3JV6oo516VnyXarRxAq4CT929CESOjaC9B93Af0UwY1WiCXrTOcV4LbJ9aylI9Nv6WJITxKH1DI7JrQz8sGeaNn9jlrqJKH4wD+mnl5AgfLlkxRwdIP7MSx40g/HAewOsNeBWO8B+MmLDdEXSOxSH3in2yKfRqfT7Lc0U3s04pTV1dbHxjg4RhR4gzbQhvGIObdQbEchwIQbHSgxaq9xIASbgQkAARdsiQygDpJx4bzcVC5DS5JgutUEescub6lEnAG1SmhgZAUTETQVkXKM3URPEkE5DZvhh9UoGW0dgN0wRhGx1gEYXrcRFhCu/5DW4DpEoBFhuvfwIi6Jt6lEIUxRLzWCwCEAAPeF0Y/QRpNoBGcndz9ScDLz56znXzgtqC76vG/cV6+OaKEFClFTCuURF6oiAEJpUMTBHhoNEQ52c/ebtNQIick83BCnqZ8BLsDOGA0PGoFiUncFyfv6DJQbSjkA5rKJy0dycEC3QK2CZAWjtnshuD2YQViBQGjBd7OfMyGd76QKajRm/n4xZBCxWxqoAAjohgeBZUhaUnA0RGKVKmggoGdafsxHebI1UFRyTdDFNklzCFBvqApK4k8ZgQmmogEIktXf3ThuRJWIbyaauOAXRY6FBfnEvL1d5blI06GuG6nJ62s+bld8E2HqXNYoiaOmrTnirxrkby3BuMRn7Pd1q1tqHu2wdQ/x2YE6aKj7gB5cd4jcSio9SUiLsBDrGV3SqM1XVAxjTSnusLNi4VhCxNOmBmwFBtSgAlaBbiQiMUYmAQC00anWI+OXS70G6IFPfhqy6tlkvPjRY76UwJDQZKOKELHhGLplMlEDw1RUq0Hhno4Tm5kDbfKv9sKNB0yiMjFRTVFJjbcLISQJIRGHSuFCiyRQBjqDreLjkQSJhgCqTtuRIl6CREYgxEypgK4whBMhx4wdu14CciBXS6vBnGgVtW8Gg42F1zktlsVy7Caa642+cUN/jXx7v35fOJAHBW6UoEu0asxqipxIBApdgrpSMzZoUNAQ00CKsQcnsCqhZjEhEKoaAiC7sCpYIKkBFc2ZSOXOSttFBq7RwUaEUmbdTUTnkpRAUE9RYRph4lgU5AJy4KV6QCtYELhKeYnjnIEnt+LmqKl3tgKovEAMD2Xm8MtF/ImK15LE+t6TMXA9wiH3PwGf6nH3l9X1iKC816efO+cAKU96PrLUBatEmJADKbQX3tzZbWsJDqzOeuKWeZkkMpkQyl6UxipHFFCBUJmkMABJR5jue9bcCQ6Uqcm7p26CugADX1PbpGVCw2Xpd7yOi3UCFL8gQp+MvocargZEQIdgJGHz28rRwptYCgV2dZqcJaAEK8QJfwwvst8iFRBBFR2MRio2ZgC0JAioSJhAb3gp1IzzpVDGngSbMFwoaHjBAQkbtzIwBCRIPRWYjPqKCkK1oEXRDWM7B0kUNI6o4kgbK+paKARaAJDaq61htILKwnCCDm2wSzCVIRQAKJy38hLTEfghEONxvSbk36cZrtV6nApoVqwBXEjgtDj9vC1wetwqWcuKAUlChSoUtGhMdhKgLJAaPMcVmm0WjfApWm+zIzkpysJSCBSwNsuArg8GNCGm3NnjHphVK9QoDV0DV2AmCksG2sHQHISlcOFiAAAReQCN5DGYDllCQMFCMV4QLXyqxukJQfI2ujCRjuCnBAyEdCUi7rBuRBT0AQsDAYD7WgwSbFwiDFEMN8xrh5JDo0a2TQzRByzQQLyE8U8x1agNkrJsTSgGKG0KJREE13PXxg5zJu3FGcjpZRKIGKndpcT3oxQICC1wAQmlUKtAirUxoRgmgTV55XKeYY8JNtsGVNIGPLL0GED1yLrcFGPnNunACChHwqyTLx+uCichqLh5PG1/t2UioACTh4YBoHWN6sccS1PCI0iCkGVKdh30v3zcIxpBd4sfDG0NtmWGuSs4CsNuIBm0eE4JfjXvE6TEsoBSlc64PjAe2pPAti8hCzt243c7R1vIWRg8Y+hSlR2oC7eDIoel084RGhyHhy1g4AvyJvHVd7CtPDgX8YFdm6/EaMVk61a/Ri5YsqH6xCHaMX+Vig78z/uw+7rNIBrCf8MahLVNcJSQ5omQ3A+MHkH1x4CL9Qq36wYOQlzUmrXg5x5e7Bkm+BSmvUwzRV/PjpdhTw5cNhQ+NrYWaASM4yHcJrRb7YsqFEhJkowfwFqQYfIFAKQgCXABNLagtO09qAkoiN621+nrLiCUMcd2PB93UyW0zAShoKFc0xwkpZCwQmgQjkUsmaik3SSwZ1edt52I5FGDW0dUjs8OWixwoSSLbchQdHDyDJKUcDv8ACjxk/ZupCWa54HBRWdN4lVCcXXWEwsQpiSZ0LvQucUngDVD9N7O+XAZwgdXkRoTkFYIMHf11HtBh7EpCI0e4GpXk4Kig1LCK4uDKpI7hk0ySXeBfX7f3fuW0igBl2UvFXgvKN21CrTIgaBRnk5RGLiHz4i+p+MeJAoC1HKt0C4SwKdMiaAUEQkgO8uFUtiiqXw/TAdK4z9SUuyx95dqEEvVBUq52AbecC8ARbiQ1V0iiDSi4CrQhXPYqWiWwKYMb6rAR7dvnxgQ6Jo940f8ATB7gj6vHeIJAV2O/vABrEc5/eTdGo8CO64q9RkZ/HvKWKaps8x68YkLwzbNPOdrDq19ddYhdV1plXcEvPkzkp0HCnCZMwwJj3CVNkHzy7zdFVKLvrT/vu4sQPYBeON/8zaWsAb0qt63PTfo++ti+MJo+g95wbdogaxaJFjrLLAcbXlI8g877ykSug2fQ8fWTtC1DgzRMKp4cFdfj33h6xkiut84dNZ5FEtGcV+jjXTSaodmzZORlnjeczBQoLb526fo7HRBkHZvmVd+Osd2YFrW/fzl5DTH+/GImUDZbIx6oWvdLjv4IKPlwEjwJE5w0x9TNTxeCbhFPBmsawBZYT0mjNHoWrP4F3oV1AhGKImCVNYZKIbbtBrtZwpA0XYbNJUcycpYgoMf4RjhWxlox1Ez0CUcIN37xsii5cIeQImICKWmUhtt7UEhBCzGsKCwXv9zn5xCKUpQkc6FDhRCZDiMpSFhEcDQm8ZauN2QSrlqDahvGyAGcaXY0kbN1Qrih06Td7oFPCgvgxcteEoXdRDkKmsr3wKi5ugewnrQGR5gosNaV2EoHVs3jobNp3C+rN7g4HHGbt+ou1AVEXdhgYNABATQk6NcYcBrag1i7TYKIJZGjxLcrfHAuCYocfFcBL1Tok1pLsHWIAB0OL5If6HXLj8hAX8LCwNTlqukp0ujbg04cGjxgAUG1Gk35D6HzkIYAUOVhl0Pa4OqFOoLOEDV4jZGD7RoVeKO/CYU30UKtKa5nzh69LQCiobV/5kZ/TbBSDokFYEF1kW3Y5N7BB2Ts2+cQNyBCOghoEh6yygIsI0dKDw4rAk9A7rrbU2rsuCG9h9rIxA8hRNBXTJLANBqPB/uYQIZAKAjgaE5CymuAezyM76VneA3eLrE4jqqYNzNSWKckfO8RN1gOUANQGE2XxlFXjLuJ0gq6Y3WQ7A1ihIOgES20UyrgiwNnJ0UYLVJnMwIHcqqpNqq2q7yJpPAovi4ToPGEAtq9jR/OLztqc5J94/NFdU46D4MNgA76uJGhtnc04Gvh6/3eAlDhJipwAvffn1gVdZB+MEUhj6MSLs4mnEAjXQN/vF/iFc5CAm+GfDm1OlD0kn/3EvvXgzjs+v8ANhTTY+Ol9H4zU3utjXhzUeFFVPMDdw9AVuh3sOfevxgqooKpLUu8GLzXKeGlw4LBU4D63nFgG1P1iYjJSnzMEEmowUvIhd/Z5xJi6xdLWDw+OzDVj8R9QUpw3vJIhVrnlX1yfWE/6gYHMKmwCwdvGbeEgDQU3gj31ihiim1kJKXuml5TG7XELGhRBr5DOKuFjEtD54Md83N+1sUZ1FqSIncUgeGPlacGAiBs+kVjMJBxYmJsSh6KXK4lQEzUQoPYn8GK4Fu8AX1fyMWaFyf9w/IwUo8RqGH5B94oFGDSBQxx6SdqD5/MMCILLO/F7EL0YokPb26ev0JhV1n0RfgALwyuqnDS3IKnEADNVMb01cRCEiDoE0iQqshLthtgYNQTZKr1rUrNfOIgcEtkPCdJJuu8YiEijnDlblW4rHpS3BsfJG+Y7x6XjUMEB6DBdbedZMAaMZ2msR8fyBu4cmtiKxK248AC8UTQuhES1rHd4qiVUZPKEcygMa4YD5R8MSw+Q29IympunKke0JzMTBIwjAEIjcGxFl2QOgZEDAZ4Q8UoXEZydgu6xEbsDg0NiNIvBWLAVsLQgz/hZRLvoO5X1kK+Nrz0sAdaROd5niskR4EA+DN8FnjHXt0zrEKjU+4sIrQTzlkV6+p6ayQJoFTWLuJMujAP+GbYBzblGwZqS71W2uCFVj2l8w2SOeKiYlgwE9AWzxA7gXAnfJYIhAFikHdaii6ThCANNFEiDhYpPhGmmqpuP8Zuta8XzWO/eyVkyO43J/e5KJnt0v5N/vFCPYBfy3Go+xwi+aIowUZAnbpHoLpBY2pX+ExngSJUBBA1fTOEiZmXhpp/7jmJkLkPYGAgQeSC2dJgoEQbPBxHHToaECppmmrvj3mrWkhf1dOucBbDoaD7vVwFrU3Ei6cCHwH2HHgp08PMTn39cYD3QBSoll653iSu7thrS1Eb+DHyDYGVp9gCe094e+ENCMHA8wM2SESoOfvhe94/ofLErxI6+PGBBdwF0/Dvz1i6iXSHfKGEyyLgXcC0345fjBkdnTEPVB6xOCJoBHS74fzjyiOwO+XFEjpCAagtVveCU7cH5VG33qkPPcVzdITizbnEW8iqiwdpQZZQwKK0SegNkM15xEGxl+fN8Jhsd8eiFSgd6fhxa90Wj4es2ctzaOMxBwT0F0fl7wwZYVR7X31icFdigcHrbg1hdzgPQKm2756MVqwIRn2GAF5i8YgQkjU8eFjLyw04TyjO2uNc/vWPpqggvn25no8YixoVD8aAfblZBkUXd/gEWYlvqsg65cqKG3RcdUZV4l/h3kUeiCkbymylBOFyIPvavwVs8a2+FxHa0ypwmi/ImPeGthpckikH29/NQ2jpSWeOUDFma+c7n7xAoRnL/mFH5KBXLV+l6xsql5fOR3dzWsROTKDwXOpvzXjFUO924+E6hgPuOCREnx5KUPu8a4XE/Hel/reqb2BXVvL/APQtPYmzkzdHhqQjMti2ysEXAbUza6BQVIYCt5XDFOAjEaZcnkJ92Mo2wcI0pEXqXWaMjFCOTpyG9XnZsaQPBJhIvLCfz5fT+M5JMgO2Tv3+8IkPKCYjg8Xc/AVfxgpp+BEoiC6ODAMULAx5BjPeOq6d/OCdLSh4Txgz1rPORdDxKBxhAma5v8F9h+OCHNNmXXn/ABv0wZtPWxiKpeg2UxskrRBsDeV6y3+W/wBoHOCLvx+R/wDrBB6khwFqenj/ABkwW+znxo/Jig8HJ/I/vHETKs0AoWbgVJcs9eQIaLQ8bFERFEcQgyFH2b794yIWRNxwdSk8dbznwZUnBVpRyjOsZ6ZetCW6YOixrXGT2LEEQ076yHv+jBXlT8YDU5ujk362LyYQoRjb2/PG/WSvXaHBFr9w/GX2JOquzzqPWVtEcmP+uWRF5940AAfXWL1ig2X3vFT9GAiwG84B+cahdr1jB7ALoUNn1r7yVgSQm4NHGKn1VEXCVRzfuqAt802DDgANHE94kQEoQN5BAJrUwKX/AAYVOrpecexbIQrY9b3lilcKC80pEoo5rP8AOekScweRuneKlME6gBNgOAHTlTj/AEoqMATVA3OWs/D5EcIKAFSwDohYlqAHSRV2XNN2KjxsAprUOAQiyccqogAoCAEAajAMKkbKE7FoVEqMwDe11BSLQhq8loej9y1EKGhwOfjK5RW7nyriQGDDW/Hf3hP+szT+AJgYSTkFxcFrv2eb+wyeP+P6M0Wl/iMAVH7gH8DHb+h/ZiajnoMrT7h5iPgNYJbKlVeVanw+WSdhCqU1Jybe+jzpBeW0htMHV1dmAQhoCa/IgtiCxAjDSpE2flB+HCztIUtgHJpocIssN17ZobCcO8IQBM0eBZ8DEMilhSaIhod9mGmqgOOKOfCenGH4AM12gAqFfEeSYLPGkQIKm4u8dF3QKXZbB99ZW6y4LRzu78v9rH4N/hN8Wa7zZ/pxlVVkCrt4XVT94lIXjNCcI1Dh3muaqNqNHQPnp5zR30RR9Y1z+wQ+9GFuVQqv7wv2wrH5/rKUh7D9/wAMLsNBs/cH7yvgwnyTFEEPkNwvgJfwTIiANFaZQAsTgVNZ0RzVw/L+KxeT8OFx+x255J81MEx2oXEGhoO8KaF4xaTjhbtHesHgU9GKg/kcfrBoFR4q5TUa47ZcJXoDwPH2fkxxdQRC8fzlx35As8YjhI97cdmKNSOxYOiPGzkx3BR6DkSMdQxak3kc/jHMBoWJzyMihzk0PzhOhK8pxZrYz7wLLQKW2a0TmeEneDeZhg0cxxLh/AVrEUHwdg4SR4EKtEb/ALm40BtQL7xlTXGkNK7uB0rpgojyTx9zGW3Z25KNJvSacACNaR/3rGtNdEzZq0FIBSgsTWY8RAbLoRF5GDYETrrDAY0o7NaoA1FMjoE1jwTbRnWglTd+YC7JDUQP2J7T0Ix3tTlrxktEOhpth575sKioOlYCl5ytAbIjTK7S75HZjQo8SblX3AYRW7RC8r4Dl+MWXVQmJSkcwJvnCRp+cfbVp+XKP0ZX9aJ+B/nA6VUABb9mI1YDsE2uEHr5yFg7X3Vnwxx+RJH/AC5bz5cGTZ0hrGNT8HV+saiBMkOWNm82rdFoT2xjMekUOisBlvDvDzlFKBGh0SjQHYu9oDUxuhwI8gTj2GH4w7YwIXQGf1hbpLFdDgObhnHGnQ+9g7/rCoCV0odjrmur1ciDBW7Ch78/H1YocxomiEg/LNxzlGkNcN4n+cMOBLRquy+wLxvrEA620OHeomDjCFowaK8nx+AxyVi9kF12gvtckT31P7XBsYR3b0TIVqzqoaJWXWr51muGlGEKohV3xcMh8fA/gu7Qg4kppm8mQikicW6i/vqagoZJCVFRNRJCoVLHQgFpqJxDBk1i6StC1NhL2YFNYaewFsj5PqNa/AqapbRFu95HG5LyINfGLy+LeAthbNKWMM1rsU9NB2l/Gc2RPUFoGuJdt4zeF3B8V4nwuQDgkKvhcEI2Nixt8g8YCpLKQ6FO/PGBALaUg7BOdOtYtJQQD4PIOUOOzDxJorzDjXl/7g2zIIRNDW0Ey/o8iiL1y0e4Hxmq+F2qNdj1PhPOGlG1IEZogPK/R7xpLAXlR4sXv8TII8KgDkcX418ZTN1leUGyGtt4xHkCUHs5bZ4PWVkZnDfsX94Ygj2HdrS28TRnBMuk+oL8OSnEt+OiVWNBIUoRe5CIgWn6HDbZhOnen6gYvGnn+Tf65x68IEgUpkmtLu4pBkW+dEEFecq3b5ScLdHbBLaAhH3w0PJC5OnNbKoaHTi4IQRZNB0JdYsxPmwauAVDtZ4yg91KntcPbMOCscOiimBkgdra684PhaPQdP8AWBYTln44sE9DcUCHwKopZMpxZobtBHfCaQTc/RVgVTRmse52bANCAAR2EL5fjHIqjvHfobYQG5SVRpEzQpRMz9WbC2bazYdT04WmuSN07ED1mBtDrYp/kJVigYKVS6NMQ+a5eBmCGgKSJN4aEs1NpGjfLhraExSYXbM03gRgNAc8G9sKCwJiDyrYOeqzWFVQAhszJ9ZSh1euZhoDpCtbuOOoQrkPKD6GRWOTWoRa1MH3vFIaiiCsGVK75XH2r8UhEMVhQjy244k6t5DOhrFe0qQMYi8eesIo0A5AZ9GP1l8Ke5Ei/vB/kKqDiHFqfOUPJjpQHXJXFVqLooTmoHrTxTDgeyKwyI5eX3iHq3XHFwckq0aXnG8JpgVAMQjTXQ5mIh1CCAXK40uINY+6gUxGpByIDJFN3CxBXZ0iCmtn7MCnRzCKGc3nt/Ayyk1OSgKg+e/OFQm+a1+XNUrEAWHr4wuagCJShULp13gSyVTVtdCDR70sZo4VKlrcCsJsGjrDNZHpaN05+pcceBeyCjvpPnOIzKkj7xqQvwGC4LySXFWx+zN5W+m4C3VGZaLbEnWPwsC5Ot86sxMTAAWg/ObdJRrzYioisr915w5K6lv3y48D3jY/vEIVQ4wIlR0s/OKVM2e2poH3gAVxhQN8J/rGC3PA5/GaQQNGGKaf43iQruF/zh0bYmmafyH8ZURTt1fvKJgVVR/WJK8EWmH8FOThQ7bnZd/GIWP85s4E42mGsU+BMCI4Stb/ABnJg/L/AMzQgPpP9YTVbH0XLF08mI+Awb9CLKTI3UF31MkCU3fqYw8D3j98J8Y9Ba7HKZXE6IRH1vHM4pllEBQVp0C1MEztSWIYCVwNqwcrmrk+1iAbV15xehT/AF3h9vbxflgYP5O/rGAJGlbGxRU+wqmvvBbYJpOGdDsd94TVdLtgEJMn0oYhshFMsvQriBCtLgJx794mFHZkEYKBKcp34flrlA2MhSUrbtmaBXwawpA8h8Z0gBe8S2AIcoDdoOV0G7NB/JrPc6YMn5nAAQPGHgjftPc7jC7A8YQIWuyRCbStesVo3JqPu0pyNHeRpTPgknoA+sV8qlamuEQZ8vBh82BvQKgNzewmwyZ9LSjOkKTS/Ywx+40i2Qx6zVN4gCBV4FQnorhgBzxbQriyQgdHkW1Mboa6aD5fynrDiJkegxsg12819ZXAILqbGTgeS25svdD2xxhnMKKYnVeH7wjwbfkKaCkPP5wAqfCpUAW7p1qeXFIinWjSpC7bPGRe0cswRejgR3hhRyljXUklCBiGEFncbmPJS2VsxvyjscaEorRomKFbNN5Jg2hVTZSQiScEh2YsIMcyigBC2Jq8xJtdw/8Ac3tLuNnwXBuAMYbfExb0bvRxiBfFOh94PJD2nOeKToyoUGczBgo/nGqTvkuVLofnKHyw6879ZYSg9rhUdnRyZSBypZVeXVXHzwRnupjxubW5ZJJgrbzxL+8evzn/AGxpTPf/AFyHp/4byp9GWGbAUl3lBtfmzX7uaS/jLTcQZok7OalblcTqeWCbSyioURB6U31dCJNIpvFSDOqFjdmAnQqGnB1qduIUIHKuL2+5cLQxazHBAKS0jarnaE9HDp8AD9IDA3XDlkwzawpY9wd7SF1gfHrVwEXEkCCspR2JgQnWQDUpRxZM19VsIAVDkQBSH2h2zptqbNoE5GkRpAtKVFRCjguVEVaCqhAoBBt1jCWwHPiug/LVqriwqAT79GBo3vA08RnALWusugeinKqbbKPu4Niojk0v8OUAlvFx5zetaHjEt+7Ev6xa3vJL+MglHus/TWfGjq/Rx0a/aPoJ+sQPAqnxD+2Kzm3CwO1alWWGibd5HNd/Gr0eM06anQS2t4eg4hgzW1ghQEQeVYz7J4KtQIW895YpfYNIuC9bqOKHiSFLBCAjkeMBsVEUVUIIjv53zjAMLYghZOtYgjHBXw4OOsF9OCQ3e13lwM6S0Wk6v4MXjObgdo80+sZrf+yYgi51/FGaanwpgeUCSnGlRxx9jA9DQHoDQoil0pLiEkOmPFIHeNbx4bVwVmiX1wJR8tyQHiijinhv8e8sX0qP1wUGrJ0CH8C0cAqs65MN11DEAHyw4J4JMPXGZ4ZlyllNcZKPI2hvYw1F+NYo11EBuKqbOPHvD7JGDXkEgqqQ5yRhbcMRAiPnBYG5ICm5zb9YCDlgtg4HzwZcoFKoblixqoXMcDCcvDF6vP5hiJhHGImJ84EFqTEZGJ71KchBdBvtWuZ2/inaXheQLnVYHSf055wPOWlMjHuaNJOHAElVkdKa/FfnLjuTR4HX+MFHaK3hzsPOHokkBfmH8ZsttgVVq3fXD3mu340ImlZHesngNWCClFB52uVKyraN+JlPJvlPyT95GN/IU+IcTM6L/goxIVPT4yLzUf8A1jbPDRT38CxeLFIt6dLABWECmiZTzC6dAxWmJGCUUJOQo0uND1AGgq0gIG9TIyXs59KaHQomWbXTANqHpSu4sCy2rC+AGHEU9mBqrgC+enAAotnpqgSuQN6GCPACSh4Rpw8T1hggEhHIgg8Pj6xkQ6KAAZEmTbaa8IOctQQNihW3T1RN2wEWLVCITG1FLEOoN14NLMAwKuHbvQzpB21So4OWHF3IwNYiCQ3Bk2tlZqpVENaw9AUDiA/A/wCuLoR4nxjNRDbi8YiNcmJSg3hw0Re6n17MsbfuXXyDAoVzQTtpSR9vjlOCXaH1C47ROn0c7LvZkchdowlZtCm5MQRJPZ/gx6eA1D5iwBjC8/zQZvlX3fycsKOf8Z/XHwCaeK+j+RjYglaRVAaSo667N3Nw1JC8HGAghvcdeR8NyOJaKbIp1gaFOIi0vgj1b1i7ywEftiNu0OTJRQzQgbbaRqLsu8MJD7NyoGj45dV/QZKzCi65McVJ7ZkxT1qc2DfJcYmclQCknCRHzjLfPfMeiGKvy3gvac1jYQOarY53BdcZyEbZJoFpEmXXLJjQFFVQh5MEWNNcrYoZTe0aKW/JyjKFEb2BxgqmWRIoBASk4HrBUgeBRFIPIq60cGQF45Uc5APkOWat7qIhtbseEpUCLDCcLsRVkCwElQ9A8ce1M8KaPiHeRECcwLqMbbRjbYvp0hYTtS8qtw5TP+gyMRPQf8Bj+2nyPmORVt2N+oxU0jj+uMFlZJn+38uMi1P86YB/uXo4wAJobJ9uR4/x/EZjrJ/uMRP8McGKAADrCeV/eRweC4oT8mXjV+cWX4QYEV7hW1J4w13TzMLSzxGz/wAxx7OQJbD6534wiJt4oeXYpF8grTLR5LFc/wDn05fYZ4rbgA2S8Lc2DayCn4FVsv1gyLRFMVRccGueOWWGO6gVext3vn04dNqB+BP7y2tsToIPHXt2ecfP65papYSoqNJTFJT1whQCJeTIahkQ0V55j48jMXAbUv0onc234uitv1p3abB2NVru6c/vZ2BUTvhjM2AkESDpKCYysWVHiCFyfHzreU6CFbINFOTg17w2/Y+H/wAME9Ble5/WH6RDk9v/ADBAKAgsnQxdVZ5Y3iaXsan0z+ZkUBCMLQmjRuHUBkCyQbCDq6HeEJqrbSKTcie/WCElkgSLXp5cnY0pSKWbingyTozWltIqnQ0mnlJuSJQ4ieVPBMMSJ7FEDcM0nVQ5UNNva6kKFc92By4CYNx/5Ngpq+/DwJfkByhXguIREaLlfGbeS2lYrpGXxw8hlVSy1Ftt1yI7385artevP4G8MCV4anqeUe6YbIssCGkJ73becNoxHoPL8YOi1H2pv44wB16xT+CfOc+am5sEPwxpEr05xAveNAbKcoD+c5Zm3HwCjzKm14IQW4GUWDGwFAFCRQogZM70WUJWkcErQgR7FkH0whoTGzrrgltgOFPLdzA9TXPm6Lf0+sSxgoqXgAB12yUOoKizWwp9YUKnf0V5v+14yCafG7/JwHZ/V+6cNnFWNDoSxfo5d4mCTKgDcGU2HCYstEkDzqVavXEyxThkMU9YAxes3D5d3XWKhHJd8JCZGVvq5Dt+MegfxgLQuL5WE2NYl3KOKKdAI1wUpKDjK9EgnwUHzmwU/FT95oM5oFfn+jDkS9SDzv45YA4O/nxa47a/2J+sAWh2j01fqDC4FmEeqN32rrWDKQ+5wC+UsPywBCKoUlHhEPY4LkYv23ZBpVUAGrs1cbMAq5yQtTf2iakgB1sBliAHNAbqJhwKqldhI4QB24CgajDpyhK1SvbXvEoXnEAoHpEGmOYQMbWplLunXC5WjVZ/IP5vu4UB1NdvI+AWlb2B6T0dqooTezJbcMHgYGupzYPFSF3IoD1iIpoNpzH4w8HJCIKnmOTjQwcZNnHW8JSttrpWLpWm9bcKwvJe2ALUCtF2XeXYnWC1k6ctuvjrIg2/A7V/3GFm2POXv1kydWjH9I1duNCIzesX52KcLDc3WorswDlrrWDREiVI08FADVrNE6NZzUSONU7h4ySZBUiFVOyJwjcOEXvoO1H5/ORpbPyhKovG1Ae3BFaqUPBwRVYHK/YAnk+BLIn4ucSOGhPHOCHcFS/OL6PRE17M2FGQ0B87M3Sz7g6IoHHt6xOOGSInBnCcW94rI3ZK8+gxbrt6hkON7XodGEEDaJU+bDXl8uc3s+XrYOHEbByxlvQHg5HHHDziVY7EZ6S/hxho72iEQHZpHgEoYwCCSnjMh0fGbNXveCj2QMcntoCtkJKkUm+EAzQQgSgCnpAV3LqQCogd6QQgUgbquIDgNKqQAPLLW+M6OGpWNiwu9pyubY0IqmJOicEMx+Bp6x6TsS4tWKJQ6OMnamWEEoceb/zBEuwjpnGPaI1iDvzgBYmI40L9G8VZJ2/+MSgn2n/mAgD+X94D4Drf/uVz4Yf3iWnHwH9ZuX4kM7yfCM/kX/2zklfKxtoh5XBy7C3NhMWG+HTSJ4EJMm+aGNLKkrChNIUjo7B1D3hqJOZ/7YGugu3/ALjFgEgI6i2jjfHOFNl2AGxGynEOZlKfIOIyr544+u5bB+DFr5yPn+MmGIoJyroMAmougUXUFdxYkd4EArSxC74Dymk2OYXNrooSoNsaO6uyAYbhkNaRFyIaCkrIKKUrlghsQIaTS7Y6uCCQ0Slb3EOrjxQfFIgE4vHDMRFYiD93QvyfeKJJAZxOQKEqAe5MOdYITQD4KB9KY+LFx2XkFWpSt4AxSnOoHXxrKUUxwCnzP0x9cjANiScxG6jpuoy+pWW77A5fjXeL+SSzAWQ4NHUOMCZQEIAcvoPxMLoKlSiafqYNpMJ3rtfsy+qGldv/ANc3E2M14MZNpsvfJi7dj6PWTzNFrsGz2UC4U1p5E03keI3PlhwuBB9jwvgM59GHN9AfSM4Uw8zzjh7bBGlEhyPesWJ9LfS9luvxjUd9A3pp03w+ec4trBpF3+r0bwGV2Q3z9iWMk9FEVS1zp9bZYHNaLRndVX/uaac1abxuabEuvbYAKnCFIVVEU2leHANBIrReAjYfH/MDLtgdQCb0/Wp5wfm8c0IZW27wTiybdevA4f2oDmFCmkZ/zDiojaDpx8hxho2NnkzZ04E5N4SAIqV2bs1i9Jt5Q7qmMYI5z/Bvgb+VwbN+MSGBgIwVEPgO3AdXYo4RUnsM4FW2sgQJjHKjZWSC40msrg7JR3EwW69rqNMixNaUqYFOOp+2Saj01rNBTaDt8/hj9J3j+BdVEugqL74CNDEhpbkHDSj9mSrUPnKDzk1fGXWblgwdUnJ/dm5A/OVch3gCSpxGpgx5AFR9hx94DWF2RnoVxczDdRUqg5CMdtayqGd6E5w8RX8nIULpLwA4abDqPj+vyYcBZgKDuZYPBwU4OACqbWwhduyGc4Z7KkB8lMZVnHwQBqZxx9X+IMY6sBF9kYEKCCIn2o/WEmbZifnj+gbt56ljgtylV/OSg+iDVxTBstsph+AxqS2zpJ+ZP/jIsDGQCCpEaERE9OKUF8pqruQpjGaE7zzSD3H7F/eAuzAqgh9gcvS4Yd/SmFuECH0d8v62Vg+eemtLPjnEx2iV2he4SXh6XCSBtEg7V1MMNLZH7nXQ8HZpgBOh2Ijx1Si7wGiIAoS1bnfJ73xjiNiS0N88o3PCMxZZnYBLt5GKvN6A2Bei81Jr6f8AGBeENehPSAuyla5ZrcL96Vqh5JwZrQcTbD9LgH+kHidfGsTblQ3Vf841jQQ/z1hoMYv1/wC4x98j6p+8Vt/DjNLZeU2IvIW3kDYVtCsaVRrY3eCjpwlmOIi9eRuTe2U5AUCkhFWmiC0N/Ob1BFEScvACa72eAgT1QK6ALKwqZDKbEdSpWIwMlA6DgBPoPxxa9e1HNxt3ij6rsCHoLoKlVdyrY+cBUoRjGy9j9LinSTrXqv8AHesrrp/FI/r94zZ1BNmgnI78XYYIRaTBEVGkOGm3XDgJZYEqKazWENqSp7P0pBoE2kZOUwXXkKRX6FiA4eyWH6t3ucHjGbAQ7A4SIbvh6uFi08SolVK5ZWBDNdM04YjcJ6qzBUfsfd6wIgxN3hP84spiTn0Yau9onsiObC2buD0AB70dJ8Bljk8Byp4TghZdluRisCgBENMoPD5ycWJkcIVoTE5r7hzOVbWv0JO+XCxABJhsPhDXdd3h+HC1im5iRm0dfVxVzJs1zjBqd+cs/wC4WnbNJP7wU4DtuVx5jgbR/OLgfHUUqMbHxkBgXVUAJAREO49YykxOLZGbtCL/AMNxxRYA+NJ0t5zV15x8tCdyxJ3hhlNoRCkG3e4HGsFyCIEnCBU2j+A4IQ4IUNVAuz06eFdiKktG3ZAGmhoUOXi160ZPQAuBPaWiO6H3/HGoCkHvjJe8e80oZ4xajUmNpZwrpHEPcgUIcbpZIRmKIOxramjUCNpOaPBqlKlQIWELyqrm+7rfZy5ElFKaB6wnpGpAQyeBRyKjgvGLVvvGgwMRmClj2yIgATi1yT2S3j2w6EB43GjziGDPIIoeFnJsmPwaG8Fj0IEf+JkriEBHXoX631gXpg0HdU0CVXQVcl4cLtbJNFHlInm4mfQRMgBK3To7sIKtyaARRi638q+MbG8h2OhRHHo/IXjkVDR1HIP197ciGpkgRtuvF9uTzwayFFVJej+8d2mmz6KVS75Jxxi/ChabkVWs1XOocWQmpMq3WqccveCNK1DqNH59YqpCz45xvN0Xv3/OWG6EN9Gv5M7Ojw8LlZHTnXkcAiBVDHLOaaCS+S16dYrLzpp5ycDGzjVy7QRW+rL6D35MI3Ktb2ZNbXlt1rDeLTpAOhz2Q9N4LVCiUKgGXgy/Xm/rYkMPJ5fLrIZrPfBJfOCOURvnKMKmo1yNRYtU6iHEsO92ChYospdr9oteyHfJCTW1l4dYNgnsrQKt3mhsYQCptjpNzoPG6oganQdArvrWSaV9ymxC+/WO6KnyBxdvU7694MLMyFCs86nHLy4Q+rfAQnp/QZbApTpZ2965xoa8qkn3IGu8qJ2IwpFSWiHMZ1c9BZJCDqsRrfDcMceZSDXpM9hMjxb+8MtAEPSlNaMm1OJjBjJZAUTVpL5zsS69HMaMcaHeucV5hCCommgz0PxlyREMU42lKwoWaaCbv73OpwAOtqxBBgRedn95UE5WbcXWsEyRSBbq3i5P4TJOAiBvtjg3+SAFW/T+ctSfbGhwIlTetmPGxcZzcf5+sEwxEF23rhf/ALiOBSewTk/OHVUShQisYWBjZCWHsgISkCyMeOMYg9WQ8igfmY/x2hMe9pnSivGDNz/4i0LeEixZGHlol8eRISamaFTOXTZaHorxxRzRcUhS2oGmFr3p4xpRW02cw9MOjpwMsc63xND5Ue8FbQ0aJsYOuMU02OFup0iFOdV1gkE2rv4xSwBUJDnh5P3j48DAnwgI44pKcKP0rNJid3vwcha1QUfWEBmx0r/3FtTkimIiNWy7x3F0RKsFG7d5EHLPyh/eU9644YtO8jWIy06HXHjDw0CnHN/nlyKvUwRCL6UfV8sZvlBjImyp3MJoR/nGjSIoB4WaMzAAAaEGv2YsyKXLxAIg15GKW1TqYsJWgNBRK7wYJqoh4juz0kx7JNmJKqCTRwTfjNDrlij4EWfG/ILdQ1AlVRtbVdXgXFm6tLQl+TL4yQRqWkPC+efON0RT2d6zdfphrX+/nPINd/ebXEYfr/ueLDCOmCsjS2ayVD1fjYygLCuTM33fZ3eCgAhiPDIw6zaIEUGm1RuayeRApmxRNAbe3fWJVEX8O1AvtxNdkQm+YQ11TBb4IOh9D8feJDPSgDqGn8YcQBNuvxQX8GJIlEHT1KbbxxaFJBa/hyc23yWqIau+dNGl3jh66H3A0TTcRecIKN6tWWUvZXZTeQFkVqDPTyOXzJp2E+3OJKtOgdr9P6wEYhNR/Kr95AGxBSF0ewfxhxgtBARQ4EtXjD6jDIA8dpdmk5DltsXMgOwLHiWBcWv1x1/fPJTpUdggueMn4Dh67Mq1OqEEcWX2BIAQmzQNaqcYK4QPTQihPU2wK55M4wcaL6O3WNaATlmRKDA0TzwVwaTKSX34kK8VxoJhhUIQKK3ZK3TBPMtKQECHRhdzICqRHu24QRdeoZ/9wWzZxgNxWC23+ZwaMPGsJC7YdCA1hNPJPMmh8D+MQdP2aFu971ZJs3iY4zbsHsJx4N48AbO0UleGtmw0ibuzAixO3ex4cQggaYrx/gXEcwip65/z85GYCNj4FNnERGvGopE9k7R4ub0ZH3CoVJkIR4Ca0Ys1IRtyHe6+DuXDUYKwL0UBklfKISusBQHJukZGaRSKheIEewOzeB4w8YmvCcRuFj4lqvaGrhioeH/WQVWSJ5vvO/N5i9ctxHQBdqVwTe//AIzLQmN9GXefR4n9ZH+Cbet/6uKKnC7BLF6wQcurKoPcf04sFd2CK55lh0p6i6pAellry0B/05dwoHZrQ/k+8Av0UvrSm0kROKRCBdJWWbWKTojN8zDksbCa1QogFGadMsw4DaPogZ++XJ4MiZd8gjz6w5n7dCRsVKaIOEYEQYIQCyBeu71gyja6NjfHP/zAyuiJKxz8TDIELoGnOyCU6TEbbkKQidenGCN0fkCfxjgdm31grkyMa4bLWROm/n5waNkE9/BkEEnKP0r9YysbW5mhHHJ+DSfvOmz97tAODjwUGy6LbtukQRnOIj5s/tYVHgLbXxiAKYXUT3Pdg1zXtGhFr4lxRgAqHQWNm9MgLskFfOBOuYlwRndrE3YTwKJnWBEdlazWy/8A3WMw7UTZnU9p45Ocb6oSR19qvHs+cIBr55U59P5xWYAIrYoah89IXlm5t8DIiage9LtDBZ82zvLPfodARy8gyvr0Lulq8qq5rAWFEQjhYOwtFd+FOVdmytbJObiyQQwOyIaHk15bBmaZnGgHQVA8Y7PdWf2teGgN+TFa26TnDbzTXAjw4eKoVkyIponLL9u5yKM4KdDQTaN3ha0rtB45b5cpUFerqb2mC2BVQShk9v2QWhmw4HSCRitIfzn/AAzVIR984LfvqE/ws99G0c/wcnLrWEgEUn0Ydu3HI2s/9HjW2VUQUmDWvt6W8jg4d4AjQAdJFYc7tzSUCpK7STkKlq8AGXqmDBkRE36wiaJHYoeN5/8ARhh8Tr+Af1nVkAIPj+LIuP7LAjtkTYgjl6t5ic9RcexLu4PGknwAdp+PnHy1OC6TRjZAnF5xttSzmQAheDU6e4v+LCDQ4+AG4xRxgh9trpyeajpxF2LCudMKmDSc8f8A3Kz8A8vRgkyu64AQL93EVAA5bjFlZmwBOgguyznto5WtYiViNR+mYzpW3zmt8DHFlis8hUI9KnmXwYwSO4ZEDiX5Dl5fOakNVO3ygbIMwfPZbAdOQ4U7eEJB2A1C8rpzQcBi5AUVEIwC85OLjfHKjSHpjwc4rsEhFBVMR5+xEwz1IWOqfEtXRXwlkChWnYmxyWn8uHSm+qjz58X+cXqaVIU5Zufn9Yd5BAfJp3Ncc/WP6b5/+sWr8/rHNDY1MSHkb/7k2q4XpOMYKIozoy3ArZkfDhBiE95RVi9quH3Gp/U5EnKap/kxoc82vvB0KA7gKECBFXQ7zgJ60sQkaAJrnGNFevJK07aO26tzYf4RUUqiIiIImzFJS7bDf1jdizdggHziCJACAmzuyOuOaOJduk5YIcTX8uXK+7UCLCipKgu0PqgQL650PjF4IqnVAXl6e8ViEIDCbOmnacu8ZUtghsHg4gHRyoc1phZydpuECQlTX2x602rAX2p1cTXx0AN2twroji3E0xnUU0caDrrLkQ5SoFgts8KNxg9Eoq7/APX4wopXlfOCWIERc9KxXRkYFU62QCGRVdHG+GZ8oFGxRqxXPetXh6RA3l3RIb1l5EPEUoIltCG4ax/81VB376NvYm9fRxNW+aINn25TfFAPaJrKyREBLU7+MoDfVm36xE6i9qUJQJu9mGZGYrgNRa3exIw1FngqyuFBU5DzGWMnnxrX9ZH9tQkLpyJ54uoZc7ZWoSdhIvGi8YQZgq8VwB2Km2qZI7SpO/O/yKO8IGtAnkUihDC7vAuTkmGIBEyhJdBgkNCVFNF8yyPHvLKdRA+AAnN2JrksVyFKaomgjJaWXWEG9AbVoAIAEN8+sL8DmmzX5/FlueLDeCjbxTX9s5RMEctXJXjW+ADNbUigcwYhzqQvOUKdhe6CGlSrRGOUu2NKtkFxGUoeBRez0ecFtw1Kyw0aFAUuTI4jzfPGML805ayC+SiXNFMCKsh0BOkTrNntQCr+MN204REIytr+8JF5N9ooIiQchw1i/wCT1NF7eRB7POQbVBD5xnY83JiMOhRA4V8+F8Zvay6GCKc2p8ZxdVshP8YD5TlXDIhEQPZ6G9LO82NUUa6aR1NPRjQL+OEBv8/jIcyjbvkuz5aB5yNIK2V2mjbvnn+ct7KUpmq4s564K7y5IoC6D1NT/mIO0D/g4hEENhL9+MtIFLHBev1jwB95QCHrNtB+cYa8TCkZyLPPvC9h6rx854XXzkRLBG2mnBbTAnfHeXL/AALX/MInbEXZgj6AJi20S402tDmqo7pkr8DoyVcEjSa41ikdzsteEKro5VzZ3htviYwJHYc0gA/uX88GVn1QHSHOgjTfGsFDao6QA0B/zJkuGtWFFKQlcBhyQW5oTs8wNjpom433zSoS9VgvbkHJKF2qKOAakgIHXs8kEx5bXSIBoeG3AdOpnyxPP1xgAaMmld6k3vjE5MlNAopu1e9qXYME7DADUCWpXI7FOIDm0b3wIO+bmhxpQ8LyW5rI28JzGZnVDVruLstcYDErC8IsedFuw3Veuo3Ct8kFfe8FfddckErN9Bo7mdM0UFWviYGvKFxnogm7lK/KO2QqLgUSqgTQgeIYGFeMwWDp6b0jfSDHFOxp+HJJXsRw2kIGtCIMa0Q9aaFAOTkabcL/ABdFuKXDgnBMFe4E5T1Ac80fGSAHsLBHGEdqIb6yh5ttlC9LCsJbuZuSDe+mwj0SRxlE0WjoqElyvW63Hi2q9ulLVQSZMliwIKRUAqJu6SrhrQfY3j8BPiOIjJTAPKugwG1QjmYzdCQLrLGhRQD0xfn/AJhVtTF2latxSOBupqFCTqB4iY8ic200KGvLTsPeUXe3f8hcEPgI7gaxpCyj9ZtymGU5orYDf2LjQpk6WD9T1mm1Gn0eUO/0uEx7gj7FmstgWiVBtCrOXX3mgeFDhwEoiaTLDykV7OVJ65MOi1koJpJqYZgt4f8AuErN20ul7jKp0iaxxWuGhGZBYDCUdHGa220riVSNj43PwsRlLnYGbvGEsBaEmqh6aBvK61gxLDS2mTUXc4/GMu3QAYhHIFkdcmAyMtDFA1FJW28BydxGrgaQKzZXj3gUxk1phy1BLss4GsdayUB26dUxBpC0E4/GDdpCC6c6U3vfOGvvjDCHHd4O8HDFAcK0PzlEDWbHplPLidqyLRoDRJT09MdN4DOEMKIYRa1VdCqGg1Glm9ka9BW7DJEAw0uXeawa+cAgX6ygA4tJsPSt+Zm8+kIJor0LPpwpXZ8iki7Zq9u7hnUIqOQQNorTLEXF/wCR20ISpOqF2BIl4StoSYhQ+DbcCvXhfAOoeydGkDGbYEzz5ESvGxiZHMdMaez24wZHK7cj4wPJ1ZLZREjIlu7rGAGEte8b3/8AnFGpSfoz+zjA4g+3NA1XqTiCeozAaLtqfRCfdxbvj3GQ3Dej/XEgTgmn0MSFxwtH5x3aEK5azaitBuMmF2oDa6d+Tjl5kuq1ItaW+OeFfSyUqihGk5b2zgkaKzPagVp0zuaUecFvOBhJzVzxsO2cDVZA1ZQZwXB1hJ6BUVpclChSjwadv115lyGghHSTEIM2yPJPeUBeDGO9zhO4jrJ7nq4m5se/akd/sw9VSRUAGi5wng+TrAEd02CTzE5rMU1vveBDONiNdrmp8GKH2H8m/eVysAZDY6AXb3igktmqd/Ps+MIJSS4j9TEjI5uC9KbwNENFKfLWCCEdBTweYmBBELA467wgIXQBEd9ueR47F5AwCQeA6TJD8LFUrAeFwma2GK6AlV4HeEPZVB+RhhGm3qQAkfWVT0IGro5+bke9JI5g1lBklAZvHKKL3PRVoSfLINAvgmEvMG/XXOJPgggqi8RHbiyTbHzuuejU4Oa+Ew8G4DJo1B+JhautUqRcRL1DnCmINX2q4w3Hd+uIcCJsQcdeCfOgwfC1AOcx7DetnrH1YQBp+f8AcYBRBNI9YoKr/wAxVywjDIpDvIAPPjFqcsCu8QergjxpyQQ1iFuvxgTo8rTT9xT3hm70OWEeRNj2JknOLwZRwbwpyGKCKfn+MYobPiY8IUQUftmAYyuwmIK45MKrq2G14MLpI8pgHZzpC7TcVkq0muaw0W1y7xKESsJU61Ku9kwx9iD7ExBSxiq6MoQkouQDnkxOdnSNBKM9prB+IQsYCEEOQUCqwYhvD1Hm+wBHSCTPPWBG/LieQDRb+APGT5mmQKS8ANHeICgEYUadn38YHlmB2yUh+k5ykYNvRgi/Qes0wRrZ4iZ64x1ySW327/8A5L7JovgJU+AchxIGa4oKUbCAXasMpAot/jOZmgw1QYWMjmM8BXv83C4bgGCHgE+C+HzkzAY3gcgekEm9RMetKS7FFkDvaHGUb0vtf2apQaaNWVGwIDMCaQLByI4SiHe7X25oIEa2dIryfvB2VKlobouk4waJHTiROm/xm7DUJB5vOuckgmJAPx41xm8voqcPrJZznOr3hw1Krp9XjF6BFPB2/wCnBNIxnjdHfiZWQkRQJ7N/FxxpEgq8l2OD+96nHOsK6t1pQ+PGKKCuRvDydoA3MuoooeMNUl73gpxluCk7ZnEpceQjojRCHRssbpcPgdCAqPZgXwRk3SAa0dNZbQ+GPu4KpXAX3nCg4Lp+XAcyliX9/WtZIHDc9ocwmvyZpqLxJ5aCNCVKOomKGGAIVIdRA2DSAYaGoVBnKI748H3zhMBOpyv5uVSQRVO15w5S/eNax0mBWGAQGznINy5YCTI3zbTgnGQYQ8ZXxiCApLs0g1rp/GdY9Mcn5xfPkMeagrphg2oKuMRanwv94MEA8cn84to/WP4MUxu4C4ZECwHF+rgF8qpXCOZ4xC90ChiI7TyBg9YV2HW2F/BPeInHrG+QD/D84JDAytaU8/bjAZjlDVvQFeYOSBjOhq0CC21R3yI2CuBumUJRZ+MSoglkIiPB7ixgW1pEINE30Mpd5FPL2C7XV29KqlW+AOQdciQ+GRB7lsdVd4az+l7876HoH/OzXjPTNriZS737xpnEYeIzPnVxU0kwD4Q/sYGRXdBXQY7Kw8isuokx6gK1aBQmrQZ2DqtQuq07RyIJtXe+W7+MvMjw9Dbklrtl1TFQlYXe5rDmToFdZGxApXxOJvFadO+nsPGAwiKY0+O8RNzb84a9zh2aDWrr2uTl6CBFACN215dY6KEQOQ/Eg+ji96duk8k8n6xYDUVW+aa+84yWdJ4+n3j6at2VeDp94IYTnGGx3zxgfFhDh7Ph5MSW4M5Hh3ksRAegb11xq4GiBq4TpxyChX0yYshTI8k7/eGakIvXzkstFAB+TH+VLcr13jJ9oY1FzyTvBFaizU/7kNXADWeG0VW4axKKRdLGQrh4wfU/pxtQVWmFgDQY2GfRN4+rK4d84eXkXTiIfIaG02ErTSDBKQ+X3KXcxPcVjLaNsh5Sktyr2uXHT6aQBFXjidYY08LFqJuQD5prIAhkQA4HiEPrGsVgRs8p43dbxCNdxideMQMbrGV0/wDxyolhn2O8NMDGGmSG8AW844MwTAB5n/4EdXWGzsGJuX/aXmUoDRoNEO+TFdSLxCgqiI9iYTPkfzkwOCyFCgm/I/jLgNdb/wDXJLD93SGxATfZTWF0Jgoj4sxx6fZh2a0p14Iu6RubTVzB0pTy6cJzndg/O8YwkZBaBtW9GQnqlm9IInY8vUuHj8RsrzXPOUA4SvJqW+TwTeHTxrmORL5kCsBXFDc4E+ureef40ZO5q81S5ObwrrrHbQic8VuTSThDJizA0RN6eF2pEJPbRDUCCPueU4ztmHom+i6PeDPe+LCo8otB6Y5bZ3kgaqqXjvGZNpdRE6hSTRcTvoDCEGyyRdrbk8gUDB4X98+M06TmAH2P36wfXWJtZ4Hw428MPWZgrKsQs5esTkDRU/LgX5AwNFZ3gEndx7xgaydqIekR+8tBBWoYTEG0LPb4wCcQEj1vsw+FgoF4RuAjv8QXk8m3CGUibRTT2WzffBBWU4YpRNoYXalOACsgmApnCHp+TED6U6nhGj9esToncIpwB+z6wkmjbQ5N39ZPFqL9SUx+cYFMUCLgnz41khW5UQvV43jvAW7cpLxTZMNXnXS8DUn6QXRzkhJC+EeWGglvAnlw2zYxD1Y/5lBE0U7XomaEPcNx3rBpWUjk8v3kNUqvgbx7wpmypil4rrAoGQ+SGusLLlFH3r+GaRRpVA7TkdDyPjLonYBadovW3ieCJrkSgF2wQR2I0V1hYpCMoMABAEAE3gRJ5XQFWAPVB4JfDAwgqdFdd2uCGIOMtMIJBGzYb/fjDXnLQp9I2fKZrUSPGa1BDU6PWA/QOPzrCkI6QxbWf/pQ5Cxousx5ygTQa95wDS53ucHRhDnELDNUTNFwU5YykNOSp+9cmblxixWAeXRnziCQHud7lSCnyPOaX65/Rh+CinBJTyyFGzzhjaG1Cvx6Mmco8T9DHVg9Pz9nOnanaCUK6HN4yVrj0f0HKug24uJCtUeVjVGC+CYgIcgrX++cA2AAHX1izScpT6dvr+dyGiPDDf78/wCuQcfejXq/esYXumPTXaG3rzgI5LerkOErYcCgX+KZQqXY6lS6xM2gKdxGKghS2IBQgYzsU+ICUS8CAE0GMN6KzBrAKV7u2lpC6psDQGyBMjiBzOTzmsbjlHHYPP7wkxEbF7E1h584YMtNreT+UjA0AgChjdtOS+bCAFiNs5y7uBkihZeY4PbrDh8NP/j+5hN6u8VZbkArspKug0PoiyqAlXlyXcXjBRVSIl53LGNNzcrJiPiRSPAuphC+4iHEL26MZFI7pCUFFkF9B0Ys0MrhnIgMvDwp3goHDxCAgJ6xVVEfwMgMfKt1RMpUPNeH7wBNgNCuHZyUHcY8JZCxcSgn1jXitAnnROYhT+cXdiQX+zgticVp+T6+NZYHiWw+FMFotDND11zSG+F/WCMXIS/xjLy79/oYuNzjKgm91vfu4V8gJRW0ae9+sSg7udC5ef0YWU2RsnAG1lN9uerp4WIpTS0jT1nF7Zqg9Zsz8rHcKIU63a5ClXgzbsQ/ZJaSLD2GjDYTHHkoNlQvkh8vGFPfkEQaB2dv/rEIQsfDswet8Yi0p94t5XWb/wDxu0W6W1dAVfBkR48pRJvYinp5xLUDx7yhuFuoTrG6bxmzCCyuQSsQJTJ8fnJMNYEQQqedjr+uSMuJF3VV/NfAY0qvHZm80lkeFwR+DRJETppk7O8XdMD4R8Ock89uHCJ6LhnLKLk2Hnm0a8phyaZvtdPAaPnePK9qEcNhNbbNZPDuVL6T/wB/swaB4t9ycjx/tYFTB4a3AyMN7Mx6iaXtfACAoGoAC8vGjh0FcR0nilb8AWsAsNajo9FSAWwBuIXJjhtqoRV5thal5o8yRCttQ7CtsCPOL+s9CFLaGzgXUcSzQ+rgwM8S5q5v9acOtYyY4Sa/zjDUGwR3k+LU1G3RnJ87QqED/LvBMzYXGQGQItrwEc1a3g/hVmiGci33BlZAI2VXZQ+8dDlWHgroL8sdBRXR08ZR9BQ8njCVaWnL0/njEXh6Hh/Zgm7WqTGAcv3m+C98H885wNV8ZZ9ATWKCBp0OycZvUgrfGBMAcYKFxRtmDWkmG9ofONHP4jEUIO6YkSmGv8FFyts+HYFN6GyGbozVegVQH3gVqBqpwEOB2n7yr3ooEAP2YW4q60Dhm+Q6ao1nQI3qr0I/+EahBWilBe5qTDmtWqoVOAF4uR3hKM0o+8dpePVY4O6TkzRiDt7wsAgJDAjtSDvZhpOIJRk0qO37BxYHslUE21AMoHoyfCAme2axxoRlkx6sLy4aFfyTOmtNriDxha4ZC1oXkAT4DZxm2LTRMggTF3ZNo/nEaVMKjkWLHnCDbvIwkBDumilOaf8AucriArGSdoHw4hypkaZHT7h85NkJAFT6G/AxHFx1bHnOl+zCT4Q/eT+CrwC6yPNWnbo+30XXGxgs0RXRqFQ+DEtagjVXgoXBTBhqFgAH7aiPDcIBOdy//U+Jv5ygENk2QOeRe5cDWEE0OG2PyMPRgiDD2BqfFuLT8CgNQC6bETvC99Ct8Xy7/GRvrVVhD9Bi1Mg0VNCans2oA8GuAouSBvcRmrq1xE1GQipRNtnWlJEEpAcHkLG9NeyayjqTR1/9MSQU/LlBZ43TBcUG0j8qYxWXxs/PGEM223q3i4WH2wxtox1sALrbSMsx+lNBr0poXlXbcISOBDTwCiThy6oIw7KEFp66cRwuXTLQNAgKrrXTSmlreWgfiXEa1KDxdzG20w266cCpGXsAF+sCVLyuPZsxKyef/Iynf52v5DKAY7B/k4Ndd4oKBvx+bExqA8jJLuqNFeXgXBUV68I34esG5UNgJIekJe5wcYxoQN0jvNS1WhRlXwd4vZxiPp/jjHkBdH/pYw3Oip+cAkZiyFO4B4pw/OJrL4Wv84hViOzyXcB4QaPTHJyGKO55yVUOwybqpsqYaYlW8fRzGYTClCwS6CynHkyqlQbMJzYBWtyatpbvEo6DvBsTF86U5+bgg82QqeTj9fjGWOuEMkby1tygcQoCpIUogJeFJRtcoSi1LgDl6D4wTMraQC3XRjz6JdCR1O81yQd4duNJty47alGADI0lOe9+Ex+hBJfJMGltdt4yXZAmw8sMcuumKaCgFe9juhaGqkAVqpEb7/rGz07edUomlg6JrDNhpJFQCBSXkFeG4J3Q0njNyLm2NLlecD5Ywxm8jouJaazfgygiKJoJNPR66uaNtI3RfR+Pq5Qq4vJQ1wP1DCgeXtpCvgmP9sCc4g6cVWrcMmmaofIS8qPi3BYKOP7DkGKXHZWxXgjPOPI6Ai3yr+aYQMeH+EMA4UGAfRGaQ01P7RgiWUgmBR26cOfzncTdJD+cTWWF7Hi85YYNfhwhW8VI7wS4vsc4JeNRKFZbAJWrwbiu02inFzla3d+0wmbvLdGLSD4ztqGI40fPsbjHl8pg40AWTYxxY/jG1Hjff9jKoqAFq/NY+zhse9QLtvNuCLsj9dRcAF1AHrCQ9W2EoePP9YZoRRUG1dD54yqr6mUbEF3+mRdZYMZ1kVKHgJskaatzKb8G4YA0NFyi5cGonhUxYMk8lRFUIaYsaTHp7gLhYPWbp1XXoY8AoKUAubHqAgkgC2ANjyuacogBA49itQHTFuJedKCuwcaqB4zneAgjK1iQ0xwMJMQ3DXkoM9GTlwwgjVtGa2XERVPyqX0DP00eAP8AOEpmutAKCVFQNjzgV1gjKyXm14wmweH7sVBZJgUCi+bgsvYq7JVB+f8A8jdp7ZeGYdMYeQRh/JncFQm/jA84aQo/nEhrW6b55wZyaGgxavhzRWcqA0Y61bjrrUCo+jOxmpLnAZNB0+EQa8iXw7FaygfkjFOl6LKhNUCyE5bsf6dhwiFXRXyYUwSLtVKs+RfPAYStXEJKkrUYEkREqeQxB3EmgJx9GKGVFZXvBb5Rr0KAhyJsdiYBmjBFSBzALQPeFKIU9yIgEndKhvHfQIpOy9fq98bwPnKUb3TxCtNktMNE1baUAGpIQOsLye8dZKjesTS16zYuCnTgjIZd0vWWlkzXnA9GaeK8/LTXMxAbSK6u2F8FeN4H+43J1HgT5xwLQhcoAR6FnHtiMNgCimsgvwNwOM2w4BFWMBSyXSwwlbz4AxEeHGnIQEolH4xoeuAK4LJjW4/CzrxpWfnHHHB4HneMZmJYRDy7P13gsYIKD5IMrLuv3A/3gYnORgff8fGknoWbi7R9I+8mx3rc5o5m0cYKqAKHl06SctRGsMikXUwAoCA+1cPoTsKSIWEgoRs1hWAr1O8UIL0XDJzxTuHeMAeaNXMNqm0DWt8oq3QxbjQ2cDbmkLgXaFxMRkZKRVI7vjzkGo8kXiLrDbVTYRwqRTYzl0wQIfehjw8ZqxACpmzZteE4m8ZUCi0HSCReSBxYASUn5AXjvBR5VaJ8hgMnik10vog3jcqhwWlv+9cdr5yYtQkZFAWB231lrB/K7nF3diL3c39WerOpN7abUeMYS2p3eLIOR2MK4SaQ3QlCE7UUaMS2SLxFAgY1ANJreAIfHLDZqXiF0eHBnYlO+ALVo0MbBeCAoLtlf4Y7pjBLlV5wGoTPIFf0YLw6hAGHO2XE63xMacT5xBo/GMOeRDTPv/8AhfwDJS4KaDp3c0gmSF5NuXq4uDu1DE9QxRsMTKgX9B2/Rh2uoXUILCYrLzgM0pNyn5MKUAnhdPx+hi4N0gVHqcj0xLZ/3JGXWUyPFdOY4PQVIQAFHyuLDOIgJFEeMS/9mZEBvl8LooMOBVLsx87UiqQdgT0JBGqL0Igfi6pgkpXW3Eege0yMAALgiHPsD7wiQckXVF1316xXqIoQv9xPjEilOSIhRUSLArbxgDLVNfB/3DRR1HWI3xwmBU3hYmeUcBVcAfGUl/Jn+Bm9TaKGQg8JZ9YyxqKqAqITiHHg54w1VMZVRT8D4+WXmIEjIk6eu8d57JSaZdxwWZeDSMtbSAAD07BwEytQF5DQ0DsWApySpgQEAPozWheyD6M2N4oX5VwKwzsYUCD3G8Xgx7cuTLXBGFk6Fs7NqUc8f+ZVhttp+I2HRvGq7kQfk1+sjtueBVAwDlxQifM0fIBH5y9DbBCJY+QMUvWJ5SGFZhfM47xf5V2tSC2kRr6GZL7EWp6NrA8YWXTfJdERVvc1vBceOraFWu8KUwCI7AcoGuUwC4BiSCBtTYUPI7JNgOIZMMAbpQGmHj3384CnYpW7iU1eI6MVV1S1bLoFmwTTJhC/cEaUYaK8ym5jJNENkDw4r0b1uJURA69bFadVnnFLw4YH4mQ1Y05f5x8pBpMa6Wkmn5ysrajQ8bg4DNuIU+rVN+/zkK0wvCm/F3hIciq0A/ObIeeuL1DUF2gLDFpB3ZLocBI0QExAY0ojo4tSI0Ni2nWaAjVDR6ALTokdsrc2ZnDoVdJ1tDoTeQIfCv2WEelVwIFUsjq5N6MAS+WCL4ceKBYS/jFFROKS7tm2e/LG9Mqnb2LTmepzkxpp4CQVE6sWTnEj7YMvBBHy3BshuJy4IkIEAcazVjGNRqXn6L8MtAo5RODyghOXXKY6NZQTvpmURvIPX03FopJrAaEBy5dxVZC7t6xPQQksUXRWmcBY3IfmkhtBsCdHHxnkoBUPZH84KKgNLkIiETXEXA72afqKgQkG27pIxEAPPgFfbX3ifRXSK5epxEmV6FsOGARRaMwij6FVoAf2BKIvRxv2zlCPCoUs+sVdSutkj3h4HHBXyTv6yM2UAFkmXqZr73vSA2AolFx4uK6xFg85Y72ZCWYlf4Yo8TFThc9HPPBRTSoIj6nZkG23GPI4m4Xr6w5pMWFOkN2XnWjeBuNHW2nyUfgyfVkQMRCcwDyHnPno1GpN7xDgEiVZxqO6Ngl51za0cN/Lb8Yuk/I5BxhzGfm/lwKWJ0lw2IUBM7ydC+0/1lBoHpv94ZCyOB+3EwYGv+DK36r9SEW4uGKcau92EXKgQ2xBDJSw7+GIBSE+g6DBRTLsP2f6Y7aczRMZoFQEducQtrpBjknInVx96ACJP0OzYGMJvRwxgsT0jlFdAP2q7dRDUVH6YkpJUPyISvvnjDQra62yr1t/eBjPkcPpxVQSravTHXnAk1dZVUvQUD+2CitbMHr5GlBlEUL64Fsw22XFIAp8U/OFJ3bAiFQjZnMR9ZW/SyJyFAnBiaTNjzAQPj+Xh/sB2/hRyTw8LvCBtOiq84j3/FAi0UYIaFgPP1OlhdoHQ0WbE9IEuqoFkSAmuy0Fn1gLSke8vQeZCxP078mwS1rBUE1hxMJdyFf51hppNPp84ahcZEj9mnyMLFK5psDstIPGXuGqwhrkqyEywjEBZuyTu6F1ioiTQQdUzmdQYCg8ofePkDwIlwFAGdjizAVAumA/SPtxuXj5ChhsF5c9dcBxICWkfjwwQcVENDaLUB76yIg2tB9Q/bE8PvAti3Z84cCRioTAOt0WFcJZr0IV1Mby74k0T7wIdVOaqChr6wKpHCP7rMaeGT9Wj94eqBZQQeU84QQt0oQpzsd4Niwp8kFRAF2eGzDDHdxGVBdg00lHFWC/OQSZeHCfsyOIhhof9lfvNeNSSNL/ANwwSCXGJBGDj4XI7t2YRCxLrEoZXL7Ocorkzy8qDdw0EzZAk/8AxMqaKTTc8ugyCDN5YKb/AIL1rWwDFV9EE2IKD5HG8sSbIybrs+zzlDsJCteefeEXGhVrip2YZ+Qb+8tlG7aQ2LyWn05Sc5u36xS3r9mXT9MSRV9YPUixnPGK/sj8ZOPmnYav7cD8EEbFwKAPHjE0QTvW8axo7AMrJgQ3jogmwCbDno10+8VPeIE+yQDoLw7F/wDq1ykh8CRXQymCA4rD3Dq8/NyNKBHIHb50ZMc8xNMMM1FBpEo8lQ8h3mja/aci2tRUiprjI+gpyaxPIeoO2VYsT7w5rEjNRVB2Jz1jB1lJHQMCJUPrBSMJLyGEHE/bkXFLGORAv/uKHrHsCtfBgEWj/mE09Cje881ScvG3/uJyVRa8pS6/rDJXBKQqAeC8ge8UKbHX/JObHA7i/azLMKDcDyacA0HmLCEYC4QQFa39Yb5nrMINFE3yNAivA70cRPeMWWoXi5KaVPa2x6BGvl7cgd0LXtKOwMiNLkln9A1QeCwPGa4e8SlggVfQ3DUCgobxEx9MCwJwG1kc6cQSpRDtQnneFPsEWDyNL353jjzchCN1dDtyqJ0qcxEVDQOVDOA9C9R8lbkjzbGUdR66ZxjMEjJT7r+M3FN6gCpxs84GdgT1iAEtNGkTcyF9ACaThwGXktb9YAb0t+ExqRBAmzrNMkVGUrwChBQEBQ2glingwFodgNCqF22N8PXGatqYIEuOgN6vOmW8z1CbRH84piKQujIYBOoFp24FeJv2yj2l+43+M1JVwoYDz7cNQu7hs2zxjBHTHVPOD4GbSL5GLTMAVcVxQea11NZCuEAvCseGQY4QuB1FvMASqa+cfMMYKwQbs7506mDDB8Q3TwH3Lg0Ph4w6RdgzfWV1QsNYQEkBtD2MQMDEVEm0ENGLXnNlS48KyIG7H72GOIqygiT5jPxirhe8UmwatcI0/TnZXAqq0AuHVpmqsDyhnAc8ikMRp8OFig2THLMXpMuwRroN8jr5Y+FBzypP6zaSoKw44KwgoeCDXtMeRcKT4sLkT7IvsjfYyq6UATW5JZ1wMTAWwAEDEAtNkx1IO/6mE1REcHgG4rtg0j6TQD41i1YALGTcrlHcNaABBwa0nCdbdwoMxxtiRDbA5V4yAk9An8404zyn+OTZ6lsL5rrI21eBwoVVFfrzl5L0nIVfy5FgDG75/wDcqJSUvD3hBNpbLBxur4vHOAdt3eZvReObvLFqlZdVgT4XE/4bjJAlAtc1O06F/ByLeVRoCWkOSWWGIMkOYeTSvzcGQvPRAgGngutvGK1oGdfxglhFLsaXrY+sZakGAImhvDGfhoBaCZagvDfGR/8AKYbm6fjcMStKIAfHhkYgCHm+N4YqwFL+MVbMnmOlNBAEofK4aQcFQUP2OGBfKgAqXuqfGVA7+YJ82ZpVmYgmuRunr3j+crCXQGEejK6EmhNv2wqeK9+nZiwtQePY8qyyo06WGEgD4ycMOS47q1QJLzyYLBISAcQOOsA0SythOF+Kp2I3TAMIpImpIaoiU08mRALuYw2m8WmY4FWDWR/cRHVpHYkdYoRc0r+DlNQQRFDXkF4udeMaAiUR6xqrCuXtiyHjOPJMemg+cDfR7ygK4ojydYAE51iBd4TEmgQTbz+8eVeQLdUNT+31mrXLdy0vNuhHkcoH9UBPP16xZUGjZyj7xX4y8OBhfhNf8Hlcm9Cq+Vxq0P4UykJnRnOnDpP4wPAy9tLq8Afy8BVyDBLjEordOX2OowawPu7DmPKXWi7JgVhjG7CexSHCxepesezUlSrXJ0gausPrE2XwWkVxQq/OdgyHhiGTFrTUCzBjEUvrBnXAQvQEMsgTZX4H95rBGHsffOUsp6E0SgcG1uuMFlgAgipaOsLTXc2B+njVTaGpwbIfaGEYTfmxHH6YSEU1X3dkn6mS9r3c13rAiIcVj7A/jH2gOX8DGi4kB1qK3gE32wUMANSMhrcfKb8VXqwBF0B/WE7dCqd/P3mvmN1OKYZCx1awxESDYgGgZOtjseMnSsOGISorgAsHxiyChU5sPCMOSaTHHSCmyZyVAgAO0GIn1rvL7nJEk9sjTxga2GrKFEio0RCb5RggbG6vW9YqtUg5NPPrNvNBqmh+5cU2NhOnp+kE9hgw6u5V3edS+cKOWU2US6d8eYHeUpHsgJKnuX/hg3J4vJuGCzjZdYByDpSVruut/vGe38QYBPkT8NyObBQDcf1iUVGWlVI6OB14ykXlQ41TzjS1B5Az+Sw3hZVAOJCqBXto8ZWAAwurJz0oKO8vUJvBS5/vWCD298mWBE3vWvzi0X75THlUro/z8ZBGocNNf+Yfh5J56ib0DRqOnGiFqQaMt96m8aO+esboV0BfrN3FNt9Mt7MU08L5cRRn5ypSHLFrT+xTw5aqu4YA1e4ofOEOAnxw3hlwud47TPluMpFxwpznU4xI24em5gBozwOH0CgK03G6/HG8UVggDORXz19YgRGS7HI9N53kQGFVyDOovH1jld3s+qcL+vtV/wDyldFH6wPoxfea5ueQ1jpwkvoBtVQA84nB2dJd3LtpLsBQuG5Wz8GCWvrjQNSA753g1/TVcryAu4b8TGLsXHJMFQCpj2pinKniKSwGqrqLjPbv3xaKS7FfQ7120sF2Ddz3mkF5q6wDJMjze1DESANTYY+rkcXzA9vP4y9BgxTARlS+8XJxEH+AwTWPlf1iiJZJw8uQWNmujps1P2YjZkEWCk1A9fzgqILAKAzzv95pJtK9lQ+MHhLyGDovbISCFZvMRicxa6ACouu2uAjpzBg1/wDMIUkMYbn7x6Nw5D4cm/VBFUbmj2LTaGEinx94MY9FvxG/jGoQK6soPPegDdmN0PjD/wA5z2wDQIOy09Y7csc8MTBYO8NgikAHnrIgcK0mBpKdLxOO8JUKMAVYum+ObgUZCsCu3cytSCdEbOzQ+8gUgAMachHY6eTFW+GNWkciO2XOKerR6HY83dxRGCohBwaV+XXOBzqglRwPD7N4K2AoWOn5mz7w6bDGNJp+sHhAu1Nk3+cQeCZqCI/WE3PrPuF0muP/AGr5wqAssAsC9PjRMbTZx2lDXsH3iXM8H3lkI0jSYJ1pnIfjFcijz3iYvc25w9NRpwk2gXfieMiPXUQVHA8Na1oOMYH31jLhhCHPyc4gNWnCqnoBcYVyOevrIY2DXPv+uHILxNw3qnWwJxvrBC2weee8bQpOubmxctyyoXKp/hjeAw/jIdLiyHGfb84W1netciPPOM6Ia8gLse5de/GMNhZZ330Pnxz5W7pau09ars8+sb/+g73h6zm+5nGI8YYJVYBzhOwJEbZvBMnNrtGCPaeQTR5y06DyGjEicOvOzHNQTkkRDAPYeXCikVmJFsqDSCRLV1jtGDGyojQACKnOpMk9GKkgJQ6BvYZMO6wju3Dw20csJmP65d/QmsreWC+dL7wWDgQ/TAkY6EeDxiE5FkRj/rvGLW88TzBbO6BctfUo4u5ydentuBYW48DIv3MXLrklyj4Y/FyhoCzgGccAVCrrQn0Q3zgl0sYbbDrI6uk8Y/360QeKAvy4fM0bKiwnHZdjx00ZiSXif0D+sNRHQgPXz5xFBrmP/uBs4Wt4ZgynbC6RfznO0oAVwsUIU5BoQWdb1hu7uYY80dP6AKQCaUsTju4RhNbjU88YJioLD3L2J95KwlqlbM47jHYGCeIfey0bOyL2dGWLvCTSPCZaXsa5+c3hT0b1lrFUA3PEwqUWRHC3KbdcJ85K1wZ3M7eoYET5VZEEpBAXUkTpHUp5AHudjtdnZzeYmEsQV+mfLlCWlocTJu5AeHsYH7kRivR5ivnFIAeMJ5/WHp1zgt9po5xt0a6OCJs2HqnnB9YbfWCbgtCvGjEZ1qtE+M6N4OzJ7txewpuv8ZukPVQyOavesOcwe0MNXgTZRwZ3ZaNvN5euPjnNpydF+SYdLyBAfEP5x+bWMlBk8f8AmDVXNtm/WVGItuLdkApqI2pIyoNjJhUIdKJLe2IKCjm6O+NZRL84soa6mEwF4Y7DkjkGnGaNO8hgRHCBPOkaTTjcUi9VQEP1g6nOLNo6N5msLGRFLQX4auP/AOh5TB6uGFLsVU9k1m2Me39GFsG+V/My9pzm62fTkPLOJhcK6NBt885MDe2uOwQ5e7gQLquAHT+2IP4oC9L1BxUQ54zrkmKBCFStwZwDMG1LxYCAQh2TZOhF1zby5hYFjhB3E4AKnQkgQ8JEvnNAqjAyYkuC9xv/AMwATCo7rz5mGEJd2fziUwA3ogYZzWubA7N2rog/NzX/AMNSDGNPKs1Q9zaKZo2x962w0tlI1126IF/+53gGmiXQrKQe3fgdL14u0numG8KgI/K/Pg56mWqxjrdQnU0esQIlq6HQj2vOFtIMax7X8ZWahVX0/wB4/qDTn1ioQ2RcPSkdzX7xv64c+MKjYnpsxwBRcCp4uYaOqULi6oJRggADROvrBtj0Owon1MgbNhE7BRp0DbIbxEwpw6ALQ8Wz3lalVKqqKnIoCqWKaK+5wniZyACJfyZvTZypiwCK9a3xhiA3DhaL9Ps8YgoK5FxABaIEBugyQDvWsQWHQpxAN1ttDfHeSYN3jyp/rBNDYx7w0aHvOU8iAqG3xzMNotqALd0ElEmyWYAojXDDy4RhQoddRGLrlqaORLmGhQdeAJGqiXqYPxCBDa6ypF+EV/fJnMNXI8vODVMugxkCMNF5T3kJQPELmqF7AZ+sRQnCP941HfJrWIo5O8Uog5h/5huonRpH+s0hrstj8OdNBQ1+8EYXCGHTlqcuMlaWrtvudTnWuYKgKYOkTzjA6HF0Oi6uVw4iLw5Dpu8dkGJ5yv8AOHRDg2DdvJvucbfjHxQpI8HgP/uASCOOdo+ex56TDTWaXsA3fnAChxjrj/8AGN5QmEAAmomQRS4h9lJtfAPYbOkReBdBAQNdQDNIh8XvGatgi1ijwRNOfzmwBh/f/ecH+bkRAIFCJq6W7zwQivgRR2JHXtwMRKcqqEgL1L4zcpjsPDcGFTgeDBDUpCx0frFvGguK8JN/IfrG+HFtMpHqV/GFEKG03fkzhBXiXGsBO0HR/WRVXeQYAF9klsSX3YvTMSpet9msAq6bDg23mW/WsD0EwJoC1ss4H8bwR9KCUplbjQUdiCFQHXrEWineq3gQRFVl/DgumdIq6Nk6vvN23ut48X7fOsIFSNEwPCF07bZ4+sCgs7FbswEoFukus3JQhZ6yYbjwvBU72PfeAUzXWMA4AcEgE1xkHNgSCNF6aoPJh3pSdKG5wZX0YpKApjcVNUBJTJwbqMgwqU8zreRMHskn+94/dUR/edzdtd/zibSleP8AmO9oKR/oCfebg7b0GG6It1hrJC3XKYesExbLbOJNPWHeoReD3gddu/8AXCahKmMrlCihGnhhrK2YgMR3RvDrFMLDm2kcl9LF5EP7xkFTq8es0wP21lAcJ0GsBqlhwGEljbQ494mgjunB+MVoArw4G+vmSZYpASGoYhDr33r85wGvIDg8OMp28ytYDAPk84560oUEwt9pizZjZpPNyGkaB3oI0H3z76wOAbpQ/A/E94wkI3Y4lds94qbvKp1m3TEwnhpkgZdGwseIvbMMWAAtAnR0d+cum8ACd/F4vnvEnWMPNhPx3jroh4//AEynYzB5MAocTeU+AO0MIAlwUgBwABMojsOnhk2htp5MjsP3iK7d4iBQvBDpu54xGjGXZ/BiMcPCNX3lgBcUB+zkc/z7jD0MTQJ8TMChLpXlU5bsBWmDISUXK7S/OEkXRZpMg2Td4p2mHAAuWD3BDBMlPak1QC17C4XFviggREQwqmxvXGAEGoDRSPSGL2qsxGBvhuvjB7WqaKC4BWjfEhA0R5NxHbid3wzjD4igciB1chflWm159SvhkjS4s0KfrCIi6HqYDqnBOeu8GFAiKP61lgVUe7MZBEvL6fHvAldNWCI/zgTqqFl395FVRRK3t7Dz7xi/lHIBHw+s2z3QvkR2zrKzrJfgT+DNLiSpQAAtQA+eDKpa0kDznONMugwOOQB1zkoRQb0444ap8YxsGsTxVVfcua341r+DBux3iv4YJ6qK90pat845uXKaPxkSmiAbrxMtapKVMCdZp1Y5cQ6yKEFHh3zjmcOkp54svzjhb/WeTTFllByXSXnzhS2SOnX6wqqRq+HLfOOh/rIwNpd/BgwwGv8A6sQ3zcQJ88ZxtvCmfVZpYClF/ATJWhdilwrsppeQ67xI2Bsj+Tji0FFP41ikqnJXw4Lvp9CXuYckavQA/d+MsiOxsh/rWbU7RS8CHfEVcWjNBSfJT+8DRQrxPV1gmppxA/JgERFhqv43mwIyhxiKgv4ytSQYfNK9jTqfJikWBdOufp3+/jOQhAFHR/WdmAXk0eD4+cef/wABWBVwgpWWH0yavogJE2NOg3wuERh1wcplUqltVWrhHm8opD5wnkS885zQvZcBOHjfNxUHoNwa6FneOvHInedZuWHoVhmvgAsB/usCgtrBYe+sQma0KlXzzigciK47eP8Abxm7nlR33twmA45OzB1uqzjkhLbTabY5SbCjWB0u/wCPbVz5IYcUaPR68EYbWi/BhHvkwBH9jhbUF9ImE4S9ridjNwH8YUJok2Beml+sFOwnluKYdhZd42EgcJM+cBva4S7wKvGv/MdrnCG8dL6uB3Yf0DHhUzsI0HDxuYTgFeJxclGIvH8/vIhLt3T5cC0jNEHH8ZWGjuTW+f5xbVPJ+DjBKlCSczZziiYe86cJpU3TabMOcDy8+MEYiKPx+cEgHfwnPnD4zoyOf9cj5Fgo9kpmk4g4j04/ie8E8QDhK3U8Yh8sGa8lmbe7Q1fpGV2ALQeQV751hUrZeP8AgM26xur/AExi8t06r8pnL67Zf8zQz+x+3GIQ7hU+jKxzYQRPNXjAH3oSc9O0+sgUOO+OoR5VnECFeD/0zfGHNXXnHsUHwH7zWuiJxfnLK57g6zVMM0OcC7SJ4CbZfXPvPMAR2APH9XCFU4DXI8c8fZhpPHUT5+MNt1CrblaDWl7b15yDewEhi64wd0+sBHK33ivRuAr5WeWqnjFhRPO093hfr55zanUN08l37MS5C9NuH4mRWGLXGAqvgMvXAF9F/wCY1BogiSw6Lo5SBtxlmgRdzzlr6CBoMLxvAZOqNaszYm3pMNYHfji5Arg7XFhEO2uMdtEuVavj/ecGDYVXZP8AH7wdEDoBIZZiXxq4jpIsHWCTZ8z8v84SRAAE4Pv/AFwR4bfL894A53gOcnSLyH95S7VZyW/zjVz7H0UuPlB4gH7A/eLuBYcb4PbjjswZzA5ccaAKPrFzEWyPjhgLsLc18M/rLBQDuT6XD1KITVSpzK/lxlba9T+MPm1D9sMgB5FeMr2AKJwR+NbKT4xKcSpNeD+ME1ELWrxt5xXpqQPWm2DaDLSs64PGTQaIeGvnHVEdGODjaPQD+8XCQ8JlrVeX+yOCjN4UP4MFyAjr19OTW93/ADmLNPybD7cTiFqqD88Yivx2/wAGeJuuE/OborzlD5BDhdFDQtcdeK9jEri78Yw8mg1frWOKM7BQ9nWE/pZEmi+MCwQeBmWC8SswMsdoAv5wJD5Iag+MAJFIOD4MeQUt/hGFwKdg38LOEuOx0dnvjJE0+Tjg4dgxCAbcXKOjHt1hHRU3gf8A0MX1GAefd5HEUaQhKEoeT4xsMmBoOj985pR7ik8n6/GPYeXap7MjoJXfeDnwS63go+xr8YrQk0l7xC5QibKoKbTiOBCSrJeWkDon4foygKA0KTj4v3mpUSONL/bxgOgBgmnO1T8OFl6FovKdCqugFwkEoCUavdCdQryq0G58zE0aeqe+cQOi71y/3/cFzsdv3lGAaoXEQtj4YAkh2ObhQ2GiBZ5/3eCAWnZtgCaG764x20Cl8S4gWRN0Wn+/jNA8GP8Acz0JAchf6ygdvR+frEN6Lu0T6fnGCGF2OuN4TgEMQBUXxgkFpwEevWNDEEE/GCqgbRt/gxOH9nzkwePEApu2OBqsdM8mZI5SH4mNSvzP6xH0j3X+cV9fyj/GJz4yZOGB1qZSBr5uHcQ731g8J3aDjhZ4LnAQGodMyG9YLgn5A3mu5FBxmmY/Riuw+cz2Hjt4ztvXjN8vUQw3UHCvlHtXAggu4Ybo9Ex7eeKazkUe8jJu61kTaxWcGK7Sc0k/Lj+i8UP7zcxtf+nFoH7QPqOcrPpfywVO9XSDRZz0OERCbB/vHcE9l+8UFM9IZUkAQnHWWoq8hptmoTk8ZBxcBLXLDg6P/MhFQa/GbSBWYwUFDvGuW15yFIQO/GMpHU8oHHpJzgu8tFeXnej/AMwOKEVdJvfwmMASujg7jiJYaGvGIHQvb4uABHupTEBQGngZHVX4xP4uyW5M3582o9w5NlNArxu83npfGUez6LfgPZpnnFRx5HK9+xzSdu0Jz9VPnENmFZQAFVcBLd0htieDSjnyAwi7anLn6wilvb/mDVQnAv8AX5wdFp9t93AJ0KbaXK4NHoj37wIoI64PvAJ6fnKoTV22+DeGgEet5OANCiX/AH+3m8XduYd4zgHkBT/X+crbDxzr8Y8lod9V57njJdjejg/3WQcIJ7lmv5/GVwZ8nPObK4VI+8Nho11HvIxNsql8cmFVruti/wDmP+Ci36ZAMbTgmcBGHUXSuApChirzhRHnBtMIjne8WoKapmyh94IzR6uBga4Ss2P3hP243rT0T9LhQX9wL9OFKnw/iGCaPg/hDCUg8zJ8YeGfwsU2PhQ/zzZyf6aZUR5CWhgq0BzkrHrG3EgINDVzCLIeEZnQ0jtgDt4pentInqy+o+cSliMEAnahN1YYwGPyoLhrAKAhKcjc8IFd/wDOW0HlH8aZ8mIy/eP6O4opnAsHblaaE+KFxR6es3MPCSV06uEkXnnjW5RfLd5vwmUVfW1t+HnwNP14yKHnkAmkPxqczWYdq0aq94KMoMuDTbIoeQEEHDKk6xisXYwRQXjbyM9DzMWUKF2vGayHYVbgufFN6xBiGpvGQTgHrE1dsTjEG0d4pJgkGB/LWGGsAIWNzp/nDbEIPd8f6YxIqePphgYiAEKD/WEwpVjQc1YwhNTJPyneV2CO+T/mJD8mgrWh1dG5l7AcGmJKdl18YKoBZAL4Hl5d+sJNdSAbldcjJwZlNs7+MeihDQTXonT1E5S5JqzT+8rElrn940gVlpf1idizfP8A7ThkcOh/7jcs+Bt94hGlcRjEhEdYgp05JeO8IzCadjnrJdhXXTYxrNwg4P247LQ8t78/7vE0AoOcMTUrCn7xSHkh8JiZ2uA2Pnr3i+sxk28S+xMAO+WHZ431lQZHYY9nnIB3tXffZ/zeOEijLTxf+54FDyP3iYCvpk9/vGhAFF9obvvHC3lZ/QxTELEUCEvthDJQVIAG1RRp8OLdD8LBIeGN7xPfujg+8DlbtT/QymI5/wBOEKHtQD95QSjkn+cvq8OxHzxg5TngYI2ucMFKh0IaxaCBdub0QpxblBU4hxibPQcB548yZsIA2XoCaoL9AbUS7jAwsJs1d93ChhBtA7fgK872tXNC4hJvGF+hxv8AM1tRHlBfA8Z0T5GZSduvLDyrhSrxdscLyF7WdLTziJSvQObXM8mdwwdIBs8S9YSg8vwA0JEhXBwIrBFAdoiJTpneA/tRPVuoEelGt4neLcYBaRMpANYvCOSQCUywgJRZgZayZibReZqNA4FLo8G0VLaMVXHOXntSLCQQaAVSnBJ4wtPTCbFed1cHHkXjLUGAbcUTB+cYaeesP+B0OWOjm1iUBIRXGcdeZ6xCCyNXS4jAKLs3N+jh6zeChyGwOvPeNoXJX92fxlQd1L/h/wDMIFlHE1wvnAW6RoB8d4UR2xqe5q5SC2LPZyf1gIDcMpy7aa3m19frE/djOKhfLUvPGHFNpQCWt+wnHfeLo0tUkNat40srE0F+SF8hxjxwgaBoAOjf4xeqLlyEqgQzXxcdA8HU+H/mLsgT0b/7i25FXtHjDRRuLtMXQGjs/nB9RQZw85CqxSU24k4bvDezz7xBUCbFox9YroFiXtwwXsEDPlh8dIsvc1gQRUvMR93NAVcbPjODKIdi8M0iNt4zj+M5pDFoJWMdTOBeqSz4f+4NGkBRL46fnKyRCQPy8Ypau7yXudY3VSwUMTKDW11+M5wA9Lv4wUpdvZXf1gp9AkLQAl2F04d4vJvvek4nGF1E11UGsNoXWWBZKUS41MVs7xssmhAHavGEAG+lYHEweHpwZmI4BUOywcAhu4wnvmGaRqpD5MMTbwxISLaSBo24BiuVW+3UP0N48H7YC9GAUVMtGLpSPGLBc501XBLi/WNgbXNx7VelL1gTy60DBF6+Fs7wYjLOByPG78MFqLbbc32rw6FjHsEPuMsW5fG8fkP/AHhxJEispT2EPYY91pVQH/0B49RD4cU8OK25QSjH4NAKXBvhr4BesquC2C9GyqbQyBgl9RqQ7igIh2whgPtEVRSkYKjZ0CcMGuLw20V3TcQTigkoYA1fCalgQfXijEgATy3bJzTm2ECptqaiQwyASu9dqVIKK1BcTK6W6Y3VTCCt24kMr68v/bISiEvGMYRMhKIcZRzZrMo0h0YKwm2DSAn9ZQHsbpMeFUVOh4/FH85rh/Q8p+b5yzczkJPpI53Yo1vwHjESb7Lg/MwwybB0cIo8aSye/rIHkag4MQUv8/8AuKyvYU2J58veaVYWdSnCGMD9c4thdPeeTeiw9YhYSVGSQ3DY+DA2E5kFva1P1m1SJr3FwR4lfvvIjrrgGQ7FE5B/zm3CbUY4Ks2r3POFMEiKyYrQpsOesHFpRNz3jQt+ITeNnQhBRfxlXJrvfOXgJohzrCirSpwhlaxHsA6/nOVmnHHz+MTEI3WjFULWoDcgqtGw+cLC1sLPy3+shvWRCS+HKe3tOnO8KJIA2394CO05X9s3PTaya39uFSKGgCK+MWkIRK/OcwaDrdNk+89rhkI7NZQZU29gf5xSThY5/Jrd7ZemArIXIKED7EMtJzgz4tMVYIxPYomIlHjuLmM3e73h0oKYBuus07Q0BqfgVaYXLJylPXm5gb73s5DXcwCpKFQow2bySeaymirSUjL6nHFwQBrJ0qmNq/8A3CZrR2WTjbvgZBFPEQGn2xzifCAyB8iUx2tMUWQPvo+2Q8t07W/JKvx6w+c2hEgQ90InTc5nYDfkZVWGoYO1vlX5yweM2tBvR6ymaZoZUOsdK6+cts5mWrvi4WZAPGWKDkX3iK942J5DAFoq+rGERtQwWmwTxgDYrZHjDGpUS4I1Dt84iUoHneTA9vxnHyx1wYIwDndCn+dY7EunCPka4OfGb8qxwdjh6fxkAQmg6m/+ZJwCIl47vOapQeUNO9dd4gEotk0x4zWGjAnTmYQONfP+8o7QA65aDy95vnohDSATWzm5u8cIaSajt6d+PWVKTSCJXPNF9YU4ggig9ABgjHSjrko/gMdfKcnAUaLbx94kAFCpsxlOvWzcbeI6j/nLgc8JZ5x9uHAwuHk9hN0XOeAGngfz6xFMMYt+SnnAxIFV3ybM+hx7R1cp1DeLMlmHQnEXIj7qSF6+ceiMP/QxuGjCGTga16+sVyNkBuh2f3lg5gNAP5ydEOhQ/jLNCJbJ8LgDEsMK11lAWF5fwYzBdlEmv5z3WkOn1gj+4DU685GqJD0F+xwHuH9P/uJITEY1tUFVODnBg/CW4xFI9W7dsSWSnbwV5SQNdoJe1K9r0GobGELodkzIFGEGtQHLWFmHkjKYgLMFeXAnGHmIoKdrXO8UKBAk0bjxiWqK3cx2yvrxsxYOBAVDrjDZDDHp1PGIlRb0Bfoma6Vb7f8AJiXtIyCWbREYEOsL6EiLCJ5yrdw9rhvV0HLQ4aj0nWWBwlE4nm2bAcjNq0JfKhgBCgoOkr9YGwQzaTnOR2ecD44wNBi5ez8sRteMtHU1jussJv6wEvOK1m95NKm8k9o9d285bRgfEphsIlLMg9jqReDcIAsamZZDRyU4b1w4+SpPboE4nO2SUWF8GCiRQpOnpRFh3iUdAgBgC/o2o0rprBc5ckXuOT2mUPlGEpeB29V0JLgkBigKlFVFBOy8iwwi03qzO/oSHJyONHNw6GgxAEbouK2tVT0pSdsCPebjiMVUrjkfFZfmr48MRix5jwDjqlklYoW9QaMo41Mm3WaVgMITIk+biEsQLws/PvHfUBK/Rzs5/Th68RYYdede/wD5kkkRO6UekmB2DG3VLy/J+csUMnHVfGK9iJHRnPeTagqrjeLVjXi4xGF2aOFQCokgrz1lYX7De/OLUjYTtziSiCHX1hmd0rps52/3imWVU13ThmRSw0oS/eL4ZkMPcwx8Cpihl8OAvQASuppHjGako1Z9vvE6qnN9keMQgAJ4unXXvHVo0NsPHWHfllmGUFUBxbyH7yHbElvu6n7ympQ5GvvHyqJrtf8AmU3d1wblTAoLee9x5zYhNCFdM8d5qd+TBD9GcGQnrnNH8s8QEXKfB6ylJsn0tUswBVxlI6mAFR7UpBDswyvf6mLqFVfLkGiuA8poSMyRdkRM1rD4whw2yAC+M29AwYY9JPJb7fGLEfPj/WLpFKV096/jEQw6LxlAOPEzYXjOYawWYQXUNn3/AKzscW7yA/j9MBM+oQiotRdg1XmPJKtlORHoMCcIPWD8KCU7ABRgHKrVy6Gk4kYgGxa2NjBSIgekPynBQ6gNhu/xH5MQmVec3N8+c1cYbBMdCtjB1KwI288HeXQ1cCdhiD+mO9i4ESJlSawGTv3AdFLIrMpAhfeT7w/VpTG3stCXBBudNEIhQm5dKpSrpX5UqQQAmhVYbRGxmtfpiIINUyUkRWS5LRQiZYmFdxQd88QwLGBUvLU09oAmprho6ZIuFAj8RBIEzopxQQ1ycxMVrMKI1FVK0gAtwfIMmhwR0BlCHA9GkQ4LWogwT1mjjnHkFBbpzyxdkBaNu/BNilCZEbjmhB9IlyLTDmJqacYIY0Ojrh/WKS4rJ55vvf6xM1sa14NdQmcCBrWhD/fjCEAknX8imL0eimif1jszdq/O+MKe5txVsKeMjkb48a+cBDi38fGXCA/J8/jBNxF4nkwjdK8dzCUN5FnBfXvOTEfLYNmFzeMhjzUEKL3feBCMoknHeKqgtD3isBXL7NHGcuMad4fwmEGrE8YuvgKRkNOKK0iAjz4THBIFiQ+sHd/utGvE3hf0iiE4dDhcmsDX8ObAMB8sZpFQy67PTrV/+YSjXyfGUSrh5Jp/t+catwPeTS6MXo7xCMuJep1gEa4xmkw9jYwjuzrDKcdGOse94NW62zbK3eJKwVlF5/B66sH45b7SJ2cb+U+sY5O4VJU3dRPDZQx49xYjgQQEgopyuPBqHldmiOlJeVhH1EFQgFtlKvPpYKZSOxEP2/MyM3ktKfToeoxbpq46GSGQi8OJaZzkTDCC3hLmwzmXW9ZYBYA5l84dRiqQsLidQJ75z3Mt5cxomsgO6vP1jUjsw9JVC8Y2DkHtlyzaQ/8Ace1aonnvHXyYkoUl535/Gc5ABkptn6yZwbMef/ctLPA6f/uNlaa8OXIk0Vs3rHFHggAaOjnBYaD9jGChU/vP/9k=" alt="微博配图 3" decoding="async" referrerpolicy="no-referrer"></a><a class="wb-photo" href="https://www.weibo.com/1199303274/R9yE5wVH8" target="_blank" rel="noopener noreferrer" aria-label="在微博查看原帖"><img src="data:image/jpeg;base64,/9j/4AAQSkZJRgABAQAAAQABAAD/2wBDAAMCAgICAgMCAgIDAwMDBAYEBAQEBAgGBgUGCQgKCgkICQkKDA8MCgsOCwkJDRENDg8QEBEQCgwSExIQEw8QEBD/2wBDAQMDAwQDBAgEBAgQCwkLEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBD/wgARCAIGArIDABEAAREBAhEB/8QAHQAAAQUBAQEBAAAAAAAAAAAABQECAwQGBwAICf/EABsBAAMBAQEBAQAAAAAAAAAAAAABAgMEBQYH/9oADAMAAAEQAhAAAAHt+2TggFYDw/nrLXqN56mpMCUEGiGoYCgwPA9DWMZYggbnTqt2ZdlKVrwQslaUXgeHkeBAUGNsQ4GjQPA5jxTogT8FtquGHuTo6AUmqTUDFajZZamY9r50zpqWuijWejmr1TbHMiy1bpWGpWQMQGhBLqDpTVWXWmpR2HNtojSnaUetFKE4RBMGAjTV3kNVaxy0EG1HgaEYTBCiQPIrj8iwEY2jQLMuQLDVYVhy8GA8FDw3iUPAgICg0PAoThQmrbVwHBiwexBCAFjojqzSJk2WBU2n0heki3EOdnEpqVJumOhNVZdZNgTCKOSDL9TeauNSpwjohVHUi41UaahI1taypBQCZCMAzebRkh9ZqNu5J0EA8hgObjFIONDkNHBNTAgIl5jAvTXgaD3MjlwKCgoKDgeCgwGDkF4HopjJCpjGtZweQl6NqMdNVGO0F0TgGDrCsDqgMaL3ziYorbdSfcxshQxEZUQQJwp1h1IdZVEmoXnJAVpohauVL26+d0Ve8edxl8SCQdUMVGmUS7BpKCEoGI8i20SYXY4aIQPBWmnJqDEnggOYQmoQjCRzM0gpAUHAoOBwKFUYeauuAjJwgC2FMKSqKKrUVxyivAgCR0AnG8VNNEYMOpb8fKJ07PzdPIqXWs7v3lWtQMqMZcwCipRURiYCDZLaFdVBLgHCCMs0riXYKhRuakBUODEToBS6rceB4MBwVBhkC0eCcCgFAcNiGptQ8PNuErRCarp+DzmRkomBSFTCuDwUJQys1qmtGFgKYwQscm1VEqt0rQvIFDHDkZKiAEQdk8j5q0f0hrx80VdV5O3i9z2nn1MEz1MTGTVipVp4lCFlalCyrRAIPSxFzvk4WodJjYgdPScDgUHjVmCi2E9AqVBwNBwICAgeCBAdMWDESIJjKDmBw2iVzIOtDHNUmeQ5kgigyTLiJGUpADWnVWwgAGmFFkRqqJomBRDhjRqEjIpb0GEBEz4vnjeN5lXROnk5nNdU4u7jGkdqw1N1mxngr51PanuVRIJQYCBUb45aoj7LAVBQaOMIwP8Ady+Bw/CcHgws3ALoNSgODweDwIHgQGjRDg8CAERn0qoX1Q0LQiYXmyku+CsUfhOCwLwU0wwtKDB51MKEIBhulmGogHxVNkDagqc6RKS6neFhaOA2HhCKn6Pvm5s66p5/fxfaOxc2x+okqXCRiIfQqPArImceuR4+r5uROjUjGDWDRD2VGd26cDjVoPB4PBRHy3Ouq6TKKcEBAQPB4KSByY0KKEH4UoEmyAU1pK86AqiHhcQXTvtzjlJeOJHgptTocPIqhweCgKaXbCmMcOomo5hW078F4Sg8JgrKhG08i3Bsy7Odtpnu8OjmWi6RzbFMmJRS0gfSHNCW4Go08vSvsegim9OwnbTJJXwshE24Nd2cYVONlkDTR1owzheOu7qTYpLQ5IYnSCUPDvtEWXmEwVEQ2BMKmngsddzrmQqVBwVxihUZbUeC+gwO4IQNiebHEEgCgWS0OkOsOrLmDNhr5R1PwOFKEgRDjAH3c+R17M1z+qb282wmd2wLbedGIdhrnPH7zs0SEcuSKfNLnMUurZvQTSBGiBUFT5npGRubBVipss8L6u6eaBg4BwB5dAYuXySNCQui1OsuYWrKRcCbJAjBB+BwMTjB6Hs8HMMNd1rmZuXg9kovBy6LrI6Q5RMWGYRfCiqIhOGeTiVEAqhTVWJCqVwBwc+YBZ4N1IdRkKM+2iNh3cxzqxpR2QF2Qa0X14FITn2yHj94htRXgztnU83opbECx4+lk7WHuY6Wyi3xRdMw1YQ+Xv8A0OGywgwgCo8DQGp45adDrPwkCUVQBw4kkY4L4ygIFcHSTUBYrEZWbqXsN65sBoeDIp5BPuSSp4keemyrERWRRTqFFhRjtSycq0hos2zMUZ0GjQM+2WSCM3mb6LL96XJlOrJEyDY1UavEhUWQn5tiPi+jh9Jw1GozrJt5motjr0tCITRdl6SaOw1Tw1yfztw4WeDvHf59xjWOCMIgjDyAao3aRKRkyJAkBQ8CBTQLCgk5ldUyKowxRXmrUvpXThGNAjRjwqtaWLGoCzZZO0xqKqKCdVPGMDTQ1Jo0TvC1A9Qkemps3I0KtWs6vXIuzlloh6PFb1II2Q6axzF6kjpz6S8qGG3IvL778VAEDJhG5uoLCaTbTuSEEamLaqoJ3Ghade4FXNcX0J1c1JDmTisMsJSKnDcwQqKuHBIJRQMgQg0Q0HDvhYBUYWamHSRXHFFdS3xiHTCuAGkxySmgkXoUPCFsYnFDp465HLUBpOgEdipklZcELqQNLLTYu50At6mPCk0ApZ+l2zu5bnTYXPsjna5fJVnfSb+PYrMPlpxTyfSgRo0TIy9JyqqByaYKBtGgtSNqTssmO851aesauUmuXg4EBoRCjaeFloIq0FRGnCHk5k7ASA8Sg5uQEDwxCBQIiIET0tTXacD2ROQbRCbMpxpj4qrFiM75wMax6JmX0eBBoKwM5LLTVBOAJ2i2mWApCWaGGQl6rv5DHbMBVq8rTxYt5qwmedbHXL+J6tJGTuRZWoiy5MlzFNkrm3UHbknU3bhbmVCMupuYoc0yqQb2KhRSgoMbYiqEwWAmacDwUUiJAViDcJyECmAJgRqdotFnAtsQUICG8aLUoq56icdchlYu1TuWsmFOOWKUK7m4KyjRTZGKrDrskA5eU9QwrMxoBqYxigp6wKcdc35YqzynB6Woy05v1YaGKgYUDbyzDRKphE1BBqyzQ650RRsshfblQ5kKHh5nKs7e0xOqjL0lVRUpkayR6AIyU1JU5BjGEh00aJItNMCYGIaEekJcjdcnNE8djMrIZbjRVWZnSC+mfIlXT8tC0s7LMzZBKYJGowlZOKYIGVmh9IY5VMPNiA3ssM7naQkvAVl/P/Tj5Vltse81hbeYDj9NifCejHuGe/Y862l8zWSMEs53DmTGKyTOjbYQDmCQIQCTRsEQJlk6ngznLBXmtXN79I2TGHObMDamBQz6Zils4e0h6BEYZIfOWVqWsAK1SH2moCN09MyAPzshLzWOgyjSw9Lc5DbPjTf2HCNySB4GoUHNAmzwkTYCArXms0mcRDFYZaYSdb9qi09T0mJI1LR8E0OXdGexiOm3hQ4Pc0mPbxvs8zoGes+Hob7Ti22/AumfIIvPhxu5CM6/nf0xebElpQtZlP2TQCdXPaAztgVgGYKHiQPBo0Z9hUepJ1SFl84d9JUAbWUGCA0njmW09Qgaw5Jo2aFyCbIOYwkbpJz5s7Nmbk1S43U8yH9V52jTkohQjvh6kipzlRV0VUyFwjKEOHK2zWQdZYsxaaZ+R0OKxvdqL10GxcT5c3F2J4N2dp6Xz2+fb4b1OD2rmW1yak34cF3+Nxe8+aXLRayX95a81ak1KwHzjl27HfbXZWex56ejKJcZzR5MnNCJobU1mW3MwwzADT0V07AFGiidpOkmVlks7garMzFITaOVOzuFc2mUlWejYhj0kfK+rWsimvHgO7xuP9PD9kc/VevGaoeqREFSqKgPY6NK+XUGx7RGHZWbs+j83I8gsladHNlLYec76MeaazvxK6zAOMB0dWh086xNi11Xb46/PtV+Y/Q7KV/XlqdPm4v1vmPmqkLkjaIo+9dOYw1AHNeT1OWZ7Ary0+WnTKzudOE0PjqioFjO9JyVR3kTtJpovgwH1HhW9on8T2B4t908tTDYTNy/a/JeuQWG3NPG9XB+R6jeTexKr0a619KW47zw3P1k56Lfj/Tm+X0J1aq4Qf2+Pwr1/l+4fPfeRObd801Y3KwlqPNRRrjejzy3F7b+f0LE1DZofW+fk9b5Ady9IHo4o+Xvv3NBa0VOgU5HbLZd/DlMPqjNc1ZbEL5BGXcVrmtvAXPdoseWD5/7C4hKlvb4fOPR+e+brmESjnT+ujDrGuUQfP8Ax+xh8uqlpxzI7HWAu5GNWN+PgsbC87PZnQevlI+p5+l9Xz73qec+4Xi7I/z77m2jzGp2mqX6P8A25fI4KsmG4O/CeB7eM870NSl9G+t5xIMVx9vR9KyXxP6tFn0yvlvPFtq7vwcI+i+J7x8x+gRq8t1cELxlx9m8sJ0B9OXiHt/JdD4vR7B5P1frmbq8tv0HxIUnfYbhU87nrqNs+Z8/YY0wsS83T6J6nk5DL3dNv5Kq7rzhQVTpFIUA59Mv4X0/Tub03VFLp8/O9Hn/ACV3ePVcEQ2yr6meG0vJgcE5fU5lh2yVjLeHQ6zr6ZQ0dp6OCva55FfNWW3a/tPj2aZy1LZbELlt078/+7sS6XPRzpmdLl3s+NlfpPBbGg5ladI0xvl+lnPE9RHXZu/l6t0cmB4u7ob1yXx36mH5Tmfs+OO7/nel+d9P0Xh6eH/V/nfY/lf0fPR6Ifu+dv1xOPZILnMzkT5O/D9PgdC8gv7dsHo3ifZ8wJr5I+/N6Jz9za5M7pkeLxmPdndM80FHPq7r6XlevOEcYMDSuCYvNUSsRjrxXzfV+uvH+smpUrz5R6Hg8R7/ABaYKGyS2BPaCN0nxTl9Pi9Rez10lweEO15qFxqtOfHTp0O4+eMNejdOVmoPXGtJuBZAH8l9TlfY5Lvznre39HofpfLiPU87llxyhaNTupVsw5cZidL09XavO9XUfQ/MBsb6BHXyH579M5Z6HwAPo5o9s+sef7Wp5fpMz7f572TyPqacc2F7uYbGms9Dy915vpTYau836YZ4XhzY5v1gb6XWH+h7oer45nRx9mzvhrzt9XETjT5bz9EPebRaTl9P6h9bxtPeQIbAuuYFZZKkreaczxoL4n0vefP9wR0+d8q+z8uJ0wUFBAYEIr0v6u4vSh1x42+aIXcH3835O2rt54zTPtnR5+AjXWVOJDqHVzBNc6TVcK9TYQd8n0hXNVaFBtQ9mL61p+jNo6EPO8ZmktLrOVz0JZ+h0Xk9Daer4ObvHbZ9PEeD6Xlvo/LvR07y/aMRtju3m2/V43VOH3sb6HiA9cqfN1munk2HJ1avzvQd5v1QTyvEzOcmIiWa5b9pfYunwejGHK8fQrcnft+rz7nVwfB13AIvlv07n6e1+34U9ogJgo6LWfVRy9Epp5zGua8XZf8AD+m3+HZ80ev83zPu8hwIDgQUIQCUf0Vx9/WdF8wvCnpjsW8i9A9REz7LyxwmWwOltujCbbjzWsyjlRILyCnB6Jfk6bU3ah/O2t8q7uTWayrD0vtORyvOTmPXzXTHFPbonD6N7v8AL2vTxbp6fHOG4e89hyduo5eyHoytXj0zbn1GfYF6POy95qysjQxp07z+01n2ce87rzvnRo/PYj1oi9jzouvl71N/POXq6+senxBLXz/nzDu4n1q5lprtMPpH1/HyuH1Wivzrdc2Vz9W/XK5OVyFjqnz8kz4X1UmO3xZ9F8dFWagoKDRQtVw8HYsOruMdPyt0cNHTDSrDPHX4PB9uTzjd45TxdnTu3izdcwO6IJebsJEkWuPtPcPaJbfNfNta857OTq3l+3W0xI+p5e40yrZBk6cNwfQNXl6zi7Lvo8Fyol6uP5GTsUlCQOky/oieiupqPNwZ+NbuNYTojpHP3HurmBchz3Lq2uWM/LQm98v24YDfm7Fzd4fr4TnH20GdHnHL778+04+e57bjbh7x6Xn1KY5OANZWeXWgSavtdFrHj/D6cHmexXePzf6XkK0gSB4SCjZUBQKzfXOfv5f1+fXc6Y4xJ21hxtfcmfNg9UCjbo7xrNX0TKkYPKsIoc/fkfL+mijaBHIfT+ZOrqtcPYwrN9vnDurh6r43RtPS35xj7OU6/mSWbguvoDm7rWvF8q7ZY7XJoWA6Ij6FjSvPaUOeQygtE+PtXg7Mh7Pk7DU4Vxb6vzNuve/52Z59cdnvkLZ7q8bPzta7fPC7Ya7536/pVSPXRiqw53v5x8XUuvmt3OVWlhWjZR4C2InOAbzPYpc/Tj+7zON6c6MlE0Hs8Lw6Yok9Hlueqs7tywiMvDY6ac6jV6X3bjlTx3JdHNI1YaF2lSrtsZWTE5dWJ4/ZV42FOl7fOk6PTE8mcfCuhRnxz0MCXk9hXs35TPq5br+dxVY985ez3N26SzkHd5nNNcWhKEqOvZ6W+Pqv9XH0BVodBnP3YfyPY1vo+Ic9Lj5743vg+Pk7t9J5WO59nlZfm9CvrEe3lZn2fCFVOv8Alvtes9Pn1nXP3lUvFgZoISrYuZZ+7v65e/8AV8/8g4ehYz3KVmd5/T0GHToTn+TvW8OUJhNE9ih4K4+gcfp2FeZ7fLF3lCmRI7BthxvLsVr705cxqqprnTKs9nPj83zTm6wQChmmKHNwkZ9xaZsDjEeqbvh0Wcafxu0z6vDwqenUYejw3L3Knd8nhrwiH27n79fHRgyAc5UNZuRtzfs8s3jt0vi67vdwd3i+bc/aZfNjefpqRl0Gph24sva+gO7fEc+xKscFyKu+wV0cGV9byotoueZ7Pf8AHXkPL6ITp87YvIAPPkso0svMZXqsvT7v6fzfx7ye3tfK+o0182Q0omnNmsN3+Vzrs8R4kacHgaEIdT5PQ6F5v0ZLXyfmT2vBrJTFfQOvBtd+gu50Xk9HPAp0BwPdnNw3PbGzpAmgtGmoZlnRGdlZhU6L9HQ1x6OcNbjpsqy+fs+7pMdOKx9DEdPk8i14q7Or49XXef2s9HXmV4+TvOpSxnZ5uj5unpWOtHs4voXN8L57HLns8rIp3X1Yvo5NbTJ5KKuq50c+exmwSBly3VX1MNZWvV+Tbk/L7I2T2vGT6fOhFMqyqrqGO4We/tPo/NfLvJ7Gp4vdHGhfi7gG+VjKgnVjyn1vjHiRkgIDQYHRvP8Ac32Xdxj1Pl4dOTcVW+qx84dE6Z2ero+brkc7osw1nUt8eE4dQqGUaIDKJEUyQFkAuheqcll6l182rOd0VpuPvwXN7Gx6/O6Fr5sCn5gtcoudpl0/QXH61ufW5D2fOce3824mgafi7eiuMx1c/Sedcxx0oLOupLSann7ecd/F1XnQkIl1idOalcHgEKxtXZ6s+y/QeAP4+ip8/wDYZrk7c338ei38uq4ja22PYdz1pUdi7/B+X8PR6hxe1As4x160w3TwZjTPDXwNErPAoMBQ2HP6JJTjevy9dXIXcQQzFZaTS9zs8fy+hg42KVmHT6908hDm6ZIqIIwqJwo561ySjum8HWYLH1BErTXw6bMKTpm+T1dx0ebJeR+KDRpyDDv32Wpnnuln1M3kEZz3kGpycnfF28FKje3rnK8zjUco64MZVpebrw/bw9J46ZnvMuwNXOztDfN0Eikx6j3SjSuP2Pll4/cGmIMWZ14r8dBK+Imro59Ftad67fE+WsPS6Jwe2MczpxaTwb1Pn6tTrObXo0jKm0ApsaFkotl0cQ35N7fJ07THHzAfNl6zltVUZ6fWjmvBNNQsIZ1oDTA1jQEPCoBGpCh2jZ7W+TLGe2w7DfP0ZKtBFZkFPS89OV8HsnFV6c1zqamj0TC/bu/kqtTSpBqc5GffTuejqvZ2/XDK1kyvHbw90+fWa+e3gz6BHfwycvRpqpvBUG+IzXa3Co9elfTMN7fP61VOintyAayOXz0SOY6+R1jLT6X7PJ+ZMPQ3HD7ERLTUUbcY9b5l3Rn0fzdyIw6CoskO0x9GWvOref0ZXJvNFwmMdNHTE885fPWGO4fZQfm6Oo4LGfV2nm9r5v7Pnoqx65nb3WNrPlznt/RGjrNpyP5+4twfQ4rn1Hen4+zM+hZ9ON4vUG40fcene6qhWUV6os7E5xzqYrOnpWdfVoDsv7RQrulWCNuMr+XPS8eM7yb1654+zHWeT6bOPaDvmxGOY9Aq9bG9kAeyDXDmzbqEkDNuW3HTZUaLi1Ed+JK+b6D9H4r5jx7dnxfQ43o82iZazM4d6HDa7I6B5PT4WbpaSQEO5TF0steX0KYdY2w43OZlXjIcDia8ajNX8N9GX5blzoX9E3er1CydPl38m387nW3ld0ljR4O4wwu1dEG7x0sQIo2nk/TCeeuZ+h55966qCDD6UxjyP5JHJTA1VAuml2efoufRCk0WUMKU9e2WJXKIenoymfRqt7yqorpqVub6qq/Iz8ckvF67dpq9BSy2E1pjtNCD5jNqzGeTz7iN1j9fO0kdFocuLdcjtY+p+/4D5az728X2bqVSctBfJW246vZxTceOecZdlkWlRRp5zTPUmHf6ipeGcFHNJNBDOleeNjb6g+f9PmHmdprq7z3q9I3WMxOoIeL38fF7ed4ESMWgKOwdEajTIxnjSuDvkfXD40rdPDU6/OscfrJl7/WL8nN+ZuLfLVfZFx90mvKdrkGVuMfVHr5MKzvV6Gr5swoxtaX8+rMaeaW1689VHr6Sqs7tCPurDHPz8/lWcS1vPvmNOgprypII6uEth6QXTmNYax45UuqhkOLbinD6b9D4f5lz6dtxfbRvmI64kFsZrmjqcxOnMa+fD1GfFqZoZbzt4645NI8Or2+kGopMVJxRYgKOvdld749+K/N/RFPV68wtOZPnkjumIyW3zI9qk1TC7vnmk9vqun743J5q6rS8nuZLy/pdF2efajky+2l3P2tJpz7fLzsLw70I7yHBpY78MttyXc0xO308OMOgxPae5tc/pqf05tEuQbnYKuo+z3P6QC/Oj16tpv0n9PPGV0uWmHXRRfmZzAl06pcOkP2eXuebrxVc7tIn18rSvY2s6B0aeufoHV8p81Z9XTsvonvO8TXWtxoIEE9mLr5/FXzZxLRKsTrnWFpVznTC61ccacelHzgztbdPa/Qjp/n7Csev5l5PY43pwFJWjii092L08sVU12MZBcjxOH0/oz6o+W41m+L3tfBUjcB4/r0/Z84zHqkdOc05N88ZfiU1THpGDtGM+kLfLcjLRR6WvOLKR02M+YTp1GzQRstvy54zZ5R1uMO6/jzM2dbqQXT2dHtmYfLA09557OspMXNcyc9Ji+Ay0NrMgrjeAwua+LoW/wA/8zZ9HT8vopCHMJVmi3xyCBsNfl4d8OCJLDEANqIidw+a2ZVG6wVxsZ9Cd1ltZ3HMtNlr8rYb8Jm9LnpRqbSUw3omCwqsJvTlTl6ctz08FCsxPP7JDHfMdHBvuPtr3NvH6W/fNZbJhW5Oshl5OL0u9k86s9xehLMxmuOnz15XrrqsVeqZTn51q9Xy+hrc4La9Azo6y2nPSz6J+nzg76gx0I+SR5kki7SoDLS6K/XNXeVdyxXMtWVyPrLoW/z/AM1Z7dEz+gcJTU9XNRnspVygs/SM1xcxrxcESRauxQlMw3brPqe6AyhoqRL6jpXUqMV2c5icaQTXzHw9kBQgDSGpuCVOeXbl2x2U811Z4b0fE1FRSy9HqfL1Y1xnwFKbeW2sn1dVfZKr07yzPJ1lePzsy4gXTpt862/Ll8dQWfVvN3pp1wl+mRA/v5Eb6AZ2yvjL15g+ezPz9H6vn7YirSrnHnSDns2hlZrhoExroFR3kNfELVlRKRFAdhx07o+d+c402WP0JOogNTDVCe2vXMJiz9PjL8DMGZhBPOxRQtoPUbS9DC2HmjFbk6UvKVn+gHf8+1WRT5ZzdHHObqtoPw1B6FY0KbVNqqwVrWR6+IKU9UTMK8UVy2vQ4Q03L6Gr6fVu1qReBdXS4eibDx8n0egV5fYb18c3RkJj29Zt4KGOfnt9XHbeQePXAml98mpfAVegHP1hD80nXIQKFmtY2zEej16/HDrUGZ+XQqL2nlnHmMHRVPB7fRun5759g2uPuE61jVkHYqOohfFzzPv3WnJzQ8jnRzU5rXxcDMZUeEcXVuc+3HvsgWkjKL84QR9rev8AM6LOysWkv5e8/vHUpxMRSoqCaCgo1R5rF63kagtE9DyvwRsjJgZDbOx6/TX2ECQ+frbbXzIMvUHVyU56NFr86Dnvx0evrq8kbPcKN9VXjmb487HrU565XiSeEa9BynKHn3nZRxno7blcg6e7XvAlXBi53MUiKyCvEy5jcj5u9UUK59lr43LZrT5+zfpjEUFsydzjrPKCL6qmng8jjkrKjUVAVjbzUV9d+0n1mpmXjmDTPX5QZdX2l6/yJZUfx0vzWazv5O5ummKMbgkkmGo3IUbhYzes240+Zq868CNMJYAxuUOqntbStBc9ME+jsb8jMx3BJ9fX380LLFrfTaeHno9QLPp6CuAnXMCn0SyzLXwTmmZz95iAz4Bi6NFXG5Ap5mjp09eeLnoGmTzqjGIPLJ1lM1KtSVc4hTf18vl5OJw6XonTrtxs2R6Wyrq22nEHnp4mvCROzF12xbnLXncWvTcvqSJlarmzE9OY08gWdH3d6XyY+kVz0KRcw/mHk6OYxp5Eg5RvQ8bwcEgZbV5O5O5rbZ0gNFG1EJg4mF10dTftZuPZ6ft83znD7bW18s06bROPXYrx3Wvz2Pz9BV2Fa4oV1Ap9S6+bdX41g1DR6ddZ4I8u4dZ9wafPzhdnQ6I5qZ8+Knt0LkgZ8uXl07585aEVzpjJBV9JdXBzCb59z9NRtoKE6fh76uvc16R6seTniDYBsaTWAJQipjDoef0jT2SZwJXKA088FN/Ufp/Ma2GaS8neVfG/F1Zmbem4bweChMHglAbRz/YLRO3ybBsBrTRRBGFBm9j3+g3vl4+k7Xr8RgMvZuXx6cww8e8LcaG/HCZ+r582208ysu3O5+g9yLOPDqqC8/P35kBNmaYyYd4vrC+o2FcYxaI+TOz7W/vy/kQ+fruHM02dj2iKr6S6eLmo+c4dD5usDGmgwFT6Pfb12uz59PGoQic1qw5fchXMgbHL6Eke4afngHu7T5obnH0n7HzzR389NRDvZ18RcXcqbBygoPB4Sg4GAoDsumuTf253goRBGEQqgVmuqv0twd5EMtn9PeXnNrhJG15KW+Zj5+X5e0MfPZfk5IkY+QbXKoqwHM3Qo8KyqqtKEIfS19hbP3ar5suunT1yDx/OJ4dUztCiCwnaH9NdPJz5HJ8eo/DEjQPNKnXcwsPaXzp46GKIhUCqnE0gayPa0h7BVEZnznT5by6PrH1/nBmelCLLMny0+XOHsRNRuCQHBKEoeBBIATPokz1xHd52lTLxTURCQIwgo7Oe4Ay+p11cmrvz7s55g5hc+7WLXT5oFXLyrOXVyvSosUPMaDUPTsJ1CbA4AmBQ0pp9Cns+GEc81nHOrygFS4JwqMmRIP6X6OTDD5Hh0m0DU1aaDAYy1SmuaLETDCdNaOLnToOdDPcdPofHclePzC/mTE+t3zv+aJubdLOZbcw5ejN4aeokHMEiGjkBovDYErQ8ullrluvjOy4kE5aIaxAho+iD6QHHXrtOCHL0hM+rjNfhBighWDCnO+YZdF18Y2kjVQHB4SBGGnis+1KnIHhOCMO+Vvpp9356XlDDhtCJAMZEOBqwh4fR/Ry5QOL49OkQIG1HgUGhE1TtQBbZfBqqsDEis3qp7Zj6B766Zw4e/kyk+x9Beh8tErFzoEzrl3Nu5Ew5QcEg/A0FTQIgrudnQQaywUQFIiR5jWMCuz6YfblcvdunXqK5NEuLij5s6vOJXNZXWKwEbMObwVKmFpwSg0GBtc3jdE5OdDUSB5hovqS7OPnB4Ima+Vk20Y9FlU1z9D9HMDFw7HoIqiog4/AoNaaCMaELK4nDeD0PA7Hrapevqq5hDeRjwRFej3fu+bGjFRfNOXf0vwPB4KNQeDAjG5NooWq7TAQJAUGoRkVDAqB9C08hy/UaDXKyvZJrMBp8rylcb2NHYoys6gXzHlbnIgUIThGCBtYrG3Pg8EyfhKnZQ0SggODXCyTcbLsklN0n0DvzUGuC5dBCaJ0hw0BRKCAgIHgaDA8DQQD8+lpZ9YzWlEMKvmiNd2t7PAC465bDV6JwUFCQFGoODwIDB+FCHg8LzGBCCMchlEQRB2Wh2Pu46Pou+dHzIaPUzc+bzevHuVGbDJtiHKIsDMDuQAWvNQj8GrkDsGsUHA9HmPCVCo8CBtBZCmwJwkByO+7c/hcUx6brUYUxuGokBwIHgQEBoIDGIB2fTnj3jJJm8OcLxWP1qL+aeO1BOChMHgkDw7IRgoKEYvDYDQYLzGhGxGMBoKDAQNvl7WgfVfft6lcOHrxOZvyefUnA4FBQ8EoamaiEEpVR+RMLXyYmm4FBgpgcNQkBRKBICos4OQZIRMOw7YSKfnWOi+nbDwMH4FQrJBKCA0GA0GgwDc+wcj6JhnJT5lfyk89hs8fycyJQUPA1kyPA8bQlCMTQQPAwPArIWIxoNCMGg0GBAPbL6DrxqSMPmtecQfFg3NVihbQ8Hh4EAkOsIeyqDQ6FBgrPB4HBIjwOYoOQ9jg3CVAHMoBRH2nTE4Z/N8dBFUgFBVxyA8PAgNBQcEbIwjCJBld2wXthI79TfDxy/nM8+b706OP505OzLxcoKCg4FBwPCMcgNDwIHgYKMEYjFYwGBCDAiBAiArV9zj3eJSpa8Bq0oPIKEbKTK4IHgUDAGAjDOBWDczWLqVB4KDgUHCaEg5wUNEICPwKCh2PXDTkfNkdBua8EQXAUHgrPAgKDWIDQYFZAZvcR6VyPcJ1lzvT5iAy+zO7zjeGvzbz9eNjTyPIeDwaDgePwKDg8DAYDWOCKiISAwGBEDAjCAIgnbFJaBE7CyWDHTpICg0PA8PMPCNBXQAZqJMZTel5jgcDg8Cie25Dg0IBB+RIEgdV1x1Zn80xvopJARuQajcCMUGggeBgIHkRsrCDOS0aJRG5eL6x9DytBnoTy0+S+TuGTT0NCIJQsgg3AgeBgNBlJGeQrcQowQIwjCIIgjCIGhQasjORenIxVIAxQ8DQ8xwea8GiFq0OAWnnxj3MrHh4HB4Hg5CD8E4yAqo1B6XStcdk8/mTPo08j21B4KNGINQaCAgNBA8BoRMMkykJoPBQ+qPQ8qXLXjnJ24nDZAkBQex6JQaxqaA0FaaCM8yMEkQGUQAwTRxAgRhClYihWklc+tuXVr9/MC1OWZWZ5Ch5iNPEgFkdHQgeRkGwLHA4UoOTcJw3NIhG0HOh4nAgdD0y3FZfL+fRq03jUTgeDHXgaLw/B4GhfDUiDDDM14suA0JgUX0708ScHb82FQJuBQUJQ8HmSAiEBwMZXZOiOhoMkYxrGgooBxAgQCiY0IwrBCn0NKMK1GOYqXmXJehatCgZSAGzoyD6QdVlWDBqJ4nCcCDcCDUTxzA0XmKlutI3tZfLmfRrlTwUHCkG4cTTAUL6esFUDK0VQQJBkBb5rLjACYjsXPaOePleDwTptaVkqbhKEQPBoeYgQ0QA8GIaxoMEwGD8inSaPyXgiZGCgdnTbGdqpyaaIhpRBmWQgjPBOi0PpqSoKiwDAgSAoPBB+B4eCUb2MDwkDa1HRLx+U899urUPB4HsIgXSzLbAUNtLmakZngz7JAjC4LpIc7AUBzJ006iHB4aA5jw8DgULKHMaELIWRg0GIYzwohxh4EBgME1N7TQQcImBeHvs2Q0i255GUNaQXkMBrcwShKFoeok6PKRvmVSEG8SjUGjkEgTCVtA8CI1tx0e8flLPo3SbgcNGSAbS0AzSWKbCssp9AFjWF0PB9LAA0DwakfOBSKUx0eHgeFZkgPGgNokC5IqUFNjV/O6LVClIDWMF5EY/Axpo2iaDQaxA8EIPDoiWsEg80LlLSgoWAlHI14bkpB3A7GgqgSnzSkEbeCh4cRNtW4Ubnw3ijDSXHVLy+R89uhLR4vDaDmmh4CSW1QJp5YLoHRVh5thxI+zFBTCMEAI8zmOzkeRIDAkG5kTHtWQcDZI2OZXBidNqUHgsihGxGMBgKDQQI2QhIEYIBdLoYiAWGuXDBB5jkPHIDROGpMwEg7EghNCUcvsBskB4lGoKNBIDgYGhvPq94fIGe/Slp4ThsZ4FBBRBMPTiOjzbMyLwNBQaDwcxqPCx5Gtz0lVTSODweZFQ0LSHsiCAHB5Cg0Gy4bTkRg8EYoeBoVw8EDHoVqMUA1GXJMp9CS0AZ8ON0OhwWpU/NOBwKKQGgUVdlgemLZzi0IZ4TRyo8xAcJg1A3WfXdMPjqN+oTp5CMcxgujjHBCidjWX5CrUwwIZhqVETdgCbWbUiQxJOwmpo0mR5Dwr0Kj1DweEIOBQ8HkNG5ENJgKDgcDwYDQ8DEVqPJI00cydNq2jw+uSj0nqMGLAW0Q5pwKCg8PA4SFG0dchxBQFy23TaeHgUbheFqePoyvZgVqeya83xjnv1eNFEraDna6QjPsKiuNQMHTU4KAwTg0IYdmjQUYHFgBYdzs5qSNFQ9DgYDAcElE4QggTBADRvRWBGpwehrJAiCIPB4I2nIiZKKIaCcFcIw1ifZYK8unRx20ObkBBPF4bw8KIfgkDQB0XNuZGzmNTRH4GDnaQIUeAo12vfl+K8t+uzbRyA0PA1kYp2dRSJVPICx8jmXEQMYTEOUJwaJgf/EADIQAAEFAAIBAwMCBgIDAAMAAAQAAQIDBQYREhMUIQcQFSIxFiMkJTJBIDQXMzUmMEL/2gAIAQAAAQUCiOzKbwZfqmo0K4UcmnWydIfdAz9CmjMocaPiuvv18fungz/aP8t5VM7R6kzx8Hbq1nj4PJmk3pwthTY8l5dtWpxZ2qX7SlFR6+/TLpdJ4LxdenJeC8F4rwZeKjUrSGhKkNoykNRNfjw5I/23r14Q7U25dC/FXRVopdS8z2UySq2jpu6ibJMS0k8hJQ9y3XqTksp/MX0DfL8hpjKvkhSbkIrptvKko6OLJRszLE1MXXokxUpWwXqsn9N09FUlISCkInpdl4yZNOcUxU2UD5MoHNJeVU16cU72WKA67hFPKUlGEltv7DktxuQZTk6dchv+Modpndl4tNdPFR+FOKez479Nf5M3woN8Wweaqn6zN8O0mddeMn+U3yzfu/8Ax6Xiul0nXXS6TRZmlbaW9NVQ8Wj9tfSZZ0BM6BGtVN5nzZWHQdSPsTy0blHMabwz64p66K2eXk79+E64XQuFzINSKDGf9JFmraSsz73eWfJTzpKWfYycW1l6ZEVAo6pVb+pUocltUNzPmoHZNij7Wxe3sdpDTZnHhJSEdSGmy9J2Xiv1svVuT8jHip8iukvzpdj+63LV7bbuW/kn05ZlxFUW0rqJ5G/oNKG7SoaINij1JvFfLL9Ml1KKaTOni8Uzqda/23w8k3wu1+ruLxtiv3eLrvr/APTKPa76XwulOdQ8fRuMfx6jI0GlWb4sVqbpkRhqtLUsiC1TSrhFPGC9LtQoUaelKyqpWFykmhKb9xrZ5ykvU8XhX/MLMHF0omDdMSK6jZB4vJPJetF0/SeqHXo0OnErUgoJwWThyZe3uiozMgq9PTqTci0GVfIYyUdbNsUbs+1OJXYp5t7L21ijj5VagEDBfPXcGXmix/fCYVf5biXHcwe8ynPzx7LM0C1W4FDp8bQof3W0GquQRm1eoBYq7IWM8E3bLpfspt8/5M6b7N8Lp4yZozj4/P8Azb79Ky0ZNq5dDW6wVLfl6o2e73Ck+TpkPXgjxR752fWJQ9LzMedsrndfMlGrtRqZlK6utrTHkv1SUWZlKUuvUaS8XsfX5N7S2bSi/IaIl7RdI9Of9PiLy7B6qbC55wrp8qDqWXaylnEr8eZ1IG9e1uinj0u62XdDp4DL21KcRlMSa9hJTE6TiumruiolHVL81o/buS8ZLwgu4su3WF/Sbg9dwuk3l19v3XyyuFEIe3CEkp4hdb+puCKrfd1DWBmoTquXp9P8MnbtRh19ul+yi70v49p4r5XTpkzO6nZXWpaQMFLZGZflybV/erl+KNtV2eODVbh3kxEyxYwoHhWzv0pT6R+jAWuuTNKd9xLwio19pqlK6utWmO6eUpqMFJ4VRe6cl6HlKoGUl6whGRh8aN5Y0vmfJ/jYNd3D+nH/ALhnaJ0p+Cg3w8mUW7l2mdeX2lTS6kEJJSzAZJ8YNPjxZH1tl0C8sBJI9npPF6CU9bRb0xZL2wy6deP26XwvlaPYHK9Ov2286b7dfbrv7/LK2oe9WYwU1LCuZ+tsVQ2ps9euHNV2UXrxTMnZMyacaFZoAVqW4JFS3X7YrZvXsda5V4SrxgoKAYla7dMytMjBxqp6hFkfNQaMWndCprdKKvOl1K31JRad0vTdmhWzKV8IK0peUppoqUq6V69841i/riFZNa/Isvjd9ZQW/mCbelxHW+n4k8+f/wDXL/0naL+Iv03/AOwPNm0PTjNWdKFUnTylUq3eS8vJfH27T/KftFFjAUaf1ElfYJwXZ2L8zIy8elnZ126dPVU69CleK8V0ul19uZVS/Ecgsaxv3/8A0uyZl0yb4VlcLY35uYyvFz61WffSvzREVVyO21V2lGqGDY6hiCxeOWBUowhUou8nk/z4pu03y0nhVFvXNV/RN1dddFdtjQjfqyU7Z2O81OfuFCp7ZQrjFp2wip2KVvaZu1KVdSi5VqqFrjOIz9Rg1a7XIeJjbjkg7nEjiOQhcrF41q6XH9Fra7G5s/U9D9Qv05foij/6E7vTVcWU7W6hWoz9RS7Tt1Hy+PNX30C06v1Dg1o3CuQchtz83EwKp7WPSp8s45Up874vWrPqLx2Kn9S8plP6n1r/AMm2qrkGXaqrx710ul0ukcIxoVVjlcWFfzEZ/t1/w6+JmB1qe3mwU+RUMn5Fe7+83b17DbvVeDNQwRmVeUBBG+xHJ/A5Cnx4dNkaQy95tCqjkMeq9bPtUHhOLR+f9NFX3RoesSVk9QyVUQg4g03kQpYoudzsvl0/9QzVytl5Qrad0nU7kzWWyk9NTwpJuVY1VTQHn00fFdOoxT/pXqI+wWyF+FmTX4Uy6Obon8cv5Hn/AJ8EppWDcLx9DKvr6ie7j0Ru5FjVL+MeL0K/6g8a6s+pmJBp/VAVm/8AI2ler+a8x9Gr6gciusLwee7zicC5XRJ/p7vXpvpl0o/TYJQ+nWKquAcbZQ4TxeC/h7io7elxeteplqzFybFbx+TKP54NR5Jo0PTykaSp2cu9QsHmxBsQCcrbGlnSLqjOWrnVKzkQEFPk7pt3UIXXJSV+A1b1XxdR46BFQyM+tQqjU3Sm3xGH2MtlQK5kCLAyfcQXS+VaMOQp4gMlPj7svR3xW/Nmjr8/CbCF5bIsysQbPHlFFaTMp2ztfpRg3V1rWvGUrXd/ic2ZM1lq9Wpn9uVfC7k/GMq0DWw9Ju1067UWXfS/d3j4OczTnc1DwmAbbNsiF06sa+iFX5GNzefj8968M+eZncN4edH+CeLVsPxTjsWrxMStNWKM239QwA1Xx/lXLZ4/HsjCi9i8+08mUpxZE6gNENXnmeI8OemyslzKNybl2Oy/jUNfxnQmip3DVKexmVqzkQUlZH3i/hwux9jE0c7PpsN9zVZCpYWfLWH/AIYi7fgraFGVQyr08+1QhG5egYy9MtdGMmkevM5eqYyneSmIIXupp7oWwKcgZZkfbw91QvdDL3Aq86HTvWtHVOoJC5joWFfkgr5TjgzVwGI7VVepZYTp9RKj5RvHdPIbooyNltVL2LuMVO34ayU17SdirGkoUeCOyMfRc76cYxKfD5/itVz/AFc2YvPOMkxu5Rx0eBX1E49Sn+oppiYv6k6ax6tIEOd0Yw8buna2MmEI841y9SEXaPi3dggxsDPp3j2vLG55kr+NtfNkb9SMmgYfN5VzJsnjuJhN63alLprNMKljubZQqlzDY0Fo7G1KQ3HdXRenimbRC0LOAQ9LM8YzTVydem6/DX2qGFnwUM8CCjGMGfv7PFpNPMzZo3DyBtfxZl0m7ddOrRarnsxgpL2B1K9xuUr83CCq0s61R6mzspMo/Yst0T+ufub4Rq3b5J9K+a9TVsXtS5r2FSIomRbVkWeYIwtgZFOaOx90LnEolWvRKZSqIk3snV2NG+QmdWHZO+NbRiVeoCUtJq1GMYq0imhiOVcdFRH1I49Sp/Uu++f5n6jaKnxzn2tXL6cXDaZ30yKqiNVyDi7gfUfHIYDRB0FpMyto0Zw/CkxGIem+VeSORIESYlxE3rpZmZqfi30Zra5rjYaYTmXL1Hh3EhBLuLUBqzlvIcSz/wAjlWsPp7G9OfGBIxY7FpsfM2NRBZIgTRHU6ulvg2l31kj1wfSgy96TNeZ6rLDtTxl93m7L1HT3OntW5/8AN9Vl6qaxeaaxeTLtl8J4s6mALarcgKtSusFUNyabksXj+ZvKXh4P59yGeNV+XZH3Hm6e6S9eS9WSlLrW68bBz7YhlEPBQ7tUINFMzKXwpWRZWFdP6V80dzDjmVK36lZrL/yLrmPLR+pJqjxzmh6p+nQ3Y3COIUKjL4sIqyQou79rqVcCTqqyWlGTtFkbi5OktrgfHhKuETJtzLDSWg1Rr10P6R9WafVa9RVVY4pkfsfo15AdpPLeWoSrjXGmv5rSRNn5loJuIzIenjuQKrCw8+wwSndl/BRz1RlyvGgLzTJ8quQZ5KmcVJO5dyGpnFqx2ZEbGNns+pv6DfiuRup1Zk16FVaYrQqTbBcU2vXJMbVJeo7rzmn6thj3Tnl9uu3Teaexopzx4L8tWvyR0l6mvYva3zTABRUahIL1miokeTGPIMs279Uuu5/5jx9EiJNNkZWQUr4J72Vzu5T/AMx3vgLTGMyZ1VNBvhnlfGLSIexThCCfRGqWoADr208QwoXVZeYNZRrsO097Qdqto/p9y2DX8xAoVn1BGRXKtnRnPm+4PMHmOsZeTbCNtuoeIpcmOrYnnNttecW8yMbVF1aqo+4v3anIasi2BLjkeFIxImlV8OtuBE8q/j20aqeJlDygPymqPo8x6K5Buh2SJ5ia0cvXBsjo8pgpafLZL3fJFIrWsYgFrlX/ABEFKrl2uGv4lNPeHGOQHoDi3tlDjpFi/hWS6sXjNeM16cnTjdr2Tr25DJpm1qOjdBV7VAJDaD2RcgySdiJph3TVOyb1V/NX81d2rymvKad5qLyZasXlXLylL1Iyn4Tk8/L3nzbDo6te8JgvyFS86b7I6gMnol7yLeFbTI8WlbZNWWDsii9IhiOK1ynMLkAaht6o8YctAm1vIshk3JrJx97ywtNk7pKr4ll904uCMvVEg3qC2qAo3nYPBniPZJt6kgO8oDlehQFr6OZS3Mc1pY+5lkoEwNolzr9/AXPaUpVxUrbJKql649Oi/wDrM9UEVq5YcbuXPcvY6eq4mbSNCiUhV52yjEV5qOSX1TkkTerjVztDjQrL8LkUprsmh5EahCrzm7cUWTMNOtujk+qGyjqh9flRF+WFTa4q/LCr8uKvy4ifUCdSLzpKGiAybUz02mCvyoa/Jir8kMm0R1+QpX5CpfkaUxsHXu2XukXa11N1kWhVc0CbCnkRH9SGujRX+ToXvh3UihXV8c6+R2bZVULeNnAS3RLFfsSgxGxmvKzkWLWpblly8+UEKOTyi5fwlO1S4rnQU+LhTaGPsBptblQar5j4PTyEG9e8lY1krbWrDZ1+LqtcLKrHlGatuaD6mkblL8rygxTw9vQg3FMxrjML8fXqx2fxfErJk4HMM6iGHja+dUC5tMmfeubklu4JC1yOQnITiHbj4k4tXksqsoBkUOHVKuVkZGl3ELNJK9ScqbG9GEVGWtO5haO4+nFu4rzj15M67ZdpsYhfhiV+Ju7IEoDYjc48MhdIMtXchxhnH3cAlxgaDEVmSFpLuGBqDCqPHJDDCRW7xsVB7IB6vnAZV63GJyGGwylPj1MFHBpmv4apdv4biylg00xDHz7bCZeNjeq1lw8KrarGlHryqz/UPEPmRAgijSmx350GjiWuXpWXVknGg8J5UXRT9O4epXwLMgqeJDVL+HbFHjZrL+GjnUeNGWy/g82Sjw69Nw50Vw++NQnCbSKSvpbjzjT9Kqur+AcrGVwfIcisbkQ5RxB8e7apkERneK0TrimpzzJyhheS5Vxjcxygt7H2QyKzMEjiNMI4PL498fwuPBaOCXwXP60MuQp+DkCZ9GPTn3N+MBX47PTZYC1IAAD+TxeNsZuXef48cEgUZMLLaT5Ac1HKyYM2dnK/MpeMRNG26GX0rBB4VjQunL2klXyvmsoF8v5d6nmFpNmcZ49ahc2kNeoarp2vXo1cIdWgcSuQQ/L4WkvyxlVVyS0QHj0qojG8Ty0NynIJaJVtkbfIiJvHsKxjBuMgKvU5AyHP+ocokW86sshZxOm4EYEMSyDzesJ67asym2HpxoQdvyXfHEHzg7YRiCqeOuZSdk5nHNvh8KdXloVollFddNMe4r9K7iu4/YowUI3/AF8J/t268+lbrCZSq0hrq7C7XW7ZZKdTRhASmA9Q0rCRRvKBItER6IkCM9pgla5N9OWLnfnP6XDj/wAE/KHhbxzit2i/HpVGSWzV4cturepDzIZZ2qVWoHDSawl2r0daRpevq0YwhnMtQl4cgOrfgfJKCtNo+lH15xX5HxaOgRc1PIMgqwzeshMPWsJlMp5yup8qPXOTX8uoYjnd+erOV8b067y+NF25mPvzcrC5ndFuPadD06OPnIbk/FyFQTmkoimFtXH+pXSsrpiRynjwiu3MnUVnHtEuVHHuRxrLxKRLwuQCjuRzHRrjHlBhkqABdFBcexQLSrbJR67fryqjPqN0XXrelYVjR0jYZ9I7gEZfXZMlzwEko3jo8Q/qM4w69F2TRvZTIprVJopLeFrr28ZL2o69nUmHuU5NW8Cou8abbU4nTlU1Mh6a2q9Ttttp1jiU+rM9rmqveNcKW9MuRc1tEWVuf7pxziyLDC3jPamFWbkgn3iWZrQz4Rvr9PRxZ62p7SyuiDQZe6pipSpey8mXtJCznLnhNtmx9uMXejvTj2vBf/12zIdvxZw/KTC7BfXIFjX1Y+o87u2UeHB2uPg5oisjZ04dJCt4th3r+FaqlDN3h17nk9CI0rbVbDgtyiBjvCrjOgNZPM4UJIXX43Qo73ICrfR2ymlxvOuQ+PhjKc4M3uxK1fpZUmIhw29ePFR1i6Q1h3go2TVPuJxIIhVV7qmlhNL1Z1mjwnA4aUaSiIx5jp6leiHuE0crbXGm9d/rL2rSTUUQUqR5L240V/irzZ0xkbTFSYV05ubS0uRhxV23J3lt6dMfyWgXQxcnrI5nxURF6NetUC3pSm/9VGfrESZ1pcsOzLs6+evn2Ch3nQy6or8XC1fj7J1tnDEL2t0bL8t511B100zp8lCMLCYt4yh27GPH2j+7rL0ibDzH8e/BA3OMTk6g21ndLpvPd2LrCS/Ugzz9WQ5Fh6zDzmTn11v+drU/qAHU3/kYd3H52xNv5qcLm5GTNS5syE1tUorQutHsos3LrDYn3hzzqCK6uJhFWC8HEqazNlTZfktUZ0vHtH4Ih7H8JNpRIRgs62i66+W7dcWv9vvWEfMPezlRoGFGmZ2lGoYQKLUwjUmldJPW/Uhx5yiP4LSaNXN/Rp8/Q8oR9emUSj4r8mYvyxLL8m6lrPXB+bgzmNofkKfGUl43svGqVuYJCUyKbQ0QQxOfbx4AmhoqNb9Gk+FQNvhByfSjyAca7VzOhwxdJ4C6ZhNN9075TNFpYXHjOFcy7LFql25tlGnZnWixsmw8nuIi8V/jI2U7KOVVFC4b/b5UYy7+nAFYWKos/nzC68PdDiYSu5RgJKy/WmR2ns7Xr2utvgA5cNbj2vjKgu8Zn1NWxwcudYouQTA+kR6pek3l6aaHTy0CKI16GpKdWlsvGwrZm1kNB2edbL1xl7gVe6EV1+dbA3Gwb1rgDBNU0/PNqjHQrdQksT+XywqXYlzfpacuyDxB1Rd5xuPrHUZfzOSfy+XSncpXPBaW9KhsfZJNt1tuOass9j6CCLB48phZZlWi3jrjJlgxvlbJMM827pg15s5YnG90zQpt9r5HzhKqmfqyh7akWcrrL6qpMneyUCPL0aJU+iAKPa8nzBo1wynreIzIN8kSqYottZVARsIj5HnyXWs45kcd5O2lbN2drO0fC++nWA0tbHIiXTPzks4E7UMH4Ryu07jeIXjgJv8ALnrNbYHpvU3qRjdkkeel6sq7rbm8e5ruFVlhmbe2pxbBuHgQc91pbVvEyxe7mve1r3oygcK06maFU7B6aqNYEl/Fma2HY+kcECT+b/TLXUuQAs78hzl+dBd9K73Qg1bXvG+miWfy/OumPCt40v4c+vn3V6jxVhdMG5BsVPbVy/ZHb8jPX4/6/wA8yb0+RXysjGzzkUfFs98W+wgrlAfzxWDuDrjzcO2hr41BTJuFzKQ6/Sbp/Umj9jVHYvSKFliXwDOs6g8pynSHZT6pd190dbdzs6VHPw3bkPK/flj3nQrt9G8TjFU6z8Ma6wovO6Oz8TVFX4MogQTJvELrziLDGwrpQ+pNtjYmPVccaP5wUGbssgMKvW+o3g5pZWkV4suukBzDk2ZWH9UeQ0LjPNM/ksyb2Gjy+vyhKEIkEXD+pxsGdQkTISjMinr8qzLmBBmfo5em2npblX9strqpjoZehW3/AI05TehfpXeqvpri1x/g3jFUWweE1sdH+deKZfcN20ffm2TxJvcCZmYZK5NxS4FvMyFjn2oWMjCSpRhZl1vPJ+IQwaqrtCskG6ODOXsif5POi+oC/mfTPnrTlomFuXe1d/Qt5NefkakoWc/j47A7Nbab4Vl7uvUfDMPt97VozvQ8RzhqBahot/neTb5UFNbC8j0Z8id2zfbi32nzyRCuM4lehr3DZ5b6ZUiSKDRa2vPrYU0m0gh0yJ9WqrB0XrBGKmWLVsm3VDa5U2fRMNVceRyVg2rc1Qpgpks++xfU/wDUH9PM+qZNvy2/sUYudoap2nb/AMH/AG7QRxABOfpy21q4rmKwNqLpNTWhs6IeVfjk1TsyvKP4odb+SNpGZ+BjVmX2wgLq5VBWazX4OfIvYsU4GWJ8/tOG9cojSknpn7KyJAjWShN7oejAkw/LpE5PqHaci4znPU9OJGdlaVOQLaMbrzlO/ArnZXqUxhVxmyMSLZQjLLMrqiYaxHJ2svuK5Ne0ZSsXoXxkJns4VFiMulWd9Rm8S4Fih3lkXHkyGsZPe/o20WNVglyi1FxJEo9tZQQJaiifQ1LrHsFYj4vHPFrfNzZykFHy5fa1l+JmUWFTn7NEY1VOCQ0q7Kh7b5wyrWmIIK8Qava5cTzovFzyBLIalZVcNWSuqJjWaDpyleL5N67NHlmZZoLjeTbkT8XeXPdb3mt/xk68ulF19PiZ2g99vYZIi6J8BidTlevbG/Z0iWnY8/toN0RoVSzzbjYybi8P6a4iUq5FO0o2Sd/1STR/T6rswbzeRWfSc/t/1wHhXHnpHqGjFTpK98LcmJ+ccoeBPHcjM2Dee43stDAjCa2sDQYoCE2KuKJDH4mfP8hyuioc7XOrzgzi5F3RZ3QRefF32AmrztgMdCcTN2yOQ8e/iGbZ4ha5IFXXCPoCoj0HQxPq2YgWiXCoX1ZNli91+FVhTPLVZ/6Um709XSld+QzCzCtTRNGCY4f3heBbEEej+bIsuulcsywzbID2OgWsrlmS9S/MGhdmCWa8Z3RtiRktdICIhvkGIbXi+z1vQphsxmQBeRLdvqrNCnOTaJUc/PLslbcz9pvu6l+0130vp6fKJJFrUB32v3VZ1bpfrr7+51bSR4gJ0NYSNeoVXAUM0qc7G6d6RCpxhJlC1u4j2zauMq3vvrqZjOrb7rB4chInbd+qV1Qv9K2SzSF0B3sz9CY1vK9IPUGEp7gFaUZMfj0XLbOle2bohnn8iHYvI5jW9uR4+U+2b7N0uEFUUb2g4zLydxoVmWPLKjfkR4zCgrQzPaSpxdW+3GEDcKEIyW1yigR8Gt9oyXEVmZLHA8jHqGlp6c6+K8YMvq29/wBOSHeiyuPVT07ujaVTRA+PJs6mrLuEohk5Qs9CugcfOHwpeeQfcf8AlHLPp2/d7ZI+fUV7e6jReuf8YWE44OiOD5Qd+ay60LdMqvX55oEU5lvzOLt4xf7O7/Z3ZSTftmHW553Jy2aVjqE5O2f0WORRaLf2vJGv/Jt3WBXHoXa28Vl7Fp1fHCfThx+UID8dDohLDyYRhWbFNVuLVs2wwX5QX0/JdB1PZ1b4ljaW4Zi8VvohdJxbPcxm34gk6Xu5+8r45MseqmwMMBo0co0jzsvkVnN9OdXDS2o0xraptpDxJo5DlfiDnXaigdLGFg9Ix0KzPcVxrpg/uRh3Pj4a5FFc7aShmlgXR9tRdFydfKJv5NiUe03GZcb/APn81/SXYG2q08y7Fs9joaEhaqhrj5vZLFnX6eZCFVPI6435VNNcwqQLhp1B0UrL3gg8/wDiPE9eegJKivexLY0lgH22CDvffrcaJuF1AoG3tx+NfLjgSTOPCDjnfUuf968o+TSd0zu6+E/2d3Upd/bCzfymjoksUVZJVvFo5Mu58sp9RnftdK9uh3F97VVEcapp3Rl6rerK39cpNFPbJPZdJS83R4nrCNjbrL2mtTeVm6hleJhBYYhdbh1aOJmHCC8L45IXAws3HA0uMtkcmJ1NOvlJH6pxslXy/l8mhyF5oTT47XmWcnsrFzOS16UOeWeW9J0y801qxed3BZ3LdfVjRwl5W5r2GOPsfpu3Ky7Rs6Q2YgdcW2PvAq3IBtuPziM4HSZcZl/I3IVWFl00VVFHSfMfRexepXTO9nlPHhOEQK50D6cq5jtKHj7atlOErG0CI1Kt/dSpnW8ma4Qvit0p71NEe3EIJ3iQDQ5cibrj+nnwOQGRCD8lGsPwpN4vWofZ/wB06/3DJwtAa4B8XPs8oqT/ADBAWtUXdQ+hxRl2rOpVkHjCL85Wr9wmDA6JR7cl5XTlX3/UDTirefckmp8y5PYh5cnNrIzNaTkPY084D8keEJWGNeYPRDkXIhzUBfbfVTZczZ5ds1KtjQ+Oa2po6x9RVtNxd1OlzaEo8gk/xG2yt8UivRxR8kUV9LCnobR/Diq0BxcwlaXGqqxn8mfHr8tTlbf2v6f6Qw0KbQTKrNzSvmRsB2q7JsLpAySvUnyCIE31pGNZtWC2t8tgSb3e1WP5FbGdU70ZxQvt6GROeUO0r5+hn6GjZbilUFC6OxMgzG1LXb3NlaNtuLecKINmzadj+aMyy9LU477UPar/AGKlbTyTI0DCa/y1OnXdsaUTa9AimsWfuLN6GTMSpRX+/wDak/TN2uO5A2kJYAbFrBA7Bpu0p/KZn7yrHyNaPCuNMpcP4475moJrZxZMvW77bV0hc8XL1vx3HTb7JVkWtJ5NCKacIvDYaUiNin3cr5SfhVUCCn3yqh5nGcjJ1BI0WZco2iV3lQtEBPMteJWOPj0ENyccmRRe/wAdnsk8lxdeOG7t064TOuyiXUhz/wCrntl6eBOPKZ9y5BXSnm8pcd+dnlUe8TgFQ1xZxOXnBSLe+Up+qgtdoq0x3Wo/66jI1pqRSYNse0po1ywb9fbI0RBfRrhKwi+dxEvKvSnW9jRXHctr297PPzjAa7o6eZWOqK7E+VKS9hnQVugGPC4r3dodVleVgZ4dWnX8KPt6+a1ZYY7F5ZsXjPXECuDOL0DNESqOkZXfmw/dvhf6f7S6XkuK60cyMNYVqiziSJUCz9TF4kNpWQ+nuaHfyjxY7C0XPz5yZpii/jBiKPdy9mRFtLjp+joboePq5B+JaTe3DjZP/BJtyr+nZUlD6dVsocBAiq+GZkFDBywWkBRqDUgQCH0yJyuBLhAn3V/iJqlBEam1eU9g7yud3oQd8Wz7b/VX1BzKwtPpcVsvE2mpebU5WdB+exOJLUBC50QhW8eM1zjr8ji78e4FZ4bfM77amqIssKJJla2dez3+6eZWpc8g6bPWIn20CXj0bb51T0qvTC0Ha+y5njIuMFddK13scirKviBmmHylEKcaRNI0tpsaXaY+vdWrdOy963kRMAwbNqo0Ymyy5RjsO10okNOPOfAu1iLibLLZnNZKycY6nMDxD7OT6V9bv2/b/b5Xb/cbLPuzzH/G5VTetaMHdGuXxXC62yXi6z9S/OqflmZJz+WVacHLOi/5zRauvYPDkBzkOQ1O17mH5KaY5oqWk6kZJ05bsuUbR46JNLJnwm/zxZy/laz9yupl6YB8pKUfgAKqV2/rF5ltj95nHd6kwUiLeWoCHrAVcLtHbPwc8BoFTg3VN5JdFpkTMjIPInLGDH88Y2z3YK1SM48cTjduRqaQQerV/DmfQMU06SR59Xv6o92vY74VEmqNrsteI+WUdI3PssEjh6tzUcU2I2i8VOIrr4mPZKPGM30BszKzTaPKTRzgL2twCPC/JP8AF82yESg7ndxKa5iwjCdpefnhU8l4+1eednk7lLdPp+MOeWSqaDRo9S2FKZiZVHeTnM36OP5Ap48sPiNEY5XArGngcCjG/I+n8VPM4VU49vGhlob39EYTYTdxPjxGimFayrVFpHaoa3tvOKk7dvH596687GlKc7FOD+T2fqizsxBHIBsifK9WSlyLWkp6ujYnvIsX6vx01wqU4Yor+utfwhbjyHlaw4VZmvOzL1HJnVI4O7kLDCQrplTYPQToEQsAK9dUFX3mX2SBawgaYwZlNjNeC9kfdXiWiAeV+CRUr6t2IUhzi6x4a0zQ4udEgb0qo+hqDUcV44Fok8IBuunh5Nqp4vm1oT2QYsK5aaCEG97LKj6lDi0y8ZQXsvd0lCP7ajRNKeyWrBoWUju+zT6ebtl3WGn6RptFJkCdEzwscmoWo8oO4J8vQXCAfQhK+kaGz23P9CU4KmF0rr3eE4zG9qZ8FuzMBxOLNmn9RjUR6TlQezOl8u86otGTRWgZO98vKv1b8fRvLzdCGVkCy9cwuNTr354atZ7IdqGEZNTySoqVMq4xtZo+pZCdcyxiDWHviSIGPfXWM9k+L5tMY5WXCfLKh6Iy/fgXT54d1cRbgGLsC795qNaGHt2WuPRN4TomZWdSVCMNMj2dsbdfKOumXbK8cOk4E2UJ2aAtDUV1wiUYI1THBzYK2pizGh5kED0L8b6B07fe60c0ejezhsqBdNL9MYJotaLIJwqMu1iuO6HqW4/pg4xdRTd+OnCUaZXQKmtKErqxaraq/wAlce/5C2Nd8rBGONo9L8RmlBj32CW6hNdKAss04X3w9/oYsCFLj3HGGsrGnOFtlWnV8y5F3T9QrTI2XchyjDyc9zMtZptJOeXP1Civ0ZvGpRrxi7JtTdc/lU9l+dIa7wrDjOJ1zVqUbSbs8CeNii4+bx0Db0DNiyjDzq8mgKNjTq9No/t6Kl6lkvChX+w9u/F6y0RxbKzBuOg6o48zqBoclpaVL2SVukPN7NvKqr3zKCpS/fgb9BQaflRp2ToLm1RlgkbYUB0m16IlWcWERN4wv6iD7FxTRXA1hqdFyTMgg+zFzAgqNH11VpWESHwh5SqysVov+MHvLkScLEQ3Nk2zG5U5hoTRaZkRKTKxgxSPeHy9xQx+vUS5oEnriZWn3PRVIlEiTh9eqWlohwczZenRfVPbU9S2ZJcQh62FKtp/LzNtzXfwMqr9MGovXEEz5j0wiXcd+Bj4etXFDm51MZVhGVZWmTcdX/nzjxhzR9+Ayo0SioVbVVay7M0sd+J4JlhnB9YqoQEvHBP1pkSlK95D6dobxInfQ9jtGyXk/FKA/dB6xlMCb9Tl9gwxGLYXfn+OfDxGNvsuvnbGqqV03lyXJ9tddI2DZoUih5WkTGgwwll+pH3lBDlG8ksjVdCq6x7KZQXpui4tUO64Na3trWjAmkGMatGUHlkF+4rjr0hHag9mvQEEI17WPFiTsWykWb6o8JWg1B7FVsIUBmEnaeliwH2ZPRRq1vTqkw2Kp5AVVA2owtFN358wivNovhEqyumT1GlkGgl368IKJWvC8n8qOqTzq7gIEk0/k76bfYDk3jy3c8L32Vozfj3laX+cjZp+9PjBsFxybL9Mh8ugKmun1Krq6B7JRlbCo6+6z9dszs0Rq5U5QdpO/X5Z9gw0a3pYuyFtsOfVvLlgmJvWDXcJzy0Lxzil2d62YPhilTll3FVn6mgLYTEUZ7lqN7aydfY9EYzD1La6rrn8YAE1woqKjFce5GIMPEgA9EcZxiIS4hG2RMGgUXKZBNXGcuNRA9RY74hgFt9o9c9A6yFB2wUVCDtUgRLYva0Hk8YqTqTrblD3y4poRDOuk19+e93qEwJcPAZvbXA2NLFoeukrQFgUbf7XSJ2AfY0QKk/Q++LoCUbsawyOPDn0SOqccKc9udkr6R8Kl9jTzLo05HHGU505hVI27fPZq0s6rL2pGV/luo/znr0JzkPQDskyyDdOliTfUshPUEgNn65F9GjpetXLMPHJyq5SFz9QZaXG5aFd+FtgD4fiDSCUbPTM2mGTEZUw2tBnMXSPjs7Reneh+I8qvf8AgbXnAHgoAY8OL8ZHEzXwYA1/E/qC3XLQAL55oOfVHNChn05oxIVeNk6MCc7MDbvJe0eo3+1mGVetMqEoU1z9Gp5PF5z81l2/ya6/OTerB4E3wcPkmmK93L9IgQq2I9XFwJ3WN8tVbXNbI1lwm7vPhXl6xpl+RdbZVYYPGGBpUMcZdVXfK2Tp/N16cnRfn5KMpQlj6V+hDHD0a0XVVOeeTIK80cNhhCBjYFENXdqRjXaXuX/j4e4OpFNrrJ0xvd0VmEmxouAcrbak6FuVt1vAnIlGPHOqMinQKsLCzAbqSA62Npe1W4mS+fi8dzb6ZexxEYQLoyqPFGqOncUQXDUOsCJ1jxqLTbLiAtHyrKYJqZEFHh3cpvJGL2JT1N+WToch3AaBvYUHjHcS2OQXB8JxvSyeP5t2kx2SAAFyC4rFHP1J5GRA20bAz5TopFHqFzGAoAj8S+pL/wD5EDA+3MywXjl5gEIBAwBjk8fJBZFwvDYsmmwfkeTOiuIsqZ2fzZWxeFd1I9yfOuVPrjuBdEuud1dac1lIutS1JMrLLr2zAbM4H05quHpTg/k31L4vMQ38cSsoWwaLBStUc+bOwDr2EkwDps+S/HSX4aia/h8KS9jTkyxC8v2h02Eur/nF8iqtorxpXQIq/nKA9ldR2lpsBKRhcP6eyWWTZjX7WXfRoT/HEV2HB8fJixvI8/8AhvUzNOWjfUxYtZQUxxBKYA49VF1pYRAO25MrvyUFp4RZ4gmBq2FW5GmNcw/ri06Ptqtqcs9/U9ziZz3vi6dpdmLhl7dAXFitio3O07r9+/VoO3uQk5pMeOCV+P8A8EqgKWdqa9spFaQQgQQhwkMv8g74nG9S6yGUQZXcGDKwDKqGgBU/cvqm3W6GQa+RnCn3ZgAFswsTOHkBx8UOsgi2GfpCxbWP09ORb7RkjI2fpWhZ52VNQPUTfZJUeFeRxzTro0brwrVcBmXr+Hcqbk8TGm2Vxm0W/wDJwhV+arXg7KiS1M+jUCJxpDle1roszhIyiwcV7Vl7b5YVMLN1EJ1EGEVGqtlvN+ii1qLpenbR5yrckWZ1hcBxr5cmFFas885SJKdcfLIFj7cMW2gOwKvO1azK9HJJqNlk5s4Xak/eXH6Y0pjC61Lao3c+P/ltCptU3Q/G2Z0aq30BM+XvNDbstzSC7rHzMSzRcLAhL8pyMQIc7ZPEfGwzvchZpGkaNu6h4YkdC0fjvFtSiVGESAVThBgG6O0DVZtWmW5dJvjoCXGPuA5T1RzztVzgAoA141BIjYuIbVFZ+lO04Koq7LzBfRAG/wAPqs392p0Z24Y15n4XNrPnl8fzLPa42ZKrR5FUw5V8fwQueLWdlmN7OuXjbEOIxg1tQwqta62yV0p1RdZWxMhT0naUd6U3/Pk+ZmyfUrNK11LQLeTyjJo/Ci/k3NcdyUXnDDVhDVCaT1OowrZfpTeLNIsZlZpjRUtOlPrOyNIsPiaTRVL3tLO2vKtfnDjoyDKIegAehO6d+lml0U0NTnljeoaNO8f3NFRMzM9sqVL+g9ylmbm3ATSgHdyasCuHFr6/QJu0qNjfEu0AOPhtUCN+NB1uTa1FbvqWSwuK6pJKoB1Y73Icgqyf4eNmDxeOaNUBtDORubI1hOqdnUhZwYUcSGbATj+DlWBhY0L/AMnTTXvZ491dj5ZNWIeAHfTt8nBHrZs+H4aAQdeHhtnVxEPHocO4v8KIKZPJDZ2q+qsGgcGbRRxWgryw89z78zEbRnWIJo17esDex0bryj9P+QJyuHtza/0Nn+o9x97+XqEe1nP5m7PLC8GNn7ebkx/XDzGeQc3Rc2qb27oYpqWoIjYoSRg8DBtW/wBGXv4e6fWkpal/UzL1K95rzZeS8vjyXmtWTSJmsev1Tf2Xa76TyTv21pDVwy9QG8SrW8FOohn0uSwg9dtssmXucMPiQtsw9DLCH0t67OHB4/sDPVtbMo6exolQzuN/ky4yyCPz27kitSBLObI43qAe5P2PQ3+SnG31hinm4fEMiyq2jGDG0ac8I3b38+F1mnk3g4m1VpUZxxejkYeLjk7tNmw+CaSDEW7bz/SuI02MyNkGZ/Hy6b4AADu+LjhjjVhzEEzKSbfwrbRubngcjgXR9SLGNAAiANxZt/PryAuZ4VAmfz/MDlRyz8lpbekUZWPD2VHH4lyK5zVXpDtF4XDwcamm5psUdJ67ISqtaixBSrpIJtJurBEZ4OD2bqToldrO02/Uqxq1TCEHqkmfuO5hCb4hEbBbvVTz7Xmmm68l2zpn6Zn+2h/25rB6+/SdmUv2mHVJ2hGuHHtSEMWREamIBzNM0eJubsS2gtRwLSgdfkQR5R5+K9+Lx3KFqfY/F0aGvqUtn8a24vM88+3kHIc7QuEwcx4Z+Bk1D6m3XmhaXItAesLB1vWA4ycaSYSAbXyLAxb/AFrBNKW1yLZLoo1CbpaPId1pWUcjqFBLyayqBtSvXFG//IqckWsNC6JOhma3uq6Ix0444Ga1GWJQNRhvsZ4+NHleNDLw6LDc/wCoblCneuVbSxFi/pLlMFU2HZ1uBvwY4533SKdMUIcnOsFxLa3rV0LnpFupgPZNprZaDxQtnpk+Xqv6Y4FNhgsgx6nae002fymrcqyKal4PV2oOqo/zPqJXTVyP7N2mXyyZdsmkml0+pX42TWHLontl2yf7d/Z/luO6VoQuOaJBh8PRFmFKo3BqwDAz4bMatzkO3VW8DydHAwA9C4raxZSOtyxp5PHqM2gnY1hhNDkeyRIDjNhxAYdGo3Id3FttN1Mii/M44PnjDY2sLDW5LpvSZlcspEDwdir3huoOfrzLDv3LKw9fbyeKjU0B6F1hVufHOMfQ/CnMJZ+X0HAxyjtxrZavNL3ov5qfbRDZNJXXql9MuCt3gfVCiyzcGpl7TxXSjKUF7heFNy4ydWC4IcOQl3m+oXq1V2FW1dQp8PReXdNzeIno0WKQkoqFtdogtV5jVZBNciqGEhq1XzA/kofW1g0NuBGpx4Mouq3XJ9D8tt+K+E3yvlMzu/Tp2im+E7QZza/WHksh+jV39uu06ft1N/TQ85UxzdH2crN72wktEyE83REkPp4tMtDVyxfb8fIAoz8nWlHV5Nfp2F0g6J2Tx7DkKZuACMfrXA053H9kaVVmxOnkHLdN6bSeXZFmTn8xuzFHZ0b3sIvuf5Vny0Zuy837BLkMZllkZq36PYBFmWl4t4Yt4ba15gt+Q2jnWyuDvnSWSqssm1xbMkCsV2Xa4N84H1Tb+849jQutqlXPxXS6Xg8n87IrA5Z7FZntSqZ7LTjM1rG8IygCPXMXQv8AVfxUZzis6zzGqp8K/wAjoPL3EyrjDgnCqeuVcZ1SVjD9BEXRVdvatIhQNKbSk3SdfH2Z+l+6ZvuymEI66oDULqrY/K7Xf2kpO6k64ZWJIzfyQHq41niWBcpEMGdiy349qiGG5PEMuzwgEDnbnKCh6GztS+7Mz+QWAmbu5mFl381KNDo39IVyDjCbP99sov8AIE/6ppfDyXl2P5r1GT2RdcXoH2cHMvbVsG9H3Wc5X5EgMPJMo5Q2LSZ4Fk10PW8ozkpfpaHwzOvp8/lg/VN/HUqb+Vou1s0/2eb+m8W6Zmeb8i06M+Tykha5vR/Kdnsue+cLI/bpYo9ZMbrBfYh6FbDaIY9Q1l41tdGdfOmweqKsuoqT6MncYgiMSt7P9n8d/Zvsyb7u67QxU7bzK/UpqslRYLPXOdu607rz6XknUulxbGtLyNhtao33hOZm8c1KNiXJclrhqtuduTxvVLc7eshZqaG4+hVboT9Iu+0rQIqlS4Uv6h5fPkvJeSd/GVd/hYV5V3/Kr7eLQXUfth7l+CbsWDC0bbPWDuvRAQ/k95YgNkjZuyZl0pt3YmdfTmX9i+q//col3THq3O/4OzqFebbV+CpvlZbRmtZHRlEm2UrhmEmwhFU6bBKHUgJrCHd5XZvhIbo4zYvjB3j21d84V+9sLQ+TO1p2Z4DXk3mT3zPXK9afppmTQXh9v2Xa+V8qh6vWPjnAaRehQ1UPJpEapt0A2ukvJP8AZ06zNa8LMF3gyyayQteJuS2AJxvkBpB+t6wcQP10/KujGCtk1Y17d6Tu/izuPcV0xHku1+72f5drTr7HVcurJN4WdrtWfK+nt8DQKLnspN0LS/tm2OKfqBMLod0sp/raqP3+m7/2b6tR6tFfsbJ6kQ7df8Z1tJvQjFSqdQ2dMVQ5E1ybVjByCrS5RlKKoMlXLMIaywwucyPbtbRbTOVKYSM2lCnu26Xj12tg1gRGZdKMW+3a/dfCd/s7xXan8qnh+caFDiXHRm9PhbEXS4zTYUQSdKME/TJuk7KXws+yva43Vj5o1geZMWdPIxtO/wDADU16FN/qZc4xU7otMqyyUYSjCo/+YZ6z9S9exrYyiu12ofMpfuof1PFe12py7l2mXbPPN0CcwzlmpQcF/KivWiye2yS3H9wMzqc2Zo/EWreUWX04n/a/q18oT/0wk9b6tcYGLr7d/bpeKlVGS9vWvSZl4pmXyyzoQurCjVCysIf250v13Z48l7yhSthFnvayWjqVAQttsvs8WTN1926Xx2nTN2niy8VJR865PF5L02ZNFPFeC8V49KTJ2iz8Q/mYHOqXsu4MZXXlfwvIYifKfbPy0sSi6ZTV3W27BFk8/TnVRjUPDZrqpJhJ4vVKE4yjGStret1V/n9uPO9w32j8Lvt+1XLxf1puu3f/AIU/1XG/JSd5L1rJxjJ4v5eS+m3yD9Wa2jUH/wCpXT9UL5Xz9ul0ul0vFdfK6TsullUQsWXYOLYJttEjze8ryuiR+OEUmrGYrefw+U3X367Xiuvt27rpnTxddOvleLrxXinbpfKdM7r4+zsnj0uFExYDntLXh5AJVwQW6PULZxsbWL5KE/ur62r0C9AAdF8no9O7Y0Ll8u6pm9UvUinhGbXUvU9f+PXwuL3NTuaQ7iH/AHf4/wCfF/GwmdfhJMv2TfK+mr/031X+RslpuHOQVCi0yY9KMPN2+/iul0uv+HSyJNG/Rrb18sWq2JddVYJDxpPYu9m77TfKjW7pq+l8posukzd/aU42R+GdP39+/wDg/a8F10vFPDtdLpN5RfU1m1+P/Tqxq7+Q45FxGRpSxBOZ8qjOjPsv06/BeC8V0uvtW/Uow+JwbqcfCpmiooex6SOXQ/uy66Xwn7dM32b79LOIcM7kQrC63TJlQEWQvxkKV9P3FaH1Vb+gEf8AQhbGhbbD07GZeKaK8fnr4+F0uk8V0nb7ZZVQih6JAURZ0EllkyhoWtHS9zQrA5j2NFmTdL9k3S67X7vFnXwmbteHyzJ3deX3f7Oy/ZN+67Tt5Lrpfs3ak7xnhXF3AcX1ntr5KECZUVWxN+RXEYoqn0Sek0ZOqwirF7NoL+31r3rQUTbXn+qSnD1J3UvWv9eK3H91h/fpdLr7P8Jn+3S0a5alMc/OpZjgaFccWQvhfTn/AC+qjf2oP9vH4V7+om7XTLpdJ/hN2vFPHpdLxXinXHyarCrPEZ6zoPoSvH0o6Q8bSfbzWlhZPIIchwr8M1ky6ZP0m6+3S76Td9/C+F0vBeK8XXj9uk8ek6dk6dk6fp3ksbUlkn3hD6WdfsEdy8JRhLqzWHFgf64dac+9WX33fbpdfYMn0V7X5nDza4ayp+kPH3XF/FdLpdLr7dN10mrUO4P0h3nZlf7X+md19PPi/wCqPzi5/wArwZeHahCyNnS6+/SaD99ffpPFSi/VdxeYWDyKrQr9xGxeAwGbZ+qXgyFul2WIHsB8g4uZgWrp18rx6XfS/dfLL4XXwzO68V8J2dP39uk7N9m7UmXj0nZ07Mn+FJfu9RRItce/IKI9tcmat92j1bHEIaHiul0uv+ARUY1z8oxeprokByoXGP5j+PT+K6Xj0ukzdrpeK6XTsundY0m9xOD12eHa9NeLLgP6TfqZ88dzv3Xwul19uk3X2/2y+U/f2lLt36U4NJEByiqORT6v1hS1FeKhLp6XdXMNcJp1hRP6Zkyf5TxdQZ0zLpfK/b7v8J/lP9um7fpO/SeTqUvt07LxXj8ddLx7Tf5DP4W2VxlcQ/rh6Avgvj7d/bxXS6+2eT5O0IyVg7WNljTA1z62gSzJmXh8eK8V4LwdeCdkzO6qeVNhzR910vFdLgr/ANz+o8Y/w1l/+1vhdN/w+F+32dOy+WT9Jm+YU2kOPjX3K3Bq9G6iuufoeq7URgvBeCeP6vexGbe5OXsyfv7M3a6aKZl2u2Zddrtu/t18/p+3jH7fKdSZmf4+37P32unZOu2gqCp0zsr8rM62ilX2tGUXazJste5iBXHmul4/f910g8vRMcYKQtUrBvObmO2xX3e0EzJvhePz12umXXz0vGK9NSqdM85N0ul0uD/Gv9RPni2Z/wBhmXX36X+v9+cXXfS7XXbdIWQrTkcFXC7Zm7TIvulUYP7csWFLO7zeNM5Q9uSiv/aZKjLz7bGst67TM32Zu/szdJnT9sul8LpSZ2XSZft937d+l+nrx7j49u7N118O7du7Ly/T8qUfJeL+oM7SFrH8oFj+pV6bd9fakW8l6uLaCcHjgajtBCuTv6pbedryyy/ew9tfYqB42ucB7K5+nf014pmXTrrtdds7L5UW+3TLpl12uGf/AGef/q4pm/8Ab+VGEe0/6Ez/AKJSZNBpP0umQdEbp0l1SrvxKr2tpuHn2yZPDpwpkU2USrPoMEkKpvHy9J1l7kyG5TqU+w8WZ+l+ypp9axm6TL05M/SlJdLp110ot2u4weS8H+3bLv5+V/ryX7q3w83ebpmeSZmdePxJpOvFRg3ebY8b6qWjXaF5sRx4q6xsPOGdy8MR7eSadjW333P4p+2Uf1JvHumx6bAC4GwlJqTbR2nXpZcwp9Ov9Oy8HZl0vhl0u+/s0V19uIv1tc7+eIZ3/eXw6/Snimi7IHPuOROAVRHpl49LxeE6K6tCiyRmVX7qk6BOPWynVZVNuot+6DJsFtn4FiaIEwLPlAmRGGJvmVazLpP+lM7rtl12u+l/mox8n6TRU+mU+k7Muk/79LxXXSdfLJ/2/wBfK66TeLJ+mUIeSl2v1d9v2J+kgM4uVca9S17sprYnj2i39ffpdJoL0ndNW6HItEuJPqIQkoX1FBRdaWdYJZ10mfpddLwbr93aDqLdv8su+08WTsvFuuLdx3OZv58Oz/8AvpmX7JvKS8fF8gwcC4fdqtvJzhD1eJYFO/wkgC5iENbG+q/JLrKscwSum+giokei+MmlCyMnZ8zR9nPRMAlQ7R7sqJ7b7OytnObfumX+otBlKUneDJv8e3T/ACvFBhOZMmuNFrumeX28l8uvTdemyeLLuMV+68GTp/lfsvB3fpM8q5ZhT0kRhDzsm0VyMKF9C8XTQd1GD9enHvxdf7/d+mQ0oUTAsFto8O0TVWy0s1xJeDdsy6TR6l07qseSlGEF/pul8LxXGn/vnMW74iB/3/hf5P0v9Rk7J/2+OhjrwpCatRbFY8LFOi2M6DLK1XoV+oTtfMrZvMY+plOAp1Jg1VFn3ndbQUz9t5L9Tp4yg7OmZdJ/l/lN9nk3ad2677UnZd/Ldsm/dfDfbpOv2X7s8W68W8fFnb/aePx0ipTqpGJjYO3cXjTO+zYymCuaLQTx6Tfv4r9ky/3Fk7P2Bo2Z8gjPfUlenRC2qEatPN9pPqTt18eK/wBying8UzJ/l3ZOzOuP/p2eU/r4mJ8HRXXbeC/03ymgy+F8Kt/FCaUvDwCMpMypszxlF/2b5Xy8Y+S67X7p++/GSZ+1X17aLJmXS8Ip26j+68f1PCPXwzSsXl2nd1GPaatOyb4b/fTr5Xh2zxXj9m+XsbuUYu7NDp2ZfDL5XXb/AKmafVuZx26FZFY/mqq/5Z4Y5Y1tM6J2U1whHxX+2/b576TeKj8O7fGcbbm3VWCljyqi0L6f0aeewRCdl+6Z+mjHxTpkzdr/ACWF/wDW5E3lxUf/ALfj2/xJ2jLr926dkPwsy0DSyhRhQhGprPAqakiwfApmOOQvKZB1+fmNGooUzarx/Vd8E+JtuLZAKPHiY062RGzfOy5AN+lN+l6H/pvJfH3/AHkvJkzsu2T/AKl232fxZPNlH4XTtKXa7TRdMy8UzdrrpPFRgrGdOyZu14rx8Xn6c4vCSHshKiDrLPkaM0LJtD2hkuSZjQTwbtmXXS/ZM32+fHqKaTd/pWXpTAsHlAmudcXe8OFlZoBAVnfcYv8AHTJl4x6d+kSJjUZf6mfI8o6e2zvxmt+r4fK8WTNF0/ww1jU3+7zrRd7WpPpBmIfVpj22rTy5a8PUHzqjJ1ag8HpDH0uRbF1ubQPXlmlVSOzrx45msM2wUXEArV3bZ24vkrP379OP7fb/AE9cl+yf4Xj0vSUYtFppo9qCsn8u3ad/Jd9rpNFop/0qPyumXa/1H/KU+28vn9Pfi7KzqK8e367jHt1dXX29fS46RIM92sk0Y2V3FV1zRorDmMmj0vnv907fH7yfrx6+f2X+T5OnYE7W9ytJ/UeNRZWeJYDf4PBM3TWLt037d9KLu6yWeWnqv3xxviffbt4uouzKHm666lJnivL5qKtHnlnka8bBveSK6hY7+Tt4+L1tCHS+HZm8Yxfp/l0/Ul5RX//EAEQRAAEDAgQDAwoFAwMCBQUAAAEAAgMEEQUSITEQE0EgIlEUMDJhcYGhscHwI0BCkdEVM+EGJFJD8VBigpKyJVNy0uL/2gAIAQIBAT8B7I1Fyjbz44hW7B83dXV1fhfsWRAWVFoVlbjZW4aqysmK4VgVkWRyyuXe46KytxusyzcbLKsvmGagjgfOAXVlbtW/MX4ZSsiyhbK/CyyBcvwVj4pu3HMs6zrOFfhlBXLauWsjlZ3C6vwusyvxtxsrLKmaFZVlRFvNjzVvP7dgaoiysrdq3Zfso9WqysrcbcbrMVmWZZlorBZAuWFkKylarPZB4Kurq57AKdvdEq/nB278SPN78L/kiiouAAKMYsjGFywuUuUVyyshWUqx43V1dByzK6vwygrlt7Z9H8oeF+xbtWKsrIK1uzZAeZtwtxKiVk1dOI7dgsoWQLIFy1lWQrIVYq5Vz226tIQ89dXV+J43V+GqsrecA7NuO6t49m1tk3VOUSCaracLq/A+YurdrTts3Wx/JXRvx08zt2wO3a6sO1ZEjqvWE5QoJq6K10QrcD2rq3C6urq6urq6t2gnjXz9uLASCVfs37F0FftbL18N1bsaLftAIvyGykjIPfCNmd0hEB4TO4VzmJsrPFCVlt1nCuEVdXV+GqvdWJWVZVkXLXLCygKwVlbs2VuJGYAq3mL8L9sXCIt2L+dA6qytxsr22RvxPal9IKNry4zSaEdfH+fcmzU7OZE913XPz2u5SyNLMsZF+tzfT22VNNTw3dm71j0v193RStpSwNY+1r9DfX+E6wOnCL0wrNWUIgcbq11bs3ReFnWdqzq6v2bq6C6WVkdPyATj2hZWV1dXHYuroDr2LeKvbbzk98yaB+pfh7ub/wC4/QarnQDp+w/kn5LyyAf9P/4//qnVUB/6dv2P0Cebu04Qemsq1V1mW6A42VwFm8FmKsTugAtuzbt3KBJH5C3CyLevazcAgFurBWCsFtx0Wqy9qysrK11YhX4T+ktAuYL3TI3v9AEpwkj9Jtk45kOEHp8LqyDVkVyFnWclWXsWVWVuBCsrKysPMt389YoDr2CNPMDVW7NuOgVyrOKyFZFkKyFZSrKyyq1uNlPumQl57iswGwGZCjktaXuC/Xx8B9+1Ody7ZDuP8IkS2zaHxTrcIdHrdaBZvBXcVlVgjYK2ZctWIWbxQsVZaI8C8BXcdllPirFZVlKseIVlZP34nsWVlZZVlWXtkcLK3A8TxsgL7IRE7psbeqcxt9ArK191kWRZQu6tOiaSOicTdXK1KJcruWZy1O6qdwpjyIhEN3an6D6rB5GwufK7pb/5BSxNdE2KR2oJJNx19RIPRc+IveH6DLYW16/91JPDUUvKZplA18T4W96k1seEPphZFkWUqxVysrigwqz13vBZneCzO8F7lqsxWdE33KD2NXOXNPbyhZVYqxKsVYrKrBWVlbzfRWusoWXwVnIqxQFuICDCgwBZGqzhsVneNwuYDus7VnPQLvlZHHquUFl9S1V1dHVEorI4oFzeiz+Kq+9ayrAXua8dQPgLfRQaU0o9nzXlM9suY2Qa5xsAhBk1lNvn9+1Suzm4CsoR+IOGyvfZZL7oWGydqmq6zhc0IyrOVnKu5WVlZWVlZWKsVYqxVirFZSspVirFZSspWUrKVYrKVlKsrKysrcbq+vGytw14tjJQY0brOxqMoWdx2C76yO6lcsdVkaixiyeBXfCz+KD2q44lyc7g1Zx0V3FZL+kVy2KQNjF0e8291IVG85kyQZdVdpTj3lmAV3FWHVXCzIvKzE78ALJw4WVvMXV+F1dXWZZlmV1dXWZZ1mKzlZ1nWa6uVnWdZ051+Dgh2N1YIhFBe0qzUMqzgLmBcwLmBcwLmhc0Lnepc5c1cweCzDohIVzEX3Vuqb3W5ijlOy2XMKzp173XMzCzlspTqo/STLZUWtRFioY3SaBTQOiKurlZir34hPNgrlZlmKzIPWYLMg5EhXCtwC0C04adjVWJ7Oi0XdV+OiJuisqy8c1+JcnG6Gnnr8QEEde6nuzGycMpXRaoutus10W3WWXwT2XTRZ9lTMiLLuTeUzZVhvLcKlOVt7I6jUKSBjttE6MhWQFuF1dF9xw0V2+KztCzcGhzkRZA6rKztW7Q7YR4WVllt2bJqyOOwTg4bhZSiLILdZVqsyuVqsq26L3cLo9i+qyXQbYom2yZuib6obKypIRNK8lt7NvrtfTdUrIua6epIc0WGm1z/AuVTUjGQvdMPRcb730HT+VHTmSjdUNvcOt7lNS8up5BOwuf2uVy3SOGVWfGzOw3bcjr0XNcHOba+Xf5KqfllLCNRoqWZp7nVXv6KZSTv1sm0QLczWg/H9+qq6JsTOYLe7/uijx6K57DYralBgXop2pRAA7ACsrK3HXjlVuFllWVZVZWC0XdXdRPA8GtJQYVTfhSgjVOpTlsQDp1aQpKME2LDuNjf4J+H07jrpvuLKupBT5cpvcJoN7I0so6J0b27qy2V+NytSmwySei0lNoKjqLe02UeDyyfq/a5TcADhe9/wBv5TcCiedNFURsikLGoENRnsmG4unIaNTtNEE4hnrQnDDJm/U23yUdTPDT5GCwve6kxB7rZd9CfaNPiN15e+O4g7ovf79SdVMDxPm1LLe/ZR1L43F+59aNSCzlZe7c+PX78FFiAY7u6eiPE2HiVUTuqHlzvFUDM8zb7IDkgZRtvbvfD9tttk7vNyXvbw/bbfx1GoTiL36+vQ+5w0PQLFc3Js6/vA+Y38fejfskW40lJmGZSRZFZA9FK1rdlZZVmWZByusyzpzsrcydLGxmd5sqnGw3uwC/rVFik1ROI5OqNPKf+p8AjBOBpJ8F5LUf/e+Cjo3/AK5XfJVEJZTuDCb+1eVTn9Z/dc6Q/qKirJ4T3XKLGAdJQoqmOYdw37DjZt1zo/FGoZ0CjkYQHOGi5kD5RFTnNdU2CEHNLYryKmj/AE+Pj/lcuNmzndOvh7bISa3Dn9fA+7qs77ZMx6D0P+yxnJJTEtte99rG3TqqM2nYfWixxGuuh/bpu3qjAzN3mjfx9Xu2Rw+nkGrfiPH1p+EUx2HxH8o4HD6/gjgcH/I/BDBIr+kUcJpohmcUKiCM2aPkPoqXk1Lb/M/5XksLbXsAettPmrQH0m69fV7VmcxltvZbb/l96rGsS8nj5LDdzvl0PqJ8OiZdxstGhVQ1YG9ShorpoupRqmtupiRHot91NSNL20r76gH/ANrbfO9/asPpIJo5DLbvd1v/AOW/8KGKJoa3L+ll/Y7R3xsR4Kme508vQNaQPkPnf2quDS5jRpbmAe4Wv++q8ibHyi7VxPe9h9XsHxWHUjMQEhcLej89fgpsMZWtL6Ztjf3bZv8AAULWx1McTeg+evysngR2zi1vHu+4Eba2TgfRff8A9X/L1OG31Wp08fZrqP8A0u91isUa1keVotr4EdB0P0WUnZWKsrFZCpRY240sjwyzVyHFpe9EI6JyurlCU/qQcHbK5TnaXKfiFMwekpcajH9tt1Ni1RL3RoE+R0hu48KB2WpYfXxsFZEXFlKzlvLPDhdXQNtVFiM8f6rqirDU3024OF2niNaYrAzlxCM/eyjNjlWUP9Jcq3opwaTr9/f2UIuYcrfv7+ysTjJo322+/vwUXphR8stBt9/f7IMb+lv39/5WIzPpCG5dSqGtdM4tm0UMXN9FTu5T7FRvEsmRqxaJ/kxbaxB1+/BOhcwXWHOljmbk0urN7xPXT/B/nojKGnu9Ph/LFiFd5Ky/Xp7f+Q9XqUzy+TO7cpuj7INcVk1F+BveysALBPQsFKzMMqI1IU+INfme02I1b7xZwXPmd121Rrqkm7j97oVL/wAS369/3upaqomeHvdqmVcjXl51uLfCypa2Sk9H1/EWX9QqbAA6AWVNUk1BmKpcTDjYi3s+Vjumgg9z2aHX/wAxLT79Ey36NvAfVh9Q6KrpTN3Wkaesj4O9idhjoBmk0+z19ycTdXKuuYpHhx4wDuXTKju5Xpyc6+gRRV1a4WQhB7gpRdhRBKLSFld4LlP6BcmX1fuoY5GSNdcfvxaxz/QF+NVh9K95e5xBP34LyN/gf2QoJD+k/Bf0+TwPwX9Nl8Pihhsvh8QqGmfTvOYK/B1K9ourFQD8EhYK3/fR/fRRDRTVTIjlVd/qV1PaOBov1unYzVSPzErAawzyjPuq+D/bSW8PvUf4TDZyw5olgY6/QdfUtA2492n86rEpHPmzPQLb3VBL3bgKtkAIKpJmiUE6KQCRmS2n36J8TuQU7u3Y5CTLsm1rXGz/AGe7w9d/FT1DKVuaTS32A3/y+Ka2mqpM5u6/w9wTY4amMN2c259u1kz+7dSVgapKwHUBOqZTtYKGpA9PUpkrSMyL2lZxsFDEfSdsnemQNrlSbaJ50KDtAnPaUH2IKc64WawsFnVP6RVPGZHaKRvdtKfeRfQb94KQm2aT46j3OGugCfPy2XlOnuePjr4qqxJpaY4h+1xf3diwRYEW2TWZiofRsiQCnSsOypReTVTMyOsjwjtbVHujRN10KOqyNO4REQ0siYv+KzM/4hXHh8Ff1fBYbLEIjn0Kq52SSlzdVFidKyNrRofYpaOj5fOm69VVRRQyZYHXapnZSgbrKsvE7hBUzcz9U4tcMpVXFy3qm9EhYE29c0Kpd5PSc0FeXvM/Nd1VTNz35k1jrZlS1MtC5s0fRYvVCOmaQ/Vw+YQ3VNUyR0rMh+7lf1iWnJYR80zEXzPs7ZVcrhFomVk8ezlFUcwZwjI5x7yBuy9/f0v1uOhA2Kf3nEojhTVYpiDI3M0eq/7KatqIIW09CM1r7/4Px9YTHOifn2OqF811a6mpeVawTopL6KGB5OqOmiPC7mRgFSC5cUdNEWa2Rastl3F3VlzC4CbywMr91TMJJWFx273Xp9lM07jfh3TYeLTpqfBVNR5KzN197Tfc6bHoFNO+d2Z57YNlO3OBIh3Rpuj6+FOR3cu6qWB1vFOpyuR61CLhEX0WRZbapz+qzLMsyzK6hOaMIiytZOmky5VE125UuV4sQrWVkEeD29UNlREXTrKvBkksOihbk0WHv8nn5gWLV4dAKccAwk2TIhkso7XDSsUm59S7LsNAuqos0sGRutifopXGR9ymk30U1W6aPIVuqZ1nZVo3ZMN4mk+Hvy+r/kCem6vZE8AL6Ki/1DPhoMT+/wCFzsp5TK4yeOqadFRR5nZj0U7mjQJ1O14uzdA6pybG550QpiCqrRgKee8VYbo2BWlloqUx3/F2UFXRtGVsXe01+HxQlAtp96/yuSS7J+q9lTEZ3+3+VSMHKuB9f3/lEjKD09febptruLlYtNml5Q2Hrv5ljy+MDw4EJxsoqi+rVzXE3uib7q6p+o4WUp/SpTd1vDtUp7lkRdBwA2Wf1I6i5Tgsp4AJyCkIfEQ1NbdQAhyfIWNzWT87goScxuqdt5XD1H5JxvvwhmjHpBGpjtuoMR5D81lIeY67V5O6/e0TC6kuYX7p+90dCnCyam6EOTpgE3F5mMDANPv9vcgb68Sqsd+1lKDlsqenMmp2XdibdMJkbm8VKO6bKOJ0rsrVJFHELZrlM74IYoWObq9Vj790IuyvupYaLK+NwALiA0+HdBHuJ3ULmOiL35c2U+HTW/0+SxJ0YqCYn3F79NP2TpqbLLnt6Ulv20+WifPTSVlw78M38fD2fJc+iDhb1eH/AC/hTnD3W8Ndt/UdlHVRQZnQObsB3r+u/wBLepUmuYqgINP7/Z8fZfdSSiMF/wDg+r1OUhu4nzNOdcqOicU4ZgoDY5ewx4j1K8q12QNxdF+70G9TwvbsUh3HEBO2TtSoYw2LKjS3UjOWbcLWVE53L13uq+FpZHOwWuoWguR21UT84U0IPfCgaTMfYUewFHMWIvK3RF1EY2C5F1k54zAJlJJcZhYKpm5DsjBomyB4OZQxNce+VJUGPZeWnwRrCzQhQSc1pcqghy06ozxxjvFVdTGWAOOhPwTJQ5oIRJdsn/gtFuqoIW1cnLd4FTRmkmcxp2NlFNePO9PfnddSekV6QzOQaC26s0EXRt0Qt1Q5dtU4gnThRDukqmmLGlt9FU1XcyMOidv5ljsjrqrdsR1RQUnckuFvxy5l5MU64ZlRYHNylZAsrUQ09EAFlb4qzFh0Mc83LJ3TcHpxuShhVKOhUtBBG27Gff7qZwuqenDO8/fhcKoDGHO5TFjnXYqWlE/pGwQa1vohPcx1C0X1UhyvNkZ5HDKSqc2ct01nLlPgf5Cmbld2QF5I5mr0XBujR9UdU3Yqklc1paEY5C3OdlJne/VGJzRdwQykA9VMLw5kVOO8qUktICkpaiNrpnDRVD3Pc2O6ZGG69ViL72jCgqJYm5GnRUxJhbfdTyB7Q0dLrCX8upHv2WLOvUu9vVA6K5To3OOi5T9kyNznZQFLSzRWzN+SfSyxDM9nyWoGya13giw2tlVnjosNivEWv8VJTvtYKfMLNd081TRc59uinkEjy4bIlBVA2KgN28Wbp7sqLrrMrq6uu90CyvQjcqNzqaYS+CdjErvv/K/qkqdiD3Ns5PkzG6p52ynKd0+tLHlrRom1j7qZ7qgqItzd9R1P6GbIIE+R/fip/wC4eFM1t8xWcLIp/T7MergFWx8mzQgeDOqw4Rl55guqucf2oxYeCqrm1lmcRZU1bBDEG8sE2U0sJaWt09SKn3Cpqh8Du4bKGokmla2Qki6xakbBLmFtfBWspn3lJKFnkBqY3KLJ+pUE3k8gep5HTOzu34jhtqoJ46yOxVdKwRmJvRPKpo3SuytT43MNiEdlTUE07c7E1tQNLbKWlzBxkHeOyOmh8wyngnYX3y2UjPJ6f8L9W5RBG6KClbdqgdrbi1OGdcsLkhTObCqYlwu4eZAWHssS5Si0hCBVPYuuU7e6gGqaB1Ra3k8tuyqP7nC5Gygdnasx6J9HmlOZSUDh6BuoaN0npaKehDW3j4U4vK1YmfxR7OIijYzOmVghdmjapcQFQ/OW2RqACql1g31hEuK1vwm2amuy6oTvY7M1VOJz1rQ2fp6lnCfA4alU/dlBCNXMeqJJGq5OVgLVILOKsFoFdX4RNcJA5irqYQQEDVPWFPyTA+pRfifiMCbFHL6LFzBH+GU1z7KKF8mYSqsiYYS+3e8xSxiVwCJGTK7ZSNBGqPFwyOXMcVnch6WVW4XspoxNIFbXTzFrr0VQn8NxVSLSlCyDrCyNlBzC252V7KnrGwNyyqscx77s40xVDEHykgX02UtOXjM93etfx/dOqgzdCubdOrQL5UTfVUes7ViBvOgr2THukdqhwKqtY4z6uF0FNfI1E8bLL4rlBpzhNkp2ayuA96gkZVP7puFC8X5btinUmdmZ2ilpMjc1+OVBpOgUYy6qtk/BcCN05YYTz25QozKwZQPioZHRuuAopWP71tSjZ8otspHtjGhVdFF5I4N8xhLW5XF6qJyIjronSuO5T5B0TZgs6ks4Jh0twzEPJC5nUrmBZwonEON0B2rq4WaxWa6of7blO27WvQCsqOJrzdPh52gdZWZchx2UjryOIQR4U7XZrqmc+J+do2T6p+UX0Cr4C1927cLHdWWHt/HCrdZ3IIhQjvhEKysqhv4MZ4FWspNY2njZN0Ru5PasQlZE/LNFf17LB8TpIHFmXJf3oDMc3QJ0nMHdVRmyFFoC0V1SRulDg1SxcsC6meXU57ydZUFua3MgIr3znqgIu73imCIM9I9Uwm7S2RSYjNGcm9k/FJntLDbVHXt02bl6KokszlqQ2CdYC3Ang1+Rc5cvqgRaxCcwLKCnUpv3UGEKyssqsrcXboKg2cE1uenPq4tkMZuEMWFvRUj85JWXS6YC7ZZHXtbVQ0zXekUGCPQBCJzE57425UJCdLaJ9EybVcgM0shAy2qZDTtjzDdGihn695f0nLMADcfFSU3MZy44rW/dOpJopgy2qcLEoDhKPwGe9FqyKCjkqDlYpqCVjeVuQnUUwZnyr+mzkB2XQr+jzMdlkICOEyBtxqUMFIdqdFHRZIi4bhV2FxVkfKdtv7Lqb/SMd7sJsqWJlHT8k9AE7PGdE2Gao1aLqRj2GzgvIZsua3CN+Q3XNDtSUXZoHAJyoL81tld+xZ4q77N7iJc1jrsXcuMzOif6R4AXVlYqxVlZAJj3RDMCnOLjcqTU8DorIhX4Xv2LoBGMhmdX7HXg0NMjQ7ZTZo5CwdFHWTwk5SqBz3xu12WW6e1mUZd+qATh0QCjp4OXk6lWEGjNk/O/vlbhOa5vRMcToUC0nVPcNwVna59guUXG7VzQ1Me+yLCO9Zc4yMsQhUTQMDy4EevfqoQwyhuQsedfH78FiVFA6TQ2d7LC/wAVHhsYZ/bfn91viqildTnNKCFS0rKqlJJtlX9OpRkcLnxCNLBFIXxt0XcYe71QdmqDZcp8mgT2FzeXfRNJ1c7UoSODrXWbPoSjlCu0N2T3CM6uuU+e6jDKlw7oTm+SjLGjT8xw5qqI8j7HdS0MdkzCWZSS5OgkabWTI/wXEo6qiID23TculnoZcur+qcNDlk6oiYP7pGyk9I3XVNV+zsnG6ccous91dekULBElHfgGFW8FYhBAKOHZ7timxue0thZ3fX1VRC6mlMT9xwAb1WVlt0bdOD1iDrVDj46/uE1mbUrCpOXKQ4bj/KpI2TVAFtAOqraRrIuZGdL8LXdZNbdwCDTG/lkJzi0nKFDC5x1KDLHRSPEg7yaQTZyyW0CDW7qRmTVqzuc2y8n6lNa62iZIXtyqHl0tG+NzA6/VPxB8mHNisAQdPv3qsdWvghrbgW+/oqiWN8jxKc0btb9b2Qjno+/Ec7L/AF/wncnE4uXnyk9D7z8FLBVUoFmaadPHbb90yvZfXulSMjqIy0O3WH1DpLxvHeCcxxqHNb96KOItAzaqSRjhlCEnL1adVK9oF3EXR7g0RIDTnCa9zwGu1CqYWRN03TKYSAFxUTDH32hSAtbmaqY+WDPeyaWCbvqqjjnd3NFFSB4sSpWNhbYKvH4RFgnKlbnc1o6qTCS2PNm1TqCpa7KWp7Hw9165jgb3Tt030k3btOPB5usuVO1TGjdWT0eA8UA1ZRZR0ok12CZDGO7C3N6zsqW0d87bnorWdebU+A6LEo2k85t9fHjYeKPB6rx3mu8QP4+iiffRU7slS373VRUct2WHaykm7phvpb4hEWbmTWAapwTM8LM00Qdpv1HxTXMmhL2FQtc8WYpIjzLXWTkmx1KbI7NlDVK9kYQdmNiU1pJ1RbJeyk/CHfKbN4prg5Sztf3boOYw6oT/AIXKI0KiezN+KLtUUzIJC6neQPX+9/BSmnks6X/KY6qY0PpnZmg/RNqqeezalliba+/U+1DCGTWNDJvffoB4/wDZYlSvjY2RwIf8CPd9Vhzi03d1VLJUzteDoVBHNLTPzO1CEDZaYNcblcmJzAzwRvGLrlPqIuYFHIH9w7p9M6M9/wDlNmsC0qCXyhpvoEyHexupGOziKEbqehLQHvOyYXN1TZsxzFCNklypuSInNI11RVC60jPanzhnsUFblucu6mnifJctTsNiqn5xoFVYQ5hHJ1UmF1EGrwspZv2fWrqR9tEToi7NsgLbq4QTkNVlCgkv3SmbqGISaWufUuTDS252p8ETLODfuMTBnZ+H3fmuTZwiftuViFTzX5GnujbtPVXqxh9vzv8AVRMIF0/R1wqyACFlQ39SbTeVtuFJFLSycp3Wxum54ZS5Zc9gOqbT1jJz3r2UrRA7OP7bvv4LmZW2B0UbC/qmxyWzFdxrVyWO76fbMWqnHKNgLlPFzmcVUSEnKmsC8mDmaoQGxsmRMfq5FjWPA/SssUl8qYbu0UQEbvxApZ+YAAbeKp5W5uTKM3h6tVKyNoMlK/K7X4+tMxGemZkqBmuAPinOw2tlyQ9xxPssPkpcLngaZISHN9EDYn3jT91NHkzB4LQ3f/uNE1kZGWKymie4dzRPa2FgvqV5XnZlsoIGMvIBqpHPdquTZwTYIvRzWKZqSzqg5zLeKlme42OyeMo0UcsbDYrNkepsnLJCKptwoKyma4Ry7+FlVT2qBHGzKCp2OE7Y3AWPXqoonx1giL+6qxogmewOOo8VA6ekojfY3U8bJaNjR6YRHYl07vCRveRumvA3V1lBQYnbpgtrwBLTcKjiZNHzpDZqEskwyUoytQbFTHTvP+S5hfMOYoGZg5pb1VdMczhHp9ey034EXVR/aB9Z+ihvfRPbpqmTOkpWA7fwhWRxsGX1H91iFQ6cmO1/A+9DDJ+WZD0VG3m5W9b2UVBUGocOZ81LLFHeJ3oH4OG/8p8Zppcj9vFPaI9lR1LdnJz2T91SuEfcaVmyd5Nc6Q6Juf8AUU865kMu4TpCBshLmFxsonxBpcqh3MaWlMYW6hd4a2TY39U7lkZSNVG0GDKdU8NL8h6KKojhcGO1bpdOoqGSN1Q12Vx/nw/ZPFZRSXpjdjPD+FTYtIGxx1DL65ipsRoJw+VzdSbD1fspHUryIYZdQNSdB8kHMay+YEeN1SueASeqbK5x5QCnkbGNUBm7ztk2JrY8ztVDVtZKWWVVO539vdeVvqH8vqm1WSbkPKdJyKjlBu/VSMqIJWsdsVVRyQzgB2hTtlTGxBVbWDypgaPD5qsqXuqmADw+arnzuqGffVcmR1c25WJ0JbM1wPRVdSQG0qrAJZGNp/SBCqdJXWFtTwKabG6J8VdSjW6K0O6yq7gucUBcocaSQNkAfsqqvsOTBo1Grl2CEznakoVEjTcOKo6svdy5db7eo+Kd3Tbt1DfwL+v6FQtcO8pNysGi8qge0bt+qEslxr0t7lm5GoOYI1QdBmbqTp71TZZZGxjuglQYZeocBJ9/unOjpXnr+l38p8L8nkb9yTlP0UPfJppNHDb+EIQEZDF3Oia89SrczQo2b6Kc52VQx80pnLgF7qR7zr0UUpLdlES1Xy2c9Odz+63Rcsx2AUkErjnKsbKGoMTsgOhWaKM6p88QJyoyEMz2QlcdioK6FsRFVrpYXVVDhMMUJe63s+yp6OiYySoZJ3en3oqHDKetpgRIO7fTxWFYa2tlcXOt+/8AKpHSUsxgd3rk29yxVwjcxsosnMETbll2+N1WzsggzUpuuVKapha70rEqppeTWBzTvZP5DK+/rWLyU7JWub4LFKwcxrgOiq6qWoniLVXMndUD3Jyg2VZJAypZb1fNVdY0VLC0eHzVfVuMzMoVQ+fyxrh6li0NQcp+qhc2d5nm6KjifHIapVcrapzpm+P38uxa6yosunxuCylZVkK5aDQCtFceCB4Rm+hVkwX07FuFlZZVkVS3/bn2j6qMgJ5toFgMxikeG72Ujxy3kaXPwKjzD2IyFsdh92ULs8wznqqfD6d077S/JBsNL32Ou4G/tHgmmZozyejmu0+B3Cqv99mlAtI3cffgmHy6DnQjvDf+draoRl5snRDS6IunCS11TXB1Tyc1wmBpkvKjE7ou9G7L0T7u0QaWDvJziDdCdwIchXCVuW2qN7BzwosLqasGdkfcCw2kbXFzM2W3imPgoK8MqLOH8rEqqCOqi5be4eioK2mbiOje7c766arHKijnqGCMAaeHrWNMppKdrRa91X0LIqBjWne38qDD5IMOMgP3ssDjqoGvk1sq2pdFFHMenz3TpDjEBkd0+C8tbVUhpW+ksFiEd4qlRPknrBGz9KrIZXVjL+r5qai/3up6hYpSM7tz4rFG0zYmOCnq8s8WUdAsQqJecLBPUOyqIYhUsv6lUS07atnuVbUx8+MALEKt4nBaFis8zo2kBct1TGyMblSO8gh5B6qfDxDR84dSFbgOFkVbjYIgLIuWSuSgEEDY3TdRdAeCsrK3CysrcZxmp3+75q11crC35KkevRSAbJrsqdNcZQm5iblZ3BUcLKhhubO6e1GSolD3OH4eh9imqmVbzPELPF9PEKSF9BKZ4fQ09e6kyVDPKKb3jqP2CdLfQ6oPy6rmNbqszt2hOz3u9NjLu+TomyZe6FBFLUutEM3sT4TSyZZGkFV2DTU8PlGYELDKWgljc6r3HS6p5KFlZy5O825Cx6upWVDX07LC3hbULGMbdVUVmsAtYrBsRrXwFrCd+iw+lqHVpb7d1iGHGKpu8+CxqnpKaOJ/gfosJoYJpi7wTsPbUYnlB2+ix7D3tcxjTdYvDURujib0H38lidRUUlK2E/dlQVjhQcsjV31UVOyva6AbN0UBNHKaMfq0VPTDDKoOlVQXuqmzN9FVNN5FM2aLUndSTTS1oUsU0lcL+IWK0r7tHtVXSgU8eY/dlPJFHUMa31KuqwZwAFL6RUWy8na6pZmPRTxU4rBc+CqjAypZ7vmsSq2CQWHRYjXB9MDbwVG/mRicbhRSf1KXLIquUxTMpz6N9U9uVxb2TwiiMpsF5I5GgI1JQw8WuSoqGN/VeSNC5Y4DhAeibvp2rrMsyzIPBaWPGhQp2N8Vlpx+k/v/AITXxsN2M+JTw5ybCRug0N40zmhneKp6isaXZW3YQi2lnbzaXR4Ps6KGfkPLJf7T1SEYfUsLbEO8dR7T7FickIf3NCfAWCu0kA9VMx8Y5T2m/sUeETNg57bWtfdUVLFiFRln0FljFPR0srWRu0t8VT1WGeQZcguW+CwXGRBU/hjcLH8TmlnDvUqh9XV0HW1lgeHyyZ76bIYc1lf3j+r6rG8PgiYx59aqZKRtBcW2CwbEo2NeAFHiL24jdo6lY15VLIx+uqxfDJfJA9xHRYbQSRwukWFsqjUmQXVXVVBr2xv9Q1Ule6bEtRt9FiuJtqJmx2+yqssdG2CDdSzvwWfL1+imisBiP/H4qsjkxBgmG30T6hj6J0bfSaqWqkmh5r+mijqr1mg8VPPL5aMvqWKOqCWqqppZGxNcpWQtqxf1KpmiFW0AeCqP7jvaVDsmQPfVMLj0+ifSN8tu4+CqGQNq2XPh81inkwc0qaWndQ7dB0UE7XUrhGOqyshgzt9JYcefJnqPsqpy81xbtc8BxJ4Ufpmys7YBRgel81yeduhkGrdlVyBoAGiugUDwBsboOvqFmWZZlcq/aCchxPG9tlh+LSUh8Qo6SOtjdLEcrtCmSRlvk84319juvxUOCZIc5dq0m3sT3GGrFdI240IvtoLKKthxyWzGi/h4L/UeJO54NvV+yo8SqKija0HpZYXBUzVIBv1WM4ZKHMJIWGYWx1I0ud4rCqWCOrbm+9FjslLE5hbZHFmHDsoH6Vg+IzF72sVaKo1hJvuFi9BUOhDnePiqXC+dht3O6FYDS07XvD1UVFLSYhdttCF/qPEmGOPIPH6KvxOeqw73N+ilqZ6Wjsev1WC1piY57huqPEI6mvzu8SVRvpn1csj/ABPzUENPXV5c3b+E/EYsNdLb0rWCdR/1WEVChq/KWmg+/YqGr5g8mjCoqHyarySnQqGqFPUGnKpKiPyjNbxVRWN8sFh4LE6sue0NCnZNLURtdoEaVvlveKxRsbJu5unDVR6KlEslQ3XS30U1PasDnO8FVsiM4eH3WIOo5wMjjomGndR5dfBYbHFC0k7FT3ll/C2Vc+HkZItHFSwOp4WNfubn5cQroqyw+xmy+KjhbG4gu1UrrOudlzRyst7lQBxFiq5mUjVC1ldBA8GvyLfzQRQ8xQ4e6pYZInWNim0rnPMdToX/APyt9U+rq6GHlvP7qV1PiGGshG/yUOFVGG/7g+4hV0cVZTR1TtTr9/BYJV00FMRcaFQYkIq/ujqfqscxCaTJb1rDDWT0wtdUlHL5SAfFYphxytLiqSkp2Yfd/gd/esGrqenmNvDosYxIGpu1qxPE3y0WjfBYVJVVVIWtv1WCUEz6gg+CxTCuXU6u8Fj1JTwU8bj8fYvLKeTCMjN//wCljGJR5GRWUU1LHRd7e3zWC4fDJI54UEDBTTTX6/NYXh5Yx011FgL5XmSf9QuFFXup5TSfd1NQ+QSip6k/sVUBuEyhzVUTOnEdQ3ZYjQxU721RVEYMxK5kMlXdo+wqipvUhoHgnyTT1oUlMRWXkNlVxQmbNmuPUqkxiQiPZM1F0CbK6vfgHOZsnYhz4uU4W9ap/wD6c0mXqmUktRLzgdFUSjEqjk9Wg/Lsu4QOySNKjyuGZ2uvgjnlOS37IQPz5TspbNGdpWINs1jh1Qbosh4DjH6Pmgih5inqJKd2ZhsjI7EXCY6ZN/X9/VV2K01VZt/3TxJTV14vRP7WX9ZgqaflDRx0sq7Dz5PliGl1/p/DnOD2udbZTUENHiXe8R8VjtRTRxNyePRYXiobT2a3qv6hJ5XoP1fVYm+rljbvusMw6WWlu8+KwXD2eUWceixilpoZh7FUPpP6bcWvYfRYNijY4XNaL6rD8RkjrbAeKxqWpmla71LFcNmlomvf6lhlIyKhe+R3olV81FVzAtuAsQ8knhy08n38FSUUlPRPlCbTzsw2/i5OfLQ0ga7r9VW/6gldI0tFm2VZStjhFYv6g+upy936Eyk/qUGeTf6pk48hkgbu1QmXE6M5/wBP0UFVDTgjLdR1EcEnMyKWuLpudG0BOqJZX5nFbnhN6Si2TduxdboPdUgQPPsTqo4TFy/v2qGnyQPrW79Pv29goqysqTvEPd1UuSIc4hSzxn0jv6tUJWyuLXDMPFYgW93ItVnWhWyB4MFmq3mj5rAoPK6nku9Eg3+/an4SZZ7RuVJRQyQPhn3HwVfQzxzZm6joVJXP8k5LtcvVYViUzZXBulwsXiqZ6gPPULEsJDqMSud4FYPT0scLs/j1UlRTQVnd/wCX1WNYg3kDKOqwyrqJYMsfisMpqmSqAPrWN4XK1zCbdVBhhfQau/SVgrKGmY/yg/uUK2jpa3nR6jNfbosVx9uIFvLZaylxiqqGctx09gRe52/A6oEhZ3eKjks7vahQUTK+lEv6gsOkNbKaR/oj7Kjp2U9X5EPRKjqpIqgxfp+9VFTR0815Nn/NU+ICindTjronjI4halBqGUJvCf01Hsm7dq6ZIK14jqD71ipfTEU8exTiHOJHC/B3Gid+A0+F0J8/4b+qcIrHJomUeQEuVdJmlIHTRCQ8Bfz8bQ5uqlaGjTzNIydsTqmL9Ph61hlfPnzHWyxKtnilFQzTN9Oi/wBP1UFW28mjz0WJUkPlOeD0RfT3LC6unp6kFf6gxJjsjox4p1VU1+G5G+HT1LAMOlnL2uNlX4U2GrdmKxOOiZAW9Vh+O01BEYy2+vRMxYwzc6Jqq8Zqa23MsvLqnLkzmyvfiOPTsU1bLE7I3ZYhEaGIVcJ7xU5eYG1bPSJsqsR+Th8fpKmmmr4CwekzULEIacZam+pU0nOeZD17U/pKLZN27N+JmedCewEeNBUGKGyp2SiX8QH6KWjeXmS9x96LyuRgIJ+7J7sxuUwDKFcoBZeDQfOU7twpW5m24a9uhxNlJByXj0je/sVGaSWHNobqlp4MQlNIRpusaoJMLF49R8lgtce8KnVtrXVPQtFU0l3VYthtOyEO31WH4vR0FHypN9dAo8Vmp3l1PopKieqfmmfcqVgbGLeZPajk5ZusKe6ueYpfRCpn2mkik2A+ysOk5Lj5VspK8Qyl1HoE51+3P6Si2Tdl18xfiECrBZVROyqnqy8CPW6lJp4CLZipQ50D5TwZCS0KwCL7IAuTW2TAr+bjcI3XUs4tZvC/bOFw1MceQ2db5/dlVYZLTRWbqoYqjDmis2VJin9XmySaOP7LFcHhp6fPTaHw8UJ5s9nHVTTyyn8RxKumpgu6ym/sj8hHLIxw5arw0PhfHtufv91XVflcuYCw4jtT7qLZN2R7duF1dXV78MypQDcqkhyMPMsVzrOEbTb2qrIMb2M6cGyGyAugODRc+dyqy0WnbpKh9NIHtcp8VnlA7twoq5lRD5G8b6p+AyULPKG6g/BNxyV7xFJ3m9FijY46omI3Gh+H8p+p4MR3T5G8rKro+eY4tNwm1JbSujO5Pw4X7ViRccJ91FsU3bgPM27OFvsXKQucMwFsq50mcOkFyPgmi4c87G6yi6yP4BNaXLb8xgjw6MtJWIUjuaKiP9P2EP8AUImj8nk0eVD/AKfbVXnj0PwKr43snMbhqOAsEDfZZUSwRW6+Zbv2jbor9nr2AbbK91PuFEm8NvPYc7K4qUOfct2H7KagLoyb6funjJBkA++q1a+y5kiAJ2TY/H8ydlgernAqjqIqZ7oJv1D7CqsHlfKXw6t+Sp8ekw6LlO1HTxCxFzKiFtRGb62R9HgDZFxP5Y9qbook19hbht57DYzI52VQNOVSVD4yWyfBMe5812i3ijrU9/xVm+H5zBLc7KsXpXth5jNwfgsCxWOKPl1OjvFYnhzcVnzw6ErEaV+HgU791fzw84OxdTdFEhwKHncJj5j3C6IvKbkDTxTntezM4KKBlzlN1WOLKpx9aFUy3poEHUfm2uLTdqwGovVhkxuD4rHsO5RPk2o6hYNiM1AM79QsRrXYhUGY+72IC/5poV1rxm6KLdDiPO0LjmsEyLmjvnXonMk5PLvY+pBslLv1VXrM6/jwY8t2TH5vzbHlhuFhmIukl5dVt4rHauCaXJTjbc+PCN2U+eabXHmL+Zm2Uab+Qa90Zu1QYm9rw47qCtins9518FPVNkluSAApnZ5C4cAU11tUx+b82HFuyPYsd/NXV/OnszbKLdDjdX88JSEZL9lpTb21/ODVFjgLkIjKfPdPyE2yj3Q7N/PW7DWl2yjiDdfzd7cKQta65U0jbJxv588R2Lq624aLbgFLq1R7pqt+VigMnsVg0WCH565/IX8yON+MvoqP0vy4R37AF+JFt/yJt08x+krcK/m7ea2W/E8ZfRUe6H5Zv/gITgB50du3HftSeimDvIcB2bdm3mm+fa3MiLH8iEfMHgfMW7IbdHRX4W4Seimbob/lb/8AgZ38xbifyUnoqPdD8rfgPz9/MEBDhdFX82e2/ZM3XX8uPzh4m3C3mCjwHnN+wWNDL314O9FM37A7RV/MHXgeI88CWm4V/PHgVZbK638xsh5s9gcXbJm/aHZI8yeP/8QAPBEAAgIBAwIFAwMDAgQEBwAAAAECEQMSITEEEBMgIkFRBTAyFEBhI0JxFYEzUpGhwdHh8AYkNENQU7H/2gAIAQEBAT8B8r2YkL7V+dr9tfazU0LJI8RniHiGsTNRq/kvtfeRXZTo1mpFotF977NFDRXexSNX2Jc9r+4//wAFZqLZXe2LJJHiv3PEXwTafZGkcDwzQzSyi2amazWakX5GjQU+9lmo1dtyS72WX9l/vr7X9q+0nTLQmLzUaUaTQaSq7amajWakakUmOBpZRXlXAl3ortZfmf71c/cSvs+CyT0njST2PHkLOzxz9RE8aJ4kTXEtF9miihooooVmpmrzrmvsUUbll9q8/JX3X5rL+zZZqP8AI5aez4LMh79l57ZqZ4kjxGeMxZdXsajxImuImu1Lzv8AIf2mUV+7b8l+Tg1dmzk4Z+W5kPYfB7mQb3KK7cCf2FD5NaWyG2/Lb+fPPix/f2L81fsG/J7+S/KnRtIjFrgnEjKx8HuZRlll9l3svsofJrS4G7KZTNLNDNDNBoNXmYuPs2jUaizcooooZRRX7h+azHheRakxRZobJRcWQTyC6TL8GTBkfsS6fL8DhNcoqQos0yNDPDNBoR4aRqjE1o8RI8U8b+DxmeKzxJGqTLl89qKNy2aiyz3NRZqNRqLZuaTSaSvM9i7Iu/JQ4lFfab8t99/sdJ+DJVVIeOTppCx2/UeC1siOu+/UWsTo8SfueLIU5M1MsUL5NUY8Dlflojib5PCPDZ4ZoNPlooa7xVlFIry7m5ubm5bLfZkdu1ryMT7V52/JfayyzUzZmkp9tLNJUTpK0uu25TND+RRfz36p1ibR4nyeiR4fwLG2XGA52WX20yZ4fyKCLSJSs3ZZZZZf2KXnrz12lLtYsjui/LQyx7drLfls1GvyaWaCoo1RRrPES5LUuGOEiqOj/Bm5pG0Kn7i279X/AMJlCg2NxgeKzXfKPDjI8E0Riavg39zUlwObNQ2Qlt5L+y/tX3sscvJDnzv7F9tM2eGvdlY0a4I8U8U1jkahMUrNViFKhTs6Xgcvk3/wa99txR+TePAr7dQtWNlKI1KR4RpgjWlwObFb4L08s8RHpY8bNLXdFihKRphH8jVH4LNRqNRZZZZYmWX3sssssssssflsvtYuPsOVEs3weNJCyyaNTZIXa2LWzw5e44L5FjQ8aEqFGPuaI/J4a9zb+06JUmL1OzOnKkiNp2jS9qFGUZ6mLtn/AAZrSPERqiXEUUz0I1L3PR8lQ+TTD5NMfZn+41F8nhL2Fh+TTX4ocJy5FgPB89sstF9rLL+8+1llrtq8moeRDyMWV+5cJco8OD4Z4Uo8GibHj/5mVjieJBcI8Z+x4jfauyER39jVjiyUVP8AuHhl7HQf071EJx4slKOtbnoNSNafAi0Z2njfbng01+RrUfxG3LkiMo0MWJnhnhoUIo2RZfe/PZfbbtaLRaLL72WWWX2RVmja39mWRIc5Pg0TkLDIWNLllQRqguEeJ8HiTFkmjWnyjTBnhfA8ciu+4o9qvYWORoguWalH8UeLMxt5XTElGdURQzJCeq0aZCj6DTJmhIt+xpZoNCKS7N2Rfayy+9l9rEy0a0Wu1FFd+S627UzSUV2ckaiy+0e0Rtv2H21NGp1YpkZXt2Y2vg1y9kaplSKZpkaWaGaGaDQaDQhX8n+TTE8P4PD92WJdmjSl2g4tUaHB3E2kRGTk1I8RidoySSIzTLZfZ9n2irZRpNJpNKKKGLV7m5pRpQ7XCNUzfutQnIdNHpG42X8DUjSymblyPV8Gle40ikU/YV+4jXtR4g3fbTbJdlFkRld670V2ooooru5CbYhd9mLG3ujS0Ry+x6BuuC7RmvUVJmLaBk9WxxwKbRGcWJobsSs0mlGlKRZbFZUhpkpuL4HLdC3Gtj1HpKNMhahtFxLXsblD7SXZG5fyWixq/cUSi6NYpX5mbe4nEsTHx9iu1DQu1ElRp2NQnYvJRjdY0TuqiSdvYlSnpPyjqK0Dwxk9z9Mq2ZDA9PJmwyj6uzyRR40uLMOZylpEyPeRXk8Uw5ISlU3R11KelMjRTb7azUxs1Gt/JrLRsf7nqG/lDmvgUm+Eb+5sWjXXsPIyy2XIUplyZH/HfYbHIyeqJ4m4sn8i6jIjps3i3ZLg8aD9xSvy122JTjHljz4/kl1cY+w+vP18kQcpxuRotciwfI1WxFeRRsxR9CHFOVsWNHhp8mn2/klFM072OBGNI6t6cTLvdnG4jpUtdkdDj/I6vbuxO++bLp2Iz1dp/Jjl8niGs0mkn6VZ4+3G5F6rIwMaU56CHj5MrxY4WdH9AlJaupdfwj6h9J6fpuneTHyhdXgj/wDa/wC7P1fTN28X/f8A9D/Uem//AEL/AKmT6jD+zFFf9zo+pWTqY+JFVfxsfpcC/sX/AEPBxr+1Gbo+nzqpxM30P3wy/wCpl6XL0/8AxI0P+O+LeVHg5D9PL3ZKDvTHkeLJDG8mTYy9f7QP1GSXuKbY/wDY25r/ALnRS/qpGb/hs10LI0LqskfcXXZD/UMh/qE/gfXy+D9blk6HjyyMrnjdDzSZ/UYsW9s6HpFkfiS4ROktyrkQpp32RJ0RGYuSH4intqJzaqhtkvxRD3NfJkk8dCy6PyOqd4mz2F/AjpnvYpKqLXdySIO1ffNGLe45pemPblEV20nhK7Q4tckoqXJHp4N1FEfpXWZJ8HT/AEDJzlmYPovSYXre7IY4YlUFRZ9RWvpZr+Booo2INRlaMWXxIKfyaiyxu9jN9OwZd6r/AAdf0K6TS4vkZjnU0Ps9syPqW/SzQx7cEdeTguUOSNyOiyf10S3iSbTo1M6fF4m8mdT06x+rGQxOe5PDp4YsVo6KSWXcU0zqoxnBiYnRgw+I/wCDCrj/AIJv0lo1bFHBdkRkXRD8URx+xpijRH2NK2NMVwOCZKCmaInVY7x6TN0zgrRzz2w5FDk8dN0hRK7OJBV3yP1E8f8AdETKrcRHvqRKEWjp6jli0akhTTPEj8njQ+Tx4fyZssJ45Rp7ok63Z7aiHUwlzt/nt7nTfU/qEI6McIuK/wDfz/k/Ww92v+p+vx/8yP18PlH+o417/wDYf1LF8n1LqsfUY0osYou7I54stIzP+pZ9Ql/8tIaJZknR9O6bxcfiS9x9DhZmwLFKonTSrNH/ACf2mdacsl2wvUiUWQ2e5NWyqYnodozdRDFHU2P6ncuDH1UMmx0+B9RLSv8A3/6mrwY+GqQsnhX/ACZN4ig2JJcs0RJR1cGh8Hhs0Epr8UQ3giPIkVuKLQ4iVFDiZ/xMs9CI/wAC/gjFydRMXSu9U/LwWXRk2Z/aKMjI3ptGOWpCKJEd3uPYjadniT+SMp/JqyP3Ln8nq+T1fJ9Xw55NeFufTMken6aOPJ+XudX9Oy5M0nCaOnlk6fFoyswSUoWjp1qWxLb2LLL+RScluLgW7M7ahsaZReowZNcDPyfUP/p2QwKZLoIPD4cTpcH6fHpHJcDUZy3MeCLndHsZsUXkbaI9J4z9JLo1iha5MEIvJufp8UvYzYvDelmlLgkqdGZ3kdjVMjGz6d1Ell8FvkWKM5a8hNOaqJJ0izHKM3ZHQickL57xqUtjH+KOSy+z7cG5nlSOsl7DMWN5ZUQxxxqo+dqzDk3lH4JLVz3a2oV4iPUo8f8AgnITrccrKuiMFek0pGxaLRZnXrY8aojGnwQ6aPUP+stjqMGCcPDxr/oYE8fD7uKZk5RjVLci+TFK24s6rgi29kdLLRDcyS1bnUXkxUdLD37OSRLK9ex72YVURcGZeoxxWKHpHVOzF00cc9SOGdUtUNaLsyKmf6dkzepuiXTvH6ZnA7j60Lp4dXCOWO1kNvSiRlk1EgnyyOR+/ZDmorcedUYW9Rj/AB7J98l+w4z+SizqrpGdtyPc6KFQ1fZ0KORte/arFjNJoi/YquO2UTLMW3qI+bql6i6N37jiYeSMjWiybfCNPyeGovY0NZFIh6TL+JCKlKrIqMTIthv+mhLtlw5HwxdNkvdEulb4Zji4qmajSp8kP+UXqRB7Jk1tZKmnEWGTH0cJMxwcY0zq3Uu3QYouFyRijLRqUjFBqWonPSbz2ZlVSr4IOpHUdTj6XG8uZ0jo+pz9U3N49Mfa+X/t7Etn6jI1L8TDGlZj3ghOdpjuzHxuVLajTLT/ACVMjrHFy5Oq2o6peshHW9KIqlX2cvyIijjy6Hk2Quj25GqdDWlKJHtfezqvbu2Y+SPBPJc9R+oaMWRZENWUrPqEYRyenj2IPlGabSFLfYcaRjm16S14QvIxqxJdr3MniSdJ0Sm8MlGzJ1WNR2Z0l5IXIqjLOUfx9zDhjLZk/pMJu2z/AEWOT1RlQ+m/SpYluYI0hrYjjyT4RgxS1NpbonHS6FBLk/Tapa5u3/74G3EtTe5khU9MRKkYvwRwy9z2EM3F26vlHUYVlR03TPG9xfZkrVGBfIuyGqdFFF6dxdSyFa9TJTt2axzbLZqfya2ajqHUbPFmeJMU5XuzDDYzw6ie0IuhxadMowybWlGPUl6z6p9TXR5oYsbVt7/+X+/sZJvI7ZG9QkpLcXTQTsyLYex4lwoxS1Lysvsh8o6xcDkr0+5hqMdiyVptHS5dPWaP89um/A6iGqSZGUdooxVBOTJTb29jooczMuDHklqkjqFWR0RTJcGNe4/ntDLGMaZ40R5YcizwfuLNB+54kR5I/J4kfk1wfuddN61KBHqIVuY6atfazZPDjsYo6Ipd0T9n3kRjqNJpYkzQzQaY+7P6aNWNGZxyQ0n6eCPAifp1JkY6DN1eWMf6S3MkXnSeRbmWOjZohlUEPgz/AEjp8ub9TJbrtXqIcds7lwKEu2H8fLPaLkdDml1CcpEhEvY6pbIkpSZ9P9KafbqYynIWHN+rjlrbt0/D/wAmeOpCiorYxTb27Yo1jSRvFXIm9TL2Q1qIqvNJadzFF3fbLJRVsUlLgj7k80YbMksX5Mx9TTWj8fszy5MTSqzDk8afr9hb8eTmHeUqRDJKPseNL4P1D+DBCWZWjqUlLTB8GkoopGxXey+04qSpnVY3D0ojaikT47J72Q47UmTVMUSXUeFGkjH10X+exk6qMfx3MfU26l26h1hk/wCD6YqxP/JJHBPNNy0k3KSqRojHkcop1EwZJK9zxE5Uxc9un5kv5M7qjxLMb0bimiHUQntEy7waF02LmhxV7C9UmhKl5K7NuLfwdJnlmldV26lJwM2leiRJZIf3bCimrscYmXqI4F6UYZSvf7HUSlGL08kFp39zG2nt3ZCWl7nhRPCiZFUNQiytRiyvDicfk/GP2LFuSVC4GiUE3faTXBQ4uT2Mdpb98hfsOpC6bVwPpGR6Zv8AI4Ot/wCBI+nqsCJnCJVROehGTG+ZM6ZXcmYv7ya9SE6HLI5aYmPI4t0SbmtxLeiVLkr4iQ23ox53NaGSx5ZL+nFs6mM+mj6lR08mmz/UsWfqHhwb0R6nVLTXdl6SbtmH80M6qGvHROKfI9LVMeB6n8DuGN1ydPDLJ+sw6/FV/Y6zVqWkWPVJChGPC7KNjxKiaMctUezjqxpM8L4PBZHHRlhsmhvyWWWWyMbiaaJciYxmZuJDJo9i2+EKPpXaD27ZGqJyj7shOL9zFKPF+T6g/wCgzov+CiXBk39JOOlMilFtRM3ojbI1HEQdTlH+UafchKtVmpy9Ef8Ach/TelIqV3JklW5rS4Hb5I/wdO/VR0mKco6sWSv+59V+n9T1CU9Wqv8AYhjdNHTdCunk3iVMx9Po3YiijKlz2x7TQzL+I7+D1G4/8EemjJWQ6aMZavsZK1bmFap6/JYiMnE8VHtRXwKTNVcCzrTuN33vuu0N4jJj57uKlsz9JvyRVdnSNSW5LqP+UeSUyfBCRqoWfJBekhnyydD1x4Z/Vk6ybkc8sUeDD1fjx3VGz5Y0pxNJOGqNGTGqUWY43nkhbwHVmXrcfTK8j5I5lJ6l7njY1NRyyJygzN1eLArkR6nG46r2J/UsEGo2LMpq0Q+qfo8voe5i/wDiW9pUZOpjnyOfyKSJZIr8mKnweIu0lfB4bIxqa7ZvwZt8jr5EbkeCtrJyplllll9nHXsJaVSErOR9l5XwblP3NSTpGtXXnx/ixbo0xZ1NRaZrYn7FiY2eLk125G87bZq0qpDlo/AhLWh7DjJ7IakuC0vci2iWRCljbH6dz0qmheoli1yU74Iuthys1bGrw88mx/UcSW8jrOvlnzeBwv4HkjGPhZFaXDM2uHSpw2I5FOWrJG2vgyfUJ4Va/wDM6h5erV5Lf8cHS+JCKjNaUY+lSzPKxdNL8ZOlZ1OCE4eHhZl+m5IwU27ow9JHCqgZUsS1GGUcqsvStiNcoTNbNSJS/qJdsv4s/wBh/wCBHpI/ijT/AEHInz54Ku0f4OB+V9d06V6j9ThSTcluLqcT9/8AA5Mb2ov2LpkXavtqZ6hdsX4kI7DdcHXYnmx7OjPPTA6XO55HHtwhk407HGGbayahWlF3GkWtNkPVvIcbRihqY8SUhxlf8EWkirWwrapkcvqqQ5KLFyWNr3ODLghn/Il9Knitx9RKWbp88MjSv/w/g+sdI4pPErjL/t/BHRh6WPix4X/idTjllxXjWm/azo9WOVVSMUZuWv2Oo6V9V693QvpM36tZD6bUoycuDHhSk5MjcuTJ1koZfCxxJVlVENnTMjcNoqynoMeVkupzrJb4INz9RiXqvtk/FkX7IU0OOrgcSPBlWnpl/JLnsl2XZLsiKORl9l22tqZqlFvYWSbnqXJ0eTrGlL+0c5e5kalx2xP+3tZYuO2LggSW41qjQsCnvkMOHRLxPdsju6Jp9mtWxPGoOzLoirs8dYofJ4viK6FHX+R4L/JsxvQuB5Mk5UJSb0tlaRu/TEprgdSJJR5ZGfp2PFUZKzxlNbEcmnkjKMyvgkoy/NEIRitMeDqcCyuvYX0vp4u3b/3Yuh6aMrUEaYw4Rmy+DHVQnJ8mtReka08HiKjLh8ThDjpkSkkKSqxS1PYWNRM8ZS9K4IScdiO7sZP8WeHZ4ex4cvk8XJjjpW5jzt/kZerhlxxgvYfJXdd0LtwPybn1Xo1jl4y4IYFltx//AKYvpm+qZixLHHTHjv7GJVv2svvh4ETYjHcck4Nkm8O5CUZx1EnqjpGbWShrW5kx06kSxbelH4K5kYwzybTN4+ki5y5Iycd/YWf3o06/URuPA2+GSnFOiSVXFEIvT6eSpL8hRRGCmLHtsQi0tyOXU6NpbxPUi0bmh+5CMYx0Pgc8uTJphsjwtG7ZLUylf8ik9O424bnp5NEYr08EczWXSL1e5LHLmPIseqPqFGthjMkG94mKElH1OxfwUtNkd0NJyP7vLD/m7oWxflXTqjJjjli4S4ZP6TpybMquS2xIZHbnyvbtilToXJMjyZYpTseLJOe7McFiIdXiyOoskX2yY45N/cUpxe51MfFjsdP0kunn4yEnk3IxS2ZO1GomNSZr2opy3G4vdiUb0s0NekrdEoixuzxYJUJteuJOc26s0aobGKsaPFojOEivg0tMUWhxbdozq5J/A2qtlXwcE5yVkkpQTZCCSFigtxxTVo06lbLVbEd0MkQj6SK9JBKhVpMbtEVb1Ef5F3avbzX3Rhhqd9mjLG1aIwvk8NEopGklHbYSK733xy1Mm1wQ4Otk8VSRSL17PkxdD/UalwaWl6jUL1I/lGbFq3Q4qDGpT2Ri9Ox4kXIafI5KL2Ms1HZClLhi3eyJ4/cebIpXJmTP7RMbcvceTRF6iP8Agx2lpQ4bO+R47Fglj9/SY54sj03uU1sYnJi1PgTd0bpknsTipKzBGVOxCjb3NqE7iK3Axp0Y47CVWY6oYyN0yEXpIR2IJaTE4kttkSe2k/FF97LL8+KOmJv3mtO5ZPftsX3s1Gs8RnSztk7bI8HVw1w3McdUkmZorSKPqGlFUjVYnYxbGbCk7IScSPq4Mk44OTHmxT/yPEnwSel8C3VoeWUmadSHgjH/ACPHF7kJRiyemao8PSriYlmcvSfp5WLA4qm7P00JRpox9FhjbSPBUVaIxIbcEX6rG7kZH8CjexXhuiqdk/lGyVkWtJGXpISIXYlszGth8DI/iRT0kE6ZjjsYoqz8ZWfm7NVuuz8iI7Moo0mkit9zxUjx+zJLUqHcdmXsaiy+1mosvt0n59qMiuJF6eDc0bkqWyKQp1KikVR+WzMsNJckOPiGPFcjWsb0mSG1xFLR6aGlH1SFkbXBoyPexY7VMeBHhLTsQhsRjvRNJMk1pIvYiSbLqJCVECPqZL8htx3JepahvVEXFF3sKtImtJjkiMvUyN0yCpHsMUvSRb0kLpmOLIR9RNVsVoRBWrF2bovsu2vSjxR5aPGPFZrky35M6r1Gq9hvby6TQzQzQY6xuxZdRqY5MWlEsq9hzb75VPXcSNTimbrkasfqRmxyq4EMeX24I4fcl0cpyuTMHTvp40nZGNnh6WShsY4qhbSMjL2Itiuyao0+kx0Re5J2S4ElpsS9NkVtYubK8RF/2kXp2K3JRpmn0kYrSY6Itbkb0kU9IuCRa0Cl6CLekx6inrJLfc5dEtlsV2l3QifHdIbIrs0NV2lHUqKceTTZoFBe4kvPDjtJ7eavYcEjVRXuhzKTVDi4GNWSVMlVEJUSe5NtohZW5NURrSQdMb9RN2JNoxxEqkVciaJR0xHwO4xIx1o1aHRJV6iSrclLVEatWSWxGPpMcaFSTYn6DHuty627WlEjL0kZ7UQk0OXqJzsjxZG2yUtXHZ897LQ+3Jz2h3luPtOGrtZZfnhx2n5tT7atqZq+BxUmfgxy1EfSyfJp9NkETpMclRCRJ7k06IRtCXqJ7MnLYhLYhyNVIirKdk23sPknKzxKVI02rNWpUR9YlWwpWtJOzfSRXpsSSiKS0kZbEU3G+z5ortfZR3GtWyNSiqFHRG+3PePZ8d12iUhZEWPvPaX2odp/YsXBpaNpQ3GmiMvVuZHZbcaIKyUdzT6SFWTe5OVohdH9xOJKPpMVUQdSMjtkbiQe9knqZa1FapCxojLehw0svSx/lZL0MfqN5bCgqpjUYx2Pbtj/AAHyS2l5eCMqK8V2SlvoJLuhFs1D7JFEDSOBpa4L7ydv7UXT7S48/PZOjxDV7kZJo072TjsQaSIypk2xJtEFbJrck1RCVEpeom2zeiMXEap915L0OiarcbtWVasbslHUrKstIc0h6pD7YvxHyZPPF6TF6t2SN+6Vd3z5I9rGNDQ/uSySizHJye/2ERq6JxSIRTVElpFIadEI2JKMzJIU9iLdkotlbUJUJLyT47+/kpSRF6nTK3ojyNaWRnXpOC78uL8SXJLny1vfZCrurH8l95FUWUJUPkolJGrtP7maNKzG6fbZeZHht7olZutyL1GSPwarRCQ4uTNMfc2XCLt968rQuPMie26HxZL+DlUx/PnxfiPklz51357uJZqHyMoovs2xQHURuzJK2aPXrv7c4ucaMeF3cu1D8i7LI4mpMtS2JQcTV8jSohx5Pftz51547kfeyuz3Qna82L8SRLnzovtXau9DQxKxDLLocn2m6X3VIs3NzjzOmqNKNLW5q1Dx+5HdEezEVv2QvNxPtXmlz5F5G0nT7YuBkuft35X2/hDLNPecqG7+7ZZf2eoRgl6dLHCt0a/ZkWe4zftvZRx55fPkor7NCikNJ8lUYuGSJc/sGf5LV97G0iWT4L/Z15UZ+CG6sjP2Hj1EVpdM9y+1eW/LLgXHnr7WL3GSgnKyu/H3GPbtwP8AasXnzP0nTS9mTj8EZ1yJ6tx/Y28tEOP2FMx7DH+wl247JbGkdr95JUtjHO+TJFMitKJC472izcortx5I819zjtXfFySH+wkvcvuu0oIlHT+xr7coe6I3yyx7m/sU/copfaf5fa58+LkkP9hyONbnAu7RKNko1+/RqV19yX7HHySH+y8NewoV7+RkkPZ/dX3brupIX3WL5/YYuSQ/28mlyZMt8fdYvuNWSxKSEqRlIrcQvtX2oX7DH+RIf7FeXJmWNFyyO3+yYvuV9izftXZ/ssfJL9vJEbXkk9Kvvd8fsVdb+dnPey32qv3EPyJD+9favNL7FFeVfffehkZN/de37CHJIf7aVV91dsmTwyL1K/Nf7qu68zkkJ35YfkSH+2ZXnXlX2a/fJ+a78sPyJ8j/AG7H+xf7O+0ZNumvup/ajyS5+5d/cf3qH+w37N12fZif22r8i88cuaWbTp9PZck+fPfkr7HHkY912vtf23+0Y+y+40PbuvsLklz9tMf2/wD/xABVEAACAQIDBAUHCAYIAwcDBAMBAgMAEQQSIRMiMUEFMlFhcRAUI0KBkaEgUmJyscHR8AYkM4KS4RU0Q2OissLxMFNzJTVEZIOT0nSz4hZUlKM2RcP/2gAIAQAABj8Cu3k0HkaCeIPG3EGsR0d0PC8iftct7nKbfjUcfTjBFhcBGik6y8LN+eFTYZ/Ul0PdYfL76ytXaKzJWVqzDyZh7a4cayt4gjiD20Y5LbVONuffVvJf/h9auPlt8jY4ddpN8FrbYhtpKe3lW/CjeK0b4dVH0d37K2GAjLcuObOfbS+dEbb1sqLb7KtHOR7D9xrdxkh/fYfaTW7jVI+aWDH/AC1w+H/5VeQKO/Vfxr9op+rKD9tq4P7r/Zet9yvijD7qa0mc25GrDQ1zqRVtmmlSPU20sx+6syK//p6/ZWsso8ayzWYd4vXpMHD7FtW9hGX6rV+0lTxsa9Hj0/eFq9FiYX8H/GtEY+GtbwI8a1WurXCuHyda61at5dBV28mgrWuisf6swbDt9320+Gkx0GWZcp9IBTpi5QsmEAEjHmvJvlXWta41Y1ccKzLVudZri3ltQdGyyJ1TWa1mGjL2Hya0T/w+PybtoBzoxYW6x+tL+FZIR4nt8vm0BJucpy8WPzRRnxc8XnTcQDfIOyrIGb4V6kY7635XfuFehw/8Rr9tsx9AWrNJdz2sb11a1tVoltWR2zE9uv216bDwSfXj1+Fa9DZv+nJakTDRS4Y5tpaXXkdaIknLn+7S3xq0GPxSdxNXOKz/AFoxWoHsrhXDyaXrddxVts1enw0TfuVv4Qr9Vq0xEkf1hevR46E+OlbuRvquK34XHflrStPJqvk0byejwrnxNqumFUeJvVo9iD9EXr/xAHaISPsFbyYhx3yD7zRxpRB5s6y9be42++o5Z4cR5s2kDkDJbjYGjJhFldm0ZW0BXnTCeWN4xogJHDl7a9NA6/VN60xCj62lZlIYdorT5FjVxwq9XU0M3s+SJoxvDSx5jsrOv+3kPeP+JrV/Jmla3YO2s2JvHEOEfb41YAKorfxKew3q0Mbv8KZothEvr5r3tbl38KGLXDGHD29GxYDTtqxlQW5KL/hXFvfb7K0HurhatBW95LJV2q1WiS57aCxBpz3aL7/wo3qGOXELFnTiSO/lRGYSg/3NXWPL+6a41wrq1YrXVrhXfWlcPJoa0arrIa3ZXr0uWT6wvXpsEn7txWqyp7a3cYo+utq3JIm+q/41dY2I7heuoa/q5PjIx++rxYDDqe0RirXsPJpU+EbhNGye8UcFMt5YlkhF/VYXArDTO2bMCxR1DKdOFbXD4DDRPa2ZIlU1vYVB3pun4V6HEOn1hmH3VmhdT3q9m/Ptr0yOR9Jcw/iH416bD3+khrSUofpCro6uO43rd8mnk0+VtY/3l7azqbg/8WzyIe69IqTKQzZd3W1Wjkzt4VtFhMsh4Mx4eyvRQFB9W321fE4hR9Z716bEu/1RaikMS5/WZtcv8688xQs/9lGfU7z3/ZTa3rStT5Na0qy+U+qBxPZXo1z9/Afn83oRkGVjwUDdoYXDQksQpztotmAI7zoaui5jrYduldDHG4bLnyB4y17b4uO+p0ihjQLE2UKttbVjkxM0kioqZQzE241JGwYqEUrvHvrVn+H4VuzEeytJ0b6y0SHiI8a/Yg+DCt/BP+6a/q038NbykVvA+6tTWrCt1r1wPk6nwq2StL1o5rSdq/rLe/yaVqfJoPJ0t0dwUyDFIPrjWvN8HkSSOZ0TPw4n7qGe1+dvk3mw6M3aRr76vE8kftzD46/Gs0E0bd+qn8+2t5JWUd2f7KtNhwbcchr9oyfWFehkV/A3rMasK4VcHya1esw1jbiPvq4PkvV/JavSSIn1mr9vfwBrcjdvHSv1bCg+ALVzQexf516fED3lq2087MeQGl6XGJliiAGWMaFtaTPhVeS28xYkVuIqD6It5TvDPbn6tDGYpbnrRIe35x76zE6Ue+tK18mla1oKzyMqigIIrA+s/wCH58KG2YyNyH4Cry7i/GsVN0TPf0UiiROOaxrE4pOkVR4XXdkBIN++ge+uim+n/qFYn/puPhXSH1U++pC1rbJftrUXvVzVhVq4/IuYUbxWtcPGPAWr9h8TXFx4W/CtzEsPZRxGM6Viii/vOfgOdDCwLippGNlCQ3zfGg/mSnuLD8as2Ab92vSQuviK4n3V1hXZWreXhXCuj8bwTGRNhmPeNfwqKXlI8cn3fd/wvTwJJ9Zb1ubSPwa/21eHEofEZbfbX9pIv/ufzrJiMKt+7dNb2ZPEfhXopUbuBq3k3a0rfcKh7Twr+tKfDWiFSRvZWWPDqD9Jq9HAy+Edv81emnyjsaT8Ku+KHgFre2kni1vsrcw0d+21z5WSGzsvWPqr40Z5yTDGfeeyh2DyElrCvRi9ElqE8mq8VB9Y/OP3Vneta1rTXyaV86gZWAvw7/Dtq0MQT6Tj7vxrO5aaU8zqf5UC5yeGtQQYmGQ7cXZl1I7PHnUw6NxyOksZjzr6txzHGp+jOkovRk2fLwI5MKx0bSLLBMIpIZl4ON7491Cui2+m32rWI/6TfZWP+qn30dN3Yj7azEC9ZQTeutR53rerKlWT5GlHEY7ExxRj1nNq8y/RvAvNK+6sjLcn6qfjQx/6T9Isl+KZs0luzsWtl0dhY4gesw1ZvE8fLxrfUMe+v2Kfw+Th8kY6Mb+BmSce+331gsYn9pHcfA/fVxz/AOJasksauOxhet9hB3hrfA6V6PpEHuyXv7RVkxDezUfGjnaMC3MW9tMPO0D39XK2nsqwxyr3PNlq8uJUeAvV5ZZW91q0wqn6299tZIkVQ3zRarDgDWnhXZ5dpKwVRzrdvDB2+s34UvRmBGWNdXYUsEQsq1cmwrLEKzSNetKzH9ly/vP5VmetTarAXNb7adlboq/vobVteS8/dW4uxXtOp/D7aJUGSTmx1PvrfPPgK3Rb7/IcSJDHPa2uqn8KE8Jlhf5y6hh9jChhem8Hs54/2WKw69U9jKeXtpcPOrjDsfSKwtu9opJYXDxyaqwro5+x5P8ATWIPZE/2Vjvqp9pqy/8AL09/86y8WNZmrKovWeSrKPdWzjXxop8aux0q4GlHEYmVIol4u5sBXmX6PYQ4uVtFkZTqforxNf0h+lGPkiB4RjVwPsWtlg44YLizOWGdvFjW/wBL4QeOIW/21v8ATGH/AHTf7K06RZ/qxP8AhW752/1Yh95r0WAxbeOUV6PoZvbP/wDjX/c6f+9/KtZWj+uv4V6CeOT6rX+TPg2/to2T3iuj3frQM0DeI/2qJ+2NT8K1Hyr1v4qIfvVpKX+qteiwzt4m1ZY4Iwew616OKRfCK3xNemlK/Xl0+F6vJigO5VvV2mlPutWmHB+sS321g4niiVZGdSuQWtkPH3UxTARJm47MZfsr0c0i+IBq+ExNx9FipPs/nXp4Cw70uPetWlw+g5o1ftih+kK9DIrj6JvRbs8uRF2kp4IKE+LYO3JR1VoYbD3aaTQAVlvmkfV2q7HXsruq58hJ0gGn/U7vCsx0FaV2VlU1aMZjWRm2knzE199coh9HU++rQpmY8T/Ot80LVwq5Hl83xuHWSK1yG4UX6FxDRLI2bLKpyn6rc/jV/OIJo7ZRla9vCtniEz4d+svI/wA6wmK6ImR1UtmEjZSp00qaIas6MB41iz0hBshIq5d4G/HsoSg6bIi/fcUZ8Ri4ktzZxYVb+mMH7Jgfsre6VQnnlRz91WE87/ViP31aDB4w+KqPvq0XQ8jfWnt91fqvQF/3mb7BTS//AKeEcSi7O2GksPbe1COJ1XN1VhgBJblxpZ+kYr6bu1eNbfu8qMmHxmGwrHQlJipt+6K/W+noj+87fbXpunQPDD3/ANVb3S8reEYFb+Nxp8Co+6tZMS31pR9wrXo95PrTOPvrXozDDxYtXoeicFIe6BX+6tOgYP8A+MPwrcwmNi+r/O9Xw88nhJER8RevRySkDsbMPcfwq2IjQ9zplNfrGFdPqm9buKVfr7tXSZD4MK6V6LWPaIMYJ0s3DMKjWTMsi7oj5nwpVd3hLcpCv41v41T9UZvsrcEr/u2r0WEH7zXr9XiU/wDTjzVwmHuj/Cs08yfvOSa9LjCfqpat7av4t+FaYRD9be+2ssaBR2AW+TJKguyjSkXYbym/aRRzMM45Ds+R6eCN/rLetEkXtyv+NZ8LjL9gZdff/KtwmQdzBh8da/WsMB9ZSlBRGYieLda1eixK5m4lzYn30Zsw7qPSOM/aydUH1B+NZYuPbVyfJmaiCcsI0a3Fz80feauVso4Dsrj5O6ssKGZvonT3/wC9frEoij+Ym6KGEE5lYGzGJcyp40PNOkYpifUvlP8ACdayonureq1qt5NavV8l93h20MDhmEyzKybDnHpx7QPGsFjYYCuH2UaMAS2bcO8VXxHOr4zDSPCqejVI8u+eJtfw+NbCKFmillBN5MrABDbhf1vuqSSTC5iwUaPZbjQ++t4AHmAb+SdOlJXjwpyiRk4jeFu3nas+FxJxI7sRr7hV/wCjCx5Zpn1+NX/ofD/vC/216LobBL3+bpf7KLJDFEq8woFq826JXz7E8AR+zB8fW9lLiP0kxbYTDDVYbWP8HLxOtfqGFAc8ZXOZz7fJqfJq2WjtMQNKyYQHEOeOoyitUSNOOlfrEsxH0Qor+pyue1spP21ZcHL7xX/d8vv8npcRGni1f1nN9UGtnHhpZb8jbWvR/o7Gl+eUj7LVcKIe5muPxqTFx4uP0di2QkGllxOMQl47O562bka/rETEG45/bUkyYiNFElt1b256Cv641/qCsywxz+Ln+Ven6FMdvWSv67iI/rVfD9Is/gwNf1s/wCv63/8A1iv6wh8UrrYf3Gv/AA/xr9lCfBjX9TH/ALlf1M/xitcJL8KaKTCTZXFju0YQODda2pFNJNE5dzyXStcw8VNdb4V+1A8a0lX31pIKxE8O3VA+UW6thz7KXC+Z7a+tyVGlWkxOVPmWOvjWscQ71TKfhRaPFPF7fxqRIMVGch04jX41aUSsv8X2a1lkXU+rwPuq28vsq+2X302Gifqde3HwFBmFlHAchWlFmNgOZr0EBc/OfRfxr9bmL/Qtp7udWjQIKzFtRzNX6QwMOIb5zJve/jRfAy4jBnlrtF9x1+Nf9mdJ+dxLwXPy+q+nuoQfpB0IyHtsYz8dDQLYxoD2Sxn7r1tH6Xw1voNn+yvRecTn6KWHxrJ0R+j7yt7ZPgootDg0witxJVV/za0V6dxgnxDzHKVu2luHDuNB1kisdbu+X88aypO1uQghCj3tpWWTFKhGpzzm/uW1GPz4XADf2vPh/ad1GMdIRyOvFFdgR/iNWP238hwmKgE0UnWQ86z4LEYjBS8QEfOo9+vxq+A6Xjx6DqrId4/x/jQT9If0dli5bRAV919D76zYOGaac+owy5frGhiOlMb5r0e+oReY7l/+VBsJhxtQNZX1f38vZat2rscviaLGfNb5uoFWEqMezNm+yj/RPRk8i/Py5V/PtrZzdJRBzpsYPSG/jw+NZ8e7op5zMS38P40Msed/nPzpc2zjvwFXjW1ca4nyfrXSkz91byyP9ZvwrdwkftF/tqyKFHcPLlYAg9tek6PwreMK10diF6PgWOV3iay2Ge10P+E1YaeXjV5IUbxWtI2Q/Qav1bpKS3zXrfhixA7RVsXgZoa3cSo+tpWZCGHdXD5Bhw0iq/bWUE2oTQT7nMX0vzogRqSkyqwPNDzFeh6PfxNdSKL8+2vSYu31VrekdvbWKwhmZQDuW7L/AO1QynEG4nAa2hYZu321AXw8TExqdUB5VdsND4BBTQxwpHGOuR+eNZMPeNeQFf1lqytOSOyt1yv1dPsraySPm9Vvm+FNlLG9rsxuTW+1uzvrdGRfnNx9358Ku5MrL28vwrjb6tbqms2IlSMf3j2r0vS+F/8ATO0/y3r0IxM5+jHYfE1s+jug2duWaS/wAq+F6J82vw9Dl/8AuUYukumEiifrIZfuUWrB4N8a8kWJzZpI49EsKLYDpeOQ/Mmjy/EX+yr4v9F8Lio1/tPN1kI/eXh7aEeLhkwZ/jQe78Kz4PHpivBxp7KRZL5SdXHqcbH32qA7D5zPra5Yh7dw0IqPDXVjGzuXaQ710YDS30uPdTZ5oYBIFVs7ZJB2jvo/9pxYh9bHQn1s3A9rGpY2IYbOPUJl5tTMvW4L9Y6D41bspdCfCvSPsweQ1Y00UZ84xI0yIbn2nlWfHTno3o9/V4Zh9Xi3t0rYywGY85XkIb4UZ+genMZhzx4XX+IWoR4nHYPHL9YPb2imzYfIfVyvZfsvVk6UwOFHYzXf2Zta856d6ZnxFubvkX8+2th+jvQK4uUf2hS4X2nX7Kv0z0kyxn/w8Gg/Pvr9VwyIfnc/f5cLNFnvBvgKoIvccTfThW812q0aVuLaudejxUR/esav8tph1sKyYkfuG5+F6uDf/g7+HjPsrMJzhz9f8a9H00JO5gT+NZXjWTwFqusSDU2vr9lGALlPbTYg891fHyMxXrLa3zu6omPz+dcK6tdWuHxo/TzLxq3ZP+FQxRC2VbV1ryt28u+so0QfHvrSrcTWtdtZS12+aouaLyuIUHvopA/nk/rZNR7W/wB63MHiZbctEX76ydE9BKe7el+y1ejwkuHB/ulT/NrV8d01Ii/NLyt8ALVmx/TGJe/HLhivxN69Kks//WlI+y1egwXRy95VCfeaEME+HF+Cq61pPHf64rOZVYczcVhY732jMNG4bpOtbz1pVsd0dDN9Jk3vfxo4yLpOXoy3C5zr7B1vjU4xGLmxCrOVile+q2HC9SQ41GzNBIse71juqR/F/mFRgYp8MQhgbe1utivHq3W5o4zDOmJbYgIialV5lm0+zWpJcSwfLPlsLsBnYO2nMcPfWIEEMxh2l2UEZzuC1gNRry7KjV5zPCZjISzX0sStu69vd5JekpldlgW9k4nl99Fov+zsAe+2Yfa32VmbG4Q4kcZCNrJ7Pm+6tngMJjsfJ3nL8Fq8eHw3RyHnYZvvNZ+lumMTiT2ZrfbXocBET2uM321iF6Wkwy4ZbbCIKCT26UP6I6BTDR//ALhyUv8AujT7aUQdJZiPUkTd/PsoRSdFwYmFf+SB9i/hWzx2ExGGkHEWzD8fhX6lJG/dfX3VoLV1jUuc8Urfkr0ku0f5qa1/2X0b5tEeEsn8/wAKuem5L90h/Gv6vlP0SRX6viZ463MZmH0tftr0sSt4VvIy+GtaTD26VusD4eRopOq4ynwqASftIhsX+shy/d8jelVfE1rPfw1r0aSMa9Fg7fWrWZI69P0hIe6t4O/i34VuYaP2i9WWwqz6isTMi5tAVB7KCHSw4dlAih4iineSPeRQbOFvyJr9oK6/kDDL1gafX1xrWmrXIA9tXJPee2uFa1ppWWFWkPdwq+NxIj/u1OtZMNGFA5mtrisVOR/ytpuewVtgDILfsr6Udhg8Olv7sfhVoHvf5o0rc09lb5JrNKwUd5Ar0vSEf7tn+yiMJBicQfoRClWboaUYcNdgWs33V/UYViG6u1Ri3vBrZr0bhmItn4j7TV8oz9wpUwnQi42O2r21B7KLSfokLDifyK2fRv6PRGbnb0lh4AUcd+knQ2Mxb33EItGo+rb+VOcLgmwwiIXIRanxL9WJjHEPDrH36eysPhlIGcytr3Qv+NTYuDD5VlRIlRkbdC8DcAg8TpfsrDNBaUifbTbQmPMcp7j3e6hiZCGOIkkGRRoinW+b2D31Ig4K/wBwP3+TELhComKjIW4XuKvjumXlJ4i5tWeOfDE/Tiz/AAN6yQ9KYZQOQgA/01f+lMHbvT/8aEKdJYLFSH1cOmb/AE0FMjRBuVghPu1oOcFE03Nptde6t3BYQ/nxrewUXscD/VW90UD/AOp/OsuI/R3ajsO9X/8AieMiPbCWHwsRV8IOkI15LJGxH2fdQXpHo9XHaBs2/PsrzfovoWYzSaAl82nurP0u2IjQ/wBnHHk+J0oea9HRI3/MkcMffyr02MTN2RqX/Cv27/wD8fLwrq11K0zCtD7xXP316RPev4ViEljZVxE+dL9419lxQaFVIbUHjXZW+zHxrgTX7MVbXycDXA+ThVvIG+iRWdte3vq3bWc699LJ6pT4j8isiHKSL3rR1bxFvsr0mHP7pBrfUqe9Kukyv3A0+ZyotvNW3tYP28h2UAo8l76drbqj8fZV2viW5Dggoxo2wTsj0Pv40Zo5J45OOYPf7a9BjtuBylT/AHr9b6Dzd6XH41qXhde6ryYh3t6ixkfbQXAdB4h15XGUVaPA4fDDtY3/AB+yv1zp/Z9oiU/das2KxmInPPNcfZV44o7jmyFvtq23jAHsohZ0Ptq7ZDW6CR8KO06xpZ8P0hi0km3YYYgTmtSDFt6Nf7FmsT42oYb/APTGSMf8jX8ay4qGXDN2SRkVMVxsC9XjIB20+H86hLJK/rjgWJH21g5TIuRNpc34XFbQQwljrn0J99ZxKgH1qth47k+s2ij8atcsTqzdp8knhXpZFHiazYiYDx51k6H6MaU/8yTRazdLYyWRf+TGMqVlw2GEY7udExRjaNpm7BTxzE61uKz+FX8zlv8AVtVm2UR/vHq7YyIfUXNXpMTO/hYCs0kHteQ1+qYGN3HzI/vqyqIF+NZ5pix7eNZZAzeLV+r4pgPmtqK44f41/WYv4q/rEf8AFX7dP4hX7eP+Kv6xH/FX7eP+MV+1T+KuutddPfWrR/xCv20Q/fr+t4f/ANwV/WsP/wC6K/rEP/uCtJY/466wrjX8q6prhWkZr9i3ur+ryfw1+zZctzRXW4rIX3SdCdKjhhb0eY5jXhqK2jrfLpX7Fq/q7VrAaythwQRrTnDSF7stsyg2qLzzERxZVteRrVfDGSUH1gh1q+kP0nGvx0rPiOks7fXzVuvM/gPxr9T6LxT9+or0OEaIdpkP416bpIx+D1fG42aU/W/Gh+rXPbnNbkTIe1Xr/s/pSUAeq+o/Psq02EhxA7VH5+yrY6CTDd5iuK3OlcJ+8uX7aujROO0R0QYoqzMyexasiknuraybzDqitpfiaMe9durl5UgaPET7TqZYrg1bDdEpCPnS1bpPpY5Txjj0H59lGBXu6C7Azaj4V5xh8ViY9dLPTNLjvOMJdW1UX41hXlUboKC3MCsS6IAQU/ziocJLi8PHJGLHPcVuY6J0txiYP99bQ5miI2GXNbTt8asXeV/VijbMT7qyYbAr0fGfWcb599bfGRzYiU8Wl5++rARR+J/CrPjVHgl63sVIfCw+6gmFQk+sxN6EkKqZE+cOsKQiMhEHLtrZE+iAuc33VZlB9lZoZGQ9xr+uRCC3/L36zS55W+masqADsHk41xrjXGv6k38a1/Uj/wC4v41lOF//ALFr9bMEH/UxCL99WbGIx/u7t8RpWbC9HY2cf3WHZvurZ4iDERN814ip+NWGKSM/3gYfdar4SfCTf9OYNTTyQgqnHLqaaXEYWSyBS2UdXNwvUWKw0aZJVDC7a2q+MnwkH/UmArSXb2/5SH7wBVsH0J0liO+OAMPtq8/6NdLAdqwBvsatnLiBh2+bNG4PwWv1fpPo5+4Ta+6s2SG3j/Kv2cPvrqRVwX2XrPPOka9rtapEwPSEWIcDK2zbMFv30/iaturfiTakmXGhlAzXtx91JKG76kTWzLpao8TtZkLi+XaHSlwWCxk2060jNIbIteh6Zxi99xTYw9OTusXqtWLTFT5woRkF721NMBtsTi8zCxux0/PwpJJcTOkbC42bZ7j+Kjt1x0zr1h/tWvQuIPjnNeh6JmTwW1bmCxP8YrTBy+2da/YEf+sKdBYGM2N5O7wrWeMfvn8K1xi/Gv8AvAj929E4LHCST5si2BonpXEJHJfqwi4t4mmcTG4F9Etf41tMB0/Ph24Gy/zr9S6cw2KHZMpQ/f8AbTS9L/o/O0MYzPNhZlaw7ctQYfobBYx5XfVp7KgTmTburZQbzHSosGjaIpzsOX50/IraYhQygZb57kHs4U8V1vF1lycKRnhiigkXMsm2zMf3avJiM3dwpulY7vGWLbeEnd7ARyr+if0jjMMjaJjFY5Q3aRy/PCpuhuld+CYDVGuGX1XU1h4EdXyF7svPeNvhWM/c/wA61hZ5OjhIzZt6wN949tFv6KcHtjksfdemwqNJINN48awzHBQbQwbSbMd4/nSsrTyRt/y1si/Cv2N/FzX7D/Ea/YH+NqumHXavon41nvqKLRoyi/GjJARGpPWXsp4Hdt1c7W0vWz2GZvmqzE1/VkiHfISftq2Vm/eNbuHl/ias0bywW5lrj41s4mhMI/tUDXPv0r02Lt4GmK4p84FxvV+sSmO/VHbX7d/8P40S36Na3/5Tr9+tZcYD0bHzbzQ6fxXr9d/TjEyk+oVaMfHSs0SQY09pnLf5TX6p0Xg4T2rBY++tWj9386PnEkWz55hpR88l6NB57HQ/4KLdFz9Lyty2EGcfED7ay4Z+kGwnMSyCMkdmUsakXELLklN3zBDmt30sMGKdYY7xhNqRa3K1CXpfoXpCa+v6viI9f3et8azN0LPgiPWxWDLEfva0Nh0zhO4Pu/bas8U0LDtC3++ss64eQdjRX++i+J6OwES/OCGP7CKPmn6Qy4Y9mGmZh8L0P6A6R6Tx/wD1MGCv8ZvR2nRmHBtpmK//ACr/ALQ8/ji7MEqE/wCE1bpn+kmm/wDPo9/8JpZMDhYoFltbJEY7jvvrTMNTfShiH/OlKxkc6e7U1s15UBru1KgGociJe2/CmncGTETaueyvTvx5DiaME0EUWHk6wlXMW/d/GplwkaQ4c4ATOQLahjc6Uwkd4YsWJ9RxCEG49ov76GD6GKJBB6POOC25L21kjIA8a64rrCusK64rrCoWknQecehI7/VP2++uIriK4iuK16vvrgPfV52sliun0eHwpZImzhhfQisoiUD6WtJHK3ogmcgC1zRxUnO4Qd9SzsxuRnuakE6c+t8aEQW5IyeI5Co0khYsqAEhr1a+U/SFq2ck0RzaZON791P0l+j+TDudThy1gfDs8KHR2KkmBh9V/wCzbnpTYXFnMs5BzDlWKdDdWRSD+8Kw0eHYBFLj/Ea9NZ/E1AhvvRrzvzrzqKPO7YQR256G/wB9Akqjd1zQEkkcy9mbWrltn486MoQhFFy8mnw40Au8xOUdgFedYokljaNe01aLENho+SxHLVxjZ78OuaGB6RxEiPOMkciesTyNZIsRp2GIfdav/Dn3r+NH9X4C+6b1+y2H1tTTCOaSeSPU514e/SimHw7SBfWe4v8AnxpXnWJYh1t0/fTpGbBTYKooDXc511quT0ViFHNg6H8KtjejoO/YY2Nz/Dxpnn/R+aY8z5qjfGtlhOhNi/z2xmzA996/Uf0kREPBYsWZLezhVl/SJT7TF/lrP0l+j/8ASZH9oMcfsJr9a/RTF4O3r+ag/wCKhbpMKeyRWX+VfquLgm/6bhqaMLqRpRst4WXajuJt/Os0mRF7W0Fek6ShJ/ut/wCyv1X9F5+kPpnDDL79az4L9H8N0WT65xb3/wAJ+6tnL+lGIQdiZm+JNbbG9O4DGEeriXcH/C16yYT9FcPPb+2wob/Ul69F+jmI+s1yPgKyS/pBguj27BhnJ/x16f8ASrEYz6EeIAX3LSz4fArtV1DOM+v71db1uytOFG9CINbn40HtrzoFj7BUGL2bSlUsF5fW/PZVsXP5uBwUWrPgA0h4ZufvNaRon1mv9ldHYUTD9dSSGSwtuKVf7qiw9hlMklh3GMm1W2Kjw0r0c8g8d6uqj+9fxo7YMlteINXw+d/rbv211o4/e1ekxLN8B8K4p/DV45cn1Tat3Eo31hWWRkJ+g1z7qIbDzR2NryjKKvHPDb6BvXpGVvrPWVlQg7w5933ikDKN1edFcG7cLZ77oqIST7VyCC1ZXGlKgUHMeVRwDi+rUk5GiFWPsNbiAVAGnaMzThG2a3YrlPD4UmD6NieCR801i29lXt7ybColwczIuIgRozplBJ4n2cqTB4qKNo3w+YM633rnn4A153Hh40aSXJGFW3r5VqXoHpiPzvDy7mUcR4UOi4UEACCXKTcgtfQb2uoqBn029gjcc27f7jWE6dgxISPZJuyA3txoOWjdFXLdT3UbkjutQ0t3tXpYTtB1SygH2E1MjCSPd4Ox/wBqDRvY15s0l1w8ahV7L6/h5ejpfm4qI/4hRvfy3Jtalx3nAMyNmRBWyzwIzcM8QsfbQedkJJNtmlhRdjZBqwHM8qYSI4GmVR5M2ObHYw/38rH7LVeHoqBSOeyW/vNW0A8RVsQsEg7Hymt/o/CD6j5P8pr9S6ZxWE7o8Zp8a9F+lMTDsmgV/jxr/wD0+Kt80yI34V/2r+hSy/SjKTVfGdG4vo9vpwyJ9lxWXoT9OZoc3qSTH7N2ohF+kzpE4ylogV3R7a2nSvTEmLfntJ8x/wAGtf8AYn6OzYluTx4T/W2tPFB0Vg8MUsT5xMW0PDq16f8ASFIO1MNhR/mY3q/SGP6Qx3dNiNPhX6v0Rh79p1Pvo/qyAfWqzCAeMlZJZcFb6Uor0v8ARQ+o6g/CrYPp2bC//T4tv50MJH+kU2NEinLHKL6jW+a3ZRtWzWPu40bFBY8rmnEkpzAaC1teyrODm+aGu38q2MqBIrWC7TW9Xy4iIbQnccPwoN53HmyMfSx5D76Pm89wAn7OYNqfGsBi4MO8jwLMqjY3B4XvY1B0zNhQ0wm1hvl4i1teFW2MqMDb0gsPfVo8Zhf3GzGvSzu/cW0+FbuQeFekyMO+tzEGPwev69E31v5UMsImN7bko++htMbBFmNhxY3q8/SH8RtWVMVfh1IqtDtZOfL+df1EKQdSzW+Iq6h3tryZB7aaXDpDIYHtIPWQnlpW0xyNCgGZzbcTxJ41Y4ybEkco4zWHngw7QxsmYK/HWgW9c2pUy6xC+mlecfS09lE5TbTSlwz4HQoGFpMp+ysDjkhEfpjIVzX0GZazyvG8myy7InlfjanV1BQh4wvLIxvb33oHF2lYJstfWF7g+NNhjDupjdpbkUJzff8ACkUxquyvlyi1tCPvozjEttWVQxyrY2/PbV29IwEpAvZQzcLD2mljRbWUC16bDlt1rFlvbw+ypFuvVCrm3Le338eNbTJkzartDe/M6+7StFIX1sm+o8VOo9Y04QoLkCyOf8p/OlK12XDojMxHM2qTFyvdpDcmhaP48fJHiF60bBh7Ki6Rwzbsi6j5rcx5ZOjcLpsdZNbXPIUdv1zwNK+YrtuY5OOdCPauuJTsNtoKZMRIWgHVZxvigV3e+2tcB76/7tl9thW70OT/AOp/Ktj/AEeIt25LSaDTuFF9j+qiMybUDU91jSZYEIde3gagj2LbVpcsiZequmoqWIwQbMMREQeIvzNSQxYqJckhXeQnt/Ci+IkiihvujLv279afDYOcI8gykvc3XmKXznAYdntreMGtiYHVPm7RgorPAsCH6Mf30UMQJHdUfSLHf2Zj04WvWnk9Kpv85TY0Wwc22HYwsay4jDvHbtFZXbKKLe3hRy1hWGm/be+qR99ERozC/bYVfPFH7C34VjMEduzQSrEgh56m5bsoT7KeffysucXC9tWmiLk8N4/m9XgRU1HZ2cLitRC3WsGW9yffVmhwwuFUG5X21tGw0R1L/teXKgcjgJ9Mlc1teVLpptkuPFRVw8qtnBuCOPPgeVWGLxB3LWK35/fRMeNdd48IyvAd1Aef2NgN5WP2itcRC3jGRW9FA3hcVdoF99F3hiVANSaZBFa19O341tYHy29VbBr+6m3C7RkDKx3h8K3Zt0Cy3breFArmmJIAzE2D/M7qbGYqyYfDgsdLW7V7wO2sR0lFh2jTFMcwfrHW4OXlz5+tUuBeGVpJFykhRl++gcehPm8e5kAT7BWmnZVrcLUQv7bEDX6Iqzi4v21G7gkPe9dHyyRpIJYZV14aZSPtqKGOMKo5AW51L0jFlzRytHYrc+klzE+4rb6tYXzcz2gvisSG4mMEDlpwLe6pJDOSRNPs9dFaPeT/AA5gawW7tGlxKyOxGrcXP2VimZs2281lfesLs2Yj3WFY3Zlkj2WTDBCQAy6XDDjvP8KwwgZ2W0pYMb3OTdHvpYMbM0kWy7Lm4kyfzNSYqQWMkxXQ8Aoy6e0H31iDFLnDAKShD+JIPHnQaPJbmIeOz46qeNE7tgLXF93dN+9fiKXO97njmDdvMViZYJdGsr8t0mxtXA1wrhXCtuuOeU4reMdrBCOzt/l5O6iOjkDvNGL3HMX/AAqTE9IM0hOig8qnUr+wIZaw8S6bS1iDw76KjhGulGR+AF7Vfcpv6LlWN818ko0v4igcbhHQE2DDVf4hpW0iUDvtUQYm51Td6xNRiPDlZV620kXX3cKhxrGJdi4a19W1rPtmzcdBajJxdjcseJrXySbKHaOp3UCceHrcO2vRjIm0Iv5q/V1t9g99KZFmDWjJyxMPW3xr2CnyQNxOUNxtY/HQH20mdbQqWzXtr2W524fGtTX7Qe+v2y++tZF/iFZJUWQdl1o7PBNEfozAUvm4Kow1u2Y3A7asG3Q1YSVSGdJkLW4AX8vS0R9dRJ8f51IvdW2RTZ9T9atNePtq+JxaR3+d/KrwOGHaoNAz5hmfKCR6xrK+jcKif5zw/cK0ew/P576vJP39alTA+kJ0LngtSYfEQi6LmD8L0okgZi97WehKFKZieXZWbY57MoPbYmr4Ms4Lgm3zdf5UjkEq67QGo45IC0Uy5Tz8PupFVQuTeB5kfOH4UdocwO9x0b8HplMqru5XJIBt8yx9bvrFCGVykeGfJrp1TxqKLH4jaSSTSWJ7lv8AnxrNJIub31eM3y0FQG9687k3ltmo4ibrP2Umzvwve1RhiNE7KTFElvNp2OnJSpH22rCB5kSSdBkUmxbS5sK82RxOMuxxSKxGUo5yPy7CNKzPLCu1Upctq45+NLstn6fPGhB4m1mt36a+FYVnl/YsNndhvMVsPtqcJskhSXI+bhnAvbWlSNgFjkz6HmHufiKSdsQuUsmVgwsbG9qK54mkL7TWS5vcfeBUBwyI77UR3cfRNzRw/SGzWWZtxybDXv5V6XMNA/pV0+iA49lDObHgGf7nHe1JsUa9wbkAi1u1fEVicLHLhZ2KhlCEg6WPOis0TxnsYWrjUeB6Pi2s8psq3AvS4GXoiaG/GRhuAfW4UmEkmiKIWscm+RfTW+nktUaquiZrv3cftNLh8QCzM2RW5EViRIulsoHbWEigjG7cX9hrJblzrKOfKus3xp3sVym5OzvTQ+eYfMeKtu39hqaePARJJlJWSE2APgNKhztIyQyABc9wv5satcVpMg/erexbDwW/31rjcT7IjWsuOb/0jSnZ44680NO0jAKupJ5VtpJLLbN2aVljYg3tvaVmJFOOwXpopUgDWB35bfdWbY4G3bmet6HBe6SrMMH7Ec/fX/hv/Zb/AOdFRHHcdiN+NCeMHJFIFbdtbMOHwptGDjVrDlSm5zK4a4PwoRYmOTC36rOLqfbQkJHbU9uE2F/+NSp80Cni1N6tc+Fq83hi1G8SeXdSRLIjIvBTHQxk0SxyRzpccuPH41rbtHcOWhrDv3Rn40PR30volzSB0tlbeBNyOPZWzQZIuI4nxoRR7w9bdqGyyLmkC6GmS2Y7S+8baEXqRFjBk0ICvYnXtqSN3Zc+jMON+1h3dtNC+EuAcmZtF+NBAyC3IDQV6Mre+bL2nt7qOxXaMdQDYX7S30qOHPQGRRxd3Xf9ut6x3R0cKMjgrtHYjdIINhXRUJO9LtXA72uo/wAooxNHZuN9E5nv7qaE5lz8y4++pI9pJPZt0o6gcueg+NLAwKox4XBv7q83xBAkQXstzfuow4iCaFG45d/8KX+jMVMkWS1hdaM8+NlWEjgXJzeyosQCDiEhwBwnziCwNx48D4U6YvdcRyLEAOsNu2e/eG+BrCWlaPY4DU5eLGU5hr9UV0kIo5HTPh8yoC2VJGvNlHeBr7awJaBNiZ4Z5Vzb8dkK2t3aVj8H5zEqzzvMjWNxmvQkJhljTDiJSw3r3Y34c82uopcTiCqIuuUWZm4ABrjkL8PnGjBt1ijIQHZ3vovu62vb31hFmUK/nPI6dU1Hh43yljlFKI2MjAa5DlJY8LoayxH2Icje1TpxNNPPNHh0Gt2zRN26W4+rWToaDMRwlxCglT3fzp8bjpmmmkN2Zq4CritlhOl5gnY9n/zXoDFLhsUOeZMpPu/CjhlibDYoDNs2a4YdxoMRctoKWQRPquUne4ceYoaBkUgUeLm2p7axfSiXDoNnGey/H7vfWebLntlNPfdqwZ9O6p8bDj8REghiJjU6akjt+jWzxTbYlM4zk35dtf0lg8NG2IiCaZesOryoKujixuDesIvQG3ZsZhoJCqam7Bvd1TW0xnS0MUh9RpXYj3C1A4vp+bvEafeT91ekmx795lA+6skzafTxVvvrKxwPtxf/AOVZ/wBphraFTcE304U0sKnZgaa6eH+9ANhDf5oYfcaCYSfLEh3UtXpI8jXKkXJ+2vOOkow2IGg6+q+yo+luh8TLiMHiPVsGeJuynV4DdOtu2+ytY1Piz/jQjjSJdxn1UG9lLfdTZVK3Vc3KuloX5bGUex7f6qJBNzS7a2Qa2POnw+IwySxBeF1/IpYGe+z3QSb7vKsAf+bCw+B/Cp57aolz36/zqYYuL0MILGxIP51psXwVidzsFbbkAFpZwpCHga83aO8Lrvvcdt6lXpSTKL5Y+WvIWrDN/dp/manWRzYWt4WB/GlklVzGgv7qDQRjYRHVxrxpZI23srXIXkATUUjgsrKG6x4k24HvHbWzyZhcKbcOFWiw+VWNWynQdXnbllPPwo5RcDs4e6tH1BqNr6NU2Oj2pZF9JsnsWTt77U+Px8RKygEJFJlPVFuI8fdTy44kZo9FbetxsfiKXpDFtkTotUXZjQ5+Qq02EQ5dQ3Aj21N+wkWKd0V85G1QdW/s7KBxCKvC+zBNT4zCYVpdlGzZtnoLDmTUjyNfM17+WNJG9S4rogbKIhcHCrOyaxgm3W7NKi6QxEcDurw7IqpGXaKl+f06jn2AQDM8iADqrss3H67fCs4wke2ccMmVnOUG3xPstVsLBLEA6KbrZtS3aPmhT+9WpVSSP2drLlNm4jXNxFTxmR1Euy2bh8pS1s3hfXhS+cdImYSPlfd1FwdO4XKUr+cyzBVIzE5S3hauj40NxncjW+lh+NPipgPRAm7A2H51oSMOGoz763PYw14U2MlGckZYEJEiseC68RzNbbGYhpDyudF8By+VeosbhZCksTZlIpJBeNTEHuTmbXlX6tiCu7lykKoPuFPAbXjYqa7TXmstsuTebsPOiZOqTYG4INENLkHBjX/eif8AuilwuKLZMThmGn0GDD7a85weJkzwbhCy6eBBW9Nh7ZgQRfNw+FYfD4Lo5VxbzWzKts1+0+6sLhcMwbGJCqGUIDZR4+NXOKmHftSPsr02IdvrSE1mKp7avGV91Wzj3UI8pZ1tYW7/AMKV58wLKTGO034H227DvV6OXKG3hIpFj7bHLw7eyg0KtGzb65ezmO/8a2+NzRi26rAg39tLt9YrE6iwou0vHiBpVnGZew8qzJEkLHUOotr3ipYNiduu4bDXg1MmuVDl193trGxSJpLgZDfwIb7qimRCu0HM9mlMOZGlKZtiPrtlvUtwCFbKADpp/OuiMQLaSbLTvv8AjWMw0kbZCHiDX55tKKLIbuoLC+grSlieMhnsw8KVCoNuBvwpcINWYZbdtBWYjYstx3isPJ/d/fSnFYhYVkhQ3PPrfyopiZLCS9snEfNB/POopoIrNItmDHmL3+FQnLsXbQ7LW99LVIsEbZEAlRm4kaG3w+FPCIMyg7rMetpp8PsrfwcMB5ANmvTgZdH4g7ufv+aQOdZ42zre2YNxNTxw8Lr/AJRSNz40IJNVdhp3WrGZQkwwOYvm7AbdldGR4jDK8ueNJGJ+jw94FPJEqRh2zOR6xrD9Grj5I4x6SZV9bsH21lgdViTfccmPhXm3SEOFfDy7mfYgWB7bVjOicGT+sRS2ub2Zh8BTK6lWU2I76yIK6ytblXm8iB4p7qw7vxrC4bDLHIseHWO8q3vcnLp4j40sMGChMW4brEbEZV4Bbn1k91NtcFs8WHVlOQcLrc3sdfjoKc7NiDCAGXKQX5X0B7de+o/OnK71n2drdXj7x8aPmjHakWFzxPL76eZukLwpncINCNcw/htUiiQltbfWstr/AMNecFSuHVc+a+mW3DxvXRkCyLcRsb8iN2/2UqSg9V1zK1sy3Bt+e2mXg50bLuPc8dOB0oYRDuYVch0tvc/uHs+Vaspq1S5/7IiMHu4/f5JZr2VnJvUUyJtWjYNZ+BpYtosIKglUX8ayy46dl7NobVdzc9/kwkn0snv/ANqbZjr8/nLW9pUvSEw9GNEv8fw9tCZxdsU9/BeVZFGnk1NHSl2Y1oZ9Tm40m1zbnYeNF81vACt2/bobXpYV6iLb286jc7yp6vwoujtHb5w4e2t1w4PHerNOno76Jn4mpOk4mUSwZVyq2hHb+eyoXYHJK7mx7dCdezWjs8M3m0yFc1uo1vvF6kjMNlhBLMCLc9KGRiuvEUcTLhBNkI07aGG6UhOWZy29yJroeaFFXJjBe3iKbGSLdYnViO3WpZ3sDIb2HKtBQOIhkR/n3zVlTEL7jTNiMG0ufTaB7Mvs4V5yJEw2Df8AtpCPgOdRkYwII0a+RcxNqi89wDOYUCrdvz3UmNw/o1QrtFjHZ/vT3VfRTCUM+tw3Gp4Fa5X0kZRfVPH42rDuYN054HzntH+9Q9KQKjxs5JjvyBNuPClzoAhNyc2o94oyNIerpw0H300YtlU6W4VMw+jb+EUF59lRx30VL/n3U6Jh2sYxIsgNh3/HXjWBxGJkVljxIDHvzU0jSMXcZLbTdXXjbt1qXHYK6Ft5yx08da9ITmks/wBLX76jkcKVU7ysc1BS13PKnxc6bIWzyPFH7j8RTRxREMN5SwtcUdvINeVMy9VFy+01hHa2ZU3XsMy9tqw06TzSR4eIvMhcnP6RlbxIFRxRLiNkMQpJu6izXBHfyNLHisII5NmI2uSSxtre4rAvHmULh8IZBl4kMQ3260EOHbzpDGOCXJBGtx99MNo99iV1ZjrsgO3tvT6nPdCA+q2vvLcnx7/sqBMbh8a280jGAqpB3ctye7NfvrCxSk5Sra8110NWcE7PThcGx7PG1TYuSxWFD9JCftW7WFPK7XZmJJ7TRP8AwJ8Ab5ZF2g8RU07mwSNj8KNjp2UHPI3qKUfIiJYKEcNc0EleTcNwV41P0fhyWKy7NL+t2Vheh4W0bdNvmjrH26+2ikTbnA2q9F0w0pQa5sula1ZdazCI+6t/j41kMmR5Aclxzr/vJGGt7RX8KbaY2Z9AtwigX01FaowW1rtz76IUX5VHhi9vnr23rPDuZTcFeNbEyJtB6pFvtoSRNlI+NQZ5o9us2ojXgp5/CpEgxEqYMBQRG2UsbaC45cTWK6KknkkCscoY8d6x1p8XFOJFQ7Ii3UZdLH3Vs5LHXgBxrG4aNShwU+QaKQ2rWPD6NbZb58FKJF+qpF6ljHFrAdlZezj5eFQpNGhE94xmF7Ny+I+NekktqDlTix7/AIU2IwcSyXdSF6qsM2p91zerYnFqOrpGfWEe8LcON6bARylXlGZZDqQ54fhWHw2IxOaSWBhny30W3I+NbGCKSYGC2awvx4ChsME3XViWYCx7beF6j33VYWMNlOnbSHCs7W3Tvdg0+FSdHRyekiWxObhUmG86aLZrtBYXvrai39KSi/YlRYjzorqdCt+Bt21hoW3mRSxk4XB5fCp4NuAZphGq59SNCdKwSxscsk6BwByvrTHBvmIOV7SA28ddKi6PSdGzt6Yi2vb7NLUMZPh8zWG4hvbnev1OBnTqtbkO7voTh2zZBr49lTEich7RkRaN+dBUkQju4iAh2nFd3+YrM18/A0FaUDnw1NYVlDAFdL8eNYbo/AbqvDLNLay81A3iD2ngL1HhHmkXDRiFZJM11DNnNjfXXdW9Yvzd8V53A0oULCixmz2HEE8KE2M2yzON6OSQNl92lSYfApi45Z2K7WRidiCbXvexFvd9iToWCTXdAD1WIj0I+aMp95pZMdg8TJikN0DZSDqfpeGuhrUj31hBrrH99LhMLGHvAhF/nXrC4aeApNinD2zA7qjh3akcezyGrVwPurgfdXA+75EOMiYho2vQ82nfZ4pFcANoU46j3eTLfdFLBI1hmyE9gp8PMtnjbK3j5cww4ky62trXpeiukAO0wm1SYyXDSBA20F104W+2vOsOcIEybNdoWJUezv7+dbFsXhbj1xhmzf56MX9KSx39aCGNG/isTTo+Nxs4k623nzU5i6Pz5Rou0Nz4XNWi/RjAr/1cYD/oNbvR/QcX8bf6RRxOJ/o50QjchidfiWpbw4cafMJ++rCZR4IKPp5D7AKlXChpjCt33tAo762+NgO1PVHza3xquhrMprFY7DxNOMMm1cdg/P2Vh3gbQoqleWYaVLFjI5Fmw8TYcZdPSBm11420qPBST7Uxxi72tc/m1SpG92k2mn7uasZicFOY2eS7DkwOtiOdFIsPhoZCLbVAbjwudKeGR7ecp/iBuPvrK65kYuGBHEHlSRtdlFzYfVI++nXKVE95EU8QuYgfZ8iHGHBZ8TDkyL6oKjrd92117e7WLpmCNpGxEabubTKQfub4V5vCul8ummTQa27L0BLPvG5yg5ePd+NJGLixVAAvfaujX7dqn+H+VRO6rcDQ310poosuZeIHKsciqpWHGSK4ZrWPChHhjBs5NdG19gqXF/0XPPHt2zWBsRek3NmJFZAOHK/3eTJ8yRhWG4+kS2i35/zrD4DBkTzbdbRygJlUKbjeOt9Kdh0ZErIu8VVSR3aVnxBZUIzkLoFX8inYRZMqgAHt7fto2Z7Higbc8aQrMt4xbKL6XpijLkJIWyk8CRUkfoTlKt6QMBxofs2GxVbLw4Dh7qlwaOdZzqOYOo+FFkQyEetyqGDE7QMg7K87baB4VMWcpwBtp8BTy/0g5O48zMti6hCpB3dRwax7/Gp3PTRLPhxGuWJ1s44P48KbD4H9JGO1MhjjaKVtLNzPZm/wiott0tqOuuxY7TS1Tqv6RCFn0YKjadp8baXoTT/pntI1KtkPBuNx9lYTFTdNQIjAZVPUcjRv9VQwuVlglw6uLHvNmU1tzittEuHyb/WzZ83w0qNo9oYZIQ2vVzc7ezL76zamuAFak/I4mt7XyJC2kKeknJNrRjjUk4TIh0RL3yryHkI51LH261gul1H9bgAc/wB4mh+7ynwrI3U4E15vhIgFvfQcTVwDVpdFYUQGkfU9RS32Vvbv1rit0KfqlfvNdYr9b+V61xL+xqkSGYvKRuiXq37zf7qNpuhY1PajOfjQjn6fwcYYXzRwIoFCDC9NnExyjeawt7MtSYS8kkmJ1kYUZJHWKFeZG9SSYvGPHMy3WwF/dWzjxGN84y9ZraH6vZUiRPtJW1lkYWv7OysJ0lFho5Oj8RPsjGygiNyOGvedKToZEyQFA7bo03cx5eFdbnakiLZfTW/w1iUHZH/9tfJE3R2FwccwRc8jJnZD4nW96vEXY3KrIU59tZcQmxxA61juP/8AE0U2hfZxItz7/v8Ak4ToiPBBplbIJGfSxbTT20DDjXiVtw7Lc017KlkzXkTfue+/4VJPMigAXB7ba6V0dL2YsL71aoxhJ4Yjn1MrELUuIcx4jEPpeM3X2URKI43kfqi1zQZkZWT+6N6xMj4txE7t6PZ66nVb9lYbBQYiIGKZY2te9z7+3t8mJT5uIP2CsLHIqHPHL1u7LWLmU4eKVVJR0CB+ft7KwLqrFvXz9Y8By41ugJHKMuUDWmd2ErlmDDtN6ziMqOdAhkseRSljz5zmY7gB4tfn41Jh3Lgst7bJa2iABc2UD2Ci00gTNrZdTVoossafONftI2HDTlQIBKrvW7WNGPLnVxZzyI7PCnwuY3RiPG1QwnKbB962vVNbQjWsZhsLFnfay6fvVlxOFdLe0e8V0J9WQ/4zXRmJGNji2WBhQg31PH76BxMzFH0jEcgvfmbnlw99N0Ph54HSNNoDIbSZgb6cqKniPIfk37Kmxm3kwT7rAXDIO3Tj286DQFmixYDGa3q8geyt4W8jHtpDfQ6Vi8MBmlwEgxCduQ8fvPlyk20pYjiGGUdXZ3++t3FKPHDH/wCdXTF4Xhfehf8A+VJt3jkTW+yjK3PZcmlgjh2kuW5jHBBX6v0dGP8A1P5VpHh09/41YdIRpfsymoZpulcVknfZrsU+OnAeNqZF6Y6R6oZGmYxrLf1U11burLNjJ3+P31BgYc2edwgvp7aiwOHFosOgjzHsAp5mmEMQ68p4nwqODBK2zW7FmFsx/N6SfY7RnXVw17d2nCucTCgxHDR+7WsVB6x1Hcw4fGsdhekZ1ZMJ1e2+a16fzUXfKcu7xpMTPfOjgtca6U+Ituzxxuv8IH3eTNG7Ke0GsOsuuX0End2H7KAVd9zYA+saxDzz7OMZQCuufdHDurPgZhOPmto1M+MSSGNOQXeattg5XWQAnYym7N4WFFSCCKwl9fTKfjSP/fgf4TWKinkt1TwPZ/vTenuzr4WFRQ4sR/q065sgtZlNuNWxU7uvZbQa/nlSnoXGhyn9m4yE+3h9lR47pibYCJs4j4sfHsobNHO2CyKM2guKeaDFbGS+qtbLfxFWxkcUjxvc5lzEVmGorpGIHqy/iPurDYqf+xz29tvwqSMYRZNpfNd+N/CgYIjhRbMM5ureF/51u4qHNpbeP/xouwGzvo4OlBl4iljOJIH1RRkWJSM5GrWrEQNuXkKjM+6gF/jwqbA4o2kjkPGrqqeNWnlYRj1V0FaAKPzzqSCz7LuX4fZVogG7s33Uzww2BRXd/USwtx9lYSHDy7Xa5g19Lbh4e7ydImFSSJ5uHZmrPh8UiOumpOorYHCxSGIesi2X948KMJwZD8SqR307dKLymOJiSu8c1/3e3xoy4mSHacnsd4dyipj0f0aqtEVLzZj+PkPyhiXOYwHZ7IEC73vmPdbT2UySYJZoTbqsWXxP5tTtioFZVF7GjlFrnQVloZeNebYtgQL4efwPP7DRLdHksO2VrUT/AETD8aj6QwyvlmjLKH0IynWpb9bMaBB8aV8UzataMKLk9v576l6aljdI2vsM2hamxOKa8+LbO3cOyspc2HdWuagwVtO+sNMzPFNhbBXTXMoNwGFR43DhxJAmWG56nf3nWr7vurFyMS00WHOxjUcS2hPsB+NLFiSwkVd9TxowmRlhi4W7aihjW2799RKshgxCDLfk2tCPEyyRtyz7yGjHhVtcZnG0sOy4q82xvJpxJA+yukJUhcQzBsjWOzvcGlhzWjo4roZMwG6+c2zMOYrBYnG4GQS4ctE/Pd5HTwqxPkxWE9e4k/dtUUm0WBka7S25W/PvpBgF2ao2zztoD4DjSR40odoDkZDcG1cZFvzFF8LGdsRbOxvbwosTcnUmsNftJ+BoG3DED7DU8csYYnJb+Fr/AHUcTiYmfL1V5X7uypCEyoxL5e+s18g7DVoFKgd/E0sZa+Y3vWF/+nWpAx76hnxYLyBbbMG1/rV6H0KjqxImWvOUky+cKHfS9yb/AImkfMuWM7y2swNDFSJnlfqKdQO/xovM1l7TRbzg/u0UkkkNxrfmK3X3G1XtrzzERuUB3Rawa3bV8NhwGbhz17TUuJzPI/WYng57aTFTvlke2YD76WM4o5TwuK38eMtiTuUs0gZ1OhDNw0rZwIiDsUWrKkOcnThelila7G997Nx76w08OS43tHPEi3C/k6Q85com2xGoW/M08uAxarrnO2jJvflXoMVgFHrBCy/6ajgijXOP2hEyG55c+ylkx+CxIVEu4VOPdccKTDwxnBljluFPxqXo/CIqRspew7V117Tp5D8jWuFTu0UbbUqtmW9xzrEy4VFRIkL6OT7PjVpsTM/cXNIxA1Ogr9Z6XSJj6gTX40mJxHSkmziYMcwCjjS9IYWVJI5Blkym+opJm6yHZv3250w7+2sNgo7hYsIig29bS/21njVFK7pOY2bTjWlj4UmJxc0UeFj0y5tVSocM0z4JI0Gz20ZCi3byolOlMAw4Lldm+xa/rGb/AKeHmb/RWiYj2QW/zEVvbcfW2a/Yxr0hH/8AKt//AM61fC/vM7/Zav2uFH1cMx/zMa2zdIGED11hhj+OWmfB4pim1ZFYm+cA2vQji9/bUbN1o+2tjezFi8R+6jCxEq8cr0Hw/SMkNj1JdV94pfSGVXXXLqtLM0mIhkEmcSKb+wjsqN0d2eaDesAAl7W599YZZ8gtAhvbW9qtt2TsYVHiIorecqWcgbpbt8fJh3tZHOzfN2GpMNNG6x/PHvp/XMnzgeFLMMPIcLBHlz5dAb6+RsUmHlaFTZpAhyj21vMQaHPLGxFvCmP96DRF+Mf+tf51hhf0as59ulKh4XoGZrWGgFdW1jfxrReqeHZWBxF+thT770kTAWv/ADrC5Rd3vn8b1t3OnCMdvfUE7yBM60YYIiS2hJ10rTj1deVFmf3mtxA3eaLScaiw+U7zgWApcJi8CztfNctkcd1+yv1PD7IHiNoWrU7zvalaaFWbipN/9qWV+WtKZQcraaUMsXo1HA1bYhQaG0iTea1ytYkIu6GBB5eFRJ5rbeADA16BlBzLfML6c6xioASZpuPgaKebR9WMX0qZVw0YRAABes0cKAlk1BqZ58M3WABFYjD4MAKNzeLafGmjmjwrLlIN49auNPljEQ9HYo63DrExVhUfR7aTTHazDmB6oNdwrzwpuDdX28/IA8jHxNarRhVVMRObL31mMU4J5ZR+NTbLoTCK8t12gGZl776WNC8+VQOPD7/jT4eJEdnFg+xBy6cb0EXKQp4vZ191Bccj+cBdSvVY0J4Jbo/DStXaiRfX6VaW8ly1qg8xxuRHzBsh5i341nxGIkkbtdr0F/5UjfjXHgaBpTlIN9LVs8SfSJoTQlABWhiMJOsY9Zb0MNicPGwZbpIp4j7qeJLEyYCR08VAt9tYcZQLjYuHYBgRwsOelNd9RqKbDYwX5is+NnDa32cGre+2lNkwjF2UlXkKye63ClzR7WDgZDfTv0obPHySjrBOqaeJZkNjrYZQNefsrP0lCt4TcZBbMPpWoYaKWJYwLKq3t386S+AjtF1BsxrSydH9GYaPUBiY7b2m7ccKPR63RJGHUOoPtqLG9G4hpY8jhjIlgpy6a+Nq836Q6TWCXda6x3ANuNqSeJ58RPDu3i4PxINiO74VLE8eQqxG8Na0Op50Wz35jvFdEsOaSD/FUZYfWolWJuN32imXDgWhALu78BUMKOJzFmvk9bXl20fMcKofseZA3uvUiXw8bILsDMGI/hvQcYqJ76bgZiPhTDEdLqiqOOy1v2HWhI+JxGfNbkAaCYbzvJiE0Zn/AAqWTG4KSeyiONh1mCi1DLNNC7WsjgE99KuDmhkCyMwzbpY0M2DZgR6ln07dKYJh97wtSrMmWzcLVspZY1t6t+NagX+ymxOORmj2gXdHA0yYbECFfmlSKwjYXG5iZBovDjTWrE5mKjatqO9K3cdJbMnb2VPmxchuL1hsuPcE3J9386kMGNWT0nOsRm621a/vpm7KM00Zdtrly5rX4VfEdGT2GhKzk/hX7HEp9Zm+6gzPMoPP0n4VpjMSPDP/APGtPPpPz7KvguhWc9stv50krYZY8pKoqtx1p5JGzMxuTRxIhV1XUI39r3dvupo/NXijY74kW5ivpm14jXrcvdQyFruSch9QXOnwHvoMEJ0zaDhVnUjxFC/CuFLGuXPxyJoPCiciG49Y8Pz+TQusgRvXv+H869NztqFIP8qCxrJbLburMxXusT20elvNomgUgXYbxHzreNbuzTwX8a/rNvC1b+Nk/iNayu1R5w19tIdfBfJi2j6wkcjxyClDFpNqM1oh1R30sLRIbeymw8+GjbaWaPMgOU/m1KzdHYYZj8xb0UdAuHxAuq9hH5FbXByd9qw8zSpGd4MWvp4Ui5s+yiMYPaMv8qhxOE6BZTC4yy318TSCWISyMl2CA7tMVwY43BuB7r1IuMjkie2kYIv4k9lHzrFWikOYFOuewd1JikxDxrfdXN1+2nfA9HIC26zhBWzxWBcvlJtImUG3dRePD5I+suuU0PP4MKWNighg3y/aKkmw5hiZhYmfs8QPupcsMBCaehk4jn7KjwfSXm0Gzsy6hj7hUkT4jKIQGTnfwtxrYy9G4lJFFmtEShtYcLaVJjYsTFLHGMjLnVNOH4UIOkOilx8WzVwM4MiqdBY6Hly7aV0lwzC+UxzOxKd+ntrKuOZoOuuTj3j3W5VgujlSXE4aPOFO11434gdtYlP6Hw9z+ykMrP7963ZUbLHhTPbVgiix56inaRZI2H7QRuPvo4dvTCNW0bTK3ZQkjxmwiz6liDp3VtZU3r5czJqRWxwxEUWbXKDcDvvT7OKUfT1Jb7jUYKYhtnYWVLfCpI0jZZIhdrra3j2VbEBH09Rr6d/ZWza6NNvbTa8W7CKE0m5Jc5QdDassWJYQBLa9YVs4JlJPabZQNLU21xOGdLXKnN+FDBxqHd9L9tKodLqAN5bfGnwrvuTKMzA9Vgb6UbYOUra+bLoRUOMngKs+LUIT2XH30807hEW1yamyAE7YaH6lSk4JL7vCiyYFLMndUW06O9S+nsrWKSImSpx/eN9tM3Nnt7h/Ogx5uxoneAGVdfz2U42YN+dJL4NVyO6t/rGs7WA7azHqroopkiFkiQyyvyVRWF/R3BYONDF15exBz8fzzpuk2w4ST+zSNjHnbwWmnWCORydoUtYH2VYLiOY6ttOzjT7aFyrEiNn/AD3Vm5+RkkhKhRci/wB9H9WnjVDvZVNvcalKYSaQIt3a2gHbwtWZXPZ84fGgzEN3Wv8AZpWFxJwqSK0lwoBOoOoNSL0riZJCwyskfVHdTxIpZVOh7RypEMIALAE1nSG4HHO9W81w/GxvMdD2fbWGjw8aIpznd9n4eSRTznP+UV5rPnGUkbr8eWtPiMZHNDEEvHZDZtNLdvKoYi+zPVDdh5fGnfbb8sptsxbKe73fGoJsSWzRPZr9/OhkbjUWZgIDGVKAaUzNqAL+yoXwckksOL3ozf8AwmoWkw2aGTlDvkeNqvi8CkCrZ1kWwa17W/3oYqSeQ7mRl4m/HjUpSf0Q4M3GjDh4IsQHvm9FcmovNMQIF9WOQ9W9EYxmnZSCcugvTbUSkFOqGt7Bao081Zc2sZZN49u8fjSbLGsN7MwQXGniaJlneYnqjqBR7KbF4xnjiyhkkkUsb9i/zqBsP0jLAUKqyerIO63jUmJMszRulmb1eH4isb0Ps5X2gOn57jUD4FdjjYAY9nfdKZr2ow46MQYlV9YadQfiaZhE5yElXTXmALj2UyrljFmC7M9nGiYcRtYW47PR/dUuFfDyREi6s5Nwb39162OJlTDzQaSId2/fTea4rZrI37XsGW5pt5nIAOcjL7bdtRZNplOuZuPuoYRozHETvOicK2WGgl2CjMqov2mnyrwNiew02FnxMZU8rm1QyRPJZ7rJIx43ta1OQ+qaC+tQ4yd7SEBkUDl39tMzQmzbiSd1NioJM8g03q85fFGJIzaw1JNLHPkn0tG9tfz+NJ/ZFevl5ikvGxNrNIHPH7KUQSy5Yjw0y/yNYFIgwzTIX2h0tf7aIIp2DAeli1P1FrCviddgzMAg5kWvbuqZYVADOLOx3dFHOjhcXMzZozGhDkhWPMVFt5njkXR7xgjMNDUsi+s5NQJlNySxPbQJJzHNYe2kz31e9ZQbUsaPx3bacaXKmvjV5Xy9wrYRnSkw8CF3c5VUcSaboFOisRHj8ayiSVl0k7gez+decSqpeIZpJed+6vPpEIgByRgcE/nQxvSLTR3W53gQOzSo2eZo1d7ZtgSAvztKTfBLC5GS2XWiK4issAYNDyYcvb7qhZhNLmFrO4s1BXtkO4wJvl5cvxoZ8KQsnAqbFh2hR99SySAzSZbJE75jfxtUpxUgwkObS/HvtQRJ4sNEeLSdeThcgVBjo2w8mUbKRoW91x28a0oytjsGEcI9mksdCun20yt0nHcxpHopa9vA99RNhZmkiCbubiNf5eSbulP2CpQAtgxJ7abDvlRYYsoO0feNjy9hpsTGeq21UfGhPKGY5swFzbxtQGIw+YtKcysvqm/+9TYQxyEo2617aUi7ZmsNQftrxFqw2AXpCSN8TNmCN1FPfcd1DCRYcbZo86asbj6PZwp/PoFyBcyCSQak9tqIkVcDEvXZFzCTw7KlBx5xSLJmDsvV+jahJ0RLD6Q+lcDLYW52415pg4smGfRpcvxNZomxs2Ha+aU93zdKWVQWRRe0kt17uVbcGMlFIyxrZRejH0Phk2n0bJb21H0l0rPCHym0YN8jfZSxuGmZzlydt+QoT9H4VY8wF/SZjbn+RTpJtstspeSyW8Bxoxtil2sKlTl5g/Gs+H6QZZIzzXkR/vUcU2CjxEjXBMV90Wtbtow4LCsuQXYSdUe01ImNj2TMhGZW0IzX4jxqSXC4oYhA8jIjHkALDwqT+lcNcIFU2HWY9nd7akfo4RyYdyBIoNyCAOR4+yvOsX0duQ3BCNm3dePZxqBsodHbeFzWHURbr8mUUxjcxoy8jYcKvisTGofVgJCSaaHCvsXty4XqPFyYgJcZ8nHwpY4Cdpa1s3OpQciFBvsvM+NZ0LNIUOXK1rU+1lCQq9vpU5TDBi7EZpOsRRhwWHyZusp3QneaBxHSB26HctwFLm6SuUW3V0Pxp1xZ2r5rA+qB4VKMBHkdd7OGOnsrCYRIGujrxblfySO3C8JP8K0Th8unMCvOMTjxb1EtfKPfpTJLZpM3W7uyp2xeDlUMTkaGbLft04Uwg6YlwTDULOm0De0WpF6NxGGxeUWARyD/AIgKiw3SmEeJ4yxt87W+nvohcFlA6oq5WupmHG16zuthxvTMCSq8fGiTT43HcBux/jW0jxp2S677Zl8NfZRhw9osPAP3Wf8APupo8ekkLSaNfqsO48KEBi2gYlm2UmW33fCr5Hk2et1lYZfs7asWOVer6TP8bmi55USWNzXnOGjly4g2OR7ZT2a8q2JE8sWu0Cx6L7abETythYOGZwLkDsFSYforPDGBvTMd40rxZsViTmIvqL0FyyYjLrcjc63Ic6xGKExeb9nCr1/R0EWV4/6wVPWf+VFUUkgXoWOYML11TWHi9YRAn2733+TERf3l/h/KnsAL2NvZ/KtuXwkjSLuocVkK8dTUUgiJMkKNry0oQyi+yUMpvz4GpIFu1utbhX9K4cj0S2b51xbT7TUjQTPNGhQEAakNpf2HWmVv7NivuqJjhXjzuN7KNL+2mwUkuz6QwwIEn55GmjMJlmRfTZ+KmpMXNJmUNZQG09tLD0fI8Ktd5Y4xmv7zu0sM2FaFD1Rfd+FGTHtIQy3y8BlqPEohtawW/BfCgJMRsVuMpSnhwmNmzceuLH2W++lEU5zRDIyA9Z+ZrJ0haXDQKXYBuHd3/wAq2/R3R6xSRC4cDhpSyzzrh7rZYwMxt39lNhMQrSHL6IoeNRyyRuMM262cWseQrJJg9mZbDVbe731AJsPLFn03uZotFiIGvwAY5vZcU0og2ovvu1iU0+HGpukYsSY41beIB3tLH7qjhx2BknhZ0vdAXNtL5RW06Pk2eSaR8pGl7aaHUU0mNLYpIlz67+diff2UkePwxjxATziSRdQnd2+6o8T0Zj1eWb0iIz/Eet8KEuNwxhEJv6XgT7K2smKSJi1xzt30EeBZSozXOpPtpcHgsrFrAi/DvpNlBGkh4tYMzUy4xcTBADoMtge81rjWMIbqt/KhHhVJVhdLW/JoYPYzvPD6nC3f3UY8dG0bPqRpY+0UrwS5ZAwuM91YUskMIJJ562rZyRBk1utNLBmIkfXN6vdUU8EVskq3a3EZqeOCfYyMpyyZc2X2VkVc5ZYtPnVfHYCGOCLUbSZbD2Xo45emIMPGg9LHAhbh2dmlS4gxzTGK+hAUG3hr8a2XR3RUEeQ23t7nUGJGCw6PHMC7LCF04fZalj2pzqRbWx01rGo75ky50I9Ug/fw9tOoc8epS2QLccKfEHwqPO2ltbV5lBwi65+c/P8ACvGos0Z6o6tERTEZhYi9r0mCxkOwydWWPmfpCn2UsOIzAXCsDfxU0W81RCeaej/lV4uk8WluBkIepY45doFcgPa2bvpMHCLkkD2mkWSDMwUAntNPhphdHGU0cIJ1aQtfcj5eJotjpdtIU4ch7K2+MGyw6+qOMncO3W9Sw4dlgw4QHd6xF+Z51DKMab+b36vhXnC5ZjFhzMCPUPf8KJZcxOpJrQKPLIsRusdox+6Lfd5DBIN3EW17CKIzGOygLp41J5ts9sIzkztYX4c6UsFVsPKYzbUa61KQyZ4pNfA/zJ91OqxCNczWJPHLxpMU+MsP+XbQ3F/ZxpAu29IbBgu7TF9QwElhz7vh8aidsENSNMo7KjxMDlcTGVZSP7SI3trSYuGy4mLrx363cafDQ4OSGWIZc4ayp3G+lXVyxJBJy8R9b7qEPS0irAbM0Wbf/lSYyaC0ZGYZzo3YLc6XzeRIllNteAHs+ykecGeSI575zb3UFwsKQzHqlFA17KZJ8OXkfrzNKyknwBtUmG6OjkO1AzWYt+eNQQR4SSLan9pI1hbv51Jis4xGSzMUNso/CnZtWubm+vKlaBhex49vKk86lUsdUV+HDtq67MOmuW491ecuIQwF0jeTU9lFplEeQkSBrcezXjUmVliJ4ogVb1JiFiaRZcoEi66a15/tVgDxta72JNrVFhFiGIw6aktoSAo5+/jVsfGI8RiTZs+hA7jWLxWDxbIxVYE5hR3fGocKZg6RxmSQZuN/rUcZNBNhnlfLHFEBJf415i2EnxaKCQY0Nx7KxAmumImYjeGUheyn83jM8US9YcFNMmLUhzyPMVFhwiZmsCba3PO/GkhjVVVOPM1Phuj4GxH1RfSosP5lIk2cCJcurVmx/R7xwHmZl/GkxGFxEBQtv798g7alxH9MHzj17oCM1TSYnHYvFSA5tyygDs9tEwdDoGByhi5PLyRW0vHF9tYnNLu7/f6tYhC7WObu9WsTwsAed+VStAjHW98tudYiFotM3M1N0jm1Xqnlepz0hm2UyMlz2dop8KoQmQK8beqQRV2XM5HbQgHMg1dCCU4XrO+pPkyfNNZjwr0Tkd3KrsmvaptV4sdKO6TeHxp8OYsOC4ttEWzDtoyEa8qk6SkF8mi/W50Df41ummfDfto9R3jmKKwosvSFwZTILpGbfE0888uZ5ONYzM18kKm1uW0ShHnvYWox59ZAOPrhfU9ovUkSHMFYgHtrQeXM/FtfIHQ2ZTcGm85IzRcxpmodIQYcFW0V86ab2tr+BFdIPKgkbLHYmxN7anSnw9gY5gCb/RP86cTR7isz3kNhc0IoniDBbnKdLUsDwPs1G8/YL2zVDj43E8sEgzBdLqf51CW6OPEev3eFIL7JrecQNx9bVa/pjDgqkSKMRH7ONJ010exe4zSIvA99CaWKTL1h2nXj3CtpbeAu5mGa3h76thoScaBubMlr+ysM/SloIc2eRw6k+Feax4KGPkXHWA+tTYh/OmaNs0cix2TQ6GtrjkeDDIbsAN5z3d1CTBK20l3VQyc/bSrK7TTEbztoL91SwrJlgz5G1ucvOmGB6P2OUbsiX1/GhLiHkmmBu77QoiHkLVtsWizsWtHtDmAX8ajlwjx4Z3kCs2Wwy+HbXm0bsBbrX41I2FmjV1IBVvWNYTE/0fiDFHmErCM20PD7a2kGFYqOpdwoI7r0BJgpknQZc5jLfypllnSKNFvnvr7hSrOA5b16VOj4WjG02kmza2aukNnhWkbgm0QKD7dKw8OLw2HimDbwZiLW99FJ0YNMq2Zbmw/IqLDz4NcTGbjfCn26g02M6CEWC2eXbRkWS5H20JIHwhjw4JYmX7gL1+t46PP18sQJ+3lRwmJ2+Qiw3+dSRw9FKJsImyhlIGYqQBqRUpkw6ejDZSdSDajDMZW9GbaWo6vdG5tyqRpZBZZDWME7a2trUhWzatrl7qLWqCQc8Oja/WNYrPcKM/P6NYp5ZE9b/LWIeabU8eXKpIzkO6/fU6oq204J40vRmFJO0tw7Kh6Mbr93ZWCVlzuI8gPtvb4151KjbNObVtD6zgVvahqsoy99XRlNbUQOVPdTGKN/R2z6cK3tD31owrMGse6uRqNbtI0hsoqLCCS2UXOg1POv28n8VXBq9HpbBxkw41t/6Mv861FqxSONZoCnxFbQetrQIGorq1wrq11asVrehT3V/VR8avGBAsoPMm9rU6yTTNIxs0RYCJ/fTx4SCXCpLxjdrn/aoExEpyF8pYW0vUCtNtV31191AxftLHL393upmlUKQCuXjutyp2UIDFwXUkkcBWH/AOzZOA4K3ZWyngdIpVEN/wDlt8740Eh0kEBjxKWtmXgxqKHNnwUwyxNfgSL2qCWHEfqzSekHMpztrevTFY4s1okisL95qRsLcibRSz9nKpI4cqQyndllbQkdlYTO646HPvbMEn3U0s6TI+bKkb9vbWXEYtlly6NGAcv41sYzHPj8y2kkHfplvw/GlbFSu8qb2dTbe7u6sRJAHxEWb9qTSRR3lfkCdKVPNVdHY2ELZteV6jgkx8MUyNnyMpflaxPtpopNjC0MouWO7f8APZSvPjIDAo3pYyTb2VscJB5y0S8Stvbeo8HiZQmKfKrEnqGop1xAa+44Uc+VNiMC+ISTKSHbdNxx0rHTYx1aeNb5rcQaz5YxKUQ5rWObS9T55JeuSN/uqabENKQV3swuONYmfEIJFhZsvvsPhS4do33CO/Qa1BBJsi9jbMLHX/asXhQbmUhnB4BbcKEKMRtTkH0waXFyXGHdrsrdp40mJ6P4ggXHPsNLipgo2/t0qfZg5BnOi8d2s6x2OR+feanist9376mgYPoNLaVj5JZTdpJDpryqUbbOM50Y9woHurDH/wAov+dqxDqLXLcF+iKnaUkDfPW7qxZeXgp4a8qePbMd4js5VIDJxW+r1i8S5Dxg7uvKhj060ZzH7h+eypMOozNhkzoe8HX4XpkR8ygXqLxvSxxLZbe+hnjLueS1sFw+TSxbup2brIctZcQfRzLl9vKt2H2Gt/CR/wANX2f+M16CRoj7xW3xGIRtlrHbtpUm6ycx5N6rVJgZxuyDQ/NPI08E0WUxHL7aRiLXzqf/AG2qWL/kysldSuFq3avlJrdStVrqCtxRUOUjibj2V1tDQR5MoXgxbgaR3YMI3DW4g2NDbxboz3HZcWrznEY6IMMuvC550TGDMx7dFppZnKIzZsnAGrecMPA2p9ZMRHKwMiMb5R3Vho4pFGLXOgOu+OPxFR4PESZsNIECuPVk4X7qjwOK0kuwk5G4tb7aQtOgwb7zuqW07U7aRlSKF76bQlz/ACpejI4wJI+oqa5vCoUxeHlg28mzDuNBRxLabI7kguS3s515th4/RqMvVvvd9Ni8N0icOygWhSLNrfiNaxEBFhE+Uu50U+FKuKnGIia+b0eUX7KGTCQBFWy3y6dw7K83j6UyoeClO7W1RLhdpiHy9a1ec9HYRIcRkVybWqTasJEzWaNjm0I/3r0uJdmYMnZ3/dQlkKXaP1npZgVNsr7o/PbW7H6zLvVjISsmWWIdVdOsPxqONx130zLyH5FbZ41zMvL6R/A1PM0bL6vbw/3rEYuUrvvrmXs/3qbGrlzWJurcyf8Aeg0cxKoVUAjsqHHMoLz3lFuFjS9LX0hIkD/d+eypooE1IzW53FTYVznmRboebDsrzac2COMgv2/7U18vMtdu+iIxcZX1C95qbYLITu6jlxrEosPM6nU8axJl1zFyBfuqUgl3JY7q3HAVH9UfZWEP/lrf4jTmCFusLA6n1afIlt1/VrFOz3BDga29WmzOt9pf4CnDTDqler315tI90nYMLjnYChJhnzE/aanxIFn2REfJrc6fo63ps2VvCnt6tC49MGtSExsGPNaGVc4Atc1JhwOsw+FfCjBIu/EOt2iiuVwV7ayxQM9ZI4dfrXobosedb0hUHgbUSMRJb61XBq4q1RdIRzzR/wBnJs2tfsNbZzI54HPIWNjp99YrCRLlR0SVQPcfJvCuXu8lttGPaK/bH2V6zey9WSD7qCyqtlNxa4rZyYU6D1ZP5Vuq58Xr0cSA9puatiMXM57LnX2UM9okHbqaz2zt2nyh2xCwyK+l21rDyNidliElsTmtYnspcLj1aSBojc9axzaG9ec4VrY3CrryzDt+FYkYgzxrhQi7m62bsHjX9IGMzYdOMZkv4nSpek+jeicksUdtoqBbrzFcEhhc6s8qm3ZoDxFJ0bJPFFs32QCgtblrS45cRLtQcrGPdzCpZFwM2dny52ZtRamkiCxATZuI1FZpMVlKSBtNe2nhaSSQmXXwsKUgQq6yMvaeYqAgO5Obh7KzRQqP1a+uvBaxEBIFwpGQeNf2mUSuNX8agLFRoaCu7N6FO7hapYQI7owb5x1/2poY1c+jbjwqLCHMTltw5k1Hg5MhUsAt05Af7VNLDa7K77jUyJMy51NtL9apZs6sGa5PDQfk1Ljukf2MV3sz7tyaDcFHwYVJ+j6/24K2/wCWR/tTYJzvvu255qjxMl9hOSAfHl77UuFjdYhnziw5a0sO0IBRNAuvKjEZLKqsGJbjqamtltcc71jZIk4DkLXOtSZVsWDdwqZpZLuc/Fu6oVb5g+ysBa+kBGp76RhGblV7rm4raNEo3W04niaxEjpswc5UBPo1KjZgLjmKN3fLtHH7TxpJJWATZcb8DrXmso9Cv+XtoQ9H3LEDQHqjupJZRaR8Ohf6w3fupg3MUNndWvQtEOFtKygKtx76G6L0bCwo5igBQ3LcKLl1UfPbQGjBmQleDJwa9dRLt83jWSbNnv1tbUVZr5t1TbjXWFZDJe1breSTDPwlW3gafAyxukodRvDmGv8AdSYtQ11i2RHbW7Co8TerrMg+jl1+ItWuI467rfhW8xbyamuNvKw+gPIt+qgJNbpt4Vxrh5Y5IYY83M2zZjfv+6pYMfFMJFk2+1i1FgOGXurClR5xhJsyK5XLdTXneEe+zXLa3Xi0sfd9lQQJBu4rJNIM3BuH2UOhsLiWV95ZWXjcm/31fEMzIBvSg9fup1lxOmfNw7v5VLKULEOHux9tSHOm6R1B31OFicgMONS5IFGo4m/IVNsW1GXgt/WFT7VZDvA72lZnlRQcRfTXiagkmu2UtxNuylVdlqjLpr2inSMltwndXvFBYoLDapxPbaoDFyZhupQicPdoWXePjWI20q6hdF9tMpzHWRd5u41tY9cjX0e/Dh91RRbcrkW/C/H/AGrYLIp3ETs8fvrARw31iRmyv9H/AHpYmzXZQu8vM8fvrCzyplibEXcjQFfyKOCZMw6j5fVHIil6diO8NGXmL6XpelJpCDJqe5qEuHS0iMDccc3hRxmXI8dnGvDXWhCJVvdVO9TwiReo+tvGpXkmvrxtWLxI3pXNvAfk1eOIXynv9aopvN1YNKVKyLoRSSDB69mbh8Kw+LfDoskcwjVlv1SCbfCsK+Tf2UbMx1te1GHziJNGFncA8eypIpsTvkkdRm4juFPnjchgOEf862uBwUxAbNcqBp762UcLA5SrKcvPwrNi/wBt29/ZW2m34g1z3nup8dhdThnSNvbe/wAbVenm9ZZSKMjDL38q2Sx2WmDDq16R41/epWzhz2AUkq4QJCer28Pjwpcu66ks5I0I8PuoYhsPGiLmUqBx48bUDFcZTZwvConCFAptlNcK3qvGfJatnIAuJj/ZS/j3U+HlXK8ZysDyPk1rSurXOuFcK4+ST6o8k3bu1x+RblVyG99HZ6bpHwrBYaWDMokUA8eJ7KjfAnMuDBY/SiuR8DUckcaMiLYMndpUuNc3U6AcnFeZqRdP2kbc/wAax/RinZomRkA7CL/fQKxuQ0YN3Ps50TLKBmRG0HeDWIzO5XdJufGpGOxFwPpHhUhRWIy34VOqRHgp1PjVoAbCWM7i+FRtL/zfXbuNIJ8QBlY6Bb1+1f1halmmEQaytvamlsrMFkHAdxpckHVYrqfz21iI+Fh6g76aZ1OzF2uW7UqbEmSM6ZffxrKmcxmT1W9Ud3sqCE5SWYtvDs/3ro/CGNMqxDN4D/aocLsmva+h7aw2GwQYmBrO3C4/JpOlkAzKuYL9Gpujy2U4eMtdvWWpE1W26b/AjvrEYB+uym2uuYcKxnRka5dAV7bZheo4s9jmvxoRx5o1KAZmbtqTF4ifaXzWuOJqSaVs2d8xvqesB91BfOI1LKRZnA502Hlys4vlTKT7aw+IiCxCTNoF7zUeAfEM8ORZcvfqKhmaQ6IIx3ZRa3uy16TWuAU9+lejatthpGRvo86B6Ra1zuk9TN39lKuCBTZN+TQw7RKJWGUX+2sUZHzri7Ze7XStL3oBV0y5rUm0Y691EZX46XFQyxgC+63kjfsYUBhEaFljNyJm07qWdXCltGLvc3FXj/andZ7nd9tebyYfMG1LDXNSg33GNcWrNG163hlNWv5M1SbIftEV28flXbXy3Hxrbj1lt5HU80/4DYfKJY2YTZG5MOw8qeDBsz7d3QrINY94D8+FST5MxLWDIaRcTcyqWS56wbMa27sXhjObaDt76XziTWfDam3Eg/hUDpGzlgRrpwt+NXi0bYuAF7r/AIVKJg2qf2jd9ZpcQBuDgtNtGc/q9/8ADUuTJ1eBbNzotkYndI5DhXoolWzjvNOX2mkptZe4UyOJsm1kG8dOdJtZwg2XIX5mi7O7dVqkjyoMr5tTfl/KpIIkdtGXRdPzpS+jVFki6xbxp0nEu0uWG4tuFHzmWFCq7uZsuvtqDDZWIXKDwPea2YGqYe3V7/51ljyFtpYcuGlTRvJnlWTRjwuB/Oj0YqndJ49vOkw0Z/rmbjy5kfntrY4cbg0zfRqDHM1hKPa350qcQtrMjNZRfiNaTYRNdeJcCkikgPHgJONvZXmyCNE5XuxGt6TDTY6Vkv1L7vuq3JPJh7+rJJ9pqERRs5OGXgPpPUkJILIFl0N+4j4r5bq1byDxq+lPmlu6jdv6y/Nppr8rt/8AGoOiJVuiHfHZ3e6sRqFBlbKfbWh3rcTWrrw5rRmGbRb1nnGrvW61Zlag2HMiNkCuqtx/Gv6P84yL1iG1FejWNkQkkO+61JspDC/ODNf2d9SNiFGaKRTp+e+v2jfw1+12ijk9CPFxbNjzrNHJceS9YrFjqF8qfVGg8unksBc1atDetK3ST4i1Mq8Rr5B9U1r8jQWq1WPKl7VN6xE8AUy3zC/K9jf42r0+HsVW5ytzrB4nAg5JVOVWGj7xBB91bKQBHtd0Jvm8Kw/SMbMmaXKyjgLiomnVmyvzPd/KmjXIArkZVp8PHABusl27v9qjMOaxjtuL3mgjk64a283PLTGSXOxiO6g7xW2xZ1yC2drVI6ABFIO6vHWpxGHOUry7f9qCebHWdd6/bULeeRRtlIKi1680kmxE0xhCmw0zW76kjwmCjO0IF3J5XqaZMQ8bqDKMhI56/C9ZpZWc9rG/kR+0VxrrEmo5FxBhPDOPVvpeh0et3iOr82bMb5qi6SjsZiyi4+B/PdS9MX9NGwCjvvY0mNCentmFuN+a2rJhwQ2ENwbalajxDbthnyg8jx1qWJ5GLI5U0JdmZRyI1rfTZIOLvoBWaKHbzj1zTOeLGuNJ/wBR6wx/8qP87VHmO65MTfVbSmQjVTY/IsK6x0oRTIFkGscnJj2NUnSeJXZtHe/dpqb0WfLmkclb+N6CvOU7stJkGoGtje9SRTWTQ/ZSRrwQeTrUAZMl7IfjXnUVi8NrrfNr20m0we3Ni1ioABHPSgz2D+rmNlWsVhGmG2ObhcgnuNK21bUCuFdTWrZ93ySYhzuxKXPsontrj8i48vHy32IoSBAq8DarxyA+HyuFcKm87yenhjVQ3Aj1v8orZ2MZkPqt+NeZSb4w5OW/HU3v8aywXaCM32i8Q3fUi4xi04McqvwYWYae6mbIboVN3b89tTJNKtrq27rW0ZVBabrOfnf71FJZmG8vdUYjgEeZSt+PO1K+MxghjYEfm1CbCrJLuZSToL1Lg1wMCKIxxu3AimOFlWLPxsgozT4l2Y871e/kB8TQW4GcFD4EVauNW+Y1/f5e3wqHEQSLHisINic3Fez3ip+hukIcoRSQl/f8am6Knb0USZweR8KkhxJyQl8uvLspcQd1MUCknfep8NjQxSFrBU1bWpZ9nkEjs4W/C5q8crp4NavSSO/1jerUPIO7EN91YRspN8P/AKjQ5XqPFr/4iMOfret8b/I2fAd3OuFKl7EnjxFT9ChRLhrW4WZefLlWppM4zb11HdzolGKnw5U+FSY6cr1vg+VonezZtPCm81liUkglcu8daTClBGXtfj/FW2iizM+l89+dPcHNlPGo3Dx6qDxNXvWrXq0UdbWbcUdtSx40+heNlbvuK0HyOHyuFTRu26NRTJ3VnU2Iq2GiYj51t0e2tm2IWVhxZeFcfkx46Mi6Z0APMZv962cazoE3dOrUfSMchzaxK3a3fXpVyOnWU8GPdRTo+ySPqycm/CpCIAbxZ9T7akjFkDx3GUW515wMSHdlXVWzWP5FIkuGyx/tOOoP5vQihjOVWuBmP+1Hzhix2wGvdX0TwoJ/zAV+Hk18vspWHI3pgOB1Hkdb8r1qxNdXyLik3o23ZY/nLWE6V6MIbzsrdh64I0J+ysDisHpM0upHqC2orzrDyqoQDMx5/wA6XCKmo60rG7GsRFK5Z5oibk8WXX7j8gDs8r92Kb7FrBP/AHB/zUt6Ya5oJL/ut/P5SpLjnw0/aRu0cnSyym2thc0IIo0mkHWe1RYyfDsyEXXLwrOuZRpp2URinZW5NQ2/Hh41cD3VeJswqeGTcLDd040+MdYjEtlyAWpJM8eGjT1VNyq1sQ72jgZVJ4G/kVCDdRbhVoZkI+uK2jzKR3GrKBLJ2Ct8+CithE/o4dPFuZrY5Vte97a+/wAvHyW+TH5w1o8wznuoNgW2mHkju29m4nl8KZIN4tp4VnBse6tlLima1MyR+jTrNyHyoi0YMWyVsvCwy8vtoZhIpvnfS9N0ZpL62Xhe9bWK8mHTW/rX762GPG2jO8X5qPvrFJhcWyrGzKFXsBoZ1zkMb5j7aGvuqO/rAgfbTvfh/wDL+dSED1yw1rK2XWkk5KwNOE4X0+QfJhMYOE0eviPIt+HOinYfKFrG9GYl77DLJCD6t73t7be+ukYcTZCm6L+r2t9lBMxESdROQ8kWJCnKrgmp4cwCK5y+FaAtVuqO6ifZ5Zf/AKv/AErWBI+Y/wBopRbW51psI3VxUbR+3ivxFW7Pk7y1dBl8KtQWObdHK1ZcfgYpPpZda2eFwq7LlmoF1VQvAKK0NXK3pjFpYb1/f91J5s0kDk+kQndvyapMS8TSNY70XAfnWvTFTJiELDn4eTPtDrrxFXfDwue9BWQWRfmrp5CqN6aXdXuHM+XXycPl2tWFxSdJtDtVGcbLaDN3EHT20+1Es5TrGV8o9lrU0TwzKFPWQuRTNgejJ5vm7V9AaUSMI4Y/2cKaKvktetPJqaw6YiBXfYhbroTapEfGiCVuCyMOFf0pBKW2TlAwHA8j7q8ykbJNHp9GQ0cRAqwTNvOORrE7aEqZM2ZOy/ZU0TtYIQfz7qyBDy+NRs2gzFdKZ5iBaza+ypJId4aWI8KsFF+y9cABW95RR8j8zg8Tf2MP5eXN2+W9JjcI2+nxHMGsLjujXyLiYyjrexW3WB94ree/hW5GPbVixro/pIf20GzfxXTygVnRSQOPd5MSOzE3+Aro5voy/wCivbQkXihzCmZOpKBIvgdfka/I4VoPkcakVpCm+huBy1vRw945hiFAPPt17iBeniwkuyhk42udoLGosItnMOUsya5RRZDksK/ZCrswFWTWsiWfEdnJfGjLM5ZjxJ8ugrX/AIGlZopHQn5jEVdyW8da4Ve3l1Hkt5MOVYZkLqf4jWHmChbAr99Yvo6UreSXdHbuLf7K8/hBlw8eoX1lP30mAxBaVOLH1k/GsDizMSk8XBQeR/mKM0MRdZoytqzR4VYt3iRy9tLLiMfumTLlHbf2U7ysxOzuLm29WWIWUqLCr1mHuoE+Fd3kv5ek+j+cuGLqO9dfkX8l2WuNq1N/kTx8Tg5xIPBtD5NDagrNe1Zl491XPxrFr/fr9ldHW/vv9Fe3yYY33orxHw4j7fJr8nj8ud2vdALaE/ZUYGIUtIuY5LFr6njy7KVCrs2inMcmvP3Vn24W7Wkz8/m0YEc6sV1ri4/drNjsYkfde7e6jD0cpjB4yN1j+FXzX/4Pf5OHyeFcPlyRI67aKQkofmG1QPCpLCXeHZpTS4clXhxFzbiLjrey1CLElUkG6pOgc15wBs5Qc0nY/jWFixGHG4CdRf3UBwCvl9hFIJcUlwmVgDWxw2HLC+a50oja5F7FrMxuTz8mYUpU9Y1ltXdTNV/Jhsx3ZG2beDaVPh7WyOfkWt7/AJeIwD8MXh2T28RRRuKmx+TjR2SR/fWB+tJ9i/hUqnExRRFt663f2V6JGnPa+gqVnyDZrmVUFh5Mo41rWv8AwmzZdRzNqvnU5bDLe96XYsrZtG2qg5DakSdnnI/Zva2Xup1hfgxyW+Ff1pv4vkdta1r5NfIoEKJl5i9z/wATh5ePkzRuVPaptWWcp51FIBl+cvzqxUMybjqgFxz1rbdHoZIeUY4igMU20iQXY8x4Vhx0fIGkmYyHMOoOA/PdWM86fNJkNuXLT5YzXIobNL+yir2+qONZctiTRuSPZRvwtrUct7ZWBrzrLlGJQSj2+TRr+FdU++tPlwYkf2bg1OidRjnXwPl9Dh3bvtpV8ZjI4/oqcxrHphs9hsrlufWrCH+9b/LTDyDN1Tut4Gmj7PLrV7/8GaR1BYrlAI0qMQJK7o5Y2QHeIrZRTsm6pADWIY8rVCZoCmW4B7W56U7o5cBr99dWM+2jFPGyOuhVtCK0Hlua1rT5PHhXCuFcPlaeXStTXDj5M8bsh7VOtdJ+nkeRBE4udQut/tFL/SFlbgjngfGnYy+b7HfkYDQnvFF3XjoO4VpwkGXXt5VLEfUcjyaC9bkLV6bERL7b1qZJfAWr9XwyJ3nWvTMXXs/lWaNDbw0pQddK4btW8nReO5gGFj3/APEwWIiK5tjkfM1tR/tV8Z0hm+hCt/jX6rgBp60hua9JO1vmjQeTpBe6I/5qwx/8x/oNN7PLHL85fk6Vw+WYHtkZSW03qvgsIxWEemKbov20cQ+GMkZGoc5iO/2USAm4tk3iANONSMvzjXGgcbFlkHCVNGo4d7vE2sUtrBxVhWoq/wAnSuFa1w+Vby2Hk4+T8KvXbS4kAlCMkq9qGv6Q/R3FRlGFtle2X8PCl6NGJZsMjb1+2rqtR6i6uptfvqaSZ3BZr2Ar0eEzfXarRrHH9Va9LM7eJ+Ts5OqefZQcvxHIaVl3da1Gnb5J4/WwkwkA7jx/4V1NjV6mRb3ibX6p/mPkHQVjR/dqftqE/wDmV/yPT1pXCgGG6PkafL4eQYzDGzLRwWJ6P3m1vC2p9hqSHBEGM6XfrqOw8xRE+JDtKtsga1vxokVwrf4dlNgsdHnRufNT2irt6XDv1JQPge/y8f8AicPJer+TWtRqPJrXDyXNSx4eZoxOuSSx6wpqtJ1ged6VkSwuOVK//NjWT20ZtmcnzuXy9K2Ux57tFhGT91ZdfxrNxXtrGYE/28B+GtW7Pk6fKfDN1cRGU9vKmj+abfIxS/3P31Ef/Np/lem/4PCrDycfIWNhfya1tIuNZOlMDh8bbQPKvpB+8NaEOF6Liw4vfMCxPxPyLq1SR9JKhw2Xfz8KmXo2Rmwub0ZfjWp8mla1wrX/AIHHXyaeW/ZV608nDyd/ZWmtPQvqDo1uyheYtbhy3awcg42ZG9h/lWdfLa3ylw0nsNCwv33rLYMTpUDgXjY5T2gGpF2Y62a/l4eXjp8jSllHFTenkUdferh5cQv/AJc/5hSEf/uEPwanHdXH5OnyOHkFqte1ZYo3fwFC/DmU1t40GjL6cWLCsm1D/VoggHxrgK4eUtq2RSxC9lbG2xwyn9mDx8fk38morjVvLxrjVxV64VxrWuuDpfSrVwrWuFb1vZ5OA9utZhHG4bRkZd000iWClrhRyqUyw7RrAKPtqONT6MG6fRNG192bNp31shrWUjTl8q1cK/VMHK/eFq3SeMwsJ7A+Y+5a9BBiJ83BmAjH30dimHhHZHr8TXnAtZv9/LpXH5HKtbVxrdalWReqLfIk78O3+ZaB/vUpvqny91XrQe75HfXfXC/h5P1iEt+eygrSZk45V19lfq0YiJ03Ty8OFbSeQvz1NXXBIBwdVUZtftraRm6N2G+WsxuaLr22txNfsmP7teb4cgv67ckH3nuqR4TvEbxfXNTNpa/L5NvJpV8tX+XrVvJrWlZswrVr1pWvk4Vw18nrA91AsSbdpp4V9ZQ9XvbiL2oplu3EeNa1p5AmHwzSE9mtBsZs8Iv961j7q/WMfLimHqxDKvvP4V/2d0RCvY8gzmsr4khPmroBWbaG4140AWXapyrd4nlaipZcjArvc7UGXKyHUc7dxq9gL8qtxrj5NKuKuTVquOFaircu7y6Vw4xN91MRyaP7a9h8nZVuNeNWC27+dWPwoixJrhRB48qI3NoBdVe9mrzV8LHFNfWEiy27u2s+F9HcX3jpRikjO7xvwqyAe2t4aVp9tbaLgBrz0qyZCo3cknEUFsBC+9mP2VuHXuFcVqB5T1gM32mlwUb757OVWBDd4rWuFBC6pf1nOg8vpVIPYfJYVwrharWrwrWrCuNajyaVyrWtKtavQZsvLNx8luF+2rZa4eTSspsO+1CK4tvAd4qMqkgJX2cKubd99KEmGjsjdZmOVL+NX6R6WVu1YBmPvOlXwvRu2PbMxNZYDHAnC0ahavLKzHvq9WPktb3mhNDmVhrpRk6r5d5e+hpoSrAeO791OGZWRu+9XXWJuB7O7ycKHKrnyaVfjXGuJ76Omv21wNca1qO/NG+ypj2bL/MKUdt/s8nVrsq58jbICycb0rx+lXn237KIkOtuXbVmBq8bi410oK0S6jgD1DWsu2hvqCuo9tdaIqw3kk4g0fNSwPzW/Gtjsmz/ADSKYbK7MLeFZFFqzKbr63fRPXSSPQAV2xt1W+6utSMOuAoH8I/Gtq/Fq1PkGnHh5OdcK63GrVa1hWnk0oeXd+Rwt5bA8Kta1amu3ydwoDQ6cD+b1wT3H8a008KB8ePbQihwkk54XUWHvq4EECn1k3yPz40xnnxErW4l72poZC1weLcxXDycfJ4eS9+PkEycR286hlBXeUhl00pHRFyPy4BRVpCXHEjQ+yi8cfoT1Te9X5VmCfyrnV/uq3AVfgK0rhWgrWuFvZQJWoFPY/8AlNYz6OT/AO6tR+37PLerAk68Ksy00ksJe46y8VoJOpiU8CHuBRZYwGtpInP8aySw5kHOg0aZNPfQLHcOhrey5erIDTJhoyF4hieFIJ0GIUc06wPhSmNTe+tlGnupg2EuWvvZ7WtzvamRhYjl2VdTWWTWFuPaKC4h0fS+VDf3Ucrad9CRonCEnW2g10F64eTWhnN7aDy6mtRet3QV3eTj5SiT4eK2t5ZAtNGsyShfXXgfDy6muFWy1xtXE+ThXGr+TdWvGuyrUGA4Gthm3WFx+fdQeRQBc3LH4V+1Rsx7a2sRGeEX7Mw5+TTyc604VrwrXXwqxPCrUHaFJVvvI63FK0SoE4KRpYVszqb8V1vWycNKr6WsWIHsraQXaHt5jx8t+PfXV8gOZB4uPsq20V/q38h51xq9YX9//Iax31V/+4tR/Wq9XUAeHl7j9GhVhQMR8VOoatnkRH5gtx8Kz4U5TxymsjLw+ytm9yANLDUUHll9GeI4/Cm2EWa/N62+1Oc8xX6xtL8mHb30wlZG5h+/svVocSJB2cx5L1wpskpOXduOdtKuOFaeSzDWr2q9qvWnyLc/J2/K4eS9/Lwq4FXq7G1cx31e/kvV+IrDzo28tiD+fCvORbVc1/m9opWijHDi76/CjmmGW9r5tKzw6wvw7jQuPZWlbp4Vc+/ydtcTWl/Jnjv2sO33g1toZSmfUgHQd3wppWiL/VBJrZtEBfRb9nYaLQ5tieZHDurjx8nCvV18moK37edW0sK05VccqvWF15n/ACmsf/0/9QqL64oaija1cNK4ca4mrm9bta1awN6SHEXe2u8R8DSiF86jXL/LjQfCoWB9XnVm9x41yq9XvVsxq4q7aX8nH4+SJz6y/f8AL0Nat5b+Tsrma0o+ThWmtXrTyaCj2V3U1rafnSuFXFWIGtbta3HfWW96sdSjUcO/rjRtLD31mcC/vpVQcrWtUkVgC5424H200Ug3kNrd9K0cuYnlarWNXueNXAvXb7a1F/u8lwDXH3UJgcynR4+0UuIRmkUqb5eXuoZgTroL0wMIcqdFB07xVkYlW1FxWvvq9aaXor20RYZT8auPyK1W47/Id2sL9eukR/dPUf1x9tXFcfCtNB41rV685kkSKdheOA9ZvG50p8LiVihxsCZrqdSd3jqb3v3aijHeFMsST4meZc6oG6ihOBOo/IrKWw7yNhvOoZYYtldb8GW1u+sNh16Pw2IxU0KzTPPHny5tQqjwro/pXDwRQibFLhsRFGboeBFhyuOXdXSGYQYbD4XENDtZWyqN45QO010WcRHDM2IxeTaRG+0F1r+iH/R/BNE85h9EjLIova971M5xuGhw8cpiEszdc9wFzQwEbwl3iM6MJNx0sTcH2U+NjxuExCwkCUQsSUvw4j7KiebGYSGSZc0cEktnZeXcPaax8OGaDC4bDNqztlVKil20U8E99nLE2htxGovXOrGo48jDL299j99W+Rxq1dprXU1u1wrh5OdcPLrWUeXSrjs8nV9tAWGY6W40BwrdqzeQNxP20bYYq5+a+78fxrSp1Zu/WlZeXdehJFHmkW2YtwB9lbSRxYetarhZQwN9Ysub4e2lxkbrcAK+lvbRGvk45qGtfdWtWvXEVpwrjQDWMDdYH7fGrYSQutuWnvpFzuvNrNr/ALU0LKGRhbXj3WrZy7wvowq1u+9dpoairmrDhXE351FP/SDNjX1Maajw7vfQIOtYY/3gvXSY/wDLyn4UrfSFWOl/hVhRWhY8ajmZb5HDZe23KsS2I2MzYnNlmlSxBN7XJ1FuxezjWEwkBaXzRMhnYayH8ipI5EDpOkSypthG4eMWUi/EGpZ1wqwmeNIf2wcBVA3FsNOA41h8Xh3jEyQrFNG8oXVRa4J0OldH9E+cxSOMYuLxDq10TgAL+F66QwOFxcAmXpOXEIGkCrKjaaE6cq6EgmxmGaSHHGSXJKG2YunE1iIE6TmMLO4GRuK3pcTg4sFNjDIwk85dBsV5WVjY+NYPEyY3CuP6JlhZ0YBdplk0ty4jlXSsbyqrPDGFBbVvSrwpOksNjcKIJIkzZ5FVoiFAII48uV66Wx2H80xeI2q7BZZRs8ttW42asFtJ8G8kMsokXD5AEvlsLL4cRX7MVftrL+58bf6K4eXjVhbyXPyD3VarZaB4Ea3BtRLamuJHkGlX8mnOjflVmqwo9nxoi1rUQq1fTtrUX7Kv26VpyrlXUF+2gTwFBLArNo9LlA1OmY8DVp5M3DRRpRREC3Q30poU6nK/ZRqxqw51arMb2oAWAFXtzrXiKC9utXVQBWwOYwynVb0TABGIrq2l7+HZS3ubW62vKnE+8pG9pra3200BcNlXMD3Vx76N+POlN7ird3868OdDSjrwF6h4bjqa6VH/AJab/JQNcBc0ONWYcKyZtDWS3fxrrac/IHjezLwopDliaLf7vZT+cG4ymxHG9HTjQvzo3vflWcHuOlXogjjWnOsvkFcK/8QAJxABAAICAQMEAwEBAQEAAAAAAQARITFBUWFxgZGhscHR8OHxECD/2gAIAQAAAT8hzDnvAaJoKDUowylMnVIiNmmwbi1IFNwuS25Rc4HvYxyCkzXDZziZLFHqOhlJrKiDOLpLtTNLBVVxNblnFLpMAU8M6d8zUJYWTe50dJYQUKTvEG47MDhMP3oXg+fuIsYi2JKViylwhdmCmswKaiEJd8pzD2S/SlW1LdZnhibpDRULtBA6W9ZUonBnyfr6nP1ryPD+8VGr8MMaz+IcI0bc1yfZzx3jdZFqmekXHvyr6Z+NC9oFhDb9jK/cAF3xuuPY3KbXlN3rU6iOx7QN51++MCV/CtIcJdvPWOalGQGyILvS4TjgoZEXgxjbvCjKoBRswWYDi8u4FxNtH1o+lT5kH83NLe6P0Tqg6v7T49E/COsv96ivtiosbIeNntM8AYzQlejEN0xdga4uUSM55OVHma1m7i53D3IhSTlY4Jmolm9I5vCuImcMM7zY9U+0VxYDsFT/AEOVKxn3uUIRP/KzBzN0mF98R6XxHkBH1kGk2yF8DrCxobX0jneeY+ZKOBGHXAun3HszOr23/HiJbiYhbnUANTBZFDC3E6o6zAm5QzsmXZltKlIOCB8oXxETArVoJSC8Jj0/l+Nz8p7DBbueNys0mpWvXVlfI1e+I18vWJBfij75+Iddq0r8uJuc6S/5NRb4fxH7j9Pah8t/MsL1oXzD7rMR+NTCPvDMqsSVrX5Q9VmMNseBA6GVUyr1PzN8XTSqCwvfp6wqAHGzC3gIZQIXufeK2/CovVfT/wALwrHNJ8TMKeYbkHRiMd1RfvNrfK/5ubXuz9amwR0avph70U36Xcx5+5XvEPmk4y4vpiKCbxZBfPP6ufH/AP0uEIHvj8Qv/obHsrAmDiCfeHNRyT4NjzU/fDgCurfERg2smosed59oPnKqxMfXD6S0PbljWdZKXv2jKO6B96lPe9LV9XEXf8lkbFxa3EGnDFuNQGmM7Y4muSO41eNRBz3oPuW3YfmZLVzmZmayHzEJIKyY6z8PHxAqtXScro945nI4MRNIe8LMROYWlTOmG9TUOsv/AMDO0SCgWwllqUne48JSXFZb7v5+5QDHg0BOk/i58TNx6uH7+JSUbu6Ltjq6NXzEfarQvYFvJzBfXIfNgTd5/UgFQztFXDgAg9Vh5QZslzglyJjCXFltFq0f3XUrcNL1+7z/AJcJo7GaDy9WrS3mWAJ2Mv2IJc4ZKGAEAcWleYNPvHeZ8qMGKeJQpo6NSlDMWz2hdfUcuDl1+s+9CZUHqwbEuhfeLZff8Fm7zsE+T8zBMPC/Iue7yH6QfuVQ+JTh9iabwb9mkSADg33qGLAcGJ1Ns7UoUGS9UPzcEBLA0vUgkrcMpMrpX9Uyqlhy7LC5sudhd5arN6TwAe1vmWF5pTe9BC3Fdtb5gKVDWn7P7iFKOHPks+Z3iqQ+IS3t0nI9om7gYbk7doWd2JA5LgL8/wDiJwZd0dD+zj2hWkruKMCVSa6xWgUMDC0ohhud/wDwMf8AioEvVuoHJvI/ER2PjMc28V7xYHt4H7n/ADL5BHap0JrzNEJ3GempkWugH8w3OuU1evsqF6+dYX5vw73KQawS3278ErnIjulmcmtKWEFW1ubebhyD7cHrDIbvvy7fQhUKdcHxz62xbwd1bUdg6RDguTVrUXxLaxFhtYpjZIgKsUFuQNRS6mxN66QfcE48hd+Jr34he1vVu/czhHWj9ymh9Uh+on6J+0wjl97GJdZ1XFGW7mIgxel4SxgPSL+cJFixgBj2orAV6TqhjpBYHYesCxI7iVAivkQTpcuxhBogbzNaA2pa97nGSnhxNhIEtcV+V6XNkVexfaGYzHKoPeJwrarXxsS06BPmZQG0Xq9EZin5EFzzZJmZ4KmvRv7mNyOP13DL8V/SUuLlNRXpU7gdJSs+OkrGpr0TODJzMhcguHolCGRyPWU7yXNM7bq5o2mUMwzPg+CYCr6O/wAm+7wH5mv5EfiCN1LBN+SoP7zEvAmLvW5jkowzO+gZX+x1aGAdjH1PBqH9IBxmE7WVgWS9B1YrQHl/5qON71jb+MwgukvmJgMEIM6IbQy/NJs1EswrOLtiu3p3exb2nZzHR7G31QiiRXHg8P4IINit0/ofMBDsmoQF3u7yfEofvZME7AqtMQNp/BlemlPSbU4onTePz/nmjsLuOUxVkx7EN9VmX+l3mx92KMGkVLuUdpLrTM6x6DPjkfpBNDufmamyeWhoXetvzD2bSKt0AVdifGjskC1ekwyk5Q81HMLsX8TzVSlgb8+f8iY6g5QxwwHMoageFIk/YeFqvuPSfzJBff3gzBHUSwsiIpOY5/8AA0KrVVPFy/bjt/c/FS5EMl/uGU2AB0oPgz8CXYTxcPI3KoPrp/PEGBXyfbcsFiORDK1s6T3PEwrVeIv1O03nrN/aZBfsD7mk4wWX6YnK32L6/tKd3nKfixFXDPV/N/iYR/xtSU7Qcj7jmWcx1h4BWvyvxKWYqf6HWb4yGJgkDMzeWZ43ew5cavoB1ZmlZX54g4Oj1mdqvXMLUB0IJTMdNT8FR3Fh2uXVt5dQ12rtD+Gy8+Az6BIpCXYl9Mz3PghUNG3B+HsSocGjJ+j5gIjRpukjkeWKmXtKFaHAPDUEHaK9vk7K8XzkK1+DBlXwLLWo6uj+Iv4Wp1Lh+9Na3/WVUzYL23qVKfhUQSkdGaCnKpFK76Gp0v6zsBywzqF5gJzCValOxFTqm0K9RfQ6vYzLb6taOoZf4k3ZiPqDV4vwSlTCx6htQbJn1ZZgA8x3zvrcMvqo3P8Ai/1/4AR4y8wlS8xr7dFh8H0mQoZjtBYeLIlSpX/tSonSW8zuRbCQmIZ2MDR7MsFDsZ4wPaWGH019B8TgR0J9v9ICWDxKj8IBSioC0xdlK85jd4eEH0L+pkq8j39bPqHgDukD4v5iweTp+TFEjaAfEvFyLmdyWnYnbpENkGiP9kFEVF3p+3RAJHdkOe/Q7+JSxdEWACXcDuxC+3Cx+wnYVsvI5f7fjfXtPhQjnuy5evEwWaXg6EsNhdp0RzbZEteBl+DvBcLaAp7Gny7xs03LPK/MrM92V369I/Q2y1y6soFscCTvAGO/o9lgazdeB69QcchDymrfWuQdl2IJ+6hsps5wk7yFi7Jw9p/Hz/mG7qiGe7P/AJlEY2b5doVS7JRUylsMrRcBHt3fUIVAX2R4WQ26QjAyZgGrBzKo4TF7mTUhfrmDX9cB2H5a8MEZQ0ugBr7A9wn2KooS3xo6S23WvioK4XU+phidg/IE5M/wwT59P0rLub3I+o/7mKi7eF+7EP8AZBfEv/8AC1eXvRQH3hzY6dmCn0mkt+8COtAesrH/AIqVKjTgDmb2Diq+04huF/NT0xq/rcvJ+lV9k4IOsB9D8zV7BJKyrqfnZ9TLJ6CPovzPV3qH0VTDwEhrQ1UIq67Vl+Mfd69JPFV9xGiPH0g944vttYex7s306xp8P7mC6UV/Jj5l82ZRFekRoY0lMM0QSjb++70O8AGs/Gjl7wwupwX/AHoWxlVhLl6HY4nh4Rt9cCIDYysuiIYWsuWbH3edalQzgJxRZe5pEMpXtUvV0X3mIu8b6Hqj2gBaNs0fVg9Ae8TWJe+3vylE8etf7AANBwFEUztUwcziMHVYscN9o5TcNaHLfTrxGumIRctaHyzMdBsIPQK51Gd05H1Tp3TCeNi2zjdQ1cinaGpWHikaG2zMAWeJXD+/aDKhdOHlagzmDTovdKD14tfUgdH80vwnk8/yeOe/Bv7OGr31X0yIThIn7qDxC9iYwM+Yqk5Co+G3oMImN8nQsclcb/VEfLOSP7lnlgXX7/POU71vK8YIfdDz9AZnBD+9WW6Edc+zO2OJvgGXBzxlV/hxLZ/xoM0Bn2rH4fqYRLqZ+alVYPFvk4lCj1UQB2JVVVDGctQ8A6jYiBZo51d4nB6wQ85VDqS7kMcv4D5fxGXWrn6QEXpToi9swyw/LdEXgf8At4T5lAd9L3ur9TE0vH9CcV+qv552Kuh8S67iDblBKxKs4bVm6h+pXq9E1jvC1i2FNjC/5KXmdxKGptJNII8PEYsB5C/cmvw4L1DUHdH414r7CX6MOuPv+p009MHbVwtuZnl92HwuHfHnwTLsJee8vd8GOsVVvlDVT3Y4QFiiLqWsq5HY/Qc0YACjwDgqOUwJeZmWBOvtLDUyfJ19vZLorOdL3dp2uu09/qBQc+lzggv8afCFNSuBDC0vpuWVPkxHI8x4dktkLS8RKKcGvdiZheBZXToSVWllVVK4csClKIpg8C8RfSJi9l1jdYK/sOqZ83LtFmdnT0PNqkQtQHPUdk5hyO+AHrRDSEN2/gUMewnMmXMTvQnrC+TjfkhfuZ6eYgEUi0COtxJszcvoGV2w7xGvVD6On/KZiVlfrEOxR2mTGYJFHbGY7/s+5FZi8s2b1AFlfygfxBOJWvaL5jYCW2/fURjWk18qVMAqEP8Ag/1Lecy9xnTGbu7or5qpYdCMH2hfKB+sRS1aCPtfynQOKdddM76wSQ6uWXYSq+ZeCW2NEo2UvvGy5eAqNjBnrHQ56UPvcveDAv0sSv8AKP8AN/cIC7wf5shH8D8VHAD8vOrI6v8AB4ZwE/vrH/ml2/FX4iTKeD+oEz6Tx/D7fmOAIKuRPMKBSu3iFrXqzaxZdAY/vSH1gf4h1PugznzlfcPxFlL7c6ZEzTC18usvKoLFeopD7lJ0oL/JXwTZs8j3AMoi2gsX6b+Y1dfRtRvXBrPLfSFrr1Cz7opwHWfKzCrep+k7UbyBqUoCt3heu9jLx50kCWjwET0PVhBHawBGa4hZ7G3x5jglrdKN8PtbAgecpb7f3iWgm7enjp6TGmao+zV7xpJ6FWLnhpuvsXhM1uTV/vV/QQjgtxCetHzA6zL2va7Gm/GfnmPxGkq5VvYfcY4Zi/eypTTgzRweXBUqZDQgxnXZ02THBGK+dr36RwOMiJ1Sr7xlBdAaJNu5GfLMnr+uBB13/NgNuZiZVp0ya7gz7bEgV+PHjCMWjpVg9J22ZRz7noQVMODH3HsX6S5pNGdp35Xi5gV4q/r/AIBHTkTHkHMKiPZD5CYPVi6I8LPue6SjcO+fcnwiJ+0w/Rt7E9oK6XmuwceyWUnuj0UYldenaCvFG2VYHryxOlNl7k777x5q7F/lfqfVi/hNqZ3aHlX/AIZj8aUgsSYvzE+yC5OegsMbD1gGkHQj3S051Dgi/r6kvvMj1Un5snC41kD+8TVKboH8fU2Eaur+6lIIvF6+riZUnlWSzcY5apXWP1gt7rmveK5AlFvBFFLg6Tsd8PlZuSU15WVmn3GYRnnr6/Mcf11Mbhfy7Sjd98PqWQZWVVxXeCbJIA4CHVadiJmfKFo3iUU3iwYEhcGkNhfV8GcNQdbyx6vLAObfMs4e0CMTcN0VfbCNEjyFuqvDdV7R0dGRDqwrSV2+ht9LY2N9wfD9oJ3iBd+nj4QukdBfzHXY3jL6uYb61ifmX+t1PohFOCJv7D8Rd12TfRPzHEfMdXlJD4xTdJ6p7wSbJssl2vbLW4yL6ZcNZLPol4ObkOu6Bd7i6+CsjPKrqB33PUidczYqIe9B6xj64LacqyC2+puDgtybcWLEdRDhRNeS3HUYLa5L5KsrpEcTU7W8aqOhlVY1b6/uL7SPXPtEMHQovcsgVnG+mWaJJP7aAA9Nfjl7Tm89x8X7U6JyzG1XW0B7VEjPpZ/gnm4MPYr3ClH3h2JT3ivhZSTnH3S+RKnLf0blX2hRrerus/yHedwUFJ0XX8zKJWqQWzusx9pKFjk6uJYgWhixbih2NwvUGwm/DHDi7kbH+CqejmeAlVzLes0H/iHpLcIe8sj3XPZ+J748QOk5hluctsr1gXlncJ3ZUYCycxHNR9zMT6aJU/nmaTiBAyPvfP8AyX4KGS4NXvjF75iwCgXTfQ8Vt5m11yHnk+3zLJZd3CYJYtjLaWupwy7LXuXK9yDUdH5TrwBl1dOGS/sIDowr1gxjFvLUxOEW8g8rt9uIVLF2XtcrqsYJEYQqLWp09HxCdza/5H1oiUhLcjTuuD7OsqTGEqnv/i0q1MZa591XmWLrQLj0kH27GyylW0p/NuZv2j82vaVV8cxupKT/AKiy0EKL36DKdA9jGpx6Ue0O13CtLnqDfWWEHwylt6FwBTP+Nq94awz2romT4h9LKeSDWbxbUaZpCmDumyPJRc0eZ1gxcOCdrXMTKahJ9UOaLcBojhs8F7Waek5hBjxg60jIbVWlBmK2Q3R5gsNcZ8wJfdtarmgPGfZAQ7Zn5z+qSXCE57THot1WK+PLR9iRjqwhT7faEFHKKL82/EdCkcz969JQDJtecZe63iLy50kdl+B6Ji1m1V7bjWDao+lCTwBRAH1CmF3WH3s/EfT0ZGtPrM21m4th8R6UW6V6uj3mFWkcp1HD2U0EWUpDF+36nwF18S9bPm/qpuz1h9j9zEerB+LPiVt09R+k1q7Bjf8AOrgf/JuwvyimPnl+cK/l6y6HV+ZfqfE8kxoroH6RvoV4J8G5/wCR1z6AfYP3OC/Qv5fxHb6j/wAk+bFo95UaU6AQKYbhMQ1G1DlePTW+Ijl5qSi3Haij0iQlRIA1WrpHtlQt0lJ9j5ljkLwYX9kBpMZr7mqznOdHMRaW/wCGSMHs/LSj6sW+t/XQ/wBnBdRUWDxGBQHzELJ/pePvtEMWLNP3TL6UQgR2gv2mFkBsKcrpinl0SHq8/NRUxfJf7v5RUCoHor1No+Qma71/E7kO+8JZehf0WVOAeD+/iUS2S0OSzLOpgSjJTyAWGGjRYgtXXdi4XDAJR4IFltpHKePHvDpgvJRLW2xRfTivKzIlp72hfHsjy3AzkxQRMs4jDh5cvDuY40zCiwFvGmYwEQPn+DKaGUy98mAExYAtCnA8y0WsCEWYXSVJ2VmHkADtf2VDiUfoCI2mx+p36gp8X+p6B13siHdajXsRdZSLWsPaGr9V1nrQ9LuD2DA9lYpdTFu23btWdwDNdefmdkCYyX40MVAeNfTC1sf9s+JDV80i8jRhB2clO+kgz9lwGnSle8pNQax8gfB8zkq8m+t+kByFuv8Arh8wq/DyaVuC8MG047jZS3zKc+lY6ghohrBnbH2Ylk8xFWYlQEB+43zBjkZQR1TgmBF9IT21Es5JO7+ppPWLqEgMDiHYwTAvz7EDap9oPFLBmwPmEPdn3GvuAmONq9oGErhySkxrun0wHbpnkbPn3RrvBrM2O+mu0/N9Qb3P5bqcXcQV60nzBrArr3fgl06yqqyxPPFeIAraj1OB9vfwR+qaEyod1lAQLae6f45JpX6T5m/mE1TFuL+NVE/5yDXqtn5nqppfjP5EsNcyv6lf4hNcebpnWLx5lIP3FX3w9rhQlv8ASCfMc1HRkfMNrju32fSFvz0B9g/MaDeZnuFj6WVC9M8ZgpeGhg5cicWxr1lBOt27X1x8yvJIJQLKK65tXOoTta/gvB978ROd5l3rRZe63BHWHPxcW4GDD4LBdiCZ1LfQeowJ/kppDVvvOY7AX6szu5KipS/uRHX0e5Mj2WGW2/3FQu0wKVJ4zcq8ZJSg8aei9yyQsGH/AH8ShvGyk/v77y5CbwHydsA60S/+n4mc0OW7dXn4jtVO6L9T58n9pafo6q9hgY48oPsm4rovpX8wLx+j+11KDo6u770uZM7+fxLBb3S3u/qNiLWW49ZUP4ZXqf8AdnQN6ZQXd4z+A/Mw/gzQ+JDmmdw8CL/un5HMrHbuWBoHZOjPMOEn89YaR/56y/b8Bg2D025r5Mei+6C39Ev5PpB8j0j1LxFpGY0GQxqXWuZK7wvQNhIXjP8A27me+rL9pVI1fA9/7tHjel6LuXwf1H/wyi2Bq4/7BCDLTmvOOCUQAU+B9ww0CrPDt3v0iC47zR64PQIz6ybL4ZhF++X7iemQkPi/uGIl1aHv+MCKDvX8VBBuq/8ApPdH3/dTzVAK9Gz4mR0J/wAqBqV2YfxGUu/63D8Q0czh39IXF3KR9bhVNZyMs7DSAQpQS2mpaiz2B/Muw2U8X/z3lcTm5e4/usdSfq4vDEt8c34v8RUDr956YYbWRZSdNAqBxJCofWoumdilwC3Yl0kCH9JEXMp98Oz+Zks9z7eda7wK9FIRVAPuqll9FpeycWy7hq/UimuN98Bh8esTftA0oBBji76Mo0vufkRS/Sx8xydSPorU3IYAeqZ5xLeAiaHhxMGsI3On8xPG9NopdiZ8ygJVMZn6PMX56v8Aj9x9tkUQ/p/8CxJJSFa9X9sD3BcAvRz/ADED/d2YA6zn0T7S84kQq9Ira/6cBC6Nx8z+aAnLf0kE2V2tF9KlEqqK0WBe4tBgOs6lQ/xZF8CWxBCWwn5+QidO1THlKkN5Io4d1gnYKpnmwPeUom6L9VwAS9VswBZU936jYHoXDULyjr75h92FjFd5GltXDCQ8EEKy4tJV2p3i40aPUM4DTMAAWGXMAe3Kk3jJMOV1VBmCiX17rf8AdYBfR0+LLhYfi2ZLDd4jbkl4I/ZL1lmk50ZcZ6ARQf6UGzdlPuLGqLgKvrRfmfyDe8HhU1i9D7gFUf47h9jSqNafVCeFMc0/1JFreFfiLw+L+4gtTr3WLr2jCwg83PU6QXhm39RGNUdhT6B+YHifPHqEEoEAp5eSvKSjtQhLNw9X+6l0GpeCKOtFdmv5xARoaLA4yGMb3liCqBt0HJlz6koYl7A1RhvPNGN6vdp70/UHlabg9SqUXp6xnms7wrVLrWIspRZnZ0SaT2eSMz7A5Iq4yMSpVwpH+cqwh6XaJR2yXoR8Q+NQAX4Wh62ekVaKtiK+oZ7MM9OEI9F/MWz7x/MHxUew/mdUeU/MX6WW2ny6SnCsvPWHYlAdT8XMSRN1aZPPpqNGOVYTFWayjLYr/lKnHrGfX/a5Q92ZAnXL8MHuPYvzFA3gj87/ADC5GvMXTP43FA3ehK+tfiNvKDAWMSmWDnsbcaf/ADlVKeVI4w39EQmLf9IoX+ckr9bfGVW1bD7Ce5Keicf5Vzpr1QAdOG+u8S7dtvr3u4rZLFL+wyBeuuezRCBNjdun0RaBgitpQA+Zsl6oLdcBAxpB62g/mDGvSB+yU6aHWPcnzPePzHK/An3mfRh/kj3loBxxvui+CNdOYX628kaf81tJ94UHZQh9Da8wAFq+Ib3HzqG2svJ37RJSizqisfs9pSuqGimQPP4lB0YF5hGydl8l/wB7zv6Ul149ASNz037cHTr8ximtWM6dP+QuAYoXl/ogAhwCmagarRL9ry1Ws8Ki4qWPVoxodu+ju4gkOzyV5V5e8/68UZPfgH75/wBGYf2RyTtuq/QUemFNit5udnvwB++HXJ5lGacY7ZaRV2aPV62vllDYicj1l6lep6QwOBQWJmt6+YQxl1BDnwZ+Ykei1TRn5y13gwXLbkdjs4mjUV7Sln1feDvZlkGYgxWxqS6VA5mbHVphe4Nj+r18Xc1MkAgFdhTA9PWUTnCYZqn1Z3w1sf4TGFRb3c+YHTDosMxRNLplqWtHIDgw9M79Jy2pMD4mCM5QB8w0pJZQ9iXE1IZqB7nxAwcmlCzrxbMcRK59vXeo/GsO0PO3ysy4mVaveN41UlorHzXvUeq11AOeeWBCGzgHbxqYaxdYHpg18wrkW/FKewi6EOGdQDUWwsxytYMlM89oDkykC93n/koQDVKf38sQaE+h+o23p+H7jMHWF8YQR0HCPS2Rh/zHlEsLVpF0RSmIwKy/4s6/6tvkPtKe62AvdSyidnk9U+0GG8/mGZwCLHPEzVPFzoH1qLb8lz3GFNF4t+Ujrl/9Nw+JwKtSfSo9YfVjtp8FSO9svnilep1S+Yb7l8xfI79Tq6Yw9akpsztO+qXADn06tpeOhlGLxfzBUDuhUO06FRMBHqhjmIyOstq/i49IGKarijYvcMwBolssvze+1S3S1dcn0ZuecH7CvmMtqTDYV7pgTdRg9gLnRhyb+5PhEwfOfmbal0sfpAbWGnB8N/EIojxTnXd8TW9sn4Ik9Lv4IqqhCKsZPX+GpwF6BfuVCiJx9ImCaBr9xzA/cA939Rv4Q6amAcYMLMv44lNaOaUUReeCt9YDudTJRtJviXRFZp1AwdHK/wCxBfK7D5fVgezx0Gah5WIqxcyNGlvGQXmK3hil0tIV6uWlvpH3jfL+3wDk0RlmgaBitxodpYwjk3O76uGizvYKwyOtZnUeilnUtaaj+hQFyr8hhNY6x6nQtNqOL4Yb7qLnyOpOCdfLXWt8QphLZkS83xxDFwWwma4m10zOjMSuhqrb6zILt94b6OEZs+W/YRt2y0jmW4A5lRsXrKmiBUUawyVaAjhIVDWbMr5m7XZ/sA57QOcOxVrnuMexGgZoKecsKPCmyXinv+IVmvaCN5/ukUmnjY+4wldLFIhLpq5PjZvg6/gEMkg0z42mqL1x6KhysHVr3GFUN5RvcKGZpLmi9H8ELI8KQDsVX5uKPKDGlqwF0tMYiGnxyijOAIHqlIaV7GHQH8xsjXQT0RD3cifaUqFjWa+5CwcNNn/MBFS6E7pWVfljbvbflUYpwvVH7guup67QtgfeVsESAMsThMzZRLBbjkmqKS183aDi295nvAEvUrUnFpTuDzqKlDdSsEXrArjCL26wDseUs45vdrVZgpsesISJDL8EPMYVQ5kl6WTFGvQXvX+I/Hg+ykLoemJiVxMGZvx/7NkXjW4NPuvxEhsMOB1cJTg6PI6OC8QpsgolG/GLlJVtOtriozwxTGi6dR0PADM5wHHzNNyo1nRLqpbxXU0jBT5eSE/eaUaGHWntOICWhfrRMdTOFVha6lPrACHMvXp0g5NuFPyPT2Ztw2jHgfm45NhSni6gL7AwmSlLcRCiI3WzzWd3CuKEzhZ6mzjpKJwnxlx2wVojyOgNFhzz11YXt6xWgeGnSAiwuor0CtcschMH4JdjClXWdAmLpuoA7NHU3mOuOVKwdNQA0jY7U3ZMmduzEpW2ZZbWthqnrRDdxaAVvoDYth7QpMGALGTpisHaZ8yKkyL0OD1S0uFfSaPAPrU6U5heK/E0whVloO5lGqNJi1cAE71nmfD+5WFjJomFmC2hjZ26ddypENP4bmZsLvqxVPPMvG70og/MPAcC7ArNb15lZQG0mzy3uN+7vyghtynUHHzLLRdB78IH25s0JrK/EVPGjLgwKve9F1A2EnHEyJxn7PEoo7ePNi8tXhxrOIPZRQ4DlNPTx0i0yqdaoaTP83HFFZdrY2BipjNAwQTZi73mHlG5QPNNXBGSqHMtalFGyUr67xDAUtPzLyKq05WQN3MXAPEdKp6xKGcYAb/0jqWrWHEygwTpf9qFGHhpjczdFXAxHwBU5XgcxyCQre33goBa/wC2MNRwlULWhV7iowVlYa5bzijOSc1A8IZv4Sqz9syxbAF7wcEnAeFMW+pi96pJnescQMat75Y5Ob1NBTXIEYULzARL5oW/uFvqQgkJFaLgprXdwCAXXcng4vE5sycrtuzRuFVW9teA6efEKVOPXPuv9mNNC42k78n9nEe0543fMsxERKluM/hFR2JTIMcdHv8AEGZYiXpFWcbfzG7aiG4zyK8PQx+Zx2iZOY7d9HdhvGjgRa2OsdnXWI4Dx2pYOCVFOVhGGjSldPZ7yz3ze2+HudCdtWimjt4iVcI92/zKLvqXJ9p6QSpaTSoSaatsDnvK4rs3lR8oiVrRwWnR5m293qkI73T7rh1qALQ3wWKOjEcRne2Sg6I6oZV1Ci1WezjXTEvhK3a3RBeroEFN2Iur1BYDHBuW/SxoK5d3WaDCVVqC+VN3euJgZJbjonu7hymzNboV4Fnq9GMVGrUwHqZTuRoC5sVjQxzLh9CMrEkXOfUd8xPpn2WEdWw94V/VG7oUB6lQfvFVEW5sMNrq/hKusT0BH1CLAZm3LXvuV9mv134NS3AWXGdn3N2XQHvHpCvWoDtX6jNV+BYiilBzXSFt/XCKN1mBrkTG8y9cgb9xvs31qb0WuNsqnjizvMNrjhQoxVOunrUrX3dKUpoWlFdom9zK0BprxOU44dl2uMudyx4oCKjtXcCtr4YAo6zCfAyrUsvcHDhOYyMBVkqlw3gcV31EqPDSrMjovm9xNsXEpVQW8W6DExlDjIqMzdqe4zy4ibUV3lG/ZQ/wH7lB8D9kcPJl/nYMmuk72yQzUuFzSob6d4W22u3p6Q25z6aTbj58zQ3uVJxAGuqRwAaOL6kMqDUGgb1oePMOkZmHRRRXiv65lINKs64sdOErtFupL4Lpdf52gDHK6Xo3z3+JqKTg/Q/zCitKPj8E2BY1XXjx8+EGu1lKvn+7EOxfkGjt1z6fMFJLkAX6l5JsdAKsU9L5mObGr7O3FcczMC8LyAKV0vUxmg/hSm8jdsvpABpheLyeRxFF6wUcZZxj1VqIqkouoy79e5kxttbPv+JwTNdPKi9MLlKtwIwow3rXvFBJdtA9hmABhpdvR6wIGilNblX7mcQ2Bs0XfZPSPddq8C+DsQJGilpPeVCmMcqf+QoRciWioneBhrr1BlbVCppI5JbHkc1DtDsrawu7d72xtfVBtUnodt5XK1QIwCBPVTCuYgWwJFguwDsVKskGfDN9YZn9Ww2O85IF2CuZN11ofuNMVlVlaB3f3MEhEAwvDL9zMUILCsqPIb6oHndmV0vy7pE8XX6zRnvHMtwmWKIqjnUtZJLKw04e8euiYdjw8tEuPP1dNMvSNEedl1RwYdncU4Zyq1LlT0CkVWvdehbDmeVmzWTrKdasK5Jg+o2XxwcZPbcwDZejP7icIrjoOfo94ICUef2lZOyZjharrB4Z1m+x2y+f+NI02/WMDBhOvQLiHzVf5cT8V+1Sr4ig8lmfrT9MDFQOAbnSnLAr/JpKuRbuplRcGkac3faUo1oWuLcB7st3/BmZwQKtsc1b+Ilwut2PcJRaMN1h+pnhn8FYzj0TdUIa/Eu7la4SIrdt53XagW6fgIwnO1ROo/ufMRFYewJqAgjQV2TPTQq+aF+IN7mwPR0+N+zMvBzM/wBxLaXWGVclePaZjnFuRp1KdzEyEJ5ve4Urr/HGnJ5QtQ4CuuDoL9Wf1LH+oxYGouSwc1Rv3jw+xcixfAsTB07Rw/C1WWZN9z4JaeHGuKv9TMt39JmjPTcxrNGZQrVd5gbRSgXCMaeI9lVtQCXlFaAg/MQL/DTtN10/HIO7mdatuPZwGIRD22qF4S4FlMGQ9AjxtQMW5ZUiEOICyygjShqS8f8AN6xOSrkKoxkrcHISENRviMlpyhFcuS71F8vCDeSppL606Ox8w+h5kQ+VXxLGeDQbt6dprx6/1bZhFxq7AD3L2O2VBUdIatO6novMTrQADs8Gs3cyhWgpXaduJgXF4tgVqzFVWW+NTDgEs9RfGBlYVPgKmKt2izONUdd6XJSBCg8mjnS5cCr4vjyrB0m7eeZVnOayb/2OyHQLbe03dJR7KrRbUOzXosFNDlrux0mAt3lQMlPGAczZsWFhUqHf2alwuRZf0diH+dBIwpkTE8eY08Vp6RqjNL3UwjFJenMOK65KPXMZirsDnft68RRjdgjOwpqY8bmhgnd03/eYPA6hYHKbHchbTuFPChNcoDVpL9lMvNeIFKnAx/ceYsjDizzDXIbRyU+D8QjCUJcCKo4cniaETA0xmsjlim1f2zr4D2MkwgDfqGU+UPZur5gUV7n6xN6xeHM96MoMnOZ+Yxbpq42h1WJXWZdZPBUZ7H0Q2LTethmsmpuiBOzuXz6dpbmvoRepZS+l8QayQb7PWxuPk5MJLFlXVjntnqgHb1Lp3cKlUAXqv1mR8LSsMll4QNvZYvrsd4tWMjRsv2le7ldJnXFdNU8zJaheK/Lo9eYha8UJGFYu6me6W74/uHhnTNAUe8C6CBZfPTSNAbZaxunciPLyRrmLdq381v8A7GlGWybAGq1dPpLQ+Sq7bQ8krnmXSXOXhUPFxYVOuPJL1v5gbwsjuHfWcFfMOpsToHYjwa/yWykG220bFrQaeSKDTsV20R6JnwwpnM3Znus6FyAby0eCuVzLBLdMuvj+67luBrGbo6d+T0nLypnKVsBZsapt8XEtBhlsNlWaXt1cAUOJbE0Ddhdxw6jdVMnNYV9O9e/jr7GuRFuY8zLIsqGe6l94/DCyhoBrHbX3D+bpW8/QjZmiW7lb3No7x1gPVcR/Jh4kTxKArr4YLY/qCm17+xAqlC3kFvDWV85aCrZhibccu8G2GoYCtsXqLyBinJMwDy2ACUWCwXnZG29U6Vtqyym2nsxnXzlbTRrtZ2nSE6RvptvH4vF+G5ZgVq1hntjbxOhazWTulhYUKavGlHTLkDV4KBoBd6Svv4OA6aB4lywi51LipMVUED01yfiAEsHaTmzgO1ViWqjoRd+f/IhyahsUaZ0yKpAsbCv2HXWYo6J9oeZdA5ZcP64nb/46S5Cs9eoec2pPGuzyJt6QG25yoemm1YzZ+Qd8c5Fd0ZKMxA+kC3Rh1dX1O8tHa2hr6ImZLesvvct0d8i/xAmbckZ5acXuVEjRO8ZUeqAQjVesB7qcHWVGImaleJTzB8ME5MZIEhfF4thEsFjcXGVORtTgXVZCjs7J3jYVNX6zcgXlF9IgXJqiz3REDtOdhs68zhyFbXNXPTU3gEYbG1Phv8xFCe2FIt/mYByXcqYGA6jfRX7XJQtjgcZYUqqrkG7rO39cPo8B+SLMlk6wdXUJw56M0Y+LmZhODAO7afWUYnWA9R3GPYvgbVesSChfVhMTaPw/3CQiqMqLsi5Jlp2+Bt6WpQX1QKB07vLuFSHCYszF3XN+Smb1ExzQHXH3dYWOifqlrdLeHnbUU1RLxUzdgVOiWuSfQ54BhYAiR4QBprDZvMXmAA6qfmJlEL8H9Qbent9pWf3WCb47Z1WV7vOKHPENxkHwkpdUN1xHtK7DqJyy+qD9ZUN8s3xLUQEWsKr5c12Zfbyo0RoIMl66PSWQIr4SoL5KxFvBYUg2QlbXnpO8Sp+ZQNVhkJdnQLhhX9zbqrFBqt9eKp4DVyLKrEgYwdljGe0exhgUHZhgxMVWhQ0fQaKOJFyY0ni61X/XtaGRugylelypKtLMOU2oU9IqEDDam2cZD6xqQug8jDfFVa9omKUbVCh5g77nPWMsWI4Y2JaoUZG8XDEoYTYqvzrkr1EXIf8Al4lxYr2MuWNkG5XuYLH4ehAij5hkvW+7cqzS7obCjiUx9PpXebPzDoxkdL0uL2esrlztq/bihOwJTxC9TJ/2Jqd8uQXPKwaXpyd1iNpyytGvrd+HtGdsOGX5AnU/EDc1F7TosSXi5dI4V+Edj7eeZmQto44aLq5dwayts7hiOwzj0bZe8oHP2YppLmJF6/om+HYARIWoAWFu5sGv+Qezlyw3ou3XakcDOs7UYAytbzuFjJeKYTfb3AS7ahUK8FZ1jjHaOWmdBioAduUENJW9e0eX7hdC3NXr/M6xqLAFI0K+vR2Eb4e8GtANF/J8xPTPYfaoqzKlEXrbh8sIMO3q2Mgr2O8Pflw9MGQy4MsZthYo+QQ1o8qcTGNLJtsXXNODk+5YQVHwTfgZ/wBEdvgGI8UJtUsoN70lJqVxTtmVieHc8ViqHQuvxLsJY4E3kCj0YyEpKa2zVTOftSC3XZPJf0wl8bbjNQJeNydpZQNBtbPEUGScLgvxz2zlqAVS7jO0OOpvXEvIpcWhVps4Kf6oSMiLLRaqPQQ1r35bbZY041KtMAPGOXj77QOnK30UvNtri73WiBZKFhRgtp/ZirlznWhT0A94fQLRkORGr1iatoM7NU0JRZVd4TYA8ha3RtJPXuCAK4xGA58xxAgXate9X6qmXacAvZNpYX7pmgIQgg2MB1d7dwNBvbbRRo1sGALmFVmuEVwGnU20kOzIU5DY65fdj6prgTYL5jw/mY12D0rORPUjwnW2jllDsRWRcMGiLvOToxXmGwgZLDeGz8PwS8yivZTOo48Qj155koD2NvadH/lxDw4U480s4DUs7gsdxwS0Wctu+ZWIpfkFp7vgRYRyHH6lnTJArDYOp5lKkTMC+hCRfmhMM3sUIPrgSJ6qrknGDcYRTlXP699AEHKi5ORNVmuGA2sRs/RC4luEpFAGv3A1U6CEGf49MTIG6UK/H4XOWca0OickWrc0h60W9LzfaExLQq3Mcjq11ZuArDyOzvxmLZYau0LhNOu83ARlTqOj5hVyXV+gcsd3MZvR6rv4KCzeT2NmvjBdwt3xku01tQpczMYMtVNBtZRemghXOrBNSqw3y1xurhzD0SmtO4PC49CCs3AxshKp76sit79bAft2uexRqQsTh1mLu8TkxMAMGMc7IJjEbY5bHlYVAqgmrSjL+uPYnZIXRbhwmm2JSyJVcut3w9JkzfpqV+5M+MM1j73cFNsc0W7eECorEsju4+0poe1S2XasVfnrCbbIFvg6ZX0uFrehw15mjqvtibk6lNG6J2Bimr5jqIVc2yV3e2o2tbb6jaqHdgGgoRZysYrl+WX2Dfga84g8HZzxl77aqDbgvgCuWcmRWrHeNs0xld5DrJSrtMNFm6zI63K6CNPH3GpgFdUmHuwZeI3TVym8XLisKDyxkmnaXsiLwUBkChukV7OkAAX3SL178QrFnKxdurNwCG6nNNaCnf8AT7QOVFJNMkmgM+Feuop0LsheLeTr8kd2K21ABc2DPiZR+9P9Glu33EWJcxlG+MQLK7DWOTwmJeyewIwe59GVHdiN3RQ6Lv6Iqh3phn0uOeeLsYk/8Da1UoK61aEUM8xafWqgapNRTBa80cdmMVTLyVeDWi+SFJyLnWdW1mNw0g/hF9Gbh8Lb61Z6VEaq5iXohq+qzCM4+YD7I/Vea/aDDZesK1ajGdVE2IUEcdY1yWv9UE/NDfFRlnWe7FTH4Vpwf3LZnG0yQZw+ssBcAx3HWra7o2yc6+gV3K94m0gVKdLSndmf8yCxWtej0h30I6Gw+QjssYiRksbRSPvWdYFKOKgXk31DykcZbCWOHNxzBFy26x1sR7EfWLT/AMRkTHSU9NW1VViFk1YqjFHkqzYsWZsz2Q+CNKXCABnsvXkgwbsFtC8W0avbfiYGdNQCD6FkM7T968YAAWNl14zFru0wNP1C6brBDL6c9oEEXVMOQK4pzO6SVSLsHJxfaMytAhQ0YD4DGYm/8W/zKdfLsyuk3HrFhdplgqjUwlvGTktza9vMLaFayzx6s7aijwqXhs/SWn+Nk9RXzGLmMsugrzX1HgO8QUeZdpKcUHOqYgJyTozWc8JlwaLXKPl6sE2iIwfzBAoLVza9YqhukMhO2bfaiyuEEKwKjEDmuNqFiIZWxyg5j16kdLAAYnBnh5wVllUYJUvBktmazjZrOLXIHTnQWUdIs3uqwyOJMFvWIOJ1QK1iz/pOkT2x1JfTBrmHgCZ87Bh9CGU6ZV9N0bE8uYurDWnDc1ouKPzuFIjyxLalbgEPr3pcadjCNVdOjNd/HllvaZWhjJ2m95lqJ7ew+n/SDi7iJ/B/aWJTpO7L/Mq8Q6L+5hgXtfKMMYZvUenttxSZ/cECVBpjlo1Ga9j+CD+dT7CzeeMD6xkYHj+wnQtEna8F/lKIQGQOI4gWWCYyPaWitEYymQB5mnwlFSsHgtgQI379CuH3guHM5XocB9zWJrbFuDq4Z7L9Yq/bgro2+23rLeCyJgYEDIuKryMdH8Q0IL4Y6xJcOB64z8e0wsg1wjTd83OrMwUi0nQwTIh5gBidZZKKnIo20dCPcAFqm9nP8WamG0YnCV/7VlU492ANZ7ysqrmv2u/gJbimzUxkVdwsC5VvF8zUIUtqjJjrmfS4VPSCs36GSWkSKNJ2G26iSZCVXrbGcW6/JrcF1htuuc/cb5yoTOOCr5rpmdom5UsZSlMdqge8LIQKyfw1r/yGdn+f6MpFwE3s6/ukW0agIZX4ZS8hAZLMjfQVHODMZDcgWGKL0YrxM79u2LO+7Kb3uFD0CpjVm6SereZZCjaIGr4HxZkN8H9UPXce75nKwB9kTpTtmTgOhQSqHwj1jgXWZt3RUIljuFeCisveL0Lc4lI8OeY1ExvH9VBxxjac1JvTliammLigeaBQPKuIpdbNaPIck8591PHrSrU7UaoQjuGBTZwFoVfbUGl21iKoMKKvmzpcQjSUjwzf0/8AFyx3/wCdYNG1OQk69me4Uw5YGWDcxEGvMkockWmai36lS7aMpWNxjf1/2MnC52HpMkFZT/wXVDm1dQfihVZ5cMxLVdxFw8wIsPhTGC9MjgO9cCe0Gi11DicYv3mS98fQmGL93zLHYIfZcqJWlja1alWcrRq4pTnTNastk2Bwxxjo2uV+YFm3hgLduwZfEptr9jb5WsszEfw+xCYp7BaDu+XtMS4dAKwt29cHiIqNFd18wPEi0bKC8wYdS7a3orhSDaml1SrwJjrLmcURarHf6giX6oyZEdOyYQvHZ92MF6zAm6tDKsji8of2PVlehC+QL4mGANCoSpxlZecjO7MV+k6fiO2G3c8Rwd4OVAHzqGJ3vfaBoBSOEYd/hT8B/EqdvJhkjMF1lCsRg1RZKJwdNy3eb1pVrrndwVJOFko7wOqg6LVjC8Baz5jGa1e2Pdy8+IC8BkAoqIavl58h65lG1hNl8Lfkb8SorZkTSQ2QCp3g4x0Z87dN+yDmarCchbKg9Tk9je1veaEsWAUQOB6YHp8QTttvHfFmnzUKktFFzScaaz2v5hPK7YcdR8xsy3WKQAa0ze/WUBI9e4EcpyMs6/V9ntuMq10c+v6QGIAS5F5+WHaVaLw/ALMpBwrKF2vet7heyDyBilBej95m7zAxP1tR3LuXzJlGrOlNedw1acr8OFLfrHdgCw4dF8y8ipKo0ovG+jD1mDQMTAdgX1XoVzLUyQXLVZpm9QW12mAJwjmHf/mBZYAbZbVFry0q7ejEcdlgEGwHFY4h+VWN6JgcJ2IXyxTmODkx5l/RKrCeKdPgiSt6/JShtbeEH3C2AY0ENYcj2xFsT9iOYHR0gGl3zRjBj3QF5aK9UgLi6LvnXM3WEvS9ED8gBGhDjR+49CqzD9QZz44ZupdKl3rCMQXhqK3WStiTO+su4t3LNlduUGLwj2dJc5Xyxi677p1cLoOOjyDv3/60TCACE2jtwYgzxqswYXwA/knkm+EDSf5WHMfFlYVam1roIoGtczjrjS14mCj6O979oQsl2xMnPS2PM0gK8htgB7znATbEpNj5Fg+0yBE3RMb85CK7Mk6XyoS5ZRnbgr1loUxUG36LbyB17esdMtRtWUJwXjo34mnFj4PzLBxb9LfkSYEqX0uIDHoNQezoHbzl5YCvRMWN0R1coWXs19LKOa3Ne/71hq2HMdSz8Q2+Sg3zf+wZcdamRWys4x5gVsVRQXq09oivNlnKqe8L7XMkYux18kYq+7Q4ejp9UXR7I+YKtVpDvjpMZVK8dCJGqpborp5uYaQkEIt5V2l/dXd31VwEMNyvii8KwZ+u8dWGFWnRobqr36QqGwK9+5d0LAZ0ZxmN81GFNXT+1qOghukL64lJbYAzZ5PMDcijEA1TeIEQ18lybLiI25qNaw1B2oYZYLQFB7AhldH1MQjqJxjhe/mLr72svch/11iMqv4MQmoFgDsXPrE4IBq8lW+pYqCeIlG5sswTxKWK+Wo44pMf3CUBpnjJ7TrVgRaVtFtKhIjxRezNMo9yMRHW2rwo/MTd1cUbXia1PWbMLXb6l4uRPIFexPW4aTAjaHxFZORXdV+WItFMgaaU1vqxTp/DrG5wG2hl2Be19Zh0exsi3UGrvTCoIs++JeK3/wCtQhW0dudgnaxDtg2K1rtPwt9zpu/mc0iT761dpoZ73zK7k4GrtN2l4mTXfSrmWJvqGnmKKXg77/KomoOR3Z2ZnWdxfQ0HpHl3S0Zusc79GAMxog5HumUpteDZnOkf2YRmaGwVqtR1TwQx4mIGZ0eoy+/MtdUztJ2hx/f1MiaBaNDRPGGc+1aY4Vvr3IXnADtqi11oldg8stJSETo6Rmjehfr4jG5cWN0v5jH9dcXAawOrR9MWDNHvY6PD8zCPdztYdvRmzxGF8A7IkLNt1wLcTCTs9j/cW+LJrYXl9Q/JMt1+PxDhQVDsjFYoq46cQ1uNSkKCjurZ4TgTZfwes2093faJU+qXMXoATSdLL9YIsK5wK0L4MRlQp0PfJ8R486bzV/mNPinO/SB63sB0IZYhptVS4rDGw9VgAdCNrL+2NYbxed8xENLW8wv0V8z5G4zp6yuF0fK4Gd1cY3wGu6XkA0BQz3Y74SdD2e0vN22ap7+I+QuQHfiYbfm0gL0Obi9UharK3cZCLN0aI9SC1LtuPXmXf/hzEyQvOQ8xQH9MS611ij5GeTq8jbI4GmusFSkAznVcdID0JbwXrTasj6G4kyodJjO5/VOcGKzmNS0GBnfUpcIJWOqtGhrhbz15mTgJSLbu19/aGeUADT64pd1r0mX8LTo3uWP6Ea2K21MgouITFod2plQSgX3HoncFUfzGu7p+tn5zc5U57dQ4ibHBOlQiop3JwyhtNmxj653wclcy1EqB3tWupGsBRRfAvTGVeQAVKy7DNfic7Cn7hVyY10nSsjOicDlvwDWa/cLSQDjxgpOGjPeWmWOqQ9I9+7Gu6otChuy7K2VnzFrtxMOVByqn8mrsP3OvXkfDoD8MXAwSgc5L3n3iIIYqeOaDAeGx7zMpFySkPUPaIW1mbDorY78XDjvJaGqx9DUMruT4Y5PR1xyZW2CwuQaYlYoPRL0PFgTjfaVQh1EtkCrOpFdzg3f9JiaF+4m06TgwLKd0lg10Bvh9uIAAGE+AtK7bal5GoSr1Yes9eVVA5Jas1j0hRGLpQOg4Gw+kHfh6FnRyc8xJLMRG+S69PmEJCValb1bX/Zig5aK+BVBBXXINA31K53Fla4oHVzH3OfaoNfVWsfuL/X4DcDVXY6q7upk6egipzhnUtFyIY+Y10UmXe0raQciwlM7GCy1bsLf3DAIX5hwnVQ9PEQoFRbsEXGrWj+40aKtd7Sm1oQAeRCISmTusywG5l1er4Rg1Cr0b8noxGgVbnGAS833HQnurqFAn5PssV2NqWwMLjHobj0UlcsAQsbQQ5NJTq6WXRkp57m2sjQpVVvK82aj2JTghPOEvT4TLBlWNHV/HvCZYeKIa5kTKrC5U9nCjua6Xz+otdcb514GrdbzFawCaCjB1esai5rNLXnZ9fMJ0dLVN+CuKz8TLwC7zouvXrDKUTLeMCY0us3dS/t4D9pv36D6jto9v2iV+7MaWNA1O3/dJa7ZzTQ6okMqGDUbWXbxKlV24V4xmae4ECNp0v6zmZdqddRkRsatjHrBDlWens9YB/o2gw6D7R95nSrBbXpiEBEoUevaUt4qlimoNxThrcS2zaBarJDqbBwQoWiMYfXulk9mFbsUAGDHTicJARdWrYwbL3KYCNw5yd3XVjGiW6ovCxnvfzDWdpG8l0IZrPX9znGKHcBn5v0lNu6POfZ8cPLUD8dqa7TFrOs/UVUscjWUKE1n6gk1g4G8VywOajVrrahcqgs6GL7wBJaCIsddFvXUHPlEJHXFzcvEUulgtrTqo21WmY6oIAs5sboyZs06j2KsFFSsW8NFTWrLVm+w8jrCD3ThiAV0au81K5uRZngNF9+Je0sobg2awgpfXniCdNlvy1N3jJLQ1/L886iJuZwRseBarpF4dNDe24oPq8cxBn5AU6wUMfPrMpvJ6WiCtMJUybo7wrNuMSs1oiK3jNHGN2RpSSIQzP3vrGaapZn4LxV88fa8zllY1NnHjvfMMby0FOQwX/ZgR4YvYj/ajhaIIOuu4WS9BUAdHn1gFBKQ+RY6Y9n32WSceo9JlC0dBbR8pAYtE02j9wxWFaOA38xTl7/xD58XJ6h4O0dhW/ssNRnF8oejB/h5QmVMD1sD5CGpvcnL/AIiC4FVSV0pEgCMCHUtf3MYdNiJgdg125mJuHwK3LeJZwyWfCjQfboOVJw+2sbhOFaPW4vRTH3AKAnWzUtNPRZWg1Z2Ii6DRRmdVReO2oDGPs+3h0u71Lh5ZgqjPc5UvFqv1e0AOAsNL/wBm5lNVt3joMcYw5YJIVEAi9cMH6ihY75HTgNcGpWLIR0AZz85qP1DpFKaeL71My7Op1nqVOhhEAsPbBxcfEv6opOeJZc44fUFdFet48xxSoolseSdTCIx4Oj0hPFY8Wok5ZvS/TZpRhb2HoIHjc2jZkF2ZS+UzesGqGFr8Ep6Xg5I94hhFpvziG82w5f8AhjgGIcm7suE57es0jyhaODr2fMN0sGhWYct60e8P/ZB2MGnbVc7hVrkorxlusV8x/Yut0tuM9+2YrhN65thXdbVSDgwEcoKz3M9U5iZR0pCs9xX1K20PX1oWUX6jGYQ+eozcXJyYP9w52iqnZZZqTWCV0WK1nYsxGAYS5C22AILHTUyU9LDBeH3ZWXUszHHThfSC5O6i2OcfPSG+SBtf9YwveUNgKkds7dlQC5VTgO+1avNAnS4kG628Jly3vZcxhiVdQigfsq4xd6VR+Onr6RQXpuW2c6pmgy10XG6oBx+NNP5iDidtkd8Cuud9pTBctUeua7b9K8Rt9nelhszQe8B45HVuLurfSBF3LVYOg3ejplzG32wHtfN4ZunKceCdJM1DGmMIzw0OQzMt4th3ukB9PHSVSVAnVKvUs6eIqW9U3SV3hfmMTjwaHWZcbKjPVRfyuL1jsiQY1hQN3Koi4L7KKE90ACJ/sSm7+Ev90z5cJlLkLS/eNNEpMC+6zE6Dl0gC8mekRwizYw3ZkX1htLD8VthKQTvVr+7ywye+y/UuDRz7YzNPSXEc3gtRHpfBzCJgOYc57O18Qi3YL8Qf9x7W0ATOozkXkDpo2JZ3CqhtM0UnZwEspsvZ960u+4mqSu4blN6xnvWy0wes08GciVvEsdlWtwismbKcdY8zpLua/Wb9NehV26WbOrvNTmMC33h4qZ4u0XZgtGoeIBR17rK9T6yxvpPA1Qe5rtCRxl5mlYKooPL1lvAS0ouyXi+IjqEUi5XZZoz0JuKkySreYVqDbVfPU7gwxnOYG126jE/MsayBNH8f/C4dVPI2odrz+Yj207SoA1puk1OnbvRycQOQsLvTuTeUPF/iURVypVyadQLCEXdPRGQuTFfHqyMJucKu1rvKMKsZFrJ5HPeB1LrWReZcV05lmEdkH3Cm19on6wNpi8lORt78RpDllyNN0PYd/eLkCvXHqtZ5mYjBRvhTTLvNVPcrgpNq3trM4NKfEYw0uuIiwhraVnKj0Y1KEi+FvaqdXmYixw32Ar2hMEN+MpaqdaTZxqYolAXOrdXepbeULU71gNX+iU6OnMNN6LsZv1hovJkLVwGDer6TOwhqvbMnW0p6w6FcbkWjXMgRgMDRbrbtMjWEfC0V0s9EUpWccFvaM8qAIbOoBE7W0dwYqNCuy02ciGlhMsA1dqnI9pby87L4bIgvNa3voAeIFpFu9kr7295WHLFoOS+SCLALLPl2mJflQWvRm93ecFVCjNieY3m7fPePdOPU9QMdrfmHZwDYOmMc9L9pRD3oOVnoEz/Wkf8ARPaFNarT+Ahrb+R2hpfM297HA9ynE5wVYAi1/uZi/WLupbjN9QOq3xL7QWHZvyl9no7wAdi3fQF0c+sPvopm6l+qswZwIjAtq0eKYfjtAgDjoOs1WPFpYWMPqlhXojru9WGaNRYNx6AeswQmG25TBbLu1/dO0d3qVJeUMDWdHNa7sSV7ajqbOLNCXnOper2rvoF89OHy0yxHhbwW95s/UhWeCzV46JjB0kicOS6Jy1HT2kqg932T/Qe9JbniuYdtXUztsYWz8mMQjR+QGNOlHuyzYE8BGDesxUWGS/0MYP8Al0tWGhv+vXEF3kJnl5i067Rq2w12GMGjej8wUbMsL8p4083LGAhrEQxBKd+I/wCTMqKO80fBm0B2T3QrJD6yl+8PSJ74QHOdeZ7VShPXUtlSXblX/dY7RvIjY4y5lT7dW01gaxk71Dsfgyy0u/gRFdg85U/TKJZWu5s4gU7DbR71dAPp2lSuy1F3vAIY6lZYgtaqdV8sXVRmkqnG1dC+C5iQMXq03F56ymh6lBacPbrB+hTLGvga6dJWngyELyOS/jXmNjHC7Y52XBOXdYFvOztM34k2TknJ15QMmJJzyxXRc7iIDcs1XC3bvmpU7pcoZxRlR447xDWlk+Q6lvHe650QtyvTnTiC4hbWLjhLhOr15i66DL0cKqdtmxll6VAOxCRn8np3DLajJ2Ws9iUqHZ6m09QuIA7sulbxANK5lq+VHGso4IJtv2lQ0UfjNLga2puXisn4MjjMdaxctDm3en81BBaGoPKzbXGPqZcUDL/ltJpwA+RKqc7ody5xFbJvPacwLkRhE7Ws57a95mgkg9aurPQiCMl04M26ut9JgmGUMnOzjnmOoYJkOTqPj/YxejsMTOV7ysH0KHPEbtAXYF+6iB8FTzblfSVyoULOtsPrFrD4DKoKrvAa8VotZG5PaFKmolcngZI9vHUwDvocxQHM27bHLl3palzlT14TsSwvQz8AYqAld4YPQPyOpuEYIu+dxOAIItTxh5jU4LDlqvuF9Ngz1Hpp47swnMHFZ9RValqohEg8PUlbXZsJ/B19IYRs4Fy2A9aiOzosVc3TKqrMB+ibmrZEQvhxcw7lDnVGydmMyyx2fVO53Js0uhm7cWYnG4MlOaXnnGsEd7mw0JzJoXSszLnBbZTr9xrtBK1Q6EFKJq5dTI9f4QVSLC7euYNUTsRsk6jUe8tBKwH/AJXhamVZVfb8SqMQcq8u8sFtmLNAisIKn8l+aD48FcRK9xlKV76WPIipoOdV36fcqI71aEKuwTdUoqIb6wytp5BhT8EXESiOqgNfGvIB6ha9PWO4WCqGqNdxaNDzLxHo6nBs7b3FhMlnZWmFtsHDLQVMx1kqiu7N1cpqSFu8B4H65hoAKhDYFB07NbgNL2X3WRR/EwBUvluFWxxKLz9HpSGsfLA2QlcUtVjGxM88EHLbi0riohCvCC21m8v8i2HSIGnr/hFVgWWy9IecwEMLBfeFfXdS1tpmhrOBrtCYd4NXwpPd8wXGwj/QZ6O+ZadpwPfa+P7dU6vdZRWTueICSALOUayL+IJYgvyIWla8sxcQNg2KD2HHxGPvddYKVWobDy1r5Ug73Gw4EAtbfdp/UCZTEloSWPq/MzVr4FatycvtC7EKrAwK0XuBFTW7wuvaJGY2t7Z8P+QWlVgM9V2e+JwLq7lOr0LdzYScorih5P3N8T4hvTZpFpmF2xM5F17ywoRepBBsXHiCAOq5c7XZkbuNGkicBFt8ReWqiuQkD0ymIVIxtjbmWRUcoKpDzOxq+u2+0SkngB4ZfBDfRHVdSJYC2xtbNP8AbiOjYpKpZzl+CLp+iVNnGLT0jhaSrtT9RgMOe9EoqjteLDEW2IbuNdSXNGfiYCZYPqMZ9jCmKcXn96wbQO2dtomQgrB4Zq05gCqadWZXLe8rK9PzGUnJcK7bg72FP9GLrvLZ/cWQwcgnYmnQHXHQ6EXSN2FIxfLHABxzXJ2nTJLSwvrPUES1b7gDVzCQ6FI8e4llbz1ef/HekA2JzBSuBWIf3SHiFijgwPdZBzK9CVgqLMRe2PpZe6N2a9FMFsu0dh7vvAjvDgKrGLoPQ7TI6kXwHpdf5BSVjagrrmhrrMXFw36us52nyQrZxVJfi5QtxqEF41uusYbtnNVGnbreJToatOmMubl9qzNz2DFqVhW9jMz+zqKD0V3qYKBEmsjDGWjneZRgpWtmsqy+Osu47vDZYVqqzdRupITNCi36q1LS20Z4Y8H+JXtCtLgU4gPWQ7nCuymY8lPnH+PMPH+gToHT1biq1X9QZzh7kgErtqNg3ia4c9qJ1lsw4661Fiw5XRreyjPSHWjEGWCa1o9ptAV6oYIxXJE3YrOuHHRz5jbgnVu4LsO8uJmW4WabOOmL73CONjZwOL7PvKcoJEGeeXHM6h8VMoVtFXqZxtKWGcps3CY11fAqIv12EnkTVsa4JxKSLHcZdziMyDLcs4dB4mcU3KNdOrp4b6SmAwhgILVdywfSWqsV3ziIQMtwAsqvkG5hjfmFQpVV7D9QWrTl6XxDes2FXTtEOJoXBbKxkrqU/wAkNF2hLripklE8q4x0qDSsr18TFahlvdXcRc5dG/DtLJhHPPNp/czneFWuxr1v6ZfgOjl/AmiLTeAM941qbCDgi+wAx4geWMukrVnpdMpwJ1Unmak4F2zdfTMKnsKnTqDRZ9U4teHT7kpTN3HQnHYZmc8M5nbOxDA/xKfnFECp6z6UU73OYoU0jA63/iVVyffGyCCN5uWvwhZ0zfneXBDJJiHpTcMG15r9GBFoZzHc1uYg6Om8a0NdUekOkRuIvTW19XzqY2eJjGEzAi83b6K/yYntobmX1WmiT2VkNzok257DJ30e8yP22F3cd47uO5bxZZCwes0AGWPex4uzMqV3QZQ3uc/7DQClPUCkmB83GZvApM8p8/Mf3jfHKz3bTxMLOVDCNdvmqxuZK2+aAUtGrC+Os2KCIbGcugldViAb3k9Nn0IVqAvHNyFSt9zBA7dFOzrTkY7jDAsHNJ1C7mBUDxzdugxz1mca2yT2m81eYHMG7Fdg7BgTW5tsslcN8PScrOCHFWBze9TBMdqNox5HrvMHCSlieOPEfhp3PsYzV63XuDEvvy1OBdfUpbPG7oX3szUpIVsDbB05mssgX0e8p592hw30qNZ5ySn9hBEquKFFz7IogVGwAZg9ClFI9yrleqhDat8fZL7g5KsGHHWWcCjedh2/yN5XZZ0E1zn4lhwSaNHWo0iO67JwQIZVdrGE9KCtil36wMrkxVeYC2w0CVBc/hE6ykW/gA4FQ2ytxctR10eIFe6qrddTwAL2H7l0+jA4f9lDwqMio0PrX/YIA0jX+hsjyceZn63pERnJNP8AZmaphN+kevLPqrmfFnbT3Y82KORy1GMJQZxls+5caoZ7vpXrMciOxl5kPNB9yY0zsftlu84+6FGWAE8mVAvEPs7xsirDHaVUoIrzgc+gywY9K31eK15jX6LHvR81GWZ9Ouz4ZS5d4158SypaEqz/ALhtgHfMfhWuNQC0reW5clE6dZaVHOWH8qGnHAVqLrrYHYOO8p7BAwRc8+Il011NGsf3MUohVpCZbawuKvO4uvHIu1Xf4jyVa76PHJ5uAK/lNR+cWAlc8jj4lYV4UNgVps95RKWm5RT0f1wUaxLUIITvZPMRdLhDaxVtpvV8kEN1lnHI4SS0Xqsi/IC63895no6nJ31dZrtDxStQ8cVasj/Jl1lzD1aeZb1cw6LsD+6R62MNocHO8e8oClbMGnCXXMtSy/wDNPTiXNrLlysGWed8cw5F36abEMf9j/EzwLqx9FzMpPMqk/JAdeMB+aRPTW81vC10jsc1dfHiDrZHI4L7HnrDpKC8OD1i1tlwcGTFcsbrDzS8MLQ+jbBYXtFbV6bXuoERhNuuiutEAuiO9Tk73KuAM0kunoUh4qGyTpCzT6GKsnzRHtfoztk2gyDw0epKCXpC6FuX+XFS0pFl3Wpe4IKt1xDV9kBHoMB4xqMsa7OKO8fSpyDib+YYivr/AOH1nEoEsui0eszyZclDNmLjp0AD1wllvnswzt2F2O/aVMnGgT+JCJBVhu+R7fohdVOf9AjCVLZNdXrDVqdB4ohdYZVlDr4YZhUHpKrernHsSp65mDWhb02/coFccJf/AJKXVy94n6gtKwljLaa6MhcUNzyZe0oWB3Gr6QNKgQpReT2uADJULSpJGBXBM4mM7w+asX1PaBxVsWBbC/SHR1PzfzBC9PVmnl6VmATGfVEsL0GWpTitnRFqsvqfxKlVlw0p71MSketfD/ZjnDOjFb9ZT8RzhriW6G4p/UCbyUWB8xdeGkp7EX+4nwH7lUKPPdeOkw9IPCO9lcBP6z4mfxN2ZMsUFAHARE6WnDwOFbrtFFYCRsCpd3YM8jHCudwF+e39RD+LJbEu3Cw0nvzCneC4usFQdcZjNvIuFysPJxDFgnjPLALvbKRjml66vek+Z2/iWiua5YXWuAZDDWXGM8QTRmQ8BXHWOuIu6Lfoh48fftIXRyUox3eZcx6k5eh0i1Zoy4fJ5JmBxfdBi5gPu3a7P3Mb7bX8NTDYlXQruygmQsBhT17SxuClOyw9iA22+7wIDoCNF5D6IgbzAteu3DHq3IHD/cHWu5uLUq66wxlTF7Bo7ceGU2Bg2tafziD6rX7C3gf1KRF4K8J0F6JWHtuhCebazmNpJcBtpmKQcTwJb/Qg+vvMxtELCKL9oGx4ybKKvcqCGy7nQj2cakmiYEorXWy2FV1xo/5LKlOZpmzUUCNOLPLxKDcpi2P6lD50uhKc+IRV77t2XtAaHJ2Ofq5PEDuAEemdV9OkU1plyVvr7xoS82rZe1Qgjx0lA1/JUKBrLy2t+vqHRYDYd7ihkNSxms2qYepO2Uj0X+MYMiN0h144iHVFTbDs3qYcGUQq9O1RLJOQ0Kuvaf8AamIzgNzNXSrTFUpl/YfRpjIy5oAHLPsnaBpAWO/Mfjvqyy/lqqp3X4DLwt2OobvvC2zBZcBwRGAYL6ZnzUsDdF8/7N0jqyAnxR8soNEekIYp/pCiInHbcr0AXYbkWrg01GqaFGyJdHR1K+Y1dc1V+1Qnzo4PTvZNywpQjJAHnT4nHUSr+/rt6xIpDTpfS9U/MRwq6ssg5hRAl9FhwxzN5b7eBx5jqLcA2P6gooPbYXdpsg1Q8COqPCdMjw+ISqTSy+DrB3MGlk6PEITeQPdGLljg1ENdSus2knfnsevWFSiiXbDz0i4GhfQYY/keWfKpb5X2g9GukZUJ+mYvnpAlArs5ezolzWhbUOPoRUhMLNA69X2QqMT4dmcNiUuAd1bl09ZeQaTH5Bj4vmUIxvlUKP3r2lkYgdDSvpx0jowsXZVA83KKzVbIQB/yESZAlx1x21KWnIE23pcV2g6gMd4Iq0uqVWe/2jLQ1BHC2Jt7BRB/TF6WNKiMcQ1agLWZZpyOJihQLbIxfklGiE3CdG3cJMXptAF+7OSyCWzyOsxi49vFl489ZSD7ZX0DbPrzAUK9w4P3z6zRHy7t0vmB1qlmk7eAI204fD/yGAxn0/EpAm3azEQFKN3jmMevh9TgJ3FwMkWcj3gvhobTlnotV4mTt2DfN4Z1DNHYAV5EafeMqfALNPrUuh4peesrqw7eEDw2gywtrJGGT1GR2HVCx09wDTLcQtjDoRHT4ZSxfnDnIjUM9S4ryJdmRlqv4ohziCpwcnbMwukekw5smzBdjtdXH4F5QYMFR9UoYyMXKsJhXe+YkcJ3epexvXvD7STpoUuudb6TdEW7K/JXzF/7M7sCYmiFaVBe9H2jqv8AQLt+gnJhEvIZjErKhrhXmV8Sr4J3eJXY+/mOLiyN3KddnmVON+tj3xGeLBTY12rmBDO8c317wU5aEUXj/I7B9s3dekaSS1HqQ0jXrXfSB1YMByq6t89YQMle5XV3thnlSjebXw7Es6LDOO32dExKkKXCuKhwMOtgK/eExLuoS1R9fMccvnAbr3Z6kbwsTnZeybru8xx5QFI9fDR6kqvW1Tjsv5YwO85Bk4XZxnoSySDr2nd7b9ZfNrLTQcd8y4cAsD+XLju1tVFYt7bneQ5TwNcI8Bwf3coLiGc9uphNBz1jZpwoAcBgupVJEYBndjwwQfsOABp4e6IKVOzUKa6owBzb2f3KmVi1YO5yeZb3Xcgdj7RQtmCrxz/E4XqU+Vc/bCZrzlY2L93Gxo5Xqz6gBkWPGWVteIWR51G8o25BKWoaepr7YVEhKjCNjRb/AJpgghULP/HHtzHtgOFWa4Yd8PmX2cbCwn8PJMMHIXq2etT/AIktED4lFU/ZjOX/AIxewRUARp21+CD4jnBMGIOrNFUj3gDEcKePaBm/idPmKdDXQJ7MochZ8k2sg61d6ifuK4R95Zj7iHAxQ2yt30l9CVQ6wE8X3su5UGukK3hy3IF5Fb731AUOkDOnPxxO3bCcDnsDncKVB8b0nQzKaQDLbtdhLkYdU+SNtcrzdR34SmEF8A43zM+K9XdTcNxbbB1QNBS7YeRmGrA4NA/XSWYvLe5C0VgVWdo8xSPapTE35Jgss2H2+sAk6zG0/cWWgr2QaWOhkVGm+YarpvXaOvaXVtrpFGG+Oko7GtnvGFI4uDGtAofE9PqON9LzNvwlA8kF1FTHs+8wCHDQxsdMvuHV41qK/wArw9YEvcOSAfB6HZG6h2wvkOX8jGOBRvlwPj8IagHWVpRXFjml6RQAbdbeEqaFk2wA/YlL7KxxwZr4jiOQBmTemNxGXj+f+/Uq5ly23ZPQDq6WkmZ0zrc/REnedkUtHbiFt55G4qo25tpld24aQ/ldPEe/S9ZNLo8Tc6P8GAPv2gjt4YMv18zjEI5Kqv48wGmPasjj7l6uADmuszG0+eGDnA9mdDeR0jHbehN112W37xzzDWS9lcy44VyqcY+XGvMRMKqzq6N86/eIYHizRkp8YekxxAwV5Y+ZxIbovzB6U6ZVD/y0J4L9YF3smBnMYLi1riBHI0BlhYrFbuBQXDOKzPUTBN6/sQ+jGdz/AMt3ATBlWkccMemWJFXUReL1RYDatUEvJU7EBEMBnvZCwHi3mqcmfq7QMlvyp9nu9Y44VkGoPR4wxOGbjPscVMlaYuzCr0YMRrGqqkz2VFqwHO5B/PMUk5xaqHR+UAl3nVOSu8Hzyc94ZQphmg8iwtjKhHboiVV1/Ab9YuaRoaPeHxXU05Gdd4f1xdGkTDabfaDbFl0ArKMWcXNpXnVTKivuA7MTRyOOMEbu+0L3Za2yw9NI+TESwrNJB7WHN3LUYeeB+SD2tSVtoDzS13mYJrXi7vGrggamNajtmYgjIiOBo/vzKYqLFx1R0a9ISpTzTR4v+R5KKt2jUplUrBHbGpmvnYo/MItAlLV9S9egy11KiOBHjJgZkXPx/tlGw9vA5+lj6Rc48+iR5RMZwiq8BcWlWaXsjJS0G5Xo9+3rN3Rp6bHyK/MxO52jWC+I0ecdxx68Rz5JhBEBhMy4C1zP99Z3HtgtWToxsyKdAWiNW4DjI+o49alcw/wAEPDP6lzlYHlt47/EM0JVka8m4vhta7TCtGAvnFa3TQw87lDbw8LfqbjKucuR0d6gzgWGExUdC0kztj0mDHzGhhu2AMY9ZeN1zzFO2COHmVbPdBtmo9UTm7I9XiKtMdvCWRnYdHVpnHzQKLxbNHq5qC+lRqsD4sQQlr4uAdFddXCpRLBdbrdjrmGEeWjNcsVWaAyZG/ollQv9TEELaAVwQz68RmIErdC2xFUAMVeOKWyvREC6y3nPPSZCqSRfA8xxYQbda2PWUl/VVutai3sL1nWlHW2+/wDsopR86tDcrs2YnREzU59kP8ierO8e8bqq9twk81WYKHcIffoku5DN9PswHtTEM41DDgvxx7SxioUpXIO5V+e0VoeS5WD44b8wDxhrBOL4Grz1lTbOCqNXzLkh630nyaP2h0tzAHErmkXR+IvoFNDX93LiC5vwz/I6/wCFQ9YpeYmhyZoHq5ZUOJq+IDjiEYKzZ6x6gtOT5JzevGMR+3fLMjFy+U8Os68PVhOTT9wvQuGMU4rrHMROZXeMNxo0M8Mp0tjqtCobuvRjj6Jm2u1kLnu6+5gipZLMDFlp1grHrVkpMKit5qDRhl2ZIthmoKcH/lu/pyrh1DwNopR3jRSzMhLSlheI7mLngInaWxUWOPRS6/UXr2DLI+mZ1GHh8jwSjpCTbodfMVhT3cb9f/KHE4EGHcmx63SVq0bW3Osc/EXLXTDBwOcZ9J6gVO+c9a+5VYVfUaDqX0xxEI9YsujhXaWFe5gDGcm2dGDBPDbxQIKUshVQ1eOunSXGDBU63sXrL/wjoElTYV2IalxT+UHzUUZwTLYuNNxsQzzqOPQ+GYcPN6TBe1g5P5+n+XCPuodIp1zBXiXs1rWP3Gx/CwShuKw/Qf7CB9Rjfi9YNLgvJeDs998wwWDIE09mvPpE1H7DtPLR6zJ0lXMoyjdZT0i6l3a39+ZYNyHsv3GR0Tcim3o+KD7wWLXeWp3mZuMLO7vOF4r0rmUbNLajjntC2W2UzeL3LcdcVXrZfzE2EbOj9xZgbDiAK0o39oMYCbUfZC4cJLwTbOzOCJ3AqYM4Tl7+Jap5CoA3hy835wThswFLFO/eEnclasV4EegIsgB5VbZWkfAeYZ0X0BBzo8z3j49IZ7+++jtC3ipf3lklDdkvNMQDlT4jTuy0ai9UwJzxeL51nXSP3IcBOBdMbZlqYKLZX9wjSTh2uV+/oorUFtqLvYvq8Ey5qIrK+8KDDKJKkXTQsxjw1dcOYB3IrVfk4uoDMmCulV5sQzxZFQnrB/K+fqWNL6bfTR1jxWW3IHvVfRKOyUWCND8RDoKXTrOZGw5yfpcTIA0V36PEHa3Qm8/mOtU2xAu2Vx0dQ8+ePS5Y8wkaDvFIpOn4dmCvi/WDXMPM5VTo4fiXUjYXDC4WwuZmy9/73giiszQ7B2C890rHFNYBn7F9iMXKVXZt8s9aj9PR+rz8XE/dB12Phhsv3wTPqJsgjoXSHeBHO2/aNGOL+vMCg05F71GvZL/boesdLwqmVUItab9Jbqphqj1INuLqqhB2gy+MGaoK+oFUk4X5RUoGxgZ3iAOiqwI3l8ShLCsRcLeh9BrlM+2qUYe4PxL33a6ImF7Ytdb7VBRyILBp5K6+ko6QJ+TEB3MWviMJj4aTJgolKLSOf6T17SwsYZ7l7KB6Spv0RsdoYcSlliKpOZEd5gRYYlKDVt7ArcVymk6qTfL9mCDc4L6OffMwXbe7ysPo3NC6D7Y295VOId5gwxLM1FpAZ7e1TCu2vDK+IFrwuwwpmV8tBWjqbVesrxdS/IrvxXtcrc6kVVxRr0lHeWxbmzTeE15O9FZJfIj+BL2DdVa2AlPhmP52h/dk1NW/cW0KtLS4VOxH6TBXnUlLs9dwx1BR+A3Fm7y4ccpLRSc5hhoPrBXOhhkEpEPkzT+wZ+clKGbg7h3hRnfBKDA75Q/BdDEKgKCfO9A/8c7aXvAsMT7Tz7HEGNXAOkP5+JQA7D5/aay9KaL75DMUwUc5H9pTMoBduanYjmMtuMzAMPETi4hTj/wLLIcJFgLq07NzErDZ9wy9gaGXiKyeEmstccRU0/MGtArHjRF9uKrECKW7k9ekZXJhEzuu+7+kXm9wFPWG7Alp3ZgpUbaB9peCmAJgmucdptXAYlIaNIXZ/La+0bEJgXb5irMD0IIXzLJd1HkLLJxjx/4tZmgbjoWHxUvKR2ht5LmIAWWeQH0Le8vFBg3+COv6uHpShxcGfVT2zGVubCxHJw8D1hJR2iZw4vgh0gBKTR3l26RiXINWouKS1pC0GjqsvETNQZsPrA5dS5N9Vww4GG2d51ZwZc5nAy1zc9ZsZ3RZ9Rlcf+AuhucQA8cQfWXljpOJR2I76B5b/wDKhUCS+ia/BKEYLadCKmj0XB6INKpJZ3N9dmId0L7/AOIhDSH2nJZ5zXMPIqPeQP0r2lUv/wAAUmWdROu8z5xCSFtT0istxN3j/wBJ3wLIWyg5/SXAXKBuC3rRc898CSihfd2HZTZxcXNBixjpfU/BDGUH486iyp2C8S4K25j0ZjMVJXsRaVJOXMuxUKq6li9YPK6iPMxOY4yccQ4kvJGqTsIi1FNzpmLpqAOUpFlDvGZlrOSLTcQ21iWPGZxzcrYkDe17jrWOse2XDkP0uGkiuiX8esrGtX8Nnh/u0TD0T6Y4Xqd4O7LoxTjLyHxFKDNK1S+2NdyUPjfxLYQqxL9bYILb+LcxXJ2k2sqGSvqauWZg9nin3j7ISi7XMFdMB7wWhqekwGKZ0Bb7jnVOHa8fH/o95TZvlwr0hBgnMx1l8EKiTsa8P0Rh1MDuQAhxHC9xmgw+7Xx+kNrp7bJmXIWGDyqFB1jZPBEoUMVLz5xLOKjAJbi6lEYbdpsZpZd+OJf/AM4MrtKdROJhB2iktqcXfG+cVcIrkjTqyiH3mO/BEERer647cMTUNHcMBtVd+8G1efZd8IYEUNcZZWiwxlllTUU8CAKDKXY/M3LVHGbirwU+qVV+IoALqF3YVMNcckQAzFOCaRrozOgxO0sjlcbqBUbblSmnMoGVEGQuMvG9lHgjsYcWB8IfUqXaQscPUv4lQWxkX8nU+T5jfLluTonZwH1LCWjCBRXe3tGClRYgpdcynMOE8Z2n/gGCNgxGxDshpdnWb1dJlyVaenEZllYq1ytq+T9PmoQtm9Mx1U0e/nFSuNRFKvU/JHHFnV/CvzBRb/07ptWqgHSWilbfNYvMDnG7uqHSgqKYHo+6B/66caluJErK/wCZ4gd+Rj4mYdSY6xGf6QYmct9J1SPTGjJJL1g/CArj7p3fEDid8yWRjAiHW18mu0SdclHIK6YW+0yyKUoWVnk9swIg+imH4f3Yk9bOHqX5bHKrY1yKSx0SaQJmq4hTFjAdNxsvUmMHE9BHLr2nqJ67Fzg06y/ektd0JeeR3iZwRVuVglOi4Um7TtKOS/LK6yl1iLZeCJ2PSWanEnS59YMIdIBinJH63xeRLHfcisRt5Xd6H4YGHRZ6Lk+76ztPBjoBBtkU6YwaRdx9jZbpFafwJtTzdRzKXZm9iBkV6Ufd/U/PM/r4mcZ8A9GIBnLSv+E2TXWpl93PJKvuJbHCYIXs4ce1TEqUsHwQ6p4wK4i/hAeZ2OYWKmPRnDZOe0Z1gch7sRGremReuJfF72A8E2y3EKufYf7gpD/r9EDg/mZyG2Gqr2xDq1db5MQcoam6mmsRJ5h7h5gvU7yhscdY42kbE3wzGImKhFKrT069rgJnEbRsp7PtLM7lwlbN2074lxvuj0fmprjMuGNDp3G2KzbqsPZ6nmbFYH+xLpldEu2hMmXxLsZlZQyrN46EBde8wZROxCb09pfGEWVEeP8AzmlrUDE6Q3xUF0HHMvohBkJ5m/aUFgV3geULjVg0NFVLf6i4XF8w8lCdyWHQOxDJncOXpiUiAbb9LnA5xiOhm9Bk94KkcFC8NG5tpS8yXuLuP4Pj9w56Kb92NXU9WpQf8ndKVq4D0hC7pUu0sFHVk2vdzaeJK3FzfejhLxb9bMdYX1NIdsM4ThhJU3OXZXEyagDMtwxiWvS2VALVOz+D3iXZZVcS9kneL1j798qB0M+X9EpU6o/MQbt5j33rAINiXxcTWILkIFGSBWBU7sxKQsC9cS1alEdVVyl1W4fl/wCZeDNjv0SPTvMcoig2dXVu2Jn0xtDR5DUcYJHZV1nkZrPWp0YVSdpK7Thb7/UDdp+gJwy+l7jnscQh3hVjUBdkQio1VYQvT0nAgwsajTBu4JjFQwzPF6QCZPEu4uZ590oanIvipfL0myyuk8hlnSicmZoCATezD2jF55WPLi+sbqeZUcqYrbp9vl6sqq3fSUApg3o9Gr9NQRHCU5/yPRC2nRX+KikrdHVUVzPbAm449oVWCBKLeHeKC0A6g/UFPowlYS1hAap+XMx8ta7HvKajV+T4JdkZwYZYmfE6kAGbhusncD8zTDDHEMwYWO22GIXKfV8idQBnBPdwPDAKMeIOhJfj+4ez/wBXrMzAcH3DWtbplgo8XBdYN4qVVFbcS5dnxUA4lHSVX/CWeZ4rmdTplTzIGeOsoACvAB8alnNxzAT5itKBvECa/sYHSwXqsJDF+q9FlEF71Ld4o3EUi+nEV5FnonW+PMPFuoT9brtA0F04l+Sbm3vKmYxxg6GolLx4ICOY5loxcs3MlkteU903tyx0MPL3gLnERT3CtrLfPPeKukbaZxL1n3RHCVF3fY+Yq+Tq6LUlmpq0g5jDsm25p0Fc0ph6kbF7VVughbtec9ZgwMalqsa+pV6h0EvyTwlNkdtRed+K5hjXnTH4jEGbjTZ3/rlqaxNBWSBkLeRtvNej2iPENxUEq8DmA1p63B+nMy7mYf0zA5+4psvOozWCywqnDwCUB5mu9veFc0L0Jp57VKOob+fMYVzPY/M0xzfkg9zglmsdp4lAZ/crl0cf5NNN+kxpC6tqqnRXpMFEUFVjpOE46yxVozuXkPeZaeFQUBWx17XDPbjQN4adRHhyxf3BocF4ECs8VRRTyno95RhBSuBVtNs6UisW6vmWZzXSUXFwljf5gMVMJNu0p003WJYZAdJsGql1zLyEbWcPaZcH6iLySyN4NeYebtAa2nRiW0+YoLZivBqOu5WEJ1Ib4knlK9bm5leg+DFeIA0fHEK2quKF6zuMHIg7v+IS1QDV9C9yiIxjahQHqsYOWUbpEl2FsrqSiujNZre5UbvTMgizg9kq6Q9Ed7lZ0yqbzYD5qf8ACEb5GesuPglWRybD0ggJIGjFv+viUl7R46Q3Jxy6mS6PzDLWRKJHjJ3l9tufDU4KxqFcNb+WcAXeVfDuxWc1bh4B7+8w3yUcwQvSFroiSLp1AYrSvzP7HUliPLzWIVyc81G978Irel8UYg0PKw2WwhzLq1g7sj1GYjFroj2AIMr9FmUq7rk1UveZG9hn3Yg8qjEwz4ERJ8WQoexfrDKS8Hp/XpHEozPbTbduce+4IPcxRy0v9zKIpVLfSVQNA1svtOkTqJH1gRY7s3n+B61AS4Rrrhe3xMaSThRFLkmxm4NeJcTjtKejHEXJcQFrJ5mltLJYq4luZbQEKLfmZ7jQpNTkVHMXTUaZgNx9CNBnfOILAKdairJHZAerMLszmmWNXTwxxZbz0jrK9XaNsJ4uN9gldm3UjStElShIo0ck47sECjSVXln1lC1ZUzFITAH7By7VKFqbTA68oG80CbxYxlZmPdC8PtKapr2YalVd3NrndCoC6rOWs5NwY4B46HLWOYodhoS8x5qm4moxZ/KOJc54oNHiaf6RsFXIVUVqr2yjS6au7Jldhg/UXSTjxFSlY7wt7DF12mWgImqnaCFvKLWNQAoWZNqOkuUaU/mKLN9O9P3FSroStOe8SLcuZvC+6MGG/pBKRO7tv7xFgZrs/wAlQI74gOM9amk57Dz0lwcUfcZOTviPMabu4NrMM/1xQ+BS+9ZOEzeK8Q0Z1c3Z9opeY65nWANO6hWgHgygghvY6upxFLB2o8K1ms4zslBVChi87HY+JdVIs7EG4u2YzQcTjOKPW48UtmzQv4iwUOpT7kbFUrtDiRUH9A/J6EDRIkd34JjxXFVeZXYT831m3J6QYrZuPKZiXK9UFDmXiLOleZmszg1ys7HrAYHzEpcXeSois+zFKDDlNyh6VWrbGVrWePuZCljgUSotR78QGis6T0G8kBzplTWvMSaWweA9Nyy4TApTN16fMx4gLVa5Eur+NlOp/MGhwGOoeIKqPBHbY9GOVcPxAoj1qywzvW55gEjgWvG4VzCOepBZF11l9Ly0Ih/esShGn4d+kvmGhrdKxj15q4R5lzPUPhEZBdtAWXb+CUjUeY9XPmUuqDt8RMFVZDOYhTPQQoDXbcbq/XB/VLlWvrWZwwys6HvC72cwRM9dHP59YjVqjGfpiUhaDxUu04BgCU4TSaLjMpg17vxP7xrm4/hQLb+pS1ZvOIVaRiwq5iVBXESykXV1fQJRDixOhY67eeJQqA4KctI1K4E3fpKUikNsTw9LD25vLfySoUYwW/XOpbpgg8zWOnJGVbG9YGXKnHjrBC0ncb1XpUZwUwd9fP4mdh23u5dW2T/O83w81o5c48eRlebZ/o7/APgStnF4wtwoMMlRyHS0S1i6GXWJ8QRoF3mBvCLyWloPJcBAh68wELOWz3LiGDXpUc3uVXOOkWg1LOvVlPLHVuJqlDiojZb4qEyrMVXRMn3rE7nC7Zi2TA1bgM/MFWLx7MXJayVxMmE6hr2hWn3ouUbbrVfFw099yvRhFLnU3o9fqQ0BNHvG6YsAkNhbTQY5q4onhWHSa7xW2h/amnDC/ZmVyDfU6S+wvq7yzAZ3PI3GagaDdZuFiVUmg6TPGXOxQlDsd9YEOFngVb78QzqCAa5Y04ipFDgPbjdX65l6AOy8+sBUt4OrvcuNLpKLRpyJAPWnvMHwHVwdijoYlsUUafHtCstMueh9SpYLiFtPYnrA1OvCJjubH2CKvJ90DGJwN9syjn8zBcOHdLbBWukE+kOBbujRTX6iNTznmnS+dxgk4W21+mnLeYQpxyMDbuuP8zNfWSDjwjpKcPA6fSJLjIJ0u8GszhQRif2ZMTOBDV3i353KjvlsLuZVV2/EWEOgyKXoertj9kUrcLrXUQubjbgOXqP2dic51KbTkd7bZ18MUpr3gGJu67QY0EVPKVm6M952EUVY7AQvS2Yac8ymxQfMAvQxfEqPcVG6sF5TH+1RnWzC84jZU2G19vpFbJWX3mzvBvp6zKrI8szye0sOkbKW63HkHqjjPNM1oTxCwZL31KzXJ4incZgvFzHQblVvnDE5q2buAvLI61KxkraIwlau114fbF1AFrWsOnj8RbF+SrWbMS787K1wsgY6X16ymv75mbGZU29CYSsM1dF9YjoA1bycRQrg0bJjDBxpMhS6n6ld8UrPMp9VQJ7+XMcpcFhtVuzjmZa7ybIx0xfPWWNNmUzNJQ6YvgjxORTbqjw8Mu5Xs5qIGQt57RDlVuV1Co2Bx1lHhzyxFWVoz7spnpEMBWUdHcL+YY4B33LDLEw8+0oN56qZYlusxTFyFiYg5/aCp464V/cSqDvTKHCkzEUKucqO5usYKbNfuI0YB8ky+0ViYwt35gvp6QXzFbqx1eqQpQ2yJr+/UTuwdoh1XqoEYwLBfqMGCWDS/RZNgKtM4rmhy148QNWtvD6UamirmsvR+/xK60bi0rC1X5xj0mwiYGHvx7e0BzVeYj4zEZkDmVQdHiVO4WZnwShuYk6XUyUgLttOrogBQ59YF8He5TgLhnFMtDnul10q8wFrgWRKbdKHMyX6iryva5scyucL5i8jKV+SGFXdwK307QTBeY1kDx1JgA+sUpsMdWGcOpaDhTfaORfg4lYwvxmF7t1OUjPCo+tBIkLY2ym+6n5lCNKKcaRxpLv7CFbZxbWNRGA6ld07Fo+ItZTqxLBwrd/MKksVvdMLYgz/AMVALOuHxMMV1VdxF0Lu8wB1Vy/qPS72o895Zyl6tV9A7pCaL4ZlgXYPDnrFYSMUYrjn17RnYeCKK8BbWfr1U08An3ueI4jBbSaEquiRplwztxHnVhyzJdp1ess6nSmnUj2vAs5xAd2yMSsx+XSo0kMOluPCw5ytwNPkXw0ajt/MFAxc4J3Q21mW5oJZjl6LgsUjW79ZmuMN9ZgNNa5mR2HEHkgd0wDA4y8Db1PeFOMsnN2GbEM2+tsuc/3rE5VWKMI1V9I2RJ4Wpl2DKMwHNXhjVa4zmA4Ds6DLBlbnYwit3Ltol+RH0EKlbnsxPmLdoiWanS67QtAK11SwYPaIGCplpdnScH45i2tt1lGa80PVjmX2NbtlF1z0xKD7Q4ZIWLTlFytauJ3IQSVGcNOjufPdtc9H9iYJuRTlPWUGb7pg1hVYQ1U5YeQXR4mgFC7vBKRn+P7lxvNWQzWnSoFHFd2bcc9zzFwuwBF7oaBwmHZc4rFx95Yh93iERDl0TvyV632mAGzd1+Mw1ZXhf3rEPAPe4AIIqiloC5vB3QhynXBmauNbvtMLKzygmsyqAavoltJ/2hQ4SU6V3UUzNSIxOoDi6mA/Cwpm/Gd3zqAA1khHp47mJm8r7D2mK6FWZT2iN6aubCvTHETQo6785qWmsLxUEso1gSsPEQ3mMp1doIwLXU1KosqyPMQpQJWjwwQuL/TMwf8Auk4FRysupgGaf25oNH88wLHyIGMtViYa19dmhAe1rnpALXS/KCIdII0Iyydc8YOWWbBypiysOj5JsYLLwLxyNysdh7VbcFUtpVYJZGiFrsaWXxYtFja0gGC0GqSuhiJmSjCkB7ZRGnfMsgyusNHEzqsS697oA8FMU3Vd5hABN90Gm26zupfF1aekgCXi7FwIHmT22snFEESDFJCgC1V0AxulG0sslASzCcyuv3xchWIaxpsoN0TMYVv4lyuviYHMczdelxQxBerAS/c0QOVAOsOw7l1bAPRDq8xZ8uwxWBUbZuxvjrMzWKurqNrYJXqPeU6sJwpc4ODEaWDTpEO8W945lPZRbsFpTbiZOWrFlf8AeZQ566Q1oovPMvgzVVvLGmUTdJjK6f8AstaYbH2WT3Qipfu5mK0HqSVUR0bR9o6IRpdQtrOfeHN3UxM9NV6RBMG/Nb6jh5JfiCQ9tvjvntEEaU1ZntfxHrLk5/MAlCEtslUBT8zeOPKFDpfQ4/cEXM5tWWdRyU/iIwtdvJ4nDq3c0tg5xjB2HoZz7YbsZaZ8Yj9wFa+RwdDpvUXLmw25J2mcdOxUIbJawn4e0BYBm1nJMczdamP+yz6cRlNc/qC5jotQaNOi3jtMaDtB3yxdL2+iHsC8RaFWtUJ5zPI522T5gthzrhoeIGq1XKPr+YTyVmtMohMOd3CeVaxRVvqmQOXdRYJooVJeOUKf4RODNbruzmBMXLesFAr6r0LFQcDxCUGRVrHWLjr94BgBAtOKmBQ4qPR7VqmMzYcCzseJMt6cQY9aM2qa0Odd5huqaWKBNlSsF84IXCsbtDVVF4ukWgkVtVhd4gIFcCCoOcCyoBjWavn0U7JoRv1LDsKUFXzdMLXLKg6QO2w7xK39k1dCXcdUV0KH2+cUo7MwDBSwxlKfEysa90QWTklAAMAZuo1Ku+ZWzdsNW4XKY9cK5FjtlTJRzC/JMpNGVysMh2FdZas9ajOBuoQLWuhOL3zByxtUxw3lrrMOwTtg955Au6MvMLA5GOsKEKq291V4hwIXTd+ZSKcFHAQs8vkiyalEeL5hpEoGe5cHdQliCyX61F1HsWq7UonfUtR7rtlt1XaJc8/7iFjBLcAa8+NRHR9VcwPiITEp1jXELkQWEoxcw9PzfH1HpQLXT+xGwIOpdbnhZLC3sxeNy3Ls9iYxAZvNtSzg0DIrGPeVbHYsd6s4FY8sLBEigWsU3jrBUStOLYfDm+IQGKpleQj13Aew8QrBz8K7TrCN5mIW22HGv2mVVV+biZRRsxN6dI159dQtpWN8ly/TP5sXYElkHAU+sWS4f37lPZXvdzvncOr8RNe3RgTHtuDuQRRyFMX0y0Gnr0mCAKOrSOHLX47zFcFAbK6YMTiatlMWzuenToEXv7wDetAdFv31AVU3j1/mVYCntFsqXoZoOeYUXZVdJYCaJ3U//9oADAMAAAEAAgAAABCZvSJv19st3kgfJm0t/wAS20FEPUEsVOAvfOdb/wCeQ8LxVv8AsWP7Gq+s3qZUdttp99t/1RLwaEibiIK5xam2sIO5bLYut2+X/O3krK/X7t9/v/Nu9UMVSWCiWFY+eWQ9SRGusaJozyDa9t03LLNG1d9/vgMmm6kU0WBFnuz269xu9nI8t6nuZ/8AeyEXFaS+FWWXyUDO8fWF7QRJ03BWpuhurCqjrP8A2oV3/wDvvo5t1cjkIfVDmW72Ld5XPpS1xi08Fk+3umgZ/d/59/8A/Y/5rgAa7u4gX1FE7jMM9Xq4lh4nnqwliSQ5svb467fb/d8vGnL7fX1FRFlSxMc3f6BcnJx/YSjWRjXEtGzILnRCIlYn2XbRvuDylA/SdSvf4PWw5KexO794xpaZuCGowPV5luLpRuBB91bWLKcDP9u9lTANivaC42U1SkgzIzrg/bCtld9iXEgLfwkPmAr7PXhvJBY7XDX/ABHGlDB0Xb7X57yyapqt5w4P8CEF81H1xdX9wq1PqUFhwiPV2sIxp50apO68iMHw0PgRoWpC06CA3/re+BL6944+nu+jR+tksmceV88soQEEwepsqFLtV8LHAJu3aqNDeW3fjHcSrwzguWHbJBayK+/2ZvZWE1Vyy+5BnYC1trL4bmaPUXfOf5DVRHvfdYuKu7r1z0M0iKjg9qNTRVMzzXIC3VQQgDrxJQ1t1HgyQlC40pFQykolBt9cJ+zXfbQIa8R6j3mEvkS1odG416QyvZDHfs4bWK9G+imDDFJCfXI8qhTEOGbBLa2+j5PmAm58tzVwGWip7nLRq0ND2cvx843mvaRymNTbBofbQNOq9++1Z7tNr9N3aBQv7/QrH63ypqu8uWg8w0WLQVQzEAy2u5hZJy8VD92HcSQNmT7Qj0HWnRYdaMXunxFqhfJ5mpN8chVQUY9D6lfjKRff1gd1lqRQuklnFyqZAhM1ENHrjzYScKOg/wCoRv0YuL4lIwuTsmfJ8r0xRQ7qQCAj2VkBJkVncZIwLM34opPu6HsNn4ogB4PnmnwTa8+iQ7h2Vb4XscCKIsHo7d0uG3hRDf8A/EeKr46FdIuMJ+zAABrPqe20PILDq6B2Rz/TxErOj5Bgmhj+NaehwZYB/dPkDdpKcPQBCRjkC/mzK8NCJP8A+gLJgrZqscwpjBqqxXu3LxZceaAmWtoKNgp6Zl3bmzX+kadnL2RINa9Vc+eFnT/4eW7Q0URbiCT8a+JIKWUyHI6hGiXTusIE4CkqLdolx01E3+Ye/c/kWuMWoPiLaoZ5VJfyShDmZ2N1yjq172gLHjKb/m4iFqsidJRVTH/XkBDQwC03KkaIzHbX0jekUdntwLDe+6xRQm7EbvSmUqpkapsWhpkoECH+joF97v6kYM8tI4r9p3edRsUbhn1jzSQG3INvcxH51LOMNEJL0PY8s1/aGjutbRq5aXhO+PZ4RE5w0m7diOP5Op93sIVJK2vGBnAi4z3hPctmBUm8EWndmHp8XQTYlTsxa6wf0nA/vJNIwlAOLhTAzviem+d1Is7NlYN6gofQ2L2YX1IccXUWjON2qtkcCFXLOOjHzpU/diVesH6/ogueBWuhXO4OTB1mCjBQD8jEseD1d+jTEh2mIYLfy4/G6y79E7j0OQjwQ1vfCxWjtQJQ1Iws8VBiUGvdhqAoadvPoOMKPKz67QtYo4IZ2CdFbLNgR4pzRNtOVdY/c9V92NOK7TzSTaY7BTG6+3UNoXOTAdom8svmqhitBPWnVOwT3Bq3ucSH+8PIBFbUIYG38Jxy4gnJTuhZvcm0HF2u93/HSS9YSSXm9WvDmjn0aTyJICVvMk4+Dj6JQBwvB2Hvbdh+jnPoMxqEqLcf2KKUyBzWQj8cXtt1mcOW/nTX54tJUs13CvEOjAu/6ii+37iUS3fe2dv0AGahP86ZQDy9hqkEekvzLJbNDf7VH6T6QTGC+bjxDiEllU5qq4j6kiEsMks/iFmvRqmuKR8t6V0CaSWHm3aQdjO8Fun4aFIlRPtlsv8AbGZtmoiZFRrxt2BnK/Ms/MfOGf8A8qMuFaRBf5uiBaXSMw/DPaQfMenZmztlybZ05vS79tvb6sSQaTsHyXPT4Iy3R5Nr9dBw5X+0/feqLYBLm14anBtX7U+rJPuC9L/b78z/AOzea2DW5vgaDeP4XZXm+7Sx+KYsy7ye+3iO4l+++2/v0yff+bj593B9a++H/XzaUh/94e1E39k3cOjzw3/3n+++ufn+3sQqdkkmXJeUhqIL87rowolFnln3xOs5W/y/l/8At8239nsO67JSb5hY5ALyILZvL9ZZbJZCBWr8Gt999r97Pskns1nL6mCLZILHJbJ7VbLD1JdbADSAIwAtcu/v9d/vlClnvt6qk7bZZPVh2kpTaDLCrspaQAAaZMZmH9/959908Ek8voSJ9IYAgpw8021v6wMmcRKiCQSWtL96t9ns74sks3GiDjrDqZAE97kQnLfwFPOKjNwGAQVAdKhH/wDf1fYBbYYog8m0lE9Xc9jlj3ay/brVNb6RgR4jFArHHZ5Xb7tHWLcHocksJfuAJItdffz/AOc4t1/xGZa9Icz3putDeWXzx4wYA+LB7wUD/Ewk4V18m4Ii4H4eO5pui/0yktDFxGCflL4jKdBNTon+2Z8hU0utX1+F4Fja3Nfg6v09sdx6diKqTZBklhtJ2aOMu13bW9lKeor2RpDTCF2z2c+4srW5Id3oJttspsoipSXW/u2sp15q/u/b4LIgDcjxj6nptFJFP1AJopIEFYRwlUO3ufZAPmnG8hrkVPM7on/XSR0BJEEJl5gNNkAFS7XgmHg+lVk9Id/avjbRsPSc6wc11//EACkRAQACAgEDAgcBAQEBAAAAAAEAESExQRBRYXGBIJGhscHR8OEw8UD/2gAIAQIBAT8QHtLvqKagDgW4nHQ/6bSoxX0O+msRX/yGvhC66KvLF4g1glHiKcEC6X5ylv7fqPn9Cfz+uJ/fxAviPi/KUNsrs/aWGbZiIc28TBmIJ4wDmIRBslpslzLmFtdAVBSDIQCCMoZWN9RRKSWwJUvospEyTLPQlwet/EMppBxLmoNxLjTUP/hCtxbehLXBNSxqCsEh3MDlmkyjmJdkX4iDZJV/iXE79IrGgyQBghSB56AWWMd46SuGUaYlslpsgIB0y4MgHcA9EHozKZeXJTcrT3lLTmGFPx5l18Cpl9uj0GeSX0qP/MFzPwscxSZKJpD0BgVDEWLKWFOldEszFcG2peL5jRjAvoMS5boDh3wDLUUi8o0xLTEeLlDZDm6ZTpuj0uUNzGjmUKEWy3mYlHEp4/4Kjo/BdfCE/wCI0x5xxPCUsqASuIFYJTUD4KuBArpiVXQBhmtRUoOLlXucJMtU7OdqZaZXqI9FDiVcSmZgiXl5QdIWAY07jxp4Ol/DmGXbbH4LlsvvKGU8TJuXLl3iWk2dSDEuoRcwdARKYSyLMx6Cm2EqmMA6BEqFCjcoi4l8dKgdTOCHdDsdQDlmrN4RtGEuJXUxOtXPBLeIrLojvF8QmjEeJR8VRMEp7h0P/G2GZRKTUtzAyjKJcWOg1Kc9NspS0O6YOJcW4uIHeeYYl3KgRawSne4AS6ai3ggMOoHSAIvg1AI1x0VBTznOCybRtNpro8oIwc/BUqVNTwltvwrc9HXHwOq94wf+IfBqYYhMmmFiqzADpR0WcS7h0ZUTtAgG0VXPQIkItStt3MEu4FsACVNQWko3mWuOOhXPTeIogCBJFFWZrFRDma6ajU8p6QJAKthuVbiJW+j2QtlgERUQSkpK9e0fhVIyppHcr4qlPSmUymBcoSglwTcB9w/MU4ZiVKeJablIJLCLmyGECx4Eq8TeCBCVFICsty0mYICUBbKUuWGWrMxfw2SsJazLkTYJZ6mz3qPMB8lPQhEGc9y5DqUguBIptiJSJekXtLHEGs9IKHcyjzAcvQdgnilZhxK9JbLXZKIs6KesjnKNMqAypUxLCUly0Feg1N9AtlFLw7+/3lzHwWMQZiAMphXMW+msQKgdFqI5Q7pSBUwQfOJT90syyod4DcrqdCmavPbMOC6PEyBOyRsdqbu7Aj7UsAMMAocLpO2ZV4bkOCqqg3dgXqrJaAoF2CoGhtzD1XiH4sWURShoTSm3dwIHZ3qvpnpXJO1DsQGiV0UQW0Ka6kO8awWoX3AuJZl2U7dL6ZgphEXBqCu0IpZLeJb0uYmJiUTErzKvmV5leZScyrlmSpmZlPS6lhmIC7gJ5vQaCFd5b2lJSW5e3UFalOUpojnL19ZUVhnqW6lJCBfaIaT7F/kgjmPK/ZPuhol+T82QC5xBx8j+n1ho6+lfS37y2ZEf7Eowppl+ZQmZplSpftOUxPCOm5uQLiWRqU8wHoCVKlMqB0A0xwRb+CrlPSug/EWyw1iIYIRmVKlEKMynQDLG5RtPFKuJ3CFaEW5V6lDcy0VMMxJXULgmYQNXB6dAHmKOpYCdoLOZYh/ZmOpOwv21CLUeRDjueIeR5/EFvR4xbiNQTB7RBpqPNuemaV1G22G6EslsAaOgI6iS0zlf+Q9O8St/8a6XMyiYbTZXRjWiVKlSujvoLVNvgqCcwo8y1xBLBmXaIQdx6HsTwQoyQruIXEXtlxVTUQdxFQ4+kBgvv97+X2g5fb5rOMVlzj7R6LWcgtoMq+rRyLiWPVg6aL9jh76mnV1oO94r3Od3EFEpMe+no6GWrOoPHPFOQzLbAoEuKWCeqGEZmGBO5lZhEWS4pVziq66E76VUROgGUmDZMPV10+C0vF9SxKmyoRahHUolDCLRMwUwLwQAKJpMpCHdEwNzcYBwucUe8DwQkQ6lJ3Y1lrRYlZArVRBmXtmgP1lP/suwXAaxG5CBroPzTn0qpd1OxAasB+f4zUtjgTK1sNADaVa45nYBOlcFzYKllsyvpEJNpZLBSmWxKjxnEdH2mfZT7B0tQSzzBE8sD5iTRmUu03SmeImPCA4hbcNsldXK9kXwQYtBEGieKY+Ghlkw0xihPEQl08mEgEp0JUDvKJqXLv4DEvSI2l+sS5tKuLgRyRlQqE30ewqZpzFsmISDCEyqCboeMnMgDZcK6gpLRvMEoaIBLFuU7flAKYqdkV3lv8QS7PZoM+fyUwXe3HzWX4iuMpVDR8iiXgLC0Q4MrxWj3Ho6mnAYDsfl5Xllox6spdR5OJfE3Bq3NOMUGbmO42biMB0R4ori4ozvZ5QpqUcvQM4ninilXE8Eq4nilPE8Mr4nii/E8LPDPBPF1C0tLS0tAqOoUmWE1KvXRaUkWLzL7TJuJtkMQqcM6EbcVLIHMWB8ROyphulJ3ixxSK5gmpaalruAGZaURxLXcR0t8R0yvWH6yF1XKzu4mlbuRB9pVZhQKBMQCoThQ0cEobylWp6JwCEDeHoAS+YkpKSjpUqJUrp64+cG415m08IqBSpSF2phLVcST1dLyRUvBcolzLd5ZjSVqnERaJQbWGSDTcQOIUqAiUrLgmTiFMeW/rEe0NCo9yeWeaPS/FKR6I+MV3NuQnvAcwbEwSDS0ohb1KHf2r/XMrFljRmLmh6KR0lo9JpjQGI1HqmsDO5mmTvLSjoCUcuIagNMY0nLBG2XRbGNgzkqJ4Ii5ITRPBKSpS6WdqLCj0WHEQZqVSANygcwSYZQb6NJ6o9k9Z6yzxCVEGJa7lSBREjQMGiagk2IqZl3l+Jag3qWS+qzKeZfE8kAOIFgiAeIFBHMNdRXUHARMoNvCaruMSh7KzeNe0Kw4IaCzcbm/vM9ZeRr7R/CPoxd09E43GLkSvdRbzUabxEocK79JlgIY2RtAiAnM6dE1qAy5XmPZAqVbG5TCJqokqUymVNRJxLLqGdyu42xUrkRjiBCFiHNMMt30LilIeuIJOZBbENpTiAIoaqUbIj4h4S3SFOYcQ8Yl4i8MoIPaOqHIVAoIuUAbPEa0LCF9wZF4CrIBVhRbtrvOCMUGSFFBWoKsKvct7JKNhoo8uVYAWORSUHkHHqmY98wI5qvxmoVFS6vH8eZfiqDWWFuqDJtl42WwUqk5BeUDv2mGJbc5NzHuVzLQV8f1fWYEg1g7YS3GOaGV7Dtuxi8ApjxjEcmgrKszfqNdoO3S9G7VFNs3GAuCMoIdwLVuJoIGpzKYh0sjFO0VxEYDK7I3zAJY5iO8rtBMPKA7wEAcx7ko7Y+UUaYSb6ZMSI4jsEKOtdaveMDt7RtzVMja9w5jCioxHBnLPrAorru4GtY+kwZyMN/g+sYRtxA79XfB43NJT2SU9YLpFO5RxLTmWanaj3yAWbfP0abwt/SOZHbDJVmaDPrM4BxpftZ39MylrlhUXG6Q5zXaMFpfIncjGl8ztPnFuxXFa9+g4xLBB3hYK72j2xELskTmqC6x3Kb3C0ksh3U2G9UZbbgHIB6WqQ4teBMUdrdql7kI59rAb8y6lgZy5HnvVPhSDkaIZsYWYaaopV6SimrYtIheAcgYCsd8xTBtN0Xleav5sw62UwXxmu7kx6Rb2GQAFNXoi2r1y5gGOYDVKuhllVIbgR01CRyRytPcCnediRGhsZsNXVczPoHuw0agrljmVK4juno9DvtCzGcol3yjnoRuV7QlqNdx5RTqLYlPYrmX1h3a9jb9JVAlqoDO/xLNGQonzT+yPOvk/cSWz0T8GY9IoqWzOH2jsfNfuc75j+5em9HJ9ZXUfJk+W/vLMf3fLcG4mcTUvuyFFv0Q+x+R+5VCxt3R+YYvBzSZOKTOM/OOGDgzn10/neZUpqhkA21bbQONrFWIHBFGzp3rdnEJs1LSsrjTZM7iaDNZBsy5TCtw+DoOQGQsborUvzs+8rKBRl4PzL/ACJ7Ozj5aMPq8QuDdGnbcNtpnwd5bq1brToqubrv4ljKfdevLfby4CsxWj9Rfb6+cFsHgnyPTv7/ACBY9qBnPav7jxlurukKzSY5xYv1ldVc02NXnPY1jiu24IxCoAru2kzo5expAAdm6HEoRRju5DSmCDjCorsXxTZ6UnsTS9Ft34OcSziM7qISde/5JQVz4P79y4m2rPBldVwQAAjlLZeiX2JQ9I1VSJCxazMPy8EDWLb7tOzTKC7Su0EIq7bsFvC01KUz3KtS9xdwMS0aDhoqveHJzZg/7VVtGKbVD6myUqljYFqsF5KvtDKqGSVgoqrug1gMIgPdSErHFWVb25Y6VhKpdryQzsKM4hhy1gHTSSC1B2VdosKIWsp0VjwRbbhNuWVQrtXTbKpp4AbXftzCndBwALRDXKKI8Ut2g0FYl41ElQuNriCjz2lDHa5ZbZh0jADHiFWoFklCwktz8lv2JhE8nB+X6QDD4i35v4CXZL5mOZR3YfPEDEQl0oQrmpZ3JPk1NSkowHRpmIweRfrV/WKlphKthg8MIz6Z9mN2dfuj3nDr+XL34xAwKtZ7Zc363xvZghaAU3j53l3e27vklDtfZ7vNXz84JRGjIWUHpWO5zzCRlS/ly16Y0OLipPMtm108Xr3L4ODvMXjJg0fIxrsO3MBsULScPL6u+Wu2JUlTInPHPPvrGsQGrsP9/XyxFArO+f128R6FFYdcalEUCnLecN0hrQ+WFGYYbJtC7TC9z+74iKy7iHQ4x5LeSFNQRoitW036fPLKAbtkuvKLzyDx8mmyWtq94MLtNIMuMcn6iUZg8uHEJM3MOiEwNh9x/cY7SAWTvS7Co5N5L8941S1IAFAmkDB7Q2lpGqDTQazQuC6OINoMHlgphnGQ3eIqBJQmGs9q3bfLzFgtYvtj9w1E0NiYepb22RepgoFFAmfNO/1AYzsOMVR3oCoe9v2NXSuBacj5lZqudK3gaD8zEoul7PCbDknbVeICXybFGLPBtgaxGlrzVij6Fn+iC6IZmAM3LgbldGP68QBbuP8AYC1mJIcMFMpBQcqmO1fzjHez9opiLVUU/wBS0we6Q/8AAjEwo6cMOlzZTdCxsaZxMpOkCy8+W8c94O4X+92foEfmC/0+8FN/k/ULpfx4jVUJ3uNZS4ZVGSKqXUs8X8/7Mt5fulgvj+r0v28cxWm0vzn2T34aySrcTKzneAr6/KNDW+KhtghGs3jiJdve+bat2XR3BKB8ysC8t0ByObdU0a8RHpWLogcGCyqzloOC2EtIAY4L/NzSNQFYBbvOpQEcavykrjHz/UAq1MB2dDfQLiUQNLiY9aqCbArLdYZbpyQIcy51KGLaayAyqxZSN+GQFOALA9T7sQeI1FvAbftozUYhaMSjoa/UeAWef1MpU8j+/wAQtR5D/ZTT9IpaZitQo/WTHeLfrUz9j7FQjyP4my8/TVy8pzSQyTUHFhv9f2ojkP7+9oVbcuf7vqMKO0OiqCHC1hOSZy1QXJFAMdxVeUpjCzq5uIMLeqjoHdc3Z5lBy7FQBAbSmae234FtkVHz6Erc53AKgSrjMdzqFlsCqLzD2cKxMQAqF4D5RHD8iA0PkRXXyCBuD8k7gfJ+pZo221quL88RTKNfaAHosBvV8fuPw62C5vWuedRrYsjv2lQ3Vx8blu8BErUDErZ6yriGPAiOioqtYdeYr/pxPBV/ZI9WGrtB41nGyorphNnGeZ7bqKAMd4QOcrvxz84TG5Zh7jqy3G/SKrQir3etgdu1RtEHmw6xgQxxiE3fVlj1aazqcqHzjHt505/UBv6faVdSNXpYWt2IHEVPe3bbXGecc8zkIwMzbBCO+WrN+c1cpmKFHdTCF1d0qiyo7vYhrzdnMNiIjBLju0CXq6f7jNR+VT5QQOicPU2gRQOiLacuO8Cke/tAMn9mGYvEo8v97eYAzBCPrMvSz/fJ+UagparNev8AmT6TAGT9v6lBIp0Eu3BRg+kqlGtN+4bC3Lg+kNhzpottgvNo4uNLy/Cy5cFLlIUCYAAPl99sN18vlGqxuIpodbu/r48RMGIcuQle35w1XjMoMBgkpwTbxdRDKcEv3iulEe3ylK5k1AK1jW861XbtjiKbcQVg1AijU8JYgrEaNRAAYsg2hGQXtnBbT8x0rmCOw+1l/S4aZdqpzmziLULUgC+IuIYgofEcUao4INQkipldhx88Md8v8Sgdv1Ag++rlArtLNuGUha4dtuuEwG7awysDBqZHHRq5ctCsRewcrpM045xWJQ6ltN5b/cqowoyyC1jSwHF4fnMF4gy3K0YFpGEI4hrPfiWlnP8Ac/ODCcQF7ogusy2DuW9jT88QPmaWbLpWHRfJ3z2p0FC89qux8qRSDaVKzd79Ezf/ALAWYPDi4x6U0pQvBQyVlpqmC2TrgYEPfKb8zMN28hblq9b1Fv4V6XHb3RGAqst4jZdI/bmKCVxdkpBnwShJhLqHv6QO0+6Guj1uXYwNoEKr3z+4PIAvwfm43ukAYKWEpITuYuJWcEBfyT+9opaIRSbcQsS7lAhxmv3k+tRRlbDLFdD33NJDLl3nnIn5v1hqa3bQZgNsFm+L/sxan5YzSVWnyelPMFCFo4blhPebVAsSxDf92hvgJe260lrY4aZ2MU25iZZzUSZICNFXcEFxWIno+6FoYCEa93s6+lS0tq/vnCA2sGearR4vmNB6iCkBHqSypfh19Kjz7gAzbuykIqbHOpqHAKbZAClGhQ7fLBJnQoAFsCzo7hXaUW5QVmBKTHenYsqJ2bwBWKQDmjLOuIjgJa0Oa5pcUs7UDuAsrSuFq0HdTS1ahjMqmgDJe1QF3TCtN3EnuprHeVDA2LtWQycE0YOK1NfUz56o2Ygyx3N2/DfwOqDSZ1JeEu18CrO6AjMOJaP7S6FRG0ejU1njoEJamFIGshh+8ENajrF3LZVFKuy7L+j7HpDoAggUXVlV7xM3ntACdJbUZJWbKz5lQ976TavgdMZ1e95q91/e0e2rfdbYrkwBTFl2Yzg9ZZzlYojN0be33mLjQ2e34gmQ9s5c12zLxoprvcpkWS3f1f5FMn3/AMgolZr6RwDZKCcMQaCcb/H4lIElucfJzVe8IjCWV2qYEYla0C30ef6vExfLyLXnj/yX57LGmsD58eIFvr6yyrBUhFW0oLzxr5ancDP4+25qimuZmqEc0r7/AJlNP5uVxlf3j9wWoyQ5/EsyFa/3pAq1s2Zq++SvcfxFafgfhcDxAbOn0joqd7Ll60EAnS4aYtA8bYIRK7Qtzfz/AMjfdfWUzX5SxoPaPP8ARKOX5EBsKOccZgJf+X6jVWe7/kQ+7VfvDGGCFWH4QxmFFxU13ohrRR85a6DC6/LEKIDGCrrl8vLNcWsdqa+0blLmtiHW8xKUxa2Aq+DJ9iBSI3nGs/Baal24gprFnnLi9DXc7d4oiPXL59/QNRrVysWL0+8bXC3D5ttMVPJ0Ruk9vvEcaAHP6zKf0MUo9pCDtviOS/H8/qCJFt3vRevt5qIVytrlff8ABiGuJn8TAXa9XHJ6F++Zd5atrl4iKzkGi5Hh+sSzdqcKfcKqaDq7+cUjlig7IE2tZNr5T0ioqz3yvFbz/dmE6RjN+HZd/mCg/DEQBnUZRVgJLwhlL7tEHYvz7IneYarL7v8AekW+ly4/DSrTL6G4bFcDwalUWJcQwnbqKEE2xVPVK3M4duYWhZxEzau34T8yssCu1kKOPz+VjzDxgPvuIY4g263b+/EsJBrMRYCu01jBohAizN77eMxq3d2fsr95rUZa8Hj7r/ExgMdeMRVzO5yfU/cAID4GK5N0Qm5zbl9D8SgJpgsHiAK4GDe88nEr3zpthH04gZXov2l5Zp3mAOgCtZ78fmVGmsWX6sFzd8EbLJ5MMRyBYqlX2i3xHhRisV5xuNGIRqwx8sQDeVCAY4Jk+r94LOa7NPz4lq7WX5sFDp3RLzC2DZGFdmPJx/d4LHDWgsjLUCDbU27QQZaj1g7yqV1zVfJz4hMBxNYr6uvEC0MnQ+Eah7apY0meTXymuKcHjg8TUKmTUwJZyu7nqKSGrekJMU5e0TkBcd+hUxPSeWXLjnLLMS6d6PzLK7v3lDZKhKKfsxgxq5W2GzLNxDT35v1uFE9+hkqpSXsjXRvX1a9s94oEhjilwcPHZ57TN+k5/UedR85YK0Mj+KI3qVp7n3lxPH5MEqXZLwcpn02zi47/AMv1j+xaumywq9FXNauXECG1YcjLhtPEC63BiUmT2ikjwQDqqa3FcRNCF4M38oZR9BANs8wBsaC2u8XAqKSgxGSxmLceKnV977nMRQ0trNqf3pNowvd9oFJErMHXI3oPtM068RNDti8Yf7iMgsNW/nc19KydrrP7elV8S+LDcB2pw1nxMPRlrDvAuaP2hmTzQnsQpjoWSs3Rn0mg0IXz1KI5gTSSuUaGJnHD+InYufpKDB0BxTfKD2hXbLJ4cngiRbL6MrutmZZsaclEr5bfB2zM0F1NnPIaKO11MNGyEh21deIqVtgAefxCQ7B9r/MwuL0gEfCHyYKhjUSE9yPxDURUV5lC3xLiVRMwtLELwVx/f2oQtDQg99xsGHJGHAgeheb9teZXPa09uPpGXNWYsSCSM0XFou9xFyW9sVDmHoFTS1xmIkUqUUPfOoEwnizH1mUWu47RqKkNvf0nNZxnMGLmrvyI/j4lprosrkp58/iDjYenE3U+8UJKcEcZlLl1kzDgIn5iPUhbOGBmV7r9blRNcfb9y+8x3lyzvKSziOFGyGx/tSjeSn1MQUuaauWsa4jZAVmgp/P1lVRFV0tueDWpcjllHcNOJS6g6DHMGXBZxjOG/UYihQVgo+2Tw8yha1M+sSoMUMQtLLuz9oil3/BBbFWpWzKFgoNlniP4icQQgb7zKsqJBVMtxJbGArcwDsIrSeGsmfS41c0pWnu4r7d6ghW8j6WSl2B+XrLrMGukgI0lmGKukN33qO/Bbxz6/wB2l0eofSAOYs1R3PSEAIHug27X/do0QqjjyHf+syEWcm4BFNsf7Fa/jZRfcY3tbYVPLKIbYREzFtiK+gY5MugSySjSTMvH2gIS7L6hGMRKp6GNpb235hVNpZcId3kLTf1jMc2yy7RaisrvXhUSMB4l9lPLxF90vpLGqvn7Rw2N+np+I3eiva/WA9BEkA13JUQKbKsx/YhgjE72N95S77KFFPAuV7bjOuy7a9i0WVnK+GsREX2opxdcP8SvPdiXUDiZn+aiXDsj8cnfEIU2Ws43+ZlwH9xuafYRdXFFgHrCWUaoOO43k+UZN5Nm77V+vEarrF9q4wy1Y35bZNc2aPrAoPLdJXFYFv1hllRNlGzyt8fmFi0rDX28+kt1034/u0uWHzPr6uY4aYlBjzV5hjBK9yO6jCi3s+k3h12d4KgN+IAC5/P+Szfn89JRo1b0rRlh4pY2QVzJFNWuO8Zvax5GUO4BRVShuoW6WULlKzBqZGCWG5bCenPrG0tly4/b03E0v0vMb9smuzOUvwQFFyc8OIAYYh+L5p35SgluIUPNHM0HwqKn+SKk1g9rlIlO3bzMJ35hviQDrG0z/VPMJv8AyZJEHN6PWDraXxqXFGHiYktxbAOri0/3G2VNi7sy5prUZ7miWFwuy8vdoytkJJoo3QGUaaeFoo83ErYARMjrQ7pW77kAhFTWbNePk4lvNkec0/IzDtaXYvWsW86lV22Byh78/wDkqkg7q+9H3joVusf+9ogFsN/1yliDOHnv/EocNDm/l2l/AObx/sasX+73EppGGCRerKv08w+AHFaPDCGCx+XHh/EGgG7d1Zzim5RhYrru5tlSpV2Z54gXzbR4iVYW8jENr41Xuf7FiePESqqx+0KgIhujuSka5vvBWLiMNu5e/mUFRFu8tg4kVEegxHMI8o7l5C4WCsFjqJDK1FUYljJLrh0AMxr7ygNmec4q/TfaA0w3t/OPMOSkr9fSGYpyqcKz6P5qZoPMaIkoDVPkH8x7kmId2CCauq/CBB5mjirLorkr0lODgx5H244gFTCEtBq2JBWfXsnjtBTeVrTMnQd/3EDKusy8cNBK1OOLjTXjmFRYzEy83FOuee3y9YJK6ru/j/Zule1v1iNAuq1ju/5FXAqULEMDY2KbxTNLPjhS3yYrauI5bAzj/eUe8HXQoKGC69X5VhjJabeQvddsAEsOxETXL0XsHYWwFq7gsDSyUNLPBTIS5Sho767b4vzUdw5ZEad5rzMpWF7pq8/WYSVR34S/Blx/alLM32QPf9Qdppl/99cynQu6Z9CNH0Y9dSnIXmrT5a92ogVHn5XzuLhOFx2lHHftfiAoceIxYUL/AM3DV0nfNsNoHGH9QWNt437Eatv1qvuy65V02/Z/yW3YppPTvFFbUoPmzHF7ePnCDxS9Yr1IjqZmOUstZkoIZdwxLIblWIscpxMETjBFoNbuBIJb2iYWZZzDEVU0beD18+NwNckRwDyHHqvoS4KLQyeXtWuJXJb+AZoe2f5lqslIGzGKeTiBUrN3MmY2xCbEu/8AErg5twQEOlD2wfvMtAgKBedl/wBWpUctdImwfrkxFJ6iGGZRmJqHMtgclUNjbdVu9i+i9Z479pXTW3iojTrzG1mMkAKD3ixS0mDR6+s+kWP9hsW9NzMyPuwNQE20QerQe1Hrr7xEVV+fzmcJS8i1Xami3On2tuiTzWZ+eKwYcJMPMYBajbkrdGw7y7Fi7K4VoKa8nvKlsNJkcApzs4Zg/haNiqzT2ZubeEqWEbQbaeUoptVORhG1ebC9pazOi8tedswZBjR975ilTyG+HivMRGbi3OH54GLZd8qP9iomy7LlMAXmua/2P1D2QGnPb+V6SyNHz/8APaVJ02XjPp3lnAa1n07+0HuDRinn2ldh7M5863UqVz9ITJkxFkFXXN/5FoY4G6ZrAW9n3l0jflLIF7rr8SrK/IMK+aQa9gxNELjtT7xNpneyJqE3EqX0MD2RTuEzvgkN4o2UPBHeCNumC1E8Eq8hqAcoVRNoVe65omDXaGj5/d+sYAYL719N+0tWoMeVGLeNZ59IUTTBD5xWtN8nXNy8vThHfcA+UGcS3zClgiO0DIfMuKJaMGvxLE1gdnzNiSmVuy8F1nnfOeHm5V9i+sOa0tFuaArXtABvh4fS6tYrt647x8lYH+869ZaLDrNmi9wSNF8vP1je0zDSBn7yjtHD/YjllVGKiTW4Cqqo1tYpbTGNnuPzAIWPEuDZ1L5a/OoeYuANWjj1jhXVk1lR2++mV6AoC1XAXb1Y5oLay62BMPZ+sLgGGKqBeDNVd3oNscCW0GVlwK0dHHzi6UApS9VU+nJChUxqsnrtvn6x0i5/alVru/zutV6wZUj4x/5Mw+dvPtDxcc+vF19Y0SjfH+x5TwOP39ZjJ8sZBYefH1IYe1vErnL3i5inxcWgNma9OIQNms98kAFuZ9T+YIF6Gvw3Ve9y9qhuqzgQvBMfcbOzXevaoyVRg0GF+eN7ldNgG1KX94jpR2yZx7QcqQru2Kh9/aUReI41CqgHXjfr/kS4qm4QQihAJidhB2M2ZmVGYZ3ExZm+69g39JhLUt5fV37Ge7CS7MGdrG+awh34liytccXfB9uZotrzu7JsgcZ4Bo9Yt7mOtC+lSVa119Q/SWI2lR5EYRaJ4FV86D2YrA0lcCAfr8ppZXwIWHHOvzK1AC6XMEW0gH1cfeGDu57iOgvG+kFXZ/L0m2d8eHf9mXfiE29/X/PMs3l1Xy8QnDC7PH92iTcft5ilSmXxVUpFsrzcufN4iAZF4hO8IIFo4nOS6/MED6QFU819o0hgJZqFl080j8yn6+zCdhDFq16XdPnDLPU8GbQzQOm9PaaLuAyCr1UFrMe8GtJZki6FR3QuvfMFabcC9rux49ZRDNjqhyL8VWoHSg4ZiqAtjFfXvFmYVQZ8lo/SMXZYHmoVc8vpKY+NTMa9hvXao4SzBQlot/3xEMFOahmdaVzjcYqT589otsSuTbnnBRnjME0O/vj7X7y1DQ1Ry0lxXFzcJ94/7IflB1fM8pRdmuIV3iy9xmXi9nlivOT1rRZ6yii0rzeB7Y+8APsDtmekylMOIi3tMOgWiaEa5GGqxpqo1UBVRxBGN1m59eH51b2hqFGPNYa9n5ygJVdiNNpNeJTkfVjBnKJ5MHshtHEu+qVroQRDt+v6JoGGK/Zl2tlHgA/a5fqGCrsqr/eI2evRGlb3BuQADuLp7f2IAR2ijTftgLq+0EA548kBjitGtmKZHDTndcxAUVM2WzK9XWnExiWy1F1yzs2UVmuCKo4f76whth2xFW0DDEGIQYeFh7a9Y8St75b8e3MSRjsO3mJ0s1qJUNXCpNvASxZSs1huIEL7y4dsaV8TBEmfEPO94X5objUBYSDy9sfOZ1T+/wDIq48kXXvXpXpVytFW2yprjTfaPjUZFN3Rzw55O0ypSirKrLRaMyxYASsDisCLrQ75bVnx54zxHaZbdN8XprntACVacHsBZfbiHXVBbpo+Wzn3hQMAHHLj2+sJbNwYG2m/DWYT4a3nvUo7zwORfHpDJlR4yLCYr081AFXXLywYqKh6xLJ7LhmH/pNvn+kaCmeFcwVl5+zzB0577mKH+zCc2Hfu/ivlCBrl7hT72iVNuYRgriMaSa0sieyWegWlYMRRivvPElTNwi7joS0MB2SmCgQgruUeJSGUHJ9B+YXS+0VIUMAXJ1mrT/2HWEDTyC15p15jRrbf79ZcjaJxTbPuPjUdeJF+7ljQFZ+r1jgJavvPIvCk3JQtXgo751TiUOyeqwaEPmr27S0w4CemKAHKhWdwOWUA5ghxNcx3jS+mJwc94wO3J6dpQrlj2hSph2lFBuBufmVPrXaZkVwcyumeUF5guHOfpmNcoXjIbodu4JQhYcu+TtjHnEo7yCFomic2Xea7QWe+m1aw0Zwj33C2tSYMKX3rFNeY7WQNE2q4iyLsNOB/cX+Jw3xb61AEZtOHLSG6grTZgV794FlFwTamz4y/ScCG3sgtPf6jBm2CvGNP4YkTCOHjuPmNgoU7d/THaGy975esAPPweCEWn8Ikh93IP4hExejzFLxHD3YUUe8X1wvd4W/L2gEBjsvmd8I8ckFZo88s5o3buf5AvoVuNtp+Ljjpw/b76fWMsdyvGQ+dxoQloDxDvgxGxiUm4g7IhxFRA3Flkt0NYhCUqRVrZhfLK9FQkmkAJqemrfQfmYIk1Pcb0WUfWpayuAm3EEMk4CgixhhiFXoSvf59oqFdlU4YvuUnPEvsNPYg15rPF+JkzQhwA2EyaKGu1ZhrHqop3aAH+5iGlRqsB+5ZU5ZVA3HFcfzC0mb9MeIPijFsHkxO1dgqHmvzK7hV4Rp5zuAsiLBbBwOs5TUWrJVKFOnv3hEaKGeLr6hMAuaAsc0eKhQS+R8eO8rDhYHcPEdo5pl2v9QBk0sePL6doGKXlc5T7a7QjunDyvvxcGNpeul+OSBTwXttDz2hlvge+O8Xb1gycD071GFGzI91a9I2zuLsrk7t/WExmyO/Z9z7xEMHyp0+U+5BYpNPi8W+pn1gEKKL0qtev0lWDhNHYuPS9R8EsJPd6TxJagLLT8u83LAN+WX99+8efrBHgy+iwA5OXpBMp9zF3Hyd2Efmt9z/AGORoU3xa/mYEoPsflmbpHwzg9838pzRSny6ArAqE1xAnI+VFqfOD0ifh/8A7AlVZ6SndXXd/wDJ4z5Qh6ZVwIXaBl6FExLJSIJWPjLJAVhzsbzfaLKqPFQVl/YflBBhGxUpNaQ+ZE6OkNJN9KYBHC2bKuwaVrNqN3HbAlHI2E5vVnuwwdrRyDiyjVN2cOSXF60aDijnt3nW5cQCzb4KFaszjHguWNyqDm+IjEQbR75qU04ZApV8XmuO8vlUnGbqsZDi+JyYKlLyR14qANhguTdJd1u8+sqa5Dg7PntK7BdO+l/faOG2i8hinwSrM8jbz2lbd8Mb93eWqORl9O1dpvCuwX2vNRuTk8d5QUXuzu/TvOCATGDDfjvK9BfJXOO3nvLkGXvwH+syvKXDyvr6ziwcTzb27wuGjPGlvfmLRFHrlf8AkHHWrDOCr1DG/Lsrn159Y9nwfQ6+/wBZrZZ8d3rX7mmGFPTl9rhO5cl/j1qO3c5eGLIbdD0gODp4rtED3XN8B+YHq0eX6ntQh5juv+FmyYSlK24ZAEVf2EJNXJ/CV0Gnhe37hxA18hXiZewGqqzGIuf7Xg9u8uNA7efL03feXbOh6L0GZZK7TiJcC0G649Tw/acwb4Mv7+kEAGu2xUw5IHyZwZp4P/bhmZOSAerDcYhxCAmIkVnjFBdx5n4V9BjoFsCpz8AKEZlDooSnz5/9lRcELukfmd/xMXg8h7lPGletalyOpVbDffGfXmGWQBlQEeyY7YahMBuGA+RXbamfTU5mg5Pc/uUBi1A7KeWFYrNmuHv6QUSx79zx5ignGmOX1iaLMmXy9JTUadZePWWZrY7aE/EMkLDRbhe/r2nLUO3A+JqdBltse1wk8LDtdZ9u0y5FDlrT7d4w3Fgvs7lwbnbHHqhDRaYM79UDloGSs5PbzDwtq7a+feUIQ8jBdfiG6IAWd09uwfOUxUVw8YH4lu7VDbZq+xa33qCp6ndeR/t+JQuR17Zp8r+ctdDXpzXp5itaB9yr37VBsscPqZE/uZfDuaP7mXtt/hM0GnzyTHWF/wAe0IO4eOCWh4BzrcvS8wFgiu0pC2jFPuSrALs3faU6RWjsrLDynit+p4lwmrwq+PMEZwUt4q9mIgb/AI8vp2ijhFehyv4feHjkD0qn79+g1FcwIMy5uHI0hPz+JbkN3wB47NJfrGbIgA5Hw9vMqZaA321gvk+VZ5j3kMLv/wAjNbZdTEhC5gHRlZqWCyUypXQldaixDKnVI9AOlWEtMms7PCcQlcIMVVCPsvJh+UQIHtlly7znwzSs33W/kr7h3lRbT6L8i/8AiwMLEreFuloruYFQUKDOh49XcLDtFnHZCkQp0PTzCGwt8G/Yg60cMvqcXKqduj09JbG3lfZieQ/TyekXsyG3289pbANu/wCu8szFjGDIc+8REFW3ydrl27hYPFfiJPeeRz2a4mZBqFB2HNVqVgjnjgo58ssdMjkpvTPq95ccABhxl832h1YrrW6V95SbWs9jL+IgwFJttrfpWTszVUWn6KPDy+nErbSK7n7/AHM8a5/Z6fiaWifJ3fpn3iJ3eF4ulK9dQ9XiueX/ACCAMN6gNd/lcowQD04X8yj0WZXwQadS/u+kHl1q3MZQIsF6gzcpFRi3KK81TsGv64jOafwevMc41t/R4+xAKK9BvSvA0T1hu4Zgk7+l6uBPlzBbwoKrv5mu8v8AIGSiFNfX7ZLqce8Ci2vDk4gqkTAfT/wnmE+lExsRCVU0g30b1BAjj4VUPwGPSqjLQlSeolN94pdgYOwNJ2cV4pEMYq0Hf6fWaMAONqFnzsxpiqALL25TufU7Quo2C8GMhfrfvDxAVjO7PHac8l1rRov3h5Szg8POuI5uZba7esAIBXkwzBR4FGnnH3lSAYNtv9nvKVba1jt6xroyNvl7syzm8AuLcRqPyOD1h4xp34f1CErdMFafB5jXBtltyV+ZbTLKrjDW+aYMYQM33bee8Rc5Sx4D1OVd4mRm0prwfWbS9TxXfxEqaBfPc/S5c8K0bpfuV+I3Kt33rh/fbEpPx+4D69/SFd91c+D2H7SqVpZ4rP4fnCDKnthZXqFQgZq2xwg7xdb9mWmPHPFeJu3e2PtFb3pvn3YhwlTUFId8xGL5dJ4/8+0IVu8H5/x7QEmY273z6tPlC6L3CalqsjazKMsZJUKO2rNfR4iBddCb578TYAgqsGec/Qzuu07CIpWjacbd57lMbfQzn2z71fvC+aICVFDAlGOlIQiuoXg6NcdTpCc9UnOOjjDBph2iIU8GPqGKLItFlYPJfB2lcV+U2KsR9/fSQZfbQYrtfbvevMcQEFOTy331uPWeB2Tv6wC1obcGFP6pdetoDud317QQpZyeDzXHaPaGOB6tzJPA2+H1jIuWi+CHe5pl8PnxFrFg32rx5lr9IO1+fEBDKRMF4boKvR3iIwUK2T5Dh5l/Ivld3XAY13ZUQACgMGrat0czeVjFgwShlhVvnKB9JeI/aL67FcPrvxMMgu/kPft6sZ6hV8VZfnEKl2afx/OI2azROAG/Nl+8Eyy13BfDXn8xkeFJWSKxD3Z3dT7vTTt0qowt1BExT2i3H++fnMgpC+l0Ce13MRArKDE26K8dLjYFtnyfzc2nFqcmDjVfUxHhiwWqtOsJh/mI6s5ote+KfEMxgUspx4iQalRBg3uBcpcS6Khr/kPRmWkRRhqXHqvQ9XQXYdNZrGfrBpSjk5fSuLnYRWtOAr1oYyChQtJzV7vtuu8RVqg7DaFO1PtjFS5wWJg8XweI+gtC3HZ/csAtaj8c8QKGjnLyOvbmAiuR1XA+ZZgbm23fb/I7B5FANBt9OzKKBFQW93hquHxGVRWqO/qsUqLtFDO8HrFK16D0PTcDBzFhcFew58+0BdYWnZ0+SrH1IBWAu5tz9T3iiLBfr3H04ggXRR2P6vlGcw7T7NeNX4jDMpfnKrUVd9DEGK/bNvrMMIPHVlwrow7IxWd12+U3BaqMTogTfVxS6X7X+4IHBdOOHpznnHvLOiujFGMfwvTdxoArRTf7ZtfpqWGRZlF6IJEYE2zGiWCiG5f/AAWXFVfWWEagqaMy+Oi9WdQCjOlUnbN4+UuS6zmrr7zHqZHh5PfGNWS/luk2PJx2Ex6aj6OYOQpVvcD3zeZiRYa4Wu/mEcaDb3HtUeNggC1HPg2u2Zw6JaW1fbV48xw5OcfY/Uf+cqDn4hzK46Ds6jErajT0FnjOj7xzmbV8qgD2Wu3MFTq77Pf0eP1M5ldYOd0dr1cZ276HRy9RQ9P3M2dAah+FSonMKRWXbAO4FUyyK4iNHVkI7beXJi8W3xxXvFUk74FU7H44y8wTC/tWHGt9oxys0faG4QMCZN1AmktlqqG5cuX8RQ5nZLmK7/npaF/EJtQtMiq8nizBNRYwKopr71DDbtL3VZp8I65plNVhU8PH6+8fpjo4J58PPbwQhcW+sUvqiv3h3RXcQI0HhhkzEqMuXL6XUXob+Bh6+bfTkfFbiN3sasxh8aetwkrOA9OX+wYlxmRcKIsOuv0m6K47/iroqKIC8xPGowFNQ7oC14r64+9TEImkM82PkefO8S4cMY3e9Z3kreobNAR98t879JdsKSuI3KGNufh46kuX8DmZZJQ3KgBFv4nrButl+mo1vMsGvzF1euC7OTjSD3+UoTteT59e/wA6jwo47jz59+OeJewAk70v7oshA5gyzgiaXP8AsOBNI/Euul/BfRZkRPnw7ds/eYOi4NWQnpKohUGOmr0mh0nJHZ1ZfWpUpK6jUA1ZTF0F7LvzDaEnwehqxa557TvAQIFrKvBfN5rtNDdJxbVnOe17ZwYUbgdp5RS+IAKPgPht6X0Gpb/xuskpwU8vp+ol3CbTjNr0Vr5QDTgXoT8L2127TFvjOTl8drPOOZVqw/8Ajp9o4C4uWEqFRqzFhd+kGm4okqJXwgSPf/I9NS5coehb8DjqtiK1TFK2bUyGYkuFply/+lbsBrdfmZoiVTZTB7l5wY4zKWjJs4GgwOd7x6Q2t0YrZ5e+G5VnsfszxTCCCZ+Kb+K761/zGKtkJkrDyNfkOPSGmplDKPyHH17zgb19wdw7PzlXBZdxq8/WDCpQLctWdQJcG+iVHq6xLvPwNHx4Zh8O8c4jcX5xb1F5dAVo+G5cH4SjgGKu86r+Zjgq7XCV7K/TEDBA1ZFpsN1nv7ZGPjF0u72rqz0x9YLgZbPvl6p+O+l9GX1f+aaTlHEzALWO5c+zUvAPtafD2fovyigb1FafKcLtT3uDbW3cTOfduaV8Y1Lj0K5gy5gVLlxel4hGWS5cclMeMy+i1Ky7aVtuU46ZEyLlkuXLl/BcuX0LENeu/wCuWQhBsYHDffPEobaUursObo4574u5Tc6muw5M+ZWik07eI0LSA8H/ABuJ0ely/wDoGRE5MTBM6ysvgz315i+VeQ8Hc5rZ5jPX0DsPDx6du0x2jgdho/L5WKWuPjuX0fgBynxX8WwY5US9bldHiNh8HCz/AKtfb/R+fnGakejnGHvzioYilpwG9Hi7+cw1qWcCuyu+s79I1+1vvKjGUA+f+I9ElRJUr4H/AI7DVjs8/fvfcz4lN1aHLt2Q78+ldCW9InzIVWY1/wAL+CknJ9kfjWpToKNnTn4dUzX+7TkdR/62ir9QesCu/Fa8esKw/YsL4aumtnMsoTC8oZ+j8+WDoir83rIqbgmuf+B8T0ub/wCV9arjLxB6FamLDH/BzBlOh6LUuXLlxphLlst+I8Zs9IquWy6h3Sn/ACcvRiI2TyEbF6niC7ibNywcvjPh18Br/lXQKol+ATG+8X/kk1LslmFZ7xz8ZmVUMTcMHRg3NfrFU5RKjqEqYS/+FxlSohKfBqkJtlj8ZLlxfivoldL663Ll1BqLbFMbUOZbPBUT4r+DPE9Zgg30GSJUHMc4l0xpIAm0vl0WlEvlLsmBDk8wXO0bMrEOlX1v4jrT0TqxbjuhVeJgf/Kwl9H4BrJFNs8x6rUWWBFOJmJcro9LqEWRai9RqJzEuZbg3BuIYa6KXAZhiOZU5hjo46XDMTMXqdHEr4EGpRi+t2rrqiof8HHUz1ehKHslzcr4AtplAV8lShG9QpLgwVxGLDrhlRpmGugXEr4BqPfqG5roqamT6KlwYxm5dRYsqalxJUrpcX4VfUa630W8v/PUuGelTXQOlh0vpczaY4JFJcNS83FvqXCMuXcKtEcNQa6Vi+iUX0OCBfRcqDHEqUvMQm88QUxL6Y6I3BqeZc3MIM8k5r4Tpt8F30OldLly4Ny47oamIu+l9KlwiwZc1L+IW1ErUcYgG+m/hDUFdEqWkuEDmJbCkcZiWdAuOLNQd19C8TDM3mZpjo9ZL61L6JAi9Lx0s4l9HEG+tIObh1Stw+Dn4Dpcub61/wBbqKkxbxOKZ5lWQCJUC+gKgsF9eITccwiXLoicw7xLiJvovEyEtcQUoLDNpWJWYPHS4vW5puXL/wCA30BUd/DcuXNsep0Oj/1S4KdSWxJVdNSuYQKZ5TzLRRt1MyiDmuoZuWxOZpB7wvmKyu01qXiZu46J0DiNMYHSsfBqJK+DPViVMS5cf+mpcM6hH/oqm9xaSJEKJZydHzKJSTOpWKZVkFdAXBcSmITTKvLDDLh1slsQ6Nwsls+lFTUzSx43LtnNR7RY6GYlZ6LUULfBbc9J5g3E0I1c0lyp3f8Aa8GYpbY/8huLEubRLm0LRXAloXjAtiBqa3Evqlx7Oh3EpicwVi1DJAXfWs9ABDMqsTCONwbmbmQYGYM3BzUVIr6pcSAZIa+BalwMzTNot9P/xAApEQEAAgICAQMEAwEBAQEAAAABABEhMRBBUSBhcYGRobHB0fAw4fFA/9oACAEBAQE/EMcjHOGaBErMw9D6Uh04Wyo4l4qVDEoyS/ReINRbbl3/ANbj4QsblvMNJgTcZC8EB2Sjq4PmV8wLoQfUF7/UpL4eKhTqZNRNpTxFtwSEg8DwogMpwsoy04oQvBHgK4qBXGBYpUPQSESV4lcVcGOiXDgb4SuLg1/+C5d6lBrkO5uVKIAj4RbcIqoNQLuaBhqAxQthUAqCEHvLO2CxXUQiHUsQKEBeIGDdyku5cxBYrqJcDUtEwHC11KhEg2XF7g6xDzlJfAcpOq4FyuuHgZhwxK4uD/zWpYwiyr3zUSplL8S0W/8AgRECi5Q3CQuplFqLL4qUeuBPU9kWRUCnDc6hlmEiDPQ44AykoOUshukJZREGM2NTJCsrBHh524fRVlMRGnkf+TmDWCEqUTEuXFgy/wCSxYoudStmWW42jNolM7RKmyCbgvcv7g3cG0yksgMrK8ReNZaAalMv68FAU0eqiJZc1KEteZSWRG+Hk4qlRpjgZdQ9VSozDJBal8LDMRLQ3zcvlansjDCIwAqdQ5wszrG6ReLwSuQu4H3AO5XmBbJYqABmZoN3FmGYf+FgGbf8hKcKSJnmuSOdyoEqZlepfEYlyqly4FzoJXGuF3zZtHxg9s8MBk7ooYFUzdpsl0I8EwCUYQkRUs3xvjMtmYC4JdmWBRzDioKaZ777+sX7Eyp/5JKedyopFItZljqJAjXUvjPCTUuLW5lhjhYLwToOCLF4EWo9SOIvN7MaItecwIwBRBlBsTQiLLhWGMoyiVipqMwMwDDOoyXCOjF3hZgg/UPDBZ5GX8z5wDBH0ixIrMNf8Ku5Se0i5lLd8akpECEpGLTJHOeL9C1qVeWEYvJFrB6GVbLDEFlAxLZfoaRtQqHMJ+Zv2MtUCagH+xDCoNlf2gmX7Q6x+08eLdQrqD7Z72K4WGjDEGK7lLBGuiLj2Zb4nvTzpZuLfL95TjhqBbh5QLKS6RLkMrlImW6l0pwTvjSAJR6XSyKihnmmU7gOuNiWkV5Yt8hcowelF1uZdwPEUb9RMGZn8n8EHdj14/qaLKP9iaQpNUsXz1/9guUu/fxC+4xo7/8Asq0qJdzfMsNy7GywnuTH3ly4sWDZlMIEMS+CJjLwwQ4biHcqxQuUDcu5QlYSwmtwTzPrM+Z8p8pcMLSHgnsS72S2iYrYJwWS5csNxFxEZaUzPUplSpUowQ5epG3cwimXId0v2plpiUpgkx2ynbcT95/EdYngP2P7nnfz/VTo/l/cBjL7/wBwMZlRvbH7IPpcreVM94lTNMyxt2IiJfiGoQrvKuC/mdP8RO0uHlxbS0p4lsGYjw5lEST/AIA4uWcJZLQwZnQRljJGQs9TPcqBEvEuFxNxUSPeCkt0z3JaRVhLqK6iCZMUYQFgkt2x2GGlG2idBxDeMwSzMvkiKFSv9qA21BiynVybP4/ZCNTiaPLFXExSA2CTHuGwQpgxsZ1OriNsbxXMoV8VACUmSCPo3HEua3K8cV66RoZYSksRnErvi8RY8XLlkvudTaLWY53x1GXFrcVAaxHcaJVmHYZ1CNNEs7mW2UZjeKZgBrqUe5SJoxsEuYuvMoElxLYo2zVEVrp/cBHp4hGbslkrR/sz5bOx+0KZYbOZoGP7ip7Sv607kj1s2BuOxKOXsmohurefaQmjMtS0VLQVRKlpaXL4WnzjIJWV5No8bgUwbFS+CuBxF7i289RYW7AMGVqJdVjtMt1E9sV6YTGkncgizMpN2yjlgGiJyqgmoDysRoUiUNeyZr6wfzCO1f6YllsD7fiNKybtvH+6lpLtSvbzcwsgRBd4nWJd5i27l/TMlSS28xUpJ8SvNxrtQFEs6zB0imVKMqH95NsjVllfPqya4PeQkAupZKcFS136alSpXDKrgU3BTUtPfLIJWIAi3GLREEBpuN1iAKFx6R8RfGhQsh0Ja4SdpXgD0KjtMW4KAktc0zMlIrzDEfeJX+U2MviApwuv5ghQ2/luKWmL/UMrKiJakN7coG4h3KzemLAVQlclU0B9WZJQZzDioODdTYh5sO+dFDqI2gCWMPaWlyyLfFksgJSY4WHc9yHknuSkpLJZwpKT2SzLubRqshRQSG5cuXBlRxiI0TGyuuV8s0hO83wC5oEfJOwuEO6TUW7jBbIs6gFy6wTLUqyzcaWFLkqeRfEv/tlpdYlQiDMC/aEXXmEq45BiVNNkQ3zAkMpbihWEuzDyYFubhLqPLDXUuXhFpcuMFpfAJVEcM8E31Bm4OouolSyALEQoG9Q8Usbh7pc6ihsgoFiJ8Jdw5uEYFpAEgVhjeaixIZCN2S3GsRUWwDiEcURTEU3cv6h4PRpbzPlKeZ7kB1Db1fpF+ontBmTEQNTslZueSIrWYdcq1lFw0M0Y7BhHMMHt43wS0JgXwIVCqZQxKMDKRTuouquFdsxLGXFqfONm4fJBB8mPpLfczAfMXRYjZCgwMo1e4GyZinrE9xHc9yFO54GF8UYdSvrB6YdM9lCC1FTcqYJesERWxw3L09Si40Tc3tQNZjoIq7iMqMUymWgjcploogmDhSNrRFDcE0QTMGVZUjLuImWA02TdYW0HYcsVXFLiAtI7jDthsJolWym+zNgVEFk3JclO5Z1Cy0ShgY3YieyWaILNXKoL7SgEfrEOWUlxfulHT+J4GAbZ2D8TJknmV9JS7gpYiwBtgxLMO6lTa49ZAuiMM0geZUzVyvSHjFdM74JqJcvVEs4cBqVdRK4tS2OJQ9yjzCjufWUe5VGGClG2YaYWyzKlsNpuYe8UTNlXGJwYg1bEAVLn7SrO57SiQUkApeZmSbEGo0Gi4CptARaJdZcTGbjZZH4IMT9//kAww45GmUNEI44RdBC3zHUI7gG/mYoe2cKNEU7iwQ4Ya4L7zLdkv3wrqLphuLBBnhwj2qINsp0XHqhpFOYBiodBAalTIfaAuynAHmEAanbDaLUAWt30j+45kP1KlmhetNyhRSMpk6hgEBozrcalEK7lIV3KjRhOjb4FmiX1Q/m/xBGij7/0RoXDEl2VDxeftEdoLpKIFS7WOog3Fw9P9zt5WoRb9/sz3HqDprjL6bggQrkzFTOdwCCWg3F5mXzj8/3Bsf5/vbTBZ/WfufdmFVrpf1Am+x9oSjXrkWSpfDmPEhLqCm2Y5DfFS3iDO4t7g8r4lqHbVX/OYqCUn5lm4G7NwPNimPZ3/wCwh8oW/fR+YAaUXauLr+YrVH88/QhwHr7j+oj88K/ZMvgBAFHGvrd+0ND7L+oaX2D+pUj8hT+IwIn2wfvr9R6k+jH31LhYgrhikAT7maqgmghUl5V1cCnD3vHm/nEZKke3+tx37H++Jsg+39XLdnTyQ/YxDiLqk3eauGz9mHQfj+mDYX7f7cUx+DAtWX7j/XUE0H5h3n8xZpCiG9Qi1/K/zLYo+D/yDLbj3/8AIOhgobL/AKpQTwe7/RNCnQ1LyKovf9y7ZrCwJpFUo0YaEex6f2xrLjL8R6t9tfTJACdqf3E2l3T93+pZR1WPn/MUBrNx1lj/ANqOr2/qGcH7Z37O5TdPp49xlA+PnGPufklytePI9x1hme9LJZwGOS6ly1uV2iXae8oWUQL1KRZLEaEwkZ3FxElEH3qvm2UgB7Fv7qCQfOv8FfzKhh7TCB7sftn+IKjAm2IHDK7MFbIJ3QfuXGGMIgtk95bor6Pxr8Qq0yiKuIxwX/MVwzB9d/U+jT9kywmSWUZVbiTGpSs+f9/vpARd3/v9uC0i0NbP9/sy13BSqiEGa9ncKs17RMP4JmFp+/8AUGPYxL8vMclLLYhR/vk/qJg9/n/2Jf8AV/Xz8S4DBoELeVYuZIO5ZaIAMxStmkdzfYzJ4lFIscP0bGbHmFMYg9f/ACA0EACH5i+yAdu/7lkLDz19YoL/ACMV1kiPf5/hJcUf3+oG5rgVKxo3LJTqXXGtFXoImIVK3PKUvMogg3BMLHafiMwzY/OSMB24iRR2+zE8V9jBbmDXkhHQRcwKGcFzz/4oP7m4YDCuKYrTWPbaewxXhtDT/wA9ok/zv9Sv+pjvH7v7ijP4P9y2Ej4rpmntKQamHcQOYVlBPkgo+x+yXNm42Iqfb8zpstg9mbg/MutYzIzp+6m1AY1b+4YMR8e4Ez3CsK8RdsMxbI/jv9n+4OGY+sN8083n/fWJdHw4z7PX6nRXd+3v48JgD0X2/V8xytlD43MkgkXSFNXf3/8AIxp4jfhKNSwWxzTmZB3RAn+eYyj7Rok9vzuIESk8xVLLcsxBYvzCyxK/qY+MM/xp+zjcqJb8I/1CltdYfzzuVLdJluNUdLBWhDVLHYVCtgZaXNQQK+OPLVS+7Omvux7D7s9/92K9v7yx2+7C4I1Xjef/AHqF5hfl2t3rXvFwBVLXI5rTUH0kv6e0PvZ83+4qUup0xmaljX8S++DGTPidyOuzA8L+ZUZzULmTOn2/ZKyrtj8Kdj77p9mfUK/eXW2Y/FnxK4zH9MM4y+Jc0jU/pixCALPG5lGL8f1/UV9H8QCkWv8An08/EK47YlSTNSXxhifPX31GaV4p/s/Eq9qnryQKTuWIlVKRFk/mDMQiR1wGI7i+1B2mRcLS1iWIt1BVljbJCAj2ecSF/vJn33rzDfX7lfuVor11qjLTKjMiqKmWZi7lfOpRoJbz+0qi0pFWZ0DNz4Bv+oaUKcQ25jqEe/CFHPc81feIakZp6f8AbhAQ3ZpT9P1qN0k3ngz3lmt8/wAR6tv99oNjvMdZdfzL1hWT9w71lzmGaTIdP9RsPqEAtl49oi0wQfPAKTtnlI3/ADD4n+45T/yDQvePqSm2G/5/MdEvfn6X/EcI+xL++qhRkSFKiUOw18xUsQ4PJDuax+pZbJUgyxMbgR7s1l2UXpUUrZrl11LDJG7lsyecZlwl3NwqX1Bhf7BMzcfNPvX9TLTv2w/bT+Jnxl/XXqCJx7XkINYjOVlXeZQpH2gdFSpqMQgXcwK6lxzw8XCUXOyHijdlS5tX7wgqjUM6VlHTEHlm47Qee/vBa8182P3p/cILvcY5QwKRYvUIKQL3yf1AHBKuBuY8aiLQEGn2rEoxkgAoioTrUdiu/wCZ3exPqSxHw/JKkN4ftKAN39F3HLTEeKtwM1pAW4CtxEZbxftG2Q3VeK8Z/iM03ZBFG5kMlwGPs+2/zKiUYXb86A2q4Ayx0XmCjy/oWVJcOAal0+4foJSCtWvvmpqF1Z57gXFTBX2D95lFUgqv/alMrqv0gw/MQuZwdX+O8xx7vqe/uQjHqOKgBIyZ0RKYlNXA5Uy2GMK7g+IywBlgxHfDKkysSllY1CM1NjEF4zfZBI9wSpTAFMwBcQXuA/z9/LK1OpVkxD96MV9xy+o0R8/zDZfoEpe0sOKiBBgSUVY5xuIppvMZNjWpl7NrLIYa12S/FR12RY9XOT/2V8E9Vf8AMu52bqtsa7zLkHiKZHvUPYgweX/zcVW5HN+Zk1Akgsl1R4p1XnL7ygp1UKg9fzME7lEcR0EtjLVJuWrMs6m0uGeEAX1CA94xh+j1LzlRVuX6zSvRXFMeDdRW/BgqOYIyeEtwHggihIiOuAvlF7CBQPUabYsjaLS6iy0EV8RAIJluMfPKcyjdPhjXcChVdy7MssQ+AjKhZoWiLElWe8PI6ovo8QB2YlLFkq8l1/ECrJS1uyfSfQl4iQhnQxztiLomLQW3cCU6XUJQUVco6ieaV8f4lindP5/iMV/Bf3xsmkYvPn/5CQ3ig+YZXA0GowJ8TIIwBjFwhnxM6TOrxUAoN1KIa6JbmCG0/wDLMRo/BjbuAgtubEXssD6bmMFPid1XKrkhxiMGpndnB8uoqOXv57ntxvmV+U/JxbFYkdS3iYNS1PLF7WBQPNHUiQm4d1/H9TDcLkP3CBUMhvuYbI8yP1HmeBHcs1Nwue4ddmvzGAzhx46Vp8S9Y1FHBuGr+hj9oLnWYlQ25iBqKvqiKDUvLhO//YhLlTbGiIi0pxX4l2NSZxXhdn64ePwoYX1DRNw3BBzmW4pcxtpglqsPsD9RTUCwf7BHjctqXFgrxQKlvaIdam8PV3KS1EPNNstfv4l2Wc1DlLhxz/Rlm0HUvvz9IzZGjgaRlXHjMplS6YRQJ7f7zJTGgx5gxD2+ZZ2ypKsq3w+EDNSsURhszZc2Yij7FQpN1NPmOWNmjJ3EFJcvDqXsY7D/AOxGh8uoSGZ+0XA/T+bZufNT9S4Hf8CMpKYo6qHEtFbLKvc2/WPk0X3jRWXOtxBYZdxNiEFO4IU/qv3ETT2/9jMyuS3xHad4gsvyYCgxLsX7VKQlTMBjSYl6PwgJIfOyMdj5iMvL/Eobp9UPG3zGNdQCM346+ZSjw9cJXqAdmorN/wApludSqmBGOEtQgtjzFi5SHRAp2x9qgFHbFl44S22BwGIpIXeAgIYo1BbNcaZzM5cDjzMRBwckuCpqkuwAwkIDAPzABRqKqvH8y4eV/dRXRFyMQw2s0WWPcx/R/sS2KqxUJh1Z+bi3nxLDevM+9hvR8eYdZq/qVzH4lLtafiI8r9iFD9n+Y3AD4YCyO36f3f4lO8hQy1MvDFA7qUVvu+U3T3UMnV1uKbg3FbEi1gYoayHAWbWT9z6W3MxrGMOGoqLfSI62Ebbzqvnkb9KrrBd/xAZ2zXB9JSyzlmwZRkje8YhmHqGZd3xPdI+7LMBUa8kteoRQ5LeJTqIT3AHE7pWoze5liYs77mlRiKtnvKAOiNmpZRlxm8G1RcWxBzFbxZdRagnvJ+4U+N/bMYBVaZVu/wCpkxb/ANmDJXM1ezfvPfz+SJXPX/yAr8FV8VCwOXK8X1ANYqC4YOj+ZSs0bx3DSQZ1RABWsoS1UJeISgfa9xWYrgLfQtv9wJMMuIm0/u4i4gp7pgItg3CYE2mbriILaityRFIwfeLg4rZKrHB6VuS26mD57gWykzFxFO4ql6GoAQ7o1jsag3cOocwnKCYj0jGoRmtTcms2hrKUpmO4S6I9GEwXxChqMcsrZ4hCg+8RwlQjZMw6yQAEEfE9+N3n7QEjPmJm3PcS3IvXVdTwAGtalxmRckGNvUzBbb6hXpSD4geCr9TLp+IRT7/RuFjAqCnL8/75lo66XEZ7dFOfrVSvt1By1cs2DQzej+YA0w6kO/j69RKg3umv7IL8CvzL9jETsjK1cz1KuKKh8MRDHiB+CJLFbsZSuma/iCV4RKiDdzXLKm4FLlYptgPGEZYI2kEFQ16TgxMXc6CBSZMo0YvmWeeV7ypRKIFEZfFKWMq2zNVXj69fzKWo92iupsXibNA8StiTeYyA3d58TPOzqEVVmMdsMF/aXawfmd8nmIKzR4lYdvaQGLNwCGtwHSEGrvXvZWfPn5irCLheIlqblylCF38R8gBLlu/DYW9LXTuIQOLGhWtZ13HvUjvZ8o7Y1UKyy5+2u99ahC3Orv7j+JrWFlPs+v4IiN0Dn96/2Jk1er+1VRglQY3R2e2f19occKhau9FrKbg6Bv3bvKb1+YULB9fvFKVl/GpsWuFEFIklS/uYT/sxL1CtURYDcATJMhudTwQoryEyjep1wWagWxLxAMS8ESFQ0IlyzDCiDZwbqpxcCBdLSIlEtrLK/H+YwKIjRiO18xoLuCY4s1Li7uMzRLAzQyYQLgjc2LnW6+Z40Gb8zZKEYMWRKmomKgOTUsF+0FSf/JQlh1L3hcLuXVYlCM/McLwJpdy+bUzZn2mB96FbcRFveAWhyRD1hfultdF7vP8AvmK0i5Bw/wDspA9WJS6bXWO50jhjHa1Zrx+dS1XGqu7Vj/2KmanYnz1cF8A9y5eZYui1/f8AEr2YlVdfTEHLRc1WAjMl+Hf3gTHVFZPPk+JiOkdXA2v8QkT718S4BQx8un3qAJ15jinJEY0dFb+X+ouA2faWWOmLKMDtCVTMs2YgoGJpJR72v9/+TbCqagblWwbJnqd8cENZdwgzFtBZbLaIXNOBIG8Pz/s+9VKQU8P/AJ/cIvhn4+ktUWbzlr27PbqKq1fEqFT4jjaXABVMUthGuRmMecLSQS3n2JerxAwLR1181DerYvem6x7Yj3IIzqDioUTIKgEaROaW6/8AZcTWayp6ICWLirWcVEo8/wBRChIXFtHhh3THmWhGo8t/ioGH8kqDr1BoEPPh94mO8SysQWyCNsRWhT3n21PHxcFsyMwsNHlPxdTKIfa/3DLAPYi0LXqNH3xskDLEhhXFAh9Tcoq3KS4ZNioDfmMKEWMG3mU6QIqhwN0eJYWxCAdTPipLoC3msfzAMKhh0xnBTEuV3MmdgQKmTbolVqGcEPKMTEFJ3BKzL8oAE894fOPMOHk87X7f/JXdo8EDHQntLpzBu0HLFDLAdynmYoqMyRDShLWgce0WJmgyp7HiB20sPHZioIrDnvxX9TBgwCmAvavqUCFFhg+ksYp+pWEWxilglu/5TFbaN9vpA9dMS9ZuWmXHCwS00jRz+Zcw3UAvUQUJ3pCRVRAKyWHkh3YlLIX/ALxFbEw8FwjGruUVphwLR4hQqmcUMxS+otL6hQCCbMOvmWwhl4PKVDsfuM6cHhg79y+CSiKpaqZhCa1C4R2vUtXEqyB1AqGy3f6jBxXBRlGnUtqDLvBKC4QN4GHcteJUnaMABC3iXEFy4ECGyHGSdxZTXOoloaj8GWAG4zDV1e/ET2KizKXUBcm4LjhK5r7wWJsroSvmV9Ndw9RsjqBmZxfnEGAmCUimCWCFzrNdRWDVTFLzMtwRX7zdL+CK34ftE6wfpCgKFosCLWWJdsT2hhIhdXcsBXtU217Ol95mKpfEZ8kqmWKeyLhQ6lZdMyMlQIQgi7SuaaTRiWuGKCcQcFCXkKrdIDCzDCbKY6iy+oQYRfAtlw9ENRJ5YIiuCFQBMssQgyDKm5QQCFuWS/Ee3YMJSTbn4iRZ8wOFWWHvzXmV2oHHmum/EF1WylalgdeItfmhiWww8TBF1y/pzXiWC0JBM/eUGRev7iPHA10fMPD2MqMTxiINdfO5bdrzHJmRWeDwAiw9kMUx9Pe9viGSXwhZGoDnZL35TNCLhEUBU6+gUZ9IraXMN6zzmTUBbmAjUMsQwxaKWs3hUmK5SpZkyCY/NAJUkMynUSpiwPcp1BFqVCLCpdxQBnyjkiUy94SkWCdMMFRYrFJcxxGFdMo7iPbBYJnZbgU9JTrAbPIn779oO5sjIVwCV8/1U6iy2CRjVYgOvrBenTEFYEifBA2hC8mMtNeDKFnKuk/OZUaqpXI0srQL8nUxNIyxLtNjENc11HqE/WYCi0eO5WWD3m99/Hx4hSgP5iBjUCl4BQMJSCTDgI1nHZBLLuAfBbMvQR2z3g2mXA21RqgroaxYBjGkWoRPxMMzSNVEvLLouKLK6idxk8oLqPlAWmU8y7gzBVSwwbQqrl+FxrGFyzH3mCmNQFWblwS8MKsBiDycRnsYB1ESakBzLinTMDsi3dwVnTsiNerhXeJX23AR3eJStnMl767jCmPVwbTB6nmmCxKMFS5EIumMSsqWUJe0JQphiQA3KgrCKsGh1ETvDFopUa3BG3UAvCzkVLKIEzHVWOQw5mTRLNJfJgxzeWFdyl0FO8UqUJlFqOm2LGhcCyhGmpeTvM9yUkZUwgS3tRM2WzPFSzmoJ1CAXbMSgC6j1RBTKugi3tNzyWivxGwaZb1rNo2TNuCpCdy60vtEsJU2AMRND0/xKdpmVwkYsxSuA+pBaqDawihBhmEs75UIyibhGFIBwBdFVGNuoGyCRkMkEFdMCgmUAygNwTSJP6xyuafibQBVM6veNVTdAfqi1YV8CaUFAuOIuCCe7gBiJLNwNzuZcvj7cE77ixIWJWpYof1FaJVY5qVfHZFlUOeDg3B0pgFEtUSyKHxfqCrLPiphhrGKECxEWkodwuwjrYIIhlBoldyPReB3KMCmAgChxNwEVCIHiHC7tJmCOMpKuUANsRSO4TTjFSOcxQvcC5KkiKtxcyPSoKsmZdQE+HAuHDNQsFQ6iNTUCio0omk8koCSmJ4ipBXBl8wjThlFly/Ss6cjwYb4FvcCUMEaA9f1LIQvDDFEshA5sVAm7ggRjKVxEbkyjNhDwhJk4S2sTaoi3FzJZjBBRKDiNToiIVQhNMynGSKCiFaMpsYhuCqEprMiRsaiLLqENjLQpmwvFC7blp1Y0TtAbnzCcG0S8kqssQZJWbgVxwKwxKYh4YbYt8XF9O4yqjBjk9LbZiMwO51oHkCOWQ8toaEhIMqJXFD6JsMExi0R4CUwllw20AVwcUypEVRSyCMs+niOG98CVB3DWgQRS0j2IIZQlhjQMqvQLce//svhLlZlsWbhAuHWAKR1AzBimBXEomWGYZgXF1MC2DDxu2TsYvuJGXbFl8rWXgt36AdemOcCyOYhgK1FDSVyUSIJaUJmLIpJZeEEjVw7XNo8ytqK6s7CAT5ZVQmFkqVM9QdjTAIY0tQhTR1KeaAqGEtTTZZepaIuuFnMYNv5lkJdwihl4pqRD8Us2ylklQW6lThBhpEdXD3iizXO44dwtKkB4Mcsq8xv0b9VUGU9XKTcdyrhL52ma5ppaUtYmCmMyj2HhAYqapwCMU2MHSKdRKIlk3Bfx51CSpU+ZniqALY0o6h2dMayg0oj2EENEu3hJg+BdoFFeOSV5ABXnhG8QdpU0gHXIzcoMkBcOkZTZiUgMTfEXFsRTcblf8AuVDAwzYlxN0faV6NoJYUNSyDAWYZTtLU1EuYrBis4J1IS3BGMICuQslxUzy4epfXCR0wlNkIgyqQrJNV/mfRo5eU1E2SsXD0XDi4HRKDcxpNEu8xBsgiHlNVQ1qZtQyKeC5wxe4iWylXc7UxEpsaqrx8154qVE9WWeVILwJuBG4Tv0bcYBMQZbAU5UhdNpoSUMIxKlhNOX4mlek1EudyVHWINl+gAbmggoSpqRgZTNZi3zsgtuCOvWsQbgKiXKEAIgxPUoiEuMMQ64W8TxRRUZrvUypXpQxF+ZgbmmWIDEGoF5eSO2Ik5Zo44hhJTE7sxsjyKzZVZm3rfkOVUV6D3lEJMupUKIas9ApKXXDym5xESUymAxIFc2wi48JZDTO6YUEBRUsYZbzNyoMu7f+KcVxaKZaWy14PEMckQRJkRfxJcIBV3BBSy4iUzCqlIRtiBaV45eTSQcJcwjhKZVemswFgEzFrCC1kQGBwMGZ8MbPQl8PrqHJCiKqVM3iVnMp5m04y3f/OvTVxKgXHwgN+iumYiBp9QatuErNxIDFnURSmAPQmJZg3K5NuKw+gV9CmUyolZIFeimGM2Au59oeUAvHCgtiPNSpUriocXsIFShyQMoM31EIqx/wDwm4KZp62YBWDDesfGAcYmP+CCHtDMyajGxTLYSoWynv0nNWT34qWagkrYuVHM24qVxbDMr/iLTECvmFrEyksqy0CUxvv/APFh3K8esBKZkBqBFTEGgmk1cpdy/RM5ntlTU3LpBuVm+MHySVKlQJUqVwvhcq5RMwxo4GUGZueqvSZlSpXFSQgxDDU9pcDhmyK86/8Aw2gN5l4uYT0mJqDTKiIpCkdKINKgXaV7gGp36KiRPHOAf+SAp4q/QlzZFTBn11KmoHprMQFM7zEKdxLkgNSpixAFMtyiJX/a2F98V69QYlzWpuKsSrLmEqV6AndSuAmFPNSpUqVKlSpiOM+l6QenZKlf8AorgntM9pPibtn7c1DBSVoIt/8AQXKJQQbOdeq7YjaMcFxGLmSwDmua9CTUNkKtn6SuL9Ny7jLJX/BHUJUv/mPrNuEdaeur9QrgX3w4xC+oN8/E1BHXFCpWlT3vMYBbYFDxLsJYYsXN+g9ChuHjFWZbmBLl8XxbxfBGAir6bDgzqEI13/wpYHiVmo+CCO+bJnu/HEbv11i/SRT0bQenMqVAqVLiXuBNR1BrEJfATTlntmWoD2ykrk3KsqBRX/SufvGVHBDirYCeh99SvtC5cObIcMuMqyorBs5wgX2N8gFr1MC/Qmbh6SvLKCKR40y4qLJdItIVDUaSzRAXuA4E3w3Oqlx3fA/8QlM1iVNTVO80jCPtDi5fPUpGEs1BXBvcbI3yJLs4HcW/RiInBbEaSsXyAwVytS/XccxLhcVSpV98MSyYBhyRb9BNS5uYIZJ8Qev+NS5fCxqLKTTgKm5VTcq4kt1DJKqJxZ3CupYbhjipVynjUOvQFa4c8WuCHDv0AFovwXGNiX07gVArhjqMFsrMS4FcGISocOoAGJcbg+ofQ53MOLqLz6sA39BlDVenRDazWVKogSvQlyqmty5VyoF4YeJSSs2QPRkZjZiVwI5OQuacZvhJtE4vi46l8FoFep5uXDxKlS6xB/5VGVncHNyz0bhAac31CaJsgs4uX/w1v1hceVtuCn1Ari816KzFqXEhyArMvPorkl36XdkYsuMDcTUg7jct9aXG9TUGAnDKlRbOK518DrnXOeKN8bhCjjXFcDBxxmOJmRLlPJguDbCPtD04RdcGJWb9DywIYmpc2QA7lwKEdzGDUUqag2X6nfFS+IlcCmSK98VxXLoUHbZ9TzxiIKwjqdcjxRavPAXAliPFzr0AK5bzsw0P+/2eHpx4Su5qC6hk4G/SJXiLHUG4+h1AqVKlQ4dxhwSswUS7htg4m48PFS+QolhZAOaIKkVl+gLjzq4mGSalzBmDfFSppzHGpixgM74r1f/EACYQAQEAAgICAgICAwEBAAAAAAERACExQVFhcYGRobHB0eHw8RD/2gAIAQAAAT8QLKPLbOJM4Dp9YBqdg4yYE87OS8uJM2oiCyCBAREEcVc8cmFdIR2abuCfKOiMeABqIjty9SVEtvuj906xCI7SZJE57yDnblQeHeHLKqEeQ4w2BE4FzbUDk/vBbVTlMnDsHJMkDhUdY0EFvkzWjDpkPYgdOuMCmDKcrf6zdwPoP/DE1VRDkwnSX72cLg4FxhDpPjsdUY52mMbPzlzVbjf1iilPLMFTwwCCacIRXGSiNbPOCnLAS8XjGIPHIYodCXi8YMQ06cXo/GCp8NxFsfJnWpx5ha7wEOTAoOfecgn9GPe74Ya1El7C6FPY6qEVoRp9KmhxWIAVimuKp/8AfMRaAKB+20Yusl+qDMPYPLxK+fHOjcVsOLazPD/MCyfq8TOeQHX4gTNAdEgeAIb9frJDeY6+zdF/8zSJdJ/KD6uGmq6/N7cfO9H+Js7MqpX4X7YnkXkd3Ck+zFok0URG9jxjRFYTub/rApDP2DSIuzkzSARHMgHQADb1gYDoKf5wte0Yn7HOQV5Pv3a4kb02v/TGFgj6b+DEQE8Da/TiRceC7gYITuT+W56VUT+WA0gdOH1F8g4X5EMQST1gWm9AMdDI5uD9ACtj6x6DPcyScXY7MaLJwOmQmTsAR+sF2F62GX2bciAh5yLNed5wSuExWdog4PnD8R0ePjJdUshBY9xvPwx+ONbdQqRHj3i5CI35sqhDymyXFj0eM0c94n5cWJOJh0zIXcNwx4VE4xxI7vOaoj3ijvt+jDR6eQOM5nTOhe+pxixoiSRs5GfH+MLwM6c66+8UrSwXif8ATNlGr8Ov94IprfBeF33Hw8hh8gwLq4vY8rsj6GYaHjzhDqaFxU3lHhZOcYGxM0PjOAavGPgObDAJ8frDU8mAN8mLPIxG5cNn5dx6lcb5NYJxV+sZRvHa4dgDar4ymKJq3zwJ4p5eCjLWCBY8pqc6IF0Zaardy6IXwmGPjNtcEbS8znyA4SvOfmxU08G6mgyjgckL50Y8Uoy/yvxjkJ7Az8WfuYitL/e/15tEnLg+Nzi6u5/OCXJKM7TJJnsH9YwkjQUHwnGV14gwJ5EY+p24wC7U21mqGI+NwB5B4Nezi3WFrwRRKFE/kHTDm6vlYOGlnWNxuzaNeE0fORxxdz7Q4I1O0P1IfrGai8NfszZ2J8mseZC9zAbA7SYiBHh5xRs2I4j0m3f0B/eRh1wH9MH4xQE3Gnx0F7hG+AD8uOmJ4I+3AfrHqsJ/g0cKbDeBH5w/FhoCHgMPKvtN4CqTx1l4gOP/AIlmyGq/3GfXTJPlDK3xBxflf1gxfGwfwEfzmh3xpn/ADOHe+B2BSBCeJe8a4rHxBiu1NAdAAeIFE45XUQ4Gjbua76KxSZqicufLN8D0B9zSfbh1Y5H7Qn4OVDjob/ZrFobesKSnWFvlDKMr0cih84u2HIcZCp8S/rBZZjSvwwE0kaYzy51+qY+cSUU2M0ehDfqw/lxlTG69OCUohL4ZLGkHcXON77G9irYkCSFNl0Hk+yiKGhFU0h+f+9YltuwOg7b8/sxKEeeX8Y+wR7kygl7vOPhxMNPBhDZRwq1xi1H3MBzuZx7MJOQRHv35wIJ135xcI9GEJzhKwsNsdDvrfB2hkvBG5Nonn+OgQbOVAAN+jKWxygvktxhCdEH+24Gw8AaRDnbU5AkQjCrURZCEjUaMFNJ2AQo/nQfzjHjcNx8SvyuCm8AfvTb95ZvHg3hIP2M3kdA8GSbbwbcIFK6TnLQx2q4zQiXOqqzj074Pae2CocEbxiirm9Og0DF/g5eoDhieIqSwMVHZxhDIEQ+LWr7swyrRjc32XNYITibnvNwq8bxXTXwmIU1mmEkij4cLNLPQxab6B9YtI0+G/wA4U2GlQz8ZuGl+v841BA8pijLNx3wp2vX8sXBp8GSY/nSvgLmnpShE+CMNKXTF/VHABwCAnpS/xlu89D+qP4xv5oX5KMXIKaa85DjkUPy/0ziih8kopfa4PU1qB8GNq6E85uH6TN0wjoJfUQH1lY9vlmngN9vnNNBTDssa5irI04q3uiC4PD2XeGvIqDfa+wuErroHXop+3jHSX2SQA+2QW3YU80B94cLOq/gYRiY1+cQPvERXz98KTHAoC1i0BLyuMpa7yYjtodZvLCcD+GMNmBzHzdYYaBOXvdMuaZVtG2YPPResaBENiSd/zgm7kIg8ejdXfLSIL2EFKdnkRojsSOLFN055PfnEkCBVCV6f4wQAgpt57+sbAAfLjdLWS6ZGXEdHEWKe8J+/WK6ySCDleDB/XAfip/WTqVnVA6CgiXYgLrFgztHXzWHwHfac4JpqBBHARNentkrdRx+ovT+YfjAyi1Pg4D+xkMq7K9NufZhw1ay/CFAqAF2QqYY1nkFb6ZaDsTlBrPojQ7561MWMo5b/AOjgmoF84S8IHRhpom8ehpyjjCEHVO8TqDvfGTIrgJHpQB7Kad7F6uJVx2CLzZ7NXrCNYPs1l27vyMWAvAfD2i+JN55MkWTM75VqkCvGBjp3AtbChNJvvAcpq0kAFo4OsMT2oolbswFOg8GMp7upIHlwE6MQkSERR/b94QLZRAfg/wAYADq7LH1MKCxAURhye9c5X8sgCmCwivED8UcPEtlUPahMbgDnkfeo/OFFd2lV9msaonHLXzrNZM8MfpwZa8d3DSS98HE7qNWtY8g52R/GKz7AkwOdsu+sv99qj/ThqZ0rgSCE/wCnHusONBwEST1m7avL3nFU9GIiYDdZp/0JEvUCP/GPm2yRBoFDrDRnFyRRuimraFULxVxsaudKd4r02OaJ+QxoqHCj0/qTKBXI0PmKfAMei7iD9aN9o+soO9A+TEN9mWFRy998z5GJCRpb/Mj7cT6rUgfNa+HDbBbvXyecbYCKnV5685UXVnhJ/wBzgWEdr3p4/wB4JJKbC4kgMkpyOufrBN5TX17Md3GFWXAd8U7N8m0j3mRAnJ5xa8xPJ8PWQb8TXI4FtiqPH/pxmmlTDIaPBcXSR0n+FuVULz+2w/bNYe/9YV+sE3D0E98fykygOe0PrWDZ47Pl8IFwVG6Ko2O0DlaQ+sqg8yXdsXJYtbyOIsH6RSQkm4uUKQ4rPEBk9snPObAGcYkrF96+7wf1z1y5DW5vtu3StjDNC7NxH3txxmuuh/Dr1x84QFOIP5uEUeZvL9dGPDUwJbWgOXEr9ZrFQsdaNrgFRfxCoL5ADC/ZhUvXc+41cd2t1iO5YS72Ta94OsYBg78/IvbWOqisHg1lKccOiOBUcFQglpSQIACAZROh+Mm/OWHJfz95u7LfAp95rjsG568c2/KVrC+bx8esAhcBKD4zcAbyWZYGj47P3gE7hCcb88ZegPSzBjR66/OCu54e8EqoPIuUFZuk+XZgqiPO5+dcREPkJ9J+mTtSaiveEJx2CfsBlyy0EHjGb2vrE7tCtHfGW6iG2YxQNS78mgM6F3hNMeZd+lfy4GJptA+Rj+saQX237DLb/Y/xg8wF0mkyWhrowFyOKebhwnIIWFEhlwH2jJ8s2aUM4ATfdMLdziMorNkacJhR6xqoD6zg8MAGaTF2PHpwSkY0vmDPkxRG0Tp60JPWCJ68tvk+wDAnAOv0OkPeU+Xa/s6g+oYfH+X8fs/kY4OmgPxf7DF6E1zv6xKDQ6dJ/kxXfv8AtfVwlQIcup8Y03SF05ReXZ9m7XkYNQ/QSn7ywyCPD8cp/WMFoW3XcC/eBKLxBJ5Ck4jhtDYWX0f7jBXZi4+5zH9H5nmp+rkkaUOPzftiwK1oPGEmK46QSiCaUOUbptiaYNsbvCWwhoGmPRzXLohAHAHWcKEOca3DgfMO8pVNnGfR3g4Y9mMbXwc89YAk++Lahw8qb0jQYvulBtfnGcASrv5MskgvDT29YGFIZ4f6/nCFN6S/cxNK+sHo/wC/rBPYwOvf/vWFXBTT6QPzeYTNbNowfC7PT92A5TaH6HFTghhG+qP8qP0HLk5xY5UQ9JohPINRsxVysIXHU7u4lnTjsSxTsG4jvC4IRhPgyO6Mdye4k5EWAN2fyMDjti/I/vCceRWpeM/8x1hHEPPu6wbDqOx6nnvfvHhElGb+nfvHJtFSPz5wle6MZ/39Zp4zBFA8PHPnA0i91Bod+v55wLAixt/VMXhGSmI0CpgTiQzegWhy41UAEB4fC/GC+bS/KNp1RdDjRj+DKgq9ijFtEwTuXt3tBnjwKiBJR9k2dxYXQcYAj247NdZxieQn6xDAxqYj6nGAFboN/W8O83EWRHFrt84RswM8YLRMFZhnETzE+FsZZw45joYk8AJ6d4Iwo3c9sh1ic6/+EesTjFQ6PeRUU+sB2KTDCcec2w+1N+BMeY5oJPCUvjIdbu1/LX+T646ni4UeYAYWIOVAq1dpqSdtxkkVfSAMK608pwFOhsHwOlxs6Ni9d3/KzXeI+JGVHnphN3kvO7CfrEBsQgfgGsAVhN2yO8ZCAym/gwclgVTl+cLGw6pz+MctW95t8GzV6A5V6Db1jX4uv1i+dqTpTOZN7jgW+DKc7cYCceV2+Ve1ar5cOUNVwEbpzP46xMdgROoG14MUJ0oW+IHRTR43oYWoqqXDi2mgbwooDhovS9DiqYFBgt3Xl64cRQeFX9nLgnFGiB8q8H6wMCdCN4aPQovjjLgoh9HkfFh0Mi1xbdzWa+x6MnBVKfk59AOt4XpgKrw0dvyvTiaTYFC+34+8AS2XCQTl90bWxXjZKZm2nBiiuiiYRU6J2KE2Gza2G3KmL03AIigeFN8MUFnHgRewe6vDzzlINUP2sUjMSV9b9Yc7KwzGiCKBduXe+51zlOQSnU7fBxhKL049fOIgkch/HJheGCouvQx5EJVV6WawRxSF3w/OV8mKWKaQ1xghJAOl6/nGsj8lPnjR+cMfP5jBL0HK8XLwo9vwBG8MKcGEeS8+393Ueas4z+MQm+QK7CcDK7bBgm+HDECs5Cf8zEBw8lX6GXNFwg/5es0wHzGI0G9fngn84ssl1jnuFzN+4X2mdKCoc+RKfeQbH8ZpyZtuZA5LYq39ACH6x1nW4j6DD+cSWdv9r+8SiDxWA4YjvEzH8cHdmWkchWg+8pnLE79Ff1hLb5fo0h+nH3/sRpn+tqDgUzi/0+dBPeII920x6EL9GRexgD7vEyTOP4WciD6Qoe0fSTJrEBAPBV9vXVy/HlGTVVodHG3W3Hl1x8Rg/wArFG9v5qf1wCTisvNOr8pjU1kgfcASesMlC1dF55B/ljw4aQaUtYxen7eJl49FxljjYYO86IPs8e54eYzUINp8p+R/REVCPzoF6WO+hJDE47CoTh2BaHyu1x9Wihy/4xEMDpdH+8BbHcuabXgJ2+sRMsgxL4JdBzo5LIB9EAPWaRC48YRCi1Cv8Z1k5IH3BXASe6hA8Dy+A3j1OmjT8IT2zOlmh6kD4AC+/eOceOpyXYtysvL6y4CRTo+a8t+J8YdUTDD8Bx/txGU9gwPGAHoOmv8AONtmhxxrNyJdB3fjxmjRH6jwYMUoeQiXFI2CnOYERGCpTo4hJkAoViUAp9lXaubOzJyJtmgCRSdlMsSqPSRe0RxaS5AkcASWzo2hvWNNdJBheNTnBDWgoJzZ5QUppe8oAhuMSgivn4yNREbaG7LrxgYWlTV4Fk8bMgu9bQeAX74oEBG0PUgfWVTzWgeZ+DcCjvKpfyMV5aDnsgHtxWDFnAAN2BAWcC4g9AIt7r5h8zLwDpg2yUvSzIijBmGp0RK+FP8AGFBBsif4ZZKQd2r0H/JwwZGDYeWZjaXWvtJ+ssGHdo+Zvzh48yZ/AsBJ8EtfHDDHY8CS/dfVymdG/NylfjinLQ5PxSsLaTS8+AGH7YQQSPyNKn7xYaC4j6RfS4TZePzQOOd0hErig4XDkuxyrjG7PkEHN7oQab2rbCbm/GKwbUtfCE/eCPTCK/dcHjkQ0fLA/OOqlD8qF/rDKX2f6Kn6HJTK2CHyhkkwJ4AvQE/L9M3x2gq+2n0mTjryT8VLn/jamAGWrg+cP5uIIV60YPgE4ytQABCAWjou9fjkHJ17gqSgRXaResqFRMAFA8q16bmkzyH3g1tHzZhzDjQi0Ev2F+mMOcj5iEU8EyKde4+57Hf6mNgbtfDH4T4MCnVp+L2R+RYqx28Hzjk+Sa43oCWfgBAL8Gs8ZaNcLSdG2fHLkvaoFj09GFPEZKHhZF4PjFTlqnOIPtcQxJx2vgyK2QoaSbC6DdsmsAMURFIA4AAmVgB4ZlEU/lxdDxUDw5fg7eDvWNjVBh9TZvW7hwXnwYourrvLbwMlrhFBzFCPFvMwlfhH62xOto97xIQFeeTyuD7BoNff1f1lQnmrIes/YoddZugOAvjziHClTfOA+2zy+v8AjZiaAnBqph1sZHW8gRimlNREnIiywUNg0jT5rV0CkASMKNhFgzeC1GOItJ1iYoKECLMRcVxE8LWeFxDqrCDicrRHgVPwYU5E518Y0BZEF4xowd9LxyAuFkfEDV8DA5xwpXegk+sMShzL+hj925KZXIn97H3iwEH8lVAAc3rJCxeVMDsEg1deYTjxg9TSU2jwYtINUNNi+bs252zcFNtNnzi1CLDUf1irRJ2Qr8HP6wdRo2sI9X+N5si7N+QSH11gt0MFMvMW2An+MdlJAhGoKMJShvjD08KDPF5ry8x94TUtwx8KH5y/AMIw9AuePDFoJ9MgkuR+LLcvEXzX6fyYQ2CIm+K0+TDFM/tPWX3vGDzpu/nfbxH8K0aJhoBK0aHLppACZQEG271o6xl7acOMiCiDsXeHxlEcYATTA3J9tZzOk8ekj84VxnZ/lA+nAGRzOB80lfe+XwQC9HqkD5TL5HMWPmifGMwx05+ZnuJ52/jBuL9eIeQ9j/GSk21xH+8SZvtf28Um6n++cLqD3n7TIQB8D/WbFM8igmvFxbkQRCpcbF0aNLzeNcYzaCHKis1w6wLGvkmV/wBA/wBZNIPh/qweoPS/w4NV/R/hwV+YO5ecFUqwndK0rtMdsABve3Vm9Snw5O5x9k9sxVTSK4e2H25Pkaq/QVlXUD9Yu7Mx0rA2ERpCCBQulg/Aw4+0MqoXaT8P4My0Y6d+/wAsAkG0QDli3lPziyDqTsUHCrwtG1wIKxsPgDozY2nkJ8H+chGGwSmqsBeqg8G8VofCL7NB9TzHkcQjFWyHsXTB5w2TACX4Gjnl47xs6EQd56L4GLObjQeIgfAyhrtuvyfoYvSbUqHW7R2XjeVxazicgk97jWJC8FNOtj9ugbYYYHZYF4EyfSXDAU6JZ5BH2xXSQ9WVw/P5yBVwHHRA5Xgu8pIVvHNWIsGG2u4V/O21HddjHkF2YlPH4kwknyPRhKmaBdiIm6T7xHG54HSqNTh49mL9NIROwII6bjY81ah+SF/GRO1rnDVqKJduUJAEREMjG9sR4OwPj0ZsOAEXofwL/GKTpzA04XPrPGNnjbPzQ2+UyPbBcFnbqgi+lxaBrEJkbtSQiBORDxhNM8If8YPYIkA/gwET0fTwb8ZlTR6Seyfq+lha0WQA98vm3xmxkUUu3NuoY4BMh+A0fRR4cMHm3om4gnhlPLjSAxyugG5Fmqsx5JumzCIf4XIF0wf73/nJkngoPQm/TJwaeevxy+abiH9mO/BUP4DOVuR8uNcMM8EjpMIS7aFvnlwDCDwcyFEKR1Rwse8CAfRi8m3pyUULiYHcH05WHc/QsU/OaNJspHyEn0ZEHClfvVMi/Jon4Bf74JHhoRXzDr8X7xrk+Or4RfTiLxgO32KZEiEe8a0E/vDBecFKIStwBUCYw0F9QD5RJzh7woKoQvXAfnFwx01ZK6D2dAu8OemRk06DORADcSlOlv8AoYFgzwiPzv8Ahjutmwhfs1/GEJ4hIfRX7ya0loDHJIHJu3eK/A4awAqt6E7NXHkxaiSp2VuKFEoNPUP3g1Wp60GOJCJvultTKBVW3aVStVcALU8f+c4FrCb2IjlwL20b5YJ9phZ8oDCXGEArbF3vBMyMhXY9qvExCTAVWPBVvIA8YpTjUrw9XpbTkOMb8BG2wM86BhiGtK1P4/xH3igBmpJ8WynXjPSC/Xywmbcnok+rgNNtfNQkYWHTbxrqnxeCeBL2cJ94ue4BhlC74kGRhHodNFsZTZE1t07mj1okw8h8Zt3BuDsG28n6wpgayXwS3dV+tuy6tb0lNW9H9YUEGy2ToMBVEstFMd+wgwDK7wKZsx76AGYXFaJhpdZMPcilfCXCjkDHDbKg1KFpSIDRIAwN8NrhoFHir6HtOwKyURB9j+8H9QMrATb3iGMZGt6v+4uCl3C2L75/WIrGjV+34kJ9nD2QquuwoUI1DnwyY56fHAvPAPIXeGb6B6Qyf7u41pNKvxmHaBwAGZwIhz0reNjwzGcNWm8IDOU4oE0ScvoIXxjcHBZ+npNcvgYFJlZuq56cSemTSB8I9Wz0sy3UDrCQhwEE4PkuoDZACgJtMg+UH3h1MJZMX5biFy2435xgqeX4Ax+mCiN9ibpgkkXx4wMhGOQLfWN00Az4zVDto1twTVbo5XGl0+Ki8+yYQBxiigeEfGeUxtaGDpDZXeJgfnO7IbrvrFOUuAVB59/WGxVRP6k/bIP4opfPKYfTjitPAwfdPrIEwUoPlaQPjAnkejEAYVoY0KDTIzwUnZA2shCnLQmbyCWeYh+QoXyPGLpFBunZDj5MVEprKadEVjj9b069uV4g/JXHzn2YsnBjBNs8DER0/J/xisT1AjX17+xi1gP1xAz9uRmZmsIuHqgh4OvTUA7DyQPWAOuanlG1/rDTRSU1+P8AOBtg7Nv5yoJdoHGV7zE6RvICTsAPGjVCItOnKtTULevhN0PQ8pSp7qVQ99TiY1Ar8m4R8F71xgQ7QrxYD+Ey75QLD50/Tc8OtuHmfqTjO1ou9/ykZxaJfyUI+kx6H9GX3P742EC6HQQY1m3YK+BtnjpzVDslBQ5WucA6+pSAAYk5oCHnKMryC374yxELRTT5N/jOc+oY+AG9gxioKvDsVPTVhxrLTC4QLqBWAS93LXkCUTXmHcPhBHNmJrC9fnPIrAA6OxkBBEgKCbdiED43IlsuMejThVYEUJ+cJMxEgn3Us1O12EdoCWaLkuKFsJgwQr1WnjC7a4VvKAVPmmomHsg+/cL+IxrlY1k6bB6YvpIZ/a7JBYeyfTFhRaD4Us+l4mUfBXO+R2PplirK2qFB1AAiOiKXJaeUKwPKvDQpmk/m6Q43tq64zcrtKg5/JDnYSKofaQwQK9IfZI/eAh9DRhtSr2g/GEmrirYPX3ilanQF/eADGx1ngTd0h9Zy+kA9ARH1fOsX95UByGuvGj4MAT1iPjAuckCiXPihdGLAXljsp+VB+GQmloKP3X6zXI+kfaT94ar3sz+nGYp7ouATg7yoPwuU/li7PkMv4mLO8ZowTIm+nOij/tXCn24r7E/eDfVxAX8r+sl11rZH2LP3xlQQ7aJ8Ifplu7cth8MfrENe082BhtBQvsDafnKZlUM/AZ4hcz9iY+pD8JKARlII47wMKoKCOmxUCu8GxXDL68mGqShXld+Nl3hqIkwDB7F/6cY6dbA6chZf/MFXV6vP1Y3Bt3fbObA0M9Ckr09ZodggQv6BOfWVwYJEAA8cKvRVx0w6tQ8HRGdB5VIogQR5frIFIGg1wueSbH7Z05CHQ62weSzrbFcjsaTp+BUJ2OAxItAvcPnzcWsVh8s1DO1HnicYJWIrw631A1p6OIEXXFg0oeR6O8HsoBvQbUZXiYipOkv9ZuAu2iY0sjhz9/2YOOLyYfG2Y6KcC2/ZnGi65hAgBtpvZS0k6xGMNaBEWH2tcYfyZXtIUGoDJUg44cwOI7sSdznjjJrZItqwKwu+PTHBGBAnKo4e85IdtlG2z5AcRXVTz6lyLLj7EPN3m5x7mDpdATgwLt5NU1fMG9JJurU7VmLoX0NPWAoYaAvtSb4gqhdC3YT0QSgO4vF5wZy6EzNJWw68M+0HxpeCHWJ/tkdOAmQAGovKITDzfCufkBPrhwN9y+X9JzggEP8AwDFZxgohyrpzYjivfBL1C9MVmGoTqBDq6Z5d8D7jXD22JGhDXmZdvPVf3g2nB4FPRha9r5D8PCJRqVPpDGHs04fAT6GVQnQN7L8TNgNoP728jpiRa31FWBUF8J3g3MkAPFO1zvwh0QQEqW+f0I9ZAqG7Pk6/S+cib9ctH06/Gaika06mUFmdVxj+zmrxKwzEYuI0fQgfjvH1ZP8AZEf3c14nzx+YwMuDT/Cr+srZZ996s2L2DitMPvkEWqCgiN4xCMeQ/GQXOEV67+V/rGHwSH7A46C280fBbkePGHWOu35zxTmiiPK4+cetvlT8zNia+MeFA5K7/OVFSr4T9YDCU92kVY1Z1dIcV527X+tYz/YgdE86/jE6zcWyX4PPxg/T0Vwh8I+cIMArtYbKhkRG971lqsdq/WoD8ZoBWls+4Wflwc8hBXtgA5hVpggKM4dv9YAsZAAoze0MKIHq7HxYNlfI0na8AHiNaWl9hj3WLy/fx/WJ0aFfbdz4QEdjgLTvU1GSnhpbPPWHUFvNE4sM7Xwx6qkoPNFfg4heZUGeCG4O7ewkelr40+MbRICJdpdDsBxsuGwG0U8xC/RzgJsRf17la4w4/v8AAWReKuHnoof2zn0pJj5/KrN+Fgx+sfnBU11EQk7APxnMj8f4GYvd3asvLkY4sgF3nTScYwi1QRYgIcpV+mPMvafwgXlQbCMC1MmKNFKHjZB5XC0bs6kWyXa12uKkfl34/mw6Dta3aCdQ67POILoGkhJsTKdDkcm60KKzSFNbziRx8+DbuR43PGeHlKD2NzSpLJP5WeYCjw8mAlAQkOA0HAHQBxhNtXrFHRye1J88YOHUQPw5x4Z8xaOTTXxcv0DeR5DTPirFZjQdzVAD5pw5YzGka/5k2uBdJT0ZsNWp3PDKahCmjtTgEahKhxp4i8W/hg9hFkz4JXFBC7sjy6vw7zage1fCj94WM3te+h4D7B929UW/WC9QIIHX7LedOitJ9LafMfGXjOtv+Zw+dveUDAoqoRscIP1hYa40B4Dg93PA55bONbzbqB+MIzF4/wA+BtK9YA9Aff8Aly3Ypqjv7c5iHx/szsiPL/hzaS+rf3he9nhH845dAqH94OQgC8P5y+czgD+3E28eK/hwF+h/1YYqjx/XOCXHpH+2Q6i0624M1J+B+5ggFhtLwFzLGXrNIbzf+cQwu8b/AC3IFCPKQ/Ll17MhFm/fE+8aciFugr4E+x1hVFiAIoqIlhWHI2XVgtoZKhob5nPxjQ1x6vCBeARXm0YYqNGkEi/AfeJotfEwFv5f+MOk3sn9YpYRHSib82vrFeKM0VCV79/lMdJTV8OrKALqL85ZKq2PpqFmyia2yoWYs3kISdq94CLcD8AUnx1kUWeGvh/bxnlOHn2f4socGBU9ZQBF6o+v887sxBv5h/hwNCJ5dPxPlqZNjiH0Yn7GP3bxq+9/z4W5Y9/++FjG6oAJ+S30sdvTr4Um5+M6ow+FkB+s4VvRV61X8ZNdEGNjBX95poIARZXcCobwUrkHW7TsfjfDzkJoMbrgH8ODo3Niz5h2WSbI0NwNXt3BuBGW5F7KbyZU8Oh5sJ+WG8qD+IUAfKzshF1UvB8yZ6tgNV3sCDtwGACSjBRasPN5xChAHZvS7hGQ1wYvTA41yGhtidoKwexwucolpfw02PHFPMyMcZBQSB5Ghwpd3Ej9Q26YpDiOkNLVqmEHp+KU6h8YC/gQeNBPlcKGQDUB4k494jzTGvy/wYAcHVr6R/Dge5FWe4TECqF64HKPPReNWIDg6TRQrjbMD1TtQDoBGze+cfupDo8AO9v0L3LCANggfSTOdpyQXsbr0JjBDfC/FWHor6OcFvyrS+ognoOFDIgIjogYM4neJuSmD/Y+HKNGnrP+LhFqPAuTKP8ARhFp6wH4ffORL9t+JccgnAJ8xOBKJqL5tVsD8kvygH6zwHl98lHrnJ0dOTB73T7wumjogFBwLV4AchFUjwiCIahZw7QaBPMk0g4y985rainogB8AZQSVjt6cfIjKUh2xfCHtTNeQpjC37aI4KO9KF8fkSPeP+y9DjYfrkLisTE5HTDQuzZp+ffLsvDX+slXThBiA8qLfsAwdvlJJAXHWN1nUQEF0ovG8QjPWuVolHoJ5Bbut48G200CevPWcbaKbQp52Yd1Xgo1xG6jHnWGiO1dpLd6TxvrBdtYKTaAqsDynRAN1DgL6Oz4nzk8YLlpESWyz94Q1qUdKyzTtXR97GH2FZAIA15aqaB4Yp0IiPTqRIZqfumQoQKm41I944KhzrP1rgIfGG8fvJ9C6f57JBfL+MYVh76/4uThU/pREVQ78icjkPwQsPxP7wHQd8J9nDEGu26feA5aje551BXlfJhyR9EGEBeXAmt9DPZ5dBZHtnjLDPhpmzbmkR6JiJPqpPwIv2MDfm5l5SQK6BhCFTryj32JGSotoAjNyw327+PeVoCEFiR6aVU7ojhFotxtbwppQg2DiN0FYnLHBp/kMAtwTYgJTsoVbYTm795nuNvH++cJUXW88FBh2KDSmBdY2woahLsLFoN4USM1XlWuI9IawNLNRC2Jrhek75Q22/jJ/WOgDTo1gSAOOsjQalXPDVzCKGmUegYQi30cbSOKdHaoQkHIqLhtMUa2uBo/DDqA4qX7zrJ3nP1nlfAA/c5I6W09iE6Dd8sPOHA0FKPk3h5HzcnoOnPIngVPWTYPLQW3IMD6ISTJp6N6D3hadHWLgAiTfg/JGbL5JX6//AEGFmTzvvoD9Y3etM79cFiF+WAT+BxMVdOgFBCrVepjqhCsrnaJOoH57y5LfxCgnjA+0lKd6JGzZ14ctsk+8dVFURQdkm5wk5rp4mpoD0MfInzkHGre8C8HYPjGJTNpvK/8A+DG0miUTyir8q4NpT2DihoKwPg/2xhvV5v2gfuLhs5RUHHYvnpjlzVnBg2Jql5s1gjTShQtBWC6TjxjUiTKiCUR5WsmBQIbbgR62+8UEZ83h9sMI2kQK6D64GGGk2k/AweE7+FWMXrbuv2o4+8rqoIG+Hb+T84KiEApraCa8/NjJJoJu1C5weAbrrCoopoXwg/ZcBDQUsvNtV4P3jPSK5oDiTvQRjwvsCmAOlXQ7WFh5wxnZbRu9b/5uJ/ZQiKKClO93SJm4g6sIHZBgseP1lkAqbq+QTS8C/hh9HRpBCBv0TgDaZGCEAvZvCVV7UQcMNiWeMaq+gvhwbwC0oS1LQihAYzHYsUg5AOxAOIZBgtS02GgbZabDCg3Fgh1jYvZV3Yb/AGrkDVKo7Uqu1zy7PTA1JwNd3eKSYtGlfBkLLCbUp3gRr5HRjMgFAUcTipvjiVsvUZI9p3h/lhP6y0Jm1KA/BidMaUQibBZpdnk3foJRQU3o89XBAYjvL2Iftxtx1GDaDQMG7XrD+NK1qAG4HDguaMPs/oy5JoXUWIGorR/MB01idAKPIzGFyNVP4AQgXZqrLhaVGUpox5s5zgqZvCaqib+d4ASIGuAHylDgNsN5V+z8G2uy915woGAyvJovcUVMFldqU/1V6Em4CaGvgUN5riBX08IoR2IjswmpSCq6w9riYhUdrwfAawHDnZBxOwJo6xCikyGRkE+RpPBjrqAOnVLA89ZEqiB8eLp11MRqjTgc0B61a01j3HEmqodnpK84Ihy7cLl0IXbcXJmeiKlVpqpQTSph+gkj2hX8/QMqhB0dZseCPZw4eVvFV7LlAhyp7Bxm5afjZi9knMo/w/eB0apMCwJSzRlNYXxntKfau9PdX2i1Wb1rZZ8WlC2DAElkTbVrTqbCjenWmlAKapp8Ucf6PJQdqqhONG1vdfshGMefe5goCDBXp5wLUq4j0yPyTLABhRddR+8UpJW9+696zfAU3tdOp+AHCF/PGcCwwYZ5VT2oX5X5wEt3JPuz4MyEGgedsKeS5rzxrvo/rsNixqg/mw9E2uDEX5TGJLChGTVUPzqFFaOz7Y4PaAfnAS47nXxSX2mNG/Hau5I+0w2Oe8D5Lj1jzkDRadEvifWLtRvHdqfzp6cAsXJD60J7Q94Lui88eYJ8q9YcfdAn4Sr7MuuP2653X8s38qH4IqX2ROphPgX6A5AHVaV/OBlK0HQ7487eZg3U74U+32c9Zv8A6AFBfJrW2XerrSHHBIyNfXGbi6N0r060ssvkmAAY3FdBCpQgIHaZAyF4MukgYIBW4B21INyKwb4IesSf8ysH7MtTEwIsK7gK74ecQMYIm8HEUB4DNWul5ateFyagmgjPEOED2J/XSn4PeBLLNkBUCx1xtiygbq4uDFx0mJgoRedA+qn6nHGw5bt9Wvm4UtsxH5VNvvArthQPoP8ADFgleHl6VX6cflEr/UP0Llk3w5zRKPrrrJ0JKBLzuDAS970/h+BjUzRUDVrYofx6YY04sDg/H25HXCoZE2hLssKHJrCbJQBcBHt0BrjC2rjjPlHXXi4RddTEQichYb5+cB6BrBRrF1FfhTrZaUsI3Y9VC/eaM60Hf4P7zZlyCd3WS0iImTc8i/N4qr3AoK94ou7l3AG3waBx1sN2VzyU7wtNSSrwHslOnRxgJDKaiCrG7RFB3pjFD96hsJYG7NxHHmPkw1EIxBpy5zfqNXCzQIw6zcurwregJpIhzxhhBOUZ7RDB2kJvN8cNahICCgRVEw2twZ8a2OoDucZtn+RilpqpPgp1Z04Q6aefrx413jKQwYVm8FHa+AMaFn7xbpTN5dPMBEPcwgIo+TfvV+cbYY5AJryT/v8AXvNAK14NqvQYVO6KpkdNkCCLqxuW8ihNeQBntA/qot0ExQibLy/HHnB42FZA/Kp9PWV0gSouSb0W66amzhRo07mGiTtYcH8cbIj/ALcHSRAInEusFRjhW+Tb/GKKq6DHyGUjwaLfCVn3kSa0Zeqf4sIJ1R94hTrpzYYUTPIC/KOEVJBsvAVxDCTSEdEpZNEtMQakhBDyQjWt5tT/ACZ8SH4VwkmT4Vww+bkTdqpKuZoemxNJizT0afB34MYqFpuvA4erh23TSn/McOojaRJJmXDbhD84KZdrz5pDE+vlo9r9otxsIWgh7BD9YsrinAZCtDWS5ZhUt5QhPvXkycBAdKKUWnd1rbhOgikE8CKbdgxr1ktIV0tiYibczbvEw1Qpe9kDblVS8OGBSAsvAiA0eXeLAxk7Jy3T5wusCPDjm3SORiReQ4FuzgTeQcGrMTYIGhEiUxSTer6ZCqLR863lLw/QwBv2c9eMrU6Ud8In75Y87HT5x+RzdNkYZPby4ABnBx+LnDJqm5/wcZF8WCfQj9sQWcsDwUB6HJOjZRWFnIcDw4m2WJkqB6Oo5IMQ3hluwhju4ERBAHTiBCc/Z5MVIUE8VSgGnO6Ccx8AbtRKtbpLtr1LiMnyTilgbDRdNmwhsI5HP+E6JeBZjzrI0M4Bt9ayYojWmfQiRXQ3vFexrkeMWOSc3px9DAQLUrDGmH1ackTrDS0P5PlcuvHaj0rDb1rnF6dkvNFXtpeIwuX6lhAkYU8EPHvC7+tYm+6U2oJwxkHj4ksBGSwKd8VYpQpMWQApQNZGCgwrA+q4DxHkTgx6qlZNUcdOiP6wGFSgsIspS8gxOcZqqczQzkhb7JoYErLmBq4dchcEGXC08UVdNzBdBbhcGpnapkETGWo5MhSbxB32NUBFg0hV2kP2Ko1HIMwSFRnZOlvJ7ulAIAAYl4SXte5gCPM4ANdEEDQAGRcLDRQbXdK+J6wDyeMRXcehRfJQy5yjwA98bF7IKIrDaYwKvg3tZv8AP7wuFMFW0FUVo6PAMFAelUo5XtdAnrxcJMcqPwzLY8LXZMliYgEaCmu4bGvQZ3aWuKAAwGx9pyXDMhSRACXbt41xrBI1WUh9tZur9mwRVt3o/CY0NFimGhUON876xIJFjlDEqAPlx03wy4UIDVXlVELBLmuwoqRxE5dIxUCLwcDUWSKejZaKqbIaSBpogst6Lo5sjXUAkUrg4DWkn5TzocTHIF2sSVRcOEKQIQBpBdXZtvDxboyANLesRVVUNaAqBQf/ADItsV4zgGO9o/vHsKS1TvywT4IZoWACE/rxg2e40D/vxigVcU/p/wCZwPfeT5Th/G8AGa1S51yP4yGJ1Snp4fzhiego0M8HPDDNUaUrQRPQlD7Ia0Y3QHFsvKdPfHOSq+ItUIoqdCCG7DE3ZhGyWkRFQPRswSmCNgH6P5+81+2PUIAGduzzyNoAx8XBZqNgpZRpAcDEQqREETeh5EilXrhEEB7CBd5b4wHFpbyWsAnOGL0adWkvU16lm8WCWkuEpR5RLN8YxYgAHMtaAij9txnceBHojrYjfnDFkvleOCQcE08uEyi4wg7bcr11cEc0koq60EA7eZmmgMo80S8o4sC7y2g2Nb4MJ1tvUVusgqm0ACuuZ1TjYCVHco+TQleQOPJErbpKQNrtXwS7vWqtU1jjIEJN8AePGJGodHm7lqiLsPok1W2ogqo1BA3tbDTErCar9t2J5BaFZIAvvRAN7CHeGj4wr4DhrWk4QHXiQjfgnUA05A1QFkIMFNdF2+sG1HdCyYCJrBFpN4GwoAHSGgdAADwTGzMwiInT6UfWLIkl1CtkEaXuV4rKkgrYb+u8RT11oA+AT94dc0G0c4XSfLjg/wC88gAG1jQEaIfamxKDjAIhaLklFQ4B2NStCY5TLU1okLji6M2qECdLQaHX0TwJmzdPhIDY0+EzrI5SAq7AaBpHyDFIJAoBAoWKvDmpmBI8NQg7ilAgMd4IFDgYgSVrlxjaM/iADjXg0RIBjBwao4I1ICDAhQMEBwIe3HTSQ5J0QVHz9rgFGtb+8L0t1UAAyqdcOIETw1DENh+JkBT8hl366YP84s9DAM4ipABgwTlghSk7yhyIS8G37vHPr3g5dkBFBCC9gockXA61QLQE2AJ78486zfkomtWPWyYW6XRFuzhmqer1jghELoUt7YV8twEM9WhC687mLhVhTR64whOsjdDayoE7isSVtqTUgOwwWBigxwxE9iGAel6KU2hNXe8IJDkIL7Sjb2uqENIUYKtRVigangbZXBZOGXvdm1DEaqA7TbfiQy1YlSlQFKqu+8pho3/5YHGqKeN7wDV/Gqg5xqEA1Qqi095M0tg1ojTCQlBGig3Ge9EQGTUM9mVEaZY3TFHSyhZTUdIS+gwBJtHQj9uKdbpn+XDya/P9+NIovBr+DiCWCcb4f3ZXsCLH/O6BxPH58+AQTsEvCUx3QoncKbduQb41kJIRWBdrQrGa8xYUr4OsZnlPeRPxyvm/87yAHfgTf1nsoCjERxGuftEy2zRYUAl14Jo0ovHSC29joZAmgTZxaZkFq6SgiMe3XAW1i3G1PR1s6OJA5MWCoqNc7eW7QMkQDfebyTE2hFeEfJ7POFhWqiElQ8ppTg+TEBnXhQAEERNwdKwWqyk3NgUU0BRZd5RbSVsooDol7r7wO2MFIIUVSLQdrGOESNaTRDKNnb7dhA5Qr1mGDQONaXHw/iQSFIQih1wiiLXcKEb0zTUp2EOA5XJWqXIg6RrnE3UIeGMKbE4NoYsNjTbQViaSU3ugpUAIaqtc6aH0dYJY3zVAkCJA4FlXcHOHhOnyYJ7cpKoTe9QPtxKgouAeNbrxaax2VFSKBpO9CKjh7NbIegfVIfHnCr5ndljpoKo0uDyU7QHFPB2wKTMDPICxunByzeBrX3sRESNoDC5V6DXI1srCRBrg5yiJAKVh8jnIJVKu0kQ1YVyI4bq1tksRiiFRPGSv4VXwXt43oBJMcxFhJuOdJl4RNJM49cBEksUDRsXmYmezOAyWxScF1uqsiwgtMgoXlNtYgdIA0N4UCDFSIaUL4SCwNaIdssLxiSDivU3i8U4tkcfcT9khcyhaca45p0wnYRSDQc3jXJye6gQugj4bidMO0C/xhSNVnkaoACqoAK6zw0R7MVUDwldQaYgvcOWoKQsQEEdj2M26TJXQz88v6/3hHSomggWm6zYOctJAdFEJuyFA6rpcJVQaIK+iLfjy3B4TaUoKe4vs+jDYxIG5SD5Ir6XsxUwG02Mh4dfuHJhU6BJGYZPQYaqCW0iztO8dINoC8hkvCI5Kh8D22YU2F8zcxXM+qUOBNKcz1mmZJug+0/tMip75F/Dw7JXf9E39Yc+p/lA4qjfpDhy8WgYORmvOI2Z0nILg/KybEwUUOeZw4h81BSFIdM1up5uA9pRRKAXtADtQOcDcqR50/pjzIG84oyLJtteSBG6gQ1YGiqoc94MAFX5agMdUiP8AZYNIuvWz9/4ZoyFN2xweVQnvHdhC4lBAhTps1j0uGhBDKrLNju4vhwAIafLTmzcXDTjKQrJHbfZJymF9ldqFEMkSTAilf2vxlruI21ETfIF8+LBxS9wpGhuPZN68QyxJbikuwPZ5jTE4yblBA4cZANp8GHkJioUjTsveASVtGwSWLZE9x5BykFTqDCRQ5FLrFWItXwcwTQPl8SUKKuk5uKDgZktgE0UqUszuJnYo8g0U8TyYjYPCBKFUdiuOHTzAUSuiQDDOCJdnGL1219JqSAS7d02bzbknBejAW+k5Sb4OKdADomjNm0wEh4N0TQVCAakQw+qrlTv263DG2VUt/sAtalJwYB0pgsHRdWOT5x5sExBYYKU6YTUgBIr+A4BGIF63cqNv2SJPa0oRV8kXE3I0DKDgReNiyLEQfCqI74751hUs7ZKWCBBo6NF2agEJnCl2VO4ONZRZWKkEa0oNlQ3kkmPh4APjoaxp6xE4CIXaNPztzc0c0RgNYLy616yYjfuwwpNNQusEIxqbAiragANbjz5os2ICNAcjjnAUalPomLIaFBtMZfMgln3bNLGBRcUiPYtQKbc1bDK+IID3HTVy10YWbRYIXN5uFWNODGdIyA1hDQCkKhg6NqhQ3eSk2Gm+S+5F9FAlZZvmYSGoI3gAjQQIPpyw3HuzsuHOWbhUYjCKJXoUUswaAZYphigiKeA65IgxSvQAABoAAAAMCQ/EwmbzYh8iY25nC18hi+oLvCX/AOysC37HrHDSmK4sT5IwNIEFMAaVohjfbRuNFEzWlyDIijVIbFQmIIOTdYW3iaEeVbcaxTOp0IQ650HEwLg0cKvb6BhBuDBCzZwgqpG6S8ZKSYam9qLVKmtc+segIhwGjNV8E84kA8oH23DWtVvACoefS8skxMsGXkRBg04eGta1GWAryOM2HeixSNk4gAmy0G51kJPHZxwUfSOZlh8bHfCs/LAQTsM+gQPtfeSIrZkfAX1MKhjRa+VHBJEwSmbSmwKcN0EbkzpJIBS11Fm0wLtfa1Ao7DIiNjgxBfOKtlZuhakTsOkIvwOCQJdFSBXAgpsQQM4TFtFGXjBSLATEGxFISjZMKExJydoQ2bZzgOxMIEvCx+McdAzdY0RSbyl1hGAAcN6AIX4KBzIHwj1HZrwB28FvGTDIDvtueGn/AJxjbc4hBAeDts9ZeG5OgyKeKoAIHCsbdT2iJR57hxAqkF/0J+j8Y0YOIpJXmUSdvhcDfFSQRR2aDsFDxuKGsaO0NOJs5JoxrapXQjlrlV+pgecZN2CDmDrSWlo5yYDyxTEBQNx7OcdVq1nCicO5JzVc4GC35KfpMbElkrFk3/SMdb94naoB0CujglXCTsNnxDQxKDsbgkBxQIcjShbCBSuJ+iZxC+ODU053B4cqFACbqBppvZhp2A4kNhUIQ3OcAIrUYZSbS6RZiTIyVK8lApdD4IzIUopbAC10FLyB7wS6Op9jlXxgZs2tAixg2USC/wCREBxJXUnRkeYkKiaG7KHTqXA7JY2+1QBCC994AZaXrRFQUqGjXzhunhrICzGgyT8sZD8BwiBwEAWBKoE28dFKATg8njBS67UmquScTvsyJd8mXGVBEKTYNjRmqu8MmX0sqiA+6vVg63JwCqbQDg3IoRgOlmkZYbF2nZtWgiE3vpBoKdqMA/X0sRWHazSdhhTqnTjSdGueCGSHKjxVbIRNaIOGxIdeQJWUQ07A5VHNwGjodwkACKNMdiIn1RWc1VvOHvIDS806oAnT3rDqBUNCdQwKp1uYYWkb4BCtTwDlKzPD8SO6JoBj3XBAsTDpAHgyZhsrAynWpcfiSoRNjOUUThFHTlasIQarCLujSogRjaUmI7j5Nsug2YzDl7OgsUUWpXGxRGgDleso4oBY07tSNSCQlxlZycCIFsIUvv3CPg0MjR5FORnk9Q0esG8EtFFrtB4ysTduNJTXqbmHweHSy4AgtyEUVFAFNPN4y0fQwp5jaM29RHACBecEApEIODcMJSRB3ovwYPygT82MUORthi5BLUBeEdYNNaS4fUco+qgJNO11yKihdYq82xCnAx6AA5MoO1ielKBoi2UDls5iZRmai2IIJOVBPrGUaVVArqhg6alUCDU5IfNwVN2TS9JPAQA1i4rAA0ltc2SSYy4YeF2TCenonc5CpMYKPDXmSfDcD1+bYVor4HdNsUFpBgHLE4gf5XcyXIIE1QPWuMK+2Qujk3w4R2EQGGdhBo7U4mLAEWM1CAqFmp2VIu+4EQCqu3vXwY+c4OJ2VBukDjjHpLpIvP5Wh0vvNZetUefOAQiaIxnzAiPYiawYWpFSbw0hu4ju9ZORiYxLgBraa84J0LrQKPmirzrCF2Ffl4K7LrkTuLA62i8zTdRYgWzwNAjBMeIDMxIlmVXYvBoUSmI6jOVMqHUku2Gk6ymrTsGSlTaRFGJFDAA592wDQ7qUZgOa9QHBIi6dmFGAC4C4gpk7A84Ugc1IRgWgqO5pqmAMAhQQPa/1jmg2/H9v7dYVVz5HmrpBH4ZZ1goE4USqEBEaXIcV5loCGG0jRTCoK/Hqacgpbvaxc43KxKjXi1NismnACpY4NtGdjsakgnrpKgCYAArbCMYlaBgBDTBEDAPvGKkrSRB2IkmWZGrdDy4cFVVu5NKQu9c6x3pnqBBSEtDEE53OXn6SIsAc6FrnDdDdNqhclcAiw0LuBIGsORMhbWbq1scfOBEeNC5OusoF0cN1bGQmsB80RVjWkLSd+jL/AI1wAeCh3STlbwnMEs7Rv0sYCC1IYAFwD0OFrDFNeklxrQJNo01cgX0zY5dhvidy7g03Ayxf6ibjnWK+/QsR4KDqG9FuUgkK5br1j+DBp184wLcIL0vOAQvQ+MqYgGgxMVcrER9gPhgQSWVqYEb2A/Q5XeJGHEx6kFSbLvzijizdnby6aBOnnHhbRk8mo/GV8nYX5bny/WPH4r86fCPJ3uaTegbX+TfeyUdNkt+GX85dKJMoouJAaaSODNdlM5w27ChHZDBSGBGXfOKEfS/57xtNzoacQK10HvA5LwtjjmQF5RQ/tyBC1AyKO0bEIkDoiCABj0JEAVgCSyPWFm9AQVlAnhs6MSGzdbEBedIvkc2MDp2qV8cYDKiKFNFAivv8YhoSerF0OzBJxJSkqIDaIbdjeSkuupJQUJWRzYfE4gDEGgdx1V0tsahBMoQJicbrUwzb6mUAYhhNQ6AjLggDRu3fJT94apyjtSOrDzjmh/O8CCAtKw0hmS7DaA3Ly87OTadwIWL2gn3mo9ACVYdBZvby1XDyKWUcnjHJmUzBBaBEAA0MZXF0UJ0qv1ixApwxQhBoeFAvEUyEaUQBUqzYj5QyGsxUqTgaJsagg4S7BJCqsmjgyE7NFSuDbkHWzZYA6CKpMwAQ9BR5Ns0m7YCwAUFt0uF0rVqkw0CYGMVoqaOehd4ApyBAGobTgpgwhEwaAWdo80+GPvV5CijlMWmoCZLQYPIUBCt+3FFSuoirj9YGNIoiLLfa/jL3gyORB9/pcTcB09SkgGgCodH2AWZQkml4CI2QToNJlHUaFBoWgXA12QHKcAzLWOhQwcfyBEFWKk/KvWOgjaPUlgGjpHNNsBpQhyUhib4YqLeXis0FURLUoqCgGET+ST8KovZwS4ugazDZd0hy525ulqeFAe8PfSoaqBZIphnCMSrfFzKHQPcDBqqi4opSAlHIQlLgBmYGkIARdJa7SKgOelAShG2FFKS4SebaS6q1Nilhrgmq0kgeWBKOyCiL7j/3EIocNSobi9lAZcdwRKvuQpVQElAeTALdgLvFojv3UJFgXc2tyG6wbugYk0esKJ5uoVPaqvzhevTDvb/8KAes0swWZwGe5zl3kMqQSohRpy3angeo5vVOlAfKwPec/wAT6sB1gIQmCjMPDOA2KS/dMXMWbXLxouqqO+gFVAfOwwFQRAxNgEAdchhI7LtgUIOourLiIRCYrBdDRehdYZRKEhHQGuExPCUU859ltHKZN+L8YVwg3vT8YMeVK/xjA73/ACV5xmgSBqzZo2YQFwsiFaAG16cAgFuJ0qNkjDlZLrDwqM+GqGzSVsO2zf6CkgvINlU1xHvAlDXyLfJi8HBAIV0RTGHZrRj7ZUKQdaYtaRDWu8XGfE6QBWbiB5ecYvEjS0XjJNji5Tk02xCiChXwuHMbDMBgjQicmgNGfVCHtACCxTFw/N/CkJ7IPRAjEltaqBt3rg6t9YwVmMA6f0EVIi4XwBN2AvICXqJxs1kH5tWi8QnYRx7xt/wcucGSaPExSAcIbSR4wn7TYJNNQU3sduUhlpUWSkJQEMGATyMCTBgN3QbWlyQ6NdBaPRZBviDDiKAXbqbAHbBzitqjFs18YQXRPiAIM05bCBcU0YW1YOogrECCsdxziBJnEB3srvQdkeN2lNXMtkWCc6W0mH8TrAoxkDQQLARZsV0DLUFIDP5zX2s8Ccdr4X8YsgQphQyXXKcObs54ihFaV8/WtGx59vpNMOqbLoWtAoGDfo8DTpiD6oPBRlWkRKj0StmWjGfrYdAJiReL7TNFQQFI9lZwfa4uEWgVoeBZAMa/jrAMCFaPKxFcHsNwFqdLZ03u3QKE0jinQh3gFChswt0yGskQ6+CF1OsKdFShqiaXoHQeMqA9DIjU9y/eCloBGIFWCwjCD+AGOgRRjZC2CQCwkblpmnpJ04c9gxo4FygaDmQ4x0+5awt5WzB2NwhqE5JOMo1QI8saz0hpRchri0FVyYD6Oul5/SvGNuRh1Go2nXH5McHLhUJoA1OyqboIalVqHtyGsjYmyXTSVE8V4xSgYG3BaXtos/GDIQe/9GG4B/46wgQ/f+DCKb4xcOlyk2kAPLgkTewuL7Ch0ijhj7lgMhVQsnAsSxWh+DEHQjJAI+f0YnkV+1nT+T6xVqJ6UM9ao93CNuO+F2fpwKGA98ynNIvZKKg9H8g5epl2bdAAVC1lQyS3YUCWjUC6Q3vFDhLM7ME9Gu+LlleTC1z191POThPYOWAyO3SGPrYd/wBA0ljgw6Suj9L9p8bh40BH2/Tck3EgJShGiAqjSRco0oaEVUsOtzFmxNsfUuvecQZIcfXEe+BxwuAAEmvALm8XJanzqX+jXnFSwAkEnHib+sHsrcd4JzAwIg6NiOhRSzDygWJoyiMGpy+eBSwgzLxtoBR96fYsFLGwqG3l3VVrRBFeFBk5X1kXDFEWwB7jOSO8aZM2aRPwoxl1NZt217Kwe1Il2D0jajUAaoYCk7zeWj9bngKDfAbxqBCpIA5OUu2XhMRw940G1sr4xyL94DIubXHuNkAUpyqkafJ0ACB5DCNyZBI0bRbRTdQ0AdpIJPTZFHuclUIUMvvW6cAxU4xcG7+QNfacZWuwbkA8N3yHMMSY7eDQfDGv8bH4i+lWEdjSGjOQx8c100Zx2O10I1CbqmRpUhEaMDpMufdXDJC1pts5B0IFNLw548/Zn8q+8dEqaCKpZWmjnBhd7OhCqErN9XeFeQEEwXQKS0hSBwUNGnOCtXkVK1hc6+JKUCN1qeEZAx75wsHQcK8cusVIBiBvKNnSbbxFFo1FwjgMpzvwYTmkNwqkGyBxYOriCmtWAWWDWrV27MZvEzMmhzEbcYG6hjHmVwjxinuIj6fw4cxkRpzIpJFundYLLPaLPNJbDXA4PkJiQDABEXxsuk2GNysAFSnIXA/fffWltDuUbFUYpspVeOGwFEU6LCdRbXZAdihia2PXFp7KhoyRAFY6jOE1EwUB8bgjERRCWnNE58NjUgyweDWj0Ck3Y4E2PFujG9rw05Y0+IvrGXtQOj8r+2GvR4RmEs7+METRAy+w9awOj+HiAZdjs+8UbkopbdQjoppNwmLm8KV0tdA75snGbm3GbYOSeMWrY75I/wDHWICjI0Qv2F8mIAffrCB/dwWVVwPhP4cADzSxoWCjGCWMBZwOolBilpdq3a11VWrJvGBRB4T6xLm5TAlVYFPyDCAakihOTBHcu5rB1Xw1uLw/447aD/Jv4JkeOrWD8YZQ0+b9HfowyoPFAATBq06NY8e4r2hiJ3b8YrDtcgoZnSCAxfOMHCEr4pzupE3dCHmt3hrvYAaVebCO8CgywJegO1k1cCP4+t7UDqwVCc3NfkzfAoOlyDW8aOcy2NZAIwuzeGEzJwBuzKZpaIOIN1YgIVxVdA3TABINlLLHaCrfY8ZBRgXRV6Hhy5KnZAJtS4q7ETUwLb5nCAFl3AoIgEpJWJwZsbbIHswG4CHQBW8yhUoTkO7Uqm0DahPkFXOMG8DTw/izg6Dyg/HnEUU8XKrenE0cB9CE3sVQdHhBAwO5G3nPabVBA7brfWCQ9tPdo4GrrgOXOR1YdJf2GAKauMpdcECB76xfooFJC3MaAGebgmjEumMvgsFpXW8IqNK1CIY7uSQW40LJFxyFwCPASVZsrRujJO0Ze9hA89+MqugzwQ/nDRoKF7EaRXetPWRHfUT5mwQowQ97icfRtAIAlMG8pnjJaqbDVLVc2vvibQIqLptBC5FzLwbCIUZV1bOdoaALUrQ0ob2Ja/S/X0B+Y7oCOtnWH8Cx8ESMPogdnWEBQ07dCG0qAWpzi4CiscBS7BefMwUXuYAOwav5yTuKg3NGbg8nO+NOdWMGVcdDigFwTq2qeYDCjpQTRU4cJZdJW92H5JzhphcptSLmTSzt2OknCjegf7wZHAJ6REBqbezLkuOjBdiwoDoTzgQgkYPMxsrXKVxVJK1eppw4V5qAnGwSn7OGCmf5bIHSRYmD0HBkQYiPCOFaPLERYEd98YEM4IuNXMMhqOcE4cYQxsScYAVtABs5XJbCJmD1ALrnLaYUHr3vLt0NuJIFSvWRWeb8mp/B+sMkFe1xDsH4hiHleM+2NnMBp0od8mKeAEBaLF1ILX6kz/o0HQwYqCpwoz4HpE5uSsSnVNA1EdA2NUgC5ZplqhpdRUFvOVia8Cf2fo5XAmlJ/f8ATjCkSs30S8HVhAyyFUecoAKMBUZYMjcKkm8m1uLTAQJv6PkcjGx7cKllCdCzhAbYgJpqVxqpYqsAdjIPnb1oZe8k0bOW+qyt6o9JMpkXDSiOoAI1qKTEookB5RNkkxQfsiYDqhO9hLrND133p9NiDTxhD+kUYkiDQozphlgRQNPlBCoW+dYmMJX4aEhTCC/GIEr0RLwpq1ddJ5yRtPDeIag0aeSjY5XNRTo27lYo5UxKyqSUKgFoJvVUMq/SkBZmAgdByLgt+KgHyz7/AMs1DRQo5G17IjSCVIBlkKEbmClFEYi9Yx6ExEeEesMkSS2I79THNCiuxe/bhVnHdAShJXw5fJhy1mubkn4Pb7wo09Q8gsleAPjkYEyHypdE8UaeesShQHEq/gh2Tm4GLwjUjqKCDTwi12dk0Bibl145ccAJOU1IgG8qJ42Cih6IFRq8AU0rIvQrVHCPY4LCaGhTfuPrGbMgaBdpuHS8nfGOamFGvABgW75wtPEdwAMQTQibDro7KMKIBaDobshaudQti3Ra6Cn95DrSRKO2LtAenjCYOA1pvfUDsrAeLCGFt5D5ay2197SqWQn16MclLdCvL83jny4kIio35HHZ3A3DpURXHOjCMuQLM8tv6j5yZ0YMO5BloxUBwo8362kROlpNaSesgSgGSgQSFAuwPOHWi6EBg0Crdu1Ajxkv6MWPeJaNQ2wLrxiSnXjG5JVEwrotC0YazREsJxAUoMXDPGSjg0IABLNS4aeg853AgxaGyxDuyJyoioqUinM2ZtRlLeRoXQpL0uSAbVgdhbMWL7woe8Yx4zVnLxikuXGWlILU/KpgQigq3L5D2f2NhpKii4Z39YCjHrRyYoluxYXR/BhoX9BhBcAznbU93OnswOVXFLG+RjPwq9V0QIl6esQiHQcrwAQPRl1KUyBmxAJ+yCTisve36xzxpwT6YuWOsEuqAyrTcLWB/NWXAihAFSjgGERVrZoJehCdV8Z8ukM+9mSTaInMT26TC5mZAo0wECwqsIEggMwLhK4dhU6hiJEhQExdcaqE62jgy0OVawACpzWOWbObEUu0tIDQ4GEqEmWaSewC3okJgVrzW1EB40zAsTLruTrZQTrezIWz+spN/VCPXZEVpRIV7WgRCVXZYtuoOikXok7XeF/k6opuIkXhHrA7QLqYIUbXhXexoyTJoiNQs5E1Ng2I5f65pdtAA6vPtgxMiTxiKqmU97p4CPKB+9c4WeiujnpsrY0mVgu2NLAwmqLSUHfwCBOPsA3UQpQDsyXpDUoPPa/rALnC7ZEARLybsHVhYQKFVe1cqBm8M06qqq3dH7we7yaIdgbTiOuMNw+2VboZK6GFj23ZtW42m6/gNQyhzLsrZHnrmapiU5ikdK9HY2h0aVrdtVxOvXhw3GUC1EOOsVArRACLzdHS2YOtmoGgdAdCo7ARAadgf5gUuy7bd3CSKQGgUR2Iutlw3mvEJokuGkpNpYXlhceCaKBtCBHlMM7SV2JDk+YfeJ+OL61A+WrfWA6djCJsr2J3x9ZeY5DkhEbpyKDebc23CQEh2NtaDG0Ex0hmgHZZ49AnHSx2pPsyou2pzK0wRNVQMgwTgB2q8gZD7RkNQh8c/ODIOm9EipruKanDnh2jUx0rUq96G1cpQ8YbAlZziC9Yk0ABOx3y96MDjAA1dchEHLDV1m/qhFVgS1JAxdODB8xyxOU6BCHNl5B1g9uxg7x4AI6QV2wa1WiwFNJEFq67wAAK8RXkAANa40uQ3qUeSECVd2MEdhzLQ2sQBcsUo7sol9CppJegBsXRZjdYwxBwt846PlcYTvbDaXAUGnGaEK4rlcRI7YDYXQ8jxg0gdM43EBK2OjWIBqC7n2k79ZeJybdVzfAX7MBK0aq8An6Pph7EJdQDkFofnnG7x7eS5MVhcn6jbupp2t74LvFpR0lBfeEPsbk7bg1BTWw5J6uJAKCqyJ1c4chRKr/TDaEmj8pLKLKquCxkG9xWSQY7woDKaQAnkGfrrLI53+0fsYUGj5IoJ8JfvAit5/lFfrC8b/FkOEN7k/udv9Z1wFoP2T9Y8QwrIImkiUcsKsswEzYVoiSdpbILfyBTt3vrFCkCiQU078pp5MNCxaEN8DwcFr4zj3Yx5OQZ2Iz1hz8qlK2VemX1V3kPIQTNTmTOUYUxEb8NZdyKQ6ctUYFROe+SSGIxOE1gKIy1QgVV3pfvG4hHk04vc47uKWeRsCAKI/Gy3FUGaHHnBoiO5wG+dRPKDC3d1I9GNooDHThaIY204p0rNHZFavk95ZWxuqIcA7x8SecOFI6J3Rh2cvZ5M4PXAx7b2DwXm6wOmPhwEPjKd1PGLDb937zRDjv9RjvgcXOmEiiX00fLDUCBAELEe+fxkrPAJo1BA89G23sWKJRWDp6aKeC5t01aFLT1MIICeRpiPzhwwPGWoeV1XiZB8oQbWNWpsGOGandi5IO49zRJg7bTG3WA53fzgl5Tm4ECTXbv4xphl1eaUdSE+PDMf8gBajqztI0OWoBpAaJQO5We8I+QqKIW98DOOfbxg83QoWQBWBeEPWDCXHlg6sAlDfokpjuhrzCoPgaOXBaMTWiyIjYKidJ5wGf0meWVTHYqYesNYOQnoqfrAs3cldjZrWIA3EBFGLtQ/GcYuKfEprETrpoCEiF46eHLvE+BMLAqpmnb20S50xBgo40FvnKm7iKbICOAtBeM5Itpa+7OhcTxaVR0RXnIdhJWCtPa1nGgYW9Qs9fhiq4vkwvC6POsWIGospCCR3eD4Yg4o1ORbbF8LgmB9ul4L1iXn+c0FfzhuKX5xGhfnGlVcDzifkw5QLARNh8nhB8PpsA72xja2LeQiqfb4xq+YgEeDbBS8Cmkq3p5Wd41xwAg6bPBjiC6dDcuzyDCCcop2DXGLDVMg20HlHDUZ1VAJCQi7L4TajxT2lWmyqMCJnSmyi4gWjgThBhNk9wsIyboYpSxVJrt2oYkHmoi0i1qwYbdkGlY+540mPQLwn8DF4bJQL/zlQz4QrflxaqbJZhSEdgP3hzaOYmcZUQ0CO/eeEChv21y96R3/wA045qKZrKOzX24QaBa3so/05abY1VK8G3BPmonYnVNPseKYCO0YAeHk3mwMbOTfh9P4uSdf4MpDoHQROtIowOIoWFV3fuQy8xTEahQqK7bsYKEGs0uoDu1fxkctKB2ttATeyciUTV6WzSNjtjQNA2BhlrgbGwTwGE6Y6CUaGaBHcXYthvE9GhbvCDF02BsFaafikCUEPI3ZViYXmVlpWqaANNoMPi3xvMggI3cptMo4IEDAotRIHJGRIHOM8mCBSiBW8qsTaOLG1JEa5OMUGSFOpcK0kRXO4v6eSDiLtUjhSbMMnSaoAg6GAdityKz4ClgOJpIGk9YKmuux/HMX8YQw7GhEYcCNH2U6cWprKQj0nzgQWoBWUH+u/sxhM0KaTnIu1hy2bhoPv8AfCV213kWuGGtImaHABdA6A8YzntJyGxrN0IkqaME0YlTdHkG9eZhb1DqCivjbq9cY4xYJIEZVdVovZmy4DGBvXOk8hOSZqgGm4w5J6eGUU5A0XGBRNRVDHia4KzUVY7tEnDiB/JeAkgjY3UsOBBu+MDqCQ5ihh5bKEoyzQO28jezDvVgUa1BpN8imshLT5oERH3O1xoj47CB4A3o6xVmdY0BdgjLY1467kygrVHR31hnFPKUQdaUnOAJDSe2u8pjXVwDje0fnIvWcpGzrz/ONL31mny7cnNazIds8Pzj4iNUS9csv0mex2n84qqQHHKuv0P4z0WuoxQeRH4cdT6LfPoE0aedXDmEorczyfk4yMmlAO2tzdP4xcU6gKfmO8seCLQT4RfxiXLUESPI+fRllN1hhqpEGmhc0xKs3Vdr8ejowjbw1TwvIVVtDk90GWgI6LQ4oRhm2xRBOTtANFInIkWusLwTZWrobtBf3wUk41ckJALnaVI74zasURx9hAotBV1TeGhidroIghFEJyDh11tJdIr0FbHbVHJDOjcDR4UgugNtOaZxAQGhA22He7oWHKLrpQ7Bo3ZXiJMEuHwKoJJhQ0AAuFpNfKPyw2rr2f4Zms36f0DP1l4p8H8jjKaINKenN5rincf1jkkZFQYTwoGGW9SCtq9kaO/bGQViKbVC8R/WW22KAjo1Qp3jQjhaBL2L+HIOTzWAQcasea94ikkdZbegfXGKys2MajFCztvcFHnnQL4nIvH1inu77eoEUOEAbwHkzVcpfAK8ChyZ404zHRCQaJY1twuAauEoEHYuqtusDmhhRINW7qxIVMAwSC1CJq2g7dRuIf0XQMV1toHYUwY68CThW3YE1KcFkUHTBcaRYuUhDDiY0QVQVV3dQbUXAa5GbFHbClLsjGtoPclBRJ3G001pwGDz1GcktUza7HHPX2tURipYZUnlicsY0ojCuuKGAkzQoRyqNSFKAEypXlX620bFVgKGB4mlQRojaWgHY1RnZJlhvEgLCEQU2fHJaRaIBAg1Lj6mweHBNcOgWgpgGlEoV2QBexaSzBO5WPVDvqs2NJcXsZir4bGQE5AFMFcSFkChbkAOgVayt5IAg0A0bgQ2eIaIYJb/AFkwTALRdyBufxfFqGCEobLR0ShVjGwAkiqq6HMCDC1PC6UjruKx5y3wysSoQBYLkvQR9BslUGugzSJNgeZUrLztSpdAjStJNdBsHSaERI4cXTT9x2Edr8lALCeBqKUeOG9utp5q9qCthtYsHvSUPYmcoEcCg6G1h58YpDrJkDqkiSJomnGRK0BI7AbgrlBzakrtmhaWousMqm2GMvsB7THkPYDF3UMC17JKgpLzHfWEo2K7dErwY3ZdwT0g893B6tCjTc6/gMFYwJdL5s8D13Ajb7fwYXG8c5U/C/8AMSjyC2KmoQAJ8G+cqlDOXZwRXcpgEVSUQJtDnd6+uM4fhCc79fGGYbHP8DwJ5OzGFjbcihoOms+Pyq2iDStX5db9BwGOKgk2xVYXjnTd0dxE5bHgE60qbUAY3PV3hrlJom6DL+d3yViBexh84sLdw01ahRz7hcIH1ahAqRRXEHT3lsqW7cq24MDKHkxmdgPqDTRUgjsGkwlc+Ear22gDYDQIBSctIqE4C2IIwHHNoGCIA84JCxaOtGcVKdBgqAAsQU4y6H6Nq/eRlGFBswxiAeDZzyzQOuKxxpYHajsUUeLMtA8goApToXNDEOZGhaJHl2x9YnCMoj090aRo27XcJE67Vqq1bgJNs0yg8YQS3xoKfvCZHCNsp2jrpOOMaoNAh0k5VO73gpkgFCvIdJPnHaJLoBeAuLLxiYxbImA7GKCoPn2lyibB8J4bnLe0zovOiK/y5v6OsoRPTTE6WnUmlDTrw3swIWAKAslQ15De2NAmy1gVdOHI4VP4sSI1zGAi8ZZh4MfQrvBwICoMSttFe8GK4KkemAc3v4uiBY7uzhhja31yJDuyrLVdAJRCJLi2ADyG9qArgDPWEoN4NEPAA0EzcKmm5gvQy2TWPAtcgY68iw5AgPImDJZOT2RvCGp28Zkw4i2QARG2gUBosHLDzRU4DuG8CAE0A6IBVQoOCFCq40lyNrdFaNg0E5b4cy7ZFBKM1m8Q0UV8EAN4XSWLAQ1wzVQUMXaKCoaJAEd7p4yzKedjpCK1KPbIlUkerG44QAAxmmEJmJi0aqERG3gMMybN6ktBhKAgN2riJFU7nuw0WgEBo8VxRM5AAKwRG4g2iYgsiym+/wDUj2Gg3dWqGqIAcrs6BjIDIfbQ5IE40WiBcftwQCDoAF8g1DJiZaWhQ1tLCbmPXJ0BLTpC0IhvqoCrHQBdnIkhpSOCtzlPtUAbTbjy2UgmySaIa03byQ5YmN12ypAiJQcEqY0TlWZwaOSiUGvPJMsgTkNsjdBHCt4wqVby5CgAbOoB5JuovT1KAmg5JHytJFRKUofzvDQAIK1tDbhR9fI70uSQ1FO4GQj51zXFF4FPqbwc4iZRpEQQJyGOhv8AaCFU6IwIfywyiFNw6a654wecCEBIPguEeYy9hZdXdjygG2Ik9iTVHstrEh/a4kK4A7fnNOGeTQKw5dbU64F7Op7DeOfn4wQkNQV6p4+Z8Zo5VtokTjtd5GO+AIZyqgGOcrsboInCFCCg76X12FNlOyo87xLEzQUZ1CKgemgDkO3u/wArlj2UEbgs+cIiApzY6U7LjTUaSLWGjfpLszuMdH31iulO4un7wE7i0eC3RQIygYDJ0/BiBIkFQUNCJInlSpQdN2rNKrsa4kZE7krMUtL0qZi6DoQENAkBGjd0wS5XXsoDwoUGRMEV9YwQEYA6DqnBzvYPBGOBEGjy0ZuByPTikR7IdLowVKkxJFXxCsQf5kBRgZm/6EwhDWadc0qtUKTFGtL+f9OaBDm04fENtE3huIS66h8s0aBw5U865EsKIqBynzizdRZnYijubI8rTci6kEETQhXip2ZYtEACpRUBPmcmCva2rx4KJYymzw4uxF295xtDM0ETaApozRYmZSSbULaO0CAGP/FqmtR+x6LTwYNyE+LRqgCMOSqiCmFYIOhczU3oRUS5xpYGiEE21EDCPfJ4BswpW3bDsMFGQ5d0E6GqSNhcLFjYS7EjWp8g0ISPJHcPlArV3uC0iJJJFe2zUVKm5xQpKeBpSUQ7QiWXJE7TK8h0qcrsH1kxqIHqhgckNCpg/wBlYF1RINILkKyZvlyLUAUqKNg1iiGsvHvxlqnAoSXVdBBTNAEASlElmmGi9c+TRoo5FYHGxt5UKNNiZq3WmAZ4JNEaQ2g78F3h1eqPGwpXdHLmakEZEnEEQB5oLjKtL05obFvfQGsr/tCRRrr5HGPAmJBqYnh8cp7wSVUeLfHWsuO65F6je0qMDKHSMUzeglrdLKVHfTEHgW27AIFTQMPLoVUusI2RBEdyFNGLov5UpSqDvNgcSKNLhNHmiHJHSzKT6YKV0NBQDGxAhnBEFkOBIV7cV2VhfLRJkyQtC81htDEXCGd6MK3QTTJAcRDFTVUTXkDd34Om+hRo3VAlKtlAm1vPaJBeXGzwGl2QxHwCJEjocb8KObHezk/lkihsKNA2NmlxjMzUZOxDtkV+X3iBmhZqKrRSwPFtoavXYoOGbHfR08YU3todS2E8bptTC/oEkSKSRFfN1ij7EewYgGnTjc3iEtD2bCk/IjneAgCTfBQNkKr+tYWQVodmXozVnA0/wlh4wJw4GmznvlXB/JBgD0oTkdBXZSJBupSzRfXrCWSpRKSdBgaQFdC5pVBMRUBQAhrkSMNM8JGB829NqPK4iN4k9RoCdPI8yOOC6/kJbU0fIuzBQZz1dAXqE2Pl4wdZQI8kkEIJJbnVqoebR9mZrcyGFWvGQBLyGgyTEb0y7N5nVVZ7lsQOZ1EyFBEFkiBQ9GkdZawRCNFpoauqxRph+EBcNimppeahq8hdQlrgNWJ2hFTa3G436cYyAaBqTW2Q/usesJpJNNNGu1ztHNA7b88ZqXmfCKorEdOBNKp1R+jF5Kj6d0nm+uOrirxgy1eQn+8Vrai8Urfgy4VAjgItQAFSI72s4uU0wBeMEeycNMG7OYTQOi1nA+xg1s9GJ0NHSAU7owMNtrQBKAjKrsBLj/sIASAGnGtgtdizkA3Yf9gDdwe87MAAFlRJV144znkBEaXQkZZWtO05aSNOLpxhXfQaqumhYiUClARIrRzcHE3aC8iGxk0byzrwCWMXoFVUVd4XAJpaa5btYhHdMLlxtCwoUtkQARkFdVaQ1i7qUI2EZNCTsWapLZ5DuaswJMwoo7iMabHkWACEnYhxDN6IdvQNRbbqpGgDS9G2MyDt2w5CoQRBfIrBNYh7gjnJbaroigu0SrOELjHbYGjjo3pERFkJDlNdcPInOjvAFR3rUqMmHmw3YHKQ2o0t073EyQnlBKoBA4UpoKttjZsvNFUMbEcI8OYgJBoRiwcVAwLkDyIRiWC0oQyqxktc/okhtWEwIIV+ltWyoctOOvtUyuBsqY6dXQH9RUxRRAhFFFIqmVZiAvCLcEBvHLvGlkBZA39gukDCTAiBj/LFa40QDCRDEM+liuwBoAxoAMMG9kIB0pK8NbTboxsPAEa8C/5A04SF1G1SNRQLC+SLipAgKUHDAkTRNF1la3SQpi+si57p5iqFfykPVgrfDhsOc8pXaANenhdd4D1f6oxEW9zgyhoitkwDBE3VS6sx6vSj9uCL9mjOfIqX4uFLwp/GXh3dSUDlRJ7wSRleu4cYyIesKGNM6vWwDQlDVXOQF6wEAtWwHWUB0dNxV0g0RRxzjKTEBLyiL8ghxiPpoSSMDg5O9HWM9ugbhm4ouSjgIhFaKIivIiBzd3py7IO4j5R7HTbu4JwBO9k/yYRSC3PYJ3uJ5mEGWDDQ3JyNYaiTaNUui6xOg6sdAlXPHnHtRoJpLVPHGW7YesNq1VhWDbAhgnrILheDghWiDIJvDnIi8SGTVDrnho/B5etEyILxz04D9NQAwAUEWD3kArct4B8A37yv3RpIEbqov3kkFg0Dw3SRHpBxgaAhDAmCHgXanOlkfpaiUOEo0gQ1MYQ6wS00QDTqxsyrCXrAfKojonj2zkdxqSnmOzBYDXDfSboCHlvdETidN9qUtW56xeRwiGg4msd18i8ZAfXCR7DghnqY7VyPlRWC/VEOa3yMuxXLCludl6B64yHkxFTgAjG7CmsHCXwPagamgkonMw/kiRBwjtE6FeZUCOychjuMF1/JwHHByn0jFNJBx/kMqKI8ttVTQ4qBZwqbQgI/Bv5U6EOFLz6r+ecfDqkbzhVGIlBSRXY9daohVEmC0Dgy0HOpRjyKTxTbmofIjxtWvQYXjSDBZZQdgKFSUNLoaOwmZoaAFYn2GLYVGTBAMo0GnbRvQMJgVKlViIStLTRVrjMoBAK7IJ4U9ZA2mkUcgCzlDawxboInt0Tqj3iR2ctMQBacrwD2R0xCB2VBV5JWNhvOAJiaDweUeKccSSOTrRGjaXEiPgzR5AlaKibpHZLzicXPba2tQjUQ4UGgGtigFwmN7AKNjcAk4fCaJRw402w43qyHAtKajY2ii70YY5ybTESqUoFnKGJ0OURUBwDXcDxHFsThn8UAMA6HjeCvwNzHPcQ0bg6YtphmwqKxq5RjgeTNqIRF5FV4B0OJ/wCqgk5eetHyQHWSwDZ0FR0Pt0U3mpfY1BVsAeQwx0doggUXRzS1ZrIpAhvdTYh4qTkusOllzzEGKSAgDw3hIdm6yDVQpDQdPC0xE3BRB0BJVpXy4Ba+Vlguew2lG9EGiQibCteqRHd1VDBjOL6CJqhIVGyFVrwjuNEyroW+DE+JcjODYBGhBJtXiS6khsKDRoZxlgd0+1MqnPsoK31P1gG7i0uSMVfjQGFpoJ3deL3zfeVi410kWdtJ4xw6CBzDwJoTjFkxK1Jns2OKPxhuPnQAAdkRoxcQkJTOwtC2y3rJvpwJBJVaajvlm0wUiYYAMF4A26MfyxUo0fsX8YglBuHBPHCCfHeNeQdi937zRFeDxhl6oF55DXzcFEDQJhNP4t/MB9TBftTQvkGl+mXN0IBPCSHPCc4qbCIGJCGhAM9xxcEEptzRhRbD6Ch+CB/hhwmH2GaP/Jy5Ra/Y4fc2w6084CxIEPIyit5AimjnB0cI0DouggdYnqHGUsA1PkmMBBIW3B4Pg1ISBjtQwbtJXGqO0ptMse+ijHlELgtM9XLOA5orD2YrFIr7Hb5u/vDhx+cGxagfImRMGoA0p5E6BP3KLvPiqGKtoG7m6cY29Ud4rUaF4w3/AEvQeQne+DGEUAyaCjF1JPwwELktG0aBoWvZUJhBpSOCOBS7ZQrYd28ZQZSqtqPHgwgchBKetw3zb15tboI1OiGaxdpiN/uNK7ZN4cwytshtWzugLbAwzkIc3N2SEsacByY1LAZglSEFDOCYyQpdEQbdi2E3uGIzyr03JoxkG1dpJE+IJSXGNLQ0TWI43NWoC3YRsvE0xdQ5QAUIbe/C3RL5OwZcmtoEo8bVGUI46iQRD3C3WmStYusXKcBWxNu8jqCDMU218dg55S4eeqRQ75QlrsOiGa5UFVBBqNyJCcqmx9hGtzAAGBgoGH2rKKhAhITTYQgcDi4WETqONuwhyUtXqbF70hbUdQXWoo22ytGDqgSrfGUw5gRCV0jVlGGZqr8t3NMU2ADCqyCvdm4Q8eacDPBq0yUlhhqGzStlXGRaudQBEUPK03gbeoqQKTUDCRvO8g/9BmYG4DZEe9PiGqGKhodzaNR7xfUvCIbHQWIElVbAJKgBqIHWEavfFRqGYewGmo08+IcuTqEhTuGwAQbVE3kngeIIha0+3XGDwNBRq3ccxx8Y5NmukJWHEOPGCqFkPJkNIpr7yZo0TZ065oOd3GAMOuA4V7qt5xIO3a0XPoHeLgnBkgcBtcWd3kPhEdj4PGFW6LdogdcVm/jbc+f5RqFnGsCC5BsgFsH8YzDUecqSnLcJmNShQHkeGPnUE8i+fV28wNuMpdbbTkq7db2OEFRZcEAtiEc8Fw69JEHIi2m5KdnnH9E7oDQPiYCUWXPIpdayKEldSJIUrp3vEIiYIz8x1Pd6cvQoUlnkAmm4by7DC7Iaur4y2CdLT94moY4XN1Zl5PxkKNrpR91G/K45rKVVIAean4ywZw32SqdjFdASYGASHIA9AcYe0LutYYbwjMZExSjM98D8E6AxUZbqq3xPOA5SrZtPqn6xABRygck+lmGaSyAGiTdveC0t9V/fGHpUesS8HQzDIgvDNfnIFJ08fvEa28/ymplsiOjDPowcqgrYgj/D7yqIG84XhjZibZG5RCaCpQNCDLXApkI4I4oh1B5mvjEDgkqKuNKLKk8EZwtcbCHYSDFbw/YZGyosCtSvrEjztzlgtq4hvDAF0dMeVrEMZaq7j6x7hprMCgQv1vu0S71wK7txI8gLwZ1DH7AwRIHTam2WhCwCGlgAhDcchwTbtINRi7zBOypCRBlYBA0mwv6wSA0SqI8aQAohM0RdQjnvKkLAiLMj4Al5BA1AWMRxKoJQvYo7W7ksFk1ikUAEUQhFV2gbAxluxbqVHQAg6R1EKH0+M4FOAgRlgMNWTqzwbIDsp+DhKlda4NewQRCqc5MYiChuIKKB0QV2rLEOwly6aBGRRuVB3FbgY1WlQWowZhQWv0RRIFFoVc0CLUaIDaCgIkBUFzTViYRYdAG+nICXHXMdF21OoSu1WYG51UJRxN2hvRg4P5W7yTlSxNKZrPSTAxk4f4cNZ2jAuweS4e8ERiWoieSo69YeRkGlvaMF4MJU9ns0B5RzmsVSb8G6qDu7HRw1ildpA+akXoj6UbQY1CNcNwOuCauCWpzaqBwOF5R4Bs5L6pA3QhAs/a4MoDe0lI00n5847DRrDQoaYi/OG1khsXpv1iAKQW/HpSub6x2WABEpUzjfrNyVCldAgXJo1b84Zt3D8Y6WBKhEoVphSa8NMxSd/wBYGfqgG4qDBO+aZW6TDU27R/BwsKSCJo2aywaQhUgFFUgd6CzEbZt24h1CnnZ3iDh443fxqAdVrdMd24DYO27Y/lgKEXVoLoTzI4BswUiVw2I6/dw2K4Z0PRPfl6xcixEfQAhaKnP3iKpvWgavdfjLDadhKOXVVD5+cqMyAH5HEvQUD8D+8WF7yIfvGkK6tHyK/hxBIu9CWmiRgdtuIiamEc4D2a3gEE05Jq1gHoDxccYAzqYP2I+ynC4sNEXyC90K7pOsLcYHSQvx+8wCL0y8/wDh/GLGg6rnHgM14TD2EfzgIAalP8GOvTiG/hXJxbTyL8jr4mPRvQ0PfNyTGl5z4esUkKNjB1o745xzgrhIl278uf8AeQGsBCPdTph+cIfUWD5aAbNOf3id1+rUAGEGxekLlLURVOoDtd7TSdwxxCWmchqIkrpjWFJBWE8HLhND57wl0wFEAL2csQdGyjXhSCHXgkM5dxDkNcBDujQtjlPLnGBNcKAaI3pwcKDZarklBpnG8GWfZYggpEDtAkyc1hIxXgQCqnQF1zqrAbGQsiRHsxkMxxDvvzqFrRcNQTBi0PtBQ30yOAkiHUHKqGkNMkBaatRZRVXsQGEgzDNh3Vo5TUYqWbK1msZotCgVBDkCU35pRQRlWbOU/Jd/HDBpZpwO4dsRGZmXRTNUQAIrRvawEOMTpjTtlWtY8FsDDnFUd8UY2mLKppzkKh+RpN00wdw1m9m7Om9d43h2QIN7CeHecoEmlkN0r794LWn5YDfNC42WC6gmIOnmuGbPAWmhT5WKB6IqSHN/0YJrGwkjduB11gkKKRARtRq+/OcnJ8LpsGhxnEbqUJLEj6YCI67HGcPmvyFORLOgH0KBpjA5RA2zvPoUJzFXrKM9cbcJ6hTx0DEVfzhQoOqHgNvstydZwqJacjdPvKE2oxrZ2FcQiqyIKDs7PM+eEORpaK3Ef5xtJnyU4geQ6gc3jQRT1wqVAhIwcaxytra88MkJY/KNh5cikH5Y9r195dDvpZNA3N7eU8ZrmQAATSeXxyZSCCRUveh2OGBNZHhy6bj3nFpsfWtQ0kVOFujFiyCXfIdTh/Zti+fUEU3tiD1Xi78tN/ileh703BusAnIqD0ZBTsqHdF3svvKxBrx7EEfPzziNxmiFQbNQZfBlsZkJAIb2UWHWTnTUHvv9fzhjVVlVIdAleHnTySSIWOQGxOH2YtIdBvtOZ84tyNQkipDaf04k5CCr7aN1/wB5yIqUtBZbs5NYfzYaxdHOFPHbLQ08c4o8vT7xzgn0PamqgqJ1y/8AaEdKXkbOxveGf454JPlX3jPJLtZvwY7tRw0Py6OfGc9tRgz585fEdaKHlesTSARzONg/H4waVwwCjE4vF7xMx1YS90p9OV1lKgnQkbgxaprSQi3S63DjCafArfpRHT/vAQtI0vxviI8E1/IoB+sLFIkVWGna9HeGyJQNVCtJ0cjAbH0ZL04+hfbhVwvT/eDLu4FORBHgdsAbtY+MTwCxKAcFjQQhEwMESn5iU5TyhQwwqpTgOS4JkD0YmLQRtJM4AlCO8mr4r1gIVDY01SEGu3awbaAbQhHp23SSICQAJ2AoGucarepCyKlsO3blaGpYFV3gCRi3iEM6YGJRAbwgOslQhI6ja0TugM5jQLvZPh/BjO6IS0GihV3hMvitipBvBccKiU65qE49Z3MAY0TXlhNykyoHl+A8YvYYMSI4dbp1lW+vwC+I/bAIEUwNNe388K1dSrvRQxybLNzlp/HIyVmwMOQ8dOVCEbFtK6RxJonFA0qhdWu8TXemaQk6E/WN7/YSzUTXlw5ID4xRLodE7MVERskYS8dk9ReGOibo77ACZ0k72EgiigikfAOufDOdRukEItQDxRG3FxK3OWWmoQtAZvBMAtJQBVlFVK7+cmwGtFISedp3TFI89GZMBVyy80hRO3wnMvOFVShIVJyykqwmRZyTaQUvr1zjv1GlLwo8nGUmAyZ5RV3gdseT5kKusMFCMIkji8cT9mQSBuQAc9bfNyfoCJIB0mG1IDsENTy/bG2gstKi8lA74cOhSNSsDnaQ5BdJlGQbA40KQAOVd0xmlWYfC15vljuwxChaa1zxhZJSJeyfDxkbyFhACpygipqfA3EE/L9kaIPCL5eMc2tam1QfSGXxCStFaz7/AIwGVOJBC0HYaXeGrMoWc08CKUpo0zebPvPOF04A6F2JgWrZBfZAtVHR4jl5Ou6ZtOjQ34TU3X4ugDUdKckFAvOQ1+1hGi+gwOFdlygdh0uGWHGXs+s+jAAHEa7aENRENNzFH5iRTTCuhrWOC4aOj71mxRNMr2QcGzCIBo573cvp3hxtzQH21yj2n84wiPN1l45xob+o5x+H0n6d4oNgdpg13AyVK/jFQSD1nbjbR4UdcD9OGwBvAXzOLgKKWTbcTVHPVP4x4sNHDiKILW09Bku7uYA5sIoJojBAKrd44qSI+QMBhsQdm70na5gI8lWpsVXnCXq1cT8GIl2IkY9YEyI0mjworW8MeEKOFpqBL5CLq4gObY2Ai8UOpPk4Exh206K9ustsEAEWR9hkQFPQbBTPtkW0Gm7BF/hgsR+6OAaafLh0Eo4NiUelxDCiQBs1Cehg2KSqRZsHPRcuDyT3c4P3XJjkYibgLrzjRI1LfBjhY9sEuWBqA4v6ZUMoHu6oj75xQjAEFUpEODJUfRWFuoA7OnOEYHkLcBMU2HNwOgo5wPJaF3NM6ifeVjgtFs6QFHPeLrOukGJFHyuGIrIao+MCk8uzOAdsgPMI7iyuMtBaY8QhEKyCIXo9Y/gIn8pfkb2uGPth8oYqpw5L23HCgOSKcQsi9I6SgVLmEqjw3SVs5hipPu+hURtOjR3cO15qJbgUHl8685Q5+wo1lIAOrveLGkeRNj0KfHQ8wQbVQ0lNNedXEu4Ar8IwagTjkjitmqFIotEPE47OoQ/qJ6Louw607aQ9gLPiYCNp7Mq6G+KBEU2J/GEIVa1oYBeFx1ks3wwnlPw+qATZBgCJ3VyDiy6HMiRCCJEjxppaYDeVFvbDcvIXY+A4vOsjeE4AGkcSEFY6wPkBQ8nsAjpyeQtuCBCP5H3hF6LOSDQ844ScXQXl7Ti99ZO3Mdjwm+OPi4eJFptXh/3jB8i4u/AVyqDBjMqCNMOefGEkTYPUSyS7TQ1ceWDgKBEUSgrp2K43GQAILji0DClsVaDpMVqHQybr1faPBVIe9vMC93neKtEHuYqmR2jjod8mI12TIRsMA79oZnRbVInXJvTa8SBJCXkRM+tdQwCpV4W43LjxoN5OrjsP7f6yyT9IMQib7bcCEcVBBbpePrAtkfZjsIB23b/3xm9Owjvlf84y41cIrZVG32/P85GCz3vWHur7zdbwgEjryTAJmwBSoCzzA/BlYpu0e4Pet5tetV2gD8ij85BNCgUQYlfi1gdEKS7D4kZCAa6ZohjAqNZHQKaTWGICdqmvgEXp00xgeyCG5pHRMZw2hrLPmYxTKqDtwrYQhioquuI7xfssUoKSHR4cIYldQPAM07xP9tICAsDVc8gENAjxiEJEw2Gyr6XBj6orBNVXlzTCxL60V7DYYYLoKjzifIw0qirWTvTmQI6wBCFU+IYLmYhBPsaodZuYzVlbIfyd4Wd7EGG79Hh8ZVbtzSnJopx1ivPWECFy/wBuN0hfF0Q7rfbKylGwGEXLzwSewGBQ2wH6MSoOd1JtmwrDEgAAQDe1gLVUunGRLWjwEeUoaRjsAnN/pGk8moHr6ks82Sc1NqV4OgIZCHYEoCiwEdQaPWKI6u0lpCtNbVusd3st28SNcO3jKAKXpV4LoeBzi7q+B+NZBFV26LkYUUABBGmw3sxu3N/2jPnRsyCTsDUA5nBHCZxKQzJolILrlcNlxF3woVgF8uD40NwULRPmbc4IQrVJPycOGiCchJ6TWUqTwojeNP8AGFgFRfFPT0DFgKrL3TYrwdC1gXJs2qCOUpWc73NXFEEWb7FwJV54GdmOkHgSNHh2I08POWijsICBCeljveRjCmriS7WD83XnAcfd+zw5P9dYMt1ItaPBuc97xsAY7wW/X4MQ41hqqIYgpY7RDTiDoUnYKNVEk2HrDFDUkGoBtDoMagaMUaQBoxxPsikmhuJy9uNjG8FYoKwQ5OJEKkGU+iB52JwGT0Q9aYyMOja/GGWhqP8APw4aC/PDkNPZlqU0fNySDszazPYz5Ve8sRRPe8BqKWrZ+JkIZPDhw5lgHFyMwBdG8zzr7xtIzaYvOw4hemwrfrAvAQ0gwx3mrSrrYI/eHACJzG7+k/DgVhpcUGO4+C/SxQQ3p0PxlEoBg7Su2fGA0FOrgeo2pS/p19YiLP5x0Bo/xhqVMAGDR+wm8h4w+nydI5ikpwJNFnyTZeahm64dVrDuDNPUAA1yzWbKXxlWd2ohLuCkC4eodCx9echZFsqXVP4d4nDePuJFtPROTO/XSIkilE8jBYJx4g6Enjxmz2wF16L15wud3GgbV8jrFNQNdJIrfjhlN8zxkTgOcQp7TRFvBeWAmBaxDopMB9Qa0iTcHwuUoS0HS6L+eCYySmWNj6TD5qUrRmxGLrzj7mtxaUQFhN7cLBXLJgyUfyY5qeLUOQHpecDhpE2XKXefTLqW7dEHU8c3nKHwaWhYliJB4WQoCaBNxdjUrKbaARAGs2ArGaLyGpsVfgAoAxYQgHB5EXBVkCAs10jmvQ3XEE69qWReNoXw1MTMuZdcC0gk4TDnF0wnIJ3wn3heesjYIzTaQevvGyUNwsDZ7m/Hq5TU5RoFk2nrVzaDbXUj/Ywi1yyh0C7Q1/W7hb46XoHgyL0kgIuSAUT39YhE+FxBsT4y+DbW0/DrF3dk5A+HWQRzDufIMX8uI2pZQC2zhVrlS+BQqhtbRNaG6Oq1o5Ew6GpB4cJDXFHhiEpaKMzbKPjeWgxAohbwBtOEQNDXLzyB9G0KwCm+i7+DCqWfaBsNS0T4HzhEoV2dKJ41f3nqhNH6chju4oGxExGS2SxUuuEBqbYNrmoIDyqhvvzMLw6LIwDpBjINOrip1iFaBdCDTUsoK0rC2Kolrp6dU1XoAGpbP3h47IkqehvBRXRRf0a+z7zSYKF2GIgF8fOR086Mr+pd1QG+x+SyMvxR1ki4PBjtdXlJgENjTRz995LDAVHoA2uAJW4BEfGFvUqdHY5b6e/BkBA1wrhA7MDt4rXvDEDk1oOvsX9YWxIjmoHlpZw/1iq9cBx+br8YG0lZrEpVPL1lwX8sPCE4Ej+VxkXsAavxicFIHd8XKWjUo5/yTLE3iQSwdhwjdiIqtZymdh0GTj6Se5R20ObQJTGInIBzY0PcRDkm1R6xbblp03Lck4zyuFUSuqDTvxgbG8EozO29rOQQF3RYR21WApmIQSVCTQ5cjacNipSqb9YYesUZ6o6HUvxhUroJmgUH7uUpQiaJoAnywkjwQEPdT4YyQQzSPUHCN585s9kAAskzutrJlxoXwgECoi6uFyWNoxr5WcJO8BqV1CIIRvQ2d7w/gzSLjYuCldXl4zrxa+Wv2OaVV2o/WWTmVEmpW+j8ZsK40UIPUFuiciIOAobbXkisqXRvUa7UaACd2Boc0cA4zqmnuinuiB97MGAoftAFU3ELy4WeWjULZGJrXlxMiSIG5odqEFd88RBZenbt9YTrTCD0VW9iZc68afy7ivAfrnFhTBtydAztBeXAU2yvFX+VwFUeCXHHRY5LV655MuQKERu/6YwhcN9WT+ZczPml3ERfpxHQ34N5A0RuISHzgbxeqP1M4/CpPB16fHHGXF7eJCa9OCkAM1iNh4AADY2NJ9rpAOO8o+hOA62vGucOoxMzYEboTY9zDAXznZs20UYaZqZGwIhpR9tjL0YJToqu5VPowjash/yKGBwQiVWKGkQea7DCDVLOuCRAsaGIVuo9EyBmAVEL5CltavCU1SK+jLRE5bMO8FaQCJKlt2rMW5OgYUMM0xTzijgtJrA3uhPB4yIC2d3CSPtdX/qxugrAeW/GbTiJOJdpNQfd11lAaDl6yVunxlAVU+cVlxEUTBAEl8YOB7OUdYAO46kwQIzoygo1fDGW42EB9DMoJ3IRJXaHM8X4zvS/AxKU5Oe8FxDru5D2mcYCSOsQtAjQ39Ygnbw4Bz+jznlGcXECIcE67W91Oya4zkeyk7+IcvwwDVUoKJhp2Qb3SOx8oRRHSNngDZHDDNdEFC+MoGdVLeQSU0LKXRP0yA4WmgaUAfBecnbHK9yBo+JcK+kTEyxsccVxjHXTQq000HXZiH+xO3zG6cLjVVaQHVvJOxxiEyJyO6k72GSbxfK4ZK0ZHbZvF8WmJAOg0AfWWEmVV3/1wCyE/Tlo3drwsX8YJsWHT8FI/wAOIQ9i8iacRRF6lwAZEGcwJ9LftxbqXouBFoXbwPrJkuyn0px+Mg/2YPQbaoDmTBxs7QPFbVDDS5OV2rBwS6Lmhk4WdZYp1wKVukow0fDNd6WncDoK6RxxMjAWuVQkGI8ERfOt9x0gajQZYWWY0VG7T+RhZUJGP8U4llccIiQBklWnjrGEjST5f7zZquVM7Ue64wK2zDv4/EHFZTlNdP3/AGmVLU94ho0ja4DS2nlnxh451U8mIIbdKnGtEBc2hjSbZ72fnE9U1ZQgRdaR0/SLTY16mhpAkSKaqZ4hO6j0esKuMAi1hTSjDf7xZTdOKcFZrhjEY6TzVpj1aJ1i80w8j8msC8J8Yjzxh4UomLqDehREo74e6cRWNYkEFDfZjvmA1YiypXSohAMtg+YKWgpAU6sbB3FkS2RHg/WByNiAFLGXeKQMsMb3XFK5RB3B4/WPOC0y+jI3dbsRhyqwD56uaFm2MrlHDP5weRt84k1bc1YfvDXjTxvLNi/OsakmurcJdZHvWWQgOjnHcVBLdHwvPnBOWa9n3d8/8cuSliOE2P5DBF8gydkmGrLoJTsmj23xlDj8DzrBA0oLLJMI5zzd5SK8Y4z3GvOsVC7ecO2vxhAXVuB2QJMI84lM2uw1LfOMJRkioRIAJIeb8Y5DKbaxYnB2nsNMbX9XoSg+EAk6SVcZxhKWIIDyO8OkvBEOhsDb4MnHhDswKi0OsY1I1KSnElo12ecCaU03kQgA0rhOsHKrBmrFelMBVEvLPT7xbzTOF/nF9YBnchvq5KkD3h830O8ed0aB6uOeiPfNX/GFx3y+AfxrBHUVSXZ/NxGivMZmtXSHkuoexv6wrgfP/P5yMegJ/kub4JOE1lo60hbs3xu8rToMCfWV5cgQawOJQKjoyHQpTnq3XS0pg1gifE8s75VERj4Ow1AAOqIqprh/ihEZZeeRc8dzB0ni6x1X/LO4/GsF1RoPX+5m3mp+cUaH1ic8RoWVsAfQsvmr+GKsWjXpT+s3RDjRvPoeGvngNr+8Bdadf7ypGdALiVyXrjeKC3HSMuPpB2Vckk0peV15ixw4LI3elHfXWJkqNVNC2oMl6HvKdiB8Bgh2z7au7aqT5wKHg2R151lrK9dO7zV3yeN4X4C46dViXi7xW7V73ZZfiYDywB+5rBfrRLIWB9L1B9RqTu9QKaKI3aeGsegXSgcSDsqvc4KVGFUCoGne+SgPZhUnIKcYFQHqEQHv1jSjqpB54crAOgB6pioia3J7YOOsBJv0TvFR51KdV4XXkQJzkBlcPbJHl+AxaDZiCu3lyQiPgysq9magQL9LgDwt9h/dwBBE8Eh+MXywO7hSk9a6zQALTBHW9nBfBgyvBmmjGH5tu5iwtzhXtGXoddvhItVVB0m8OsqCt6yE2Uox4U7TOFoyQXR0rPkdvAobAQPea1nx0w7S/POCFQ75y5m2YVOCqKxABXZG7ytii4BA0iq16GaQxHARJQCr7DeSHBYK8A5YJ0QsAYSgIOQIXyQFi8smQYlGUnXk5JDILcYjITatL8APGLw0BEXtXv8A24Cht0VcX6/lmq44b2DOXJ9ZuReSXgfN8OcDIWQJ39/OIGaDETa/GI5fzSB/WaFH2uKjd/rNgDw8YRq4Qv1jUHDzi0DUdIXXn9BxReWNpTJqLqPycVI9y0zu5LgjecBgCuvH/esZYq08dzjyYRlWERNeFhAt2c0eZNMTs3EeIkdYpU2lTo/Ir7xbdx4oTFJRNXhc9bWG4iJtVqHZDvAPF7/683/ZgbTxclqLFDo5/wC9YBtepniTXVwVGL35H/TgRw0vY7nnHheiuFk+rkeYAzZKC8Ma8Lzg+2Ck2MwAY298ZogIza4C1e3BywkJyeMIFmBsKch+TF6xquvxhpYFEX7wPwVjIGoOgGs1UCShzzu+OEeZimUTzdol1fLiwnlhvPzmsAovT7HThQ2ocG+fDgdtrvQvKrVbwGqwSW41QgSaiKQjqVyjIAVVJu8OOaK4D3JkdsVIEeHh0cBnx738YqCkni5f3nziXn2DCB3pS/O6/nLZ2HXeGSCiF4+wZo+aMJQad/Och2fGMVm8FwTYIOu3CgFUh0P7v3i3tD6MRHDrWsEmssAMDQ/9+8AV75hcHf2sx2ACLgRrbu9FBcrIGx1mmj3qllELOFv1ggIFxVso27AQ+TTl2DuNZKChCglXYBG2Z4ofRBDwO9G8vd6kF4/3jWgOyJfjNhQS9O8EQi+MNMtPG8ltdNm2kU3w9AdZoz27miuKbLwbwJanSwkLyCLOCbwa/hqHIHXTYW+VBgRS50IU4CBWiKum3DRgXFq3A0Jy3RZi72m+MCH/AAmThOglUSXlL6zjeD8Omvdjn6xm6BKiQF5afli9uCDTleKJhX4cbHvVaxBZ6L0eNq/rE9inbboj9Z0uHeC3uJwOQ7JB9F/rLgLufuf1kDxgoqtGyaXwI+33hSrXwmfBHq5qxXeOm9fNwvJ1x5xjvhffP1lCDtam+JjY/iFgjkNPZpEQQvJT2Id7YLVlnGLwGdLT6tk+8NDxwt/r/OQTdWifWMcHjkfVdqj7MjCx+cCppTYkCv8AGEkCbjdrtnfeBtu7/ohsvS6dx5MQiuy+MsEkZ95o7JzfhsDY2P8AvEO4Ge2D9T7wuwkwDH40fY4hp395fADB1VF1rR6w2DgdoFnwYaeUt2/1iJVAedYfh0qusEgb1OcuH2NYKJYOjWLLtrVxLU11hVIImnn1iwHzUggbaTgkPMF2uqQLyhaNUGxHWEQRH5NiPfXlTYjM3eLmhTxEkUkEC0hpAhCGhby+PBgREEeBfJrHl4V0fjK7qga5cPksPxA78cvM7qeANX1OjoDjNsUWh4xA1qc7MXkNOeW4SaWb3v8ABnB08YaQz2SmIIqcXIC/mc4C0Sz4xsj5rlHcRebrKBZeOjH+qV6k3ZX3hu7oQDgGnADdegzbHDImHHIOcBTlVaKFmtHvJUVcaEwEa66esRilOdXNdHfOGJ2K8x454WRAaqtewdu+bXbKsZaMQ9iE7FqZzNFBjt+2chl5IEKhkRN2g5SCGvTG3hoCBhYWgwa7xZ1xWAig4LQ7eTJlGIAoiy0fXI93N4XJBsenGkLY8RACCaVfnKfuifJTY1ve9mGmvR4TsySyk3H7H/GEwQMLBE18Lm91fZPTgmX0YEkY6fU/vOQFeb5xF1Dljbs5WiHbP95oqY+HGRA26xEMeTm5RKGx65uCSqHvH+bJNS4k1cUIfzz+MCttFgL8/B+M5Is9Qzo+M7IH3xhRRXylp6BP5zirr1laR6hT8mH/ADnX2QP8ZsQKp7ImzBl56afIvfzzic2hOoYPmVnnff1iFIIG30OHZ0erk8gGBoJ+Rn+OLwPiu/xh0CXHc3PfeJ2fbxlC3XpG9mFFgNdpZ+rz1lAFR5ExAkO4J+uMaIU9u37y7Ci9YPereOsW3kxI2s5CLyp3m1ps6ONWksQwyAPJQuwRGYnNgmicN1CGxJwKRXqPR2mN8pODRwKl0gihXlzT2cYdFVRl9FFFPSmasDR9dRfMnvCC6mJ9ycE8V9mFgzotr3ikIf1kNSHL5w4RAcGbqj1duOCtAdc4QVAaS84wga8iYwloHM/q3BkjVfR+8gpQ5HjAtPirMkzYZxhyKIJ8ZwhvlzmqB8EirgMtN+mEQI7x2g9mcZG+HGJoK7NGBs2pCmUPCNMAMY3eqpp3IiVqorQF76IJ1354KaKWUt6tHER03FtOq4HKAXIhvgHipoYzaDqIR7WgDYODjYWJCgmmeMu6WNAqXDpFloNv6u/WI37dlqug/DHvVilWnkK8HqYiJao18VmvhMZZlSR5V24p4F+sXKDV4Hi42wFElelTV0/7eOYoRGuJuW0GpenGp9q+a1+sjIEoPSnOBvX5YXk4jZUfRip8U6af2GDNxcGl6Mpup3vrL+C9g8A/lfrGLU96xBu2PGJNTi6N3DaQfOIVQZ1gTwjmpEEukwvFWfvFU+IRI/scQNF4xU8Q94ExKOrT5wVghZjzsYfziru2dPQfywdOEBJYjZEIstkq5DKXjPmPs9L3hk3JgCcQYbt4LhWG6Vh4zZSkQpOhU34OXgrnBrbEFTx2av4xP0m5gTNiCpP8YAtRZHT7X51MOVHji9YLdLfeKZSmJSk3sceJw4qvP4xfAMnqGkGrp6gSoeQOHvkMmcGZd8hTkTCQj3EINsG8JdhATd1cGEsEkWbLCyBiU1obuG3bZpns3MC/gaFTiXWCqjt7X/3LN8m5TNSD0bxkRI6sxaADoHCwl43/AKwo4/mHDFPE1LnnIeNf1gjUltexb6AGaUlykmO4h7Np9YVuRGxo+8WCpzuYaWPK6mFVavGJ3YTxPnIgMD3Ac8p7vGRIU8Ewk6vFE05VFXeFvNHXebmAo04MpEptZMGiC84fFAKiCMo8UNesTmd/pFhVKERQEAiLU6carrSW+neB2TvkLZdzPQFu8bBuF/Ww0nwTZwIAPWcNFozardkUOMJBDgADexm7x9FCsO7ngceMCaEwIa4YC8DkTST3jgT2w/JE9ZJhDYWfir+s3iabK9QHpzvswlWsdUDOh76w5EtJ2vDUnzvICRYHMoR9sVDIzSAV/Fx9gwdIKf2nVnWAUUD244q/IDPwfq5wTnks/AP7Yp5NV7/vANZ3zMoaKeLmgDSoCofGUTb7zsl/rN5wxoQALHUW6xeNTqgKr3dt95FebvHkQP1MFPngAeVQn3kDJdlQ8dF6biSbHUAiAQlcecrPxXhR/Z95MAvcXr9cYkCkep/jNB6Qrsv4HFqpJuFOL8YqKFeOHEOzTbmgpH9H4x2HaqeXANBqKXnBVQewcOMAWIlO36YhXRwIabv1gkATFpExVmjzil2LQ+xyTb7ORJEyokIizpNLT9ZO8VURRtOkmGbhFhxCU3WJuEJg1fd5Qql086FnnOTbZI9iLpxBg3IPKNjh5IeWYRoawKvmJgUPAX8YuwNn1mwVHrLmtHRwucS1yxrFhKI44mFOIO97ffxiF00aSlDR274NwXgXCAalMeBi6BrmgEl0lcQXA+XALDevGAQQ2esgL1xr+jDwEoghxpu+/wDjks+yAB7xarJusP7uI6X32zELEKujKxqbDwnOXt3BN77t2c/xgEVWu6f3rnDQPG0aCSXdDymIdAN7j8Aj0lx51jgeH8UPkdapxQyziUpe01sg2AxIvLhC1FVA/wBYm0LSwzWKW3eW8t/tP6x6OBlYR5FX9ZBRURwgdvgxShWmedbX9YuGpwK/JZjiQuNv80MBXCbPztK90dfvRJdUQlIE/tjSRnAB3713i6A7DfZ07n40/rFoQBgcoWHxu/R4yiBd+8uLPTRWg+D+eBBBPNcQVFcs4ZgUYJseN4zsTejxigpwxw1M8dYYGRfC/OEnCl44wLynTXOEXTuY76CL0Fq3C4uRVqKreNPpq95GZOy/lKBviJozpRQtbogY29y82r9844DYrbV/hwjmlv3gMdDRMFnt+MIStA0gT2fj8YpVpwOyfOaDiCc60uvJhTSh2dYw5Dxz6zgEOnGtGAfYsx0sQocj1YcfGOoy8xNmMUVLOOMcHYrVd+uHXGc6TATffI7ynkhuOsPOPzjWm6qWsGyaeUF0vQYsJYMKhVEGH5CP4t6kukN3G5NOFMGNqKBIQAQ6CLMBazIEOFDR8GvGAQcX3jRKqi+RE9QZ1N4P3NXAGnXALyeEVJ3UrXjAdR11/OTI2Nen5zSpBSHDgJzLQ1PnFEHqrPvEhzfT/OL6o1LcfAtttvzvLl0ngc/NzgQRWVh/3eNRiJ1vEc/kbxSIHzXeIcHjXJnPBybH941Qr3xo/wA4Csb7dT/vjAMzyr9kzXyuGQwEAE2efuZECBQB/DlcCDjfLf8AeO2qDYlPGssUHgbQODVz2AkOSHrJjNEVhIdKBLIli4ZAoK6SPJtJxVFEQ4F1IlFhoFtuKDh6SCBRFpwN+RkOO8CiErgSbFq/nnLosz0JbTte8iVQ0pTOZtzvA8CEFY+KJ9YYh8LAeAsDEBxx1h7oWfWHAS7nWc45dY0cJQKZN/HPmVhgWPLVh2RwkBnS48L7J0/KHu8mIW0BwfD48/Dmi7i/jN3Y6OmFZp5zFBdfnKl0fnF6ZTguH0GbxE2/OBwXZ4ECIvbXrgObiID86wKwQ1vh9l3mmGQpGdns9cOLUdhcQsUx3ZIvwMAGwhRbffOPbUejT/nBPMnSTBAUOVAH8mHdA1HrxfONO4t/49c0SwPmF/yxSLZtM/W8k5Ly8v8AH5x4nQmgFJJyGxM0Biuk7xAPtb4n/uWq+/OSHIV03K4AHdQxcTDBMHLo4POQQuh8Yw0bd8/xgGiBuhjFV6TzihirU84pgJqlMb1NICUVxs0eH3kR1KdslVrZLDcM1DOVoqkWqhBA84sS1PTFugZAYdODDRbQBa3GrfwGLNxC9L9NfT7XjCgXSgc21h5+RopgG9yF9wkdVEFFjLJwsZgaTXXvFYr5cYjcPiq4NyOFnWGC1HhYYKTB5OM6AXW3IwVO95SvbpU/nELLV3U/jAhiaVGdaM5kLuKZxGnWgA8AZd2WoU5CoZKz/v1msU/ZiY3p5bwM0nsZslQs0E+Dn5xdm06KOvUxzFVizeHiSyDFvXzkFuiINPGw/wC1+atCSo68c+MGiGOPjmPr1mnWu6xyG7ikYHALd1BDlD44xvdggkpCCtXDulwc5J58rjvlu/nK5FCHCKqnTTfPG8sUzpoSm/kmUxB3enC4r8oYJpXpwIWAeN/nJqEePOULsOGYmaUMERnxj4FJFQNNkAxto9R08KpVWeR7m3WBIaKSFtbny53y9SFrlBeYI41wvOJ304s+J8mKGKOjscPk6ucXK6szcFE7P7MqBCTmZMbB4u4V4+8XCRdjv4wYIK0hyfeLOmjbeZ8ZM+Q8z3zkaUFsIfe/85PWi1Hm/RY1qL/YBgv/AJhA5A1Nz4Tf5xgvZIHDgmxo2QmAGEROEA1ga2yOutZ9RjFkG3pPTGIqfALPvAHTPBs9+8FU066HAVg9nDk7EArX/OT0hojs/OOgD2FzS8u5eM2BlSzlP7y4BewK/trBu/Rs6w7IlqNmUjV8jT/WA4CEl6AQesZFCe+zE1Rpuh17pl5hQ926Sd4umIWv4bZD7QEkECHRdgdGMNKuM9X4Z30HAPe3DN9IAS0uRpAiMmJexEGnaQ5bHaCg4ltXZ7wTZ12eD/eBgCXcPGAXlcBtm1QGvlyLlqnRm0DecYGVFcJoPy6zlnlrb+cBHM8OnGkMnEmMhGyrkPUZfWGi2iKrggGCcdZsKkrdt9TI2Rsg676/jBEVpCCHZj6Nhs1Ia4+MWtQKNqaoZuTd3sxsEV5pJ9v8YUc2Wlmvffz+soinHgzr/wBwUFKolN784GxoiFonpMLLBQxXiwZ6sN5csBSzt1i2WECnibsLuf5wa15vAKw1A5IzUcDk9JTJrSjvg35wVsgmkCdg9N4vPpxdoH5XZirSt6HnF7CqPCu+tmcQFfGWbfAr8hh34PE4yQAvxXJvR0ENc9hdF8Hcx59TUCs0vnnT594gyY46GKQ41uJcp8ZdTICsThnzOMU1JGhuJYCJ7HOEfTvjHBRdjxNec3RLudHMF9+826ldgU484fRdNLbPjX8YXFEY88+Lgmga5Y+utnw5YaTvgBPF03NOqYg3+si2jwBr/tY+4EoJw2H1hhscdIaTxN/jG1q4qKHrCG6cI1PbcQCQSDJL4137w9h57VDwRe3/AHZ/TO4E1Hf/AF/OCZAFTZfDrDQUCla/nARKqk1Q+NzePMU7Lp/31hdISjHXmnZ+Z7w2qhqCsfGp+PxksJJRl1Pvj6wIEHwdfet/GQKlyDXOB2DREn58YJoIdrW8mi96UX3iDklUh+XV+zxj19roCcrOIc+MVTJWWjSghZHHYAoxYkTawkuVJo9rrHU0A0JqVoRE7JEWmaczlCcavLxoV9ZC2uolnxggwCmoTGm3JmjhyIVBY9Q4DqqGzzkESG/HSTT8Bo6rtSSjCCAd+3D4LOR6xNEbKgaesnMB60XApB8G87wQ7QqsdDFJsEpybIPxwr6y0ofLFDSDzmgAL5M58djWDYsJQumGR11Fh9ZyDKMLZ9mCtb8n9YTQ3KHDXvqYMduiIcT3i0AhBYoU4om7rk1TeNLKUJ178YMm8mu9Y2hBEiDz89f6wREVCR4/PjDHoIqBfYv/AA5bR5bN97fz5/rKEp4N6tBD8feFuD5DEhXYnf4znWxMlAqwar4uLKnTpPLmcv8AObKp4E9O4oEdRfbhys9EIeAeZ5xnWwD5kddib+N3eJVAuqOs36idcfGMRABvfwZst6lPGJDqnpP84AN6E1rBCeG/eAeXWjWh/nNGu8B5+Jzke8Il3Gy4mJth3SLwoK6Q52Vp6aUkySfAFLSGDThXodLamzZOTA8IDPKG699LwvG3lozoo/c0e0yvwLaVa8xP4xTZTRJo6U7OefjDQZVUYO/LNYUJuRqfqT+e8WUkaLAHOuQu7OcQAAOj4ZpdEf8AuMqeJNEiHb384ISi9p6511vLWpvYNDzJfx7yIQ1aLH+U95s9oCaEk5YXtvrJ7IFqpPBiJSibt+cjfF2bdeX3jcISvl/rIpAe9sX9/vIBhe/j3/8Ad5XJR4Y98U/eUKU7Efs/jBxBwJXPjW8ABJguhrxz+3B4ESVUnaP8n5wLtTYm/FJmoAPkfWQQjhIJfXjLQ0JpeTxP+9ZENAmn7wXTjTS5ZrfAv04GZQgck83vAd4A7kWiRt3/AKdSCkwNRv0ovDy5S9KU6wDsKPJBvTgSYVULdA/CRMcWcgxpNCtJPjahQVpfqghBtCvYOTemtEbJpK98fjD72JthwBki9PLgheuGzyARPZpwgLUKmBXjkU4JtRVoVnFBFza3AAVgYQA8EwugOvBkAQHzg93ktbMoK3lLD8mC2QJwc0leDwMCujjU1/eAK+5YfOIyp3uCfXOAglEAIfOdKrxzhorc6xtCUdI31s3/ABg0p1NefnHb5wVZgXw3/usfJqA7sc6CFX/v84koQcJ/3OWFAKkWOAriejn5j+sYtHPRr6D/AB944RSs8YoAHlieD3v9YC5upJ34d/w48ALhsQ9YRUhAeCOp8+8sja13J4Aanz6xNoaoEr9XEGNUkVfn85Z7BVGHfcsxHQtISWcm+mw3wZqtAKq4AdEfhxj4FLMQTGkR4FGZCRThf6cAQv1P32YUYC+DIahtVj0Bz2Pzg3n/AOWIj4MdkC3A/wBJr5yS5pVnlNb6/Bl4wdYXgIJXRlJSQ9Q7N894839qAEa0pQ0vpmbZI1YgCQQRzEvJtyXYSqcIpFMERLZyADBsFLHQgbfh3hNKEJJeKWBYG5rnAJ2SIc/KddnvGiWprgHXi3dL+sGipK/ZkpxhoMUQgfnh/n+MQIErjR3tBaauElxNEG+KG99S/wB5GI1t40pXSKTn9ZzGGaD5XGxTfvJECc9lTh3r/jHLBtKDztQbPLcoiwAexpyl1q+Cek/vKDonbl7x3fWV9nHPWFUV4Ow33iUO2Q+R/rBoIKliH/fPjCxG5AaeLVCfg84Tcl2JS9X/AM/WRE427i8b5/6ZU8iAaEhsA2cVrnDsBQBgUChy2b93jOrAdCPh276y+w4HgTDZ6SveG25HyH56WbtWJeToNwK3dFwxUZoiSDhKKq7ICbcQuDQNFvIRddJxA8iKpSdjdhLqmMlhwgtmwdb/AAfeM1OyTg+OPeUzXqPNfPWv7xOKDCFNodIooSHksJUwBA0zUjg1kiOHvxuYVEQhTTtqxyQUUAlMG1q3g4wYVCWpnrjFv7gFQ0eFzvY31ihqvtC5qeZrXnJKDgDgeh/Wb0gwFMIgDSL24IJSqTBVUFcaBV4MqSKb/wA5BLrQU/jGsptCKCR5RHedZmoPnCgwJsBUP8Yhij4jIUgNNW5yaeXRgxENrE+cLerdG/OsnwhQc/3gIa8o637cG/ZuEFZFsMP1i6ceyRxKOnLWn0ZAe/o5mFqw2hwerlgI8xH27ni7xOAlZsAA0DSUwQvJfJBrizAKUYCVm0gPKuBDaLFp1an/ABg7LoVwca3VMiItGIr695Q+lfD9ZQRoLty6WDcMRiL0TxVUGkr38Yt1i9EW9gEIavVN4iPRAKPZqc8tOsfN+ujcnQxfF0YKC2cWPgE+VwfTnMJ3QH84DYHSldQH5N+cCPm6u7/3jCUROB89PiZLnLmkHu8NyBQi1b2hubecQRUCYuts0b7g895o+uUBe3EJsMoxE5dsPEmg6XRBNhF2jI0SQCGBeuN0MrguTWAeCygABys6yOVmigCqQQqAozcaAaC1Gbrd9NZy4CDYUeO/9d8YqgjYChvW+XXxx1hHeTBG3sV8eHKFcLRumr1NE9cYW0SFAgZVC867P6x0IBIiLTSCn+/vKj10QSXROyTj241K+BCfLYKTe23GOswpg3QEE7b6OMrDOn09zX+/ePbJ2EeqnOshDVoSHG31zj5JGG0OTDIHJV6jP5xlPQL7KT9YoIQvZeHXLDWME+9DXvQcHP1iUAOhKeKkPv8AWaynFHnjwHpuOT3UvA+tPq4YEZvNwAq8LeNbTBi3oOYkCioTaB26Bzh6IIflF7H8ZYbxF4V6e/zp9brNAekbNINE3qY/4LN4GRboR0AyYkODKQg4mg6EQr1Yxy3qUUAqwJYF7aYedSSAIgaBKwpDrIz0R66sTcUiWu93B5YdX1gAvBGrsCbU1wUUBA62+L7fxnBrYAtEU3VFRedjBTAWKYzUvgxHdEPAdu3V2Xb0Y67i+Q+b8mDMJVN0VLNjuo5aYKDrnX119Y8EZwTEtQDlLzhCxVBDaKP0mMoNG0d6PjA4CbiY6iBqJP8A3EbIVRi91+/3irX6XGAQlVI6whpxQTH1aV75wyTETiD53owMKnawFP8AusWvlvquCmwDTbrKo48mf8GNBunDsPOKIMQ+SfWHtGtoa+sV0gk2+3j/ANxSi2qh0+0/7rB1hPnXr24BQlrXYULF2a5gvWKhp7NbJrTwOvOsSkCrwQffV/1gPlbtPpWP645wh3MQIJGbtN/kes2Wosz8CXpwFQFQB5SKiO4Mbw4zePpLOoLKRALIvYSH5cOCgCNPK9r/AHk4IA5E070JST1lSjjZQrGWl5G55yq4V2aBzzQTsLbci4eam61uAGPs5MEKb1ZP+fO82nz004koaPS8eN7xFKuOjt1oH784Eh6ciHgfzg8MXjdv+MCG4i1s9+DfeMICSkcvBtn3lL6bJOlBOnk3omwcaqh6kqIgNwbqeAwXYRzYYK62jmk1iU7rRq2zosCgwOJgXOHYoHlUTwBhoBM0BuRKt8LfRzPjIQd1tg7uw5O7jWWSiRr4Lsw8XlwSGt1STj7DAorCEQXl6/GBa6lsey99cc/ziGuajsSRp+8RCjQIQaF0r51fnDmLmDOyvIdM9YWxaKlRDs88n5wUUUoBXzv/AMx0D5G133gKgRsjw5G+sGZvG+FD+9fGFU6Q5nJ+Hz4wRTQ0blD6LzjoMmcth5/7WTA2FNguu+fX4w8KgV2wNGxdBx0ZWIMKWNFLH2JrxiKJAk9+kQ8JLwiakh2FBsTkRaV3MTp0mEbCPGh2CGOsZ6pjh4SLSMeKPDC4koSFggWclOe5yqYx7HQ0TtNne9buOA6lhRoQVoVeHYuaXxv53LzoRphe8kOZ6K7ESuwAuXgMcsIVQA2HQXg1DzDJHqWKAhEpTwayqMS/XdNPEzUnbpmo6dPP+tYyckvFCQCzYwbTkmCH3ZYQAACeRQNmbwtroVqhAzkNYk+xV7gU6/exJSYYTQ7q7c2puU6fGLdhaodGTkzGAniAf9Mkb6HWGQftHWKAZfZ+PGIjPk1F8d5VCqU2vvf+sQDMcen1gBdx0a4xpInwj8uLMg6rjAD8BLco1mvdkF0huGa4ywvN083QEGh25NYUw+Qte9Y1Tr1Sa7nnFtdjaG35zeFBgqqfNxTN9Bp/d/eKTnqtc/eMasqnhbqd8TtxoITpBVNfXP3m85paK7dfDpXPOSoG3XOALZsXS+N7nnjLII2+njuEJcOwgigq3RnAVSAXk448zWAj9Eb35509veV11AFX13+stXHqqyi33PyZwjn3KoE7XwN9KTI1ImwKcFGlgHAxdWAio0NiaO5NObJTrIOrSupV0w5D5i1LaO+I/wA4rHIcEZrv/t+8TACimqHev5wRW+xYdOXD69YV4vJvzP1vIZBC0gtqoUnh/wAZANcnBKOntf8AvpqgCEdCaBt/EPzi17zGtpZxxz1lGlAvOEO5wOKmxiNFQEgYIUHkrVQeMWc4D8WWat3gCoG5hSZajxWwQUbeA2pwNSatVUhu5NOzNkgQhw7bnUHX+MPDFSijHU7fP/uRNr1FozxH54wkIc1VUZu9eXq4ruxh0p61tj9zANYuXSbdtiVG/nFYIMHDaUq+EezGgHcUuvv09XWJBKrBA/lPn0c4buNq9vWn5TsK9ZEDB2KL+frf7zqItHd4Z/nOYm09qv6cV7if4c5jY4BCHLVv8Y6MplCE27VfL2b44zQSK5F2cu5rfnWTg9CLtwL/ACX4cWLSyRA3Q2VXUu7y3kzYDuCbSE54vWLuCaKK25Ks/OXJOpGcIO9O4dGAgISUYBZHcRaCcMHANfG4U82jey9ct4+5cyIOgooSneudZRQNssJp1p2ljLCZYYcqBHdUIWQ8dYYs+Qi0Kr0GjjpkSuSBNAkB73kQ9bhhKMPoQVhqFuo1wdF0ohQSEUo2FCo37gWIlAQD47XpGbI8ZCv1evsxZCsFLb9dYUV271hzKjYEi9Ej2c3A4IEalMbSNheNYUJ/3rLWSKhdljzHezk7wLQzqSvvCQxp4/jFIvPFj0XkGn1jgUBpap405Q1hviZoIOsAGAbeBgnAXIXjz84/NHgH/riNJNBN3+MEB0Rjbd8S4pIpvgcwYIWrt16nDnIUcgpx7/1jJwFNNX/P+s4QJvXP5yGAPAtz63O8ilTs/wA842Aa3UHHgxN80VR+Dkfu5IrzlsO33jUKLtDv1/4dZLXWEkB00+PnLbnVCBrVw2iWgnXrv+/jyQOj4U+3/X+c4hJYt8O7qcb38Y5GYi4EDkG713+MSeCgUPcpz3E3xjO5Caxi63QBdDgLjMm+ZQmQarWsTtcabsNmCOQQUUWCA3GIaSzB3lXUcIVS5EowQQTTUbq74ynXlANVPKfDvjzm0DUCw2Pf5nWC9kWqX5DXeAjQ6B2Ak2k+2uORHsATNb9f6swrdUopvw3eH9xjeK62o2TEoqYTVaO133xMgwQXWujACQIl5lHh3vIjSgTQTYebu7pFKVt2rQbHpFgjeQ3mm8atLpIdTCVQCFaVHIRhY7BB5INJKaBOanve8EN6vINfF/1hzYAJLhU9vD/nFsbjZBHX63jsgvRRO0Q5IHNMYR50ROw0j5Pz1gAfAJeWkXzxyNu8EEyoNd9jb/zjpyZazasJqQdn3mgibsb3f6r/AHiDaLcgBpdu5r25dtrc9f0GAZKg15J/ec+DtQ33NnfGIo2t2zUkGvG/rjWCpQW1FNnB5fW3Gbc6FVPXU8/WTmqtYLEG3196DeAjrusN1pkm9lukxLaKVgx4HrOfIwRbdS4SmhX4ZE4N/hZOcH1ckIR5C2grUboGf4hA5DQNUYhC6AzjbKkDUighIb2SKWOAiUqBIjxOMgApkfDxjpwOpC/PXzcACmob5O95RrMmgPrKN73KPv8AyZSSUp9gOvgwUeJE8ZHRr9McOqVV5V7yQdlIo01e6H250yEC6yiGo5e8hjPkXCT5KBzgISqHkxSKV1pjmb+Nuj/OQchuAX/vGDKF3NH8YOqLN9+8Ldkt0L77cQOtHaHb+cTFAWnZ9Yx4DmwK865ftzhkolZ9b6+fGR1SKpn4/jjJEo2CwP8AnDRAXR2/8xfywcRVU1DR/nKAz2cB2TnIUFzaTjTYX8z1isKVLyh/vnG0sdbI919/90kMQDTSuisPFNvRkTYHp6B33+7fxjaDpoAKkPXnn8ZfI4kAq62cJOPvHdEMcJwCyy3U8fVCMFZzuUIUB/VwSKdIYTa9M/54w65lTmcnnnw6woQCLBXmsoAixkLsUMKWyNpuy8ka543dieEDZo86tOeqNwwTjpARRz0IC96JFYR0HsU+mo84gj8GB4ApRBRR0ivqjNJSe4j2z+cjkBNih0OC8zu7wmJQ5WEt3J++M2pAQEZ1XnrCxw6ULdo5nM9YGEC6bR5Q43Npkq5WvTy1PPW+O8notLLI9jVDnRNuHT/WzKSNTWNG61ho7koOYnUIl5tZgaqCUleBodvfWplSQxKtSkGkabyKY+y67CnIK0gSkTq5DG72PJoprvk+e8AaAC2I8pO9PQ+TLaSyKRHAUHw1gQ4CBg0lAQPDyeMZTJQ4BR4+XmRjqCLGACTcCoHc7m+ebkK26CukK0UI73vWJiNN/Q6jr8e7jGJnyPMONmtyT7MeMpaA7pbI974wRPM+QGfR+sakmlG4FKoIbpqFCMk4nHzlBgqu10G1IaH5xIH16FVNvc+2HyqiOim//TrfBkqc0IdDY6fBU+8avmL0VEzzKVwaC9TZCFNksGBwGnoobJBNt6AHFfsZvCWVaOlRFCNVbniqTdT6BQAwXyyVbEJNko1hc2bX3hIrKC7jBhFYAfAiZLDYqgaopyd+juroVhsN/dxmgyYUQEoxruNGROEBNYEhXNxr5tEm+ao0pvNmOPzKbuZNvrExfuDwzWK5i8YE4Y9oJumAdUUxZq3/AH3jMFumxcTYVRCqhezB4PdCHOLEHOBrVsUOjKoFXpKe/wCsFqNQ30vjAiVdag+jeWyhjxGWoiKK2fGFNk13A+sFQTdC1mxQDo3t+cLQANJJv7cEqr8jR9DgpYfKF7+vGRKpEJ/feAaNA7dHAzYExdDwt3/2sUKDxGhODwfOakrEUcPzg4qN6P594qrUcwQPxhsmmgDv58ZujJbAQx9m0fOBRrxECL4uv7ygQMbLxwApzOscqgizwAe1JN3HtBZZwW7A5Rx4OjBWskESr2/45/eKQNFEVR2XXewfE8SEOUdqJSzSb0GxxB5+8oQglE06MnHON7+UZ5hLNRTlIaxsCaQf/bWAjCyk0SV7gfxhBQXzRCltOdE6PLOMKXJ3yWgiQM5xIxdygU1KFeHhbXluhQV6m3AKcGybMaXNrIerUUyUC81Tw6tAnArL7POlwxCi1Gxk2Dn68YMsA63jgNiLzgTYIclfbV+MNYAG0VReaadz2lwFGgTYi2ct+CZazEQgg6s5l8D7yY2zLg0MI19LEdyYyS6GGkK+i74477xpTYkdm+mBSape/vCmqqYtgwBm9gxluRCRJC6OX7dELxrbncU4mw7DU1aKm4mGfYN2RUOhotVGvaMbDryDeeqPijsw9WqDGrzwlGXe+sQQ+CFp06nl1ximNgyjX51sf1msFKCVh46e8AKmqBriD4G03z1lBI0EccVzdfE98jQzBJLMCAKjdB4hgKIjcokX12PWUNwgil3rru9byAkEiET+dgYv+moYipyDqG2BlUO5rWF1NKY6kQOPbrxi4W52GioXX5mCYTFkPbQvnzgP1lkFBNQfvF/jr1Uuo1txBAHV780pSk7A6VZKsxU1ODGVDZUA2S7JJXEJibFEctne2RsJtEamJvLsyksgS984oBdpo3GblPHgEWtSLFM5FwpEqldXohKxU0agWMNMReRI/sVclrznwkAtxQhF6WVuCUIS4o+wh5KKEAsBeBx4yrGmCTU7ITbDRjWPhb5E2FKEw/O1/SBjmksRaTEkVbAg/eUmlC/OB0EhJDgy+DXpy7wGB7cAR0joDT53gyTqZdQeyfvGwVVQCszShTcdYJEa0cF9d5CNk63DEAXurnnAJOwq9fvG2eHrtc5wvhCO+fnB7Yzu+D4MEaoThDRII3dysCFW9CqtX2vveEazTzVO7xO/P95QKO17cFOWI8RDxPOQ/BrZ35XKa6avwXR/vDD7ArNnnBSkCfsn1ZcWKk01u/eBgLF0rAoX68YxQNFuKfmc/wB4R8CLQ6cQ8TbePbkAldzRSrp1l6oICjg1c64wDvMrEhqm7L8riGAJTd6ab8YsYOuS2OD0/rnBxG7JUWuNf+fOIBLcA8DPObbbprfN/wDc5HSSs0ngJ9L96CvgqHZJ8BMIxG0TQQaqUr16cnCoh5l4qxRo3aEbyOO27TKoZzsMJVKmgYdr1w8YKhVPD8HGjfWQdKat3ym/Hj7wigRljTyFm9HU4lcan0AAAkh40B8zKNhQ2MdrbV14MAwDFki7oTXGLlboSQHR5OHiYrCRokqhpG8ONhJINkm+tAXn+cKlW0OKpOELPXHDiMfennFaR2d0JpfIgM93SqO809iaWaGrYIr2gUmjQoZQ+9aGKHucmwrFyugR05Vw4dT95RUQd9CrtzZpJzxmnOnCWBw83n/ZiJoFKwBIU7QAcFPzJRgPBVUQZIt7wDSE+JUfjYcdfG9i6RBCCDe3wPrWKHYgTTJoq79YYig6mqr/ACX7yEWs/GBajHJp1Fnqr8YSua0EJZDfOtvfGBPOHDSHNk16f1lFKwMoiD0+c4GGvI2KkW66584EsTgobJC708vl1kTRR4eDs/8AMnWmR0ow1aps3dmFlV7ClIaDZghparpONWrhECSPE4KIlWXYaGFXiGtHRlr2IKGng4mWZ1AQBS7bCaS7JO8hfDKbAjWNuj4yMct+AC64jgJhDFXtfvibvOCiDfo0e5/Wa+Y2rryTxL/O8u6CJFu/94YELuuN/v8AWR1+/P/Z" alt="微博配图 4" decoding="async" referrerpolicy="no-referrer"></a><a class="wb-photo" href="https://www.weibo.com/1199303274/R9yE5wVH8" target="_blank" rel="noopener noreferrer" aria-label="在微博查看原帖"><img src="data:image/jpeg;base64,/9j/4AAQSkZJRgABAQAAAQABAAD/2wBDAAMCAgICAgMCAgIDAwMDBAYEBAQEBAgGBgUGCQgKCgkICQkKDA8MCgsOCwkJDRENDg8QEBEQCgwSExIQEw8QEBD/2wBDAQMDAwQDBAgEBAgQCwkLEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBD/wgARCAIGArIDABEAAREBAhEB/8QAHQAAAQUBAQEBAAAAAAAAAAAAAwECBAUGBwAICf/EABwBAAMBAQEBAQEAAAAAAAAAAAABAgMEBQYHCP/aAAwDAAABEAIQAAABHwZY3eqHQs82XM6ro+1eljQ5MSNHskaQAtUgYjOypFTbFMltyue5JQqbBYPn3myjtDijZ0+H5FVrOyzq1ikRJVSGrdo4eSGNQRMctZfk0BqcdVJUmEgDGxNBjFHqYrB0lpPYNrn/AEYdM4+ojlKTG1Q0PCEqRP0jRjQocz68raXocrnS5KJCZkPQ9NRKz567fOt4eJ6pSkHc6q56V2xEh4nkra9U6rohoMc+ayk3QZW5EhDpY5o0uXtnaer515hvkfL7+e8XQklyEuAmVw0Zfab9K1YWKzhfBOzH6e8/o0kqQJ7CIMmiaIYNoNkGh6TmBCO2O16koSBzSXJkGUho8DvjuuXoPUuacCjcKOnBlwhgbGORSIPyJMOQBGkCLZEqaZqhtVFxJpcu6OW65bssh8zLHK9COz+5w8u8rpy+Ou+68+gelyjuQ3mLSWVOX87vFhs9BEFTndWF33cUiLtuDuz/ACa0HBvzXjuT1OWKxTm5s8VUaTZQTrMzVBZ0TBo0EACjjAx6DoMmqao51vG3zpgWSLWamocgYyCI0gNQgKLnvTjv+XoM5GyvTiULc1OmcoVtlqXHZkuPpIdJHogXFVpETVQ9Mz3K2SKLgCBKZ8z5wTmpE/aK35KvMjX+xy5nj1oc9rq8uufV+KffNE3DQGCqPO9Cu4+ig4Nm3HU/X4p+0VXmdYuben5NKaaupcbGslx03tJ+jt0rPOszrNzlT6Y1V6oOOchwPTjhDHEY4GDMgLCy44BZHE0CiIB0HA6JMhE81pHOerDp2U1HTy1jlyuZvjS9fFzrbm6Jrz15OR38qCui2np1K1tldrOtutbWem3neQtFGSkZp6FD4159gRVqAMyPjvq8Y1/XnT8G+b1m+qLnu5+q+75oLmHrmK5cKo4OrD+J6NF43Y7edv249J9bko+bTPeZ1808m1Q3eSRpUqdPldp2kza7REvOqS1Lbk5aEeRSrWWNOMNZcpElMKbWFCSIgeajXMbSImmUTbmjdHC3o4Ym/ND0wqLyq9OLK5eibTk2HR5cK+XVZ9PS+X6CcX4XLpvpu3Fzv0/kKbo86XOro6gZ9Narr53izoIAJkedkOwnSctbBVLK5n436DMV6KlJIxflb6rGtV63PgfP3LjVY3dOe4/SeZI3zh6Zo0K4xXH0cY8j0tD4u5+ubXqjXIuvU4cL4PqM5KBnVbKo9Mp0gUE6XO0J3NrZaO12MFtPHdV9F81UF5X0XZIjtRbkNw3TAWmFbUwNuStvIOvN7XmdryrfOPTm8JxOmz7lZT7+Y9wa8Z9R0Tk92eng/S+RuMevc+d9cWb80ebz3X4eC9T5AU9Fg59WA3bo6I8dTY0fOiLQIos2FuKq8X6XdeD+mMKlq89yPP4XZYVdWYmpkOzJWuT6r6/J0P0OZAjXETbKoJ4L5Hp2XHpbeP0wtXosNKvXN6mgpTJqNjTc8pG81uL9bKyDU2WV2ulVnXdTrWJ9LxLf1vlz6cylMTUmfG1tOkJ5QLyK8ivOU0coevMtQSoV5yah7RbxalYODVjtOT2Q1Ob6vDDpjbc3freL6Gfl6CmY6ywHrfERdMitOjpjx0lecjTlS+cRfo3HPQydBxuFaMF7PoHG3S/E/TsrNVnDWQl1s0aHqZqNy1O3VZLtImV2T2T2eO1uHhRc+nKvO6K+Xg8tHRpqeRzEs7alCs86otosYuNeUHjcPoDuLTF1VOzdKCavW6Pjf0fx136XgaDs8eZrzK0ObeqQI06KJEEczGTvG+gqfc+cISpPgMJXE6NZ+e8bTlmxvaZ9ea6fIBWbmrXLfTcP0N7zex5zjfS+SperyQsInIrNs6jy9AMbEvmJpzPvnW83OGFDnVhok6NnTtXzf7Pzfi15dhrlcdajQucAdOXBKLt9YhYsuh9Fexw31wtLhXjd1PTreLpt1OWasOdCSunbNMnWVvLV1uV2aZgo8rsfu55nhvI8VQdgWg3I23XXI/pfhhaY7T0vmiVE3TmfLNQ1S1pjFEiZalA8CDcS0dlJPy6rnDtFWdzh6U2OmNeGD9L5SLWfgnGeg5vVueX2CTrz/wBT40bbaUgn07GvnSo9n1Rsu5kvwSbxdWbr5nVmtQ6s/C7P8h++/PPJ0ZHC6BW1rT8lFKjJT94ZsVA1yOn6x0n0Oey3g3Ptxnk15152xnJZ0PzOFWdqEFDtoi4VedGVbhrb9U2V5UfNp0n1Y5r5mkPIO6rbfRuieK/QfFgudz6Xy57yOnJ057mNqvo4lEGbKSrGTUhgrzRHgeTJTnRrHeei5/S0XN6wrxzHZ4Wf34/B5E4zusezYeb9bGvLnXrfEjLdUmeZxR8vQNfJ68XIFPR7PqBG7VSpy9OaRWKE1ufV375z9kg5657G/m/GqaHY89avltqmJqq3vWu6cnRXSOnPV7Z2ND4dnz1w3l1wXnah6Ezz6fKrrAaTGpw9CejpXp4dN9LDG8jpOPXX9Jh8byfLo3lqBJ1/tObznlPa+YuvW+UuejhYGhjU14S1dN0cE3PS75/TrteS2y66vbjo+jgVrwPJUXkTs993w/QNvDM9Pk02/AJ34CEmeU3HfceX9jWdHl4n0Pnmqi3mYlS3kBjp8M+nI6sWlMnRk9AculMO3LeN9xznzfpKrPq++e7nmRUmXHT4ZzVzWK6/zdXMNMJHLC2aL0c+1ejibfM0hZfmpOVzs3gML4h5XRVcxEohaG5656Z0zzprpfqcttrENoUs2NzZvzWR5tLpPnuF6eb2vdz8O5/Pw3ufH63s8a0nZlSFxFlS6mVeF7n0AvCDeEepjUla8h7lRGI1/L6pZup6vIpNM0BpSJuJIovMe274/aHfPiu/whqzXlIebZ2KL1ZCndipoTNeFaETHyepk/iP2vlx10OkxQ/RzpxegxXhkU1snI8tec5KtzNLqdo9DHXb5qHhIJGorJ2dPlwc64v5+vNefTY9cdp9LnTWX1AakDDRUrOlTG0NoLAxb8qy3D07D1uPKnnfP3d8prunyrB5z51qtOWNUAjaXpzT9ObwCdKJzlk34RKlxJpez4vbrdeOg6fKkLSdG40IMenMSs0rK25PWtcPTzPb8/BuB1JRenQ1Zeco00bY3Dn1F04ZV8+C+M/bsvw+7gtpjCez741ynzVgnP0RxDY8mNU1VqZU+YjTWBpRNZhXMe5EhnHtMpNQ5ngRgGhMTOlY1jAaA5fgcDrQcqqvM69j28+bvk+fPW+Hv09F0eVHix78AqkZSTcu+Ymmfg8DFRXD3L3I4tXOgx66fXja4fUhNWJuaI5c5kGL5qz5fWp+ny2WeEoGIRiko6USDcSGds/89+hZLwP0Ctdc+2jRosUfXe+UoL2HC7MRaxDZHtRaQmCabSQEYgecqxQelB5NTpslqgqH2INABJHimt1802XDzuaMcuLLjubfCtB05223P8yev8AWNN12eNKarnEfTlLWbFTZuRpg4SDfUtT8EisUH4HEuArzYWKbe4OSpIXZnk5IEbBNJGmDZozkgerPzPKkcomgez25t8N+8hjambxOkdLy0Cn3b0uE4wCenNHs5K6pjaR6l6kPSWaESmFNEpQ0aVGP4d3ZbiTiw4acRBw8J7M4GqaMxgDSkjRDh2orHEzer8HMPd/PWvPdd/gy41sWW+fbntOCm143kjm31CSPuT6ZKghAJ1JWask1i9yGNQrQ94kcJLEXKrHwR8+hjRryZNyXm9y6oQPAg0Bk3Q+F97jvnf0fwUTde40qqaMfpcctKl0zkKvJ6sXd4rHbY1W+Dds3bZ28O95t6XDpw3L2X7Y5Dj0VY00b101ICknTY1lATJIsvnNRvQls8x9TyRc589GpyhdAm8TrzbBXgPc+MqK5d12+NLTLpy2GPfEeNHrxeY+8I07NlzNOdhT2pJmjfhNczb54k7+Bk09y+pamMufXMxOOt2sIQ8kzzM0EpqbJpo3ufJ85+K/cmYdwB0LmYIW82yD9WHrzpdsOkY9XR864HtzSKPpfDfLaY0PTzyazftkS1aZtvJ2Lx+hXZ61GOmt6OXHc/oY3D1brfyEKlT0AeuqPJJeSaZavn1JntnXQqXNHhc46R7yyd5dNW2Qvl3MXgva+YzvR5+z7vn3XgNMrzIwjJQQpBMc5mOZyUdVYGdk0DTCvcucV89BKgc1LJlVmrnziOUNXEndBkIe5k1kq0rM+hWnNMmhRZXML4D99qub0sn2cWe6vNk3VyEnKg9vOfXGPrjF4u7daRVkx07JV9K1NSTX1lAdHct0mNF+y1Lnricd+h783POfXHY9M8uwqCdvjAbrLz1iYZem5uyrhsHpBWHP06ebh46DuKvfPYpGR8w+x85mu/wCd2PZ4ZduQaaoJpDpo7nw2POUZhYFaHeUh52ZMklQerrazgvV5mRXYktrKIMbIkdAi/AVSW8pAlrOry7fUINRFqIPj/Vj/AD/9zqtc6r6H4iq7/Fh+X9aa1Nyr6T7eUrTR88i8snTwAba19P7ZWIiIUCg4HocwiHjaNqTWeCviuRPz848M2tdQY+jW4ruq5Ap29xQY7XHPvGG5F8PenKxL5o9vzC9fzGr386024JuHaKpidHALLcytumLr5wCaqdcImQnRTWjw9Bryo9uKNfMtLzkLPKgtQVrJM4xo3i77j4r9Bt89KX6T5Sr9/wCYK1XHQCNUBzSih/G/r7fB+yzHRzaH7v8AD+e+H9/a8vq+0to/p/q4ORxp2G5O1HEJBAuEc+itRatLlQhoeKcxo0l5zh7tf08WSHxxVUptHXLmiKa0uwJQd3nvHAQ5mdZ20C8wtNDrGW1kseWvpga5t28vqnu/BSt/OkZ7DrKvYoAnWRrzky2l7cdt879p5zn/AKD5Ame194v0Wh9Hza3s8YPn+za/N/Yg+l+MrvR8QV5GqRY9I9ecNxEx6qX4H9ZH4Xv3WF+9zwY33/5YF6E35hqo8bNTO4yvwX7vdcvbKzsXf44+f0LdXLy669Ptv1Px0ZVYMEHhOCPOZA56a7Klk0uYTdUnLZrKXTqnVSuZ+P8AQdG9PwfnZvKqgIk0rjPjbz5whzlDhYXo70YFB2SDPXrjpjVrOo5620RwY9YYULXbvqvyST0ebZc/br/l/uqj0PHD6Pjxp3jdnlQ3F78/9jdfn366mebPtPzjMeD9dI8T6YH3H5pO+4/IW/lf9C2fie/J+g+To/1D8JlpzPkv0aV8H+pyfQ8XEfZ/mOT+N/QM51aDh2nH06K/P2ZgT0OfF/b/AAJPS8d1KHj0R42xHyv6tF5fTmxc6b02XReKs6axXH0l9B8x4Yw8DgcIMvzVUqyqOC56Z1OChjLRrp1z3O89GnIiuFNYZVBTqg6bPm7XmxzrrRsZWfDdPS82JVMar1WwjgkO7Hzfb1GOpMs/m7183UmB9Dc/lzHz2fL6ug+Y+uk68OZvXT9PmYj6D5a48z1aX0+aj+Y+4Tne00xq9J5zl2We3Jpr48Rr0arn10O3DS/oX5BpvK9rK+B9rM8L6DMdnNgPT8Gp0K/uxdhpb81dP8IqulR9Lufc8LT+t4GU7cqXj9y4w6dah/k92M3eLz0id+15z+kTDqC5+qPb+ecNgeBwhy68qSpVnzNlpzYqmAgSkowTGdluezkkVEccJm6Mbxdfw2yuPbWDp+niss9R59LAExomsaLd5423y/t23zvs2+HmZXqy519NwjrPceD7egxrP+95+o594LjO46aHo58D6HL1vHbPYdEDfPfeR1BTo3pZd/DXyo3D35rv5em89O5751342/PczXnuMH81fb/MUPLvpjn0vI5XD02eZn+LTJ+zzOq9VcXXFXTfovIn+lvdZ9koVRy5ZbxZ5FVZ3294NXdIpFp9k7c6sUfgUHBDTaABfJcVk2Ws1bpnBLhrW0z06OnMmtURhtM+et5tmi9HzqbyfcZls3p4XQ35dU6bmS5afkQ9M+h+ZrYfFe9FyxrtCweDeT0ZvTFl+ickHl2k9Hj13iegnPOWtdJ5+l6zoN8TTUHV1XmdsjG+fezw77ks+Fv1n2mewWVVGvO+uN75HZVbZ3Hdx1/Vz8h9Tz4eXJbczFnpi+s0HPUrpmDrntcc97x1oPoNK7PTDZ3hjLRzl0/TDJec+W+5pX9FlVRQ+jJG0GBUKJwFG9EJHzw3BCfN281s2sYPpaxak6d7hPWyDDEq4N5prFAThJKVxSTfqevHsMdrvK85V61Kx+U+g1nHz5Xpyj9M9A4OvEV7ET0vZqHyRuWdp9B8RzTk9bu3ByixrHHRvdeV+FYGd42lYfTLrmC9pjz/AFrYef16Tz9q70+HM6v01vtuRnL0xCsaRac21h08/JPf+Z6R4yfx7QPZ5r7l3HoVndy4w2yPWSN1c+btS7Ki641+uNlyVZeJ14D7PiodLeXKSHNoNoNEGkRMicdyFlvnUiXaO9W5nsvooefRXVgZxlenKiDsHH1cv35s/jrl8tmObbDqseXsmcXZTen5dV6HnTQvTWIFhBb5a1s1Ojq6X5nv6Hv8fm+Hv1/k+s8xrtlO9D53nvb4fcPm/Vg8m+I9jj6ZxbEyse03/Prk94ujOi15amnJ8zvseLfJ+7wypee9Lzu2eX1z8ryGXRmfX83sfi9vLvR5sNp4uh4idKX2efPZ6R5pnRMPJs1W95VDrSs6aj75cx6503j66jnGfb8WSVU0WBlTOrKJITsnMAQ0EYHhfSzZWXQ3ABc7GFGnUpdfWfOd8JIdEzfCazKF/wAfftvn/otj8p9HVa9FdtlGbT1/DouzzonTia8sH6PmtqNRZ0jw/uK/g7qs5sX3c0bqy2/ke09aX1eN0c8Hl2mvTOTWuw15z6XN1HlupbzquCrj9HLSdXH3Dz9Ljk15L3J/Rn1byuzKGlT2ck1Kk6I1nn9ljzbZrs5+He18+3mmWTM0mo2IdBCoek2/GWFlF0qfxWvUsd1xc+depuZH0nPnxwG4Y6HDdqPAoeBoICAgICht401CNsiwjqbeUmYym2fPOjijY66IeRVQAcK98z25czY8vq9J8X2rXyOitOr3XkeYZioHteFg/pPlMtobTyft43N0afjzy/VrYT1VPRxYb3fjtPh0arh5AaEjLVYqJ0Y3WWk/GsZ157/zOmguMd9H4/S/O3vvN6q/pzf05Mx0q3WT7eaS5PNnkm53XbQaaJybmlqKLRGa8EHeZWTGDWHzYtCBtMvn5z9/m0nsVWqwIAHVOHtCxyGscDgUI4s9cpc2udxk60fUpdhn0DcFVcp7fIrFNnh0Vt9E53D6vOy2epESsN/Z6VGmew8z0uieJ9AHzPajd/i4r6H5PLb5zs3qOPe25fak41jPW16j8x1Vz2o/X1q9vCyHr/OM0gCaB4CDahQUGNBam2tu8EVEVBRGYJoIkBo5Kcus4g6jl7+mcPWgkYFoLTENCPQxnhKMiGIz74NR6PBT9ukAqOhrf3B5HpqHkBqaXfLD3ngtMuZSUkX6lfbPqOV7fo5hcHcOdS49IqzyTcjn9PjfpeD0jn9mVh25vq8jecXt8c7/AJrS5dtD1+Tsm4dc5MHncNs9FHk6x836lcq6f8f707pwieT1z/S5bjCMV60cN/Qvl/pT8i+uy/1vi82+78Dn86+B4IMiFR4EEMIlrWXgAfk2JoJBeGqfhIDgizVXO205uoFQgKCh5HgchGKAwQYxY/bi6R081d17QUVQ4aPtXh7MfefPtIwJGUiogKmxj5c1yOl5jC9DV7Tj7upeF7cHPHjnu8/ZfD+jyPu/M1mnRZ83rrh6ENclH0eN0TD1V6vCz/d4cTGYkVgxs5t++fnH1Gq5rfcJVrw65X0zS44ReLSx3iF0InteVzL735zGl1AijMhWlQ8HJo0FAmKhU0Y1CgNgGOAaBg5BUDbIJyINpAGwY2CaCMciWgooTbg23fzjNKtEBUAcTk1OqjCGgzBOZY68Gg+oFQVJw5Kq2shu7THe1np3XF7uf6fKWO2Hj356i/znoPf4FJ1+FW4aR4rNw6HLSLZFs1fhen2/5H0pXPsuWkSwHo824xyp+XsuZMz9B5eF+6+azQ6KbiJkY5DwKDwcB0ARGYjbU/AwTWMBgRmQgcBZECbLhWiivMgLBMYzwFFIljRUaEWiUiVM6r08Yee0CKpbmK2Tg6JDJLRB7o2fl26rH6CdxdHJ+753BdngNoVjFVmGmedtUVZWXjdCtE9Ntze1sOL3ONev8H0u+cOWkTOsWiklhnTqOG2lnbNXILmJrnQUAANS2kBEaX17OrZYYDq4z4oA8q9/MMggEDyCA5AEeZFYAbARiIY0BuOAAOhyFANIyFALLaCzgQQaQ2CHW0/BMhzkhVOi9PJuG1anQ0RKWw4e3SaY5GVMnq69wfaWOVZ7OKbDsuteYG+WX3yyfX8/vOb6iLXm4Dp8DQZd2d28QLUMCBCd6RzuCdHM4eViZ1DOm3i+6cfRqIXzp2RpvJ9ouxzj1OHacvrQtuSZyb4fo4q3q4u6cHqdGrxuLd3Dna5rSJeLk+Xs1G03OmGvedIBkSxrIRVZBKRACLQNgRU7KZuwCuzvo3zXqVm0A6Maju5qrr5gsIxCWJyEzJeZHGoEaBT33N3yDoF6vglx2rJqppQ6X1X+e/qeN9Ty+Z+15Orz7Zj2sst5OKqOvLQcPXU7GR68ZWXfeY41T2HW0lzRHmdMx6cdrxZH1fg7FLH5dFk4qUoiLJad95ejo+WnJ+nnh8X0UGPZw3q/DItul+Z9jnurytBWg+btwfofL9Vx26VnwZK44x2eXdxLiXixuffzvPv3fXzdXc1bHNS09bDvZbE46eYtQNJgtRwC1WMxYY0fWZc/w+6T4Xo81+m82i9XzwBFT1k1kaycn4ADmuIjZQ6rz+3b5ejBbkdPjwNvKqlNZogE9r+X/WsrZZdfBv8Au4yeR2YXaPdm1liTePKHqja45idGXe0244k9XP8APpoq8frOfDkvQ8DBmQVV/wA/TRa8znXV8Nus8/XieX61ejyeR9/zuq4vZ2PJ7/OvV+Pq33a/x/sst3/M2Gsj5vV6n6Px3ROSaqTnuvLhejjtVnIJjg0fEo9W16M/r/O7EaIMAw8HOlezqKlzXUV1KpAlTHZjw5en2alHRCCI1SJwgoU9OivaCAwjJ3cqynp3PL7lPE1HVnc87Bno7sxi7+PVCrunl794H6PQ78zKwp9lseftv9M8VmZ26jZxVk9u4Nz+Vrhfe5aDp2EZ2fT8xmb8rHJSpvTc/RsubrtIfJvT4NV2Y6vg6LCOrM4++bbhFKx/R4/W/J+ro9cua+h8907L2M9hfLu7wfoPl9LrS8qql4u8cPv50dkcLFZnFBLzxtKrs+lk2g4HA1PGKuOqtfU6MnNU47R2tHpEcMQLlqrvVy1OMiOGDC2DLS9wwACBRMDqnLphdunm09mgne6WcF6kjCsKStLjFWxGi1+jmT102TsuWNDioAqXo1xXR50e1X6cFrj2dK87pqe/zaj0fBx9eTgVQVe15+jp/N0zYuoBnqcMPSKalMzqquY+2XsNR0rcL5XW5FSwF72KjY4LtfNcFGacc038wtSgZ80t1nLUem8MvQ2dadY0h4PAyEHxnLfhDpyPAgCs+klj0/bEw+WN8/S+m4fhiBA+f7XQlXOxduRHCOAWUDVjz6biX88b60r9CfPTWzYtOO7wQVZJbrjbd/nXWH0WY5fT344eW2M5ejEbYaOcYHXhXPkvtvL1ledyrXzcOqMVqefp6LydmgRS0prjE+jzS+rC5x053FMtUKLnWNnnWYz0vNYNmyaROS5JO3VsL+j+Rw06O8+V7+aGszCaFS7kSjki5/UTDti9/Bb9WDhK08HByLg9OLjtD3w12uGUy6KVrp2mHUd+Vw8AqpI072TKlkCUPijfT0coR9FQ2tvBB1TPlF5/XfNsyj5307Z56h5vNPglZ3GMwaa6WMMx1/PHsvL23PN7k7k9ypz6IkZBxuG8Sex8dzW+LMK3j1XP09C5O22jSscytsbjs54UnO+zLnGd2jJyOl0smngU9Gqz8sd56IcxJ9Lp/PXeeW4cVVBynq82prAzlUPFBLjqrTn9BMO0KeI9Pzn74naIIjTgD4X0RJsNZPB86MaL2cM70/H8GXnWJnr0LXmEqan4rCRp06o59nr1VzOmpCdgERP5gqfsTKrTHoJtjw5e/Tg2C2y6aLq5c9p58Bi14pAMEwVpRoTt0HJ63NNvDr3FO1ET0nP1dJ5O3RlQmqup6RWPLu3Ch7cZudVDY8a5+LzrorbYOa1PUlpnScaRoXe0cy8K+nuS0Hh5KXXkw+/CMTwKkoOV+4vcdGjGRkck9XzluXtKCMjJ7/wvf8ELXBrmVluabqu3z4Hq+TLSCFdGtvpi0bUNTYmdqijbRXkRDh2Ci8jnpZnsM9W1NzTpny+A12089OqjrN2+Li5vpHne1zLs+cV5xL5Z5M0mGVKT8m1uNz9XSuLv0WOwdIyfbzRN5vdCZlnyHqx2TVZndVo+iGeYyvHjiUS0TUUpeqpaEjmEX2ONfovlkUlXNYnTm5H1cFqoaBEpKHgbLsjcfrgYgRGcn9TzzA4EBicNrpXje4JwxyrSzZZun7OKi9Hy1cqiEtLK8moAPwDSc1AnadePhqHUJ8zfZc1UaQHp1s9GXPRYqmzfO1fQx5x1mtc4OXTxeuZ5vAeM28LCuW6jO0ms7HXseL0tBzdJWshtnkvV4IGmdKt9XZCiMlURhxYL2561tGExr0VdaTThqI6sxBM6Ob2N62V9HcmkeXEDJPPnWvn5rWLBTHCWkYJq0tZ9LkzdCxAVjnPgaCiaqYiTj0QbmdnoiBMkTaa4Q+nlQGNU47gkTGCRDQG1WK7F5oFu8etvydRnI89K5tTp6QvRuno6azyrAaFPvnT7N1Y6/wCc9u/0iVU1oZmKkObPK4Y5k3Dh1XZzZfu5dT2c+FyrOCpZ2vaW6aopUZsNGvHzzNC0y2Luuh3r1pseiDrydRyf0byuNLgp0RHJd/OC5i1LRwmrSZra11OfoUhWGpIDUNBwIDARNwNBqrwICAwGse4I0JpoVgTGmBHYIXgDU1hU1T5nR35eurkuEWuU1a1gUahd+uOy5KkTfOVXCemPXNSLu/i+rZaSgRk4EXPl2GGuWZadPLtdMPmHuxp7mFRqqWyqMJjUDR9B6OfSc+/O8duZ1BitsTeVMXO8FUap0CC8mvsXnYURgoMq5J0+X55xwCyDTjtSF06bPr5BorVMMhp0gNHcjDybgQSAoImg2hCalo8HmnMskV4ADzmG1HYIEAYCBwWLx6Rt4cyonzdvMLnVW7rW+oz6kqOrRWoU1w1vjfRDIfRfP75gijUciKkzWrc7rXm1QZ5T8j9+Vpop+md8qFK52nrNJw0UWb1LZ4qo1y18aQHNujnwbO1Y8+n1FzoSYArYrkO/mU9YuYqBhTXUWtOg498+a4nrEFltLSTweGwHJtBAIhQaAw8Lw2g9pA8DAYBAjCEARDbGDAEJwaHXgbfLoaw1iiPUgROzqvKjPW3z9HqU72U6hS4x243nXngPB9YII0JoCN4PofRyTVVmFWjD7TEazFzLdREsyxrWZk0NO90mZlrnHnlp0C5v2q2K6plfccjXZDaKKL5lr52b15IxUgHIYPH69eyh6HPpqw5vpOPa2kUoeTchFSg1oKHgYPA1PwmNtQRpBqkjTBxmmiEAxMGwAiGzyJ185tvNGPpNc1ZecyDV5TmjegdUJv8ARnP6siOiOGH9DmqnSeL6cy0jEZXynWvovo4SgSkGWyaamxOIKwtPQ1mTuZ4GGEUFkBqGAhyKnf4aQ4q6kqYrBbcWG284JTFRQr3WfrsujTpedQE+V2oTMeLcS3JrL8x8VJioukKHgQFTED5aUguSpvG0GCQAM8CiaxU47XhMBgFas+jxIIby+bNUbKM9BEUk7wyoLesw9XbPpkc3XJ3wo+nLm/lerF1hzGpx5Bs+ierhthDCOmNM9SaazPN0euZlQVyEC0XNwGaI04PNBQdVORHl0cXnb5uY9PlhFHVRVckWZvsa9eswyTWCZmqQgo07+Q6FKUGJtAwKJgOQ0PFR0PBwFCG0YZJFDwCYIPA9jAYSgxiG1db+XAvmmNQCulvilKZudVxdYOuNeuY+xptHGw6Z22HAPN9V/RlATGnFROms5ca3bDqinK0SkpISWtJNnQQHNGaAObpBE5EjANU+AkubLoJK1xx7o8kDTQDNBHDroy19XSpL+XTD5zQiEB6bUEQ9Mg2pvDwnC8DU3Ag2h5N6bxNBGNEibgQGggMYJiiYDHPhyKxTo8eEOmNOq3xPcanKATdUtIrJB09nO6QaFWnzn5/W5W6bQpBo1TtC6uP6iJzVMYoSZgsQthDCuy0maQNGHKtE8s2Rpgb6HLHZwrC8+G9HkxXDAIAk87fZQV0a1G8gYnzJusZ5Dg8goOlqD01TcNwvCQApuH4l4KNicoGJ+YMPA5HgADmeBgm0hJtaQBBZ7eZVac1Wru1W3282ylXOSqywsr3W1j0t7WxjXk78ZgCZFKjFQp0jjjNdPw9G3ZZlGmpTbZqxuHtAmmyy0q1Ovz0i0kBrNBnUiXbo5J0ebk9eN4IkIeO076s3shdQgRPMMxhXgIhAeggeGshEIqcJRvBgnB4fknAgOT8AhuEjBB4Hh5N4vKhVImhD8II1E5yvR5NWIuXobnp8ayMtDGb5cZOirSAte2z6Z46eIbeO5ohJWiMeiMFu80VR0zNNGIbipKt83LVEWklVPKLNGi5dOQqLOjo2p3x806vM8BBjSRPn2nqOK6rKtpKUOY1TUFTYDgKhwKCIWW8bkeBRtEQPA4FR4EAING5rwIMIlGVHmmJvATSjYAgADE5mnOJMSuz05Nl0eNKM7zOKc1jlCCWu3ssej8735pWkE1jRNHEHevI6IIxjI04GMkgoGQ8kwyA5ozkiY5BlZpa6hZ1CtrHplSqX0Ym+/o8mrlsS5o3SttQ8Hp+BgHQ4PJrIgypeGQFR5iAgMQUBCjsQDjMAgQGB4HIiMeBQGhjGgoMGwTBvA7y3nZ844WhnAM28MqdGKXTelxiiAZqODCZ7mIqkuJYTiYA4apzTmPDypQQRBlEoOqZArtRWqq1XHb0MTXlOFJDn1+rbKupSDkzTfOm3A8FTcBEeDyFCInKRJQiFBBvG4QBoJUiAwFGoR2DE5MbHpSG2gwBAoeBoNAYKMIODwMFu+v56bWE4zvZzgKssuoaY26hdah4fgI5mvOuV+CUQ51YmdarjFFEjaoIDmiicN4IKAVulhTq6h1Ql9OXPn1pIZk36EE6OwyTpKgXKqqODwRNwEB6PA0HoWRU1B4KjwOGiTg8HgQEBQaDQG2YK5o0ityRoII2g0TQQGjjD8CCQTR2+nFsOrxJZE4xmyoE6wlcVXnzvUAA8VhUoKCqglXzxhFFSkNQ0xGiA4PMek0EHJagKqU068uKsKzJeeenRXzSorD36NEdPU5WrlhS543lG3AgyIcEdEoHIYARmQVCh5D0KAwUCB5BwEAmOQ5jkMBBtY9DWMAQPG0EE0ADakxtQQGgMGuel9fzorwtTFHJJqdIBPER6w22gQUppooydcrtHEwiAVMJCKO6EWiHg5iJ+aciMVn1p1U5ZCMY6yZrtax1qjkz9nYqugwlTz7fMmKCA5BRtByPJkE0HANNUOQ4EQ4FB4DAQS0OATI4SgcCAgRgYBRiEdDW0BiGNNKGJw1BoBAJPg3XX4LdOTQmFa6jFXRFolzzH2EGoOFJaUQggK0DREAajjKpCxE0bYUNDgaCMrlVIteiPluZnJO8YbX7z6M+aqnv1K7iy4bOYtwQcNBOQUaAqHDRJRtExNqDo8BQchAQCoaDWeBQ8ggxNIHghhGBgWIQgaxqBggeBAMN42k14IE5zu+35p9Z2JlXlxyrwzsZnCZ+wxNAeyW0NJU4g4Y7QV084TcVCtOVIMAwJmBjUYcBVRrTfvm0055J3iVtZUt2+fZLY+fqsDn7eUYVMbFQ8EQ4FB6GN+RHByDyGDwNByPAMUgbgEDgVHmFTGA2mAwBMRDgiBaxcdgKgICAYIDAUGg8NPt58vp8bQmPgqCxl6swgKszl6g3TUEalh4TBxk4Q5AW1RPWbWxDUZQipRi2gJMYVBWdWu2eG1nDK1phVs4fTKjZx6BZ1pWctY0bkBBoFASJAEQ0bwGDgNIRCB4FBUlDwKN4eBiPDa00ThhEwaB4GB4PA5ObGlVrk5HgaDQjMjoOzyJl5bbr+btnhETpXqwNiYY+elufcJglRGnieDBsCGMadxUzFMkmENjBK1TUIYNBQpC6Vaa547lc9AXjzpu309SnQk0rfLB0rCD8DECAiJAMCQhwBBg/JSJbgaxySjKhBDAg0BgKmIFacBQjgwAgwHgwHB4Gg0Ok0QwADhBA4Qh2zGiu+r5uS4r0QDexLsnw89Wjs+0IxDYwrRUKNgVyYxzXNiJ4pAq4YxqCjGmxoCdQXRrTSVjvVgFViK9bqc1fw4jMonz9nhmBrBIcDUSQUHIUHA1PwNQQPCehozBGEQGj8hgCBwzicJowjcJAUGsABA8F7y9NZvh0TWM+mZkUTgkAYfgsNfKvNeG5W+HfKZdNyaW5zctMWR2xio7ApuaKwwgIjjhFHczAkkMKMkMSDGUoIFcqriqFa3zx6Cc8lOrPa2kkFUNrl9OOl4JKGttQgFQrPIIgoeB4NQVNAcIYImcIYKIQFVeAAjDe0MHDhoYDmSReAIIBQaDQaDAADQMHgCBnHS+z5dzxGOkWtc6kBvjmxU9P/xAAuEAABBAIBBAEDBQACAwEAAAACAAEDBAUREgYTFCEiEBUxBxYjMkEkMxcgNEL/2gAIAQAAAQUCtUvKGbHy1wCYhejPBXcHGvY6R4XMkxtvN5KXHV8fnq2Qn2tradZKh5MQpuK4MuDIo2dN6cSYlpaVmxBQjkmeSYSikXYZ14ukzWgXkyCo7dGMsrnGpE8bgeoLcMcr1wxpMxSzjYsRQwwRinjZ1xZcE7CtiK2a4yuuztiqwOmpUWUcVcV/x2XdiZeQu+67punl0itgvOclu3ImqmS8ONeHGrGPi+7ePGvGB2GoOiqxsno101GBeFEvCBeES8OVPXlBbIV5IM/VcGeuXsDDm8XjAOTYWq4rzotjbAk1uNk1uNd8XTcXXBlVs8y20rzY2z5FjE9izGU4VsDSsV4MNSsU4MuNCxbjtjHl+n709+H68llKrM+xTEmdnXFO3F+0KjhM3jjGF4omkHLdKwmNmKapJFMYoJgJN+dMSkpRTNJgoK6q8JI9T6jKYmvWK8aDqPqIpaWT0wZSNl9yY13wNN47rUK2nM1ydOTrZOnN0L7WtopIhRW4AZrU0i7d2RDUdNVhZMKYGTAuDp41C3d6qZ25NpaZad2YVxRzQRoshXBfcpDRFkJUNWR01QV4si8EncaJJsZtNiwR0qbMYYIEd3p4FNl8Uz3cx4xfuD3990oeMNqnsJgsajkvRCUgAceOrtFaitwSrKW2r5oAcsrD1JDCXdF08uk8qeR3XLbWIvHPkP0b6VajumD1FCO4eBNkLY1L96nJbkqVLUpGTxkE0gKOYSTEo39WqhxHTtx2A7bLLV+b9P4Kli7IgLx+PXdPVrJ6sCerGvFmTBkGTS5IU0+URWboobaz3W8+KvyZ6FR2gssAY5Rx0mXA3XZ0uEXLUS7ka74LvPt5ZHWid8EXkZPtG5tFM7kYRKTIVgXm2Zl4uUnVyXEYpQX+m5F5OPJNNSZefjhT53Gxp+pYHTZ6U0WWypDJZ6jmUlTOys3T2UkcelbTsPRsAqPpqjCJY6CRR4qmC+20lEAyT/dRJNkAGV6lswxuSNR3wszjemxta0ITqL4SYyOK3d8mAbHJcvptEAmL4yXkLyeTJmbIlVkydt6dqraAXl3dPKViknkxQ0Op6kty3KM7s8WOilu8WnaKBxnjNMcjKvOBLixNagKOapdCzHbblBjf/t8yvEz2a3bY4nFjBf4c0cafIQMmyJSLjkpE9Gd0FOJT0cRI/axYi9ei68auvHZdohTSW2TWbTJr1lk2UkZfe4hQ5YCZsnGsl1ji6EmC6voUjl6j4qbPd1SZzFwNW6ieUp7vWtoD6Z6tvFnelwxN5v09wqsdA42GOTCZGunp5NnqZjJY5oet7IIOuxd4+tKZvH1LiTUWSxMzBFTlTY+svAqiwwRiuAriy4qxVu4WacHKzRK1JT825JLBTORY/GlVV+kPamAHadpeWMty1nwMrFaeOJFGKfuMtypubq5kHx9vLZmwTyQQ3AlteCunbckMuOuNdhzvnyzy9M5KSS5XmrDQOSMfueTECydsmKWWy1ayUj0o55Xht1Z3CaQE00NlWassJtk4pKdELEFmaNgCO0UYhmIoYnyd6RF5kyaCFkPjgnszkudh1xnJBTlJNjZF4XFONUE93ERo8xgQRdTdOgi6swyfq6s6/ctwxbqTJm/7kn5SZnHkT5efd/Hz5O1UwowEGMsPD4gbx9Dymq0RrgLM6/jduocRat9UELM+TtjZm4+gFekdasaLG451LhYk+GnZ3xt+Ndu2KG3ZicM9k40HVGVFB1dmEPWOXFfvS8ssw0pZ8G/i4LFDBPnMaRWHCc7A1+JT5nHHiXtBYMrcjh90kkmryd23Rtw5CuQpxBdiN09Vl1ZUhLGsxKrWhkEQ4PBbip1sfZsUKeTyPZpS3DykFeKaxG4V7rkNXhMUnCOwARNOeo2KeewABZx8ki7kJygUjD1Z3KdGPJ5CEr0seLpt1TgHVbqTp7X7kwqLqnHii6xosv3mLr933nX7szEjz9WZoHLqTKyI8rYlTXOSeWHTzAwFZIg52nWriaKYlBhYBjsVscMPBtcWdhi2gpyuoMXQ7MzxV624zOk8nJiNxGTiDFzW2ZsxceKLjtAPvel8CXDS+ScQdMzr2yLmn7JIoKhIqdVFRqL7bAS+1LE53H3JouqJ+31DEMN3I5+e5TgmmshFc5TFZhkqnDbgJrdoq1St3a/k6XSsp9vizIgidFEKKN2WTx4ZOnPXoYmXtR4ypEbSqvSryOLWYmntalG3U7LWihIbvcP42oZezGuEcMJXSCMZw73d5FZmtwFG5TTx25a55SaLM0rXSdSClk7di1cDD1Zh+wxMvskWvtQMhxjqvjHOSOrQN7EbPI9dlFAy7DKKuxM9SWOPt7bhxQRbZgQRM616eMpENbk8dLuGVV4yqgEEUuTjhjOxKbfFVnEVDPGRfNds3U7QwRzSFITOg2T8dIts4ktinYHXaTtItLaIQdduN00HrxmdeIC/ZmDGWx0rLXt5LIBWy2XlO/Z713nHZsvbHFyV4fMCSXjAddskzSkXCavmjphjbzWqnc2mLav5MaE9rP5FpspmIchYsjWkOhbu7rhYqgX8gWZdPXowStHFQKZ8PK0/YoiITCEGQgJxpR8E7yOMMzwwDB5E8bRtXaQKx1ThGbPsX221TbuYqV0BOz8RJcWTgCEBZcOLdoE8MbpoA0NcUIOLTTDLS7IsLwsz9odMCjftonZBzOODnXmOP5QUpHbINMMRQSiPyTbUTxKvaAmE+SZ3WRtySykz8G5KNflEKdjTm7O0gu+3FCYun/Ok4M6eJk8S7On4EmA3fM5KSlb6hy73MlJIZhBN2ZfKMl5k5yd3tqnbt2LOqlqgdydUaU+SuMVbEY0ZgJuQb6jtQS2HyxT0K0th5njpTNUrhWtWLB2iC9dllfc9StZ7sl7HWq0NICrlII23kENchkjjhCcsHQxktLPYKKkjmFm3EykbuGJHG3UkhQ4+2RLHycZdchA+KZ2NM/CSeP8AkbWmKPTstL0y9L/H/DkTr5a06hiiN3xpsLt4rSQymcFUQrsEIldl41LE52ZOP0Z/nBaCNo5+TSTyBHsnTvsde4xWpdtt04r2iBiXKSJCb7bkubr/ADek5Pv6Ti/ZO1DKr1QQGT1HBRtzPj6b2I7GBq9yLAxyDXb7S9WqNuLI0Jaip2465Bf7+Jx0kUUP9nHF0eHVfSUeOj5RcIJLEc3ejjeB4yTkPcC+c65yo7ctqCWfttUu3tyNFYixOPt5iTqTHtQWNsWY1kcsGNxtp64Tvx2UTxRjagKPP8fDnLmUOxkrnyH+jw/wkW5nikOSHToQ0X4TbNExiXF3TxgAaZfJfNe9wcu6M9iAe+ZPUlnkMtM7yRwq9c78bunQj72JKvwFO4ip2ZqzotO3IUDsvyz6jdiZ035970Trgzri4O5G6CYk0ouvbt8RXmU12hZWKta6sx0lFkKGSr5XHzPPoamRKNyeCwgquQHFFwpVma/k8c9KnjOkprMcWKwuEiirkc/bFlK5do2hsxdQ9DRVgnh4RyUggq14GgO3KaEqgEZkafUiM3F25NNiOlZXJu1XjztCPJs2OZq4493hz+OkYMZRkyM0sdiM5rLQOcXnRZHE2sXPZrlA9M3dnBxBvgoGpSAJdorvgNXijOU/hVelj+EMlAezTKvbr5R4wsclv6aXBlxdV6UkgxdsIyssx5G4c5Pp16Xt0zEvkqx8JBFpHt7Ku/F1r0KEU7CybijidiFfHX+cVwTw7XYJeO7rN5WXHK1l7Vp/JdfORAOlCRcb1Glla+W6AKqNWjC9ytgsAcGRrHj7EM0UkVgOIVIM000DPHD232HkcP53LjJuu/EWddQdJVcrHar3qNgrXOMZ9Ii3J09gp8vLmeiadipT6UtWlj8Nj8cxaRbdcNoIuK7ZOpIiEY8HBUt2sbSysVboSQrjC8eR8KpYj6nw1jGV6Wq8oFxIuxZQUoSKU5arwWjjne1IFuG1ytWbsnYoEMox8WnmlkmN17+nyZuSjkcVSiZwnnjrDLbHj8eXpbZn5Lmy5OqoyqKKXhdB/HcXXEkDJm+LA7k/EUwk30djTSaX5WndcTRytAEuRKYMvZeay7ruJm+kP9CZxdnd1exGLyayXRWerosHlbOQlxklWXH9O5e7Jhum4sU/BcVx+m2ZHMIH5Ea58lcpUcrDl+gLVNDir8kmM6OtTzQM9WEoZpX7YxomdcENUyXjCK2IJ5JHXrZBFvnGLvfZkbN92YQXV9iKzgXB+NSUJK0nald4KfZONnTixNsxUfLbk7tyLi/pN9Nuy/zb8dO6iZgKhKJxZICdNrUVdpF28bGxS45eXVZHKJE1jSeYljrnbK7PG9cyjJ5uGhLSE/Ql8ue1yblyFbF3f8c3BBYElzERyV17Txyu8RyNyKRNRsupchbE4p5zdpeAi+2XLS7rKXjOMGLx9aR5IhPyK7rya6e1XZPcrorsSKzG6exCya6wP5/cNsgye7Ea8mqvLqMnvwJ74LzgT5BefKvLuku5fJauOuBOu1Eu1EuQgiu1I1aFmyIhOJdTVadnFCKwbBPNZjKKRtA5kxr/ALGf2o3eN4zXp1zb6M5M7Sr4Oxj8fkwt3EGQOGGQildh9G+lt9N6WtvpPtDvTH2ztSv2nk27+0zLimFk6/C979r2y+Jp4HdZWx2m3tg0El7RWsZR7dfmikLlXeTuubMMtq7HK9nIujt2mM7FpPMZJ97fW/itAvitLS0tMm0hyNLvveosnyOMZBk8Uaa5j3f7hjttk6O/ulRlbzEVKAs/CCmzEoCGbuSNNdypR07uXKvytmj5i0mRirRTQ1upYmi8eCLLlErl/HX6nNtUeX3cpJE0NewJVpwd2deiHW25Jn+nLSf6MzMn/G1yFMTOtvvbsOnd39OGncWZPxUjtsf6yLS98toS0u56E3d/S9LXp9L4rQujkGGOWYppNM6uOIPQg8u1Bp37LqLrPCys3V+JX73xabrPEuq/VOBnMSN1N1NNDNJ1NyYc/jiE83g3XndPTJhoyo7EMS82qnyNQHCzFIvLjdPZhZr+Mx0WQapGakp6Y8fIzdiYW8iNrB8ZF3LALvimcKGRawMSe9KYlcuwxU79uSLk7k0kQIZ6fcqSxlastxU2PGwENGvFHOHbmqnrMd1yGNwBSMoPEnjyMMdaf5748lydbZ22yb4MxMTf67Ppn+m2UetmfzZ/5OXsH0uS5In9tvie07EKZnd/a0SYSduDsvkva9rScXWyZZi2wwgW3kdWxY48RAUA77cvdZV/hAD8Q5SuhllFeUSwPUtrFFFPjc/SvU7WOk5rkBJw29aSqpCdxkhCR85HkYpv5javTOFjgrOOQ4pzBZKQHoMAX6HTz9o5K1YCmkxddRwwyh4EW71PEfuX7YDBHi5CF8eas4yxBWl6iuRE9/M8BLKlK9nNxS46a1ao181u9jLsV7IZyMY8pR4/dv42HRIXIXgvSQtfkr2FFK+3cuZrTutMh0y/CaTbvyQgRETOP0AtA5bW04Jvitu6/C9ktOLE7p3cn9pk6Zf6Rsy7jO3cdl3E0yM9tbsdyaNncD5Mr8nGvRNmh/kkmaOfXNHI7VB5uXTz0ObRYWdslD4t7FZi5hrGLy9DNU8rhZ8eWjBoiE435Cq9mWF++EycgcPCrlGUcUKjvYuccjFXnhyfZw2ObqW5PH0ndlcc9xp3Icnmna1kepgKHLUyEshA6gofcZ2G2z9my6ydzJ0SDK2Cez07kbt4emerTiu47O4ek9s+XTkzy4zERMGcvRXxHNUsjTuV9/cA5uxOTr5r2Te+DRC6eLmpgeN2FEDOoohdgKCFd4nOCQkx8lKwuPjo4yeNxdn4r2gBtbTuuTp3R717TbTbTu6ZOZOz81818yFwldcpWXNkdaFztVotWDlgVqU54YHMIoBDjxXL0LiUPabWEsvAcWSdZC7TGzBlsXEdPqWjFLQttZqZLF27sj4XINGXSmceeTpjOzO3TOZAS6d6g3FgepYpJ8PmJ2/Z2eKxaqZEa2bxXUuTbI9PZmrXrYDIY2/nrs3aqvyhvx92IYZWJoq7M1iauLX3BX8pG0lLLw+R5pSFBmPDna6Zo5xlcPDE8o8bqpPS8U5MGbZa/VvShsL4TEnTaZR8eRaTMmIgc3aQBZiTyRMnNkxJiF0JC5M4s5sKBtMQ84ii2zifIgcBgc2ECDckbsvknUhPptszflmdkbemd2eViZO/tfhMbO39lKwM5SaU0vqnW8611LYKTIDH/HXlj7exX7S6dX7U6c1+0ummU36bhHLY6YzVNzpXdRRxVpLY+QGOievQ7hCvJLQ2jFeYaa2vMTWmTTA6+Du8K7ArxhddhtS4mhK+QsQ4a9cyjSV3twJsnKz3LskkMXsbZkBwnYebmYlksnJUlb9QLLKb9Tpqyb9SrFgcbmpc9DVztwKsuYt34RmJ3D/7DaPdaApmKnEUb4+Fgas+2rrtAQxxsC/u5xPtnZCwuzj7icmemYTm+LheOKr2xvNwl4ySwsEi7C4+vipSLj8k/FF+ZZAFhNoox8aGrLysO84unMyiN2JbTEvyu7wTytLJNFzayNiJQbqwzSeVlY437JUi4+A6y2RlxmOj/UHJSSY66d6gRGnkJORko6+0D8W6mzdzF28VYnsY72i+DPkMbGhyONNCzyDs2Usssdap1LMct63bqNY6kKGSz171GCPrrqhfuzquQpLl22jOQReYk23ablHEOVyMbS3bdtxkkgNsrbWduTTg9YdPE7JoXddCNxj6hxsIVWluxHF5QGGTteRw00MpMO9Kf/rjk+cvxfk4r2Y11NydBhZ+3JhZhEtoWOR4cTa4jlZakXnzTI7D3K8dKLtyVhjksAIqCQXU4xiXZkdnHi7iKJvkV+u7vYJ3rW/5RyN6a049yEZpY18WeQCFfGRNM4uTsQNOwnFaTyAbNHHqPEY1jixuOZpZiqj9zRaJfbcavgIrSZkNkSIbUQrq8RmWHlOallerI66s9SyyF9+tbi6hdlj8xFKdDOEakrd+tUhyI2iijCPKWrcGVO/lYwmzkaxV0chM9GbIM+Ay6/b2d4hgMtxn6fy3iDasmEkkkqB+JeWewAcxYLCwqyGNpy1Rxd6XpanFULqmJn6ZkjGNFF3h3xcn0VV9iIHIcODHWRwp0Ggxlq4FjHyVkAwoh4PixZy7u1HbYTt02vHHfhif7i5Ib8lkoB5DDO0bjabbzDLAFyYF3mmTtH3GmYUxjYGWyUdrL5DsSy3WneG7ZJ4s+4NjpL1p4X0p7ATBaHszQzto4gJOxaPmCsyTwGGS4ocsyhzEYlFdisqKRu3NbssXmRp0/wBNLS2IMNqcl5Fx3yWIizsfVGSbF1LNp1LfJPaldNan3DkGWIzxRrFZLtLJVoFXmqTh1hi7VXJjDUsDbhxsCjsVKxdKzdym8dt3CrkXGvFY8eyGTaII9hJXmeMamS34cyuUboA9CclVxchnDShVGSljn6goWL2HlnsCY2I3VmWvI1KpVvxy1quNfByV2mlbvFGYPFUyNmEmsw3AGpXqW4gq5BPE9ByuFt7JSKrS2FvpmlaRSlTPGZBpbt/qGADHJ/y0aeTuDWxl4bB12a39rotF3JHtTySVVfzzwxxZSWxNkrk00dILjpjkeXB0vuOTksNDDLkJZBr5Ap5oD8icsLGrElzHXLuTsQWaf368NTpnJTFkP0/w80c36cG0f2WGCzNENWStmHjiaSvIuzOnilXZlXZlXZkXbNT1ppoMWHjw22klVSOxG2dundyFiUid0EUkq8O0yMSF6lsoCwGbEBr52rZxGMuwU6VjqGnrM4nyLgYTLcW6byoj0Ji5448hkMnHfe/kXQTnLlTsSeV3pk5l9PS9LYrE1Q1DRs2LnlyyWrTUjjlxWAuqL9PLs0xfpxl2r4nIPSoNcozR+VXoX4Y78kU8eVoLD25srLYe9QYLk+Qz5WwgiyBDYhw2JmtP5YVhmlGxFHb92a8FkA6axYC2EiMf25Riy0Vp5IyudtsvIWPyNWHIZCGjipca5z1rsOYrHRnhPgNXEgSnrxugaCJedUkyWVMRiOyXGvbkial3b1mO/PEDYT7pjI8Ph6pjZAiAJXVuzVE8jZkpjmsmUrHqRcH1dss8XbZEZ65mtmtktkuT6anSZeFQUoQVKlp9jOKpYsWDvcXGdHXisMHReRsPj+lIqYVsnPXCHI5a5YkqZeWLPR5GlV+4dQPUt0M3YbC4S1DTsTVwsNJCTVBOTJS8a92DhaXgWnjHB5Uoh6YzZkXS2ZBR4eYJSgNsZjpDrwZWetYahYp9q9flFsZDPPXarZlt2ensVAFap0+T28PinU96eKZsntpPCrZGKTxQG7DMsnBFYnfHY+FnsiIPZ9x3WF8Zkne+Fzk3kywyXIL1xYqn/KV5gVvjcHKx28uZPfijHInPJBjKjPk+kMLlGzfSlnCzta7b1qN6w1jEZGN8jYsQlXrZ7MRN0jm40/TFzngKFnCO9ynZZs1QdW+ssXTGx+otjlL1DmcrLhb5xJ5YMlWLHY7IR5GOtUl9Ei4p9M79e9PIevunNfvvpx1++unV++unE3XXTbputun3X70wCs9XYCxWERnUtIfJcSsS0cTduqfo2wNbCVGu3XY3Ptnyi4xrH3a9Mq2ahkfIlTykNnGQxu1zFwP51FzyfUfTfgSdRtE9nMZS0LuTCx7LHdTZ7GA3WkU8D/qJahjP9Rb/ACqZ6TP4yGxZOxVtBXHPU7N6Xp3G3MNNI1jt0wfnbNjfgKltcCDNlNjpMrduW6sNTGBPYisvPkH71bsUYrJwWRgmtSz3sNmAKTJEM2Pw1euMsGFuzZWObDT0B7MQTsLZO4LV/OeRNf7ckBBVgK7Nu1IxsGbKZR5asSkvxTRYXGAF2G1wYjHteLTsSyZaRR5po2tWq98Jb0+7nU71ypxZXKh+374tNiLQvD/HJit6kyoscbyRPcqTsZu4IbgOu8K8FnbwF4RrwZk+Kl2ONPuHj5EWPnJTY2YAwAxSWWhjimxoC45bIljaXSnVUl6ebH47F2Xey6KNtiBM9yCLISSUJYXq5Bx6fy2Yt5qS7kM3rjtcUGGyEsRdOZAaz9Kc6cvTt6hA8HFqADHYkxsUrcLcKrZ6OvFVyOVuMfUUkR0ctNkZoQq0jHK7K71Abylf7oeLceGASZq9isVHpqYizk+VEXO8SG1PNm47u0Nv40boG3e5NlngC/JdYhC3C55aXyQr3ZwM77OstlxNRUsx2aRZCpnIKsbxlia7jkrcuOXRmDlvQtVxWuqK/wBkWPs9qL7hBIENzuqxdHhJafj5m5hunxv2WN8VTpNZe9btKXJgwzzysrkYZCmNuyobXKOpYHjNziVgI5EEY96UbjyjbsA3kWFDalZPI5uNmVotyL5pnlZvm6xNgYbNnUdyq782aPNVMBhfCszE5yOUDIWKQcjMFCjSzeJrwy9R4Ul3Jcp0LK0sJR3ZYWxeYx1YqtvpecrFusMc1XHm/PGMxXxFsj05TtwTdIscwdLXK17IUMhVr+Fd5dvIUrM1i5YfF4qli4shK8CK/OBZSae9eqWJK9iPKyCMWW7JYmPEZC9LDiSC3hu9loZoAgmqRTRYankLtwcLjeH2KPF1fuYrJYzO5OIrU+MEsmNqfHVoacEjicfVGGanD0b092aY+OzZaUAGPKM7jlAB81F9+p1Z4hq94ADNSBfxTjYx7BbPuhYcRsS/GW1/MVx+3zdZC0onNoHytvxGm2U9mV4yvG8pb79cndQQfPyyjGS2RqaLkHGReK68Ul4xrsSLsmu2a7cq7JLtGu3Iu3Lygsd+MLIyrBnkJY7jydnxndDH8Oq8blspBH0xTgQ1qdaShnuo8SF+w9i2zg6YHUNPdevZytVR52Ga1QsYm3NYx2LAZ4ZuzBhpbENnG41pY4YqUlvNjWWR6gv3zg5NNLmJOEN8nlOeGUKzjVueLSyE+WwleOOCayD0sqNYn6uHUPVIgv3cLv8Au9uNPqbxSbrcWduv4tYrN08deD9RIGWZ6xpZijg6tYCgzjM4dTBws50bFZuoyBv3I6yGUjvRxRvEvJk21onjr3pa7FlLUisWrkzY7x7Up4vHQF9jxrIsRjHcsHi0WAxPH7LjXebpvDyn9mxbAODxLIsJiiTYnHcTwuNNvs2OoMePodzwIqbHwdzqxbcCZcXRdDTr9jyr9imv2KSboKZ1/wCP51/4+lUvQfZH7FiXkrdP4+2T9EW0fSGSiR4bOxLF1noUH7QpyMkLECyts7VuKnatEfT12OHFYu5kiyWPtYyEqpmE54kTajCwg2Uhe3Lk7a7gQlT6ilFq+bx1yK3cEI7GVqxxXs7MTNNPYIaLi0fTWclEOh8qVj9jZjHtY8mg+N6YgarlcVUx9erdxMsM/Td7JFZx2TpzeJf7QhaN+FlmcLANqfuM8xISmdbl0ckgk85M2IzPjiWZkNDm3jH9wyEmzxE/3k5EeXmkf7nZ0OUtRqTJW2TZS7G/3nJ7sZvJhBh81dkvOd4C8i+invJ7F9l5V5eXbRWbjJ7dxFftMiu3WXnXF5tlfcLDJs/K88lorERmjOQE9gSX8KeKNdmNdpkccUbWcniarXuvsDVa5+pMxjks1Pm5jsSG0sMbNS6jz2KfG/qgy/eI3VZB7BiDChimNSywwtVrdPc8xHkJopMZlCOi8dbH2AhyMOC6WyV63dw2Bt1LVVunHq9N5A4Ta5RnixFg4pukf5gxeIBZKxOd15ilOPHkZY/pGSzVr4u5jMqN6SVzqXQFrmlHcjIBnjlHqLCy2aVjHS4uUciXbz44zLVMsHco9i2vFsa8OfTU7XJqdteJaZeJa19vsG54ydxr4WxBYcdM4m78ZBTAbPwIV2zZdudduwuNh127DoRlVmFpIwqS4+duqK8hfuCdfuCdff5HX303X3snTZjTfeHdfdV91X3VmX3Wup78M0FanNBILicBgzp4SZSxiy2sl1RhMUrv6jYmur36m3pFc6uzdp5Jp7BP7d9/RmUnyP5xOTxku37q9QZuiqXWkEstPOY+0PUdOnmqOKs2Yiq0gKHqjET2osLVxlFWb/YnO9xYrpHdzMb5DIUmrhPmaWMsA+SjA+3PYezcgrR3pXsz15BGxircdetFFJcX2yOY/tlRpZzlqtJUuZOZ8XNBUjsDE4RWJVOVevkreYYIJJfJLKXytTsyYWXBmXFMK4cUwemF1JyFMRO/yd+2TJ+SZnXyTu65PvuFrv8AFNcN087oJAlEZSrO8cRudV+JAQrtC6eEmTsTLci5Evm6avKSDHkSKOpVZ5pZ1snUG46hMRtJ3EUcjrsmnZ7cphHyJcNrXFdowiyNGTHZDgTv/wDuR3WnQy7QuJqKCzJIVWhInpFAcfUGUrR43JYwZByFxh6hhsZbHYyCZqGVq3ogK7sMSQ2SOnSpMF3x01aWV5Z6tRWsyUjSTmbu0jo6uQcqVvKM1bKhGMmWhGQbhmWXsu2O6eyMbUWy0DrJT0LSK7XNZTIwErExTFJYOdXY5Asfhcl+F+VzdC5J35JvizmicV/VPJ9OTruP9HT6ZGe030/CGUZWOMo3huELj25RKBlwNcV22QwMu2DI5RjaS5LIhgJ30zKMNp34hJ/WWNxGRpN6NOzarRnLOFQ7A2KbRY6thJCzUnSN1qEcEcF6zjsLkmu9NRwQFyRGJM7aGSPjHHNJAoeopSEfsN8beKu1RlgjYoCvUyPqa3bhxmWxUgP25xl6YJpasktWp4jkp7Fam17LlKMkxmzRNIWD6EnnKx0hFkKr/p5UUXQMAPP0105XR0+nIjetgheWGhHGw1ndytMiv34C6UwWTyNXL14Ru27L2FBDpZKDuQfNMJOuBJmJemW1Gzo3ZlyZbZ0WxX8i5uy7rrmToi4p50crl9GW/o+2QzohE0xzQPDkwdCcUqcE/wDGnsCjkNHOO+/pQRWLT+ONZHboAtdxzYtygymrgz9pXcNLHh3AQ62pzC2NaatcerL5TPwIc3zihpkV4IoaEofa6NI8hi8dfWN6ftFLBVw8qv8ATdG2NHC3r8knSGSijgu3sbLathbs82Zb5MEBOqU+UrqtFWyc008NNZHqDk01mWVf5helspmjxPT2KxSctLrrqGU5Onxgr4rPjVnr4rGxZa9P0/03cihxmF4VcNh4n6h6ciozUsbHayWC6VxlhjPul1Heiu3a8PJMtMSstPUsvetEeJksZK9kMc9AAkTyhsJok8DyoaFskOGyEifpvItHJhboO+IuosROiw9hWcdficSFzsUirQY6xAeQnwOOmCHpyWRH0/YGSxj7NUe2xL5gu+uUJr+qG5aBNkjT3wdd6E1usy70Aryp5no1JCifFQ6jJzH+ilnkROuRLydDnKMFpqvS/kHB0ZSiQVspROnOpLDqhQtOVauU7ZV3gqd3sWfMqyFK9Hx/LaKCg9meQZchXPIV6+Vu1XghhzmCo2YKPS9oYpMvisaMtuWwq+SlqQEZubh6o4y7lZsH0HSooQeJs/11WxzxHlrcVmrWsx1sq/TiGoXWFoMfhqsWV/4cVcYaMN1ocgEXTeSydjAdIY8mll7yzs5fbIIWNcWf69S1j7HGOSP9P5sdSzWTgbL2P27YTdN2kHTU6pYp4AauzKTtwlLFIbSQPt4FNGMSIHRASlqQWWyuHip1MYLvkO0WxyNoB7uE7WUuhckeNxWP7kp1z5Wr1IGrbX8TI+ANz2trbOQxysqmFxtep96i7l25S3WGrbq2QmgKQfTt74K/MbNWzTvJHkIq0OK1472X7mZGvBkIcmMYx2imcMtNWKa55wQ4V5o8l01YrqHA3ykr0adILbVme3mXWKG7JkRaGnDa6njhCe5YtG0Rmq2EJitQtBcCOWU8J0DYsqwdTBUhy1iU8naO9jpMdLGsdm5YoI8hYtx56pXKxick446G73m6hsnDVkzLTySZAOPSlD7rDKYSKaR3fKZGKaOXVE2fgbj6/DyRhZhuUJ8eeHrFIsbD26DgWh0uK0i0Kx9r7x1DNKzI2RR7U9UjClys0irmznWdl1C3HD4dnbJvpkW0ce08QLKtFBQoVmDGYms88vjygL0RT40XT41HSlBYvprI5SmPSRlHAdPF02ij3akq4S3Tnjt2KbS46azK9aTxisqeEq8XcFQ4yTg/TwW3k6expRzPkWDGUcgVaKjRcs3ioWMZJYVJf/iwNyYJY7vcintB2chkWxk0mWOB4QyV2VsZisW1vq94wlsTWjiEjVbBSzPXo16zPIr8b94M9Lei6b6oavb6iyVazLBHOQsYVk2V28uCsFlKdynbWdpNJQoVAltPPXphlZaN6pBQsseF6eCOKaR3hnkeOPOXvGZhYWug0tas/eggmYmMWcfky6jpvaodJ0Wms/FP+eWmJNvl1bkXpYuPqf7BisB1zBLVLq7pmRZnq2pVhxvVlTI1OmT540oiddl2XWI8MHhoz+4eKyep6OgKfGcl1JS/i+1EFHpir35HoaXhLxPfgo6HcDpDHRU8F1PS+ySR5UnQ5WMK5zOI1ocgKC7/AAnOUUk89GUcfl6zueYpsRz2SuSTQsstd9UjrwjEMU0d+WGAPuESz1jvlTgKALnZpnB1DGwU4rd2vc6Zxtme1H01i1ker7c6llllIQOQ8d09bsqni6lNpOKjuHam7ErHaulMqP27GK1LJaaRjOgFbKducyjq0WvXpqs7xySyV7ZSdR9TQjP1V1HLBjrQ3E9k6FbFQ5zIw9iOKs//AA6mUv8A22Bt7WmIY9xSOzOoX2xx7LLQZy8PS5NTf7vW391rOvuldl91qp8lW11xlYysuRSF9HW9P+n8gyVyqMbhj4nX6mQwVunIIhDqDxot+HAnpVeT4+q6z9Ucn+oOJqxxH+nVeOxdfEV0+DruvsUS+xAs3Q+1YvpLMx5HBWale7SzHS0uHtAdiOEDyhwXoGNzydl4YCxzDb51Hgrywn5OGVXqqxoZcXlFapnfOGrXxkOTktmWUszwQjb5BFC4xQ25Kxm93J1cT0zGB5LqXH0myPVeRtvtyIWcnpdO2bb0cVVoizizT5avCq/TOWyrvmo2OparWI74vcgM/JmnzTQn5EvhYu5LdKaeAmnaOtbq3zkhlkkpjjZKDKza8mCQbWEudF9MXupUMcAD/HXrWrY1I5p57M34Wl/s8fygNcXEjuT9yWxZCLGHp+/78nS8lNY2mnWaa3dsBh7DxU2rBb5dHkrdaOSeUTiLo64UYNlpmb7vOuur8lrD+S45Mc66DPROmzUBob9R2w0sdn9Seo6khwfpwfHLtKLrvCuQpnZZbGRZjHBZt9J56KWI4bFeO9VyWAmx1q3jBydU5YaMB4+ndKthI8XLdEpZHvy2Lnjxko7hae1Gap5+5A1bqKGw0lruR3bEd2pQoY+KHLVyhDHYeK1IfVkNOvdz+SurekI7ej03atKtiqdKMODBYyMFJQ4bNZaKndwGEV7qa1ahnmGpSitFEx5maRsUZ+TPTitV2q03illGrZp53x1kr/kFSyL1ShHIZoY6c9eGHLSyRdPdLj1E38UUTGMYTsMZ5C7LkrW9iPtgLg7sxPYF0AE6I3CJpx5Xn/4x2nhTXkN/S87aa4vPFFP20b7F5p2TWZ2UXb5OcBPCMcc3fbXliy6gM7lUifveXtPaNNbJPkhBYG27Z37m7rpuyVLJDn5WTdRGg6gDkOequsn1JXpUMtkXymUqH2W7UVNX6EWRqvO+Hsyz46fIT04rEs1SLwrcUFGvay12aIbl9xZMTqPbuzS8oMhYrEGYqHI+VwskOQtUpZWltWwsdsSfZPR6etW3pYWpRGMQFr1qtWiq1ctnnxHSmOxC6y6kntLEDkJlmNbp04J3nxuMMcjifGetLZWKaaqc5V6pcwlvV4wuxzY+hJLkK3jPTv8AZTUshdbp3oeznssAQ1YNMLZu5FUr57M1bQSDwQqE/i7IXd0cbmwiIKSRgHvx88h/8003cmY31z2u5pd1HM6b8GPJjLgmk9gJ74tq2bxpp0NwwTz7U57l8sk9o3Xc2u8y7/vyyVSXtztbXmLzXVQprktrByWIT6VxqwFzvwVy7NZiXUGCqZ2C7gcxiLEHnZOzLUryVQMcUMU+PgyQ9RYnjeeOKvJw8TYkooJ3UkksDs0MrV6LTFXx0Myy8IVoKOCu3jodP06KBh52LkEAS9RCSrDXGSxkswUcnVeWOr3pIZa9lrj5I4mChlJrTSeGUFqvUrH4c1ZyyTxyY05bMk+Kx5EE9vEWKNWM572Lr34p6suHt9N47J9VVgCKnALepSksS9XvzqREcc8nIRB9rWj/ACvQr+rHLGClkCaJoX7ubl7dBgdcXXF1pOLo20g9x6nRR82avC6Y5EBOTZP0O3+jOrUvBbTuS5EuSeRdxDL8+6u6u+sHEVZH7aQVylry0LsV6q78HBu4c8lqOLG9RZqXJ3MZQuqx0l06zD090Naf9p9HK1icqTXaFt6hx5AKGMuHRH7nVyRUsM3ct4ho4Ia7hBSw9AWD5P8ADjks7WqRj3coXkNipa0p3J4c5HVs2s8L2Mg1mN4bkzDZyE8y6fx8t161WIK+Vy9gygs1Y8e2NxxK7jfAlrS1e1mYwBqHGMJQlGXE9JWeqLEcdfH1tIyc5Mvmnx63zWQHt2CPYCT7Jn0DqGEjKQe1HlbLW7HbXZXbXbXFcVwXBtlFybv2xTtY5jauCLW540d/IuUWUsC1my9tcHZP9LvuQidc3XJetutqJ/5ndcliIe9brD23rGxNMOiMXZUrxY6ey/OKvI5GDl3MxUkhk6pqZLqosj9xpAN8Zk3VbxsAyCUcMrMIM4SRxO09OpKocRVaM8bGzWsYFqv2gjju3oKimjlOPI5THzY7EjXrw5sZZ3rVcpVlmCzBFjMeEhR4+KaW907TNo8KNQPuxNJSz4i2UOa5PjWKSCrnGgkny1eWWO3TafM3oGbEynIsJgsh1RZjjgoV+KmmfvZHKQ4qtKxoH214eTV/5IwLTt7HJXwxcOMv07VbMZERDhtcdLiuK4pxXFMK4rh6cV23XBcV23dPGhH00ZG/HaeFTVSImiLRCKcVxdOyJnUbMxuLrSw1TsV4X08MnAiHuCXpHreCyLCuyTT133GxafL0pMRJLm8hM8MVSqvumSZMNbuf65mwmcsZSHKKpzSkBj5CKdoI6mIzF6OngMTho8pdlv5jJyvyG9ZpNjJb8kVWWrYhyU8dZ61iSVmBmghsUnr5Q/HM7huq81qQqVGftwQcVNjassWTiOEqmEkaHLYmOaPojo7IdQ2Ioq2OrCymnaIp7UWOx9iWaxIDtKBhweZmcYi4lL2edL/mWMphQy1HC2zxGQsSnPJw0t++BbYG04rW1xZOK4utJ22uCYHT1P5OD64Liy4so75iL6kXa98EURMnHS0nZadcffFY+mFy3ELnLF6W9KrOymhckTI9ssJlvukR3Hx8zakG9XG/T6p6bsVzmoZetH22VvqHIVAs9WXacNjqc68MnUgjD+4K9lQ5+tCq75rKNRwVGjGQzu2fs9qgVOaZUcX35KdSlAISWJWrHBcaEe9cmtk9YMxbhZsjauWKuJaOa1isfdlOqOEOMqR02yNWSa9kqcdGC54+Q7sFiXBwU89nwiq0K7KaVoBlKGu2QyEmRsCXuNvk7FyP21jkARwHPFj6ENSLZCuqY4pblKdrEbDt9bZlpaXFO+l75cdrTOnXt1xXrTcCWlxTC7ri61p227Obsu5Jvi2nBcWRCy4risdNHSr/AHS0B1MlHMz/AI/iiGtOV6eSWzEitxOo77U7OR6ogtBhbDeFZIojlrQZWrYhu0ZxtG45al5ONtVvKw4wDewuLha3hsM3Ol080Meam6LxF+fJ9NS5aIaeciC5is3ciLorMRxfsrNDXtdH5vGwYq2YK507liR4PJix4vKirWCyCwWP8JstYlNzzTNW6myPega6xxFarymIzXa1rB36pdEdG3Mq+E6VodP2HbTu4gg/nHMZN8jP/jNydtgi+SM4xiKdykxlOR44pZN5TJDWj+JrGbhyKZtPpPpALmZxyRGQ+mESX/W39l/vBadELoWEUzcm0hbS7b8eLLt+/wDsRRuycDWk4rinZaJU3N3eNcWZUJmvV8jM5PhYRd5RBxlrRkp6pKWs7Njdfa5655WlhCMI+so77XWw9bUXJ1208XFdsQYoogVAu1kI9Omd1v4uRJtOuGk5jAoiqC/c0nnkT8TWQ6TwmUkpdP4elD9qxBCWBwkim6TwBIuhemyX/jzAu/7DoCouji5V8e1OEgvHni9KOQ7M2fyLG5lyUrqN+Tl/V7A1mmnOYsPj/Jl4sKtyR1QtTlamfe4dtmnZMy/Cf8xySV5LN2zcfiy0viib0LCyIUfa5PyZN8mbmzcU69pgKRPE7MIOy069OuDOij99l2F2ZaZRG8MkupHkFQwBTqTPs8Y/ZryRDKMkcoogZ1PC3HprI6J5XpT5WFgenaC7DJ0nh5DH8x5ADvlkIivyXYGtz2oY5vYvVnp2o+L6dlKzsi9MTJhaRNFTEu3S2FeBPST1Z2VNpRm0C+LORiv94kLsx8YRJOwrn65lbPPZNqsP4TqXZMDkKMzJWXMpKdcrU8EQQxySBrM3Wlfk6LevHlGyEjOmf6ek6YfbfTt6XBlwXFOBugEmZmJbU0BEbC4/XSfht9Mti7LScfba2Ys60g+cUjMopJBnG5JqUe0NSfTzAiBTM2zYwLH2YMnSZgNqdRqo8CRScSjr1ysXJwq2MpYCkWcdo4XdZKLkPQU72YCqTgorGWj6muX8xWz+SzGXx0+Z6mymBotmtMGegTZrHkvuPT7rysC7RzYyKeXJ48A79clJp2FATk0nFo4Wfn6Zo+Zll8pHioCkIiTe1I7u+j1bujBFo1iceVWH8DkLb1a3L2yZfhnZD7Xv6Mz706b6fLevfri5aTfjZIZGiLTLiyJ9ISEkTLgTt7XxTMydlxdcVx2nZN+OTR2JAcFITqTYPTyH3OqZe68jShK/vSMVi7cmOuj7Qntdwk8c5NqRlKQmBmEsUscdmPsOI2Acx6OklpdSu0UjW8Uc2bz2NmtWOqaVieh1FTO/gcSJyY1q0aKpGnxO19uFkWOZdW0WHpyCnHkMX0TX7/T2Ca2+Xs3svX6u7uSBq9vJu7QSSHamDHUrNmW1N7Tj3F/UYo+RW8p3E/HlhcdtN6UkjK/a8uyv8dN+dJmbTab6M/0b8P8AQiNlGXJ3TMtrtCTtxRaZekzMte2El/jMS0TL8KOUgP6+lxZ049+ExUw7XTs/Ai/7KsvEpNcXB3TtpHBNIunbptH/AGZpQ1xidPWBPWZFUdHRdeEafHlKpYTCWLP03IepMSztncYSbKYyRNagkFxm7jOSZxJnk4PJJtoz02Tpw5CrSxbU6eGwzYuGrhnrZ2/hZbWcKPkoYWGR9NNn8kdm4y18dswu/u9bllkWPpncnERANyu+ZvODOx7XF/ozP9Pf/oz6Te1/jmLLltiX5X+aZcvf+OOy4izPtEXFclvacH2njd0Qr0uLM5bWjZbQyOJTBxYgIlWB66rzeQDemrmxx8WdSGESmnkkTd6GTE3QyMAySsLEaaeRNPLrypNea/GG+xhFcElxjjXOJn70PLjG67USerES8bihe6DDPk41Hk8zGjzmaZRdQ3xAOpSZD1LE7fuCovv+NTZvGoMxjUOYxfczXUMTw/2T/hi0v9+Opn3NDEc8lCkNOuzDyvTtDCZnKfpmDgZ7ZltxW05cfpt9FzW/TN9Hbba9aTpvp636RbQu/L5rt6XBOPEnY98ltcnTkz/Tjy+j7daJfghnZ1K/0x9kgk/2qbgZ+mlbkuHFGMrrD5iHFWxcXHucn5aXLbsbMuTE0Ppy/wC0bXFyk5Kb0ZTkDtYd37xChtExeRKKG7Imvumu+guC5eVGmsQ75wugaImJhZGTANmQIpYwhOEh4/RnZO3NZC00MSwtDsR70Mu2bKWvIlTfR1r2fIBZ+Q/4jYmQ8k2lpa9p/p+Ey26JyFmkJ13ijfugScx13GdidN+Fz0nJMyZEK07NxX4T6dnYV7JfJhqMD2y/syidjA49v2wjbJ2TJPjmnILmYiBkMhIpiZPK67rqFy4z7BAXeihm9yhtphd18xTOZohNRn65aJzIkB+3fgZM/KMvfcWPn4W5PT2H2rIc4MJbcSuBp29pn2vUUNufyZcPjHuzBGjFpFm7vZhZB6f/AD1pkzen9J2YfoREoxJfhevpt9/Qu67vEPFmIWHe35O+mdaTxCS7TMuyCYWZCYu7bT+07bHh79suS3tOn9Jkwvy39ORAdecbAMXFq8pAmLkNh/UsfMu1puA/T8L/ABgZMIo9amMlRNSC4ppj0LDYjkCeN2nlXlEu+W/IJNOmkc0UvJmmdenRmopGjvytzCxvtyTMUdQ3Cy+rMA/FyEYxvZErLVYJLM9GqFWEh4DPMEATznZm06/xN6X+aTe0Tuy5r8r+v139R/P5XH6OKF2L6OnQuK/spazE48k0ZM6dvq7JxZa9uzE2yFPIu4vZfTFz8J2+Sn+KqSO8btzUlb2US7bIPkiYVwTAhjFmPSkb0D8ZG+Yu3Bwd2TyE7GDOuG1wdlwXDaaNk/pm9uxaUxmmN/Ki/khmZ9Wm4IS1NQl2NmJhlyN/uoWJyw2NavDwhdGIgs1daRfj/wBHZ13vltOnB3EY+L9weTaTe1sWdtOtMuSFN7be3jByNfhMSZ2WhXFlxZPvQ/hHyFPK7rabbv8Alek7e3bb8XZOLO3BaToTIDpkBxmWyreopJHBR2vfEJF4yFmFflMLMmZ1y0O9ohZSaZVz9Sxsa1wfXMSbTOyd3TL5L2tOTN+PkpvxN8XonoLf9cl6W/ljp9qSBrdWWI45MFjWlL5Rvt2fK3fFh/K16/Kb2v8AH0607Npl6Qs62KcRZ2kd18mXx1ptO3tmT+1y4LnyL8Mz6UpuLDJLpt8V6XtFJxdrCExNfyijkcn2zraJN8k/tOzb/CbW0+l6dfhVyeLGxO8j8uIylyfelVkJx5f+jOh2i0n9tK3uEtPDJyU0QpjbRadvQp22uBOnZadcXZ9Mid1KTqZ9qie47O3DIMn/ALUT09ORnWRxXmWoa7QiQd4TkeuF2y9uz/v0b8a9Lem9Jvwy1tyLio3A29cfy/rTen/K7gMTsJjwFkxM6/3b6eHa4aH19ZQd3/1n0vlogfbRu617269L8r8LvPxYxcHJmRfnlpVwOxLaJt0QR7Rfl1Rbkn474kn+gum/Bj9JB0v9hPS5cmMNLQM/okw6Tx+n5MvkKY2TmzJz2pVLtYsuVZ25R3mU35qGzPVkJ3j4oIWRA4rP33OQW5k/baN/wy36bTi7fT8rXstCnkJAXvWk3sfppmTsu2zqNkTaTeidvbJ0M0ohGwO+tu6/CJmJaZk5bZuaq07F6Sev2ZHAWTxsu064lxdk+064suLMsGIM58pDjBgGT8ETcv8AcYPwKb5OC+S06Z9O2tcHJcDjT/JFpQkoSZMWk+lzFFFt9NopdOcju/J05OyL+tgvU+1hy/4Yf9d1vdn0VRnIsZDMxQgYNFLJ2shaaCCQnOX4phFOafbpwJRxnvuITZe96czd+SZvbMn4F9dJhXpaZel/r8eXJM6f26La0vab88lp9k217Qk4FPkb84b19Pf0f2jbSZvo/pVZzrTVIwImFS+lI7bD29H403l9u30dtLk6ba0LpwZn4sjFBtiDSETBcRdpBYXY3TvIm5Ezs3Hkn9k6n9vY/rhX/wCLEXxvD7sQNrDUfIlgAnaVjEpSIByl0rB69/5r17ZMfF+6vjrtRri2xb322WnYWEuIO7O76buevymf3t2ZkyfTLbLk7uTkncWBvbOy5knb6OTOGtLaf0mdyX+f634rdEX58dkcXUqVqlGKEcpRh7FiSt09C9WlkQsYMrOS+0Vq8ENypczkGLER+1WvIt40wqlhJ+GRxQlmxpFVoPXDbs69J9fQV8nQnIKkkJPtadlG6DibM5g5cTYg0uDsm3rb627rbMjdSs27Cwxf8es7sNuNtn3rk1GrFBA5yspJuay9iSKPS9b+PH/W4p25JhYX5Py+TuzsnLS9JmfiQszNGzpmcV8mT/Jx0zFp22+m5Lb65M6f8yy8lGQmOk77fnpndb96F1xZEK9fRx0sfkgqsE0Q2vPxc1bqDLw34YLVSzXzFyORr0DZ+Jpa2MgvFFl6wvXpVo83mLE9KONqVqePyYJhGhlq45S1Z8KzkzMpsOuCNP8ARvTt+eT65M7EidCWkxact65mK5mTO7rek7km0i1o39SqwsI/8UCuM3j4KvHDDF+JLdjunO4w2rMt2X26N/Qg5O7E6J1y7iZ24OzOL/FhZltM/Nvy7aTHpb9f1Hh6Zvbxu7P7TE658X/IFtiKIdjHxb8t/rMyk0z8/kEhLk23W1ra07D/AJy+nL0RKIe4XtnZuadnYq0PkWOAxMLs6P8AExL/AFvSxHuF/wA//8QAPxEAAgECBAQFAQQIBgICAwAAAAECAxEEEiExBRATQRQgIjJRYQYjMHEVQlKBkaGx0RYzQFDB8GLhJEMHkvH/2gAIAQIBAT8Bs0+d+UnZFxau3K/kT53LlxDLlyMlJ+ksW5LnczC5bkVca1LeexblexmGy/NcrmYzFy5fliNXCP15vyX8m3Od3sRTXm08iGlvzsOzJNbIhKx2JK1uVy45WIzT08qZmJ1YwV2VMTKbsUo9yFXtIWuq8zjyuy5mMzuZi9zQui/4eYzfg+6v+SH+NcuXLmpf6nUj8nViOr8HUfJDHrtybG3HcpeqGgthxk9ZDqDqDqDmZ2UavUX18tWtl0RK8ylT+RRykdURlZF7G/O/JoWpbllS89jU1LmYc7Gb8CxYsW5YfWU5/X+hcvysaGZEq8Y7sVeEu4nm2MkjK/kaXyZoLuOtBDrr4HiDrv5Or9TPEzxMy+BStsjOzOXEy5fk1cdJVpNMpw6UUkMqtxi2iSlbOXM3K5Gbg7ohi4teoUlKOZEYpq5Oy2JQa9wilkeglmdh07bcnpuNW2JaO3Kxc3HoJ35uSRe/mualixlMplLFud2XLl+VkTlGCuzCySoq5Ux2FpaTml+8lxrAR/8AtQuN4OXtd/3P+x+lcPLa7J8T/ZiVMZJvVnib3Fj/AKFTH0oRzydj/EcL90R41J+2oQ4xiLaTuLjVdbpM/Tsl7qf8xfaCj+tBi49g27XIcUws9poWLpy9skdW/czszMvzupEdiXyJGljNrYUrSvYVp7aEk7E1njkZVprJkidEdMatyuUqeeOm5hko6PflJZiqtCccrKbSV2QrId+wtDMZtC7YpGexe/K5a3PKmJW52MplLcroujMjMZ0daKHiYIljKa7k+LYaG80VPtHgqf6xU+1uEXtuz/FfU/y6bP8AEWMqPSnY/S3Eam7SHjuIZrvEFHj1WlTyVZZn82MVxypWg6TejOnFQ6iijxmXSJh6s8V6WyjT6cbRL33LqWrQ16JS+SccrMfjniqno9pn1IV1tchWiRruOzPFVfkhi5d0eKi90dWky1OWo6MH3FTlH2yf8WKtjIbVJfxFxHH0/wD7H/L+wuNY5bz/AJH6ex/yv4EddhPUq2smkU3ZG/JqWbMRtFDZa49FclDK9RosjIjpIw14zsiLtpIRPXQUHVnZ7GIw+wqcoVMpCneDkLbQy5pWJ01F2PyL2PyLCujNqXT5NmYnVjTjmkLF0n3PE0vk8TT/AGjxFP8AaHi6X7Q8bTXclxShHeS/iPjWH+R8ao9r/wACfH4raD/l/clx+fan/MlxzEPaC/iS4ti5LSyJ43Gy3qFSrWnpOoxwg/ddmWiv1S8e0UU8sY5pWK2LhCGg8RcdZjrNnrKeHw7pKVjEV4UKN4lSu5O5gpzz+lilKyTFUyxuOdzNZWOM47pQ6Ue5m+RerclR+D7ykRxVtyGKQsQjqRL8lUsKodRirSFUcjMzK4x9J076kPbYy2IxvsLfUknfQ/MUhsiszMRHuJDihwJRIz6cril1FmiUq7zZWi3cik9hNbMkoLYzLkpk9dxi31MzM1h2ExF2jMpEUlqYvEdabRiOLVKMsp+nZH6avuPiifY/SMX2I4qEhY2jIqYxXuh42UtGdc6xnuV4VaCUpLRjrnWuOux1dTq/I6+hLEnVk1oKUpuyJZou1yhalBZipxFQjanuTrTqL1M1MHKnDvqUMRCb+71PVbY6cn3MTGlQpOdS5WqutLM2NHt2KdbtISuiWGjUKmElH2s+8iLEyRHGvueOI4m5Gun2JVI2I1IsjJROqdZkal9yO113FdblxNjmk7G46dmL4GripKfuJ+iVi/KFLOhYWMkQwqjdIyWI3loZcmovkne+olfYvfRluWX4HEX15Lnfld5FYq4jJWqR73OK072kTinqjM47mZsU5b3PEVFoKtJ7M6shVpodeVx4iRHF1KZPi1LGcM6dV2qQ2+p1pXOqzqsc7jk2IWZqyRTnKhP1E8zeYo4OrV9SRjaNaMF8E6bpr1FkblGUIu8kYXFwnG0ERq5kKTOKYydao4X0QnrqOxvpYfoIV7blOtHuZYy2J0vlXJUYS9uhKhJMyWL/AFFVkiOImjxUiOMfc8auVNX0ZBO1mK3luPfk5ZdxvqT5001GzFeLzIhUc3YT7EVl1NzUdxaEZKQiUlDTse3bm27kWXL837ETtPEuX1Zj6eaBfKycM2g4uHuEna6JSakWUizEy5qx/LRuLcSS1NN0XKeWb1Z4GTjmi7mTw6Vu5OhKctFa5RoKNJU6rPu4Mx1VKhfuVq0q880zMfmLR6lDExp+2OhRr5itWnCnKQ9WWLjZCMahVpOBGq0U531iQqfI6UJ6jo6aDhF6M8PC2g6KJUbvQdBoy2352aF9T6l7FzKt0W0uPXQv3FqWMnqzFSN/UiwmyMzRbGxH16End3fLNcv8llubDim9TfYk8opZh7C1fJcrEr9LQVCpRf3iK1nCxXhlYvWtTMp6T3HenrbQdaFWJLTYzpoWpls2WS0PyZK6WpdmndnpLpojKNyGLqU1aOw61R9zDVK1VrXQloTnGj6pmLxfiEosSESkOZhbaXYssNEzEpeHnL6co3RlbJJik4PQozjXWV7lalleo7xFVkiGIsQxV/cdSEtCy7Dgqm5PDSOnURZydmhcJxj1VGX/AOr/ALcoL5O/NOw9dub1FJtjmZpy2L9iw3yjP5Lib25a+WxKrbYcm9WQlZl7lyMi5tqbi0pjpxqxaZjsB4XWGxi42Y7dxpTVpblDpqP3rKtLpvqU9iv0HT9PuFHM7I6ahe+5hsEunnqMlhYZHUg9EYNUatO0rXRxDKquWBbuWLFzOzP3KUHVu12KdSnCFrWJ4+MJGLxssTK3YV+wrmiG0aGHk4zTRCKn6pMxk3KnLK/SK6L67ki/yJXQ1KOxSr9VZZkqSloypSlTZ3FOwpsjiXHcpYmEtyjSlXnlpas4Z9m1bPjo/uMPgcNhF9zBL93JR57FxCpqxPR25tJkh3Yi/JcoysJ3Q9ucnYUvknWSJVJS8i557ikZ0kX+6ZGo4s4xO9GMlumYt9eOdr8zqWd0iVRTjmRGcZRsyCnTu76MioxlmXY6l55+5Odp9RlXFTlD0PcwrjK8Kmx7ZMlUlUd5O4uejMpOBgqKydRvcrVY4dfUq1VNaDu1Y13LNoymRjiYSLftkilGah6pGNj903cUl8GZE2d7F7ErMzxudXSxGSZPD6XiNW3LpGeL3OE8NnxXEKhSf5/RGAwGH4fT6dCNv6kvwL2I1GSn3ZczJbkp325255rGYuKVthTXcukOrFbDnccvIkW5XL8k2Jn/ANb5cTT8M2KauVaSp1HEotZsjK9GFLVEpWWaJmcXmHlnqipbZM78lqP6FyyZ3LK5exnV7mCqRnTtFbGPjf1/2He5D1PUj0e7ufdbjnC2iJSU9USl8ITZw3GdP7uo9DFYmnKlaxVqxewmnsSiWsyckZme7cd3sj1RKVdx0kXo1Nyth7axRToTr1FSpq7ZwDgtPg2Gyfrv3P8A72Xmt5G0ZkZjM+V0ZkZjMOXkWi5XfLUsyzLMUCxp8npLxLrsi7+C8izfcUWiP+W+WOinhpkpGIwyrQjVX5GIou5DLWpnsllP8t/QWmxLLPcnG2xqjJc+jLJodL9k9SZCeupeD3HkKeNlSgowHUd7sctbkFfVlkPXQvlLiJWuUt7lapanYcb6oWg2ZvoOTYjc02Losmaw3I4ix9juGRnfiM19I/8AL/4/jzfO5flK99D1FmWLfhqLaMkjpzOnM6czoyOjI6MjonQFQR0EdOJkRlRpy2P1WOn8Fam3TkvoZHe5UdsHJfUvJloRlfa5WpWWZCa2Z7WXszL2Gu6LGW4jcbb3FuW+DK9jK0WRZN6Gy0N0T02LrufkU18kt2QfyZuxpYsNCjqS9CLvsamSTjm7CuO5mktDCYSePxEMPDeTsYbDU8HRjQpbRVvJYsa+VMcrHVOujrwOpTZeMtmKMnsdOZ0pnSmdGZ0ZlK9rfhWLFi3kewva+dSOScolSP8A8Gbfz/Yi3mHFSVmU5qKyspKjbLUiY2ilL0oik1YUshlW5azLPsNZnoOLi9TtoJq41ys/gqX2ZCFo3LWiZdCauZTKRWg7ZiBJWeVjaWnK6G1e42acrl+4pFk9j7E8KfUlj6i02j/y/wDjyIvYuIltyTLikbk4WGhjQpdmKTRTxN9yLT252ZSRZkYNstklqVfU7oysyMyMyDWtizLGUe2hnkJVTLVLVXpYimotMz1LaEJVO5xCOTFzX1KyzYO3/dycUtUKxWjZ9SJSxNo5TFVYyakia6bzwJyjU3RD4LpaF3vEldnuOnYjBtji9jK0WJxvKwo/Qt9BTH6iyQtTRaHcihu/qfNajRYUGzJZ6nTT1OmOj8FOmlJXehwuOHWEhHB6wW3N8ma8qmwmyMbb8paOxGVuU6fwONhoaLuOwqlinVtsQrXMzexqUnaTMNlqVFGo7IqYHDwg5xq3fxuYiPcwqVWSpMi8AtKlX+RGrwhbzl/D/wBEsTTzPLsPFwPFwlKyQp/+D/gfuNVsajw7k7nRqW9xKFWC9xeonuUm5J3OxSp9R2OM0uhivzKlvCtfX+xUdpWFoXjsy+V6GZN3sXezMhFa6jkKbiNka2R3tclWlLUhUktmOo3rfUlNvc6mhDfMJpmY0LpDtuZlySIGg7DsJLccralxZdj0/A8sXsRlTXYUab2R09bJHA+GvAYCnQnukToxKlFI6sJtxi7tclzrbEXqS5OK3YoRMpsSipHh4/J0YWsdCmPDQZGjCOwoxRCeTY60CLSdzMijUitbkpxmhRt6rjXrY7binFjymHahLMfpD/xI45v9UeOstYkcen2IVXiNInTmhUtNSdH4FFxdmRg2hx6azH2lirwkj34aRXS0lyd2VL5bkTtczJmrNtycHfQUH3HEcZIyvuOi/wBxKmokYXMuaNl2I7Hs1FJSepJwUtCyMhkEinFDs2MloQetydNbxKTT9LEtOW+g4WZ7T7J4GXEOIRze2OrEieh9q+NLh2H6VP3z/kvn+x9kaCp4JzX60m+W3LMN33LmddzR87Mk9fxL8s7RXqWmzq3drGZnVKE3OeT5PAVu9jwVVbng6j0R4Cv2RQhWw2s0eJZ1ZNDqSjqQn1JaniWtCWJclZnG1nw6l8Mh/lTTK0FYVJyenY6EXG5GjHVOROnODynTc1mudDJrdCp66sqwyu5B6Dp/BK8SOqJRT2KOs8l9ytwqGXPTuUcDljds4hGNOplRGMpJWOm5nSa1uZJblmJK5oakdDhvDK2Pnp7fkw32do047FXgtKnDRa/U4hwbNepTXq/qRpONpJ6CoWebsQi46SLDh3FpudLPofZDha4dhM8vdPX+xuVbpXZxOv8ApPFSryf5fkcIoKhg6cF8f11LLuOg8uY8LUEjIONixYtzUYvckktvJZ8rCRPh9WnS6r25WMqMqMqJwjfYUV8GVfBYjpK6PEVPkz9XSbEo0vVBni6h15VnaRcchTKcrspe+zHCLK+Gp4iHTmtCXBMKoSUb/wASWhJuNT8yj6o5fgktSrC8cxQeZWHFS0P8uWpKCqIhScHlMD9jMbiqees1C/zuY77G4zDwzUnn/qZcryvcwuDrYyoqVBXkP7EcTlC7t/ExGKr8M/8Aj4mL6i+R4ypWk5NnDeD4r7Qr09nq+3/9I/8A47hGnrWdzinA6vCq2Svt2fyV401/lkZLaRV9MvSUuGY3ELNTpSf7mVKNXDyy1U4v6l+5GjVlT6ii8pwfBLCYaNJr8/zEuxKjfWxi6bUrFaPRxU0trlanKcfyHdq5TnGXoma09Hqh0cyvApLLUWYpWgkokahmTK3AuG15550lchgsPGKilseGorsUrU1ojqL45a87csxnSIO5IymUymUsWEVcZSqYXprew0RWhYsPQqYinF+pni6P7R43D/tDxtD5PG0brUsi1uWUnLorqI8dL9khVq1FmjH+ZOpVpLNKJhMQ6srNFPEf/L6VubV0TdpNMxOkjBxlWqZaau2Yf7GSrQz1pa/COJcAqcOjdaxMLwXFVZ5qMLoxOBq4R/eqxiIp6Ipt7H2R4bTxeLeIqL2f1IQRUoo+1H2XeIqLE4SOvf8AufZzgdDhOGUUvW/cycYZT7c4KnicA8Rb1Qf9XYpRcm7fBwDBU8DgadOn8L+L3ND7U4GGL4fVUlsrr9xGtUhsddTlsrn2R+zlKvFY7E6/srt+ZClBLY4xwbDcRpZai17P4Ps/9nvE4mbxS0pu1vqVMPSh6YrQj9BSdxYiysVvvCjw6hHW2pj+FUK0NjHYHwk8vYrUHe5CrKO4mr3RTyydzB8WoYmCcZa/AqwqxGukKopIUr6Dm46HV89iwtD3Mt5XEsLXQloRafK/LF4VVJJi4dB9mfo5fDP0dH4Z+j1mtlZa2govuZTJL4I05PRo6dRaZP5EY1L6xsvyIcPg4rOhcOhHVH6OhGWeG41bR85fZPBSeZtlT7GYGrq5SOF/Z7CcNqdSlv8AUpJRRjMNGrFqS0KGFh09jH4CnXg4TVzhf2Wj15yxGsU9DHfZ/AzWXIv3H2bwNThdarQqLR6pkJFSSauZHUPVS3Kc4yRiMNh8eulUV0YjhXD5LoTppp/Qoxjh4qjHZHUSMfSWNw86F7ZlY/wfxHrdJR9N97/zP8CRjH/Md/yOEYaeAwsKFTeJGasVqySKKUFJx7tv+JJ3M+Vma3qF62OJc9yOK8N8VC0dGPgMqfvn/L/2f4dpzXU6l130szB/Znh1WCbi7/myXAOEUXqv5sWCwFLWlB/xKc5R9p4mXdDrStcp1JLuUq6vZmeMi3K5fmnYnPO7si49xtPYSt55ItbUlqZeVy5TqZSOqvyre8oPfzXLdWp9EYWi6slpdE6dKEfaOmkmyGFjiI3aJcNqZrI/R1Wxg8P9360R4bUrXlYq0pYapkmKtGI68ZrUpVlksipOLIVLOxGCWrIwi0Rk9kKgpbkF0n9CokPM9IooqWHMymr2MThvUpXIxhElSU9SMVfUk0tkJqUtUTj8GNlVeI6cvb/yJ6FWT2iU6eXc+hRg4T+hXskXEycor3FozVydS1S1NFHDymvSLCdFXtoSglsVoKK+693yUvvVaS1Om48oysI6jMplRlRlRlRlXNq/NLlYcRa6GRvcjh4T13OlCK2OmdM6fexkOI8PrYyKVJ2sYaPSoxhJ6pIuis7SKNWMUKrFly5YylT0RuYWhMSeXKtETXTadzPG+pJfssjWaSsrseOVGV6qsv8AuxDj+MqNxw9G6Zi+I8ao0uvKkrfxt+65+lq2Ng8yjL6d/wBxTcakVOJUgtyhLJsZI1HdlahpeJCm7DpztZFKm46MiTSaHVzyycmroi4JZZFaq6mkdiNNMjeltsVJWZCpS2TK2W10WmypgVV1ZXw06KEhTje1x2voNtEs1Q6TirsehGUKzyjoWi8pHotJKFhQw61sdWN9hyvqS1Gn+qxYWpupsWZaSFz6aOmdM6aOmdM6Z0zp8kjcvYzkVmZJSclbYVOSeZlN9LQdRSNzVCatd6ja7kq0UrLUU6jd0PPLeR04iXJTYqlzq6niJCcqk1J7IweMpUYepDxMKlVynsVasL+j+jIOGb1sp8Rw0qnRSutr9iOHUdncw+HhGN3uV55XaJTrdSOpicLTp4iUUu5WjRw9K9LZvQUXV9x0cr9I55USUq25Clk2FLsxpvWA8VGGjHUlUMnqvc6linHNuSgmiVPKQROSihQzO7FTQ6dkKqKaZXtYqwd2kQppGQlUdR2iK5KCkrEYuk/oSppslKo9rfw/9kdNyxblUlYpwb1ZYz5pC5XLly5fncbLi5RGWuUx2tYdZQ9KVzqTv7S+ty5B5U5P4ITX6xTpU3qZDKRwNacc8YuxW4Ji6MM2U/w5OVPNGWpiuFVsJHPPVfQyEbQfqR6J+1mVwFWa2RDEzeiiPFOLtKJheri3anEpcJjVhaofoCNFuOHq/wAV/wA/+jCKODX3t2/m9yjXjVXpHQll13KFLQ4snhq6xEP+2PFzxVaOcgy+tyTcp6LlEbV7opsxVNO0xSsOSuWTs/go1YyZKaK9eCeRbizW0Q51HWtNWRG/Y6k46kqqcMxRUp6ipv5MS3BXZLU0sTl6bEFYT5PXkxR78ruOxK+53LjlaLLF2jNdGhcuX865tFvknLXRipO98uo4PZk6eVDRZlm9OeEx3h395DMjD4vhteOXLlb+f7mGoKEc0JX/AKElXjCz1RTp5l6ZEowy5JGN4RRqR+5Vj/D9dq9yfAcRGeWW3yYnhOJwscy1R0Z/BOEqbtNEKyqejcweG8FDJDd7/wBidZwgQqJmNc5ytR1Zh6s4T9XpZDGQ3loQxMLHGEqkFYhT1KkWmiEc5TzU9DO4vKXkynHLoKVmV1UqU/SN5P8AM0J1Ip6EfWdHuhzklZmHXTV92KtMnJSjqZxzsZXVWW5C0VZEWYtJ02O8GXu7kud+TLF3bm3yRW9MeVudi34W5c3MJTj75jnPd7sSckrGJrRg7SY8T+yiEs2rZ1oJ7mk9UZDKyhgMLiKKaqWmQo4/Ay+4b/cYX7UVYLJiI3KGPwmJ9UKuvxsQjrnkv5ihLRtE8U1LJBC6k1qz0U4fevQxn2hoR9OEjma/gYvEVsdLNiH+5bGHrKlOLtoiPEIVEpvRs63WWWGo4ZexF6nQp11eZisBdeh2KuJr4ebixcdrdPpySZHiKj+qT4jmexDiaj+qfpX/AMTx/qzWFxO36p+lP/EpcRUJOTVz9LRe8SrxSFWDg4aHVyO9iGMcNbC4tb9UnxPMvYLiDX6ouJv9klxOUlbKeNn8Dx0vgjxCpFaIXEaqFxOt8IqY+vVjqUVnjaR04rsdGLOhA6EDoQOlAdCJ0YHQgdCB0YHRgdKCMTFUY5ojquejEXN+WUymVljKZSxYuhzS3FrtzvlaVtyFRUlYc5S9iIqS9xWeao2RpSm9ELDSW5QwDqlbg7pxzpnSa0jIUa67nVqR90SlxKdH2SaJ41Yj3vUt8Mw3FMXhdIyuvqYX7Q05u2JvH+hUxlBUurCorfJxXjeSXSw6u/nsVqtTEvNiJZvp2HLtE6Mt2QwtV7RKN6cVTqRJKVP1QKfGnBZasWzxLxDzUtCnj3hk+vsfpvCW1l/U4t0Mdaph3r+RKm4uzMoomUsZTKZbmUatpymtDOKSY3YbtcbURn97G/8AESuR1sdVkajk7FKTReReRmZmZnZmZmZnZnfwZ2dRmdmdmIrdRZbEdRLzuSW48RDsOvJ+1DdSW7IrLyU2aPYUpoqVq97bE6XUtqQgqaFCb1sSeXcwnDvFS9CKvBatOGaLuTbjo0YOoumnExFXqU3DS7MPgm361ZDwFKcMuQxWHeHqdMp8DqV6edmK4ZUwsssinwmtNZtio5YeXTzZn9NSPVlrJ2IpRY5kacpEMBJIoUZda01oNRgrkWnK7FFFahHuWeyMTOpVoulbUqQq0ZZZlOnBK6OL1qNJZI+8p3TuzMXLmYzmYzmYuSeZWOmxU2u5kfyZH3Y4N9zp/UyP5Mn1Mn1Mn1OmiMUiM7M8Svg8V9DxX0PE/Q8T9DxK+DxP0PEL4PEr4PEL4PEL4PERJYiNtCfqIrLzXLxEe2p4ib2iN1Jbs6a7lree7Qp/JG36pQxCpO843KOMoVlvZ/UxlD7u5wvE1c6pQWhOrLPY4vh5UpeIk7p/97HCOjV30f10I06fUuiUFlKVr/kcXcOvCZgsVTq0W1OyRxbieFnFU6LzyT/d/ErV6+Lf3stPhEYqHtM3ZGW25RipTUSj00ssScowdkSebsZ5WsynaWhOr0USrqe5GN9io1fTcnShXs3ucQx0MJ91S1n/AEEm3mlv/qLfj7sXky22LcsvLKKJby2FozOdVd0RrStljIwWI8LO89hYjD4j/LlqcQa0zS1+LnC2qitCDKqlTV5KxLFegoVaesquxxfiWFxC6WGV/r2Mkp+9/uFBR2Ni1xenYepFtO5RxVkRr0/kWIpd5IeIov8AWRLEUlD3IdaE1e5GpTXcpVIdpEZwh3OIcSUFkoP1H1e5mItNfiX/AA7/AIF/NcW4l5lsdylhqldelH6Krbo4bgIUoar1GI4dSqrWOpxLglTCxlOGqRa5l5Lfk6fwPPEU7kZszp7km563OH8ZqYV9OaWX8h8Yw84O0k/5HjVKTypkozra1XcjFIuWbFGzEripfJ000dEdK3csiyNBj05ZbiivgrQSeg32PoQdn/rXzXOMXN2RJOOjLMW4vI6FVbo+eWEodetlKNGnh4pMliYQ0SKOMipa6EsYv1VcrOWIi4y2Zh6NGisjjb9xj+GUKkW0tfoYXg9avK01ZFPhODoR9ULmM4FGSdSjp9DD8OxGJk1BbFTgGKgrqzKlJxlkmtSMHbTnnY3Ge6FBQ1HKxrISXKMLiWXlUmynTp4alFtXbMZXw86Dzx9XY4bgvFS9WxxPA4XDpU4L1EOGRqQujC8Pw0nkqbnFeHLBWlF6MwWG8VUUDiEMNhY9Gmry5V5ZnZG3OjGnWhmsdBN2KlPIJGUymViizKZDIZDKZTKZDKZSnGKks+wsBQrq9KR+ip/I+GVr6FbCVaGs15b8rFvJaxh8PUqxvLYnwuSpOpFkReTw6btY4jwWNem5QXqML9n6tWOaq7EOFQwss8ZEp3dhxUiWHjLSYoOHpizJFayZKWuQV6mlyleziNzutSN96mx1qcYaIpYnqSys4zw6GKqQmt3uUMJToxypGP4Vh69NzVoNf91JT1tEUJS9xFJbFRZmW5Qg5EYJGx4hT0gcO4ZmtKu9TG8Ow9al8P5HVqU5WizD0KmOq5ShwSNKHpf8zGYedCpmm7mG6lXRbFbh1N0W4+4hh6+MrOM29DEUfAemE/UzfVk/azZcnywVZxvTL5tSerLGUsWLfiJtO6KPEatPSWpTx9CS10MZiY1fTDbkyyJQRYylixY1RuUuGqEc1TcyQcdD2xyPYxnDopZqS1J050naa8lOt09KpiMRGULwPEuaUVuVa9pZCKUo+opxea3Yc431M+TTsThFleMFFKJBqGncg6kZ5olXG6e3UdWVTdlNaek+7p63MTxB9ZSekUYj7SW9OHjf8zEYnEYx5q8r/wBBJISvsQo/tFRZajQiNP5KFDrTUEUeHUVH2nEuFxyuUBYedHVowmJSj99Mo0sPKF5WOIwpwqtUzhM1RIY2nTgcXxme1jD4npbEuIQjExWIqVqvpdl/U+r5V6qSsj3eRNxd0QlmjdDEvM9Fb8F+RiHzt5HZK7KWDqVvVHYhSVCnkSFJzeVvQco0JHUjPQhZR1epiacMVH6ksJUTsh0OnTbnuWK+IU/TEqUqiVmRU4yvEjd1czQ55X6US9XcdGaje+gqnpRVqaZkYep1XqQhHNeJGn6sxVSqVBUosr47DYWHqdifGUq+ejG6+pVlKvN1KhawlfYhh2/cRjGGxZFZJ1G0KFiErOxQxnQqZkrn+IMPBd7mM48qq+5j/EXHJ1aXRlBakcsJ2n/I4ZjsK4tPSxxB0cRSk4xbtsUG75b6HjKFHSOpicVhMXQtLRlOpKPpTPG0KdNqnHM/k78q1XIrIbuLceg1y3KE8ry+eKHG7HD4MrFAlBk1Z/6GKzLKYXEVKH3L2HVuUrZRx7sjTvG45WYnGWhla2JNnXfwiLgnqiDlrCIqKj6pItfUlJxdiNPO7nScvSivRyOxKl6cpLPQn6ilWjc3foRi6+Hws8+Ilr8LcxfGa1d5cP6V/MytvNLklchQb9woqOwmOSRXquTyIhBLcersWstDNYukJ6Df6pbSyIxctTVbkbXJPKhXvqOAlblUmoIlJyd+e/JlODm7IhhZRJ+nRly6Lly5T2v5q+4ua/Bt5KY3cpS1syOWxGpCTsVU6avEvG5ke5GT7nqW6sXMPxSrRavqvr/cw/HaHf0v/vclivEL7uVyMHV0vYo5aWkiNSBHFxUnYjmrzuVJ62K6zblXiGFw0tPV+RiOM4vErJD0R+n9zJbfklfYhhm/cRhGG3JuxmKksxaV9NCnFwb1HH1DTHtY2Ix+RencdpP1H5E227ItoKeZaiaHylJRV2Tnndy/NDNzC0XS9T3M1is76lzMZi5mFCSSVhUXa5NSt6T74hGTWo7orvRMzmci7kdjOZjMX5X8z1NmLUfwYOeaahMq0la1MTyU/oZYy1ZleXM9iM1e7HWUlYzLltsUq9ShLNTdmYbj8oaVlco8TwuKdoys/roVIW0IrMr2PH08JG89Cg6dSLxVR+kx+NrYyb9Xo/gRgo8lqU8K3rIhTjDbk3YlUHVb2M7HG+4udkiyT1LIsTenLQcbassKPzyZsirVzvyXEbmGoOn65FyWxV52LFjPlGxt9hNrci1uhuL7HEElTVvk15U9HqRejLikXEyTsjON6GYUzMZjMbsUnHVDfVV1uJmErqUNWVHmdo7HhM9mmTwl4WgyWGUFcm4R9KOrH48t/gocQxFBZYS0I8dywtk1KlWVV5nuXlFWvob8qeFlLWRGlGnsM2HUsZrk5XdkN5SMsy1LsUH8l33E7GfNsPVai+BaElbV8kjqJaCRvylNLcrV9MsS/lprNJIp0Y09hlyXtHqyxlLFhIjsSV0Sko6NiqL9pEU+5Y4h/lr8+W3KGxlEreWWxcuXJ1VTV2eNXZHjJlGt1FruRqWfKM8pGspblOu21G+hi8T04rL3K9WeJlmuYdKU1nOjSMTThFQsuxVwk6VONV7PnZdjVF7Fy+ZlPDTlq9CnRjTOxJ5dx1/gU5TGop27jvFajErFrlktTO76Fm1qLTk2JNl+zHK+g/kT+ROK25xMTJJWH8+bBQzTu+W5YqO0eduVuUfaeslTU/cjw9P4LtdiLujH6wRYyliKLFixYtyft8lepnYuUJZHcTzK6ISuuUS9jNpoRqZdyM8uwsVYrdSpbTYxUs9KnCPYk06Kh3JUISpN31HBwWpKp2RGbZDDyks0tEU8PCntyZOoolSs58oTy6Ijdq7JLtytybGtRclqJ9mQoOWpVw8qau+UtER+oudSqqZKTk7sXlp03UZGKgrIb5XH5bFhV5o6kxV5dxV8uyHiZCxPyjEVeqrItzRYsWLFuT2LcsRLJDQ35LlQqZXqRN+S+CxONzL6dDpsZmMz5ZUx0Kct0U6FOOqRVh1NGIlJRKlUlO+xla3ZcklLQUrDZKUUrCuy5lu7mRWsNJbEt0JXRYpuS3ZKpenZvkmrX8lSfTWo5Obux8nzhScynFQVkPz2LfgvnYsWLFududjFVM07fAhoT50K1/S+SfJMYptFjXmkJcokrEqy/VHJskxMepkzFsrHryzXlYijR6o2Ze+4+SXK77Gq3FzSuSkoK7KlV1Xd+WMW9inQ7zMonbnGSRp+Bfntyfnt561TpQciT01FyaE+SdmUpqaLc9zQuiVSxKeXUlO2pnSVyM0ZkPEZdiVRzeorI7DaE4scvVlMvwTTjrzyp6iRmvoZdBasRltyazIjp5Erl7K5Wq9R/TzUXafNi/E35L8O3lxl5WidNdyVK23KT7Ht50pODuhYiLN1dEVdGxOnd3R0YlRaaDWaBbNEj6olLWJUXp53LmVPWxYtyzF0aF+S+BMgteTuJa3E7Fi2vLc9piK+b0xF5Fd6IVBWI0Enflp51uWtv5N/Nvytyt+FiYXhm+C5cn6WImyL5JkZEfaUmk8rK0bamqZ4mn+y/KiS08t2ZjfnZGUsWMhkMplZZlpGT5I6K3NLQxNe3pXJc1HPsQgoc7/gJuLuiVSU/dzXkdu3K3lsWLFuVvLKOeLiycHTllYio7vURLVidhMuJmFrZ1k5UX1Y2ZOOV2531sJ62L62L9hjTXNc0erc1GZi6JfQvyt5VzxFfpqyG78o86UbL8a/+oxUNep8iLXHTR3GiPJEJuDuiNTqRuilUdNlaalLTnLSSZJWkmSsmmS015MkZkXRdGjNC8/kvP5PV2Z94XmS1WxZ8kMsLnFWWpUqqnEk3J3fNcqdK+r/ABF+Gnb/AEEoZ6bTR9OUSpDJK3Nc8PWyPUZGXJY2g+54mi/1jrU3+sXjIsnzlON8vNC35MuZjqozmczXL6CnYTNLmhZGxOVlcqTc3d+S5To21l/qb/hJ25X5oxNNRlfkjEU81HOu3JiLlxNIw8+osrNi5czGdim0KsxYia7jxVR9ynVyvMxYyDWp14PudSPyZl5bCQxGZDZfQvoLniazbyLy0qaSv5V/pL83zv5LeepHPGzJRyuwihH02ZiKXRnl5bFxaiRCbg7ozKcVJFhmUymUyDiOJcRqXZnZ1GhYiS7nianyeLmeMkLGPujxn0PFoWKgeKpniKfyKtTfcVSL2YjE4lRWWO/lRHRedfX/AGSdBTsQoxhsWMXRVSObuuUhCLiMPJp67csvKxbyOJa3KxYsZUZUZDIZWZWWZZmpexcWotdEfmbc0UYZnf8A1d/9JX0pya5M2FIzXKaFUy7HXfOxYyjIjVmNcly052LeWxOOlxCFuVF3FrzScnZFOORW/wBvksysVqLoyysZJcoiehcv5W+USaEWNmKzMqMhlLDRYtzsNXjyiWJbGz5b6Io0cmr3/wBxx1PNTzLtzlo+SmZi/kuPkue/K1hMuX5XL+RI7c1ykR10KNHJ6nv/ALlKKmsrK0OnJx5T353sZmX/AAGLTyJ/gI3GIjymiEsksxF5ldf7OuW34WNf3zHyXJ/grk0Itflb8GJLflDlMZhKn6j/ANynJQi5MlJyd2TfJcpfgryXL8l5bckIqb8oiGSMNFud/wDXXe34MKbqaRJRy7/hcQbUFybvyXKe5byX878rRYt5EIq78kIYqTqbFKCpqy/2dNxd0OtN7/hVoKpBplVZHl5Lkx+4t57l/Jox815kRKu/JFKDkdFCX+6Tp9Wcpt2Vzw08+T946DUc6aZHDuyuyrRvVklokVqTpyT3TMwuS/B2L35XNPMhFXflEhDJGxbna/8As9GtGGkkTak9PweI4hw+7gUklTzQs5fXsTknOMm17X/yULKE0/8AupVj1ZdRPQlllUnJWbMU81ON2tH25L8BedFi3liVdRlP3LyP/YF+LbyVJZIuRUk5ycnyRHnP3cv/xAA8EQACAQMDAgUDAQUIAAcBAAAAAQIDERIEITEQEwUgIkFRFDJhMAYjQEJxFTNQUoGRobEWJGBi0eHwwf/aAAgBAQEBPwH69Y78mcZRT+SxOOxbKJpqVp9KssFchVU3bytdbdLEuRPpYnBw3kNlzIbuWibGLZTj8jkmJ2Lk3Yi9i5cuX6NlzIyL9N/0FBs7Zgi3S5TlZSl8IyL9Lly/S6Loui6NjFlBRS9RVUJO47ex6jc3Nz1GUi7MmOkkOWKwYq8ccinXyi8i6ZTvfZkIOPJVUW1FmWNWy4KMnNNluljElB+Sw0dspUJT4KWmjTVytK+xWop/aS9Ls+shl2hVm+R7cmMGdtHbZ2YfBKDMWizLFjj9GzZgzt/Jil0v5pemh/Vi/QxZiWR/Quxtm5YsXSMy0nwjs1H7C0s/cWl+T6WJLFxdye6HDcVJ8kPS92UMJepkbT+01UuzX3G055EdRHLFHbFSuKkKmkYJlei6b8lihRvvIjaBVq/A5XKsrS2NRS7rUMtym617Wui/sclhxt0i/ZjTiZ3E9iVVyRcuXLly5sWiYowRgQ06krs7JaxcyLly4mZGRcv01G0YQ/BYsy3TCQqfyKg5cIdKcfYl6eSVWB3F7JizfERUq0vYWkqS5YtDL5FoF7i0MV7C0qXCPpxUrGH5MV8nbidtGCnsiWma+0lQdrsVOVirQvuhRlTsfVS0kIte5OtHV5SfsJxtuaNKVdU5IjOnl20WLFixKKkrMqaRp+kkmpYsqamafpRp5yqXlN8FKvCqvQNmp7sfVFk6nYWbZT8Qpyl6uCrOEvtYpRgv3aPq/dlPVtO0iFaNTjo4/BxyJqSsxxxZDpYt0v1sYmxkZHdkjNmZkXNmWRgjtnaZ22Ys3IUqs+EaqlOU20Q0lefCZHw7UP8AlP7N1Hwf2fX+SHh8v55ENLCPsdux2Badydkf2an7I+jjH+Uekh8H0kT6T4Z9HP5PpKg6El7HbsYIxRZeT+7ZOe4rzjiTk1yOUeSp+8hn7HajOkrO5VpvTu8WUZxctxVFp6ncsaSpjV7kmd1iqCaYkWK9d0p78GulUnvA7koOxTdnemzSJ05NopVe5E1MJzliuCp4dLhslFRlixvF7Ce+xjDmQ6SyuY4/aUbtblx2Y4tcGSlyRWO3ktcsi8UOoZsuzctIxZiYCptioSfsLSz+BaSb9iPh1Z8Ij4TWfsQ8GqPln9kqP3TF4dQjzI+k0qXB9Ppmrdseihe8FYp6NReSPU3a52L8k4qA2cdObITuUKPbW5YcBwHC520Omdtoxkbl7Gz5RhB+w6NN+x9NTPpYEtuR07ooxxlZmoimzFJEcb+pkatPt2iVXKcrojGLliOLW5QnaaUyjVVWOSExSZ3JIVZmucXTu0Tp91ZQJ1HF+pGnnGlHIq1oUaV4mi8QTTUSpXjOlmirVvIqyTluWx3Fs9xJOVmSV36SMHa6ITppXZWqrLbgq6jDexTrxnwbMpxT2ZgiNNylaI9NU+B0J/B2Z/5Tsz+BaefwLSyYtDNi8Okf2exeGr5QvDofItDSXuR01JCpUV/KRxXETKXsZT+T1fJZsjSb5O0dswsbWHOadiEHOW4oWViqlYsjG7LWLGlo5PJljgUjZmA6Z2zFrriYmJihosQqKX3HdKnJVq9x4Dp+5KmUqiimqhnCTsiVD+YbiueTH4PD5NRaHIU2KoRncqU1WjixpUHhI1Wjjj3Iu5O8eCpqZcNDpNfvEyNarKO4o5S3HTy2ZKml9xUjhLOIoyXJVSssHyb3xYqVzZrchGMo2Ix5gUan8pSrLKyJV3C+Rp4JQTXuU9LGaufRI+iPpD6YdBnYkdi4tOh0vgwMEU3Tq/axUztmAoGBgKmYmyFZkvU9hULvcUVHjpVTZKDXJsXRDKcrRIRxVulhxLmdiNS5sYpnaR2R0x0xQHBjizBioolS+CpXlGpb4Jz7j4LbbkqcXHkjQdWGTHRsrop6twjjIsmhVpR45IV5wX9Sk1Ujct0qajCViWs1EGT11SdpEKlSo/UVaS5ZOzexKSTS9iK3fwP0rfn2LyMovYbk04scrQxZFrO47Dbasbp7CirWMN9iFKUG0UKDjUy9jVcyKFO9GDXwaWXsI5LDSMEzBGKMEYIVNDoxkR0NTTa1SpL0SvcxMEYoxLdHYklNbCaJVIrkpSjcUsuDfpNP2KlJp7jjYsaekoq/k5HElFm4mKTMhS6WTMEdtDpna6VqjhJSRVcZPJHuSV1YwsJYo/COxkYY07Dox5KMFN2LqlBWOela053iOeccWh0/5kOo1I1E+4sCEceR422Ptlb5J+tqBWozopfBVclvAp51Fxwe7TKlFuWZBeo01KlhtyarTSi84cCe+53nHewt1f3E5KRqIqUpXKaxoxX4RRljI5QpF78H4Iq6OOtui80rxO97MvmKVluSleV0bspR9ZCCgrLq/wAEqblyyULEYJteVuxGVxxGhou0ZF2ZsyFMUzIy6fdtImseBK5LYrZQ+0VSaVmOvj9xCopcSIwyXI448ja5O7lTxRRlZYM5JpexOmnG6HFxdjGMltyVIMd7Kw4+m7Htsz8EpykrNn3bIjXnjaHJ6l9xp6EtR/Q1lLsWUeCg6l9ipJRhkjUU294EI2+7gzvszF3KyvUZGtCqvQxclN3Q9i1uBbmLixb8jVjgTPyXI7ssf0N+kk7DpKRgkVIxiISctkUqeDv1sWKhuyD9aXlsSvEjK5yYjgOmYtG/uXsKaLovbc+qpf510mSWxuiUcuSpRuhZR4O7v6kRbbvApzxtkTgmtiOmz9Q4U6fsY47l2RV2Y2K1J/dH/Yp7u5WoW9WRUqJqxb2FGfAoStkRpy/mIwI09yl4fvlUIwUVZI1dB1LEaGEVEhCysV6b+DtdxlT907IjSc0VKfdnh8ojR+nn/Q02pVfZ8lF9OCV7+kjLJYyKeal+ByxRllwVat5WiKq74sq5wlsae7jd+SxiYk5Y7DjJsVFtFKjgi3S3Wpuhu2yKStJX587jjujKwpX6WuWHC5KmypJU1eRqfEr7UGVK1Wr976Nl+jRVhP8AlI3fJKW5H1K5OlKLuindvGRRUoqyIxuJKI7XubJbl0iXNxoqUVL8MrwlD7xRtLglH/KWdjTUu7yVaClwUdBJu8mU6MKX2rqyS6bPYdHCV0SpxlyQ03q3Lf8AmEirp41YWZoNNOhXkv5Wv/gpLBmIo22HFolZl3axjtiJenFEaSy3KytZxOURiorbyboyMirN/aRi5kVYVi/S5fpV/oSavsij9y6WF1RYxGKduRdLGr1C01NzkaivV1Mr1GQjZdLeaxKkmU4XlgkOV21Yp0JVN7WKdJU9zIyL9LXO22dtmNuSpSutypo0/sPpqr4RS0M/5tiNJIUUi/S45mRyW6XHCL4JQxVxv99FkbMpyj3MRrYjJuNyfF0RqOQt9mWT2N0L9C5yNFWLUtyi7bdHK3BeZ6y0hKxYsaijf1IpQakQiywuiRYt1cT1IjMlUUI5SNdrHrKl/b2LFi3Rb+5cv1tcwYoJCSXCNzGXwYSMGKmxU7CQhpMd2zExSLl0X6yk/YV2Yv4MJGEzF/5jFfJjH4MkipUUtif97E44Ke9RNiKc7ScSDJJwkWuri36b+xH89L9NzL5LIcWYyNyVFSd2Y2LdL9LX8k+CEfUL9LkcDxfUtfuI/wCvVcF+mJj0pRpuHqEqZ+7FibI28li3llUjGR34jrQO9AVaB9RA+pgfUxHXufUtH1UvgeomOrUZnIykx3L9J/dEVX5IVFcuR/vl03ZCXt056XL9L9eC5cv138m/R9GW8lznrfe3kq1VRpuo/Yq1HVm5y9+iG7dbeVojBv3Oy/k7Evk7FUw1CFKcfvid6C5O/T+T6in8nfp/J36fyfUU/kqNSm2NIaMS3nyZkzJou+typzHrF3SYn+/Q0cDTJZcxZSl8l7D3Ls9ukdi9+j63EXHyXEXL9X0S6W89unjOp9KoR/18kmJXMSW76bFixY3W6ITUhMTsRmTy/kMctipQtwPbpsZRJNLk7kfklVjY2krohJQ2Z3Yndj8Dqr4O7+BS2uzOBlAziz09M4/JnH5M483KjvZ/kbIvcou9NWI7VSLbLkZX2JR3IJ8C9WzIxcR9OORbCMhyRdWL9EX6W8zF5bjZcyMjMlJ22NT3O63V56otd2ErG3SG76SlfguyG6Ghq+6IVPZinfguRdxxU+R07lWlcdNLkcYrkyh8E4p8lSCSuPYoPaxVXudqZ2pnZkLTyO04x3Hb/MOSW9yMoyNh1IxO5RvcThJ+n/8AcCircFTZExSUeTRT7lLYX94R68iT6XGxIcb9HBsUEiURRF0v5rdX5bdNzc5Q4seSMtjX6zv6iU48EKrISuYSjuyJJ22L9KRU+0g+nccdkZy9xSGrkHidyVzuy+RVZR4ZHUySJVpT5Y7yJ01Pk7Eh3tsVIzkOlISlAc21YTbgiOXA4yFkV457H9n/APuJaJL3For+49A17k6MaG8zKi/YlWxfpKeo/wAw5qpC6JTSYpxlseGpqLucVEQ+OsefMpF/gv1yFK5cvbfpyP8ABv0yL9G+qaGJ/I+vApHJ4vX+m07ty9ukDwrR9+eUuEeKzyq2+ELknFvgwZgJW4HG5g0PJDV+UJWLiLFjExMSxbrcuX6YxO7hsjvs734O+yVb3Z9ZSPqqbPqqaPrKPuys6Wo+0+nXydlHZUtiVNU4WQ4IUEnc0tlIl9yIy3HUS5O5udz8EZxZnjsdy5kRlcZmLcZdkuLkdQ72ZOtd7FF5IurmVjMui/l1uuhpI/kr+O1ajtcoeK1K093t+DSeJ9u0ZvYczP2G78Fy/TLE8b1f1NXGPCOCk1I00Pp6SgjWTzquRGVmKsm7HeiN2MxPpcuX6SlNP0kJOSvLpwZIyL36MWspzn21ybdLmRd+btQLdreA5SqLGR9NAhSVPjpYsVfsYpexcjXqQd0LW1Lq5EteJPZ3EQlZ2Jq25e25yrl7Mcrq5qv2j01CeEPV/wBGm/aLTVpWmsf+i91sV9RT08c6rsj/AMS6JSsm/wDYoqnq13KT9J2lHY1niFHwz7vf2Jfte8/s2ND4lT19PKlz8EHL3Gvghutyes09J2nNL/UhUhVV4O5YdampYOW54rXlXquaHH3fIp4+lbGmwwyKD7lCMn8FOSiy5JNbo5M7ckndFRZO5KncUWiHiGqgsVInqqz9xVqz9yaze7O2/npby3MrdEZGSMzITRckR084V8/a5fpwZEfUzUThQljJn1VH5PqqXyfWUfk+spfIvNcuVN4sS8keCnuivKNOOU3wV/2kjTdqUdjQeMU9c7cSK/iOnorGpLco6qlqFek7lOVuSSPHdVKhQ7cf5is/chVPA/HFTh2dQ9vY8b8Tq62r/wC32KWbkfs3WdHU9q+0ibWx4vqJ6jUTlL5HF3PA9TLT6uFvfYcIvkxcTx7xadH/AMvS2+SdSTfJ4d4pW0c8oM8d8bWm00exzNXNFWrVvVN7ksk/UVIq15cH0Mm7rg70aXpp+xV8Sry9zw/xKrF7M0er+phf3IVCUU+CzJXRV0k6bd0Okdk7LHTcS1jCL3O35b9Oekr+w3bYv5LikXH8kdx7D3LLpUoU9S8qjJaLTr3/AOT6TT/J9Jpv/wAz6TSJX/8A71uXRdF0K0irrN/QPXy+CPi8MrVOCMlJZLrU/aKtQ+6xR/aivL7EjxDxatq6eEuCrVa2NNqZU5qUeTUajKfJo9XUoyygzxDx+XZitPtJ8mi8Y117uT/1PFdRHW0oVY8+6KlMjTs7CqKkdyM+SVOpf8Hdr6JdyLszSavXT/fxk1/qVcq375+44I09X6ScavNhftBpHRVVvf4F+1Lm/sVjxCvDVVZVY8Mxy4KGmcma6lnin7WRpKKg9ipShJbnZWOKka6t9Lp7LllOWRGmiMO1JGh130s8nuiPjkZ8R/5IeJuWyRqPE9TTezI+Ia2ZOvq2uSetq05WrQsR1KkPUTysY3juVKPujFouuu5uWGhKw0/YSa5L+S3VMZuXLlixWp5GKRZEF6Sat59RV7FL8sr11GEsXuL6qUssyVSDqKECp4rq9DNRpP0r2IftPp3RVSSd/gf7T6OM1Hex4qqmprvs7xFT11G3bVig6lal616kT00pMWns/SanTONTJkIfBKhjBSJScjuyhKzKyildFStJO5L94vyUnYhJU3l7let9T9ws6MtmzR+IZwlTsVZTbKdZp2L5Q9IopPcqO8MUU703dGgVLs9yC3K9P1ZFN47lWu5cEq210ayf1NBP4Zobtu5CFh01e400tio3CdkaPSSsqk5f6DS9xpS5PSVe3WWM90amP0rTi9mUJqsQ3ii3SxkzJmbM2ZsyZfplZC6N/HS4pkrI7kUPUSWx3ZPk7wqiM0ZI8P8AEKWjb7qyuV5qpVlOPDfSH2k43MWXR3InegvcVeD9yE1N2R4hqabtuarUfT+hbml1dSqpU3wydDstdvcg5yak1/oailSu3JnhvhdPXVYqG5Dw+jRirysdvQ16uHcdxaWlRltdFaDhJxkRbvYqqVRbjbpxsinWadpCq2dxV45XaKlTNXJR9indOw9N2qfcGrkT1ReUOSlFUl+SU5DXcX5NHFRhLL/QqUq172NOpJ2Y5QiUfFJ6fZcFPXU9UrR5JSvt7E05f0HGLuzSUoz54Z9JS0095HepezFWpv2NXlBKceChqJd6Kkr/AAOrJD1Uzv1JDu+WJ4sko1FaSPrOxK0oWX4NNLKO/k7svg7r+Duv4O6/g7r+Duv4O6/g734HU/BcyOC2RjY46XJLIxshqwizvZCjJ8CovljVNKxeK4R3Gy4mSjGXJ2EuB6SLFp4k0qUGo8s13hdbUTWDK/hGs7eNG3+5oPDK0U3qY7/hrc12mq1IfuY7lH9mdXKP1E6mL+B+HQdT17/InS0itQ2J13NHabeSIVKjgshxlWfq9kVJqntEVdvkjB1BtUeB1snuTpX3RSlCPoqn0Eqm8d0OnGlwKrJQxtsQpd1XRXmobxI1ZXuyhLMnsUqTnK/sVJpIz+SNXLZkqdhwkmUMrmprxSjFLc1NaT2O9JSsUYzoQ3fI6dncjVlFikq0b+5T1Fo7mn8NoSWab/8A3+hqKlOk7Nn1sJPYVWPItyNO5q6yjHGJ3lPaZRhanHyW/Jb8lixYsWENEi5LrLpYsKKsOJVjeSRKP+QqVKi2My49VSjLFyVyn4tppzwuf2/CNXFw2NN4lR1UsI8/nruukqanyS08fk+nT3TJ0VDllTVTpSXbH4tBpOtErY6iPo2TJ6WpRlk+CVWi6mxUTi9jTy7scWV4Ro0ZYlaJg27FOMadH1MkTiKDjZMqo0VWSyplSFxQaRSbjkl7qxrKE4wsUqL/AJjSaOWPcfBLt33kjGn9O+07kkj0S2KWmvUUYmtdOk8VySqGhSrPFFZN1XYqU2afTp1M37E4+3uOndkaOyKcFFsdPGba9yVeph26e1+RxhHZkKG/BHFlGWLJ7xaKlHF3KFB1NRFe1xMxTMbdLGI4K3S3SxbpLgjuuiY/JDdiZcltv11Ol769EsWanT+KUd4vL+n/AMFWvqKtbGqrf9lPUKc942Jz1EfXBJkaVSTjWWxpfFqtOf713R/4goZY2ZR8aoVoZx5+DTeMafUz7XEh1IrlkKkZq8WY478Gt1luDT1FXlYqUc9uTRQhQpWq8ElHC9PdFTQqpLKkVNHU2Kc6tFWKldpclCrGpB35KrwZUamOEZQVQlZMq1+7LcdJs0tShp6mVV7Ciq7b07yRDTTteSK0sGfVWdjTYVHwa+v3JYeyHSpspQcZekdM7DkUpLTTztdlRylNykT3ZobwrRJ0rtyROlcpwIK8nJkY+gUN7CV9ynSzZj62Rowz/JJWRSXrsQgkrIl9tysrbM8NXc1Cv7Dj5MzIuXLly5cuX6cFi1iT9jZcdKNOUldHbS5ZJ2MHNbotjt1q6nUUan2XiSraTVL99b/UreC0pRfaK1DV6Glhh6V78n9sZvsrg7tFPC526dJZEtRShG8I3IV+7U/dQ39jReD1/v1bsn/uaejR0sbUESi5clfQqbvFktFOG44yg7x2J5VYJsjUqaePoNLrJSlaaMYyRU0ilwS8Jy/mIeGYK1yfhLl/Mf2L/wC4/s70qKZLwnL+Yfgjf85qPDpV6agpW+fyS/Z6T/n/AODSeBVNJVVaNTj8E4OpG1yr4aqqtcl+zzbv3P8AgoeCOjJSVT/gl4Wp8yH4NH/MU/CFTd1P/g+igfQQJeH0202S8MozP7HofLKPh9Cg8kVvQ7xMct2xbcG56i8uROSViFecFsNtu5eQpTMHe5FuJ3ZVPgndo8Mh6nPy5IyRkjJGSMkZGXRU2+B+nZl0bEty1z+o7EPtSJTUVud+LdkOq4kdZd2ZlH3Q3TMIPhlXRU633xTKeijQ2pqyLGo8H0epebjZ/K2NV4DXgr6az/7Fo63c7VSmzw/wdf3tV2T9vcoUoUVjQjj/ANipJeqQ9TFbRKniemp/fMfjGknTcoS4KPjmnrywbsdmlX4kmeJeKrRXpUVex4X4i/EX2ai9RU0dWL/doo6taJY6t2KVWFaOUHddL2Lly42kXSLoW5YxO2On+TD8mF/cURRLIxQ0kNJHaiOnFFanGxjBmMDtxMInbidqPyYRO3H5O3H5FSi/c7cfk7cfk7cfklQSXJoF6H+goylwLTVPfYVGC+6QnTjxEnLLpFmbtZkqdOX4Keno/wBS9hu46tOOzYpX4KleUF6iGopSdmQjfdFRWZCHqyJ1R1pKV7lKoqkbj1apuyKeqVRXJauERYyWTVidWK+0lKTQqdt2S1EYrYr+OU8tzV6yFTS5aee79vcSq1p2JxwhhF3JRne5p9ZKEXJcilFPKd7nhc9PR1EdRJ2SKGoo6qGdJ3RrpV5TcWtkfsnQ12Xcl/dfn3/oSa63Nh2NjYukZCqo7qO7E7sTuI7qO6jur4O6vg7q+DvL4O9+DujfcVj6V/J9Ovk+nXydj8nY/J2Pydn8nZ/J2TtHaZ2ZEack9yr61saGDp0vV5fp5fzbH09NcyE6cPtiOtMvfq+iF0uOWX3FXTZ/azU6DUU7u1zQ1qlGqoPhmqpRkrs7nbfB4dqPqF2oxsatSp8MTbib3Ki9Oxo04wwNTTqU3ZI0enrReVXZF4U/sROTlyY+7FJS4NTJxpSn8Gtq6iU25MxdWH7x2NM1p1eLO7eLbZP1bxNPGnN4VeUShLK8FsVHP+ZGmU4R9f2lLVV9LCSg/Szwbwer4lL6ivtT/wCzaCwgti1v4GxYxMSxaxbLgu0KRfz3MjdlrdIK0EPbrczZe/S/kv0XS3WxYlRpzeUo7lagqq2JUHDlGng4qyjsV1ju2QknshQ3Jwk3aBpNNUpPOqx1FH7SUrjLjTkQjYcYOLizU+FQlLLkr+G6tvaDF4Xq+VTf+w/C9bDftv8A2NF4brHqYuVN2/oajRaiFVqMHb+hV0upl/I/9mKnqKcrOm3/AKMq0a9X+V/7HgngVScu5ql6P+/6llFYxWxa36a6W/TtbgTuONzguX8lyzYo2L9V9qGX8tixew68Y7Mq1ct1wT1UqTKerjOyfubFy/VMyRZD2Li22K+mjU3jyfRzudqy3Z3Iw2ghyuMvYb6Srr+U77jIWp/AtRfZIzl8F5fBeXwK7ErjSXSpVx4KVRyW4lbclK/8FYt5rdLJjpjVhdLCRYsSajyJ5faYyP5R9E+mUbH8wvcnLGNyU5ew6E6vJ9POHuTpd12kYxg1P4HN1FeLKNSa2J1FFDqTlwxajGyY6kUfUx9xSurryXMrEp5dL/HWU1AnOUnv009Jcs1moqd7CJ4dOrKb3NRV7a2KFarJ5PgnWkmarW1KUM0tjQax6pboqzwjcp16lT1PYbuUI4LclK/WpOUWlcy2uR3MTEwMTEsWRt0sWLFixYrRqOm+193sS8X1mjnhq6f+o/2horiN2R8a07ipNNX/AAafWUdTtTf/AA11scdMUYGJZm5g/cUEitOMd0UdR3HuiXA/JJ1oPY0eunCSjPglXUXYlWnJ2sQj7kpF5v7SMVbKaK0434IQildELJ7ldX4Ixa9z8EU0hwTWxSk6Kfwd/MpVJxla9zG33Dkv5Ridhu/STUVdkqreyOSOlfMytqKaeNMp1pRexU0tGvH94hKnpIWgiWscnuUainsTsuRVWpGcKUPQKrnu0Pcp/cicr+ScFLdl5Qlb2L7CkZmRkX/UlFSVpcGq/Z/TV3lT9D/HH+3/AMFbwfxOlP8Ad+pHhehnp4513ebLdGJ+3S/wX6X6XJVtxxjVX4FHHghqfaTMlLjySpqo9yGkUWdq0jtei6KialdFP1rctZbEvkl+89ijFrZl9jv0/tb3FTFFLhEnZm8ipS7lNxjyUfD7b1WRUae0F0bSJVdvSQeUEyxKrb7STf3Mc3coVbS3HVz4J6WOXoiVJTg/SaWcnG8yuu4T005M0lHEnHI7TuQUKFPfeRfpCD5Zz5c4ynZryMt1W+/VdF/ANF97IdS2xU3dxRct2KPuypNt/uyLjUnsQbjwKaFPKokulLTze4tnsO9tzuXp2THjJblOKXB31KeA0OJUj6bI1E5RSKlSXCZopSlT9QqnwRozkzsrHGT3FsrLo3YnXtwSnKXJcoR9KTRJ3VkVaV1dH0rcPULw+pIp6Gz9bJaGMXlFnqcbo1VCummtzTqcJLcfz7nZnLdihVpT9G47MnTln63Ybv0hG+76It5ElfcfmkR46XLikU3t5b9Lly5cv5qnplkj01VkNGFhxjIew6Ck848jlfb3FclGre9/+DtVv83/AB/9lG+JKMeWX3suCbaZJsp1JRdzZ+tlKTd7nvc5J01LkqUIXs2aWE8cYLYjShDndjbfRuxOulwOTlyMwbNNRjCObKlT4I7RuNtyLZCTZJbkVtkLclaJsyxyypa3pO5G9rkpuXRRyZbzNpciq017kXnuixizFmLMWS5t5F0pcdLiYzIuXLi46MuXLlxO5WI+ncUri5HB8iZ/QmmvUKnf3Jxa4Z2fy/8AdmNOX4HpZ323HSwd2OcI+xW9e5g72JUtj7EU3tcurnYnNfBT01Gjvyxyb56N2J6hLglOU+ekYtjaX2lGkoK75PS1uVLSXAm4xLojsxbk2J32LWXpMWiMdrs9zgqzsrIQxK4lbz1LSMU9rlGNrIsW6WLDnHJu46yvYha+5+7JOKYtymvUYmJawzAwMWWHwIl5VsNXRwLm45bXQpu3qGvcTbZqJOMdjTqWFmSTS2O1LopNDnGatNFTRQn9jsS01Wl7H5HL2JQlUdokpzjakuTTQhQjdLck3LnrOulwTm589IpvgjBL8i03+di08Ll7Lbpfpu1c3fBexe/S5yRn7FydW2yGRZyyMbeZlSWXpRiR5KXz5sbiQlH3HFP7R34YlJcP/k0Um579ZEvYsW6WLGJYxMDAxMemKlsxfu3izgcbjp5rkUVR3SJVJ1dmiDsi19/MqjRJU6n3IlpI3umKOI179ampjHZEqsqnIi1+BUvkZQpKKyfIllyShi9ixKSR/TpZoTaex/UkvgW5wXO3fcqVMNhX9+kIb7EabvfzSdtyU3ISuzFkfuILFFy5cuXHyJ2Ipy4Q4P4G17dND978k/OuSxYsPYb6cMlDIZwRKqVrFOjkRUKStInxsZz+CDvcU7u3Sxbo2X6T1EYlSvKZ7kE5bIjpX7sjp0YW4Q6Sb2IqxLc4E77DgnyN4vYuXMbjdvYTuW+D8dJ1MUN336TuUdtz2v5qzajsWYtmZbFH1TSL+S/SXJ6RTcPtO9Mshmi+5ly5cZcv1v09y/V+S5NHI+SysK6JZTWxONVnbqEHBe5HlsS9Vy7uXLlx1FfFclStOWxfpTouRT08aSELi5J+yFt0uMgb2GWuyUbHBJkZ79FLezJtR4JS6cEY5biQvNyJW6rYuXL9LlztQ+DGI6MR0E/cVCBLTL2ZQpdp3Ll+ty5cuX8q6SQxDV0cnHVSsUaiXsZ7l49FAxXTJo7kydab2KM+08h7lODmUqSv6dynSs7yZknskWsQk479FEUJNk/SJbCljsZ73LlPe5Jq5t7DafsW3uJlS0S76xWb6ryWuSI/wVy5kZFxPpfpfpcuIYxoXS3v0t0ZG1hxy6K3Vj6SIJvgjSS3kfgopKI+RPEUrDs0cCY1aNyW4rrYyExfkvbgk7Ddz+o5IlPEb6Ms5OyIxx26ryZWGslcSt0cb/wt+jLl+lxbi+OrXklse/TgjKxeRhP5I01IUFLYjC7sYXdiVNmEj6dP7hRx2iWuR+4hF2GnFEY+nIcrckJZbEVcZ3GlYcrmHyPktjsTXx0aI7MlZk7Ib68uxGOPlQxvpDgY/wCNpl/IyyLFrmInvYk7MRQq7YyLlOW59sjiRLaRU5IcmRc2MYkauO1zuXVjul0zYVzcaIWJP3HuybMhNDkrWLFSpiSqNrohshC2/nk+lvjo+j6t2Qmpbr9Ljoy5f9KD36roxly/S+5VvbJFOWRBxcLe52q/+b/j/wCxeWHI+rLGJwJvpdikxSZmxVWd1ncO4jNHdR3vgqSu7m1ukmQj7lh9bXErDGWEuj48soqasyFKFL7F1fkV/f8AQuXL+dbF779Irq15KkbbkWVV2ZXRB33O5LpbbIttcttcs2riOerZcZLhisIRYsyG/I10uIsW6PpwQp5O78y6Pour/gU/031h8db9GvJzsYYuxUhnGxRi1Gz607ODRB3i0Q3uiG+3RM5GmWdi2xG4t9mY01/KWpfAlT9y1Mxj7MheL3Zfo10v5G78EYXYvLGPv0b8/A/1Wr/wCdn5F0fkkroiy3TszO3P4MZ/BuhNrjpexFO3RdFz0fJYxO02ds7ZFWY4+onFt3HeyN8S7Rkx7kUJW8lhR6Mf8Jb9Rq680HfrF2lbox+SW24vJYsYowj8Hbj8dO07mLRZlmW6J9MiUvgi/kkO/Je5f26Pp7lOO1/Kv1X+pbzW8lxeZOxz0m9yMsl0aLdWrkdtmX8t+ifksYmJiYGBgh00ds7Y6bO3IwZhIxZJMp03zL9B+V3tt/ginYcmy5TlZ26PyvrfzvrcuX6X81i3luPql+s/8BXP6Fl/gV/8OTyV/Pb9a/6z6L/EqcrPytdN/wCIv5GWOOj6r/DeBO68jRYt/EPzc9H0X6nJb+Ft+rT481v8Pf8AgK3Ylb/Bb9F/F4q9x39v0J1I01eRGWSuv0qK38z/AIp+Vv8AwdpPZiowi7pfpQdmc9H1f8WunA/4O38Rj1scHJYse4ttjIuXE9i9/wD0PXoSqO8WQTit+j6M56c9KavuPnoxbbHsLn+JXVj/AEvf/CUJW/Q//8QAUBAAAQMCAwQGBgcECAUDBAIDAQACAxEhBBIxEyJBUQUQMmFxkRQjQoGhsTNSYnLB0eEggpLwFSQ0Q1OTovEGY3Oy0iU1g4SjwuJUZLPD0//aAAgBAAAGPwKN22ILBlYCypA81uxS7SOrjVlneB4p4eSWOWQF+VwyyMfQg1W6wWrroR4okOzejtre/ki0EVCZJCwOc+QNoeX8296fhmMeHs15fzX9nOwesZp39yur9WiqNVXr0W1xIdfQU1Rnhjaxrr5Bot7cd3o1W4Cz7porSZvvCq9ZAD3g0W0I2Ljapbr5LBvweIw8sc0uzkvWg9yzMstlMG5m9mvyWwxJL4HWEnFvinccrb0+aAwjwZKUc7gzxWVtTzPNUyhez1clRdlvmrU/gXbcPL8lvyPJ+8R8lvVP3nkqow8NfuBUAaF2V9GFYde88BWe53gvVtr/AKj8FxHicv6rflp4C/mVcF33j+Gi7DfJQQNYK4nGZ3d7WVJVQ0KyvQr6Oq+hZ/CvoGe4L2/43KxeP3irTSn3NW6X/vALfmib+7+q7TH+BIVA+/IOuoZOjGYl0IjpK1shjzXKbg8RBGHBznZi/Pr3BVnxL3fZELmhVDcODzIofirmI/vK0fkuwQu3T3K0zV/aGfxL6Vn8QW0kdvUoC12vemTwZJMoylteHNHClu6BmDgyzlG7ChknAtPNDCmzc/0ddSpTFiY4ZpHbJ1dPD4fFOOMkzTSuzGmgWHgxWKELmtcRmFWkFPZE8nDB+2lyUaLak+8KeWZ4cNs7Ia8P2fSoxY9padV+rPSvMKrX7rtCqNv3rm5ZZGhwdqCKrb9Exlstbxg7v6LY4qPKfwQyOzN5KhNDyKqF+CpRGWDCRuvvNpqgYHOA0La0I8VVr69xRFGV8k9meSB+Qk5OXuUcMHSeIy1syM0HwQ9IaXSUoSZK/BbrMvuX07G/ulXx8YX9sDvAhWY9y3YaK7mhdry69fMrtL2vJbz/AIqtCqxQ250qt7d7i78lvSn90UXYB+9vfNaq91ouwq0Rb/8AxsOf4nH8lSl6K6sVfro+VoK3czvgvURW7gXLe3fvOp8lvyn91q+izfeuuyAOrLRfRrea1b8sY96rLLCf3arcgz/cYqR4KSp0rK5Brh6MToHyAV/iJVD0jhW+Lg75BU9Lw/8AkvWVjS8/3fJZRM+F4Jq0fBFwe5xDt8F1PmhH6pr62a42+CG13bnR9d5RvmqcO15cM31RS9E4QzNfl1odFLLmEr8hAGW7TSydJNlcwODZGNu3v+XxT8NhYImwxSDLlFPV8f58Vb9ijtFYVYdP2cz/AKM3osrBResWaNwKwrg2aWR5f6tltzj40ubqGMY5pPaLpmUdl4CvHipRHE9z4hXcFncPxWxxDCx3eFY5ghlN+RVTZXXpmC7Xts+sqjXSiztUMwG8xyxDsFJJvxtzsea0Ne5X0V4Y/exXHzC3c4+PzVWOl99Fu1/g/VbuYfvldp/nVXaXeR+Sq+A0+4VvwtPvT8BhejYfVZTmeScwIrYCi9RLm/6bK/FetxOz++1xPlp8VvY3N3Vyj81WF0NedQT5q1St56s5VzfBUurNK7C7KoQsbjqV22Jc1vg1tlnyrsr1kzG91VYl3uov6vhjTmBX4r1rgwcnP/JD+lOl42H6rdfK5XqOk8CTwzSjN/qX/uMLvuvr8lXPI7wjI+a7L6+LfzXD3uoqRQt8c4Ks2FtfsSOPwavVg15NgPzK3Hys8Yh/5BD18tePZHzqg6TFYr/PbT/sW/V333vKzPihrzdnPzctmJMK0f8ATj/FHbdJZ669m/l4q2KnPgX/AJLtz/8A3EcJgM7tSC4Vc4e4dyEfSWHaZG23m0OvFPijis7eFeSfi24eQx5do7Lw71lmq1rdPsjmpJYpTsg1wofisOWMi9dHmdfeND+VlNi34k7UXaP8QE+/QKeKSc01B76KHaND43H6pv4UXoYf6wNrT9nI8VBXqZAR9pSYQRnPHxccrT70+KPCAOZxNXNPgUcRPigIYHNzhumVH0QVaylhQcKqzG+9yjlw7towO3hpa9a/BPx82Ob6PJvBgddz66f7UUsmPe8Yd49Wx4z5dBRGTDYz+py1EsWbKT90H8eShxOGExBAe9pFq1saeK9bhYS7ZuEeaOted/d8kXRyUo6jq6DRZH2urOzjqzNXpGHFH+03g5UPa0uh4rED7PyTQ/NcV0W3o4t5in5oO2feuwt2NescwHxurVd7l/V4M3eKu+SrTJ7wPldZnzt8q/Er1tXfv/kqzYPDHxjCo3DRWtZgXZd/EfzW66Vv8963Xu/fbX5UVWvB/corO/8AuH8lrJ8Fvt/01+Svh/fs3BbzYv8AMVRGfdQrslejSz+v4MDDx0WG6PyTOfdpcAKZ3O11W7PH7t5esxLvefyXrcVX7tB+ZX/pfRGImcNHCOvxcFWDCDDjnLiB8mqnSP8AxJsweEZc78lhMI3HPxEmKdcluXU0/NUOIx1fvt/8U6VvS88Qb9Zod+S9R0i9ze85fxVSJnHm1ZBDGWjhJEFSXo3Cn7oIQ/8ATY2/vEr1jXs+7E0/Mqp6UmYP+gPwCp/T3nJk/JbmLc/wxBP4quzzeN1bDx/wqzGj3LTr2DpJoXODXHgQp3ztDy7Nd4o49/chhTDNK1prC5g7BTgzEu7OUbtCW96MT5Nm4ED3VutrPMzZl1LHep4LDyYbpFj6hzmZhlrQ6eItZRYej21FXyZcuQgpmIc6Oa7g9pFjrwGi9MjuACI2Hh3/ACTsdin7xcGutfMf5PkrOr90VW6H+SszzK9kfFXk8go9uT6O5l3VpQ+5NrIRhpd/MDXL4lRvzBxZWrwhnc+tKdqlqUp+qdiCHbC+4011pl/JbT2mnK61E3C4fCjERyx6ZiKGtanyRje5vo+UkObfL3Dis8VRldlrXkCs8rH52kNbbzTIts8BhtdMGdwDWW5Up+izvL6SVrRGOZlaZXM0qA3h8kaPYGBpfmc/vvXzWTaNNOIVRvN58VrdbWKzvg5O2xLXMN20ue5QvcW+vub8D/umv9Hzbo3qHW/6INDYAH9qjbhMY6Kr6UuaVVIocn7tP+5etnt96vwW+97vDdC3MKw/e3iPPq7ZVM7iuzIV2CryMb4uW/i8OP31v9KYcK/SDT4NKpt5n+EayxYTEynuC9T0M/8Afes0XReEZ4vqVTb9GwDvbVHb9NNY3/lMofxWaWXETn/pjN5r+rwzMHAbSi9Kkq1xAHbTZQaOGh1XpL5XuZWnIqrogfvXWxqGsBrYIRxHs8VXeohu8+9dGYmPDyOgBDpHUq1gBquyPFUFAxvZC/8A2VXZllA8163Dtcfcvoiz95erxFPEKjJmVWjfMLseSsXA9xVBi5m+9f8AuEnvVsY3+AL+5f4tX0UadgsRJiDJGSWNl3x4d2iw+3wmJgle542mUGN3KnEKaDF9K7OSCjXQ/WDkyWFuHkdJFJs3OtoNK8+SzSPjY1wFTnDj4LDxZgGDjlqU+OLLBLFKdkMoqN7Xu8VLicUwmSu87NUEjwonOw4YA+jBmFNeJqtnFmaOzu2qeawznOrE1/rHEU05oTxAgG1Ct5vXZy201TszbL3oy4dsr2tBz7+gPAaE6oejT7LOBVqjneyuIglpUHyPzTei8PjXvxM9nl43YWju4pzIsPtXPIflZaug1XpTDmNaNiF6uUTsNip4CHaE03tTRf1h7Npfeb48Rx0Qb7cJ9ZU5Q7hmUjpA2zam9r6Js8MYzZ9eDq1qqGFreLCL6cEW7M19ghlCByUMTS6spyEZu9ZMAWnZgsLDHdzcvH3j4p0ZxsbqGjQe06/+yyl1Hji1UPrGL03DDMHerffQUTXxYzENPAteQosZ0pMWOlA9WwVdXjQrtYiv2rfkt2YR+D2herc1/wD9Q1WwrD/8y3cCz/O/Rer6Nj8yVudH4cf/ABu/NZIo4Qfsxt/FZTjMnhlC3ul5P4yt/pGUn3/mt/FSlAt2zieYQ/qzwe/ksrcLE3jWgqrUCrtqK8z/ADQmxE2ZxocmbUJgiw0TpHi+XgqZRbRVVm+arsSeabIWa3N0S1rdKCyDjEK/Bbrxfg3VNDj5HRZqNW8SVl5d62LLFw56BWcsrWV9y3vKq/RWX6KoJqqBwKtTyqrqjwf3rhWZGfBfRe8PX96tyV/wXacpW9L5do+uUyDOzQD3aLLMIt3KGtbe31gdLH5pssk8r9thzJVj6AubfT7qhkbE1oieSwl1XefuCE8wdI0OvRtd7X8EXS5ibOHPuUrHyuL5S0t4i3PxHyWdxDa9ltNQvoJdhShcLW0Tx61rdBl4pu1tGxvE3r3o4XYHLTPm5d1VR7x71a/hdaP8l2XJ+Emy72h+qeakwvSDJnVq05TTnfvQxeExEU0bXZb9ulbfJDaQsYySnrBwrRB0WKLpSN5+QNOleHimOaMpl7NOF/1BUQz7YxcXcM1j70AwuII3Ga1Jt5quH3zYvcdafyFLE1uR0nbzt3gT8lHh5XbTK7eAt5/BNMD2Eue1hobMHNRF7482SpFbA10+CJw7WaOj0BzVUhe3IDVjXt+ssras2hG+KWJ+SLm5CaitPZOlUzENdaNugF31GX81OS5xAzEcj3KSDI7PS9FhsUzaHdrKJHW08F651Ws3WjuW0Zmv3quQn3qzD5qxerPVH0ysu49yNcsdNBkr8U5wbDThkjAROW/OiuxdhXsOdOKEr4tx+juCpwCoPFUr7lzVd4U0oFkawocKCnUGNPnZAUBroQUA7LzVIcubuFkGudYdVc5a48RwVInOdS1V2acFXaWPIJzpS91PrHVOflCrqtLKrGq9veq3cVdpHj1Vqu1VdlfRhXaHKzSrF63i73haBCQNkLRXccQQsnROFfECaiVsw3Qo5pQyd+BcYwXntDvQxOGw/qmtyNaxnAaVCEMXqw7eLM+Sh8ENuIM53aa18kcZG9rYaNqB2q6aHxTopnCQUpew8E6Nhds3ZhTPWhpqi8QtYa7MC9P5pVNkZACx1cuZlaOUuCJ+kDnSudrpomyxtB4VHFXaQu2o2PyvjIrIa3bcAGnK6HpMgZILUyWcO5YdzsPGHxsyuc6MOr3XTnRvc2rq14U8OCGAgdm9sNLstPPuUbJ2NhdG6va1vWlAnuhlcTHG3MHGg8fxp3qIS1c//wDGi9KyvEOUgllN33fzqspLGOLHU38uV45/zqifS2tD3BrHgWf/ALJha90crG12bq7/ABqjhIoBVzyLs3hf48k3dytIc4H+fFVoW5m+r3bFRw5MrM+0P2bBv4BHfaxt2dmp/wB/yTtvMN4VoDYhHerlqN75KTO453WrWgI5U/nRNLiAXOB1705ja9o6eKbezRvIsr2dFQkKo6qZR5KrSiKa6rsrsrRcUWNPChTMK+Or4zUOFqjvQNKK7ergjlsVrdfRVaK3pxXrL1FDbyV90E2ogWA3P1U14bbiAOKzvjN9Krh1Z5Id3xXqYA2mtAq/gqVHijEH2FqKgbdcl2xVc1ZgQIt70LV7l/hreut0rQrsrRclr8FXMtV2io+kMPimPY9o3dCWePmi/AOeyOW9AcqO1d7OoNVtHDeHNAmx5rdf2hvXW0ncHU+r+KbBA15zuBFGE/BRzyuc+TMX0caUbWlluygxaDNw4KPDCeK9M0jlDklbsmkNrXXmq523XH+FTS4B+0MjchIqCL6X7qqJnoRkfC5hYCwkNA5JuGxMLQyR1ayDSo+PhzRaWNjsRmZwrcGvhlun4rbsNA5rwK/EUTxE4EBxJfUh1Uxkz62dUx7u9T9AjIWF08ByOBbloK2t3XTdjFBh3UyuObdkrqTwvcLa4zDs3gC18UntHtfI1Wd7HsOawPxW0jw4kDXA5wLct7y/mqGN2sUcjd7ZDRtCQEY5JsxNHE/MIUmDGMdGXbR3ZsBVOYxkWIkLWulY6/HT5hDH9GNL8JKfWDUxKkMIa51KgutotXVzaH+e4KufvdzBW6W1OXyTnsIrnAunivFfBVos3Bbp1Tc3NE0ArwTjXL3FEEbyserUhUDqrVWKosp06ssjstr2W0ZI14Gvgm5GMbmdSh5KjQYy8WcmwYiQOLXVCrpppoidHNNRVGV/VZesZVbsJa1VoVI4BzqDks7tCteK7SNCrD3Erl1bz12gt2Q07wqu3e8LttI5hUNEN9q1BV7dX6KSkeY5TbmosD0pgZPUvBjyh29H7QPHvTZJIcjJqviIOYFqDILud2wdEXyQPytt2SnPxWFa0B+6zT3FPkYTE2hqGvG6eHuQfFjBs8u9WuvFbjzE822jBmqPfRSQw4ssZFV2zy0baleKb6VhpW19ratH4IxwMc6V1GhxdVQ4Zs0bDDIM9XWIt+KZgCZC+JlncHN5hVv5rLJh20e8Fx41Pf5J+Jj2roxlOckHjcH4LMN+naAPwUjHM9VO3InxgE0JzOAtw/JSekN2gIRbG3gTTXgmmHFveYWkGmpvU/mi+ZuSjcvuvrz/AFTMPiMXK5sbt1hdoKIQiPdO9vXPhVP9HyM9rcaBUD/YFGSOMDLrzp/P4oMgj2bWmr5HDdZ3D+eSjggJbFkyipF6XP8APcmjAyzmpzzNae20G/uTcRgK5HuBLMtQKi4PLgaqKdsJhD3ZXtDwaJuR4Dq0NNPFertIKi+nHldHM010IpqUC5uYCUGnmiK0JOhsqofFbtwdQszeyic3gjtg0lltLlUf4hb2nJWCblbmKIcLjgqmLTVAZd6utVp8VutV+pud1BxKIzksdYd63pC0IUlc5uipUrM8nkLIMpoVy6qrfiHusmevbc3aqNdbuUz70yKi0OvVWhVwq+dlug0VVqu0qZlVtver0IVn2HArtX7wq/iq56eK/tmH/wA4K91GyVhIY/MN4rZ9GSHCTMuxoPq6+HD3KTC49kscjAe0a1C3O1y8VTdaDxNwiXbt20LefOqzx4hzXZhr8rItxED92rq63QhzbKOXcLnaN41+Kz4XPiCe283GX7Pcq4fGkQytDtpkPPRbMQEums1z6uq5bZri2PKdylFW9k4U3jpT4fgjHIxskcguCKghS4voqI5e1lBuzw7kwF7gyzTbVQvMjNpNJkMbdfE89E57pHhwsBWnf7kXsYGPrmF9Py4r0k7spbR7WndJT5G2ZZvPhqqQMu4HtWWStRxNdVlqd+25vE+CE+Ple2EaRGxcPtcvBCKGNrGDRoURl0EjWkjXKdSoMNFCWygPiLmW4WPmE3LFFm4ZzcHlUeSf6LgTsnvLpDaub8Lp+HhxDajfZe7qUsfcjHjWFsjLZWnUdy3CzI5trHvTYC4N2lNdNEYMRhnUcKte24eOYTX1Jjf2XUVkHAg5hoqtJoVvy0IGlF6SN6J1WlAszZzpTQIRhESb0nsWsjPPKGveDbkFJPFPXLzQ2zYszbHOVkha1oDeAQ/Lq1Vyu0stXH3oytLQG80AWsb4BVrqsl6DS63uqw6tUCGiveFV0g0HgpMmbZhaLs/FaI0b8eqous1fcq5uPJalcVUFarh1XNAFHHhpbuu4qs0z3eJWqodOr3lHDY/DNla7gdfcVJN0cw4uH6tPWM/NRxStMbXuLDbs21Xo8LJLWEzZDU9/JSYJ5adk6gOYCvIoxSBr+e+CtvFJE0ttooDhBtYnRZ3QE1Y4JjGQCKg7A4IuDb96DXZLcVUFjRoAq6lGLTJ8uH893U6TChsU/hZy9DxMUjcjLZuB5hOOd5kLrNrb+bJrcQxpCyinD/dNF48PHeSTWp5BNf0Y0QzRN7JO7IO+vG6JxvqI/YaNfFD0eAZvruu/zV+qq0VNAVtGt0s9p4r0/oprG71ZIXDs8yDqPksmJi3hdrxwKJxeNAgBts23f+S2UO7kkLG2rTVHBugYI9WupcFbKf1kdd2UCzruJ8NUGVq06H8EDQG/JZS4ZqcGhqrc+Dk4RhwY7dN9Ux77hpqF6VGKkmt16RKyrs1e5VjFGuNE+LEZsh0txT2sab1DRVZ5XucVqVp1WC4dW3Mnb4DRa1J0FFua1RdapVOrVWPVRk7OdHDRb8zbcAE9+dzvcu1RXC0VaLiFukrtK1dUdVv+asergjLJYBZy4nkqVrlFOrj1+8/NVaCRy/JB9wfuoPxmDBkGkgFHD3oydA9LSTR/4cj8rwvRul53wSSEDPIC4uRgMzdxxbnHOqa2OBxiIo98m6FtDO+R5FKV3R+zqhIOFj3hVzVVY3I4bHQB3I8W+BRxPRsz8QwezTfA/FNghwM7qdo5DZNf0pFsoIxSgoXP/JMwuAw0eHiYKNAuvWvLvFajrqVdwVm18Vqql3xVdo0fvK8zfELK2POSQKlUFabfh4qm1eHg5teKnhNRJEWOLSPtUt5rVRyO7dRUK7aDnxWZpJPNUfm7rrKNVRwNFUtKoaqgzUV/krr9VTguK0t1VeMy3GuGQrObUtqKrVVLsreao9ziVRsJKytwgB8Agdk3zXZYFqE6CV5yHREZPfSqO6D7k0NYVxXZRo0j3K91UWWqqrNXGiu9F7jQDVECwAsEe4VRzG6oy5VcuqyNgY7vH+6o6QCwtkQOdl7uqh39Wq4rJJExzftCqdPFhY2yOJcX0vXxRzSNFua+mZ5r6Znmvpmea+lb5q0rVeYL6RerqRyWZ0myA0AX9r+H6LfxUhHK6+mPkVZx8lbOfcuw9fRuVsOt3DNX0bfJcleai38UvpHuVoXFfRRjxeFtMTPDGxpG8ZAAhvW2jd4e5DM0Yhlf3vNYh2bENkjZmDHaWWqnwjpQ1zaSx5uI4qhho3u0VAVVfaV1pbkVUi6sFoqgldpUcOqgQDQuyhHDukd6LnOuVSvwVAtNVWhWi0HUE13IrtN81dC61XaWq16q1VK9VitaoYVhvq5ElEHRSHgDROmfZzqEdwVoh5lBx2tKhw3OSDnNk7GuiaMzrmmrTTxqnRxNzsGhovonD9xZHS0drl0K3pJAvpXeaoSaoeSuu0V2j+07CGWsrCdwG4FVvFg8ZQql7P8AMW65pp9pWp5rLao7nfkso15bNyoKeX6r0mXDzZK5d1gPyTGEUkkplYXUca91EaYZ5f8AUzi/xTc3RxiefZkPyNboiKOCJ9LZjUVTfTHxl51fEDTyVWTukH2JTRZpoXinEp0pdNu8Gi58FFhsQ3Es39x79W+6qiizV2QDa+FkM72Pp30KmZtWgyRObR1uCoonttuEW8FUknuKow7N/foiC33hVbw6+SoStfitfiu11WK1V1XruKKp49W9p1dordqhZWCqtFojZDdWiuPgtFmy26qKtE6R2jRVOe6hzrkUDUaKjuyN5ykr9WwVmHyRc2Kag/8A67Fux4s2JoIo1/Zsd/lxfmr4fGe+GM/ispkijJ/xsPk/1aBNOHkFdRHKc7H+B1H82Rw83RGR7ecv6Kj+jIyO+T9FlxHRIpybR3zX9jnYa8GgfIqjDPGfBf1XFtkP1SxwK3xT3VXb+B/JNGZxzGgpG4/IKrCCrM7uyVUyQpuP2Mm2mLgSA4iul+AVWwe9qvVo03gtGoOjG0b3FDDkYgPpWzCQPeqbWT3of1p7x3u/Reuc9nCrFDDhZQYpmnOXvq48qErdnyfdfRZDPI9vIio+KcYpM1BZrhU/NEbKSANNAHC5+K2kjpg46kcfJb+930oVaePNSuWt1FlbXfF8qlblplkkH+orZzYiQD7Di35IRtJIApc1T2fVcQocv1TXyKyuKqQUHQm2q/rGHaSeYQ2bMjHt0VRenJaFaK2q3lcCisArhDq1XaVRVUIrRVCNlXKtFp8eoIIgihCqSFwXBAVC1C4dXBUt1XCEDeNyt4eS7RHiE9lRcKrtX39yD3jK0ig5lfTSD/4x+ab33Usg1ay3vVQ9hV3M8iu23+ArYOZJPhHG7CKZO9qa/aZm6MlFnRnkVs5xVp7D+DuriO5aBUxjHA8JGWWfMTymbx+8vVu2T+67T7uHuWDLMIx5MvbEtB80PomcjnuE7P0jJLnNTtMR+S3/AEc8e1VN9aI953GiqekI68K3Uoxcpmw9szcjgTfgfFekYPFSuErfap8QpeiJTJ6QyRxb6oUy205cbL18zmP/AOnRDbT9o5d6QC/vWb+iJK8nFetZsx+9+Nk2F04q1jaF76Cv48EMv+iv5LNvgd6aDIBm+tuqR8cozhpyZh7XBGN08eZuvq0J8hyuGYO2fClV6QMMA/TPsL8f/E+SBZJvggj1P3acPts80ZMaazF7sxy0Qjlx5kYC4Ob6PyryCOGZhKxtAcKVBcOOuixLY43Rtz1DXaiqZm/mytqrB11pQotyscCePBNdmodKBZc1KfFZmO4rNdVVH1K7Jp4q1lTVBojJPJZRHvdyo5tOrMu0u1RePVqtVVBBGvVp1Ba9Vq16uKuEd3v1UjXxyskGuYKtldqea9yZIdY+5b9cziu3H/nN/PqeRxeAqZ9eNU7R7I9ebyssuAjIPip8NtKiN5A8OC2+EfrZ7D2XhbN7A6M9uN2rFtYi6WB5oHDh3FFsrOz9YUVHG7bHmFY1Xqzk7uBXrI8h+sE6DExMkY/gdHKmHaKfVIFfMomSOCjdQ5tx5LMIoQCdW1cg2eIyNLtB90I4rCYfIahsbOHw96kw82CAbIwtOtlJgnElrBmZ53WG6WMO0Z9G8VpfgqwdB4eOulcV/wDst9mDhy8dqf8AyTQ/pX1hAqOZVWPzDvYv6Ti9HGUgEvsaj3Khka798oA7L3yher6E9JbWgLH1J9wBX/tYY77TJh//AKliJoMMd97n0A58s1EIfR5sgbpVo4Ac+4JuJxsssLXu2YBpyeef2nea2rsY+tdfL/xHknl0uekxFf3QpdzNTaWQHRUzsLK6XKZc+WjL/osnSeLGJmewP2ucuzDQa+CY7m381mRVQdFrRZC64WYBbjgOCyZ+vNI6gXq4anmVWg8lZ9Cq5xm58VlddW05KzVQtorAdQLhmVMrPJWA/Z1WqoVSvBd6rVdtdvRdpXf5rtpzg3tGp7yrBWdUd6bngezOd2o7Sy31BRkLt47o/Pro76/4IinBSX1Wqpieitu94zZw5zT8EQ/o/KzL2S7OQUZOjoQyVuhykcfHko5CBkmYHZT38Eww4qIxtFPWje/i4oQiPo1nAP3q/JMmZ0xBGG+y1hoVmm6YhceeyP5r/wBwgld9uOg+CP8AXcMRypp8E6T+kcIW0oIyw0XrY8KXC2dshDvfa4TjPHgHxSEVoSwj+FN9HginlqKh0mUdlRNf0W1jI69jEMdX4qIw4DFTPe2r8kRIZ3WTMRHjKACnZN/cvQRhWzMkuX/VpevwTZC6mYA2Wd0PpJDgclQ3u5Jv/oWz3hvbTT4KmZ9f57lDHG57GvxFHDnZXp5FM2npI3T9CXCvkmhkuLJvuyvfQoM2bf4/0WGwkr3NZIx2XZ3q6qBBnodNf54LLiHPe3UB0ebgnObgwai/qAE0xR7MU5d6gMvR7ydm2+xBR22Ey2JNcOR+CZ6PLn2NWE+zThT4qI86otoFU9VFpcK5K0WZx7K7VlRpst1arU+9WTeStUhUDb1RGUNpdC1+Bqshbdbuq3lqL96sRTq1/YvZUVDSqzjiq5lqs1R3rguCAo3n1XKzmmyiNT3nkmst6pgB/n3okaZarJK9raE61VsUz4/kv7B/rKp6B/rcq/0Y3n23fmnSYDpXK06NkjrRH1W1p9RpNfeqYz/hyeWntXHyK2r+hHxsDSC2SLaFD0LoaSM5q1bhyKrDQuBDmwMr40WgVMjD5rsNX0YX0XxX0dPeuwVoVSnwXYXtK6pvUVZcJETQtrlFaHVS9H4fCjZREBozaCgTw6B4ApeN5DtVUQ4//MJV2DXvTQYBk9KjOhqL0QzRR6dyj2WLw+G7VpKIZsfhZ23q1naQIa4cjVdHvbmcWF76Fx4O0VP6OjtpvlZD0Q2o45iVRvRjB9rMbqV0sLY9iQBQ80yOPCxu2Q2fHgpMJJh2RiZmXM2tQnQl1Q0/JQE6XTSOSqGjSpNKonMyv3qLNt4s3LMjV8Xf6wLKZorfbVNtFXnnCvJDbUVVsnK1FqAfFdoLtDxXbaruCETpKE2G6s0ZkRcXO8lko4O1NUKUt9qi3nsIVcw81cUHiuCsuKFOoVFO9SYjSL6KN3Nya7KHTuudpeiLhHva2FiEWujus4YbceCq0X5c13KgKsFU1WatFu1Rz3bzTYgNFiK8Qfmsvsk/FVc1auU+Na1zzGLDXz7kGn0RjSe0Y3W/1qHFl15G13dFqVqV2iqmqoCo24fsGIEkvAGp+yVFNiHZpHVqaUre3w6s0srYxzc6i3+kR7gStzpAe8ELPBM2UfZdVXJCmljdvRtqKo4aY1IJGYQUAIBP1u5DaYmIl1gxrDX5owS42KGUNrlflr4UzVX9uxI7m4WKnmnf13HHKaWhZ/4qnpXSXay8B+C9Ixj5ts/tbU7yJ9IyW1X9v/0hdoLasdvMcxwI+8t2Yj90fkm7XZvy17bQhM1sAc3iDdaj+FYR0jrNedBRanzVqq581j2/9I/9ydjmbkjzrw7/APtRfBNFuN7TmN70Gw5LnjWlVHtGNBa7lRVJFkcjiPBH+arTisutUDdV0VQU5NIGvchLPKIvsgVK2mGkbMPq0o5aOHisjGOcSi/NE0/VL7rJPDWbv08VLI4hljTKEDJmMzXZRRvaCDHTPBHALLJXLwcCs0ReOa2crnU4dyo0G44rdhcR4Kj4qHvCAA4qnPRHDSyljHm7uR/JRxxkbPtuaHWz8aJ82xfipH3zAEMYe4cUMO9xzDtVHCtf58EGtuQNQhFMXZeAdwRbYhbSO44hZmuyuWWUe9GhXEBWW80KgLqcsy2uzo4/aKFYy/uqaIMhiZGzuC+ii/hWR7QWuFKFV9Bw1P8ApNWVlABwC169ndp0076LtNPK2qw82zJzsLdBYZv1RfORuu8A0UBp7kY8EQ0D+8Op8EXUe8ni4r6JnxVJYPIoHDzlknjQoR45ucfXGoUscDwdtEdme9PkOHhMdXZvWsrcHUKORgm2oAzVHBdIsikoTI57aitK3W1lxdGjlE2qGSOcktzEupdEPdsY2RmQlzrkV0HemT9HYaSSNzL1cNUf6l5yNp81X0PDi3Nv5oVwg04SN/NTnYhuWPN2xwQlLWV8CvWNFtKVVQHV++rx1TcBJWKjS/OLr+0ONvq/zzTYcRjHte6+XZfitlh8a5xpWhjIWJ2chdma34J+Ic3MIpGWP3/1TWyYOp2eaz6e9OjhwfrG65TWiryWWtupsbGFzzYBGPGTFriK0A0W1B2kR9ocFmjw5LfraD4oekMyfj1Gh15J8rxXJp4otPFaraYZg2rhvitKosjdTLqtMyMUrKUu2ylt7BKsrFSRyagEhbrteZQL4mNdzAQLt5zBYIbQjNS90Y3sqOBpom4eV4AaSX0HsoljicjmjMeFf9k+SJxfo7edZObEaSAAm9P54LIZXB41DjqU5+Idea5aRoFlinu3hSw96yYoRyRizd6l+dkchOXgqKoWU3RGiOeIkDiqq5W8bIFvBVIajV4e3uX0fwQ/ZzPcGjmSnNjg2jaijmu+1+V1l9F4ca+SwzsbA6N0JeWtPiNfIJvRkDr0rKRbMTwW0ldUnRWNPBfSuVpT71SUU+0E2PFPzxnR/JBjnVid8O9enEUNWtkLR2hwKHoz96VpJBc1p8k/pJkROGlaMxHs2pf81lknYz7/APumAbCQgEbshpRB0IYwhpbUE6cU8YYOy7Y1t3BUaHEHgWIZP+H2055kwPDozSzA2qxDY45foHkHZ9ytEPJepgZmro5nD3IVwUdONIyv7DJ/lpuIwuFnEjXU3GGpC7c4ba1+9f1ieVsMYL3uzdloWSfCSNJrmInO7ewN9UdjA81GU5pnEeSmbFgfWyAFg2xteumgWylGV0e4WlvJZp4w92cO01QdDBsjeozVTTFgZnnKCaTfossuBmZm0rNr8FPM1ulGt5gLNn8V6PJRwdY96na95cWOLfI8FscSwFknAqVk7g8Rm3hzRHoDcgtnaMqlizbvaDlWq2kQJdxAF0Di53Bx9hnD3rP0fK+GQcHnM135J0E3q5YzRw0R3Q/IL2svRGjtM9ltgnxvNHA+YW0gwzi36zt0fFAY1hjiymrwQfBPwzZm1Z2u4cCszsVJnA1AWxieZnC1hdUngcw8M4TrmylnMgBpu1PJO2mkr86dKInmLnwRkfAcvM6BF0lMkIMhWUGjSeHFUG5EN0AJwFrnIO6n5JkL2Bu9lOb2UBDiYnSO7LXR0r8UzCY3BZBIPVyg1Y/wKyENEbxUODeCAwXRAmZ/iSxZQfjRf+pjAxR8o4s7vivUOnik4OoKHyROGx+Z49hwpX3r0XFxTMkad5rrFF2FzMANNU6CVtX8zyVTJkqv7REvo/iF2PiF2Piuyux8U+IMFXDibJ0ZxEDwHV3JQcqYYMSGZTf1tK+S9ZJtb67TNRSzONsxKzc9OqkcbneAVTA5bzSPFUPYOq9Gmc8t1jIY4+5YjDS7bPG31ZMEl+XBM22CmxFOAwxr52RaOgukjbRzbJ8mH6Clax4rQENp5BUb0Juc3vV8Jg4R31r8Vio34yHtNNIgOR5HuWKib0lPRkr2ikh5q/SGI/zCsO6QvkftW1LnVrcLE5HPj9Yc1Har6eTzX0rldy1Wq1UWHk0lG3l+77Dfx9yOKowQ5yTndqm9HTFozmwpanNEekyB31yeKfHNgIt4UdJ/eeOZS5cfCzDt+jkfq7uopJDjMJnZcMDjvDxooIXAtlDd4d62OLBlBdnyn2T7kYIXOEM7bB2rXBbQ0jB0LzSqOIxABiZvvfGa2Upw8VXSPMmtKVW1xUJDBfMDUDyWSaOVsUwDakEVAuVkaGiNosAs7DlNF6T0tHliBswHt/kFssNGIgNAwWRe2zwKoAG50omQ40xStf7DuHwTvQHPik1u7MD4r/1DEsiI4D803ES4gTxsBIjI1dwrzCzQsqBawVAN13AoOzeoewGPuodE2WNwYwiuZ51UuJeY5Hv1c3kjhcW0SRu58FNA6QuMc1ATxjIt+Kkw5OV1mhMmx7gWMsxv1uKjY9rWtdo0dr9E5kjIXiMjLyW7hY4ZJItWimbuUYHNxKyA24BA2oHV962eHaZKDM7KPZCeJ87Z3vDd8Uc0C/5JkXS89WyUdlaKOB8eBQcMJHVg3HSOzGvvWStT3FE5HgHgdU2DESB5PYazQeJQcyWoeDwuEx8zw90dmurcBHk7eCpyTOj4zlihbSw7RX03wK7ZXbK7S7S7SoXVCNMJDva+rC/sUH+WFOcNCyLcc45GgaNKlfz/ADQQxOLHa7LPxKysFByCoW+aNGrMNlA039Y69PAJvpHSL3FhqMjMtPNFuCdlbXnxTIBjH7x4WTQ7paVjqjNs6DxAt4q/S+JYzNd82JoHd3BHB4fEYOWM3tim1/7k14lwm0IANcRFp73J+Kx3TGDwuZ+Q5p25a+LVIw4pj6OIzNdUO7wt1xKhbFCXBkjSS1tT71PHijs3PdnGblzX9VeyXjRrhXy1W1GGLm1c0ZXA1IFSBzNE2b0AhjtHOkYPmVlbgA61SRNGQPfVeswkbfGeP81/W2sbE0Z5CJGmg9yEkWGL8Xic0pyi8bdA3usPmmnFxNEx9kmuT9VHLsWbdldnIO039Ew4tofJMezWuW9E5suDfHA3iWUag+SdscHscS5HBQkymQZmuBoMvGvJNOK6TdEYxwe0X7gvR4cRMSTQE7ubzCjilikIDgWPJzNr5aJ8Uh3mG9CqteSQVlwkYBfvtY37WqFSDIRdUloac02KAiO+9yp+azZ5XubzNk6NnsnSquVc7tEYnW2bdO9a3W0Zeo0AQe3CPeztUrfy1XpeOYc2jInez4qmfTQBVbTaNBIXR4wsD5mxvO1yjQW/JDNhZBTkFsmdrSiriMS55ro2zUaulY40GaN9dNLFR41xGKwgs6Ro48Mw4Iyn1kld0fVWd0MgzHedXQcUDAwvjcKneu381Quc2SI5hXVNdheicTJ37I5fNEYno+cGm9TKcnxXqsbG9moqCE+XEgPfJ7TTohNjIY5HYUiRpJ5cFnGKkodN1Uq6V/1WtBWTA9HRwj67rn8ERj+kJTH9QGjfIINDfa58FJGWMkmaM0bCOKynDw7Q1qwxhpTWYarWXoDel6KoK0qqXX9p/wBCvjB/lr+1j+Bf2wfwL+2t/gVBjWfwq2LZ/Cv7Wz+FTQsxkdXsLeyjHm701oIIFytmDpqeQRODiysFi4vyD3uWdmNcTSpFczE0sex8LN52U1CFKhpq6vNZzTv8VQOr4J88j2CU7rA9+VEzOiDeGzeX1+AQw1A8ZhZze9GLKIY2V46+adHHHJMfqsG1cPKyaMfE3DQZSSJS1rg63CtUzBQYZ+IdCN1zRlHxVMD0Zh4e99ZD8bKk2Nlyn2WnK3yHV2QPCyMWF6TkMZ/u5DUfFMhxPRcMOUi7WmhpT3jRBmH6Obsm07DQ6w53+aLmT4ho5GNqhkxmK9XHOTKHCnZFacuXuUlMTEIn7zHGS1KIBmLwotvetFymP6NmwYMlRKTiWADv1U0mIkw8riKRuZM0gc06r27TKXbE8Qsj5GBgqWR3t4o7UUj+qLV8fyQLnnuDbBZOCdNI+hbFXMONNa+9QR56zSPELfNDZjPLTekd2j+SbtwHEXB4t8F6IDV7nBo7+SAjAc/23HiqPAzcHgXCkwccZdI03PBelYTYvPGPP2h8l6NJBI2auXZlt6pr8Z62XU/VaiMRBGJaUD22NEyMu2sc30Tufd4obTelOvd3BfVQxGbeYb+C3SmYeI1kkcAmYfCua1jRoFSocttHE3bBp3uPgg+QmnKiqd3wTmVbIx4IcOY71i55TWKCRwj5kVoqVCrl96bjsRAwmHsVFSXdyy7Z2lSM2ipfQnVOMTQJmioPNbP6wzUKMBwxe0jXaa+6iBhwczAdA7iF68sadb1/JbrWSWJ3XJzZWEEDis1dF6Ph7n2nnRbSKQjvaU6VzdwucbezdZmFes3StGq8kPmVTbQea7cP8as+D/MCrtIv4wq0j0p9I1Cgi5/Shf3Y/wDkCvPFl7inRub/AHZFDonZGiqnc77LfMoRws3bsDaUuNXfFPbLUSCg2bRYt5rEf0dDT0l+0eBpX+T8UOzE1UcZZdBurK2LKwabyMwOm6PBVbK8eDysNPnJ9EZ6wGu8a1b/ANhQkGNZudiMsazL7zY+aEOKxM7Wez7AI92q1VltosHK9nMBDEMEbwfZa+4W1b0i3bC+Ut3T716XimB+HDTvNrSvD4rtXEW0dXh/Nk04l7WClaOuCttCMtPbiNh+S3osPi2/8yMZvNGGLDxxXzZSyg/0o+idDumyj+6qQB7kY5uji1w1BfQ/JCDD4A1P27Jr2b87PacKjyQnxOCa8srdj6Hy/VbBjMPEwXyNbkp71kLXDNp3+CBIrbgUXPZnI1FKrENlJDWNc7X2dfzWHmleNzNlHfRULkXAF1qKOZsby2Kge6lhco79VyyqWYWL3686Cn4IONjxWD6QyjaROp5qu0ABHintezNwuFh4mMc6bDyiUAXrQIPmhkjH/MaWr6RNwGHrJLIQS1grQBVi6Nl97mj8Ux/SWEfEKObHm0qs2Jn1vkagYcSWnnqFIMc2hjbnDh7Q5r+lOkiRh/7uMW2nf4LZ+gwEH7H4r+kMPV0DrUPsO5IOe7t3TdQQL96bDntXMe5Zm2awZWhX1cnb2jaBMdW4H4oDlcL0/HM2ojPqmcCea2jW0aLUaKDyQ/rJJcNGE2RbtnsyjeAdY1/kJ8bmhmIju2Rtj+qDDM7K7UEoRloq06qlcp8UXMzMrryRc1u9xDbJrrOAN6p5YwZcxpuBUEipt5P4lkdIaKpnCMWaEV9v2lbGlXxqoMV71vY2P+JMjOMZIHGgy11RDyGkmlKqSHi8bvjwTY3y+uzUyEWba9fGi9JbKRtLB0d8oBvVZtplFdAs4oXcDqswNjdS4l7qWoCeZWzxG2eQbZDQfJWwkx8ZFF/RkDiXSO9WDUgBzj+CdHMwseCQ5pFCCsrH7p1bwPuROK6Hw0ubU5a/A28kQI4GB/sSMp5IbLDRxt9nI2hREGJkje/61wnYPE4YNc2x3jWvin4BvrGndym9QVlh2eEmeBTvpzVXdLRjNr6s7v5oBnScTItRM0mvhTmnvBhxjNNowZXt8R/uhH6HNUmzdmTVM2ceIw83DUO/NMb0/DHKTo91pfhc+9E5nF7zXepUBZ4yTfRZyXtPes+HZmflvRbPFsoHatK2RBkp2XN1PiETMzZlxrvClVJPNAH1aKxnseNFkbg4g37oUbI5HjCjfeQez9lbGCkcQ7Ibaqf66ruDnDe8+KlwpdsooDR8h58h3rI6SV3fm/JE9HyySsaS8teauHE0Ks6tdKJrcDhC01BGchvems6Ywz8M/gT2SfEWTMNh5QZZXZWoRseM2XeedSUI5GB2ex5FHH4JzmxD6WOvZ7whjcWSHTb9facsrS4e9ZpMpykUzc1xK7XuXo5nEQiOdxPFnFvyUeHh3Y2sDW9wVS7TisVhnPLQ6OtaKMF/cJG6FF7nHe1RNe1oOaZGy5N3KpdoiWmhJQG8C1orVNPJoQkz0AtcrIyYCI7uXiu1fvTnE15+JQle+r8ov8KKQEGhcaVWZvabqtq17S3LXLXRGOmct7NbJ0bsHI0a5iNUMorxN9e5dn/Utf2tevVZhWuqa7svamyCT0fEN9oGgd+Smkxcu0bZsYbS/M2/m62bWEOdukjhVCtuDR3BNDc3ardQYTAQZowc8sjnBjR7z71XpPpuP7mFYZD5mgR2OFD6dl0zag+PBNgwj8NsgcwY1jAL+SlxeJjlimmcXuINiT3UVpwfvNp8qqz2H96nzQdtJGP4kCrFlhLpWjgN4eSbNiWPjOarspt8UX4eDDzPmN3S73wKdJBh4A8XzFlP9lSLERveL00TZcViHMrqBTd95QYX4kH6zX2PzW1hkfVvZabjxW/LfkhFD6sDQnX9FtnuzX7X496G42Yd1neSbXaxivthZZKStKkDBbW6riOy0ad622DleBxYSpGNxEjQDTLqPJNL4RY1rHufiqejP808OwznZjU34clVuEk/i4IsOEeK/bUpML3B7qr+xSH99W6Ok/zFPjH4N8+d5MTC6ghHIL/2p4rykH5Kbo+bot2WQUDtrXKedKL+ksMx+bDvyXFdW/qnbPM7YnK7uVPRXU8U/DOwpLJAWkHiEGNw5oFU4Sv7/wCidC/DFod9v9FQPef3lTe8/wBE5h2m/bt/og2MOIH1nfoqGJtOCkhdG4DLUvrbwWIwOKgY6MNDstxdMjZ0VtWyPyl4kduDn2lvRPd3bQqvo72+EhR9XNe30v6IDJiLf80f+KqfS7/85v8A4rO8Yzw27f8AwWzDcZT/AK4/8V9Hi/8APb/4rsYr/Ob/AOKy0xVK1+lb/wCKpTFCnHat/wDFB7fT3l7w2jXh3mMuijb6O8Oe6mcPAOnKlPgpNi6S/MrK8AqrQ7xWtur2Vdyu9WeFq1dpq1CzzzMjbzcaBbCLpOKWTlGC4eYssuH6Uw0jvqjVZo2F47iFWPDPJ7llPReJeO6MrDwPhpLIM7w7Vp7/AHUTKvqRUtHPh+KpHER3uRMj6qSsjsjTRorYINw0D3k8ltsQ+KK1g5yMldjA3d2jjqeNEcTDjI8RCz6QNFHgc9UJZ2w5XirTNlv4cVkIFeJjzU/n3ISYfFuaHaE8fks0OP8A4v5KzY3BNmP12dv4LSeEjnc/ghHLimSs5TAg+YWzGDja7kHh/wARdFzsU/DiPgTZGGUuLm0sqRnZt8yqRNLubis75Mzjw4ISNwDr6ZnNBp4FZcSIGtkG64PsPHipJMLPhcQwjejvU+6iaZY3YXN2Q+OQA+FWpuP6X2hlnGYRt3WtHfxTsdhJskbe215rThZUxfSAb3AI4r/h6D0yKtHOG5Q+9GDF4RsMg1a+RoK22xDm5gN12b5IUgcA7NSxvQXQcITdmf3VpVOcYuyGk356IxOYMwfszfih6vWo1Vox2S7VE5Oy0O1/nmspjFu9E7P4p+E9Gz7Z+eufT+aK/R4pr9J+ibH/AEa2un0nd4IFvRrP8xD/ANObvD/EQLcIy7ajeVRhmioz6r+zM0zI1iaaNz3TvUx2bm0K7GGGW92lVIw/8B/NPkzx2bwbqnvzta+WxGW1FuuZ5LSI+4/mj6uLWmn6reiitY6/mgDh4+/WyFYWX70KQNdzvov7J7VNeHNf2T2g0fmnUwgNOzftI0wo+zftFfQN81XYN80yT0Vm4eeun5raOiDL8CqEea7NlQhcVdo8l2R5LsN8lWUxtHfZVkmZTyR2REh+zvfJE4PCOA5k5fkhNjtmwtFAWNWRrssY9mv83UbmSODyK3CDosY58YtvHMPzCDelMCSPrxlD+iGwP57283903WcyG9a041VuHEqojcR4Ks80cA5yuDfmgYZfTCO08XbVZOjOkWw27LIi005ZqqSV+La2aM5KSygEnldQHpGRzTkHq2ak96dHgc5ky2YRma/u5p+N6fbI1rRYONXOPu0C9CEUII9psQB8wpMFiK4h8hGxa23vTZZpMNC43yF5t42ojhscxnNjozUPQM2Khhz/AN28mvvTZsU7CwQgbzgSM3gFscNA+WpqXS/zovWSOZ6ttq6cfxRih3ncVSSsp5NCqMbFE4izcq/r2GBZBR20zbpNbEc0I4mhz36IF5ikLScoYakeaG9QhATsa8sdmbUVvzVXZnZuCfF0bR5kts5Db3LZYzBMjkbe4BTSezS1qIf0i36I7sg7Xgn+isGHbHkyNHcRS6HrhYkjePHVU2rdKdo6IjaMv3lZtsyta1zHVWfHa/aP5LtxaU7Z08ld8VxTtnTyRJfFX7x/JFu0j80yV0sZDTe63blA7FhppV6o2CK32/0Q9TDVtvpP0QywQigy/ScP4VaGCwp2zp5KzIP4z+S7MH8Z/JUBg8yjV2Hv4refD7qoxOlDc/FNxMTdoG6hVGClqftBCmEjB47yvh4/4yr4dn+Z+ivh23+3+ivhx/mfoqDDNAP/ADP0X0A5fSfovoP/ALn6IepFvt/ovoxb/mfot8Ae9SMgzVLSK0sEDmqzig5hsVQrcPuW8KL6ZAYzF5XP7Iy6oiF5eeTG1/JZcNh8v3nU+S/tWz+4FnmlfIebjVErKOv4LdffuVXQt8QKfJAxSFjhpX8wryGVg+tvfH80048SRAcG0LU12HnFPFSHZRmWAF8Tz3cPBHD7CgZ2jXRXF7HOTqm/0ecPGbbR5dlNO8ngm4WAYXpCc3e9rtqB4DgtjHDHCSKPLGBtUHCVwI5cFHI94Y0jM4nmsHjYmXidkFu1yXozsPtpGga3+CjOOa3D7NwkaWAAn7OXwRdgMLR5/vpd5/6LbTvc41pUobJudwv3L0hwa57vKijgZRolNDZMjhysb3LbseyKov3quOcJWjRo/FGXCnZGlLLMTmbpVNmwLo2h/az2y04rZx+uB7RGpWykGUt4OtRCSNtGk1q40Uc2Jha6VrTsXHhzoi6Q0Drc6r0nEnZxR8OACyAZIm6NWq1+Cu5dtbrlcqpKoCFoCu0qdVnCquVcqgotaKtVWqplC0RjctnLUs58lna4NJ48Cqmyo64Wq1/Yt1bxoqv3jyVxlYNGhUTKHgsyoQ5bsnmtGJvpOIk7VS6tT8VJldmo6x5qnUWE+abiCz1bnFgd3ilfmFNg3OZI6FxBLNESVTv6s9UWkaIZSo3xROeI3VP5KjhNG7iaVW0weM8DXKU7DYtu1jcMjq2N+8IubKYXOFMsvZ8wmkbzOGS4+CrGXxtiIfI4to2nf4JjehmsdEe05rh2u880JZoDRo3nNNQgGvumxvw23cNBSqbPM/0OQbwZEd4+5SDovD7IymskzzmlkPMlbWZxJNySi0HaPHkFka7d5DT9VvOW5DJIQfYbWibMyCQZDYZTVBn9HzsBNyGOWUtOXlRB4na3k11k5oBoNDTVTmh7PBMa5wa53arwW9PGP3lG50jCY3g2cLiuirt2fxIYfJtaGuvyQxE5o0C3Jqpl3PYajmGulOrVanqoCrmqoOq4VHBWdmCuq06tevT9ioWV+qqxZXk0VWqy4FXatOupKyxBZn36qlZUAQ5o5rdxY96+kB8F7X8SsmQxNzvc4ANF6rFSx0aMM3O7N94N/FYLFtc7aYp0oLeFG0p8yulYsHCIoBFJh43OO7mNvzWFgM8B2Ez3yXN82XS3cpsTkDXTzOfIfaobhVxWFit7bbO807G4TGbTZ1c+JwoQK014qhKa0ClNTzT8t6a0TYmG76BZonkEaEIM6Qw0OKaOLm0d5hVhnfhJD7Eu83z/ADW29HdJD/iw74p81Q2P2VnweIc37pp8EcF0swysNjlOR6gw2GlbDFE3Lkd2vyWVj94g2N/kqiVsbXOJeC0jKPsjihhejo2YZmXVo33raSEkniSiwHM/6o1Wzzbv1WGnxTGPILNQBw4fmg1rSXHRrdShiOlxso9RFXePjyUOEniZhXZGyPkiFSHX9WO7/dUb0niGk2BLApPSunHhoIDXBmX8VR//ABXJ+6zP8isg/wCJcUa/8gj8V/79jf8AKb/5raxdNdIEV/wR/wD9ERh/+IMbJTlH/wDurdK43+F35qh6YnH771J0p0h0rihhHMLYPWOBc/63gE0kFmyizZnO1vS6aP7qPQfWK2jhvcuS2jNWLslcVquCuPJUaKdeq1+CsPguxX3L6MLT4L6MK/z6r/s1Co/qq0qkoot1wXNXYSrV8lvFo96vQq0YaO9eqYAKVJLqL+svaw63X0wd4KgGiyqhbYo26sBio8DNtpNrtjldYAjLXlxWGiaABFsa0HKMLpSR7gC7ZCnPfr+C6OworTBMkkmb3l9QPi1GRsZ5lx1KqJGA95Qli9aI+05nJZmPyxjVx0/3RgxDZn5hlJqskMbaG29p705sUTInAbrxqT381tMXIIIW13w4EnwWwhwOGGTV8ozHxqs3RTjHI0XBG678k9kMdNmaOc80DSs7JsPLTg1/5oxtkkiI7Ta0ReGUc4ZirKjwHDkV6w5TXSiyQ4qvHKbtA5muia2Hd2b2bUt7Lj3eSaZn7xFMoCEcZy5Row/MreNAeA6mvEZgw3GV/wCATXYSMPl0dM+7v0ujRHBYQ+qhfldQ9p1EcTNJISPpDU6qPeaKirHE+sHesRL0jLTDQvLRCw0D/fyX9kdBk0MchDvjUI4dvR1G8C17q/NNwskLHl/tzP3ieVE3EYLFxxxPNHhz+z4FDDOlLMPGwOfIzVw/MlPnxfRsLcFGaNJG9J79U3KwMijGWNgFmhZopawwjKeTjf8ANbV7fujl1ZSLGxU0L81Izu96LQ7L7ymYHZ7z63BXrMzuFnLewzvNfQyBAFknkqxh/wDB+qsP/tqgp/llF+2i8MhRpJh399HK5w/8J/NWdF/AfzXbi/hP5puXDNmzcW8FsZqYd/KQFq27vWClRkNR5rDsxUBdA52+1pvRGXozEOP2DqPEJ20xbIRwL2mifG3FYVxZr6yizzNblJIq2Rrv51VWkqzgVvMK4L1cq7QK3412aKlfNXnaF6uLOeblldLlHIWTIt2h0Y4m/wCSkc3pDOe02Nw9nhfiU6rqmuqs8o1yu9y0XYQfnsUcZhqwY1gqyQe1bQr+uYnIdXMZcj3raYXFYps2js9HD5BOZiYJBEGVa4Vy+aq+zRzVcFG4vHFoqnvOEkw+GzZmsDfwR2MBH76e/fdcZhxCZLJA8tpmFG8UyQdhwo0LcaGgijm/WRgwz6v+2dByUzYXVbEKUzcUXPdTKbtUTGgNc11H0NyxCHCMjiZSgGXT80ThYAMX9aKPKHHvCE3TWJZhY26trV/6IxdDYJrn0oZpLlZpH3ro1tB5J2Gw7ywudnceKcXvua1JNSer0fo/DOmcLE+y3xKbP0nTFz65fYanmSWoz5m/YFBb5owYBomfz4JuJxk8hLxm2YNGt9w1K/rbc2XRxF2qWmMxDpHk5WtpQt4E1/JMnfjH0YA7ETP9gfVa1CGDCve0CmYyOB+aY2FzjCTq7tVTKxtfO6mYuvTuAWTF0b9R3tRnmO9Oi6Yx72YKE1z5q5z9keCbIMTifQ4OMpac32RbRBjG5ImWY2ixjIXUpG5pPfRNadG3pTj1aKybjIhXLuv8OCze2n43pPECKNjMjSQTvO4W8EJ8NQwf3ZA1HNfQu8leFD1bUA4NWgTGvLQZDlaOZRHyVOXUX0NBfRWBNe9UAb71kxEbH+IU0+ExEsTab0datKw9PrBVa3eHJbKZomZydr5pzps0RpcGMuPuohFg49nhot1rTx7ys4tRMc95Iz0NSvWklteadNhcKH5bupwbz+Su1o81vuFO4rNWgOja1cswaeS3hRZZGjxXqzmCbPPKySZpzOB093NbN8O8zdqbvpyUeMwMA2jd2SMtW0woDZSewOSyTMLbLVU6pH4Bzjk7TVlma7e5qSWPezVp4pkz5t4tzacUclfu1THtJZG5maWMWv8Ar+Ca3Pla64p8lXOa+zR3FGTMHPbq0jVbdwo2au738kJMS8NYPNF8EgMWgAFKFNZM5kbSNdoLItYxjzxeQDXwTmbKOJ2XMCxoHy1To3Hebb3oPbhpSwgg2ujJjcSI/B6MPRcFPtmqzYiZz/FUY0ucdAFD6WXN2xo1rdVNGBZryNUAyKSRxsGsZUlDE9NkwRf4DTc+JQgwWHZGAKMYAsz55Cfq5qJ+H28odSoDTXN3FM9Nwz42tOZpymhPiU0zP2kh7Vabvch/VXPYdbZh5IYx8DGiJjnGLLlry3SLIOLA3azONGto3JYD8VSOJz3d11kmje0VaQHAt8US32r6/FHO+3G6kxeJe1+Fs0EtsAOR499E2GJgbEzstC2MRue0eSk6Mw7Q5lTtXc76BRuA9S85HDlyVK7rl3dT8PJ2Xiidh3PqR3LCtGsmILv4QKfMqGPKBlbyWnwXYPvWi0WZ2mqmxVawYSMti8Tavv3lRguu9WTm5tRRQzW32jVUqAVXisTb6o+IWFJ+sPkrBaUVytApTs25nUAKbL7VMykFOyAUYw45TYhaLsrsKo0CdjxJh4cOH7LM/N2qaUAK239K4F8db5c9e/Vqb6DV0bLObSpd4ppjZSDsvLBVxPj7I+Kim6OLpNrUGNw3mlTzdI9HT7eaw9XuBtO0eJRgOALopTRr+B5EOTW9InMx3ZeOHmnOwga5ve6hPuTjNHlcbCq7SzyERmm9XknSOxEP/wAe6ae9bLPLA4XrmzJvReGxDnvivu2zN4XVOkrU9nOL+KcThYnO47Sjitp0fh25q70dbHwQbIDFlNCHahYmONhecu74oyT3fXK1rvZ5polO6BpRbM7zSdFHCJ6tlbY94WSObMdd1bZjHOkc03rZvvUuL6RxDWyzUrldp4I4bophy/4knH3La4mZ0ru8oNDST3IOn9W3lxQ2LA2lL80JMQG+qdY00HFTdLt2b8I2drP+oaCvuWxhETGgboBoAh0XjcR6mTdG09g+PJRmKY0bXh2kJQ6ONruzmN3e7VZsVMa8MgrVFgyjPujOai/Oyjbjy70dp38jqkeFPmjg8A2hib2Ro0eKkjmwzsSW3pGd4fzZQ4FmZuEIM2bNfLXsjzQizMiYewxp0H881NDipg9gHaAuORUGEzVZM7dfqFHJhcPE5okDDI67n8z4eCZCxrWxstRjaBFrO2dE7AYR3rpLyOHsD8ygGDROHvQYe2zRZXLuXehi4x6yHtd7VhTTdbGG+9ziT8FQclU16q3WarvBbKOufEnIPu8f571JFgJGHpCXEDaB8ZI2WX806X/iHH4Vj3H1bYo35hzzUHgh/wCpsr/03j8EybozYYxtaSetylvK2pUsuKdBhHsJAYZLutwRj12Tqe5dotCuaqU33nMHxWDDxrJH5ELsqiuFusTMLmo91XtHOiybKoEVj7tViDQ2axVWipVXCMeWgcMpXo82+2SR9ajtfzRelta6XDTdknSvI96ayVuWHNpwpqssTXnMasDb+5bTEdHyFztwbtyPcn7HYxQ5y4bXtU+6nYaZveWuPaPMcig+Z0cuHjfSh7TT7kzGFxBf2xE+9k2CCdxDdXPlNT4IgsdWv+J+ic30htAcqbM6S4NMwbdDJMKWbWuia1jtb5uaLg8OH1UD2PtDgjneCfCxUboZXG/wTXsjD+d0cXA07KwfzYVRp0AtzTJcS/0dpHv8l6TiMTNM4CjQ+zfhdNfihGZGaNzOPwqtj0fGIIxYHj+SMs0jnuOpcaoNY0k8gs09Ymf6iiI2XA15oUCOG6NgdipR9TQeJ4J+Ix8sEwjNL/QtP/5FCjoXNAHqw2zvMXCe/D4bNiHn2tGeCPpQJLWVGc/LkjioKvvlbXgeSL/S4g51u0Hf7LfDdsz2o75k3HnejgcKfeU0mMhf6xx4U+KyytzmFlMwdkp3d6phIsBLC0UH9WjqO6iezF4GCKJzaFwwQZ8aINZK0PfargjiovV/4l+3yBPFYbGO6M6ObDPLRjDEA4tp2+4KkEcURG7VjMvEKKLPnLGtYK6nvQNn4qbsg8O9Fz3FznGrnHieo94p1bRnHXxWVyqtizDBmH5ZxfxUMT+1E0l576UW8aBdr3r6S6rn+C+mTMrqtgjt98/pRF7rk3/YssVU/wCGfmqii3vmmCM3fimD4OXQ7adpmA//AMYX0TPJH1Y/hXYCsxqwXRMRIbEGB+Xld7vgsT0FjG+tiDjC7TOz+f5ssVE8f3DCFVcVS61WI6Qbd0LQQCLXNPxTaOZ6TBm2rRahJNCpsJLldHNHl3hoaWPmmGTM/DkVBZcHwroUThXsdE3QN7TQmyYxrmYf2jnFQPDVMd0S2YNNjXsH3odFY+Ogy0LnXp3jvUWGZJUyHLwJCbL0eyN18n0bePeqYno6GhGZpYwOqeI408VvRYav/SH5LZ4hrZAeWvkb+VV6qVjZG8Bah7wvQAzZOJB50bxTXbIyEC7zcproX5fHT3rLNWjxw5oNhc0uPAIuxTRvWylOAYCfmjDF0XKc5OZzGFyhnxOGMWydmIkOvuRDsRtXj2Waosw39XYeR3vNEvJPNZWi6D8RWKP/AFFeqi3uZ1V1sIa4jEGzYohmK2/TcwwmG1ELDcjvKlh6Mj2WGbaNjfa8e9D0l/pc8g7JfRrFE44QRnDsyk7SteVFsxM2It3g5xoKVQidLtBGNQe7RMdLI8F76iptotlYZe246NCEcUFWsIGc6n8kAzFyejv0jrxQjwLQx9bv1d58F/WJKuPNemzhw3aZdcxUsOIbIcO5v13H9FIG77Ro7gQeKbj8fmZ0aw8bbU8h3d6bFhI2sZG3Zg935JuEMt2UoPaIsn9I4waVbGwcTy+CdisS71kvk3uCqVWvXkdx6mNihq0lzd7mESYW0Hep5Ps/iFqtVr1UKzw4eZ7A46MJQkc5rLVvwQ9Pjc6EVrl4q8crP3nKQ9Gte/D13C7VZZGlp71KA8ii+ld5r+0OULHyZqYgH/SV0XiaVMUeC+FFUxhb4K1oqbYX4lY7FF4pGH5TXuDU3pbBSNOJwW+KcW8f58VMKdrB1/1jq8FmqFSnvU/R073NE3Fuooaj5BSsw82c4d5jdwEre9GUbubL+imhlDSJGmleDwLFMdiY3QRP35mNOo8U3+jJzDn7QLqhzeOt06GTElpHaa4X91k0SnEGRw3XgWr5L12KEoyl7jloWACqjxGDa6rf7gNromR+iviyWlFKfBZpcFnee07LqfNZHsbK1AsNHN0bJ+DtQhV7qcpN4eYv8Cqy279R+izNO0bzF1KyRjXRFuXNxqsr3ip7JcLtcquxTMredl6c6UTRm4+q1SMy0e00bHDcU4VKIL9kw+w3qytFaqs3qmnzXq2b59o6p2Q3CG3lu7sgXJPgjPin/wBG4IXJJ9YW/gtn0bggZD/evbcqRrHRxWy1d/upI8FhIow1tHktq4+9CRvO6EJko08ytsIoJW9msoqB7k0zYbBHI2rtwZ0cKWMqw6XeUY8PVsdeeqtRw4ghEtGWrrdyI2pynjStE+VjmtgjtnmdQfqUI4ZWS5D7NvmtlJS17cVHicS2mGB3ubh9UJuDwUbY4IgGgNsKck6R7gADRPxc7qNa3M48gBVbZ4yRMtFFXQc/FE8tQrrK+4VlmWYWHNZnsrcfOiDcpvIY/IE/gnoRA63P8+auevVXcqfirR5wUNnnYANAAjtDK/8AcTnsjc1xsbUXrIA770NfwRMUUbKtvlaArvVc3kEyKGN7t/Md3uWGzi7I8PUeBWq+kV3KpkFu9YzGf4gf8XAruWdhp/V3N/1hdtaC6q5vkuKkxkY2ro6UZpW9NVNj3w7IzOzZa1+KiZNHtYZWNzNI+6B+KpHvYae7cvs14+Cdh5qAi8b/AKp/JOwWJjELobZf54LbOIFwbtaQfMI4+LpaVpY6lHbwvY2T3DHu+jc2j9KuGtFtsNjTnbQuidx8F6SWgMpTxQPpDP4urn4rcdlOtE0lpzV7TdVeS/2rFA4uIBwvmpX5IvklZnGhr+CMkk8+LlPdkbTknQxeriaaljd1nv8A1WygdmYONNT1NdJ6pnM6oGFgzaFxuVXLRGWaRrGC9/BB/RmHGHwrtcROKV+61bV7fS8VxlkvdOwUWZsW2yty+1l1KbJiIphHSoe9u7Turqs8BiNhm5UUj8URsRrHGe3Tx4J7I+j2taeOY1ag7BSbdmptvNTYYGVL+zTiU6LEMEs1d4OdYJzms2b21c6lHX8Cn4nFkyND6uDrVKe+HYsa1v0YAAPuTgzXLWmUUrVNLWFh+CEFM2U9kobYiEEA0c2jQFPJiZD/AEdE+jpf8Y8Q1DA4SNkcUYygMGg5K9FFPOS2N+JaB5E/ghhcLJUP7btPcgQaEJryPsuWzPC3VQ6LKKc1a6L3CwQZlNdrs/flqjTinPGmg/Z1Q8FSqo6Vg/8AjQ9bH8kc9KL9UCOp2zkLa2NDqtU5/Jjf+5WK1VytFWnUx/MOHx6tVVCGAXPPQLYz4ugNCcgW86d37w/JN6PlcXPw4GUnVzB+KGHluALHkUBXXRNZIxnpEf0Lz/2nuWZmCpl7JcPx0UsgwGIGVtJdky2aq2O1kwz9HZ6kU8CjhdjHJHsydprn9508E6Z8dYRRzIJBu318bof1TD6fUasHsmNzOjq/v0UeIkLQXmlBr71qg1knxWTEsEo71Vjwx3I6LZuxsUYHtGqmezFXackdteagijeKvbdoPzVMuyYPacqtbtJBq5y3ac058jw1tbVQiwsD7e27h7kcRi/XYnUGY1DR9lqbOMUWRtNgPw70/CsjOcsoJT2gmSYlrXjMctdO9F8mKoXWRwtqsrltpXkUzBBrQ1p9o0803DvD5qEDcFPii7DMmgJFKuNfJeljK8EVrx8Lps0RLXUW2nd6uvarfyRLWTjxI/JBkjnOi9kjkjiN+9g0Wr4+a2UsYjqOBvULa5sza2fRPkwtIIGbu2eCau5NCbgsK1rGRilhoFQKjPomn+L+arDYOF9HiTaEdwBH4p+DxBu24PNv5re8AURVeN1dV9rghXVy3pGj95FjZG7wpqtrUU220/0UTyPD9rRN+6u01esazNpUrsDzX0SqW0TD1V6n/cHz6qrj1a9TB3nq16t7taO+9x8tFmC0umzwuyyMNWlCdtB9dv1TyQbXtaIfZUrcCAZ8u4HaHuTOjTgontmrviMDZc3L+v4Jk7a8A63xRc1kkJuR678CnuxJmlc67TK7s05ZaLc6QjDeA31H/Vnbrcuh/JYaFkf0YOYUpdCERDdfmsQjisTFno6jmWuFINmxpkFmuNKOqmyvbWOlag2VcxoPIBGRrtkw1a5/ceA5puJrtLDfdoPci7KGggouBWTCA4iRg38vZZ4lDEPxTyQ6rWsZYKsoMobzWIlnxRaY9PDkq5W7OLcaNa96OMjjDm5tCde5B+IyBryctLlCvZHHmspcSG96fJJIYYvafSvuCaIpZmlpJZo4nvpb5p0EwGcHtJpdJWW4LPkmZcHBJUAuLq5r+9Z8C5ohLr0uGhBrY87/AGiSjPGXAA5i3wWbNLtibt4rM972VPtHRVxU/wDUG/SvYLuP1QmdH4CFsUcbcoDfZCp3LZsNmkZym4PCNa6agzVFmN/Nbz3F3ElR4gatWXVpGZvUFRU99e5bted1ujcZYX6tOv8ATq4K64qgnP8ACFXbkVvxQadm7L9YGvzWZsEPusiW5AOS9dh8x5tcm0hLKcz1XHUPurktfLr/AF6vPrzvFWwjaH8Pisn1B8eKylUI6jJSsUoyyeHNR4iJ1WxZn2+6pgO03XyCJ5r+nMBuzw3maPaH1vzWGxvRmKjbCxmR0L3EbN/NQYl2MbiHwxBhdIaGunks42LXtecxNd5CMytq23YVc1vFNe4vp3OKAJ071T0cPNPFAPwDan7KbQyRnkxxAWdwe7/qOJATI2TbrH5jRNY3skaLZSE5j2WNFXHwC23TeIGCge2ow7HetkA7+Cb0XgOi/Rog+vaqZDwqtsWxwOa2rcoO8jiS1/pEjsuXKKPT8QGbxZv7W3vWWePj2xRwPvTHz5d3gnmbYRtI1poeY70XYXE4gDW8e5+ij28RDXXzi4UsGXdZ2am4uqPZvGwoKlekNiJeSTZYsvb6wbPLmNPa0/nkix9S0ihB1ansYw5ZNalerZRhprqPCiOyp3eKDTK3Mbhy2OLaYsJhTSSbi77LSo8Dg4wxkdGgDgq9yEMWuYZ+5BsNHTyNAjH4lPlkcXSPOdzuZ4q6Hgtl3LeuvBNkkjLnSGjBw81FMyVrXuG8wuvUaiidhIq5nWd4LRadfPqv+wLLQ9WlOrvV0GsBJOgHXw0srrs/sVA0WnDrhB7WIO1d90afz3px6syoVyX9FYnR9RC7/wDH8k1165nP8LALvCqPZ5r0/Af2afdcz6juX5J2CxURdiKkUopHOxNXOoeFPCv86KjII6DSlF2u+gWTO4UdUmqy7Su8hvGhdZH1hzh+X3LfeAWmlgiC7eVDuezfj/NUHtAwkOuZ93+XBOxAj28wFTLJeqxcs8uculJZXhyHgsoYQ9oF62TZfSGv5ZXaLbva/Ld2+TdP27Ru2oU+SDddS44EJmwie1ts7jYIYyWbMxooAw2rzVMwBcOKfFiMW/Z5bZefBGrt7w4INgzl/wBlEYkDaNd9YGhRZBhw6o3nO+aIGFAdX6UWPkmRR0tYZRclMxHSOMdE7hGxlXLa4GV9eLH/AIL+ssfBgID619KF/wBlqjwOBibGyMUDRw6o4/akdl8LV/BNxOJ3pXtbbi59E/ESu33eQ7gt7gqacige5WW0a/cd38UIITuDtH8l6K/PHluw5bAp8GOYQWEtIHBw0P8APcnSyneKqCrNBqKbwqq0ty6zbw6tVT9jmtoHkdy7JV+ssfh8PMMuXfjWnu4LRaru/Y1WismwSPIGpoOHFST5dxvq206qrI4qrCHeCoQVVppS6yzU9IiPrBz71mcKsfZ/5rMx1QRw4qbAueWbUNIeBWhFws0T80obWOVrabRqbi8bhZdi+gzcO6q/s038JTHOw8BDnBh3T5oufg43NsDc+adK/AB2mki9JODfkADgMy2ww8oD6EaK2HmPuCBjwkeBg+vKak94ahjMQ5ub/FlPP5e5BsZAbXe3eCnIFKMTsVGwmtb8qaosx2eIAV2lK/FelRxsL62JAJP5IvdE97Qb7MKTDmOJmIP0b9OHFPOIayjTRoPZ8U+FrWgZeHFNijkoyM5qcFze++4oT0qdo2VucR8r6FGmFjgjPFjdFHh3tqC5xqPa0p4p0zXDbNuGu0cFSVmzzWJadUY8ObE+9MfNGHlunfUW+YQfI8OD724IdHZ9lhGM2slPaA4BMwmDiaxjBRrR7IRKJ1PAJ+KxElGxOzlx+7RHESDKxto2fVCObmsqpyQWXRzlsGN3q2WyrX6x5qriSK6ZUcXhQPVAMeR7Xer9pljVZai/NaadVlRWVqLh12C7PVXgtw166fM9emveqUW64t8FqrdXj1aFPxGxdJJJua0DR/PyRMADQTduqAlDYie+yutrMXU4AcU4gtjayzA46lUkjBW9FT3pmLw7yx7PIjkUAGFvOqwp9iWJpHkmu4BHDSPGV94pPqH8lLgj6qho5rhUaoH+lJh3bqlbG3epUe5Z8tXOhDqd+qtq+H4pjHi5YYysrheNxYsM58TZBmNneCOKknxwkec1S9rvwTYMZ07jHxg5g10TNfdRNZH/AMQMIAtnwY/Ap0MmP6Pe14v6t7SjDB0mwMIoWCfdP+lSQxxwuLxTP6QCV6RiCWRM7TgKj4Er0WHFxTOfoAx1SnP2GR1a1LHD8EYw6JulN6nuW7DtPCVqzswcubihNicM/a63YeeihxLq0qRQjRNgORxboom132EE/ZqNPgsjRV3yQzZmtYL5dSUzDwkxg2O0rQeSLhWUa1Zx8E7H9M54cC3Rps6Q/gpsRht4vGVmYbzB3lfFVd4BekzOoJIQfC6LWOPo7DVo+seaqjbVV04LXxRLzlHMrOeaGJkBZyoFvWKy6vfpQ0p3otc0EFPgrzb5dQ06w0NzE6DmiyWJzDyNqKrhYKrTZXcBXmteq1Oqy3RQ8aKtKfj15lqszQqEKy7KqP2XYelnD469RFNUJninB/iqDTgi99aBUzW4CnVa6q4FYD7ELP8AsTJY8XJFiGxN2gbpfjRPweJJ2sGveOaOIkwz5sO8toW10pSlUP6+5n2fSNP9Ko7q0VgAES0NGa571hncpmfNauQoeKbpyWo+oVpo7KqZdHI7+zvqnSRCBrvrMa1pPknBsx/iRyyv/iW8Gmra3YCvSJIpcPKRUnDPyh3uTYo8E2RpN3TnO4+9AnoyK5pZzh+K/sBF+ErvxRz4aa32mn5hWhfzvGw/gqx5W/8A04/AoOjxYHKrXD8USOk2a3IqSmxumfNsxmYDQNHfTiUHguGDhwv8b3O/RGR38/zVNlIoGvc2nJf0bhH+qi3ZDz+yqckG6LdPUc2hVXO8ByW2kZWJnkSqC9L0qg6cigPKqdKRqrhF1D9I5fkh1iWF5Y4aOFiEPSpny0+sVY9W8tdUQPJaIbFzj95uX8Srtr4Ld1VHOr7lrXqsFk4rtLtBadWnUH7I050XZ6myNGi2jOy+4VFsIJNrfM9zdM3U007SzaLtLU9R6OxJ/wCkfwQxMQFHbKKn2c1/mo8dg3BrgKsPP7JTZG6WqNcp4hOefSG5jWjZLDqk6P2Za9jQ8GvaCPR2VzX5NoDwITcAc21czO3kUzDPrnlrltZZm66pr45o394chZHWxTrcQpByIKcfAqWItq0tqnRlzAQVQTR+atKPcVaU+a3J3Cnei2Z5daypT2k7VEZzWyrnF2oCvNXc0oscWGq3tcq4JjhZsUunhVf0fhXUnku8j2AfxWVWV1bzVm1PBPaDmy9opkLbV17kIm7jWilArUoF6Mytu11iWlgarkq9WnVUnr/VVVadWq1PVdZ2vKFz16rKqHqt1WV2hysKdWyAvG0H3HqcwaPaX2P2Uxri2WSV1G1tS/FBg4CiyuVQtFlCbJGcrmGrSmTht2u3m/VcE7DSgGOX/SeaMOTLV7iV2U3vUmKe5jXtjo0njfT4rDvdFXbPEOatmVWFndCxwMuzLjq2vEfFQ4mtHQyjyVQi4LE9Guc7NC7aNv7J1/nvW5PI395S9HSY+fZy4UTRgu0INCsDgzjXej4yOQULR2m3WAAkaY8TiBA/M3mLfJO6R9GhmDHAOBr2TZAu6LgcBplNF/7Nl8H/AKI7fo19PAFVOEcz/wCIK0zo/wBxw+SE0ePBFxRxdbzT5DjsO1utXPATg2aL3OCGlSE3vCGbW6zO4J9NEC80AaaoNJsjGwtOJkuxvLvKLnuq5xq5x5qqzcFVUaK14o4eM751I9lCg1Kqe2/VZa+9Z67x3GouJqef7AVKdVVdaadyr1Xsq1NOuqoq6GlOquiqrHqqqOWi0X5dWmiuuauEN+1gVvKtVmBuLpuIc0Ak0IHcmgc1fUKyK4raP+gl3ZR+K+ydDzCo43HUM0b7K9R7kA+QCiySZXtPAhGOXZvYdQVRtKDkURRRupSOasJPA10+ICsdF0f0tA5tMO2WOYHi0tt8V0djMO2rsJiQ533CKFMfh4s8kM0czWjU0csVhWxVc+E5RzIuPksGZW0eYG1B1rRbzVw8kbj4r9Voscct2tB+IKjIAPpGHB/iaoHaOic9h8cxXTODfiZvUTsc0bQ7ofU2WG6OGPn2M+GLgzNUZhX8lQYs+QQb6VrxyBZp5Xv5VKkxZZmMY05lPxE7s0j9TyVVQaKlEXO7I1Wzwwo0e0EaOqOZQxco/wCmD80Wolzt0DQLOPoxZv7Fvgqqn7Flp1aq2iOavVZULVWq06teu1T1dpXX6rO11HBV67qyDvqDrdA42ebeKHVmpVaUVmo1sEejpZs72fRVPs8kCPcrgrtfFdpWurNCrlCqG071vE5QeKY/Di8Lw5viCtq/B4mM8hQj5queZlf+WVUYsD7zSFu47D1++F6rExO96Y8ClFQsXZV2kfurd4oh5sFNg5exMzI6nIqPCMeXNijaxrjrYUCxOHZJUSYh84+zmpb4LF9KAgx4pkYcORbZdHdJxOZ/VdoJK8WuCrSvBCyDfsWT4Ypz6OwBuUaOPE9RVSt7VPhzZY2kiipRUqcgu4jkjRtSLABEPaQKL0ONxrYuodByVBQAdWnxWq/Xq1/Y14clbqvbqGoCt1049RuQ2thqrdVEKrKuS1ohR2b30661VRRUKogOB1QeNHKgaq13tUJbVOvj1UV6KgVAmYhjqPjNWoTttXUcjyQsVqjddpWWtFJXgbItd9ZvzXZFlQtQ3aLRVK1avVykeDlRmOxA/wDmctzGy++/zX9rzeLG/kqDY99Wn81SfDRSnncLe6NaK8pP0VH4OQeF1mDZQeVFQukH7hVsT8CquxjG3pdZRj4Xc98J0PRkgkLhR0jdAOQWvVdV4LNb3p7vrON0IYm5i7RNirvUue9GvL+SnSSZTyqdUXuOZx1K8FR8mRvPVaLVUQsb9VvchVUoj1alVseq/BXVCPgiCq0Ksq0WVUVlceSsVTq5VVAa9dPh1clUhEFtnGqpwVDXuTIfYc74rwVKqvXuNoOZRbicazZS2cPqn6yBHJbtFm6qdRQpxsUAVVqzDihexVK9RBdqs1eq6pRUoqELTqqyhXZVaUQfiYmyxnjS7V6rQiy0WqrwXcjGLukGUDu5rmvSZGnaPHkESaX4UrRbryfErZM7EVvHvWqoVVadVWsDqaivBZq15de60fsaKl1StertBaKqs2q+iNVvR2VS6i1Wqtp1cVUt/YsaFb11ZcVfqpW3jostR81C12mcJyGVCq3QqlZWraTbybFF0hK1jBlaOQ6qFa2Vcqs2iLnLT3oOCoswuqUV2FdkrTRb3BVC7JVFRbtEcvkVdpBT4a2eMwWbNdNqjxXor9OCzcHLIFbwTnvdutuUZXe1oOQVXj1ceveeSO6GjuWzNMtef5L0Zho6W+nZC0Qq1G1lxVVVUVnC3V3LULx71c6LmuCoVZWXrCXLd05Hq/Rc1orqmvKysSFp8VRuq5KpWU6KoNlSq5LXr1WavW2RhpkNVtG8fmiVvcVXqr1a/s6oAKlAjG9VYqUKpcHxWuYLUeS/RaLSy4LggHUXZQKo8V71C6vGiqg6lUbKo5qg1p8VTLvLM94bTtHkvR4rR/FyGHjbdybA1rqNNK0uTzWm9TRGSV2VrbmidK81JV0V4KoPcqaKiot+oVQVWyy6fs6VVKaLeWq1qq1Vv2e9B2dw96oNOdFVz6q5qP2B1WVNSqFafFUWaq0WyNaPssqyt4K506q0WnVZaqxV3FB2UKo6qrgeqyof2a6Kyuteo8lESdHj5oFUVctKoFC622gOpronYeH6OuvNUaFme2kst3Hu5LIWCgHivV1YacdEMGxxOzJz8qq/zVb9VmmnKq0VFZVRoR3KubwVFxBWq1VAVexVFVarLVBgpc8SG/EohWVVdarMv1Vh5qpqOrQquU+9VoqOHxWWy1sgVlB+K0sfiv1VgqWWlE2Vrt4GyGIboRVVJVea7Sobqq4LW5V+ugHVf9inXUdWh6qNRqf2A7vqso0VaUuqVsFVUzXTsO89sa8k6ORtHNNCvSZXbo7F01xenN+NLLPv1ksylqLMdVZW6rcFSi7KuuFeAQrr3dXBWouS3h1d6rotVoStOrTVVAvzVVfqt1ZctVTKrdWaR1T3laqlerXqpUKiFTQK3vVajriFbuFfig3mqDqsteqvXT9jwVFRVFFQhdypSysFUlV6szVe37DD3AoFVPUFRMnitXdk/NBsUYaGgAAp5cfdwPgn5nHvcQnTmw9kV0CpUK4XZQa2pQrVVbWq4q7j1VquCqRXkqtbS6uFZqqAqoLtUKobqjG8FbUK6os+W3FaHquOrMBX3Ki71dVWg6tVWq1WiyknLWtF2lXiOrkmwgdo0VGijW6BGY+A/Yp1WNV2Oq4/YN1VWVd1dmq0K4rslarl7lqCr9V0VUqL7vXXqFEL6/BF29v+6iu19vkhBEfvUWXXgsuYVpeyHf3rWvBa8FWvxVANe9Zb1COluCpVcea0PdZDcN1f3LW60Hj1ZVS1FcIsta91QLLSyuVevuV7owh5MbqHJwK9Y4tH1qVojkW6VWi0WnwRyrQoxYdmd4bny8Ssj+0O6hVCFY0Va9RJH7FaKZ9N9rbeHFZBqbJsbdAKLKr9T3ckerVXWisrFVc4ImvVRXoqUBB7layIc2x9yzNcWqrj8FusVgqgrmtVr1R/zx6j1Buqyubmb8lQMGc3c6qyllKakXT5KA5aBrXC6LnvqXcTxQ1r3LtUPgi1pPgsvvqqChp4KubxVyqhVq3KiR7PfqqZN7nWyuT4d6p+Cq3hbVWoV2fFcfJX6rtK5qxVcoA7l2rqjh1C6ALeq/VwutVTqD2OyuGhbai2U2LdIPtUf8St7q/Xq5LtIrTqbI0+NdF6SDalvHj+zM/uWpWqp12V/JXardVV4riQqkqoorOWpV69VOq6r1N7iVrbq30dykbLv7+5AQxBrR9Zq2b3tDfay2RaweZt5pmFZ2IBl1rU+KykLjqrLMT8UQG/FXb3c1Yd/uWoVFUtzKmncrVXa1CJY1EEO96zUoFWnki1ZQvFcbdyoqVQAFa2W+KU7kTevDq1WtfHry/sW4fselTziKd4zRYci7vHkn4XFNhix2HjzHKe1p3mta91wqE4dhjhbNiMROzO2IO7LGt4k1H8hUc/DSSuw3pcUkEeyqyujm6aVKwuGZgMLicVNC2eeTEx7TLm0Y0aCy6O6XhwcUIkxjcLiYWdjNY1HcRW3cukpGSYfB4PC4mSPaSuIaN40aKaroRsno83pOPLXSRnMJWVZb5r+hn/APDuBdC/EGCsLHNkaM1M1a8E5rcVDHBC7ZCSQ9o+AQwodES6Patdm3XNpWoPuT8XHioJmxEbQMcasr7kx0uLwkUkrc8cMklHuHyHvKx0eHMOGw8Drl5o1qcdtFNHK0lr4zY+aPVdW6qrddRbyp8gtOvvX5rRaLeViu0tF2eqnV++QstFVNjjBdUkMFKWqmwj61XOrqearXMGjso56FpNm/imQYZ2Z8utK2FUQ6tVXWyzvN+XFbq70fJEjQK2lFvaAKuWy0dVDfKraiqP9lVV096zAKvGnJePd1UrSiF0KhXPgg4N04c0XNY1u9w4IAq5XaWUU8lUa10V3N9yprTqouaqOpzZoGuGoc1tH18VHiNkKMeHFv1qFYsTyYbESYnNSWVu+CdCTqKWs0cNVg8JA503oceU4h4o6Q/lZSRzR7ZmJjhbLGyZsUjZIhQEZtQQp54oW4eWdkcJZ6Q2SjG03Whumg1WExuDxGHGIbAyHEQyzNjNWimYZqVBFF0d0R6TC9/pzcXiXsdVjOAGbQ2rVdI4DCYuDbs6VlxTA6VrGzMdazjY6fFdA4eXHYUyQdIGSYMma7ZjMzU+5Yt7+lJXYcyPZGA6xFUJsOzDS4kvIft3N9W3hQOsVh5n4mBw/o+SMuaQBno+1Peuko3PaHPiZkFbu9Y1N6Sw2LwwilZHnzzBpiIaAQRrw4LpPFwHCYmfat2LZJRkLaXdrRyjbJLhnPYZA5sOWjagU7NuqoKv+yaLRadQVVmrqqgrNbr4LvVSq063t+0gnt7vwRxTrvfp4LNejr1rdGKKQ0v2u5Syy+xfdGtk6aQ3ciFYour3lbyuAs4tlVTXOTlCq7hyW6bjRZuJ8lfiruda67uqtFSiqrWHci6uiz140C96qqrMeKy18VSiFFmCoqAcaIVWYC2lER+xVB3Pqou7qqqKx0VVRR4YW2rg2qEUYo1ooOrw/YLeaK//xAAmEAEAAgICAgICAwEBAQAAAAABABEhMUFRYXGBkaGxwdHw4fEQ/9oACAEAAAE/IVzHet5ixznnnUVUmXzQWXypqhgGhpAKTrHmvqG3bNAhyaqsd8+oAqbnL0G9Ss/ZNzXb1yEWxbQdSxRwA7O/X0SgM5csNZL+R5/+jGUDvX4OYtrcljUX6JViMI4aja/zC/MpqoOKeGh5L+Iqrf8ALpjQBu0sPplwZc5lK/MX6zZdNAD8U/mOEf8A4DP7iWurFKeW35lZ7xS5VJbEx3XJ3KGts1Vnn+vqOwHylgq4RbaltDsglBjvl8vG5sG50L7YaKB8kyS/DMr7U8Qs6+0Fk384irZ8n+JZr939zn+j/dR+gj+JhYD/AG+VmFC2yz7gXwQCYrBHUwSrgfmKmK+I4lxvyVILHp8bWb4X6I6xvND8X9iZwrcYn7PqWD5mxH/HUtoP4kqjYscFesn1BHseILhB9y7SEcut2V9/sQd4eqD9R6z6I/cf5Mv2y76A/qm+6/5YCfmoZK2hn+DDC6B5j6ErE1ULQ2i4ruag0mxXt/mfAfR+Qv7Yna27Z9oNbsqECwI9xJaZXdRXL2UaNL3ZP+NT/WfzMHN+1fY8f69RIqPbUDlgbuut63NyLrXQY5xWZaIYSMm7scF1q+4QG0Y3RfmqTcNnHCBQqvkEHJZvegOP/ZW2D3AW1wOLL/iHbiioOwc0zjggUHyC7ZitZlxZdShtnj7pw9wUvaIaJ5FOxKXC+4hYc2qv4lhMfgTNC7l4jAHVTE9SwK1H75p7ETvrvsbJfjXMboWbfw8SuR/s9w/AmcUMWAKZgS9L/r5jIzwEzoECu6cIn9/mOBuYLf8AcRAPMDutbavUrmouUb6r97h7CgLfh/M2r8J+oCp9j+mGgHqv3DuhX9x4ljR7MH+0uW7v6QXfyx1IDCC4dBfRbMiFq6lHAd4/oiAsHOj7YDlrRZ+9TlKcgPxcfxOUE6ftd/xCretnT1/SWuVQdRANlAvKficAkYheGtzWCfF/rJYPBZKmOkfcKvoqGYX8Sm1PxB/4iVEcXb9Qt0ein5m6SufzpiMXYeAV6v8Amcq96v3dz++3P0tS+gAxQFHxBu2h2Uf1NJh0ShnTuLLBXknJt28ZqKeEYQUdI/ZLROoG/iyKB7rXwZLAs3mPqnMtMQxde7XKmy/5+7m/UEsNa1n1KGwOVZvp0WV3LaA1jnzYv+4iVdCEhWO9bc/5APl03LA3i/3ErS1nWjVyFwqo88Q8jb7s0DmnDO6QTmWA9Hfn+Eqitw+U5CchLJmRSPJM/wAjPHiDGAhnUSQyagfiXd/qY1cdTMBH8R0cLR1ZshdKOgDwogP+Ia2XbO48PI9L7hZwBsrRBnLg+RjwxKpD/bhIeDXjwxeydSmC5BczTF3uPA+mH+/MyV5lu+R8xLJTyTp/K6ffzCDsVlcaEGKr7mbrrnEA17IMpfiEPwwuEXh/sjCy9EfgJQ52hxL7q/iaq30/aOyB3UgdNCC/4/3LZG0vKVClXWWPNPge/wAsQY03gN7B+EPrd3/RftEDq5/kUr2/LgIUFI86iAQw7mWyhpwpEMY0FsL6mixhTQvNVM+7GrC4/lHpzGpmCjbbdsvqXr50o/MD2zg0/wAICvkH8K5FgrwMfY/biVCs5sfayDKbXS/q0D0PXRrvuSYasf8AbEybGsB+7/E8Vav4A/MuLc8WGf0XxLKm/wAsSsTCzux8WrG604yPgjwBW69viv8AeJhWyLNniuL2dFLHGs3eWUoem8y5p2n5ZTPgP4Uf+R/SXMCVAWQpPhW+Y78RoXycIdkEVRgry1xR4rcYGNwAusODG4OnDLNr0cZ/9m6oqliZVrkP8TMvYIttLe/9YhKu9WTK50bPqPArg2jmp7ocvn4hmYRALU59hHVUG+zPPeJR3K6llWSjGwNolRbe1JMFbyJWwF/UvEsB1XSZL5jKcK2Zy4y6cKS9yo0lgYvG4DBHof1CeWFFNgWqqg+45LZfELCzkzlkOGDwdhVxOTu/hlptHcWcTjpXhoYpapAAEcLyyY34YpqdILzzYyvvDLLodRQ9LHV/XUpqlYL5TqVvrbzOOrscMyYX4j64c1D/AA+YauDkYNnD5jWM0K+/+zOhzPsEQ2KjVsPzAo61tgxbrkpdXENEl4YOMTTe4p+G5+t/96lk9Kin3wnPbZyD7tBlMuyy/B+oUtV/b8D8S/pTb39QAxEFJA6aju88H+oqKI8I/oxBRwdEG+ToX52zYweIhMI+b/uUtr7EdZIcjfc4W9Al24ean3KGr2RmNqXenkdG+5TrHlXn2JM4F934wfMQlgdjB9Cv1L0ni7PZ/ROSYAM+4fcvSRea97YmDvHq+f5Si7qzFAdsZYJQuLKDFcx1Q5RJTWrVXq08kqF/JA9SKS/ND+ZXCf8APlg88NYqwIu6mLZ5aP8AbAYyf9yKRF9hGyPsf2mE+kmcU8CBYDXqcVS0sYPy+cFxjfbcJWplWcczLd+WttbqwLce5my2bBOnOH3LpbetoasnFXGCndLMufT+SWmfBrCleYcuPKg3zM0rPGt9pAMkrnZhe06KZVBJjY0rNzjC3H1L6VB6DWDWU603E7fY/WVLd9P3U/5I/Vxb/r/ScgPUfu4Z3ytVfjtwypHAKtQwGQsa9fWIvPYXx6Ea5m1Wpisli1p/aV6spoNittuH/k/fyCh16ZgPs4lNgTWntucLXIWzXeW81zUpBi3C4CC+r9+JjK824zbFPH0Sheffi2q48xKIVLtmqZ9/eZdLa8m2/RdXxOjdHkWlmRel3KuklhoIvhbXCSk25FpZ2c8Qf1odP5gaFTtrXuYDJzdH0vD0xRHBuA/RupWf4pspZ+3xLELbCUomGsV9oTVKtvRlX/ErBZSZ9Jh15ZvvaPdj7VPjj8z61iJ+38xfEyX5FprGvUpcHURC+RB6fEpZ599R0N+AibjOzf0Rj4gVmWI86FI+JH5mGyaAtmxKcARzvmgf9LEiCc0L4upcQy+Y/wCoraqzne6FfmNR3cY+cxtetd1PKMCou2t+91+Jt9xmxq4J4q/6TJ9Uq1r/AFzjyQ5b4+5WOyNmgj4LRt7YhDlS8JlrHMuGGjJwb11KCJYSvnE813pYpHEev/ZpSb5FsEaBvAYFtriv+WWNB0WSzlwpZzAd/wDSa40MtJcQ0RAYQNiz5n5IKhHt2Zxfir+p3XeJRiQi+6Ms6sl/F0D1ZHHe7kvQJrw1SgwYAlU7yZ4amUSI6AZD2LRTZ8rAvKluoTa0xYX4azuWL+WDYg4w38swTlzwA4AKxX09y5qep1hmurNf8jpgtq4Fqa/r8Q+drJreluKT3FLI4Nlepto93OfHnEC20AAlaBdbZTwfUZS41NoQKuAo3mJSYFvKcAYTsThgBS2YBuwDCjhfnqcgniZdXata2W2E5cKqNIiUMoZ4PMpLDhNJFS6cU6/MGRC6Zuorp6+XolnaSuJ4UFCpN9V5jTynSOSNd+zeaWCAbESUoqzkf1L1th3aKPpT3eoBxsBRhZlvK/czn1XnQ/zupVebCNbl2cF1cVp24xO2aRsnC9Qln3ClCN1n26czECxkzWc+sS8on+1/UbrStKqoz3TrmYybfNxzMPoMMi8mmu6qBhdekVK81T8MBWx4tPeI8rvZfxC/wF/iG7/lQfvM8f3Jv3GTX8j9pRUuQfxQRUHR+iFL1y6QWJFXtlXdsYCJFi3k0/aGM02Sx3uOm9ZBF0owinxN7HDaqbMc1EatVb9+d4lRr+KqhWHO8SxV/tAw2mqZ4v8ATHv1IrbPN/mE4gxbW/P+3DTT+KxYMmd0OMSmFxWt8e4GdYPPPmUMO3dZmABtVi5gcPkgpwK2nM2VRtRL9swLpyqRrAs9Re1ceYlKuuIdtPCV0Fy/9gYbnsggDb6JQuL1/Em0N6V+MTSB5Q/jEpaPox+oag9keDno/uUI2GWEGERXsVYzCwpM8pQwSx2UckdtiNYcK7YOOnuL+d0eHPXHks8ymqe0vM1uoEgBqJ6OLxhfuIvYaAXXxTjpGddP5gpqmoZAMUp04FVxvbMj49bJHNlaz2d8TPRhcIOdLzk/UtY6OS7y9KhgCdKbCV6/wj3DeLn7jdge0/uCdgu+0dDEdqBTo4VcFvviDIdGILr0Jv8AZl4utUl9iZChWIN3gzRW2gbcnEOklylUyGtYpFXUter4k0HR5fWqhSynCqK28E41UTspg1+uM+D5IuE4HgC9VyvjdmojHt28gKFfM2Dlssgq+s3d+Ims5tpCn5P7pgl1ZDH6cV1zqZ3QCdapF7zn73L3mqCAWNuNnfUxv7pboAz07N06uIgEtrJ08j9C2Lu0YCns4/tqoExFxuOKPOYzTWG0roduPUIK5Y47e4QCuW2J/wCgE8G7Rs1AvvEs/ti7FMTL0/3cp1mr5jO6eoeNohP1FlG7cMkuNb5lYuFeY5LUtO0IZ6s+AnPjeZRlkMWTeBnRYLEVvKCc6YqCtgHIzE4FbtW3+I+0QBHNSxoWuo69nnGSygpkLhPOjbJbvXxHiqvV5SztdWZYbS1xmPGGBwUN3K8PcvJzEKurC6vohnlQ1b9f7qU0jQYV/v1FaWbteYK2b+M1LO1hy4jkvfEyoamwS7B62Wc3qVQAtPVxN1rWoLr+qjkqW/f9y16PNT2XVNEdez+YX6dxHfgnghX/AETGrq0BV3V89wrmiC9aXnJ/PEteYcw1RAGnkL9wMCBEXgoc1UvBMIgCVdmW/wAC99V0T6qA0wbS2i3AZD0douAvT94gTm4IDUAVgs3vHEfgAlyNHf8Ajc4nCXnZEfAept98DN1Xrb8/jlmfSzac17zBi0p4r3L6KgLzgZtl89S1HU0FkpfTW+R8DEoUGVW7e0Xn4ww5FaAZhwlbocUW+38Iaq+RoZk2baq/HiMfQkEpBPyKH6xE+CC58uBHAfmMqOyKxW7LWvtvkxbYaGnDTj5Y85xtAWb8bW/PU1GnVqcX+37rGxyats/hg8njJFsTWi5/gsUWc+VmqnfjI+IzRyFpAIO2JHAMoOsY+7i6b1ag6rnWJU6FDCst+TZ9WR8CJY+U8GrgRlN9BQefMzA4KVWJs+mBurkK5rUoVrwtyQRQHmqiH7awkpO+2AwueqSx4lOZ4X0riNYPm4O3Su4GvKZdVYjwFFRG3Jq5RVUKsx/iVDdxzKDY1uIhfPEAxQ6xESRRRT3uIpVnklVqKDM7XCNLaqKNmWPUyqLqhz0HxCVQQ0p3c2uOCR0zDQBzt+YIyA+ogbZrvErn/wBhQA23XzKeTXCUv7mlC+2c61LGjeB8wzLl1/2WeENWqe0utgD6gFWX6l4RdwH/ADLCxFWtH5uUAVdOmN21eEzObDwS231TW7Uwe6ReDTxLOnwiqDx4jfH9BJq6crG+mhPRTEIqQkZejnvdzwyD8jd51LpHYEykSX6MUmJWqEZ0TAMiAUS4ZvXrwzoDs4JZgm+xJvPBZvUyFA5AWemHR1C5dVcWXS/Eum5cIFyKvy/EDhAWU3ZL/wCxArLIsjVWzfBHJxORXk3jGe/EQqS2EUVxgdP5S++IRsrb1dLeHltY5RS3SPI/8zGl55BYbrOrfjwRZdFSIdTFcvFPa+hCa+GHl4gAAC84ANDIfBAlVX4OSxjj4HyotNE0NNg1kofOLZZSJrAxSlctfR2ls3nAvApq9WcDC2xtFNq0X8f93CMFCitBpwXnwHmhasWC7uPBf1Z1BkSXdgvOcJ7G7ht9gr4O8au8QNefYppaq/eD2TvzN2TXk74+ZbMOGBq97g0CuDH+xAjl5e5TC7ylqA7t36igBhh8SmvHhcJR4bIVA+VDRMECPR4CBzNgbwTyPknnn1Vw0UfJDHLeJrL7TLzNSrV4x3csVdoXVTe4IuMlli/6gx3XTi3+xO4QAt7ZwShMfBei8cZlkgBd/wDe5c21CqA7njsTY5sdxYReJZtVx4hj34gjoXN4/wDIczrIW2+e4uD5KK4l7ylSKFN2VLzDTSzqGd5ZbsPUAQ6HRhD24YzecscTPWiNVZXhZ/XAnh7VjUz2Pdk9h5zBvkPMLvjVA0/BM4DKynkYyewZacNRTQDpXCOjj6SBxP4NK1w2Z3vRKZ2tLF/7LKZKbH61CqkvrHmyuAr1O1s1prBc4LXmuIljoZ8NMTLN2TWQS1Qx11AkqDuIssYXl+GovZBgMx8/D8xj0s2ThtK/EBnitPOcXSzlwXMiGhYJrA4PDmF1MTtsz/cCNgVsVdK1B5o3nHaHXGYFVQ6O3t8f4mPer8BZS/GKf4gITv04B8Uz4izohKUvC4DVD5yMBh1gClOHjnrErBPdO/t3tbC+ka7V+BnBrflLP2bfWc01goK5gMCxk9C5B8DLibCw7l5aszgdxLrelfLZ3uFCZfJ8djzX4bm9w8C0u93fgKwhYRk2lv0+dvJBXRAmE9sAst5GM2tt6Euu8Lit1jBdYUdot59GMxt3LdV23g4/EomWqZM6HR/zFQ2IpDaV/aK0LPYc+YAAxfMRS4YctD5BK21vZzDQRTtXxC73ouatNf8AIigZ/BLe9vhhuI5UvVxkOwq5m12VxM9FcmNxgC9vDWvcW9eYYNapkzmABfPMAG2a6DTAcCXar0/EKGsbC6ubeK1Ov7lS7DD585nvs/8AxEwHULmCo309RN4N4tIhk+Llahuh1TFLZkbrxAGqM1v3Fba7TzmW0bOtRgEA9pRxnjFSm/kStYO/MJNzgTQ2ly4/UPcdRtht27irND5nEG9W1G6xdkVC/WLGEbJ2AfuYTDoFS01vhqE6aW6V8xsbs/zzDKT5rX6joAmoz/mESjczsPL38iYzxDlCrHSdJDoF3VToyPn/AJMZ4FLxJ4ju8uHKrCaT9WXLf7RwoPk9+oZPVQvJ55PiUXrLiiyynNQ7oynVopAtoxk/jD0QghaZUM/mOgE3HQ6Ew3WvEqRuSRmstA8GHP6huF/1BuzF8h/xFLItsHZL+RuLz8vy9xh0ZFhZvnnFfxUoUpZULSqujXZMrZrcDVPpdHGNziNjri3d+XlLBXFoTpqjdZ8vuVtyFsPZWKQfzCoGwbGhaW8n+yyojlr5jrz38Q1ACujIxXTr5mhcwMtWzy0V8yrwaNR7ZnJanPB6LT6cy6BCSpsmdA/srEeQ8C4meAVVKrD3DjJiIUvgx/8AHMWbJsqtiXYm+6dmQwsXPiD5WdP7WMEi8N1UyeaTEw8VX7ufqaAoNfYsz1uvUQ22YL91r+cyoox+Zm1B6R7RqN5hwzZzX+oI5QC9GizzMg1NcuyNblvcqz6KGzi+4d6MUVo67lWFl0EfUNR78z5D1+pjMs6sxCjH4SzzBrBb4lHbfkmK7RcwBqMsIss31UTwefRvMNLobC/7isIe7RkWr5inr6u5wJKGYeAImSWrsL4gE3JdfKO61KcOX71DRQx3MKhc7gZu2u5YCwvF6TKKEbq0PRKF26SoNvhJa1lRMO0zcCZneVKdvEw1ivbKnvFwzJrRFxWMxj4YiHrM/wACLWtdDUOqKVNw8WPDUDPFmh52DqIFIUQUcIfkZ8cwjXDha2jyPHiOkc1tPC/1m5fJoxyWY7ud4SGF7uYlNcbqY511KkTUIMfy4oYBvHq8cQrHfNjAwb82DvzQSk44oK/cHsMl746/cuQs6Dz/AKYgKpiOMXg2ecY9m+YQYVIZyV4cGZelg06lNOrc/Rh34v0VWTZm2XKUulNNNJ5a/MIDWGwu3dv456ihE715U4Ozz8jLQ0A3UpfC2968ylkSt1/D0UeIzpfghuvF/wCqZuTVeoYso+CXLXh3X1KyF8AeoQLUyHBPRmDt3DRRsQv8WfiUYKNKstHGHlzBLoStwKGHb4hnVB/Mot23e95l51RzHcGnhjnLDyHeY/l4gU2NMi/U41a4T/sqEqy8b3pgEEyUD5IyjSi4JYggime5nm2DUDtXqYupYFPKjWH1KP8AQIFe74lWUKzWplwN4jbN2uXiauj+Al8A7SZcQ4ojeNXHgayoaXhxXdxOnhRdRJomy+MfmYLtkWLcpx1NxtlRTWVfkINisPiOKlwXv6Q5bnsPiPvSvA/c5tg6jQIbidsxtuzioRvJsqoLLddmJlt/Ey2JbMprrWo6C54EFHHC1dYnSqeH0Xt6m9+TofEoKr7n/wAXJx9pRxB84la15ftGSHw2PcUh5tsnk/iO7GzV6Z+8ToRDvm6fxB2LARHSllHeiJE2CVhSq/iICQSl5OzwXFHGrj8Hx/yeBUv/APAVGUsiuKcv9b++4VgAepxW+oTLdGG7DI+pkRnk6px/uI1FW7umnHH7xKzcWTx4499+JWXMWB+vu4CUPNa+NEpAM+Iha/EUuCYzx5h+HCD8a7VzHNSGoXzcMyk0gEmdv9mZRZDFRV/mE2g7U57/ADKeaSB5td1z6MViWzrwPKnf9juaBlaeo5SYAff5g1TynPlD39wWbIpexuSwkjC45rBCBQdyl1zXEqTC1tLUarWNRTp+oi8Z5jyS1ZM2Sz4MRPL3SpYfcDUQ6eWVYvJQZI/rGmRPxBlRfLPGhtzPIhGaYItF4KaY0Ex23R6iDdYfcYYF4f8AkT1rxF6Qu8PUUrvBbNkldWM5+kwGAOYItpM4zgrkmYTha8SoadSi29w1BspxK4m4q84mNmucZMSCBa6IpyodRW2Eb6niMapto7ljXdoIGV8txMJKBTL0XGUBbotD+Z6BATNcQlLoOMks7jsis0nwQ5RF1uROE2s025ZiIEmrPD/0gCxvjH/hYB/BhjETND5m4HzO+PggIDnaq+Opa22L35cZg9tn91hT6qAmPXC9+GpU/B/tNSw8zJuid55Zbgn3/cdYIcaz4RFN/wB9Dl9S4AX59x+5WK8kkbEKIy324mJKl7C8iCq+lNU9fwlwa77LtitExZ+0rGdtEwPs/MzOXIteob7r3XuDVwDfkl6MH8kyIRvZUSU/aqNmhs5ItRoPEAK15B1Kvl4IRY8RdPPiBRNrLRwspk2Ktk7lnbcwgE7fucj8XzLM2uW0DnPrUrtoKmwHKXJz5gLoCp6M9EN5bzEFp4IGuVTymxHsjvE+TKXwtgfPrUw4EzkZWVd9NyjlK7tG5QYZ0B5lpjhS/R/P1MWLG10m/iMwrQeiNgVsNeb/AHiY4p8f+kqq14z8PM3MNmGP/NSynqg/LZXqYGZqvx4n6ZKWy15DB3W4D+cItSvtS/0lKLFvKPz/ABEe06Ptldn5iOB+4HqV5uVQ25+IC2ZogGXq5sc6sfqWWB6/5gLmlOWJcvyv6hZL1rIS6g7Vp8VcWZLwAF+xMgaQsrny6jxoadujklLZ1R9Mj9QKba73gpCC6r/XAmc4KF8hk+Co/Jl36TGi5f8AceNOffUvPxBIOwp8W5NhWTmMA0PWlxtn1GtYZLPvh/EvOZJbLPUtFas5IxaLPXlGBXDtE9S27os/fcthh5SAbsxdoxf4ZkIZItpsXjmYPh+YKGQnEgwPhSUW7fZLrC/cOuxvljat9ynaUKIvgx7zLMKo4udtsRIDHWW66xUe49IveD1AHYfUqDQcsrlyPHmDB79SyLM+pepbnC8oqDh63BBF63iMhqV1G9meHHFK8TYVVC/Lf9RUul+INaH4i+hubegr/UujVfr1KiOLuOLYv4jgNv7PHzCSbse7X4/dS3NPjKWIpWA/bFXaHBILYg0hHoJ/gxADWa8P5QD6elvPfwRte5MddiZkyWHFhNBnxJ+ASjsoPkI5fghqfGZY1jP0DhuELSORj5rUEicVRE35aD5gbQ9mk+JwrCpXLPNQNnODL9XLh+WilkFhXLjmA5R0TQ2Vkha0H3Fd0GbcVE1F5H9kVC//AAARgJq0nJMaA8CfeUvvKlrq+z+on5W8hoi+7DGY83t3Z+jFbNs7fT+ZRT2IB4Ky+4FFMLR2dIPjisH5XIhdH5vmH+5jBPQFPW4ou6dBvtgogKA8Qu46NaX2v8ztp0A8rlhUr+sYpeN73CgsW1ccugwykteC4gd9ZfuYygdv5ibDkhtN3caavjEQWjpUpwKbwxtiO05ETzDAM/cc2y+Ims2eJiu3NwHn8MuCD3CRRc/MW9+t5iW5LcpKVPUxIU5IK3swVuZ7AS4GNRcBFMpgHqVlmHcMVVH2QJfx3AwHKVtiVlHMflKWKL8yhbnESNt2/oiAiwBgvcQ3sDNaa3MBxSRdhQOzx/tQArE4uqTQCkX+Yr39sg/uH7hYPjSbq+iAO1j5yXTzX6czdnPk16PTh+mFjaqfV0+P/ZZ4PTpjaESm4OwCteZeDTiI91uAMKVxXQ5/24qR8P8AzP8AiYs7MBDOhml71k1AYbtfgGSoAl1x0PNFK9SkUDZ/fKB8SV2vPHuWS4bK3wpco+yljCsOHDmWY0DMHCUd4SX9s9F4snFm2nLMgRwhPyFfmVdVpH8GfmUONtG/YmH4ZZbw4N+wCCtRDioqZoWdL/EFCPQT+IpnCvPMvWDavZ9CW8QAumUDTDNcy1yKA8P1Lrz0OmgOuk+41Wch2HOP/fEPNMaN83b6Mcde4XXOjHMC1Tm12W8EXUGDQsqBi1lw3GchkYcv5gwGz6ziZGwjiBXhG7qe7QxE/bFmM1qaXIPyTbP6UI0LlXiU3deYciXvMsdh5qOkUgFbCPeohUF7uBngAjZ7yAxgvfPMvSQnPERZS8xvlXS4nPtcTTNkSencU7IXYfUyIrVykgr4i07VvJK0D8RPMYFUxYtwQDbN8TBNteIaE9JVrmJ3UcCspV1MDmyxBLKldZ0kZW+tRDn+7JkItU+cTWg3ytNfmvuNRs7NtxYTIcwIqiMjlp8UsJsVtqBKhxl93ldh4Iw7+P8AaVSlG5u/8Khm6MT9BO+niKyKGx/7Sf8AAQJmUW6H+dMwjKpLJ88fMAJMU4Y/cFFIdJzG6i52+CVqsMg/nzKF4WNl2X+HjxuHuARbwF34c+2FVncFR8JY1jpr4yH7nH38fkGY8Qrs84piiG1Ui0sJyZ9SwkdtyW6dpMewoXajufJ8EIhMElX6IzCFy6+11MUwBb7Qx3M0zOe/1KnYs83Tfg7uWjOsKfqClXbcS/tgL0QMy2FeYewiH83h+Yy2CMDJaQvvqBdyUxVQM9fqj+HJ3Xqf+j4tbwM57pZz5fjEeO/saGZdhzmv5md/ZsFJZmrMSOaghseQD0+JoB/LUIiDfcSyUuNsS19sDJITRmURR21KLMOV3KRjoLUL4JSZbuBmsfMtIDFBllNR51jlEuLxlkw3BcWmRM0yIqA5OYG7Qh9pRAw5LlGylQvQgnCXfBPiGcEAOEPAZhq16qXFoPiYNN3iYH9wvfHzKPfzNl/nNqy68wt0V+UYoYWXDbAJ9xU1bxC5le1hiFWS0e6mkEzxHncJGN2/ZM8Q9kvWi4hs2sxDsedS1nbfAn8xA5Sjq7v6D9yvEa4Tgcp/CU1iqBvs9QPMCP1ML+cw7yU01XDiY3eqsC28OnzqULvoE4WOjtHqvFgZirnOLU6QKff/AGDdkaLDfdM/iEi3n7tz/qlMfwNEIo/aKfADH2x9SjZbXhu/mWkY5Bd3V3McGo5eLV8FX0kFZCdP8lFfTfxK9RclVBbTsjddVXhrNUePzK0MvhwtbNb9zFZEODWlGvnEDWQJu1mqa5fDL/8ARxWQ/uae7eZt9o8hGhlludAJdBAk2qELLfiIFLuRNUpEmBEFm4bQj0C8iQCLXNqKhaRkW8ihDvRcdp32o8tA+eGfcOaEK015jFy60LyLx6fqc2CQFrZzmYpIiEBdqkHyMgGCbD5z+WLlXmKPxGKGJZFnA8MDGbpplzrd81zKG7KUwCsTqXHU2SkW1+JhLActyhAjuZ/kk50feY9bZAHS+iyX9fDTn5qVLuDiZw6NTMKFrqbFL0uD4jrzxico13U67jqoujsS9UReWsRgF2L/APmbAyx5FeYsBV0jBbuNeJqWn8wlQac9xWwXFt1s8xV01VlKgv2jR24DSb0hTnIVMU0FmuLy8x0Fjh0r/SZqEq3XX5lJdVhlddD1KcJOGoZAKc/4YajV3gv0y1lN7b4vIh0R0o5+oTGZhCHdLPhb8R1x4CGDops9kMtApYpSWNc88xw3Bht1jcCKKUybPzDmPu5mIzhEy/MGoo82/wAy7fwrE5D8plBov3TCo+yOnjxe3qCu+eriW6R01zzhs7iNpxtQQWZyLM8GBcEZOpagpSOHVRG4Mi/zJQxNrV16q4rwqbkOxSoFNEDZb+Zkg3Az1rP+xPDsx04mzbwa/THeTtYgVp5Y2DOvgZXrtYQcg1DgqudSx/MqAGqCrI19LM4S8+YdOqq2QmYvMDQg1bGiIBecqpQAOn4lCS/KLKQsKiKZsaoe/wAywg4KqfOpcAjiy/zApBbGRC/dLSY0/OW4t+IdGIQqRAru3dksCftAA/llqofMFJgjs+54i1Veeo+HTNxRS2tPruNdge6fsytQA7z9xB/IQZfGcwUSqAdzeTDVyy7zl+SvmIQVVTBgUOVdsxi4kZi7xnUqkHT+jrvcxZq9cBlxj5iVDsZw/MSnlDseorjrPM9P6jhrLxHSo39xVWGOoJ0D4iPE4lpa/iVAdA38kJnwt8vLGdl+qA/BFFHktaf77h7SuELPsgwJkhN/ICC2ryMNuZj+ItHkwPrKXbNpZ4xBf2wb/NNj9ksUL3KioHmY6BsL39HZMzkdIvp8JfCB8P6/aYi7/uomNB/uyRkG8l+kvVAOr4qvz4lsRPKIM+aWrgWFfWLMWlzAcUsBz1xLJXrV4H2FqLRture9V4RS7wlPvGsZKavLVYL+A4nIMb3U2r37IxPzd/iJ9DjrQQUfPD+YS+8HS61i81+IvyMCpZWuY7bfCV1AegpfOYBOKN9wxvU2VXliDd35IZ0tbZwtwcaR8wSvMgKKLKHgzS0zkoxbTR/rj/sAQQKWi/mYjRY/Myeu7ViVsOcxbbDZ6jWAaOpe8Dqh/wCzNu23j/sy1X7c/mNBG7MMzxdMcusTOJcmvyXOYdUfxDi/mYOA8KYf6KVME50P0qWDNS4eoTdwUhDCsuoifaXTxzZ6j9rTQwzZtVPnz1Djri7mcjpdv6l6cspaeplGHUtfuipmg0P1KpVh9Qx7Ozgs/jMDhDDVizgd+vOI1xsnqoQ/KK2sGIGRYca+BFoGuHMfFd8HkEEJk3VajVNnZ/MexFVKGFNCV5MZpkYuUUIb4je5eJhi6FUUrl3dBKmzEqxC6wf9nmsV20oFiclfMAKVOv6oIRGoCgIuYyzcHa3UtpSoNMZPOSEWuawY2pMODZ+Yup0UsACUl1ZvIdwBPRQVG6AGviO4gk/p/wC+JyYtn/zFLX+/+pwx7/jf7gwZo/D/AOTKN4Cr3d/v3GCUluHhOFmcYqrLHKVjmKo5AWExk88jxFsVUHZTfhjLnf8ABYlC4xMYXmjWpSuBGlTIQFw3FXbN+oopwQuackFSibc1flFKfZQF+LiynYK2MuF6lqvsQ2F+fEJDPtkP58QyeGuH6m0KfNdePMFVbFu1xVEBlabc8PnygBYCE3bvLsj4tvxQTn5gq5eErZz+ZYOY3UlRNzwNnSHOwa9bz6g0GNXcS7z5PrUxTyuXWTYly00tNR3NVyaI0EmnPP4lVaKpq3kg2sHJ/JAWHdNY9HTFDTfsnBD/ABzKgypfNPn8S4o1k3N6qYS4AtQoBXn3HCIXU3C8CborL1El3tuXn4/qJSvSFxUvmunOpWZOuLI3B0E2azH3hdsKcpLJT/XuB55Rw9DNhsH/AEhwjw4+YsRrBldGmk7WOTiGVVlr0Ui8MSxfT6neihGXB1h+jMic5Snp/uWE9iA9GDLmEDwQvzEPxBV07zwLyeDWsSlWBtnHuv4lusPUJ0WdSntp31H4SnhngkLYk4pI7CrxAeGAquGyW1SHMyY3WQTvN+8GV8f76gxiMtcPOWATukHywKq8FnFyPDPtBC2xIpF2H8mziNmPqzNHkIlQXt/LS9B2+KjFVrP4JdoPCNYHzDHZ9pcP8RxGexTb79ku4vrTfohwdXJbkPZdHphUz01C2BeK68zJP0Tc4GtGlRoUcps/P8JfFOqbL7rthZMFve6byZY/Si67xvFfULgLzr4ZpyOwfmpoQLAa6aziV+V75mmSAC+80HmXXnSk9KRjsubSvqL8H+eJeyar9XBqPXeCu77fs+oDLRm5DV6t/ccmgsvEKLTdFWMYXTRB5EtTIs1rgeS6h3HerRCW0jPXAH5DTVPOOswkiNbNqscc4jDQzQFnK0l2dlQr0SsEIZHaL2vOIQ2mauupZ3aeoDBMDIYqErI71+umYHkLnPIj1/MGwtgqvhKt8ZhXtfzz+5cYi9cwsCGln8I4kNqB6vb1CKVteim8/Z9TN3CTY/ces2o2H3uBsOxS3VnuEibbVCcksYbsPsWfiUBmHjjAq+e+pZKop5f2GamhEYJOJUNj/EcH02C/XcrSgPgI1IG3VL+wipSxftyP7ggKXTJu69fqD9Jo+Az9StdAKxjWDf8AyXwLjygyq7Qi8r2/8hQITR4DD5p+ZdNYRUT+a/8AJ3xkR5bNY3WeJlk96AYM800wQihN8Cnn/cy/2mPtSqmgK3k8ZUfmVJHiwb0IwL+u7M+6mcpRv4Iga3B5Bgrm1iHtCMhremNzVUHTbf8AjMeV/wCPM836f3AOf2f3Dv8A0/uYQYGC2y6br1MHdFKECuOoPdQ0p8Mo1BGfcCpa6wTjXBZj/wAKPiMnf6CWVWNWnzM1U9kz7fCE3XU68kP0Tor6H1GHJENi2M7ifqDYbbFN5sRRtd38RR9UYGnljiIPY5pA/EVrggxs+P6mj/clA5zLo6CXAQzADSVBAGFF4hGV7/vhNTp/wGsfbMgnnd7c4qsVj3FNp8o3axV2z2R8p8zsf3K5Gxuzf2N+qJXLwKeSYLepyXphxrQ1VD9T3+Mr5GomybhyCjkHHrxNbsAbXo6xb5PihflQo+i//agCW3GeH8Ecu6LHgo/hM/asfgM8Zjozv48BYXo2BBnWz3UXdVVBddKzg8kvnJr5lXqo6WwecXA9IWJR0S/EbibIAxcpV910Z7zK3OOkX/ZUlkBhfD/upahvALcWKAOTwrt8nuXwbd09Xz+fuLh6rBYnlv6hVCQHB/wPXmB6GEYD/EUVX0l+EhS4MW2L+C/SS7GsgPQLuc9FlYTBkPMxHLrm7HYzjhKqy+dUfUqwEbWxc+sVmVQo3XtZOs/P7SLTDKBrf/nqILRctu+W3fWZZZRoBVwvIWfD1C6SQo4AyOnlgIoa0W1SQsQC/wB18kKeumE66rP4TEl9oCxFoumiZk1VhzTLL4I4fT/5f7xAEuVcr9w5AohezgvwZmz29GCr/jMfQDnG8et4j7QfEy/LfVMRU5Dbu99XK8V/14gE6M6Jd/QTzfonn/RPP/EtVowiGYcQlKlLV1ivLGurTr/nCGe5VoXRG5q/5/8AUSkyzrs/X+MQBH0hBKHK7Io69VAKk/wSxirZ6LZgtPPiJ0F3beniEs7BankzLO9FUrGRh7Xx6g+/VycN0qDUtAinbXxNSRsKqa2biIUFLQKBaWjzOLQdE7ORnyYI0EWGwvDqv3EJ2Q/OTUz7mti/OvwmWcYSrkGwyozBDoYPzp+YreFYh5FR8T374zIRbSNH2d68XK6tnKPpAPcZQZVKt8X/AOCZySg0lVs2i7I4n+8AaKOeYVVqEmeGqlIsXn9biaoLdBD0r/JMzwtq8n2P13M0KBs/f4YhSyWg2X2VX4gBGp+E+TpjngmxlOSVZlsqBSAOMj/5UpFkHqpyPjHD4loPDX9cWBk3e+CL+nmPW/8AYmPs8sGo5HOcTDAfLDkb+LmN5BLlSS+qJ6NsIwqwKp7dpmVlpEocl2+H/wAILTwREkBWHOIHNx32cg0Ns+ogY4VZj4lHs3Jj7lgFtqr47iOWhdlrsLKIIVeg4ZMtcmD1CLrUF+7MJVjgylqd+O4ZmAIX5H25CA7aEUHn4hu6kTa8ix+Y5ntZC3OE/g9y4L5b9ucP3ECUBbAcXOO477JufgcXVxtTWyBTxiKr+bN8uiKfZyl5Aw/MYYMOH9uBPfcxhIl7Zf8AM7wxolybiWhe1qqgdmgbH2GJV1Eq0WZ6UfxB3QdMAC8w+KogZwviUKaRS1HSW39Q/uWf+qgrX5UQsn3n8msQLaveOiHixlKmGp/RlgrgfGvucVz0Ez2IBfJeM0DVmHgVmshfWaxn8Mfsaug0ZzlrDmrlU6A5LAa8Qq11Cy5Rf9/qIat3h8QNk4Zrl0v47lRwBcO1uD8y+9Opqqd41+44yGVBOilVwudWThAnwVvp0MoKaDQWC93XjUxqsszN5RfyXEh0vKD1/RLpGYxC/AfiUi7GvuZxTbkWPiDyemw+hNPkSX78OOgorDWhfeJljwrD2Cxfyl4SbuQ8bhtGwGQB8mWTJxEzwcYYxbf4mKcbUPKq1OAliQVzd3R1DJ6DorhbY6l8ujGqezq86gWohWhcgjgzCx+IPlpANtDNcDi41hwzfMcxUbhx+ywn3MFerilVrg/ESj7CTx08ECHxWZPLiEqeNGX/AFChYXyHMzi+cxR7CMmGd2wGhuup5TL5jVVNxn0eb8Tjc8P0H8v4hC9fq/Y9cziYz2+xxkfcJqNzeMvoi/Q3RiGIgTzWP3Utjev4m0vm/wDYN/EwgvLV9wxXQbtjeoQoF6stuv1PGh5D9Ry9fbpiPUWLG2CHSzawKlvl/uBQLd2+I5ZW2FWNqlYfZPx7le2PgR6fMwvmEGC4r8D9ysjyY8zz8wS50goSrr+J0UIAHDko1Ks3HDV1Z8QbvRSlXrOE29Absew6jVD2BXEeAEdx69teyyEsJqxs35Jd9CZIFtZ9xgqPY7j1LZnhZRj9kKI/j/lEtWDgV/UbcUd0jtokLEbv95gQaOPI3vco2Xl/C+ZS3jxhf5l+5CrW/iJ5XALwz/EqJDGvM3fUXrJ+omFC4qIJo3np38QAEmv549sYt7SaFsjsxRRjZryrGvQNTuX74spiqvbh1fzB3IzpjjfcE5WjihMOxpJ/Mv2ls4Vi+dDzcqWNmNezTyeMSuD4B+mn5TNaLe+5k0h3YE37jgXn8eZv7r9rH41cOi8SsnWV/NSxXHQVoODpBHYXlHB+ftMMRwtgxYXGxw7pqeaxChbZmz72z9r6iF9vvOKw0G6Moe4aG3P3YEjavpUHyMpk8yafKQ9TMpA+EV/JFAuo6inpmFS5efO1z7owQDenN17tPxEkF5TOSYCypXeaFK4jzcHkl9rhP+Jke6b35gxRwAaPPuVbkjNyW+BiIvQJK9+S+5y3eMrKV1mhq3LReTrgJ+2AhlAO0bk6oiB6/cG4QVdjGPf6lRpYsD7la8d5lOmSDVdteairNZtB+GKAVgWn5MLVy94dlg9vPx9zYyQfyDn8ynZhnBF0edQQn7yqbXX7ftZPOAX9MwdineUMJ6ePzEEHJ5yvcAVpr8dKl/HuXdK/ouoXVqxeX+eZnDSrl2a/uBCtsG04gH5g3xeM8ayr7bfWbj0Co77Xwfu+pZ3hSgG6B/sbissIBPUbP0yim2Wdwc/5mYZ0xn6vhaXecni7D3EpV+ZTZ1xTUqDVEH0xuUufAZflP95jhhyHlrvUBhloazwMtACU0XiXnUNl5SXmh7SvySxW6Zdre2ak5hdab3+IsHw/8xsV+T/sP0KfCNek8pf03HD2DlFGw5qKt8FF7hbFfRcwt6tFdudlBWutlQ1Z35gRVVmvxEpexz57+pTFb23t/UAYoYFbmNHtmsB9XfxLt3ZXh8wBXoj/AJBMT9BKM31ar5lHe7SORO4uUeQ8SsMRt7p+lw+BKdc7843xrgYdAQwaviIFHTFX0FS7GqcAclvUcatVSm1XO5bbALNOHf4tMeoANvqAMVnw6gpkUVfoc/aq5lcsciuQaff4RoquEsDdYz8QJcTBa4o2hkweE1teZwHO4XKYqAsGvX7eZgo0wzzioC2uFj8MwppH3vF9wD4ggvY8PmHukoh9ly7RHMnkSWIpvbl+vEI0Nmtn1iAcDs4vK98Pu9ZA6SzHlFVvij5eRp7nMrmKto5/zmNTpMqr+ERhbVYyAF+v/JbQQ5WyGRLWte2eI3kYoPSMz7lT5QP5fBt8EQ2dA6G4NKxnJfPE0NPLZ65q8cWTHPHIXedeJmfGrFsGhYkNWx/EZhSYbzxDCsWU8GXhoc7bfEqlI/A4D6mOIC3hFWI2Eqka+IE2kVX2D64mQ1ewGVjXrgdDn9SlZJmxT/WZ5M2VgxqoMKliohxlVKklPyqj2sS2R9fmIt+aHPSxjceBpLiC6y2wr+CW5Inlj+iEXFTwHMDwdkpgmQqrKxj94guUjks/89bhdju09rVEvJUR9F5c1/crwKPO+pRzOivqeaI8x8M8wPGI9P2z0zNt9wENS5Xm49ThXWEfEvhMDcXd/kOP4qiNoInPBwVGd5mCsqx/tSkK1Dd9njMRLFdJ5rfxF0p1YijIDvAi1kmby8Yn8woMweutHLDbRxGZVES7NBlM9PdkW0tM9wRb3mI6FeP4UZYytt5ZwY19xncmm7yLPzUGcgJZ3nCE+31NCsqYAGPAcEzBGhd9iZhtrGzLwKF+2pdjNrHopl8Bi4wxZoU85S3xLaVyr0Hzv/ET2VVGX8RUMoZZOf8ALj9gfOcc/wAJV8QZpp/zn3KGr2Zqo5HID3UGUYE8v/IUZeoxFbJ2aStCBS/2sMvMyQq/FIr2msC4nyYn+fML5mtAwPiW+KsaqHUAoIJivnRKY3OU3+ofNNbpv6lS2q0VdDbkL6PMXb8grgAZaQuDwHzBY3JhwLj2jUFpq2jczQoCHxKBGCouz6WGrnTkzLFR1sRiZz9yASn9i/1OIWpWeQWaFHRGHhJSwfUbWWrM1+IRE61S9O9QabEhbk5JaKoSq5cvqcKQwgD6hwIACZDbE0EaD1iolUFa/gn2+RlivZOh/wDnMKVhwhy3J3SLuBR5UuKshRfOB8o19k9xHTogaLsGNoy4oJeXzd4Zjjvg3A6CjFa/+QC7+0tcF9Bc6AnefuaP7pd/DO1oik3H+ximJF0kdpUPmcV4Fq/py/BKVIc0f3C/RC57wxX6ix2DqTnDxR7IXd+F5n8IROO3W0f6/M85TBqLTG58DGJahSqY+9EzMSbBOrruMQl6q4eer1uMrk8xFLD+JqOBJFXYV/CUZvHH3Az0us/hGQZOyv5IX9PlvlL9kCx49SGqsqXTvA/uFHQq5PyUmkIOW5Ck5ajcFQLtauzL333HWMVv8sf92WL9ynLc4fjmVzLz+ZCw+IFsxvW58noY72QuJnCq/vqBSWfoqXfuI6bsETFkyp1iriCFAztooL33Hm8U1+8TjQoR0XUXOiauBqPhZkslKVLwbPOPmHCgFuXDzWL6uAoxb083wWbmJEy4Bv8ACVAYx4WT+JXQZB6FszH4AF3+o4x+tqEXrPDseokuK/7UbI1LBgGKqMbaIiuW1fzl0BFV6/0XMGt2bcPqYYVELcPrzExPBWyVvXqDsL2TjEyqwZLfqe6GD3j8QFG+Vk3jfiZxQ2W1fLmN3JiVou4SQlVYeVOZRnQQ3GiomA1xb+5ZQZVSBaYqhX0/4SwpW0YPX5RxkfPP/vUFKd6JqMgRcxAUu35o+YLNPY/85py6hcmL9DP1LQ6gH6P9xGy7A+0wfj7nf9qJlUmdpYO4ltqhhgAJswZlrWs1NYHodRHe5ld/yiY3HX6ge6g802rCEwbQB9tEJAfl/R+YQk8H8LP5jc29uvOcy941GsPXK5Zbhl4H2Rpy4UH+PEOakOBf8flhRBKDzLm6MJidJqCn2bci3ue88HKNheM3FGKPwFbhfRKXCwOPRb10TB94BnS1fcpozGAG18ZPncrMrArw0wwvt4m63LC3hWBxjZ1HCAcBvZmPeYvueD7rfYVm64g1btdeNMnq5XS1bRXml6sxhm0wikegNeowiZYTxVILz1DeEDU1WA2YXuHmnvLq2jVEecAXg9wnbc3E/G4QzpDT7/8AYsv8ELnlMvGGMJaif7BFPmoga6ExwvLgj9U1OAHSd+ZenIu2K/mWDGMOF8n9THClBk4SrElnNQ9hGMSlNjnJrLecd54mO9BnArbLUBAEcGkUtcgX6hrYPlF1rV5lqEADeatcTlaF1j21uGqnZHm3GpXT8hdn3ZmaK+hVH1IqPcmQSlbf1LlEQK6jWLwXUDgFbodVwMCAGVHG4RQAQ207/EgbRJnjp9CBih690k5HivB1KmHy5ISWXh/rjmA7Xe/xNpzdttPqY8o5VL9yHnjD/dWZWLLWz3eKx1FXD+D+JneW5bhvKdnPLGdbveWYZN4A2zcKs5j4OoW00wV6R3YlHWGsB8NKgqzF5q+PxBrRh0w7WPQ7Mq/HxLLV1IfGZlER8XE3OeWPzEN/uY6P3E+JW7l8B8z83+UtVnh/Q/tLhe/i/O5VUC1H7QNha9zBR7iZqoC/iYPIEXTb3ZiOd8jAbPFr/wBn4mR36uh7MFDito7wWxhG4uGPDmpR82hhF5dv+8St5C7Nm7rN3fqX7NBxymQB/pxC+xWqhjO4t/HOJqXHCPTQ81fniC9sB/waDE2ERagCw8JYc/LFT3NtyPjSr99S2pc/tquIeKpoPdGxsalva5qXycRdt9j3KIn6IWvl/qXBCCGCCivr/kNKrIdcvvzuNDRs7yuA2ZW+dEc/DNRMcvWpX8DrYP3XHFQyVdjk9y1QBmyKv768ecI7ajjKZwe4Zfh1WgKjAUT65qUQfyO5by16zLuBxTK8VzMRdC9idHnBHgqj342+ZZn9I7TuD+kSu6Z8R93X4iRZ307lmAfJPtJ5gTIDqZpc8xMgbgirq81ce9JM1GNmgimyvuolSvTM9JidaziflRNgGYAILPDFco29gH/IzHVjaaYjR5Kjqz3CYIZ0EeqeV8Tsfv8A+ML518IyI+Mvmc61ydys1IWnSpcrur8RgrjuZBHxHb9UR7FE/kL8weKJVoXKaHGYVUvOooYujbgiqbwbSQ+vulj9qlernFu6IFAaIO2DUFys3AJbhTNbBathMm13kG48wwD21m/dykPHImL9fJYFJquoZblPhrFn5qbI7bh8OD6gBkSVtSvV2Uz33NChwKN3YfAWuiDIXxW8ta+cQ8WM73DSoVFm8US67y0oXV5nnq99T86I9A+ca6mxFTtcymXKafteIy+dj5u/0l2u68S9Mwj7DqIB8c36ToKHgvNYxCdBwWCEuIHke8ssB4b1BLwxaJvWbdla81EQhvpywZ1ghgHVRjBL/FcwF+MxsxKoA1MMQDcKasXWemu2+obOyHAcH49w26o0PL3KQSo2Yqq/iBtteYTF0t8sL2YaNjrLFZceZZA/uJuu/mI/yT94DLQPgGXtWHyyy8DfTEsDVdkeTP1P9iC+LqIFI0BZiQYqrMzQglCyzPxPQMMWAOIDLT4iXITLAy/dPieD9Q68oxE4xLygd3LUql+hlrT7lTQRf4jHkUDiW4xwVmIPqY3/AN8y8NvzSyXUpgUOKjU93+LF78FKIaVmCA5bmFW9vrcEZika0+THOoSWFDDlPGvVdsQbhZZu65fmV4gqNlYGNL0YmqjyysPW77VxLFQm107n8gYP/ZWbfJGHeysLPH9TFVIaD/HtEuZgaA+rYPxHiYL0r61BKDe0+1h/MA59qAV9PgSXlUsfx/llmhSgR99jvTCa7iVmrrHuuJv21qnKq/t1uDt524xwjZBsHnr5mXQMWxvnd+KJaVCdrRR+RZ7ip/olp0EYKhkvlGnr7lXnwdmyVUflNlZsdlGBrDQn8THAQE4tu34/MayH+2aFXX/oWalZArr+jK3TRsa8zmclt/4vENfiwmpP82V5LgP0a2sULzk6tOhlwHBmIQVzz9QV8EBGeyITKnoepQ2b05SJSqY1X5QLt8EJpv5hoJhCUflLVtV4h4MMukQecWKRhTxHlQZo+EieLv2guFLCnxAmrx5nDql2x/U33Uteb9MbWM4+Z4Pqa2ybGuyZYHplenLqJ0Lu5wd/aGt9zl9SioPQw3eYI3BCoyvmLApVL1ZwnZDMs+UcyAnZTNcU8xLW9EoonqU6/MtBZklCo1h4TjS0Bmsz2w6Xe+XDA2xlgecfki0UVQrsvlbgS6J4/qU+5SWnu/F/US2pRt+q5ynCVmK4rUNM2H9w/mXSN0aG6doGL6RGYoee2OtEXSAbSuvj4nb5Vr55/UDkWrUbHyeI5ZC7RnwgI4n6uWfJzKVqiFl6uchfDGjxRo+OoQ2GqyUccyiTYNruXTUXOi7mw1bWfL31wyBkVeqiNYo3Hf8Akh21XqP+/MeTgmIoAdWfm9/uZ4s7iL16JUGi5SPPbOtbl1sNexlZ989dBavguiWoHALJ0ynjTXzEIItoHp0rO29xq6bm5rieUiRJDjV7tRfxXiCJHxRw0FeDm7mkaob4dlOcPPvAFXOHEMOrFeN5qNRSpdNN35Z3j1QRwGA6weI9Waw4rkd5p8Ylwcfjd+56tRIjQo7Jbapq6o5H6qYiY5/shXDYtaC5arGgGX8ynFSuL5+ooUDnTK4odtcfmUTOZV5Tnn/qUyfNI2hrl/Ew4ENAh+5lTbBpfDNW6OsMC1IeX5Wxsh+Ffea+aincEua5oVUPgO5H4tmfqUKVu2z8mfnUboM2o9KOJ8Ue9V2Xs9QIkAOWVZh8PuOCHxZ+Jk/NTr+5HlD3iFq6PmA0FgNEPasemcB+UEZDmoZ9Z6/qZ5p4H+zKLgtMSDxs2Zlaq4KBQQX0PUyXWcN56GYiwscXDJbZ/wDg5o1YwPWJd0CjFFPKJi+Jx+Fadi1i/GYi1/V+g6O4q4gV/wDbxKtG5QM1uAvMxXh5DcuBY/tWlrgW89SnPwW5NR0oGCry+SJbITsLn1ndRzpuVrx94ZXO5v8ARvjJemN6KYbPYCGCvtR3z3K/YhqTP/suDBLAlvp4PcIO6wNvX8puBf4yG7hLwur/AEfL6jZZtEe39FEbTWDUDzSjxKCBiDQKAvB7zGyDpbFwLlc/EYVmaPuFsAEf0nrfiGKLQ5fg5+ZcgUKUfyAXz4hm4t1+Sf274vcyy9F4rg7Lsi1FX/GXjxCUTDHzVYzmi2Orj1byZyUagXLb/EIUfGEK4BfoIjta7yAvOFr035WBJH2U7Bi97v6lXMgm0HT8DxG6rorXT2NG0xFz047DYHB3vVHg0PhymA3U1Ih3lSpnqnkRf8oVE5MQxuhBd0lZ9lD22+8fJMHOy/xMkz9+6hVbyl+DLfpv5/qpw/ofuI2121Btg9suatoEOkLmFTTUv6GaK41TMWkFjJLMoly3KJTwISuUZm2q304jcucW16XUFkb2wrX883K3WUfic/ZBtZXJGqDvR9b/AHcHU+8KYX+IlsFI3yfIv6Jb2VW14loGNg4wv7ZVKm6Kqr5/MYN1zq58HuKv4N/7hQJqXbK/EzjkD5HR8wAsC+gH9sKgLYyPEvtxjlMj4TWPczj+pQExnWnJmeowVXs4eiVKSBGtWlcXWf6mXYieMveKl6o2L0njuWYhGVWRy0w25ZFawZQ4a/UAPtS88RMqXHBfm7rmPlWMKezdxBA96EvzFLyb0tY6B+3cEowiwDx/nco1UAv5XDKQy4yl5ivRgyFdKH5haczWfRr++Ja/kpF3zxv7l9mSWB/Ea+UHTDSf9jE2OD++aYe73DZrQMw/QRMC03W6xAoJxm9Lr9wBAty/+n8TdcY4Ho0SpUVAtfE19dRkHPX5lVYMZUcEWct4Z4CNrTJhXj/R9sXVSpX7lBuyhD6KgTtnqZYX8R6wBHMCwc339MectRo8ahfmpze0HrX/AMR50HvrdHAXz+M3E6aoKlQTdJtnM1B1YrmUEESr0OcRfjMRjh0DkmLVDJh8q8igyLst2wKDc4wnFHV1+ibJoo44/P8AcqgOUseXk8viWdbg35HXJ9TOrZh89zeHKOx1Mtr36ZfzO8LOyDGy/wBEt8/UwgW6jQ2fhIK189KWq7MYU78ytevPcHj+GYCwUGzoruefpgD8gP06lsY8uIDnB7S+2b3LGEbJm8lq8s6fyRo+g6lZYKbZcq6sJChhlaXb1csHH0Nyi/ojd/IQj0mVstzWa1cIQZvs/wBSsJYlVUYLOWeyMaPxA2A8wWrBbVInkYgX4fIBoppMuPpm/wA11VTQA84fmHxW3Qe2L+vqAULfzKN5G8VTD0X8WJJ61XDZ9RV0QUAM8ll0FHnOojkYyjLobrHF3vmaFnfXqmjKJIbKP8DLq5C3Kba/uFWkudkBfNMY/mOOZaGvx6a6I/3I+lYxhVNgqj0b4f4nHCrIceQ/iNG2V6moOPqDZ5k69aq/l1MS7s9RTIAqW7i/z1BHbQuQF4ccfUqGQCAJ8ykyRgZy8/mfDMISq9QFY3EW28+YtGhoz4HS/DA2rZwaU5t80Sjrriz5Bx/tTfZbbqPHXeIos3ALuZbVrs/qD2YOSvfxMCpsYGLK/qLQJW1t/EF1fN4vNbCSru4xjXHqbr4qxVhOzVOseZqq0F8jjM5GIE9BH5VUtg7Y/M26D0xCJI16q00zNVlx1DgrB7azedp5D+D/AE/m5yamSnKmlLFRdzlWUX7moy9+MiUhXyrRdd8uZZbpctNF69/3MbxZdjWOA5jGwVrXRLra3DdGIYTNpV0dTOrUDrIX+ZhB7eXi/wDwPiZ2uo8+JS/ih0jFcYL8vH/yFTDPBg2lUNT6EnOX639xdfUyh8P9Q2HBwdRmyyZz9wQCV87mqKVg9SnBXm3+/wBUaUbtddv4HqDqEFDamdXf8wHwR0ZeBAMU8XMF7Gx7uc5QCjwy2ZyGKzBAkRR5DDzUvi0vyUn8xGzSeJatPbMPevC6P8S9u6V9mvxUeSLsFhneIsqBmrfW5QID53H/AGzDsPBwhjBMWJw9jC8pKMF8HwdQy49fEOyYk3kqzzHTCg1U69+HJcPiJW/wFfp3DQCtTFDYr3+obuSC1tx/x5lE97a1+jR4cvFwQ1mcbtoM9U9EUQ2fkIXwYa8Ix+iimTpfDh05xxNyigsA4/muIB/KIA8UKimoQtNxlXa1u+QPULvDjhO+yA31tBXpnO//AGIkAWRSuWYVw4WVKPYJWW3mbhPDVvJn3L2i1P237v7YHVdcsy5bcZjs1wf8g3Qhaz5QKFgYtj8PzMt43rzxjGfIEUPzX5xMKgsBh4NPzOVgyI2AZAtX1GUhJh/wbhVwFvfylphZ5+5xk26XpG40hIaDq6sWzF06a7lRueo9thCSlnyTR6vqM9Uwkrzrw/MEDDsmRvLbQbjEM75AZtU/4ihFRTUHbWJbyoPHDL0YYxU0Nyrj8Pf5hqk70TFkbY0W3zKPVUeyLK+ruMcEks9a5vN5dQ5eokpbjb/AVrMHSQAVLgYMHz6u2A1yWTJW6tWrdwjSXby0Fv5jnOT8hv4Lx8EyQFmFuWXinHXTHkgyj6PUOzcwcQdhkmNGHrMdDScynOX4lAqAOlP8EqXtIOHLpf8AIGwKfNQot+aDWGcZ66lUNQO8sEht2Wam4yskM7Cm5zoUnsv+iZ7rx7/1zb7LzpUyJs5vm/iV9UlxtRniEDCROIyNveKl5TJfKLVJT8jAKd0EXg7Lv0+UsVX766/mdmcXZKN5cX/yYcsjWI56rXRuUWFAroC6TmDvGe2mBd1SZ9y4oLLB1g8UfuWBQA0PJQ7P7uBxZHBsDkC73UA2UerBhhnvUQ9CF7urPL2x16BilLbDEbzpHI46yKmPcGMzNDdOKWdbT1HmIt/lezj+2FGxLZfTLANcOf48GFbLPinB9QaBpaaT9+j3A5iufw99VAX1LFWMa6MQCKT06v1cVFalLj/wLhmu/DMsSZLw42xReLIXC0YAxNWdQY5Dn91A6cKv+hO8ANy/zqKrjsuV9y7BWgM/7P4jgYRVf+EqpiTmWufuWNa61/sTENTkjjfUuGfRbn82seoZpKPknPZd/Uay2AytHevEUauuAD6PmZK8acF28Gbma1CBzbBOL6gTTqaNuO9SwMfD9iVgaCxcv/EKixYAYFhfPPnmKGjvcnR4Oo3axlu/nv8AudXbSV3pK+7DzENAKhMOqW1Vig8VCgD9+SO3MSt4Q0X0jn4GbqlhtmaaB3TqY14ytg2/DGIIVObij+77lppN8HHgI2sgaRiVMZ5mCxeeIAwMjDOgUwyVAc9xgZIbDk/GJ2KZYlsNKA9v/ac39pXgx5mbe9xKC0yzLYxXRJSExTLA7YF+0vWoZsuMiNX5hoF2X/tgF9VBwL/NzDCLqNRgtfj9sr4XzIPWD5lQxrp480ccXUfxLAhXIyyAd5ijytXU3zYZM/EyoFlNfos9F8oZHms+x7Q0bGF6H+YBVdT8TZx8y8ATqPoHJWG/EJI5nyAmfMCIY1ZXIOkr18RAMJL+X/PMdARqMTPGfwwiXZFdmwYq91rPwcnOnuuWsn1jjcLlQAOemlKr31L4EHBquHJ4zWAgVUbSG1vgnJn90nTehD4iPzDGwcLhxuuYCEZGB3Nd4MG/HMOTwLbXo/CkuQlr9ZifMKKd0Ufuv2CY6oPh8VX8SkC92te0cwGSOXOJrj1KQoZXVo0LWf3ENdgaMObefxH6V2Dur6H1c87Va+3bMB2xCS1WC1/1MaMQvJb+ONxsGZdr+ZirhF9wLx1W/BBYNthqv59b9wsClql+1f8AyNCrrYWU5UF25qVI9YVptZ+Jgh8nMTFyVo+JegAkD8ZFdszIsKNNg43csURt8AcBk+tx3SZmVjF/dzfXgdKhjYOYr6tZkRlL8qHjAvoGZNGXZN7SmfXPU0D1vp7R5XiAqpOTGX/FG1LsDADolZgu+8zQvs3lH9yzizWOffy5/wCSmcL/APeUCl0b7P8AVLUbtFTCPqErlpqE1gbfMLMoIXnIt+Y5V2/5sPqApIFQX3fUM7fuBxVMw9R1Kcq+4lTo8xFgV5pFAprZZVfPuZuO5Y/24wPHuv0xYJTKt8S6o93Pthkqu25N1KRv8wrWQYwm97H8w7UDdTTU5qObwUw+aZ16gKofmp9+Iw8CPqH9JDHVthHX0xQy+H1b/E797CH22V43Kir4ityTkqxlcg5OdA0e71xPEpf9dC9QhiuU5zC9JaljEC7k4Dtyf9mxokbz9tJ88TPHC6KOK7pkdQk/FmRns9YrxHNlDGRoB21i+5aKsFOgaPFtdxy9Yywb11fm4FKWlS0vHIzcCDef6lTM16MbqAFGzI4lYOylil22yFX2m/m5XsILI+UZ+ScDEgw/RYj7LLpcANv++YtTbVg7V59qZwhFxUdfcFCrdYN8ThlLC8nglBY5M79TcXQlc4z+iJUzZvl7hIED+0R9xMdauYPD/n5lQeqmX6r0awsTEdhW4W0evzFRT9FyJlrNZNPMtumkwGFlrFjzn5j6RsAh2bPsY6y4lipsTnjJ3HaOgrf8FZgjAxdc4oafcsu5lDzNDvXiOxzxGdNcTMzDRzQCb5a4oyBuHaoprfyRDUFhmHzEkYtkrq2t4gZYSYQzZ1bdvF9wGzqgCaf3z+9iFcy5O5nLYYdNTcgTrddF/wAyxRAryTxZ5vzKMm726jLTxEMB+UUgHYhhS13bExIZr2SzICtRz3+hm+DIPzLW2n4CFHnmEF5bTi6jjNWM/QjUgOxq4VnDqvb3AExY6t9SiNvpbu44Beu0u7TqPdt7hoGOsp0ywW1H4lVLm/UocjMAwpbHgOYHoeLiAgWZlmEcan+uO8cy5rMOd/Vw0IUB5lUFBmAt03t9dSv94X6grfJd0tK8jF/EbBeo4/4amQdl+3UAuBB+787h4ZhB9LTmt3hGENRHmYL05zfxKiQRXZY2X/tQYYkzg8WtbckvbOxigV0C1Gpv7h/mptRF9f8ArMpe6uYV/mZ6AMJmWw8awJRJbML8fEE5Av5mIlX9tq66o6zLIk7b45VwGcwE0Lpuv2+V1DuOaHV8HyTRmYVvsOJRVoQL6o8G/ljOFasoy8M/czUrhDXikLvlsH8DxaJcP9HUU7QTTasqj1z5ZWgV2XxZz3xGxCsriv6j9KIYNmeTbdTGhA4Hauty/mMfceyV4jXzr7zLGIO3fVMm8/0SuUai3rR+JjQdHN5V/wCJa3W6puNtQEIUZZlr/koUwl83v4dIeD6MTRi7WXP34wwB8g+Mg1eW8ShyPiq49ubZRSpxOZFyZMRv1/CKWWU916vX0yyoB8v+m/iAnT2BmSJsv6jZppIPcqpl5hiF2i+sO/8Af65RZPsRJnEe0VonJ/vM5I2Cu3/2I1DjiHMs4cvawghr3FtfpLqK0/UoavPf/IFthoWJ9xfd6gaDh3dTLH6v/kb2D14hVn4ltbTDbUTyNXq0tk/UrUrPnMbvymfOOps/SHfqIH4X9wgceG5UIKfgX9FfJgd9ZDc0PaWFeOr/AFLXhosvv/keJY+Lc3fNfhmBbtn4/wCyggrbe+g5erlf6qhVZCt453DBIFPAGEGbzqG0QSwapcl46zCkCVZG3IveZdlR0KOJYD1/+kxAi8KH73KV7MWmG+bi2TULeXe7/UMi13cE/N+Iiil5F6Q/ZGFBGnQHNvklgzIatvDnA9bzFDvKcKYrQ/cLRwC/EUZG/pIjyEcAv4+qyzjgCO13d+f1LK4nK/8AyYmko0i6H1j3LySxtKmLeWtxLRDUDtTnj6m1Qg+RrW5Tvl4MdR8GzUualUzPAWWyy1tFEekZgb21TOPFzEyADeaXysOzGLY8AwPRNRWK3DVefvOY/l8vZ4qv95l4KjpvYpqV1dHSb56f5gbMLq94MkxirkKyNqbeXg9yjV98Bwee2OCOASyo8oYcfgmVMudQ5rl+s9S+QrYtloW4z4iX+BOPHxNoZ6IhbBqYcPuMxjF0agURpwF/6oox5Gzfa/7Uccn3HlT3Uy4+5UzxzB1gvOIxMV7nJ2GXQ5QYqxgIqgoH+iLRXkpF/mIoeir7QtRNVvhAp4Nbr5qUHwQyQ/ILo/iCH/yBOTqCmFlqHX9sFdfYlt2v7RfUUUu4GrsxFjz8xEN4yinP/wACfzGE0/D6ZhiLl5ttr7uVszxmD8AmATEucpEM+Dyf3BBWX5CLp/JKwWgNVapj8RqRptff/JT+1UY5qf5m+5tnuQSuBmys7xDhEAsGi8vctmrQM0dZMvg3D5xvlsmcSjvOWIAjHEyguyzzN9MuMbtQE8fEy9geyMUQu+veNLcL/qlrIWLdVXM5PtBreDPQVOCbctv8XFKxY0WbWnr1bqGgGocUsoxt+pjHe3087p+o+XwW8r6caphNDaKLx2sxF+AoLQvSNP5hUpBRxbfMJ4xeXUgHTvGYqvOlbOaLuMFAU7VLq/UGxqp+kt2TeTmWWsfeodrQjsf8y/eI8A/gME+iEsK0QZkytpecxqUAV1c6FveZw+HJTo5/Uzoqyu/MProCu3iPvj8JJOsdD+4LHaLnlgXVF+8QnlQ3Vh9Rfzr0FvQBgsXbZLs8h/MoC2Ksf7iKB4r6jNdK9zBkvkSbv5GNzfclQ4h/qiUF3bQMfn9Tgpnj/e5Xk91Cubc8Ra0kDd1wgPGo4YX0TJq/4lTU3Za2yg/TLLcBujUv9TMyx5bvzLQYgogpw9RSmxGIqALV6lBX6mhz4I7QWnhCig91A3QuFu/iXbKlL4gBu7S9ivhd1OhGnEATj+MlPzuLlNxLDMzdA4qWcOIq64g5zQaztvX/AB1G+7mJyoyqpvDnd8xBfPsETI+IjVEV63fHt7PbtMwbAOTormGUhC3BjRnd6r+C3iLQrxcKqSHgf65TYCJmGZjQG/Chx/EpGwAxk4/3iFsN+TZYivZwIuj+Y9iV55t49RYgvk2cHcZDOp2njX5Z8Tmf2tVxcpvgBYLKOgFEZkAAlEGlzAs/4gO5UtgO6fXMF/SJecMcURgbfFN389d1LtAUKnbeqhqCLAkl2PFY8dS06Qrb3/yNQS6K9HX2kuIYUUc9F8cfUNEegt9Q7BgLxRsG3qvcpaGJdnbgIkuWbbPGn3b6iWo3TsD51L0JvCHlX+GJ1jbTz5X8MAZs5Q3Z2nOg+LNGfWj+/MwDtw59Qil0nWSzGX4WVcb+/wAzV2qrSaB4qXhl7eZh9WzZwxg21SMa9axFddZuqnY/84lqYL/n7avcugOA1+Mb5r1cdBJlP4VdeNuIBa9WtZ/36JRCHq8epcZrtazyZ/1susIOBmUGr7jYzQdw6Ctq3Ml97mhPQqWUqq+YeJjMvVxOr1smsf8ABLN7aQzF+IUwIly58sUI5oUNyeRKzl+2calc8/Dx4iHY+pVNK8xq2rc5nOD3PUmH+41X8CA5PiWMQwhuxUF5cYIV2AUsea9AfcWT3xN2nrUaNYebmIH9o3LHFQKWDp2PEzsBAFV4J/szxjCt3p6/UNbXw5USLbcoDWVjyPuUkYfDkK4eE/hJWDlq6X0azq6hXlvLZGS5NCX7RJrQ0UP/AIhZS1kKyHXqY9GS+K+IiRRQw48+Jh31vRT9xskM0lXQ+3GYneAUg/JxfGI8o/y+YZx+ZWeHaOIyQXPEZJYotdniqvGj8QuX1aLf4/OZZqkB11/hnHUCs5YenR5yzJWeZGLsW3XBdKxGno3p9rmDnpBbPJ3HjTcoPu6m6cEQyHsxqLV04h/HxzAxcUgqy/D6zDUKclyCGB1mKjqUyCbynNfriVOSISrdD+ysSn1OYvyRZXvlNMnFqZ6uGtkbj+zMN27S15cQw0o5Pj6gv3vwh96iBP8ADvLz9cTGgEo9e5zeFtojErKVEiU6mvaB3LzmhFV4fjn4gFZ9pf8AmNQXTNA6Ytp/390A3EyYt616jHb4g6f4+I4grgaA/wAQVlq2dwWuo1tjK0D5hh30r/UIUnZetQVRANTmAK75lz94grIYxVf9l4NL4YgckrIShc4r2qYlx6R0NC40ExFa4xiczvqGyAIMOV5iaWNcfjEch5OOoTDdTergqoqMmq+4LZV4IuFaHCqem7gs1cih9/GLMzCMINj/AB8yljhiZsTlejrJ4ug+Jja+2p+qVCMHLSXyvAzVSaLFeI61l2uW870ini6r8TbaE2v8qLP5IwNjy3o3vXP6mWHBoUPGpnANM7V/xL7hZcAp9kLJutdbJ/ZDzejqsPxUIctHsz/MoF8qxd6fY0xjclnl+YxP8xeTulGJwLg7YOriWpvzHozoQc4eWbg4z/VnKcS//wCyye3EPMQ1Dtl6rM2tmU+W6gbDS2mqyvjBnwQLkbVpjq5z06FIeqi2dUz7h6qXX6Uovha9/iBRmFQ/+3LpScFUGxr5S+FTPQ5qBYQ82iGfAah6kGqz7weYxAMLtKHKnH3NFBD9J0OXn9YTrp3Ze1WqMAEIO1s/f9Tz419sJSbZcUy+J1qFH9Xr75m2y817mG9kKAMcCMxHe6Sjo67vETX5w2tRe5spqsbef5Il82jOfuiA2ti149N1t/xhAtTEXh/9jsL+9j9SrPB9XLACR5LjTBiC2Gyqu8aJb3dDf6QQx2KvKmAYUOTXUx67ZhkCNbTKNsSulHuU3wfUqsHFc8wA0EeiLKHebl4VTs26nQpImXM6YLr3F8o/EQV9kQrQ9EU5+oAp08EGYaTpghdy9KaNxNX5l27fTqZAnoOaO37PmeCUG8HiXsotGqVde/5iDQwDgmI4Yrv/AH7l3Nplylsc9SkyZ2UQO3bzmyj+YpHBwqmLjlGP1JQvnvgefipSehYupMacR7OFtZ8Zsuaa1UqAE8TKulXFW9zNesIFu/cCzwxTqtyhij0IMBToZigBF9t3FU5loviG/DYybgMnz5ZXBlqPuJazpl5RmGUwVVZ8RGgXy9y61P8A0ARZTwhHmqX6n2EcBunoqBEMz+LiwxsP+oweuxvsRJwsf+GRENUw5D6JqhaVnxaVma0dOsmPjuHNaDQu+yxW1cxuI2lwp+j/AG4szQmvuEiE3QKH6mDwALhn6FZ844lAJjDEWqMu4SD1qChTkwvMqdeg5Y7VXwQmSXTXSJQoEe5ZxgrvqEAXqOjmrrX+52ymDo4IgMHiYSB/INTRbxwuoOm3jUasY7mFBLjSLvJEvvDgSpR+TFzDkx6gPTP/AGEVD4XKQF9PU8p9S8hgyn8AIJH+gIhBVtkgrtOwwmDg04vcAKcnTG3BfiNYNtcMsm2ipTGwuO9Ce5WCsR7jfMtpx3HJiaEqYdbBOivqIHtl+YCBR6vx94gjFXtmtb0x4KjZszEa0s1AuwG5rl5qc4d4m1r5I1wge45+HHzHtqJ6Ug/UWTHBoyyB8wDuwTB/D/MQp1dWx0HUoVdZI7EP8Fq/pj6FKOdWPMfwLsMQ5L7xcT+gsqq86IOmBB8Q0tdUl/2ZTYauyMclMu42m+YmqSpxHG/Ng/X9w42i/Z/cyuzF68TsBxCWokLg5zhlaw4uWL7nCpWWecy2+0BUC6cToTRCkmD4QxvLxxNiDZRvJN/fw6nl0cvBG+VD5UC/c2dhHO16X/eppRDxDi8K3CQWTOeu5cOBGQqEPaZkD85/HB5lDdlutDf+9Qp8AS6v/fuXhuFpTPj8wDTM7lN9Z/2p8ktAONxRU8ji4fe1SpyOoU034l6Gll1Nq3ELyvUwP+SublFa4+UArN+YjCzvDcbHLi75jVKb8yi0V2zOxjRiGNC+MYgW81Wv1DKI1zPPB3HfHc0ty8Msov6iUou63KJNeo4wK4ibpLs4gGA3HmU83/FTAByxccfUwcQdchb+X8y5iPg4VQq2xGZXedDI8zpJj4i2H3BXdC0lIud84hOE5gbATddr+8niIVKlenH9poQQe9X+I3OD8SxOsDp6/wB5hEarg+W8vCK/44Jal7vUK3IPCMJ6y7g+CK9Z3eesEBzjEQYlIB6MnCPhJPq6eERSh8tYO/cdJWs4uVXqpX043bfHMFQW+MnR7SUBhsn+ZeyF2UW7pK/CZ+Sb+FnPN1Eqw5Fny+n5nGQBmXyzLpYVwJaS2FTA8W6NS0mg1HSr3QLYYRoB55jW7IGCZIccVV7p91X1LaR0eT9Rn247iIHtw9mYLSTlW61W2asMV3MuiWVGpIc7/wBfqC0VMFZt/wAwLx7jk8fEtevziP8AcYX8hnjf+8Ru/VvCxYsZaruKxXNx1NdMwUq2W+l8wcMVc0186KjFtegINeXaLX/SGD5nKgeDUHmqeI8FP8xBYawhMrAF8wLRv1+JplMW6sqW5Eb5mfB9MQDd/mIYHzF0PjMokZHZiohcnfxG5mzogbrLXuIrgrm0obU6mw35MXdp+4l2HhKGZfmWwTnjqi5iq9j4lgCsKsjNSSj0y8BmiGFWK5ShoYanCbqsvmozp+8NajxDj4/pZh7C7BOyWM4AHwSrBUEgORi6fiNVN24AK0cm/iB8ObA/CSg8cnD9weZHoGj7ho+zEehe6AO4LCfh1D9NgWmej+YMot6zKfxOXu9Ar34uIwcD/wCsR9x4dX9CvCd7hywL8RV0Y96TBV+dv3AodFbfzNoOeoW/QqUz8DLzvjev/SLcIuGkCfzF8lSwIzwlmTGYJmXzQhUa7bb9kftU5H9cpWKEYr7rRMiKAtWYC/mWdjfB0A6Ilcce4qSob8xyYAMeZZ3Hs0EuqLhyJ4OIMsscOXy+Yq9SP8/zDYBoq2ih8wCJfbKAC73LDLh6qjupRzrcq6bluO4FpZ9tzZpm+4IUY8FfmGLR/MoLam8gxqZUNPH+8y3GyZATCtVG8Parmb8s7lslUQ8IEYGlF8XHMkYK0lctrz/ECvl3BETlpiNKOomRANp9ZhQqV4NzS8reFwg3Ohmud/zHOmLl8gZ/EvpCYbY/UcBFfqOslEX33f8AuZRiEGolMry0CXaqoiFmhlqqt4jF42dwfE/MDiGgP5g/j+k6YNU8qU2RWcThfeF5LemLyPtOCpT9jBM/6lN6sh0uV6Hb3v4g9KcpyLhrk11fX0MxTf8ADZKu3bW/4uZeeiiwQ8LJfeJ3LWSyUheqQmdC9skImnRf6lAtmF3NhOscCM2PzIAZPRHNjnVLPr+0XZMeGh+oR4VG1CV83EVbtwIANCoctdv5RJ6wGLn7GvglaT8yyxAIucEJ4LYOpaR5EVefOovBb6mFysTXh7ii3DDBxv8AcuHnyq9TMRlFSjp3+vc2CGk/jibLat43EUNq4CY9TBhxmEZ8cJfojR08zFAcGdzjDxKy3incvFbUzgRq7e5W1jfXE3LLOswFmK7qCrCsvJs8Rpl6fVyqJzzuUKgL6zAYMrWdRbYU+8fmWccWSwe+fqFRZldXgZyF3qpZyGIE3dXY9zdNKzX+/wBUK4SgdBdf2QX+tzArJCMUj7E5h5uNHtLqFlf9RflnwzIpZgYbVp0wQEYQccoqjTLGMkv0oI2RCRaJrHf9cQZXS2+df7NjzBAqAgMvKYgeGGdLxDdLcKdum/uJFfkrEXtqeDVgZLlfcvD1S6lgIC15uOkI1QawHmoKlXu0M/E+ziv5xB6X7n80VW3iA/AlItA7OetU/wDsh3lWfHzHkAcafkirdB7fzBqPPf8AAMTVvyX7JVAyLsM+mX/COB+Z9n0DJ5c7/nVoAD41LF8HitzMYc2ryM18wygFb/lcy8Nvptj3cb+XxMNK+U6/Xx3LhsJrInVn1MrHSaLcV+c+JoCH/WtfUCpbbTXr+YLMRTHD4nAWviGkjxfDMKT5s6jIoVv4g3jENAHNpWUCp1Bguc8BASjXzU1g09uI1gOIBKA87J/43AGkKsrXRLSqFawGFkkr4jeuJtbv8QJwhqPkMtulXklcCmeO44ad1MoIOa4TIpjhgnHcuOH8yqrw0VxKd2Gbil2H/kyazXNVA2W2o6hm+K4/5Hkyvfcuq8GfcMLUgTTU7BgNEvFKKRckc6N9xpGPWpVWZvDBIisVjcdlMAtD8QjB4AmNGdfoD+/HolRiISJ3gQVmUJUDxVLq1/MuK9MGv6lRFtR/vNTsWQ11SphUs1nk6nOpg5LXmNtIWGQSaxc4LzN59phrXmJNPONxNMYM3fxEDZc+IvGKFMZIx06ubvcINDWQGjlfPEN381MxS1v9pwTySFZaCM2w/sT6p/v+TlkAZ+mKuI0dw5POpnaLOAxXL1dy6UzB7f8AgxBMhb/dSgUZ9R3jllQuoVlMR5u+O4gAaKZRUcbhXqVXphzKM7vjG4A5HzKDFnNZogBlNQN6E3uo35xOIrezzEtDBfojaGQltrX3LFj9YsqtfUvXkktDxLZwh2OJgATkvEoMbS9yoxr5hOw9or4WnuZx16XEqqmtUNwEW0HiUao7meHL1EbeAhVIt0RGxfE0rb+IsAXzzFlIFN2Ti1WlwUCw7rgncr/vUR7LltGbm2lTG0EK7uWg0dErTfgdQ2gAuAwE0c7mo43uUrZ6Oo7EvMpy3SmZQZoGKwbjmjOQ1XMLdd+I5e1BdEbNY6biVYOLJXzeDuBDwlc2ndYhFYPUSqHdRSRUErW8m4lGb7PqIHAd01DyvKeyO80HG5Ru4uVVaV+Y1TDPjKMezzFV+yA8L5Sy1XeZf9xHoJwW6Ne2dqQzX+OfEFLAqHtw5nDNVCrfrKNehDLXpq3Wnzlgd2Fxt/cpYu8O5mxVMVupaW3d8sr0w55v+pSDT5lub4mEQYDmYxTfJOaV0qo8tS26MxFl1XXaJyPbGZaOF8qlKcbesS7yGY35EGqiaujXOIeK3fglqbqj7ixkxvCWARX4+oGqD9aiXGuRmevoEcDQTJ7/AAgrIHs17ljf2g9CcQDPMwsCxFTYXLHlrqOUjTiExGv6mXhLBXOp1qKb18ywlAelO4ACufimSN2E7ERWA3FviXilqKqf4ECtDH4XKGmWM4SXcZRAPUONjzFrStSW6FQNrhiyZMHDKj5CGocWODOAfmPUvWJYV6iK0GHqMUVqVqvoazMSuG0sme0PTVRacbpb+4cc3e9kftyhGA4nIbULtHDbsPUJWzKqJiUto4MqYA2U9lL0S5UoGLocr+JeVTe2PR1/iZJdNlC/W/iO4fRk3jB+vmXdhjGg0eolXbiYsf8A2A21daEycyKq1LZzuaYXU04VlIeJt1ZuZoBveoYWFi9TTC15r/myOWlNRDYC8VxLc8451Fva1r2TCFpPUQokxmbN97GA24fdRG85NQgpk5bvMAvLuN7u6r4gaqC+oxc5IU9rlcWu9WVZ4Q3A6AsaYxgsr29e4thpLLdEz6E7B3/caqsRtK1zDbV6jChXG9MG0u+DcZKuzqGofcwHwit40P8ArlMogdZiKU2HwSnChTw8QtDtcRNUtFSoeYwhX7j4NZWNz4GcgslZws3MuDzFCmemPFB5IcgmbmAUDEnojfpY9c1zPUyfMNFtx2NcQEqbPwgjJthRdh3G1D+44RNwOT/SA2UwUxwkJcWikI0UC4C5VNjEDBMxKHnEPpjdeb65IhqAVq+KZemCpf4DHn/k5Jyyqc/jcDopaAHy1/nE2isF26d4txHCrYcH6TC5eXuGKGn4mIBjqHwZxACZWg9QKLk33/v8Sxt51Aag7MVMQ24Roce7luB0LIwD42uI5rLnEs2deSWNIRqkwXL3XHliNmk8wOLPiB2yRUA0FZ+gjaoeMEbWyzyPqfKckuFt5xLGwDeMQHObdQctuMkWqFhXrxMXXJjDL+G+ZxFusvivqV0pfc0oxvQglB+EW1r9JZdLz8RLd8ZfuYjbQKRaLGLa8Opcw5YI0M/xSplahXNBfEstiHMe8WG2IeWRXpuOW/vDVOYxNWEQw4lK4Jbl8EwHdRHj6gyEwzvEGWuNwAhz5hQuscx8xgdytgjd3AWr6Ze1YisshlzWZUCmtS1miyFHe2duqDlmpiITh4DuCqb/AII6/MwLDymNTX5OPzLPweFOIcAYRza34r9w1R4t0V/zzLEb16HR/jxE7xIntHZh+5rlvjM2KfX/ALDG8ROOce5vzTvETZ5wzAFXdUf9qVFaZauvv1C0vzz3NbrjwXKGtYcqxMy2S1Ck4zqEUAnF3fuWmcF9SglE8ssCNuDqDXfa8zoKgtTc/mL19TglDTwqOijGJsAPb/44ChyfFEatgnj8wo4lqzAO4I0oON1Meg19jnMQrcKCord55mSv3kZwhPC84uZ1jiqqpbAVv7lcrb8HMu8g7xMKgH+6m0tam6+5exN+EdMio22W5gGpqXOWPKrVKQZdR4kBRMgszbEGUmsMv3MJlUz4+5eAjctyqv3HvWe5dIOuhA60fJWStRtuvicUB1FiUeULGy0ZdumpmCKlJhh1mN5Y3DI2dkGeTqA8kNMr+497up3icjZ1AWjKQmN0SgYsyMFtzMZrSzg6eax9TW/MB+ufMvUG7eR7b/8AZobi2F10VkDiFpmT/A2sBtpNcYmUUl9xu9PuXtKWwrT4hVAL4YNXiDx+GIsLYvMTLK9YzACzTTXuH1Xjhl8VM+Yt8PylAl3xiIh8RX14lqiK7cg/HEAZ/FVeIMByaxv1BoFwGTiOPXhgD3MXM4eeRb/yMZnQTXKX3uWbPUG2hhDgWYVqOB3T1A4J/c/RBK/VSwAOIvg91uYDb5QaftMO971NQBdb1FABH+Ihi1cxsOB6qDS2hg3CsEV/upT0yOH/AFRFs3fU/PQZtzri4XWNj8xnVnb+ZgqauIOCW8Y/6seg38R3W/uOmoqprmMozhj1QltI+JrWPcqcPuEdIg4bgcIHzBsR5CGKIjHlChQD4mwgQsPqlYEXxLlWjOUV4HMpVT5Npm/VgNX2TqvTFhdKGvEuWBOSypfqetNTBfjmCnpmBuXiNNKd3KwGYteQc/dExulkc6sddjzOD3HFeVXWs47mD904XZnvNuI4UUoM5viswjpG1NtYt53qKkrNL2/2pTk0vLOO/X9xrd+jUKgHi+0XAnUORM8KHgJRVQ5Z3UEAWVW9TK+CYea9CQobDj9QaPZXfmpyHrnH6lUZKzNKv7hpAu2ms/UzqEDJeTdU/wCJVzomE/2p0umS0G5+mYjtYVaMDDku5QpoFzyqN3ic33Grwlm3jEpPMx9w5lxqwvmsev4gByJvJWazL2DHLOXFZu7nS75jmGnNxXt+Qlwm6HAVovLnRmXLnKWJ6RLmYo+o68B8XGoptvUciqri7iPwFQEMVKPL8mmWKKUe4XsvzNF910tv1KzO9Pc4IU89saZpgftGnOBb4RfkYXEQa+NzLcZiXk5fiZBn7uDLSnlh0VLKtXhg2/W5o/dBxcYi4qgOoEi08ZXB89DggVg+Z1CndTGoCOpi+JtKT3EtiKKqS+40chLA7E+lFdXL5i1Pczb54hIvLAQxh2zT8sqB5TdM9VRgxEoIsCzv6z5mR70Bb1r4vycx+ZrUypVL2G//AF/X3LFL6C3nvEX/AIRAeWOB37iQwvOLffwzEahmlUdXAZKOqXdRN1B8n73qAwADkptOiIsL0qx4McAGifgRB+A5vwSVb03jNia0tWXK6zwfUDNWLTevuGS/ejuDcuUNjD6jy3eOsRwbnNw0urZp/UMUNu28w0MisDURgELWMVKdjGHiUpF3hWpaIo2W0a9wUoORrMVk6xiVyb/ETyPmKForhKeB11US9iinPMraqGLzaKrLwweOaS30rBLPN/iY4SvUC2Gs+Eaqt8ypwuEw9rzWqg2K43eSJgJDTr1qHT65A/xBuQw9I/TUHqocs15mAuVGtTtFOWpN0HiviIOR6Yj3CvAR81+JSFRRMEBsDEpiDWWJd10jmP4M1gepbH5QPBjVQzgTsczcR7hKAqO4K735nCdQUZa0S6L6/wDgTlqt+Yxaj2qMLznUqGzbjuNpSNrbl3/GYS/N4b9F5/uA0FMDw/34gkFpTSKd0szGJdr75FlOBeCVXYMYDjxOCoeBgP8AYmV7hduT9S8w76V8QaPpo2fzAvHjYx+9Ssl5RatfD5l5YDS5cwbK4aN17evqYBxkz55rceEC0OH7ioihhR3BIE+LX/YsbJQV3hjrzPDfiNloOf8AyeVkEIpoNbThmuOKr3NEcWp4jFzltwiTIznUOgLzzBV0sPMMYlwwrjNSzOQpXGb/AI+4zOl9THeSfifRI7b3G3UXGvcQK93TiUreK0EaYMfjEXIvN7lzTHwlBZeap3OGTPnH3BfZNXiYIOk9SUG/jnqG7UlajmJEOkGaU1o6JjNqUNsHK6stlZHnTY4LoIXjkZXltmptjQhXavECWtzsAXWS04S9QUzYuFVGgwEQouHtYTus4IJmdGORpA3GdViIWUrxdAq8uKzEW1RY5fYNwCGCa5QtgS8WXK3HWSdOsnFEObPC9Cgq1XoGERlsatmAiYwk1LnubNa8RIEYyg0xdop4F13BwHjOQlTAfwTLTabSBMJ45hVlTwszhsOIpw/9y1VM6eo/pIDyPcdCj5nIOIGzRjU5MxlDg3EcEZreD8AgBJHB4lKtXuYxJg0od8xnlMhZ2td3/EvC2nyTi87losAnjNe3H4+ZfGTnToA+c6JawILY3MLWynJqBYsTyy+YI4BTYRZmKN1Zg7mdukemPMSTyFMCNXQ/PqCvs80h+Lgd4C2uPiap8iVvTZXzH3K2fEGcDnP+fMRtxpf9cFq6VjAlpRqqxzrUpewsr07xHpli6bV6+YS9j5jSPlZ31LnDg7nZGTLqZBa9I6IvK2PgSnZixavDOfzM8SXjqFbLAyPcfInq43bmLwLg1XAl0CedzJFDvx6nphIi41bumpjJjeMcxAWp5vEpw2g5GtLl/wDBjnIpvHHGIGOTrlG6GqgYXjlB12rJmezyZzG1WBoDRV8tWiuqLdgFUmNZjmXN0bYMe6RrHQA0cMp1w3p0fgWIwXuBNbtwVgxlvJA5kRL6JqqWRrziD66cX+RNlSj1VqoLKLM5zqZQwamkwrSsF3iFXYQWCIHOBfiZWtSgKt84Ub4ixOTVmFYQoKvnTKJJO7wKya2WeY7c/iLqAC3l8So2Rc5jLCLgFdS5sa4Y2LV8RmL/AClTi/n/AOxzDkG8fMaw/SAwtsOIMxzWUwc0yMq2mBkE0ax3KbgNLR/JFLU3tm/KWB7IdFpH28eICgAHBHiowGVhGckguCIVN0yxMpASuAvBRBA6eAdD3KszFKcXC+LzZHER0U8xLfGKvNZzBWAFFPmPCCyBivOZbZxprVwKXWNviEHUrQ5d/qDzhe2OpkamAHj+IJiK6satrDsTmaAL5LPpiBdj+pYXGVywLrR7m1627q+JixVLu0uXLZVWwzo93qLtn1zLoO3XPl/qGqQXWV51H8waYdpt71DLjDGW5vAN4zFhUv7JgC6yRNaNjJMNcKL8TgDmDLmw5dwsXa+GAFLJeqZp9TJW7mGGKfzBHXw3MFzV7gVUqmJVaXljthwzqCXSZhlmT1VeLmHngl0Unctfvl4mWpd6Q4MRlMEj5nc//9oADAMAAAEAAgAAABAg+IPqrWcCLnPOaBfD2id09omFLZotu/x2JG59+8wxVl+K1yVAGw9+lgQOdGy6LRnXFE938BTmWWamHbLHFxeSLa881m5x9elqg4o7o9s6J5qWhdj8FRaT8TnTV0buZjmdkdjfQ7sa6qyovghHP5X8x3FSgDw9WvrVrIuUB4JJQCKXBBUVmb/OfGLeimu4z9lWHXu45pIXH8+2T8A0Tcp49A+64p2tmw0trcLIixmUIG9IMkF+Sk6R0EoIxRFdbaO56qsPrhsWMSd4hhQ+2tk8GjqYnuoROqDqzI+UJhRqWYivXSHT820EzRfAcWrNlxG3VNXG+lC4Kn5RxQ2APoT+/bzRNxlNIWMYqZOuAk9P28adjSGTx2WgLKJKxCpc9bZvnApE2zYZLglTHRrsYgNdwR07RFRU0lJwP4H3d/vpiQElxyBC5lq3L2gwM7ZDBsRdYkxJQlDurcQ20209U9Hc1JzMnng8eytKCYP9t0ohKNBFe11chJmeR3rZHM93xH3uo2w0rwl4ZUgu8CZPniiqM9kqSpFTuXOFnnVeYHZXpy0KAfQjl+WcNoGPm2hDXk18k01YTG46b/tp9/rP0f1dotxyxDgAxNBdntynMaZycrPnY4npQXdJeT+4nJF40SLrTPA/6iiH51otPT0xOCvm9CFBzeDxjIBU9DUjfRGUEYGLoL0rCQUYuUa82WrwnnXiACGc+m+K01FHcgQ3vjZUH9z2GwtoB2OWPI6ETo/4zndZB/WUnVpTV8hHPGN/cpDHn9BSd82YBehxgDaqCO66vY+zPuJoPuyYIqs1A2p7aM3ZcX6qvVNwsS0QJJxJinvmqORm9HL7vRVpqi7SfRFAhBfiQ2tOktx+8DA0eYQZ/i5WCU0kWlkOcka2xgH9wELY+XJI23a0noPd0JaAZdoOgU8AaJ1lI45bCO2Zw0jQL8iWHUT6F1hzBZB/Z44ILLXUhD6thciFEXFDMF9c4gi+NWRzt1BHxQwZTv0TeArgCVpsyR+3tJd5VpQihQ1eOl5NL55KYrbIS8ZAWDdjFNj0bLEHR3npJuqcr0CRZpk8W9pslir1a7FHGXswCFz2jIYlVxNS6LOOg+rUAIfNmf32hDCgdpJR+9kOshw9BbUDwd78/ePgp83WZAazqTMz3iMjcWkmZ2jH6A2KpO8KDDjDNu5me99DxiFWJWNnYCb8+q/gZZ4Q1m6LVQeC5tBGkdTZAW20t44MSMv2is/ynLsKGlVtXBUcWQrSQDHaCijdgWyP6KbT2mTQarAkJFSmSF7FhfNdD/mza+C0DU0rQsjg9TFynvbdEe4LzjrFe2GwnTOy6+PIEU5gCPlABkXIJYjTFY3ZB0iN5OfNRypdLaRFQ/XdIB5lnX36/wBN3ZNR7X74Cjx4gfTrxbic1wPeop/JPck8KuXrbJN4A9pnLaRtcxrNHSRGl3vmZCrzfev5RK99rGG4xSUwHbpLZfB/bL6HYgNaM/xA/ENMBisd62iux3XSnAdLJhF04sGOyc8cb2BUT3tw5b0uz7ynkQIWxlrjB3lYdRx8IgaxO62CRGgZPmBSHED0h3ky7V0QPSJJK4xgXDSRmCcIFhAsmiMSNPNplqVMAILaki3cdyGGUmYZch18ostLoCX5AMZJD/rATxlBgAzO3BfNhFC1JR6OVtG5rJisk5sUzGzf0NvmvivpTcJsFOnxmOitnIMkcVuxprLMqcNlhTzrT5X2k5n23DRll5MvwkmSUImjd4kSB+jEfGfZlDA+MJBd3jPgnDpiIwyCy25JeLPhg7JhpOksbu1zUNfSZIuZ43r21l2aluhJWf0MVCULxALTlxusH8ArX1o7cnRJ7FbChcD2Nv16ucOxIxKj0/XYT1RbNW3xJnzy77nB/FrChNQED8y9WYkzTpm8iUul/S7maecSmldf6yBRM80EmTZwTLtCKWN2C7JzMpEkVTmX0HSZ+71wR5w8K3s6NY6XDGpDdeG+xKawxkz+1F65HRaZWzZo+fArHXkj3Cs8Zen0EfS9Q2EuPBl3FiCR16mv4/MC6W7lamy/MB7bAE7RmNRrFLXQZC1AlLRL0vVF4wHoP3ydbft3bRw3fw75vvTPAAcNxajnh5fC7bvKfSKLNy3cHPt/h/ie1xvrMnZ/GZQPaayr1CAyxL02+Lh0FiYRpM7dPAM/3eTCuUHekSMIfcm5Kk7Lef8Ao/8A9BZF4Ld0VQZ+dtvmlu0WyshmoNv478JTC0OWT2ctdW8WoJOK1rf9P5nCRpA8tCqsh4yng71qk2cQdKTn687R67u3ApaYrzMx/thku72OOOb0tRjZikiGj7ElEUvjYOkBJfsLLZToGS119/WijHGgBYa1VnbDX0C/U1EkEE8PE4nWLdjnbKxx4u2bdmW33m1VuNP7HrLKCdaxFkGCAocHUAm0dWlDTSE/j2BspAq8U1m/t/rdJgDt6qnwrMfWnLNH83bNilIRE38+xtt0m6HwWIm5L14I50pPkokusZXv3zzma2lsELYbzS91kum096KkQVxt9waE432Ov+/rk9nHnrfJP9X8OBLsz8tsvtmk89j9HlFBY8rzhJ51nfEY8xvnpHZlNy2F6IPVbG9lu0vfvvlnttzNsEACovwdL5TVQJYEhvzD5YDTambTJ/tmks1G+ZupvvttqvYK8M4jZD2UuTf/AHvb7NiQizAEbyT+3PVaff7blb7PDObNOZ/9JrCemy/9+pZbKAmGwJMuy6X+ZXkPezZbeg76m0+HzbdYnbgLPiKGMlSHeQ02C52y7QbjbD7x/oLjalpiyCd28D8tAsgBYzyz3/wHnGXCT4Ij+i/a7fn99/efSG6aclnn/8QAKREBAAICAQMDBAMBAQEAAAAAAQARITFBEFFhcYGRobHB8CDR4fEwQP/aAAgBAgEBPxDFTN10KYlW5YCMLzWTNW9F9FuUMvodApiZEFQ4SkqSuGGY9nQQHjpQ3ENBMHEa3ApGFR4tK6HQlLKQB0FpBS3UtLZmrlueiIgluCLdsZs6i94K3mz6GZoijKQqCsWWg3Lrp6pcYKOggeZmXLmIRiNEs7yu2AURzKxceUYU+spmmZ1FsEbp8ynbcsiCUIEbh1uXOCec1onAx+7jh3Rjsd4KcESVUGDcoYNYgdpRBwdYl9LlTAVERfKUdAvQzFrqnSuZjllAoi2Wu5Vyqly/4XWf9l/qXr+BjpTKSXCUxLgBADoTqPCC7Rez6ypsEo39MQMWxOX78T9qhbUWKZgyyhK2Rw1mCXhNvZnvwYSDdQzmW6ipAGyBn063LlTllu1tg3YzEwSG04/MskMeJgLhhZKlpAwbnMRGEuMIZh1qVKlS0rhMIIw9DqiZS1lQxEDU3ATUzLy89cKbnmZRzT2wiKlO8sYQo2xPU0QTVH5hd2FGq95RsHvOSY7VvaaAX4n/AFp2Kn6f+RDtfWWS7j7RYwp/0MeQnpPpLBb0LRA7gEANxQmiCDu2v9jRwGMRashiJVMXmE9ssq5WAHzMSUzjl9Zaj+IhoZY93QAx5RTCIn/JW5sBaqBgipNYiq4QR1ETHc0xAq+gdk0EYywAsgMp6USyW4mULyso9FJaKJUp4lEub6aPMM7gnMXJrM5xuX3bjtm8j+4vTb4b+1x/L6KPnD6xxj9D7sKsR6t/QlG+PBM1DRcRaasd0h8+kEQPaRfxqbEPV/uBoHqCffsT8srXf6f2IXV+P8lwIfI/iZX3rX3m9HokOIfSX6YvtZZ2y3pZzmoKoYmDT39IKS1nuAO5L9U15i0MPrAeuXKRlWIIfDE5RSHjDd0TsyiUNRs0gNXc9El+KqZ9cyzMBu1BBUrS5VzKdwexAZkMagHDLKyDdMUSLbYOszKZdJ64DvKEsJREuhSJx5E5AmXYtaleT+5jkvpn7XAbPgBv61D86x/cawz3bf6irC+Av5V+0BcHgz9KqIAXbcO1CHv5lPIqQAx25fhjgWPF/eKy69MRi7UylrmG61fiAjuPPMOhWAHpMmB63qO60MH5feX2PpLFh+/veIKup/sEubLEXoYFgvyM7t9/zMifdM8b0L8xD7y/dftCtnqKH7s9T+An6L+5jsyihX5iVwuKg8QbZl1qHKvP7UNFYIcwIVmUDiNRHci0XiThmWNwVg8RKWQLppIZABz3lirqXr2u/H9MDAFY/qGBUjI1kTEZqYWtQNKJzIBw1CAs1G4gjcuRRP8AEMOIzw/kiWz8kHw+Zso/BJDtF3wL9iELs935ilL9hHIPcH4j7Q9bfapXLXz+WVmD0D8kHETwp9mBZh5b/uVsQn90f3KdLdqJXQW9ri5Kw2EmrYqaiatgtv5jICqxf+zj7xr9/MYOR0bYlHPh18TPK/fWIaVTxAWI5bxw6PTzFGl/j2/2d1l9PsTBZp/fSNlp86i6fiaY74iDJiDu8wF3dwQLuLiRDmcIwBucdPDGu/3Cyu2MEDI/eCaxhBukCBnKbwlhUwAGeZsGXMKzlEHcUcRyMqfq/uGOwj9I5imVTBKed+hxj1jNK8V7bye8eAgpqXONy6HKITDFfgmKuJiuKmHMG8RKiQkAUxIJdZ8YirYBoDiM8KgzVkHwe+IJpLFMsZKDc4ggqJftDfyRI5qIuzUL7rEb2BY8NxiqjtZYxiPFLbwOycW5UBuYR29/9mcfCHDNc57b+kbOegxmVpHx+/rApRqKgsXJwfvaU9IOe8wthxx6RX2vYf3/AJERVcK5fEZqz6/1EMGD4i1BZ8f9hOev32hZ24JS0/vrF90FucRvzLljMA7JXp+/TBbBEaqdyle0aNRxmS6sBBC3mLdRHrLMMxVWsa8iQVzNK6iVqqhUGo3g3LBuaJBUIeMShxNZLjL0/MLlOYMgyy5fCJsHvArcM2MFdRXh4hDMVe52QBfMLDMwcwb4iHrj7xdilXjMCyb36wRDf1guouRmS+f9m8Z9kILzFynfaJtc8ZiliTL8D0L/AAfYliFs+JjtYK4iZZmQt8/v+y16xMaKOZVeRqr2QNF06xiICsvMYNcju+0KOA+Irhv6xBTWl6zHWm6/MCzj4+9TSGmLHKxUHZ+/Er8sTVQ/fWC1DUxD9/EeQitREqh4gPJKo/v0ijv6zFphGhgu7hzx2Z9SFbYFiYFQoIXAGULMXmFMsXtl8MqXwiNiolNMxNB9S/Te4WWVx++swKiAbFXZADazDmWszCbYhaYjVy1f7uLQgbKiw9OJaUxrCupV5mXESOd38yxzL9xl+nGf32lKV/rwwUtzx5llTUcIqhKim36Ts5Pedw+f+Tx/MXJQviWND97zbBMMiWVtyk2Ziau8ShGCNABzXbv3lKEOxyvy0Ti0FPx24hJlGz933hla1rUXHRsvnnvLJZfp49JQoP376jnMVuGOT9+kMGjlV/5cSrTx6QxCgbrWKmW8wpmvtNcmvSK1iD0/IRBQshNcQeIywngUoBl6x6qns1FnT9+IRqn6QaLQXBcU7FSu33iWQOJ+9onW0qikLrY20xosuDwEuLEaNiYIpaYFuMRlxQkQWyzDKC4GFah3ZfNa7l5jtIL0TNhmW6S1ZkXggjMRNwDZhwMpcQJC1qFpZ3xfzLeo5z/yJSl7XGpgmKaYlpw+so19mUp2eMpANdZXceYjBcekQBa7fpLnCA1A3l8fmBad+IE29nEcB8Sjpo98Ro+WJWr/AMR6u6LKYXr9uHewfqZiiqB/cRQTcAmXUBKiuoysc7M/EQY3pDXsW/MEcu5mU/j7T9WYRpSXiEPoot2EY0bhGcz3MKVPlCkcYNwYbJn6Ms1Ky52Nr7QMo2AKiDcYbQA1KzGdcRHgmY+ZiudoQzZqXewiHu8wpmUEvknDCGKwIXtjyYAbm8SmWaIxp7xyy2XCwszPFhOFzEhmWCFpiKx8wisJTEdlv5h3MFi/xxEGA/aGnUfn+ppps/rEdwxa48w+aZrF6fuZZVLHFZCtyrF7nMoydltWeNQ8dA1qXp/KUOI2bT6y5oxM1VAcA9v2oGor6v7hNBc16bhTP2/2Z2x1Fa8oF+6jsX99pZojfi2EzeeckLBGDP6QeYHhz8uotzG9n6IqKGKwrMfIxy1SfvMDmjmO6EMblUxmXUPik2wguEDrGHjs4MvwQDuXqz73X9+sqjvcFvq7fd6AdK7TOUzhtpicJZnNxxFG5tbmMKIkKZZY27mldF2yQbjU8uZdeZvMR3OeLEMzcuOjbAmHS0yQrpiGo3YN/SFm/eJYBh6+fsy5yDTh8na9PtE1Urvn5hAC/QPaPmvHYhoL8EEmNrpzG66A3kPtUTAubax9pawDD29n7y6zY4zT795ZWa3X4tZniavPEVcFQoxcu9/2ymy5mHLND2g15AprtzyfSV9bWsduZUL25/f9iNlRAow4iXS6l2yCZvUAwLzTnXtLAD4L/wAll++2ITuIWoMPvGnNCnWpXH8RDCWAmiNFtwHb8S7QzMVJY2J5bCrRtfx3aIOHQy1l5Xb+1FbXUK6GTokFpAczE5oWyRFGQdFRiqJdSiuVldkdWo7E0soEMytlq4iR89eVlIIS8R0FsjrSQLONnEQDhPvMCm9+e8svi8ejkiq9EyMo8dot5ZCwaiO3P3PzGxBcrayvmDWLMwgo36y36/fpAHp6TZ58TABqDYuZVUwYIxLkC3jJ+79o7EFGN296iVAgwMO7+7grkXjH/Jho/MzBV8zGXtUFX7MFdCS2ovr1/wBjMdmd8+0ao1DMs8+Yq0UxIW4hARI7qMfveLSBghgrtELIkoDLTgRJSwA2rgIBINb3HsfAe7tlVGK8Sme0aGSEYeeoG+IsVcsiXQRxGLNRVjcFJTRdy53JS8SuyeDpXTuMqcyucX3sr7zmj2wS/aEdiM7HihTDQOL+MypwRbAcr1Gz3pPiVCFJn1hyHJv1jeBZ/ca8n6TAPDUwGq95cL494Fiv3ild57y6wEXBPrBMqLYeIBeFKqdpmGquYl2Kt55lGDPqROIQZq9PmaEkEMOoqrVzAOI7QmAprOZUGm+24woly4j8E05TgIOKnY4i1KRTIQ0JbYQBSVEQufsfgPQ6I7bgS5jM9wDdxlWxG3eO3MvydCVLqZZbMsy9blyzE/aoeT4ni/hKbmWNsLczlMB5ge52ZTshTUQdkQN1D7cByo6TaPpElFQvB+pDEW6mKL5Nf3KLOcxBwsprc1OQ4ZQMLJloiFwZ9P8AIoWn0YEKr7wNgjmEJYqWi0tEuf8AJQZ+0c0uGjhDkgT3fveZMo+MSr5S+J/alzlHLL6wNrGi0y0EZlNytgx/7IK2/WDvE1fn9ILf8gvcA2cTVUPR3fYt9oJlEHod/Lt89HUC2GUpA/TKf1ZT3PllPf6zJr7yncM2yhKctx5PtLG4IkrWU8UOx9SPangh2IPRQsgweP4oQqUZUzExDuVRUDt03T6OEQSkju8KfDUq3VK+YwEZc2me1h9Yys8Nf1CgxRZ+7nlDX7uZFuO0LcsOeYJB1Li3cKpI/vtMyOPSLdljtDI5hBcpvUV/xKhojIGl+0wx/EtRuYwMLu4Awv0glK+kuXeEtluKJs5GGUGWNWMNbcAhDrJFySWVUpVZmFK4N54gulNci/M8HofU9puBWY6ghydOkVKCbiMaSxzEMGJma6AiT+9gtkIVmd4LcVKe0s4iKhBuIUAjiHUFWpINMW4cjMtsooiXJL9z5lpcWzK/0iM0/SUbPtLjZ9Judph/xIpN7+kBA3b5z+YicL/Bj5vlgNwjSh3/AHMyp9f0mNhDWf6idw+j/sKWoSWMaiyKDCV7w2o59ItqW2NV6Irp+kA5PvMiOwxDcAMfr4hXBaBxxAWxn98wZqB4TDSOVcO3MZ2Wu28xSrX6xDhmS2ZGoNNTMGPeXspU10OFzkUxVJBaui8vOoqgKkc9783d83cbGujohiJWX0OpQ0SpcIOIrIRUx7M5YZZjx+YbKXrSV7eIhFYRK7/tGqfuYO6QftvG4JANBF7049rPLCEJFAq0+rUSUCKYbr2mz3uI3Tk13rj6QOr+IAIb8H9wlogDjH2lBhLvdRIGK0iwv6pf894tV+/0JZG2vxEQxrWqheAD+PxMD4+iLi/mIALCjvRGBaRGNjzAnieO0pevrAsjXmWuCMMHP/Ydmzz/AFBFUelS5an1qMWHcy4Vkjay5iDNjvBbG4JaWIsnEvNNRo5e8VMkW8QH0lLimoka+kC0QWB/kDIYuUsCOtj+pRLilNH1zFKYyvwf9lnlXtGXvM8LmvQuvaKNQ+zERXRSCKPnt7xcXBeegd5gCYvrBgiMfBGSWrM2qb2Wt3mUy77wLZG7DH76w2oJoPrLWUtM3cQrmHfhKh8xsd4ZRRIYru5TClFxUzMA6uos/wBf5BbB8/5GuD2f8j9NfeWg1XmaS/WOhyfUqLRq+pPCyG0j2Cg5xL2W0j9H8sUHeSvxDIbMRbsIg7Ss9sK4vDkgihxAojTxMVm4t8N+IrayzHCEMoMeI1VCHwjtjf76RDQZjjWl9pcpW2YCsQ3x7RJS7jVkx++Ji4YBP+Rm8QzNBDgZ4opR+/SOBLH6fSVxa+0EoH78QKNYgBuemI1gPxC3zMznbaw4N8te1walNo8bEhXoPg8eWeGKsuQd6D7jExBNpcH4nDEGaD4mChCu7hRpl3qd5mQy2Wy5dy5cuDcMzUVliDDGvEESQogfM5MfvtFXggcnL7QEpfJ/qc0fMrND7kRfyH9wFpX5v7RXghbAQcQR7I0wYiQimO7wPyJ/Up6B94h5j1u8vSFIS7/dwQJfaXA5NNmYGEU+dS1sTtcsuCesftNw7HEVBXs3L2r8TIJulMACoYZJQqL8Xn6Q0dZ4lKW6zfPk8TBSjun9xsFmPMpUFQA8o82mYpMQGUBAyUgQsojoOafQ7st3bV8r3jBvXqimgBoKPhp8/MyAcj/J6o16LAbrDnk9Tt5gL8+sIblQApRBp94V45eDh+feXSJWiWuZa8BgPjflXmdp6vrk+rCDa/aCl1LEJWWKjaUlJXQ3f2itaSiYlLxHsSu8pAZXswHduarjzKdQtncE4njnhjG0+JboHTo7RVbIJv6CKNKjx/Uaq2eH+4eH4jQRgmOyJeIg5JUtRZFZn7wGkjy0t5rTcKgWfrMKUJURowmUmEEzt5PeX3Hf7iZGXBADj98SgJLj3x59Nw0QyCz7gCvRb7hE5QcFnwbv5vsQT00wn3loO4BfnseXEo0U4cvpZ9YM2ReAFdxvN+PmVQsXQAX+/wBzhBqU0S6xlHYNOUlKR6QL9Lv6w8LdwuB9xOT4xF8s9lucxrjOB+GMpvrlunk0WSpy7jH0J4lQEfhpiqtHDw200er+/WVyGh9TLDQGoF1ZmM4GV2Htb9oT3fDxAd2Or71CNKacfiGr8n3gXfsymmiy/mLAQYPSU4juRk89pY/RJShBQW8Yjr/Ux26o9t8dB7ujroqjMC7nIlK4MwTuEerpe8ieJg5llnAeLK/qJkJQRgGDjrcqRDUDdPrEGvsf6gGj6X+oerezM+GA0YolSpzEfJWK1Cz+3+RHZDwmKs9Ri6hUY4Wc+y9bgjd5MuKb2Q89NAGbmClGi69WW+81VXqS2RedHpbX0lIf2Y9mqmdYItipdgAVerafYH3pjQElypk4brYX2yxfD3w95jgIplWtX2NAeu2WFxT0FTrAIfGR9SUQGk+lc69oMmBl7ha936Y1FRLeyniRY/j0YAjx6RAENNAP++YMOLkpwwrvnV857QWAjs+2DK7n9aeYtgNu0jfqGMabmltKr8RUXwisNzItyzbmKG2XEDNLPaJbMmxggIzX3RaxSm2yMDRcytjyV+YJuCxDLLQTFg6mp6JUzMzMuUrGu4iVW4GSAIUTHRJYYmUtg5mKoZXMbNS2o2yqrqsfMJzd++IPr5WWN/eghFXfMto1LGDPEZfy+IjfryQt2v68QYPVP8bmYJr2nFPtLFL9v3iPk6M2K/P+R8sDyf1GZKyrV13rtc0qF6VsdRYABWKNQOQ03KdYQuk3b37V3uV4TxSn6fmNUxUsIWJehLMerBCZQzE+seYrXkS0XEJ7xRBFES+9JftABo1Sv30mGEQDwYPjUUUuYQFYsbBKavmoqxaBjXcZdZqvExgnfSr9M/ePJdwppLUa9N+e8RYY7uYkrn1V/aiPmxQBC/CFZihcuYIkdeC4U13xKjT4vBXUOmh8uPMo5GHFn2edkywE7M/GWLFoc2P9YJlYcSvQHrLMQ4XKH5EQWMv3lkp3lJZLOJasZmZV2vMFDU1P4WE3rpykEiKOXhYZZTllL3CCBEB3TUW3pLsJbLZmXLlIrH/r/kBLBuolsenMXP0i7MeYBvZBU86qChzG43gHF0WSkldv+w+m30jQwlTwERbjKCKcktEWu7vDuT5iVMOFdSs4j3gNBZ+6lIRXeKLw+sJDBCrGZc1zB3J6Sw0SnOEPvmNV2PPpiveaBPKoI7oVDi3I15gEEyjhUpFUQ5VcZq9bXT/kzUo4Qsx7cHrGp5vH959n5iAA9pU7C2tHgM35uBTEfXzNW8QQCcKOi+YAVcB1jxdLxypmDtHHRNsqZRBxErC4Eugef38wJDhLpBcRVRN6gx5Je7SZVM3al36RLOAXugCxqgIrH1t+k5qvWU7yksxYZicX08vaZgmt+VyzNbyVhXzFBT4WN7l2lV4E5uK1oHiFcdbu1vgpu39qFbRjC44FMa35WYwvLWQ7ot61dRrgGUCU5UuztzNfCX59+z3JXp7wQHC/hmJ8Q3RiKrE2KIhyQJljmVlpdZIWSWhxd8xgTDn+otqBbyWyUqOHcWUIXBX1RO9HpF15O8DiDsymBfDNRxAQhHjGIeG4qdicJV+neHeIO/3+orqAzm77eSOZfbEfCeW4zwD0KhA3GGQe5EZR7LF3SI6XDuRDzKd55IjvKd/rPX9Z6/rCnMRmTMC1REltwCCa+K37B9M5+0xU4vPJftz34IYs3/wiOOOh4ILdP09YUtVFrqvFC484lFKPL+IPxRX+yrNW+c/eKRUgNYiIYMsrGgCAzye8c3Kt4Lf6+sM9s4w4OJSWa8/0SscHo/kgZFojVF1fNeZZNAeDP159pQwV714PPd59IzPMH75XyDCjQ5xMjbLbaIb+Ll8rHaNJgJMq6O0TfK/BCwskUrp7QrDRCt+U4k6RrkJY1Li5RWY0mmEyxEdQnMV45GG0d9NAFzQYOZiq2IksHi2vpBjWSLIqeVf2faINMXx+sLxfHRHTHOCFWyIQegZWemV7Mq8SnaL4g06lGWa6MulMsoZZQRJYErzR1SvBdXfP+wuiK7r++0UruhB84VfFfmZhj6f5k+IPQF+fvMdS9wQkuaghhusDaX3/AMuY846THpf+TCDktp4swxqe0yNkDBQ9n+nMvWH5mRJmxEfME4/SXa2i1vAeWLNacKP0YpVngHm/cQ0Boq+SsFdtpGNrxxG2kI2p+oj/AIqHBhdHmpVRAiUbjIbxggHEyjFC9qDqZGOYhKXMg2h+JcBiHEINa4IRZP33gFWSr7xFqLNs/SLeITwiCLFOKEGzzNVGeYxTzPY9C4aE2AyhuMxZW4WBQ2prmUIUmZUv3NRLmEDgGIY5giWgiXLZcuWzc3mDDDDGSyFIsBWHBz3zOChy/PPiW7c+IVi7iLid5iGkSmmGGzcDCN3w+zr6TFDsGPu/EL0j5tfviIBPAVXysVLJcmN4TvMJmc5y9qz8/iI1eeMwxVb2f9l6+/Wa9nJ7S9Kdvhl0x6lfeVhKnrj0ePezxLkNCn009OfMbKRHJ8wCFJntS6YND4eF9eYQ2uR17MCqrLxUdcjn1h50Ep5xA5ZlhTZFmkCYlJfrDxSsnNm8cxCA/D5lYVzvsxyRIlTu12s7E+IhpTNqgjLF80HL6Ql1ECEyzHS6p3B3icSqndEmMbFyihqCxVLiO+im6O4eYphjcvqVKlSpUqVKqVBpMI0Uq4NAyW16Ze+O3eLHcLXr+Nc+0s47vO+a37XBmp8/BO/vrg/uMfgfuYYrT1hsBj2SidzFDSeMYT6xW0Dm6J6f2TQExZh9xw+lkLserdfB/Sx3db2U+cPwRX4df30uZSflfg0eV9poo9TP4iWDOatHz2ivG11Xz5PTfDMp4awD4y++YDLINawNxrEo05M/v+QdgRapp4YQUxYX9SFAWQFW91n1uMFSNQqOPibC3v8A5Mt9/wDkEr74h/1/kQpfXOZ9X+QJ/v8AyMztovX0jvPzGDWK2fOpSAuL6oIr7/8AIDH3f5NL9f8AkDw+f8ihH5/yIcInY+sdBZ73/cCqj4f7g/8AT+4wGU8VOYKmOFriKmPaZ4PrEzT8/wCT1vn/ACJbzPWh5Z6377QIrP77Rbv++0S8zkJ5g9HmOCJcWwTLdC8tFQcaZYlNAT2lTauUkBYJy3DxXfxM42old8mIhSjq3tn/AL5j1q2Fz9yqXTIsIPab5jPANwXYvxBby9Y849P1n06VD7/iXCSuUB+Sl97hcu6e0QyPa8ntCqN3G/gVXwyi6k4N+MN29t+ILFPdsPGN+mJeWuNB7EVAqOxBjR95X6mNBNFFUn3glSJ2q/vCXkmP7jykOd+x/wBiN7gfcIIfgT+jGuEYSx72hcqij6QDhaZa1cKF3xcSW3BPzUGoev0gvhcvn0uXbdKmwIVDVDX91BtZqvrBNjVfWENmmo6s7NRKYDYxukOvlr9+ZTdtr7ZlTggHuiNHQeToL6ILxPFBuJTxGZ7c8M8Ewai2qEQ7Jk65muubVQ7St8T80s4JPE7hfWGYzCQu4PxPKfSVAKP7uOCVDdc4/WEAynLvMBo69GWKwZeaDaxiNHFVGV1m8OPWCoGvvCvAGLwvp++sslZ7XAtRekUZZDaeIOIL77+koBS67Powckt3W/oRoQHdT3YWPZN/195XKxGcHRSaUMEX0548S85UpCKxsm8MR1oH1jvs9OvmZSDCKjc3Aeg48vYguNspKysK6gzTCumdlxC2ysNe6eSCPdFb7vxqKXyfiWA7ZinfO/eeb39+8EOF395YoFjMCcoDyxWyZInPDxikUIr0CnVBd0I7TEotcFMRMGGugvco7x/po6F7zgf0iOcvWB1Jdy4FsCpjiJcNZjmkV8qfj6Qn6ob+HH2iIMTWHxx8MO72FkOKbZczKVo7V88xWlFVRjtgF+GE3MDOQ9u8LUK4YOjWYCx9H4ig8GfbUCLsZqvVai0OAVHmxXxLZR6A9+WFUKmbsiwKzGJgZUAVKQ2/SLWgPmNQvebDDM6Fn1g9YvzCArEweQlMCl73Caj6Hk+fEdNayrtljk6VKj0JX8Q/nUrq0z0T+FfxWplgBHEcqzSpUuVAHGFCpuOGZQkywRDBmXG2OIYIypa6mApdQq4/fn+4JiV2uni8fDr2m9L7ot+qfmI3md1v4Y9VowK3wRVaHNYfeWCUd1j5lILzFKgG1aCvpLJmOdPqy+uDssezuzBCKFEsgatxKiotpA4GyNQlR2z8wuPkEKx8hEiXepAiOPJEMH5Iy6C/JMRT5InElq+xVqcPb1mbXtZV2sLlcS9HW/5XN9CFv+LuH8G0WX/G6hLnpR0WiKhtXDIlxK6piYBYN0hzR3lAUvpKvrbe/Pt2lavXJh+kQLazuqv6G5cYloWRXZiDuB4QJnPpL1c+YoxBmNShyJpaX539YWErWFZ5W1fOJUphm14dnL8RLCLsL/aIvbHBeD7QWgqIMQzuIaNRFRDMv2hV6iawymLHklGX7RHpiBqKmoUw4CXsiAPCXNIuIxnfpZ1vqZlf+BK/i/wvoL65df2D9YtRTBuINppLqMqJ2tV2YqFvMcASreogZQa4PxFbD6H90TCKuyQJdg/dyrABs9feBAjuW+f7zCSHFFfQ37zC8uX+odanyrKAHxaz0vc2BVK4B7evjcynOwt/UI6pDCOyHoLqIm5rJiVHeEQQww8SzW2AlsN69GzdQxg6aBCQitvNeCJAHEFcb9O9w7lQ33WKsvnDgO7d/EzyuDGz4efSJWWCnZ/ZFtKNr2IKCgW2qf69q8+tUQb3UeBLqXTZP1hfMwr6ywkVIq4LpUJeW7wvFmpeeuMndDylLq4kWbZ9JfffZz9MM3Y16QFKPvD9Dwj9o2bl9LZ5TfQTSRvdTLMGJTD0v47THkMh4mLUwjrMuXLA5HzXeAiBnGL8PmGat0bf8hVWuazDC45zB75mhKn1Wf3MDP8ASbT2e88CjocJ2l+0O8YfpJfNSt3W8QKH3lMg1IKx+XGIVDRwYs8wF8gNgfhXncMWT7fPPtM4/Y6OEa4IUlMQsmU3MCW3NWL4vx3hi0WQ0Hr3YxEBMf28RaVDDye39wMn37TMceaRb7agtNircpXHxzDla7Rq/V/EGBBkRbHxGBHBW32LhMVRkOD14e0VVlrH8EdR0V9GO5k9f+T3UtlmOCMX4guioAxA10eqy4Xz0vTT4gFlPO/n+5bnbyRgiadwGIXZgCwieJTmHTaRoxAIK5NvEM0HwYIuRyiFOXGn2loA+ei1MRxRZ35/2MkqoYMae3LBWmNTTT5qHprsfxLChjFyn1GP3JMGYHtEYtKIgnMb5vbmoJ9xMP8A0f7KgWS6bX9IIVgVWJyoHtOaHfA9jb9JY2O2vYGPzNLEVCZS9XBB1cyxBc/GNhFyj0vulv1uAxFGqq3tR+IFfDulfivaHGlfNfbMVWh71n+4bdHjXqR5TvDmhdwwhWYVNyMVYnXvdNfRx6y1bM9LE5+0GqO4lkubhvcR7fcTXrKCpc3uPTcNYmv4OMPUc1NIdcIzIkFsdYltVMOt1M1UQKj1Qv7jEvcitbGDKFH1iuYEFbBGYWHPeMCyQPu/SWjNl/vzCANeJsQkCfyYgP0tekTu78Ym6XluNkb9IALMdu0VXAPaCQZ7wsWHH07a3M2KXjvALqUI6fL6G2Ie/M8+hx3jMZfp4PEBpEwjMqiGUajsiob/AKgK1zHsahDgPaA925Aa9Ww+soVnfT7Xf7mKbfC8get3Z8S2YQ3g34HX1hxYjDzfarv9Y4AWVAnrnXcldi2WFO5nICfKh8XKIJGkzfCVY539ZU1B5eP8jwwttHkH7UeseXeLeoXISxbHQhtco1BqYhHth+8DFy5fXiqlzfabLUS8JXxEWnEAgZljCowMxzKgSpUCUyrldaiQFWZ7rR5PELG/eI2UxEccOkP0mt127RSko1p5gcgV6X+Z/wAb/ZQLGMpYS6WC4Dnt+IO4IBRXniWylLsxjBS3cRyUxgcTvHZu4CpZNHI3X8OPdIoB8qK96o9r9ZZLa7Vt+YAaiOguZRUQGjKNwTMzZPvAMMvP/GXqOPvAwAx5izAy6jK67os4BMQQ9txVqLBZFwmCXK/g/MTkhmicy3u4gUWDTGhPEFSj9sUurYKkqTFK95WFdMG6beiwemFzmIJZMTIZUDrzKuc9MJUqN8yixFmbn7zBOkpWQSvfaNjoTCMvENkye30JaGrj+j8xtVeS8nsPzUqSryjiNPtv3/YCQv2z/pA2qFfb9xEtbjbS5nX1iUMrlOVjju8uvu+JeHwLL67fFQCvJhjER0Jn8CC0YlsDFm7cTwJuunysQMrbgOHLBCE7Tpd2grhBY0ijrVdFKzBz++8wOE2orbYJVx3BrkepYhvJAtRMC5Y9IoXUvQIllz1RS4jRxE2S5NpQ/SBUZlmmKeZXXv5itQEDKQEvmB1DvLmWWS+0oKguKFrXmLFoKKjvLQNTa5BmLr3GohYu0CoWG2Rumoeh+9tS+TuGPk0yq9aMPxp9qhTxL8jj6xbJy5r0lRt8dpY1DjOfjn2hCbKnb3/r5hEIs0GFca37wbEMQKonBh9YBRjcLaUHaMSCUkt2ogxKrMw4YNQvPxMk4AwowMIJyQRg2xuBE7JXmDzDqpZYzFGotRZctHcpVEcQzxATazNqUxxKRUFGgxMQhYxruewzlL7RKhXtFrbez/UXgGH2ejLMxiyrzCs4Zfo0MO6VWmHQC9ACLkmcaYHDPrKWyDNhuO7eiFFbfDqb5vOIttcV5D+FuKVmCNsSyDhTk9h17VHU0ru1L71/sdKq5f6mZrlV4+NQXJgLgnAhCsZd3LpbDwIrlOwHMN432mUFS4AiAdv393EFMIeTMRBKMoKaQmDM3RHxBcxRQv8Ae0vylEUpWpuEjwht275imZj186tQOhnvzEBbKXU3wjMZcpWUJkgwmAI3TH0/7EoCfSWarUCagwfrDKIHCUQ6nmUgdBiLe5UU2lpecEY8l7wfIH77y34JcVzBjKyVN8xK1LzK8r8K98ysVQa7fiJGsHyJUxFLlXMRgba74jFDcGzhDQ5jRdS4FkFYwXQg1hnvKS0IXALhEaJaqq/fiDIEzXvNRIbIhvGJZNYyEzOOCbIDyRDaWXlCMRoEW5uU5gFbYhKS4zjqPHH3lneJSoZ3LmVK6KmkqWp6Ro4SB2V/vmD/AOmGNCZCv32goefw/wADiqWh3SvRaOJn0BcqaPXH75ftNoRBEMpbjiXREO5VW6nEo6p4dw3SxAAVNnWlc/1LcLVvCU4/2VXwbloZfB4/bhZFxRhgGAvdIQUt7xJbUFzliWsRLxFwy3u1BYMuf89pcQUspKoh6YBY/feV2S+IkN3EXkh1sSgNneF6gbSZaVBcqbnkWMlmRUqo9awa6SLelol2yulSoWheBAOvEWbuCKAy1YyzYfvxHCpCBVXQkSGiJlevWVBp0VFXk4PebXEpisg1Kc0m75ggIxDlMIg3iIoQ3RVHOhjZBtzOcEWsfiL0/iCDBUoYOJkGKHb7xhU2LT6TJozBLTSlrmCxaw9r5hVqUKG4tQEIaUPP4i4YJReJuX99Y6XGNGajIY30BS3zCv264Bvoc46M3o7zhLMIypcS4GJVs2lJcuH8GJNpUqbzHPSAjFLEqbXHUS+iwGvvjuXStroMxNvEHoblke+01JjzErdxay83HLAYT6RKcQRjLCNRmGXSoqImmRRLQ7k1lhoMsozECjMeCJEPVEQS2ImGoDeYahcauyHFsy5jmNauI9bBGMBi2VBzHMwIzKXk7QAUEZ1FWBEXF33iqa1Kt63KlQg6hvooZUTtAiROJaVBiQOlVKlLr9PrMS2Vt/fWKmMrbl2OjgktZvmUTEGoNMQGZbaHMO3Gq1cq4SnhGykpjLm4Lo5l+UW6PJhmmZQZZQdJAtZzHBc23F1iGFEDYcQ27YrK/d3G6Y6buDTUsAljRBUgLFomARFyPWadb6EwveBUuZsXTXS5t6VN4gTxNanZEqWmtdNS5cvpfEVHErFxBqBcSuiXAttG/X/ktKym5n04E0O8FckpSC4GZGYjDijwdyuaeKWuPiI/BhpPFQ4HjEoVRK0weY3ckUlVFFso0br6Ta5rhh3DGy0l84Fd4l2IMNOGe/eIFTKSUxBi2UOAOoF2xGOECydmXLsEWamunMK0ZmCXMPX1BrUHl0InQhAuBcU6E2TWItGJXKBnoFRamJnow1AlI4xHMSZhEqb64lvoiu4ZFW2VFRxgkoYWocfSLh5xFVdMKK6lOPsf1HrVGIA1Ln1yQgUtL9cSuIt5SXRFaiBqpWIWpQ5llwzzfWN2+hZSD4kHE8EEXpEFuXcXNzNmobuOqgmjcGEsdTfS+hLw0x8tcqjEdQRa1L6AbdC24GKgB0VuNuo01AvcpKqVcqahcgiDYRWRLxRBUMHVMwwhRmQbNekc/VlpJWcx0quRnXyxIi2zIiFPXaBdQbAlxEiIoMTmRPJPRLtkoFwLc3BRsi2zEvScS2pZcCiyWGxiK2XBGmAXMnXQcwziOGulw6HS+lpLRpLg0y83GquXRLP4J2gV/N8TZmZHEDvF7dFO0k+MHyH0ioiBmJwYqbjnInXTSEdxD71CKS49h1CYbwz4FlwenzK0hh7R1mHJBragTqC2pWhLtOKblSVC+6dw+0eMygWyZKZfNTkRoy14i2FwtGotm0uC54ird1FECMjX9+niH8SD03/AvUjXEXEKl3LFn8Fz/wCCnUrmecSvlqUjaBFnMx7XSkY7IdApWHot3L6BNQfMDYHyQJhEiCmNGCIOCXNsyk2TVkYOZqJeSKllmCJRsmbiCjRUuZShUG1SXkqU+J45fCCz0dFly66NCiAdjLuXmUcwrR/E6X0GWdHqbzKN9RqF8ykIoRl30sItQR6KrhV5iOOgXFKU2/o/j2gVMWd2F9OhxZFMSurC5Q+3+faAqmGEUS50OUg8C/M07+YZS/mEMKIvpDgIO6fMG0y7llVHGY3C0ocxdo6IaoHERpuAsMRL7SrLjJcQenmG4erliS+jUHWq/hh60MzF/wDA7o1BtiuXFrUtDLmLmmc4lksr5iO+gX0GugsFxnUPaWMcPEVeHHpKsiWqECKcsE7Sd6P0gO0BExJKTbEU1Fwy0tGaocEOVNGoc0Hfhz1OMSj2e87oxbbcE5hs/KaQTHB8yiXEC/0m+t5gthRHtLxN56HS6lVyol/zGpeYtuINb/8AbX8FvoNdNvTZUOs6xM2Myo2RzxOmtxWx1Moi8ylBtM9CMvzHsiJHBcNQXJCBCxKnEq7l3EEiellVCSUaS8WYrVFS2oqMMFy5S448DpbqA66EJuV/K4RrjpVysQOZXPVZmXXRbLJf/jmX/Em4neAftCVTMW0ozLKoZli4Qd/pQyvQl3DWCAczATFDtFUw5uIDcElPHQg6GdSohUvx0ICZhCY2IGIdKei1DPJBMxhiWwiTUr+L/K4N4jgl9XrUGo0zBiDLIsH/AMSMScQVenEQ+x6QDD4lxFyrCEeqWS4ai1EJzAbllMV4ZSLBbJdKQBKy2YQW5UcYhTUsiGIIZQDlLboMBYGWDMuHmWVXQ7Sn+dSofxMRb6XH+YzCyugdGB/48yp3Yy9uY4jlhwEGsysqFpXqsziuJ0uSacQhOI7CPCKMvobQ6IMKJT6EdsSx6G4IdP8AF0TMqy+h08/+NVDP/wAAwTn+CzeCPVRl3GXNkCovEe6WK5x0VwC6lMH/AAVhHfQaIQ5ihczc1ON/jdRYRwwhzUGJv0yRyHEANDGVUC4FSpXQ/gEuMf8A5blxV3FUvoC5UcRYeZYRR6cwGnx9pgXHMPMYcyoY6PR6qOZRmKorIiVMIFSoN/wMwmkxRCLMILIKZefBDzAdxbZVEDpzLzX8Blyrm+t/+ic/+A1L/kMcfw1oBcR7mUFdDUC4geg31eidF0SMO2Wg5iuGIVKJUUwK6DjEwZBubxQrAXDI0RAi3KqblV/IlQIM10YH8bhn+QRRxCuf466tIWkd1/5Cg0uZgLli4FsCwxOCUmoN9GnS6hmEIw30GbhUryQbzBm5WZ6dBbMJipdM7+u5jBcANQxL/wDC5uDDq066svE4/iFxOlxl/wAzCUkBpX65/wDC+oEydQ1NIcZfoNdGekuWhBHUYEAjUqZmRmWQf4YxW5m+JHgiOOJTlzCMEuFS7mv/AAIxl9B6XLhK6VcvodFOmv8A0vrcuX0uMQgsFvPpVsaJS0o3hKuxjsYVdOr9vtLYQuQXNfYvywqj3GAl+zQTWNkF/CS5VRYg6gcPV3FjgmmAlxZxDMqU9RxBVpa5ZniAHLmWW4AyqYXUTTX/AJM1Cb610IzzGHTUW5WL6W9Av/wIcLublhHQ6HXXQUal36dveHQsN2MOKFD3zFIsFiVdYVit4x6RJGUK+EExWC7QqiqrfxN8wUKVVZd0x0oUspi6rB9z5hqbdLqVHpc0XGtwjuBccMrEQDEFykAZl3LlQ6MhMIqaBialHUk1LuV1x/Al9CHTzN9fEqXUCy4lRjgrqRXiUSv/ACIWldfDhFRtYx10a6gz/8QAKBEBAAICAQMCBwEBAQAAAAAAAQARITFBEFFhcZEggaGx0eHwwfEw/9oACAEBAQE/EHBFj294FeooGIzY3F5Ill8SotaVAZgSoEJcdEuMJUYaWlp0suCD0JLJc6C2I8hE4McMzHbBSQnJNZ1HKyDlwwMomUj2y0tgcxBFEUy8ac1F4ML5fgelLroR3wGUNT0giKv2Pm4IKDYMWS8yi+J4I9joMspZojfG+LzKHce0o0+seyPeRdJY1FGZ3CDcTxQmuJdYQbGHIc6q4bMa+0AYbIUmhuoYrtYnNMu7dzHRq8dAQTBOobNdGJ3jA8zvHERqKay94GXUyBzDmsy4wXiBINsZg1FbCGjG6hmQssjRbFrD1BboahLlDmLF6J14hBtwBBpRQmHwkX92D9zaGD4VCbnghXb0BDSPYmlETuXNynLOIwxwzlr8of8ANick9n/IHD/Pus8L7kFhhMxZ3llElNF1GaQ/yXxsD9CHeuZnLEuA0l12/cvDKNen5g0uPFe+kJKSWEMPRiX0eFPEpUYI1VrKNjcQqKv2gEUHLuvDDvFLnxxXf7wztuOFRKVGWIkBJswBpmcSuMvB9F+3TTtG8UjG/TK95eDcw2RONf394jTRF8x6LIcykrLy0FYfGWfVzBQaCGNrRBuIvKZq6D5Z8ogcYDm4JufKUs81gPVmmD5McZfyJ3xg0hUJCvMbVJ5x3oexPDFNERbUQATU4nULuZSncQiPL3/EZTTp5gg3yZrhluoWALZrUxjOHRSvEy5iLwqueI2Lwxe/pHaQo1j52S/PBLCBTAH6Zu4CjrLXeKbpwxzzBBxLk9YIWvdN1iWCguq1eeIfzjzzBhc3FS4VVdEJskCjHUKnRYRhZl1Bsw2zGUNEtDBGLbZeBZSVAaWbmep2yJ8fSIYiHRKlwSkejXoEJtR6QXb2iHA9U/MD2D+8Tvj0P9bg2LeuY0lRxu4AC4gtT5E1Ee04NJ2VPkRv+GPCIh5+ZNsv70i9h+s8MB4gWiUSpURqJS+YsBZx6xPLUrZwAWq1PeBmhmnUzmXsqPQ14dag8AW4+RX/ALDtR3Z0AJTiEexDRsbol2rz3jBsb/0l2VdvtLp5MMDDaP79TtSf2o4yn7iH7/8AIaFfibAvPpz+4SqsfmVC98xz1tYU3OTMrAGoyBzHK1KCMusSjb0nYItLuJnLpeS8szSTACiIw0fsX8TJYTQBDHD5Tbj7ExV18rMIL8o0UfY/cDhk7y7XKNF5Qe6hLablaEpGhja7EobZQrzNYjmpRxA2OmJqcRlEoYglkjwHsStk+04d9fzFTX1nhfeEVQJd46JUCEa68kFxhe0rqCtfmPiu8ePpUOYH2hmXtHQ4sf5gzTOwwcJFYSCM4Y1rSf1RqXVeZXObT5FfeKGV58eC4aFt3T2xzmDsrdV5PxHM43l05/uO0uD8ZmKj6exh8zHVd8R++HXfv94OxZw+fxKSo72wlkzn5P8AZjxahVP9uaWxj61AbXvGNTBXgiorgY5LYDr6WX/qxf6T/jThH2i+PqQspr3/ABGFv1PxCbHtAc29Cba2aO3qsD2R8oA4BLWKW1FSFx/KFcQJK8JUEIlBt0QdWShUjgQsxFLc7UE8Ikdxh3Yl1LIu4yIyiIYiA7RkJzPVE4uYqYXO07UTMqse8q1qeKKoSldI7z4RGTJlScd/PaUaJ3EYhYMe80WDf0/7A8g1ftjmJr3PF6mThY+fH94iBSy3xqvp9JSFi/7PbEW55rjlvUI/R8wHLT9vrGTtFfNzUbq91dwr2O3v24Y4kcp8pgXw34j6TxB40jiJmMv/AGLfN/H+RhfNzEFVXrmcPS7loTniCYcyxm4MwxLmC2YJuCQYxDcuC5Gnx0QEDuCkKGIO8zllBzMFspXUu+US69Ryx01ZghupPVKuM+soAMwSgqZbnMRVwWs5UFRBFNRRK55YqwRdxXSv6gDjMe2RkiksMnDaEVJq5WX3EZrMfXnvDcQO8bmM55fOCSyhEDiF6TPczV+neLO/+R+ksM3m/wBQGUp7cef1CXh81f8AZmMyv8QyFYBzs59Yg5y/u0Vl8lPL7QAEb1xe8/Tj5y4ZL9TzMUIm+2MfNgLQ4u5gil4qO9syxqCx3deYQHCPzhUrRag8edm6v/YXBtCFvh+0DDCn2iZXEaNMogBLGoZxEtke1FeJ4+g2MuqWPBoT63nyyqXUs4iUwxK8yggLvPSIBUvBRa7wsMoEaIkpZlmdyxUTuB65YF6mZqHdLdThSxsnZYBzAVAZhdRzIysg6JSWVGgK7eOk0pw6MSkhsd4CtPvEugzDCFMtYTgOUjTEClkzLjPeF+evnEHQ+0AbKDetXn+uHccxE1cN/P7wRe9Sl0rW+1/4TQNDnOYhoq9PnvLMT/ivW4QJs3e/px/EbHyP9z2iif7Y3uoIYgX9j9xUPDefnz6SjaKM3/YhtaG/D+H6RVLvs1lzz4lGg9s+n8yqgpaeOLgQra59IRdh9ElQ8fYJQSm4lWeJTdFG1BwMyKIShnnKDxBwM1uLjEt0SntKYgsLgbophaquIeZdR2OYqI6DhlQpSw3iDFRiMkNQG1ArEEuJmNRHAwYDKsM7PQnfDcQszBRAzBYBlIuI1i61LZTDCeYEUcy4C4ywzQ+XnvqXEoPH9UuWp9JstIMqGFQqNSP0lXsDdbhcIsHf6fzFG+UK7iBbD7ywKl19r/NysMHP99PaYURQDaV47Si6OVv7XUMMTt+IlNB9agNOmUDir8wVpWuf1Lwb4Xe4BP8AzL9UlqYmMHvn7QCd3s/u8+xnESyfD7RJdOP7tBwcd70f3EMi0IW+0CVp4ZctN5BbEvlPC7mGIwQqaiOUw3LspmI5IjBqU7SmEpKRp6JkncragDimd3TQUtdyyMFdzaXpojZaRvXSu0QWWEHEQwJZqUMQraUXEslWoqgiLrHSXxAyiOH3D89EcRGkRzM3IK4zUAnbwxRS8/u8uYfqXLNywm/MBlsSgNn5zQ3fE4oZdvzv/YqE8ob/AAl2Zi/aALZb9DxGFb8wK21z/e3iFalhq9/xxEFbv9zL0qFqY4X/AHbvCXp4Ofn2gysHBAKGLL70/uorBnIvryynBrvBaw3cTXi6/v8AYbj9/OoQXvn3/rmFNYIRN50hjSHdaiuJTshas1G8EHRMCBgrGLoYESiuV47myNPad1WX1yjfmPAgMXMZ0rHmJlqzBwDoBnEIosTAgUEJAp1AnpLqCcy9A4IUGYnSJ5gwBxEr0eZY4m38XNqvzx7aldFt0BhKZJockYskpU5ml8yTc3Y5pjAAqb5uBvL++cQhZlajBCPk+/P5+cyWQdT/AAfWZrBHHpCDCu/kf3Mrym4xctCDVjA1Yzfd7ThrzzKZUpAuUErK1MZYgFGLdeJU/lzGR4f64oHQPlh9ncWscOoNKViP8o5cdYmSKJO5h2uiC02IjFmZF95SBRHMzuekXRMMsLS9Q1GbqiPtKI8JdYj5ShFuI5XyiIFRVE8xULOLjmWIKptcCYJcqFeSbwy5qDn6eXtGNw7cHy6xSXccQiXE4jHDXKGhdzapMVPqgj1m2AIiVi3BxRSNtVFYGBULIIu3ZxFDcvgjs4rvfjWIBVzQkLEJhCMEWxGKyniYFM3CoyBlDYzwwFbn/IvKGvdLEWI7SjojiNwFp1A7SFEq8y6gnRUnpLVkxEhaomZNwx5+sKNwjhcXcAQXuF2WPhcHyxM0XMGtwe4LmKty7I0DBBiBW5Q5hpiVpnGxolAWsa6nTx39WbQwxCMTFbSXdMvBs6D4S5ilrmKXkZSNTzJ4IPxOXOQQTiYcTek5fUolMH6lO847lOIUwQgHBnZs547IRbkJ3I7qYDBpgfMgDYgySlXAeKMEZv1Jhp1KAahvIK53HO5QxBjDKEq8jMWxg9CDGGOMSjUrmdBoBRxAOJVRQZgVmowAIsOILRLrZi4ZXmUd5UMS+3SmVNbjXOchKlvP+D/ZXQ0I5USjlg6jTUROIAcH1g+T3ljBUHGpebEGljMX0o6lEqV0ZDDwx26lUs2yvp9snCIYVRgVom0qFFxBiYc9Aq1MG8zBUUSPMLFQN3iURqyXXvLMpSNkENkSyWG4dzBeZjMOSOMMDhLVZDviNksZl1BBkl3FzBueBC+ZhDUGIOZuDiDlmkC0rvK7Sp3I1VwSUOZrVFxMsq+qpLQxLe8sbjiGeI5lXKczSwaYFKBBzCY8wDSD8yClnqVEFqp/S4f8DL/0Z/a4n/1DhEQWKJbiIm+t9BrU4FgWIAoljcXvMQFw+908z0MGYk7fmAkFVkU2ShgWqUbrg4yzEW8IoYYq5gDic6hcQuCQBGXiOUUFFIq4mMYuGukbLIjnopgNZgQXqHEVxLSCIZc+jg+e+gQ3LmiPiSn8/qKyBeJQ4iOlxlLESuYVxxiAkFbZ6MrdYezEfB7QqpnqzHmJckdtV0QVm4PdkEdvSuwKce0e2LpubPtKu8MK/pBRhlxtql/34Zc0D+r8nvAzFX/fwwKUU6ioHMBnZK2/2phGUuVLwm2SV3bzDSOAuLmAuY1hNBMCzUvzAEGswEuKi56oo8xoy6l3MamVtl9o8QAUanpN7lVBuUIIxuSxiKh3S0RbxG8K3J/fSX0Nsv5EAY1PT0EWgt6K9+YTDSeUT1yFArmDBXKOKGWadx6hC7pLGmkJIzpEaRVQ5jKCw+0s4gfETuo0zCDse8JYO7/vnK/tQQuVYM/9/L7yqi+fr+B7RAPZ8n8sANFZ/wBjxHLgbOCn+/7L1fH5isuIRvcqm4DbKNkVyyrAynbAEqiiA1dTCQHCYgGjEIalAxGozRLSZYW4lhlVFgmYX3gvMVcQ4QMLETdylzAdk7mKGFlnJI4+WL+e5f3F2lUDDCLmVKHTdzJYMvToDcETUYZcQcyI3prW/shFVfImzZ+Uev6BGlr9IJFGmGqlsPMagqsi2MRiyDIcTsIEuyBcRBd2QCX9n7ila+n7hqj6f3C7L/L9xG+78QJZ9EBSoejLVPoGPOFiwftHMvvCUUWJ/e0ciWyoCGYVcRhHEcYlJLLzMOpYZxKVAHcEXMXOJUPM5UYyW5ily+MCHdC5mWwsZmLFiMLqDWGIcMGKjmNoUyS7cswzGUB3GoNfYPn+pawW4jkHO+Xg/PiOL4D7seB0V4JTvOWYOzDUYE1Gdw2qiOJrUej6p65h10SCykrKSyKcQYq1LjUv/wBQ7ZFU0EzYv++cc0H2lq1T5MHK+g/iPl7rxDfFLVy1lGEENwBARRVk2jzG2gAcovCpe7FAbOfDEpQ+046Y1KCEKJvBDTKi4qYBudpqKqkoAfWZ11xEFcBqSjimXMpxLY0zx0u7muCFhldpqiUrB9H98petHytpf9r2gtiZg3BzuAb26BmIt6g8oi9p+fL/AJB5xKjcqpxn15ipd69sTIG5UERdytcv3lpctivgKUg+QwLslxQW9Kspp0bxMz8k12+cvhL4lguWjJbiXK6IJTLOPqw0G/7mVqafT8T1PeXTzlQ7o2hqDO3Escwwn0Ilqe0ylLKup80ixPVUuQRC1N/3mDuINyNhUbTHud+1eYeZblp9xVe1SpOneIwhyxtoO+n3v6QkNXb+xKYCbzdLA5xz4P4iKh+Zv3r/ACXaw2tn67MVgx97zZi6W7IH7yvcdxE9yAuUcD4suL/eUDxxHF8S/Hn0lQWh7/qK4fL11NPVD9JZCswA1xFOOWGxphpklqIi2w4XxB66PR+8TVtfgnaXyIGSWdpe/Snb4W0ptGnMoaiuMdC3EA7iNTymmJcWLHTncRdhXvLXcbylIKCUPDH+rP7jKGn6WZwPoYryRmYYi1LlpaYjxAw+CMuDTBgkFoxHQOTqZ2Byu/lMW+Lv6f8AJWEdm36StH0PQC2Q69Nr70b94osPVxvgqtS13McdvbtFKuCh4P2wAqDBYGzyCj9K+cA2eSIxmweAwHyIOHl4QvRw/maRElip6y+fIyN+h28/9ipYL4XJwnZ/OyXhooeQdfNz7Q/cZ54/bKfT5X/czu28f3JHaS7dovNWz3Zj7AeZun37/XEHtW4VUzKwhhgBIdYDmXRTxFjEwjMVwThmeuDLly+hZ4QIFpfzlSkVFWVLYUnGzCEIFoFXEbSjIygm2IA3WM+IpX2JQ5+uJb/nvHMy71/1CjBL8yhzPNFuZg3LlXKHfA1nb5mcZQIahi917EBrY5E5OoKABjP/AGC2sfX8wtSWujn1j0NSg0xhDJ3ncJUE7f2ZrsL8HVH39KgLwc7H1/yP6Us5Bf8AMMuY2PE7G2Giy/eaoX3QPQ+DhqqfS9QZSDyrYeQvb68+83HEpULRB1hvMeBYug77XrfPzl4o7Lbr1/UxjUb4wYuIVK4ZCXjXX5AUfXMCdmJe1TW4oDX95nHg/MMNRBjcNBzv+/tTZKGa5lxx/wA4/wBgmE8ZvMegeMH3riB7+hX2jmw+MH+QPnOe/wA9MCwZnGq9IAnlFTgjxp4IDKZUVFmKlStRHwVDZlSugnUqty5eUxNUQQ0S0QtS14JaYyzUqHalFSVAZRKlSpXS9Tsnpy/5DQjOni5g6o2mpew5q1f76R/ek2Hvvf8AnEC6eHDHzePrHAWF3ij621zX1iI7NJmIjWByf7PUMeSXIoPMr9mF0xHogbe0VYJR0CsXxfpKccR20wlByzK6eEs3vwxIHeDUoyqc8f8AYlu2LrRrr2t51cVDqVTYi3aINTn/AHv9IldjL+P+QQg3n/Iarwe37iAZtjiDeb0r+94TNIEI70tJt49YHwAW+rj8z1HfDGm4t5dotaqWduJWB4YWdJoePEtKMx2vBGavZK9uteToeTrblkCZdLcRmYTuQZLKjo2swwq4JzxNsEduWcwIwx7UAqgaq+/rCwpCHYW4JM8I1CJFyprmV4WJrY030Mt/LJSr54DEueXnfP8AZgW1uPHf1Gn6QwG3etG4GFHGGj0/UDRaWytTCGN1xXfsQCIHoQ9NE0PopKCV1bk+c38ENZviOHVr6S2cfZIcAcgwBPMuUxHcBKZWj6ypmLNEu4aU6jHGWWbFws2Bp/yJ4zVj3/UW2vlmBD95gtsxkMa2dr9zv949i1y8zJ0B1/kGSrPr6QzCwpPEVgM5Ml+0vqv6l/SC00eZTG+849e0xBF/nyYDawBiat1KNM+r/EWm8TOR2uIUAciWNrz9y6+Qk9IhKgnQq/hYKWhUpgJmZFwwuCWdRWkVCsEp7xCUTal8nMPS/aoc5iGod4zhctWgVyzKFviGr/PMcK4rUqKi9nMyFb7zMu4XYTt356czGgBTbRdv9qHGYeB+IEIFVY8jf3lnc+S32Ugcm8YrXmnfiH1Xx2F8srkd1bZTeWdy4wLNFxSb5OxUXogCLEyJMGbXmNcIJNbC1KHndMayCaRxUbU292Uwr58XMsa3LHR3mRIyzAbThgTCNxRmAV3iZY7mDMAKYTmZ7AF9riucSLx/YPG9TDSBGhPSVAUISWs0/uCQW7wlD4yfrOPE9X51CsK+32u4KlYSwsl23cfvnucfuVarjuNoL60bl1MvQl6U9cv3IA5i0wkH3g8wDMwIWIHAQtwQXmKwICtwTm6iHmAB2gSiO5+ZS3R9f6otZQ9pZcy7xKB3YuY3xudlDX9zULjeY2+tfuMbTwVfpsfTcuLeLnIyx3N4SAbZC5Z6fuA39GV1FHmDCHw/5+4QWNCiGMgc/uU577kNXx4icnpgkMtZ+cstlQYKoFuhS3H5hRzuZSoN2X3zBFqFg4S/b9dGQzXzi+g3u5mAM+MxJYl+dExeMxCv1z9iaZWLrt6bnNiWvH1j8ySMSv7IirX2laKZVXWJRtMypuPu4gY3W5ZHbE2xl3AY7/50mDFrbO3Hu/b1mbssZtgHcjAQGDfw+3/YGwr0lidJKR2hfpefpLcR2JdRHtEu4DtGWlE7pUBEbgEOdRZCGSVNMXaVd4l8X7SziWw8RAqOEoryxLJeK4j0v3jXzN/WB4U5VNeqrfeI8E5KoSxODlz/AIRGiPNbO0Stpk3hH+zHozb1jzx+4mtL0jW0Hzf8ny+hxfo694KoFeZWk+jf2iBb9v73g2BqWXhqV3AHzlpqTi4B/qpajex4jaZaPaXrh78yyCX1YxE8K+p/sSiV7WSPhy8RXO0oEA0GPGIbSRLpkxnZXEHL4NnqbIzABtiYCpVFGUArGpYxATcX/fKGbKQUzLFEDdkPXv8AeNXatsDgjcC8wtTfp6wjklLRxG4rqG5G4lQYIdhyy5uaQbmVR5eID4h0Gv8ACcILgwHaCuB1MQOz7Y+8DZiAHMq+lpaZ/wDgwslWxG8afWItGKVcIoMdDifiWZoBGQczjq0vtUw+e59vWFQ2eKifPh9GGzq++frs+sFInAK1d5d+9S53XxdAPyLS/VY5lp8Nf3ygjUruoF8evyleRGsa/MQBb9it8lZzELsyrtfLj+xGVW9rlYI3i2u9uIAoH0xB6KI8g8SvbPeUzr3qoHNbi7b3zGyp7TAj7R+6+0sZr7fuK4idoo/Caoe37hDqGVOVeuDmoHQfd+YHu1q1JyXfJED2lwfTMOD5n/SasH85nfH0/cVz9v3CTLP5zFXbAsjEYcekcVX6fiZLLPl+Idtv1l+5Sl6FfWX7UACXvxDABPb9ylbGfH7hoV7P5lQB7P5mi79P3F+T2/cAVZ7P5mjQfT9xO8ez+Y4Tocn7jWYr5/m5lxor6/rolypXXBvgKTAOoCwPR+caqaZdzL7ogb1FK4AbRLUSSX51MErKymEJ7ihZVGuowAlE+S5mUHAqezYfIIs3Ky9uxfmsPzJZAjhKoetj80jAs9s48nFEyu3gyr6HjEpSDt2vnLZc+Y9V84mgWfP7TPx2ERfTH+w+x92q+dLUSuA7N/aKW1V4vmGTnHgSr5e0eovzD2zKrb6tG/a2BDpyIxxosiBcyX1nZEBfi5af247Hepo9alBcpCyFzJu4wnd/2BUyzf0hgrb/ACWoXsuAhnZcO/xce5xcA3xcuN4LhVzBJU2ahsXBu8p5Zx2xOy2eVDvMFgb5JRd0Sq+gXahgfzf4hlXfo9M/AzRX0le6DyzlT0P9ZyV65+kt3QekXvEYNsHZzNJa8ZPb9wxa/wA8RvbOicoj6kA3nM6VDQqymUV6xnEzGCBQfaAWjbKBf+R+iWEZVkxFL6TJQecS7Dfr/XN5zB48ZPvZZVUGu3sRaT5ynOOK+2mXb/e8dSppfNS6FjFxStKXn1ls7O9B8+X+xLEZVoXh7Z3KSE5/sjG7CJm73y8vmMWHk8nhyjzrjxMIDExLJSKsMw5JfbPT5gSglYBuumtxKOJXimAt1DtvTKx3YYHthaagq8SnZh/yQ7j2le72nqe0w/T9xTv6P3Ln6QXeWOZZzHggtgDG0GgpVixYsuB7Hqmyz6H5uckeXMUUNHjEtuxKIM0lx1MpdQWyagv1iXa/Dr6Spau5n9zeoUnrFjoxPKmGSM3bn5riGiCeG5bVlqEXTMeJtYZzX5ymFxzV+x/sA1k7u4xbuYFtEUo4m3KLP8jFlv8AvlHHAPmvy4ixK/3e5a8TdUD7n2jVdb25PzGGgtTJVff+4jVkdYo/frLqsrMMUr35+sV4oXS1zX+38pYpNx38Tsd35HNYtAYA0HaC2313AikuV0olEqWamCVKlHMrUpMsRJKxTsiMtoApgXULal1BJUqVMShEmoMaeqUEqHiMi7ihuUijbmKVxahA8kW4M0qcQysdFRpxA94IyMIiRm+YFNjv/fiDIdehGtLuD7sNg88dvlGrLuVphC63tAdbxzFMKe7uIrcxXmNNE3kTbBFRGypYDgYK+9biK98mEwfm32hwFvZbGfSGR2pthVeSOd4ZFTjuELwdfxqV6iPgxfb6czLJfN+IJcMsO66AbDb3x5gBSBQGg4CJz5mHpXVLlESPTSbj11KmugRzKlXuLzjkQxZEXB8yktlsVi4QDkx7JcWKquxGsKcQ606lqzGgRDQY1ogiy4sw4iGMiXAqplFqd4PaKQSKZmaoQwIwPBr21Ntd1v6/2VFpH3hWofP9uVUR55ju1ivLO1Acm5fMM1n5/ELgbOz94t5i9CT+F7ylyPf9QhdHv+pdpo/vSdolhxNPaNnk/wAQDaWYJdTHSpXwJKhiblyoB0DpwlYuJ1Mx7YKRDTHNRNoqm5aCw6I9qVrygjqUAHtFTEuYM9LRSXFKVFi3SDixmBWq9YLdjxGsqPr8oPg3pmb0O1/aIC+ssHecFTbb3Yba7jbsTOOGXyy5ddHmlCLZ2jSHM3Ds5e35hIWO3EJ5GziE4hY0Dfb/ALNEzGy/OfaXq5YkjsX7sRqCc1/ZlsMvabg8Pv8A9iK2Lacsu0a6igW3AhWfSAzIg1Gbd4uK56aJUFPiE1ZWXJbmFiyEKCjZ1fF7xA5w7LBfDk+W4wCpsEs96uAhvI57NafWovYszT9wHZl1AGeLAYadkU4lHTLkoidkE2nBRFwJyV9e/wA4gHQAO4bogV0sqcRKlXfj0g6N45gV7RDUMgZiRkTAaMKFmO4cxGd0txhFLQ0MRR49fWF2XML2B4/Erkq+8EUIl3EF1E36Whqcan1i6SmYr45isqrlyv4IdNHiEy12cJ89zDZ/vzlNJ7QFBSdpW7pRHJycJ2lOgByBiZpf7xFa4QZ7y3j4HjcRlRQzDmUlYmN9S4vEFhBuVXQPgfmK2OpRPy/w9xAwizCIHixp+/rO5wE0eDwfmMVjEtWIi2YYl3AzBODP2mtwt0w3EKGpSXMHlALoeZRt2QaYZ6YVq5f3MSS6lm1mXZpmwcwpEVp5TBT80TSwcxTmfOKB4iPe8Qz6kJBghVVEzCFOF4N/3vCKB9/foBay9b1FQ7RaXxBwz8/iUlbnNSqRA3fWWzo9X7yipshMM/24ypjHOI6z2nKgmBKiBO5dRTMGWYEgo9/hVKSSz6TeWVBNJ4lYlUxUrt0jczJvJDEYbiRIEdR73DU5iC3LvrdkmW0yzYpm94gRl5Dj5nL9I1ELoxrefp2lg0+p6m5iNJhx0eC1+x0CtxA2fVN7WNepUWczANYKIpIKpLaGIqF9Lf2jAgyldQEpTAzcT9qRuqOgZLAxzYzagnBEEWN+8xrDU8n1jRqlmYaDv/ZhVVHiXMYzxf8AkqkU+ce/P0iIUefzdSygDuc6XpEOj1/EGuK85xXO6ltaySmK1XR/sfA1Kdy9wQFmDHKJXVthHePguG46KiMJYQ7IVIAWyyBl94sunoU6MZlATbosGXBltIkEB3yS8qoGOQ15iDgtgDGfr4e5FFCvoiJhjqifzm5Zxg6bdx1cUatrUUQ2ZRizNqXcdssl+hBBRC2niaEBwRQX5MzMmF0Sq1AFsxecRtQXDMcErVvvEcvEKCyzMIJj2nKkP1S9LiZlZ5CwMtvvADhgFTAgQg9hGVXEw5i+CACB0cxjDbUFvaWu5L9Bh4J3CXe/HGuu03L2GKkFzEZbfrLS7LS0SXi5sjpl3oe2D5liBLYbAZVxFVKiChKGlhjyhrt4/uYNrXu/bX0lDYnOaTzx84J/o+soNZeIxWp4mLKipVoCoINQR0WYimCGnug+GGGfweWaZ5nXt/2eBdpiALWYbOIW41Mro7zAi3v+IRyr+xFoi2IYUQqd8VLKUloK9EIKCXYtVAm1hYEUL1NsTuwwPMs4I6ogCj4BiVkinMYJeCmDiFzsREDUolKlKiEC/WBozFQ6zLiUscRhslaO5Kysd0NVGF8dK8NAIXkmUp6PRWuFUxpt+IUojXgWi3MuEcZL7RdW1weriGWW3f8AsZcvM7bRK5mlZkWIEvpGC5seMxKAbItocRSN1Aw0IJsc1zmKXBFDcw+bNk6adEg2YifSJQUuIjEmXMeEpHETSYhXQloaMwKYVio8QbhtuA3IxK2xm7lNBANSq+BiqC741Lvi/rU1w7gagqQbZWJUb1Jmy1UysF9UnDD5zGJZAqoP53iYa459SVXTWDoIJVysbNTGZKRDKR6N2JRElEtxjKcI3CXxY9GXobOeYwCAR9o1SROclPwXXS+4ETqfSBgEGymY9iLRmciMQyxKky0JQt89o6wFQjsa9Jq4eZsVkyu5hKxKunKApG5cvGEq24vzBcDcRgdUwYtiUKtsotWWMZXzQlsM9E60Yfy4jUEwX4v5XX3hsShJTowmfRuliZBk9YMu8oDtLn03+kuNMcwWlQcRmo5lB0HQoxkUuW6JbEgAF3Mo3gcwjEYMsZ1epjNbMFWIO0Rh4YTnjplMOlE7oswZliNLRFuXKMyhDmOD3fnECyqWcMqF6l9ILg8RcRMpA1ay6xTCA72m0ajVuKEpqMbNb4iJW+lBiJSpQ0dXPXAEt4Y25nE9q+twRKS5ZFhNzB33haMZNSvn6S7NwA4Yq9L/AEl+sswhylxcdF3BijLCXDZUSpcwwOmUNkC0NQtbmDOMNzJNevEHFKZ45a0W3ufmEscxR8YYHEe6OOJW5y72fmOKxGQEuP5wd5fTfeUSoLtvHYuE9gma5aYlyK4FLJlVPzKuOkwag6mp2YDQjq4bWqDWpYy5jKIralGpmV1uJFoticoI6VKaHVLS6xHCYRdV+qFVVHqil/3aA0uU6d/3mJbqjIm76MpcXow6PLoucwa6ZNRyesoz0KJgl0qBaXbcSGMkxW0EpZ4oFwUup45VGIaSxIwwwTFQFqR2V5grUdU27uiDlzEtCNChTE0cy+85GNlwSi3AYooJZB3FKrAHCKyii4KxGNRUVMsaZ3FNxKjiekwDiBnoTmJiVBwUaYLYtx63Flxfix1IUmEIQysRzGPRSpdQEpLs2gsrpCGJjYhmPCJWYOYKkgckfEtMVBbMuDFUU2X0o0IJ9GJx1BAQreLCjMSIDNmpQXxOGJbOJkRLxBbFsJXcuABCVRaiWiAK5jrnfSoXEaQCkTPTbpnUaC4J3CoTQOjG7cdoCTcX4q63ZUSoS5cqX0uGEu+g6FEpBeiCnwiX0uzEqEMwKgu0S4MX8alhcVbFEkuO5TaIqgwClwqqWbUEVVLRwEZhFC7lNkpUpTUZ4iOEqoDFwRFcsI8pTEMQAFFcxhzqWxVM5MGWZPMq244ti4kA0SokYbgtmDctiXLFGCmZF9a+G55h5mpcZvfVa630aSmXmDLg9LqIBZe7IN7lZxMuoAKgjiYsaKY1lcMR0CUr7Q9EoKwv5sX3pVEi37x84VxUSNhK5kAbCog4onIgKqIMyuCe87EYqLgCLL2jjt2/UrZNcqkTuUgglmkblJTMCog3HdTdbY46V3jAtlUYnCRzBpAVNZbKMYsBFaIZbZLem5qPQYZm9zHQrm0LQ+O+lVO8rpkYgUVFDmWgYtzdCdg5hCpUDUdoe6HmoROi25YqMFMqAV0VlJTqxHMLOYlqd1BF3FwZQuWTDcEP1BtkB4nKAxczbe5TuZwJW3hTc0xHEJknAiomTMtSglQXFxjiMSnYwxKL62gczMYkYh87/wAJUWNLZL7zLDEupToLS5cGX1VhgDTpQWxzEtnJKGV0tV1AcRg0SmCeaGGDrC3t6llnUGhxMW5Zl0uUEcGClhEntKyrlOGDuz1wHTEqop1DcR0FOitjF3iqYiqqAEgDouajnoAM8xUImNwiX1WKmXoyutdHodK6MagVTFv4iVcMMWWTEBN9GJaVBSLC2BU5omZcuUC2mEQ2U87GVLIl+zJA+byxGCz3EGsRbhY3LGGWb5lr3uXWMa6cMXZ+qATaafSW6ajR+WZkEiHUQlVQUCDTMaqA2xoS4KqGzQV0XrZlK6gCxp63ceyAOj8LNTzAzfURXXcr/wA2CLfaMvorOhp6ka43ESJlRPiPfRJ2gPpIhe0G3MyYmYqYYiqlVuY2YOYLgO2IZewwoRwlPKorJhxmGXv1XaM4QBR8HYQjL1YT0gUfBliXEWVUfic4jdQlTKL8OTHwnmDUziB1SVK65RzOIBIIASyDEukQlnQJXRVdR7UUwiBtgiDiJWHE3CPZj2I4TI3ASY4jRmGHqoybIExY5gjKDAxihSU2GZUrqAOjiLmO8wOmpZvo9bR/8blxTqAsqjMJRxAvLKRKhqcSvIxfEzsg0s6YiTMdM0YC4FQBTEp4pbvDpbB6LOhRGpRKRLPGWiOxEdorESnLMNMRqUs4aiHEeUnYS9V8CdAqXFcuDHfRiwt6bm+qXKlRx0PgZUqXDES5UIdPWUExEJXR6a6tepvJkUxPM6CyJA6izG+lwt8DDcvEylS5eWlpb0LMdKhXMpEyuiXEgOZTjoy9vox6BXxCMquiro666hc56VGahEJQ6fgvqmOl9bv48xGGol/BZ1KqXLlzZ0uX0eg9NfBfQZcGLmXfSrJVdQthgqLWoxcDmX1el1Al30DvGMq+nPS+g5jHpUuD0uWdB/8AUabh1JUS5USo6gD8QL6MOh1uv/ARhjotMuEHQQAixbjNyqx1uV0Z5m9dL+J6DHpfxVBoqb6v/piu8IRO0SdiV8KrgVGMN/EkqvjWobjRqJNQ31A+abijnpa7fg1Hol9LelRK6Mv4NdarpUTpTBl/+W/huCqyVSdAlQNkesSuh0YQb/8AV6HmXOOq1mHKLUV9Muj0uMeiwz1CGnR+OowLiE18FXKrpidhKrpqB0uujdY+E2ZVQOtXKQx8AQKj8df+D0egWdBiQaxFJeZuGPg56Oel/BWK6qqXHozUYRlS5ea/8bl/DRv4S0Eqh8C10v4Do/DXSuiSvgOjGbI1DU3DEuJRcbQb6Lha/E9CLfRz8Gpvqy5V9CLFAzJECxbLxnrqbmuhJaHELiP/ACBSxx1upcVfCRm/hPguDLI/BddDU2nHXBll0cSr6t9MXHv1ZicdFjPX4HfxVNS//IGiyYsvSz7SvhrpXSjYMXF1GPhI/Deelxag9HHQ+B6BiJFHJKBFiLcNwOhGbjiX0eiX0uLTEGBbGnVhK+AltzXwXDcfj0iAVAjhFpKKMbrKFQzSoqlJSrmTSSvEwL+IOj0uuldGblR6VKz8CdDUYbxEqLLl8SwywR10vPS+tROm5cS40y4tysZ6JCVKlzfQOGJn4yVKxK6GKz2XHtBAr/v7csYhxCoom8KKI7HmaCO1aicHUDCeYrSoqWIWAYaXUzE6E2dHGOl/CRxNy5Urq9CTWYsxYmtyoGKidNdKlTOHHwJEqZicRIbl20xw1HUOtXLpl2QYZ6vQLlV0v4Uv4Fov4BbUI0dHMMdXUqf/xAAlEAEBAAICAgICAgMBAAAAAAABEQAhMUFRYXGBkaGx8MHR4fH/2gAIAQAAAT8QU7/J8VIElgIaNtgUbPAbhA3QUNqbhmMkotUkAi9hJrFjjFBU0ouDwpQFQximmqZvEvLjn2obnWECUjBKGOnXJkuKTFuynXD+MFUrhA3qDZ9ickZ0HKww0wRDelLcd5c87hzzhNXJZoMTfP8AJ2e9duKrPDHUxmI+8kpo5RQa94ZrJfbBxoLpggs8XvDyLlAOqwnfrCVyqdMZZOW1/C6yyzKzXkezlgC9Y1RAZf1D+nEFgaAWxjr8YXqG1BX3ZfvJh/uKQL94DvDtG3gYPycV3QEUslQ9tYQhQgo5BYLbTjWLtu16Ppm8to3YUuO19N4JjvDqFYk8zylZ56FxW0EygPYUes3go4+VNSLObwbQY5eZHs5V/AcGS+67I/l/Lj2+taq/W8sQGdSf24raacu3+P5xV2ZvUr3y/wA5BXOq/qONFezQAH3P5mBqjaDIfkYG3yozd63jLIkX9fmslzHn6pwvHvFQgYF0+D6yguHY5yUfHkxr1Z2JiyS8aLM0weqSfnDbOaSN8mV1m6QPyzIoeBCx55j5xOpwoanxB8YeQk2vRsPw4bR5sreWj8BiTS9AAPoTABUc4Jb2zCYMHDtq/rFFzeu2RClfGGGAANJvtvzm0Z/J0fJjfjVK3fhrr85uyS6IfQTKPlrHrwhgqiXpPy3kNJcKC/H8zFgSTZIwrGNcz+Q/eRCjtNPBsX43hKmCEtFbR4iGKOKX44bKNzVOuxM+QD+0yevT5TrRcKaLAITolxZGtrD7/wC4mxNrFUvm4uG4dufgcXpB6fyGA9CsO09beMa6zxOhQ7gvQI3BFjrkOAAG5dDibZyO2gBviTJ0rQhTwYl5nNBlo48WgNJQjBJt+RkFZFF6Mk2w9o27rfi7EJcI403NAFqjaoAvgGKloDECQDlKNKbomkjk2uNDhCgC2YQF+V1loToq8TUgjzhJMStphtwx9SsLb8T4e/fzkACOW4xWvrDwEw6cjk46/wCWnhmAVhUwfbw3/WTg4GJ8jlFASX6eMn9IjwytJ6yYXbLEpqdDTPRHJB3KJOHmFXAdbMmleeoD1yfw9YpGVNd+HjBgGdhOfrJiZyov4xlOXk78dZz2wkgHxqOm7tuarpz2bZKnlt53zlO/gP8ApgP9sk4Glh2Bz+FMW46aUJKgBBdIpHHgz+fYOQqrHJtu8fZV0w1qKw5ryrVie+oOPHLKTnhH7owc0DgX8RilTenb+m4AKJOar8YkgIaZP3/7gUg9VX7zkpL2f6yuNX0OK3ePAWe7HLXLjE38XxhylHTT8GA8oiEPtcYDBwWT8mbUAMh/MJ+M84aOPgJ/ziRLWqT8B8BcDO0ENTvl/Y4GLB8s8pM/DIwaomnxlbA2BT54ycLRZRMDnLCdYgsBeENd5Az4Kdb3y+SdKhwN8ecSZAkNPxpwhDA7OfnFCaWBw+MNbGxZTBauuIHOLCEkPpXCMpSsE9sP6zbOkTB8hD85BPJRV6BT6BjGgtAX4i63uDgdIXcJ8qg/BrI2nAAF4NpjMUTrJ75ZoLKkGH41kWiKAYfM7wCC0aE8Zermw/8AbB6H5jXVJhaKuf5MmHGojfPge7vpy1XtRHhRycHeXdmhu3ci/C84tVNhps+MIWOKm9kcG7RFE0QSYrU8ira6Epw1yRMY9hCnsFGg6CNjZUZgjAGghDzvG00pifLWyiR3TsPd7pgHXlwyVCQLBDZeBdQFJsLFO51krjQmwiwRV4dXwsgrWHbVskBHIbYhR4hnQNNVF3Bh1WBCoKN6xri33juxzv5iTh7ZCaRyBWKaq7fs/Z94ai9BjIdDGtNzaVZNXdabeT2LTuHvFJ9cCGWRx0pt99ZXijXRIk4REfCYrZ8ggFsFUoBuc4NkyCQQDQ1HlV5YCgZbFogRGkhQezMgVQQViFkF4pziA4k3T+nTc0stf6F+S4M8OKc5GEIoa2decAsyHCP8Hr+RTArhMGE8Po+O+S3FfMO5+PeKhCEFNHX0D4584Pyc7NWkqm1hrdDWrKK4Odc31l+SM2Oe084TY8H4aMPxj+qtn8xLBSJ0bz6o/eWUw2AhT544oIIw2P0afnAUWegh53OAw3/xWudAxWZ+bhCL40j+P4ZIR3hSAGxSVBnWbGJzEH0fzMQztnnqBj7cJYJ8X5SATxeTwzvCztV/nNA3mKPtf5DL2T9B+MRbWi0cP5wOobPbfvWOQt1QP8YTYjVGrnDQLwyhpGn24UQXF7O633jOUS2mQ+K6+sXVpQanG8BowqicP1mqKcJ/Fv8AWXdwrI/LCfjKbftZ1wPq4KW+JPxZ+0cbsZZ5LRkeke7MLm8h29fgvOI0Q2N/tr4ycd+oPsh+8bmCrrv43/WLSdThXfdnN7wtRtEK9MCsSU5KIk7RN/nnEb3BBJFeTZiBu0UDrQLPfO/OR+/KyqIEmt8c4pcqx/Jtn3gqgQMr26JXmTWvDJx0RvojscHmafebiVNS+hB0PeUcLaztaW9k8p24cGaAI+AI/Ge5+3DMLPhBTNUIUCXSuUxMGBQxLc1RhreGdMgSGSiOaoOiLTC406VdoKj0EIujKDzJMqK3I058HvJ+qITE0SSAYL2MTS9qsiWqXajtHTFEaA0EAyiNbgiRwhGim8IC7gijbF3g4tyNEpAOx1AEvaGMP5O0wXIGpbN48C3IvKYvZiKLMJ0sT+R6feB8E6erob86+MQBXupOSNhboCLyZYxEpaUI1AGuXgyM6PbQrxIS5tixR6uQEO4Qidg2OAfSF+wGfvB1zeQawIAGN3SPJ2wlpcKgIUgr2Y2JCGHkBaGLpSgoEsA6hBG8exjtmHPKlJECqIwCqVyGXYK7AFGqMqDQyNaBSdjuKk0aoEQ5wbIidhfet64OZgCQYVU+nv7/ADlMauxQ9p/kypovL5wV0nETivTydLvSmJg+geUDo9nZso5FsNT1ufziQGjseYfp1mvBcSkIs015mUcUAU+YnmaTWWLz4FSljzvOI9dYCUNJ4PvBE1Yoh9MLMgNEz90/WP6jsqBxB8u3AiC6ma8qB+M06cAJvphX2/vGb7QGAdiVfD+WRjlNeGgVWX+c2OwdIAbJrw42LnX4aE/GWm00S/tX7x68aafl0wRFm1Pfj/FiR3JNv6g/eKvOKL8v1jaK4P4dLgvloDPaIYXq7rZfhNZG2ubgdaY8hG2931coqixglIWjyC6w7M9AIWWodSxswA5NVQD4uxxrBZroD/Dl8LWEfHGY74V+H/LFoWyAHh3wYTbMWgaaIOHlzcTAuXO5eoVzzgV8TfEhdVeT0Y2oZGxXWhTW/PUwzeCKIHdHbp/OLCNheLHQ4PL8uLUCVFrzR884adAgk41wjQ1qsv6v0YWRUCQ9zWu81tSRQnMVnfb6x9WB7CzWPVrSFb9hZpwXR/KPFtUgf7w4bOA0qNnmbyXCA0iGGyVpARwiAa41nwYcPUKCBFqldil1pEwKh0C0k6BJ2JKJRlBatMiKAUoBUIq4oArA0QiFMlbyL1guzF3jy4jwolOUyZ6VxeZSuLpb4Zk0M0xZPaQopuVJkw8kldTSimrGthWp8kzS9qYnhdZOZvPkYgIbiOgjBXImonEq6l6DRQUG+cQPyXOKgbov6a/WNpqPFgQ2R87MUFz0mDlM/gUlAFADdgAuKiJ/RhKINIipFHG3++wVfJlQJY2FPWYNcFJyEAaRUVQrMDAhF2QghEbquGWxKttS7M0U82amUVLGdTFMNJxaJK9RseWE0FsukBKZNekgFIaMZ2Ip8G4tySjEDS3dJ17yrv8AjCBUHnBGqotTctWwtBhwJbWyr3g5ZURPoUA3AHGuMSktQm0syFSVDKTHosI6FjgIfCxYNuPVlsg6CGmnBLKYytzh/g4/R+cLkWNFdAdmF9SBpDgHB9NjrPJrk0kOtIizYjHFOBs05ABsR4eXkVShW0BQDtSU8xcYhdG4lKzyp48LMAiyJQS6K/jEIXkUB5oH0HK2oyfNND+szmTyaPhDfYfrNVAn1yVH05CDKQAn43gwgB4PDhIVdbMxFUb0lyUgbQYvw4snjsQnDTB3lOwvyMxEyU2H9F/WFptu1foL+sVGJp/wh/WGtkIyPXH+8cmkA7fCqfxmxpGsZtQCf98OSMkSU3vkcPH6x33rsUkA0IoO+ON42JK0q7Ppk7fON2qCjfZP5AxSWJN0QrAyHHWvXN6MdBOiuy9KGs43BV+AAOm6WlzkHBrU62tnjxg1nZ22Lo2Gjad5tTVIrrahgRcX14zZF4kQvAdVLPPKGUCxO1ryHW9mjx8Y/GUTdabXg8rrxkvU2II7QkGnlb4mNY0Qnmo2/Pr5wGyz2Ih6N6PjF1kGgSHArX1MRoEAIxnFRPUwmGGkbe5qlzSohQxnGywHI/LZ7SLz4M0oLsvwF/ODqnnDYfdYDd4VPzQXO+cdKfPDgVaDSeODTxl7A1xl6OT7xQS8tvyZKikED5tz+f8AeClH2jV9ayunX+Qgt0imjdXhsbEoCNdoIUBE0xsjb2ssICkUFqbMmIxC7K8LCRyVEcVkd0uUng0mwO95aA3tVOOIvRZ0htU1gl0Tz6DLCxjc01ow5ySADjAF6NqwgAgKxIiusEk4w3VCdaU+D4JyJIfG0VGcsa0Vcp/DQs1SgpGdWOzAYFC8JhX2ZxTCeIfaZp0dDsyo7AusCibXUURQXAe7PBMwOAsAIbRM3ZWnYK1KbLROQQrkFhlAWoZyyxpgFxPYDqCgsBODoAyKYB6BOOhAuuu38Faeck2go+dL8FiUokB40dFVot4GEUOIVa6bH2IJTqmNC3UQBdbbBgVR1SAG6NRRGroUVAMI7RL0CAHqekZEfELBdpO1zi1YAfYQXjSqJW6BCw2bqu2BlDfhSGUInl6m3lC0KYaVBKoAICbW7wIQDaLXPBDpvs8RLLkGZrC0fP8Al+GBvYj5hBzkLQsdazhyDJaBABsPxmjkWwoIyS6NRS5NJbgPFKvNpfxjqi7+hgP+YmppA/Wb5UCc70Pr/HK1p8y/QP5wEX3QpPWkuIgVtEUTlWOsKJjRxPOlgEhDo3c6r8YiG8yfwAw2GgXI7/oxRt4RRQ0RvLC7wRUVntUIkuo/nAhNzqAk293I/dIIoJYg1ZeVcXF8hUDj1px4iG5CfnZgx4712+Jzkx0zvRDhwV1s2cipUilcipuroU0PIWdnrYJ6svxx3iWs8TwPXdN3JhF2BUpDk0Kby6Qk3OlsPAjvnE4o/RBAOEnQ5eOCcvKO6BR40B/KDFEBQGAAGiGvGlwkupSwJq1q74l3jKWptblnJXT3bfc+h8iXhBR+vGnEVIgBuWKbh1t1seLhvjogeDZyk12dXkiEYWr9kijztJ7uUCSpuj1d2r9OJpqEB3qA+7lgDYEkcdFv1hS7aLVU97n+8GgRhoqp8YSTJUhL+ly5adqv3UJ+cFFjgAd8cHzxecHCaN+G51+cElAbgPrZbx1vDxdwCT26cawm0QVyaegD8Lia6m2maEqT8ODCtvIMedo/D+MHFE5V0vOk1g0rzh5DGwqwYUzEFLkF5wBtG5SLwyISB2Dm0vb5GRNDSdGhjYmU8IUvCJyougigwWikEESumJVvBTZGsBdaICCmlIdYEGPoKQu+RZ2kYU99HsAolIuzapeduNoVnkaqJsq0S5uYmL2kNxBLDlMAiGTXMAeDIRCrAcA+H94xV7kTOi9WDlO6w/vFz0DQ+Ycp4B0f5AYI7QEv6WTsCubQDscMTSl3i5rTiICQXhO2zHmqjaFZEiurpKChESQaFIkHKIjsIUrfBOEUGClUvYTDJmpHCDRDGgSCjTV1i6Y2RVAFWRdBhvZmgYm5saUIkbKL1sLLQ6dCPyWB1rEmRZAIr2gLJSyUo8Y6lRhtsagOasNAauggqK4BvLooCQ4ZB0Kl3shr06vG4BKSoxa9AFIG+RS2XY5lKRAg1TAGU9nN6FFdLVwIhrA1CzsqdmKuZIXXRvJMfQxs0Emchg7CrNbABzTfKe6vBwcnG5MJkasIGhOr2UaHvJxZ4yEuBXysN64DOUAAptuPjny9N3nJklNmPOn/AFgFH3f0wuvq4hADlQj/AD+cRwYzUf1hwN02KaR3WBDEocJyBUepsFL1eMXC2xMCoBPG4duJ1KkDU4ANfOQvNpQDy5mNxFBZQPmYrtRARwM4L3k7I10Jygkbq0BQpgvOnw6a9+8RRDRUS8MTeIRbNxwWi/GCcEoQNE7n+9YpIIEsShxqV5uaCRrIywS9noPdxkJIRGt9Vngx99iJaE5s2/XnKkAK4uyb+Tf6MbKyHD8c8ns6wdHUt1Ano2EeLN3OaC1Ubysa11E3NYyeZegLety97j5yzqbR3I6MpvPLE1TtZsC3xg6LKlY6QhU69bMi/rtZeay/O9/dy4u0mFugqPd+lwK8jK4IDYbjBpDcCMKiI+G2fjxhQB/hfg/WNNsi6B8TLxtUXx+Vqfe/GEzOCCp8cz7xUKBZITnYkxc4AcCT5f8AfeNRx4W36/1jSs728PqiYVHdGHk8GObrl3yeXh/OEBda6lD5XGpeeRT8QHEOsnigeqtcuJMkOaLXRxggCYW3LmnmdZAkJ/XObX4pUQq4OlSQk2s7Bdg7DR6dl1voOffun5wwU3QbgcYoAAXVu42+joglhwBL6Wlm9PjjCra6pcVCaFpM8twvoyAo6J0IIHPERQd7RQBWxttCx00mo7rXHG7lIrTShLbTjLSEGiTR0iNhETkaWmyynr3gMhMHOBKHqYdzWsJdA00IIlo2aLmbFTHfh1h9i8SYJllBLlBDgdVd8dUETOxibOyB2gNANRmkBxUhEVVamNnIADeABaCIEjrARIPkADh4I7VA4tO4A2AS9FXBdKTAyIUwJpuySBiwlTBIVogkUDraUtDSPJNrqBhuhulA5Nmw4g4ShXYkigXEHY8LMJNwarqHcYM3ZRPkLQ6pqRCwGBBFYHIOgCQGhSYJesnW7VYK/cJ0AdeFE4ggnhKm27cdpDvDmrFV2KsGUURWlxhwA8rlKpwEaWEqlIAPQIFBU4wdsl10eSbRpTbAcbo8jxFGl7BhaujCj2sAIjwAJBRLN7ipBjK4nOlOvHjHhBqUu7x2aF83GzBHpKA76YX2HiVymh/s+8RUkqNH8p7wbEjhJt9k3jtgK6E+A5xBbbRWvi5wZNUBLZxs0ayQoGaA/wB5JqMpCz1hokN2M/1ihBU5Yeut5bXYgSl407DePz2mCECaEtFL4WJKLHOHm/OXsSqGt/OESqoVuAWD/wAy2UHLTXZOOMRIE4b4V4EU47wGDBDUOk/8zpGG8CXU2ap76xQs3K4gRyDqz5yTNAGciClscvFx/VytEeBpOTW06xZC9kJsgbrc32esRP2xknQvCSMxSYNqGldmQZyIRdniTfziBUAJQ/KD8rDvrIPCNhcB1rhnLi7/AKpAgFCRGC65+yrFDLXQI5anXsuDqbFJs3DTfqdd4DFFWgfs/wAMvjFLBga+NcYquIEE+d8F1hyKLvTg1JvGFDxfp29/6wVljAutyB7xGM0H5FrTeTACpCl9GWzOSiz3gOwHb2+OecZhovZN9974ziMDdf4mVQG10uSqjfQ/15yOD7QL313gUqtQ3XvK2hvgn+sKQe2nD8YTyDbF989OFbFcikYGMosCCbWlaKgzlwv/ABVtGmwnK8kyfkEEVNRrvY+Nt5xdhHSvoWw3fz3jGMhC5cvRTgNfGSR2nErdDfUvJz3jPqQRbccQHk14J5HdwQ0Dr1GlaJjQhzzjsws5CNUZMLm3kw7LChG02HMwf7Fd3YbzPjaveFIc41FEnImMSbM/7zAo1GAUU8AOJIjiYzrTJTZ0DsA7pP2LGljVQE5Nlq4CEtgCg8kSNpdmCSys0TcQBwpVVLXeQOzFBKfa1pwYXWqwcBKMQ2raXAshno0BDULQQERsWfJIqcKJoBCqxyJpQxoBIaIIyYimV/wB123qDsQTwJg5tFXpcAa4roAYDI0twRDgCmoeK4CZSFlgsljrpXWlGUkbosBFekgduRekwQIvqAOERwAL5aZQWKw6RWgrZFlbIIARu0JOAEbQwsUcggFCMGFAFAs0xGAok6c0TyzhV01vAZru1J1pVDt32Iil9AEqpmx4DAA6in3i95acN4/cyHUgNie/0wP9nfFHvFgVf2pN/XxhwBq/N2HJj1wzoJ88fHvBtd7TTwH56xENIALbdFda5wWAaDp3+XIoGNsgsBjYdDIeeJgZKKiLQdQq3nrB3XjAFfesGylrbz+zIIjVXR5yQnlulPZvWCF6gbwfGHwNH1cC1tKUJoMjIbcogUNtr0dd4JkmSBiAt0hQ3ZXrHZBZqkSuOh5beKaJvrtG+fRf9LgQ50U50OAer2Dzg2InEAEDlYa1vxw1ipDdBOB/jOEBSXKz4N4WBKaNWNvTmotMiknBILG93RUAkQkd194Qo1ESOZKCa+Zu4zfdHTNN0HG+dzxuiRGhpZdk/X4xBzWUCaenFg4PRTjnGJNXhpXfnEXQQCnHRnFGKaM35f8AWEIjsAV+80YyvYS+HK2YcKB+nX/Mtlx0JB2ecGt5hQb7I45ipjNC8pedv7xuMIJQt9y9cY6Ezi0J/vEc6GyLuPeDAY0iofesrBSWHE8857X3tiAQWpFwIiLwImXZ6BfUhxrb4QZvaMRCA1HUaALoEFyZQxAiAsNrZE1ziESJMD4ksALHnvBOiJOBR8DtOL6cE3CKd6iFLkiaHkxOtJUlQANYht2nRSrxLf0RkLA2VDoiua1QgoiSul0kM4FXMGLA6WzO/eKwKMFY9oCwgdPWHXdHGwIoPQoUDyW3NbPBkKMEICmd4KUq+AXbibOhXcG21EgFADWN/ApVZJCRCHhhzhbHEaoLrLVdL8rh0jrwq2YBCl1JboL5cKaVsngvgG24Ro8KqmoADjh3TogCF/4bG0BtwOAZeZ2wZrkAroQA+8MDHQhhGigQDo5GlFJbgKBApkQcPCmJ2LHjUsl4QGjp70DdjoNVF6pdAlGnmNgC0tgXaqXNyL/j3VPWPka0/bfUzhqCVABQUJd66KsgeSJjt2gYUyijcsq2ADCpSnARrGINg10JTIMlLQIGgLtnEg+RVxNMIcj0YRisAeO5hhGiQlXSDaWbByVk7eqwXR5D/bl45B0O00vfGNBFocEwEEdNrQ3wa95bp/vp7G9Te8jksVsDyV8YbEwvoLoGGcIoGl4ALtd6eMGsMOQ24l+dYNIRQYx0vlmWmj0a++XWNQAUhTfv/mOk0INvFNYGdRENHhvq9ZAqAoh4IEDgQNeba/3vFetB8x+bnlGpUz83N7REGKesmxoKFqjbdPGGRJUSIolHXw1hskjxByBvj5xMd9ndFuwAWb0/Q1pVXa6nlwSbyXY0Ukrp3tqvHH1gBCosArsAnE5XnIKUcR/q+cHW0qBRPC9YGCj2Q9Z1egVzQ40/KXXzhVdZCw0NN1fGRmAA7a2ECAabq5uECDKoHXleYZDQrWhR+PjK+Q8ka943hqkA/wAMYR5dvrhrBtlBj733lYXXfpvkx98wKcDiL9YM0pqG/wDDnCq0O1H8s0Enra/jDdAoCRrm71iAxaG4+J8YWjgqBBvkF/8AMe85ABp4DzrvrCGkt/gqG8Dw783F/fI/j1hO40SFd1RPnDkYLRsORl8bbH8MFp+YDSCPDV8n5B+sc1bhouwGwpgliB1a9U1FO5GmHLNpTYqqEMdBrsudPlctBKcGcmyd8YsLvAY4oEZrkaG87wkEUAlQt3TV7aS+VYkleOhNH5F1s8bYtkpUU3N+sWOWUWU4AjREoKxyf7KlgOwfknnAZ/FqNZG0A2vJwQCCLqhwNTD6JibwCAASLCagv9uDcCdWXEL0UHyvEyCM4g/CURHhxgMGivItd9RGgjw1RvNMWH4IIDVgmzIxlzPcwBVt4JIo4MsdSRPs4WoqapwTAxtu2rkEKSldISJEZJq0toHY0c7IrSkOgRobMnKnZMEAMzwcih6LVANAk07mHmC2U0COlLc0fgiSQa1dIi6aFHX3mWehAUVAV1irhdTDm4HBavXPLZHybooidgDyWQ2AtFobogTQgMNIoCSDTqpWFDKFZFrKKrZYs0UEFl00CEZ/ud0w60NRSQcEi/UmkV0YbwHkBeaiZrcBgQEGubbYE0mVTKQB0vVyjN6q60UIyUJNrU4Gs4dBTTuWaaETBLUKo8Hkn0Y6Uoisa2829e8OANs4dhXfE+s1zuh3W9CoNeHBjAkIkqBsgvtGYIELfUhLzQmjqvnHLb2jNHEB31owBrGGmalYEfm4UUQElc/kvWsfqNEcOakd7N/WzN5avQQNwjA2O8FhTgqRwXZqa6y3bmwt8zjFEG89oYo0HYGn36wIIGLGecuqJNOu+d8fWXgFTtDm+++c92yeFQAfBrXIesd1rNbpCcL0e5hwBcDpTcW1+qd6cCL7YI+et5NtCImyzgn7yQUUlMIdA+u/d3hk/DbucfzMZrWJqm8dQ0vhhr97wqGxLEOWio757k8R3J0OrUWnbte8CDXgaP55cH2I7ANGMhdhFP8AObxvYk4Uj947FE2o89SZRBhUCfjNl52U/XO8JFLCBzOEwsLDsBDl3i0Xs468x1jBquWDD+MVK6Nmt/U94hFQ1B/e8jtIkYK4iw1HjHy11/3CTTREcCGG268RwDutPjo0PoMav+b/AHiCAhXT5Pbg6UObf5x52gDgRe15mLgaLB0weQ0nV1cJVHOTIAsE0irdBJCZa130Ba5+WVA5iByaK26JJJjyMrLRUZFjNQw7cM8qqJIxFHhKWiJw5ao2gwJQKCiEUNSaTPR4oGOxoTAAd1hD8rAs3JTT4wlM4LoShpWe7NUyQYAYBTaBF+WeXbgHyAIQJygV9XfPh4IAWd6f09njEV6xe5Z9AfmsVyB84vpydOKFJatfIh0k8nqSlkWoBCjNRUwjEAEdxMExVaE0uCjc2gA1GFVbHppNq6jwyAgbKOWm9thtZL1qhyiW1OERsT+UiWEZoyksF2mE/wBTVQIvpbUuhHNndww91bDXAPKCNGxPX91msSHBsDoejn25GlUA8Og/vORwhZg6104QoFeFurg91Wyw5eU53kzt5qMbPI+aBlgelsVFV1s2XdU2EwaPeUH33hLYdHeb0o4AslAkUrBmLASAWGvbBULpbBZzOzXhHTNdKSoUUz2lQ3lJ05T4fvbmiqR3TN3ZhkcAykfAmlhzrvxvSoMGXhQO54cXi6hycBB6dmAIktSGl54Y8ZOMaEJuxARr13gKfRcLe2BCHETHoMwJbOt3tNnHfWM0sUJSK9mQ8+TOfi4M8WgAbvoyHpzu0YAjswqBIFcb8e8QCIKfgfXzk2I23hH+cayPpAf7M6OsDe8mWqBSAdvMMprw2NrY5FKPBhAVcxU80Q53r0eU3eCYi5TtdVw2BC+b+Mec75gZ8YSqg14rNn994tjA+defOTbG65XXjWGWxeKxtCmOR2bF9D3iaiJcB6InDfOSBgJQbDnp+eTFIDyhda43itwrc5hhreRo618YFBmdaXXWKrQCNA+Mv/h2Nzy5HcTZrufJibqKQl1PO5H+3GDKlbNXqfecEGyg/nDLy9zT/OJFL254xKPAiP8A5nE0A7rjY+X0GSy000V0nA1/GO+Yy9mv+MSbF+JjhcSmD6J6xZoC1r241JwQeRzfJFrrcJ086dNihkI61lfiCnNWxs97liHm8GI3opb05B475qtD9fN+BxppXRLohILBHwYqCQ9Qey2eJupLi457guraJFit/LhZc7gM0qq0VWMIJmhoHowhrjF99YPTBNxMG+aOvMT2ojvgYYSMR2o9/GMRcbX3gPCRX8Ry2t8NKZQG2QW6OQVXQpoXZAVKG5FgW0VmiOK0kgWmAFQYVMGh3VoI5uXNQpiqEqqq7KDI0T4fwAwEH8vT/X4x2qemboLdXDietCmMA6l0j/fvKJ8MoH0YC1HUmdivQB/eEC3VbPTc4xRzhvhDT86w8Jg2ABpU0XkyzTOUmewbHo4SHNfjRp9NyVb3iwVpYSgIbyLpOBdpAjJF8j8jhnEQsAUftI584NdA1C8xEP6YOQb0tOeZd3mecgisEMfl3gAKaa7ffhxWgSKwoa61fOWa3Qd4PCZgsfX/ADCM2jsOlOPP5xSwTApvz+suRhdkofs1+cU5why/jFLtsI0PW8LSB8C+5gG9t1rfhcSwC6KBnvxipAm3ZvTpJ84tXI2KIu3vmnximI3MjsSGb070YGUhdAccesYSAIQlXg1+cBgIiQl9D/TORXtkdWu8VoE0D8utJ11mhMBP4i0+cWjW0BA8YWNusBQfyaxwIaHA8jmCXiGOKhugFFrPH/c2wnkHGlz/AHeNqalEauOTE968Ytibbqze+8iiQCIt0+eMUQSREXX8fWQRL2Z+slRm7Vf8GGWLArkx3E7BD+GD22Gm3XxMQUEdDQPziG2ts8nH6ylMkdj0VysWkOrQ6/eIK4rRd9/OAVrg1X8YDQglV3vFEgQxt8hYdzBqdlVagpzPB6xwADuTT5To/eDPWwujp8YQ1QduURE94bzwSn7dZqP6aQcIOhPOA6+CpLsFVYIZpZqByXlynlev92A0/C/7MqGPyZQK+mVT3CcTY3pT+M4AB5HL1EJxXlrs/XrLySCYJdIKp5IdHKkAl6N/OPtEE/i4MJO4L9QMUmo+R984MA9yXEWgcXjsHzEMCzwQsPxMDvT7G/tYQB3Ts/vOEF3oH8ZH8bgb/nLlc2kAP4xBZvtP0YqEHIg/KyAsf1jiouDAIESldbLwOyiwCyUVrF5G4KDAgAF5jxyQYfZABcGAXke7Y0hvm1JyBpMMWcUoHzXxaA2uJnfFaAJbTE44eOcGT9VdB0Edc4/YkuCXGjj/ALjdRv11B5+fWQAGpBL4N5Zw9Ow6HzTLEgHyHoXjDflR2PUcqi1kX8FmI2blHd/DiZlcXz86n3iqm0AUv7wPWKixA+srkSoK7PGVxEXY9X0B+cegAWgCnzkfoAGuqsUafty2bXFflnjZoBZk/izadJxvlxC2pqAjObkJc9qfnEapqq+f65sheat/MxCIyqgayDoOnHP/AHFSgoHmPf4yyouBS2eXqdecFZtVC73hURqc+8aoc6XEG66CDvrHU24eT3cSKAAQpfnJA4ONzBwlulcnz64wNCK3bef/AHHbTojYznCoR7bxjABd2S/+YnlDKJtJ8mDRa0huHf6wnaojNtyfkx/KXWvBP1ktNkJsRHsL54dxGKx0ms64J+AMAU5pWjTWikXnnBQDeqVMb5o2+ezEejuJNLo0lrzgtYAASHnTSprN1I9u/wAOIuw7NyGEVlmOp5scm70K9L7cTUhyrcNJpU61tPT++C1bxz/3Gen8YX0ehBhdN3tc8E372f7w4/0TDjQ+ckjZqjilvXxlea4IyhQNHU2eTEr4QH2MDBQVgs+sdK4FlBiS8JkaRCLiJMypb9Tb6zkLiIvKiD2kyhF/poMhxBVIRSJnLbr3jUwYKIigpuOOwkrIjovF46XGp+nKnkULsTrowrABxdKi57T4g0AKnez2wE4Utl4Sd+uc7e0hf2zO9FWChorn+Dm67CJDAwRnSKI4Ng4pC0e3PfeIou6dE2EtrrBqF0BZG23fTm9C5V3vKcXXjyz4558YTyor5ofoQ51jirlPb4QUcnnAbbPCyyvx079YlgelIv62YJm+NLD4MohN8KnvUxATtogej+vnB7Z6KH2yo2zg16N41EzTwPeI0tl2DiLOg6UIH1vNoYLs/hyP1Fqof9yC7496M2aUngnnXOIBvB5v3gpMGlu4NJ8E5XWmc4HFBSqs9dfZgEV2bC+7vNCMVVFdaNYIL37Sk+OMWrysnK/OOsALZjXLg1DdbxGQrewG5uySJbX84i4GOAMFE0c8cOJ4BoNq84yrRHMrb/XAaLwQJ731/rEECJUP1+cAHGUp5/P6zlUtJABB+FgeA8VbwVNrOXnocWlBEhLMgJ7zQ1w1uGVvSpppv03xkQKJBzxGZbLuhlRfybxXj6p56+z9XAttABG1MnAab4LowAJvaJTrgwMHYhrLCvk5wwxODtyqdDgL0bAffZFfhnHnZLa6s/KcSbQPItViZwqBFhuS22HrpAJ0imJouVrYon/9ND/OFb8/nxbJaKfbha8IDJ5py2yVbEHQ2A6MRmmJtsNg1U073xm3sHxM+8IFKMGixH00Xq4dM7r6DFPuOCkaCIERHRpHADDwfwk/rKUH0pfErjRoeTi1hahY/WsB60C6BRxVAE2oYoCNGyPmE1lWYJsy9Jv947nSjIUoOUZvrKZjZC+Soj94NqXoLrikTvkdczWXmpgVHTdv3E841jc8PcmStBFMaNrhJ+Tb+MPr8DD3O4eiyok6aeMTOvGbRU6+puBtqg64yTvwCHVIfsyDYtpQ+m/Il8YcIVaXQW+AocdmJDhDBSWBeerhmlsJNvXnn7xgoCJFXkN+MTVgirtKaXdW94CeS+CqbvxjXQ3ChgoGAAJB2+fxhVqo7suhD4+OMIYKJop8b35x1tSTM1wI9vfZz0Wi2LQd7LeO8ZOCBrb78YgIEtx34cosF3xKd+eMELka4fswYtYMF+k32YpeVQVD3reGhjTSH5wshDzu8p4q4OvrGqBA0gQ87xbjoLonOWiqA+W/WCqwFez/AHzjLKZDFc5ykUkaOASpthtrvbcvE6ASznHv1dh2GcEPHSfWKkMIXf3gCkqVW0uuPeIDyTSJziHgk0iOxMurninECJTX859ttJ8+cdk42g7/AMYGRoaHP8ZoL5E4+83qOdtM2cupU0nh1gkQkjNH68cY43aTtceTrXO/uTgcAGkGoG0+bXXjJxAIqKdvi/Wbygm5O5XTjQIJcjIg65/txhugziNF88v3nAeZJoKPqmlg0DcHNQiTelm/MPjDPdWPLufpD6wXogo1/grhAadgNPoN5pQThV/EMRpOq9wOC3fJtok9gLxTBKYgx0jQoUoSR1UXHa6LHdeHl7PZEGdO9tE9PThg/BOTXXSYheLaieEeT8fWU54fStW3yG4i9FOvDDoppRvrYUC4tFXuF+gkm9cOvhSaaCqhEnguwUgKKbhVvW9YznFj6vC6tjWRA6QUJw0rTKAgBWUScnk5I8HSvuPxctQ0EglogGLGsl1CNZqGWVwNdiOKK6unKOmg8lAdyC0kerW8/TJ10XKrAWOyCKqYLNUQJ8inzya/AmhUiprdeAO3x7wyJbVXNaDIqu7GBAAKGm+1w+3OSKRwp4i/XOMPZNQHZe1GvJkvdKFPZKsHO8t/lhSonA+8MBAo+IFcuNcDzhVKTkAkW8E+8NGI3XZJB0t9+yJ8lTbWyBb4JlyNQCUOzvQErvVx7Smj7CAY00fG5jQjBBtW+1abua4AtZwiPMlycMBiTaPXgvPcwSBBSicX5dcY9iMo3895TN432S6+jOdQM2VqkzjQvfxh3ZfIarvrr/WGDuyT+G8pRLTCb/GHbgYv9TFUjJESJ8nzg0IRsYB0lQUP2MCrJN0/3m0/hCvXXLiaycsl78ZoZWwP7BvAtEKJDR+siCoXg54O/jK3rj5+/wDeANkIBz+OMqAKKhauFWQ0N3963gycwUGa4CQ0swUrV2Uts0GJp7oN1gCy6WvvEkJJpW877wRQvmHKE066MqVEPGWItBeMiwOo4H9/kzlb6zOOLgwoAl1fS3+7xIYhigB9nnPKCTYHX/uVkZ7/AN4rhCMCBoOAs8hgg3l5XLkwNIpOMC6gIdh+7jROL6HvWbnG1AlH8FyosrIogJ3UfiunKwAgtDf3vIrQJCz2NGBPGaPgxgQQl4zfmOB/hKg9qnQbcVCQPPshD00+Wrq5U1J7HcfZidhfqCqu61cvUa1u4fArHdPSi+p7r0eNw5iTrAS93qmE0qoAKeFmXGBTV8Vc+NCe+sJoQKaA06XvnJLvnTjpHV3xjrQwFIdLYf34yMY7pY+B0vJ/HOa5DK3E8jvQo0rQgMNXDsKKrsp7yofpLHIdlI8i3BQ3LMaCqUEVO1kwSRAY1VrBIvWGxWzVK0EBl4oXm4WqJLdiNyTkcc4StdhUNkcBhd3zkx1DMVSo7rdaHrF4uWJ7An6xOgkE5rdJG9A3OGYBJBfSBTTtr1xijYCuSe4MggwugQlgQQQ4DxgSnMLqgb0nuwuOeoCppsgryNPJgJFd9QujFZttPilQAm5VGXooD/hi4R4+q4ToaPGsEjaeCJhwWePfZNlukQteYHvw4Cg6yGlGtEYvPoxI3CpnBa6LMmLgHdKCmD/0IN0O9Q2NnRc2zPqlQuENCaBiK9ju7ADh0QAV2Lyz957TgK66J/esLG4HE9G/jAhZVKG8et4s4x8qLRD/ALhLC9aJfjQYZuVBLD+95SOxkRH53lLe21qfjKepCMFfxmj2BEnn4wqLVCrvkODK6RqXTzjg4ZYMXe7g2kQ+g4KeJ5+8ReICWvE+H44wp5Qt/BkcfOS4As8942onbfx1jAB5KQfrGwteGK/nGpU2X+Q7w3vTZfxv94YIglkS8cYoqtAKMD1jQKLRvWdA8qVfvA1qhftf/cDsiOcskLt42xPTKrof7x4G1Tl/GbsKgGupi4JGa8N85Ggu2APBjSAbkFH1w5uBO0ANGTzAwUSTqe8uNDBPoIyYyFLlUAUvwaxUEmtD+TDql57x7yQVFQLao129azS8Gh1oGfTCPIWO52ONA3ulONR0tdc49eV7+8Js1QaoDP243oHWbQPDlyLRNvtJ/nAqq+sDLzhByCFOClib4xCLhekbNKAl+HNU5AWMNgYxPwzHKtdwXcEQdfxqRhUb7HZIOR3q2qoKQEXGjOzQ3FxFxbcrsGoDSjERJH3NyAVTg403w3DSdW6d6nMEN/ViogDGz0GT5eN0SFEdyAjW6b40YMY5UQaRSdKRoS0cZhptG+ktrwVzqq34T7qDBCjaZw0ZYHrgBAB2w+nd8dVsgKuCAWLlqelCtJ4pBRXYBDLMkIN4AgivRpnlls3Tpy7PCm34y05LiBYETTXuiupgGqe80QXZOZ3MM2yipRKpK7T84dRvXKQAKEGKxblDgEYoEanep9YjmR5PgUFF5enHq5LWyxKHKXwecFNN0I90rx1cRKnqKSATXA9mKGibKPDa4f18Vms1nUSmli3zHEKTjDW7EWFm3wGObRZDKxSOwvcdRWEzeVWsVCee9cbwBAdKxQIheX+ci+zTY0BAr1NKpwUQfRAp/wAuVOzDfBH7ma7bCHKpofi5QE05njv8TBPhaIfT11+Md8idDh4/GKinwNV/eL7uoBaJp+T/ADlzpBhNuxvmYyKUPWvjziOuM2F89m8UNVg2UPzgro3ga+neDwCE2n8eskhaIIHzqmHjsUH6z/DHU2QBaw0usZaCQjxZzLjglaMb/PsxzXe8KbX4/ea3tiro/H/N5GQCmkfW804iYLqHff8Ad4mMC+sb18/xhytFUa6+OXGqKRyKIfnN4JyL4+cYGrWaXjG1DoEf04FI4jl/H4x4IdAa54yi9bQcnvnF7gCIqI/LT/vAlCMFoda9hgOg23ivq4DviEn15xNSoJadUvWEwm9ZqfJdb97MUURT3B54/twzSV7ublwc47qCDI9weGqPEO8Bf4XxDWta0ZE0go2nL8D5ZvHO3x1TSbj0+8VImwIp07v848VBU28n8HIkwUbF704EMiSpPL2wUDBBI64M8x8Y6K46UgAb0DzGXM98p3DSryH5xPaKu3oQANNnEwZnQdY0EaK9hE1zkbh9hIKdO2sUkh4f4OESkogOxNXCT54FL7U/vHQMelithHgsTMcdDf8AGTcj2BxcQPQJkZvlhJm1cM7DZ31gRdqDD+M3Bv5FD8n+cI2k3xMEQQE2gPZd/eL1S18qRAUvbkyEADVdVQ0NunnBaouvAFITcZNLzMQNf7vGzT6ZHyI4RLyCbTs4MVCqHQoN4U0rz+BWpQpo06T4S4iiKjK73Xph7ZXeI2zkRQdg9gDs7pRkMHTe51Xgyy34DVKeXg/eSBhpFGhB2PvOGQBo2ggJBtbHjD62UPuhaKNW3rBqmO13eRo/lynvjgcKJtE0e94e8+6kCqbqH9qtl3iRquwm0NaPGNnhCnS8e/nvAmyZw03sHW53m63xabtl17dHGMfqIACwmnZ594qS6nogiuVepjuI1DZHjFEYAPSa0YoCIBaDycxytMKaCnxNnfjNslgOelB5v84EILWqno044Z00S9fzh5Cutv3rWNklgVbZ1DFcwTmv0ZEZIqJ1OxdzXeS8RVtzyqCb6xHATSKbA5dbpPjGcrcwPHmON3bfGGliIBa9aHn8YSFMPF67cfHGMU5tDkZQ0a5+PjHnlhY+hmGnddnwp/GNQaMF438+P3jU3Lno18ZxwNcpvmMy6yP1V94g1A2BpSbQvXryZD+2BnUilAHdlZdTHJy7NKecLEAWT7TA2g7FEGht7Te0qNBimh6r/WPhq2uw23bB4crIcqgtqsefyeriradHeXfbcEs1yhHrm4T98GTUAGNk3+c5puAf8PGCxMcNUfjAl21xHr+hjZJR2L7pw1fwHjLTyBtQ+7wzoMaZdBt1Dfxy5MIWZbydpYfzrJ9QE11ioA4EQIbYwGjE9iI9dw0M3c9QkQKqLYFdPLzij+9Y6l/llI3PbIK1atYCISAYfelQM6+Py8BjbghQ2Igg1/3zl0Gq8BhJR4Av2jHtA1Afyxm7lxpPyZnPCgwfNM+83fDpy42CNbYOlhahueMKY4Bs0rZq4VDjLsjFI1q4Ghi7ZijIGCHJD6dFvivxNHe6IFuLvi4Z2cgTt0Nt+zKIoAmO2Y9OfZkuUKltdAXUPAPGFaO8qE7EkeG9Yjd2aZPtK/rAw4lEpwvBggCVLqrs5MUozvkjWz1jgEbao00o2M0I8mOLxIUFLminGPEq/LvVy0n0qVQpo16xptwBjc8rvn9esFIitHoPzgSuPSqol3q70+eMJ9GOz2VKvgzbFk7G6tsVrnlvDR7P5MfHKEJBqGWDRWVIxVEiLwR0ET64x4UaR0vOCjAsXSbTXz+MGi0Ab5GJe/xgpDAV5PIz72ZGFg1FFudTJiHYMI+SayJpc4/HR+8VCV0Uz8rEgh2IQNa8saiEK/7vrCyOWETb0b2YTq6tZ6ADvi0u5k3QUhR3UwlhTqDTGNtTGA8RHiRxmUAELe1dB84Vb8refyS58zLhMPckETxAw3OcgQSgaDmo2Ou95f2YKlO6AHIyE3d4iQhIclsX54T7zrwQjQYWqnInfPeV0ygW13oHnGiNNchzRFo04ELBFd7ahYlHwmHWVNzIbNR86xPCtoITTsMgDqDfJ4MM3eZhJYuFgs8D0OKAwEEZ5yhaoGuI02k6IaCMIWLQgxTcsuDyUKLIQIHOUG40iZTQB6kEaDGHthy+B8x1uGA85VMppGt6uHwiLfIvH8Y+EW03Z52cj6Etm+tf3nDXuQx9neb00oHOjx1rA84Qj+MBOUu117wIBXI0/wC8OFdgYb6usldcEJGt35xEqkgqeVaD15yQ+IxZxQNvK7xlihy3t/OGeZsqIioicPeGboVAj8ZMcIWEQANBldl+MOp/Gbxh5GNnU9LFc6NolPOA1iDGgEqpJsexGDg8FbEgKIA7zhcgjUeRJQfG3xl19Wid14PaK8zAHTbUX8n8mXAR1Rw8bFLvH0bxyks2fyHf2cgNED9oGj9HLa1g7KbwdN6ad94EEkHVe0mXKhNNYsVsz9dOUHQStK5aYHuFvFf245ZwtqFmg0d5XomnkkLBFqHGFYJdA3cKrKJDh4wKGKM3qJWDtA2wDEdqoElU5qb3Cz6zRqwE9Hhg/O8qtAhH4E+uMc5wKtTiz9bilnD4iT7x+MRLGQHaPYaB/GJGvR2vGzkfeBBkGx8vwcP34cgdMkkH7y3rjLBhESIDXT/J6yXdJHYgI2hE84z8koBUeumphbclQEYvzwrNqgesCDR2+zDmLGBEMVrgWvSmOdMarcr1KBUecFHNzDAJ3G4TSBe7nB2RG21zvXH+8ECKnt4hya3XWsEcFeLgtbXToG+eclf3aKQN0tI2fDrLUkAknZIeOrxi4yGjn2JsPXnJgpNRG69n68YMM8Ou9d4v1gYipHsK+Y4VSeCHbw77/wDMb76FZseZxfD6yo2Ac0CqFLHzz7xDw94g7HsN+TDSAsqtFd8a34xInoHorE1QLbtxqtNLSB++D7wHoJTUF2Wb2cPn8KpaG7Wix+PzrjnFWHFdRa9vPvAapBBDCAl+eTA3AA51N0i2bPWRSnmDJYNMo32eMpFqRRxsIOInGy4URa7HgEofnvNAxZEnJpAD7NhvEAO0DAoAFFhYrd4rQAGTp5C1Sb1xymAmE+ilrRHGpKeXC6lR4RutFW/5OIdYbChQZjyDWt3YQIBs8i2D5bdC3jCpYruwNTXi4qRKauKlCY9F9MXnF1Q2Inj/ADkEcBUr+cFSUxhAeHmWZsFASapo+8FkjR2DTblEb22YIADacAF5GlblC+ml+KfnA7CdQft3/nOj/CAeJyZ+7PJ+co7cXT3HAB6vIecE404Jov5xO1+cETsC7mFQNqHzgiSYriDE1odDAzjOAe0MclY8hSjRpwL51Qi0pQATlLzdERoFZoORSPGa1li4A8vo6MW+qgcfLyvxMqvoBkwcZQWT+7hmAHQSJ29Pr8YjloPtuF8+7k3zwbsWCBuxz6Wcm9sw8skLMxQdy3a+sjO+fY2Idq2Z9hOY2BjGBHBCvGE0IrQ62FL2v9YAM1MbBEq7tvrrNOGUYhZuFBpvOhNMNSACEvaw20wOSdngBTZNo7861ubggowWzTpPyZrf0oTGjIY1HxrKJlz7TFpt33+8f13J1VXjtX84GQmMCHlyWc+8n0lZd7m0ZfXnIEYW2n1xgP8ARHwVcl8jjnDE0gIRSKRc6ZCuMXINJDTG4xwC8NKILiBjoAUJhpGn6IoI6eeMdnepNNGEda784osQsHgaUSIn+cFVBqCA1QCrpbNATFfjMGixBN1jvmSA1xptnALuC7mrMAkNJ5ktxcliynnAj+xtKTlABQO5pxNKQDhqP6Wf9xsfmAhsWef9HjCDmwiTekIOjW7kJ+6dpPwLRNnWGKAa2PUloI6HtrN9Xei7hLV8hTeX15Ebi8zgUH2Ka3hzuDlEXy89zDSELK6PLn+cGoXjKWqrFoDjS84kCRRjskSvcDmsGkNlto8aHsURpbhghQTVNTRG78+cCxI8xgRwvOmJ9igTg3SoH6+utYk50+5qgCdnLs6zeCzb4QgbX0XrHpRZeyga2ACreNOC6zECadaa8nd1zi6qS4uBtF0gdq+bijEJsu1uh1q/WL1ygo2dBsAtmA0WktaD2zWqtpM07diEXgbNrWaMQhgqHzQ1jXvALUO0ARVAkCs6wK5rDdgOBVs4a85EY+AQkGcw68r5c5X4QUqLUItUPpgT8npzgvFQXVHWOBZa7BCHIUDZXhkpSUTfB3OgvMHAT0tMJVCGcJPBSlCQKlTmWNLUpdAMgYm5TyjGB6V/WWRTZcdqHz+PHGPj3sINqEO+F59ZP+GkddhIvgl5cAncTKC9DUKPfOBRhKGBuvrxiVXGZIoPaJr8egIiVipxppq45mUzbxgGwDInLP5ZFIfGRvYGZSueGwTEIpG3AgKVIC7Bs3kUHKUUaoCuABzACCoM4YUCuWe+OccnnCtxVA0nEvHcrxAmlbJf8BmC9oDx4z8/vEk1can3JN+Yaw1LhZJfrIN1vYb7msXq/wBv+yd5JV+2jrdTdg1s4hhhQwoAqBB7CPg5sJU9Ld6kiLqY1YbCKhUY2Px1wokXi74FcUdOoN6ynsHjvKpF7LHGHGZh+/CNbbGbclA9hoCya1WWM4yTXsaMGiBo61j31VP84odV0ahGoBG0vU25uY5Ky0Qsctiu4KzuItf3gvJHCqZzpfeJysni4rjoeGS0j12/eIhiHig9BanKHJmpsrQKNJBuibPTh1ZMFJ5QKJNxpNNWYiFjhiIV4A55Ock+CheqTwEDr01gc3lDpRUiOROC7MT0dbWREBRoT5bTdWFA6gTtgT1i4XNZB4JEGbL56wR5xqioHZYou7psqLUFuDs4A6RQHq5cl8IVVcKVdH+SEA4yoaClk5YzIzIQU4qZbDhyYEaXUSqAUjTpmF5WOCR4PO+/O8IIVyz493fWy3wvU5ZGaY3qIU0TTUrFh9urqAq2u3twokXPIVA0076XouEh4TlLqPnjnIKhuo81TqaSOorcYaxSCtC4XsU3doxRFiUKApz/AOky4GAQdEqciwVA0jLSUGD16QnQPJiuwAiDws6SuvEsyhYt2Ll7UqUQBzXKWcGRbRrRNoEOXePBGN5MDUFTLbvjAeXbSfAmCsTZ5wGFtOLdCFaXue5jttDIUUqMKWwwDi4XcEYOgTZZA45OoYuqARUgUBSTmjbwHd/GlkRa2m16hjUWLExbQA07FB1PAFmkg62HHqZOqw5qn2L/AAHRgF0Rlu78tAH0Y0vTxESHLYeUMTMeQpVWnRCSLjLZomx9pvQDqVMOUspM5MattNHQSX0GIK+HYfks7wis9GqNIFAs2hrkxIkAU4QnTzQSzsKhaAbWqtl/pchSqIAjfIxjgckeVuIG3etk9Llpq2rIeNPHMvvCYKEIm5UTfIutxzjEmry4OofeRs49YOij5/45Yv8Ac+MCNp/Txg3R9f6ZGQKpAdIk2YCHCK7ZoZo125dfmE8DmgwFiiqX94F1XB8kP6cHsSa+Of8AOQlRNQb4OWxnpvxiyIRZfABrGf1wFno17xaAu+vj/Hr1zgJzRKxaLsNIb1rAsMLjAgwp29CYkICxjZhDoOTiazYzuGCqJwIS7d+ctAFbmwGaNKduwUl7fHKMAIhLEunF1VpUdGgA2KcLvest0we8zRAW6XbveHdjn0UERYrpYG0UGZsVIehR7EyiEeAKLP8ARjMlfwZFWhqal8sZD+yRroEFhtFYAusVgZAgjkHV9bvVwBrczjtqBGx1gpOEEDxob/DGbRsyBGUURIpsJcAeAgUHUN2zU5ze9kG+0cKlR5E04pkayTM9kxQ+RwS2O0miiArtqgGt1ek/2xQjUCmg2FKCm4R0OwjIp3KBN2l32MaLCuNjkEZBuHlKDgVW3rxosqE9g6hwt0VZhTjgQKrytU0LoHBVa4x1CSSdAJFSAqWTGthukIqQJSorMoNZJ4oXkIgbExvM1VBTYVJsPROcXgP0Tp1MOAEOECNMIRfITj35m/A7TS2hyBPLfjjWC5IpyDwU5cBBOXwOeVEWWCBQvG10Zo/OpMsq1OEm52mGpoxNWx/X/MGNca021Pr+MTWxCmg055VfJlQi7SVPHZpx2rMSg47EV+bg0osedA0LSJOCYHRP4ac8vWgHZUwXWacGnAHX4+8Yd1Cs8HfPR1XnnEp/fYGFSIHpawOmEaOzq00PWFXERkjdr6Cb11itpKWlYQuWDTjjWt4PcNEaQqKOxd4MxjpbGa3FWorUVjMlgdwDdsm/K+91VziIMXm6URtjVHFuoEOTQLpImhoX6XWkqI7pVThr5woOK5NwIY0cBUpLttVVAipCILnB7YiGVN4wREH0W5zmxEd4KW14NG3jEAhzEZQjtOA7gkUOwBpKuiRFWKHD5x8QBK/RJ0afP1l/NRcnoS/q45QHucdFpAoWLtMLFJAp6li2/JsjMb6cd8JwNC1YmjIJfSE7hPyevOEA6PZZFbqwLAVagiiBaEZ0+cqcpRdmk8rZeN/nKidCwfpblAYSOvfwYmMtCUG5/XOaA8+x/wAYf2f+MMBF4D/Tnr7xb+MZ2vo/xjU0cr/pwm7aUrG5OXIkgRAlIaftL94F4NeYBfCRPhwMlNtuEr8AT8V7ylwgFUtRp8AgLONSp0YVSYvDOzTnMK0/5PRzNTmdK6weFdw1aKu03bo2JbfccxQIxc314ZClBXsgn51v3kqwkhe9NpgArNjA9r2FhvqnlvCvuPSmyTZJPCyT0XmxFo2Kq5AMeA3aoQAiRB2fJ1Cey+hJGCMmINZTbYlJIENdIcsUfANl97AcH1xKKnaEhA4847DJXlGjf2/lylGKdB6AXjkXGFWWATmAukzSOGE2iEA7ETVKsKq79nPg1vDsRGvLlMgji/qtSXbXj3QfA1fIlQ0TqPLcmsBNg6QJFoK5u8arMtMDcTXisAA4wbq8o+kJLpQ6U22Lo4ehIMN2SKDts4UwR1mKQG7pinGHZRQYWzV4BvBbRqBIQLOfzpwDkVYENS8w8g1m9Q+OnBkZ4gf48OHAMiyiIU2rNBiSGjyZZ4lh1QDNYEB3GETyo6Ojmu8oSeqYdoVcmtbjTWMd1lrW/AYb1syJEwR95OOgNE7RUHxnSPY0OmUscvAIeKBSAD0/XjFtmopwrAwdi6PpcPwtOaAJxRIpGiKbwgKFVqbTjYzS3nlMTlzU2GjRiewzd2ZfE2PUQCLCkKIE7Aixq90CweF+3c4BSQZo7LzcSozgVkWcIovS+sRPEvEg7W6N4hSOlyrVj0CvSzvk4F7KFt2rtWq4q6WB4V1uauvnH6hUCAtFJJvkiY2GAVDe3hd+ccBM755nj1L7yMO7zkTdMux2XsuWGq8pxm3VqaBA0jIy0R4EnPbxO5kJUELKhwHAi3jczik9YYQIlAqEQNYhAkBZNALQdt65vG8gQNYCKgYkKpzWplCzhAZtdVARhJFTGWhyvBAE55HvWUapIXAMJojts+sQA6vc7Q5QUt1y4McAZyaTK7nB5dYmRt4QFU0B219cpSCO2KqlPF+sLwYHs9d+fzlAqCBD4DbLX5nnAqWOVR68nf4cSJqoi3ZDwobzvYXC+Rw/eFhnyKsNTx0ZxChq1X7uLPN0n85SOh0NfnXLg8Fo/wBc/rFbKl5Hn/X8eTGGVcD3P107+PJQuAkHEqs8QtOjTjl+nz4cQVI0M+ahzc5F1/Xg438PplGy8NMJvfjEmvmAZHx4y4ok9b0d8Qn3hKwpA+ZTL0FXQYbHeDggqNAvESVMSpFsIQcJAY70tMCBoCu8ZBoMY8HE7uNMQxSwpTYnRY+zjFCggAtL5G/bWb0IdUlCJ1a/eUANkU/GKzOGylNxqs6I87LbZFwdtG5pRrkcACJPAuwFRujy5wp5QVVcSz4UkuhV14C+pcfIO26Ar54FUN2zeHC7UwaDIS0qAVdC48CgtQNHU+w8hlsS6FLQU2kJTUZZhDAEcIow5Tm7XGU+mXF9bBsQTSFnIJbD5TirTuafiYmRUvcoaZ4GsSCRUxvFC0NowBwiSonAuOLjMReNqoD848q+KCyob8FdOtY2qNe82vHfCjARHZyA+Mo29DeNC7sjQsi7a0WvUVJYo1Qm8BVToXfJU3h/7KIB0JNvxcaiZ0JaNNpxiunUrSGnIM8wo3Bo7sA2Lrmmb6JvNVt04lv+QYdwBu02ad+D0/m1ThoUUJQ3vWG9YqI6k5/ODcdAJWnX2cf7xdKIbUgJzK+K+W63pACIkrxu9a5+gi0xBrt8oEvDU5xyklbXZ1Dy4FQGvE50fAnmHvQHQ2hmeHBQO67HGQ9CUJwALd+f1kFir0HmHxT7yMOQakAZRF1Bchv14SeEn2ZoMcG+QZYu98YBD0C+FRr14csDtQ5UOKr+QB71gisYbYcoNfYiDrFup7kiGi0JFVoGBRRJ5PQbad3BgRu42HIJ2myIlS1XYIWxa3e/35rlSMkRZFXYal6njeIBHrvILuWLs2k7wgrzVZLVeU1Q1GSGTSirZuCp7PwfOENTpkEgpNkfvqZ8q1oMD4FS++NYEodDCSA6UtPeFpIwIi+FZAu3BGMHRkDdMUANteT2xLiBA4D8mk/zkgLtEpau0t7UDPSryFa6FGEQDyBVwMyKYMaQfPnAegdl9L3HYuIhWnZXgKIJ8/yQG8gKWeEVYcLtpZnIB1Et2CB3SeJbiNTUbdYFjY99ZuggQWtGcSYWboyN2aXfeN6ydmt33vE5Ldl9zZ6wfpmg31vAODi9xEsN1XkngwChlUoD6m/6wAoOhS4nJUFwPFXjn85xm0P60n6ZP9LQFiyRX5c48ArDpEJfjR5wFhmhlc+pj+TBBEXhcCCAhAELYGxWEhaYbCVp0dZHuCOoFdymoh7284OsUqlSQTVL6HnzlVV5xANfeBHn5oh4ba0G9sdMaOR6R0nz9Z8jpA/jNJptQe0bTY0Ibx5FzoQsCBtEpM1uKUCbdgW8W/3Dl0sLnSGu8Ch4k0BGjiPc4BmNkqj3lqW+HT+8a5CL+4RhV53LdyYQUGNCQFPa9icjgA7sSNXZJQNvBhbnWGsbdACqg5cheVC6GB3wBvjtnGIFSkVRaPNDSresujNu4yUC8qu1FysuiQQg8gI8tI+McgEQ+u2FG+TX1g9uFBWqQlAbgoAq1FA8oqgEABs8BQQmw1LjwNLVCXl1mpkg6B3A5/rlhz0CKcVranbHtwcw0r6rpO4OHkTSWegQk4KaO4I/vKWSgwLpWC67xGlQZ2sG7AjtupVwl4ojQEEAMEiROvOJS6xDgBw0hChfZgMdRJ7fnVjWr7uUKVJGohihIDQ6fA60aaoAktFWgEV0GN6Q93VNH1PzjbyDM3RkVdF8KxJFNKBfBPd/9yae2AENLZewDc3G3sYcorOigmjGp7HAXvNgHkp9ijYE0gqdXgsCGcHo4gWwbUsi79OEdV1HgRwtjTSEKG/UxFQo1MSbCu2bqTa+R0+zAbE3UypWgjQjb44wGSQlZ0juG3FXpAjH55mAFQZaYCiGUunXVuGIeHiQPwAyYs7OAG3/AJh+umpICionVHpmaqA+C6gEdB0ScbxkSmGgnBAONHXGW0RZ1Rv6k+xyFVqlJqfIUf8AOg70qVbmgbDj/uDxqulkbfFX8YkmpCWq0J0EZcVDybeSK35uV/FzBrYtaVrmPvJmwwJ0B3PZ5d7c5gIOB9fK5oAtGqZfJ+rJw1ERBO3iBfOrZgpg8czEvIj15MEXjdgB5Xv/AEZJh7oYAetlSSy6uCIgugmgGbM3L6XIA0S3yQehjANaDFMRE6WaNAHk4C3XQA0b8fnNYLzjX/eLuT9f9wF/k/6wDc/xm5A+l/7g+A/Iv8rmyegWKKlfZnimeMZmibGqOQguLIDRvm4Va8Eh7K5lKPvzgCZ1PUXJJBadUMBdOsmHCaB2rFU1gSK/ChPOprrYh5dJHEJ2ghtQjaAti7wPyjS8EEOoqdci8txuZdLhvOA0SGl4PDqveBa/CcEwgoBntFULjQsrgU1OCQBFF3F3h8npVyAClIWY3uEUb/cP4Mtv2zfCJ+MPTNkCm0qCXaePLFLQ0WlA288XnECWsoDtBKolumHs8kHr0Qhqqc3eOgFR0k2xk0CnWaLwg1NoEt8mJHID4p2E1VaN3gyObkVNBE6pCXcw9A4aVNgFIeRdmxlobJDviAKi+eNbw2A6hcHVQIF5aN8ZwayltLAdUbdnj4xevmTjPyuxUOGkFx/MruQaBTaafozXq1xV2mxLzu++TF5XnCFa9xXTrEJihWGPW5PCbMGCDUg8i8fH9TMyle2yH9uPUO6850u+l160ZxvpSvzhmsn2+i3e3nsTwzZ+tdADTR54wcCKD3QdTjeNKOx1CrupshxjYOOhd81/ZkyBAqL5Z8BKmMxEaESAFXQFI0NDUjJm/lX1LkAn+2WjCBQkCA1Dl83JoMVj2irPPr+cuSvQWE0s6xFR3nM+0F98YPWJh0UUQpqa4ODG5dtBjK3lLPrD+fvuAg68BX6l3MS46DY55Q3rrHVuICYonf2zeL3O36HU3ff0YSkNj/of2Y8uBIJoTDUTvVJ3g4wgKANCwsJ3s8K1WbqXQSiwLEvLcebsy4BQRt0J53wIuK4vSiou99qesmXkkAccj4yWdoaAW9v1+8pIKYTtF7ecce0EowaqeAOes1I2pA5aOmGrT9D6ups1xxjqh8BU/wAc2VzWZaOwEIUkFeULL5wvJ/WFOzlzPieMni0TV7mhutc+8CblEQ3REoE5DgfsjhqFLx34w3GnSrqcjhS92NG8cafxcJEKIg+tYgyhMQJAOt81QYv+gcTkJOUQyi3jwL+c6YJ2T/f9MEWXXJmPF2l4/wBZydeEj2wGNKYwC5UG8vwrrFTIqGRkFPlQ95bQ0Xr8ckfUuaIZGdH1lIJ4/h5HIzZ4TsQpsyWvuFgPCU9nfIaOPrVSfOaJLt6WBXR+chs1vg04NcXjVktar/lqkWw4LF15yYJXhuVXkNqc5CtfZAzQSJml5+LqORBEyOjHk6C0mU0ippgBKdo0Hxj+5bfdgLTYVN5rGexf6EF+Iylz2Reih+52GHBNGqZ4ET7MgZiBRBrhHqPrFFZZuTjTw+nNTeOc2AkJDZDfnNMGRWkUez7j8YVJFKSGHlciq3hyWOAUKvZ0VhUbmkL6NGgeXs/k85TIbc+58v8AnDhmBKbPH7b7OM7HuAPcu49PRl2j0CA0tAgAmqaFynbVjgFpQWbNu3I8uST+QI35+Rg8TTcmq1Fm1DXWH0gl0UijUSubQxJUosG4KobzCaOrMM0dAWB2YQqKU8mTUBCTphY8jwnC4kfht1UWTgDtBzlhwvCB2bBgbAWDhnjOqlgYW86UnOsGYQggbfaH+ZkKmzd0bBEFbyoPryy6PDiMId3nF09sauKgp14NeRjl4B4eB/wwmvIeneDQQUxUWzfanOfL0UCLvvhVkvbjoGUUWNhrvs8nvGUu9uKvTrNmvGAa5bwAP6/7rDByC4EPwKvvBPxgczHJ/bjaOx1vDr+b9ZBdJBR8CbwIw65Aezt2+TJpo4oUdGaeN6cfcjVAQpysZ9HvCwubwBi9IpZ7cKc35iyQxFe63DXiipaXrXIH9jbL+BkgQyDvew3d8hwcb6xPZ9ELrh4wrv0cToGnK6j0eZjhdqFcuXXrrn84ZRioN/IR8j4yWnX/AM41Bfxhm0CBXTw6on5+dCCgBm4VTwCor2sUt1rXVRdRiuvpgYJ3s4PJh1JqekwcKVlEK2a0vON3CgKjnASr4/nDPamg36G+bg9Jo0sc6/8AcDlHQcqfD/vBQUL1Nf3horrYnGHHOtF48ExZb+ha/wAf5yYI7PxDgd4UIvt/wZoQSHNnWhzot+CxdcDc+GJEOwtNS0vmL27QzSJSLhxA+RHm8EDSg8yauEELel+cJNKqTxWEx9veGDvO1GjgR3sb94LYlZKCJyKoTWR+OwKxOeNKvew1gMGhRQrT7d4qdCIH8YrMKEoF0IVPEOcfACZuAvCAiqhebDOOXXxEoBY4HnYayBAwbCISoulvfnA6YCfBuAU0FEDHclfO6ANtG6coHOBZwVYVIQXboaWDD226nYVirfdHeXX+VRT4BgOzYRMg0arY1r3lMe3WWsyKFJEN7CNgyJRWYq5PR58bbLEHWW6SgblDQbqqRen/ABmhtA3M0N3mwCWm4xLdGhS6lrzvGYkQuxtS6OPzhySohrodn+D1h4QJvOYlDosPthcheBgDQOGxwJTQWmt1r5TgCq6ArxhZnChUQS04Hd1XDTjJFUd23ZvAFJ0n45FLBE4dZoPZYCjZ3t/nBVDdwwrEIBK3d3HkWTFc6gSUpRORMDHBkhLSXReYecMbTYB28CQGxpG2JXEgJzpF2HYNnKp9FAicLogLsA8YgJlIGDpPkMcVuJw0+gEHqAfrBoo9RAqJWtK324ykk8YgF32APxggCCCIJ8Av5HNaoJu9F6A/iyTMAbUIFZmjBVXlZC4IeTwIMoefWTkAogPtrDGLL3cUtC4U5cKBJExsq+NVw6ByGIIDhWnxgeR1rovo/gxiHn3cE9ej8YAaSCap8jgYXyJAEnjzOfWUqrWBXzvmmJQIBvT2Nv5c0FFpsxo3yt/u8sYgBRLxsJeOdZ0Tidg1jv8AO58YgtZLBXpjRxuPxiZQaXKbD0W93Lh+1OZ53z94ECa6Fvlyrt37cTojb8g32fzlrS5/2Ma6gOB5Hz3izZFI4mfTo/GIq9jKnh67wAQLPGirD5L+cO3SdyXaJRvxjiu9U5HIpT6h89ZRSNfKCjrnWAGfwGmlPhzODF2sapEBA50nvGlrRdG/2ZtRL2L6w+JKvIP4/hzqiNG3+sNz7SGapZULx9ZqVrCD8Avzp7w5q3aE9mP1lE4ewHJ5398c0qvy8rXbPGJBchXPgMZ2l0DziEEiFj6McjLry3g8UiukLLiNwwVjbafHGNk2RofaxU3tvOx1h7XxNHmyA+N/nD0iC4IYU3xBPWsJiV0Om6ac6SF51iSE5uQSgh8W+cYwMB2hLpEboQwUZiq3KoqyiJDeDKLUGIx0gCywHk4BVy1hSrQiAEkQaKHSBYgIiKsLp54gBdd+OrsQ9Pi5HUAbq6BusYLaBbCEAgC+bjrhG1F01I+B12MC7dATdsQKkEUAq2t2eGlxlrSKEo0kw3FZSD0S25rUyRLFf0L48GCwKSJ2Rk6OAt4Hq1tWpiQo0CVS3hiQdMuwrLawQ4GN4wx0B8H2ryrN3fzgl+wpVYA13tS6wkNNjWVxXakQO3qfPfniPGiMaJFLiI+45+vBJqwKfFXB+pHwhVAaAq7cnBmuElSV2aEB1J6yMnBQZJHjTxhmlfhnhtQvBK3GBjOgb942N50DtcFWhGnQDgv0BXRgmGiyjEDlFEKvGoDKaC5ToZyh+CodrEFHrp+8WKFo5D75wQhvQh58NcSIR6dP34xmglKdPW+sQ1zaIn2M1iSob4OOJmnKthf8MVmhKuPeAAkhKZ8XjKqwKp3+uMSswhLf5yB4ATmn83Oo8sry/WLhD8msCKB3uvvFjuamde+31lYDSMVn6w1mB25V86zX4Xgmz5S5teEVd4idU9D5LxnOtUt9J8k/GHtQxrPbP6dd41FkotuzK8tweGBVi9JmxIeTEeD4XHoH2bwukFezDjC313hehj5WNaB3XIwcQKr4mL4api8K7/jE2l0LgNiRVAq+EVHOSl2wddb/AM40e3imvZD/ADhaWTZHHfeNOT3p/vDilam7JoFvKzmMmW4V6HAN598cZvJHSNtvmYPRdMEE3l4Nmt8HjeQ08YOdbaL44xWnpFG3QOrvRgCySPaeYdAbwqeCqRxaUFmJKQ2R1xx76zc0K8i8/OCILRNG4rrj84OmmMViiLS0NxyDHj7YKheEDL+q5DnSMVXoE9uCbdktBJsTtFMnt9EhaVxt4T5mhjphRbRbFAqJ66tOpABxgMBGkAFGDhKa/hKO1QDIQzS2tRtqpQV2CDnGnw4BpvfgyzEsFCjUwDplfea7xJyqPCoKaAKVAfeqAvlFRpXTNylp1C0q14yUUk80WbyVLanMzeIMH+F2FR4XjAbGBAiBnAcYBA66OZsE4HKd/OE/AoSNr0P275wAjvMAVS4Xibx2tOQt0y/GXhgY4H8gC/PHZgqWIhsaSqc9YtDSKxpBtwwzz6FObHouY7U5wMDATgEA38YV50gsIDV7PZFJvIy5ykHUuvx8Yw9TvIqFd5kAFWrhG3Ryx83oVP1iNoiQPOr53vo982eVzUAOue3v0mV0Uc9z1gyXSDAV/wBYkOk1QX11iYGRd7ofnAwA7aH1miA6FD9awAMSa38B8Yrkp1+m+MRd9eYyji9Sf+4bxjg38eM29FCj9ZKS+G4PpzcZq8V+HGEYXRycK1APK/77yFVnwf7cFmHlMVNLQbxvY+3vECk14OMOGR0McIQ8gB4xPJVW9fWDki7ZQcCMaBJZlwjbvQw++4vOVybnEIGnhrKTy5H/AHwxJc0MMVxRoj9s1jalUXywo07bhziOg4wxUA2qYZZwkaC8B8awLZd0Lw/vzhtddJKf5xKh7VW+tZQpV/pvAUCgXBxmbFAIaVvnN/0JkcQskYsmyzH61aXngUoNU0QN3aa9A7CupSiHXYYhWFq10vAf6MKNaS4gRwnQYUFaLaMYBOpQb1RMEuZEiDkStl9uMZsBCl1a4sFRCxXhHA6rx1xgImgT2DpZw8ayFom8kSvPpzldn6MHNJg4bD0XFr5UwDoUAW7CiH+hcbgSsc35qrDZW95Z+AaKXQ8AG4Avk5zSxu2TnY+oV6xvgUoEFGmWwRBIg4QTzLYNSoq1Qo1iuGdABkFidB1RoeMWa169CgAUEE0UyhiO/ADaXYbB8hiotqpnVVe8hZcJI9oIXYpwOJhY06UwnsdWDGY9DB006W3WKWDizD77cs8Bquuvl1k33mHeWj8i8TphXw0YwbULUZzAKzZS2woklOLhGPyqPFYKDZx6Yqk+m38TcMeEiB0vInblNfOPHHkn8LY+DxhROxw95PtNLIIUFFvYONZBpW/3xc3Oj5EKn3+cpcCXwAA7kKDC4SUVpHEu2xVYAAAAVFmtTcu1Xg1Dw1yPU4D4I9+X/hjmA0DU8/4frERR5Nv8ZVEBwkl+MDoa9BlA9MkfwGSwUnOflcMAnW+fzwZusmq1VmKKolSbzac3Gi4TELGhCfiYmA3ZUz8Zf3HMH6c5cu+J65ywAdjD83Ks26LRD+M4zbUJx3RuggE+ZmlRHRy/OsgYG8XhcFTw+XrAik3Whwl+e/phoETy6T7wTevCqn4ylCllyJrsNV+R/wB5sozUB/nEG0cI3fzgV7RRn1ioH4yyP0bzgXNmh9jX84nYTSdvmTnEAKnOx+DnAXqSIStR5PziWeQNJ2HZ0mk4xNEmhmFCHIAJ1DXf1gKH8h7cqJJolTxvGBixpMRYH8v95ZiPJUrdJDKGt1mu06ZqpD2P4zTplAIoO0Is9YGfaNOCNVEeIolxMwKLZeLYO+68ri4ERsEThtpvepe+08SWW80cxtU6LBK9YC6DKHSUOuDmUuzbEMgYAUGPL24FhKYdHkCq3w4N4kLpIToGgQ9EHW9431zA2iaU8JCseF0C7Q1IlpuA2gOscq2vEnJS7PKNQNwU7SucJ26KBSl5y215qxQ8nO0/efh2EMBmjS0T1juWiwEWnF52TKia3oob/WbxrSMe1R+QnziG/LRF0VrjseJzmsns18aMKLQdNZSjcKQBV0UJrsAkVMBDM9NFADwcD72uN+KgUVOjXJo9RcEO0vnbvtWtpq4gbgbawDv6yQdUHy1N3uIB5A5LBuRpSUyEEOEYGb0VUdsX93IE/MG4zFKkdUb1GzBJYAhQaC7la4PKEadDBG0HQA8YOtQtSzkC2nwBLhL2YoINqoE2HoVqVJ1jad0p6dnTjLeE1cohVlO6U6C91KV9VKoCig5SMQQVRkklEAVBYpZ7dSwolMdyRUjFyRAopwAaCQa0ABxhPyxrMyNQByLXIWTyG+Pue3984WK0d3vFsOg0neF0dbA20SqqnDgQSrNCeOz/AKxm8LaLEFehdv8ArBzXFo50kgDav43hXF6Q5DnTXOdFc6B339f2Y8ri1a3NG570+shBdik/wxlBxycfXL/WTRAaT749f9zUH8Pu9707ff1lCBcTt0MTeth398Ao7BdfMc/GWKsRgz9r+sIwttUfnTDZSFUM6gjOOnjnWMZwNgPaAdsEnBUBAtNHtduCB729KSuHkPFOQrNCHwIA7ock0vOLzUvjOtCp3veveLcmx0yIKQ72aJLB5TVkEzcJWJ0waKAV4jxupw4xoByEuGgMPZpldWvyYbs+prkNUcXOR3tNfrKIkiw/jOUOtOMfzk4B2FX6hcITjonLyDn7TAiH9ABBlC9OXEGLQ9rDuJAI7LpBmMYzNsIQbrsOmtpF9lt7p8YCgPA7FwgSXToYpPRYHONmGYVDErA6kjbau31m50iOCYIyhb06oqfcjSTliV4HI2OJnHIJRnuRwdfWWeTpbNUSuR9nZyJBLBAO4DynE6wkk0YMN2CO6JHBhXmEtxoSICQcYI143V2tJdXjxnEgKIrtuUOQH6LjczeBoqPkAOGniEC3gTFp3wdHGj3j4B4VxIpiARsQ45xM48ihAAHeuzT85o3wBta8gvNtnOKacm6BjOWB+/xPY6WzZ6WUIT4TB3HGcUry8nZa27pcYIs10VnBsKPDNJhEmXLYxm3lKOZWgKpaXlR7FveVIUqwYCohA8wlxrbQRKsVE3o9wDnF+SIsSigQEWF6DQMjtPXBd/kyP6VQj3JFvhfg3iRpWIVNV3GNpuxOAJgxkmaWSY6AAHJUO0aTu7IILbROgY0yd64WSAGBhsLKgzhgcPZljmg1qMQq1QRstdhBwG6sFHQu9BtQWI7TSHUpV0QcVHLRvWIrnFhb0eUOfI3gTE3hKkKiFDs2SP2NAVDsjEDI0UYXdc2BF0hLghFQxH4t6YqISw9DDXEZZhDoUNGuA0GvNVEYBpoL0i7966cGSSTndsHYDj3c6iBfBDr8fxiWILT7MFxjYh2YSaIzlr6Yn/SwDmRZYD08BjWVa4YSsI6mudmH7raojyqyDvjyDgXIVFXYeTTJDcTYP5Z/nWNBbKC7+v8AGEWFbDsqa/xlckaI8rPfv+8Yx20KcpfCl41yKGO8lQh9Cz+M2TqRRZ4D31iCiWrY9d88+8guhoQK9dBnYYLf62fNxO1TSV2O3fDw5xLxVTyCr4TJ2lsjERaey+mBZNveW/8AOTr8Dm80GkLs6ucPBVA40Cq+J8GUZiKjWjvPkT4zSuyBXZK6GlYB04MSkyRm2dDHQFB8P7HGG97WCqDknD+SiYvnX2iJUFtsBrreGy3NH7GsJmTyFCDiPyh+TCAxhUQ8pPoFHQ84o0yIqNhW0B9E0eOX0AbXY4RHVqkfJ/jNKmebVddHnuYe7HSk4k47xa0OuLkFakbrYBsZGR3l/DipCpgKoo0g6MAiAjmuQKd06Ne83Ri99vaKC3hd4BCAs3Qn/v4ymhHm+8UR3eMBh7y2VIuwxdo83FDCO4J5DnfaecH4+GqKBTo25+y4kHImxbp7H4+TAK4CC3QtVPHEu+DV3n5UwDsYVJDohLMJQHroEQIy8184Rb+QIYiq6Ct1oySih4ejRo0IPLTY6wNtBAFQGul4RJ1TBcPFSidlDmQWogmKuxGa1XbU8hOGtKD06qS7UFGFd004WMLhRabtVU4PJlkXsNVAIUdIo4bxYFiHUhR5X+OXG7tjW9ARR2wNPA4IAzQDC2arvRTin1DdKtdu9vKDWprLX6kLn7H7IYhVJ1LqA224EbawaFtYF0StiwLiRqDFXku4IHrOkGIQgBzO2Ha5DagR94U5aodPFhimHFy1EU1UOfTl14aGvhwfB+8lNv7UNTOsgu9zgAWGoI2GhgFSoq6ANZF4POCUIsOSBN0roTi8C9IwRP26BVcob0AuhSSgTS6ZQbEIXloa7xYyRJxpNHrXxm6eJwCJoS08bcjizYhrS2CNBlaCZeXpgz9+ufGMz2sEow5EkAuyEhWHEOnQBfR88FHQd9Sk9ISdhXjGHfUxnjQ68yDzgYhikj7W/IPB3BwEVOzgXH2794dsdvw5ZyFqzj6xsmH+YSnhOT2GXwwcJeEvCT85UPqKi0Ds72B34dx3WHHGA7njK/KRUR70C6Dry6eMKBjWPbtoP5N4UpygOMHC9mjZ+8dzDORfT3d9Pe/Aexw0AKtBxOafNydPfRTjSQSrGBcsORVoqOe49b9h7wtXSWa151/d/gkWh0Kw3OP+cYrWU5Cj7veMXNBYAbOzZ2YECKKFV6prKRcRNvW9/PWV8I1tcR3nGH37afziGA8gm/fGVokhwbO+7x/jzhawBZ+TX7xFV66m4v4JkqAABVch41lzotpYu/1/GJygicVSfvLAgDxG0n28YSH68sPvjKBd0vHF0ZeJDEqipA3c1mb3tPokd73ziDooAWwVAL6DgiahJQBSiU5zciabNCENotTOgTGOFKy0xEwQUSgOW0ZWlBIczTaI23TDd+/J0SugCL3MzguAghy0AspTh2t+cSqQiS+/BHFQBDp4YJtNOjmOFaL4VDcLxKGbl2mTLWb3kF3wgdATU1dp9c1qKIQEC2FBwWXneIc3CQpyGDXmJ6wM7ZmkSRBCUN6Xkhh3CACNtABdLXshmhg88B5agVLzFcWhmw6knDEeQlAImBYoqdMgikY7WiTGe+G2D0RF5RXXkksbSIQZKEXWo0LVJADWxAAeTW5N4I1AnkaBHYqHnQ4y+igXuErDz5Lrt8lY9OCk7Xwd95dR3oPIoaLRo06xx9QhsodyDkNenOn0TK26Iw5dKWHF0cp4mJ0GwgCYhIiolw8c23Ly6BSXG+uXvH2kbIioqq8cpp5gKVKAGBruuDTwQ0wUGEVlDuYLKiTpNAhCkET5W1Iv5pIdDimBKHeHSjkgFC0TgRmzreVgSxEVayE5D2wqaqgqE4h5FPQbzaX6Z2p5UCA+E3inoQbOJDsQEcgDECPAHggEHLaWlxcJWoZsAFoKKh1ohiMdpNqUBIQoPThvXyZBKtghSqgrxiv2DgWMPaKXhZC1pCRgY2UFIl2t3oCTGuFPBBQRKFoBkIQsarUFIfbHRq0cOt9A8Ol5TuOGj3La4+Au+aulecYIAQH6eUnuOKNSVaRKPs3hUNBbxN/afn5wBeBI8YpiivV/dZu7wZq5EoahRLZnlaBNPNxocIvI2Pn8CshUC7pArE2JoOe3HAq6PAgwnEVdXnnjH2oQNjay7k0D/wAy9mqJtHwHnd1rfzjJ5g5dnk9v7YxOqUAFR5aVHt60OiGFAgaPqVQeuUaAuiAWmVl2q4mBJ6rAQquhGJ+O3NgQQZohRd1A3FHJvkFMIgSqiNTl2Az5cBYHC9v4/TtsEAQfHjJRZ+B0bPGv4wfgSaidQwE2mdFofhqekw1Fj0+PP8YBwQgYC8686PxiqjQqsP0bxAJcQcD1N/R5za89okJ7GXydxwHCXYRAIx2CJ5uQlCqGqbPcxxUEgVf5PJPnECiHcJzOOtav4xBFQRN6deJt1767SLCRScnfr/3LyvV2KKWK3x66yRDkF0jjsFDsQRCAau3qwCOnBJFCHGag5uo2ESUKCX8MlaLEfbKpS9uBBMdbZgzFKKkYfIAqMGIG3VKCbAxON4KqEEIlSIDgRGBZrg4I3bcSLWCoRAWsgMCqhAAF6Oxs13LK4oCrUR8N5M5f6ig7cFhkAZ4ojtUNeAqhcrARKgMpnBNc1+0x4zZVVIk5dpELXNkwqCtU7YfgCTC6QaqZaaiupq/ODtJxlM7i0GpT1iS0+ooNzpYprV41kJsTJFGzpA0Bw/YZ4aAVXrlIk1/ONZjdxBabRUXp+WckhdpJs+W1d65wDrkbxphBZzGtx04JoWQ22jorbXQY6NVe4JbPEGFynEP32NCiT8pwfLAfHVlE4qvS66mbump6ABvnr3jllE6GwA9O34xniYBteV4lnGQ4gTsHan4AzlvVOcFbUezymsbhivUWkLgscYRE2Tpc+7gIemcARL37bgba5su4M4dOBEqUeSqIPSEdZJJmu5ArsaDV4yX56AwkjEEFkIDuYzVj3gLWHdunISS0AkrqoQ0OgVoVDoSQoaqKoDosTB8FN+agdUOyCPOTFg0QNAMxyOzmhw8lHMAQWqFEeYjiCNlB2xUh16lwWM0TJCjHAKovgxS6H8nkVCPNsI4BpjJFXCp0cOSu8vnjIZar7FXvlZT5QxGaUfWjtOCoyquNVVTuuHDla8DmPr38+c1GmBNiiF9nD6yGGHdXzw5wnKrpOb6efzicAix1vt1/7zim7m05ec5VoDVaUp3GKCXbvOkxqUcb0QNcA6wCRmANd+4dQwL2XVSDfl589/GOVG6RAOd9/wCvnEse47CVez775MqwNwH+DixnrIXCvOwA8YoLT2iq1cCYY0YgAPilxBkgEO8D+bSlIF6wR1gJ5gKTXO3jnH5o0AXCifx5xSEMVQP38nDtO7YTlO6rjRW4QI38v8Y8bPAOzyQm3z/vChzM3QH5HY/OuOMTdFssSs/Jv+uDobuCAaxY34xT1wqFOZuAF4TeMn8wdB8vkby9SLWkmt8k4H7jyZHzldHN4Po+/wB4qA0Dg34SeuH34xLoTxq8jT51fjG24E8XFOjQnEvMVlYk0zqrKmUHIyZXZbi+N4jcjhTB60ksi6EluF4QQKEV7EFihSh3DhoNpdjbVFGl8YQMAdrY5yFIbPGBKsSlAg8gUbV43i71BRVq6FQbIryK9cBUKCuONRxVJ0OlWL6QJXAwCke2EzOvuAXnvvD7mBsNQkq9kOssEM5Xa6IRRYR3Os41fwWpIWgR0ojG4bCTUWgg1FjTHcxB/QgxMoqccoutaMmWBLTCqeIATZOd5s+9uV8Bzz/7MJSELFjDxQHh53zGQeAEM9KkU/HHwgBwQyANoOzxGrzMo6hLcPbYUIY843IllN60L86035x8d0hPZt8aHgb7cYh1ro5VW8r9YH0xcUvEAryxuhg30lZwdvO+dYx6aywurfJp7MSFGGaVQ/On5xOKYksAzx7bIXTgTjyI1S7TVFRzo5Nb8guatpNpYUXNkr0ROwY2kDSN6pVYRsgyjYYN1Tvlm+fS/FBe6DY8T25Tbo0Q4lykscc8Y7yHtkGAt6jZCPOncMuULKV1eA22QZME0AGjSDyoKdNbUVUvAVt7JFgpbsqtwK6Ii0gvYOWt7XLD/WAKuhO9BpSDe5mxA8ggKTdzQ2CKoN6GMBaHDYnTbTLmEkp06AEEUL8OAOZMpUUtUJ6rbMh1Gq4dToCVyDyEGlKQjATbuV4d+M3VQSNvdWkJKdECeWY4PGeCJ+2qqDABi655vX985GBAlavr+fzlgKmjQPn5x9A6Q3HjDDTuTt8PyOMyg78PN52OSmnMIl12qfnvJ8ZwZL8Ydrg3sp70fhnJsXkFjjG08JYhvpF8dP8AGUAVdN78f3/OCezF2+nxxhPpiLx7+dfxirarsAqD1o9BhlqAsS7SHvxjqWGZASFFBoHjnhXBBtR4cb/r5wT1LR4kYoKNWS7uAeKSjHv9OIj4p3Da+D/yxVqHYPGv+ZQWXzAs5wsgCA1pNnOnvB1cqo0xerpfeCbgCg7vv+mBxQEgUQnev7xgG32mzfj3PPj3j9IQkVcV0Y77PPzZgVQQrd8hz995E2Sbu0eyFo8KGmJr0ZLO++X5wMVREKobiP5+Y83IOiooqVNRfDxz0YQ1CxIp6/H755w2s6gU+Dvrj14mHat3+gYYRGrspbl+zq5LasqSqojQ54dMEiGPLuTnTW8Mcj71HgRa62jTJfkUeufVBGqDgiYsz2QqaH2GyNQ7Qfa0cNkOPAR7XHYxt33YODYdB5B3awzI7upsbYpBQXxwQY7oBHPTtcX/AB51QAXfQWJMOn48U7usqsd7xosQUCbk74OM4i8IxdMJTpes9pbjeRS8HyO8sR3egcvcWb6usCqabBAULX30S4URTIFteLC4DrdK4bETDc6JYqbTvnnW0Vh6WLMLgHgpyxWySQeFI7kmyG0XCG21jeRcWiXOjjDnlRU0r39Ho9Ytwr+W8/ymStUjIWABysJ7wKWuJZOv2H8ZEZTgwilfwa7mSm4BHqjvodfWXUsUONA6VC6Btd5FUYwohCiAnK5rhg0TRhOQ107XbgxTvCgKBQAA448YyVkEbm+67CTcmK3DITt11r946RZoJSEce/Nxiuo6NT6eBRir4S1b0M2EQRspOSNNRKBW9zRiQ2BaNjbf4xJ1bO9IHg+8dE0QJVIk/wDMdce8ux4eSKTBg/BSk5im/vEgSPHdGjG0k5YYL3d+Hj4AGiUEq5rL00IclJZQEeroeWesNflpmnpGGwwRcOmCAtBBJz+1iLg7h0CVXgN2E5xLj5KPRAqkeCq/BhQAywnQ2MGqgQrsqFynJC0B72PzkPecD1Ev1gmId6Hj+eMsiI2nR4DFCTZbfeVZWrUHo5fnWI5f8SEINe9JrASgDCFA9KfnCQB0T7DBFIDNNa/Z/TJwYmnb6zjfQCdYBpNiLb/OCALhFXJ4+/4zYYzLye9/bgPYgqkUPX+c75VAacnK6fzgUKhO9xKmo6HQ/Zk1YGNm9l5D8ZpKAcCsR6d3c85rTYK5dFGtvc2+8L8qtJ3xL3vnE5YNn+mQV00Xbz1hLhAC0o18sJpMDQa+Gpk8QIST++MeaUTwPyzt2Wl/7+sqAMBATWK1am+CLz6Hj4zfntFV03of7rNFK1ogkzAHYinyIePpwl1QUg42x38cYlPcqQl8S/d7c2ESCSPps12YV2bkejCDY07d7zj/AFrOohyO1hzhyJNnSDcOeS+dIAAtm6QfsQ6musb3etomtbZm16KMiRJgh14tIG15cjr/AIE0qIQ9B5YEN3oqhQDmU0rlw9HVAUkDgaKmlYZEnlB+zpbKPkAmOsszoRDdB4T9ZyW1s6d+WO6otSOzBlmmGlf/AFx1pXpnS/OalAIgnERuWiXgqcsT24jHvyjguGNz0CDg+Z1ew0p+hesTvVvIwCDfEowR2k0CtZ3sHoFTEPBiv/BnYctoPLHEj9hcF8vOA8sttNx6ZNsniYxQYOhVBZpR0T88uwmQNBQr5f5MulZR1UA7WhhtwYARDoIobkE9JKuWnY+xVp4IwAQheyakUwrqza3CQWFYDAwERKEETl9pG8OrN8klsBr4oauEolHPQuiVS1Gritxafmlot09rvbgIrwlM2xFXBBw0JFIj8ndfIVQOXjWpZrCAAKx2WjTD+uOIA8KAqi1S1VwNCHXRwoVCfvJBjipsiA0OpX7yKaG4QD1Buxml4lyzf1F8CVK8sZ4CbcG8sS7ryom/AYzfob0AQcilUpY8BC0V8wIESyIKtazdMuLVs3exfbhaRVXgAd4YBJqEoU3FPF0baaR7oqJImqLjU5LhvafbyiX6xCLUR+Go/fzfOcclguprc6kzbFdq7JhEOzNJ3AwPqKCzt/AOshyEjFE8a1l1mgBeDudpizEB0gLW+JLzUJN5DtlJzY/1ifGSi0E+ZfvFDfgOzib8I5Q0l8Tn/wA/nGuRb/Ey5AZeV6wRGzzSde/v+ubN4UPwYp5DJjzp/vHxkJ/E0gFWo8eOHBFsUyrvYE4O/fgyK+dzlXfW/wA+cCg6jXP3h5yKhLTn/GbiKw1Adfr/ALmyJk9+6nZQ001l59cG+v8AftyxJ272j/GXVg4VX9Lf8ZoCKbXh1+HOdF7I41v5xhXKUDevHn5mbCoGuHAwQRQ+N4xAjUPl/hjigyorrW9ZfhT2fi5YSPY85t6oyje1L70F51rEHpBanNSbGNC0FUI9hpcXcVaYPAEcKC21xCE/1QC+2pPMfOMjYTvQ5X5wNwBwCJTvQvZHS4dJCMF+guh8gXu4xYwjzShiDpyJyYQapTggleGD20ZaX+XbSWCqlEYN7IyJmkgBUXHRKA49DsAg65zK9TB2ZPOkeDm7sxF2gphZoQs1yXnzg3QV2Ql1fxiokBuxVD/eTVuAgjUeXbZFnOc72g6WK2zXa5CwhR8Vl2Y9YQ9CYWkzUAK1xqsKSIdTdVWrVt5GkDXKzGoN1V9kHm5CYy6ZrwJB48Oa9CD4GBOPrHEFS5o0DfJCbxR5AOdZsJRE4GEGtiEArKgiYBpbgrodE9EUGjpDGsKloJwUK5hextC0zb+CNySCGxEwjRohXbII4RFLoZA+augUCcjmGsStMfc3jIpSNB6u7cZxVi6jFWB2PUtJIv5tvFTyCCKLEujFXvUTwFYlNeC4clMIVTg8A5TfRrK0LmHDojV0A6U5lynSileCDfOnlec+1PImCJeWpvfeJG/nNVFZSOHsbcrEmCSI9qA5XdV7p2ACg93j1KYYFNsE21C7NAJ2hg00zCDdC1lUqrdrkoImnucv2YOVKSQB74ikN3fxGn07aEPO0I/VjErJchAnBUCasBvA9quDYCif3vJFwxCb/wAouIS4Kw02fm4FJg4r34zRa4HgP5fOUByY40NrPpP4YVYtjCvjnnLYQEJTrjneSg+RVCma1avx7yuAoNpqPsh+stchfHFwVA6eZcMR2m0mbyU42Dxtf1i0sNdOPjCEyJNO8TiFQU7jeB4bDfLgup7veKe2D2moB/f85vVRN3Hqf7xutmqRrwD35xntCW372P4+8ExvtrVV/wC4qFB2HhD/AAP95xdOIQjx5dSF/C4kKODTvXb+fv8Ah7kTjdqnPxl2XkOGt7D4zciW07JynLjlwCQtH6+8dyFH29ecWxHgo/eUAhkIq3fO8MvYT8mv5xBDa9XOG69jmzUA7FxuqRk3Q/SXW05cN7VHXOHRS6/2wF+AR9gnaFE4RTvAKkOYSM+LUQqGGAfUTyDYXsE+L4zcmkqTnQH3BMMDG9yqRBCGwunnHUoNboICCgDQHeMU4olN1EBc4BCjFik+ZxbI5URonTg0Hkk2D2AK+Oc8+IwnWR4hNY5EnG3S+rqa3xa4oNhHoFKB2oeJ7coskltgnAqXqmTs4pkiEbhr8e1y0gJR5dzkDkbTEt0o0mkVuk157cfpp2bAKgWm7NQDAYgudgQ3ImgV0Rr3rSDgMpB2aYTa4cu8GIpp40C8bcRRAIkGlP1+87T5ovKSSpARgG8c8LSCIgqCVq9ng2qhBIXVqz0vnHlCDmxUoFI0209uKnKkqVMTnry2HABwywCA17SWOwnW8IRgnRlTGq2WeZzglutBFbL2Xo/8DLG0ENBZxz625vZlYMFOlVdgG14waBAK3UYXg+3OEGHKiCCdwko7J8Yj8W49gbDsbI2bmRlyvCdAIvQ7GrYJgOpQoE7daGqNnZB3TtQ8IZ1x9MMBfdmo221ETdW0BRiicC5tui1eXbgN7gMqAjRHYdHHnCYiEUJKsgqiN3Asu8VOPblSqiqqqquIaOB4sNYeifwQqN7YNHvjzaLcrUghRQNF1s5DQDYEVh2u0DRvUMgcoIn9acL/ACIgbT1214TIqYDyB8vb+DGYaisWc6+nEsUqD5Hn5zRsN0QUVnRGHcTW0SGFJqoht4E0NPPQoVJduDqZvLZJw1cFiJZoga/vOdIUeBr/AH/WJANzfJBnO+8I+WkTR/v8/jIyT06H9b/HeLTRoEPP5ykSQUbXb1weP8YksIm1oD1xgNbFzUk6404MkZP0a6DxPONNtQ5L6Pd4wkIAwEOVKvV7zluqiqng/sxMreBrA8red4WMLwJ0aQwTCYravAFeeXIAqc8C/v3hwBonKjrjrB9jXL/HrrHKHAnrPd/JqD1wc7wpGnDFOU8/vGLYsaPqfPnHVwh45/L/AH8YpAAKUFP784Hjy/rZ7xjvUd2C/wDcAvY3OvnE7BsZpxxCohRYfclOzDZN13kAflHoPGHlAOGj/nHWgmzx9ZzA4jyYRhiuAdEb3qeRHYhOpbQSfkv5n5yx1j0UFd6fjQwHo5jskbLpI2OCW70PBh5GwnXDthnrQakxyw6EHUYILWSY02OgYhtWrRpiF04EOynEDZq4Ych1gRLfJh0zAgTQTT84sM1hBgh3pjE8mLksnVMAzbomDGGFiOTtU4pzgiNg3QNtqzZ9+sHxQE1WEoDB0Hk949NcMhuK8Dx0wjgzAVJHQIMdzw4scRJbsR6SHljxcqpykSeiKcCmF5MKAR5UbQtu6cIWYeU5aNdjhq6amY++4EAg3HXDbhSIN2EgAMQWlldmIZYbbaAdlY03fBktaEIFWke2MiM3tgyjkWac3NlPBE5wWjpNbAxRHkKeRxcb7OukOzTzzZxjD1EewmaRbGJvxjRjn5oughTZYjMDSKrFgJUUgRd1xndieInk0nD3hvw8w5krApRePBUJDx8FSa1oO053ME6E+ZUFJGsmyNbJhSA1rCE4Dap70VU1olrECoJdJ6TDziKS6sSb3avt32O7w0jpQqiLsFrtMETdfszTdr2q7Vqq3DDLUa75rm13Goi0eKr4E8mED9zaDRvU8KQJtxSpJDbSk1ysNEIEwObIaRni+dGsWBUzhm3+MsGyPQkT7r7DCLWFC7e/Jr4w4Tyl4dNxNBNBSuTAORV1oU2ix0aRjqEYhuWTQ7gqGuUih1G72S8YJShGxUH3/C71zjul7w0R/vnBgtSQi9X349a+cRb7WpJO8BYg2qb3vNcq6C8/3RjIU5U0eLgkpSaJwr3uZYgqHPELv++88g0CM9d+VzpigoKv5d5bWE8BQreNs3jV0lb4fO7z+Lc67ABLgKPXYc5CNUgrOv6YBkpQUNq2+jptd6ygV/Jr/mLNIikgANqrAy5EB7Drq8bycEKVAm+Pk8YEhdgt8mn2/tzZAmg3hSUeXg5/7+sG3WnkfWNrQFGP98/jElsPyv8Ai5oqCoa+M60goUp6/n3lFh87/jzm4LdeP94y8pmqT+gP0mNphb94U7UUOvOWuWPAfeFaewd3KRYdNsSfZtwSvkE+CvYHNYZwjA9Uqf8AMqYNXibT+XFHDBBogTpXDjTABXaC34rywTjAyFUSy4gAvITnNWL3mtoJaSOwbcOEmq9fjRZJLvzjJphStyr6j6wByGBhSD0ca9YKXBZCo7M0NH9qbS2QaqppvHM+lxuXJdkR3Z/5hoQOgEFDbsX3iaOAPauf00Y+dGwqCABWphWgRuCAIOrgVhHVG9uGHNtMmCK21TmSSTH9PBA8ikASQ9GN1DPLFq8E0ax3Gq5M2R0wg67CNM3mtNIlxC8tLssAC0QtoAXQRNq65rirqcR4LIQInR0YQ2pFUNN3QbBNsry4WrVJ2PUKAIYjoYEB0SXSg1rk4RLzYvqUEU3lHFAvDlkLv2hGSMjpQAM1hz0io12o65l1zgCRITuo6ix0FMNYG3QbQcia/l484vtkxeBNHVHYdM3CdJBBLtNqKbI9B0tDg5CKD60XFBCPG20Ya6hSyvOBJnQlSUDWCioHajA97UWra3apaqqqtqtLoR5LDa87/ePdD0mhX5AHa+sQAvyndE7VSyBTow+kxtj8oh0nNqqqrhAmCnH48nxzkEdQlXZdf3ebcgpLwoz84hgVs7Cb4+MiYrTGH+ZvsMCFZZAsoFRFegVAgrQCzEjuCo0bFcrjvfniGD2wHsO03PRegaUhrxYO4HAGbQlWkP2eGev9rzB7weSKRYexh2q4qehUYc8/6wVR3VdP5mVQLKgVn8cn+8KxL1Qrz5dz6DOTp6DzuN13/eUCkicn1Tf+Mpj7jS9Wx9/OKiDCa8676118uMq4Woyer9ec0WwuiPI663/5kTpArRgfCf8AaecMQCFrNTW1TvT5y8RdIQHrf9c5TAq6n1kehU5P7/3By8JW+f7M7OFRhiKmYrx6MuBZRoIb+FPoc3Aiidowdf33hEFUAZq/PX8escvahMB1/wAxYj6Aj66+MWBAvi8f3+MqoD6EZ594JJAMB79F1i6QssZAUJs3v3vGdXShxbdyO4preVNOBuxCNaCeDggIn9O8liQUfyf4waZWKAxL66TeNGnGC9qaX/eMlE2oJqHkR2PnCQQgDPXdPCHAdAmDjiLsPJ8ro5o8QiZiEVBE+RMohEWB2FDdyzFpT3m6SksU2JLRgohgFQuzXSiin0gAjNjL2w5wttYCVy7363hEh1SJDutie8Ok3sA0c9V7HBlhuidlEp6P13h+JAoEq6VvTy5rGYHBdbH3Hjr1hMAqx4KPHZ2CLxnBourEdRVBF0McArBuW04CjaLHkZt7xmAFIAcwYestbpCGKLRwgXm+qMookRs4BBAW0TDIKb4NuGQPCrTd0baNWk3tTflg/uMZ1DKHEq6ZTCdbVWS7BSGzY9hQmG36TJAaqt9l44mNCXrRsOy1rb/nGEC0GAKhwm1/OQ5qFUAeCxUp3c3oER8JW1R4aa73hqN5D4K4E9bIgsx+dqEJqI0fve9mLpvOX3WaocjwF6NjUCCQkrxK+3fbkHTBQVNqU5QaLmuSDsjqQNJILrfeIkZ6p3sqw43tN5vskrkRbVdKqqqqrsOZUjkRK/eETSCCaS+Apf8AuUGYxtkgO7ABVQCy0JA5/Ua1Ci8FIMBZyrpUeHx1jjRpoIl6nBkMXZWUHWvd7ypA7+K9f3xgRpFdHsnc/wBmVpCpQs2dQ08BXBj26BuHUQlAIIgG+xKgIAUC52x1wsDnDFL9N472WhppA8YFEXtO934j7YBHKtwhVUB7dExRsoiIOAr+DAiNqS6xbMeqCX+v6yDBCaA/Xfj95bQWgG26nwc2yEJyQvJ3gBIDRx1S+dvjmaMSuIB2Xav9uIyHF7DjjW940WI2YJ3yev8AmCG/BUlvdgfnDjes5k3wvW/5xMTwlpG+nTrvGUk0B2N5ftf95NspuWJ7xqeHR893fnLcCBAn2qAfKGGqakD0f8xEtboRzdbuckNIDS3QVpp/zhMivkc8a+LcW0mmlETyb/eGA1h3YDcf+8ZCJvjdnG83lBoR266/zlo4NBb9Hf8AT5yoYbpxw1WlpPGJte4ondG04CEVrF4csv0wsrsAhYmd1appJyBe3bxt6QGBqHvAVbs4zRrRDrW72TLAx2r4UIAeAqleXJZyQqM9bmFR99/xkwIonkgMSWBfpNhig5RVAC2bX5DFo1FKh5/F+8Quw83ZJ+DPr3jkUDNER14D1DoEODFUSiYKNEG0eQrORznJwkQ4xWsEtqTSbsR95u8sjdaR9GsOmgORMuSWLRzyJ97MFQC7yIK/Gn1jD7EG4lRKQYxBxbddhKvCpd757xm7wyYhSuTLouph1+X4ECk6OecbSJsnzuHrxjk7B+pJuzaquRZXxwhUM9N9YvJFEzR6daB1cHPK9rdG3l4MZ4j3VKUhNSdayz3JuVQSg0bXq6PwZFAdNrc3+nzj6VVEkLySbI+sSzRCBEgiRFd1egyfwIgjcBROaDtbDFDMN2fbuK3ePnIfDVOUOAOrjZOBQJHiZufJdwsMfNJUbOQDtPk6e4noKCFQi8tnD1w1gKFYIAOQa4EYmAeKoi0FqMQKXgbrixANu2zVNgAClW3fbqq7xNdyReXhD6MoIIgGsF0ATb7W7wg5yGN5prU0XcvKCMCMB6d/r/GEs4DkQmrMoQQhb7Yev5w02xVaT36/24S8UFz1jl/usY5BCQR4NJ9t/iI+dSRfISbWTQl6Z3EWwoJzAtbt72GDcA2AA2hUhfMlTgeB7KdCPqLr/iT49/lFTzF+XCjU4FeTfPx88YulgyDOmkeO80wdljf94FjpyDQgSW1R/GWbDYU0ANlvjvzxh8jA8kIpM2MnD8Y5ebvgO6ZuuJ1heCwrsd+D/wBo7UTAWCJ3B9nvzvaSiYozeozWv4wtySnknQvn63r4y26qKcqm36nWIUezqOgDvfeD2ngXZ065W8a/xjRQSkdzmaPhbTBvYm7knA0zfPTvN6KXdvXVfnCoNyDTXkafOBy2ge1rg5Tj0XrBxC61w6xndduzks/nWFXmtgp+MDrNoI2eNuzr/eIQb8mr75cShBtTU6vnHBq2D4yYroFZPn+zLUwGm+X/ADxiSwpEpHHFuainsgKBDShZ624Mq0F7EzYkgqWivHG9F8LrAePkAhp4bDOldGKVqE9AQJzh8gAmUY1Pgph2oVGB53V+cfOkWDd+HeABRu72f6xZDzRxmAAGsKX5acIlDC22iArEicbwIrGUgxxNqGHsUciua5PSoKgsUaeccAIVSJzRCnFrxzlwIkicP/bhAISzXf8A3nJjDxGh8P5w0ZIoJtXz/nDGp2ssKTmA27gYNY1AcT9FyxzkVYhddnPOE6cdBi716/7hpFO4OTFmEKhvlPT7wjgmo0W+fv8AeFLWtdu/9GPLhiKJOBwjDT78ZL7Z9OTvLYrhAMnQgaXn5wqkSlADoPWnIbrltBvJrTkRMJo5XO5ySu5XE+bHIg2SHLgHpzT22VFNJHw4aEyvC5jPQwUNrEpE5POPzadkntGyhxGgN2Kj6wjnImxt1EbXi8YIOXdzAOoy2haq3N9fIziBexiLKXE5stMlHyjfVMb9QXwbAe1AGNYGtiWfapXjk9Y046pCEpygfMeQRQ0Yja3jKYj3U+/xhl07ptowj11jN55xaLQu4YbHsLX4z5n+ecZIoF2Den2O/wDw1NFRFV2QQivwDpYstpDQFKQBKPxzcjgISk1gvZo6LvEu15l3aOvC9tfOqC78Bm51v18/zS9r5O4sm1MXgvJj2PA7/v2IkIQ3RuBpeo/XzQdmUHaIcD43J6PWEAjSB/nybyJ6/KF4b4U+XflU+WMhztI3cvPvFGg5Q0/l9OBIMuQVdx+P9YlFp7BHtp566+fGcQXDl0cAN9ffPOIrtF2JQkF4nN3xzgHZFU5HineO2IpImihmxtHqd4UTNdhUGVtP8fzI/EbCw26rPX8ax7HlMG9eR16OcEoQ3YSn3OfGDwrMdDOpL+fOBiiCHYbpt/swyt40HF4889+PtwiKBQ/OPoJzzZR50I9+N4MNJbPpxIdfn5zYSl89fjv5yUJghdoeX9a9a8o8S/Z/H2fvKxNiiOQeKbpyYhaZOkl11h1gPOiZdU6EEC0GaopxkjAkxLR+gV7HOFGc9TGwZtkgR2AJuLFQsx0NS0Opgl8hzncH8BkNE7uO29W4/wAQdkWZ3tTZNuPKtmzMari/Nbd+T6IONsosJXIh1cOdg9ZcQAA+CNTSr9RcIa3Egik1VOuOGDdlO9G4UFgdAYoEUCnad/aB94P9aDNIORQPe/GHb9oU0ENhmkOHxipYLagCuAonGHJhYg5iSm9VLryYYTTDgdj94+lgVXcEWjR0JM2ADkaJ5wQKrA5gvXjnA0wlB5d672YNdV8CsF+qYN4RAN3beJkiqCLVOcHngOQSHLi+usAAxwjp+R1hC1oIo04o+sKEhIN/cLgYT2SIvJbnE0YwMXjnrEQVuaeEfJ1jMakWiAt1rgv7xOmivgOPjBXdiDcb/f3mkIp7BuLPnXzhsVW7fOueb485wp/QWQbXrqd89ZvuLmLQCO30ZAHcg6uBX4B+8v4hO1vxN0CeAPnA0PGDaJTt6mwXRpUaINBI/jvEl2m2uZz+8WMhFuuiyDGpsIJ6Pf8A7hS0QTQu1m+4eX7x2pSpZo5WAX2I5UsnWpLFU1nmUlRq4emGAQa6FV5pNnK4hxGdBqySDZhd/GxA27cBB8poUQH2Mdl8uHR31f8AcDDrgRVspZ/H84de5NyQRnJv/wB7wmxOk6L65fjOSOoBnPU/vzipvV22ydzSbXDVOlNC6436/u8DCNFCcNp/g568dnoMgBIbs2HX9MBIVrW/6YFSO9pYmz7/AFmiSiyoWXnVJ/BrnCiXOatJ1l6pR5ANHnfjvr5zlBAbLHivH1gxbsB2Do+MVaFZxfEw9uzZUE2zg3f4fkRlQUiudRv7/wBYANIinaUR4v5w20CrtZLwJ+X9412au4Sec5gAcG6s4/rgyXKOy67/AI5zYN1ixd86ydQ6L46Vnet3zxhafA5d8V+v5zQBSi27r7ykJFyTfeu8TAPhwP8AzKWiANDucJPfYZoy9Gpvuqmv8YJTB0nNwAsXEqJ9Zb6/BCNqR9uDLpmPJNpaE1zxgNGASLFkReysGxx9foeOE/1mkM8qH9uLIBOvOP2gR1/jAuhOQswoBxoup/XnJmPcRyu9g/aHnCVA43hHUWHTve81/fHQg01uPqZ5tncb95FDEZgigD3ZrGrNpvhGxgANXzhDkw8CAXZpYG3xjgUujoB44Q0CcIOSucBSOza0Kd0yMVSkaI7yVAE93AEGNQKQ8HcQfdEqnoZ3jQp0iBWvMUX3ld4Qye3JWIMZxbgYbtaMMkpQ94FDU7E2m0hyBLTTjsQmm8O0wbRh6ox0k4BtA7QMAFdsTm/myh4cBn2NZISm8Mg3D25gwM9QF/JZHeMsZU6gLsfTgRXLDWC33wYEEUMNA14yJdp03Nh+MV6hRJOoe5jkwaWsX8t/xjUuiRBWL4xvAq0iNjvYHe5fRyWEZsUrr+IOxs0dE6qnarcq8k2vXtxrTGvtVGGoY5BZMmnsHnAp6A9jzA7yIvzRX7pXAd6M5k0L+BQ1689Dq+8SHqNQIHXFbnLeYYkx9QAnEWDVp643nWYyEILGoBWi35Z1M5tGtE7o98cN1RUHKKh5r8/xiohhnD8P5/jGsNDCxH6vcOf+mlbY9EbsOv75MZAvUaF24XmfveakCHbw/HsD/vGNWHHBi+A+evHDi04W1NE+fG/n6xtbRapJOda5/twNG1NoNN8HH88ZYaGUIym7V55/WWCIqQq3z7/5gEyzRHq9r27+MVZrzIPRf5cOoZkAy8r941HwIKpUXYaf9uebpIJ0Gg3bvlCe7jJKFR2L7i7eGNswDzAECdOOqW6hFZ8XAhkLsSg6hzqYHQKCalf9evw4nYqUJkHX+OsiJqO5fG+P8YmTYiO9Of4wiTWUFgXz/dZGNDvo+Gjf7cuhJRQe9gAczEhiIhKzXD8sxUiUFQ1QH8wxgIDZs+l7wRdsug7fXxcRN4aAaB/nFPyLdJOGginWtGbIpnUVsT5MaHQUiATn41jVz4uBo/kxmdnNtNTgSM6s94sCaPrnDBg/eNTI8gYX7wXA22JH45yZW/DDo1HGl8XbX8DcxLhCRIRozpJgMlgu20/OgfZ7wNBBovOFEs3CGzgjIZO2G1upunn041ihXFETldIJrrEoGFKSJZlHfpwUpYaHMdTmP1cNRmQocEXWaYIoIA63zlZyriQl2SU0XnFQbKl2qfnL7zOHS/ORTxfTWpw9rabhQXOwZuDp520TQUFGw5dnLHnm+CCRexTeEviMnVdsDDrkcYGJE8vvreaswOxvtdZWhqQAR51I/WQtqoUOt8vGaEHThH9ZIVaIAOeESd6XNa2cUC/wfzgVXIIaPwHXx5xi1A4KBdQECGWM8CKIUA+k424uknfKov5nXGODAEy/5848VpcMVB7KwDnOej9USFxUV3C6eM01GxANdMUA57d1wWg4S6EWTacZDrMAc/L5wZlY+Hdv84hcrByAktOd90vOiIyPgjqG4ia4Pq5CNGaJ1z26kDw1pDEAJAG3e0u535K4WoiCibhM4V4BU4xE8Mah8ixe5Xq6MW4Aau11x5nvvfOaRWEu032jnAzUKaKPfGtXjxm2I6DYE1wYJbs4EoV94KGUqEIO7zPPGKXKikhOePHTlBR0qCFPPeXkbwkKtvKenrzmmwuDoPnlxjUGz4S/jtgCQbuXZrf3Z8ZEfYHXr9N/1nAMc1EdVeujIRGy6c8C2c+E6701EixWqF/ejAmyKbHv/OFE0pQ98H+fjD0NBaWmMQAHDXaSnxz9ZUjyFEL0Ix/neCYoAs8Xre8QVAODRN9fvFbGMqs+WfWsnXkBHd0aPfzhC2HV23yXnWLWJumALxjSGiRKJzehEvxm/Wbgs2WadjaT8RhpIUECcvI4hqYOW3d4Py5C0QyJ6N/vnFtRBa9UyexI72ntD+wzZQ2V0R/fFwMKANV1riOzycSVSrAMgCvfvFZGGoMJ9pT3DCoo0ekcXWiDMJGQ6CuzNQkcf+49iELyd/jCUOb1YOo6uLNp71Dx0GwyZXw0fCcm9ONWkOXn8ZItbzzfrIZVzA19ubh9d6mNQEvL1iLaCIfzjw0OKD9PL1xidJVqnwBou8VOCLFAG/OCEFRhXy1EhIb63peIqQuHi/8AmQ9AU/KQ1xzPrjHjMLYqfwzDC6ELvGoYuSDEIBQ+tn4MXQJp+aYAnvQK4T06pT/pz9GctbzBFO0CePj3gKkAg9kfzziYtv7CicMcaHdx0YOQNhu8Y2CQhRQR2JRZ+FQX7HsU/O/5+8UJiRJGO7FqvfrCMgdIf9awoRbJ14zbAAqaCn01O85nXtkplroIySyoCxkauDQAgoRW0u/gzQtKE3s7Dlejx84aGqCnDw+W5rBZEDQodpdOeXrGY5Cg1DrjxQ0YZBSKbkReeHjTkuQtL0aTaGhrvzvuLeK7I2wWzo3e8BGPkxGt6qK64amhNgVUomuCP2nHpgECCwqZ/Gx7waGFthCu9OBcoqgVtAPmc35/5XoPRoUq0baH4+sVUKLpH+P73gQo003r1/Hv+cnIdKmnrj2PeVigMmr8S8cXXGLKCgdEsd010/Vy2F0qKNt3pHuO/nOaivk6kCVwcglfJwl/ffX0SQhQV/tOPxmu4I0DnodXnj1hakLU3MgPPz9ZFILLo+z7/vGJBR6gG7zvk6yqJSJCl/eXSJkkVR3eT8cGbKCUrg6JHvg8+sHSSkVTWpU1wOeLjS0N0BvyQ9frKEkulLq89d/xmuDKpa2a1tM1GqrusvPrFokGyCONd7n/ADCEBEgra239a17c5tdUSz74fO8gkFp1eeAP0uaSIrNNm/pxFJA1A42XXnEtZYb1P3+7gZGO0cv8TkNXFjpDAK9nT64wQQvapfV3f4wDkTdCLHgeVOZ9ZfJJnYWI/dy9wEv/AHE771ACDe4n5MPGB1wEzxsfhMgI185N1K24Ma44eT9Y6DTh8+6YwrUkP84rGiNR0+UVHYo85UXLKkYztHvoiaY44EPqfGD0trT/AG5DQFUesGVumnGWls+g5wJsFHypSfpxy3KEgmw84dw4XWlo6CmAaBiFmc/OSwbzbZIfeaIAQaPJ8YlKVlu9zHTCLI6PnLLygNzSB80nkUI4KIGhuL4v6phgBQIfrh4c4xCK6Y3eWc+/jLXwFR91Bv8AXrHp+IilfCunGt8Zt8LSSndBjo9YBGqCj+A178XGgZVE5bu8Z7wQBE3HvTkSAYD88TS5OBBuldqDBeeJymXvQYMaW60Jxk07+eo8BOQoF3g7gGnBrrcyEFow7D1gBIdPZrLAVsDxcvBkkZWxJ2pOgK14wwVK0iFCT0h1x5MY2YQ73dvEF30XB18A2w7cF0m4NU1R+nTp9mxfCPtySYHLkg5nBwfCiIsy0RXYkZwgA4EIY1hQSgZ7TUFDz5MKOaV4eDlbDnEINaboS6bOk4/7hkIeAtk0vZzp6xQZZryijZD6PXGJ3GNR7ArdcLHkjq47HH58UL/5xhWpuzQWmrpkXjevnE16gBOJzvjv/wBRTwu8muP9d8+ZjJq9IDwfbW/2gaNwWTwWasn9NZaXd3QXejfGudd+MVuzVOw55p4xgi2RS1H1v25zjaB5idSYdLgpHl2Xjm7vEyotVNmtrrfI7utGjIwhERrnWrOzpwI+yGlDz6TXzvjWF/WndZ8c8YfVA3AjeKS6vvGyWVRpe+dnfvXnBKqUtTR4cdBe82znjx/fnDgEhFBuh2/j85CgDYMN9fz1k0F27hxv+PPXvLkKrU5E3/d4KTdLbObu5KCi5G8PF/x8ZYHHW+FVmtd4FQ5CVSCyr4NTl13imqANG9XiesoFDYKBTghq+HO/eMU3EsJw4/XXnCmUCHweOHb/AJxk4JkRIG/Mo9GsTTJcUKl3P85DCpAUNs+F/wB4gIMBQhTpSffesbeg0enrE6CQ3rFAE1B3goDVHzcjljpdsWsztgPe8Cv0hBczBlgOfJDGyTA2ImnWsUFlJYh94XrqPPG7rIJga3/NyKwKwNHsmQYUWCzWNwXMPWKIh9zlafosbcQhfc2OBA0q067yvEK/PnIAmAHn5z4YgNxAEfLf/cKmCk6plBTIdPWPGiOiWecLQkkDr+cd2QoiMllBZH84JZt6J6wSFWvvKwEIpF8/0xaCIfbNx8O8jBLLvZ/zNE7oL6+811owo7HJjJVvVExalqhlf6P+Y96bEcdOiYsBCNeB68e8FaXTmAe+zEJQlBZRxxAe29JhFKDWhbvm8LQdPDPcjYMoVbYRqS+CHK1jHlGEIm3bprmKu8Y0AEqqTvOFJUghzoHRz+62w7KQXR7TGC2zVEhJWIa4+/WTEg0pHHh58b/7j1RUIIzcBbrs1/pxcbYLDogxjN7g87yQpLoq32+fJnW3RodgIjRZfXPGVvcFvIB4Dwutcb9AVsGIS98H+f8AhllRLUVtNWX84EkMQAIF2FnA/Op7TxS0FJC7r795et24EdvanOtTz1xjd6wCh0znjX9rlgAJVpv5DRz3vWsKV2ROg8zfr84wymgNpCuuP+esoONYW+x96zbkCjW69X3feR7FW11835xcLN3QJ97h3h44NLBDrnn/ALgSo4gAA62HL1+fOaVgRK7O07oPx15yY1FNzHqy/ODDYEhBAsnGvX7wMm9LBfRresO2dhZB0Hs568czNKiBoi4/5dzDgGCkg2r8d/n4zZ8WrIpOOOd/xvJMUbaBvD6vHxrjGAiCgX/Hx7xzuIbo1qceONesDEQEvE71Pj+3ONnDQjhTVFrfr8YU0qoEnsfJ8Za0HdNuP7cDxwESHf8AvJBi9pRBXSuvHrozWXohKChvSa6/5iEQca3RPhYPq4tNyB83WIPMQ+Q7/vvCw6DTvGhD5QyM8lB0YQgGjgMaiXWyPi5pw3rMFrgAMSOPTjH7qGPEwOjAOwfeO7M1w/4zRUr2MXzqob4cvoSNi87xajm3vz+7hC3gCM2/5hGMJYMPrrJLE4rDWAcCSlX4yhTE0H17yGv0IbmUgDzUxsZG7dspzB5E9/GNAxEc/WKfdGpNeT6xIuVlT0+8QhsvEvs7n8e+cA0W7AnJ7+MpdRlU0I+eTFAlxQafXODdMQeqvMzvaTomnR594wmzR8uMEjGniHkf5xhTprQXexvN4wHQbgVXx6/5k4D9kTo8qwHvF8RUQOQG+DWw2rxvA26WdqctU7QOkIpnTCh0UCGgaXg39Qo1QfUIkg2zXm7DialcKO+Ylgai3Rg1XOLsvNqB79ObFGj1QS7TUL+TIhCsEpqdPLf7vNqkXseovfPJ47iYAKE+J8B0N/8AnGOsa7MrVL+Hrn+FKnDz1qk9c6fPeO1AigkOKdAb+d4brXICVZIU2/6wO6W0aUvz48+MeoA4aoPVjPfOndM4wiWiL/suXXZaVpXPzoxjKBTZP26/3i3w4EHw2D4MEESIxm/zjqA1OkTeyy/3xiGSO1XcAk1rX6c1wHijbiT697Os6gYrTgg6v/u8dWksgBYvGuO3sx0SiBSScn+Xy5Cjt54dcIeN4GopQIPbT1PHC+DNIaHZr/j++8AgXVVMZy3976xmlGgeXzK/5+DNNAxl3d36i98fhugJgxw2di4IvBArjq68fxiE3Igo6NHX1kyCERgfpt7+/jETA0AKcaBl316whZuOufXWWEKDVa5079zxxliUkgt+9/jElTuW9878cn9HErY2LpemhZfGISi0rHf/AJzhVKcHinE/8yVjYDjVjzZ84EQglf8ATjzgvNb2A8HyfjJH0heJH6l16j3lQDEvZhZppb8dZyJdr1iqJPnJIiPjNVh8FyOl050wWUwjTX5xcx2bTZnA7dzFXjnlMeQ0SlqbxEwGrxWGRbNyLdfvJ8F22aeTXG/5cVV95pMChQo2YkWr1XPn5x0AdqPzzHEQPJcEE5BtJ+6OTbSFYafPOGgAcD+07xYwiptG8c46+VE2Yro24ok4/DlZY4LPkDE3H7u4P4uG+JwM9P8ANMmqQpWIBrnccaM32N4/5vE7EtORH/uK9UQSN8vjBclrfNvGUUAFPAa+PD8uH0HEtjZNe9GJwOjLUFU8rz/iYWg7gIIH4EYUs3ciolqDqYLxVDjQbI0cgdFtHCcHcIdMCAyHkFrsxg6BN5qIjZ5QRdLsyajKo4iIxg7Qb0JPR3vNZq8hvno1rzxilYYx2gt9+mdfWQ5aCjp8xrQf+ODeA6BXsnv/AJgEqCARInAR3b3hrkhQ1zxflmRI0ExLqu+SAvvOjBqAEE1ykiW0mKBLUAlodL7+ucay3QvfwdJXvW8ZJVyOQjvSmr5t3zgECvCyvn614xU0hCO3B45Xn3huoBVUT5BjKao2Zo13i2sGK1aicc8eOO7ky6WlAn85E2T233Pmaf1hdkhLtINW9Xl5509uopc+pwfrEQfIIr3t3PE8d4JGRldod3SfnKAKAA8fDj8e8BDaHGj54MUQABH19c/1zRpmAx9XfXOAMYEEeIvLzozdFYD+wDrN08d4RoaJ9uVbr9fHnvJa5TkPgQ76yReVUfAF+OtX4xAiFT5I8h/6wtQNk1U8aP7xgBoNB649/nKLSCQm/Sf594sTAVBx3j61jdXpCXtqB6+MQVO1vIOkXX59YiiBeHbzPX46wtJA2KkkZ+P5ynB1SnPXL/f+colgUHJ75Lz7yUDNiafdcHzhyxF0eDnZ94zClB5rhqO2cHtMbwKCn4M56vQJ8hg5721hXSt1jZv5MGyz5B2YbkCBYs8YIg1Kg1gigkan4cPgHBG+5m0IQiup3lU2mt7yL2DPrhzj7EujieiBycn5xw3O9pH85Bu2OtuIax7s4yVDRIdnxk0d4h5uITZvTZj6squvOWDtA3D8Derl6Z1gURdq1e8thjQGl9/OB0PIO8qAdo9ALjBtCMgs7w+vqWTU05Pmvnt+criOFdzffjrFFpOyifLmksvkAq10Uu325XdVt7oiWjZ8mlrMrgRajaRvdXfJuRLhMwhBC3dNdRrZA7Q8KFUFQsSuDyr51IcRMDbguocrUcwxWVV4p2RCEBwNsqwJKUEOnUM799ZU6UoEptB6/HnKSRnPea488T/Op5QK7HTZH/3jBXRdxnSfH356wciqRYRyhp1416xsRxEEnAoJeDuvTWJYoB4Gzni/8wwwKHvz5pe9++MHCEAEWRWut/01j1w4Bu7s0c8bv3ka1TQTk0tGav194JIERWF9JveuenNDk2hPfn+tMT7RuWBrfHE+c03QFwTVdvjzy9hZoBWhBXzOV+sTqINjF55D+/zhB8KPO+evOuM0aFaM3rmZX0S+QKBTtYZMCsQM1rrn5yNCdob+quIjdppOOk8aOfrFpPWjz575s/5m3rlBG46R98zGZxsKKdb+sCbDEFhz1feKtPkkvxzr585SdHZtAdFJx+sQaYkIL919/WMYa9zTiJ5/9zblIXSSAPoHwesYGk3hQ/rz9e8bDA0Mw63vrl34uQc4qaG3kWV+LrcygMBUG1nN3+/84ZBsirfnNfHf+duUZBpiQmzXrWFSBqXgxjw7EovZesttBwbHOt+pgipY0EIMho3zc0VQKAaPv6/5lGsaUOXR8/7w+QzISnXs5JnLgCOXZ9OvrG+mrhwxaGbnB/GQBdN45Gnh3lVXW7OMBT24aXrqG3HSd3tLvNoIOTh3lHVifjHRtXkXKkACU4cNqdNbeceoNdQyy01Ie3Ew6cF1MbGB27DjWq5TiArJo5FC3jGYEeMdRhojWCJyGSyfWHC6Zx3ggDEnbgJe23E8XHddAnGAEKBLzkPByQ+E1lOXSFtTem4syg5BPK/jNBQoM2wQQ4NMaKQAMB9/9zdVpRWNf1D7CYic1LKHpyczfvxiAgGwnpPASO5VdTbMMlZCUgqdJo7N5pGkaJJ5IX0JeREhp22lGkNPIYeKbcTeU4C9ATdjxyD+d6w2IitV0Lt5dfvN0LANS4hy64mxfOFkX1idcaKg8nAvrGNACuRp3PBNPs+hGmzSEIT8E+aYW8wJL0KLoHjXjjJjSEdB+ULC/wDMBjgTsG2fz/PnCAbQIUmHHAddTGunIso6Ka7PG/GXUqzwj6nevOCtkq3bHkcOuP8AF3kMC8B7vnk8znBRdXRbTmhsd/fjTowEaUCWOuJNo85yBrQ4D0PD7h094zvCqDfy9v1+ccdj0Ik9lcZAKKo18m3FVreB2eR5/MygJIg268fhyhhnO5+POecR5Hp8PPeMsoabZGQ8uQAqkU7+h84mae1D1s+OO/1zkrFSjU+v/fzhagven0+uP84h31HlB8/5zTEBXpOO5/fOJLwaB63OO8hikFA3wzjBb+drLt27xN3kE1I/zPrnCKgHoFO9H3/zKCC0qHSyf57xSqkJPTbTfHo/nYgLoFlV159cfjA8I7D5cXn/ALrRclHRXSmz4f2YBRLRqVrEdew4+GH0A38Te/Hj840ruYWa3ctEbRW6wTsU5qPI+sdlZUgafpMYzQ2P7+v8YwPGc8Gj+MCTQa+p6we4Cy+86gAO/wAYGS/xi8xTe9Y2VK6YxqyMN+8QqB0LpcArWsASQfDeLmEeXF6Qoj5844dUzn94ES9rT5wBFFYK/wAYcHNAkPkxeqzYquG0B0hUvi4GIosG/nAAATXFwThwoh/u+c0LrkHfzglEDZ+zFLSU5BkO7OvGHCMTRuzFYkg1VhUR98B13gpNixXQX+TNj1/POsF3ple8N23EP6vjDaUFpEfjw4xG3eWkCOdHzNZUdWzSuLbo7Ne1VK4OkiYhjlLXSahTk7w3piXSvkRadAKFw0ApwIPAclQw2r849gJIVcneudGpzLhSLBm8W2fv5kxndRCUMrWm73/dYGRCN5Ovb/RjDGLsELqQjB465+ASQrQcueT/AL3THgT7C1nLd7uuebg6Y2VQnaj8Tjx3iwmxDGnrv8TksyAKgC7wAuj15u7iKFGECtx5pvkjYXNlnqBdAkQrxo58sxzQFth2hpb+NV+mhUAdmzSfDV67ebgxwVIFJdEffjA9QSqp3rWu307xJAEXSJDlY98b88XDYhay15d/J/nCFJpux3GiTrz+8EDRoSror4/vnBhKSALCremlhwPLLkm5ILOOy615/wC4GhBAU2jx/vLi5QizXrg2/wA5t5wmksF4F3O6YlEA2PDWoswArnQJ6aj/AL/nFmxJtvc8f+4EKcowvw5r1RG4b49d/wBcZDphwna68/OGtQeBN4AgOuB3OdcY5CxEXhOZ54woeYBvw65Dj8fGAcSVGFvLrx8zLxgkDad8f3fvAk8O09e733jhQVosXbOzE5BPHIz5f3WAA2oKia4XahSv+sQSPuNHRexqeufjIMMKIv8Ab36yhGi0j+O7kFzOSkLwn/hMjJwFgKX4BW+DAIkCcEgHiGAOTrp2/wCJD7cQEB2JyyYVs14YzXY+OsEwECj4xHxQk95zQFxDWNysPQj94widuQd4kbeSMbSXreCrJ6upjovEoRlpFexMLR0NV7MWYnK8XHMBAs7+8rS9qOgfOMR5HkYoCQeen3lb72J7H/mWaj7EHyY2aljAnz1ghiqlrf4uVrIbZnqXBOShybuHxToYxywVvW04xNQIdlwyoj7CA/xjath0nPLi0EdNemsdAIrXGGYQR2ImX0gKEA7whtXwIFF1WAfPzm0k1lG9pUo1po9m3SFnaJeIRaRa5uDFnRF4uaEggNqKpBjOoGpADo5C66S3bLiCjTyBqzg7CzYupbxoPBC8SJNF1hQqNiNi14cNnTp9KW8hUfAjqzfPd/MkcSUDR8L2HXF3yUA+0gOgaWzU8G5cIdLlQjIrSar35+yYYNnEOaaK8W/HeJUSUq3pE1OupjiLSovCbI/PvVw8hq20Njwj29J8cZUaRStmwy9eX1rF2UKCkd0pKPEKOB0FBJSHZTsvWneXQSCUUKeD6veclRnoq3lJ/M9YwjPF3Yumh88PWb84RN5LodMw2KwrluiXUevOQIHYAaEDQrZGcGCycJJDEp53OrS4MRjKkmzjrn1mxgaAip7GC9dZWUBo24sOHjvn85F9gF9k88c7cCJspRdi7b/OK1Jn2CERK68T4vbW0bLaJ2wvLj1ktDiNKCIrqqc4wXTR/pJnNSGOx+O+/wC8pkNcVtcN431j65gIpwdPX+cClGu6B/jHUR2i9DDgPIBQwbZJry4EGrr1fGaDBlNh3o/X3jaFUjwb4efOvWWmoIEaaOvk+nIgFOVVfjxrHkaihzcOg45Zrn1MVCiERDX19e3FoqJwkpxbEn97wDEodK+ePXfnIDCJHkG/7Mhs0aNyBvTsccL5xjICNgpm/WV7Ro6rs+VX7w4DF5C2deMNTSThzjFspGuAIbqhxjXTa37wIoRS2v8AOcpeP4MIFWNB2fvN3E4hgBXBHtLSIj8PWdqOAN+s4UcTyY+LUMVCxjgEnDsWzANTmgF86zfqdBbPnziR/wBA9NNfkwfWTYIprffeN1ZQhGPnE3NA17Pu3GhsDRvGByk6T/eGLqVmz48Y8WETc1jqwVPDty4qN+3JMyBviK/rCj1RY2GSKwUsP71lMqJPL5wKWkBd9YJRmi3qR7kSX8kwop70hyouaLwhrQNU6ANJWECNKm2jFU64sosqzG7YADRRm54xMFV7le04V9bg9OSmoqkeJ/4D23siFPJhUlL6vGNpohFThNOvLrdfbaUwAh2B4XtlPj3h0FyOAaUDDwTlaYV6gtgvBZs4p4xumEQoUutJDjewXPNscAwAdKtL+yZE59G5BTzL1zvTBCKRIatgx8Q/1kHo0VKlqlY7NXZeliEsE0hKDjvm351WbdU6S81G7nnv4xiiM1ZhE7LI7BV2glyo1WJyjnn8d41A5vcoedmwN8650XGxHWytjd8Ovv63lJWkuhH4XTP/AHNii0j7N36Px94Q5lSoyE4rP9zD2mm71zFHf55nraMUEW3emWujf6rimJSiAdlVdznreBAOgrkb857BxAgddC/HXPNuAw7oHpwW8fx8c4o0AwPw0rm4TOIR6B43zMOEL+SMY+evziDX2Q0ILRLsIvXOH7ws952DO+P53koHJAvHmaOOO/vDtkVR/k8HdylbA0dOZ63Xp/EGAhSN03xzj/JIxtIIjrkcH7e+a6bFdhYbmJGKiiNWrqTfR+MViIGuVPqf9wzWSPB878ZSiw1zP1gB7Ahw8JDzeuucuQ5FNJNT+ONfeASk5ao8Sm/x/GJwWlisPOz+MQiVoro4vPrBdUdF7IT8sDenJIkRHY0/bKBBoyOnAUkXk8/3xljbdw5ubvuy+QzYhHmcZJkKQrreAZqNL04RyjsyI4O6Y/geNnGSwEnA05DJViiI/GIHr0Rn3fGCFQdatyxYPcMSVHgxnKDYu3NQJ508sp1Gq193JIAOAv8AOBchhCBxQqCukfjJorNq2rm7c225mlTen+cKJ6HlMJoTi7uBm88MVNlO7lEISXxT/n94k5mC0GbQ7wnWj4fg4aFNB4/4wGEtrAAnRU32VRAXfzEEyjECClvh5M2KO9B6GksNKlo2Y1Zyq9SQ0jgVGJtRFbdYWe5CRNCBXGV5CBXyCg+eTUwLacigt1mw1prh+KQcBFBDRVyhX4Vm96i4FVCnfhPGl17zQ2G0lEfaeJ9d4vYbS3AgJFOv53h0TRtWtNJLtpaGWdBsiLEKdaPuvWbunQCZZ2K09rTRcM2AK9WhGg08zd9apIgLEIOoOGw0OtmGyKKBsdUjOO++8RRnaXXjjmu+p1IlenbYCItVR814NYAJp6lE21G+eIdTG3Q2vY2fkzvVwZdMESwJpdqU1O/tQDJA9ibXVHcv4wEBrFdV4Jd7Xxx1wCFRQvAunbZf0fGW/QTEXcTV10d95OKJTZ3tYQNetHGI1SDbTXDqb24PBAG14AHfWsLGlEG3KATjic77ahVJmIwntpEB5+GXQ15anPfejR/jCBEFQY+m9a51lBVoidCtB0O1vI753ihC4V1106f7rG5NdKSA/wC+HV5xQEbU/JefNlg4CsXUDOKmy3r8YCBe+lW2ifOGBXZSP3yXzgAUY3RCi3fw+MUwCxsoRV8AQ1bs1mkNfoNP65wV7DCIetOvHvxjkMa5LQPDqLRoiFihTGOWU0UFOESj4iXlIzfATmqGAdwFifgSEihQihTIxr4NToUAYYnhJtOlaCKFdnNd4e2tE3R2wymBJR8rrSjNckIOWck01W4NitBWGwK7QGwq33MQ7YCV0SFmBBAICkZuKL5+EEYYpFTfeUJnLtLXr5pxEGjxMMFFijHrePCRVDDcYaByOxxza19/OIUN+BT8Yx3C9WzFygnZiucC8TFqATJMxqjX2x0wLCD/ADMfuCbYmDQHhe8EVRuBhIXYkOaEDOLPWTJ8Iqz58YINJLy4ThybL+gY/rKVDD7wC3C6On+ccTctCDf843aemvObULIuB4TU4ucWVUvOSosDvHc6geNp/nNAIW6/6xpjrGpA/Oc04jyoXKAKroYSuF+IpLfCLQrYDmUZV8Q6BNgfhveO2y3YhNoUCPUKTbHxhLULcaVFCo2wRQoQFJGOufX2fd2HbCbwOXST/GERJ0gANkIbe+Yzzm74k8hF828BTzs1RLjCRShK9c3NjHSdFb7b5YTowNZ2yiP5H0c/rIpVAM4QRonPE5BnOOIBkoAQBsBm1+cI5JZQCgQF6UB1PoDcrE2A8J1HZeOOcLjROtiPJSXR84GPEEQrac8n+vjNZbQlaE5aWRiu47wLNNKl+LFBvXn9hiiksE9pDwPM0d41Ja0ABrSQCOy36zyAxBYlUinr245okKH+Tr4GpjIEUsAk5da7w0IlZo5Htx4nvCbdKNwPwzW9b3hDYvmO0g88HZ1lBq8KEaa5er32fCWkA7my8GqU14+cZ3JNbYgWwDCp89OEG7YImhJ7d/rGeiBNIn64fjG+oOljVd29vBu3NYtUIRyq/T6hm9MACjre93RC4kaZQSjVt0qXgJweRkZDBS91Ou+u/OPWXpKXR5J8b9PnEilpQsfOvnAfbQQrs55zs5VJBP7588ZQomxa+E/3pHAoe33YIaBaK0nZofSUWADq2QCdnLGvlZq3+XHxogw2rl8QUj3iXSqaq4EUolaMAACleD8jMrnON2AAmqSdSvZ5uiIkiYeG63158LVJFGBSy8mgUIETtCyY4wHJiLxCFmrtUlo86JgjphFGvOQ14nobKKlkwALj3/CrTSG9MSQhwcEcyFJ2GA6T1k6s0f4NBXTnlkZLHsG3UE0FLCYTB1BQkgIuc4pMKsWK7jBzDXAp3MDmRqtLvKlzpzkCiYIob6cZCjstX8YQEDUqJ/jDRU77YVHIXSwKNVk4c424vF94rgYTQzDLsNB5M5rtw/4wRBu7L+tY18w9Lm12l1/GUUB7TZhCCIAfnGAVD94jmQz+MNaAzQq7zY7J7x8Iqv8AXxl9NNEhJhiUVKsQ587W5rJwaVm1yQvCDu4l0JFAYEAHR2/XDjrwPELWtkoATgK3En5AEFToWMIgfbjBWgMhxgQ1vml3m4SIrtBpd6pHzmjhXAqmHbJ37c67ckRC0Q28eDF6Xm4PhOL8cYEA1s6a24l6IcB84WSNtFN9I+uPxjrg1i1rezs48bvIvAqYvcF093AUIjJZHOni9F94pRqNtInlztPDk6pOoYKie9muKYpXFjKg1u9ro11Lj9Ndm7Szcn9vGLTwChyt8PHM/OOqKlD4newvzhgESaXUa3qE1rvIHa6IIgb1r+vOIgxNNEmi9nGv32IavO5eBfB1xZiCgXdTaccIb8PGNgJ3bz+1jX3hHv1CHuHPuYAJGk0dHn885cNohcKDT5Xf8uKhtFsRsjDSjrxnNhirBRuoeBN3LzFI0Ncgk8Zywshlb/sf+4DEteCcfOHBgV3dd/vn24iqqCEUvN5PXebgRwALN8BBj5S8vOXAAAg3aFntx500BQE1sA6uWCmaKTeHnzmsAZok48Yc3paMTdPn7xV8DTkUW/kwFeBy+fX3jqFWtOQdj1wZqKOVsWc5UIDiHOt/4xA2CBOHAJFa6LjjY3VbevGLBaQ2C2/rjESDdi7vz+MdbR3ssKPhdXEzAxOhl+Xle1cVDqI76xciHurV8941Ck5neJhp+8PQv+8ZUUN02f6yIEa795//2Q==" alt="微博配图 5" decoding="async" referrerpolicy="no-referrer"></a><a class="wb-photo" href="https://www.weibo.com/1199303274/R9yE5wVH8" target="_blank" rel="noopener noreferrer" aria-label="在微博查看原帖"><img src="data:image/jpeg;base64,/9j/4AAQSkZJRgABAQAAAQABAAD/2wBDAAMCAgICAgMCAgIDAwMDBAYEBAQEBAgGBgUGCQgKCgkICQkKDA8MCgsOCwkJDRENDg8QEBEQCgwSExIQEw8QEBD/2wBDAQMDAwQDBAgEBAgQCwkLEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBAQEBD/wgARCAIGArIDABEAAREBAhEB/8QAHAAAAQUBAQEAAAAAAAAAAAAAAwIEBQYHAQAI/8QAGwEAAwEBAQEBAAAAAAAAAAAAAAECAwQFBgf/2gAMAwAAARACEAAAAZDleg/R+LKdXGRyCk1plT7LLLTctNIUHEETHS8jwETS14bmKZaZjoQ1wFISNcs0s6oia5fBOM7XNO8tB0Fhpx2rvP0zPRzyrSWPMdFTXRmhjpMdc1gGl0CxRE/BwfQaaZxXVg01zdRXBGTpnn9spy9UiXQd8fObxeT2KCikKugUOhxiUKZ0EIUCwUJbk7lxUquc08v0dM93yXu/M6vNrSYKvDcyJm5oTfWHWOikRXTgQAUvB0PB0EtJENnGcDodR1UtNaCJuIYqCI8MTTnOnPL0V7zvTk06/c3Hq4y65rmhMeZaGljY7zsFS30mN2z8LoLTPFR+2fQjunDtLrlWdUryfUVF2OlXJuvhF0ry83IGmo6X0FAoOM4jwIDwEBSOJJBJXEujzb571ZT1uR70xN1yzfXibow7DBpmVOwdOEllTzHaQ5d4jt5YXt5hVPBeGpCh+BxnbPTMdLo1Ic5200g8X5paEUET8kijqHfL0V7y/Un5rwQekR7U96nlk1ksVwYmnGdyOGo2Fmo7bIVKK3zkMrcxTXSGe2XakWsBxqn+F7U7NXSBgrzL5r6EnVgx9/xZCZeg4BQJB2IrlLbdOxy2UuoS5MTlpyLzfgGHk808rtYpAwT3qVk9KFUpqs3Colxa+vhmagu2JpvqTHoxa6wNpDRZfgeY6z3n9jXWK36PCG56n4HEU3tOJfAWgiYqXGjcfVA+Z6Zqmey0i6l6yFuI6pl/W8xXRjwOJqluM9HGdpATLDxdRpsslS9Ljb6Q7inmbrmWlN87vt7LdAUK3G2VeV65vS82P2xRDIk8Y7a60BOJi7VUafWUqPM40wLPWYE1BInstuD9EZaR5O/nXDKzbu6epkkJHWOiECEyNOQk6yfa4vNcja4m2y5pHBHiz56SnH1Oc6iOvnievm6mKpb3K03E0ipe46tdITUvfM9GscXafTOey0i2kUrZndW1hm5jGS3r+SXpw6CUy56OM7nOPqb6SBp1nYLkNyhp7nVM5Oqt8/Rd6mzwo0pwgSuk1UZWdWTu+akqENAZ1jCXNE2is3s2tGXxrhOekuAQaslJGg5BDBjbg1EoYaRatnpvfC0i0dYgXExpCTIxdSVojRxPKh7eb3TOQRJp90zb65M9spTl6AXMV1c4aTiXJc2895/afPSs2qzns6qeIDSInMzUjDhdZi7zGEc0/wDV8tfby9mneWrvKxAabSA6g8aTHL0NanNOTsTFXoUqA0eTWLyrMtSMpRGVXOFINEpdYQGckpcTCTqaMPJstcNz0mQSEaOaSbDeIjQYcDbWjU7Xq9P9DHqO0uB0Y5EoRNCGBNbhTPNEa6xTS2dB5JI1J9MjbZTOdWLm2d1LPoxY74lx2huLt8ny4Zg/Gzcqm5lCU4tkdcKuFhGVJ+/gc+jxFmkB5DiNHeVt9IcZ6Bw1zvz/AEJwLwjwHQ2QsboTRVnVuN3yoPD0a5ebtpblYKBqnMVL5ycbiax7HbGJ0mpXctLP8p7kJ9N48Z04X/5ztlvE6MH+z8oqXWtH6rvvZl0D3JWus6gctI0IGmCWlMKONIaXSSCw8zgcDwIQSg4pFKUc+i5UGFS5TsMUmacg9EZA2N2BYxcwI3dRGaR3fmc+n5/dsx1K5fVSxxvH01Py/UuyLADoGKHqGwygcIxVRLK/vlReDp2XTI7RGliWhu3M1LgkfidwdVU3Vc4etv6XIbx+qR+d9KnfceIxFZ/A7Lp4NfPX3/BGYwbF6X2Xcu3MrS6SQSChFYZytig6CU1i4CE+ANoTFtIBYkJt0ytDGproeDodBKPA5lugdJuZHSb1Cw6mAGbHNQm4Z1Dnt4/elwcB3lrWvO7onj7b5SlUBBxKaNyIRyblDhkOqpllU2xpPn9Wxa5OaXQUwogjmqh4nG+Z1Z98n6DT3MrL8v6HeNRXo86fQnn0nBJ+Tun5boffP7fM/wCveTJ5Kb5rtPo1aevITFIUCRoQiWNCJaA4mJi2j0jtHae1JRIG6ae6wQGwPajoDGgFglCEcBLFBxoQJBA0IGq7LjYrsUe5lNIdtdJcVJ9sR56MsOi0EuWeQkDJBG7Bsm5YoUQVCNVvSIHk30TSCtdBTPNAH1NjLhMNq/5HQHy2fqh54vWx5ae/R4sfWwH0c8h4/QvnvF/Z50Dc9hf7Vvcr0grRbXA4NCOSwZ0GW0zoM0hNtLaSxj8LweYIHeknqFskKl0wyTvST3JQ8xAvNBDzfBBDodTQHE20NplpIXKqklLqHFo7kzSgIDkDBwXmJAQNpY20AkOB1PyEIQA0+B6WiaDNFBAQnznb3yNa528d44+6H3yp3WpHzLefT8rDpyTU0nCh6uT6a0C8SZVMO3GVB0lWkluXNzxrqBISmFUYTeabw28sCYZrssEuLGMXk3DXQM0dhKk1I9I7ktJ/pLupPU+DrOyxoGNtDazbsXGusbw280ulwOC4NTSmli6BGGaO0pN5pBgMzqOB0BDQmlEZjoUCtKpCRA/L9lX8e+duNf4m+1c8tHubbfR4RXo5FHQ56bD0ZxsO7a8rbOpri7BxZYpi22qStWXbEctIofVX6RVS1sZtMmNwaAwbCJuJkwsOQbc0jIWHRDGFAExIQCQMxTS2OWjVJqnybaXLtLZJbZnufJjljQppAxyNlQJY0dH0Bpt0GZ1HkcTUBRFbIC0OmpDXM1olIQ6Z5OlR8N9raPwHtjPUdempbrSuT1SeN9HmP1PxM/rEZy6aZ2cdUzuqYdNyzqwYWvLY6Ydcj6ZTKceFf0m2ZhRO2p1OUDyYlSUDCPHVujPm1nnP0t1I6AFJqxhSW0yBvSG0FjcBSxS26aWhiazTlN0BWpG5c0jXJmnAEBYiUisc0ko8PgcacNDQpMU02mmsnAMC5bi0droeY1TheFZ55Q+3qLjRGj8Tfu2Z/pyecHvB5evGPX+eaXIWbHvyUTHarzt21b+PZ7jtMZXLpC2xC1K0OCZPKhzZko+5Z3JWnAS0uQmuS2nRnVfVc/p5/ReHyaXla8bjebaf4OktzJ6w4cppZfa0DDSBCvshGZd05wWk6pza23DRoNKfGjaZquRUuA1Y0CPTeOfMGAWcB5U9EkaxHpOWnrOids804pFtKENON5qzXyTQfQWT+TrF9buvVjfuuFMcstofOXD1RPXEhL1jr4szw6Il2KGTIP5/VOkXLTS0BA1D9D5DAcpFPnPUzjTLEOEFCNHaX0ZtuyunOAONEpPql7c85Nu8HSWpNcrajmsS3Wqc911vQOXacy0HUzaTBtrLSqj2PRFuC1MjUkqS3PKTMYwchHpx0UoUcEQyMCEtNBzOdrBTBtOGn+kOrQ2m+kFrOBggm6TnpzaH+mbS1Aok6Lfk2kbxsp/nWw9vBm2XTATo1lMolzytUjbSb5PTdo2oWmb9kzlRxSVTTrLjk2VJ+g00ofU5LaJjuxIpRz6+G2TZ7ZMNJsvJtN8mqWnekluYYeXUaHiwsjKTFNzIMHsW0x1nWOQa3Dmpd1Ldimo5pi1wFBCBmmrOnZ8m/VHSAN5ltFortoonopC5f9GBNc7r0YO7jPs7zjRZXNyCAzYdI80OZnUjDq+jvOO0gzmb1Ho4cxw64JW0ylkkVJu0oGzU7hpc1vome4oamTWuNIdbny27uYWlDyxzTUHHXibugqzFz6qRwDb5swDhZMals7r9zOJiooTdulWyWgI1M8iIqtlUZntcSNcdDrN+KYmpIb+KJN8cwVITCzUOU7lsaiMTdzbYEa5yvTg71zPvk50zEK0omqn5UnaSyJW4zmG5VRN1azOSSciAm1ZTKqYWspFv3N+vlzbPpqWDVUuYocyITG0WTgO29Dzt3zdVhWsVti0VaPhToOg3mjxS0zd3O49HDygWG3kcQbfJFJHm9cuTV4uqa5guEp1iq0jIlJccxxNOoplF8uT1Kob4GE6VbQthGP8AVhomNJlwbfnNsz0nZpoqre2Tvoxn6Q6Q8dIvXOE1yuHXztgaoWyrKt0cVwr5gzq9Zua0ygMNqxy7Q/fjP6SyUilV4pk0tl5W8ZF6HcS5z35XncaZdkQ+KbNdbE0MR5bzFib9qSs3bDXs7aDz35NKY5qPm3Mk31YTno8zishZXwa0K2zVaiPK7HedNht9IS1FZ6VTRXbCrNKaMghGx1h3TfbFFl749n42Os1XY7eFN1i6YXXY17Ok7tlaevkV089YKv22NnqVJ51lrjXPvP3KNMr7vk2abCZhmk6fU7ihqsKzd4kkbio8urPztKD7WS+mH2cWHLMLAMted0q+yeKm3lY1juek0gt5EfKXNtFQhg2sdQPIZ82gGmylsatO9XpaWaNIJNknJxQk2aaGPWWyB25MEZVt9+dek1jk3qFz5rXsq4KlUVlhpsKbmTw/KgNOod03zl3kRMoQZtlGuE7tlttxN1M9cMWKFGtOk4ik+Q4RmXP059y9Eh1YQu2Wk65NgatVocVF/QZGaq/nKS5StF0iJ+c7IPWaP7uTTebLnjdcsOMSFgmrH19Oec/VP1kicdv1ojY0oXI+Z87bOKZmxMJIFh5DocxV9ty0a0KlaY1cFWHHaM0zsc0WaIg0plUuBcNx1l1N4lXNp6LT8hrR2KCriUV2pfJxYBAI3aTipa1JgVS6UAWhdfHedoNU9TZoKDYHaIhj9DkMey6Kny9N76ufOdctI1zbNNAp6ctnW0JY+6zbmuztXffGi+L3V3uwrHfm21Vnzyu2XOCgYWHO9U79PKoHMp+NTXT02CZnZmWpTmU1/bLPKjFePWATrudcTdt+L0lzJc+uX1DEkdGyZdkI7usW7EMI8TmWxa9SeyNQfSONJiHOow1Mh5M4oAVJJeF5uWcwYMRz2ekv081v0hKY2lNNHGgb5N0OAaTRAAm7FEjkQcBkee0dntZNM8w1x0nTNm0zChK9BzemoxJvF4dzlaptljOW3hRm8x2iss5W3LnGxIWPO0ad1i0gpERmYT332h9K01VfsyYxekPKA3yrQqBF5Tz6tp0nMtb2TF89USIDJxt5F3bfspc9c1pU1Pnts7Xjqpy40zdAdpIrTecZvz2Tm6ZtylGa57zVpzWMeOtse0cuJXbC+7ZWNIbSh8kazVFzvQNshJuAbp9THLdNRScqBmsqnWo49dv2yzrXl0jTNi0yHm03tmTtoYQzPVMqnr2uWC57AqPWwaTJTEvGLYbhOeihadV0uFqUQqdruyZZSVppGBmvxL6oTUgch0mpWYh5np6PlE9Fah6vn4vy60jg6WUFv1dMqZvu5x07g6Nj3Vfl7JHLlBDt3Vivu5Zzj1c5U01Vs5rAa1K5qFYv+GnvTnt3oc+XZdItM7NrzP8ASZHm18BhkBtFUKHomsDAouK0yBTeChhy4isxqN67h1WffGj78mi6Zx7GQZPOn03gSDPn2zOYLOGya4Y7NyDmoXcfQhS3U+FMDuVTJeP1qhWf1cmsbUldMe+doF37MDilMdjpxE6VS4kaCXm6cynke26fEO057cNK0yznj67HrtQc86U/pZk5Z5Tpa8KsT6WfGkU+Ctc3Rrns+XXEXTz95jOrD1ZS/JbdWjfiqWrrHma2Odrddxfdibs5Xs5uW5nDVKDIUhI88zehaSlhhATUgcjtuLCSYsMVjZln0u9Mq50cl/0zjGMgyCNfrfFcDB7cDeT9LUKnHA4iq1bCqUpAo6J6N6i0+f0M9DV+nKjrTMOqQjuWG0DrlHE6NnrIcvaDXnapvufeWjomeniztFrjIuPbRezmFnowCV35e5sM7Tzlbi0u6Zc32ZkcqxDXWa5uqHMqhrzmVbDiUbeJp46P0ZZBxdzrKtMx1mMnE+lztfR48+8v0bBEbZtz2C8yI4jg87l6Lc8YcTdNSSU3Io0b5ojeJc+jPj085hennvHbDXoI5GURr9Z5JIKTYNtmQGvPj8aVVJpqcAAkuOiep+CSWlxp6VEZAPL9ddEVTDqXx1rWnLIY9URT2X4zb54+w4bRpNrz7AmdDmdezzeLokNdcprM0ep2uOOnmqrWmaZwk6OLyvKuw3hXMdIkq3651jg9LE9cK3vyaVh0UHbJYrxpnncUZXK4dMfSn9Ib9XPcvH9hN8+kZ+XXeWtB3Dc7uXoqk3V1UvWmAQGStmzdsKEUqaROZea6U5hxveZIuZjoT7qRfSeemv1FiBB4EwiXZjO2OhZb5xU4pUsFmxpMLSgPJ4G+Pr6Lhyav18uFGtEu9dt6t052Dp5wRbfj6smxDfIdWf8A1PJvN9damqznlSTPYs4cG7Lrh9t35rw/XXWR0fFtOjgqes91kGquq1tHPNR4e9rWNq6coXzPUjefprHb5j4mgdOSRISazrovm+rR+7z7Zya63wVgP0nn6L5vpw+fG3OfyU7g2usDQSSL0oFE/RGOL6TdJdWydWyK21LZENtDmLFpIRDpPUWy20i9D61ZeqnQS6JSlj2uW65a+T+atHPqMzvLOtJUCwSDo9DRYNFXFhLqA1v7E9PMeaJdJM1xoXCvnDi0J1ZbPz1XseyveZ7FS9bxNB58DedhRPpZFyepq/qc09GIfJ77J3+d84Ya13WV92Nkl6pxaZP43uTnR509ydmQdWOueb6h0qT1cOc+jwWHLan1O5cfV7Pkxnt01DyttZ4YonoxBnoyKeE+v4rSpcpucx/A1smMGw0Vsz0alu8MwPOZ50zbHzqZxcJ3TLZ0yMwEukyNLabWNgtWz1Ts1tlVIDyXo5dVw6ZYnBbe/Ss/o+c7isXmwpKBEdP0pefMYwWr0DrrYOqOoMzilpm3c3UeTStbZ2avJS86f4n2UDcX5efWo1i+3llWaB3Zs+Lei8+kt28+jeF7niIed6538c56fl5z5/pS+asvP34Z2efp/B6LzOm1TM93m0LTOiUvqrHSDz+SgH9fCcNWPnixC+fPUwuOHrA1zx30fL8BUBYpEgHsk6lwHQOAGJ3LnsVZfGRQ5sNN0/5VPhXehMKkqXm1IibenI1bquxebpmnuc2pZaux5RZoiVpFDUYK3mtRD1MAtvpmpPhng+t7Z1qxaOR1kgxZtrmyCZcrr/j+sP3vmx8jp+XsxfD6Orc3j2nj6YKsLBg4bswY4dTLqTR9LCekehBV0q0zkPR8SJ1Ur5nqtGZj1cWj8XdLZ6NKWtdHJ83dXIpX9GQVuPl18v2QuDCZyrGvUxgNMmtu64+jR+vlrunM/wA0x3LLxFo42mJrPTVV9JPY6J/j7Z7h5X2HJB9kFU1D1dBMGCrJbSeNdwLLxQbMbuqz119pU658Z7dc+38LSk5EaAz6gTFMjqT+oYp/J600oNezxxu99z785RU46c+M7lTHK1ZqP+K9rJPc85XTmvN1TXn07zO/WvKKRpjanrUyIDv5LP5fqVu1CdNL34ywkTpN9HbUNsahvzbAa2/JwDVl59crXWDfHcOvg+d2rIPSZM3y+ARwfqWoedxyeZ89fScj6CpPWP2V55dZvkyc87NGUI1B9MxmgPTWE6avfj+6wtFx2bej8/Zt+Om5Or9Tb9DZ0dCaJW03dW7zc34yS849G/uHnVZ+XiK+xi5Y6TlNYCBDENR6r5E2mWqaxnreEadlnmd9G2dmcrpId5XcrhwPD0SuuXPz/wB3H/Z4ov3OC0YbQ2G03hz9z1BrzRm7aS5jGrp8D9q8w6E4qk/TeFmv0/htamr9sPM7ssafQ1KczrO07jzbZTPXp3RyvNsKzvmNzX6ikHhF5vpt+8C3WLrPt4uOffAvQyqvTlbOS9t+XqpdeJcSudk823ncvopLh6+b+ZHaefEepiwsncOaz9HPUOXQ09NU2iN2mVnJ41T+wa0DRb+ZCgg+y/seEqXTOjntGe06Iw0AKpGzJXWIaSoLbF2hKX55qHRrrGymt1F6j3bHubrnn7yHRmX8i+yeGUp+lfMQ7VG8fqHw6vOG5bh1ccOmN/TccF7nJ9Cfm/08b6XRDxR+bWpfQ+PiP2XzvVDzG9CNblSK6Ng5jDemvo3uuSjNq7Oep3hguubnYnor6A8Ptj8tqxeV94tcr7ZifS7Jvw+HQfJzpe+dS60503mZ9livTjNMRb8sH0eMPoceY7lwYV3dSNd0Bih58dk6lYawZW4Kyh61XHc+i9y6XR9Lwi0VnTGx56TAP2eYMQGY23hGiNJqK0sih7zGXdNkw7t69XiPtiTTNebq/m9L7phP5z9HGeP2O/tea1fPFb9Tecx5Yfkpt5tSN8mXfScc58v6En6PLbcdMz9q7Jz38+/WeNXryElMc3QvRq1ymE40LDhttGe2jmWbWnvXz0is8U1hduwY6bnx7J5Oj5l7+HaOPpR0dOXdHLunl+ky4N61rjI1s2jtlceik7RXOnxJye9h0fNzDvSuGaN6PbF31aBx+PI9HPUpcbUySl3opKlOKadppStN92zfWS4mFETpjYIvxamIqWo5UQ0fOjdWFuZcks2vPVB6aMr0DSZWp5pLCKYcnRcce6M5vXhIl0rr9Kw3FWVR2iXPDn/b49fSuPi9Vw5XX+qal6+Nw5+mm9vFGmTNt/zdytMyKnnTzpE1i/q/Cyw6FacdWNSvHKLkz0uc6arx6NeXb517eS5U38dURthdeT0Ifzu2Onpsvn+m+E8yiid/JEen4rrdaBlpsGXNkhyEW1j4sPdeA8XHdOLgTm2O3AaoNzAu5eQFdFzVaZKmgzvbHiqwpumisAA2PUokdXpKnXk5x/PYOtlTfg0x0ilUybNPP95jz16LmMOcvXnWb6rfOSeJNaVRBeRUPT8qv9HI6i9B5e3OPT47Tned9vE0MRmlkz6ooznlcn0YiZAh9U8mjCayvWT9eFVeVX0UVTdTetcXTLc+2CdPHMzrDVW491WxdFE+Z9/vm+szqBb+f7rzPHDF+p59bWUzfUA3+gODjn75ZfmxDyZ05xRO/Om63Xep25q21nEprtSqkyqn10KutIluLxuGdtRuKQ2V6fQuVeb0BMa0UeNVRDznu0dTlEJFki0lcNrL857kHG6sqNpB9sV46d0zplOaigqq9I+6cTygXE5ybh1Vc1xhvQ4cb9fyhqHM7alGtARcGOtJDSrFKy5U9yug9nPUIuXvnlehxsQ95fR1bn27E431cZY1n+g+h/QqIwVQ4OigccWHz/Yf5dzXYZd3k5/3ebMzoouOrH6d43bubab0xk65qdxRFzEV1ErEwG2ULvJml6pswLKka5Np02FrUnjrc1aouvUmVlTL0lZeDzB0nWW9AjOdw0ufU1BFixlaT/z/ALc753aydzm2AVEJpVOqdOWcXm4KNZQzjzQOktgeZaVvSbLpEvkZt7PmYf6nlcRL59Gj46xwpPOl7Zu94pFp9DiszjdH2iTvnkelp49bR4vpXDrxeNYJ189hp7/6XTOpseaM4nDNMOa1cXoWbwvpI/oVM97woG8bJGjp1D68zt4anx7RmsPLh1CmOQhMlW9YeVDwTipd6RC1TVsdOMqsre+uPHaRWudDNUArOFeskzrk1LlzP49GYxhZOfaz9bh5qsZ6R/B1yHk+oCNbhry1Dj6zTz5P6eMf1c/0Tjwyu3Ewxug8/ewXp36uJjlFA6e565q3o8LPs56jplQ6TlNzLcy/BwdkauFqjskZIrOmVKu6y5eEh1Gg/D+uferT7HNCucR68NJ6Vru9zF9NewxgM7xLHhlTJ/j02Lx/pYjs8mr98rUPjV1eMXpy2PHSu75Gk9JYZly1FquI4pjKt2lZlm8SbDqGt1FXoxnfaWrRcs0IQ2V8pE1CLTONc/qfK8mzwvOexvG1ksaguwoXoRTZ34DNtnmV3TFOuViyPpzysQ90ssnG8W/OzS6c7iZy+fPSWW+nJGrCnW24QcjDeQyJlGpOQpXDSakBJG8UMVV2kYOHDWXeVpoHPtTLjON8te3jRdeiRUxSK3Kx3DB48HkaGz6GRnW9dzSW86qxryO7wLN9qATRJVqUCQzbQCUczbW3NikSqLSknMBN2wjSaz7G2zkN7FoGwrFtBZYM+jH5znsNb75BK9cNYp3z6YPWmSa7S2odw2fLDduegZrQfJc52ZwnPSOLcmVtM8eijOl0f2JrfQJ3qqMg0paLcSFTIHVThq2azn0t0N/mLZSN83kuamqjpF+x0vC0pVRT7z27rq89O0qtYjn5qw5xbmwMcztLgwNP0xLdK7xaZxt805NRdQSa4iWUqQYDwMqGjBDeyusiHQaWn4WzvOx3nl87fXihhonMuru7KglwhqL6/R5jlTSm2Hfp3h+dJ8ucf20x9Ocv67h+DT6W+dTTsxwX3ZP1dx7743nzsHh+Z3zRhEwGy2bqzsnfMBNUDWsX7ZiYIFOZi3MihkH1NhUulrwzUJ4PqKdvElFO5qs7ZXPDWdHWnHaPoX1OlbbtZxuai6rNsOWq48cgo6AgUD0k7QHcYdD0uHtGmlySCmQUibdyNGwCUBJZBwejC19UcumL6bQ2nLTVX1con9J4jCzSvubTTAhx299NSb5y0z6ts8nG+b4UL2s4uHWYuFjSb4XOGcT6/qR9axkZs+TmeTGmePx0vXKpeintk9i6tI02JGSKiItbP4ZkyAofU+AkSxrBbXk6ptnKxT6XTd4tWF9EAUnqtE7GUUxboGS5U1rNQeWc6uUYHEoSwO5kyXAmBrB10gNeJvxdBAGEoOgsOoKARmJvEYLW7orKDTT6z2lw0t57FZrcvLmmy7L1+rW1rIZ46I5lIuh6Wy15o3JQ2VM047OLpOzfq2eWNXbKcwZZSeGEty5VDrjQUVwccny5lZbKMWE9JpCjINSfQUHQ4HAUHGqzrE3nThOGpycyQBCExDG2ihtEiR0nxIbJs5pAwcEnBIEJcuej4K1udxPReq3DCgpFTHR0mabYEDlkppNugI2aKDecLGze8/o9zIazNZui6wzpHD5gv39m05tW0zEtWmvVT8+igYc1Iy5GKTWZaRjK7dqtOs1taXhAzycc/n9WettQsPPtFpHNdH6s5aGPPmiV1EVFGtUsFB0OhwEhwBtNrlSHKYbQ4btHACLwR+0xlARTEU1Y3EVp8c8wczkQgdNEJQPgPI7Dx11mpi6iJc8BQlE+E9NGpIiVAoSgeCk0rHn3Uqs7KOQpW4m91LjbMqXzZfuab1czV6x2nRHadoOWARMDz+fVMeZCmTTs2m8D0dXRtcsZqMJRYPxCG3JOKJhiYOiz5ywjmj11rWhAWqUCg6HQ8HA4C2gtEEtCKOAqQYxM4KK1TIXGWDNxVAGkNN0S7wsD4+IK0UlBXglc/RCtW6KpcwVZ9EoRiUhMlwxChdDoOSXZE9Osrn2Z9pm7YkJZN3z9q+jjk7zgtuyY3ceJtWyNO1vzw/IPlww2XO5tFNHjIpJuk5S9WhVRnEcpUpQjyEAYH8YpmGc9hVRBkTWCwUCg4HAUC2ugQnweAQIDwIYJuFuVzo6SckLoh7TIQ0DZIvCfOMwlE+K6F5w9JJrAUq/RCRpG6czRw7JOUoTIlQdAxL0gotCW8Hl10XXNTkAkhL562Lj7HMXM+1z1apYrFc1LZjDRxF6PZjymQNI9SR5DNCyrDTeOmaI2VErPxLJOPDoSISGPPwtE9JULKKmQFh4Oh0FAoOAsRAUTxgwUAgSwVExl0Sz3gdeWJ58VbjLRNmR6QxCYQmzHA5IUPorHl6SVtE0qZSWKdTrzzZvKSLijPwEEskxL4jg9RXRnU9MBeahCAIDFI51ofnaP/c66euVgZqQ8lhacunYytFLZJW2dKI4ud6vkqpMtBRilqQoCIhxpJmpze54t1v1dBUOVXRrBYdBYKDoJAgEARLgXA8zw0CRQNmhLqLtNXrHP8sjIRTbtDAYIJYtnM7G+SRMupQq9EM6DS4wI3Y5ICsiXEM8fJLEUhQSRmEeurpxY2Q54HAaCSCwuvJcj39NDeA0BA5IRu3b5OaqnpQiFuWKpYngCUcHFzIgUJKCmE+cEVHSKaEupRseAo1qiAoFgsShqDwKEoRBKAYJYoEBxg2IY1aGwYkwesG0hjcG4mNHQboljntJxVnPvA35s6fiws6hFKXVDIgaxWZ9E4SeECDY114U9ek8AQAEoFB0Lltq2JYyJadNITdNuypIpqpEDdLoIKCAgjUwKFUO0TEzLPzJ+cqcuqNWhp7VlnkIhaawKHRqJWPw1h0nodBYdDrEB4OAMFNDAFgAECWIEikgGoRLSGLEhjmZQjgigspABQcbdqxTc9LEEDeEVXOYgyQ2bFPXhhoBpAkB0FAsFkS+3U3qWSlKXBpVOyphNoAhNCSpORsXR2zpNUSpm3Y4RYJ5rYvObDpq6o5annuIMshUEQQFB0CB0FB4PAoFAoPApig8AwGxbQmCZ4G4FR3niO6WmwYQVS3E5G2BYupIAqJJuPE9zrlNi5mVV5ztkwYgNQ1crKsSD1+evD1UZU8F4PB0XhKG621QJukQTcZRkdEQFjhCknhJW48fBmcmQ2R1uVlXePKshz0ddEQbMp6CrrUBUySGAgLDwKBaFAoCM8HgUCwUCWKEhiGcBLEAMBMQlb/nsYDpqH9e0aAQhLlikUSBlQMUmErQwhuxlCLady7nncgOLaCPwm7iPeWiOmePRWKih65thcDgTkuKafbMbFMQjolsAkJh1R2PkmI1AQCCKgo2EnAmVzXo83yVJnsCqjzrPPScFy1oKBQUCw4BQ8BA6HQ6HGFk8z1LzOAkEglngQA2kCVkonVqYRggAyMcsXKEDQRlrsrOYMFAUCjtWdobt0PwRtJuLyRCrbeVQy1SO0IrVzQ7hi5uPFdm4tKb9Bg3DwNw6CBda8l4FpKJ8LhuFYhMyIIQcqVnW4y7IOj1zRSiNNAT2uJ2KBELTWhQGDoKBYKBQuj8zonPKn/Kozoau5rDjEAlA2cEsENDALPB6RtYMSGBBi0xEoUk2BDJJQEQtj1U5TIicTkJowR7luLw7VeUDnsyTi2TKV0modzGicp532+X0OCSHRda4HRKBaqKXYzdz7os5xsTK1T2dGysTGgM0cFMHnpGiPQOrIBA8BoF0FQoZBeT6IgdYpnQSlymVnkLDrOglCGdJSHGDBDBggBAloYksGCAC04ajkcDiPAUCgdORmmQ7XnXWS6RmgNWoGkuQlyqc5I+iiqlJiD489Tx2w/K9/Ws1NOiniqQHAjpFL5wtvHM/U6vtlOOapNxCdE5tkISJSCESRxdQifROrWCwIBkLYQOgsOoUCw6zoKBYJAjOh4FE+GgFiQA2vDGHgQxIhgkYnKA6A2JaapdZ4OISHQSCkWILOnOg5TdpvZfQbg7lhFI0EQVEaNshgz5x6+UKHK3+rctjXNKpO9Ym9scxlZFltCzcnUaXrnp++NKzuGiq1lrCZ0lCkugUyfnH1NK9EysqFgQCgoFgQOAQFAoFM6CkdYkCgoOi4LgeAYEEltDEh0PAgBB4SGlAAEMbCU31LougMBBLBpIpFNYcQhUdoA0pMmV+LKMUtKZpo8VyaW5z71uKFVMJbhrftZt2dSdKq7ZxCPm7m3jlVsvPTujHLuTd60mSJm0ISHkloK8ZA5PFen0Dqyylt9AgLAweDocBYHZwOgsPCWIrfAWJIKDgkgoENpDgeBIIEMOBxrwJBi0oZBEDiAg2C0BpzQ5oiC0vCrqqHim6bRPk0sZEJi3TTxVLZX1zF3ON+pxpBY9o6M7U11O6SUelKhhOemc43dtskpQWWnlWjXnmmOgwSC0upuXzvlyjOxU7dHJ8M2znVX9HQGrMBA6BBLBQEDgdH4SxEYpvglI6Hg6CAQBQ8wIDDgDEsBAlLtCg4IQdDgdAQFHtYuKloTUx4UzLRhnrwBOSj8BhETNNKBaLDL4Ax4R6vEsNp1NQ0zaoaRVwlUqzlmX5749iTujgc9Xy5uqrO1LQs6VeEtHQeHM5WYjvMktAANA9oK6ICwUHSSDKCg6LwdHwTltQeBLOgtCWLDoCDgIDohB4OgdNpUhBYIFwAh4a0cC8BoDTaaKifpUmNI2KIrNnqjXBuEq0gIVDqWdNyTItxMvudfOfq8ukUb5tAlNGp7BiV3QiXQ6rM8dM6nLz6Jp/S1HP5PsjaXp+sZbjXULDoSJxEVoOwyREFBYEBYGDwLBQEBQFDwLBQKbICgQxQcBQJDgcBQeAqJJFiyBQrjtYwgqnNLkQdAYhpiGYBhrgn6fkPAmKM+x260hN2mUHNJsJuDkJsVahyjJlkeEDlUR6/M+3mQklpU3FSNTRbcpOqaxiDLCcNyt3i/pM1x8FM4xkKV1IrGlpdGUJI84a6SHUeTolgsDAoCAQDB0FAoOgoFgkDNrYtCmIDocAqJtOZRIjnEO0NAatyIlNKTa0UdzSHPWdBIGTEDdG0NeTMjgV2nRefYiFg6bQ11HQ8NZL0S0O1T9NTEI//8QANRAAAgICAQMDAwMEAgEEAwEAAgMBBAAFEQYSExAUIRUiMQcWIyAyM0EkJTQXJjVCMDZDRv/aAAgBAAABBQKg4kyvz3Jj8THGFERnfyUGMYbIHIiGY1Er9OOPSAks49YMoyZmcieMgww/znH9MTnxE85IT2L/ACYCyAkk5Fjvj8n5nLI7VZQDsrRDR2DLay4PIKInuXgiPHbDMhSgwl4XA4fPaLQmJmBwe4slvjyTlufaOdoTEmI43sZIgCyl053OZne2Y3G1h8dPaqnTjZ3YDHXWTNLatS8b7oyNm3hjxdXL85Hr8xPPz6RnMxPecRFmzGfULkYO1tDn1Q80F+ipi7lRoI7hY2ec75JggvyCXAs5DAdMM7+/CTMZVQZzYoyE/Iyye7+njOM4yf6ojIyPjI47e7O/jJcRQPPMRMZ54ga/O0uMCCnvdUcjYJtr73DnvTzzlOKePHkWURYOSGVRhifew1FE8ZFiZw3wqF2u4PeAcdze8/vzu8c+bjPN8e5BeXtq/YFWQFZIdwHt3/zyt5Yc9pV399eGYpswRfJTzxnPx/rJn578ic5zn0/36fGVhldfS3lmwrS9fb1XUIMxO6rSup7Vw1HOAPeV60otpc0MAuRTPjku1wvrhESPH9HHqSY4IZjOM4z7M9t3QQEEiAlH9uSPpAzOEPb6rGSi2+LhVA8Fb7oOfx/JWaDgdEP4yH8D51nn+1vbEw77YtS4pAZGDMSsdpESm4hTow/jG2SGPOZ5PPMRHL7Caa2MtbUkVcqaxSp3vd4q9iu9MPttsXSEjqXASoLy8C/X7pt1s91Tzz1DiI5yfiOZkqWlawtq3XapI9WdLnn1jQSsLeobklS58Inntm4SXxntbOKvePLrIQyxfXcZVbDMbXAwVV4JZWlwcw+Kc0aj07DW8i2q4YgwmCwmQeMGMkM7c4zt+OycSKefAEC6oBw1RKLPjOeM8328fPbBCPA53xnC5ie7I4yOFC+23YTXSb2+6ATk2JGxWXGGmCAe9ZgxLon4zmJgTmJGTmVLjls90wTwCOZxaVsUPjCXuEhsvZlcCecVvEzwScbS7S1sDXdcdS17LGVlJVDTgI25RGvp9O3KtHtVVwjAJH2zc7akYsaxT4ODlR8MQ4smvI5run9m+adJFJaS4Z1YVMdd7fo0ss6vQO1lDp2mNq30xtSthqeow160daoK7s+q6Vj919R4DSLAbBMZWVmuX97awnCVSGDhenJDkMHFvNeL2lsMHbFg7KuWRZQWRIlkjg5+cTECUzJYDBy9/JKhDmV98tAQzicEe7PEYREzOe2aYmslzEc52hXGw47xqrtdPfW1iPITcrgVp7FjMWkygmpBkQvtNZw2Picn7MGZjPLE4sBZKPGqHivlfI4wwwskfNKlNURR5c2e/wC2a1PtOjrJnCmBXBz3eGe7aqWyoaKy0d/krviV29YffSn5jwqPPY0pmddT4frkyGupUqcqnnIwf8nWLKK9b/7Jblqp0qyhrdLoovn00BuHSbleuVreq1tvT1am19T6zzsWti7MGTHcRoHlIlEcLD1n4znC4nO6chueSMg4zuyHmODsGjg7PB2SMG7VKAeJQ34z7zglTEpcuYsUPt8TZGQIcFhDiVrZiT7caKziw+rVjtsbNkxXRPuHhikSyeDvOr9rLMknmXgxhAVY2IhkfcMgyD9IwIjO/wAeckeL+6DjszgjFPPMfZjLQJHYbd+1KhRyrQVVwJ5hn9qIhefcR2viozviqpK82pDWsa74pYOcD3ThYhALMJ4yJwZ+7rOxSRr/AHnSJZe/aZ1tTU6W+pFotA8g0EfS06HcJbdo9S+68PWeMJdgBJYgC/IemQC5KY5A45n5njOM7ZyQztmc7M+ec+7IM4zvnOc75jPMWe5ZGBtLa8DfWxwd8XMbdBEjdVFyrZa92StDoOkMZNaVwJStbb9m7IatQTZv0wBC7NzEUK0RYb587b6K9Ok9FZ+sqWALVCChDYA01nWY5P2kqRwD5z8Z3ZM4M8YLeMF48QQnIuEcu7NNVNmzb3ZUteTMQhdcCn5X/a+eMWHMB/dsSmKjB8WmYYqUxxFFQRCr6CMcl+J/uCfuicjB/u61t16lL6p04ebCz0z4tMvplu2X07oNcdrU6p9Gr06sLCtVKLXDM74GGiAQtmdNBWdXKK8SMV+Y8OQtc5KZz255KSzxZ4uMleEkSzs4yQnmQ4zsnn7ozvjPjPjPj0iZw5nnumMGy8MVutivFdR3F4W3S9n15RD5qbyX7Tn2dWyo9RVaCKSaorrwMzHOSvJXhr7sbTNwM2Aa6fADFNQQYDJz4wg49IXM525H25sdmmiEIsXW0tX3RxnEcc8sVEzj/wAxEQCs2v2axg8dO3J418fEV4gK8ZE5ETzP4/8AvGL/ADZIhXXvRAWva7Fj9JRg36nWWcqdOais/Z6ujchuh1zqqOjanmLQ3xrDTBA3q9SsZsh5AAjOjrVl1ZTXLIqhx7fPCUZwcZ5GDnunRkXjz3gznnrlnfV4/wCKWeFU5Nac9uUZ7csmvntsmtxngz285NecJM93hz25c+OYzxznjzj05HO/jIu2AwdzeDB6ivxg9T3IwOqiyOqaxR+6KU5+4NSWP3WleFfYUFLrmooOp3ZETGD92EMjIlgiOXtzInT15E2tRVVj/wCv+/zn4IPjGz90DHYuM3PM6j//ADd0u7XLmOxEdqs5yJnmfwHy4cXHGWrdRdi+4rB14s1WCa0isSkQsNNTj9yse0RU+Xta0XpVV71+2hcrpMhdVqQHVMdKjlsTPmyCdne7O9ud553TnknO8sls4Vj4iyUZ7o5yLsxEXecXsS5jZTkbGOI2QYF4DmH15zyJzuSUxAZAhnNfP+JnbUmPHTyU0s9tRz2tLPbUcmtSzw67PFrM7dZGf9dklU5k6eSyqOdwlAqrlgKXnde57rcZFpoxFxOWjqW1o1+qXCfYJGZSWRATkiGSaYyIVkSrJVEzwPaJLiNogretLW2PpD9BsW0ldHbWJDU2oH6U7PpZZ9OCMmpXjPCgJ8ohjb9rhDpplFxlyYs90JiCck2EOynuGO0abbVKJ82V7NZQ/XrcY9wLd5Gsyuib7tQBeznzZDGwPczInP45ztVnYvPCHHt4w60cGiIGK8Fk1Jwq88EgxmfKOdzc8jIzzHxNg14GwZxGxmCHYHOBsOci9g7KZwb2RaGcg1zn8M54ALPZRns89qUZNcuJRnizwrwlKzhE4wRCfvJhP7Yix8S/4G8cYN8oyL+Rfz3ozgXFYNxWTYSWcUzz2iZz2Ezk69+Mo2OPDYiJh8Z3ujPMzPcNz3Lsmyee5PPdNz3Fic8z88zozyPnAY2MaTONcpwOuEVqup7TIJSmbJD22rnjfCFnhr8ZHExPE43xeTzAKaXYsKdh1unF1oWRKSztkx92tZxfr9w20HMtDPmZmIye2YKBnB4jOJnJiSwuMmI5kRKIiIztDlix4NExAhgjMRHdnDpmBMcgzjIssjItzGe9nIvYOw+RvzkXsi5Ge6DPImcmV8TMREQB41Izg/kkwUQiM8PEyvjC/ugJKOyc4LO44zylnmnPMWe4nItZ7soyNgyMXs2CUbTI2S5z3tUs8tIs4qlkoTntg49qUQaZGGQ3mEzE+HO2Iwh5yO0GWGnBVtwdObNuz21HEywTq5vil3qdHfXlTBz2OxxbFzkdOWTXrrKvZaNZBrbbvb21PVZhTfGXwzCVIT4/GXD2yn2ezSayqk3bx4Nd1Hr3bOKdFkTq1Tk6ghw9ZanC02ynGavawJV7wC4GwMNGYkhz8yHdGLP4Huz7sgSke3PFGFXjj20Z4JyRcOQ2zGDasZ75mDf4z6gMZFuZxdw4wtpAyrZL8gbAewNhHdFmuYhKOCTXZnteM8TBzwxMeCc9vM5KCyUlnhLPEWeI8+YyO7u+/PujIYyM8xxnuGYNiYz35xk7BnYF5nK7n3BeXGRcrzndXLCTmyrm2ScXjIazcRXVbftKLdc1BNZVr7bmZuBGKO68+3V4kQgbj33cM63k1Uca3dTPalrVNr7dcwJx4gtfPto4XyJQfs7VjtO3NQTjXdMa76m3SXKWBb3taA6irRKdtSbkEcx905POfyThrgsbTqFlzV/9h9PqTZ+l0e4dTSIh0yTJnT/ERonDE6W8wrevuVI+nbUBZS2PE0r0xFawAl8QZIz+KRPwxnFbJ+wSaXCixbJ7xdMSNwowdgcZGy4yNsGRtAyNpGfURnI2URMbUcjY1zz3dSck6+RKpwlLOFJCZ9rzntZ59pPHtc7Iyajzw6ThgaLAgKrOfb54MGvGFXLCr2ZzYKsJU3ZVkXdayztJddWpBbFuDaawqNMZWvU32E/pa/ZD9hbDDql4xtPrqrxzNaIGptJmVxyvIDtKpdr1NWi1Xs5BMFaaoEt9f7deR+UF9r7qSsLp3vcplkJnzoeLdTrm59GcjIs9SVMDqVSyXudc/O/vzsGMstFCUXgK9FxZZDEFnaic8I5w/jy2oGwLrVsh5xot9qMRETHpY/8A3ZqFTmwbr9bW046dVS/X0RlsdbtSs1w6geWr6Wv+2PpbXVcLRa0TPp6pGRoowOmzIf2nZLJ6S2MYXS2yiC6c2uHo90EfR90U/Td4Oe03sZ4t0OSe1HA2F5efWXxn1xmTvXTn1h5QvasGPqrpyNk2YVsrGfUnTn1N0YN1857uzz7u5nubEzegnr12oc7ZT0/a19G/WMWDD2Tq9c8LDdt9PgOoXNxPUfa79xPxsCuvy3iqS1un+INvxwECAnwRR3syxTs1irbKa6dfdS4Ieto7Co2tFWwFlUNgJdE1HUp7cNakwtKyjsaOS2YzzGeP12tbk0Pb4u5vk4FqztWDp7AuKlshz/sF579o5G1HA2sYOzxu7qVpHqzXZ+6QnI6luTn17dnl/ZdXupVNp1MW8LqXZZepV97tKmi1kITrtfDNcDa9bshkdoBFYjAnVOM+6vPh8gVmnzPmSQWYIRdEz9s5KxLDrRkLIcjLewoUBLd0cLY0uD3SRhu7rlhX6jJ2l6a1aau6apOuszHtRjPLWVHnIoHvwGlGe4OM92fLL9pFj60Gub+96jGXuslbGLF53ejfXauK329edzb3X4OykWxe91C93WFb47lI+cUEsm59ubBRsaXHe0ftmwEwFl0og2mC7x1i13U8MmLvei4e+huos9SWAKzdiK5bGWNRuyXomHfWdXqec4uRitbYsZPT1vI6bLP22jKOrr0HQHBTHxnaM4VWseHqqRQemq86rXrqr+7O6cAs7s2llq69Ffi6x3VwlV1dN6yKzOkaEkem3dR3d1KAfuFlXP3FqLQRaRdxF8eTUshhbKckCHZEi2IQxBPfREZ3WpXk9Savn61bPPcdROy6/aIzddP29i6rrmApdBBAGoVONXr6AiizcxbKWvGxtmTkse0vH8KSMiCcivOApjWr1FFAyqtXXsbFK1susne3wG/JbW8Q/eaoTUqw99i1Cqvklei2hQej+z25ZBSzF+3Eag+W9cLle1cyHtPsw5EY8ffgl48FxRjY8gx3rmtfJM0N8tjatiOywKTGqvkbFmI1f6ZKktMI8RyMi/UaixjtQumE19wmCuJXld+qsYsJEiOeJn0ksH5WPyyxuLevZX6p1T8LYUyix1foKDUbzWPmoXvL1Vg/vrWlF637heS8cNsfUCb9zGzZzYopKSxOqnJGmmK+52C82HVXUtLG9V3gytsX7FY6mtZwdLplYNTXKz3cqx2zqVRdsdjdFFZNXHVnNWgBnIWNcm7hrYTPhMnsPJHBWDnBqG5OrVg1a4ZzMDJZpafYJnEH1P1Xd2Ww6Skpnq0LBL+i7RmForSwMZJ6NLoa+DGtTnl2DYPWbAsKkCYOzU75PvOCoex0xeXdWp/g2C2ssnLoPy01sloCoGJbBKDugjkQOeIP7KbW07Ct5FnK+7rXRVDAzqC0zXK6b6tpiwd/VmI3iOPrPON2L2hF/ZyMP3s4v3/kXOM/EZz8zicVHyzWoAZ6S0fN3pnWiTem1sJznJVU2lDXpPc0GW0dWVpXPV+sKJ6uWcgzqC672HUrMDTW7M3OmKVajrdd0W7XEHSdchumcOfezetdX1tzpqmul02t21rxrryxKzvaonumtCvsaInWuaxmDa1o42+2SdZDyjoNzewekrMwfTdWu9jumqp77251K8lGw7sMsmZz5y5tR91xARuW+DT6OprLdTSLqpbva7XTGotCtqCnE+zHdTuNf7at1FYqTY6r2jcZsnswn90QEcXR1xyCW89PthWXZ/i1vTU3dDsein1w22l2GguLUEYI9kwZlkEZZ5z7lt+41jzC3ds2p8dPdWtezYEXU9DQ6QaFnyyMS6M9525F/vZ9QCIHYVso2BYxZfBTyMZEZxio7cAfh238mfXbDclz24Sm2GMGfPfrr21f9jaeGUZ1Orrh1VQVljeaq1JpU/Eo3C4XU36YfTuvR0zTRU167C0wq9HD31pjYFr7Trt0HZ0icUqrtxB49qGkMWrMp6b3FoldFx2L6M1BnuP06tWLGm1qdNUNsdzj4DqRrMf5vPReXtKLiZupn4KckpzYWfbU+nk+96zJnGdYtKv0307a1dXXa/Z1Ltjqa4+ghVkrSrR5fHss/GU6S7zf2vTnGdL1ByemkQKulqUqj+NdKlYut0IiWwuz8Urr4HSOsBuepOka/UMbTW3NTc83bhnMYuZgomYJQxMfxzJNJROZ3zUmM6a8Z3dFcWkjvTM2LYlPul98So4lCZgqgxAeZJBZsZR7fafwnnt3ZdKzUVO4GMHeVRgihjjT24tuwlqkxXT2/wAm493VZDrr8rrsi4W2F57u9kWrWFefg2LBlJW+KJzrW/VF5GzDI2Y5cfFlG5i9Nf8ATygrqI/2zplYrUaavkTAB5f5bLMrlPmcXzM8nM/dYzqez4n2OMBJr1mmKZ3eFhF2x1JMxrf0/X5OonMOV/qE2R0VZDvD0m2Pf9YLg9f7KunWutLrTcJZ3IzSTI2YYeHJ4RfAWGwGx6I1dothrNjpa+pqq1qbv91Tai+mMpAFOWk+qunn7mq/p5g3Z6U3sVpXwRCXPZAAHzktg4Eo4W/jOkfudqpLy1d7f14o6xrYHVOtWfuIeaLZu2IE+c8F2cCk0sMWBJbFqJVvY5duEvAbWgAFnrmYQcA+tY40ym1NowxyYxtKhZNnTFI4sa2tVgqxsn6deXDGK5Jw8K8Ocp5syq7kUE5Gsgs+knlat7PHeOa/Qs9lJgsYwzmJ7pgQL+Vs8zX58jZz8sn+61Odan3HZWaw2A+Hpfp+f+35w5wjgM6pL/ifpqqODjnP1MPjVa9rfZaome46gLsqe7tuSw3hlwyY4c0pwFn3bMNhMkiicG8gRK2UQq33Zep1q8PHyW69Cx3xtrVWa2w1dvKl325Pq1bsWdU4Z2nTmu2U7jpG9rh+jXmD7coglz3VmxDXSsY6NCIVQWSqAVysG1YnKpND9VvF7BVcNqe1Slsx7OJz2CiyKQe4mjUiCpUu6pXX4IOwqWNhkzZr+2qxYPNptI15LIWhAR3bhHmoPo2WJoxbISZsG4CjjKHlrJ9wg82BVhRpOLmuOisS/aXUFhSukhBDOl3QP7SGM2HTeur6voouK6WYZzz3/aBTDWllWZ8jOcj5b8SdnOrBN93c/wB3UnaOo6aLjYThzknA51Sz+T9PV+PRf/b9TT/4y7BLzp245t/qaeNPGybOE7uy4T34AH36z/MMzhMweCnzDlTqbamWw3lzWYq4u/Xe3wW2WBI1drjUBVrWp32xB6Opbis1vXUWL1mul2NoTljTJbl7pyIXs+l7dSE11+w9lqa1nUM1TFLJU9PJZarpk1cqrk3O2tJb1bIf7+7TnXv222N1l8FDX4OyXjNovhVqpMTZqTMt+PPXCEeMq2p1R1la98NRhLhkTWUJUbHtsncIzYbWiOvXLHICte7z6dRtD6a6ZqLrLp1aFrzz4/NPiM57WlPbspktT0d/hVh/3c/Yrnyt+cq/Jng8S74k7OdQNFW3uN8udV8S/pSf55w8mYzqN0He6OT4umZ/yfqYfzQpU7UdP9g7bqEe/SRVfMQlpY0PGMZXuqpGPUNOJ+uU8Rt6LWfUddmkM0t6l+h350ihVrX8zat9Oa6pGq0tDapX0nU7o0LQYPTtxeey2YbkN4gJHqKlh7ukeBsBIDBJ5c0tK6djQO9501rh11Lp32IUX6TXbStsOirNI2rTWPz+MeqY79lNxQRRtAWmTbo2a2kv0t7a6lAdUrSmhpPs65QpmueV6Nqxj9JuOKiXIrpOZjU1LlMhn7ZtKjLOouX7Bp3eshcbICrvdYLXFr1097Y4vdPz5NzpZ7ct90247vHz/Af9jP7L0c67pCfsX+J/PzMLEfI34ipjOIxURL+A81rOqp/7QQ8g9RN773SMc4WMnJ4nNvMTY0oQjTf/ANP1HLm5395aQJHZ7cJbpx09wsDSCObUARZHGTOd05zzmpWDLXs9dmj7FJu6yoUaIJDVtaa7fU1W1URot+Wsr7vfbtezDcIoKTuNPamlLjtpoHZjaK2mlhu7TKq+3WyWb2jVZV3cPzZ91Z+rbB61HBaHU7JutuO6kQaNz1VoLRFW0Rr3miHZSvWacRr6zVr1Op6Vr362s/Tyt09HUXS+1s19DdVqb3U6U7S4KUpPWdSs1Or3/VuxsH0/tXXtXTu07EjZTJB25PgRi1TYrWVJFAeMGaaspx/Uuw7GvXsLmnoRR2OsmAstuVm24/8AH/8A4n8i4p7Ln/x/SOL+YP8Avj4FPEusfirxy38KiJaviXWp+erJ429BUnm6nm10j96zxmF2zmxLvwQhQjP3/qBUsWNwqLFbKN1rrNwuNZO7LB28Tm3KfKE42fWufjzzsysXOBate81s/wDA27PADrLLBJdJNA+1t6tYTbhkhOr2ewDY3NOH1LV/uDc3N+rTwek21apVu3aO0Qs6Olo7e4VienR7NDs1wennWbSqw6b6GLsU/LT37rW46qfdXa0XtR1VK5X+mzt4HWULL9hPVR7Mk9M9P19LUtNq2s3afpt+tp95fde1N2hDtla41mw9nao9RwVDa9Y71jelOrrfvt/1BCc2fVFq6ep3yfLV6/6drYXWPTU5serNfNLTdbU+XbzdX7+r2Kdrmnt+6r8cKP4Fv4tf+J0l/cvjC/yccAiI8liMqxHLsVAy0P8ALZzqvs+ray/wb7SHDqWjqgQ4rKGYfGdvfYkuSA+7LFKjdH9v08s9P201mDDtfseltxrM7xDLEk+AoW+ye+C+c+cGPt5nLN0NkzTjp4T9vh6tOBUtnB62zMVNa9Bs2XT9zctu9JbTXiuCs2OoNuzu0cnW6L8rSciBBXdWmztDnxPKedKobOn2SxdIa/z1+rKt5VfQ6G0Ne3prlfedV1iMIQlesq6RE6HWSC+ndY5DT00rZWsP4AFz4X6+uzbIcYjs0HcPdasde2OM0jiVWtkJP1/M3eqEjTtczOJE3M2CfBYkfgQ4rd8FlKwMrTeq626W27KTHMsYjq3igjql7Gls6FoOk5iGRtdYm2+xWUx++0tfGdXamsS7Va/XrR9zoym+tZy1v9NRyx1Xsrr9je8r67XYd3iKbwlg7Eqjz2inm+RlFOO/b92AfEA/KhAZW57qMTHsrGhZXPadP6y8W907dNaQ81Mu8CfOf759E10+TWJqViefanrM/wCasuWM6a6M2mxDXdD9P6rLFQZFNFkEXSXTLQ6i6GtaZVbdKV0zZUpc63UUypHTSNna2UnlrvE9S4qfTW7n+eHu1ml2G0dS0Wtm52au8w3s1UPt6LpCxsc6iSeohu6pV9Zrp1123N9/v732Ku7ltbKRWNkdq4tEjtFXLV/TRaCr0pUJlLXfRdTYOubKNhtW1sbC7jKlbvbSppXGwgRvdM0PdH+0qHgKhYVsK3THdXVCFrBlRRJvmFlb9asyhkCdpsMAhUorcjLdk7K1bqG+gqW2hnSe0fqSf1mIuu9TbS/Z2bbTRVX2HlYDhwWGR2FezYuzZZi5SEtLk/HymuM2sQOto3afUIPhRiYxlOPtnmEkPfS8ndjFqsL69166G+2mn1tstl0/ZpB2yBZznOW601ndJ07DFWvurdXlzsdPrnbXY9tfW0/OTTE+TkuTl0EUPGS6k1TNFsqOrllg396djWY9ZwjlNMxvzyXS3UjVwv6md+o6qFnVdMLro1VllVi9en3GvrWCbnXc+S7t6LoTrtNtn0tJodlWv2Ig8fz3jPhq0aw1wtu9p1TLZEgbIz1PSc9WoonttjtunrOiBYrlup6QVaRs+m7tZt7X2tba6S/jpqs8R1lriktZt4bOx1obCGnZUfcUYLDhkXrAAvaunPqBZG5NuTfAsodVFRRPVr2tDdhYwNxPdNpSBZeUdv72OgibTr1LVhiautiGwSEODjK5r5ZMPcdpPiUYsknGb9HtDpsrbGlaivJiuGYH/hotB4VOEs/UqeN5br17gXumrS03tcVew6uMFPIz5Iy3eO27oyupPTjZ4p9VcfVP021pFl6SiJHxrR8enM+Rn2O67qRb0PTIlY15Ml8Ap1U1n5guWJrLEf8A231PInstXq7EyPTG6Fa4f7GqLpZaJyttq6t0trCvGRrqEN3fuU6Log4ZN1LYDIP1lYrtOwfhjqECm6DPOqD+JbEr6H0i9XrevrBMv6elOw2FICq1Gky1uet9P7uv0lBLqE1uvOpaXxaSyld09+tYnqrUxcrln4gY7s/EzHyPdxTpHaK1TGoGI4guZ7he9ZR7giSbGEd9kii9WqBT2V2xbKwFd1hmqN1tlCDlk9vl8hrNlbD8T4qFKy1d5MDp9xUtNZfhTA/8WpPdU4jP1D1rbNPRbtG7pRm40lDdo2vR1yrDNULMnWWYkQOVa4Ir9PW/7OrVQOw/TwfF0vdLnLRTKVcdhT25H5tnIHueH6Wt4qeuOv532BYdcY8dNvZaWmvzru1VZgW0zYZuXvCa5sFDFay22yM7KJdZvWdVxFWtsCrXGW6xxSDZVqhTVqXW0XDoJ8E7fZkIWh/i1slNDv8AuA5Owpndd6t8n1rpSz7a/Nke120ilsLtt9mNbr10k7Sr5dfG1uVBOLdyAh62a7Zmwd9qfZGiuT59pK0Vqtq21GjsSf0NNh74rUwuivteHYVHWXb0a7py5YxmhE2ixZQ3ZS9f2nUZWJFT3hIXNt0om+6S5lg97ICtdbSFDZuOU6pJbMV4u5HlooTVryTSswH8NKeafOFwUP6PqCydd1hWz6j17Ux/WtxTSHp/qUP2k7CsNLOmNjffdt/mwA7za9O0x12lHwsa78p/8chwvtK75Irgm1ztti6ps07hzRndLFb9v7stRQ6fz3VbWLp7SnRbsN7pYRZsAyQ3PiO1rmBFyzstbdt174FauXVV9b33VnVFzjdotDF/qezdxrPnX6UHaHparxpulpAt1Yms/IPuVpSh2+SPazrRfn2HTesWdBoqKLZd9nX2vuQmFB8Et2lsua3QbOrr3NJQjbZE6gqu/TPQt4Nhc6MrVXa6P25Gx2AVwO5N1TVrWNoLVWHDTeytYqo1bWbFQUrttWa1Hudu/TKfjKdipFnv4fQuVQ+OwT7YW3+GCmcZ3Bld9MNXrFDas9RAmmmsPfb80qQmpbYxavG7UPltGJ/oiSCduarGpfYtVWx1DvYgddYDOlqhhfsRPmo1fHfo/wA9FfbMun5X8CzGcRMz5FBr6al7mjsJ2x6ndPONJsXU19OLuGz6NULX7qtSfsUVduQVtQ+2+a9zY61WrZadUbsJcetRlk9Q0dlUYVoNjeot+rlhRJSPBjp607a/1ASmFWvVrB9Bl5q2ycArTnS+pTTpOuQbtlrZuUqhV9Jr3dX67h275LRNZeu8S41l9pQjzrFtqOoRanaeTnOk7Tam62Fy1ePzXbtm7Z0IMKzrbZ/TpG8Wr168tU2WQXU11YCJC8c6pZluxoonSCvY7S1A+IHSZnGrrr3Vu1swraE2z9P17E3tOGtqMKDL7TxTPC+kDdhs935pPXtV7hHa2t/MkAKTu6WZjVRPpPpJZ15YalP1G+yfe3MjNLEeVhH3S1QxrrNd2uYQY2JNs/BHjPuOqUsFTUjcD+1aSkNpft0q+p017fZe6Csd2k/TxVcx6M6bTOxs14nqLT6rUVtImju9pW0tCovb6rZ7OpXk6lE97Upq3tqiVWY+2fghjtHoAY/cDXlsb2onvtfp5HGi3h9tHXVJu7N6ImNgArMDkS6w4DSojtYz+zpn/wCWiZYmwgynXXE81tjUE+pKtW5tNhuOnm50ppK1TXeyZYRbCsYxrqgtpal4WPpl6MXr9nsIfsG1GOLZ00Ms2L0qqma1132G66k7R13XmzAz7MFWLtpoVtpa1+s6e2JVlDp9YNxEbeC6PrRJ6HZQ0Qk80BeHa72mvcLodO3U7GqTprlYmCj52GpP/gS5SpEomJnJyc/UP4Suc5wKyuNUsAyxHOdQurqqdKtOKFMJTSWMkfHc1/aI/d3UeebMKC1JLEUdTp16wKqON6qpisN5Ouo0+r7F5jNgJXthtdfero6E3DqEaLQCvp7S7cdjcscW+pO/W3dnYqWaV/yAcB3Ef+UxiGUdrf1DaXUuyomXXG6IdX1TtNOj933NorouvE49gKDYtiFr8TI6xb/1gce4nko0fancLnyA9scJexDOmX1rmdUVa2pVpR8+2u30qsvWFxJ6aitk3dZREtsVkUPUlNraPp2HbF42tlte9Irutmn0d1LYya+n6OqntmbRFG8VcqGueeFdpa5ex3dg8CxfuwNOwGKr7B+K6ZgZka1Yb1nXKrdNv8e881J2fSdNZxfTW3SDmXaZC5RXtb2wnZg5mHLk9Phau91bdOZFG6+0W51VTb1Nn0ns9WXjbgJrjlXx83Rg1N0uvkKWq9owNrsiZO3eqC6gQmJ6iXZSqztrWVtParRe6lZrWarqYtlfudVqSVjr+xC9Tvtbao3NaWwvWKD+ml1Pq+0jqWxZfsaWwt0bDOrtrbOnv+tIVY6i6kq227S5YPfgy2F53mvjEjJ/5QKYwHeOAkYyKKyg6KoxQmo+nVsq6FzDId2yQr1j+OrS5prj+US4bqNlSE67YgrJ/wA9n4t9KzMbvrbats7LpmsbbnUYHWu2CuVmidi1NWinXq+rNZjYGwtXgq2LNkCehybFxHUA6eyfVCbdffaU7mUenNC5QDT1y2pfZBmhv+JOjCvjKiU4u7o15Zt2njX1t8nbC0xzJ1ZWSq62nXkdvsKM63aLsSmyssVedEbHwjvqr5TAlglnaBZNWuR16Kaxn845MFk6WvM161PDSiu4whme0Dka3OBVjLvEOFMuuM1p1F2ldSWR0+o2+1rVumlxdfY1dSD0St3W02mV71VfZjaN9WbVrZBI2trdE6GwdYTa6XtW7ey6d2GmZV2fUlXK/Tty/m81VbXXENG/qLH2W4LmYiJlGqbYrQEZRoKtB4ZGCD4WA+4TerlXtOCtnUGwSBB1FpInc269vOyZaUcFreffo80WbkiJ3/i7qb3051u0y9Y6b1MVVbSuqyV0aov/AJIl+zpJxEm4bliqI+4VFKyVaVL2LePpiorrWpyentmR6jV6vT3Wt0+ur4Xuyi/aQqL165lkWzhEBZpukLd89rsa6kJcfjijasGGptDk6Su/LlK/qiq72wiNZ1PXdlxgs3OiNBU7FRureOWjIU1Ntfa1Z9wThRnjztNkkS67KKWvejWsjDq8wdZQJcxAHplFasN2O8sI+pe42Fy1eNkVqNmVWNrokqba73Teek7dt11tSklSLNWtWft5Iquu1o116im4rWo1FVq6o3kLQkFbTRaW867qtdrcYZTiy4kBzXI7teSzWWoSft5QxZGA9siwm0Nk2mk9+5ubi0/YllP/ABnJdzomGCua50rMurP5JV8v+ayFkGi0zbNinX8MWapvfuzlangbm0xK0TGjMyKRsOmtGOt25dUJFdV4rHYgD7en+pk7gtZWt664l9lWwspi8LOj6TDd0XBL/wDTvVllfpnpvTxeKbGHVYEp2D0Qd0XCLEDhuYvNsGutiu8+uVW+Dc6dsG9utniFkFlAiaT2TQUk+2Y/Gc5Oc4ujXCdihTdnoI/n5jnmIzZyfsrl2tWHR7B+y1dqyhkDs6tBOsO3cyzFnXsqstEm3YayzGvs+M9alVlyY95YtClOttDZp6+HVDvWHqG1YoAq1XdObC+3m86oGdS3oYlk8kP91QfI8mqhbDRcULFiIv8AMbgg4D7jaIgrnPEnJ/NWf4SLPC2wZIJyDrLq17S4VrrRf8zQJLabRy69TPLwsnILN1Mt1qrJrNViWxqresRF+2FtgV3rZYCFO00V2hevj7UbPkqVL9ig0uuNi+Nx15tm7D/1S6mWqn+pu6N5dcE6bXVtnlu9snNe72RO7hUK2uutwVUe1qrKpG4GfVaq53Fyu2u2O1vRdgmnWurr3ectfzB1Um6/XDtb6HI27zX7gBgGA2M+7LBR7jQjxETl/apoZdXs+oEj0/rtdW+j6q3V1mlnXWbbKTU0HlSVseprUZPUhWmDsnpu6qDQnlzjMbE5e1Va+1dhesivoWVpva2oU3n0mtsbnRhWLrCx50baxds7vkbzPuaMZEfP3FHgDiKwRmqiFnZKfbAztl0/xTGOXJi1fjJPPhZPbmgEF0qeyqOvSqbNjd3AnGjPf+nqPLuTAbOwZCvp0KlYXkc5/wDZZkAhAGOvabKltkottsxMqcyziUCobT1W8FUFk7gS1dhoNcyAgVyvzV7qUxY2QvBtgfGFggFltTCkuMqX7yZV1BYDGbHR3MPWqeLta+kL/wDN0UXFjqxhoXrbobGjE8RHxjkIsD9AoLJFTeUdhuVbDYUzjfAcZJ8no45RUbZWJVbGwB3RWibm26a6l14/XWEoeoZrmfUCmZY2Q2EvmFmNgG50xWjYb5rMJwNDyyK5dDJ1GkqhsX3UBB7QGT1lpH+7A+cgu4dPygpYeT/fAzGfMxEetSeGunmqsO6G8xGds5ZnltTj3Dz7Jmy0509E625sH2ZsWf8AFI+/Ogw8dfWpKJ8PZr7ncqrY5JtgfFcH8LhcS+x9j+9yD8ysWLANttAqQXMLcXA/EuCYl39iikDs11wXl7ZstBiob9vIznagsFP8gl3ytWolMgS7Hub1tDKpMZ0gUBd60+3WdAbPn0XP3TPGd2R68zGEDxPSlsDFdSmySvJUA2XThWlsXvuiq4VKVwa52n07cI1rbobPp3qGgjT627uX62/rNLs7F/tb7tnax6imTZwO2kR9wl2PsxxZ1ez2VEP0x3Pbs+jd9rMsgCYIlkcz3MGMj4yMj0X8GxyvaPuOUS7hWCjt9Gf3a+OW3a3/AFc508dht2zPDNjac1ft2Z0wtaOndQwQm5z4bEwtfZAbbY8hsV/jjmS+5gz8/wATJmp2YBqnLXgFw/OWAGF90hDnM7Yazyf8gYVL5ZZA/bj7fJNHE+TABpGKI57I7Gz/ACp5kNZ0MmxTq66zrdr11zOm0uwmhsI+cdPjY38/VqoOU2GB3BM8TlTbISNvqqogbO+TZnWb1wHrrYbSsRwOOvMTJW7Cgv67WQrW09PX2FZ9P293YFUXstw7cMT03VptuHTq5G0HKuxXZwLQNsbIDrn9WAs6f1IV6z9zrKkH1l02GbrrCnYR/cjx+OFfc0IzjOMiPSw94gvYL7JXBYCgGePSxHa3Wj8WwYxeaa+Wqbc30Pl9wm5WqzefNGhQTpIU5O1X/wAe1AxT8dWG9YVayTTPMROFH2hGR+Un2yr+eWa1meKF44z7JLjLBLwYGSjzTgeOCb4oWLa7Yga0QU4KhyDTDIOrEWD7noYXGg8VjQ9Qt2dG/esbW7WETXnSd73+isRyCp8lXqYRNFauKm1txtlZPV+4GW7TV1wfsydKbkVydsW2o/TC6YzvN4hufWYdFvaOs4+3C8ZuJEdR1PNJhizcL+o63RiW02liGORWmN0uvhWggf3hon07fWCvGO62EZQv7K7d6l2T9gaKaJrUpI3faUpD+NahDBj049ZHnICM4yI9Pzl0e2xrh4rsjuDADgJjJHNTd+mbF3XSiZpOpdRKL/W3SQg3rtZa39/s8e76nbuq9ZnjyMKeZGPiIwo4FBdmS4hn+F8FruMegu54qKB8UH5V55F4RgWDBFnjsZ4rWCi5Ge1u5FLYZOq2ZTX0WzyhT6koxsdR1BuC2X/j2Fx3fp1d4YcZT+H7/pSu2uKdojD3N8RZtGSyzt7QKc0O2podrsWUf07Zlfp5esHZardoM76aIHtXsE2d0kU4TvmdrMVU7JyxZctnnkLsOrDQhVqhOrChsd1WR04SKPh91p6tNdypVfv9p7G8VVMlEuE6rETJL4+YyI//AAzxEXZ721B7K0x3DMa8RVImHGSMZ25IjjY4A4zjCXGCscnkpq2e6OOc/ELGJw/yEZ+c54zvnnVrO41PTmoAB02mHI1+uXkqrhnuUqzc9Z6nSrP9UtZk/qlWjC/VJeP/AFLJeav9RNTawuuumIyeu+nsLr7p+c/fmkiepN7S3dq6PE6PbfRtlq+pdRu1smVMcP37CiCnDXCc9orO6RLp7RVU2b1qvrpR1Uoq9vZTbm5bTy3V66xlxT9fZ80jjHSXojvbk+QCGXDEMPCezCsng1wbgpiMT0Uijr95sEyD2DM67Y7IKKH9jIYJ5Pbk/wB8RkRkenGcZ8z6/OMHuD6Q0sTBLGeeGVaBQoOzOM4zjOMtZx9ih7jJBRhxnGDHjCra4nBj4/MhHx8ZM+kEY4Wx2hA65u0MvWbfkkyL0j0nKavI1xy1vHqI5A/GrrxYvbMeM7pW5V9LF14upGp1rvdWur1T09uF+OQnNEjyWq9945et3HrVfTBMs27BPssDPKvy7lhmUnPoqmJLTrq50ItsXn1DgZsPdi9M0cU3WUpDfPHA6k24xd2my2D79dSE6sir3wtPHE9ne2VT6FH3ZGcf/g7clQ5AxGduSv57eM7ckc449LkzMwP/AB6SiY40PECWwMFfkJpdxcZUt9mTHGDGRkf2zGRgq5US8JfxYVMp9IzjJ/JR7al6xGCOcfGoWyE7XDnk0BMqkpCV7S/OGdF0C+zrsjqzecUXzXSd4iUp3jJzfI07wkNhhNZVr7GSs6LfXB/aW+yOl7wCGj7cmhQgJqdNqybHTysO6SF+KxOe1dKArDGvPxyKeRbbste1l7striZCv2+Z3wfP25EekZxnGcZxnHpxnGducZ8ZxhDORznGSOcRl3jmpV91VqUCSrxpKIJS4bxnbnbnblazKsgwMR/o1wx7O1RiBJcjNgPHZlA+ZtVyowfxVV5n3HeZ/rEYscn4zpoVjptrPBR8zyQ+nMjKtxZjKA0du0+n7QkXUezkmbSy/B2NmDXsthYz3d0Bdt9uuG73YnlZjSrBTliw1FJ9j23YqFQMfRbLp/bb8o1pQ4WEqs9zJSLf+tMkiPuBYNkZFg/avmcV8qOOSP8Atj1jOPWM4zjOM7YnOM4zjP8ARL7s7M7PmYws1+qVsBSitQZcTZBZi9uGvxrqi2ctAoS4mc4nJicCWLms3zBPPP8AqMrbUF1/r9yXWg3DnCsgY77G+zmBtVCiR+Bq/Yr1iMjAj4POnw7entg/uwYyfQvxlIli6Nn1CEW61Cuxo0wNvt+5Z1UiLqgZ72j3xstYofqKHZ3IrkLy8jHXD11/2i7KfdXHvrorijbVgvhc4qvYsyXZb7cvkakB5XwLJmOIggnK4/YP3YWRkRn28cZEekxE5HEZxkhzgh252xzxGQrvLt49O3JjPmc7cmOc6flnsLdypTnZ72saIj4GIiCGckc4nOJyYyZKCr2GVpVdVYyI5z8ZNt6rV37rKARC+xXfck/deW4uwnZ134+iLclcqrekekZHxEznTv8A8E9nkP1OeZ9A09qQ3m1U22zuyf7y+An/ACR+IGSmFyOQUm0FFVMrdj6aNasLBAxBnuXHWUJv9k08mlaUC6hRELERPwgqS4Eq0A1FMwA1+OQnhn+4yPSM4/o49ePSMnOCnJGc/Gf7mM7Yw1iWeEcJUc+OIyYLOPjjJHCDJHJOYKYXOEMjNO3YHBITF3JHMDGcEcx+TW1tyGtIm3UXFA+vxX/nmxrMMDUUfjFxzJZ+Y6bj/quPnOcIvTj1fpLiRLXv7mUHDH05xDFIe+KdeAhVIZianCrNNZRY1HD72r8cbaoqPqo8/WbXB7XadpWLRyM8mMfzDHwI84tA+NCZnDGVV34U8H/uMj0iM4yM4z8en5/oiZyJ9ZjO3J/GdvMQo8mMPO2cn8fmJyYwoz7/ACiuZERgpgiWUWGwEEycLkI+7KsR5mce4isfDC7S4SWa+Oc7cNIsF2tmMIZHA+M/OcfHTP3a5pQJ9+SUz/RGcY65bODc2WSZSrj5Epz8BEcyqFzVGftMhyZxAwbmD22V/wCOGePOfvCfvGi3j2/EfxCuugsrKy8fEvzt7oyMjIz59I9I49PxkekxOSXxx8ZxnznHOcfExGfI5zznzk8524J8SNNzYMOyeMkcaLAYMcYHBnB/MMGA7inJkuPnKauyI/yeWcKp5WEtQTrX9hmiRyVzGcYxC3QzXsDJGYhEDOaEVKTdpWVO7ZjOM4/o5wvzz/L+Ex8sHntOPjn7yKBd3GS4WwmRWdwqGDkwJZ4YjJEOO0e4AXGCuZztngVfdVWTMVELB7Zkm/gP7PSMjj+kc49OPXiMGM4zj0+M+30/Of64mMmIztzjnK3b7S7XIp7YzjDjnGKmJL4LuGc+zPJGSyZyuj3B2bFeMgquA+sMld1vbNxeI77Sdbc81c0iUSOfjJiMYsGR7LtZ0/8A4m3qd3LvSreH1X1WcZxnGanVltWePJUGdi4wVqLIDiSkBmCwinOTnO10SAtw+OBjvjws59myc9jgIAMIRmBWMQMV+KZqYxBQOWGsIDL7XTysPxnbkROcZHpxnOQM5H9H59JmYwRIvWZj0mM49InJ4nOB5LunAZYXhUBmArir0kcJcFDK3dPkic5DiJztjBCKFX75zsnPEOCoM9vmjlacGC1t+DKMIFtghmP6ND8jaREvq7B9Qgt6/Zru9LAWWaVqofGdMeWveLqbWCUjhpXOQIgMdonzXzvRGeQIzyhnmz3BZ7h2C2wMCV1snD+fEWQic9vgU2HiNLabNPQEmHIo0UluKputh42zPIDGcZGR6f75jI4z44/1GcZx88enGLAcO3WCDsgYfHEQHb+c4yc7Ywu7OOM7YyRztzjBAZyQz/U52d2Nr90eCc8UxFOv99phPPsjIHO3IDFzxELy0cuVSf5kRhcMhi+zOPTQz97uZcxInhiSpqbKyMrVN5Vjoc7MB0BvRz/09u57fPbxngDPAGeIc8Y52jnaOdg5Css2OwisOdKigNfCDybahkCGSaVuqP1i7GTt9lhX7zMkpn0BpMXkTkev3ZEZEesenz6/HpK4KBUoM4HOJ5gZj045yeIyM+cnjO7P9l3RnGcekxn5yYnCGM7eY8XdLpgY7MkM7M4yBzjI+MSnzQkp192YjgAM5DU3n5PTdqcr6Nh2q+lqUs+kUIJOt05QpGtjFSqM4KIAoxgTx7I5w7VcIi73YNlhnQ/TtRVh/TrSRg9BdORi+jOmAyOlunUjZ2/Quqzc/qEEU+eZXlQe5HTXSfk1jdB0hrcvbTYlia40Ks/0DHymM/8AtGRnz6/HpHpxnxHpHrHPpM8en4yZ5ycH5kvmB+cL8zHOcRzOdsRnHGTHGEMTnEZIxnbn4kh7sj+IOzjO3PHnZnbnbnHGROVNPsnyfT9VpBSppEJ7chsjguicYqHAM2Kh+JU57UhKIXEw6snJ21IMLeiMT1JYHP3LayafdntnDluo6k7pLqMNrpL3WvTOvh/6nTZmrd6s2GFrlgPVGspNi3PakcUPMdIao3Ou7mlWyzuFHh7RI5dve5yfSPQPyv4mc/3HpxkRkccekccekenHrzEz285A8ZPp88czGT85H5nks+fT5zt9JiJkonPjieJwh+O34yfvPtnO2Mgc4zjJjKGrfsJqaajTGYLmA7RhcxAJ8ZjAFE2UqwtgXE3jgQumxc7MgGb7ynz2G4hFuyUUXGLa49//AAsaaAxhDOFHOVaVnZPr9OdNaGrUve6XFjunZW58lhDSpbAZXZH86+quvXr2STS2cy51L2gXtjSbrrf9EYOccZ+cjBwR7p4kZjIn0j1+7BPieZn04yZ5yPxH4/1xnznGCMd3oOcdscZEZ8Rk/nIGMgM4j04xiO+QrwEcRGfgZjmJjC+3NJpi2RiCFL7JnPHOdvyyVKCxfgcnYCwvdsnDc0o4nIxZip5gs8H3CyqrrAxXg7mWPKqac89/otTHHpNaOurBrmvmzofCUVgTT8KbLmhD6+91abAUke5tEytc2m/23vLP+RTvnCrxven5+P6Vxk/jnIz/AFVfXF7ate1jUTXOM+MiM54znmI9Yz4zicicj8/6+efxhcREx8fHOTE8/J58xk85zk85xn+sLicmPjOIyeM4j05jJHmalM7liusKyjV8nEQQ493YLbbLBCqRli+wiVBSXkZkLnmIjtgBkuO+SSwsAeISXYf2sKUlkRnGdIdMFIjX/jt+zp5pq07e9Zd/ARNqa9aY4371jWqTK2UVkutNd6cr/g86d2p6vYdWaONe3+hP4L8R6RGFXEp8PzMdxxnHrHxEYOcDz/r5z5nOOJjO3nIH4/3HGfbx+cHnmOfSR+PnJ+Inn0gSnPZWJUQxGdsZ2/PEZ/ouMgsEIkSjiemEzkkvIKYn4jPoVg6+2qoga9BShvUFEq6yr0+B16tuD0zbd/6ZWSpNlFnbp15sz6I33haslVvozYXepT9VZUOhHis55hjOk9GV1pvplN+3LGtltuyiqvV0rjJKla4s1zEa9S10tstqvaaj6MTS7AsVhnT1fmbEcFzn1T3fT/P9Co4hnx6R+PWOMj8xPzx6Rkfj59I5ieM4yM/1xxn49YyYnJguOCz5nC7pyKzzhGlvvyn0s44DQ9rI1qK9YezzbvQ8rkeyfjj4yR4KQ4yB+ezGTEZpEeLXGmefuxXHkvWKoU9zsAtrrWq9pOzuraLQr7gBZUpV3GvYKgq9VN7e7RzaCAXQt2F+7pWF+y2CA2NqwNSxf2cG3WwdmIpdJUNGNy+5uahRNiwMVKvS9dcBd2ocWLR37VYIr4T5qusXzLN1bK3s4+c0EDtklXKjdu/Ec4mSmtH49Izj4PO34jkR9Y+PSJznjI/AxnOfmYmM/OfmZn5jjifxHPb8cR85HGcTgqkiq6OxaKv08tsVNVqpMaNNU9kALPsgHAvEzDcV3rH2zYxtrnN/RCJ7PmImcn4ziCnxDOFkB5rFMBKubeYiRISLtzqQ5+mDxMQk87YVErntPtjIH7BgfLHC2CuJCYzs4kx+VM8eSffPczP/xAA6EQACAgEEAQMCBAQFAgYDAAAAAQIRAxASITEEEyBBIlEFFDAyI0BhcTNCgaHwFbEWUFKR0eFDU8H/2gAIAQIBAT8Bz1mvfxXyZIxwycex+2hKyUdvsr2Xp0WNl/o1o6kJ7eBZLLtm9rsxfxHwPx4klPG6OxM4FpwMfHQ/6lrRG6i71bolTOjeXJlswYnF+pMjO2SkNjLZuZf6uyL+B4YfY9CJ+WRPDky428Rl8bLj5mh8rShdVrtfY+RxMcHJmTA49HQ+f5Ozc3p/UxKWR0QjHEtsdOGqZN7HtZua6PVfRvZHIbkbxUNDa+D+5vHOhZLPUstj5G6N5vIy3OkYsCxfVLsk3MXDOytK0X69aQgoq0zyf4qogk4enRn8HHtWzsfg/Zk/HnB9GXDxvgLBkn+1EsU4L6hiMf0je5GTGitK9uwa14PTvoprs4/Qw4Xl/sJLEqQtZRWRbZGSDxSpm9iyUeomX9iM2KZ6m4+OC2uyXPQ4sjFjJTo3tj/qMxYZ5nUTDhh4647O+T+hE/IYJR+k83BhwYuFzo4m02lMpnJZeiQluPTZsZtZtftq9LQ+dG9FKjKvWjtY/FaJePJIqUeyxyskvdjUembFXBPEpE4OL9m77+yzjXB47ny+hVBUhK9LHpKMckdsjJili7LLE6E2RGJyrg5fZGKaFS7JzTROTIrczZtZsvsx+J6n9iKjijsh7MUd0qH+IY8C29nkeRLyXchKzlHJZZuNyLRKUdEYy2WWWcHBSNv9BNvslSZwMsfuoeOL+CXjRH4r+GPx8iHjlHtezGqfOiZn5El8m2ySrVprnRYpNXQ4uPemDxPmY3XRVnEdFyUSWjqSpmfA8T/oI6EzcR5INRJUJ0OS+dK3Ci0x8mLBaufQ5fC9sHTJfUj0/kjwS70tlssslK/ZjOS2WWWcHBwRa+S7GR/QoooorR44y7Q/Gxv4H4q+Gfl2jZNE04jtjiQkuieDi4m1lNCbRCKl0QlXDJRUyGCMHuWlF0I71Z1o1apmfx3j5j1ohG7aW30R5HwdkDou3wQwqH1S7G79yLfyNm3cP2oqvZA5OTksvk4ODjTrSq/SoooorSijaUOEfsPx8bH4qu0yOKUfk232SxJksCPS2/tMUJSFGhlo7Ks74KSEqL0lTKoemfxf82M6NxYpCnQsiN1iyJEHLM9sSMFi67/QiPSI+/ah6LSCOdMcHlkoo/KYsHMeWZ3Fy4v/AFFyYowjKu5DyR+/+2jEXwcnJybjcb0bjcbiyy/1mjahSovTjRMbv3NWRg2OHOmXBHL/AHMmGWLsrRJlaYcEs/8AYjGOKO2H6Mex9Ef3CHpXsenj44P+rMuF3cV/7GLDPJLZEl4GWL7HBx4PHw3Nc8HkOU+ImS9woyl0iCmoUl2etiXFDcKVDEdItm43F6UbUbDYzaymclllllllm43CkbjcWWX+hZZZftaHE/uZfEvnGSi4OmJlGDxb+rJ0XxS6/Sj2Poh+8Q/YtHphcq2/BL+GtiMWaeJ3EhmUuP8An/GZcKy8kI/l0/uTybufsSludmPK5NRfQ8u+NkcaolGnwUJcEuUVZwcFIpG0oooo2Gw2HpnpjgbDYbBwo2lFFFG02m0r2cnJycnJyVrQ/ZKMZqpH5XGY8GODsbvSiiiivauB8iVSs3KtOPbtQkhSrgw3Nm99Mb2mLPv4MvPBJXa6J4Nq0xzjFcn5mZuouy67G+SkNFacls3Ckbjcbjcbi9aKRtNo4I9M9M9M2GwaK9l6WX710UbTabTabSjb+gvZRSKRRRRRQom1FIVHiRUpMyx+xtsxYlFbU+Sc3H6WZJVL+hFxnLaPGk6Y1WmwR2TahRD6xwoWFjwyPRn9j05fY2srVaWWWWWbjcWbvdRtNhsPTPTNhtNrNpXussvRL2UjabTabDYbDaOJsNpRTKZXsihs3F6ePLbZLKba5JTkLnslFSFUFyTybo7SjayMkZNsfkirPJVSPH70R8jWkutElRtX2NkGekj0z0zYbSiivbZbLLLLNxuLLRwUjajYbDabDabTZY8Y4sdik0byyyzcbi17qKKKKNpsPTR6ZsHBmxlPRFkOjt0P7imvknGUmKC/zM/Dfw+f4jJxwR6P/DX3mRFSISrk8iW/I2YS/sKaERdjiNaLrSkUUy/fSZl+hbj+H6Sys34WVjfTPTT6Z6R6TPSZ6bNjNrKZTK05OfYtaNiHA9M9M9M2Hpnpnps2spnJbRuNxuNxuLN6R6h6h6n2N5vR6iN6N8S0y0nySyNuyLvRUTkWj8L/ABuX4XjlCEbs/wDFPlfZf7//ACbeLHyIyfvZiGIjwI3EuRrWtKKNqNhTOhPXNzCjLCvFgv8AnyembZH1I9SSF5EheUzHl9V1o/Z86oaTHB/Btn8EYOuT00ekj0ojwoeKujaUV7aRRtNp6aNiNiNiHA2I9NGxHpnpo9NHpo9NGxC4GhK2bH8D+xJi5KWr4WjXHBLlmPWz16HlRGW7oftZZelFHppno/Y2TiTlxTRknuxxj9ijYbDabTYjBWN2eobi2Wzk5stnD7IqJ1pZel6srWvckWWjcbhy/oenNiwyPR+7PTiemj00emj0zYSpKxNS1g5p/STjK/qNouNeDc2qYtEQ0Zeqk49EM18M4aGn8H1FSGpIpiTfRTOT/U2/1Nh6Rkgoobte1vTH0Xo9fnXaja/uXI3NdoWRCcZfJzpY9LLNyN5bfwUymbbNptNo6iKDl2KMYm4t6ykl2PNBDzjzzl0W2f5CB0WJ0udHpZevPwN0iJDR63rGVdEcyfZ3o9MPWlG0jHkqRcl2ZpWic9yXAvY+9I2kbzsZXsoo+CtPp+SUcI9q/axTmXN/A5SO/k2m1CgbB8HL0SKOEW30KNF6SyRj2Pyo/A/Kk+h5Zv51b0qh9EdI8sbscmc+yz50n+1i7I9HRftvR88GNvEqRHMnpJ0QmkqN5u/oW/sJv7Fy+xc/sZ7rkmqoXfsYyKpI2o9JVZtoVllm83s3sW6R6c38n5f7seFIWw3xXSPU/oQjkn+1EozXDNqZGCZs+xUkbp/YuuxTg/k+n40lNI9WHyx+Sl0iOdyN7HyT69qWkVyTuz4EY4qbpmzb0SOB6XpQtMvQuxzrgU1IX9B/oWRyOI5qXZjUEv662WbjejyOUZFyVrYxkRbS/gYuBxUuz0oi2xR6kC0/g9KUukR8fIvkeDI/8w8E/nkpYXtkiOXHfRP027iddDVxbY2QL+wox+T1IxJeTD7kvIg+kPLfQstdk5bnrhVsa+Bd8k+vb8aR7H3pEUL6H9LovST2nqnqnqG/XLzEj2SP3R4FJwdMu+vctUMRXu7KT7JKDfRtibIiwxfJ6KHhYuCitas2Jm1acls3s3M3sySurLLLMjuEaOSTlFWLNIeWb+f0fH4YyRLWiI+tEUfBAjBpWKW0k7dlGXr2xzSXZBrJwmZXwRHjt8lUNKXYobeh9Wbl+g/gQsjR6qFkicM6YtKHEp6Sl/Div7/oRKRxpZZeljSZtRtRtG70y9idX+lh0ZL2RGUIRLox9kcz2uL0embr2WbRobb7IaUjYbJLRw+xvcSM1IvVIofaEVonTsjNTQotso5Oda0orW/b09ZKnWseuSieaK6PzH3R+YX2Hn/oRytyMvfurStcfBDmxkvZEYtWyHZZY9MvXtcIiin0ycaI6qRvaN27spEo2bS2jdRGaekF8sn2ij5ooUbIfS7j2eNm2J2rMPkeO/pyo/EI+PjxxeB9m8j9To2DUfvrekuTBjeK9z7Y9dsSUuKNwp1yKNiiZWscdxkzvH0etPJd+2P7kZe/ZXvgQVbl/QnH+GpE/ZH2SbXSPgj+4aK1nHcj02emz02emPngUXEydiXBs4PTHCj0zYbKPSY8Ux4pDxlHqOBgwPyI70Z8XpySPJ/oO0RyJ8SK4tC+kXRLNGHXLHknOJjyTS+pH5mceXH/AHPAf5vKoSXB5+J+NLZBCcPliSfTMv8ACW59H5qJCamrRZHLCfEXpHDOXwZV6Lpscx7YOpDzR3Uic+aswPg8uX0oz/Bi+dUtIr6jJ3+ni7Q/8/8Az5JN7NpP2L3LhnqRHl+wnej9m56z7MEd8qM2NxXYpDPUk3wepNG5tFZOyOJzPSlu2mSGROzbNnouZ4kVjwpHlu8iM6lkk6RLHLrbyLDPdtkj0IwVRIeTLItvkQv+vT/+/wDUx41OcYSff+xi/BvHiqfJ/wBIxLyVivhps8rxvC8XLGL+zv8A2oyxg39PR+FZ8Pize/iz8X8vH5FY8SsweLceSSjjRm8Z/wCIzF48KtmxY+EKKkfl1hyXHosllk1UmZcytRRFvdaEnKX1J2YsKb3SjRLBik+UUsX0nlS3VRl5jEx45JO1qlpHsn3+njF+2X/PkyKqJfoSTEq02GwjpL2wdi5J9kJ+nK0Sk5O2LgeNZYfSZMDwy2Mo9OXCf+g8ahFbjHl9Hkedze6qFty/JGscfqXAmj1GuiT3ZVZSy5Xt4Q5SVP7HXMiGeKXJKTlKyUl+1mNrb2J73Ru28sjclyxRlL9vwX8EHXKJOU2pNmXNCUdr6/sKV8Ilkd8EJr5Rm8n0q2qxyUvqSMkXJXHsxYadfIpRx/sPXtV1/YWSux5EZalyPDLNJRiYvGkvpXwbrJqn7F2T7/TjKkY81KSl8mSe7lEn+henyNaItD9scWxcF7ekPs7IrkcYnjy9LKvsebmg8lEZJmJfLPNyf5EPBfiRkUW4vgnnWR7Voz/8hG7J1j4MuWGbiBg/AfIyx3SieV+G5fCf1LgyYls9RFRUCDp2Y7abH+7+gp7OY/bRF0hs8PFvgzyvH9HlaKPchsi+SH30hFzdInHY9umWDrcWYc++J5cFKNRRGTlwxlafJPsrWzvV63pfsXv/AM2jiUNe6Pi+o9qZkxSxT2S70iI3pEsnNo+bYpfYjnlfJlksnJiz/wAB42N/Bgwzy8xlRm8DJgl6vwzZKroYv8QszNt9n4F48ZZJZ31E8Gc53M/Fcm7xJoX+HOLHOlRJ/TZKbPU//Y6PzXhy/h4Xz/Z//AiHiXHdY41wRxSn0eF9CcWZYLKqkZPH9Nl7UN82fuNtKjFit/V0Y8SgnRk/ezGjclaFBuW1GPwXFXfJkySl9JVcidjWjRtFwM2OXQ4tC1aejWle1FiftupexwHFr2ryMijtshmUF9QhCJcs20NFULlWRQvpdmR75WSzbobDx/PVbM/+hwzyYuORoxfuPIWVZoSh18nkOcObPBzOOLj5PO8vLkybIuor4PHyZXOnJ1/cnOUrpfFFk0ODZlwznSirMfiTxXKR0YZJ40T+m7PE8eOK5L5G9nkWWOpdnlYeN8CKtm3ahEclI8j8Zw4s8PDl++fWkXwWW4Pcjx/KWTg8nxVl+qHZJNOn7LLL0hPYRzU7aTJy38pUVpfIxdFHA9HpY9E6LIxUu2enx2h/uFjk+kda3Y4WNNezL9R8iG6RBcnbHp0iHMSxy2o8iTnJwi6MHqQntu0eDm9THt+UebG42Y/3jXBmhvVEI5MT/oOFuzCqnZ6s4y/h1/qQ8Hy9ybjwYvwvJlVn/TJ3Vj/DssF/iGfw5Ri5brofHB4mTjaZYbp0QW1UjyF9e4TtXo+U0bHhXPySZEs/EMM8v47iS+Ev/wCvS+NbcJWjx/IWRc9nl4d63x/W7G9Fei/dySXOlexaQxubSH+4To79llkoFPS7YuyJMxfcj2PsSskuCHKZFN8Gf8Pw4vDWeUuXX/P9DyvBWSe66MeKOFfc8PJiwY5Sk/q+DjNEVxmxul0TknKzJmfwbklcTx7g/rJTqe6I/P8ALcFDe6R/1ny5Q9Pd/r8mD8WzYuJpS/7i/EsVcxozLfiuHLZLDJrdRjcscrKX7iUvsZOmYv2rRPk8jn6/uMjpn/EIeJ+JyUl2lyLF/D3nZ0ZHtk0dkW4u0Ys27hnkYtj3Lr9HD42XyP8ADVnifhGfyrfSPI8PJ4uRwmP2LV6NWVWiGtPw3dji8lLb8mfjK/7i1s4KHEujetP6iMWPczMqnRD6SIyLH0Ya3fUfhyxSzVE8zH6WZw+ExzjP9x5/o5cm7AqVdCXJjzPC3Fjgl9SMeVWSzQX9TK4P6ooUXIxeDntOrieZ4bwS/oflsyw+q48FVyf3FBSdG9YklZk8mU1s0llfFCluIikx9DnSbJS42roqjdXBucT8Z486Ul/QXOKhaM2i4RuHkc47Wem7JYq+RfSN/LHpPDkxfvVEVi+X/seD52DDjeOPH9zH+KRxKXJ4/wCM4VJrIuzyoqOV7emX7nr8lFc6MhkzLhdE3bv22WJj1fQjE6kZv3jjtjZEYh9EOJH4RD+PL+x+I46zty+SkY3HpjhBciwzk+CX8Jd8i5dlVycpGDLHFkUskeDxfLw+TC8fBm8eOeNNqiWFen6U3x0eT+GpTjjw9snFwk4yN1DkQENkWY+haZeVSPTqNm75ZL6eWPJzR5v4WvLyvJuqzD5ba2kXa0+SGOLVsy96QTHla6LcmSoq+DxvG/MZVj6F+HeP4311dHmYH5eNOJg/Ct0PUy8HkeN6EqXyPHBkscJGWGxVd6Q+rgn4zxq2QxKSscY/c4TpMu+texL49lk/euvZLSDpk3WQyOxcLREuhdn4XDEoLKv3Ps/EPFj5SWyStGSLxycWRS+SEZZOiWLJGl9yHjxi6yC8OEslLo/L4ktqPL8WOKNowKLyLeeN5uDFxGFHleXilj24uyGWeOMFP5MuRRlyeflwxxbE7ejMYtOkQ6ESlt5Ex9DRk6H8PTDxIxv4H0YqQ5JoSTasy5vGl9EYDW1UPG+yijF4+WX1RR4HgTxt5cg8GXyV9EqM3meh/CS+r4JZPIwx/jI8vyn5Er+DGrjbMraKcyODJMx+DJNcnkQw41fbIOndk5LTo3G5e+Yv0pketPExwn+4zNerKicqVF8ECWn4Rm/huJK30Q/D4TyOb5Zl8THkax46sh4PoyfNGTDulcT8tGP1Lk2uEbY5p/PBGDyy2tn5PFFE4TwvkxR3rcObUkZZQ/zEuxuhHjxTVk3t6LNwptGObkzLL4OhvgsyEuhcijtZF0xsujHNSVElGEbiLsw4sbj9Z+VxtcH5OC7YvTxqoox4XJbsjpH7PpXR+YfjvbFWZvMf5lZpLo878ShLDtXbNj+S2lSKvs8ettoeSEcf1GfysmST5OZcsvTciy2Mjf390xCP8wyhiKK0kR60x5HjdolGDf0oeBPpn5dv5FgcfkWJy4IeDD/MjD4GFR+n/wCycMcfpjwLBFfIsUbsnilKW5vgUuKPU2rceXKWWG2A4Sj2iM3B2heZl6JTzS5aHlypbT1pnku0tJdkTHwiasxxT7JcSrSMnHocm3zpJ0htE30if7SH7iEaGJ2rJGKDlKkZZPob4MVxwmGOScd0k6I+H68fpbT/ALHi/h35XHuy8y/7H5jnbjQ/qfJujCW4z5YZcto4G9/BLA4xs5PX28IlOWTtklydDk3pTOuxyS6I/dm+uj1JCaelaZCI9bL9sxdeyOnjRjOa39Cnigqx9kM6x/uVsyZn8LkUb5s+qMtsU2fTHmZKcPjg2KuCqK08nxtr3RJY3Dk35XwYvEnNXkPIwehKhv1MVj4OyBGe1UdkZbSXLsWqJlEpPckS/axcqzErnSPTkza4rkl2YWo2yUtzsw41ldDe1V8H4dkh+XSchZNvEUZPIS7bM0XW+PJL0p8UeTmWOCxY5XfYtsekSrdZDh2Zc3rKhQjEy40lZVEkSVIS0Q510bXfOnBYpNdClZuOyZDoeiPJ8LHhxRywyJ3XHyuPc1YvYrZGrSZBYYOjIlGP8N8EHiXMXbJzyLmSHDFldyHNRjtjyWr4QyCZXPJI+SUPUW1i8XGnuHUuKJya6MuBZlyZsSxY+CT0ivY1WqLHJynpk/xF/wA+2kPseRi9LLjnj6pf9iU/UW4k+CX7hJF7SeKWFb4s3Sm+SU/y6jmxdn/UM83bZ4O/yVbVL+5ODj9MWKMcVSzHmPD6l4CTdkPuc1ZKbxojlTsm45YkoxUKQ4jVm1H9hxs5RuHz7IWuirKMhDovRe5G+hexJs8aEY41KMbZhhJczgPFLJKzIow4j/si1kS3v/3obrgtG9f5ULNjvlo3cWhPkocRd6NfIlXLN1cnm5VN0hoS5Iq2NVyR57OyV+1RXek/8QZ4mL1chmW2ML+P/s/sM+Td9zLOFUiOSMFKP9f9jFUm5E5Pbt08TyskXUTxs+Oau0eVk3wcpf6DTb4JKnbIO+RszP6REMzxqiWXng3Fjkjcjcxpv4PTHBrRG02Mja0yIx9axZSNi+DYxqu9fkWkY7u+CMYJ8mPx1k5sx7vGhT5JZ3kjS4IKSlSV/wClf/BlqSpEcUMZk8iEXyfnYHl+X6rqHWkcjj0YPMlDh8iyQa3Ifmu/p6Pz075F5OP7kvOxQ+bM/wCIzm6j0fmsk+Pbb0oeq9k/36fhsUoSkZ/IhP6EIk9HVOzYlC2ZXHNP6fsRj6eRKRminLgfBfwYPUX1RZ4uZ+RieJ1z/wAY47JtWTdoTZHrk8h2kIb49jTZtKKK0cVI9L7G2cehSrsT3aZDF7dzFMeVSNq0QhRE18nBW18C8nKvkflZerPzmdc2PzM8u2Syzl2/YxEVwJfA5UtHoyJfvejF7XCL7RGKhwiMdr0ekicVsj9zx4b5/wBjKvr5IcqiarTHt7kfmpw5TPzLfIs8Wjc/gTpGbV+1ca3renC60n0Y+x/oU2KErEq7HNosixEPokpM/NpdRJeY38E/JlOO0pknXZz8iKEqIjZJ1rwf2HwqF73oxexDXF6IbG9INXTPJklJbCMY40pR7op/vP2xUzI9zsejd6J0Q8ijHmU+DO1o/ZaLLH72VwZDH37dps+w013pJDTsqz0FnjUjN47wy2iQ5JG9iVs9Mr4Jy2kMbm7Zj8beQ8CPyjN+H46tE8LgdG4asb+Dn4KZ1pZH3N/BvjtpLSvYht1WkHFdj2/A2dk8WOMP6mPFif7iUZx4kyKe3ZLg9Jbak+DIoLiDsl7WXRDKkKakX7WL3Wdj0l4uX0vWr6RR0YxCZZuZYhqxI9R/Bl602iVCtibJcox4FL6jx8MYrdkHnhF3El5Ep9kpnZNbXxrdCfyPWfwV+qvY9ZueTtm6cHcT1J3bJOUnbZTqrIx2mSHytXq9LceiPkNdkcikJ+y/0JN/BtyXwer5Gz02+DHd8jGMRYzabTaQivkk0jlijdWh43Lk2ts2CWlmNbuCUWbUcfBtsaroyFLTtCQ0LTJ3+qxafw69z92THXKH7VpRDHvnRHHGPRRtRtKOi0WhUOkWi0XE3RN8SU0+hlWU9XrRln/6SKbFCSMUeDG6+lmbFtfBK06N1E5WM8L6pOI40zYxxOETlH4J/U+DaUPTmtOiTtkP2r9TadaV7n78uL5j7GLXxo9vTkZZY3rEbv2tkeZD0saTHEcdfUTiTasxTURS+xDof7jOZuCyxKyG2PQvMa4fI/M/oPO2Sz10Ocmbmhyb71Ws+tMf7f5V6L3ZcV8x179mH9i1ZWj16Xtb0xdj41ZB26JeJfRPC4dmxGN3E2fLJP4MWRrgjk4PUVk88PlmTNCXyb0b0RyJfA8n9C5P4PqO+yOJya/qSw0m/sOFQUh6IWuR8iViVfyrMeP1CWNw9+XFu5Q0137cH7F7P4Tn19JKNaMiiT9jY9MJPS9YZp4+mQ8++MiPV8f/ANJHxeLMmN412fFjRt6IKO6pDUPhDSoi1tIrHu7Gvo3Enyb0b0YpOEtyVkc047a+CWbLJO/kcp+nt+B+1D7MSuX61foYMcZ3uHBY/wBpO2Mr2VpJKXZkjsdC1wf4a90ojI8L2PRiMRJ+6NXybJfY9fNWyieSc+GK6OT6imKza2bOzYr5KVCx8/UJfJGtsmPJJlcIfyX9NaLWyU6LMP31X8ninGMaZPLfA5X73pPGp9ksUoa4eIIkxSE9bHGz41ftxEv0HOpOhvr2x540rsrmNj20TySZf0G7si1fJvN5fszZK4JTtidrTD1qv0b/AFq9r9mTCnyhp3QuFqu9bLESx/Yaa7Ho9Y/A/fZaTL4LLossV/BctpcjnSijabUUh/J8at0ZJ27FyyPQiCpe2y9b/lnq9NqbsesfatKsli+w+Ox6of6Crg4oeqInwfOrF7PuX8a+RLbGhsiRIq3/ADt+6/cvavY4qXZPA/8AKVXYuWS7GmV7HpQukMfssvsfZZelm43m4t62Zp7pDEiJi7/nX2J17K/SvRe6UVPs9CnaJdik0NWNV7IQ3FFll+2/0rN6Rmy1HgYuxC7MK5/nav3P9OJ1759+xwGtIPa7PU91m5G+J6sT1UPMj19JZGj1meqx5GLfLoWHIz8pu/cz8liMvh7eYEOVpiVL+QbLL/kq/RvVavSyfYtb02mxnps9WZ6sj1ZHqSNzLZevJhxcXIjijj6GThuF4/3PRgKMF0Wy2WWS6H3pH/yav0ezr3bLKoooorWz0a+RYb+T8tfyLxI/J+Wgfl4CwwXwenD7FRQ2vjRjJTp8G+chL7s7fHtyP6Ri7I/ytnf8zY5Wcv27izcbjcbzcWy2UKLQh886Nm9kpMi+Rdj0ySpUhRbNjFFkVXtzdaIj/KWL+SQ/fWt6WWdm02GwUTYLGVRS9u6xUN6xGNjVyI8cErfQnfuz9aRVsjx/I96X/MvSii9FE2G0peytI9iaHJy79rd+5MZ0iMaFp+1+7PpihXOljFKi/fftv+fvRRF+vJ/HvWJ1YzDgl5OT04GfxcvjP+ItWtyoj17c3Zj5l+hftv8Alq/SfsoS0gt0qMjV18HRftvRPgTKKH9Ihi1rkoyeRGtqFLceFk9LOpn4hFZPFbfwSFpftyO5GHv+fooSfzq1+quRLRF/fTrSvfbLvXbqhcmX7CRHhaeL5e/x5QyqzNDY61ftfJ4/X/krX6kOxFav9Faf/8QAPREAAgECBQIEBAIIBgIDAQAAAAECAxEEEBIhMRNBICIyUQUUMGFCcQYjQFKBkaHwFTNQsdHhFsFygvHS/9oACAEBAQE/AcHN0bOHflFN64qT2LiYnkzgcrEKin4G7eCyy5NLF4nnYTV7EtyLcCSVTcdHTucLc6cJLylW9KIq8xdOpuxeUaLMbZfSa5MUhb8itfYcXyjkexpuW0nPBdii2QvEvdCgWii0VyV6ql5IjjpRCNzSWHFDgvrKbR1Zo68j5qRhqtKnPdfxKVeFR7F0LbK+erVsJadxVEyvVjBFHEqfJyR228V/p9yxp9xQSGc7FbTSVyblU88xHG6KcdS1I0xfqPl48o6a7kqb7Glrg6a5Y1LuRatZIjGS9R+RoFT1EqVmdFrcsiOwlqOmdMqRVOOqTKteVbZcEUonItjWsrlx/Tv4uvKE9CVzAT6TtNlSuqctbZh/ijnNxFjPdCxEZIp4h30yKleEFeTIVYz9IiS3uiqta3EnTexRqtid/Gp7iee51bepGpS3Q21lfK4nfOvWjS/Md6r1SJbvOMnTeqJRqKrG6OmdK50nE/MlTQ6e9rHS0F3fc0prykNuRTiTlH3ERpXOklyK3YRWxEKCvIq1Z4l3lwcZN2H8SxMKlpbnw/EVsTV83GWo1GouXLrwOXsOVjqP2OodRGuJqiXWarOKKm65G6r9XYwENN75ItcdNMpfqndHzIsQr7l4zWw4kYOPBBly+Vy5Uc7XR1Xfcp13FkJqauvBoV7rK7Grli8r8CtliMSoeWPIk5u8hu2S3E8oylTeqJRrqqtsrDimNImyI1FvcduxOcoyHeXBTptMpQXJOSgrnU1o6mn0lTHOnshuVSWuZe2c3ZH+GTxM9bdjD4WOFVo7knbkupFkWLGk0s3FF5Mmbm5c1I8tzyiSfc0/clC2yNLs7icr/mYK+qQ4iF4L5amKvNCxPuhYiDFUi+GJjyqu62ErEoPkwvlW5Nu3lNdtiMnLnK4ppu2TrQi7NkZqXA3YxGMv5aZGN+Rux6i3ZD2W2S3yTcXdFDEKqrPnLkkjQSekqJzKbl3JK5GL7CFLSTlGSE9JVr72gKNt/DJXRG8WdbexU8wvCxLwTNy7HJ2NX2Lps8olHuaIe491clD3EiirPxXyuai5cvkpNcMVeou58zLujrr2NcHuU3qNoin7lSnK90UsVvpma4oumSimVJyjyVI6t0QlKHBUrzmtLYl3kXbLXOD07sfGSOS5e26MPilU8sucmSNOotbZktuCO5wVB+YcUldk6rqeWPAkl40KKROfT4Fv4rt85PKpzseY3Rd9zUahuPseUvAjJxek3b8xtYw923fwvJ53LlzUai5c1FyyLv3FWqLuLEytZoqTjPlD24I1pR4I4lsVbV6itOEeByuL7CTHsa7C23F5nuSd8tmR8pyJ5UMZby1DngsWGrjp3HSZpaHTbJqNFamSlKq9zjxsjydio9xeJeCfJublet0KbqS4RH4tisWm6q0xv/8AG/8AF9vy3MLOem8kv4Ep7bmPxVeVJ1JS6dL3teT/ACXCuRjimk44aVv/AJ/9GnmxCRLfyooRtybGxZGk0nTNBoNBoNBbO/0HnZD3OmdM3RuPO/guKViU0hTvlRryo8FOvGqthO+Tdi5yVsRGht3JSlVeqf0WR5JeknyL6HxHF16SbuqcPd7t/kjB4tOmtbf8ef5GIxlOjTdaT2KPxmhWV0/9jq3PifxKVHD1NrNLa58Hrxw9O1a+qTvfSv68lJqMdipiadPyzfJjauCqYpVa876PTH7+/wCfsP4b8UrPqSxelve3t9v4C2iS2JN2vEwrc43mWRoNBpNzUzWdQ1o1IujYsi2dixZGlGk0mk0mksWLeGyNKNCNBoNDNLLMWxcUjUXtuijjLbVCE41FdDVxtlbE76YFu7+kyHJP0kuReNmNo05PrS3kuPt97FPFPGVLyXHYq4WhiqShU3RjMF0ZOpD8Nrfn/wDzH+r5MF8eng5dKq/Lz9/svzfJjsVP4pOnRS8jt/P7/Yhg1h5xwq4lv+Vv7/mQp6IaTHYONCjOvSV6jVl/HY/wupRxcad/RDU/z/v/AGKuLrOb3Ym5FTbkjGpGpeKMPFQ2iXZ5i8jVI1M1M1Go1GtmtnUZ1WdY6oqp1UdQ6gqlzUajUajUazWajUXLly6Lly6LouXyeSysixBuDvFnzVUqVqs1YV0XZqL+C5fNkXZkp3jYcHe/g3NyzN0NslSUuT4hh6cUppb+58rCDtTb1f0MNB13UvxZJfyPiHwKFKXV/N/02PhWGkqLnvqX/S/2Rhr+WrV80t1f7XuUsVGruh2fJ8RwdfEu1F6U+fd/b7L3I/o9hUrO5TuldilqauQjc02yUi4mbGlGhDpo6Q6Q4Gg0MsWNy7Ls1GpoVVnVOqdU1nUFIuXL5WLFi2ds2SvcvYUzUazWjUjUi6+g0It47l2ahyZqZd5fpFi5YShFw5ciOKhUTl3MP8QqwtG1z4n8SqyqWjHyrkoJKlKrSWm/YhS6mHk4O0/+CnKrh6XUk/Ncp4h1YaoEXqV7ZadrEKe92bo9aJy0EKmtDxUUxYmAsRD3FWh7nUi+5fN56RxNI4mg0ljSW8NzWxVDqnVOsdQVRGtGousr5PKxpLFi+dzUzWzWzqHUOodQ1inua0a0a0a0ajUvBJljQaRo/SeDnh4aVd6tijhI3vf7fyOvKG2myRS9V3yVKlSEPt7FGvWp7VrXft2/5MNCpU0/LxulLe777Pfv/wDphsI6NeVZ/i5X3LmpDp7WIK5Umkig04XRX4N0SWSdy4uS5KUk+TqVPcc60Y6rixUj5lixP2OujqxNaNa9y68NixpNJpNJoNJZlmXZqZrZ1DqGs6h1DWdQVYU0xWHGMjpmlmk0Gg0M0ss/Dcuamama2KZ1WdZnVYqgqqFVizVF5fEqfUhYhom0vbcq1aihoSI0pu1Ry2fYnCUJqMirgnJdSa7Lj+v22MFRVGjZZYzFU8JG8z/GZ/uf1O5JOSuVKet2WxSjphYmjR2HRlyhokrEZCEPk7jnK1i6fJ5TSbl8mWy1yXcw7nVei48PXTsmdLExNVePMT5iS5ifNr2Pmo+x81AVeMjrQ9zqw9zUjUjYZZDSXgedxTYqjOsdY6x1TrHXOrFnUiXibDsxRRoRoNBoLHSZ0Tos6L7nSOizos6MjpSMfCSpX9ilTW8/exSwyq3FBX0LsVKVKO82U66gmqa2KE3VWosYr4dHGSUpPg/wLDff+n/B1I309yN7klsQXlRIW5fSrsqyi3uONhx9iOwi2+XJLK4ps1+5eLNPsWeeEemrcVXzM6qNaZ5WOjTl2Hg6T7D+Hw7FfDfLx1FxPJZfhG2JyZOUr2I1JEKkfxjdNck68b2gfMPsfMSPmZCxT9hYj7CrI6iNaNSLly5c1GouzqM6jOpI1yYptHUZ1WdVnVZ1pCqSOozqSOozEpzhYw8HqW2xKKpQdiNZyl5FsSoqpbbgpUOnskaS1i2SlJ1ft/fY2f8AA1Xe52HfsW0kjTG7lYhXjUblaw6nmskWFsXvk2ciGi2Vy51Wjre6NdNmHjaV0XNR1EazWamdRmMvVikdGQqVjQJIWm+41C2w4LsJuC4JzkapMlzl9x77rKwtskXFIuX8HPAyzNLNLNLIRvyx1Ix7jrxOu+yOtM6sjrMVZ+x1jqtibew4s6Vh07qzPl6d7tkYw7H8DkYuCzNKvqRU24JtJebK9ty7t5ixOV1ZEqa1cDVjQShbc4IaPxE4w7HlLo2JXjtIvAsh2XY1r2OovY632MNU1ysWH4IcFzE7stks36SKNT7Gtl4vlGmDOknwx0pItKD4PuLwWNJoZoZb7mqIrPghU0bIcrjkaxXkOSiNuRpEkj8sowcuCOHn7Cw/3I0ILkskP1LJ7lonL2LF7cFy5fNpMsm9xju3YlJI3mX08j8xpRHbgdnsOLOm3wO8dnkssV6llc6g53NUC0ZcGEjaTylx4Iek7lWzkODyjCT4OBs/CN22yuPJ3PPxEUq6E5S9UR0oEaVN8yFTiNaexrt2OqOoxzYryNkXuXLj3NNvUN3zhSlLgWDl3ZHBxXLFRguxxkllcfqHk2RWlDu8ti6y3zjGzJcDdjSjT7DTfI04lx7cEi2+51rbvsVqkJ7slGzsIhHUVaL5NBp+5pXuNL3NMf3i1P8AeMFpu7MRLgtnDgRUd5M1s6zvY13GlyaW3saHwOmdFnS+49EeWdakj5r2iRxDk7WJOpezLTZ0/uPQnZspKLkKcrlaWh2RrXdF6bNEfccW+Bxmux5u+UIOXAqE+yFg33ZLDRirnT9iK2KXP0Gx8jKs3CLkhYr98h5oXQoPuSgaDSWL5xJGnYlT22JLSSm+RyvybZaNhrYv2LrgSsjpr1EE6e5UlKfY0mg0Gg6TOkzCJxkyLG9s7ERE002PV3Eu4jlbim4PY+amiU5ydzRNmmS5Y60Y8yHiKL7HzFD9wjXp3utv4FXVV80GSoVWiCqpWaF+RBuPAkyvu7o0+55/w7CozkRwdQhhp95CoJLc6MSEFDjOtJKIntfKmvDLnN3udyRUrKkvNt+ZGSqx6q2X3/8ASMP/AJayqOxrNTNRqea5JCV0JWJ01PkkrbGjuJFrjfYkNPlCgpeohG2xW/dTIO6Z2L5Mtmnbg1s1z7M6tQ60hVpCxLXKFiIsk7tvPnJJdzZDasOzNMTpxOnE0ROnEjFW2NBoNBpI2uKnGR0ICpQXbNDEy5fLEq8REBdvDLnK5dEiXBifiMZNqO2l/wBv7r+n5kMKpR+/9PzKEdFNRyqFs7DprsTTiJWJZclmT3FFt2HQmtzg2OctOkSdypBkVpViXCQ4o6b7GhiTWxbbg0mktlZGkUCzLZJErNbGksXNTyt75WZYeUW1wdRnUZrZe+VAkuPpVeBJkOBeF85IlzyR5J7ofw6nGcakebu/3v8A3/Ip01DbsU+MqnBbPSy4iaSHyM09y7RKN0cEavuTpxqIlQnE6MuS5c07oSvO5JbMvexOSgKR2HGzHa2VsmXNQ98975JXz7i2ZJdi1sr3yVidk9soUG+T5ZHy33FQXuSpJIoZ3zvlfK5PcZDgXgZ3yQ0WsS4NJpIcZT48FhSmapewzuLjLaQ4RJUV2HTa3IyaNVxjpxmrEsPKBaw/sP07j2ZOhq89iMGOWnZEXNeoqSsyL19iK9yxN2Rqb4QtXsO6NyzLMRiKkattPZCyaNcvYirq5oFDce2w00ihHqysUqKrX1EqEKfGVy+UvSyj4W/EyLvZlN7C8DG8lkx8GpZRyluaWWGbl0t2daJq1bi9R8z2HidPJHE3PmkfNI68ZDrwfIqtM61P3NRGbR0lWVytPoy0sc9cSj/mK4pJq0ithbq8CUJLZig2yo97EMDUm7t2RDD06U1uVaVNy8jsU8DTqOyl/QxeGjhlzuUKcKvrdiVOSfA0+6MPR+YelPc/wyp7lai6EtMjTdlXC1aK1TWcY34JqyuSxM3/AJUblFTavMhDvYxCvYwcd2zD+qRW8MuCj9Op6WUvTH++xHgXPgea4ysdjSxQErZPPuaUYp6pEMQ72bIO8diTsU2tXBWpOd9D3KC8qvyfLwXKHQgaIp7H6lbMdTTwdSCjexCpBrdCnT9iOIUODE1OrVciPoKDUahFpvd7E5wgtUWdadR+cnTpR9DIx21JmochzIVpRd0zETlW5MLejLWYjEuU+CLlNmExu3RjyjE4ysnZbFSrOu7zJNw8yPnpYrD6anIzSUYN7lRJ03GQ1KO1OxKUorkp4mtD8RC+IjqMPDQtyjtORUqReyZfK+T4KZfK+T8U/SR2S/vsQ4Fz4HmhD4FwajULxXKsHHc6a0i2RGGt2FFRWw9xPpy3IV1OOochzTbaItz9JKl1fKSpqn5U7km4OwlKT5LXOnF9iStGxGWiVxL3PVsh0pXshU1CJGDtqJptiWgjTUnYdoOyJNJLVlNXMO4wi1bcgtO6LWIwVicG1ZMhhNTvOQoW2ZZdxyUY6mhqVTeRKg16SWGnIWHqexhHVpeVjqqEXJlScZb+44uBFtobHlcgXyvlfw3K1VRj9z5pqykP4hGMtCPnOWkYer1oas+3guXFwcmncWxcv4dZZS5Y9ilyXLlSPUpyXcwuGq6L2JU5R5Jv2MJTSfUP8c6X6UTwrflkkv8A7JX/ANti9yMNS3I0XTTkxsTKjskUN5Njm6m5ChOl5pInXlF+QjXlNPXyQm09Jqbkhq6LpOwuCS1bSLEkQV3YcTET0SKFbqc5Td3GL9xDKntlJqKuyEtauXKNRX05VqTpyKd3yzETlTVkdN31SdxYqSjuih8S1+tdyFaFX0sgOpFOw5JcmuPuSxCi9lcUlLdZqSluh1YLuSxVV1Hbawm5byJKMuwqbbuVlaPNininSatwTxzntHYg7xQ+PCjtlqFkvDqZOVST22GQOBQlPgp0GvWW2sh0r8lXC/ukKcqWzPiHwNz+NUfiFNbd/wCVv+DT7FWr8stKjdixdOtHR3Q5rgRV7Iwqvcjs7JGNlO0YfzysNbopU+5DzSKVBXd2LCa3pp7k/huKprq1I7fmiXBPEJO1hS3TJ1IrcxS1PX2IT6buhV3JEv1j2FHy2Z6RXvdlSpZbFSq5NXIelGLqaFsQxcrpzI1oun1OxVx6ltp2Hrf2HKbVnwTpdSJ057K3BHRF+w997mqd7JCjflkaEWOMI7OQnFcM6ipu9+R4u7tFE6s5yKe3L2J9HRaImjTtdinqVy6js+SSTfmIKPpfI5Rg2inX6KcinjataWprYp4lv1IvkxHKzXHj0x5ROGokU+C13YSVKNi992Jl7knvYq7uxNX2MPC2zPk3UqdTUPAzjfp8s4MJpcNRid6hCVWNaLhwYSKnMxraqaTBUYRpJtcmNUFSdkLSmrnYolOtFXuYTG0aUnOcrbGL+J0sRFU6b5GisrTILW0kVZPhiWqjYsWMFPR5JO5J6Vc1a2O5NO4qaUrsTuYzeQ4mDq3XQmVaGngp1LeWpwJRe6ysOjGR8tG9zpRPlEdCxPC63uTwafDJYWUd5MeEbV7nTc3clDy7orPpU+OSne61DqQjHy8mqc92RepkrS2JQ6f5sgmluRjZ3FDfcbKU3AjUjIZcXBe2S4zTE80rIjtElwU+DDxvK5VHtEh75XvIqrzlXbcpxckVZOC0Iw0pRe5i4uNVu2xg35rMrO8zDOxLGLBxdUljsLiKepvzFLHUp0vK+CtiqdSm4qW5RqUcUrq9kVMdhoUm9RL4pFbxTI4uT3IzlKV5QX8ijVWpbC3VzFQ31FKei0vYn53dlF+XSNWdiwluhz6r27EESLEkJ2MX5pEVrdkSXdEHqjuVKTgYWrpeh+OrV6VilW6vg0om6XFRlaN/1k2QX42dCdTfsOhGlC5o1PYpxnclTb5NF1Y0WLG6JbkJJckZqTsjHfFqeEfTjvIg9Ub5xLW8CZcuNWRLgStFGHTsVZb2KnBHgm7EOSttNGI06d2Yf4piZY6VCMfKvz7d/bcUo1/OS+I0KdTpIr4j5p6FxE3psq4h9Zp8Gty8ustN+rcp0rbMUN7MxEVNNQ5MNFwpuFzpu17l1DzS3NUZLUinpmrxL9OdnwUsQo+VsqOE1Ys+CMNyPYqLzPK2xh9vKRJ5O19ypW0SsVKmp3KMrVEdKM3yXUNhNNWJ07booVdas+Sc1A6uqSQ2lyVsWqfA8fKEbW3FKpWeuRh5S1q5Fpq6KlenS9bMT8To4f7sh8Raprp73FT0yu+WOm+wvX5inUU5aYmjqevg6UdRGCjwIcIvdlWhGo7ko6FpY4yXJCz5HR2VhJIrx6tdtq89Xf0/x2X8DDO9GL+y8FzUakKzLFi5faxMc7RRhn+ruyXmexMXBUIvcxerTeJ+ktStDBOUnyz4RiJ4vA060uWtyUalODUGYbDRp7zjdkqVr6TEzq8InWq1J6p8ewqMZ+gjg6jd7mGwfRm78slDRL8yr8Sw95U72mYDGxxVN+6IY+hOfyyleRNRk9JLy+VFOai+C0qu9tinhox82UF7lXyuyKvpSy7kYXEt7ly1y1yfJViSdxckbWJ2SuinG+7HAqqVDzwPm005S5F8Q7tWPnKlZ2sUqUqjFQ6b4/qJOXJBRl6ZFPXBWS/qYmNaeI1Np/l2OjCo13KmHhJWiU6cGrPccLKyE1WuvYotLdPYjUhN2i872NRe5OM5VrscN7Mp0bVNPYfBJtRulcpUccsT1Zw0q+97W/5IKysJ3b8FixYWVhqxNkuCh/l7lOTnPYmLgqEfUV/NBn6Y1bYKn95f+mfo9XjUwEFB+nb+Jd+5Vut4sU6ku5OH7wqHV9XBKnGjv2IpKwrMxdCVejKnTlZsq4d/D6so1Y6v6mGnVpy6lKnv/f5kZ4hVnVh5bb7mD+IylSnXrtNL2/8A0hThWpqcHdM+V7CG7M4ILuVIO+5XEMjKzQql5WLHGwqaTsfL6nyYrCxpLUVo9KTjlSl+qVypWktkYVp01ljXak2OtFSX3P1cVdkeq35NiMa8d7f1FVenUVK81ByIVHCL5V+5B1KkdNSTf5mmo5dJI+UUVdE8LFr7kKU6KvJiZUoNeZEadSC0p2RhIxo3le5LF/cjOWi6dyjr31EVZESa1RsRh5dBFzU9uc5wjVjpnwR8ay2GMlyNbEU3SRh46bslvK2U+CPI90fpbUxEqny79Ke38j4F8V/wuc+qm4y9uxSqxrU1UjwyUvYx2PpYCzqFD45hsTqctlDv2MV8fq1IR+St977H/kOLjhkpRvO5SxmPqT+YvfTyfA/jGLx9d0sRFe+x8RrTwuHlOnz/ALGLlisVJa5N/wB/Y+EfD6tGv1cRHb8//RUwccVWrSpvyx4X3+/9SjgsTXipcR+3c+C4fE9XU46Y/wAf9r2/pm92Pgjta5N7WK3JHkSudyPqIsSvJEl50xGLV6RXw8ZS1kaUI8IxUuyIUm1cwdRwWmR9z4nir/qkOGjaaIT/ABJfzY8TO3COvNx0s6tOKVJbFTE0sN61chBV4qXYUacneJGmqasJvuSkVsRqemCuQnGxOm6isVqNKMeLyZSwnQqXX8R04dkfYTS4FPawpxGPgWxfND58SHmx+sRXqThbSyknGEUyCvuzuVtokORcH6Y4WXVhVivzPhWCljJ27IxUK0sL0MPPS/c+C/4nWpznVqfZX9/cq/CKWKgo4luf8SfwWmn+qdkfE/hdfRGOGf5lb4JXw/nmr/kUcHUw/njF6vyK3xOhgE3CBL9IfiNSWt6dPtYhi8Ji466FPTUXvx/2VsVUoyUpTufDsQsZCbUbWPh9WvOrOlazi/5oW6vky5GOrk0pmhEoKXJKio7oisqa8xYj6iQ9kTk5w3/2JLY03JQU1uToNytFEsJGnawldnxGjGpUs0ShfZoil+GCOnJ7tkvLtBXZo6ruyrhI16fnZh8NGNHpxZSoOM7l7PzdypWio7OwlOu2kUaKpLTEnBcyJPXLdidizeXIvyLiVz8jtluXWSHzkixbPVcvkxb1MppSVmKtNckcdJco+eXsVMWprg6uk+dlfYnPq7yFHSrIe4oXVjRZWF7H2IOFGW7IzjLzJlehTxNN0qqumf8Aj+Dju72/P/oeD+E0tup/VFH4d8OqJTT1LjkhhqVNWhGxg1plL7FrLOa3ItonJ9iCurjQ4KXJZLKmvMKIlaSJ8XKu8WVr6RElZ2FwR2kixTV2YiOqsTkoyce46rhvtYq4iWIlaHAsNbeo9irVdFLp9yMp1afnMPT0xsabE6dxpemRCXTVkSxE16UObqz87PLHdjxkVwam+RSEJo54EksncsixYsR4JC+jIh/mFy+Tym0ipWguWTqxj3FioqPl5HiKvNx4qnBXuLE+VMlXWny8nWm3qZCvUuTWrgcXF7lL4hGELVTD46GMvFJr8z/D8FKd5QWxVxVGhaGHirJ3MJiPmY6u5bpV/wAzksMlHfK1yOyL5spI1JC9RJXTQnfcrehmpFTeWxHgd7piKULblWlH1GNjPrOw7P1P+/zI0JvgUt9M0Q1Pe5Sh160o1FZojTsOkr6spLUVItS0lOzdrGJVRvyJihKPqIS82wnt5iE03ZCTHaOyI8EY23L5XSFKL2RYcSPBLkWcXd2fikUvWPfN2RO+ltE1OXnZQ813NEoVXzwQpxa2YpSjtEVG8tbJLSimnz2KlVLsOTsU4tuzG2lpI1ZU3qifO15LRcWuhdsgovcw+MlRbsUMROvU8w8mN5IjK+c0aSMYxp5UvX/DKDVtK7HV6l6d+G7j2djuR9JdlOm6hp07lb3MRQ6i8x0YwVitBUvRJ3Ir8cuSk9acabMNSmvNU5EstiKuVcO47ivTkQm5T1MrfrFsjpuJFb3kdfSvKj5mdyFbUXbEI2NKF9s0SzXjkYfl58jsjGuUqtpPYrST2izUqa0ik36jeGxGPdGlscfcaqKNkRSl6ie447XZrWyLxZHkjJOWl7m0nZEKO9kYCjKCblnLZCZwJlHvnLLU+MqXryrVYULzk7EW3iKuh7u//r/si5aVq5Iu7FwRp3Y0qasiDtG7K8t/KTflsOKZVoRitzHwxDvo/gYKloklH+JHJoirEOSUb7E8Mqncp4aOncVFInh1JEsHL3FhJ90LCfY0OP4RXe1i0kReVixBe+SJLw3E14J8GG75S2Jzkl5UVcbOOyiVG8RUbZ0oRkVFHTdDrdKV5nXnW2KeEquKsLAycWrlOn0XaTuyzY4yHZepGqc3YdGpFNTRTjKBGhVkrpEPhtd9rGH+F06a827PlacN0iOd8rlyOSexLJMvcjJRnuJ34P0mnKeKp0VH7/3/ACPh3w3EQqfNVtv9xkEIw/rJSWqyKjSiym1NFXZ2ysuSsk9itBYeare39owdXqRd8+SmrDIwtK4smaTSKG9x00KFu5ZMaijT7Fn2LiaYxD8TgmKDXBaWVThmGVomJ+KdSeinx/v/ANFOlXk+pTIV8THaZTxGuP6xDjQe+kUMP+4dLDP8BOhh3voKVOml5IpDVitJwpuRTb75SVionchO1FLsVK0eUSxq4aMFjacv1d85b7Fs7eCPIyHBPNcDdi+rkUYp3SJT1xLEVlR7kVyT2jubKJK7ec78ROjFqzFR0yvHNEC2SyZuWYlYsOJon7ml2VzS7FmW9xJIeTzfv4lFsdJz8pVpVIUWqfJD4fCkrS7Clp2RUvzclXi9mLExb03J4J1HvNlLBwp97ny1Km9ZGvSUtF9yNPUYizpuESEdJbYnIqtlKfkaHuxrfYw8ZUZqdj55exTxMKhHfzDvk/CuRkCXgkRlvbKQoXEtPJcpJabm1rE4JxKi30EXadh7SH4bFiKyXguahMvIu8mzUXEIc/MIfGSFurZ6hZVORxayq0FWVpFdSoz0k674gYX4ZWxH6yflF8Iw65uSoQStYrUJuNqfJiFKhUvWkYPDyxfm/CQp3XTp8EcLGKsz5CnzYrfD4JXRiMPOitXKJL3FBHy7RSw/TWp8kKLtuh4ebXBRwujd8j2GMfhja9xxfuXL5rgmRtfKacuGLV3yju7EYqMbCs0S3jYlS31iik7lZJO6+hqLizZbOzNyxZmmVjS/cSssu9hVI309xvNcj2eSNKyTNQ2OXsY7y2MDhPxVVuWGhkjEYaliP82NyELLpx4KOinG7OqSq3JEo6lZj+FyctnsU/hkY+pkacYqyRpRO0JbjnLVZRHsNkn9WPBPnN5056JXPm17FKtHiRUqxkde6tY+ZfsVKvU7fTT8Fixbw7Fy40maEtx8WE85cXyWxqNQ7CsW1ekVJ9yphoztqEmtxySQ5m+TIXb2OMtjTckirJxjeJOdbe32JatD08kJSUVr5Kj7nUjHZjHuS5+rEfOX6zwojyP9iuXL5b52LMsxpmmRYRfJbrKO5YsslDVuX32LPuRjtY9LsND5sXG8qCu2jc0sZclIlJ9hzf8AUcn2IrKr099X2yf1Uakc5XY/DTHySL/UkXZe4vqsXOVhNoQts4eZiZGyLiZV9RU5Jl8t2y2ndCrPudf7DqN5WNKLDQiqrxNCfOT+tfO/ip8DfmRJ7Cf1H+wMXOaHsrnzHZkKqfBrZTek1bGqwpmvYcrscrktzQzps0ssaSyG8uxbbJ7jGrqzyY/2ZlInLQ7jnq4F9SXInn5ktuRP6kPDKnGXJWoRpLWhdR8TI78j8oy5r5+xFpmqxqb8VhGrYcrl/wBuqTlD0lOev1E1aOxCMu7Fyc/SlHc0r3Fb68V4qqbjsdCg99RqsXvlybeOpq/Dl2Zfe+ayfgbyf7Islrv5SMYrfuOQ/qO3isX+kvG60L+l/wAjn6XY58b8LH+zXEXz0Rvf6epMXg+wlYs+wzUc/X2LrwW8Fzf6L8D/AGjgckufp3LZWQvBfN56vf6yL+K+9vAvEsn+2c+FoliadN6WRkpK68dvCzTm/BexqyYi6/YO2VhLK2dhPJ+F5v8AYLFi3jd7bFaL6juYfEOm9JCamrr6K3HnYsPYaF4ODULgce4mc+CUtJfwWLfXfheb+tqS75L6U6EKm8kJJcfRscLxSOV41xnwKfuJ3yxs7R0d2LB1H+N/WfgvY1oczU/Hb6livVt5LCjL8KMMpqV5L6rv2+gkN3+gzk48EeBlhDRwdSw6kXydVfWZc3NJpRZfUsW8Vi2ThFu7/b27HKuLO+WuxqLl2Nlx53Lmo1+xrZrZqkamWmxU/wB7wQpal5jowiNrsSe3if1LFv8ARLXEreC2TiaTSzpnTOkdNGlGmJpNLOT7GmQqd+RU4oikiUe486a3uOSHJDmhv/WrFixpODUaxzHIc7EqgpG/v4IxuaLDjYjD3y5JZJC2RPdkSS0uw/pOSjyc/wCl38DdjWazU34Lvvk79iV+ERgo8eFLSNlxPceU4dxK7O5OV9h5Pzxv9OpGT5I1Z0+CFZVOP2a30EvruY2Lfx3yeV847F1lJ2EjuJsb2ELjwRelktpW+mqcUJJcf6ZJ5S2VyG35i3LFjvYsWfA13NJKF2Sj3L5RVzcihv3PUzuI7Fmxx0jGvKIZcauv9FuVFKfpdim63E80/rN5MavwbqyQ98r5MXA99zuPgsiEL7lrcFhO5LfY0WErceCW7yh5tjh2JZR4+hz+0ai5yPLjLnwL6j4GX+t//8QAVBAAAQMCAwMHCAcCDAUCBgMBAQACAxEhBBIxEyJBBTJRYXGBkRAUI0KhscHRIDNSYnLh8IKSBhUkMDRDU2OissLxNXODk9Il4kBEVJSj02R0hPL/2gAIAQAABj8Cj8zlZiH4m7o/skHUfrimTPkkhy86KlGrt8mqyaoX8gDVf6FvoUr5bhW+ncLdKuFW1PJz6lbMhnbRZbHqK3RRw6F6RvsTsZPTKwXK2xwrGZrtbxp0lF0bCC00e3i0q+vYgLgK11ay4LVa2W4bqr1lNyq1pRZgt5bqo5VDkWlaBVo11T0K1ArPsFuEU6UeT8Gc736uGnYq4lwc+S+Uc1c5E5iOxAmV1DulfWFXcnEW6l7vJfXy9vl9q1p5OeV9e/8AeX1x7wFfIe5fUR+JT4poaZ3ZiXHmnqTG4WQlsls2XXpPsTs8l3GzTqArai/ciylbIybV1zlAHGuip6tapzy+7aUFNU2NrTu3J9iDSPJTLUcVuX6vIHf/AAO6VoqtsqFWWYG6L5nbrdUxzm5cMw5mM6fvFSupcjMhioNdHjg4IFgc06EV0VY2W6yshaQt03VXDvqqudVUZzVVlKlZnSDKssLbr0pId0KjStauVa0KynVa0CubqhctVVxss8lGsGpKOE5PYWx8T09qcWEOc/dLiOdY2b7EHZXjtFFkNyFm2ThVbyY+tyFrZFnT5KKn0K/zWJgDbdGte/8AWqoHvD46Zac3JcuHYosVtpX7SR7nAm+ulOH5lSGcO2TGNoBzhantWfZyx7Ru6SM1OjROd580vcXZaGmXgLHqRwnKGEO6N2T1JKC/YgZpg6+WN4uG04lMEDmkPYXuPTwqT3d6OX3KjlYqjteC61T6dR9C4oqxPDlR7SFuuv1q4VQ4eWnl3jRqys/o7P8AGfl706SnpJd1qexrb2FT4LLIKLMz/dB7HkdI6EQDrxQ3arKY6L0TXW4KhNFUSivvWlKdKrFZ3Sjt2V6LqrGFp6aKoq5V2Th2q4oexUOi3a1XpQQrlbSd9BwHErPJ6LDtKEEMRDfsDnO63dAQnn35ALdDexQSxvMdJA05bbuvwXnj8U7a2JdJdDJiPRhu8srVsHRvdl4j81vRTeDfms1XjL/dn4K0jv3HfJXxUbfxPot3EwnseFa6ug1oqTwCHnjjGNco535J2JmgDYo9TclWka3tzj4pkzsUxrJCQ07TWmq9Fiyf2gfgv6cAeggfNejxUR8VbI79ofFV2fhdf0WX9xecwEbQ7uV0YIAp1pscLo3AamPRt1s9salu7lFa04KdrAM+6TT1tapud5qLBZopni97oiOdwHHrTfO8JFLlFBbKR3ii2zIsRHnqXMDgW+Hd0ol0rwXfab8l6LER14by3grLeVvpZXIZTZWF1R3kuFZUcXHq8nPVxVWFFUSX7FQmquFtZDRq2UQEeH9Y/b6uoIMieA0etTQIuhYdnCMrXHSqDpHZnznNTq6UHNY5ltAqsOYcFnZrxHSqtseI6FTULnFWVqKvEdau+ntRDN5q3m07VlDqOC3wKrL4ItpVZKImu8vSmvYtn9ZiODB8UJ8bVzn8yMa/kg/dyj1vVb+Hp7VljHb0ntWbi6ykD2uL6tETRq55sAgyfZQWB+/204J7IHFwrdwFcyzOa/wW0dCL8XNWrG/tUVBM7/uFBolkuFvYh3fRXdE78UaoIsOT+FB+IkdhIuqR2Y93zWWAOrxe92Z570AfslTHlAzCC2Yxc7VW5S5Rj/EwO9wWDjH8IDFGHSmNz4edUivHqUUuH5ew82V4cBl+VVLNByxht97nU2rwdexPhjxcMk20aQds3m0PSgDE9wrfJK0/5Snxx4DFyQUbQmJx4Ct+1f0Gb90/JZpgd53NTGhzG7Q1PRZOc0tGSuTK6lD+iiXaujaULlULlRV8uiqx7m9hX1te0VVXxMPZZXa4e1c/2LdcD3/Qq4KnqqlFQNXpG171WmVp0VA6qrRarMtFmawkLeaR2+QvmoXD1eDe1UqdkNT9r8ls4WV+C2P1krucF5xifqo9Giw7AvOZyKV4+4KriBQLbtvHJ0LaA/tfNZmuo8K9nDULLoqNcCuBVclO9W1VKqrBRVLkA868V0KhsexWFFfVHA8mekl0Lxo3sRlmO1mrvOdcD5lZ8RWhuR6z+35KmioOAqUzaHhWiMmW+FBnYBa7QUfNTtJWnMS/7OtvFOxOYOYLX1qtq2+6HM4WKidxpe3TdUNwt6Jh7WqnmsX7qtDT8LiERtZhXoeiyN+0lZZz3XI+Xl7lKeUopJMPmbmEZodVccpxftN+SwTDyli4o6PMVWA13r1t0rDy4X+EJe9rwRGYhV3+JPfhf4Qw1JJ5pHuqnQRcsYd0m3D821fzcptcJn8qw8raivpmad6f5ng88IplyEHh1Ff8Ixn/AG5Fka/mGuYmlT8FnY2zeBHFEtFK6Hr4qWrq3FD4oURdXy28lQqKi08llZx8VrVb0PgVvNeO5U2zaqjXhw6jVbvkzNushbZbWC46FxtwVwqHRVYaFZXLfAp0raMozgDxPYPisrWHZ8GfNbNvp5OhvNHzRbn3h6gsGoySOo0Xc5NghblYNAeA6Shh4Heiw7dT09KIa+7N64pROj2b8p51t09dQqc5jvaFmjPZ8lfhxVDr5ecrgHrCzRuPxW+M63W7vSq6qlVWydK9wawc6vBHDcn+ig9eQ2qtnhmkl3Hi7/xH66kHOo540po3sR8hkoKnitdVKzpYa9lFE8C9A15dersoKLMtdpJWnQtk3fLBfq6lCK+r5c1BXSvkb+No9qkkHOkdUq/kd2D4pzsfhPOYi8DJnLfct7kXFM/DPX3rBDEDHxtMRdFleLDMdbdKw7sDjsW6XOMjXgXPgFWH+ElK9MTf/JebYbl5n14fnykeqRSyY9vLuHkYHCoMj7jvapn4SeB8fqASsHvX9Dj/AO4z/wAlt60ftCHdiLsMc5caCvFRkNLdQa9OqcI3bri1wGvT+Suqtoqn6Jr5MrlYrXyXHk4rXybj19XEe4/Nb2Eb3Oosxw8jD1OqryPaD0tX9Ijr12VA5pV9FWFy2k7sretZMHDmYOJ5o7Vt+U8VmceFVsYc2X7LN0eKyMa3DwccvQi8zehbq5bOBhELeaG3zfNFkOFiGfWslXexEGRsTpOdlufatnMZHdO+b92iEWCxUuHI6HWK83xzxLGebJxBWR7bH2oPN2n1vn5KO8VcLTyVVz4I1WlFSl1tsQcoHiUHTAxYYHcjbq5BrGNaxvgD8SssY11cdXKyNlRdXkxBHqwvPsQrNtKSVD6UJ0/NbdlQQOlPe43r8FEANWD3eXNU3FPI38bff9A9iD8VgY8WwyAZHOovSfwXYPw4mT5rAjE8lzgHDZo8kp3W5nW17VhhgoscMRnqwZwR7l/I55JcRs3ZXkiUx8K0ApXVbGflydvpsxkmYCc1NNVG7CfwiEgDhu7MivgSppIcUMdjJHH0TpS2KIV6hX3Le/hHhQeIEFf9S2R3nkb19FoWP9VMmfvmPdLeqiE0h9I9+XgBQfFZS/wcrOcvrD4K0re9bpae9VorgrTy1czTydSuqhxWlVe30eehRy5y9G49xX15V2sPctpicLtOoyGngg1keyppQVos02Nk72L0M2G/E9x+SDJcQMQdah9KdiDZto5o0Bme74rJgsKI6+tS6zGteklUA8mio5tVlExtcNdw71ssQyQn1m5bUQnwxzRPvQ8FXgqO0+hZarRb2/Meaxec8oGpGkfqs7fktpiKhv2eJ+Q6kGtFGjQBCmlFbVEqit5MY7/+PJ/lKbeupr+0iQUfxKPL9ke7yk5u7yN/EPKSZBDH9r1j2BSiUluWzTKRmPTZGKaLDYlubNlc3NTrRA5AwThWg1afYFGMTyDGWsbs2OErwKdHtUeIweALHetlmcadt9NEJMSH5GNDGNjnIaw9Q4cE3Dy4zHbrs4c8goYrD8qTeiOYnYggd9ViIMBjticdOZJpnRkOyk2YEIY+R8O5se6C+uYgdO7qmOwz2TZjct4dI9q3Ga6jRNbPYSbwIHBZWsqTPevYFpRWdquctVqtSueVeh7lvRtV2e1V3gvrFaVpXOb4rTwXNXNVvJbyaILRVatFotPJp5Oct2d/7ytiH991d4P7IV2MPcvSYZp7Cquwr/FXw8i39rH+z8ls5M8o6hojDg8UY21qM8dQO4JwdjMM/wC62wPjos2Hq4K6pXyUNVWqOD5OAkm4v4NWeplnfcvOvd0dqa99HPGnQ1VKsraUW7r9AkrGtGrsPI0d7Uwkaxv/AMxX7VEwU1kTRUndGvlNSKcPIzt+Hl2eYOxWWrB9gdPUmMz1bzqgWueHis8MpqbVIU7XygvifleBfNr/AOK24cKmtWV3O/3JzIiGSkmtTYAIZnVd9oIM1AsmQudSNtXdQpeqecxZtHZW9J/XxTHlrySAaoljgcxoOpOeKWfQ014ouLsxiFWkhF0zgazV1qNB+S3dn3fR0Wi08pRVc1FcquYrnK5XBVLRVUNFwWvk5oVSw0V2u8Fzj4LneIXPHgueF9c1fXNX1wX9I9i+v9i+tPgtXFWjf+8hSB37wX1D/FVZGW34qocKeC2mRzD1HVAx4ktPXZZRic3Ubq+X90LfjB/ZK34f3VstvioRxyNaskWMcwfejrXtVIsS2/Ei5X9JYqecR+K+vjAX9JjCq3FQ/vK2Ij/eX10fisu0CLXPaFicLA+MvliLG71E3BDZ7QMIptAhANhmr/ahMqcNuuzfXhBrpsP++r4nDD9s/Jf0uHuqt7GN7m/mvr5D+yB8UHb5p94fJWjJ7X/knCKBlKa3qnT4eGMSuN3mpPtKkdjHcGkZeF7314J+FLrjdBuadi2kj61zF3XQVRcwVjjaGmvf+azNLa1DhkdxJqfemz5msidQUBq6wussM0hNaUc1WNFWUZ33y10b19qo1zAOAyiyyx0NW5jQbqMd25RcjimYbBx5nZCTmd0Xr+SmYx9Gxy1a+oJcaf8AsX9J/wAK5wchusurwe1cwhcfBc4LgtFYeSnl1XStFVUoszC4Kuaq4IGq51O0K1F9YVeQqmZVJ9q557nK0jvFWcvWXFaq48l0KZl9ZVAgKkfMPFBbwaShuub2FUzvVneTVXyn9lXiHuXOc1bzn+NV9eR2rdxI8VuzjxXO9q0cuc9c8rUrU+KsVqtStFxVlqVcm6oHEeSzU51BWOOvVqiWQNZiGH+rtnHzQga3O8uygJmCBY4xVc8f2jrV/XUvOXx0hdK5rG9QoaVN+Kiibh5XteW+kbo2qe6hAZcfaQbNIRmFQaKmcEdIXPTXMqwE6BtLdSytbR3TpUKWVj5chkDdo11x15VKc7M22yFwGtBbqTcM6FhrQZhUIhrCR+JNcJP8SIL326kfTtp2FbuIjPerSMr+IKoYOtEFpHWucQe1c40KuQFzmo7osuYuarLfouC0Cq2yubq6ssvN8vFXWoXOXOXOWqvdcyq0ViAtWEKhe22o4r8Kv1BCxVFYEIkqjQKeWy08lnLVarU+Ks4+K53tVMxV6reb7Fdvs8lnrdlFe1brwqjeqriiGzaQCVe5VgFRUUmd5aNmKp2yNYQTkI/XYg2Hfc1rhGa1yE8e1ejduubamo/V1HFiHvc1hqH9ATn4EGKIM2dXDNW/iLBy2uPmo57A/ZtZcC4/XYm4dprs3WcW0JHWtWr+gy/9s/JOc6maoo7KsSJW5DCzbb+7Vt6lS4URMYQcwdlq43Fh+ulb+r8RIfYxOxGUuyEWHgs0b10CqOe+Yrm1YUHxpz4a5mb46ShO6IB/Etsar0cm1OrcwCkkdh2AxEZsoy+5S8kYuIiZrjlfWx6lXNIPBVZO7wVW4n/8a9HKw9/5IHZ1p94Knmr+ul/ct/BTDr2ZWYRkHU1Crl7lp3qoVS9WPitRdcFXKuYuaQvW8FXOuerSKy5pV2vXFVVR4Immp4qrhZOa2wPHiucntoLKorVV6VzqLdk8VdlR1Kui0XStPJx8vFFa+SwK0XQqEqlVzz1IVbU9KzPNT7loFcLn0W45ru9Pia4ZsnTxronRNnaQxriy3G1Ldyie+I0oLUpUV4rzJrAylA+au6B2URZqHMqwxnnNVYo3lhc9xLuFNOu90zDyMOWMUzlwtfSmuq3cNPJ15crfn7lWRwwUVgcuvg0373L6/Enryx/+KdndmI3hXTs9ymxeIxUUTcO0iOHjwFAK9HuUjm7ItbRjQ2tK9N/1dYb7wc720+CfQAl0tAnS4V1HDTgmR4rdfxPBHIa8Qte5VYRSlSEHxHeahiY/qJj6Rv2HKMN5papcO11DM4aaonFNLZSCc4dc9a2nJ+OcW8Qagjw1QL8O3EM4ObevgtnisNJC7sVI8azvsqtk8Fd64DrK3AXHpNgvTuzdQC9JhogPwCqwr4IqQnM2SPusVsnYR9GjgSjma9g6irTvaPvGqpHi6fs1+KAON/8Ax/mtydnejkkiPWHFMMuVwe9sQ63E2VDhgacc7VU4R1uhV8wnIPHZlUdgZe+Mrfic39hWa9cetZjot2aiBZOeu6FSPFdqOuUaUTiCUGmqNlcFXKs9c5VD1qCVV2VatVPj5NcverStW64KzldUAVwtxhcexU2dK6XVGs4oejNlV7O6iAEJovqnLmP8FZkitVvgi/ah3rW14KMyszwtzF8Y4lS4iR7YWMbU5G16aUWVlKPdVziKErYxAv2YFxw70MPPNIwl/wBWxtAR8VXCYMtbw3figBA1oPrOkaKfFbGDE4WpuXbU27qL/jOH/cf81ty/K01BaK2WwjLdlzi0t6DVHYty3t1HgsK0cIR7ST8ValSTxoqNcSaa1VT23/X6ojG1jjKHHs1QvR3QjGbjp4rNGd5OzMqCKPHShDI6pZzXfaHBZwbi6biYN2ZhqO3o70JNDo4dBRMFXCtXMArl6x8kA/KWu0roV/R8nXGafks2A5Tew9D/AJj5LfgjxLekUP5rLjsDLA/pIr71u4tv7Rp71ucfsqpkDf8AMszG0FeJ1U+lqe4fJXK4LgtxxHYVTbnvWWrHUWBZK2kUcplf3NNPaVZPZEzec3KEG9Fh5Yq8P/1q8bHdG6nyz4eDNQloLBdGXHMw75pzncNmHZPu9SIibLDfnNky+y4QHI0eIxUeWuaOLMjBDh53OF6CEfJQYjlnEOwxlJGUNFW9FUC6bEyMfxzAUKyumxIb1P09i3cXOPxUWUYx4PQWrexdP+l+a3MZCe1pVsRhfF3yX1mF7nu+Stk/7i3Yi7slCth/8bfmrYd7u9pX9Dl8F/QJ/wDtlb+AxP8A2XKhwMw7j8lzXj9r8lz/APGqbT/EvzVhl7Srk+xWB8V6xVg7y1FVzCrwA9qMeTZ7RjmVB6dVEZsG6WLEF+S1iaG3sToo9lh2yVvK/mt46fq6MU79psg0saRltXoBtqnMgblD/sk0/Wq2r+TpZtN+gbfqqmtnwuycRZr3HNT9kFAxQuA0BGHLviFu46AvafXgdGPGp9yvyf4YmL/yUm0rnc43pu06llpQm4rcpvnEbpGDUA5b0sg3TZxMHgwKKPpqtO9VLy34BbOKVmXt0TDC9r4yNVnne57esXCE2Em7fzWR7Q13sQmiNKHMO1baPXQhVdodV50w1ils/qPAq9Q74oyFzWxm7gfV6ws0LqjpY5Wf4hbzGhZCzMw9S38GGHpZu+5Z8ByjNGeg/ML+rnojhJo3xEDPp+ulSPjlu6mq5rSt/DPW/G4drVcqz/b5GvnLv2QqMind3D5r0fJmJd2Bei/g5i3fvf8Ait3+Dsw/EHfJTNwHJGymLd13EeKbPjfOnYhtaZYbkgdDR0VQGMLoD0bEsPtWfFcqnDNZDs3uNd+9aJrMPOcQ1o/tbf4VC2LCwsdnNTkvzTxUbHHeeNoK9ayv49eidgsU2scgoCjgsVldbccdHtQiedw8x3wWzmBpwQkbZ44rLx6FnZpxaqqjrFWdp9DVZsbjoIRwzvAqm0xMe/dt618FU4jMejgqMfQdi35a94W7h8/Y2vwWfCcnRyTusxmSpUdcJ5uA0ZzatVz4ekkvJPuR2mPYB92L81RrpZD3Ae5UZGArxs9q5oXM9qyNDiehpQw7sG8Oc3NvPp8EJMZHw3GtvVSRtj2DTJnJIzivTrZGPZYnFN0y5qDwaE+XzF8YfwyH4lUhLIgOByj4JxhxgdQXqXFrR32CpjeXQaeoxmanwQfFNO/IagucGivZ+aAxOJyE+q00HtTWmGY0AFfOj8k5jq53Bv8AWVoNVRxPR2BNEYDurrWI6i8Jjw3dYypPAJ1N5ui3nBg43qtnHYD2oHbNrzRenFPBI7HcepGSCUxGtRTh2psOPZztHtFiexZY5GSxu4Vr4FSfxVE4NzVqHi9uhStxzX7pGUvYAti8tobUICLYnNYctaaAhAvnjc11ud+SmxvI8Gy2bw15Aym/YqiaR9q7sp9yy43lLEYc/wB4xy9Fy+1/UK18Krf5WP8A2z816TlM9wHzX9Olp1CqMsMsz3FuXfIRNNVp5NFvQsPcq7FoVqjsKky3JdqVZdfl2GG+vxB2cfb09yGFiezLhqitKk7tDXrum4XDtz4jFHJG1Mhnw7ZHgb0lw5zuNwvRTTwu7ahRtwXK+0JzFu0qKU8VshgoMRFHZtCA4DxVOUeTMTBTjT50WV0zmdGZnyQgGIbVv1bwbgp2DxzKP49nSskzy9h5rlfeZwKDmODXdS2M4yv4HpV2bqq7FQt6i4ArexQJH2WkrLCyV7uhoVIOSMRfQvqK+xbuDhi/ER81lxPKkDXmwbHr7ltsVIWZNHes7uUMbnkiIZQeNEC7O/8AaKqMPGOsrNPIPwsCqR5nB1849367FSFovz3G7yiI2eK3ndyq9yzUVB7Aub4psETaudYAJu1i84m6zu1RMpYxnEcxnh86qE4N7HNYzKcgssM6jb5hvHsRJha6p0ymntWzaXMb0A5R4BFj7yS6Uuepfyqd0svCCL/U75IMkIjibpEwUA/XSskEBe7oAqsxwmyH96RH70XTYvDVAs0Ek18F9YVTNlp0rEull9KB6Nojs41+Sw8DBz5mVr2qQ9J+K2bK0LQFsR3lXyu7FuarTeRY6jrlb268a9az3I6kZInvZW5rxTMJiIXNe/mkaE/BbJwzD2rf7nIR58sjTWJ/QegqTF0yiPNnH2HAX9yxjw118R/pQcBQtst7L1hekwcYP93u+5bTDcoYjI3WJzqgoHZ4PEtPCpjd7KBfy7kXGwgamN+0b4rPyfPI53rNdwR9I40tRH6A8jg7kqZ8FnbVul1vOdF+JvyVWYhjx914KGHxWNyyHQCNzvcFlZiaON8r2OafAhP5Qd9XFWGD/U74eKxD3OJDWu516W61Jy1NYXjww6G8Xfr4rXyQuzaQyW72LPERVZJQYnjinP5QhhGUV2uUe9AtdQEVDo5K18UDDytKOrZoxxTGVnRkqmxYbkXatcOc6B+viiRBseNMunimvl5e2GcVpkNvCiG25ZlxH4CPjVDNFLIeGaQj3UXoeTsPX7zalZH0Y37tgs8hA+K/k481i+07nHsCz6yHV5u78ltBHRqMbhcLaNlyU16EYsFGAfWfwW3O/L9p3DsV3K5Hehh435n60VXuYF6SRxpwFgt2IV67oA07vIcY/nSCjepqe42DB+vgpMPhXZI4zlqeCfme55zi7ioWwYYy9jM1OtAtwmXtcG+8rbYl8MYBvWUGvVZebxzNrOabQA0Der9aLelxU57mgr+Tclx9r25/81Vkh2mX7LG29i9JE8fjNPevT4qBlOl9fcjRrzdBliWjM4U1QyZ3YgOvwFPisLscO4Bjw6Q1qLLwT34e8lmgcRbVZ3OGbQ1FUGmTPHY1y0d70cnTzvBAOi0ILnUQe11XHwqsz3caIMy16D1rKx1w72qGbCtq6J+fQVzD3qfHYzGEY1+8IY4hsyba+32ICb0LwBc6Jron529CGKfmAxFuouH+yfhX4OSN8mmQ2J/2V8HiT2OW7yXjSqN5Fxnfb4ItPJcsYPruk09i3ORz34gLc5IYP/8AQ35ovx+DihqLFpqSj2o+TXyUT3qbFHOXxsbK2rvt6rM7B5z0mR3zT3YeSWAtNgHVHtv7UJJHQS04vjuvNcNFa4B2daEcQEHzco4zCBvOMTt2v4ViMYeUt2d5h28jHVy6k0FTewURbhcHJEwbjoA5ooOFxVW5LcXdFRRUg5IZfiXV+CbPh+TcO2jCAcwIoafe6l6blDDRD7ov/lXp+XJXdQB+amxbsbKTE3PVzgG0FzW3QoMVh5AInt3dpPfsoV6LFHN/dx1+Cy4PBY+dv3oaDxWR/J8UfCj5AUHMigc/EP2DQwmxPapKiOGUMOzc1oZfgttPiH7znBulqU6lG/D8pPvo1w6u1VkfDI39dicH4cj71CQtpKXPl+0/h2BZpsdQ9GU+9fybLIfxVW5HRUYwyzu0jjFUH4qAsH9nmy+PFDa4qGJvQxub5LDskxMmWVxzusLBpKcGYfOQfW3qpz8AGiKVlcreBH+6ibG1o9Hx7vLu6+SDk/Du38RK2EO6yeCEbRQNFAsVPxyuWInx2YyOmOXJrp0ox4WEsAc2pJqXdqibFqnTTtflYKmhoo/OaRxk5jbMQEzbPf5uLlzdabNegwJbIeaXvzW7E70cBzaExgkLL508D7oot+R571S91qsMeT5S4uZWXdpR2nT1IHK6rj6O3tUeGib/AGj5nO5ziGOoB1D3lNHWsmZ2DnmzEvDQ7M0rzDB4OPFzWBk2hqzrpUD3oQzR0cWhwcR4qkhqB0cU90biK9SDTeyDGno8Uc2iJ2YvpayEmZtae1Od2HtQw742NA0NLoMw49GB617pjC3Z7KWrqO1trRPxUe0mc0mKuWzePy8UGviVQwfvLU/voMd6xpzldk37zVuzTsPW0U96IZiHSWrQsor/AELeQhHDPoNpXDgU+wV6LHx9mUBZnYjNU3CD3PysZrTj1JroBkIacuW1OleacptL22v63itoXYpzPsbQD4JmFi5Kw9I/Wc5peb11osrmbMfcC/4Q/E9ZgHvWfDchjDn7XnWX2L/irWt6Hyl9PYnh/wDCCCdxvXLkp4KaHEu84MjHNr5yKXGtCmQTcmyYl0T3tc9jQ4a6UKyxYXFYcHX+TH4Kj8aRan1bh8E4nlSBtb7zg33rBtlxUTxBNtatltYGmnXRFzsUxx/Gn4fFsyO2mcV+zUU+K2eGaNw1zu5o/VV6WR+Id0c1qyYHCmv3GlxVZcM8fio33r+UHDx/hbU/BZXTYm/2XaeNUG4Pl0x4cN5sgJPssm4YPEk9PSYjLQvQogB0LBxscQXPd/lT4vWG91LEtl/q46+xOAO8xgbTq/VfKcoqehSSg73NHesFmktAS6lOhpKLqWF1MDrkaEPOsxkLiaIRYSDZtjIPamT4d+VxOWvVdOe/lfETuAqRh8OS1v4nPLaJuGLy5wFTs9dBzitnGTqG1PYrIxyOeKNrur+kYjxHyQpiZvYq+dyDwTCZHHdCcWm/Nam4WLjQC1Mo6VM6MDZ4fDujDgOdfX2pg603D+bysYxgAkfGaGntWO88IfE4+lOoLuqibi8Hicsgblaa7vfxUmExm7JGbgLJWgrVEg0qjRxKzgt67qu7fVo1RhlcRTUHgV6C+Xis1czhoepZnx1aL9XYp8odu4R2bNxNWrHNe4jLia6cMgH+lE1aRS1lzR06rTj0qoY2vYrRsHVkVRHH+6s0e4dKtNFQzEftFMGIcXO1L6rLFO/4Ldma5SPIbVoHiTQe1ZckbmrfjeOjLdQTgUrLI8d6/k7nDsKjw8UgkfIaNaQmwMNcuruk9Kamuw8gDZa0HEFEOm04JpkzOFelVG0b2UC50y+skJVHOeCt17vEKuY/vj5LFslOVjpax9e6F9avrQvrfasQyN42jXjIejSqcIhV1aF2Y6LFRcoun9E0ObIw69RJUTS2Vwc8Mo5+o7l6Lk2Cx1c3MfasrWho6AgK8URVCicVQldSHYuTRb6xx7qURPrVv8vasXii05Xsy1/XasY7Xey0HAeUmhNOhWfSkg77FYrFPvs4D+8XD80W6Zt3xT6nnvATXNYaEKZvQwH2pla8/gKrDwSZ3y0duO5kfV+PWvFRmgma5uYhvOaakFjvBSyNZQWyjot/v5HH+7+IWq3ldADDk2W0w9cJLWoGsRPZwUkcmFeZJtwStGaMdY6DwUmD2kb8RswZcjs1N8W9iZdCTCS56iwbvIglwkdvO3b9q3twO9dt2lNfhC3atvwyu/PtQwOKDocQa89tBW6dP5icg6CKnuTo66LdNOxZcxJ4qlanoQGVwPEprWGhrdFuc0FrmlCsbKX19Flp3hcuSu0bYf4k2CJwezUskbYdhQZi8LK2v2TmT5dm6ZrhxYLJmLZgsT05Wx5WU7OxYnI9z2UZSDTJUdK3cGAfvTr/AOVaPxuK9Jj2NHUyvxVfOoHtHAktKq8sA/GCrSN8VOydr5GOyNIY+htdZjFygD94tovQYCeQ8K4gBNywhnUZKlvzT2RbNh4FtTl8VBJisSJKtLcuUAh1D71uNVSmvxjmV9Rrpcnato3O2p9SYEe0KjsaKj1XZK+xy/kX8pvpGxx+CzOg2TeiSVg95RjzszDX/dEFjPFbzfauYadqDpppqsAbur+kzXW7jZP3VUcou/7f5qR0uKMpra1LpxOYrFAccn+pQZeayTO7wKsq1rVDtTireShPl5PYDdu0d/lVXxOBe3MMygY7R9fbRcoSdLqCn4vLmKiZ0yVXKWKPrPjj8AfmgPvD5qKPplr7FC1uBzgN12jU7Pg9lua5weIQlIJDXVsacQnsdCBugso/TLoAE4FgvfVOlcKE5fITka70fHtC3crewKrjVcKIDNp1Kk0czFsxiGG3NkRmiwMcEkrt5zNHKKL7RaPannDYoQ5zU/Zd2tTYcS0Txj1mtLv/AHD2otinZtD6jzf2X9i2UlY28M2nimjEQRvyXbmGnZ0LNC7N906p3nGGyTcXjdcnStjOJYPWYNO0JuaMNzNza8bo3oW3vZZKb5stk5pJIoLjVbPjmz9yxbqXyMr4lctzkc+STj1fmto+Swu9yqxhodKhCZkmR7btyqkh2U+mX7XYpZWYrJBndRvVWy9Jjb+Cviif2l9dX9pPa+XdoCFchB9R3JrnPOYtFSAvQzMP4qL02Hir0sITBFO6JzXGxNUXh8MrBzibFRO8ylldXNnaywINvj4lBzHbrhmB6vId2roXV4aKSJormbzdpRQ4obrS0upS53dF6V8tPxlcyvavSFxc5xe63SqSYpvY5qkcx7Khpu1tKKGOapnFdpKH1tXgrSyDq1TXwY6LDDomZvU8E3/1N+egzksqM3GmllucqD/t/mqy8qPd+GOnxWIlhdMXsjc+rn9AU/Y0/wCZHyWCFAird/koSr6eTk9jGVOWX/SmD7Mb/gsPhuLMg9qxrzbau3eu/lqTRYePqcU+T+2xL3e4fBNFeNVhmdLnFDJunpaaLZvkJGQ69ykf0U94X1zgqmYlWlqyMClXC3ZVc+raI/g+K5tUR0rKbrnH94oQ4R+JxDv7OmYm/eoI+WuQKyYhtWBrxXr0WePCS4cB/Ne/Nw/NCbIX7OhyjUpztrSpQjbK2rulRGtzoW+CjwzcZLK1xyhmp7qqmejfszR5fyUXJ8+DYNpIIy6uUtPWKKtqqrTUdadRmzc4UNlscThhIzg9uoT3wenhNHB45zO0frRRztbXETyFteP60W0xZZI2Joa2KoueJcSsX/FkLW0yB5a6rTrouUnxTF4klfemlmiiY2eOQRSCjC5mo6ii9se87RpvZGeWJtc1Re/eq4WM7Vh+F/ehHFMWVbvBupQdHjJJGudQZwU5sWP2Qju6g4Ita4Oy2d1LavkAGhqt98bj90ORaMO+vTRy2jm0YLDect1jgDzamoK3sC/tAc1ZdjSv9pEHJghoKipoFOcUIpTNMZKcKJrg0MyHLlaKAKyLHaPbkKMbse5jgaH0dfivN2SbZranNTWtCt/Dt72rESHCNGWFxGVoB0UWJbis4mAcG0TvP4NlFU7Ml/OUWAzGPbVcXihsB86J7Wzzs3qnK7VYXZsq5zn7zrnmFFd6HkxTSf8A5eT/AClTD7jfijXydCt9ChKvp5MC8UD9lJT2I30j+KjjZ/bBn+JYp/2jby3QaHV2cawLeJa5/i4lD8J+CwbPxfBE4vlNuFoaD0ZdVARvzN3hXSqkH3FXZ26yubTvWVxqaN/1eTPKHGopuhV2c37v5rmy/uoMcJP3VrJ4KLEQekcJA9o2mTTr4KLEtx0mHx0XROx3jf3JobjDic0jnZyT1dKOUVo4HwW1nxLo2OJu5/8A7UcVhZpQxri3fNPghL51mN8vpOP7qD4sTle01BL9PELPHi42nXnKCfEPbKXTbWoeCLHMexa5fwgfkt59D/y6fFbuII/FG5Da79esVWfzd47lbNBI3ea8Wv2cVPA/EA7FwYCPWssQ0SF2d7dVA7E5BhpXvz5m2vXVBseV8ThTLXM096AwkeaMPzUPOHV1hHbP2dC5tCDm8E31C8gCjdQmnNujw1Kcx0bHOZzHrlJz3sAYIWVHW78kcVi5Q4YJ7aH8VdenRHBRT0IZn+r4W6UxkOI2kknDKKBvcntxvKT8KKVbu5hXoWwxHKcDJB9ppBVMNyhhJK8NsPcUBHiIang+/toqReZV6Xl9P8qiixRjMrddnzUW9wUjJ2bjwKX4+TnV7FLi8Lg6x0zOLsraePinbeSKj5twROZzadXci/FcsMivTJsw5S4aaTOMnGINWHEMOR+zbcQEXp00Tm5yAxzvafyWfMDlw79OtzPksQ3of81gqD13/wCQomlqIIIEaLFU/wDp3/5VJ+AJ1OhXV0AET1LXybxoEW8KeTBln9ma/vL8Tqf408cPOKhYgm+V1ury3FViH09crAw0uzDRjvyhO/CPisM3oHyQq6qheGW3r/slOY3Ust+6ua1v/Ur7l6bFvHVohEx5IyjXv8llqPJ6XmgLmP8A3itnRpqPFCXC4OMGIc3Nr8Vh2PbQ0cT++75Jhblo6bK6oF23tfsTzDig3Cc5sXfoFHHJmET5HczXh80/DjEPa0OrGGjLVp0TIMfiH4qalXZHUaOpCNjpcM71amrUzPHMwZ6VJ3Sg2PGxZ3Uo04pua+nFAYnBOmfJUsGcaW+z2oBvJ1MSXFmR76gL0+FGFJoB6WjT7E6LPUg3vnHjlROBa573ENyhhd/pVMdDs5g1pe3uU0jf7Uj/AArCiSRsdSanq3ltzygNmAMzK5h0ceC2zcTGWtuQONj0pkOK5MixLa8+txe9OhDCTOiki1izurR3UdVLj/PGNLN10bhegvbxVHgyHiaELFR5pdjNPHm7gUcFgsG4NxUjTmkzAHKHXv2rzvCPficZIdnSuRuXU+5MxEb2zeb4faOBfvZKnpRxOKI9G125moS5MxwfvOjAd941N/h3IMAUGFk5NkcI26iUaE9HeonYB8mDjp3koYnHyhz43FpdpUdfiv5Li4pchvkeCqHNn15h07dFQ27QiY2bxWIe9wbG1rrk0q6milllaG2DQ8nTeCdJnlrU0p0J+LliJymgzPQw7M2WgbYjdCke7FiJzyCMw3b14rEt85bMdhFdugq59vYFjcxAAldr2rDbKeN9C/R33StPVCCCCnbxMTq+BUn/ACvkjfya1V/oDNpVUPkwwbxgqf3lhv7xwH+MKv8AfEqdzr5HAN6tfLcV4qQj1nFCP7IondvwTGwtB9GHs6zW6rLg3x9rKfBM3t2tKAfki6vNYSP3Sv7TtaAsoBhr94ub4ISHId0HcNR5B5a9K9XwRErHQSC5FaDuTG0c1+R9WuJ6lC7ojHz+KgnzD0cxk3uOvzTpZJTK7jnumR7Fz97mkj5JuJyh+KyENc6pLLcPapo3nM9puT4qhZvcFgcI/KIJY9pzBWtD62vDpTsY7GRxPDtx+bLG8jQEjmp8Mz2iHAxVlkfIXC/EEk6+Flmwk0r8ZHVspa3ccpmYvk/z0uI3bA+1BsWCODfo2KSPdIre495Xm3J0eRx58mYtL/D4obN8jnO1Mj8xUm302z3HsyrBwRSOhD6U7OhTmSGVtWPDHag7wNitpi2xTiRoOUTgkdZobd6yxQunkbvUDa3WGjm5Pw8bnYpgytZkybwHBTO2xGHBDWgO9YsFaqbG4qJryMzczjWiwsmGkGGEmMyuOTUiMZqeKgnfjcW+BuKcy5LHBobzW0dbX8kHyt2LdllZFMS2R9x3d5vdNw2HFcO87V2z49FQmyzMzYyQekJ4fdCdDJEHMFqoNzh7XUc3pDU7dnjYW/1th4Ix4gscWmtdUYGSkRfZGiZiti1z2cK0Dh0FTx4LkyHCtMWZwhbcnMB7inxMx8kbGnLuW9qbyfypi5JMHKfWu5ru3rTGVDXEEwQnRg+2fagHODms8FssdmDHnVrtEMNscbEwW34mkDwNUJTyw2la02Trf4arz3kibDuofSRzNIeR0tCxcuIgLJn5Nkytn06+CmxDtlG1lXbPLa/DpWeMmOVvPaVJC7nw5fA1p7kK2qaCvFNsh2KTriPuUg/uz8PLoiT3eS/k3lfyMkzbogApW9cx4KDax0jw0oNRx3wSn7U1c51iL0609srmPOrKVFb0W1dHszoW9HkqeF1h4/tyNHtVSj1kpjMbhmzCO7a6t7CFXCYnEQE9Dqj9d6knc+DENY0uqYsrx1/orZk0zCle2yMuzE+G4SRXCObX7KAdS7ae1ZmgUBoqObVc3yarmoSvxWTLbmi/gFtsXiIdrGD9Y1/E9SJAGWg000CwzSdS74Ky87digXRnJkIBLejry0UuJ2TR5tTEbprQaP7qXQ5Q5OdCY5BqXULkcVicjoY7udHctWaN+Y4TDl3N51flWi8wiALS1jnO6/1RR41+WrAZHU1LQXUB/XFPkca5zc9aawQB73DM55rujhRYVrJM+pPSLV+CJuKodoUULgaTvc001vZYSLatp9p2nanxYXGbJzwQXNO86mopWyjklw9N0NfS+UkigT9pLFE+Xnxl18vQVyZjZGFzXytzv1OYGtD3LETw5z6YbQfsgfBS5BIdts6Xv1jxosC2pMjIn4wXttN2xp1WULcTs2+cTySb3Ruj4I5d152MLq8CbqSLESsfKyfPGdatDqU8Am04k/FRN9aQBxTMfK7+ieqfWPDwT5jrmDApmFgo8ZW7vtXon5mDdP4ldY45x6HClteskBPI4uJUDWc4yNp21Urn8pedYh7985MtLdvkEbBcp0IJOUDXsQTZQDujeXN9qALBmpQ9aa5kAa3NldlHA/oLLyPM0uxEjavYbgjQH2pgk5cn2sLC7NqWkcKg3TGzsDpy2rHONM3d+aY2TCmVs0hoQcuVtgNfb2p8EOKY6QM5vHRPqaejd7wmYN+MjEsnNHT3oB+JiYTpV4WykxzA77LQT7lWI7Ui96D3puKwkgfG5aeQPjlDmk2vxTZJ8YxzCedE4OpxGnTRSYrDT7PDi7WjKco+JW2fiDK8NoC/WlNVm88G9JlMbfsHivqt0WHWqOfcm5rZqB2zixu7T7VllD3xtOlB70XNkJDWm/TZcns6cTF/mCqu8+9XVSdFiG9MLx7EK6W/zJ0vJGJ2f91Jdp/XXVZMfhDyfinaPA3HfrqTMM54kzMzNLb1GZbN7SAbOaQs7Ob9Fu0xOVpsTlrRCGNxxElezspxHcpL0pUe1YaPoYT7fyWRpaHHQuNAnTySw4fCuHPe4knsDehZ34rE4uRzTGc24wgjoF0wYF5woYMgDQC2nYaoHH410zQa7NrGta7tsnvZHPgnuGXPG/MO+q8/ixjMXAOc8No4doU3JT5KZxkjtxzZqKMRTh5c2r90jK7oQbiXhjNGPfHctHuTJmMyhzyWu6RT5LZwyZ76jRNbQ9KgxQs6PPJ/jUbSL7IlGTDRyPE0ocGZcwzaA9tk04xjRipxnIec1H1uf1on4gtNzUuPBCAyOIPE8bLzcGZrMbfaOAy566D2LER8qtxODERYYyW5c1zXXsHisHhsNiXt8229HDUgymi5OZPydt43wncc6mjsvD8KlxODacNGMVh5S17rNpm49oWDw0ew2LW5czXAudbU0Wb7NHfrxVMLh48zBlBea+xDz3KHSUzhgIFK1QwobnlfKCA0ZrWXmOFf6WKzg63ajG+Oykjllk2jWFzWfrVY2XlF7I3TuY1g40rVPkZCzeNdEzFQZQ+M1B2Ysttlo83NOK9K1wZ0p+QZA71uhStbJtBmqHVrZSOcxrmBt66J55OkkjlfHlc0mrSCE7k4787X5E4OxvpqWDRavanNzZ39BFq1/XBGRsz6+sWMy+F1s2Ytxjkdu5a2RkOI59q6u/Xcmuj2j2B2Zl7+ATnCOcyfiF1tPPJqUNWN0UbxFz3WJ1otwx5M9MtK9y84weB9EeLaXPYnMxHJc4e3nZ20CdBPCdi/n5G2b36IMwGGAscz5rEdgQED8jWtoMld7h4oYeBz3vjNXZeaDRVlEQZm0LhRE7SgjsQOmn5JsUTAXP5ttSpIzszLlaXlprxqgIcwidqNahU3iM9z0ITM2hj0q7iopBiI87TXQox0cIw30j2M18VFK2WuRzX3ubJsOz2k0nMykb3yCoHgubTNTgfISpADqwpvpHNymtuPUs3TdGGaNr2HVrhULAMwuZwfGCGuNab+iMOLwpwGJHSN38vcnCSPOx3Mc01H5oxuF2/QMMrNk6xo63sWJkgbE7Z5Q45SH0PddXZWpB9qY37MI95UGAhNDK6hPQOJ8FBhomUhiFGjqCdK86MqB2prehF3Rog29OhNwk4a+J7SC0jnDSi81BJiLjLC7paVHiJmh7efoaUtxP6umYWMlhDszq60/wB0I3xZ47tOV9E7LGKcLJ7xZjN8HVN4mRv+Z6lD35XBoLCLEFR8lULGw0ksf1xUEkpe6QPk3s3ONbD/AAlQzyYZpll3yXXp+gnEYSEScHBoqFh2Z4xLh8XI6OrqEgnNT2o1dTey85RtaNIgf8TlyfE2hbHhaVHTmcae1TNw2AxEm0kZTLGaHdf80yfGYYw7EZnNfZwBqB7U9p0uz3J7H8LLaxHmNzdyfjC7aSYk1Dyb5OARm4CZpPYdfesuax0rwVwF59DIZBGN9h9UDo8VFyfGXjamlWszZeuiPnmIiLncwMrvBNa8oSSySCumWmi8ywmNidtW1bnq099FJhcZHkliO8E5wvn1TZoTUJn8J+S+dE0bdvS3SvwQzVa77JT8Tyc9jMWW3vz+rqTsPiM7S00c06qxKY7PzaJobITSuprqo8PctrQ31We7TXSqdlrpU5hwVDKf3bLYxFrmRjm5FtJXOcD6r6kDsWTCty0rUWAKkjfAN63MqthNiCywLn61QZh5y6PjW3BVLszYwFMGMo55G+eNKquIMUUTG85x4p0fppSbvyWHUNK8FmiLWDi0GtEJBIKOFakUTWCS7b5qUDT3qssobYNJPyToiXyHpBsi+pkp6pqboSWgJu0iye57szPX6+tB0M4ObStlaIu7Cshgl4+qnW0qoztRzRqhfVclSf3f+tGDFQtkZ0Hh2dClZybPtYnggwSUr3cD7E6GeA522LJQQ4d6ozM0/Zk+ao4LRS4sveJZHCxvQdpTcZnJfiGve/MeioTQdaBGjq7ja9SxfKuXm+gZ1Vu74JxrnyoU0rl7lm8lUxg0yU8FHjKDaYN4vxINiPcg6Z1GMqI6/wCL/SnYduJkjp13KaJJdpGQ51H6ovc+riXHuzFSkfZosBH9sYYeLmqRr+aIge8V+ftTZJ43Q7WOocRqOCdGcK9jM+69wp7Fh4GsJlbE0Oa0XrROieSZb7o7U6bDPBfUBuzdoaBYWWaJxDZA4nWlD7NEY58VhKNbcFjSa++lepGSR+DqAHXY00HV3LJFjWnLunMD+h2KHEzyONTJJN1u4ewNTcTsnsY4l4NLmqMhYWiT3p0Ocb4MfvQhggLmsaGtaOAUmJ0uwe/5Jj/ttB8krXaOGVOxeKZlxWKt1iP9fqyjaXXy3HQo4BoTc9SYyt2tAqoB0UJr0BfxrG30kQyzDpbwPcs1KgmhT3SXgdrThdOgk34pRQjpB1T2skGaKQtCcOZM3X5r+MYBWaIekp67fy8miKsq9N1IdBI7intbWrRoBxRaHF7nC5GnkNfsu9yrdDOHOpctdxQmw2CoMtw0UuUMPA0NEe8b1AQghPMNS4CgTmgRyymtc6yvkds3cGHTsCjdLCw3AoRW3Ys+JjaW13qbqf5q9uRri1vH2rNs2ub6xt4prB6MO4u/2WbDE3tICAE+SWB8db1HN8E6WF9mkcaLLiMOHxPAznNvC/V1oYTA4aYtoXmQDcb4rZ9Oh6wpurOoK/2Tfd5MNynFfzIuD+prqX7iPam4hu7KB6VvQerqV1kxcOZ7ea8WeO9OOHb57CNW09I3u49y/k7/APpv1HYVTYy+Ce/NusLQb3vW6wrI383D17yMyDU2Vo+sZftH6CJGsmIe72AfBbKlMx1RA6Fbydpoo3k13qGixmH1Jiq0DUnVR4XNmLRStdXHVbTO5haPV0d1oshJdW9Sb0UL81HWNT1jROtZwoR0LAxSMc4RiBwDdX5aWTsQ7khwdl3pTh60d0Xv3qKSSmHcTQFrwGtFK911kws7GuyA7wB7urgts1wc/nuYAWO8QoHTMnigm0D30Gf9dPwRxeDyMimu+WUXjdpuU6VI100ZGzqMrd9zRwrWw0TTHLHkkdqTr8+CdA+dgiYaNuRY15oWxfsnNy60qT2qTI5u0YX0Bbrelv3Vs54MQ+GMNbmdXdW5iNNKkqac9AoURG/Lm6NSpgecwsJ61C932GqijhaaZni4U2DLSPN2Cg6f0SVLnOlkz0LnZzS3YiKcPapC4VY9rWOIAJA71PgsPs/SViJI4aFNw3ELEBo3zE7L20sjsoqNF2lyOKcA4lxJJ4oPa3IQtniGEdfSm4iIehm0+6ehUFk4lwLugLZYWB8shNgwVKIxDXbSOnoqX7+hF22cIa7rIx8ePcvN4nMZ0tZq7t/MpzmlxIFauVxQ1TpMNDVkfOcXBoHitvNlijaab18xHUpMVinZWwFraNIyut7Aqxy5GtqCAKIMle7KRwTtjTdFaA85bZ0hzyHToQbh5HiS+Z9UAXAmpFaX4JrnOMhA9dMkzZat0CIErxm1AdYqjKOFc1CnYx2IijbQUc61eorNXORUkNFslvHiqQSBzbVo2lk5hed2mTtWTDwtYLuoLXUjXOa1pFTkd6WoI09mvSsVGSbOcNVB/wAtvkLXNBBsQUZuSOUMbyY83pBJueC/k38JocRT/wCogynxbUqruSMNimdOHxH/AJpn8achz4R+g2jS3N+1ohNmDZ3WzNIbKD0OHFbvLYpw9G5PGcgSHM4DQlRYB2NfJh2xuAYRpaian4SWRzGw5stDXiocJtHWLjm71vFxoDS1L+RvZ5Bf1h70XRB2YXFNUyeWNzbihLhXwWJwwewtbJUWuEBGY81KWk3vArY4iJzS3i5R4cN2cTKAVUcvKOImhE0Vsrw7M6vZZNbydKcRs6AMzV10oh55D5zi8XLcV3GX0A6ls5hhn5uazLWvb0Lacl7IbuSQSuytFaXbfgizCTNxFmtJaNb9PHVRvjbHiBXnnedf7IWzbhszZGei3KZShjsVHI2J5o+rx7hdCSSLKAM2bjTs1CdmmMbSK9yG0xbQMwGYsr7EyKflET4hjyYgblnVu6DtUuCe/D5SaejGtD1nq8keImnkgBbtXUNBlA1Pgo9oLYh7pbjVnq17gv4Q4mga1s4jFOouV4GEcatXW1QRm9JKlSY7EH0rhQlT4yOKrcrCSPV4e1QSvbTKM1e1EB9bJ1eJUJe7XUrORcqqf5vuvjNCODihisSI6U34ePBCNkYi6QFWqk5Lx0GIkNnx7DngqHk4VwuHlBftZADlA1rQ6puGixjp5H1NXjKzL1qXFYDExVczLnNLD7rUZ3uE9Tq42r+EfNB7sZPld/VshyNPeqRVt13Q87wjmiRvrt/V0x755XcAxkIr70zDQ4GeLfqBNq4nuTRK3Ygnd3rCvSnte7WmZjdAFDhsQ2kMj98MFBpVRRxbrW1HNqD0nxQkhw8m80Hdaad6DXxuBFrpkmIwz42yc0uCqj1hNtzRRD3UXTZCNsUWb1q8/tWyq5g2dHNBpVNgi1hdQu0Lv1VR9bx71mbE6RxsGjihKAIx0+qAsVDrkkc1RZmEUaKHpH0asNFi4sRG11YX0a7Qupb2obB7g51KgX4IAPm8X/NVEB11IT5DEBlj1/bagepNxTwePFRvuGtJFe9OBrutBaK9f+61p0lNHkNBSgqqITYdz87m3DiLJ80HJDMRG9g5znUr07tOzuUb4uQ4cLk1ptHZv3qpz+VcAx7WNAbs8OGUHXT3rZYXCBzgDxp39iDZpQ1zW0EEA5vf8q9qficDDhI5CAwHEy0NONCT7k7Ex43DRYiSpyskEgJ6r2TcPj/Oh5oDLijmyfsBPi5HhZHAy7i97nU7FFiJeWn7WH+rkaQPaT7kxuC5RYcmuS3eEMPyq+aX7szsoQZFAX57NGc3WHw0THRGWozSPq0kDpCkw8keVwJZlPBE3pX2pxqhJ63SsPguMkga7qHH2LCfwfi9HFiN6enqwM18dEY4CNwUy0IsuUcSdZsUT+vFSGg3GONe5E2607Hywt22LdUGlwzVBtN2tK9yfhoS1gfZxPQv5U+kcTWhxATvNIJZKWJO6jMMP3Zk3DuADWDOe5aEMFyeldOawHUpmsoTmrbinxbJrom6ufdqmbNzq1PgqBRTxCpbWo6kDiHyMZoG83xKrV1gGGZ3NDRrVH0OJNqZstfYtgzEPJdZrfNRVNwc0r4TrJmbp2BDZsO0tlL31uo5nTwPpfYuacrhTp19iEscMcb/ALUFvam4jNlDBYG2Y9JTWiOoJ52tulDzeKLJWjiGnTp60Z4sNGGYaoztFKuI096fw3HAftH8kMPsnvZEcrXh2bsstr5kJ5taBuYeJUeGkjdG0OzBpAufCq/osr9m6j3B4DbdqkccIWyZmtjAINenRMnmBY/m0HxVQLltEKWvog4cE2SOdrHvaSacKBPbjt2QPq+3FMgdEHPdNHkf0DMmh2jmrJeZldAADT9VWKLmlpMlaLDAn1PpYQxSOY6r7tNOhb+NxDu2Qr+lzf8AcK3in06h8fgnl4pQWWZ9GjtWG2TAGhuV2Q13ulZ2R5X0DC7iaae9ZU0dXkLemyB6QpWEtaWgdNTYHsQc4vib9r1T3raNlc8HQp3mWGjxUlOMlh3V3uwITjlaXCYBhyYm2zdtNSxoFtKarzbkjF4V+FqXyYl5yvB+90qbGcqbDFuoBC17jk/FwUuPxGBdUvblhjkOUeB4r+KsfD5rBO0sytZQ0pwQx/I008b2nIQ99a9faoBjAIIa5cmY+kNL1dr+uC2eC2BqbVZTurdeaxYmOIg/1t1BBiIWtxR1kAs6+rfZ4p2Dg2kkgFd5+h7FnZJtHNtmkLXEnqtVNtxRCb1p0lK7OBzuzQfFcs4zedsXMwrQODG3d/ioUcdE1zGwxEHo5qldxOJd/lasUQf6shQQM0mu7s4oQsLmtjaAKFZWE7jg2qoeaVJT1ntClZXgCqKMdLXe5NY6TL2L0k8j2UO6XW8EN8bxpY3W/NK1jh6Rwp3XTcXFOcVE2j5h62Qa+xHCRchRGNjSGyNbkc53dwQ5bxoq6TMGCma3Z2hDGBzcPGRUNfx6y1tL962D8RipOqODKzwRdtJQxv2y34pnKGFcJHNu0ipp4BT8qYySPFbSjajUfqiLsNjGRtaTvUuaJ+DgY/amwbrdBszGgDeNHVoum1aVRO2GhGWqbhwDnLso6FJJNSNrGFsMdavvrI7toFvNJ+zTTqCc57ss1q09oHSQnbPHSNwzOeWt9ikc/AFmRwMbn0bevWjJyniDQ81j7Nb1niexZWymaQf2bbpjDgwGRmrWFxJJ6TxUmJx+Obho7lrKVKrDh3SMuc7WmlO3RZdLprqeo73JuSXZSs4kVBCgle+IsjeHGh6FHsyzTRyu12cUrkk+CxDt/XR+qiZmFQD70wSytZtDlbU0zHoVQa/Qwh/H8PLvSdwCdl1zD3OUmZwFrk8EIcNOyQy87Le3asTHBI4OzA2fSltVhmO1yZndpujI4URdw4eSrUR0Ep01eezL3qTbT7OGnbXsUULcBOyMNyiR9yezgjynyhhnyMpRpaw0PWQLeKGFwnJ4rI/PkHEkdAThynC1kjT6OOI/A6FHAyOhw7nVcJMyigg5T2r81T6psjgcS2r3VEjgL26OtRYvE8rmPMc0kWYl2zr76cFsMuJMgNWzOlq4Hp6FtcVysyXBRbw+0TwB6FHhMKxjmnVzWiwXJULsS2VpL2VDcpvTW/TRRjGYdsm0bTm1oaexR4TLI2OJtGZhTO6t3Lq4dip0qn2WqTEYGgLhkdVtbKeSEx1xEm0fVvFFp2FCKcz815tg3R5MxdRza6p2BxWHjrJo9lqdykxjxUgbNnx+CdU3Qk6ZGjxP5ppTWcNs1SfhQHesPSl3u9atBlKcOg1H67KprQa1CsaOaaVWGwXnL3SUpIx5oDrp1BOfgnvY6WrXtzV3f1VYeMitZL1RwWakUYAoOJpUlNibj8QxrRTnVQ23KWJcD6oOqyYbCxNpxIqfFZpsQ6OKtgwVc49Sex8Um/ekpLqj3KOHCMGzvSmuqGLlhdma+6bh84u0EmnStrBhyODW7M1f1ppHJT6O1dKcg9qbiJy2fHMbQO4NPQ35p2KxkhZtScoamMwbHTYvNRlG3p2ca9KdisXGGXIaK1WSLDxvpo1rRRZZpSOhnBqp6VwGnUvSODP8S2cfKOKyfYhZlHsW2xM5FL1kfmKErXvkdqHOdXvUuJxvJTX7U86gzeKhlZxa4XvwX8p5Ogd1tGQ+xejlnwzuveCrgcdFMOADqH2rLynyfr62Wle9TvirkyNI8AicozZ3Nr3qN0WG21Gv9amV1i0+xMaWyRyRxRtcGE1FKV0uphI57DHiIWAEC7TlB8blMnlps/TF7ctCAC8gdwYFDnjipJho5iWuNi7h7/BHCYtppqHDVp6QnPiAxMA9ZtiO0L6l/wC6iXztHVRVidmF/gpWkc4UKpHhKO6cxW0iFOBvqmmSRju1vyVJcOx1+FkT5jI6320XjAyNrWxcsuCwRAcedlzfknYjF8ptncP6nMGMr+yCT7EYGxYeN5Hq3a5OgxWG2zYwXUidkZ33opI4cIG/aD5Hk+9MZht1459d6qZsIBHj5ic5hjbUH8Tv9k7zrl2OOOvOoXur0J4gnM1TUv2LmuC8/dg31jZWGWQUDnG2p4fJOjyzbPCtETag8Br3puKws7o5G6EFD0GGz9LWEE+1UwnI0OXp83N++qnz4eOCdzMz6RmzelNlxLzM5rs9XuJWFGHDicRQjwUhjdmjHo2/hCodUE8lWdXpaq7JozCh3Qg/Z2d1LmJ2yOWnUsPm+sczOe03RrdNircyNRFlEMh3pK+xHrFE2vBYfDR4X0jnCryAKHIBbw/xId/696NCLNoph/eu96hIOgf/AJSjgwbQapsza7lxTq/3TB/a5CD1afBFvpNl0hZW+ctd+DMFtsa8OmdwF1s+TsI1jn7ocnw4mY1jbfhf9cEJWEvo1wNb8U3EytkY24/Eog2OKSnSNEyXDAnpy84jqTpMPJFECwlr3mx7eITZ+UYZWF28x45p+CY7Hcr4luzH1TYxGPG6czkTkouc4VL2guJ7XKSCNjzSh3BW9FmlfHhmU/G9F8URc8/1spuh5zyiI+nmhUdjoHdbzVU5J5TwFOhrr/FeccszbQN5seauY/JGCON5ANS4SZan3ouxE8rYj/Vh9aeK2mFh9Jwe2rihHj4HD7zmUzfrsQdlPdf2a+xbj7jhxCyOIkb9l91L5vC2Jphaco0RztOzdI7e66qx8l2hCTZNzNrQ06dVnhsBGyKnU3NT/MfJQhE/BfXC/b+SyYfmtbXjx7exFpNK965x/dVs3gt2F1R1rJ9n3rDxfakb70/FSQsljbKRsw8V7+pPxTcJiI4om2D3Bvgzo7E7FTviw8R/rJzStOhPm5TnixGHZQxbM1z+Oi2MfJGDDC6tGg73aUzF8qHBYKFn1WyYGvcO7gpm4HDNklzfXzt3GAdFf91ldNHPhx9Y2I5a9pNFssTgYWxMbVrA1tD4IUI3tMppUJ8cmdwBucqkY2Q7MUp1nis3JrGMzGslSA1iAL2z7udroauuo24SWYGR1GjZi58OtS47+FGPfFiHt2QDctcvXRbATl0Lt5j81O6lCiyOaNjhJs8x4B35J7A5r9n6MEaUHkqhOx7ACDr5Hl5cMulFlaeaKdysiH1yl1+xNbHTK7mqrvBRedO2ZlJcOrRNjGMG8Ncpp3ppw2JElHcHVohUUPvRHQocuodZZmaGQG/2aFPd91T/APMKOL2WctFApJ3XfK6pTM4vl0PTx9qaZYx6J/gjKYI5HSmrWn5DVVDNk38X+VpNB7U5lH73OJi1PX0rawSsyZg0yZS0/hGq2Yhy2oXHpCw3mp20T495h4Hj7Vs/NwanWq/i+MiNt6BrNUMR5w8y61GgW2xE5jkrzQaV7elM2peWZDDQixa3RTF/J1dKXcB4LNhORWF/CrK+9HM+OBo4VurTGWStuF1kkmyknmM1VXOaztVKOkOgQxfKMexwrL5OLvktlyc9pk0tzWBUlDc54u3B4au7lmZh8XOeB2eRo/XcgMQ6GEA1ymRo/NUmkblrUbKN7z40p7E7O0bGu4XOAJCDQ8gDRr95v5JscxEb+t26exx07/FZmnWEKbB4uMOhfKT2LZOOaB/1b/JVspjuKvFLDjrZSN82zRNDnMlcN2QB1K5xUexB1KVFfoXzFbNxylwaBXpunNipXKSt+Rw7CsocU/NukN5zW3CLmQzO63KTFHIBh27TLXU8AmSYGCRsTjuuNBm7EMHjOS5JMT6zQS23SQm4ObCzQRNOX6o5GBCLC4l8W6dW7Rz+ug0C2EWGjObUxgPLus8VJLjAIKCz2gNd4BO2k73FvDnW60zk3Dk7V9CegM6VlmLXyAXLS657fyW05Oi4b8tKnx4J/OfGNehbY4cull3y8vcKHoFE+PEwTGN1KtLjVxQxMeBa10bahlc1Ou+pTMQ/Ex71JIy67j1gcFTlJ0szSecLCijAY+NodQ5Xk26qqnJb6sDDLLV9ebVAuFDSip5I25qEsPFZHtIIT3G2Yo9POHW0okV620unbvFFnOynSuizz5nvGldE58xuzTs8jvxhABEn1jVMnexzQQC13Cqa9tSePai+x0r4qbSu0qrNoaIPeN1vTZNdqWANDeb3oxtkbnpUxh3tWHxUdWf1RdbtTps+fMa3VeUI8KxjjztzM7sTYIG7OGGuRm77xdNONwj3Uu7PYJzcE8Oa36uOopx+ae55uUHyxsfM++9wC2kf1b/WRmmzljbWdcqPk8YMxltmszAinUtidypNy6zk980hpplrwovSYMvB40ojJsp4j/zqqkfKeyPTss3xWbG8q4mXsoPms8Qe+TgXuqR4UQj2gLG80Hgs8ccf7gWRtGf8sZV6aWc9r16PEys7Cvr5X16gfem/xjPJGGmxc0tRax+ZldHXW5uu+wVHncTkzMFeApopR1hHBYjmnmHoKMEvOamOlw5nbmNYwOduONPYpcTto3zuZnjyWAzGXaBteyncqD6FclVJO4Gsb93wp81K77tFZcU9rHFubdNuCJij85y21owHrd8B7E2mIhwOHfXaEN16h0psXJvLBJaKZH1a2nUqlkkmZu9K6Qg/Ki87lftGn+skmLI6dQClPJeFHphnMsQc+nYTp+aficbO5tdNy7u1MiwpdJI80DdCmScpYwABu8xoy1RnbgpnPe3I2VodZvQmYV73bI7zyRvBbKPLFE3msbYJ0UBiD2k7jWcFiZDq2ghZ18SEc9nuItx7U6drnTDhmdRMxZ85hpSopXd6uKwxh5Nkc17mhgeyte5RPxTA4xb26LVTi1jWOlIFMtDshc+1VPHyMb1rdBDAPtaIyYho03XtIFFHQAxNaAb2TH5g6mhAsq8ynOcjUbrjWiIb5POHTVd/Z8O9WX7aai1keY627FhmCHaGrR70zDxhofQZsp1RzHedT3hSuoDvlQ4NwsbnuCgwcdg8Oc409vtU08pIbHEGdjj/AP8ASlxEbtIK18VM2tdnKCCqgqsLWg0oaupZbObJJI8EyngOgXWyxMlW82/BOiwrajpWfEQUve9ipcTPEHOcaAlZIaNDLAdCGHJNRUknio8THisuR+7W9FC7GYRjzG6uePio5eT5msiijAyFlQXcSVTJhCekxn5otxmGw8jOhgLT8VkjhMf43UWQSgfhFVWXFErMeWxET/V89Vnkw8jftQvv+6srMQx3U8ZSqskeztuFm2ecdLRVGje3I5BskpYT9pvyUew2L8x3t1jk7LajihnNw8j2IYWS3nHNPWOHt8jZxz26qLzEYk5Jw6Tzd1H5crvjRFj+VI3UBjY3HwZHBp13rU7lh5H4DOJYNs4wyB2z3c1HA0pavgqvDmUOU1bzT0E6Ksbg8DoNfJwCmd/eOPtU7j90e9bvDXqQDAzEPPBsrWgd5TI8PylhcOHHegE2Y5evKtjyvinuNcwgh3fEn8k2DkWV2Faxttoas7/FOxGOMGJyHd2ZzN7U/wA4xWxzNoY5Zc4/ddVf1E2QZcNR1WBoOvuTht2x8aNUokzvIPO4FQ4uPJ6PhXVMxPKl8S+4ab7MfNOrM9jRYBtqrZNxTJqXJliBT9ptcFI3UR70bvkv4nwTGsOalGmrnuOnvTMXNJK2Ys3mDKe2nQhNLh5nuYatrQhNjdbJI016E1uOxLnzDg3X2KR+DYclMrS8b9O1RQvtndrmBp7FPlndKHu2dXa2pXREjRXW67vBVHPc7tcVSg8hufFO7FlogB5CAaVWXoRyi4dVMU+JdLxy5T7/AGqDBYU5shJNObQBNaDatStjGbBOzCl6qWU2EcBFegkgfNP83dzGNaTXWv8AssS/NvyTWvwtRSNlaLMyh3esbETVzmN9rqf6vJSqzuFCONViMNMxm+4ZD0a1N0xrHZY9n4XTpcoldwYdKdJTizEcKBrhzfBRumcDlfnLT6ydJG2jqXW9ToQ5P80FRJtA4HxRdzAeBXOGhVTQ84exH0DX3rqfktmYAN4Gt+n8Kymgbatj0nq600UaQMvA8CT8SszsJGT0mqsAG3sneazP6aC4Hcv5XhRf1m7qHnByP4F7aHxCJwuLZPH0Po/2hOMrd00o5twpPxFU/vG/FYadhLXMlse5Q41n9a2p6jxHj5LLJPCyRp4ObVPfgtphHyM2bjC6gLeimi89h5TjxLHPDpIpYWML6cM7RULCwYvC4iGeNxdJjIZdo5u7YN9Yg9CcxnL/AC05rTQHzd9x+8gA1Fxpdx96keKUz09iDMROJ3B9qkNHUB80WS4OLERg3D+b7Uc3Jz8M/wC3C9w+JCMnJOMxGNwdM13c2n3TY+CZHLtas6Cxor2Bq2se3bINCJGf+CpJHiHf9SP/APWm4fDmWFoNfrGa9zQgZpZZMwOproqNrzQ7xWHhIJbE7aOHTS9FmlytDBU5vVX1bxa1bV7kSI8jOLnap+W7Mnf109ixH8I8VGGvNGwgXyty0qO1NDXtr2oNLRSvYFJyrgcOdgW5pi1woCqLoUvKbjbDMOUHi4p0jyTVmXvJWnkAtboH0AnHqVehCxy8K+V3amuLWuDb0cKgoHDbWNh4ZuKAnke9vQXKKdgL4Kubma23NWXOaHUNPBPm0FbLWqx+LP3WjuqSptm3NnJpft+S+t4itO1SVLi+R2Xq1Cma4ekMNf8AE26lj+y8j2+TNJoPV6UBcuOlLALY87LTLfmojRbeEsDm/qqLHM2hcLEqU8Bp1LKbivf4oOBAtxV+jVeKIpWpPuPzTnMc0HM67HC/N60czy7erzfv16VkykG3vJ+KaCytKfH5rKYyLfCivD0oui3aOqFEJi0UO8adZPxVJ6l+z4s0dsz/AKsqLoA5lHHLT2LZzue8NoRUJ+xcHuqas9bw49yoeMsfxUEhGuIDf8LlNyVIf72P4j3e3yGP6OiPGiybB+boIojFiZWYDDiUucCfSSC3HRo9qOJMrXsvzHbvivRhpy6BuizSSbOvNANGhOZNtnCl8rf0VLjeSJJMQYXiTzeZlKt4jrRHmUDQ43IOibtMQ9uXTZ2+CP8AFuHx2ILehtR7l53i+S3tjGps7KnRYZjWMjaDLK6zWD9cFheT8DSR0jiJZzxNCmRRXDbnNfvPSV9YJK61AGVb9XFXqPs1UkTXNAtRHM7miwOiYwhznUFBxWIwAgma2YWyizb27rBD/wBUwYPQc3yVZsOMQytnwmoUXJW03WVfO4fap8FGwCkZfn7tFWlPpA1oi0ysDja7lusFOlBj3s/ZB+KoPIU4/dTcV9mfJ/h/LyQwsmIa4VeDcEAIh7S1rtKmy2LMPHlZretVWwUJfYTTveTx+z/pUhdWtKhtEG5W77uHb+azPkqNsAPFSEijHxZMminY4XDzXylxXaqPYFVgzD/EEIsSNoOFWgJzsK3KMgrTyZqCoXo3EWXqcfUCq0N1+wFcmvGn661SYva2w1+8s7ZXmw9b7zh8E3azyt5tb9bq+yiG+5xp0nXL81uC1eKc2umqGaQnTTtorNvTifulOp+rJ3d8V/GGIxp2k4zxNa2za9KpiG3OX0g9e+vagL7szT7CsNjh6rgXdnH4qoNQU2RdRVH8o4OMGlGSOyuHbUoPblc06FjwQsodfoNj5HRsleGkXyAMb03J3u9NZiIBJJkGRzL166/FBgk2YHNMlagd/wAE7I7NESXOyi35JuIjbocrgOBQyMzud7kWRbn2iLlUdOXHNzL38VnfhcMyrqN2dcyZNjIJZYW/1Wat/j2KObB4qEQUsGtytHV1HuRft8o6xcD4I8n8kRMgw5k9JI0c9x7NUJ5Y8725nbxoajSi2jsU5jq5t6U+Gt1lgxpe8332n3rKIXNlHAb2bsQw9X1dehFKo4iEbvFlVVjyxw8UzlPG5ttK2rG1oWgoed8qQYf9up8Uf/Vo3fhfmT4OTMTnzaUZYdaEWss7jcqdtnFsRFetD6WQR0o7NmHFGJuGjzy85/H8lcKrWjw8rx94qR3Yj6V2VgqG8PI3Etg2lW0PTTqWZjZL6jKAqBuQdtVFh2yb0jg3RYfBxuk2cIo0m/fY/BPdE28b9kKk1JQbt2RmO9KnQKKZ2JY5ufO3Ll3uFP0E3F7d7hsS7TisPi8OD6auZ3SfLXy5uATq7p6lmjNe1ZZKs69Qi1wrbnBULAaK8buPrfkjSouePUVv4h3G1f1+gn7STNU2v9/5INa7XLX94/kmDEAO5oO7wzPr7wh6Qg5ej7nzVA7p+CkftCb69Kq5hc0HSv3vkh/Jqm3x/LwVQ0aAeATrN/dHSVhJ8PfJE1krfsuopY5Mftow/OwtF2V9Uox4l8rmH7TaBZHC7TULDuJq6EbF3dp7KI9V0Rxjt3KaRsjDkpoa3JX8nLo3cDG8sPsRjfyjK5v2Z2CX8/ai0YfC2+88fFExYOSV/O2k5qSexOfKyl60BJ96OIpvIANEbBag96xURnyDK0G3HgVHDDyhSjiHGKlX9qcGNDbXaFs3jdrVeleJaWY3gFSONuYcUAHc7UO0PahPjOWsQ7CySBh2ceUXJ0r0UK2GFxplladYRUk9qMUTxhhJvuDd6Q9bjwQ2TKyHXPvPPX1LZSwFtuBTZY375IdUJsHKnJhje314mhoafu3qnQYXC7WttrLavcETFiDFm/s9z3KHDScoYnK929SU6cUeTIhHHDgmiZ1Xc7Tie1baXlCNj8jnCPZjUOAy94NUxjuLqdqlx0dsjssY9iewg1y0Kt9PT6L+u6r9pyc3pFPI0dXlhx5h2uxNch42ReOSA+oAGaXT2J45Wl83d51tg1rSQW2tp2p+xbNO4sdHRsdK17UzCQ8ktZLGSWvL6jXsWzdyXG4bPLzqXOqZhTgYIGsdm3NU1kjrn6NESEL6helaO1F2Ek11b0r00Wz62io+a3Z2e1Z9s3UnQ/JanwWj+5q5sp/Z/NbuHnP7C/oc/wD2yv6FiP8AtlGmBnNfuFf8MxH7p+StyXiT+w75LN/FGNP/AEz8kR/FGOH/AE/yX8iwuMitS27VQyYrkqTaRV327Nub8V7puAxcbsPiQNo1jvXA1oR1KncsTyc488bRvaFRbJ1xI0sPb+qqV/J+0hebvYHEtf3FAs2clOkUKa3E8mjd4iFp9oonEYZtKn1UIYsU/K7g41RfIxtSbUsU8QYVwEfOdJYNW0x+KLuqKlu2qxEGDx0sJnoC6QBwFOugpqs7g2SOIZRsnA5R2aoAkOk6BxWbMyPqDrr63RZW6qx0Xm+YbscYAA43JPvW4xu7xLU5sptJd2S1lTmxjg31u08UZHubc6cUHxUewnTVYeHlY7OFwkznPl0aaX7Vg3PIzvwczpqy/wBcOZ2dij86vDtW5x9zisVyzduBgdIIB0jh7LLEPYYojSSY5zugNHX1KOc4V2ylziJx9bLr71I3IG34dqZhyLREvd20Tnu5xN/5ypNFmGlE0KhRGzlz17kHN08mnk1+jmOjVmPFbKQ34HyUVSqeWgWqjw1a5j7EM3J8ctrmQZlu8k4L/wC3atzAYRvZA0Ldw8P7gC3sRFH+0AgZsUZnu0jhIce1buBxh7S35r/hk5/6oC3eRX//AHH/ALUB/E1yK084/wDanfxkw4Jw01ka7wCoOUfCGT5K2Oef+k5U84md/wBIrnYg9jFhHYETM2LrukAGtF10v2pmOc3M1jt4DUiie/CTOaYwDI2RuXJ2nT2raj1aPRpobhbRjd1/vXNXMC+0VDJylvPaA99Llh4NHWhlbuXe8AadH66kcRiMkMQ3WjVzihJOWR9EVd+nWEKXbSyl2kjoJta8O9OwxcHdBpTM3gVzAqaeQCwNKNVDXsW6SAVSMEqjjlC3HkdijLy4nI63YHU9yFGH6nN3rC8p8q44iWSRlMNs7Ek803XmmHjHm0NgG2zOT24clrAe8rk6KKeMMj84ZENnUjNd+aq3DfS/AJxkvtZnF34QjkZlHQj9O5+gWkVBRc3E4bJwLpWg+C2biDl6D5DI/HT7V9y3zet+2qo0mnCvkoqfDyAKQ9Sa3pKqWFZBoPf5NpxNmoRynsKureSv0GmN5bTiFsxypjWj7s7gsz+U8XLH07Z3tVfOpiHX55W84nt+jmdzWbxTnnj9KKI6Zqnuugaauf8A5iqjhf2o+c4Vu9/WQeid4Dd9iy8h8vv/AORMdke6u4fGvUmQ8u8lGWNu4Jcuzd8itkMWIHu9SfcPyWU+R0ros2wbnuLNPSVsMBSUetOa5c56+Kc3F4lkmVzS4RnnDg22i85DM+Qej6AtrLmvoOhRFrqPPvVJZy7hm0ogXsbbRzeI7PJdbR0wb0CiMpBaWVcwit/asjmsk6nNWVuHjA71kbx0awUQdylOMI37JGaT9350X8n5KjxFufiyXV7hQD2r0GA5Pi/DhW/FB8csMRN/R4aNvwUTsdjJZstC3M5N2lnvdSJtdG9Pf8lFKMPt6O+r+0CCsrJjGY3EgA9VPciQ+py5rDjRPc1o12be7XyV/nKkD6f5eRteiikdTiFZhfQVK3MK/wB63onDuVFbmiw8gjl06VundVz5L+Vr6WPkIIsVSm9ESD9IN9eXXs+nj8bFz8PDudp/2TO1/wDmRRI+0r0WyZNuH+ryhzP3TZUxXJ7A4/1mHdl/w6e5V5I5ZkMf9m8ZCP2DVvhVXe2v/wDX/NSQgARSv3+4qmGEULXWLyavPZ0IbNznht3WpVC9qkkZlTOK8AGUomCNjngdATjHyfiW/wDLiNfFPf8AxPjHOdoXREUC38GGfjlY33lVlxfJ7HfexjDTwKyy8u8nhoNSA9zvc1Njfy87d4RwOPvot7FY+Xsjaz4lej5NxUh/vMR8gEPNIm4djyLR2P72pVWxVz8y+qllMbqR2ceAKjxOU5nSZaqPZtIpHQ9qa50YfsxWh4pksl8pAA6kJsA3I2F9WfNbQMJeXZqrNM2gpQ9BCYwdFe83/wDgrI5m2V+K0WiFipWZi0tOavBOmkloHHLZb80juwIgNxD+3REMaG57nqHk08mzkJye5DZ+SnljzA8fes8NCOjiFcIPpZ406wqPgyxyVIGagb3rMW1Z0jytbwrdOI0Fh9PHyuFd+46g2vxWSv1bQD2qqoHEA+TM00IWXEtZiW/3tz+9r7V5vHJ5rJSoEu8w9+o8Ci0wssac5SCPYZWWq/CwknX7qq+PC92GYPgrCKx/sW/JAx5OJNImfJQGLHPrICTRuUNRrypjAAafWlU8+xDu2Vye+d2cyaF7qlSzGSmy0blJzfJNw4xMzY3NzZnMvm76WXnOeMg2pXesgHvBPUa2W4fBjz7gvTmVo6RFT/MQgzzdkmVhyAyCo67LB5W4dgjlJZJlc7Oa6aLGN843XvrIGsoKpsZM7oBJY5ABmUeaOQjJa4Fu5NjZCG3Brq496v0px41QqSndyr/O3VvLRUP0NE6bEQFzGnLW9AVJhocMxzJaZQW1qe1FwwuSMmrstwEKMpTjmsv6W7NTStk7M+PLqar0ZBrrTT6GZpos/j9AYaLA4h8kXOcC3KePFeYM5FzySCoaZwmwYpowzXguyxuBcaU496dIK0ErmeCLH12bzpXqWfDSWPCtQszY8vSBojVSy/dp/MYl7dX5z7E5x1cfpDaP2ddJPsHp7Fk80e7LarXmhRw4xOA0zbrZz7Ss8eLhH4Wv+KzDENznXdKoMQKdQ0TXGeS33Qt/bSB1eDboluCnsaWla33NTYxh30eQ058S40WLiOEjlMQGV1D81hgzAQjaN+yDmKdPs2UbJQuaxoosLhvP3tbLgwateaNlOiijkfI5kj2sq5xpUrljCMeCGZHN6ysLO6MHLgtiaCt+xYKJhY18EuatL66rFGUB0shqDs/G9be1DBj6vNtDpcpl60bRM23MqM3ZW6zsFG507oBXORr630QA0g8an6FHNqqDy6+Wpkd9DN9B0WHxkbX5yXNc6/gh5xPh9rxyNofBOhwzdq57ctaUAWi9YFcPolvSt3vC1yu6D5ZWsn2YJ6KraHEulozU2T3tbR1KC5Xo2XzF1uHUmt6xSqpg4yCGVczpWTEDZSDg7ReiFzoOlSNOo1+nVPb+L+YaW8uYIClht3fJRSYLZuYyFkVSa/ePtUw6KUTetlVL91yPWxQ9qe3rWanFYlzSd9nHsWBxOJccPHlrnbd1Ka0U+AijHmz5dtmdz+FFG90+1DoXONb5HUsEzfoWnMnSyVDnD0lRp2qMTvysIy1aa2RyMeW8N0qjmUDRvV49i2z3Bpplykjp7UKzMvWu9VHJITIRTd0pxQZ0u+BWyY6vFxosznAjsTmjgVT+e08miv8ASFb9y0Wnk558mn0KOFRXRbtRXSqogx7C5vT0LNW3SnSFobU1uLrf/dVXGnUmsDbVTHBraMIu46qXHRziN4O62vBHb4ekw0c3igMTE9zeDWyZb9KqQd4k3NVWC3Usr2kHyjyURb3fQt9FjHwvYZqSNrGRbwU3oDvNygdCY4x8xuU9akzMIz6IPJbZuWhKYDiItx1eeLo58THQ87eNvYq+dio+6aJ2XEvo5lLQ6e1Z3uxRI51I239qc2KLEkybwLy1Vbg5HOgbqZz4LZR8nYcBwz3zH4ppY3DszW3YW/FEnEuAzUFN33I58RK7teVFXjVN/B8U4dDj7lQDgtsQH5aOpXRVdznXKvqUUD/P38laq608llqqrhXtXBUpfyaH6OQtqHOtVOcObXSqoSqDpTgCq18VUOBKu8reqaJ5IBp0hB2U3cGiyfA9jWVdUtHApuZ7tehNy6K6yyMBCrAaj7JVHCh8lVVO7UR1/wAxIX4qVxb0vKy7V12dKicXE6p/WxRHqR6no9dFK40z1Ab0rMSpWdShpxapWnjlQ6gQo7+spXUrRyde+XRYYlCd9G2oKlGssYqSTvhVD6yaDLomMpSozuHur5Czgu5A9H0afQt9Kn0NFp5LLtVwrLeXzVHAlulAgWMJJuPkqOBBGo8oP3reTUAlFrhWic3pWi08jp36cE5x6VG0V3X5gjJI6Ulzvs0QaZeJrZC9gbla1V/JSRtV6E5h0cVSlCEM+hcKrERQfVtkIZ2cFK5+HkDQ/UtNFp9PEBRHpam9T6IdbFH+Kim6iEexDZuq2hoVQAmhTjlNHNpXrUQyXZWt1UOa2psetEucC6uqA2lcpzaIjORn1tos9SeHcm5Wnd5tVUp4/vHKNthS90ZX859+xF/2Qi9xsUf/AIG+itb6OmqoD5fmtEOKBY8CRra0bdOneaF32t2pXOb4+TgsoTbaFDM2/UuKrlVKBNYD1leb2ytW62Nenp3AI5WvzdOay5xPcppI9IaEhBr6FzLLPGB2fQo9tUHRvtW4KxHanYTHtcA0kc4gexGTAYjO3g15v4rZYiJzHDgfoTxMkyuigfOBTnZb08jjffsbptuYLXWTJYmpuiMt2rKI2+CsB4LmjwRAGvUr+9c72o33lzqUVACexXa7wVw7vNFQ5O9ytJHQcKrexLR1JwknN3F26EIxEXffOtFZqMZsCiOhB3UiOv8AmS6v06hcw26vJRdv0LFarTs8guaJ2VzxUU1WfePWrDyBXQWV7bjQhaFWCF+Krl9K9Go1KpmoudVaOVRG6ikhkFNrTU6oxHmf6VqqtsVzVZaeTE/rgpSLHMVSOSrehbDFRt/C74LPgJqfcf8ANZMRC5h8n8YsnbE3Di+YVz5gRkpxqi0/wf5ONOOxV2AftL6xviqCRntRcZNepauVg/xXMPivqvevqGr6tn7qs1o/ZC3XU7AnekO7rvKjnLUrUrRbjCexUyhvag5sgLzwoqzY3IegkIw1q3g+lEfvbyy/Sp9LTyVVVqg8TOD9Ru2ThiMW3qbmqfYUxmGkrG08086q3iqhxHkrbylaKoCorlUyo7QlvRQfQ0WlV9X7VdrVtn0yR304qp0+jQ3XDxQc674faFWt22WoVL1HQtVr5Jx0p5+8feq8VQrZgGQdCyuwUrm9BhNEZMJC+LqJFF9dho2njnPyX/EsN4Fc4+K4rRafSs1bNh01osug6ApNlVpZRMlc7cnbmYfeFTI53sWVmHL3HhWvuWaTAMjpbeYfiqNe0DqYF/S3D8Nlv4uZ3a8qpPkDXeoKdyp9Glfp8fJXymtadRW7GFZUVCFUK3k01V+PktVVVirqvkrXyVQ8lOK83j0Gq0+md5vYtkTun3FVqgI2OPYFUxho+8QqibD/ALxToMZJsaaaHN2Jzhi5jm10RLmyPFdaqseFqehziVQYGAH/AJaysAb3LMaItoADxoqxnQqu117FZ5cexfV+1BjYaucaAKN3KeLkbiHXdHFSjepb2Ixp6g9v/iqFmIfS95UXfxaHAfakf81tHcl4cDr0HiqOPJ5cPUiha93ZYKSDkPB7AubQyupUdgHlni+0xU5bzUkcJGRA0LLdPX0LNNgszxoMz3nwCdhuQOQ34KF1jI2Gj3d/BTScouado3LsWnNXtPD6R7Pp28vX5bfSoqqvQtVpbyUVVr4rT2qtFxVqLRV6F+StdfNVQuq3otpTedZqvfyWv9IPEeyHS+yj89lc9w+zZUjjB4VN/et1ttFS91Sq2c4ze8LJO4yRcJOjt+aNXAH2Ku1GXoQzuQ3rcQiGBUEfejlZGGnqX9X+8t2Qd4WgPYUYpsuZtK5XBw8QmSYrENZNhfRTFxHcT2oiXlFkr+LYd/26LZchchYjEOPF3yHzQlx2OZgR/YQxXHaV5xi5n4iT7cvDuOiZjcFh6SRt9Nu0qUR028lkeUcUNnh2cwutmd1LJ/GELXD1S4qv8Ys/ZJKqZg79mvvQa0EAdPH+Z0Wnk1V1p/NdC6vJY+WoWi6vJ1LgtVdUKsuHiubwVtFoFp4LL0rMbU08l1b6FW7kfF5QcxodJ9p2qFPaqCNoA6LKlPFW7FneGgUsVuip6lRrfastQAPcqbQnsWTO/dtU6o3e8DWn5qrW7vElEMlpl1oquD39gJWRkDSQOZUnvX/D3fvBUoFYLVNwkIzOd7AmSS8ljGYnJm9Iakns0HvQeMF5pGywtRipAyPadJ0WRjy4tG6Ok9K2UpzbYb/Zwp7T4J8Dv6pxb3+QY7GkEFpyw3qR0nqXnmJNBl5unY0ITE1zG6ZFjG+gm3HEat61JhJdWcekdP0x9ABoJqqGxH09PoarQDya+Sx8tJK5bq5R3adCqVwshW9rKtB5Luqgjx8tD5AWyZSt5tba1XUq2PeubfyWctvNXzdp/eWwiblFLLLmPkpm0WaZwHUqto1vXqqmQ9pRyU7blbz6Bc6luJW9c9I6Ex8eVzm3p0WWYOoTzmn4dKyk0bdp0ujNiHUysLslOc71QnTYhz9t6uzvVGKa8jLMcTqOtXmYD+MeURRNzOdoFSMAzy86U6dybDO8x5LucUZKudThG8NHemtbHR8hqadCbh42mjnVLyptnlbkDsmfj2dwAUmLa2kobmqBzu0dKigOj3AFRwV/k8R4eshhoLQQWHWelHpQ7U3FR3xfJwyv6XRcP12q/wBO3lidtmAHUZtETUZiOGqySvaOi+v0ahU+l0qyKvXyWCqjoqDiuKA0oubTyaaqi6PJdcRTXrVl0qtu5WVBxXzXQrBMwzPW1NNAmRwijWigHQFrW/SrNtwrdWB8VVwojs3U7lnMhObiSnRvFxxRdmy8QASs8jeb1WVxoKlU9qNLk9CrlQGa/QRULe1Jq6i52dxbzuHZQqgjcHOPGy5wPh5RyhjI+fzWG1Qm7gy9nBMmyh0zRuCunWjiZSTHAd6vTwCkk6jTvGUJ02Gp5zO4Nj7K3T3zzbXEhpLyOBpzQpd82aRXpW0HqNcfZT4qTEggOpRpPSs0jd0nUGqK70yb1dJB9pnEfHuTMfhm/wAlxVXMp6vV/NZhal1Vx8LLauu/r18uX6NaXXYtT5K0WqrTRVqr6K9FQFZidVqFWlUBTwWq0NTxQv1iytVcLdCq2oHuQk2L8rvW6VoVY+KpQq48VZfq6HzV7laKfF0ufRg+9br6HijU17EAxCXaiN+rYqXcn4XEhkeIgbXnc7TW9wanouFT0DHRxtlmmmZnEYdzWtboTcfoLIX4d0joPOI5Io9nu19ZthpU/wC6wuFGCw+JlfDtZnztz0roBWwXJ/KsOCbCJcS3Dzwt5tdQR2j3LlJ0eTDYXDzvZtHGjRvGwprouSQGQSbfF5XPY+u0ZVv52X8WO5DwToXTmL0TCHi9K6rEOM8MEEchjEspoHdlAV5lVhe6LbNdn3HtpqD3HVOxLMVhZ2wnLIGuNWV7kx78ThopJG1ZG5+84cOr2rHYfDiGGBmrnmjR0dvgozmbNDLXK6PQmtwrZgPIzlPHx5cIw7tfWPyTWCZpa6zpHc1orwRhjf6OOzyz1kzDYOFuaV3DU9q2MdPWzHpcV9kF1TJwFNAsMyCWhaS6rSpGRMc1xaeGtlleWYOH+8u7wTcM6faSSDMd2lAsLBSwZmd2lYirfq6PB7/z8tV5niDmGU5SeDgP5y/kItQ9SF1VVr5LeTN0LgjRUK3rLNotVrZV7lbwXEWtRbwtoqZkN7iszmKogf1GicWMY0t4OeiJpWh5FaEZlXFQ5W112lfFfySM5icrSCaBOwszTICBVlOavOsMe6mv5ote2hHOFFp5dNFRXorlRMqdMzgi7Me/UIdHBMdkG6a0CxLptk50jXUkkFweBPG3QFg8Ixxf5tFl28oo6Q0/Wqe2Vm0biGRCZglEb2vjFARXUEKaTZbIzMbFlEwkytaOY2mmg1UGMjljMzMOIJIZZWsILfWGaywXJjsSx8gxbcVK4HMwcAM2ml+hY7Cwzx7RnKMmIZV7QJWOtYm3BcjwyYvDufFjS+TJI05BVutLKeIcoSbFz3BtH6ivUtrhI8NLii8h+3e0bFtqbrrHtWGnkxELv/TpInPYQBno+1O/oWOYXNzOjY0NqBm9K1DlGDE4cRyxszZpQDGQACC3U6cFyhiYvNcTNnGxbJIMhbxOt1hNo7DSPjkkzNjy0bXLQUbY6IANf/3U2TlFrcZi3DMB/VR93rHtWVz3EDQcAttK/chqQ2mp601tavlq4u/Xen8oOFSN0dS+pLugF1AmsnY3I2wYLAKjOZ7k7dDnHQ9S4qV7vV3B2BNk+433LF4KVtGiPxqpMI5wcYzSqa7rp5Cytswf8Ph9IKqzB1M1lRV+hXy16PJRVWXpVESsw4KnBCug0C7lZGguaUK4eCssu2Y3xKePOHbjc4tSqBfh3X5u9VZW4OPK4VusjGhrY1kb6vHVO3TXpFltJWamgFU4RubGAMpo1bUYlzi2xzDVRxvG485SB0ninSjntpn60OvrRrwRQ4VVQhUmiZFwJFfFMNTUNW+K0ohqVUhH8cYP7wWza5wA0HBU2iO6ATbpQIcdEHCtF1IRSN52tD4qlTa1QqvvR+Qduqyu4LOENp6wzU7UMtbcCbJ0rtHcArEL/8QAJxABAAICAQMEAwEBAQEAAAAAAQARITFBUWFxgZGhscHR8OEQ8SD/2gAIAQAAAT8hXKEXvYLtpqu7cKwqOYIuW856P5mXdoQBSwnhNhoWhzLggeCGZHxzUpDusO8yr6pUuNP/AAhTdcRo0mf+jUc2DL93FFAnSAbaxLwkaypdlP8AwhMBzLMpAoIuxzMMtEJFO6TzbENcQ4LmK16pNhoaWxKPdgOO1csR7Pd1/h/Zb6AO30Xc6PMqW3HiOmwswFMusPYdWGYwxgIaNumPOKsviLgU1UyazhcrmS+rUHZjrNlxBG22N0R6THH23NMD1meQB0ROo9YZ1PUdzCIO7ZjUWU5w5wcnXiKQfxg962/HmYnC+k88IpbPdd9dPp+Itj3pzd6zKKcMHT5dYlt/EyyNuIhuK4qoYGOiZLLXeapddpmqFvq5hvFopC97RmeB6ZY/gQ5FBKDV1F+5MIfL+sbc/wA/eGbeO+azA401WuIpM9goD9T2e862xQsLWvWV8NGPPKY1Cq55f5iTPQgrk4Z+ZpVZVdb09+fSFA7PJdX6hLvirKylorzXv1GVNgpuHuLYPHduJft3sg9MkJBtM/8A0Ze+BlSpUqEszNsxZd5mbOjLCazOei/5QGeE8buhdCS441BZE2mKcD8X56T6EkvXxLk6XfQP7miphkujFD6NXMdoTdWQ0nqticU86IKGHBcCkcXEwNrNwgG6BuYYTyQBspy5jK4eRh+ymzcCzSY2vXFj7KXzK4oU3K5DLpdeGAbWmDzEjVN4VTK0hretXB/MyKkJm6HLnx9iVknDlVeseidBAmq7MR1AnaPlwb88xnNrVGK8veaTW7JgaNy6bCZlmxN5dYYYUGhXSdVxKC5mwcO45KGrjWjHCjVQSrM8kv8AjB6Y6BwHUu6+2WW8Oit38TV83MpQFF6Z9rTm+DcJs25jAVt6VvvGCGhQ8nKl8+wTGT1UhSpQ3hs6wMVdr0qmtneetcRIezjAA83NF9OLaE4Sbwu3uPqyyg5OMYcRgoiK74wNXNHJgbntGdon/b7/AOFLUqbbYrSf8eEFJ7KIq90cMt0O5NFenCDah8sGoBvETpJftY/8B4lgoOf1NrsBWvzfxjaocNrj++pafWMmKzlz0x2lLUfK6hleeTg9GAbOZyukW3EMgKM7hb02uvtEbIOYWHEd6j9S60FtIpRxmu4vuozeiVFBc/2isD6shy3NmiGbPetxaLBsJHFQO/K5JgEqf1OBUtZrOn+r7xkUFPyB/h53KyKZGB6D87itOUq3MfE9WcCM6jWyqO+oNqWsRM6KrcGVXm2u0Q3GjQCOcQo5fTqRTplxy18olQmLRP1zGUKbofaFQ+t5f5iDi7ZlkAxaF1AWrFxIJzLPPG3ntK19Zt7z9TfQ9P2QCiz63pQsdWe89FlPwECjjKZkzx+7b4GUb8FhfhLW9DeNPaXfsTBrYPXA+Z7PMMM2FQUfOdV5l1qIOFxBfr7yhBV2i3eLT4lpzAGKIbB2weUaCCgPsesrd7ewL1aolsxDa10Dwx/qJclbv15SodHVF9HMsi114imVqdeMZ2ToR7Zc3BMdTUVWVeZgRFRDuIuL1/412+jDZcgnKvLJGuBjvDhD0qO2nzmDBaOLXQ0jBVEVKt7wMwLTz/kxxul2Og/9fveUlVOZjlUiW35Pbfg0XehEquxu+mYRal/W/wDff1iJVuQfFcePaMZiMPo9GOqD2mYp1CNIYesTWu5TivLCY04uULA8LGnxBqepNdstZwrsgjpUjvrK0q4vrR0YeH+ZdmJw3qV1N8jpMYrGZro/puOtnNoceHf2uaSHQDDyDl/LqKsO8ltOqjwPk9O3rEK8xyNbi7+ImRuVlXyHqpbiLYglnXF1BNI3mlsqqC+paxuo/CdH9kvWV/W404rI2OCuvmDrlJgZN44mibyfmKGihKrKmQ16SuV/KgZulIeSvoonYWHuS76ikDeFWdam6wzgV0tOoMapjKqKItI8oAfrAdac/wC4ylk2a2F15qPpYyCp2Ooge7S9Uqw4ZRaxXwcWfc3QScI4O6cv9tAY1jIs89HhjxCSC5A6/eRzHup4zBy03kiS+lgxliNuosqr7dZRxT4ilr6sfM0LHNXzcxnuG/tAM32ofiaKvlT4NwxuSWIEaC5QDHCApjGpXDubqAvU6GUVGfSIr8PMeSopcCusa3SRGsn/AIhFMt9UiKgtdExxK7PqP8TYgWm3+OyWnp28D8RQAH7Hh7fc47oJY8F9vT0lVCurVfY/qjgMpeq6Q6BvWxc0tuC1N9Kf31F6U9uEjwgOgHlPmBG9B5iqiRCASdOH6mrF56M30vHETfE3OWQxDaKfI0x6dEwx7hw7goSB56xMw2hv8h/sxrochbv+D36QTCyDCfU/S+krUBoDQRq1+QXUBuastPHj7l1S5u1H91qVq875VoM6u3drc6rwsmSk1HBNR3CjEwwmbucHvC6s4eYio96DHCHnBGO/hPow1DFB+25QjlgK6f4JRvP/AALfb84yiBarpT5nN4Vvzh14qiHoHCWBh9wdH+I4PXMJvq4c2xcSGfVRqGjg6c7PBlhOYK6X69yjETmkotraO1G9zAR8pZ90mtBwK1hSumpnf3k8P+IC9dGbgDkNSgz13O05IfVAFdMA6GVtiFmWX/whconFTymOQOmp3r0f3PkjR/Mr4F1s+4W7SX0hwcSNrOpfjrlBKzIzJs5OZMEDIUd5cIyvMlHQ9MYjl9pdVU24IoqEozmOsNg/Kg7EYMbed+j3m2fUV1DC+fWOLyVn/wBWUv4ehydyXEXL1L3IOYhAHqtFfc4USGweRT0YzpQ51IFeHFt31d/uIHIdORDMR95qDO4jfxlBjngzNyA3WnpKZnvdx/aBsm4B8w1Z74dS7r5EIB9rEg1EL3h/B9/EpoM26n1v5dsEDxRGP8u+/Go7Kp+pjWF8kYcwLFlz8QVAYbTqX8RqRb9kPM5wqekzQ4Q4y39S7rUdPKnin3lBS0bjgAgh0q6M10uCiXUPPuDDrbTsqH/H/VcwydWKV4bQygN1u/7Ix07JVv28GVGltoNXJCFrTvx+paKYLH3E+Y2GC+WZNHzEpFxtrrOLncO8GAWQW+eaPeXKYpaGc93EpL8Gi7ZHB+JiVKVpb19oAi7xAHMNRLcuZlo1Fp/w5oZgSznfeFWT1EMMBlfGBKSXwFDnRXBkWTcJ5VJtvKgTdL1f9p4wgfiS8bw/zuNgD0L8p14MpGHKL7I4ujKMz52fESr0dl1ThfiUzZWo+c17TIdzznnZiuKrppe5266ysnau1frBZoMLLr3MsrxWc9mlHgv1lCZrYx0EUezKLs2St1p+EvcyFz5B+yVRrkxxPOOe1PEacErgxFvUxydoVs8iaj0cvj9pS6gV1FvUlmincic/vtMqX0ZSS3tNXflOBBBy9DrOQ1gL+Xvo7cietH8T6jPiW4csxOqxEGn3MbMunSa2BkK28sz3KvBK3+QawO5w8ichd9c+yLmuFlMxFl1vvBCC21y0mF+YN6JY5gbYxfHrNkP8nCNYrE46jY6Xs/MtVvUbpbsziHqxpfhCkZDnedeWbX3g48MmAVvxvmOhhkKa0YNF15qkKOqN3lirF1JdTarYj8NyhslKJMZHoO7e9NiB6CpfVY0DRFFgL07RnrezA2Ptn3h2c7gHK+OvFRqeeLERV/wlBHpfqGp70fxC+Lt/7n0WJEF+nY6jfGYbS9IZ4yltSenMGLV3pHzMFZfM6p0c5lrY9JrB40xdHoSug2esvoZSjhiXxcDm1SkUW9IaknYPkJgik4cz8J64Gw+nDC0mql6BipiSvrftgJGPVE9EELM5QPstRY+NZ9GkXqhS83ruVIQzb+Msv2Mex7xDHBuNf2lLCdGXRBUAngM+9zEKaRW4ZcepFiBcZ6qZgFvcV6JwwmKx8QFpGLrk7SolFzQvnMss0e8OGNxuXu9CUn1tlC4P0ZfaYTdWVAcDXtPXklLBxQVDVKYBqooCrSgucbHEpinGR+ZgOs9uIt/i96Gycr9U3Tz8Rwx4feWz8qPcr8wT6ttvNIry7nZhGJEKpqO1Es4Yw3F/JBuv0KXQOhVBsNUri1qUTOgHoM9Yc/ci+mH3glZdhKtERwriFdJxergKtV7u0WJyEKaKMOGNeY8cKk9VWaxMVQsCnUGpaKeL864DPm+CAEIf0AbvyzLkJqka1b38OO8UOVjSL29al0icrXl61LrLhW6+LixV/ZmCuBTmGFGh1lfEK+UOEQT+SaPqLQ/GNQzKfDi3JQNDDvKnhMSsFl5m5Vs9jBs28S6xZ6TF4XOR8QthSzFfENzmgal2Uaz3IcrLNuYcrlwzUxyPSNnMo8RiC+ET7GoDMJ1/RMj5qMD1aPuUR76GH5HGBr85/wBJcfg0+q7xCuVLd3Yp+paz+VJ43esO/bFZP3MANQ6cujiUSqrmUW1GYYanaOD3e97H48wA3lg26vQ789OLMizwKs3R+XP1DZOeeIuHCYodbiGQHq6yocUGoKAYQv59YtEA4zxX/sqLfkBCJtFn5ZRrzZfAXMAVoL7gSxridmNQR1CN8CsDPrH1xZHX9otQhgpqCjd9vvOPJ86GUji3fQItc5CrnN1KPK3BT8ZrcbElJyZtu7QeE1BqRtMqYUca07JBdCjGBkptbcf5HTXYobTF8u81msM4FAr5hw6hewZDwNdOI2K6+yP/AAJtSGJ2p4iUyqLdq0/UTXLuCKFjpolh1xLWcJfx6RCnWSha17PumU69lTLqAyXO8zrEW3DO8MXKsqb5j0FlE2DmXPkThGS/TVA4vHPWC0+sUj01iMADsOPMGj3Uk2zHRRes4YDIl3xmcJPfMQdmJmOT3ML/AIX7hkEH8cx85Gkm9Zb+GP8AuEzXl8Quz7pVu/qj1L1fqJsekf1Gl2K8PxAhVf41K9PpXhOW0SlhnOJk2XUhs07IfCP5QAFfEW9TBY9r+IYrfbM+9MqgGtH6mNfZ0V93FKcKzCdLg2lCy13ZZ9cY1MVuFo9XMO0+bIDVi7aUE6Du/qBYvFWr+oBu+kGu2sF0Tpl+pURb5WORNGYEk0Tkk5P0qLVd3HtBS3Xt7zBPseh+o1MmLKFcdeKleIIOf1y/E4e8D9iEZ/iOUrUZYsuK+0XexH4gxTZVvqZZygh/my5eCrIr02bYoFX4h3qdpbG66C8VG19U6/aOJzaUO9q7u3p2g8cVbLsmzPwh6rtHoVcbd9+k4+Kcx1sZcvgVMZNgGHnuVY4MRVS/JU6WwtQ1Ntsl483fRlDtCmlPOV95R3aiBS/Bfl7RdYGwBRUHBhR39Znzig5wlvaZeoDtmXRmZPYjJn0Vx1CPKl91NZbRS+mdQJbEzqXYLqcKyWwNJibJK6wIAHcQAu8vUs9I5jHtENEpIg4HJuWMpjrWYpxZ+pBFMYepiJah7xKzfLAyh7Nk+mP7TM+7DY7i5WuxuU5y8ToPUTvzsVMGRZXvLGs+uJUToZpMShQuONeJhy68+Yo9Ar2Y41LNdJ6Zittq1UAwOuXPvAuJ3afSbAPGPqJ19cMLo9ohWj3EDteN/Zr4g3HgYg9+R/pDUb0T+ptfweI78g+BvolvWLIjKF/JNn7M8J8/84Ds946lwO09Yly83FY2LB4qPPBBVzTrG6ANjAsLhuWSFvMrNZlb2pZTfjrUduIVAAybR010a6zHA/CrnRX9mLxHOPDbxjBjqiWq5lS1hoJg9o3UyYsLU8MDpAeg0GnP+QTxqNq7J/s6z0Ph/J6z+jFXXI7B2X168S3ZbitsuzxjpuWTqytu/Ptkhzc5JoxSmhWq6ynjmVtdLzFupABXokoI1oy8VUBGNbvH4YewE8/qiQZ7f4jWuy+p1gmYzR364lgZ40hbzhn/AHOcqa/qhsoLxcuOanp/sQI/kwVzIxlXN1cc8zVEaD5a/EXomXeGo5OkTWJ7zjTqGUAeMTiN9J0YrNXDdLXWZVD0/wCC4o+YYFCP2MXAR4jDf3jc/KP190V0OjMN8F83qLV93ZmHVP8AJesO5i0FRTKx6Yh3pgphytbAKOtRpnRmtwsy1uJRgG1lgLnciRSTzLlK9JVyw3pL+uB5ISQ5gnBLfXGi9xju6iWB9EA/X/qVHZ3lTKeaiSkLVwtbV54mSBaJLHFrDDpcbUs+O0sFXCALcwzSUS3CGrppPmO/StkuhevR4dTNaN3Cpp4O+3SYLlDHPSL3XbrMnMarlvNmNuOsrH2cEK1t6jXS4+E14Zrp1tO85mbJzIFUXVE/fD+pbkc6mWELC0l1PTAfOKi/+sgbUJlr7hMwd9bKX29sG8JatORKaKr92CwQXJoh2ZvaY942BW6sTFiOZNy17amtVxG6u5+o11GU8IY87+I9WJjfkb9YcLDBq5w3h9pTOYbnTWzCWS8X3tv/AM3vHxTrT5JhP82+qljftulfdy0sOi/ojHK7GBfdgyznhgZGzo79YVDKsDTrUwoFw01E89Yi3S1AB7KWUJ8IlnPtjUbhIyj0/wDJfX3I2U5HZl+uXEKmQXiohkr5mq/ebFbCGV8MRsJ5WMvzg4svYzKN7Nw6gFcpYjqMz1nUAeHlH2qq0CQ9jEUXlNPjrCJaHLCLR2zKih3GJU2LjEaHflc1T1RMu6do2KCDOx6S1qZawhX1lHEbnHoiLVLtuX1ltmdUnSOFbPQgGKYNabWrmieJZaHSVjpC3FuDNWMeEMPejKCcLLN7us5qrsloRKOpYnqxB39Yx4H5Tr3qFa+iFsKrk154inO52eGeBvo7UinTTluvitpzzClbL1TodLZtrhPMzihfrWeoydXNxDpKz0tEjx2xbG+85Nrg8ETU+S++Zd6pZqM2u94cSwoiYyVRYLOrPCUZdFqgo81W8Nu0U7tG+q48gmHlzKoybXk9ywgR4tH4wuIXg6MJqrBwi3Lhv1FaXedSGHMejb2778+YEfruHCxrAIdVN4hrBm5bdi7LveISWDqh12p1ovsxglLoVdrX8QT0Rb/CDKW16fvlFlPPKOyz+8znwdmGB6MIYYXNRdDFz9alqbh2br9Mn1EYmxlXrv3gra8Cfkj16cBL1wEIZDN0pFGb0Mfylp7aifiJTvYfGQjWVMoowZXO8EfgZlFLLS6IIw5VgrrFhj1/QgqFHeRU5QeLlksbypizrfHFkVKFsQyBL2esWHtl1KrHPY4YsFoUPlxLiNe1p/XMrVZW4uFPSrqpVv20LhDzL1t7y8TfqD2dy+PdIHBTkCWV+Ic/M39X2i7sA8xrIpphlYvbqUyul4buJyJR0sSWENpeI5aY1vhkMZe0fctPV27TPDyxcU0DwItYEdoise1BdaP1NUMbk9Ywp2ewBstbe9Yz1lsgsKMYD27dFidmbRlL5eZWsdDO4O121mvrDpYVafPVTAKiO4TkVdTOjapm4zf7dJtEkI9F/SAOJjmWqXdQpyb0lbgFgLhlcadcCdYpvyXg0RvZpfFaCWO2jFSzq96hoUYN3Bk72QuF4zM7iH5lxmUQDff2gCHQVa6r4KhYQ9lnns6fSX7bf3Q8F1UjFl2e+vk3AB905RsfPqROnMrzHANu+tdvtTxDyQWnCexJvOZy6qPd9RnCU6QQbDwzaXvMr6fpB3ZaT3g1R/5CvhB2hMh7UY1Tl4hFGYmjlfrBOU7ptfqOjqS8kWxR+6QKvyTafGcM91SmeOAc9UBqDTFQsKcHb9CTsznnfWJNXTMVeL9Mw0OPIqBRxcq3cFjoA+UGwjshSCSl7WlaxrJ7kQphZb6ONDZ1WXwXtKnlyePzMmh1cNuFpJq3uCjq8IS83mDsOL/9lKgVzjZxp1/7KAkoItvWBlyGlh8RFUxkCekuy8M4+8UL8eGKXRg2q8GR2BVwK/qXLyB+0lVdbtMcGH378Bl9r+PacpeqP9EzY8dH5qFJDrXABcNpyhM65yBtcLzBcE7UZWaV5ozEJwbAYruVzFxMvkqWLiWBkvVpMNybhcBRQwxNdvdGHrAYBl01L4cBua7ygZuQ7b1FrNG8I23nLqa5g4MvBNKRQEztov3QZbbU1HV6+JWTbLu5WHA0FgA0XVtuJVAhMxvBjvuCjKvLT9LD7gweDJXgBpN2586gDyHAsz30SzJXKmwV1w16XDh9B6UX5IsHdFXtBItXNnFbiveXDZWjP9xHU0GnTN9vW5q31X01n0h+icm32XzXTo9oJBuqcejiDGYoVymsQm8dR2H7gJHkjI8wdZXRJVTRp1o8LgfTvNJbC8kX2qxhbfY6nqQOHhsHxAN2HS6J4zqTLo3NhPaszOc3Rp6YfEV9ArM+x9RlsHJur/DN9p9GmuY5Pgp0uZUL2inXoS4L10OkfJGBRUdduZRUQCV11SHHwyI9EP8Ahcw/QsL6h/p48J0y1ava9XviWa7g2iVsnYjLpux3or+JhtZSzoN4DOXHHoaNWD1sI9rjTxUDXytpzBMIWOw2e2orhgpADq0v7/MPLuT+31gPNGy/Z+YF0LZHPaJUpNNv7lsvLT2jZk2S4fAmPMwd6Dpl3YFZHieQ7R2QL6mIzTfkmWH3wktct8B3LNvToR0hsepCVacH6G/W5idMAUCLUFeH903Bd2/tFgOhd3mjPSHrKHW65oLDMxt8YEOrgS/aWKXPq5TInNU/UtBUB5Yki6jH8Y0Wr2WVTS/GX2r5DfxN4zCdZ4Yv5VWE0mctVs4lwFI2wZeAscDnzHDU5MM6Dx6x9+ALo2VyQ8qIbmutW4nvt42H5UrBCxT+HD0icga+Detx3Nq/Us/iO8HNjEDwpOEMtYumk+Llm4bLsf8AkWulldNu/SviZuxPAoTOwyepy+3uS2os5hu/jdS/BjkH4f7AIX8Fgdz1/wBla0UFexZ75Y4Cl2iUzeWP4jObd4unBNzOcFLot2br0+IfWpqK7GoiJxXUGQpznmVs1xdvfGdHvElAWrEeJgpRw6gUV/6Rg742gAVKN3O8M6zz2YDTqLMr2PxF4gtVX+7+IuDD1H2I9q50Z+in8Myq5by31XzFlLeDVjoOxzGo8CWgqr6scNL6TC+YMFgzyWQIyli5BA5HBr5i119WclvQ1O7MmEKE58W2uwtexLqQ1HRuIdrK9YSewvK8vb8XOQvTVlKDt6xtStFfmL+ZgWQUKi8NeaiPlLiPBwbrszc5y4Pig+ZleOyY9bRBD7Sr06kqFIAb7A8nf6hLUV2dmHM14Lx3nRffRAg9PH6okzdQYloefzGYJwd/lVPEnv8AdxJZ9AfC/wAoekm0ny+oxafJNujQr3mFsovVMbVztnHzX+zPXQkPlmMd2IRsaupb0mCqcnF2X2wAfTk2Tlfxg6RsmuFy843KMEyFDuzcC+uCE8vqSpbfylxRQAxH656Bwd4QeaK8daH3IkaeKLa+OZZF3hIePOoYbxUVXpSD3uUxnRQ9GXxpaUDy2r+I7yTNK9D6t5IR5v7kvdl5gd8Buecn+GYw21qpXgYp8xFoGuKmIVpb5AaaJduUhFdVt4tfX8mygG7SgqVv/wC0XOCymrzYPXrN1LurOfMpD1oNv1ic8L34hBsuWXV+IaIjAOrr4x8wEHTrDYcH92h75BWuP37yzleYO+SY54lVDXnLE4euyg/uXhFip49H9TBqz7jk7DpmDwW9tUfd7R2Rps1g/uY/Vk9IpByKQEZx97sLXrpcRjUu31Y1XzEaOswDpATwhTH0+Y8gZioj2/MUwGw4vDCZtS2padZRDX65YavPxDfkC7AbcJsTZqUV89497Tk0l/kp1bdSzW2INoClB3V0mpkJiXXP2FPHVLHxWzQHVDxi+1mYQO1eB+bR2GLikvrFlWNTgKkHWSYg3lq4rxEq17kOw2Ej7C5wJpAHImUWtBWZ+bCDMpq2f2z8wVMtwpbXZVcwQhVes9jYM2jcOR2D5l8vecz3RlkeqPgm6Q0h7iLMDLdf0IrIbc5/aOhV4mv3PryzGF6xvbs7EtYB52jMYjNeLlvlmKXb+9ZpjAdPD+s+IZok+d2ced95crZ3AbTVtUAOggao23qOyLyvxF08SEklddpv9oZAAzSi5iYBv/Ynr9eY8ZTN8Ytfb4QHblK+ig+2Vr2645P8+Y4Ldiduh7Z6wImOn1dBYjl1toZ1zzLut0MvGDTVW+jqwCwu09kpfmFYb1T+Q+IV+Vyj2YTPqspw062mnyilEtSBmZT5IRTh9dRFiqWoFXe1j5hZpHAdfa37lVXaiENmGepfT17y1iRGxrm8P92lq7GiWrqsN1eWjvLrbtSh/J+vmYAWYhm79/xMAGtxyd40ByWXj9zpiXqr+fUtG1W3HofPPWHroWQUJswv+qYnvE6At4RsGLtcqI9Nocl8Y+eZkhOGbjA5J0C6s3ZT07S2AdDq3aoj7OIIEe5G5L2t/EX6Dsx2i2sbdKQkUw4N+9Q67Lm+M7UgnrbSX3f5RBmms2cP+bhPgNh7xFvSUJ8GQ6QNnbyb7CVD59CoFrug/X1+ZhA4Ek1OdN9u8FPlKeAyX1ZjEsuVLOgUUYviFpVeQK6ZxkmKRyj5H+Sh7bCx70IFyLbkteWcOI2Xo6we35SlVljiPf8AGN0a1HCUuWEvi7zNzXsAGFJsRPSEniwB+/7zFvKKq/dBLmP2IGoQFDZVbTSw+yVNQBlTbOc13lUkoRkVL5b+JlK1INZPZx0jQ16oP19pRDcJ80VY+jDe+Spt8HnL3iGXcg+RUHLblgU6AmiHCac08Y/vEIVuqAep+B6sMhRQvDocI/qXhDvBvBAHBUtqrOHHxAXVVAFFlEUjC56PwuGH/Cu4YYvrLQDvtKFa7OaQ+Be4U1IHidVmfqKh8JDLLqKIDNsc8jMoQt03tr2IAS9I+YDwkrCB1SZoItexrNfTAkhUKq1nNw9nm/VVAFsHdUtj2+PaDtj4I/ETct1hm9QspoqKALIOVreXTM6XaKzmqnOoEEP7cWi3sdCeU/izM+U21LHNUGk4ZaXU4ObKCzhfhcojUGWdHO7pxrET3LbX2Rqs1bdRPmvaPAwXpzLZgVFc9HmGaXWsAn1Nk8+f5XDlJU7nUdqCWs8aM5Vx7xeRJTCuaXdYjeK14C3NH7iuGFdo8Fnnpztih7EKULXNPoisDXIkbhuw/wBQqtH+9owawA5b9ZzGN5L+JUewF29PwlV4zKuc8sr4s/iA+ZpYalBmOF2vvMBrcZA1f7l4jHaG7m/WUcgeKPkuDVUjwXLbIH48CIjloKIK60PpM6vWoU6Vv0mlI3AepLHVKbyCq3WAiemCRyiXk/XZIz6gY9T+JaulJPRhGnyL4Cviaao4ChyHfWWEngi+xWG4pENJIqs8466DZaPDF0aNNplihlljL1tNPbUXF3YsJ0TFDkuj2hLLqmpMkXl8bCHp/sGZUf8Aq2HiaAnyLX8ToEWreqkZ1eFn6sF8waBDMGbdFxH+ZBXVtbvB01iYwsmqZQOxBph4005G9R160WejNZ64jQ7s8cv89oG5TLAULb69FdJoOf8AiUVMKWq3pOKAeVV8b9Jvd6/l96PSaKAtziM3xPqH7jUVeOn8S9Ae83f8geC2+Fb8EsdTSToEexgDWeBo7Erd6i7f5xnP7l9gNQMXVWDs6jKw0PSbkHef8RdUGVSHyCi9ceYgMRWjK6jfaurQwqvf8xv7lFiWeVvnpUxjeUFmFHArI0M1x14zKi51jQqIGt10PSPhHrGhbwtlrt6S9Sh5mBH2SFWC3brmJrPerov6ndArhEnFBGf7E5iV4bOE7XCjpUsbN+kfNrN91176JRLEFHhrtC3abdLsFFPj1hyCUlnbbcdPHmOlLOVCA6rl7Qf5GufrMU0mNLm6gcHBIbN2MIxsnofqDEeybg2kOgOkK3BLzQyl0xQxpVLfCTIivVp+kHPfCphrCeDKfVNBIxmmWNVyKX9VItGiGsWgqqdbwEDBO5b8SkA/K/5xME81MTBF1asM6yTICqshSM1ikcK8S6HoND4gDVXlimvIxtgnXEfKE0ofiLuw+pCFQ7uFq+773OnaK+m/+cRhVfd8HillAo94lD6So3OMyckPag73MtPqcl40rIPpOzCPk12HQDQYDxC7bFIt9FPNGY73syQL5NkJLCwAoBiW82HXwhb5iFgW+6/ZeYsJaY7wJBZ1KyreK/UXEcQGguhayyJcY/h19JXjPn8mosHQYGOj8xUyfGLFsFwQuODd7D+cywNQ8z29ZoBOq+V6BZLIoMBTSdPEWLOLo+vSL8q7sg+oWIJHlBT+kGlUw1ZUAOIc3A0QAb38SgIl7wvwPpE6oUYLs2uBYUXW4l8rXa5Tinpz563QVzMJNJh12L1xZYdIxxqcS7w5/tQ05vqrrT9OTh4l0HuTr1dpwxljNbZoosssgpRZrJcDD8Kg3ZsxjtjYwLosU2328RsWBMOZlBVsEb7fE48lY4hWC7NMBkFv8AwUAu43yelekA5k9smtW7I2Z2WY+5TZaWCT3qVOAKtI5pxo/sxcJrM3RRL8i79YtCWw4XLfnLUBvq5PxDNtXdTJfyvkQUcV+sBPmOLYxWP6MwmBnEMrPdkrSj24zOyDvlMSvOvCHsMtGVaZ4jXy1LJLKqltu1yq73yIjsPm4inZpcxDdY8w0KqIXcWKu+I6fKXdvR+5Q2xU9u9rW9cSjXOy/wDH5mQFd2n2sliLS2LO2FkRdnNCMFiBFWVzFgilboUO3TLEAg0suv1MgDhuHQ3vgmx6eG7vaHmQ6QwtI/FBQ7r0qj5ZnbmXg3LmfrhV9bjudY9K857TEzFgDqRDXiZMdCJkCq6aEso+wrBzBPVavyBNHsfcTLfQmn/ARSg3i4vnp7BXTv1/ykN0D0sP0hV+fg/xM5bfY4MMSUzel4isR7o4sQLpULXUHrGxv1DQvCbeVV7xNKqw2rGeIC7IB4f1Fe5tUGNYGgeJl1dA+42XbkOpwhA2nTRdYlPioDCdIdHQ/CDWNRSt+4ypkZFLK22PXDjDCa9QE9P8HeFU15S7X+RXSW7la2D4FPF57RUotwvqnMXJGun6HmJFwUPw319ZYyBNB7vVxZiWNRKOSBGuUPkjcxmzRaVuDtzKd/TpvMTKjTQclEfxHLBasvLP1XvAlUEut/qm0Vi9qX6RIip0TvR7fEE4Gdg6vxLaBGHMp0S0mhHPXsxxCAUAG7qVr1lmyrcRSv1LEFnvP3K1cELxsbznUviXvUoQ3XVDXxCwLU1heDIi2nSL64lDtnAPW7sja7YTZ4yQAqPAgra8YYnQpUqyQ+l9VmH0ccr4d45PaZeIpCzWNGYw6O02KBNXt+JgGaVg/MVy/c+6llfLZ7XXoUVKdT3/AOSA+OdJbvERDq0stUGlrGu8zw1xc/CZc7eR4AXzUF6dqOnC0tdbg+kPNz84UsmvDvzlSts6zdvQrefjG4W/nO8wlpar5iNZTFKmcTMesazKJpUJXcpdgeTZNDZ3qPmOsNwOf4MVK41HJp9x3mqk9Ns0fIJ7uvZix/wxvGrWWcq58fr+4w5WT7B+VLwv/IzcoGbEgLCljvxU6xijVT1E23J3asxKgxxDp6tQGC4CF36S55n0lCqKJpDC5TCBcjCj+T3g0brGaDvuiDKV2K8lVZvrMZq6dnkVFdKRC2cBXeDxBEFuoLMyhdHqxCCzY7wOsIXK4OHcrR0zTris/wCZT7IG81l6u8HCNaFy+GBPCv2hJzMG2b15jQTuhg++O5DWK5nx9CucnZHXdVqrMOBMnHP2Z0zFixPybpmGD8zMEEUbfwd4pUeItvV3+JhGWkBBXXw4rR3Zmpuc2u/5zCokiF2Bf0BaJ4R6E52YKJhWEMcGd2V+pR+ZX2rFF8zy0mKOGuYrF5g0e9QFg55H5iyFFFau+4TS2hvx0PXtBnNT5xphoMjf5hTB2ur/AEjMDgYBUKhEhqNmqw2dbh85MQDQFvFSuYKdHeFKuOtWaqJ6DcIaRrQVjGerC49MxVsmtF6p4lBsRfOicVQVslXhLNnHMemWiOdQDd22iumlD1HI9CW33BLKfxxwS3qYlm24XxEp7AuGKvik6sf+n7SlexHQlKNZGglhf6SwQ7s2BCtx7WZ5BfEC9taw0yuagTAFdVRn0uJiTaK9cU+I1xAVZ318Quj3Oc/+x4jgnTfMDpSGnSrZ8kugyzv+MScPj7P0noxvvNU6gaKt471AHSCrgDDW+JTHI/D+IlxjkD7hV3DywgpRavHDHsTtlZtToXZCrw9kLNvsP3H4Def+NUFAwrcNg2d47Qj3qaM5o3vyPN4hO+2DNGsDGJbUtVOil/UKDwChYKlCeItDKgxAeFwmZnNmAs1LLsFY6xOgQikcjR8x0BnYb+plNP8AVAEtTCKHhXu24BadDVnwoPWO6H3mGC1ECeLH4juX68vabWezsdbpp/pE0y0agyfEQEvXsGIGUuDAwO4SmqKWpwh5+fERIxZxNX0dDX5KNG5qnurPx6ytA14G73M/1yxqBm3Cl8dN3Kat9lxbuv8AfSWM3hVcF7/2zcR9VvBh5cw5NvyqiHQ5SOWsqhN+WveJgNqqW627zibtAqtuS8QxGrgo+5LE2qzDwpBWTR/DinXmH3+m12aq+1QPur/BDl3FA1l0f6pzDUAUNeM2X/gPg+VUdPdOYHZZLGWU3ZWhsWiA3bV7/wDZtMbcdqD14mOVLYkOkZebj3RO6Y3V0/aXNLflLHTj5gvXVb2m7XQZuXEnPonX2BcpyKPkUoL+rgC04tdXmz9yiabh3rF9oxsu8qynfFe0F24UmOuGZF5MwcLZuDtvVdxFUdYQZTd3NDPuxbnovG/4iXt35ui1AqdC/wBOm3/s1jyssvJqHYDTfj/yLYWb3HzDb/Vx3IIECp0MTjg7ECF1xdW2lMtrtfsmDWjVoMfVfxBIfIr93rFmoSrHrON9iW5EpmbVqfyX5lyAJjnNrm9cViZgjmwHp4VdEDoYXofQic2VswJ4M4esWJE1rUCHbfi5UcA4AKy1nKggGLKAdN2P3Op74B1JbOLuHoP98w71VbycY9pWL9UF6WQt+YV6aLUUbpe+VSzoympttOtFSrYtpLVYbarNsbOGIueAj2Znqz8GlK2L9sQUsanDWvxESs+AH8xmIYlg2wx1mwZmMzZDIF3XHpMu0C6DVWHHbzCJQljXgmF9XR+YXzURPp4Rxz5vU1T7m2wrt7KIydyvwDUblKB2KQOamIpHGXR2rouEiUDqtpM2oXFeNRa4Sq9gfAzvntD8ARToPq/iN2EN65TtSA6Cb9NbNpO/gZYR5GhubM5gmflU41HD22kNI8PLtFNntyHghNwi5gNLxo26W4nbq6QwY5a5iAEO0A5pzX8xoFwpHU8Z/wAmDGpUY8uu4YosW3367NzJquChR04D9VN7yhNk9m5VdURz2Q87vWDqpZUUOBrultYj5izClBu4GOKk4umUNoRtqM1m8H9cxAC/4xuOGvWaC9Td1YubS4v1YtIFdUTXf/g9N2YeRm2aZYrg65luEZ6Tlbh++b8RbSbCd8/uVzPeOz9mKLMCgdEF9TUTYLfdYT9EfTE3PT7UmCAC0VIAu3BiF9c3S9ysD3fuK1yxU6FwbEg3YjpdetP3LP8A9AO+PMvi3KHKY5ltMB16yu0MSi8+y5fmxAAAbeRobVjB49raQu1gW9V3jnvF6qzbfEHtNCzdKcwuY6O3geJnEjrHx+USrRje048FHNVKOf3t2Ze0v2eTdPiWc+dnQfCherFm0LtpDOFZo7MFIpfedWg04fsgc4jA/HN2ZH/2WEaXUYrCXGfiNBjQxYp1azg0U8xXjqtVXg44y8Gokb6izzyUeY2oSPgPxEUjXe0bdcMzWwgEA4HC44Iu6Ix/jJ5V0YnGkDggzTWjwEDPDRbwEZO5xqVUfWLdoMuOsv56yNVd0XXG6vvECKi6IDe1h2nDytZ1W0Pjq508LRN95RjgXXLnEhYcTYcb8rogoSVV3fQKNvOeIyxtu43UqNRT9M99zibNCGkpZddI10ywAcRwVN6W9ag5QnRimjYwB3twCtKvJKa4BR47C4KmSy5opZpYc9Hidm1vfSdinV+KYHheLnNc/wCszidyrs8XoqY8bTuGqq9ozoMaU7Gzz1lmaYvposF89fTmnoqK2CsMsrn0uWJequ8kttdbusSuo6ruvD0/q6vo5bxfkRBa0rG3Q9oNpxiBpDCINRgMLC/pmqw2/smPZMXKqxcQQr9pgqA3XxFibgobK6zZkHaBvJKGC2rRRDorN67y244y6OQ5wfEf6ivZbRpcTaaohXBgy0uzZBi1VG0PMeWOubOtKamV/tzHDZcRf3GPxFdyukR3gJo54lC8FvgNw+eYIgXRLyQDGba4yt8zftNvH36SrlTgBXv2lGxIYoM4RKCuNmdQAx54l3xT1m1JuUgMidQe0bPv6jhuh6G+ktXomXQd46xjzNkmYHSprtKftvV6P2jatXeYAwlEtAq7i6fqEkIx3CurYg3jPWCRb58wdKSYOoUQWZpBrvKG1G6NFK3W2TOoN3plbQ121C1inploc5Wulu8W4Vic7P3HAPYyjAjV8230icqvAoBg7cEhryIDxHZelEZSPcK9d5RxsY6F1l0i1zyNtKaNHnzL3vmBQvRw43+a8ywyxojXXP4i2N3Qs0G8CnK+ksV+umghxp7wEJsruyUVTjCzpfuyeaos+iK4G18sFa9FfmwFMr3MjO1u+/WBWxyCUPSjHeIrB+uPxCAtSHeS/wAwF1gQuAv2tnzUwfehHf4l5ScrJXK/5mEdB76M/wB5mag5weYL7wbV1R4WPWZCtTj6+PQqDCc7AY2xmq7RzZZaWoGJVozkP5itXMuWUFeG8PWtesMn3W/MOFViv6zIX63FnHZFK1NgCgKLKOh7yvXaRbLDSWXkrE4rpB+rlT22lVc7MMBbObbQgsA2q21XuLpjcv8AGoIVRuxa66OOvSJCmgS4oaR/BUcIqWoh6hH0nKjQ4ejDveVOYlcvOrnFNJRpn+7RLJmsfkFeysQ3WwTqpPI504Elu/VuqgsNBlqjlmALQepspTx/agY80bOHHzLQGi7o37XxUS6ATujQXzi4SRFIRz1LiooagtxRmOTmk+JGSpaIf+6UaJKY/LEM7pHrnOuw7UiJG7ZN0HPsPIlU6cm9cfaZRi94FgMniKslEHxBYG3U33m0Gww5/wDB2l8GV4xiMYdbaPDfjkW2bC+tRbFl1bT7iZf5OBK4NDo6uCVFF+uDZbc4lMaNFnCdovMI89dBgEg1VXh7xBjERulbJnV1MyYyKXdC1l+JYQWQKuHLi8WPtGBrem6Vh6+8OikM2cu91jJCrsMDSjuu3VqYtUAGcHcNsY+JXjrkHwdPvGD1cIv1ML4RVL0gqQhzTuF1WITGtvJZ8Zh+OWUFwqs1VPYHDGOrmNbZvzkfU6y/WljsJotzrtXSGXW2ixZeyWHMyx+JNTRmuKCs6CqzirqBAhMbpph9kxKUTRSXVp+TprJLlzYlsde0VNNfknPqFkKMXSvuKJqdKXUXpFjMDoW1GeswqXVOvAcqZlmVN2oZ7UwXK4AX0brCHZZ9tHVW7zjoRh7G6PBATubW3hJcF2qMK+kouJtNPEF0dfVhud42iLJn1lmpQG6I/r5jcIWJ1tXkc3viHoLKmy+ttUcxbxy0p6OXrBZQyOadrM745R1V2E/mGeaISsGAVW8GeV+YkMbNBsz2c1+XMd+wl8ykWgx4jAGGdDre5bVi+iD9eTc1EExrNJSfEI5SGmei8esVntxTc2lXxHhRZRuFtx/sV+roigb6njfpCDNATO1Znh58Rzq2IyMuMt6a0TNO7MUHi+q9OZoLRfq+d3ZMHgbAyO+3AjhzrAP6pnWkpSrK4pKh1NAsBb08zF4aFeGLvrKEqXTKV7evQlnhyk2vTn3iWP3ACm9rN95ZmGI6gvQZJnclHOPWvczqVEQCrvBp94jrLIL1KDXGopq90+d2hQDiRyQlA7+e+4fgO8K+C8eZm+GD37jseLhz4scnh18HtGmZKzDdEf8AgbMRLkX7pf3GYpbpbjHWMByazpyv3nZo/JPEi0+fQCw2/wAXNH3tfVlOAkIwU/H6h2WKEv8AyaOI4qao6y5EMCy34IL7w+px8LHqVTFANxBocqAeDHRLEY2VyK2Y3SFYsvGx08OtSgcJbhHVqtX0gViqZdXYPf8A9Ys5sDYtZOG6T/IIoDYWl59yw8BykrUS+A0de8tabWZHAYxoQq5KLdanjH3LL3wACr5V14NXczsQxtdcmCXYNzXF/kSAKFtWX13OEvspbwDc1WMOkXTIuEH1zYwHAutlL/xRzFzS3RVKnPL6g2M9TCZOn+dJ9/lifRTI+6llbo9pdbHiU11EZvZB7u1dGN5ETdTkOOrwZg0WC5WLnNVqYcK8TqArKuFtVqVCFjSbxQ9NnxFmkCt7zY8mY3EQaV6fTMWHx9kMDgPioazfL06MrBTt2k7FPQC/Ubc669Y1lF2g3kf7gljCroy9M5L11ltAXG8nzDsJuW2+v8jYioKF8Zvf9mNNXHQvRjPfUPeya+y2BbXVoMu99wjCkxiboFa3FQNCrwvg/OJXCTUonzaFxIvAhirHP77YifIHK73FXW//ACDvdS3V8cHTTKvNXBYKm+y/EJULocei3XNQFN5QuDOTBk/mVYlS+dDfaHfoXld5Ky+Y1zoW5g0s3fTg1qaneKsfT9SgelAtO23rxBlwyeE7YW+oCDr/AOE4C+Fzlr3f7t0nQG3v4faXIt6G47eUMixp6RZH8KoWh3hVZSWQGFneNwli/AfzLeCaHK6ra7k68Sgpy2e7zL/Q9OLseuO0u32RfoMPxLlgmyAlfWK7QOK6svETzqOZCGdUX6xklo89ajZggB4a/uswiUCJfIe1PVlRCx1XseYPHPpH2EFr8C+svfeBIcFzNYE6Z8Om5Z0pP6atfaHJY4HQbjvOHciCoCb3ZbN1Sa5WY7uhuYs7WHPMoWwL2h8BNTKrfUMqN0XlSzxp3YQ+coI2onu/Q8pEBRtJL5tnPjpAKBItJujnnUyCkCXgeGFsClgReLsdLKxjJASXJCwCxoJxhbWC+6OfXfEd9qKu8y68urXfQKReftzjBlnD4HoarlgL1CeZgvtGT1VpUFNMFeTAfhuYy2IxFGdxTl8DWyNA8BXWY3LU/dgmPzLgT26LHbli1mUg4/lToaC6MscZFo1g3BkuDBWRX+7zC0rDu+4fZ7Q7fTjk5hLqcRktCutYjqlADgVehM+kufa1zhRceOYre1lPh2hAfdAefP08EwrxBAwfPpAq1qNtbTHMXD3SvgDZy56+/tNaIFi1fLg0zCPYDEpa9v8AiT7L3TQNL4aheJgen6gc1dqhYb95cBtWw5v2D0mD41EXlcP97SyY5hK5/c32EAh3YPGeGPWlvtThxAujPk7pXtFYmqBXVG3XeVXMBbnkt9symEuqDPOHD5iKBygUji7HPDEsiwyDs8TxAzmQEqdHb6lwNSq3owxg1V6jZFUOprkJk0G76NFRu1DjYj5MdbgKzoV6QXm+r4QoAKCW5YDLfpI+XEd6kFK6r1L/ABzH0QQEtMo9D8WyZZt1z/rNvEJalMae1+CKEVNa/uYUwr0B2x8ksX5zu775WKvElO3e6sn1CfJwESzXFYPNwGrVp5mQrEXKhuK8cUe5qMwtb0z/AOQ5Uhri0r2YWIOdd+7b6zLAgwsawjRiNhzgrUu+h4Osu0YBMUT5QHOQ5X/iW2CdVoU3mzVTMQYO6urcDgmeOIDAoOBgQOpp41BBEBHaatja/d5iXW6zXSynDjk9kDAIyIrYmqx1XdbRYWLxRoWGaD85zEaALnjCsr5X9QbUIKinLzg8uLMLA3IwQA8jizpvsx8Bxm+rXXZuC+yYdZZrQz1Y8QUwUbexfF9PEWWrlih8JiVCHBood/iZsdVqk4L3Ev8AcG03b8kdK26uwVLlmBLI4iiQtDmcUCCtMv8ADMdK6yc8EG5i5re3Vl2BKlX2T2SqFgaz2+Ir2Z+R4F6xBFlOEznbG+NwPyBK+BUKd2ux2m9LgC3f3N28KOfDMM/jDEVZXLX+BnEuwUunvMNZzkMd4CypLZCSgsUF73r6zniWBCqpzEZMEjVja5Pepl9CukdcNEV738RWHZ4Xxxvnc+CfsK0W1wRrm6JyFcjvEw6AEsAuaKNeOxogxCpV0Gzp6TaRcFe62wDEh8xcMF1MEIa00787l4m6ujWDprfmMI1gUh1e8qzL51m8dCX7aThIGAGmcHWtxILdhY9mBUyZm14Azzm/edUi+5le5BZR8iXnr/dZYEpSdVa+GJWBYcll1mb7tb4kcBypcCJNnlb6y8dj2IHrGAnQLEeEiXR6t8/oQhwBrF3vUK9B7Nb6XfYlyObvQGx9DzHXbKZG9Fnf0aibVTyBr0YHlFKuBj1gl1h0LnO8WczIh3fx/wCzOtPq9e/JjtCJVilNr4gyFe3NXH79CPGzZmFp5rcaiVBtw+Ez0oHZmNySj1q6c+rERzFoF2GO2MxsPglj0OJu2BsHBgoubigNmsZnBuh66K0j4b5zV21dbE6Ha71nNblwWYkGh7hPPTDzCOLaiGmFI0503jzHQNgDKGwWjdFZ8TZbPsx6T1NFZ3CT2xUlsluL7CvWWrHKcSUnRfPaGsWoFCwXGvR6eqCsABTJ9BV3AvYy3WnPn+6QDDkdUdlH5uUchBSt4U7ls+0dRvag0G8nIl1GCiZi0/lvLxUulNBrUaQ7k+sI1CVigv0RpLTkGSMxtfaH1oHbv7SqDH2dLg+faE91xNZbL3GoY5VDVMA6yuM5x/ktgc3vZEydZZ1dstidV7Y6LAKHYJdvohsYp0LTuVhPo73kpReevEepGdjtbzLvvRRbqFnVpFBrSN7PmWuBE3OGHIxZslTCgJAyoV9u0dSub0utCwaznNbYBap2/UD65hOj/UBae81c8Gy9pjFIWHHH4QoUlAvsO3n/AMlQMaz1rQRxrpArrXKXNAu13zuCNJqmD7dMS8hIAYtQTkT7lyCrLoLUc205wRo1UEJWqsbl6C7X4mZNVCMTgXfXRKiKNGF9tzOYA+UpyJswYx4lRxR5eZYW8B3bns7dp2CQcGsNdT4qLHbGGgI1fDX0Y9rhfScKEfK/B3gFhfIudks13xEv7gvWrJm5VxPpH/g6jEvc/wBME03bSk2vfCp3SSZ3HP8AkOgAoqQoMq58DcTPg0KdD8Rq3GJ75v4hsTvsZEhMxy4OTjrubeUHLOz7QnGasODtNfrf3NPSWs/kjMulnhIuBmq4LrPEa2zkrmLUehvlzOhcCHkIxi1wGHgX+cRaxDFBWVK0CnLF0fHAfK/I7tmE1iSo7L8g88TOYMNM8Aroze+0P5kei10GTgOXLqD+K4Q4sqvqx65tdPB0DnOx6y3lSuSrujh8XBKmyHs6hQ/MYxVOmmjNaIIY6zZVAVxXPpUsJob1k11jhRrK+f6RiXeprMwNQzSWGpdOrl8mUnoWVUbF8YA9SE24VqHVHSbcpO+LgngqDzPzKNKqsyp7wakDMA8u9X7ShJ8c5Z+CXfIOurXg/PE2eNOumCWDikhvpt46RKVLcvzqXuM15pGD3jpR5cApTgnymMNDeVy+o4mK9jINYxpHrXEqVwIN2sOEK6wBFlkz6LekPExogybS8egwrzaHYywNdvixmHIAVB6tl/8AMQmuzf3Tf9U7MUb9xxR+pQlGyuzeCuOkHBBtVhV6Iz0TeedrLjEHCy0RItX8F37eAgtE2tyVeOrc+6ABKWWgWfF7eLF5as71MQaiGuEfQtGi2kMHR29T4jSjNU2YzoQxq89I4DBk6NdzxKBQRjXYWlc8woRq16palxVFR2na15vPLjoZzmogc7R9NSxAsIw0V+4gZ0Wozhc3VwdTp6Syt5xGmE9HxNhixWIuKzfeLIYLlBQZHACr1p4HSWjB6JS2xLahE6VjHt/21i1/yEcHGIxzIOqnVf5n97+Zk3Y924xeRZ6waHHmPNxS3UNQjc76E0Xk7d+sa6a5w5WNG5Ciy3mYnsMzLlhnWGBihZbh6vYsdmYbIwxj5erXENUxQwPjMUit0LPqxZf6VG97uc9KgbbfoBy0ibQrfCjrgyoBixQOWPoBxvqUMNUDPpkUVYuBml2+Obchp61C3eskrpgr4eJQiPLJ2S2MBj0NJnZWXUdAle0cBZh4g8Jae3MKjK3uQegZ94HJhZj6BHKz64+BfkxLge33zlll91xDrrgqTgwteS2+z94XuTa2AOoj3InEeIta25untU62L8H4lqBdk7w8qAY4G/sfMskDUf8AsNqFk27/AHUrpfwzKufkv8iP4e8v/Y6kmq1U9rfiJ5Dh5OLN4r0lIGIaDrTEcIVgcIM2fUy/jRVNtEFZ6SmgtJklFP0lRxhCebzt3XuMdGzBlWlw3ZlxiFFSDy+lWR1VFYI+zqqJp0DXvc3EsBnxSjCSUA7NHLMFRA6811wn83ABjApeycIXjfWYgKu7No95zzQ52Z0e7CvNvsOlHt9who33rG/CPeTw383KbnLZ4fd4A6KPNUJaAgS4AvdQtYa+6acDOBdYzzTGJPMTvRo2406tm3B/1iq6/wC3iHgC+uYoJ0pXVdQNiFYZdlsDxOuOfWwGeOfuA3fAzvm2JqD8CXUewsqsFinTPeY3UDRCelkLJcP77vWLt7mtFdVXaOFUog5b6n6iOuoBO69WHpGtJKNFPBS/3MA2jA8o4SpzwVp1aH2g8ASxG7gV/wB7Oaud/wDwgOd/msvVrXW8H7oaA6jCBXMsE8UUB6K+YWFVHyIwHtuLXbLmbyPO5z3CEL52Rd1uPBXdZxEEGbAcF4+InH2XD/PqLa5jRZPAstx8QHV+WpSKP8c9UsyzbPQF5EooBeaErkXsV0lEHoNAGLsPUZgfiBsHTvPStxu9S8QtbWxjSCOtNCxkwHHMZqVUPkw1yHdsm64k8cOr0gITuSr5kHc4XVcwaWFIUdVba79Y2IBbYDycFiWIwyp/9zPaHfdFCYF7F+owItLyIti7IAJghmUPZV518ETmZmre6z3mW6llqDpB3SaX9QUkBZcbbeV6riYRyXpdP1ne9ysNF/LUfcFGCuGXlpfuAwe+/mYgHFB57Q5mQ6LAGP7UKhuryECqczVf3PtNq2HRBEQWYMRgdTa77xTTKUnReM8pS2App1/ESJ1dWiwZ2yv8xWY437eksTzID6RNyMFfKy+8qmgCOjXwNea6Qqhq9Iy+rLxe4nGDHytNPqvvAjitDRXX5nb++Y7ntDDVNgm+jOSNrDuhrelLx069pt5VPZL52z4uULtqFTu+3EuX8VotdGVuXAO02XQLHi99mntBrXiqvf8AUs0F4MelywhgdZ2dGDBMFWZbGnyD7+sRa46HkW/zLOPJQoUlmoDoPqMbKU0rMdXHvFrvGKJY57QwbGIXwcaofvlBbz8KYfMsXNFfoHUL00By4CGlwRTNcJjpkoGB3Gl65Ti5eLDJkQNODkj2cMxsTy6hZHNzLdKFUgazbBAzmiLgmrK5YcWeVrrSZUAa13fxcrw+6hC6cgfmNUqVa1Z/qYVWy2aYyIjz/wAwy1VFkHRhViwxjXsi8agzXvrmL1FkKvpqOE0KViTWgxZ8vymfCvEht9NRu50Jibzn0cnMSCKKDXEeHf4SN8ivVhUk947ehZgiVvwE0ttcmcIBh0MFhntXXzKBt9tA7HrzLpVGoweoW/tM8iQ1AFr9XeJiv8B4lk22hUvWs5Qc5m3yWUVyrTnVQujcrJlK7xjLgxqMoELq/phnWkDngsPmMB0VxzNnWSZQt6vmURcfUlQcJlOSPEUXjSCYHpK0Uq0nCg/y+oTKRvC7gN+zjf4jLKSyTRt1pfuNVTcWTgw3KY97hcsHNrfVrmvm7tXrf0QSliodM19QFJo/lF0OociXPmVZiBXzv8/MP6jVCuGXHy7SzgIBMYmGWGBbhtDviXbTq2nqVUJ6Pis6AeLb5mbWqjSN81Wnj7m3lnW+L7fs9ol95m2VfE10QUh0eDWO0OY5jSkzvzbzEgOmrBxw3WO0E5prwa4P/IMMY1YuSnK38ymggeeS9/hlDWaA9TDWlPERp7AihTEDi4tPiNHlXxNwyJl+CvoIkr22yt+G0lSuOSPnBHiw0X08PiMjZhs8C/hzC1mGHoaaHaN4gpIw6+6DtO+44ZPicFsFeazB4tBdUJbv8bYVA6hQ15DZLSTsKMzFE4bYuoeYy11sPkmlsHVczqRB1Q65jS4yH3+tt+XrD4JJxP7LxACoAhRw3DpgXXCXdOmf0h6faRnbq4ywIq1qAVl8f6g0A29EIrl3L4qZbXD8oazAF7IhHxSCbck1h2Y7QD76SexUVnaLaMMKvt0gp6ESWcYY6uzOK6iYTiq6Jkz4cajd5zsVqq3brmUs6mR1SMLZxTHdb/LXxkAw9eJv6pdd/wCcShIIp2gUcQkd11K+nSpeAQC44Fc4go5Q5Ww5604DjpODQAAJY2X3m8jTtOhhmGlzW2dgLrG8SmPnAC8NSWfqPIM2W9kFCsq1oZUNL7dhE818ygQ0VHKNTkouLKX9Q0RGosyZPtWfIx+JfQW95dOluGeqMPpM1WoAOYz3QNUK0uGF1rcND5ieomIzz+cJjBrmD+gLxnaXCdErTlPKHPgN3P2S5/8ArUKbv+7BRVaXW4BCli5YpPQtH8ZfUoDcDV21he4fEC0ZOng6mR0N7hkK673o7NdPwl6l+zC2nb6gBPAkC5yDN6KxuiZZl6yyy8/3EdNbql6bc4PhvrNhiehX/sI7vy+2+MzR951p0ohJapaQH5PEZV2xMqnV0PriYR0xoWZaY3KcK7H6wj7QzwehNDgyoba6cd5Vs4htO+33mLq6vmIOV4DfiMSyOlfHZ1ZRv6Ll29XeMYKIgqln6kvm9sKi+LXZmNeLzFA575yrXNzPdcHvr1YIqPs82MK9cRUJ2Ol6g7dynvGElgzecX4NO3UN2qz1G3DE2rrMvVntAD8zgqJjPYcHNasowOWMQLkmCFpdjiu8zgsqPEylspKw9RAFAFstdfEScBll4s/c9cEq+ouHNVd3HwiC1O7fWFB7xQflgJ0YtXc8GL9JSieAM9DB7Swu9tdQs3kytTOyRwMzbpfWZFgKyecI7l/uUGnJ6dB/ki2JYc+pmfUp8x20Q8ui5VegxkYhvkNcV69p2bY+jqoyOoEgN8OU10u0SVHqxY/UcpGgKcCA/L7QCP1nbsOGjmou/CmVvC2Axa71qa6QjQxzXf1IUs6Ceww76uZk8U/NnM5a5uZg4QWyhz5qG4wmugfncpFzKguPaqpoZuo622GFIzaU4Dv6zAV6lleB3uXKIaPalM1tQnO4c3r41OzSEA+IL5zk4H+fX/MW6/AP7ijOEJpCQTjsMl/BlYQDF31X/biuVpg4abg1DA2mAc4+YTEovVbr4zMiYEtuejV2xkDPWsLWnWn05lrcmOnVKvnLFC1epcHqpT0OMr95cONKmW75V/ntNJ4A9y9gVK8RbamVb66dpwA9vIHY/UzmB0vpleMwKyasqO0NoCNaeo9+IHJEbFKW1V4rH1hlQBQNgW7tcT0Au8Gfe4tCbDsrs4nTKWX2WNb/ALqC84pE95eafs0mF9YbwQAjH+hgox67JQpC8ib2nR8MQN2fwanumqvzNVB/O5aIDk/c37EM0K5Ie9U6lFJQNWvP6iJfrph8TCjRrVb7MbuNM220kc1LR3I2nlbNQe4TApDFs0FGgs90wuA/4WP+MIKcd4ZFXo0Y2Hr7oOC9reX/ACLAearpOhFG6smkE8gWEL/txgpVgwD1v4YNajYzNsN019t7oIwJSYC1VjiImt9zTX6KfMv36pLwKqpy6vHeNn0ZIrsFyzGM/wDRvS0+Oi4O0ODlBauMVhzNFrKT8nHffiXK0Bclq35bhwQmkEcZ66uHXKSgB4/LuGmL2i3NFSkpt0tF+hXrFNZJhR/QgqAYHmlXimqlAxBvWwur0c+sveCCj0eBRrUUydNCumspmBDkiko77D0ZlcHKoWj0YgPIXwZYazRwNDTz6kP4oUUrznpXWaL2ABDL69oIlQlRTp3laFBdmQ5Dp5jEbMhwVE54/MYNQDHQNX8oQQrBgFOv4Rro6fxPGtmdPyxOxUTI6/gzK2ehsdXjUqEMMjdTLt05mxn1cFn2BAzpa8GvRGdcO7oLdc1hBjc6xvL1Z94oU75GqG8nrMPucweC/dhxi5WoBIrLg2qjON9oCJm8DnzfMAxZd1T89pYXbBf+PWJKOLg5UOJVjQEq+64BgIW5efWD2dyWTjGzmExFfzTGnUI2VFlsgu269CUArHsED15+X7+kHdSI/wDr3ljyAQ+QsRiL0UfiX2VNmp5aT0GcbionvZgGzfrd/iP8E/af3LQocjD0zEmTWNgjjzUGL9cI25wJxaxmv1OywVxmFV1463KP7RnFY+63qd4IybIQlw95G2kFrpjqWsZ8S/IRBWhYyF3lKM7uy3UOFMt2jyilq4AXf1il8UpD4mZeFPB4jHrnzoQw5E9v2gIlqyTgHVeIPlkQd5DPgfMxMnAvIVnPQOfSDWbHxnGF/H1hTkJ8jkw2qcdY+doHmHzfp6zenCb+lQ9SCWyoLYhpxi2c7hKGDucRU1lcS+X8Q68zazCJ03mAOAPSl+ft52DLYFbve+rGQ8MAzyV0gZfsFB1MXfXIQUe08z5eb0gvaG61dkYjHp4jS2Z11CNha4C4PWZpuq3+j1hkSjCnLBrPiCz3+WytKtx9QYT4pxXAALs9ZXlArxNVKYvWHQRxvcjCGAL0iHPvAQoaoVUcd7coEq6zMV2XcSWxAq5bNuN0P0UJLQ6uU/8ALAAoNv5iZoG5wTp5ymp289+/5gKJot4scHxDtYUrmug2GCN41FBwIGOWy7/pLqGEs0D+Kb+gWs4VjfmbqgLK7yHLZRCppqUve4PFyyGNQ8MjlX4himHNGXOOowLuadi2S5e3vLI7b0xxaHDj1YQSxVS79sECIC5OTVxdAhSMUr6RigfLCmtB2VfNh+IdcuHNQ1klQvV48cVD+s5qKoDj5d4pow9gls0L6fuUvLDM02+74QUclZOxdfYjpmNjxEuNnsl1f0QrBTZmwnLHb1j1O5Wpyl1pyPSJ1EyketazU5GzYPTOetszkjEJvvj1g/q5lqd/cD8S0Ac9jRH3PiU30IHDj0AktOjuE7EU7UCHzFjKLCBs7RnpiUrccdWYUumqqV0b8iwncUrSuGNy5T6NObQJZ++vWbIF+MoCQfR/3EkEXnLYCtGLdMOW6LbqXegWtOv1HqS5CY2PyK8RL9azvNfm7tr3NoZg3ywibv5TKsp2pWRgVWpmxc5VxcQkxMLekzljlcGRABL6YfmoIFKVodg8VlmgAyaHqmWLvJsdgmDiMHS47z0dmPBpNg2dJQ+A7sdjuY5d+8Sudjnc8pTN+RNnxYDpA9fMNJuyvGZxiLTM5gpGB0H91JZUHC+Z60rEYuVBN8e8MdryC/edWFQLlMvc9QLMBtdjtBUgMIOZs1HrS29xKLDid2CEySRLNKbrWMkLF3dqJHVqBFHV6ksqoMgHY+0rFsNOAKPuLs6cs/u3fAT4j3asUbqj0hNDhkrehvxycRY3q4RYYrpMnhVeapLdMXnvDbz8fBW+5ca9I59+h/dxBTmdE1o9Y2DIhXw3RfrGuSz0qWUA3bRrTtmD5uFaH4iG5TXfqgW4ueAX2jaFlvR0iVF1SjY75hcOh7YRexu1/O04BMAGncZf4wY+W5qLgtU4/twBh4tMb30hDGrhnBhIcLlMJsNvfMbij1PpX594eR5noNeYB6EZfOar2ziglo0V1j+u0ES76IZjldIF5NypnVNhz1fkmYmD8ySgn3P9Esbnd1KPat6QaSZs52RcEzMmpeOpjo9pX3r4Lz938xsjTfWM8wqOFUQK52qsXB1uNQ1igNpiv4/9MFSKmHbxEuvFC8tGWEmitgMvAPVE49mU0bKHn6XLTpPI3jmjpMsIsYSvKiWW0PvbWveU92tqCuQVCZELMvoXl6CHBkK2iGjouDX3NvgX9nIHJvOsVVyw5Axd9G/lllHN59AmJwG66R4rxLT7oTLdrz6e0u7CWKTx+oMskwFzsZ9pWti8hlZ7rDeWIey4CXA+BO1rxjCccQYJ42N1noxFChLNpYy74feOooXB2lsEd0ECX5a30mMtGBdeIYKZ3vJ6ShVBQ6Vwvl8Q1HwQC9xPrM7JU+Y/QKcmbC49EEyfwHkDALeNkK7A02HBzG5jttZ7YilsB6FSlhscIxhfA/OFQt/OFbBO4x6wy99H1IsQvEBrbjt+opE49hbrPn4hfBknW8xYBCmdZUFgNdjiXXIVFBXBkZWrkNJjwyz8XJQ9bjANYNLj3du69JUNRR+ZqBbUPNcnMAMrG364FIU/Y8Rc6hSig1+IbW1ZwaDeelwBtq3rnU8CdTDs2DqeE2bG74tv19or5Sxz4v8AveMDNfgfmFPOB3637hkE0t4Nn2XAqNZKneXB94XEHxGyyu78Eoabhppu9XrzmD/NjYvaHfGh9SnrKAACxOSIbw5hAI4LGYmCvTEBH094G+xQerUcVOm+Bz/yeztqbquC4S/qHfPnrH/glfsp1sZbFVsGsRGAE6dWLrsuDRB6FAB47JHwTsqa7CNWUaTb8/U2EULBJdOuNyltYFY85Kwe0zFOwB4Lgp5evEZelrO4GsmujUdwqtz9VlD1X4CApViaFLhlRnxxzSIY50OlVLjV57S+drkzdUCrVMXUVXNAl6hQv1h2FYDg6o+pvKVgKbM5vcAvbOZXc6S2/wBiGorm+8Jteqe2oEEuii/P4macQcg8Ss4wsA8qylvg69o6y3u2v9efMRgBYLAN4jU0a3MMAw6WJC4YObTNjFHxcXcRmB9P6Tmw7ysh4gqWQxOyYfMu6xEIs8Try1Gei6SXwlRU3aHrFcs2tj9SmPyQ5d7nOhSFu8C7eyUpjkDCLP7mP0YwHJd4zwwMHoWK6G+vsuotil26FhF3xW6+ZoClitTf3xFCpkMQrdWJlucneKq0zOuzTsEPqey78wvE1hbql+MEYVNDibyfUMfDDVdZQwu094IMYuavSr09ZQVGyrLrr2AgVTRytwt+TL6xYF2Nfj+UCpDd0sSIRUr2L2/CcCS+zHo7Q6lZ4G1lbzkuBhhbLJknrhEMNAc87+9ywnCoS+H8RzBUGvqJm4WzYUXw1MHbS0ZmDD2OCU6o6gazR3lrUgh8jISDVBOs/sY/u0q2gFWCv4gLFaUvqhgA82La4tqTUIqE+FrAPZ5IcJkfUNoeAnuX/wBmMl5s36Sx6FEpva6veO45SDb0MXM6MU2KMWtAvhzcdQvXlEMX6P7gGCO1bW8eZqQK3PfmEcF0qiFTU1axa8jtDATOFFZV1yi8escQm1AuiwC508S9AyP/AKSxiukPjNnfsz/MxXHqjrvqdfWXoBOkbdd4g+nIjvc40NPXcTchUOLzfmJvy7XW9L1ONpwtReXQZeSTNVhlMoYesWIR1ENK+UW1jzT5qWaoMN17xcAepl5e2ZjoeYasfxUN2lOIGcQEp4gdYODB5CeJjA5ldoJ6JXBu3zzLd8ifX4lsIXW8krE5FoEF41DXUEsspKCoS6evSCKgHD1WX3EFh1t6ItPzj6Nau4FaY/cyDFMzbJR56zkKXWfcSmzofMMnQobNV45lIQyj0InkmG/5a8kwXlzEYC0xESxwcTRsdGIeA0pdDpUMhO8DitafMp2VeHq9JQ29A01Bt2T0H/jrKUGDekAe0/7nQWCuP6PEDBzuv8pa2RzMeGkQdgro1D1zoFq6r9oKVMnE72g+sMhRFlcDTVWPWClwaBLLkBq2PEMuldPz7TjyQ9B+E9oDa5lWEGDmxr4i1AMXDyU8lR9/k59nxKcTgH1tfEK0TGWriDDX+wlpTqIfBj4gJkEze0X17bgsH20vBaPcElcRYSWDI2F673CedGgFTP1PdYdBgLi9z0leldhR+YFXodYEKFZbgZYdIRvF3lqy7lj1esP5+97xo+8MtjEwC9tautYHcUZeemVxyL6gRJoYT+CbB8Y5f1RQhipVVm1ie8GXsbNml9Hl3iNd208imM6vUT2So26lLzsZbXsy3OIMWqXATDZLWtR6FPrwAFAwHdeusy7JWWc8R/uY1dqVMV2xBU6BDEP+HeVK/wCX3iZSG2HzYBbFTq6XD1ZcaHpHm/Nw+YPtU10jbibEPLUMlPXSH5sQbaIZ/wDAxR5nv2l7sjwq9aAVVntKkskqtTKpgWdIrqlRx8cAsIjASG3pyh89/wCgRUp+V+yYyl/qqaU9KiyqrdY0SL/v3ZAPLHZ8Mfyh2LvX8CJKR5JGPm0awYO3ePNg+nrALL/DcnSj5/8AOXXowQQwn2fWX8BwpbQF6TDKK/yS8todSFYRz0g0HB5Mb83GuQ2e33CGyy3mVq850jcD2n/hxuBeKCibQD1C9kV3ftMv1huhoPRW2S3atr2L9B6mp17ji3k48LcGdca2Xt7Z9KljJqRmzmg/Y9MQ3yZd2uBz75jiAQCm2+8W4kfYvjiWFJG1dfEtfShwTFohxnyxlFHruoThMcIAsbQ6xHxg/uHzluRUGgNRcb6ZmbK6EN67H9xGAOBzTWV/USXdfKaMljxREUte4y3/AJHr1wb6HzUDKiuDxDQd/wDoCoEoMy5l4ka1czKxiVA1MNDT7xBhoW12U2MHMcLsPRJd0TW12RHvrZlW6OwpTuTTbcfQgOa+2Nq5qKvchpdA+YhuwIfYHvA6G3v/AIiYSM/guF2Ct+4Ioa9YIrYlWtT6yUWyZMwvzLYLRKR9JxSox3zCjg7p7LxMjBUtvzMl5VcvEVxIc1B4C9mcwD4h1QJxMfmGxuKekH6Q3Qwfq+JePlEC6pzAHWi3PU3uGDhLxTwT8hAzfBpA1muPivM7QpIPFLl6MH6ccmnvKjd6iLWA5rgeaiIYhughxst4rOYC2xlc5Q9G/eB6qvGk7eO0SBkuyzuSZebd3pDL1dcMR1Y2kJVal4KcdnsZuJbWKueU7i+Jd89IA5gdq1YNj0qHIMw2E9dk2DM8vzFhnKsifBBVJm4vg69cJsQ7Q4bH/guFgWoU3HoZc+q2SvtOaBNovNho/wAlT1foBleV+kDXsii6knsy1xyTWpJWR0f6iTvOxQw2av7laK7gVQfyucITJgIHmFOP+ekJUNSpTctzGNs9ZWBz2lb1Eg55di5jZVnuiJsv4jEtc3eWX2m+IRzkB01+SNAr1/mIXQB1hAJRy9CaPWB7f82Mm9CddoGTOwzzHaMpLxcF224mIYCrI4rQ38f8bbsFPibleCI9JxN4QLUojGWFZlSpZuZiFaxz6Barp957I9YmrhY/yqXdjX6WOuCWt4cXBDLt/USVzslIQ9Nus3z5weyA1g42tyidcu6tQhHgy0bi/JZPRKvrhwa3CYwUgOzQjdVVrTlD7uGuzaTp5/q6wMMyqL8oF7eZviW42qu056oeF4V992Fdx8GGngqvhMymcoAbs0qDsvhV4vVMadnEKuoCT2+9FMxs6D1V+K6nFJZ0z58QGMFEvEwvrO5oJSZ7VxMTELea5feYhgbYpeJqLIcDgg7GRvjlAl49nU/cAPGHilxWukQ3UE78qNEyuZRA9oKhaCm8OydfxKLhNNcs6PxA3WJQsTxHO0nSItDhjO2VotnhOJiq8LIRSGzMIcA9Bi/mY/k68hefeb3PP+ZfXOEnwYxYGAZ7ERLm7RZsg10+m4sgV1HcJpi0o4Y6xDsTLsP5ICuG4K6pKoORbT/hUc6HeId2P6e3M3PmGE+IQWGXqcnhOSFR2gf8r/iHSDKKW4s39paOLyrXZMqEjvADuJ1mcGQI6h3ZMvsEMZllt4XFT+C4rwskwhT7G0ns668xLJI/5UIAqQWtD5igBapKgLW/CYIXJIOMb84/aQ21S18y3Ygx/qlOaZgg6HHmEbYKkJTnQ3llh1esNsGTvigtHBieo6TiCJrnov2hWE6ey9VhvuN8RKrbAVlxuuvE9n0lrKNRznM56Gz6YBy2dsebt5iMptdj6H+xOysdYqnoxDxtxm4UKkEVazzMSulRB1riLTqwpmFXdBAg4YZ4lUSq5qC9NznAc5lLviWtJrhiAotq5pkIg8kqAYG9YZlUuWsxMN3jzAmSnaHpwcWw5O33FTYE1p8D/ZlJ8r5H8SoHzECb3VxKXaU3dOs54tPXM2u3QeJwiN2p0EDdX3uKIAboHDHtII6Qt1L+yhSzudElIZEUaOddusO72votYWtNSz0svKcPubUhwwF2lNhmak/Eydv9A6SwMHvFlKSj1nNwgf8AAZJuRPtDIZr65KH1EaNqc0GYn7mPlAhmmg77VOertBQEMoq5KxUN3ujIc2BcxJjlpRe01LU+MVAdA1e2dwTJjQY/IsB4BcHuE+JuFJkY1BlITZTIVjFx1qUBe2yKnu+tAdKfDfmGsKIx9EDG4L53n9adHA0cznFo8NZmy+88iVurfeH+RBLeIudRLZV3txR0uP6Dt7u6fhW6zWL4onF67y1p3MlxjWYgbBRmze9o7bkAuhtq/BLjqw2yoAWdMzrAhWZnRdQViWRM5DkX8TLp6yj/AM3D1ILQPcuDgDVBCzd1Uq0x1z7Qyb81GreJhIOhVTgOI441FJmMNEy9JkpE/EefbMoMHceURdHF6cRPAiscOyy+YqtW3IeQfv0lwNpT6+BOR7Mx+GVuLPWN1tzswrKEqVFO3TKoyd83jrOAwteI41UaHCo0sZGhC8YAqImcLX5V1XacCtuGnc8EEDOlpf8AMaESdSZfPHeJZ8p5Hl16wIQ6BtKUxAHRvXmPpCZSqJayEp6Sp7IB6g+Vx1rRqDRNnmOZoNH/AAjUuMFR0kKrfG7eVabGng5IldaBdhFmeL5Swv4udvumDc2J13Fta6RkvsB6krwuVl6e8sqBfoPAbL0XDkibNLQV6X6xKKDRSWzGE9PSHIKMU78/iDQ+FCKop6Eu4mAVpQ0uLgDM1Z2c77R3dXAlqrb1mnWYdmV8vSpkIpYKXxj+zLbW1Tt5Ob32mKGrq9P8zPDx1Dp7fiYZLaMEhEw1qdluJTtMNww1LuDmdkBeIEAvMDw3E6bnZnjiawJDb0mWBls0uscVUEwKfmHl2JWHE2fhqLaK7x4ZDTtO3Ly95mP/ADHAi8VlVvEY55+ML/hVA1HdLxFUQ0uMPrFDGzM7hBufVzKJHOKodrBaUm/IPzKSgNcCMalyVuFCJGAsOZqIXFPRTuMRHxsdjKANnuDhTUoDg6MudruWZrcvU7M6YRtHMyCKrJ9iAv7w0tUX/nHUBcIqZlpqhdLWxfks7zHBrSIrqxpx3S2Kr1mOfVSaSCPW0UvO9x0zAc2WklD2tonorGDL1AD08VvvM2g9GrZZzAbL8Ce9qYPsAfJguCiAAvDwoK3KxQoLowWn9lTfYwBaUK4eyay7NyZWXmXsx/MmApf+JHzDmUHrEhZY/jntNDLYTllJ7SDj0J4Yjm0HMNZeYE9yZTQDjvCzlgaVdyjUq2IYKZjjEcacxVm9RzWJeYUC4LA0ZTAg5PMMYgvLfeb1vdDGpYd0FIsl6IplvvOr6EDICeYDNQ61DmYcqcWek0SK9CLWGNpqMHxc9COxB2GpQbHHZD29hmVdMPkojHbiZidlmCwhRK8Zq8QsVvDo0XxNIjBqzVS5QoGN9JcIuH+xLfugyeGLXw2JCUZy4Syw8xYD1/U6B0TsnYP+kXX/AIoO6CpDpuIktiZ7iIBq273DBvljjooX0guDN7+0cb4iyY8XWm/SW4bj6mMVd473k9iZwzp9pRcm1K0kYWUp/bGoDIp1ECboC6i0mnDSIsXczSOeARbzbUcMW59pRrVSFf6fqE0be0HgHMu3TwgbmAvMGIL9IPiDXKBWYs2AneZMEVIKvziC2p9Ims1Mb5mwMStMEpo+sz/sBVX6ysg9xF5IOcx0EwFVMVDe2tx+AY9C6zVQpXlu5bIL8IIFBZMwmT2FonYGH4jK9kSL6LxN+IMVqz2VFycjmcgBTi+0yCsa7QND1id+scTSNWJjdTB0VXETC7xmg5u1MF8aS3BFvoWtvdxHItADM/DCvozTGNX836TNhDzWJsGIkTpKZSaeT1jm15afuOmsFEpgJGIRxnMWdXRban4RAGCqycZ7x3kf9alf8tPVAY+h3xcRD11AgOQ+Znjue8qAMo+pSu6sviacIq2TIo1h/dYDnqKY7JZFSpRiyUIUm/ICrazATEUs+rVTKSRuOneI9WEtzY1nOpblla6yiaGcz76yzS6+4XbAF9RLi2zSqG/iLBp/Q4PaOIKRZlY2YXJDa7NTxLmmZS3eYPMK4KmKxqJ6QVuFuZR3mGMSsdY6xcsLqAYhTWLxDd34JdZrE8HXaOVi14ji8u6aGUcVHOtwyMa6RViWwo7ukSrFOl7hrhgyQ7jGx7gDus/hhUoh4MaufErXVjtBVr2mWYEOBlkb8ygNxcVs1nvKCiKEdfLLR0TaDUVdQTe7szCuQOLXHLrnrCFkcINL6B0vmfhaK7qS20b+gYQLK75OH+6TyELSttAiDz7zQ3DJBq9JMQsaD+uB2mPwlEjNHHXLtD8p65HbR+I84DNf+/8AHh/wILPww2Per9p6vadmx+lHDq6PSrOMwS3WZuH0TXySkuH9Yla9cnP7l6+a8QN7lCkTG1hQ8CWMKM9XCtz4wS/zMIOv0bltUuxF2pvo/idekovbU2+m6XcxqNrueM1K4lrCORR1gT8sRQCgHWZrzSdYmzFguxDv6wAB6ylf4h6qgqF+Za8wpweuYYRNS6alcXjpDJiUdLmOWIAXqUVHjbLtMO8aeZlpMiSr/KXaa6DVwKzVjLcnPtKlVfeNbhQ5s6xBmpkhKy3xnERCwaF1LRf+PV0OuIqVN5VvuwuS2AHaMiVlYu18RFLTW03K2DgCZ8y+ivSXOgumpuuFLO0qzBycnQiO8lls3YS3VzPih6E6g9P9ilMQ5oImLZTRS8fMuLFq+Vp9PwxWx4lWfDgibaK6ykgMl8oB/wCQgb8w5NGPjcRXByjHzqAK54b8q4+Ic3m7MenD195000ph8On/AJytcPLADpL8GekUBpEBHvBqnubMS0HTKVBvAmVk5OlOonoflmh7ZK1W/wA7R4Svdgx+Rt/MOGTgG7fomZVNAfiafqm36gkyyCtskfsh5orSvZcwcesYwOHknXbT6eowErwy9z8yopg09Z6WnNUMM/MFhmdH3DEvRl1RDkZZpK7wMCN9ZV7ekFmfllL6b5lYphkCsp6EJkcbG2s419w1FTCExkyfME29ozhnrWIVyujU0mOsvQrEtdkI9cTaWNiWdoOQHpOLI58wQyX7mBCH3A3TWxsfAR6jbVmZgcI7olOFmfeB2JiIDj6QMS6a2fuPWdpy4PS4CuiAC+EVNholXEo0Q6JyZmHaPDxMmHi4joeh90fv3jDkzr5Kw/3Rm/WdSgT1WUJ5tfQlbxBeaqONOOfSZn3ASVTrJ7FGcaS2U8RooUN89UqLB7qwv6tx1HcF+OP8yJUz7uNOX3MsxPZ+07EozKdy/idqW7PaFz6KXPSZEH7FxgSWZttz+JiSquXka8pKL6Gk/aBK9Bel9BKFdZWB6NsOJWqbj8kYvXhj6xnBOMr8xNsLysLi520GAr0SwaqUAEh3h29YWTD6QfNQHZcBKoxEbt+5bdVXSHQj2RbcK21FS48YmsGIcZraUQz39czOuPiOcL6BFbRNbPaNFqVBcXxMjNOqJpatKlHEo1ewbzzEuAUc1dYDYzrtM1FjXDKye5MNjRnWYhyy94woFdO8oZcZjQ/HEEZS2IRwb/Vjn/LgcTrCGOZwHMLUdJdVjEBBabWI36aXnV7P5idjPSPCbNzLbqp+JmFADWkPxDSI2w+SI0l00BrHEX2e6tr4lXx/5JYb0awt9YOld4AH4iPmVWcxwmcZMdty2T1NbgMvdrDOKANwV+4Lb8eEMsRe5dQXu3uZ1N2/HmEN7j+B2lsydrc41gIreCi36f8AiVQXK/MfygWs4peSG+rHiNAgM9Bfe8S9aqrmB45iOuxPJT+IgULrzwV2KVfYcxPmdfeb7lSDYfvTh6+s1o1JNuqrKNPXE38ztUE7wO00Jnk8DRMdTXHSdSYhmukBlWXE4uATIzCgzUY81AgcnLUHd3DUBrAMAlc/cDveZmizmArr0gO21RYaycQDZMYywD0BGKwstS5XH8oOVo943XSWpNJYaquuY2GLzXWPbKtscwOq5oeUqfcK1C5uuvOGdKZbmSnH9zGtRWiMk4nvKbLcvWcD2qZFiHpv1mPWNy6uK2i1U6LR/G3MqHUfzj1hihbdvXqwxB1eFbhosrbxFakeeH/yUsBcN14U1ECw0u+wwqNic1S/tTEbeQcds7hog1m/xNyvMLPmVuvsTLTTQP8AT8xgARul/cb2sPD9RV9I+o6/ejOQJGQllYHfEGvVWDXOTT5GGheg29H2Y0xDz1waGLwurZQ79voMuNWlV660JhOW1LqemTwSkdsgU6zNQvcEphVx5m6+5Z1tkB/DGXnVX7aPZD0ajmET1PTUtKtmGzfMP+GwczZe8I64rXZC2uINPRnzCYArflB5qdQ2vvLbzBEmbn3gcNagA1Pcud6qYgDCPC1t3WIM4uAM6+Zrx0nlU9f7iN3C6vUsD1Y6w0QEtY94cxmjdwMPVcpOfKNRPhLmoJm/7tNZMruY5PUxALjw5M2Dfh1JczfJlmSJsWqgnAB/PSBWS1svSPgmB6S6k5mJ9nnpM/fqN8G4mr/EqzxMNheOek62fl37f4RTLNaF46TJbGjZKcyeQZlAFo2xXp0Y6pFQ47717zF1VUZFRTcX/OJcJquvh4lAvFG6LgP6tStlRghh1rbKwblk19JTW11qr7OnM27qnDzZK6jfEd70VFYN9QKdXr1SWsvv3zcAS3pLzFEs3imEbddZlAzEY6y2w+jDKVIa+ENvmoZHmzLkdze+Id1SAUWZXAYltTdIYK4ejyVDXWsppDTDvGzOBRxsrCL03XTcwD4SlDGHwdjuxGCz/LN0N7EDxfsVN8Jga4h2SOMx32m3/gK3/wAlMUrtN7gO8V2HQBLE3ARKZbjzMFQLLuFeMXMUZldekRlFO8oABPEMiiLxLH7SxZY4ICibesyy8sTO1nMR3q1/sBZToY0/udNqnrC9yAS7rDni0nIFxzHQoOXh6y2rDjYo9oVqp0Gc/plgsBszj+7zqCqes4rRr5mCajm/xMKkC85l5DR3ncWt0c4xAzzkBlI83FMUbzZZdZjuvNSZOmZSEGnBKlV0NxAAJxlMRWlZnSr7mAKKcqQVQoVeWbPBKDC0GiOIAoKXt7wxob46fMwqsaC8ykidbPtMs5fBr443ClQlmQXz/kp5eeAX8SyXdgGP98zOqqUydKv8yvIIDBodNv8AYmifKdrdOD9mIErtNMrd2/TmXgdSG7SiYBqOIfhrBRM4QziHXfP5YCCz7Mea+FMy+zTJqfaWZuI5VQQBVg0PZdu/7lPY0V09Luswe+YD35TGIM2Dfty+ktwUhyauscH3FWqa6nmhrPwkRXdK2J4rVsy8w7EUlurz8R5ajDQ48NAdp022PV/CL2ik9JQTd3HXqnpn27IVVFnrDLUP+WMGHaNmtJhxFRJFapqgI79GDAtC0UeErcXIumy64P3K6gbdSPuWsL6QIJR0lkoGHLDxkjTtJU2Y4j0B5ZUOfBEDnKqDmBMSj0xM5C77xKdH4gPLtecj4lPQuTcXQZxXf+IWey3ijDEavxgiYlXTROLT395xBViiq/OoAHqN8xZ1ScYlNbC76x2wccNQwKPQYmC/a1zcUbpS4w0/USF4tU3lev10mXdDtADqF47xQ0PQQm8Acb+YUKX1aIAWu2sUhkS6bJcUOb8y3gveQllZju8sfk/mHmil60T8RTWcWb3gHNT2X7wmEBQ4XrfYlMN1zs19eI5uovk4uH5pl33Opzf7nFYwZd8Z+5rxRV6jXtg7bltYGY6Hp4x2Zhtt+Fy0TiYX7RrVHRqqPScoWrZ4rJ7xMEqosi1p3x/kChLC255sAenmFvjVgTlOKv8AsRavlXl8/wDChKjtLTbgPC7jXvPAtl+HiZtnetR+FcQcKUDDh5Dn0gUqsDssHzp9GNKLKyUsvGfa4pjqWMqLdBx+6iLbmTt+LwPeoxesp0tD5EWF1rR/yyl0wED7S6HePIckCqrt12fqr37pSgTgFfsrp4ic1BqCVZPEHRMYOauBjGJbuEwsqJvzAt7Y3eT4l5egCpVHpaz1hSqoSCcMrhhtwNazcZgszMzDs6VPDPQncoomMCr5N5mB6mGZh3inpA9F6TNrhuACOunaZhsrxAacWTHMsvIum7YCSfHN1+J2G73gs4h28RUwGtDdTYovrsHTEDAxvA8xHi4L/jFuLzYMc9YqLuwKYYHUuL6KqXRkeIyrauBvfVjKIpd4plw2YaeT3gLUOartFhUu7DCNqQnrqUOcOKxFlFrkuhNW9B37wMaxMBBo11i/dj2iVo1Kre+O8Frl7WddI2IeacGdsL9Msh7CqVAvHYd3VkE4kaUlWaB4xoFBsHfFlHHRnV0SgHAQ45IOfbE3V8Dame0pwra5zNasxcUVyl0ACC4aHTMrSFAEMN4UzmLJaYdQ7mjyGclYYsvbOjqjHFLRRcroRNYE+g4GuIINCtZxdjFvF7jgrdx+zZS+LG5oAVHRpRbbyjkqK7U0UEbrjnmW56QXqJMWzSEEbC5ex92Z8olXFDl9GrleouQ4Vfwd4Y8ygZOq6b9CKq7VLzn+4Jfr2grWve3TOZUrSAcX/eviC8TvJyC9VWyMRCq4BwHvu6lwhC4BWqy3f4nE6fkfSveIGo91AfSmRXJF17RjShw3MsYd6Ifn3ln/AKQBIqahoxPLULM6glgYIdZbixR15lDLMoyAVpw/GpQKbQG4OBVIfJ6hLWePPSa1kLzU5EbFkqg3yhvtg8wVgzqmbLi7Vn0gjlarwZiPHfFGEjw2BoM/+QaFVVUzqAcgw+iWHk6G4EL2wst5vmWFsXVGWLknGD+ZuSjq5/cWV3V+11MjCWYbrfxAxppxzgyI/Guk6SPUdlAR/vSXLFA2Rtpx2mYZVnK3R6ePE1AQx7PWotGZkQ/MC2ko9Jhdl9zrLTEdbcv/AGaB1vi/EKtLDf8A7MJ1oNUZci3LDZde14Pi5S8dPnHXHeMXSlNhptjv3lNq7FJyMLrDmEWrjKJnqdjJXNc6Pur5Aotms2uqLozZ0IGA45ld1g5smuOMqLwrKeczYhQG6IyqyT3SiJkMrajSm3TKGMejb3QNmMPeaKqL5VOxWrxXWav+wjSpyaYowQVwaZ2bqrIDleIDMpiqyiu3T4m5yzsIXI0zxLiBnSDlAygq/SaqlkyFIBlmk7yrgCj+MO69Rg2Is+BXZlPvEteAMEyE0fy8PYLqPJVQxlK+D3MPfw+0AL9nz1jlrY9QGszWS/vhgyluywLnwmUY5HXCJJcYFBV9MH7fWZ14wemFCzVGLufaYZwzklTNwMMwB4KHvDMeJ2/4LhgHpLKLlg25qAqhao9Kv7hWKesHfhC+sRTG53eGId0MB1lCxd8yy+iOJXALmCjdo+PEZyxB0e+aqdqmVKuiUVa2guwsZrpA2otfk/8AJSRnlDgrPfiCu2WHR0nDeWftARW+8o8/V6F69ZYETb2DWtbuPVpWyG6/ty5aEUyfEb1JoOvJ+o8VShW4PY494pZFZa5VZi2BUnGOWrhr4Is60h1xBIsMSeFmajCl3iFmsvmdxvXF71LLCl/QwxZak5JdOekCWxsr8wCAUZR/u0z6o/UuLX+CD8wRVwz1zplgYD5Z8xAeLK5pIXTQcWLmsx2Hd03ZnlrzJTuZcyXbXNf2JajJKfLMMJLmDRW6gwxk05q449LUB4dzKalsmGtHfp1l0NkYHJjrVXM1sEacD4R7ss9Qa0es6AN8wKyJgrQ6Lcxrmscht45lZKt4T21E2qRqx/c//9oADAMAAAEAAgAAABBPFEbjlipcwMk2Ro79sHbEnQP2rs6czczjqE9992/8lS1/3dyj3XZei8kswp51XwYHbNBiM13eVgB8mBt79vtCrsQkRb/jUFjwf4VWXkM/zWZzQUpW6lNjyIoFyV9BHOEhczQi+0hiiI7k2nmyblE1NzIGpOvpVTOuOBJFphZO5m+NZksAKkjueLo65ZTIlHYjIjaI0FHajMeEeg97ko2cPokQAHzrGNvtYokLJB53iraIEm7l5+LnEf1wqwtihloHztMTaUu9+874lEZFwhr4K9X06pWgZSkc1DevMltuLMSDdtPTxXnSaAUm81mzeCizbFZ0TLQ4NIs/DYGRiFmqzzXqmnMzHuqNNKCU7pZslVEnHSGIZIyscNgMQxmZ3twSCjh8nTlrINyKqICS51hD8ktuoq2BFYRhGMs9HDx9o4WaXrFc9JNTH1CBitPgsYdeOTQ2hmoyMk6D6iW6OZWf836wc51sZ/seAjDZ0aH2XDa0iwKE1xNAKjaZCAvJmsubA/ImwSDFihunK2SMjj5bFnieGFt9aOmlqjbsKStthvBuFGKPgX7MycfK3K5Wm6tKEWlyILe6Pttv+4fD9ZqVEyPlwIC4TsHdBljQDuhvWALpuhvJnigwBpXKxFnIHkzR51zMqdlau/uDonjYilEnyIfSBF80iU+0bJhSLKOlEZnRZqkaLDeTotsrLSXSoOLEvPjIdjYxTHT0Z3Eb20NKGHAieF/k7BtyGsviq1RVTx+hkaSrNsA8dAVL3lqLtHSwJP8AuFQkhf3UGOurLU4CNMvP2AftBkbCJ7tpgL1737Jny/yumiZ8E1U0Z3KYNwdi+uxodIlmviUMw7jcPpWgpzNbxjlH6BVuEV/TZpjyMm59KT8Kfh7SBxXczRCUA8omPucC0Uz92n3R55G+CAWaPwHrJvwqWdzUGO9H1xIQHzcS+E5Hv6TUgfwozxmk8NfPTu/JVDQPJxvfF+CafR/Psa/IXOudha1fyk4qG9HXq1PrrwAznlEODpLeMW45NF56I4/BW8RaLHDeajkmKr7ZUnE/233R8Ja6CN2STJSxhSQF7hRRcWe8rh8YcTXrz7cssyMxQXKdTQGpevQOc2I7CrpECROBJ7Bh3V5AWWNFkbvbKQmZnV671HzW8B4qUT7Tih6i8WhLefs4of8A6+IMD8Ga5bGS1WEk6UEIAS9poWK65ITLTFofDGw9dkH2eeifsiXzfGAwBw1XdvB2/ZNqR8C5KNsNLbR8p0ZLsHhRmp6xce+WGZ4Bi4/0p6wNnb14JdFxO75O+XQZlfLmXhR6nafIfgIXydfx3WZRA5WKFhxDp0/iMKwAgpTB4xgM6LDp1DJQAYWv5FMHZ+UNoq8/vXX0S9uOzspi+Luc8j8ieyd/K7Ssi+p97UOewbMQ7pD/AF1hAS1kJ8r/AH4OSE0gF7XnP3LeWVzKw76ZxrdlI/6T+L0Bf/qnb9T+IxbhQ4YtooGn6KZI1rxsN9F9GS8gaxvH1fPjkqSoBwA0YnjtfTiTinASBg/YJcsBxj0yUkQxKx2wyboPEJiwEF/+9nCecfrjfy0d53Sts33jPeV8rWMW54uqOdPYZR6A+kDReNtOCCZaUK5xyB70ar9Mi8gqka6Sec9SBrpfAJkWrRzgfc/yd/kCD1TCCsp/OpBJeUxP0kSn+7pKX8C1ywU24F7qokCWo3BrcB9nndT5W7gpuro35tZjflbwWVzk2hA1lzoa9REapgn2Cc6fyi/UAU6NXRH2JOcDFFpYtBUgXh/RiYcdlFyraIn2pn2yTaSqsChtXvzO36jjcJyUp+a3p3pNJm2hphZVltdFUrbzXImqkfSTs8hs8w8EsPeV8cJs8hlDbMAABhKCkfM8J/Z+IRBLq6g2jeIWAvVfLaXFY6EfAlcSo+e47zbyXl9fKlKtrPz7C/0hWaAD3UcrTS3yudqidNnwn6fPAt2Cau/BVZHjnkgsOudSkdHSI26bGyWyqO7/ALqMOUu13nUhHLOnekOWBVMVAHl8UZFLnRVg/skllvxX3307L3vgn1NS1nc0+vG3cVgboptrFpmArUnE9lktl26fgYqdzcXOul2P/wD5vf5epw7yz70APfDgCROmq5JLZGPvnsLGtH9mN/ZQ35L7JI4HnFujVQyMndlc6iaX3JLZZdPt+nEj2N/vreAEZ/5tJIR9OitmOQiZ9IHiI9e/ZZZLbPvri3a+/wDe8GM/7YDbe7//AG/15oy3YKaeGfd4DeElusu333zYkUbewl3Lf7xDbsmI+v8AiXNO0me70aSHc3g/Ndd//t9vtSKKvabC2Vfvd1znrP8A6fpxVDxbeRP0V4WD7/8A2+//AN9zYTL++qatqX1nLRwTB/tpHtuaQNzWYhtRbjt/l9tvpZ6QDRpa4uhNFF3uvK683vXrjOs8Mo119j7rTf8Ab/7fQneyS2Jop9XPodJuCkjM4s3mO7WPmZaicPA1Ol3T/wDvp4IFBt0VS75gqG77BiAXV1vkVEpvCzk1r6Qpw9lnXrmssVNpFugqThrGQQ3zLlvTH9VH6vepZ0uupVaZHts0MJEskls9LiogantJ7f8A/tkkV7y2GPXRA/J6KQ5YVSLbZJbaRDbZpbimCfLZods2rOrR+zbREjXBxWOG59b0kwzLZLIbD9rqW2mCWmpUONcmOaJSQq3PspGj2xGr5pYMN3iAA/Ppc09cdiQA3dLZtowKnLGivBi0kLtmMcYR44zQsBvNNff5x+3GGAHaY1Nqf6T8a1ya4eA6j10RlfDS5XIF/wDfbfb7+SNAhMHYHDGychgbMlNHopSjsjN0pY9Fn+T5ffbbf/8A38dSRx5qU/7/ADAH+lQNwaol3n//xAApEQEAAgICAQIGAwEBAQAAAAABABEhMRBBUWFxIIGRobHwwdHhMPFA/9oACAECAQE/ECN9NBqqpv08/WEqr6b1efaCo6ncC4XqFnMXCOs8VNwTqOObhFXcHZgdwFxCkW5fBNQYS44XBzBojZiBhKYNwXhBjFs81udsHmNZMEagwCsQBlCDERBNXBqihM8kRtPDFDcaTcHCNYAriup5sXwTQDx+9Qb3kLpiDO/+1Q7I7giIemepHKbOvONQvEPcx8oXRKtqJiXBKIQAzi7RSVqsRm5LUe3wES4ifGHfBwOJcKNkSUwscQUacCUs94rUSLxLXj1IqszFYgmoFZghawS0anabiDa4iito4zAnBCOZUuJFShnmg4rEEC5Ywnawrb+H+xqv35wMlYtw5RKj+BfjuLCV5jwZ5F6veNRLIEd39kixkAA7z59c9RCvZt8nWOk1jceqz+0MA07d32w8zHZ2Zr5xmskU1qqlrmRmK2GBU7gDG40xEmEqBxuICyKcAQE1HY7imhAphh6yuKWIm+WvHlK75/fvC1bG4rP24S6Xt6wLFyhqGAkstyXcCrHMLq1EHyQYyjwQOswpaRVuKItol4TKn369HvKHn3f3RLXaXRTUItJKHI9f4g9zMGW7/wDJVxVu4yM1Eup6UQdRTuBeAcstUcLH0Z6EpOpcKe5ZF4dP2g11EVDbHhiXmURRbqMrGHQHvNc3ECGYIwhXUDeB1ElSoFSrimAQ6QSUJgSgl1qWSlKlCQa4UjcW8TEp8f5TDP8AksRalIbI4lYMfiO1r09P74lIBi6RDCXcVu4DwQgxdzEsUKMxHqnzkd87bjygAaCb3EgeYhjH9EpAfZ/sGlQaPE0CpWIivcUbPtNbolOiHdf1lkFoti3FUteI+CCtajhqIdkGKWpZqUgQFiLysfxKWWCgm0dkTgvqJKjczNsInVk/v01hfzmyolQZuZiFUg6meiEcI2XVEF0PAXBIBZTmEeoVAVogFb/H9wcdoLWFFG4q5YFXEMo9pVQqOxluMrT/AAxdR6EcYX6gMIBUzWS5c1IW9Rsriw7xtF4eZcaCVUzDhffxEWG43Moq7lmBlXc9aWhnojQb4uW6g+JALai61K+JR5K8oJqM0NajUzHcvEJQyq1MwIQvfIuVWpqN+U8M9mD2H78p1klWkv2mYqohiDiOLajO36S81HdJhHUy2DxTFJcqhmPggDeYxs7h4wq6OMsRLSsQGCxneX3H75hwJCG44u2ZfTUzlG3UHcl6Bdzu3oRt/gI4zFm42KO36RVxCnM34d8XFmIsnfA3weyEWI4SzipQyJahbcqEHJBNJtJUY41wfAaxCIrEeDPgkQyspwVsRi6r2meRH8BgtEFpILKRVrTf6gmojuPRC/ZKq2IqkQ0QB5gjUvNuYAwUyyg7mHcFX6H9f1NqdzDBM9yhslbMUQEA13BIZh9ZdmKrbxfAcOSbBMz5wVaIKKJs4ZdY47Qd8UvM3EdMDyheYFW3qID3Tdex5+0aNj3h+ILQ8T8B7waif17y81GBjcSNxdUgLNR9EUdSx1PFhCsPGZbh4wcAyzUfSPxVKIEqUSwplTdRBQRbGrywyxBruIaibSuaJQyhwNWESpnHHl/cSo489RRFoiIIgpHMYG392ypPz7f36cF3bLlQxDioMJpnTDHbww8FVfGu5RCPjMB7rDVFd5IfNhkG2Oj6v0iKmM1st1v2+coaK8W9eKoiaX77JmoX9nZ9P6mmvXccAz39eoLbgzTKaiJ7l42zKsoiWXSs8EohGhLXBvC0vG0vLS8tlOFYiUljzUpuZlp3LS8t4jAwL1KSU3bmFdkTqIONJvPy/r/ZVGmVNQG4gMXh2xqDodfCcGprjRKgJsmkFty+KIImJmhK6jKMLfl9L8Q4jxHB10ylTu19jz6/YYIH1f38Qlv9D/Ylk/28xFZuIT5QFXbRKPENXWXSKZEVTcoJhKcv4qSnwAFxLEky1LRZeeuF5WlJjxXLy8VBS0pI3C4jiaSpCQmoEQGZdw8phFqYeK0XPHctEv31AdrKJ7p7p757p7oB5lSojGK2IEvG4gNLjV7iRR5mPMwQpxLINti4IqL41LSjEwqc5j+LR/cyWrP9S9flT6rrHWYlgwU1DSbRx4P9j1VEqpiizaxMT1noQbxKMTwz3SqWijxPOFuFYBlkwykWlJRw8JERHgaRb1FEqVGjhfJcuD4lspISuTAMfGX4sr6i9S0pIzUq+LJcRcaGYmJR4GFJWVlSVgMAIyAl7eIKMts3YYgZa+sxZn+0wrhN+JYmvWE6G+FNQVuACoiA3Cd6jYrEllTxo0YhDalez4CdR4EigoVhFIdoiDcK4oiXEsSxEr44sNCLjK0sQGUs1Di5G/EbmHMQGpUovMsiWV8SvBhjGWkXdS5L8VUv3AqXBgVbyMuLquipZkgl5TsNx2t36xV9Mv785ZXzUIfBlngt5LgpaNvUVFRKXdflf6mQPeFMVYgjRlETudETMUmpeZi3QUxBiYjzLncsS8v4lvE1yMsci8vxOkpKyzcpxbiR1HhRMYRkxF3A4g04PJySrNpjCkDCR6MupZAJRKSkrKysylZVEVHCiKicp6g+Y7I01MILoS4U1K1bS1GYGF1QNq69D3dB5+sAFCPt/kB5lHGbYQVl8RUPBEiJ4l9xYpjzcGC6mKJTZMFGdxB9MYtNyxgEElnXJ1IAAFG/xBpGFqr9/wCod1OUI90Q740Z6cr6iXUfFLEzLGYKlsUeo5mkMTERFIM9HC09cQy/Up6leoDMIdCKrUES8HCcNzYuVYCJhPniYEXqhoyp8JSX0ghXEWilslDklgFwTuEwTG3qiuv7izci1ukBANRDR+4JtFWCC2pf2QJmHnK6yiDhOMIZhbcWbIpHwZTF7QdQzCG5Slu1+z/aK6lUuB24HuD2TVqqVUoueFvnuIBbKbZ003TBMCZaRp60PUlexgLKNMMeKoTBKHgq9RNRL1HwSvZPTibA2waUZYyBEI8ADKO4KxqfMQLjk2DcF0XUzbgNGN0xKfP5g92GYlu0Vqdr+ZhcW5isYhZq5gBz+9QSvUEWpnErXNVmPEHqDliwijGJZtOtmM4Bnie33qVYqX8RZKeI+KWKiXQxb1HxRTqZkD3pRuW2VEWYZgamIiZQawwwiReo7iGJUSKlVCMrjBuUlUpPZEcEHRqdpIkhVxKdx8098SbYHBuCYi02TLolYzWG62IYDSNbqDWpfhxQqlxXVRblY4A6lszUQtQFG7RBtwC3x7RlGLhNwnqe6AMHrSr2ykNJBAOrg54uXe5mqbmKqHlFv4FXbhDslmoUNQk44wVpxAKBKhjaLqXGK98SOidCBZR3GrLChUpC87EyeBAMR8ItK7eNuqObuGFhGKVEXZf5jYhhslkJe4TvYg3uIisCblepRLZkkXDDQEImZdyrDUVqDiXARuLumMkoWQjsqLSzD543cYbRC0p0x1EQyGKg7s32fxMn4N06jswC0wwslCDS4HmJRiUuZaFIbHt/MLQA3BeaRLuvaF886WZtQXZUPKAPdwkBA1AT2SgjMK7gjbHFksnctF8zPqH0WagH3m3hVbYzqleIHaK3HiWHcGLqEr6iJfZlXKl8BuhLRqYs+GChLtCPhAxSokq8y0y8LgDaGspMU4ljLiHfECHplnSmeF7jwyIQWKVLgPH8s1S+XmLFQQQTqOUxBZjG7AuU7gAyy5iHUXE+otVQkY5VgVsoLxDUPpLdcDMHZjhISxuDGlHPWYMRV4tzYQWcpQE1MUzd7cFWxQTFljVdyrnGHNuWJeZcYgKgq+IVsrAwCKSgZgOoYlIo8Xasp7hb+P8ASZxbBmFbqIuFUu5gzFvggVBSHVi1GoQaRmrl6/x/sse4NcDowk8kYaeZje39woyyGJaK2ZRCCxPTEJlARWsgMdzBUxEMXHUbDqvzmWw+cCxJ9PqhnFpv3BhgtK9P6mSNwXCKaaDztQ/FwDBO0LNQVt2/aPpp37fedw/aIsAlKFuZXDMEW4wBFHhVcBbFpkqGrQ3GhhHcJQfJYpcxla5Y6gvEv4h6YCYYZYvqEMClbmAR7StEAb+ETLcvMahzGNV5juF8wE7gp3LYN9zMSlMdRMApL+p6MNHpa+hb9otkUg8DcKAfEQxPTPTgS2wZmBaIFai9WB98N+lh+zFu2qVlZWZQpTPyWmY93D5MOLzUfdTYKXbbLjiBKlcBHewZjzDZyZTbgIbuWcxMoLaiWv8A7L1pcthKTESpXFs8gleI83v/AMgoDz/DMWFAvHqYqLmWIagJi/iIM6PWLqYk1BDJEaihdZhaXLTMtFu7iEVigvV9aP4ZfmCdRwxfEMb5p3KZ7pcwiIQJKE2UyRkiYngKP35wiWjCFvEuXxuVUqVKlQUrFMx7WCyJxuVW4aCCgoZZIWFVWAGwn0qNsNQgxlSjisB0ztSCFrm1zDFtRvqOwRyVH3AqvtMF3KQzKuBKQfUgKxGmY3GqTxBlwdRromEXtKWIxtEYJIylEcQV8MGOZTJV3KhsOse8PeK1uWRFYjSuCGF3+oPX3w8OuepUqBGnFuAuECsCV4FhKuZnDwcMzeV1GTMW8eNXMTX78kxFl1LIkjLbmkFqLi4Dkh3YHRFDEA1FmoIqD0mBcMqmoBAhV6xpVdwLsYgamxUaOh84DAT5/rxKPLduvpWPkktTKy3eK/eoLzGwepgiBLtjXUR5l+sSpfbFH/JtmMGoKXcAY8n4f84IwdRM1gvcrbMXADcCh4rR7wJUJUNe4QRUqBbLQK3HMo5PSFRPWZd0vyErL2p9AT8s04YQYiZlR1O3o25TGF3LbjGMAR8xPFAty0TBirKmivEupC1qgKu4XExcekp1Ea/MHs/EQifMFnZGLUHUC+2MNKY4IHswx4wMABt/WNVuIGjcEowYYqtURfkTUSYR+vEuRs9f6aC1mZX500960J8rlLBc0wx4i/Ir+yLuB+398CsNxXIfbhCsPfECmvs3Bc3LBTEQDZa12lLX0lxHn+5o/SLHsPzKqBmWMDMwPeZwFxK5NxDipTAhv3CbP0fwhCtXf2mnJiaR5qKVUZaxKWaRBbzrhsLOE8xGFgwcRpQOpSFxK5jmtEHZbJkHxMVdS9W2uhf9miUl+OH5zyP36xeD1++ZZnzAOeP5gJY+CMAK2sOYDH+8HFR+0TYHFMPjNIPY+iSjcY3V2us6/MT5b2qfQP8AYgyUGdVQderCCxoKt+5jvwRcD0XmCAOhAo968z38Ke+CBfg3r09ZSej+IxRw+sugt9YYzQ5jNOu43Hkd8DWAamxCv2lUFufv+3ECj0Ese8LvO89TEm/JiLUNkIH1fxAq9ImMHqSsXK7lEqoGsM1xuVUDm88BNz3ln2fyY1DG18Bg5qyKlrMrLGVebgx8YDhlo2/vUwl1LE2zslMWfT8Twk/qB0kpB7+ouvzNGMG9XXbLtSx+8V7Ve8WUyOo1mVv1/r5QGSWy1QXa0fmKtPR5ox+IITmn2jVt/r5lnGSUNgYld1amAaZ/ajZ3tlznz94pOSURUXb6UMdXIBdfN/yLqFdlS8gdnt/cJIA8C/m1b9YOZYZjJdEWLeO1n0h2EOaiIcNeI1hy2/1MOL9WKvKvUkHCz75+8T39uM9UyMuCnf73K7QcHcNwM1MxYcNzES9S+Erg1LlzJ9yoHSvkn8RZLDk5qGJ6o0kfGINxYqj5JmYm+DgaO0vUu+n8sS2iOkoDH47Yhdpp9qafrDl8hNGwcbbP4o9DC/OI+JgUGS/pbMImsGHui3+IzKpV/RGEHcQHZr3BlY9v79Yb9ZV5/MMqnn0RIDI0xY9a/m/vK+l1/EIqsVv599Qi6ayr6OP4jvqaPuj/ADLsxEEcwmsID73iWhLH8wlITmqhVKIeKRYBl7OlLqDr13BbIBVvuJaiZHWSJdsBdQ6MqoYpw2S+FrMpBpZyqxxipR1LxFBwj1yODhi4hiBEzAdS4Tul/C2Eerdfa4+Ch+48niG5ksVZjStzNJr7xG2W/MI0r5wVs2UpKSA7Lr6xxsVUZcdQF1Z5cnczWO5vP01vR9dxKzCbBHdvaGUtTRCvlE6NJelTH9wUHF7esv1/fMsTODfuS1BrPy3KzaVCGZN1ACIDy336AspL3QwF/MH3itqMa2zqZvhMRXHXfyjHRd67+nylKIHoymR3AuckBGdfT8SgCNjRojcxC7lxmNR0iSveWfT26+szJ1EK0RVBNsRrEEIFzMU8oHUzckDslkHqEKrMBuJm4DcaNMyxzAqYIc2xoxYPDxmYuDPUl3uA6+KFP1O5Xt3TNw9P4neZZiVZkqXXDohgsuNrTEO2Gn6wtflgMxDpj3Wqv5wBuKDB1BVPaZmcgenn5QJdhcFalfw7f3HC8ADjRa1VrBbi6tX0uKPZZ8ij8RtEAIziHOJevcjQqqDtKm8S6XXcJYq7tbx4J89fmYQBRuaxg3X5/uNVKbIC4GYzLODoa7MtlaY4jBjaIG8meYYE1H5RRgSVBl1BdwW5QiDFNENrZ5uj1wn3uEqHoLr73+ZhAxceALULwFjuU6jiCpcwbYmX4lyAZog97/iIyG+cHSGjZEcHc8MupTaHpMKypUcxqAKCvn6xkdwKjuE++LonjKhqJVF8yqXLy/b2u/8AZUinjzKVXDvZ6wDTpPlWP6lSS0fzDkev8S63cC5fyg6sVjPtaww6S0Fl1YzmIRK7wn21DrvPg17uDzRefnEX0YbErrPjOILML66qrsbh2r92brzBbyhLfUVz3MGYii9n79pXRcfqhKg2yf4iEFtsbwh7WOehTXpj3iF0ZmAJdwRh3CSlYCF2Bv1PjusfAcNDcpWCWYJSGJRazI3FdtJYqiQRdxp3BDEWLzOrhUMN/aY5RBibWxzGXUv1ApmdhxVqIUlMorU8Rgnt/cypdTCFwlEGhGaEeZnGqbbqt2Lb9+sTKNax36/7KEKu1/fxMkzQM6N+le/iXdNMY1Xl/qLcXIEAn3ntP77yiTL7SncB14hoVLZVD6dn+koINYGAfOKzMDq+gw9zXyzFRAZt/J7+dxNSK3g78+PsQ8UBo8bx7uEWaKJvH8whT39oWEPUCw8V/MWZ8EWpYQlwXwn7ajuoKJiruWsaNNndezeYQW53UVUC1xRPMVynfGOaaZ54fbktjepqKXCuuL68G/Sa8Jq3z6B/5K08d9MV+0QOoYbZYGImUMojpqYcpBziBW5SQ5zPDAqWxU2u2+jxky5ix/L8zTlHcBQPmeCCxJ6Eox6Sgv8AWyHuAmZbHOCVDcG5vwG1EQadwOd0Ln6fzAP2KPHcAKagBjLSqap97obhZPcQg+8uO/65gnavvNGWhGl3/krBKiFIc+Cu/p7wv5ZEbPa5VI9fv/HrFqks3AK0Noo5xr+uCU1CNmx2q+YDTMoYDYP4mAmGftLjMaKRyjEttxc+lT3yuDkgVsloJCHE2OIYnUI+UWSRHJFfcrxAxW2rKuWhWvq/NQMm2e1vylUZDgLz8tQc6ULocZ+0YKGQqkp8J9PTURayrhWprktwLhG2zLG5haGppcZ1rZGtQxh+Ck9EsYKeLivKVCoQTb2szDbBNpvwMNmP8L8kU55HsxoxENG/MKsYlg+txL1lvCn+IMzftU+cdRAWy0gM4p+2IZxzZVf4TK/ZwX97PxKC8zTxXziwuTfoX4g40jSe0NkZczIzMp3MqLiu3rMkjGN0mfeUXvGzsjAan+6hZHcVWAGr035PaJGaMSgY3UqqEIJmFJqUFDWYMnaO2gLiED3mW3wfzFqLA5/OKIaG8g/uJSJnoN/NlaqmjNZ85hjHrELCzW47gEDbEm310enq+2ootft/bU2Ct+R/i7+0aFj99SVVQL3HESlTB6Jm5cuCGxqbRyrFzNkxXOClrysQMWShgu3csBN2XcWY4FWh0tFK8YfE99ZWKeKpqvWDHkaYrLo+8Yw9u2pbF30iOy/SmW90vPnxGgDOmDWvyQIFnZ59JrxfDf5qP0LZ0ynVXmtBX/jGIyw8GPm5jcD4Fpfe9/fk7uWVIZbJahOubnylFURLe4wcBFvPiZA9Sb+5+JtijcLmCJUt4obad+0fcYMOm/3tiVPnKfqihplnUHyvmH5YVA4xTaPnGPvMVQdt/SpfUKoB59HxKywGcN/WGNBqVz5iDTqb22IWHpFzDCr14o7XOyKrKefzPHCPrGFAe5j7QLViuQwdVVzHuGoYly+dosZiXqWmJvkcQ4qYfvtFhNpLeo15i9AGj5YgUWYUiVzKVmCXcpXs18/37xJWbGxs66/NweAd5DHj39oLA0xrXncS+s7W/wBr6Reg06gqYHvHqThBFiYgu/MqSsdRLD9ZcLjX1iTVvzDSBgwrIgZLlQMl9QGiCRJiPOXwlhlKPf8AhiwfWG1QvmvcoHgsrnmCFVtTPv3X72SrlCNLv1ddRoFR9Yvv7JMQ/pn6w9+ZPsf39I2h0f76RtIG/eJ2SY9CbpB46Z2jDC0oNKveAUYkdy6/u4gXp/Hj+al5G5pRFO49EG9RhQxMgHCiUSozaLEYCXUW0+8GD5xrZ7QB9YpXrgNxrBhFTi9oQe9x64KoYzDoBZXBvkf2kwF9cfw+2I6uJq2rfktsPM2vY/BEeSILI8r+Cj8soqLYW0Z95SK78eJZjDCr5isK/fnEInmlZ1AHfdy7neZdsV8DMMJXCkFy6CC98KsUDwDNSx9R/EWXpmUBcZW112dl6/fENTNJszuRGIthCIQs5P8A2V/qWIYqUwp0KR+mfzNIL9B1Xr576i1UG8tVX1jGvr5X6wStgjPT6QWlhRMit3Kg2bIhadQqBjlwSGhbOwlZ1C7BPQhlbQAQOhmFkNxKvUsbjjUowWEFc20RSU8Wy2fKDL8v5goSrgTAyyXOlghjBFj2H81+WZ9E0H+0RRda85r6Yfr7+Iqsrfb+qiX095a+rML9A3+/aIyMtWf1cLF8svXzCkwjCHAMFLysWcxwiWV8ouTh1PWQxZMLWYLhWIqrjZEVnlMJ3mFDXBYqXuyXOYpfxDYeRiA8ohbIaBCiMGUYTxWIj+UDt848xSLYCnutgzIAq4tPkZ/iWb/vmj2pz9ai1g9W/wA/1UEnoeN7+f8AE3GL9R99ymGGHZ5z6+v4lfBAj3jqtmZ1YJTn9v5wG9wB5rKaRLzGyagOSVRAwcNoNaUHX9xRPScaM43BGpZGMVwL42iUHIEsbNl6Kp9axHHN8JaupeoQqOXEKbCAZkUH27l4hZ6XX5glEWbKf0mBCeu4ggfsHp2rM68e4f1A2J4bT9+vyjWKPYqA7i83G1FMTG45tA6VlfGuuoquj6EeqTnciotmUYgSogZlJhgIRVmVnhQmgeOH9F/MNRjXjEI0lffb52WxPIhOO5bSUMQs94U2Pn5gP3YhoRjJdeoa8nc7o+0+YJO3sq/aOjEOvX9xEzUK2Oj38xK0u/Hyh6TS24mAS2MFsZlwOvTUInnz8+JBVSrco6RjqJpinbMEp6lLsmsRvKIacFXA06hVxDOP3qvhEs0O/wDP6mnFSgzM84/ej9+c/uzfvoilb5UsuVAPAfmr+88++AV91sBiIorpD7GJ1M8kzV8yIsJ9z+47m42kybuJkgwjYYiBRqKfLE7sQQ+CMsuioIkhm5QrTqZrZUKhxkdmVUNh9H8kEwtWA396frUpJvAfYB+alFrpBiLUGdqgiDRn/O/e41O8PKPzogcNJr6RKbjfz/bjZklNRry0Hl6r1YDaLumw8RsgrA8Zq/d/EsEHJAsXFzEPWKmyOAbjZaxs3XE2iYrCM0u0u5Cp00Wohlu5dkneg2cWXC8wBzwWbRHWYmrjUqNJcuUgesz3dd9ff8xQo9XZ8qlPQPAZ+WZlfbyU+3iGgDyD7ht9IRXnn/38zJh9Y2VKUaiao/f/ACFEQux7MosL7wu2JdUH5vvBSErurmCpIlj5Bf8AkoBXSJFuIq7m4Qa1LillEBMAqXHDFwxiA29fzLGMZ7/ghitt/KPECO4w3g/P6SoTPfzgBRih1nP9xf1X+RJXAfknklwQ4Ylwj3D8sz3qAjeKycuQMfKJkwKXMYFypZKMD9xMJbViS+pbuK3dQY3cKaimDqhmTDNgRDtCQmioOkHEskwWJTGuQIvcLSerGbTSBQhAYmnqXsdP74gFZfmKH8EHU+2AV9ub5YttsWiVLDTMmp2o/wA0sAgdsrU6m0DSyyXCEqByL4HfF4WGZmLPeEI0O67mBl1HiMtYRjG169P8mWGtpkWtP3+pWr8oyRjKG3B15/o8sKVbwGANVX589y2rFz11KrYCCWn1g5uXibQQlwVP31lWfviZLY91MnfAQ3GmBqKMRIDEyhqiZZjDdfFUwRVamOwl4jduW4ZYcTAF03XmClCAFUiNG5ZkgmAWYFisRdBUZYlbojRIKSyYdx8pVsUASmLg3kh8OlwjgDuMYw5ivi4asIPMvMSp4FmDeMRT6Qt8j6N0iQyMsz9ZaR1LTzm8MtS5cGIrJZyELtuYgcKjhO4UTwSkAtROa/cRzqYghuXLuUcCGlcScLTfGMW7TCjiynxLhILKIoW+SWM2bJlzAKII0Q4Bq7li0TW7ncKXPpmrq39YANPnR7wTSn0Ypls8woLMt8DJSVCzcoVxbSJD3grHAXwcVhSBbR7iXMISomYcXLEOIwWjEW4FhUPM+7J9Sr/OmJ5KU2hjGfx5IcES6DD+P5logPW78+PXz7TrFZGnx7efDHdB6QZuMupfjjwi5zqTUMbEOEDMQvBA4o/age/3BEdn7gjaofuYSoYMyhB4cgMoG7Yvq9QhwRKgqaRYmCK3fIWZoEValRWJGJXzHGyWGBkTQJamoYYNZzV/PxK8AOj/ACUMya8fv1hyTTuLSBVCuzE3uNly0tFWuNFR1T1hTgPgwyjmuHDU1iWcGMckUoajl994IbAsrx/MsqH5iq1f7/EaN9HXieUstvgZ4Rb4zlXLlqYgQ67gJFxUx5ikokUJZLqWT2lwgNLmU436wQWjkLaHz4iATDMppNpnEMo5H7y0Ai1mDFETxAzTIXVGmu5Z4iBplcSo3lwEJVsMAxE4URLt1EgRiEaGU+5MFEUzF4hqKxBsGHAf8GYtzApnvLFG7l3r4VjklS5c64q5Wo64JcYruncBwhbcWnoJ7ZQLZ2zwxQondx+tKu4xYCMsxEJS0YwwxwBl+FCgNzC7WUoc/iMkNxU6wWkUqCdeK8RiG6xFyQYaNzFRqIGcEFCzwo2QFxYohiXggW5im0z0Vp6Q/wCTFOp4S5RzcK6+IQ3UThjnEs4r5C+aBTfDRu5czFeZeJuOeM22XL4WXLlBHUMGCah5TQxDZEiVw1HcQlxFSj5zq7R1SOoQ0uJQCRY3FrAUtja/N6mGSAdU+cCwwcMptmCsL9YdSU92EW2o6Yrwg98dzXD/AJ1H4Llzcrh1No8PPqqW3mPiIbQag3wdXFwWVGnGnG4wv4KIttwmbMRwEwlGnDEF5xqj9Z68Kp3MmORDCBdQGwyy6zqkvAH1iPcG1f0YddrlLX5/+x0QfN/qFNp9P9l6wEhtREfNqjUOFq+odQQiIkbj6y8SwHiXqlCoQ/41Ej8YxWys5qpuH4rg+fHaEdQOf1e8TgQRYr1QuryfPOn7SxZkjTMGWMsebgReZdlzaeHiXGEua4SQUUlmZW7ujG5cBfWU0S5g3tiAo7iFoi8D9Id0SwGKo0K36wKBMuuz5S+xACMH+idj9YGjvZBV4dutykbi3XrE1TAUgVKxx65m2ZDxxcH/AJVEckr4GaNQh0Iy9JbqFhzKrlgYLQ5w7l1Ot6/mXGMIXOwhRzNnm4qK4Ss0iqknZHl4upiPcTatEUxjLghkVg6m8AA3UyWsHnAFrAOXUqB2JThuX4aKU/uGFjEtaZxUQG+q+UMj11KlI296Ny1ZnvOog3AtUuw3fKnXwV8V1KFjzfwV1bvqFgcRxUXENRs+AVwXUGXs8xUeHJXggVncyTM9oBwwISqxjFRFXcY5ggQUEVtfGKdxFUbIiojkqXqX5jthUCAhnzAKYXLX/JklZvfpATOTHylUHhgCl7lMrE0iG/WONEvuDcTEowkGBYZYK5qvhWmudSkW4Nf8LTXNEpOvhBGdZlngYOwzCiXqFpMVHC5l9xCZ4C9wHMKUI264VHBMY35v4KRIrxE0JmsRSCzBSmnpLKVi4Xq7SVjbMkVeZnm4kahbKOoCkESrzxxQtlnGBxHMoT4FSWhlFpi5uClkX/mvxPIvi4oZLY3gyQBO5XBywO5nTKOaBTL8yF1CuG8TJDgizLi/AtcJWrcS19YC5eCKFkWmYJELV5l534mgYu2LEVjFywLQnUTAjhFmIX3PdHAM3NZUECioc3XN3/2fg3ykwwb5Rud8BozFzib47iqO8QZUSPzytQyhBZyjbQgAGAKEVkIo38CqLfBZCLCTY9omJ3mDVQEQYRYxsVKRbgDXDCoqqOJoIOJQLZbMVsqKi6hs8H/cjxcv41xPJE6Qbzwix8Ilb5a64uB5hUv1mHcsYFzBuMrzwoQKhMVMcIFDiNCLPNXLNEa9QQVLxU6i8KkJ3LOGXznijHYhIbsbeYsFgmMbH/xr/wAKzG4naV8JqX8Ad/DVlyhhm1cl9xb4G5phrih3LMkU4UBH0cXyoSpE+4lt4Xrg+pRaCGridRjZxGtBZuce8T/BnuPzlG6/RjgVcynIy7/4XLl3xRPdBL8d5qNjczuXy8UwWPrHwiVx1UsCvhOnC9x3zTgoRQrOTOKMSw6uL1p68t7nqRfbHzS0bZTApgllTcSsZmU6bqBtQPZ95qJPBPIyxLMVJgBVCCgPhW5cuXLly/hQdyvjY4JeKnXwkbOLlyuTL+EUgQcLikU4Rmy2EtDzgZSCahiUldoLGA6RUyYF5h4+GVdJ45KVReKZk8v9OUZugchhKMJlMxcV5/8AnNYi0xb4qp68OpVwxEuJXN1j/kE4AwL74I+ZSeuNOfJlnU9TgXGLjpmT1SxYJqPQRrUQowsaRnmhmeqAGoJtm18KqWHJNT/49RjSXbcW5eK49edM1mJHE38G4Flwdzb4srKc5EGuDeNrHC+4VzwgiXiIVJPQgLAhiL2xSrqEErMSo7ohxc0gaJiCYooeUqWcvAR4S5QhBSuFqb/6rXBajSJcqbg1NyuLm8Q3NcDXC38DmHiJOowLgqUmYeUpMJa6iOILuB7gUK8TEKvMod8UAsMq4fSbxcrkJZo1KCD4jCJHMTAWFq9ytbxS4Xe6fzy8DHgIFuJXtvgi3xAwbl5jSDcvNcOM8BqLwl8krjU9Z6yo8pc1yz041PWG5qX3DhgLh1mAiUysxmzgziGOLqbgSuaCK8wtYFbj6wMgRL1AXwWUwzVbe/SACm9Oxg08Giiarw8G47kbIFEeaINSyMKReLxUKRbb4uCk3y/H68bly8zczLT353KOA8yhlTSFmYcXcyvipbVtRlGlh612+8RwhQqLlqJi5dSxLmGItxSkLUtByoxuDOZS4IzbBNIASF3WVLqWP5r5OJsUon4/DMHEeJZFDNl8m5bQWmGo/wDwBKhyQ+D1ldzMt3EEYwZ4sz8FZgfA24gdc0VcDiCDqoobX5Q7RbWYF1PeEcs1hlNEDPAtURxFKuFsRxLuPuYLicCWQxMNkPETF+R/mG4g1Fm8CiPDguOzBlxeMfENf8jhx8FQJUoCJUMyu5uVE8TF5jTjiwslc38FzXIviQyoFTCDRKJWKiVzVkTEGK4//8QAKREBAAICAQMCBwEBAQEAAAAAAQARITFBEFFhcYEgkaGxwdHw4fEwQP/aAAgBAQEBPxBzMdjY5r5mo4BX16EWyWRYLKlxtsMalyx6DtBHqs2kCtRNI8DDRnoPwbRJS7iuJecpixFMmIhVfnLHD0lZViOSTEKh95rMZaGWwNR0vmW7xLlMWbjw4bjmB8MqpNiyF4SrpmPEDvM5QC0kzEARVWoHOZq1N6QYti6QEqMVx0VU18AXKjBqcfAqTRMNBndgP8SmglB7NSlO4M1c55YFxZvUXMValU0j4HpNgWniCVj5jRgp8K+i5fwLUW4vSo2ZEokzKyi9kJWYgLEdNhdRSy3iAJS4JeD3EyMB0vlMl0o0lzKLqEa+SIxpFbCOWsQ12RIWxnjUwEE01CvU5SKLCF+JcaCJaFRBwxk40IQ3LcXLJhMp3/AR+JpFuEXpcuMhataLq3sRrzfF+Nwdcu7vEQBirPbcS/tP7mDtPn+qN+Ud3+phgI8WsYioJAFAly0i3iALIPW+l1FUMFl4ls0u4X0x9oCtuKZMTcMqTokLhmzo+YT37P3FdP79RUHBCE5KfeUYzydolpY2bjlDKKqXmIhZhMV7gFNY5BLYq4zeI9oDM9QnAPZKjtixLu54OWay8CYNRbbYwxGRA0H5iUWGXBQf9i1GjXQhlZWeaCRrpwQx7sp3FbyMH3LuZ5oNpi4lywYExTpPb/npCs7ZrzZ+JSutB+W3vGNnp4CqnEukHtN+f3vLcT2gkqqm4Ym8jAcM8Kim4d8LS7iCV4hoLWDMyxx0QLLjncooB0QdRBhqX5bgFHCC1hEXTD9n2Sye4YlWesHDiNqD3lpafvMmZ5JVy0IzBFxEqGtEt+DAIsNYhLKXKU4uaavEqnScksZJaxOk3voN7PkAP0jS5O3/AJxKdiKLroA4nqluWPelBoZsMcwYxHL7YttTsSBgVFVpT5hnB9Z/H8wE8J/yW2KoxzlhhZeF+h+5YHAp9f1UwXDUcWMuoRZA+WbhuMfgm8xH6gLqUYtRK3Auu4zB3A3KNyUwBythFipZqNJ3IjQTaJC7YwBbqZCY7/r9xVekIWyl3xMO5EVQNRUp3B4YAekmtHM/JKTMMbSAksG4kNXAFZQsam2IK3KNkyqMWtS7kd5mLcXtMy+gZJikwwRjgq4horpUqUMHmAMddb4qYwa8ZmASVCG0SMtMsz+FQgDn7RApZZUkBUKwRyQKhLi10XMId0JJpMM3Ye809vU/5DiH3lzaiLsqfOIeC3C+ElYTMWZ2O94oykNRilm5gciXpq2qmUI7fuUQ4OCVcUFEwIYWdszWYKLhjc7GCQlJKDD9D/vUk4i9YnFh8URu5mFU0upQ0yzNVzOOINjnoxi9COBlyy0IuKl9DpZFuJTs6DomhAd5BZojXhLdpS7SKgaA/meSXKcfXtGoCgjZU2xuntT3789/SPU6hKZcGNMIvLQUtBwUb7nggOlAKy9SHok+X7gulid2I7amINwGBivJ/txFcua5i8sRmtsUKqUFmJswluY5LlBRj0gVuyWHEyV0bte/7ghtWTPcKStOJLJUS947d4jNZesDtChR0UItxZuVMIvpI4tGjXoy06q+jqJEuErvg3YdNAvOD8/ZhtRAFvI5ryosFjgLZRg4wNT50X8oIkQRh4t7mJ2Aiu6I9MgpaqcKFR7hgcEotGDX3itZs5js47012df3eDe2ZY2we+C8wHDFxUV0KjDC5SQuFulfBctigxB3DdA7sbN3LEocEumbip1UaZcei4KQi5M5CFwbi9ZHaX557cw+gdpXtGjiEUz2S4n6ItGOlkQhHpcU3zGXGJ1enMMa6VanG5dh+lt81UAnLpIL2a9MtQFNS7v6erDOci1lVVfPC16wYsl+5oxh1nJsXXKY3GAZo7E72sluNPpqEKGuCj1qLAhwBcvgNvtA0sNKOJajmlATG9uGm6R0nKM609oK1dkA8Pv/AHzi9lMU8P8A2JN1/T/sv4leGHAliWIBzLQg5ovF5n0GsoIA9B1RWMuUtFcTD4SyKMU4l/EYoj5dBKJRMNtFQIW3BOzMXmef3LB2TeJpVK+T37QystjnrqDfR66TfFLnSX8BCLOINCjvk7hpdct6KjVgWLORvbyKZ8OLwzvsxnfnHjnz3zKy6KmlZEOy2HktxmnGyLR0VV4EqgPyztnQy2X0ABf9IZJU4WZMUXSIo2X3MMi6KuJJsC83gB4tcu3WqCp7Fzxdbf14EQzc8+fSYFKlTXj87gYmbs7tNe5f7gdGGn1Uz74mTEYolHTWioqXjBqgXQKblHMLqF7jqpnLTKYdFJlKxhvASk8UoynQ8MRwRDFuU4ihM5V7hCrLMCU8jKVoPF5+bBxzuEF2nplrslvaW9p6JhLg3MtS6WCAGNxQsNTPaW9oC4lKMLgjBG7tKqFqoZ08+My+KFcgrq7APLcpz2Ji2mPT8xZkmVs2UGTwa8ztt4onap00nO24wrrxMBiLzgAwN16sCFEeSDALicoi5w3QawXlvgO4FUhlur81UVAzoWWLM7RUAUwpoKgsYOkHZKfEti8SVETFiKFy70lkUSx0ApfUGWTuIMh3wLzE94FhwL1DPULS8plR7pRMQUzQJYRIY3AwgSE5jDDKlS62QSYldADGKSKy2Ky2Ky0IW6J7kJKsT6gGrdOjXzwFrAZYy9tdtOD2qMFkC74P3Dd5iiCI97NYymlNzHEXDV8eMemEhjRZKx4c88+YnHQCcNvNaa/UomKbL+z8/lHFIez/AJj5dBq26I5DUFTPvH4XMxVSqN/3vO/ZZhHCGiPnC8cxqAqAEoYlgMTBSMMtYKWIjNQuGIMhJCChJAaiIJKSyKSkZtOZRgpgVGmWKuDfS0o6BK0tCASuuiPgoK9BRlRiLiF+gpuAQ0wo9SP434uAtC25Oa7D03WflFjwAU573qnRCWVAt9mz7VX1gzF6W5X73rzZuPVDJWAUwXm10LgVaxFcgBYFqcsA3SYEbIKFCoBuyw3beN+spPKTkuNRQ2VGYwDp/wCQWsxYWRsySlBpTHUDqrgil84WUP5wVkPb9RZTUOcJ/Jl+xgnMa8MH4S7TEvMDvEIgwDKsQ/B1bl+lREYDHngyVheLJR3EEAFsAYNZFv0ypplG5R6F8RKMkpUplstGWiiIRLoIblU8s70yWwMQnAYg6lLYEVt9H73UGh5Cu6VXvVR8Cqxz359ZvbMUpHJlvJW8cR+taXJnF+0dgQC/O7dwAqjOYeTKrdObqn5BKeICW10H13weksyYeqJektKJlR38cwAOswlbgAtMoJUoxBcR3FcfEdmK0qAscTiIWaGpbiUJaWsyhDfE4C+cR4V5jU77R4YxJu9I799f1Dk+qHMp42Y8emE0IPpId0grUpLMTKQB1KqVNo56CIKCgiW6G7dwRAcw5kVi/MuRzTuY8TEm4niJlXBFeId0eCFkW4J2IdmPDKdxiXucW147RoAWV4vPEbF0Hz1FbH7YgZjuvMwV2bu8+nmWEV4YXLYhcAlBu55oBMn7eZQlv8QGjzKAY5RXEQiYqUvpD3FsWO8RpaeYoKgpjn1hRxA+YF0ncTLaIcRQ3HMqfFl7MshF6U2A6Sfsnv8AuA1rvBLPSJt05wWmKULMAcEHtuJMqfMyyiWF1FdCeAj2CaMW7+qJ4YPLJZESveV7z1QXeHlAsjKeYd2PchzJiCeeC6YD8WLl5QjWTUabynjF/niXfrbb/cQMt3WVd805iBy+y8/glExYOW2lzM94BANeW8rimjyy2vugLNIUD0IUhBo5iWhquY/NhTscf5FQ1accNcOoicHvf4/2NNzklZuUMutczBlpcwjGMdTvIFxZNPJAtrKgBWUnkgGFocTAYiPDAtpE2YA5gtsAFsTicRmHNWZbtK9pmWsyipkab6WLuJck4pVmIsVLE70DULTHRamdFxPZgkOl07YiyBLbaC0MGhZ2JVDswsW7Q1CPiKjiiGbzOyMV/RQhjcCnEU5VBRTEMN2GY/B48RJw/wCsoaq6/wCRcMaWlwS+DEUXgI/EwLDy+nf8S2Vr0lmrzX1lJDEVmcigafuliCzW46E3BmmC8RQU8P72lWv58p4QioqiFIMdKh4lqNwpEieIuBUZtlwjLyxzqN9qHPmIpG009BFYLmQVUaqkQ6gDAqAOoWlu0IHNMdwltmyIZ2XCSxTUV3ixEx+2b/8AyHezTy7xFMWwuKM09Yl0wThbNEKlVunklXEWg0JdzKioVyykEalnaBUAYHmVMe5ZiJ3tjsFPWHooPZHYQW7GUIvVibucKUUxYy8QLKIqDxLgSWOYAqpwNkNgMVicQKmzqkGEC4KwfEFqOGn7MBUamXmVFTDlAP1SyUiKlkyWS02NzeF+pMUHziC0r3gH5CI03BaEX7Es6ndRTBDv5YuKEbZJbSBNw4rRKgLF6EdoJk0fpC6IAFEZkvo0NZis30lEoMblMsWyBcToLvUqEAiq1KzN5mFoQ8zuEvtVvHEZDWYgZaqdQCqAObmNh/yCVwbEBzLxWosgmD4nN4gjknkI8gg8hjy/REv8Ri3dRXDl0VXQaQZisf7MR5hr7ho1LAmOGDDhRbzuWcyplgbj+9o6IsDdB/e0K8naHe2O+vzh3Qtw+kxdaMzONwKCXkLNFxNzAVMrxNBCjSpcx4ml7zEZnlxZi4TJEgqCPVwXAItSxRmnpPG6LhqKC9esSXJFOUPiFIUhVvodSoKbmsL2ZtbR3bFYG5hgmFsaC2I03K8GDRY/5A0p/e80jcWFNvaMJziGVgRXQw1yR4KnfD5wUSrO8w5htDpVykFEwgtemUaQeEVRIrtKCsRNd/Etahqp7zk72uc5favzEEpH1lYsL+KMaF3fn9zElULdsO2KuE4iC7ExLhdRT6x2m2EyFQf/AGmWbhuCAV0EuTBRwgWNShOodBYlxcS7CUguaw8kC0WMvYC1fEdDYpaasU2a7a9IrQhFIkvBuIKN8vtKjjE6AuRMntLVyOUZqYiCC4xOnjmAqYNc4b4H5/2WEoPrn1jWE5qu37g0YzdwDxGHEE5li4pMMRzALbM2WK1CqBhmSpVEJiOVscFRJhL4Y5BORHtkt4J2wiWEJz19P9iqRaKnohXKQnKKU/KIVZNCIYwdSxKOoPQ3ghsmKIdLhFhFIWI2VcwSOrQnHAXS3gA5t5wqxSE7QXzPANX2+0PtEuaFykA46I7xvZA9XORM0IhxL4TsQpo6a6BARaQtsi2uolDDZuIS+0U3WYKg4iEkdll2ViJRtUQh+aIeI0j2Sq3BtMu8SrMYWMR2kLbCgEO6USoswdCl0ff9TCK7ZnNUxZbiUzDxTO8QbiKFdBYxFp3jmVGDFvpcvplWYV66LyQ6uI7i4pS8VaDcLSRWbsN3hG/SgDQKKg9XwmkIMFiVgBqVG6VYjU0BNcJzF1SLqYFxuCqyBVTlG+8Ys1GikWbNzS+IJQ/P4iJx1EEYiiYxy9pTi8xbpNVFiNyrlJRKBg6cMRCxEGAmoGVJbU5TUqEqvXCky4QZgNJzOZl+ILFkKaQtZlDFdMw1HKh6nEwGMuMXFqFovRfRcUQhRLXmKekHq6i5RYoK5gXZBfTw4hCkJqgX0ZaGcssaRFeKjkkJS4oZlhU2qqIyoTRvoodoBl+4Y4Jk/twKslrqLi+6CqZoy3yGPnLVLg9t3CA394lTb39/zA1/qJYaIf3n6Q7aaiYF1TmEDThO4l90AhyQVuOEIAQViVLiyJf6iYldKoLiHhCTUddKJljUHE5vbLmkaS4r9CKhl9V6Fstl9LiAtlMOU+0BY9pudDpvLGXDDM7JplGJZHz0KMdC8KGJUg7YvmccqLGYNc+0vUP75yzQfSKb6ILG4rhK22C4IozA3BwFJBqrcy/WBQylMLJaZ77bgnNMp1+Zkktrjf7hJrbHdcHf66mzFqttny4h5AO+SZH3+d4fSy8f6xlVw7Xriu8xF15IbYe0bEuxH70kDMj6/qc1o0g2zGwa2PVjhqLUKhYLYG9b4zjUT1nYG3z+IwAiyPWVSCg8/uaHS4suLOaMYNy4sZcuXLlxV6D9mWC9IBl46gdN47nEdRUUZYlwNO5NEh8ABo9BfCSmc3zX8QgdJmMaNl5gao+aKN60BbGJME8wlpzQ6FTyn/JmIXv4+sqmQ9oIs/nylhWhjA6f+S477wouiWjAm1k8wOSJ6Z+cEuq81s/yMuokKbZbmAF3L7CVilTGYLjDx+5dMvMCBtfvAoo2cOdu4TfTj+YIS0Kg3KZPUi0AFNYE9LguEWnAmnxhZQDvf29IMM3xAML0cxHrSYjJyYi33leJfWNCpcYuMuR0PQNdFxYg94Nxc10uZL+4gLHH7RW3xMIM9Gcmb6LERWYxVQWOlh2dHr56Gqlj4iSUxj1/yYhLJMqhxACpnB/d5RmIq2MSjW/vF3fN1z6hzLosP9ucbm38Q4DbuU9s+HUss6jZWCEd4jAt1EVBiBaD+CxIGy4gVxcqAccQeOPtHZavxAkb19WaYLf9+YltwRSTDRwfX9RXTT+8P0iMnEFkRBQmQFmrneiRLPvmho0f3Mdtx2hwr5kBsT+9oFr7v9qIV4c3s94eOo/flxHMahhYARYiscJyhFwDFiE6X0uMIA+iVwWdz5X7Sib68PpLnhqF+eYNUrKbvXRuo7dbZhqFsRVeFHELZaiBK3KPMvpb08iBfofxDCRMzsghsIPaGPmS5VC+ZoUwIcV/P1lxuv1MryuOqgTta9TXicnMOycYV4PzKCZn0lk8xi5rMzAxmjunmUVI6MAwr7pfLiU71/vlHQY3T/kuW24gi7I49qmLmNczODcpyvMQoM/iMphht8rhrENkVo4AR1CtfMAMy3fEoSooOOJTu6FbKe27OPeWlqNHauc538ouy1zZx3IlzJY2FnAW5fVIc5vZPvFhlpuZtwQYsEoDQR1CLLJubemZqwWk47+/p6QG5f7X5gd4YafJn5SttxgvJXFxs18cf3mcCoahvG9xU+jvos2hIhkmW4rLjeyecqVE6DaIRzp2/OK+cwMy1KTS5rcWtYhUJROZuW40iDpZZwNuZimHP0HaGqruoA3rfcfky0ROLjzn+8RODAtpOVLDlTuc+8vYq8+qFXiYS1Y6qxAuXCFzdu+Y9KrdAcerqY0Bl/6XBVox4odWAD0/2ZWiHsYaagSrqJRMxrI+7FZyQM3M2AriXWqowDzAkWDfncHXpF5jtfUXPyjLsd+n95hEMPf8fmJhETez7wS25lz2/T/kGSCPp/2BeAPeH1utl9NE2A3vtK/Kg9HCzWOGL9of1FDFKFcY/wCzDABZR7ljjjXMZk2+fOpZSYN9iGWVC0epjMTP3kuVLrWPpDixy+cQBQ8RzthgvcMrpwFHrncBrJr3/ELRa6MYGDpniLODUHkh8AkHZXE1WboIjtg0QV+CXJMkGBG8JatOxq58+kVR2P0BPoQpIEy1dnJ4vvEVTuUPIu4qKmW1YT5Z9jMSCZCKw6hdF5RqC8ceZQVVZgBaMtZZuTA9EW0N9pb4t86zxLCpbR+R4PxGubGzzPZ0bZluGLd9mxcvpf2hwBCio6YiIBZiCCoSt4lLTBTW69e35JmbEwbkvy/cOBKlRCJUeVO2vEpU1YqA7+kDpBsWYHmHvj++02k+cID6o0wx25jjMzr+uaDJV++YK+pb9o3utuB/NRrBX9vtCW8veNQFJ+YwzR8zzKdlf9uDA+WERMDiOdznvNIxQym6I2g2XNsINN9CzcC5UxRLoraxwavAZutRwKMGIWswVkwQ7Q3i4Vj+xBWOt13YpFZTL8hOOz3qCJsJfuStvsv0ZSvzMKGj/ePSVwWzXJzUo1dS7x94eijk1i95jd0lWGNHcz6mIiaAeb9sZ9oXhHWHL/Zt4j1h32/36/KWpM9l/P8AMqYDd4rvRFoTGMEdx9o73ytwq+r++ss4csShDiA/CDthoxEyli0gLZSbovkgnTCZmc2MW5w68PVa6EWHYmFy3VHfu+DmM1qg+fTtEiuSGAA3RfziFwhwVV+mdsvaavhy/LFSiG/RHedne/8Anyg/T3M8QcA39ZhX9DP6mJvNf3f8Rvt/MMANv9zBgOFj9GzoxdgnTRxab8VefDKo8n4iHSumLVECGIeIvPSIuUr3jwhVOY5vn9TDBi43E6LSrl2O8WQjW+9lQuuS8WABl3MBn9U1qvcTM3y1jjF+iQqumRXvdY+UTySUwcKLPGXyZ+kGq76B/X5WVEWRRb613/cNmN9bfmBKmChvP4cVqHzhsQv6RoIqsimUtxfGohdgLjXz5lE1uOILlRDpD2/UamHDPtE8of7EfhmBnmTFXe/xKqO8qNEsFLb384KyQc9AJXlMEZJznuTMvyR28SWv7QcydikFtgRDENtVDgO2r4P36SjPXdbwhhzvKQje/QPTj5WzBAHaWouVJQuu/wAoeFqF0ee87xeluxvN+b195lNcyvMG4GHnPyqoVOj54jUMHMump2Hpy/qAJD9cwdBXpMSMBCmpYmGY6t7fmAWK/cCBtBwaeZiSWOIgBpSUrFo07Xm7mON6PQiZ6jhTZLNx6GJ6bai8keCMgmHgtY0bXmUwTXBi4FaYxzzUrRUFHu79pqP9u6YX3S5XWXSjj3L+0Jppeb1rNVvzuV9Bd13e8tUlnPmoNcdcE1jNN+pDeHOMb+0uxBxn/Y6HmuzOu/Y94F2di+2IYBXAcrWPSPA09I4TzXnvzE4RujzznWDZ6zPee0FaNQBeHr8m4PQjl/PMqzd+YEFs2giYi7RuYIoF6UmVyhlDYzsQpNy1EcsCNFrc7hX/AHDHzrgpKgS+RjkCOB/vzMbZHv8ALX1gU6X4t91wegSp6fr82voRNOzlt9P+RKMxmHhPrLA/qqvt9CUgNVp+V3FwOBnGbOzjWvaXtTdOcr/bhFFByt/eACRy0pb59fRjVBXaMCKbjvoSyLgcJdBrjtFoNjeZXLPl9p2IysDR3iki2sAHfe3GEuzvZQDRHAlU/Pz8KsGOJ5SiZu4MWJCkoTaguUnQjVqYiaRwEUTwm/77zvJnwMvzsfeY2BUy49VoyW7+3zl/y8YuO3b+zx6Q5cV/VLDZS6r8wkwqtsr0Tn+uWYvCLlVU5tPl3ZaOmyxcHav2m8gsgw3lcGLZRCFxbpQulLnwV3bhpgCJpEmwpQmIjDC/24CApA4Ja6gzKAxO3mRBKL0lhNL/AH5mcu3iAQraHzlKd4AOYivZH2lJQUwwmIeNX3Z+3PvAsJ3rnOqPMGSB2UuvOD7wLbW6whEj0N/X7sVDgHRxChU4OMnDV/OUcL4GPIFf24HYGMl4OSu/9W2Vioy1i+6/vcUWb4r8/qYC5aJV8anzUDX5uICOGOPdogUtCyyx/F3D3eXp9y4r27zW/nDVXDn0mmJcd8SisrTMTX+Ebq4Y1FhCtjMCO4E1A6BMmUdG0wiEhLoJuLlXufjojupnDl3k39OgDF03va7xEGrCFFXun7wYxNa5ZZw+GJVCH8tDYGb3fpCKvdMr7fLRKmAyq6riine7ZUslBNVSi9kqs+MR43cIvulDeC754gjRSG2K4bW774+sOwoNNHurnP8As9ngote+FvFUwS/BLpfo/wDHpGrp7EeTR4wDiiyUUGS8mmq84wwJUeaEHK9h6crWE7JHZFsxlHqhIXeXZOM1mPhCsJpheolHqD5l/iYUy28JLlv++sSEbs8/eLXY3MlTQouiIhRqKsvmv3Ko6u+69La+nvAvf7hf96UxQM72f1MVUPivu3Nl2XP9zCrfw4zLPnNfxUtT4nf7mVCMtDKhD5rR4gRWXnvGAaIrBaGee/oRhrpEhLyShBaOJhhUYpIQoZhlmYmS42IoNQJrDSgMD4FmKujMiZAlgzMgC5uIq33zHTKiEJHtBVJpiWvZr5y3Gtj9j1mGgAOWOPfuZiTQOheGxfHHZfRtzgIqotL7cZfaGjna3T3Lu45ki0aLb5sr3PO4SV2qyq8Z5+8O205I8U3xWGYTdbABQ13q8XxuFQGV6k7Kt/JPSE7gLs0e5x4FHmUclmDnwGvnLrimLvz2PMezSpCizD2UKuo8mLjocL7wTDuTPcWuC75RaSrlkB5mqHJ6n3qPL/esW+ByLby5DHb1l7llcSAsYe3Nf3mNLh94QEdhxX2goGhDlAg39D7Sq92aPL4/rhRYs7RoVamnKty6dH4lDF80pCU8RGaHb3/u0KD7wIpQZi5Cnj++03DcU5cSqKGBbMoQpMRlRBVqE1lPDBEu3DxDjpGptAMpKolpkgcGU7ylmBHQSuiorK4FRMBN/pEYRjvUvQpeUXwzHgEFC/sTwiFKUDYzEFuZl9M95gkjqBj2hmelHCKPw+cysH9cEzChF2Fc1irfxKdhVUAfbmVZ8PrNLmLi4wABCPE5iCK3DCyAwsQiBLLeIkvB/Ygy/mG4aRFZ/czLE8KmiZCBHxMpByaT/IdUopmG2t6qT5zPcP19f7zAAt7Lv/I3YL3vXH7f9gylXXjiEJc+saVMXFrTmMUINTiE2X3nb3w4PlBpaiopRWA7whOiIM0/WAc3DGMAQL1Fbcs0xctzCLkbMXW5d9KuY7S2Kwiu8wjZl1NpdsBocy5AjdMMe5LVLe07pjXf/YTqj84ppw7y8Vx5i1m/WYLBpEtYqaq1flMYI0grCOSlOK3Li45W+fMu0bC8PcvncO8UMPr+mcTQ+p/yWj1mldFlpgjzRAhFMyGIilwXMiwIDGJrs/iUJyMoA5CIGZ2YiyFZjBOG4KIebtHNzJLGKN3V/j8w6he2L96X9CVdBrgT+99wyxPDTdc8fW5Wt/x6Q7lIjwmax+TcB4xF33frLzgnYRBwqWmgJQKH0lwf7jFCDw/f8TmJSCKwYiDawBaWspQiDlZ30VszKEByQ1lMYXboEVyT7dSUdHUyb6xRTPWPUR2ekGvWX+S/mx5iB3iqihzMkPvbDryY9pObh2DiZNYaotM0lDKwYYY5HiA9h4is9uQp+cbK8JeW9zV/9gtSv7cxIUarzBWpvcUwXFHUQlwhRFrMEqAtxi4G3p999yGGPuZwYmoboOa2e2T6QN6BsytIWZitEqzauIsKfaUZo9r+sKKUE+X1l+4hEbW1te3pVY3FL7O2ftq2XJZ8+IFVEtqXpLdGImWsvMd6WAx2ml7kS0FSnMYOogl2b8v9uMuYwHNxCZ6MFwIwMGGobYYhMJfUOlrDzMmnpLgCqPBuO6w48ek4rSrOVznvMaD3hWo52HEIO5DUmPKITUu5lBSSizKhcswaFu48iXwTELEC+9f3pFQ5YaiWDLNyDE4I1UdjO7C1iOKcywh6FpczOiRWF1mPL0/MC5gDazrd/OiYRwoYG1eHvVn8TJOBn1rP16AcJVBudz4zgxxcJAMJLBTTAadS4Ny8F547wBFAqlUvdx9M+1zSS8rviw9Dt3lgzLaojXRAVMxUI2mYINQ5mGtlWGmVOXSBDe0qUJ8mIWoj1PzO1ickAZhBuSXrCUxSjPSsdG9kLxEMyujpPiZC6JGC2Z6exb/kVVB5MzFVcMhliNN9YFlvxLtBqKGJEjRdQW8wntJoiV5LiJaX3qJQLvVQKBeq3UvBPt+5aO2RjAHl/n6S+WXeWvaPbyAqzo4zGxmFGiW1FxKzUujHoBuFNzMFWfmULynBUyzbalB/rfEbjRGhcl7nHvnxBUUmkI5dmVaxOYkagv8AODLkRkgLz9L/ABL+IBXjkpRWL/MRFlvfeUsSnEBssBzWLXcSwTmFSpV2wJzAKn+oJkK9/sH4mv8AZHM5lJcS7QOLjkmsm02jsgweIVddMOyE1FZKtRj+VLBe8K6oqW4sb9nfF+Yzajw1ft2I9orxf2iWF94/3+0/6jKNfe/uOUP1/cpXsETaEXt/kYwAkXOWAmK/qhkpTLX0P3BUlty3p94CYHjoYiod8RojFHUoL8MJwRQ6YgiZEqcS/SUiX3rM3PiNmZKmodom2uPeMo5SqZzADvKpTomcjz2/3sSyCzm8v1gA1HJW5SRRogslbqIYhKESoFgYH9zEtH9URZiojmBN+H5/yNNk8wNUf1ETX+5hhUOWRU5g0zAjuG4MdB0OmWCEI2wjrYg+XmvEP58CmUgKCJOqFXQwaWVfa8G4Kax4izbt3/7MKcwa6rXA+jpm4OIfdx94aqCbCMGjGYwVg+RKJiWVFzKHTrtf984d39P3MFdPZlrfJCLScRRej0dCLmJCWTJ9oQhqOiF53pgIETmS1lKcQ13LEyPWEhOYGJ7QEpxDZ69DDBUY5x04wLxFqZM3iJ08YriKtMaMf2o6f7f6gyipZMf2Jt/d4lMzJiNOJlrpGSK2CyCXRqANxCWS4BCBiLqSmpUHXzihFnD4iDkhwgH3U9OCDg17/wCQqKRIoeUwKoabp9N/QgXBba+39iVWIw/axIw/IjN69GORg57esRPKXqMRyqhUFrQRcFS39YNDjtal2mZHwHoILNuBxBGpZ3HpkI8hKC1nopVFfWCkECANwsjUWBxClbXmAFNy0+TphdfFqWJlN5XaN9GETGP7EBu/WIa/tRE/3f8AUE/3rHBRFKDT/n7lr/O3+zCQxHL5EJl9EGoQjroqVMsSziUxbtjBJmYKhro7gAAeGNeXzBBVxr3H3gEhwADX8RwCjoO0YR9uYFbDMYeZa8sBwsYwBOO7/Uet30xBwgIcBKIytqcALC/CNvtUXCcLMwxbi31et31vorEVwNN9Mm+tAS6iln1sUOHNn6heLs9oodg3FNiOAoS8fCTnpRMkpxL7ymOegj1RA5mJqUSxzEk7ohbLVDLDomKJm4YmcLXcDwnpiLnOczA3FJpcW51FkLTXQG0ZjOoqcxajgAdzMxkwxVrBKZupTg1H+yWiXDTHDv8AuI6nA168QV4S/WsxQ5XFNla+sFlzBKYEXHVf/ALcTAqO09KTYlSqaeo1qJdkd9BJcu5j4j4OIamJiUOjwmWDpKYF7irxHRUIrIAxQQ1Z2mWINYYCuEQKlOg41EAtQWBlbhnxHUsyr1pmfEsWTCXxYHMcSi5hXcHBLV2ILphvcfc/c5HYe2JUSFu3cBNw3ZXl88V0tHLH/wA1TcOa79I0rnMKKD6zJt+AxBdseJFRcAy66Grhn4D4G8SiAHmdj8T8etzbNzFs6Ah1EqyWJZL8RUkdagayBYaVNMCaVMMxXMu4FCsQDszDGAxdURhjHpLXc13LC5VaqAQVHUGvPabQv+uNxuujv/zJbUW+hCj1zxKSYKoj70qgFtYNwLi8dCJ0PgWU6JzBz/6viZqVNTwhEG4A4YLnc7MWycwXKC5wXHQzNwMluYlILADMCxGpKHMe7CMELxE2mEYuW0grUN8lwM+JhroqPR/8bg/Cwg1BcDTcq6Xc4yJ7QFeJolSuhqVD4HTlm+gWRCiKfWWb3/5pbMs95Urrp0sQnpEAhUFT9v3LafeJiCJ2IBudiKNxuFvMRC4azFiExAVkuFBXEaw85hhU9I2Zi30uO5bHq/8AncuEOpLuDXDOs2XtYNvB2iAYiilfBcv4MxWJFsY7G4NzCXN7h1r40u7lXxIKX47/AO9vM4AX3C/eCFU/SDFMdQTaZqV6wqgJT/f9mv8AkzioxOeJQFe3+wXUaB9IugeKhYARGdkxMtQjvoBGWiPRu8/+d/FpAqAXRT3iNg9EJgGHiDL/APErKQbNVFbqZ3CqhVZljUK7g2xvpUr4HUFHxkV/09YUbgZjqotMNSq6GWdiG5pwLFzUW8ypgilSrcQMTXTeWKagz1JfR/8AhFIYZiegYtxfBmDfwhEOmpfMuYmUwagRoMygClxFjUORFUHzL2IfC8wyfHUMLGKcxoKgDE7Rt0usVBe0VeKjYpYa3BGVAJbFZ46aweIsuZRL6sf/AGPhtwgNxcOmoNwfgYUj3SuJVogt1KIzUTdXCt3M9YpkhLcegTvD/wAKFE0Jd5isGzo6mAjNy44LmFyuYQJ5jkgznoF3LiwjNMTo9K/+ElGUCNQKOluYvTI9vrAz2MOhT02VBKmTcqutczSbLCjVQYbIN9RaQDuGcy1YmZcCwuYI6+M3CycJBzU8EplM4zuckiYxFUEySnUOiriJZiazFRc9JUd4jN+or4KlSpXQJUqVK62loCUSuldci1MK4vO9StCzxb9vgQGZVSpnqLVO0jcAlGWiEDzKmLj4BdJq30AvDMM3BNPgGlyk5lRBgDUKdKmAgHRMQl9bineGI2weYlSpzGDpd4iv/wBnaEM6lvhPgqsxIyCYUV0Ogsu5UvplAzTcqa6XLuSckBl1uGZXXOFzMczOR0A69Bpi6K4rbfiBWfNhUWXLlrM9bqX0oJniJJbKlRGzHhzFrBBSC89GLfwEr/yC+hErD1iqXfQ/yIUFnt1qpua+Al9WTG+pLqGZiMuy9Rc3Ej0CsEFPQXF30qCBmo0lK6VOUOWa5c8LK63B4j01LeYsMwxMhMcs7SUjcVVqw7cq0TEW9wbjGL8ZpK+EtCkCmAitgVghKvpUqag31r4SXfS4QhnEWsErHRCBUcypURaiYEVRFgMaS4PEJlmLiWou42lnqJjSUNxWxPERftPN9pbi2DOftDu1cupuBZUwsOUzhoDR6sYRYj8VfAmOoFfAZ6HSurDrVTzD4D4Bg1/4PQ4EQIxjyhiWZJeDdDaUlO+uX6TQshjIzLtEXZNuX6s0BUuwmBAuEvshmlji7ncy/q56EZUZX/pUroSvjMdPPxDU18G/gvosvpgJfW1xDKwBMCJlIrEnKYJvEsLuV0lqJcRUSooYyobZzxVGYBeYNQlWWIvm5GXTqLYiz0eiwlxjGZpVBBZ/489a63GJcqLBqblf+IV1Gpc3LroYiwbl8RhWV0GGFRktXM5j5gDQ95cdKgPAJzcyJqXL6AriGMkFLIOJddEsNzWD+9YCPKVQyxoS1G3StDZ9ur0SE5ir1GaMVrTtCBL+pUqVOIagV/5JfUldACpz8Y1KFb/8WBWIsJUWo2iK5YqX0wY6vfpTnoO0yc/AFb5jdULpOJXoiCH93l3R1KA6P7MNwmDcxtETcq4lxLCVQa6PRhOYx6IJTFrCC0KP/d/86mpjmCfC9Lly4bmIwZc4oUR3DtcCL5Uvvx8pTI7xyWFAvvBHBG/MQYWqMFWWBbqoxtKS4qzBJj5csop5lBal5IBg/KClWNquJai4M0A6g6egTYnV6cxj/wDAEqH/AJKErHhSnacclZuJcYx8K/AUZj0MRwXL8Eu53zYi09x4mBB5mgItxcKCzcVo3xMFBejFFJGO3SLwfX/Pv6QIoVHKjmIvSJUGm4YWLtg2Ti4oJDRUqA6idB+F6NYP/wAB0cfCtRBLsF2Zpc8QYL3Bt0CoRViX1rqtSoxxBjpdS76BKtj3ly810ZdQM3Hp/8QAJhABAQACAgICAgMBAQEBAAAAAREAITFBUWFxgZGhscHw0eHxEP/aAAgBAAABPxDaU4jwaIMjjRvDNuqQERD0OBkZAtmhfrDCh+O3LFqsE84k1PK+uHfB89wydbZTaXj3hVstVocuHnXiusMIVh0jkfocb8ezxiVkxAUh4ZzkwWC5dsrLByJxkMmDRA0GcrLmvu4gUOR584tptQcKdgztZ88UPVxkm5koMKYtDnk1nD5yEy5JqcjvPMNII+ZjBedSljgKN4JS9TLLF2io/MwhCGRi+R6yo4KAB8p/8yR4dQ9zpwAYT1KQNWxgHNTJyGT8POKFdgHC8hnIt7gfbyciQbI0AZkU3V9ZYCzur+eMoJkTfj5y3W+gP89ZYETmhxgMCvveSrN924yLjaVrxjm9TntO3OAGxBDKUI4U/nzhY5HkH1jBJ7DeKUo6cigvIGEPNDDKl7RgI6qpn/zISiCNJ4Hz794RVSm/Q9HnAtTSyfwv5xXKBLcd89YV1BlDggaalJN0cJsP3xEwbZJFfYveMAAHWvUmNDYYg/vDuCAURFaw5N2yO6bJcxKrhXR+cQyJE2TmesrN9cg/Th/5iPEWMCbL/wAMYiKmv5OKaE1rcyWdLUd8f4xpQGj+UX8ZvgXAr3MWkIxvS3nfvf3hu7R6Vx/fvz7anBEjJ9d5EGgegjrAbl9BJ/jNtWtOH/NZGKDqXlo/f8ZvCnLH+RikpV3oweWgtGnQzYTZ8hhVgB6JxSpA7afJilBWlaA2dU/EOsgCsQ2QRg71kQ3dCIQhw0FKcnxm0Tg43HKAOjQVe3BIgHVUTFzcD9ieZegpDEkg7bpIx3dphNOh5JJbJp5ERYBOIhlpOL6sXHwYNJwmBFBo3Ph7x86Nlmx895pav3gwHS+cfOLHNdOBXGtmbOzEMAZisq4dMlwBoJkkZwYFIVib3DLoiOUl+sdOGbOnNFkG+W8Z7VbXr4w/ZfDMst92/eXR4GFsys6L6BWAuUJywoa8wdHZtAQR9bOrs089NPn3nJaKCV9fxobE8UZxZBnar/PZvDMxIoibm++clCgWwZ6HOAk9AX4wHOnAh8YhsNLf9Yon2OB6HnEkrc2B9dYrai7hPEcXA0zyY4adOD3MOoiKn4zr4FY+8dkAYY616B594XS+xTfzxj14cDzlQ/MsdZNCxo5PrDVGklo3x1nEkoYf9eA5bMWKUPQ6T5ZeBVxJi1f3UIXPFQqERHBRrpUGASx5Dh+cG+NUqtQ6wNbcKlf71g/9Khix3HfVyO4rwkD7W5PlQR3fV9a/OBK1APUJ99fgxIktuSaonr/zGwdldb8JG8LvBAgst5gf3lQBSzen76yKCDbT+v3/ABjqmzjma/7iWhuiHyf8wwGqYcT3jFrTIcGsKjhbvnZmwPYDR/rkNoV1uP3/ALeXDo4W+eeP4xbiSLPjnIkE7LNf4yGkFMUSd7mJARmp4dnALB1kNx1KLHUKFcVizrLAjkLhCCgMwMLgtlFYYd7jTR97pF1QABqSyHvAiXwNoQxJRNo7aSlcxZj23ABXKFajrClIMJ5hpUJi6oRW/wBCXVQAwhsihpsEBQkHgicvK4USQC4d4PHxgkA2LL6cNbQAOWNzGdhiDxidYC6DAokmQDAFcLhm/cNZYYTDb1nmBDrBRScrt/OEJQXUvx3kqF0w4NXI24H4c/H+XEli7g5VAr6w5+YmMPad8TA3KB7xDd54wsqpUxZyeT5eDvBJjhE9zXhYr2Ca3Dfk9+vDo3F5DgrIj7SCtiWFb00L1UkrE+vt6j5h1ndYAv8AuXTzhwlKQHuH89zIqS4Mb8uRHbIKU5+c85ROjbwOXHskcgn3d7/WMFg0BPnA7tIFPWuzFEvQSeTcEy9NL6r+sEBcbCHkWCnzss/1msN5C364wc+Mih+C4wjTux+8Bh4tij+ct1YmjWMAloVL+OsrNAYnbjUjV5FOh37eDtx+uWVSOtcmvVVgGwygWiEoLQahukS3BeszqPPlOxewsgzFqLrmtZHVWa2B3gF0C4VAGpwKI81jVKddE9HAJ0WdvOG6gT8tujjEKkVxo2HkvZ34xYsUulrka3khrYHPKV1gVKSxjyvvCfyINLvTnzjZc40+LqxnJgoatpWm9YYPG5cfrDuC3syt6WVuADa+jIBrTGDSaOmm6OnOESLScQCy1qcD4MgMg3yfqGDjGAe+sdvwjzh5DtgN9GEI80SPEVq/WPIoLI3xN35y0RBP4AS/WCAHrQDy0w7znLLtn/HKluoR7QNNKJYInF3uTGNMYOCR2B6BzpkWZnaal4cdzGD8ORvhGnQ6HWb45bCE8b784TCjFGJqR5985QjaIaTZYfeOc7sEWgEqv3iXzbNzVNNNRPeDMovCQAThIfx1jyVlPMTUNesKEs0So+eMMpaswGjTL3Mjovl3gYfhhymDeGvGFjY8pgzSlZg318L0YCAQ/J1MYLp0OHIuzAO4+dGOhY75xsY0qfIXhzVIfBr8YW0Hom4pCJrYnxgTK7crg6B50GHTVoiOEYa8omTJSRYk79e2LGmAQ3FN7Et8kXBYUpAXDVADtP254lQma1d6Z9VBcDTALBPVaGgoCpFEaJGIprbW464aeWAnfYRHapO3KBRiVM1ljn3A8+H/AMTmh1x+Quz38fGPeepTg9ZCYTpDPiZxpyKic4tBnKRzz/jIelHgF5POSCCcE3kDg4+FoCNT+n5wkSvE29UsxbKgB18bwMIIsE+RlI6rprHAh1CT75zQzu2fzwLJsCPuYNdyrP8AnrH0FqwN5Bwdxt6G5OGjJtdNlbETmGUSAU1DFo/KpRWqodflMyg8hZNdEDUxBcyKSVA4DtWV0PBCEE4UqCgo0XW3gT+UtziPhAQ+0jrao6MhtalyS67XnEO3FATQ0utJ5PeADE5vQdkk8b16B3OtA0+z/wCYmQRwxsuuLz13gaKfLWilZRhCeLygEBeBmEIJ42t+5/jAAGIHvsFV9YiMBthvg2eNiQRY2YquDnnT/gZsJBD7Ji2zH+o2x0NOHFPKw1lvKF7xYEk9zwvML3eNYuFE3ygFShM4tgofASCXflh2lkyBe1+cMk2lVFR0s3x1lCLnp5BZ5d+uM49OiOAKN6hgdJ1F8o67XGJm3KJ4KYJl1xvB4/4hAaY2rVRZphTpKlCK98Cx4nNBOb2u3n85ULVTiuOMklvvW/3jEwDrr8Yd6DwwSZDEV3pB995uErkLt7yjTd0v0bnMs0Hk9g4OARyvvyqP0ZXpukT5VX4M17LmfywT94MLzwOfgcIbRPJiaJiiBzhWwd+HDiENDWcQXd+8qAg+VhpV3haesYCG0dOjvNt85SDKMIO5rGg9glyx9OphWngMJWBs7wpGqIXCr2QCq+Ax1w9mL/aNvG3WJqJBguNdHR+/euLpw89XQ9swFF0NEdicnaS6WGshU7FhKBwPPJHNcaueEAzjwDRrQ+hKhYgOuy7DfbMj2oq8yUfIo3kUaYZW7Vxl42+Z07QNjdQJV6HiNd+/yKCbYyezyYusi8nKaBeYx2yygqHxmprCCk9UxKC2x9kwxH0OehOMEkMpXP14xUEvW4/7jwSSHn2Yodfjf9mKWG2ET5OMOqMJvAxJy7HHywUxukjoORTvZ4rgw/NDYotbqE0qFNymZsZYHLH6XRojhseEPQ4JwYPMAyyiU/Ae+AzWPOFVUgOaLV21ow/EhobBpvK/BdYAGtYS3HZSGthdRhWW1BEJAjdK+hN4moEQlFdEjfMneUbsmAamiJ5lOuSZZNG9hylG+nzf2uD3Gq+xzdslHzTRxcsFnd/jb/7iX6pGroKFN4wDRKMSyGjwFOVmarp79Ydhlgui/a/5gWV/TK0QgCi8ZSaY68/P8ub5X/jyQIgcaPt2eBugWC1818Ym/PaRM8g5Ahi6IUOXqGrbgALuAw0XaXu4cGBQQH3r6MX06aUY+tYJzM4UIJSDSuUR1uWjG2iGu4AJt0g9jblKkhR2KRD8DlNGcCTFB5Fn6OMswgrlVy5K6a5LlHTag7wa9iYUeLryYsEA48gf36TFNq2C8zw8Zpv8vGT1kUjiYlfduGCXtC/qYcaHev4Lhx5RBXzN4DGTi/3Sv1jw+jQ+Xb9YenCSp8oD95qHrUD3yzYL0Ru8buhInc84ZhGwET6yByDnGUYEqm/gwW5cIdfBj6D4U5w+XDTDlNxN794hLEUQcmd2sZ2KvBhnQRXlvcHlTQzEPZNqnxhfbA66hFPPrw6dvqMXsUoYoc8Mzs/LWaN1WqrweRwd+gXEjrdpyHeXK/AdGUHA6i26JDkNsJrbiV5IMFL6VseXXbgH24nlgIAdxB16RXbAB5fDOxJrhKPDl7hhHk+hx+G9BJf6P8PxhqBOuPc/5iOkwnlPgwwiKkq1m8PNaT7mNHgAnydj2YnNBqkH0YZrOf4i5QRha/0cm0lvj4z1skf4xVc2AXm/oO3RkFHnbGNeN8ltA7aAKwGaybNoO3q0ByoZJYRAg7jl7V0NBFpVFteKMX4wllfOucQOsttBB9sheesFPdFNbeeW/wBZP+psjQddtBvVHcisauANJ0lMq1bchrOTxAVuu325BwhHDvQOLONZEMhlqMs9acHCR/EwGRCHnLjs1RrVOyVWeXKqL+bk9UhI9F/nL/wZavAeg0f+5uw3zPOPbblGPThWhR+K8cHcscZR+qR+TOU2cIObumHXeaRb7AoSDgd3HmQRw/hOucNGiHboBjWvLp1g+/wyhgmxThiFXL8SYiTTtbkdaXk33SXNd2pEizRtInfFXmQ8cnCtPAEYp34cFUcUhLB74aaFeTE2pIYuBAbFwupW6ylpCEkA4nWVJbaBH84kSqp53gOSPk852LjIcGUJo+sZEIABz94dbVDw9e8Yzm1EB399/wDzDFY6HZffX95GoKepgoQmn5wCeC7/APM5HZidl8cfreHCT825LNjjaOTAE6/EFwWXyLY/w/WQz3lf5BlxpylfhwAJbR4P3wqM8U34kzfh9EfjLR3bPGaZQQdp61joF1bcdHt/WMj2KPAhdoFjoUuFQney9DC05nDV5yM36l+pr+Yb84QogddO2ZtVUae9LECD2h2qJt1/GJmNVVNGm9ID4xCoxLX5L0oDtRj6RQgw0ZY3V5+CCukNdNMEpp0BnRllk2gtjkOeh5t1NWWSSUKmg0HJQis17DSE6sfWm8jiJNYJfwHPz2bF4C8EdpseRxCuQbV9L+8NaU5EyeFfNxOyeBcupjsjiULw1fbzkgRTYbHHngiNP1gqSL41hE3WW+ibyfwcqGIUPOi9nGp2oD5GHaYdJFKvD4XV4BqZ0QIxCHY1oNAaACZd7RgdsIQrTlT7d/73gIZVZxh1ntBrUVfPj6w3REAzgA587v6wlGoCbAtDsBh2k1zlSIKKklKsILW+mKpaVUibjTb1khs15bBvz2fOKa0wC25n0fRiGGijw1MIcHlwZ1ZC5EhOA7V5YeMWzoMZBOz8N/WbjwDfeFIp9ZQU7z/Acc7fgz2TZGjrXOJGh9owCWeQSyPc6DoHWrtAtyAFaAmk1yY1/lCFxQcSCVqMIGPckpFkVi0nvE24xNBJJ6TfOWKJenMP5R9rIuHNcvm7ggOhQm1XeARtHQqQctbo6mhuAeiGiTsLnTwSOxxajEa2UEbgeFpiaxqJtTwYl7rvRNLtKJM5J/KzRsnL/GGAyzewdYYqproPw4SCiUApTizB+iyP4YTfaqP5wKdrvz6xIEDwc/OPy3anjH9NAToKCJqnPCnGWTB4vL1vvIwbK1sV3d8fy44Kr9LlAbCBHJbJktg7ED9D/wByhbVJSvi8fvFCvMdaw2NIesG4aekxAQxOGYlSLqf8xUY83UymaiJqHvSTNWzkm34EwhJSHOPdt+8eV9d38ia/WPmjvItotJ6RPWHCypC/X+n3isg2W5fCk/nfxi8I6JnnevSPzgcxZhBpbrmiY/2LwI8k67D5xSmjiTyL2+DXnBm4TcdBST6PjE8HGeTjSL57uPtsFTr7n9YogmIabnJ/vjBMr9I/p/vG9/VlxCEdTi44IuQE7t9Fd7Zrm5Fs8onjYQRE56jdKrOmCqHtG/Q/VN4aI1A7Hr/mP85vwh8YlUMW7Ga6makqcnjLNIcDT8442c1wv3l2Ro13iP7Ns1doJU4eDEAqKpN01apdiLoDYj0BFHOdt4AwvAABwQ69GN4YkkRr6w4dkoF9sf4ceIqzbjn94YCWte1/owKWLU8qr/eUC0qJEg173fWz3hw3aJeS+BzDww6zaY6QWDRjy9ezHntKctA7s5/vGTp1l50avUfeXtBtmyml0c6MNy7M8YDBj6mveEQMYAy1EK2nPE1hCdUlzZPKfhv9YR67wkBHVG1l3/WXjwPaKIjX2jLQLgyswBLSHALO04ofxvBq3ogt+53hLSI8RavO0K0D3MDyeiPic+xO0mDkWsQhCGJtNkQVgTpxDYaBIYKC3SfbAKVAJ4GhdXlyfpoamdW+bjW5K8JNNTUbbkRe1UuRQQoBpNXbzgzwZ+ahhBC0IUdscwhCirwNEWC7F46mltNWC10RIe/cwgRwALsQ1pCniTWDyxS0nuhljXQoY6d4czBG7688uKiJHpwZt4Rxssnu5z0OeXGQ1K7S0+zNwiSyn6xS/wAJL+8HJ7BRnyTIO3IoHf0jifA9h/3Di4IwU+5cbEjlX2IZzpvhf2Y0l+7vzMDosA4UXPba3Diq4vFLnHBQKmF+n4/8y7FPMmn6wLz9JvDYQmwg/GsSR39ZE8l4g/1nV+NMnAHe0/rNeWGC7JeojPzmwTfCzX4xgNG4F+B/rAo4OQf5G/zgIH0/97BPc9f8TCIne5/bDDDZs4+QwpQiwip7/wCZOSiBUD1FL9GSyrEp6wjtrhPZzjXcBsO+Ra6ZVY1wqEoIryDUneoV4JVgh9u7zSaPszaQqyxH08mcNqdIL88P1v1kEsOnOMQ3aPfvFcWAQg+iZdCg5Puo0kiq6TwQU5SkClDs7vwJosH1IbyEq3UIsrewcC89DI6Gj+ft+leRVXzgqoIiIBOv1gDdJzoMcKV/31gFoRHLkmG/CvxOs4bArVKqq5uqv8YkhEspYc602O9A9wbT6YElXgK8usdMJI7FsOvH6y5KijagnHHBik0i8guOy35mMkAkFquAaLDueciqhxvJtfzlIhopBN1Y74k1kVcKEaU/D/1hNGMkoCu/r43jNAICiLbYreoBRGFclMq6lZWC4QpnIU2yHilBIiuwomlKCLB8DFMlIDDliWnhMNpsK9V1wBxMjJUH5SOAeTaXdr+jzG6oQwqOBNhWG5HThNPE1rGDpEapk0wwAKGGrrCl8JxROnIwX04+0FkEKu22+XGbSCCDboNilDSTAJ3VExZqKzs+MR4OO2IUXi7AKgtMTEwlppeYMrsoQSYcCG6YXvkygsECggOQq/XvIC8vONlVfjFpXvGiux2GSbDfjBEyaAesHohhfZ3jXEdEe09ZFrEd44wbKAAVlwjsY7Hz/wDMgoBbvd41lYWpsD8v4yHpLdB/7hdXrXje+Jm+fKuDGgpHfX/zD715MDXMb/JgYFVjpH8HzgwAKSP2E1+c3MeHyTaLvEaJCnb4UmRLKgWv4mBgUY0J+8Q7H1TAbaJ/8MPi7Uln94s5c24PHvj5zSrPy/vB7ELaavrLwMcsP7HK4cln/pig/wAL4wVFz4f+F+82wPAF+8cZAtQf3hxLsu/HJ5nnGtgmwvxhHII26oDsRsGOw5nRFxV2IRFXXbet5VsC4EyxTydnJvFQVoa+wmIiINIoadJflxjtY6h/oH6s6ZkVE+nw94dHDBs/DTmqp4UUuLPiXu8Y5DQhQiobNENCGnabOJLITapWaLx0TWEJNsP+bBqrQxuiBIaD+cEDOgDr88nFolplPzi6tG3W+9efvBD2SBZ8Y99eFteCemLrSqhy2u5eV1wGuDKOTBRSc7PNPrCuMiGba8c4mYfgvoh09YuYL1S2nlpyFiknEZdDZWtXzhHvYCUxDkQvaXVgE0LW6GBk58/8FhomnmfxgUkE6M4LlSUJVcK6XeaYXJf+gfzMUuaKB3IjH31m6/gnuhbDsnXrJNCsDbBplAtzTea1DeGI1mjQshyCEqJS5Xf2SKch5ydlVYSiIlBlHVsFh+MqheoRtNnh0Zb7lMt6Kyqtm1SaEGU6aUlUl8CSb7yupKceR5w88cAv2g84AnJV4HiumsvECsNVVe8uMQogEELURqgg7chYiVggLYFAjWuLDGY3N3cWIygLRwmWrrKl/eDG6UXkRDwBuvpbcHFwUib/APHFJLdnZ9T95au8zn7c0xqxDT+MeqIel+0xkaPIsySIPKPePLlwfOJ0wLb8YnJxSHFxtvgvFZzigKG8O8QqVUNMzTo1GGeev4w0J4P9/eDdY3Br/wAwhqO+Rg14BgPrERPc7B9D/WFrW2T9Hj4y2E2dvU8/PeOlK41uk2+6xxlb9o160YcIuIzHuTN8U2HD8v8AzIeg61fGu/vNxNNtJ8YYTpY6j8HIGGRR38AFwYSugKn2mJoYSLZ+HAZWzpX6VLgxAE3ZX09OBiiaHkdQxYGXG1P1gqvI1z/Fx0z6j/OEQdyj4fGs3r96EDd7bH6wup8j8oQ8ypzreGbYFowAq9H5mSGKBOak187k1MTMO1ssm09B+MQE9Jd+x1zomCZeCDB5pTHp0Ts35Icf1von7L+8KFE8a/nIUioN/Ft+8gIcrCl8tHrFBUeLB9jv7DKfzxV/cZz6v8Wn85Ooq8hP5GFaf0P+f1hwC5JP9hg0SrYOPjBRM42P9sW2A1tGc9c24/6xEFXfFT+c0gn7/wBf3gT9ln57q1gRBeSmKunehcAB/PV9ueVHgqsxjzYJt+c2wAEjp7/HGbQixdV+usW7pWAu27mayKNhfOxdEaulzi/dVjUQKNQkFg2QVUrByOoVdjnnEeIVh0cGiLsRhFaCdnwYU6GPg14ijtsyGG9o0Nb3MG6vODQqoCqi6BeDdeRBr7sNmtkbPOJlKqIeYh8AH6yu7/D/AJjVMVIRdoJVDYo3rAZDszrUuEJQvAjbgN+qLh32hpSYqK1MG6YTKOkIOSl1ErCOBAaXeIA8ZCMp1o0VvnVyfigdIz0dfOKxAEnY1Ff4xFuICwnnXGY50b5PYfGDCka2zXL4Nj1hwXWIZKCHe/4+jIdGb9en/wC5urgVNfEwGAER0Kz36Y2dOqYmo9YE9g14f44dQUdV10zrHCqmzh/bxjCEm7H6XDqFIkUZt0YuCjCvZkTtzx94seVRA9X1lvJCLGuurrHYYHe23h/i4y6DxIJ6uOVnXYO/v/7mnfI7Mj4e/wA5yMaAq33gWLfNz1loCvabwTWwyUyQrRq2/rGJ54HnBSBNbkP1csyWqo/Wa05ImBEXny/rCeNOv/Fy3LgRD57wgeQVHKd43xAkHX5w+uYoVisCRqupkfDDQO17/OGgNGLHLsNbj9e8CEYwdxr0eavrDENEQHf/ADIJb2eYyb4/OWtk2UUcA8yfxnAAKpx+NZVu1Yr6Tp/P1zkF0dPWTEpPFmXYOClPv1mqh66YEsvN5yCUvgyQFfTr4yjAng2/nHgoP0/jIAPyVl6L4DV+8GYCMC/vNnTeVH+aZCDp7/1vD9Q8of59ZohB1pmxUYh/SNxkEVMKfeFdymy8Lxx+/wA4pppYETpChjRY0DQrZze6awQbbVE3eiaJ3z8S42kLRbPXy8/vEFtBR63vj73k7l4HrNIvvNU7hI8o73k3Z3HCwsCvK8xCsCoFArkmhgYy3SDRseFC0tSq1OiY6VNIANmEOeTmxvQpKLgMd4H/ACoQJslEUULoaEyhsT6ZC1prbdbVPJLoEtmMRiHAlSrv4nNgLWtiIPJgKNGwTougEeKdDYGO3NRYLS1GQdFUoZjjZsgEW3ihVBgqaZgBJdPKdNOsteE4K6l1S2aslOciqAUK+ByP/MSUhFWvAjf04iooO40CN0kzbhwbYaUddeuOLMeth0aS7/h+8LxBt0In4UewdmSRcqnnOpDyFHIlHAJmNSCGS8HcXQ+ccQM2FV3RQ1uKcBgH/uzbaUAKlDtaYHvioH8lvvGY5IIa/b0/BirAgI38n/GKG8gCp8rfPZjoodcx41AaOruWY1CO0tLRFI/TiEjdiwUdN3v3+28sxjk5qD5L8dl64InJNkIJsxjU6UIm5PzlBYW96HfJrGlq6AOj/XDWHi8vjV343MIkNGiroakecAAOKkbX649YuEnPBa+HFCg28UP1/wAyxWQOiTlhcIByQSPrg3hAcMXT4lymrwR/5iIOHRoZfIRF0086yqSHdi/rPDOOh/OOV01YefOIdKBGn+MLVchBNenYnxjiptkDWtTg6Z85oDaUEoibEpLwO3EVEhk0S8LULvW/ezdCwKw5JOW98wxgJLmvZz2DhyvN2IdUNRWbLrS9MZnNHRJaYSkDYvw6xqi5FE9U6/OSyX0bTf3/AL8Fs0qBo6/TjaEuyqb8c/jK5sKlr+OnGRZiElekRcV0D9l+8FQQ8brgOsnscJgDYbbwxNkCM+O3fqYaSrgdfvF7kGqV/GCbfLTn842O4/8ApxhrI9rgV04PbnXGEuzwKs86+MVspCsZ57eTuZdARogPHWv1m4sbA/asf59ww+syUYzQSAk/1wTKoIAQJ6MR1SmwS8W4EZFguSmlRI3z4wLSwesVlEITkXstM0PS6FilFp9jo8wC5S7A7IosDdDPduNDiKEWCB0SYJpMyKIgvEGwdEByWsEA1eiga5FD9hw8CBbXP2OcSIXKjwKYFIKaYrkcKQ59w752r5cpbToNWEVLVyWu8GJSulZl0ahV7YNqJihIBq33GjhlGQ/ERMdb4XuZFOMeOko7AL9V0OLF4mW5XqAu/VswIsQIQroVIO9+7omMoOa6Wun6fzkJ2io15jy7f1iaU4ANO/b1/EwvABrEufvX84s6VnIb9Bkek1yJimYmyvXqYlrVYYX7Dcdm5cNhN2k6I8UW4qIIrTnwhF0FgGRKkpRidGi73vO0Ejb+Ux+HCAK0NZ6hP1hznGWh8mIl3k7/AIxcvxy/Q7zxTCcH1Q/IYjU+qnxXf9ZfIH/rEH4w4zDImuDekaeUPVUnFoDNxrl4wOHGAAqyBxX0eHNakm1L0BCRXnrDd02Mj870Hz9qfQByt0VPRiCbYD1PhawAl0LHfCJddX5wvhCWtS+bV0FVJiGNVCx2BTR/JlxcoiAaaeg/WHACgvOkEkwXN4+35w7qBVQ34Ofe8qQxoB28jtpz44y5hQAQXxX8b+8FpbFF7GnGUmtBQRjeAMjkWgDdqBb+sVGhTRQ1rc55nGVRNPKh9jvvfWW5wwil2VA7T6mrmlroJAP6T9HK0F2C68xT+OM3hQiw+x8Y8ZaVGfjCKbz/AOnDgq6rpkAlh29feci/uh8p8YAG3SOfAJMKUFvaP4evDHJ403MB+P45SWo4BT93vNooZYG78H95o6JeEvjeK4ZUHQ8jP3kwJA1Cv/zERMLsG53lAMdVk3jhrjdFuMlQHbuYkQOohHe99eMipRa2Pl2vwYfLq6G2qpeL9+cc9tdlPy8/gxBEhAQ58fXHXOIpc2Xv37zQiZwPDjcV7EfjD6PXScmFOll3T5Un4cLBdUdI3IEtQCcwFngXLPLux06dR3DHRMGrELzAGqQEK5xwKwqIAkAhxMDWs/SdQBaKBxVSVyScxnzYaGHPfdM3WI/UKhWutl2eHLSu43NcqqdQees0yDAMDsFIaIb65yNqmw4PgZv4x7TJ0W7RtAbVDegoEexlAB4gkUIwQhSCgFA3UqHSd7twYI+QO7ti9puQqc14lt6zlLwUrACggfkcWqyNtDI3trYBV1pb3m+xUHQALoQJNuw3sU8ckLk07ZFPJ8YSVaQap0v1fC5x9iFKOx9dGAsHfZ0hPUHmmEbN6AP2nROkMOnadAC5wKBY9h0QF6GBC1diYnMERp005MlFVZhs4b32dxrGJGk0jTOI/eX0tKM+Bo+8penir8uf58Y4AjJsnrffasSquQp5BA+LkVRHej40D8LkBApA/oZ+8vbeAtkvt0D84hntU8e+fy4hPor13eeV+M1g/f8AYMH73zm3leRYE1zyGHtZ4vj83OIYC6Cj1PBlo6uUivGtD36yEWxEELeTOXueh6wrTrxdJ9FHmBkVwiTQkD8Zoy8hOtf+4tEbx9cmQdd23w2RKRyEPs3NmCTgCSCh2CbfBamdG3qT6MRhQ3XgloPKo8Q1oA4EkNOJY61sRBUAcO7xlnnrVIFI5KV7Q5xY4TQdLg58KaIdYgVV7jCQIVKXkOeA9tCcFH0Ovx3zjg55DDwqcOS+fmYRyh1m6VqiXf8A7GqAeAx6Fv2HrFs91aHwVyqUJtj9nHArceVX7B9XBUAbC/bhk3Arof6GL9qFqj5nAIUgN+vNbgKXOjj+Tl+8SJ78uzj3lliIVK+Noy8eE5H43uNkDahpyb5YRUErWE+prA0tyePg396yIGJaqHXEflXnGaT4X04mAwubBPPJrBCcFY35b188YIlaqkHgPJ/rgKVLUSHTN+ussB7qxnjflxxp0ESnq3IITDaf9xL9mP8AuajXCRvPj4cC27yTaVg3I8lOUG/jrrmnhF0Y0Xw4FzhMQLyRJ2B0JvIvi4MRSIi1UbSafWqGWufEHK3zqLm0OqySJB7MbrMsAJtgzjlDFQYx05WEaSKBWGz3NuFEozAwK80boNyXIGp8lvbpvj2AOsGbMYNtOrZBO1eVqg4RK6ijZR43+HDBDYAqmptonxFcPs4o1gH2JjqL0Ii2a3584UI1SoLArA3TfEYLcIlSsXAF+SSaYTnAQ30kEkZKG60HqhjevKcaCt2GIZpEJOYX9ShogGBbsoG5i7Aq6rWjlU/vNcFS07ROWXWl494wtGSIaVmg89AfOAYbQDtBOm6+ROsHhVFF3Ke85fjDZnwyvpFwvBBUJWUNv/MQwK83ip0Jr8/YKEvwC/lHj3jxQbRlPQSZ48RI+pp7hv8AeaNo6CnS4r8GX/gvVtkPfntj2i6sQ7FIni7myF0bkdtb/YvjFMPgpCYOyUSHnb0GlAulYnM68YCkXbj+n+sjlDud/TkN5MgfwYZA2dLr94FLWwn+LlAr+2D2iVwU2ScYYFYMCpJsXjJZO4BP0wqKex+gv848F7iA/eXFNHAiKmuIKueLjthG2ytCBqcBfLjiqqIvAKuWt7w6iKBUEaLZlOhzcBck56Gxpbwl4VyCY7zIKy4kVVPWQGmICCHyER8+sHYqKwXg588059YwBEEgxOWkQTyB5MUA2lUrHsAJCOo7GteNzcyQUN0MTUtbV2CgUJL4MEkmUKkF0IOzp5E+cB5qXrflvWM5ynab5LL+nFzTsa+h6xUvmE+Gk/v6wFHG4tei694iyHmrX3Nn3caSuo1fZ3+Lj1fCs/XH84URid6/zm0My+YBfoOFXYyBTKp5OUOrzHW1lPyHaPS/lWyS1QPBZMk5cHGycNYMYz/6iMoTfNTRZ8OkIpZ2qncDBaQqZp5deKyM4UeQAGuBDjNooKCzwsH1z1gbfovFuwu3F+81d2HAH5/vFmRClQ+MpghXbg9cvH/MVjfhYfw43Eemj8AJcOyIakRtr1R7v3gA24YgDADkpfBk9fMhvTeK5CXlKwNEolICojUvSiu8HMyBkQFk0mx5fOGLgKWg0veC2s24RQRr12kLoU9NwhfLWM2Gng2DITKcICm+TrCgNyRg0QG65Bdbw1LQAYBQXL8vzh36IVcwHEiARojCpoBKyldd3T3J3isjjBsFlBHtoJuwtuxm9/oIMXGgKiKkOKxuFClwiqEcpU3w0BvQXFs5FAYUgtYcq7h1kZy3Rjtm1q8a2bNFHagnFGgkLQdkubYXHg0odtLsbpXDryMiTJdpom7swOOlwyiw4c0W6AomGRrkN8itTuXgcdo+eoARXKB4Lj1AkBTAgCchUdnZlEaIHOQmx3TAb8QAFI1IoKF8gmWnVpSJsTWTX3gt472mFZOAVaChRLPawXFW/cnanWVg8VT6aX4ZwYiaT5H9MQyvNE/OFFUOxU+Df05dXRYhgM7ITW5Bo3mWrrFpFnCV5t+1xINwuzALGxP05qFJujLlTyqfzM8IWFH6ZgZAgLT3gRVOOBQWzk6854hCKwHwZAhNDgz3+95dKYlBzUlErsyunE4AvrXtUmzGNyxTRAgiCA3XWHQCQJyLcAFV0BUmSleWiMIKkFQhwY+NNI33zczJoAf2BWdCN3MAKgVriRwAfmuLjmRAXbonwvnBLUka15lP985EkM7Y2S1ZrknsEOxATCtc0rsHHdDHPwCtLoHp16L7ZleCjoOsjxkJ7HsXiUprAIXQ/P8A8J+cP2Ju9P8ABg6I1PX0LfpgNON6B7T+TKXgIr8j/FgYcvxYAD1wsFAN6Jewc+xkx1L1OINeCl6uGtJTo7FaA6Ic2N0u4o1jdOPW531jQIkVhOaQ+sjpDwr7oP8AOKgkAKnZ4B1zzdDghvltu63BTpA5Fjj8Cy4iOa14F0DnRKWx3OiTHe6vMnwaX3z7zlYexV7+XDLfMXD+8dIPVGZ98frCh23X/H/mBXOB5X2yAVXgBcJG0p+KpA9wbqFQzqahOeSj+fsyRv1YcCAtdbhgAApQdBeb4+8GoEVHrQOlhHLkoGgadQRxkVypa8IBL0XisSBYCX6s+87FzBeghvCVBdEqPcXeE0bh5+gVy0B7Zg81X0OTVAG4oICsLlMSUKa9YsprlynlGG4bh7y+udSNAUKC8OxmD9kIcHHsqsbdczYJkETzo/7lbMfv0DYFjwyS7QGrEjSGqqyXXYe8N6GF4RrQR0Ov72CjRGFJtXu1PW+s9mGhsKqhrWzwc4tqZSpQTzCZOFcuPGWJVYEOkgXiI63GFIqopWzjQN/TeVPWKHXYEQpzUP1LGQcgNclbbPKY5j0gUy7ODbzHXeNVgB5DwOx1tekvOR+4IZJBuKj4RChm9ozSkT8R2cNS85JOONVgz0/nigek7tuxPxiZWoA+EeTKl5D5jEL5H2ZP4KwkQDgo7Fr3gQvbXtlIXqtXH1MpW92gfFfeTdA6ofJFvhcYSGBa1FDwAwk5bdIGHE84pm1br/e84yBPORG/3MlKLXivjEG+75jb+jAG2gdBSUgWlYW9b11fBHPbM0ISIb5Czq01q4jUTuU6NqvVuI+t6WoFCeGRESiOMkGgdMk+m2v1jCwTGw0RKhpwGtDBrnoThAPLLaaeMVdG5RhDwjv95t5vUrB3yRfuYAcVDhcxg/xjxC9c4ianvl/jbSBBcBtKnPHLxGaqhoxsKE8eAGmIHNw88AmvrD4UZ4LASAuhDty4BoKyplgOwKnb5MKpnXEFYleet5ssdniYtAu5HvEh1XbL/HjJ9lQNI26s1vxlVFNP/Z+5dZTxyBOqWbVekNb7x26FKgXbX8nVduGktD2iCAnDTugXF0duiBNhAE7AHsXeT7kKFSKh3wP59Y4fTJbsGU1gg9qpK0pu7vHB1sMDH6xOmAafVbc8sW25CovZqdu2++mKj2ZGF84eZFY4eVwnfkzyAcPF/jJFEtFnzAfvGy1XoB1t684XQCIi/CfwYwEXmEbhWF9uNa5VXEP3fKfw52wGwW04LvCvyYBE0BgaVoeoKtiAZsXYvUELoNkAxd3y3coAg6aCRHeRlIY8euVZLxu/KAYluoIATNmA31jkPeLKDiimhQDQMEg2WPYl+Dg9L+evOk+hnViwF8FH0YIbgiF+9zHX6CoDbQrH1dxAKxBaX3jzQnXtT2Jy4XfJhkCJWSNVsNgBy2gOGkqN3dAAIa0or0lqoPPNv6yIGk9ZAeCcoEK5x1upI2Cmt87FZhcCqTrJB7ILxAhMpcVv2KR1BQg9qFIJttIFXCVYbudC6xwJdEkBQYXjvtMVEmx1wEZwDfqWrmoW+igLQe6gnek3cmSA4ilC6EIr5Org5S135IhRYkQbQOCC4hqZWig22SGa/qEWEpTp0RON2ghfI0k+eeIvFw76FlRQbWJtRArdjxS90wkSifBvAMqbUftcDV+gBv4WN2JYj+64JMwBzhOc2Tnu9YskYEHhHT/HHRNbUT1QrOIvj77RYany4L2F2U3gcqHzkxavUzYCxofOBRSJOt4hJIw54Xr9OHUk/Ixfxc4scOK1xDVD5cuML0Uv7nYvtEAsU0U1lwtZ4/BRSt5C0CJpy0oC4RWmBdUijtE5XqOE0AIt3oQnfIlSW5JFy0BdqgNUWIK4MGIK4IaZkUUI+D6We4w1rJ9jSb7fvLoXvRl5CWmrp6bM4WMeKH88VFFEUOg0b304+MkCA3cshkbdEREQLkpY8xUIO1GRwO8bQPAOF/LB5IkSrqET5D4wSW3KXnkxXiH6xUZUrQwJCgiVHRggsbC2LaYDNh57yEgKdIb1tYxHRu0ABieZqrIan54RSUFv63Z+Fh4bu57pD8qHSji0+gHtrfqEZprCrOAlbyuAtG2nFnm0+P1nO8QE3icG/wD7lWIYu9gte2HByg1uTewt6YLXJ1bDWHTamjqDI/OLfjw6+WCfVGaXDSAw4DSyWmsNoEFaCAAlfbhjBUuhNsP+jLDmDuNVuJ7QloMarGH1kgDpRUvp7wZEOJbFXA07+unA8hK2AAPwH4w4SRzysz8T0GPyZAWEIgV6AzrnKlxGcbwNJoALkJQEgQJZNv1ivSfUTSv2aN4Qd6kdNOhN8F19j1OS66AASVI2JziSCo9Uhm2M2AnN1bRBfBRNdCND4SVpqedb+JJ+cbL6pofcuLfYR6GKRdQuHWWiV3sVHGgmBYGTKVQbaImyBd63CNva2GmaXVPwUKtiOxZ6P+mPxIPGyaBNBYgI46u0H3ChjJl2MeHFuBREV6AbaQsUtYRLklCC8tO0kezEVAAYAgMWkJW8NbzcYBEgIHdvK7d7PQIE1qE1aPo/eSevUoGLZFE8zQbxwxyaCESbdNy+E4HBTi0kW5MHwHLrxkGNgEqwADpKIYxNpjrG2oMT0AxV544l1mIaRuohR2VEV6zfH8x6sBIrpoQUEfkdII7y5v4DIbnSu04eMOE4bBco7geRE/IxBTL8ihTR665yBSlQMXSWr/tZGNmJ9fF3/wDGHpAsL0rU8nEykoOhddPWG4FN4EXALfeGG30DhD9FoYHAa6TmHP5wEQcp0q3+zG4R1UmaEVdo8zXLu9oHxhCxssEgquGa1r8ZzScQgsHo+Or6wUaf17QAj3lwZ6lP0qpd2o4U89FGgHMJqV/OWVQFpsiV26DUADDaUm7/AKQ/GWSk1DfA/K1lnm0+2TT4ML0pTxiA+2dxwrNy6pRwRa1J6xwoyQYaABpOUeMQbr1C6amCkE67wjVLLgBgy3XjHAiNcJ1/0e2+GwiyCtCAeV7wVECdBCQrzLpaVu9zFtF+bPWNk2/LkCb2etXjC+0WaEWCukwF40jg1eq1vQ2n4cIGLTgI1NaX0ee83hmPw2aSfhOL0wonPyP2/ORE6QovT89AXGwkTm0gvEaPfGx1lbcZRMFAvslXA0Kjt6xxgQ4QEAD8YxNpEC408ld6CvJUkNQ7YjmpRJ/DFzCWuki/lMggaHvgdlV4HGzdAsgOm941fnG6BkERqnRXVcSdKQ7CUewuDx8pJLuPF/OGSKhI7QV9cY8MF54P6xhbNoMEgQDx2d3Kb7ACgbn8nvDHFwoBOK88GCALwwgiLqwXRewkvKUpwjlnMdqoAsc6QDlxdAu3jJEHAHgNB+MWipWGW+BvBAUN1RzKUy2YE3/HGuOYMAWujJWnC7Irqd4hc2MBCN6He/Da4YKmLnGhljW6ryd5N5CwclaBBbQOjGnNIQvRgYmm0V6UAdigh0RbEG/AYu6UQA5UqtCoLnFpwLpCcMXGxxDUj2KPiXZi7h2eNC8+PU5fOCfBqgLgOP8AOMNKI1z2R++ePOWqhaCSlFRZvdc3dxnEaVagoaiLv4OHHyqSBEGm4N3jfhcTGgoPKBseRwFryplYBt7Jgvku62vPOaAw22mw8uwUp3dTLk/U6kBhi1rgO0/buyqHsRd6jilBP2E6SiF4fvL1boItLKnrJsEW0ovDr+N4AWBCnpo6dYMaYUhZ04fWBRMPjZr85fpSObVqOzh+sWaBJP2+saZSShkEqE+s4JLaE/LX8mHKE0UP9YplUymG4KIDPeRhsAbx7qv0Y217Kw53ga8eec3Kzq5oP52/WJK0IbcxDn8ZyhI6FBoJLteOcSAevocObymjoB1crViAR8YI2IKq1OW8eLPGD+I20F0lI5Y+1WmR21xcoPyCo+YypxhZG/Tw41ESwPHPjCCwiL+CYBmFQXw+X/mFhYVdy5gZU58DlJcUU3xgEQk6mDa+kH8dY8RM4CjGwBfeDkjsEHxbMAirX0CCo37cYbDGRlEHDeE0+lYQNIAOY7wI8O3BYxQUB08195Zy4GXag0ajiNGgR5RIfDx95LtAE8YjcYaOj3jRbYPjNKFTR8haX5MmTRNesIPTNWaNYYogoWZT5R+fDg4PfHIdjmLRxzl2r6NsgHigKFdmalxZpPenJdKxa4qk3Na3EiKcMiwO3wYLcJh3AQbqKcH0xwUPOAEPqTg/OnsPDfOxzjxVLXmf0MHbBDZeQMs2VqHgnHWCAFFi7gFF++BO1gREFLZe5hyi3pKT0CLJIDw5VVPNEpWKKssl8jDjFeWrgrhRKDMI/Zuodv4xDvJzV74xEWy01Pd6wxpxUAEcQ425zZs3tIkHShgh2b76pUty0wrHMlcRYRAjWeCxZhwMnAsqDNesW1MPWzSoIIvYumMwkJVHmLtSnNp0rGg7i1FpHnQcEoIciMrqLRQHQRQim5tzCUaiAggZGAEK8DSlZwN6EqSJxiiItA5pN/DxkAEVXVC/An5/QacUXKqG+dT4L3oXxiSSFa3Gj40/DItoEVIhzYne5PnE9JAuKRHzU1/ExTUK6SrwuxIvrndVF2oVAq1v0eVox4XJGzxb1qfOUY3qzQEIQw0K0zBMPDNLybgny/OETcWUBoFQrd6dsKhobRDdFBraADe0bd+ZoCQ2BWqjgJwtY/JWKyMrpf0H84NJukn40eecWnoUkAhAmTTG+8fnVM3pbp9h9ZuqRRw3hwK0cW4q5GkNGtW4ViaBG22RR9ZCsWrhdxBzgJQPso6AU7YAcWZTlNWhYNbPnr4ktiM5BA22S9DuZVPSpoPQQMaHBErb8Box9NRZ0GqS9aph3ojZsC6KsDzfeNaHOgIqIQVTjshvExAN6b3LHXKM/Bgkh0AvICH4/wCYWeobjdFVZ0nGIRgqfPZErz73nCDFhYXr5zjyUPb4O/8AbwZjbVBAtdNVvXgwxyS10s3r34wjQlAmI76PzhQALCxvzOPRVEm9tNoJ58/W58AgIANb812/+5NgeTf/AMDOL6ClBjOY9Hcx0amEcfqwDVZ30a/5xirwz6wn7mLP4feNKgqhCIt37hrzhB3drlvSZop7KJfkwfTeoKM+TZgE6AAX0YCzRiUbicgtj6fGMFJZqzNDmG/R5xKlh5MB9z3McuGSnSoN7OXWnFbX85y7xye2hfoVwZhhxPIRfY6j4ecCTj1Ev+fx5WEsL71+nkLmwfA/twu7oupXalvh2ZVkmjrR0d4VvrDtCmMOEaHIduWG2gk3AtB1oTVOEp/LkhYAitZqXlwrRyNaK/pkRV6xF2GUQ80HCEa9GysCIWaHBwYJA/BxZu6XpJ4xRIGwn9sJuBDK6Wu56WTNjUxqkBiPrsx1ZQSxlx8JjhomsQWokJTwiuGaM1Zd8q3gANLllZEuRym2tt0giLhRbF3cDsXYfA604+LL4Cs7HIPnZQPwH2n3giucECNQ4w4M6mdxvrRNhQ7ogNopGXUDg6LQEgPZWqBoQFZAEaRb3NTAMhFlVEdOdOzk4xC7FJFWIiDEVZvkxoaKErOr3pTkVwK7jy6x1+HqYy6nhULCnGoDuJgZhBkiT6yQD4eBgRe0QRIbn6Hzg2eI0kRApCxNnnnTjU2HkuyIjyXkikKzhUbhNgXS60dS+VUCiLoKX94ojeYiP4THBvKs/vBqreKTsPRRhDW4Z8y+D+XIdppijxTFlXEnFdqc9K4hDhVpCeREMvRIYo8in84YkbAgNsth5Hv6zcHcIQhBROYyh1TLd5RlZmicHgJvDpRxIRPwn5wWqaxNceE7rCyHUbF9c0FP37HQxWYUU8PFbQBPRo4KH3DB8CYpHZWw/wBTgCDYmGQAqEDoE4AyQgOhj44MFgRbYXKB/OXW+SgXYaCtCKuq9HUkoPurx3mkWIPSGIN8UGcYKFYnAKC0cGg5VwVTGKa8Mg/Fyz1TKDs0e/WJbaOElIOgYTc2pAnYeqr5l5d5o3BZ3o6+eP3gAb3bZjp9Old+ccKA3V7lmeUD3ziWkFaZqPGttnjt6iPubuBkRCRh8hdX5MObUjEp6TZ8m8VWuY4Y6l9qv+w+M0MRDZGtu6N+HEdOvcu8PNEvpwCbxuXeeX9DjByermoBRCCqBt8qH3hEpPB2VF3efE+8UVLWuSx7B/M5QI0hroJ/aH3ju7+4gH94cK7UgO5p+zGU29GxjZPDg1Dw/wAn8XEgAIAah9YFrGqouDRctBYCLvZD8mbnqHzipBqXCuac2WUPTXBAH4G2Ddf7rIMmAUd4ABAMj8mEOIMUZTpnmc4JSk02R2qHTQUMJKXrM5moSI7yruMgYgQ1RMRCcCCqF7mG3QiNnZo+XHA01aV5IRH+sCtZVNSKTRpd8U5L5l3q7OqsJq9poWZS0X2E7GpMo8WEBzSefQ5Njwxfjo/rG3SHgICvXAaR1zkAFt8EdvAod7QvGX2EGCFAqhNHyEMLG5MlEa9z8ny5yHVi6GbESqYTQGKuA4Kx0QXzVcQsww1l5Axm43gWNhzMELXK5RRtK1rkYZdS5U4tAYQNsFOJF0gqzks3PJ0twxsxy8BzQnlYQdZum7gVJYQSzNa8zGDgYq0yULKI3ppU9Fa0WkMqc5f+WJZAwQobS6c2xWzhUnAvDx2+3KQQl2dGj+sZiJ4W8C9WM9YqNrVoOOjAcx75zkPxZPCRxOE/ZjZCdgpqdg+skFQAgfjBzzHnOQ5/K4kKyG+gOshlRqBkPETp0nfBYbKIqwgDHLx1xiKEC7ri7WQ5FQ9lpgItQjUaKIEv/wAxDQ7FAVqEdVYDNQNoTxsD+SZAyASEgNrI4m0SFdUG3Z5B26ytdKHBR7ibjy1kkJPYSBiCpkXVmSyedoiU3PAzbrIUjVwW8QiGg2ZQUosHrbeOeL84APBB3xo/7+8feCQb2u/1+82GQUOtf/MZBUUdaP6yRRUh5MjTJIquNx/OIGkpq24whAJIAlMNEpt2fJ5PnEnm+TsBX9GBA5aHsjo92fvJBLMIOz0U+KJ+sjI2omw6mzXZmpRCT3kxS3D7bgp8XAZHmDX4STLFAKl3Pwdescii607Wedn4Phzb31j13ho0IDpbr7s+858jm3g2xmiH31qIU/It/C+sSWd31Yfyyp+ivxfy4sKqdy1WAEG+V6znxJcxpYoGdZcA0hFHXRvAoJF2H4EOFESoYPXl/WP4oVTNA110bbjLtN/jBjPESabqTjJJvRu6w6BvnVhoVjImkR58lw7P8fnKBQl6N6xrQreUzPUnTqiNtxtig0Ctbz009RHrKuF4xAhW1voNjxZhYgpwCVwIDlYd42Fr85ViNLyZzjx76clA4BhTyTjA2JJwEKfza4wBfTbo0ppb+cnwkH2Qg2gCgsI8YSnvtVPA74bgvrhGZOOf/eKmNITvYDXzHL4SVKGwpkIXlkoQaAzzro5eBCMe7ksgV2hNFxVG6j2DXW1y1UutkYEwJwvXLhUz5qCRLGhKg02YWRDwxsRSdiMM08KR24RlVJhoYu7XBoLM8yAroRIr9uRSxrS4FVugGoMqGgKS/MEHW9qKI6Bdp560XaDFyl1JVHSwcro7s2Dyp28+SY7VAx2p2KFBp1zois4RbZhF0t4Z3tPIKqVXoCcKkKwmGjPEAKB3oIyFMGIZsYlC6bQBN75dxfxQOGAHXWDFGqiRvStTtmMV0LdUlpnYjreJE2fpa8rxInI4gy7WdL/xhCyAELACbSvGeIl9uv8Aa+skmyLW51Djh/GRQSxATmotb0C5xHS56CnqewDF4yiGRPmSJaHFreBrgbyzrdEqybMANaUDrmX7MYIgEN04fFDKSBvhDTCxLsBUsaZr9vnA4Tgep15BnaqGx3n3moAKUCCanzlUUWk62Yxags6a3WGoA8jbT/zGZl3b0YfbjFpXn+H/AHBqR7cAOergwxWR8YpzwAUVJYzWuNawdVxD065/Hj5xSju153/w5QBSFFRsDeto3fE7oeAR7cmQFCoeEaHw8fDjC6KCFWVE45eOP3h0H18BmgYacSb04DEYFBr0T+jhQwm7O9D6uMh78bv3X4PlzS7OMAXeJQEAgAlW+xBPCY9OvJttOcSag+GbH8nG0HFb5/8AhlOeFPlf9Y+GB0znxv8ALmpQKNlE3fMxImrDYwrA2c4OnQxRPSmBQ0BpelX6wdIcMna2AvLo/vLirckQW1wjsPtlEKTw4xFEvZ4D8v6//ElI3PCiGhLVCEjbcSeweTXYUSAABql2EMMaqhfdVe7gO0VOHBFSLab4YQhNDHLoMWdPeCKwYJJQoBo0XZeMefaVbHBQFa7Y1rBZUrAcIjAlfkfVkh7UbyKhe7dqiwAkiIA4UpTYpJGplAsz8CV6oIhTJca6PUCAM0BisHamOJYrJogNUFXluE9Vw9A8cGhyPeJfkHVCXInot7uaTtuaoKCmocPG7y8/9RKe/L2PHSURIvWgxsc9gihCiIU4W6x7aEyGvywlQMmhhaDpmAqwrprbpi8VMooFMWKwCWi6QgtWgqXqW6jHEJyeRqt0W0E07bF7Zd66GG076MDnR8s3G1N23+0AH/FrD0s8uHqI+auRANADUV8NFjDpuWigo3RgWG45LqFAOtAy1WLuD6pKhIjsOypuLt1veWNC2O9X9+scksGAhIBJQovihi2GwSGrJQMAzbS4kNrwJVqghU0LWrDdyLItUYPS6cipOwOIYqQLPIJZ2M4UKTjj/VxvdAMKq6s++ZhXClZkFKFVbKBvETvRlgpU27DcC2DDDYTurOdm1M75a5RlfLUqgi0K6adN03nkXuAeIm6IMHadCzshSF0Si3XY4xnz8B0pxYw69ZZiiibmujT+8Sdez11juoNZWVtPMyz1yvqTLNAE5PnvEUFLge96/ORJ8gCEP5wXMiVECk+n4wDAgd+v+mDRiL5KP/f1ibkE/wAZvDQFPOts3384b9YgOYIH5R+sXUsODGGzAJNIjfm68Y9jwf1hUoB1KBB9KR8i4V84FFH1E4y6Xa4TiCdWAReCchBS7cVVBzhCQPLH8sHIDvQBHL4MBGUz0PF9flcQFcmsBUGBwlXyIOO6Cs7f+zCaOXugD+MoSRQvooft/ObI1uMDYJ85gbdnkaRaHZSvziW6I6WyAC74Zgb25+GIdvrWSjkr+FCYJV07aT5BHpXwYwI1ri3EqCdLRo7MvBI7oYyOh/n6xDs/bCdMcsHQDu/5gLltxFPXGPmwpZ6FcoDVSDdsXBg3WxFFoAbrm1bqRgkD2tXax66YJQdacFczUk1iZzXcl4MRJOp1i23IkHYoRnRMBlaCZSBGljxA2K98HwOaFrtvq4xQIaRYb0clzmShqpIBIAam1CV55BMikcREUg43rEnRMieHEayKOnmfYjO7UNGEmCJspseIKI6pTXQRYDP8HAUEDNAVw4o8eiGKQVUtm8QYtBoLGAoAAKVK7ZiA0htQqe5pfGNYYW2hZsK9PXM2qSsgizXfWmFYYNu68ZaQBPbbrjgBN+cJAkFVEVqG0ZVFlRqZAJBdsHkDYwR4E1pKcO0BLVcNu0elQFJC01mYCDNceIHuyAjdd6CIrAXQTAuHnmU2LADdoACg7SOqJimioRlFAzQbPw6y4LAbXKgHU4WOmnIbGg+rsmUu+QjEgbdgCaYPohktKrR4MphBBZM3bqMIJ1wsVHRHhuGnZUwQeiqHPrC2xTRpB6CY/wB4ovRQvggCFSwYgYmMwxBR0uY7txfSgk4IP0gSpfYePhganSWQU2LqYmNBJaFB5IbdRAhAmvKeAFA0JhIlFcRIUJWrUitV8n4xXE1AkCGDRR8h4Qo8ZmqkoRJGCLBhpVqSQjesthoyhGEK8bsAOx4R48IgNI4F1p2nQzXfBwX1qvgLNKQvgO6rcwQBpuzliYeHxm9STdRsuWY0N56cJGQIfC/995HbUPwX95yAmhvQUdfR+XFBRVNTDXCh2XX7wARulgtV+l+5kolhFxaiI6MJoblmSEkvrLkQKJoifWtni4R3Qm1Hnpytyd695ZojGWhbJCgp1TMI/rH5JGpR10i3GYR/CrAHjpHSzcimKA0J5AdLcFTbiqzWASgjrj94hhIU+YTbcdnp1hywt+0f95cCrcUOeFhjHyRlSKtgQoowywM8c/sDwsrMR9WiAsV8OOgRvQrQ9bZMioY43sVZSjw6xeVtAlnKTXw38c4SjykrVo3D7fnGClKSNuNX3P8Ah8rFC9m++/1lIIGw2wFCFYEK3Ji6qHtwiHKMK02VVFFp8GaMLrDeox0eCsd4jKyXAZQgUOjg/GCicrQgY/53jSipQTXH6wAlkkAFScI4nDtinrAipIr2nQnZXBXwgIEhkrKqXk6xIdd3mOdSaCEVhvDb0wCI7SpkULiXBg2pOBAcKUd6JikLwUIzbHjsUFwuMvOqqvvR+8fHMdqDCrGPBgRXYEkxYGh2XAiXGn4HBfX4w1GCzGRi39OIVRi7CHmLL3mhwQsEddARdsLtw5LOGsmgUI7sSAAiaxiiBFoKPpvm4IznaY5HTuEblLstip4IDTZKgoqsITsTvGMIANebu8A0+T0LYLsIg6AeaBywYtjBGhwDT2IkUCBKyqUiloO2MwN1gYKJNtxrXkw5PafuRm4KuHAhsFaURvdg/jje+JaUPweXl7w/OlAQGXgDfcMpPLlvKv8A3zlnZI2oKYKQ2dHWs2SdmlG09KOukGuMumE6Xijfv/3NshKUPY4Itb1iuJMdKqh63l1Ro2kWmrvIxYCm+EBCEjgRqboQoY94gwWe3FUkgFMjPCz4DJL7F8vjItpuKzEhsI06+QY7pI6kR63wcNnSYQeWaZIA+6WS9oADezGHvzwpEhXIgNFFhFwG/wC0GjYtF4xy+OhpQ0HOUKCO8ccfGyPgg1KeMKlDPNqQIodMsZ5xyN1oNLy+k/WIOFCeEBErWn9hlnQZbhxX2b9nnCWwK+M0A/xg35WzoKMAUV02RwGuseuqh0n/AKURzbJJHgUX+DKiAAqJfg5yhmBccsTToinCvDllgoKCDAIUIpFKUPeRKUbJQE4w2FRdFCKCCyCkXcuAj2a0VwKid7jDkvZQYsXorSxW2XnkNr6WpYCVCOCFG8mWGm4tSPcAeb4GYFyzCPBCmmzwbiwL6PFHkN3tjyc+QKQM8K7+BzYazg948iRBvn/phKe8NmLUTgKs2aHtlPCRAb3CEf1c16RJF3angS4OWIXuoimlagK7hgz5/iGCItV4j0ZtmapqSK3Zr8YMRaUaOl4enne+8Gczzcf7DFWiexxRVFnWMy2hKDHalqvV4cjeaaptVmdjYAKYIMF3ZMPziKMpg61BgfWAromLlJCoVDKJokJBuz01mzpdY3GGYYtUsG6ckTDdkBlIv4AaSaBjeJXOupJYdyAk1jurp0SU9DdvA3hgS1H1tgd1A6diwt8axVxoRlU6eMFZwlOEmuOg3WFo2e8AFEBUNr0MfGeUklHa7O1W4p9UYWxLLwREcveDJJSr2H8uLIfvZd34MZFwjjwOVv8A94w3WVTyYqJAdACooTPZrr69Ss9LBYdeTGy72ELs4NEpZXPh7IipNaFAq4baRMbRQQrQO7smnPW5wHU2Py7wdKByotHbHCDqYDipRTrCLVbXVux264t+x5yCUlkOLpTxzBRlFlcq7WcnFMHxb+sQlKe4nU7HtzmlD8a4Cx1FGYg6SBQeCAFY9wcZuoMqtS0U2DUKMFxnYhSA74XPvHDy0CNhDoNOnl3MUokCxaA0KQIUctCRWg9gMB5k1xkwvM46tJS8yjEjHFmh8jaQ6HZrt55wEqXcxDaO0sxY5JAqDSic1mAAqWEQ1OUAPsyOwv0o0bsv2QmEvOcKOdIgNiImxKtILQ8w6HYELQjjDqJBeKNDxoS8MiRA6csVQMKRQHjbkXRnQO1CR4aRxDgJbrnTG8AiychoANKcT1diLS1fCqVbFIKHj1rvhMYqMqqME+HgISVuOFHiEKLqKNDQQ/GINoMimxEEeE/nDLEgAaod2IHgitagaO5SKWAIx0NeYYjsTFBkMnh0u1Hw4RrSYhoTOadJeWPZXAqi47TVukpC3SWIU6cNpIIL5MIIPZIlU0gQnA2BcbGz1uZIWQHYWpNTNj6GNIpEQKADo6mOBW1keWzkbDdMAWjhIogHyNDpG6VgYflkjUIebWxAXLbBkUbko2Ccx8XDp42Gk0C815RhdzJzGVDghqIDsFeeMPKCZ0hCiyiRQpLaka7ewkIlHonlBFAwGIYogQqG1Cd7wsCh6RQunlvC6bcBLtmOvyeaFmEAGgwCgMVpGE2GAu0B42XJ0fjo9HgdCDpMEgZZAEpePNd7XBL1GWr2nPCm5Way1KSp3USDSAo7OmO4VQI4WULNfnECKU7y/OIn6ROvYCR0O3TOZU4EgSagtEQHy49RitaG/wAbYJ1bPpf4yYlULYQysJRgeseaGUQl2vKLDaslXNdAlkEJ4q6OW3ZceIIh7/ziVeiv7OF3AqarVPZyOTQ8EWkcaY62JHEpAMuqC9u+KpZEwQjqkcUOo7DzesAviPDBZgKabpQoPvuA2ddpEIdE3vIgipSThExBSMMhLq1Gdyl1TEfyC4oV4+eW0gDoELapmnTyIDWIXTNql3EutTjAvilhtF3sHpdeAGpDL1bERVN62wAbMnbQUQtUae3Tmh3Jyj2wTihosBIwWDaUERVOORwdAdSgYr8hvlDxlOMYO/EXQ7Je5vDDKbQJRhBNhTezL0C1D1tToFV4BwTYdRef/YwWG1a5o7X7/jBuuNKGxUfIszQ1y20Dwyw0+gxrgVjZ+0vzMqAoQn2Fq6eT2cA4+ilD5xoF7VJTATa4MPYmPRV8AYQGUKMRVkX++6BC4qdN8nziKgonMv0+fv1zi24kNN4BNFfWuklH8upAkDsCcxY2F/qpqIAogERiOD0aVl00740fkeByHCpK6b9FinyYXFGbwzDRb7gPhsDzdQezZzz+yhxg12FcqO7HNyTw3DYFphqA7tC38AYg8LCpJ4wdoSNkM5flfavOCkeeQG7PLTfJiaiWFKgycCSbkXbjJszu80Ip0c2R5zQvQqaPUJNypo3hZhxDh8/5MV1xP0R8zwvASbc2ukIfRiFEd89ZHorhWkoxw05BdRjxoCvbzUAm2KhwxCWTGEiA7olBjw0wn7KAlFOURJjTm1kpHAIIZGSTejopd4WBIDEwaDRXTo6TE8tQzsQPMBca5FmJagiySKGEAbgkGF1cAoTUKCAZ26SaIOveK6Dja7LArg0gjpgWhUGNAkVVBgcCE8taq8p7EZleWAmzyNqQ1kOecXBhbIGqkK8sZtx5mxROYgJQR2DT7TnCrnmLsazSvHLu4AoKBVb4gEoUZUckzmYGgTbSP1v3j5UuBISVO2QPKfOC1g2vKkNMhpceoJz5XJNpOuilEfeF8Th2sggrpsF057SPmmsZGSGAgqw11TRCuWkHRicE+PgLvrHIxQkW/G+8XrCyHiETAkNE4ZVIkgBUMAoB3fWLb8ZU51UbXKvggBN02nAuuuHWDIHBtb15Yj8DxnGlErRDSILHWYtM6aqnFL+Va86z2PJ7QH+OhwdspHmu80k8rkFEZj6LgAvitxErhab5KpvE5CexEQcc8zvouaxWiXphjZ4TvFH+5UAiM09iiSGm/qqEDyKCeHQ0oy8YiOVR9gHR1rZjylwpwjymtw62mNFCkb3/AH7XnLJBFzK3GsS62pgyzUWCpNrAhTsEckgaFJtUkE2VQVS9DCOsiaUQ0J3kk4CGIUeQEsdXBsmxEloiaNB071jT92+gbCsWitN1EXzZ35QzYpAaCRc0Zx/AL9ZBOcPHQITFEAQEFI7QGS/LJm3LJQCAPa46HF4S1OmjrU+083tiPaFU6+cSxKoBoAFuqk676CQcBNUJrQcTOgwHQjGV4k5yqhFS0AKfw/eOPex5P3iky8pRu6R6XWG9pBclzrrRGqhhOtQJrADoBHdmFEtfIP6Qn3gdUYnBadBRd40cMHNsJqxDXI+cqPlqFDSOUJxUOAmFZAsDsFJp9ic4Nequ3YDsUTfW+hYpYnYHsB8KOXAe7JSPhR0E23xiMEBzBNA8r3xx4WNm8NJ4clvy0XRgITbWLVC89OX/AE35w1xTQhrdW/l/WbsG4UiR1hCsATxtkqFwq5Gj7NWHnuYHDmSiQMB2Kugpxjx6jYopBxdW/Rk6dJi8nFpypH84Bai9yl6etYTxhAi73SiE9fWaVnBAiyLYZ89XBWlLalat4YoIAy500ilZUQrXzJ1jSsQrpy5ISBdugvIvSE1BwTZN4tdLlWh+A0AqAeA3VPWCSB2JXldOxENTkuuN1CZrBzkrp0YF23LDEAAUoFTfxiSpyWlUFrsTzQLxYyDZmvIAiurkVsbrUXRtoojUqNYzGvOFQdPOyJt5fWa0zAyldRlBsorDC3FRMspRsGzwbcQxQQkKPbpwDTRNiTQAtCzI2b1gdLp+Q/BkIRAAQA4DHvbjg8e5Y8C4KXNHwIAp0zYjqkAmBooO8eFv12luVsK8nYTd3BzzRWP5Cc2jqmsHfyO216x1syFYmJ9svDRR6oSP/pjs7NgEwnVdejGZ5H4cOGsAJLsX41yS8Tk/wVm9PlzBbJMTF6AAp+5j2IzT5McQTkJk+K0Xgf7YZd2AgC1s0JPvO1nrjgBtg0Oid4xtIK5vp0usyJEmEN6KelU2UAPE9Lh4SWIVp0AhPc95JXhwJ6jkP6QecdhYjW7PlbPgweTR+jOWzDY74xJTAEhZGebE8BMKlkPxhzUJBdFTNkaQyCpWGIM0S436tcydrS7AoWo4OMlViFMaikDGwYh2tFYoFXaAokwOiUsgCySXZ0CGFaWhbStgQqgE5GJJ6+R8tSHtZYYCR8USNqnZVz9AYcyaq9BfeYBA5OV6vREeQU2QDBIHBwWNKA1PhNH24M8glQKaaaMD7idx6oaqZ4C9E0K4vnypeSnc7sr2KyJC588vx6xELaEv1vHMIoILUROP5x9hfHW9EvLOkMwozUfwNPGpqvnvFkPQLgpQOxW6nszf/Rsa4CeLu+T3ibhRWFQEvYCtDVBhXZOAKgaJCbs55MHIr121aqHotyrKtDYhX5WF6WtdShWU4A8cbIR4QhcrELrZ5d2d4xUk8TwAbm+G+zFSjQX1U3xLs48Pii4tnkr+B8NdVGgNgaQGvxtf+5KkXoFd8OzjDeYGhvDWx8YIvQhFDqIajgdkucGaKMFOiCCQhThiylutURWdpvoGhidxhG9K0iuxOdd5S+TBCI20NtueuHOG5SoTcZRdjHjBwN2hQRxcYhTxcYqBMjcMCi7MA7cTxVXpBWwiNlqJaRgYM0XkJix6fkxbLE9coLpADi8+cA1GQoTfZdpxq7YAdANmn88TojscWoDtigQ6Wt2du8upQaKpBHs/l1gEN5SrfIvrngzVcOIpCEHJ08K5MYAfAijZoObx80iLkVAMihB0AcEpEM14KCOtLZk2Te1WrBW6CHcdIyhyaAt4MSsUXVBPh+M2nrTTyFHRQUADgylyKrlClCukTCEmIGUgUh2iNe/OPpCQeIn9ZAX6YL4Kg6KNIjEdZWoos2W8wXgJ0GUYoHsg/cR3h3eBz/J9YZrzmvnfHP0BeQbOtEbCkLoLCpGocXFpAc6UUGdCnvGKavAFU8GVLxXAaibxybg0gia4xl0GnzwwqDEJSBSEXhcfbCN+fInHtqaxOywiql3oN/IO8NOgEWHxgOWR+UL+8TYlxc8q9jMqxvAkKQ8lJvnAWpUMpSiOOQ2cbwAR4kwFZYjQ6yYXoMLgORwopIMcBB2ac0IeSHUfwztVYBIF8Gvkx0lnBv8A0kZdADQsRcaVIACgDpDYWwqA1DmR3eRMoS4NMZJvU4C2lVVDRU2J7msQRUxbUs8GiNko7IINAQQKm5WVw5zaPQEgsAlUa3AdkqpuXwiiHE5yUATTRtbIY7SZrjRXAhsFsJjaUalsdHa7MU0M8lEuHmScQiMHVvGNBMe36FU2JfgBzh7gRKW7BNYQbwNEOXvAJX0oCaMBV5Q5XY/OMWDHkaZErjAEQA1J+fDQKDTyJs7kwGPpOHvHfGT4BV4aNC+8diJtJr+IXaVabAGfcQlEEEVtF1s5xsAm1BbukOWg0HyZFZgGaFU9jy9TACFO9O1/TjUAvuqCeeVwcgRIm3kOjCp75eeOPzN/OeOKtYFHcFhTkNBIpYV0ByuFTXguKfBTGEpqvK8swM9EqbdJ/u81PuLpcDNLggpQLjsAcex2dCHdSAKPG7z9lUUnJ4dwgnBIQDKPI0Aqbx8FOVFbKsGjeLvJePQ6BKOlbFnfbxl5qQCoicAnPXnzcTFs7SgPDyq2AcXBK+gm1IjYgh09zGvKmHAWANwAaHJcQU6oZdJyG1JbuwTxISiBp21vHUMcVz4LrFAaiaIOsdF4NIeCATwDcVIqA9hFoC8oc/lwBYNCGge2Jtwq01GjZ6Y2O8MITIdpOpe2vGp7xnyRQUSKg0ju3g6uIBDPtb4Ne+Ppw4iTQGk75c5qfkIR+nHJrfn4ZFnXLRBug70SCjuuSyRTKQtb3PfNblFcJFSgSXIeX4MU7Ve+xh5dlJXdL0bVcB5gtPVSa0AAeJFoF0rHVVKDVFVdzu84lMpGzHrHhEtIOqZWUzeJvChvjD0wrQl2cnyMbV7HBBUkmuRiNxOnx0IDNgg1d++HhkAwA6CD6xIuTVmpwAecLgJoaBa3Z1PxcAnKM6Wv0R8OI1qmVPGU56Z3iwvkYlDErh6m0mOZ2sMRLc0LwTFtVIDfg7VzXEE19UH6y1JdfhhVwqTvQfyYcNQs2Jxg5jnSoAAbBvy45LcUk7Q1UgdGB5rO8Ct4dxgaA1lIMx39wQrtFdKzFxBRhFFwmwCCrgO5DECzcQsUprsyAFNilBr0EQpoDhyHs89kXHMjZpAkkwXMmgom8ACEVPJCRoRGATQXlNYqI0nPUIxtA0RHR+jKA7BIqN4F8nY9KXXL3RG7Ub4w6bcro2BpWzUPbgVmt5ztN4BpUlawJUAXoOx0D9ecSxJl8mp447WfyaLWgxMVDUtvHjCnhA0KkL7bgGilb2D+B9WJvGjTGcrLeCG8Eck2EBNNSGuNDHWU1ZvNz/N/nAGmNEP+BjDwEZOAne94YcHKXHCnisSXjH9RwSrcBrnbi6RYVpAiDSG21jxhdVBw1Dh123RcaPHfKKlXtcjjPOjK8/8Aj1j0PVq1B5UHoV6yLVBm2vFAA2ENAzlcUWLG2RGOYqHy4Kn9xAiHs0fPjFWHqmtcKgV1KRSoDFIgGKj4bkxNb/4wrYuD0RgUaxB3OsLkiXghF3HkHILEYwuXoKGhSIrZpA1I2UhAKBbNqcjgy0ituqU8EkgvGANQsTIKFa6gTaLCiWAHfdibGqytmuHKVsfDSbFFk9bvNFiggkAvEK9JPgfFWY8oEeUI05XCHP8AhtVNAAnCFjIwBAnScE3boUtNhkwN7kTYBIdEb2OSm+vjdf7HwHDIkwFzhBQAo2Ws48UhgE+01nTTbBawk6GI8yryeygsvoUWrmYEE+9Zc1yRzSFTuOy0KCbqKlQldpTcVQOdQ03RQQRxYvdfLgytI7EV3fYnoyq8QTQid0eOH71lBdJo1kYRJIJ58W02qdhNkUk2Ek4xMzR1bSNgZVo6wwuCGNQaex39YXlYaokyORbPKbcJO16rYaD32b5mIyYEjSiA1V+cqhdZVOdYv2yzZjchjLXYlHSCYocPL/y4loxCSam7/Y3hVG3XyH7OPZUxUAUr7WB0GQXYAzaAq/XjDqgzg9byJrYamsDUZNi0BYCICzdgqAsnywjbl/lK/vBtOgR95TZU03pJgsabeSlwjqz60C2BGo04cE1QFuwI0Egu1RncEXaNG8MQ842xw+YNgZXwArMvnZ74aEFumvaTD2PMIIQk64zvTAlG4dxTSaonEaLgRyr3gAwKdQ6NkG0Z5irFUnAp9GARFhJliR37aEZNLaXHRBWIYwakKjoISUAm2sEbXveIrRUA5V4J5XLZcEGHknsrWREAZcZ6QATdpTdHYr/JVoTAjUArtQgERHTkgWQjoth9BzxgmoAIhBNanxgKxWOhesrkztr7WQfbFZUoq8obQBHQOOBF+CKtvCUY21GXYH7qwrD+wykDCCrIGOY0UYr8lH5B3gdDsA1AQSHw65ylB0FDfjQCgXgyjYiqeleNna9ZT1MA6F0XW9YUjGidID98khXdf9+Mc7Wu7pOdpAxbzYqtiDyFvGM4YnzIaJ2aJ04CN0C4QHIojfP1UsBWDbUB5UKIlXHEXVUpybljF97UjQrVIBwo06o7Cg2c4DftDJKA4VoLze5sEuoCQJyG0hbGpASdTu+tJMXFwmjIhJ1pTXO0isRZixHwIlGb4OROC0bBEVSBu+alGXCWaaARSDW2tNYMMqjAnsRTeuOBuRYKiHNkEASsg3cmELo9Gk4WlGvcXrRjS1AJdm3kk3+TvDxzh1/AgbeAu+cfEH89CSoVOIQOMOS0a0bIOIB2d7dhNQQnnqiAYhmjGc2QQj4c8JFSg1MQtDNOYLYvcDiqMXGHOZZyqqBsES4AWiNzEdpOJCeXRhf0P4IUvKiEq1GaLp9G2BTomgFXqzAXvVARhSMlFGndyy3xlCIF4Duc+esWqFh5FTrX/TIX+pAdDRE0OIRxNM+8cUG2DKKBqvAiaJe3WNMxEgqRrwEtvGrg2I4DWJIE3NcDjEmoKihay2bN4YGqsgBU2KG4sEcaUB2InI4jTEOsqOTI6w9WJP4wirOcXeMYAtVH4YB+HBDpnc1HXsfnAyPCqKqDgHn1l0MTWpokLYRF3TRheHexagE1FWasMR/tauKvaxcV78sNMxtMrRxDN37gy8H5uOpKhqD74PvFTdkNlH5GA/Igexps5U4fJG7AKSiUxQBPURKk+cgSznQ3ppg21czHVYglvMpMQkdQLGAQoUtduHGFgJKSMAwUuqLTKiADup0MNiaBNlsSzCUiVTE03eznAI8QLSq4RQ7aMFosi47LTXQsKWSydGvuECGeOvO84ULKoCo8keHohOCZBByIzcOlEHbkFFEU2JuiUcOsjI6S3rmK10aBGzWF4DQKSEgLpmwcWBwacJyUfuv7yArV911msZZ7n/AxfkRShNDxvYeDL5RfC1QBCrWBmuUOiM+GPz50BCmmodZF+JUgZkWcCBbvjGH4WWdX7Yfnzll9g2NC/rrEhrY87wvc/IZDMh3sia45DK8LEdREF+RuprFIWJVbUP8AgwiVUkyK8N7kA3UxYnGjiaCSta7NQ84IpWYVdHnXIfeIUHbwEDjnw+nUU9chlb4eExQxJ3pFSNOhaBVatq6kMquA0QQNOOvMQbG1utPbvO/YIVHJKu7uXlXBRa4k8ELwQehiDsyu/Cih5kfCYy0E+0R/csVVoQKE0AVVoR0Rx29QpLhokWw6Qc7kGgkErAUBA5cYV4xQbIK0PI3u+scZNgLMRorwfU64wKcDITACoDlvHO3EuzEM6UR7IZUxu2PiSb2XKIXV0RkaBjAQiiLAQ6G9oMzDw2cPRAJpBoC78PnoVJqggDZVBKGo5Zs8wx1sXe8Z2hao6A/QN5vEMhUoQgzQBOdMPeBhzZYXEASOZA4RckP5eD7XqvOVioqt5SB+UzXNDT1gUKOm9pOTLVNjOowK0AqwYdajArXk6wQROHHTxh9otu+WouVxvQg+NT8nCPMsoe9XCPuygE2A0xInB4xV7MkKhyrsTnHwXWRhxPYZRO/Q5iNgACpUpAADjDTbg4RTesRFhEAIhE2hIWsETs7dYWrN2MtDFXZXM1SDuDTbnHA1rfCHkR2IicnGVQYIUOxR+Y9mLkNNI6H8ZvgALH86feL6a3AmuwsOtN4LXUIKTZ8XLP1bQP1/WISa0IvQrdg+kHFyFvLPFHm8H1mw5ZdAoLlDnA5GhGtg5qusjjAojIw78YQMyyI7BgA7aA5zdyDISIcycbpubxOlUfZsFKLN7Q5OVczNaGejVCaOlji/Vu+Qptw7Jp1MLSgJg4BnvSqrzMOKmapEqAJShAFxb3tYyMRAg0fOjrKCMMkb75S+wZ4DjZUY64QPFBCUGQlCb1AgRQ0xoc2a9MUdK8oojpHBGbt7IHIq6ovjNx/N3A8191wK8MYkKGKiocq87yYAaZ0F+FoTnWOR6KaW08AV6LeNR2COJRKXA8OJesj8QYAFVIcczL7S1+zEq17uogYVoLvuxz4HrHVNUBBLZp0bN8nC4r6Ww2T+MQSIagxgocjPHsfOaXisEZVfZ8WB1ivwAYqerz5xhA5HjR68XDnRSB5hPBs9dTKeBHQnyeeXrIyCd/Ow/kwIASXgB8/zhaXUWHJELlBe1cgBwQPkR8wZq4Umj1J7GR94P4AJxAsOaLWNhiaIjEfMwP25gWQ38ta+hhpIZ1enI4JptbOTam7RV9kJoC0JrjEEIjOqib6a0wY9aiMeyb4+lCdo4oirsT5K9gcgLBotUIJiHUro0qpXbJ8jSV2OBYAUTrYcskVihsUsQY6jx3hPtrjlVGhC7LWsdY5fEdxFBItXrZSHFogDSWBSZBALQSqCr6Iq7Ho6aOkwF/2DcBglTkoorlhBClIMCIcteYNcTnc62znCVqLwxkPKLuL3irT36wOdS6ihRI/mB5Y+ObVLdsu5wHy4+5sbkOJA3WPWjDlWKsPlHb4AwmyRgzwj2eGPw7vOaIA3sNE4HAQkI3dNrzALu8ZX8KEgoO2o8NVmsXQQFApGmkeoYZYDaQM5Eh7hAc3CrEp4KfOT7xAuEB9f2oY+0XIN43vCYGpgNDAAbLwZpWY1KlXhgkNgju5cEFUqDzjMNh0jw4Vp5MDCI3yIP0YvdujC10Cbp5bOV7DSHJE98j38FUEb8uFbRAUR5HNoMJBheL3lSlFNFvja/Q5UTwRVwgSNdmByZqxu8Uv5wACnex+Th+8C+WQGIuwEKrfgIdYApR08LafZonpx82kXRd/eFgz2ijdBhFRhwqdFPv3ChgdVAzeVmqM1QNQQ4FaqiZNietSrcQLeCKuBL4hjAEWG7HXowdkvZYFbClAOqkGt2BhocODoOeoaMAO4zRSbrkeymk5FuzWFIFFENrsV20zFYulAyCKDwA9GN1ssJRESAoA9TK+OaSw4Oyj50ZHzCcSzSlUYHAqYgOueegESlJEOeTDBknuNKZVAPmpEzQBerrUaphNnUNNWgI+UACZXYi1FDJYuGdqTrb/ZYTQWxb60LsVhaTnKCgjbybLhelRF4MKYrIAJdD5YUUGesN0qKNjREbwcTAokVXA219PxgB7rsmSAcEiij3K5sK5WghF8IEx0TcVymj940MtA0kvyHXOR8pAHsCHl3w9kxWIwlIpDoDNnbEhNiSCXgB9Z3IGXpNYvhYnAU595dNpX/QZt4yKTo8zSB08c/jKv9c8j/eN6ifUw1/H7yTwjkE4AXQddY10vW1zylGHsAIiiz6dfWhzQCvU2KKZHjX6UgIuogk9gC1RcJ02IA61djSWMDY4ChtpQg3vSqkaxN04i0JUh2OgVXFZIA1wU87qAulCYEDMjRGM3ahqkaEQB9aEI0MXQVtluJkKbjLKrk6LSvGjBGPE0fc6GNHujx1LTNKA1sEO+j9AN5e+JEsOM1TRJi1qse6BgWnXUntUDW0scJWdbMkak0rzQpfJS79IedaFEFBry70PCYAz6rLntYvs+jB3cAMA8o8e2v1kp6AoNeR4fPrzngq9YLb+QjKALQ9MLgEgwjoLAbiRIHYSz5EJnkDvY4SmTcEfAlXbV3vlFzmwjLSQxbWjnFkyO8WnJXQQTp7yoNRKDQUaIA5joMTYkC1yKnog6GP1Yp/KBfaFqMwtEjEQFwdjwx6R4TNMPmFwMbJETFYul5LgehOz7MJDORigAmBOBFAV8YM9XPYiqEkhtpl5e4VaBj8XIevOCWmNHRgARAm9+qzLFxeIq01srGY4JjWgIlomb+GKVR34TC75SgS43du+sRLPMAlFMHNIm5xcP7VSbvvg/eO6MMYFAQBpsujBUupZfBHKDwDflasP5RXEUCDQCQ1sKfiSpqkAABhAsBBxP5vVjbFtimw4gomFNjClNJPIhDWsH89n3IBBOdmlRoAAhRBblUTegEFvMw3SwFUAIrYrKrM+3kAAogsmgQF5QSOje2tWh1E0bFrij0Iybps2hzR3ld+o02PAPheSCCKyNwQEi1VDOy5DnAggTZTgFTsQqkbNstkABpZv0ONFqQVELpERULADC3GFLFUAIjAnATEnv5EkQRjiF3rRgAxiJQbfKlT5cEVrS/OAQF5cVT3fItXkic6zVhAMf/T2Y1JqL2QEBOY+snJNWgozwBA9IPEVPMEVvy6D3ZlTHdrQ3jBHBBbpOHsaE3ea4CAt9yDNvjAcltoBWfZdfwxGYZOlN/wA+2bAC154zb4rfLf7MlBCKcB2dtI9C4O4keM1SZEjboWMsGh7Xeqj2ddUvKIkQEG8Pek9OEA1NAKNVBFhPjq4l7iQ8iA5Q28Wh2ZUVeQFIgqigIBw8hbrfBkMloRMXlTbVIDkpjBBCKpuJEOSC/VhNqcs0zqQyf/EkJKcr1xLaaHmzyxJbGyxRexXQ7vFPAScLPKAhuFSZ5k3pQqizGu+sWWVIHcEtcHQJiN3ETbuwRRb0JbYarpVaJsPYaNesK3RAulLASt9DeT8EAi4mBNVG9lcHKTr4pHgCGG+MrzEJreB5Lq148jm2OBQ+Sj5HFDGbAxawSc8E4zhQ7k4op38/nNDNCT3wEH2PzjAWUWeL8kIfMxDoQvkOthvdD0I1YJUrwVUMU7QXu5pk3mzykLd8uREK1/QkYjOFBg/AH9Y1QhJM8k8GnRQqgUpo9jEU2j0Opomu4PWB1/dzyr7/AJ9YAG1EQCPQsfOIZYEPAj/zEnA3aeuPW/8AmUSEnXQnkmz1jXG0arILsCxgrGYbecDhxbQUFbBZjd4A+OsjA27xV6xqHRoarc49Pf7x4DQfo1Ixl3tjD3Aa2F/k+eFBQmXctfB/t3eagnBppuwPyz11hHfXOpgNUhQu1y4lubsFKFV6bt4FMRI15SQ5cbNDTsOAAqhL0gEAnDwkBHtVG0GOwqikzbnL9tRblT1ybAEOqBR3MyuhCFhypuyVJ/lDKHCCkOyIb35BNRGxhydSjsrk08Bt5tteWwLxhdO5JrqhpNoNBCriAFfGuJpWhByqmoh8iNnfkvI7FVuNjQK3EgBamnhLlEXeyahm4Ooop1qRr51QVUnCiF8mHPujyzYew00hzXDVT8Gkg2DRvQdMHBFUYcS7aig8YmK0JsUBBNIk4ZZgViQvsIMQYwSPeI5Td3CvH/MoMdj6wN6RFPYHGhy0/wCwGo9AHs48O8AIEQYDRREPeDsmTqYSeULEitW994jnpNaCfCebwY31gdB38EV5dHkenQniO6e88XElfAGacdzDS+suHE66AItciB3d76L7EB8l1iKgX59H/uGUxeI+3/MF8MBsiH4nzrDYx72j6klj0GrCji29tF5tlDXtVORxuo9+XZfjnDl2IWAjpE46cAjvkbaEeR2D385phIeEtJIAb6Q4MuQhVJqcBHlmgdY/SoJd2/YyAtDgzb8awcgI05d6mriVSIh040kTFtalVSHysPWcWxpgtICDwMVQYx8wFslEgbR+iwK0KX/G0JTega51twPxoXjyCKjL35FOsGYkRaDgCLuVAS4osHAQIANDUJJ3tgojZB3hvaInx1hOATUgYFAIQmsoTA/UjmIr5584Gk9+lmMIEDJzc49im7Y7Aiv1jvssCiVGWrw/Yw9JAATW5qba4Z4VogPlK+sVqzI3g0B74rldU23tMD5HucZcntfL6sT5+s6tNVZmoxfD+WNHMtWmk2KfNccYnJcFp8Ag1ygYuMbi1ORLDfSkwt00mQroUa5dZb1GUCNKN21RaJ3jHHpPRSTjDiMfYiC+/wDmWteZgt4ExfAcjGREQROkw3wZL/Gufhc47ueK2nU+Gm6mAr5XYeBJQJE3WYvJr+FG5UHKU2TGMQVbQgwdIXkIMDB8LQY7vJ9YRiKDm8v+ceR5xFQsBEVJ+MbOJQslfnhkku1Ah3VBA2vFqXRKw9+gnMHAOaOMMF4lSVKzxGEVdwfeb0/lKQUNDlwAgAtdeb2LAmqUbcLfckIF4cUgQDXYIzwogKRre7ZXpk0Glg0lpeyAE7cnDZ9hlRyt46+Mf1EBsaCaO+Reb4SpbdJlItNjZszlXDrCk8EJRx8HCzSEZyhIq+Qca3utrASCpWrFhON4UidM8WBzBpoWKrh7TIHwqt1KrqSQxnoTooK4AEg3YSt3yfHtBbESWl4FdApjpkiIQUspxDW446DNK3hDgJ0t9zgkpd6PdQhdHCCuLVaUjBHENgexag4xHxqdygOjANeVx63iPEIB+pjIBtFTXzgoClEAfI6mC70iKPCL7zmieIT7xHA03v8A9zmVygO+B0YUFoQ1lButBYevOXi5ezeDgMxlirPId49tRv5LgexSDeoJOcYxXUItOY/WCI3lDSJekdHazKpZbzs2HQOndyCx1GyA8j1E4zS6b8EQ8sr6xjRA6VXIAuyNBh3LBZt581GmnBGjbVzyZuGFJQsJ6BuWt8CTqDnKLyrQLFtYI+Kbp61lmnbi3F6bzl2puTJnmWtUGPzt/LhpUUhXpQFanrzq4FuZnK5sJLJqmhTHhlpw+micFQqgZIrQsYmhzGugr4Y9r4kuwRElqACMMGyWyC7TpgWNI+3LcC7dmj979ZLQkRgs8I/jCCMbEPGlKPcXfrAAoopA3yWzencwjPdUrOd9RefWKxCBcquW0Hjg/Gt2cyxgaiSwn9lodBmaIFPol2pxUmVRg+17Q28nxMOLEdcRTv8A/EyO79AApLwHOtYkSIOrvQPD2ejGLyWhG7o3snfuYA02DgUGKR6dh8YTi4DZQVKi9g2YKfbNTvkDHmT04+YMGgcbCtnAfnIU/wCu+cLof6zCbiPwAT2VPYxmTxDOf/UIB7xy8no95rVtx8YX9Igj4GPcmoiDIAUHkZLhneBaR1AQoIwK4ADP5yZDbegkdm8Nn1EjBQGO97y3lUToOCRHkZ6+ccoJ60GhfoNYq8OkHYM368e+so87w2AVYK1KkWR4a0WujhaCQaQELhIZw3TVyd0gqT2Ks0mKoS1Jt3TrGwYwwHIJKngw3SKVCaKKKc95qzZyKT3gAtMdk5CdKOzWE7KzEnJypwNPjnKrETgDQNu5aZwwPELkdtSBdsNYveQI4sQme4QNHrFYcBFEcbEOw14eCEXpRHBlDvoKuNpAMQK0JoLNhhpjh5duiMQUooFcclKli2gl4cprqXHQYVELyHAsNG7Ju0othMrKlUJb2DE+RpU22436cntacboz9pirrnmwcOSKXr2XGWNRNA08foH4cWspvDDf4xY0RjBp93LRE4Hk8gveT4GHc8esu84TqN+PIX+svkIinQL/AFjKLGnbXZ7xAPkCt2peTeTRhzQ7eMKOSSeBh/GCNjdIJQGKnCJziVNAxk1ig5Bd8uGg001OOb5fzyZCmUBaGoczfzbNp/DsUDRUelifeAWUE8DD7jJ4JspV8GRsInDGhNdE8ncRub4WGPD22iCndB4xGYZpQG7RDZStLsWgZIaKETVxSleLran3K7TqTwz8BxM7wj+aF/WBEgQn/M0JoEIr0jY9pt4OXAWxbJwChoOhKOIe7aEVgTusFZcWChVAqd+bcBRCZmms2MDeDfWSxju2CENvNnne1XCUp80SDYUJjYlISEfDlzvjB5TOsTS6B3Sw5yGNGBLOgonsUxx5q0+SH9YAFXGyId8at/SzHicFUC6Idjw1HmsOM4QeGl3ELAgsNYLzBwSntJC4eHEeS2+a6IbRzXXOsGkFaCR5aofi+dY0jFAlVa29TO9xCr2CZHQ86ZhQDerP6zzsD4Cl0dBjCFA1dcPCS+sr7UOak7tyA9WIbRYrJN8b8uMzd2iKgBpvkoVDBbUQT0P85trDLxUP2gweFrV1CfIAPN3grDnF49H2+vxv6zjB2MHJlgUxyuDEaq++8JIhBIJOBlUjqQ3i4u8RTokVgP7x6ZDAICqFGGjjgXGqEEWnD1owAJieqSrUgbo08kOusVlUBWu1proC1vRk2utiQISJwav6w9UUIIEwbIBr3CuBZom5qDBorjvvABMeJDUH+e+8Xrp86k1AIuDwqRMKrRCCpKxxXA1bBALpShXjQoJQWVg4dTkLytaL3WzDuYhB4oRRSpaCB05B8Oj4zjg6l5zStBO+fZksKxURsRdRt1pcWaEBGkHC7VBZoLgmjNtDkK3ZsEN8m3J8kSgCBUVCCacYYULYDwpDSOwIXKMFEgHIN9eQmNIwBajaYrSgPM3lN2I5MAaClcuqUwUXc28XSB8tUNJmqALysDC2yCmvJhpgR4OdYIpHGOGsW69sWUskU2zk0+44ThqqhA0iEjeOsV/uUpBheDN7OAIHBvCDTN5d7vzmqqfQo/5jFulmlSIsNrxsOctwYEAhluaOiID7DJfcG6NAC/vyinGT5xaMaJMdUaiNNOXKiwSfAGFBOQUfgBVOBbvAFZpFokQNAoAbncH3kaUMRJTgtwWrUESs7JAJ1dpMewJkXyuMNtdVw3JMCnZf2XI8T48Y6bzKnXvEoJAvji/ADKGlVflcdO7gUOge/wD31gcaoVNtIgb2R7kW5wionaaRsc9cvGsmDNm1hvpvYmLvClAga/DnBdhrNIsCfa/ObQNHQQocEQdjwYhMBqlWJtbTXGA0KXaRpso4Wm9Zfx0ERdi6gX5NdYYkRC20bQEKDudbIAaC1Gw8HTF896ZgA4TGHGyK45feKkZjSi6eH+QdZymWMbyAbdCb7+GMoj7IRbbwXA4JBFStgBYA62ec5as10tZ9L4B0phkEyDxxfylxhvAjbuX9Y07dzrLN0bQHp5NDms0Enl1V08hsuwQaYTYn9zB+nRyqn+UMMrAeohRHw4b1NE7Dk+xcGO+FJjCw0BJUWy8WGu2flDugaPwFXJsLYxQ5ZEe5Mb8zAYGwcWvNCrGl22KhKti9AVQ2gbaVg9qgQqi0SQRYCi2+95Q0HVGgOT1hAYk08IFFApNpdbu/dUS55pAg8HvpBHbHMQqJUOFNeJhwYICdUtZDU5NXWR5IE56rew2HCXQrcZI0HIyd2NUqBRZIktwJVo6m08t63IpibgujckBdhACKWFAgKIqFNkUwI2tkxU1GjgoaicFCCIGwCpbELegMrcakmA0Cicp03FiIrwNQa6tQJOEi0KIyiuiBT2dAycZVeeAKva1Ou/neMSTpHY09A8bjm5JOAhGArdtCmLYiOoaXwhAvjb11k+5Fz2ntYbdeMuKbJELHo0KGi4bRWXQW1bbs5cYcbvAhBT2QKedecSOxqLdGv4MYpbhkb7xh+zPSwBdHzmu9FT7ZwA8HK14Mf0S10t9QfD3veEEvFtlcOTQP5woEwWBqczP8JCwERoqehf7x40n6vQ6sr5wJzlMsGEiClcqG/UdLjkD1MfjZvyGVG0ea18A/ePJCQABDEWDdoQ2hvBkFmVJVFXmhUQ51gJqp0Ac2K7dkURjjliongg9oGXxOSX+BVRYJVsYDRRTYtJWwFkSFe47Dag34nIH2JOQEcd84BvabxHUhxgBpch3Bq4W6lqmWFoV59ced4kAgRFWgPfNffxFFcqmp9NP2I+8LXLi0WVAdjSO+8CC9t5iGpsd+frBUQE1Paka7do8/GbGMWRCbEfL8YFrga0KgCmlb1HOHnwjJri9H4IGEhBU0Rqmt9Djy6xHOOU6VA3GtPby5cwMFmRKxGY9nMwCggsqA47PbQ3YYAPLlFURqpaPOnjnApKqii1GlLwiF5ziY+Kag6NnyblUMmAmU6eDf9aHlpJ7jQpoVP3iG/kg4O14/nFqp5kFodyTWtnWDOgQOAkgViOxYQBNuryg0AXpXzgrZHgRgz1Q/OWKoq3SDfa38rjI50epz+rieKqnaqf4Q+2EpQ1kqkdIHXOsRQgfqzdx/7hjQaJ8EU+b44+TxCQYJaPVZxcqx1UDYrfgXoLrjH5mghPzC1tXda4ydRkAA1wuufG/3lm83ICjlHtoCE3irCbLbOY05d6t4MDGhJSyhSRB7KYN5owiSWKbQeduybFlU8goPZwrwL7xKAOMUqkd9au4eMJCknIiM7rV3/EwEeYyBsbqtHbk7ci7AS7NgzM0mDyZp5eQi1aUiGkdrxuqRepOYRwi6Xe4ccV2wELA5Ih2DjJuRJYDZ3R5p5MDOreAQUy7DrpR8ZvoMDxfVklxEBUXdFq3OsMm97uHGTwcRQdUNyRWsdrj00jUxpdHnR57wsCiZZ0omFq9mYhPEBYQEBhoC6FhYa37JjQJJ+/eRRcmayAeRWcVmSNMKSww+Qt7uFNy8q/wZqDDOw8vOWDI40uBd4qS+aTE6LtHOEBLcbtfjAAjpJjXpd4AyJk1xo+rjEvJugP5LIsqy0Ahf3itnvFKlcjeDnFI+i96zcNjdXnBwQqtiKGnut5D6gIBIBaJbFr5zVC5n6HV6GrOtGDGqG8SNgdkqVrBHHfN7BUbcB4yRal25BAayuwPLUkLRkcVgNlhcIqUZ3OhfZvDRAhvGA8BqODa6HvKNFeLxhn56Pzk97Cdg5LjGB/znGRRHmJ784ISEAFm1LW2cRzeqT5BGwaH28XSOmYK1VfHlcESxlBUBuLvzMTUsciud2y0039jIxHA8w8YQwuQp/Cyu6X+tXNhFutOAlU6lgcff85txHwR/PB6JNcB/HGIm6QG3J4g8YYdRA0BaP86w9CCNj6ID1RhklyS1ANG6CXbeGPbuApQpXsN4I44xXkDp4a0GtMbUKE9+k955gKBEyPUTwFaHk6PZiTwfgSoICdElJN0FFNeGSRSuvOZJLL0QFpeO8GJCUolNLT7w4nkF6JBpDfB4xUo1JteTTe+W/vLM+AIB0FSgAe3FcnEIFDXLJBToXeXcMTopUugbENQZ1/ksQAJa6FaW4Asy4SoGi2neyYJusBqld6MvWC+TdSSvfeNbQZwNaX9uPoIxGlTV+5iVMLAamESLdBotYBpIoENo8XMNDmwj2ngxvCTc4MOWpMgixFbVo5F28BhoMQG/cgHFeDW3gD7AQ2AAaKHKM5znzMvwgtHa6UJvKjvCVykIeIaeKhrqi1KzQVUpYOPYfCOC3yGvaUgAq7LhbPyUzRTUAp1TjGFHp1soCxbxXbUxLxQhsFKVUOoc9LgN+JbU6mkED321itUwJWfxt+MJ0gn8MIV1OcpfJhUaHnvBHRcn1cGod9GBCNOt4Oab8Yk8XNHdL4yKQVHUyA0UyrKLL5uKvyChsefvN4gt1yfODHEEGtiIhunrGGpGvTSfUw3GpjPJ1vB6W9nOVUUKUR7PD8493F4Qmg3rLCJzhtoie8uaD53XyXGw3Yk19YQgQCtcOF8/z88nGnfY694Ay8zBLeOXeRtAd47do24UDBwSJecbed+dXKgfkecm4MNumj3KfKYurhQSvcaHwGVwg0WGdUyU9VT+KyfZ8qh8QwbvSNQ8fOJZaJ0OeWetF3BjEmrJCfmGGrPc4rqg8M7pq5fp6yKEBod+BhubHNSwHJH/AAxOK1h4dvaGz4MTSu0BfydfWBHqa035xIFHIFq8LnIPYdgBZBS2Xw4wkGvhAR+iTGANI23HV5AeWY7NqINNm2hFXJlfZyavkph6wQDYnY9W5MAiga50PA8h8+MLB98jCH9fEIjRqsfjzhxWIKjREEIIgrcBNosDDz8Fi1a6wJEQatQSLdcZIoYMvlQ21WzYpwnIDnKD0lHonO0b2AcjVmYjunCiuwCCh5OBqoXgKAgpuCGiCJh4ENxf4J/GJTgcefT4zxIGFShCYtclfkM0UaGmllXiv5x+oaUeTXrEI5RAoZ+VO/WAiDA1WjEN+Hww8ZMI9VVGbt+MSIeUq0Q9+bnvjHh1sFW4/DB1+sIUGoCu0CxgeyVP7t2COE0nfS1u4lxgfAOyiFrQdc17M6UQqABbJN5dHVCouvGhg7gngijImFACIHFfQTrLlAeoXjPlK/neTR6xErw8YEF/GaWFHziBefeMCR41TGIKIEsPB4xjQaxLXLLHPtxdYww8aJDEQ68mL9MPmgkAeETkdvOHWqzO/QTfJlkdoa3smAXpyky48y2YLuVAfMBYvMrz3iDjec4/1y4Qq5oZcp0oKIXp7/rJh0zjquERDYr54wuUQnxT/wAySDGWd4wqPIQfZrH0K7+/vxw+bhB1+cmXsXvv65rJLTw9f9fnzjBNvAs+cYaa85GshiGzuJkDb3vnKJUXuY0c/Iwo1aixztXrFcGol8ZP0iYSmFBx6R+HrfODAnCUXk3hdVPa/wAsFPjrEErcJwULoDBg1CPE2D7xAqqnrofjNzwcBZzicMDkbWLENEMCkgN4WI+yfvAsKFqcfmaGATgL5jn6X84zVYUiCnQRGzRd8R6HmRtNnEAAnEYdjhFU5UxSLiq5xKDwA8lJe8Cr4wEE8EodB7EiOTk5J0hqDiFOgLLeFVp1EQsIoISxOtCr5e1kBqGbF12AcdBOtM1rNaTgiSkxmt4WXNNt9+8VRVNJuI/uvFysbJULkrH0U8IDcYSFkDfULgs5iNubhZou5komcFNOaE0qgQG5rno2vrKqC4ulMsKowF1S1MOQMTwh4blK3BDt/Lp85qvIKGdAJX8uHh3XH7Qt6henLkoWCK5KzhqYXRYSU7P7uGPJ3IECJo66xV+mqIKNFpKHTEVe7SIBzaCN6XK6ExSzguPLV74sc4dJO99xXA5ATEEn1EBWoYWHSMbjKRQPXzz9kxo1uy+srMVbrx1+sKacimbQ/LrJqAuBokYFZKGceOMFW/pdODUePMMuAJ7yhOV6zoYFA4sBlFEh/wAwkQHq4Sg1yM2YqsNdD/BgyFLYZsqj64TFEQros/uZzKOFp05kbj6XUWmCf7yjcN2hreud+TJ5ll04HXhwYObzjfCk4fvWL+1jgXu/ebIlWeDlx2sU8EcfnnHRuE4X6EeXr318cE1s/wDV7wkVlNQX84y10P14xCYYSOzELCP6w1KYn0lHSLtr1/WDWBA3f9/WTgWMbURPxlt05G02p61fgwJp9YwC49PDlGuJLvcwtgx5g8H+85tw24TybwnZ+8pvTLQNOXgfWQa4At2ACP45ZuGcz518Ijicgu5kYMStg/8AXDe2Dej6nMxwCCpQWIPKisVTe8YnGikRGzDZ2WF54uruihQNKTbWTY4FYgKhNtCPyAejB1zeaiodRqbNI4Md1RdRSo6EvL1hQ+DtoqyjKl1tJocPYol2UCDwN1Fj5xX9aCHm0uKWWo0k9NUvXeEj2EsT2jUDQ8+Lmu6S5ckioNpNuEiXel+YzBDCeYw0fA1r5mG22kB0og1f3rL0qo6qTQMns6wrTriduNnT1j4I4/JBnxWE5sjTdMB7PwDAYRgqJ2UthO5cVmVmmBDQrrvfVxLC2gpdDwPld8Zw7HfBp7dNPXwZO6KAKgr00Ib8bzmz5gBj4DSceeuBHxI8kSNqvMvEMkTGE4VpA0kh/WVkiHYJi5OY+E9KjENKFPwhivXSr6LgFq1bgaPzlHYI/nCEF+MGwo5MkAwLPL6y/HExloPJhaEHVJ1h/XrWciA2bef9vB+c74TBXSmtlL40ZZS9Dh9OFTC3uw9uOB4ou4v9ZepW1Qy/Qa847GkgeB63d/rA1V9a93NWoAGtp/Pjsy8REmXjZtZvvG1F4EdA5bO/v5b6oysD3Up4HDvnNpa8CPTX/Lg7ISZeYFzxUzl7JnwKd15fvH6RqddZfSA8Nj+MSdBghwc/4THZu/M+zgEC14uKGeBuRsr5MHGDDB2tvVN9fnEH2++HxxPeLC3+8/OG0joEXKPph9uaP2MCA6kFnIkbRm78REV0tM/jDoR7wEDYVx066p02/rENzwsDWck6yCesK0c5IEzgOwW5cPJr8Ym7Fzk8Hmh+sqjblyIX75+83Pl3vElhug/DLV3RwLXlcKOGneU8Fv1SJHgB6wY+9E4o7TodBXVcg9oGkYpYz5D4xthiNE7CBCNp68wLSiF6GyM4zR0PxHQgc9ZJIkurIB0CfwbcFYCayodVhGuWpC4e0QLAQ4k5edZVclMr5e7jUIjXCq7u22yEjkwKErBRpFeQAG6QhSegYNoEBzuKGNzkHthtiQEeNmPEcKUOmraNjjiZCmYiNI4bz3igVQgg242sWMxqHXBqFeG3ZpzUoP5NaQ0xB73gW8gFfF2CGyWilw5cERZBaKCQ8+Zi2TFs41UN++m8IbXDoSkKdght3YTWzAhsu/7/AO8ZIkru2DN/7zlUNtcMpLcq807w2GyU8EgH0TJje9GMEmu0o4qyF0HBlODRhiYBpwO7hqHMudqAw8bxGQjVME6MU5wXPytwkW0awPvXqIzKFQDN9YKAlo2P74xHgLVPvLkgtPn55wJBoEMOKPvfJxkaA9Xo/wB3jQhWzvQSOLp9l0nr3l1zCwdTessRE2kgoC6MXgZyQRjDC6mTkTa85J7Go1NtCMAsCvWLOpNqJRWclQ35csNc6md2Udss79TG4acU28CWaDbIYKri7XrTXnReuMLSiclMJszKlXzzjnE6UB8jvCXFO0Dx64fvAJ1O9Z1C+c1Zt4uEt64MdUUgnXI4GycEA8wglc+uBktWRAo+Eu9OXYYk0il7vJew84tKnoLI+i2di+MKRceomzW3i/vGZG2Pd9u/g68PWM7QA02Y24KvY4Ta+cMRyiHH1gbcI+TnNieV3lhOlcB/rSnRvc/k40mqPAuvwfxnJHxgxDXeXO94OvtZ1OFx2I1XaOB0YtKCgJHgEQCVSlKIpJGY2vFINCFLiS6iTnIMFgxHUdkPq4JYRdAP4HRlNva2xNnZy6fximJQdfahD2jnTwguWlp4ifwzaB3BaSHHXm5WYvnsJqBwCTXOVg8atCjVOiJxfWJmp7dJWAKEJCRWSo8IAIX22FNt3rUiKDRK9FdCgVNlyN+1hhG1yDXxS4aKjuoFAUER0HK7ztpR582A9cS7sblwkBLWKIXMr8C5UAaSKUWnqKDkc4sYKRKoNoSJNo3oMkNISpNPQE0aOsh5mqjaE3q3ORr7GYXZF33HDWQldBsK/cxBN4CP1gKJi2HH53+s2ncBvHnAtHDZhIN0c5xUfrHicq5CSaT9/OLMEQ0ih7xhCV2uj8pnAXktsTXn7uDrLVOr7eeMQAgA4B8YMCWz785XvqtKa8/GBGBen94zSsPR6mBSkF7pPHDioiaCI/It0cTNRxxyjqcbySsPYf8AesZrHWuiej9XGD1WB41+P+TLByg1/hhoQq0m02S45CQ4ZwJ/z+M43yOid9SBorvenHwrdKViqOqJ35mJusqAEV3ALoA+YHECd/knv84ioU8O3TfrHqLj2gnxf+Yn3G4My07WtRTFUr5cYHZfWRNFXk0U/hxB7eFYcOuH3lzQona9uP5es5oawneFUzevkLQcmnAGTZQE4N4QHza86mNMQRKpthaU2rLlUGvdhFaFQPnlV6hACi4n0U8vX1kwkEnyqWcwJ+HGFOqmbpoOluqdLnepamhQE7en94wuy5ZKxDTYnkcAOqObhIp1l8sQE04YOazBSZhlHCwAnLetJ/2Y3LfBjGPRlUHtD4/+ZAvF411lkXQYTvnHqr7xpAexQSCCGoY+tXBo6K0tYRQWrAIW/B4OMsj/AMZ/3AxQR4PP/rKXahw9zCr0Cj51/WKlBAibVtfoziF/eFGn5f3kDcUI9x2ET2F11atcQ7OUKpFbzHEGdAJdKbAK1Lgy4yaTLBI1ZU5Tk+KqaWx1lIcryzvH6eCpYsbBULLrtM1EQEWgBSFRQ3A4yJejGaVAUpP3K3HbtE5qGAwq3F8PGCCst9Bz7dB9t6x6GjSMBFcgCmE5fUgrYgJUQNF3gvQKLpQT/vnFx4oxtsGr5N8+GAeXgaeLPHz8YlCCuYXSfNwGjkr5sxRRdtpvDyFMBBgjoyJXR1h9A3r9XBGlZvh+82Dy+sGGyuj1kI7G3OBRdpz85sgek+cNNlrt6wSpS13DouAoDGo+R3MYqAXo3XT85uRkBKFDiv8AvGJgC6NfgmKax4mlv84QRdAo8YpIlMvj3/vWTEESjuZxJuD8N+c6Yilq6Y8YB9IAV50YGQQO3W3z4zSIG3Xb1/vWEasoAwiLu4oSiKmiJx/OI0JC1VTHNI/eObOJ844d/rL4/UgbbH7xTCLZkKeCLPrJ01ATj15+TGOmpgfKmD07/jDi8WGwOfv1kIe6d1fHPvLYWPBXw+P874M2rbVofR598/HOWs5ahQfx+vnnIzuOeINkSfGB98JJ6eIER4lui0A024IJOyTpp4mFMxrQ1pGEegXzmpBRKRdp72u3BKfap2+F4f18YuM+nn4eE9mGUduJRr4yQ7OPAc5RtK4NWVT9E/eAi2veEkN+XFbuuvgzYbb46MHazBnPfGE9ZfIwS6HHtQMaEilotuNOPpGEjOK+3WRUI3KYgbkdzNKV3LJaLsUyYKE1Q77Xkkec25KVmkJfM03844lInINDSNGkfnACUNz22j1OWz85rwMNrE8GPKvLrOhDNi4gzrQSeq3JtUrEo7PYuhCx3DDj2IAVgwVDHt5wlF1eFap/ZjlD7IjsUWX3cCWeetlRPlz5xlBW7Do1t9/vLVgUhXyLzxnGEi75BuG33JfObwl5YdImHQK/WPcUZgNhQ5VJ+WFoKEps3+NHwGUFANuvGOH3H3P6xQtqPzkpPLWYCdpzc4gwzj4/8xCa6rrj3gGurU7Md2mS284IRw2/lgEW9mtd3DFNeFwgG02H/mA0APnBzJufJ5wmDFyw9YAyasB3/ucnNIT9c/rIhwadcvQ/rCJKBEQ16xATnZRGdians+sYQdyNf9vBuVK8Xd5P1ciGarw2ZVdhFrWTr5/jCDCNRcPU5evnF2dNKHkUFht8FeN5OdlaBIxn3grQaTQTkqf30zJxCl9nArFBoEm/IHox5dosxnfX945Qvnf+cezXvRzowN7+t5LNyCBc2/nEYqgtwXr65xSPKWo1q/f7xV8bPaJ/GFZNKI2cdjrm4M5FQnWvIy3+MajnI0ry17yBGAi01xQ94Yqipqa7+7kODhSQDZ2YcotXvkp0ujUaXxt4AgrxhEyoyvg1lhowGIIIKejf7weRSpGTVN9HvDDVvEz6cafk7Xs3nIrrpejgT5j85x+JARnY4cxob94FC7cZzCUTrj/3GRqYfhfxi7W8b4ZiXZW4VO3hwISYD5xOrlNDb4y/H7MRUAkJAC0E6wtQCYcDzmyaLWtC/jJLpIXyCYSuVR30wBE7R8Fp/OICEIRoFa/OPk63FSw7g37n3RPRMeVdPw/rJCRQR/3nHWiNM75cAtiQq2/5mI6RrceBOKUpgyk4Jyuj1lhmPnCg/pMCpBL6Fj78fWd4ZTw2/wA4Opvujjyt5hO82UmmgACDRA2bfzgN9oAb2kCqJBprvUVnjoI5jTfbdTTWNkoSg1c9Z3tMg1P5K5oCa353inSN8/3h7znnFVHwa7wEg+RhRSPl4ffn/wBwoDsNau/OOcoNCF/+4B6Ga5kcdqVeG0MoLuKVkv8AHGADVy9MgUhND8/zgXCRrWBgj2clxj2o8Ei8/eC0W48F+Na/3GMMBqunoaOaFyjtsnRg0ourDjn14c8SjZP27msAIlSU/oyxXsdzzjcIEHo33x1+MEkosJpbxf6c1RxyNJzPjEJgT2Pw/D+j5d2NXTT188ZJQgBsciiwdhmrIFUsBeEWrohrNDLgGi9T/TFohH0T4vnWGvgZ4R53jBaXG0r9cmPpiS/Iq4kCEReTfJ6w1e2ruro1vjAdNEV37Kh8c8YMsoaiWP6MFg6PyHv3kGyQdGYH9U12Hi9UcGtQBppC8nzjUAjKBSQJZesbGa1xd1fK8JJ8DcFrnjOdU409YRHWDRivpwY3mCAWnvx/7l5FTuW/GAW4unW8UaUbD4OWI4blQD50fo74zZVg4Pw/nFkboGIOG+LiSzAJIldrBj63YBR4pps3s4yCfOkwfjI8YMebjBAmRNhxnw/jN4kfy4v9YJAx66cIE04+/wDjgPQ+Qev7yDoa03pWP1ot4p/6w45KtiCnP1h6qJYSLZ1RxOcEFKonX0xywOQUG3nvAPIYCNOl39ZG7u88IICHb6w3djBXgtCO+UeNPV0qJkVc4js3JR57gsAAKHIdj2TnNh3odBNs0xnqd4mGTl886AcPGPKoWoujxjmuQ+lB/Rgijb3CvhsBa8mPfr7vRPbIMJWap4HFmKBel0/WIBW8M55xEyd7u413ok+8Byp4twBC+J1iMoWsLeg/MnGCh8onP5wBViLt04Nj8tWYtaCSDa522Trq/nNHEHLZX/3+sL0E7Dcw0N+T6nnxntLDjDTkOmr8mEmwKgupfznyApRP9r+c3IiHWwfyid4kCZVFJef98mShEVM2PfZeMWmPB2v05vCgpSB3r4wNQbDcOzDuFOiIca6+5lyFwbsbl/8AfWN0jSc9ffvJAIi2OjmhnKWigEXZTjvHwiPWFNDzKo8nWmIBwEMhcaU8hXCGUzSO5ob/AF+rqALpa44/5g7g0qdc8/qf4wEESC1D08Pn7+cq5NEdbPOad4UZ9HfzipALp4vzvBw2pvvpqezCQaiDoWedYcicNpS9ath7c2YRSqkmzrXF4lzYa2g7famLksoD8Xgcp015Av2ECGm6wKckZ1hdHaBOPuYdERz2BJTYNeLgQQHN8t2003tY40EHmdW8S/7WI0Rqn++MmQNZHWcYNOvXyZwYuqnkjaflwbyLYoCLs0ocawJWqrIKt+sSFmWRh0SwtGoXjAYOpzojnNnIPeIJ7aaPI8DwlHpznx9YoXHAp3id5lU8qERRz0m8YUeGsVOWIjQEHTT83KA6leN2dz4mBkMste7R1wYoK1No9njo6xipHYGvQHQ1dhcaahGxHEadPNxQIoBy35Ou5xvjOfm1Q11OA9YzkowvgE6xm4HW1P3m4ybSrDk93JqBKUO3nWaIl5KOakN5mny5E4Dz/JYNRG18fyxzEMbQNwoC5aBUWRfifvEACxWwDg8POUwo6N6EQ0Bds13hxpCFc/rDqtLDTVx27QKcv/mKRAAHkZldAR+sBQWngO/zngYVfN/f/uA06UFqH+1gLAEuQwOCqvNwrVB0X45wBK4KxOXLbR4p044w4yw9bvv1/GbNYgA/l56/8xp2gLHz/jOeNRj7/wBPzm3kkojVT/OPAJhZ1z1hAkU08r5weiKACHPWDA6SjHnw+XJQtvkRfg655cW6gnFU+NcZCcVA6DnZvIUrkC6Pn9YjORGvb4+f3gCgdwTr0ff7xC0XXq9L/GVVNiNut7vEyLxRSwdD+d/rGFB2Cof7xu0VhKTYHGy8dDjFJ66GheAHBOO7iYcdBF48Cx2vONR4ryHxZ395ZVBQnX/3AYPF89r7xhsSE5fp6ckSECDaAOuf5yNwxUgbpoWapOr3iw2KpACcXE6AKOnvIKqnN216724hKAT2G/JxW/frN4Mpo88b8TIst4NF+sAAnIV/5/eLSgWKEP3jb/wWh5og4j8qClydEW/Txp50rSX2v8qIv8mTQb1CP58f5uOXRulPmsuuvfGSE62YcX8YbYEkTw9cdTE1HDaME7xToVfDjAOEIj/fnESbw2m3b10YUYC4qeIu3g6wcngkDLBqd7FZeYunVfFsHAB+m8ut13Xxv6HGIfjJfP5J1A2CtAGhKdXdMRiG7Hm5t8gFD+BXKgH0Vr8DMDUTbNfKGAUhSWpfKkp7xJXiTRz4VyCh3Wb+LkyFe/8AnIwbq6T/AFghCh2fzYXox2If5XGA6d4pQCEAQDRpcFZsJQFOKneuOP1nbVBzz83NsrjTP4xLbLtVYTHZwKXKAJgJ/DKpYB0fxX9YzhBGoQLV8eQxkedBj62vPW8aCUF1NUb10DyTYgweI2Nz7uH3Iz8NwotEqE7xgMF8G/rEUpNhvEpW7q9McKoiabr/ANwD2vkbfRLht+7bzl9QI7P+5xiY/JcgKFaacZV0A8B+O1wYkqmppHGzSp431gWhGgxl64SYRJo6yOeHkDZ50+sWIYLZIQjYhroRpmA5ojtECF1qia1pzVwAIBK1w8lRXzklKUIWfEejeNmHLXb1Tj7/APMBIl20QjiIVYFqPdP1/OCUN30Dr5/3ODYic8Do4ytXEunKKR9o+sdBO8A/B+7/AB6xYpGOxE8XX6fm5RxfPDx4+hy+sSAsB/7hqAWCDs8T7ywNGEeI+Bj/AC4KgkFLOPV8ddzxgCbUu49g55NdeMYAjvKcTe8SlEG1bffDlqICJhu7p8Ob85sm15ICeyOBALvfXzbMdAIQAtjR0755mSO6iYBjLa68xw4gIx1zhlgV43rKNbGn3jyp5SCeE8OBsRIBIXr1M7ok/LcbuarwdnNINF+S5vcj7wuWaww8TzCfxxnCmAQoO0H4wEkHrus3r4/eMRvDcb8GK29y7As83GEpN8KTf4eMBJ1aWDtrLc7fn8KXevjrAg0qV0zCT3B3J6WcvXeU+o5od1Gi0dYy9gEKKaMnsX0ZphrLp9/TxfOED+BfWsSEHP8AhyFVPLZ2BO1MQdA4DgEDOWmKg5PEFwJfrDD0k54xOU6YnfjjACQBrjdqIhf5xE9GhA9vKYScReUNnm1/TNLKKhVU8ObF4j2Y7rGbLudn8MqLlFnoEP4waBIdbUBVBJQoKcZDYAtbT0wPvDEGdtL8kcYBwKe/nCWE1oV9ubwR+cQM8tqo0fX951HK/ZMkEN3gX6vHWSUpvduAgNDnWIZCINeMMYLLNPnz4xHKeSb/APuDQeE0b/39ZpCA0Br/AHGKSCzod5F2wgiN43/u8B1DXYzFrwDrejrX4wbwE6/eEdnwNP8AnEQArQQb50EPjEDKHoc5eqxXighGHPgvBNYHGnd26xEmw3pHiHvBRF7CcBJ/W/xkWVRsU86/f/zIu3Jrugu+dZ0mSheHsnXeEwYnDa9vxl+gBG753zfr6x68QELfXXfj/uAo0CmywT59/rrJxJOFDw3eeVsNc2GOzrqFYce/ziEBpdHbKP3xhdMCaCp5fx445y2clFiA8S/udGbdAyibZwH536xPFYDCBU19z9YtoLAu8fCf7+07ECNCeHD65/rDMRtU0Hh56Od3BItF2iPy6mplnICbv8cfnJTju1ryM+/36wgG3DNr6H4wJb3sv8ZpEGuUyeiizXX3hhqmiO/v/wAwFAHkrD7xRioFhuY2HQHSPXhwcdiyHIfyfHnjBQaXVsKcvj95qZkuQ74fD1lBywGvN0kbPGPDdS9O7d/GBdbBPpboitjZIbiVJCBvANXTrugOS6sNpHTBwjY08ZSGg251R27uf/KGZCV76IVK+f8AuEACMkiHrtPs5xhQJRMtug3/AGwtwiVD2UE0dha+tc4K5gQgQRbXpZZ88ZqoxoFbpgYOgsL3tCH19YEKb10+2t4W56zWASdrgoirMFCaM5QKdQVVDzQKeD5X2BdcVVGUI9S9w4BeC4mkFHdTkTw+W5zugufRo+EIbHk08S4q2JLAahCjae+HvHBMv6CaDciXKFiJm0Iu284PRlbfOLssJyQE93BNojrgNsQB1ViHGVGFSptfSA94e4Fg3pohvk/BTKili2Vga1FKYHOGCTkGI73dHOnEpNeh1goq6vnEmNP/AHBfev6ww6UNYBSYfpwAKG/hOv4xaFiu5LkkKNXjk/1xwI8/jBwGyh1ni94SG+Pjfz9YNyRDbasNHxidNkZupvb1+MNVAj1T519Yg1kkR/j/ABjQGtaG99cYKVQRYcfVx8G2w/vWGSJIV0+8Y2E41wX/ADrLgqxHbr/fxhksk2BFv+7wNWTos+TNDLAoKD5/f+46QChwHya5/eG+i0J7K/M485GAjgbpxzxdfZ5xd04B5+O+E4xiNg6S69fswPQhqxuuPF7nOaDYqmglmyex+n4wpAY0CRDsez4/+6EFLzttJ7nPGt4lJoKj3gvjXw+bkQ2wKQ8zScX/AM6wbZtbAcJ9HbOPjFC2F2TS1ed78/uWrE78FN72CTfFC6wx5KaIqv8A3veA7xVTW/HNOvr1k0gQSKBNl9PvGKsEnfnS9YzG8HpdngM4p2qbp0v7/GJ2DOy5vzOu8ENE2KS+ucXeh8h195YFobBZN8Y8VIN4fh85qHpJw6mTgWIBK/BvEFvFzZr34p1N84CE4Q6IKQqnykN83I/eQJwlLpT+cZbDpR22JDovPvOJGKAG9KdnFf8A7igCFWo+Zs9E1smB26TubiirnZ1R1rLFVFDEAwL3Ij2DMJitBMsB+un/AJm+RUgYptByX9azaPoTLft2m1mb2bIybBED+bhyeoTgZHQ86/f3grqAlh8D+28MVQFBIqlHNmnq3eatFM06+MLWp4G/asvvj4V+Fv6wqRuMEWc6xtJbmpbF6Kq4BFvP3DELw2lENLyjwPxiWUjcryOy9o5+MdG8UI0CNZY5RpsAqCDVMeuNrXU47MM8lMqyk4gnKb0GGw0g9cv8H5wyC1u+8SSOJhdBX6AXEymPAnkcM2g8OYmapy2rTtHsGzLkzorxztHW3WOWnZx9oxRvzIHhsgBuHvE0sZ5MNlfUyRAUdDWbr7/ODyUObhaWik8OEC+mTWmYlFHjjCl0SGa1PjIOCg2nYfjGpAgA65cHva/WCgafD+T/AHrKCzdHIH8/4w0DyDnbP8YlRQL3HX7P3m9G5q663/f3l5BHZJz9cYiahwRwU3lW3QJKy+MQhokWV+fXHOKAK8DzZ0/WKKLRwu1Pv1kCABxzreDE1FF+B963gFClF5P39YbsRVdeqU7O/GKafOhJI+dvH5+Zq68AGnd3dFIn/MQoGL4Nb8keJw4GYrYQKmO0+OXxxvPBNAT00O8ZL8hJKGlq7f58dxi+FNqc7O/Pu8YMijaaa/OrtN4XCB3BqAV4+d659ZbvZfSHU5sPB/JgvOQM6jtPf2fnhHRhAEVN6eeOOfjvG5k7EGCbvPzfOnhxtoAtIOmonfBr3hPAK9iXRIaY8YnCtyhySV1rrx40QeWNCBHqf0wWwq8A7uvX3v1lYwK80djrz/71MYJzRLd+NZNw8UhFDPhqt3+7gwbUbN+P6wVRKqWfjzhlKFUvt5cWtAPSfxhhQQlHzHab3wR3dJemFkuzQQ9hZxhjwLVikpvhNeMGYYBKd1h2hUm8aLWawoCvJdM+O9YeiSAVOqehCOpPaEMbfXDARpil38IELOMhvm8cm6M0BhA0oKSahA6TvfHzlOyIguVV0wtE4y0j2MAAXaoUaAiqhg12EyIBsCBrRXmK1NtRlSppFG1Nw+TeBrmDr0la0XgmdR2+G0IXxWod65tEOcMcbUDk0op5ByImK9PlhFZaUSBobpnONdqHX6b8wvgxejEUC5sn4byU1feFPUUQCCx0fd0HOWVFUQHY27ARdCC5qYssLuCeZ/L1kWUzIQNUWpSDhuQH4QJ4D3i7TWsrtuutkxpA71SuqKHmOAQ9U1mrHAJfnH4FqmgBHG6diEw504G9AboIHAB5HFVf8zBv7cdTh0xtPaYZ3g3gysqds7QI+zKUC+8bS1jXrB0xjvECEeNa3kB3fHjCtk3DXeOHh5xdAez/AMyoUEV9c8fxkuwnCDt8x2YlPDVVNwe4bcVh/Rh7pzl+Jqbd+MUADnhLue/nGDUDqc1wQ04Bmu1/3zgbGzyjsOx6/wDuG+glBzz/AIwk21Cr/wDMYozUdlA+4+Hxm0iRNAbqw9b/AF4xGq72a/5/ucAIll4aC+MFiAjwnxa/vKMGqI+/P+uWBRvgL/7gSBAjwn+GYqM2EqO3XLXy9oecGUqIPI29aH2d7zdDaEXRgBrXjmcfWWiuIG4UrRCU0PDwBcF5UxedEaU4f5o7UAqKAUAXUN/ZXnApUw0Sd1DF154HKxzO4AmMApC69eMskooaV4pu6j0H1nARbhA9ol3o93AegApakMQPv+MICx2DprVnj9S5yz6hLBTbJ07+H1lhhtGiG67LT/OKTqiBkcGn/decTFBhEbEL75/eFoYEAJfMT1loWhINO7OesU/gBzVT2Clp4lmImajOzzTv6Q/uloV5lAdT5O/5xvFbtFCBNPP1p9ZANFIgl5+PjnZxiq2IoaIPU+xr3lChYpAG9nued7wglW074d07kedF3mkgmsroOR7OOBmsQKhaFCglagWvbfDo0DjFWlUNJ5jycOCccaGKtoAccev1hpkVqqIhG7s6nNc5jahUpxsU+S7q1ojGgViG4Vsb8J4y6JAJZ6R5UKKbEYZSSwQlNi3bai4unkzWjVMIbkC7aicPHjEwgUIXjqhedyHgYdZkiAwVWwRboiQrje2Uk64GAA1s3Bjg2nUoERiDfX1ww+CphZQ6E2/Ibp2ylhtc6GBVWCgOpHFYVWAyaFWppEIiFwB1Dzps3WK2qr5zaquGfHzi+/Acq6DeSHKIE4sQBMsA2+FZmPBSFBQ3zYXCJNWwrJkkOQayXdFaMkyMKnBT0A8TNC8zXEQaIMXlXrJq0aNHnQALR222Ylr9JfXEdgEaG4zjPPR7D2U4sKtFQsgPAXXuuDArVdcbeZI9DOcYN0q9q/1nNhQoPFBYzrXJiqTTotqk2sjWhIsGKIU5/wB3jFK7dYWAzkznhM0zUrhtL7ZlE8smNpy+XCi9jeL00LorxhMRougk3oT73iz4JiG0KJuKkNY3GPQCoGzkWCU57olfLz/v/MNFVQ5/3+PvKBb2avz/AMztks5T5N2+stAvserCujC4lZptZo28EePPesTGTR1vr5+euz5wpwIHzPUnGbERAqJPP3/3EAFN0Fr/AM2YPt7EDrd3f3msQKXbOv8AHrKowqx04V4Yfnzi7hypRHt/X6zyOOqIQix7ldZrPCDDQzynh9XjQIIiVC18SROOPzMInJDQ7r1rhCM653k6SSKC3acBp1xo61hQ4NvhaMOmM0jj2mUB4gw2V0E+8ouRClBOZaYHdfWsSEixrlKPTdh9dYICieT8JejU9TFloi0JuKvvkdcHjNSlHKQDp8fHWJUFB5OzSOjnUwShIiZDUmb1PRYHU16Pw/yKbuMFUKJXfTgZteyKV4LTgd/rftRLqjpeSB406v8AOFiqEdy+9u3n/GOaVFswnAd71+8JtVTQL1Nt8Id/gSPQGrsgJU1vw8uzGolQh/I7OtEQ94XNgAQhlNeP748xToPqJBuA9NYHMyBYQ1i8xNkBUFUotMbrLGxBBEFU+TwTKodNkAARgNy3r23JUVWu5zUjQ+S8/aPLm0xjsJy28eSJgmnL2oKTyA3E4wCvIMEAN5iDLBFRGZcagpSByl2EAWzWlgwNbVpatPCtRruwQiVTMDAUA8C8kRuEXZuIUahA6RDXkhpAdXL5SWUGEq72mcwHGjWiIJuTXQcbwiELBEB8BYOoanEDJmWwAZOFLLeZCa6DJHgN1ICHsRDqlrMkRC5eAVC+0TnHJhBsRFMhBOZvQptolbb5XIuQb6zRRFEPN2CK1o+bfK7QmgL0gqDU3AyjRXbliDYGk12hxqRaTW6IsDbvrqjlBgeu4ANqqHgXvJ8UiBcBEEIaStiUBRO9AjKGCwSb2MMs0TMhbHkmCbBMQo3AxSAyop85AEGgtCEOQyB21w+eVpm4xy4+ienG0tElhd4tlaDFluqATryrCGndihVhpJnge0NHCXgxuLzz1gqAZ4wqbJvvJJRVtMaMeX+nJkcinWKpn0bkHe2hzi5TtGESB8mGiwFII9JJxhQyBUCG26nKtVvnJzLRoDW7PzlHBO7d7OeDxvWssU5Cn0j+fnR9qssrgqnnv/eMUNkRHf8AH+mbJqsKEN759+POA0Kb5N3kZxuee8BuG0AHcGoeN/jN4TYp4eOSB/PeKgSPNCunjv5/XbaD3Vimp9anMxdzi8u1/HGQ7Fe3J2Q77k0YKA2uOxo88gB7ZrOC4EkaFbZqv/zLPVAHkwq7OzvmesJIAFV08myaP3i3BDbhAKEgq0vBSYBSLlQteOZPfzvArRTWV+O0n3ony0kTbgFHvU67jiRTYiFBOq1vZy4xmgFCRdwNJZ9+8gHwYOuJG/jn+5BvoI00my88M8+bBzQ8YAEept0d+MJIRApaeDYx5YdawpoW2soaokqXkv3gwVpuQKgdA3ZTTvWF3MRCU061z3SnGWoR2WiaH5TWOoEYVeEp6PP65AcQ5l8Oznz2YiaLNKJnHN5fBMvLUvwqdnL9bpmoRTcUDzxx9RxQJIilHWhSkdc4OYeyrXspreEB42qEMBOCL5wq3koOaDQLsdPb0Y3MtWisPK3bUNVTWNMYqQFU7V/5yaB4qoCXgjbXzNWSZvUkUmBrnCKGySppo7dFHLZUAcRzozHFsiACiRQQidx5VeaLWKYIDAbOVS2gRpaA6BYPYWW9CfBa9FRTAnP3ke7s4FthEV1ZGA2TKh+RQqX55zF3xUIAqOs01mCD7wkRakYQcV5GuQGSVKorBpzS1vGIUGnaqR6xqxgcqw3CsBdMm3HAmDYDR+2CEAnkGoje/HRZ1jYHsmbo323MOmp50Ti5P1R0rY0FBEA5E3X7E7oGAqLz4tKJsbooM17f18IC6gZuUQ7ZYrOANHQHWONPmQi8UeTFqPKKaPygdDrU/YenQ0hNKwLykHyoEc5Kw5t0RAXZJUAJJPUDE0GGCq2RJHnJahm6kQ+Fj5ZMvJ2ih+yfZkB4EmAAiF+ZhqumPDp5wAvU6qiF4VBmgesHYIG+cfNNYXlNYxEFLjgArM4A9h1txqtwqnIef4wjRSMuIVKbrVOMAPilnTlNAoXwa0eTX2ZqJW6L8s+M2TseylBDlMbtinC2gB7jKTG6IWX1t9+cpQDdm9Jv8L+HNLcPIpeX8zxrCYGzQdn/AOTJQBVp0Nz5P544yJuomdbs+dcYEJDCKjJz4m5zycPOV44ngpgW9B5MpnVRETSvjlP6xduglCsZ2smvaO9OPKNCDpvaOtc9x9bGQkaBg277bxqb3j0LpFUi3cdt/wDLvIkrsB5Dw3613fOEdwNQg58a/v6whIm+J34nCeeWG8RtggCHANXbWbD1ihYKOg3o5OVnJgc/QACx5BStWRf0YKMQmgHvUFbZ/wAywWQsCJqG3ad9zTRCELQa0i1q709awdZGiDsjLTryMozWI1ASFWZdSkN7xoL55LyDCc+j4wMAupCQ0no+QcrjEIMWkVhqaJJu8q3HiMQj4GPOuv1ghaYJqTVWh1vS7xATbKsCjgaO7cEDyIAx0DqEW1vP8YOEVjFN3W1SdiHGGUmlpQv2vX31bjAIbA5/CPjfOEKQmzah59+PvL4Z5u0Ns17b4xyxbEEV0q68CGu9ZrKFBjquArU093W2zIYY84C1oHJADXefDLYc4UYFb4GKDPUJ+yOjqSOWK0UrvtsRQEdoY1FIo3YdUiIIbeLsZi0uJixY0YRLq2KOGURiEKlQuXlJcwLcAQKqV3hKZxf8tDFW3aZiq+Q4tFLo6LkpVzR59Jt5DedKIRTNU6xA5I2nQCgYl6W9hpbUbYgHtD1lhN0hI0DQlY6L2UZzEYJIBtJML5hEoUiuwogKaYdUMLIB4aMq9N2w0B8AP2ZMd4ALjhaCQMbATRTlRa1wQZvsSbWFdke6VmOg55Ed06QpBfMb68mUNd7KvgKfQmtY5JQEy7SIrtWr2usBU00hZXkmuOfQ4muwMWcBeHzPBMeXYbfgweGu/wDEpgcKMNeh/rHyIVYJw+hmtb0WuRYr3jcO+5L7uEE4F8KYyHax+P8AXNNSyYFoHzT94BJ/1g+BhzEKd4Alycxe2BzQEwb693q8feLgtUFhV5GdYoSndS8TicYgME0AJDDcQ7DZ0/8A3Aqrt7R/+YFHYAXvv/mMacoPt7/WUpUDO9D79mF4QUN0nGte+P8A5hUqHQFFn9mFEOw0Jp4+OPvCgQIC0XDHXGbGlEsFv/MCuBTTTwlOOMJBSQuAK9c4Chj0Qi9cGvxcKOJLmqsSiatxCEJCeTRk+D578ZZOwAJtyyuo2+DAbBvLsojfNmuesVKlNAPC6W9+smDgQFdKOG/GVaJRqBCKKTr846xWi+LW8bxmoMtCiNASDs2Yx0OoBXQlXi08Mwhi0Il6KSOzteptu7XCag9qxN8O6Nw4ClMgiAQ/YND6xxd3eYqxaB4G3vnNYorUjwACHGzg840GbFAwpolnue64EqJM+eIeW62sXFmPKETltcGXnmww+sXgJIcBQgerVtUWXpEmB0oietfAYFmAgIFGMOtef/X0A0a8gvCa5++/UlW6ClXjU3z3kMxGMIm/Ju+EnWRWCBGG4I69J94APaaAKlB435y/gLU5ZT3p/wCYjZQ8xaoOgvRzv1iW9W91AaRRB21bvmz23kzalRqzkst849Amy+Ql8ziar6xrCNwbIOuRk9ubZIHTdeQ0KLA5V5cSpoG6ICoanHDx8jxRU5VnTpob5522FKwKJpqDwm+aYBq0WLSaupsXW0MoG8wUASVfPd/vBE3WhQqBKcWFVwxIZgXdyiFk4e3ldMOi3bchNujmawYCl06IXSG0agaxicIQDyBbL/eSJVWJtssc82u1eoWFqkHS1ob06bvwqGq6lriWO+ONGMmWioTq+Wf/2Q==" alt="微博配图 6" decoding="async" referrerpolicy="no-referrer"></a></div>
<footer class="wb-actions"> <a href="https://www.weibo.com/1199303274/R9yE5wVH8" target="_blank" rel="noopener noreferrer" aria-label="在微博查看转发"><svg class="wb-action-icon" viewBox="0 0 24 24" aria-hidden="true"><path d="M15 3h6v6"></path><path d="m10 14 11-11"></path><path d="M18 13v6a2 2 0 0 1-2 2H5a2 2 0 0 1-2-2V8a2 2 0 0 1 2-2h6"></path></svg></a> <a href="https://www.weibo.com/1199303274/R9yE5wVH8" target="_blank" rel="noopener noreferrer" aria-label="在微博查看评论"><svg class="wb-action-icon" viewBox="0 0 24 24" aria-hidden="true"><path d="M21 15a4 4 0 0 1-4 4H8l-5 3V7a4 4 0 0 1 4-4h10a4 4 0 0 1 4 4z"></path><circle cx="8" cy="11" r=".85"></circle><circle cx="12" cy="11" r=".85"></circle><circle cx="16" cy="11" r=".85"></circle></svg>7</a> <a href="https://www.weibo.com/1199303274/R9yE5wVH8" target="_blank" rel="noopener noreferrer" aria-label="在微博查看赞"><svg class="wb-action-icon" viewBox="0 0 24 24" aria-hidden="true"><path d="M7 10v12"></path><path d="M15 5.88 14 10h5.83a2 2 0 0 1 1.92 2.56l-2.33 8A2 2 0 0 1 17.5 22H4a2 2 0 0 1-2-2v-8a2 2 0 0 1 2-2h2.76a2 2 0 0 0 1.79-1.11L12 2a3.13 3.13 0 0 1 3 3.88Z"></path></svg>10</a> </footer> </article> <style> .wb-card{box-sizing:border-box;width:100%;max-width:600px;margin:0 auto;overflow:hidden;border:1px solid #e6e6e6;border-radius:8px;background:#fff;color:#333;font-family:-apple-system,BlinkMacSystemFont,"Segoe UI","PingFang SC","Hiragino Sans GB","Microsoft YaHei",Arial,sans-serif;font-size:14px;line-height:1.65;box-shadow:0 2px 10px rgba(0,0,0,.04)} .wb-card *{box-sizing:border-box}.wb-card a{color:inherit;text-decoration:none}.wb-head{display:flex;align-items:center;padding:18px 20px 10px}.wb-avatar-link{flex:none}.wb-avatar{display:block;width:50px;height:50px;border-radius:50%;object-fit:cover}.wb-user{min-width:0;flex:1;padding-left:12px}.wb-name{display:block;overflow:hidden;color:#333;font-weight:650;font-size:15px;line-height:23px;text-overflow:ellipsis;white-space:nowrap}.wb-v{display:inline-grid;width:14px;height:14px;margin-left:2px;border-radius:50%;background:#ff8200;color:#fff;font:700 9px/14px Arial;text-align:center;vertical-align:1px}.wb-meta{overflow:hidden;color:#939393;font-size:12px;line-height:20px;text-overflow:ellipsis;white-space:nowrap}.wb-mark{align-self:flex-start;display:grid;width:42px;height:30px;margin-top:0;place-items:center}.wb-logo-icon{display:block;width:42px;height:30px}.wb-text{padding:5px 20px 12px;font-size:15px;line-height:1.75;overflow-wrap:anywhere;white-space:normal}.wb-text a,.wb-repost-text a{color:#eb7350}.wb-text img,.wb-repost-text img{width:1em;height:1em;vertical-align:-2px}.wb-location-icon{position:relative;display:inline-block;width:.78em;height:.78em;margin:0 .36em 0 .16em;border:1.8px solid #5b8fc9;border-radius:50% 50% 50% 0;transform:rotate(-45deg);vertical-align:0}.wb-location-icon:after{position:absolute;left:50%;top:50%;width:3px;height:3px;border-radius:50%;background:#5b8fc9;content:"";transform:translate(-50%,-50%)}.wb-photos{display:grid;grid-template-columns:repeat(3,1fr);gap:4px;padding:0 20px 16px}.wb-photos.one{display:block}.wb-photos.even{grid-template-columns:repeat(2,1fr)}.wb-photo{display:block;overflow:hidden;aspect-ratio:1;border-radius:4px;background:#f2f2f5}.wb-photos.one .wb-photo{aspect-ratio:auto}.wb-photo img{display:block;width:100%;height:100%;max-height:560px;object-fit:cover}.wb-photos.one .wb-photo img{height:auto;object-fit:contain}.wb-media{display:block;margin:0 20px 16px;overflow:hidden;border-radius:5px;background:#111}.wb-media video,.wb-media img{display:block;width:100%;max-height:560px;object-fit:contain}.wb-repost{margin:0 20px 16px;padding-top:12px;border-radius:5px;background:#f2f2f5;overflow:hidden}.wb-repost-text{padding:0 12px 10px;font-size:14px;line-height:1.7;overflow-wrap:anywhere}.wb-repost .wb-photos{padding:0 12px 12px}.wb-repost .wb-media{margin:0 12px 12px}.wb-actions{display:grid;grid-template-columns:repeat(3,1fr);border-top:1px solid #f2f2f5;color:#808080}.wb-actions a{position:relative;padding:10px 4px;text-align:center;font-size:12px;transition:color .15s ease}.wb-actions a:hover{color:#ff8200}.wb-actions a+a:before{position:absolute;left:0;top:12px;bottom:12px;width:1px;background:#e6e6e6;content:""}.wb-action-icon{display:inline-block;width:21px;height:21px;margin-right:7px;fill:none;stroke:currentColor;stroke-width:1.8;stroke-linecap:round;stroke-linejoin:round;vertical-align:-6px}.wb-action-icon circle{fill:currentColor;stroke:none}@media(max-width:480px){.wb-card{border-radius:0}.wb-head{padding:14px 14px 8px}.wb-text{padding:4px 14px 10px}.wb-photos{padding:0 14px 14px}.wb-media,.wb-repost{margin-left:14px;margin-right:14px}} </style>
看起来还不错。
2026-01-01 09:28:20
谈笑风生又一年
这一年依然延续着“一年如一日”的生活,在写作之前,我把去年的总结翻出来看了看,惊喜地发现可以直接拿过来用,只需要把 2024 换成 2025 ,其他部分原封不动,就可以完美地总结我的 2025 。不过我还是打算随便写写东西,一来 2025 标志着我打工十年的里程碑,二来自己也在这一年迈过了 35 岁这条“打工人毕业线”,这些都让这一年虽然大体上看起来跟之前一样,但细微处又有很多不同。
虽然每一天的日程都差不多,但我也尝试在属于自己的零星间隙做些不一样的事情。年中的时候开始和孩子一起逛图书馆,我也因此发现了这座属于精神世界的宝藏,最终在 NeoDB 上记录下了 33 本书籍,相当一部分是自己多年前就在 NeoDB 上标记的“存货”。虚构类的我最喜欢《方舟》,最后的反转着实出人意料,令人叹为观止。非虚构类的我最喜欢《更富有、更睿智、更快乐》,这本书帮助我更好地理解了在下一个阶段应该把生活的重心放到哪里,自己虽然远远没有大富大贵,但如何追求快乐的底层逻辑是共通的。
同样地借着和孩子一起出游的机会,我在南湾逛了许多公园,并在微博等平台上留下些许图文记录。跟着孩子一起,我才发现在自己居住的周边还有这么多漂亮的地方,公园绿地或大或小,天气或阴或晴,每一种组合都可以呈现出不一样的色彩,我的心境也随之不一样,但这些共同的底色是稳重、宁静、不慌不忙、波澜不惊,或许也有平时打工太忙的缘故,每次在自然中徜徉的时候都能感受到一种令人心安的平静。

在孩子的带领下,生活的每一天都是一个重新发现自己认识自己的过程,他就像一面镜子一样反映着自己的一举一动,也像个雷达一样帮我探索着生活中那些极易忽略的瞬间。
开销方面随着孩子的渐渐长大呈现爆炸式的增长,“四脚吞金兽”威力初显,往日两个人只需要不到半个月的工资就可以生活得很滋润,今年直接变成月光,所以年初在家庭内部进行了一系列降本增效行动,包括把本站从 WordPress 转移到了 Cloudflare Pages ,最后的结果是每个月可以省出来小一百块,可谓杯水车薪。好在今年股市还算给力,在工资月光的情况下依然取得了可观的增量,这些都是今后追求“更睿智、更快乐”的助力。
十年前初入行时,我觉得技术深度最重要,后来觉得能规划一个项目的统筹能力最重要,但在近几年,这个想法逐渐发生了变化,尤其是随着最近三年的 AI 蓬勃发展,以所有人都跟不上的速度刷新着它的能力边界,这不得不让我重新思考我们工作的意义究竟在哪里,或者简单点说, AI 会在越来越多的事情比人们做得更快更好,那么被 AI 替代掉的我们又该何去何从?
由于过去一两年完全属于自己的时间并不多,并且极度碎片化,我在这个问题上并没有什么深入的见解,只是凭着自己的直觉模模糊糊地认为,最重要的是以自己喜欢的方式去探索生活,可以去发展自己的兴趣爱好,可以进行一些不为赚钱只为自己开心的创作,也可以去见自己从未见过的山和海,这与《更富有、更睿智、更快乐》一书的结尾不谋而合,也与《明朝那些事儿》里面徐霞客的一生相呼应。
而这一切的前提是距离“斩杀线”越远越好。
我大概是在七八年前开始意识到所谓的“中产阶级”不过是消费主义捏造出来的一个概念,没有自己的事业和资产,再怎么打工也逃不过职场“斩杀线”,这条线可能是 35 岁,也可能是其他的某些因素,比如说 AI ,总之,会有那么一个瞬间,一旦被迫失业,就再也没有了跟以前相当的收入,接下来就是向着生活的谷底不断滑落,到时候连生存下去都可能成问题,更不用说去探索生活了。
对我而言,今年 35 岁的毕业年龄和 AI 对职场的冲击同时到来,幸运的是,自己目前打的工还没有受到太大影响,更幸运的是,我已经为这一天准备了七八年,准备的方式并不高明,一切都遵照着长者的教诲“闷声大发财,这是坠吼的”,经过了近十年漫长的时光,如今我也有了几分底气去应对未来的风风雨雨。
2025 已成过往,站在年关往前眺望,一切都隐在层层迷雾中,愿我们都有足够的勇气前行。
祝大家新年快乐!
2025-08-07 13:01:22
一个人在东京这种大城市,要做到生活舒适,所需要的最小空间是多少?《东京八平米》的作者给出的答案是八平米,假如房间呈正方形,每个边长还不到三米,这样一个小家中却装下了单人床、书桌、衣橱等所有生活必需的家具,在一个角落里还有个小小的厕所和厨房,缺点是不能洗澡,只能借助健身房,也放不下冰箱,所有每天的食材都是现买的。房间小,那么真正的生活便向外求,得益于东京都市圈的便利和广阔,整个天地仿佛都是这个小家的延伸,也得益于比较自由的工作,便可以在最好的时间出现在最佳的地点,让自己全身心浸入这座城市带来的丰富多彩。作者站在个人的视角,为我们讲述了在这个小家生活时的所见所闻与周边人们的交流互动,那些看起来平常的小店、平常的人们,在作者平静的叙述下都有着属于自己独特的故事。
读书,实际上是在读自己,这些故事让我回忆起了自己住在 Sunnyvale 市中心的一段日子,当时的我与作者有些许相似之处,租来的房间仅为容身之所,真正的生活却可以沿着四通八达的道路抵达城市的每个角落。
在疫情之前,我在 Sunnyvale 市中心租了间公寓,面积差不多有六十平,恐怕光卧室的面积就比作者的房间大很多,毕竟要在硅谷找到一间用于出租的八平米还是不太容易的,功能上自然比作者的八平米完善很多,因此我不必像作者一样对家里的每一寸空间精打细算,家具不多,随意摆放一下,屋子里还是显得很宽敞。周边的生活十分便利,便利得不像是在出门就得开车的美国。
从那里出门几分钟就可以走到火车站,这里每天有 Caltrain 可以直达旧金山圣何塞这种大城市,火车站旁有许多公交车停靠,可以去往邻近的城镇。旁边有一片商业区,下午下班后,伴着晚霞,很多人在街上露天用餐,人声鼎沸,觥筹交错。不远处有家 Target 超市,可以满足大部分日常所需,如果对食材有要求的话,走路差不多二十分钟就可以到达 Trader Joe's 。图书馆也在附近,只有步行十几分钟的距离。每到周末,市中心的道路就封闭了,要让位给每周一次的集市,在加州中部山谷的农场主们装上自家最新鲜的蔬菜水果运到这里叫卖,价钱跟超市差不多,但质量比超市要好多了。现在我虽然搬离了那里,但每到周末,只要没什么安排,都会去那边集市上逛逛,哪怕什么也不买,让自己沾沾人气也是很有必要的。所以当时除了上下班通勤,几乎没什么开车的机会,非常环保。
大家对美国的一贯印象是人多的地方治安就比较差,尤其是各种市中心,事实的确如此,但 Sunnyvale 市中心问题不大,甚至夜里还能出门买个夜宵,大概是因为警察局就在附近,小偷小摸时有发生,但拦路抢劫甚至枪击等恶性案件从没听说过。
住在这样一个地方自然开销不菲,每个月接近一半的税后工资都交给房东了,再加上吃喝等支出,每个月就剩不下几个钱了。为了让自己的储蓄率保持在 50% 以上,我尝试了很多方法。最重要的就是记账,这样对每个月的支出有个大致的概念,发现除房租之外,开支最大的类别就是超市购物和吃饭,其实超市购物也主要是购买食材。经过规划和实践,在工作日吃饭可以在公司解决,在周末吃饭可以去麦当劳解决,每顿饭自己只需要支出五美元不到,加上超市购买的早饭,一个月下来花在吃上的钱只需要一百美元左右。因为不需要自己做饭,所以水电费也被压缩到了极致,每个月不会超过二十美元,同时也几乎不会产生生活垃圾,一盒垃圾袋可以用很久很久。这样每个月都有至少 50% 的收入可以存下来,那也是第一次真正感受到自己手里财富有所积累的一段日子。
有人可能会问,只吃麦当劳会不会不健康?其实控制好每天 2000 左右卡路里,只买汉堡,肉、菜、主食搭配着吃是不会有问题的,并且平时工作日都在公司,食堂伙食营养还算均衡。在通胀起飞之前,麦当劳的汉堡是可以免费加菜的,只要他们店里有的菜都可以放进去,你甚至可以让店员把一个麦香鸡加到巨无霸的规模,可惜现在加菜都要收费了,我这种白嫖的套路已经行不通了。
在吃饭这件事上省下的大量时间和金钱我也没有浪费。我订阅了 AMC 影院的会员,每个月二十多美元,每周可以免费看三场电影,从 IMAX Dolby 影厅到普通荧幕都可以随心选择,一到周末,我或者拉上朋友一起,或者自己去看一些有趣的影片,既在 IMAX 影厅里看着《阿拉丁》与孩子们一起欢笑,也去过普通厅跟零星几位上了年纪的人一起看《托尔金》。不想看电影的日子,就去图书馆借几本自己感兴趣的书,或者去一些不怎么知名的小博物馆逛逛。实在懒得出门了,就在家睡到自然醒,或者玩玩游戏,也是非常惬意的一天。
后来在疫情期间,这间便利的公寓更凸显了它的价值。 Target 旁边的小楼新开了 Whole Foods 超市和电影院,买菜买零食再也不需要走很远的路去 Trader Joe's 了,这样在仅仅方圆五百米的范围内所有的生活需求都可以解决。 Whole Foods 开业那天店员还送了我一个购物袋,我一直用到了今天,每次逛超市的时候都带上,就不再需要超市的一次性购物袋了。到了疫情后期,通胀实在厉害,房租一涨再涨,在 Sunnyvale 居住了四年之后,我不得不搬离了那间蜗居。
作者在书中说这本书也可以当作东京探索指南,结果我这篇写着写着就变成 Sunnyvale 探索指南了,或许以后有了足够的闲心,我也可以把在硅谷的这些日子拾起来,当流水账一样随便写写,权当记录。
2025-02-09 03:20:28
大约在七年前将博客转移到了 WordPress ,在这期间使用体验良好,也攒下了一堆文章,收获了各种 RSS 平台上的若干订阅。但随着近年家庭支出飙升,曾经眼中的一点小钱也变成了沉重的负担,看着一个月将近 20 块钱的服务器费用,不得不开始“降本增效”,所以今年年初花了将近一个月的工夫把博客迁移到了 Astro 。
因为我不想花钱,并且还希望保留自己的域名,那么最流行的选择基本只剩下了 GitHub Pages 和 Cloudflare Pages ,由于之前搭建 Douban Book+ 主页和小地瓜主页的经验,所以毫不犹豫地选择了 Cloudflare ,这样的学习成本最低。
那么下一步就是挑选主页搭建框架了,我听说 Astro 还是去年看到 X 站(前推特)上有很多网友讨论这个框架,并且很多网友利用它做出了非常漂亮的网站,并有一系列建站教程出现,比如说这一篇就包含了非常详细的步骤,虽然没有那么多时间精力去详细学习了解一个新东西,但我还是想尝尝鲜。
于是在一系列拍脑袋的决策下,我决定在 Cloudflare Pages 上用 Astro 运行我的博客。
在此特别感谢 Moeyua 开发的这款 Typography 主题,简洁清爽,使读者可以沉浸于文字,而且在代码技术相关的文章方面也有不俗的表现力。
WordPress 提供文章导出的功能, Astro 支持 Markdown 语法,两者格式并不兼容。幸运的是, Astro 官网提供了详细的迁移教程。成功将 WordPress 文章转换成 Markdown 格式之后,迁移的准备工作就算完成了。
在直接复制粘贴之前,还有几件事要做。
Typography 自带许多社交媒体图标,但还是无法满足我的需求,因为我同时活跃在微博、 X 站、小红书、蓝天、长毛象等各种平台,所以我需要一个容量更大的图标库。
我的每篇文章几乎都带有若干个标签,这样容易归类查找,并且会配上一张或贴题或随意的图片,所以我需要一个专门的页面显示所有标签及某个标签下所有文章的列表,同时打开每篇文章时最开始需要显示图片,比如说下面这样

但这个主题没有提供这个功能,那么我只好自己动手丰衣足食了。
这个没什么可讲的,就是把自己需要的信息填进去即可。
这块是我花时间最多的一部分,包括所有图片都迁移和文章格式的整理,因为有些内容并没有那么完美地转换成 Markdown ,总共大几十篇吧。不敢想象假如哪天文章多了之后,再次面对迁移需求应该如何是好,估计到时候就得开发一款趁手的工具了,希望这是最后一次吧。
完成了上述操作,就可以把内容发布到 Cloudflare Pages 上了,具体步骤我就不在这里重复了,感兴趣的读者可以参阅这篇文章的“如何部署”部分。
2025-01-01 12:23:00
谈笑风生又一年
时间如白驹过隙,又到岁末,毕竟距离去年年底仅仅间隔了三篇文章。
在旧金山湾区我干了这一年也没有什么别的,大概三件事,
如果说还有一点什么成绩就是支出一律记账,这个对家庭的可持续发展有很大关系。还有玩遍了附近的小公园也是一个很大的。但这些都是次要的,我主要就是这三件事情。很惭愧,就做了一点微小的工作,谢谢大家!
新年快乐!
2024-08-26 10:54:00
最近用 Python 玩了一下十亿行挑战,并在本地环境上将用时从将近八分钟优化到半分钟出头,在这期间了解了很多以前不知道的 Python 技巧,所以记录下来方便后续参考。
这是一个由 Gunnar Morling 发起的挑战,不过仅限于 Java 圈:编写一段 Java 程序在最短的时间内处理一个有十亿行的文件,其中每一行包含了一个观测站和对应的气温,前者是字符串类型,后者为浮点数,两者之间由分号间隔,就像下面的片段所示,
» head -n 10 measurements.txt
Thessaloniki;20.4
Malé;23.3
Rostov-on-Don;10.1
Heraklion;18.4
Alice Springs;2.7
Port Sudan;32.1
Port-Gentil;33.0
Napier;15.2
Sapporo;3.5
Malé;29.0
程序的输出为每个观测站的最低温,平均温度,和最高温,按观测站的名称排序,
{Abha=5.0/18.0/27.4, Abidjan=15.7/26.0/34.1, Abéché=12.1/29.4/35.6, Accra=14.7/26.4/33.1, Addis Ababa=2.1/16.0/24.3, Adelaide=4.1/17.3/29.7, ...}
后来这项挑战火出了圈,也有了一个专门的网站欢迎人们提交各种语言的版本。最近我用 Python 比较多,所以就用 Python 来玩一玩。
这项任务不需要考虑复杂的算法,唯一的难点在于输入的数据大小,十亿行大约是 13 GB 左右,得出正确的计算结果很容易,但计算地有效率很难。我们很快就能实现一个简单的版本并给出正确的输出,
from dataclasses import dataclass
from typing import Dict
@dataclass
class Temperature:
min_temp: float
max_temp: float
sum_temp: float
count: int
def process_file():
temperatures: Dict[str, Temperature] = dict()
with open("measurements.txt") as f:
for line in f:
station, temp_str = line.split(";")
t = temperatures.get(station)
temperature = float(temp_str)
if not t:
temperatures[station] = Temperature(
temperature, temperature, temperature, 1
)
else:
t.min_temp = min(t.min_temp, temperature)
t.max_temp = max(t.max_temp, temperature)
t.sum_temp += temperature
t.count += 1
with open("panda.txt", "w") as out_f:
out_f.write("{")
for station, t in sorted(temperatures.items()):
out_f.write(
f"{station}={t.min_temp:.1f}/{t.sum_temp / t.count:.1f}/{t.max_temp:.1f}, ",
)
out_f.write("\b\b} \n")
if __name__ == "__main__":
process_file()
耗时如下
463.26s user 2.63s system 99% cpu 7:49.20 total
在一个 CPU 跑满的情况下用了将近八分钟才结束,我们将在此基础上进行优化。
整个代码总共做了三件事,
在最终的结果中,所有观测站的数量只有几百个,因此在最后一步写文件上下工夫是没有必要的,需要优化的地方主要集中在前两步,一个是如何有效率地读文件,一个是如何在处理数据时有效地利用多核。
我们先来看一看在版本 1.0 中按行读文件的方法究竟需要花费多久,把读文件的代码抽取出来只有三行,
with open("measurements.txt") as f:
for _ in f:
pass
耗时
56.77s user 2.16s system 99% cpu 58.985 total
只是简单过一遍文件就需要差不多一分钟,这个 I/O 开销实在是太大了,这一部分毫无疑问存在优化的空间。
经常与文件打交道的话可以知道一次读取多个字节的数据通常比按行遍历要快,但需要改一下代码找出最合适的数据块大小,
import time
chunk_sizes = []
for i in range(10, 31):
chunk_sizes.append(2**i)
for chunk_size in chunk_sizes:
start = time.time()
def read_file():
with open("measurements.txt", mode="r") as f:
while True:
chunk = f.read(chunk_size)
if not chunk:
break
yield chunk
for _ in read_file():
pass
print(f"CHUNK SIZE: {chunk_size: >10}, ELAPSED TIME: {time.time() - start}")
运行结果为
CHUNK SIZE: 1024, ELAPSED TIME: 4.204729080200195
CHUNK SIZE: 2048, ELAPSED TIME: 3.5845539569854736
CHUNK SIZE: 4096, ELAPSED TIME: 3.1715991497039795
CHUNK SIZE: 8192, ELAPSED TIME: 2.072834014892578
CHUNK SIZE: 16384, ELAPSED TIME: 1.478424072265625
CHUNK SIZE: 32768, ELAPSED TIME: 1.1602458953857422
CHUNK SIZE: 65536, ELAPSED TIME: 1.0105319023132324
CHUNK SIZE: 131072, ELAPSED TIME: 0.9584476947784424
CHUNK SIZE: 262144, ELAPSED TIME: 0.9280698299407959
CHUNK SIZE: 524288, ELAPSED TIME: 0.9165401458740234
CHUNK SIZE: 1048576, ELAPSED TIME: 0.8949398994445801
CHUNK SIZE: 2097152, ELAPSED TIME: 1.367276906967163
CHUNK SIZE: 4194304, ELAPSED TIME: 1.3553977012634277
CHUNK SIZE: 8388608, ELAPSED TIME: 0.9136021137237549
CHUNK SIZE: 16777216, ELAPSED TIME: 1.400062084197998
CHUNK SIZE: 33554432, ELAPSED TIME: 1.4531581401824951
CHUNK SIZE: 67108864, ELAPSED TIME: 1.6019279956817627
CHUNK SIZE: 134217728, ELAPSED TIME: 1.5939080715179443
CHUNK SIZE: 268435456, ELAPSED TIME: 1.6016528606414795
CHUNK SIZE: 536870912, ELAPSED TIME: 1.8202641010284424
CHUNK SIZE: 1073741824, ELAPSED TIME: 2.6885197162628174
直接取最小值 1048576 作为数据块的大小。但这样读出来的每一块结尾未必对应着行尾,所以简单粗暴截出来的数据块送给下游代码去处理的话会出现同一行的内容不完整的情况,因此需要稍微修改一下读文件的代码:在每次读完之后需要检查末尾是否为 \n ,若不是的话继续按字节读取,直到第一个行尾。对应的读文件代码为
def read_chunks(filename: str) -> Generator[str, None, None]:
CHUNK_SIZE = 1048576
with open("measurements.txt", mode="r") as f:
while True:
chunk = f.read(CHUNK_SIZE)
if not chunk:
break
while chunk[-1] != "\n":
chunk += f.read(1)
yield chunk
for _ in read_file("measurements.txt"):
pass
耗时
4.37s user 3.49s system 99% cpu 7.870 total
可以看到比按行读取大大降低了用时。
到这里还远远不是结束,还可以继续优化,据 Python 官方文档所言,以二进制模式读文件时可以省去将字节解码为字符串的开销,
As mentioned in the Overview, Python distinguishes between binary and text I/O. Files opened in binary mode (including 'b' in the mode argument) return contents as bytes objects without any decoding.
因此将文件的打开模式改为 mode="rb” ,对应的代码为
def read_chunks(filename: str) -> Generator[bytes, None, None]:
CHUNK_SIZE = 1048576
with open(filename, mode="rb") as f:
while True:
chunk = f.read(CHUNK_SIZE)
if not chunk:
break
while chunk[-1] != 10:
chunk += f.read(1)
yield chunk
for _ in read_file("measurements.txt"):
pass
耗时
1.91s user 0.97s system 99% cpu 2.885 total
这样读文件的优化就可以告一段落了。
下一步考虑的是如何把上面读出来的文件块分解成行,并把每一行的数据解析汇总得到最终想要的结果。
机器总共有 12 个核,那么只有一个干活,剩下的十一个围观就是极大的浪费,并且在上面的分析中整个文件已经被切成了若干块,非常适合用多进程并行处理。为什么不考虑多线程呢?请参考 Python 的 GIL 这一段,简单来说由于 Python 在最初设计时的问题,在运行 CPU 密集型任务时在同一个时刻只有一个线程可以获得全局解释锁,其他线程都被挂起,直到正在运行的线程退出。分析聚合每一行的数据明显要吃掉大量 CPU 资源,这个时候开一堆线程去抢唯一的一把锁无疑会浪费大量的资源,最终的程序性能反而不一定比最初的单核版本好。
应用多进程之前,数据块处理中的一段代码需要优化,
...
t.min_temp = min(t.min_temp, temperature)
t.max_temp = max(t.max_temp, temperature)
...
在上面的实现中,无论比较结果如何,都需要对 t.min_temp 和 t.max_temp 进行一次赋值,其实这是没必要的,可以改成
...
if temperature < t.min_temp:
t.min_temp = temperature
if temperature > t.max_temp:
t.max_temp = temperature
...
这样处理每个数据块的函数可以写作
def process_chunk(chunk: bytes) -> Dict[bytes, Temperature]:
temp_result: Dict[bytes, Temperature] = dict()
for line in chunk.splitlines():
station, temp_str = line.split(b";")
temperature = float(temp_str)
t = temp_result.get(station)
if not t:
temp_result[station] = Temperature(temperature, temperature, temperature, 1)
else:
if temperature < t.min_temp:
t.min_temp = temperature
if temperature > t.max_temp:
t.max_temp = temperature
t.sum_temp += temperature
t.count += 1
return temp_result
Python 自带的进程池允许我们直接把函数映射到一个迭代器上,在这里就是 read_chunks 函数返回的生成器
def map_job(filename: str) -> Iterator[Dict[bytes, Temperature]]:
with concurrent.futures.ProcessPoolExecutor(max_workers=os.cpu_count()) as pool:
return pool.map(process_chunk, read_chunks(filename))
最后需要用一个 reduce job 来集合 map job 产生的临时结果,整理后的完整代码如下所示
import concurrent.futures
import os
from dataclasses import dataclass
from typing import Dict, Generator, Iterator
@dataclass
class Temperature:
min_temp: float
max_temp: float
sum_temp: float
count: int
def read_chunks(filename: str) -> Generator[bytes, None, None]:
CHUNK_SIZE = 1048576
with open(filename, mode="rb") as f:
while True:
chunk = f.read(CHUNK_SIZE)
if not chunk:
break
while chunk[-1] != 10:
chunk += f.read(1)
yield chunk
def process_chunk(chunk: bytes) -> Dict[bytes, Temperature]:
temp_result: Dict[bytes, Temperature] = dict()
for line in chunk.splitlines():
station, temp_str = line.split(b";")
temperature = float(temp_str)
t = temp_result.get(station)
if t is None:
temp_result[station] = Temperature(temperature, temperature, temperature, 1)
else:
if temperature < t.min_temp:
t.min_temp = temperature
elif temperature > t.max_temp:
t.max_temp = temperature
t.sum_temp += temperature
t.count += 1
return temp_result
def map_job(filename: str) -> Iterator[Dict[bytes, Temperature]]:
with concurrent.futures.ProcessPoolExecutor(max_workers=os.cpu_count()) as pool:
return pool.map(process_chunk, read_chunks(filename))
def reduce_job(
temp_results: Iterator[Dict[bytes, Temperature]]
) -> Dict[bytes, Temperature]:
result: Dict[bytes, Temperature] = dict()
for item in temp_results:
for station, temperature in item.items():
t = result.get(station)
if t is None:
result[station] = temperature
else:
if temperature.min_temp < t.min_temp:
t.min_temp = temperature.min_temp
elif temperature.max_temp > t.max_temp:
t.max_temp = temperature.max_temp
t.sum_temp += temperature.sum_temp
t.count += temperature.count
return result
def write_file(result: Dict[bytes, Temperature], output_file: str):
with open(output_file, "w") as out_f:
out_f.write("{")
for station, t in sorted(result.items()):
out_f.write(f"{station.decode("utf-8")}={t.min_temp:.1f}/{t.sum_temp / t.count:.1f}/{t.max_temp:.1f}, ")
out_f.write("\b\b} \n")
if __name__ == "__main__":
input_file = "measurements.txt"
temp_results = map_job(input_file)
result = reduce_job(temp_results)
output_file = "panda.txt"
write_file(result, output_file)
耗时
301.05s user 21.41s system 961% cpu 33.548 total
与其他语言相比这个结果不怎么样,不过能把向来以慢著称的 Python 优化到这个程度大概也算可以了。