2026-07-31 20:47:27

Hi friends 👋,
Happy Friday and welcome back to our 204th Weekly Dose of Optimism!
The pace of all of this good stuff continues to blow my mind. We sent the Dose last Friday morning. It was jam-packed. “How can things get any better than this?” I asked myself.
And then the big tech companies came out in favor of open-weight models out of pure self-interest, which I wrote about in AI is Oil, Not God.
And then… the Sixers signed Lebron James!
I guess the real lesson, no matter which particular stories we cover each week, is to Trust the Process.
This week’s theme is physical AI - robots, robot brains, drones, and AVs, with a little robot regulation in the Extra Doses.
Let’s get to it.
A company called Enigma is a little less enigmatic after emerging from stealth on Monday with a $71 million seed round led by Index Ventures and Ribbit Capital, plus its decision to open up more than 100 real AI-powered robots available online for anyone to control in real-time. You can go play with them right now, and tell them what to paint, how to lightsaber, to please defuse that bomb, or even which experiments to run.
The cute little robot arms you’re controlling are actual physical machines in facilities in Israel and California, taking your instructions through the browser.
Enigma is building robot-agnostic software, foundation models for robotics, and user interfaces that make robots easier to command across different hardware and tasks. Its bet is that studying how humans engage with robots produces both better interfaces and possibly a different kind of robotic brain.
The public robots.online experiment lets users try text, audio, demonstrations, and other interaction patterns while the company observes how people naturally attempt to get machines to do things. If the race in robotics is about accumulating real training data fast and cost-efficiently, this is a novel and orthogonal approach to that which doubles as a unique marketing stunt.
Part of the reason the company is able to do something so different is that its founders aren’t robotics people. Jonathan Jacobi and Gal Niv met in teenage hacking competitions and served together in Israel’s Unit 8200. Neither is a roboticist. That might be a good thing - in deep tech, people can often get stuck in whichever path they focused on for their PhD. No PhD, no stuck.
Will it work? Who knows, I’m not a robotics PhD. But it looks fun and different.
BAH GOD THAT’S GOOGLE DEEPMIND’S MUSIC!
The frontier lab exploring the most frontiers, and the one that has done by far the most to advance the state of robots and world models, is back with Gemini Robotics 2, its next-generation robotics model family for controlling robots across whole-body movement, dexterous manipulation, embodied reasoning, and multi-robot collaboration.
The release includes three models: Gemini Robotics 2, a vision-language-action (VLA) model that maps vision and language into motor control; Gemini Robotics ER 2, an embodied reasoning (ER) model for planning longer tasks and coordinating robots; and Gemini Robotics On-Device 2, a local model that can adapt to new robot bodies with a few hours of data, typically fewer than 200 examples.
With these models, GDM is moving beyond tabletop manipulation into full-body control. The model can control Apptronik’s Apollo humanoid as it walks, crouches, reaches, and manipulates objects in cluttered environments. It can also operate different end effectors, including five-fingered hands and two-finger grippers, across tasks like tying a knot, sealing a ziplock bag, packing tools, and placing objects. DeepMind says the same model checkpoint controlled multiple embodiments, including Apollo variants and a Franka Duo setup.
Humanoid robots haven’t been solved yet. Travis Kalanick is still right, for now. GDM notes that movement speed still needs work, and the benchmarks show uneven performance on multi-finger dexterity. But it is a meaningful shift in the robotics stack, with one model family handling perception, planning, control, adaptation, safety, and collaboration across different bodies.
Ironically, after the team by the name got subsumed into Google DeepMind, robots are finally getting a … Google Brain.
So we have robots that anyone with a computer can control, and models that can control any robot that walks, and now DoorDash is making its own flying robots, aka drones.
DoorDash announced on Wednesday that DoorDash Labs earned FAA Part 135 air carrier certification and launched DoorDash Air, its in-house drone delivery program. Part 135 lets DoorDash operate as an air carrier, and the company says it is only the eighth drone operator to earn it.
In its tweet, DoorDash said, “Drones are just one delivery option DoorDash Labs built to scale delivery for merchants, alongside Dashers, Dot, and our autonomous delivery partners. Everything from the aircraft to the merchant handoff system have been designed to get your orders to you quickly and safely.”
The company’s strategy and bet is clear here: they believer that it already owns the most important part of the delivery ecosystem - the network of customers and merchants and the technology to coordinate it all - and that it can commoditize the ways that it gets things from one party to the other. Whatever is at the right spot on the cheap/fast Pareto Frontier, they can choose.
Someone smarter on drones than I am said they’re making their drones less as a standalone drone play and more as a template to build standards and encourage competition in the space. Like Nvidia and Microsoft signing the letter, DoorDash is trying to commoditize its complements.
It’s a super interesting bet, like Uber trying to make its own self-driving cars. It’s interesting to note that Uber is no longer doing that, but that it is providing a demand cannon to dedicated AV makers. In any case, I want drone delivery ASAP, and I’m glad DoorDash is making the push to speed the whole thing up.
And look, I think it’s cool, but the most-liked reply to DoorDash’ tweet is:
So we have a little ways to go before people get used to a burrito landing in their yard.

Everyone is super excited about computer AI and I get it but I continue to think that the way cooler and way more underappreciated thing is what’s going to happen in the physical world, and in particular the way that we move people and things.
While DoorDash is flying our burritos overhead, Amazon’s Zoox will be zooking passengers around the streets sans human driver, sans, even, the potential for a human driver.
Per Reuters, “Zoox unit won U.S. approval on Wednesday for limited commercial deployment of its novel steering-wheel-free robotaxis, a first for the autonomous ride industry, the U.S. auto safety agency said Thursday.”
This isn’t the first self-driving car, obviously. Waymo and Tesla are operational in a number of American markets, and they are incredibly cool. But it’s the first vehicle designed from the ground-up for a self-driving world that will be commercially available in the US, the Adam or Eve of future generations of vehicles that never even contemplated that a human might drive it.
In Zoox’s case, that means no driver’s seat or steering wheel, and “two rows of inward-facing seats” so passengers can spend their ride hanging out more easily. I would imagine that in the future, cars will be designed more and more like moving rooms. Hop in, work or enjoy a movie or get a spa treatment or whatever, and get out at your destination.
I can’t wait to see the horrendous things people do to and in these cars.
There’s almost nothing I’ve found as fascinating this year as Sam Altman / OpenAI’s comms transformation, and there’s nothing that’s captivated me over the past week as much as market incentives aligning almost everyone against the market leader, Anthropic, and towards things that are great for everyone else.
I tweeted about the former after Sam’s Invest Like the Best appearance, and wrote about the latter after the open letter here.
This latest announcement by OpenAI, and Sam’s commentary, combines both.
Basically, OpenAI’s new message since bringing the TBPN guys on (correlation or causation, who knows) has been that they’re building tools to empower people to do amazing things. Replacing people is weird. Trying to do everything themselves is weird. Thinking they can predict the future is weird. Just make tools, give them to people, and see what happens.
This is both a response to how little people want the AI labs to tell them what their future is going to be, and to Anthropic’s more opinionated views. I’m not passing a value judgment here - I believe that Dario fully believes what he’s saying, and that he’s doing a principled thing by speaking out about what he sees to be the risks to his product even if it hurts him or the company. I just happen to strongly disagree with that view (he’s a million times smarter than me and in the center of this, so grain of salt) and it also gives OpenAI a wide-open lane for counterpositioning.
The ILTB conversation was a great example of the comms side of this - Sam was very on-message about AI being a tool. I especially liked the point that it’s not even that out of line with historical trends in progress, that everyone always just wants to feel that they’re in a special role in the special part of history. The whole thing is designed to deflate fears that AI will replace us and to make Anthropic look weird.
But those are words, as is signing the open letter, and at the same time, OpenAI is likely lobbying behind the scenes for regulatory capture, too.
What’s amazed me most this week, and made me appreciate capitalism, is that even if you don’t trust Sam or OpenAI or big tech, companies are incentivized to do things that are good for the public, too.
In this case, counter-positioning against Anthropic trying to go more vertical in certain categories like biotech means that OpenAI is giving free frontier models to tens of thousands of researchers because “the best way to do this is for us to empower scientists, not to try to figure out everything ourselves.”
A jab, to be sure, but if the result is that more researchers get more powerful tools with which to benefit us all, jab away.
Throwing this one above the paywall as an extra little tweet. There is a ton going on in the private markets, a ton of it driven by AI, and there are very few firms deploying more capital in more different ways to AI in the private markets than General Catalyst. In conjunction with the release of his Q2 Letter, I sat down with GC’s CEO Hemant Taneja for a conversation on the markets and AI generally, how GC is approaching it specifically — including owning a healthcare system and making Anthropic its biggest position — and what the role of a venture capitalist is today.
This was a fun one because there are definitely some things we disagree on, and we went into them, but we are both fundamentally optimistic about technology.
You can also find the conversation on Spotify here.
2026-07-26 01:25:07
Hi friends 👋,
Happy Saturday! The past couple of days have been a technology business strategy nerd’s Super Bowl plus a Pro-Progress Person’s Super Bowl. Whenever you combine commoditizing complements with fighting the precautionary principle, I’m not going to be able to stop myself from writing something.
This is lightly edited and is just my quick thoughts, so I’m throwing a bunch of it behind the paywall for the real ones (not boring world subscribers).
Tell our enemies that they may take our lives, but they'll never take our freedom!
Let’s get to it.

Yesterday, Satya Nadella and Jensen Huang, among other leaders in tech, signed and shared a letter in support of open-weight models. Jensen even set up a twitter account to share it.

I loved it, and tweeted that this was Capitalism at its best.
From a business perspective, this is classic tech strategy stuff.
“Smart companies try to commoditize their products’ complements.”
– Joel Spolsky, Strategy Letter V
All of the signatories either make open-weight models models or are complementary to them. Models run on Nvidia chips. They power Microsoft products. a16z and Y Combinator back companies that support, use, and compete with models. Palantir’s Alex Karp has been banging this drum because he wants to disintermediate models in the enterprise. Meta is more open source than the other similar American labs. Hugging Face is where open models live. Dell sells the machines they run on. CrowdStrike benefits if defenders have access to the same intelligence as attackers. Box, ServiceNow, Replit and Perplexity all get better when capable models become cheaper, more plentiful and easier to customize. Google, a new signatory, got off of its slow, bureaucratic ass and signed because Google will be fine either way, and maybe open source models will allow it to serve search ads more cheaply at some point. Mariana Minerals needs to give its comms person a raise, or send a big thank you to a16z.
The more competition there is at the model layer, the less Anthropic and OpenAI are able to run away with the frontier and build a duopoly, the more each of the signatories benefits.
Signing this letter is a selfish act that also happens to align with the interests of consumers and millions of businesses.
And that’s great! That’s capitalism, baby!
Their self-interests are aligned with our interests as consumers and businesses using these models and living in a world in which these models (and the leaders of the labs that create them) exist.
Not everyone agrees with me or the signatories. There are people who believe that it’s better to lock these models down because they might be dangerous.
I think it comes down to whether you think AI is more Oil or God, more “an economically useful commodity that can be scaled and refined to act as a multiplier on everything we do” or “supremely intelligent and powerful being that’s going to wake up and make humanity subservient (if we're lucky).”
I am strongly on the Oil side, as I wrote in The Goldilocks Zone in June 2024. My belief is unchanged since.
In fact, I think it’s super interesting that Satya and Jensen, both of whom are at the very bleeding edge of this technology, wrote in support of open-weight models. Surely, if they saw something that made them believe that these models were going to become conscious and take over the world, they wouldn’t be as openly pro-diffusion, even if they were short-term incentivized to be. I think they know that AI is Oil, too.
But aren’t they going to be dangerous?
My friend Matt Kaufman at Collaborative Fund, who is a lot smarter than me, emailed me after seeing my tweet with just that concern:
Just saw your tweet on the Jensen note and I’ve seen a few others supporting open-weight model proliferation. I’m on the fence here and if you have 2 min to type out a quick reply, I’d be very curious how you’re thinking about it.
I’d definitely prefer a more open ecosystem were it not for risks like models being fine-tuned to remove bio / cyber safeguards, and then resulting in harm. This seems trivially easy and perhaps isn’t a big issue now, but likely will be once 1) the open ones are much more powerful and 2) dangerous actors outside our tech bubble catch on to the capabilities here.
I think there are many domains where LLMs more favor offense rather than defense so this feels like a scary reality and I therefore sympathize with arguments that they should be tightly regulated like weapons.
I quickly banged out a response and I wanted to share it with you, even though it was dashed off in a few minutes and a little messy, because I’ve been meaning to write something and this is close. I’ll add some footnotes on things I’ve thought more about since hitting send.
2026-07-24 21:07:04

Hi friends 👋,
Happy Friday and welcome to the 203rd Weekly Dose of Optimism.
At least here in New York City, the weather is 10/10, it’s a summer Friday, and you probably want to spend some time outside. So let’s cut this intro short and here’s an audio version (my AI voice, so please excuse the pronunciation of “a16z”) if you want to pop it in your ears and walk around.
Peep the Extra Doses for some wild science, an excellent essay on the Frontier, and an absolutely stellar 50-year land art project.
Let’s get to it.
In Dose #185 in March, we talked about Travis Kalanick’s emergence from the stealthiest stealth in startup history with his new/old company, Atoms, which plans to do everything.
Well Travis is back again.
On Wednesday, Atoms announced a $1.7 billion equity investment led by a16z, with Ben Horowitz joining the board, which is a very rare occurrence these days, to make up for past mistakes on both sides, per Travis:
I’ve known Marc and Ben for a long time, and we got oh-so-close to partnering up at Uber in 2011. I blame Marc, Ben blames himself but let’s just say it was on all of us and in 2017 Uber suffered the consequences of not having Marc on the board - iykyk.
Notably, Uber is also participating. Benchmark is not.
“On many levels, this round is a bit of unfinished business,” Kalanick wrote. In 2011, a16z came very close to leading Uber’s Series B before the deal fell apart and Menlo Ventures led the $32 million round instead. a16z, which is assembling the mid-2010 founder Infinity Stones with Kalanick and Adam Neumann, doesn’t make the same mistake twice.
Not that it really matters when it’s Travis Kalanick, but what is a16z investing in?
After leaving Uber heartbroken in 2017, Kalanick bought City Storage Systems, turned CloudKitchens into its best-known business, and spent eight years building in near-total silence. Employees couldn’t put the company on their LinkedIn, for example.
Meanwhile, the company hired thousands of people, expanded across 30 countries, bought and developed real estate, wrote restaurant software, built robots, and learned what it takes to operate complicated physical systems every day. As part of this round, those businesses have been merged into one Atoms equity structure.
Atoms looks less like a startup than a conglomerate: food, mining, and transport all under one corporate umbrella.
Kalanick’s unifying idea for Atoms (and Uber before it) is that physical industries can be built like computers. In Kalanick’s model, manufacturing is the CPU that transforms atoms, real estate is the storage layer, and transportation is the network that moves atoms from one place to another.
Food is the furthest along version of Kalanick’s computer today:
CloudKitchens supplies delivery-first real estate.
Otter is the restaurant OS.
ProFood builds large-scale food infrastructure.
Picnic handles office lunch delivery.
Lab37 builds the robots.
Lab37’s Bowl Builder takes an order from a restaurant’s point-of-sale system, dispenses and weighs the ingredients, applies sauce, lids the bowl, labels it, puts it in a bag with utensils, and closes the bag. The machine can assemble up to 300 bowls per hour (200 if it has to bag them, which Kalanick said on TBPN is surprisingly hard), and Lab37 says it can reduce assembly labor by more than 40%. It is already operating in restaurants.
On the Mining side, Atoms acquired Pronto, the autonomous-haulage company founded by former Uber and Google autonomy pioneer Anthony Levandowski, and made it the technology engine of Atoms Mining.
Pronto retrofits existing Caterpillar, Komatsu, and other haul trucks instead of requiring a mine to buy an entirely new fleet. At Heidelberg Materials’ Lake Bridgeport quarry in Texas, a mixed fleet running Pronto’s system autonomously hauled more than two million tons of limestone in under eight months. Pronto now has an agreement to deploy on more than 100 trucks across over a dozen Heidelberg sites, is expanding to two more quarries this year, and signed a partnership with Hitachi Construction Machinery last week. In his latest TBPN interview, Kalanick says autonomy can improve mine productivity by 30% to 40%.
Transport, the third Atoms division, is still mostly hidden. Kalanick describes it as a wheelbase for robots. TBD.
In total, Atoms has assembled seven operating companies and shown credible proofs in food and mining. It is yet to be seen whether he can turn all of those pieces into one really big computer, if he ends up with a disconnected menagerie of good businesses, or if the whole thing crumbles under its own weight.
But this Travis Kalanick waging war on some of civilizations’s biggest challenges, all at once, with potentially the biggest chip on any billionaire’s shoulder and a desire to make Benchmark miss out on trillions of dollars in returns. If you want to bet against him, that’s on you. I’m happy cheering on The Return of the King.
During the World Cup final on Sunday night, Anthropic mathematician Levent Alpöge posted the finale of one of algebraic geometry’s most famous open problems: ‘hello there the jacobian conjecture is false.’ He thanked his friend Akhil for asking about it and his other ‘close friend,’ Claude Fable 5, for working on it during the game.
The Jacobian conjecture goes like this. Take a polynomial map from n-dimensional complex space back to itself. If its Jacobian determinant (the local measure of how the map stretches and squishes space) is always the same nonzero number, the map is locally reversible everywhere. The conjecture, generalized by Ott-Heinrich Keller in 1939, says that it must therefore be globally reversible, with a polynomial inverse.
Alpöge’s three-variable map has a Jacobian determinant that is always -2, satisfying the conjecture’s premise. But it sends three different points—(0, 0, -1/4), (1, -3/2, 13/2), and (-1, 3/2, 13/2)—to the exact same point, (-1/4, 0, 0). A map that turns three inputs into one output cannot have an inverse.
Look… I don’t know what I’m talking about here. Better to play with Simon Rezchikov’s visualization and explainer here if you’re really curious.
The bigger point is that these models, pointed by human mathematicians, are going on a conjecture disproving SPREE, to the point that Joscha Bach (jokingly?) proposed a moratorium on disproving until they’re good enough to prove.
That comment was in the replies to another disproval:
Adios Dinitz-Garg-Goemans! It looks like the Jacobian disproval was the 4-minute mile of disproving longstanding conjectures. Now everyone knows it’s possible, and they’re burning tokens on disproving their favorites. They’ll probably all fall soon (unless Anthropic keeps throttling (which I reproduced)).
At which point: 1) we’ll see how that translates into applications, and 2) neti neti.
Gopika Gopakumar and Nivedita Bhattacharjee for Reuters
Indian space startup Skyroot has reached orbit with Vikram-1, the country’s first privately developed orbital rocket.
My friend Christian Keil at a16z described Skyroot’s Vikram-1 like this: “Think of it as the Indian Electron. Roughly equivalent in size to the RocketLab rocket, also non-reusable.” I want to be clear that he described it that way. Apparently a lot of his “new Indian haters” didn’t like him comparing it to the “workhorse rocket for a $40 billion company (RocketLab).”
So just the facts: Vikram-1 is 22 meters tall and carries up to 350 kilograms. It has three solid stages and a liquid orbital-adjustment module powered by a 3D-printed engine. On its maiden flight, it delivered customer payloads to a 450-kilometer orbit. The whole trip took about fifteen minutes.
Skyroot’s speed is impressive. India opened its space sector to private companies in 2020. Six years later, a startup founded by former Indian Space Research Organization engineers (ISRO is India’s NASA) has joined the very small club of private companies that have built a rocket and put useful payloads into orbit.
India joins an even smaller club: countries whose private companies have achieved orbit. The other members are the United States, China, and kind of New Zealand. Rocket Lab is Kiwi by birth but was headquartered in the US by the time Electron first reached orbit from New Zealand in 2018. I say we count it.
Russia, amazingly, hasn’t joined the club, despite its decorated state space program. The Soviet Union put Sputnik into orbit in 1957, but seventy years later, no private Russian company has done the same. Communism fall hard.
Most of the world is happy for India, aside from a few MAGA anon accounts who totally would have launched a rocket to orbit if the Indians hadn’t taken the job.
Chak De, India! 🇮🇳
Director Michael Kratsios

On Tuesday, White House science advisor Michael Kratsios released Science: A New Golden Age, a 123-page attempt to do for American science in 2026 what Vannevar Bush’s Science: The Endless Frontier did in 1945.
Bush’s report established the federal government’s role in supporting basic research, helped lead to the creation of the National Science Foundation, and designed the system that has funded American science for the past eighty years.
Kratsios’ argument is that Bush’s system has worked!… so well that it calcified.
The federal government distributes roughly $200 billion in research and development funding every year, largely through a model in which scientists submit detailed project proposals to panels of other scientists, who attempt to reach consensus on which proposals deserve funding. It is pretty good at separating plausible science from nonsense. It is less good at distinguishing potentially revolutionary science from merely solid science, because potentially revolutionary science often looks like nonsense before it works. It is not good at Taking Weird Ideas Seriously.
The process has also become suffocatingly slow. Researchers spend nearly half of their time on administrative work. From 1991 through January 2025, the federal government added at least 270 new requirements to research grants. Some grants take as long as twenty months to move from submission to award, which the report helpfully points out is almost as long as it took Boeing to move the 747 from the drawing board into production.
Science: A New Golden Age proposes treating that $200 billion more like a portfolio, with different funding mechanisms designed for different kinds of scientific work.
Some researchers would receive long-horizon funding based on their talent and track record instead of being forced to invent a new project every three years. Howard Hughes Medical Institute provides its investigators with roughly $10 million over seven years, with minimal reporting requirements and tolerance for early failure. Research cited in the report found that those scientists produced high-impact work at nearly twice the rate of similarly accomplished federally funded peers. So why not do that at the Federal level?
Smaller, exploratory projects could receive “fast grants,” a la the Collisons during Covid, based on applications just a few pages long, with decisions made in under a month instead of six to nine (nice). Reviewers could receive “golden tickets” that allow each of them to champion one unconventional proposal that the rest of the committee dislikes. Agencies could use more prizes, advance market commitments, and ambitious challenges that pay for results instead of reimbursing inputs.
The report proposes regranting programs that give scientists close to a field small pools of money to distribute to promising people and projects before consensus forms around them. It calls for more DARPA-like program managers who can construct a thesis, recruit teams, and make a coordinated portfolio of bets. And it wants every major science agency to create a metascience unit that runs controlled experiments on the funding process itself, testing whether fast grants, golden tickets, partial lotteries, or other mechanisms actually produce better science. I love all of that.
If you have followed the Progress Studies world for the past few years, the report reads like a greatest-hits album. It cites Heidi Williams on rebuilding the NIH, Patrick Collison’s Fast Grants, Sam Rodriques and Adam Marblestone on Focused Research Organizations, Caleb Watney on X-Labs, Ben Reinhardt on unbundling the university, the Vesuvius Challenge, ARPA-E, HHMI, and the Institute for Advanced Study.
The report is not an executive order and does not immediately change how NIH or NSF awards grants. But it was released alongside an FY2028 R&D Priorities Memorandum directing federal agencies to incorporate the recommendations into their next budget proposals and submit implementation plans within ninety days.
There is a big risk here, too. The report argues that federal science funding needs to be more “politically accountable.” In the constitutional sense—that elected governments decide how public money is spent—that is obviously true. In practice, giving political appointees more discretion over scientific grants creates an obvious path from “fund high-risk work that consensus panels overlook” to “Eric Trump receives $17 billion to disprove string theory once and for all.”
A separate proposed OMB rule would give political appointees the power to block grants before they are issued and terminate existing awards that no longer align with administration priorities. That is not the same thing as golden tickets, fast grants, or empowered technical program managers, and it would be a mistake to smuggle political control in under the banner of metascience.
The best version of this plan would create more independent sources of scientific judgment, not replace one centralized consensus with another. It would combine traditional peer review, long-term bets on individual scientists, fast grants, prizes, lotteries, regranting, and DARPA-style portfolios, then publicly measure which approaches work for which kinds of problems. Program managers should have more freedom to make unusual bets, but their selections, conflicts, milestones, and long-term track records should be legible.
There is a ton of great stuff in here, stuff I would have fallen over if you’d told me was coming from the White House just a few years ago. Now, the challenge will be turning those ideas into practice for the benefit of all mankind.
A reader commented last week that they were unsubscribing because they thought I was celebrating war by highlighting autonomous boat startup Saronic’s Very Big Week.
To be very clear, I don’t celebrate war and I think very few people building for the DoW do either. It’s a dumb, blunt way to resolve conflicts that we couldn’t figure out how to resolve in a better way. Every life lost during a war is a tragedy.
But war is unfortunately a fact of life, and if that’s the case, I want America to have a strong enough arsenal to deter it, and ideally an autonomous enough one to put fewer human lives at risk. As Anduril put it, “The modern battlefield is a robotic kill zone.”
To that end, Anduril and Archer’s announcement of Thunder, “a Group 5 autonomous attack rotorcraft,” is a welcome one. The idea is that these are wingmen for human-flown Apache helicopters, pushing out ahead to scout, eliminate threats, and take fire otherwise intended for the people if necessary.
In the anime launch video (see: The Great Differentiation), Anduril shows the autonomous Thunder flying ahead and wiping out drones and missiles that threatened the human pilots’ helicopters. Turns out, they’re father and son, and they’re able to reunite after the mission that might otherwise have killed them.
It’s a bit on the nose, but I think that points to the way that Anduril views the program, as a way to put autonomous mass in harms way instead of humans.
Hopefully, one day, war will just be autonomous machines fighting autonomous machines, wasting both sides’ money but keeping the people out of it until it becomes too much of a simulacrum and we just call the whole thing off. This is another small step in that direction.
In nearer-term optimistic news, Archer is introducing the same platform for commercial use as Archer Halo.

It will focus on “uncrewed commercial missions across search & rescue, logistics, offshore energy, humanitarian & medical cargo, maritime operations and more.”
2026-07-17 19:43:07

Hi friends 👋 ,
Happy Friday and welcome to our 202nd Weekly Dose of Optimism!
As always, a big week here at the Dose. This week, we had a lot of good news come in pairs: two Saronic stories, two Austin stories, two robotics stories, and two open-weight model stories. So I cheated and combined them to squeeze a little extra optimism into your Dose.
Let’s get to it.
At the bottom of this and every Weekly Dose, we share some extra goodies, including Science Breakthroughs from Ulkar Aghayeva, who I first found through her work with collaborators ranking 2025’s papers and breakthroughs for their potential impact. Now, you get those glimpses into the future as they happen each week.
That’s one of many goodies we’re bringing to paid not boring subscribers, from the full version of Riding the Leopard to co-written essays with founders on the cutting edge of robotics, AI, manufacturing, and more. We’ll keep bringing you more, and I hope you’ll join us.
We last covered Saronic, the Austin-based autonomous shipbuilding startup, in Dose #197, when its Corsair drone boats rescued a downed Apache crew near the Strait of Hormuz. A little over a month later, the company has had an even more absurd week.
On Monday, three of its 24-foot Corsair autonomous boats were used in combat (not rescue) for the first time, striking an Iranian submarine and ship-maintenance facility at Bandar Abbas. The military has not publicly assessed the damage. A system built by a four-year-old startup went from prototype to a live combat mission, a month after another Corsair performed the first known rescue of downed pilots by an autonomous boat. Seems to be working.
Then yesterday, Saronic announced that it had chosen Brownsville, Texas, for Port Alpha, a more than $3 billion greenfield shipyard. The first phase will cover 835 acres, with room to expand to nearly 4,400. Construction is supposed to begin this year, operations in 2028, and the company expects to create as many as 10,000 direct jobs over the next decade.

The initial yard will be able to build ships up to 850 feet long. Fully built out, Saronic says it could reach roughly 2 million gross tons of annual shipbuilding capacity. The plan is to build crewed and uncrewed military ships, container ships, roll-on/roll-off vessels, tankers, and icebreakers, using the same autonomy and advanced-manufacturing stack as the drone boats.
Proving that a startup can build autonomous boats that are useful in combat is huge, but proving that they can build a great American shipyard again might be even bigger.
If you’ve been reading the Dose for a while, you might be thinking … wait, wasn’t that shipyard supposed to be a part of California Forever? Good memory. It was. California fumbled it, because local and state government failed to pass legislation around a proposed permitting framework in time.
“We hope this missed opportunity serves as a wake-up call that inaction and political gridlock have real costs for all Californians,” the California Forever-led labor and business coalition that pushed for the legislation wrote. Until then, in the words of Tim Riggins, it’s Texas Forever.
Speaking of Austin companies doing big things… IT’S COMING HOME.
No, not the World Cup. Jude Bellingham shit-talked Messi, so Messi decided to end England’s run in the semis.
I’m talking about Base Power Company, which after more than two years operating out of Austin, TX is finally operating in Austin, TX.
Base is beginning to serve homeowners inside Austin Energy territory as part of a 40-megawatt residential battery agreement with the city-owned utility. Base will install and maintain the batteries. Austin Energy will be able to dispatch the fleet when demand and wholesale power prices spike. Homeowners get whole-home backup when the grid goes down. Win-Win-Win.
In the very same week, another Austin company, TerraFirma, which is “Building giant robots to build a brighter future,” announced a $100M Kleiner Perkins-led Series A to make construction robots. In the SpaceX-vets’ words, “We’re a new type of company, a robotic construction company that builds the full technology stack needed to deliver an order-of-magnitude improvement in one of the world’s oldest, largest, most important, but least efficient industries.”
It seems like the TerraFirma guys also got every great vertical integrator co-founder/exec on the cap table, including Anduril’s Matt Grimm, Hadrian’s Chris Power, and their Austin neighbor, Base’s Justin Lopas.
It’s time to build. Hook ‘em. Texas Forever.

Regular-sized robots can raise money, too, and it seems like they can do more than that.
On Wednesday, Walden Robotics came out of stealth with $300 million in seed funding at a $1.1 billion valuation co-led by Deviation Capital and a trio of Toyota investors (Toyota Motor Corp, Toyota Invention Partners, and Toyota Ventures). Its robots are already doing useful work in a North American Toyota factory, too.
The Toyota connection makes sense, because Walden spun out of Toyota Research Institute in January. CEO Russ Tedrake, an MIT professor who led TRI’s robotics and machine learning team for nearly a decade, brought over many of the people behind Diffusion Policy, Large Behavior Models, OpenVLA, and the Drake robotics simulator. By February, the new company had robots in production - on the factory floor in two months!
The robots are built as a full stack: hardware, software, models, and an application layer for deploying them into real workflows, a la Standard Bots. They learn tasks through demonstrations, then improve through practice, starting with the annoying jobs in manufacturing and logistics that have remained hard to automate because they change too often or require a little too much judgment for traditional fixed automation.
Most of us don’t live in factories, though, we live in homes. And there seems to be good news for us home-dwellers, too.
Yesterday, Sunday Robotics introduced ACT-2 Preview, its new robotics model for Memo, the company’s home robot. Sunday says ACT-2 can learn a new behavior from a single fine-tuning example, generalize it zero-shot to real homes it has never seen, and perform with a 99% success rate.
It’s still a preview, but they got ahead of the slick demo criticism by introducing something called Solves. “Progress in robotics is difficult to measure because demos vary by setup. Demo ≠ Solved,” CEO Tony Zhao tweeted. “A Solve declares two boundaries: scope and adaptation cost. Without both, 99% has no context.”
They found a “general recipe for Solves: scale pretraining, then hill-climb with minimal in-house data. For the first time, one fine-tuning example can teach a new behavior that generalizes.”
Blah blah blah that’s a lot of robot words. What can it actually do for me?
And now for your Moment of Zen (3 hours of Memo folding laundry)…

Sorry the picture for this one isn’t that exciting. Merck doesn’t do fancy pictures for their FDA-approval announcements. What they do do is make drugs that save lives, which, if you have to choose, is what you want.
Yesterday, the FDA approved Merck’s Lipfendra, the first oral PCSK9 inhibitor. It’s a once-daily pill that lowers LDL cholesterol about as much as the injectable PCSK9 drugs: a placebo-adjusted 56% in a broad hypercholesterolemia trial and 59% in patients with the inherited form.
It’s a bad time to be LDL Cholesterol. In Dose #195, we talked about Eli Lily’s new PCSK9-targeting gene therapy. Which means it’s a good time to be a heart. LDL cholesterol is one of the leading causes of heart attacks. PCSK9 is a protein that destroys LDL receptors on liver cells. If you can block it, more receptors survive to pull bad cholesterol out of the blood.
This isn’t the first PCSK9-targeting drug. There’s the upcoming gene therapy, and there are injected antibodies like Repatha and Praluent that do this very well. They are also injections, which turns out to be a meaningful barrier when you are asking millions of people to take something for years.
Luckily, the other thing they do uniquely ahead of the curve is macrocyclic peptides. They signed a $220M biobucks deal with not boring capital portfolio company Unnatural Products in 2024 to work on macrocyclic peptide, which it describes as “the next wave of drug discovery.”
What macrocyclic peptides allow you to do is to take larger molecules that normally require injections (they generally get chewed up in the gut) and deliver them orally. Lipfendra is a macrocyclic peptide, folded into a shape that helps it make the journey from mouth to target intact.
This isn’t a new capability, but it’s a new delivery mechanism: heart attacks can now be attacked back with antibody-like potency in a $10.50 daily pill. Eat your heart out.
Thinking Machines and Moonshot AI
It feels like just weeks ago that the US Government shut down Anthropic’s Fable 5 for being too dangerous while the USMNT squashed its opponent in a World Cup Match. Oh how things change.
In bad news for people who think that AI models are super super dangerous and might even kill us all on behalf of their owners like the Genie in Aladdin when Jafar has the lamp, and good news for normal people, a Chinese open source model has basically caught up to Fable 5 (and OpenAI’s GPT-5.6 Sol).
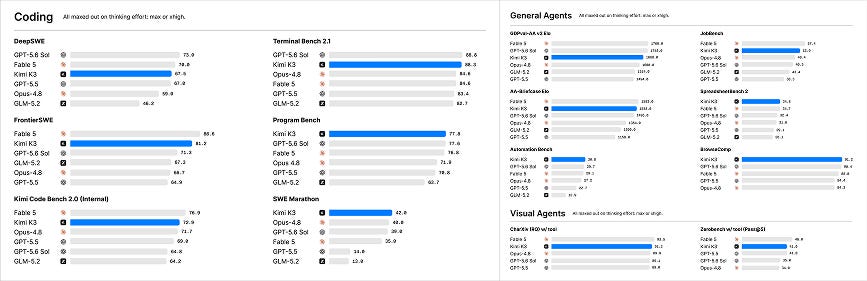
Yesterday, Beijing-based Moonshot AI released Kimi K3, the first open model in the 3-trillion-parameter class. K3 has 2.8 trillion total parameters, a one-million-token context window, and native vision. It is live now in Kimi’s apps and API, with the full weights scheduled for release by July 27th.
The big model is sparse, activating just 16 of 896 experts at a time. Moonshot says its new Kimi Delta Attention makes decoding up to 6.3x faster in million-token contexts, while a second architectural change called Attention Residuals delivers roughly 25% higher training efficiency at less than 2% additional cost. Taken together with the larger mixture of experts and new training recipes, the company claims about a 2.5x improvement in scaling efficiency over Kimi K2.
Moonshot says K3 still trails Claude Fable 5 and GPT-5.6 Sol overall. But on its published evaluations, it is in the same band and wins individual agentic and coding tests: 91.2 on BrowseComp versus Fable’s 88.0 and GPT-5.6 Sol’s 90.4, for example, and 88.3 on Terminal Bench 2.1 versus Fable and Opus 4.8 at 84.6. Those are company-run results and will need independent replication, but it looks like an open model is competing with the big boys.
This comes on the heels of Mira Murati’s Thinking Machines Lab releasing its first model, Inkling, on Wednesday, with the weights available to download under an Apache 2.0 license. Inkling is a 975-billion-parameter mixture-of-experts model with 41 billion active at a time. It accepts text, images, and audio, has a context window up to one million tokens, and can be fine-tuned through Thinking Machines’ Tinker platform.
Inkling is not the best model in the world, either, by Thinking Machines’ own admission. Its bet is that it is a strong, broad model that other people can turn into the best model for one particular thing.
To make the point, the team had Inkling write and run its own fine-tuning job, evaluate the new weights, and switch itself over to a version that never uses the letter “e.” Then, they opened it up to everyone, in the hopes that someone has an even better idea than that, which is how free markets work.
Open models competing is great because competition is great, because it means that more value will accrue to the many companies that make up the economy versus a handful of closed labs, because it lessens the odds that Dario is in charge of the world, and because open models, theoretically, compound on each other.
This seems to be happening here. Inkling’s architecture draws on China’s DeepSeek-V3, and Thinking Machines used data generated by Moonshot’s Kimi K2.5 during post-training.
Open-weight is not the same thing as fully open source. Neither lab is handing over every piece of training data and code, and almost nobody is going to run a multi-trillion-parameter model on a gaming PC. But weights are the valuable part if you want to inspect a model, customize it, improve it, or build on it permissionlessly.
Plus, it’ll give Ramp’s new AI Token Spend Management tool more ammo in the fight against bad ROT.
2026-07-16 20:53:19
Welcome to the 1,738 newly Not Boring people who have joined us since our last essay! Join 273,329 smart, curious folks by subscribing here:
Hi friends 👋,
Happy Thursday!
Just about three years ago, I was having coffee with another VC, someone whose portfolio I really like, and I asked him which one he was most excited about. He asked, “Do you know what wire harnesses are?” and I said something like “like bundles of wires?” and he said “kinda” and then told me about Jordan Black and Senra Systems.
Ever since then, it’s been a company that I’ve wanted to understand better, and as robotics has begun to take off and reindustrialization is underway and aerospace and defense are booming and the future looks more and more electric, it’s become even more relevant. I keep hearing about it from people I respect, too.
The reason wire harnesses are interesting, aside from the fact that they’re in everything electronic, from toys to Jeeps to satellites to F-35s, is that it’s devilishly hard to automate their manufacture. They’re high-mix, low volume, 3D, bendy, and floppy, among other tricky attributes. They’re often the component holding up the production of our most advanced machines, because you need them to turn everything else on, and once they’re in, a faulty harness can precipitate recalls or worse.
And because skilled assembly, and especially skilled assembly of wire harnesses, is one of the most challenging parts of the manufacturing process to automate, figuring out how to help workers build more of them, faster and more reliably, even as many of the skilled workers who know how to make them retire, may set the pace of American manufacturing.
Plus, I’m a sucker for giving humans superpowers instead of replacing them, and Jordan argues that “the more the easy stuff gets automated, the more valuable skilled humans will become.”
When Alexa Liautaud at GC introduced me to Jordan, I thought it would be a great opportunity to learn everything I can about wire harnesses and skilled assembly and what the future of manufacturing in America looks like from him, Senra’s Head of Strategic Finance Greg Brainard, and one of their investors, Sam Rohr at JAWS. And of course, to write something with them to share what I learned with you.
So to celebrate Senra’s $65M Series B from Lowercarbon & Interlagos with Sequoia, Founders Fund, General Catalyst, Andreessen Horowitz, Founders Fund, Dylan Field, CIV, 8VC, The Friedkin Group, JAWS, Sozo Ventures, and Alumni Ventures…
Let’s get to it.
A Co-Written Essay with Senra Systems CEO Jordan Black

One of the most notable things about Senra Systems is that so many people who don’t have to work another day in their lives are choosing to work there. What makes that even stranger, to the casual observer, is what they’re choosing to work on: wire harnesses.
Some of you will know what a wire harness is. It is the nervous system of a machine, hundreds of wires, bundled and crimped by hand, routing power and signal to every component that needs to turn on in any modern electrical system, from a satellite to a coffee maker to your car. But many of you won’t, which is fine, and even many of those of you who do won’t understand what makes them important or challenging, and an even smaller number of you will understand why so many people who have made tens of millions of dollars, or more, building reusable rockets in order to make life multiplanetary have decided to dedicate their next chapter to building them instead of angel investing from a beach.
One difference between them and the rest of us is that they have been bottlenecked by wire harnesses. They’ve done the ridiculously hard work of, say, building chopsticks that can catch a Statue of Liberty-sized rocket as it stumbles back to Earth, only to have to wait for the wires to turn the whole thing on. They’ve undoubtedly attempted to just do it themselves, because that’s their whole thing, only to find out firsthand what makes it so tricky to do well.
So when two of their own went and started a wire harness company, they’d seen enough to look a little more, and the more they peeled, the more they liked.
In the US alone, annual spend on wire harnessing for just aerospace and defense is something like $25-50 billion. Maybe the money itself isn’t that important anymore, but it says that the problem is big. It’s also getting bigger. This is one of those classic stories of an industry whose demand is ripping just as the old skilled hands who were trained during America’s manufacturing golden age are aging out. So the problem is big, and it’s urgent. And the answer is obvious, on the surface: automate!
And that’s where Senra really gets ya, if you’re the kind of person who likes solving really hard problems, because automating skilled assembly is probably the hardest thing you can do in manufacturing, especially when you’re talking something that’s high mix, low volume, flexible, and very complex, like aerospace and defense wire harnessing.
If you view America’s ability to manufacture as one big engineering challenge, and your goal, ultimately, is to automate as much of it as you can, you arrive pretty quickly at skilled assembly, manufacturing work that requires trained human judgment and dexterity instead of simple repetitive motion, as the place the machine gets stuck. Within skilled assembly, wire harnesses are perhaps the trickiest to get right, or at least the trickiest that we need a lot of, the trickiest without which nothing else turns on. So if you’ve been trained to heatseek bottlenecks at the system level and throw everything you’ve got at them until they’re knocked out and you can move on to the next one, then wire harnessing is the logical place to start.
And it turns out you can’t automate it, yet. In Elon’s five-step design algorithm - make requirements less dumb, delete the part or process, simplify or optimize the design, accelerate cycle time, automate - automation comes last. You can’t automate until you can configure.
What you need to do with skilled assembly generally and wire harnessing in particular, and what Senra is doing, is to make everything around the skilled assembler better, so that the skilled assembler can deliver wire harnesses at 4x the speed of traditional vendors while maintaining exceptional quality and accuracy.
Senra gives skilled workers superpowers and trains up tons of them so that they can make wire harnesses faster and with fewer defects so that everyone else can make whatever it is that they make faster and cheaper so that America might be able to manufacture competitively again.
We’d like to tell you a little bit about how, and why.
Wiring harnesses are like referees - most people only notice them when they mess up.
President Kennedy promised that America would go to the Moon and that we would be first, not “first but, first and, first if, but first period.” The Apollo Program was the vehicle through which this promise would be made real over eleven years, through the toil of 400,000 engineers and workers, and roughly $25 billion (nearly $200 billion in today’s dollars) of concentrated national will directed at a single goal.
What we remember is that America posthumously proved him right, when Apollo 11 astronauts Neil Armstrong and Buzz Aldrin walked on the moon as Michael Collins orbited above. What we forget is that the very first Apollo mission, Apollo 1, ended in tragedy.
In January 1967, three NASA astronauts, Gus Grissom, Ed White, and Roger Chaffee climbed into the Apollo 1 command module for what was supposed to be a routine pre-launch dress rehearsal on the launchpad at Cape Canaveral.

As the three men sat in the oxygen-rich capsule, behind a hatch that was designed to open inwards in a process that took 90 seconds, a fire broke out. It killed them within a minute. Investigators later determined the fire was sparked by a wiring fault. The review board cited poor workmanship and vulnerable wiring design as underlying causes. It was a bad wire harness that took the lives of those three astronauts.
That was a long time ago. Surely we’ve gotten better at bundling a bunch of wires together since?
On June 9th, Jeep recalled more than 1 million Wranglers and Gladiators, warning that they may catch on fire and advising owners to park them outside and away from other vehicles or structures.

The issue, as you might have guessed, was a wiring harness, specifically an electrical connection issue in the power-steering-pump wiring harness, something like this:

Drivers are advised to “inspect and, if necessary, repair or replace the wiring harness.”
Wiring harnesses can kill people when done wrong, but even in business-as-usual situations, they can kill production timelines.
Few people in the world know this better than Jordan Black.
Since working as a host at a burger restaurant at 16, Jordan has mixed service and engineering. He’s manned pizza joints, barbacked, bounced, and bartended, and even worked as a librarian. In each, he was obsessed with making customers happy and in each, he learned how to work with people. He loved solving hard physical problems, too. Back in his freshman year of college, high school, Jordan began working as a technician fixing roller coasters at the Santa Monica Pier. He parlayed that experience into internships at Enerpac and then The Ford Motor Company, which is where he expected to return after graduating from University of Wisconsin-Madison until SpaceX called and hired him as an Avionics Manufacturing Development Engineer. What that meant in practice was a lot of wire harnesses, wire harnesses for Starship and Dragon Spacesuits and Radio Frequency Cables and more.
Over the next five years at SpaceX, Jordan worked his way into the center of advanced hardware manufacturing, eventually running an Avionics R&D team with visibility into nearly every component that went into rockets and satellites. He saw firsthand how SpaceX would bring capital-intensive manufacturing capabilities in-house to increase iteration speed. He was often the one doing it. But highly skilled assembly work, the craftsmanship layer underlying nearly every advanced hardware system, remained dependent on fragmented suppliers operating with outdated systems and limited scalability, even at SpaceX.
A wire harness is in everything, nothing turns on without them, and everybody hates them, for two reasons.
One, to design it, it’s all in Excel spreadsheets and PowerPoint slides.
Two, to manufacture it, it’s all done by hand, arts and crafts style.
“It’s a really screwed up supply chain from start to finish.”
Because the wire harness supply chain is screwed up, everything else is. The wire harness is one of the last designed but first needed parts of any modern aerospace and defense system. You can’t know where your wire harnessing should go in a missile until you’ve figured out how you’re going to build the entire missile. You don’t know how long the missile is going to be, where the sensors are going to go, what needs to connect to what, where, until you’ve actually figured all of that out. Then and only then can you design the wire harnessing that connects it all. But then you have to design and produce custom wire harnessing as quickly as possible, because you won’t be able to turn the thing on in order to demonstrate it to the customer until you have it.
The wire harness is kind of like the fartlek of manufacturing; when it’s your turn, you have to sprint from the back of the back to the front as fast as you can. “You can get as far ahead on everything else as possible,” Jordan puts it, “but you can’t make a grilled cheese sandwich without the cheese.” (Wire harnesses are both cheese and fartlek here, for those keeping metaphor score at home.)
Sourcing high-quality harnesses is harder than you’d expect, too, because it sounds so simple. “Just give me a cable that plugs this thing into this thing.” But some of these designs end up being really complex - you need a cable that has 45 different offshoots, and they all need to be built to spec, so they’re highly custom products.

And for customers like SpaceX they’re really high mix, which makes them almost impossible to automate. One SpaceX wire harness will look totally different from this other SpaceX wire harness, and they might need five of this one kind but 100 of another kind, and so maybe it’s not surprising when you read it, but it was surprising to Jordan when he just needed wire harnesses pronto, that smaller wire harness shops would quote four to six month lead times on new programs.
Jordan learned this the hard way, going around to suppliers when he needed harnesses to make whatever he was working on work, and they’d come back with “Oh, cool, we can do it in four months,” but he’d need it way faster than that, because think about it; as an engineer, whether you’re building rockets or stringing a Christmas tree with lights, the first thing you actually need to do is to make sure that when you plug it in, the thing turns on.
A longstanding theme of Not Boring is that if a company is a bad customer or supplier, they might make a very good competitor.
So Jordan decided to leave SpaceX and start a wire harnessing company, teaming up with Ben Shanahan, a neuroscientist turned SpaceX software engineer who worked on WarpDrive, the company’s ERP / manufacturing execution system (MES), the software that runs the factory that is the product.
In March 2023, they founded Senra Systems.
In its early years, Senra has focused primarily on manufacturing wire harnesses for aerospace and defense (A&D) customers.
A&D is the highest-margin segment, the most fragmented slice of the market, and it’s ITAR-protected, meaning that customers are effectively required to source American. It is also the most challenging part of the market, and the least amenable to automation in the near-term, given the high mix and low volume compared to, say, a Toyota Camry. It is where America’s skilled workforce crunch is felt most acutely, because the work can neither be automated nor outsourced.
Put simply, the American wire harness workforce is on the decline while the demand for wire harnesses for A&D is taking off. There are fewer technicians to make more harnesses.
There is no government statistical category for “wire harness technician,” but the closest public workforce category - electrical, electronic, and electromechanical assemblers - has a median age of 47.2. More than a quarter of the workforce is 55 or older, approaching retirement age, while only 8% is under 25, stepping in to backfill the roles. Even if there were more people excited about taking the roles you still wouldn’t be able to scale up in time because that training period takes 18 months. In a typical shop, you’ll have a year and a month apprenticeship, and it’s like, “There’s this guy Doug, he’s been building Boeing harnesses for 25 years. Just go follow him around and see if you can learn something.” The industry isn’t training replacements at anything close to the rate at which it is losing experienced hands. The IPC, the electronics manufacturing trade association, calls the shortage of adequately skilled workers “chronic.”
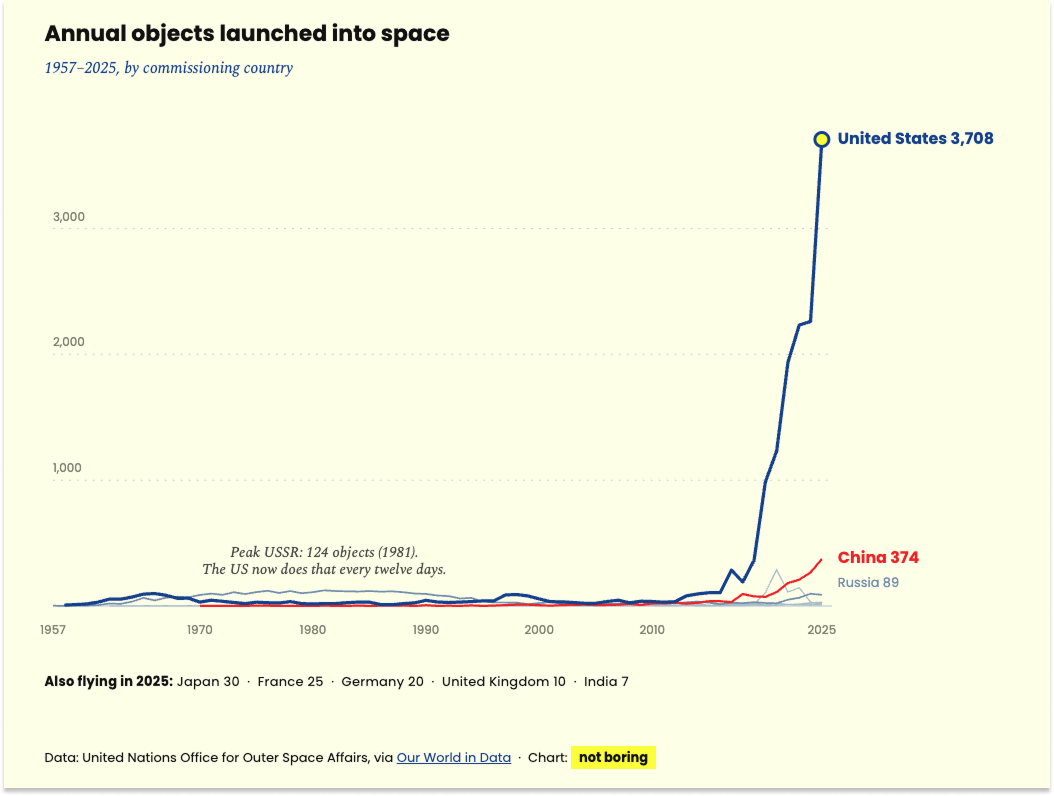
Even if demand were flat, that would be a problem. Demand, however, is not flat. America sent 3,708 objects into space in 2025, up from 2,261 in 2024, and those numbers should look tiny in a decade.
Meanwhile, the fiscal year 2026 national defense budget request crossed $1 trillion for the first time, including $153.3 billion for procurement and $142 billion for research & development. And the systems that the DoW will be purchasing and developing will require a lot of wire harnesses. As we wrote in Electromagnetism Secretly Runs the World, “Electronics comprise 35% of the cost of the F35 Lightning II, more than the cost of the engine itself, and 15% of the Pratt & Whitney F135 engine, which costs $20 million. By the 2030s, when it’s projected that defense contractors will be building the F-47, they’ll be spending over 40% of the $300 million airframe on electronics.” The more electronic our vehicles and weapons go, the more wire harnesses they’ll need.
The government knows its suppliers are not prepared. In a 2024 review of the commercial aviation supply chain, the Government Accountability Office (GAO) found that 15 of the 17 manufacturers it interviewed had struggled to hire enough skilled workers to meet demand. Nine of 15 suppliers said they had also struggled to fill orders as demand rebounded. There’s no reason to believe this is any better for the Defense sides of these Aerospace businesses.
The roughly 800 American harness shops that make up the supply base are largely small, owner-operated businesses. Their ability to grow is constrained by the amount of veterans they have to train apprentices, but the veterans are retiring, training takes years, they’re swamped with the growing demand, and apprentices aren’t signing up anyway. Worse, when they retire, their knowledge is gone with them, because they aren’t spending precious time writing it down.
So as much as Senra is manufacturing wire harnesses, its more important role may be “manufacturing” wire harness technicians to make all of the wire harnesses and increasingly electronic world needs.
This supply/demand imbalance also creates the market foothold for Senra. Because declining supply is buckling under growing demand, A&D is also where there is the most room for improvement: lead times on a new program are 4-6 months, only 25-50% of wire harnesses pass on the first try (first-pass yield), and quality is so inconsistent that many customers have to employ in-house technicians whose job it is to fix the wiring they receive from their wiring suppliers.
All of those characteristics make wire harnessing for A&D particularly amenable to Senra’s approach, which is to get configuration right long before worrying about automation.
Automation can be thought of as replacing humans with machines. Configuration is creating a system with any combination of humans, machines, software, materials, and processes to turn a design into a product. It is the layer above automation, and counts automation as one of its tools.
You can’t automate until you can configure, and long before getting to automation, there’s a lot that you can do to improve wire harness manufacturing by redesigning the system.
In a traditional shop, practically everything runs on tribal knowledge locked in veterans’ heads. This is the same challenge that Hadrian identified in precision machine factories; to fix the problem, it’s “turning tribal knowledge into scalable software and processes.” It also rhymes with what Poetic does; instead of just magically throwing AI at a problem, “We need people to get out there into Minnesota to be like, what the hell do you guys do all day?”
Relying on veterans’ head-knowledge works decently well as long as it’s the veterans doing the work, but people-as-operating-system doesn’t scale. Take training. In a typical shop, you’ll have an 18-month apprenticeship, and it’s like, “There’s this guy Doug, he’s been building Boeing harnesses for 25 years. Just go follow him around and see if you can learn something.” And that’s really it. There’s no trade school for skilled assembly work.
Jordan compares wire harnessing today to a Cheesecake Factory recipe where skilled workers can just look at the menu and kind of figure out how to make everything that’s on there. The hope is that other metaphorical chefs will watch them do that enough that they, too, can look at the menu and reverse engineer the recipe.
That doesn’t work that well now, let alone when the skilled vets retire, or when demand continues to grow and manufacturers need to bring on a lot more people to meet it.
So you have this situation where the incumbents actually do a pretty poor job…
… that is not fully automatable yet, but where there is an absolute ton of low-hanging fruit for a player with scale ambitions to make the investments into getting the configuration right.
Which, at its simplest, is what Senra does.
You know what, I’m just going to hand the mic to Jordan for the rest of this piece to explain.
The way we see it, you need to standardize, then optimize, then automate, in that order.
What Senra is doing is taking that Cheesecake Factory menu item, then reverse engineering, in software, what the recipe is, then training cooks over a few weeks to be able to cook to that recipe, reliably. That’s standardization.
To end the food metaphor, what Senra does today is take a wire harness design and turn it into work instructions, which break down the component parts of building a wire harness and serve it up on a silver platter to a technician.
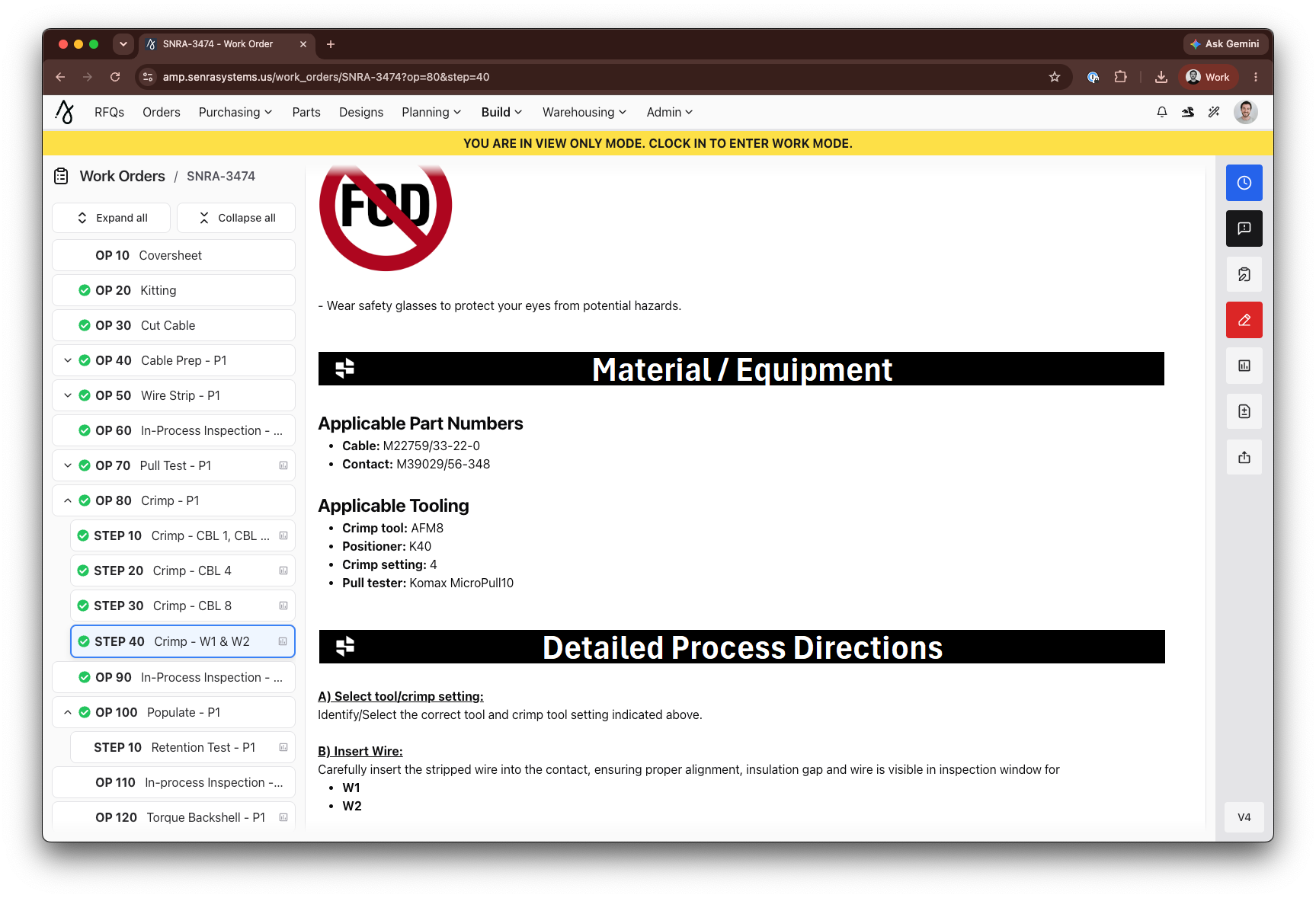
Get everything as step-by-step as possible. This is how you cut the wire for this specific harness, this is how you strip it, this is how far back you strip the rubber that encloses the metal, this is how you connect it to this connector, and this is how you lay everything out on the form board. Check check check check check, until you have a working wire harness.
Today, Senra takes in a wire harness drawing from a customer, and then have a team of engineers look at the drawing and convert it to work instructions. Right now, the process is like 20% automated, which is fine, because even having work instructions is a step-up. Over time, it can use those human-crafted work instructions to train models that can get to somewhere like 90% of the way from drawing to work instructions, with an engineer doing the final check-off, which would speed up the process and increase accuracy. This is optimization.
Even before then, though, there’s a lot that you can do with really good work instructions, each of which feeds on the others.
To start, you can train people up much more quickly and effectively. The question is how you can grab someone who has never seen a wire harness, certify them through Senra’s apprentice program in a month instead of a year or two, and get them to work meeting customer demand. The key is that because workers follow a recipe for each harness, they don’t need to keep all that tacit knowledge in their head.
Senra hires people who have never touched a wire harness, and after the four-week program, they’re building harnesses on the production floor for SpaceX and Anduril.

Those same explicit steps mean we know which parts are needed where when, so we can optimize our supply chain and inventory. It would surprise you how big a source of error just giving technicians the wrong components is. With work instructions in software, we can make sure that the instructions on how to kit components for each job, including what goes in the kit, are accurate. All of that can tie back to our inventory, to purchase orders. Then our inventory tracking system goes from being a kind of crazy startup system to fully optimized and ready to scale.
If inventory runs smoothly, then it becomes even easier to get someone trained up and productive more quickly, because they have everything they need at their fingertips. The machine runs more smoothly through a bunch of mutually reinforcing improvements.
We are basically creating a digital twin of the manufacturing process, capturing and digitizing data at every point so that we can optimize each and every part. Then we build custom machines that integrate with our software.
For something like cutting and stripping a wire, since our software knows what’s in each kit and what it’s being used for, our technician can scan a barcode from the machine and input the wire, and the machines cut and strip exactly to the specification we need.

The line between optimization and automation gets a little blurry here.
Something like cutting and stripping is relatively easy to build a machine for; that machine is a tool for the human technician, who drives the process.

Crimping – taking a piece of metal, putting a wire in it, and squeezing down with a tool - we can make a machine for that next. Something like connector insertion is such a high-dexterity operation that we probably won’t automate it for a very long time.
Our intent is to train our technicians, optimize everything around them, give them custom machines, give them better tools, and remove any of the non-value-add work from their plates.
We think we can make our technicians 3x more productive than industry average simply by optimizing everything else around them. We care a lot more about that than we do about full lights-out automation.
Meanwhile, again because we can track the process step-by-step, we embed quality control throughout the process, so we catch things when they go wrong. Inspection during the process is something we’ve already begun to automate, and thanks to a combination of everything we just described and that automated inspection, we’re at a 99% first-pass yield, versus 75% for our competitors.
And we’re tracking and collecting data at every part in the process, from inventory to quality control, in our Amp platform, which is like our operating system, Senra’s version of SpaceX’s WarpDrive. It spans the full thread: Design (ITAR-compliant cloud harness design tool) → Quoting & BOM (AI reads messy aerospace RFQs) → Procurement & Warehousing (kitting) → Manufacturing Planning (work-instruction generation) → Build (a 100% digital thread for every crimp, connection, and serial) → Quality (real-time enforcement + traceability).
The operating system, training environment, data infrastructure, and years’ worth of data give our workers superpowers, and the results have been strong. We are higher-quality, higher-reliability, and faster-turnaround than the incumbents. We can deliver in four weeks something better than they’d be able to turn around in four months. And we can bid on jobs at a 20% margin to win the business with the comfort that we’ll be able to optimize the process to well north of 50% over the life of the contract. And of course, the more we do, the more we learn, the faster we optimize, and the better we get.
In the near-term, our focus is on scaling wire harness capacity while improving efficiency and maintaining quality in order to meet the tremendous demand that is currently underserved.
For a sense of scale, individual customers of ours are doing hundreds of millions of dollars a year in wire harnesses, and they are impatient for us to expand capacity to take on more of that business. Our customers don’t like having to employ people to fix their wire harness suppliers’ mistakes, nor do they like waiting four months to turn on their new product.
If we can continue to execute, we can continue to grow our share of the market even as the market expands, and we hope that by offering a better product, faster, to our customers, we’ll be able to speed up American manufacturing on the whole. Our job is to eliminate this bottleneck for the industry.
For now, the fact that this is really hard to do well is our moat, but as we scale, we dig traditional 7 Powers moats in the form of Scale Economies and Process Power. We should be able to offer a better, faster product than the fragmented incumbents, or than any would-be venture-backed challenger if we continue to execute.
More than that, we want to be the company our customers turn to whenever they have any wire harness needs because we know how to help them from the very beginning, the same way that the expert at Blockbuster could point you to the right horror movie or classic Western or “I’m going through a breakup and I need a great romcom,” the same way that I could Norm from Cheers a patron with a fresh drink and open ear when I was a bartender. The practical way we do this is that we’re on contract with our customers to provide design and engineering feedback on their harnesses, even before they get to the manufacturing stage.
All of that said, this opportunity is way bigger than wire harnesses for aerospace and defense.
We started in wire harnesses for A&D because it’s what we know best, and because it’s the most challenging, highest-willingness-to-pay portion of the skilled assembly market. At $25-50 billion annually, it is a big enough market to keep us busy for a while.
But we want to fix all of skilled assembly. That’s why we’ve been able to attract the team we have, to solve the biggest challenge in manufacturing. As we get good at the hardest part, adjacencies are already opening up. In the past month alone, we’ve been hit up by companies making chillers for data centers and mail trucks for the US Postal Service, and a lot in between. Both the AI data center buildout and the electrification of everything means that there’s going to be a lot more wiring everywhere.
The fun part, and the part that we debate internally, is that expanding into automotive and industrials requires a different skillset than A&D. One satellite company inside of one Prime builds something like 8,000 unique wire harnesses every year. That electric truck company has just 25 that they put on every single truck, over and over again. This would move us into low-mix, high-volume, which can be more (although not fully) automated today. Doing this work wouldn’t build the same hard-to-replicated skilled workforce bench that high-mix A&D work does, but if we can do it at a positive (and expanding) margin, it allows us to get to scale more quickly and establish a foothold on the commercial side.
It’s a matter of when, not if, because we want to own as much of the $200 billion total wire harness market as we can eventually. We want to be in the data centers, the trucks, the nuclear reactors, the aircrafts… in everything, because wire harnessing is in everything, and we think we can offer a better wire harnessing product across the stack.
Moving into lower-mix, higher-volume wire harnessing also serves as a bridge to the rest of the skilled assembly market. Things like sensors, electromechanical assembly and testing are skilled assembly jobs adjacent to what we do now, and demanded by the same customers. If we do a great job on wire harnesses for our customers, we can say, “Oh you have a problem with sensors, too? Let us give it a shot.”
As we figure out how to standardize, optimize, and automate as much of wire harness manufacturing as possible, everything else becomes much easier. Because we tinker at the configuration level, we can copy-and-paste a lot of the processes and software from wire harnessing into sensors and electromechanical assembly, and tweak specifics like which machines and components we need. We built Amp to generalize; it’s a design and manufacturing software platform, not a wire harness-only tool.
Wire harness manufacturing is really a wedge into our broader ambition: how do you make the products of skilled assembly available more like Amazon than like manufacturing?
You should be able to go to our website, design your harness or your sensor or whatever you need, click buy, and get it two weeks later.
A lot needs to happen for that vision to come to life. We probably need to pony up for senra.com, for one thing. We need to offer better design software; the stuff people use today sucks. It’s really fragmented and not standardized, and there’s an opportunity for us to do it better, and turnaround outputs faster when customers design to our standards. We need to standardize and optimize across a growing number of products, and turn designs into work instructions and kits of parts smoothly. We need our people to be able to turn those work instructions into anything quickly and at high-quality. We need to inspect it all in real-time to maintain quality. We need to make new machines when it makes the work better, and look for opportunities to automate once we’ve standardized and optimized all we can.
Ultimately, we need to build up massive capacity so customers can get whatever they need really, really quickly, so that they can build, iterate, and scale their main products really, really quickly.
It’s that opportunity to unblock American manufacturing that’s why so many people who don’t need to work anymore are choosing to work at Senra.
In the past month, we’ve made two ex-SpaceX hires that we’re really excited about.
Ken Venner was the CIO at SpaceX, where he architected WarpDrive, which we’ve modeled Amp after. He’s a legend. He’s joining us as CTPO (Chief Technology and Product Officer) because, as he told us during the process, “This is the most excited I’ve been about a startup since SpaceX.”
Jessica Chavarria started her career in contract manufacturing, moved to SpaceX as a Requirements Planner in 2011, and worked her way up to Supply Chain Manager over eight years at the company. She has worked increasingly senior supply chain roles at a number of A&D companies, and just joined us in June to go back to her contract manufacturing roots as our Head of Supply Chain.
We’ve noticed something with the SpaceX alumnae. There’s a group that will make like $3-5 million and take it easy. Then there are the people who have been there long enough, and in important enough roles, to make hundreds of millions of dollars who have negative desire to retire and sit on a beach sipping pina coladas. These are people who worked for over a decade at a crazy company and loved the rush. They want to do it all over again. You can’t take the grinder out of them.
We’ve created a place where the grinders can grind on a challenge that’s endlessly deep and deeply important. We see it as validation of the opportunity that the people who’ve been at SpaceX long enough to know where all the bodies are buried are saying “If we could solve this, this is the most important thing we could work on.” Now it’s up to all of us to actually go solve it.
If you’re reading this, you’re probably bored of hearing that the US forgot how to build. That we sent the jobs overseas in search of profits, and hollowed out the golden goose. That you’ve heard it a lot doesn’t make it any less true, but the interesting question isn’t what happened in the past, but what we’re going to do to fix it.
We think that skilled assembly is the fulcrum point. It’s a really fucking big problem waiting to happen; you can’t necessarily feel it today, but you’ll feel it in the next two to five years. Our skilled workforce is retiring, just as the demand for their skills is surging. We’ve realized that we need to build big things here again, but all of those big things are made up of a lot of little, complex, custom things that a shrinking group of people know how to make.
A lazy solution to this coming crisis is that we’ll just let the robots take care of it. As you understand by now, most of our industrial base’s skilled assembly isn’t standardized or optimized, and until you standardize and optimize, you can’t automate.
When the time comes - when the brains are smart enough and the hands are dexterous enough - we believe that robotics adoption in manufacturing will be constrained less by hardware and more by the absence of structured, well-configured operational environments. We’re solving that problem first, by encoding manufacturing into executable, measurable, and machine-readable systems.
Far before automating skilled assembly becomes possible, we will reindustrialize by giving humans better work environments, environments that work for them. That’s little things – our attrition is comically low because we offer air conditioning and a pleasant workplace - and big things, like making sure they have the tools, components, and instructions they need at all times.
All of this is really hard. It’s not as clean or as sci-fi as throwing robots and ASI at the problem. But we love that. We’ve been out here screaming into the ether: humans matter, we need to figure out how to scale them.
Ours is a belief that the more the easy stuff gets automated, the more valuable skilled humans will become. We agree with ex-Uber-now-Atoms founder Travis Kalanick, who predicted on TBPN that skilled workers will get paid like LeBron James because, “Humans [are going to] become more and more valuable because they will be the long pole in the tent to progress - and that progress is going to accelerate and get faster and more robust.”
The future, like the past, is human. It’s just that we can give humans superpowers now.
If you’re out there and you hear our scream, come join us.
Thanks to Jordan, Greg, and Sam for working with me on this piece, and to Alexa for the introduction!
That’s all for today. We’ll be back in your inbox tomorrow with our Weekly Dose.
Thanks for reading,
Packy
2026-07-10 20:56:10

Hi friends 👋,
Happy Friday and welcome back to our 201st Weekly Dose of Optimism.
We’re jam packed again, and you don’t come here for the intro, so…
Let’s get to it.

Most founders understand their finances in spreadsheets, and that’s a problem.
Your bank has the data. But to actually use it — check your cash position, reconcile transactions, understand your burn — you export it, paste it somewhere else, and do the work outside your account.
Mercury Command closes that loop. It’s AI built directly into Mercury* that surfaces insights and takes action from your live account data. Ask what you need to know, then act on it instantly — follow up on an outstanding invoice, set a limit on a card, categorize a transaction — all in the same conversation. You approve every step. Command executes.
On July 4th at 12:20am, Aalo Atomics went critical, becoming the fourth advanced nuclear company to accomplish the mission by the July 4th, 2026 deadline, and the third whose founder we had on Age of Miracles back in 2023. I actually wrote a small personal check into Aalo before the podcast, back when I didn’t think nuclear was fund investable but that it was incredibly important. I was right on the latter but very wrong on the former.
Aalo joins Antares Nuclear, Valar Atomics, and Deployable Energy in hitting the target, with a number of others including Radiant, Oklo, X-Energy, Deep Fission, and Last Energy expected to hit criticality later this year or next, and deploy commercially in the months and couple years ahead. As Abundance Institute’s Chris Koopman put it, “In just over 13 months, the United States of America went from a handful of executive orders to FOUR DIFFERENT advanced nuclear reactors reaching criticality.”
This is an insane state of affairs given where nuclear was just three years ago. Getting any one advanced reactor to criticality by July 4, 2026 would have been considered a minor miracle, but getting four with more to come means that there’s going to be competition. Whoever can deploy most quickly, with a product that customers want, at the best price, will win. The field shifts from science to manufacturing. I think that good ol’ competition is what it’s going to take to make nuclear cheap and abundant.
One of nuclear’s challenges has been that utilities are terrible customers for the product. Fortunately, they are not the main customers for these smaller advanced reactors. Data Centers are, and they will fund whoever gets them something that works fast (and safe, cheap, clean, and eventually affordable).
Josh Zoffer for The Financial Times

This is the argument that I made in Thank God for Data Centers, and part of the argument that my friend Josh Zoffer made in the Financial Times this week:
The data centre bonanza is a special kind of opportunity: one where deep-pocketed buyers like Silicon Valley’s hyperscalers are willing to open their wallets to pay for fast, reliable access to industrial technology. It offers a chance for the US to get ahead in the next key technologies and to build domestic supply chains based on demand rather than subsidies and tariffs.
I’m glad to see Josh making the case for U.S. data centers (we use er here, FT) in front of the policy and business leaders who read the FT, and making it so eloquently. Data centers are useful in their own right, but they’re also a turbocharged way to turn on that big, beautiful American Demand engine and fund the technology that will carry us into the Age of Miracles.
John McElhone
Including gas turbines. Lots and lots of gas turbines. If you can make a gas turbine, or retrofit a jet engine to work as a gas turbine, the data centers would like to buy it from you. And this week, American Turbine came out of stealth to sell it to them.
What’s interesting about AT’s approach is that instead of very large, complex turbines that take a long time and a lot of scarce expertise to make, they’re making small, highly manufacturable turbines that they can get to customers quickly. If you need a lot of MW, they’ll just sell you a lot of turbines.
For now, the goal is speed, and buyers are happy to pay for speed in lost efficiency. Over time, though, whether data center demand slows or the supply chain gets worked out and time-to-power is no longer as big an issue, turbines will still have a ton of value.
The beautiful thing about turbines in the American context is that America has bountiful natural gas resources. We have an advantage there, if we have the turbines to turn it into power.
Part of American competitiveness in the century ahead will be beating China at things China currently dominates, but an equally important part will be winning things that we can do uniquely well. Turning natural gas into power to turn ideas into economic activity is one of those things.
Neri Oxman for OXMAN

Not everything in the good future will be manufactured or petrochemicals-based, though. Some of it will be grown naturally.
Neri Oxman, the ex-MIT designer, engineer, scientist, and artist working on computational design, synthetic biology and digital fabrication whose 2023 Lex Fridman appearance was one of my favorites, announced a new line of capes from her company, OXMAN, called Vigils, “whose color is not applied but grown. We engineer bacteria to produce indigo and melanin pigments, then let them work directly on the surface of a 3D-knitted silk textile. When the process is complete, the cells are washed away, leaving only the pigment they have grown into the fiber.”
“For a century,” Oxman (the person, not the company) tweeted,
One day, OXMAN might even apply this technology to garments people actually wear.
Giving robots hands that work like human hands is one of the hardest challenges in robotics. If these videos are real, it looks like 1X may have solved it.
Yesterday, they announced their “25 Degree of Freedom (DOF), tendon-driven hands for the NEO humanoid platform– achieving near human-level dexterity, strength, safety, and reliability.”
Watch the video. Or this one.
1X argues that with these hands, the hardware problem is basically solved and what’s left is gathering the data that drives the robots capabilities. It’s a bit of a self-serving argument, because 1X is selling and deploying tele-operated robots into homes in order to collect data, but any good company argument should be self-serving. And that is, once again, an absurdly impressive hand.
One thing I particularly like is that they call the hand an “API to the Physical World,” which is a catchy way to express that our hands are how we interact with the world. Our legs can walk us up to a door, but our hands push it open. Our eyes can locate a glass in space, but our hand picks it up.
The new 1X hand can pick up a wine glass with ease. It can do LEGOs. It can even screw in a lightbulb. If you want to learn more about what it does, and how it works, check out their blog post.
Over the past couple of days, OpenAI released a new voice model that talks more like a human and 1X released hands that are more human, and in both cases, unexpectedly, it feels that the more human-like features we give the machine, the clearer it is that they are not becoming human but will be very useful to us.
Long humans.
I know you’re probably overdosed on optimism at this point, but I do think the Science Breakthroughs are worth reading as an Ulkar-vetted glimpse into the future. This is the stuff that’s not on X yet. Check ‘em out.

