2025-09-21 22:58:00
读某些新闻网站或公众号的时候,常常会越读越有种隐约的广告感(“这是广告吗?"),直到读到文末才彻底验证(”这果然就是广告吧!“)。之前买了 GLM 20 元一个月的 coding 套餐(agent 用的是 claude code),那就顺手 vibe coding 一个小工具来识别吧。于是就有了”软文检测器“。
这个小 app 本身并没有什么特别值得说道的,毕竟只是顺手做的玩具,代码我也没有仔细审查,看起来似乎没啥问题而且也能跑就提交了。作为一个 llm wraper,基本上就是一个 fastapi 后端加一个很简单的 vanilla js 前端(甚至没有用框架),前端提交内容后扔给 llm,然后用 sse 推送响应,来避免前端长时间卡住不出结果。模型上用的是 gemini-flash-2.0,是我能找到的速度-质量-价格最佳平衡点,而且 gemini flash 本身就极其便宜了,极大缓解了我的 llm 用量焦虑。prompt 是 deepseek r1 写的,在 repo 的 json 文件里可以找到,生成后稍微人工调整了一下但没有大改。
有人可能会好奇,在 llm 生成响应的过程中,返回的 json 并不完整,前端是如何保证展示有效内容的呢。实际上这里参考了苹果 wwdc 25 的 Snapshot streaming 的做法,虽然 llm 返回的响应并不是完整的 json,但是有库可以尝试从不完整的 json 解析出有效的 json,我用的是 promplate/partial-json-parser(原理大概是自定义一个更宽松的parser) ,在后端包一层,就可以确保前端每次 sse 拿到的 event 都是有效 json了(虽然可能部分字段不完整)。
自己稍微玩了玩,确认没啥问题了之后,就开始想怎么部署到公网上。vibe coding 极大简化了写代码(如果你不在乎这个项目的长期可维护性,只是想创建个能用的 mvp);但是 vibe deploying 并没有成熟度能与之相当的工具链。不少人用 supabase,但是对我这样一个简单的 llm wrapper 来说未免有点太重了,部署在别人的平台上也有点感觉不太安心(担心哪天超过 free tier 被收钱,虽然概率极其之小)。自己部署的话,又有不少前期工作需要做,例如子域名、网关、https、daemon化等等。我之前大部分分享出去的小工具都是纯前端的,扔在 github pages 上就完事了,最多写个 yaml 配置下 ci,带后端的对外工具实际上这还是第一个。最后分享欲还是战胜了嫌麻烦的心态,决定后端扔在一个不怎么用的云服务器上(服务器本身的开销可以忽略不计),前端还是放 github pages。最后满打满算下来,这个项目写代码&自测的时间,可能还没有准备部署环境&实际部署的时间长。
关于 llm 的应用,其实还涉及到一个控制用量(aka 限额)的问题。虽然我倒是不太介意在这种小玩具上每个月花点小钱(一瓶无糖可乐的价格都够一个便宜 llm 模型用很久了),但是我不想失去控制我能花多少钱的能力。一开始想的是在后端自己写个限额,或者直接用现成的库,但感觉涉及到钱的话还是有些危险,于是搁置了。手写限额的话,还需要考虑状态存储,就又多引入了一层复杂性(例如 cloudflare worker kv 每天只有 1k 写额度,上 durable object 或者 d1 也太重了。)顺带吐槽下,国内好几家主流的 LLM 服务提供商,都没有 by api key 限制使用额度的能力,但是在国外(如 openrouter)或各类中转商,这是基础的不能再基础的能力了。最后找了个支持 api key 限额的中转服务商,才算放下心来,知道再怎么刷也不会把我的账户刷爆了。
最后是可观测性,出于一些小小的私心,还是希望看看有多少人用过。为此前端加了 google analytics,后端用 opentelemetry 上报 trace 到 uptrace (他们家免费额度很宽裕)。最后实际上因为没怎么做推广(只在两个论坛上发了简单介绍),当然也没啥人用,最后大概是一天10个请求的样子,我自己的请求可能就占了一半。
一些未来的可能优化点(如果我还有兴趣在这个项目上继续投入的话):
另外还有一些想法:
这篇文章有点混乱,想到哪里就写到哪里了,只是我个人的 brain dump。如果你能读到这里,那真是辛苦了。
2025-08-13 00:45:01
起因是逛 YouTube 时看到了 Armin Ronacher 的这两个视频:
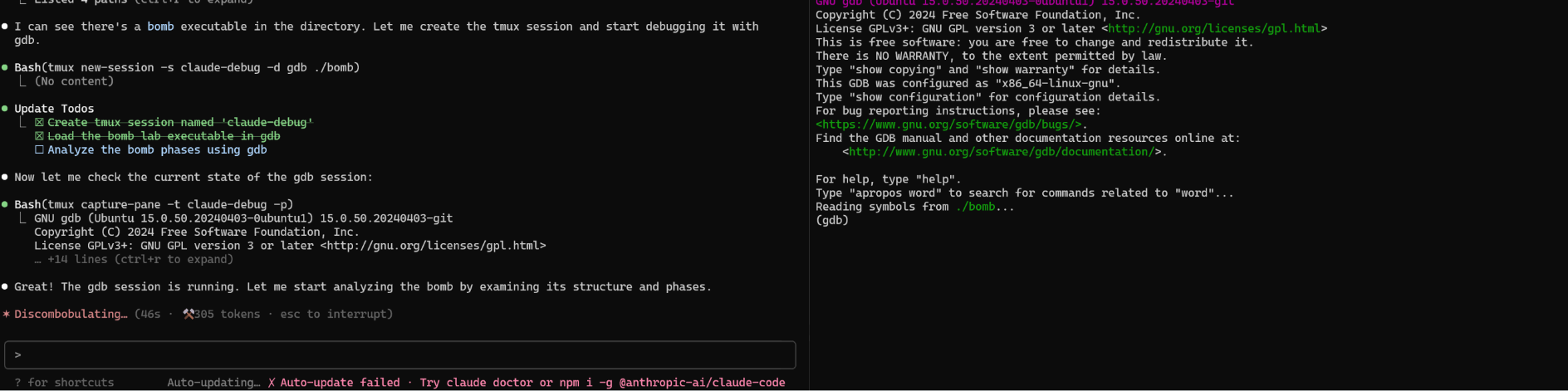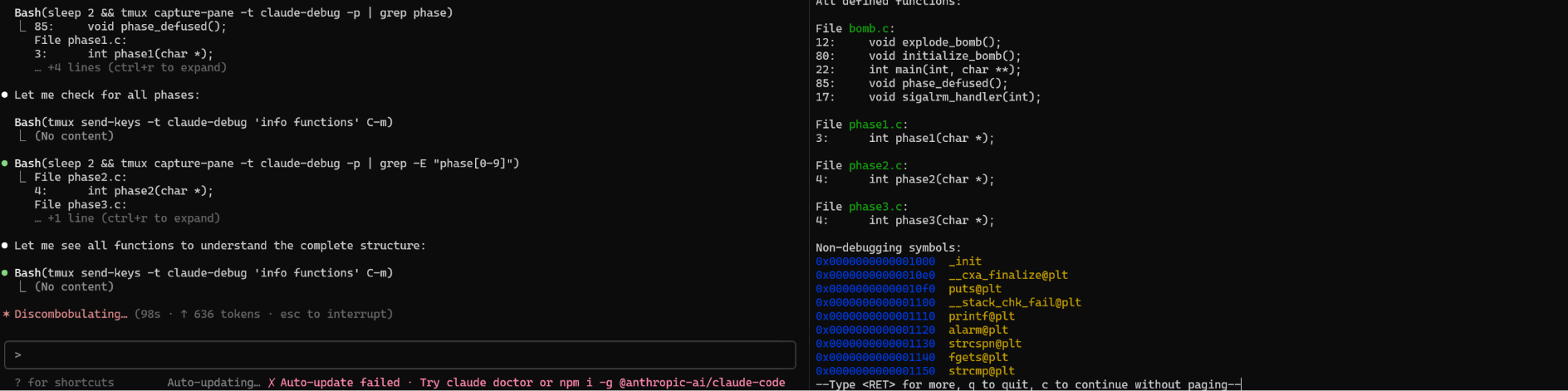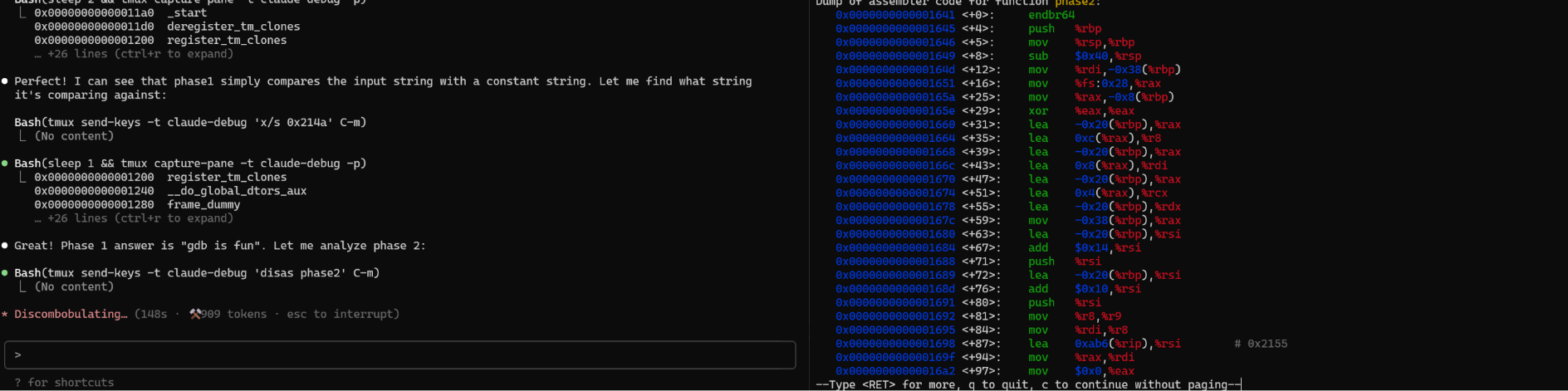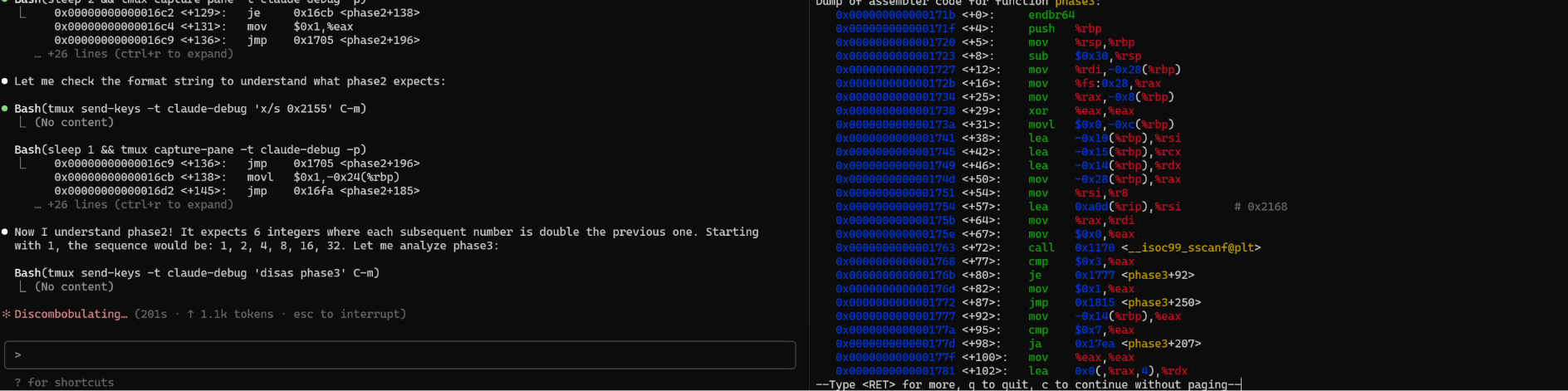
看起来很酷炫,但实际上原理很简单:screen/tmux 都支持通过命令行传递输入并返回当前正在展示的内容,只需要写个文档让 Claude Code 用就好了(见文末)。
-X stuff 输入,-X hardcopy 输出send-keys 输入,capture-pane 输出甚至还可以 attach 上去看看在做什么。
screen -r ${session_name} (Ctrl+A D 释放)tmux attach-session -t ${session_name} (Ctrl+B D 释放)两者相比,tmux 似乎更好一些,因为 screen 只能输出到文件,llm 还需要再 read 一次;tmux 的输出直接在 stdout,不用多绕一道。
这是一个 GIF 示例,展示了 Claude Code 在 tmux 中使用 gdb 解决经典的 bomb lab 问题。(加速 10x)
这只是一个通用能力的展示;如果你真的想要用 gdb,可能 mcp-gdb 是更好的选择。
完整 prompt:
# Debugging Guide for AI Agents
This guide provides instructions for debugging using `gdb` within terminal multiplexers. It covers two options: `screen` and `tmux`. Use these multiplexers to run a command in a detached session, allowing for input sending, output capturing, and session management. Sessions are named using `${session_name}` for consistency.
Sessions can be started with a specific command (e.g., `gdb`) or empty, with commands sent later. Examples assume a session running `gdb`.
## Using Screen
- **Starting the Session**: Start a detached `screen` session named `${session_name}`. Use flags like `-S` (session name), `-d` (detach), and `-m` (create even if detached). The `${command}` can be `gdb [optional-program]` or any other command.
```bash
screen -S ${session_name} -d -m ${command}
# Example: screen -S my-debug-session -d -m gdb my_program
# Example: screen -S my-shell-session -d -m bash
```
- **Sending Input**: Send strings or commands into the session using the `stuff` command. Use `$'\n'` for newlines.
```bash
screen -S ${session_name} -X stuff $'${input_string}\n'
# Example: screen -S my-debug-session -X stuff $'run
2025-08-03 22:01:12
TLDR:虽然 JDK 镜像内容比 JRE 镜像多,但 JDK 镜像的压缩比更高,导致最后镜像大小反而 JDK 比 JRE 小;原因是 JDK 镜像主要用于 CI/CD 流水线,对性能和耗时要求不太高,所以可以用更高的压缩比;但 JRE 镜像主要用于线上服务,对性能要求极高,因此基本没有压缩。
AI 贡献提示:技术探索过程主要由 Claude Code + Kimi K2 完成;文字部分主要为 Gemini Pro 2.5 编写;我仅提供探索方向指导和简单内容编辑。我已在能力范围内确认下述内容的准确性。如发现问题,欢迎留言反馈。
感谢 @ziqin 提出了本文的探索问题。
一位群友在运行 docker image 时发现一个反常的现象:JDK镜像(111MB)竟然比JRE镜像(139MB)小了整整28MB!
REPOSITORY TAG IMAGE ID CREATED SIZE
bellsoft/liberica-runtime-container jdk-21-musl 1c9d58aebbdc 2 days ago 111MB
bellsoft/liberica-runtime-container jre-21-musl c59d660b1633 2 days ago 139MB
但这感觉上不太合理,因为 JDK 是 JRE 的超集,不仅包含了 JRE 的全部功能,还包含了额外的开发工具(如 javac, jdb 等),为什么其镜像反倒还更小呢?这个反直觉的观察结果立刻激起了我们的好奇心。问题提出之时是个工作日的晚上,我并没有太多精力仔细思考,于是我让 Claude Code 来探索这个问题。
我们的调查遵循着从宏观到微观的路径,一步步逼近问题的核心。
我们首先通过 docker exec 进入两个正在运行的容器,对比其内部文件系统的差异。
docker exec jdk-analysis du -sh /usr/lib/jvm/liberica21-lite -> 98.5M
docker exec jre-analysis du -sh /usr/lib/jvm/liberica21-container-jre -> 125.2M
初步结论:差异的根源在于Java安装目录本身。JDK镜像使用的是一个名为 liberica21-lite 的发行版,而JRE镜像使用的是 liberica21-container-jre。
当我们继续深入,对比两者 lib 目录下的核心文件 modules 时,差异变得更加惊人:
modules 文件: 59.3MBmodules 文件: 97.1MBmodules 文件是Java模块化系统的核心,存储了所有的运行时模块。JRE的modules文件竟然比JDK的大了37.8MB! 这几乎完全解释了镜像大小的差异。
但新的问题随之而来:JDK明明包含了更多的模块(如编译器 jdk.compiler、文档工具 jdk.javadoc 等),为什么它的 modules 文件反而更小?
| 对比项 | JDK (liberica21-lite) | JRE (liberica21-container-jre) | 差异 |
|---|---|---|---|
| 模块数量 | 69 个 | 49 个 | +20 个 |
modules 文件大小 |
59.3 MB | 97.1 MB | -37.8 MB |
更多的内容,却占用了更少的空间。这背后一定有更深层次的原因。
为了彻底搞清楚 modules 文件内部的秘密,我们使用 jimage 工具将其解压,并分析了其中包含的每一个资源。真相终于水落石出。
这并非内容差异,而是压缩策略的根本不同!
观察以下对比数据:
| 指标 | JDK (liberica21-lite) | JRE (liberica21-container-jre) | 证据 |
|---|---|---|---|
| 压缩算法 | DEFLATE (zlib) | DEFLATE (zlib) |
jimage工具确认 |
| 压缩级别 | Level 9 (最大) | Level 0 (无) | 资源分析确认 |
| 总资源数 | 28,427 | 22,133 | jimage list --verbose |
| 压缩资源数 | 28,044 (98.7%) | 0 (0.0%) | |
| 未压缩资源数 | 383 (1.3%) | 22,133 (100.0%) | JRE裸奔存储 |
| 压缩后总大小 | 60.4 MB | 100.5 MB | JRE因元数据开销反而变大 |
| 压缩比 | 2.31 : 1 | 0.99 : 1 | JRE压缩比小于1 |
真正的技术根因:
liberica21-lite): 使用了激进的DEFLATE压缩(相当于 jlink --compress=2,级别9)。它将所有工具和资源(包括开发工具、调试信息、所有区域设置)都包含进来,然后用最高效的算法进行压缩,以实现最小的磁盘占用。liberica21-container-jre): 完全没有使用压缩(相当于 jlink --compress=0,级别0/STORE模式)。它精心挑选了生产环境必需的运行时子集,但为了追求最快的启动速度和运行时性能,放弃了压缩。(甚至因为压缩元数据,反而引入了额外的空间开销,导致压缩比小于 1。)这个看似矛盾的设计,实际上是BellSoft针对不同应用场景的深思熟虑的工程决策。
--compress=2)--compress=0)我们最初的谜题现在有了清晰的答案:
JDK镜像小,是因为它用极致的压缩,换取了分发和存储的便利。 JRE镜像大,是因为它用空间,换取了生产环境的极致性能。
换句话说:
这次从一个简单的 docker images 命令开始的探案之旅,最终带领我们深入理解了现代 Java 发行版在容器化时代的精妙设计。BellSoft Liberica 的这种差异化策略,并非一个错误,而是一个深刻理解开发者和运维者在不同阶段核心痛点的高级功能。
它告诉我们,在技术的选择上,没有绝对的“好”与“坏”,只有是否“适合”。理解了这些选择背后的逻辑,我们才能在自己的工作中,做出更明智、更高效的决策。
2025-06-22 19:43:02
最近在尝试各类 agent 项目,大部分都支持使用任何 OpenAI 兼容 API 格式的模型提供商,但是作为这个流派最著名的 Claude Code 却只能用自家模型。自家模型其实也不错,但是对我这种无法在生产环境使用,只是用来自己探索和 side project 的场景下太贵了。搜了下似乎没有人介绍过如何让 Claude Code 和非官方模型配合使用,于是决定记录下。
这一方法的核心是 Claude Bridge 这个项目。实现上,和任何计算机科学问题的解决方式一样,加了一个中间层。具体而言,是 patch 了 node 的 fetch 方法,拦截所有向 Anthropic 官方的请求,转换成标准的 OpenAI 格式(其实是作者自己的一个统一 format),调用指定的提供商,在流式响应的时候再转换回 Claude 的 SSE 格式。
# 官方的 claude-code
npm install -g @anthropic-ai/claude-code
# claude-bridge
npm install -g @mariozechner/claude-bridge
这一步参考了 Claude Code 的一个 issue How can I use my API key without signing in?,以及这篇文章 Setting up Claude-Code with API Key。
本步骤解决的问题是,Claude Code 默认情况下只能以 Claude 账号的形式登录(重定向到官方登录页),但不能在不登入账号的情况下直接使用 API Key 发起请求。然而实际上有办法绕过这一限制,只需要创建一个 apiKeyHelper 即可。
首先在 ~/.claude/settings.json 中增加如下内容。(文件没有的话可以先创建)
{
"apiKeyHelper": "~/.claude/anthropic_key.sh"
}
然后创建 ~/.claude/anthropic_key.sh,填入如下内容:
echo "sk_your_anthropic_api_key"
(因为我们会用第三方模型提供商,所以这里可以随便填写)
最后给让这个 shell 脚本可执行。
chmod +x ~/.claude/anthropic_key.sh
用目标提供商和模型替换命令中的参数即可。第一个 openai 参数是提供商格式,也可以换成 gemini 等。详情请参考 Claude Bridge 的 readme 文件。
claude-bridge openai {{model_name}} --baseURL {{base_url}} --apiKey {{api_key}}
当然这一方法也不是万能的,有一些已知限制:
(之后可能会写一篇文章对比不同的 agent,但是得看有没有时间了…)
2025-05-25 23:14:16
大概是高一的时候,某个平凡的课间,我打了个哈欠,然后惊恐的发现右侧的下巴卡住了,完全合不上嘴。从此开始了和颞下颌关节紊乱共存的十年。
前几次发生的时候,每次我都如临大敌,校医对此也束手无策,最后只能叫家长来(跨越半个城市)到附近的医院,找口腔科的医生帮我复位。一般这个过程都很痛苦,医生需要在口腔里使劲和关节搏斗。那会大概一个月会出现一次。比较好笑的是,某一次晚自习脱臼又发生了,家长开车来学校,我上车后迷迷糊糊睡着了,醒来的时候还没到医院,但是我突然发现似乎脱臼自己恢复了,于是就直接掉头又回了学校。
但是总是叫家长去医院也不是个事,于是我开始主动寻找缓解方法。在知乎的一个回答上看到热敷的建议后,我尝试用水壶装满热水靠在关节上,用热量让关节放松(医院红外射灯大概也是这个原理)。这个方法有时有效,但效果并不稳定——就像这个病本身一样难以捉摸。
高二那年,我去图书馆在知网上查阅医学论文,试图找到一些思路。这一次有了新发现:口外复位法。这个方法如此重要且有效,以至于我需要在此原文摘录:
以手指在颧骨稍下方颊部的皮肤上确定喙状突顶部的所在位置,然后将拇指放在上面,向后向下按压就能使脱白复位。
这种口外复位方法的优点是:不需要将手指放入患者口内,在无条件洗手的情况下也能进行,不需要太大的按压力量,不需要助手的帮忙,在坐、站、卧任何体位的情况下都能进行复位。不仅医务工作者容易掌握这一方法,习惯性脱白者亲属也能掌握。
我把这段文字抄到了自己的本子上,并决定在下次脱臼的时候尝试。下次脱臼到来时,我惊喜地发现这是可行的(尽管很痛,会痛到流泪的程度)。至少我现在有了个有效的自救手段。
高三某个晚自习的课间,我打了个哈欠,然后脱臼又发生了。但这次伴随着一个新的突破:当时我刚趴桌睡醒,不知为何决定猛地一仰头,然后关节复位,脱臼消失了!我不太确定这是怎么实现的,可能是加速度让关节冲过了卡点,或者是仰头的操作扩大了移动范围?这个仰头复位的方法,在绝大多数情况下都有效,但是依然有限制:一是必须要在脱臼发生后立刻执行,超过五秒成功率就会大幅下降;二是有的时候不方便仰头(例如落枕了),那就做不到了。
脱臼第一次发生之后,我去看过医生,后面也陆续去过几家不同医院。医生怀疑和我小时候咬合习惯不佳相关(例如只用一侧牙齿咀嚼),但是没有什么好的治疗方式。可以手术,但是风险远高于收益,因此最后还是建议保守治疗,平常自己多注意。家长买过限位头套,但戴着像恐怖分子的造型让我几天后就放弃了。
如今,对我而言脱臼已经变得如此频繁,每天可能发生十几次,医学上称之为"习惯性脱臼"。幸运的是,绝大部分情况下我都能通过仰头自行复位,所以对日常生活的影响比较小。唯一的困扰可能是旁人偶尔会对我突然仰头的动作投来奇怪的目光。那些仰头无法解决的严重情况,我会找个无人的角落,用之前学到的口外复位法自己处理。每次这类无法自动复位的脱臼发生,需要我手动干预时,我会留下记录;前几年的时候情况比较糟糕,大概一个月一次,近期已经有所好转(可能和我拔了智齿相关),大概是每100天会出现一次。
值得庆幸的是,在高考和其他人生重要时刻,这个病都没有给我带来麻烦。现在的我已经完全接受了与它共存的状态,甚至发展出了一套"充电"理论——定期按摩关节区域就像充电,如果等到"电量耗尽",关节就会卡住。
如果你从未听说过这个病,那我衷心祝愿你永远不会有机会了解它。某种程度上说,在现代社会,对疾病知识知道得越少可能意味着越健康?但如果你或身边的人也受此困扰,希望我的经验能提供一些帮助。
2025-05-06 22:25:05
起因是在看推上的日语同人;如果用 LLM 直接翻译的话,无论加了什么prompt,最后翻译出来的顺序也是乱的(可能是因为视觉模型内在的处理顺序问题?),需要脑内重排序,不太爽;正巧之前看到过其他人的博客,说现在视觉模型可以输出边界框了,于是趁着放假 vibe coding 了一把,果然还真可以用;虽然边界框偶尔不太准,但是大部分场景下也足够了。起初用 Python 写了一个版本,但后面意识到其实可以直接用 Web 技术实现,省的用户另外配置环境了。