2026-06-28 20:31:57
出了兴城西站,打开滴滴却打不到一辆车 —— 搜了一下小红书才知道,这和张家口一样,是滴滴还没有入住的区域,网约车在这里被本地出租车举报导致几乎没人开网约车,大家出了高铁站,只能乘坐 1 小时一趟的 K1 列车或者左转排队等待出租车。
兴城的海,没有秦皇岛、青岛那种成熟海滨城市的精致感。
海岸线景区附近也有大量的破败的房屋和废弃的港口、渔船、酒店、烂尾楼,带着一点褪色和沧桑的气息。



兴城的游客也非常少,6 月的周末、晴天的下午,从龙回头到和平广场长长的一段栈道看不到多少人,到了和平广场更是显得空旷,下午三四点广场上几乎看不见人,旁边的高楼也分不清到底是住人了还是烂尾了,因为从外墙上看不出任何居住痕迹。
来这里的第二天,住进了一家 27 层的民宿,对面就是一望无际的渤海,今天空气通透度不高,连地平线都看不清,但是高处的视野和风景还是很夯的。

晚上的时候,只能吃泡面加饼干,不敢想象居然在非滑雪场景下,出门旅游住酒店吃这种东西当晚餐,因为周围实在是找不到任何一家可以吃的店子,包括外卖基本都在 6km 之外。
天黑了才发现,30多层的小区,楼下看不到海的楼层几乎都是黑灯瞎火的,而高层已经都被改成了民宿。

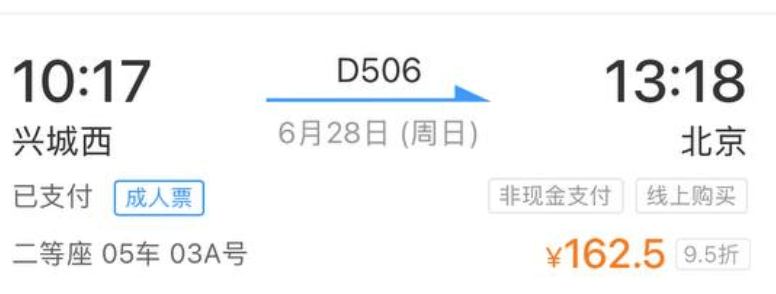
回北京的直达动车只有上午十点的一趟 D506,早早的起来坐 K1 公交车去兴城西站,发现司机还是来的时候的那位大叔,动车的乘务员说,下个月 D506 就变成 G 字头了,车票贵了几十块,速度还是不变。
2026-06-21 13:10:00
这几天 VPS 圈子里,哪吒监控(Nezha)基本被刷屏了。
有人说 CPU 被打满,有人发现机器里多了陌生 SSH 公钥,有人被云厂商发 abuse,还有人发现自己的小鸡被拿去挖矿、做代理、打流量。NodeSeek 上更直观,列表里隔几条就是一个哪吒相关帖子:求助、复盘、检测脚本、清理脚本、替代方案,什么都有。
我一开始也以为这只是“面板密码太弱”或者“SSH 被爆破”。后来越查越觉得不对。很多机器并没有对应时间段的 SSH 成功登录记录,但后门却几乎同时落地。这个现象很说明问题:攻击者很可能不是一台一台登录,而是先拿到了哪吒 Dashboard,然后通过 Agent 批量下发命令。
换句话说,平时的“集中管理”,出事时就变成了“集中沦陷”。
这篇简单记一下这次事件。不会写太深的漏洞分析,主要讲清楚几件事:为什么哪吒不是普通探针,漏洞大概怎么串起来,社区里看到了哪些中招痕迹,以及现在还在用的人该先做什么。
很多人装哪吒,是为了看一个漂亮的服务器状态页。CPU、内存、流量、在线状态,一屏看完,确实舒服。
但哪吒不是只读工具。Dashboard 和 Agent 之间有控制通道,面板里能做不少运维动作:
这些功能平时很方便。问题是,权限也很重。
如果 Dashboard 被接管,攻击者拿到的不是“看看监控”的权限,而是“让所有在线 Agent 执行命令”的权限。Agent 又通常是 root 跑的,所以面板里下发的一条命令,到了机器上可能就是 root 权限执行。
这也是这次事件影响范围容易扩大的原因。
这次不是只有社区传言。哪吒官方已经有两个相关的 GitHub Security Advisory。
第一个是 GHSA-5c25-7vpj-9mqh:
https://github.com/nezhahq/nezha/security/advisories/GHSA-5c25-7vpj-9mqh
这个漏洞影响 < 2.0.13。问题出在 Dashboard 的前端 fallback 路由处理上。旧版本判断 /dashboard 路径时不够严,攻击者可以构造类似这样的请求:
1 |
|
默认部署下,这可能读到 data/config.yaml。里面有 jwt_secret_key、agent_secret_key 这些敏感配置。
其中 jwt_secret_key 特别危险。旧版本里,攻击者拿到它之后,就可能自己签一个合法的 Dashboard 登录态。也就是说,强密码还在,但密码这关已经被绕过去了。
第二个是 GHSA-99gv-2m7h-3hh9:
https://github.com/nezhahq/nezha/security/advisories/GHSA-99gv-2m7h-3hh9
这个漏洞影响 >= 1.4.0, < 2.0.8。它和计划任务权限有关。低权限用户可能通过计划任务接口创建命令,并广播到所有服务器。Agent 收到后会执行,于是就变成了跨主机的远程命令执行。
把这两件事放在一起,大概链路就是:
1 |
|
所以很多人看到的是“所有机器一起出事”。这不是巧合。一个 Dashboard 后面挂了多少 Agent,攻击者就可能一次打到多少台。
这次比较容易让人误解的一点是:漏洞不是今天才修,但爆发却集中在这几天。
按公开资料和社区反馈,大概是这样:
GHSA-99gv-2m7h-3hh9,计划任务权限问题被披露,修复版本是 2.0.8。GHSA-5c25-7vpj-9mqh,路径穿越问题被披露,修复版本是 2.0.13。v2.2.6,Agent 最新是 v2.2.2。这说明修复版本早就有了,但暴露在公网的旧面板并不会自动消失。攻击者可能早就扫过一轮,真正变现的时候,大家才看到 CPU 和流量异常。
“养鱼”和“收网”这种说法听起来很戏剧化,我不想把它写成定论。能确认的是:漏洞公开存在,修复版本已经发布,社区里确实出现了批量中招。
很多人第一反应是:我 SSH 密码很强,甚至只开了密钥登录,为什么还会中?
因为攻击可能根本没走 SSH。
如果攻击者控制的是 Dashboard,那被控机器只要能主动连上 Dashboard 就行。UFW 通常拦的是入站连接,而 Agent 连 Dashboard 是出站连接。
也就是说,攻击路径更像这样:
1 |
|
而不是:
1 |
|
所以 SSH 强密码、改端口、禁密码登录,这些都很重要,但它们防的是 SSH 这条路。这次的问题大概率是从控制面进来的。
不同人机器上的载荷不完全一样。下面这些是社区复盘里反复出现的现象,适合拿来做排查方向,但不要当成完整 IOC。
有人从中招的 SQLite 数据库里提取到过恶意计划任务,内容包括:
1 |
|
也有人发现机器上多了随机后缀的哪吒服务:
1 |
|
对应的配置文件可能长这样:
1 |
|
这种做法会增加清理难度。只停掉原本的 nezha-agent.service 不够,随机后缀的服务可能还在运行。
还有一些机器出现了挖矿和流量套利程序,比如 XMRig、c3pool,或者一些代理/带宽变现容器。这类东西不一定马上把业务搞挂,但会悄悄吃 CPU、带宽和云厂商信用。
更麻烦的是内存驻留进程。有些复盘提到伪装成 kworker 的用户态进程、memfd 内存马、执行路径显示为 (deleted) 的进程。查文件不一定能看到,得看 /proc、进程树和网络连接。
我觉得比较实用的排查顺序是:
1 |
|
一键清理脚本可以止血,但不能证明系统已经可信。机器被 root 权限控制过之后,更稳妥的处理方式仍然是重装系统,然后轮换所有可能泄露的凭据。
如果你用过受影响版本,或者 Dashboard 曾经暴露在公网,我会按这个顺序处理。
堵住入口
先升级 Dashboard,不要让面板直接暴露公网。访问入口可以收敛到 WireGuard、Tailscale、Cloudflare Access、内网反代或 IP 白名单。随后轮换 jwt_secret_key、agent_secret_key,清理旧登录态和旧 token。
检查控制面
重点看 Nezha 计划任务、Dashboard 数据库里的异常任务、通知配置、Webhook、OAuth 设置,以及是否存在陌生用户或异常登录痕迹。
逐台检查节点
查随机后缀的 nezha-agent-*.service,查 /opt/nezha/agent/config-*.yml,查挖矿进程、代理容器、/tmp、/dev/shm。如果有条件,再查 memfd、deleted exe、伪装 kworker 这类更隐蔽的进程。
轮换凭据
SSH key、面板密码、云服务 API key、对象存储、邮件、支付、AI 服务等,只要这台机器上可能读到,都应该按泄露处理。
如果已经出现陌生 SSH key、挖矿进程、异常流量,或者你不确定机器到底被做过什么,别太相信“清理干净了”。备份必要业务数据后重装系统更稳。
这次事件不是简单的“哪吒能不能用”。真正的问题是,所有“监控 + 控制”一体化面板都要按高危入口对待。
如果一个面板可以打开终端、管理文件、批量执行命令,那它就不只是监控面板,而是运维控制台。它不该直接暴露在公网,也不该和普通状态页一个安全级别。
监控最好尽量只读。能不用远程执行,就不要开远程执行。能让 Agent 低权限运行,就不要 root。能放内网,就别放公网。
说到底,漂亮 UI 不是安全边界。生产环境里,少一个控制入口,往往比多一个炫酷面板更值钱。
Note: 本文大多数由 GPT 5.5 生成,因此 AI 味十足,不过本质就是一个事故复盘,重要的是信息准确,所以我也懒得改了。
Aska あすか:哪吒监控安全事件复盘
https://x.com/Asuka_Makina/article/2067017819099983926
NodeSeek:哪吒探针漏洞攻击全记录
https://www.nodeseek.com/post-786371-1
NodeSeek:哪吒面板漏洞被批量植入后门全过程
https://www.nodeseek.com/post-779143-1
GitHub Security Advisory:GHSA-5c25-7vpj-9mqh
https://github.com/nezhahq/nezha/security/advisories/GHSA-5c25-7vpj-9mqh
GitHub Security Advisory:GHSA-99gv-2m7h-3hh9
https://github.com/nezhahq/nezha/security/advisories/GHSA-99gv-2m7h-3hh9

2026-04-19 15:39:57
黄土高原上的北魏古都,煤炭重镇,云冈大佛。
大同给我的第一印象就是 —— 非常板正的一个城市,整个平城区就是从中间的古城开始,一个方框套着另一个方框。
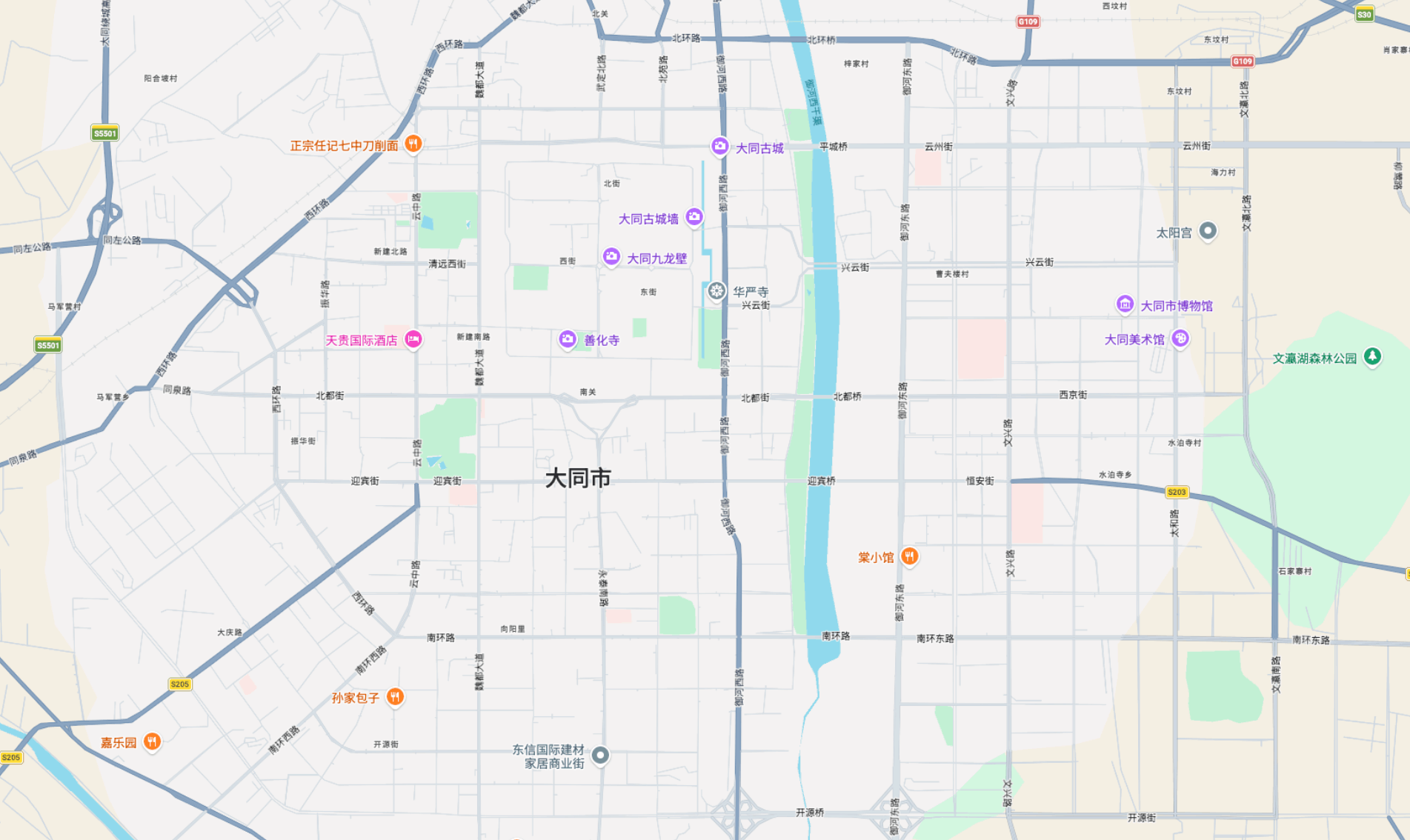
七点多从酒店出来,步行到古城,从西边清远门进,逛到东边和阳门出,然后骑共享单车回来。


古城的灯一直开到十一点左右,晚上也很热闹。
从平城市区出发,打车二十多块钱就可以到云冈石窟,大概半小时不到。
石窟本身规模很大,开凿于北魏,距今已经一千五百多年,很多佛像的脑袋已经被人摘走了,16-20 昙曜五窟很壮观,也可以直接室外露天观看。
其他的窟都需要门口排队进去,人很多,很挤。
推荐从 20 窟开始往回看,推荐参考 B 站「-小老西儿」的解说:




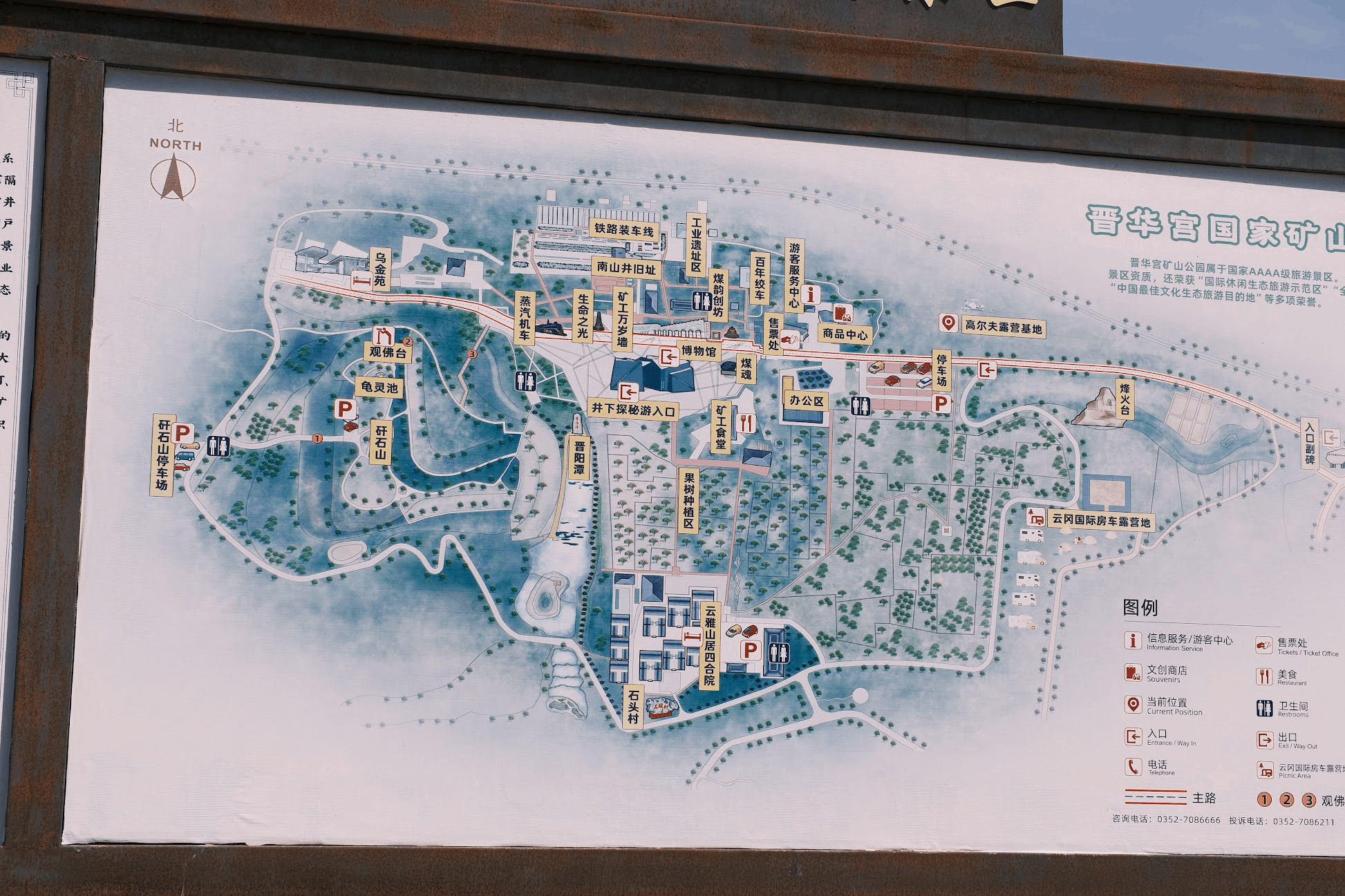
云冈石窟对面的晋华宫矿坑公园倒是意外之喜。这里是一个废弃的露天煤矿改建的公园,在山顶可以俯瞰整个矿坑,工业遗址的震撼感远超对面的石窟——虽然没有下去,站在上面看已经觉得很值了。
虽然距离云冈石窟就不到1km,但两个景点可以说人流量一个天一个地,这个公园里面慢慢的晃悠一下还是很舒服的。


一早出门就碰上沙尘暴,天色灰黄,风沙扑面。
想骑小黄车在古城里逛逛,换了七八个停车点,每一个都显示「此处不可停车」,明明画在标注的停车区域内。
骑车回酒店的路上,天气又突然变脸,瓢泼大雨砸下来,淋在身上变成泥水,而天气预报显示今天只是「普通阴天」。
感觉自己已经慢慢从 J 人往 P 人在迁移了,不管是工作还是旅行,你的计划总是赶不上变化,一直 J 就很痛苦。
但这一天也有唯一一个真正打动我的东西:吉祥天女。
逛了那么多石窟和佛像,大多数时候我是无感的,但这一尊例外。
几乎不像宗教造像,更像是某个真实存在过的人。
线下看到这尊佛像的时候真的很惊艳,就像东方的蒙娜丽莎,似笑非笑,似哭非哭,眼神里真的有佛家那种超然物外的感觉。



这几天吃了好多碗刀削面,记录几家店子:
「酒店楼下 — 日升面馆」





大同(平城区)的车道:主干车道往往是 8 车道甚至 10 车道,非常宽敞,非机动车道很有意思,和机动车道中间往往会隔一排人行道或者绿化带,然后和另一侧的人行道之间又是平行的(导致车开上人行道非常容易)。

城市里没有地铁,打车还算方便,网约车到哪里基本都是 20 以内。
2026-04-06 00:00:00
24年9月,刚结束秋招,去秦皇岛待了 2 天。
25年6月,毕业,去大连待了 3 天。
26年4月,又一个人去青岛待了 3 天,不过这次没有什么 milestone,就是单纯想看海了。


其实有了大交通 + 酒店,青岛剩下的景点就不用做什么提前预约和规划了,绝大多数海边的景点都是免费的,如果要去啤酒博物馆,海洋公园,或者崂山,可能需要提前规划/预约一下。
但实测,这三天下来,每天 3w 步,也差不多刚刚好把 栈桥 —— 石老人 这一条滨海线路走一遍。
附上我三天的线路:
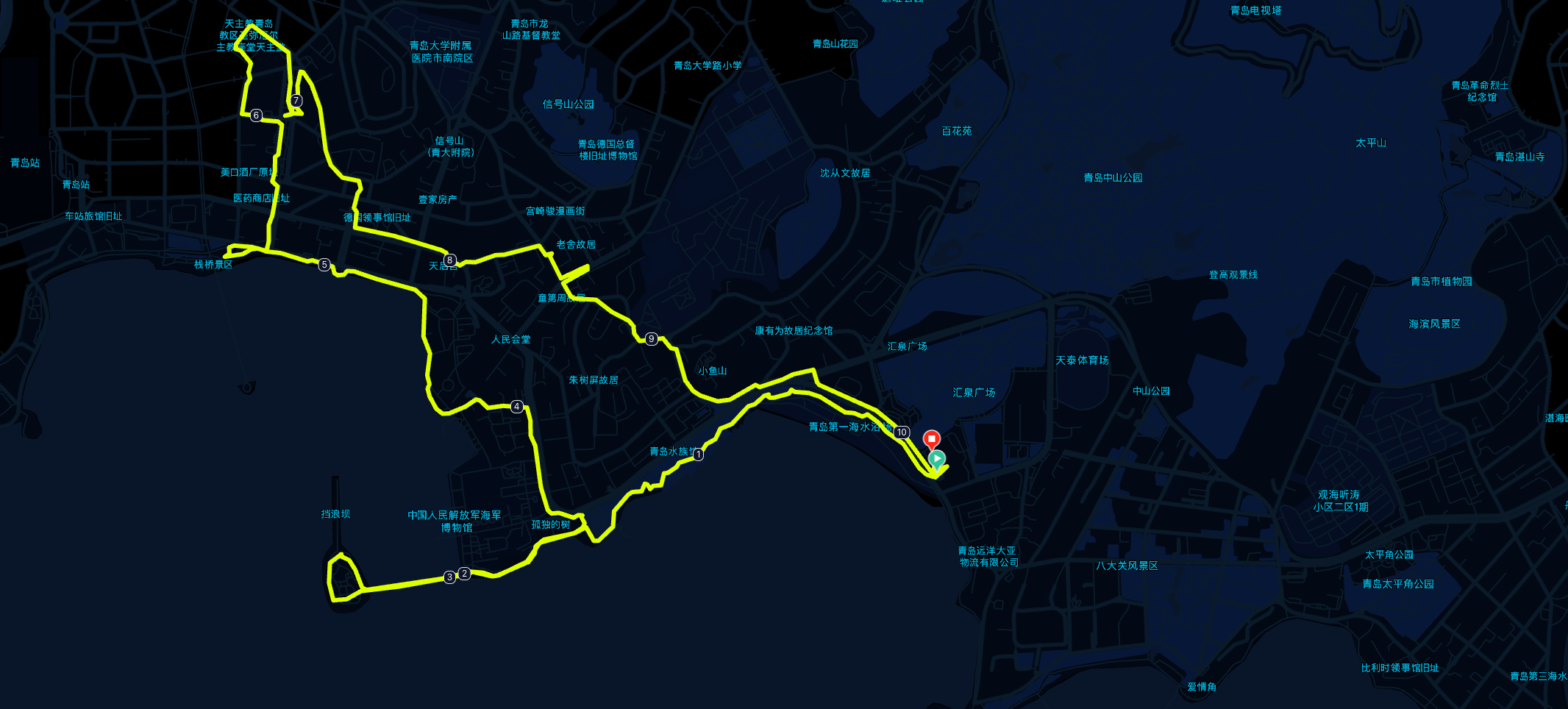
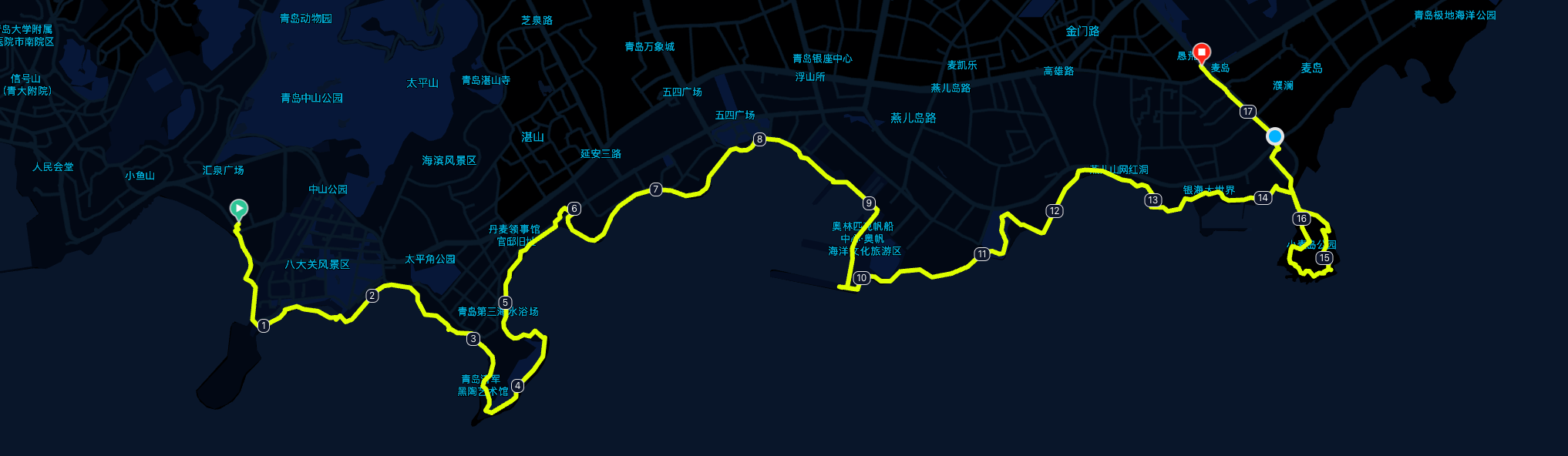
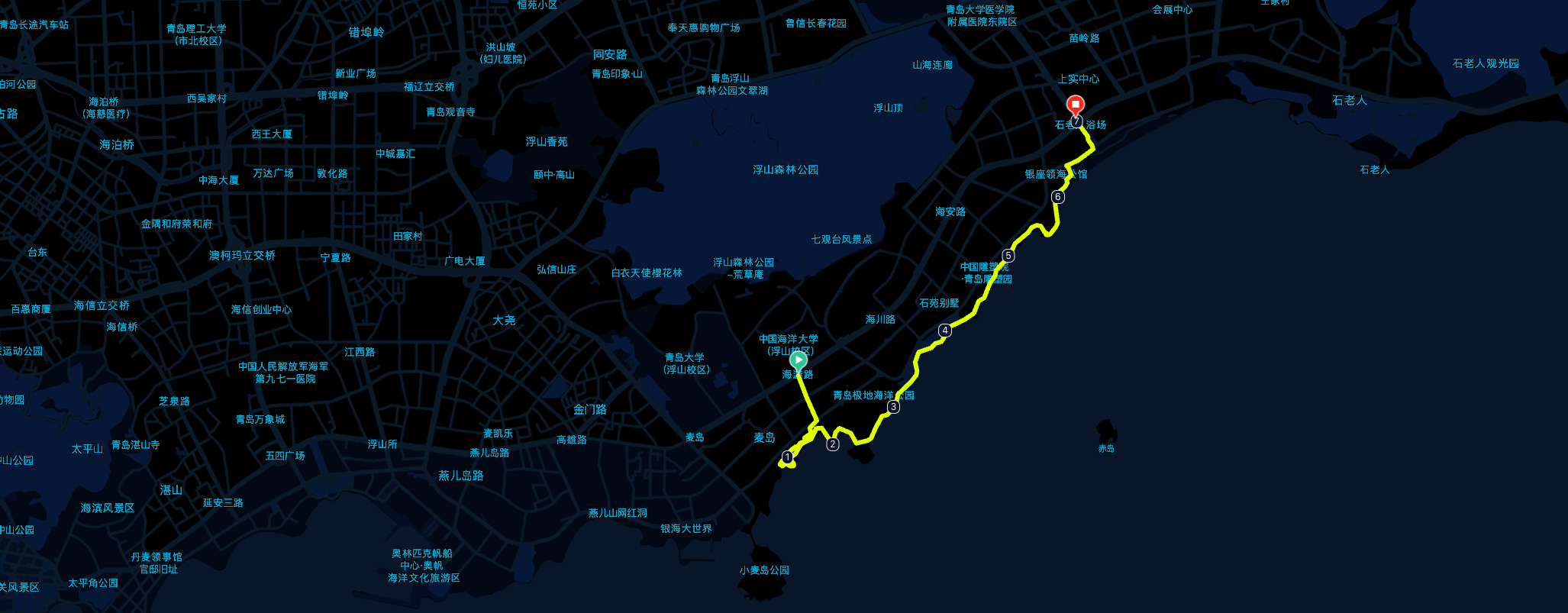
青岛站下车以后,直接地铁 3 号线,汇泉广场站下车,步行 5min 就到酒店了。
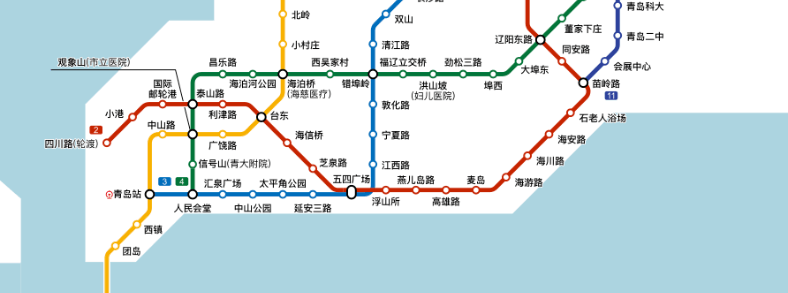
来青岛以后看了一眼地铁线路图,第一感觉就是 —— 地铁修的真好,整个市南区的海岸线几乎都覆盖到了地铁 (2, 3 号线),所以这三天我也没有打过车,出行全地铁[1]就够了。
到酒店先吃了一顿 200 块的自助,在酒店 25 层的旋转餐厅 —— 这个餐厅居然真的会转,大概 90 分钟自转一圈,由于是附近最高(第二高?)的建筑,可以看到全部的海景和城景。

第一天很不巧,从中午开始以后,全是平流雾[2] + 霾的天气,海边的天气真是非常多变,即使我出行的前一天晚上看天气还是 3 天晴天,到了当天就变成 雾 + 霾 + 风 + 雨。

所以拍出来的照片 be like:


从第一浴场走到栈桥,然后到天主教堂,最后从小鱼山下来回到酒店,其实体验有点一般,市内的景观都是人造的,而老城区的红瓦绿树在这种阴天下又毫无美感。
许多年轻人聚集在「网红墙」前拍照,凑近了看不过是两个路牌,所以当我导航到这里的时候,我甚至直接走过去了才发现原来已经走过了。
—— 所以很多时候不想去那些人文景点,总感觉有些符号营造的太刻意。
晚上的时候,从五四广场随便吃了点东西就往奥帆中心走,因为那里可以看到青岛新城区的灯光秀。
新城区的夜景真的很华丽,全是几十层的高楼,把整个海边染的五光十色。


然后回来以后到酒店楼下的青岛啤酒店,搞了一点青岛啤酒一厂和四厂的原浆和鲜啤:



都很好喝,口感和之前喝过的「泰山7天/28天」非常像,总之比罐装的水啤要好喝很多。
第二天的天气非常的好,于是拿上了我的 xs20 开始暴走模式。
整个白天基本都是在滨海绿道上徒步,文字不足以描述晴天大海的美,放图即可——






上午从第一浴场一直走到了小麦岛,然后下午先坐地铁回来走了一圈八大关,之后又重返小鱼山俯瞰了一下青岛老城,“红瓦绿树,碧海蓝天”,晴天的青岛真的很浪漫。


第一浴场的酒店看不到日落,于是就等太阳落下山以后拍了几张蓝调:


晚上,去吃了「前海沿」的海肠捞饭,其实吃不太出来海肠的味道,更多像是一种吃口感的东西,饭虽然很好吃,但是更多的味道来自于酱油、韭菜、肉沫。

第三天的天气和第一天如出一辙,都是雾霾阴天,并且已经有点疲惫了,前两天都是暴走模式,脚已经有点跟不上了,退完房以后背着书包从海之恋公园漫步到石老人浴场,走一会歇一会。
中午吃了「粥全粥到」的蛤蜊炒鸡和鲅鱼饺子,还可以吧,不过感觉不如黄焖鸡和金谷园的饺子。。


中午就已经抵达青岛站了,出来以后去了一个叫「团岛山」的公园,公园上开满了淡紫色的花,人特别特别少,即使离栈桥很近很近。
在这里坐了很久,感觉旅行的时候,我就喜欢挑这种清净小众的地方多停留一会,即使风景没有那么极致。

从山上下来以后又去了一趟栈桥,给我吓出密集恐惧症了。

前几天做攻略的时候看别人说,青岛是一个镶着金边的破抹布,感觉说的确实很有道理,虽然没怎么深度体验市内的人文,但是趁吃饭的时候去市北区转了转,感受是确实挺脏乱差的。
市南区的交通便利又混乱,地铁直通大多数地方,但是陆地上的机动车道大多是单行道,很堵,然后人行道上挤满了送外卖的电动车——因为并没有非机动车道。
和大连一样的,这里看不到共享单车,不过骑自行车的人还挺多的,没有特别起伏的地形。
总的来说,因为天气的原因,可能只体会到了 1 天完全体的青岛,但是能感受到这座城市对于旅游来说还是非常不错的,海岸线超级长,可以走好几天,也许会挑一个暖和一点的天气过来,感受一下崂山和黄岛区。
2025-06-10 08:50:32
🖼️ 多图
坐上 K684,开启去往大连的旅途。
这趟卧铺有很多好处:


酒店定在了中山广场,
早上 7 点到了酒店,直接就可以办入住了(赞一波亚朵)。
然后包放下以后就直接坐地铁来到了东港。




这一天还是端午节的最后一天,并且天气一般,预想到体验可能不会很好,不过实际逛下来还是比想象中的好不少。
几个景点的感受:
回酒店吃了一个午饭歇了一会,下午直接打车到海之韵公园继续漫步。


海之韵公园从北门进,上来就是一段超级大上坡,差点没给人累死,在大太阳下走了快半小时才到山顶,不过从山上眺望大海的感觉还蛮好的。


往山下走,为了看一个网红景点「圣象天门」跟着一群大胆的游客翻了好几个护栏和挡板,到了以后发现不过如此,一大群人排队围着一个山洞拍照,虽然到达这里花了很大一番功夫,但是真正到了之后,我也懒得挤过去凑热闹了。
可能每个人对于旅行的理解都不一样,不过我是不太喜欢到了一个地方,就要打卡那些「出片」的网红景点,反倒是喜欢钻入无人的犄角旮旯去探索一下。

一路上发现了好多可爱小猫,最喜欢的是这只大橘和这俩狸花:


出了海之韵公园南门,就一直沿着滨海东路走啊走啊,一个下午走了快 30km,4 万步。自己走路有一个好处就是不必迁就他人,遇到想走的路和想看的东西,就直接走就完事了。
大连是丘陵地带,海边没有沙滩,只有断崖和礁石滩,这边整个滨海东路都是断崖,也是一种独特的风格。
随处可见这样的告示:


途中遇到可以拐下去的地方,无一例外都选择了下去看看,遇到了很多惊喜的景点。
许多地方就是沿着断崖修建的小路或者房子,左边是树林,右边就是一望无际的大海。



第二天一早就打车来到了老虎滩-菱角湾。
假期过了,天气晴了,大海的颜色变成深邃的蓝,拍照非常好看。


大连的海边有非常多的本地钓鱼佬,都是轻装出行,一根钓竿一把小椅子,一坐就是大半天,给人一种非常 chill 的感觉。
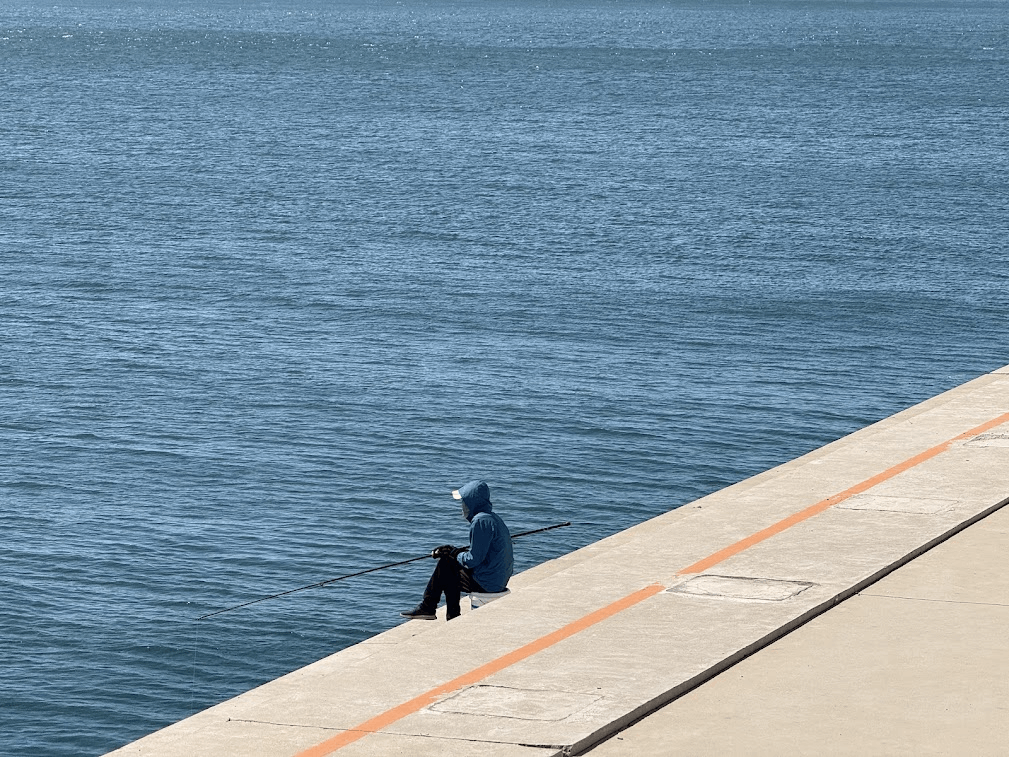
一路上都是这种非常舒适的步行木栈道,基本覆盖了从海之韵公园出来一直到星海广场这一条几十公里长长的海岸线。

走到付家庄公园,远看是一个沙滩,近看原来是石子组成的。


快黄昏时走到了大连的标志性建筑「星海湾大桥」,这个 6.8km 的跨海大桥从各个角度看过去都很壮观。


日落时桥上还会亮起不同颜色的灯光,不过当时有点冷,就没在山顶逗留了,不然俯视角下的夜景应该会很好看。

体验了一下大连的有轨电车,由于是工作日车上没什么人,车晃悠的不行、叮铃哐啷的很有意思。

大连城市的街道两旁见不到任何共享单车,不过倒是有一些共享的电动车,可能是因为城市规划的原因(没有非机动车道),并且丘陵地带很多陡峭的上下坡,确实不太适合骑单车。

晚上 8 点来到南山街,没有想象中热闹的街景,只有节日过后人们正在收拾残局。
而且大连的风真的很大,即使在城区里也能吹的人头秃,于是匆匆离开。


写这篇 Blog 的时候这次旅行已经过去快 2 周了,不过一切景物还是历历在目。
旅行这种事情确实能极大的减缓时间流逝的感觉,让人重拾起一种控制时间与生活的信心。
滨海城市的旅行体验真的极好,有时间会再去威海、青岛这些地方看看。
很喜欢的一句话:
只有一个人旅行时,才听得到自己的声音。它会告诉你,这世界比自己想象中更宽阔。
2025-05-29 19:35:05
毕业答辩结束,又因为还需要等着提交材料没法长途跋涉,想着天津离北京这么近又还没去过,索性去看看。
5月末,白天的天津,炎热难耐,走在大街上,似乎不存在斑马线和行人红绿灯。
好多好多的单行道和狭窄街道。下火车出了地铁左转,因为没有人行道,只能在逆行穿过一股酒味的涵洞。

第一顿当然尝一下天津菜,没想到分量巨大无比,一盆炒鸡估计炒了不止一只鸡。
两个饭量还不错的人吃了一个小时,最后菜和没动一样。



晚上去天津站码头坐了海河游船,也是此次天津之行感觉最值回票价的体验。
出了天津站就是码头,长长的海河沿线几乎包含了所有天津有名的景点。
如果天津没有这条海河,也许我给的评价还不如我老家。
周围高楼林立,每个楼都闪着金光,有种轻奢感。


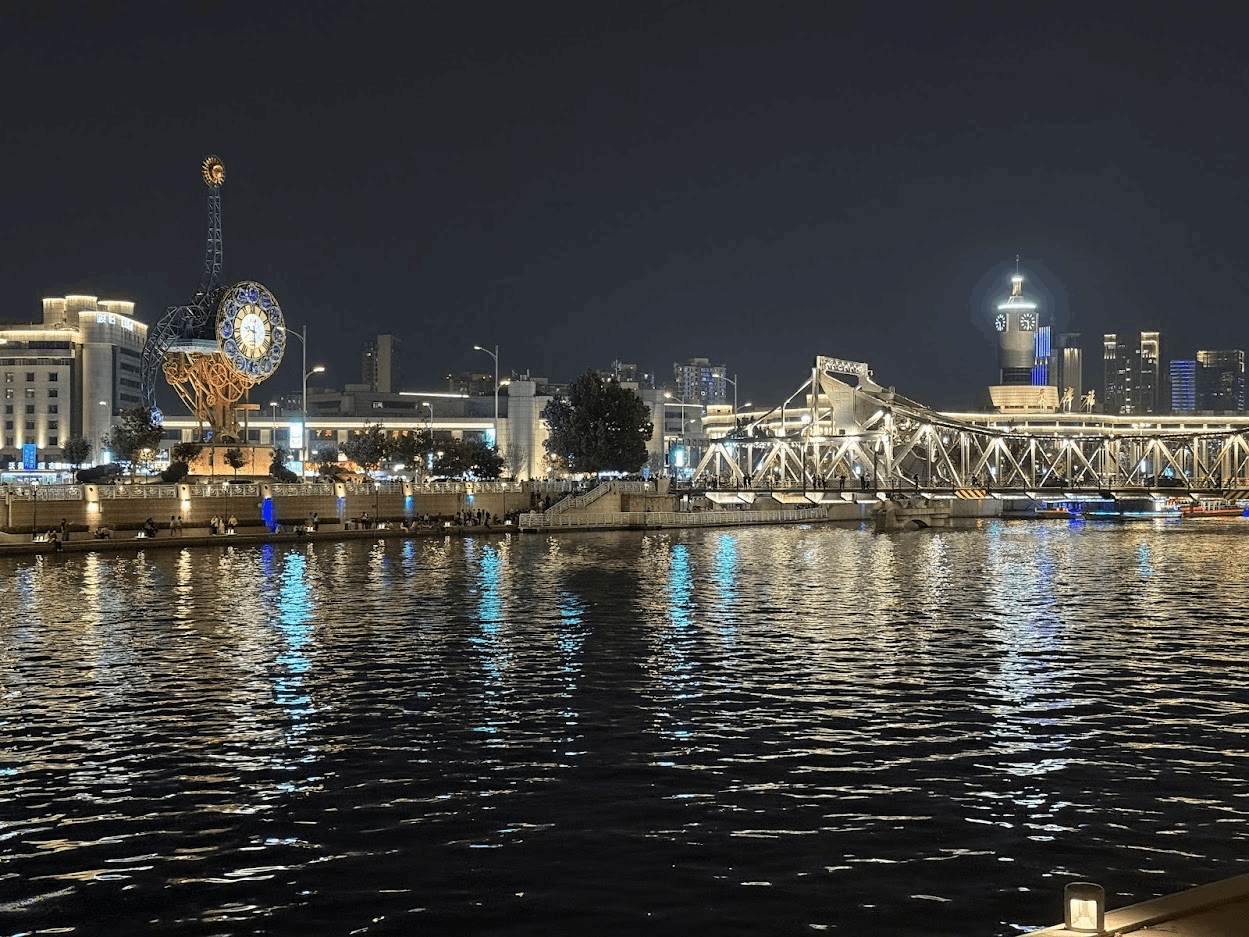
平平无奇的周内工作日,海河周围散步的人也是熙熙攘攘。
到了晚上 10 点多才逐渐安静下来,这时沿着河边散步几乎只剩下一个个卖酒的小摊贩。
心情还不错的时候,吹着晚风这么喝一杯还挺惬意。


白天走马观花的看了世纪钟广场、津湾广场、西开教堂、北安桥、意式风情街、瓷房子、五大道等等一系列建筑。
如果天气凉快一点,也许还有心情停下来欣赏一番,然而 30 度的艳阳天只能让我像特种兵打卡一样匆匆拍个照就走人。
体验一般,不过即使是凉快下来,感觉白天的天津相比晚上也差了不少意思。




下午的时候实在逛不下去了,干脆花 2 小时去听下相声。
直到开场的时候才陆续来了其他两桌人,不然直接包场了,那样还挺尬的。


第一次线下花这么长时间完整的听完一场相声,感觉还不错,主要空调还很凉快。
最后又在夜风中搭观光车溜达了一圈,感觉天津城区真的好小,已经有点腻了。
还是更喜欢山川湖海。