2026-05-20 00:20:36
This is an installment of the “Fintech in 1,000 words” series, where we break down core fintech topics, like cross-border payments, interchange, payfacs, stablecoins, and real time payments. These introduce critical but mis- or under-understood topics to people working or interested in fintech. It’s not an exhaustive guide, but the gentle introduction and overview I wish I had earlier.
“Money is not metal. It is trust inscribed.”
Niall Ferguson, The Ascent of Money
Cash is easy to trust. You walk into a grocery store, fill your cart, and hand the cashier a $100 bill. As long as the bill is real, the exchange is concluded. The trust is in the physical thing itself.
But few pay that way anymore. Most people wave a slab of plastic or their phone over a blinking machine and walk out. Same result, but the tap1 is an IOU backed by a chain of strangers. That these strangers almost always do honor it, in under a second, anywhere on Earth, is one of the most taken-for-granted marvels of modern infrastructure.
Five players connect billions of buyers and sellers. The networks (Visa, Mastercard) are the center, managing the chain’s rules, tech, and incentives. Networks partner with banks2 to extend their reach: issuers are banks that onboard and support cardholders, while acquirers do the same with merchants.
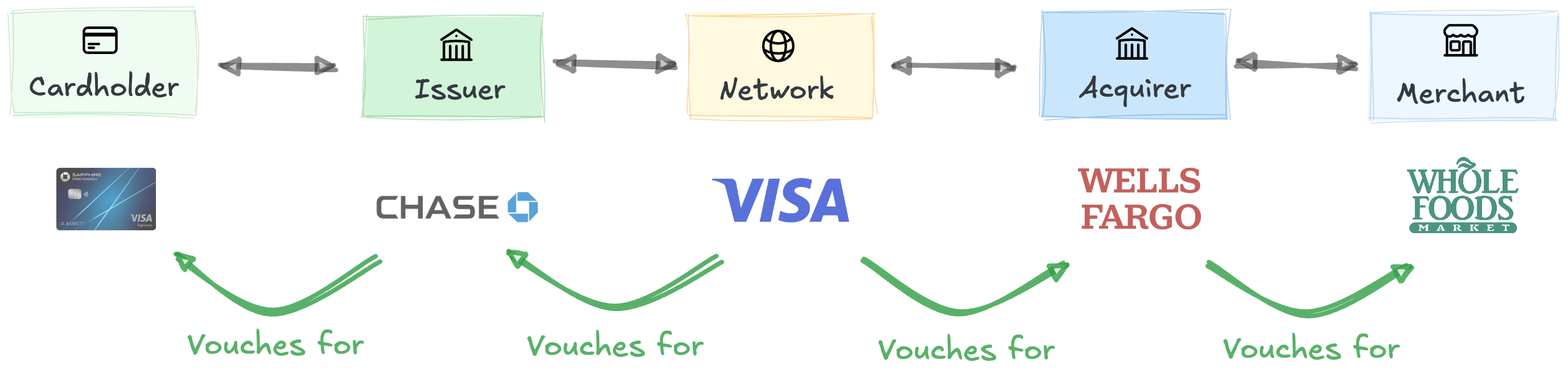
The chain works because each link only has to cosign its neighbors. Cardholders only need a relationship with the issuer. Issuers only need a relationship with networks. The networks don’t work with cardholders or merchants directly, only with issuers and acquirers.
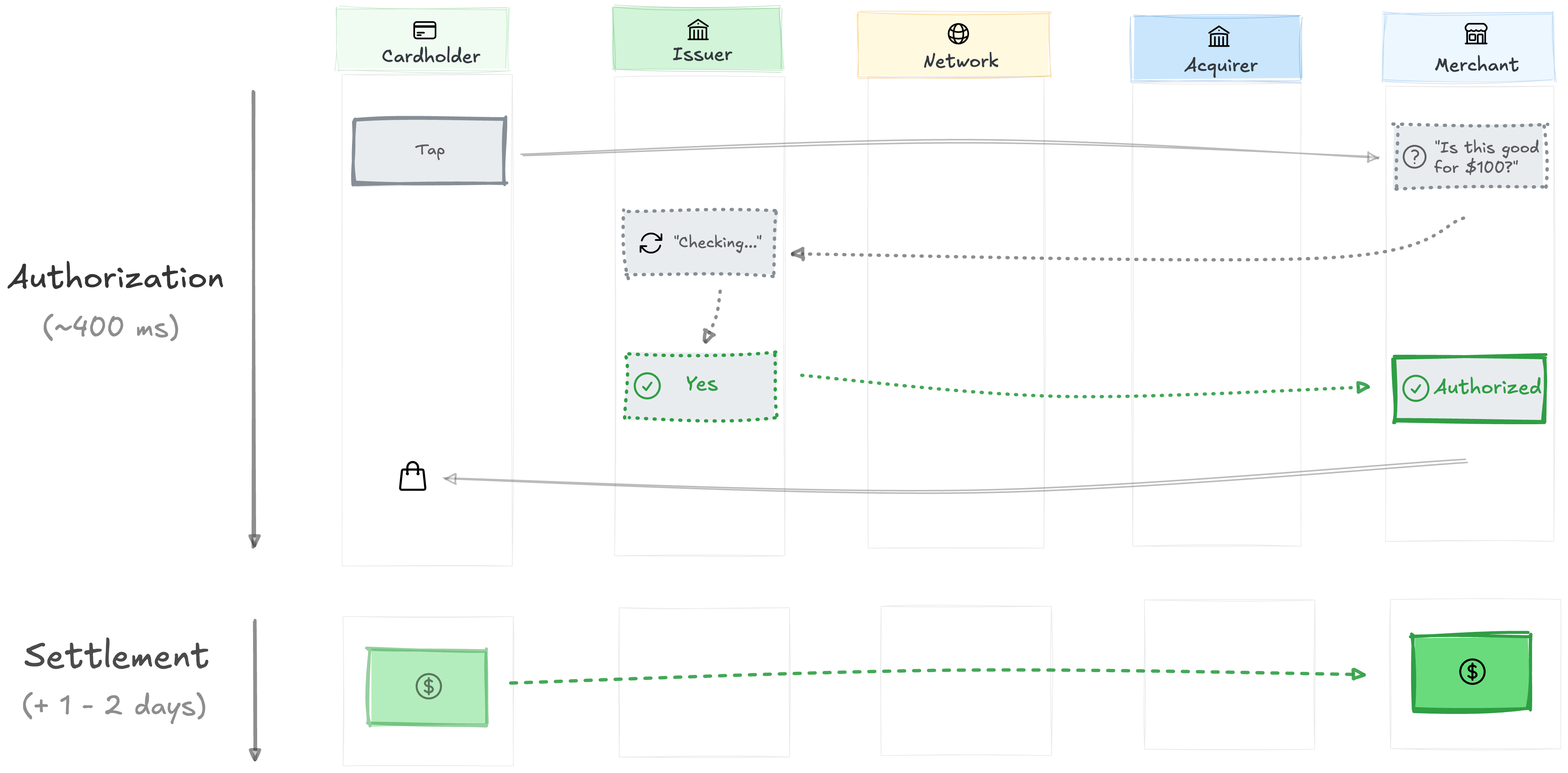
The chain’s first job is moving promises, not money. The promise layer is called authorization: when you tap, the question “is this cardholder good for $100?” is routed through the chain to your bank, and your bank returns an answer to the merchant. The money follows a day or two later, in a slower process called settlement.
Every tap is a promise made by the issuer, and the kind of card depends on what immediately backs that promise.
With debit cards, the cardholder’s money immediately backs the promise. The funds sit in their bank account, and the issuer makes them reachable at the tap.
Prepaid is backed by stored value, a pool of funds loaded ahead of the tap (payroll cards, gift cards, government benefit cards). Other prepaid programs use just-in-time (JIT) funding, which pushes balance at auth instead of pre-loading. DoorDash drops the order cost onto a dasher’s card right before they tap.
With credit cards, the issuer’s money immediately backs the promise. The issuer fronts the money on its own balance sheet, and the cardholder pays it back later. If the cardholder carries a balance (also called revolving), they pay interest on the outstanding amount, expressed as an annual percentage rate (APR).
Charge cards are a flavor of credit with revolving traditionally turned off and repayment required at the end of the statement cycle.3 The promise is backed by the issuer’s capital extended at the moment of the tap.
Same tap, but very different businesses. Debit and prepaid have little receivable to fund. Credit and charge turn the issuer into a lender, with greater risk, capital requirements, regulatory and ops burden.
Credit’s greater risk and complexity come with greater fees. Cards monetize that directly through interchange.
The “2.9% + $0.30” is the merchant’s fee, not interchange. Interchange is only the issuer’s slice. The rest goes to the network and the acquirer (see “Interchange in 1,000 words”).
On a $100 consumer credit transaction, the merchant pays roughly $3.20, split among the issuer, network, and acquirer:
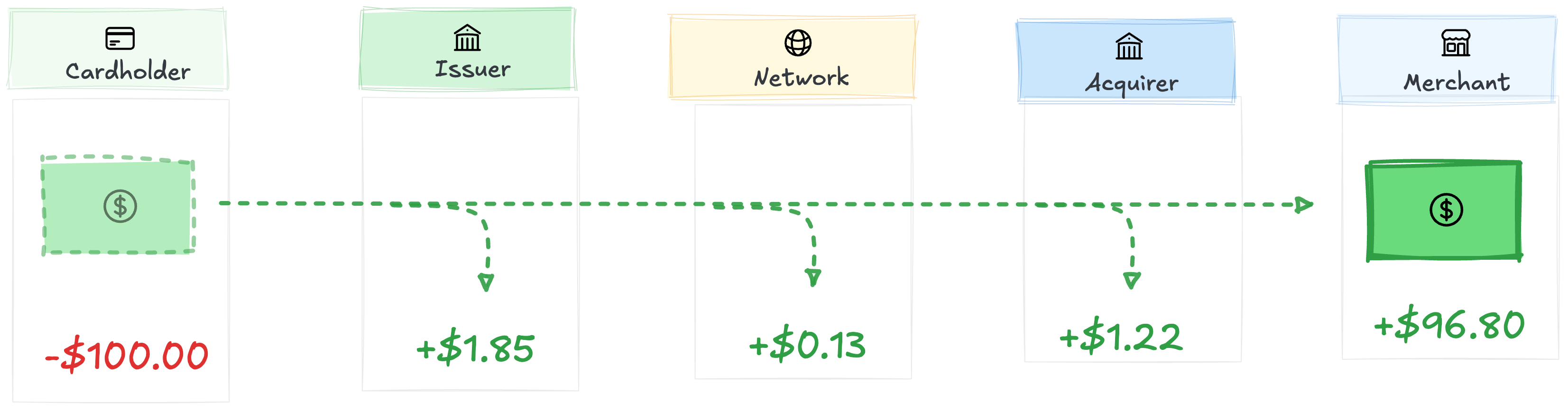
Credit incurs higher interchange fees than debit4; commercial cards are higher than personal. Network, merchant type, currency, and many other factors influence pricing.
Interchange is the foundation of issuer economics, but it’s only one piece. Credit programs also earn from interest income, annual fees, and ancillary fees. Revolving-heavy portfolios (Capital One, Discover, store-card private label) are driven primarily by interest income. Net interest margin (NIM) is the spread between yield on receivables and the issuer’s cost of funds. Transactor-heavy premium portfolios (Sapphire Reserve, Amex Platinum) lean more on interchange, annual fees, and partner economics. Debit’s slimmer margins push programs toward broader product suites.
How does a tap turn into a question (”is this good for $100?”) that gets answered in milliseconds? The chain runs the request in seven steps.
The cardholder taps. The merchant’s terminal bundles up the card details (PAN, amount, merchant info)5 and sends them to the acquirer.
The acquirer validates the request, runs its own fraud checks, and forwards it to the network.
The network reads the BIN (the PAN’s first 6-8 digits that identify the issuer) and routes the request to that issuer.
The issuer checks balance, merchant category, and fraud signals. If everything passes, the issuer vouches and “Approved” flashes back through the chain to the merchant. The cashier hands over the groceries.
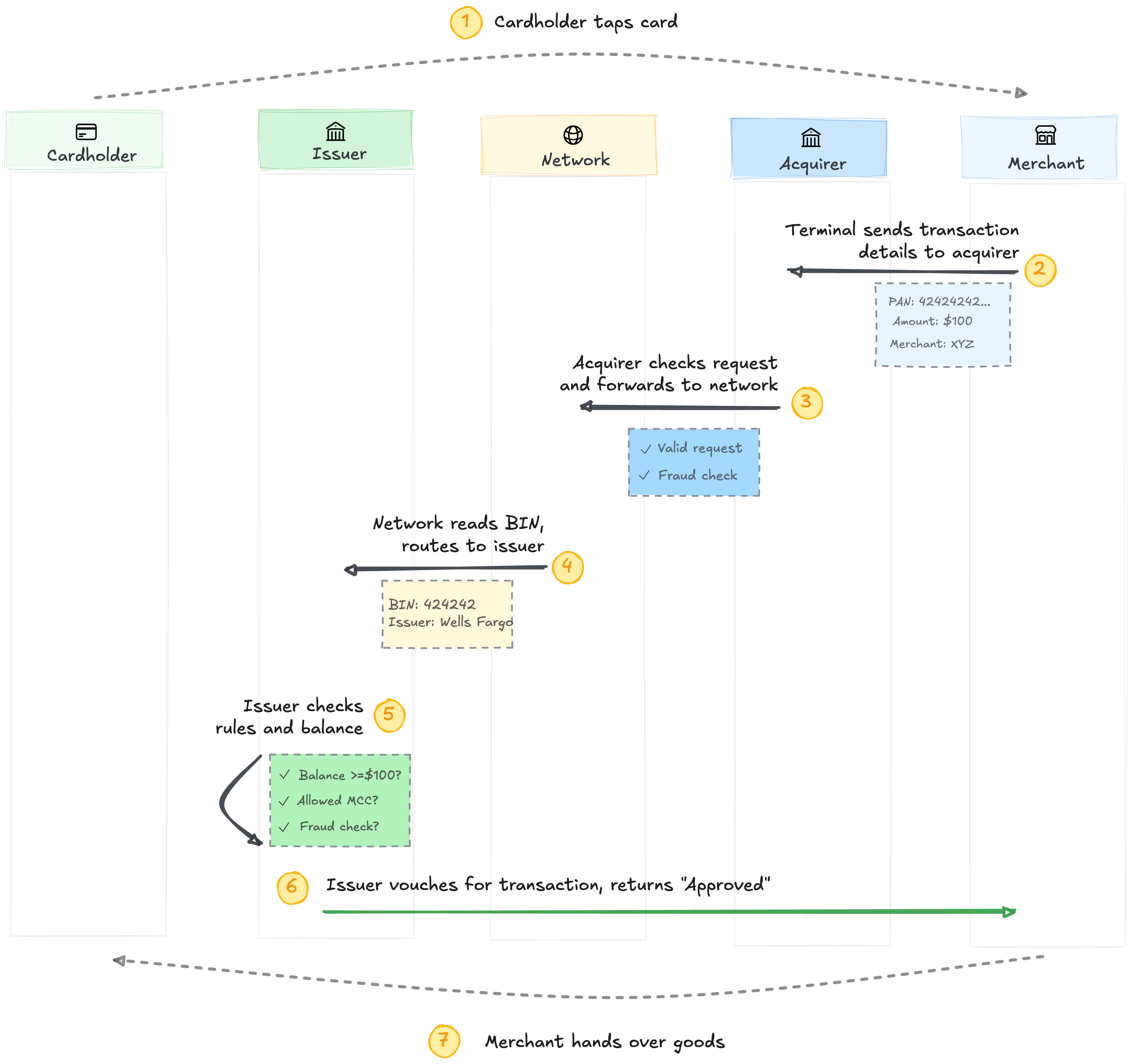
No money has moved yet. Clearing and settlement happen quietly over the next day or two.6
What’s actually happening inside the issuer? Open it up and you find work at three levels:
Transaction-level runs at every tap: accounting (is there money to back this?) and rules (should I vouch for this one?). Accounting tracks balances across debit, credit, and prepaid. Rules cover limits, merchant categories, velocity, and fraud.
Cardholder-level covers everything tied to an individual cardholder. Marketing and onboarding get cardholders a working card (sign-ups, KYC, delivery). Underwriting (credit and charge only) decides who gets a card and at what terms. Support, disputes, and fraud ops handle what goes wrong, one cardholder at a time.7
Program-level applies across every card in the program. Capital funds the credit and charge receivables (balance sheet, warehouse, or sponsor bank). The regulatory backstop: the licensed entity accountable to regulators, holding the charter, BIN, and loss liability.
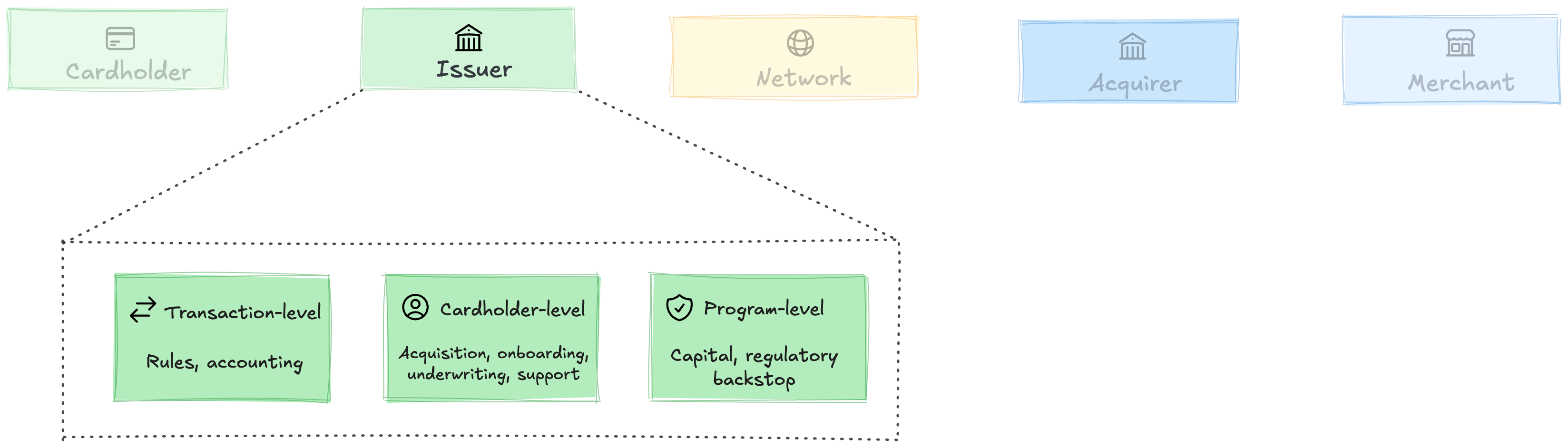
Of the three, the transaction-level runtime is the thinnest and most codified. That’s where the unbundling started.
For most of card history, these three processes lived inside one building. Banks like Chase and Wells Fargo owned the whole stack.
Marqeta cracked it open by giving the transaction-level runtime a modern API. An API-first processor paired with a sponsor bank let fintechs run accounting and rules programmatically while the bank held the charter. Each level of the stack moved to a different specialist:
Program manager. The cardholder-level operations. Acquisition, onboarding, underwriting, support, disputes, and the cardholder-facing brand.
Issuer processor. The transaction-level runtime. Direct network connections, accounting, and rules as an API.
Sponsor bank. The program-level backstop. Holds the charter, the BIN, the network license, and ultimate regulatory liability. For credit and charge, often also funds receivables.
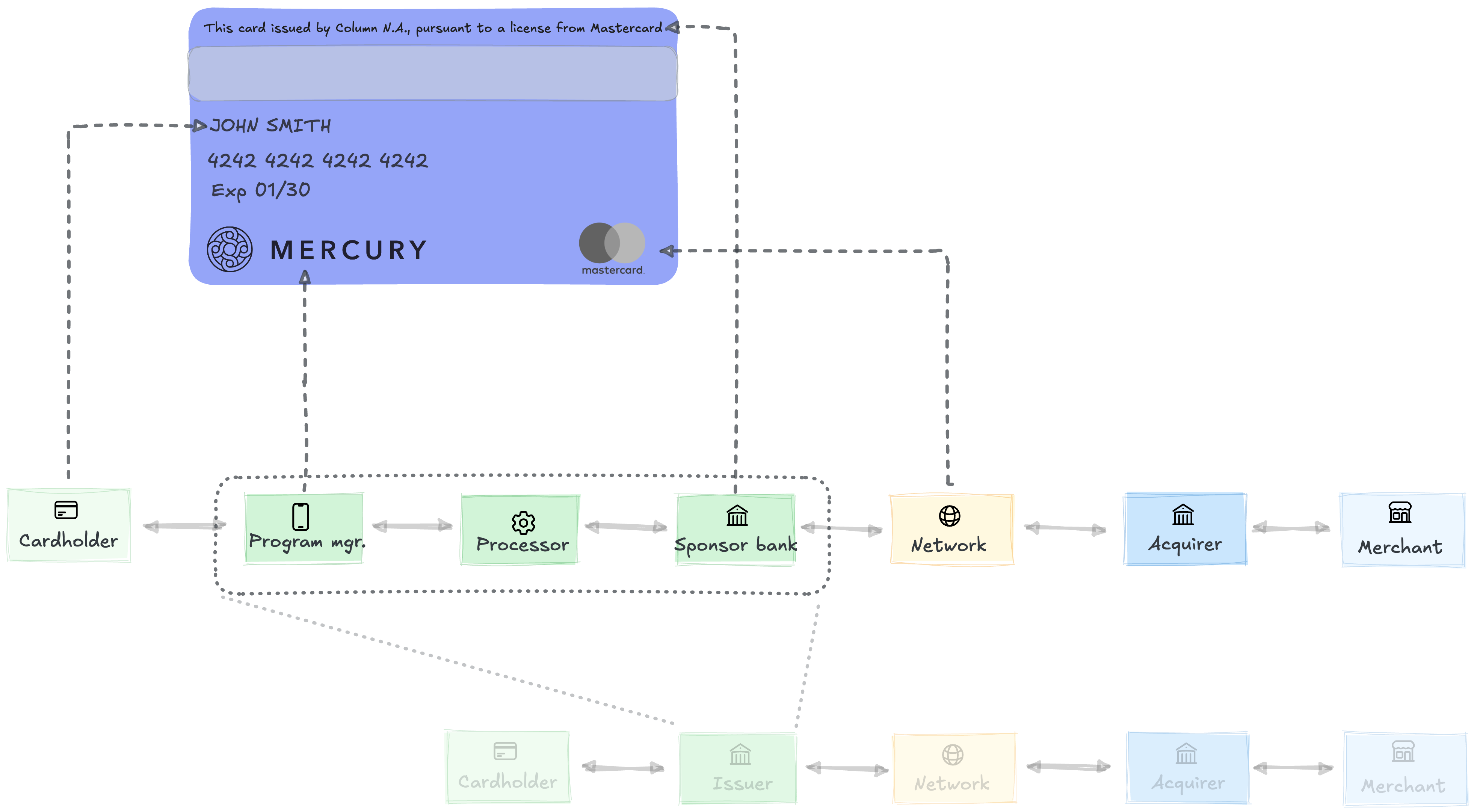
The program manager (the fintech with the brand and the cardholder relationship) typically captures the largest single share of the economics. How much depends on rewards, fraud, credit losses, and sponsor terms. Enough, in most cases, to flip who owns the customer.
After Synapse,8the stack is partially re-bundling. Tech-forward sponsor banks like Column and Newline are keeping compliance, ledgering, and money movement in-house. Processors have split: Lithic doubled down on the pure-processor layer; Highnote moved toward consolidating program-manager functions. The Marqeta-era unbundling has been narrowed by what 2024 taught about who holds the keys to the customer’s money.
Startups are building successful products, and sometimes whole companies, on this infra. Four shapes dominate. Read the chart left to right as a spectrum: in the first column the card is the whole bet and by the last, the card is one feature inside a software product that monetizes elsewhere.
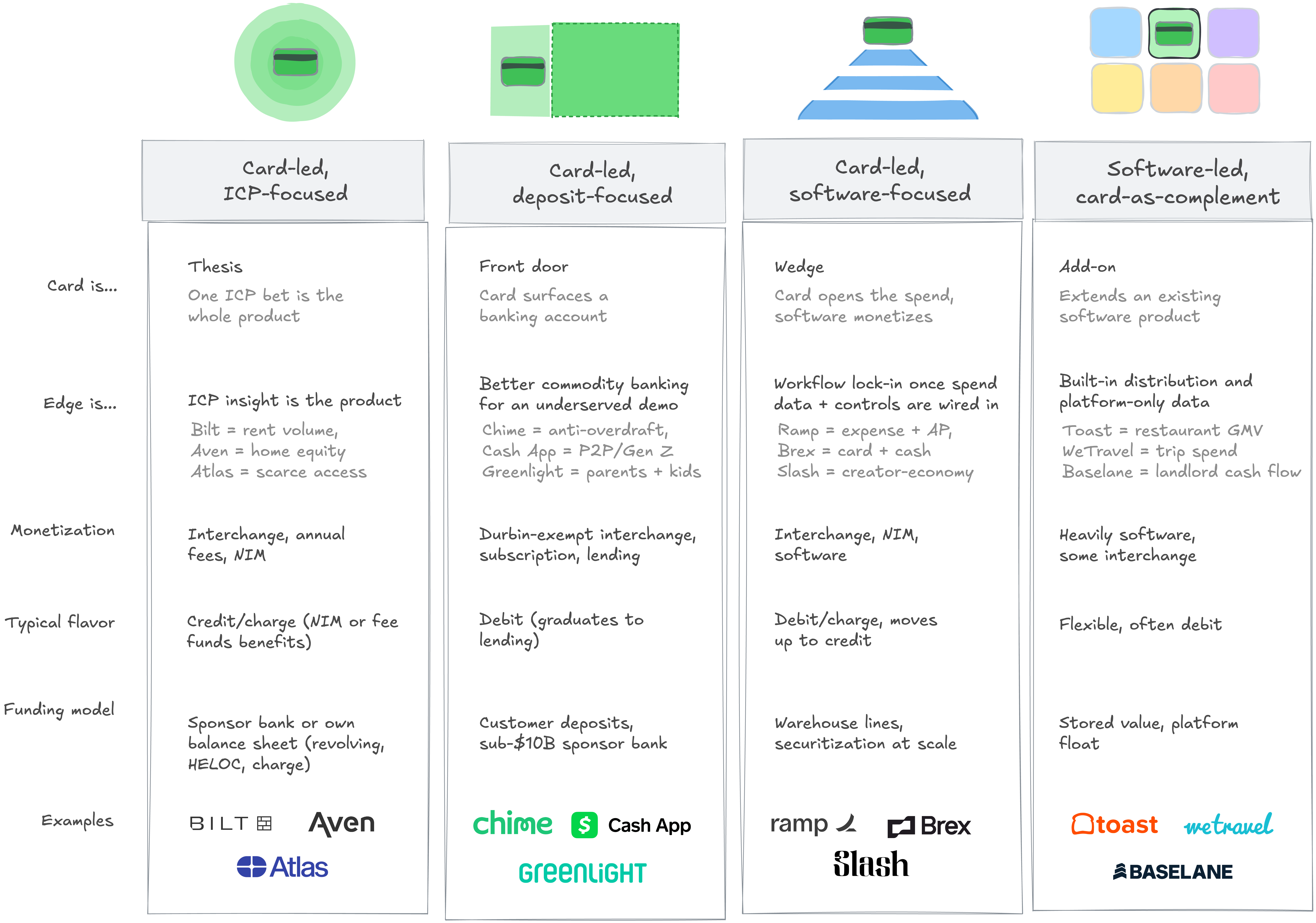
The first two columns look alike but they’re different businesses.
ICP-focused plays are credit or charge products built on one situation-specific insight. Bilt = rent volume, Aven = home equity, Atlas = scarce access. Strip the insight and the product collapses. High LTV, low-millions customer count, heavy capital.
Deposit-focused plays are commodity banking with no fees and a better app, sold into a demographic incumbents serve badly. The product is roughly the same across providers. The moat is brand, distribution, and Durbin-exempt sponsor economics that earn 4-5x the interchange of a regulated issuer. Low LTV, tens of millions of customers, capital-light.
The shapes differ underneath. What they share is harder to copy than the card.
Distribution advantage. Every winner starts with one: a pre-existing customer base (Toast, Shopify), a tight segment (Bilt, Aven, Atlas), a defined vertical (Brex, Ramp), or a demographic incumbents serve badly (Chime, Cash App). The general-purpose bank is nobody’s best option anymore.
Programmatic integration. Modern cards are software interfaces, not just payment methods. They plug into expense workflows, enforce category limits, push just-in-time funding, and feed transaction data back to the platform. The card becomes a product surface.
Asymmetric data. Toast sees restaurant cash flow in real time, Ramp sees the corporate spend graph, Chime sees who’s actually living paycheck-to-paycheck, Bilt sees rent payment behavior. Each platform knows things a traditional issuer doesn’t. Different shapes turn the data into underwriting fuel, segment-specific UX, or software upsell, but the asymmetry is universal.
Processing is increasingly API-accessible. Charter access and capital are constrained, and getting more so. Durable differentiation for fintechs sits in distribution, proprietary data, underwriting, workflow integration, and servicing.
Cards come with real drawbacks (interchange fees, fraud, chargebacks, rigid auth flows) and they keep winning anyway. Every major wave of consumer and business technology has extended cards instead of replacing them.
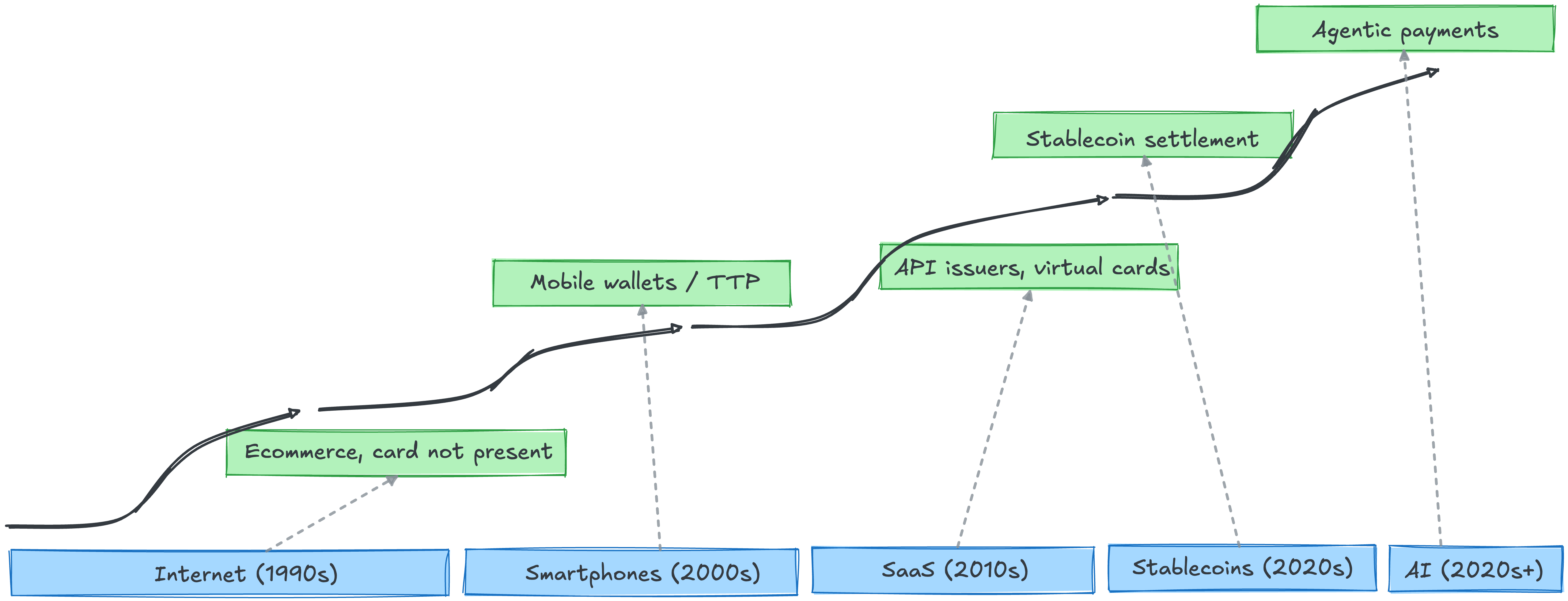
Each tech wave forced cards to evolve. The internet pushed cards into card-not-present commerce. Smartphones pushed cards into wallets and tokens. SaaS pushed cards into API-accessible issuance and virtual cards. Stablecoins are pushing cards into new settlement layers. AI is pushing cards into agentic protocols. Each wave was also supposed to end cards. Cards absorbed every wave and came out bigger.
Two new waves extend the pattern. AI agents introduce a new initiator the chain wasn’t built for. The issuer now has to answer questions harder than “is Sarah good for $100?” Is this Sarah’s agent? Is it inside Sarah’s policy? Who eats the loss if it isn’t? Visa’s Trusted Agent Protocol and Mastercard’s Agent Pay are early attempts to encode delegated authority, intent, and liability into the chain. Stablecoins are starting to handle settlement on some flows. The vouching chain stays the same. The chain is the moat. The tender is plumbing.
My name is Matt Brown. I’m a partner at Matrix, where I invest in and help early-stage fintech and vertical software startups. Matrix is an early-stage VC that leads pre-seed to Series As from an $800M fund across AI, developer tools and infra, fintech, B2B software, healthcare, and more. If you’re building something interesting in fintech or vertical software, I’d love to chat: [email protected]
Shorthand for any card initiation. Swipe, dip, and key-in all work the same way.
Visa and Mastercard are four-party networks where the issuer is a separable link. Amex and Discover are closed loops: the network is also the issuer, no slot for a sponsor bank. Every unbundled fintech stack runs on V/MC by structural necessity.
The line has blurred: Amex Green and Gold now offer Pay Over Time revolving. Brex and Ramp don’t charge APR to the cardholder but still finance receivables via warehouse lines or balance sheet. The float has to come from somewhere.
The Durbin Amendment (2010, Dodd-Frank) caps debit interchange for $10B+ asset issuers at ~21¢ + 5 bps + 1¢ fraud adjustment, far below the 1.5–2.0% credit range. Smaller “exempt” issuers are uncapped; many prepaid programs escape the cap too. This is why fintech debit programs run on sponsor banks like Pathward, Sutton, Coastal, or Lead Bank rather than JPMorgan or Wells. Picking a sub-$10B sponsor is a literal interchange-economics decision.
For Apple Pay or Google Pay, the terminal receives a network-generated token (DPAN) instead of the real PAN; the network maps it back to the PAN at authorization. Tokenization is now the default for mobile wallets.
Not literally cash. Over 1–2 business days, the auth becomes a clearing record; settlement then moves net funds between banks. Chargebacks can still shift liability for weeks or months after. “Trust like cash” captures the moment of the tap, not the eventual finality.
Reg E (debit) gives the issuer 10 business days to investigate, or 45 if it provisionally credits the cardholder. Reg Z (credit) gives the cardholder 60 days from statement. The issuer files a chargeback; the merchant representments or eats the loss. Disputes ops is the line founders most underestimate.
Synapse’s April 2024 bankruptcy, part of a broader wave of BaaS failures, froze roughly $265M of end-customer funds across Yotta, Juno, and other programs when FBO reconciliations failed.
2026-04-21 00:33:41
400 vertical software and fintech founders, operators, and investors met in New York last week for Rainforest’s Vertex conference. Everyone from public-company fintech GMs to growth-stage operators to early-stage founders. Companies building for spaces as diverse as construction, field services, legal practices, dental offices, restaurants, and laundromats.
Despite the barely-shared vocabulary, I kept hearing the same language. Lots of talk about the SaaSpocalypse and why it’s overblown. How AI is an accelerant when you own the system of record. How much room embedded payments still have to run. And more. Here’s a recap of what I learned.

The AI discourse has been writing SaaS off for months. Seat compression. Zero-marginal-cost competitors. Vertical was supposed to be especially exposed because it’s “just” workflow software.
The strongest AI work in vertical isn’t being marketed as AI. A vertical ERP that parses every unstructured customer email into the CRM is sold as a better ERP. A field service platform that generates quotes from a voicemail is sold as a faster estimator. The software gets smarter around the customer, and the customer uses more of it, not less. Nobody I talked to was seeing AI drive churn, and many were seeing it drive acceleration.
Horizontal software loves to talk about taste as the differentiator. In vertical, it’s trust. These customers have been sold software for years by vendors who over-promised and under-delivered, and the new wave of agentic point solutions is hitting the same wall of skepticism.
Trust looks different than taste. It’s the vertical-specific brand that tells an HVAC owner you understand HVAC, rather than a generic tech logo that happens to serve field service. It’s showing up at the industry’s trade shows, ride-alongs, and shop floors rather than waiting for customers to come to you. It’s training everyone in your company (especially customer support and sales reps) on the customer’s industry, not just on your product. Taste wins the demo. Trust wins the renewal, the referral, and the second product line.
The conventional wisdom on embedded payments has hardened. Most platforms have shipped it, take rates are compressing, and the easy money is behind us. Vertex was a useful corrective on all three. The founders who have been at it longest were the most bullish, not the least. Payments has a lot of room left. Most platforms aren’t close to their ceiling.
Start with take rates. The “compressing to zero” narrative is overstated. Nearly half of companies in Rainforest’s 2026 embedded payments benchmark report take rates above 90 bps. And when a platform grows from less than $50M processing volume to $250M+ volume, the median take rate doubles (0.46-0.60% below, 0.91%-1.05% above). Payments is a game of scale, and the thresholds where the economics inflect are closer than most platforms realize.
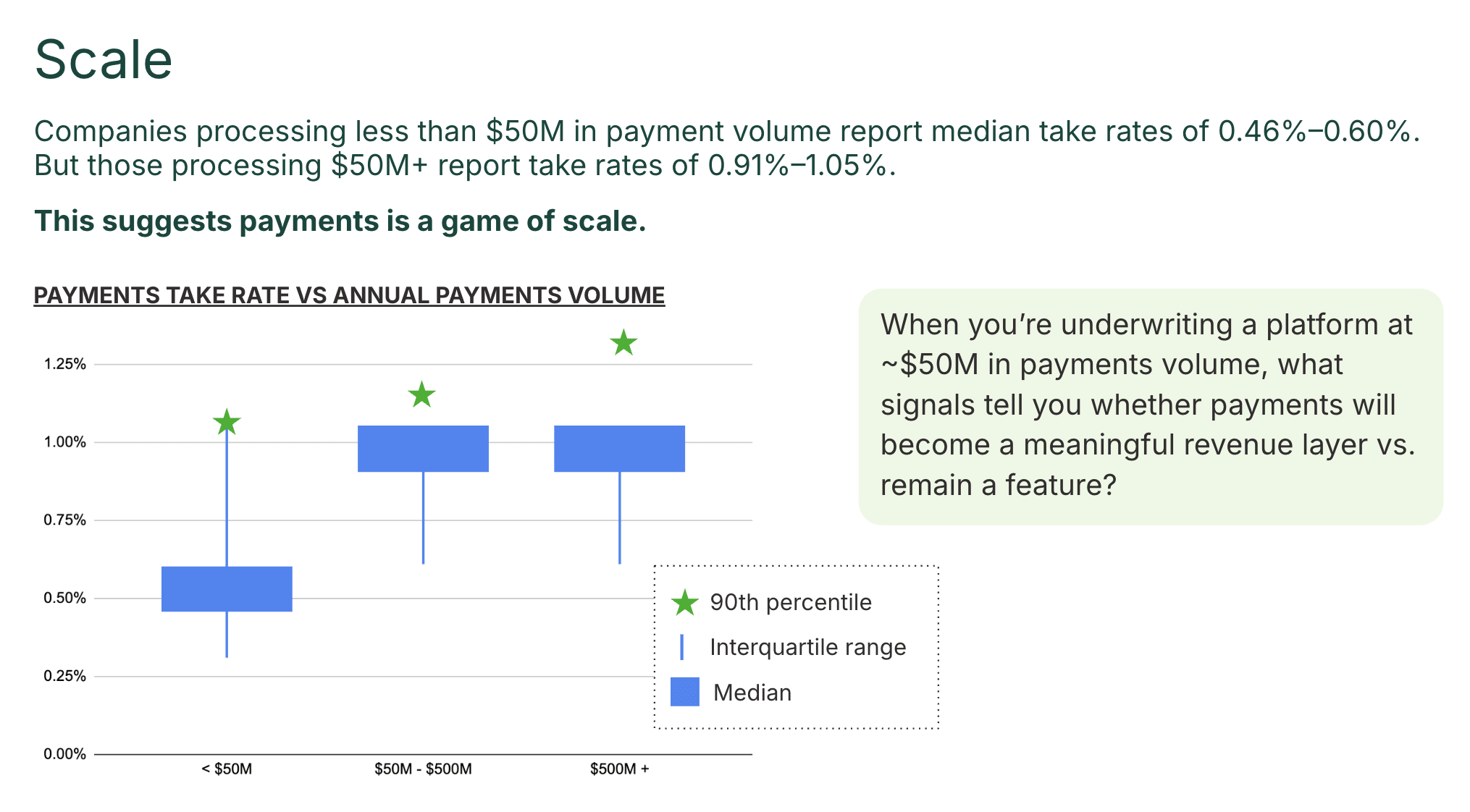
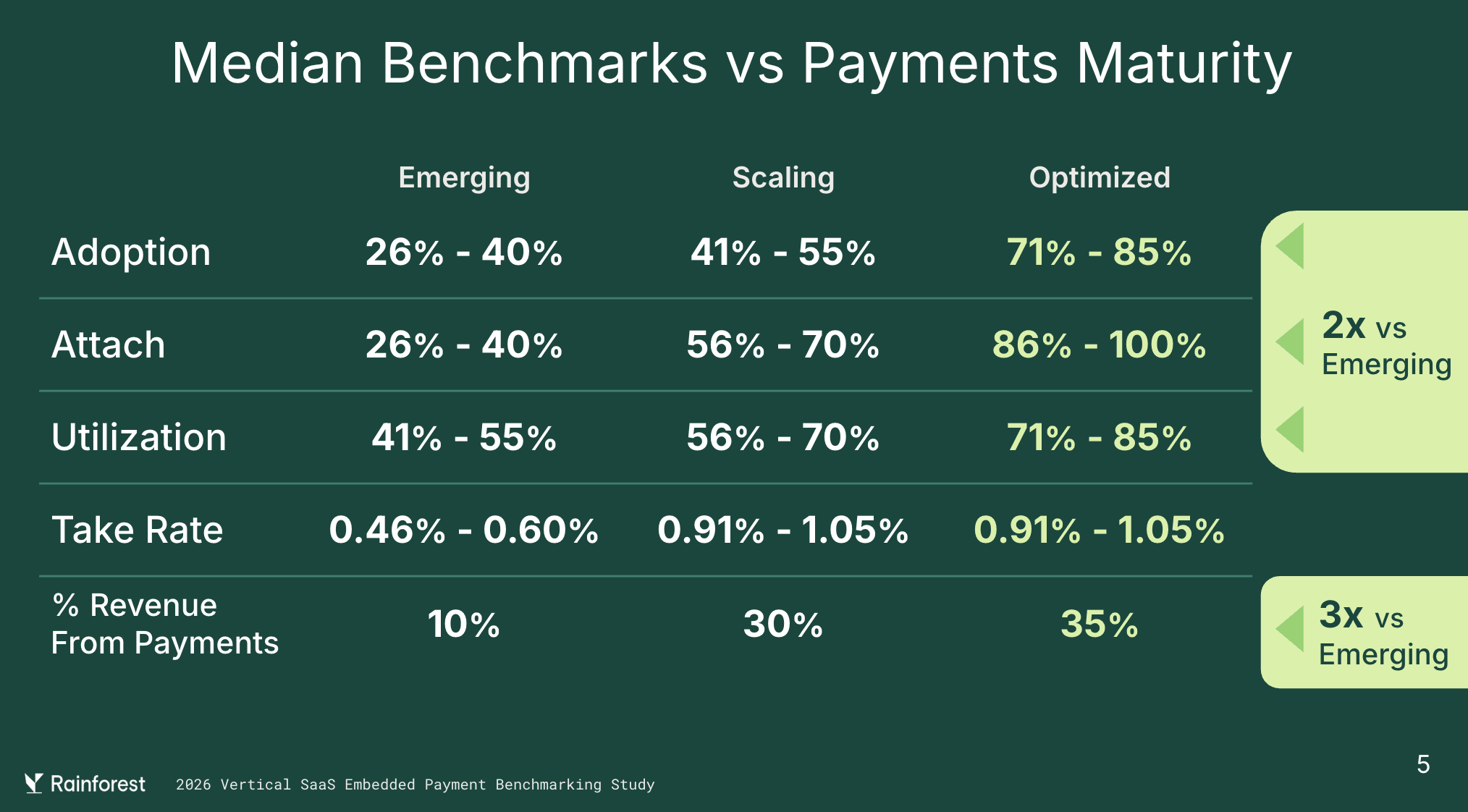
Then look at how much room is left even at maturity. Median share of revenue from payments peaks at 3-4 years after launch (35%) and dips slightly at 5+ years (30%). The tempting read is natural maturation. But split the 5+ year cohort into “Scaling” versus “Optimized” and the dip is concentrated in the Scaling group. The Optimized cohort keeps compounding past year five. The long-tail dropoff isn’t gravity. It’s the companies that quietly reallocated attention somewhere else.
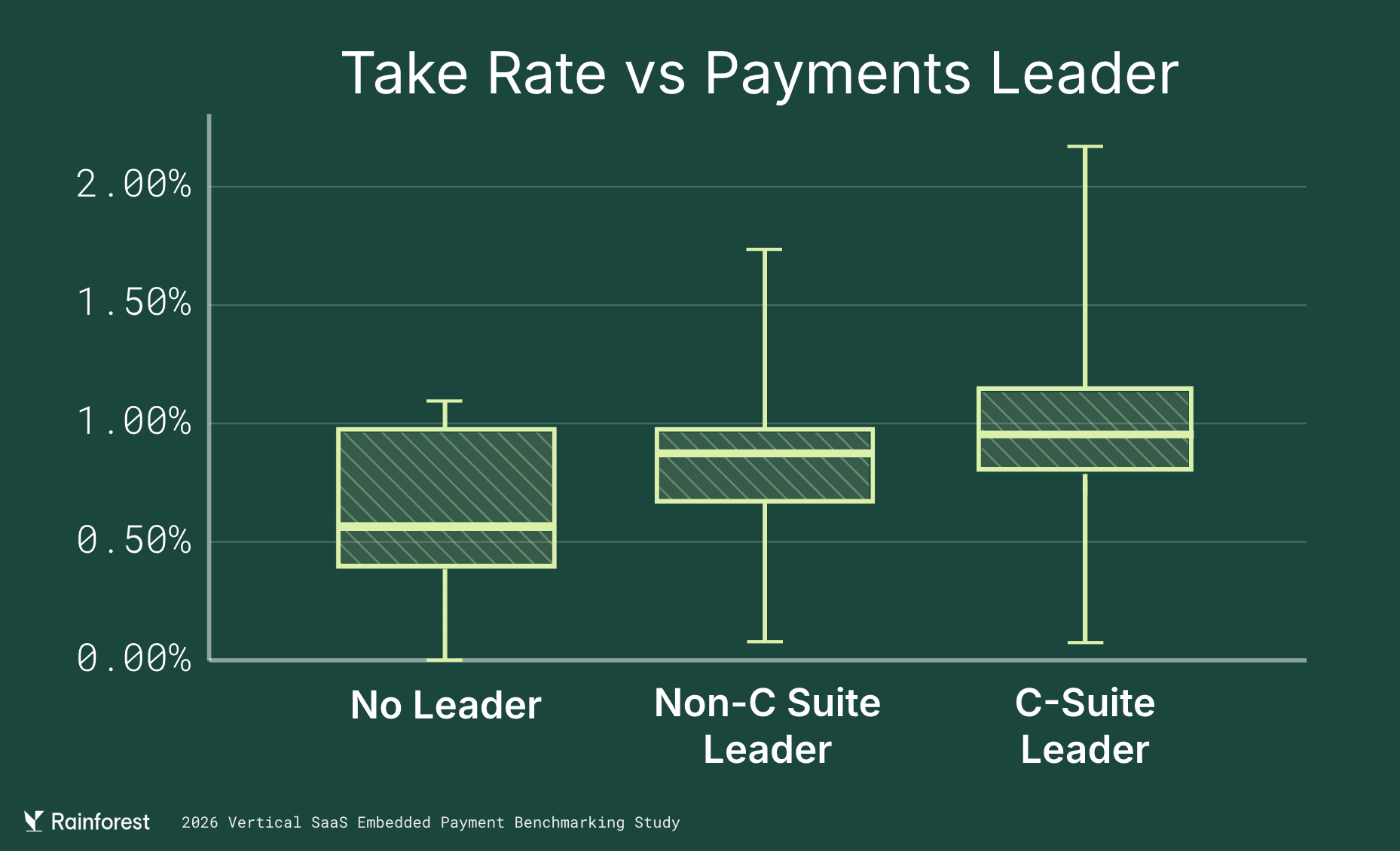
The leadership data tells the same story. Companies with a C-suite payments leader post almost 2x the take rates of those with a no-leader. Take rate, attach, and revenue share don’t drift upward on their own. They respond to scale, focus, and ownership. The platforms that keep treating payments as a serious product line will keep finding growth in it long after everyone else has moved on.
The AI discourse assumes the endpoint is full automation. The founders selling to contractors, clinics, and shop owners don’t agree. The teams winning here are designing for a spectrum. An AI voice answering service that routes to a human on the first hint of complexity. An agentic AP workflow that auto-posts low-risk vendor bills and kicks medium-risk ones to an accounting clerk. A scheduling tool that drafts the reply and makes the owner hit send.
What makes these products work isn’t how much they automate, but how cleanly they hand off when they shouldn’t. Customers choose their comfort level, and the trust compounds every time the product respects the choice. The calibration is doing the work, not the autonomy itself.
Every AI product is chasing context, and vertical software has been quietly building vertical-specific context graphs for years. The schema of a restaurant’s menu, modifiers, kitchen stations, and labor model. The workflow of a law firm’s matter, phases, timekeepers, and trust ledger. The relationships on a construction project between job, cost codes, change orders, and retainage.
That structured data is the substrate AI needs to be useful, and vertical software already owns it. AI makes software itself cheaper to build, which pushes the moats toward the hard things AI can’t touch. Proprietary context. Regulatory relationships. Hardware integration. The messy physical world these companies live in.
A couple of years ago, the embedded narrative was peak hype. Platforms were integrating embedded providers left and right on the assumption that anything embedded would compound. That first wave underdelivered: integrations underperformed, embedded products were thinner than they looked, and many ended in awkward unwinds.
Platforms got pickier. The bar is higher, vetting is tighter, and second-tier partners are getting displaced. The embedded providers themselves have used those years to grow up. The new generation is more honest about what it does and doesn’t solve, and more valuable to platform customers. Established categories are maturing (e.g., accounting with Tight and Layer, lending with Kanmon, payroll with Check and Salsa), and emerging categories are getting serious heat (e.g., embedded marketing with Reach, embedded voice with Dialstack).
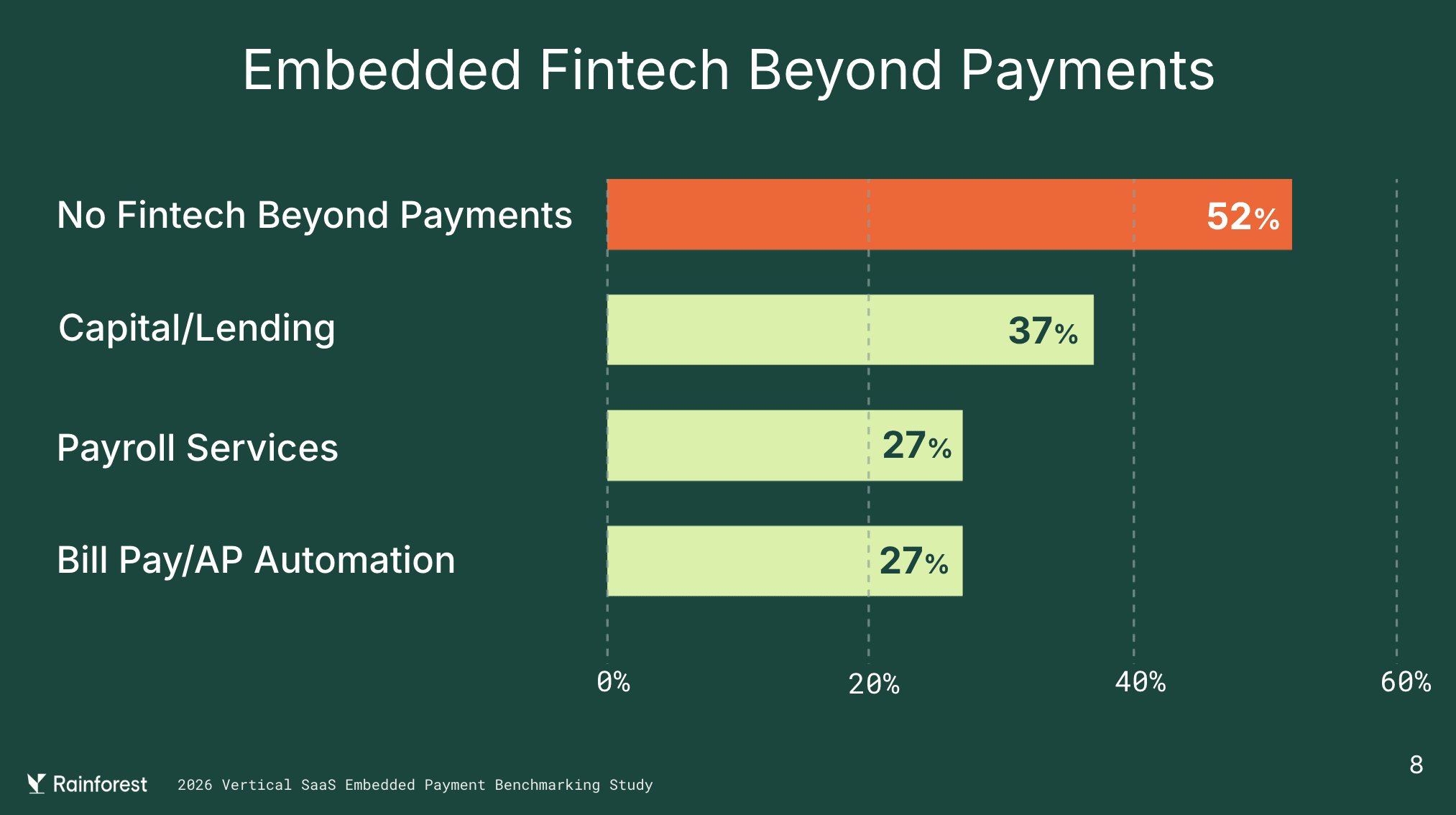
And the surface area is still largely unbuilt. 52% of vertical software companies in the study have no embedded fintech beyond payments at all. The ones that do cluster in capital/lending, payroll, and bill pay. Plenty of runway, just not for anyone showing up with a checklist.
Vertical software has developed its own gravity. The businesses differ wildly on the surface. Restaurants don’t look much like law firms, and neither looks much like a wellness studio or a construction GC. But the playbook is shared, and shared freely. At most conferences, every conversation is competitive. At Vertex, most conversations were comparative. The category is still early enough that the pie is growing faster than the fight for it.
My name is Matt Brown. I’m a partner at Matrix, where I invest in and help early-stage fintech and vertical software startups. Matrix is an early-stage VC that leads pre-seed to Series As from an $800M fund across AI, developer tools and infra, fintech, B2B software, healthcare, and more. If you’re building something interesting in fintech or vertical software, I’d love to chat: [email protected]

2026-04-10 00:35:51
For decades, this was the operating assumption. Humans were the cheapest general-purpose computers available. Hire them, give them tools, let them process information and make decisions.
In the 1970s, an Air Force Colonel named John Boyd formalized what that 150-pound computer does. He called it the OODA loop: Observe, Orient, Decide, Act. A decision cycle built for fighter pilots. Cycle faster than your opponent and you win. It proved far more universal than Boyd intended.1
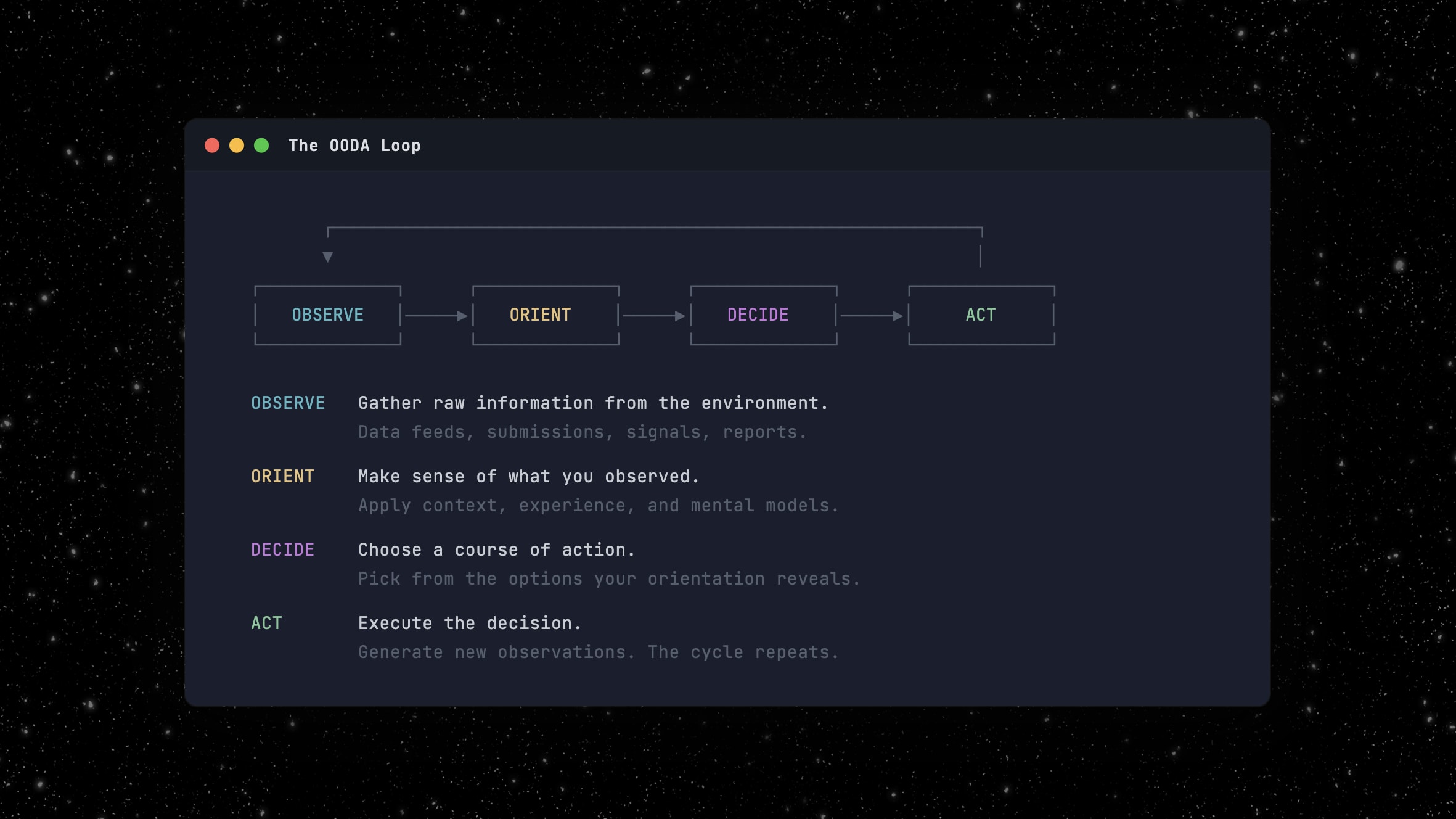
Every time you hire someone and hand them a set of tools and a set of problems, you’re paying a 150-pound computer to run an OODA loop.
The OODA loop is everywhere. But let’s take insurance underwriting as an example. Submissions land on an underwriter’s desk. She reads the submission, matches it against her carrier’s appetite, decides whether to bind or decline, and issues the quote. Observe, Orient, Decide, Act. Dozens of times a week.
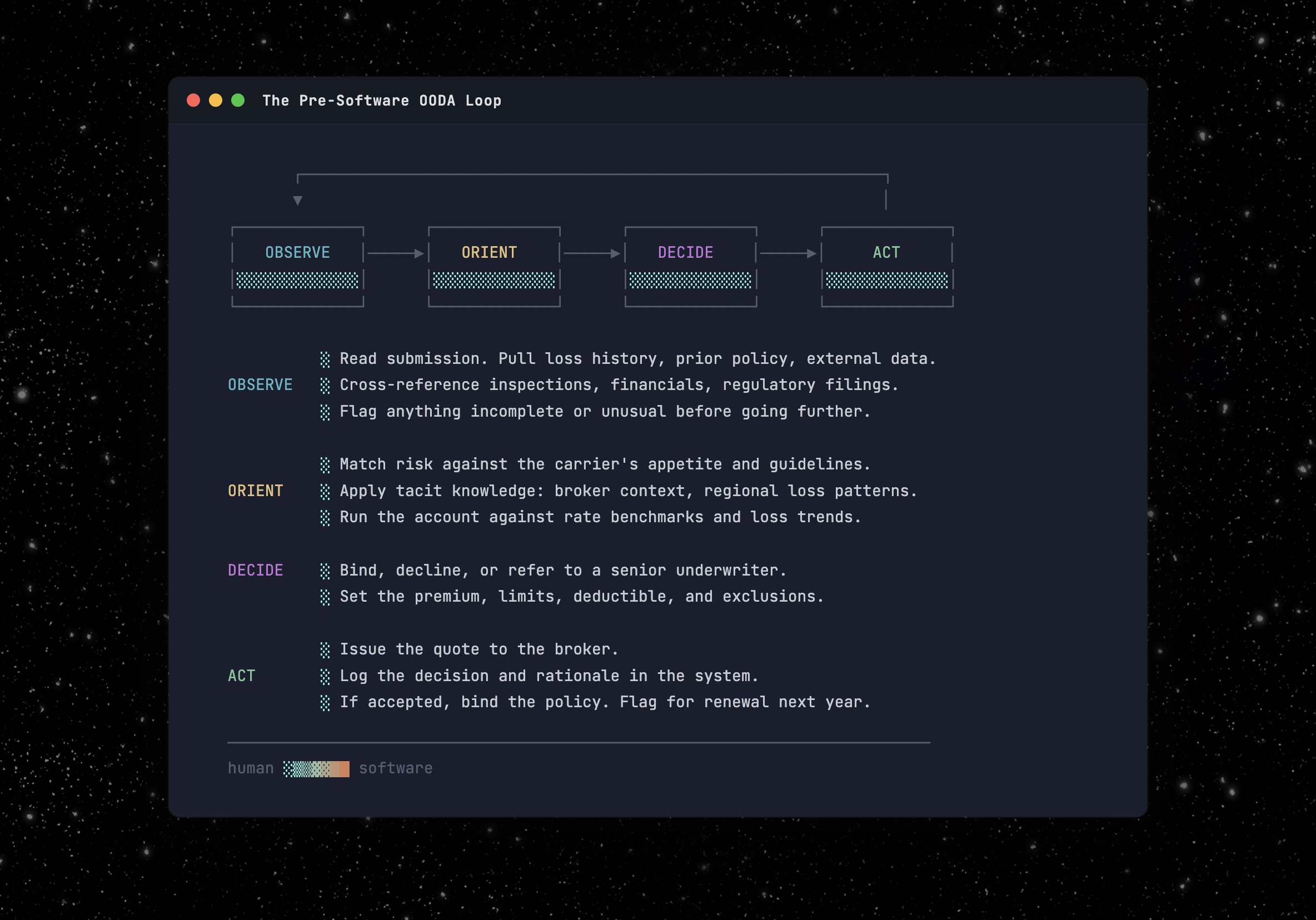
Software made parts of that loop faster, particularly Observe and Act. Data warehouses and submission intake tools on the Observe side. Policy admin systems and workflow automation on the Act side. Rating engines and risk scores nibbled at Orient and Decide, but the core of both (judgment, context, the actual call) stayed human. You can only cycle as fast as the slowest step allows.
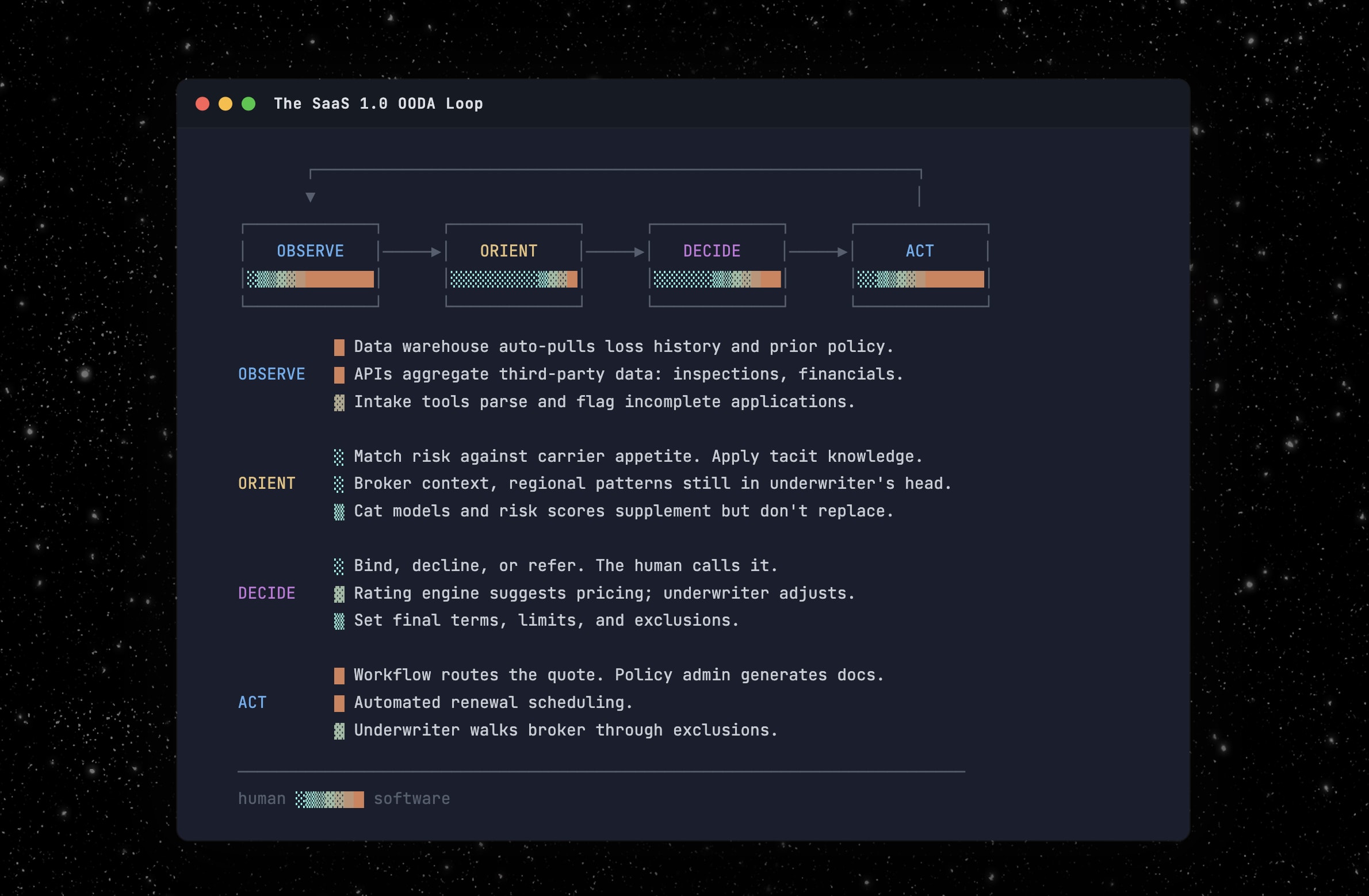
Now AI enters the middle of the loop. The prevailing assumption is that it completes the job software started: automate the whole cycle, remove the human entirely.
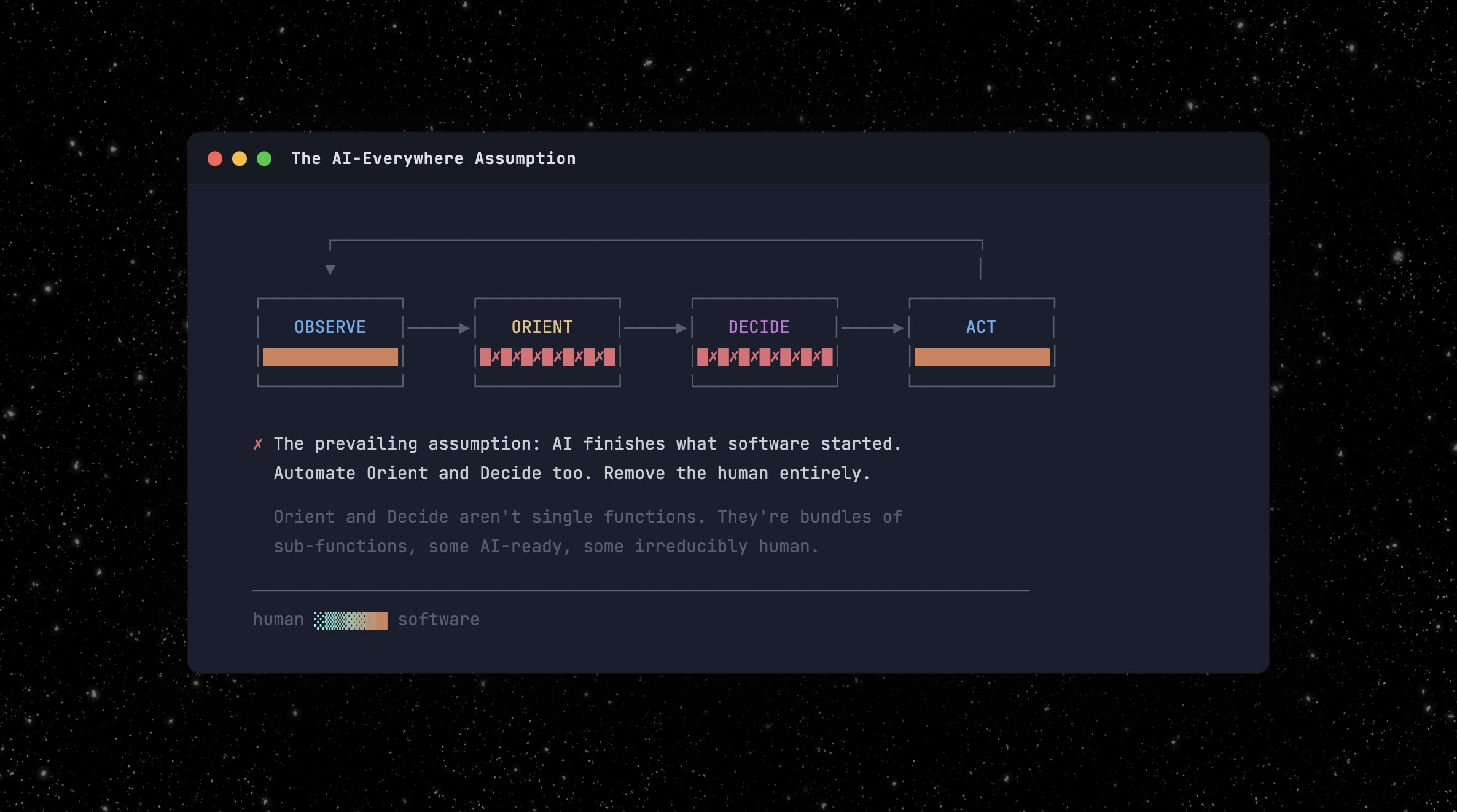
For some roles, that’s right. But for most of the interesting ones, it’s a fundamental misunderstanding of what the human was actually doing in Orient and Decide.
The underwriter wasn’t performing one function. Orient and Decide are each bundles of distinct sub-functions, packaged into a single role because they came free with every hire. We never had to decompose the bundle because there was no reason to. Now there is.
AI absorbs some of these functions today, will absorb others as it matures, and will probably never absorb the rest. Automate the wrong ones and you’ve built a system nobody trusts. Leave the wrong ones to humans and you’re paying for work a model should handle. Here are some of the critical parts of those bundles:
The pattern matcher. Recognizing what kind of thing you’re looking at by matching against known categories. Enough examples exist that AI classifies faster and more consistently than any human. In underwriting, this can mean reading a submission and recognizing it as a standard mid-market GL risk the carrier has seen ten thousand times. Once matched, guidelines prescribe the response. This is the first function AI absorbs end to end.
The context adapter. Every organization accumulates unwritten rules and institutional knowledge that never make it into any system. This function translates that tacit knowledge into judgment on a specific case. In underwriting: knowing that a contractor class is fine in Texas but toxic in Florida, or that this agency’s “preferred” submissions mean the agent’s brother-in-law. LLMs with access to historical data already do this better than any individual. They don’t forget, and they don’t walk out the door with ten years of institutional knowledge.
The loop connector. Bridging decision loops the org chart never connected, i.e., someone in one process notices a signal that matters to a different process. The underwriter who flags a claims trend to the actuarial team. The valuable part isn’t the communication, but noticing it was relevant to someone else’s problem. AI today runs one loop well. Connecting loops means recognizing what matters outside your own process. This is still largely unsolved and enormously valuable.
The circuit breaker. Human slowness was a feature. The underwriter who sleeps on a borderline case isn’t necessarily being slow, but running a second, slower loop. AI doesn’t have that instinct. The hard problem isn’t implementing confidence thresholds. It’s knowing which decisions need the overnight hold and which don’t. Fraud detection should run at machine speed, while underwriting authority on a novel risk class probably shouldn’t. Choosing the right clock speed is itself a judgment call about the nature of the decision.
The exception decider. The case that doesn’t fit the guidelines: not deciding within the rules but whether to change them. In underwriting: two carriers with identical models and data diverge entirely based on how they handle exceptions, because that’s where underwriting philosophy lives. AI optimizes for the objective you give it. It doesn’t question the objective.
The decision owner. Someone’s name is on the file, not just for blame, but for iteration: the person who feels feedback from outcomes and adjusts. Regulators require a human in the chain, reinsurers demand it, etc. This isn’t a cognitive limitation. It’s a structural requirement that changes at the speed of law, not tech.
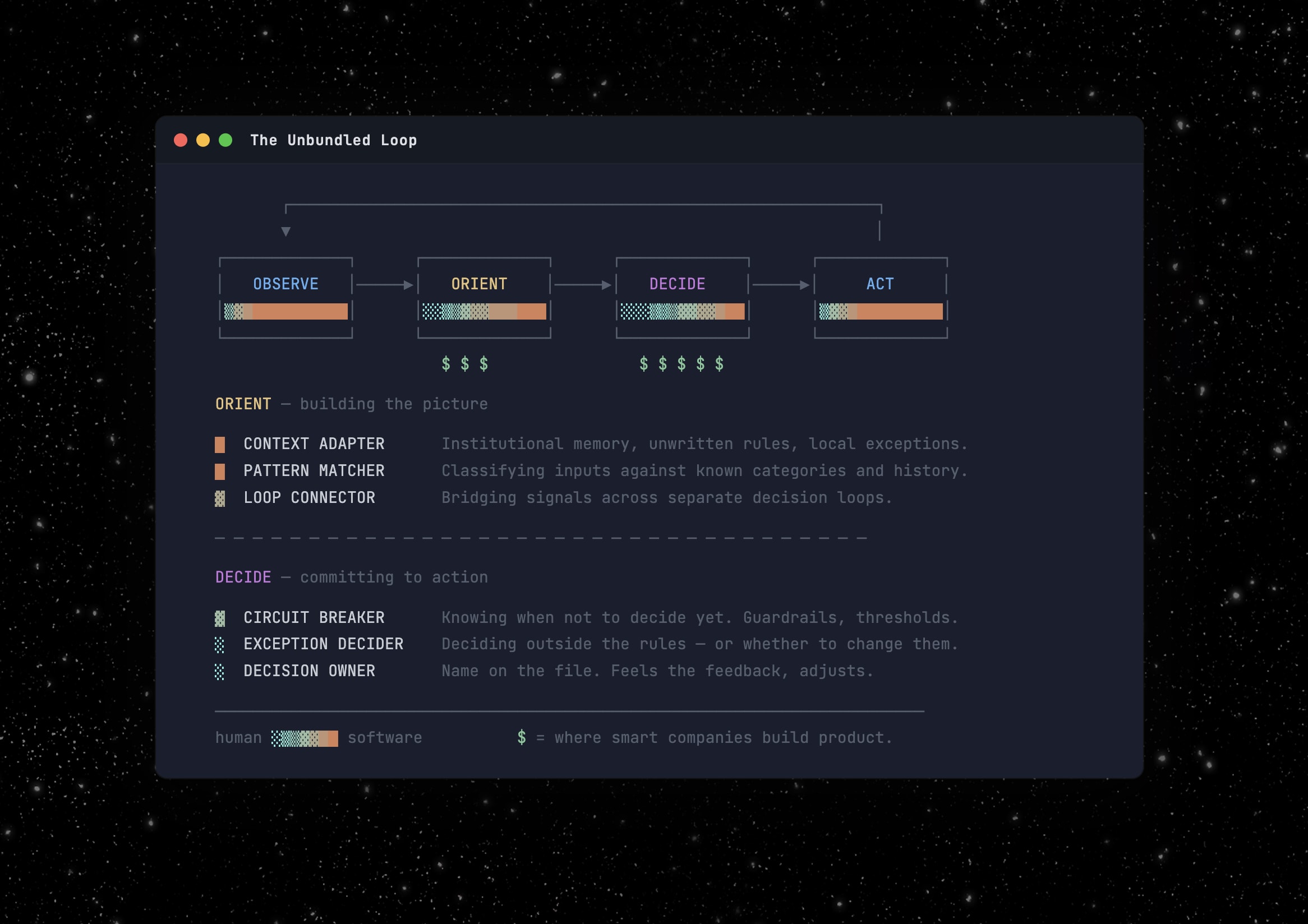
These aren’t the only functions in the bundle, but they illustrate the gradient. AI is already better at the first two. It will likely absorb the third and fourth as agentic systems mature. The last two are probably irreducible. Not because AI can’t get smart enough, but because exception-deciding is an act of authority, and decision-ownership is a social and legal prerequisite for the transaction to exist.
The same decomposition applies wherever humans orient and decide at scale. In contract law, AI agents already draft standard redlines and learn each client’s preferences, but “commercially reasonable” and “reasonable” look identical to a model and mean entirely different things in court. The lawyer decides whether to push back, and the lawyer’s name is on the opinion.
In procurement, an autopilot benchmarks supplier pricing and handles standard reorders. But staying with a vendor at 20% above market because they alone can deliver by your launch date? That’s exception-deciding. And when that vendor misses a delivery, the relationship that resolves it is human. The labels change but the decomposition doesn’t.
If your product’s primary value is executing routine decisions, you’re competing with every AI wrapper that can ingest inputs and produce outputs. The moat moves in two directions.
Down to the data layer: the system that has seen ten years of submissions, outcomes, and exception decisions has a better-oriented model than any new entrant. That advantage compounds with every cycle.
Up to the exception-handling layer: the product that makes the exception decider and the decision owner more effective (better context, tighter feedback loops, smarter routing) owns the part of the workflow that can’t be commoditized.
AI surfaces a genuinely novel case. A human makes a judgment call. That judgment gets fed back into the system so next time it’s routine, not exceptional. The exception pool shrinks, the system compounds, and a competitor starting fresh has to build that history one judgment call at a time.
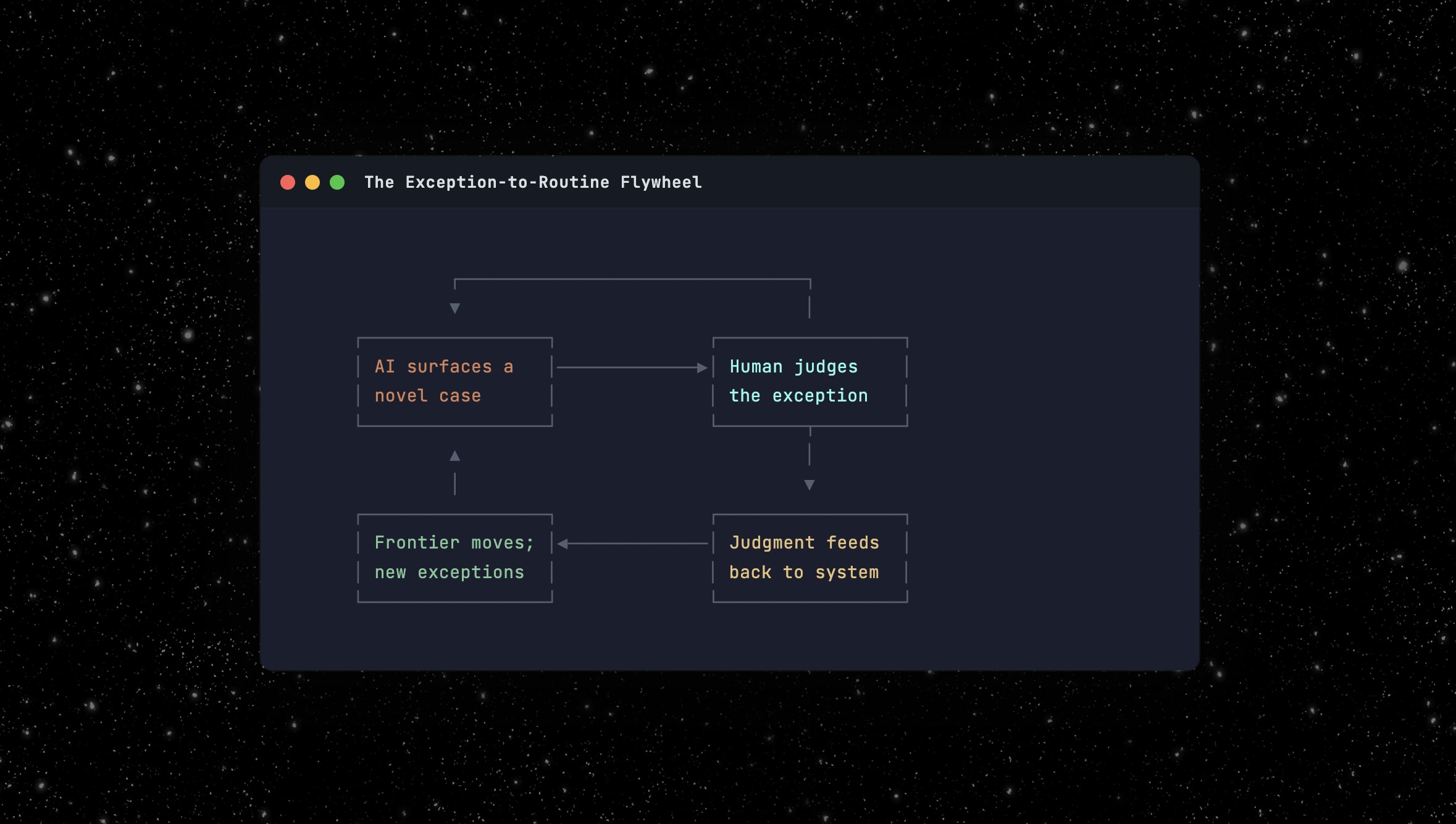
But the exception pool doesn’t shrink to zero. The frontier moves. Automate today’s exceptions and you can take on risk classes you couldn’t touch before. That generates new exceptions at a higher level of complexity. The human doesn’t become unnecessary. The human operates on increasingly valuable problems.
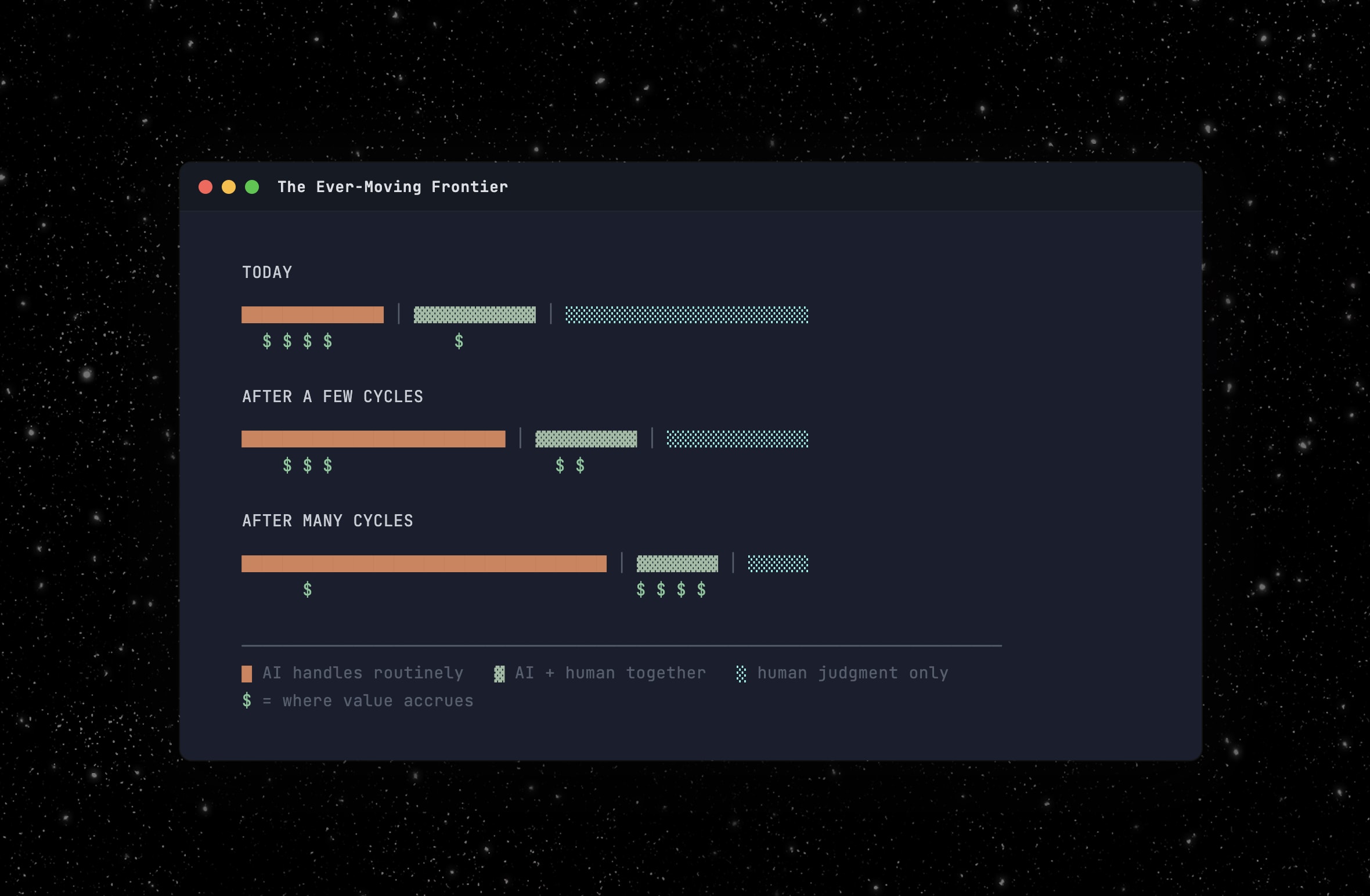
In practice this means surfacing exceptions with full context, not just “this case is unusual” but why it’s unusual, what similar cases looked like, and what happened when someone decided differently. Tightening the decision owner’s feedback loop means connecting outcomes back to the specific decisions that produced them, in real time, not in a quarterly report. The trick is engineering productive friction: confidence scores, mandatory holds on high-stakes decisions, escalation paths that route the right cases to the right humans.
Products that dump 500 AI-flagged items on a human are treating the human as a pattern matcher, a function AI should handle. Products that surface five genuine exceptions with full context are routing work to the exception decider and the decision owner, the functions where humans are irreplaceable. That’s the design problem worth solving and where the real value will accrue.
The 150-pound computer isn’t being replaced. It’s being unbundled. Every company that employs humans to orient and decide is now answering the same question, whether it knows it or not: which functions in the bundle are you absorbing, which are you augmenting, and which are you designing around as permanently human?
Get that decomposition wrong and you’ve built a fast system nobody trusts, or an expensive human doing work a model should handle. Get it right and you’ve found something better than automation: a system that converts today’s exceptions into tomorrow’s routine, freeing the 150-pound computer to work on problems it couldn’t reach before.
My name is Matt Brown. I’m a partner at Matrix, where I invest in and help early-stage fintech and vertical software startups. Matrix is an early-stage VC that leads pre-seed to Series As from an $800M fund across AI, developer tools and infra, fintech, B2B software, healthcare, and more. If you’re building something interesting in fintech or vertical software, I’d love to chat: [email protected]
The OODA loop directly inspired many of the frameworks that startups have used for years, from Steve Blank’s Customer Development methodology to Eric Ries’s Lean Startup concept.
2026-03-12 00:35:21
“Fintech” has long traded on the ambiguity in its name.
The “fin” implied lots of emails from .gov domains, months-long audits, compliance officers who know your SAR filing history better than your product roadtmap, and mid-week flights to Charlotte or DC. The “tech” is a slick mobile app, a 10x user experience, and investor coffees at Blue Bottle.
“Fin” and “tech” were always a spectrum, but the market generally rewarded fintechs for being as much “tech” as possible and as little “fin” as they could get away with.
And that’s understandable. In 2021, software had a gross profit pool of roughly $0.7 trillion, valued at a steep premium. Financial services had a gross profit pool an order of magnitude larger, valued far more conservatively.1 Fintech let you arbitrage both: financial services economics with a software multiple.
That gap in profit pools also tells you where the real money is. Financial services generates more gross profit than any other sector globally. The “fin” side of fintech isn’t just more defensible. It’s a far larger market.
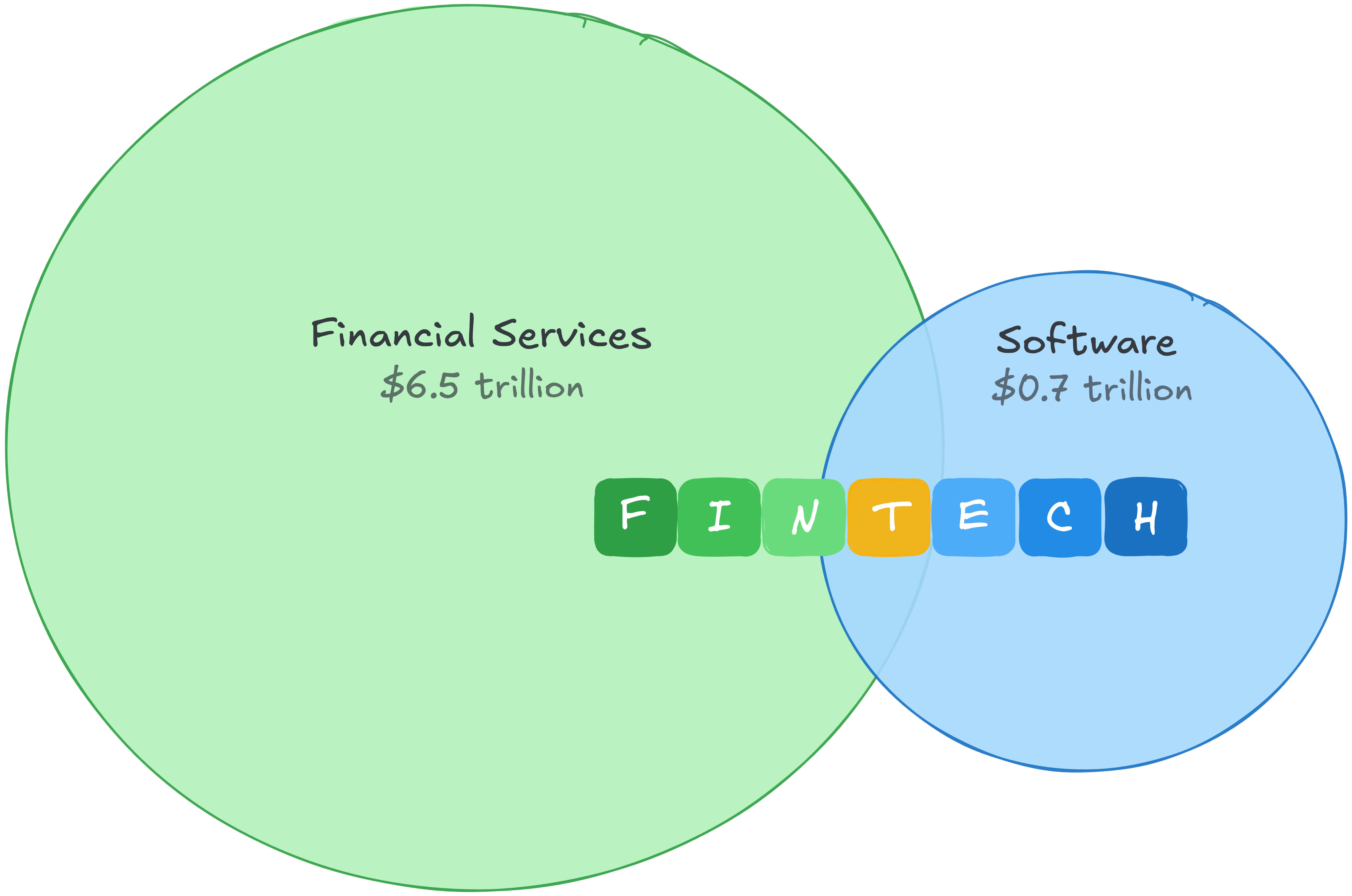
Then AI arrived and the arbitrage broke. Software valuations compressed as investors re-priced what code was worth in a world where code is getting cheaper. Fintechs got caught in the downdraft because the market had categorized them as software companies.
But the market has the category wrong. Fintech’s costs, and its moats, were never in the code, and look increasingly antifragile to AI disruption.
Software had one of the best business models in history: code was expensive to produce, but once written, it could be distributed for almost nothing. The gap between “expensive to build” and “free to distribute” was the margin. If you’re a SaaS company spending 22-25% of revenue on R&D, that spend is also your barrier to entry. Competitors couldn’t easily replicate what took years and tens of millions to build.
AI closes that gap from the top. If code is cheap to build and cheap to distribute, the margin compresses. The wall that kept competitors out gets shorter, more players get in, and pricing power erodes.
That’s a real problem if your business is software. But fintech’s expenses aren’t engineering expenses. Follow the money and the distinction gets obvious fast.
PayPal spends 9% of revenue on R&D. Block spends 12%. That’s not because fintech engineering doesn’t matter. Stripe’s engineering is world-class and a real competitive advantage. It’s that engineering isn’t where the majority of the money goes.
It goes to the fin. And unlike R&D spend, these costs don’t just produce a product, they produce moats:
Affirm spends 35% of revenue on credit losses and cost of capital, before a single engineer is paid. Every dollar lost to defaults is a dollar of repayment data a competitor doesn’t have. A new entrant training on synthetic data has no ground truth. You can’t build reliable loss history on synthetic data alone.
Wise dedicates a third of its workforce to compliance and financial crime prevention across 65+ regulatory licences. Money transmission licenses across 50 states. BSA/AML programs. Bank charter requirements. These aren’t advantages you build. They’re permissions you earn, continuously. You can’t vibe-code a banking license.
Toast’s payments segment runs at 22% gross margins versus 70% for its SaaS segment, yet generates nearly twice the gross profit. Those costs buy merchant-level transaction data that feeds Toast Capital, which has originated over $1 billion in loans. Adyen’s risk models are trained on transaction patterns across 30+ markets.
A payments company runs at 20-50% gross margins, not 80%. But lower margins aren’t the same as weaker businesses. Fintech margins are lower because many of those costs generate compounding advantages. And even the ones that don’t still exist outside the blast radius of AI-driven cost compression.
And AI makes every one of these moats stronger. Better models tighten loss rates. Better fraud detection reduces chargebacks. Better compliance tooling lets smaller teams hold more licenses. AI doesn’t replace the moat. It rewards the companies that chose to build in the hard parts of fintech: money movement, risk, proprietary data, and regulation.
So the real argument is not just “AI helps fintech.” It’s that AI shifts value away from product surface area and toward proprietary data, risk-bearing capacity, regulatory permission, and distribution embedded in real money movement. If you’re building in those areas, AI is compounding in your favor. If your differentiation is in the code, it’s compounding against you.
And the demand side keeps growing. Every vibe-coded checkout is a new fraud vector. Every AI agent transacting autonomously is a chargeback risk. The more that gets built on top of fintech’s rails, the more essential the rails become.
This realization is already forcing smart fintech founders to re-think where they sit along the “fin” and “tech” spectrum:
Do we underwrite and price risk ourselves, or pass it to a partner who keeps the margin?
Do we own the regulatory relationship, or rent it from someone who does?
Does every transaction make our risk models sharper, or are we training someone else’s?
Is our ledger the source of truth, or an imperfect mirror of someone else’s?
This distinction cuts the fintech landscape in two. The companies that own the regulatory relationship, eat the credit losses, and accumulate the transaction data are building moats that AI deepens. The ones that rent the fin, wrapping a partner bank’s license, a BaaS provider’s ledger, someone else’s risk models in a better UI, have exactly the same problem as SaaS companies. Their differentiation is in the code, and the code just got cheaper.
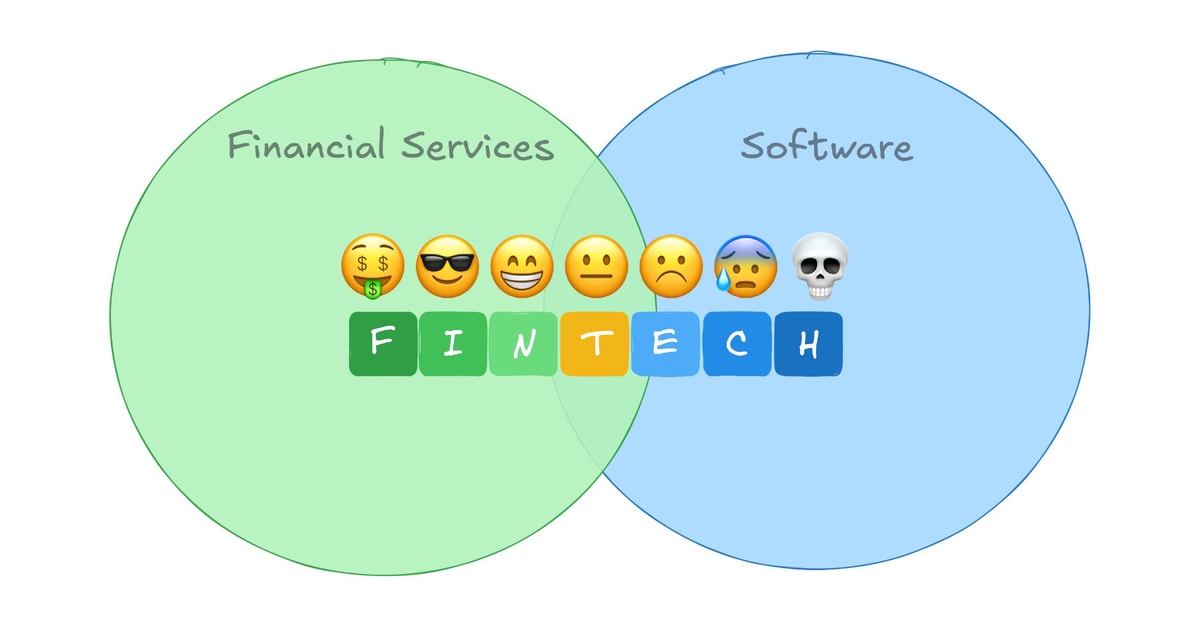
The old arbitrage of financial services economics with a software multiple is dead. The new one is simpler: own the fin.
My name is Matt Brown. I’m a partner at Matrix, where I invest in and help early-stage fintech and vertical software startups. Matrix is an early-stage VC that leads pre-seed to Series As from an $800M fund across AI, developer tools and infra, fintech, B2B software, healthcare, and more. If you’re building something interesting in fintech or vertical software, I’d love to chat: [email protected]

Gross profit pool estimates from Coatue’s 2022 fintech report. “Gross profit” is structurally cleaner in software than in financial services, where P&L structures vary across sub-sectors, so treat the comparison as directionally accurate rather than precise.
2026-01-23 04:46:55
Context graphs have become the new battleground in enterprise software. @JayaGup10 and @ashugarg argued that the next trillion-dollar platform opportunity isn’t in systems of record. It’s in capturing the decision traces that systems of record miss. That’s true, but it’s missing the key point that vertical software companies have been building these context graphs for over a decade.
A context graph is a queryable record of business logic: the reasoning, precedents, and decision traces that explain why things happened, not just what happened. Every company has one in theory. It’s the accumulated knowledge of how the business operates: the exceptions that get approved, the precedents that govern decisions, the tribal knowledge in people’s heads.
Agents need this to move from automation to autonomy. An agent can run a workflow, but it can’t handle exceptions or apply precedent without access to the reasoning behind past decisions. The context graph separates an agent that follows rules from one that exercises judgment.
In most companies and products, the context graph exists in theory but not in practice. It’s scattered, implicit, and inaccessible because:
No one logs the reasoning behind decisions. The VP approved the exception on a Zoom call but never recorded why.
Systems capture outcomes, not context. The CRM shows the final discount, not the service outages or churn threat behind it.
What context exists is siloed. It’s scattered across tools that don’t share a worldview.
These aren’t product bugs. They’re structural features of horizontal SaaS. Generic platforms use flexible abstractions that can model any business, which means they model no business precisely. Humans must bridge the gap between “what the system captures” and “how decisions get made.” But humans don’t leave audit trails.
The trillion-dollar question: who fixes this? The prevailing thesis is that agent startups have a structural advantage. They sit in the execution path at decision time, so they can capture context that systems of record never see. The assumption is that the context graph needs to be built from scratch. But that’s not entirely true.
The debate has a blind spot: it focuses entirely on horizontal enterprise software.
Think about the workflows and software stack of a typical company. It’s a patchwork of horizontal tools, each built for a broad use case, and none designed to really work together. Sure they have APIs and integrations, but even the best integrations drop tons of context as data and actions move through them. The context graph fragments because the tools don’t share a worldview.
But vertical software is different. The difference starts with something I’ve written about before: the data model.
Horizontal platforms like Salesforce use generic abstractions (”accounts,” “contacts,” “opportunities”) that can model almost any business. That flexibility helps breadth but hurts depth. The ontology doesn’t map to how any particular industry works. It’s a blank canvas customers must configure into meaning.
Vertical software starts from the opposite premise. The data model isn’t flexible. It’s opinionated, purpose-built, and mapped to that industry’s reality.
Look at Toast’s data model. You’ll see objects like Order, MenuItem, Customer, PrepStation, etc. These aren’t generic transactions dressed up with custom fields. They’re first-class entities with built-in relationships: orders connect to customers, menu items, locations, and payments as native concepts. The ontology is the domain.
Compare that to Salesforce’s data model: Account, Opportunity, Lead, Contact, etc. Powerful abstractions, but they describe a law firm, restaurant, or rocket manufacturer equally well. They describe none of them well. Configuration, integrations, and human memory must bridge the gap.
In vertical software:
The reasoning gets recorded because the system is built around actual business decisions. When a construction platform tracks change orders, it captures why the change happened (weather delay, subcontractor default, scope change) as structured data, not notes in a generic “activity” field.
The context isn’t siloed because vertical platforms consolidate functions into one system. The construction platform isn’t just project management; it’s also scheduling, procurement, billing, and field operations. One system, one data model, one view of reality.
The full decision trace is reconstructible because the ontology supports it. When everything from estimate to invoice lives in a system built around menu items or job sites or patient treatments, you can trace how a price changed, why a timeline slipped, or what drove a discount.
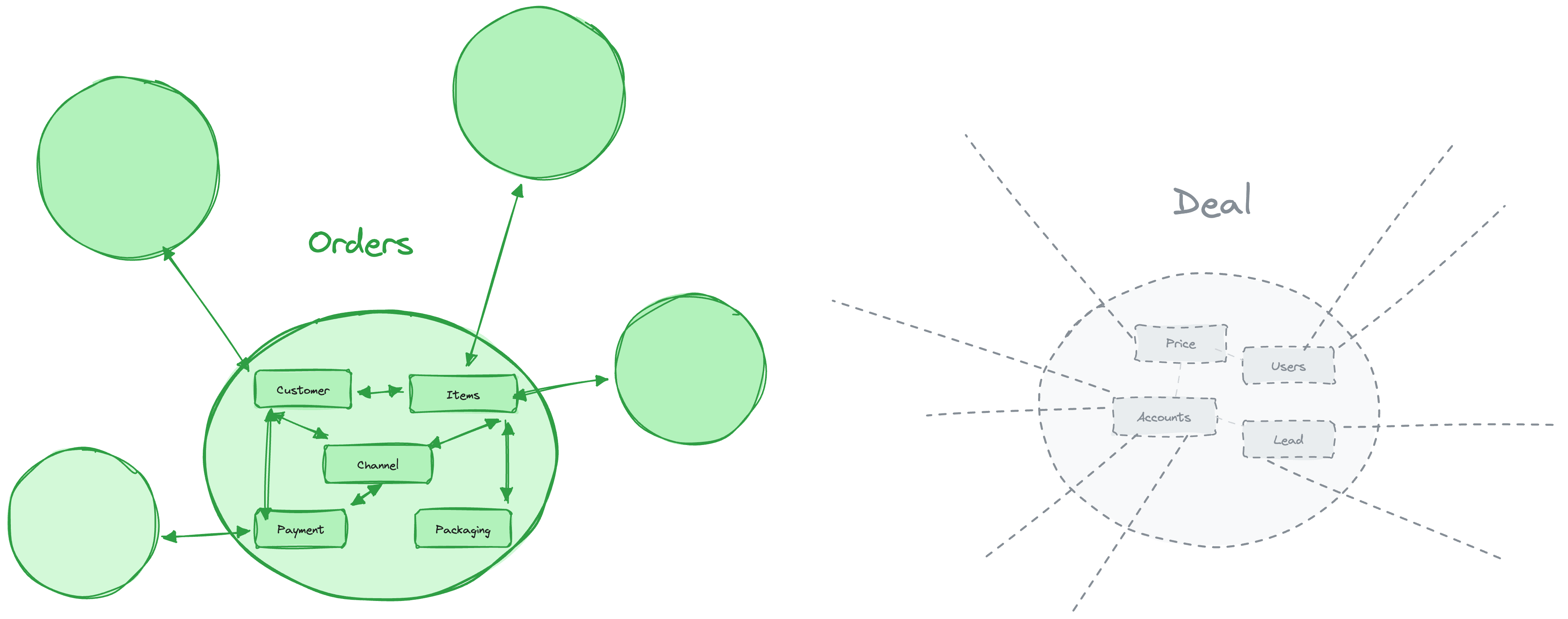
There’s a deeper point about how context graphs work. The original context graph thesis assumes decision traces need explicit capture: an agent logs “I did X because of Y” at the moment of decision. But there’s another way the “why” becomes accessible: through inferential density. When the graph is sufficiently rich, the reasoning can be reconstructed from relationships between nodes.
Consider an order in Toast. Alone, it’s just a transaction with attributes. Connect it to inventory and you know which items are selling faster than expected and what needs restocking. Connect it to customer data and you know who your most valuable customers are, what they order, and when. Connect it to payments and you know revenue by payment method and which orders are outstanding.
Now when you see a spike in refunds, you don’t need someone to log what went wrong. You can see that the spike correlates with a specific menu item, the inventory system shows that ingredient was substituted due to a stockout, and the affected customers skew toward your highest-value segment. The reasoning is embedded in the relationships.
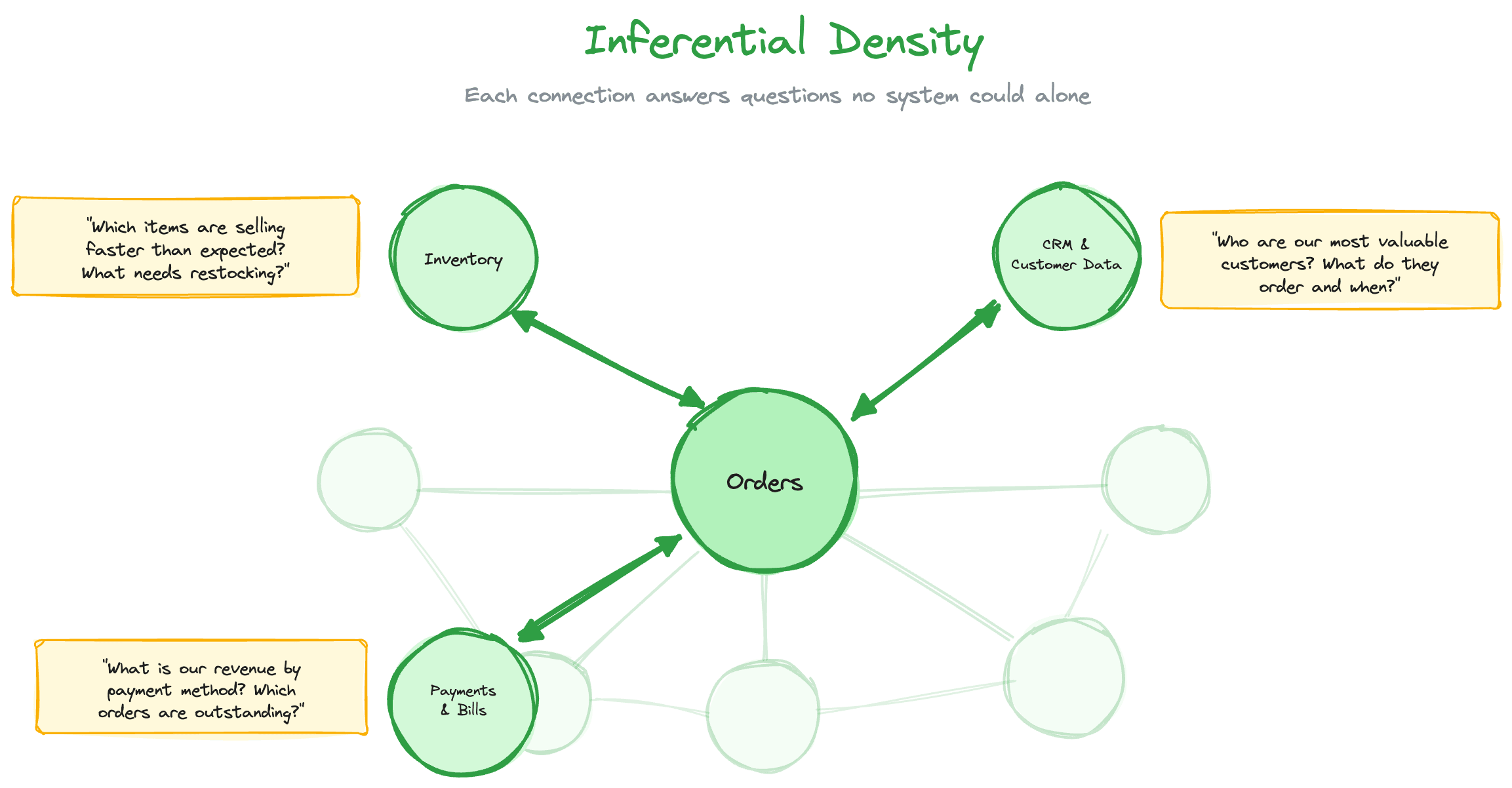
Each new function adds inferential power to everything already in the graph. Inventory data makes orders more meaningful. Customer data makes inventory decisions more meaningful. Payment data makes customer relationships more meaningful. The context graph doesn’t just get wider; it gets denser. Density makes the “why” reconstructible without explicit capture.
This is the structural advantage vertical platforms carry into the age of agents.
Vertical software companies didn’t build these context graphs by accident. They were forced to go deep because they couldn’t go broad. A construction platform or dental practice system faces a ceiling: there are only so many construction companies, only so many dental practices. If you can’t grow by adding customers across industries, you grow by capturing more value from each customer within your industry.
Embedded payments was the proof point. When a vertical platform embeds payments, such as with Rainforest, it isn’t just adding a monetization layer. It’s extending the context graph into new categories. The platform knows not just what transactions happened, but the full economic reality: payment velocity, cash flow patterns, default rates. Every transaction adds to the accumulated knowledge.
The same logic now drives the next wave. Vertical platforms have spent a decade consolidating the operational core. But activity at the edges (customer acquisition, purchasing, workforce management) still happens outside the platform. Marketing in Mailchimp. Procurement in email threads. Accounting in QuickBooks. Each represents a gap in the graph.
The foundation exists. Vertical platforms have domain-specific ontologies, core operational modules, and deep customer relationships. They understand what a job site is, what a patient treatment plan looks like, what a menu item costs. This is the precise business logic edge functions need to plug into.
The financial layer is in place. Embedded payments gave vertical platforms visibility into the money moving through their customers’ businesses. That financial context is essential for procurement and accounting, which live at the intersection of operations and money.
AI changes the economics. Marketing, procurement, and bookkeeping require labor. They’re judgment-intensive and context-dependent. AI can now handle workflows that previously required humans. The vertical platform, with its deep context graph, is the ideal substrate.
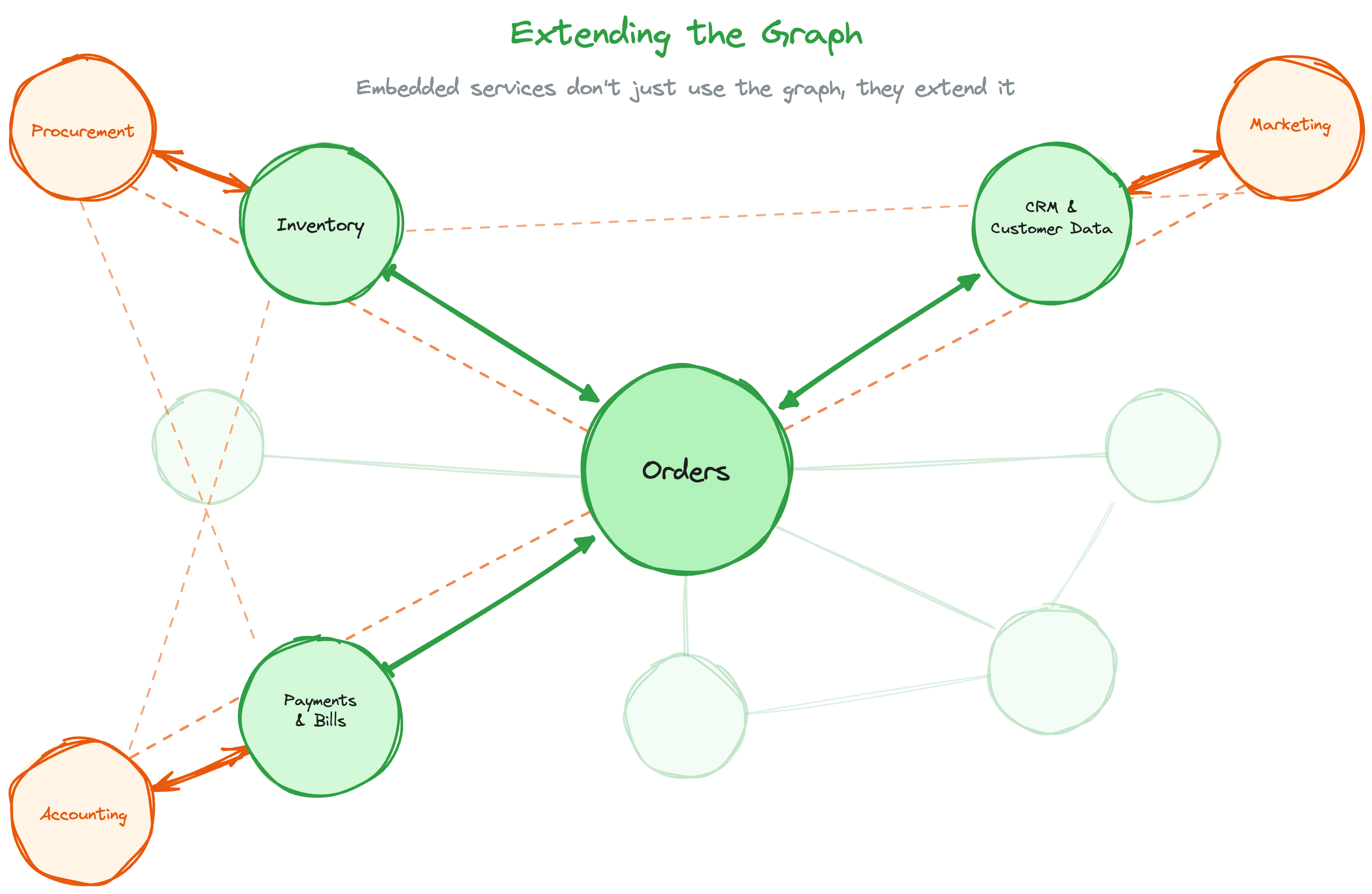
A few categories we’re tracking here:
Marketing pulls customer acquisition into the graph. Reach routes customer communications and other marketing data through the vertical platform itself, connecting acquisition cost to the customers it produced.
Accounting pulls financial categorization into the graph. With Layer or Tight, transactions get categorized within the platform rather than exported to QuickBooks, closing the loop between operations and the books.
Procurement pulls purchasing into the graph. Companies like Sticker and Faliam bring supplier relationships out of email threads and into the system of record, making spend visible alongside operations.
Each follows the same pattern: absorb an adjacent function, blend context with financial data, deploy AI, and deepen the graph.
Horizontal SaaS will lose ground. These companies have brand equity, data gravity, and deep workflow integration. But they’ll lose share to agent-first startups smart about bootstrapping context graphs, and to vertical incumbents picking off customers tired of stitching together horizontal solutions.
Agent-first startups face a cold start problem. The context graph thesis is right that agents can capture decision traces. But vertical software already owns the workflow for millions of businesses. An agent startup building for restaurants competes with Toast’s distribution, data, and decade of accumulated context. A hard gap to close.
Vertical software incumbents are undervalued. The market prices vertical software on revenue and growth. It doesn’t price the context graph. As horizontal SaaS struggles and agent startups face distribution challenges, vertical platforms with dense context graphs have a structural advantage the market undervalues.
Embedded service providers are an emerging category worth watching. Not every vertical platform will build the graph extensions in house. Embedded solutions will be more attractive. marketing, procurement, and accounting in-house. Their growth is complementary to vertical software’s expansion. As vertical platforms absorb more functions, the infrastructure providers that enable it become more valuable.
The trillion-dollar context graph opportunity is real. But it won’t be captured by whoever builds the best agent. It will be captured by whoever already has the deepest graph and knows how to extend it.
My name is Matt Brown. I’m a partner at Matrix, where I invest in and help early-stage fintech and vertical software startups. Matrix is an early-stage VC that leads pre-seed to Series As from an $800M fund across AI, developer tools and infra, fintech, B2B software, healthcare, and more. If you’re building something interesting in fintech or vertical software, I’d love to chat: [email protected]
2026-01-13 03:15:44
Risk, like energy, cannot be destroyed: only transferred or transformed.1 Call it the thermodynamics of financial services.
Every financial transaction involves risk: uncertain exposure that someone must bear. A loan might not be repaid. A payment might be fraudulent. A counterparty might fail. Someone is always holding this exposure.
Risk is balanced by cost. Interest rates on loans. Interchange fees on payments. Spread on foreign exchange. You take the risk, you get paid for it.
Risk is also balanced by friction. The three-day settlement window. The paper application. The in-branch visit. These delays make risk more manageable. Friction is another form of cost (implicit rather than explicit, paid in time and conversion rather than dollars).
Fintechs reduce both cost and friction. Lower fees. Faster approvals. Seamless onboarding. The pitch is simple: same product, better experience.
But reducing cost and friction doesn’t reduce risk. That’s the thermodynamics at work. The risk remains, conserved in the system. The friction you removed was managing something. Where does that exposure land?
Risk takes many forms, including:
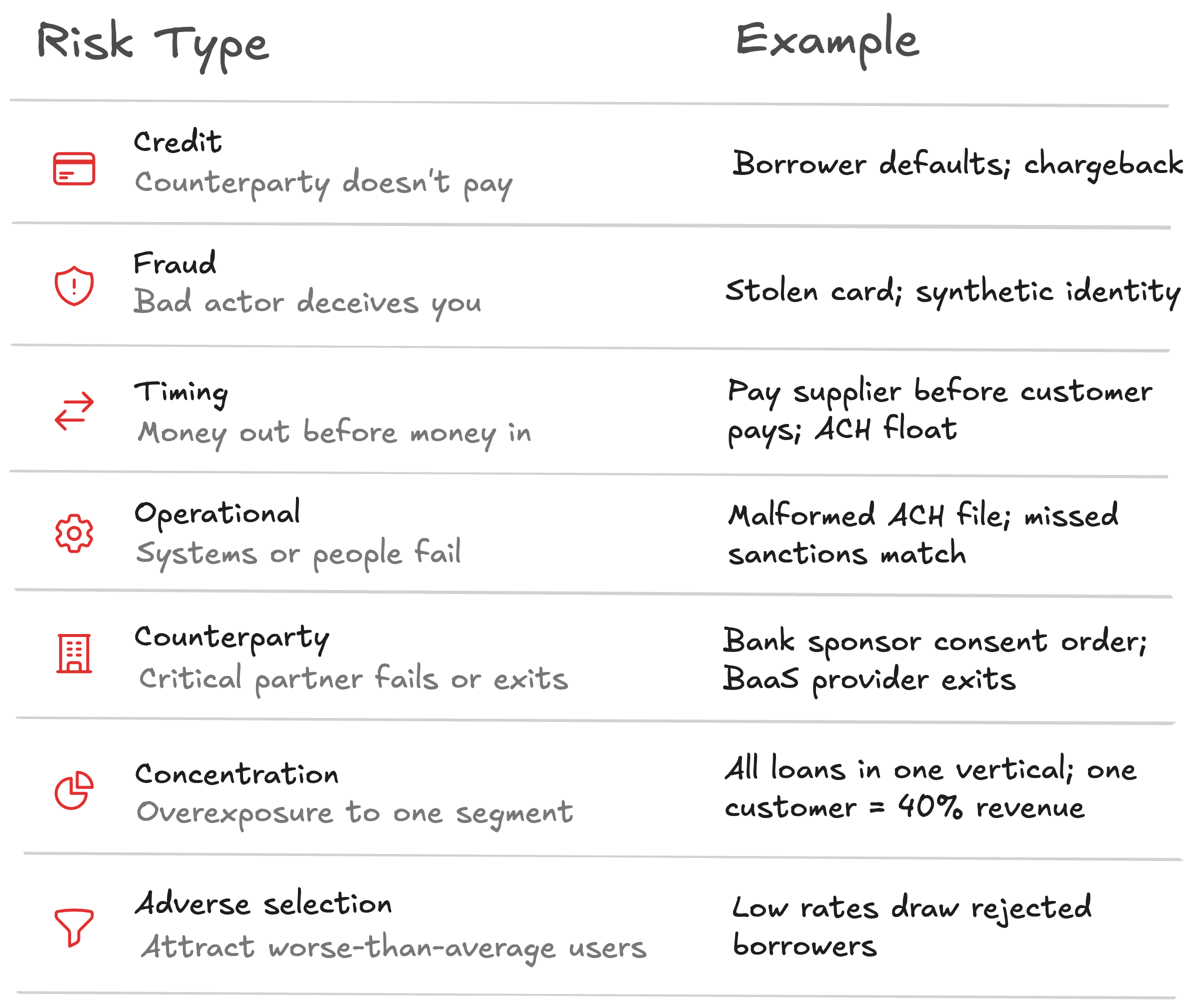
Each requires different capabilities to manage. Being good at credit risk doesn’t make you good at fraud risk. Operational excellence doesn’t help with concentration.
This creates an opportunity. A process change, a new data source, or a different product structure can shift risk from one form to another. A company with a specific edge in data, technology, or operational discipline can deliberately transform risk into a form they’re better equipped to manage. The goal isn’t to avoid risk. It’s to hold the right risk.
The difference between success and failure is whether this transformation is intentional. Reducing cost and friction without understanding the new risk you’re holding is how fintechs blow up. The ones who win recognize the transformation and build specific capabilities to handle it.
In each of these examples, notice the trade: what friction came out, what risk moved in, and what capability the winner built.
Square (underwriting risk → fraud and chargeback risk)
Traditional payment processors manage risk through friction: site visits, reserve accounts, manual underwriting. The merchant is vetted before they ever process a transaction. Square removed that friction, letting anyone accept payments instantly. But the risk didn’t disappear; it transformed. They won because they built real-time detection systems designed for fraud and chargebacks. They deliberately traded a risk managed through slow process for a risk they could manage through technology.
Toast (credit risk → operational and concentration risk)
Traditional lenders manage credit risk through friction and cost: lengthy applications, document collection, credit checks, high interest rates. Toast removes that friction for restaurants on their platform. A restaurant can get capital with minimal paperwork, underwritten on real-time transaction data flowing through its point-of-sale system. Concentration risk cuts both ways: their entire loan book is restaurants, so when COVID hit, the whole portfolio was correlated. But focusing on a single sector means deeper knowledge, purpose-built software, and better underwriting for that specific business. They win when depth of insight outweighs concentration exposure.
Buy now, pay later (consumer credit cost → provider credit risk)
Traditional card payments balance risk through cost: merchants pay interchange, consumers pay high APRs if they revolve. BNPL changes the equation. Merchants pay a higher fee (4-8% vs 1.5-3%) but shed chargeback exposure and gain conversion lift. Consumers get interest-free financing. The BNPL provider absorbs credit risk that was previously managed with high APRs. Companies like Affirm and Klarna are betting they can manage this through short durations, transaction-level underwriting, and merchant-funded economics. They win when underwriting keeps losses below the merchant fee. They lose when credit losses spike and the math stops working.
If you’re building a fintech that reduces cost or friction, ask yourself: what risk are you now holding? The friction you removed was managing something. Do you have data, technology, or expertise that makes you better at managing the new form? Or are you just hoping it doesn’t materialize?
Risk can’t be destroyed. But it can be transformed, and the best fintechs turn that transformation into their advantage.
My name is Matt Brown. I’m a partner at Matrix, where I invest in and help early-stage fintech and vertical software startups. Matrix is an early-stage VC that leads pre-seed to Series As from an $800M fund across AI, developer tools and infra, fintech, B2B software, healthcare, and more. If you’re building something interesting in fintech or vertical software, I’d love to chat: [email protected]
For the physics-minded: diversification and better information can reduce risk at the portfolio level (that’s the point of insurance). But compression in one dimension creates exposure in another. Diversify across a thousand borrowers and you’ve traded idiosyncratic credit risk for systematic risk and operational risk. The risk isn’t gone; it’s reshaped. Squeeze it in one place and it bulges out somewhere else.