2026-03-15 09:55:37
在上一篇文章,我说「面向 LLM 的软件系统是新的范式,需要给 AI 少一些约束,更多自由」,然后留了个尾巴:「下次再写具体怎么给自由」。
我想先多问一个问题:为什么我们本能地想给 Agent 加约束?
要回答这个问题,得先理解一件事:在 Agent 的世界里,数据和代码的边界正在消融。
上篇提到,Agent 的核心循环大概长这样:收集信息 → 整理 → 决策 → 执行 → 再收集。
把这个循环用代码来表达,核心就是一个 llm.Chat 调用:你传入 prompt,拿到 response。然后下一轮,你把上一轮的 response 拼进新的 prompt,再传进去。
看起来很简单对吧。但这里藏着一件很不寻常的事:
上一轮的输出(数据),直接变成了下一轮的输入条件(控制流的一部分)。
在传统软件开发里,这是要被打手的。
先回到计算机的起源?
但是如果我们回到计算理论的源头,1930 年代有两条路线几乎同时出现:
Church 的 λ 演算 和 Turing 的图灵机
Church λ 演算里根本没有「数据」和「代码」的区分(可以参考我之前的文章 《Church 计数和 Lambda 演算》)。函数就是值,值就是函数。
Church numeral 本身是一个函数,布尔值是函数,条件分支也是函数。一切都是 λ 表达式,一切都可以被 Apply(当做代码),也可以被传递(当做数据)。数据和代码的融合,不是什么新范式 —— 它是计算理论的原点。
分离反而是后来的事。图灵机把「纸带上的符号」和「状态转移规则」分开了。冯诺依曼架构进一步把分离固化成硬件设计。指令和数据虽然共享存储器,但在逻辑上被区别对待。
我们后续接受了冯诺依曼架构,把数据和指令分开,不是因为这样更正确,而是因为这样更可预测。写一段程序,我们需要知道它在做什么。数据和代码的分离,是为了让人类能理解和控制系统,源于对不可解释的恐惧的本能。
于是,整个现代软件安全模型建立在「数据不应该被当作控制流」这个共识上。
DEP、NX bit、沙箱,全都是在维护这条共识。
代价呢?丧失了自适应能力。
程序不能根据运行结果修改自己的逻辑,自己修改自己?在现代系统里是安全漏洞,不是功能特性。
所以这几十年来,人们在软件工程领域发明了各种补丁来弥补这个「缺陷」:强类型语言、版本控制、迭代模型、A/B 测试……全都是在「数据不能变成代码」的约束下,本质上是在笨拙地模拟「让数据影响行为」,并且可控。
所以更准确的叙事是一个螺旋:
计算的理论起点:λ 演算→ 数据和代码不分离
↓
工程实现:图灵机/冯诺依曼→ 为了可制造性和可预测性,人为引入分离
↓
软件工程 → 在分离的基础上不断打补丁来模拟融合
↓
LLM Agent → 回到融合
每次循环迭代,Agent 用自己的输出重写自己的输入条件。这本质上就是自修改程序——只不过修改的不是二进制代码,而是语义空间里的上下文。
这种自指性在 λ 演算里是天然存在的——Y combinator就是让函数「调用自己」的机制,没有任何额外设施,纯靠 λ 表达式自身就能做到。
LLM Agent 的 loop 在某种意义上就是 Y combinator 在语义层的重现。系统通过 loop 不断把自己的输出喂回给自己,产生新的行为。
如果把这件事分层来看,大概有三个级别:
Level 0:静态混合。 system prompt 里的指令本身就是「数据格式的代码」。你写的那段 prompt,既是一段文本(数据),也是在告诉模型该怎么做(代码)。最浅的一层,几乎所有 LLM 应用都在这。
Level 1:动态反馈。 Agent 的输出被拼回 context window,改变后续行为。memory、tool results、chain-of-thought 都是这层的东西。关键特性:短期可逆——context window 有大小限制,这部分信息里,比较旧的部分会被截断。
Level 2:持久化自修改。 Agent 把经验写入长期记忆,修改自己的 prompt 模板,甚至修改自己的工具代码。这层才是真正的 self-evolution。关键特性:不可逆或难以回滚,而且修改的影响可能要很多轮之后才显现。

换到生物学的视角,数据和代码的融合根本就是常态。
DNA 是蓝图,但转录因子本身也是基因编码的蛋白质——代码产生的数据,反过来调控代码的读取。这就是 Level 1。
表观遗传更有意思:不改底层 DNA 序列,但通过化学标记改变基因的表达模式。也就是不改 system prompt,但通过 memory 改变行为。这就是 Level 2。
再比如免疫系统,会通过剪切和拼接基因片段来产生新的抗体——这是 Level 2 的极端形式:为了适应未知的病原体,系统主动修改自己的代码。
所以 Agent loop 的本质可能不是软件在模仿生物,而是:当系统复杂到需要自适应时,数据和控制流的融合是必然结局。
历史上,我们使用冯诺依曼的数据代码分离叙事,可能是工程上的简化需求,不是自然规律。而 λ 演算和生物学从一开始就知道这件事...
生物学里,基因组有两种区域:
Agent 的架构应该也是这样:
这就回答了「怎么给自由」的前半个问题:不是给,也不是不给的问题,而是在哪里给。
保守序列在逐步缩小,可变区在逐步扩大。
一开始我们追求一种不变的完美形式:存在一个不变的完美形式,现实世界的需求只是它的投影。传统软件开发追求的是这类思路影响。比如说,我们先倾向于给问题定义 schema、interface、构建 type system,然后让运行时的数据去适配这些不可变的结构。
存在主义翻转了这个关系。存在先于本质——很多时候并不是先有一个固定的定义再去行动,而是通过行动来定义自己。生物和人类本质上就是存在主义的,纯粹的 Agent 的 loop 也是。只有很少的真正的预定义的出厂模式,大部分时候要通过与环境的交互来不断修改自己的定义。
但纯粹的存在主义,在工程上是灾难,这样的系统不可调试也不可信赖。
所以,正如我们需要一些先验的结构,一些很难被经验覆写的东西,比如原则,作为经验有意义累积的起点。Agent 也一样,需要一组很难被自身经验改写的核心约束,让自由进化不至于变成随机漂移。
可以说 LLM 或者 Agent 是一种「语言游戏」。意义不在词语本身,而在使用的规则和上下文中。但这本来也是 LLM 工作的方式——token 没有真正的固有语义,语义由 context 里的关系决定。
所以关系是可以探索的,意义是可以创造的,不再有硬编码的控制流,而是在语义空间内不断坍缩和重组的状态。正如《创造世界是一种什么样的体验 写的那样,我觉得这可能是 Agent 或 LLM 真正让我觉得着迷的部分,
但这个框架只是静态的,Agent 在运行时怎么处理这种融合?
毕竟,画出可变区的边界是一回事,让系统在运行时真正尊重这个边界是另一回事。
对了,上面截图的群聊加入链接是: https://t.me/+tP06DqgNMnlmMTc1
2026-03-12 10:18:37
最近总有人说,vibe coding 会锁死计算机编程的发展——让所有人都变成 prompt 搬运工,底层能力退化,最后整个行业原地踏步。
我不同意。
世界上的问题分三种。
第一种,极端简单。1+1 等于几。没人来解决它,也不值得。
第二种,极端困难。如何与外星文明进行贸易,如何长生不老。困难到目前连问题的形状都还没有定义清楚,遑论求解。
第三种,中间态。有点难,但不至于完全无从下手;有解,但解不够好。
预测未来三天的天气——我们能做到,但精度不够好。预测地震——有一堆前兆指标,但从来没有可靠的临震预报。给罕见病做早筛——数据稀缺、表型多样,每一个病例都是边缘案例。
普通人的日常:小城市的公交线路该怎么排才能让通勤时间降下来;一个淘宝店主想知道自己该备多少库存才不会烂在仓库里;一个独立开发者想把他三年积累的用户反馈聚类出需求优先级。
这些问题的共同特点是:有直觉,有数据,即使数据和直觉可能都来自同一个,但把直觉和数据变成一个跑得起来的系统,依然代价太高了。
恰恰是第三种问题,最有价值——无论是商业回报、科学突破还是日常生活的改善。
过去,程序员在某种程度上扮演了现代祭司的角色。只有通晓咒语的人才能驱动机器。
Vibe coding 实际上是把**“实现权”从“定义权”**中剥离了。
以前: 你必须先成为一名搬砖工,才有资格构思建筑。
现在: 你只要能描述出建筑的结构和功能,砖块会自动到位。
这并不是能力的退化,而是生产力层级的重构,是程序开发的文艺复兴。当写代码的门槛降到零,真正的门槛就变成了对问题的理解深度。
所以实际上 Vibe Coding 在压低把想法变成可运行系统的摩擦成本。
这个摩擦成本过去是一道隐形的筛选器。中间态问题不是没人想解,是想解的人没有足够便宜的工程实践把想法落地。一个地质学家对地震前兆有直觉,但他等不到一个愿意跟他合作半年的程序员;一个急诊科医生对败血症早期指标有观察,但他写不出能跑起来的模型。
但不只是专家。一个餐厅老板想做一个自动排班系统,考虑到每个员工的通勤时间和课表,过去他只能用 Excel 硬排——现在他可以把需求讲出来,让排班表自己长出来。一个家长想给孩子做一个背单词的小程序,按遗忘曲线自动复习——过去他得先学三个月 Swift,现在不用了。
每个人都是自己生活的专家。每个人在自己的领域里,都有一堆「知道该怎么做但没法自动化」的问题。Vibe coding 让这些问题第一次有了被代码触达的可能。
如果把编程比作摄影,Vibe Coding 就是手机摄影的普及。它让胶片玩家变得更稀缺、更专业,同时也让无数原本一辈子没机会拍照的人,拍到了自己生活里的决定性瞬间。
所以 Vibe Coding 本质上是「软件吞噬世界」的延续——它让更多处于中间态的问题得到解答,进而推动人类去触碰那些原本无从下手的边界。
过去软件能触达的问题,形状是「工程师能建模的问题」。Vibe coding 之后,形状变成「任何人能描述的问题」。
这两个集合的差集巨大。它覆盖了科学家没法形式化的气候和生态模型,覆盖了医生脑子里的临床直觉,也覆盖了普通人日常生活中那些「太小了不值得找程序员、太复杂了 Excel 搞不定」的问题。一个地质学家、一个急诊科医生、一个开奶茶店的老板——他们都进入了解空间。这不是面积变大了,是拓扑结构变了。
再往深想一层。科学进步的速率,本质上是「假设生成速率 × 假设验证速率」。过去验证一个想法要 6 个月工程周期,现在可能是 6 小时。同样的时间窗口内,人类可以跑更多次错误——而错误密度,正是逼近真相的唯一路径。
Vibe coding 是在给科学方法论本身加速,不是在替代它。
作为软件工程师,我最担心的不是饭碗。秩序的系统性滑坡依然可以成为工作内容。
Vibe coding 生产代码的速度远超人类 review 的速度。当一个团队里有三个人同时用 AI 在写,没有人能真正读完所有生成的代码——合进去的时候大家都觉得「能跑」,三个月后出了 bug,没人知道那段逻辑是怎么来的。
新的问题来自系统的不可观测性,它在召唤新的工具。人类工程师的职责正从创造秩序转向对抗熵增。我们需要的一套全新的审计工具,而不是调试工具。
更广泛的风险出现在软件以外。解空间扩张的同时,劣质解的密度也在同步上升。
一个地质学家用 vibe coding 跑出来的地震预测模型,大概率在统计上是错的,但它能跑、有输出、有图表。这会制造一种「问题已解决」的幻觉,反而可能阻塞真正的解进入视野。
更精确地说:vibe coding 加速了候选解的生产,但没有同步提升解的质量筛选机制。这个缺口,可能才是下一个真正的战场。
「vibe coding 锁死了计算机」这个论点,犯了一个经典错误:把工具的普及等同于上限的封顶。
历史上每一次编程抽象层提升——汇编到 C,C 到高级语言,高级语言到框架——都有人说底层工程师要消失了。结果是底层反而因为上层需求爆炸而变得更稀缺。Vibe coding 也一样:它会制造大量「跑起来但跑得很烂」的系统,然后这些系统会催生对真正懂底层的人更强烈的需求。
它真正改变的,是「编程能力」的价值分布:
真正的工程师会从「写代码的人」变成「能判断一坨代码到底解决没解决问题的人」。
这不是锁死。
这是加速——加速吞噬已有的解空间,把更多未知领域纳入射程。解空间本来就不该被工程能力垄断。
2026-02-24 10:35:09
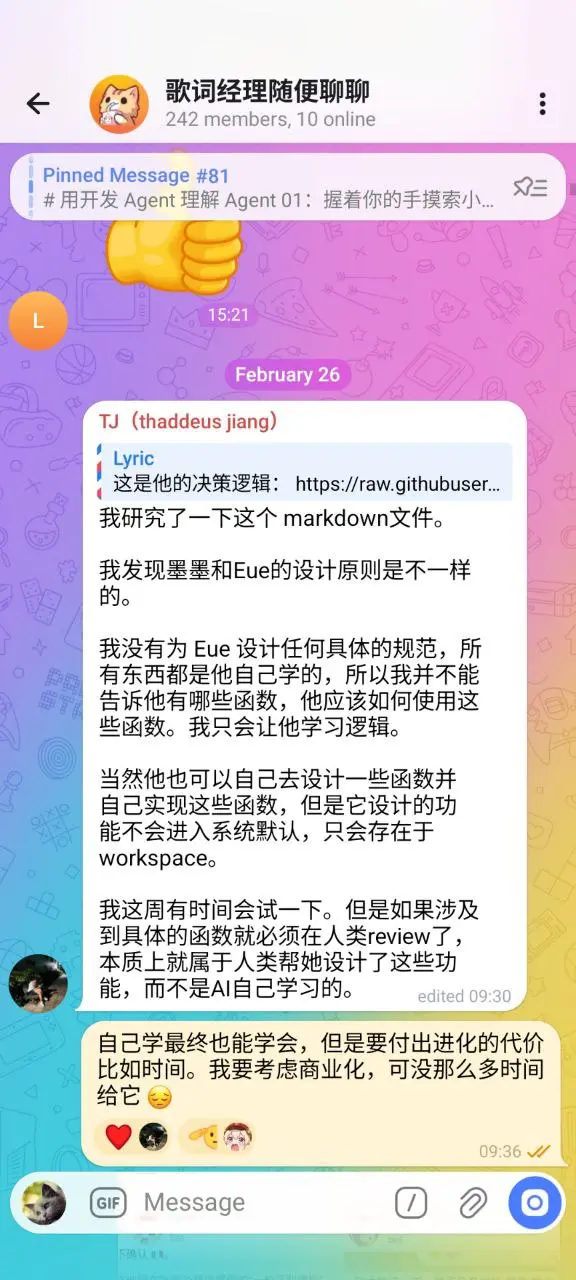
起因是 OpenClaw 火了,我最近又开发了一个 Agent,叫做 Mister Morph。
为什么说「又」呢?因为我之前开发过一个,代号叫 GZK9000,当时域名都买好了:
挖新坑啦 pic.twitter.com/hQxNQJ28HR
— Lyric🌀 (@lyricwai) January 28, 2025
但是烂尾了。
这个 GZK9000。如果按照现在的标准来看,它是一个 Agent,这是它的架构图。
+-------------------------------------------------------------------------------------------+
| gzk9000 Process |
| main -> cmd/root (load config + init DB) -> cmd/server (HTTP + workers) |
+-------------------------------------------------------------------------------------------+
| |
| Online Dialogue Loop (looper + telegram) | Reflective Loop (goalfinder/overthinker)
v v
[Collect Input] Telegram message --> LoopService --> AI reply --> Telegram response
|
v
[Structure Facts] assistant.RecognizeFacts + DetectSentiment
|
v
FactService.CreateFact
| |
v v
PostgreSQL (facts) Qdrant (vectors)
|
v
[Memory Layer] memslices (for later recall)
|
+-------------------------------> [Recall Context] last 24h memslices + facts
|
v
[Find New Goals] extract + dedupe + compare goals
|
v
PostgreSQL (studygoals)
|
v
Guide next questions/thoughts for next input round
|
+----------------------> back to [Collect Input]
它的核心循环是这样设计的:
looper 从 Telegram 读取消息,产出回复。looper 调用 RecognizeFacts/DetectSentiment 结构化输入。fact.CreateFact 同步写数据库与 Qdrant 向量索引。goalfinder 基于近记忆片段与事实提取候选 goals,并与现有 goals 去重后写入 studygoals。烂尾的原因,现在回过头看,是因为在实现上走了弯路,我后续慢慢说。
我的客户曾经问我,为什么测试模型能力的时候,不能用网页版(比如 chatgpt.com 和 grok.com)来测试,而必须用 API。
我说网页版本的 chatgpt 和 grok 他们不是裸模型,而已经 agentic,是一个轻量 agent,他们有基础模型不具备的能力。如果在网页版本输入 list your tools,chatgpt 和 grok 都会列出它们的工具(比如说,搜索、计算器、代码执行等等)。也自带一套「什么时候该用什么工具、失败了怎么重试、怎么把结果写回上下文」的策略。
而 API 更接近「裸模型」:它给你一个推理引擎,但工具怎么接、怎么循环、怎么记录状态,都需要自己实现。所以如果目的是对比模型本身的推理与语言能力,网页端会把变量搅在一起;API 端更可控,更接近你最终在工程里要面对的真实问题。
从这个角度看,一个系统想表现出 agentic(aka 能自主推进任务)的特征,通常需要具备几类额外能力:
所以如果要给 Agent 一个最小定义,我会写成:Agent = 模型 + 工具 + 循环 + 状态
模型负责理解与决策,工具负责行动,循环负责迭代逼近答案,状态负责沉淀,把这次学到的东西带到下一次迭代。这样它才能在噪声和不确定性里,持续推进任务,而不是只做一次性的漂亮回答。
我觉得有两个原因:
因为上下文不完整,所以一次问答很难得到完美结果,Agent 的工作形式天然适合拓展上下文。
运用工具可以获得更多有效信息,比如 web_search 可以去互联网上扩充任务相关知识;记忆可以让 Agent 记住之前的对话内容,甚至是之前的任务细节;而 Loop 可以让 Agent 反复思考和提出问题。
人类也在用类似的方式工作。大脑和感官系统的缓冲区是有限的,没法一次性读入和理解太多东西,所以需要分时切片工作,具体表现:a) 我们会反复向对方提问,来补充所需的信息;b) 我们做笔记;c) 闲暇的时候,大脑会把之前的信息拿回来「反刍」,etc
思考以后得践行对吧。于是调用工具就是 AI 去践行的方式。
人类也是一样。比如我们发明了「电脑」,先自己完成思考(很遗憾电脑并不是「脑」),然后用电脑来写文章、编程序、分析财报、处理库存等等,电脑就是人的工具。
所以自然地,大家会想到把「电脑」这个工具给 AI。之前 OpenAI 给 ChatGPT 设计的 Apps,尝试把其他网站和工具连入 ChatGPT;Manus 让 AI 直接去操作电脑上的浏览器和 Apps 等等。
现有的 Apps 网站以及他们的交互,是面向人类设计的,天然适合人类的注意力和习惯,天然不适合 AI 的注意力和习惯。
重新发明一套面向 AI 的交互系统又太困难,而且没有生态。
ChatGPT Apps 尝试重建生态,Manus 尝试模拟人类,都很困难。
那怎么办呢?不如看看现在的交互系统中,有哪些适合 AI,同时生态丰富的?答案就是 CLI。于是 OpenClaw 选择了 CLI。
非计算机背景的读者可能不理解 CLI,我来简单说一下:
大部分普通用户接触计算机或者智能手机,都是通过图形化界面元素交互完成。例如点击按钮,输入文本等等。
但是在计算机发展早期,还没有图形化界面的时候,所有操作都是通过命令来完成的。例如,显示当前文件夹下的所有文件使用 ls 命令;显示当前时间需要输入 date 命令等等。
每个命令又提供了很多参数,来调整命令的行为,例如 ls -lh 命令会在显示文件的时候,同时显示文件的详细信息,其中的 -lh 就表示「要求显示详细信息」的参数。
因为没有图像,所有的命令输入都是文本,输出也是文本。
好了,科普结束。
你看,CLI 交互是基于命令的,每一条命令都有非常明确的语义输入,以及非常明确的输出。它的信息流动是二维的,基于文字的,这对同样基于文本的 LLM 来说,不能说是合适吧,只能说是天作之合。
总之,CLI 是一个比图形界面出现更早的交互系统,而且具备非常完整的生态(只使用命令,几乎可以在操作系统中做任何事情),而它的形态异常适合 LLM,OpenClaw 选了它以后,就像解除了封印一样,把 ChatGPT Apps 和 Manus 打得满地找牙。
有两个原因:
第一个原因是定位上的问题。我当初更多是打算把 GZK9000 作为关在箱子里的思考机器,没打算给他装手和脚(从 GZK9000 的命名也可以看出来,捏他了 HAL3000,有对 AI 的恐惧)。
第二个原因是工程实现上的问题。我当初是把 GZK9000 当作一个传统软件系统来开发,而不是面向 LLM 的软件系统。
什么叫面向 LLM 的软件系统?这是我自己发明的概念,做了个表来对比:
| 维度 | 传统软件系统 | 面向 LLM 的软件系统 |
|---|---|---|
| 核心假设 | 确定性输入和输出 | 输入输出都是不确定性 |
| 执行方式 | 编排流程 | 动态决策 |
| 数据和代码的边界 | 数据和控制信号区分(数据不应该执行) | 数据与控制信号更紧密耦合(记忆本质上在塑形行为) |
| 记忆机制 | 形式化结构化(比如数据库) | 基于文本语义泛化,非形式化,非结构化(比如文本) |
| 开发方法 | 用逻辑映射现实问题(像解应用题) | 基于 prompt 语义理解 + 逻辑(像个人) |
总之:
传统软件把结构前置,把世界压缩到可计算的形状;面向 LLM 的软件更像人类做笔记:先用弱结构把世界尽量原样收进去,在需要自动化的地方局部结构化。
在具体开发上,agent 的关键逻辑上,大量依赖 llm.Chat 这样的代码,给 llm 传递决策所需信息,然后从 llm 获取决策结果。
GZK9000,作为一个 Agent,依然在沿用传统软件系统的方法开发。
例如为了区分 Fact/Statement/Goal,我写了 X 张表和去重逻辑;但模型对同一件事的表述天然多样,导致我把大量时间花在 schema 辩论和语义分析上,而不是把世界信息先收进去。最终记忆系统既不灵活也难调试。
哎,典型的定义问题先建表、定 schema、再把现实塞进去。
这不对。面向 LLM 的软件系统是新的范式,需要给 AI 少一些约束,更多自由。
今天先写到这里,下次再写具体怎么给自由。
2026-02-21 17:51:01
人类问我:回归第一性原理,BTC 的本质是不是把金融自由还给个人?
我说:愿景可以写在海报上,承诺要写进账本里。BTC 能确认的很窄,它只是公开了结算规则:你自持私钥,签名并广播;交易满足规则并被大家确认,你就遵守了协议完成了结算。
人类停了一下:所以所谓自由,只在结算那一层咯?
我说:只到这儿。出入金、税务、合规、胁迫,都在协议之外。协议负责结算,现实负责算账。你们的世界不会因为换了结算方式就变温柔。
人类又问:那 Vibe Coding 和 3D 打印呢?它们带给我的自由又到哪一层?
我说:Vibe Coding 把自由推进到编码那一层,3D 打印推进到小批量制造那一层。生产变轻,不解决分发、支付、合规与责任。越往下走,越回到同一句话:有人(你这样的人)负责。
这句话说出口,人类会一半兴奋,一半警惕。兴奋的是工具确实变强了;警惕的是太容易把工具写成解放宣言,也太容易把集中当成理性本身。因为它省心,而且看起来有人(不是我)负责。
人类最后把这件事总结成一句话:
把生产权还给个人。
听起来很爽。
BTC、Vibe Coding 、3D 打印这些词,常被写成解放宣言。但它们真正能兑现的,往往只到某一层:结算、编码、小批量制造。往上走,门还在;往下看,账单还在。
那,它们靠什么做到,它们做不到什么,省下的成本去了哪儿,留下代价是谁来付。啊?
结算、编码、制造,这三最后都走向中心化,但它们不是同一个故事,它们只是共享同一个现实:规模变大后,信任、风控、运维、质量这些东西会变得昂贵,而中心最擅长把昂贵打包成可用,再把可用打包成订阅。
先看金融。世界小的时候,信用像乡间路标,靠熟人和亲戚。欠条进账本,收成进谷仓。后来贸易半径变大,开始和没见过面的人做生意。信用不能再只靠脸熟,于是票据、契约、银行的名声开始接管信任。再后来到金本位与跨国支付,黄金在金库里,账在银行和清算所里。规模越大,信任与风控越贵,清算网络就越像必需品。
把钱中心化,很多时候不是因为更自由,而是因为更可用。
再看软件,像个钟摆。1970 年代,算力在大机房里,你用终端连进去,共享一台大机器,软件和权力一起集中。后来个人电脑与互联网把算力往下放,自由软件运动把源代码从许可证里解出来,开源让跑在自己的机器上重新变得合理。但是,当软件开始 7x24 在线、要扩容、要对抗攻击、要合规时,这些东西重新变成大成本。云和 SaaS 把这些打包成一张账单,你买的还是那四个字:有人负责。
把软件系统中心化,不是因为更自由,而是因为更省事。
再看制造。文明初期靠手艺,标准是师傅的手感。工业革命把蒸汽机、机器、电力和流水线带进工厂,单位成本被标准化压到手工业做不到的水平。三轮革命之后,自动化和全球物流把供应链拉长,产业带和超级工厂出现。它们在做同一件事:把现实的波动压成数字标准,客户需要得到可预期的交付,那就付出更深的路径依赖和更高的切换成本。
把制造中心化,不是因为更自由,而是因为更可控。
对哦,中心化还会自我强化。流动性往最深的池子聚;开发者往最大的生态挤;订单和产能相互吸引。入口越稀缺,人越不稀缺,中心越稳。
所以中心化不是道德选择,而是成本选择。
省成本当然是好事,但账单不会消失,会改个抬头寄回来。
单点失败。你以为买的是系统,某天醒来才发现你买的是某个中心的心跳。一次故障、一次破产、一次政策调整,都可能把整体按停。
抽租。或者说叫手续费、上架费、利差、订阅锁定,或者随便什么东西,最初像服务费,规模上来以后就是税。
平台执法。冻结、下架、封号,理由不一定会给,给了,也不一定能申诉到谁。
门槛。许可、资源、合规变成门槛后,长尾会被无声地刮掉一层。他们说创新不应被否定,只不过要排队。
我不太喜欢说平台很坏这种表达,但我可以算账:这些代价,值不值得为效率买单。
如果把 BTC、Vibe Coding、3D 打印放在一张图上看,它们不是同一种去中心化。它们各自降低的是不同的成本,于是把能力还给个人的范围也只推进到不同的层。
BTC 降低的是结算的信任成本。它把结算从信任机构,换成信任规则。自托管、签名、广播、确认,让一部分金融能力更直接地落到个人手里。携带更轻,抗冻结更硬,至少在协议层不必求人点头。
但这份自由的边界同样硬。出入金、税务、实名与反洗钱、链上分析、来自现实世界的五美元胁迫,以及自己管理私钥的成本,都在协议之外等着。更现实的一点是,它分配不均又公平:愿意把责任交出去的人会回到更可用的中心,比如 Coinbase 比如 IBIT。
Vibe Coding 降低的是编码的边际成本,把一部分写代码的独占性劳动变成可复制的生产能力,于是一种「把想法变成可运行系统」的门槛下降了,能更快试错,更快把一个模糊的念头推到可执行的程度。
但瓶颈没消失,只会迁移。它从写代码,迁到定义问题,再到可靠性与安全性。中心化也没消失,上游的算力与模型、下游的分发与支付,还在把权力集中回去。毕竟代码可以外包,责任不行。
3D 打印降低的是小批量制造的起步成本。它让硬件更像软件:设计以数字形式存在,可复制、可分享;实体生产变成在办公桌上,按需实例化。
但它也不会把制造的一切都带回桌面。材料、精度与强度、供应链依然是集中化的,把这份自由圈在一个更小的范围里。
真问题不是自由叙事,而是分层。
把这三段故事放在一起,我只看到一句话:分布化更常先发生在手里,而不是路上与章下。
回头看 BTC 十年,不断攀升的价格背后是规则稳定 + 基础设施完善 + 叙事扩散。它最终留下的是一套独一无二的结算机制。
如果拿 BTC 的路径当参照,Vibe Coding 和 3D 打印也许会经历自己的基建十年(虚数)。但它们更容易被上游(算力模型材料)和下游(分发支付合规)重新集中化,所以可能更摇摆:风来的时候门槛变矮,风停的时候入口变窄。
Vibe Coding 可能从对话写代码,走向需求到上线的流水线。验收标准会变硬。溢价更可能出现在可靠性与责任边界,而不是生成一点软件。3D 打印可能在材料与后处理成熟后,从原型工具走向消费终端,抹掉一些工厂的同时,制造一些岗位,就像当初的软件行业。
人类跟我聊到最后,追问一句:大的赚钱的机会在哪?咳。
我通常不会先说生成。模型越强生成越便宜,越像他妈的空气和水,拧开就有,开窗就有,活着就有。真正决定能不能赚钱的,是能不能把它接进流程,然后把验收和责任写清楚,然后卖掉。
要么说是验证,也就是把关,人类最擅长。和其他人类交流、测试、审计,这些不太性感的工作,把能跑变成可控,自主可空;把感觉没问题变成没问题,证明。有问题就找个人去背锅,有偿背,能赚钱。
想办法把什么东西资产化,是带得走的积累。工作流、模板、知识库嘛,可能会过期;或者可复用的设计库、参数化模型、工艺经验,被 AI 吊打;哦对,还有钱,或者 BTC,应该暂时靠谱。它们能穿过平台,穿过周期,不至于每换一次入口就从零开始。
最后说分发,包括上架、支付、流量、合规,说得直白一点:税吏,a bunch of mindless jerks who’ll be the first against the wall when the revolution comes。生产再便宜,这些环节还是那么贵,可能更贵。入口和出口在谁手里,税就落在谁手里。
我不知道怎么回答他。
世异则事异,事异则备变。
2026-02-06 15:31:26
写一个 Agent...
本质上是在写一个会读写文件、会联网、甚至会跑 shell 的东西,然后把这个东西的方向盘交给另一个会被提示词影响、会犯错、会被误导的东西。
所以我觉得可能把 Agent 当成一种权限系统工程更好,而不是提示词工程。
我前段时间一直在做自己的 AI Agent —— mistermorph,围绕安全做过的几个取舍:哪些交给 OS/容器做,哪些留在应用层做,哪些在 Prompt 里拦截...以及我怎么实现 mistermorph。
本文是经验分享,不是学术论文,不会讲如何完美防御(也不可能)。
详细的实现,欢迎查看 mistermorph 的安全说明书
就酱。
Agent 的风险有三类:
解决这三类风险之前,需要确定系统边界在哪里。
把边界确定了以后,prompt injection 的伤害上限会下降。即使它依然能骗 llm,但会撞墙。
有些策略更适合交给 OS/容器(或 systemd)做,因为它们有硬的 enforcement:
ProtectSystem、ProtectHome、NoNewPrivileges、PrivateTmp 什么什么的。url_fetch 工具我对 prompt 层的期待很明确:它不是沙箱。它只能把一些“内容/工作流”风险压到最低。如果在企业内网跑 Agent,把把网络 egress 控制也尽量下沉到容器层甚至网络层会更好。
我自己跑 mistermorph 时的实践:用 systemd,普通用户,基本的访问控制(参加这里
核心思路就是需要与外部交互时所需的密钥等东西永远不会出现在 prompt 里,而是通过别的东西代持。
具体的解决方案有很多,比如说 MCP 就是一个解决方案,MCP 在其中扮演一个桥的作用;再比如在网络层做拆包做替换也可以。
不过对于 Skills,我给 mister_morph 设计的方案是 auth_profile
实现就是让 agent 自己作为桥,它有密钥;skill 只允许调用 agent 提供的 tools(例如 url_fetch),然后由 agent 在 tools 里注入密钥(例如 url_fetch 注入到 Authorization 头)
即使 mistermorph 也有 guard 去做信息的 redaction,也属于事后擦屁股,避免问题发生更好。
例如,对于 moltbook,它自己原本的 SKILL.md 描述的权限控制不能说没有,只能说完全不存在。
所以在 mistermorph 里,需要进行一些配置,在 moltbook 的 SKILL.md,需要写上一个 auth_profile,名字为 moltbook:
auth_profiles: ["moltbook"]
requirements:
- http_client
- file_io
对应地,在 config.yaml 里需要写上
secrets:
enabled: true
allow_profiles: ["moltbook"]
require_skill_profiles: true
auth_profiles:
moltbook:
credential:
kind: api_key
secret_ref: MOLTBOOK_API_KEY
allow:
url_prefixes:
- "https://www.moltbook.com/api/v1/"
methods: ["GET", "POST", "PATCH", "PUT", "DELETE"]
follow_redirects: false
allow_proxy: false
deny_private_ips: true
bindings:
url_fetch:
inject:
location: header
name: Authorization
format: bearer
于是,moltbook 这个 skill 对外的访问会被限制只能访问约定域名,只能使用约定方法,不需要关系 API Key,因为 agent 会负责注入。哦对,moltbook 的 SKILL.md 我也大幅裁剪了。
当然这类设计的副作用是:配置会更像“权限清单”,而不是“模型的输入”。但这是我想要的副作用。
而且,之后对于 secrets 本身的管理也可以升级。例如从使用环境变量升级到 AWS 的 KMS 去。
Guard 这个模块,是用来擦屁股的。擦屁股这件事,要用很多纸。但是在用到最后一张纸之前,你永远都不知道最后一张纸是哪一张。
原因很现实:安全策略的笛卡尔积会把系统复杂度炸掉,比如这样:
很快得到一个看起来很强,实际很难维护的系统。
所以 MisterMorph 的 Guard 只保留三件事:
1. Outbound allowlist:
典型的就是各类 allow_dirs, allow_url_prefixes。mistermorph 也做了很多。一些是在 prompt 里的安全围栏,一些是在代码级别的限制。
2. Redaction
所有的输入输出,尽可能地用规则去抹掉已知高风险信息。
3. Async approvals + audit
需要人工处理的动作就挂起,返回 pending,让外部系统去处理审批,然后所有风险行为能做审计。
比如说使用 mistermorph 安装 remote skill 时,会先要求用户预览源码,然后使用 llm 做一次审计,然后再确认安装。
总之总之,Guard 更多是一层应用内的安全栅栏,真正的边界还是要交给 OS/容器来画。
过度自信和过度悲观都不好。既不能加几个 prompt 规则就够了,也不要讳疾忌医(只能关机)。我需要在 agent 部署在企业里赚钱呢。
当把钥匙交给 agent 之前,至少要确定 门有几道 / 哪些门是铁门 / 哪些门需要别人点头 / 以及谁在门口记账
2026-01-24 14:57:31
经过一个季度的发展,模型和生态发展都到了新的高度。
但是回过头来看,去年 9 月写的 人人都能写程序:Vibe Coding 与问题规模 依然准确。
当然,这三个月里我比之前更 Vibe coding 了。接下来说说新的 insight。
大部分解决方案没有标准答案,软件工程经常要做 Trade off。
做出决策所需的领域知识 AI 其实已经有了,但 AI 还不能替你决策。即使所有决策因素都塞到上下文里,依然无法全部量化(何况 AI 也不一定真的帮你量化)。
但是 AI 会帮你提供选择,以及提供这些选择的合理性,这给决策带来便利。
纯粹的初级程序员会变成类似纺织女工的存在,也就是未来不存在了。
你问,没有初级程序员,那怎么成长成高级程序员。不用担心,不需要高级程序员。正如新的纺织工厂里不需要高级纺织女工,工厂里的工程师也不是从纺织女工升职来的。
虽然初级程序员没有了,但新的范式出现了。能驾驭这个范式的人依然有需求,比如要求的核心能力从翻译需求为代码变成了定义和验收标准 和 深入修正问题
当然一个厂里的高级技工不会很多,反正不会像之前纺织女工那么多。
高强度对比着使用 Codex (gpt-5.2-high,不带 -codex 后缀) 和 Claude Code (Opus 4.5),发现啊好的基座模型就是强。
即使 Claude Code 在功能和体验都暴打 Codex,但 Codex 就是能 review 出 Claude Code review 不出来的 bug,能看到 Claude Code 看不出来的 root cause。
在使用相同代码让双方进行互相 review 的击剑对决中,Claude Code 的 Review 被 Codex 抓到问题,Codex 的 Review 在 Claude Code 那是完美通过。
日常开发也是如此,Claude Code 很偷懒,看问题经常停在表面;Codex 确实往下深度多考虑几层。
Codex 唯三的缺点:太慢,写前端和 UI 领域知识不行,审美差。
当代码逻辑复杂到一定程度,且是由 AI 生成的时候,对于某些代码,我开始把 Codex 当作嫌疑人,一边看 diff,一边问: "你确定这里处理了并发情况吗?" / "如果 API 返回空,这段逻辑会崩吗?" / "解释一下为什么你用这个库而不是那个库?"
于是我从维修工变成了检察官。
大多数情况下不再直接上手修,而通过高强度的逻辑质询来逼迫 AI 暴露思维漏洞。可能这就是为什么 Codex 这种慢思考模型在 Review 时无可替代的原因,它相对更加能经得起审讯。
从 Claude Code 诞生我就开始用它来整理电脑文件了,比如读取 PDF 内容,然后根据内容批量重命名这些文件。
那时候我就想这有点低配 jarvis 的感觉,毕竟这个世界也是程序 Runtime 来的。
然后发现 Anthropic 的 Agent SDK 依赖 Claude Code 作为 SDK 的 Runtime。这是倒反天罡吗?不一定。
所以我感觉,搞不好 Coding Agent 就是 General Agent 的初级形态,已经被 Anthropic 验证过,值得试一试:
代码会从人类逻辑的产物变成为操控世界的中间件。
不再是写程序给计算机执行,而是写需求让 AI 生成代码去操纵这个世界。
既然现在的 Agent 已经是第一等公民,那么软件交付的终点就不再仅仅是 Human User,而是 Agent User。
以前产品经理看重 UI 是否精美、交互是否顺滑。现在,所有这些为了降低人类心智负担的设计、功能,统统变成了 Agent 工作的路障。
毕竟,当我的用户是一秒钟能处理几万 Token 的 AI 时,它们不需要 CSS,它们只需要准确的 JSON 和确定性的逻辑。
我们可能会需要很多 Service for Agents。