2026-01-28 00:00:00
我最近在读《毛泽东选集》。毛主席教导我们说,要将理论与实践相结合。那么就我所从事的行业,根据我观察到的事实,结合我学到的理论知识,分析一下程序员的阶级性。
传统制造业需要厂房和机器这样的生产资料,这些生产资料一般的工人不可能拥有。工人要生产,就必须被企业雇佣。 而软件开发却不同,基本上只需要一台普普通通的电脑,几千块钱,几乎人人都能拥有。也就是说,大多数情况下,一个程序员独立拥有开发软件的能力。事实上,早年也存在不少由一个或几个程序员开发的独立软件。那么从这个角度看,程序员应该是类似于小手工业者的小资产阶级。
但是我们身处一个资本主义高度发达的世界。十几年前智能手机的普及、几十年前个人电脑的普及,造就了一个巨大的软件消费市场。面对这个潜力巨大、尚未开发的市场,金融资本虎视眈眈。他们绝不会让独立软件开发者从两三人的小团队开始,通过挣得的利润慢慢扩大规模、完成原始积累。他们会大量砸钱,帮助创业者孵化项目,给创业公司估值,给它们投资,帮助它们快速扩大规模,为的是获得它们的股权,从而获得这个行业的利润——也就是产业工人的剩余价值。若不这样做,这个新兴市场的利润就与他们无关了。这样一来,软件行业迅速地产业化、规模化,诞生一大批颇具规模的软件公司。
具有一定规模的软件公司能够凭借规模效应,快速抢占市场。这样一来,独立开发者开发的产品难以同企业中几十人甚至几百人的团队开发的产品竞争。 如果某个品类尚无产品存在,拥有庞大资金的企业一定会迅速组建团队,以最快的速度研发出产品,以便快速抢占市场。如果独立开发者的创新产品开创了一个新品类,在市场上取得了一定成绩,那么企业也会立刻组建团队跟进,拆解、模仿、改进独立开发者的产品,推出自己的产品与之竞争。在大多数情况下,企业的产品会打败独立开发者的产品;或者企业直接出资收购独立开发者的团队。越大的企业,在竞争中往往越有优势。于是在短短二十多年的时间内,市场已经被各大企业瓜分完毕,独立开发者基本没有生存空间。
对于软件企业来说,要开发一款有竞争力的产品,需要组建一支几十人甚至几百人的团队,开发两三年甚至四五年,然后才能发行并盈利。这期间需要承担这支团队所有人的工资;且软件发行需要一大笔宣发费用。而且软件发行后不一定能盈利,这需要企业有一定的风险承担能力。所以,软件企业通常需要庞大的资本,这其中主要是用于购买劳动力的可变资本,而不是电脑、服务器这样的固定资本。
普通程序员虽然拥有开发软件的生产资料,但是基本上没什么用,只能被企业雇佣。这就像在工业时代,小手工业者,如木匠、裁缝,基本上没有独立生产的可能。他们要谋生,只能进厂打工,成为工人阶级。
在过去十几年的移动互联网浪潮中,有一部分程序员创业成功,赚了很多钱,实现阶级跃升,成为资产阶级。他们当中一小部分人当了老板;但是更多的人,虽然创业成功,但没能一直当老板。因为这是一个资本主义高度发达的世界,如果你的创业团队真的有潜力,金融资本会想方设法收购你的公司,反正他们有的是钱。如果你不想被收购,反而有倒闭的风险——可能有接受了投资的竞争对手开始迅速扩大规模,挤压你的市场。事实上很多创业者本质上就是炒作概念,讲故事,提高估值,然后卖掉套现离场。这些人能赚到一大笔钱,然后把钱投入房地产和金融市场,希望由此实现“财富自由”。但房价会下跌,投资可能会亏钱。如果投资赚的钱不够花,还得打工贴补一部分,就只是小资产阶级。如果投资不能稳定赚钱,那么也随时可能从资产阶级跌落。
在市场开发之初,垄断尚未形成,行业还存在大量创业机会。一旦创业成功,就能赚大钱,很多人都想找机会去创业。我称之为“创业机会主义”。再加上行业的快速发展与技术人才供应不足的矛盾,优秀程序员有一定的稀缺性。为了留住人才,让他们不要去创业单干,企业愿意同他们分享一部分利润。因此成功项目的程序员,往往能分到可观的奖金。这样一来,他们便具有小资产阶级的性质,因为分享了一部分利润。
但是事情正在起变化。随着产业的发展,垄断正在逐渐形成,市场逐渐被各大企业瓜分,创业机会逐渐减少;再加上产业发展放缓,人才不再稀缺,程序员的奖金分红也会逐渐减少。这样一来,程序员的小资产阶级性质会逐渐消失,最终成为单纯出卖劳动力的无产阶级。
AI 的出现带来了更加不确定的变化。一方面来说,AI 会带来新的市场和新的创业机会,相关领域的从业人员可能因此暂时成为小资产阶级。但在另一方面,AI 正在威胁程序员的岗位。让 AI 参与编程工作,会极大提高开发效率,产业的劳动密集型的现状可能因此改变,就像流水线工厂代替旧的劳动密集型工坊。由于训练 AI 需要高性能 GPU,这可能是一般工人无法拥有的。因此在可预见的未来,高阶 AI 可能像流水线机器一样,成为资本集团才能拥有的生产资料。如果是这样的话,普通程序员绝无可能保住小资产阶级的地位。
总结一下。程序员本是类似于小手工业者的小资产阶级。但是随着产业的发展,独立开发者难以与企业竞争,只能被企业雇佣。但成为工人的程序员并非完全是无产阶级,因为市场开发之初的“创业机会主义”和由此带来的分红,很多程序员都有小资产阶级的性质。然而随着市场逐渐被垄断集团瓜分,程序员的小资产阶级性质会逐渐消失,最终成为无产阶级。创业成功、当上老板的程序员自然是资产阶级。被收购、套现离场的创业者的阶级性质取决于资产状况,但是他们的阶级地位并不稳固。AI 的出现带来新的变化:新的市场会带来新的机会;但高阶 AI 可能成为普通人无法拥有的生产资料,普通程序员可能因此沦为真正的无产阶级。
2026-01-08 00:00:00
我最近组了一台 NAS,用于同步手机上的相册、自建云盘存储文件、同步 Obsidian 的笔记、存储和管理影音资源、搭建 Git 托管代码等。这篇文章记录我是怎么做的。

主板选用云星 CS246,一款专门面向 NAS 的 ITX 小主板。它有 LGA 1151 CPU 插槽、2 个 2.5G 网卡(可加钱升级成 4 个)、8 个 SATA 3.0 接口、两个 NVMe 插槽,很适合用来做 NAS。花费¥429。
CPU 买了个 i3 9100T 二手散片。4 核 4 线程,带核显,可以硬解码,做 NAS 基本够用;TDP 35w,比较省电。花费¥135。
内存条选用七彩虹 DDR4 2666 8GB。说实话 8G 有点小,但是考虑到我的腾讯云服务器内存才 1G,苦日子过惯了,8G 凑合着也能用。花费¥119。
固态硬盘也是七彩虹的,CN600 128GB。Linux 系统盘 64G 都绰绰有余了,不过现在能买到的 NVMe 硬盘最小也有 128G。花费¥115。
机箱选的是疾风知 N52 NAS 机箱。它有 5 个盘位,硬盘仓支持安装风扇给硬盘散热。选它是因为我觉得它比较好看,而且相对便宜。花费¥229。
电源选了个 TT TRM SFX 350W。花费¥159。
散热器选了个铜芯铝鳍片的下压式散热器,花费¥27。硬盘仓风扇买的是利民的 12CM 无光静音风扇¥17。
总共花费¥1230。算下来,似乎并不是很划算😂。但自组 NAS 图的就是 DIY 的乐趣,为的是自由定制的权力,便不计较这个了。
系统安装的是 Ubuntu 24.04.3 LTS。我理解的 NAS 就是一台 Linux 服务器,需要什么服务就在上面装就好了,这样最能自由定制,因此没有选择飞牛之类的 NAS 专用系统。主板装好后,插入安装 U 盘试下能否点亮。成功点亮后,顺便也把系统装好了。

我本想用两块硬盘组一个 RAID 1,但是现在机械硬盘涨价严重,就只买一块 4 TB 的西数红盘。反正一块硬盘一时半会儿坏不了,等后面硬盘降价了(希望),再组成 RAID 1。
为了后续扩展成 RAID 1,我把这块 4 TB 的硬盘组成一个单盘的 RAID
1。首先使用 parted 创建分区,执行 sudo parted /dev/sda 进入
parted 交互界面,然后依次执行
(parted) mklabel gpt # 创建分区表
(parted) mkpart primary 0% 100% # 创建主分区
(parted) print # 打印查看下分区表
(parted) set 1 raid on # 标记为 raid 分区
然后使用 mdadm 创建 raid:
sudo mdadm --verbose --create /dev/md0 --level=1 --raid-devices=1 --force /dev/sda1
sudo mkfs.ext4 /dev/md0
然后挂载到 /data:
sudo mkdir /data
sudo mount /dev/md0 /data
# 挂载持久化
sudo blkid | grep /dev/md0 # 查看一下 UUID
echo UUID=ae65b749-4e1e-4209-ae57-15ec83578c5c /data ext4 defaults 0 0 | sudo tee -a /etc/fstab # 配置写入 /etc/fstab
Mdadm 的配置最好也持久化一下:
sudo mdadm --detail --scan | sudo tee -a /etc/mdadm/mdadm.conf
sudo update-initramfs -u
以后如果要加硬盘,可以执行以下命令即可:
sudo mdadm --grow /dev/md0 --raid-devices=2 --add /dev/sdb1
我对网络环境有几点要求。第一,不能只在内网访问,在外面也要能访问。第二,要用域名访问,用不同的域名区分不同的服务,而不是用 IP + 端口。第三,同一个服务在内网和外网的访问地址是一样的,这样回到家后不需要修改任何配置。
为了实现内网穿透,我的方案是使用 Tailscale。Tailscale 是一个基于 WireGuard 实现的 VPN,通过 UDP 打洞实现内网穿透。如果打洞成功,则可以直连通信,无需经由中继服务器;通信速度取决于带宽,非常方便。
Tailscale 非常容易使用。在机器上安装好 Tailscale 后,执行
tailscale up,访问链接登录账号,即可将当前主机加入这个账号下的
Tailscale 网络 (Tailnet)。
$ sudo tailscale up
To authenticate, visit:
https://login.tailscale.com/a/******
同时手机上也安装 Tailscale 客户端,登录账号后,也可以加入我的 tailnet。这样手机和 NAS 便可以随时通信。
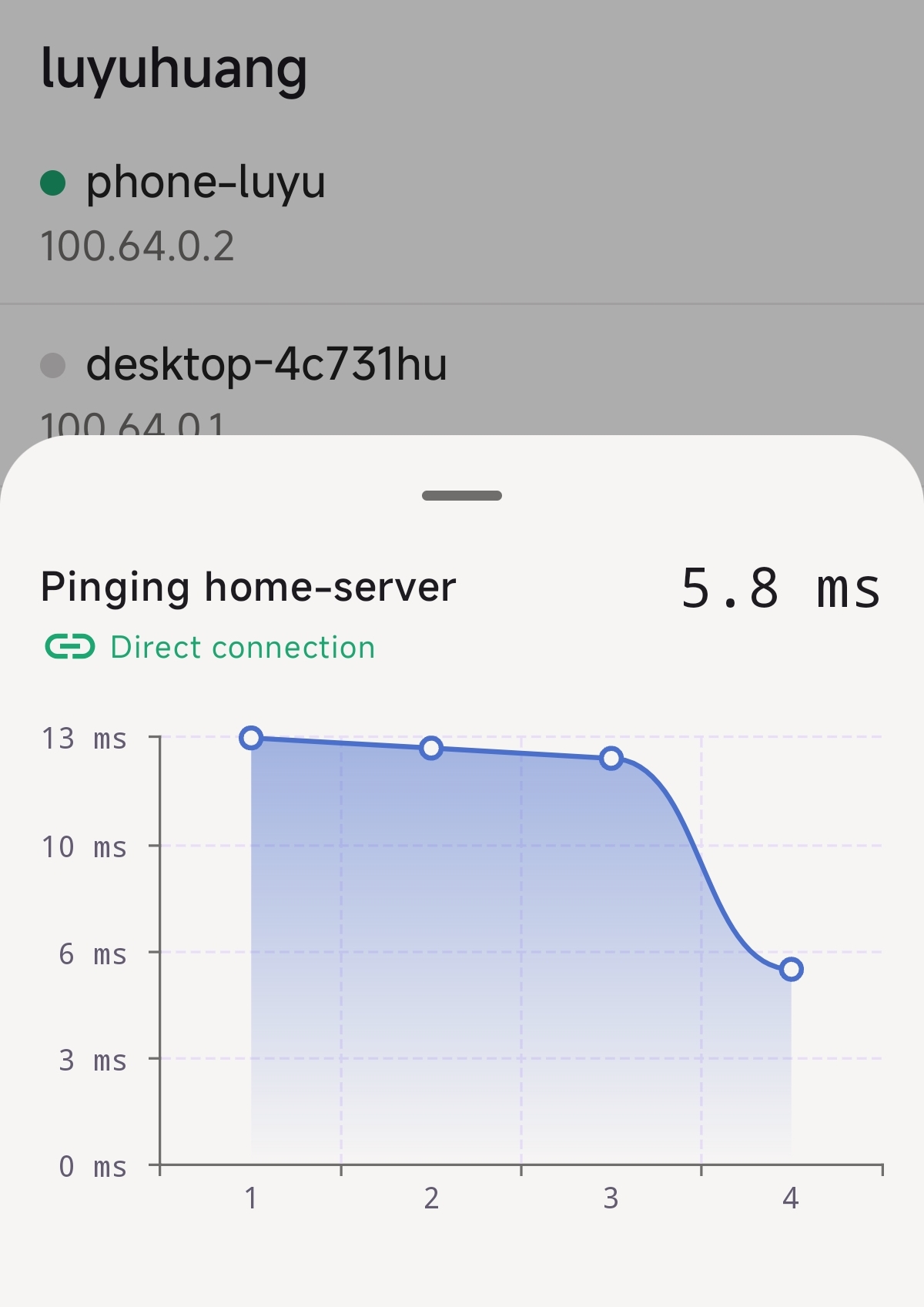
NAT 打洞也不是总能成功。根据 Tailscale 官方文档,如果通信双方都在 Hard NAT 中,则不能实现直连。就需要通过中继服务器(称为 DERP),速度很慢。
| Client A NAT Type | Client B NAT Type | Expected Connection |
|---|---|---|
| No NAT | No NAT | Direct |
| No NAT | Easy NAT | Direct |
| No NAT | Hard NAT | Direct |
| Easy NAT | Easy NAT | Direct |
| Easy NAT | Hard NAT | Relayed |
| Hard NAT | Hard NAT | Relayed |
好在现在宽带基本上都提供 ipv6 公网地址。我在光猫上开启允许内网设备使用 ipv6 通信,让 NAS 拥有公网 ipv6 地址。这样,使用 4G/5G 网络能 100% 直连;在外面连的 WIFI 如果支持 ipv6,也能直连。
我的目标是在家里连上家里的 WiFi,或者在外连上 VPN,都可以用同样的域名访问 NAS 上的服务。这首先要在 NAS 上部署一个 DNS 服务器。我使用的是 CoreDNS,它的配置非常简单:
.:53 {
bind 192.168.1.2
hosts {
192.168.1.2 nas.luyuhuang.tech
192.168.1.2 immich.luyuhuang.tech
ttl 60
reload 1m
fallthrough
}
forward . /etc/resolv.conf
cache 120
reload 6s
errors
}
这样的配置让 CoreDNS 监听 192.168.1.2:58,在
hosts 中配置域名解析规则。其他域名默认 forward 到系统 DNS
解析。在路由器中将 NAS 的 IP 地址固定为
192.168.1.2,并将首选 DNS 服务器设置为
192.168.1.2。这样任何通过我家路由器上网的设备都可以通过域名访问
NAS 上的服务。
为了让连上 VPN 的设备也能用同样的域名访问 NAS,我们在 Tailscale
的控制台设置一个 Split DNS,地址设置为 NAS 的虚拟 IP;并指定后缀为
luyuhuang.tech 的域名请求 NAS 上的 DNS 服务器。
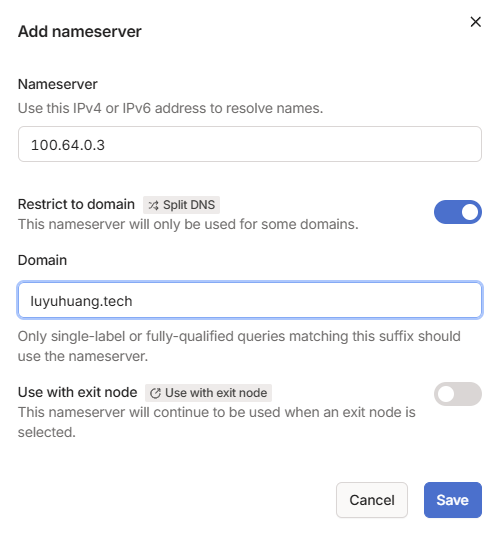
由于 NAS 的虚拟 IP 和物理局域网的 IP 不同,所以还要让 CoreDNS 监听虚拟 IP,解析结果也要返回虚拟 IP。
.:53 {
bind 100.64.0.3
hosts {
100.64.0.3 nas.luyuhuang.tech
100.64.0.3 immich.luyuhuang.tech
ttl 60
reload 1m
fallthrough
}
forward . /etc/resolv.conf
cache 120
reload 6s
errors
}
这样,例如同样是访问
nas.luyuhuang.tech,内网设备解析得到
192.168.1.2,连上 VPN 的设备则得到虚拟 IP
100.64.0.3。它们都可以用同样的域名访问 NAS。
我是用 Nginx 作为所有服务的反向代理,这样可以统一使用 80 或 443
端口,但使用不同的域名区分不同的服务。为了简单我直接使用 Docker 版的
Nginx,简单写个 docker-compose.yaml
即可。因为要反向代理到各种服务,网络模式使用 host 模式。
services:
nginx:
image: nginx
container_name: nginx
network_mode: host
volumes:
- ./config:/etc/nginx
- ./cert:/cert
restart: unless-stopped
我的域名 luyuhuang.tech 申请了 Let’s Encrypt
的证书,因此可以直接使用这个证书部署 HTTPS 服务。简单写个脚本同步证书到
NAS 上,这样也不用担心证书过期。
这样服务配置起来就很简单了。例如我的 Homepage 服务(下文会介绍)监听
http://127.0.0.1:4000,Nginx 这边就直接反代过去:
server {
listen 80;
server_name nas.luyuhuang.tech;
location / {
return 301 https://nas.luyuhuang.tech$request_uri;
}
}
server {
listen 443 ssl;
server_name nas.luyuhuang.tech;
include /etc/nginx/ssl.conf;
location / {
proxy_pass http://127.0.0.1:4000;
proxy_set_header Host nas.luyuhuang.tech;
}
}
这里介绍几个我的 NAS 上安装的服务。这些服务都是用 Docker 安装的,安装步骤都很简单,这里就不介绍了。
Immich 是一个自建相册服务。它自带 Android 和 iOS 手机客户端,可以将手机的相册同步到 NAS 上。实际上我这次搞 NAS 的导火索就是我的小米云相册的容量满了。它支持 AI 人脸识别、以文搜图的功能(需要 GPU 支持);支持地图足迹功能。我用下来体验还是很不错的。
Cloudreve 是自建网盘服务。它的网页端功能很不错,大多数格式的文件,无论是图片、音乐、视频,还是文档、压缩包,都可以直接在网页端打开。它支持 WebDAV,我用来作为笔记软件的同步服务;支持离线下载,我用来下载影音资源。它还支持各种云服务的对象存储,不过我暂时还没用到。缺点是没有 Android 客户端,iOS 客户端则需收费。
qBittorrent 不用介绍了吧,著名的 Bittorrent 下载器。它可以与 Cloudreve 联动,作为 Cloudreve 的离线下载器。在 Cloudreve 中创建离线下载任务,调用 qBittorrent 下载,下载完成自动存入 Cloudreve 网盘。
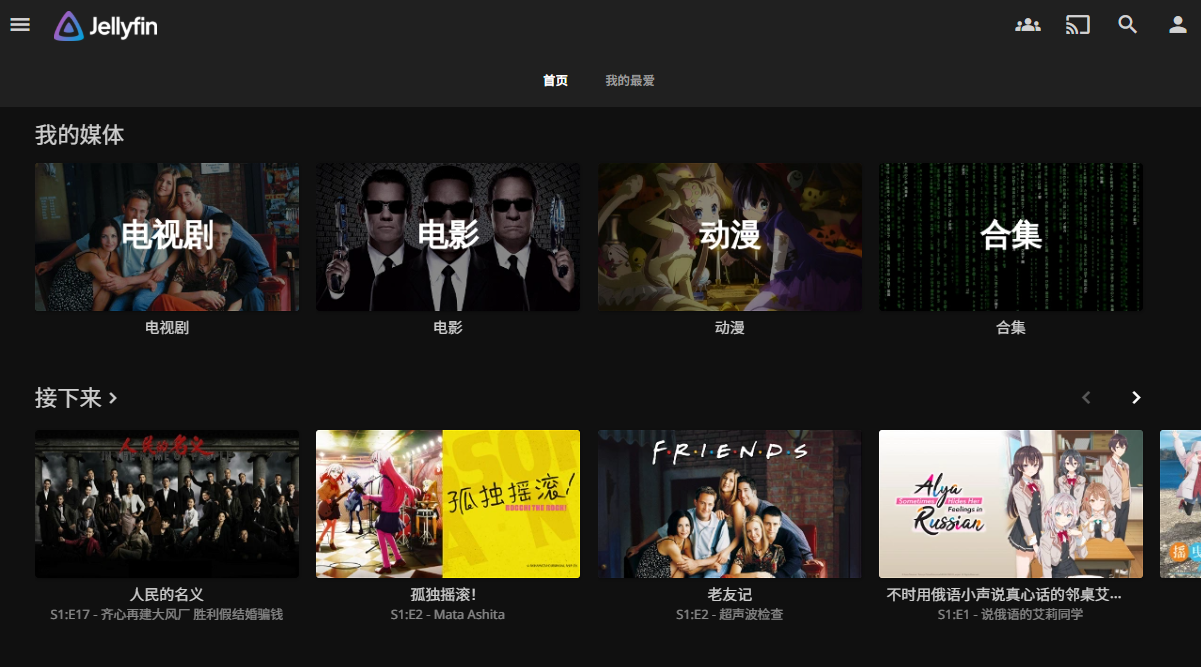
Jellyfin 是一个影视资源库。它将影视资源整理成影片和剧集,并从影视数据库中拉取海报、标题、介绍等元数据,方便观看。它能保存观看进度,并支持服务器解码(硬解码需要 GPU 支持),方便在各种设备中观看。除了网页端和 PC 客户端,它还支持手机客户端和 TV 客户端。
我让 Jellyfin 通过 WebDAV 挂载 Cloudreve,使用其中的影视资源。Jellyfin 本身不支持远程挂载,我使用 Rclone 的 Docker 插件,让 Docker 将 WebDAV 链接挂载成 Jellyfin 所在容器的 volume。
volumes:
cloudreve:
driver: rclone
driver_opts:
remote: 'cloudreve:'
read_only: 'true'
dir_cache_time: '1s'
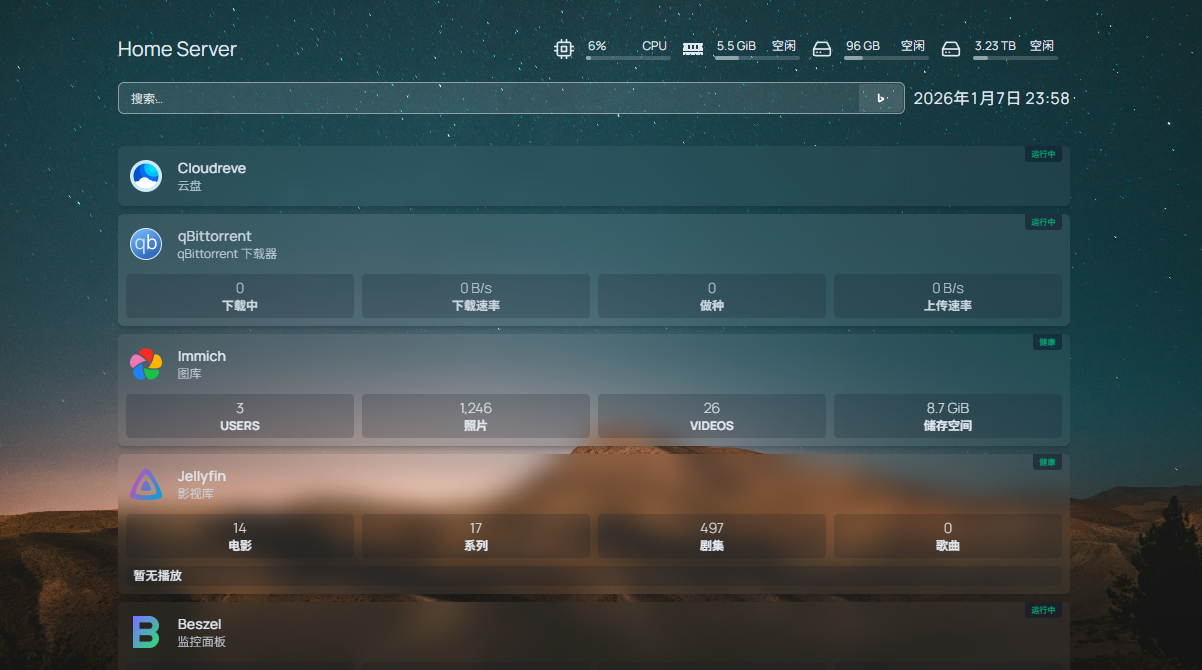
最后我还部署了 Homepage,将 NAS 上所有的服务都集中到一个主页,顺便还能显示机器的基本状态、各个服务的运行状态。
2025-07-27 00:00:00
一直以来文字排版都是一项复杂的工作。计算机出现不久后,人们就尝试用计算机取代铅字处理排版工作。现在计算机上的排版工具有很多。Microsoft
Office Word
可能是使用最广泛的排版工具。它容易上手,功能丰富,能够满足绝大多数办公场景。缺点是文件格式私有,价格昂贵;面对一些复杂排版需求(如公式排版)力不从心。随着
web 技术的发展,HTML + CSS 也可以作为排版工具;Markdown 这种可以编译成
HTML 的简易标记语言广泛应用于网络文字排版(本站的文章都是用 Markdown
写的)。但是 web
技术主要服务于网页设计,缺失换行、分页算法,也难以应对复杂排版。由著名计算机科学家、图灵奖获得者
Donald E. Knuth 发明的
来自柏林工业大学的计算机研究生 Martin Haug 和 Laurenz Mädje 不满足于
.typ。
= 这是标题
== 这是二级标题
为了展示Typst上手有多么简单,我们直接展示一段Typst代码。Typst的标记语法类似于Markdown:这是行内代码 `inline code`,这是*加粗*,这是斜体_italic_,这是公式 $e^(pi i) + 1 = 0$。
用空行表示分段。这是无序列表:
- 无序列表
- 用横杠 `-` 标记无序列表
- 多层列表
- 缩进表示多层列表
这是有序列表
+ 有序列表
+ 用加号 `+` 标记有序列表
- 同样支持多层
```c
int main() {
printf("三个反引号表示代码块,支持代码高亮\n");
return 0;
}
```
Typst还是一门强大的编程语言。可以调用函数实现各种样式:#text(size: 15pt, fill: red)[调用`text`函数插入自定义样式的文本。]还有#highlight(fill: yellow)[`highlight`高亮]、#underline(stroke: 1.5pt + red)[`underline`下划线]、#strike[`strike`删除线]等。实际上Typst的标记语法大多数都是函数的简便写法。例如#strong[`strong`加粗]、斜体#emph[italic]
#heading(depth: 3)[这是三级标题]
等价于 `=== 这是三级标题`。通过自定义函数,可以实现复杂的自定义效果。
#let myStyle(content) = { // 定义函数
let styled = text(size: 1.3em, fill: yellow, stroke: 0.3pt + red, font: "KaiTi", content)
return underline(stroke: 1.2pt + blue, styled)
}
这就是#myStyle[调用自定义函数的效果]。

Typst 的安装非常简单。如果你用 vscode,那么最简单的方法就是安装 Tinymist 插件。它是一个非常棒的 Typst 写作环境,能实现实时预览。
也可以在官网下载下载软件本体。Typst
只有一个可执行文件,执行 typst compile 即可将 Typst
源文件编译成 pdf。
$ typst compile test.typ
Typst 有三种模式:标记模式、数学模式和代码模式。默认为标记模式,使用类似 Markdown 的语法写作文本。数学模式用于编排数学公式;代码模式则用于实现各种可编程功能。这三种模式之间可以互相切换:
# 号切换到代码模式。#
后紧跟代码,直到整个语句结束都是代码模式。如果有歧义,可使用分号
; 标记语句结束。[...] 切换到标记模式。例如前面看到的
#strong[`strong`加粗],方括号内便可使用标记语法;这个语句将标记文本传入
strong 函数获得加粗效果。$...$ 切换到数学模式。如上面看到的,标记模式的语法与 Markdown 相似。基本上每个标记语法有对应的函数,后面我们介绍函数的用法。
| 语法 | 含义 | 元素函数 |
|---|---|---|
= 标题 |
等号的数量表示标题的层级 | heading |
*加粗* |
加粗字体 | strong |
_强调_ |
斜体强调。中文字体一般没有斜体,所以一般不生效。 | emph |
- 无序列表 |
无序列表 | list |
+ 有序列表 |
有序列表 | enum |
| 空行 | 分段 | parbreak |
`code` |
代码(是否为行内代码取决于是否分行写)。使用三个反引号可支持高亮:```c return 0;```
|
raw |
$y=k x + b$ |
数学公式(是否为行内公式取决于是否分行写) | 数学模式不是函数 |
更多语法见官方文档。
Typst 的数学语法不同于 LaTeX,但比它简单。Typst 中单个字母表示它本身;但多个字母表示特殊值或函数,类似于 LaTeX 省略反斜杠。如果要表示多个字母本身,就需要加双引号。

与 LaTeX 用花括号 {} 不同,Typst
中函数参数放在小括号里面,不同的参数用逗号 ,
分隔。上下标的用法与 LaTeX 一致,^ 表示上标,_
表示下标。此外 Typst 的数学公式有很多简便用法。例如 !=,<=,分数
\frac{a}{b} 可以用斜杠 / 等。

详细用法见 https://typst.app/docs/reference/math/
Typst 是完善的编程语言,有很多通用编程语言的特性。
#let factorial(x) = { // let 定义函数
let i = 1; // let 定义变量
let ans = 1;
while i <= x { // while 循环
ans *= i;
i += 1;
}
return ans; // 返回结果
}
#let a = 10; // 定义变量
#a;的阶乘等于#factorial(a) // 调用函数

下面展示了一些常用语法:
| 语法 | 含义 |
|---|---|
let a = 1 |
定义变量 |
let f(x, y) = { return x * y; } |
定义函数 |
let f(x, y) = x + y |
定义函数。如果没有 return
语句,函数的返回值等于函数体所有表达式的拼接 |
let f(x: 0, y: 0) = x + y |
带命名参数 (named argument)的函数定义。命名参数自带默认值,调用时是可选的 |
(x, y) => x + y |
匿名函数表达式 |
42, 0xff
|
整数 |
3.14, 1e10
|
浮点数 |
"hello" |
字符串 |
10pt, 1.5em
|
长度 |
90deg, 1rad
|
角度 |
50% |
比例 |
1fr |
分数 |
(1, 2, 3) |
数组 |
(a: 1, b: "ok") |
字典 |
a = 1 |
赋值 |
-a, a + b
|
一元运算符和二元运算符 |
f(a, b) |
调用函数 |
enum([a], [b]) |
调用 enum
函数,传入两个类型为标记内容 (content)
的参数([...] 切换到标记模式) |
enum(start: 2, [a], [b]) |
带命名参数的函数调用 |
enum(start: 2)[a][b] |
语法糖,与上面的写法等价。标记内容参数可以放在括号外面 |
x.y |
成员访问 |
x.flatten() |
方法调用 |
完整的语法见 https://typst.app/docs/reference/scripting/ 和 https://typst.app/docs/reference/foundations/
Typst
提供了很多用于实现各种样式的函数,例如文字样式、段落、图表、表格、列表等等,称为元素函数
(element function)。Typst
的标记语法基本上都是元素函数的简便写法。例如用于创建各种样式的文本的
text 函数,它有很多参数。下面列举了它的一小部分参数:
text(
font: str | array,
weight: int | str,
size: length,
fill: color,
stroke: none | length | color,
tracking: length,
spacing: relative,
lang: str,
str,
content,
) -> content
font 字体weight 字重。从细到粗分别是 "thin",
"extralight", "light", "regular",
"medium", "semibold", "bold",
"extrabold", "black"
size 字体大小。如 10pt,
1.5em
fill 填充色。如 red,
rgb("#eb27ba")
stroke 描边,可以是长度 + 颜色。如
0.3pt + red 表示 0.3 像素红色描边tracking 字母间距spacing 单词间距lang 语言str 字符串文本content 也可传入标记内容利用 text 函数我们就能生成各种各样的文本了。

完整的元素函数可参考 https://typst.app/docs/reference/model/。下面列出了一些例子:

如果每次使用自定义样式时都要显式调用元素函数,未免有些太麻烦了。Typst 提供了两种语法用于定制样式:set 规则和 show 规则。
Set
规则很容易理解:在文档中显示任何元素都实际上是调用元素函数的结果,那么
set 语句就是用于设置元素函数某些参数的默认值。例如
#set text(size: 20pt),那么所有文字的大小都会变成 20
点。

Set 规则作用范围是当前 block。所谓 block 就是内容块
[...] 或代码块 {...}。例如
#set text(fill: red) // 全局生效
#[
#set text(size: 20pt) // 当前 block 生效
红色 20 点文字
]
红色默认大小文字
#let bold(content) = {
set text(weight: "bold") // 当前函数的 block 生效
content
}
#bold[加粗字体]
正常字体
Set 规则非常实用。有些元素函数,例如 par(段落),
page(页面),
document(文档),我们很少直接调用它们,而是将它们应用 set
规则,设置它们的样式。
Show 规则的一种写法是关键词 show + 选择器 +
: + set 语句,表示将所有满足选择器的元素应用指定的 set
规则。最常用的选择器就是元素函数,例如下面的语句表示将所有的标题文字设置为海军蓝:
#show heading: set text(fill: navy)
另一种写法是 show + 选择器 + : +
函数,表示将所有满足选择器的元素传入指定函数。例如下面的语句表示将所有的超链接的样式设置为带下划线的蓝色文字:
#show link: (a) => underline(text(fill: blue, a))
选择器除了是元素函数外,还可以是以下几种:
show "Text": ...
所有匹配到指定字符串的内容应用指定样式。这在某些场景非常实用。 
show regex("\w+"): ...
所有匹配到指定正则表达式的内容应用指定样式。show heading.where(level: 1): ...
元素函数支持 .where
方法,返回一个选择器,只选择指定参数的元素。这个例子将所有 1
级标题应用指定样式show: ... 所有内容应用指定样式。如果
:
后面是函数,就会把整篇文档传入函数,这在模板的使用中非常常用。详细用法见 https://typst.app/docs/reference/styling/
Typst 很适合制作技术简历。在 Typst Universe 中,有很多简历模板。我们从中挑选一个,例如 basic resume。我们执行
typst init @preview/basic-resume:0.2.8
初始化一个 typst 工程。使用 vscode 打开
basic-resume/main.typ 便可以开始编辑了。
首先使用 import 语句引入 basic-resume 模块的内容。这里的
* 表示引入模块中的所有符号。
#import "@preview/basic-resume:0.2.8": *
接着用 let 定义一些可能会复用的变量。接下来是最关键的
show 语句:
#show: resume.with(
author: name,
location: location,
email: email,
...
)
resume 是 basic-resume
模块中定义的一个函数。我们可以看到它的定义:
#let resume(
author: "",
location: "",
email: "",
...
body,
) = {
...
}
它本质上是一个有很多命名参数和一个普通参数 body
的函数,将内容 body 转换成一篇简历并返回。而
with
实际上是函数对象的一个方法,它返回一个预应用了给定参数的新函数。例如函数
let f(a, b) = a + b,f.with(1) 就等价于
(b) => f(1, b)。那么这里 resume.with(...)
就得到一个各种命名参数设置好了的新函数。这里的 show
语句会将整个文档作为参数传入这个新函数,我们就能得到一篇简历了。
接下来就是简历正文,也就是被传入 resume
函数的内容。其中的各种语法我们已经基本上已经介绍过了,这里无非是调用模板中定义的函数插入各种内容。例如
#edu(...) 插入教育经历、#work(...)
插入工作经历、#project(...) 插入项目经历等。
编辑完成后,点击 “Export PDF”,或者手动执行
typst compile main.typ 就可以得到 PDF 格式的简历了。
过去我总觉得各种排版系统都不是特别好:Word 排版效果一般,且不便版本控制;Markdown 排版能力弱;LaTeX 古老且使用复杂,编译缓慢。直到发现了 Typst,使用过后立刻就喜欢上了。本文只是简单推荐,而不是详细的教程。如果要深入学习,可参考 Typst 官方文档 https://typst.app/docs,或者直接咨询 AI。
2025-03-30 00:00:00
Clang 是一个基于 LLVM 的 C/C++ 编译器,与 GCC 相比有一些优势
如果 Linux 发行版比较新,可以直接用包管理器安装;但如果发行版比较老旧,就只能编译安装了。本文介绍一些编译安装 clang 的方法。
Clang 是 LLVM 项目的一部分。LLVM 是一个编译器基础设施,它定义一种中间代码 (IR),并且能够将这种中间代码编译成各个平台 (x86, ARM, …) 的机器码。这在 LLVM 中称为编译器后端。而 clang 则是 C/C++ 的编译器前端,负责将 C/C++ 代码编译成 LLVM 中间代码。因此要编译安装 clang,我们就要编译 LLVM。
我们进入 LLVM 官网的下载页面 https://releases.llvm.org/ 下载 LLVM 源码。LLVM 10.0.0 之后提供整合包 llvm-project 下载,包含 clang 在内的各种 LLVM 组件。以最新的 20.1.0 为例,我们直接下载 LLVM 20.1.0 并解压
curl -LO https://github.com/llvm/llvm-project/releases/download/llvmorg-20.1.0/llvm-project-20.1.0.src.tar.xz
unxz llvm-project-20.1.0.src.tar.xz
tar -xf llvm-project-20.1.0.src.tar
LLVM 使用 CMake 构建,要求版本至少为 3.20.0。进入 llvm-project 目录,接着创建 build 目录,然后执行 cmake
cd llvm-project-20.1.0.src
mkdir build && cd build
cmake ../llvm -DCMAKE_BUILD_TYPE=Release \
-DLLVM_ENABLE_PROJECTS='clang' \
-DLLVM_ENABLE_RUNTIMES='compiler-rt;libcxx;libcxxabi;libunwind'
CMake 这一步可以传入各种参数,这里介绍一些常用的参数
CMAKE_BUILD_TYPE 构建类型,可以为 Debug,
Release, RelWithDebInfo, 或
MinSizeRel。默认为 Debug,一般设置为
Release。DLLVM_ENABLE_PROJECTS 启用的组件。llvm-project
中有很多组件,除了 clang,常用的还有
clang-tools-extra 额外工具集。包含 clangd, clang-tidy,
clang-doc, clang-include-fixer 等。lldb 调试器。Clang 编译的程序用 gdb
调试可能会遇到各种问题,最好用 lldb 调试。lld 链接器,可替代 ld。bolt, polly, libclc
等组件,具体可参见 LLVM 文档。多个组件之间用分号 ;
分隔。DLLVM_ENABLE_RUNTIMES 启用的运行时组件。常用的组件有
compiler-rt 编译器运行时。如果要用 Sanitizer
系列工具(如 ASan),则必选。libcxx 和 libcxxabi 是 LLVM 的 C++
标准库实现。Clang 默认将程序链接到系统的 libstdc++,但如果要链接到 LLVM
的标准库 libc++,这两个必选libunwind 实现堆栈展开的库。如果要链接到
libc++,则必选。libc, llvm-libgcc,
offload 等组件,具体可参见 LLVM 文档。多个组件之间用分号
; 分隔。CMAKE_INSTALL_PREFIX 安装路径前缀,默认为
/usr/local。CMAKE_C_COMPILER 和 CMAKE_CXX_COMPILER
分别指定 C 和 C++ 的编译器,默认为 gcc 和
g++。后面我们会用到这两个参数。LLVM_ENABLE_LIBCXX 是否链接到 libc++。默认链接到
libstdc++。后面我们会用到这个参数。如果 LLVM 的各个依赖项都没有问题、这一步成功后,便可执行
make 开始构建
make -j8 # 根据机器情况调整线程数
如果一切顺利,执行 sudo make install
即可完成安装。安装前可以执行 make check-clang 执行 clang
的测试用例,确认没有问题。
要成功构建 LLVM 20.1.0,GCC 版本至少为 7.4。然而在一些老旧发行版(如 CentOS 7)中,GCC 版本并不能满足要求。为此我们需要先用系统的老版编译器编译一个新版编译器,再用新版编译器编译 LLVM。
# 下载 gcc-9.1.0
curl -LO https://ftp.gnu.org/gnu/gcc/gcc-9.1.0/gcc-9.1.0.tar.xz
unxz gcc-9.1.0.tar.xz
tar -xf gcc-9.1.0.tar
cd gcc-9.1.0
# 安装依赖
./contrib/download_prerequisites
./configure --prefix=${HOME}/toolchains # 安装到 ~/toolchains
make -j8
make install
这里我们编译的 gcc-9.1.0 是用于构建 LLVM
的“临时”编译器,我们不把它安装到系统目录
(/usr/local/),而是安装到 ~/toolchains。GCC
是系统编译器,不可随意升级,否则可能导致系统其它软件出现兼容性问题。
接着我们用刚刚编译的 gcc-9.1.0 构建 LLVM。
cd llvm-project-20.1.0.src
mkdir build && cd build
cmake ../llvm -DCMAKE_C_COMPILER=${HOME}/toolchains/bin/gcc \
-DCMAKE_CXX_COMPILER=${HOME}/toolchains/bin/g++ \
-DCMAKE_BUILD_TYPE=Release \
-DLLVM_ENABLE_PROJECTS='clang' \
-DLLVM_ENABLE_RUNTIMES='compiler-rt;libcxx;libcxxabi;libunwind'
LD_LIBRARY_PATH=${HOME}/toolchains/lib:${HOME}/toolchains/lib64 make -j8
这里我们用 -DCMAKE_C_COMPILER 和
-DCMAKE_CXX_COMPILER 指定 C/C++ 编译器的完整路径,也就是
gcc-9.1.0 的安装路径 ~/toolchains/ 下的
bin/gcc 和 bin/g++。LLVM
构建过程中会执行编译出来的工具,这些工具都依赖于 gcc-9.1.0 的 C++
运行库。因此我们要用环境变量 LD_LIBRARY_PATH
指定动态库路径,确保它们能正常运行。
因为这样构建的 LLVM 工具链都依赖于 gcc-9.1.0 的运行库,我们要设置好
LD_LIBRARY_PATH 才能正常运行它们。
$ bin/clang --version # 直接运行通常会出现 libstdc++ 不兼容的报错
bin/clang: /lib64/libstdc++.so.6: version `GLIBCXX_3.4.26' not found (required by bin/clang)
$ LD_LIBRARY_PATH=${HOME}/toolchains/lib:${HOME}/toolchains/lib64 bin/clang --version # 需要指定 gcc-9.1.0 的动态库路径
clang version 20.1.0
Target: x86_64-unknown-linux-gnu
Thread model: posix
InstalledDir: /home/luyuhuang/llvm-project-20.1.0.src/build/bin
$ LD_LIBRARY_PATH=${HOME}/toolchains/lib:${HOME}/toolchains/lib64 ldd bin/clang
linux-vdso.so.1 => (0x00007fffe95c9000)
libpthread.so.0 => /lib64/libpthread.so.0 (0x00007f470cbbb000)
librt.so.1 => /lib64/librt.so.1 (0x00007f470c9b3000)
libdl.so.2 => /lib64/libdl.so.2 (0x00007f470c7af000)
libz.so.1 => /lib64/libz.so.1 (0x00007f470c599000)
libstdc++.so.6 => /home/luyuhuang/toolchains/lib64/libstdc++.so.6 (0x00007f470c1c0000)
libm.so.6 => /lib64/libm.so.6 (0x00007f470bebe000)
libgcc_s.so.1 => /home/luyuhuang/toolchains/lib64/libgcc_s.so.1 (0x00007f470bca6000)
libc.so.6 => /lib64/libc.so.6 (0x00007f470b8e2000)
/lib64/ld-linux-x86-64.so.2 (0x00007f470cdd7000)
前面使用 gcc-9.1.0 编译的 LLVM 工具链虽然可以运行,但是却依赖于 gcc-9.1.0 的运行库。由于系统的 C++ 运行库不能随意升级,我们不便将 gcc-9.1.0 的运行库安装到系统中。这里比较合适的做法是让 clang 做一次 bootstrap(自举),用 gcc-9.1.0 编译的 clang 构建 LLVM,并链接到 LLVM 的 C++ 运行库(也就是 libc++)。
cd llvm-project-20.1.0.src
mkdir build1 && cd build1 # 创建一个新的构建目录
cmake ../llvm -DCMAKE_C_COMPILER= $(realpath ../build)/bin/clang \ # 使用 ../build 目录下,用 gcc-9.1.0 编译的 clang 构建
-DCMAKE_CXX_COMPILER= $(realpath ../build)/bin/clang++ \
-DLLVM_ENABLE_LIBCXX=ON \ # 使用 LLVM 的 libc++
-DCMAKE_BUILD_TYPE=Release \
-DLLVM_ENABLE_PROJECTS='clang' \
-DLLVM_ENABLE_RUNTIMES='compiler-rt;libcxx;libcxxabi;libunwind'
LD_LIBRARY_PATH=${HOME}/toolchains/lib:${HOME}/toolchains/lib64:$(realpath ../build)/lib/x86_64-unknown-linux-gnu make -j8
这里我们则是将编译器路径设置成前面用 gcc-9.1.0 编译的 clang
的路径。同时设置 -DLLVM_ENABLE_LIBCXX=ON 链接到 LLVM 的
libc++。最后注意环境变量 LD_LIBRARY_PATH 除了需要指定
gcc-9.1.0 的运行库路径之外,还需要指定前面 gcc-9.1.0 编译的 LLVM
的运行库路径。
构建完成后,执行 sudo make install 安装即可。由于 LLVM
20.1.0 的 C++ 运行库位于
lib/x86_64-unknown-linux-gnu/(更老版本的 LLVM 则直接在
lib/ 里),我们通常需要再配置下动态库搜索路径。
echo /usr/local/lib/x86_64-unknown-linux-gnu >> /etc/ld.so.conf
ldconfig
这样安装的 clang 就能正常运行了。
$ clang --version
clang version 20.1.0
Target: x86_64-unknown-linux-gnu
Thread model: posix
InstalledDir: /usr/local/bin
$ ldd /usr/local/bin/clang
linux-vdso.so.1 => (0x00007ffc6d57c000)
libpthread.so.0 => /lib64/libpthread.so.0 (0x00007fca001ae000)
librt.so.1 => /lib64/librt.so.1 (0x00007fc9fffa6000)
libdl.so.2 => /lib64/libdl.so.2 (0x00007fc9ffda2000)
libm.so.6 => /lib64/libm.so.6 (0x00007fc9ffaa0000)
libz.so.1 => /lib64/libz.so.1 (0x00007fc9ff88a000)
libc++.so.1 => /usr/local/lib/x86_64-unknown-linux-gnu/libc++.so.1 (0x00007fc9ff583000)
libc++abi.so.1 => /usr/local/lib/x86_64-unknown-linux-gnu/libc++abi.so.1 (0x00007fc9ff33b000)
libunwind.so.1 => /usr/local/lib/x86_64-unknown-linux-gnu/libunwind.so.1 (0x00007fc9ff12e000)
libgcc_s.so.1 => /lib64/libgcc_s.so.1 (0x00007fc9fef18000)
libc.so.6 => /lib64/libc.so.6 (0x00007fc9feb54000)
/lib64/ld-linux-x86-64.so.2 (0x00007fca0ad52000)
libatomic.so.1 => /lib64/libatomic.so.1 (0x00007fc9fe94c000)
参考资料:
2025-02-16 00:00:00
在 C++ 开发中,内存越界是很头痛的问题。这类问题往往非常隐蔽,难以排查,且难以复现。为了排查这类问题,我们可以使用 Address Sanitizer 这个工具。
Address Sanitizer (aka ASan) 是 Google 开发的一款内存错误排查工具,帮助开发这定位各种内存错误,目前已经集成在主流工具链中。LLVM 3.1 和 GCC 4.8 以上的版本均支持 ASan。本文介绍 ASan 的使用方法和其基本原理。
在支持 ASan 的编译器加上编译参数 -fsanitize=address
即可开启 ASan。例如我们有代码 test.c:
#include <stdlib.h>
#include <stdio.h>
int main() {
int *p = malloc(sizeof(int));
p[1] = 42;
return 0;
}
虽然存在内存越界写入,但是使用常规方法编译后,是能够“正常”运行的:
$ gcc -o test test.c
$ ./test
42
加上编译参数 -fsanitize=address 启用 ASan
后,运行便会触发 ASan 报错:
$ gcc -o test test.c -fsanitize=address -g
$ ./test
=================================================================
==65982==ERROR: AddressSanitizer: heap-buffer-overflow on address 0x602000000014 at pc 0x5600b2a24202 bp 0x7ffda82b5c70 sp 0x7ffda82b5c60
WRITE of size 4 at 0x602000000014 thread T0
#0 0x5600b2a24201 in main (/home/luyuhuang/test+0x1201)
#1 0x7f7eee24c082 in __libc_start_main ../csu/libc-start.c:308
#2 0x5600b2a240ed in _start (/home/luyuhuang/test+0x10ed)
0x602000000014 is located 0 bytes to the right of 4-byte region [0x602000000010,0x602000000014)
allocated by thread T0 here:
#0 0x7f7eee527808 in __interceptor_malloc ../../../../src/libsanitizer/asan/asan_malloc_linux.cc:144
#1 0x5600b2a241be in main (/home/luyuhuang/test+0x11be)
#2 0x7f7eee24c082 in __libc_start_main ../csu/libc-start.c:308
...
ASan 告诉我们程序触发了一个堆越界 (heap-buffer-overflow) 的报错,尝试在地址 0x602000000014 写入 4 字节数据。随后打印出出错位置的堆栈。第 10 行 ASan 还告诉我们越界的内存是在哪个位置被分配的,随后打印出分配位置的堆栈。
ASan 的参数有编译参数和运行时参数两种。常用的编译参数有:
-fsanitize=address 启用 ASan-fno-omit-frame-pointer 获得更好的堆栈信息--param FLAG=VAL 传入,LLVM
使用 -mllvm -FLAG=VAL 传入:
asan-stack 是否检测栈内存错误,默认启用。GCC 使用
--param asan-stack=0、LLVM 使用
-mllvm -asan-stack=0 关闭栈内存错误检测。asan-global
是否检测全局变量内存错误,默认启用。同理使用
--param asan-global=0 或 -mllvm -asan-global=0
可关闭。运行时参数通过环境变量 ASAN_OPTIONS
设置,每个参数的格式为 FLAG=VAL,参数之间用冒号
: 分隔。例如:
$ ASAN_OPTIONS=handle_segv=0:disable_coredump=0 ./test
常用的运行时参数有:
log_path: ASan 报错默认输出在
stderr。使用这个参数可以指定报错输出的路径。abort_on_error: 报错时默认使用 _exit
结束进程。指定 abort_on_error=1 则使用 abort
结束进程。disable_coredump: Asan 默认会禁用 coredump。指定
disable_coredump=0 启用 coredump。detect_leaks: 是否启用内存泄漏检测,默认启用。ASan
还包含 LSan (Leak Sanitizer) 内存泄露检测模块。handle_*: 信号控制选项。ASan
默认会注册一些信号处理函数,参数置 0 表示让 ASan
不注册相应的信号信号处理器,置 1 则注册信号信号处理器,置 2
则注册信号处理器并禁止用户修改。
handle_segv: SIGSEGVhandle_sigbus: SIGBUShandle_abort: SIGABRThandle_sigill: SIGILLhandle_sigfpe: SIGFPE因为 ASan 默认会注册 SIGSEGV
的信号处理器,所以当程序发生段错误时,会触发 ASan 的报错而不是直接
coredump。要想让程序像往常一样产生 coredump,可以指定参数
handle_segv=0 不注册信号处理器,和
disable_coredump=0 启用 coredump。
有些函数可能会做一些比较 hack 操作,又想绕过 Asan
的越界检测。这可以通过声明属性
__attribute__((no_sanitize_address)) 实现。例如
__attribute__((no_sanitize_address))
size_t chunk_size(void *p) {
return *((size_t*)p - 4);
}
这样即使 chunk_size 访问越界,ASan 也不会报错。
更多参数可参考官方文档。
ASan 需要检测的是应用程序是否访问已向操作系统申请、但未分配给应用程序的内存,也就是下图中红色的部分。至于图中白色的部分,也就是未向操作系统申请的内存,是不需要检测的(一旦访问就会触发段错误)。
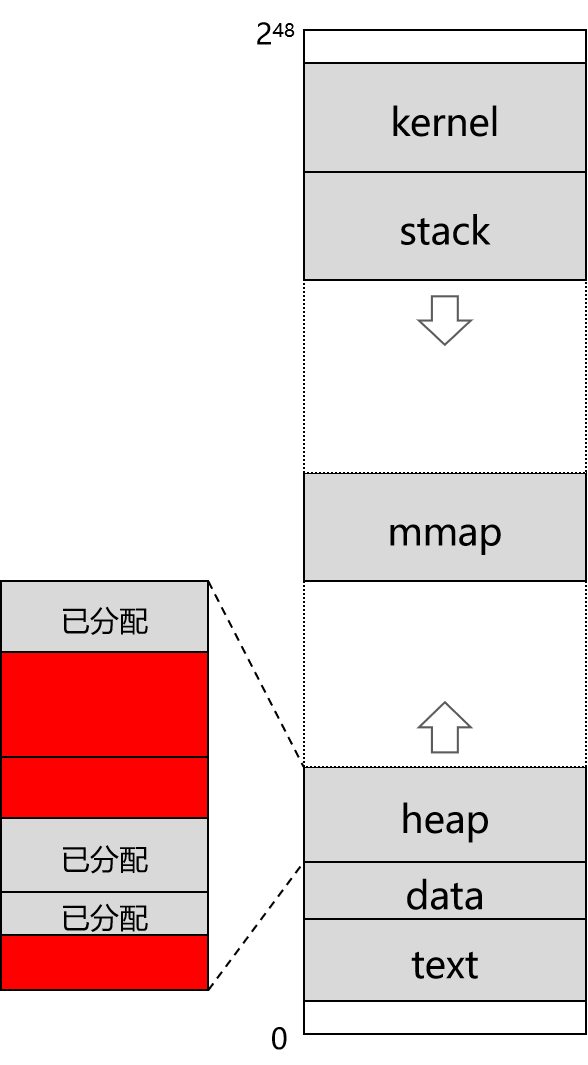
ASan 会 hook 标准内存分配函数(malloc、free 等),所有未被分配和已释放的区域都会标记为红区。所有内存的访问都会被检查,如果访问了红区的内存,asan 会立刻报错。例如,原本简单的内存访问
*address = ...; // or: ... = *address;
在启用 ASan 后,会生成类似如下的代码:
if (IsPoisoned(address)) {
ReportError(address, kAccessSize, kIsWrite);
}
*address = ...; // or: ... = *address;
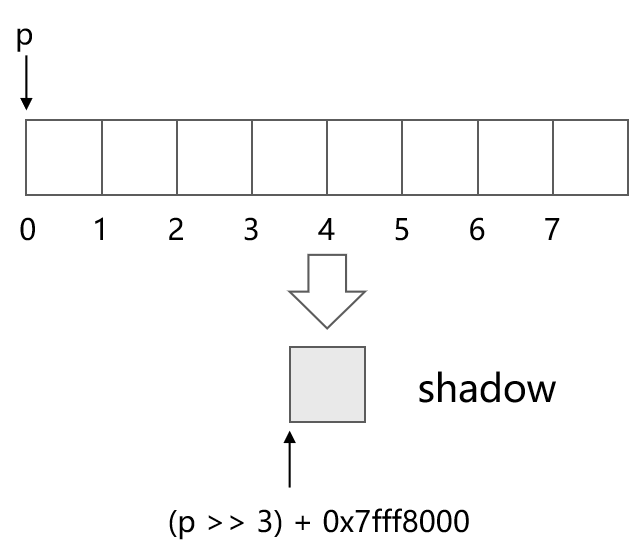
为了标记内存是否为红区,ASan 将每 8 字节内存映射成 1 字节的 shadow
内存,在 shadow 内存中标记这 8 字节内存的使用情况。64 位系统中,地址 p
对应的 shallow 内存的地址为
(p >> 3) + 0x7fff8000。
因为 malloc 分配的内存必然是 8 字节对齐的。这样的话只有 9 种情况:
例如 malloc(11) 分配 11
字节内存的情况,如下图所示。第一个 8 字节都不在红区,对应的 shadow
内存值为 0;第二个 8 字节前 3 字节不在红区,后 5 字节在红区,对应的
shadow 内存值为 3。第三个 8 字节都在红区,对应的 shadow
内存值为负数。

这样,整个地址空间被分为 5 个部分。HighMem 对应 HighShadow,LowMem 对应 LowShadow。如果一个地址对应的 shallow 内存在 ShadowGap 区域,则这个地址不可访问。因为 64 位机器的虚拟内存地址空间很大,这样划分后地址仍然很够用。
| 地址区间 | 区域 |
|---|---|
| [0x10007fff8000, 0x7fffffffffff] | HighMem |
| [0x02008fff7000, 0x10007fff7fff] | HighShadow |
| [0x00008fff7000, 0x02008fff6fff] | ShadowGap |
| [0x00007fff8000, 0x00008fff6fff] | LowShadow |
| [0x000000000000, 0x00007fff7fff] | LowMem |
这样,每当程序要访问内存时,ASan 都会做如下检查:
char *pShadow = ((intptr_t)address >> 3) + 0x7fff8000; // 计算得到 shadow 内存地址
if (*pShadow) { // 如果 shadow 内存不为 0,做进一步检查
int last = ((intptr_t)address & 7) + kAccessSize - 1; // address % 8 + kAccessSize - 1 计算这次访问的最后一个字节
if (last >= *pShadow) { // 如果 last >= shadow 则报错
ReportError(address, kAccessSize, kIsWrite);
}
}
*address = ...; // or: ... = *address;
假设某 8 字节内存后 3 字节在红区,程序要从第 4 字节开始访问两字节,如下图所示。那么有 address % 8 = 4,last = 4 + 2 - 1 = 5 >= shadow,因此这次访问是越界访问,ASan 就会报错。

了解了 ASan 原理之后就能更好地理解 ASan 的报错信息。ASan 报错时会打印出报错位置的 shadow 内存情况:
SUMMARY: AddressSanitizer: heap-buffer-overflow (/home/luyuhuang/test+0x1201) in main
Shadow bytes around the buggy address:
0x0c047fff7fb0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x0c047fff7fc0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x0c047fff7fd0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x0c047fff7fe0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x0c047fff7ff0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
=>0x0c047fff8000: fa fa[04]fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c047fff8010: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c047fff8020: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c047fff8030: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c047fff8040: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c047fff8050: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
程序试图在 0x602000000014 写入 4 字节数据。 0x602000000014 对应的
shadow 内存地址为 (0x602000000014 >> 3) + 0x7fff8000 =
0x0c047fff8002,也就是上面 [04] 的位置。0x602000000014 % 8
= 4,从这 8 字节的第 4 字节开始访问四字节。而这 8
字节后四字节都在红区,因此访问越界。
参考资料: https://github.com/google/sanitizers/wiki/AddressSanitizer
2024-06-14 00:00:00
协程与线程(进程)[1]都是模拟多任务(routine)并发执行的软件实现。操作系统线程在一个 CPU 线程中模拟并发执行多个任务,而协程(coroutine)在一个操作系统线程中模拟并发执行多个任务。 因此协程也被称为“用户态线程”、“轻量级线程”。之所以说“模拟并发执行”,是因为任务实际并没有同时运行,而是通过来回切换实现的。

线程切换由操作系统负责,而协程切换通常由程序员直接控制。程序员通过 resume/yield 操作控制协程切换。resume 操作唤醒一个指定协程;yield 操作挂起当前协程,切换回唤醒它的协程。如果你用过 Lua 的协程,就会很熟悉这套流程。不过 Lua 是基于 Lua 虚拟机(LVM)的脚本语言,它只需要 LVM 中执行“虚拟的”上下文切换。本文介绍如何用 C 语言(和一点点汇编)实现一个 native 协程,执行真正的上下文切换。这个实现非常简单,总共不到 200 行代码。我参考了 libco 的实现。本文的完整代码见 toy-coroutine。
所谓的上下文,就是一段程序之前做了什么,接下来要做什么,以及做事情过程的中间产物。例如我们有函数
f。f
需要知道下一个指令是什么才能接着往下执行,便是“接下来要做什么”。f
函数还需要知道之前是谁调用了它,以便把结果返回给调用者,便是“之前做了什么”。在
f
函数执行过程中,局部变量要存好(不能被写坏),接下来的指令才能正确执行。这便是“过程的中间产物”。
在 x86-64 下,“之前做了什么” 存储在栈里。函数调用会执行
call
指令,把当前函数的下一个指令的地址压入栈顶,然后再跳转到被调用函数。被调用函数返回时执行
ret
指令,从栈顶取出调用者的返回点地址,然后跳转到返回点。因此栈上存有所有前序调用者的返回点地址。
函数的局部变量通常储存在 16 个通用寄存器中,如果寄存器不够用,就存在栈里(只要在函数返回前将它们弹出,让栈顶是返回点地址即可)。函数调用的参数也是局部变量,存在约定的 6 个通用寄存器里。如果不够用,也存在栈里。
至于“接下来要做什么”,其实也在栈里。上下文切换不过是调用一个函数,调用者在调用它之前已经把下一个指令的地址压栈了。当上下文切换函数返回,ret
指令自然会跳转到接下来要执行的指令。所以上下文就是 16 个通用寄存器 +
栈。
所有的协程共享同一个 CPU,也就共享同样的 16
个通用寄存器。如果我们要把 A 协程切换成 B 协程,就要把当前 16
个通用寄存器的值存在 A 协程的数据结构里;然后再从 B 协程的数据结构里取出
B
协程的寄存器的值,写回通用寄存器中。我们还要处理栈。不过栈与寄存器不同,x86-64
规定 %rsp
寄存器(也是通用寄存器之一)存的值便是栈顶的地址。不同的协程不必共享栈,它们可以分配各自的栈,上下文切换时将
%rsp 指向各自的栈顶即可。
实际上我们不必存储全部的 16 个通用寄存器,它们有些是暂存寄存器(Scratch Registers),是允许被写坏的。这些寄存器的值可能在执行一次函数调用后就变了(被被调用函数写坏的)。编译器也不会在暂存寄存器里存储函数调用后还要用的值。参考 libco 的实现,我们存储 13 个寄存器:
enum {
CO_R15 = 0,
CO_R14,
CO_R13,
CO_R12,
CO_R9,
CO_R8,
CO_RBP,
CO_RDI,
CO_RSI,
CO_RDX,
CO_RCX,
CO_RBX,
CO_RSP,
};
struct co_context {
void *regs[13];
};
有些寄存器有特殊的用途。这里我们只需要知道这三个:
%rsp: 栈寄存器,指向栈顶。%rdi, %rsi:
第一参数寄存器和第二参数寄存器,调用函数前将第一个参数存在
%rdi 里,第二个存在 %rsi 里(剩下的四个依次是
%rdx, %rcx, %r8,
%r9, 不过这里我们用不上),然后执行 call
指令。接着我们定义一个函数做上下文切换,把当前通用寄存器的值保存在
curr 中,再把 next
中保存的寄存器的值写回各个通用寄存器。
extern void co_ctx_swap(struct co_context *curr, struct co_context *next);
Emm,这个函数没法用 C
语言实现,我们得用到一点点汇编了。其实非常简单,我们只需要用
movq 指令存取寄存器。代码如下:
.globl co_ctx_swap
co_ctx_swap:
movq %rsp, 96(%rdi)
movq %rbx, 88(%rdi)
movq %rcx, 80(%rdi)
movq %rdx, 72(%rdi)
movq %rsi, 64(%rdi)
movq %rdi, 56(%rdi)
movq %rbp, 48(%rdi)
movq %r8, 40(%rdi)
movq %r9, 32(%rdi)
movq %r12, 24(%rdi)
movq %r13, 16(%rdi)
movq %r14, 8(%rdi)
movq %r15, (%rdi)
movq (%rsi), %r15
movq 8(%rsi), %r14
movq 16(%rsi), %r13
movq 24(%rsi), %r12
movq 32(%rsi), %r9
movq 40(%rsi), %r8
movq 48(%rsi), %rbp
movq 56(%rsi), %rdi
movq 72(%rsi), %rdx
movq 80(%rsi), %rcx
movq 88(%rsi), %rbx
movq 96(%rsi), %rsp
movq 64(%rsi), %rsi
ret
不懂汇编没关系(其实我也不是很懂),只需要知道 movq
指令将第一个操作数的值复制到第二个操作数中。%
开头的标识符为寄存器。%rsp
这样不带括号的,表示存取寄存器的值。(%rdi)
这种带括号的,表示去内存里存取地址为 %rdi
的数据。如果括号前面有数字几,就表示这个地址要加几。movq
存取数据的长度为 8 字节,寄存器的长度也是 8 字节。
还记得前面说过,%rdi 是第一个参数,%rsi
是第二个参数吗?所以 %rdi 就是
struct co_context *curr。96(%rdi) 就是
curr->regs[12],88(%rdi) 就是
curr->regs[11],……,(%rdi) 就是
curr->regs[0]。上半部分把 13 个通用寄存器的值全部存到了
curr 里。同理 %rsi 就是
struct co_context *next。(%rsi) 就是
next->regs[0]、8(%rsi) 就是
next->regs[1],依次类推。于是下半部分把
next 中保存的寄存器的值写回寄存器中。最后执行
ret 指令返回。
注意 29 行写入 %rsp 的值就是上次挂起时第 4
行保存的值,这个值我们原封未动,也没有做任何栈操作。因此最后
ret 返回时,栈顶就是 co_ctx_swap
的调用者设置的返回点地址。一个协程调用 co_ctx_swap
将自己挂起,便陷入沉睡。当 co_ctx_swap
返回之时,便是其它协程调用 co_ctx_swap
将它唤醒之时。此时寄存器被还原、栈被还原、也回到了返回点。它便知道自己之前做了什么、接下来要做什么、中间产物是怎样的。
struct co_context
仅存储协程的上下文。我们还需要维护给协程分配的栈空间、记录入口函数地址等。我们定义
struct coroutine 表示协程对象。
typedef void (*start_coroutine)();
struct coroutine {
struct co_context ctx;
char *stack;
size_t stack_size;
start_coroutine start;
};
struct coroutine *co_new(start_coroutine start, size_t stack_size) {
struct coroutine *co = malloc(sizeof(struct coroutine));
memset(&co->ctx, 0, sizeof(co->ctx));
if (stack_size) {
co->stack = malloc(stack_size);
} else {
co->stack = NULL;
}
co->stack_size = stack_size;
co->start = start;
return co;
}
void co_free(struct coroutine *co) {
free(co->stack);
free(co);
}
co_new 创建一个新协程,接受两个参数:start
协程入口函数指针,和 stack_size 栈大小;这类似于
pthread_create。co_new
分配协程的栈空间并设置好各个字段。
要把主线程切换到我们新创建的协程,这里有两个问题。一是主线程并不是一个协程,新协程跟谁交换上下文呢?二是新创建的协程的上下文是空的(19 行),切换过去肯定跑不起来。
第一个问题很简单:创建一个就行。因为主线程已经跑起来了,要切换到新协程,主线程只需要一个“容器”把它的上下文装进去。直接执行
main = co_new(NULL, 0) 创建主协程,调用
co_ctx_swap(&main->ctx, &new->ctx)
便可切换到新协程。此时主线(协)程的上下文保存在 main
中,当新协程反向调用
co_ctx_swap(&new->ctx, &main->ctx),便又切换回主协程了。
为了解决第二个问题,我们需要对新协程初始化。co_ctx_swap
将新协程的上下文复制到 CPU 后,执行 ret
返回栈顶记录的地址。因此我们要将栈顶置为协程入口函数的地址,这样在
co_ctx_swap 返回后便跳转到协程入口函数了。
void co_ctx_make(struct coroutine *co) {
char *sp = co->stack + co->stack_size - sizeof(void*);
sp = (char*)((intptr_t)sp & -16LL);
*(void**)sp = (void*)co->start;
co->ctx.regs[CO_RSP] = sp;
}
因为 x86 的栈是从高地址向低地址增长的,初始栈为空,所以栈顶应该指向
co->stack 的最末尾。又因为 x86 的栈必须 16
字节对齐,所以执行 (intptr_t)sp & -16LL(-16 低 4 位为
0,其它都为 1)得到栈顶地址。然后将栈顶置为
co->start,也就是入口函数的地址。最后我们把保存的 rsp
寄存器的值设置为栈顶地址,这个值会在 co_ctx_swap
被复制到寄存器 %rsp 中。
现在我们的协程已经可以跑起来了。写一个简单的例子试试:
struct coroutine *main_co, *new_co;
void foo() {
printf("here is the new coroutine\n");
co_ctx_swap(&new_co->ctx, &main_co->ctx);
printf("new coroutine resumed\n");
co_ctx_swap(&new_co->ctx, &main_co->ctx);
}
int main() {
main_co = co_new(NULL, 0);
new_co = co_new(foo, 1024 * 1024);
co_ctx_make(new_co);
co_ctx_swap(&main_co->ctx, &new_co->ctx);
printf("main coroutine here\n");
co_ctx_swap(&main_co->ctx, &new_co->ctx);
return 0;
}
把上面所有的 C 代码复制到文件 co.c,汇编代码存为
co.S,然后执行 gcc -o co co.c co.S
编译,运行试试!
现在的协程虽然可以跑,但是使用起来很不方便,需要手动交换上下文,也容易出错。我们需要实现 resume/yield 操作。resume 操作唤醒指定协程,也就是当前协程与指定协程交换。yield 挂起当前协程,将当前协程与上次唤醒它的协程交换。因此我们需要记录当前运行的协程;而对于每个协程,要保存唤醒它的协程的指针。

协程切换要遵循这几条规则:
基于此,我们给协程定义五个状态:
enum {
CO_STATUS_INIT, // 初始状态
CO_STATUS_PENDING, // 执行 yield 操作进入的挂起状态
CO_STATUS_NORMAL, // 执行 resume 操作进入的挂起状态
CO_STATUS_RUNNING, // 运行状态
CO_STATUS_DEAD, // 死亡状态
};
我们使用全局变量 g_curr_co
记录当前协程。每个协程还要记录当前状态和唤醒自己的协程。
struct coroutine {
struct co_context ctx;
char *stack;
size_t stack_size;
int status; // 协程状态
struct coroutine *prev; // 唤醒者
start_coroutine start;
};
struct coroutine *g_curr_co = NULL; // 当前协程
struct coroutine *co_new(start_coroutine start, size_t stack_size) {
struct coroutine *co = malloc(sizeof(struct coroutine));
...
co->status = CO_STATUS_INIT;
co->prev = NULL;
return co;
}
void check_init() {
if (!g_curr_co) { // 初始化主协程
g_curr_co = co_new(NULL, 0);
g_curr_co->status = CO_STATUS_RUNNING; // 主协程状态初始为 RUNNING
}
}
接着实现 resume 操作和 yield 操作。根据上面描述的思路,实现起来很容易。
int co_resume(struct coroutine *next) {
check_init();
switch (next->status) {
case CO_STATUS_INIT: // 初始状态,需要执行 co_ctx_make 初始化
co_ctx_make(next);
case CO_STATUS_PENDING: // 只有处于 INIT 和 PENDING 状态的协程可以被 resume 唤醒
break;
default:
return -1;
}
struct coroutine *curr = g_curr_co;
g_curr_co = next; // g_curr_co 指向新协程
next->prev = curr; // 设置新协程的唤醒者为当前协程
curr->status = CO_STATUS_NORMAL; // 当前协程进入 NORMAL 状态
next->status = CO_STATUS_RUNNING; // 新协程进入 RUNNING 状态
co_ctx_swap(&curr->ctx, &next->ctx);
return 0;
}
int co_yield() {
check_init();
struct coroutine *curr = g_curr_co;
struct coroutine *prev = curr->prev;
if (!prev) { // 没有唤醒者,不能执行 yield 操作
return -1;
}
g_curr_co = prev; // g_curr_co 指向当前协程的唤醒者
if (curr->status != CO_STATUS_DEAD) {
curr->status = CO_STATUS_PENDING; // 当前协程进入 PENDING 状态
}
prev->status = CO_STATUS_RUNNING; // 唤醒者进入 RUNNING 状态
co_ctx_swap(&curr->ctx, &prev->ctx);
return 0;
}
除主协程外的协程结束运行时一定要执行 yield 操作将自己切出,否则它不知道该返回到哪儿。为了不让使用者手动执行这个操作,我们将协程入口函数封装一层。
void co_entrance(struct coroutine *co) {
co->start(); // 执行入口函数
co->status = CO_STATUS_DEAD;
co_yield(); // 已经置为 DEAD 状态了,切出后不会有人唤醒它了。这里 co_yield 永远不会返回
// 不会走到这里来
}
void co_ctx_make(struct coroutine *co) {
char *sp = co->stack + co->stack_size - sizeof(void*);
sp = (char*)((intptr_t)sp & -16LL);
*(void**)sp = (void*)co_entrance; // 设置入口地址为 co_entrance
co->ctx.regs[CO_RSP] = sp;
co->ctx.regs[CO_RDI] = co; // rdi 为第一参数寄存器,将它的值置为 co,这样 co_entrance 就能拿到它的参数了
}
这样我们的协程用起来就更方便了:
void foo() {
printf("here is the new coroutine\n");
co_yield();
printf("new coroutine resumed\n");
}
int main() {
struct coroutine *co = co_new(foo, 1024 * 1024);
co_resume(co);
printf("main coroutine here\n");
co_resume(co);
return 0;
}
resume/yield 可以用于传递参数。运行上面的例子,我们发现
co_yield 返回之时便是其它协程调用 co_resume
之时;而 co_resume 返回之时又是其它协程调用
co_yield 之时。因此 resume 操作接受参数,传递给 yield
返回;yield 操作接受参数,传递给 resume
返回。这样方便在协程之间传递数据。
我们在 struct coroutine 中新增一个 data
字段用于传递参数。协程切换时,如果要给目标协程传递参数,就对目标协程的
data 字段赋值。协程切换后,就能从 data
字段中取出上一个协程传递的参数。
struct coroutine {
...
void *data; // 参数
};
int co_resume(struct coroutine *next, void *param, void **result) {
...
next->data = param; // 切换到 next 协程,给 next 协程的参数
co_ctx_swap(&curr->ctx, &next->ctx);
if (result) {
*result = curr->data;
}
return 0;
}
int co_yield(void *result, void **param) {
...
prev->data = result; // 切回 prev 协程,给 prev 协程的结果
co_ctx_swap(&curr->ctx, &prev->ctx);
if (param) {
*param = curr->data; // 其它协程唤醒它时给它的参数
}
return 0;
}
我们重新定义协程入口函数,让它接受参数和返回值。第一次 resume 的参数传给入口函数;入口函数的返回值在最后一次 yield 时传出去。
typedef void *(*start_coroutine)(void *);
static void co_entrance(struct coroutine *co) {
void *result = co->start(co->data);
co->status = CO_STATUS_DEAD;
co_yield(result, NULL); // 协程的最后一次 yield 操作,将入口函数的返回值传出去
}
现在,我们的协程库已经完全实现了。我们可以写一些例子测试一下。比如说我们可以创建一个源源不断生成以 n 开头的自然数的协程:
void *number(void *param) {
intptr_t i = (intptr_t)param;
co_yield(NULL, NULL); // 初始化后立刻 yield
while (1) {
co_yield((void*)i, NULL);
++i;
}
}
int main() {
struct coroutine *num = co_new(number, 1024 * 1024);
co_resume(num, (void*)0, NULL); // 初始化为以 0 开头的自然数流
for (int i = 0; i < 10; ++i) {
intptr_t n;
co_resume(num, NULL, (void**)&n);
printf("%ld ", n);
}
co_free(num);
return 0;
}
运行结果就是
0 1 2 3 4 5 6 7 8 9
这个协程就是一个无限流。我们还可以写一个将两个无限流逐项相加的协程:
void *add(void *param) {
struct coroutine **cov = param, *co0 = cov[0], *co1 = cov[1]; // cov 指向前序协程的栈,这里要立刻将其中的数据取出来
co_yield(NULL, NULL); // 同样,初始化后立刻 yield
while (1) {
intptr_t a, b;
co_resume(co0, NULL, (void**)&a);
co_resume(co1, NULL, (void**)&b);
co_yield((void*)(a + b), NULL);
}
}
然后将 0 开头的自然数流与 1 开头的自然数流逐项相加,得到奇数无限流(0 + 1 = 1, 1 + 2 = 3, 2 + 3 = 5, …)
int main() {
struct coroutine *num0 = co_new(number, 1024 * 1024);
struct coroutine *num1 = co_new(number, 1024 * 1024);
struct coroutine *co_add = co_new(add, 1024 * 1024);
co_resume(num0, (void*)0, NULL); // 以 0 开头的自然数流
co_resume(num1, (void*)1, NULL); // 以 1 开头的自然数流
struct coroutine *cov[] = {num0, num1};
co_resume(co_add, cov, NULL); // 初始化 add 协程
for (int i = 0; i < 10; ++i) {
intptr_t s;
co_resume(co_add, NULL, (void**)&s);
printf("%ld ", s);
}
co_free(num0), co_free(num1), co_free(co_add);
return 0;
}
运行结果就是
1 3 5 7 9 11 13 15 17 19
当然还有更好玩的。我们可以实现一个斐波那契数列生成器。斐波那契数列可以自我定义:令 f(i) 是以第 i 项开头的斐波那契数列,f(a) + f(b) 表示将两个数列逐项相加,那么如下所示,f(2) = f(0) + f(1)。
0 1 1 2 3 5
+ 1 1 2 3 5 8
-----------------------
1 2 3 5 8 13
所以我们可以这样做
void *fib(void *param) {
co_yield((void*)0, NULL); // 第 0 项
co_yield((void*)1, NULL); // 第 1 项
struct coroutine *f0 = co_new(fib, 1024 * 1024);
struct coroutine *f1 = co_new(fib, 1024 * 1024);
co_resume(f1, NULL, NULL); // f1 先走一步,让它成为以第 1 项开头的斐波那契数列
struct coroutine *co_add = co_new(add, 1024 * 1024);
struct coroutine *cov[] = {f0, f1};
co_resume(co_add, cov, NULL); // 将 f0 与 f1 逐项相加
while (1) {
intptr_t s;
co_resume(co_add, NULL, (void**)&s);
co_yield((void*)s, NULL);
}
}
int main() {
struct coroutine *f = co_new(fib, 1024 * 1024);
for (int i = 0; i < 10; ++i) {
intptr_t s;
co_resume(f, NULL, (void**)&s);
printf("%ld ", s);
}
}
运行结果便是斐波那契数列:
0 1 1 2 3 5 8 13 21 34
不过这种写法会创建大量协程,性能很低。仅供演示(炫技)。