2019-04-21 12:06:00
首先参考Github链接
Scenes & Animation
Direction Vectors
Text
2018-10-28 21:35:54
【阅读时间】
【阅读内容】结合Leetcode相关算法题总结二叉搜索树的相关算法,包括基本的二叉搜索构建和应用,附带一些关于AVL树,红黑树的基本概念梳理
二叉搜索树(Binary Search Tree)BST是大名鼎鼎的搜索算法。在算法界,$O(n)$ 到 $O(\log_2 n)$ 的效率优化大多和BST有关
用白话文来说,二叉搜索树是一颗对于所有节点左孩子 < 根,右子树 > 根的二叉树
相关例题:108. Convert Sorted Array to Binary Search Tree
已经给出了定义,Leetcode中有一道将升序数组转换成平衡二叉搜索树的题目。根据二叉树遍历一节的内容,中序遍历的顺序是左 ➜ 根 ➜ 右,再结合二叉搜索树的定义。观察知,二叉搜索树的中序遍历就是一个升序数组。那么问题就转换成了,哪颗平衡二叉树的中序遍历是这个升序数组
因为题目要求平衡二叉树,保证所有子树的高度一样,必须二分输入序列
假设输入序列为[-10,-3,0,5,9],根节点一定在mid = (start + end) // 2 位置,由递归思维:假设再次调用的函数的返回值是已经完成的子树,也就是说只需把[0, mid-1]代表的树作为左子树,和[mid+1, end]代表的树作为右子树即可
1 |
class Solution: |
相关例题:700. Search in a Binary Search Tree
最常见的二叉树操作,查找一个对应节点,平均查找长度为 $\log_2(n)$ 。二叉搜索树性质,左孩子<根<右孩子,按照规律进行递归即可。省略迭代写法,只需要按照顺序进行一个节点一个节点顺下即可,非常简单
1 |
class Solution: |
相关例题:98. Validate Binary Search Tree
【输入】给定一个树的结构【操作】判断这颗树是不是二叉搜索树【输出】True or False
① 使用中序遍历,结果是升序序列则为二叉搜索树(前面讲定义的时候已经讲解的原因)
② 去重复操作。①中在遍历过程就可做判断,不需要重新再做一次升序判断
这里实现使用迭代写法,递归写法比较简单
1 |
class Solution(object): |
二叉查找树中的删除节点操作,详见链接
需要分为3种情况进行讨论
2018-10-22 15:53:27
【阅读时间】7 - 10 min | 4300字
【阅读内容】结合应用场景,总结有关二叉树遍历的所有算法和对应Leetcode题目编号。基于Python代码,给出完整逻辑链。希望给读者一个线头,让你永远忘不了这几个遍历算法
遍历的含义就是把树的所有节点(Node)按照某种顺序访问一遍。包括前序,中序,后续,广度优先(队列),深度优先(栈)5中遍历方法
| 遍历方法 | 顺序 | 示意图 | 应用 |
|---|---|---|---|
| 前序 | 根 ➜ 左 ➜ 右 | 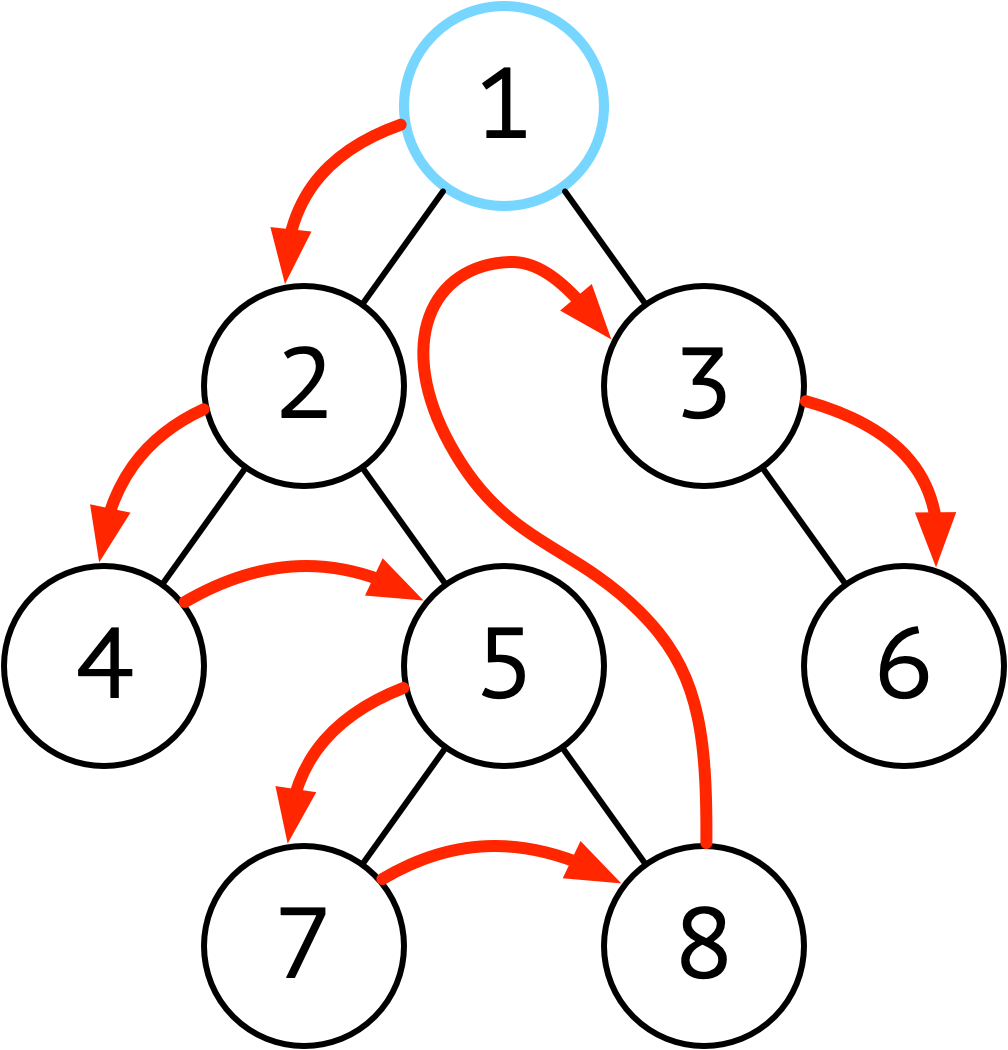 |
想在节点上直接执行操作(或输出结果)使用先序 |
| 中序 | 左 ➜ 根 ➜ 右 | 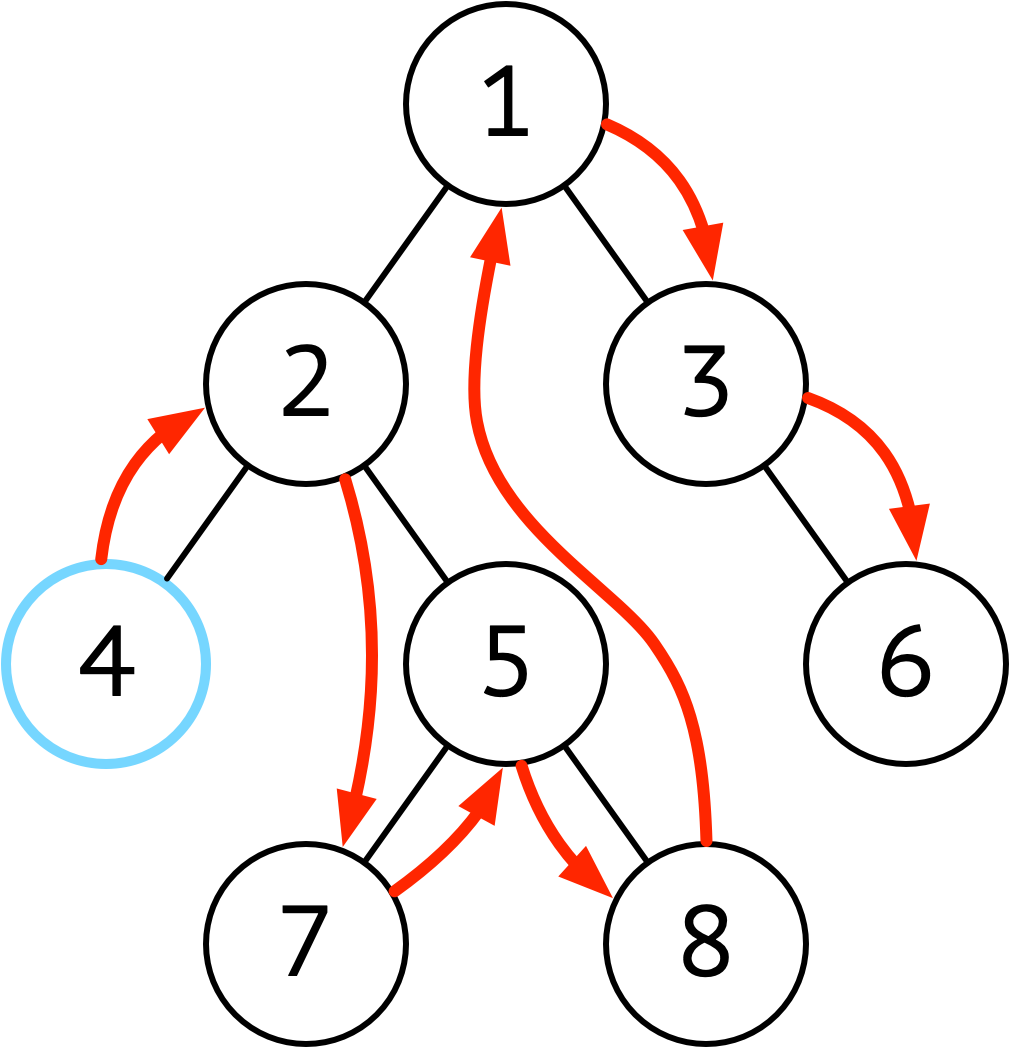 |
在二分搜索树中,中序遍历的顺序符合从小到大(或从大到小)顺序的 要输出排序好的结果使用中序 |
| 后序 | 左 ➜ 右 ➜ 根 | 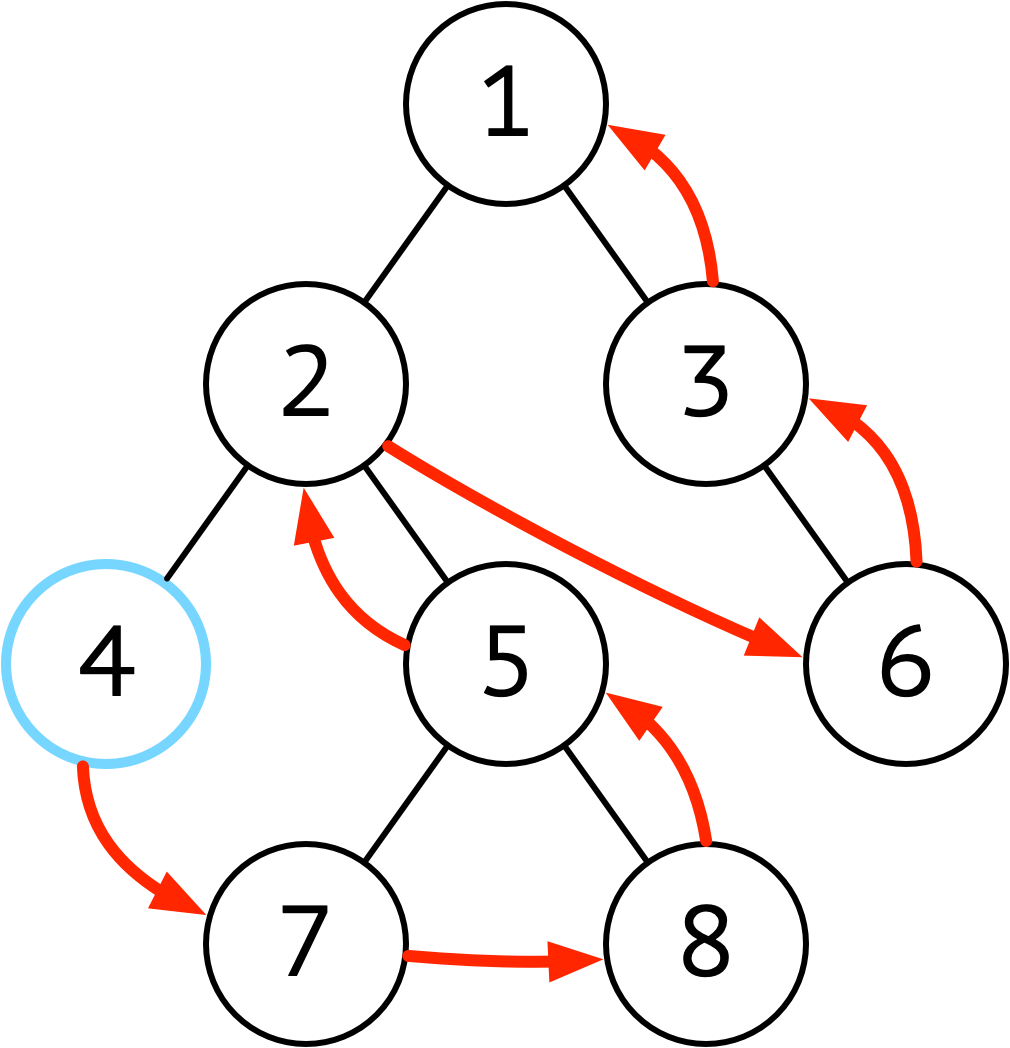 |
后续遍历的特点是在执行操作时,肯定已经遍历过该节点的左右子节点 适用于进行破坏性操作 比如删除所有节点,比如判断树中是否存在相同子树 |
| 广度优先 | 层序,横向访问 | 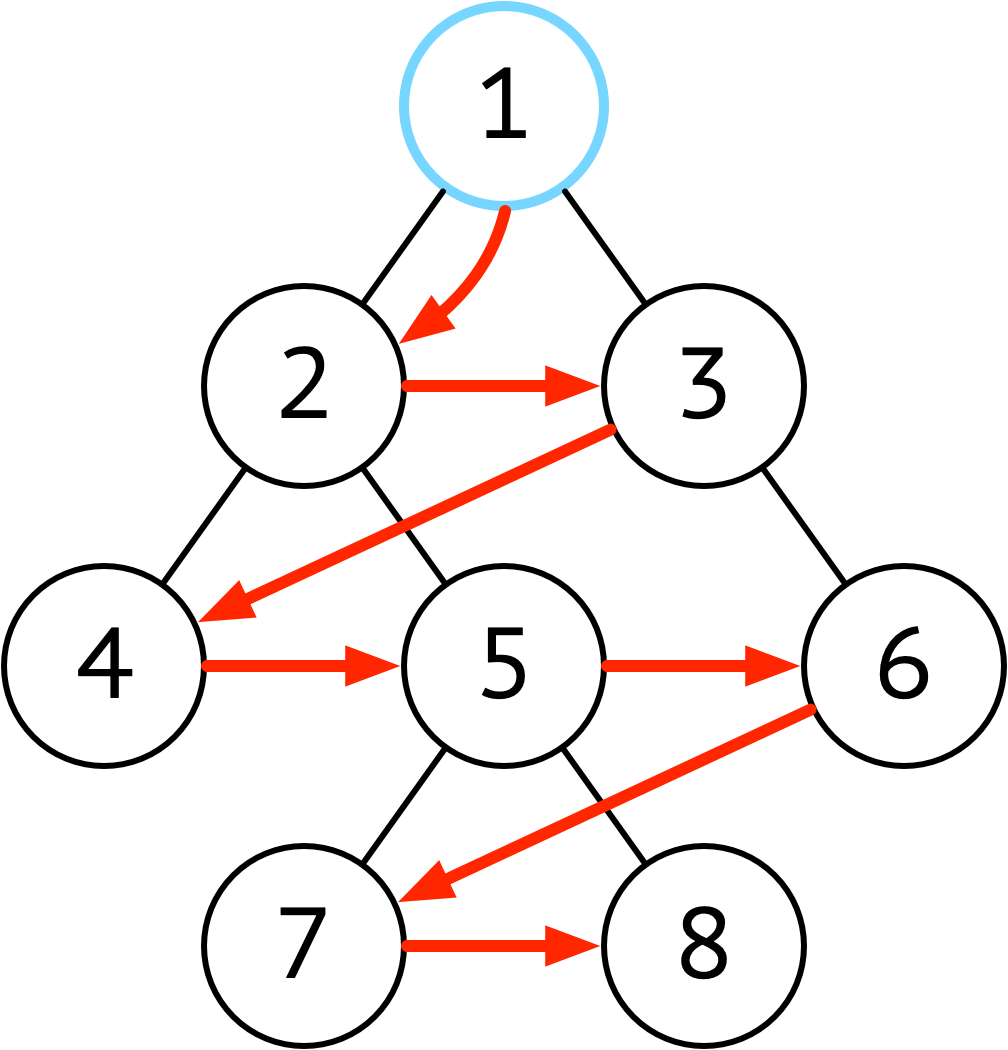 |
当树的高度非常高(非常瘦) 使用广度优先剑节省空间 |
| 深度优先 | 纵向,探底到叶子节点 |  |
当每个节点的子节点非常多(非常胖),使用深度优先遍历节省空间 (访问顺序和入栈顺序相关,想当于先序遍历) |
关于应用部分,选择遍历方法的基本的原则:更快的访问到你想访问的节点。先序会先访问根节点,后序会先访问叶子节点
需要说明的是,递归是一种拆分思维的具体问题类别的思维方法,其核心的思维我觉得和动态规划非常类似,都是假设子节点搞定了我现在应该干什么这个问题
先确定Python语言下的TreeNode定义
1 |
class TreeNode: |
需要输出遍历结果时直接输出保存val的数组即可
关于递归算法的解释,博主打算写一份【直观算法】汉诺塔问题最全解答,过后可能会更新,是一篇小品文,比较短,这篇文章只是希望让所有阅读的人能一次就直观的搞明白汉诺塔的算法是怎么做的,永远记住它,也搞懂递归算法
三种遍历方法,都有一个特点,无论是先序根 ➜ 左 ➜ 右,中序左 ➜ 根 ➜ 右,后序左 ➜ 右 ➜ 根,所谓的访问顺序,根是最重要,根才代表了访问这个动作(在我们的代码中,就是把节点中的值加入到输出数组中),⭐️而根在的位置决定了是否可以访问的条件
比如对于中序来说,根在左的后面,意味着,只要当前操作的节点有左节点,就不能输出根里面的值
对于后序来说,有了这个直观理解,对理解三者的迭代算法有帮助
在线刷题:Leetcode 44. Binary Tree Preorder Traversal
所谓递归(Recursive),即把函数本身看成一个已经有解的子问题
定义函数preorderTraversal(self, node)返回以node为答案的先序遍历结果的数组,假设它的两个孩子node.left和node.right已经搞定了,即可以返回答案的输出数组。那么思考最终的输出数组是什么样的,很明显要满足根 ➜ 左 ➜ 右的规则,应该返回[node.val] + preorderTraversal(self, node.left) + preorderTraversal(self, node.right)(函数返回的就是一个数组,只需要把它们拼接起来即可)
之后再完善防御性编程的基本步骤(保证函数输入有效),按照这个思路就可以写出先序遍历的递归代码。Python代码的特点是可读性比较强,这样一行代码简洁明了,能简洁的表达上面的逻辑链推理过程
1 |
class Solution: |
当然,如果不使用Python,在语法上无法写的这么简短。常见的标准写法是使用helper()函数,具体实现见下
1 |
def preorderTraversal1(self, root): |
同理,递归算法使用系统栈,不好控制,性能问题比较严重,需要进一步了解不用递归如何实现。为了维护固定的访问顺序,使用栈数据结构的先入后出特性
先处理根节点,根据访问顺序根 ➜ 左 ➜ 右,先入栈的后访问,为了保持访问顺序(先入后出),⭐️先把右孩子入栈,再入栈左孩子(此处需要注意,出栈才是访问顺序)
1 |
class Solution: |
在线刷题:94. Binary Tree Inorder Traversal
同理于前序遍历,一模一样的处理方法,考虑访问顺序为左 ➜ 根 ➜ 右即可,快速模仿并写出代码
1 |
class Solution: |
同理在这里也附上使用helper()函数的标准写法,代码上来说,只变了名称和访问顺序
1 |
def inorderTraversal1(self, root): |
核心思路依旧是利用栈维护节点的访问顺序:左 ➜ 根 ➜ 右。使用一个p_node来指向当前访问节点,p是代表指针point,另外有一个变量cur_node表示当前正在操作节点(把出栈节点值加入输出数组中),算法步骤如下(可以对照代码注释)
① 访问当前节点,如果当前节点有左孩子,则把它的左孩子都入栈,移动当前节点到左孩子,重复第一步直到当前节点没有左孩子
② 当当前节点没有左孩子时,栈顶节点出栈,加入结果数组
③ 当前节点指向栈顶节点的右节点
1 |
class Solution: |
如果想要精简代码,从逻辑上来看,p_node可以使用root代替,这样写只是为了让代码更可读,和逻辑链相切合,方便理解
在线刷题:145. Binary Tree Postorder Traversal
同理先序遍历,代码如下
1 |
class Solution: |
节省版面,使用helper()函数的写法只需要改变函数名和访问顺序
后序遍历访问顺序要求为左 ➜ 右 ➜ 根,在对访问节点进行操作的条件是,它的左子树和右子树都已经被访问。这样算法的框架就出来了:只需要对每个节点进行标记,表示这个节点有没有被访问,一个节点能否进行操作的条件就是这个节点的左右节点都被访问过了。
因为栈先入后出,为了维护访问顺序满足条件,入栈顺序应该是根 ➜ 右 ➜ 左(和要求访问顺序相反)。代码如下
1 |
class Solution: |
还有一种迭代算法利用后序遍历的本身属性,注意到后序遍历的顺序是左 ➜ 右 ➜ 根,那么反序的话,就直接倒序的输出结果,即反后序:根 ➜ 右 ➜ 左,和先序遍历的根 ➜ 左 ➜ 右对比,发现只需要稍微改一下代码就可以得到反后序的结果,参考先序遍历,代码如下
1 |
class Solution: |
从上到下的层序102. Binary Tree Level Order Traversal
从下到上的层序(Bottom-up) 107. Binary Tree Level Order Traversal 2
按照层序进行遍历的的过程,有两种说法,一种是按照层序的从顶到底的(level order),另一种是从底到顶的(bottom up),具体实现上来说,就是输出反序即可。在具体问题设计上可能有区别,但是基本思路不变
广度遍历的核心思路就是使用队列,即先进先出 First-in First-out,这里很关键的一点就是以层来作为入队和出队的判断条件。并且因为按照层的顺序,是从左到右,所以遍历顺序(入队顺序)为左 ➜ 右
基本思路参看代码注释,逻辑比较简单。实现上,使用Python中的自带类deque来实现,新建为queue = deque([]),入队为queue.append(),出队为queue.popleft()
1 |
from collections import deque |
226. Invert Binary Tree,就是一道基本的树的遍历题。有故事说Mac包管理工具Brew的作者Max在Google被面试这道题,没写出来,被拒了。之后Max去了Apple。个人感觉,对于遍历的理解,如果是真的根据逻辑链理解,且对递归有着深刻的理解,那实在不应该写不出这道题,因为真的很简单
题目是这样说的,要求把一颗二叉树的所有左右子树互换位置
假设左右子树都搞定了,那么当前节点需要的操作为:把当前节点的左右孩子互换即可,写成递归非常简洁
1 |
class Solution: |
因为对于每一个节点,只需要把它的左右孩子互换位置,并且依次遍历即可,使用DFS或BFS都是一样的,这里用使用栈的深度优先搜索举例
1 |
class Solution: |
二叉树遍历问题最关键的逻辑链记忆点如下
遍历顺序
⭐️遍历顺序非常重要,即某 ➜ 某 ➜ 某。如果这一点你不太记得,我认为在考试的过程中可以尝试向面试官确认,某的带选项只有三个,就是根,左,右,全排列也只有6种,长时间不用不记得也是情有可原的。所以在这里非常优秀
递归 ➜ 假设搞定了
确认遍历顺序后,写出递归方法的核心思维是:⭐️假设左右孩子搞定了(搞定的方式就是调用函数本身,替换自变量即可),现在怎么做才能得到最终答案
一般面试官会继续询问迭代方法如何写,这里的核心思维是:⭐️关注根的位置,根对应的就是出栈输出的操作(在例题中就是添加到输出数组)
那么根据遍历顺序,⭐️只要根之前的左或右孩子不为空就不能出栈输出,要继续入栈(办法自己想即可,每次可能写出来的代码都不同,但是思路相同。需要例子,可以参考中序和后序里的迭代算法部分)
2018-10-11 22:39:43
【阅读时间】10000+字 | 17 - 22 min
【阅读内容】Google面试题:100层楼,两个鸡蛋最少用多少次能测出鸡蛋的会在哪一层碎
分享者是最大的受益者,感谢您的阅读!知乎文章链接,走过路过求个赞,相关问题答案
有栋楼高100层,一个鸡蛋从第x层以上($>$)的楼层落下来会摔碎, 在第x层和以下($\leqslant$)的楼层落下不会摔碎。给你2个鸡蛋,设计方案找出x,保证在最坏情况下, 最小扔鸡蛋尝试的次数
有时候仍的东西会变,比如瓶子
这道题目的整个解答过程涉及给类逻辑思维,工程思维,当真是一道海纳百川的面试题,也难怪Goolge会以这道题做了多年的试金石
利用抽象思维,符号化题目描述
⭐️〔题目要求〕找到 $x$ 层落下不会碎,$x+1$ 层落下会碎的临界层所需要的最少尝试次数 $r$ (r for result)
使用等价思维,如何计算出最小的尝试次数?使用函数方法表示为:如何计算出这个结果,找出公式 $r = f()$
假设最后结果设为 $r$ 次(r for result)。使用归纳思维,先看只拥有1个鸡蛋的情况,思考什么是最坏情况。你可能说可以直接使用二分法,请注意,只有1个鸡蛋,必须保证找到临界层。所以,1个鸡蛋的情况下,最坏情况为 $r = 100$ (楼高)
大多数情况下,我们都低估了理解题意的重要性
这么思考还不够究竟,缺乏抽象思维
通过逻辑思考,可得 $r =100$ ,但有没有一个抽象的公式化结论?或者说,如何通过一个公式算出 $r$ ?接下来就来解决这个问题
假设临界层分别为 $x = 1,2,3 \dots 100$ ,因为你只有1个鸡蛋,不知道会在哪层碎,所以唯一策略是从1层开始一层一层试,对应的每个策略都有一个尝试步数(比如 $x = 95$ ,从1层开始尝试为95次),可得到临界层 $x$ 在所有可能取值下对应的 $r = 1,2,3 \dots 99,100$,最终选择最坏情况,即 $r = 100$
可抽象化得到待求的符号表达式
$$
r = \max_{1 \leqslant x \leqslant N}(\forall S_i(x)) \tag{1}
$$
公式的语言型描述是:对于每一个可能的临界层 $x$,得到使用可选择策略 $S_i()$ 需要的尝试步数。在每一轮 $x$ 的遍历中,取最大值(即最坏情况),为 $r$。无论临界层 $x$ 在哪一层,只有一个鸡蛋的情况下,总需考虑最坏情况
这道题,对
1个鸡蛋问题的深刻理解异常重要。只有深刻理解基石逻辑才能更好的解决问题
依据粗条细调思维,我们有一次试错的机会。可以思考,假设第一个鸡蛋在 $k$ 层碎了,意味着什么?意味着,待求的临界层 $x$ 一定满足 $1 \leqslant x \lt k$ ,记为 $[1,k)$ ,就把待求量限制到了一个更小的范围内,可以提高找到目标值的效率
也就是说,使用第一个鸡蛋做粗调,碎了后,用第二个鸡蛋,参照1个鸡蛋的尝试策略细调。下一步,问题就变成了一个策略问题,即❓第一个鸡蛋应该在哪些层仍
在某层楼,丢一个鸡蛋,有两种结果:碎了和没碎。这句话是一个极为关键的信号,背后告诉我们这是一个树形结构问题
把数据结构与问题描述的勾连能力是衡量算法能力的重要指标
下一节主要分析这条树形结构链
假设第一个鸡蛋的楼层策略是 $k_1, k_2,\cdots,k_p$ ,其中 $p$ 是仍的总次数,楼高记为 $N$ 。比如如果你选择在 $20,40,60,80$ 层仍,那么 $p=4$ ,根据题意,有 $1 \lt k_1 \lt k_2 \lt \cdots \lt k_{p-1} \lt k_p \lt N$ 。画出树形示意图,如下图所示
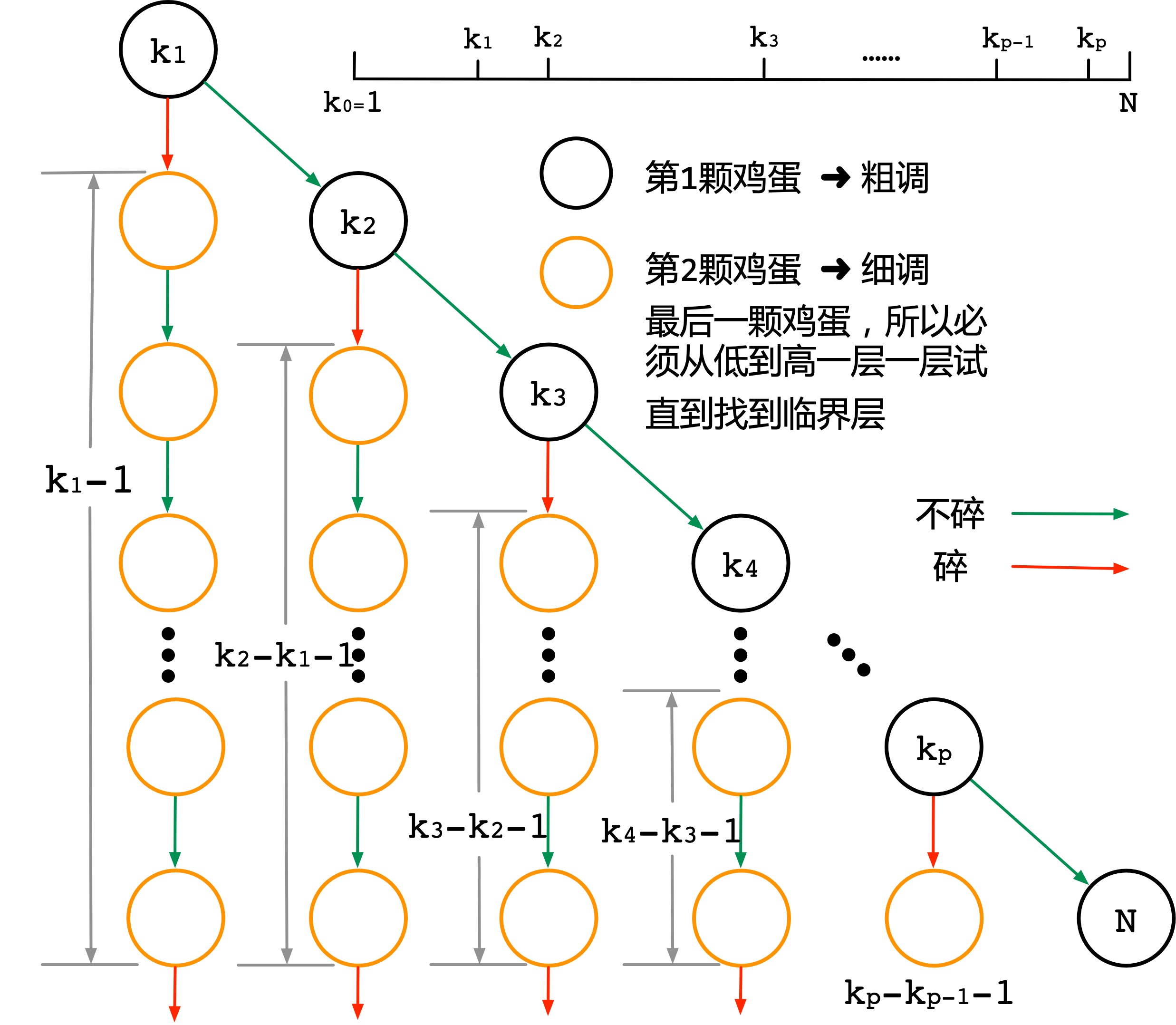
图最上方的数轴就是一个横放的楼,$k_0 = 1$ 为第一层
〔解释这棵树〕在每一层扔下一个鸡蛋时,都有两种可能,
碎了和没碎,分别对应了两个子树。一旦碎了,那么就使用1个鸡蛋的问题思路来解题,直到找到临界层。在 $k_1$层没碎,那么需在 $k_2$ 层继续尝试,直到最高层 $N$ 找到临界层(上图的标注不是树高,是灰色图例标识出部分的树高)
观察这颗树,怎样从树中得到对应问题的答案呢?
〔输入自变量〕 $k_1, k_2,\cdots,k_p$ 〔待求〕最小的尝试次数(即所有策略中最大值的最小值)等价于➜ 求一个策略组合 $k_1, k_2,\cdots,k_p$,使得树的高度最小
如果还是有些无法理解,此时,最好的方法就是看特例(举例子)
🌰 比如 $k_1 = 50$,意思是在50层扔下第一个鸡蛋
碎了,那么接下来的尝试方法就是从第1层开始一个一个往上尝试,直到49层,所以我们的答案 r = 50 (不记得如何计算这个值可以参考一个鸡蛋) 没碎,那么第一个鸡蛋继续在 k_2 = 75 层扔,假设还是没碎,继续从 k_3 = 90 层的地方扔下,此时碎了,那么第二课鸡蛋就需要从76层开始,一层一层往上尝试直到89层,需要 89-76+1=24 次,第一个鸡蛋已经扔了3次,最后得到没碎情况下的例子的答案 r=27 次在上面的例子中,$k_1=50,k_2=75, k_3=90$ 就是一个可选策略
体会最坏情况下的最小值的意义非常重要,或者说,尝试的最大步数的最小值。如何判断对一道题目有没有完全吃透,看能否清晰的走完每一个例子,就能一窥一二
⭐️ 接下里需要确定树的形状(同时也是确定策略的过程)。从直觉来看,如果树的形状倾向于满二叉树,那么树的高度最小。❓ 如何证明这个直觉的正确性呢?既然要计算树高,那么就把每一个叶子节点的树高一个一个列出来
$$\left.\begin{array}{l}k_1 \\k_2 -k_1 +1 \\k_3-k_2 +2 \\\cdots \\k_p - k_{p-1} +{p-1} \\N- k_p + p \\\end{array}\right\} \sum = N + \frac{(1+p)p}{2} \tag{2}$$
经计算发现,所有树高的和是个定值。那么使用反证法,假设这棵树不是满树,因为高度和为定值,那么必定有一个高于平均值得树存在,记为 $T$ 。根据最高树的最小值的要求 $H_a < H_T$ ($H_a$为满树的高度),答案是$H_a$ ,与不是满树的假设矛盾 。所以,是满树。证毕
再参考树的示意图,所谓类似满二叉树是指每棵子树的树高相等,比如列出下面等式(每一行都是左右两颗子树相等,比如 $k_2$ 那棵树的树高即 $k_2 - k_1 -1 +2$),一层一层带入,都换成 $k_1$ 的表达式
$$\begin{array} \\k_1 &= k_2 - k_1 + 1 &\implies &k_2 = 2k_1 - 1 = k_1 + (k_1 - 1) \\k_2 -k_1 +1 &= k_3-k_2 +2 &\implies &k_3 = 3k_1 -3 = k_1 + (k_1 -1) + (k_1 -2) \\\cdots \\k_{p-1} -k_{p-2} +p-2 &= k_{p}-k_{p-1}+ p - 1 &\implies &k_p = \underbrace{ k_1 + (k_1-1) + (k_1-2) + \cdots }_{p项}\end{array} \tag{3}$$
根据上述推倒发现规律:要满足条件每颗子树的树高相等,$k_p$ 的表达式是一个递减等差数列,最终必须在第 $N$ 层尝试(最后一次尝试走 $N - k_p$ 步,必须覆盖最后一层 $N$) 。即在最小可分割的整数等差递减数列中,令 $k_p \sim N$ (趋近于),前半句加粗的话翻译成公式为
$$
k_1 + (k_1-1) + (k_1-2) + \cdots + 1 \sim N \implies \frac{k_1(k_1 + 1)}{2} = N \tag{4}
$$
解得 $k_1 \approx 13.65$ ,考虑到,所有尝试楼层都是整数,第一颗鸡蛋最后一次1颗鸡蛋的尝试区间需包含第 $N$ 层,所以 $k_1 = \lceil k_1\rceil = 14$ 。如果不明白为什么取上整数不取下整数,试试 $k_1 = 13$ 或 $k_1 = 14$ 对比一下答案,看看谁的尝试次数少即可
有了 $k_1$ ,带回(2)式,可以知道第一个鸡蛋的尝试楼层策略为 $14,27,39,50,60,69,77,84, 90,95,99$
使用这个策略,带回(1)式,假设临界层从1到N层,分别计算所需要的最多尝试次数,可得 $r = 14$
如果楼高 $N=200$,可计算得 $r = k_1 = 20$,策略为:第一次从20层开始尝试,没多一次尝试递减1
⭐️ 到此为止,2个鸡蛋问题解决:找到了一个明确的函数,利用抽象思维,写出它的表达式 $r = f(2, N)$,而这个 $f()$ 即求方程 $\frac{x(x+1)}{2} = N$ 解 $x$ 的上整数 $\lceil x \rceil$
2个鸡蛋100层楼已经解决,深究下去,H层楼M个鸡蛋的问题呢?Leetcode有这道题:887. Super Egg Drop
刷题多的读者会快速反应出,这个问题是一道动态规划题,但在这里我还是想用一种推理的思维来尝试分析一遍,逻辑链上的关键锚点才是知识的精华
如果你通过观察题目,快速确定此题可用动态规划求解,这种能力是熟练能力,类似弹钢琴的熟能生巧,背书的死记硬背。与之相对,即分析能力。很有趣的是,这两种能力的分野十分明显,前者对应高效,后者对应求知
如果你需要快速通过面试,找工作或通过考试,那大量做题才是最短路径,可学习的目的不止是谋生,还有一种更高级的快乐来自于钻研本身,心理学管这种快乐为心流
回到问题,总结一下,通过上面的解答我们有了什么一些什么直观的结论
① 1个和2个鸡蛋的问题已经解决
② 理解了最大值的最小值在本题中的含义
③ 答案的值只和楼层高度有关,和最低楼层与最高楼层无关
以这三个结论为基石,想一想这道更一般化的问题怎么解决
首先,最容易想到的思考链条来自一个设问:❓我们能不能尝试把鸡蛋的数量减少?即不断的往2个鸡蛋的问题上靠拢?有一个很简单的办法,就是扔 ➜ 扔碎一个,鸡蛋数量就减少一个
照这个思路,进行一个抽象推演:假设在某一个时刻,我们拥有 $m$ 个鸡蛋,需要实验的层高为 $h$ (h for height),此刻在 $k \in [1, h]$ 层楼扔下一个鸡蛋
假设我们已经知道 $1$ 到 $k-1$ 层楼最优解的值,❓ 那怎么用一个函数来表示这个值呢?首先看我们需要的自变量有哪些
2个鸡蛋难题时的结论可知,第二个自变量是此时未知情况楼层的层高(未知情况只楼层范围内还从来没有用鸡蛋尝试过,无法缩小范围),符号化记为 $h$ 层(h for height)⭐️ 用一个表达式 $r = f(h, m)$ 表示楼高为 $h$ 时,还剩下 $m$ 个鸡蛋时的最少尝试步数
因为在 $k$ 层碎了,所以不用考虑[k+1, N]层的情况(肯定都碎),并且因为此刻这一个鸡蛋碎了,剩下 $m-1$ 个鸡蛋,用式子 $f(k-1, m-1)$ 表示已经知道的 $1$ 到 $k-1$ 层楼最少尝试步数的值,总最小尝试次数为 $f(k-1, m-1)+1$
在 $k$ 层没碎,直接不用考虑[1, k]情况了(肯定都不碎),同理,计算出此时楼高 $h_{now} = h - (k+1) + 1 = h - k$,且因为此刻这个鸡蛋没碎,剩下 $m$ 个鸡蛋,即 $f(h-k, m)$ ,总最小尝试次数为 $f(h-k, m)+1$
此时,我们已经有了三个表达式
1️⃣ 楼高为 $h$ ,剩下 $m$ 个鸡蛋时的最少尝试步数:$f(h, m)$
2️⃣ 在第 $k$ 层扔下1个鸡蛋碎了后的最少尝试步数:$f(k-1, m-1)$
3️⃣ 在第 $k$ 层扔下1个鸡蛋没碎后的最少尝试步数:$f(h-k, m)$
那么,假设2️⃣3️⃣的表达式的答案已知,是否能用这二者推出1️⃣?如果上述逻辑链成立,就可以用归纳思维(数学归纳法)算出任意 $f(h, m)$ 。因为1️⃣只能从2️⃣3️⃣推出
〔推倒 $a$〕考虑到2️⃣3️⃣是一种策略选择后的可能性,根据上面的分析(最大值的最小值原理)两种策略中临界层 $x$ 可能在任何一层。遍历所有 $x$ 的情况时,最终尝试步数的结果是其中的最大值,所以选择2️⃣3️⃣中值更大的那个
〔推倒 $b$〕1️⃣需要仍一次鸡蛋,尝试步数 $+1$
〔推倒 $c$〕$k$ 是一个自变量,在这个情况下,可取到 $[1, h)$ 中的任意值,⭐️假设2️⃣3️⃣已知,只要在定义域内穷举出所有 $k$ 的可能值,并找出最大尝试步数中的最小值即可
接下来就可以把这个逻辑链的用抽象化的公式表达出来
$$
f(h, m) = \underbrace{\min_{1 \leqslant k \leqslant h} {\overbrace{\overbrace{\max [f(k-1, m-1), f(h-k,m)]}^{a}+1}^{b}}}_{c}\tag{5}
$$
有了具体的公式,为了锻炼工程思维,要时刻保持严谨,思考全集和完备性,再来看看边界条件和自变量定义域
依据题意楼高 $h \geqslant 1$ 且为整数,剩余鸡蛋数 $m \geqslant 1$ 且为整数
$f(h, 1) = h$ ,当剩余鸡蛋数为1的时候,答案为现在的楼高
$f(0, m) = 0$ ,当楼高为0时,无法尝试,答案记为0 ,或者 $f(1,m) = 1$,表示楼高为1时,最小尝试次数为1
现在反过头来再看,计算机学科中,有一部分专门研究这类问题的工具,即动态规划
上面的符号化描述被称为定义状态,构造逻辑链被称为构造状态转移方程,而背后的工程思维是拆分思维、抽象思维和归纳思维。再究竟一些,动态规划是一类特殊的图算法。
之所以要研究这类问题和计算机本身是一个巨大的状态机有关。动态规划提供了一套工具和思维框架去优化问题,找到最优解。思维框架和优化方法才是最厉害最有价值的,看到后面优化部分的详解你就能直观的体会到这点。
这部分,通过一步一步剖析优化思路,和对应的代码实现(使用python,所有代码可在Leetcode题目中AC),希望能直观的说明一个问题,❓ 到底高级程序员和一般的码农程序员区分在哪里?
每个人都有自己擅长的领域,管理大师吉姆·柯林斯的第一本畅销书《基业长青》,书内研究了18家企业成功的秘密。
后来,他又出了一本书《从平庸到伟大》,对这个变化的界定是非常严格的。平庸意味着这家公司的业绩低于市场的平均水准,变得伟大意味着业绩保持在平均水准的3倍以上,并持续至少15年。他研究了1435家公司,只找到了11家
通过研究,他总结了这些企业的6个秘诀。其中一个就是著名的三环理论,如果把企业的三环理论推广到个人,就是问自己下面三个问题:我的擅长是什么?我的热爱是什么?我的机会是什么?
而选择三者交集作为一辈子的努力方向大概率就算是走对了路
作为程序员,可能只是你开始职业生涯的第一步,后面如何发展,需要对自己的追求和个人能力做一个更深入的挖掘,才能有个定论
下面即将剖析的优化过程完美的阐述了作为一个伟大的程序员需要什么样的基础能力(至少在算法优化这个小领域),这需要长时间的训练和极强的天赋。如果你感觉想出这些解答很吃力,相对应的,你又想这辈子有所作为,追逐伟大。那么应该尝试去找一条非程序员的路努力一生。毕竟,计算机思维,数据分析和机器学习未来会成为像数学一样的基础能力,无论在哪一行都对解决问题有极大的助益
根据思路直接写出的最直观代码。如果对递归理解的深,容易读懂。用我能想到最直白的语言来描述就是:假设子状态的结果已知,现在需要做些什么操作,就能得到此状态的答案,并且把这个答案返回给函数(借鉴知乎回答的答案,加上了lru_cache装饰器用于优化)
1 |
import functools |
🔄〔优化〕Recursive(递归)的写法虽然清晰明了,但在工程上有调用函数的开销,系统栈深度限制等弊端,所以最好写成循环版本,否则在工作中可能返工
1 |
def solve(h, m): |
🔄〔优化〕分析一下时间复杂度和空间复杂度,时间复杂度为 $O(mh^2)$ ,空间复杂度为 $O(hn)$ ,很明显,空间上可以优化到 $O(h)$,原因是状态转移方程只和 $m$ 与 $m-1$ 有关,使用两个数组滚动即可
1 |
def solveSpace(h, m): |
基本到这,对美国FAANG的入门级SDE,就十分优秀了。后面的所有的内容,属于高手的领域(博主完全不是高手,只是好奇,所以阅读了其他人的牛逼的解题报告,重新做了理解和整理)
对于这一套状态描述和状态转移方程,优化方向在时间复杂度上。思考,❓是否有一些数学定理可以提供答案取值的下界呢?(找边界是剪枝的有效方法)
🔄〔优化〕这里需要使用数据结构中折半查找判定树理论。假设我们对鸡蛋的数量不做限制,那么这棵树

就会变为一个满二叉树,而叶子节点数量有 $h+1$ 个(因为最大尝试步数能取到的总数就是 $h+1$ 种,需包含0次)树的高度至少为 $\lceil \log_2(h+1)\rceil$。假设鸡蛋 $m$ 的数量大于 $\lceil \log_2(h+1)\rceil $ ,那么上面的树变成满树,无论怎么尝试,答案(树高)都有一个下界(不可能大于这个值)
如果还不明白,即在 $m \geqslant \lceil \log_2(h+1)\rceil $ 时,这道题会变成二分查找(鸡蛋太多,随便扔,就当楼层是排序好的即可)最终答案直接取 $\lceil \log_2(h+1)\rceil$
🌰 如果还是不明白,上终极杀招,举例子。假设16层楼,但有4个鸡蛋。根本不用设计,二分查找即可,效率肯定最高。比如16层楼,只要鸡蛋数大于4,最大尝试次数就是4,可以直接算出答案
1 |
def solveBoundary(h, m): |
这时候时间复杂度优化为 $O(mhlog_2(h))$。此时,如果列出所有状态转移的过程(行为鸡蛋数 $m$,从2开始;列为楼高 $h$ ,从1开始),如下图(红色框表示 $k$ 的移动,蓝色双向箭头表示 $\max$ 操作,然后还需要加1后和之前的 $f(m,h)$ 进行 $\min$ 操作。下图展示的是 $m_i=2,h_j=11,k=5$ 时的情况)(这幅图也能帮助理解下界优化,注意 $m_i=5$ 和 $m_i=4$ 在 $h < 20$ 的情况)

🔄 观察发现,有一个很重要的规律,即单调性,写成公式为 $f(m, h) \geqslant f(m, h-1)$ 当 $h \geqslant 1$ 。如果满足单调性,那么又可以在搜索时使用二分查找。先姑且不考虑如何证明单调性,工程上,在资源允许的情况下,先尝试,看看能不能得到正确结果(用正确算法和这个尝试算法进行验证)直到验证在很大的定义域内都正确,可大胆猜测这个猜测性质是对的(不严谨,但效率较高)
通过这一层优化,体现出了理论和工程的分野,即你猜想出了一个优化方法,当然可以先直接尝试,不管这个猜测的条件是不是正确。
反过头来仔细一寻摸,总是心里不踏实(可能出现特殊情况就让整个算法崩溃)此时,理论出山,用严谨的数学逻辑去证明这些结论,让算法具有完备性(本题单调性是正确的,证明过程参见参考文献)
另外,观察和总结答案的分布规律也是非常重要的思考手段,你会发现,这简单的一句话说开去,是一个新的学科,名叫统计学
1 |
def solveBinarySearch(h, m): |
🔄 结果的简单特性部分挖掘完了,继续观察上面的状态转移图,发现很多项是相等的,那么可不可以找到,在某种条件满足时,状态可以直接推出,而不用进行 $k$ 的遍历搜索?这个时候就需要从状态转移方程本身入手是挖掘其中的数学特性,这部分不是非常关键,较难,可直接跳过
$$\begin{array}&f(h, m) = \min\limits_{1 \leqslant k \leqslant h} \{\max [f(k-1, m-1), f(h-k,m)]+1\} \\f(h, m) \leqslant \max [f(k-1, m-1), f(h-k,m)]+1 \quad(1 \leqslant k \leqslant h) \\令\; k = 1 \implies f(h, m) \leqslant f(h - 1, m) + 1\end{array} \tag{6}$$又因为 $f$ 具有单调性,可得 $f(h - 1, m) \leqslant f(h, m) \leqslant f(h - 1, m) +1$ 其中 $h\geqslant 1$
上面的式子非常有意思,使用标准的逻辑推理来看
若某个决策 $k$ 可使得 $f(h - 1, m) = f(h, m)$ ,则一定 $f(h, m) = f(h-1, m)$
若所有决策 $k$ 都不能使 $f(h - 1, m) = f(h, m)$ ,则一定 $f(h, m) = f(h - 1, m) + 1$
那么,是否可以构造这样一个决策,使得状态转移直接计算呢?具体过程略过,有兴趣的读者详见参考文献
假设这个决策的楼高 $h = p$ ,推倒出当 $f(m, p)<f(m-1, h-p-1)$ 时,无论任何决策都不能使 $f(m, h) = f(m, h-1)$,所以,此时 $f(m, h) = f(m, h-1) + 1$
也就是说,根据 $f(m, p)$ 和 $f(m-1,h-p-1)$ 的大小关系就可以直接确定 $f(m, h)$
1 |
def solveTransferFunction(h, m): |
此时,状态转移过程时间复杂度变成 $O(1)$,整体时间复杂度随之变成 $O(m\log_2{h})$
在这种依照题意直接定义状态并找到状态转移方程的方法已经优化到极致了。那么,❓ 如果从不同的角度定义问题呢?
改变对问题的状态描述方法,用 $h(i,j)$ [h for height]表示用 $j$ 个鸡蛋尝试 $i$ 次在最坏情况下能找到的最小尝试次数的楼高。
当尝试次数 $i=1$ 时,$h(1,j)=1\quad(j \geqslant 1)$
当使用 $j = 1$ 个鸡蛋时,尝试 $i$ 次可以尝试 $i$ 层楼,即 $h(i,1)=i$
核心思路:每一次 $h()$ 所能尝试的楼高必须要尽可能的大,这样才能做到尝试次数最小
在某层扔下一个鸡蛋
综上,状态转移方程写为 $h(i,j) = h(i-1, j-1)+h(i-1,j) + 1$
而最终结果可以写为,找到一个 $x$ ,使得 $x$ 满足 $h(x-1, M) < H$ 且 $h(x, M) \geqslant H$ ($M$ 为鸡蛋总数,$H$ 为楼层总高度),其实也就是用公式描述的临界层的具体含义
1 |
def g(h, m): |
这又是一个全新的状态定义和状态转移方程,同理,可尝试输出整个转移矩阵的具体值,先观察一下总没有错,如下图所示

从形式上来说,不需要滚动数组,在转移过程中,使用一个 $g$ 函数即可。在最后输出的时候,只需要判断g[m]的情况输出 $i$
1 |
def gOptimization(h, m): |
要分析时间复杂度,挺难的。通过证明可以有一个结论(具体证明详见参考文献)$xM \leqslant H$ ,再通过一系列骚操作,可以证明时间复杂度为 $O(\sqrt{h})$,空间复杂度 $O(m)$
至此,Leetcode上这道题目的执行时间打败了85.7%的答案(虽然Leetcode时间并不靠谱),做这道题的人不多,前面只有一个答案,思路类似,代码写的更漂亮
⭐️ 这一部分是【直观算法】系列的最终目的。求同遵异,寻找每一道算法题背后的工程思维,提升自己真正解决工程问题的能力。博主对自己的定位是【机器学习+区块链产品经理】,但同时对技术也有好奇心,喜欢钻研,才开坑写【直观算法】系列
把语言描述转化为符号描述的能力,符号是信息和逻辑的纽带
沟通的效率和信息的冗余度成正比,所以一个人能否把同一个概念,从不同的角度,用不同的案例类比,抑或各类精彩直观的比喻表达出来,这个能力很重要,它可以让人们更加准确快速的理解你想表达的意思
⭐️ 学习的真正本质:是在一个领域内不断的去建立这种沟通共识的框架。举个例子,学过线性代数的人,只要提到矩阵,就能想到变换。这就是都学过线性代数的人交流密码,如矩阵的逆 = 一个具体的反向变换。没学过这门课的人是无法和学过的人进行沟通的。这也从很大程度加强了人们沟通的效率,所以,学习带来的终极成效之一其实是降低了人类社会的沟通时间,提高了效率
再举个例子:机器学习中,提到正则化,必须建立一套与之相关的知识架构,包括,过拟合,最优化函数曲面空间理解,范数等,成树状结构继续推而广之,这每一个名词,背后也对应了一个更加直观,更加易懂的描述方式。但是我们需要知道,如果我为了表达正则化,为了让你明白我的意思,我需要用一大堆描述性语言,那我们两人的沟通效率就十分低下了
这也就是知识体系,一门学科,一门专业的最终含义,学习是为了构建这门学科的通识沟通框架,降低同行之间的沟通成本。当然,这有一个必要前提,把学习的目的理解降低沟通成本必须是你做的工作是规模化的,涉及协作
如果你是爱因斯坦,是能开拓学科新领域的0级工程师(来自于吴军老师谷歌方法论),独自想象钻研。那么,学习的本质可能在于给你更多的角度(认知能力),更多的工具(锤子锯子)去更好的探索这个世界的本质和规则,在这样的条件下,关于学习本质的描述就需要调整了
从结论出发反推逻辑链
数学归纳法,使用已有的条件信息,归纳推出待求的内容
对于这道题,首先考察的是程序员的粗条细调思维。工程中经常会有对测量精度的要求,那么是如何做的?比如常见的千分尺,首先是一个横向的卡尺来接近目标值,然后用一个滚轮形的第二级继续细调。同样,显微镜也有对应的调整方法。都可以总结为粗条细调思维
首先大步接近最优解,再调整迭代速度,更加细微的接近最优解。机器学习中的,Adam优化器也是用类似的思维来设计的
问题是否能拆分几个黑盒,只给输入输出,里面的逻辑链做到精简,或者有已经可用的轮子和算法直接应用的能力。
能看到这的读者我衷心感谢您的求知欲和耐心(我写的比较啰嗦,为了权衡不同背景的读者),下面的一部分个人认为才是最重要的
到了这一步,基本压榨了本题所有的潜力。但是,下一个值得思考的问题就是,这道题目对应的算法在实际工程和解决问题的具体情况中有没有什么应用呢?答案是肯定的
🌰 如果要找学科分类,鸡蛋难题属于运筹学问题,典型应用是破坏性试验,如测试汽车、飞机、火箭等的若干极限性能。举个例子,汽车保全乘客安全的最高碰撞末速,那么为了保证能找这个值,一定会用类似的思路来解决问题。
你可能也已经发现,具体问题一定还是具体分析,但这道题目对应的工程思维更像是工具箱里面的一种更强大的工具。
记得罗辑思维中提过一个问题:为什么物理学领域老一辈的物理学家现在拿奖的人越来越少?其中一个重要的原因是他们熟悉的物理学工具没有新生一辈的能力强大的。不同于数学这类逻辑学科,物理学是可验证学科,实验,测量工具和理论工具等都必不可少
博主笃定,算法80%是要为解决问题服务的,勾起人们学习的最佳动力就是举实际生活中遇到的难题是如何用这个算法解决。从这个侧面,有关字符串的算法就非常能勾起学习的兴趣,正是因为涉及到字符串处理的情景太多。
关于鸡蛋难题,总的看下来,完美的诠释了直观 ➜ 抽象的思维链条。所有高效的,精简的算法,就是要找到事物或者逻辑发生的本质规律,如果不谈完备性的证明,用图表和直观的性质来描述,这道题目的优化思路并不难(相对的,完备性时间复杂度的证明才是难点)
关于剩下的20%,此时又想起黎曼猜想,所有非平凡零点的有关性质。趋向于无穷、所有、任意这些定义方式是人类为了寻找边界而设计的工具。趋向于无穷大,趋向于无穷小都还有很多问题没有解决。罗胖说,创业者是在开垦商业的边疆,那么理论科学家就是拿着这些强大的工具开拓逻辑和思维的边疆,在一片荒芜上安营扎寨,仰望星空。这可能就是人类群体中最有魅力的事业吧?
【参考文献】
非常感谢计算机信息学奥赛国家队朱前辈的论文,对这道题目做了完美的剖析,也勾起了我的好奇心,一探究竟,才有了这篇万字长文
2018-10-04 19:18:48
幕布版本总目录 ║ ⭐️ 推荐文章 ║ 📝 正在更新
﹝信息流转学﹞2021-07-01 信息流转学综述
﹝机器学习﹞2018-01-19 微信跳一跳解题报告 ┃⭐️2017-10-18 深入浅出看懂AlphaGo元 ┃⭐️2017-05-27 深入浅出看懂AlphaGo如何下棋 ┃2017-09-30 Pandas-Wiki ┃⭐️2017-10-03【直观详解】什么是正则化 ┃📝【直观详解】什么是PCA、SVD ┃2017-09-20【直观详解】拉格朗日乘法和KKT条件 ┃2017-09-19【直观详解】支持向量机SVM ┃2017-09-12 【直观详解】机器学习分类器性能指标详解 ┃⭐️2017-09-11【直观详解】信息熵、交叉熵和相对熵 ┃2017-09-04【直观详解】Logistic Regression
﹝理论基础﹞⭐️2018-09-20【直观详解】通俗易懂了解什么是黎曼猜想 ┃⭐️2018-02-18【直观详解】让你永远忘不了的傅里叶变换解析 ┃⭐️2018-02-16【直观详解】泰勒级数 ┃⭐️2017-10-06【直观详解】线性代数的本质 ┃2017-10-17【直观详解】线性代数中的转置正交正规正定
﹝区块链﹞⭐️2018-03-03【区块链】共识算法与如何解决拜占庭将军问题 ┃2017-09-25【区块链】比特币与金融、ICO和监管 ┃2017-09-25【区块链】现代区块链与新技术 ┃⭐️2017-09-24【区块链】一文看懂区块链:一步一步发明比特币
﹝计算机技术﹞📝2019-10-01【教程】manim 动画制作工具┃ ⭐️⭐️2018-10-11【直观算法】Egg Puzzle 鸡蛋难题┃ ⭐️2017-10-13 程序员技能图谱 ┃2017-08-28 Xpath-Wiki ┃📝2017-07-01 LeetcodeNote
﹝能力提升﹞⭐️2018-06-20 那些值得一看的TED演讲附全文文稿笔记 ┃2017-07-29 PDF复制粘贴去除多余的回车符 ┃2017-05-13 English-abbreviation
﹝原创﹞⭐️2017-06-17 幕布-全平台笔记思维导图工具 ┃⭐️2017-05-13【散文】有关中国诗的那些事
﹝清单和百科﹞2017-11-05 Dota2-A帐效果 ┃2017-09-18 Dota2伤害类型详解 ┃2017-09-05 Dota2机制总结 ┃2017-05-14 【摘抄】清欢 - 林清玄
2018-09-28 16:00:20
【阅读时间】5min | 2k字
【阅读内容】TensorSpace - 是一款3D模型可视化框架,支持多种模型,帮助你可视化层间输出,更直观的展示模型的输入输出,帮助理解模型结构,输出方法。Github
机器学习入门?先上手玩玩看!
TensorSpace是一款3D模型可视化框架,一动图胜千言。官网链接,Github链接
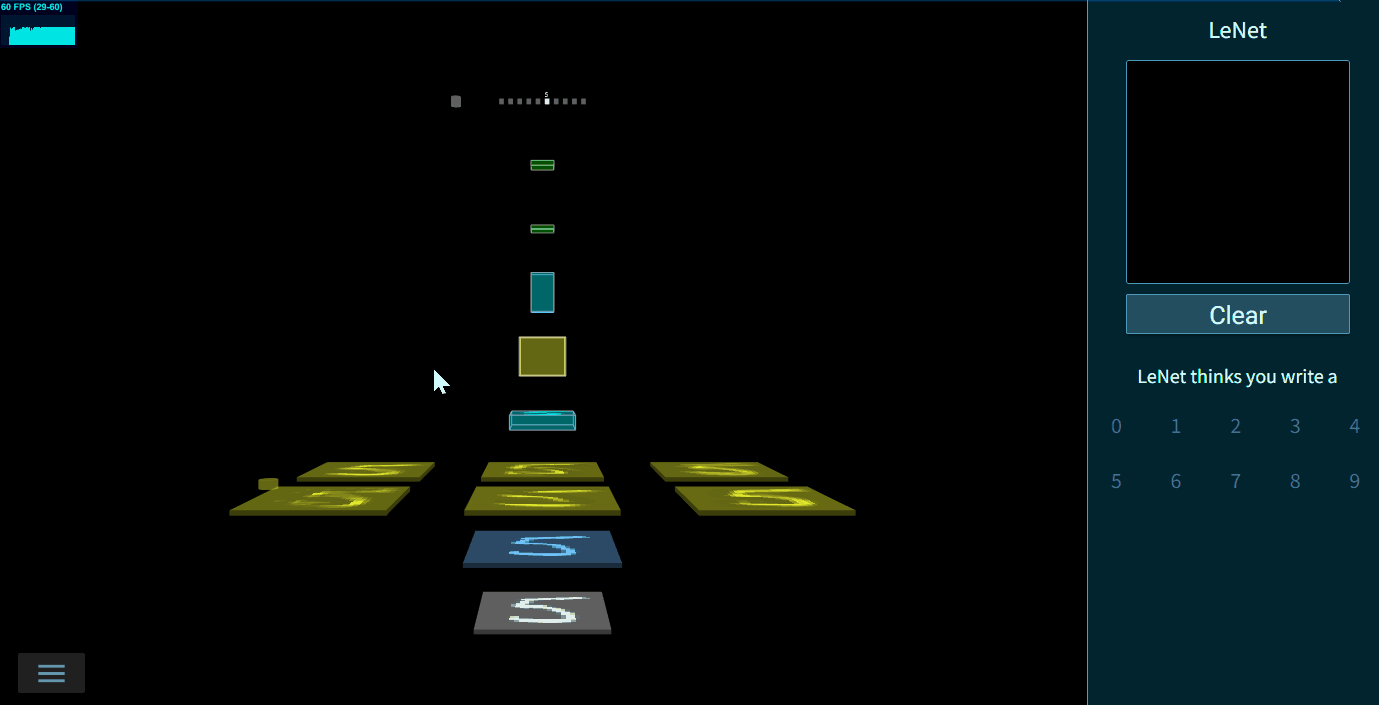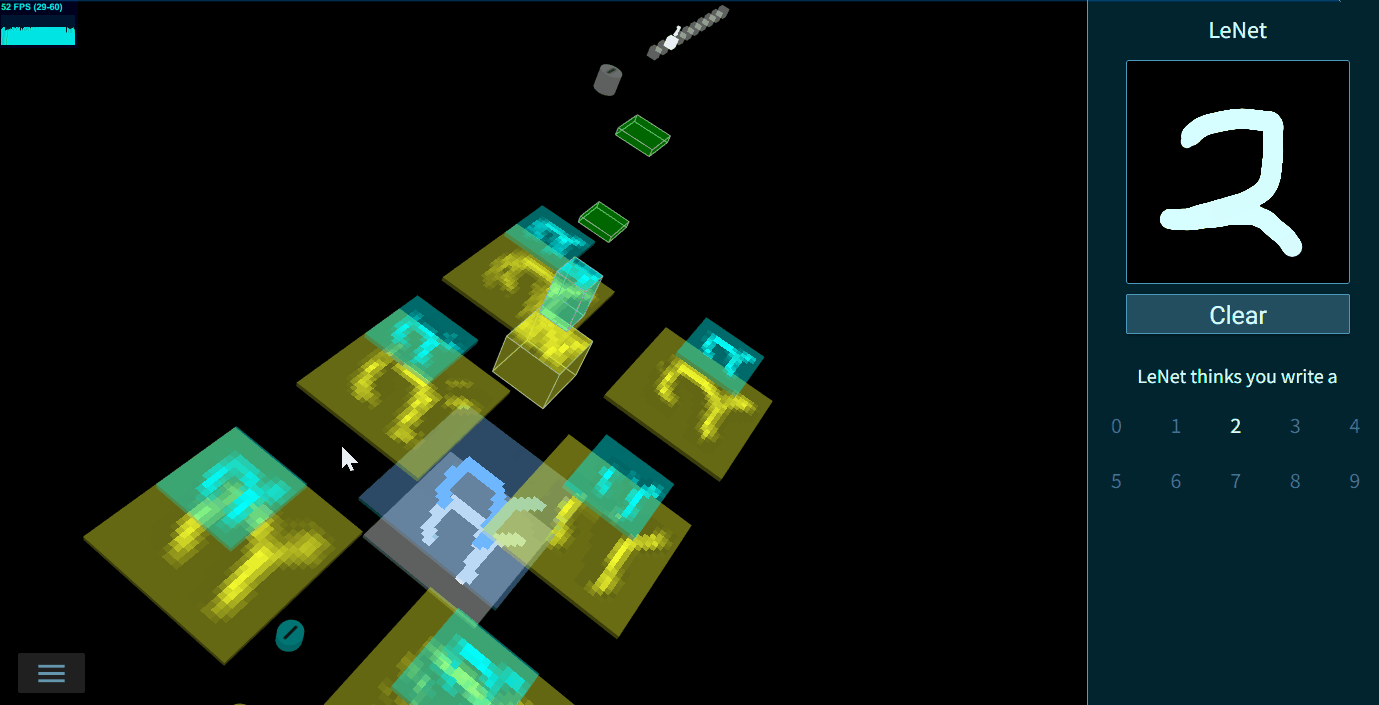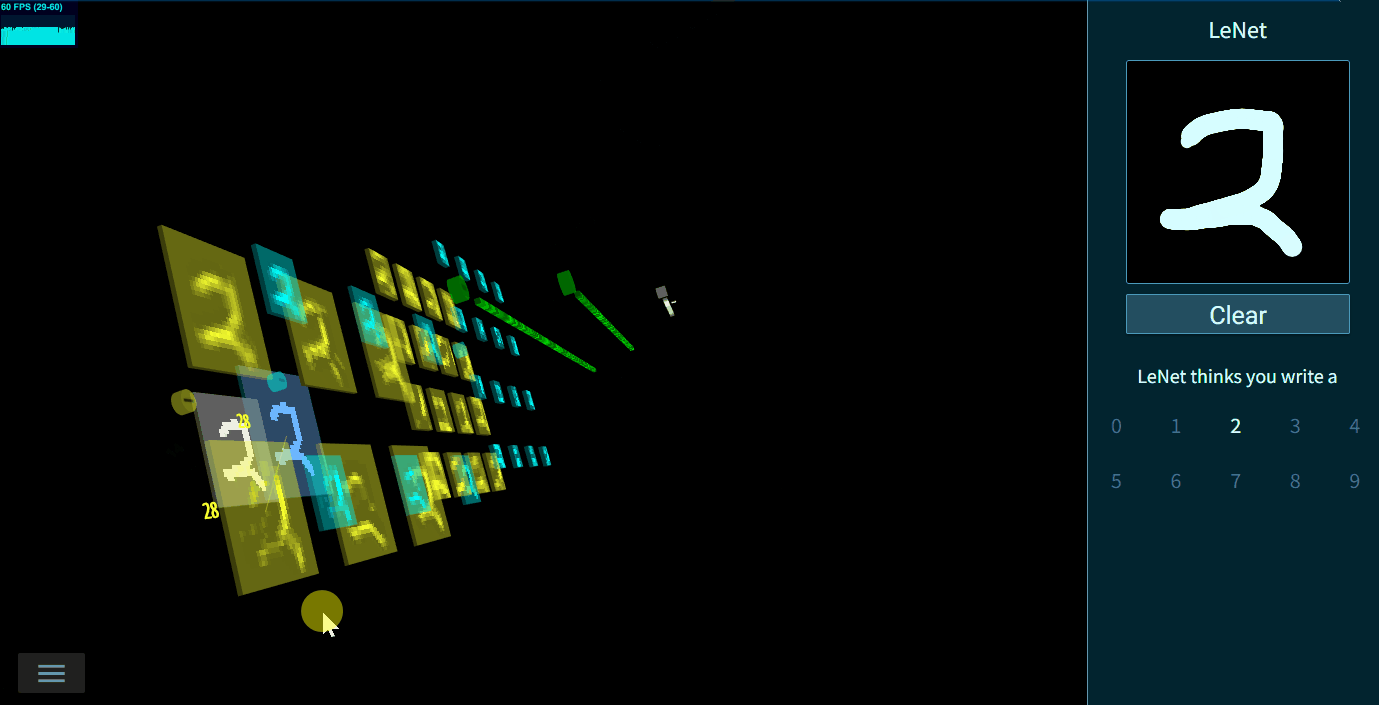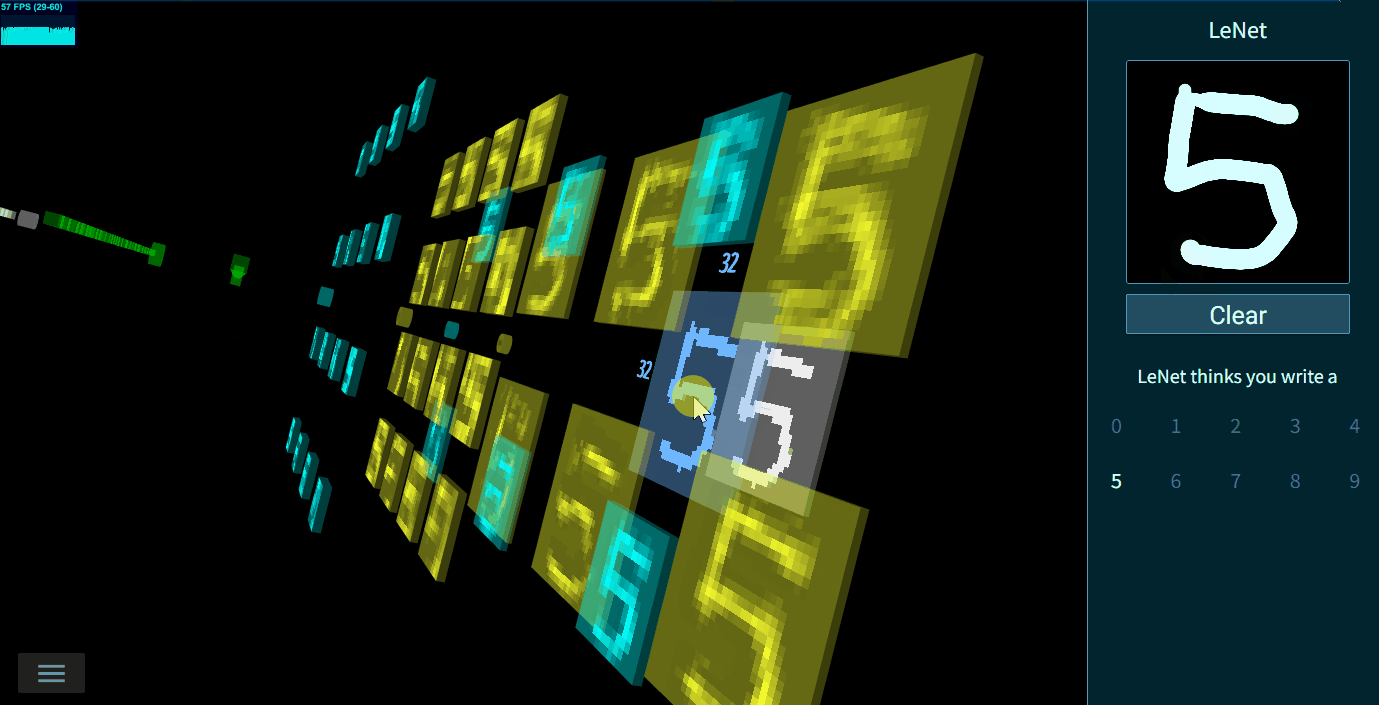
⭐️TensorSpace擅长直观展示模型结构和层间数据,生成的模型可交互。官方支持手写字符识别,物体识别,0-9字符对抗生成网络案例等
本部分说明:❓为什么要使用这个框架❓这个框架主要解决了什么问题❓我们的灵感来源于何处
在机器学习可视化上,每个机器学习框架都有自己的【御用工具】,Tensorboard之于Tensorflow ,Visdom之于Pytorch,MXboard之于MXnet。这些工具的Slogan不一而同的选择了Visualization Learning(TensorBoard的Slogan),也就是面向专业机器学习开发者,针对训练过程,调参等设计的专业向可视化工具
但面向一般的计算机工程师和非技术类人才(市场,营销,产品),一片空白,没有一个优秀的工具来帮助他们理解❓机器学习模型到底做了什么,能解决一个什么问题
机器学习开发和工程使用并不是那么遥不可及,TensorSpace搭建桥梁链接实际问题和机器学习模型
市面上常见的机器学习可视化框架都是基于图表(2D),这是由它们的应用领域(训练调试)决定的。但3D可视化不仅能同时表示层间信息,更能直观的展示模型结构,这一点是2D可视化不具备的。例如在何凯明大神的Mask-RCNN论文中:
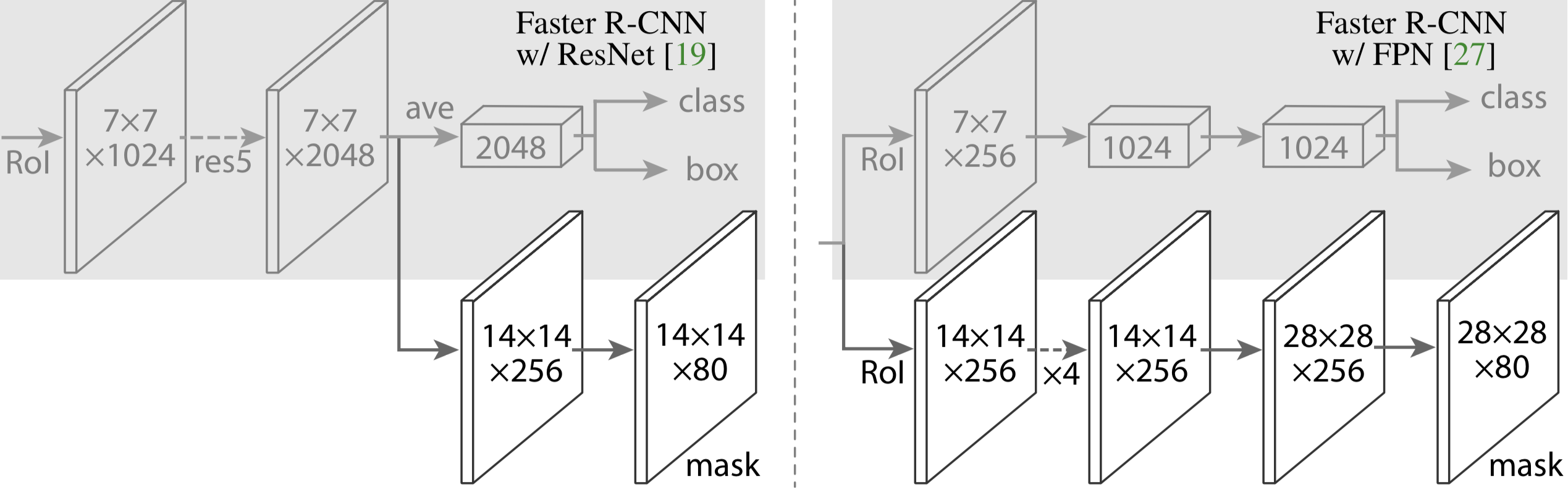
有这么一幅图来描述模型结构(很多模型设计类和应用落地类的论文都会有这么一副图)而TensorSpace可以让用户使用浏览器方便的构建出一个可交互的神经网络3D结构
更进一步的,利用3D模型的表意能力特点,结合TensorFlow.js,可在浏览器中进行模型预测(跑已经训练好的模型看输入输出分别是什么❗️),帮助理解模型
模型就像是一个盛水的容器,而预训练模型就给这个容器装满了水,可以用来解决实际问题。搞明白一个模型的输入是什么,输出是什么,如何转化成我们可理解的数据结构格式(比如输出的是一个物体标识框的左上角左下角目标)就可以方便的理解某个模型具体做了什么
例如,❓Yolo到底是如何算出最后的物体识别框的?❓LeNet是如何做手写识别的?❓ACGAN是怎么一步一步生成一个0-9的图片的?这些都可以在提供的Playground中自行探索
如下图所示,模型层间的链接信息可通过直接鼠标悬停具体查看

3D模型不仅仅可以直观的展示出神经网络的结构特征(哪些层相连,每一层的数据和计算是从哪里来),结合Tensorflow.js,可在浏览器中进行模型预测。由于我们已经有了模型结果,所有的层间数据直观可见,如下图所示:

可以通过 TensorSpace Layer的对象属性方便的拿到每一层的输出数据(未经处理),工程和应用上,了解一个模型的原始输出数据方便工程落地
首先你需要有一个使用常用框架训练好的的预训练模型,常见的模型都是只有输入输出两个暴露给用户的接口。TensorSpace可以全面的展示层间数据,不过需要用户将模型转换成多输出的模型,过程详见此文档。具体流程如下图所示:

用TensorSpace构建对应模型这一步,下面一段构建LeNet的代码可能更加直观,如果要在本地运行,需要Host本地Http Server
你最需要的是模型结构的相关信息,Tensorflow,Keras都有对应的API打印模型结构信息,比如Keras的model.summary()。还有类似生成结构图的方式,生成如下图的模型结构2D示意图
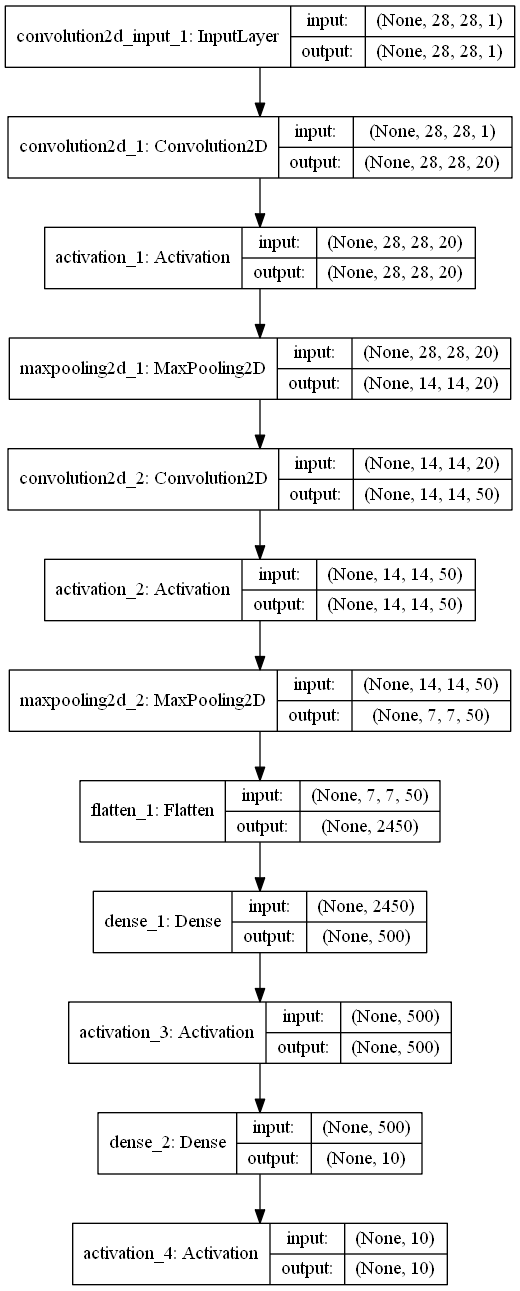
是的,你需要对模型结构非常了解才可能构建出对应的TensoSpace模型,未来版本已计划推出自动脚本,通过导入对应的模型预训练文件,一键生成多输出模型。但是TensoSpace的Playground会未来子项目会力所能及的收集更多的模型,在模型应用落地和直观展示这个领域努力做出自己的贡献
做这样一款开源框架,除了填补3D可视化的一般解决方案的框架空白外,还思索了几个可能可行的应用场景
前端(全栈)开发者,产品经理等
未来,前端的重复性工作可能会慢慢减少。最近有一个原型图 ➜ HTML代码的项目,另一个2017年的开源项目都在尝试利用机器学习自动化一些Coding中的重复劳动,提高效率
机器学习一定不会取代前端工程师,但掌握机器学习工具的工程师会有优势(这种工具会不会整合进Sketch等工具不好说),既然入了工程师行,终身学习势在必行!
TensorSpace虽然不是能帮忙训练和设计模型,但擅长帮助工程师理解已有的模型,找到可应用的领域。并且在接驳光法开发者到机器学习的大道上做了一点微小的工作,走一个可视化的Model Zoo
机器学习课程教育者
使用Tensorspace直观的在浏览器上显示模型细节和数据流动方向,讲解常见模型的实现原理,比如ResNet,Yolo等,可以让学生更直观的了解一个模型的前世今生,输入什么,输出什么,怎么处理数据等等
我们只是提供了一个框架,每一个模型如果需要直观的展示对数据的处理过程,都值得3D化
机器学习开发者
JavaScript最大的优势就是可以在浏览器中运行,没有烦人的依赖,不需要踩过各种坑。有一个版本不那么落后的浏览器和一台性能还成的电脑就可以完整访问所有内容
如果您的项目对展示自己的模型可以做什么,是怎么做的有需求,私以为,不应错过TensorSpace
用TensorSpace教学模型原理效果非常好。提供了一个接口去写代码,搞清楚每一个输出代表了什么,是如何转化成最后结果(从输出到最后结果的转换还是需要写JavaScript代码去构建模型结构,在这个过程中也能更进一步理解模型的构造细节)
现在还没有完成的Yolov2-tiny就是因为JavaScript的轮子较少(大多数处理轮子都使用Python完成),所有的数据处理都需徒手搭建。时间的力量是强大的,我们搭建一个地基,万丈高楼平地起!
我们最初的灵感来源于一个真正教会我深度卷积网是如何工作的网站:http://scs.ryerson.ca/~aharley/vis/conv/(源码只能下载,我Host了一份在Github上)
这个网站的效果,也是团队未来努力的方向(大网络上,因为实体过多,性能无法支持。为了解决性能问题,我们优化为:不是一个Pixel一个Pixel的渲染,而是一个特征图一个特征图的处理)
使用Tensorflow.js Three.js Tween.js 等框架完成这个项目,感谢前人给的宽阔肩膀让我们有机会去探索更广阔的世界
感谢每一个为这个项目付出的伙伴,没有你们每个人,就没有这个开源项目破土而出!团队中负责开发的syt123450(主力)和Chenhua Zhu,设计师Qi(Nora),感谢他们!还有负责机器学习模型部分和文档的我
也欢迎你有什么想法给我留言,或直接在Github上提出Pull Request