2026-07-31 07:08:39
最近,Anthropic扫描了一批旧书然后把原件销毁的骚操作,在网上炸了锅,焚书坑儒的帽子直接就往上扣。
不过仔细想了想后,看着那些痛心疾首的评论,突然觉得很荒诞。这些人要是真这么在乎文化,那些旧书在二手市场上几块钱一斤都没人买的时候,他们在哪呢?说白了,这种道德义愤只发生在热搜上,永远不会变成下单付款的动作。它是一种廉价的自我感动,用别人的行为来给自己刷一层“文化捍卫者”的金漆。
在此过程中,我也在认真想一个问题,那些被我们供在神坛上的旧书,到底有多少是真正有价值的,有多少只是我们舍不得扔的情感包袱。
我家柜子里藏了有一堆六七十年代的《十万个为什么》。老实说,除了那点收藏价值,里面的内容跟今天差了一整个时代。随便翻一翻就明白,它解答的那些“为什么”,在今天的孩子看来,有些简直是笑话。这套书还能留着,不是因为它还有用,而是因为它承载了一点私人记忆。但这个价值只属于我,跟人类知识的进步没有半毛钱关系。
还有那些老同志退休后写的自费书。我家里收了几本,他们走了之后,这些书从法律上讲就是孤本。你说它们有什么价值?唯一的用途就是证明作者曾经活过。但这种证明对别人有任何意义吗?我觉得没有。人类几万年的历史,不需要靠一本没人看的回忆录来证明谁存在过。说得不好听点,这些书被扫进历史的垃圾桶,不是悲剧,是规律。
问题在于,我们整个社会的知识保存体系,偏偏把这些东西也养着。版权法保护到作者死后五十年甚至七十年,既没有商业价值,也不能合法公开,只能在保护期的牢笼里安静地烂掉。说是保护知识,实际上是给知识判了一个漫长的死缓。等到刑期满了,纸张也早完了。
我一直觉得,真正有价值的知识,不需要被印成书才能获得尊严。我写了差不多二十年博客,四百多篇,上百万文字。写出来的时候就已经被几万人看过了,转载过了,讨论过了。它们活过。真要在退休后把它们收集整理印成书,不过是把一个已经完成使命的东西,再包装一次,锁进书架,等下一个时代的人来猎奇。这不是体面,是多余。当然,我写的东西本身质量也不高,但要说有些内容完全没价值,倒也不至于。但那又如何呢?
之前有人跟我争论,说孤本必须留着,万一几百年后被未来的学者发现,可能改写整个历史的认知。这个说法乍一听很有道理,但稍微想想也站不住脚。
历史本身就是一部无情的压缩机器。公元0年的时候,历史是此前几百年的细枝末节。到了公元1000年,那部分就大幅压缩了,人们更关心近五百年发生了什么。甚至到近现代,二战一打完,一战的那些反战小说、回忆录、战略分析,有多少还被人翻出来看?倒也不是被禁、被毁了,而是被更新的、更近的战争之殇覆盖了。连这些曾经被亿万人关注的文本都会沉下去,一本同时代就无人问津的孤本,还想在下个时代翻身?这个概率,比中彩票还低。
更残酷的还在后面。即便一本吃灰几百年的书在后世被人中彩票一般翻出来了,又有什么意义呢?
就连那些一直流传于世的书籍,都被改的面目全非。比如说,我们今天读的《论语》,就是汉代整理过的。汉代儒家,要的不是孔子的原话,要的是服务于汉武帝大一统的思想。比如说《唐诗》三百首,有人学者考证就被改动了上百首,连《静夜思》里边“床前看月光”这种全民记忆都是被篡改过的。更别说被重新挖出来的那些书籍。像我上半年在看的《王船山诗文集》就很典型,一个明末遗民,满脑子华夷之辩、反清复明,结果他的文稿被曾国藩翻出来,删删改改,变成了晚清理学正统的代言人。你看,就算一本书命硬,熬过了上百年没烂,等它终于被人发现的时候,也逃不掉被肢解和重塑。后人不是来理解作者的,是来借壳上市的。作者想说的是A,后人有自己的剧本,需要它说B,它就只能是B。
我过去一直觉得,保留孤本是为了留给未来一个公正的读者。现在我明白,那个公正的读者根本不存在。存在的只是一代又一代人拿着旧书当道具,去演他们自己的戏。所以,保存一本孤本,本质上是在保存一具可以被未来任意借用的躯壳。它的价值,不取决于它本身记录了什么,而取决于未来某个时代的人类刚好需要什么道具。
想通了这些,再回头看Anthropic那件事,我的感受完全不同了。
那家AI公司买了一本一百多年前的个人编写的百科全书,几千页,手工编撰的,锁在私人书柜里从没人翻过一页。但扫描完,注入模型,几亿人现在可以用自己的语言向它提问。然后他们把原件销毁了。
有人说这是焚书。我笑了。焚书是消灭内容,阻止传播。扫描后销毁,是内容已经被完整提取和激活之后,处理掉一个多余的物理容器。焚书是掐灭火种,这是火种已经传走了,扔掉烧完的火把。把这两件事混为一谈,要么是思维懒惰,要么是刻意煽情。
而且说实话,AI做了一件人类自己做不到、也不屑于做的事情。它不在乎一本书是不是垃圾,不在乎有没有人看过,不在乎是学术权威写的还是退休老同志的回忆录。它把所有这些人类看都不看一眼的文本,全部吞下去,消化,提取,变成可以调用的数据层。这个过程的本质,就是知识回收。人类产生了海量的知识废弃物,以前它们烂在纸堆里、烂在图书馆里,没人处理,也处理不了。现在AI来了,它像一台巨大的知识回收车,把这些废弃物全部拉走,分解,提炼出哪怕一点点有用的原材料。
这比让它们在书柜里发霉,或者被版权法囚禁到腐烂,好一万倍。
当然,有人会说AI会把知识学歪,会产生偏见和幻觉。但我想反问一句,人类保存知识的方式难道就完美了吗?图书馆也会迫于压力下架某些书,档案馆也会把敏感文件涂黑再公开,出版社也会在再版时删改。人类的知识保存体系从来就是选择性的、被时代所左右的。那些号称中立的公共机构,筑起付费墙,把公共知识锁在特权阶级才能碰的地方。这些机构凭什么就比AI更值得信任?
AI至少不装。它不假装自己在传承道统,不假装尊重,不假装自己是一个公正的守护者。它只是把所有东西都吞下去,等你要的时候往外吐。粗糙,但不虚伪。
其实仔细想想,我们对知识的期待,和我们对人际关系的期待,或许是一样的。我们不需要它被供在庙里,不需要它被擦得锃亮,不需要它永远正确。我们需要的是它活着,在我们需要的时候能碰到它,能让它参与我们正在思考的问题,能因为它而产生一点新的东西。
一本被AI吃掉的旧书,它没有死。它变成了数亿人可以随时调用的一个片段,一个数据点,一种思维模式。它不再是一本完整的书,也不再属于任何一个作者,它融进了知识的洪流里,变成了谁都可以伸手去接的那一部分。这难道不是一种更大的存在吗。
我写了这么多年博客,从来不在乎它能不能保存下去。我只在乎它当下有没有被人看到,有没有让某个读者在某个瞬间觉得被理解。如果有,那它就已经完成了自己的使命。我不需要那种被装订成册、锁进图书馆的体面。我的想法能留多久,由它自己在时间里漂着。如果哪天没人需要了,那就让它消失。
真正的知识,应该像空气一样流动。而不是像一块石头,被供在庙里,等着人磕头。
2026-07-29 08:35:58
前些天一直在知乎和微信上跟人讨论央视曝光的湖南江华县水稻种植面积造假的事情,那个十几万亩的差额,是靠“两套台账”硬凑出来。
虽然确实是弄虚作假,但网友们意见其实还是中肯的,大多能客观看待这个结果。在这个过程中,我也一直在想一个问题:明明用卫星或产量估算一下都能知道结果,为什么这个造假这么久才被曝光出来?
后来我想通了。因为在很多人的脑子里,一直装着一个根深蒂固的念头,农村必须稳住,农村必须能兜底,农村是最后的退路。为了维持这个念头的正确性,就必须在纸面上维持一个体面的数字。至于现实撑不撑得住,没人较真。
江华那十几万亩虚构的水稻,不是凭空捏造出来的。是某种流行了几十年的观念,替他们提前写好了剧本。
说实话,“农村是退路”这句话,我小时候真信过。
那时候想得很朴素,大不了回去种田呗,小时候又不是没有种过,10多岁就已经是家里种田的主要劳动力了,还能饿死?
后来在城市待久了,过年回老家的次数越来越少。今年年初回村里探望叔叔,他跟我说,我堂侄女,也就是他孙女,是前一年我们全村唯一一个出生的小孩。
这话听得我一愣一愣的。我们村户籍人口最多的时候有六百多号人,如今一整年,只生一个小孩。而这个小女孩,将来大概率也会像我那些堂姐表姐一样,离开这个村子。其他在外面成了家的年轻人生小孩,更不会带回村里来养了。
我试着往后想了一下。可能二十年,最多三十年,我们村里恐怕只会剩一二十个退休老人了,这还得是70后、80初那一代,对土地多少还有点感情的。再往后,连这样的人都未必有。
那一刻,我突然意识到,“大不了回去”这句话,嘴里说出来轻松,但真要回去,恐怕是养不活自己。
再后来我留心观察了一下,发现身边信这句话的人,大概分两种:一种是已经出来了、而且没打算回去的人,用它来安慰别人,也安慰自己;另一种是本身就不愁吃穿的,想着回归田园幸福生活。
而真正被这句话影响命运的,是那些被默认为“可以回去”的人。他们被假设成“很难在城市扎根”,永远有一个可以离开的选项。
于是他们在城市里的困难,就变得不那么紧迫,变得没那么受到重视,变得没那么多人在意。“管他呢,反正他们要是待不下去,还能回去种田”。
江华的新闻出来后,我特意去翻了些公开数据。像全国粮食产量、杂交水稻种植量、农业产值、各类作物种植面积等等。
过程中就看到“中国农业产值是美国6倍”的说法。这简直刷新我对国家能力的认识。
以前总觉得美国是大农场、大机械、大产出,又是农产品输出国,产值应该远高于中国才对。但结果一算下来,中国农业人口人均产值比美国还高50%,养活全国人,早就不成问题了。
但更有意思的不是产值本身,而是这个产值是怎么来的。
当我把数据拼在一起才发现,这其实就是一小撮专业农民,加上亿万在城里打工的农民工用“业余时间”干出来的。
也就是说,现在农村真正全职种地的已经很少了。大片土地流转给了种粮大户、合作社、农业公司,靠机械化、规模化在撑着产量。剩下的绝大多数散户,基本都是到了退休年龄的老人以及在外打工的人农忙时回来帮几天就搞出来的。
就这么个状态,产值就已经到了人类农业生产历史的巅峰。再继续往里边堆人,其实也没任何意义。
毕竟,经济学上有个很朴素的道理,人的需求是有上限的,更何况这种生物本能需求。十四亿人,一天三顿饭,吃再多也就那么多。总不可能吃三餐改成吃5餐、吃10餐吧。
多进去一个人搞农业,也不会让产出多多少。他只是稀释了本就不高的务农收入,把一个人的温饱问题,变成两个人的勉强糊口。
所以“回去种地”这件事,不是说能不能的问题,而是它压根没有经济上的大规模可行性。你是可以回去,但回去之后那块地给你带来的收入,能不能支撑你过上哪怕最低限度的现代生活?这种经济账,每个人都会算。
其实讲起来,今天的90后、00后一代本身就跟农村没太多交集,特别00后,基本从懂事起就生活在全球最大的工业国家,而00后到现在,差不多就有3亿人了。不管他们户口本上写着“农村”还是“城镇”,他们真实的成长路径和城市孩子已经没有本质区别。从读书到日后工作,整个生活框架都是城市化的,绝大多数人甚至连锄头都没拿过。对他们来说,“回去种地”不是一个退路选项,是一个天方夜谈,一个完全不存在的选项,甚至是推入绝路。
不过,一说到锄头,我又想起我自家的那几亩田。
说是田,其实就是山坳里的几块梯田。翻两座山头才能进去,整个山谷就那么一小片开垦出来的平地。2009年我还在读大学的时候,村里说有个退耕还林的政策可以申请。我爷爷坚决不准。他说,把田退了,以后没饭吃了怎么办?

他怕了一辈子饥荒,骨子里只信土地。
结果也没等到什么惊天动地的大事。只是我毕业以后,再也没回去帮家里干过农活,家里也没多余的劳动力。那几亩地就这么荒了。荒了十五六年。
有一回我好奇,打开卫星地图想找找那个位置。放大、再放大,完全看不出那里曾经是田。和周围的灌木、杂树融为一体,连轮廓都不清晰。更别说路了,十几年没人走过,哪里还有什么路。
我爷爷大概做梦也想不到,他死守着的那片田,最后不是被政策收走的,是被时间悄无声息地吞掉的。连同“没饭吃”的恐惧一起,变得毫无痕迹。
那这个“退路”到底退给谁看?
答案可能是退给数据看,退给报表看。就像江华那十几万亩水稻,长在纸上,不长在地里。
这些年我断断续续读过一些讨论三农的文章。某种学术论调反复出现,说农村是中国的“压舱石”,是应对危机的“蓄水池”。
我以前读到的时候,觉得挺有道理。后来慢慢发现一个问题,说这些话的人,好像都已经不是农村人了,他们也从来不问“蓄水池里那些水愿不愿意”。
他们告诉你农村能吸纳失业人口,但不告诉你吸纳之后这些人在农村怎么生活;他们告诉你土地是最后的保障,但不告诉你大量年轻人已经和土地没有任何关系。
他们用一种极尽浪漫的宏大叙事,把农村描述成随时可以托底的底座。但为了守住这个虚无缥缈的底座,普通人付出的代价被悄悄省略了。
最让我难过的是,这种退路幻想逼着许多普通家庭陷入极其残酷的“双重抽血”,包括我自己也是其中的一员。
我们为了在城市生存,年纪轻轻就背上几十年贷款,掏空积蓄在城里买房落脚;同时,为了留住老家那条虚无缥缈的“退路”,又不得不硬着头皮花大把钱去盖一栋一年到头住不了一次的房子。“城市一个家,农村一个家”,两头烧钱,两头受罪。
那些漂亮话,没有变成任何一个人的退路,只是在舆论场上完成了一次自我感动,最后全变成了我们肩头沉重的双重负担。
我并不是说农村毫无价值。事实上,每次回老家,我都能看到变化。路更好了,新房更多了,奶茶店、快递驿站、外卖甚至以前的摩的都改成开网约车了。
但这些变化,恰恰说明,农村的活力,不是来自“退路”这个设定,而是来自城市经济的辐射。
那些新房的钱,是在外面打工挣回来的。那些奶茶店的生意,是靠回家过年的年轻人撑起来的。乡镇上快递驿站的包裹,里面装的是从电商平台买的东西。甚至现代农业的种子、化肥、农机,无一不依赖城市。
农村早就不是封闭的世外桃源了。它和城市是一条线上的两端,城市这头打个喷嚏,农村那头就得感冒。
如果城市经济真的出了大问题,指望农村能独善其身、甚至反手兜底,这个因果关系完全是反的。退路能成立的前提,是那条路本身走得通。而现代农村这条路,每一块砖都是城市铺的。
写到这里,我想说清楚自己到底在不安什么。
我不是说农村不重要,也不是说不要建设农村。恰恰相反,我觉得农村真正需要的,是实事求是的关注,而不是浪漫化的想象。
我担心的是,“农村是退路”这种说法继续流行下去,会变成一种精神麻醉剂。它让决策变得不着急,让资源分配变得有理由延后,反正还有退路嘛,急什么?
但事实上,几亿人已经走出去了。他们在城市里租房、打工、养孩子、交社保。他们的退路不在乡下,在城市的出租屋里,在社保账户里,在下一份工作的面试通知里。对他们来说,真正的安全感,不是一丘遥远的水田,而是眼前这座城市愿不愿意接纳他们。
农村土地充其量只是为老一代农业人口在过渡期打上的一个临时补丁,它完成了它阶段性的使命,绝不是给新一代人画的蓝图。
写了这么多,我其实不是要否定“底线思维”这件事。
人总要有点兜底的底气,国家也是。但这些年来,特别是18年贸易战以来,我越来越觉得心里堵得慌,好像每次外部压力一大,就有人冒出来说,没事,大不了我们退回去搞小农经济,自给自足也能活。
底线思维是托底的,不是挡箭牌。托底,是让你敢往前冲;挡箭牌,是让你心安理得地不冲。你可以把底线设在粮食安全上,设在能源自主上,设在产业链备份上,但你不能把底线设成“大不了大家一起回到农业社会”。这已经不是底线了,这叫投降。
说句不客气的话。如果真有一天,发生需要大规模“退回农村”的情况,那一定不是我们自己的选择,而是被逼的。是产业升级被人卡住了脖子,是外部打压到了你死我活的地步,是完全脱钩、全方位制裁、被从全球体系里硬生生撕下来。
到那一天,问题根本就不是“要不要退回去种地”。
种地解决不了贸易制裁。种地也挡不住大洋彼岸的航母编队。
那是14亿人在这个地球上被人按住头往下摁的问题,是发展权的问题,是能不能站着活下去的问题。
所以“农村是退路”这句话,放在这个尺度上看,已经不是对错了,是格局太小了。它把一场关乎国运的硬仗,聊成了一个市井算计。
你越是想着后面有条退路,脚下的油门就越不敢踩到底。退路,有时候不是保护,是拖累。它让你犹豫,让你给自己留余地,让你在最该一往无前的时候,忍不住回头走几步。
而那一回头,可能就是一代人的差距。一代人补不上的差距。
我有时候会想,一个能造出航母、大飞机和光刻机的国家,和一个还在盘算几亩薄田能不能养活人的国家,看到的世界应该是完全不一样的。
这不是看不起农业,也不是看不起农民。而是说,我们这一代人手里的牌,不是山上那几亩地,是工厂里的无人机,是生产线上的新能源汽车,是112个垂发的055。这些牌打好了,农业自然有更好的活法。打不好,谁都别想好过。
与其花力气维护一个虚幻的退路,不如把全部家当押在向前走。把产业升级的路蹚出来,把核心技术的关卡啃下来,把城市的接纳能力和社会安全网织密。让农村不再被当作兜底的容器,而是一块被正视的土地。
这才是我们这代人,唯一该走的路。
2026-07-28 09:52:56
上半年GDP数据公布,湖南被安徽以300亿元的微弱优势超过。
300亿,放在两省经济体量里,几乎可以忽略不计。但真正刺痛人的,是趋势。五年前,湖南还领先安徽2500多亿。短短几年,安徽靠着新能源汽车、新型显示、集成电路快速崛起,“芯屏汽合”成了全国知名的产业名片。而湖南这边,工程机械和轨道交通依然能打,但在新赛道上的存在感,确实有些黯淡了。
消息出来后,湖南人的反应挺复杂。有人焦虑,有人不服,也有人开始认真剖析问题。
说实话,这种被广泛讨论的焦虑,本身是一件好事。
我是一个在广东佛山工作的湖南人。今年佛山GDP在省内被东莞超越,但说实话,这个话题几乎没什么热度。有限的讨论也大多在给佛山找台阶下,强调佛山经济和地产绑定、大环境如此。跟佛山这种有点像“认命”的状态相比,起码湖南人还在着急,还在想办法,还在不服输。
但看了很多给湖南开药方的文章,我越来越倾向于一个判断。
湖南经济的病,不是没人开药方。恰恰相反,药方早就开好了,而且开得非常准。真正的问题是,药没吃下去。
就像一个慢性病人,治疗方案已经有了,医生也叮嘱了无数遍,但他就是没法长期坚持服药。今天漏一顿,明天忘一次,身体稍有起色就回到老习惯。长此以往,再好的方子也无济于事。
湖南现在的困局,不在于下一张“发展蓝图”怎么画,而在于这张蓝图怎么从纸上,走到地上。
如果我们翻看湖南过去二十多年的历程,会发现一个令人吃惊的事实,湖南在很多事情上,其实是有远见的,动作甚至比全国都早。
先从交通说起。
很多人不知道,湖南曾经是全国高速公路建设的标兵。2005年之后的那些年,湖南搞了一场轰轰烈烈的交通建设大会战,连续多年新增高速里程排名全国前列,一举改变了湖南“南船北马”的交通旧格局,包括后来通车的全国第一条高铁武广高铁,一半都在湖南。到2025年底,湖南高速通车里程已经突破8000公里,这个底子放在全国都不算薄。
路修好了,但口碑却慢慢出了问题。
这几年,网上有个很扎心的说法叫“绕着湖南走”。一些经常跑长途的司机吐槽湖南部分高速限速变化突然、电子抓拍密集、货车通行体验差。你当然可以说这是网络情绪的放大,不能太当真。但当“能绕就绕”成为一种被反复提及的集体经验时,就说明有些地方确实出了问题。
路修得再好,如果跑在上面的人觉得提心吊胆、成本更高,那这条路的含金量就打了折扣。交通枢纽的本质是服务能力,硬件只是骨架,软环境才是血肉。而“绕着湖南走”恰恰暴露了一个深层问题:我们擅长建设“看得见”的东西,但不太擅长维护“看不见”的东西。
道路如此,制度也如此。
2011年,湖南提出建设“法治湖南”,并出台了《湖南省行政程序规定》。这个动作有多超前?当时“法治中国”这个概念甚至还没有被正式提出。湖南已经看到了问题的关键,一个地方能不能真正吸引企业、留住资本,最终靠的是规则是否稳定、政府行为是否规范,而不是给多少土地优惠。
这个“药方”开得不可谓不准。当时湖南就意识到了,未来经济的竞争,本质上是治理能力的竞争。
但后来的故事呢?“法治湖南”的理念没有消失,但现实却不断地“打脸”,一度在司法文明评比中位居全国倒数。现实生活中的很多操作,跟这个理念之间出现了越来越大的裂缝。像央视焦点访谈曝光的衡阳耒阳童车产业园招商乱象、民间屡屡诟病的“关门宰客”式招商、一些地方“先招商进来,后面的事再说”的惯性……这些事情反复在提醒我们,文件里写的规则,和现实中运行的规则,是两套东西。
药方开得好,但药效在层层传达中不断衰减。
为什么药总是吃不到位?因为对一个地方来说,最难改变的不是战略,甚至不是制度,而是习惯。
官僚主义和“官本位”思维,就是湖南身上这个最顽固的习惯。它不是什么大奸大恶,而是一种渗透在日常运行里的惯性。
前段时间,常德一个国企董事长在办公室收礼的视频流出网络。画面里,嘴上叼着和天下,桌上摆着红票子,最让人心里“咯噔”一下的,是桌上还端端正正摆着一尊毛爷爷雕像。
每一个元素都那么真实,又那么荒诞。
尤其是那个烟。说句实在话,我们这些在外面工作的人,平时在外边很少看到大家对某一种烟品牌有那么深的执念。但在湖南的某些圈子里,你递出去的烟如果不是那个牌子,就没面子。这消费的已经不是烟本身了,是一种身份表达,是一张进入某个圈子的隐性名片。而很多人明明工资根本支撑不起这种消费。
当一张名片比一纸规则更管用时,经济运行的底层逻辑就会发生变化。企业家最怕的不是成本高,是不确定性。他不知道今天是按文件办,还是得按“名片”办。
另一个更沉痛的样本,是今年上半年发生在永州的“乡镇公务员”钓鱼溺亡事件。一个年轻生命逝去,却撕开了那个乡镇日常运转的灰色一角。当时媒体对那个事件进行了深入报道,背后地地方潜规则和基层运行逻辑,都让人触目惊心。
这些事情,和我们谈的经济失速有什么关系?关系太大了。
那些招商时的烂尾承诺,那些让企业有苦说不出的隐形成本,那些让年轻人才最终决定买一张南下高铁票的日常遭遇,背后站着的,都是这种惯性。一个习惯把企业当管理对象、习惯让规则让位于人情、习惯用形式主义应付顶层设计的行政体系,是不可能支撑起“三高四新”这么宏大战略的。
财政压力,又进一步加剧了这种惯性变形。当收入下降、债务压顶,一些基层行为就会走样,过度执法、频繁检查、拖欠企业款项、承诺兑现困难。这些短期行为,是在把地方最宝贵的长期信心资产,拿出来变现。
官僚主义不只体现在作风上,有时候也体现在制度设计的拧巴里。
比如湘江新区和岳麓区的合并。本来湘江新区是一个承载重大战略的功能区,涵盖岳麓区、望城和宁乡的部分区域,应该是一盘打破行政区划的大棋。但最终却变成了和岳麓区“区政合一”,拿着一个县级行政区的壳,套上了一个正厅级的架构。
长沙本身只是一个正厅级的城市,现在它下边的一个区变成了厅级单位。于是长沙成了全国少有的、政府组成部门内设机构全都叫“处”的地级市,动不动就是处长、副处长。而岳麓区下面的局,现在也全是处长、副处长。这种名头上的膨胀,看起来是小事,实际上会把纵向的行政协调成本推高到一个很不正常的水平。这本身就是一种用形式上的“升格”来替代实质性改革的路径依赖。
事实上,前阵子长沙体育局女干部占车位问题,很多网友第一时间都是被“处长”二字吸引过去的。老老实实叫个“副科长”可能还不至于引发那么大舆情。
另一个老生常谈,是长株潭一体化。
这个概念比国内绝大多数都市圈提得都早。长沙、株洲、湘潭三市的地理距离,甚至比很多已经融为一体的都市圈还要紧密。但喊了这么多年,民间的吐槽是:这更像是湘潭在一厢情愿,而长沙的发展方向,一时往西,一时往北,一时往东,真正向南对接的力道,始终没有发挥出一个省会该有的全部实力。
结果就是,长沙越来越强,但它的强更像是一个巨大的抽水机,不断吸收周边的人才和资源。而产业外溢、功能疏解、真正把株洲和湘潭变成自己产业协作区的动作,太慢了。一个省,如果只有一个超级发动机,其他轮子都不转,这辆车是跑不快的。
耐人寻味的是,2024年开春,湖南做的第一件大事,就是部署全省“解放思想”大讨论。
这恰恰说明,管理者已经知道病根在哪里了。
一个地方在年初、用这么高的规格来谈“解放思想”,本身就是一个极具象征意义的自我诊断。它相当于公开承认,我们当前的发展受到了某种思想层面的束缚。而湖南最需要解放的,正是那个盘根错节的“官本位”思想。
但思想这玩意儿,比制度难改多了。制度可以发文件,习惯却长在骨头里。
就像对非经贸这件事。国家把中非经贸深度合作先行区放在湖南,这其实是一张非常精准的好牌。湖南的工程机械、农业机械,比如我老家双峰的农用机械,那些结实耐用、成本低廉的产品,天然适合尚在基础设施建设初级阶段的非洲市场。
但现实呢?民间因为对非洲的刻板印象,普遍比较排斥,看不到这里面广阔的空间。而官方层面,更多是把精力花在了办大型论坛、博览会、签约仪式上,停留在展会和形式主义层面。真正缺的是那种懂当地法律、能打通清关物流、帮企业把货物变成利润的技术官僚和服务体系。大量企业最后还是要绕道沿海、依赖外地贸易商,做着“为他人做嫁衣”的转手买卖。
连现成的、符合自身产业特点的国家级战略都吃不透、做不实,这不仅仅是能力问题,更是意愿和惯性的问题。
如果只看湖南人的表现,你绝不会认为这块土地缺乏活力。
邵商,从过去被认为湖南“最难治理”的宝庆府地区走出,如今把打火机、箱包、假发这样的小商品生意做到了全球领先。遍布海内外的湘商网络,从来不缺市场嗅觉和生存韧性。在科研领域,湖南籍的两院院士、青年学者,人数常年位居全国前列。
我有时候在广东参加同乡聚会,大家聊来聊去,最感慨的一点就是,湖南人在外面一个个都搞得风生水起,为什么老家就总是差那么一口气?
大家的答案出奇一致:官僚主义。
人才外流、资本外流,归根结底,是因为本地还没有形成一个让规则战胜人情、让服务取代管理、让长期预期压倒短期不确定性的环境。
那些在外面成功的企业家,不是不想回去。他们是在等一个信号,一个让他们相信“回去以后不用靠递烟也能把事办成”的信号。
湖南GDP被安徽反超300亿,一点都不可怕。这个差距,以湖南的体量,真要想追,产业稍微回暖一点就回来了。
真正可怕的是,那些让年轻人默默订下南下高铁票的日常,那些让企业家在深夜决定把下一个工厂建在外省的瞬间。
湖南要追回来的,从来不是这300亿,而是一整代人对于这片土地的信心。
药方真的已经开好了。“三高四新”的方向很清晰,国家给的政策很充分,民间的活力也从未熄灭。现在唯一要做的,就是把那些已经开了二十年、甚至比全国都超前的药,认认真真、一口一口地吞下去。别再用形式主义的糖衣把它包起来,更别因为怕苦就偷偷吐掉。
这需要一场真正的、触及习惯深处的自我革命。
而这场革命,没有人能替湖南人完成。
2026-07-27 06:24:30
前些天在微信群里,跟网友讨论“向上争取政策”这个事情时,我突然想到前些年停靠深圳盐田港的船舶,因为需要经过香港海域,一趟入港过程,需要先由香港的引水员登船引航,至深圳海域时,再换成深圳的引水员引航,由此产生“二次引航”重复登船、重复收费问题。由于引水操作本身是一个高风险行业,每次收费都要数万元,因此这种风险叠加与重复收费,事实上增加了船舶靠港成本,一些船舶因此而绕开盐田港,选择其他港口。当时,很多人都建议深圳向上争取政策解决这个“历史遗留问题”,但似乎国家层面并没有出面。
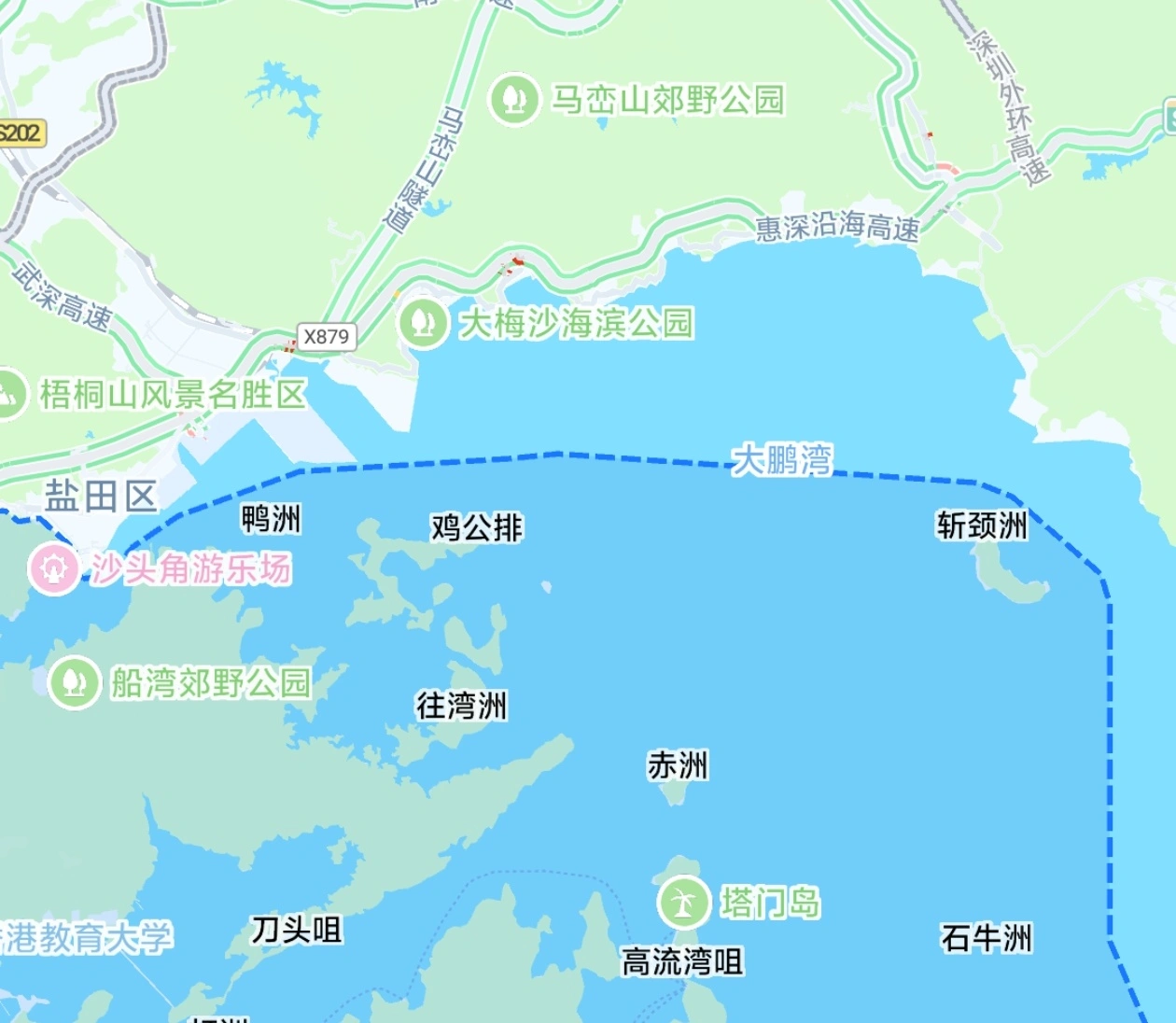
不过,那一阵之后我就没有关注那个问题,我还以为这个问题一直悬而未决。直到上网查询才发现,2022年6月,深圳与香港之间已经达成协议,双方互认互引航员资质,由一名深圳或香港合资格的引航员提供全程引航服务,并只向引航船舶进行一次收费。
目前这个三年期的协议已经续签至2028年,在首次运行的三年内,双方引航员合作引航累计2.1万余艘次,平均每次降费约3万元,每次进出港都能节约了近1小时,作业效率和安全性都明显提升。
按正常逻辑,这个问题至此已经得到圆满解决。但当我查询这个问题时,却偶然发现,其实深港之间“二次引航”问题并非只有东部海域,在西部海域同样存在。最典型就是蛇口港靠近深圳湾一侧的码头,进出港时也几乎都要经过香港水域。
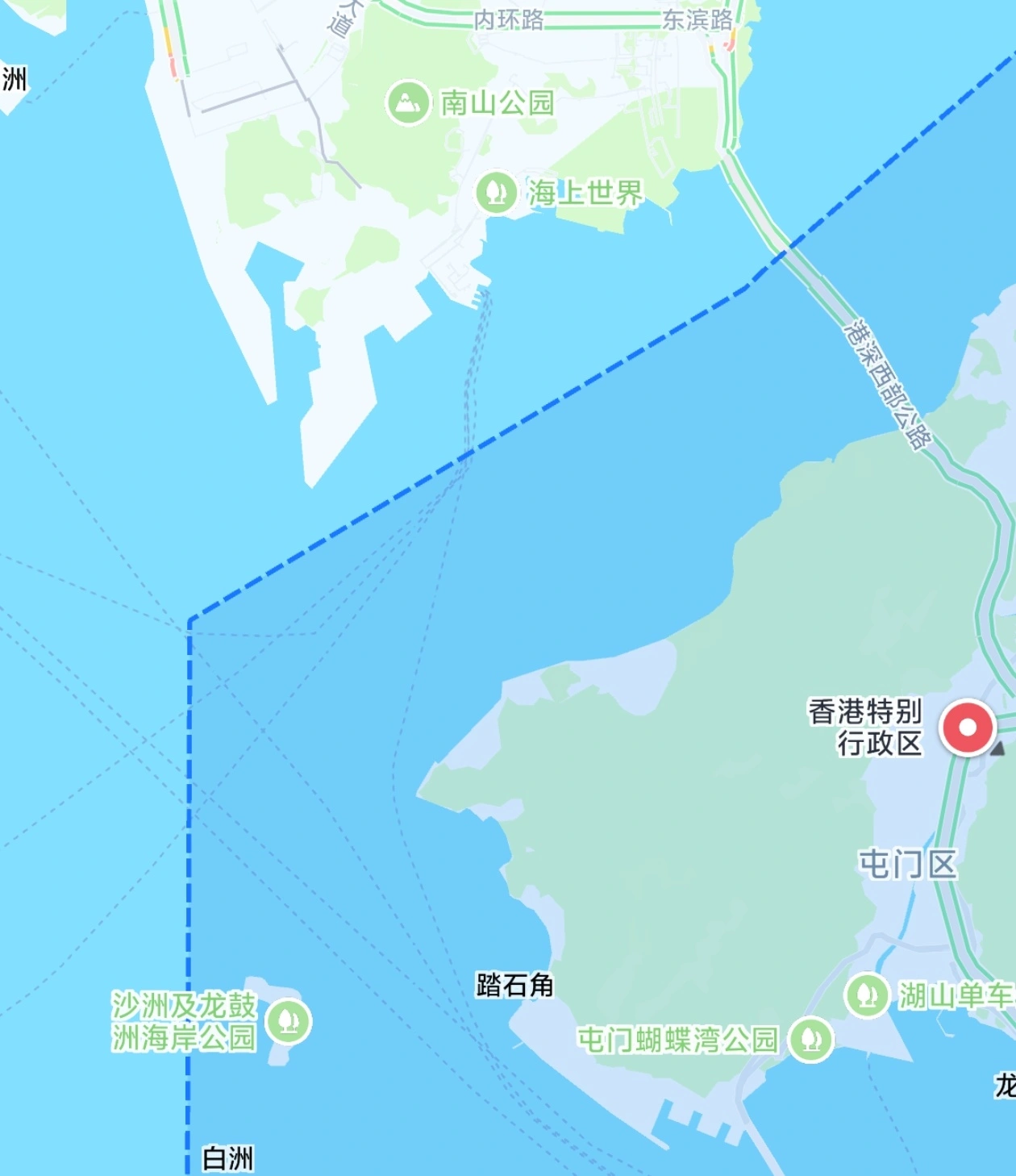
不过,仔细研究一下西侧这块海域,却发现事情原比预想复杂。相同的问题,东西两边,呈现出完全不同的状态。
更进一步发现,西部海域这种“二次引航”问题,还不是一个简单的管理协调能搞得定的事情,背后是历史形成的航道关系、法律体系、港口竞争和利益格局共同作用的结果。
深圳东部大鹏湾能够解决“二次引航”,最大的原因在于,大鹏湾本身就是一个特殊案例。
盐田港的发展,从一开始就和大鹏湾特殊的地理条件联系在一起。大型国际船舶进入盐田港,需要经过大鹏湾航道,而这片水域长期存在香港和深圳两个管理体系交汇的问题。1997年香港回归以后,随着盐田港不断发展,双方实际上形成了一种长期运行的默契。
在很长一段时间里,进出盐田港的船舶虽然经过香港管理水域,但并没有严格执行两套引航流程,而是按照实际港口运行需要完成一次引航。换句话说,过去二十多年,并不是没有规则,而是在规则之外形成了一套更加符合实际需求的运行方式。
真正的变化发生在2020年前后。香港方面重新强化引航管理要求,要求进入香港强制引航区域的船舶接受香港引航服务。原本已经运行多年的“一次引航”模式被打破,于是出现了船舶进入盐田港前,需要接受香港和深圳两套引航服务的问题。
2022年的港深协议,并不是从零开始设计一个新制度,而是在新的法律要求下,把过去长期存在的合作模式重新确认。
这也是为什么东部问题能够比较顺利解决。因为双方面对的不是一个陌生问题,而是一个曾经存在过、双方都认可过的运行模式。
对于盐田港而言,香港水域更多像是一段通往深圳港口的共享通道。大家解决的是如何恢复效率,而不是重新分配一套成熟利益。
如果说东部大鹏湾的问题是恢复旧有惯例,那么深圳西部面对的就是完全不同的情况。
蛇口、赤湾、妈湾方向涉及的主要是珠江口西部航道体系,其中最重要的龙鼓水道,属于香港屯门区管辖,本身就是香港港口体系的重要组成部分。它不是一条为了深圳港而存在的航道。香港自己的港区,包括屯门、青衣等区域,也依靠这一航道进出。
这意味着一个根本区别。
盐田方向更接近“香港水域服务深圳港”。而西部方向则是“香港的港口、深圳的港口以及珠江口多个港口共同使用一套复杂航道体系”。
如果说大鹏湾是一条通往单一目的地的道路,那么珠江口更像一个大型城市交通网络。这里同时连接香港港、深圳西部港区、广州南沙港、中山港、珠海港、澳门方向。
因此,西部问题并不是简单复制盐田模式,把一个香港引航员和一个深圳引航员合并成一个。它涉及的是整个珠江口港群如何协调。
更重要的是,龙鼓水道长期以来就是香港港口运行的一部分。过去几十年形成的引航制度、监管流程和行业利益,都建立在这个基础上。如果改变规则,影响的不只是深圳一条航线,而可能涉及香港整个港口服务体系。
这也是为什么同样是一年几个亿的费用,对于不同区域意义完全不同。东部更多像是取消一个额外成本。西部则可能意味着改变一个已经运行百年的行业体系。
一个是减负,一个是重新分配利益。
很多人看到这类问题,第一反应是,既然香港和深圳都属于中国,为什么不能直接通过更高层级协调解决。
从法律角度看,其实并不是完全没有空间。大鹏湾协议已经证明,不一定需要彻底修改两地法律体系,也可以通过合作协议实现引航互认。所以,法律本身并不是最大的障碍。
真正困难的是,规则变化之后,谁承担成本。
引航并不是普通商业服务。它涉及专业资格、责任认定、监管权限和稳定收入来源。如果一艘船原本需要香港一次引航、深圳一次引航,未来变成一次完成,那么一定有人减少业务。
同时,还会产生新的问题。如果一名引航员跨越不同管理区域执行任务,发生事故之后,由谁负责调查?责任如何划分?保险如何计算?监管权如何安排?
这些问题看起来细节化,但对于海事管理而言,这些恰恰是最核心的问题。
此外,香港和内地虽然都使用中文,但长期形成的法律传统和行政运行方式存在明显差异。内地海事管理更多依靠行政管理体系解决问题。香港则更加依赖法定程序和司法机制。
例如,同样面对船舶违规行为,内地可能直接由行政机关处罚,而香港更多需要走诉讼程序处理。
这种差异并不是谁优谁劣,而是两个制度长期发展形成的不同运行逻辑。大湾区规则衔接真正困难的地方,不是找到一条相同的法律条文,而是让不同制度背景下的人接受同一种运行方式。
深圳并不是完全等待规则协调。事实上,深圳西部港区一直在加强自身航道建设,其中铜鼓航道就是一个非常典型的案例。
近年来,深圳持续投入资金对铜鼓航道进行建设和维护,相关工程投入甚至高于单纯引航费用。
如果只看经济账,花这么多钱维护一条替代航道,似乎并不划算。
但港口竞争也从来不能只看短期成本。航道建设的价值,不是节省今天多少钱,而是让自己拥有更多选择。
如果一座港口完全依赖另一套制度安排,那么它就容易受到外部规则变化影响。而拥有替代航道之后,深圳至少具备了一定的主动权。这也是港口竞争中的一种常见逻辑。
当制度协调存在不确定性时,建设物理基础设施,就是为自己增加一份保险。
当然,工程替代并不意味着制度合作没有价值。恰恰相反,替代方案越成熟,未来谈判空间可能越大。毕竟,真正有效的合作,从来不是只靠一方妥协,而是双方都能看到的共同利益。
现在回头看“二次引航”这个问题,我最开始只是单纯想着,一艘船多换一次引航员可能造成的浪费和不便。但深入研究之后才发现,它其实不只是大湾区规则衔接的一个案例,更折射出一个更大层面的命题。
我们习惯把香港、澳门看作一个省级特别行政区,这当然没错。但如果只看到这一层,就忽略了它们的另一个角色。这两个地方,本质上是我们这套以成文法、行政主导为特征的陆权规则体系,与西方近现代以普通法、国际商业惯例为特征的海权规则体系之间的对接平台。
香港的普通法传统、商业规则和司法体系,澳门与葡语系国家的法律联系,都是它们在数百年历史中积累下来的制度资产。这些东西不是在1997年或1999年之后才存在的,而是已经运行了很久的系统。
当我们说“大湾区规则衔接”时,我们真正在做的事情,其实远比“深港两地签一份合作协议”复杂得多。我们是在尝试把两套完全不同基因的制度体系,放在同一个地理空间内,让它们能够共同运转。
“二次引航”这个看似细小的问题,恰恰触碰到了这个深层结构。引航不仅是一项技术操作,它背后是一整套关于航行安全、责任认定、保险理赔和行业管理的制度框架。
深港东部能够解决,是因为双方在这个局部问题上找到了共同利益的最大公约数。西部迟迟无法突破,则是因为它触及的是香港港口体系的核心利益,以及一整套已经运行了上百年的行业规则。
如果我们在自己的领土范围内,连一水之隔的规则衔接都无法理顺,那么当我们在国际上面对完全不同体系的规则对接和竞争时,难度只会更大。
这其实才是大湾区建设最被低估的价值。它不仅是修桥铺路、打通物理连接,更是一个试验场,一个在“一国两制”框架下,探索不同制度体系如何共存、如何对接、如何融合的长期实验。
东部大鹏湾的协议证明了只要双方有足够的共同利益和妥协空间,规则差异是可以被技术性解决的。西部龙鼓水道的困局则提醒我们,当问题触及存量利益和核心制度时,解决成本会急剧上升,时间尺度也会拉长很多。
但无论如何,这些问题都必须在大湾区内部先走一遍。这也是中国要实现民族复兴,要从“陆权思维”走向“陆海统筹”过程中,必须经历的一次制度演练。
这个过程的复杂程度,可能远超我们最初的想象。但这个过程的价值,也同样远超我们最初的估计。
2026-07-17 02:24:30
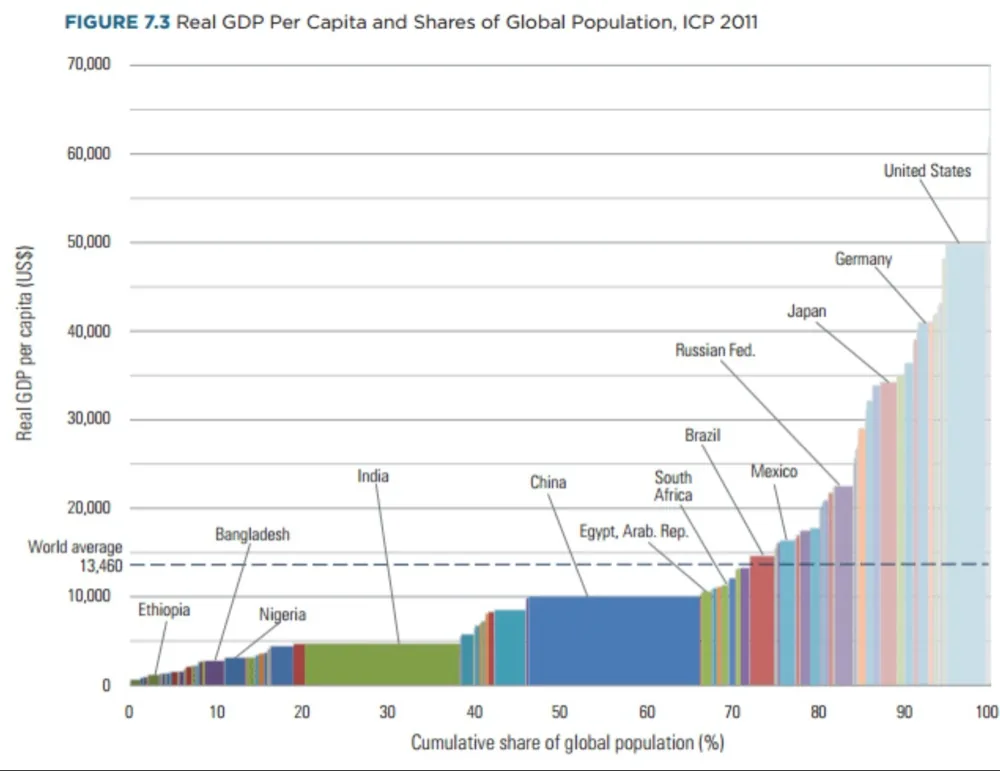
很多年前,我在网上看到过一张让我震撼的数据图。那是一张用“面积守恒”画出来的人口金字塔,越往上走,国家的人均 GDP 越高。最绝的是,图形的面积代表了真实的人口体量。
前几天在微信群跟人讨论这个话题时,我突然又想起了这张图。可仔细搜索一番,却没能找到那张图,只找到一张近似的世界银行2011的图片,但这张图其实跟我印象那种也差距很远。这张只是横向将各国GDP按人均数值排列,其实看不出那种震撼的感觉。
目前,主流的关于这类数据图,大多采取桑基图、马里梅科图等方式来呈现。我也尝试了一下用网络工具 Datawrapper 和 Flourish 来画一下,结果发现效果并不理想。
之所以,金字塔这类图形更为直观和震撼,主要是它契合了人类数千年等级秩序的文化心理。金字塔的底端,是庞大基数的发展中国家人口,但他们所对应的往往只是世界经济份额中的少数部分。而发达国家以少数人口获取了大部分经济利益。
最后,我放弃了寻找现成方案,开始自己着手来制作这个图。
数据图制作过程比想象中麻烦很多。一开始,我想着用 Excel 和 WPS 来画,毕竟像 WPS 会员有非常多的模板可供选择。但尝试一番后发现一个比较严重的问题,就是图形与数据源很难匹配上。
我使用的数据源是世界银行最新的人口与人均GDP数据,在这里边,它细分了217个国家和经济实体,以及47个区域或经济组织。其中,大的国家比如中国、印度,人口都有 14 亿,而小的国家或地区很多人口都只有几十万甚至几万人。最大值与最小值,相差达到数万倍。这种情况下,对于 Excel 图表制作真是一个灾难。
后来,我还是老实换用 Python 来制图,毕竟这过程中需要调整的参数很多。
比如说,在一个普通大小的数据图中,不可能做到把每个国家和地区名字都显示出来,那到底展示哪些国家名称,就是一个值得研究的问题。考虑到每个国家人口最终展现在图像上面积的巨大差距,最佳方案显然是按照最终展示面积比例来设置。如果面积过小,则无法显示了。
比如说,将全球人口画到金字塔上时,需要严格计算每一个国家地区的人口数据在图像中的占比。而这种占比,实际上需要对应到金字塔中间每一级所对应梯形的面积(除了最顶端的是三角形面积)。
在此过程中,经过数十次调整和绘制,最终我做了三个版本的图出来。
这是最接近我记忆中样貌的第一版图。当我把最新数据塞进这个动态生成的金字塔模型时,视觉上的冲击力非常直观。在这张图里,全球人口被重新洗牌,从下往上按照人均富裕程度层层码放。
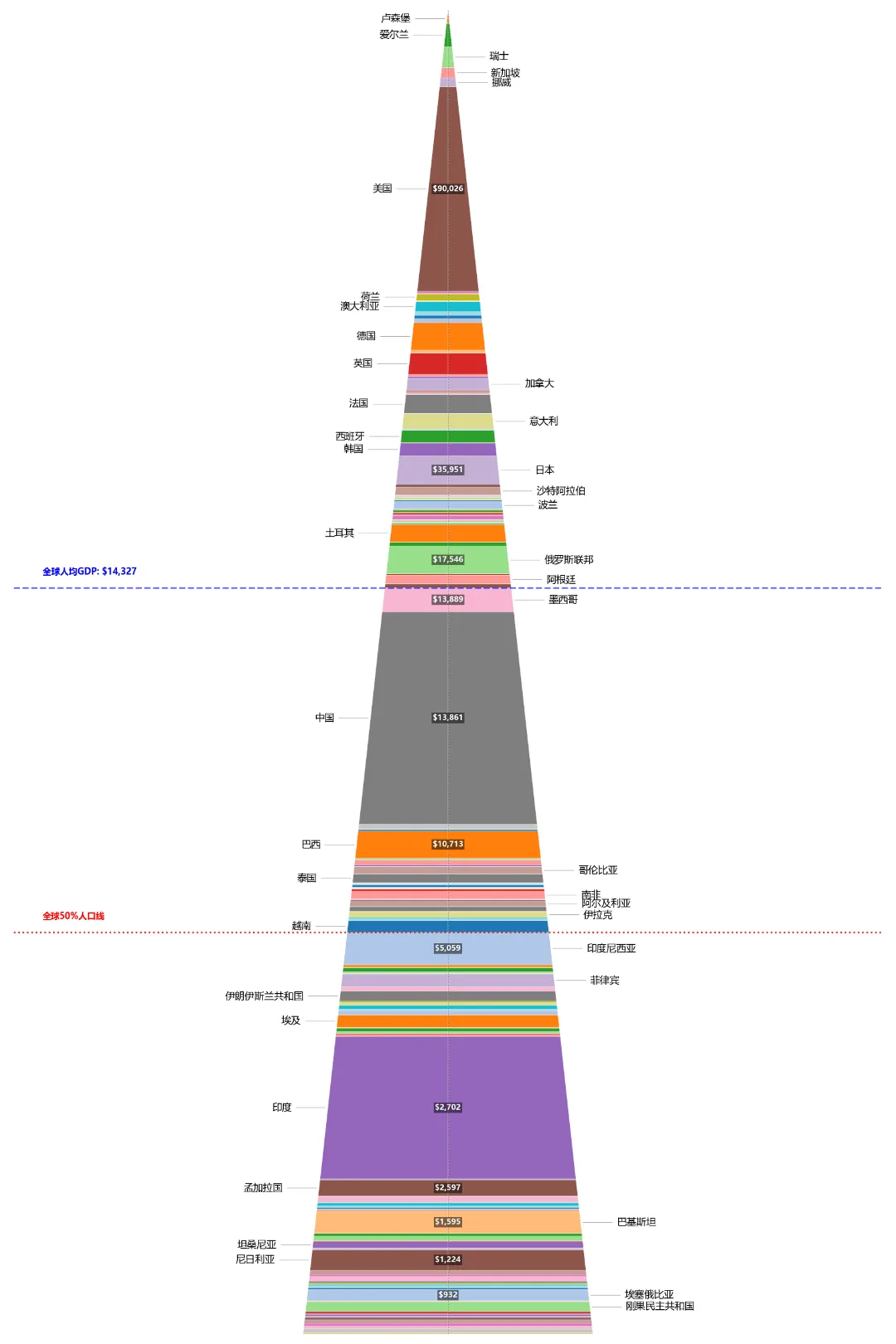
在这个金字塔中,我画了两条线。一条是人均GDP线(蓝色虚线:$14,327),另一条是全球 50% 人口线(红色虚线)。这两条线一画上去,整个图的“灵魂”就出来了,它无情地揭示了三个让人深思的冷酷现实:
一是中国,正站在全球人均线的“临界点”。从图上可以非常清晰地看到,中国以一堵巨大、宽厚的巨墙,死死地顶在金字塔的最中间。我们距离全球平均水平只有一步之遥,在我们的头顶上,是跨过平均线的世界;在我们的脚下,则是更为庞大的低收入群体。
二是财富与人口的极端错配。看那条红色的人口 50% 分割线。按理说,如果世界是平均的,人口跨过一半,分得的财富也应该过半。但现实是,红线(全球 50% 人口)被压得极低,甚至远低于蓝色的人均 GDP 线。这意味着世界上有超过 50% 的人口,人均 GDP 甚至还没有达到 $5,059。全球最富裕的那一半人口,拿走了远超其人口比例的绝大部分经济蛋糕。在金字塔最顶端,卢森堡、瑞士、挪威,以及占据了相当厚度大色块的美国,他们的人口面积在金字塔顶端占据面积并不大,却在支配着难以想象的财富。
三是被“平均”掩盖的真实世界。按照世界银行最新数据,2025年全球人均 GDP 约为 $14,327 (这是通过对数据库内所有国家和地区数据计算得来,与新闻数据略有差异)。但如果你仔细看图就会发现,真正能生活在这条蓝色均线之上的国家,其实寥寥无几。除了欧美、日韩、沙特等少数国家外,金字塔的大部分肥厚部分全都在这条线以下。也就是说,世界上绝大多数人,都是被金字塔顶端那极少数“超级富豪国家”给“强行平均”上去的。
这是我制作的第二张图。虽然金字塔图极具视觉冲击力,但它在数学视觉上有一个不可避免的物理缺陷,为了在逐渐收窄的顶部保持“面积守恒”,高人均 GDP 国家(如美国、欧洲各国)的纵向高度被无形中拉长了。这容易让人产生一种错觉,误以为这些国家的人口占比也很大。
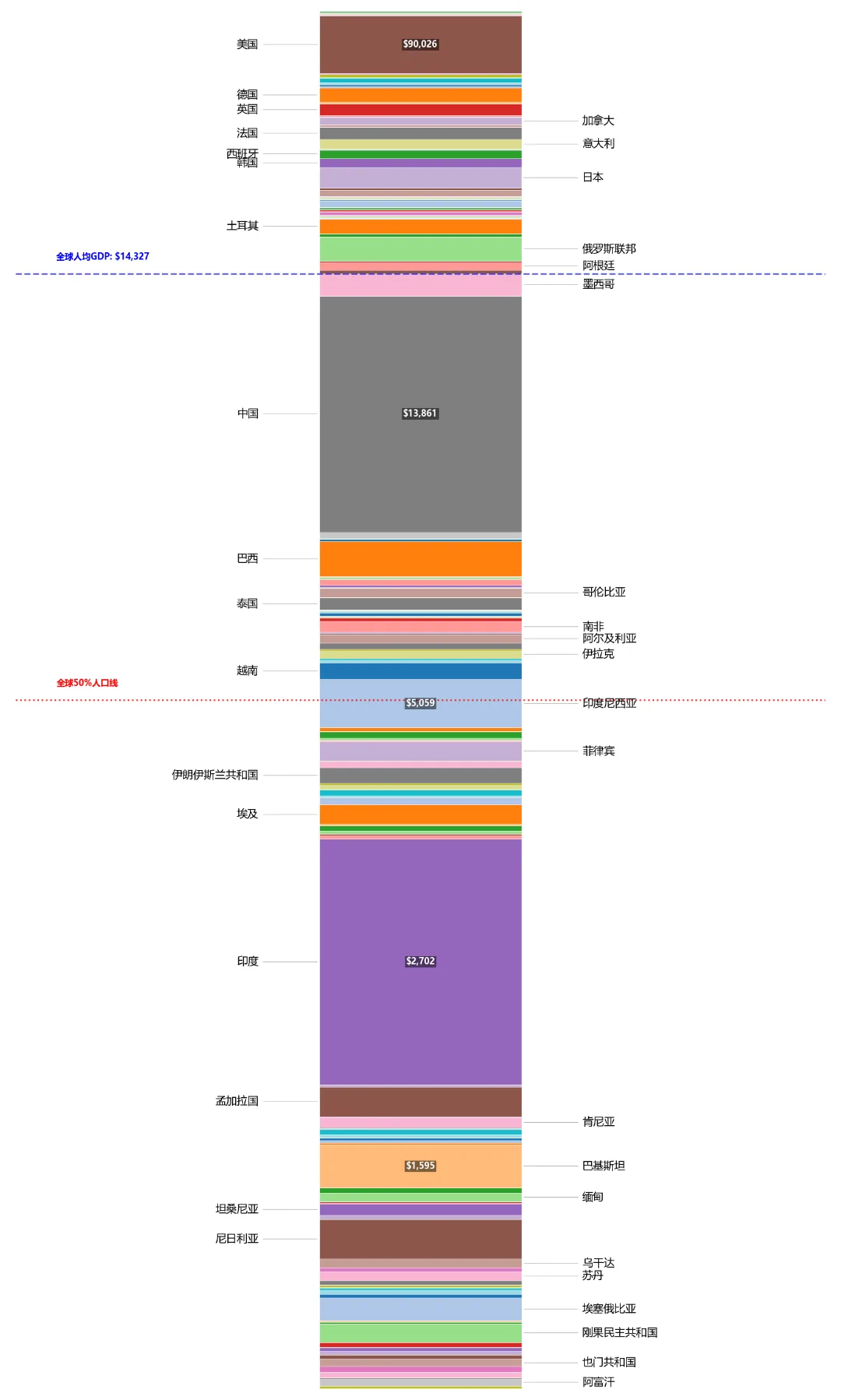
在这张图上,我同样保留了那两条线。但与前者明显差异的是,这两条线实际位于整个图象上端约1/5和1/2处。与前边金字塔上几乎三等分图象高度存在较大区别。
这种高度的剧烈位移,挤干了金字塔由于形状带来的视觉水分,将最真实的物理比例直接暴露出来。
真实的50%人口(红线)回归物理中点(1/2处),没有了金字塔底部的拓宽掩护,红线老老实实回到了正中间。这让我们能更直观地看清,14亿中国人实际上整体处于全球约24%-40%这个区间。我们前边需要追赶的,已经不到全球1/4人口。
柱状图相比前边金字塔图来说,“二八定律”的视觉更加具象化了,全球人均 GDP 线被顶到了最上端约 20% 的高度。也算是用最诚实的几何语言说明全球真的只有 20% 的人口跨过了这道平均线,剩下的 80% 全都被甩在了均线下方。而除了美国之外的发达国家,在整根人类柱子的最顶端,窄得就像是一条条细线。
不过,柱状图在人口比例上做到了“绝对真实”,但它的局限同样明显。由于每一层的宽度完全相同,它完全隐藏了财富的绝对总量。由此,我后来又做了第三张图。
既然单一维度的图形总有妥协,那我干脆将它们合二为一,做了一次更大胆的尝试,左边保留人口金字塔,右边则用来展示 GDP 总量。
这也就是我个人觉得在逻辑上最硬核的一张。
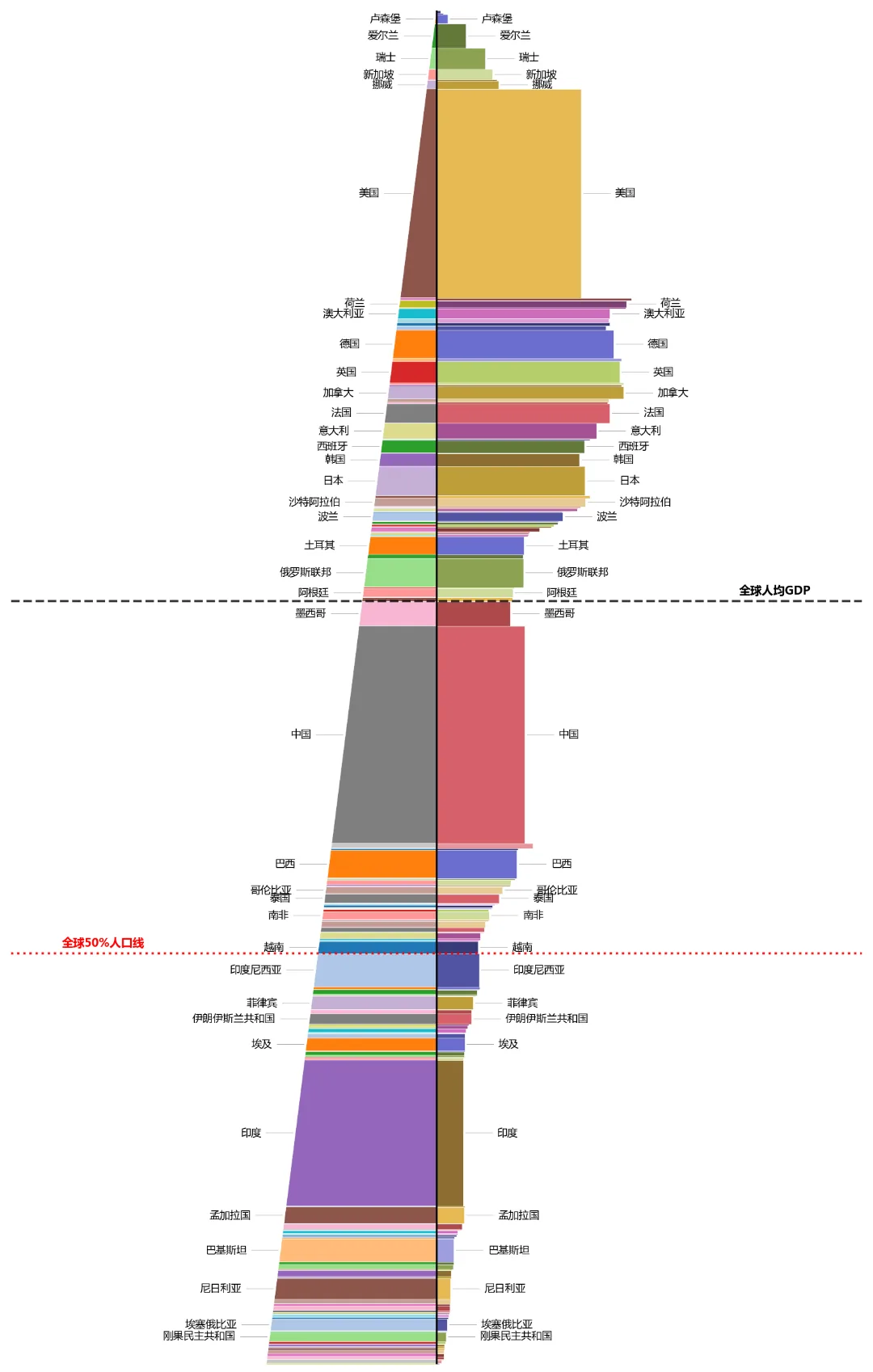
为了让这张图在数学和视觉上同时成立,我重新推导了左右两边的几何算法。因为两侧是共用 Y 轴高度的,而高度已经由人口比例决定,如果右侧色块的面积要严格代表该国的 GDP 总量,那么右侧色块的宽度就不能简单地用数值进行线性映射,而是必须通过公式重新计算,即 宽度 = 该国 GDP 全球占比 ÷ 该国在图中的纵向高度 × 缩放系数。
通过这种“面积守恒”的物理约束,右侧每一个矩形的面积,真实对应了它在全球 GDP 总量中的真实份额大小。
当这幅图最终呈现在屏幕上时,两边的剧烈反差瞬间让整个图形拉成近似于平行四边形了。
一是顶部与底部的“天平倾斜”。看图像的最顶端,那些人均GDP极高的发达国家,在左侧的人口占比小的可怜。然而,为了在如此狭窄的纵向厚度里塞下它们庞大的财富总量,右侧的宽度被疯狂拉宽。在几何视觉上,这表现为右侧向外狠狠地飞展出去,撑起了一片巨大的财富羽翼。相反,在图像的底端,那些基数庞大的发展中国家,在左侧占据了极其醒目的视觉版面。但在右侧,它们的经济贡献却被压得扁平窄小,几乎贴着黑色中轴线,缩水成了一条条勉强可见的窄缝。
二是中国在中轴线两侧撑起平衡的巨塔。在这张“平行四边形”般发生剧烈位移的图谱中,中国展现出了一种极其震撼的力量。我们不再是顶端那种偏废一侧的极窄触角,也不是底端那种几乎隐形的细线。中国在左边拥有一堵厚实的人口高墙,在右边同样拉开了一块面积巨大、极为扎实的红色经济板块。在这个天平倾斜的世界版图里,中国在左右两边同时撑起了极其可观的面积,真正成为了维持全球人口与经济引力场平衡的“压舱石”。
三是“黑色天堑”之下的无声世界。如果我们顺着那条代表全球人均 GDP 的黑色虚线往下看,会发现除了中国这个体量庞大的特例之外,几乎所有线以下的发达国家和地区,其右侧的色块都发生了大幅萎缩。这条线就像一道无形的天堑,将世界分割成了两个部分,线上是人口极少、却极度膨胀的财富世界;线下则是人口巨万、但在经济总量版图里近乎无声的底层世界。