2026-06-02 14:50:18

As of 2026, there are four major forms of agentic coding products:
| Phase | Product Form | Representative Products |
|---|---|---|
| Transition period | Editor & IDE + chat side-panel | VS Code, Cursor 1.0, Antigravity 1.0 |
| Transition period | Coding Agent CLI | Claude Code, Codex CLI, Gemini CLI |
| 🤖 AI-native | Agent coworker chat apps | Slack, ClickUp, Slock |
| 🤖 AI-native | Agent command center apps | Codex App, Cursor 3, Antigravity 2.0 |
We can split them into two phases:
Phase 1: Transition from human → agentic coding (2023 ~ 2025):
Products: Editor & IDE + chat side-panel, Coding Agent CLI
Phase 2: 🤖 Agent-native workflows (2025 ~ now):
Products: agent coworker chat apps, agent command center apps
Compared to Phase 1—where humans still wrote code by hand or constantly steered the agents—the primary user journey has shifted to orchestrating agents to handle work from start to finish. The agent is no longer an assistant living in a side panel; it represents the core functionality of the product.
In 2026, there is a notable trend: companies are redesigning their existing products to be agent-focused. For instance, Google launched Antigravity 2.0 at I/O, replacing the VS Code-based editor with an agent-first layout (i.e., an agent command center). Cursor 3 did this even earlier in April. To quote from their announcement:
We're introducing Cursor 3, a unified workspace for building software with agents. The new Cursor interface brings clarity to the work agents produce, pulling you up to a higher level of abstraction, with the ability to dig deeper when you want. It's faster, cleaner, and more powerful, with a multi-repo layout, seamless handoff between local and cloud agents, and the option to switch back to the Cursor IDE at any time.
This shift is more significant than you might realize. Leading players in the market have thrown away incredibly successful products used by millions of people to create something completely new. Clearly, these are rational, careful decisions backed by comprehensive internal studies and metrics. Is this the final form of agentic coding products? Not necessarily, but for the near future, agent command center will continue to dominate.
What about agent coworker chat apps? I love the concept, and I use OpenClaw from Telegram every day. But the question remains: do I really want another chat app? Maybe not. That's why I think WhatsApp, Telegram, Slack, and Discord will maintain their positions while becoming more AI-native. Besides, a good coding environment still requires features like code editing, debugging, and linting, which chat apps don't provide out of the box.
Today, if you use Codex/Cursor/Antigravity, they look and feel almost identical:
Antigravity 2.0

Codex App

Cursor 3

A natural question is: what's next? I see a few directions for evolution in agent capabilities and product design:
Needless to say, agents harnesses will continue to improve. There is a ton of exciting research into dynamic context, safer sandboxes, memory/skill management, and subagents. What I find most interesting is that Anthropic "abandoned" their belief that "You don't need a new agent, just create skills," and instead created agent teams and dynamic workflows. If I understand correctly, this is a loop:
People have been talking about proactive agents for a while, but few products actually support them. Jules is one of the exceptions. If you haven't tried this feature, Jules scans your codebase looking for TODOs and performance bottlenecks, generates suggestions, and notifies you. Once you approve a suggestion, Jules automatically creates a PR. I find the performance tips quite useful and have already merged multiple PRs this way.
Beyond that, agents should be able to proactively maintain a codebase by completing tasks such as:
Some tasks may require external triggers, like a pipeline that automatically converts GitHub issues into user prompts. What is even more interesting—and has yet to reach a consensus—is whether we should let agents proactively suggest new features, let alone submit those changes without human approval. This is very different from standard maintenance work, as the problem space is open-ended with no single right answer. I'm looking forward to hearing stories from teams trying this.
Imagine a team working like this: previously, engineers produced 5 commits a day; with coding agents, they produce 12.

This brings two major challenges, which will only intensify as coding agents become more capable:
A possible solution is to build a coordination layer that syncs context across agents and accumulates a team memory. This would act as your team's ultimate PM—someone who knows what everyone is working on and proactively unblocks or helps people when needed. Much like the human brain, long-term memory would store lasting team knowledge (e.g., design choices), while short-term memory tracks immediate team progress and workspace status. SageOx is one startup embracing this exact idea.
I'm putting verification at the end, as it is always the final step in an agent loop (if there is one) 😉.
Many people don't realize how important verification is. However, if you examine agent trajectories, almost all coding agents perform some form of validation at the end. For example, an agent might launch a local server to test a newly added endpoint. If a test fails, it will attempt to fix the issue and continue looping until it passes.
Does this mean verification is a solved problem? Certainly not. The biggest bottleneck remains setting up the test environment. Not all verification is as simple as sending HTTP requests. Changes to a frontend, for instance, typically require browser automation or even recording video and screenshots to be evaluated by an LLM auto-rater—which is a non-trivial process on its own. What if you're fixing bugs for an Android app but don't have the necessary toolchains installed? Yes, you can connect to a remote sandbox containing all dependencies, but then you have to figure out communication protocols and address privacy concerns. While it isn't too difficult to build a custom solution for a specific requirement, turning this into a generic, out-of-the-box component for any coding agent still requires a long way to go.
2026-02-02 07:16:25
I've been at the Jules team for ~1 month, and I want to take a quick snapshot of how I feel right now:
Googlers working at Labs are more ethusatic about programming and technology in general. After returning to work, many would share what they built during the holidays, which is unheard of when I was in Ads. Of course, this is largely due to the fact that many work on coding agent and want to have a playground to test it, but it still feels quite different.
Teams work quite differently. My previous teams use Email + Chat + Docs evenly for communicaton, but the Jules team use Google Chat 90% of the time. This allows the team to communicate more efficiently and get in-time feedbacks.
The Jules team (and Labs in general) moves a lot quicker than all my previous teams. This is within expectation, but it's still interesting to see new features added to the product every week, compared to taking quarters or years to launch something.
I can finally learn what I want to learn, and more importantly, not feeling disconnected from the rest of the world. Previously, reading articles written by other AI leaders/labs feels like a pain: "ok I learned a context engineering trick, so what? It's irrelevant for me." Now, I can use what I learned on my daily work. My 9-5 and after-work life finally doesn't feel like two different worlds, I'm finally a whole person without schizophrenia (精神分裂症).
Building agent is quite engineering heavy, and most techniques are about overcoming the limitations of LLM. e.g. LLM can't count line numbers, thus I need to prepend line numbers to diffs before injecting it into the prompt.
Using Python, the language I'm proficient with, feels good. Yes LLM write most of the code these days, but language proficiency can help you make wise decisions, avoid pitfalls and anti-patterns.
Pivoting seems to be a norm here. I will share more when the time comes.
Overall, how things turned out aligns with my expectations. I'm excited for what's next.
2025-12-24 19:45:29
I work in Google Ads in the past several years. Over time, I've seen one pattern came along again and again, causing endless pain for developers, that is, creating mini-frameworks.
First, I'd like to give readers a sense of what I mean by "mini-frameworks". Imagine a company with 1000 engineers, and they share the same tech stack. Over time, a team finds the shared tech stack unsatisfactory, either because they have to write boilerplate code over and over, or the performance is not good enough, or whatever. So they decided to create their own framework on top of the shared stack. You know it's a framework and not just a library, when you hear engineers present the work using concepts & terminologies they invented, as a way to actualize their mental model. Framework like this is what I called "mini-framework", with some common characteristics:
If you work for a big company, most likely you've seen or even done this. But why is it bad? Being a victim myself, I can share my story.
Over the years, my team has been using a Google-internal framework to write server code, and are gradually migrating our org's codebase onto it. This framework is well-designed and maintained by a dedicated team. We're generally happy with it, though it has some itchy points (not pain points). Being a strong and ambitious engineer, my manager proposed that we add an abstraction layer on top of it, with the aim to lower the barrier for org adoption, and solve those itchy points on the way. I was skeptical and tried convincing my manager not to do it, but failed. Eventually, several engineers spent quarters to add this abstraction layer, and now the fun begins.
First, one author tried to adopt it in our existing codebase. People thought it would be easy, but it took like a year. Why? Because during the migration, they found that the abstraction cannot handle certain use cases, so they have to spend time patching it to make it work. In the meantime, other people like me were writing new code using the original framework, this again added new requirements and workload for migration. Eventually, after spending way more time than initially planned, the migration completed, and my manager decided that newly-written code should use our own framework.
You think this is the end? Of course not!
Since I started writing code with the new framework, there wasn't a single time that I didn't want to curse and quit the job. The framework is so hard to use, it introduced so many concepts with the intent to hide complexity, but ended up bringing more. Since I'm not the person who writes it, I'm not familiar with all tricks and hacks. As a result, what used to cost me a day to finish can now take two weeks, plus I have to constantly ask the author how to do certain things, and even booked pair-programming sessions. As I heard, other team members were having the same complaints. As for the original goal of driving adoption, ofc it didn't help (if not making things slower). What's funny is that, this layer is supposed to make people outside of our team write code more easily, but now even our own team are suffering from it.
Looking back, part of the problem was caused by bad design and implementation, but the fundamental problem lies in creating the mini-framework in the first place. I've observed other mini-frameworks, they all sort of have the same problem, just some worse than the others. So I've come up with a few thoughts to explain why mini-frameworks are bad.
First, mini-frameworks lacks feature completeness and compatibility. People often think that they can magically "hide the unnecessary complexity", but in reality they can't. Even if the mini-framework can deal with 80% use cases well, they often lack the flexibility and features from the original framework to satisfy the rest 20%. DSL (Domain Specific Language) shares the same problem, and that's why people hate it so much.
Second, mini-frameworks violates the ETC (Easier To Change) principle. I first learned the concept from the legendary book The Pragmatic Programmer, and it still astonishes me that many programmers (even experienced ones) are not aware of it. Put simply, it suggests to write code in a way that allows future modifications be made easily. Creating mini-frameworks violates this principle in two ways:
Third, mini-frameworks is a realization of the creator's mental model, but it's not everyone's mental model. People who tend to create mini-framework are often more opinionated, which is a good thing by itself. But when you create things for others to use, being too opinionated can cause problems. I would even say that sometimes (not always), creating a mini framework directly reflects the author's ego, and they chose a framework because a tiny library cannot carry "the significance of the work".
Fourth, mini-frameworks tend to cause tech stack fragmentation. I generated an image to show what I mean: part of the system is migrated, others are not. As new layers kept being added, over time it gets worse. Not sure if other companies are like this, but at Google, I've never actually seen a code migration fully complete, which is kinda hilarious.
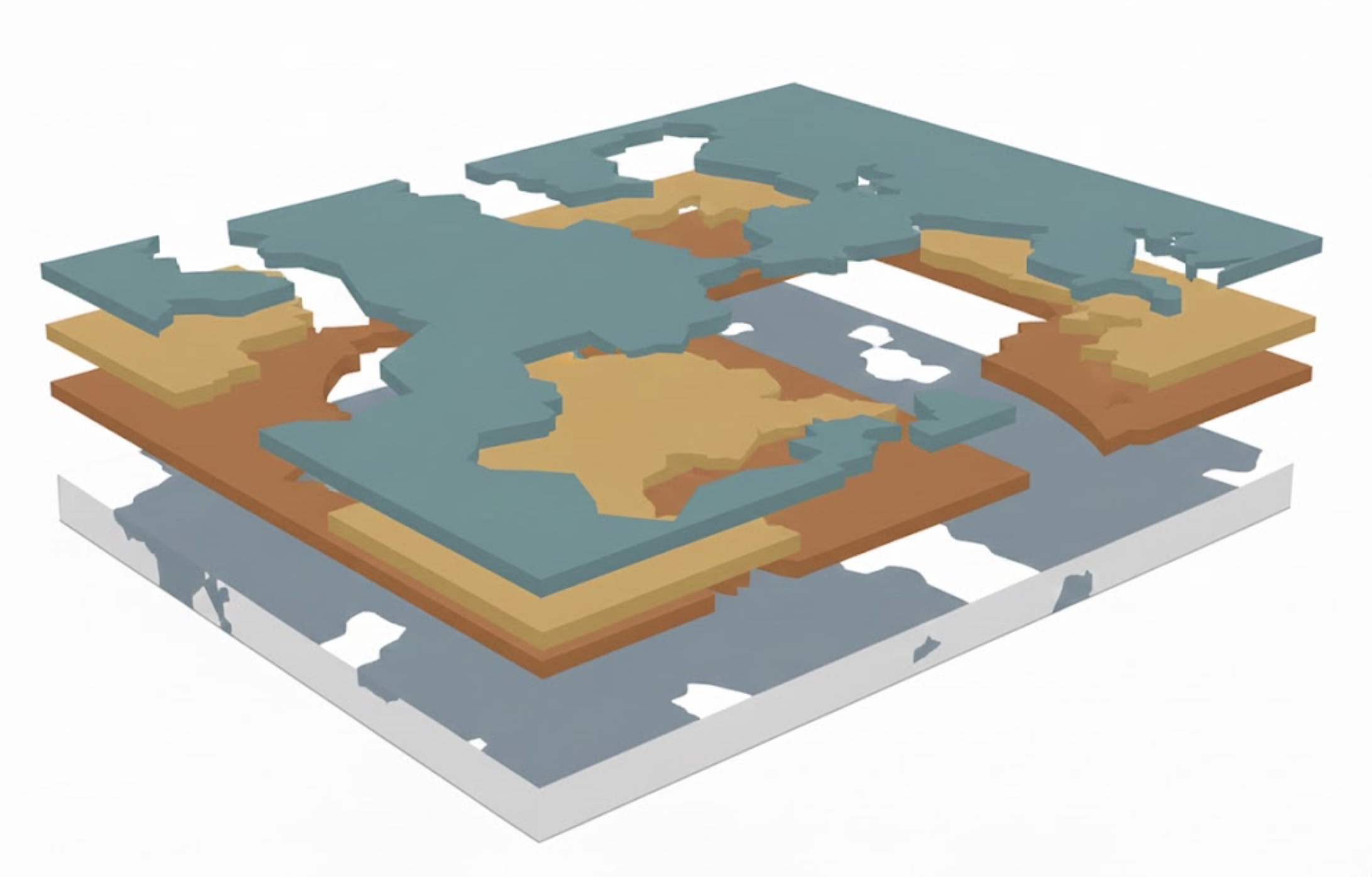
Last but also the most concerning: lack of maintenance. Unlike shared infrastructure owned by dedicated teams, mini-frameworks were often owned by those 1 or 2 people who created it. Once they left the team or company, it becomes really hard to find successors — sure other team members may know roughly how things work, but certainly not as deep as the authors. Also, people lack the motivation to maintain existing stuff, because you don't get paid more or promoted doing this. Therefore, mini frameworks often die with the departure of the original authors, unless it has gained major adoption before that, which happens less likely than not.
At this point, it's important to clarify what I'm against and what I'm not. I'm certainly not against adding abstractions——because abstractions are essentially, the program itself, we can't live without it. I'm against adding abstractions in a wrong way, and in the form that's not needed.
Let me bring this up once again since it's really important: The real and only difference between a library and a framework, is whether it introduces new concepts. The line can be blurry sometimes, but more often you can tell easily. For example, a library can include a set of subclasses or utility functions around the original framework, as they don't introduce new concepts. But if you see a README that starts with a "Glossary" section, you know it's 99.99% chance a framework (people may still refer to them as "libraries", but you get the idea).
My point is, we should be really really careful introducing new concepts. If you can, avoid it. The cognitive load brought by a bunch of buzz words is heavier than people realized, and especially, what the framework author can realize. Words are the mirror of someone's thought, same with code. The authors create concepts because it is how they model the problem inside their brain, it is how they think. That's why they claim the concepts are "natural and straightforward", while others are struggling to understand.
So rule No.1, avoid creating mini-frameworks, create libraries instead. But in the cases where you do find it necessary to create a framework, my suggestions are:
Link concepts to concrete business requirements, not something in your head.
Start fresh. Don't build a wrapper around the existing framework, build your own from scratch. Yes this would make it a major decision that requires more discussions and resources, but it avoids many of the aforementioned issues. After all, you have good business justification to do this, right.. Right?
2025-11-26 15:25:23

我们常常抱怨工作让人疲惫,然而这之中亦有差别——有的工作可能轻松,却无法给你补充能量;有的工作虽累,却能带给你新的能量。假设前者每天净消耗 10,后者在消耗 20 的同时补充 15,反倒是后者更可持续。
2025-10-20 12:17:51

Today I tried three agentic browsers: Comet, Dia, and Fellou. I gave it a real task I wanted to automate: extract data from a webpage, and write it to a Google Sheet in another tab. The task requires clicking on buttons to reveal data, which I thought would be the most challenging part.
The results were quite disappointing.
Overall, I see two major hurdles for agentic/AI browsers:
Problem 1: Webpages are not designed for AI.
Webpages contain a massive amount of redundant information, which wastes a huge amount of context, interferes with AI's judgment, and slows down execution. Meanwhile, services that convert webpages to Markdown don't handle dynamic content well. I feel this ultimately needs to be solved by websites and content providers, for example, by offering paid, AI-friendly Markdown APIs. Trying to handle this entirely on the client-side is extremely difficult.
Problem 2: Screen Reading.
On a Mac, for instance, reading screen content relies on the accessibility API. This creates a problem: if the AI wants to "see" the webpage (rather than just its HTML), the browser must be the foreground app; it can't just run in the background. But the whole point of using an AI assistant is to save time so I can do other things, right? If I still have to keep the browser in the foreground, I might as well just do it myself. Allowing AI to take screenshots using browser API might solve this to some extent, but it would be less precise than the accessibility APIs.
If we're just talking about integrating an AI sidebar, Comet already does a great job, and Chrome is about to catch up. But they are still a long way from being true, general-purpose agentic browsers. I think the future directions might be: