2026-07-10 12:34:30
by Kahlil Gibran
Your children are not your children.
They are the sons and daughters of Life's longing for itself.
They come through you but not from you,
And though they are with you, yet they belong not to you.
You may give them your love but not your thoughts.
For they have their own thoughts.
You may house their bodies but not their souls,
For their souls dwell in the house of tomorrow, which you cannot visit, not even in your dreams.
You may strive to be like them, but seek not to make them like you.
For life goes not backward nor tarries with yesterday.
You are the bows from which your children as living arrows are sent forth.
The archer sees the mark upon the path of the infinite,
and He bends you with His might that His arrows may go swift and far.
Let your bending in the archer's hand be for gladness;
For even as he loves the arrow that flies, so He loves also the bow that is stable.
2026-06-29 22:55:30
时间过得真快,Rick and Morty 已经播出 13 年了。
在试播集的时候,Rick 说的这句话——「你、你的人生还长着呢,而且你的肛门现在还又紧又有弹性」——我就不理解,为什么肛门不会紧?

“Y-y-you’ve got your whole life ahead of you, and your anal cavity is still taught, yet malleable”
但 13 年之后,我理解了 Rick……
由于肛门不再紧致的问题,所以我上厕所不会带手机玩。厕所里有一块太太买的硅藻泥脚垫(非常好用),上面有一圈比较「正能量」的文字,如下:

由于已经使用半年了,看着比较脏。读者可能也不会有我这么多的时间去转着圈读。所以我把这段话抄下来:
Life comes in a package.
This package includes happiness and sorrow,
failure and success,
hope and despair.
Life is a learning process.
Experiences in life teach us new lessons and make us a better person.
With each passing day we learn to handle various situations.
平平无奇的一段话。但是我读过一百遍了,在某一天突然发现,这说的真有道理。
—— Life comes in a package.
如果没有失败,成功就没有意义。正是因为有失败的几率,成功才变得值得庆祝。
如果没有悲伤,幸福也容易被忽视。
读过一些讲如何处理情绪的书,其中共同提到的一个技巧是,不要与情绪对抗,要观察情绪,就如同对待天气,认识到情绪的变化,就如同天气会变化,让情绪过去。
但很难做到,不知道如何操作。
我海藻泥开悟之后,一旦想,Life comes in a package, 就非常容易理解情绪的变化了。那些焦虑,是因为关爱和担心;伤心,也是因为爱。
生活是一个过程,而不是一个结果。当人老了,回顾自己的一生的时候,看到的不会是最后到达的点,而是曾经走过的所有的路。
这样一想,路上无论遇到什么,都不会是遗憾了,无论遇到什么,都可以勇敢地去面对。
2026-06-10 19:52:00
这篇文章写一下服务器的网络方面的调优经验。如果网络的带宽使用在 1GE,其实没有必要做调优,默认的参数基本没有问题;如果有 10G 以上的网络带宽要求,就需要做一些优化了,比如三层网关,四层负载均衡,七层负载均衡,大流量的 Redis 服务器这种场景,在 25GE, 100GE 甚至 400GE 的网卡上,如果不做调优,可能无法跑满带宽。
本文专注于系统参数调优,不涉及代码方面的优化。(当然代码方面的优化也是非常重要的,在高性能网络方面,通过优化代码减少指令数,提高缓存命中率,性能提升也是非常显著的。)
本文提供优化思路,具体的性能差别需要设计实验来得出,虽然我们做了大量的性能测试,但是全贴出来就显得文章太长没有重点,所以实验参数就不贴了。
这是一个 TCP 的 ingress 大体的流程图。
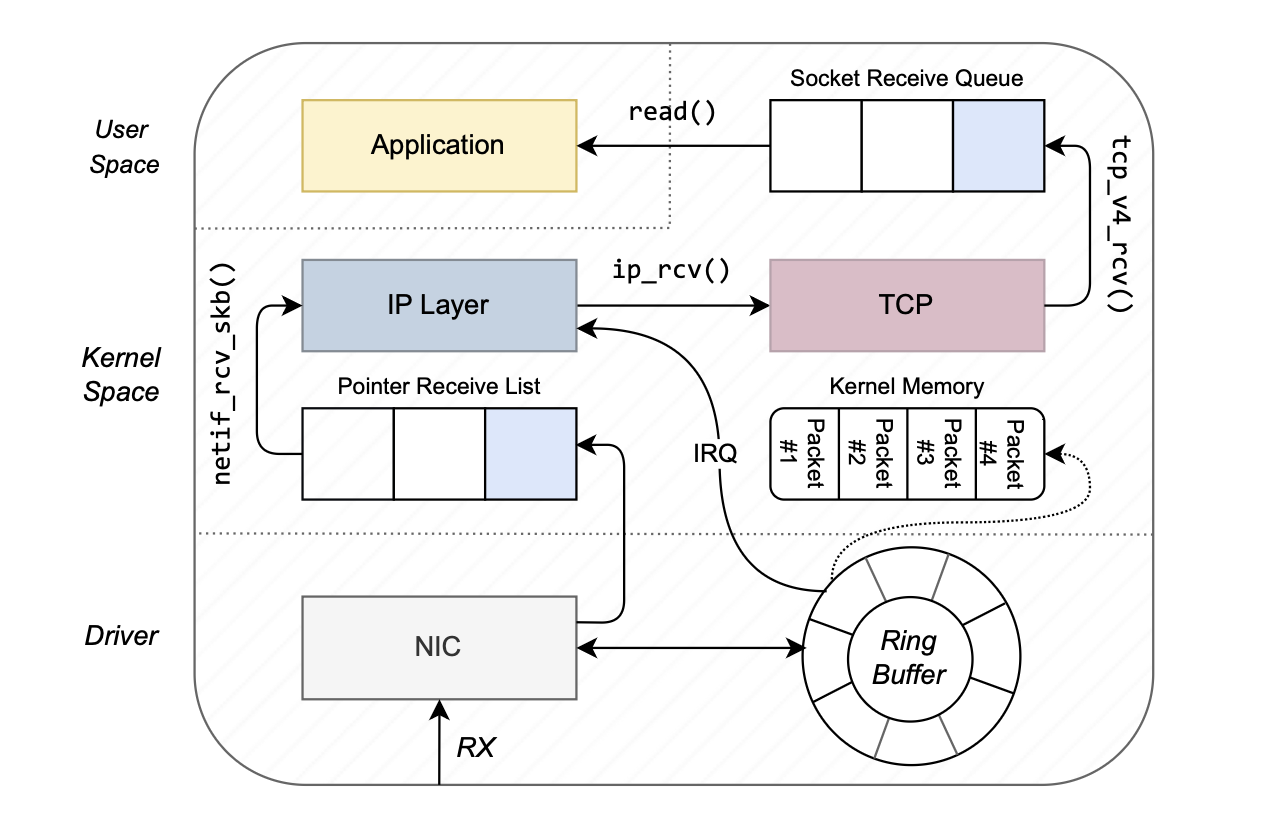
Linux 网络栈的收包流程大致上可以分成这么几步:
我们按照这个路线讨论需要调优的地方。
首先,网卡是通过 PCIe 接口插在主板上,如果 PCIe 的带宽小于网卡的带宽,那么在第 1 步就出现瓶颈了。
可以用以下命令检查 PCIe 的实际带宽。
先找到网卡所在的 PCIe 地址:
$ ethtool -i eth2
driver: mlx5_core
version: 24.04-0.7.0
firmware-version: 26.43.2026 (MT_0000000531)
expansion-rom-version:
bus-info: 0000:31:00.0
supports-statistics: yes
supports-test: yes
supports-eeprom-access: no
supports-register-dump: no
supports-priv-flags: yes然后用 lspci 查看这个地址的信息:
$ lspci -vv -s 0000:31:00.0
31:00.0 Ethernet controller: Mellanox Technologies MT2894 Family [ConnectX-6 Lx]
Subsystem: Mellanox Technologies MT2894 Family [ConnectX-6 Lx]
Physical Slot: 5
Control: I/O- Mem+ BusMaster+ SpecCycle- MemWINV- VGASnoop- ParErr+ Stepping- SERR+ FastB2B- DisINTx+
Status: Cap+ 66MHz- UDF- FastB2B- ParErr- DEVSEL=fast >TAbort- <TAbort- <MAbort- >SERR- <PERR- INTx-
Latency: 0, Cache Line Size: 32 bytes
Interrupt: pin A routed to IRQ 18
NUMA node: 0
Region 0: Memory at 202ffc000000 (64-bit, prefetchable) [size=32M]
Expansion ROM at b0e00000 [disabled] [size=1M]
Capabilities: [60] Express (v2) Endpoint, MSI 00
DevCap: MaxPayload 512 bytes, PhantFunc 0, Latency L0s unlimited, L1 unlimited
ExtTag+ AttnBtn- AttnInd- PwrInd- RBE+ FLReset+ SlotPowerLimit 75W
DevCtl: CorrErr+ NonFatalErr+ FatalErr+ UnsupReq-
RlxdOrd+ ExtTag+ PhantFunc- AuxPwr- NoSnoop+ FLReset-
MaxPayload 512 bytes, MaxReadReq 4096 bytes
DevSta: CorrErr+ NonFatalErr- FatalErr- UnsupReq+ AuxPwr- TransPend-
LnkCap: Port #0, Speed 16GT/s, Width x8, ASPM not supported
ClockPM- Surprise- LLActRep- BwNot- ASPMOptComp+
LnkCtl: ASPM Disabled; RCB 64 bytes, Disabled- CommClk+
ExtSynch- ClockPM- AutWidDis- BWInt- AutBWInt-
LnkSta: Speed 16GT/s, Width x8
TrErr- Train- SlotClk+ DLActive- BWMgmt- ABWMgmt-
DevCap2: Completion Timeout: Range ABC, TimeoutDis+ NROPrPrP- LTR-
10BitTagComp+ 10BitTagReq- OBFF Not Supported, ExtFmt- EETLPPrefix-
EmergencyPowerReduction Not Supported, EmergencyPowerReductionInit-
FRS- TPHComp- ExtTPHComp-
AtomicOpsCap: 32bit- 64bit- 128bitCAS-
DevCtl2: Completion Timeout: 260ms to 900ms, TimeoutDis- LTR- 10BitTagReq- OBFF Disabled,
AtomicOpsCtl: ReqEn+
LnkCap2: Supported Link Speeds: 2.5-16GT/s, Crosslink- Retimer+ 2Retimers+ DRS-
LnkCtl2: Target Link Speed: 16GT/s, EnterCompliance- SpeedDis-
Transmit Margin: Normal Operating Range, EnterModifiedCompliance- ComplianceSOS-
Compliance Preset/De-emphasis: -6dB de-emphasis, 0dB preshoot
LnkSta2: Current De-emphasis Level: -6dB, EqualizationComplete+ EqualizationPhase1+
EqualizationPhase2+ EqualizationPhase3+ LinkEqualizationRequest-
Retimer- 2Retimers- CrosslinkRes: unsupported
...关键信息是第 23 行显示 LnkSta: Speed 16GT/s, Width x8。
16 GT/s 是 PCIe 的单通道的速度,表示 Giga Transfers per second,PCIe Lane 每秒传输多少个符号(symbol),PCIe Gen 4 每 130 bit 有 2 bit 的编码开销,所以实际带宽是:
128b / 130b Encoding * 16G ≈ 15.754 Gbps
一共有 8 lane,15.754 Gbps * 8 = 126 Gbps.
上面的这张网卡是 25GE,所以 PCIe 的带宽是绰绰有余了。如果是 200 GE 的网卡,就必须插在 PCIe Gen 4 x 16 或者 PCIe Gen 5 x 8 以上才行了。

这里需要格外注意的一点是,我这张网卡虽然是 25GE,但是上面是有 2 个 25GE 的接口的,做了 bonding1,所以实际这张网卡的带宽是 50G。以此类推,如果是 100GE 双网口的网卡,PCIe Gen 4 x 8 是不够的。
可以用 ethtool 查看在用网卡的实际 PCI bus 地址,都是 31:00,说明是同一个 bus,同一个 device。
$ ethtool -i eth2
driver: mlx5_core
version: 24.04-0.7.0
firmware-version: 26.43.2026 (MT_0000000531)
expansion-rom-version:
bus-info: 0000:31:00.0
supports-statistics: yes
supports-test: yes
supports-eeprom-access: no
supports-register-dump: no
supports-priv-flags: yes
$ ethtool -i eth3
driver: mlx5_core
version: 24.04-0.7.0
firmware-version: 26.43.2026 (MT_0000000531)
expansion-rom-version:
bus-info: 0000:31:00.1
supports-statistics: yes
supports-test: yes
supports-eeprom-access: no
supports-register-dump: no
supports-priv-flags: yes我们再来看第 2 步,网卡把数据包的信息 DMA 到内存。
现代网卡得益于 DMA 机制,在网卡收到包到写入内存的时候完全不需要 CPU 参与工作。
——其实这也是一个优化的基本思路,CPU 本身就不适合处理单一的、大批量的任务,应该尽量减少 CPU 的工作。
Linux 里面每一个进程都有一个虚拟的,独立的内存空间,CPU 读取内存的时候,需要 MMU 把虚拟地址转换成物理内存地址。
PCIe 设备直接 DMA 内存也是一样,不过用的是是 IOMMU。简单来说,设备 DMA 的路径如下:
NIC -> IOVA -> IOMMU Page Table -> Physical Address
IOMMU 在这里负责将设备访问的 I/O 地址(IOVA)转换为物理地址,并限制设备只能访问被授权的内存。但是这里也有一层虚拟地址到物理地址的映射,会带来 overhead。
如果关闭,就可以节省这层 overhead,让设备直接写物理内存。但是这样会带来风险——如果网卡存在 bug,就可以写到其他内存地址,是比较危险的。
也可以使用 pass though 模式,让 IOMMU 使用直通模式运行,这样也没有每次内存写入的翻译成本,但是对内存有保护。配置方式是 GRUB 的启动命令添加 intel_iommu=on iommu=pt. 在 pt 模式下,设备通过 IOMMU 的开销很小,而且只能访问特定范围的内存,不能越界。
如果每次 DMA 的时候都申请内存,会有不小的开销。所以比较好的方式是事先规划好一部分内存,这部分内存就不回收了,直接给网卡 DMA 用。
这个功能不需要配置,但是需要网卡驱动和 kernel 支持。
可以通过 debugfs 查看实际网卡有没有使用 page pool:cat /sys/kernel/debug/page_pool/1-0x00000000abcd1234/stats。
(如果没有,也不一定就是每次分配内存,可能用了别的内存优化机制)
网卡把包写入哪一块内存也有说法。到这里就不得不说一下现代服务器的架构。
现代的服务器一般是双路服务器,里面有 2 颗 CPU,也叫双子星服务器。注意,这里说的是 2 颗 CPU,2 Socket,而不是双核 CPU。
下面是浪潮 NF5180M6 服务器的物理俯视图:

厂商一般会提供服务器的手册2,里面重要的一部分就是逻辑图。
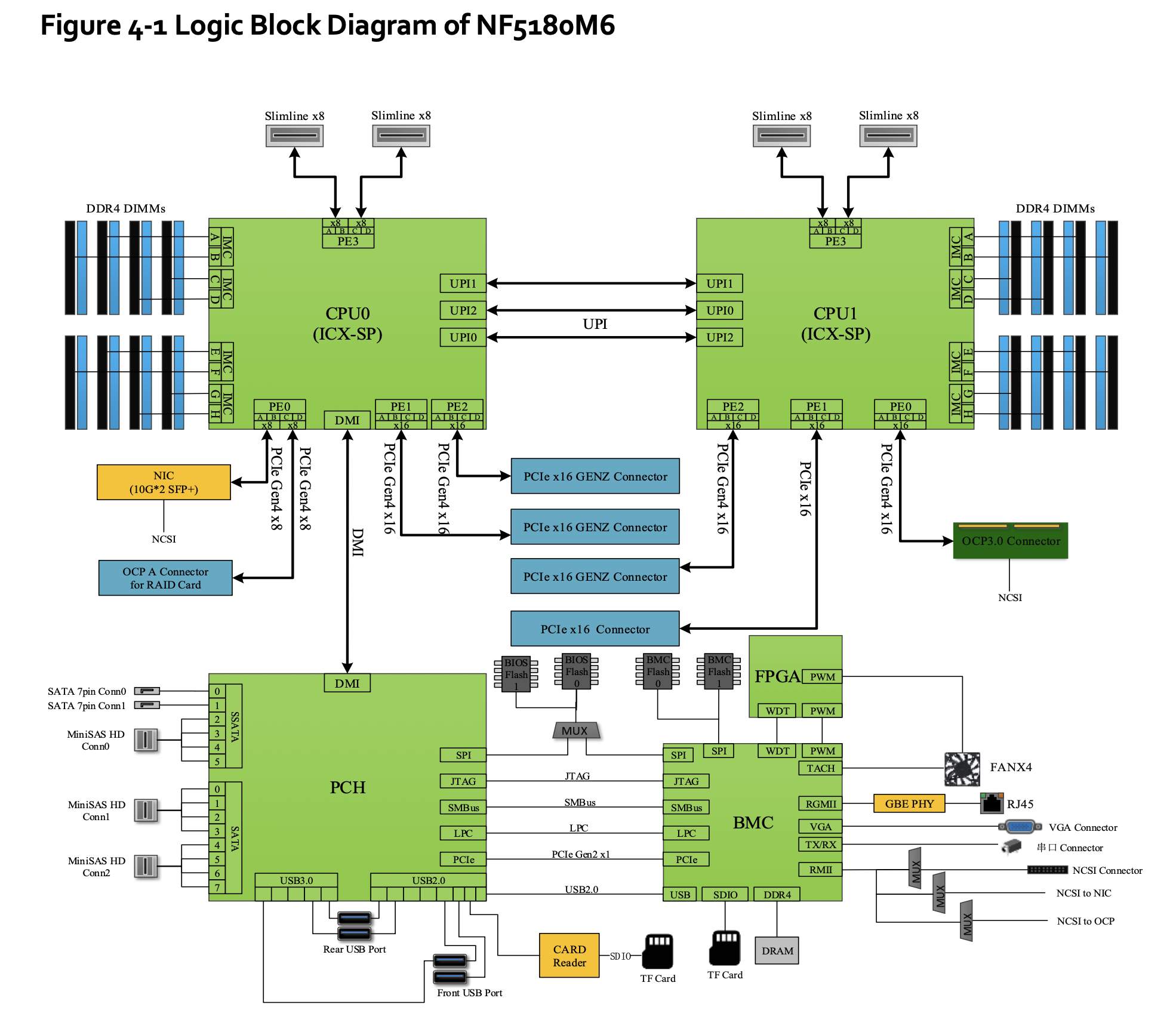
图中的一个重要信息是:内存也是由两部分组成,一半连接 cpu0,另一半连接 cpu1. 这意味着,物理上 cpu0 访问左边的内存比较快,如果要访问右边的内存,就要走 UPI 去另一个 CPU,比较慢。对于 cpu1 来说反之。
用 numactl 可以看到内存布局:
$ numactl -H
available: 2 nodes (0-1)
node 0 cpus: 0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 40 42 44 46 48 50 52 54 56 58 60 62
node 0 size: 128069 MB
node 0 free: 119511 MB
node 1 cpus: 1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 41 43 45 47 49 51 53 55 57 59 61 63
node 1 size: 128965 MB
node 1 free: 115027 MB
node distances:
node 0 1
0: 10 21
1: 21 10NUMA 的意思是 Non-Uniform Memory Access,意思是 CPU 访问不同的内存,速度是不一样的。从上面的输出中可以得知,逻辑的 CPU 0,2,4,6…62 号访问 node 0 的内存较快,访问 node 1 的内存较慢,CPU 1,3,5…63 号访问 node 1 的内存较快,访问 node 0 的内存较慢。
这就启发我们,所有内存访问,都应该尽量走 local,避免走 remote:
这样性能才是最优的。
从逻辑图可以看出,一个 PCI 设备只连接到一个 CPU。我们可以用 sysfs 来查看这个 PCI 设备连接的 CPU 所在的 NUMA 节点:
$ cat /sys/class/net/eth2/device/numa_node
0注意:这个文件的信息本质上是 ACPI 提供的,数据来源于硬件的上报,但是有些不守规矩的厂商可能没有上报正确的数据。最准确的信息其实是上面厂商提供的逻辑图。3
即 eth2 这个网卡是连接到 node 0 上的。那么网卡驱动在初始化的时候,应该从 node 0 申请内存,这样,后续的 DMA 都使用 node 0 的内存。这部分一般不需要调试,驱动的内存初始化一般都是 NUMA aware 的。
网卡 DMA 到内存之后,接着是 CPU 的 softirq 来处理这个包,我们希望 node 0 的 CPU 来处理,而不是 node 1 的 CPU 来处理。
首先,找到中断号。(这里,我们以其中一个 queue 1 为例,多 queue 我们后面继续讨论)
cat /proc/interrupts | grep mlx5_comp1@
115: 0 0 998453167 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 IR-PCI-MSI 30932994-edge mlx5_comp1@pci:0000:3b:00.0
180: 0 0 43 892854366 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 IR-PCI-MSI 30935042-edge mlx5_comp1@pci:0000:3b:00.1由于这个网卡有 2 个接口,每一个接口都有一个 1 号 queue,所以 grep 出来了 2 个。以第一个为例,它的中断号码是 115 号。我们就可以对 115 中断进行 CPU affinity 绑定:对 /proc/irq/115/smp_affinity_list 写入 2,就表示由 cpu2 来处理这个中断,即 cpu2 来处理网卡 1号 queue 的数据包。
数据包最后会通过 socket API 来给用户程序消费。(如果是 XDP 实现的 L3 或者 L4 网关,就没有这一步了),用户程序尽量放在 node 0 来执行,性能会更高。用户态程序绑定 NUMA 的方式很多,比如可以用 numactl --cpunodebind=0 --membind=0 ./app 来让程序尽量使用 node 0 的 cpu 和内存;或者在程序内部使用 pthread_setaffinity_np() 和 sched_setaffinity() 绑定 CPU。
在 200G/400G 的网卡上,内存带宽依然可能成为瓶颈,可以用 pcm-memory 和 perf 来检查瓶颈是否在内存。
说到了 CPU,我们接下来继续聊一聊 CPU 有关的优化。
首先是网卡 queue 的数量。有一次我们发现服务器的带宽使用上不去,流量一高就会有丢包。一个 CPU 的使用率 100%,其他的 CPU 空闲。这是一个比较常见的问题,原因是网卡只开了一个 queue。网卡把所有收到的包都 DMA 到这个 queue 的 ring buffer,所以只有一个 CPU 来处理这个 ring buffer 的包。一个 CPU 是无法处理 10GE 的网卡带来的流量的。
这种情况就如下图所示:
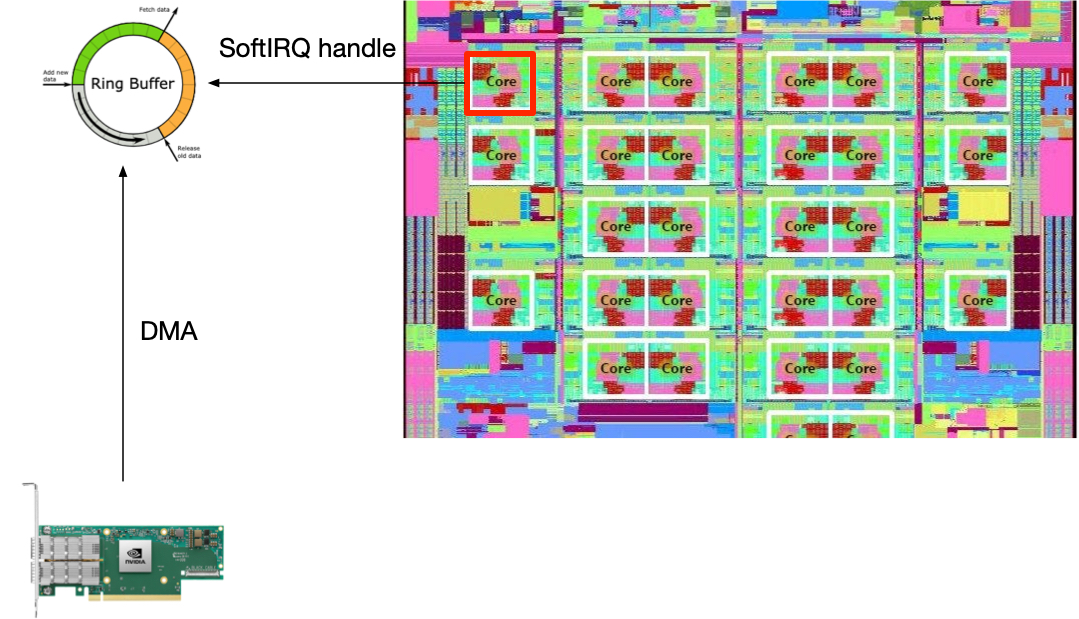
解决的办法就是让更多的 CPU 来干活。
但是我们不能让更多的 CPU 来处理这个 queue 的数据,原因是:
那就只能开更多的 queue,每一个 cpu 处理一个 queue。
这样,我们就需要网卡支持把收到的流量放到多个 queue,但是依然要保持 flow -> queue hash 的一致性。这个功能叫做 RSS,Receive Side Scaling,是在网卡里实现的。虽然 CPU 也支持对收到的包分流(RPS/XPS),但是这个工作也要在一个 CPU 上执行,而且太慢了,一般不用。
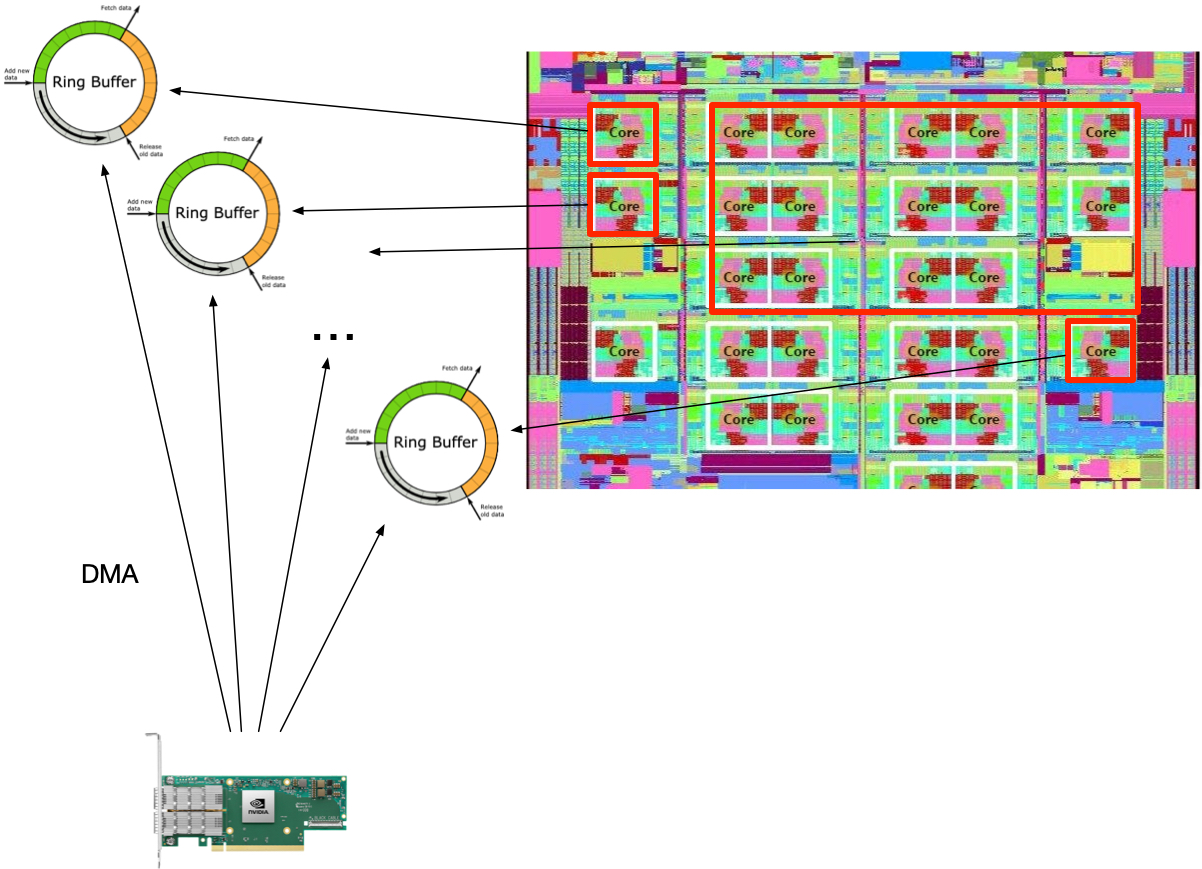
开多个 queue 很简单,可以通过 ethtool -l eth2 查看当前 queue 的数量。
通过 ethtool -L eth2 combined 8 修改 queue 的数量为 8。
Queue 的数量越多越好吗?也不是,我们的目标是尽可能利用多的 CPU,如果 queue 的数量超过了 CPU 的数量其实也没有意义。
以下面我这台机器为例:
$ lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 46 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 64
On-line CPU(s) list: 0-63
Vendor ID: GenuineIntel
BIOS Vendor ID: Intel
Model name: Intel(R) Xeon(R) Silver 4216 CPU @ 2.10GHz
BIOS Model name: Intel(R) Xeon(R) Silver 4216 CPU @ 2.10GHz CPU @ 2.1GHz
BIOS CPU family: 179
CPU family: 6
Model: 85
Thread(s) per core: 2
Core(s) per socket: 16
Socket(s): 2
Stepping: 7
Frequency boost: disabled
CPU(s) scaling MHz: 100%
CPU max MHz: 2101.0000
CPU min MHz: 800.0000
BogoMIPS: 4200.00
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr
sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good
nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 s
sse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsa
ve avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cdp_l3 invpcid_single intel_pp
in ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase ts
c_adjust bmi1 avx2 smep bmi2 erms invpcid cqm mpx rdt_a avx512f avx512dq rdseed adx smap clflushop
t clwb intel_pt avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cq
m_mbm_total cqm_mbm_local dtherm ida arat pln pts hwp hwp_act_window hwp_epp hwp_pkg_req pku ospke
avx512_vnni md_clear flush_l1d arch_capabilities
Virtualization features:
Virtualization: VT-x
Caches (sum of all):
L1d: 1 MiB (32 instances)
L1i: 1 MiB (32 instances)
L2: 32 MiB (32 instances)
L3: 44 MiB (2 instances)
NUMA:
NUMA node(s): 2
NUMA node0 CPU(s): 0,2,4,6,8,10,12,14,16,18,20,22,24,26,28,30,32,34,36,38,40,42,44,46,48,50,52,54,56,58,60,62
NUMA node1 CPU(s): 1,3,5,7,9,11,13,15,17,19,21,23,25,27,29,31,33,35,37,39,41,43,45,47,49,51,53,55,57,59,61,63在 node0 显示有 32 个 CPU,那么应该开 32 个 queue 绑定到这些 CPU 吗?
这就错了,其实最优的方案是用 16 个 CPU。因为 Thread(s) per core: 2,即这是一个 Hyper-Threading 的 CPU,每一个物理 core 有 2 个 thread。
如果看下 CPU 的分布,会发现 cpu0 和 cpu 32 是同一个物理 core,2 和 34 是同一个,以此类推。实际每一个 socket 只有 16 个物理 core,算上超线程才是 32 个 core。
# lscpu -e
CPU NODE SOCKET CORE L1d:L1i:L2:L3 ONLINE MAXMHZ MINMHZ MHZ
0 0 0 0 0:0:0:0 yes 2101.0000 800.0000 2100.0000
...
2 0 0 2 7:7:7:0 yes 2101.0000 800.0000 2100.0000
...
32 0 0 0 0:0:0:0 yes 2101.0000 800.0000 2099.9990
...
34 0 0 2 7:7:7:0 yes 2101.0000 800.0000 2099.99900 和 32,2 和 34,它们的 node, socket, core 都是一模一样。CPU 的计算单元是 share 的。做网络处理,我们的瓶颈不在等待内存,而是在 cpu 的计算。超线程并不会增加 cpu 的计算能力。(不要被 Intel 骗了!)
相反,如果使用了这些 cpu,反而会造成 cache 命中率下降,网络处理极度依赖 cache 提前把下一个要处理的包 load 进来,cache 命中率下降意味着吞吐大幅度下降。
所以我对 IRQ 绑核的时候,只绑 2 个超线程核心中的一个。
或者在 GRUB 启动的时候添加 nosmt,这样超线程的功能直接被关闭了,系统启动之后只能看到物理 core。这样比开启 SMT 但是我们只用超线程中的一个逻辑 CPU 而言,会节省 5% 左右的 SMT 上下文管理成本。
话说,如果只使用 numa node0 的 CPU,那 node1 的 CPU 不是都浪费了吗?是的。
如果要低延迟的网络,推荐只用网卡的 PCIe 所在的 node 的 cpu。但是如果要更多的带宽处理能力,可以多开 16 个 queue,绑定到 node 1 的 cpu。这里是带宽和延迟的 trade off,在网络调优方面,很多地方都都是在对吞吐(带宽)和延迟做取舍。
网卡收到包之后,会先通过包的 5元组 得到一个 hash 值,然后根据 RETA(Redirection Table)选择一个 queue。
通过 ethtool -x 可以查看 RETA:
# ethtool -x enp59s0f0np0
RX flow hash indirection table for enp59s0f0np0 with 16 RX ring(s):
0: 1 2 3 4 5 6 7 8
8: 9 10 11 12 13 14 15 1
16: 2 3 4 5 6 7 8 9
24: 10 11 12 13 14 15 1 2
32: 3 4 5 6 7 8 9 10
40: 11 12 13 14 15 1 2 3
48: 4 5 6 7 8 9 10 11
56: 12 13 14 15 1 2 3 4
64: 5 6 7 8 9 10 11 12
72: 13 14 15 1 2 3 4 5
80: 6 7 8 9 10 11 12 13
88: 14 15 1 2 3 4 5 6
96: 7 8 9 10 11 12 13 14
104: 15 1 2 3 4 5 6 7
112: 8 9 10 11 12 13 14 15
120: 1 2 3 4 5 6 7 8
128: 9 10 11 12 13 14 15 1
136: 2 3 4 5 6 7 8 9
144: 10 11 12 13 14 15 1 2
152: 3 4 5 6 7 8 9 10
160: 11 12 13 14 15 1 2 3
168: 4 5 6 7 8 9 10 11
176: 12 13 14 15 1 2 3 4
184: 5 6 7 8 9 10 11 12
192: 13 14 15 1 2 3 4 5
200: 6 7 8 9 10 11 12 13
208: 14 15 1 2 3 4 5 6
216: 7 8 9 10 11 12 13 14
224: 15 1 2 3 4 5 6 7
232: 8 9 10 11 12 13 14 15
240: 1 2 3 4 5 6 7 8
248: 9 10 11 12 13 14 15 1
RSS hash key:
21:9a:d6:8d:f0:54:bb:c4:6c:5a:b6:d2:2f:b4:01:f1:51:c1:d0:79:7d:cb:7b:02:ee:c9:63:78:75:2a:51:cf:af:69:3d:d3:fb:6a:c6:1e
RSS hash function:
toeplitz: on
xor: off
crc32: off可以看出 hash 的方法是 toeplitz,一个有 255 个 bucket。举例来说,如果 hash 的 value 是 9,那么选择的 queue 就是第 2 行的第 2 个,即 10 号 queue。
RETA 也可以通过 ethtool -X eth2 equal 16 (平均分到 16 个 queue)指定。
可以发现,即使 ethtool -l 显示有 32 个 queue,也不是说实际使用的就是 32,如果我们在 RETA 里面平均分配到 16 个 queue 的话,实际只有 16 个 queue 会有流量 (IRQ)。
选中一个 queue 之后,NIC 会 DMA 到这个 queue 对应的内存。接下来我们要绑定这个 queue 对应的 CPU。
通过上面提到过的 /proc/interrupts 文件,可以查看这个 queue 对应的中断号。然后通过 /proc/irq/115/smp_affinity_list 来绑定 cpu 号。要对所有使用的 queue 都进行 cpu 绑定。同时,要注意只绑定物理 core,不要让一个物理 core 去处理多个 irq。
我用 Intel,博通,和 Mellanox 的网卡的 RSS 都没有遇到问题,RPS/XPS 可以关闭了。这个功能可以理解是 Linux 软件实现的 RSS,ingress 和 egress 方向。我们已经设置了 RSS,就不希望内核代码再次调度 cpu,造成 cache miss。
关闭 RPS 很简单,把每个 RX Queue 的 rps_cpus 设置为 0 即可。
for f in /sys/class/net/eth0/queues/rx-*/rps_cpus; do
echo "$f: $(cat $f)"
done开启了多个 queue,每一个 queue 都有一个 ringbuffer,这个 buffer 的大小可以用 ethtool -g eth0 来查看。也可以用 ethtool 来调整。
这个值其实不会提升性能,因为它不影响处理速度。但是把它增大可以提升稳定性,在流量突增的时候,有更多 buffer 空间,可以减少丢包。
但是 buffer 越大就越好吗?肯定不是。
首先大的 buffer 会带来延迟。比如在 10Gbps 下,buffer 是 8196,如果 buffer 满了,流量稳定 10Gbps,那么每一个包进来之后都要在 buffer 中排队约 8196 才能被处理,latency 高达几 ms。如果 buffer 只有 512,那么徒增流量会直接被丢弃,但是每一个被处理的包都只有不到 1ms 的延迟。
另外,512 的 ringbuffer 很小,所有的 descriptor 都可以放到 CPU 的 L1 cache 里面,大大提高处理速度。
这是稳定性与延迟之间的 trade off。
为了让用户程序不占用处理 irq 的 CPU,造成延迟不稳定,我们可以让用户程序只在特定的 CPU 执行,跑 irq 的 CPU 不跑用户程序。
方式可以是通过 taskset 设置每一个程序的 CPU 绑定,也可以在 GRUB 设置启动参数,内核参数添加 isolcpus=0-19,这样普通程序默认就不使用 0-19 CPU 了。
这样做对一些管理程序也有好处。比如 LACP,ARP,SSH 不进入隔离的 CPU,即使网卡流量打满了,SSH 依然可以工作。(当然,更稳的方式是用带外管理)
CPU 有 scaling governor 设置,目的是在 CPU 空闲的时候可以进入低频模式运行来省电,对我们来说性能和稳定性更重要,所以可以改为 performance 模式。
CPU boost 需要管理。临时的性能提升不如稳定的性能,boost 可能会升高温度带来降频。
我们可以设置 softirq 的处理预算,让一次 softirq 处理更多的包。让 CPU 花在更多的时间在处理 softirq 上。
net.core.dev_weight=600 设置一次 NAPI 最多处理 600 个包,默认 64;net.core.netdev_budget=3000 设置一次 softirq 触发最多处理多少个包(与上面的区别是,如果 3 个 queue 对应到一个 cpu,那么这两个的设置是,一次 softirq 触发之后,每一个 queue 最多处理 600 个包,总共处理不超过 3000 个包。)net.core.netdev_budget_usecs=10000 让 softirq 一次最多运行 10ms,默认是 2000;echo 2 > /sys/class/net/<iface>/napi_defer_hard_irqs 设置 NAPI 在连续 2 次空转之后再退出。默认情况下 NAPI poll 到没有包处理就退出了。这个设置让它空转 2 次。本质上也是让 cpu 多花时间在处理网络上;echo 200000 > /sys/class/net/<iface>/gro_flush_timeout 这个让 GRO 等待更多的时间再 flush,这样可以把更多的小包合成一个大包,节省后续网络栈处理的包,提高 PPS。(但是对于 XDP转发 程序来说作用不到,XDP 工作在 driver,在内核的 GRO 前面,不会执行到 GRO)。最后来到了操作系统的 IRQ 处理网络栈。
如果每次来一个包,都触发一次 CPU 中断,这样中断的数量就太多了。
我们可以告诉网卡:收到包之后,先不要中断给 CPU,如果一共攒了 64 个包,或者时间等了 32 usecs,再发送一次中断:
$ ethtool -c eth2
Coalesce parameters for eth2:
Adaptive RX: on TX: on
stats-block-usecs: n/a
sample-interval: n/a
pkt-rate-low: n/a
pkt-rate-high: n/a
rx-usecs: 32
rx-frames: 64
rx-usecs-irq: n/a
rx-frames-irq: n/a
tx-usecs: 8
tx-frames: 128
tx-usecs-irq: n/a
tx-frames-irq: n/a这就是中断合并。
这个值的设置也是 trade-off——如果设置得太大,那么延迟会升高,但是可以节省 CPU 资源,吞吐增加,适合存储类服务;如果设置地太小,延迟就很低,但是资源占用就比较高,适合低延迟网络,如量化交易,游戏等等。
——如果我们让网卡在包比较少的情况下使用低的中断合并,在包多的时候使用高的中断合并,不就完美了吗?
这就是自适应的中断合并功能,在上面的网卡设置中,可以看到 Adaptive RX: on TX: on,网卡就会根据实际的网络流量来自动调节中断合并的参数。
CPU 的资源很宝贵,所以硬件优化的思路就是尽可能的把工作交给网卡来做,网卡的 ASIC 芯片很适合重复劳动。
比如:
网卡支持的 offloading 越来越多,根据使用的协议可以看网卡是否支持。
参数调优,首先要明确调优的目标:低延迟优先,高吞吐优先,稳定不丢包优先,还是成本最小(比如省电)优先?所有参数调整都是在做 trade off,不然的话这些参数没道理默认不是最优的。
提高性能的思路无非就是:
可观测性也很重要,无法观测每一个路径的成本,也就无法优化。所以不要盲目优化,先找到瓶颈在哪里,再去解决瓶颈。
2026-06-03 19:10:00
RSS 上出现越来越多用 AI 生成的文章,我想谈谈写作(尤其是写博客)的意义,以及为什么用 AI 生成文章是不好的。
写作最初的意义是记录,如县志,日记等等。这是写作从未失去的意义,写作是可以让自己与自己跨越时空的对话,阅读自己几年前,十几年前的文字,经常感慨万分。人会随着时间而变化,比如我自己以前认为中介对社会没有意义,这个岗位消失,也不会对社会有什么影响;但是如今的我认为这是无法被替代的岗位,对社会效率有重要的作用。又比如我以前曾在德国生活过一段无忧无虑的日子,没有烦恼也没有压力,每天最大的问题就是晚饭吃什么,如今看到那段时间写下的文字都会想起那时的心情。如果没有记录,自己想法的变化就难以被发现,十年之前在写下这些文字时候的细节就无法被回忆起来,读一本书的时候想到的东西就会随时间消散,当初纠结的事情也永远不会再被提起。
所以写作就像创作时间胶囊,可以让自己与未来的自己对话,与过去的自己对话。
如果用 AI 来生成,那么写作最原本的意义是无法达到的。试想一下,如果用 AI 生成日记,那么将来的自己大概是不会看的。
写作的另一个重要的意义是思考。
我记得在十几年前第一次写博客的样子,拌拌磕磕,自己心里想的观点,写到纸上就只剩下 30%,读起来幼稚地可笑。但是这样写了一段时间(没有读者),几年之后发现可以顺利地表达自己的观点,清晰地向读者描述一个问题或者技术了。
论点或是技术,在脑子里有一个轮廓,如果不用文字描述出来,其实就是水中的月亮,只有在尝试用文字向别人解释的时候,才会意识到自己没有思考清楚的部分,需要再研究研究,才能和别人解释清楚。如此之后,虽然这部分技术会随时间遗忘(技术如果不用的话,肯定会生疏的),但是看到当年自己写的文字,自己的解释,几分钟就可以捡起来全部的内容。写过技术博客的朋友,应该都有这样的经历。在工作中遇到很多无法将一个问题准确描述清楚的人,也遇到过能一针见血指出问题的人,我觉得写作技能起的作用很大。
AI 是无法代替思考的,用 AI 就一个技术生成一篇文章,水中的月亮还是水中的月亮。
写作的第三个意义是与人交流,表达自己的观点,影响别人。如同本文一样,为什么试图说服你,你应该写点什么。知己难以遇到,即使遇到了也需要彼此发现是志同道合。如何发现呢?如果我用 AI 写一篇文章,你用 AI 来总结阅读,那么中间隔阂太大,基本上是难以产生共鸣的。人与人之间的直接交流才是最不容易失真的。
除了交流,更宝贵的是表达自己。表达是所有人的需求,高质量的表达可以带给自己自由和快乐。这样解释起来比较困难,以我自己的体验来说,我真正发现写作的乐趣是在没有写作压力的时候,不需要写 600 字的作文,不需要考虑总-分-总的写作结构,不需要考虑阅读的人怎么想,不需要担心阅读量,可以把文章写的很长(博客就是如此,就想一张没有尽头的纸),也可以很短。表达的欲望就得到了实实在在的满足。
显然 AI 也无法满足这一点。
博客还有一个意义,就是可以提高工程师的技术影响力。这一点 AI 依然无法做到,目前读到的 AI 生成的文章基本都是信息密度极低的垃圾,很有可能起到反作用。
话又说回来,无论用不用 AI 写作,博客都已经没有办法带来技术影响力了,因为以后也不会有人通过阅读博客学习什么技术了。但是博客可以带来朋友,所以,还是要让写作回归它的本质——记录,思考,表达,与交流。这些都是现在 AI 无法替代的。
2026-05-05 01:34:37
读其他的书知道了《金阁寺》这本书,就找来读了。读完合上最后一页,心里久久不能平静。说这本书是「惊世骇俗」一点也不为过。
书讲述的日本战后年代,一位有口吃的贫穷青年,被患有绝症的父亲送入鹿苑寺成为建系僧人,母亲最大的愿望,就是看到「我」成为住持。书中的「我」痴迷于金阁寺的美。因为在寺里发生的种种违背于「美」的事情(抑或许「我」本身就是这样的一个人?),给「我」带来煎熬的思想斗争。心理的内耗由于无法了解,「我」的老师对此也不做评论,导致「我」越陷越深,沉迷于自己的世界中。想要承认错误却又因为懦弱而无法行动,导致最终的行为是通过犯下更大的错误来祈求得到老师正面的批评,越陷越深,加上母亲对自己的寄托沉重地无法背负,最终犯下被世人唾弃的滔天大罪。
因为年轻与贫穷,能力受限制,无法掌控自己的生活,我对这种处境很有共鸣。我想起来初中的住校生活,一个月有25天都住在学校里,8 个学生生活在15平米的宿舍里面,老师会随意进出宿舍,翻看学生的物品,没有隐私可言。每一个人都被贴上了无法摘掉的标签:来自农村,如果你学习好,那就是人穷志不穷,是大家学习的榜样,如果学习不好,那就是家境贫寒还不知道努力,是耻辱中的耻辱;家里有钱,如果学习好,就是家里有钱但是还要强,如果学习不好,那就是纨绔子弟;长得漂亮,学习好,那就是天生财貌双全,学习不好,那就是心思都用在了打扮上面。总之,老师无法将事情分开单独看待,无法接受一个学习不好只是不努力,学习好是努力,和家境,长相无关。
虽然这是和本书不想关的东西,但是我想,就是处在这种环境中,没有能力做出改变,才愈发想要尽一切可能打破这一切。对于虚伪之人,「我」能做的,就是做出不符合他们预期的事情,不让他们的预期得逞。书中的「我」其实非常软弱,尝试出走,只是遇到警察就被遣送回寺了,花学费去嫖娼也会受到妓女的教育,没有人看得起。最后火烧金阁寺的时候,也是被一连串的事件推动进行的,中间几次打了退堂鼓,如果不是这些机缘巧合,可能最后不会有这样惊天之举,也许就是一事无成的落魄僧人,被寺里赶出来,落得一个流落街头,最终被人遗忘的命运。
生活在自己没有能力掌控生活的环境中,能做的,就只有顺从掌权者的想法,必须要小心翼翼。这和掌权者没有关系,即使权力的座位上是一个好人,迫于权力的不对称,也会带来极大的心理压力。三岛由纪夫把这种压迫感描写的淋漓尽致。如果一步走错,会陷入深深的怀疑中,想要打破这一切,放弃一切。甚至希望事情朝着糟糕的方向发展,因为这样的话,也就不必再抱有希望,可以心安理得地迎接最坏的结果了。
三岛由纪夫的文笔非常好,摘录书中的几段:
在描写口吃的时候,写道:
显而易见,口吃的毛病成了我与外界交流的一道巨大障碍。每当我想说话时,第一个音总是发不准,这第一个音成了我打开外部世界之门的一把钥匙。遗憾的是,这把钥匙从没打开过门上的锁。其他人都可以通过语言自由自在地打开自己与外界之间的这扇大门,而我无论如何努力也做不到。我的钥匙生锈了。
对口吃的人来说,最难受的就是如何发出第一个音,这让人备受煎熬,就如内心有一只小鸟想飞出去,但浑身沾满了黏稠物,只能慌乱无用地扑扇翅膀。好不容易挣脱出来时,已经赶不上对话节奏了。
在我挣扎着扑扇翅膀的时候,门外的世界偶尔会暂停脚步等我赶上,但在我赶上的时候,那个世界已不再是我尽力要赶上的现实世界了。当我费尽全力挣脱并到达外部世界时,才发现这个世界已经瞬间发生改变,完全背离了我的期待……
描写看热闹的人:
看热闹的人在一田之隔观望,后来人越来越多,大家肩挨着肩沉默观看,连头上的月亮好像都被挤小了。
真是一张不可思议的脸,这样的表情在刚被砍倒的树桩上也能看到。尽管色泽还鲜艳,但成长已不再可能,被迫沐浴在本不该沐浴到的阳光和秋风里,暴露在本不该属于自己的世界里。有为子的脸如同那有着美丽木纹的木桩,想拒绝这个世界,却被拖拽到这个世界上,呈现出不可思议的美……
描述金阁寺顶的金铜合金的凤凰:
我还想起屋顶上那只金铜合金的凤凰,这只历经几百年风吹雨打的神秘的金色大鸟,既不报时,也不飞翔,似乎完全忘了自己是鸟儿。但是,如果认为它不在飞,那就错了。别的鸟儿都在空中飞,而它却展开闪亮的翅膀,永远在时间里翱翔。时间如风,掠过它的双翅向后流逝。金凤凰以亘古不变的姿势,双翼高振,怒目含威,尾翼伸展,双腿稳稳站立,翱翔在时间的长河中。
…
临近闭园时好像来了一个旅游团,从金阁方向传来了阵阵喧闹声。围墙外的脚步声和人声虽然吵闹嘈杂,但经春日的夕暮吸收后,并未有尖锐刺耳的感觉,反而显得柔和且饱满。没过一会儿,脚步声如潮水般远远退去,犹如这片土地上来来往往的芸芸众生的足音。我抬头凝视着金阁顶上的金凤凰,此刻,它正沐浴在落日余晖的残红里。
描述自己梯度之后的头:
我刚落发的头上泛着青光,与空气完美贴合。感觉自己脑中所想之事,与外界仅隔了一层薄薄的、敏感且易破的头皮而已,这是一种奇妙且危险的感觉。我仰起光溜溜的头颅凝望金阁,感觉它不仅进入了我的视界,还通过这颗光头渗进了我的体内,与我融为一体,跟我的头一样,在骄阳暴晒下感受到热,而在夕阳西下时又会凉下来。
我在绝望中等待,因为我相信,这澄清的早春晴空就像闪亮的玻璃窗一样,虽然我们看不见,但其背后一定隐藏着强大的火力和毁灭一切的力量。如前所述,我这个人不擅表达对人的关爱,父亲的死及母亲的困窘都没有在我的心里激起一片涟漪。我幻想着某天天空中突然出现一台巨大的碾压机,能将一切灾祸、世界末日和人间惨剧,无论是人还是物,无论是美还是丑,无差别地统统碾碎。那个早春异常灿烂的晴空,似一把可覆盖整个大地的巨大利斧,闪着寒光。我期待那把斧尽快砍下,不给任何人思考的余地。
对于友情的描述:
是的,有时候我甚至觉得,鹤川是一位炼金术大师,他善于从铅里炼出黄金。如果我是照片的底片,鹤川就是照片的正片。我惊讶地发现,很多时候,一旦经他的过滤,我的浑浊不堪的心情不仅瞬间消失殆尽,还会转变成纯净透明、光彩熠熠的感情。当我结结巴巴、踌躇无措时,鹤川就会伸出援手,将我的感情翻转过来展示给外界看。一次次的惊愕让我明白,如果仅停留在感情层面,那么这世上最善和最恶的感情其实并非截然不同的东西,其效果也是相同的。而且,从表面上看,杀意和慈悲心也没什么不同。我想,关于这些,无论我如何费尽口舌地向鹤川说明,他也不会相信吧,但对我来说,这却是一个非常可怕的发现。因为鹤川的存在,让我不再惧怕伪善,但对我来说,伪善只不过是一种相对的罪恶而已。
…
瞥见那一抹青痕时,我顿感不安。眼前的这位少年和我不同,他的生命将在纯洁的末端燃烧,在燃烧之前,未来隐藏不见。未来的灯芯浸在冰冷透明的油里。如果留给未来的只有纯洁和无瑕的话,谁还有必要预测自己的纯洁和无瑕呢?
描写下雪:
究竟顶的大门今天依旧对着天空敞开。仰望它时,我的心却随着雪花飞舞:飘进敞开的大门,在空无一物的究竟顶狭小的空间里飞舞,接着落在墙壁一片生锈的金箔上,失去活力,停止呼吸,最后变成一颗透着金色的露珠。
希望破灭之后的绝望感:
这时,我心里产生了异样的冲动,如同有满腹话语想要表达,却因口吃妨碍而欲说不能,话语一直卡在喉咙里燃烧一样。我想寻求解脱。眼下,不仅是母亲曾经暗示过的继承老师衣钵的希望已然渺茫,就连上大学的希望也已荡然无存。我想从这无声地桎梏着我、重重地挤压着我的窒息感中解脱出来。
…
一种可怕的不满让我们这样的人和这个世界处于对立状态,我们和世界必须有一方肯妥协并做出改变,这种不满才有可能得到治愈。但我讨厌渴望改变的梦想,也讨厌毫无意义的白日梦。但是,我又喜欢在“世界若变化,我就不复存在;我若变化,世界也将烟消云散”这样的问题上刨根问底。这样的确信,反过来倒像我与这个世界的某种和解、某种融合。像我这样肢体有残障的人是不会被世人所爱的,因为我有这样的想法才能得以和这个世界共存。但是,残障人士最容易陷入的陷阱,不是和外部世界的对立状态得以消除,而是全盘接受自己与世界对立的状态。于是,残疾就成了让你和这个世界格格不入的不可调和的存在……
在这个逃课的午后,和煦的春光和阵阵和风就像新做的衬衣,轻柔地触碰着肌肤。
这是因为美可以委身于任何人,但又不专属于任何人。该怎么跟你解释才好呢?对了,美这种东西就像虫牙,它通过与舌头触碰、牵连舌头、引发痛感等宣示自己的存在。最后,人们会因为无法忍受疼痛而请医生将之拔掉。当人们将刚被拔掉的血淋淋的、脏兮兮的、茶垢色的虫牙放在手掌上,一定会说:就是它呀!让我痛苦的就是这小小的东西吗?是它不断对我宣示存在感,让我寝食难安吗?像这样在我身体里顽固存在的东西难道就是这种死掉的物质吗?这个和那个真的是同一种东西吗?这个本应是我身体外部的东西是因何缘由与我的身体内部结合,成了令我痛苦的根源呢?这东西存在的依据是什么呢?而这依据本就存在于我的身体内部吗?或者就是依据它自身呢?不管怎么说,刚从我身上拔下来的这东西绝对不是我身体的一部分,也断然不是那个东西。
总的来说,我的体验中仿佛有一种神秘的巧合在悄然运作,宛如一条挂满镜子的长廊,一个影像无限地延伸到深处。新遇见的事物,清晰地映射出过去所见之物的影子。人最容易被这种相似性所牵引,不知不觉就走到走廊尽头,迈向那深不见底的幽暗深处。命运并非突如其来,它如同一个潜伏的影子,悄无声息地渗透进生活的每个角落。比如,那个日后被判死刑的男人,平日里经过路旁的电线杆或铁道口时,意识中或许时常浮现绞刑架的幻影,甚至对它怀有一种莫名的亲近感。
因此,我的体验中没有堆积物。没有层层堆积的地层,也没有足以堆砌成山峦的厚重积淀。除了金阁,我对世间万物都毫无亲近之感,甚至对自己的体验也未曾有过特别的眷恋。但我深知,在这些体验中,仍有一些尚未被时间之海的黑暗完全吞噬的碎片,以及还没陷入毫无意义的无限重复的部分,这些小部分正在悄然聚拢,逐渐形成卑鄙而不祥的图画。
我经常思索,这些细小的部分又是什么呢?这些闪烁的碎片,甚至比路旁丢弃的啤酒瓶碎片更没有意义,更加杂乱无章。
尽管我如此说,却也不能就此断定这些片段就是那些曾经被塑造成美丽而完整的形态所丢失的碎片。它们因毫无存在意义、缺乏规律而被世人当作丑陋的东西,惨遭抛弃,却仍在各自默默憧憬着未来。以卑微的碎片之身,无所畏惧地、诡异地、静谧地……憧憬着未来!憧憬着那个绝无可能痊愈的、无法企及的、闻所未闻的未来!
…
我非蜜蜂,故不受夏菊诱惑;我非夏菊,故亦不会招来蜜蜂。所有的形态和生之间的融洽已然消逝,世界再度坠入相对性之中,唯有时间永恒流淌。
细节的描写:
这时,背后有人影闪现。阴沉的天空渗出一丝微光,摆放在玄关的鞋柜上的木纹瞬间鲜亮起来。
…
看到了永生的幻象;而具有永恒不灭之美的金阁,却让我感受到一股死亡的气息。为什么鲜有人意识到,其实人类这种寿命有限的生物是无法根绝的,但金阁这样具有不灭之躯的东西却很容易被消灭。
…
那天晚上她留在金刚院里的血,仅像早起开窗时,被惊飞的蝴蝶留在窗框上的磷粉而已。
书中对细节的描写,真实地不像虚构小说,于是读完之后我去查了金阁寺的维基百科:1950年7月2日凌晨(与书中描写的时间相同),京都市消防队收到火警,称鹿苑寺起火。等到消防队到了鹿苑寺的时候舍利殿(俗称金阁)已经燃起熊熊大火,消防队员无法靠近。这起纵火事件中并没有人员伤亡,但是舍利殿被全部烧毁,创建者室町幕府的第三代将军足利义满的木像,观音菩萨像和如来佛祖像以及众多古本佛经被焚毁。
经过事后调查,发现鹿苑寺的见习僧人林承贤在纵火事件后失踪。后来警方在寺院后面的左大文字山发现林承贤已经切腹,蹲坐在地上。经过抢救,林承贤捡回一条性命。但是被判处7年的惩役(坐牢加罚役),最后病死狱中。
在现实生活中同样对他期望很高的妈妈,经警察传唤返家时,从行驶中的山阴本线列车跳下保津峡自杀。
金阁寺在 1955 年开始重建,今日文明世界的鹿苑寺舍利殿,是根据在明治时代翻修时留下的图纸重建的。比重建之前的还要豪华。
《金阁寺》以第一人称书写,其实和作者本人,三岛由纪夫有很多相似的地方。三岛由纪夫也是体弱多病,不过后来为了不被身体的自卑困扰,开始健身,变成了一个肌肉男。
三岛由纪夫其实是一个变态。
三岛对日本传统的武士道精神和严厉的爱国主义深为赞赏,对日本第二次世界大战战败后社会的西化和日本主权受制于美国非常不满。经过长时间的准备,和盾会(也是他创立的)成员,跑到日本陆军基地,绑架了一个中将,发表演说,企图发动政变。
各位好好听一听。静一静,请安静,请听我讲。一个男人正在赌上生命和你们讲话。好吗?这个,现在,各位日本人,如果在这里不站起来的话,自卫队如果不在这里站起来的话,宪法是不可能改变的。各位只会永远的成为区区美国的军队而已啊……。
——三岛由纪夫,于总监部阳台(译)
我已经等了四年了,(等著)自卫队站起来的日子……已经等了四年了,……我再等……最后的三十分钟。各位是武士吧?如果是武士的话,为何要保护“将自己否定”的宪法呢?为何要为了“将各位否定”的宪法,向着“将各位否定”的宪法低头呢?只要这(宪法)还在,各位是永远无法得到救赎的啊!
然而,没有人回应他,甚至嘲笑三岛是一个疯子。
三岛随后从阳台退入室内,按照日本传统仪式切腹自杀。
1999年,在富士山旁边建立了一个三岛由纪夫文学馆,来纪念他。

 ︎
︎