2026-07-31 22:27:10
带着单反漫步泽西岛,用镜头记录海面上的船只、薰衣草间停驻的蝴蝶,以及岛屿上不经意的光影。旅行不仅是抵达远方,也是放慢脚步,在一次次快门声中,重新发现那些容易被忽略的美。 带着单反去了趟 Jersey。 镜头掠过海面上的船,停在薰衣草间振翅的蝴蝶,也偶然捕捉到天空中的无人机。旅行的意义,大概不只是抵达远方,而是在光影流动的瞬间,重新发现那些容易被忽略的美。 海风会吹散记忆,快门替我留住了它们。 📷 Jersey · Summer 2026这次去泽西岛,特意带上了单反相机。相比手机随手记录,单反虽然沉一些,却让人更愿意放慢脚步,认真观察眼前的光线、色彩与构图。 镜头掠过海面上的渡轮与邮轮,停在薰衣草间振翅的蝴蝶,也记录下古老石墙、退潮后的礁石,以及阳光洒落海面的瞬间。远处的船只缓缓驶向海天交界处,近岸的小艇则安静地停泊在树影之间。泽西岛的美并不张扬,而是藏在海风、潮汐和不断变化的光影里。 旅行的意义,大概不只是抵达一个陌生的地方,也是暂时离开熟悉的生活节奏,重新留意那些平日容易被忽略的细节。快门按下的那一刻,留下的不只是一幅画面,还有当时的天气、海风,以及站在镜头后面的心情。 照片或许无法完整还原亲眼所见的风景,却能替记忆保存一些坐标。等到多年以后再次翻看,希望仍能想起这个夏天——泽西岛清澈的海水、缓慢移动的船,以及那段被海风轻轻吹过的时光。
 面朝大海,喝一杯咖啡,把时间交给海风与阳光。[/caption]
[caption id="attachment_72339" align="alignnone" width="2048"]
面朝大海,喝一杯咖啡,把时间交给海风与阳光。[/caption]
[caption id="attachment_72339" align="alignnone" width="2048"] 树影之间,几艘小船静静泊在泽西岛的碧蓝海湾。[/caption]
Jersey 动物园。
[caption id="attachment_72338" align="alignnone" width="2048"]
树影之间,几艘小船静静泊在泽西岛的碧蓝海湾。[/caption]
Jersey 动物园。
[caption id="attachment_72338" align="alignnone" width="2048"] 薰衣草随风轻摆,一只蝴蝶停驻其间,定格夏日的温柔。[/caption]
[caption id="attachment_72337" align="alignnone" width="2048"]
薰衣草随风轻摆,一只蝴蝶停驻其间,定格夏日的温柔。[/caption]
[caption id="attachment_72337" align="alignnone" width="2048"] 远航的渡轮划过海面,驶向海天交界的远方。[/caption]
这个是在 The Lighthouse 灯塔拍的。
[caption id="attachment_72336" align="alignnone" width="2048"]
远航的渡轮划过海面,驶向海天交界的远方。[/caption]
这个是在 The Lighthouse 灯塔拍的。
[caption id="attachment_72336" align="alignnone" width="2048"] 无人机掠过阴云下的天空,以另一种视角俯瞰岛屿。[/caption]
我们住的面朝大海的酒店边上的沙滩。
[caption id="attachment_72335" align="alignnone" width="2048"]
无人机掠过阴云下的天空,以另一种视角俯瞰岛屿。[/caption]
我们住的面朝大海的酒店边上的沙滩。
[caption id="attachment_72335" align="alignnone" width="2048"] 阳光洒落潮湿的沙滩,将海面染成流动的银色。[/caption]
[caption id="attachment_72334" align="alignnone" width="2048"]
阳光洒落潮湿的沙滩,将海面染成流动的银色。[/caption]
[caption id="attachment_72334" align="alignnone" width="2048"] 一艘邮轮停泊在泽西岛近海,安静得像海上的一座城。[/caption]
[caption id="attachment_72333" align="alignnone" width="1365"]
一艘邮轮停泊在泽西岛近海,安静得像海上的一座城。[/caption]
[caption id="attachment_72333" align="alignnone" width="1365"] 透过古老石墙的窗口,凝望城堡之外的海与天。[/caption]
[caption id="attachment_72332" align="alignnone" width="2048"]
透过古老石墙的窗口,凝望城堡之外的海与天。[/caption]
[caption id="attachment_72332" align="alignnone" width="2048"] 礁石散落在清澈的蓝绿色海水中,勾勒出泽西岛的海岸线。[/caption]
[caption id="attachment_72331" align="alignnone" width="2048"]
礁石散落在清澈的蓝绿色海水中,勾勒出泽西岛的海岸线。[/caption]
[caption id="attachment_72331" align="alignnone" width="2048"] 海天之间,一艘小船驶向辽阔而宁静的远方。[/caption]
[caption id="attachment_72330" align="alignnone" width="2048"]
海天之间,一艘小船驶向辽阔而宁静的远方。[/caption]
[caption id="attachment_72330" align="alignnone" width="2048"] 退潮后的礁石与浅滩,在蓝天白云下铺展开来。[/caption]
[show_file file="/var/www/wp-post-common/justyy.com/jersey.php"]
[show_file file="/var/www/wp-post-common/justyy.com/slr.php"]
[show_posts keyword="Jersey"]
[show_posts keyword="摄影"]
英文:Some travel photos, Jersey - Blurt版本
退潮后的礁石与浅滩,在蓝天白云下铺展开来。[/caption]
[show_file file="/var/www/wp-post-common/justyy.com/jersey.php"]
[show_file file="/var/www/wp-post-common/justyy.com/slr.php"]
[show_posts keyword="Jersey"]
[show_posts keyword="摄影"]
英文:Some travel photos, Jersey - Blurt版本
2026-07-30 22:47:13
微软五年,一座水晶杯,一段成长旅程 五载同行,水晶为证 在微软的第五年:一份纪念,一段新起点 五年沉淀,继续前行——我的微软五周年 加入微软五周年:一个值得庆祝的里程碑 加入微软五周年:感恩一路走来 庆祝加入微软五周年 五年,一座水晶奖杯,无数珍贵回忆 加入微软五周年里程碑 五年的学习、成长与影响力 加入微软五周年:旅程仍在继续 水晶见证里程碑:加入微软五周年
MSFT 股票在 2021 年 7 月 5 日(周一)没有交易价格,因为纳斯达克交易所因美国独立日假期(补假)休市。 最近一次交易价格来自 2021 年 7 月 2 日(周五): 收盘价:277.65 美元 调整后收盘价:266.46 美元 开盘价:272.82 美元 最高价:278.00 美元 最低价:272.50 美元 因此,若要对截至 2021 年 7 月 5 日的投资组合进行估值,请使用 MSFT 每股 277.65 美元的价格;若计算历史投资回报率,则请使用调整后价格。
微软2026年财报发布,正式收官,Q4周报全面超出市场预期,盘后股价最大涨9个点。核心数据:全年总营收3318亿美元,同比增长18%,全年净利润1337亿美元,整体净利率40.3%,Q4单季营收900亿美元,同比增长了18%,大幅度高于市场的普遍预期,AI业务交出了两大里程碑的成绩,一个是AZURE云服务单季同比增速高达43%。全年营收首次突破了1000亿,管理层指引下一季度增速还会到达45%左右超预期,这一次的预期本来是39%,二是微软的365 copilot的付费席位突破了3000万,几乎都是企业的批量采购,全球500强企业里超过70%已经部署。万级席位的大客户数量同比翻了4倍。非常牛逼。目前已经交了合同还没交付的长期订单总额达到了6780亿美元。合约 平均周期大概是两到三年左右。未来两年的增速底盘基本已经锁定。微软发布2026财年财报,全年业绩正式收官。第四季度多项核心指标全面超出市场预期,财报公布后,盘后股价一度上涨约9%。 从核心数据来看,微软全年总营收达到3318亿美元,同比增长18%;全年净利润为1337亿美元,整体净利率高达40.3%。第四季度单季营收达到900亿美元,同比增长18%,明显高于市场普遍预期。 AI相关业务交出了两项具有里程碑意义的成绩。 首先,Azure云服务第四季度营收同比增长43%,远超市场此前约39%的预期;Azure全年营收也首次突破1000亿美元。管理层预计,下一季度Azure增速仍有望达到约45%,再次超出市场预期。 其次,Microsoft 365 Copilot的付费席位已经突破3000万个,其中大部分来自企业批量采购。目前,全球《财富》500强企业中,超过70%已经部署Microsoft 365 Copilot;采购席位超过1万个的大客户数量同比增长了4倍,企业级AI的商业化进程正在明显加速。 更值得关注的是,微软目前已经签订合同、但尚未确认收入的长期订单总额达到6780亿美元。考虑到这些合约的平均周期大约为两至三年,微软未来两年的增长基础已经基本锁定。 不得不说,这份财报确实非常强。 [caption id="attachment_72311" align="alignnone" width="1536"]
 还有擦拭的布/印有公司Microsoft的LOGO[/caption]
[caption id="attachment_72317" align="alignnone" width="588"]
还有擦拭的布/印有公司Microsoft的LOGO[/caption]
[caption id="attachment_72317" align="alignnone" width="588"] 这两天微软2026财报出来了股价大涨![/caption]
[caption id="attachment_72316" align="alignnone" width="720"]
这两天微软2026财报出来了股价大涨![/caption]
[caption id="attachment_72316" align="alignnone" width="720"] 加入微软第一天的股价是277美元,所以分配的RSU股票数就是合同上的股票金额除于入职第一天的股价。[/caption]
[caption id="attachment_72315" align="alignnone" width="941"]
加入微软第一天的股价是277美元,所以分配的RSU股票数就是合同上的股票金额除于入职第一天的股价。[/caption]
[caption id="attachment_72315" align="alignnone" width="941"] 这是我收到的第一个水晶杯,每五年会有。[/caption]
[caption id="attachment_72314" align="alignnone" width="1152"]
这是我收到的第一个水晶杯,每五年会有。[/caption]
[caption id="attachment_72314" align="alignnone" width="1152"] 水晶/Crystal上面和底座是分开的。[/caption]
[caption id="attachment_72313" align="alignnone" width="864"]
水晶/Crystal上面和底座是分开的。[/caption]
[caption id="attachment_72313" align="alignnone" width="864"] 底座刻有名字和5年[/caption]
[caption id="attachment_72312" align="alignnone" width="864"]
底座刻有名字和5年[/caption]
[caption id="attachment_72312" align="alignnone" width="864"] 从美国UPS寄到英国,大概三周寄到。7月7号下单的,29号公司前台通知取件。[/caption]
[show_file file="/var/www/wp-post-common/justyy.com/microsoft.php"]
[show_posts keyword="微软"]
领英: Microsoft 5-year Service Award: Anniversary Crystals - 五周年水晶纪念奖
英文:A Five-Year Milestone at Microsoft Anniversary Crystal
从美国UPS寄到英国,大概三周寄到。7月7号下单的,29号公司前台通知取件。[/caption]
[show_file file="/var/www/wp-post-common/justyy.com/microsoft.php"]
[show_posts keyword="微软"]
领英: Microsoft 5-year Service Award: Anniversary Crystals - 五周年水晶纪念奖
英文:A Five-Year Milestone at Microsoft Anniversary Crystal
2026-07-29 23:14:58
这次泽西岛之行,让我对当地独特的车牌文化留下了深刻印象。岛上的车牌大多以“J”开头,辨识度很高,偶尔还能看到数字特别的个性车牌。除了车牌和部分法语地名之外,泽西岛在交通规则、超市品牌和生活方式上都与英国十分相似,既有离岛旅行的新鲜感,又处处带着熟悉的英伦气息。 Jersey泽西的车牌是J开头的 泽西岛见闻:满街都是“J”开头的车牌 从J288888说起:泽西岛独特的车牌文化 泽西岛的车牌为什么都以“J”开头? 开在左边,车牌姓“J”:泽西岛自驾初印象 人在泽西岛,却处处感受到英国的影子 泽西岛四日见闻:车牌、超市与浓浓的英伦气息 小岛上的特殊车牌:泽西岛旅行随记 除了法语地名,泽西岛几乎处处都很英国 一块J288888车牌,引出的泽西岛见闻 泽西岛:既像英国,又不完全是英国这次泽西岛之行,给我留下深刻印象的一件事,就是岛上的汽车牌照几乎全部以字母“J”开头。 在岛上待了四天,我们只看到两三辆挂着英国本土车牌的汽车。英国车牌的字母和数字组合比较多样,而泽西岛的车牌虽然也可以自定义,但基本都以“J”开头,辨识度非常高。
泽西岛拥有独立的车辆登记系统,最常见的车牌格式是字母“J”加上一组数字,例如“J12345”,因此在岛上开车时,一眼就能认出当地车辆。与英国本土车牌不同,泽西岛车牌通常不会通过字母和数字组合来显示车辆的注册年份,整体格式更加简洁。除了普通的“J”系列之外,岛上还有少量以“JSY”开头的特殊车牌。车主也可以申请指定号码,而一些数字较少、排列特别或寓意较好的车牌,则会由当地车辆管理部门公开拍卖,所以像“J288888”这样的号码,往往也具有一定的收藏和炫耀价值。[caption id="attachment_72303" align="alignnone" width="864"]
 泽西岛的车牌左边的国徽标注是GBJ:泽西岛部分车牌的左侧印有岛旗和“GBJ”标志,这是泽西岛注册车辆在国际通行时使用的地区识别标志。虽然其中带有“GB”,但这并不意味着泽西岛属于英国。泽西岛实际上是英国王室属地,拥有自己的政府、议会、法律和税收制度,并不属于联合王国。英国后来将本土车辆的国际标志由“GB”改为“UK”,但泽西岛的车辆仍然继续使用“GBJ”。从一块小小的车牌上,也能看出泽西岛与英国之间既密切相连、又相对独立的特殊关系。[/caption]
旅行期间,我们还看到了一块很特别的车牌——“J288888”,挂在一辆奥迪Q7上。后来也见到了车主,不过并不是亚洲人。看来对“88888”这种号码情有独钟的,也不只是华人。
下次再来泽西岛,我打算体验一下在岛上自驾。可以落地以后租车,也可以直接从英国本土把车开过来,大概和前几年去怀特岛时一样,需要把车开上渡轮。
泽西岛的驾驶规则与英国本土一致,车辆都是右舵,在道路左侧行驶。不过岛上的部分道路比较狭窄,开车时估计还是需要格外小心。
虽然泽西岛在行政上并不属于英国,但除了部分地名带有明显的法语色彩之外,岛上的生活处处都能看到英国的影子。
登岛第一天,我们就去了当地的Waitrose,买了牛奶、面包和饮用水。没想到英国本土的Waitrose会员卡在这里也可以正常使用。岛上还可以看到Marks & Spencer、Co-op等熟悉的英国品牌。
从交通规则、超市品牌到日常生活方式,泽西岛确实充满了浓浓的英伦气息。难怪走在岛上时,既有一种出门旅行的新鲜感,又经常让人觉得自己似乎并没有真正离开英国。
[show_file file="/var/www/wp-post-common/justyy.com/jersey.php"]
[show_posts keyword="泽西"]
泽西岛的车牌左边的国徽标注是GBJ:泽西岛部分车牌的左侧印有岛旗和“GBJ”标志,这是泽西岛注册车辆在国际通行时使用的地区识别标志。虽然其中带有“GB”,但这并不意味着泽西岛属于英国。泽西岛实际上是英国王室属地,拥有自己的政府、议会、法律和税收制度,并不属于联合王国。英国后来将本土车辆的国际标志由“GB”改为“UK”,但泽西岛的车辆仍然继续使用“GBJ”。从一块小小的车牌上,也能看出泽西岛与英国之间既密切相连、又相对独立的特殊关系。[/caption]
旅行期间,我们还看到了一块很特别的车牌——“J288888”,挂在一辆奥迪Q7上。后来也见到了车主,不过并不是亚洲人。看来对“88888”这种号码情有独钟的,也不只是华人。
下次再来泽西岛,我打算体验一下在岛上自驾。可以落地以后租车,也可以直接从英国本土把车开过来,大概和前几年去怀特岛时一样,需要把车开上渡轮。
泽西岛的驾驶规则与英国本土一致,车辆都是右舵,在道路左侧行驶。不过岛上的部分道路比较狭窄,开车时估计还是需要格外小心。
虽然泽西岛在行政上并不属于英国,但除了部分地名带有明显的法语色彩之外,岛上的生活处处都能看到英国的影子。
登岛第一天,我们就去了当地的Waitrose,买了牛奶、面包和饮用水。没想到英国本土的Waitrose会员卡在这里也可以正常使用。岛上还可以看到Marks & Spencer、Co-op等熟悉的英国品牌。
从交通规则、超市品牌到日常生活方式,泽西岛确实充满了浓浓的英伦气息。难怪走在岛上时,既有一种出门旅行的新鲜感,又经常让人觉得自己似乎并没有真正离开英国。
[show_file file="/var/www/wp-post-common/justyy.com/jersey.php"]
[show_posts keyword="泽西"]
2026-07-28 23:30:53
Jersey机场虽然规模不大,却是泽西岛连接英国本土及欧洲其他地区的重要交通枢纽。机场布局紧凑、设施简单,从值机到登机都十分方便,也因此给人一种小而高效的感觉。本文记录了我在Jersey机场的所见所感,以及一段只有四十多分钟、却颇有趣味的返程经历。Jersey机场位于泽西岛西部,是这座海岛连接英国本土和欧洲其他地区的重要交通门户。机场规模不大,整体布局非常紧凑,从值机柜台到安检、登机口,走起来都很方便,基本不会迷路。机场内的商店和餐饮选择不多,却也因此显得简单高效,很有小岛机场的特色。虽然面积不大,但航班主要连接伦敦、曼彻斯特等英国城市,对当地居民和游客来说都十分重要。
 付费手机充电器/1小时2英镑,30分钟1.5英镑。[/caption]
[caption id="attachment_72269" align="alignnone" width="864"]
付费手机充电器/1小时2英镑,30分钟1.5英镑。[/caption]
[caption id="attachment_72269" align="alignnone" width="864"] 付费手机充电器[/caption]
[caption id="attachment_72270" align="alignnone" width="2048"]
付费手机充电器[/caption]
[caption id="attachment_72270" align="alignnone" width="2048"] 和泽西岛有航班的地方/主要是英国[/caption]
[caption id="attachment_72271" align="alignnone" width="2048"]
和泽西岛有航班的地方/主要是英国[/caption]
[caption id="attachment_72271" align="alignnone" width="2048"] Easyjet小飞机,准备飞回LUTON[/caption]
[caption id="attachment_72272" align="alignnone" width="2048"]
Easyjet小飞机,准备飞回LUTON[/caption]
[caption id="attachment_72272" align="alignnone" width="2048"] 准备登机了[/caption]
[caption id="attachment_72273" align="alignnone" width="2048"]
准备登机了[/caption]
[caption id="attachment_72273" align="alignnone" width="2048"] Easyjet的飞机应该是airbus 320/中间只有一个通道,两边各三个,大概不到200个座位。[/caption]
[caption id="attachment_72274" align="alignnone" width="2048"]
Easyjet的飞机应该是airbus 320/中间只有一个通道,两边各三个,大概不到200个座位。[/caption]
[caption id="attachment_72274" align="alignnone" width="2048"] Easyjet的飞机应该是airbus 320/中间只有一个通道,两边各三个,大概不到200个座位。[/caption]
[caption id="attachment_72275" align="alignnone" width="2048"]
Easyjet的飞机应该是airbus 320/中间只有一个通道,两边各三个,大概不到200个座位。[/caption]
[caption id="attachment_72275" align="alignnone" width="2048"] 准备登机飞往泽西岛[/caption]
[caption id="attachment_72276" align="alignnone" width="864"]
准备登机飞往泽西岛[/caption]
[caption id="attachment_72276" align="alignnone" width="864"] 在Easyjet上点餐是要钱的[/caption]
[caption id="attachment_72277" align="alignnone" width="864"]
在Easyjet上点餐是要钱的[/caption]
[caption id="attachment_72277" align="alignnone" width="864"] Jersey的航班信息显示[/caption]
[caption id="attachment_72278" align="alignnone" width="2048"]
Jersey的航班信息显示[/caption]
[caption id="attachment_72278" align="alignnone" width="2048"] 欢迎来到泽西,Home of Bergerac 贝尔热拉克之乡[/caption]
[caption id="attachment_72279" align="alignnone" width="2048"]
欢迎来到泽西,Home of Bergerac 贝尔热拉克之乡[/caption]
[caption id="attachment_72279" align="alignnone" width="2048"] 打车到机场,这个机场的标识很不显眼。[/caption]
[caption id="attachment_72280" align="alignnone" width="2048"]
打车到机场,这个机场的标识很不显眼。[/caption]
[caption id="attachment_72280" align="alignnone" width="2048"] Jersey机场的停机位也就11个左右。[/caption]
[caption id="attachment_72281" align="alignnone" width="2048"]
Jersey机场的停机位也就11个左右。[/caption]
[caption id="attachment_72281" align="alignnone" width="2048"] Jersey机场很小,只有一个免税店,没啥逛的。[/caption]
[caption id="attachment_72282" align="alignnone" width="2048"]
Jersey机场很小,只有一个免税店,没啥逛的。[/caption]
[caption id="attachment_72282" align="alignnone" width="2048"] 泽西机场的航班很少,一个屏幕就能显示完,晚上最晚一班航班7点多,就能下班了。[/caption]
回英国的时候也是直接入境,没有人检查护照,下飞机是从 Arrival from Republic of Ireland and Jersey,从爱尔兰过来的也不用过海关。(降落Jersey没有海关/Passport Control,回英国的时候也没有!)
[caption id="attachment_72283" align="alignnone" width="864"]
泽西机场的航班很少,一个屏幕就能显示完,晚上最晚一班航班7点多,就能下班了。[/caption]
回英国的时候也是直接入境,没有人检查护照,下飞机是从 Arrival from Republic of Ireland and Jersey,从爱尔兰过来的也不用过海关。(降落Jersey没有海关/Passport Control,回英国的时候也没有!)
[caption id="attachment_72283" align="alignnone" width="864"] 降落Jersey的时候没有Passport Control就直接入境了,没有海关![/caption]
[caption id="attachment_72284" align="alignnone" width="864"]
降落Jersey的时候没有Passport Control就直接入境了,没有海关![/caption]
[caption id="attachment_72284" align="alignnone" width="864"] 在Jersey机场的安检,没收了很多防晒霜,我想起去年在巴黎机场回来的时候,问安检我带的防晒霜能否带,他说你放边上就好。[/caption]
[caption id="attachment_72285" align="alignnone" width="2048"]
在Jersey机场的安检,没收了很多防晒霜,我想起去年在巴黎机场回来的时候,问安检我带的防晒霜能否带,他说你放边上就好。[/caption]
[caption id="attachment_72285" align="alignnone" width="2048"] 从Luton起飞,降落到Jersey机场。[/caption]
我去过的机场:我去过的机场列表 2004-
[show_file file="/var/www/wp-post-common/justyy.com/jersey.php"]
[show_posts keyword="机场"]
从Luton起飞,降落到Jersey机场。[/caption]
我去过的机场:我去过的机场列表 2004-
[show_file file="/var/www/wp-post-common/justyy.com/jersey.php"]
[show_posts keyword="机场"]
2026-07-23 23:38:17
娃在Perse私校的第一学年结束了,三个学期的学费合计超过三万英镑,再加上滑雪旅行、校服和各种活动费用,养娃的经济压力远比想象中更大。虽然私校学费昂贵、假期也更长,但这一年里,我们也看到了孩子在学习习惯、自我意识、表达能力和主动性方面的成长。私校买不到确定的成功,却能提供更稳定的环境、更多的机会,以及相对更集中的学习氛围。孩子负责成长,父母负责托底,接下来的几年,我们还要继续一起努力。 娃上了一年私校后的改变 三万英镑学费之后:娃的第一年私校生活 他上完了一年私校,我也交完了一年学费 一年169天,每天178英镑:私校到底值不值? 钱包漏了个大洞:娃在Perse的第一年 中产返贫实录:孩子上私校的第一年 一年学费三万英镑,私校买的是成绩还是环境? 娃说Perse是个Scam,但这一年他确实成长了 程序员养娃账单:三万英镑学费只是开始 私校第一年总结:钱花了,成长也看到了 他负责学习,我负责赚钱:私校第一年结束了[caption id="attachment_72251" align="alignnone" width="550"]
 01[/caption]
01[/caption]
 02[/caption]
02[/caption]
 03[/caption]
03[/caption]
共 169 个上学日 按照 剑桥 Perse Upper School 的校历计算,从 2025 年 9 月 3 日到 2026 年 7 月 2 日,统计周一至周五的正常上课日,并扣除期中假期、银行假日以及学校公布的教师培训日: 学期 计算方式 上学日 秋季学期 72 个工作日 − 7 个期中假期日 65 天 春季学期 59 个工作日 − 5 个期中假期日 54 天 夏季学期 57 个工作日 − 1 天银行假日 − 5 个期中假期日 − 1 天教师培训日 50 天 合计 65 + 54 + 50 169 天 学校公布的主要日期如下: **秋季学期:**2025 年 9 月 3 日至 12 月 11 日 期中假期:10 月 24 日至 11 月 3 日 **春季学期:**2026 年 1 月 6 日至 3 月 27 日 期中假期:2 月 16 日至 20 日 **夏季学期:**2026 年 4 月 15 日至 7 月 2 日 期中假期:5 月 25 日至 29 日 **5 月 4 日:**英国五月银行假日 **6 月 1 日:**Upper School 教师培训日(INSET Day) **7 月 2 日:**最后一个上学日,中午放学 即使最后一天只上半天,我仍然将其计算为一个完整的上学日。 另一种可能的计算:170 天 如果学生是 Year 7 至 Year 10,并且把 2026 年 6 月 20 日星期六的 Prize Giving 颁奖典礼视为必须到校的一天,那么总数可能是: 169 + 1 = 170 天 不过,按照通常只计算周一至周五正式上课日的方式,答案是: 169 个上学日[caption id="attachment_72238" align="alignnone" width="2048"]
 娃在家的学习的地方[/caption]
[caption id="attachment_72239" align="alignnone" width="2048"]
娃在家的学习的地方[/caption]
[caption id="attachment_72239" align="alignnone" width="2048"] 我去学校接他,好多车排队,得等校车走了才能走。[/caption]
[caption id="attachment_72240" align="alignnone" width="864"]
我去学校接他,好多车排队,得等校车走了才能走。[/caption]
[caption id="attachment_72240" align="alignnone" width="864"] 和娃一起吃午餐,主餐5.1英镑,水果/饮料免费。汤1.99[/caption]
[caption id="attachment_72241" align="alignnone" width="2048"]
和娃一起吃午餐,主餐5.1英镑,水果/饮料免费。汤1.99[/caption]
[caption id="attachment_72241" align="alignnone" width="2048"] 公司楼下的餐厅 Food Lab,最近世界杯。[/caption]
[caption id="attachment_72242" align="alignnone" width="864"]
公司楼下的餐厅 Food Lab,最近世界杯。[/caption]
[caption id="attachment_72242" align="alignnone" width="864"] 吃完午餐,娃玩了会手机,这是他最放松的时候了[/caption]
[caption id="attachment_72243" align="alignnone" width="1152"]
吃完午餐,娃玩了会手机,这是他最放松的时候了[/caption]
[caption id="attachment_72243" align="alignnone" width="1152"] 我打趣的和媳妇说:这号目前还没废,娃的手指很长,弹琴的样子真帅。[/caption]
[caption id="attachment_72247" align="alignnone" width="2048"]
我打趣的和媳妇说:这号目前还没废,娃的手指很长,弹琴的样子真帅。[/caption]
[caption id="attachment_72247" align="alignnone" width="2048"] 吃完午餐下班回家。[/caption]
[caption id="attachment_72248" align="alignnone" width="588"]
吃完午餐下班回家。[/caption]
[caption id="attachment_72248" align="alignnone" width="588"]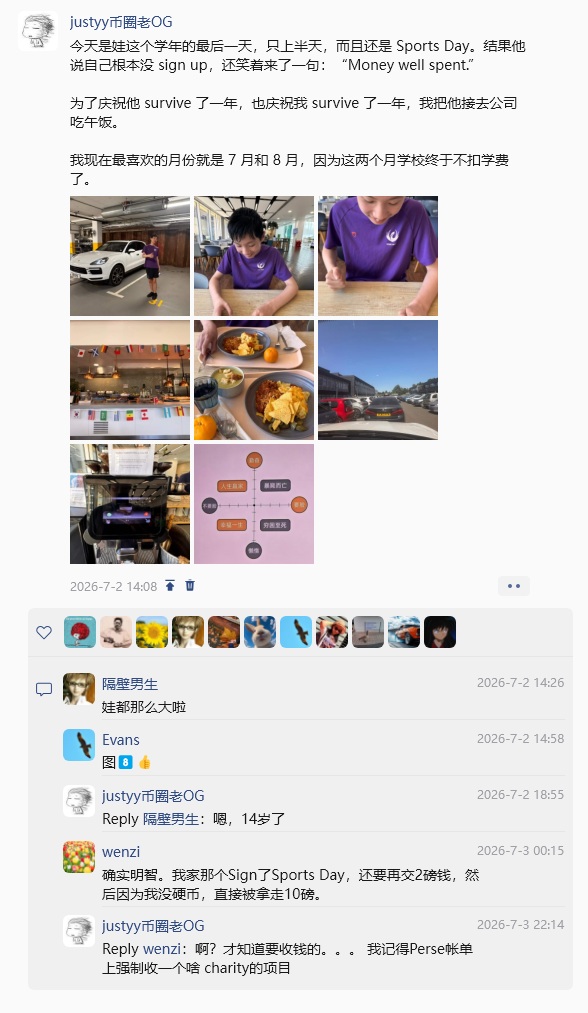 我现在最喜欢的月份就是 7 月和 8 月,因为这两个月学校终于不扣学费了。[/caption]
[show_file file="/var/www/wp-post-common/justyy.com/private-school.php"]
[show_posts keyword="私校"]
我现在最喜欢的月份就是 7 月和 8 月,因为这两个月学校终于不扣学费了。[/caption]
[show_file file="/var/www/wp-post-common/justyy.com/private-school.php"]
[show_posts keyword="私校"]
2026-07-22 21:38:36
去年夏天,我们从剑桥出发,自驾前往科茨沃尔德,当天往返,前后开车约八个小时。原本计划住上一晚,却因行程和天气变化改成了一日游。我们在当地乡村酒吧吃过午饭后,陆续游览了附近三个小镇,欣赏河流、石桥、古老石屋和宁静的乡村风景。虽然行程有些匆忙,但阳光下的科茨沃尔德依然给我们留下了美好而难忘的回忆。 一日往返科茨沃尔德:八小时车程,换一场英国乡村的夏日漫游 盛夏漫游科茨沃尔德:一场匆忙却美好的乡村之旅 从剑桥到科茨沃尔德:一天走过三个英国小镇 科茨沃尔德一日游:石屋、小河与英伦夏日 八小时自驾,只为看一眼科茨沃尔德的夏天 匆匆一天,慢慢回味:我们的科茨沃尔德之行 从照片里的河流、石桥、广场和石屋判断,当天去的三个地方最可能是: Bourton-on-the-Water 中文常译为“水上伯顿”。照片中有小河、石桥和很多水鸟的地方,基本可以确定是这里。 Stow-on-the-Wold 中文常译为“斯托昂泽沃尔德”。照片中的开阔广场、停车区和蜂蜜色石屋街道,很像这里的 Market Square。 Lower Slaughter 中文常译为“下斯劳特村”或“下斯劳特”。照片中的林荫小路、安静的石屋和溪流,很可能是这里;当地的小河叫 River Eye。不过也不排除其中部分照片拍摄于附近的 Upper Slaughter。 Bourton-on-the-Water:小河、低矮石桥、河边草地和水鸟,都是水上伯顿最典型的景观。 River Windrush:穿过水上伯顿中心的小河。 The Model Village:照片中成片的微型石屋和红褐色屋顶,是水上伯顿著名的九分之一比例模型村,位于 The Old New Inn 后面。 The Cotswold Pottery:照片里的橱窗上直接写着这个名字,地址位于 Bourton-on-the-Water 的 Clapton Row。 The Chestnut Tree:模型村照片中的建筑招牌,在水上伯顿也确实有这家茶室和餐厅。去年夏天,2025年7月26日,我们从剑桥出发,开车前往科茨沃尔德(Cotswolds)。
当天我们游览了科茨沃尔德附近的三个小镇,其中印象最深的是有“小威尼斯”之称的水上伯顿(Bourton-on-the-Water)。清澈的温德拉什河(River Windrush)穿过小镇,河上分布着几座低矮的石桥。我们还参观了当地著名的模型村(The Model Village),并经过了科茨沃尔德陶艺店(The Cotswold Pottery)。原本的计划是在那里住一晚,安排一个相对轻松的周末旅行。不过后来行程临时有了变化,印象中好像是因为天气预报不太稳定,最后决定只选天气晴朗的那一天过去,当天往返。 现在回想起来,这个决定多少有点“勇猛”:从剑桥开到科茨沃尔德,再在几个小镇之间辗转,晚上还要原路返回,一天下来足足开了八个小时。真正留给我们吃饭、散步和看风景的时间,反而没有在车上的时间长。
下面按截图中图片的顺序,从左到右、从上到下编号,共 52 张: 第一排 在科茨沃尔德的乡村酒吧翻看午餐菜单。 长途驾驶后,先用两杯冰凉的啤酒稍作休息。 乡村酒吧里分量十足的英式午餐。 色彩丰富、摆盘精致的一道主菜。 简单而精致的乡村酒吧料理。 午餐桌上的清爽沙拉与时蔬。 从剑桥一路开往科茨沃尔德,漫长旅程仍在继续。 沿着绿篱环绕的小路,走进宁静的英国乡村。 树荫覆盖的乡间步道,为盛夏带来一丝清凉。 坐在户外餐桌旁享用午餐的孩子们。 长途旅行之后,终于可以安心吃饭了。 蜂蜜色石屋排列在古老的村庄街道两旁。 绿树掩映下,一条清澈的小河静静流过。 穿过树林与石屋之间的宁静乡间公路。 河边展示的科茨沃尔德乡村风景画。 蓝天白云下,古老石屋构成了典型的英伦乡村画面。 第二排 水鸟在清澈的河水中悠闲游动。 一家人坐在树荫下休息,享受难得的悠闲时光。 盛夏阳光下,科茨沃尔德乡村中的蓝裙倩影。 坐在乡村餐厅里,记录旅途中的轻松一刻。 漫步在安静的村庄街道上。 巨大的向日葵,为夏日旅程增添了明亮色彩。 古老石屋与乡村花园之间的夏日留影。 在户外茶座享用下午茶,感受英式乡村生活。 遮阳伞下的悠闲时光。 古老石墙和木门前的旅行留影。 蓝裙与蜂蜜色石屋,构成温柔的英伦夏日画面。 古老石窗与爬藤植物旁的乡村人像。 一组记录科茨沃尔德夏日之旅的照片。 安静坐落在路边的传统英式乡村住宅。 阳光透过茂密树冠,洒向林间小路。 绿树与灌木环绕的科茨沃尔德乡间公路。 第三排 白色小屋与蜂蜜色石墙相依而立。 游客穿行在古老而热闹的村庄街道上。 清澈的小河穿过茂密的树林。 绿意环绕的河流,静静倒映着岸边树木。 孩子们坐在河边长椅上休息。 乡村酒吧门前的黑板菜单与古老石墙。 石桥横跨温德拉什河,连接着水上伯顿的两岸。 水鸟在温德拉什河中悠闲觅食。 河水清澈见底,水鸟在浅滩间缓缓游动。 树影下的河面安静而幽深。 河中的水鸟与斑驳倒影。 阳光照在流动的河水上,泛起细碎波光。 水上伯顿模型村中的微缩石屋建筑。 盛开的向日葵,为旅程带来明亮的夏日气息。 The Cotswold Pottery 橱窗里陈列的手工陶器。 蜂蜜色石屋构成了科茨沃尔德最经典的村庄景色。 第四排 阳光下泛着金黄色光泽的树叶。 夏日的水上伯顿,河岸边坐满了游客。 绿树与藤蔓环绕的传统英式庄园住宅。 树荫深处的古老石屋,安静地守在水边。
 中午到了在小酒馆歇息/媳妇[/caption]
[caption id="attachment_72206" align="alignnone" width="2048"]
中午到了在小酒馆歇息/媳妇[/caption]
[caption id="attachment_72206" align="alignnone" width="2048"] 河中的水鸟与斑驳倒影。[/caption]
[caption id="attachment_72205" align="alignnone" width="2048"]
河中的水鸟与斑驳倒影。[/caption]
[caption id="attachment_72205" align="alignnone" width="2048"] 阳光照在流动的河水上,泛起细碎波光。[/caption]
[caption id="attachment_72204" align="alignnone" width="2048"]
阳光照在流动的河水上,泛起细碎波光。[/caption]
[caption id="attachment_72204" align="alignnone" width="2048"] 水上伯顿模型村中的微缩石屋建筑。[/caption]
[caption id="attachment_72203" align="alignnone" width="1365"]
水上伯顿模型村中的微缩石屋建筑。[/caption]
[caption id="attachment_72203" align="alignnone" width="1365"] 乡村酒吧门前的黑板菜单与古老石墙。[/caption]
[caption id="attachment_72202" align="alignnone" width="2048"]
乡村酒吧门前的黑板菜单与古老石墙。[/caption]
[caption id="attachment_72202" align="alignnone" width="2048"] 娃走累了就坐在石头上歇会儿。[/caption]
[caption id="attachment_72201" align="alignnone" width="2048"]
娃走累了就坐在石头上歇会儿。[/caption]
[caption id="attachment_72201" align="alignnone" width="2048"] 绿树与灌木环绕的科茨沃尔德乡间公路。[/caption]
[caption id="attachment_72200" align="alignnone" width="2048"]
绿树与灌木环绕的科茨沃尔德乡间公路。[/caption]
[caption id="attachment_72200" align="alignnone" width="2048"] 阳光透过茂密树冠,洒向林间小路。[/caption]
[caption id="attachment_72199" align="alignnone" width="2048"]
阳光透过茂密树冠,洒向林间小路。[/caption]
[caption id="attachment_72199" align="alignnone" width="2048"]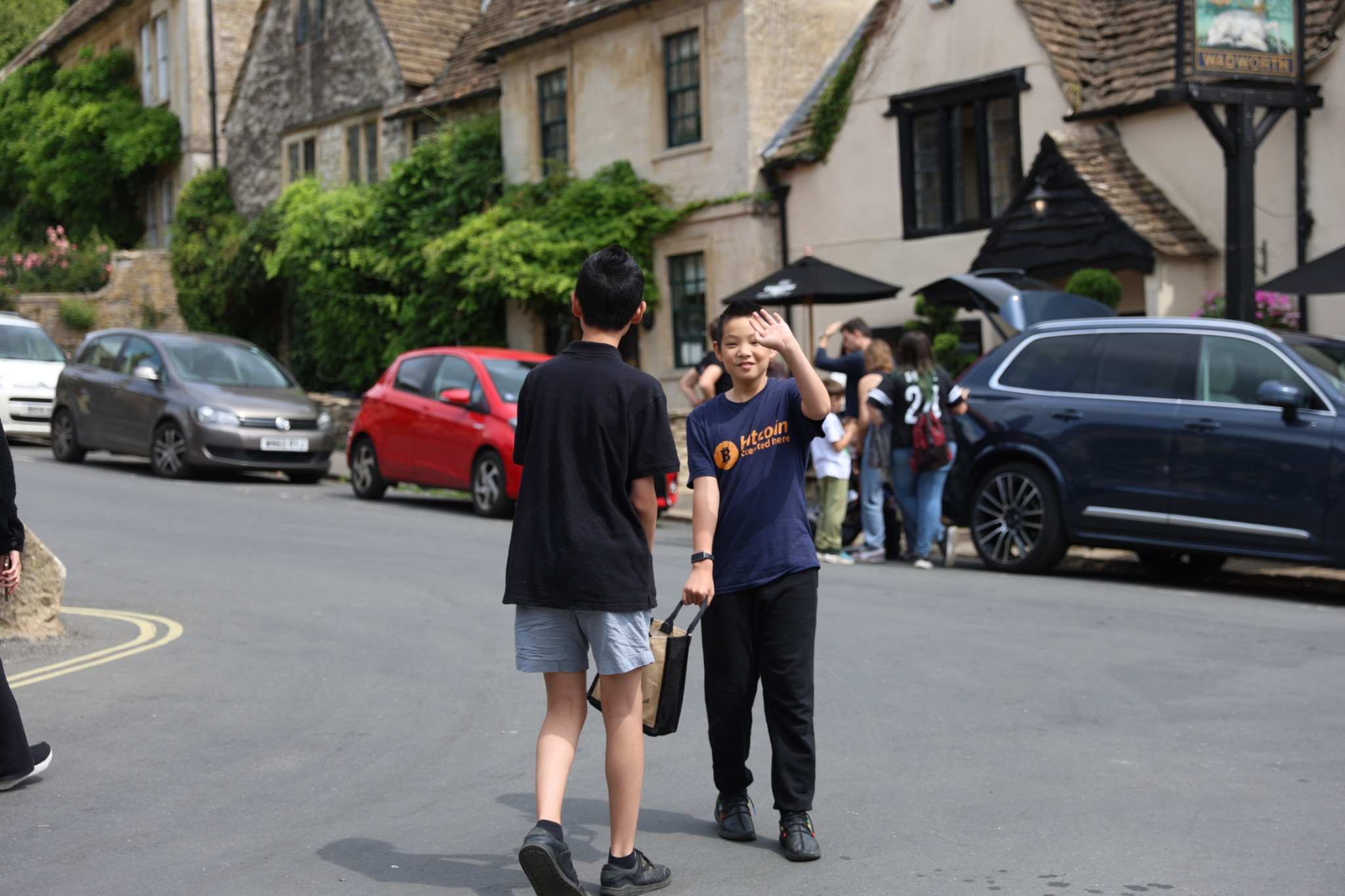 开了三个多小时终于到了小镇,在镇中心的小广场上。[/caption]
[caption id="attachment_72198" align="alignnone" width="2048"]
开了三个多小时终于到了小镇,在镇中心的小广场上。[/caption]
[caption id="attachment_72198" align="alignnone" width="2048"] 蓝裙与蜂蜜色石屋,构成温柔的英伦夏日画面。[/caption]
[caption id="attachment_72197" align="alignnone" width="2048"]
蓝裙与蜂蜜色石屋,构成温柔的英伦夏日画面。[/caption]
[caption id="attachment_72197" align="alignnone" width="2048"] 古老石墙和木门前的旅行留影。[/caption]
[caption id="attachment_72196" align="alignnone" width="2048"]
古老石墙和木门前的旅行留影。[/caption]
[caption id="attachment_72196" align="alignnone" width="2048"] 小树林鸟儿叽叽喳喳[/caption]
[caption id="attachment_72195" align="alignnone" width="1001"]
小树林鸟儿叽叽喳喳[/caption]
[caption id="attachment_72195" align="alignnone" width="1001"] 在户外茶座享用下午茶,感受英式乡村生活。在酒巴的后院里,吃着简易三明制[/caption]
[caption id="attachment_72194" align="alignnone" width="1024"]
在户外茶座享用下午茶,感受英式乡村生活。在酒巴的后院里,吃着简易三明制[/caption]
[caption id="attachment_72194" align="alignnone" width="1024"] 古老石屋与乡村花园之间的夏日留影。[/caption]
[caption id="attachment_72193" align="alignnone" width="1024"]
古老石屋与乡村花园之间的夏日留影。[/caption]
[caption id="attachment_72193" align="alignnone" width="1024"] 巨大的向日葵,为夏日旅程增添了明亮色彩。[/caption]
[caption id="attachment_72192" align="alignnone" width="1024"]
巨大的向日葵,为夏日旅程增添了明亮色彩。[/caption]
[caption id="attachment_72192" align="alignnone" width="1024"] 漫步在安静的村庄街道上。[/caption]
[caption id="attachment_72191" align="alignnone" width="1024"]
漫步在安静的村庄街道上。[/caption]
[caption id="attachment_72191" align="alignnone" width="1024"] 坐在乡村餐厅里,记录旅途中的轻松一刻。[/caption]
[caption id="attachment_72190" align="alignnone" width="1024"]
坐在乡村餐厅里,记录旅途中的轻松一刻。[/caption]
[caption id="attachment_72190" align="alignnone" width="1024"] 盛夏阳光下,科茨沃尔德乡村中的蓝裙倩影。[/caption]
[caption id="attachment_72189" align="alignnone" width="2048"]
盛夏阳光下,科茨沃尔德乡村中的蓝裙倩影。[/caption]
[caption id="attachment_72189" align="alignnone" width="2048"] 一家人坐在树荫下休息,享受难得的悠闲时光。[/caption]
[caption id="attachment_72188" align="alignnone" width="2048"]
一家人坐在树荫下休息,享受难得的悠闲时光。[/caption]
[caption id="attachment_72188" align="alignnone" width="2048"] 水鸟/鸭子在清澈的河水中悠闲游动。[/caption]
[caption id="attachment_72187" align="alignnone" width="2048"]
水鸟/鸭子在清澈的河水中悠闲游动。[/caption]
[caption id="attachment_72187" align="alignnone" width="2048"] 蓝天白云下,古老石屋构成了典型的英伦乡村画面。[/caption]
[caption id="attachment_72186" align="alignnone" width="2048"]
蓝天白云下,古老石屋构成了典型的英伦乡村画面。[/caption]
[caption id="attachment_72186" align="alignnone" width="2048"] 河边展示的科茨沃尔德乡村风景画。[/caption]
[caption id="attachment_72185" align="alignnone" width="1365"]
河边展示的科茨沃尔德乡村风景画。[/caption]
[caption id="attachment_72185" align="alignnone" width="1365"] 穿过树林与石屋之间的宁静乡间公路。[/caption]
[caption id="attachment_72184" align="alignnone" width="2048"]
穿过树林与石屋之间的宁静乡间公路。[/caption]
[caption id="attachment_72184" align="alignnone" width="2048"] 绿树掩映下,一条清澈的小河静静流过。[/caption]
[caption id="attachment_72183" align="alignnone" width="1365"]
绿树掩映下,一条清澈的小河静静流过。[/caption]
[caption id="attachment_72183" align="alignnone" width="1365"] 蜂蜜色石屋排列在古老的村庄街道两旁。[/caption]
[caption id="attachment_72182" align="alignnone" width="1365"]
蜂蜜色石屋排列在古老的村庄街道两旁。[/caption]
[caption id="attachment_72182" align="alignnone" width="1365"] 长途旅行之后,终于可以安心吃饭了。[/caption]
[caption id="attachment_72181" align="alignnone" width="2048"]
长途旅行之后,终于可以安心吃饭了。[/caption]
[caption id="attachment_72181" align="alignnone" width="2048"] 坐在户外餐桌旁享用午餐的孩子们。[/caption]
[caption id="attachment_72180" align="alignnone" width="2048"]
坐在户外餐桌旁享用午餐的孩子们。[/caption]
[caption id="attachment_72180" align="alignnone" width="2048"] 树荫覆盖的乡间步道,为盛夏带来一丝清凉。[/caption]
[caption id="attachment_72179" align="alignnone" width="2048"]
树荫覆盖的乡间步道,为盛夏带来一丝清凉。[/caption]
[caption id="attachment_72179" align="alignnone" width="2048"] 沿着绿篱环绕的小路,走进宁静的英国乡村。[/caption]
[caption id="attachment_72178" align="alignnone" width="2048"]
沿着绿篱环绕的小路,走进宁静的英国乡村。[/caption]
[caption id="attachment_72178" align="alignnone" width="2048"] 从剑桥一路开往科茨沃尔德,漫长旅程仍在继续。开车8小时 338英理,刚到家,累死了[/caption]
[caption id="attachment_72177" align="alignnone" width="2048"]
从剑桥一路开往科茨沃尔德,漫长旅程仍在继续。开车8小时 338英理,刚到家,累死了[/caption]
[caption id="attachment_72177" align="alignnone" width="2048"] 午餐桌上的清爽沙拉与时蔬。[/caption]
[caption id="attachment_72176" align="alignnone" width="2048"]
午餐桌上的清爽沙拉与时蔬。[/caption]
[caption id="attachment_72176" align="alignnone" width="2048"] 简单而精致的乡村酒吧料理。[/caption]
[caption id="attachment_72175" align="alignnone" width="2048"]
简单而精致的乡村酒吧料理。[/caption]
[caption id="attachment_72175" align="alignnone" width="2048"] 色彩丰富、摆盘精致的一道主菜。[/caption]
[caption id="attachment_72174" align="alignnone" width="2048"]
色彩丰富、摆盘精致的一道主菜。[/caption]
[caption id="attachment_72174" align="alignnone" width="2048"] 乡村酒吧里分量十足的英式午餐。[/caption]
[caption id="attachment_72173" align="alignnone" width="2048"]
乡村酒吧里分量十足的英式午餐。[/caption]
[caption id="attachment_72173" align="alignnone" width="2048"] 长途驾驶后,先用两杯冰凉的啤酒稍作休息。[/caption]
[caption id="attachment_72172" align="alignnone" width="864"]
长途驾驶后,先用两杯冰凉的啤酒稍作休息。[/caption]
[caption id="attachment_72172" align="alignnone" width="864"] 在科茨沃尔德的乡村酒吧翻看午餐菜单。[/caption]
[caption id="attachment_72171" align="alignnone" width="1536"]
在科茨沃尔德的乡村酒吧翻看午餐菜单。[/caption]
[caption id="attachment_72171" align="alignnone" width="1536"] 媳妇朋友圈/九宫格/摄影[/caption]
[caption id="attachment_72170" align="alignnone" width="2048"]
媳妇朋友圈/九宫格/摄影[/caption]
[caption id="attachment_72170" align="alignnone" width="2048"] 媳妇在小石屋前留影[/caption]
[caption id="attachment_72169" align="alignnone" width="1024"]
媳妇在小石屋前留影[/caption]
[caption id="attachment_72169" align="alignnone" width="1024"] 古老石窗与爬藤植物旁的乡村人像。[/caption]
[caption id="attachment_72168" align="alignnone" width="1024"]
古老石窗与爬藤植物旁的乡村人像。[/caption]
[caption id="attachment_72168" align="alignnone" width="1024"] 媳妇/古老石墙和木门前的旅行留影。[/caption]
[caption id="attachment_72218" align="alignnone" width="2048"]
媳妇/古老石墙和木门前的旅行留影。[/caption]
[caption id="attachment_72218" align="alignnone" width="2048"] 树荫深处的古老石屋,安静地守在水边。[/caption]
[caption id="attachment_72217" align="alignnone" width="1365"]
树荫深处的古老石屋,安静地守在水边。[/caption]
[caption id="attachment_72217" align="alignnone" width="1365"] 绿树与藤蔓环绕的传统英式庄园住宅。[/caption]
[caption id="attachment_72216" align="alignnone" width="2048"]
绿树与藤蔓环绕的传统英式庄园住宅。[/caption]
[caption id="attachment_72216" align="alignnone" width="2048"] 树荫深处的古老石屋,安静地守在水边。[/caption]
[caption id="attachment_72215" align="alignnone" width="2048"]
树荫深处的古老石屋,安静地守在水边。[/caption]
[caption id="attachment_72215" align="alignnone" width="2048"] 夏日的水上伯顿,河岸边坐满了游客。[/caption]
[caption id="attachment_72214" align="alignnone" width="1365"]
夏日的水上伯顿,河岸边坐满了游客。[/caption]
[caption id="attachment_72214" align="alignnone" width="1365"] 阳光下泛着金黄色光泽的树叶。[/caption]
[caption id="attachment_72213" align="alignnone" width="2048"]
阳光下泛着金黄色光泽的树叶。[/caption]
[caption id="attachment_72213" align="alignnone" width="2048"] 古老的小城镇[/caption]
[caption id="attachment_72212" align="alignnone" width="1365"]
古老的小城镇[/caption]
[caption id="attachment_72212" align="alignnone" width="1365"] Cotswold Pottery 科茨沃尔德陶器/街上看到的 The Cotswold Pottery 橱窗里陈列的手工陶器。[/caption]
[caption id="attachment_72211" align="alignnone" width="2048"]
Cotswold Pottery 科茨沃尔德陶器/街上看到的 The Cotswold Pottery 橱窗里陈列的手工陶器。[/caption]
[caption id="attachment_72211" align="alignnone" width="2048"] 盛开的向日葵,为旅程带来明亮的夏日气息。[/caption]
[caption id="attachment_72210" align="alignnone" width="2048"]
盛开的向日葵,为旅程带来明亮的夏日气息。[/caption]
[caption id="attachment_72210" align="alignnone" width="2048"] 小城镇上有名的 The Chestnut Tree[/caption]
[caption id="attachment_72209" align="alignnone" width="2048"]
小城镇上有名的 The Chestnut Tree[/caption]
[caption id="attachment_72209" align="alignnone" width="2048"] 狗子很开心的玩水[/caption]
[caption id="attachment_72208" align="alignnone" width="2048"]
狗子很开心的玩水[/caption]
[caption id="attachment_72208" align="alignnone" width="2048"] 河水清澈见底,水鸟在浅滩间缓缓游动。[/caption]
[caption id="attachment_72207" align="alignnone" width="2048"]
河水清澈见底,水鸟在浅滩间缓缓游动。[/caption]
[caption id="attachment_72207" align="alignnone" width="2048"] 河里的天鹅[/caption]
[show_posts keyword="旅游"]
河里的天鹅[/caption]
[show_posts keyword="旅游"]