2025-07-18 20:00:00
在 LevelDB 中,SSTable(Sorted Strings Table)是存储键值对数据的文件格式。前面的文章LevelDB 源码阅读:一步步拆解 SSTable 文件的创建过程 介绍了 SSTable 文件的创建过程,我们知道了 SSTable 文件由多个数据块组成,这些块是文件的基本单位。
这些数据块起始可以分两类,一种是键值对数据块,一种是过滤块数据块。相应的,为了组装这两类数据块,LevelDB 实现了两类 BlockBuilder 类,分别是 BlockBuilder 和 FilterBlockBuilder。这篇文章,我们来看看 BlockBuilder 的实现。
先来看一个简单的示意图,展示了 LevelDB 中 DataBlock 的存储结构,图的源码在 leveldb_datablock.dot。
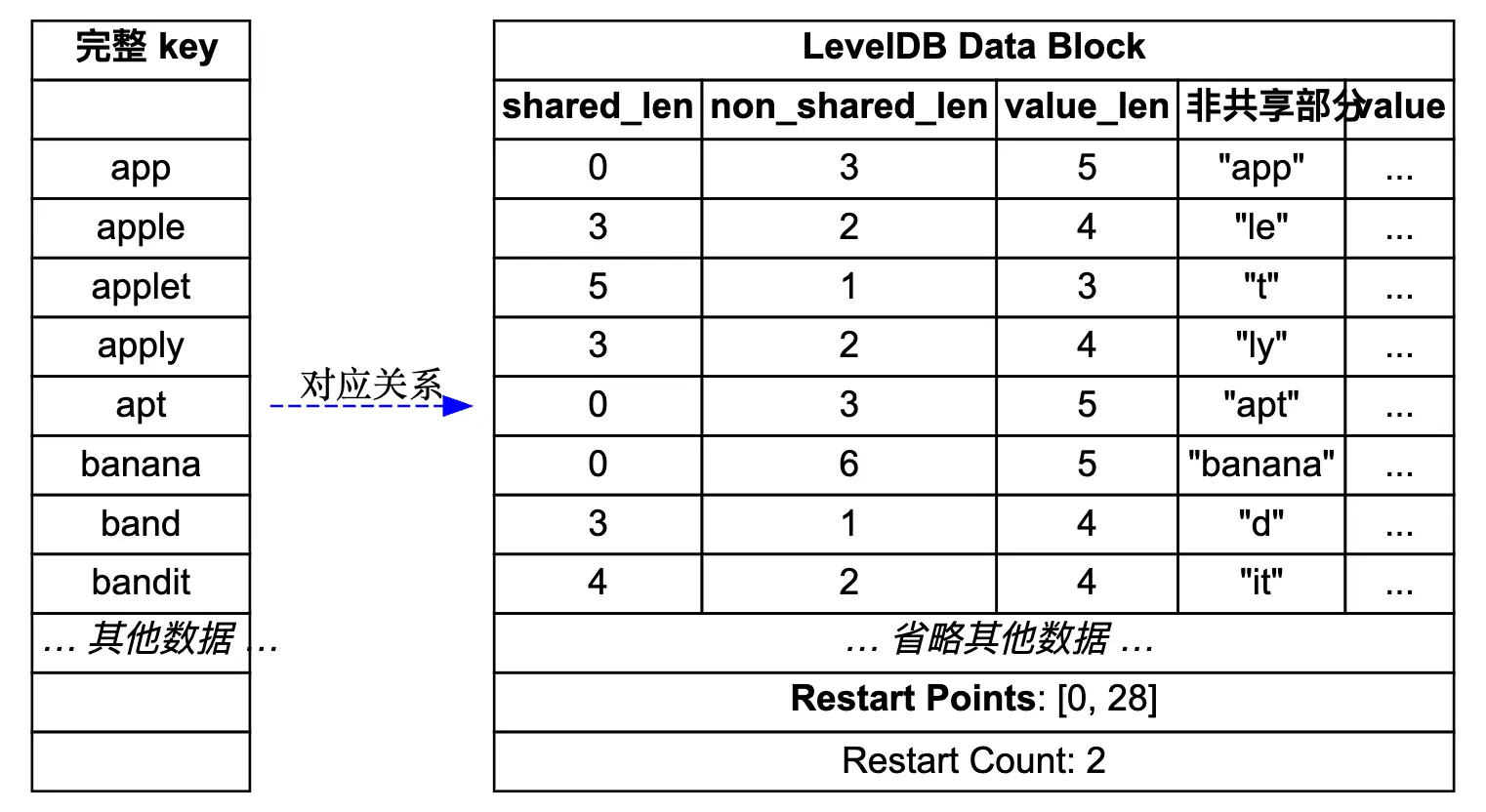
接下来配合这个图来理解前缀压缩和重启点机制。
我们知道这里 DataBlock 用来存储有序的键值对,最简单的做法就是直接一个个存储。比如用 [keysize, key, valuesize, value] 这样的格式来存储。那么一个可能的键值对存储结果如下:
1 |
[3, "app", 6, "value1"] |
仔细观察这些键,我们会发现一个明显的问题:存在大量的重复前缀。
这里的例子是我构造的,不过实际的业务场景中,我们的 key 经常都是有大量相同前缀的。这种共同前缀会浪费不少硬盘存储空间,另外读取的时候,也需要传输更多的冗余数据。如果缓存 DataBlock 到内存中,这种重复数据也会占用更多的内存。
LevelDB 作为底层的存储组件,肯定要考虑存储效率。为了解决这个问题,LevelDB 采用了前缀压缩的存储格式。核心思想是:对于有序的键值对,后面的键只存储与前一个键不同的部分。
具体的存储格式变成了:
1 |
[shared_len, non_shared_len, value_len, non_shared_key, value] |
其中 shared_len 表示与前一个键共享的前缀长度,non_shared_len 表示不共享部分的长度,value_len 表示值的长度,non_shared_key 表示键中不共享的部分,value 表示实际的值。
让我们用前面的例子来看看效果,这里看看前缀压缩后键长度的变化:
| 完整 key | shared_len | non_shared_len | non_shared_key | 存储开销分析 |
|---|---|---|---|---|
| app | 0 | 3 | “app” | 原始:1+3=4,压缩:1+1+3=5,省1字节 |
| apple | 3 | 2 | “le” | 原始:1+5=6,压缩:1+1+2=4,省2字节 |
| applet | 5 | 1 | “t” | 原始:1+6=7,压缩:1+1+1=3,省4字节 |
| apply | 4 | 1 | “y” | 原始:1+5=6,压缩:1+1+1=3,省3字节 |
当然这里为了简化,假设长度值存储用 1 字节,实际上LevelDB使用变长编码,不过小长度下,长度也是 1 字节的。这里前缀压缩的效果并不是简单的节省重复前缀,而是需要权衡前缀长度与额外元数据的存储开销。
在这个例子中,总体上我们节省了 (1+2+4+3) = 10 个字节。其实对于大部分业务场景,这里肯定都能节省不少存储空间的。
看起来很完美是吧?别急,我们来看看读取的键值的时候,会遇到什么问题。如果我们想要查找 “apply” 这个键,在前缀压缩的存储中我们只能看到:
1 |
[4, 1, 4, "y", ...] |
为了拿到完整的键,我们要从从第一个键开始顺序读取,然后重建每个键的完整内容,直到找到目标键。这样会有什么问题?效率低啊!我们之所以顺序存键值,就是为了能用二分法快速定位到目标键,现在前缀压缩后,我们只能顺序读取,这在大块数据中会变得非常低效!
那怎么办,放弃用前缀压缩,或者是用其他方法?哈哈,计算机科学中,我们经常遇到类似的问题,一般都是取个折中方案,在存储和查找效率之间找个平衡。
LevelDB 的实现中,引入了 Restart Points(重启点) 来平衡这里的存储和查找效率。具体做法也很简单,就是每隔一定数量 N 的键,就存储键的完整内容。这里存储完整内容的键,就叫重启点。
只有重启点还不够,我们还要有个索引,能快速找到一个块中所有的完整键。这里 LevelDB 做法也很简单,在 DataBlock 的尾部,记录每个重启点的偏移位置。
查询的时候,根据尾部存储的重启点偏移,就能读出这里重启点的完整键,接着就可以用二分法快速定位到键应该在的区间。之后就可以从重启点开始顺序读取,直到找到目标键。这时候,最多读取 N 个键,就能找到目标键。这部分逻辑,我们放到下篇文章来展开。
整体逻辑已经很清晰了,接下来看看代码实现吧。这里实现在 table/block_builder.cc 中,代码量不多,还是比较好理解。
这里我们先看几个内置成员变量,基本看到这些成员变量就能猜到具体的实现逻辑了。在 table/block_builder.h 中:
1 |
class BlockBuilder { |
这里 buffer_ 就是存储 DataBlock 数据的地方,restarts_ 数组记录所有重启点的偏移位置。counter_ 用来计算从上次重启点开始存储的键值对数量,达到配置的阈值后,就设置新的重启点。
finished_ 记录是否已经完成构建,会在完成构建的时候,主动写尾部的数据。last_key_ 记录上一个键,用来做前缀压缩。
BlockBuilder 中核心的方法 2 个,分别是 Add 和 Finish。 我们先来看看 BlockBuilder::Add,逻辑很清晰,这里去掉了一些 assert 校验逻辑。
1 |
void BlockBuilder::Add(const Slice& key, const Slice& value) { |
这里代码很优雅,一看就懂。我多说一点这里 last_key_ 的一个小优化细节,我们看到 last_key_ 是一个 string,每次更新 last_key_ 的时候,首先复用共有部分,接着用 append 添加非共有部分。对于共同前缀长的键来说,这种更新方法可以节省不少内存分配。
在所有 key 添加完的时候,调用方主动调用 Finish 方法,然后把重启点数组和大小写到尾部,然后整体返回一个 Slice 对象。
1 |
Slice BlockBuilder::Finish() { |
调用方会接着用这个 Slice 对象,写入到 SSTable 文件中。
到此为止,我们了解了 LevelDB 中 DataBlock 构建过程中的优化细节,以及具体代码实现了。前面我们没提到重启点间隔大小,这里是通过配置项 options.h 中的 block_restart_interval 来控制的,默认值是 16。
1 |
// Number of keys between restart points for delta encoding of keys. |
这个值为啥是 16?如果在自己的业务场景用的话,可以调整吗?
先来看第一个问题,LevelDB 中默认是 16,可能是作者经过测试选择的一个魔数。不过从开源出来的代码看,这里没有不同间隔的压测数据。table_test.cc 中,也只有不同间隔的功能测试代码。
再来看第二个问题,我们自己的业务中,如果选择这个间隔值?我们要明白这个间隔值主要用来平衡压缩和查询性能,如果设置太小,就会导致压缩率降低。如果设置太大的话,压缩率上去了,但是查找的时候,线性扫描的键就会增多。
LevelDB 默认块的大小是 4KB,假设我们一个键值对平均 100 字节,那么 4KB 的块可以存储 40 个键值对。如果重启点间隔是 16,那么每个块中,重启点就有 3 个。
1 |
restart_point[0]: "user:12345:profile" (键 1-16) |
二分查找最多需要 2 次就能找到所在的区间,接着扫描的话,最坏情况要读取 15 个键,就能找到目标键。整体查找代价还是可以接受的。
明白了这里前缀压缩和重启点机制后,其实整个 DataBlock 的构建过程还是挺简单的。接下来我会继续分析 DataBlock 的读取解析过程,以及 FilterBlock 的构建和解析。
2025-06-27 21:00:00
LevelDB 中,内存表中的键值对在到达一定大小后,会落到磁盘文件 SSTable 中。并且磁盘文件也是分层的,每层包含多个 SSTable 文件,在运行时,LevelDB 会在适当时机,合并、重整 SSTable 文件,将数据不断往下层沉淀。
这里 SSTable 有一套组织数据的格式,目的就是保证数据有序,并且能快速查找。那么 SSTable 内部是怎么存储这些键值对的,又是怎么提高数据的读、写性能的。以及整个 SSTable 文件的实现中有哪些优化点?
本文接下来我们会仔细分析 SSTable 文件的创建过程,一步步拆解来看看这里到底怎么实现的。在开始之前,我先给一个大的图,大家可以先留个印象。
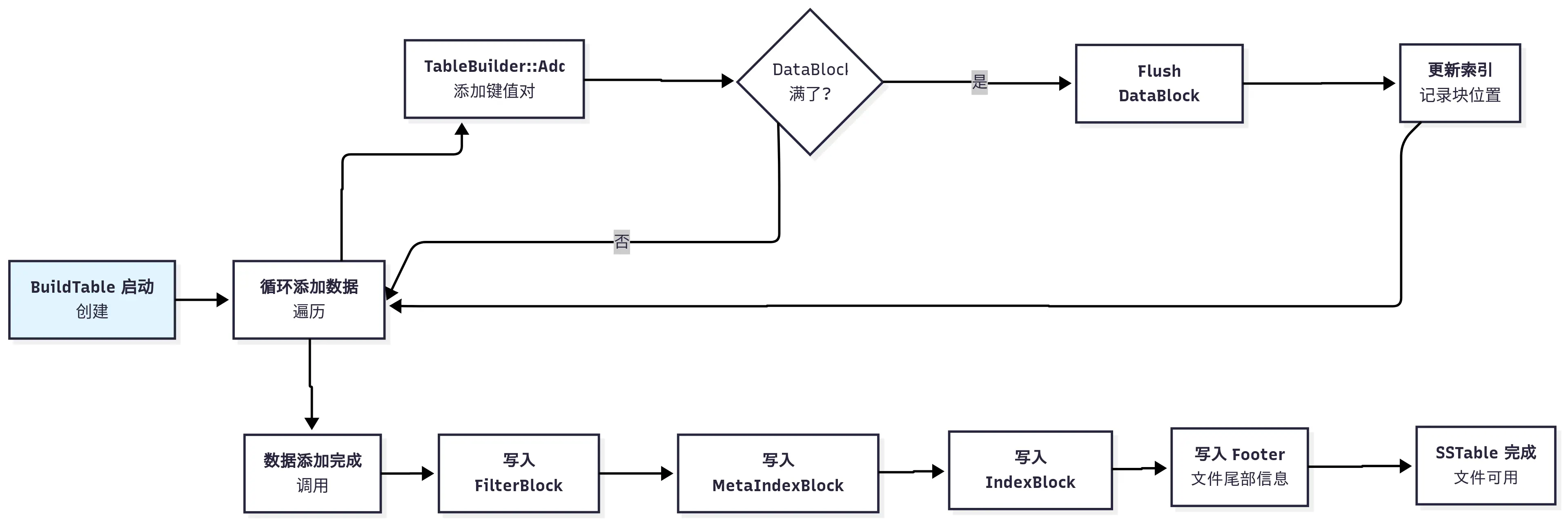
在开始之前,我们要先搞明白一个关键问题,文件格式该如何设计,才能兼顾高效写入和快速读取? 下面我们从几个基本问题出发,来推测作者是如何设计这里的数据格式。
首先,最核心的数据,也就是用户的键值对,得有个地方放。最简单的方法,把所有键值对按顺序放进 SSTable 这整个大文件。这样有什么问题呢?首先读的时候,如果要找一个 key,需要遍历整个大文件。然后写入过程中,每次添加一个键值对就要写磁盘的话,写 IO 压力会很大,吞吐上不去。
既然太大了不行,那就分块吧。计算机科学中的”分而治之”思想,在 LevelDB 中得到了很好的体现。我们把大文件切分成不同的数据块,按照数据块的粒度来存储键值对。每个块默认大约 4KB。当一个块写满了,就把它作为一个整体写入文件,然后再开始写下一个。这样整体写入的时候,就会减少很多磁盘 IO 了。
这里我再多说一点,分块存储不仅减少了写入磁盘的 IO 次数,通过配合
不过查找问题还没解决,还是要遍历所有的块来查找键值。
要是我们能快速定位到键值在哪个 DataBlock 里,那就只用遍历单个块就好了,效率会提升很多。
为了解决这个问题,我们需要一个”目录”。计算机中也叫索引,于是 Index Block (索引块) 诞生了。这个块里存放了一系列的索引记录,每个记录都记录一个 Data Block 的信息,根据这个记录,我们能快速知道某个键所在的 DataBlock。
这样查找键值的时候,只需要在 Index Block 中二分查找,就能快速定位到键值可能在的 DataBlock。索引块只包含一些索引数据,所以整体大小会小很多,通常可以加载到内存中去,所以查找会快很多。
有了索引块之后,我们把扫描整个文件变成了”查索引 -> 精准读取一小块”的操作,效率会大大提升。这里索引具体怎么设计我们先不管,后面再详细分析。
通过索引块,我们其实能找到 key 可能 在哪个块,但它不能百分百确定。为什么呢?因为索引块里记录的只是 key 的区间,并不能保证 key 一定在这个区间里,后面结合代码理解会更清晰。这就导致一个问题,当我们兴冲冲地把 Data Block 从磁盘读到内存后,却发现要找的 key 根本不存在,这不就白白浪费了一次宝贵的磁盘 I/O 吗?尤其是如果业务中,有大量读不存在 key 的场景,那么这种浪费很可观。
这种判断不存在的需求,计算机科学中早就有解法了,常见的就是布隆过滤器。布隆过滤器是位数组和哈希函数的组合,可以快速判断一个元素是否在集合中。本系列之前的文章LevelDB 源码阅读:布隆过滤器原理、实现、测试与可视化 中,有详细介绍布隆过滤器的原理和实现。
LevelDB 中,用同样的解决思路,它支持设置一个可选的过滤块(Filter Block),在读取 Data Block 之前,先通过 Filter Block 确认键是否存在。如果不存在的话,直接返回,如果可能在,再读取 Data Block 进行确认。通过这种方式,我们极大地减少了对不存在的 key 的无效查询。
看起来一切很美好了,不过等下,还有个问题,我们怎么知道 Index Block 和 Filter Block 在 SSTable 文件的哪个位置呢?
现在我们有很多数据块、一个 Index Block、一个 Filter Block。问题又来了:当我们打开一个 SSTable 文件时,我们怎么知道 Index Block 和 Filter Block 在文件的哪个位置呢?
最朴素的思路就是可以把这些元信息放到文件的固定偏移位置。不过如果放到文件头的话,这些记录发生变化的话,整个文件的数据都要移动,这显然不行。
那放文件末尾呢?看起来可行,LevelDB 也是这么设计的。在文件尾部,放一个固定 48 字节的 Footer 区域,里面记录了 Index Block 在文件的偏移位置,以及另一个之前没提到过的 Meta-Index Block 的位置。
这里按理说 Footer 记录 Index Block 和 Filter Block 的位置就行了,为啥引入一个 Meta-Index Block 呢?作者在代码注释里有提到过,主要为了扩展性。Footer 的大小固定,不能增加更多信息了,那万一未来有更多种类的元数据块,比如统计块等,要在哪里存偏移。
所以作者增加了一个元数据的索引——Meta-Index Block。这个块的作用就是一张元数据目录,它的键是元数据的名字(如 “filter.leveldb.BuiltinBloomFilter2”),值是对应元数据块(如 Filter Block)的偏移位置。当前只有过滤块信息,后续可以任意增加元数据块。
这样整个查找过程就串起来了,先拿出尾部 48 字节的固定内容。从里面解析出 Index Block 和 Meta-Index Block 的偏移位置,然后从 Meta-Index Block 中拿到 Filter Block 的偏移位置,最后根据偏移位置读取 Filter Block 的内容。有了 Index Block 和 Filter Block,我们就能快速、高效地”按图索骥”去查找键值了。
前面已经把 SSTable 中数据块组织方式分析完了,这里我画一个简单的 ASCII 图来描述 SSTable 中的各个块,方便大家理解:
1 |
+-------------------+ |
不过要怎么提供接口,怎么把键值对保存为上面格式,还是有不少工程细节的。这里顺便说下,LevelDB 代码中的分层抽象是做的真好,一层套一层,把复杂逻辑封装起来,方便理解和维护。比如每个块自己是怎么构建数据的,都封装了单独的实现,后面我会在其他文章里详细说明。
本篇文章,咱们重点关注 SSTable 文件构建的工程细节部分。这部分实现在table/table_builder.cc 中,主要就是 TableBuilder 类。
该类只有一个私有成员变量,是一个 Rep* 指针,里面保存各种状态信息,比如当前的 DataBlock、IndexBlock 等。这里 Rep* 用到了 Pimpl 的设计模式,可以看本系列的 LevelDB 源码阅读:理解其中的 C++ 高级技巧 了解关于 Pimpl 的更多细节。
该类最重要的接口有 Add,这个函数会层层调用其他一些封装好的函数,来完成键值对的添加。接下来从这个接口入手,分析 TableBuilder 类的实现。
TableBuilder::Add 方法是向 SSTable 文件中添加键值对的核心函数。添加键值对,需要更改上面提到的 DataBlock、IndexBlock、FilterBlock 等各个块。这里为了提高效率,有不少工程优化细节,为了更好理解,我把它主要分 4 部分,这里一个个来说吧。
1 |
void TableBuilder::Add(const Slice& key, const Slice& value) { |
在 Add 方法中,首先会先读出来 rep_ 的数据,做一些前置校验,比如验证文件没有被关闭,保证键值对是有序的。
1 |
Rep* r = rep_; |
LevelDB 在代码中 加了不少校验逻辑,确保如果有问题,早崩溃早发现,这个理念对于底层库来说,还是很有必要的。Add 方法这里 assert 校验后面插入的键值对永远都是更大的,当然这点需要调用方来保证。为了实现校验逻辑,在每个 TableBuilder 的 Rep 中,都保存了 last_key,用来记录最后一个插入的 key。这个 key 在索引键优化的时候会用到,后面会详细说明。
接着会在适当时机添加新的索引。我们知道索引记录用来快速查找一个 key 所在的 DataBlock 偏移位置,每一个完整的 DataBlock 对应一个索引记录。我们先看看这里添加索引记录的时机,当处理完一个 DataBlock 时,会将 pending_index_entry 设置为 true,等到下次新的 DataBlock 增加第一个 key 时,再更新上个完整的 DataBlock 对应的索引记录。
这部分的核心代码如下:
1 |
if (r->pending_index_entry) { |
这里之所以要等到新 DataBlock 增加第一个 key 的时候才更新索引块,就是 为了尽最大程度减少索引键的长度,从而减少索引块的大小,这也是 LevelDB 工程上的一个优化细节。
这里扩展讲下背景可能更好理解,SSTable 中每个索引记录都由一个分割键 separator_key 和一个指向数据块的 BlockHandle(偏移量+大小)组成。这个 separator_key 的作用就是划分不同 Datablock 的键空间,对于第 N 个数据块(Block N),它的索引键 separator_key_N 必须满足以下条件:
这样在查找一个目标键的时候,如果在索引块中找到第一个 separator_key_N > target_key 的条目,那么 target_key 如果存在,就必定在前一个数据块(Block N-1)中。
直观上讲,索引最简单的实现是直接用 Block N 的最后一个键(last_key_N)作为 separator_key_N。但问题是,last_key_N 本身可能非常长。这就导致索引项会很长,进而整个索引块变得很大。索引块通常需要加载到内存中,索引块越小,内存占用越少,缓存效率越高,查找速度也越快。
其实我们细想下,我们并不需要一个真实存在的键作为分割索引 key,只需要一个能把前后两个块分开的”隔离键”即可。这个键只需要满足:last_key_N <= separator_key < first_key_N+1。LevelDB 就是这样做的,这里通过调用 options.comparator->FindShortestSeparator,找到前一个块最后的键,和下一个块第一个键之间最短分割字符串。这里 FindShortestSeparator 的默认实现在 util/comparator.cc中,本文不再列出来了。
为了更清楚地理解这个优化过程,下面用一个具体的例子来演示:
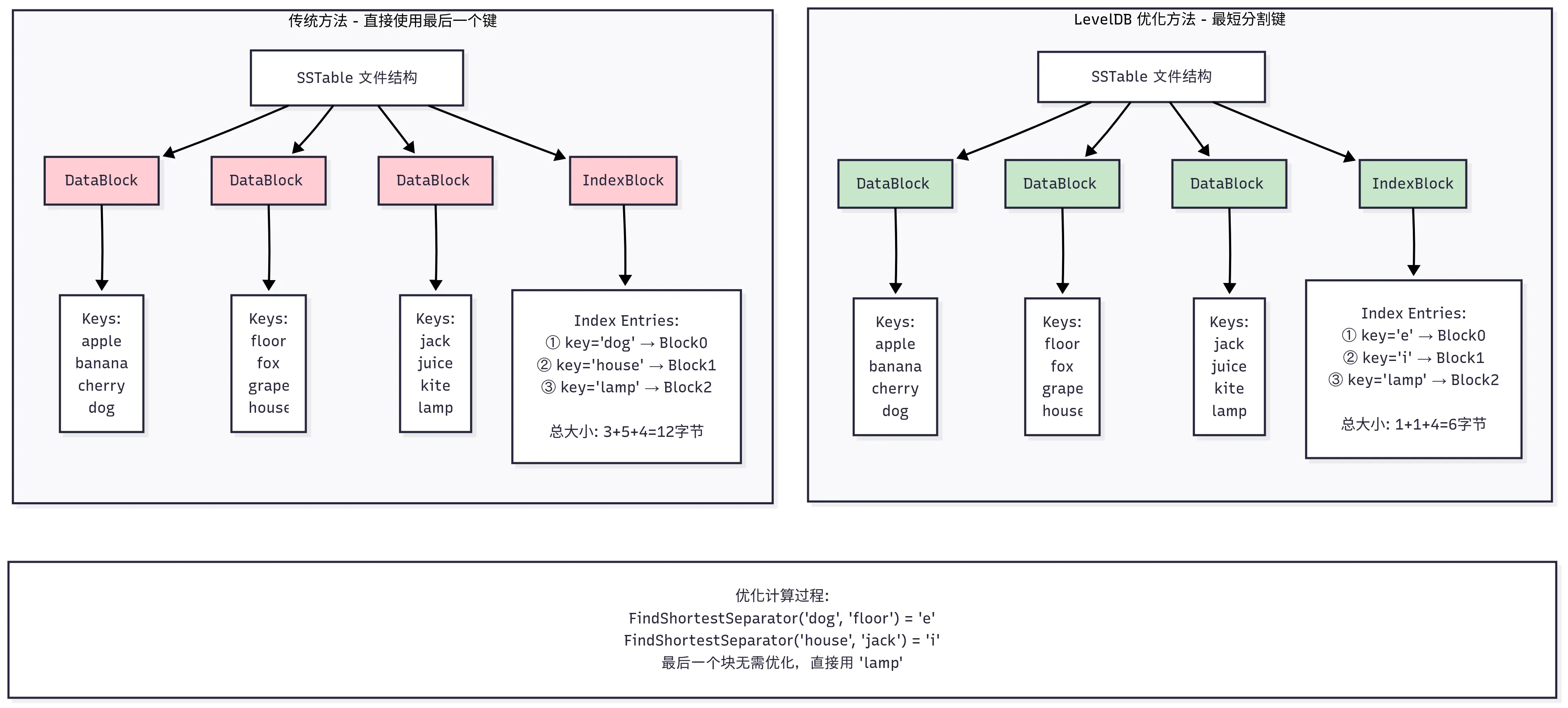
最后再聊下这里每条索引记录的 value,它是该块在文件内的偏移和 size,这是通过 pending_handle 来记录的。当通过 WriteRawBlock 将 DataBlock 写文件的时候,会更新 pending_handle 的偏移和大小。然后写索引的时候,用 EncodeTo 将偏移和 size 编码到字符串中,和前面的索引 key 一起插入到 IndexBlock 中。
接着处理 FilterBlock 过滤索引块,前面的索引块只是能找到键应该在的块的位置,还需要去读出块的内容才知道键到底存不存在。为了快速判断键值在不在,LevelDB 支持了过滤索引块,可以快速判断某个 key 是否存在于当前 SSTable 中。如果设置用到过滤索引块,则在添加 key 的时候,同步添加索引,其核心代码如下:
1 |
if (r->filter_block != nullptr) { |
这里添加 key 之后,只是在内存中存储索引,要等到最后 TableBuild 写完所有的 Block 之后,才会将 FilterBlock 写入文件。FilterBlock 本身是可选的,通过 options.filter_policy 来设置。在初始化 TableBuilder::Rep 的时候,会根据 options.filter_policy 来初始化 FilterBlockBuilder 指针,如下:
1 |
Rep(const Options& opt, WritableFile* f) |
这里值得注意的是 filter_block 之所以是指针,主要是因为除了用默认的布隆过滤器,还可以用多态机制使用自己的过滤器。这里用 new 在堆上创建的对象,为了防止内存泄露,在 TableBuilder 析构的时候,先释放掉 filter_block,再接着释放 rep_。
1 |
TableBuilder::~TableBuilder() { |
之所以需要释放 rep_,是因为它是在 TableBuilder 构造的时候,在堆上创建的,如下:
1 |
TableBuilder::TableBuilder(const Options& options, WritableFile* file) |
关于 LevelDB 默认的布隆过滤器实现,可以参考LevelDB 源码阅读:布隆过滤器的实现。索引块的构建,后面我单独写一篇来详解,这里我们也不深究细节部分。
接着需要将键值对添加到 DataBlock 中。DataBlock 是 SSTable 文件中存储实际键值对的地方,代码如下:
1 |
r->last_key.assign(key.data(), key.size()); |
这里调用 BlockBuilder 中的 Add 方法,将键值对添加到 DataBlock 中,关于 BlockBuilder 的实现,后面单独文章来描述。哈哈,这里 LevelDB 分层抽象是做的真好,搞的我们的文章也只能分层了。每次添加键值对后,都会检查当前 DataBlock 的大小是否超过了 block_size,如果超过了,则调用 Flush 方法将 DataBlock 写入磁盘文件。这里 block_size 是在 options 中设置的,默认是 4KB。这个是键值压缩前的大小,如果开启了压缩,实际写入文件的大小会小于 block_size。
1 |
// Approximate size of user data packed per block. Note that the |
这里 Flush 怎么写磁盘呢,我们接着往下看。
在前面的 Add 方法中,如果一个块的大小凑够 4KB,就会调用 Flush 方法写磁盘文件。Flush 的实现如下:
1 |
void TableBuilder::Flush() { |
开始部分也就是一些前置校验,注意 Flush 只是用来刷 DataBlock 部分,如果 data_block 为空,就直接返回。接着调用 WriteBlock 方法(后面详解)将 DataBlock 写入文件,然后更新 pending_index_entry 为 true,表示下次添加 key 时,需要更新索引块。
最后调用 file->Flush() 将目前内存中的数据调用系统 write 写磁盘,注意这里不保证数据已被同步到物理磁盘。数据可能还在系统缓存中,如果操作系统宕机,那有可能丢失没写入成功的数据。这里写文件刷磁盘,可以参考本系列LevelDB 源码阅读:Posix 文件操作接口实现细节中关于文件操作的更多细节。如果有 filter_block,还需要调用 StartBlock 方法,这个方法也比较有意思,等后面我们专门来写 filter block 的时候再详细说明。
上面提到 Flush 中会调用 WriteBlock 方法将 DataBlock 写入文件,该方法在下面要提到的 Finish 中也会被调用,用来在最后写索引块,过滤块等内容。WriteBlock 的实现比较简单,主要用来处理压缩逻辑,然后调用真正的写文件函数 WriteRawBlock 来把块内容写入文件。
压缩并不是必须的,如果调用 leveldb 时设置了需要压缩,并且链接了压缩库,就会选择对应的压缩算法对 Block 进行压缩。LevelDB 这里也做了一点压缩性能和效果的平衡,如果压缩比 (compression_ratio) 小于等于 0.85,就会将压缩后的数据写入文件,否则直接写入原始数据。真正写文件部分,调用 WriteRawBlock 方法,主要代码如下:
1 |
void TableBuilder::WriteRawBlock(const Slice& block_contents, |
这里在每个块的尾部放了 5 个字节的 trailer 部分,来对数据准确性进行校验。第一个字节是压缩类型,目前支持的压缩算法有 snappy 和 zstd。后面 4 字节是 crc32 校验和,这里用 crc32c::Value 计算数据块的校验和,然后把压缩类型一起计算进去校验和。这里 crc32 部分,可以参考本系列 LevelDB 源码阅读:内存分配器、随机数生成、CRC32、整数编解码 了解更多细节。
上面的所有操作,主要用来将键值对不断添加到数据块中,这个过程如果达到 DataBlock 的大小限制,会触发 DataBlock 的落盘。但整个 SSTable 文件还有索引块,过滤块等,需要主动触发落盘。那在什么时机触发,又是怎么落盘呢?
LevelDB 中产生 SSTable 文件的时机有很多,这里以保存 immetable 时候触发的落盘时机为例。将 immemtable 保存为 SSTable 文件时,过程如下:首先迭代 immemtable 中的键值对,然后调用上面的 Add 方法来添加。Add 中会更新相关 block 的内容,每当 DataBlock 超过 block_size 时,会调用 Flush 方法将 DataBlock 写入文件。
等所有键值对写完,会主动调用 Finish 方法,来进行一些收尾工作,比如将最后一个 Datablock 的数据写入文件,写入 IndexBlock,FilterBlock 等。
Finish 的实现如下,开始之前先用 Flush 把剩余的 DataBlock 部分刷到磁盘文件中,接着会处理其他块,并且在文件尾部添加一个固定大小的 footer 部分,用来记录索引信息。
1 |
Status TableBuilder::Finish() { |
这里构建各个块也比较有意思,都是用一个 builder 来处理内容,同时用一个 handler 来记录块的偏移和大小。我们分别来看下。
先思考一个问题,这里有这么多类型的块,每个块都要一个自己的 Builder 来拼装数据吗?
这里要从每个块的数据结构来看,Data/Index/MetaIndex Block 这三种块都具有以下共同特征:
所以这 3 类块的构建逻辑是类似的,LevelDB 中共用同一个 BlockBuilder 来处理。这里实现在 table/block_builder.h 中,也有不少优化细节。比如前缀压缩优化,对于相似的键只存储差异部分,节省空间。重启点机制,每隔几个条目设置一个重启点,支持二分查找。后面我会专门用一篇文章来详细说明。封装后用起来比较简单,以 MetaIndex Block 为例,用 Add 添加键值,然后 WriteBlock 落磁盘就好。代码如下:
1 |
void TableBuilder::Finish() { |
而 filter block 的数据结构和其他的都不一样,它存储的是布隆过滤器的二进制数据,按文件偏移分组,每 2KB 文件范围对应一个过滤器。所以 filter block 的构建逻辑和其他的都不一样,需要单独处理。这里的实现在 table/filter_block.cc 中,后面我单独再展开分析。这里使用倒是很简单,如下:
1 |
// Write filter block |
这里 Finish 方法会返回 filter block 的二进制数据,然后调用 WriteRawBlock 方法将数据写入文件。
上面用两个 builder 来构建块,但是用同一个 handler 类来记录块的偏移和大小。代码如下:
1 |
BlockHandle filter_block_handle, metaindex_block_handle, index_block_handle; |
这里 BlockHandle 的实现在 table/format.h 中,主要告诉系统在文件的第 X 字节位置,有一个大小为 Y 字节的块,仅此而已。不过配合不同块的 handle 信息,就能方便存储不同块的偏移和大小。
至此,我们用两个 builder 来构建各种索引块,同时用一个 handler 来辅助记录块的偏移和大小。就完成了整个块的构建。
最后我们可以来看看上层调用方,是如何用 TableBuilder 来构造 SSTable 文件的。
在 db/builder.cc 中封装了一个函数 BuildTable 来创建 SSTable 文件,它就是调用 TableBuilder 类的接口来实现的。省略其他无关代码,核心代码如下:
1 |
Status BuildTable(const std::string& dbname, Env* env, const Options& options, |
这里用迭代器 iter 来遍历 immemtable 中的键值对,然后调用 TableBuilder 的 Add 方法将键值对添加到 SSTable 文件中。Memtable 的大小限制默认是 4MB(write_buffer_size = 4*1024*1024),在用 TableBuilder 添加键值对时,会根据 block_size(4*1024) 来划分数据块。每当凑够一个 DataBlock,就会拼装相应 block 的数据,然后用 flush 追增内容到磁盘 SSTable 文件中。最后调用 TableBuilder 的 Finish 方法写入其他 Block,完成整个SSTable 文件的写入。
除了这里 BuildTable 将 immemtable 中的数据写入 level0 的 SSTable 文件外,还有一个场景是在 Compact 过程中,将多个 SSTable 文件合并成一个 SSTable 文件。这个过程在 db/db_impl.cc 中的 DoCompactionWork 函数中实现,整体流程稍微复杂,调用比较深入,等后面我们讲 Compact 的时候再详细分析。
不过这里只讲一个点,在 Compact 过程中,会在某些失败场景调用 TableBuilder 的 Abandon 方法,用来放弃当前的 TableBuilder 写入文件过程。
1 |
compact->builder->Abandon(); |
Abandon 主要就是把 TableBuilder 的 Rep 中的 closed 设置为 true,调用方之后就会丢掉这个 TableBuilder 实例,不会用它执行任何写入操作了(写入中一堆断言来检查这个状态)。
回到开头我们提出的问题,文件格式该如何设计,才能兼顾高效写入和快速读取?通过深入分析 LevelDB 的 SSTable 文件创建过程,我们可以看到作者是如何一步步解决这个问题的。首先SSTable 数据格式设计有几个重要的设计思想:
在 TableBuilder 的实现中,我们也看到了不少值得学习的工程细节,比如:
其实 SSTable 的设计回答了存储系统中的几个根本问题。用顺序写入,来保证写入吞吐,用索引结构来保证读取性能。用分块和按需加载以及缓存,在有限内存下处理海量数据。同时用压缩和过滤器来平衡存储空间与查询效率,用元信息分层来保证系统的可扩展性。这些都是计算机软件系统中沉淀多年的经典设计,值得我们学习。
理解了 SSTable 的创建过程后,你可能会产生一些新的疑问:DataBlock 内部是如何组织数据的?读取 SSTable 时的流程是怎样的?多个 SSTable 文件如何协同工作?
这些问题的答案,构成了 LevelDB 这个精巧存储引擎的完整图景。我会在后面的文章中继续深入分析,敬请期待。
2025-06-14 05:00:00
计算机系统中,缓存无处不在。从 CPU 缓存到内存缓存,从磁盘缓存到网络缓存,缓存无处不在。缓存的核心思想就是空间换时间,通过将热点数据缓存到高性能的存储中,从而提高性能。因为缓存设备比较贵,所以存储大小有限,就需要淘汰掉一些缓存数据。这里淘汰的策略就非常重要了,因为如果淘汰的策略不合理,把接下来要访问的数据淘汰掉了,那么缓存命中率就会非常低。
缓存淘汰策略有很多种,比如 LRU、LFU、FIFO 等。其中 LRU(Least Recently Used) 就是一种很经典的缓存淘汰策略,它的核心思想是:当缓存满了的时候,淘汰掉最近最少使用的数据。这里基于的一个经验假设就是”如果数据最近被访问过,那么将来被访问的几率也更高“。只要这个假设成立,那么 LRU 就可以显著提高缓存命中率。
在 LevelDB 中,实现了内存中的 LRU Cache,用于缓存热点数据,提高读写性能。默认情况下,LevelDB 会对 sstable 的索引 和 data block 进行缓存,其中 sstable 默认是支持缓存 990 (1000-10) 个,data block 则默认分配了 8MB 的缓存。
LevelDB 实现的 LRU 缓存是一个分片的 LRU,在细节上做了很多优化,非常值得学习。本文将从经典的 LRU 实现思路出发,然后一步步解析 LevelDB 中 LRU Cache 的实现细节。
一个实现良好的 LRU 需要支持 O(1) 时间复杂度的插入、查找、删除操作。经典的实现思路是使用一个双向链表和一个哈希表,其中:
双向链表保证在常数时间内添加和删除节点,哈希表则提供常数时间的数据访问能力。对于 Get 操作,通过哈希表快速定位到链表中的节点,如果存在则将其移动到链表头部,更新为最近使用。对于插入 Insert 操作,如果数据已存在,更新数据并移动到链表头部;如果数据不存在,则在链表头部插入新节点,并在哈希表中添加映射,如果超出容量则移除链表尾部节点,并从哈希表中删除相应的映射。
上面的实现思路相信每个学过算法的人都知道,Leetcode 上也有 LRU 实现的题目,比如 146. LRU 缓存,需要实现的接口:
1 |
class LRUCache { |
不过想实现一个工业界可用的高性能 LRU 缓存,还是有点难度的。接下来,我们来看看 LevelDB 是如何实现的。
在开始看 LevelDB 的 LRU Cache 实现之前,先看下 LevelDB 中如何使用这里的缓存。比如在 db/table_cache.cc 中,为了缓存 SST table 的元数据信息,TableCache 类定义了一个 Cache 类型的成员变量,然后通过该成员来对缓存进行各种操作。
1 |
Cache* cache_(NewLRUCache(entries)); |
这里 Cache 是一个抽象类,定义了缓存操作的各种接口,具体定义在 include/leveldb/cache.h 中。它定义了缓存应该具有的基本操作,如 Insert、Lookup、Release、Erase 等。它还定义了 Cache::Handle 这个类型,作为缓存条目。用户代码只与这个抽象接口交互,不需要知道具体实现。
然后有个 LRUCache 类,是具体的缓存实现类,它实现了一个完整的 LRU 缓存。这个类不直接对外暴露,也不直接继承 Cache。然后还有个 ShardedLRUCache 类,它继承 Cache 类实现了缓存各种接口。它内部包含 16 个 LRUCache “分片”(shards),每个分片负责缓存一部分数据。
这样的设计允许调用方在不修改使用缓存部分的代码的情况下,轻松替换不同的缓存实现。哈哈,这不就是八股文经常说的,面向对象编程 SOLID 中的依赖倒置嘛,应用层依赖于抽象接口(Cache)而不是具体实现(LRUCache)。这样可以降低代码耦合度,提高系统的可扩展性和可维护性。
使用 Cache 的时候,通过这里的工厂函数来创建具体的缓存实现 ShardedLRUCache:
1 |
Cache* NewLRUCache(size_t capacity) { return new ShardedLRUCache(capacity); } |
LRUCache 是缓存的核心部分,不过现在我们先不管怎么实现 LRUCache,先来看看缓存项 Hanle 的设计。
在 LevelDB 中,缓存的数据项是一个 LRUHandle 类,定义在 util/cache.cc 中。这里的注释也说明了,LRUHandle 是一个支持堆分配内存的变长结构体,它会被保存在一个双向链表中,按访问时间排序。我们来看看这个结构体的成员有哪些吧:
1 |
struct LRUHandle { |
这里还稍微有点复杂,每个字段都还挺重要的,我们一个个来看吧。
这里 LRUHandle 的设计允许缓存高效地管理数据项,跟踪缓存项的引用,并实现 LRU 淘汰策略。特别是 in_cache 和 refs 字段的结合使用,使得我们可以区分”被缓存但未被客户端引用“和”被客户端引用“的项,从而用两个链表来支持高效淘汰缓存。
下面我们详细看看 LRUCache 类的实现细节,就更容易理解上面各个字段的用途了。
前面看完了缓存的数据项的设计,接着可以来看看这里 LevelDB LRUCache 的具体实现细节了。核心的缓存逻辑实现在 util/cache.cc 的 LRUCache 类中。该类包含了缓存的核心逻辑,如插入、查找、删除、淘汰等操作。
这里注释(LevelDB 的注释感觉都值得好好品读)中提到,用了两个双向链表来维护缓存项,这又是为什么呢?
1 |
// The cache keeps two linked lists of items in the cache. All items in the |
我们前面也提到,一般的 LRU Cache 实现中用一个双向链表。每次使用一个缓存项时,会将其移动到链表的头部,这样链表的尾部就是最近最少使用的缓存项。淘汰的时候,直接移除链表尾部的节点即可。比如开始提到的 Leetcode 中的题目就可以这样实现来解决,实现中每个缓存项就是一个 int,取的时候直接复制出来就好。如果要缓存的项是简单的值类型,读的时候直接复制值,不需要引用,那单链表的实现足够了。
但在 LevelDB 中,缓存的数据项是 LRUHandle 对象,它是一个动态分配内存的变长结构体。在使用的时候,为了高并发和性能考虑,不能通过简单的值复制,而要通过引用计数来管理缓存项。如果还是简单的使用单链表的话,我们考虑下这样的场景。
我们依次访问 A, C, D 项,最后访问了 B, B 项被客户端引用(refs=1),位于链表头部,如下图中的开始状态。一段时间内,A、C、D都被访问了,但 B 没有被访问。根据 LRU 规则,A、C、D被移到链表头部。B 虽然仍被引用,但因为长时间未被访问,相对位置逐渐后移。A 和 D 被访问后,很快使用完,这时候没有引用了。当需要淘汰时,从尾部开始,会发现B项(refs=1)不能淘汰,需要跳过继续往前遍历检查其他项。
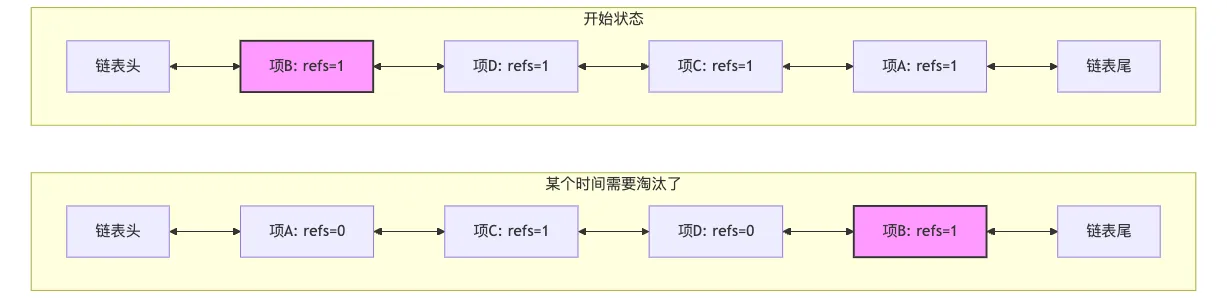
也就是说在这种引用场景下,淘汰节点的时候,如果链表尾部的节点正在被外部引用(refs > 1),则不能淘汰它。这时候需要遍历链表寻找可淘汰的节点,效率较低。在最坏情况下,如果所有节点都被引用,可能需要遍历整个链表却无法淘汰任何节点。
为了解决这个问题,在 LRUCache 实现中,用了两个双向链表。一个是in_use_,用来存储被引用的缓存项。另一个是lru_,用来存储未被引用的缓存项。每个缓存项只能在其中的一个链表中,不能同时在两个链表中。但是可以根据当前是否被引用,在两个链表中互相移动。这样在需要淘汰节点的时候,就可以直接从 lru_ 链表中淘汰,而不用遍历 in_use_ 链表。
双链表介绍就先到这里,后面可以结合 LRUCache 的核心实现继续理解双链表具体怎么实现。
先来看插入节点,实现在 util/cache.cc 中。简单说,这里先创建 LRUHandle 对象,然后把它放到 in_use_ 双向链表中,同时更新哈希表。如果插入节点后,缓存容量达到上限,则需要淘汰节点。但是实现中,还是有不少细节部分,LevelDB 的代码也确实精简。
可以看下这里的入参,key 和 value 是客户端传入的,hash 是 key 的哈希值,charge 是缓存项占用的成本,deleter 是删除缓存项的回调函数。这里因为 LRUHandle 最后成员是柔性数组,所以我们先手动计算 LRUHandle 对象的大小,然后分配内存,之后开始初始化各种成员。这里 refs 初始化为 1,因为返回了一个 Handle 指针对象。
1 |
Cache::Handle* LRUCache::Insert(const Slice& key, uint32_t hash, void* value, |
接着这里也比较有意思,LevelDB 中的 LRUCache 实现,支持缓存容量设为 0,这时候就不缓存任何数据。要缓存的时候,更新 in_cache 为 true,增加 refs 计数,因为把 Handle 对象放到了 in_use_ 链表中。接着当然还要把 Handle 插入到哈希表中,注意这里有个 FinishErase 调用,值得好好聊聊。
1 |
if (capacity_ > 0) { |
我们前面将哈希表实现的时候,这里插入哈希表,如果已经有同样的 key,则返回旧的 Handle 对象。这里 FinishErase 函数就是用来清理这个旧的 Handle 对象。
1 |
// If e != nullptr, finish removing *e from the cache; it has already been |
清理操作有几个吧,首先从 in_use_ 或者 lru_ 链表中移除,这里其实不确定旧的 Handle 对象具体在哪个链表中,不过没关系,LRU_Remove 不用知道在哪个链表也能处理。LRU_Remove 函数实现很简单,也就两行代码,大家不理解的话可以画个图来理解下:
1 |
void LRUCache::LRU_Remove(LRUHandle* e) { |
接着更新 in_cache 为 false,表示已经不在缓存中了。后面还要更新缓存容量,减少 usage_。最后调用 Unref 减少这个 Handle 对象的引用计数,这时候这个 Handle 对象可能在其他地方还有引用。等到所有引用都释放了,这时候才会真正清理这个 Handle 对象。Unref 函数 其实也有点意思,我把代码也贴出来:
1 |
void LRUCache::Unref(LRUHandle* e) { |
首先减少计数,如果计数为 0,则表示完全没有外部引用,这时候可以大胆释放内存。释放也分两部分,先用回调函数 deleter 来清理 value 部分的内存空间。接着用 free 来释放 LRUHandle 指针的内存空间。如果计数为 1 并且还在缓存中,表示只有来自缓存自身的引用,这时候需要把 Handle 对象从 in_use_ 链表中移除,并放到 lru_ 链表中。如果后面要淘汰节点,这个节点在 lru_ 链表中,就可以直接淘汰了。
接下来就是插入节点操作的最后一步了,判断缓存是否还有剩余空间,没有的话,要开始淘汰节点了。这里只要空间还是不够,然后就会从 lru_ 链表中取出队首节点,然后从哈希表中移除,接着调用 FinishErase 清理节点。这里判断双向链表是否为空也比较有意思,用到了哑元节点,后面再介绍。
1 |
while (usage_ > capacity_ && lru_.next != &lru_) { |
整个插入节点函数,包括这里的淘汰逻辑,甚至是整个 LevelDB 代码中,都有大量的 assert 断言,用来做一些检查,保证有问题进程立马挂掉,避免错误传播。
看完插入节点,其实删除节点就不用看了,代码实现很简单,从哈希表中移除节点,然后调用 FinishErase 清理节点。
1 |
void LRUCache::Erase(const Slice& key, uint32_t hash) { |
查找节点也相对简单些,直接从哈希表中查找,如果找到,则增加引用计数,并返回 Handle 对象。这里其实和插入一样,只要返回了 Handle 对象,就会增加引用计数。所以如果外面如果没有用到的话,要记得调用 Release 方法手动释放引用,不然内存就容易泄露了。
1 |
Cache::Handle* LRUCache::Lookup(const Slice& key, uint32_t hash) { |
此外,这里的 Cache 还实现了 Prune 接口,用来主动清理缓存。方法和插入里面的清理逻辑类似,不过这里会把 lru_ 链表中所有节点都清理掉。这个清理在 LevelDB 中也没地方用到过。
我们再补充讨论下这里双向链表相关的操作吧。前面我们其实已经知道了分了两个链表,一个 lru_ 链表,一个 in_use_ 链表。这里结合注释看更清晰:
1 |
// Dummy head of LRU list. |
lru_ 成员是链表的哑元节点,next 成员指向 lru_ 链表中最老的缓存项,prev 成员指向 lru_ 链表中最新的缓存项。在 LRUCache 的构造函数中,lru_ 的 next 和 prev 都指向它自己,表示链表为空。还记得前面插入节点的时候,怎么判定还有可以淘汰的节点的吧,就是用 lru_.next != &lru_。
1 |
LRUCache::LRUCache() : capacity_(0), usage_(0) { |
哑元(dummy node)在很多数据结构的实现中被用作简化边界条件处理的技巧。在 LRU 缓存的上下文中,哑元主要是用来作为链表的头部,这样链表的头部始终存在,即使链表为空时也是如此。这种方法可以简化插入和删除操作,因为在插入和删除操作时不需要对空链表做特殊处理。
例如,当向链表中添加一个新的元素时,可以直接在哑元和当前的第一个元素之间插入它,而不需要检查链表是否为空。同样,当从链表中删除元素时,你不需要担心删除最后一个元素后如何更新链表头部的问题,因为哑元始终在那里。
删除链表中节点 LRU_Remove 我们前面看过,两行代码就行了。往链表添加节点的实现,我整理了一张图,配合代码就好理解了:
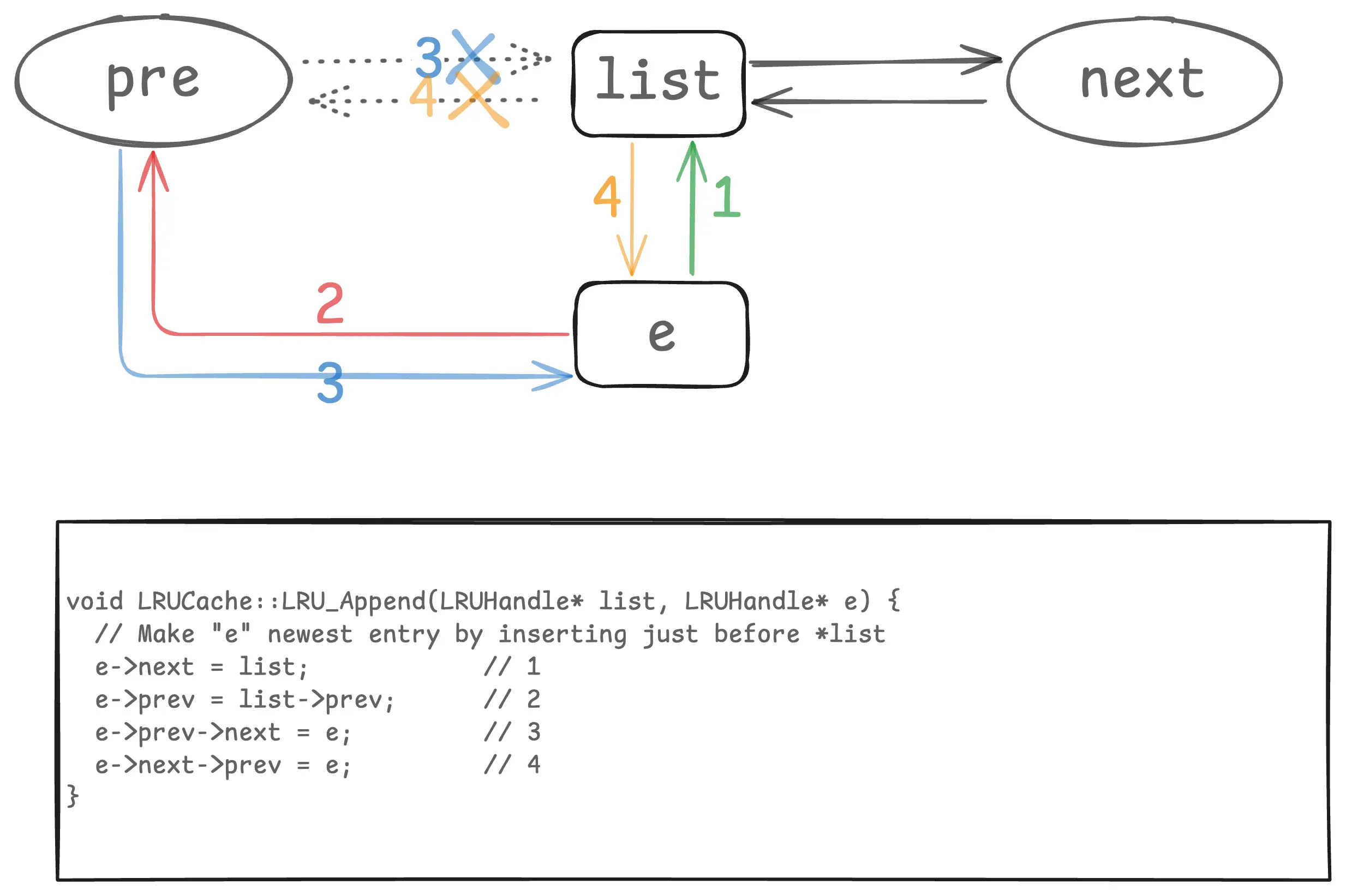
这里 e 是新插入的节点,list 是链表的哑元节点。list 的 pre 和 next 我这里用圆形,表示它可以是自己,比如初始空链表的时候。这里插入是在哑元的前面,所以 list->prev 永远是链表最新的节点,list->next 永远是链表最老的节点。这种链表操作,最好画个图,就一目了然了。
最后再补充说下,上面代码中有不少地方用到了 reinterpret_cast 来在 LRUHandle* 和 Cache::Handle* 之间转换类型。reinterpret_cast 将一种类型的指针强制转换为另一种类型的指针,而不进行任何类型检查。它不进行任何底层数据的调整,只是告诉编译器:”请把这个内存地址当作另一种类型来看待”。其实这种操作比较危险,一般不推荐这样用。
但 LevelDB 这样做其实是为了将接口和实现分析。这里将具体的内部数据结构 LRUHandle* 以一个抽象、不透明的句柄 Cache::Handle* 形式暴露给外部用户,同时又能在内部将这个不透明的句柄转换回具体的数据结构进行操作。
在这种特定的、受控的设计模式下,它是完全安全的。因为只有 LRUCache 内部代码可以创建 LRUHandle。任何返回给外部的 Cache::Handle* 总是指向一个合法的 LRUHandle 对象。任何传递给 LRUCache 的 Cache::Handle* 必须是之前由同一个 LRUCache 实例返回的。
只要遵守这些约定,reinterpret_cast 就只是在指针的”视图”之间切换,指针本身始终指向一个有效的、类型正确的对象。如果用户试图伪造一个 Cache::Handle* 或者将一个不相关的指针传进来,程序就会发生未定义行为,但这属于 API 的误用。
前面 LRUCache 的实现中,插入缓存、查找缓存、删除缓存操作都必须通过一个互斥锁来保护。在多线程环境下,如果只有一个大的缓存,这个锁就会成为一个全局瓶颈。当多个线程同时访问缓存时,只有一个线程能获得锁,其他线程都必须等待,这会严重影响并发性能。
为了提高性能,ShardedLRUCache 将缓存分成多个分片(shard_ 数组),每个分片都有自己独立的锁。当一个请求到来时,它会根据 key 的哈希值被路由到特定的分片。这样,不同线程访问不同分片时就可以并行进行,因为它们获取的是不同的锁,从而减少了锁的竞争,提高了整体的吞吐量。画个图可能更清晰些,mermaid 代码在这里。
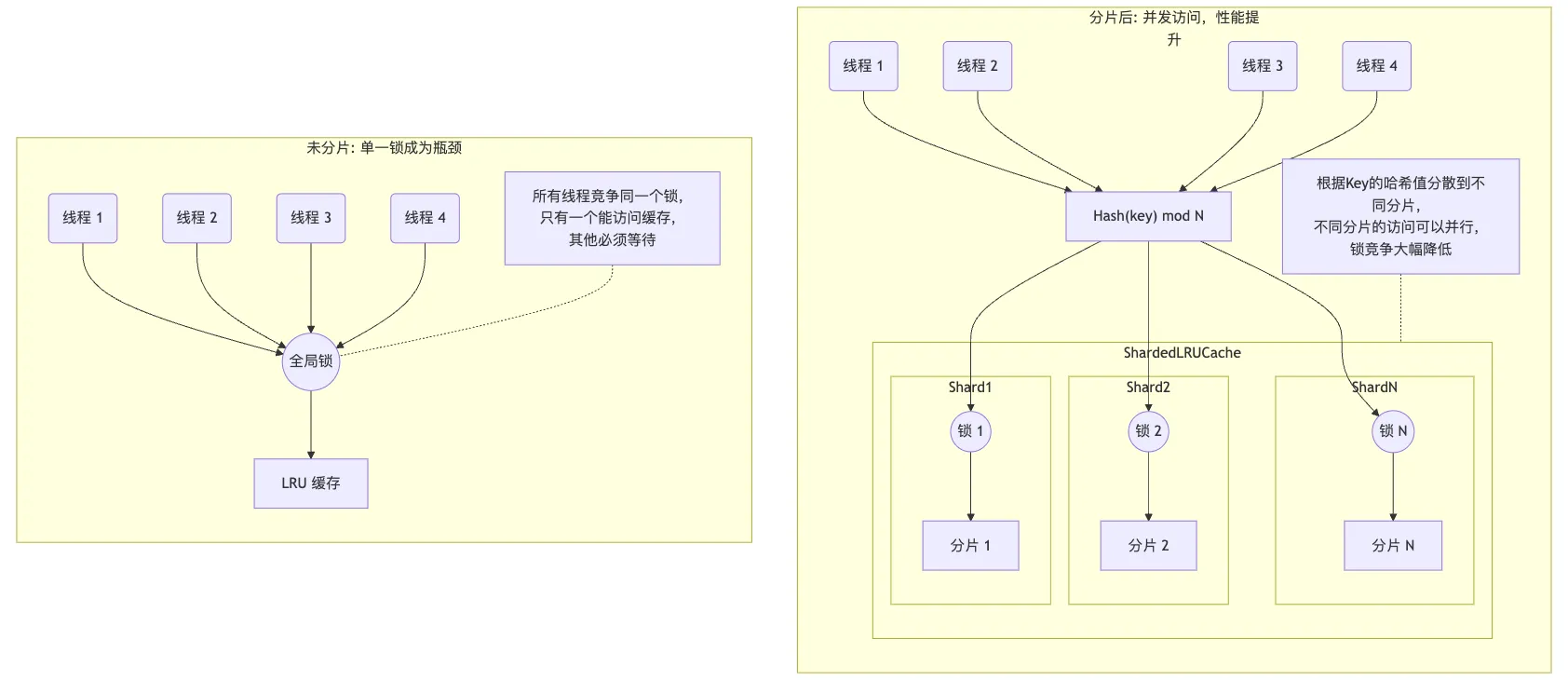
那么需要分多少片呢?LevelDB 这里硬编码了一个 $ kNumShards = 1 << kNumShardBits $,计算出来是 16,算是一个经验选择吧。如果分片数量太少,比如2、4个,在核心数很多的服务器上,锁竞争依然可能很激烈。分片太多的话,每个分片的容量就会很小。这可能导致一个”热”分片频繁淘汰数据,而另一个”冷”分片有很多空闲空间的情况,从而降低了整个缓存的命中率。
选择 16 的话,对于典型的 8 核或 16 核服务器,已经能提供足够好的并发度,同时又不会带来过大的额外开销。同时选择 2 的幂次方,还能通过位运算 $ hash >> (32 - kNumShardBits)$ 快速计算分片索引。
加入分片后,包装了下原始的 LRUCache 类,构造的时候需要指定分片数,每个分片容量等,实现如下:
1 |
public: |
然后其他相关缓存操作,比如插入、查找、删除等,都是通过 Shard 函数来决定操作哪个分片。这里以插入为例,实现如下:
1 |
Handle* Insert(const Slice& key, void* value, size_t charge, |
求 Hash 和计算分片的 Shard 函数没什么难点,这里就忽略了。这里也提下,ShardLRUCache 这里还要继承 Cache 抽象类,实现 Cache 中的各种接口。这样才能被其他调用 Cache 接口的地方使用。
最后这里还有一个小细节,也值得说下,那就是 Cache 接口还有个 NewId 函数。在其他的 LRU 缓存实现中,没见过有支持 Cache 生成一个 Id。LevelDB 为啥这么做呢?
LevelDB 其实提供了注释,但是只看注释似乎也不好明白,我们结合使用场景来分析下。
1 |
// Return a new numeric id. May be used by multiple clients who are |
这里补充些背景,我们在打开 LevelDB 数据库时,可以创建一个 Cache 对象,并传入 options.block_cache,用来缓存 SSTTable 文件中的数据块和过滤块。当然如果不传的话,LevelDB 默认也会创建一个 8 MB 的 SharedLRUCache 对象。这里 Cache 对象是全局共享的,数据库中所有的 Table 对象都会使用这同一个 BlockCache 实例来缓存它们的数据块。
在 table/table.cc 的 Table::Open 中,我们看到每次打开 SSTTable 文件的时候,就会用 NewId 生成一个 cache_id。这里底层用互斥锁保证,每次生成的 Id 是全局递增的。后面我们要读取 SSTTable 文件中偏移量为 offset 的数据块 block 时,会用 <cache_id, offset> 作为缓存的 key 来进行读写。这样不同 SSTTable 文件的 cache_id 不同,即使他们的 offset 一样,这里缓存 key 也不同,不会冲突。
说白了,SharedLRUCache 提供全局递增的 Id 主要是用来区分不同 SSTTable 文件,免得每个文件还要自己维护一个唯一 Id 来做缓存的 key。
好了,LevelDB 的 LRU Cache 分析完了,我们可以看到一个工业级高性能缓存的设计思路和实现细节。最后总结下几个关键点:
这些设计思路和实现技巧都值得我们在自己的项目中借鉴。特别是在需要高并发、高性能的场景中,LevelDB 的这些优化手段可以帮助我们设计出更高效的缓存系统。
2025-06-12 03:47:42
在 LevelDB 中,所有的写操作首先都会被记录到一个 Write-Ahead Log(WAL,预写日志)中,以确保持久性。接着数据会被存储在 MemTable 中,MemTable 的主要作用是在内存中有序存储最近写入的数据,到达一定条件后批量落磁盘。
LevelDB 在内存中维护两种 MemTable,一个是可写的,接受新的写入请求。当达到一定的大小阈值后,会被转换为一个不可变的 Immutable MemTable,接着会触发一个后台过程将其写入磁盘形成 SSTable。这个过程中,会创建一个新的 MemTable 来接受新的写入操作。这样可以保证写入操作的连续性,不受到影响。
在读取数据时,LevelDB 首先查询 MemTable。如果在 MemTable 中找不到,然后会依次查询不可变的 Immutable MemTable,最后是磁盘上的 SSTable 文件。在 LevelDB 的实现中,不管是 MemTable 还是 Immutable MemTable,内部其实都是用 class MemTable 来实现的。这篇文章我们来看看 memtable 的实现细节。
先来看看 LevelDB 中哪里用到了 MemTable 类。在库的核心 DB 实现类 DBImpl 中,可以看到有两个成员指针,
1 |
class DBImpl : public DB { |
mem_ 是可写的 memtable,imm_ 是不可变的 memtable。这两个是数据库实例中唯一的两个 memtable 对象,用来存储最近写入的数据,在读取和写入键值的时候,都会用到这两个 memtable。
我们先来看写入过程,我之前写过LevelDB 源码阅读:写入键值的工程实现和优化细节,里面有写入键值的全部过程。写入过程中,写入 WAL 日志成功后,会调用 db/write_batch.cc 中的 MemTableInserter 类来写入 memtable,具体代码如下:
1 |
// db/write_batch.cc |
这里调用了 Add 接口往 memtable 中写入键值对,sequence_ 是写入的序列号,kTypeValue 是写入的类型,key 和 value 是用户传入的键值对。
除了写入过程,在读取键值对的时候,也会需要 Memtable 类。具体在 db/db_impl.cc 中 DBImpl 类的 Get 方法中,会调用 memtable 的 Get 方法来查询键值对。
1 |
Status DBImpl::Get(const ReadOptions& options, const Slice& key, |
这里会先创建本地指针 mem 和 imm 来引用成员变量 mem_ 和 imm_,之后用本地指针来进行读取。这里有个问题是,为什么不直接使用成员变量 mem_ 和 imm_ 来读取呢?这个问题留到后面解读疑问我们再回答。
好了,至此我们已经看到了 Memtable 的主要使用方法了,那它们内部是怎么实现的呢,我们接着看吧。
在开始讨论 MemTable 对外方法的实现之前,先要知道 Memtable 中的数据其实是存储在跳表中的。跳表提供了平衡树的大部分优点(如有序性、插入和查找的对数时间复杂性),但是实现起来更为简单。关于跳表的详细实现,可以参考LevelDB 源码阅读:跳表的原理、实现以及可视化。
MemTable 类内部来声明了一个跳表对象 table_ 成员变量,跳表是个模板类,初始化需要提供 key 和 Comparator 比较器。这里 memtable 中跳表的 key 是 const char* 类型,比较器是 KeyComparator 类型。KeyComparator 就是这样一个自定义的比较器,用来给跳表中键值进行排序。
KeyComparator 包含了一个 InternalKeyComparator 类型的成员变量 comparator,用来比较 internal key 的大小。KeyComparator 比较器的 operator() 重载了函数调用操作符,先从 const char* 中解码出 internal key,然后然后调用 InternalKeyComparator 的 Compare 方法来比较 internal key 的大小。具体实现在 db/memtable.cc 中。
1 |
int MemTable::KeyComparator::operator()(const char* aptr, |
再补充说下这里 levelDB 的 internal key 其实是拼接了用户传入的 key 和内部的 sequence number,然后再加上一个类型标识。这样可以保证相同 key 的不同版本是有序的,从而实现 MVCC 并发读写。存储到 Memtable 的时候又在 internal key 前面编码了长度信息,叫 memtable key,这样后面读取的时候,我们就能从 const char* 的 memtable key 中根据长度信息解出 internal key 来。这部分我在另一篇文章:LevelDB 源码阅读:结合代码理解多版本并发控制(MVCC) 有详细分析,感兴趣的可以看看。
Memtable 用跳表做存储,然后对外主要支持 Add 和 Get 方法,下面来看看这两个函数的实现细节。
Add 方法用于往 MemTable 中添加一个键值对,其中 key 和 value 是用户传入的键值对,SequenceNumber 是写入时的序列号,ValueType 是写入的类型,有两种类型:kTypeValue 和 kTypeDeletion。kTypeValue 表示插入操作,kTypeDeletion 表示删除操作。LevelDB 中的删除操作,内部其实是插入一个标记为删除的键值对。
Add 实现在 db/memtable.cc 中,函数定义如下:
1 |
void MemTable::Add(SequenceNumber s, ValueType type, const Slice& key, |
这里的注释十分清楚,Memtable 中存储了格式化后的键值对,先是 internal key 的长度,然后是 internal key 字节串(就是下面的 tag 部分,包含 User Key + Sequence Number + Value Type),接着是 value 的长度,然后是 value 字节串。整体由 5 部分组成,格式如下:
1 |
+-----------+-----------+----------------------+----------+--------+ |
这里第一部分的 keysize 是用 Varint 编码的用户 key 长度加上 8 字节 tag,tag 是序列号和 value type 的组合,高 56 位存储序列号,低 8 位存储 value type。其他部分比较简单,这里不再赘述。
插入过程会先计算出需要分配的内存大小,然后分配内存,接着写入各个部分的值,最后插入到跳表中。具体写入过程代码如下:
1 |
// db/memtable.cc |
这里的 EncodeVarint32 和 EncodeFixed64 是一些编码函数,用来将整数编码到字节流中。具体可以参考LevelDB 源码阅读:内存分配器、随机数生成、CRC32、整数编解码。接下来看看查询键的实现。
查询方法的定义也比较简单,如下:
1 |
// If memtable contains a value for key, store it in *value and return true. |
这里接口传入的 key 并不是用户输入 key,而是一个 LookupKey 对象,在 db/dbformat.h 中有定义。这是因为 levelDB 中同一个用户键可能有不同版本,查询的时候必须指定快照(也就是序列号),才能拿到对应的版本。所以这里抽象出了一个 LookupKey 类,可以根据用户输入的 key 和 sequence number 来初始化,然后就可以拿到需要的键值格式。
具体到查找过程,先用 LookupKey 对象的 memtable_key 方法拿到前面提到的 memtable key,然后调用跳表的 Seek 方法来查找。db/memtable.cc 中 Get 方法的完整实现如下:
1 |
bool MemTable::Get(const LookupKey& key, std::string* value, Status* s) { |
我们知道,跳表的 Seek 方法将迭代器定位到链表中第一个大于等于目标内部键的位置,所以我们还需要额外验证该键的 key 与用户查询的 key 是否一致。这是因为可能存在多个具有相同前缀的键,Seek 可能会返回与查询键具有相同前缀的不同键。例如,查询 “app” 可能返回 “apple” 的记录。
这里注释还特别说明了下,我们并没有检查 internal key 中的序列号,这是为什么呢?前面也提到在跳表中,键的排序是基于内部键比较器 (InternalKeyComparator) 来进行的,这里的排序要看键值和序列号。首先会使用用户定义的比较函数(默认是字典顺序)比较用户键,键值小的靠前。如果用户键相同,则比较序列号,序列号大的记录在跳表中位置更前。这是因为我们通常希望对于相同的用户键,更新的更改(即具有更大序列号的记录)应该被优先访问。
比如有两个内部键,Key1 = “user_key1”, Seq = 1002 和 Key1 = “user_key1”, Seq = 1001。在跳表中,第一个记录(Seq = 1002)将位于第二个记录(Seq = 1001)之前,因为1002 > 1001。当用 Seek 查找 <Key = user_key1, Seq = 1001> 时,自然会跳过 Seq = 1002 的记录。
所以拿到 internal key 后,不用再检查序列号。只用确认用户 key 相等后,再拿到 64 位的 tag,用 0xff 取出低 8 位的操作类型。对于删除操作会返回”未找到”的状态,说明该键值已经被删除了。对于值操作,则接着从 memtable key 后面解出 value 字节串,然后赋值给 value 指针。
除了前面的 Add 和 Get 方法,MemTable 类还声明了一个友元类 friend class MemTableBackwardIterator;,看名字是逆向的迭代器。不过在整个代码仓库,并没有找到这个类的定义。可能是开发的时候预留的一个功能,最后没有实现,这里忘记删除无效代码了。这里编译器没有报错是因为C++ 编译器在处理友元声明时不要求友元类必须已经定义。编译器仅检查该声明的语法正确性,只有当实际上需要使用那个类(例如创建实例或访问其成员)时,缺少定义才会成为问题。
此外还有一个友元 friend class MemTableIterator;,该类实现了 Iterator 接口,用于遍历 memTable 中的键值对。MemTableIterator 的方法如 key() 和 value() 依赖于对内部迭代器 iter_ 的操作,这个迭代器直接工作在 memTable 的 SkipList 上。这些都是 memTable 的私有成员,所以需要声明为友元类。
在 db_impl.cc 中,当需要将 immemtable 落地到 Level0 的 SST文件时,就会用到 MemTableIterator 来遍历 memTable 中的键值对。使用部分的代码如下,BuildTable 中会遍历 memTable,将键值对写入到 SST 文件中。
1 |
// db/db_impl.cc |
这里遍历 memtable 时,用到一个友元类,为啥不直接提供一些 public 的接口来遍历呢?使用友元类的一个好处是,类的职责划分比较清晰。MemTableIterator 负责遍历 memTable 的数据,而 memTable 负责管理数据的存储。这种分离有助于清晰地定义类的职责,遵循单一职责原则,每个类只处理一组特定的任务,使得系统的设计更加模块化。
最后来看看 MemTable 的内存管理。MemTable 类有一个 Arena 类的成员变量 arena_,用来管理跳表的内存分配。在插入键值对的时候,编码后的信息就存在 arena_ 分配的内存中。关于内存管理 Arena 类,可以参考LevelDB 源码阅读:内存分配器、随机数生成、CRC32、整数编解码。
为了能够在不使用 MemTable 的时候,及时释放内存,这里引入了引用计数机制来管理内存。引用计数允许共享对 MemTable 的访问权,而不需要担心资源释放的问题。对外也提供了 Ref 和 Unref 两个方法来增加和减少引用计数:
1 |
// Increase reference count. |
当引用计数减至零时,MemTable 自动删除自己,这时候就会调用析构函数 ~MemTable() 来释放内存。对象析构时,对于自定义的成员变量,会调用各自的析构函数来释放资源。在 MemTable 中,用跳表来存储 key,跳表的内存则是通过 Arena arena_; 来管理的。MemTable 析构过程,会调用 area_ 的析构函数来释放之前分配的内存。
1 |
Arena::~Arena() { |
这里值得注意的是,MemTable 将析构函数 ~MemTable(); 设置为 private,强制外部代码通过 Unref() 方法来管理 MemTable 的生命周期。这保证了引用计数逻辑能够正确执行,防止了由于不当的删除操作导致的内存错误。
好了,这时候还有最后一个问题了,就是前面留的一个疑问,在 LevelDB Get 方法中,为啥不直接使用成员变量 mem_ 和 imm_ 来读取,而是创建了两个本地指针来引用呢?
如果直接使用 mem_ 和 imm_ 的话,会有什么问题?先考虑不加锁的情况,比如一个读线程正在读 mem_,这时候另一个写线程刚好写满了 mem_,触发了 mem_ 转到 imm_ 的逻辑,会重新创建一个空的 mem_,这时候读线程读到的内存地址就无效了。当然,你可以加锁,来把读写 mem_ 和 imm_ 都保护起来,但是这样并发性能就很差,同一时间,只允许一个读操作或者写操作。
为了支持并发,LevelDB 这里的做法比较复杂。读取的时候,先加线程锁,复制 mem_ 和 imm_ 用 Ref() 增加引用计数。之后就可以释放线程锁,在复制的 mem 和 imm 上进行查找操作,这里的查找操作不用线程锁,支持多个读线程并发。读取完成后,再调用 Unref() 减少引用计数,如果引用计数变为零,对象被销毁。
考虑多个读线程在读 mem_,同时有 1 个写线程在写入 mem_。每个读线程都会先拿到自己的 mem_ 的引用,然后释放锁开始查找操作。写线程可以往里面继续写入内容,或者写满后创建新的 mem_ 内存。只要有任何一个读线程还在查找,这里最开始的 mem_ 的引用计数就不会为零,内存地址就一直有效。直到所有读线程读完,并且写线程把 mem_ 写满,将它转为 imm_ 并写入 SST 文件后,最开始的 mem_ 的引用计数为零,这时候就触发析构操作,可以回收地址了。
看文字有点绕,我让 AI 整理一个 mermaid 的流程图来帮助理解吧:
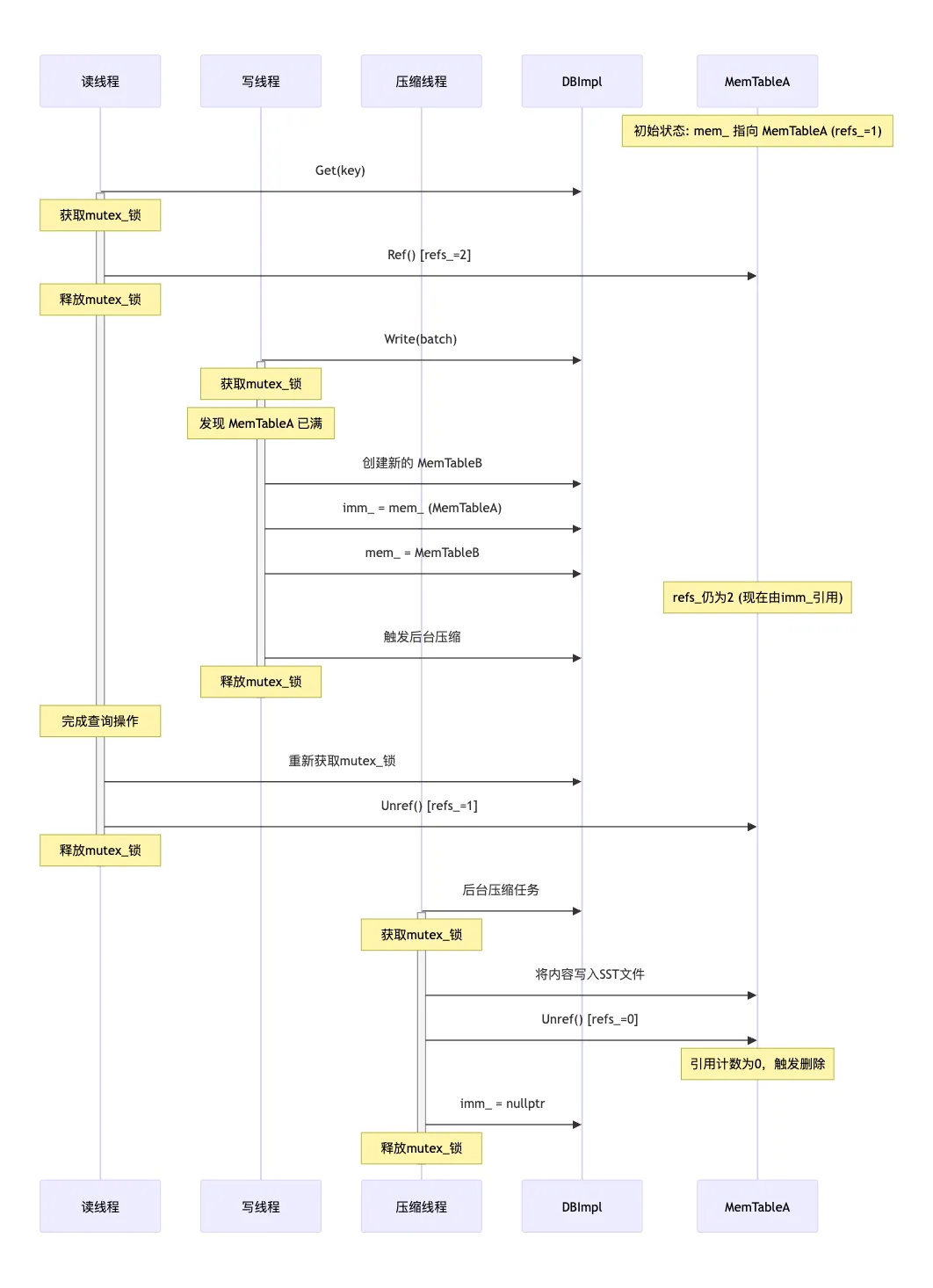
mermaid 的源码可以在这里找到。
在整个 LevelDB 架构中,MemTable 扮演着承上启下的角色。它接收来自上层的写入请求,在内存中积累到一定量后,转变为不可变的 Immutable MemTable,最终由后台线程写入磁盘形成 SST 文件。同时,它也是读取路径中优先级最高的组件,确保最新写入的数据能够立即被读取到。
本文我们详细分析了 LevelDB 中 MemTable 的实现原理与工作机制,最后再简单总结下MemTable 的核心设计:
MemTable 通过细致的内存管理和引用计数机制,解决了并发访问问题;通过跳表数据结构,实现了高效的查询和插入;通过特定的键值编码格式,支持了多版本并发控制。这些设计共同构成了 LevelDB 高性能、高可靠性的基础。
2025-06-11 01:47:42
在数据库系统中,并发访问是一个常见的场景。多个用户同时读写数据库,如何保证每个人的读写结果都是正确的,这就是并发控制要解决的问题。
考虑一个简单的转账场景,开始的时候 A 账户有 1000 元,要转 800 元给 B 账户。转账过程包括两步:从 A 扣钱,给 B 加钱。恰好在这两步中间,有人查询了 A 和 B 的余额。
如果没有任何并发控制,查询者会看到一个异常现象:A 账户已经被扣除了 800 元,只剩 200 元,B 账户还没收到转账,还是原来的金额!这就是典型的数据不一致问题。为了解决这个问题,数据库系统需要某种并发控制机制。
最直观的解决方案是加锁,当有人在进行写操作(如转账)时,其他人的读操作必须等待。回到前面的问题,只有在转账的两步都完成之后,才能查到正确的账户余额。但是锁机制存在明显的问题,每次只要写相关 key,所有读该 key 的操作都要排队等待,导致并发上不去,性能会比较差。
现代数据库系统普遍采用 MVCC 来控制并发,LevelDB 也不例外,接下来我们结合源码来理解 LevelDB 的 MVCC 实现。
MVCC(Multi-Version Concurrency Control) 是一种并发控制机制,它通过维护数据的多个版本来实现并发访问。简单来说,LevelDB 的 MVCC 实现关键点有下面几个:
这就是 MVCC 的核心思想了。我们通过一个具体的时间操作序列,来理解下 MVCC 是怎么工作的。假设有以下操作序列:
1 |
时间点 T1: sequence=100, 写入 key=A, value=1 |
那么不管 Reader1 和 Reader2 谁先读取,Reader1 读取 key=A 总会得到 value=2(sequence=101),Reader2 读取 key=A 会得到 value=3(sequence=102)。后续如果有新的读取,不带 snapshot 的读取会得到最新的数据。通过下面的时序图更容易理解,mermaid 源码在这里:
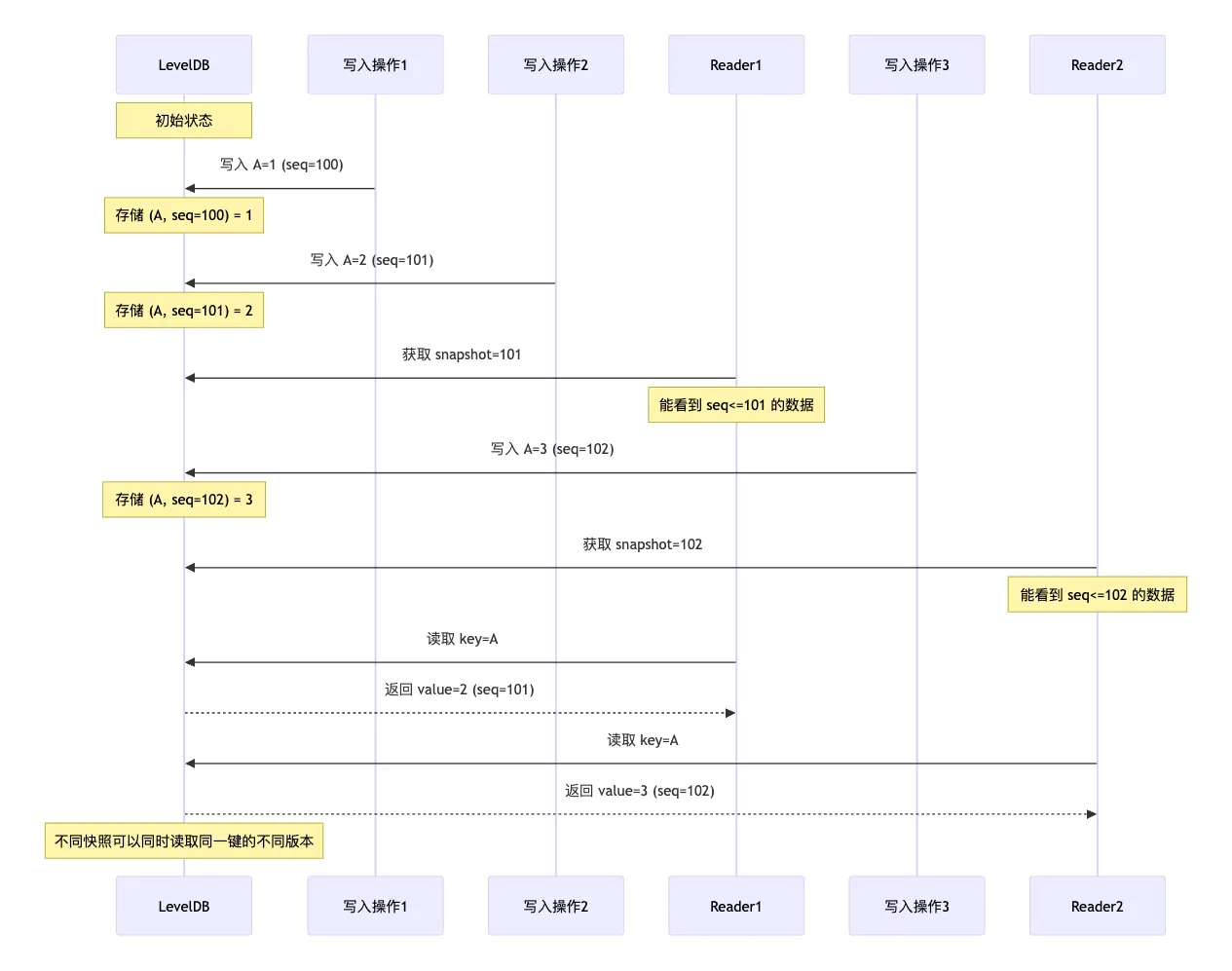
MVCC 的整体效果就如上了,还是比较容易理解的。下面看看 LevelDB 中是怎么实现 MVCC 的。
实现 MVCC 的前提是,每个键都保存多个版本。所以要设计一个数据结构,把键和版本号关联起来。LevelDB 设计的 key 格式如下:
[key][sequence<<8|type]
LevelDB 的做法也比较容易理解,在原来的 key 后面拼上版本信息。这里版本信息是一个 64 位的 uint,其中高 56 位存储的是 sequence,低 8 位存储的是操作类型。这里操作类型目前只有两种,对应的分别是写入和删除操作。
1 |
// Value types encoded as the last component of internal keys. |
这里序列号只有 56 位,所以最多可以支持 $ 2^{56} $ 次写入。这样实现会不会有问题?如果我想写入更多的 key 那岂不是不支持了?理论上是的,但是咱们从实际使用场景来分析下。假设每秒写入 100W 次,这个已经是很高的写入 QPS 了,那么可以持续写入的时间是:
$$ 2^{56} / 1000000 / 3600 / 24 / 365 = 2284 $$
嗯。。。能写 2000 多年,所以这个序列号是够用的,不用担心耗尽问题了。这里的数据格式设计虽然很简单,但还是有不少好处的:
我们知道 LevelDB 中键是顺序存储的,当要查询单个键时,可以用二分查找快速定位。当需要获取一系列连续键时,可以使用二分查找快速定位范围起点,然后顺序扫描即可。但现在我们给键增加了版本号,那么问题来了,带版本号的键要怎么排序呢?
LevelDB 的做法也是比较简单有效,排序规则如下:
为了实现这里的排序规则,LevelDB 实现了自己的比较器,在 db/dbformat.cc 中,代码如下:
1 |
int InternalKeyComparator::Compare(const Slice& akey, const Slice& bkey) const { |
可以看到首先从带版本号的 key 中去掉后 8 位,拿到真实的用户键,之后按照用户键的排序规则进行比较。这里再多说一句,LevelDB 提供了一个默认的用户键比较器 leveldb.BytewiseComparator,这里是完全按照键值的字节序进行比较。比较器的实现代码在 util/comparator.cc 中,如下:
1 |
class BytewiseComparatorImpl : public Comparator { |
这里 Slice 是 LevelDB 中定义的一个字符串类,用于表示一个字符串,它的 compare 就是字节码比较。其实 LevelDB 也支持用户自定义比较器,只需要实现 Comparator 接口即可。这里多说一点,在使用比较器的时候,用 BytewiseComparator 封装了一个单例,代码有点难理解,如下:
1 |
const Comparator* BytewiseComparator() { |
我之前专门写了一篇文章来解释 NoDestructor 模板类,感兴趣的可以看下:LevelDB 源码阅读:禁止对象被析构。
这种排序规则的好处也是显而易见的,首先按照用户键升序排列,这样范围查询非常高效。当用户需要获取一系列连续键时,可以使用二分查找快速定位范围起点,然后顺序扫描即可。另外,同一个用户键的多个版本按序列号降序排列,这意味着最新版本在前,便于快速找到当前值。查询时,只需找到第一个序列号小于等于当前快照的版本,不需要完整扫描所有版本。
好了,关于排序就说到这。下面咱们结合代码来看看写入和读取的时候,是怎么拼接 key 的。
LevelDB 写入键值对的步骤比较复杂,可以看我之前的文章:LevelDB 源码阅读:写入键值的工程实现和优化细节。简单说就是先写入 memtable,然后是 immutable memtable,最后不断沉淀(compaction)到不同层次的 SST 文件。整个过程的第一步就是写入 memtable,所以在最开始写入 memtable 的时候,就会给 key 带上版本和类型,组装成前面我们说的带版本的内部 key 格式。
这里组装 Key 的代码在 db/memtable.c 的 MemTable::Add 函数中。这里除了组装 key,还拼接了 value 部分。实现如下:
1 |
void MemTable::Add(SequenceNumber s, ValueType type, const Slice& key, |
可以看到这里同一个用户键的多次写入会产生多个版本,每个版本都有唯一的 sequence number。用户键一旦被转换为内部键,后续所有处理过程都基于这个内部键进行。包括 MemTable 转为 Immutable MemTable,SST 文件写入,SST 文件合并等。
这里 Add 函数中,在 internal_key 内部键的前面其实也保存了整个内部键的长度,然后把长度和内部键拼接起来,一起插入到了 MemTable 中。这样的 key 其实是 memtable_key,后续在读取的时候,也是用 memtable_key 来在 memtable 中查找的。
这里为什么要保存长度呢?我们知道 Memtable 中的 SkipList 使用 const char* 指针作为键类型,但这些指针只是指向内存中某个位置的裸指针。当跳表的比较器需要比较两个键时,它需要知道每个键的确切范围,也就是起始位置和结束位置。如果直接使用 internal key,就没有明确的方法知道一个 internal key 在内存中的确切边界。加上长度信息后,就可以快速定位到每个键的边界,从而进行正确的比较。
接下来看看读取键值的过程。在读取键值的时候,会先把用户键转为内部键,然后进行查找。不过这里首先面临一个问题是,序列号要用哪个呢。回答这个问题前,我们先来看读取键常用的的方法,如下:
1 |
std::string newValue; |
这里有个 ReadOptions 参数,里面会封装一个 Snapshot 快照对象。这里的快照你可以理解为数据库在某个时间点的状态,里面有这个时间点之前所有的数据,但不会包含这个时间点之后的写入。
其实这里快照的核心实现就是保存某个时间点的最大序列号,读取的时候,会用这个序列号来组装内部键。读的时候,分两种情况,如果没有指定 snapshot,使用当前最新的 sequence number。如果使用了之前保存下来的 snapshot,则会使用 snapshot 的序列号。
之后会根据快照序列号和用户键组装,这里先定义了一个 LookupKey 对象,用来封装查找时候使用内部键的一些常用操作。代码在 db/dbformat.h 中,如下:
1 |
// A helper class useful for DBImpl::Get() |
在 LookupKey 的构造函数中,会根据传入的 user_key 和 sequence 来组装内部键,具体代码在 db/dbformat.cc 中。后续在 memtable 中搜索的时候,用的 memtable_key,然后在 SST 中查找的时候,用的 internal_key。这里 memtable_key 就是我们前面说的,在 internal_key 的前面加上了长度信息,方便在 SkipList 中快速定位到每个键的边界。
这里在 memtable 和 immutable memtable 中找不到的话,会去 SST 中查找。SST 的查找就相当复杂一些,涉及多版本数据的管理,后续我会专门写文章来介绍这里的读取过程。
本篇对 MVCC 的讲解还比较浅显,介绍了大概的概念,以及重点讲了下读取和写入过程中如何对序列号进行处理的过程。并没有深入数据多版本管理,以及旧版本数据回收清理的过程。后面文章再深入这些话题。
总的来说,LevelDB 通过在键值中引入版本号,实现了多版本并发控制。通过 snapshot 来实现读取隔离,写入永远创建新版本。对于读操作来说,不需要加锁,可以并发读取。对于写操作来说,需要加锁,保证写入的顺序。
这种设计提供了很好的并发性能,保证了读取的一致性,同时减少了锁冲突。不过代价是存储空间的额外开销,以及需要保存多个版本带来的代码复杂度。
2025-05-23 19:39:14
大语言模型刚出来的时候,只是通过预训练的模型来生成回答内容。这个时候的模型有两个主要的缺点:
为了解决这两个问题,OpenAI 最先在模型中支持了 function calling 功能,他们在这篇博客: Function calling and other API updates 有介绍。
这时候,我们就可以告诉模型,我有这么几个工具,每个工具需要什么参数,然后能做什么事情,输出什么内容。当模型收到具体任务的时候,会帮我们选择合适的工具,并解析出参数。之后我们可以执行相应的工具,拿到结果。并可以接着循环这个过程,让 AI 根据工具结果继续决定往下做什么事情。
我在网上找了个动图,可以来理解下有了 function calling 后,做事情的流程:
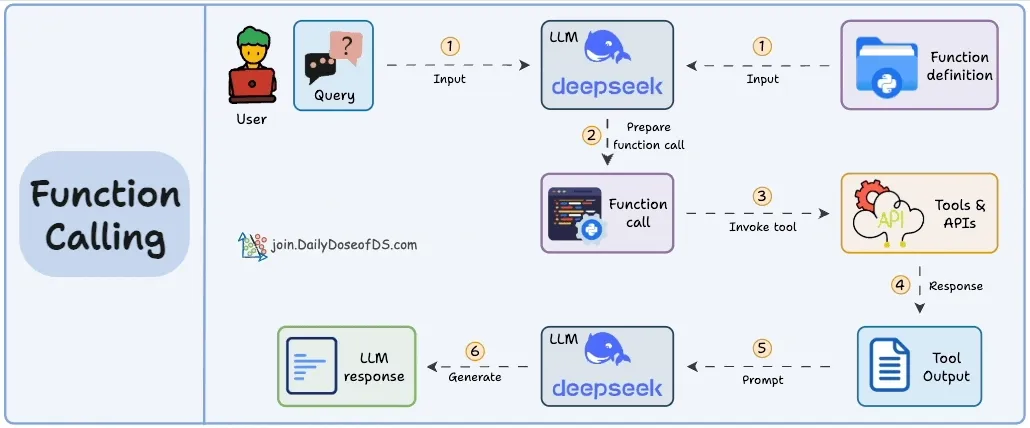
当然这里大模型只是根据我们给的工具列表,选择合适的工具,并解析出参数。它不能直接去调用工具,我们需要编程实现工具调用部分,可以参考 OpenAI 的 Function calling 文档。
只有 function calling 已经能做很多事了,派生了不少有意思的项目,比如 AutoGPT,可以说是最早的 Agent 智能体了。
但是有个问题,就是不同厂商 function calling 实现各不相同,开发者需要为每个平台单独适配。另外开发者还需要编写代码来解析 function calling 的输出,并调用相应的工具。这里面有不少工程的工作,比如失败重试、超时处理、结果解析等。
计算机领域,没有什么是不能通过加个中间层来解决的。过了一年多,随着模型能力提升,各种外部工具的丰富,Anthropic 在2024年11月25日推出了 MCP 协议,引入了 MCP Client 和 MCP Server 这个中间层,来解决解决 LLM 应用与外部数据源和工具之间通信的问题。
当然其实这中间也有一些其他方案,来赋予模型调用外部工具的能力,比如 OpenAI 推出的 ChatGPT Store,曾经也火了一阵子的 GTPs,不过目前似乎很少看到人用了。
目前比较流行的就是 MCP 了,这里有个图,可以帮助你理解:
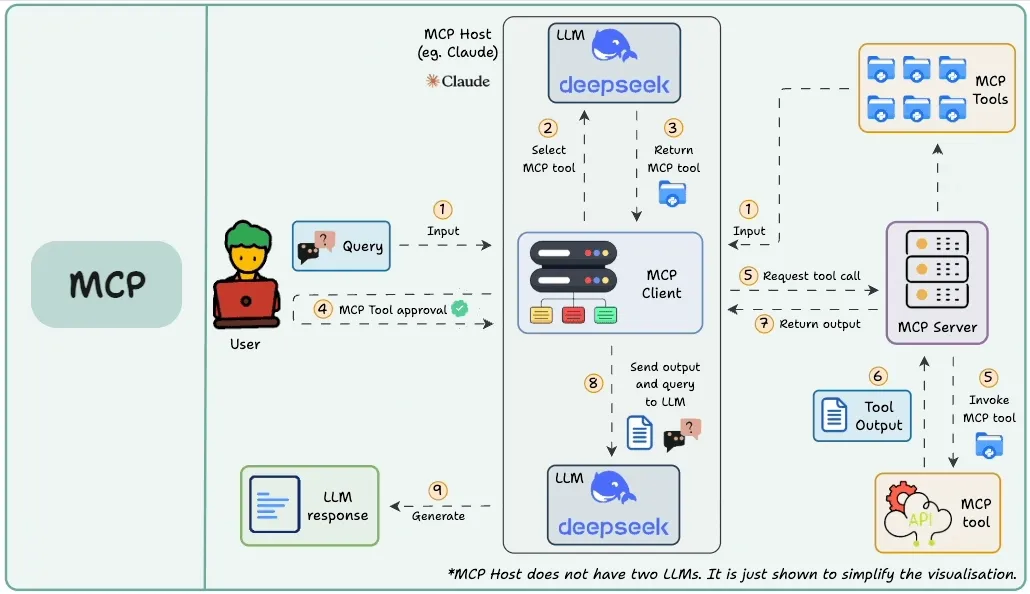
咱们这篇文章主要是介绍实用体验,所以关于背景的交代就到这里。如果对 MCP 的开发感兴趣,可以看官方文档,介绍的还是十分详细的。
在使用之前,我先简单介绍下 Cursor 使用 MCP 的方法。Cursor 接入 MCP 还是挺方便的,对于大部分不需要密钥的 MCP Server,基本一个配置就能接入。现在 MCP 发展还挺快,所以建议大家直接去看 Cursor 的官方文档,获取最新信息。网上不少教你如何配置的文章,其实都过时了。
这里我给大家介绍下配置的整体思想,方便你理解文档。Cursor 在这里相当于 AI 应用,它内置了 MCP Client,所以你不用管 Client 部分了。你只需要告诉他你有哪些 MCP Server,然后在会话聊天中 Cursor 会自动调用工具并使用它的结果。
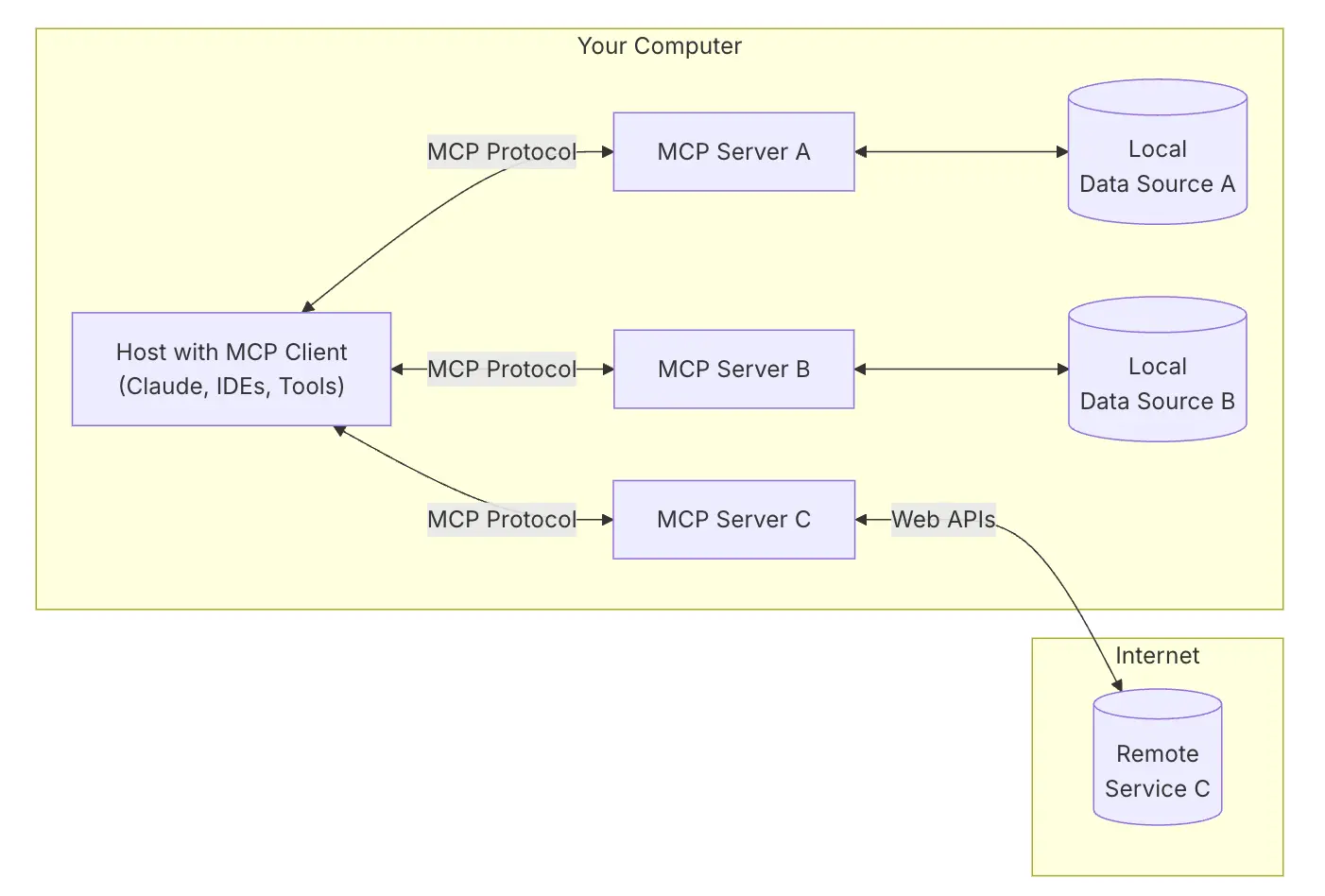
先祭出上面这张图,方便你理解。目前大部分 AI 应用都是用 json 文件来配置 MCP Server 的,比如 Claude Desktop。Cursor 也是如此,它支持全局配置(~/cursor/mcp.json),也可以在项目中(.cursor/mcp.json) 配置。
目前 Cursor 支持本地 MCP CLI Stdio Server 和远程 MCP SSE Server 两种方式,关于 SSE 可以参考我之前的文章结合实例理解流式输出的几种实现方法。本地的 CLI 方式,其实就是在本地机器启动一个 Server 进程,然后 Cursor 通过标准输入输出来和这个本地进程交互。
这里本地的 Server 支持 Python,Node 服务,也支持 Docker 容器。不过前提是本地机器已经安装了对应的语言环境,能跑起来相应的启动命令。这 3 种方式,我都给了一个例子:
1 |
npx @browsermcp/mcp@latest |
有时候 MCP Server 里面还需要一些配置,比如 Github 的 API 密钥,这时候就需要你手动配置了。提醒下你要把密钥配置到环境变量中,千万不要把密钥上传到代码仓库哦。
具体到某个 MCP Server,你可以参考它的文档,看如何配置,应该没什么难度。配置好 json 后,Cursor 会自动识别,你可以打开这个 MCP Server,过一会看到绿色标记和列出来的工具,就说明配置成功了。

接下来终于到重头戏了,咱们来体验下 MCP 的实际效果。
之前就经常想着让 AI 来自动化执行一些网页任务。比如自动去某个站点搜索、浏览指定主题的内容,进行回复,或者导出一些有意义的内容。于是试了下微软的无头 playwright MCP Server,给了它一个比较复杂的任务:
帮我打开淘宝,搜索苹果手机,找到最新款的苹果手机,给出店铺销量最高的几家,并导出每家店铺的销量和价格。
确实如期打开了淘宝,并真的找到了搜索框,输入了苹果手机,如图:
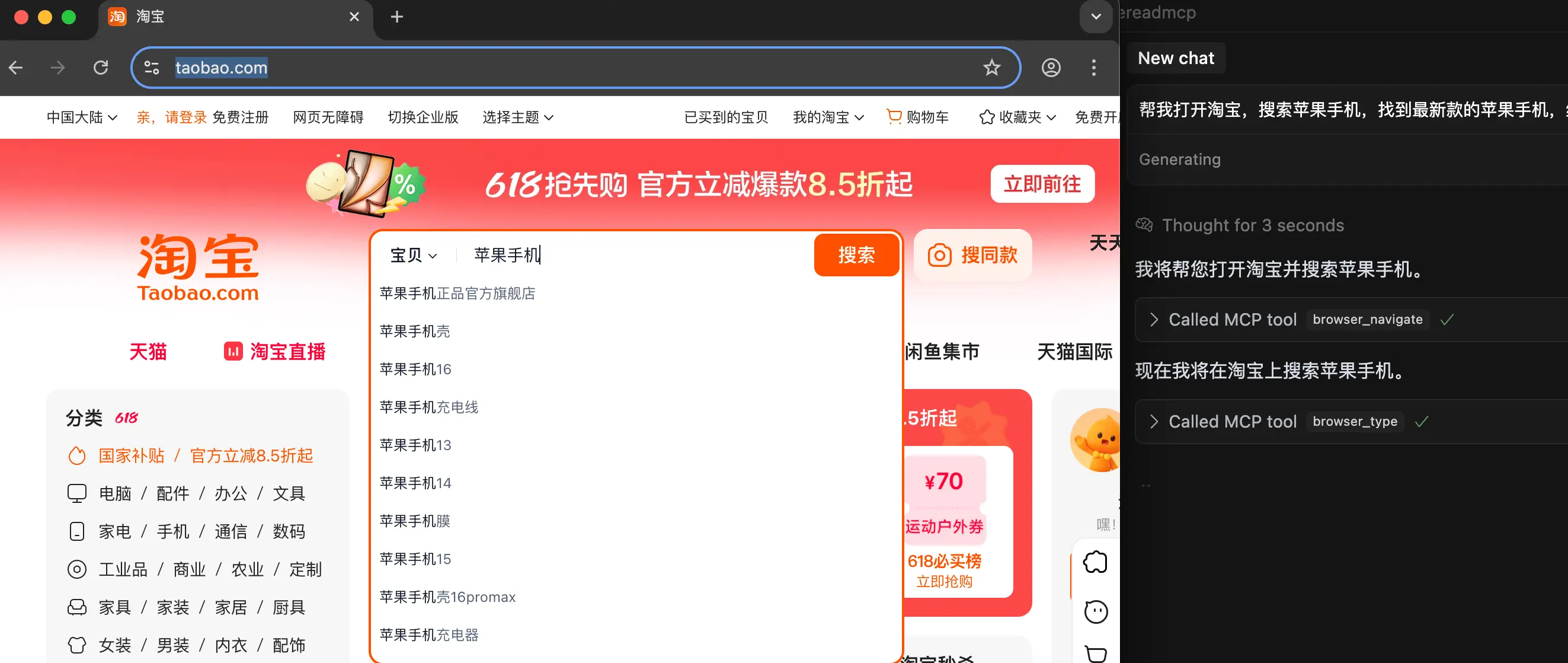
但是后面弹了一个登录框,Claude 3.7 在这里卡了很久,也没解决。跑了一阵子,最后的输出是这样的:
我注意到我们看到了一个登录弹窗,这可能是因为淘宝网站要求用户登录才能查看详细搜索结果。这是淘宝网站的常见安全措施,特别是对于非登录用户通过自动化工具访问时。
让我尝试取消登录弹窗,点击关闭按钮:
我们看到点击关闭按钮后,淘宝网站依然要求登录才能查看搜索结果。淘宝网站对非登录用户有严格的安全限制,特别是使用自动化工具访问时。
由于需要登录才能查看详细的苹果手机信息,我可以尝试使用其他方式获取有关苹果手机的信息。例如,我可以使用网络搜索查找有关最新款苹果手机及其销量和价格信息的公开数据:
最后开始联网搜索,和我本意差的有点远。这里登录态确实不好处理,我找了另一个 MCP Server,它支持在本地浏览器中运行,这样可以登录后再让 AI 来操作。这个工具的原理是,在本地浏览器安装一个插件,然后 MCP Server 来控制本地浏览器。
使用下来,目前登录态是没问题了,但有些网站有部分防爬的功能,页面元素做了些保护,这个 MCP Server 还没法完美的操控,比如没法成功点击按钮,另外滚动起来也是很卡顿。
其实目前 LLM 操控浏览器还是有不少难度的,最近一个比较火的 Browser Use 项目,它除了用 HTML 元素,还尝试用视觉元素来操控浏览器。整体前景会好一些,等我有 Token 了再来深度体验下这个。
再来试试 Cursor 官方例子中的 Github MCP Server,它支持搜索仓库、代码、issue,创建 PR 等。我想到一个场景就是,遇到一个火的项目,可以先让 AI 总结下目前比较火的 PR 或者 Issue,然后看看有没有可以贡献的地方。当然了,如果 AI 找到有价值的 Issue,然后再分析代码,给出解决方案,并自动提交代码,那这个价值就更大了。
当然,咱先拆分问题,来个低难度的信息收集:
LevelDB 这个项目中,有哪些讨论比较多,还没合并的 pull request 啊
这里用的 Claude3.7,竟然有点死循环了,一直在 Call list_pull_requests 这个工具,参数也基本一样:
1 |
{ |
查了 10 多遍,也没自动终止。PR 查不成功,我换了下查 Issue,这次还可以,用 list_issues 工具,查了 3 页,参数类似下面:
1 |
{ |
最后也给出了一些结论,如图:
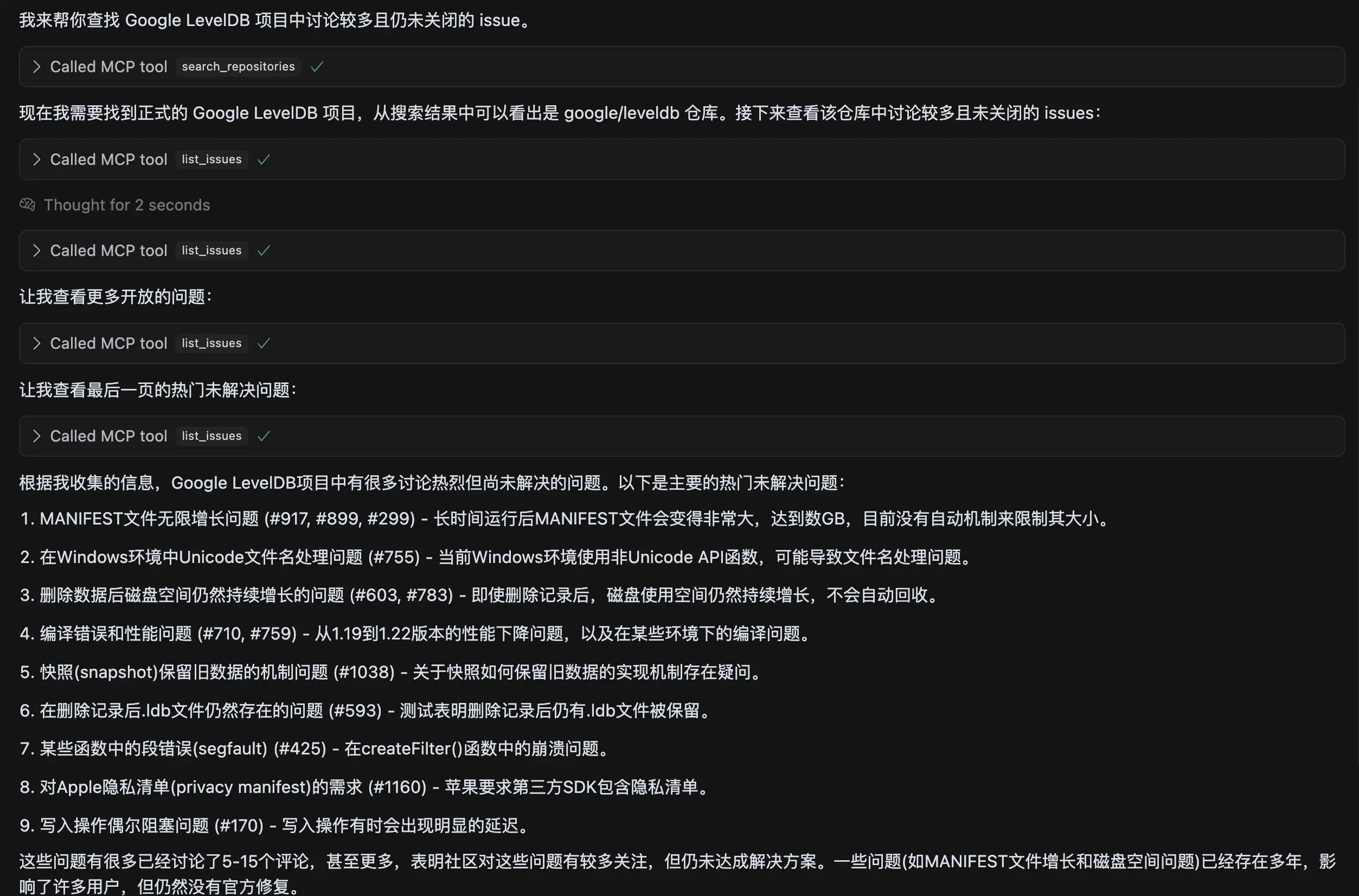
检查了几个,没什么大问题,这个我还是挺满意的。遇到一个大的项目,能够快速找到大家讨论多的 Issue,然后分析下,确实能帮上忙。不过我怀疑这里没找完,只有 3 页,其实一共 200 多个 Issue 呢。
然后继续聚焦其中一个 PR #917,让他给我分析下。刚好今天 Claude 推出了 Sonnet 4 模型,用这个新的模型让他分析下。不得不说,针对这种拆解开的小的问题,AI 分析还是很强的。
先是收集了这个 PR 的评论,PR 的代码改动,然后还拉了这个 PR 提到的另外 2 个 Issue,综合了这么多信息后,给出了一个详细的分析。分析也十分给力,先是问题描述,问题背景和表现,接着是提议的解决方案,社区针对这个方案的讨论焦点,比如性能影响,作者回应等。最后还给出这个 PR 的当前状态,从 2021 年 6 月提交至今,还没合并进去。这里的分析太惊艳了,看来后面遇到一些开源项目的问题,还是可以来用下的。
这里是截图:
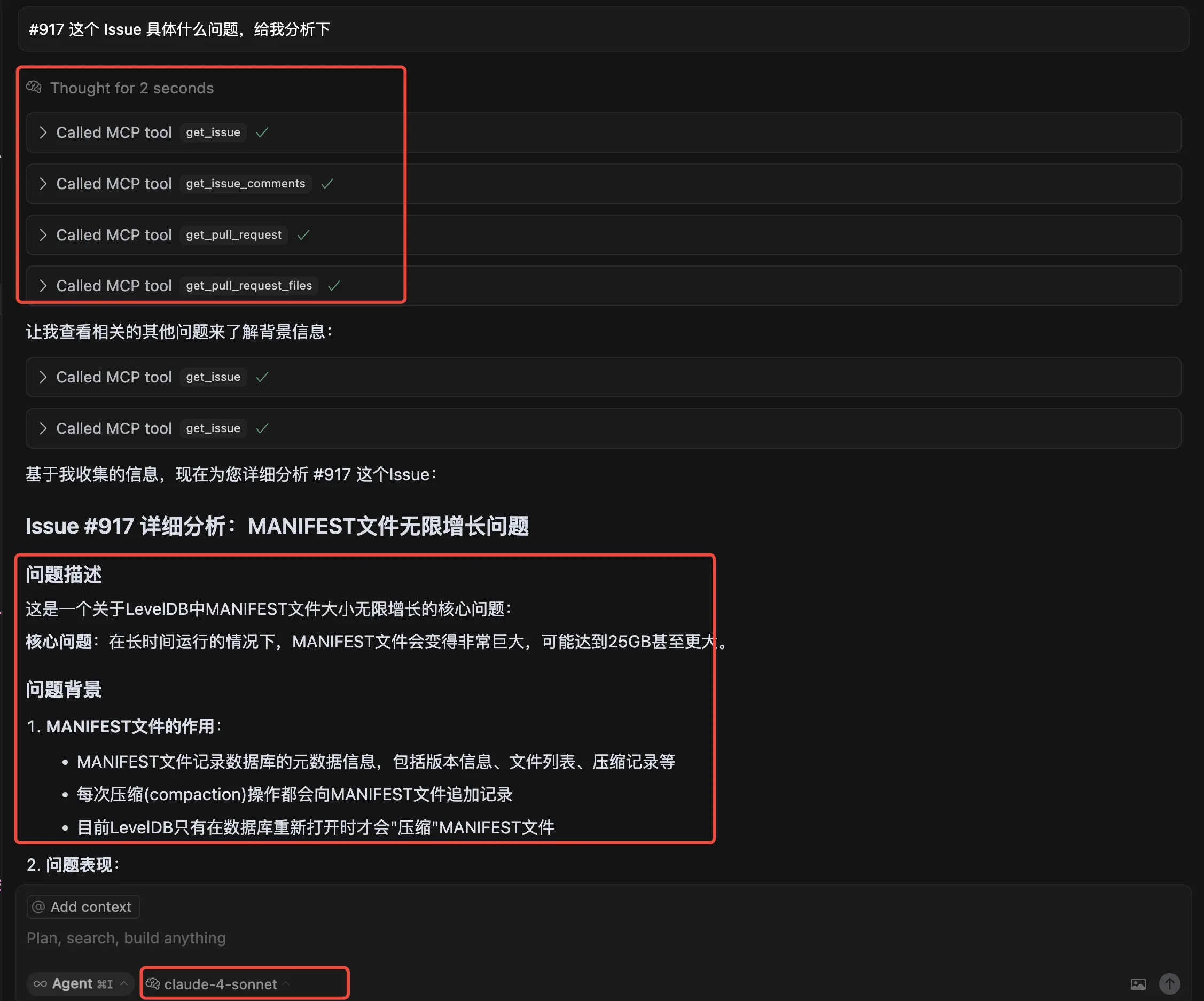
当然看了下 Github MCP Server 的文档,这里不止是提供了读仓库,读 Issue 的能力,还有修改仓库的能力。包括提交 PR,创建 Issue,创建评论,创建标签,新建分支等。我还没来得及深入使用下这些会改动仓库的功能,等后面有机会再接着体验。
有时候会经常根据数据生成一些好看的报表,之前还有 AI 写了一个工具,来生成动态柱状图。现在有了 MCP 后,可以试试让 AI 来生成图表。其实有不少很酷的生成图表的库,比如 echarts 这些。看了下现在没有官方的图表库,不过找到了一个 mcp-server-chart,它支持生成 echarts 的图表。
这里有最近 10 年中国各省份人口变化的动态竞速图,导了一份数据出来,然后试试 MCP Server 生成图表效果如何。
直接给它一份文件,然后提示:
@china_population.csv 结合这份中国人口变化数据,生成一个 2022 年和2023 年各省份人口的柱状图
这里用的 Claude 4 Sonnet 模型,成功调用了 mcp-server-chart 的 generate_column_chart 工具,生成了图表。不过这个工具返回的是图片 URL,需要去输出里复制出来打开才能看。其实 Cursor 支持输出图片的 Base64 编码,这样聊天里也能加载出来。工具返回的图片地址在这,效果如下:
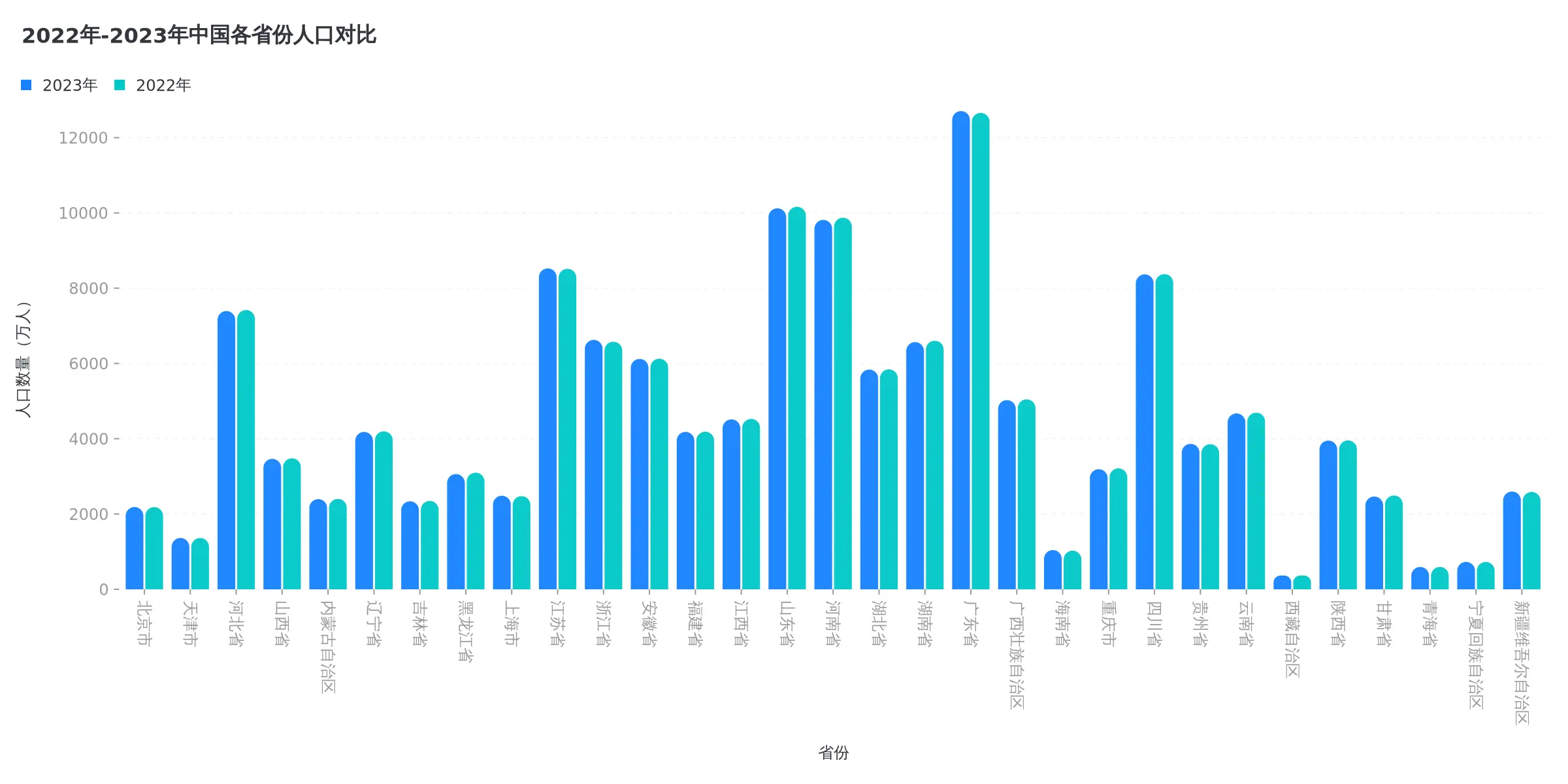
然后我发现这个工具支持其他类型的图表,比如折线图,散点图,饼图等。有个图我不知道啥图,但效果还挺好的,我就截了个图给 Claude,提示:
参考这张图,生成一个 2023 年各省人口的图
它先分析这是一个树状图,然后帮我生成了结果,还解释了下。解释超大矩形块是广东省,占据最大面积,提现了人口第一大省的地位。生成图地址在这,我这里也放出来吧:

效果还是可以的。目前这个工具每个图表一个 Tool,支持的图表类型还是有限的。
目前的 MCP 还是存在一些限制的,首先咱们要明确一点,MCP 协议只是加了个 Server 和 Client 的中间层,它还是要依赖 LLM 的 function calling 能力。而 function calling 会受到 LLM 的上下文长度限制,工具的描述信息,参数等都会占用 Token。
当工具数量太多或者描述复杂的时候,可能会导致 Token 不够用。另外,就算 Token 够用,如果提供的工具描述过多,也会导致模型效果下降。OpenAI 的文档也有提到:
Under the hood, functions are injected into the system message in a syntax the model has been trained on. This means functions count against the model’s context limit and are billed as input tokens. If you run into token limits, we suggest limiting the number of functions or the length of the descriptions you provide for function parameters.
MCP 基于 function calling 能力,所以也有同样的限制。MCP server 如果提供了过多的工具,或者工具描述太复杂,都会影响到实际效果。
比如拿 Cursor 来说,它推荐打开的 MCP Servers 最多提供 40 个工具,太多工具的话,模型效果不好。并且有的模型也不支持超过 40 个工具。
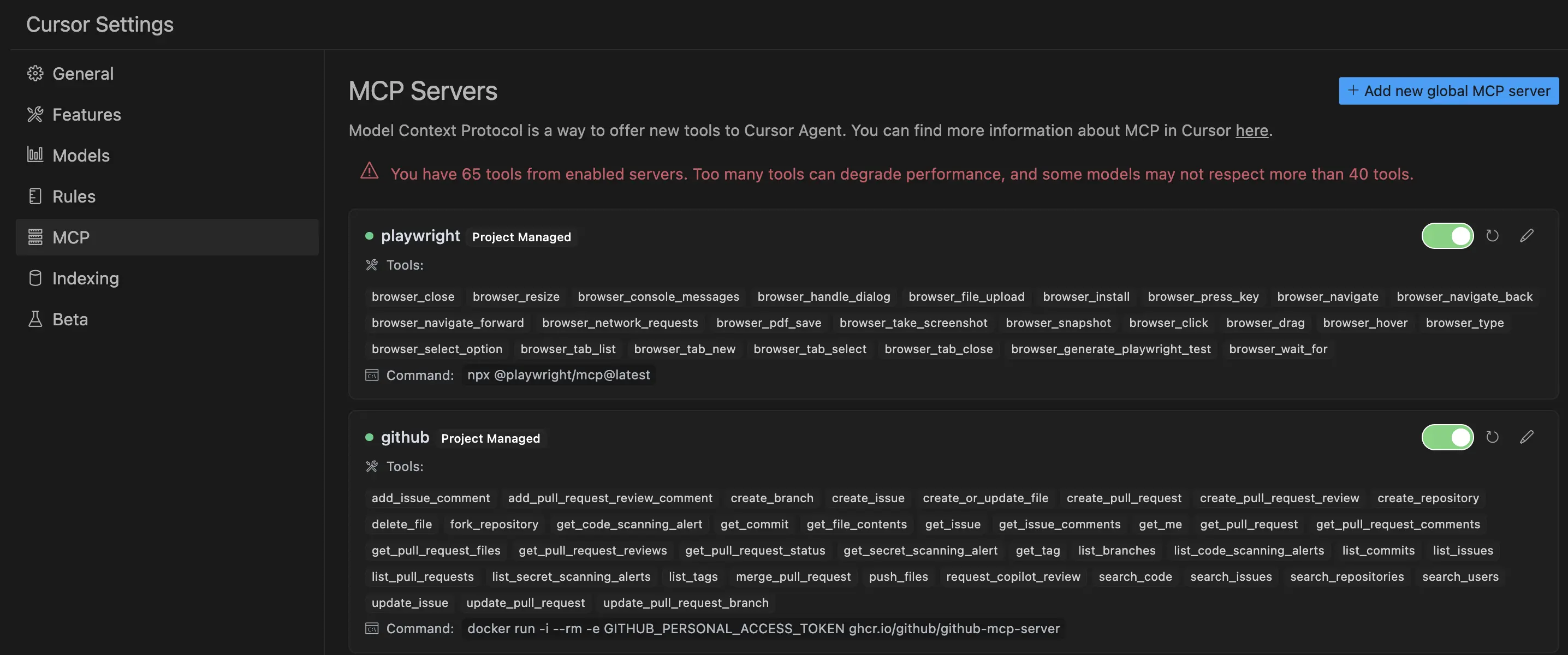
好了,咱们介绍完 MCP 背景以及使用方法以及限制了,最后来聊下 MCP 的实用价值。目前市面上有太多 MCP Server 了,Cursor 有个 MCP Server 列表页,有需求的话可以在这找找看。
大致看了下,觉得有些 MCP Servers 后面可能会继续尝试用一用。
就目前试过的几款,确实有些不错的亮点功能,但还不能让我觉得有特别大的价值。尝鲜之后,也就就束之高阁了。也就 Github MCP Server 让我觉得后面可能会用得到。
不过文章还没写好 Claude Sonnet 4 模型就发布了,号称世界上最强编程模型。推理能力也有很大提升,等后面多用一段时间,才能有一个真实的体感。或许随着模型能力提升,各个 MCP Server 的持续优化,有一天终会变成大家每天都离不开的工具吧。
不知道各位有什么好的 MCP Server 使用场景吗?欢迎留言讨论。