2026-08-03 04:47:53
Yesterday I wrote that a lot of the special functions that pop up in mathematical physics are solutions to second order linear differential equations with polynomial coefficients. More generally, holonomic functions are defined to be those functions that are the solutions to linear differential equations, of any order, with polynomial coefficients.
Most special functions are holonomic. To quantify that statement, I went through the special functions covered in Abramowitz and Stegun. The large majority are holonomic, thought some common functions like the gamma function are not holonomic.
This report goes through the functions in A&S. For those that are holonomic, it gives the differential equation that the function solves. The large majority of these equations are second order, but not all. And the coefficients are nearly always first or second order polynomials, rarely higher order.
The post Holonomic functions first appeared on John D. Cook.2026-08-03 01:57:31
In this post I mentioned two series which I denoted t(n) and c(n). The former is the number of unlabeled rooted trees with n nodes. The latter is the cumulative sum of the former, i.e.
![]()
The sequence c(n) is also the number of constraints on an n-step Runge-Kutta method; that’s how I became interested in it.
Now the t(n) sequence has been cataloged as OEIS A000081 and OEIS gives the asymptotic estimate of t(n) for large n as
![]()
where C = 0.4399… and α = 2.9557….
The cumulative sum of t(n), what I’ve called c(n), is also cataloged in OEIS, sequence number A087803. However, OEIS does not give an asymptotic estimate for this sequence. I’ll give one here.
(Update: After looking closer at the page for A087803 I see that there is an asymptotic formula, the same one derived here.)
The basis for my derivation is to assume the cumulative sum of the asymptotic estimates gives an asymptotic estimate of the cumulative sum. This is justified by the fact that the sequence is increasing rapidly and only the last few terms contribute much relatively to the sum.
The technique illustrated here would be applicable to the cumulative sum of other series whose asymptotic form is known.

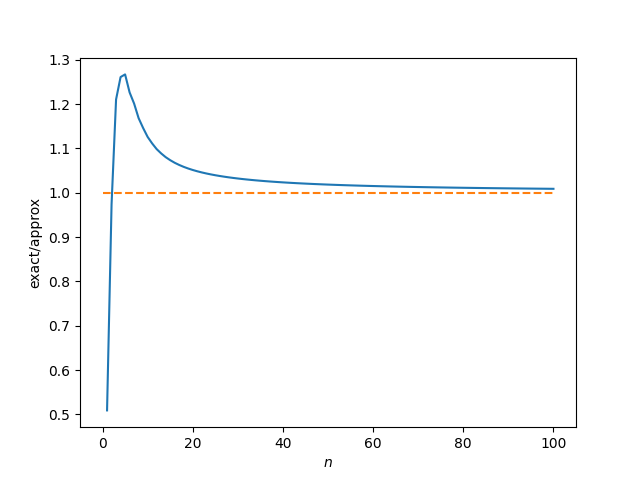
Here’s code to visualize the rate of convergence.
import numpy as np
import matplotlib.pyplot as plt
# from https://oeis.org/A000081/b000081.txt
A000081 = [
0,
1,
1,
2,
4,
...
51384328351659326880337136395054298255277970,
]
A087803 = np.cumsum(A000081)
def approx(n):
C = 0.43992401257102530
a = 2.95576528565199497
return C*a**(n+1)*n**(-3/2)/(a - 1)
n = np.arange(len(A087803))
ratio = A087803/approx(n)
plt.plot(n[1:], ratio[1:])
plt.plot(n, 0*n + 1, '--')
plt.xlabel("$n$")
plt.ylabel("exact/approx")
plt.show()
Here’s the plot:
2026-08-02 04:18:41
Second order linear differential equations with polynomial coefficients form their own area of study. This seems like a narrow class of equations, but it’s very important in applications.
This class of equations seems like a mathematically natural topic, but why is it so important in applications? I did a PhD in differential equations without ever learning why. The theory of second order linear equations with polynomial coefficients is too complicated for undergraduate courses [0] and too well-established for graduate courses [1].
The explanation that I was missing can be found in the first chapter of [2]. The PDEs that are common in physics are separable in various coordinate systems, meaning that in these coordinate systems the PDEs reduce to ODEs. These ODEs either have polynomial coefficients, or there is a change of variables which makes the ODEs have polynomial coefficients.
See this writeup that looks at the Helmholtz and Laplace equations in 11 coordinate systems.
[0] You may see the simplest parts of the theory in a section on solving ODEs with power series. But textbooks don’t go very far for good reasons.
[1] Unfortunately, a lot of really useful topics are left out of the graduate curriculum because they’re too well understood to provide thesis topics. Or the problems that are still open have been open for so long that they’re likely too hard to be cracked by a graduate student.
[2] Gerhard Kristensson. Second Order Differential Equations: Special Functions and their Classification. Springer, 2010.
The post Why polynomial coefficients? first appeared on John D. Cook.2026-08-02 00:15:53
Combinatorial problems can be interesting for their own sake, but they are more interesting when there is a connection to a problem outside combinatorics, and the more unexpected the connection the better.
Counting the number of unlabeled rooted trees [1] with n nodes is a pure mathematics problem. Designing numerical methods for solving differential equations is an applied mathematics problem. And yet the two are closely linked.
Let t(n) be the number of distinct unlabeled rooted trees with n nodes. The diagram below shows that the first few terms of this sequence are 1, 1, 2, and 4.

In an earlier post I showed that designing a 4-stage explicit Runge-Kutta method required solving a system of 8 equations in 10 unknowns, leaving two degrees of freedom in the solutions.
The number of constraints c(s) needed to design an s-stage explicit RK method is equal to the number of rooted trees with up to s nodes:
c(s) = t(1) + t(2) + t(3) + … + t(s)
This is because there is a one-to-one correspondence between constraints on the nth derivative of an RK formula and rooted trees, and an s stage method has to satisfy the constraints of all stages up to s. In the example of the 4th order RK method, we have
c(4) = t(1) + t(2) + t(3) + t(4) = 1 + 1 + 2 + 4 = 8.
The first few values [2] of t(n) are
1, 1, 2, 4, 9, 20, 48, 115, 286, 719, 1842, 4766, 12486, 32973, …
and so you can see that t(n) grows quickly. In fact, it grows exponentially [3].
However, the number of parameters in an s stage RK method is s(s + 1)/2. The number of equations grows exponentially and the number of variables grows only quadratically, so at some point you have more equations than variables. That’s already the case for s = 5 because you have 17 constraints on 15 variables. The system has a solution because symmetry considerations render some of the equations redundant.
A 10th order RK method requires 17 stages. (See the previous post for why the number of stages exceeds the order when the order is greater than 4.) Designing such a method would require solving over a million equations in 153 variables, and yet it can be done. [4]
[1] This is a slightly contradictory term. Unlabeled means the we don’t distinguish the nodes. But we do distinguish one node, namely the root.
[2] See OEIS A000081.
[2] Richard Otter proved in 1948 that the number of unlabeled rooted trees with n nodes is asymptotically C αn / n−3/2 where C = 0.4399… and α = 2.9557…. The cumulative sum is at least this large since Otter’s estimate gives the size of the last term in the sum.
[3] E. Hairer. A Runge-Kutta Method of Order 10. J. Inst. Maths Applics (1978) 21, 47-59
The post Counting rooted trees first appeared on John D. Cook.2026-08-01 23:58:15
The textbook version of the Runge-Kutta method for solving differential equations has 4 stages and has 4th order error. For lower order versions of RK the number of stages s also matches the order of the error p. But in order to achieve error on the order of p ≥ 5, you need more than p stages. This is known as the Butcher barrier.
Before going any further, let’s back up and say what we mean by stages and by order.
The number of stages in an RK method to solve the equation

is the number of evaluations of the function f on the right-hand side. For example, the textbook RK4 method estimates the solution at each step by

where

which requires four stages, i.e. four evaluations of f.
A differential equation solver is said to have order p if the local error, the error after one step of size h, is O(hp + 1). Then after solving an ODE over a period of time T with N = T/h steps, the global error is O(hp). So, for example, if p = 4, you would expect that cutting your step size h in half would cut your error at T by a factor of 16.
John C. Butcher proved that an explicit RK method of order p requires s stages where s > p if p > 4.
An important example is the Dormand-Prince method. It is a version of RK that has order 5 and 7 stages. The clever thing about this method is that you can make a 4th order solver out of a subset of its function evaluations.
That means that after you’ve evaluated one step of the 5th order method, you can also evaluate a 4th order method essentially for free. And by comparing them, you can get a sense of the error. If the solutions given by the two methods are substantially different, you have probably taken too big a step and need to back up. If the two solutions essentially agree, you’re probably good to take the next step.
For an explict RK method to have order 5, 6, or 7 you need at least 6, 7, or 9 stages respectively.
The post Runge-Kutta order versus stages first appeared on John D. Cook.2026-08-01 02:59:02
I was digging into the Runge-Kutta method for solving differential equations and a line from [1] piqued my curiosity.
These calculations, which are not reproduced in Kutta’s paper (they are however in Huen (1900)), are very tedious.
The calculations are a set of eight constraints that the parameters of a fourth-order Runge-Kutta method must satisfy. I wondered how well Mathematica might have done at assisting Mr. Huen in his “very tedious” calculations if it had been available in 1900.
I go into Runge-Kutta methods in this post. Here I’d like to concentrate on a step in the design of the methods, namely solving the set of equations alluded in the quote above.

The first thing to note is that there are 10 variables and only 8 equations, and so the solution is not fully determined. What we think of as the fourth order Runge-Kutta method is in fact a fourth order Runge-Kutta method.
One could argue that we should have b2 = b3 and c2 = c3. With these additional equations, the system of equations has a unique solution, and Mathematic finds it easily.
eqs = {
b1 + b2 + b3 + b4 == 1,
b2*c2 + b3*c3 + b4*c4 == 1/2,
b2*c2^2 + b3*c3^2 + b4*c4^2 == 1/3,
b3*a32*c2 + b4*(a42*c2 + a43*c3) == 1/6,
b2*c2^3 + b3*c3^3 + b4*c4^3 == 1/4,
b3*c3*a32*c2 + b4*c4*(a42*c2 + a43*c3) == 1/8,
b3*a32*c2^2 + b4*(a42*c2^2 + a43*c3^2) == 1/12,
b4*a43*a32*c2 == 1/24,
b2 == b3,
c2 == c3
};
vars = {b1, b2, b3, b4, c2, c3, c4, a32, a42, a43};
solution = Solve[eqs, vars]
This returns the parameters used for the version of Runge-Kutta presented in every textbook.
If you keep the requirement b2 = b3 but substitute the requirement 2c2 = c3 for c‘s Mathematica will return the coefficients for the so-called Runge-Kutta 3/8 rule. This method has some slight advantages by some criteria.
In 1951 Gill [2] discovered a fourth order Runge-Kutta rule optimized for running in extremely constrained computer hardware. It’s a strange method, with irrational parameters, but one that was a very clever response to the limitations of its time.
Update: See this post for a discussion of the parameters and constriants for higher-ordered RK methods.
[1] Hairer, Nørsett, and Wanner. Solving Ordinary Differential Equations I: Nonstiff Problems. Springer-Verlag 1987.
[2] A. Gill. A process for the step-by-step integration of differential equations in an automatic digital computing machine. Proc. Cambridge Philos. Soc., vol 27, pp 95–108.
The post Solving the RK4 design equations first appeared on John D. Cook.