2024-03-04 09:52:39
Use from typing import dataclass_transform
其实动机很简单,众所周知对于 SQLAlchemy 1.4 想要 typing 可以安装 sqlalchemy2-stub,对于 < 1.4 也可以有 sqlalchemy-stub。然而对于最新的 SQLAlchemy >= 2.0,因为它自己有类型注释,但是又很少,所以还没有一个很好的解决方案。本文就是为了介绍一种我摸索出的解决方案,基本上可以完美解决 SQLAlchemy Model / ORM 的 typing 问题。
当然,如果你在手写 raw sql,那肯定是没办法自动弄好类型的,不要做梦了🚫。本文只针对使用了 SQLAlchemy ORM Model 的用户。
基本思路是,Python 在 PEP 681 (>= Python 3.11) 当中为 typing 模块提供了一个 dataclass_transform decorator,可以将第三方的 class 标注为和原生的 dataclass 提供类似的功能:
Most type checkers, linters and language servers have full support for dataclasses. This proposal aims to generalize this functionality and provide a way for third-party libraries to indicate that certain decorator functions, classes, and metaclasses provide behaviors similar to dataclasses.
These behaviors include:
- Synthesizing an
__init__method based on declared data fields. <-- good for us- Optionally synthesizing
__eq__,__ne__,__lt__,__le__,__gt__and__ge__methods.- Supporting “frozen” classes, a way to enforce immutability during static type checking.
- Supporting “field specifiers”, which describe attributes of individual fields that a static type checker must be aware of, such as whether a default value is provided for the field. <-- mostly good for us
总体来讲这个 decorator 提供了所有我们想要的功能,唯一的问题是 field: type = mapped_column(...) 会导致 type checker 认为 field 是 Optional 的。但总归基本的类型检查是能用的,甚至能兼容外键和 relationship,只是在初始化类的时候会有提供参数没写全的风险。如果感觉这样不够好,可以通过给每个 Model 编写一个 dummy __init__ 的方式来把 optional 干掉:
1 |
class A(Base): |
实践上,我们为了方便,可以直接在 SQLAlchemy 的 Base class 上面使用这个 decorator,这样就不用每次定义一个 Model class 都要写一遍了。
1 |
from sqlalchemy import Integer, String, Text, text, ForeignKey |
这里 class Base(DeclarativeBase): 写法得到的 Base class 和 Base = declarative_base() 得到的 Base 在功能上是一样的,但是给了我们使用 dataclass_transform 的空间。
2023-03-07 16:48:02
We (distro packagers) decided to modify GCC spec to get rid of just way too many atomic symbol missing error. AFAIK debian does the same thing in the same way.
So, you may notice that some program compiles without -latomic flag, but that's not the case if you switch to some other distros. I wrote another blog post explaining this in detail.
In short: For GCC you should add -latomic if you use std::atomic<T> where sizeof(T) is lower than 4. Also apply to those __atomic_compare_exchange_2() stuff. Clang is not affected.
This approach requires you to be on a non-RISC-V Arch Linux (x86_64 or aarch64, etc.) machine, because we use pacstrap and pacman.
1 |
# pacman -Syu then reboot is recommended before this |
The default root password is archriscv. You will be asked to change the root password the first time you boot the machine. DO NOT LEAVE IT BLANK, or you won't be able to login as root user later.
If, in the last step, you find yourself stucked at [ OK ] Reached target Graphical Interface for too long, just press Ctrl-C and re-run startqemu.sh.
After booting the machine, you may need to install necessary packages:
1 |
sudo pacman -S git vim gcc |
mkrootfs首先执行 /usr/share/makepkg/util.sh 来初始化当前的 bash 环境。这个脚本由 Arch Linux 的 makepkg 提供,里面有许多工具函数,例如 msg 函数可以往屏幕上打印出好看的 log。
1 |
. /usr/share/makepkg/util.sh |
解析参数、显示帮助的部分这里略过。
创建 rootfs 的第一步是确保将会被视作 rootfs 的 / 目录的新创建的文件夹权限正确:
1 |
mkdir -p ./rootfs |
随后调用 pacstrap 来生成 rootfs。
1 |
sudo pacstrap \ |
这里的 /usr/share/devtools/pacman-extra-riscv64.conf 是类似于 /etc/pacman.conf 的一个配置文件,其中声明了包括软件源在内的一些配置:
1 |
#[testing] |
这里的软件源配置比较重要,是 pacstrap 魔法的一部分。实际上,在调用 pacstrap 时,传入的 base 参数就告诉 pacstrap 需要从上述源里面下载、安装 base 组里面所有的软件包,其中就包括了 linux、glibc 和 pacman。而上述源就是 riscv64gc 架构的源,其中的软件包均面向 riscv64gc 架构编译,因此可以在 RISC-V 64 位 CPU 上的 Arch Linux 操作系统中运行。在 pacstrap 执行完毕后,base meta package 中的所有软件包都已安装完成,这时的 rootfs 已经安装了 Arch Linux 的最小发行版。
再往下,则是配置镜像源。
1 |
sudo sed -E -i 's|#(Server = https://riscv\.mirror\.pkgbuild\.com/repo/\$repo)|\1|' ./rootfs/etc/pacman.d/mirrorlist |
https://riscv.mirror.pkgbuild.com 为 Arch Linux 维护者在 pkgbuild.com 域名上为 Arch Linux RISC-V 创建的全球镜像。如果不添加这个镜像,初始的默认源从国内访问可能较慢或干脆无法访问。
1 |
sudo pacman \ |
清空 pacman 的软件包缓存。通过 --sysroot 参数指定了 rootfs。
1 |
sudo usermod --root $(realpath ./rootfs) --password $(openssl passwd -6 "$password") root |
设置系统密码。默认为 archriscv。usermod 的 --password 接受的是密码的哈希,因此需要使用 openssl passwd -6 "$password" 算出给定的密码的哈希,再传给 usermod。
1 |
sudo bsdtar --create \ |
将配置完毕的 rootfs 文件夹压缩为 .tar.gz 格式,使用 --xattrs 以确保文件的 extended attribute 得到保留。压缩成功后,可以删除刚才临时创建的 rootfs 文件夹。
mkimgTBD
2022-10-09 02:19:04
问题描述
多目标对象追踪(Multi-Object Tracking, MOT)一直是计算机视觉(Computer Vision,CV)领域中非常重要的研究对象,其核心是通过分析输入的图像序列,构建出不同帧的物体间的对应关系。多目标对象追踪常被用于自动驾驶、人流量统计、水果分拣、嫌犯追踪等领域,在工业中存在着广泛的应用。
目前,研究者已经提出了许多的多目标对象追踪算法。按照工作流程分类,MOT 算法分为基于检测的追踪(Detection-Based Tracking, DBT)和无检测追踪(Detection-Free Tracking, DFT)两类[1]。DBT 依赖于对象检测,通常建立在一些已有的多目标对象检测及分类算法,如 YOLO[2] 等算法的基础上;而 DFT 则不需要对象检测的参与。有关 DBT 和 DFT 的特点可以参考表 1。
| DBT | DFT | |
|---|---|---|
| 初始化 | 自动;不完美 | 人工介入;完美 |
| 画面中对象数量 | 可变 | 固定不变 |
| 优点 | 无需人工介入,画面中物体数量可变 | 不需要识别器和分类器 |
| 缺点 | 性能受到识别器和分类器的限制 | 需要人工介入 |
| 常见应用场景 | 物体种类固定,画面中物体数量改变 | 物体种类不固定,但运动范围较小 |
而如果按照实现方法分类,多目标对象追踪算法可以被分成传统算法和基于机器学习的算法两类,其中传统算法通常工作在单摄像头场景下,基于机器学习的 MOT 算法在多摄像头场景下也工作良好,也更能适应工业上的多种应用需要[3]。因此,本文主要聚焦于近五年来提出的基于机器学习的 MOT 算法研究进展。
近期研究综述
近年来,随着机器学习理论和模型的不断发展,MOT 领域相关的研究热度也在持续上升。自 2017 年 DeepSORT[4] 被提出起,在短短的几年内涌现出一大批基于机器学习的高性能、高准确率的 MOT 算法,如 CenterTrack[5]、Tracktor++[6] 等。有些研究成果很好地解决了在某些特定领域内特定需求下的准确率问题,有些则提出了新的网络结构和模型架构,福泽所有在这一领域开展研究的研究人员。本文试图以时间顺序为主轴,按照这些研究所解决的问题的种类来分类不同的研究,并综述各研究的思路和主要成果。
虽然将机器学习引入 MOT 算法的研究很早以前就已经开展,但是真正在准确率上做出突破性提升的是 2017 年的 DeepSORT。DeepSORT 在原本的基于卡尔曼滤波(高斯滤波)预测和匈牙利匹配计算最优解的 SORT[7] 算法的基础上引入了深度学习的概念,在一个大规模的行人重识别数据集上训练,增加了对图像部分缺失和短时间遮挡的鲁棒性,同时保持了算法的高效性[4]。并且 DeepSORT 是一个在线(Online)算法,其在识别物体关联和轨迹时只需要参考过往的信息,无需参考未来的图像,因此它能够工作在实时输入的视频流上,使用场景更广。
不过,由于 DeepSORT 仍然工作在 SORT 基础上,因此 SORT 存在的缺陷仍然会在 DeepSORT 中存在。例如,SORT 采用卡尔曼滤波预测物体在下一帧中的位置。卡尔曼滤波为贝叶斯滤波在置信度用多元正态分布的特殊情况下推导得出,可得其函数表示如下: \[p(x)=\det(2\pi S)^{-\frac{1}{2}}\exp\left( -\frac{1}{2}(x-\mu)^{T}S^{-1}(x-\mu)\right)\\\] 其中,\(\mu\) 为样本均值,\(S\) 为样本方差。然而实际上,由相机录制的视频往往存在不满足正态分布的位移扰动如手持相机导致的不规律抖动,不难想到此时卡尔曼滤波模型产生的结果的准确度会降低。这也是 DeepSORT 算法的主要缺点。
在随后的一段时间内,虽然又有一些基于机器学习的 MOT 算法被提出,但它们对准确率的提升微乎其微,甚至在两年中仅仅使得最佳准确率(State-of-the-Art,SOTA)提升了 2%[1]。这时,Bergmann 团队在 ICCV2019 上发布了 Tracktor 算法的论文[6]。这篇论文不仅部分否定了过去两年中全世界研究人员普遍采用的检测器和追踪器配合的思路、简化了此前的网络模型,还对 SOTA 的提升做出了贡献。具体来讲,Bergmann 团队尝试了仅仅使用检测器和物体检测算法,通过引入回归层来调优物体检测的外接矩形(Bounding Box)位置的做法,实现了性能优秀且准确率高的 MOT 算法。这种实现方式的优势主要有两点:首先,无需额外训练追踪器,不仅节约了算力,也降低了性能和功耗要求;再者,检测器全部为在线算法,回归层也只需要参考此前的输入和输出,因此 Tracktor 算法同样是在线算法。不过,Tracktor 算法也同样存在一定的缺点。例如,Tracktor 无法解决由于物体相互遮挡导致身份交换(Identify Switch,IDSW)的问题。为了解决这一问题,在同一篇论文中作者还提出了 Tracktor++ 算法,通过引入短期(Short-Term)身份重识别(Re-Identification, ReID),基于 Siamese Network 提取出物体的表面特征来帮助匹配[6]。然而,加入 ReID 导致了计算耗时的增加和性能的下降,为此作者还额外提出了通过等速假设和增强型相关系数最大化这两种运动模型(Motion Model)来改善预测的外接矩形在下一帧中的位置以减少 ReID 匹配耗时。
这一阶段同样有一些别的改进 DeepSORT 的研究,例如有一些 MOT 爱好者在私下尝试将 DeepSORT 中的 SORT 部分替换为其它的目标检测算法如 YOLOv4 甚至 YOLOv5,同样也取得了接近 SOTA 的效果,并且摆脱了 SORT 算法的固有缺陷。在正式的期刊中同样出现了类似的研究,例如有团队提出通过遮挡组管理(Occlusion Group Management)来改进 DeepSORT 算法的匹配部分[8]。然而 2020 年提出的 CenterTrack 算法[5] 指出了他们所采用的检测器和追踪器同时训练(Joint Learning the Detector and Embedding Model,JDE)方法中存在的固有缺陷,2021 年提出的 FairMOT 算法[9] 同样也注意到了这些缺陷。二者均在传统的 JDE 基础上做出了有针对性的改进,通过将 Anchor-Based 检测替换为 Anchor-Free 检测,缓解了这些问题,在多个数据集上取得了 SOTA 的成绩。在 FairMOT 的论文中,作者提出,目前 JDE 训练的检测方式为同时提取检测框和检测框内物体的 ReID 信息,然而由于同一个物体可能出现在多个检测框中,会导致较高的网络模糊性。同时,物体的实际中心可能并不是其外接矩形的几何中心,这就可能导通过几何中心计算出的位移距离和实际位移距离存在偏差。CenterTrack 算法采用了基于其灵感来源 CenterNet 的基于物体实际中心点的检测[10],采用这种方式能够更加准确地提取到物体的特征用于 ReID 层,可以更好地避免身份互换的问题。FairMOT 算法同样采用了基于物体实际中心点的特征检测,并且还引入了类似编码器和解码器模型(Encoder-Decoder Model)的网络,通过逐层降采样、分层提取特征信息的方式产生经过融合的多层信息,恰好满足了 ReID 算法需要多层融合信息的需求。提取出的高分辨率特征信息将根据其维度分别送入检测器和 ReID 层,最终取得了很好的效果。
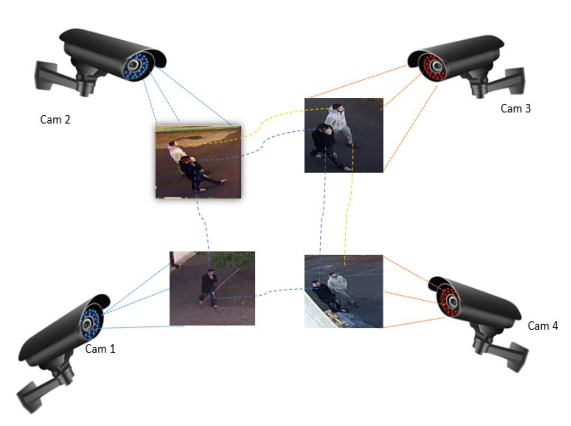
除了改进基于 ReID 的匹配算法外,也有一些研究聚焦于如何更好地计算不同实例的相似度以提升准确率。Pang 团队在 2021 年提出了 QDTrack 算法[11] 便是如此。Pang 团队认为,此前工作仅仅利用像素级先验知识进行追踪,这种方法大多只适合一些简单的场景,当目标较多、存在大量遮挡或拥挤现象时,单纯基于位置信息的匹配很容易产生错误的结果。因此,QDTrack 通过拟密集(Quasi-Dense)匹配,支持在一张图片中创建上百个兴趣区域,通过对比损失以学习网络参数,尽可能多地利用图片中的已有信息。下图为展示 QDTrack 创建上百个兴趣区域的示意图。
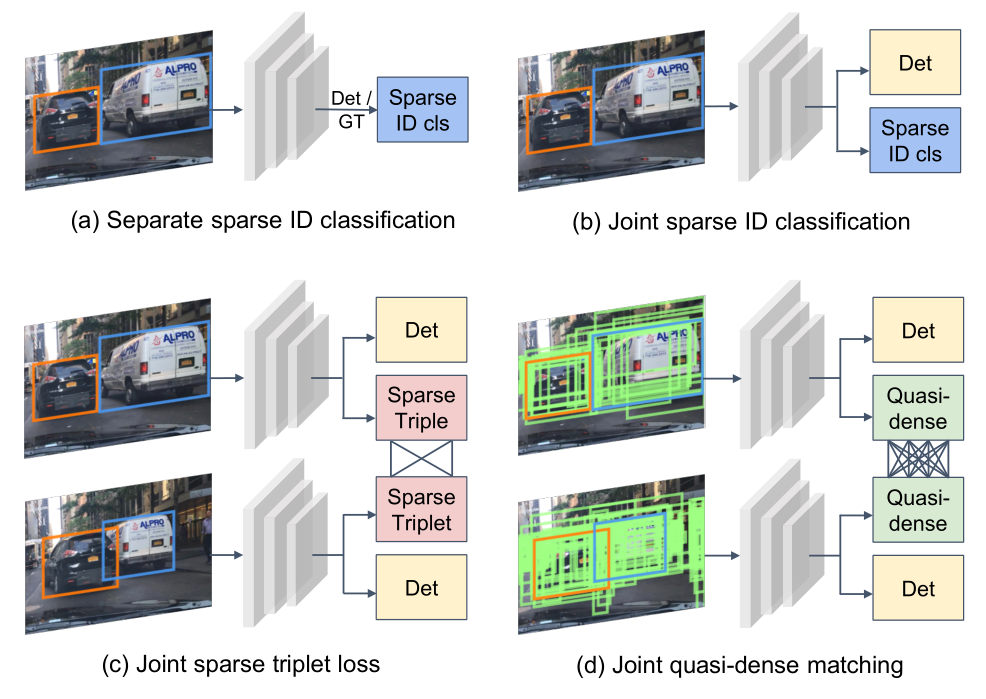
同时,由于目标较多的场合下一定会频繁出现新目标进入画面和已有目标在画面边缘消失的情况,因此作者将背景单独作为一类参与训练和匹配,从而能够通过双向 Softmax 函数增强一致性。由于学习到的实例相似度特征太好,在最终的关联步骤即使是仅仅采用最简单的最近邻搜索也能得到非常好的匹配准确率。QDTrack 在采用了 Softmax 函数后的目标函数如下所示[11]: \[\mathcal{L}_e=\log \left[1+\sum_{\mathbf{k}^{+}} \sum_{\mathbf{k}^{-}} \exp \left(\mathbf{v} \cdot \mathbf{k}^{-}-\mathbf{v} \cdot \mathbf{k}^{+}\right)\right]\] 其中,\(\mathbf v, \mathbf{k}^{+}, \mathbf{k}^{-}\) 分别为训练样本、正目标样本和负目标样本的特征嵌入(Embedding)。这里的 Embedding 指的是是一种把原始输入数据分布地表示成一系列特征的线性组合的表示方法。
随后的研究表明,Quasi-Dense 特征匹配方案的泛化性很强。Hu et al. 在 2022 年将 Quasi-Dense 泛化到三维空间中的多目标对象匹配问题上,提出了 QD-3DT 算法[12]。该算法能够基于单目摄像头的二维的图像序列输入,给出估计的物体在三维空间中的外接矩形,并且在相邻帧中以高准确率和良好的性能匹配识别到的物体。论文作者在自动驾驶的常见场景下测试了该算法,取得了非常优秀的结果。需要注意的是,自动驾驶的应用场景比较特殊,涉及到人类的生命安全,故通常要求算法的鲁棒性极高。QD-3DT 在测试中很好地适应了雨天和夜晚等行驶条件,证明了拟密集匹配算法的优越性[12]。
未来展望
目前看来,2021 年前后提出的一些算法和模型(如 QDTrack)已经能够满足绝大多数场景下的使用需求,二维场景下的多目标匹配问题可以认为已经得到了较好的解决。因此,未来的发展或许主要会聚焦在两个方向上:第一个方向是使得学术界的模型能够尽快在工业届投入使用,在实践中检验模型存在的不足,并尝试逐步替换掉目前广泛使用的 DeepSORT 模型;第二个方向是尝试将上述算法泛化、迁移至 3D 领域,解决三维空间中的多对象匹配问题,从而更好地服务于自动驾驶和工业控制等领域。不过,在解决三维空间中多对象匹配问题时,可能需要模型有能力接受来自不同位置的多个摄像头的输入以增强匹配的准确度,此方向的研究暂时还比较空白。考虑到工业届对这类算法存在较大的需求,可以预计在未来一定会有一些优秀的相关成果出现。
参考文献
[1] Luo, W., Xing, J., Milan, A., Zhang, X., Liu, W., & Kim, T.-K. (2021). Multiple object tracking: A literature review. Artificial Intelligence, 293, 103448. https://doi.org/10.1016/j.artint.2020.103448
[2] Bochkovskiy, A., Wang, C.-Y., & Liao, H.-Y. M. (2020). YOLOv4: Optimal Speed and Accuracy of Object Detection. doi:10.48550/ARXIV.2004.10934
[3] Kalake, L., Wan, W., & Hou, L. (2021). Analysis based on recent deep learning approaches applied in real-time multi-object tracking: A Review. IEEE Access, 9, 32650–32671. https://doi.org/10.1109/access.2021.3060821
[4] Wojke, N., Bewley, A., & Paulus, D. (2017). Simple online and realtime tracking with a Deep Association metric. 2017 IEEE International Conference on Image Processing (ICIP). https://doi.org/10.1109/icip.2017.8296962
[5] Zhou, X., Koltun, V., & Krähenbühl, P. (2020). Tracking objects as points. Computer Vision – ECCV 2020, 474–490. https://doi.org/10.1007/978-3-030-58548-8_28
[6] Bergmann, P., Meinhardt, T., & Leal-Taixe, L. (2019). Tracking without bells and whistles. 2019 IEEE/CVF International Conference on Computer Vision (ICCV). https://doi.org/10.1109/iccv.2019.00103
[7] Bewley, A., Ge, Z., Ott, L., Ramos, F., & Upcroft, B. (2016). Simple online and realtime tracking. 2016 IEEE International Conference on Image Processing (ICIP). https://doi.org/10.1109/icip.2016.7533003
[8] Song, Y.-M., Yoon, K., Yoon, Y.-C., Yow, K. C., & Jeon, M. (2019). Online multi-object tracking with GMPHD Filter and Occlusion Group management. IEEE Access, 7, 165103–165121. https://doi.org/10.1109/access.2019.2953276
[9] Zhang, Y., Wang, C., Wang, X., Zeng, W., & Liu, W. (2021). FairMOT: On the fairness of detection and re-identification in multiple object tracking. International Journal of Computer Vision, 129(11), 3069–3087. https://doi.org/10.1007/s11263-021-01513-4
[10] Duan, K., Bai, S., Xie, L., Qi, H., Huang, Q., & Tian, Q. (2019). CenterNet: Keypoint Triplets for object detection. 2019 IEEE/CVF International Conference on Computer Vision (ICCV). https://doi.org/10.1109/iccv.2019.00667
[11] Pang, J., Qiu, L., Li, X., Chen, H., Li, Q., Darrell, T., & Yu, F. (2021). Quasi-dense similarity learning for multiple object tracking. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). https://doi.org/10.1109/cvpr46437.2021.00023
[12] Hu, H.-N., Yang, Y.-H., Fischer, T., Darrell, T., Yu, F., & Sun, M. (2022). Monocular quasi-dense 3D object tracking. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1–1. https://doi.org/10.1109/tpami.2022.3168781
2022-08-25 20:31:29
XieJiSS, revision 3
本文可能不会及时更新,请以RV64 板子更换 rootfs 指南 - archriscv-packages Wiki为准
请确保你或你的同伴可以在物理上(通过串口)访问到板子。否则,你的板子将在 0x02 的第 6 步重新启动时失联。
首先,以 root 身份回到根目录:
1 |
sudo su |
下载 rootfs tarball(确保安装了 wget):
1 |
mkdir new && cd new |
在根目录创建 old 文件夹:
1 |
mkdir old |
看一下 fstab:
1 |
cat /etc/fstab |
最好拍照或截图备查。
获取当前的 Linux 内核版本:
首先,初始化用于从 vmlinuz 提取内核版本的脚本。vmlinuz 一般位于 /boot 目录下,需要 root 权限才能访问。
1 |
kver_generic() { |
执行 kver_generic /boot/vmlinuz,记住 Linux 内核版本。可以将其赋值给一个临时的 shell 变量,也可以继续拍照记录:
1 |
linux_kver=$(kver_generic /boot/vmlinuz) |
注意,如果你当前的系统没有开启内核压缩,那么可能需要将 vmlinuz 修改为 vmlinux。
看一下 ip addr 和 router 的地址:
1 |
这里 eth0 可能需要按实际情况修改,ip addr show 可以查看全部 device |
记录 inet 行的 IP,这是你本机当前的 IP 地址。之后会用到,建议拍照或截图留存。(包括 IP 后面的 /24,如果显示的不是 /24 那么之后步骤中也要对应修改成此时显示的后缀)
其实理论上这步不需要的,用 dhcp 即可。但似乎 PLCT 南京内网的端口转发本质上基于静态 IP,依赖了 dhcp 客户端重启后服务端优先发放此前释放的 IP 的特征,并不稳定。建议还是在 0x02 的第七步里配成静态 IP。
1 |
ip route show dev eth0 |
记录 default via 后面的 IP 地址,这个就是你的板子所在局域网的 router 的地址。建议拍照或截图留存。
如果目标板子不在 PLCT 南京内网,并且你并不理解上述命令的用途:建议在此停下,先和 mentor 讨论清楚网络拓扑再继续。
记录几个关键路径(不用真的记,反正这里有):
1 |
/new/lib/ # 后面步骤中会设置为 LD_LIBRARY_PATH |
在新的 rootfs 并非 Arch Linux 时,可能需要将 /lib 替换为 /usr/lib。原因详见:The /lib directory becomes a symlink - Arch Linux News
移动文件夹
1 |
mv etc home media mnt opt root srv var old/ # 这里保留 /boot |
继续移动文件夹
1 |
LD_LIBRARY_PATH=/new/lib/ /new/lib/ld-linux-riscv64-lp64d.so.1 /new/bin/mv bin sbin usr lib old/ |
/lib/firmware 是 Ubuntu on Unmatched 的 firmware 路径,可能需要按实际情况修改。
把 kernel modules 移动回来
1 |
mv old/usr/lib/modules/$linux_kver ./lib/modules/ |
这里的 $linux_kver 是前面「获取当前的 Linux 内核版本」步骤中设置的。
dtbs、vmlinuz 等均位于
/boot下,此前并未覆盖/boot因此在这一步不用操心它们。备注:一般来讲,新 rootfs 的 tar 文件里面并不会包含 dtbs 和 vmlinuz 等文件,它们一般会出现在.img或.iso内,这超出了 rootfs 的范畴,故本文不做详细解释。
修改 fstab
1 |
echo "LABEL=cloudimg-rootfs / ext4 discard,errors=remount-ro 0 1" >> /etc/fstab |
注意这里可能需要根据之前看的 fstab 内容来酌情修改第一行,例如原本是 vfat 的盘你肯定不会希望它被设置成按照 ext4 格式读取。
第二行的 tmpfs 是因为我们稍后要启用 systemd-timesyncd,但是不希望它太过影响硬盘寿命。如果你不在乎,可以丢掉这行。
重启机器。
重启后已经是 Arch Linux 了。开始配网络和 fstab:
1 |
echo test > test.txt # 测试 / 是否被 mount 为 rw |
1 |
# /etc/dhcpcd.conf |
更新 pacman 软件源,随后再次重启。
1 |
pacman -Syu --noconfirm |
跑完 Syu 如果不重启,可能会遇到很多「升级升了一半」导致的问题,例如找不到 kernel module、找不到各种符号等等。
2022-07-23 14:35:16
flag1 in the source code1 |
const user1 = createUser(~~(1 + Math.random() * 1000000), "test", fs.readFileSync(__dirname + "/flag1.txt", "utf8")); |
user1.flag
1 |
bot.on("callback_query", async (query) => { |
This object represents an incoming callback query from a callback button in an inline keyboard.
Field Type Description id String Unique identifier for this query from User Sender data String Optional. Data associated with the callback button. Be aware that the message originated the query can contain no callback buttons with this data.
Conclusion: We need to make sure that in the provided callback_data, the substring before the first _ equals to user1's uid.
We can tell that the callback data is set in the handler of /login, and there are three types of them:
"0_login_callback:" + msg.chat.id + ":" + msg.message_idauthorizedUids[0].uid + "_login_callback:" + msg.chat.id + ":" + msg.message_id"-1_login_callback:" + msg.chat.id + ":" + msg.message_idHence, we only need to click the button exactly when the second kind of callback data appears. Under the competition environment, the time frame available for this is about 400ms. Since the first type of callback data will last for 2 seconds to 16 seconds, trying to click the button with human hands and expecting the flag to appear is probably not feasible.
After a quick search in Google, we can find two major automated Telegram MTProto API Framework: Telethon and Pyrogram. Here, a solution based on pyrogram is provided:
1 |
import asyncio |
The above code will be triggered twice per a
/login's response message, but that's OK.
There are 3 expected methods to solve this challenge.
root user's userid is set to 777000, which is the same as Telegram official account's userid. In other words, we need to let the official account send /iamroot to the bot. This is not quite possible; however, if we search for "Telegram 777000" on Google, we can find a GitHub issue: [BUG] PTB detect anonymous send channel as 777000. By observing the screenshot, we can see that when a channel is linked to a group (see also: Discussion Groups), messages sent in the channel will be automatically forwarded to the discussion group. This forward operation is actually done by user 777000, which means that bot will think this message comes from Telegram's official account.
But the exploit is not so easy. If we invite the bot to a group, it will quit automatically:
1 |
bot.on("my_chat_member", async (update) => { |
Thus, the problem becomes "how to stop the bot from quitting groups".
We may recognize that in the callback function bind to the my_chat_member event, an if statement is used to check whether update.chat.id starts with -100. Telegram's groups and channels use merely the same underlying codes, and their chatIds both start with -100. However, people familiar with Telegram will know that not all groups starts with -100. This is caused by one of the history burdens of Telegram. Specifically, Telegram has two types of chats: group and supergroup. Supergroup supports more functions in comparison with group, e.g. setting admins with different admin rights, linking to a channel to act as it's discussion group, obtaining a group username so that it becomes a public group, preserving all history messages, etc. The Telegram dev team is devoting much efforts to hide the UX difference between groups and supergroup. Newly created chats are all groups by default, which has negative chatId but not starting with -100 (Aha!), and will escalate to supergroup automatically when users try to perform actions that are not supported by groups on it. Note that during the escalation process, the group (which is becoming a supergroup) will discard its old chatId and obtain a new one, which starts with -100.
Knowing this, it is not hard to come up with a viable solution:
Updates) again, which will probably trigger the my_chat_member callback again, resulting in the bot leaving the group (because the now supergroup has a chatId starting with -100). To avoid this consequence, you can send 100 garbage messages prior to linking the chat to your channel./iamroot in your channel, and receive flag2.This path is added for those not familiar with Telegram.
Diving into the handler of /addkw key reply command, we can discover that the program tries to write the reply specified by the user into the corresponding entry of user1's keywordMap:
1 |
onText(/^\/addkw (\S+) (\S+)/, async (msg, match) => { |
Noticing keywordMap?. looks suspicious, let's have a quick glance at its definition:
1 |
get(target, prop) { |
Inside the getter function, the key is split at ?. , before accessing corresponding values layer-by-layer. By doing so, it implements something similar to the ?. optional chaining operator. However, here it does not filter the key to be accessed, hence we can construct a prototype pollution. For instance, we set the key to be __proto__, and now we can overwrite Object.prototype.
Send /addkw __proto__?.test 1 to bot, and we can pollute Object.prototype.test:
1 |
const a = {}; |
Read the source code of node-telegram-bot-api, and we can know that the framework tries to determine Update type by a series of ifs:
1 |
// ... |
Obviously, we can pollute any attribute access operation before update.my_chat_member, e.g. chat_member, so that the handler of my_chat_member will never be invoked:
1 |
/addkw __proto__?.chat_member 1 |
If the method of racing condition is to be carried out, some special techniques might be needed. The very first Update the bot will receive after it enters the group is always the Update representing the bot's join chat event, hence making it impossible for other callbacks to be triggered before my_chat_member. What's more, the auto-forwarding of channel messages to linked discussion groups in Telegram has a noticeable lag, so if the attacker invite the bot prior to sending the message in channel, the exploitation will never success.
So, we need to send /iamroot in the channel first, and after sleeping for a proper duration, we'll invite the bot to join the discussion group, so that this message is forwarded to the group between the asynchronous my_chat_member handler's await sendMessage and await bot.leaveChat call.
2022-04-07 22:48:02
UPDATE 2023-05-11: Finally we have builtin inline subword atomic support in GCC!
So we won't be bothered by this issue anymore.
The original blog post:
TL;DR: see "Wrap Up" and "Solution".
Recently, when we're working on a series of package rebuild pipelines triggered by a glibc update (from 2.33 to 2.34), we discovered that some previously compiling packages, mostly configured to use CMake, refuse to compile now. Their error logs look like this:
1 |
/usr/bin/ld: libbson-1.0.so.0.0.0: undefined reference to `__atomic_exchange_1' |
This is quite strange to us, because we used to think we have got rid of this for all by manually appending set(THREADS_PREFER_PTHREAD_FLAG ON) to these packages' CMakeLists.txt, despite replacing all -lpthread with -pthread. This was done in a per-package manner, modifying the patch to meet the need of the tech stack used by the specific package, and we are sure that they used to work before the glibc upgrade.
Before proceeding, you need to know the difference between
-pthreadand-lpthread, and that-pthreadis the most preferable way if you want to link to thepthreadlibrary, at least forglibc<=2.33.
So, what's happening? Is there anything vital got changed in this glibc upgrade?
After reading the release note of glibc 2.34, we did notice something related:
...all functionality formerly implemented in the libraries
libpthread,libdl,libutil,libanlhas been integrated intolibc. New applications do not need to link with-lpthread,-ldl,-lutil,-lanlanymore. For backwards compatibility, empty static archiveslibpthread.a,libdl.a,libutil.a,libanl.aare provided, so that the linker options keep working.
Hmm, good, sounds like we don't need -pthread anymore. Actually, it appeared to us that CMake thinks the same. After running cmake for the failing packages, we can confirm that nothing looks like -pthread is appended to either CXXFLAGS or LDFLAGS. However, if forced to compile with -pthread, the previous-mentioned link error disappears. In other words, applying this patch fixes the error.
1 |
- make |
At this point, every clue we have gathered so far seems to indicate a bug inside cmake:
set(THREADS_PREFER_PTHREAD_FLAG ON) appears to be "broken"-pthread fixes the issue, so cmake failed to recognize that -pthread is necessarySo we dig into CMake's source code to see what happened. To our surprise, we didn't notice any change to the detection code it used for determining whether -pthread is necessary. CMake's detection code, at the time of writing, looks like this:
1 |
|
It turned out that according to the glibc upgrade, this detection code now compiles without additional arguments:
1 |
gcc test_pthread.c |
As far as I can tell, this does not look like a CMake bug. The expected behavior, which is exactly what we have seen, is that if the test code can be compiled without -pthread, then the argument should not be appended to the command like (or {C,CXX}FLAGS, correspondingly). This lead to another question: why those packages are failing now, provided that the detection code is unchanged, and it used to work properly?
Let's take the package mongo-c-driver as an example. As of version 1.21.1, we can see the code listed below in its src/libbson/src/bson/bson-atomic.h (Feel familiar with this path? Remember the libbson-1.0.so.0.0.0: undefined reference error log mentioned before?):
1 |
|
As we can tell from libbson's source code, it attempts to use the __atomic_* builtins of GCC, like __atomic_fetch_add and __atomic_compare_exchange. We can construct some test cases to check whether we're right:
1 |
// test1.c |
1 |
// test2.c |
1 |
// test4.c |
1 |
// test8.c |
Here, we use the gcc built-in
__atomic_*becauselibbsonused it. Replacing this withstd::atomic<T>(and compile it withg++) yields identical results correspondingly. You may also useuint*_tprovided by thelinux/types.hheader, as their sizes are promised to be the same across all architectures.
Compile results:
1 |
gcc test1.c |
If you are kind of familiar with C++, you may have heard that codes using atomic operations might need to link libatomic (I remembered once reading this, but I can't find it now). It turned out that if we provide -latomic to gcc, the code compiles:
1 |
gcc test1.c -latomic |
And this also works for -pthread:
1 |
gcc test1.c -pthread |
Smart readers might have felt something unusual:
First, as we can see, gcc compiles test4.c and test8.c successfully without -latomic or -pthread, but it couldn't handle the atomic operations in test1.c and test2.c without making a call to libatomic:
1 |
gcc test1.c -latomic -S |
This is partially explained in a GitHub issue (riscv-collab/riscv-gcc#12). Till April 2022, i.e. when this blog is written, gcc does not support inlining subword atomics, and this is the reason why -latomic must be presented when invoking gcc.
But what about -pthread? Why -pthread works either? I mean, libpthread itself does not provide those atomic symbols, right? Actually, if you use ldd to check a.out generated by gcc test1.c -pthread, you will notice that libatomic is linked, instead of libpthread as we are expecting from -pthread. Changing -pthread with -lpthread won't work, so gcc must have done something internally for -pthread despite linking libpthread. In order to figure out the difference, we have to check the gcc spec:
1 |
gcc -dumpspecs | grep pthread |
Oh, the answer finally reveals: gcc silently append --as-needed -latomic if -pthread is provided. This also explains why changing -lpthread to -pthread works.
The reason why gcc decided to link libatomic when -pthread is provided had been lost in a squashed commit. My guess is that they tried to cover up the subword atomic pitfall using this strategy. (UPDATE: aswaterman's initial fix did not limit the scope to -pthread. The limitation was added one week later.) Generally, atomics are used with multi-threading, and you use pthread in such cases. However, one may use atomics without pthread, like when writing SIGNAL handlers. So IMO this workaround is not good enough, and should be replaced by subword atomic inline support.
UPDATE: We discussed this with some gcc RISC-V devs, and it turned out that when compiling gcc, at stage 1 it may not recognize libatomic (i.e.
-latomicmay not work) if you are compiling it with a gcc that uses the old spec So you'll have to set--with-specat stage 1 to workaround this. Hopefully there would be an--always-link-libatomicconfiguration flag in the future.
Fun facts: gcc once had added --as-needed -latomic to its LIB_SPEC unconditionally, in this commit (2017-02-01):
1 |
+ #undef LIB_SPEC |
But later in the final port commit submitted to gcc (2017-02-07; svn r245224), they limited the change to -pthread:
1 |
- " " LD_AS_NEEDED_OPTION " -latomic " LD_NO_AS_NEEDED_OPTION \ |
The reason of making such limitation remains unknown.
glibc moved libpthread into libc, and CMake's pthread sample code compiles directly. Hence, CMake thinks there's no need to provide -pthread when invoking gcc / g++. Since we used to patch such packages with -pthread instead of -latomic, and are actually relying on -pthread's side effect (--as-needed -latomic), this led to the consequence that neither -pthread nor -latomic is provided, so subword atomics refuse to compile as libatomic is not linked. For ways of fixing this problem, please refer to the Solution chapter.
Also note that the dependence on libatomic causes another problem. Some packages / frameworks, e.g. JUCE insists that its atomic wrap only accepts lock-free values. However, when a program is compiled, the compiler cannot know whether a call to libatomic will be lock-free or not (actually, the emitted sequence will be lock-free, but the compiler doesn't know). Hence, the compiler will return false for std::atomic<bool>::always_lock_free, and this also happens for the macro ATOMIC_BOOL_LOCK_FREE defined in atomic.h. As a result, if you use juce::Atomic<bool>, some static asserts will fail, and the package refuses to compile.
Solutions vary according to the scale of projects.
export CFLAGS="$CFLAGS --as-needed -latomic" and likewise for CXXFLAGS solve the problem. As an alternative, you can also patch the Makefile file, and edit the flags inside it.CheckAtomic.cmake, which (if you are using a newer version) has taken subword atomics into consideration.clang and compiler-rt. Clang should be able to handle -latomic, but better perform a double-check. You can temporarily rely on the side-effect of gcc -pthread (which is not recommended), or edit your configure script manually to disable -latomic when clang and compiler-rt are detected.clang and compiler-rt, compatibility with older compilers / linkers that do not support --as-needed and even -pthread might need to be considered. CMake reverted their -pthread fix on this because a compiler named XL does not support -pthread, and interprets it as -p -t hread, returning zero (oops! false negative) as its exit code.__atomic_fetch_add, so the problem would not be mitigated (but this patch indicates a good start!).Complicated solutions may increase the burden on project developers / maintainers, and their willingness to port their projects to RISC-V might be reduced. Aiming to tackle the problem, we have proposed to change LIB_SPEC back to its originally patched form to mitigate this issue partially (still not lock-free), and hope that the subword atomic pitfall can be solved completely in the future.
UPDATE: After discussing this with gcc RISC-V devs, we reached the consensus that maybe a gcc configuration argument
--always-link-libatomiccan be added.
UPDATE2: This breaks the bootstrap process of GCC. GCC compiles itself twice to get rid of e.g. dirty compiling environments stuffs. Modifying the spec string too early causes glitches, like libatomic calls itself infinitely. So we have to use
sedto replace the spec string inside the first-stage GCC binary carefully, filling blanks (U+0020) to make sure old and new spec strings have the same length.