2026-07-07 08:00:00
Ampere eMAG 采用的是 Ampere Skylark 微架构,虽然是 2018 年的处理器了,但也顺带评测一下。其前身是 AppliedMicro 的 X-Gene 3 微架构,用在 Ampere eMAG 芯片上,用的是 TSMC 16nm FinFET+ 工艺。
只找到了 X-Gene 2,即 Skylark 更早一代的信息:AppliedMicro X-Gene2
为了测试实际的 Fetch 宽度,参考 如何测量真正的取指带宽(I-fetch width) - JamesAslan 构造了测试,实验结果如下:
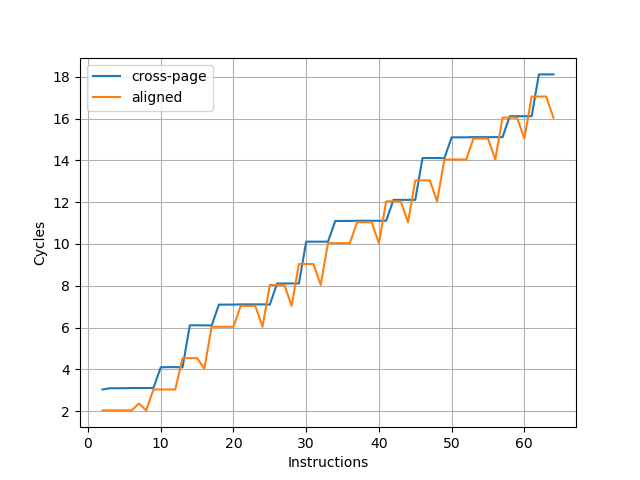
可见取指带宽是每周期四条指令,并且很多时候并不能打满。
为了测试 L1 ICache 容量,构造一个具有巨大指令 footprint 的循环,由大量的 nop 和最后的分支指令组成。观察在不同 footprint 大小下的 IPC:
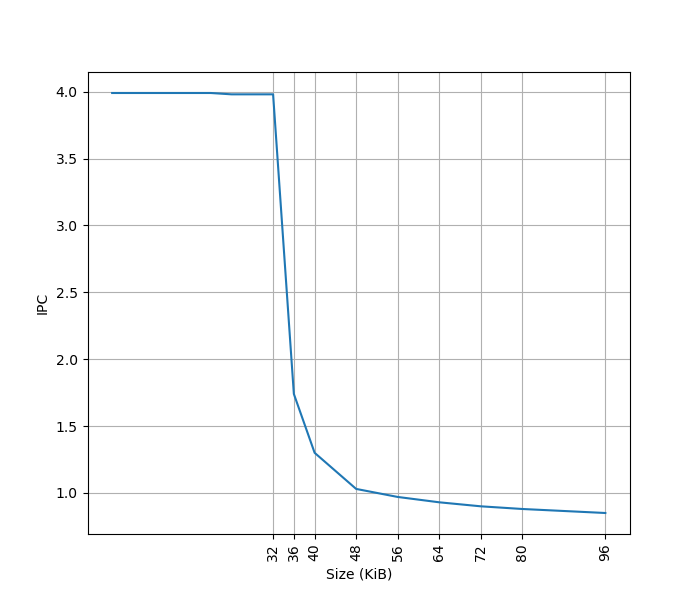
可以看到 footprint 在 32 KB 之前时可以达到 4 IPC,这对应了 32KB 的 L1 ICache。
构造大量的无条件分支指令(B 指令),BTB 需要记录这些指令的目的地址,那么如果分支数量超过了 BTB 的容量,性能会出现明显下降。当把大量 B 指令紧密放置,也就是每 4 字节一条 B 指令时:
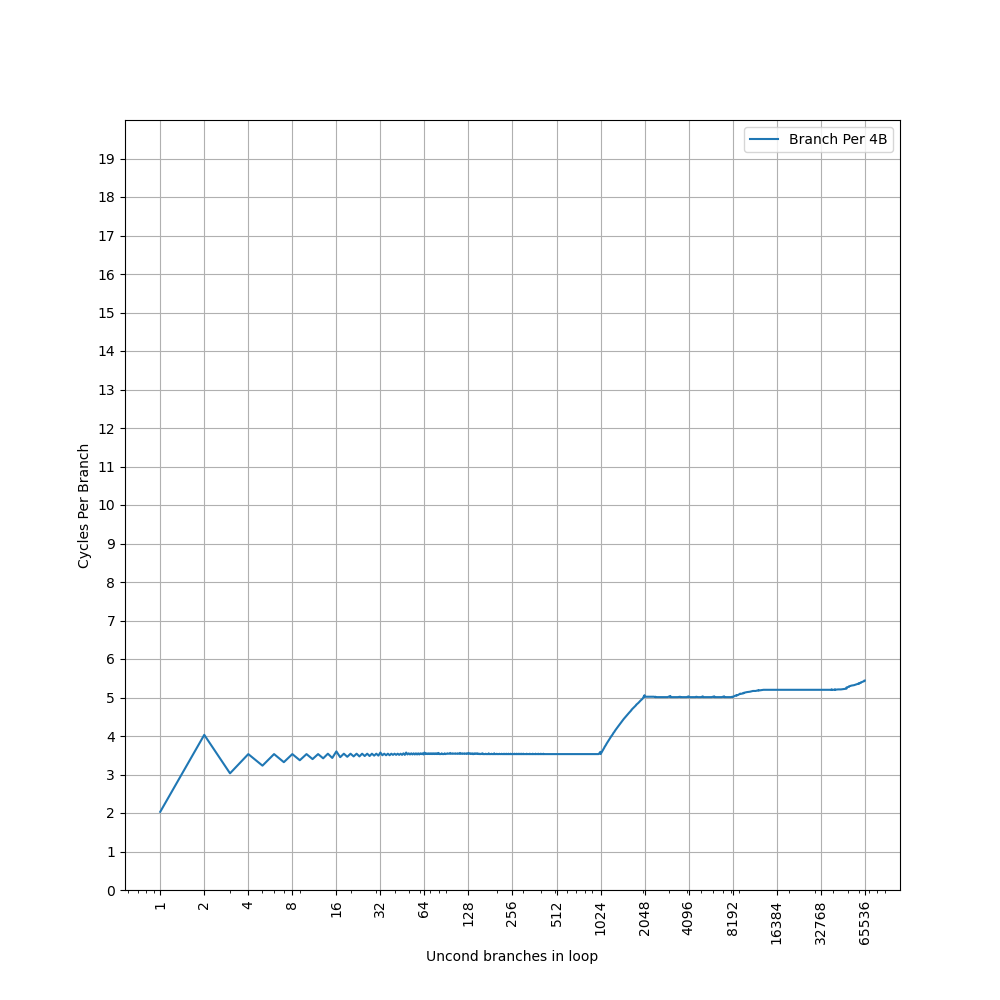
可见 Skylark 的 BTB 对分支紧密放置的情况支持不是很好,在 1024 个分支之内的 CPI 达到了 3.5,这一点在较早的处理器上比较常见,比如 Neoverse N1 的 BTB,不过稍微新一些的处理器,随着设计的改进,类似的情况比较少见了。之后到 8192 个分支,CPI 达到了 5。接着降低分支指令的密度,在 B 指令之间插入 NOP 指令,使得每 8 个字节有一条 B 指令,得到如下结果:
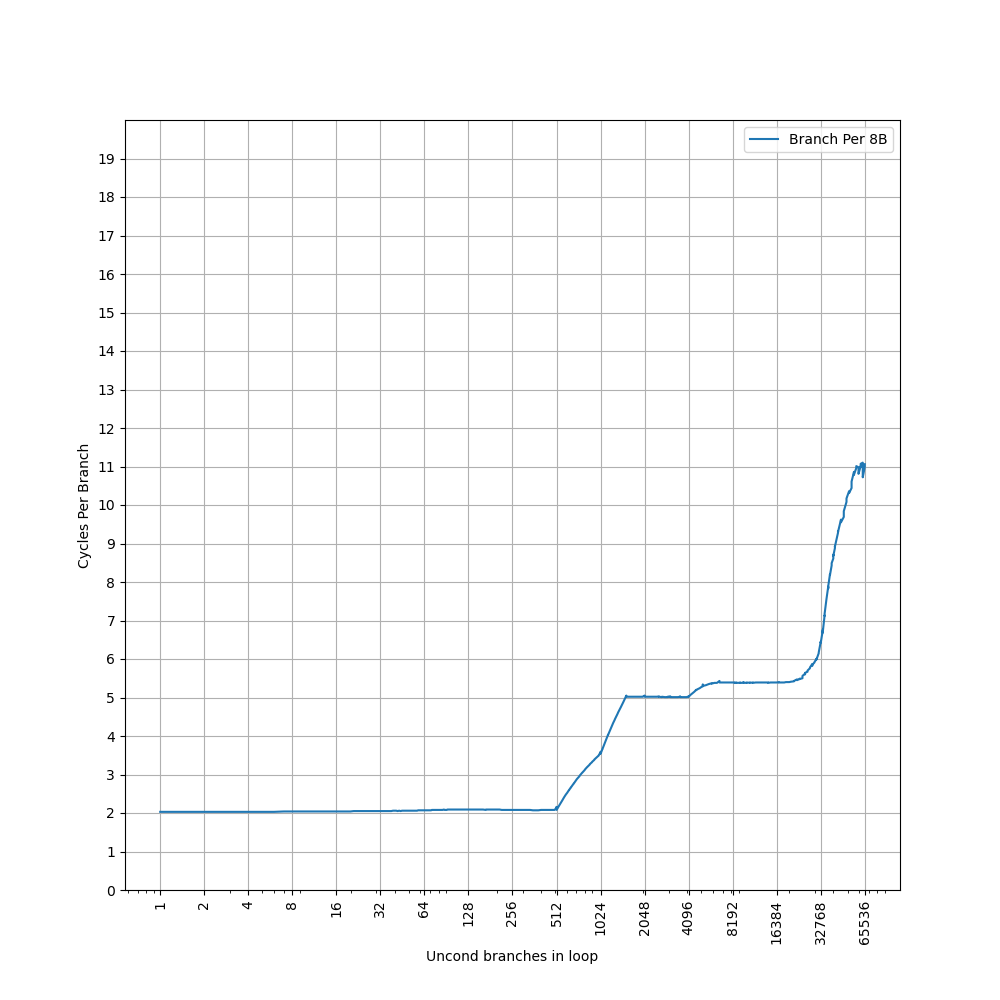
这个图像就比较正常了,CPI=2 持续到了 512 个分支,对应上面 1024 个分支的拐点前移,之后 CPI=5 的拐点在 4096,对应了上面 8192 的拐点。考虑到它的 L1 ICache 是 32 KB,正好对应 8192 的拐点,可以认为 Skylark 的 BTB 是:
构造一系列的 B 指令,使得 B 指令分布在不同的 page 上,使得 ITLB 成为瓶颈:
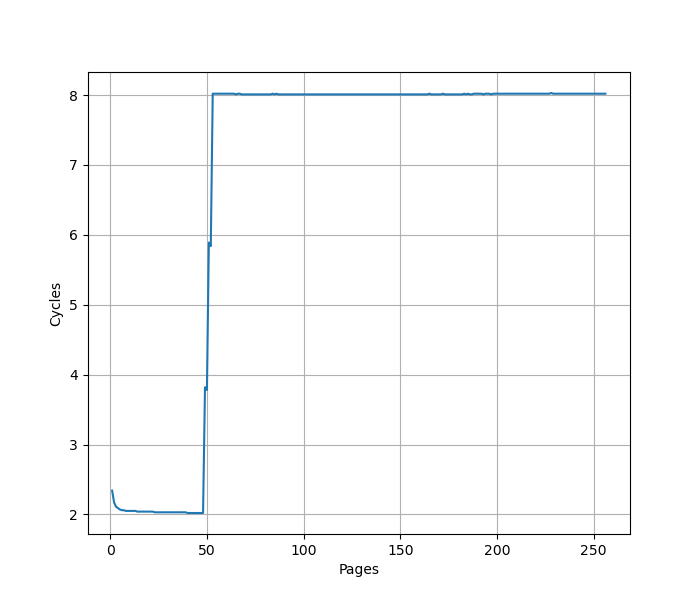
在 48 个页时,CPI 从 2 提升到了 8,意味着 L1 ITLB 容量是 48。
构造不同深度的调用链,测试每次调用花费的平均时间,得到下面的图:
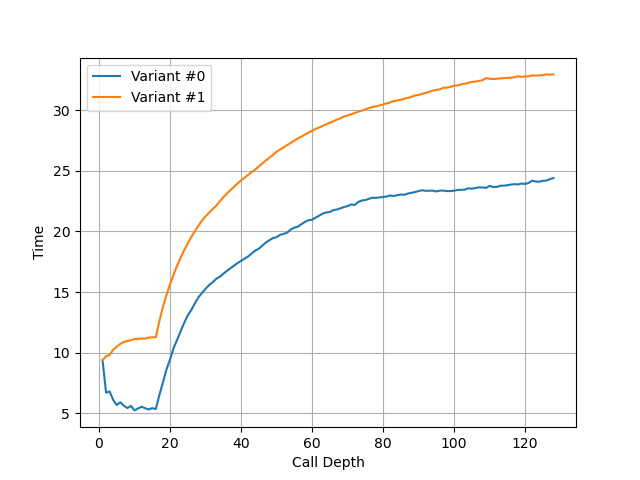
可以看到调用链深度超过 16 时性能突然变差,因此 Skylark 的 Return Stack 深度为 16。
构造不同大小 footprint 的 pointer chasing 链,测试不同 footprint 下每条 load 指令耗费的时间:
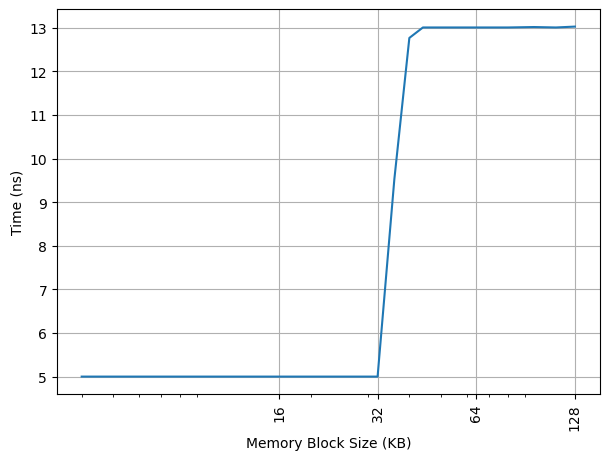
可以看到 32KB 出现了拐点,对应的就是 32KB 的 L1 DCache 容量,和官方信息一致,访存延迟从 5 cycle 增加到 13 cycle。
用类似的方法测试 L1 DTLB 容量,只不过这次 pointer chasing 链的指针分布在不同的 page 上,使得 DTLB 成为瓶颈:
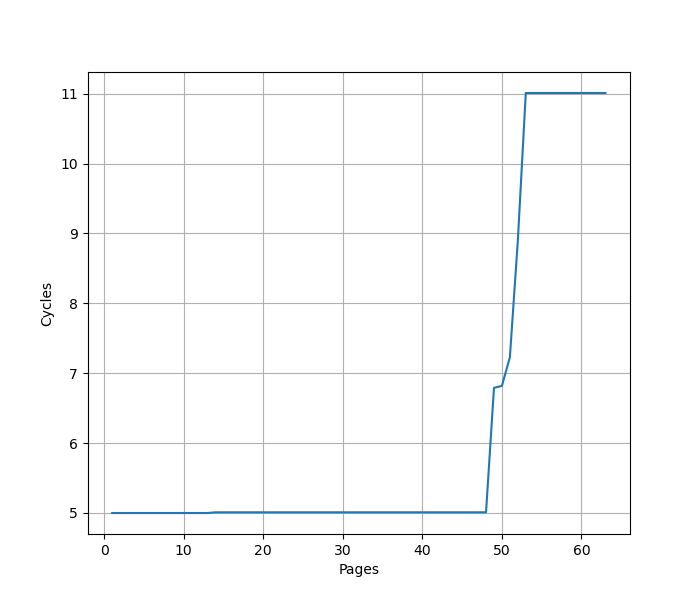
从 48 个页开始性能下降,认为 Skylark 的 L1 DTLB 有 48 项,访存延迟从 5 cycle 增加到 11 cycle。
针对 Load Store 带宽,实测 Skylark 每个周期可以完成:
如果把每条指令的访存位宽从 64b 改成 128b,读写带宽不变,指令吞吐减半。也就是说最大的读带宽是 8B/cyc,最大的写带宽是 8B/cyc,可以同时达到。
经过实际测试,Skylark 上如下的情况可以成功转发,对地址 x 的 Store 转发到对地址 y 的 Load 成功时 y-x 的取值范围:
| Store\Load | 8b Load | 16b Load | 32b Load | 64b Load |
|---|---|---|---|---|
| 8b Store | {0} | {} | {} | {} |
| 16b Store | [0,1] | {0} | {} | {} |
| 32b Store | [0,3] | [0,2] | {0} | {} |
| 64b Store | [0,7] | [0,6] | [0,4] | {0} |
转发的性能分以下几种情况:
从这个现象,大概可以猜到,Skylark 是以 4B 为粒度,检查 Store 和 Load 的覆盖情况,如果 Store 可以完全覆盖 Load,就进行转发。
特别地,即使访问的范围没有重合,也就是不需要 Forwarding 的情况,如果 Load 和 Store 在同一个对齐的 4B 块内,或者 Store 跨越了对齐的 8B 边界,也会多一个周期。
一个 Load 需要转发两个、四个甚至八个 Store 的数据时,不能转发。
小结:Skylark 的 Store to Load Forwarding:
Forwarding 能力和 AMD Zen 5 比较类似。
实测 Skylark 在下列的场景下可以达到 5 cycle:
ldr x0, [x0]: load 结果转发到基地址,无偏移ldr x0, [x0, 8]:load 结果转发到基地址,有立即数偏移ldr x0, [x0, x1]:load 结果转发到基地址,有寄存器偏移ldr x0, [sp, x0, lsl #3]:load 结果转发到 indexldp x0, x1, [x0]:load pair 的第一个目的寄存器转发到基地址,无偏移下列情况需要 6 cycle:
ldp x1, x0, [x0]:load pair 的第二个目的寄存器转发到基地址,无偏移Linear Address UTag/Way-Predictor 是 AMD 的叫法,但使用相同的测试方法,也可以在 Ampere Skylark 上观察到类似的现象,猜想它也用了类似的基于虚拟地址的 UTag/Way Predictor 方案,并测出来它的 UTag 也有 12 bit:
想要测试有多少个执行单元,每个执行单元可以运行哪些指令,首先要测试各类指令在无依赖情况下的 IPC,通过 IPC 来推断有多少个能够执行这类指令的执行单元;但由于一个执行单元可能可以执行多类指令,于是进一步需要观察在混合不同类的指令时的 IPC,从而推断出完整的结果。测试如下各类指令的延迟和每周期吞吐:
| 指令 | 延迟 | 吞吐 |
|---|---|---|
| asimd int add | 3 | 0.5 |
| asimd aesd/aese | 5 | 0.25 |
| asimd aesimc/aesmc | 2 | 0.5 |
| asimd fabs | 2 | 0.5 |
| asimd fadd | 5/6 | 0.5 |
| asimd fdiv 64b | 22 | 1/lat |
| asimd fdiv 32b | 22 | 1/lat |
| asimd fmax | 3 | 0.5 |
| asimd fmin | 3 | 0.5 |
| asimd fmla | 6 | 0.5 |
| asimd fmul | 6 | 0.5 |
| asimd fneg | 2 | 0.5 |
| asimd frecpe | 3 | 0.5 |
| asimd frsqrte | 5 | 0.5 |
| asimd fsqrt 64b | 76 | 1/lat |
| asimd fsqrt 32b | 48 | 1/lat |
| fp fabs | 2 | 1 |
| fp fadd | 5/6 | 1 |
| fp fdiv 64b | 17 | 1/11 |
| fp fdiv 32b | 17 | 1/11 |
| fp fmax | 3 | 1 |
| fp fmin | 3 | 1 |
| fp fmul | 6 | 1 |
| fp fneg | 2 | 1 |
| fp frecpe | 3 | 1 |
| fp frecpx | 3 | 1 |
| fp frsqrte | 5 | 1 |
| fp fsqrt 64b | 44 | 1/38 |
| fp fsqrt 32b | 28 | 1/22 |
| int add | 1 | 2 |
| int addi | 1 | 2 |
| int bfm | 2 | 1 |
| int crc | 2 | 1 |
| int csel | 1 | 2 |
| int madd (addend) | 2 | 0.5 |
| int madd (others) | 6 | 0.5 |
| int mrs nzcv | - | 1 |
| int mul | 5 | 0.5 |
| int nop | - | 4 |
| int sbfm | 2 | 1 |
| int sdiv | 7 | 1/lat |
| int smull | 4 | 1 |
| int ubfm | 2 | 1 |
| int udiv | 7 | 1/lat |
| not taken branch | - | 1 |
| taken branch | - | 0.3 |
可见它的执行单元不多,只有 2x ALU,1x Branch,1x Load,1x Store,1x FP,其中 ASIMD 拆成两个 64b 的部分分别计算,即 FP 的 datapath 只有 64b 宽。
用 NOP 指令测试 Skylark 的 ROB 大小:
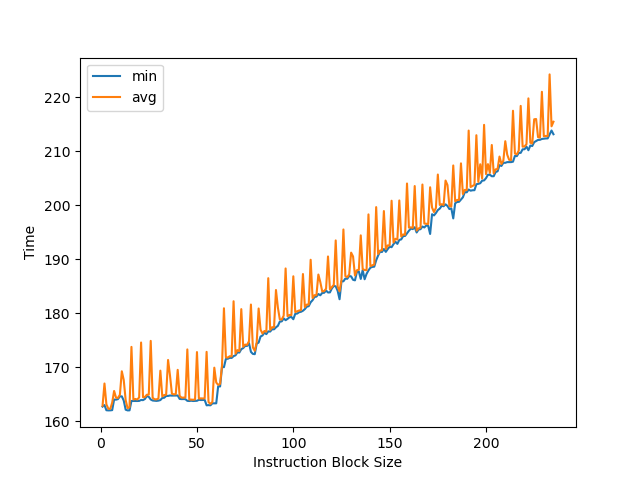
可以看到拐点是 60 条指令。
构造不同大小 footprint 的 pointer chasing 链,测试不同 footprint 下每条 load 指令耗费的时间,这次把容量扩充到 L2 Cache 的范围:
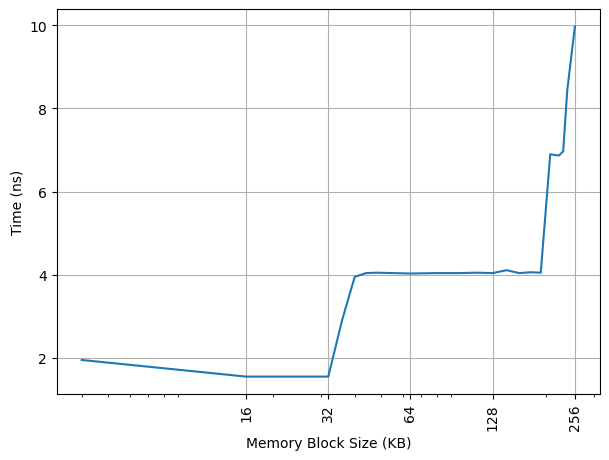
可以看到 192KB 出现了拐点,对应 13 Cycle。lscpu -C 报告的实际容量为 256KB,意味着对单个核心的数据占用的 L2 Cache 容量有限制。
沿用 L1 DTLB 的测试,继续扩大测试的范围,找到新的拐点:
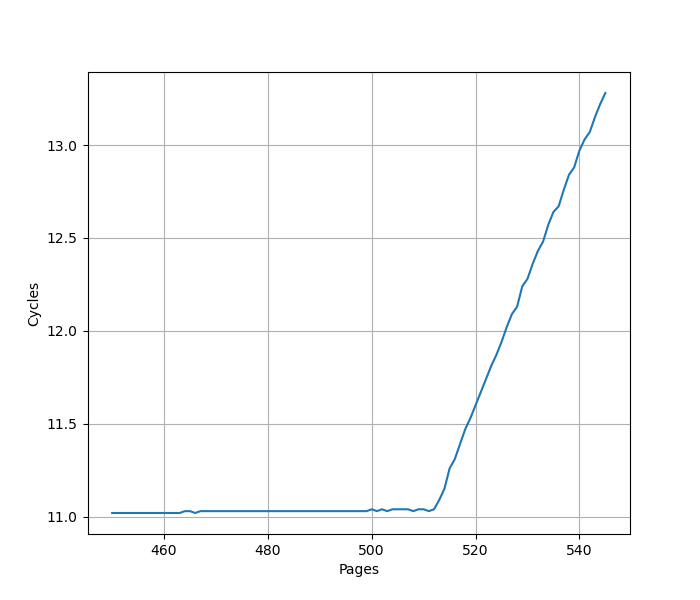
意味着 L2 TLB 容量是 512。
Skylark 是比较早期的 ARM server core,配置如下:
2026-07-06 08:00:00
之前分析过 M1 和 M4,趁着机会,也评测一下 M2 的微架构,给出一个从 M1 到 M2 再到 M4 的发展脉络。
苹果发布了 Apple Silicon CPU Optimization Guide,包括了一些 M2 的微架构信息。
网上已经有针对 Apple M2 微架构的评测和分析,建议阅读:
下面分各个模块分别记录官方提供的信息,以及实测的结果。读者可以对照已有的第三方评测理解。官方信息与实测结果一致的数据会加粗。
Apple M2 Avalanche/Blizzard 的性能测试结果见 SPEC。
为了测试实际的 Fetch 宽度,参考 如何测量真正的取指带宽(I-fetch width) - JamesAslan 构造了测试,实验结果如下:
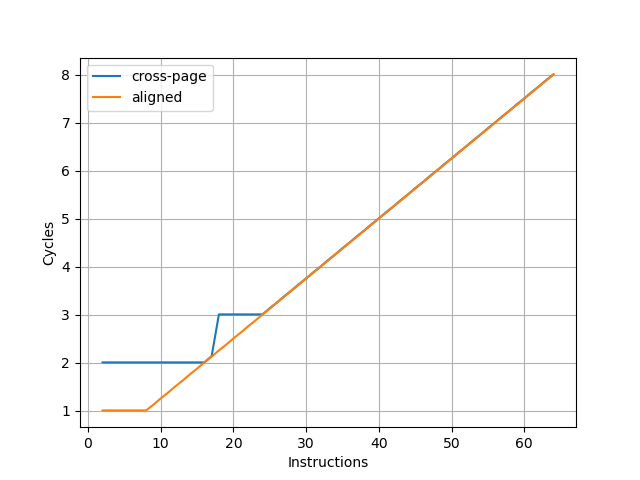
可以看到每 16 条指令会多一个周期,因此 Avalanche 的前端取指宽度确实是 16 条指令,与 Apple M1 Firestorm 和 Apple M4 P-Core 都相同。
用相同的方式测试 Blizzard,结果如下:
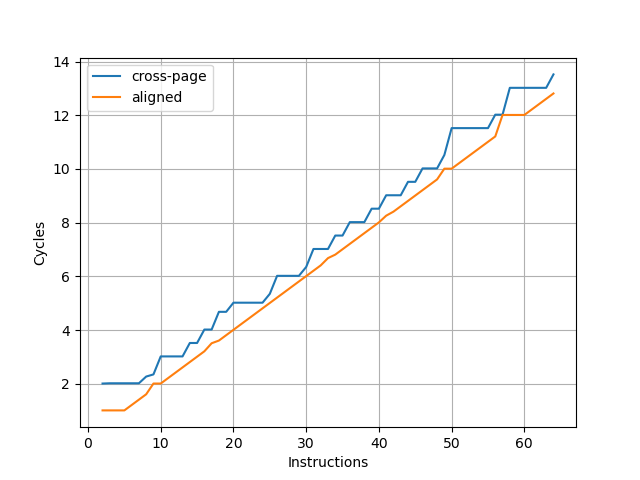
可以看到每 8 条指令会多一个周期,意味着 Blizzard 的前端取指宽度为 8 条指令,和 Apple M1 Icestorm 相同,不过表现在图像上不太一样。
官方信息:根据 Apple Silicon CPU Optimization Guide,从 M1 Family 到 M4 Family,A14 Bionic 到 A18 Family,P-Core 的 L1 ICache 的配置都是 192KiB, 6-way, 64B lines;对应处理器的 E-Core 的 L1 ICache 都是 128KiB, 64B lines,其中 M1 Family 和 A14 Bionic 是 8-way,其余处理器(M2 Family 和 A15 Bionic 开始)是 4-way。
容量和 Apple M1 相同。
为了测试 L1 ICache 容量,构造一个具有巨大指令 footprint 的循环,由大量的 nop 和最后的分支指令组成。观察在不同 footprint 大小下 Avalanche 的 IPC:
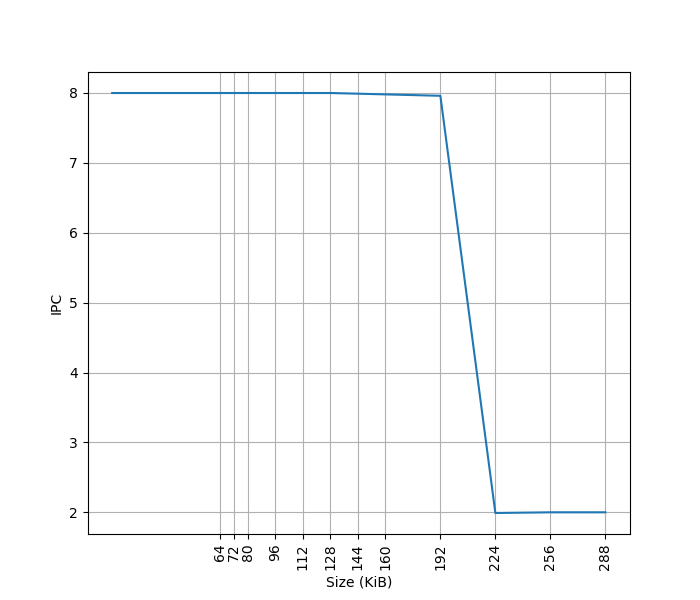
可以看到 footprint 在 192 KB 之前时可以达到 8 IPC,之后则快速降到 2 IPC,这里的 192 KB 就对应了 Avalanche 的 L1 ICache 的容量,和官方信息一致。虽然 Fetch 可以每周期 16 条指令,也就是一条 64B 的缓存行,由于后端的限制,只能观察到 8 的 IPC。IPC 与 Apple M1 Firestorm 相同,不及 Apple M4 P-Core 的 10 IPC。
用相同的方式测试 Blizzard,结果如下:
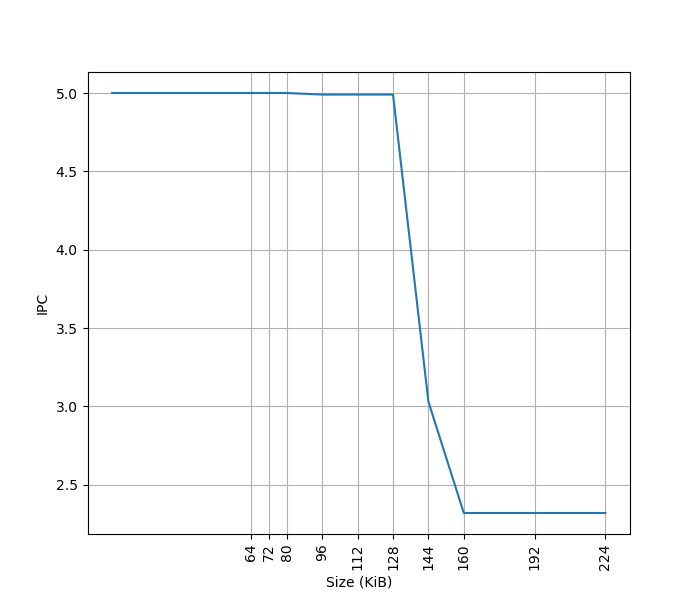
可以看到 footprint 在 128 KB 之前时可以达到 5 IPC,之后则快速降到 2.32 IPC,这里的 128 KB 就对应了 Blizzard 的 L1 ICache 的容量,和官方信息一致。虽然 Fetch 可以每周期 8 条指令,由于后端的限制,只能观察到 5 的 IPC。相比 Apple M1 Icestorm,IPC 从 4 增加到了 5,与 Apple M4 E-Core 相同。
构造大量的无条件分支指令(B 指令),BTB 需要记录这些指令的目的地址,那么如果分支数量超过了 BTB 的容量,性能会出现明显下降。当把大量 B 指令紧密放置,也就是每 4 字节一条 B 指令时:
可见在 1024 个分支之内可以达到 1 的 CPI,超过 1024 个分支,CPI 先升后降,在 4096 个分支时 CPI 等于 2,此后 CPI 逐渐上升,到 49152 个分支 CPI 等于 3。49152 的拐点,对应的是指令 footprint 超出 L1 ICache 的情况:L1 ICache 是 192KB,按照每 4 字节一个 B 指令计算,最多可以存放 49152 条 B 指令。
降低分支指令的密度,在 B 指令之间插入 NOP 指令,使得每 8 个字节有一条 B 指令,得到如下结果:
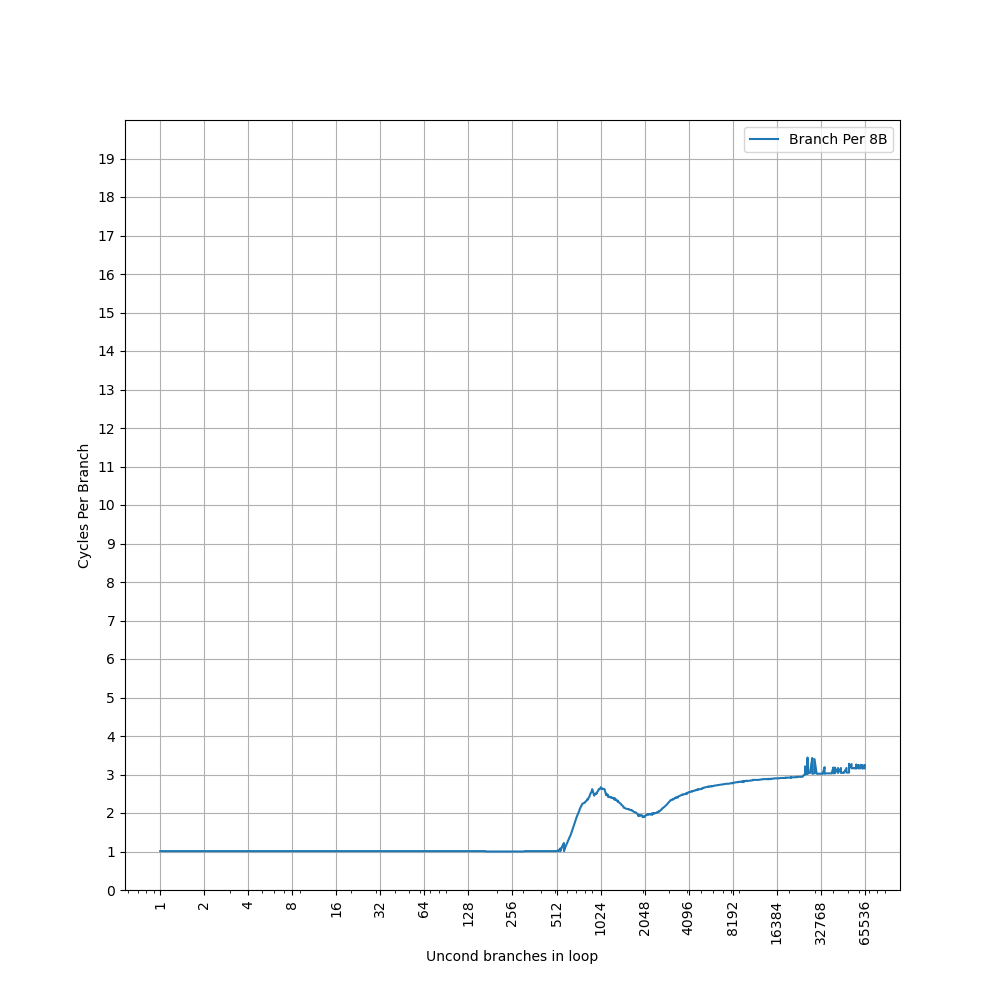
可以看到 CPI=1 的拐点前移到 512 个分支,同时 CPI=3 的拐点也前移到了 24576。拐点的前移,意味着 BTB 采用了组相连的结构,当 B 指令的 PC 的部分低位总是为 0 时,组相连的 Index 可能无法取到所有的 Set,导致表现出来的 BTB 容量只有部分 Set,例如此处容量减半,说明只有一半的 Set 被用到了。
相比 Apple M1 Firestorm,Avalanche 在 L1 和 L1 ICache 之间多加了一级 BTB,从而能够在更大的范围内,实现小于 3 的 CPI。相比 Apple M4 P-Core,Avalanche 在容量和延迟上都有差距。
用相同的方式测试 Blizzard,首先用 4B 的间距:
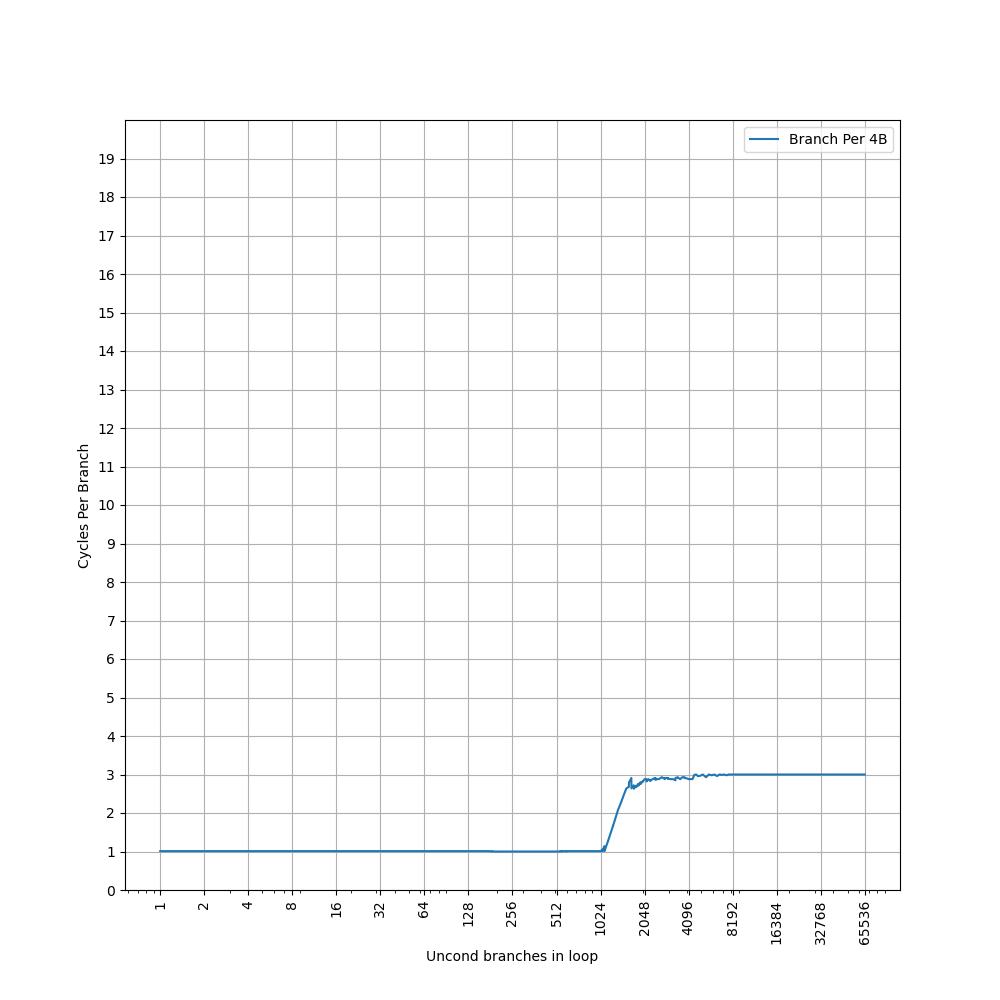
可以看到 1024 的拐点,1024 之前是 1 IPC,之后增加到 3 IPC。比较奇怪的是,没有看到第二个拐点,第二个拐点在 8B 的间距下显现:
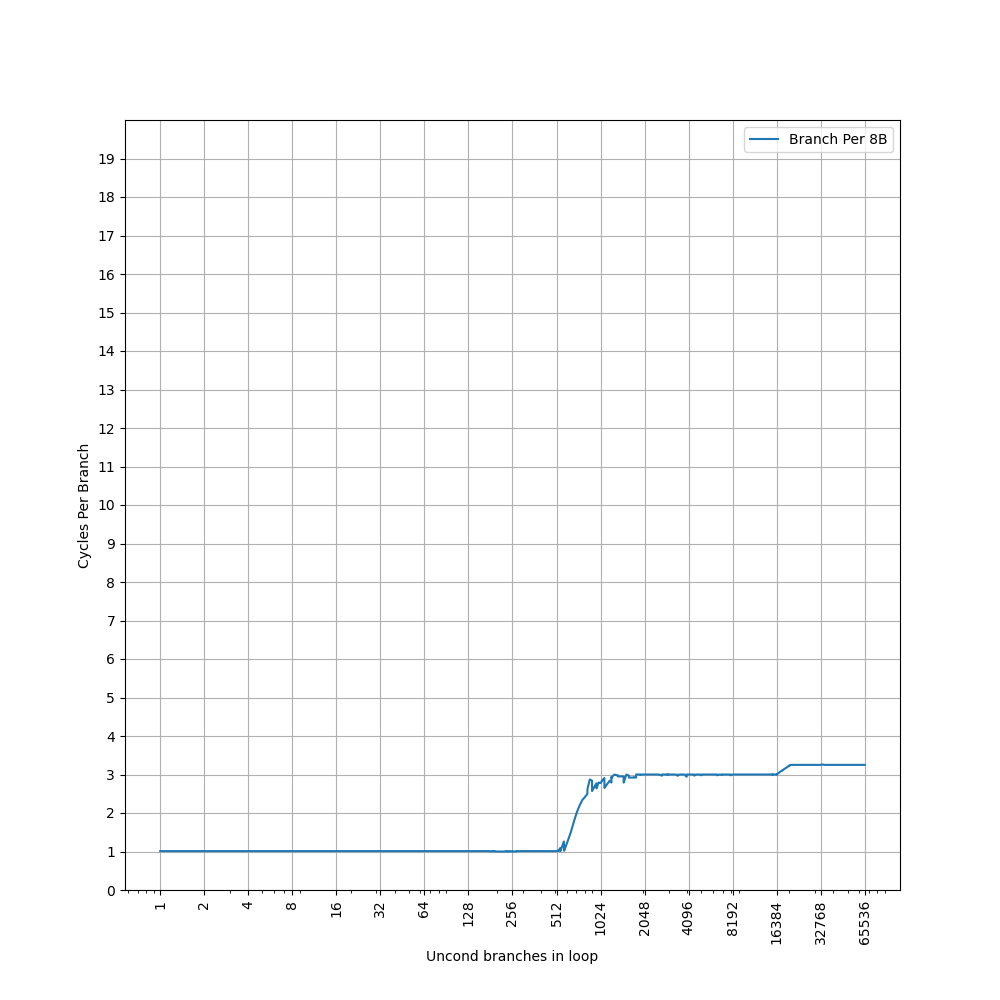
第一个拐点前移到 512,第二个拐点出现在 16384,而 Blizzard 的 L1 ICache 容量是 128KB,8B 间距下正好可以保存 16384 个分支。
用 16B 间距测试:
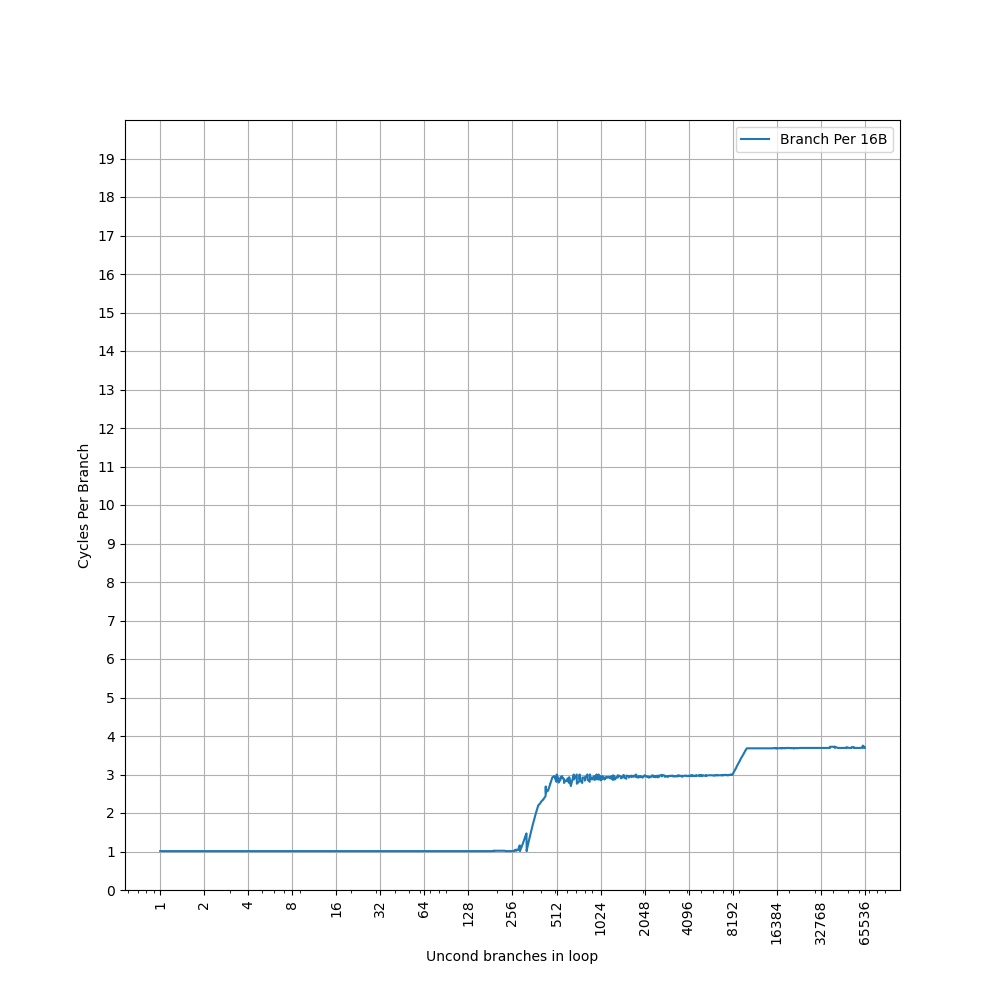
第一个拐点前移到 256,第二个拐点出现在 8192,对应 L1 ICache 容量。
从 BTB 容量来看,Blizzard 与 Apple M1 Icestorm 以及 Apple M4 E-Core 相同。
官方信息:根据 Apple Silicon CPU Optimization Guide,从 M1 Family 到 M4 Family,A14 Bionic 到 A18 Family,其 P-Core 的 L1 ITLB 配置都是一样的:192 entries,考虑到每个页是 16 KiB,对应 3 MiB 的内存;E-Core 的话,M1 Family 和 A14 Bionic 的 L1 ITLB 是 128 entries,之后的处理器(M2 Family 和 A15 Bionic 开始)则 E-Core 也是 192 entries。
因此,M2 Avalanche L1 ITLB 是 192 entries,Blizzard L1 ITLB 是 192 entries。
构造一系列的 B 指令,使得 B 指令分布在不同的 page 上,使得 ITLB 成为瓶颈,在 Avalanche 上进行测试:
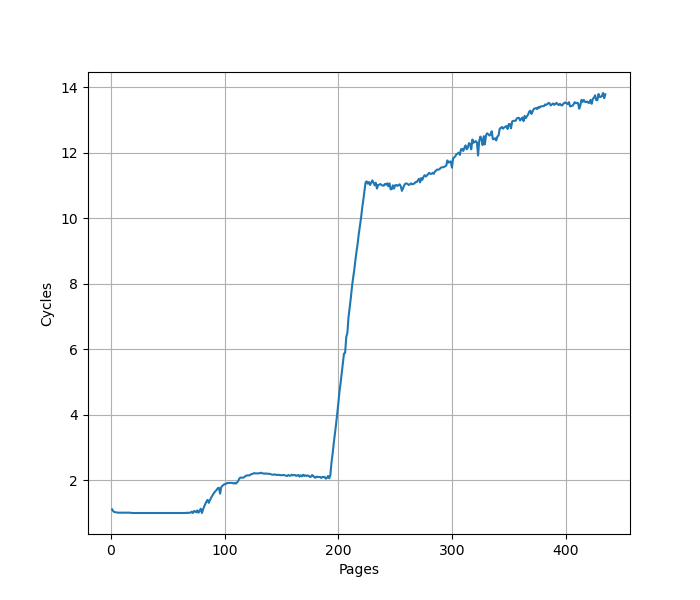
在 192 个页时从 2 Cycle 快速增加到 11 Cycle,对应了 192 项的 L1 ITLB 容量,和官方信息一致。
在 Blizzard 上重复实验:
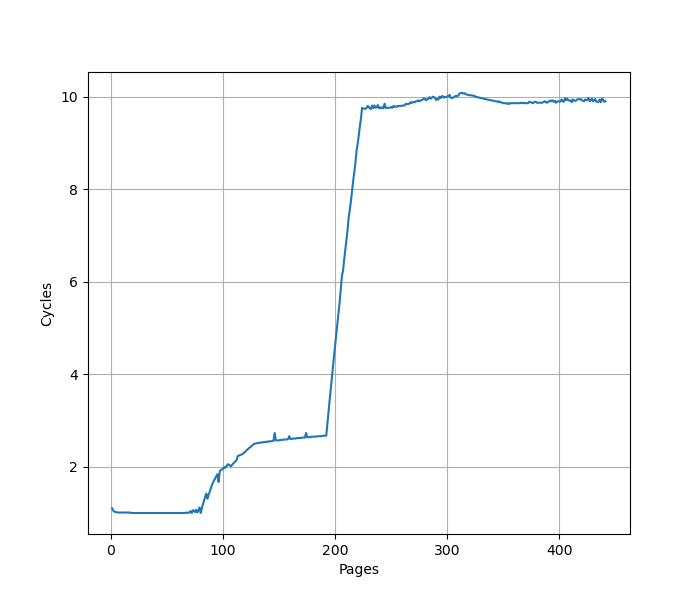
在 192 个页时,性能从 1 Cycle 下降到 10 Cycle,意味 L1 ITLB 容量是 192 项,和官方信息一致。
官方信息:根据 Apple Silicon CPU Optimization Guide,M1 Family 的 Sustained uops Per Cycle 最大值,P-Core 是 8,E-Core 是 4;M2 Family 的 P-Core 不变还是 8,E-Core 提升到了 5;M3 Family 的 P-Core 提升到了 9,E-Core 和 M2 持平;M4 Family 的 P-Core 进一步提升到了 10,E-Core 继续和 M2 持平。
从前面的测试来看,Avalanche 最大观察到 8 IPC,Blizzard 最大观察到 5 IPC,那么 Decode 宽度也至少是这么多,暂时也不能排除有更大的 Decode 宽度,和官方信息一致。
构造不同深度的调用链,测试每次调用花费的平均时间,在 Avalanche 上得到下面的图:
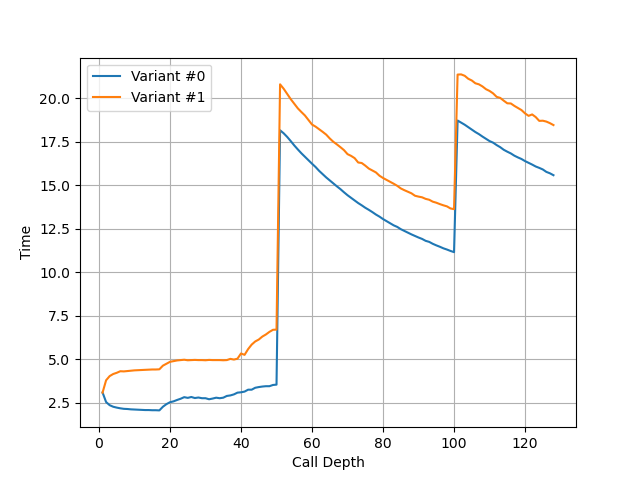
可以看到调用链深度为 50 时性能突然变差,因此 Avalanche 的 Return Stack 深度为 50。和 Apple M1 Firestorm 相同,比 Apple M4 P-Core 的 60 要小。
在 Blizzard 上测试:
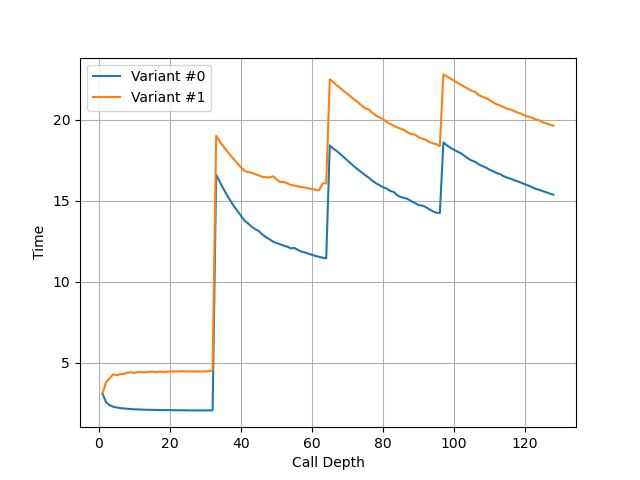
可以看到调用链深度为 32 时性能突然变差,因此 Blizzard 的 Return Stack 深度为 32。与 Apple M1 Icestorm 相同,比 Apple M4 E-Core 的 40 要小。
参考 Dissecting Conditional Branch Predictors of Apple Firestorm and Qualcomm Oryon for Software Optimization and Architectural Analysis 论文的方法,可以测出 Avalanche 的分支预测器与 Apple M1 Firestorm 相同,采用的历史更新方式为:
PHRTnew = (PHRTold << 1) xor T[31:2], PHRBnew = (PHRBold << 1) xor B[5:2],其中 B 代表分支指令的地址,T 代表分支跳转的目的地址Blizzard 的分支预测器与 Apple M1 Icestorm 相同,采用的历史更新方式为:
PHRTnew = (PHRTold << 1) xor T[47:2], PHRBnew = (PHRBold << 1) xor B[5:2],其中 B 代表分支指令的地址,T 代表分支跳转的目的地址各厂商处理器的 PHR 更新规则见 jiegec/cpu。
为了测试物理寄存器堆的大小,一般会用两个依赖链很长的操作放在开头和结尾,中间填入若干个无关的指令,并且用这些指令来耗费物理寄存器堆。Firestorm 测试结果见下图:
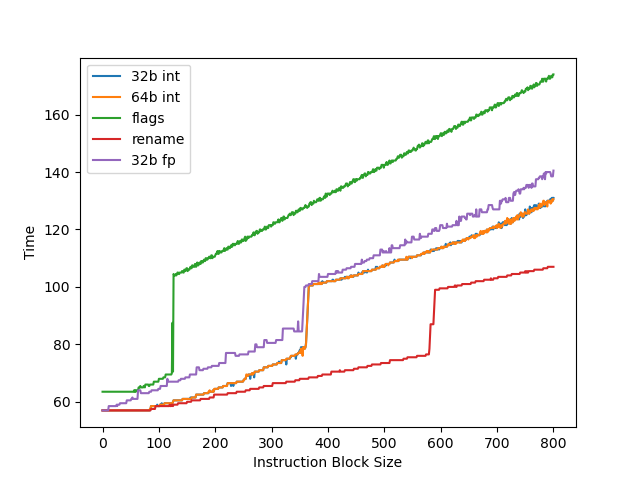
Avalanche 寄存器堆容量和 Firestorm 类似,没有 M4 的双倍 32b int 寄存器优化。
Blizzard 测试结果如下:
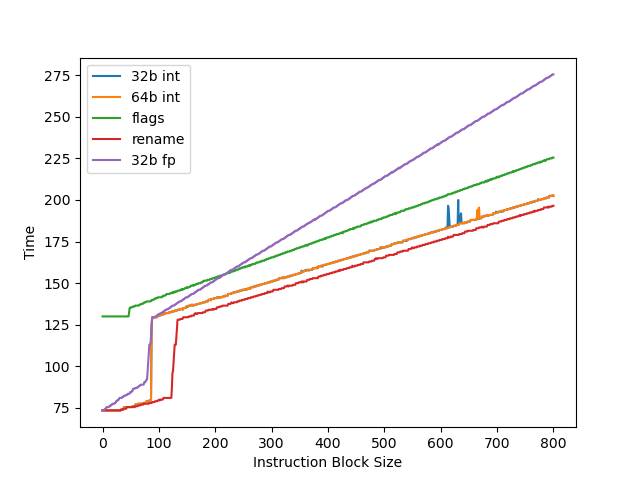
相比 M1 Icestorm 有少量的扩容。
注意这里测试的都是能够用于预测执行的寄存器数量,实际的物理寄存器堆还需要保存架构寄存器。但具体保存多少个架构寄存器不确定,但至少 32 个整数通用寄存器和浮点寄存器是一定有的,但可能还有一些额外的需要重命名的状态也要算进来。
官方信息:根据 Apple Silicon CPU Optimization Guide,从 M1 Family 到 M4 Family,从 A14 Bionic 到 A18 Family,P-Core 的 L1 DCache 都是 128KiB, 8-way, 64B lines 的配置,E-Core 的 L1 DCache 都是 64KiB, 8-way, 64B lines 的配置。
构造不同大小 footprint 的 pointer chasing 链,测试不同 footprint 下每条 load 指令耗费的时间,Avalanche 上的结果:
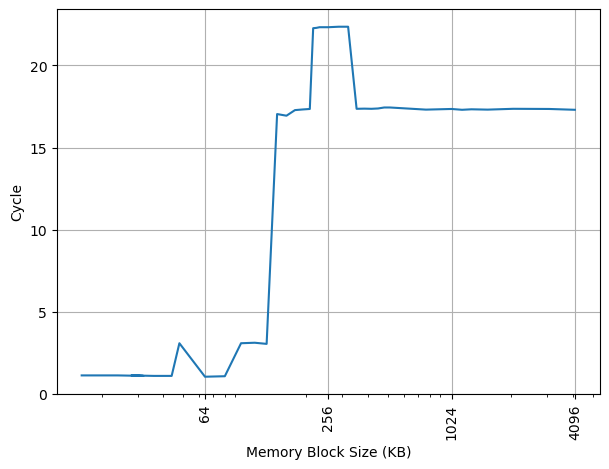
可以看到 128KB 出现了拐点,对应的就是 128KB 的 L1 DCache 容量,和官方信息一致。当 footprint 比较小的时候,由于 Load Address Predictor 的介入,打破了依赖链,所以出现了 latency 小于正常 load to use 的 3 cycle latency 的情况。
Blizzard 上的结果:
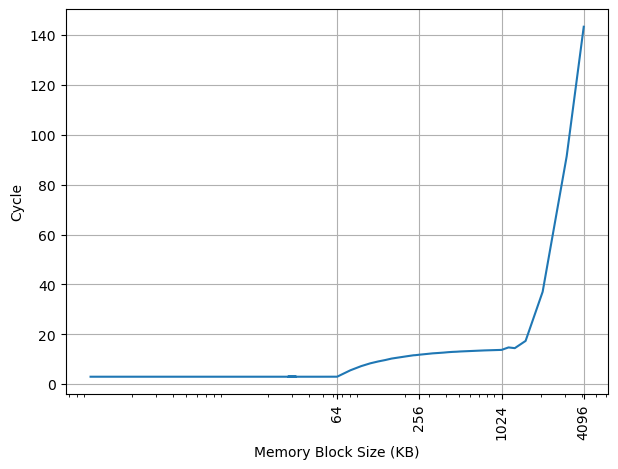
可以看到 64KB 出现了明显的拐点,对应的就是 64KB 的 L1 DCache 容量,和官方信息一致。L1 DCache 范围内延迟是 3 cycle。由此可见 Blizzard 没有 Load Address Predictor,不能打断依赖链。
官方信息:根据 Apple Silicon CPU Optimization Guide,对于 P-Core 来说,除了 M2 Family、A14 Bionic 和 A15 Bionic 的 L1 DTLB 是 256 entries 以外,其余的 M1 Family、M3 Family 到 M4 Family,A16 Bionic 到 A18 Family 的 L1 DTLB 都是 160 entries。对于 E-Core 来说,除了 M1 Family 和 A14 Bionic 是 129 entries,其余的从 M2 Family 到 M4 Family,A15 Bionic 到 A18 Family 都是 192 entries。
因此,Avalanche L1 DTLB 容量是 256,Blizzard L1 DTLB 容量是 192。
用类似的方法测试 L1 DTLB 容量,只不过这次 pointer chasing 链的指针分布在不同的 page 上,使得 DTLB 成为瓶颈,在 Avalanche 上:
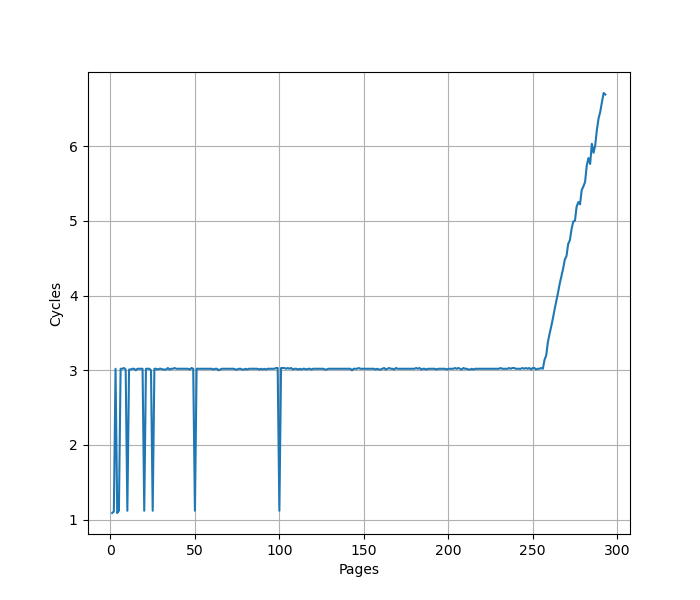
从 256 个页开始性能下降,认为 Avalanche 的 L1 DTLB 有 256 项,和官方信息一致。性能出现波动,有时候能实现 1 cycle 的 CPI,主要来自于 Load Address Predictor。
Blizzard:
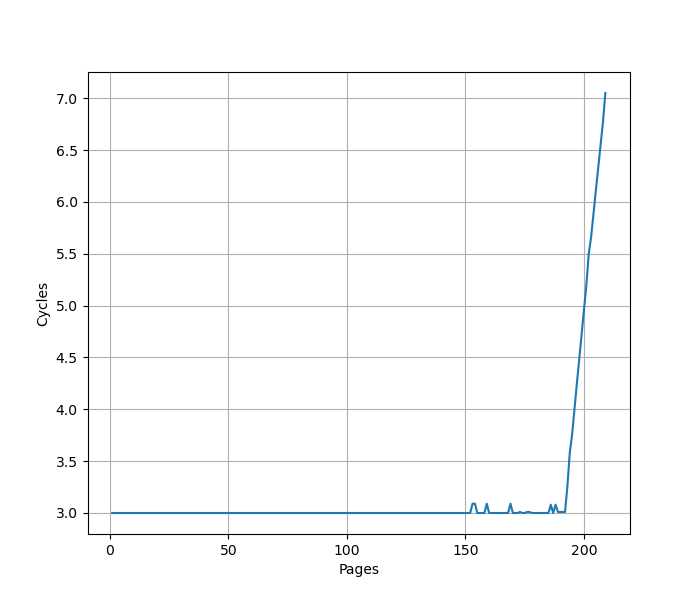
从 192 个页开始性能下降,认为 Blizzard 的 L1 DTLB 有 192 项,和官方信息一致。
针对 Load Store 带宽,实测 Avalanche 每个周期可以完成:
如果把每条指令的访存位宽从 128b 改成 256b,读写带宽不变,指令吞吐减半。也就是说最大的读带宽是 48B/cyc,最大的写带宽是 32B/cyc,二者不能同时达到。和 M1/M4 的 P-Core 相同。
实测 Blizzard 每个周期可以完成:
如果把每条指令的访存位宽从 128b 改成 256b,读写带宽不变,指令吞吐减半。也就是说最大的读带宽是 32B/cyc,最大的写带宽是 16B/cyc,二者不能同时达到。和 M1/M4 的 E-Core 相同。
为了预测执行 Load,需要保证 Load 和之前的 Store 访问的内存没有 Overlap,那么就需要有一个预测器来预测 Load 和 Store 之前在内存上的依赖。参考 Store-to-Load Forwarding and Memory Disambiguation in x86 Processors 的方法,构造两个指令模式,分别在地址和数据上有依赖:
str x3, [x1] 和 ldr x3, [x2]
str x2, [x1] 和 ldr x1, [x2]
初始化时,x1 和 x2 指向同一个地址,重复如上的指令模式,观察到多少条 ldr 指令时会出现性能下降。
在 Avalanche 上测试:
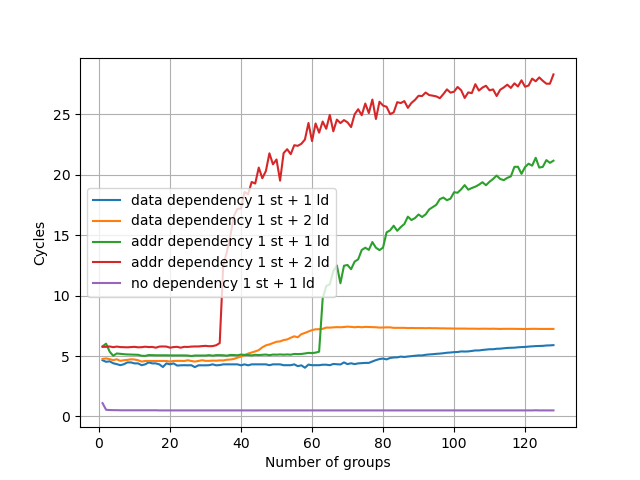
数据依赖没有明显的阈值,但从 77 开始出现了一个小的增长,且斜率不为零;地址依赖的阈值是 62。相比 M1 P-Core Firestorm 有所减小。
Blizzard:
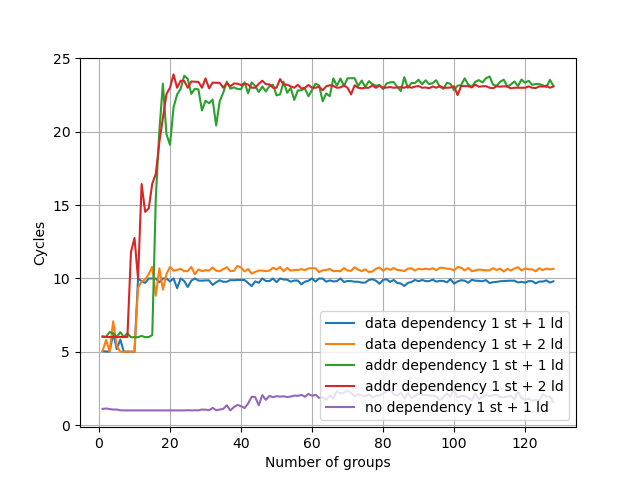
数据依赖的阈值是 10,地址依赖的阈值是 16。和 Icestorm 差不多。
经过实际测试,Avalanche 上如下的情况可以成功转发,对地址 x 的 Store 转发到对地址 y 的 Load 成功时 y-x 的取值范围:
| Store\Load | 8b Load | 16b Load | 32b Load | 64b Load |
|---|---|---|---|---|
| 8b Store | {0} | [-1,0] | [-3,0] | [-7,0] |
| 16b Store | [0,1] | [-1,1] | [-3,1] | [-7,1] |
| 32b Store | [0,3] | [-1,3] | [-3,3] | [-7,3] |
| 64b Store | [0,7] | [-1,7] | [-3,7] | [-7,7] |
从上表可以看到,所有 Store 和 Load Overlap 的情况,无论地址偏移,都能成功转发。甚至在 Load 或 Store 跨越 64B 缓存行边界时,也可以成功转发,代价是多一个周期。
一个 Load 需要转发两个、四个甚至八个 Store 的数据时,如果数据跨越缓存行,则不能转发,但其他情况下,无论地址偏移,都可以转发,只是比从单个 Store 转发需要多耗费 1-4 个周期。
成功转发时 7.3 cycle,跨缓存行且转发失败时 26+ cycle。和 Firestorm 具有相同的性能。
小结:Apple Avalanche 的 Store to Load Forwarding:
在 Blizzard 上,如果 Load 和 Store 访问范围出现重叠,则需要 10 Cycle,无论是和几个 Store 重叠,也无论是否跨缓存行。和 Icestorm 行为相同。
官方信息:根据 Apple Silicon CPU Optimization Guide,Apple 实现了 fast pointer chasing with a 3-cycle latency,要求后一个 load 的 base register 和前一个 load 的 destination register 相同。
实测 Avalanche 的 Load to use latency 针对 pointer chasing 场景做了优化,在下列的场景下可以达到 3 cycle:
ldr x0, [x0]: load 结果转发到基地址,无偏移ldr x0, [x0, 8]:load 结果转发到基地址,有立即数偏移ldr x0, [x0, x1]:load 结果转发到基地址,有寄存器偏移ldp x0, x1, [x0]:load pair 的第一个目的寄存器转发到基地址,无偏移如果访存跨越了 8B 边界,则退化到 4 cycle。
在下列场景下 Load to use latency 则是 4 cycle:
ldr x0, [sp, x0, lsl #3]:load 结果转发到 indexldp x1, x0, [x0]:load pair 的第二个目的寄存器转发到基地址,无偏移注意由于 Load Address Predictor 的存在,测试的时候需要排除预测器带来的影响。延迟方面,和 M1/M4 P-Core 相同。
实测 Blizzard 的 Load to use latency 针对 pointer chasing 场景做了优化,在下列的场景下可以达到 3 cycle:
ldr x0, [x0]: load 结果转发到基地址,无偏移ldr x0, [x0, 8]:load 结果转发到基地址,有立即数偏移ldr x0, [x0, x1]:load 结果转发到基地址,有寄存器偏移ldp x0, x1, [x0]:load pair 的第一个目的寄存器转发到基地址,无偏移如果访存跨越了 8B/16B/32B 边界,依然是 3 cycle;跨越了 64B 边界则退化到 7 cycle。
在下列场景下 Load to use latency 则是 4 cycle:
ldr x0, [sp, x0, lsl #3]:load 结果转发到 indexldp x1, x0, [x0]:load pair 的第二个目的寄存器转发到基地址,无偏移延迟方面,和 M1/M4 E-Core 相同。
Linear Address UTag/Way-Predictor 是 AMD 的叫法,但使用相同的测试方法,也可以在 Apple M2 上观察到类似的现象,猜想它也用了类似的基于虚拟地址的 UTag/Way Predictor 方案,并测出来它的 UTag 也有 8 bit,Avalanche 和 Blizzard 都是相同的:
一共有 8 bit,由 VA[47:14] 折叠而来。和 Apple M1/M4 相同。
想要测试有多少个执行单元,每个执行单元可以运行哪些指令,首先要测试各类指令在无依赖情况下的 IPC,通过 IPC 来推断有多少个能够执行这类指令的执行单元;但由于一个执行单元可能可以执行多类指令,于是进一步需要观察在混合不同类的指令时的 IPC,从而推断出完整的结果。
官方信息:根据 Apple Silicon CPU Optimization Guide,M2 Family 的 P-Core Avalanche 包括如下计算单元:
P-Core Avalanche 访存:
M2 Family 的 E-Core Blizzard 包括如下计算单元:
E-Core Blizzard 访存:
和 M1 一样。
在 Avalanche 上测试如下各类指令的延迟和每周期吞吐:
| 指令 | 延迟 | 吞吐 |
|---|---|---|
| asimd int add | 2 | 4 |
| asimd aesd/aese | 3 | 4 |
| asimd aesimc/aesmc | 2 | 4 |
| asimd fabs | 2 | 4 |
| asimd fadd | 3 | 4 |
| asimd fdiv 64b | 10 | 1 |
| asimd fdiv 32b | 8 | 1 |
| asimd fmax | 2 | 4 |
| asimd fmin | 2 | 4 |
| asimd fmla | 4 | 4 |
| asimd fmul | 4 | 4 |
| asimd fneg | 2 | 4 |
| asimd frecpe | 3 | 1 |
| asimd frsqrte | 3 | 1 |
| asimd fsqrt 64b | 13 | 0.5 |
| asimd fsqrt 32b | 10 | 0.5 |
| fp cvtf2i (fcvtzs) | - | 2 |
| fp cvti2f (scvtf) | - | 3 |
| fp fabs | 2 | 4 |
| fp fadd | 3 | 4 |
| fp fdiv 64b | 10 | 1 |
| fp fdiv 32b | 8 | 1 |
| fp fjcvtzs | - | 1 |
| fp fmax | 2 | 4 |
| fp fmin | 2 | 4 |
| fp fmov f2i | - | 2 |
| fp fmov i2f | - | 3 |
| fp fmul | 4 | 4 |
| fp fneg | 2 | 4 |
| fp frecpe | 3 | 1 |
| fp frecpx | 3 | 1 |
| fp frsqrte | 3 | 1 |
| fp fsqrt 64b | 13 | 0.5 |
| fp fsqrt 32b | 10 | 0.5 |
| int add | 1 | 4.4 |
| int addi | 1 | 6 |
| int bfm | 1 | 1 |
| int crc | 3 | 1 |
| int csel | 1 | 3 |
| int madd (addend) | 1 | 1 |
| int madd (others) | 3 | 1 |
| int mrs nzcv | - | 2 |
| int mul | 3 | 2 |
| int nop | - | 9.5 |
| int sbfm | 1 | 4.5 |
| int sdiv | 7/8 | 0.5 |
| int smull | 3 | 2 |
| int ubfm | 1 | 4.6 |
| int udiv | 7/8 | 0.5 |
| not taken branch | - | 2 |
| taken branch | - | 1 |
| mem asimd load | - | 3 |
| mem asimd store | - | 2 |
| mem int load | - | 3 |
| mem int store | - | 2 |
测试结果与 M1 Firestorm 基本一样,这里就不再进行深入分析。
接下来用类似的方法测试 Blizzard:
| 指令 | 延迟 | 吞吐 |
|---|---|---|
| asimd int add | 2 | 2 |
| asimd aesd/aese | 3 | 2 |
| asimd aesimc/aesmc | 2 | 2 |
| asimd fabs | 2 | 2 |
| asimd fadd | 3 | 2 |
| asimd fdiv 64b | 11 | 0.5 |
| asimd fdiv 32b | 9 | 0.5 |
| asimd fmax | 2 | 2 |
| asimd fmin | 2 | 2 |
| asimd fmla | 4 | 2 |
| asimd fmul | 4 | 2 |
| asimd fneg | 2 | 2 |
| asimd frecpe | 4 | 0.5 |
| asimd frsqrte | 4 | 0.5 |
| asimd fsqrt 64b | 15 | 0.5 |
| asimd fsqrt 32b | 12 | 0.5 |
| fp cvtf2i (fcvtzs) | - | 1 |
| fp cvti2f (scvtf) | - | 2 |
| fp fabs | 2 | 2 |
| fp fadd | 3 | 2 |
| fp fdiv 64b | 10 | 1 |
| fp fdiv 32b | 8 | 1 |
| fp fjcvtzs | - | 0.5 |
| fp fmax | 2 | 2 |
| fp fmin | 2 | 2 |
| fp fmov f2i | - | 1 |
| fp fmov i2f | - | 2 |
| fp fmul | 4 | 2 |
| fp fneg | 2 | 2 |
| fp frecpe | 3 | 1 |
| fp frecpx | 3 | 1 |
| fp frsqrte | 3 | 1 |
| fp fsqrt 64b | 13 | 0.5 |
| fp fsqrt 32b | 10 | 0.5 |
| int add | 1 | 4 |
| int addi | 1 | 4 |
| int bfm | 1 | 1 |
| int crc | 3 | 1 |
| int csel | 1 | 4 |
| int madd (addend) | 1 | 1 |
| int madd (others) | 3 | 1 |
| int mrs nzcv | - | 4 |
| int mul | 3 | 1 |
| int nop | - | 5 |
| int sbfm | 1 | 4 |
| int sdiv | 7 | 0.125=1/8 |
| int smull | 3 | 1 |
| int ubfm | 1 | 4 |
| int udiv | 7 | 0.125=1/8 |
| not taken branch | - | 2 |
| taken branch | - | 1 |
| mem asimd load | - | 2 |
| mem asimd store | - | 1 |
| mem int load | - | 2 |
| mem int store | - | 1 |
测试结果与 M1 Icestorm 基本一样,只是多了一个 ALU,所以部分整数指令的 IPC 加一,其他则基本一样,这里就不再进行深入分析。
首先用不同数量的 fsqrt 依赖链加 NOP 指令测试 Avalanche 的 ROB 大小:
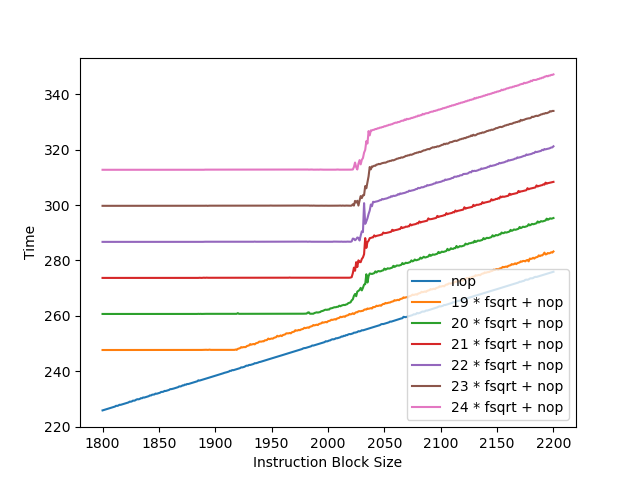
可以看到当 fsqrt 数量足够多的时候,出现了统一的拐点,在 2022 条指令左右。
为了测 Coalesced ROB 的大小,改成用 load/store 指令,可以测到拐点在 292 左右:
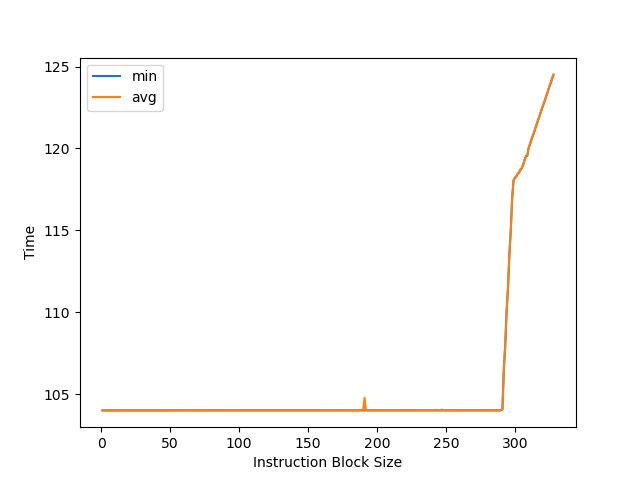
2022 除以 292 约等于 7,意味着每个 group 可以保存 7 条指令,一共有 289 左右个 group。相比 M1 P-Core Firestorm,Group 数量有所减少。
首先用 NOP 指令测试 Blizzard 的 ROB 大小:
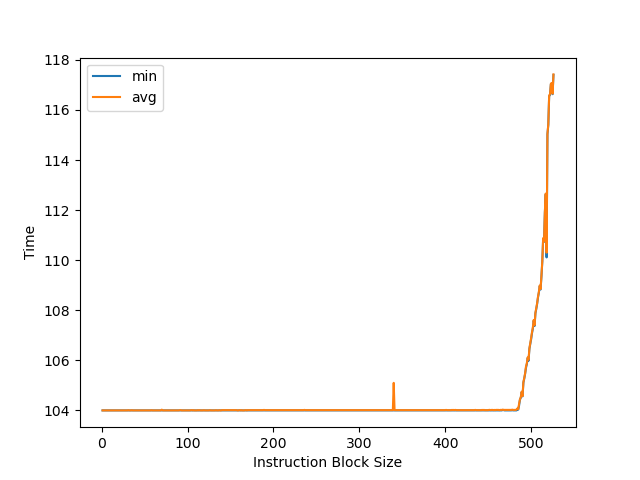
可以看到拐点是 486 条指令。
为了测 Coalesced ROB 的大小,改成用 load/store 指令,可以测到拐点在 74 左右:
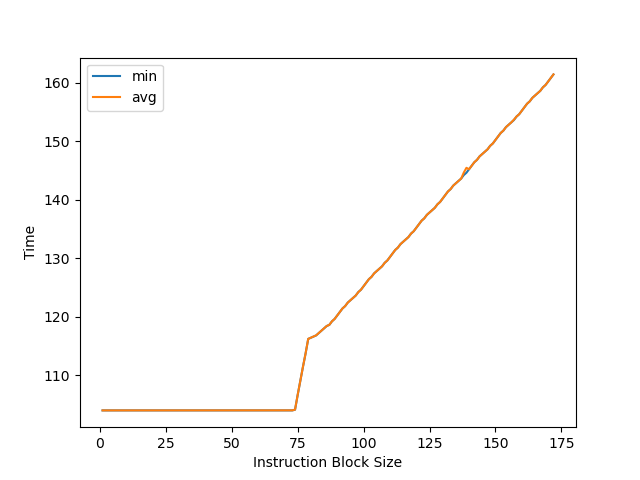
但是 486 除以 74 是 6.57,离 6 或者 7 都有一段距离,比较奇怪,不确定每个 group 可以放多少条指令。容量上比 M1 E-Core 有提升。
官方信息:根据 Apple Silicon CPU Optimization Guide,L2 Cache 配置如下:
官方信息:根据 Apple Silicon CPU Optimization Guide,Memory Cache(在别的处理器也叫 System Level Cache,就是 Last Level Cache)的配置如下:
官方信息:根据 Apple Silicon CPU Optimization Guide,P-Core 的 L2 TLB 容量,从 M1 Family 到 M4 Family,从 A14 Bionic 到 A18 Family,都是 3072 entries;E-Core 的 L2 TLB 容量,M1 Family 和 A14 Bionic 是 1024 entries,M2 Family 到 M4 Family 和 A15 Bionic 到 A18 Family 都是 2048 entries。
M2 相比 M1,在很多方面做了迭代:
指令集扩展方面,M2 增加了 i8mm bf16 bti ecv 的 feature。在 SPEC CPU 2017 Rate-1 上,M2 P-Core 相比 M1 P-Core 有 16% 的整数性能提升和 9% 的浮点性能提升,而 M2 E-Core 相比 M1 E-Core 有 33% 的整数性能提升和 31% 的浮点性能提升。
2026-06-13 08:00:00
使用 ARM Neoverse V3 核心的 AWS Graviton 5 最近上线了,相比之前的 Neoverse V2 应该有一些改进,所以测试一下这个微架构在各个方面的表现。
ARM 关于 Neoverse V3 微架构有如下公开信息:
Neoverse V3 与 Cortex X4 高度相似,这里也列出 Cortex X4 的相关信息:
下面分模块记录官方信息和实测结果。官方信息与实测结果一致的数据会加粗。
网上已经有 Neoverse V3 微架构的评测和分析,建议阅读:
下面分各个模块分别记录官方提供的信息,以及实测的结果。读者可以对照已有的第三方评测理解。官方信息与实测结果一致的数据会加粗。
Neoverse V3 (AWS Graviton 5) 的性能测试结果见 SPEC。
官方信息:64KB, 4-way set associative, VIPT behaving as PIPT, 64B cacheline, PLRU replacement policy
测试 L1 ICache 容量,构造一个具有巨大指令 footprint 的循环,由大量 nop 和最后的分支指令组成,观察不同 footprint 下的 IPC:
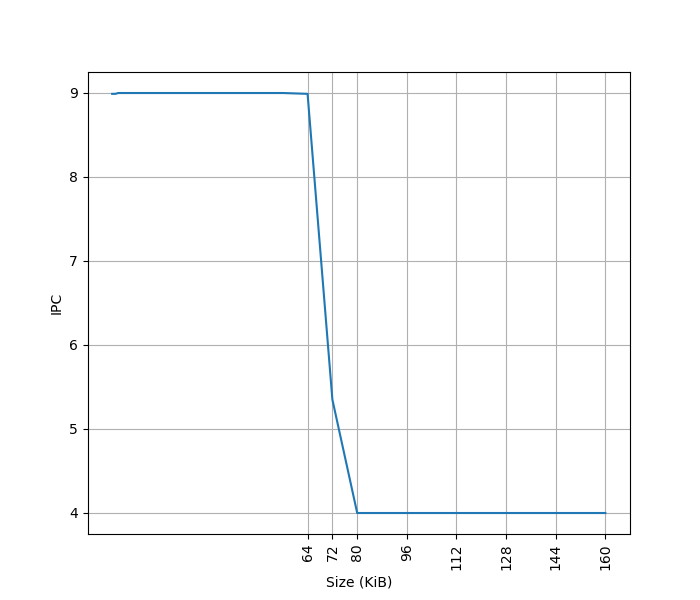
起始 IPC 为 9。Neoverse V3 删除了 MOP Cache,不像 Neoverse V2 那样可以把两条 NOP 合并为一条 MOP 来提高 IPC。虽然是 10-wide Decode,IPC 只能到 9,应该是遇到了其他瓶颈。
超出 64KB L1 ICache 后,IPC 降到 4,说明 L2 Cache 可以提供每周期 16 字节的取指带宽。
L1 ICache 和 Neoverse V2 相同,只是去掉了 MOP Cache,增加了 Decode 宽度。
官方信息:Caches entries at the 4KB, 16KB, 64KB, or 2MB granularity, Fully associative, 48 entries
构造一组 B 指令,分布在不同的 page 上,让 ITLB 成为瓶颈:
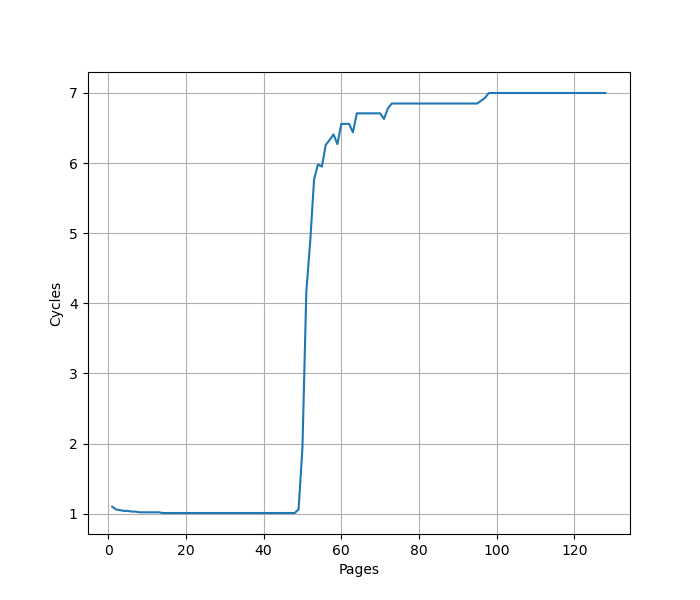
48 Page 处出现拐点,对应 48 项的 L1 ITLB 容量。之后性能降到 7 CPI,对应 L2 Unified TLB 的延迟。
进一步增加 Page 数量,大约 1000 个页的时候,耗时从 7 cycle 逐渐上升:
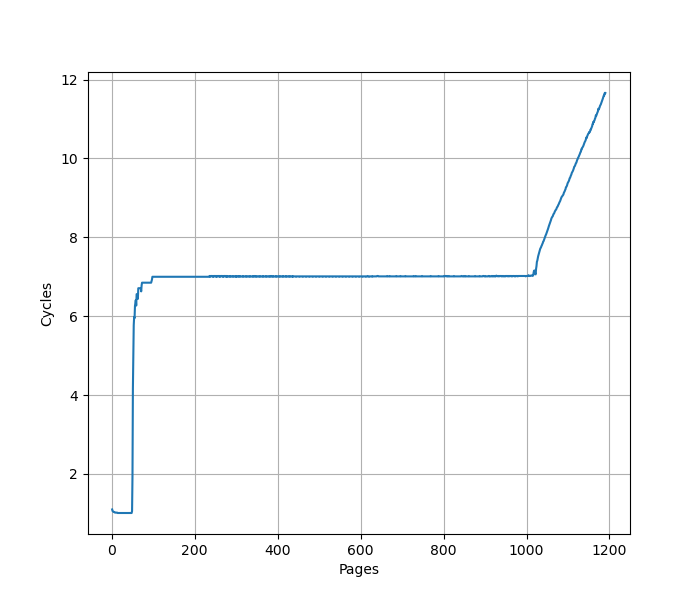
L2 Unified TLB 一共 2048 个 Entry,猜测 ITLB 能使用的 L2 TLB 容量只有一半,也就是 1024 项。超出后需要 Page Table Walker 做地址翻译。测试时要注意避免 Huge Page 的影响。
L1 ITLB 和 Neoverse V2 行为相同。
官方信息:10-wide Decode
Neoverse V3 只有一个 Decode 路径,从 ICache 过来,不再有 Neoverse V2 的 MOP Cache。
Return Stack 记录最近的函数调用链,call 时压栈,return 时弹栈,用于预测 return 指令的目的地址。构造不同深度的调用链,发现 Neoverse V3 的 Return Stack 深度为 32:
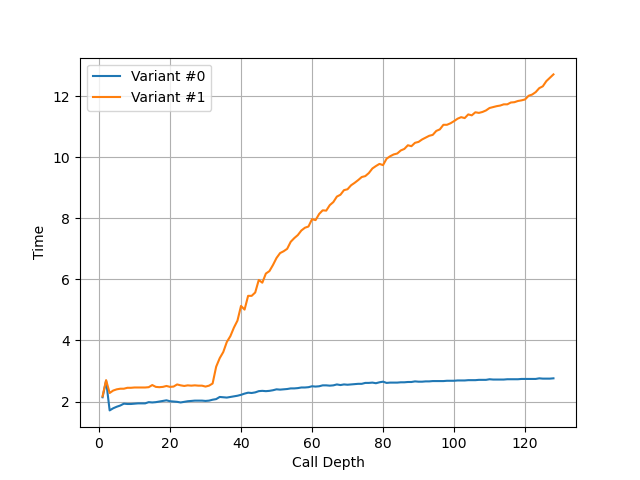
大小和 Neoverse V2 相同。
构造大量 B 指令,BTB 需要记录它们的目的地址。分支数量超过 BTB 容量时,性能就会下降。将 B 指令紧密放置(每 4 字节一条):
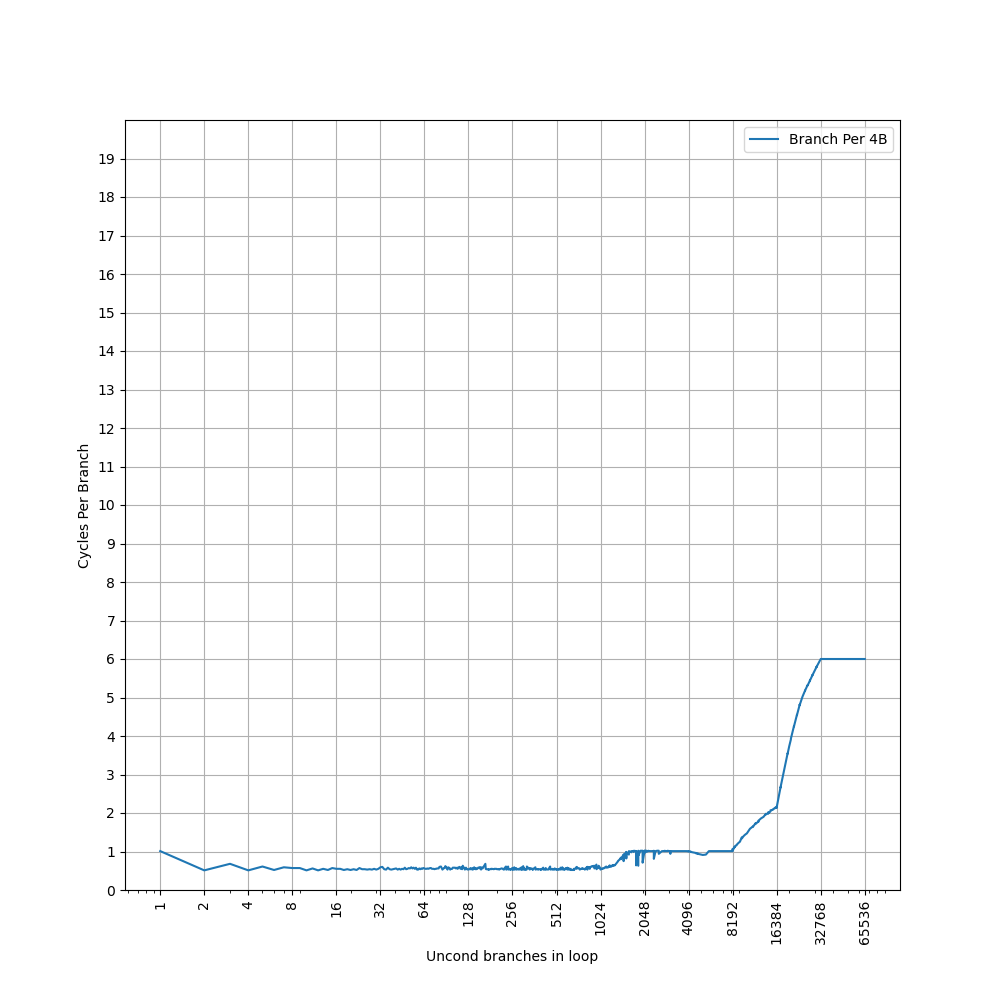
1024 条分支之前 CPI 约 0.5,说明 Neoverse V3 继承了 Neoverse V2 的 two taken 能力。之后到 8192 条分支之前 CPI 约 1,到 16384 条分支时 CPI 为 2,到 32768 条分支时 CPI 为 6。
性能曲线和 Neoverse V2 相同。Neoverse V2 的 BTB 官方描述是:
据此推算 Neoverse V2 和 V3 有相同的三级 BTB 结构:
主要疑点是 16384 条分支时如何实现 CPI 2,目前还缺少解释。
利用我们的逆向方法,观察分支地址对 PHR 的贡献:
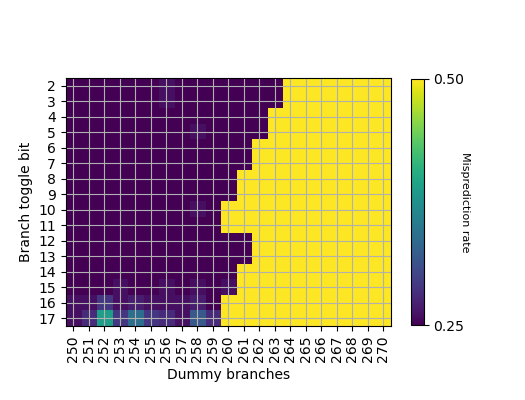
分支目的地址的贡献:
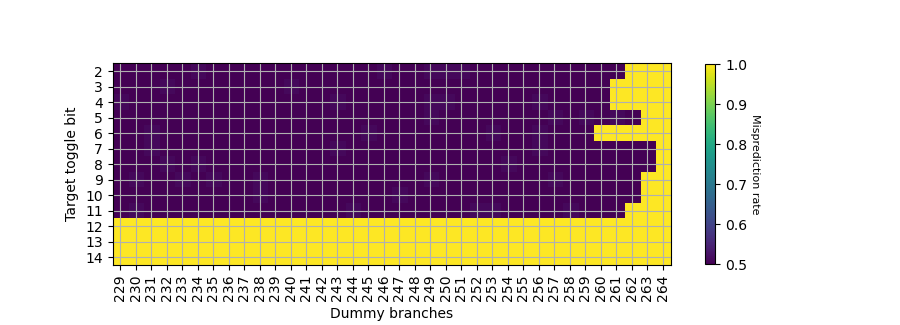
找到对应位的异或关系后,推断出 PHR 共有 264*2=528 位,每个 taken branch 左移 2 位,footprint 从低位到高位如下:
其中 T[5] 没有找到异或关系。和 Neoverse V2 的 PHR 构造只有很小的区别:Neoverse V2 中,T[5] shift 次数是 259。
官方信息:up to 10 MOPs per cycle and up to 20 uOPs per cycle, with the following limitations on the number of µOPs of each type that may be simultaneously dispatched:
Dispatch 宽度和 Decode 对齐,不过限制不少,实际很难跑满。
测试物理寄存器堆大小,用两个依赖链很长的操作放在开头和结尾,中间填入若干无关指令来耗费物理寄存器堆:
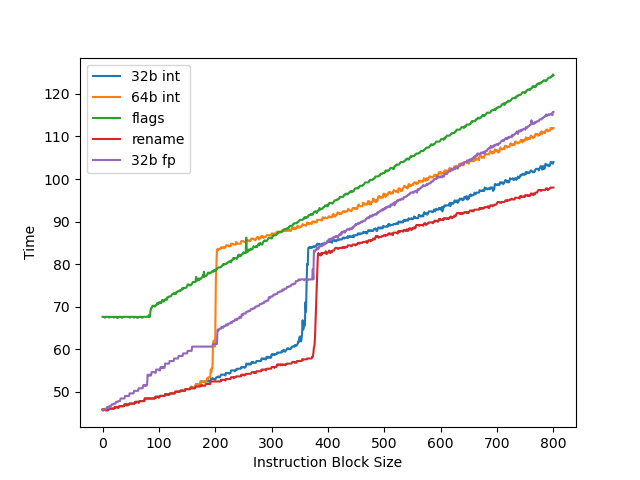
官方信息:
The Neoverse V3 core allows data to be forwarded from store instructions to a load instruction with the restrictions mentioned below:
描述和 Neoverse V2 相同。实测以下情况可以成功转发:
对地址 x 的 Store 转发到对地址 y 的 Load 成功时 y-x 的取值范围:
| Store\Load | 8b Load | 16b Load | 32b Load | 64b Load |
|---|---|---|---|---|
| 8b Store | {0} | {} | {} | {} |
| 16b Store | {0,1} | {0} | {} | {} |
| 32b Store | {0,2} | {0,2} | {0} | {-4,0} |
| 64b Store | {0,4} | {0,4} | {0,4} | {-4,0,4} |
一个 Load 需要转发两个 Store 的数据的情况:对地址 x 的 32b Store 和对地址 x+4 的 32b Store 转发到对地址 y 的 64b Load,在 Overlap 的情况下,要求 y=x,前半来自第一个 Store,后半来自第二个 Store。
和官方描述比较吻合,支持全部转发、转发前半、转发后半三种场景。针对常见的 64b Load,支持 y-x=-4。前半和后半也可以来自两个不同的 Store。对地址的对齐没有要求,跨缓存行边界也可以转发,只对 Load 和 Store 的相对位置有要求。转发成功时 5.3 Cycle,有 Overlap 但无法转发时 10.5 Cycle。
小结:ARM Neoverse V3 的 Store to Load Forwarding:
和 Neoverse V2 相同。
官方信息:8x ALU, 3x Branch, 4x 128b SIMD
实测以下指令的吞吐:
官方信息:1 Load/Store Pipe + 2 Load Pipe + 1 Store Pipe
一个周期内最多可以完成如下 Load/Store:
符合 1 LS + 2 LD + 1 ST pipe 的设计。相比 Neoverse V2 的 2 LS + 1 LD,同时 Load 和 Store 时性能更高。
每周期通过 load/store pair 指令可以完成的 128b 访存:
Load 没有跨越缓存行时,load to use 延迟 4 cycle;跨过 64B 缓存行边界时,增加到 5 cycle。与 Neoverse V2 相同。
为了预测执行 Load,需要确保它和之前的 Store 访问的内存没有 Overlap,所以需要一个预测器来预测这种依赖。参考 Store-to-Load Forwarding and Memory Disambiguation in x86 Processors 的方法,构造两种指令模式,分别测试数据和地址上的依赖:
str x3, [x1] 和 ldr x3, [x2]
str x2, [x1] 和 ldr x1, [x2]
初始化时 x1 和 x2 指向同一个地址,重复上述模式,观察性能下降时 ldr 指令的数量:
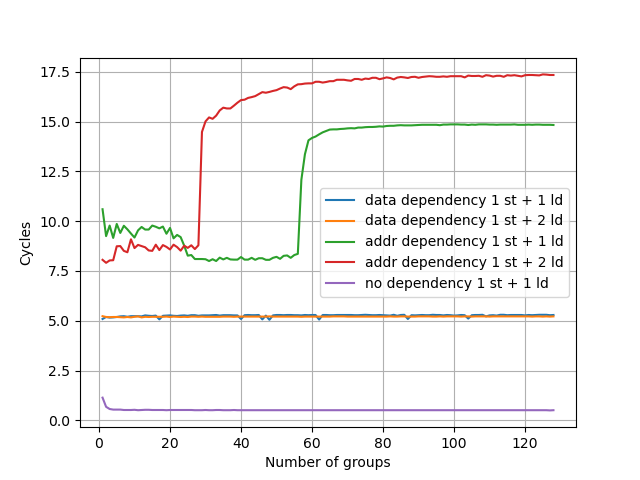
地址依赖的阈值是 56,数据依赖没有阈值。相比 Neoverse V2 有所增加。
把两个串行的 fsqrt 序列放在循环的头和尾,中间用 NOP 填充。如果 ROB 足够大,执行开头串行 fsqrt 序列时可以同时执行结尾的,性能最优。ROB 不够大时则会出现性能下降。
测试发现大约 768 条 NOP 时出现性能下降。Neoverse V3 实现了 Instruction Fusion,两条 NOP 算做一条 uOP 和一条 MOP,所以 768 条 NOP 对应 384 MOP 的 ROB 大小。极限下 384 MOP 可以存 768 uOP,但实际很难达到,容易受限于其他结构。相比 Neoverse V2 的 320 MOP 有所增加。
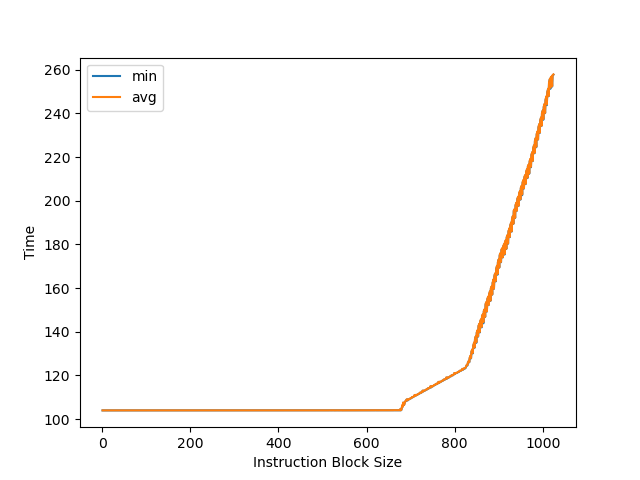
官方信息:64KB, 4-way set associative, VIPT behaving as PIPT, 64B cacheline, ECC protected, RRIP replacement policy, 4×64-bit read paths and 4×64-bit write paths for the integer execute pipeline, 3×128-bit read paths and 2×128-bit write paths for the vector execute pipeline
无论官方信息还是下面的实测结果,都和 Neoverse V2 相同。
构造不同大小 footprint 的 pointer chasing 链,测试每条 load 指令的耗时:
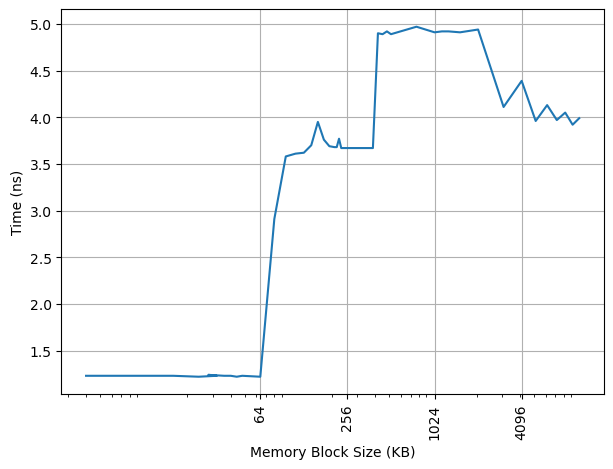
64KB 处出现拐点,对应 L1 DCache 容量。之后延迟先上升后下降,与 ARM 采用的 Correlated Miss Caching (CMC) 预取器记住了 pointer chasing 的历史有关,详见 Arm Neoverse N2: Arm's 2nd generation high performance infrastructure CPUs and system IPs。
L1 DCache 的 load to use latency 是 4 cycle,没有针对 pointer chasing 做 3 cycle 优化。
用 FP/ASIMD 128b Load 可以达到 3 IPC,对应 3x128b read paths;用 2x64b 整数 LDP 只能到 2 IPC,对应 4x64b read paths。要达到峰值读取性能,必须用 FP/ASIMD 指令。向量 128b Store 可以达到 2 IPC,对应 2x128b write paths;2x64b 整数 STP 也能到 2 IPC,对应 4x64b write paths。
4KB page 下,64KB 4-way 的 L1 DCache 不满足 VIPT 的 Index 全在页内偏移的条件(详见 VIPT 与缓存大小和页表大小的关系)。此时要么用 PIPT,要么在 VIPT 基础上处理 alias 问题。参考 浅谈现代处理器实现超大 L1 Cache 的方式 的测试方法,用 shm 构造两个 4KB 虚拟页映射到同一个物理页,然后在两个虚拟页之间 copy,发现相比同一个虚拟页内 copy 有显著的性能下降,并产生了大量 L1 DCache Refill:
copy from aliased page = 8778731053 cycles, 55305 refills baseline = 5298206743 cycles, 31413 refills slowdown = 1.66x 这验证了 L1 DCache 采用的是 VIPT,并在正确性上做了 alias 处理。如果是 PIPT,L1 DCache 会发现两个页对应相同物理地址,性能不会下降,也不需要频繁 refill。
为了支持每周期 3 条 Load,L1 DCache 通常会分 Bank,每个 Bank 有自己的读口。Load 分布到不同 Bank 上时可以同时读取;命中相同 Bank 但访问不同地址,就只能等下个周期。为了测试 Bank 构造,设计了一系列以不同固定 stride 间隔的 Load 指令:
Stride=64B 时出现 Bank Conflict,Stride=128B 时所有 Load 命中同一个 Bank,只能串行读取。根据这个现象,认为 Neoverse V3 的 L1 DCache 组织方式是:
这里讨论的是缓存行级别的 Bank。缓存行内部也会做 Bank 划分,但主要是为了功耗,比如从 64B 缓存行读 8B 数据,不需要把整个 64B 都读出来。
官方信息:Caches entries at the 4KB, 16KB, 64KB, 2MB or 512MB granularity, Fully associative, 96 entries.
用 pointer chasing 测试 L1 DTLB 容量,指针分布在不同的 page 上,让 DTLB 成为瓶颈:
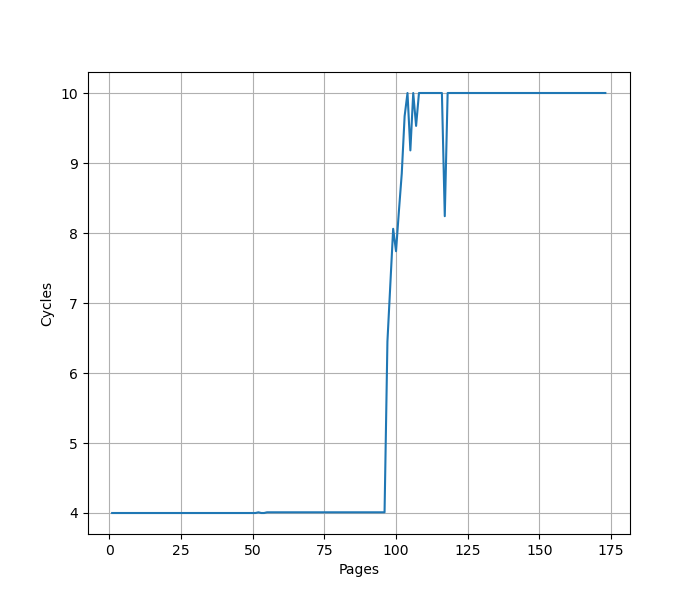
96 Page 处出现拐点,对应 96 项的 L1 DTLB 容量。超出后需要额外 6 cycle 访问 L2 Unified TLB。容量相比 Neoverse V2 翻番。测试时注意避免 Huge Page 的影响。
官方信息:Shared by instructions and data, 8-way set associative, 2048 entries
官方信息:2MB or 3MB, 8-way(2MB) or 12-way(3MB) set associative, 4 banks, PIPT, ECC protected, 64B cacheline
官方信息:128b SVE vector length
Linux 下查看 /proc/sys/abi/sve_default_vector_length,SVE 宽度为 16 字节,即 128b。
Neoverse V3 每周期最多执行 4 条 ASIMD 或 SVE 浮点 FMA 指令,浮点峰值性能:
128/32*2*4=32 FLOP per cycle128/64*2*4=16 FLOP per cycle与 Neoverse V2、Zen 2-4、Oryon、Firestorm、LA464、Haswell 等微架构看齐,但不及 Zen 5、Skylake 等通过 AVX512 提供的峰值浮点性能。
Neoverse V3 相比 Neoverse V2 改动不算很大,主要变化:
整体上是一次稳健的迭代升级。
2026-05-29 08:00:00
本文同步发布到本人的知乎。
继 INT Rate 篇 后,本文继续分析 SPEC FP 2026 Rate 的负载特性。
测试环境与先前的 INT Rate 篇 相同,这里不再赘述。
推荐阅读:Evaluating SPEC CPU2026 和 SPEC CPU2026: Characterization, Representativeness, and Cross-Suite Comparison
Cactus 是一个计算框架,这里用它来求解真空中的爱因斯坦方程。命令参数如下:
实测数据显示,运行时间为 103.4s,reftime 是 858s,对应 8.30 分。不同编译器和编译选项对 709.cactus_r 的优化情况如下:
| 编译器 + 选项 | 时间 (s) | 分数 | 相比 GCC 14 -O3 性能提升 (%) |
|---|---|---|---|
GCC 14 -O3
| 103.4 | 8.30 | 0 |
GCC 14 -O3 -march=native
| 83.9 | 10.23 | 23 |
GCC 14 -O3 -ffast-math
| 101.2 | 8.48 | 2 |
GCC 14 -O3 -ljemalloc
| 100.7 | 8.52 | 3 |
LLVM 22 -O3
| 94.6 | 9.07 | 9 |
LLVM 22 -O3 -march=native
| 90.5 | 9.48 | 14 |
可见 -march=native 能提供巨大的性能提升,LLVM 22 在 -O3 下比 GCC 14 快,不过 GCC 14 的 -O3 -march=native 又反超了 LLVM 22 的 -O3 -march=native,后面会具体分析。
通过 perf 观察性能瓶颈:
ML_CCZ4::ML_CCZ4_EvolutionInteriorSplitBy2_Body 来自 src/repos/mclachlan/ML_CCZ4/src/ML_CCZ4_EvolutionInteriorSplitBy2.cc:占总时间 41.30%,下同;ML_CCZ4::ML_CCZ4_EvolutionInteriorSplitBy3_Body 来自 src/repos/mclachlan/ML_CCZ4/src/ML_CCZ4_EvolutionInteriorSplitBy3.cc:31.26%;ML_CCZ4::ML_CCZ4_ConstraintsInterior_Body 来自 src/repos/mclachlan/ML_CCZ4/src/ML_CCZ4_ConstraintsInterior_Body.cc:6.71%;ML_CCZ4::ML_CCZ4_EvolutionInteriorSplitBy1_Body 来自 src/repos/mclachlan/ML_CCZ4/src/ML_CCZ4_EvolutionInteriorSplitBy3.cc:6.44%。这些热点函数的代码模式都是类似的:在三层循环里,读取对应三维空间中的点的数据,进行一系列的 Stencil 访存和浮点运算,包括大量的浮点乘法加法减法、pow 和 fabs,最后把结果写入对应数组。从指令来看,就是用大量的 SSE 指令来进行标量的双精度浮点运算,没有进行向量化。实验的时候,还观察到了编译器对 pow 和 fabs 的优化。在 -O3 时,pow(a, 1) 被编译成 a,pow(a, 2) 被编译成 a * a,pow(a, -1) 被编译成 1.0 / a,不过其他的例如 pow(a, 3) 和 pow(a, -2) 就只能转为 libm 的 pow 实现了。如果开了 -O3 -ffast-math,那么 pow(a, 3) 会编译成 a * a * a,pow(a, -2) 会被编译为 1.0 / (a * a)。两种编译选项的对比见 Godbolt。代码中,出现的主要就是 pow(a, -1),pow(a, 2)、pow(a, -2) 和 pow(a, runtimeVariable),其中 runtimeVariable 指一个在运行时才知道的数,在代码中对应 shiftAlphaPower 或 harmonicN。fabs 被编译成了位运算 andpd 指令,直接把符号位置零。
开启 -O3 -march=native 后,其实依然没有向量化,用 AVX2 指令计算双精度标量浮点,依然能看到对 libm 的 pow 的调用,就是上面提到的 pow(a, -2) 或 pow(a, runtimeVariable),不过其余的计算部分因为能用 vfmadd132sd/vfnmadd132sd 而获得了性能提升,同时 vaddsd 相比 addsd 从两操作数变为三操作数,还允许访存,进一步节省了指令数。而在 ARM64 平台上,开 -march=native 就没有性能提升,这是因为它的浮点乘加融合指令即使在没开 -march=native 的情况下也是可以使用的,见 Godbolt。某种意义上来说,AMD64 上开 -march=native 有性能巨大提升,也是吃了先发劣势的亏:基线对应的处理器太早,缺少很多重要的指令集扩展,这种兼容性负担在很多其他指令集上不会出现,例如乘加融合 FMA 指令很多指令集里已经在基线当中,在这些指令集上,开 -march=native 的提升就会相对来说更低。所以现在很多软件会曲线救国,为了保证兼容性,针对多个不同指令集扩展分别做手动适配,在运行时根据可用性选择性能最好的那一个。如果编译器能很好地自动完成这一点,将会在保持兼容性和开发便捷性的前提下,带来不错的系统整体性能提升。
不同编译选项的情况对比:
| 编译器 + 选项 | 时间 (s) | 指令 (B) | Load (B) | Store (B) | 分支 (B) | 浮点标量 (B) | 浮点向量 (B) |
|---|---|---|---|---|---|---|---|
GCC 14 -O3
| 103.4 | 1423.6 | 747.8 | 110.1 | 9.8 | 677.0 | 5.2 |
GCC 14 -O3 -march=native
| 83.9 | 988.5 | 711.9 | 89.5 | 8.9 | 686.1 | 2.6 |
GCC 14 -O3 -ffast-math
| 101.8 | 1387.7 | 742.2 | 103.4 | 5.3 | 641.0 | 5.6 |
GCC 14 -O3 -ljemalloc
| 100.7 | 1423.6 | 747.8 | 110.1 | 9.8 | 677.0 | 5.2 |
LLVM 22 -O3
| 94.6 | 1323.1 | 659.1 | 96.6 | 6.1 | 659.0 | 15.2 |
LLVM 22 -O3 -march=native
| 90.5 | 1054.5 | 690.7 | 119.4 | 5.4 | 681.4 | 5.4 |
其中总指令数来自 instructions,Load 指令数来自 mem_inst_retired.all_loads,Store 指令数来自 mem_inst_retired.all_stores,分支指令数来自 branch-instructions,浮点标量指令数用 fp_arith_inst_retired.scalar,浮点向量指令数用 fp_arith_inst_retired.vector 性能计数器,下同。需要注意的是,vfmadd132sd 等乘加融合指令在 fp_arith_inst_retired.scalar/vector 计数器中会被计算两次。
从表里可以看出,-O3 下基本是一半指令在 Load,另一半指令在做浮点标量运算,这个计算访存比还是挺低的,这是 Stencil 计算的典型特征,在网格邻域里,Load 一个值进来,做一次乘加。开 -O3 -march=native 后,因为乘加融合指令的加持,指令数减少了很多,但因为乘加融合会算两倍的贡献,并且那些同时进行访存和计算的 AVX2 指令也会被同时计入到 Load 和浮点指令数,估计微架构是统计的拆分后的微码数量,那么总指令数不再等于各类指令数求和。这里 -O3 -ljemalloc 带来了些许的性能优势,不过指令数上并没有体现,它的性能提升主要是来自缓存局部性的改进。GCC 14 和 LLVM 22 在不同编译选项下各有千秋,大概看了一下生成的指令,其实实现方法都差不多,主要是地址计算、栈的使用和寄存器分配有一些区别。
值得注意的是,709.cactus_r 的缓存缺失率较高:GCC 14 -O3 下,L1 ICache 的 MPKI 达到 118.6B/1423.6B*1000=83.30,L1 DCache 也有 125.6B/1423.6B*1000=88.23 的 MPKI,在 SPEC FP 2026 Rate 和 SPEC INT 2026 Rate 中都是最高的。因此 L1 ICache 更大的核心更占优势,32KB 时遇到的 L1 ICache 瓶颈,换成 64KB 可能就消失了。开 -O3 -ljemalloc 后,L1 DCache 的 MPKI 降低到 111.7B/1423.6B*1000=78.46,在指令数与 -O3 持平的情况下获得了约 3% 的性能提升。
palm 是一个天气预报相关的程序,做的是 Navier Stokes 方程的求解,命令如下:
实测数据显示,运行时间为 174.0s,reftime 是 1320s,对应 7.59 分。不同编译器和编译选项对 722.palm_r 的优化情况:
| 编译器 + 选项 | 时间 (s) | 分数 | 相比 GCC 14 -O3 性能提升 (%) |
|---|---|---|---|
GCC 14 -O3
| 174.0 | 7.59 | 0 |
GCC 14 -O3 -march=native
| 157.8 | 8.34 | 10 |
GCC 14 -O3 -ffast-math
| 168.4 | 7.84 | 3 |
GCC 14 -O3 -ljemalloc
| 172.4 | 7.66 | 1 |
LLVM 22 -O3
| 144.0 | 9.17 | 21 |
LLVM 22 -O3 -march=native
| 118.6 | 11.13 | 47 |
趋势和 709.cactus_r 类似,-O3 -march=native 对性能提升巨大,LLVM 22 也明显比 GCC 14 快。
热点函数:
advec_s_ws_ij 来自 src/advec_ws.F90:9.80%,经典的 3 维上的 Stencil 计算,访存和计算的比例接近,基本是 load 一个点的数值然后就做对应的乘加,用 SSE 指令来做计算,有部分向量化计算,例如 addpd/subpd/mulpd 等,每条指令处理 2 个双精度浮点元素,不过也有一些循环没能成功向量化,退化到 addsd/subsd/mulsd 等浮点标量指令;advec_u_ws_ij 来自 src/advec_ws.F90:8.80%,同上;advec_v_ws_ij 来自 src/advec_ws.F90:8.54%,同上;advec_w_ws_ij 来自 src/advec_ws.F90:8.24%,同上;diffusion_e_ij 来自 src/turbulence_closure_mod.F90:5.14%,有一些比较复杂的浮点运算,比如 min/sqrt/div 等等,还有位运算,用 MERGE 来进行 ternary operator,无向量化,用 SSE 指令来做标量浮点计算。以下是 advec_s_ws_ij 中的 Stencil 计算代码,按 i,j,k 的顺序进行三层循环:
flux_r(k) = u_comp * ( & 37.0_wp * ( sk(k,j,i+1) + sk(k,j,i) ) & - 8.0_wp * ( sk(k,j,i+2) + sk(k,j,i-1) ) & + ( sk(k,j,i+3) + sk(k,j,i-2) ) ) * adv_sca_5 不同编译选项的情况对比:
| 编译器 + 选项 | 时间 (s) | 指令 (B) | Load (B) | Store (B) | 分支 (B) | 浮点标量 (B) | 浮点向量 (B) |
|---|---|---|---|---|---|---|---|
GCC 14 -O3
| 174.0 | 3416.6 | 1267.4 | 271.1 | 155.6 | 779.0 | 318.5 |
GCC 14 -O3 -march=native
| 157.8 | 2710.0 | 1212.8 | 242.5 | 147.1 | 785.9 | 172.6 |
GCC 14 -O3 -ffast-math
| 168.4 | 3373.5 | 1204.7 | 278.0 | 134.0 | 612.8 | 363.1 |
GCC 14 -O3 -ljemalloc
| 172.4 | 3368.4 | 1259.7 | 260.7 | 141.6 | 779.0 | 318.5 |
LLVM 22 -O3
| 144.0 | 2640.4 | 835.5 | 216.3 | 90.4 | 179.5 | 609.7 |
LLVM 22 -O3 -march=native
| 118.6 | 1643.8 | 586.5 | 165.6 | 67.6 | 180.8 | 306.7 |
开 -O3 -march=native 后,能看到大量的 AVX2 向量化指令:vmulpd/vdivsd/vaddpd/vsubpd/vfmadd213sd/vfmsub132pd/vfmsub231pd/vmovupd 等等,每次处理 4 个双精度浮点元素,向量化程度很高,如果放在支持 AVX512 的处理器上,性能可能还会更高。相比 709.cactus_r 被 pow 等问题限制没能向量化,722.palm_r 的向量化收益要明显得多。LLVM 22 在 -O3 下比 GCC 14 更好,是因为它在热点函数如 advec_u/v/w_ws_ij 中成功进行了向量化,而 GCC 14 仍用标量,体现在数据上就是浮点向量指令数明显增多,浮点标量指令数明显减少。LLVM 22 下,上述热点函数被优化得较好后,flow_statistics(来自 src/flow_statistics.F90,时间占比 5.79%)成为了新的热点函数。它能向量化的部分比较少,因而时间占比提升。即使开了 -O3 -march=native,也还是用 AVX2+FMA 指令来做标量计算,时间区别不大。其他部分时间降低后,它的时间占比进一步提高到 6.95%,类似 Amdahl 定律。
709.cactus_r 和 722.palm_r 的计算模式其实都是 Stencil。物理相关的模拟经常做这类事情:在三维空间里求解微分方程,数值求解时需要对每个点的邻域进行反复计算,落到最后就是 Stencil。
astcenc 是一个针对 ASTC 有损压缩图片格式的编码器,运行三次,命令如下:
# 1. linear astcenc_r ref-inputs-linear.txt # 2. hdr astcenc_r ref-inputs-hdr.txt # 3. precision astcenc_r ref-inputs-precision.txt 实测运行时间为 49.9s、72.1s 和 53.8s,总时间 175.8s,reftime 是 840s,对应 4.78 分。不同编译器和编译选项的优化情况如下:
| 编译器 + 选项 | 总时间 (s) | 1. linear 时间 (s) | 2. hdr 时间 (s) | 3. precision 时间 (s) | 分数 | 相比 GCC 14 -O3 性能提升 (%) |
|---|---|---|---|---|---|---|
GCC 14 -O3
| 175.8 | 49.9 | 72.1 | 53.8 | 4.78 | 0 |
GCC 14 -O3 -march=native
| 157.3 | 44.0 | 63.2 | 50.0 | 5.34 | 12 |
GCC 14 -O3 -ffast-math
| 160.5 | 44.6 | 67.2 | 48.7 | 5.23 | 10 |
LLVM 22 -O3
| 134.0 | 38.5 | 56.1 | 39.3 | 6.27 | 31 |
LLVM 22 -O3 -march=native
| 117.2 | 34.4 | 48.6 | 34.1 | 7.17 | 50 |
又是 LLVM 22 相比 GCC 14 有明显优势的一个基准测试。其他对性能几乎没有影响的优化选项包括 -flto 和 -ljemalloc,这里就不具体列举了。731.astcenc_r 是 SPEC FP 2026 Rate 中 MPKI 最高的那一个,高达 5.0,相比其他大多数不到 1.0 的 MPKI 来说很高(第二高的是 737.gmsh_r,MPKI 达到了 3.33,第三高 767.nest_r 的 MPKI 只有 0.83),也比 SPEC INT 2026 Rate 的不少基准测试更高。下面分负载来进行分析。
主要热点函数:
compute_angular_endpoints_for_quant_levels 来自 src/astcenc_weight_align.cpp:18.93%,主要瓶颈是在中间的循环,在用 SSE 做一些单精度浮点的标量计算,中间还有一些对来自 libm 的 nearbyint 调用,进行 round 操作,从代码来看,开发者有意识地写一些适合编译器去向量化的代码,比如用 vfloat4 类型来做一些批量操作,还有 vmask4 类型保存 vfloat4 比较的结果(vmask4 保存了四个 int,用 0 代表 false,用 -1 代表 true),再用 select 函数来进行向量化的 ternary operator,可惜编译器并不领情,编译出来依然是标量 SSE;compute_avgs_and_dirs_3_comp_rgb 来自 src/astcenc_averages_and_directions.cpp:14.70%,模式和上面类似,在循环中做一些 vfloat4 和 vmask4 的计算,但 SSE 指令都是标量的;compute_quantized_weights_for_decimation 来自 src/astcenc_ideal_endpoints_and_weights.cpp:13.34%,在循环中做一些不过因为涉及到量化,有一些 vint 参与以及查表 vtable_lookup_32bit,这里 vfloat/vint 本来代表的是根据平台能提供的 SIMD 宽度进行一个自动的映射(定义在 src/astcenc_vecmathlib.h 中,比如 AVX 就是 8 个元素,vfloat 映射到 vfloat8;SSE 就是 4 个元素,vfloat 映射到 vfloat4),不过显然这些在 SPEC 里都被禁用了,fallback 到了 4 个元素的情况;compute_ideal_weights_for_decimation 来自 src/astcenc_ideal_endpoints_and_weights.cpp:9.57%,主要瓶颈是在一个 gather 操作 gatherf_byte_inds 里,不过因为 SSE 不支持 gather,所以是拆成四个元素分别进行 load 和标量计算的;bilinear_infill_vla 来自 src/astcenc_ideal_endpoints_and_weights.cpp:7.80%,瓶颈一样是 gather,即 gatherf_byte_inds 函数;compute_error_squared_rgb 来自 src/astcenc_averages_and_directions.cpp:6.39%,瓶颈一样是 gather,以及 gather 之后的一系列向量计算,但 GCC 14 都编译成了 SSE 标量计算。原生 SIMD 写法编译出来却是标量指令,反过来也说明,如果能正确向量化,性能还会有明显的提升空间。进一步,如果开了 -O3 -march=native,向量更宽来到 256 位,还多了 vblendvps 指令来实现上述 select 函数。前面提到过,LLVM 22 明显更快,下面看看不同编译器和编译选项的对比:
| 编译器 + 选项 | 时间 (s) | 指令 (B) | Load (B) | Store (B) | 分支 (B) | 浮点标量 (B) | 浮点向量 (B) | 错误预测 (M) | MPKI |
|---|---|---|---|---|---|---|---|---|---|
GCC 14 -O3
| 49.9 | 835.7 | 259.3 | 55.6 | 63.2 | 188.6 | 28.6 | 3136.0 | 3.75 |
GCC 14 -O3 -march=native
| 44.0 | 652.4 | 234.0 | 46.3 | 52.9 | 184.6 | 28.5 | 3148.2 | 4.83 |
GCC 14 -O3 -ffast-math
| 44.6 | 780.5 | 259.8 | 54.6 | 49.3 | 159.9 | 43.2 | 2139.0 | 2.74 |
LLVM 22 -O3
| 38.5 | 829.7 | 235.0 | 34.8 | 36.1 | 68.8 | 155.6 | 1095.5 | 1.32 |
LLVM 22 -O3 -march=native
| 34.4 | 620.9 | 179.5 | 17.7 | 19.6 | 42.1 | 125.7 | 823.4 | 1.33 |
从计数器可以看到,GCC 14 整体性能比 LLVM 22 差,是因为 LLVM 22 做了更多的向量化,它浮点向量指令明显比浮点标量要多,并且错误预测明显更少,MPKI 小很多。下面进行深入的分析。
首先看 GCC 14 是怎么实现 731.astcenc_r 的这类 SIMD 原生代码的。以上面分析的热点函数为例,一个常见的模式是用 vfloat4 的比较加 select 来实现向量化的最大值计算:
这段代码在 -O3 编译选项下会被 GCC 14 编译成这样的汇编:
vmax(vfloat4 a, vfloat4 b): # a 向量保存在 xmm0(a[0] 和 a[1])和 xmm1(a[2] 和 a[3])寄存器 # b 向量保存在 xmm2(b[0] 和 b[1])和 xmm3(b[2] 和 b[3])寄存器 # 虽然每个元素都是单精度,但每个 xmm 寄存器只保存了两个元素 movq %xmm1, %rax # rax = a3 | a2 movq %xmm3, %rcx # rcx = b3 | b2 movq %xmm0, %rsi # rsi = a1 | a0 movd %ecx, %xmm1 # xmm1 = b2 movd %eax, %xmm6 # xmm6 = a2 shrq $32, %rcx # rcx = b3 movdqa %xmm2, %xmm5 # xmm5 = b1 | b0 shrq $32, %rax # rax = a3 movdqa %xmm2, %xmm0 # xmm0 = b1 | b0 movd %ecx, %xmm4 # xmm4 = b3 shufps $85, %xmm5, %xmm5 # xmm5 = b1 | b1 | b1 | b1 movd %eax, %xmm2 # xmm2 = a3 movd %esi, %xmm7 # xmm7 = a0 shrq $32, %rsi # rsi = a1 movdqa %xmm5, %xmm3 # xmm3 = b1 | b1 | b1 | b1 comiss %xmm2, %xmm4 # 比较 a3 和 b3 movd %esi, %xmm5 # xmm5 = a1 seta %al # al = (b3 > a3) comiss %xmm6, %xmm1 # 比较 b2 和 a2 jbe .L14 # 如果 a2 >= b2 就跳转到 .L14 testb %al, %al jne .L15 # 如果 b3 > a3 就跳转到 .L15 # 此时 a2 < b2, a3 >= b3 maxss %xmm7, %xmm0 # xmm0 = max(a0, b0) maxss %xmm5, %xmm3 # xmm3 = max(a1, b1) unpcklps %xmm2, %xmm1 # xmm1 = a3 | b2 unpcklps %xmm3, %xmm0 # xmm0 = max(a1, b1) | max(a2, b2) ret .L14: # 处理 a2 >= b2 的情况 testb %al, %al jne .L16 # 如果 b3 > a3 就跳转到 .L16 #3 此时 a2 >= b2, a3 >= b3 movaps %xmm6, %xmm1 # xmm1 = a2 # 下略,就是分类讨论 a2 vs b2,a3 vs b3 的四种情况 .L17: maxss %xmm7, %xmm0 maxss %xmm5, %xmm3 unpcklps %xmm2, %xmm1 unpcklps %xmm3, %xmm0 ret .L16: movaps %xmm4, %xmm2 movaps %xmm6, %xmm1 jmp .L17 .L15: maxss %xmm7, %xmm0 maxss %xmm5, %xmm3 movaps %xmm4, %xmm2 unpcklps %xmm2, %xmm1 unpcklps %xmm3, %xmm0 ret 很奇怪的是,它首先用通用寄存器把输入的数值拆分出来,然后分别比较后两个元素 a2 vs b2,a3 vs b3,用分支来处理四种可能的情况,这四种情况是已知后两个元素最大值都来自哪里,结果针对前两个元素又用 maxss 来计算,为啥不一开始就对所有四个元素都用 maxss 呢?结果开 -O3 -ffast-math 后,它莫名其妙就学会了这一点:
vmax(vfloat4, vfloat4): movq %xmm0, %rsi movq %xmm1, %rcx movq %xmm2, %rdx movd %esi, %xmm1 movq %xmm3, %rax movdqa %xmm2, %xmm0 shrq $32, %rdx maxss %xmm1, %xmm0 shrq $32, %rsi movdqa %xmm3, %xmm1 shrq $32, %rax movd %ecx, %xmm3 shrq $32, %rcx movd %edx, %xmm2 movd %esi, %xmm4 maxss %xmm3, %xmm1 movd %ecx, %xmm5 movd %eax, %xmm3 maxss %xmm4, %xmm2 maxss %xmm5, %xmm3 unpcklps %xmm2, %xmm0 unpcklps %xmm3, %xmm1 ret 但依然是用 SSE 做标量,而 LLVM 22 就懂得如何用 maxps 指令向量化:
vmax(vfloat4, vfloat4): movlhps %xmm3, %xmm2 movlhps %xmm1, %xmm0 maxps %xmm2, %xmm0 movaps %xmm0, %xmm1 unpckhpd %xmm0, %xmm1 retq 剩余的指令只是为了解决调用约定的数据存放位置问题,实际在函数内部计算的时候,通常就一条 maxps 指令完成所有 4 个元素的 max 计算。从这个例子也可以看出,为啥 LLVM 22 比 GCC 14 要快得多:GCC 14 多了很多无用的分支来解决 select 里的比较,而且还不能向量化 max 操作。即使给 GCC 14 开 -march=native,它依然还在用 AVX 指令进行标量 max 运算,真是难绷。上述编译结果可见 Godbolt。GCC 14 的 MPKI 那么高,其实都是这么来的,也挺搞笑。我还测试了一下,发现相同的代码在 LoongArch 下也没有得到很好的向量化支持(见 Godbolt),因此提了一个 issue,仅考虑向量化 fmax 内核,用 vfcmp.slt.s + vbitsel.v 的优化实现大概是目前 LLVM 22 编译结果的 2.9 倍性能。这里有一个小冷知识,就是 x86 的 SSE/AVX max 指令都实现的都是 a > b ? a : b 的逻辑,而 LoongArch 的 fmax 指令实现的是 IEEE754 的 maxNum,二者在出现 NaN 时的行为不同:前者只要 a 或 b 出现一个 NaN,就都返回 b;后者只有一个 NaN 时,会返回另一个非 NaN 的数。
主要热点函数:
compute_angular_endpoints_for_quant_levels 来自 src/astcenc_weight_align.cpp:19.80%,描述见上;compute_avgs_and_dirs_3_comp_rgb 来自 src/astcenc_averages_and_directions.cpp:15.37%,描述见上;compute_quantized_weights_for_decimation 来自 src/astcenc_ideal_endpoints_and_weights.cpp:12.40%,描述见上;compute_error_squared_rgb 来自 src/astcenc_averages_and_directions.cpp:6.91%,描述见上;compute_ideal_weights_for_decimation 来自 src/astcenc_ideal_endpoints_and_weights.cpp:5.68%,描述见上。热点函数基本和 1. linear 一致,那么各方面基本也和它一样,GCC 14 生成大量分支和标量 SSE 指令,而 LLVM 22 能更好地向量化,避免一些无谓的分支。对比如下:
| 编译器 + 选项 | 时间 (s) | 指令 (B) | Load (B) | Store (B) | 分支 (B) | 浮点标量 (B) | 浮点向量 (B) | 错误预测 (M) | MPKI |
|---|---|---|---|---|---|---|---|---|---|
GCC 14 -O3
| 72.1 | 1091.8 | 306.9 | 78.6 | 91.7 | 245.8 | 30.4 | 4928.9 | 4.51 |
GCC 14 -O3 -march=native
| 63.1 | 851.4 | 271.2 | 65.2 | 77.4 | 240.1 | 30.4 | 4890.6 | 5.74 |
GCC 14 -O3 -ffast-math
| 67.1 | 1036.6 | 311.0 | 85.5 | 73.7 | 200.8 | 54.3 | 4077.0 | 3.93 |
LLVM 22 -O3
| 55.9 | 1107.9 | 276.5 | 55.9 | 56.9 | 111.8 | 129.9 | 1943.2 | 1.75 |
LLVM 22 -O3 -march=native
| 48.6 | 825.2 | 209.3 | 30.7 | 34.1 | 85.2 | 139.7 | 1411.6 | 1.71 |
热点函数大多还是和 1. linear 以及 2.hdr 一样,就是多了一个 find_best_partition_candidates 函数,来自 src/astcenc_find_best_partitioning.cpp,主要瓶颈在 a / sqrt(length) 的计算上。这次 GCC 14 在 -O3 时倒是能够正确向量化这一步,通过一次标量的 sqrtss 加 shufps 把结果复制到所有 lane,再用 divps 进行批量的除法,不过其余的热点函数还是一如既往的编译出很慢的代码。下面给出性能计数器上的对比:
| 编译器 + 选项 | 时间 (s) | 指令 (B) | Load (B) | Store (B) | 分支 (B) | 浮点标量 (B) | 浮点向量 (B) | 错误预测 (M) | MPKI |
|---|---|---|---|---|---|---|---|---|---|
GCC 14 -O3
| 53.8 | 711.5 | 176.8 | 62.0 | 61.3 | 177.0 | 9.3 | 5119.2 | 7.19 |
GCC 14 -O3 -march=native
| 49.2 | 570.5 | 161.3 | 57.1 | 54.7 | 176.1 | 9.2 | 5113.1 | 8.96 |
GCC 14 -O3 -ffast-math
| 48.7 | 655.9 | 168.3 | 64.6 | 49.8 | 156.5 | 19.5 | 4227.6 | 6.56 |
LLVM 22 -O3
| 39.3 | 729.9 | 149.2 | 42.8 | 35.9 | 75.3 | 77.2 | 1906.7 | 2.61 |
LLVM 22 -O3 -march=native
| 34.1 | 544.9 | 112.5 | 28.0 | 23.2 | 52.0 | 87.1 | 1445.7 | 2.65 |
731.astcenc_r 用了 SIMD 原生的写法来编程:vfloat4、vint4 和 vmask4 等等,编写时就是奔着 SIMD 指令去的。只可惜 GCC 14 辜负了开发者的期望,不能正确识别代码意图并利用硬件指令,还莫名生成了一堆分支来实现 select 函数。相比之下,LLVM 22 就做得好很多,该向量化的地方就向量化。同时也能看到,像 LoongArch 这样稍微小众一些的指令集,在这些代码模式下的优化还比较欠缺,无论 GCC 还是 LLVM 都是如此。
ocio 是 OpenColorIO 的缩写,和 731.astcenc_r 类似,也是在图片上的处理,不过更侧重于图像处理,而非图像压缩。该基准测试包括如下四个负载:
# 1. lut1d ocioperf --spec-validation-offset 101 --spec-validation-stride 17 --spec-validation-pixels 131 --bitdepths ui16 ui16 --iter 100 --test -1 --transform ctf/lut1d_halfdom.ctf # 2. mntr ocioperf --spec-validation-offset 202 --spec-validation-stride 19 --spec-validation-pixels 132 --bitdepths ui16 f32 --iter 200 --8kres --test 0 --transform ctf/mntr_srgb_identity.ctf # 3. aces ocioperf --spec-validation-offset 303 --spec-validation-stride 23 --spec-validation-pixels 133 --bitdepths f32 f32 --iter 20 --8kres --test -1 --transform clf/aces_to_video_with_look.clf # 4. heavy ocioperf --spec-validation-offset 404 --spec-validation-stride 29 --spec-validation-pixels 134 --bitdepths f32 f32 --iter 25 --test -1 --transform clf/heavy_transform.clf reftime 是 875s,不同编译器和编译选项的运行情况如下:
| 编译器 + 选项 | 总时间 (s) | 1. lut1d 时间 (s) | 2. mntr 时间 (s) | 3. aces 时间 (s) | 4. heavy 时间 (s) | 分数 | 相比 GCC 14 -O3 性能提升 (%) |
|---|---|---|---|---|---|---|---|
GCC 14 -O3
| 139.8 | 6.1 | 11.2 | 67.8 | 54.6 | 6.26 | 0 |
GCC 14 -O3 -march=native
| 105.0 | 4.2 | 10.2 | 49.6 | 40.1 | 8.33 | 33 |
GCC 14 -O3 -ffast-math
| 139.4 | 6.4 | 11.4 | 67.8 | 53.9 | 6.28 | 0.3 |
LLVM 22 -O3
| 128.9 | 6.8 | 11.3 | 61.7 | 49.0 | 6.79 | 8 |
LLVM 22 -O3 -march=native
| 105.3 | 5.4 | 9.6 | 49.3 | 40.9 | 8.31 | 33 |
可见又是一个 -O3 -march=native 带来明显提升的基准测试,且 LLVM 22 依然比 GCC 14 在 -O3 下有性能优势,在 -O3 -march=native 时基本打平。下面进行具体分析。
热点函数:
OpenColorIO_v2_2dev::BitDepthCast<BIT_DEPTH_F32, BIT_DEPTH_UINT16>::apply 来自 src/ASWF-OpenColorIO/src/OpenColorIO/CPUProcessor.cpp:45.16%,主要做的计算是,在循环中对取值在零到一之间的单精度浮点元素,乘以 65535 从而放缩到 uint16_t 的范围,加 0.5 后 clamp 到 uint16_t 的范围,最后再 float 转换为 uint16_t,这个过程被编译为 SSE 的向量指令;OpenColorIO_v2_2dev::Lut1DRendererHalfCode<BIT_DEPTH_UINT16, BIT_DEPTH_F32>::apply 来自 src/ASWF-OpenColorIO/src/OpenColorIO/ops/lut1d/Lut1DOpCPU.cpp:33.70%,在循环中对输入的 uint16_t 进行查表,其实就是从预先计算好的数组里读取 uint16_t 对应的 float 值,瓶颈是 SSE 标量间接访存;__memmove_avx_unaligned_erms 来自 libc:13.28%,memmove 的 AVX 加速实现;__memset_avx2_unaligned_erms 来自 libc:3.55%,memset 的 AVX 加速实现。对于这类可以高度向量化的代码,-O3 -march=native 的提升是很明显的,在 OpenColorIO_v2_2dev::BitDepthCast<BIT_DEPTH_F32, BIT_DEPTH_UINT16>::apply 函数里,体现就是用上了 AVX2 的 256 位向量计算以及 FMA 指令,正好把放缩和加 0.5 这两步融合在了一起,后续则是继续用位运算来实现 clamp 操作,使得这个函数在 -O3 -march=native 下的时间占比降低到了 27.82%,那么依然在用 SSE 标量进行间接访存的 OpenColorIO_v2_2dev::Lut1DRendererHalfCode<BIT_DEPTH_UINT16, BIT_DEPTH_F32>::apply 就成为了主要的性能瓶颈,时间占比提升到 42.85%。
在该基准测试里,GCC 14 比 LLVM 22 更快一些。以下是二者在不同编译选项下的对比:
| 编译器 + 选项 | 时间 (s) | 指令 (B) | Load (B) | Store (B) | 分支 (B) | 浮点标量 (B) | 浮点向量 (B) | 错误预测 (M) |
|---|---|---|---|---|---|---|---|---|
GCC 14 -O3
| 6.1 | 106.2 | 23.3 | 11.7 | 4.2 | 2.6 | 5.0 | 2.6 |
GCC 14 -O3 -march=native
| 4.2 | 63.8 | 22.0 | 11.0 | 3.6 | 2.6 | 2.5 | 2.5 |
GCC 14 -O3 -ffast-math
| 6.4 | 104.8 | 23.2 | 11.7 | 4.2 | 2.5 | 5.0 | 2.6 |
LLVM 22 -O3
| 6.8 | 106.1 | 23.3 | 11.7 | 3.6 | 2.5 | 5.0 | 2.6 |
LLVM 22 -O3 -march=native
| 5.4 | 72.5 | 24.8 | 11.0 | 1.4 | 2.5 | 2.5 | 2.5 |
具体到汇编层面上,可以观察到,GCC 14 和 LLVM 22 在实现上有一些不同,开头都是乘法和加法,主要是 clamp 的部分用的指令不同,为了解决 16 位和 32 位的位宽转换的问题,GCC 14 主要用 punpcklwd 类指令,而 LLVM 22 更多使用 pshufd 类指令,详见 Godbolt。虽然总指令数很接近,但毕竟硬件执行这些指令需要的时间不同,所以体现在 IPC 上也有一定的差距。开 -O3 -march=native 之后也是类似的情况。
热点函数:
OpenColorIO_v2_2dev::BitDepthCast<BIT_DEPTH_UINT16, BIT_DEPTH_F32>::apply 来自 src/ASWF-OpenColorIO/src/OpenColorIO/CPUProcessor.cpp:55.41%,这次转换的方向反过来了,是从 uint16_t 到 float,于是计算过程变成先从 uint16_t 转成 float,再乘以 1.0/65535.0,当然这次就没有 clamp 了,编译器依然能正确向量化,不过因为位宽从 16 变成 32 的问题,花了不少功夫;OpenColorIO_v2_2dev::ScaleRenderer::apply 来自 src/ASWF-OpenColorIO/src/OpenColorIO/ops/matrix/MatrixOpCPU.cpp:41.52%,代码逻辑就是很简单的对每个像素的四个分量分别乘以一个 scale(从 out[0] = in[0] * m_scale[0] 到 out[3] = in[3] * m_scale[3]),不同像素的 scale 来自同一个数组 m_scale,理应是比较好向量化的,但实际上并没有向量化成功,这是因为指针没有标记 restrict,编译器无法判断 out 和 m_scale 是否可能重合,只有在不重合的前提下,才能直接用 mulps 向量化,见 Godbolt。由于 AMD64 缺少对混合宽度计算的向量指令,其实很大开销是在向量之间搬运数据,而非进行实际的计算和访存,这方面,RISC-V Vector 的特殊设计还确实带来了更简洁的指令生成,见 Godbolt。不同编译器在不同编译选项下的对比:
| 编译器 + 选项 | 时间 (s) | 指令 (B) | Load (B) | Store (B) | 分支 (B) | 浮点标量 (B) | 浮点向量 (B) | 错误预测 (M) |
|---|---|---|---|---|---|---|---|---|
GCC 14 -O3
| 11.2 | 209.9 | 56.5 | 33.3 | 7.5 | 26.8 | 6.6 | 1.9 |
GCC 14 -O3 -march=native
| 10.2 | 159.6 | 54.8 | 29.9 | 7.1 | 26.8 | 3.3 | 1.8 |
GCC 14 -O3 -ffast-math
| 11.4 | 209.7 | 56.5 | 33.3 | 7.5 | 26.7 | 6.6 | 1.8 |
LLVM 22 -O3
| 11.3 | 194.5 | 56.5 | 33.3 | 8.6 | 26.5 | 6.7 | 1.9 |
LLVM 22 -O3 -march=native
| 9.6 | 149.4 | 58.2 | 29.9 | 2.8 | 26.5 | 3.4 | 2.0 |
热点函数:
OpenColorIO_v2_2dev::Lut3DTetrahedralRenderer::apply 来自 src/ASWF-OpenColorIO/src/OpenColorIO/ops/lut3d/Lut3DOpCPU.cpp:50.74%,做的操作还挺复杂,每个元素首先进行一次乘法,然后进行一次 clamp,floor 和 ceil 后分别转化为 int,再根据 int 去进行对一个表进行间接访存,查表的结果再经过一系列的加权平均完成计算,向量化程度不高;OpenColorIO_v2_2dev::MatrixRenderer::apply 来自 src/ASWF-OpenColorIO/src/OpenColorIO/ops/matrix/MatrixOpCPU.cpp:11.55%,进行矩阵的运算,把输入的四维向量和一个 4x4 矩阵进行乘法,得到输出的四维向量,向量化程度较高;__log2f_fma 来自 libm:10.02%,计算浮点 log2;OpenColorIO_v2_2dev::CameraLin2LogRenderer::apply 来自 src/ASWF-OpenCOlorIO/src/OpenColorIO/ops/log/LogOpCPU.cpp:9.76%,判断输入的范围,如果小于一个阈值 m_linb,就用线性的乘加计算结果,否则就会调用上述 log2 函数,结合一些乘加以及 max 操作来进行计算,向量化程度低。不同编译器和编译选项的对比:
| 编译器 + 选项 | 时间 (s) | 指令 (B) | Load (B) | Store (B) | 分支 (B) | 浮点标量 (B) | 浮点向量 (B) | 错误预测 (M) |
|---|---|---|---|---|---|---|---|---|
GCC 14 -O3
| 67.8 | 1258.9 | 299.3 | 86.3 | 100.5 | 260.6 | 28.0 | 146.6 |
GCC 14 -O3 -march=native
| 49.6 | 873.7 | 289.0 | 84.9 | 84.0 | 257.4 | 14.0 | 135.4 |
GCC 14 -O3 -ffast-math
| 67.8 | 1251.5 | 296.4 | 94.4 | 109.9 | 213.7 | 43.8 | 150.6 |
LLVM 22 -O3
| 61.7 | 1152.4 | 416.6 | 136.7 | 133.7 | 329.0 | 15.4 | 168.5 |
LLVM 22 -O3 -march=native
| 49.3 | 857.8 | 342.8 | 92.6 | 84.4 | 329.0 | 13.0 | 151.6 |
GCC 14 和 LLVM 22 在 -O3 下的性能差距主要来自于 floor 和 ceil 的处理:GCC 14 生成了一系列 SSE 指令来计算,由于没有 SSE4.1 的 roundps 指令,所以实现比较复杂,而 LLVM 22 转为采用 libm 的加速实现 __floorf_sse41,它的函数体就是一条 SSE4.1 的 roundps 指令加 return,虽然有函数调用的开销,不仅要 call/ret,还多了一些寄存器到栈的 Load 和 Store,但总体还是赚的。不过,如果处理器确实没有 SSE4.1 指令,那么 GCC 14 又该比 LLVM 22 更快了。这种取舍,在不开 -march=native 的时候确实无法实现,此时只能猜测,哪种情况发生的概率更高了,例如现在来看,有 SSE4.1 的 AMD64 处理器肯定是比没有 SSE4.1 的 AMD64 处理器要多。
开 -O3 -march=native 后,因为有了 vroundps 指令,原来的 ceil 和 floor 操作可以用向量指令代替,相比之前的向量化实现(GCC 14)或调用 libm 里的加速实现(LLVM 22),GCC 14 和 LLVM 22 都有不错的提升,来到了同一水平线上。同时 fma 也成功融合了不少浮点乘加计算。
热点函数:
__powf_fma 来自 libm:26.17%;OpenColorIO_v2_2dev::Lut3DRenderer::apply 来自 src/ASWF-OpenColorIO/src/OpenColorIO/ops/lut3d/Lut3DOpCPU.cpp:25.69%,模式和上面的 OpenColorIO_v2_2dev::Lut3DTetrahedralRenderer::apply 比较类似,也有 clamp/floor/ceil 和查表等动作,就是最后的计算部分不太一样,也都是标量的 SSE 指令;OpenColorIO_v2_2dev::Lut1DRenderer<BIT_DEPTH_F32, BIT_DEPTH_F32>::apply 来自 src/ASWF-OpenColorIO/src/OpenColorIO/ops/lut1d/Lut1DOpCPU.cpp:15.63%,模式和上述 OpenColorIO_v2_2dev::Lut3DRenderer::apply 类似,不过查表的部分更简单,因为只有一维,但也是全程标量;OpenColorIO_v2_2dev::CDLRendererFwd<true>::apply:10.88%,里面调用了 pow,导致 __powf_fma 占用了很多时间,其余部分做了浮点乘法、加减法以及 Clamp 操作,还是全程标量;OpenColorIO_v2_2dev::GammaMoncurveOpCPUFwd::apply:5.41%,同样调用了 pow,除了 pow 以外还有一些浮点运算以及比较。不同编译器和编译选项的对比:
| 编译器 + 选项 | 时间 (s) | 指令 (B) | Load (B) | Store (B) | 分支 (B) | 浮点标量 (B) | 浮点向量 (B) | 错误预测 (M) |
|---|---|---|---|---|---|---|---|---|
GCC 14 -O3
| 54.6 | 1013.5 | 209.4 | 57.0 | 80.8 | 253.7 | 5.8 | 32.0 |
GCC 14 -O3 -march=native
| 40.9 | 764.7 | 204.0 | 54.8 | 70.8 | 260.2 | 3.3 | 31.8 |
GCC 14 -O3 -ffast-math
| 53.9 | 971.0 | 202.1 | 50.5 | 80.6 | 252.3 | 6.6 | 29.1 |
LLVM 22 -O3
| 49.0 | 861.5 | 250.4 | 77.3 | 102.7 | 215.6 | 29.9 | 28.8 |
LLVM 22 -O3 -march=native
| 40.9 | 726.8 | 206.9 | 55.4 | 67.3 | 255.6 | 25.7 | 28.5 |
LLVM 22 相比 GCC 14 的主要性能区别和 3. aces 一样,就是 ceil/floor 的处理。此外,就是和 731.astcenc_r 类似的情况,在遇到向量化的 min/max 操作的时候,LLVM 22 会正确向量化为对应的 maxps/minps 指令,而 GCC 14 生成的代码就会比较冗长。
736.ocio_r 依然是一个比较适合向量化的应用,虽然它不像 731.astcenc_r 那样直接用 vfloat4 格式,但因为它是图像处理,每次循环处理一个像素,然后每个像素有四个通道,在很多情况下,这四个通道的计算过程是一样的,因此也非常适合向量化。而 LLVM 22 在 -O3 下做出了比 GCC 14 更好的指令生成,从 floor/ceil 到 libm 函数的映射,以及更好的向量化实现。当然,开 -O3 -march=native 后,GCC 14 和 LLVM 22 的性能差距非常小,说明在两方都开启足够的指令集扩展以后,基本会收敛到差不多的代码实现上,这也反过来说明,GCC 14 的 SSE 代码生成上有一些欠缺,可能的情况是,并非 GCC 14 不能向量化(因为开 -O3 -march=native 后就学会了),而是尝试向量化后,不知道怎么用 SSE 表达向量化后的代码,于是退回到了标量。
737.gmsh_r 是 3D 的 CAD 软件,包括七个负载:
# 1. choi gmsh_r -option gmsh.opts -nt 0 choi.geo # 2. mediterranean gmsh_r -option gmsh.opts -nt 0 mediterranean.geo # 3. projection gmsh_r -option gmsh.opts -nt 0 projection.geo # 4. gasdis gmsh_r -option gmsh.opts -nt 0 gasdis.geo # 5. Torus gmsh_r -option gmsh.opts -nt 0 Torus.geo # 6. spec gmsh_r -option gmsh.opts -nt 0 spec.geo -clscale 0.175 -algo del2d -algo hxt # 7. p19 gmsh_r -option gmsh.opts -nt 0 p19.geo 各负载运行时间为 17.1s、11.8s、11.2s、16.9s、9.2s、13.4s、12.8s,总时间 92.2s,reftime 是 459s,对应 4.98 分。-O3 -ffast-math 和 -O3 -march=native 收益都很小,LLVM 22 反而比 GCC 14 更慢,因此这里就不做具体比较了。
用 -O3 -march=native 编译的时候,发现如果 CC 只传了 gcc,而没有传 -std=c18,就会在 4. gasdis 这一个负载里死循环,一直报错:Info : Symbolic perturbation failed (2 superposed vertices ?)。经过对比,两者的区别在于是否进行乘加融合:-O3 -std=c18 -march=native 时,不会进行融合,而 -O3 -march=native 或 -O3 -std=gnu18 -march=native 时会进行融合,见 Godbolt。在其他程序里,融合对性能更优,但这里很不幸,融合了就会导致死循环。这和 -fp-contract 有关:
-ffp-contract=style -ffp-contract=off disables floating-point expression contraction. -ffp-contract=fast enables floating-point expression contraction such as forming of fused multiply-add operations if the target has native support for them. -ffp-contract=on enables floating-point expression contraction if allowed by the language standard. This is implemented for C and C++, where it enables contraction within one expression, but not across different statements. The default is -ffp-contract=off for C in a standards compliant mode (-std=c11 or similar), -ffp-contract=fast otherwise. 可见它只对 C 语言有效,对 C++ 无效,实际上就是只对 737.gmsh_r 有影响;虽然 709.cactus_r 也有 C 代码,但它的主要计算都在 C++ 语言的部分。
接下来针对各负载进行热点分析。
热点函数:
netgen::ADTree6::GetIntersecting 来自 src/gmsh/contrib/Netgen/libsrc/gprim/adtree.cpp:18.40%,实现了一个 6 维的 KD-Tree 的搜索算法,主要瓶颈在于中间的数据依赖的分支 if (node->pi != -1),预测错误率较高;__ieee754_atan2_fma 来自 libm:6.64%;reparamMeshVertexOnFace 来自 src/gmsh/src/geo/MVertex.cpp:6.03%,根据顶点的维度进入不同的 if-else 分支进行处理,错误预测也比较多。虽然用到了浮点,但计算模式并不适合向量化。毕竟是 KD-Tree 的搜索,MPKI 高是正常现象。执行了 204.7B 条指令,错误预测 744.3M 次,MPKI 等于 744.3M/204.7B*1000=3.64,是 SPEC FP 2026 Rate 中第二高的。第一高 731.astcenc_r 如上所述,其实是 GCC 的实现不够好,完全可以把 MPKI 优化到 LLVM 22 的 1.3 左右,那样的话 737.gmsh_r 就是第一了。
热点函数:
meshGEdgeProcessing 来自 src/gmsh/src/mesh/meshGEdge.cpp:36.55%,主要瓶颈在循环中的 gauss seidel 迭代,标量除法和比较耗费了比较多的时间;KDTreeSingleIndexAdaptor::searchLevel 来自 src/gmsh/src/numeric/nanoflann.hpp:33.50%,又一个经典的 KD-Tree 的搜索算法,根据输入的值递归到左子树或右子树;InterpolateCurve 来自 src/gmsh/src/geo/GeoInterpolation.cpp:6.53%,递归进行一些插值的计算。虽然用到了浮点,但计算模式依然不适合向量化,因为中间的计算结果还被用于 if 分支,分支内也有若干浮点计算。
热点函数:
laplaceSmoothing 来自 src/gmsh/src/mesh/meshGFaceOptimize.cpp:11.73%,主要瓶颈是 std::set 的操作,,而 std::set 是用 std::map 实现的,因此会调用下面的 std::map 的代码;std::map::_M_get_insert_unique_pos 来自 libstdc++:7.49%,std::map 的插入算法实现;__ieee754_atan2_fma 来自 libm:7.21%;reparamMeshVertexOnFace:6.66%,描述见上;std::map::_M_get_insert_unique 来自 libstdc++:6.09%,std::map 的插入实现;SetRotationMatrix 来自 src/gmsh/src/geo/Geo.cpp:5.01%,代码是多层循环,适合向量化,编译器也确实向量化了,不过时间占比并不高。可见,该负载主要还是 std::map 相关的操作为主要瓶颈。
热点函数:
MakeHybridHexTetMeshConformalThroughTriHedron 来自 src/gmsh/src/mesh/meshCombine3D.cpp:30.18%,主要瓶颈是在循环里对 std::map 进行搜索;parallelDelaunay3D 来自 src/gmsh/contrib/hxt/tetMesh/src/hxt_tetDelaunay.c:9.05%,实现了 Delaunay 三角剖分算法;hxtRefineTetrahedra 来自 src/gmsh/contrib/hxt/tetMesh/src/hxt_tetRefine.c:5.18%,主要是指循环中做一些浮点计算,包括加减法,乘除法和 sqrt。瓶颈主要还是在 std::map。
最后三个负载,其热点函数都与 4.gadis 相同,不再赘述。
各负载的情况:
| 负载 | 时间 (s) | 指令 (B) | Load (B) | Store (B) | 分支 (B) | 浮点标量 (B) | 浮点向量 (B) | 错误预测 (M) | MPKI |
|---|---|---|---|---|---|---|---|---|---|
| 1. choi | 17.0 | 204.7 | 59.3 | 25.6 | 39.4 | 22.1 | 0.3 | 744.3 | 3.64 |
| 2. mediterranean | 11.7 | 190.7 | 57.4 | 23.2 | 24.0 | 28.5 | 2.4 | 71.0 | 0.37 |
| 3. projection | 11.1 | 109.0 | 29.1 | 14.4 | 20.3 | 13.3 | 2.2 | 183.0 | 1.68 |
| 4. gasdis | 16.9 | 157.8 | 46.3 | 17.8 | 27.6 | 19.6 | 0.2 | 689.9 | 4.37 |
| 5. Torus | 9.2 | 77.3 | 21.9 | 8.2 | 13.4 | 9.4 | 0.5 | 380.4 | 4.92 |
| 6. spec | 13.3 | 101.4 | 30.2 | 10.8 | 18.1 | 10.9 | 0.2 | 546.1 | 5.39 |
| 7. p10 | 12.7 | 96.3 | 28.8 | 10.2 | 17.2 | 10.4 | 0.1 | 529.3 | 5.50 |
可见整体的 MPKI 还是偏高的,并且很大程度上归功于 KD-Tree 的查询以及 std::map 的查询或插入,只不过这些树的 key 都是单精度浮点数。并且根据上面的分析,确实相关的代码不适合向量化,浮点乘加融合还被禁用了,否则就可能不收敛。
flightdm 是一个飞行动力学模拟器,该基准测试包括如下八项负载:
# 1. weather JSBSim --nohighlight scripts/weather-balloon2.xml # 2. B747 JSBSim --nohighlight scripts/B747_script1.xml # 3. x153 JSBSim --nohighlight scripts/x153.xml # 4. c3104 JSBSim --nohighlight scripts/c3104.xml # 5. ah1s JSBSim --nohighlight scripts/ah1s_flight_test.xml # 6. orbit_torque JSBSim --nohighlight scripts/ball_orbit_g_torque.xml # 7. orbit_torque2 JSBSim --nohighlight scripts/ball_orbit_g_torque2.xml # 8. orbit JSBSim --nohighlight scripts/ball_orbit.xml 各负载的运行时间分别为 5.9s、14.7s、10.9s、11.3s、24.8s、8.0s、9.8s 和 8.4s,一共 93.9s,reftime 是 716s,对应 7.63 分。开 -O3 -march=native 仅对性能有 2% 的提升,-O3 -ljemalloc 反而能提升 4%,-O3 -flto 能提升 11%。LLVM 22 性能不如 GCC 14,这里就不赘述了。下面对各负载进行分析。
热点函数:
__sincos_fma 来自 libm:6.75%;__ieee754_atan2_fma 来自 libm:6.41%;__strncmp_avx2 来自 libc:5.04%;parse_path 来自 src/JSB-FlightSim/src/simgear/props/props.cxx:4.43%,路径字符串的解析,拆分成多个 component;__ieee754_pow_fma 来自 libm:4.05%。热点也挺神奇的,都是一些 libm/libc 的函数,flightdm 自己的代码耗时最多的居然是个路径解析。各种优化选项没啥效果,也不足为奇了。
热点函数:
SGPropertyNode::getDoubleValue 来自 src/JSB-FlightSim/src/simgear/props/props.cxx:5.65%,看起来是对配置文件的解析,然后从解析结果里提取浮点数;__ieee754_atan2_fma 来自 libm:5.42%;__sincos_fma 来自 libm:5.25%;依然没啥好分析的。
热点函数和 2. B747 相同,不再赘述。
热点函数:
SGPropertyNode::getDoubleValue 来自 src/JSB-FlightSim/src/simgear/props/props.cxx:8.45%,描述见上;JSBSim::aFunc::getValue 来自 src/JSB-FlightSim/src/math/FGFunction.cpp:7.20%,是一个带有 memo 能力的类似 std::function 的容器;__sincos_fma 来自 libm:6.04%;__ieee754_atan2_fma 来自 libm:5.35%;JSBSim::FGPropertyValue::getValue 来自 src/JSB-FlightSim/src/math/FGPropertyValue.cpp:5.11%,调用上面的 getDoubleValue 函数;给人的感觉就是,不是在调用 libm 计算一些超越函数,就是在做配置文件内容的提取。
热点函数:
__ieee754_atan2_fma 来自 libm:7.52%;__sincos_fma 来自 libm:6.82%;__strncmp_avx2 来自 libc:6.57%;parse_path 来自 src/JSB-FlightSim/src/simgear/props/props.cxx:6.12%,路径字符串的解析,拆分成多个 component;SGPropertyNode::getChild 来自 src/JSB-FlightSim/src/simgear/props/props.cxx:4.05%,遍历结点的子结点,通过字符串比较,找到匹配的子结点。热点函数与 6. orbit_torque 相同,不再赘述。
748.flightdm_r 是个没意思的基准测试,时间很多花在了 libm 和 libc 的函数上,自己的代码就是在配置文件里来回遍历,我愿称它为 libm 基准测试。除此之外,表现得更像一个 SPEC INT 2026 Rate 的负载:字符串操作,内存分配,很多小函数和 lambda,适合 -O3 -flto 优化。最后看一下 -O3 下各负载的情况:
| 负载 | 时间 (s) | 指令 (B) | Load (B) | Store (B) | 分支 (B) | 浮点标量 (B) | 浮点向量 (B) | 错误预测 (M) | MPKI |
|---|---|---|---|---|---|---|---|---|---|
| 1. weather | 5.9 | 106.1 | 30.8 | 15.4 | 19.5 | 12.9 | 0.6 | 11.6 | 0.11 |
| 2. B747 | 14.8 | 260.1 | 80.0 | 38.7 | 49.4 | 28.4 | 1.7 | 25.6 | 0.10 |
| 3. x153 | 10.8 | 193.3 | 59.1 | 28.7 | 37.3 | 20.0 | 1.0 | 20.9 | 0.11 |
| 4. c3104 | 11.4 | 194.6 | 58.9 | 29.1 | 35.7 | 23.9 | 1.3 | 18.2 | 0.09 |
| 5. ah1s | 24.7 | 407.3 | 130.0 | 61.3 | 77.9 | 46.4 | 1.6 | 49.3 | 0.12 |
| 6. orbit_torque | 7.9 | 152.8 | 41.9 | 22.7 | 28.3 | 16.3 | 1.1 | 24.2 | 0.16 |
| 7. orbit_torque2 | 9.9 | 191.4 | 52.5 | 28.4 | 35.3 | 21.0 | 1.2 | 17.1 | 0.09 |
| 8. orbit | 8.4 | 161.6 | 44.3 | 23.9 | 30.0 | 17.2 | 1.0 | 16.3 | 0.10 |
乏善可陈。
终于出现了一个 SPEC FP 2017 Rate 的老面孔,此前是 549.fotonik3d_r。fotonik3d 做的是 3D 空间里的麦克斯韦方程求解,又一个物理背景的基准测试,一般这种三维空间里的偏微分方程求解,必定会有 Stencil,下面看看这个猜测对不对。该基准测试只有一个负载:
reftime 是 1156s,在不同编译选项下,749.fotonik3d_r 的运行情况:
| 编译器 + 选项 | 时间 (s) | 分数 | 相比 GCC 14 -O3 性能提升 (%) | 指令数 (B) | Load 指令数 (B) | Store 指令数 (B) | 分支指令数 (B) | 浮点标量指令数 (B) | 浮点向量指令数 (B) |
|---|---|---|---|---|---|---|---|---|---|
GCC 14 -O3
| 131.1 | 8.82 | 0 | 1408.5 | 375.1 | 120.7 | 30.9 | 5.4 | 527.2 |
GCC 14 -O3 -march=native
| 114.9 | 10.1 | 14 | 670.1 | 274.1 | 82.4 | 27.1 | 5.5 | 249.4 |
GCC 14 -O3 -ffast-math
| 116.7 | 9.91 | 12 | 1117.6 | 378.4 | 120.8 | 30.7 | 4.8 | 396.2 |
GCC 14 -O3 -ffast-math -march=native
| 108.5 | 10.65 | 21 | 599.5 | 276.3 | 82.3 | 26.9 | 4.8 | 204.8 |
LLVM 22 性能和 GCC 14 差不多,这里就不单列了。可见 -O3 -march=native 和 -O3 -ffast-math 都有不错的性能提升,下面进行热点分析:
power_dft 来自 src/power.F90:30.92%,进行的是离散傅里叶变化 DFT,主要瓶颈是在循环中进行双精度浮点乘加运算,GCC 14 把它编译成 SSE 的向量指令;UPML_updateE_simple 来自 src/UPML.F90:24.73%,主要时间在进行三维的 Stencil 计算,果然物理模拟都离不开 Stencil 计算,GCC 14 编译出 SSE 向量指令进行计算;UPML_updateH 来自 src/UPML.F90:23.26%,依然是 3D 的 Stencil 计算,采用 SSE 向量指令;mat_updateE 来自 src/material.F90:11.04%,同样是 Stencil 计算,采用 SSE 向量指令;updateH 来自 src/update.F90:9.78%,也是 Stencil 计算,采用 SSE 向量指令。由此可见,除了 power_dft 以外,大部分时间都在进行 Stencil 计算,这次 Stencil 计算的模式更加纯粹,因为 GCC 能够比较好地用 SSE 进行向量化。根据前面的经验,这类程序在 -O3 -march=native、-O3 -ffast-math 以及 -O3 -ffast-math -march=native 下都是有很大的提升的:
开启 -march=native 后,可以用更宽的 AVX2 向量,并行度更高,同时还能使用浮点乘加融合指令,例如 vfmaddsub231pd。
开启 -O3 -ffast-math 以后,power_dft 中的核心计算,实际上计算的是,复数乘以实数再加复数,如下面的 Fortran 代码所示:
subroutine update(Efreq1, Efreq2, expfuncE, Efield1, Efield2, n) implicit none integer, intent(in) :: n complex(8), intent(inout) :: Efreq1(n), Efreq2(n) complex(8), intent(in) :: expfuncE(n) real(8), intent(in) :: Efield1, Efield2 integer :: i do i = 1, n Efreq1(i) = Efreq1(i) + expfuncE(i) * Efield1 Efreq2(i) = Efreq2(i) + expfuncE(i) * Efield2 end do end subroutine update 在 -O3 时,GCC 14 会忠实地实现复数乘法,然而,实际上这里的 Efield1 和 Efield2 都是实数,转换过去的复数的虚部只能是零,因此通过 -O3 -ffast-math 的化简,直接把实部乘到 expfuncE 的实部和虚部即可,这样就可以简化指令。如果开 -O3 -ffast-math -march=native,将可以结合两个优化,直接用 AVX2 乘加融合指令 vfmadd213pd 完成这次运算,不需要像 -O3 -march=native 时用 vfmaddsub231pd 同时做加法和减法(原来的减,来自于复数乘法的定义,在这里减去的总是零,因为 Efield1/Efield2 的虚部是零),详见 Godbolt。
小结一下,749.fotonik3d_r 是经典的浮点应用,大量 Stencil 加浮点向量运算,并行度高,适合向量化,还能享受 -ffast-math 带来的浮点计算顺序优化。
又一个从 SPEC FP 2017 Rate 复活的基准测试,上一世是 554.roms_r,实现的是海洋模拟,不出意外依然是 Stencil,它只有一个负载:
reftime 是 1575s,不同编译器和编译选项下的运行情况:
| 编译器 + 选项 | 时间 (s) | 分数 | 相比 GCC 14 -O3 性能提升 (%) | 指令数 (B) | Load 指令数 (B) | Store 指令数 (B) | 分支指令数 (B) | 浮点标量指令数 (B) | 浮点向量指令数 (B) |
|---|---|---|---|---|---|---|---|---|---|
GCC 14 -O3
| 169.8 | 9.28 | 0 | 2620.6 | 874.8 | 204.7 | 192.1 | 193.3 | 709.2 |
GCC 14 -O3 -march=native
| 149.5 | 10.5 | 14 | 1317.9 | 555.3 | 125.0 | 126.6 | 164.9 | 365.9 |
GCC 14 -O3 -ffast-math
| 162.8 | 9.67 | 4 | 2518.6 | 854.5 | 204.0 | 178.5 | 134.0 | 711.7 |
LLVM 22 -O3
| 165.6 | 9.51 | 3 | 2434.3 | 834.9 | 190.3 | 164.1 | 231.8 | 687.0 |
LLVM 22 -O3 -march=native
| 152.1 | 10.4 | 12 | 1423.4 | 551.4 | 131.2 | 140.1 | 259.8 | 350.0 |
从以上数据就可以看出,浮点计算很多,高度可向量化,因此 -O3 -march=native 的性能提升是很正常的。
热点函数:
step2d_tile,来自 src/step2d_LF_AM3.h:20.37%,主要瓶颈是 2D 的 Stencil 计算,向量化程度高;pre_step3d 来自 src/pre_step3d.F90:10.43%,主要瓶颈是在循环当中的浮点计算,向量化程度高;lmd_skpp 来自 src/lmd_skpp.F90:8.91%,主要瓶颈是循环中的复杂浮点计算,浮点标量计算为主;step3d_t_tile 来自 src/step3d_t.F90:7.04%,主要瓶颈是 3D 的 Stencil 计算,向量化程度高;rhs3d 来自 src/rhs3d.F90:6.04%,主要瓶颈是 2D 的 Stencil 计算,向量化程度高;t3dmix2 来自 src/t3dmix2_geo.h:5.86%,主要瓶颈是 3D Stencil 计算,向量化程度高;step3d_uv_tile 来自 src/step3d_uv.F90:5.85%,主要瓶颈是 3D Stencil 计算,向量化程度高;_ZGVbN2v_exp_sse4 来自 libmvec:4.66%,向量化版本的 exp。还是典型的 Stencil 计算,向量化程度高。开 -O3 -march=native 后,向量宽度增加,加上 FMA 的引入,自然带来了不错的性能提升。
femflow 是流体动力学求解器,求解 Navier-Stokes 方程。该基准测试只包括一个负载:
reftime 是 1467s,不同编译器和编译选项下的运行情况:
| 编译器 + 选项 | 时间 (s) | 分数 | 相比 GCC 14 -O3 性能提升 (%) | 指令数 (B) | Load 指令数 (B) | Store 指令数 (B) | 分支指令数 (B) | 浮点标量指令数 (B) | 浮点向量指令数 (B) |
|---|---|---|---|---|---|---|---|---|---|
GCC 14 -O3
| 188.7 | 7.77 | 0 | 3862.4 | 1358.5 | 797.6 | 117.5 | 562.2 | 676.0 |
GCC 14 -O3 -march=native
| 95.1 | 15.4 | 98 | 1736.9 | 619.3 | 356.0 | 65.2 | 286.8 | 445.4 |
GCC 16 -O3
| 153.6 | 9.55 | 23 | 3178.6 | 1109.3 | 673.3 | 127.2 | 56.3 | 930.9 |
GCC 16 -O3 -march=native
| 83.5 | 17.57 | 126 | 1457.0 | 501.1 | 281.4 | 61.1 | 47.2 | 545.7 |
LLVM 22 -O3
| 124.7 | 11.8 | 51 | 2703.0 | 857.3 | 475.5 | 60.6 | 40.8 | 930.3 |
LLVM 22 -O3 -march=native
| 88.7 | 16.5 | 113 | 1392.9 | 495.7 | 269.4 | 42.9 | 41.8 | 471.1 |
可见,LLVM 22 相比 GCC 14 有显著的性能提升,同时 -O3 -march=native 带来了更加显著的性能提升,是整个 SPEC FP 2026 Rate 当中,-O3 -march=native 带来提升第二高的基准测试,第一高是后面会看到的 772.marian_r。GCC 16 相比 GCC 14 也有不错的性能提升,开 -O3 -march=native 后反超 LLVM 22。
热点函数还不少,很多函数都是个位数百分比的占用,大多是一些算子:
Laplace::LaplaceOperator::local_apply_quadratic_geo 来自 src/laplace_operator.h:5.49%,内部是大量的浮点向量计算,并行度高;operator *(const dealii::VectorizedArray &, const dealii::VectorizedArray &) 来自 src/dealii/include/deal.ll/base/vectorization.h:5.36%,两个向量的逐元素乘法。其他还有一些 dealii:Tensor 的计算,包括来自 src/dealii/include/deal.ll/matrix_free/tensor_product_kernels.h 的 dealii::internal::even_odd_apply,是 Tensor 双精度浮点乘法的实现,这里 even-odd 的意思是利用数据的对称性,把数据拆成 even 和 odd 两部分进行计算,可以节省计算次数,同时适合向量化。对于这类负载,-O3 -march=native 开启后,更快的向量长度带来了更好的浮点运算性能,同时还有 FMA 指令的加持。
LLVM 22 相比 GCC 14 的优势,主要来自于把更多代码进行了向量化,对比 GCC 14 和 LLVM 22 执行的指令数,可以看到 LLVM 22 执行的浮点标量指令数比 GCC 14 要少,而浮点向量指令又要多。GCC 16 也是类似的情况,向量化程度逼近 LLVM 22。
nest 是个脉冲神经网络的模拟器,忽然出现一个熟悉的面孔,也挺难得。该基准测试分为三个负载:
# 1. cuba nest_r cuba_stdp.sli # 2. structural nest_r structural_plasticity_benchmark # 3. Artificial nest_r ArtificialSynchrony 开 -O3 -march=native 只有 3% 的性能提升,LLVM 22 比 GCC 14 更慢,这里就不进行编译器和编译选项的对比了。三个负载在 GCC 14 -O3 下的对比:
| 负载 | 时间 (s) | 指令 (B) | Load (B) | Store (B) | 分支 (B) | 浮点标量 (B) | 浮点向量 (B) |
|---|---|---|---|---|---|---|---|
| 1. cuba | 14.1 | 176.3 | 54.5 | 21.6 | 22.4 | 29.2 | 0.0 |
| 2. structural | 24.6 | 413.3 | 136.3 | 42.8 | 52.5 | 93.2 | 0.0 |
| 3. Artificial | 48.6 | 1125.4 | 392.6 | 150.5 | 160.5 | 163.6 | 0.0 |
总时间 87.4s,reftime 是 793s,对应 9.07 分。下面进行负载的具体分析。
热点函数:
nest::iaf_psc_exp::handle 来自 src/nest-simulator/models/iaf_psc_exp.cpp:25.75%,处理该神经元接收到的脉冲,更新内部状态,主要瓶颈是间接访存,把脉冲的强度写入到对应的输入缓存区;__ieee754_pow_fma 来自 libm:11.96%,被后面的 nest::Connector::send 函数调用;spec::poisson_distribution::operator() 来自 src/specrand-distributions/spec_random_distributions.cpp:9.87%,生成随机数,以生成输入的脉冲;nest::Connector::send 来自 src/nest-simulator/nestkernel/connector_base.h:8.29%,负责脉冲在突触上的传播和 STDP,主要瓶颈是间接访存,以及内联了一些脉冲上的权重计算,还会调用 pow 和 exp;nest::iaf_psc_exp::update 来自 src/nest-simulator/models/iaf_psc_exp.cpp:6.91%,在每个时间步对神经元的状态进行更新,主要是标量的浮点运算。算是一个比较经典的带 STDP 的 SNN 模拟,主要瓶颈就是脉冲传播和 STDP 的突触权重更新,向量化程度很低,还有间接访存。
热点函数:
spec::poisson_distribution::operator() 来自 src/specrand-distributions/spec_random_distributions.cpp:24.26%,描述见上;nest::iaf_psc_alpha::update 来自 src/nest-simulator/models/iaf_psc_alpha.cpp:13.71%,做的事情和上面 nest::iaf_psc_exp::update 类似,就是换了个神经元模型;__ieee754_pow_fma 来自 libm:13.37%,描述见上;nest::GrowthCurveGaussian::update 来自 src/nest-simulator/nestkernel/growth_curve.cpp:6.60%,主要在用数值计算求解微分方程,频繁调用 exp 和 pow;nest::iaf_psc_alpha::handle 来自 src/nest-simulator/models/iaf_psc_alpha.cpp:25.75%,功能和上面 nest::iaf_psc_exp::handle 类似;nest::Connector::send 来自 src/nest-simulator/nestkernel/connector_base.h:6.60%,描述见上,这次没有 STDP,权重是静态的;exp 来自 libm:5.39%。和 1. cuba 相比,换了一个神经元模型,去掉了 STDP,结果主要的瓶颈跑到了泊松分布的随机生成,其余部分还是比较典型的 SNN 模拟。
热点函数:
nest::iaf_psc_alpha_ps::update 来自 src/nest-simulator/models/iaf_psc_alpha_ps.cpp:13.26%,神经元的状态更新函数;nest::iaf_psc_alpha::update 来自 src/iaf_psc_alpha.cpp:12.37%,描述见上;nest::Connector::send 来自 src/nest-simulator/nestkernel/connector_base.h:7.19%,描述见上,这次依然没有 STDP,权重是静态的;nest::SimulationManager::update_ 来自 src/nest-simulator/nestkernel/simulation_manager.cpp:5.66%,核心的 SNN 模拟循环,调用上面的各种函数。__ieee754_pow_fma 来自 libm:5.17%,描述见上。研究 SNN 的应该很熟悉,nest 是个很灵活的 SNN 模拟器,但单线程性能也确实不咋地,主要精力花在了多核/多线程上。不出所料,nest 的神经元更新部分没有向量化,所以挺慢的,而脉冲传播和 STDP 部分本来就很难优化。总之,这是个难以向量化的浮点应用,从上面的性能计数器来看,一条向量浮点指令都没有。
marian_r 是一个基于神经网络的翻译器,又是一个神经网络推理,意味着又是一个 -O3 -march=native 非常有优势的测例,如果像 706.stockfish_r 那样有直接可以用的硬件加速指令,性能将会比 -O3 快得多。该基准测试包括两个负载:
# 1. TildeMODEL marian-decoder --cpu-threads 1 -m model.alphas.npz -v vocab.spm vocab.spm --beam-size 1 --mini-batch 32 --maxi-batch 100 --maxi-batch-sort src -w 512 --skip-cost --gemm-type intgemm8 --intgemm-options precomputed-alpha standard-only --quiet --quiet-translation -i TildeMODEL-spec.en --log TildeMODEL-spec.log --log-level off -o TildeMODEL-spec.out # 2. EuroPat marian-decoder --cpu-threads 1 -m model.alphas.npz -v vocab.spm vocab.spm --beam-size 1 --mini-batch 32 --maxi-batch 100 --maxi-batch-sort src -w 512 --skip-cost --gemm-type intgemm8 --intgemm-options precomputed-alpha standard-only --quiet --quiet-translation -i EuroPat-spec.en --log EuroPat-spec.log --log-level off -o EuroPat-spec.out reftime 是 1579s,下面是不同编译器版本和编译选项的对比:
| 编译器 + 选项 | 时间 (s) | 分数 | 相比 GCC 14 -O3 性能提升 (%) | 1. TildeMODEL 时间 (s) | 2. EuroPat 时间 (s) |
|---|---|---|---|---|---|
GCC 14 -O3
| 235.2 | 6.71 | 0 | 88.8 | 146.4 |
GCC 14 -O3 -march=native
| 78.4 | 20.14 | 200 | 28.2 | 50.3 |
GCC 15 -O3
| 150.1 | 10.52 | 57 | 56.0 | 94.8 |
GCC 15 -O3 -march=native
| 77.5 | 20.37 | 203 | 27.8 | 49.7 |
可见 -O3 -march=native 带来的提升巨大,高达 200%,在 Apple M1 上有 47% 的提升,在 Apple M2 上更是提升了 92%,这种提升,之前只在 706.stockfish_r 上见到过。并且 GCC 15 也比 GCC 14 在 -O3 时有明显性能提升。下面分负载来讨论。
热点函数:
marian::cpu::integer::affineOrDotTyped 来自 src/marian/tensors/cpu/intgemm_interface.h:82.28%,主要时间在 tiled_gemm 函数里,做的是整数矩阵乘法,uint8_t 类型的 A 矩阵乘以 int8_t 类型的 B 矩阵,累加到 int32_t 类型,最后转换到 float 再加 float 的 C 矩阵;marian::cpu::ProdBatched 来自 src/marian/tensors/cpu/prod.cpp:10.30%,核心部分是 sgemm,这次确实是浮点的矩阵运算了,虽然被编译成了 SSE 的标量的浮点计算而不是向量,但考虑到时间占比,也无伤大雅了。可以看到,主要的热点部分,和 706.stockfish_r 的 nnue 的计算模式完全一样,因此开 -O3 -march=native 后,一样可以用 AVX-VNNI 的 vpdpbusd 指令优化,见 Godbolt。同理 GCC 15 因为更优的无符号扩展实现方式,性能比 GCC 14 要更好。具体的讨论,可以见之前 INT Rate 篇 中 706.stockfish_r 的部分。
不同编译器和编译选项下的对比:
| 编译器 + 选项 | 时间 (s) | 指令 (B) | Load (B) | Store (B) | 分支 (B) | 浮点标量 (B) | 浮点向量 (B) | 128 位整数向量 (B) | 256 位整数向量 (B) |
|---|---|---|---|---|---|---|---|---|---|
GCC 14 -O3
| 88.2 | 2038.9 | 217.8 | 57.8 | 53.2 | 58.7 | 2.1 | 514.6 | 0.0 |
GCC 14 -O3 -march=native
| 27.6 | 423.0 | 131.5 | 25.1 | 47.4 | 59.8 | 1.1 | 12.8 | 47.4 |
GCC 15 -O3
| 55.6 | 1353.5 | 173.9 | 22.1 | 53.2 | 58.7 | 2.1 | 184.7 | 0.0 |
GCC 15 -O3 -march=native
| 27.3 | 415.1 | 128.9 | 23.5 | 47.5 | 59.8 | 1.1 | 12.8 | 47.4 |
其中 128 位整数向量来自 int_vec_retired.128bit 计数器,256 位整数向量来自 int_vec_retired.256bit 计数器。
热点函数:
marian::cpu::integer::affineOrDotTyped:78.96%,描述见上;marian::cpu::ProdBatched:14.25%,描述见上。热点函数和 1. TileMODEL 完全相同,其余的分析对 2. EuroPat 也是成立的,这里直接给出性能计数器的对比:
不同编译器和编译选项下的对比:
| 编译器 + 选项 | 时间 (s) | 指令 (B) | Load (B) | Store (B) | 分支 (B) | 浮点标量 (B) | 浮点向量 (B) | 128 位整数向量 (B) | 256 位整数向量 (B) |
|---|---|---|---|---|---|---|---|---|---|
GCC 14 -O3
| 145.6 | 3352.7 | 370.4 | 89.7 | 98.8 | 123.8 | 3.6 | 815.0 | 0.0 |
GCC 14 -O3 -march=native
| 49.7 | 777.2 | 228.7 | 36.6 | 88.3 | 123.9 | 1.7 | 19.9 | 72.6 |
GCC 15 -O3
| 94.2 | 2268.5 | 301.7 | 33.1 | 98.8 | 123.8 | 3.6 | 293.6 | 0.0 |
GCC 15 -O3 -march=native
| 49.0 | 765.3 | 225.2 | 34.3 | 88.3 | 123.9 | 1.7 | 19.9 | 72.6 |
772.marian_r 鉴定为 706.stockfish_r 的 NNUE 翻版,热点就是 int8_t 乘 uint8_t 累加到 int32_t 的矩阵乘运算,整数向量指令比浮点指令还多,建议开除 SPEC FP 2026 Rate 籍。
lbm 是 lattice boltzmann method 的缩写,又是一个流体动力学的应用,依然是 Stencil。该基准测试只有一个负载:
reftime 是 573s,不同编译选项下的性能对比:
| 编译器 + 选项 | 时间 (s) | 分数 | 相比 GCC 14 -O3 性能提升 (%) | 指令数 (B) | Load 指令数 (B) | Store 指令数 (B) | 分支指令数 (B) | 浮点标量指令数 (B) | 浮点向量指令数 (B) |
|---|---|---|---|---|---|---|---|---|---|
GCC 14 -O3
| 105.8 | 5.42 | 0 | 2232.2 | 473.3 | 242.4 | 14.5 | 1108.2 | 0.0 |
GCC 14 -O3 -ffast-math
| 95.8 | 5.98 | 10 | 1892.4 | 419.2 | 192.8 | 14.5 | 1009.5 | 0.0 |
GCC 14 -O3 -march=native
| 131.0 | 4.37 | -19 | 1669.6 | 550.3 | 309.8 | 14.5 | 1228.8 | 0.0 |
GCC 15 -O3
| 105.2 | 5.45 | 0.6 | 2218.9 | 468.9 | 242.4 | 14.5 | 1108.2 | 0.0 |
GCC 15 -O3 -march=native
| 111.0 | 5.16 | -5 | 1777.3 | 509.8 | 282.9 | 14.5 | 1108.2 | 0.0 |
GCC 16 -O3
| 105.4 | 5.44 | 0.4 | 2218.9 | 468.9 | 242.4 | 14.5 | 1108.2 | 0.0 |
GCC 16 -O3 -march=native
| 110.6 | 5.18 | -4 | 1777.3 | 509.8 | 282.9 | 14.5 | 1108.2 | 0.0 |
热点函数只有一个,就是 LBM_performStreamCollideTRT 函数来自 src/lbm.c,占了 99.35% 的时间。其结构是从当前轮次 Grid 读取、大量浮点计算、写入下一轮次 Grid,中间还有分支判断,访存为跨步(strided)模式,难以向量化,生成的都是 SSE 标量指令。对于这种标量计算密集的情况,-O3 -ffast-math 通常能通过调整计算顺序、复用中间结果来节省一些计算。
开启 -O3 -march=native 后性能反而下降,GCC 14 倒退最多(-19%),GCC 15/16 稍好但也不如 -O3。分析汇编,推测是因为对栈的访存指令变多,抵消了 FMA 乘加融合减少指令数的优势,详见 Godbolt。注意 FMA 指令在上述表格的浮点标量指令数一栏会计数两次,在总指令数一栏只会计数一次。
综合来看,编译选项对 SPEC FP 2026 Rate 的性能影响同样不小:
-march=native 对很多基准测试有不错的性能提升。毕竟 AVX2 相比 SSE 不仅在宽度上拓宽,还增加了很多好用的指令,可以减少指令数,还有 AVX-VNNI 这种对 772.marian_r 特攻的;-ffast-math 也有不错的提升,尤其 SPEC FP 2026 Rate 有不少浮点运算,完全按照源码的编写方式去计算,往往不如调整运算顺序后来得快。但也要注意,-ffast-math 可能会导致计算结果不符合 IEEE 754 标准。-flto 和 -ljemalloc 对 SPEC FP 2026 Rate 的多数基准测试效果不大,但对 748.flightdm_r 有些许提升。还有一些常用的编译参数,比如 -static、-fomit-frame-pointer 等等,目前没有做太多测试,以后说不定会加上。
SPEC FP 2026 Rate 中 MPKI 特别高的只有 731.astcenc_r 和 737.gmsh_r,其他最高也就是 767.nest_r 的 0.87。731.astcenc_r 如此的高,完全是 GCC 14 编译的锅,换成 LLVM 22 立马就正常了,希望后续 GCC 能修一修。
本文深入分析了 SPEC CPU 2026 中 FP Rate 的负载,供编译器和处理器的设计者参考。从编译器的角度来说,可以集 GCC 和 LLVM 之长,进一步提升性能;从处理器的角度来说,针对程序的瓶颈进行优化,也能进一步提高分数。
2026-05-29 08:00:00
Following the INT Rate article, this article continues with the workload analysis of SPEC FP 2026 Rate.
The test environment is the same as the previous INT Rate article and won't be repeated here.
Recommended reading: Evaluating SPEC CPU2026 and SPEC CPU2026: Characterization, Representativeness, and Cross-Suite Comparison
Cactus is a computational framework, used here to solve the Einstein equations in vacuum. Command:
Measured runtime is 103.4s, reftime is 858s, corresponding to 8.30 points. Performance under different compilers and flags:
| Compiler + Flags | Time (s) | Score | Improvement over GCC 14 -O3 (%) |
|---|---|---|---|
GCC 14 -O3
| 103.4 | 8.30 | 0 |
GCC 14 -O3 -march=native
| 83.9 | 10.23 | 23 |
GCC 14 -O3 -ffast-math
| 101.2 | 8.48 | 2 |
GCC 14 -O3 -ljemalloc
| 100.7 | 8.52 | 3 |
LLVM 22 -O3
| 94.6 | 9.07 | 9 |
LLVM 22 -O3 -march=native
| 90.5 | 9.48 | 14 |
-march=native provides a significant performance boost. LLVM 22 is faster than GCC 14 under -O3, but GCC 14's -O3 -march=native overtakes LLVM 22's -O3 -march=native. Details below.
Performance bottlenecks observed via perf:
ML_CCZ4::ML_CCZ4_EvolutionInteriorSplitBy2_Body from src/repos/mclachlan/ML_CCZ4/src/ML_CCZ4_EvolutionInteriorSplitBy2.cc: 41.30% of total time (same format below);ML_CCZ4::ML_CCZ4_EvolutionInteriorSplitBy3_Body from src/repos/mclachlan/ML_CCZ4/src/ML_CCZ4_EvolutionInteriorSplitBy3.cc: 31.26%;ML_CCZ4::ML_CCZ4_ConstraintsInterior_Body from src/repos/mclachlan/ML_CCZ4/src/ML_CCZ4_ConstraintsInterior_Body.cc: 6.71%;ML_CCZ4::ML_CCZ4_EvolutionInteriorSplitBy1_Body from src/repos/mclachlan/ML_CCZ4/src/ML_CCZ4_EvolutionInteriorSplitBy3.cc: 6.44%.These hotspot functions share a similar pattern: within three nested loops, they read data from corresponding 3D grid points, perform a series of Stencil memory accesses and floating-point operations (including heavy use of floating-point multiply, add, subtract, pow, and fabs), then write results back to arrays. The generated instructions use SSE for scalar double-precision floating-point without vectorization. During testing, compiler optimizations on pow and fabs were also observed. Under -O3, pow(a, 1) compiles to a, pow(a, 2) to a * a, and pow(a, -1) to 1.0 / a, but others like pow(a, 3) and pow(a, -2) fall back to libm's pow implementation. With -O3 -ffast-math, pow(a, 3) becomes a * a * a and pow(a, -2) becomes 1.0 / (a * a). See the comparison at Godbolt. In the code, the main occurrences are pow(a, -1), pow(a, 2), pow(a, -2), and pow(a, runtimeVariable), where runtimeVariable is a value only known at runtime, corresponding to shiftAlphaPower or harmonicN in the code. fabs is compiled into the bitwise andpd instruction, directly zeroing the sign bit.
With -O3 -march=native, vectorization still doesn't happen. It uses AVX2 instructions for scalar double-precision floating-point, with remaining calls to libm's pow for the cases mentioned above (pow(a, -2) or pow(a, runtimeVariable)). However, the rest of the computation benefits from vfmadd132sd/vfnmadd132sd, and vaddsd becomes a three-operand instruction (compared to the two-operand addsd) that also allows memory operands, further reducing instruction count. On ARM64, -march=native provides no improvement because the floating-point fused multiply-add instruction is available even without -march=native, see Godbolt. In a sense, the huge improvement from -march=native on AMD64 reflects a first-mover disadvantage: the baseline corresponds to very old processors lacking many important ISA extensions. This compatibility burden doesn't exist on many other ISAs; for instance, fused multiply-add (FMA) is already part of the baseline in many ISAs, where -march=native brings relatively smaller improvements. As a workaround, many software projects manually provide multiple code paths for different ISA extensions and select the best one at runtime based on availability. If compilers could do this automatically, it would bring nice overall performance improvements while maintaining compatibility and developer convenience.
Performance counter comparison across compilation options:
| Compiler + Flags | Time (s) | Insns (B) | Load (B) | Store (B) | Branch (B) | FP Scalar (B) | FP Vector (B) |
|---|---|---|---|---|---|---|---|
GCC 14 -O3
| 103.4 | 1423.6 | 747.8 | 110.1 | 9.8 | 677.0 | 5.2 |
GCC 14 -O3 -march=native
| 83.9 | 988.5 | 711.9 | 89.5 | 8.9 | 686.1 | 2.6 |
GCC 14 -O3 -ffast-math
| 101.8 | 1387.7 | 742.2 | 103.4 | 5.3 | 641.0 | 5.6 |
GCC 14 -O3 -ljemalloc
| 100.7 | 1423.6 | 747.8 | 110.1 | 9.8 | 677.0 | 5.2 |
LLVM 22 -O3
| 94.6 | 1323.1 | 659.1 | 96.6 | 6.1 | 659.0 | 15.2 |
LLVM 22 -O3 -march=native
| 90.5 | 1054.5 | 690.7 | 119.4 | 5.4 | 681.4 | 5.4 |
Total instruction count comes from instructions, Load from mem_inst_retired.all_loads, Store from mem_inst_retired.all_stores, Branch from branch-instructions, FP Scalar from fp_arith_inst_retired.scalar, and FP Vector from fp_arith_inst_retired.vector performance counters (same format below). Note that fused multiply-add instructions like vfmadd132sd are counted twice in fp_arith_inst_retired.scalar/vector.
From the table, under -O3 roughly half the instructions are Loads and the other half are floating-point scalar operations. This low compute-to-memory ratio is typical of Stencil computation: load a value from the grid neighborhood, do one multiply-add. With -O3 -march=native, FMA instructions reduce the instruction count substantially, but since FMA counts double and AVX2 instructions that perform both memory access and computation are counted in both Load and FP categories (the microarchitecture likely counts split micro-ops), the total instruction count no longer equals the sum of individual categories. The -O3 -ljemalloc option provides a slight performance advantage not reflected in instruction counts; its improvement mainly comes from better cache locality. GCC 14 and LLVM 22 have comparable performance under different flags. The generated instructions are similar in approach, with main differences in address computation, stack usage, and register allocation.
Notably, 709.cactus_r has high cache miss rates: under GCC 14 -O3, L1 ICache MPKI reaches 118.6B/1423.6B*1000=83.30, and L1 DCache MPKI is 125.6B/1423.6B*1000=88.23, the highest among both SPEC FP 2026 Rate and SPEC INT 2026 Rate. Cores with larger L1 ICache have an advantage here; L1 ICache bottlenecks at 32KB might disappear at 64KB. With -O3 -ljemalloc, L1 DCache MPKI drops to 111.7B/1423.6B*1000=78.46, yielding about 3% improvement with identical instruction counts compared to -O3.
palm is a weather forecasting program that solves Navier-Stokes equations. Command:
Measured runtime is 174.0s, reftime is 1320s, corresponding to 7.59 points. Performance under different compilers and flags:
| Compiler + Flags | Time (s) | Score | Improvement over GCC 14 -O3 (%) |
|---|---|---|---|
GCC 14 -O3
| 174.0 | 7.59 | 0 |
GCC 14 -O3 -march=native
| 157.8 | 8.34 | 10 |
GCC 14 -O3 -ffast-math
| 168.4 | 7.84 | 3 |
GCC 14 -O3 -ljemalloc
| 172.4 | 7.66 | 1 |
LLVM 22 -O3
| 144.0 | 9.17 | 21 |
LLVM 22 -O3 -march=native
| 118.6 | 11.13 | 47 |
The trend is similar to 709.cactus_r: -O3 -march=native provides a massive performance boost, and LLVM 22 is significantly faster than GCC 14.
Hotspot functions:
advec_s_ws_ij from src/advec_ws.F90: 9.80%, classic 3D Stencil computation with balanced memory access and computation ratio, essentially load one point value then do multiply-add. Uses SSE for computation with partial vectorization (addpd/subpd/mulpd processing 2 double-precision elements per instruction), though some loops fail to vectorize and fall back to scalar instructions (addsd/subsd/mulsd);advec_u_ws_ij from src/advec_ws.F90: 8.80%, same as above;advec_v_ws_ij from src/advec_ws.F90: 8.54%, same as above;advec_w_ws_ij from src/advec_ws.F90: 8.24%, same as above;diffusion_e_ij from src/turbulence_closure_mod.F90: 5.14%, involves more complex floating-point operations like min/sqrt/div, plus bitwise operations using MERGE for ternary operations, no vectorization, scalar SSE floating-point.Here is the Stencil computation code from advec_s_ws_ij, looping over i, j, k:
flux_r(k) = u_comp * ( & 37.0_wp * ( sk(k,j,i+1) + sk(k,j,i) ) & - 8.0_wp * ( sk(k,j,i+2) + sk(k,j,i-1) ) & + ( sk(k,j,i+3) + sk(k,j,i-2) ) ) * adv_sca_5 Performance counter comparison:
| Compiler + Flags | Time (s) | Insns (B) | Load (B) | Store (B) | Branch (B) | FP Scalar (B) | FP Vector (B) |
|---|---|---|---|---|---|---|---|
GCC 14 -O3
| 174.0 | 3416.6 | 1267.4 | 271.1 | 155.6 | 779.0 | 318.5 |
GCC 14 -O3 -march=native
| 157.8 | 2710.0 | 1212.8 | 242.5 | 147.1 | 785.9 | 172.6 |
GCC 14 -O3 -ffast-math
| 168.4 | 3373.5 | 1204.7 | 278.0 | 134.0 | 612.8 | 363.1 |
GCC 14 -O3 -ljemalloc
| 172.4 | 3368.4 | 1259.7 | 260.7 | 141.6 | 779.0 | 318.5 |
LLVM 22 -O3
| 144.0 | 2640.4 | 835.5 | 216.3 | 90.4 | 179.5 | 609.7 |
LLVM 22 -O3 -march=native
| 118.6 | 1643.8 | 586.5 | 165.6 | 67.6 | 180.8 | 306.7 |
With -O3 -march=native, heavy AVX2 vectorized instructions appear: vmulpd/vdivsd/vaddpd/vsubpd/vfmadd213sd/vfmsub132pd/vfmsub231pd/vmovupd, each processing 4 double-precision elements. Vectorization degree is high; on AVX512-capable processors, performance could be even higher. Compared to 709.cactus_r where pow and similar issues prevent vectorization, 722.palm_r's vectorization benefits are much more apparent. LLVM 22 under -O3 outperforms GCC 14 because it successfully vectorizes hotspot functions like advec_u/v/w_ws_ij, while GCC 14 still uses scalar instructions. This is reflected in significantly more FP vector instructions and fewer FP scalar instructions. Under LLVM 22, with those hotspot functions well-optimized, flow_statistics (from src/flow_statistics.F90, 5.79% time share) becomes the new bottleneck. It has limited vectorizable portions, hence its time share increases. Even with -O3 -march=native, it still uses AVX2+FMA instructions for scalar computation with little time difference. As other parts speed up, its time share further increases to 6.95%, similar to Amdahl's law.
709.cactus_r and 722.palm_r share the same Stencil computation pattern. Physics simulations frequently do this: solving differential equations in 3D space requires repeated computation over each point's neighborhood, which ultimately becomes Stencil.
astcenc is an encoder for the ASTC lossy compressed image format. It runs three times:
# 1. linear astcenc_r ref-inputs-linear.txt # 2. hdr astcenc_r ref-inputs-hdr.txt # 3. precision astcenc_r ref-inputs-precision.txt Measured runtimes are 49.9s, 72.1s, and 53.8s, totaling 175.8s, reftime 840s, corresponding to 4.78 points. Performance under different compilers and flags:
| Compiler + Flags | Total Time (s) | 1. linear (s) | 2. hdr (s) | 3. precision (s) | Score | Improvement over GCC 14 -O3 (%) |
|---|---|---|---|---|---|---|
GCC 14 -O3
| 175.8 | 49.9 | 72.1 | 53.8 | 4.78 | 0 |
GCC 14 -O3 -march=native
| 157.3 | 44.0 | 63.2 | 50.0 | 5.34 | 12 |
GCC 14 -O3 -ffast-math
| 160.5 | 44.6 | 67.2 | 48.7 | 5.23 | 10 |
LLVM 22 -O3
| 134.0 | 38.5 | 56.1 | 39.3 | 6.27 | 31 |
LLVM 22 -O3 -march=native
| 117.2 | 34.4 | 48.6 | 34.1 | 7.17 | 50 |
Another benchmark where LLVM 22 has a clear advantage over GCC 14. Other flags like -flto and -ljemalloc have almost no impact and are omitted. 731.astcenc_r has the highest MPKI in SPEC FP 2026 Rate at 5.0, much higher than most others which are below 1.0 (second highest is 737.gmsh_r at 3.33, third is 767.nest_r at only 0.83), and also higher than many SPEC INT 2026 Rate benchmarks. Below is per-workload analysis.
Main hotspot functions:
compute_angular_endpoints_for_quant_levels from src/astcenc_weight_align.cpp: 18.93%, main bottleneck is in the inner loop doing single-precision floating-point scalar SSE computation, with calls to nearbyint from libm for rounding. The developers intentionally wrote SIMD-friendly code using vfloat4 for batch operations, with vmask4 storing comparison results (four ints, 0 for false, -1 for true), and a select function for vectorized ternary operations. Unfortunately the compiler doesn't cooperate, producing scalar SSE instead;compute_avgs_and_dirs_3_comp_rgb from src/astcenc_averages_and_directions.cpp: 14.70%, similar pattern with vfloat4 and vmask4 computations in loops, but SSE instructions are all scalar;compute_quantized_weights_for_decimation from src/astcenc_ideal_endpoints_and_weights.cpp: 13.34%, involves quantization with vint and table lookups (vtable_lookup_32bit). The vfloat/vint types are designed to automatically map to the platform's available SIMD width (defined in src/astcenc_vecmathlib.h, e.g., AVX maps to 8 elements with vfloat8, SSE to 4 elements with vfloat4), but these wider modes are disabled in SPEC, falling back to 4 elements;compute_ideal_weights_for_decimation from src/astcenc_ideal_endpoints_and_weights.cpp: 9.57%, main bottleneck is a gather operation gatherf_byte_inds. Since SSE doesn't support gather, it splits into four elements with individual loads and scalar computation;bilinear_infill_vla from src/astcenc_ideal_endpoints_and_weights.cpp: 7.80%, bottleneck is also the gather operation gatherf_byte_inds;compute_error_squared_rgb from src/astcenc_averages_and_directions.cpp: 6.39%, bottleneck is gather plus subsequent vector computation, but GCC 14 compiles everything to scalar SSE.The fact that native SIMD code compiles to scalar instructions also suggests that correct vectorization would yield significant additional performance. Furthermore, with -O3 -march=native, vectors widen to 256 bits, and the vblendvps instruction becomes available to implement the select function. As mentioned, LLVM 22 is significantly faster. Here's the comparison:
| Compiler + Flags | Time (s) | Insns (B) | Load (B) | Store (B) | Branch (B) | FP Scalar (B) | FP Vector (B) | Mispred (M) | MPKI |
|---|---|---|---|---|---|---|---|---|---|
GCC 14 -O3
| 49.9 | 835.7 | 259.3 | 55.6 | 63.2 | 188.6 | 28.6 | 3136.0 | 3.75 |
GCC 14 -O3 -march=native
| 44.0 | 652.4 | 234.0 | 46.3 | 52.9 | 184.6 | 28.5 | 3148.2 | 4.83 |
GCC 14 -O3 -ffast-math
| 44.6 | 780.5 | 259.8 | 54.6 | 49.3 | 159.9 | 43.2 | 2139.0 | 2.74 |
LLVM 22 -O3
| 38.5 | 829.7 | 235.0 | 34.8 | 36.1 | 68.8 | 155.6 | 1095.5 | 1.32 |
LLVM 22 -O3 -march=native
| 34.4 | 620.9 | 179.5 | 17.7 | 19.6 | 42.1 | 125.7 | 823.4 | 1.33 |
The counters show GCC 14 performs worse overall because LLVM 22 does more vectorization: its FP vector instructions far exceed FP scalar, with significantly fewer mispredictions and much lower MPKI. Detailed analysis follows.
First, let's look at how GCC 14 compiles 731.astcenc_r's SIMD-native code. Taking the hotspot functions analyzed above as examples, a common pattern uses vfloat4 comparison plus select to implement vectorized max:
Under -O3, GCC 14 compiles this to:
vmax(vfloat4 a, vfloat4 b): # a vector in xmm0 (a[0] and a[1]) and xmm1 (a[2] and a[3]) registers # b vector in xmm2 (b[0] and b[1]) and xmm3 (b[2] and b[3]) registers # although each element is single-precision, each xmm register only holds two elements movq %xmm1, %rax # rax = a3 | a2 movq %xmm3, %rcx # rcx = b3 | b2 movq %xmm0, %rsi # rsi = a1 | a0 movd %ecx, %xmm1 # xmm1 = b2 movd %eax, %xmm6 # xmm6 = a2 shrq $32, %rcx # rcx = b3 movdqa %xmm2, %xmm5 # xmm5 = b1 | b0 shrq $32, %rax # rax = a3 movdqa %xmm2, %xmm0 # xmm0 = b1 | b0 movd %ecx, %xmm4 # xmm4 = b3 shufps $85, %xmm5, %xmm5 # xmm5 = b1 | b1 | b1 | b1 movd %eax, %xmm2 # xmm2 = a3 movd %esi, %xmm7 # xmm7 = a0 shrq $32, %rsi # rsi = a1 movdqa %xmm5, %xmm3 # xmm3 = b1 | b1 | b1 | b1 comiss %xmm2, %xmm4 # compare a3 and b3 movd %esi, %xmm5 # xmm5 = a1 seta %al # al = (b3 > a3) comiss %xmm6, %xmm1 # compare b2 and a2 jbe .L14 # if a2 >= b2, jump to .L14 testb %al, %al jne .L15 # if b3 > a3, jump to .L15 # here a2 < b2, a3 >= b3 maxss %xmm7, %xmm0 # xmm0 = max(a0, b0) maxss %xmm5, %xmm3 # xmm3 = max(a1, b1) unpcklps %xmm2, %xmm1 # xmm1 = a3 | b2 unpcklps %xmm3, %xmm0 # xmm0 = max(a1, b1) | max(a2, b2) ret .L14: # handles a2 >= b2 testb %al, %al jne .L16 # if b3 > a3, jump to .L16 #3 here a2 >= b2, a3 >= b3 movaps %xmm6, %xmm1 # xmm1 = a2 # omitted below: case analysis for a2 vs b2, a3 vs b3 .L17: maxss %xmm7, %xmm0 maxss %xmm5, %xmm3 unpcklps %xmm2, %xmm1 unpcklps %xmm3, %xmm0 ret .L16: movaps %xmm4, %xmm2 movaps %xmm6, %xmm1 jmp .L17 .L15: maxss %xmm7, %xmm0 maxss %xmm5, %xmm3 movaps %xmm4, %xmm2 unpcklps %xmm2, %xmm1 unpcklps %xmm3, %xmm0 ret Strangely, it first extracts input values into general-purpose registers, then separately compares the last two elements a2 vs b2 and a3 vs b3, using branches to handle four possible cases (knowing where the last two max elements come from), yet still uses maxss for the first two elements. Why not just use maxss for all four elements from the start? With -O3 -ffast-math, it inexplicably learns this:
vmax(vfloat4, vfloat4): movq %xmm0, %rsi movq %xmm1, %rcx movq %xmm2, %rdx movd %esi, %xmm1 movq %xmm3, %rax movdqa %xmm2, %xmm0 shrq $32, %rdx maxss %xmm1, %xmm0 shrq $32, %rsi movdqa %xmm3, %xmm1 shrq $32, %rax movd %ecx, %xmm3 shrq $32, %rcx movd %edx, %xmm2 movd %esi, %xmm4 maxss %xmm3, %xmm1 movd %ecx, %xmm5 movd %eax, %xmm3 maxss %xmm4, %xmm2 maxss %xmm5, %xmm3 unpcklps %xmm2, %xmm0 unpcklps %xmm3, %xmm1 ret But it still uses scalar SSE, while LLVM 22 knows how to vectorize with maxps:
vmax(vfloat4, vfloat4): movlhps %xmm3, %xmm2 movlhps %xmm1, %xmm0 maxps %xmm2, %xmm0 movaps %xmm0, %xmm1 unpckhpd %xmm0, %xmm1 retq The remaining instructions are only for handling calling convention data placement; within the function, typically a single maxps instruction completes the max computation for all 4 elements. This example illustrates why LLVM 22 is so much faster than GCC 14: GCC 14 generates many useless branches for the select comparison and fails to vectorize the max operation. Even with -march=native, GCC 14 still uses AVX instructions for scalar max operations. See Godbolt. GCC 14's high MPKI comes from exactly this. I also tested the same code on LoongArch, where vectorization support is similarly poor (see Godbolt), so I filed an issue. Considering only the vectorized fmax kernel, an optimized implementation using vfcmp.slt.s + vbitsel.v would be roughly 2.9x the performance of LLVM 22's current output. A small trivia point: x86 SSE/AVX max instructions implement a > b ? a : b logic, while LoongArch's fmax implements IEEE754 maxNum. These differ when NaN is present: the former returns b whenever either a or b is NaN, while the latter returns the non-NaN value when only one operand is NaN.
Main hotspot functions:
compute_angular_endpoints_for_quant_levels from src/astcenc_weight_align.cpp: 19.80%, see above;compute_avgs_and_dirs_3_comp_rgb from src/astcenc_averages_and_directions.cpp: 15.37%, see above;compute_quantized_weights_for_decimation from src/astcenc_ideal_endpoints_and_weights.cpp: 12.40%, see above;compute_error_squared_rgb from src/astcenc_averages_and_directions.cpp: 6.91%, see above;compute_ideal_weights_for_decimation from src/astcenc_ideal_endpoints_and_weights.cpp: 5.68%, see above.Hotspot functions are essentially the same as 1. linear. GCC 14 generates many branches and scalar SSE instructions, while LLVM 22 vectorizes better and avoids unnecessary branches. Comparison:
| Compiler + Flags | Time (s) | Insns (B) | Load (B) | Store (B) | Branch (B) | FP Scalar (B) | FP Vector (B) | Mispred (M) | MPKI |
|---|---|---|---|---|---|---|---|---|---|
GCC 14 -O3
| 72.1 | 1091.8 | 306.9 | 78.6 | 91.7 | 245.8 | 30.4 | 4928.9 | 4.51 |
GCC 14 -O3 -march=native
| 63.1 | 851.4 | 271.2 | 65.2 | 77.4 | 240.1 | 30.4 | 4890.6 | 5.74 |
GCC 14 -O3 -ffast-math
| 67.1 | 1036.6 | 311.0 | 85.5 | 73.7 | 200.8 | 54.3 | 4077.0 | 3.93 |
LLVM 22 -O3
| 55.9 | 1107.9 | 276.5 | 55.9 | 56.9 | 111.8 | 129.9 | 1943.2 | 1.75 |
LLVM 22 -O3 -march=native
| 48.6 | 825.2 | 209.3 | 30.7 | 34.1 | 85.2 | 139.7 | 1411.6 | 1.71 |
Hotspot functions are mostly the same as 1. linear and 2. hdr, with the addition of find_best_partition_candidates from src/astcenc_find_best_partitioning.cpp, where the main bottleneck is a / sqrt(length) computation. This time GCC 14 under -O3 actually vectorizes this step correctly via a scalar sqrtss, shufps to broadcast the result to all lanes, then divps for batch division. However, other hotspot functions still produce slow code as before. Performance counter comparison:
| Compiler + Flags | Time (s) | Insns (B) | Load (B) | Store (B) | Branch (B) | FP Scalar (B) | FP Vector (B) | Mispred (M) | MPKI |
|---|---|---|---|---|---|---|---|---|---|
GCC 14 -O3
| 53.8 | 711.5 | 176.8 | 62.0 | 61.3 | 177.0 | 9.3 | 5119.2 | 7.19 |
GCC 14 -O3 -march=native
| 49.2 | 570.5 | 161.3 | 57.1 | 54.7 | 176.1 | 9.2 | 5113.1 | 8.96 |
GCC 14 -O3 -ffast-math
| 48.7 | 655.9 | 168.3 | 64.6 | 49.8 | 156.5 | 19.5 | 4227.6 | 6.56 |
LLVM 22 -O3
| 39.3 | 729.9 | 149.2 | 42.8 | 35.9 | 75.3 | 77.2 | 1906.7 | 2.61 |
LLVM 22 -O3 -march=native
| 34.1 | 544.9 | 112.5 | 28.0 | 23.2 | 52.0 | 87.1 | 1445.7 | 2.65 |
731.astcenc_r uses SIMD-native programming with vfloat4, vint4, vmask4, etc., written with SIMD instructions in mind. Unfortunately GCC 14 fails to recognize the code's intent and utilize hardware instructions, inexplicably generating branches for the select function. LLVM 22 does much better, vectorizing where appropriate. Meanwhile, slightly less mainstream ISAs like LoongArch still lack adequate optimization for these code patterns, in both GCC and LLVM.
ocio stands for OpenColorIO. Similar to 731.astcenc_r, it processes images, but focuses more on color transformation rather than compression. This benchmark includes four workloads:
# 1. lut1d ocioperf --spec-validation-offset 101 --spec-validation-stride 17 --spec-validation-pixels 131 --bitdepths ui16 ui16 --iter 100 --test -1 --transform ctf/lut1d_halfdom.ctf # 2. mntr ocioperf --spec-validation-offset 202 --spec-validation-stride 19 --spec-validation-pixels 132 --bitdepths ui16 f32 --iter 200 --8kres --test 0 --transform ctf/mntr_srgb_identity.ctf # 3. aces ocioperf --spec-validation-offset 303 --spec-validation-stride 23 --spec-validation-pixels 133 --bitdepths f32 f32 --iter 20 --8kres --test -1 --transform clf/aces_to_video_with_look.clf # 4. heavy ocioperf --spec-validation-offset 404 --spec-validation-stride 29 --spec-validation-pixels 134 --bitdepths f32 f32 --iter 25 --test -1 --transform clf/heavy_transform.clf reftime is 875s. Performance under different compilers and flags:
| Compiler + Flags | Total Time (s) | 1. lut1d (s) | 2. mntr (s) | 3. aces (s) | 4. heavy (s) | Score | Improvement over GCC 14 -O3 (%) |
|---|---|---|---|---|---|---|---|
GCC 14 -O3
| 139.8 | 6.1 | 11.2 | 67.8 | 54.6 | 6.26 | 0 |
GCC 14 -O3 -march=native
| 105.0 | 4.2 | 10.2 | 49.6 | 40.1 | 8.33 | 33 |
GCC 14 -O3 -ffast-math
| 139.4 | 6.4 | 11.4 | 67.8 | 53.9 | 6.28 | 0.3 |
LLVM 22 -O3
| 128.9 | 6.8 | 11.3 | 61.7 | 49.0 | 6.79 | 8 |
LLVM 22 -O3 -march=native
| 105.3 | 5.4 | 9.6 | 49.3 | 40.9 | 8.31 | 33 |
Again, -O3 -march=native brings significant improvement. LLVM 22 still has a performance edge over GCC 14 under -O3, but they're essentially equal under -O3 -march=native. Detailed analysis below.
Hotspot functions:
OpenColorIO_v2_2dev::BitDepthCast<BIT_DEPTH_F32, BIT_DEPTH_UINT16>::apply from src/ASWF-OpenColorIO/src/OpenColorIO/CPUProcessor.cpp: 45.16%, in a loop over float elements in the [0, 1] range, multiplies by 65535 to scale to uint16_t range, adds 0.5, clamps to uint16_t range, then converts float to uint16_t. Compiled to SSE vector instructions;OpenColorIO_v2_2dev::Lut1DRendererHalfCode<BIT_DEPTH_UINT16, BIT_DEPTH_F32>::apply from src/ASWF-OpenColorIO/src/OpenColorIO/ops/lut1d/Lut1DOpCPU.cpp: 33.70%, loops over input uint16_t values doing table lookup (reading float values from a precomputed array indexed by uint16_t), bottleneck is SSE scalar indirect memory access;__memmove_avx_unaligned_erms from libc: 13.28%, AVX-accelerated memmove;__memset_avx2_unaligned_erms from libc: 3.55%, AVX-accelerated memset.For this highly vectorizable code, -O3 -march=native improvement is substantial. In OpenColorIO_v2_2dev::BitDepthCast<BIT_DEPTH_F32, BIT_DEPTH_UINT16>::apply, it uses AVX2 256-bit vector computation and FMA instructions to fuse the scale and add-0.5 steps, followed by bitwise operations for clamping. This function's time share drops to 27.82% under -O3 -march=native, making the still-scalar-SSE OpenColorIO_v2_2dev::Lut1DRendererHalfCode<BIT_DEPTH_UINT16, BIT_DEPTH_F32>::apply the primary bottleneck at 42.85%.
In this sub-benchmark, GCC 14 is slightly faster than LLVM 22. Comparison:
| Compiler + Flags | Time (s) | Insns (B) | Load (B) | Store (B) | Branch (B) | FP Scalar (B) | FP Vector (B) | Mispred (M) |
|---|---|---|---|---|---|---|---|---|
GCC 14 -O3
| 6.1 | 106.2 | 23.3 | 11.7 | 4.2 | 2.6 | 5.0 | 2.6 |
GCC 14 -O3 -march=native
| 4.2 | 63.8 | 22.0 | 11.0 | 3.6 | 2.6 | 2.5 | 2.5 |
GCC 14 -O3 -ffast-math
| 6.4 | 104.8 | 23.2 | 11.7 | 4.2 | 2.5 | 5.0 | 2.6 |
LLVM 22 -O3
| 6.8 | 106.1 | 23.3 | 11.7 | 3.6 | 2.5 | 5.0 | 2.6 |
LLVM 22 -O3 -march=native
| 5.4 | 72.5 | 24.8 | 11.0 | 1.4 | 2.5 | 2.5 | 2.5 |
At the assembly level, GCC 14 and LLVM 22 differ in implementation. Both start with multiplication and addition, but differ in the clamping portion for handling 16-to-32-bit width conversion: GCC 14 mainly uses punpcklwd-type instructions, while LLVM 22 prefers pshufd-type instructions (see Godbolt). Although total instruction counts are close, different instructions require different execution times on hardware, resulting in some IPC difference. Similar situation after enabling -O3 -march=native.
Hotspot functions:
OpenColorIO_v2_2dev::BitDepthCast<BIT_DEPTH_UINT16, BIT_DEPTH_F32>::apply from src/ASWF-OpenColorIO/src/OpenColorIO/CPUProcessor.cpp: 55.41%, this time converting from uint16_t to float, so the computation becomes converting uint16_t to float then multiplying by 1.0/65535.0 (no clamping needed). The compiler vectorizes correctly, though the 16-to-32-bit width conversion takes considerable effort;OpenColorIO_v2_2dev::ScaleRenderer::apply from src/ASWF-OpenColorIO/src/OpenColorIO/ops/matrix/MatrixOpCPU.cpp: 41.52%, simple per-pixel scaling of four components (from out[0] = in[0] * m_scale[0] to out[3] = in[3] * m_scale[3]). All pixels share the same m_scale array, which should be easy to vectorize, but it isn't because the pointers lack restrict annotations. The compiler cannot determine whether out and m_scale might alias; only if they don't overlap can it directly vectorize with mulps (see Godbolt).Since AMD64 lacks vector instructions for mixed-width computation, much overhead goes to shuffling data between vectors rather than actual computation and memory access. RISC-V Vector's design does produce more concise instruction sequences here (see Godbolt). Comparison:
| Compiler + Flags | Time (s) | Insns (B) | Load (B) | Store (B) | Branch (B) | FP Scalar (B) | FP Vector (B) | Mispred (M) |
|---|---|---|---|---|---|---|---|---|
GCC 14 -O3
| 11.2 | 209.9 | 56.5 | 33.3 | 7.5 | 26.8 | 6.6 | 1.9 |
GCC 14 -O3 -march=native
| 10.2 | 159.6 | 54.8 | 29.9 | 7.1 | 26.8 | 3.3 | 1.8 |
GCC 14 -O3 -ffast-math
| 11.4 | 209.7 | 56.5 | 33.3 | 7.5 | 26.7 | 6.6 | 1.8 |
LLVM 22 -O3
| 11.3 | 194.5 | 56.5 | 33.3 | 8.6 | 26.5 | 6.7 | 1.9 |
LLVM 22 -O3 -march=native
| 9.6 | 149.4 | 58.2 | 29.9 | 2.8 | 26.5 | 3.4 | 2.0 |
Hotspot functions:
OpenColorIO_v2_2dev::Lut3DTetrahedralRenderer::apply from src/ASWF-OpenColorIO/src/OpenColorIO/ops/lut3d/Lut3DOpCPU.cpp: 50.74%, complex operations per element: multiply, clamp, floor and ceil converted to int, then index-based table lookup with indirect memory access, followed by weighted averaging. Low vectorization;OpenColorIO_v2_2dev::MatrixRenderer::apply from src/ASWF-OpenColorIO/src/OpenColorIO/ops/matrix/MatrixOpCPU.cpp: 11.55%, matrix operations multiplying input 4D vectors by a 4x4 matrix. High vectorization;__log2f_fma from libm: 10.02%, computing float log2;OpenColorIO_v2_2dev::CameraLin2LogRenderer::apply from src/ASWF-OpenCOlorIO/src/OpenColorIO/ops/log/LogOpCPU.cpp: 9.76%, checks input range; if below threshold m_linb, uses linear multiply-add; otherwise calls log2 combined with multiply-add and max operations. Low vectorization.Comparison:
| Compiler + Flags | Time (s) | Insns (B) | Load (B) | Store (B) | Branch (B) | FP Scalar (B) | FP Vector (B) | Mispred (M) |
|---|---|---|---|---|---|---|---|---|
GCC 14 -O3
| 67.8 | 1258.9 | 299.3 | 86.3 | 100.5 | 260.6 | 28.0 | 146.6 |
GCC 14 -O3 -march=native
| 49.6 | 873.7 | 289.0 | 84.9 | 84.0 | 257.4 | 14.0 | 135.4 |
GCC 14 -O3 -ffast-math
| 67.8 | 1251.5 | 296.4 | 94.4 | 109.9 | 213.7 | 43.8 | 150.6 |
LLVM 22 -O3
| 61.7 | 1152.4 | 416.6 | 136.7 | 133.7 | 329.0 | 15.4 | 168.5 |
LLVM 22 -O3 -march=native
| 49.3 | 857.8 | 342.8 | 92.6 | 84.4 | 329.0 | 13.0 | 151.6 |
The performance gap between GCC 14 and LLVM 22 under -O3 mainly comes from floor/ceil handling: GCC 14 generates a complex series of SSE instructions (lacking SSE4.1's roundps), while LLVM 22 calls libm's __floorf_sse41, whose function body is essentially a single SSE4.1 roundps instruction plus return. Although there's function call overhead (call/ret plus register save/restore with extra Loads and Stores), it's still a net win. However, on processors truly without SSE4.1, GCC 14's approach would be faster. This trade-off cannot be resolved without -march=native; one can only guess which case is more probable. Today, AMD64 processors with SSE4.1 far outnumber those without.
After enabling -O3 -march=native, the vroundps instruction replaces the previous ceil/floor implementations (GCC 14's vectorized approach or LLVM 22's libm calls), giving both compilers significant improvement and bringing them to the same level. FMA also successfully fuses many multiply-add computations.
Hotspot functions:
__powf_fma from libm: 26.17%;OpenColorIO_v2_2dev::Lut3DRenderer::apply from src/ASWF-OpenColorIO/src/OpenColorIO/ops/lut3d/Lut3DOpCPU.cpp: 25.69%, similar pattern to Lut3DTetrahedralRenderer::apply above with clamp/floor/ceil and table lookup, just with different final computation, all scalar SSE;OpenColorIO_v2_2dev::Lut1DRenderer<BIT_DEPTH_F32, BIT_DEPTH_F32>::apply from src/ASWF-OpenColorIO/src/OpenColorIO/ops/lut1d/Lut1DOpCPU.cpp: 15.63%, similar to Lut3DRenderer::apply but simpler 1D table lookup, still all scalar;OpenColorIO_v2_2dev::CDLRendererFwd<true>::apply: 10.88%, calls pow (causing __powf_fma's high share), plus floating-point multiply, add/sub, and clamp. All scalar;OpenColorIO_v2_2dev::GammaMoncurveOpCPUFwd::apply: 5.41%, also calls pow, with additional floating-point operations and comparisons.Comparison:
| Compiler + Flags | Time (s) | Insns (B) | Load (B) | Store (B) | Branch (B) | FP Scalar (B) | FP Vector (B) | Mispred (M) |
|---|---|---|---|---|---|---|---|---|
GCC 14 -O3
| 54.6 | 1013.5 | 209.4 | 57.0 | 80.8 | 253.7 | 5.8 | 32.0 |
GCC 14 -O3 -march=native
| 40.9 | 764.7 | 204.0 | 54.8 | 70.8 | 260.2 | 3.3 | 31.8 |
GCC 14 -O3 -ffast-math
| 53.9 | 971.0 | 202.1 | 50.5 | 80.6 | 252.3 | 6.6 | 29.1 |
LLVM 22 -O3
| 49.0 | 861.5 | 250.4 | 77.3 | 102.7 | 215.6 | 29.9 | 28.8 |
LLVM 22 -O3 -march=native
| 40.9 | 726.8 | 206.9 | 55.4 | 67.3 | 255.6 | 25.7 | 28.5 |
The performance difference between LLVM 22 and GCC 14 is the same as in 3. aces: ceil/floor handling. Additionally, like 731.astcenc_r, for vectorized min/max operations, LLVM 22 correctly vectorizes to maxps/minps while GCC 14 produces verbose code.
736.ocio_r is another application well-suited for vectorization. Although it doesn't use vfloat4 directly like 731.astcenc_r, it's image processing where each loop iteration handles one pixel with four channels. In many cases these four channels undergo identical computation, making it very amenable to vectorization. LLVM 22 under -O3 generates better code than GCC 14, from floor/ceil mapping to libm functions to better vectorization. However, with -O3 -march=native, the performance gap between GCC 14 and LLVM 22 becomes negligible, indicating that with sufficient ISA extensions enabled, both converge to similar implementations. This also suggests GCC 14's SSE code generation has deficiencies: perhaps it's not that GCC 14 cannot vectorize (since it does so with -O3 -march=native), but rather it doesn't know how to express vectorized code with SSE after attempting vectorization, so it falls back to scalar.
737.gmsh_r is a 3D CAD meshing software with seven workloads:
# 1. choi gmsh_r -option gmsh.opts -nt 0 choi.geo # 2. mediterranean gmsh_r -option gmsh.opts -nt 0 mediterranean.geo # 3. projection gmsh_r -option gmsh.opts -nt 0 projection.geo # 4. gasdis gmsh_r -option gmsh.opts -nt 0 gasdis.geo # 5. Torus gmsh_r -option gmsh.opts -nt 0 Torus.geo # 6. spec gmsh_r -option gmsh.opts -nt 0 spec.geo -clscale 0.175 -algo del2d -algo hxt # 7. p19 gmsh_r -option gmsh.opts -nt 0 p19.geo Workload runtimes are 17.1s, 11.8s, 11.2s, 16.9s, 9.2s, 13.4s, and 12.8s, totaling 92.2s, reftime 459s, corresponding to 4.98 points. Both -O3 -ffast-math and -O3 -march=native yield minimal benefit; LLVM 22 is actually slower than GCC 14, so detailed comparison is omitted.
When compiling with -O3 -march=native, if CC is set to just gcc without passing -std=c18, the 4. gasdis workload enters an infinite loop, continuously reporting: Info : Symbolic perturbation failed (2 superposed vertices ?). The difference is whether FMA contraction occurs: with -O3 -std=c18 -march=native, contraction doesn't happen; with -O3 -march=native or -O3 -std=gnu18 -march=native, it does (see Godbolt). In other programs FMA contraction improves performance, but here it unfortunately causes an infinite loop. This relates to -fp-contract:
-ffp-contract=style -ffp-contract=off disables floating-point expression contraction. -ffp-contract=fast enables floating-point expression contraction such as forming of fused multiply-add operations if the target has native support for them. -ffp-contract=on enables floating-point expression contraction if allowed by the language standard. This is implemented for C and C++, where it enables contraction within one expression, but not across different statements. The default is -ffp-contract=off for C in a standards compliant mode (-std=c11 or similar), -ffp-contract=fast otherwise. This only affects C code, not C++, so in practice only 737.gmsh_r is affected. Although 709.cactus_r also has C code, its main computation is in C++.
Per-workload hotspot analysis follows.
Hotspot functions:
netgen::ADTree6::GetIntersecting from src/gmsh/contrib/Netgen/libsrc/gprim/adtree.cpp: 18.40%, implements a 6-dimensional KD-Tree search algorithm. Main bottleneck is the data-dependent branch if (node->pi != -1) with high misprediction rate;__ieee754_atan2_fma from libm: 6.64%;reparamMeshVertexOnFace from src/gmsh/src/geo/MVertex.cpp: 6.03%, enters different if-else branches based on vertex dimension, with significant mispredictions.Although floating-point is used, the computation pattern doesn't lend itself to vectorization. KD-Tree search naturally has high MPKI. Executed 204.7B instructions with 744.3M mispredictions, MPKI = 744.3M/204.7B*1000=3.64, second highest in SPEC FP 2026 Rate. The highest, 731.astcenc_r, is essentially due to GCC's poor implementation as discussed above; it could be optimized to around LLVM 22's 1.3, which would make 737.gmsh_r first.
Hotspot functions:
meshGEdgeProcessing from src/gmsh/src/mesh/meshGEdge.cpp: 36.55%, main bottleneck is Gauss-Seidel iteration in a loop, where scalar division and comparisons take considerable time;KDTreeSingleIndexAdaptor::searchLevel from src/gmsh/src/numeric/nanoflann.hpp: 33.50%, another classic KD-Tree search, recursing into left or right subtrees based on input value;InterpolateCurve from src/gmsh/src/geo/GeoInterpolation.cpp: 6.53%, recursive interpolation computation.Although floating-point is involved, the computation pattern is not vectorization-friendly because intermediate results feed into if-branches, with additional floating-point computation inside the branches.
Hotspot functions:
laplaceSmoothing from src/gmsh/src/mesh/meshGFaceOptimize.cpp: 11.73%, main bottleneck is std::set operations (which is backed by std::map), hence the std::map functions below;std::map::_M_get_insert_unique_pos from libstdc++: 7.49%, std::map insertion algorithm;__ieee754_atan2_fma from libm: 7.21%;reparamMeshVertexOnFace: 6.66%, see above;std::map::_M_get_insert_unique from libstdc++: 6.09%, std::map insertion;SetRotationMatrix from src/gmsh/src/geo/Geo.cpp: 5.01%, multi-layer loops suitable for vectorization, and the compiler does vectorize, though time share is low.The main bottleneck in this workload is std::map operations.
Hotspot functions:
MakeHybridHexTetMeshConformalThroughTriHedron from src/gmsh/src/mesh/meshCombine3D.cpp: 30.18%, main bottleneck is std::map searches in a loop;parallelDelaunay3D from src/gmsh/contrib/hxt/tetMesh/src/hxt_tetDelaunay.c: 9.05%, Delaunay triangulation algorithm;hxtRefineTetrahedra from src/gmsh/contrib/hxt/tetMesh/src/hxt_tetRefine.c: 5.18%, loop with floating-point computation including add/sub, mul/div, and sqrt.Bottleneck is mainly std::map.
The last three workloads have the same hotspot functions as 4. gasdis.
Per-workload data:
| Workload | Time (s) | Insns (B) | Load (B) | Store (B) | Branch (B) | FP Scalar (B) | FP Vector (B) | Mispred (M) | MPKI |
|---|---|---|---|---|---|---|---|---|---|
| 1. choi | 17.0 | 204.7 | 59.3 | 25.6 | 39.4 | 22.1 | 0.3 | 744.3 | 3.64 |
| 2. mediterranean | 11.7 | 190.7 | 57.4 | 23.2 | 24.0 | 28.5 | 2.4 | 71.0 | 0.37 |
| 3. projection | 11.1 | 109.0 | 29.1 | 14.4 | 20.3 | 13.3 | 2.2 | 183.0 | 1.68 |
| 4. gasdis | 16.9 | 157.8 | 46.3 | 17.8 | 27.6 | 19.6 | 0.2 | 689.9 | 4.37 |
| 5. Torus | 9.2 | 77.3 | 21.9 | 8.2 | 13.4 | 9.4 | 0.5 | 380.4 | 4.92 |
| 6. spec | 13.3 | 101.4 | 30.2 | 10.8 | 18.1 | 10.9 | 0.2 | 546.1 | 5.39 |
| 7. p10 | 12.7 | 96.3 | 28.8 | 10.2 | 17.2 | 10.4 | 0.1 | 529.3 | 5.50 |
Overall MPKI is high, largely attributable to KD-Tree queries and std::map queries/insertions, although the tree keys are single-precision floats. Based on the analysis, the code indeed isn't suitable for vectorization, and FMA contraction is disabled since it would cause non-convergence.
flightdm is a flight dynamics simulator with eight workloads:
# 1. weather JSBSim --nohighlight scripts/weather-balloon2.xml # 2. B747 JSBSim --nohighlight scripts/B747_script1.xml # 3. x153 JSBSim --nohighlight scripts/x153.xml # 4. c3104 JSBSim --nohighlight scripts/c3104.xml # 5. ah1s JSBSim --nohighlight scripts/ah1s_flight_test.xml # 6. orbit_torque JSBSim --nohighlight scripts/ball_orbit_g_torque.xml # 7. orbit_torque2 JSBSim --nohighlight scripts/ball_orbit_g_torque2.xml # 8. orbit JSBSim --nohighlight scripts/ball_orbit.xml Workload runtimes are 5.9s, 14.7s, 10.9s, 11.3s, 24.8s, 8.0s, 9.8s, and 8.4s, totaling 93.9s, reftime 716s, corresponding to 7.63 points. -O3 -march=native only gives 2% improvement; -O3 -ljemalloc provides 4%; -O3 -flto gives 11%. LLVM 22 is slower than GCC 14.
Hotspot functions:
__sincos_fma from libm: 6.75%;__ieee754_atan2_fma from libm: 6.41%;__strncmp_avx2 from libc: 5.04%;parse_path from src/JSB-FlightSim/src/simgear/props/props.cxx: 4.43%, path string parsing, splitting into components;__ieee754_pow_fma from libm: 4.05%.The hotspots are quite unusual: mostly libm/libc functions, and flightdm's own most time-consuming function is a path parser. Various optimization flags having no effect is unsurprising.
Hotspot functions:
SGPropertyNode::getDoubleValue from src/JSB-FlightSim/src/simgear/props/props.cxx: 5.65%, appears to be parsing configuration files and extracting floating-point values;__ieee754_atan2_fma from libm: 5.42%;__sincos_fma from libm: 5.25%.Nothing interesting to analyze.
Same hotspot functions as 2. B747.
Hotspot functions:
SGPropertyNode::getDoubleValue from src/JSB-FlightSim/src/simgear/props/props.cxx: 8.45%, see above;JSBSim::aFunc::getValue from src/JSB-FlightSim/src/math/FGFunction.cpp: 7.20%, a memoized std::function-like container;__sincos_fma from libm: 6.04%;__ieee754_atan2_fma from libm: 5.35%;JSBSim::FGPropertyValue::getValue from src/JSB-FlightSim/src/math/FGPropertyValue.cpp: 5.11%, calls getDoubleValue above.The overall impression: either calling libm for transcendental functions or extracting configuration file contents.
Hotspot functions:
__ieee754_atan2_fma from libm: 7.52%;__sincos_fma from libm: 6.82%;__strncmp_avx2 from libc: 6.57%;parse_path from src/JSB-FlightSim/src/simgear/props/props.cxx: 6.12%, path string parsing, splitting into components;SGPropertyNode::getChild from src/JSB-FlightSim/src/simgear/props/props.cxx: 4.05%, traverses child nodes via string comparison to find matching children.Same hotspot functions as 6. orbit_torque.
748.flightdm_r is an uninteresting benchmark. Much time is spent in libm and libc functions, while its own code just traverses configuration files. I'd call it a libm benchmark. Beyond that, it behaves more like a SPEC INT 2026 Rate workload: string operations, memory allocation, many small functions and lambdas, suitable for -O3 -flto optimization. Per-workload data under -O3:
| Workload | Time (s) | Insns (B) | Load (B) | Store (B) | Branch (B) | FP Scalar (B) | FP Vector (B) | Mispred (M) | MPKI |
|---|---|---|---|---|---|---|---|---|---|
| 1. weather | 5.9 | 106.1 | 30.8 | 15.4 | 19.5 | 12.9 | 0.6 | 11.6 | 0.11 |
| 2. B747 | 14.8 | 260.1 | 80.0 | 38.7 | 49.4 | 28.4 | 1.7 | 25.6 | 0.10 |
| 3. x153 | 10.8 | 193.3 | 59.1 | 28.7 | 37.3 | 20.0 | 1.0 | 20.9 | 0.11 |
| 4. c3104 | 11.4 | 194.6 | 58.9 | 29.1 | 35.7 | 23.9 | 1.3 | 18.2 | 0.09 |
| 5. ah1s | 24.7 | 407.3 | 130.0 | 61.3 | 77.9 | 46.4 | 1.6 | 49.3 | 0.12 |
| 6. orbit_torque | 7.9 | 152.8 | 41.9 | 22.7 | 28.3 | 16.3 | 1.1 | 24.2 | 0.16 |
| 7. orbit_torque2 | 9.9 | 191.4 | 52.5 | 28.4 | 35.3 | 21.0 | 1.2 | 17.1 | 0.09 |
| 8. orbit | 8.4 | 161.6 | 44.3 | 23.9 | 30.0 | 17.2 | 1.0 | 16.3 | 0.10 |
Unremarkable.
Finally, a familiar face from SPEC FP 2017 Rate (previously 549.fotonik3d_r). fotonik3d solves Maxwell's equations in 3D space. Another physics-based benchmark; 3D PDE solvers invariably involve Stencil, and let's see if this holds. Single workload:
reftime is 1156s. Performance under different flags:
| Compiler + Flags | Time (s) | Score | Improvement over GCC 14 -O3 (%) | Insns (B) | Load (B) | Store (B) | Branch (B) | FP Scalar (B) | FP Vector (B) |
|---|---|---|---|---|---|---|---|---|---|
GCC 14 -O3
| 131.1 | 8.82 | 0 | 1408.5 | 375.1 | 120.7 | 30.9 | 5.4 | 527.2 |
GCC 14 -O3 -march=native
| 114.9 | 10.1 | 14 | 670.1 | 274.1 | 82.4 | 27.1 | 5.5 | 249.4 |
GCC 14 -O3 -ffast-math
| 116.7 | 9.91 | 12 | 1117.6 | 378.4 | 120.8 | 30.7 | 4.8 | 396.2 |
GCC 14 -O3 -ffast-math -march=native
| 108.5 | 10.65 | 21 | 599.5 | 276.3 | 82.3 | 26.9 | 4.8 | 204.8 |
LLVM 22 performs similarly to GCC 14 and is omitted. Both -O3 -march=native and -O3 -ffast-math provide solid improvements. Hotspot analysis:
power_dft from src/power.F90: 30.92%, performs DFT (Discrete Fourier Transform), bottleneck is double-precision floating-point multiply-add in loops, compiled to SSE vector instructions by GCC 14;UPML_updateE_simple from src/UPML.F90: 24.73%, 3D Stencil computation, SSE vector instructions;UPML_updateH from src/UPML.F90: 23.26%, 3D Stencil computation, SSE vector instructions;mat_updateE from src/material.F90: 11.04%, Stencil computation, SSE vector instructions;updateH from src/update.F90: 9.78%, Stencil computation, SSE vector instructions.Besides power_dft, most time is spent on Stencil computation. This time the Stencil pattern is purer since GCC can vectorize well with SSE. Based on earlier experience, such programs benefit greatly from -O3 -march=native, -O3 -ffast-math, and their combination.
With -march=native, wider AVX2 vectors bring higher parallelism, plus FMA instructions like vfmaddsub231pd.
With -O3 -ffast-math, the core computation in power_dft is essentially complex multiplied by real, then added to complex, as shown in this Fortran code:
subroutine update(Efreq1, Efreq2, expfuncE, Efield1, Efield2, n) implicit none integer, intent(in) :: n complex(8), intent(inout) :: Efreq1(n), Efreq2(n) complex(8), intent(in) :: expfuncE(n) real(8), intent(in) :: Efield1, Efield2 integer :: i do i = 1, n Efreq1(i) = Efreq1(i) + expfuncE(i) * Efield1 Efreq2(i) = Efreq2(i) + expfuncE(i) * Efield2 end do end subroutine update Under -O3, GCC 14 faithfully implements complex multiplication. However, Efield1 and Efield2 are real numbers, so the converted complex has zero imaginary part. With -O3 -ffast-math, this simplifies to directly multiplying the real part into expfuncE's real and imaginary components. With -O3 -ffast-math -march=native, both optimizations combine: the AVX2 FMA instruction vfmadd213pd replaces the vfmaddsub231pd needed under -O3 -march=native (which simultaneously adds and subtracts; the subtraction comes from the complex multiplication definition, but subtracts zero here since Efield1/Efield2's imaginary part is zero). See Godbolt.
In summary, 749.fotonik3d_r is a classic floating-point application with heavy Stencil and vector floating-point operations, high parallelism, amenable to vectorization, and benefits from -ffast-math computation order optimization.
Another returnee from SPEC FP 2017 Rate (previously 554.roms_r), implementing ocean simulation. Unsurprisingly, it's Stencil again. Single workload:
reftime is 1575s. Performance:
| Compiler + Flags | Time (s) | Score | Improvement over GCC 14 -O3 (%) | Insns (B) | Load (B) | Store (B) | Branch (B) | FP Scalar (B) | FP Vector (B) |
|---|---|---|---|---|---|---|---|---|---|
GCC 14 -O3
| 169.8 | 9.28 | 0 | 2620.6 | 874.8 | 204.7 | 192.1 | 193.3 | 709.2 |
GCC 14 -O3 -march=native
| 149.5 | 10.5 | 14 | 1317.9 | 555.3 | 125.0 | 126.6 | 164.9 | 365.9 |
GCC 14 -O3 -ffast-math
| 162.8 | 9.67 | 4 | 2518.6 | 854.5 | 204.0 | 178.5 | 134.0 | 711.7 |
LLVM 22 -O3
| 165.6 | 9.51 | 3 | 2434.3 | 834.9 | 190.3 | 164.1 | 231.8 | 687.0 |
LLVM 22 -O3 -march=native
| 152.1 | 10.4 | 12 | 1423.4 | 551.4 | 131.2 | 140.1 | 259.8 | 350.0 |
Heavy floating-point computation with high vectorizability; -O3 -march=native improvement is expected.
Hotspot functions:
step2d_tile from src/step2d_LF_AM3.h: 20.37%, 2D Stencil computation, high vectorization;pre_step3d from src/pre_step3d.F90: 10.43%, floating-point computation in loops, high vectorization;lmd_skpp from src/lmd_skpp.F90: 8.91%, complex floating-point computation in loops, mainly scalar;step3d_t_tile from src/step3d_t.F90: 7.04%, 3D Stencil computation, high vectorization;rhs3d from src/rhs3d.F90: 6.04%, 2D Stencil computation, high vectorization;t3dmix2 from src/t3dmix2_geo.h: 5.86%, 3D Stencil computation, high vectorization;step3d_uv_tile from src/step3d_uv.F90: 5.85%, 3D Stencil computation, high vectorization;_ZGVbN2v_exp_sse4 from libmvec: 4.66%, vectorized exp.Typical Stencil computation with high vectorization. With -O3 -march=native, wider vectors plus FMA naturally bring solid improvements.
femflow is a fluid dynamics solver for Navier-Stokes equations. Single workload:
reftime is 1467s. Performance:
| Compiler + Flags | Time (s) | Score | Improvement over GCC 14 -O3 (%) | Insns (B) | Load (B) | Store (B) | Branch (B) | FP Scalar (B) | FP Vector (B) |
|---|---|---|---|---|---|---|---|---|---|
GCC 14 -O3
| 188.7 | 7.77 | 0 | 3862.4 | 1358.5 | 797.6 | 117.5 | 562.2 | 676.0 |
GCC 14 -O3 -march=native
| 95.1 | 15.4 | 98 | 1736.9 | 619.3 | 356.0 | 65.2 | 286.8 | 445.4 |
GCC 16 -O3
| 153.6 | 9.55 | 23 | 3178.6 | 1109.3 | 673.3 | 127.2 | 56.3 | 930.9 |
GCC 16 -O3 -march=native
| 83.5 | 17.57 | 126 | 1457.0 | 501.1 | 281.4 | 61.1 | 47.2 | 545.7 |
LLVM 22 -O3
| 124.7 | 11.8 | 51 | 2703.0 | 857.3 | 475.5 | 60.6 | 40.8 | 930.3 |
LLVM 22 -O3 -march=native
| 88.7 | 16.5 | 113 | 1392.9 | 495.7 | 269.4 | 42.9 | 41.8 | 471.1 |
LLVM 22 provides significant improvement over GCC 14, and -O3 -march=native brings even more dramatic gains. This is the second-highest -O3 -march=native improvement in SPEC FP 2026 Rate (first is 772.marian_r below). GCC 16 also improves notably over GCC 14, overtaking LLVM 22 with -O3 -march=native.
There are many hotspot functions, mostly single-digit percentage each, mainly computational operators:
Laplace::LaplaceOperator::local_apply_quadratic_geo from src/laplace_operator.h: 5.49%, heavy floating-point vector computation with high parallelism;operator *(const dealii::VectorizedArray &, const dealii::VectorizedArray &) from src/dealii/include/deal.ll/base/vectorization.h: 5.36%, element-wise vector multiplication.Other functions include dealii::Tensor computations, including dealii::internal::even_odd_apply from src/dealii/include/deal.ll/matrix_free/tensor_product_kernels.h, implementing Tensor double-precision floating-point multiplication. The "even-odd" refers to exploiting data symmetry by splitting into even and odd parts, reducing computation count while being vectorization-friendly. For such workloads, -O3 -march=native provides better floating-point performance through wider vectors plus FMA.
LLVM 22's advantage over GCC 14 comes from vectorizing more code: comparing instruction counts, LLVM 22 executes fewer FP scalar instructions and more FP vector instructions. GCC 16 shows a similar pattern, approaching LLVM 22's vectorization level.
nest is a spiking neural network simulator. This benchmark has three workloads:
# 1. cuba nest_r cuba_stdp.sli # 2. structural nest_r structural_plasticity_benchmark # 3. Artificial nest_r ArtificialSynchrony -O3 -march=native gives only 3% improvement; LLVM 22 is slower than GCC 14. Per-workload data under GCC 14 -O3:
| Workload | Time (s) | Insns (B) | Load (B) | Store (B) | Branch (B) | FP Scalar (B) | FP Vector (B) |
|---|---|---|---|---|---|---|---|
| 1. cuba | 14.1 | 176.3 | 54.5 | 21.6 | 22.4 | 29.2 | 0.0 |
| 2. structural | 24.6 | 413.3 | 136.3 | 42.8 | 52.5 | 93.2 | 0.0 |
| 3. Artificial | 48.6 | 1125.4 | 392.6 | 150.5 | 160.5 | 163.6 | 0.0 |
Total time 87.4s, reftime 793s, corresponding to 9.07 points.
Hotspot functions:
nest::iaf_psc_exp::handle from src/nest-simulator/models/iaf_psc_exp.cpp: 25.75%, processes incoming spikes and updates internal state. Main bottleneck is indirect memory access, writing spike weights to corresponding input buffers;__ieee754_pow_fma from libm: 11.96%, called by nest::Connector::send below;spec::poisson_distribution::operator() from src/specrand-distributions/spec_random_distributions.cpp: 9.87%, random number generation for input spike generation;nest::Connector::send from src/nest-simulator/nestkernel/connector_base.h: 8.29%, spike propagation through synapses with STDP. Main bottleneck is indirect memory access, plus inlined weight computation with pow and exp calls;nest::iaf_psc_exp::update from src/nest-simulator/models/iaf_psc_exp.cpp: 6.91%, neuron state update at each timestep, mainly scalar floating-point.A classic SNN simulation with STDP. Main bottlenecks are spike propagation and STDP synaptic weight updates, with very low vectorization and indirect memory access.
Hotspot functions:
spec::poisson_distribution::operator() from src/specrand-distributions/spec_random_distributions.cpp: 24.26%, see above;nest::iaf_psc_alpha::update from src/nest-simulator/models/iaf_psc_alpha.cpp: 13.71%, similar to nest::iaf_psc_exp::update but different neuron model;__ieee754_pow_fma from libm: 13.37%, see above;nest::GrowthCurveGaussian::update from src/nest-simulator/nestkernel/growth_curve.cpp: 6.60%, numerical ODE solving with frequent exp and pow calls;nest::iaf_psc_alpha::handle from src/nest-simulator/models/iaf_psc_alpha.cpp: 25.75%, similar to nest::iaf_psc_exp::handle;nest::Connector::send from src/nest-simulator/nestkernel/connector_base.h: 6.60%, see above, but without STDP this time (static weights);exp from libm: 5.39%.Compared to 1. cuba, different neuron model without STDP. The main bottleneck shifts to Poisson distribution random generation; the rest is typical SNN simulation.
Hotspot functions:
nest::iaf_psc_alpha_ps::update from src/nest-simulator/models/iaf_psc_alpha_ps.cpp: 13.26%, neuron state update;nest::iaf_psc_alpha::update from src/iaf_psc_alpha.cpp: 12.37%, see above;nest::Connector::send from src/nest-simulator/nestkernel/connector_base.h: 7.19%, see above, still no STDP (static weights);nest::SimulationManager::update_ from src/nest-simulator/nestkernel/simulation_manager.cpp: 5.66%, core SNN simulation loop calling the above functions;__ieee754_pow_fma from libm: 5.17%, see above.nest is a flexible SNN simulator, but single-threaded performance is mediocre since most effort goes into multi-core/multi-thread optimization. Unsurprisingly, nest's neuron update code isn't vectorized, while spike propagation and STDP are inherently hard to optimize. This is a floating-point application that's difficult to vectorize; as the counters show, zero vector floating-point instructions are executed.
marian_r is a neural-network-based translator. Another neural network inference workload, meaning -O3 -march=native should have a large advantage. If dedicated hardware acceleration instructions are available (like in 706.stockfish_r), performance will far exceed -O3. Two workloads:
# 1. TildeMODEL marian-decoder --cpu-threads 1 -m model.alphas.npz -v vocab.spm vocab.spm --beam-size 1 --mini-batch 32 --maxi-batch 100 --maxi-batch-sort src -w 512 --skip-cost --gemm-type intgemm8 --intgemm-options precomputed-alpha standard-only --quiet --quiet-translation -i TildeMODEL-spec.en --log TildeMODEL-spec.log --log-level off -o TildeMODEL-spec.out # 2. EuroPat marian-decoder --cpu-threads 1 -m model.alphas.npz -v vocab.spm vocab.spm --beam-size 1 --mini-batch 32 --maxi-batch 100 --maxi-batch-sort src -w 512 --skip-cost --gemm-type intgemm8 --intgemm-options precomputed-alpha standard-only --quiet --quiet-translation -i EuroPat-spec.en --log EuroPat-spec.log --log-level off -o EuroPat-spec.out reftime is 1579s. Compiler and flag comparison:
| Compiler + Flags | Time (s) | Score | Improvement over GCC 14 -O3 (%) | 1. TildeMODEL (s) | 2. EuroPat (s) |
|---|---|---|---|---|---|
GCC 14 -O3
| 235.2 | 6.71 | 0 | 88.8 | 146.4 |
GCC 14 -O3 -march=native
| 78.4 | 20.14 | 200 | 28.2 | 50.3 |
GCC 15 -O3
| 150.1 | 10.52 | 57 | 56.0 | 94.8 |
GCC 15 -O3 -march=native
| 77.5 | 20.37 | 203 | 27.8 | 49.7 |
-O3 -march=native provides a massive 200% improvement. On Apple M1 it's 47%, on Apple M2 it reaches 92%. This level of improvement was previously only seen in 706.stockfish_r. GCC 15 also significantly improves over GCC 14 under -O3.
Hotspot functions:
marian::cpu::integer::affineOrDotTyped from src/marian/tensors/cpu/intgemm_interface.h: 82.28%, mainly in tiled_gemm, performing integer matrix multiplication: uint8_t matrix A multiplied by int8_t matrix B, accumulated to int32_t, finally converted to float and added to float matrix C;marian::cpu::ProdBatched from src/marian/tensors/cpu/prod.cpp: 10.30%, core is sgemm (actual floating-point matrix operations), compiled to scalar SSE floating-point rather than vector, but given its time share, this is tolerable.The main hotspot has the same computation pattern as 706.stockfish_r's NNUE. With -O3 -march=native, AVX-VNNI's vpdpbusd instruction optimizes it (see Godbolt). Similarly, GCC 15 performs better than GCC 14 due to its superior unsigned extension implementation. For detailed discussion, see the 706.stockfish_r section in the INT Rate article.
Performance counter comparison:
| Compiler + Flags | Time (s) | Insns (B) | Load (B) | Store (B) | Branch (B) | FP Scalar (B) | FP Vector (B) | 128-bit Int Vec (B) | 256-bit Int Vec (B) |
|---|---|---|---|---|---|---|---|---|---|
GCC 14 -O3
| 88.2 | 2038.9 | 217.8 | 57.8 | 53.2 | 58.7 | 2.1 | 514.6 | 0.0 |
GCC 14 -O3 -march=native
| 27.6 | 423.0 | 131.5 | 25.1 | 47.4 | 59.8 | 1.1 | 12.8 | 47.4 |
GCC 15 -O3
| 55.6 | 1353.5 | 173.9 | 22.1 | 53.2 | 58.7 | 2.1 | 184.7 | 0.0 |
GCC 15 -O3 -march=native
| 27.3 | 415.1 | 128.9 | 23.5 | 47.5 | 59.8 | 1.1 | 12.8 | 47.4 |
128-bit integer vector from int_vec_retired.128bit counter, 256-bit from int_vec_retired.256bit.
Hotspot functions:
marian::cpu::integer::affineOrDotTyped: 78.96%, see above;marian::cpu::ProdBatched: 14.25%, see above.Identical hotspots to 1. TildeMODEL; the same analysis applies. Performance counters:
| Compiler + Flags | Time (s) | Insns (B) | Load (B) | Store (B) | Branch (B) | FP Scalar (B) | FP Vector (B) | 128-bit Int Vec (B) | 256-bit Int Vec (B) |
|---|---|---|---|---|---|---|---|---|---|
GCC 14 -O3
| 145.6 | 3352.7 | 370.4 | 89.7 | 98.8 | 123.8 | 3.6 | 815.0 | 0.0 |
GCC 14 -O3 -march=native
| 49.7 | 777.2 | 228.7 | 36.6 | 88.3 | 123.9 | 1.7 | 19.9 | 72.6 |
GCC 15 -O3
| 94.2 | 2268.5 | 301.7 | 33.1 | 98.8 | 123.8 | 3.6 | 293.6 | 0.0 |
GCC 15 -O3 -march=native
| 49.0 | 765.3 | 225.2 | 34.3 | 88.3 | 123.9 | 1.7 | 19.9 | 72.6 |
772.marian_r is essentially a 706.stockfish_r NNUE clone. The hotspot is int8_t times uint8_t accumulated to int32_t matrix multiplication, with more integer vector instructions than floating-point. It probably should be expelled from SPEC FP 2026 Rate.
lbm stands for Lattice Boltzmann Method, another fluid dynamics application, still Stencil. Single workload:
reftime is 573s. Performance comparison:
| Compiler + Flags | Time (s) | Score | Improvement over GCC 14 -O3 (%) | Insns (B) | Load (B) | Store (B) | Branch (B) | FP Scalar (B) | FP Vector (B) |
|---|---|---|---|---|---|---|---|---|---|
GCC 14 -O3
| 105.8 | 5.42 | 0 | 2232.2 | 473.3 | 242.4 | 14.5 | 1108.2 | 0.0 |
GCC 14 -O3 -ffast-math
| 95.8 | 5.98 | 10 | 1892.4 | 419.2 | 192.8 | 14.5 | 1009.5 | 0.0 |
GCC 14 -O3 -march=native
| 131.0 | 4.37 | -19 | 1669.6 | 550.3 | 309.8 | 14.5 | 1228.8 | 0.0 |
GCC 15 -O3
| 105.2 | 5.45 | 0.6 | 2218.9 | 468.9 | 242.4 | 14.5 | 1108.2 | 0.0 |
GCC 15 -O3 -march=native
| 111.0 | 5.16 | -5 | 1777.3 | 509.8 | 282.9 | 14.5 | 1108.2 | 0.0 |
GCC 16 -O3
| 105.4 | 5.44 | 0.4 | 2218.9 | 468.9 | 242.4 | 14.5 | 1108.2 | 0.0 |
GCC 16 -O3 -march=native
| 110.6 | 5.18 | -4 | 1777.3 | 509.8 | 282.9 | 14.5 | 1108.2 | 0.0 |
The sole hotspot function is LBM_performStreamCollideTRT from src/lbm.c, accounting for 99.35% of time. Its structure is: read from current-round Grid, heavy floating-point computation, write to next-round Grid, with conditional branches in between. Memory access is strided, making vectorization difficult; all generated instructions are SSE scalar. For such scalar-compute-intensive cases, -O3 -ffast-math typically helps by reordering computations and reusing intermediate results.
-O3 -march=native actually regresses performance. GCC 14 regresses worst (-19%); GCC 15/16 regress less but still underperform -O3. Assembly analysis suggests increased stack memory access instructions offset the FMA instruction count reduction benefit (see Godbolt). Note that FMA instructions are counted twice in the FP scalar column but only once in total instruction count.
Overall, compiler flags have significant impact on SPEC FP 2026 Rate performance:
-march=native provides solid improvement for many benchmarks. AVX2 not only widens vectors compared to SSE but also adds many useful instructions that reduce instruction count, plus AVX-VNNI specifically benefits 772.marian_r;-ffast-math also helps notably, especially since SPEC FP 2026 Rate has substantial floating-point computation. Strictly following source code computation order is often slower than optimized ordering. However, -ffast-math may produce results not conforming to IEEE 754;-flto and -ljemalloc have minimal effect on most SPEC FP 2026 Rate benchmarks, though they slightly help 748.flightdm_r.Other common flags like -static and -fomit-frame-pointer haven't been extensively tested yet.
Only 731.astcenc_r and 737.gmsh_r have notably high MPKI in SPEC FP 2026 Rate; others peak at 767.nest_r's 0.87. 731.astcenc_r's high MPKI is entirely due to GCC 14's poor compilation. Switching to LLVM 22 immediately normalizes it. Hopefully GCC will address this.
This article provides in-depth analysis of SPEC CPU 2026 FP Rate workloads, for reference by compiler and processor designers. From a compiler perspective, combining the strengths of both GCC and LLVM can further improve performance. From a processor perspective, optimizing for program bottlenecks can further increase scores.
2026-05-22 08:00:00
本文同步发布到本人的知乎。
最近用 SPEC CPU 2026 跑了一些基准测试,打算结合测试结果做一些深入的负载特性分析。本篇主要是分析 SPEC INT 2026 Rate 的负载特性,SPEC FP 2026 Rate 的分析请看 FP Rate 篇。
本文测试环境:CPU 为 Intel i9-14900K P-Core @ 5.7 GHz,Linux 发行版为 Debian Trixie,编译器是 GCC 14.2.0,默认编译选项是 -O3。其实这颗 CPU 最快能 Boost 到 6.0 GHz,但时不时因为未知原因(防缩缸?)在单核负载下也 Boost 不上去,具体表现为每跑一段时间后 CPU 核心就会强制降频到 4.7 GHz。故退而求其次,选择在更容易稳定达到的 5.7 GHz 频率来跑。能稳定跑到 6.0 GHz 的只有那一个物理 P 核,其他 P 核也都能上 5.7 GHz,降频了换一个核心即可。6.0 GHz 下的性能可以参考之前的测试结果:INT 和 FP,基本上,从 5.7 GHz 到 6.0 GHz,性能可以按频率线性放缩。本文可能针对同一个负载给出多个不同的运行时间,这可能是因为多次运行导致的性能波动,也可能是因为部分数字包含了 perf record 的开销,不过误差都很小,可以放心对比。本文所用的脚本已开源到 jiegec/spec2026。
推荐阅读:Evaluating SPEC CPU2026 和 SPEC CPU2026: Characterization, Representativeness, and Cross-Suite Comparison
stockfish 是一个著名的国际象棋引擎,该基准测试包括如下三个负载:
# 1. 1to6_classical stockfish bench 1600 1 26 spec_ref_pos_1to6.fen depth classical # 2. 1to6_nnue stockfish bench 1600 1 26 spec_ref_pos_1to6.fen depth nnue # 3. 7to11_nnue stockfish bench 1600 1 26 spec_ref_pos_7to11.fen depth nnue 实测数据显示,三个负载耗费的时间分别是 47s、77s 和 72s,共计 196s。reftime 是 1260s,对应 6.4 分。开启 -march=native 后,1to6_classical 时间缩短 10% 到 43s,而 1to6_nnue 和 7to11_nnue 时间明显缩短到 32s 和 31s,总时间 105s,对应 12 分,分数提升显著。下面逐一分析这三个负载的性能特性。
通过 perf 观察性能瓶颈,以下列出 1to6_classical 的主要热点函数及其时间占比(后续各基准测试均采用相同表示方法):
Stockfish::Eval::evaluate(const Position& pos) 来自 src/evaluate.cpp: 19.16%,inline 了 Evaluation<NO_TRACE>(pos).value() 的调用,里面主要是对局面的评估,涉及比较多零散的访存和计算,没有特别集中的热点指令;Stockfish::TranspositionTable::probe(const Key key, bool& found) 来自 src/tt.cpp: 17.91%,主要的瓶颈来自于随机访存,在 first_entry(key) 当中有 &table[mul_hi64(key, clusterCount)].entry[0] 的代码,其中 mul_hi64 计算两个 64 位整数乘法结果的高 64 位,因此访存地址是根据参数计算得出;对于 mul_hi64,GCC 14 会忠实地按照源码把 64 位拆分成高低 32 位分别计算,而 LLVM 22 能够正确识别出这段代码的意图,并直接用 AMD64 的 mul 指令实现,这个功能在 PR #168396 中实现,mul_hi64 对应 PR 描述中的 Ladder;事实上,Stockfish 原本的代码里会用 __int128,此时 GCC 14 也能生成高效的代码,只可惜因为用到了 C 语法扩展,被 SPEC 禁用了(汇编对比见 Godbolt);Stockfish::MovePicker::next_move(bool skipQuiets) 来自 src/movepick.cpp: 10.36%,里面比较慢的是 partial_insertion_sort,找到插入位置后,还要把原来数组里靠后的元素往后挪,留出空间用于插入元素;Stockfish::search(Position& pos, Stack* ss, Value alpha, Value beta, Depth depth, bool cutNode) 来自 src/search.cpp: 9.49%,搜索逻辑主要在这里实现;__popcountdi2 来自 libgcc: 7.52%,被 Stockfish::Eval::evaluate(const Position& pos) 调用,用来判断局面上满足某种条件,内部实现就是位运算,有兴趣的读者可以阅读 Hacker's Delight 这本书。开了 -march=native 后,能观察到 __popcountdi2 被内联为 popcnt 指令。经过测试,开 -mpopcnt 后时间即从 47s 降低到 44s,接近 -march=native 的性能。可见仅开启 popcnt 指令集并消除 __popcountdi2 的函数调用开销,就能带来明显的性能提升。
-O3 编译选项下,1to6_classical 执行的指令数为 531.8B(instructions 性能计数器),其中 Load 指令有 135.7B 条(mem_inst_retired.all_loads 性能计数器),Store 有 59.7B 条(mem_inst_retired.all_stores 性能计数器),分支指令有 56.0B 条(branch-instructions 性能计数器),其中有 2622.8M 次错误预测(branch-misses 性能计数器)。可见,1to6_classical 的 MPKI 还是比较高的:2622.8M/531.8B*1000=4.93。即使是在 SPEC INT 2017 当中,这一数值也高于 531.deepsjeng_r 的 3.16 和 557.xz_r 的 3.49,低于 505.mcf_r 的 6.24 和 541.leela_r 的 7.71。
使用 perf record -e branch-misses:pp,观察到主要的分支错误预测来自于 Stockfish::MovePicker::next_move() 函数,贡献了 27.48% 的错误预测,主要是插入排序的部分,一是循环找到插入的位置,二是循环搬运数组内原有元素。其次是 Stockfish::Eval::evaluate() 函数,贡献了 17.42% 的错误预测。再其次是 Stockfish::search() 函数,贡献了 13.06% 的错误预测。
开 -O3 -mpopcnt 后,指令数减少到 453.9B,其中 Load 有 124.2B 条,Store 有 53.1B 条,分支指令有 46.1B 条,错误预测还是 2.6B 次,光是内联 __popcountdi2 的调用,便可减少 77.9B 条指令,约占原来的 15%。__popcountdi2 本身的实现包括 21 条指令,此外还有 __popcountdi2@plt 里的一次 jmp,和 call __popcountdi2@plt 本身和前后保存和恢复寄存器的开销。
后两个负载的引擎从 classical 变为了 nnue,涉及神经网络,因此它的计算模式会不太一样。通过 perf 观察到 1to6_nnue 的主要耗时函数:
Stockfish::Eval::NNUE:evaluate(const Position& pos, bool adjusted) 来自 src/nnue/evaluate_nnue.cpp:80.59%,主要耗时在 affine_transform_non_ssse3 的 sum += weights[offset + j] * input[j],即神经网络的推理过程,它的计算过程是,进行 int8_t 乘 uint8_t,再累加到 int32_t 类型的结果,默认编译选项下,只能用基础的 SSE 指令如 pmaddwd/paddd,而不能用 AVX;Stockfish::TranspositionTable::probe(const Key key, bool& found) 来自 src/tt.cpp: 仅 4.81%,瓶颈和前面分析的一样是随机访存。分析 Stockfish::Eval::NNUE:evaluate 的指令,可以看到,它为了实现上述逻辑,核心思路是采用 pmaddwd 指令,进行 4 次 16 位有符号的乘法计算,累加到 32 位的结果。但是,在这之前,需要先把输入的 8 位有符号 weights 和无符号 input 转换到 16 位有符号数。其中 8 位有符号 weights 转换比较简单,而 8 位无符号 input 的处理逻辑比较复杂。首先,它对 input 的每个元素加上 128,然后当成有符号数来看待,这相当于对每个元素减去了 128,把 uint8_t 映射到了 int8_t。这样,input 就可以用和 weights 相同的方法进行符号扩展。但是,这样会导致结果计算错误,为了纠正这个偏差,又减去了 128 倍的 weights 之和。汇编代码如下(Godbolt):
1: # 加载有符号 weights 的 16 个元素 movdqu (%rdx,%rcx,1),%xmm2 movdqa %xmm5,%xmm8 # 加载无符号 input 的 16 个元素 movdqa (%r12,%rcx,1),%xmm10 add $0x10,%rcx # 对 weights 进行符号扩展 pcmpgtb %xmm2,%xmm8 movdqa %xmm2,%xmm9 # 每个 input 元素加上 128,即减去 128 转为有符号 int8_t paddb %xmm6, %xmm10 # 符号扩展 weights punpckhbw %xmm8,%xmm2 punpcklbw %xmm8,%xmm9 movdqa %xmm2,%xmm11 movdqa %xmm9,%xmm8 # 计算 weights 之和乘以 128 pmaddwd %xmm3,%xmm11 pmaddwd %xmm7,%xmm8 paddd %xmm11,%xmm0 paddd %xmm8,%xmm0 paddd %xmm11,%xmm0 movdqa %xmm5,%xmm11 # 对 input 进行符号扩展 pcmpgtb %xmm10,%xmm11 paddd %xmm8,%xmm0 movdqa %xmm10,%xmm8 punpckhbw %xmm11,%xmm10 punpcklbw %xmm11,%xmm8 # 计算 weights * input pmaddwd %xmm10,%xmm2 pmaddwd %xmm8,%xmm9 # 结果累加 paddd %xmm2,%xmm0 paddd %xmm9,%xmm0 cmp $0x400,%rcx jne 1b 对于这种适合 SIMD 的代码,开启 -march=native 后通常会有明显的性能提升,实际测试也证明了这一点,开了 -march=native 后,时间从 77s 降低到 32s,Stockfish::Eval::NNUE::evaluate 时间占比降到 54.20%,此时主要的计算指令变为 AVX-VNNI 扩展的 vpdpbusd (Multiply and Add Unsigned and Signed Bytes) 指令,即针对字节(weights 数组元素是 int8_t 类型,input 数组元素是 uint8_t 类型)元素的整数乘加融合指令,和的类型是 int32_t。核心循环如下(Godbolt):
1: # 加载无符号 input vmovdpa (%r8,%rcx,1),%ymm0 # 加载有符号 weights 并计算 sum += weights[offset + j] * input[j] {vex} vpdpbusd (%rdx,%rcx,1),%ymm0,%ymm2 add $0x20,%rcx cmp $0x400,%rcx jne 1b 如果 CPU 支持 AVX512-VNNI,还能进一步扩展到 512 的位宽:vpdpbusd (%rdx,%rax), %zmm1, %zmm0。需要注意的是,单纯开 -mavx2 仅能把时间从 77s 减少到 50s,距离 -march=native 的 32s 还有明显的差距:即使开启了 AVX(Godbolt),由于没有开 AVX-VNNI,不能用 vpdpbusd 指令,还是需要先格式转换到 16 位,再用 32 位累加器的 16 位整数乘加指令。Stockfish 的 NNUE 这样的计算方式,就是奔着 vpdpbusd 这条指令去的。因此缺乏这类指令的 CPU,或者虽有指令但编译器未加利用,性能就会明显落后。
例如在 ARM64 下,对应的 USDOT (Dot product with unsigned and signed integers (vector)) 指令被包括在 i8mm 扩展当中,有这个扩展的话,-march=native 性能提升显著(Godbolt),例如 Apple M2;而如果没有这个扩展,开不开 -march=native 就没什么区别,例如 Apple M1,此时就要回退到类似 AMD64 那样,先扩展到 16 位,再求和(Godbolt)。RISC-V Vector 指令集扩展则有 vwmulsu.vv 指令可以使用,得到 16 位乘法结果之后,再用 vwadd.wv 指令累加到 32 位(Godbolt)。LoongArch 也有对应的 xvmulwev.h.b/xvmulwod.h.b 指令,得到 16 位乘法结果之后,用 xvhaddw.w.h 指令累加到 32 位(Godbolt),还可以进一步优化为用 xvmulwev.h.bu.b 指令,优化后的 transform 函数性能相比 GCC 16 快 37%。
除了是否开启对应指令集扩展以外,还观察到 GCC 15 在 1to6_nnue 上相比 GCC 14 有明显的性能提升(编译选项为 -O3),时间从 77s 降低到了 49s。观察生成的指令,虽然仍使用 SSE 指令,但指令序列更简洁(Godbolt):
# %xmm5 初始化为全零 1: # 加载有符号 weights 的 16 个元素 movdqu (%rdx,%rcx,1),%xmm4 movdqa %xmm5,%xmm8 # 加载无符号 input 的 16 个元素 movdqa (%r12,%rcx,1),%xmm2 add $0x10,%rcx # 将 weights 和零比较,非负得 0,负数得 0xFF pcmpgtb %xmm4,%xmm8 movdqa %xmm2,%xmm6 movdqa %xmm4,%xmm7 # 把 input 从 8 位无符号扩展到 16 位,保存到 %xmm2 和 %xmm6 punpckhbw %xmm5,%xmm2 punpcklbw %xmm5,%xmm6 # 结合前面的 pcmpgtb,把 weights 从 8 位有符号扩展到 16 位,保存到 %xmm4 和 %xmm7 punpckhbw %xmm8,%xmm4 punpcklbw %xmm8,%xmm7 # 每条 pmaddwd 指令进行 4 次 16-bit * 16-bit + 16-bit * 16-bit = 32-bit 的计算 # 两条 pmaddwd 共完成 8 次 16-bit 乘法和 8 次 32-bit 加法 pmaddwd %xmm4,%xmm2 pmaddwd %xmm7,%xmm6 # 每条 paddd 指令进行 4 次 32 bit 的累加 paddd %xmm2,%xmm0 paddd %xmm6,%xmm0 cmp $0x400,%rcx jne 1b 可见,即使没有专用的 vpdpbusd 指令,仅用 SSE 也仍有优化空间。GCC 15 通过 SSE 高效实现了有符号和无符号数的符号扩展,获得了介于 GCC 14 次优指令序列与专用 vpdpbusd 指令之间的性能。这在 SPEC CPU2026: Characterization, Representativeness, and Cross-Suite Comparison 论文中也有提及:For example, gcc-15 reduces the instruction count of 706.stockfish_r by up to 3x,不过这个数字是相比 GCC 13 的;相比 GCC 14 也有减少,不过没有那么明显,详情见论文中的 Figure 10 和 Figure 16,这里实测下来是从 GCC 14 的 1342B 条指令降低到 GCC 15 的 1015B。相比之下,LLVM 22 生成的 SSE(-O3,Godbolt)或 AVX(-O3 -march=alderlake,Godbolt)指令都没有 GCC 15 高效。
-O3 编译选项下,1to6_nnue 执行的指令数为 1342.1B,其中 Load 指令有 182.2B 条,Store 指令有 61.8B 条,128 位整数向量指令(如 SSE)有 229.1B 条(int_vec_retired.128bit 性能计数器),分支指令有 77.6B 条,其中有 1612.9M 次错误预测。它的 MPKI 只有 1612.9M/1342.1B*1000=1.20,主要瓶颈还是在上述的神经网络推理当中。
GCC 15 用 -O3 编译选项下,1to6_nnue 执行的指令数减少到 1015.3B,其中 Load 指令有 175.0B 条,Store 指令有 57.8B 条,128 位整数向量指令只有 97.0B 条,分支指令有 77.4B 条,优化效果明显。
GCC 14 用 -march=native 编译选项下,1to6_nnue 执行的指令数锐减到 446.8B,只剩下三分之一的指令数了,其中 Load 指令有 119.6B 条,Store 指令有 44.4B 条,分支指令有 48.7B 条,256 位的 AVX VNNI 指令有 13.2B 条(int_vec_retired.vnni_256 性能计数器),优化效果明显。
7to11_nnue 的行为与 1to6_nnue 类似,瓶颈也是在 Stockfish::Eval::NNUE:evaluate 函数上。开启 -march=native 后,时间从 72s 降到了 31s。GCC 15 的性能提升也和 1to6_nnue 类似,从 72s 降低到 46s。
-O3 编译选项下,7to11_nnue 执行的指令数为 1253.2B,其中 Load 指令有 176.1B 条,Store 指令有 61.6B 条,128 位整数向量指令有 212.5B 条,分支指令有 75.4B 条,其中有 1547.5M 次错误预测。它的 MPKI 只有 1547.5M/1253.2B*1000=1.23,主要瓶颈还是在神经网络推理当中。
GCC 15 用 -O3 编译选项下,7to11_nnue 执行的指令数减少到 955.3B,其中 Load 指令有 169.4B 条,Store 指令有 57.8B 条,128 位整数向量指令只有 92.3B 条,分支指令有 75.2B 条,优化效果明显。
GCC 14 用 -march=native 编译选项下,7to11_nnue 执行的指令数锐减到 425.9B,只剩下三分之一的指令数了,其中 Load 指令有 115.1B 条,Store 指令有 43.7B 条,分支指令有 47.1B 条,256 位的 AVX VNNI 指令有 12.0B 条,优化效果明显。
各负载在不同编译选项下的情况如下:
| 负载 | 编译器 + 选项 | 时间 (s) | 指令 (B) | Load (B) | Store (B) | 分支 (B) | 错误预测次数 (M) | MPKI | 128 位整数向量 (B) | 256 位 整数向量 (B) |
|---|---|---|---|---|---|---|---|---|---|---|
| 1. 1to6_classical | GCC 14 -O3
| 47 | 531.8 | 135.7 | 59.7 | 56.0 | 2622.8 | 4.93 | 0.13 | 0.00 |
| 1. 1to6_classical | GCC 14 -O3 -mpopcnt
| 44 | 453.9 | 124.2 | 53.1 | 46.1 | 2639.3 | 5.81 | 0.13 | 0.00 |
| 2. 1to6_nnue | GCC 14 -O3
| 77 | 1342.1 | 182.2 | 61.8 | 77.6 | 1612.9 | 1.20 | 229.1 | 0.00 |
| 2. 1to6_nnue | GCC 15 -O3
| 49 | 1015.3 | 175.0 | 57.8 | 77.4 | 1258.2 | 1.24 | 97.0 | 0.00 |
| 2. 1to6_nnue | GCC 14 -march=native
| 32 | 446.8 | 119.6 | 44.4 | 48.7 | 953.8 | 2.13 | 5.1 | 36.3 |
| 3. 7to11_nnue | GCC 14 -O3
| 72 | 1253.2 | 176.1 | 61.6 | 75.4 | 1547.5 | 1.23 | 212.5 | 0.00 |
| 3. 7to11_nnue | GCC 15 -O3
| 46 | 955.3 | 169.4 | 57.8 | 75.2 | 1224.7 | 1.28 | 92.3 | 0.00 |
| 3. 7to11_nnue | GCC 14 -march=native
| 31 | 425.9 | 115.1 | 43.7 | 47.1 | 922.9 | 2.17 | 4.6 | 35.0 |
1to6_classical 类似传统的棋类引擎,有比较复杂的分支和访存,所以它的 MPKI=4.93 比较类似 SPEC CPU 2017 的 531.deepsjeng_r(MPKI=3.16),属于比较高的一类。而 1to6_nnue 和 7to11_nnue 的主要瓶颈在于 i8 的矩阵运算,能否用上硬件的加速指令(这里是 AVX-VNNI)对性能影响很大,分支预测瓶颈就明显小了。整体平均下来的 MPKI 是 1.85,并不算高。
ntest 是黑白棋的引擎,该基准测试包括如下负载:
实测数据显示,运行这个负载耗费的时间是 140s。reftime 是 592s,对应 4.2 分。开启各项优化编译选项,-O3 -flto 相比 -O3 能带来 4% 的性能提升,进一步 -O3 -flto -march=native 相比 -O3 -flto 还能带来 10% 的性能提升。下面分析它的具体负载特性。黑白棋的规则很简单:只有在某个空位落子能翻转至少一个对方棋子时,才能下子,否则就要轮空。翻转的规则是,沿横、竖、斜八个方向检查,如果该方向上从新落子到另一颗己方棋子之间全是对方棋子,则这些对方棋子全部翻转。通过 perf 观察性能瓶颈,这几个函数耗费的时间占比较多:
flips(int sq, u64 mover, u64 enemy) 来自 src/flips.cpp:34.80%,最主要的开销,根据棋盘状态,经过一系列的访存和位运算,先通过 neighbors[sq]&enemy 判断是否有敌方邻居棋子(无则无法下子),再计算下子后会翻转哪些棋子,主要是一些数据依赖的访存,混合了一堆位运算;solveNParity(int alpha, int beta, u64 mover, u64 enemy, u64 parity, EndgameSearch* search, bool hasPassed) 来自 src/solve.cpp:14.21%,进行 alpha-beta 减枝的 minimax 算法(negamax 变种),遍历棋盘上的空位置,首先找到那些满足 good parity 的位置(用 bitSet() 函数,汇编上是用 AMD64 的 bt 指令判断,因为黑白棋里,双方轮流下子,走最后一步的玩家获得一定的优势,所以先找那些能让自己走最后一步的位置),调用上述 flips() 看看是否会出现翻转,如果会出现翻转就尝试下子并进行递归,之后再遍历一次,这次遍历 bad parity 的位置,流程相同,主要的瓶颈在访存以及依赖访存结果的分支;__popcountdi2:9.65%,因为没开 -mpopcnt/-march=native,故需要它来代替 popcnt 指令,用来计算场面上各颜色棋子的数量等等;solveNFlipParity:8.95%,与 solveNParity 配合完成 minimax 算法;solve2:5.38%,minimax 算法的一部分,处理棋盘只有两个空位的最终局面,此时判断最终胜败是比较容易的,不需要再递归。这也是典型的棋类引擎模式,整个 minimax 算法占了 70%+ 的时间,为了搜索局面,有大量的位运算和访存,还有根据访存结果决定方向的分支。果不其然,执行 2688.3B 条指令,其中有 647.8B 条 Load 指令,255.2B 条 Store 指令,228.2B 条是分支指令,有 6.1B 次错误预测,MPKI 达到了 6.1B/2688B*1000=2.27。通过 perf record -e branch-misses:pp,看到 solveNParity 和 solveNFlipParity 一起贡献了 60.37% 的错误预测,主要就是上面说的,循环内对 good 还是 bad parity 的判断,以及链表插入时是否为 NULL 的判断,都是方向依赖数据的分支。
和 706.stockfish_r 类似,它也有不少的 popcnt 调用,那么打开 -mpopcnt 就会得到不错的性能提升:时间从 140s 降低到 126s,减少 11% 时间,指令数减少到 2286.9B,其中有 586.9B 条 Load 指令,206.7B 条 Store 指令,187.6B 条分支指令。而即使开 -march=native,性能也只是进一步降到 122s,只有少量的地方用到了 AVX2。
另一方面,LLVM 22 的性能在 707.ntest_r 上比 GCC 14 要快:同样是 -O3 的编译选项,运行时间从 GCC 14 的 140s 降低到 126s。深入研究汇编发现,LLVM 22 在没有开 -mpopcnt 的时候,它的行为是,直接把类似 libgcc 的 __popcountdi2 的代码内联到了程序当中,省去了 call libgcc 的开销,不过代价就是代码体积会增加,实际执行了 2416.9B 条指令,其中有 542.7B 条 Load 指令,202.9B 条 Store 指令,168.2B 条分支指令。类似地,706.stockfish_r 的 1to6_classical 也是 LLVM 22 比 GCC 14 快,从 47s 降低到 44s。
同时,GCC 15 相比 GCC 14 也有性能提升,运行时间从 140s 降低到了 130s。分析汇编,发现主要优化点在 flips(int sq, u64 mover, u64 enemy) 函数当中。性能区别有两点:
if (neighbors[sq]&enemy) 条件成立的情况下,需要执行复杂函数体,需要 callee-saved 寄存器时才会进行 push/pop,否则就直接 ret,因为检查条件的时候并没有用到 callee-saved 寄存器,避免了保存和恢复。GCC 15 编译的 707.ntest_r,实际执行 2429.3B 条指令,其中有 610.9B 的 Load 指令,206.2B 的 Store 指令,224.7B 的分支指令。707.ntest_r 在不同编译器和编译选项下的情况如下:
| 编译器 + 选项 | 时间 (s) | 指令 (B) | Load (B) | Store (B) | 分支 (B) |
|---|---|---|---|---|---|
GCC 14 -O3
| 140 | 2688.3 | 647.8 | 255.2 | 228.2 |
GCC 14 -O3 -flto
| 134 | 2656.3 | 623.4 | 251.3 | 200.9 |
GCC 14 -O3 -mpopcnt
| 126 | 2286.9 | 586.9 | 206.7 | 187.6 |
GCC 14 -O3 -march=native
| 122 | 2230.0 | 588.2 | 206.4 | 185.2 |
LLVM 22 -O3
| 126 | 2416.9 | 542.7 | 202.9 | 168.2 |
GCC 15 -O3
| 130 | 2429.3 | 610.9 | 206.2 | 224.7 |
结合 706.stockfish_r 和 707.ntest_r 可以看到,popcnt 还是比较常用的。但可惜 AMD64 的基线并不提供这条指令,因此开了 x86-64-v2 或以上的编译优化选项后,这类应用便可以通过一条 popcnt 指令免去 libgcc 的 __popcountdi2 调用开销,节省因额外 call 及 PLT 带来的性能损失。相比 AVX-VNNI,popcnt 的普及程度就要大得多了。
sqlite 就是大名鼎鼎的数据库了,不必多介绍。该基准测试包括三个负载:
# 1. main sqlite_r --memdb --size 2000 --testset main --verify # 2. cte sqlite_r --memdb --size 2000 --testset cte --verify # 3. fp sqlite_r --memdb --size 1000 --testset fp --verify 实测数据显示,三个负载耗费的时间分别是 69s、12s 和 25s,共计 106s。reftime 是 528s,对应 5.0 分。开启 -flto/-ljemalloc 对性能影响很小,-march=native 甚至带来了负优化。下面逐一分析这三个负载的性能特性。
通过 perf 观察性能瓶颈,这几个函数耗费的时间占比较多:
sqlite3BtreeMovetoUnpacked(BtCursor *pCur, UnpackedRecord *pIdxKey, i64 intKey, int biasRight, int *pRes) 来自 src/sqlite3.c:24.66%,在 Btree 上进行搜索,根据 key,查找对应的 entry,中间一个比较耗时的部分是逐字节扫描 pCell 指向的内存,此外还会经常调用 sqlite3GetVarint 获取 pCell 保存的变长 int 来实现二分搜索;sqlite3VdbeExec(Vdbe *p) 来自 src/sqlite3.c:22.36%,用 Loop+Switch 实现的执行字节码的虚拟机,执行编译好的 SQL 语句,VDBE 是 SQLite 的执行引擎,全称是 Virtual Database Engine,模拟过程会维护一个 pc,从 aOp 数组里扫描字节码,每个字节码是一个 struct VdbeOp 结构体,根据它的 opcode 字段进行一个大的 switch-case,一共有 176 种不同的 Op;gcc 把这个巨大的 switch-case 编译成了跳转表,也就是把各个 case 的地址保存到一个数组当中,根据 opcode 计算出对应 case 的地址,再 jmp *%rax 过去,执行完 case 的代码后,再跳回 switch 开头,读取下一个 opcode,再跳转;目前有一些解释器会直接用 C 的扩展,用 computed goto label 的写法来帮助编译器做这个优化,或者更进一步直接在每个 case 的最后跳转到下一个 opcode 对应的 case,拓展阅读: Android Runtime 解释器的实现探究;pcache1Fetch(sqlite3_pcache *p, unsigned int iKey, int createFlag) 来自 src/sqlite3.c:8.26%,对应一个用哈希表维护的 Page Cache,用于在内存里缓存硬盘上的数据,主要瓶颈在 pcache1FetchNoMutex 里的 pPage = pCache->apHash[iKey % pCache->nHash]; while( pPage && pPage->iKey!=iKey ){ pPage = pPage->pNext; },对哈希表的桶里的链表做一个扫描,随机访存比较多;sqlite3GetVarint(const unsigned char *p, u64 *v) 来自 src/sqlite3.c:3.70%,恢复内存中可变长度的整数,比如 [0,127] 范围的数字用一个字节保存,[128,16383] 范围的数字用两个字节保存,更大的数字则要更长,最多到九个字节,这种压缩表示还挺常见的,多数时候可以节省空间。都是一些比较经典的数据结构和算法的应用,Btree,Loop+Switch 的解释执行,加哈希表查询。一段 Vdbe 指令序列的例子如下:
sqlite> CREATE TABLE test(key INT, value INT); sqlite> EXPLAIN SELECT * FROM test WHERE key = 1; addr opcode p1 p2 p3 p4 p5 comment ---- ------------- ---- ---- ---- ------------- -- ------------- 0 Init 0 10 0 0 Start at 10 1 OpenRead 0 2 0 2 0 root=2 iDb=0; test 2 Rewind 0 9 0 0 3 Column 0 0 1 0 r[1]= cursor 0 column 0 4 Ne 2 8 1 BINARY-8 84 if r[1]!=r[2] goto 8 5 Column 0 0 3 0 r[3]= cursor 0 column 0 6 Column 0 1 4 0 r[4]= cursor 0 column 1 7 ResultRow 3 2 0 0 output=r[3..4] 8 Next 0 3 0 1 9 Halt 0 0 0 0 10 Transaction 0 0 1 0 1 usesStmtJournal=0 11 Integer 1 2 0 0 r[2]=1 12 Goto 0 1 0 0 能看到它的实现方式是,扫描 test 表的每一行,读取 key 列,如果不等于 1,则直接进入下一行;如果等于 1,则把所有列读出来,加入到结果当中。
这个负载的主要瓶颈在内存上。执行了 896.3B 条指令,其中 252.4B 是 Load 指令,105.1B 是 Store 指令,178.0B 是分支指令,错误预测了 1.5B 次,MPKI 是 1.5B/896.3B*1000=1.67。
通过 perf 观察性能瓶颈,这几个函数耗费的时间占比较多:
sqlite3VdbeExec(Vdbe *p) 来自 src/sqlite3.c:41.15%,主要时间花费在查询的执行,因为这个 cte 负载,其计算过程比较复杂,用 SQL 实现了数独(递归和非递归版本)、Mandelbrot,还测试了 EXCEPT SELECT 语法;sqlite3VdbeRecordCompareWithSkip(int nKey1, const void *pKey1, UnpackedRecord *pPKey2, int bSkip) 来自 src/sqlite3.c:7.37%,比较表里的两个行,会调用 sqlite3VdbeSerialGet 获取行内的数据,再根据数据类型进行对应的比较;sqlite3VdbeSerialGet(const unsigned char *buf, u32 serial_type, Mem *pMem) 来自 src/sqlite3.c:5.95%,反序列化,根据内存中保存的数据类型,解析对应的数据,比如整数或者浮点,它的 switch-case 也被 GCC 编译成了跳转表;vdbeSorterSort(SortSubtask *pTask, SorterList *pList) 来自 src/sqlite3.c:5.95%,实现归并排序,主要时间是在通过函数指针调用比较器函数,以及根据比较结果进行归并。瓶颈主要在解释器上,与 CPython 解释器的行为模式类似。执行了 306.0B 条指令,其中 82.8B 是 Load 指令,39.6B 是 Store 指令,62.6B 是分支指令,错误预测了 40.9M 次,MPKI 是 40.9M/306.0B*1000=0.13,处于很低的水平。
通过 perf 观察性能瓶颈,这几个函数耗费的时间占比较多:
sqlite3VdbeExec(Vdbe *p) 来自 src/sqlite3.c:30.66%,主要时间花费在查询的执行,因为这个 fp 负载,其计算过程引入了不少浮点运算;sqlite3AtoF(const char *z, double *pResult, int length, u8 enc) 来自 src/sqlite3.c:19.18%,实现从字符串到浮点数的转换,因为 SQL 内有很多浮点字面量;vdbeSorterSort(SortSubtask *pTask, SorterList *pList) 来自 src/sqlite3.c:10.44%,描述见上;sqlite3VdbeRecordCompareWithSkip(int nKey1, const void *pKey1, UnpackedRecord *pPKey2, int bSkip) 来自 src/sqlite3.c:6.76%,描述见上。瓶颈主要在解释器上,不过因为 SQL 语句的设计,有很多时间花在字符串转浮点数上。执行了 554.7B 条指令,其中 132.3B 是 Load 指令,61.3B 是 Store 指令,111.5B 是分支指令,错误预测了 392.6M 次,MPKI 是 392.6M/554.7B*1000=0.71。
各负载在不同编译选项下的情况如下:
| 负载 | 编译器 + 选项 | 时间 (s) | 指令 (B) | Load (B) | Store (B) | 分支 (B) | MPKI |
|---|---|---|---|---|---|---|---|
| 1. main | GCC 14 -O3
| 69 | 896.3 | 252.4 | 105.1 | 178.0 | 1.67 |
| 1. main | GCC 14 -O3 -march=native
| 73 | 905.3 | 273.7 | 109.9 | 177.2 | 1.62 |
| 2. cte | GCC 14 -O3
| 12 | 306.0 | 82.8 | 39.6 | 62.6 | 0.13 |
| 2. cte | GCC 14 -O3 -march=native
| 13 | 303.6 | 88.9 | 40.0 | 62.6 | 0.13 |
| 3. fp | GCC 14 -O3
| 25 | 554.7 | 132.3 | 61.3 | 111.5 | 0.71 |
| 3. fp | GCC 14 -O3 -march=native
| 27 | 555.8 | 142.7 | 62.6 | 111.6 | 0.69 |
通过上面的分析,可见 sqlite_r 确实是比较难优化的那一类,大量访存、计算和分支混合在一起,对内存子系统的负担比较重,难以向量化,开 -O3 -march=native 后运行时间从 106s 增加到 113s,产生了负优化。整体来看,执行了 1760B 条指令,其中有 353B 条是分支指令,MPKI 仅有 1.08,主要由 main 贡献。
SPEC INT 2017 就有的老面孔 520.omnetpp_r,不过运行的内容也和以往不同。520.omnetpp_r 做的是 10 Gbps 网络的模拟,而 710.omnetpp_r 有足足十项负载,负载的多样性有了明显的增强。十项负载的命令行参数如下:
omnetpp_r -f randomMesh.ini -c General omnetpp_r -f queuenet.ini -c OneFifo omnetpp_r -f queuenet.ini -c TandemFifos omnetpp_r -f queuenet.ini -c SmallCQN omnetpp_r -f queuenet.ini -c Ring omnetpp_r -f queuenet.ini -c Terminal omnetpp_r -f queuenet.ini -c CallCenter omnetpp_r -f queuenet.ini -c ForkJoin omnetpp_r -f queuenet.ini -c ResourceAllocation omnetpp_r -f queuenet.ini -c AllocDealloc 实测数据显示,十个负载耗费的时间分别是 24.6s、7.8s、3.8s、4.6s、9.1s、3.7s、2.6s、9.4s、6.6s 和 14.0s,共计 86.2s。reftime 是 486s,对应 5.6 分。
首先分析第一个负载的热点函数:
omnetpp::cTopology::calculateUnweightedSingleShortestPathsTo(Node *_target) 来自 src/simulator/sim/ctopology.c:16.22%,实现了经典的单源最短路算法,且由于每条边的权重都是一,实际上就是 BFS,主要瓶颈来自于随机访存和计算距离的双精度浮点运算;__do_dyncast 和 __dynamic_cast 来自 libstdc++.so:4.73%+3.24%+2.22%+0.81%=11.0%,代码中有一些 dynamic_cast 的使用,如 Routing::handleMessage;Routing::handleMessage(cMessage *msg) 来自 src/model/Routing.cc:7.10%,模拟路由表的功能,主要逻辑是内联了一个 std::map<int, int> 的 find 操作(Godbolt),在一个红黑树上进行查询,读取结点,比较 key,走左子树或右子树继续查询;cEvent::shouldPrecede(const cEvent *other) 来自 src/simulator/sim/cevent.cc:4.64%,一个 cEvent 结构体的多关键字比较函数。整体来看,它的瓶颈分散在比较多的地方。执行了 306.4B 条指令,其中有 98.7B 条 Load 指令,50.2B 条 Store 指令,62.1B 条分支指令,错误预测 661.2M 次,MPKI 为 661.2M/306.4B*1000=2.16。开 -O3 -flto 后,指令数减少到 284.6B,其中有 91.3B 条 Load 指令,45.4B 条 Store 指令,55.7B 条分支指令。进一步开 -O3 -flto -ljemalloc,指令数进一步减少到 279.8B,其中有 90.3B 条 Load 指令,44.4B 条 Store 指令,54.3B 条分支指令。
randomMesh 在不同编译选项下的情况如下:
| 编译器 + 选项 | 指令 (B) | Load (B) | Store (B) | 分支 (B) |
|---|---|---|---|---|
GCC 14 -O3
| 306.4 | 98.7 | 50.2 | 62.1 |
GCC 14 -O3 -flto
| 284.6 | 91.3 | 45.4 | 55.7 |
GCC 14 -O3 -flto -ljemalloc
| 279.8 | 90.3 | 44.4 | 54.3 |
用 perf 观察,其余 9 个 queuenet 负载的瓶颈主要集中在这些函数:
__strcmp_avx2)__do_dyncast 和 __dynamic_cast)__printf_buffer)还有些 omnetpp 自己的函数(如 omnetpp::common::StringPool::obtain(const char *s),主要是对 std::unordered_map<const char *,int,str_hash, str_eq> pool 进行查询和修改操作),散落各处,每个函数都只占用不到 5% 的时间。对于这么大比例使用 libc/libstdc++ 中函数的情况,标准库和内存分配器的实现就很重要了。
基于以上分析,尝试了不同的编译选项,结果如下:
-O3 -ljemalloc 后,十个负载的性能都有了一定的提升,总时间从 86.2s 降低到 80.6s,分数从 5.6 分提升到 6.0 分。-O3 -flto 也能带来不错的提升,总时间从 86.2s 降低到 76.1s,分数从 5.6 分提升到 6.4 分。-O3 -flto -ljemalloc,则总时间从 86.2s 降低到 69.7s,分数从 5.6 分提升到 7.0 分。类似现象在 SPEC INT 2017 中就曾出现,-O3 -flto 比 -O3 快 3%,-O3 -flto -ljemalloc 比 -O3 -flto 快 20%。
-O3 下,执行的指令数是 1447B,其中 291B 是分支指令,MPKI 是 0.78。虽然 randomMesh 因为图计算,MPKI 比较高,但整体的 MPKI 被其余负载拉低了。相比之下,SPEC INT 2017 Rate 的 520.omnetpp_r 的 MPKI 足足有 4.33。虽然还是同一个框架,但是负载行为还是出现了明显的变化。
前面才提到过解释器,这就到 CPython 了。该基准测试包含三个负载:
# 1. resnet cpython_r -I -B coreml_pb.py -i 2 -a -m Resnet50Headless.mlmodel -d 10 # 2. mobilenet cpython_r -I -B coreml_pb.py -i 5 -a -c -m MobileNetV2.mlmodel -d 20 # 3. dna cpython_r -I -B dna_bench.py 600000 三个负载的运行时间分别为 31s、20s 和 20s,总时间 71s,reftime 是 479s,对应 6.7 分。开启 -O3 -flto 后,三个负载的运行时间分别为 29s、19s 和 18s,总时间 66s,对应 7.3 分。-O3 -ljemalloc 影响很小,-O3 -march=native 有负优化。下面具体分析三个负载的负载特性。
还是用 perf,统计出热点函数:
_PyEval_EvalFrameDefault(PyThreadState *tstate, _PyInterpreterFrame *frame, int throwflag) 来自 src/cpython/Python/ceval.c:24.09%,解释器中的 Loop + Switch 核心代码,对 Python 字节码进行解释执行,主要的瓶颈也是跳转表,根据 opcode 计算 case 地址然后 jmp *%rax;PyUnicode_FromFormatV(const char *format, va_list vargs) 来自 src/cpython/Objects/unicodeobject.c,4.51%,把结果写到 Python 字符串的 sprintf 版本,主要瓶颈是格式化字符串的解析,找 % 的位置;_PyObject_Free(void *ctx, void *p) 来自 src/cpython/Objects/obmalloc.c:3.48%,释放 PyObject,Python 有一个自己的针对 PyObject 的内存分配器,而不是直接使用 malloc/free;_PyObject_Malloc(void *ctx, size_t nbytes) 来自 src/cpython/Objects/obmalloc.c:3.15%,分配 PyObject。剩下就比较零散了,主要还是围绕着解释器的循环。执行了 651.6B 条指令,其中有 180.4B 是 Load 指令,104.1B 是 Store 指令,136.6B 是分支指令,错误预测仅 7.9M 次,MPKI 等于 7.9M/651.6B*1000=0.01,可以忽略不计。开启 -O3 -flto 后,热点函数不变,指令数降低为 618.0B,其中 Load 有 176.6B,Store 有 93.9B,分支有 128.6B,错误预测 48.6M 次。
统计出热点函数,发现前四依然是上面四个,且时间占比差不多。可能是因为,resnet 和 mobilenet 负载用的是同一个 .py 源码,只是用的模型不同。执行了 438.9B 条指令,其中有 121.4B 是 Load 指令,70.5B 是 Store 指令,91.6B 是分支指令,错误预测 9.1M 次,MPKI 等于 9.1M/438.9B*1000=0.02,可以忽略不计。开启 -O3 -flto 后,热点函数不变,指令数降低为 416.4B,其中 Load 指令有 119.0B,Store 指令有 63.8B,分支有 86.2B,错误预测 35.0M 次。
统计热点函数:
_PyEval_EvalFrameDefault(PyThreadState *tstate, _PyInterpreterFrame *frame, int throwflag) 来自 src/cpython/Python/ceval.c:36.75%,描述见上;_PyObject_Free(void *ctx, void *p) 来自 src/cpython/Objects/obmalloc.c:5.31%,描述见上;PyUnicode_Contains(PyObject *str, PyObject *substr) 来自 src/cpython/Objects/unicodeobject.c,4.59%,Python 字符串的 contains 操作,对应 data/all/input/knucleotide.py 代码中的 chat in "GATC" 判断;_PyObject_Malloc(void *ctx, size_t nbytes) 来自 src/cpython/Objects/obmalloc.c:3.52%,描述见上。主要热点还是解释执行,不过因为字符串的 contains 调用次数较多,所以 PyUnicode_Contains 时间占比有所上升。执行了 394.9B 条指令,其中有 113.3B 是 Load 指令,62.1B 是 Store 指令,77.1B 是分支指令,错误预测 228.1M 次,MPKI 等于 228M/394B*1000=0.58,也还是很低。开启 -O3 -flto 后,热点函数不变,指令数降低为 379.3B,其中 Load 有 113.4B,Store 有 58.5B,分支有 71.6B,错误预测 223.8M 次。
各负载在不同编译选项下的情况如下:
| 负载 | 编译器 + 选项 | 时间 (s) | 指令 (B) | Load (B) | Store (B) | 分支 (B) | 错误预测 (M) |
|---|---|---|---|---|---|---|---|
| 1. resnet | GCC 14 -O3
| 31 | 651.6 | 180.4 | 104.1 | 136.6 | 7.9 |
| 1. resnet | GCC 14 -O3 -flto
| 29 | 618.0 | 176.6 | 93.9 | 128.6 | 48.6 |
| 2. mobilenet | GCC 14 -O3
| 20 | 438.9 | 121.4 | 70.5 | 91.6 | 9.1 |
| 2. mobilenet | GCC 14 -O3 -flto
| 19 | 416.4 | 119.0 | 63.8 | 86.2 | 35.0 |
| 3. dna | GCC 14 -O3
| 20 | 394.9 | 113.3 | 62.1 | 77.1 | 228.1 |
| 3. dna | GCC 14 -O3 -flto
| 18 | 379.3 | 113.4 | 58.5 | 71.6 | 223.8 |
714.cpython_r 就是一个典型的基于字节码的解释器,在一个 Loop + Switch 结构当中完成解释执行。整体 MPKI 很低,只有 0.17,即使开了 -O3 -flto,虽然预测错误多了,总指令数少了,MPKI 会变大,但绝对数字也还是很小,只有 0.23。
SPEC INT 2017 中的 502.gcc_r 便已存在,当时基于 GCC 4.5.0,针对 gcc-pp.c、gcc-smaller.c 和 ref32.c 进行五次编译,这次 721.gcc_r 对着三个同名文件(其中 gcc-pp.c 内容更新了,其余两个不变)分别进行一次编译,基于 GCC 11.2.0 版本,命令行参数如下,相比 502.gcc_r 有所简化:
# 1. gcc-pp cc1_r gcc-pp.c -O2 -fpic -o gcc-pp.c.opts-O2_-fpic.s # 2. gcc-smaller cc1_r gcc-smaller.c -O3 -fipa-pta -o gcc-smaller.c.opts-O3_-fipa-pta.s # 3. ref32 cc1_r ref32.c -O3 -finline-limit=12000 -fno-tree-vrp -o ref32.c.opts-O3_-finline-limit_12000_-fno-tree-vrp.s -O3 运行时间分别为 44s、21s 和 51s,总时间 116s,reftime 是 686s,对应 5.9 分。开了 -O3 -flto 后,时间略微降低到 115s,开 -O3 -flto -ljemalloc 后时间进一步降低到 111s,主要针对的是占用时间约 2% 的 malloc/free。开 -march=native 对性能几乎没有影响。
与 502.gcc_r 的行为类似(见 The Alberta Workloads for the SPEC CPU® 2017 Benchmark Suite 的分析),721.gcc_r 的时间分布在大量函数,除了 ref32 花费了 10.76% 的时间在 dominated_by_p、5.92% 的时间在 bitmap_set_bit 以外,其他函数的占用时间基本都在 3% 以下,没有一个特别明显的热点函数。
其中 bitmap_set_bit(bitmap head, int bit) 函数来自 src/gcc/bitmap.cc,通过位运算,在 bitmap 里把一个 bit 设为一,比较特别的是,这个 bitmap 可以有二叉树(splay tree)和链表两种保存格式。从 perf record -e branch-misses:pp 来看,这个函数主要是在设置 bit 的时候出现了一些分支预测的错误:它首先读取 bitmap 原来的数值,判断该 bit 是否已经设置,只有之前没设置的情况下,才会更新 bitmap。这样的好处是,可以节省一些 Store 指令,但也带来了一些分支的错误预测。此外就是链表的插入逻辑,需要判断指针是否为空。
另外,dominated_by_p(enum cdi_direction dir, const_basic_block bb1, const_basic_block bb2) 函数来自 src/gcc/dominance.cc,做的是基本块的 dominance 查询,A dom B 代表从函数入口到 B 一定会经过 A,这是编译器中很常见的一个查询,由于查询次数很多,会预先通过两遍 dfs(一遍从上往下,一遍从下往上,上对应入口,下对应出口)找到基本块的拓扑顺序,然后根据拓扑排序的结果来判断是否有 A dom B 的关系:DFS_Number_In(A) <= DFS_Number_In(B) && DFS_Number_Out(A) >= DFS_Number_Out(B),也就是从上往下遍历(In)的时候,先到达 A,然后从下往上遍历(Out)的时候,先到达 B。其实这个函数并不复杂,而且 DFS 已经提前算好了,这里只需要读取计算好的结果,但是因为它把两次比较做成了一次 cmp+jl 和一次 cmp+setle,导致容易出现分支预测错误。从逻辑上来说,这里可以改成完成两次比较,再对结果取 AND,但由于代码里是 && 有短路的性质,理论上第一个条件成立了,就不该进行第二个条件,更何况第二个条件里还涉及两次访存。这种实现确实可能省下一些访存,但分支预测也变难了。如果改写代码,先进行两次比较,再进行 && 操作,就没有分支指令了,不过访存次数也确实变多了:Godbolt。
三次运行的性能计数器如下:
2.2B/470.2B*1000=4.68
0.91B/243.4B*1000=3.74
0.61B/403.7B*1000=1.51
各负载的情况如下:
| 负载 | 编译器 + 选项 | 时间 (s) | 指令 (B) | Load (B) | Store (B) | 分支 (B) | 错误预测 (B) | MPKI |
|---|---|---|---|---|---|---|---|---|
| 1. gcc-pp | GCC 14 -O3
| 44 | 470.2 | 125.6 | 58.8 | 99.9 | 2.2 | 4.68 |
| 1. gcc-pp | GCC 14 -O3 -ljemalloc
| 42 | 467.2 | 125.2 | 58.7 | 98.5 | 2.2 | 4.71 |
| 2. gcc-smaller | GCC 14 -O3
| 21 | 243.2 | 65.0 | 30.3 | 51.8 | 0.91 | 3.74 |
| 2. gcc-smaller | GCC 14 -O3 -ljemalloc
| 21 | 242.1 | 64.7 | 30.2 | 51.2 | 0.90 | 3.72 |
| 3. ref32 | GCC 14 -O3
| 51 | 403.8 | 118.9 | 45.8 | 86.1 | 0.61 | 1.51 |
| 3. ref32 | GCC 14 -O3 -ljemalloc
| 49 | 405.2 | 119.4 | 46.2 | 85.8 | 0.61 | 1.51 |
整体指令数是 1120B,其中有 238B 条分支指令,MPKI 等于 3.37,在 SPEC INT 2026 中属于比较高的了。作为对比,SPEC INT 2017 Rate 中 502.gcc_r 的 MPKI 是 3.13,两者差异不大。
意料之中的是,用 GCC 14 编译的 721.gcc_r,运行得比用 LLVM 22 编译的 721.gcc_r 更快。
随着 LLVM 的发展,SPEC CPU 2026 终于是把 LLVM 也加入了进来。和 721.gcc_r 类似,也是跑 LLVM 的优化器,只不过输入直接就是 .bc 中间代码文件,而不是 C 代码。它包括两个负载:
# 1. transformsplus llvm-opt_r transformsplus.bc -S -O3 -mcpu=pwr9 # 2. codegen llvm-opt_r codegen.bc -S -O3 -mcpu=pwr9 -O3 运行时间分别为 62s 和 53s,总时间 115s,reftime 是 507s,对应 4.4 分。开 -O3 -flto 性能反而变差,不过开 -O3 -ljemalloc 有明显性能提升,运行时间降低为 59s 和 47s,总时间 106s,分数提高到 4.8 分。开 -march=native 对性能几乎没有影响。
有意思的是,用 GCC 14 编译的 723.llvm_r 比用 LLVM 22 编译的运行更快,不过优势并不大。下面针对这两个负载进行具体的分析。
使用 perf 观察热点函数:
llvm::InstCombinerImpl::foldIntegerTypedPHI(llvm::PHINode& PN) 来自 src/lib/Transforms/InstCombine/InstCombinePHI.cpp: 4.06%,对 IR 中的 PHI 结点进行处理,这个函数还挺复杂的,主要瓶颈在内层循环,遍历 use 链表,有比较多的随机访存和通过分支来判断 LLVM 自制 RTTI 的类型;_int_malloc/cfree/malloc:2.38%+0.89%+0.82%=4.09%,大量的内存分配和释放,因此 -ljemalloc 能带来不错的性能提升;llvm::DenseMapBase::FindAndConstruct(): 1.69%,LLVM 自己用数组实现的哈希表,主要瓶颈在读取哈希桶内的 entry 并比较 key,随机访存比较慢,近期 LLVM 也在做相关的优化。其他有很多小的函数,占时间比例不高,和 721.gcc_r 类似,也是时间分散得比较开。执行指令数为 572.8B,其中 Load 指令有 137.7B,Store 指令有 78.6B,分支指令有 118.7B,错误预测有 3.5B 次,MPKI 等于 3.5B/572.8B*1000=6.11,挺高的。
从 perf record -e branch-misses:pp 来看,错误预测挺分散在很多个函数,每个函数比例也不高。从 Top down 来看,有 40% 都在 Frontend Bound,有 19.2% 在 Bad Speculation。更进一步分析,发现它的 L1 ICache 缺失次数为 12.6B(L1-icache-load-misses 性能计数器),对应的 L1IC MPKI 足足有 12.6B/572.8B*1000=22.0,可见主要问题是 723.llvm_r 的代码量太大了,L1IC 存不下,BTB 也够呛。
使用 perf 观察热点函数:
llvm::InstCombinerImpl::foldIntegerTypedPHI(llvm::PHINode& PN) 来自 src/lib/Transforms/InstCombine/InstCombinePHI.cpp: 20.85%,描述见上;_int_malloc/cfree/malloc:1.91%+0.72%+0.65%=3.28%,描述见上;llvm::DenseMapBase::FindAndConstruct(): 1.29%,描述见上。整体的情况和 transformsplus 类似,只不过 foldIntegerTypedPHI 时间占比更高,其他还是有很多函数耗费很短的时间,分散得比较开。执行指令数为 415.9B,其中 Load 指令有 100.4B,Store 指令有 57.5B,分支指令有 86.0B,错误预测有 2.4B 次,MPKI 等于 2.4B/415.9B*1000=5.77,依然很高。
各负载的情况如下:
| 负载 | 编译器 + 选项 | 时间 (s) | 指令 (B) | Load (B) | Store (B) | 分支 (B) | 错误预测 (B) | MPKI |
|---|---|---|---|---|---|---|---|---|
| 1. transformsplus | GCC 14 -O3
| 62 | 572.8 | 137.7 | 78.6 | 118.7 | 3.5 | 6.11 |
| 1. transformsplus | GCC 14 -O3 -ljemalloc
| 59 | 563.2 | 135.7 | 77.2 | 115.2 | 3.3 | 5.86 |
| 2. codegen | GCC 14 -O3
| 53 | 415.9 | 100.4 | 57.5 | 86.0 | 2.4 | 5.77 |
| 2. codegen | GCC 14 -O3 -ljemalloc
| 47 | 411.0 | 99.3 | 56.6 | 84.1 | 2.3 | 5.60 |
LLVM 和 GCC 同为编译器领域的双子星,在负载特性上也有相似之处:有很多的内存分配和释放,受益于 -ljemalloc;时间分布在大量小函数当中,热点不明显;MPKI 较高,尤其是 723.llvm_r 直接一跃成为 SPEC INT 2026 Rate 中 MPKI 最高的一个基准测试,可能是因为它有大量数据依赖的分支。723.llvm_r 整体的指令数有 991B,其中有 205B 是分支指令,MPKI 达到 5.98,即使放在 SPEC INT 2017 Rate 里,也能紧跟在 505.mcf_r 和 541.leela_r 两位大哥身后,成为 MPKI 第三高的项目。
cppcheck 是一个 cpp 静态分析工具,输入 C++ 文件,提供代码的分析报告,汇报数组越界访问或变量未初始化等等问题。它会分析三个不同的代码,根据命名看,应该是从其他基准测试里找的。747.dealii(成为了 766.femflow_r 的一部分)和 770.7z 不在 SPEC CPU 2026 当中,应该没被选上,只有 738 diamond 以 838.diamond_s 保留了下来:
# 1. 738_diamond cppcheck_r --force 738-diamond-record.cpp --checkers-report=738_report.txt --enable=all --output-file=738_bogey.txt # 2. 747_dealii cppcheck_r --force 747-dealii-data_out_base.cc --checkers-report=747_report.txt --enable=all --output-file=747_bogey.txt # 3. 770_7z cppcheck_r --force 770-7z-SystemPage.cpp --checkers-report=770_report.txt --output-file=770_bogey.txt 三条指令的运行时间分别为 27s、22s 和 33s,共 82s,reftime 是 359s,对应 4.4 分。开 -O3 -flto 或 -O3 -march=native 仅能略微提升 1% 的性能,但 -O3 -ljemalloc 能显著提升性能,运行时间缩短到 24s、18s 和 29s,总时间 71s,对应 5.1 分。
下面对这三个负载进行深入的分析。
热点函数如下:
multiCompareImpl(const Token *tok, const char *haystack, nonneg int varid) 来自 src/lib/token.cpp:40.82%,字符串匹配函数,比如用 abc|def 去匹配一个 token,逐字符比较 token 和 haystack,匹配不上时跳到下一个 | 尝试 haystack 的下一个候选模式;Token::Match(const Token *tok, const char pattern[], nonneg int varid) 来自 src/lib/token.cpp:12.08%,也是类似的字符串匹配函数,语法有些不同,类似自研正则表达式子集,它会调用上面的 multiCompareImpl 函数来做部分匹配;ScopeInfo3::findScope(const std::string & scope) 来自 src/lib/tokenize.cpp:5.49%,循环,从当前作用域开始寻找对应的符号,如果没有,则检查更高一级的作用域,一般用于从变量名找到作用域里定义的符号,主要时间花在对 std::list 的遍历以及 std::string 的比较;Tokenizer::simplifyUsing():3.57%,把 using N::x; 变为 using x = N::x,里面就会用到上面说的 Token::Match,参数如 "using ::| %name% ::",来做一些模式的匹配并进行相应的简化;cfree/malloc/_int_malloc:0.47%+0.33%+0.45%=1.25%,内存分配相关。可以看到,主要瓶颈在字符串匹配上,它的实现就是一个循环,用指针去扫描字符串,没有做数据结构上的优化。执行了 399.9B 条指令,其中有 81.2B 条 Load 指令,35.5B 条 Store 指令,108.9B 条分支指令,错误预测 173.2M 次,MPKI 等于 173M/399.9B*1000=0.43,不算高。
热点函数类似:
multiCompareImpl(const Token *tok, const char *haystack, nonneg int varid) 来自 src/lib/token.cpp:27.42%,描述见上;Token::Match(const Token *tok, const char pattern[], nonneg int varid) 来自 src/lib/token.cpp:14.55%,描述见上;cfree/malloc/_int_malloc:2.14%+1.57%+0.53%=4.24%,内存分配的比例更高;Token::simpleMatch(const Token *tok, const char pattern[], size_t pattern_len) 来自 src/lib/token.cpp:3.88%,又一个字符串匹配函数,换了种格式,比如 "abc def" 代表匹配 abc 或 def,这次的瓶颈是 strncmp 和 memchr;TemplateSimplifier::addInstantiation(Token *token, const std::string &scope) 来自 src/lib/templatesimplifier.cpp:2.98%,在 token 级别上做一些代码简化的变换,主要的耗时在对 std::list 的遍历;isAliasOf(const Token* tok, const Token* expr, int* indirect, bool* inconclusive) 来自 src/lib/astutils.cpp:2.55%,判断两个变量是否 alias。依然有大量的字符串匹配,不太理解为何要设计多种语法,并分别实现多个字符串匹配函数。执行了 303.9B 条指令,其中有 67.3B 条 Load 指令,31.5B 条 Store 指令,82.5B 条分支指令,错误预测 298.9M 次,MPKI 等于 298.9M/303.9B*1000=0.98,也不算高。
热点如下:
multiCompareImpl(const Token *tok, const char *haystack, nonneg int varid) 来自 src/lib/token.cpp:32.25%,描述见上;Token::Match(const Token *tok, const char pattern[], nonneg int varid) 来自 src/lib/token.cpp:18.82%,描述见上;__memcmp_avx2_movbe:8.99%,被用于字符串匹配;std::map<std::string>::equal_range:7.34%,红黑树上的查询,外加字符串匹配;__strchr_avx2:7.34%,被用于字符串匹配;cfree/malloc/_int_malloc:0.37%+0.27%+0.17%=0.81%,这次内存分配的比例较低。依然是字符串匹配为主。执行了 505.2B 条指令,其中有 111.0B 条 Load 指令,43.8B 条 Store 指令,137.5B 条分支指令,错误预测 421.0M 次,MPKI 等于 421M/505.2B*1000=0.83,也不算高。
整体看下来,727.cppcheck_r 就是在不断地做字符串匹配。一个值得思考的问题是,为何不直接通过 tokenizer 将 token 转为数字,这样比较起来快得多。在 token 级别上做各种变换,就在不停地对 token 进行字符串比较,导致最后的性能瓶颈,不是在 cppcheck 自己写的字符串比较,就是在 libc 的字符串比较里了。
各负载的情况如下:
| 负载 | 编译器 + 选项 | 时间 (s) | 指令 (B) | Load (B) | Store (B) | 分支 (B) | 错误预测 (M) | MPKI |
|---|---|---|---|---|---|---|---|---|
| 1. 738_diamond | GCC 14 -O3
| 27 | 399.9 | 81.2 | 35.5 | 108.9 | 173.2 | 0.43 |
| 1. 738_diamond | GCC 14 -O3 -ljemalloc
| 24 | 395.0 | 80.2 | 34.7 | 107.5 | 171.8 | 0.43 |
| 2. 747_dealii | GCC 14 -O3
| 22 | 303.9 | 67.3 | 31.5 | 82.5 | 298.9 | 0.98 |
| 2. 747_dealii | GCC 14 -O3 -ljemalloc
| 18 | 291.0 | 64.5 | 29.2 | 79.0 | 287.3 | 0.99 |
| 3. 770_7z | GCC 14 -O3
| 33 | 505.2 | 111.0 | 43.8 | 137.5 | 421.0 | 0.83 |
| 3. 770_7z | GCC 14 -O3 -ljemalloc
| 29 | 501.5 | 110.1 | 43.2 | 136.6 | 409.8 | 0.82 |
整体执行了 1211B 指令,其中有 329B 分支指令,分支指令的比例足足有 27%,傲视 SPEC INT 2026 Rate 全场,这都是拜字符串匹配所赐,读一点就比较一点。但同时,MPKI 仅为 0.71,在 SPEC INT 2026 Rate 中倒数第三,仅高于 714.cpython_r 的 0.17 和 750.sealcrypto_r 的 0.14,说明大部分字符串匹配的结果都是很好预测的,比如比较到第一个字节就对不上了。
之前第一次看到 abc 还是在 yosys,它是一个 EDA 软件,和后面的 734.vpr_r 都是开源 EDA 工具里的重量级人物,分别实现了逻辑综合以及布局布线。该基准测试包括 6 个负载:
# 1. twoexact ./abc_r -F twoexact.in # 2. beem6 ./abc_r -F beem6-fraig.in # 3. mem ./abc_r -F mem_ctrl.in # 4. vga ./abc_r -F vga_lcd_miter.in # 5. mcml ./abc_r -F mcml.in # 6. des ./abc_r -F des_system90.in 六个负载运行时间都不长,分别是 6.3s、10.1s、13.5s、32.3s、13.6s 和 17.0s,总时间 92.8s,reftime 是 459s,对应 4.9 分。
开 -flto、-march=native 或 -ljemalloc 都没有什么提升,性能差距在 1% 以内,属于是油盐不进,各种优化都难以生效。下面进行具体热点分析。
主要的热点函数:
sat_solver_propagate(sat_solver* s) 来自 src/berkeley-abc/src/sat/bsat/satSolver.c:75.33%,应该是 SAT Solver 中的 Unit Propagation,寻找那些只剩下一个变量还没确定的语句,给它进行赋值,然后传播到其他语句;sat_solver_analyze(sat_solver* s, int h, veci* learnt) 来自 src/berkeley-abc/src/sat/bsat/satSolver:15.85%,应该是针对出现冲突的语句进行分析,属于 CDCL(Conflict Driven Clause Learning)的一部分;sat_solver_solve_internal(sat_solver* s) 来自 src/berkeley-abc/src/sat/bsat/satSolver.c:3.80%,是 SAT Solver 的入口函数。很少能见到这种瓶颈如此高度集中的情况了,不过确实,SAT Solver 大部分时间都在做 Unit Propagation,出现冲突了就做 CDCL。唤起了很久以前在《软件分析与验证》课上写 DPLL SAT Solver 的回忆,当然了,abc 的实现肯定比我那课程作业要更加复杂和高级。主要的瓶颈就是一堆访存以及依赖内存结果的分支,在 SAT 问题的解空间内进行搜索。
指令数 53.2B,其中 Load 指令 13.8B,Store 指令 3.2B,分支指令 8.4B,错误预测 606.2M,MPKI 等于 606.2M/53.2B*1000=11.39,非常的高,接近 SPEC INT 2017 的 541.leela_r 大帝。
通过 perf record -e branch-misses:pp,可以看到主要的分支预测错误来自 sat_solver_propagate 的几处变量取值的判断逻辑,都是依赖数据的分支,难以预测。
主要的热点函数:
Cec4_ManPackAddPatterns(Gia_Man_t * p, int iBit, Vec_Int_t * vLits) 来自 src/berkeley-abc/src/proof/cec/cecSatG2.c:54.65%,CEC 指的是 Combinational Equivalence Checking,该函数内层循环遍历 vLits 中的每个 Entry,通过位运算按一定条件更新 p->vSims;Cec4_ManGeneratePatterns_rec(Gia_Man_t * p, Gia_Obj_t * pObj, int Value, Vec_Int_t * vPat, Vec_Int_t * vVisit) 来自 src/berkeley-abc/src/proof/cec/cecSatG2.c:29.01%,根据 pObj 的类型进行分类讨论和递归。热点依然很集中,不过因为缺少领域知识,不太明白它在跑什么。运行 255.5B 条指令,其中 Load 有 57.2B,Store 有 7.3B,分支有 40.3B,错误预测 192.0M 次,MPKI 等于 192.0M/255.5B*1000=0.75,相比 SAT 来说低了很多。
热点函数依然是 sat solver 相关,相比 twoexact,sat_solver_canceluntil 时间占比高了一些,达到了 8.46%,不过整体的特性基本是一样的。运行 151.0B 条指令,其中 Load 指令有 43.4B,Store 指令有 15.4B,分支有 24.2B,错误预测 1213.7M,MPKI 等于 1213.7M/151.0B*1000=8.03,非常高。
热点函数依然是 sat solver,整体特性一致。运行 490.0B 条指令,Load 指令有 143.9B,Store 指令有 54.4B,分支有 76.9B,错误预测 2092.8M 次,MPKI 等于 2092.8M/490B*1000=4.27,还是很高。
热点函数终于有了新面孔:
Abc_ObjDeleteFanin(Abc_Obj_t * pObj, Abc_Obj_t * pFanin) 来自 src/berkeley-abc/src/base/abc/abcFanio.c:12.57%,逻辑很简单,就是调用 Vec_IntRemove 从数组里删除一个元素,遍历数组,找到匹配的元素,把后面的元素都往前挪,这个遍历匹配逻辑是主要的瓶颈,其次就是移动数据;Gia_ManSwiSimulate(Gia_Man_t * pAig, Gia_ParSwi_t * pPars) 来自 src/berkeley-abc/src/aig/gia/giaSwitch.c:8.87%,实现模拟过程,很大一部分时间花在一个自己实现的 popcount 函数 Gia_WordCountOnes,它没有被识别并转化为 popcnt 指令,而是用 SSE 向量指令做软件 popcount;Abc_AigAndLookup(Abc_Aig_t * pMan, Abc_Obj_t * p0, Abc_Obj_t * p1) 来自 src/berkeley-abc/src/base/abc/abcAig.c:7.03%,计算 p0 AND p1,先做特判(如 p0 == p1 时直接返回 p0),若都不命中则走哈希表链表遍历,中间有大量的多级指针访问:pObj->pNtk->vObjs->pArray;If_ObjPerformMappingAnd(If_Man_t * p, If_Obj_t * pObj, int Mode, int fPreprocess, int fFirst) 来自 src/map/if/ifMap.c:6.72%,依然有不少时间花在 popcount 的软件实现 If_WordCountOnes 上;Lpk_NodeCutsOneFilter(Lpk_Cut_t * pCuts, int nCuts, Lpk_Cut_t * pCutNew) 来自 src/berkeley-abc/src/opt/lpk/lpkCut.c:5.47%,瓶颈在数据依赖的比较分支上。运行 208.0B 条指令,其中 50.1B 条 Load 指令,15.4B 条 Store 指令,39.8B 条分支指令,错误预测 534.8M 次,MPKI 等于 534.8M/208.0B*1000=2.57,不低。
再次出现了新的热点函数:
__strcmp_avx2 来自 libc:22.04%,没想到瓶颈居然又出现在了 strcmp 上;Nm_ManTableLookupId(Nm_Man_t * p, int ObjId) 来自 src/misc/nm/nmTable.c:21.56%,遍历一个哈希表,哈希表的每个桶是个链表,遍历链表中的元素,寻找匹配,主要瓶颈也是这个访问链表和匹配;Nm_ManTableAdd(Nm_Man_t * p, Nm_Entry_t * pEntry) 来自 src/misc/nm/nmTable.c:12.19%,经典的哈希表插入算法,把新元素插入到对应桶的链表当中,主要瓶颈在判断哈希表中是否已经有相同 key 的元素;Nm_ManTableLookupName(Nm_Man_t * p, char * pName, int Type) 来自 src/misc/nm/nmTable.c:5.78%,同样是遍历哈希表查询,只不过这次用的是字符串匹配,解释了为啥 strcmp 调用次数那么多,其实是在找哈希表的字符串匹配;Gia_ManSwiSimulate 来自 src/aig/gia/giaSwitch.c:5.49%,描述见上;spec_qsort:3.98%,好久不见的熟悉面孔,在 SPEC INT 2017 年代,在 505.mcf_r 中有出色表现(指瓶颈在 qsort 上,且很大一部分开销来自于调用 comparator 函数指针,开 -flto 后因为把函数指针调用内联,性能直接提升 13%)。这次又回归到经典的哈希表数据结构,且混入了大量字符串匹配,最终瓶颈落在哈希表查询上,然后对链表的访问的空间局部性也很差。
运行 135.7B 条指令,其中有 29.7B 是 Load 指令,11.5B 是 Store 指令,23.3B 是分支指令,错误预测 372.9M 次,MPKI 等于 372.9M/135.7B*1000=2.75,依然不低,从 perf record -e branch-misses:pp 来看,错误预测主要出自 __strcmp_avx2 和 spec_qsort。
各负载的情况如下:
| 负载 | 编译器 + 选项 | 时间 (s) | 指令 (B) | Load (B) | Store (B) | 分支 (B) | 错误预测 (M) | MPKI |
|---|---|---|---|---|---|---|---|---|
| 1. twoexact | GCC 14 -O3
| 6.3 | 53.2 | 13.8 | 3.2 | 8.4 | 606.2 | 11.39 |
| 2. beem6 | GCC 14 -O3
| 10.1 | 255.5 | 57.2 | 7.3 | 40.3 | 192.0 | 0.75 |
| 3. mem | GCC 14 -O3
| 13.5 | 151.0 | 43.4 | 15.4 | 24.2 | 1213.7 | 8.03 |
| 4. vga | GCC 14 -O3
| 32.3 | 490.0 | 143.9 | 54.4 | 76.9 | 2092.8 | 4.27 |
| 5. mcml | GCC 14 -O3
| 13.6 | 208.0 | 50.1 | 15.4 | 39.8 | 534.8 | 2.57 |
| 6. des | GCC 14 -O3
| 17.0 | 135.7 | 29.7 | 11.5 | 23.3 | 372.9 | 2.75 |
综合以上六个负载,可以看到它触碰了 abc 不同地方的代码,所以热点不尽相同,有 SAT,有看不懂的一些 EDA 相关逻辑,还有带字符串匹配的哈希表查询,其中 SAT 的占比是最大的。由于 SAT 的存在,最终的 MPKI 足足有 3.87,在 SPEC INT 2026 Rate 当中仅次于 723.llvm_r,超过了 721.gcc_r 和 777.zstd_r。
接下来就到了 EDA 的下一步,逻辑综合后,进行布局(place)布线(route),这就是 vpr_r 干的活。该基准测试分为四个负载:
# 1. jpeg_place vpr stratixiv_arch.timing.xml JPEG_stratixiv_arch_timing.blif --RL_agent_placement off --place_algorithm bounding_box --max_criticality 0.0 --init_t 512 --alpha_t 0.75 --exit_t 1 --router_initial_timing all_critical --routing_failure_predictor off --route_chan_width 300 --max_router_iterations 20 --router_lookahead classic --initial_pres_fac 1.0 --pres_fac_mult 2.0 --astar_fac 1.5 --router_profiler_astar_fac 1.5 --seed 3 --sdc_file JPEG_stratixiv_arch_timing.sdc --pack_verbosity 0 --netlist_verbosity 0 --base_cost_type demand_only --inner_num 4 --read_initial_place_file ref_JPEG_stratixiv_arch_timing.init.place --place # 2. jpeg_route vpr stratixiv_arch.timing.xml JPEG_stratixiv_arch_timing.blif --place_algorithm bounding_box --place_static_notiming_move_prob 50 25 25 --max_criticality 0.0 --router_initial_timing all_critical --routing_failure_predictor off --route_chan_width 300 --max_router_iterations 20 --router_lookahead classic --initial_pres_fac 1.0 --pres_fac_mult 2.0 --astar_fac 1.5 --router_profiler_astar_fac 1.5 --seed 3 --sdc_file JPEG_stratixiv_arch_timing.sdc --pack_verbosity 0 --netlist_verbosity 0 --base_cost_type demand_only --place_file ref_JPEG_stratixiv_arch_timing.place --analysis --route # 3. smithwaterman_place vpr stratixiv_arch.timing.xml smithwaterman_stratixiv_arch_timing.blif --RL_agent_placement off --place_algorithm bounding_box --max_criticality 0.0 --init_t 512 --alpha_t 0.75 --exit_t 1 --router_initial_timing all_critical --routing_failure_predictor off --route_chan_width 300 --max_router_iterations 20 --router_lookahead classic --initial_pres_fac 1.0 --pres_fac_mult 2.0 --astar_fac 1.5 --router_profiler_astar_fac 1.5 --seed 3 --sdc_file smithwaterman_stratixiv_arch_timing.sdc --pack_verbosity 0 --netlist_verbosity 0 --base_cost_type demand_only --inner_num 1.8 --read_initial_place_file ref_smithwaterman_stratixiv_arch_timing.init.place --place # 4. smithwaterman_route vpr stratixiv_arch.timing.xml smithwaterman_stratixiv_arch_timing.blif --place_algorithm bounding_box --place_static_notiming_move_prob 50 25 25 --max_criticality 0.0 --router_initial_timing all_critical --routing_failure_predictor off --route_chan_width 300 --max_router_iterations 20 --router_lookahead classic --initial_pres_fac 1.0 --pres_fac_mult 2.0 --astar_fac 1.5 --router_profiler_astar_fac 1.5 --seed 3 --sdc_file smithwaterman_stratixiv_arch_timing.sdc --pack_verbosity 0 --netlist_verbosity 0 --base_cost_type demand_only --place_file ref_smithwaterman_stratixiv_arch_timing.place --analysis --route 这里涉及的 Stratix IV 是经典的 Altera FPGA,如今已经是时代的眼泪了。四个负载的运行时间分别是 21s、29s、18s 和 19s,总时间 87s,reftime 是 461s,对应 5.3 分。开 -O3 -flto 后,时间降低到 19s、25s、17s 和 17s,总时间 78s,对应 5.9 分,提升显著。如果进一步开到 -O3 -flto -ljemalloc,时间进一步降低到 17s、24s、15s 和 16s,总时间 72s,对应 6.4 分,相比 -O3 提升了 20%。开 -march=native 只能带来不到 1% 的提升。
下面进行具体分析。
因为这两个负载都是做的布局(place),所以就放在一起分析了。它们的热点函数是类似的:
get_non_updateable_bb(ClusterNetId net_id, t_bb* bb_coord_new) 来自 src/vtr-vpr/vpr/src/place/place.cpp:jpeg_place 占比 13.98%,smithwaterman_place 占比 18.26%,遍历 pin,根据它的 x 和 y 坐标,找到 bounding box,即 xmin/xmax/ymin/ymax,主要时间花在读取 x 和 y 上;try_swap(...) 来自 src/vtr-vpr/vpr/src/place/place.cpp:jpeg_place 占比 12.39%,smithwaterman_place 占比 11.46%,选一个 block 挪到空位置或与另一 block 交换,评估移动后的 cost,如果新的 cost 更优,就接受;physical_tile_type(ClusterBlockId blk) 来自 src/vtr-vpr/vpr/src/util/vpr_utils.cpp:jpeg_place 占比 7.59%,smithwaterman_place 占比 7.75%,看起来是一些间接索引访存,先读取 block_loc 里的坐标,再从 grid 读取对应坐标的 type,这个函数会在 get_non_updateable_bb 和 get_bb_from_scratch 等地方被频繁调用;get_bb_from_scratch(ClusterNetId net_id, t_bb* coords, t_bb* num_on_edges) 来自 src/vtr-vpr/vpr/src/place/place.cpp:jpeg_place 占比 6.73%,smithwaterman_place 占比 2.78%,和 get_non_updateable_bb 类似,也是求 bounding box;malloc/_int_malloc/cfree 来自 libc:jpeg_place 占比 1.62%+1.26%+1.06%=3.94%,smithwaterman_place 占比 1.76%+1.42%+1.11%=4.29%。开 -O3 -flto 后,能看到的是 physical_tile_type 被内联了进去,节省了频繁调用函数的开销。考虑到这个内存分配和释放的时间占比,-O3 -ljemalloc 提升性能并不意外。
-O3 下,jpeg_place 执行了 273.7B 条指令,其中 Load 有 84.5B 条,Store 有 26.9B 条,分支有 51.9B 条,错误预测 781.0M 次,MPKI 等于 781.0M/273.7B*1000=2.85,不低。smithwaterman_place 执行了 245.0B 条指令,其中 Load 有 76.4B 条,Store 有 24.7B 条,分支有 45.4B 条,错误预测 661.9M 次,MPKI 等于 661.9M/245.0B*1000=2.70。在 bounding box 计算 min/max 过程中,能看到一些 cmov 指令的使用,因此实际上已经少了一些容易预测错误的分支了。在一些没有 cmov 指令的 ISA 下,可能 MPKI 还会更高。
到了布线,热点函数出现了一些不同:
ConnectionRouter<BinaryHeap>::evaluate_timing_driven_node_costs(...) 来自 src/vtr-vpr/vpr/src/route/connection_router.cpp:jpeg_route 占比 9.35%,smithwaterman_route 占比 6.91%,计算 cost,有一些浮点计算;ConnectionRouter<BinaryHeap>::timing_driven_add_to_heap(...) 来自 src/vtr-vpr/vpr/src/route/connection_router.cpp:jpeg_route 占比 9.34%,smithwaterman_route 占比 6.82%,会调用 evaluate_timing_driven_node_costs 计算 cost,然后插入到 Binary Heap 当中;ConnectionRouter<BinaryHeap>::timing_driven_expand_neighbours(...) 来自 src/vtr-vpr/vpr/src/route/connection_router.cpp:jpeg_route 占比 8.14%,smithwaterman_route 占比 4.00%,搜索算法中的一步,遍历当前结点的邻居结点,若满足条件则调用 timing_driven_add_to_heap 入堆;ClassicLookahead::get_expected_delay_and_cong(...) 来自 src/vtr-vpr/vpr/src/route/router_lookahead.cpp:jpeg_route 占比 7.86%,smithwaterman_route 占比 5.14%,计算延迟和拥塞,也有不少浮点计算;BinaryHeap::get_heap_head() 来自 src/vtr-vpr/vpr/src/route/binary_heap.cpp:jpeg_route 占比 3.14%,smithwaterman_route 占比 1.64%,就是经典的最小二叉堆的实现,获取最小值,用的是浮点数做比较;malloc/_int_malloc/cfree 来自 libc:jpeg_route 占比 1.10%+1.02%+0.78%=2.90%,smithwaterman_route 占比 1.62%+1.49%+1.08%=4.19%。虽然不清楚具体算法,但看起来,就像是在做一些 cost 计算,然后通过 BinaryHeap 选择最小的 cost 去做一些扩展,有点类似搜索算法。
开 -O3 -flto 后,能看到的是 evaluate_timing_driven_node_costs 和 timing_driven_add_to_heap 被内联进 timing_driven_expand_neighbours,节省了频繁调用函数的开销,这个函数的时间占比提升到 jpeg_route 的 21.40% 和 smithwaterman_route 的 12.48%,类似的事情应该也发生在 get_expected_delay_and_cong 身上。考虑到这个内存分配和释放的时间占比,-O3 -ljemalloc 提升性能并不意外。
-O3 下,jpeg_route 执行了 424.1B 条指令,其中 Load 有 130.6B,Store 有 50.6B,分支有 79.0B 条,错误预测 1094.2M 次,MPKI 等于 1094.2M/424.1B*1000=2.58,不低。smithwaterman_route 执行了 305.8B 条指令,其中 Load 有 91.0B 条,Store 有 36.0B 条,分支有 59.4B 条,错误预测 609.3M 次,MPKI 等于 609.3M/305.8B*1000=1.99。
各负载的情况如下:
| 负载 | 编译器 + 选项 | 时间 (s) | 指令 (B) | Load (B) | Store (B) | 分支 (B) | 错误预测 (M) | MPKI |
|---|---|---|---|---|---|---|---|---|
| 1. jpeg_place | GCC 14 -O3
| 21 | 273.7 | 84.5 | 26.9 | 51.9 | 781.0 | 2.85 |
| 1. jpeg_place | GCC 14 -O3 -flto
| 19 | 247.0 | 69.2 | 22.2 | 47.8 | 774.2 | 3.13 |
| 1. jpeg_place | GCC 14 -O3 -ljemalloc
| 19 | 261.5 | 81.9 | 25.1 | 47.9 | 764.5 | 2.92 |
| 2. jpeg_route | GCC 14 -O3
| 29 | 424.1 | 130.6 | 50.6 | 79.0 | 1094.2 | 2.58 |
| 2. jpeg_route | GCC 14 -O3 -flto
| 26 | 356.6 | 103.2 | 33.5 | 66.3 | 1075.5 | 3.02 |
| 2. jpeg_route | GCC 14 -O3 -ljemalloc
| 28 | 411.5 | 127.9 | 48.8 | 74.9 | 1080.0 | 2.62 |
| 3. smithwaterman_place | GCC 14 -O3
| 18 | 245.0 | 76.4 | 24.7 | 45.4 | 661.9 | 2.70 |
| 3. smithwaterman_place | GCC 14 -O3 -flto
| 17 | 222.1 | 63.1 | 20.8 | 21.8 | 662.7 | 2.98 |
| 3. smithwaterman_place | GCC 14 -O3 -ljemalloc
| 17 | 232.9 | 73.8 | 23.0 | 41.4 | 648.7 | 2.78 |
| 4. smithwaterman_route | GCC 14 -O3
| 19 | 305.8 | 91.0 | 36.0 | 59.4 | 609.3 | 1.99 |
| 4. smithwaterman_route | GCC 14 -O3 -flto
| 17 | 264.3 | 72.9 | 25.5 | 51.5 | 590.9 | 2.24 |
| 4. smithwaterman_route | GCC 14 -O3 -ljemalloc
| 18 | 293.6 | 88.4 | 34.2 | 55.3 | 594.7 | 2.03 |
734.vpr_r 的负载分为两部分,place 和 route,其中 place 主要在做 bounding box 的计算,route 主要在做搜索和优化。开 -flto 和 -ljemalloc 后有明显的性能提升,主要是靠内联了热点函数以及更快的内存分配。整体指令数为 1254B,分支指令数 237B,MPKI 是 2.51,处于中游偏高的水平。
gem5 是大家很熟悉的模拟器了,在 GEM5 里跑 SPEC CPU 2017 养活了很多博士生,这下终于完成闭环,在 GEM5 里跑 SPEC INT 2026 的 GEM5,自己跑自己。当然,735.gem5_r 的 workload 就不是 SPEC CPU 2026 了,没有继续套娃,而是跑的 RISC-V Linux 内核,以及生成访存序列对内存子系统进行测试。这也是唯一一个看到函数名就知道函数来自哪个文件的项目了,实在太熟悉了。包括如下四个负载:
# 1. o3 gem5sim --stats-file=run_riscv_boot.py_o3_10_--max-ticks_10_000_000_000_stats.stats.txt run_riscv_boot.py o3 10 --max-ticks 10_000_000_000 # 2. timing gem5sim --stats-file=run_riscv_boot.py_timing_4_--max-ticks_20_000_000_000.stats.txt run_riscv_boot.py timing 4 --max-ticks 20_000_000_000 # 3. traffic_21 gem5sim --stats-file=synthetic_traffic.py_LinearGenerator_21.stats.txt synthetic_traffic.py LinearGenerator 21 # 4. traffic_74_ruby gem5sim --stats-file=synthetic_traffic.py_LinearGenerator_74_--ruby.stats.txt synthetic_traffic.py LinearGenerator 74 --ruby 运行时间分别为 16s、21s、21s 和 31s,总时间 89s,reftime 是 487s,对应 5.4 分。各种编译选项的优化效果:
-O3 -flto 后运行时间降为 15s、20s、20s 和 29s,共 84s,对应 5.8 分,相比 -O3 提升 6%。对四个负载都有加速效果。-O3 -flto -ljemalloc 后降为 14s、18s、16s 和 26s,共 74s,对应 6.6 分,相比 -O3 提升 20%。对四个负载都有比较显著的加速效果。-O3 -march=native -flto -ljemalloc 后 12s、18s、16s 和 26s,共 72s,对应 6.8 分,相比 -O3 提升 24%。仅对第一个负载有加速效果。看到这个性能提升的幅度,结合前面的经验,已经可以预估一下后面会见到的瓶颈大概是什么类型了。
第一个负载是用 O3 CPU 模拟 RISC-V Linux 内核启动,热点函数如下:
malloc/_int_malloc/cfree/_int_free_chunk/operator new 来自 libc/libstdc++:4.78%+3.46%+3.29%+1.35%+1.16%=13.29%,这个比例无敌了,不过确实,Gem5 有大量的动态内存分配,比如各种内存请求,都要 new 一个 Packet 出来;gem5::TimeBuffer<*>::advance() 来自 src/gem5/cpu/timebuf.hh:3.05%+2.43%+2.39%+2.28%+1.98%=12.13%,用于在各流水线级之间传递数据,维护一个滚动的时间窗口,主要的时间花在了 rep stos 或用 SSE 指令 movups 对内存进行初始化,还有调用构造/析构函数,涉及到一些引用计数的更新;gem5::o3::IEW::tick() 来自 src/gem5/cpu/o3/iew.cc:3.32%,IEW 代表 Issue Execute Writeback,后端各执行单元的时序在这里模拟,瓶颈主要是 rep stos 指令,用于初始化数据。其他就是很多零散的函数了,每个函数的耗时都不高。开启 -O3 -flto 后,热点函数变为:
std::_Function_handler<void (), gem5::o3::CPU::CPU(gem5::BaseO3CPUParams const&)::{lambda()#1}>::_M_invoke(std::_Any_data const&):20.80% 实际上是 tickEvent([this]{ tick(); }, "O3CPU tick", false, Event::CPU_Tick_Pri) 当中调用 tick() 的 lambda,就是整个 O3 CPU 各种组件的单步模拟被融合到了一个巨大的函数里,仔细看里面的热点指令,其实还是 gem5::TimeBuffer<*>::advance() 相关的比较多;gem5::o3::IEW::tick() 来自 src/gem5/cpu/o3/iew.cc:8.58%,描述见上;malloc/_int_malloc/cfree/_int_free_chunk/operator new 来自 libc/libstdc++:5.55%+3.88%+3.72%+1.45%+1.22%=15.83%,随着其余部分被优化,内存分配的瓶颈更加明显了。进一步开启 -O3 -flto -ljemalloc 后,内存分配时间减少,热点函数:
std::_Function_handler<void (), gem5::o3::CPU::CPU(gem5::BaseO3CPUParams const&)::{lambda()#1}>::_M_invoke(std::_Any_data const&):23.20%,描述见上;gem5::o3::IEW::tick() 来自 src/gem5/cpu/o3/iew.cc:9.19%,描述见上;gem5::o3::Commit::commit() 来自 src/gem5/cpu/o3/commit.cc:4.56%,模拟 CPU 的 Commit 阶段;malloc/_int_malloc/cfree/_int_free_chunk/operator new/operator delete 来自 libjemalloc:3.12%+1.02%+0.53%=4.67%,明显变少。开启 -O3 -march=native 带来的效果是,用 memset 调用取代了之前的 rep stos,进而可以用更加高效的 AVX2 版本的 memset 来进行初始化,优化了 gem5::TimeBuffer<*>::advance() 的性能。
-O3 下,执行 211.1B 条指令,其中有 69.9B 条 Load 指令,31.7B 条 Store 指令,43.2B 条分支指令,错误预测 175.5M 次,MPKI 等于 175.5M/211.1B*1000=0.83,比较低。
第二个负载则是把 O3 换成了 TimingSimpleCPU,相比 O3 模拟的复杂度低很多,此时主要的瓶颈挪到了 RISC-V 架构相关的代码、缓存模拟,以及内存分配上:
cfree/malloc/operator new 来自 libc:5.92%+4.56%+1.55%=12.03%,依然有很多内存分配的瓶颈;gem5::RiscvISA::Decoder::decode(ExtMachInst mach_inst, Addr addr) 来自 src/gem5/arch/riscv/decoder.cc:8.97%,实现 RISC-V 指令集的 Decode,有很大一部分实现是自动生成的,在 src/gem5/arch/riscv/generated/decode-method.cc.inc 文件里,这里为了加速 Decode,用了一个 decode_cache::InstMap<ExtMachInst>(实际上就是 std::map<ExtMachInst, StaticInstPtr>)来加速,因此大部分的时间其实是在用红黑树实现的缓存中寻找已经 Decode 过的指令编码;gem5::BaseTags::findBlock(Addr addr, bool is_secure) 来自 src/gem5/mem/cache/tags/base.cc:5.19%,用来实现组相连的 tag 比较,就是一个循环比较 tag 找匹配的算法,主要瓶颈就是 tag 比对;gem5::PMAChecker::check(const RequestPtr &req) 来自 src/gem5/arch/riscv/pma_checker.cc:4.86%,实现 RISC-V 的 PMA 检查,属于 MMU 的一部分,逻辑很简单,就是循环判断一下请求地址是否属于某个 Uncacheable 地址区间,如果是,就标记 STRICT_ORDER,避免重排;gem5::RiscvISA::ISA::readMiscReg(RegIndex idx) 来自 src/gem5/arch/riscv/isa.cc:3.34%,用于读取 RISC-V 的 CSR,GCC 这次是用若干 branch 来分别进入不同的 case 处理代码;gem5::BaseCache::access(PacketPtr pkt, CacheBlk *&blk, Cycles &lat, PacketList &writebacks) 来自 src/gem5/mem/cache/base.cc:2.84%,用于模拟缓存的访问;gem5::PMP::pmpCheck(const RequestPtr &req, BaseMMU::Mode mode, RiscvISA::PrivilegeMode pmode, ThreadContext *tc, Addr vaddr) 来自 src/gem5/arch/riscv/pmp.cc:2.66%,实现 RISC-V 的 PMP 检查,属于 MMU 的一部分,扫描 PMP 配置,逐个判断是否匹配。开 -O3 -flto 后,readMiscReg 被内联。开 -O3 -flto -ljemalloc 后,内存分配的开销降低到 4.48%+1.34%=5.82%。-march=native 影响比较小。
-O3 下,执行 333.9B 条指令,其中有 113.9B 条 Load 指令,57.8B 条 Store 指令,69.8B 条分支指令,错误预测 202.9M 次,MPKI 等于 202.9M/333.9B*1000=0.61,比较低。
热点函数:
cfree/malloc/operator new 来自 libc:6.01%+4.62%+1.44%+1.40%=13.47%,依然有很多内存分配的瓶颈;gem5::SnoopFilter::lookupRequest(const Packet* cpkt, const ResponsePort& cpu_side_port) 来自 src/gem5/mem/snoop_filter.c:5.93%,在总线上对 Snoop 请求进行 Filter,减少缓存一致性开销;它用一个 std::map 来维护状态,查询和更新耗费了不少时间,是主要的瓶颈;gem5::AddrRange::removeIntlvBits(Addr a) 来自 src/gem5/base/addr_range.hh:3.39%,针对地址的 interleaving,进行一系列位运算,把 interleaving 的那部分比特去掉,保留其他的,具体实现方法是,找到要去掉的比特的位置,从小到大进行排序,然后把要保留的比特分段插入到结果当中,主要的瓶颈是 src/gem5/base/bitfield.hh 的 ctz64() 函数,GCC 14 会忠实地生成循环,GCC 15 会生成 rep bsfq 指令,如果进一步给 GCC 15 开 -mbmi,会生成 tzcnt 指令,应该会变快一些(Godbolt);gem5::BaseTags::findBlock(Addr addr, bool is_secure) 来自 src/gem5/mem/cache/tags/base.cc:3.18%,描述见上。开启 -O3 -flto 后,热点函数中 removeIntlvBits 消失,时间转移到了 gem5::memory::DRAMInterface::decodePacket 和 gem5::memory::DRAMInterface::chooseNextFRFCFS。开 -O3 -flto -ljemalloc 后,内存分配的开销降低到 4.08%+1.39%=5.47%。-march=native 影响比较小。
-O3 下,执行 226.4B 条指令,其中有 65.5B 条 Load 指令,31.3B 条 Store 指令,50.8B 条分支指令,错误预测 749.3M 次,MPKI 等于 749.3M/226.4B*1000=3.31,明显变高。
相比 traffic_21,traffic_74_ruby 开启了 ruby(不是那个 ruby 编程语言),因此瓶颈来到了 gem5::ruby 相关:
cfree/malloc/operator new 来自 libc:4.43%+3.52%+1.29%+0.98%=10.22%,依然有很多内存分配的瓶颈;gem5::ruby::Cache_Controller::processNextState(Cache_TBE*& m_tbe_ptr, Cache_CacheEntry*& m_cache_entry_ptr, Addr addr) 来自 src/gem5/mem/ruby/protocol/Cache_Controller.cc:4.44%,维护缓存的状态机,还挺复杂的;gem5::ruby::NetDest::intersectionIsNotEmpty(const NetDest& other_netDest) 来自 src/gem5/mem/ruby/common/NetDest.cc:4.03%,做的是一些 std::bitset 的与操作,这也是主要的瓶颈;gem5::ruby::MessageBuffer::isReady(Tick current_time) 来自 src/gem5/mem/ruby/network/MessageBuffer.cc:3.94%,维护了消息队列,判断当前时间是否有 ready 的消息;gem5::ruby::Cache_Controller::getDirEntry(const Addr& param_addr) 来自 src/gem5/mem/ruby/protocol/Cache_Controller.cc:3.80%,根据地址找到 cache 对应的 entry,对 std::map 调用 operator []。开启 -O3 -flto 后,gem5::ruby::NetDest::intersectionIsNotEmpty 被内联到 gem5::ruby::WeightBased::route 函数里,成为占时间最多的函数,占 6.45%。开启 -O3 -flto -ljemalloc 后,内存分配开销降低到 3.01%+0.83%=3.84%。-march=native 影响比较小。
-O3 下,执行 391.5B 条指令,其中有 103.2B 条 Load 指令,54.4B 条 Store 指令,82.1B 条分支指令,错误预测 1246.0M 次,MPKI 等于 1246.0M/391.5B*1000=3.18,依然较高。
各负载的情况如下:
| 负载 | 编译器 + 选项 | 时间 (s) | 指令 (B) | Load (B) | Store (B) | 分支 (B) | 错误预测 (M) | MPKI |
|---|---|---|---|---|---|---|---|---|
| 1. o3 | GCC 14 -O3
| 16 | 211.1 | 69.9 | 31.7 | 43.2 | 175.5 | 0.83 |
| 1. o3 | GCC 14 -O3 -ljemalloc
| 15 | 189.5 | 65.0 | 28.0 | 37.0 | 204.8 | 1.08 |
| 1. o3 | GCC 14 -O3 -flto
| 15 | 193.8 | 65.0 | 27.4 | 39.6 | 163.5 | 0.84 |
| 2. timing | GCC 14 -O3
| 21 | 333.9 | 113.9 | 57.8 | 69.8 | 202.9 | 0.61 |
| 2. timing | GCC 14 -O3 -ljemalloc
| 19 | 301.8 | 106.9 | 51.8 | 60.5 | 202.9 | 0.67 |
| 2. timing | GCC 14 -O3 -flto
| 21 | 324.4 | 111.6 | 56.2 | 67.0 | 194.7 | 0.60 |
| 3. traffic_21 | GCC 14 -O3
| 21 | 226.4 | 65.5 | 31.3 | 50.8 | 749.3 | 3.31 |
| 3. traffic_21 | GCC 14 -O3 -ljemalloc
| 18 | 198.0 | 59.2 | 26.1 | 42.7 | 723.3 | 3.65 |
| 3. traffic_21 | GCC 14 -O3 -flto
| 20 | 216.1 | 62.8 | 29.2 | 48.1 | 745.4 | 3.45 |
| 4. traffic_74_ruby | GCC 14 -O3
| 31 | 391.5 | 103.2 | 54.4 | 82.1 | 1246.0 | 3.18 |
| 4. traffic_74_ruby | GCC 14 -O3 -ljemalloc
| 28 | 363.6 | 97.1 | 49.5 | 74.1 | 1200.3 | 3.30 |
| 4. traffic_74_ruby | GCC 14 -O3 -flto
| 29 | 361.3 | 96.7 | 48.6 | 75.5 | 1204.0 | 3.33 |
735.gem5_r 四个测试跑的是挺不一样的代码路径,第一个 o3 的主要瓶颈就是 O3CPU,第二个 timing 的主要瓶颈是 RISC-V 指令集相关的代码,第三个 traffic_21 主要是缓存和内存控制器,而 traffic_74_ruby 主要是用 ruby 模拟的内存子系统。由于 gem5 高度模块化,有些时候一些可以 inline 函数没有被 inline,所以 -flto 可以带来不错的性能提升。此外,gem5 很喜欢动态分配内存,运行过程中有很多动态产生的对象,比如 Packet 等等,所以用 -ljemalloc 能带来不错的提升。-march=native 确实不太有用武之地。
整体下来,执行 1164B 条指令,其中有 246B 条分支指令,MPKI 等于 2.05,不算高,主要由后两个 traffic 负载贡献。
sealcrypto 做的是同态加密,只有一个负载做测试:
运行时间 108s,reftime 是 536s,对应 5.0 分。
很奇特的是,开 -O3 -flto 性能倒退,-O3 -flto -ljemalloc 性能没啥变化,开 -O3 -march=native -flto -ljemalloc 性能进一步倒退。但是,LLVM 22 异军突起,以接近两倍的性能超越了 GCC 和 LLVM 的其他版本,仅用 50.5s 跑完,对应 10.6 分。可以说,完全就靠 750.sealcrypto_r,才让 LLVM 22 在 SPEC INT 2026 整体性能上超越了 GCC 14。下面就来看看是怎么一回事。
首先还是对 -O3 的 GCC 14 进行热点分析:
seal::util::DWTHandler::transform_to_rev(ValueType *values, int log_n, const RootType *roots, const ScalarType *scalar = nullptr) 来自 src/seal/util/dwthandler.h:25.65%,这里 DWT 是离散小波变换 Discrete Wavelet Transform,上一次看到小波变换还是 Ghost Hunter,没想到在这里又遇到了,具体到指令上,就是一堆 imul/add/shr/shl 的运算指令;seal::util::DWTHandler::transform_from_rev(ValueType *values, int log_n, const RootType *roots, const ScalarType *scalar = nullptr) 来自 src/seal/util/DWTHandler.h:16.58%,应该是 DWT 的逆过程,计算模式基本一样;seal::util::multiply_uint64_generic(T operand1, S operand2, unsigned long long *result128) 来自 src/seal/util/uintarith.h:11.60%,实现了 64 位乘以 64 位得到 128 位结果的乘法,也是一堆乘法、加法和位运算;seal::util::dot_product_mod(const uint64_t *operand1, const uint64_t *operand2, size_t count, const Modulus &modulus) 来自 src/seal/util/uintarithsmallmod.cpp:11.48%,实现的是点乘后取模的操作,调用 multiply_accumulate_uint64 函数进行乘法和累加,最后用 barrett_reduce_128 进行取模;seal::util::dyadic_product_coeffmod(ConstCoeffIter operand1, ConstCoeffIter operand2, size_t coeff_count, const Modulus &modulus, CoeffIter result) 来自 src/seal/util/polyarithsmallmod.cpp:9.08%,实现的是 element wise 的模乘;seal::util::BaseConverter::fast_convert_array(ConstRNSIter in, RNSIter out, MemoryPoolHandle pool) 来自 src/seal/util/rns.cpp:5.88%,这里的 RNS 应该是 Residue Number System 的缩写,指令上还是大量的 imul/add 等运算;seal::util::RNSTool::sm_mrq(ConstRNSIter input, RNSIter destination, MemoryPoolHandle pool) 来自 src/seal/util/rns.cpp:5.40%,不确定在做什么,也是大量的运算。总而言之,既然是密码学,就会有大量的整数运算,其中有不少的乘法和位运算,在素数域下做各种操作。执行指令数足足有 3113.4B,其中有 385.7B 条 Load 指令,161.3B 条 Store 指令,78.5B 条分支指令,错误预测 450.0M 次,MPKI 只有 450.0M/3113.4B*1000=0.14,全场最低,甚至低于 714.cpython_r,同时 IPC 全场最高,达到了 5.09。从 Top down 分析来看,80.7% 属于 Retiring,13.5% 属于 Backend Bound,说明处理器基本在全速跑指令。
开了 -O3 -march=native 后,确实生成了不少 AVX2 指令,但看下来,生成的指令序列还是挺复杂的,有大量的 vpunpcklqdq/vpunpckhqdq/vpermq/vpblendvb/vperm2i128 等指令,并没有在进行计算,而是在不断地倒腾向量寄存器里数据的位置,见 Godbolt。此时指令数降低到 2757.7B,其中有 370.0B 条 Load 指令,126.7B 条 Store 指令,268.6B 条 256 位整数向量指令(int_vec_retired.256bit 性能计数器),76.1B 条分支指令,错误预测 431.0M 次,MPKI 等于 431.0M/2757.7B*1000=0.16。虽然指令数减少了,但 IPC 降低更多,最后性能反而倒退,实际从 108s 增加到 116s。原来的 -O3 版本虽然每次只处理一个元素,但指令的并行度更高,IPC 弥补了指令数多的劣势。GCC 16 的 -march=native 就好多了,生成的指令少了很多数据重排的指令,基本都是 vpaddq/vpsubq/vpmuludq/vpsllq/vpsrlq 这类计算指令,向量化方法不一样,见 Godbolt。
那么,LLVM 22 做了什么优化呢?执行的指令数直接降低到 1213.6B,其中 Load 指令有 302.8B,Store 指令有 109.2B,分支只有 57.2B,错误预测 1093.9M,MPKI 等于 1093.9M/1213.6B*1000=0.90。以 seal::util::DWTHandler::transform_to_rev 为例,可以看到:seal 为了实现 64 位乘 64 位到 128 位的乘法,它自己实现了这个过程,不仅在 seal::util::multiply_uint64_generic 中有实现,实际上也内联到了 seal::util::DWTHandler::transform_to_rev 当中;GCC 14 忠实地实现了这个算法,因此指令数很多(见 Godbolt);但其实,AMD64 的 mul 指令本来就是一个 64 位乘 64 位得到 128 位的乘法,所以 LLVM 22 直接识别出这段代码做的事情,然后编译成了 mul 指令(见 Godbolt,甚至如果开了 BMI2 扩展,还有 mulx 指令可以用),而且这种 64 位乘法保留高位的指令在各种 ISA 都挺常见的,比如 ARM64 的 umulh,RISC-V 的 mulhu,LoongArch 的 mulh.du。当然,seal 的源码其实已经考虑了这个问题,在编译器支持的情况下,直接用 __int128 来完成这件事情。类似的事情在 706.stockfish_r 的 1to6_classical 中也出现了。然而,这类依赖编译器行为或具体指令集扩展的代码,由于 SPEC CPU 2026 的编译器中立性,都被去掉了,都会回落到最通用的写法上。此时,就只能依赖编译器去自己识别和优化了。
但这样某种意义上也无法反映真实场景中应用的优化情况,因为很多应用已经实际上和处理器的指令集扩展/编译器扩展共进化,实现的时候,脑子里是默认有这些东西,再去做的调优,甚至会写一些指令集相关的优化,用一些 intrinsics,比如原版 stockfish 就有针对 AVX512/AVX2/SSSE3/NEON_DOTPROD/LASX/LSX 的优化。到最后,就是编译器又实现各种 pass,识别程序里的 fallback generic 代码,再映射回高效的实现。其实类似的事情之前就出现过,网上用来证明编译器很聪明的一个例子,就是说识别 popcount 的循环,直接翻译成 popcnt 指令,然而很多程序直接用 __builtin_popcount 而不会真的去手写,这次只不过是换了个 pattern 罢了。当然,好消息是,C++20 引入了 std::popcount,可以一定程度避免类似的情况发生,只是来得太晚了。
相比之下,Geekbench 对这类指令集扩展的优化就比较持开放态度,愿意针对指令集扩展进行针对性的优化,比如经典引入 AMX/SME 对分数的巨大影响,当然这也让它被人骂 AppleBench,只能说见仁见智了。
与此同时,LLVM 22 明显生成了更多的错误预测,用 perf record -e branch-misses:pp 找了一下问题,有 46.81% 的错误预测都出在 sm_mrq 函数当中,主要问题出在它内联的来自 src/seal/util/uintarithsmallmod.h 的 multiply_uint_mod 函数,它最后有一步,如果结果大于模 p,就要减去 p:SEAL_COND_SELECT(tmp2 >= p, tmp2 - p, tmp2),学过 Montgomery Multiplication 的话应该很熟悉,因为它只能保证优化后的计算结果与真实结果在模 p 结果下相等,但是范围会更大,最大不会超过两倍的 p,所以需要最后做一个处理,这里是 Barrett Reduction,原理是类似的。这个 SEAL_COND_SELECT 宏是这么定义的,此处 SEAL_AVOID_BRANCHING 没有被定义,实际用的是上面的 ternary operator:
// Conditionally select the former if true and the latter if false // This is a temporary solution that generates constant-time code with all compilers on all platforms. #ifndef SEAL_AVOID_BRANCHING #define SEAL_COND_SELECT(cond, if_true, if_false) (cond ? if_true : if_false) #else #define SEAL_COND_SELECT(cond, if_true, if_false) \ ((if_false) ^ ((~static_cast<uint64_t>(cond) + 1) & ((if_true) ^ (if_false)))) #endif LLVM 22 使用分支实现上面的逻辑,只有在 tmp2 >= p 的情况下才会进行 tmp2 - p 的计算,否则就是计算 tmp2 - 0,指令序列大概是这样:
# 初始化 rax = 0 mov $0x0,%eax # 比较 tmp2(rcx) 和 p(r10) cmp %r10,%rcx # 如果 p > tmp2,跳转到下面的 label: jb label # rax = r10,即 rax = p mov %r10,%rax label: # 计算 tmp2 - rax sub %rax,%rcx 如此计算确实少了,但是分支预测错误率又很高,除非硬件上做 Short Forward Branch 转 Predication 的逻辑(详见 浅谈乱序执行 CPU(三:前端))。GCC 14 是这么实现的:
# tmp2 保存在 rax 寄存器,p 保存在 rdx 寄存器 # rcx = rax,即 rcx = tmp2 mov %rax,%rcx # rcx -= rdx,即 rcx = tmp2 - p sub %rdx,%rcx # 比较 tmp2 和 p cmp %rdx,%rax # 如果 tmp2 >= p,则 rax = rcx = tmp2 - p,否则 rax 保持原来的 tmp2 不变 cmovae %rcx,%rax GCC 14 通过 cmov 指令避免了大量的错误预测,就是这点差别,造成了 LLVM 22 相比 GCC 14 巨大的 MPKI 差距。如果 LLVM 22 在这里选择用 cmov,那性能还能继续往上提一提。事实上,LLVM 22 确实也能在很多地方用 cmov 代替分支,但为什么在这个具体场景下,最后放弃了这个优化,还需要进一步的研究。
LLVM 22 开 -O3 -march=native 后分支预测有所改善,错误预测从 1093.9M 降到 612.7M(MPKI=0.54)。不过改进不在 sm_mrq 函数(它依然用分支而非 cmov),而是 DWTHandler::transform_from_rev 和 RNSTool::fastbconv_sk。这两个函数同样有 SEAL_COND_SELECT 宏,但此时 cond ? if_true : if_false 被编译成了 vpcmpgtq + vblendvpd,相当于把 cmov 向量化了。标量时 LLVM 22 不愿意用 cmov,为了向量化反而自己给实现了出来。
750.sealcrypto_r 在不同编译器和编译选项下的情况如下:
| 编译器 + 选项 | 时间 (s) | 指令 (B) | Load (B) | Store (B) | 分支 (B) | 错误预测 (M) | MPKI |
|---|---|---|---|---|---|---|---|
GCC 14 -O3
| 108 | 3113.4 | 385.7 | 161.3 | 78.5 | 450.0 | 0.14 |
GCC 14 -O3 -march=native
| 116 | 2757.7 | 370.0 | 126.7 | 76.1 | 431.0 | 0.16 |
GCC 15 -O3
| 106.4 | 3071.3 | 379.1 | 161.4 | 80.0 | 416.1 | 0.14 |
GCC 15 -O3 -march=native
| 117.7 | 2701.9 | 379.4 | 130.6 | 77.6 | 406.9 | 0.15 |
GCC 16 -O3
| 105.9 | 3020.1 | 381.1 | 158.5 | 80.7 | 430.3 | 0.14 |
GCC 16 -O3 -march=native
| 99.3 | 2492.3 | 328.0 | 123.2 | 81.8 | 433.3 | 0.17 |
LLVM 22 -O3
| 50.5 | 1213.6 | 302.8 | 109.2 | 57.2 | 1093.9 | 0.90 |
LLVM 22 -O3 -march=native
| 48.2 | 1126.0 | 299.2 | 108.7 | 53.4 | 612.7 | 0.54 |
753.ns3_r 和 710.omnetpp_r 做的事情类似,也是网络中的离散事件模拟器。它包括这些负载:
# 1. mobile ns3_r mobile-scenario --simTimeMinutes=3 --RngSeed=1 --RngRun=1 # 2. tcp ns3_r tcp-pacing --simulationEndTime=500 --useEcn=false --RngSeed=1 --RngRun=1 # 3. lena ns3_r lena-radio-link-failure --numberOfEnbs=2 --interSiteDistance=800 --simTime=200 --RngSeed=1 --RngRun=1 # 4. dctcp ns3_r dctcp-example --enableSwitchEcn=true --flowStartupWindow=0.4 --convergenceTime=0.4 --measurementWindow=0.4 --RngSeed=1 --RngRun=1 # 5. wifi_mixed ns3_r wifi-mixed-network --isUdp=0 --payloadSize=3072 --simulationTime=25 --RngSeed=1 --RngRun=1 # 6. wifi_eht ns3_r wifi-eht-network --simulationTime=0.2 --frequency=5 --useRts=1 --minExpectedThroughput=6 --maxExpectedThroughput=547 --RngSeed=1 --RngRun=1 六个负载的耗时分别为 18s、15s、3s、19s、23s 和 14s,一共 92s,reftime 是 613s,对应 6.7 分。各编译选项对性能影响:
-O3 -flto:时间降到 16s、14s、3s、17s、19s 和 13s,一共 82s,对应 7.5 分,相比 -O3 提升 12% 的性能;-O3 -flto -ljemalloc:时间进一步降到 14s、12s、3s、13s、18s 和 11s,一共 71s,对应 8.6 分,相比 -O3 -flto 又提升 15% 性能。都有巨大提升,只有 -march=native 影响很小,仅 0.5%。下面来进行具体的分析。
热点分析:
cfree/malloc/_int_malloc/_int_free_chunk/operator new 来自 libc/libstdc++:6.99%+5.66%+4.15%+1.83%+1.81%=20.44%,又是内存分配密集型应用;ns3::LteMiErrorModel::GetTbDecodificationStats(const SpectrumValue& sinr, const std::vector<int>& map, uint16_t size, uint8_t mcs, HarqProcessInfoList_t miHistory) 来自 src/ns-3.38/src/lte/model/lte-mi-error-model.cc:9.57%,首先是一个循环,带有一些浮点运算,做一些累加和乘加操作,然后是一段二分查找,看起来主要瓶颈是在二分查找上面,此外在函数开头还会调用下面的 Mib 函数;ns3::LteMiErrorModel::Mib(const SpectrumValue& sinr, const std::vector<int>& map, uint8_t mcs) 来自 src/ns-3.38/src/lte/model/lte-mi-error-model.cc:4.39%,又是一些浮点运算,不知道在算什么,还会调用 ns3::SpectrumValue::operator[],做一些浮点比较;ns3::LteMiErrorModel::MappingMiBler(double mib, uint8_t ecrId, uint16_t cbSize) 来自 src/ns-3.38/src/lte/model/lte-mi-error-model.cc:3.53%,主要的开销是浮点运算、调用 erf 函数和做一些查表,__erf 函数占了总时间的 1.63%;ns3::MapScheduler::Insert(const Event& ev) 来自 src/ns-3.38/src/core/model/map-scheduler.cc:2.66%,主要瓶颈在对 std::map 红黑树的插入。首先能看到的是,又是一个内存分配密集型应用。开了 -O3 -flto 后,GetTbDecodificationStats 把 Mib 内联了进去,时间占比提升到 12.68%,但还是内存分配占了最多的时间:7.82%+6.22%+4.51%+1.90%=20.45%。进一步开 -O3 -flto -ljemalloc,内存分配的时间占比终于降低到 6.23%+1.78%=8.01%,其实还是挺高的。
比较少见的是,作为 SPEC INT 2026 Rate 的一员,mobile 涉及不少浮点运算,还包括一些对 libm 的调用,比如 erf/atan2/pow/log,但实际瓶颈又是内存分配,算是半步踏入了 SPEC FP 2026 的领域,但又因为大量 libc 调用而被拉了回来。
-O3 下,执行指令 257.2B,其中 Load 指令有 66.6B,Store 指令有 35.4B,分支指令有 54.4B,错误预测 631.1M,MPKI 等于 631.1M/257.2B*1000=2.45,并不低。从 perf record -e branch-misses:pp 来看,主要的错误预测来自于内存分配器以及 std::map 红黑树的插入算法。
第二个负载测的又是不一样的代码了,这次的热点函数:
cfree/malloc/_int_malloc/_int_free_chunk/operator new 来自 libc/libstdc++:7.02%+5.20%+3.68%+2.29%+1.56%=19.75%,又是内存分配密集型应用;ns3::TcpTxBuffer::NextSeg(SequenceNumber32* seq, SequenceNumber32* seqHigh, bool isRecovery) 来自 src/ns-3.38/src/internet/model/tcp-tx-buffer.cc:4.35%,是一个 TCP 协议栈实现,这里做的是 RFC 6675 SACK 的部分,想起来之前设计的 TCP 实验,这里主要的瓶颈是循环里对 sequence number 的更新;ns3::MapScheduler::Insert(const Event& ev) 来自 src/ns-3.38/src/core/model/map-scheduler.cc:4.05%,描述见上;__do_dyncast/__dynamic_cast 来自 libstdc++:1.80%+1.55%=3.35%。-O3 下,执行指令 204.8B,其中 Load 指令有 63.5B,Store 指令有 41.4B,分支指令有 45.4B,错误预测 148.1M,MPKI 等于 148.1M/204.8B*1000=0.72,比较低。从 perf record -e branch-misses:pp 来看,主要的错误预测来自于内存分配器以及 std::map 红黑树的插入和删除算法。
第三个负载测的又是不一样的代码了,这次的热点函数:
cfree/malloc/_int_malloc/_int_free_chunk/operator new 来自 libc/libstdc++:7.78%+6.13%+3.13%+2.08%+1.52%=20.64%,又是内存分配密集型应用;ns3::MapScheduler::Insert(const Event& ev) 来自 src/ns-3.38/src/core/model/map-scheduler.cc:2.41%,描述见上;__do_dyncast/__dynamic_cast 来自 libstdc++:1.73%+0.82%=2.55%。-O3 下,执行指令 46.6B,其中 Load 指令有 14.2B,Store 指令有 9.6B,分支指令有 10.4B,错误预测 53.4M,MPKI 等于 53.4M/46.6B*1000=1.15,不高。从 perf record -e branch-misses:pp 来看,主要的错误预测来自于内存分配器以及 std::map 红黑树的插入和删除算法。
第四个负载测的又是不一样的代码了,这次的热点函数:
cfree/malloc/_int_malloc/_int_free_chunk/operator new 来自 libc/libstdc++:6.30%+5.56%+4.03%+1.53%+1.43%+1.12%=40.61%,又是内存分配密集型应用;ns3::MapScheduler::Insert(const Event& ev) 来自 src/ns-3.38/src/core/model/map-scheduler.cc:6.94%,描述见上。-O3 下,执行指令 225.3B,其中 Load 指令有 71.1B,Store 指令 43.9B,分支指令有 52.3B,错误预测 295.8M,MPKI 等于 295.8M/225.3B*1000=1.31,略高一点。从 perf record -e branch-misses:pp 来看,主要的错误预测来自于内存分配器以及 std::map 红黑树的插入和删除算法。
热点函数就不列举了,基本还是内存分配,外加 ns3::TcpTxBuffer::NextSeg。-O3 下,执行指令 291.8B,其中 Load 指令有 88.8B,Store 指令有 52.7B,分支指令有 66.5B,错误预测 201.9M,MPKI 等于 201.9M/291.8B*1000=0.69,不高,错误预测的主要来源除了内存分配器和 std::map,还多了一个 __memcmp_avx2_movbe。
热点函数除了内存分配,多了 ns3::InterferenceHelper::AppendEvent 和 ns3::WifiSpectrumValueHelper::GetBandPowerW。-O3 下,执行指令 194.3B,其中 Load 指令有 58.1B,Store 指令有 32.6B,分支指令有 44.0B,错误预测 372.0M,MPKI 等于 372.0M/194.3B*1000=1.91,略高,从 perf record -e branch-misses:pp 来看,错误预测主要来自于 ns3::InterferenceHelper::AppendEvent 内联的 std::map 的查询代码。
各负载的情况如下:
| 负载 | 编译器 + 选项 | 时间 (s) | 指令 (B) | Load (B) | Store (B) | 分支 (B) | 错误预测 (M) | MPKI |
|---|---|---|---|---|---|---|---|---|
| 1. mobile | GCC 14 -O3
| 18 | 257.2 | 66.6 | 35.4 | 54.4 | 631.1 | 2.45 |
| 2. tcp | GCC 14 -O3
| 15 | 204.8 | 63.5 | 41.4 | 45.4 | 148.1 | 0.72 |
| 3. lena | GCC 14 -O3
| 3 | 46.6 | 14.2 | 9.6 | 10.4 | 53.4 | 1.15 |
| 4. dctcp | GCC 14 -O3
| 19 | 225.3 | 71.1 | 43.9 | 52.3 | 295.8 | 1.31 |
| 5. wifi_mixed | GCC 14 -O3
| 23 | 291.8 | 88.8 | 52.7 | 66.5 | 201.9 | 0.69 |
| 6. wifi_eht | GCC 14 -O3
| 14 | 194.3 | 58.1 | 32.6 | 44.0 | 372.0 | 1.91 |
与 727.cppcheck_r 类似,753.ns3_r 又是一个内存分配器 benchmark,大量时间花在 malloc/free 上了,此外还有不少 std::map 或 libm 的调用。-O3 下,执行指令 1221B,分支指令 273B,MPKI 是 1.39。
作为 SPEC INT 2026 中唯一一个压缩算法,把 SPEC INT 2017 的 557.xz_r 替换掉了,也能见到压缩算法的变迁。从没有被选中的 770.7z_r 来看,zstd 也是成功杀出重围,被认为是更加重要的压缩算法。它一共包括八个负载,但其实压缩的都是同一个文件,不像 557.xz_r 那样会压缩不同的输入文件,只是在代码里对输入数据做了随机修改:
# 1. b3 zstd -b3 -e3 --verbose -i40 cld.tar # 2. b5 zstd -b5 -e5 --verbose -i25 cld.tar # 3. b7 zstd -b7 -e7 --verbose -i12 cld.tar # 4. b10 zstd -b10 -e10 --verbose -i6 cld.tar # 5. b14 zstd -b14 -e14 --verbose -i4 cld.tar # 6. b16 zstd -b16 -e16 --verbose -i1 cld.tar # 7. b18 zstd -b18 -e18 --verbose -i1 cld.tar # 8. b19 zstd -b19 -e19 --verbose -i1 cld.tar 这里的 -b 代表 compression level 下界,-e 代表 compression level 上界,都相等,其实就是每次只测一种 compression level 的意思。8 个负载的运行时间:11.0s、14.5s、13.0s、11.6s、24.5s、10.9s、20.1s 和 25.5s,一共是 131.2s,reftime 是 644s,对应 4.9 分。
开 -O3 -flto 或 -O3 -ljemalloc 没有什么性能提升,但 -O3 -march=native 提升不错,运行时间降低到 10.5s、13.7s、12.6s、11.4s、23.4s、10.3s、18.6s 和 23.5s,一共是 124.0s,对应 5.2 分,提升 6%。
以第一个负载 b3 为例,热点函数:
ZSTD_compressBlock_doubleFast_noDict_generic 来自 src/zstd-1.5.6/lib/compress/zstd_double_fast.c:56.82%,主要在对数据计算哈希,寻找匹配,进而用于压缩,具体算法没有仔细看,挺复杂的;ZSTD_decompressBlock_internal.part.0 来自 src/zstd-1.5.6/lib/decompress/zstd_decompress_block.c:16.63%,解压缩的主要逻辑,会调用 ZSTD_decompressSequences,挺复杂的;ZSTD_encodeSequences 来自 src/zstd-1.5.6/lib/compress/zstd_compress_sequences.c:10.91%,分为 bmi2 和 generic 版本,不出意外 bmi2 版本也被 SPEC 禁用了,只能用 generic 版本,逻辑也挺复杂的,没有仔细看。-O3 下,b3 执行 181.4B 条指令,其中有 49.9B 条 Load 指令,17.7B 条 Store 指令,19.1B 分支指令,错误预测 543.9M 次,MPKI 等于 543.9M/181.4B*1000=3.00,属于比较高的。从 perf record -e branch-misses:pp 来看,有 78.98% 的错误预测来自 ZSTD_compressBlock_doubleFast_noDict_generic,主要是在一些数据依赖的分支上,比如 if (MEM_read64(matchl0) == MEM_read64(ip));其余有 14.91% 来自 ZSTD_decompressBlock_internal.part.0,主要是 if (ofBits > 1) 等分支。
第二个负载 b5 的热点函数:
ZSTD_RowFindBestMatch.constprop.0 来自 src/zstd-1.5.6/lib/compress/zstd_lazy.c:67.91%,对数组进行循环,找到匹配最长的一项;ZSTD_compressBlock_lazy_generic.constprop.0 来自 src/zstd-1.5.6/lib/compress/zstd_lazy.c:9.12%,也是比较复杂的匹配算法;ZSTD_decompressBlock_internal.part.0 来自 src/zstd-1.5.6/lib/decompress/zstd_decompress_block.c:7.80%,描述见上。-O3 下,b5 执行 273.6B 条指令,其中有 61.3B 条 Load 指令,35.1B 条 Store 指令,28.4B 分支指令,错误预测 562.4M 次,MPKI 等于 562.4M/273.6B*1000=2.06,属于比较高的。错误的分支预测有 78.92% 来自 ZSTD_RowFindBestMatch.constprop.0。
第五个负载 b14 的热点函数:
ZSTD_DUBT_findBestMatch 来自 src/zstd-1.5.6/lib/compress/zstd_lazy.c:85.74%,也是在循环中做最长匹配;ZSTD_searchMax.constprop.0 来自 src/zstd-1.5.6/lib/compress/zstd_lazy.c:9.04%,根据 dict mode 派发到不同的实现,实现也挺复杂。-O3 下,b14 执行 197.6B 条指令,其中有 48.8B 条 Load 指令,16.5B 条 Store 指令,29.1B 分支指令,错误预测 1609.6M 次,MPKI 等于 1609.6M/197.6B*1000=8.15,属于特别高的。错误的分支预测有 94.94% 来自 ZSTD_DUBT_findBestMatch,比如 if (match[matchLength] < ip[matchLength]) 的分支。
第六个负载 b16 的热点函数:
ZSTD_insertBtAndGetAllMatches 来自 src/zstd-1.5.6/lib/compress/zstd_opt.c:38.62%,这里 Bt 代表的是 binary tree 二叉树;ZSTD_insertBt1 来自 src/zstd-1.5.6/lib/compress/zstd_opt.c:35.15%;ZSTD_compressBlock_opt_generic.constprop.1 来自 src/zstd-1.5.6/lib/compress/zstd_opt.c:16.50%。-O3 下,b16 执行 129.1B 条指令,其中有 29.9B 条 Load 指令,11.2B 条 Store 指令,18.0B 条分支指令,错误预测 652.1M 次,MPKI 等于 652.1M/129.1B*1000=5.05,也是属于特别高的。错误的分支预测有 40.69% 来自 ZSTD_insertBtAndGetAllMatches,37.45% 来自 ZSTD_insertBt1,比如 if (match[matchLength] < ip[matchLength]) 的分支。
第三/四个负载 b7/b10 的热点与第二个负载 b5 类似;第七/八个负载 b18/b19 的热点函数和第六个负载 b16 类似,就不重复了。可见 zstd 会根据 compression level 选择不同路径,从而在压缩率和性能之间做出权衡。
那么开 -march=native 以后,发生了什么?能看到的是,由于 BMI 指令的引入,一些位运算的指令数变少了,比如 bzhi 和 tzcnt,还有一些是三操作数且不影响 flags 的运算,如 shrx,有点类似一些 RISC 指令集(如 RISC-V)的对应指令。开 -march=native 前后各负载的情况如下表:
| 负载 | 编译器 + 选项 | 时间 (s) | 指令 (B) | Load (B) | Store (B) | 分支 (B) | 错误预测 (M) | MPKI |
|---|---|---|---|---|---|---|---|---|
| 1. b3 | GCC 14 -O3
| 11.0 | 181.4 | 49.9 | 17.7 | 19.1 | 543.9 | 3.00 |
| 1. b3 | GCC 14 -O3 -march=native
| 10.5 | 170.4 | 49.9 | 18.3 | 18.9 | 543.8 | 3.19 |
| 2. b5 | GCC 14 -O3
| 14.5 | 273.6 | 61.3 | 35.1 | 28.4 | 562.4 | 2.06 |
| 2. b5 | GCC 14 -O3 -march=native
| 14.0 | 250.5 | 59.7 | 35.4 | 28.3 | 559.1 | 2.23 |
| 3. b7 | GCC 14 -O3
| 13.0 | 228.5 | 48.9 | 25.8 | 29.8 | 599.3 | 2.62 |
| 3. b7 | GCC 14 -O3 -march=native
| 12.7 | 207.4 | 46.6 | 26.0 | 29.8 | 596.7 | 2.88 |
| 4. b10 | GCC 14 -O3
| 11.6 | 207.2 | 41.5 | 17.6 | 32.6 | 516.3 | 2.49 |
| 4. b10 | GCC 14 -O3 -march=native
| 11.5 | 184.0 | 37.8 | 17.8 | 32.6 | 569.6 | 3.10 |
| 5. b14 | GCC 14 -O3
| 24.5 | 197.6 | 48.8 | 16.5 | 29.1 | 1609.6 | 8.15 |
| 5. b14 | GCC 14 -O3 -march=native
| 23.7 | 190.1 | 46.7 | 15.9 | 27.8 | 1612.5 | 8.48 |
| 6. b16 | GCC 14 -O3
| 10.9 | 129.1 | 29.9 | 11.2 | 18.0 | 652.1 | 5.05 |
| 6. b16 | GCC 14 -O3 -march=native
| 10.2 | 124.7 | 30.7 | 12.0 | 17.3 | 646.5 | 5.18 |
| 7. b18 | GCC 14 -O3
| 20.1 | 265.8 | 57.0 | 17.0 | 32.6 | 987.7 | 3.72 |
| 7. b18 | GCC 14 -O3 -march=native
| 18.4 | 259.2 | 57.0 | 17.2 | 31.4 | 980.7 | 3.78 |
| 8. b19 | GCC 14 -O3
| 25.5 | 342.0 | 72.9 | 19.1 | 41.8 | 1060.6 | 3.10 |
| 8. b19 | GCC 14 -O3 -march=native
| 23.4 | 332.8 | 72.7 | 19.1 | 40.1 | 1050.2 | 3.16 |
整体来看,-O3 下 777.zstd_r 执行 1827B 指令,其中 232B 是分支指令,但 MPKI 有 3.58,仅次于 729.abc_r 和 723.llvm_r。
综合下来,编译选项对 SPEC INT 2026 Rate 的性能影响还是不小的,比如:
-flto 对 707.ntest_r、710.omnetpp_r、714.cpython_r、734.vpr_r、735.gem5_r、753.ns3_r 都有一定的性能提升,当热点分散在多个函数,且很多函数都很小时,开 LTO 能带来一定程度的优化,本质上挽回了因可读性而拆分文件带来的性能开销-ljemalloc 对 710.omnetpp_r、721.gcc_r、723.llvm_r、727.cppcheck_r、734.vpr_r、735.gem5_r、753.ns3_r 有性能提升,只能说这些软件做了太多的动态内存分配,有一些 benchmark 直接就是内存分配器 benchmark 了,此时替换 glibc 为 jemalloc/mimalloc 都有不错的性能提升,不过最新 glibc 也在改进 malloc 性能,不知道改进得怎样了?-march=native 对 706.stockfish_r、707.ntest_r、735.gem5_r、777.zstd_r 有不错的提升,一方面是诸如 AVX 等 SIMD 指令(对 ARM64 来说,比如 Apple M2,就是针对 706.stockfish_r nnue 的 USDOT 指令,开 -march=native 直接给 706.stockfish_r 加了 33% 的分数,而如果没有这个指令集扩展,那么 -march=native 对 ARM64 没啥性能影响),另一方面就是一些位运算指令,比如 popcnt 和 BMI 扩展;事实上,现在很多软件在实现的时候,就已经考虑了硬件的加速指令,实际编译的时候,往往会直接用对应的 intrinsics,但 SPEC 禁用了这些 intrinsics,退而使用它的 generic 版本,此时就非常依赖 -march=native,以及需要编译器正确识别并翻译为对应的优化指令还有一些常用的编译参数,比如 -static、-fomit-frame-pointer、-Ofast、-ffast-math 等等,目前没有做太多测试,以后说不定会加上。
本测试的主要编译器是 GCC 14.2.0,因为它是 Debian Trixie 的编译器版本。有意思的是,即使在 2026 年,随着编译器版本更新,硬件不变的情况下软件性能还在持续增长。GCC 15 能给 706.stockfish_r 生成更快的 SSE/AVX 指令序列,LLVM 22 能识别出 750.sealcrypto_r 的 64 位乘法模式,这些都是很好的例子。此外 LLVM 默认内联 popcount 的优化实现,而 GCC 会转化为对 libgcc 的 popcount 调用,前者代码体积膨胀,后者有额外的 call 开销,这些都会带来可观的性能差距。这些优化其实很具体,完全可以互相移植。在 SPEC INT 2017 时代,基本是 GCC 性能压制 LLVM,而目前 LLVM 凭借 750.sealcrypto_r 的优化相比 GCC 14 扳回一城,又被 GCC 15/16 反超。随着对 SPEC CPU 2026 的研究深入,未来还会编译出更快的程序。
SPEC INT 2026 Rate 中 MPKI 较高的有:
作为对比,SPEC INT 2017 Rate 的情况:
SPEC INT 2026 Rate 整体低了不少。当然,这是每个 benchmark 的平均值,个别负载可能更高。但无论如何,终于不用和 505.mcf_r 的 spec_qsort 以及 541.leela_r 的 if(randint(2) == 0) 搏斗了。当然,SPEC INT 2026 Rate 也有很多的 MPKI 是来自于 std::map 的红黑树或者其他数据结构,有很多数据依赖的分支,也未必很好从硬件上优化性能。能看到的是,应用程序开始意识到分支预测,并通过 ternary operator 来提示编译器生成 cmov 指令来避免分支的错误预测。
目前的测试仅限于 Intel i9-14900K P-Core,还需要在 ARM64/RISC-V/LoongArch 上做类似的分析。指令集不同,结论应该也会不一样。此外,目前的分析集中在 perf 统计的热点函数上,还可以做更细粒度的分析,比如统计各类指令的使用比例,以及 POPCNT/BMI/AVX 等指令扩展的使用情况。
本文只跑了 Rate 1(单副本)。多副本下内存带宽和缓存竞争会更激烈,MPKI、IPC 等指标可能会有较大差异。此外,分析集中在指令级和分支预测层面,缺少微架构级的深入分析,例如 L1/L2/LLC 的缓存缺失率、TLB miss 等,这些对处理器设计者来说更直接。功耗数据也未纳入考量,综合能效比还需要用 RAPL 等工具进一步测量。最后,PGO(-fprofile-generate / -fprofile-use)也没有尝试,PGO 或许能带来不错的性能提升。
本文深入分析了 SPEC CPU 2026 中 INT Rate 的负载,供编译器和处理器的设计者参考。从编译器的角度来说,可以集 GCC 和 LLVM 之长,进一步提升性能;从处理器的角度来说,针对程序的瓶颈进行优化,也能进一步提高分数。