2026-07-22 08:00:00

opencodex 是一个本地代理,把 Codex 的 Responses API 翻译成任意 LLM provider 的协议。你可以在 Codex CLI、Codex App、SDK 里用 Claude、Gemini、DeepSeek、Grok、GLM、Qwen 甚至本地 Ollama 模型——也能在 Claude Code 里同样用任意模型——不需要等任何人添加官方支持。
Streaming、tool 调用、reasoning token、图片生成,全部双向工作。
npm install -g @bitkyc08/opencodex
ocx init
ocx start三行命令,Codex 就改道了。默认透传你的 ChatGPT 登录,你随时可以再加别的模型。
Codex CLI / App / SDK ──/v1/responses──▶ opencodex ──▶ 任意 provider
│
Anthropic · xAI · Kimi · Google · DeepSeek · Groq · OpenRouter
Ollama Cloud · Azure · GLM · Mistral · Qwen · GitHub Copilot · 本地 Ollamaopencodex 在 localhost:10100 起一个 HTTP 服务,Codex 的请求先进这个代理,由它翻译成目标 provider 的协议发出去。对 Codex 来说这就是一个 OpenAI 兼容端点,对下游 provider 来说请求格式就是它自己的协议。
五个 adapter 覆盖所有主流协议:
| Adapter | 支持 |
|---|---|
openai-responses |
OpenAI Responses API 透传 |
openai-chat |
OpenAI Chat Completions(及所有兼容端点) |
anthropic |
Anthropic Messages API |
google |
Google Gemini(AI Studio / Vertex / Antigravity) |
azure-openai |
Azure OpenAI |
一个协议层解决了 50+ provider 的兼容问题。
这是 opencodex 最核心的价值:把任意模型接到 Codex 里。
以下 7 个 provider 支持 OAuth 登录,不需要 API key,用你现有的账户登录即可,token 自动刷新:
ocx login xai # xAI Grok
ocx login anthropic # Anthropic Claude
ocx login kimi # Moonshot Kimi
ocx login kiro # Kiro
ocx login google-antigravity # Google Cloud Code Assist
ocx login cursor # Cursor(实验性)
ocx login github-copilot # GitHub Copilot(设备流 OAuth)登录后在 Codex 里直接用:
codex -m "anthropic/claude-opus-4-8" "解释这个 stack trace"
codex -m "xai/grok-4.5" "写一个 Rust HTTP 服务"
codex -m "cursor/gpt-5.6-sol" "重构这个模块"以下 40+ provider 走 API key 方式。最方便的方式是通过 Web 仪表盘添加:
ocx gui # 打开 http://localhost:10100/v1/models 端点自动发现,立即可用完整 API-key provider 列表:
| 类别 | Provider |
|---|---|
| OpenAI | openai-apikey |
| Anthropic | anthropic-apikey |
google(Gemini)、google-vertex(Vertex AI) |
|
| Azure | azure-openai |
| OpenRouter |
openrouter、orcarouter
|
| 国产大模型 |
deepseek、zai(GLM)、qwen-cloud、qianfan(百度)、moonshot(Kimi API)、kimi-code、minimax、minimax-cn、alibaba、alibaba-token-plan、alibaba-token-plan-intl
|
| 国际模型 |
mistral、cerebras、together、fireworks、firepass、nvidia(NIM)、groq
|
| 网关/聚合 |
openrouter、zenmux、litellm、vercel-ai-gateway、cloudflare-ai-gateway、cloudflare-workers-ai
|
| 代码助手 |
github-copilot(OAuth 也可)、gitlab-duo、umans、opencode-go、neuralwatt
|
| 其他 |
ollama-cloud、huggingface、venice、nanogpt、synthetic、parallel、opencode-zen、opencode-free、xiaomi(MiMo)、kilo、mimo-free
|
也可以直接编辑 ~/.opencodex/config.json:
{
"port": 10100,
"defaultProvider": "deepseek",
"providers": {
"deepseek": {
"adapter": "openai-chat",
"baseUrl": "https://api.deepseek.com",
"apiKey": "${DEEPSEEK_API_KEY}",
"defaultModel": "deepseek-chat"
},
"openrouter": {
"adapter": "openai-chat",
"baseUrl": "https://openrouter.ai/api/v1",
"apiKey": "${OPENROUTER_API_KEY}"
}
}
}${ENV_VAR} 写法在请求时从环境变量展开,key 不会落在配置文件里。
Ollama、vLLM、LM Studio 都行——只要暴露了 OpenAI 兼容端点:
{
"providers": {
"ollama": {
"adapter": "openai-chat",
"baseUrl": "http://localhost:11434/v1",
"apiKey": "",
"defaultModel": "qwen3:32b"
},
"vllm": {
"adapter": "openai-chat",
"baseUrl": "http://localhost:8000/v1",
"apiKey": "",
"defaultModel": "Qwen/Qwen3-32B"
}
}
}只要是一个 OpenAI Chat Completions 兼容的端点,填 baseUrl + apikey 就能接进来。在仪表盘选 Custom,或在 ocx init 里选 custom,输入 base URL 即可。
接入后,模型会出现在 Codex App 的模型选择器里,带 reasoning effort 控制(low / medium / high / xhigh / max / ultra),和原生模型并列。
用 provider/model 格式指定目标,Codex 自然认识:
# Claude Opus
codex -m "anthropic/claude-opus-4-8" "解释 stack trace"
# Gemini
codex -m "google/gemini-3-pro" "写 auth.ts 的单元测试"
# DeepSeek
codex -m "deepseek/deepseek-chat" "写 SQL migration"
# Ollama 本地模型
codex -m "ollama/llama3" "重构这个函数"省略 provider/ 前缀时走默认 provider,或者按模型名自动匹配(claude-* → Anthropic,gpt-* → OpenAI)。
opencodex 支持在配置里指定哪些模型出现在 Codex 的 subagent picker 里(最多 5 个)。复杂任务交给 reasoning 模型,快速任务交给便宜模型:
{
"subagentModels": [
"anthropic/claude-opus-4-8",
"deepseek/deepseek-chat",
"google/gemini-3-pro"
]
}在 v2 多智能体界面下,代理会自动注入委派指引(首选子代理模型 + effort 档位 + 模型清单)。
opencodex 通过一个运行在你 ChatGPT 登录上的 gpt-5.4-mini sidecar,给非 OpenAI 模型补上真实网页搜索和图片理解能力。
gpt-5.4-mini 描述图像内容再传给路由模型两个 sidecar 各自可配置开关、后端(openai / anthropic)、模型、每 turn 最大调用次数。
同一个代理也给 Claude Code 用:
ocx claude [args...]这会启动完全接线的 Claude Code,路由模型通过 claude-ocx-<provider>--<model> 别名出现在原生的 /model 选择器中。Claude Code 的 OAuth 登录保持不变,不影响。
如果你有多个 ChatGPT / Codex 账户,opencodex 能做池化管理:
ocx service install # 安装为系统服务,开机自启(launchd / systemd / Task Scheduler)
ocx codex-shim install # 按需启动:每次运行 codex 时自动启代理
ocx stop # 停止代理,恢复 Codex 原生配置
ocx uninstall # 彻底卸载ocx stop 后,原生 codex 就像从未装过 opencodex 一样工作——零残留。
默认绑 127.0.0.1。暴露到局域网时设置 token:
export OPENCODEX_API_AUTH_TOKEN="your-secret-token"
ocx start客户端请求头带 x-opencodex-api-key: your-secret-token。token 常量时间比较,防时序攻击。
opencodex 把「Codex 只能跑 OpenAI」这件事拆了。接入成本几乎为零——OAuth 登录一键搞定,API key 粘贴即用,本地模型填个 baseUrl 就能跑。对于已经在用 Codex CLI 或 Claude Code 做日常开发的工程师来说,装上它意味着你可以根据任务选最合适的模型,而不是被绑在一个 provider 上。
项目 MIT 协议,独立社区维护,与 OpenAI / Anthropic 无关。
2026-06-26 00:00:00

上一篇文章记录了轻糖将数据层从 Supabase Swift SDK 下沉到 KMP shared/ 模块的过程。但当时我们留了一个尾巴——ViewModels 原封不动地留在 iOS 侧用 @Observable,承诺"暂不迁移"。
后来发生的事情是:我们食言了。
随着 Android 版本的开发推进,23 个 ViewModel 中有 21 个需要双端共用。继续在 iOS 侧维护一套 Swift ViewModel、Android 侧再来一套 Kotlin ViewModel 显然不可持续——同一段业务逻辑(拉取今日血糖、构建时间线、计算 PGRS),凭什么写两遍?
这篇文章接着第一篇往下写:ViewModels 如何下沉到 KMP,以及在这个过程中遇到的本地存储、平台抽象、订阅管理和 Swift-Kotlin 桥接问题。
第一篇的迁移策略第 4 条写的是"ViewModel 暂不迁移,保留 @Observable 维持 SwiftUI 响应式体验"。这个决策在当时是合理的——Kotlin/Native 编译出的 StateFlow,Swift 端拿什么消费?你总不能要求 iOS 团队引入一个 ObservableObject + Combine 的中间层来桥接吧。
转机来自于 SKIE(0.10.13)。这个 TouchLab 开发的 Kotlin 编译器插件能自动将 Kotlin 类型映射为 Swift 原生类型:
suspend 函数 → Swift async throws
StateFlow<T> / Flow<T> → Swift AsyncSequence(底层生成 SkieSwiftAsyncSequence)enum
有了 SKIE,一个 KMP ViewModel 在 SwiftUI 侧的消费体验几乎和原生 @Observable 一样自然。
经过 23 个 ViewModel 的实践,我们沉淀出一套统一范式:
// 1. 单一 UiState data class,承载全部 UI 状态
data class HomeUiState(
val selectedDate: Instant = Clock.System.now(),
val bloodSugarRecords: List<BloodSugarRecord> = emptyList(),
val timelineEvents: List<TimelineEvent> = emptyList(),
val isLoading: Boolean = false,
val errorMessage: String? = null,
)
// 2. ViewModel 继承自 KMP ViewModel
class HomeViewModel : ViewModel() {
// 3. 私有 mutable flow + 公共 read-only flow
private val _uiState = MutableStateFlow(HomeUiState())
val uiState: StateFlow<HomeUiState> = _uiState.asStateFlow()
// 4. 使用 viewModelScope 管理协程
fun loadData() {
viewModelScope.launch {
_uiState.update { it.copy(isLoading = true) }
try {
val uid = getCurrentUserId()
val records = getDailyBloodSugarRecords(dateMillis, uid)
_uiState.update {
it.copy(isLoading = false, bloodSugarRecords = records.map { r -> r.toModel() })
}
} catch (e: Exception) {
_uiState.update { it.copy(isLoading = false, errorMessage = e.message) }
}
}
}
// 5. 状态变更始终用 update { it.copy(...) }
fun clearError() {
_uiState.update { it.copy(errorMessage = null) }
}
}几个设计决策:
uiState: StateFlow。不搞多个独立 Flow,避免 iOS 侧需要多路订阅。data class。Android 端 collectAsStateWithLifecycle() 直接解构;iOS 端通过 SKIE 转成 AsyncSequence,一次 for await 拿到全部状态。_uiState.update { it.copy(...) }。不用 _uiState.value = ...,避免竞态条件。HomeViewModel(),零 DI 开销。以 OnboardingViewModel 为例,iOS 侧用 SKIE 的 AsyncSequence 桥接:
// OnboardingStateHolder.swift
import Shared
@MainActor
final class OnboardingStateHolder: ObservableObject {
@Published var state: HomeUiState = .init()
private let viewModel = Shared.OnboardingViewModel()
private var collectionTask: Task<Void, Never>?
func startObserving() {
collectionTask = Task { [weak self] in
// SKIE 将 StateFlow 转为 AsyncSequence
for await state in self?.viewModel.uiState ?? AsyncStream<HomeUiState>.empty {
guard let self else { return }
self.state = state // 驱动 SwiftUI 刷新
}
}
viewModel.loadData()
}
deinit {
collectionTask?.cancel() // 取消订阅,释放资源
}
}核心就三步:for await state in viewModel.uiState → 赋值到 @Published → SwiftUI 自动刷新。不引入任何第三方桥接库。
为了更方便,我们还写了一个 Swift 扩展来获取首个值:
extension SkieSwiftFlowProtocol {
func first() async throws -> Element {
for try await element in self {
return element
}
throw NSError(domain: "SkieSwiftFlow", code: -1,
userInfo: [NSLocalizedDescriptionKey: "Flow completed without emitting a value"])
}
}这样一次性读取(如检查某个标志位)可以写 let state = try await viewModel.uiState.first(),不用 for await。
Android 端直接用 Compose:
@Composable
fun HomeScreen() {
val viewModel = remember { HomeViewModel() }
val uiState by viewModel.uiState.collectAsStateWithLifecycle()
HomeContent(
records = uiState.bloodSugarRecords,
isLoading = uiState.isLoading,
onRefresh = { viewModel.loadData() }
)
}一行 collectAsStateWithLifecycle(),比 iOS 侧还简单。
迁移前(iOS @Observable ViewModel,约 300+ 行 Swift):
@Observable
final class HomeViewModel {
var bloodSugarRecords: [BloodSugarRecord] = []
var isLoading = false
var errorMessage: String?
func loadData() async {
isLoading = true
do {
let dtos = try await repository.fetchDailyRecords(date: selectedDate)
bloodSugarRecords = dtos.map { BloodSugarRecord(from: $0) }
isLoading = false
} catch {
errorMessage = error.localizedDescription
isLoading = false
}
}
}迁移后(KMP ViewModel,约 370 行 Kotlin,但 Android + iOS 共用):
KMP ViewModel 写法如上所述。iOS 侧从 300+ 行缩减为约 50 行的 StateHolder 桥接层 + @Published 属性映射。Android 侧从零开始,直接消费 uiState。
关键收益:
StateHolder 极薄(纯数据转发,无业务逻辑),像"遥控器"一样驱动原生 SwiftUI 视图。数据层下沉(第一篇)解决了远程存储问题,但本地持久化还是分裂的:iOS 用 SwiftData,Android 用 Room。这两个框架的 schema、查询语法、迁移机制完全不同,维护两套本地存储的代价不亚于维护两套网络层。
SwiftData 是 Apple 生态专属,无法跨平台。Room KMP 在 2024 年末随着 Room 2.8 正式支持 KMP 后,成熟度已经足够用于生产。我们的选择很明确:将本地存储也统一到 shared/ 模块。
@Database(
entities = [
BloodSugarRecordEntity::class,
FoodRecordEntity::class,
ExerciseRecordEntity::class,
UserProfileEntity::class,
// ... 共 14 个 Entity
],
version = 12
)
@TypeConverters(InstantConverter::class)
@ConstructedBy(AppDatabaseConstructor::class)
abstract class AppDatabase : RoomDatabase() {
abstract fun bloodSugarDao(): BloodSugarDao
abstract fun foodRecordDao(): FoodRecordDao
abstract fun exerciseRecordDao(): ExerciseRecordDao
// ... 共 13 个 DAO
}每个 Entity 都内建了离线同步字段:
@Entity(tableName = "blood_sugar_records")
data class BloodSugarRecordEntity(
@PrimaryKey val id: String,
val uid: String,
val value: Double,
val isDirty: Boolean = false, // 是否有未同步的变更
val deleted: Boolean = false, // 软删除标记
val syncVersion: Long = 0, // 乐观锁版本号
val sourceDeviceId: String = "", // 数据来源设备
@ColumnInfo(name = "created_at") val createdAt: Long,
// ...
)同步策略很朴素:向上同步时查询 isDirty = 1 的记录推送到 Supabase;向下同步时按 uid 拉取远端增量,用 Upsert 合并到本地。
Room 需要知道数据库文件的物理路径。iOS 在沙盒的 NSDocumentDirectory 下,Android 在应用的 database 目录下。我们用 expect interface 抽象了这个差异:
// commonMain — 接口定义
interface DatabaseFactory {
fun createBuilder(): RoomDatabase.Builder<AppDatabase>
}
fun getRoomDatabase(factory: DatabaseFactory): AppDatabase {
return factory.createBuilder()
.setDriver(BundledSQLiteDriver())
.setQueryCoroutineContext(Dispatchers.IO)
.addMigrations(MIGRATION_3_4, MIGRATION_4_5, /* ... 共 9 个迁移 */)
.fallbackToDestructiveMigration(true)
.build()
}// iosMain — NSFileManager 获取 documents 目录
class IOSDatabaseFactory : DatabaseFactory {
override fun createBuilder(): RoomDatabase.Builder<AppDatabase> {
val dbPath = documentDirectory() + "/sugarlite.db"
return Room.databaseBuilder<AppDatabase>(name = dbPath)
}
@OptIn(ExperimentalForeignApi::class)
private fun documentDirectory(): String {
val url = NSFileManager.defaultManager.URLForDirectory(
directory = NSDocumentDirectory,
inDomain = NSUserDomainMask,
appropriateForURL = null, create = false, error = null
)
return requireNotNull(url?.path)
}
}// androidMain — Context.getDatabasePath
class AndroidDatabaseFactory(private val context: Context) : DatabaseFactory {
override fun createBuilder(): RoomDatabase.Builder<AppDatabase> {
val dbFile = context.getDatabasePath("sugarlite.db")
return Room.databaseBuilder<AppDatabase>(
context = context.applicationContext,
name = dbFile.absolutePath
)
}
}两端的数据库文件名都是 sugarlite.db,通过 Koin DI 在各平台注入对应的 Factory。
引入 Room KMP 后,已经安装旧版本的用户本机还有 SwiftData 存储的旧数据。我们写了一个 SwiftDataMigrationManager 来处理这个一次性迁移:
// SwiftDataMigrationManager.swift
@MainActor
final class SwiftDataMigrationManager {
func migrateIfNeeded(context: ModelContext) async {
let dao = Shared.CloudSourceProviderKt.getMigrationMetadataDao()
// 检查是否已迁移
if let meta = try? await dao.getByKey(key: "swift_data_imported"),
meta.swiftDataImported { return }
// 从 SwiftData 读取旧数据 → 写入 Room KMP
await performMigration(context: context)
}
private func performMigration(context: ModelContext) async {
let descriptor = FetchDescriptor<UserProfile>()
let oldProfiles = try? context.fetch(descriptor)
for profile in oldProfiles ?? [] {
let dto = profile.toDto()
try? await Shared.CloudSourceProviderKt.getUserProfileLocalSource().upsert(dto: dto)
}
// ... 同样迁移 BloodSugarRecord、FoodRecord、ExerciseRecord
// 标记迁移完成
try? await Shared.CloudSourceProviderKt.getMigrationMetadataDao()
.upsert(MigrationMetadataEntity(swiftDataImported: true))
}
}迁移在 App 启动时执行,完成后永不再触发。旧 SwiftData 模型代码保留在项目中(用于读取),但新数据全部走 Room KMP。
Room 数据库经历了从 version 3 到 12 的 9 次增量迁移。下面是几个有代表性的:
| 迁移 | 版本 | 变更 |
|---|---|---|
MIGRATION_3_4 |
3→4 | 为 food_glycemic_responses 添加同步字段(is_dirty, deleted, sync_version) |
MIGRATION_5_6 |
5→6 | 删除 food_name 列。由于 SQLite 不支持 DROP COLUMN,用表重建模式:建新表→复制数据→删旧表→重命名 |
MIGRATION_11_12 |
11→12 | 清理 exercise_records 中的缓存列(cached_exercise_name 等 5 个冗余字段),改为从 exercise_reference 实时查询 |
表重建模式是 Room 迁移中常见的技巧:
val MIGRATION_5_6 = object : Migration(5, 6) {
override fun migrate(db: SupportSQLiteDatabase) {
db.execSQL("""
CREATE TABLE food_glycemic_responses_new (... 新 schema,不含 food_name)
""")
db.execSQL("INSERT INTO food_glycemic_responses_new SELECT ... FROM food_glycemic_responses")
db.execSQL("DROP TABLE food_glycemic_responses")
db.execSQL("ALTER TABLE food_glycemic_responses_new RENAME TO food_glycemic_responses")
// 重建索引
db.execSQL("CREATE INDEX index_food_glycemic_responses_uid ON food_glycemic_responses(uid)")
}
}在 proto 过程中,我们发现迁移脚本中的 CREATE INDEX IF NOT EXISTS index_xyztree ... 在某些 SQLite 版本上会失败——因为 RTrees(R*Tree)索引只支持局部创建,跨 schema 复制时需要先创建虚拟表,再逐行 INSERT,最后重建关联索引。最终我们在 migration v10→v11 中直接删除了不再需要的索引,避开了 RTree 兼容性问题。
迁移 ViewModel 和 Room 之后,shared/ 模块的代码占比超过 85%。剩下的平台差异怎么处理?
Kotlin 的 expect/actual 机制允许在 commonMain 中声明接口,在 androidMain/iosMain 中提供平台实现。轻糖有 5 组 expect/actual 声明,每一组都很轻量:
// commonMain
expect object PlatformInfo {
val platform: String // "ios" / "android"
val osVersion: String // "17.5" / "14"
val deviceModel: String // "iPhone15,2" / "Pixel 8"
val appVersion: String // "1.2.3"
}// iosMain
actual object PlatformInfo {
actual val platform: String = "ios"
actual val osVersion: String get() = UIDevice.currentDevice.systemVersion
actual val deviceModel: String get() = UIDevice.currentDevice.model
actual val appVersion: String get() =
NSBundle.mainBundle.objectForInfoDictionaryKey("CFBundleShortVersionString") as? String ?: "unknown"
}// androidMain
actual object PlatformInfo {
actual val platform: String = "android"
actual val osVersion: String get() = Build.VERSION.RELEASE
actual val deviceModel: String get() = Build.MODEL
actual var appVersion: String = "unknown"
fun init(context: Context) {
val pkgInfo = context.packageManager.getPackageInfo(context.packageName, 0)
appVersion = pkgInfo.versionName ?: "unknown"
}
}这些信息主要用于:App 启动日志、提交反馈时附带设备信息、Supabase 请求头中的 User-Agent。
// commonMain
expect fun getDeviceLanguageCode(): String
// iosMain
actual fun getDeviceLanguageCode(): String = NSLocale.currentLocale.languageCode ?: "en"
// androidMain
actual fun getDeviceLanguageCode(): String = java.util.Locale.getDefault().language用于 Supabase Edge Function 的 Accept-Language 头和首次启动时的默认语言选择。
// commonMain
expect fun generateUUID(): String
// iosMain
actual fun generateUUID(): String = platform.Foundation.NSUUID().UUIDString()
// androidMain
actual fun generateUUID(): String = java.util.UUID.randomUUID().toString()用于离线记录的唯一 ID 生成(在同步到 Supabase 前分配)。
// commonMain
expect val platformModule: Module这是最"重"的一组 expect/actual,在 DI 初始化时合并进 Koin:
// iosMain
actual val platformModule: Module = module {
single<DatabaseFactory> { IOSDatabaseFactory() }
single<HealthDataSyncRepository> { HealthDataSyncRepositoryIos() }
single<SettingsRepository> { SettingsRepositoryIos() }
}// androidMain
actual val platformModule: Module = module {
single<DatabaseFactory> { AndroidDatabaseFactory(androidContext()) }
single<HealthDataSyncRepository> { HealthDataSyncRepositoryAndroid(androidContext()) }
single<SettingsRepository> { SettingsRepositoryAndroid(androidContext()) }
}// KoinHelper.kt — iOS 侧启动 Koin
fun doInitKoin() {
initKermitForIos()
startKoin {
modules(sharedModule, platformModule) // platformModule 来自 expect/actual
}
}iOS SwiftUI 入口调用 KoinHelperKt.doInitKoin() 即可完成所有初始化。
// commonMain — Room KSP 自动生成 actual
@Suppress("NO_ACTUAL_FOR_EXPECT")
expect object AppDatabaseConstructor : RoomDatabaseConstructor<AppDatabase>这个是 Room KSP 编译器生成的,不需要手写 actual。
5 组声明,总计不到 200 行 actual 代码。我们遵循两条原则:
expect interface 抹平会让接口签名变得奇怪。HealthDataSyncRepositoryIos 目前是 stub(所有方法返回空),等 HealthKit 接入时直接替换真实实现。expect fun getDeviceLanguageCode(): String 比 expect class LocaleManager 好维护得多。每个 expect 只做一件事,平台实现零依赖(不引入额外框架),测试也不必 mock。KMP 共享模块里的代码要能被 Swift 调用,需要经过 Kotlin/Native 编译成 Objective-C 兼容的 Framework。但默认的 Kotlin→ObjC 映射很生硬:suspend 函数变成带 completion handler 的回调,Flow 不可见,StateFlow 变成 Kotlinx_coroutines_coreStateFlow。
SKIE 解决了这些问题。 配置很简单:
// shared/build.gradle.kts
plugins {
alias(libs.plugins.skie) // 0.10.13,零配置
}
kotlin {
iosTarget.binaries.framework {
baseName = "Shared"
isStatic = true
export(libs.androidx.lifecycle.viewmodel) // 导出给 iOS 可见
}
}不需要额外的 skie {} 配置块。SKIE 默认启用了 Feature_CoroutinesInterop,自动将:
suspend fun → Swift async throws
Flow<T> / StateFlow<T> → Swift AsyncSequence
既然 SKIE 自动桥接了函数签名,我们设计了一个集中暴露 Kotlin 能力的入口文件——CloudSourceProvider.kt。它使用 KoinComponent 从 DI 容器中获取实例,以顶层函数暴露给 Swift:
// commonMain,通过 SKIE 暴露给 Swift 调用
internal object KoinProvider : KoinComponent {
fun provideBloodSugarLocalSource(): BloodSugarLocalSource = get()
fun provideMembershipRepository(): MembershipRepository = get()
// ...
}
// 查询类操作:返回 Flow,SKIE 转为 AsyncSequence,iOS 侧做 for await
fun getBloodSugarRecordsByUid(uid: String): Flow<List<BloodSugarRecordDto>> =
KoinProvider.provideBloodSugarLocalSource().getByUidFlow(uid.lowercase())
fun observeMembershipState(): Flow<MembershipState> =
KoinProvider.provideMembershipRepository().membershipState
// 写入类操作:suspend 函数,SKIE 转为 async throws
@Throws(HttpRequestException::class, RestException::class, IOException::class)
suspend fun saveBloodSugarRecord(dto: BloodSugarRecordDto): BloodSugarRecordDto =
KoinProvider.provideBloodSugarRepository().save(dto)
// 单条查询:suspend 即可
suspend fun getBloodSugarRecordById(id: String): BloodSugarRecordDto? =
KoinProvider.provideBloodSugarLocalSource().getById(id)几条经验:
Flow:如 getBloodSugarRecordsByUid() 返回 Flow,iOS 端 for await 即可响应数据库变更。suspend:如 saveBloodSugarRecord(),Swift 侧直接 try await。@Throws 注解很重要:不加的话,Kotlin 异常到 Swift 会变成 NSError 的 generic 错误;加了之后 Swift 可以按具体异常类型 catch。import Shared
// 持续订阅 — SKIE 将 Flow 转为 AsyncSequence
let flow = Shared.CloudSourceProviderKt.getBloodSugarRecordsByUid(uid: userId)
for await records in flow {
self.records = records
}
// 一次性写入
try await Shared.CloudSourceProviderKt.saveBloodSugarRecord(dto: newRecord)
// 订阅会员状态
let stateFlow = Shared.CloudSourceProviderKt.observeMembershipState()
for await state in stateFlow {
self.membershipState = state
}不需要任何回调、delegate 或 completion handler。这就是 SKIE 的价值——让 Kotlin 在 Swift 中几乎跟原生代码一样自然。
通畅的调用路径解决了,但异常处理是另一个容易被忽略的坑。Kotlin 和 Swift 的异常模型差异很大——Kotlin 没有 checked exception,所有异常都是运行时抛出;而 Swift 使用 throws + do/catch 的显式错误模型。当 Kotlin 的异常穿过 Kotlin/Native 边界来到 Swift,会变成什么?
Kotlin 和 Swift 的异常模型有根本性分歧。Kotlin 所有异常都是 unchecked——你在函数签名上看不到它会抛什么;而 Swift 通过 throws 要求编译期声明。
先看一个反面案例。假设 CloudSourceProvider 中有一个不标注 @Throws 的 suspend 函数:
// ❌ 不加 @Throws
suspend fun saveBloodSugarRecord(dto: BloodSugarRecordDto): BloodSugarRecordDto =
KoinProvider.provideBloodSugarRepository().save(dto)很多人看到编译后的 Swift 签名有 throws,就以为 catch 能兜住:
// 编译后的 Swift 签名确实有 throws
func saveBloodSugarRecord(dto: BloodSugarRecordDto) async throws -> BloodSugarRecordDto实际情况比这更危险。 根据 KMP 官方文档,suspend 函数不加 @Throws 时:
CancellationException → 正常传播为 NSError(这是唯一的例外)HttpRequestException、IOException、自己定义的业务异常……)→ 被视为 未处理异常,直达 Swift 侧后 导致程序终止——也就是 crash下面的代码看起来无害,实际上如果抛出的不是 CancellationException,App 直接闪退:
do {
let result = try await Shared.CloudSourceProviderKt.saveBloodSugarRecord(dto: record)
} catch {
// ⚠️ 这个 catch 永远捕获不到 HttpRequestException!
// 异常到达 Swift 之前就已被 Kotlin/Native 当作"未处理异常"终结了程序
}普通(非 suspend)函数更严格:完全不传播任何 Kotlin 异常,一旦有异常穿过边界,直接 crash。
所以 @Throws 不是一个"让异常类型更具体"的优化,而是一道 安全闸门——只在 @Throws 声明列表中的类型(及子类)才会被安全地转换为 NSError。不在列表中的异常,仍然 crash。
@Throws 注解告诉 Kotlin/Native 编译器:“只把列表中这些类型(及它们的子类)安全地转发为 NSError,其他异常仍然 crash。“这就是为什么每个 CloudSourceProvider 中的写入函数都加上了精确的异常声明:
// ✅ 加了 @Throws——只有这些异常类型会安全传播
@Throws(
HttpRequestException::class, // HTTP 超时、连接失败
RestException::class, // Supabase REST 错误(如违反约束)
UnknownRestException::class, // 未分类的 HTTP 错误
HttpRequestTimeoutException::class, // Ktor 客户端超时
IOException::class, // 网络 IO 错误
CancellationException::class, // 协程取消
)
suspend fun saveBloodSugarRecord(dto: BloodSugarRecordDto): BloodSugarRecordDto =
KoinProvider.provideBloodSugarRepository().save(dto)加了 @Throws 后,Swift 侧可以按异常类型 catch——而且只有这些类型会被安全捕获:
do {
let result = try await Shared.CloudSourceProviderKt.saveBloodSugarRecord(dto: record)
} catch let error as Shared.HttpRequestException {
// 网络超时 — 可以提示用户"网络不稳定,记录已保存到本地"
toast("网络暂时不可用,已离线保存")
// 本地 Room 的数据仍然在,下次同步会自动上传
} catch let error as Shared.RestException {
// Supabase 后端错误 — 记录日志,静默降级
AppLogger.error("保存失败,后端返回错误: \(error)")
} catch {
// ⚠️ 如果这里捕获到不在 @Throws 列表中的异常,
// 它不会被正常传播——程序可能已经 crash 了
// 所以 @Throws 的类型声明一定要全
}关键收益:网络超时不报警,后端错误记日志,两种场景的用户体验完全不同。
一个容易被忽略的细节:CancellationException 在 Kotlin 中不是普通异常,它是协程结构化并发的取消信号。在 CloudSourceProvider 里做错误处理时,必须遵循这一条规则:
suspend fun initializeSupabaseAuth() {
try {
val loaded = sharedSupabaseClient.auth.loadFromStorage()
// ...
} catch (e: IllegalStateException) {
AppLogger.i("AuthInit") { "本地无保存的 session" }
} catch (e: Exception) {
if (e is CancellationException) throw e // ← 必须重新抛出!
AppLogger.e("AuthInit", e) { "初始化 Supabase Auth 失败" }
}
}如果吞掉了 CancellationException,协程作用域无法正常取消,可能导致资源泄漏——比如一个 ViewModel 已经销毁了,但它的协程还在跑 Room 查询。
不是所有函数都需要 @Throws。查询类函数(返回 Flow 或 suspend)通常不加,但前提是异常在 Kotlin 侧已经被 catch 掉,不会穿过边界:
AsyncSequence 的迭代中,Swift 侧在 for try await 里可以 catch 到。这里的行为不同:Flow 中的异常会被终止流,但不会 crash。suspend 查询(如 getBloodSugarRecordById)有风险——虽然"没查到"返回 null 不需要异常,但如果 Room 查询本身抛了异常(比如数据库损坏),不加 @Throws 就会 crash。安全做法是在 Kotlin 侧用 try/catch 包裹,把异常转成 null 返回值:// 查询失败返回 null,异常在 Kotlin 侧消化掉
suspend fun getBloodSugarRecordById(id: String): BloodSugarRecordDto? =
try {
KoinProvider.provideBloodSugarLocalSource().getById(id)
} catch (e: Exception) {
AppLogger.e("查询单条记录失败", e)
null
}只有在 Kotlin 侧把所有异常都 catch 干净的前提下,省略 @Throws 才是安全的。
@Throws,且类型要列全。这不是代码风格问题,是 crash vs 不 crash 的问题。一个遗漏的异常类型就是一颗定时炸弹。@Throws 的异常类型要精确、要覆盖全面。别写 @Throws(Exception::class)——到了 Swift 那边还是区分不了。花几分钟把 HttpRequestException、RestException、IOException 分开声明。同时确保可能抛出的所有类型都在列表里。CancellationException 不要吞掉。在 Kotlin 侧的 try/catch 中判断 if (e is CancellationException) throw e,这是一个机械操作但非常关键的习惯。即使在 @Throws 列表中声明了它,吞掉它依然会导致协程无法正常取消。@Throws,必须在 Kotlin 侧消化所有异常。把异常转成 null 或默认值再返回,确保没有任何异常穿过语言边界。会员订阅是收入的核心。在迁移前,iOS 用 RevenueCat iOS SDK,Android 还没做。如果各自维护,两端的行为一致性很难保证——“免费用户能不能看到这个功能"这种判断必须是一模一样的逻辑。
RevenueCat 官方提供了 revenuecat/purchases-kmp SDK(我们用 3.1.0),API 与原生 SDK 非常接近。我们在 commonMain 中实现了完整的 MembershipRepository:
class MembershipRepositoryImpl(
private val userProfileRepository: UserProfileRepository
) : MembershipRepository {
private val _membershipState = MutableStateFlow(MembershipState.FREE)
override val membershipState: StateFlow<MembershipState> = _membershipState.asStateFlow()
// PurchasesDelegate:接收 RevenueCat 实时推送
private val delegate = object : PurchasesDelegate {
override fun onCustomerInfoUpdated(customerInfo: CustomerInfo) {
val state = customerInfo.toMembershipState()
emitAndPersist(state) // 更新本地状态 + 同步到 Supabase
}
}
override fun configure(apiKey: String, appUserId: String?, debugMode: Boolean) {
Purchases.configure(apiKey = apiKey) { this.appUserId = appUserId }
Purchases.sharedInstance.delegate = delegate
}
override suspend fun purchase(packageIdentifier: String): Result<MembershipState> {
return runCatching {
val offerings = Purchases.sharedInstance.awaitOfferings()
val pkg = offerings.current!!.availablePackages
.find { it.identifier == packageIdentifier }!!
val result = Purchases.sharedInstance.awaitPurchase(pkg)
result.customerInfo.toMembershipState()
}
}
// CustomerInfo → MembersipState 映射
private fun CustomerInfo.toMembershipState(): MembershipState {
val entitlement = entitlements["SugarLite Pro"]
return if (entitlement?.isActive == true) {
val expirationDate = entitlement.expirationDateMillis?.let {
Instant.fromEpochMilliseconds(it)
}
val tier = if (expirationDate == null) MembershipTier.LIFETIME
else MembershipTier.PREMIUM
MembershipState(tier = tier, expirationDate = expirationDate, isActive = true)
} else {
MembershipState.FREE
}
}
}核心设计:
_membershipState 是会员状态的唯一真实来源。RevenueCat 实时推送通过 PurchasesDelegate.onCustomerInfoUpdated 自动更新这个状态。user_profiles.membership_type,确保后端也同步了最新的会员等级。configure() 方法接受 apiKey 参数,iOS 和 Android 各自使用自己的 API Key 调用,其余逻辑 100% 共享。iOS 侧使用时只需一行:
Shared.CloudSourceProviderKt.configureRevenueCat(
apiKey: Constants.revenueCatApiKey,
appUserId: uid,
debugMode: isDebug
)续接第一篇文章的五条原则,补充后续迁移中沉淀的经验:
StateFlow 通过 SKIE 转 AsyncSequence 的体验足够好,不用再为每个功能维护两份 ViewModel。但 iOS 侧仍需要一个薄薄的 StateHolder 来做 @Published 桥接——这个成本很低,一个 ViewModel 的桥接通常不到 50 行。expect/actual 不求全,只做必要抽象。5 组声明覆盖了 UUID、语言、设备信息、DB 路径、DI 注入。不要为了"设计一致性"强行抽象——HealthDataSyncRepository 的 iOS 实现目前就是一个 stub,因为强行抹平 HealthKit 和 Health Connect 的接口差异会让代码更难读。PurchasesDelegate 的实时推送机制也很好用。少量未覆盖的高级功能(如 Paywalls)可以直接在平台层补充。CloudSourceProvider 只负责从 Koin 取实例并暴露函数签名,不写任何胶水代码。suspend 自动变 async,Flow 自动变 AsyncSequence。新成员上手时看到 import Shared + try await 的组合会觉得很自然。本文基于 轻糖 SugarLite 的真实迁移过程撰写。如果你对 KMP 跨平台开发感兴趣,欢迎下载 App 体验。
2026-05-19 00:00:00
SugarLite 最初是一个纯 iOS 应用,技术栈是 SwiftUI + MVVM + Supabase Swift SDK。随着 Android 版本的需求提上日程,如果简单地把业务逻辑复制一份到 Kotlin,后续的维护成本会成倍增长——网络层、数据模型、业务规则都要双端维护。所以我们选择了 Kotlin Multiplatform,让 shared/ 模块承载所有跨平台业务逻辑,iOS 侧只保留 SwiftUI 和系统框架调用。
这篇文章记录整个迁移过程,从架构重构到 CI/CD 适配,踩过的坑和学到的经验。
在引入 KMP 之前,我们先做了一次架构重构。核心目标很简单:让 ViewModel 不依赖任何外部框架,这样底层将来换成 Kotlin 也不会波及上层。
重构后的依赖方向:
View → ViewModel → Protocol ← Repository → External Frameworks各层职责:
| 层级 | 目录 | 允许导入 | 约束 |
|---|---|---|---|
| View | Views/ |
SwiftUI | 禁止直接访问 Repository |
| ViewModel | ViewModels/ |
Foundation | 禁止导入 Supabase/HealthKit/SwiftData |
| Domain | Domain/ |
Foundation | 定义 Protocol、UseCase、Service |
| Data |
Repositories/ + Data/
|
任意框架 | 唯一允许导入 Supabase、SwiftData 的层级 |
这次重构的价值在后来的迁移中体现得非常明显——当 Supabase 客户端从 Swift SDK 换成 KMP shared 模块时,ViewModel 层一行都不用改,因为它只依赖 FoodReferenceRepositoryProtocol 这样的接口。
架构清理完成后,正式引入 KMP。项目根目录变成了这样:
├── iosApp/ # 原 iOS 项目整体迁入
│ ├── BloodSugarApp/ # SwiftUI 源码
│ ├── BloodSugarApp.xcodeproj
│ └── ci_scripts/ # Xcode Cloud 构建脚本
├── composeApp/ # Compose Multiplatform(Android 入口)
├── shared/ # KMP 共享模块
│ ├── src/commonMain/kotlin/ # 跨平台业务逻辑
│ ├── src/androidMain/kotlin/
│ └── src/iosMain/kotlin/
├── gradle/
├── build.gradle.kts
└── settings.gradle.ktsshared/build.gradle.kts 的关键配置:
kotlin {
android { ... }
listOf(iosX64(), iosArm64(), iosSimulatorArm64()).forEach { iosTarget ->
iosTarget.binaries.framework {
baseName = "Shared"
isStatic = true
}
}
sourceSets {
commonMain.dependencies {
implementation(libs.kotlinx.serialization.json)
implementation(libs.kotlinx.coroutines.core)
implementation(libs.kotlinx.datetime)
api(libs.supabase.auth)
api(libs.supabase.postgrest)
api(libs.supabase.storage)
api(libs.ktor.client.core)
implementation(libs.koin.core)
}
androidMain.dependencies {
implementation(libs.ktor.client.cio)
}
iosMain.dependencies {
implementation(libs.ktor.client.darwin)
}
}
}两个点值得说:
isStatic = true:静态 framework,避免 Xcode Cloud 构建时的动态库签名问题。api(libs.supabase.*):作为 API 依赖暴露,iOS 侧理论上能直接用,但我们会用封装层隐藏细节。这是最核心的一步——把散落在各 Repository 中的 Supabase 调用整体下沉到 shared/src/commonMain/kotlin/。
为所有 13 张表创建 @Serializable 的 Kotlin DTO,统一用 snake_case 字段映射:
@Serializable
data class FoodReferenceDto(
val id: String,
val name: String,
val name_en: String? = null,
val category: String,
val gi_value: Int? = null,
val calories: Double? = null,
// ...
)每个领域实体对应一个 CloudSource,封装 CRUD 操作:
class FoodReferenceCloudSource(private val client: SupabaseClient) {
suspend fun fetchAll(): List<FoodReferenceDto> {
return client.from("food_reference").select().decodeList()
}
suspend fun fetchPage(
page: Int, pageSize: Int,
searchText: String?, category: String?
): List<FoodReferenceDto> {
// 构建 PostgREST 查询...
}
}在 sharedModule 中注册所有 CloudSource:
val sharedModule = module {
single { SupabaseClientProvider.client }
single { FoodReferenceCloudSource(get()) }
single { BloodSugarCloudSource(get()) }
// ...
}KMP 的迁移不需要一次性完成。我们的策略是"新功能直接写 KMP,旧功能逐步替换"。以 FoodReferenceRepository 为例:
先让 Swift 能拿到 Koin 容器里的实例。在 iosMain 中:
fun doInitKoin() {
startKoin { modules(sharedModule) }
}在 commonMain 中暴露获取方法:
private object KoinProvider : KoinComponent {
fun provideFoodReferenceCloudSource(): FoodReferenceCloudSource = get()
}
fun getFoodReferenceCloudSource(): FoodReferenceCloudSource =
KoinProvider.provideFoodReferenceCloudSource()Kotlin 的顶层函数会被编译为 Swift 的全局函数,iOS 侧直接调用 CloudSourceProviderKt.getFoodReferenceCloudSource() 即可。
在 SwiftUI 入口的 init() 中:
init() {
KoinHelperKt.doInitKoin()
AppLogger.database.info("KMP Koin 已初始化")
}改造前(Swift Supabase SDK):
import Supabase
final class FoodReferenceRepository {
private var supabaseClient: SupabaseClient
func fetchAll() async throws -> [FoodReferenceDTO] {
let dtos: [FoodReferenceDTO] = try await supabaseClient
.from("food_reference")
.select()
.execute()
.value
return dtos
}
}改造后(KMP CloudSource):
import Shared
final class FoodReferenceRepository {
private let cloudSource: FoodReferenceCloudSource
init() {
self.cloudSource = CloudSourceProviderKt.getFoodReferenceCloudSource()
}
func fetchAll() async throws -> [FoodReferenceDTO] {
let kmpDtos = try await cloudSource.fetchAll()
return kmpDtos.map { FoodReferenceDTO(fromKmp: $0) }
}
}变化就三处:import Supabase → import Shared,直接写 PostgREST 查询 → 调用封装好的 cloudSource.fetchAll(),新增一个 fromKmp 的 DTO 转换扩展。
这个模式可以复制到每一个 Repository,团队按优先级逐个迁移即可。
引入 KMP 后最大的挑战是 CI/CD。Xcode Cloud 的构建环境默认没有 Java 和 Gradle,而 iOS 构建又依赖 Kotlin/Native 编译出的 Shared.framework。
在 Xcode Cloud 的 ci_pre_xcodebuild.sh 阶段安装 Java 和 Gradle:
#!/bin/sh
set -euo pipefail
ROOT_DIR="$(cd "$(dirname "$0")/../.." && pwd)"
cd "$ROOT_DIR"
export GRADLE_USER_HOME="$ROOT_DIR/.gradle"
export HOMEBREW_NO_AUTO_UPDATE=1
resolve_java_home() {
if [ -n "${JAVA_HOME:-}" ] && [ -x "$JAVA_HOME/bin/java" ]; then
echo "$JAVA_HOME"
return 0
fi
for version in 21 17 11; do
if JAVA_CANDIDATE=$(/usr/libexec/java_home -v "$version" 2>/dev/null); then
if [ -x "$JAVA_CANDIDATE/bin/java" ]; then
echo "$JAVA_CANDIDATE"
return 0
fi
fi
done
if command -v brew >/dev/null 2>&1; then
for formula in openjdk@17 openjdk; do
if brew list --versions "$formula" >/dev/null 2>&1; then
JAVA_CANDIDATE="$(brew --prefix "$formula")/libexec/openjdk.jdk/Contents/Home"
if [ -x "$JAVA_CANDIDATE/bin/java" ]; then
echo "$JAVA_CANDIDATE"
return 0
fi
fi
done
fi
return 1
}
ensure_java() {
if JAVA_CANDIDATE="$(resolve_java_home)"; then
export JAVA_HOME="$JAVA_CANDIDATE"
else
echo "[Xcode Cloud] Java not found. Installing openjdk@17 via Homebrew..."
brew install openjdk@17
export JAVA_HOME="$(brew --prefix openjdk@17)/libexec/openjdk.jdk/Contents/Home"
fi
export PATH="$JAVA_HOME/bin:$PATH"
}
ensure_java
echo "[Xcode Cloud] JAVA_HOME=$JAVA_HOME"
java -version
./gradlew --version在 Xcode Build Phases 中添加 Run Script:
#!/bin/sh
set -euo pipefail
ROOT_DIR="$(cd "$(dirname "$0")/../.." && pwd)"
cd "$ROOT_DIR"
# Xcode Preview 优化:跳过 Gradle 构建
if [ "${OVERRIDE_KOTLIN_BUILD_IDE_SUPPORTED:-}" = "YES" ]; then
echo "Skipping Gradle build due to OVERRIDE_KOTLIN_BUILD_IDE_SUPPORTED=YES"
exit 0
fi
# 解析 JAVA_HOME(与 ci_pre_xcodebuild.sh 相同逻辑)
# ...
export PATH="$JAVA_HOME/bin:$PATH"
./gradlew :shared:embedAndSignAppleFrameworkForXcode这个脚本在每次 Xcode 构建时调用 Gradle 任务来编译 Kotlin/Native 并嵌入 framework。本地开发时通过 OVERRIDE_KOTLIN_BUILD_IDE_SUPPORTED 环境变量做了优化——Xcode Preview 触发构建时跳过 Gradle,避免拖慢速度。
Sentry 脚本与 Widget Extension 的构建循环依赖:错误信息很诡异,排查后发现是 Sentry 的 “Upload Debug Symbols” 脚本和 Widget Extension 的 Embed 阶段之间存在隐式依赖。解决方案很简单——把 Sentry 脚本拖到 Embed 阶段之后。
Java Runtime 解析不稳定:Xcode Cloud 各版本镜像上 Java 安装路径不统一。最终的 resolve_java_home() 用了多级 fallback:系统 JAVA_HOME → /usr/libexec/java_home → Homebrew → brew list。这套冗余查找策略确保了在任何镜像版本上都能找到 Java。
回头看整个过程,我们遵循了几个原则:
@Observable 维持 SwiftUI 响应式体验。本文基于 轻糖 SugarLite 的真实迁移过程撰写。如果你对 KMP 跨平台开发感兴趣,欢迎下载 App 体验。
2026-05-18 09:00:00
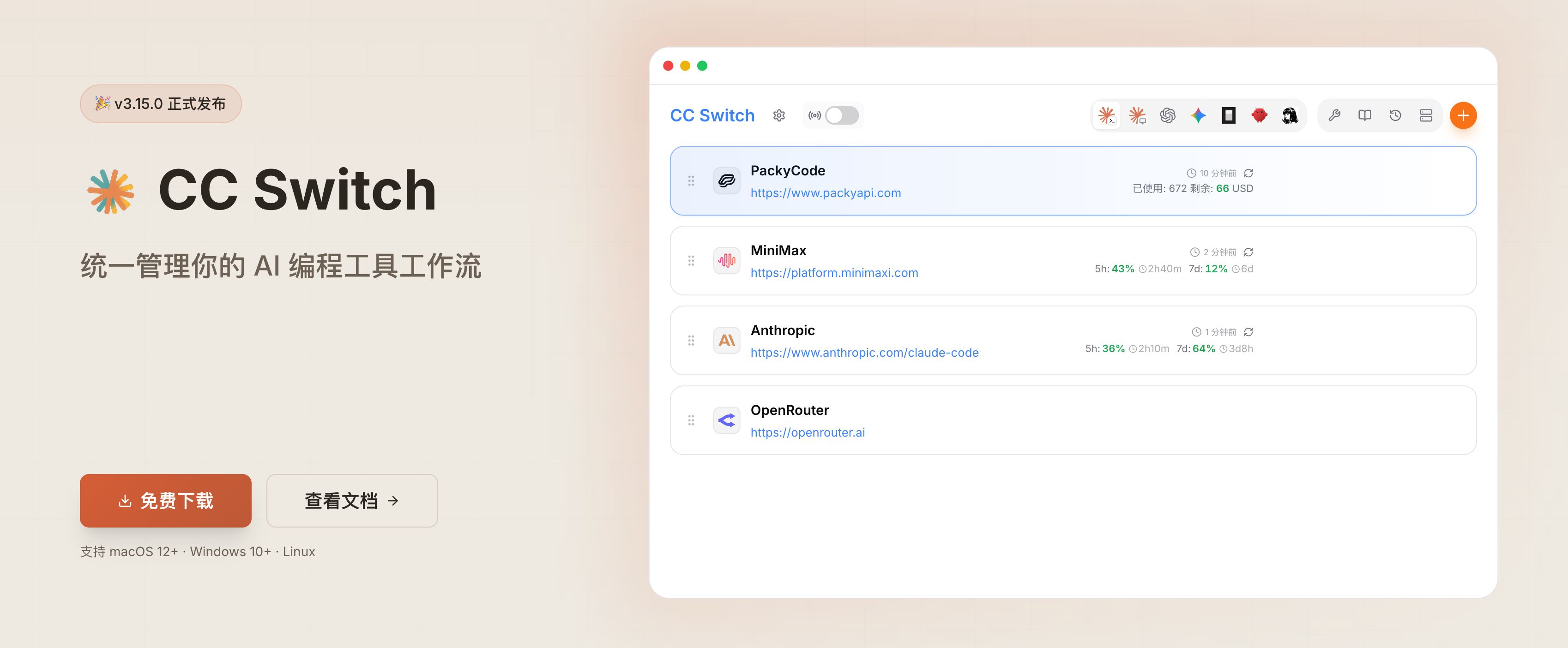
前面聊过 cc switch 的基础用法,今天单独说一下 CC Switch 里 Claude Desktop 面板的配置。在 3.15.0 中加入的功能,专门用来给 Claude Desktop 这个官方桌面客户端接入第三方供应商。
CC Switch 中的「Claude」和「Claude Desktop」是两个不同的面板,分别对应 Claude Code(CLI)和 Claude Desktop(桌面客户端)。区别在于 Claude Desktop 用的是自己的 3P profile 配置,而不是
~/.claude/settings.json,两个面板在图标右下角会有小标记区分。
Claude Desktop 面板能做的事情很简单:
支持 macOS 和 Windows。Linux 暂时不能写入 Claude Desktop 的 3P 配置。切换供应商后需要重启 Claude Desktop 才能生效,它不会像 Claude Code 那样热加载。
另外有一点需要注意:Claude Desktop 的 3P profile 不走 CC Switch 的 MCP / Skills 同步,这些功能在桌面端是独立管理的。
左侧应用切换器里选择 Claude Desktop。

如果没看到入口,去 设置 → 通用 → 应用可见性 里确认没有被隐藏。
大部分用户是先在 Claude Code 里配好了一堆供应商,然后才想把这些配置带到 Claude Desktop 里。第一次进入 Claude Desktop 面板时,如果这里还没有供应商,直接点 将 Claude Code 中已有的供应商导入 就行。

这个功能会帮你把 Claude Code 那边的供应商配置一键搬过来,不用重新填接口地址、API Key 和默认模型。导入逻辑大概是:
ANTHROPIC_DEFAULT_SONNET_MODEL、ANTHROPIC_DEFAULT_OPUS_MODEL、ANTHROPIC_DEFAULT_HAIKU_MODEL 会自动转成 Desktop 的 Sonnet / Opus / Haiku 映射[1M] 后缀会转成 Desktop profile 中的 supports1m 标记导入之后建议逐个检查一下模型映射是否正确,尤其是 Kimi、DeepSeek、GLM、DouBao 这类非 Claude 模型,通常需要用模型映射模式。
如果没有可导入的配置,或者想专门给 Claude Desktop 加一个不同的供应商,点右上角 + 添加即可。
三种选择:
对于普通的 Anthropic Messages API 兼容供应商,流程很简单:选预设或自定义 → 填 API Key → 确认接口地址 → 关掉「需要模型映射」→ 添加。
在供应商卡片上点「启用」,然后完全退出并重启 Claude Desktop。
注意:Claude Desktop 不会热重载配置,只关聊天窗口不够,要从托盘里退出或者确保进程完全结束。
适合供应商本身提供了原生 Anthropic Messages API 的情况。CC Switch 会把 Claude Desktop 的 3P profile 直接指到供应商接口:
{
"inferenceProvider": "gateway",
"inferenceGatewayBaseUrl": "https://api.example.com",
"inferenceGatewayAuthScheme": "bearer",
"inferenceGatewayApiKey": "你的 API Key"
}适用条件:供应商暴露的是原生 Anthropic Messages API,模型 ID 是 claude-* 或 anthropic/claude-* 格式,不需要格式转换。直连模式下不需要 CC Switch 一直开着本地路由。
「手动指定 Claude Desktop 模型列表」是个高级选项,大部分原生 Claude 模型供应商不需要填,Claude Desktop 会自动读 /v1/models。只有供应商的 /v1/models 不可用,或者返回的模型名 Claude Desktop 不认识时才需要手动添加。
如果供应商不是 Claude 系列模型(比如 deepseek、kimi 等),或者接口格式需要 CC Switch 做转换,就要开启「需要模型映射」。
开启后,Claude Desktop 会连到 CC Switch 的本地网关:
http://127.0.0.1:15721/claude-desktopCC Switch 在中间负责:向 Claude Desktop 暴露安全的 claude-* 模型路由,把 Desktop 选的模型角色映射到真实上游模型,按供应商要求做 Anthropic / OpenAI / Gemini 格式转换,并用 CC Switch 里存的凭据访问上游。
支持的格式:
| 格式 | 用途 |
|---|---|
| Anthropic Messages | 原生或兼容 Anthropic 请求 |
| OpenAI Chat Completions |
/chat/completions 兼容接口 |
| OpenAI Responses API | OpenAI Responses 兼容接口 |
| Gemini Native generateContent | Gemini 原生接口 |
模型映射模式下,Claude Desktop 只能看到 claude-* 形式的路由模型名,真实的上游模型名不会写进 Claude Desktop profile。
模型映射的核心思路是:Claude Desktop 现在会拒绝非 claude-* 的模型名,所以需要通过 CC Switch 做一轮角色映射。
| 字段 | 说明 |
|---|---|
| 模型角色 | Claude Desktop 可识别的 Sonnet / Opus / Haiku 路由 |
| 菜单显示名 | 在 Claude Desktop 模型菜单里显示的名称 |
| 实际请求模型 | 发给上游供应商的真实模型 ID |
| 1M | 向 Claude Desktop 声明该模型支持 1M 上下文 |
举个例子,如果想在 Claude Desktop 里用 Kimi:
| 模型角色 | 菜单显示名 | 实际请求模型 | 1M |
|---|---|---|---|
| Sonnet | Kimi K2 | kimi-k2 |
按供应商能力选择 |
想用 DeepSeek:
| 模型角色 | 菜单显示名 | 实际请求模型 | 1M |
|---|---|---|---|
| Sonnet | DeepSeek V4 Pro | deepseek-v4-pro |
按供应商能力选择 |
三个角色的建议分工:
| 模型角色 | 用途 |
|---|---|
| Sonnet | 默认主力模型 |
| Opus | 高质量或复杂任务 |
| Haiku | 快速、低成本的场景 |
如果供应商只有一个模型,只配一个 Sonnet 也行。模型映射模式至少需要一条有效映射。
模型映射模式必须依赖 CC Switch 的本地路由来做请求转换。这个开关默认在主界面是隐藏的,需要手动打开。
去 设置 → 路由 → 本地路由,开启 在主页面显示本地路由开关。
打开后回到 Claude Desktop 面板,右上角就能看到本地路由开关了。

状态含义:
| 状态 | 说明 |
|---|---|
| 开启 | 本地网关运行中,地址是 127.0.0.1:15721
|
| 关闭 | 直连供应商仍可用,模型映射供应商无法工作 |
| 正在加载 | 路由服务在启动或停止中 |
只有开了「需要模型映射」的供应商才需要本地路由,直连的不用管。
如果其他应用正在用代理接管,关本地路由可能会被阻止。先去设置里的路由服务区域关掉对应应用接管,再停本地路由。
想切回官方登录模式的话:
CC Switch 会恢复 Claude Desktop 的官方 1P 模式,把 3P profile 清理掉。官方模式不需要 API Key,也不需要本地路由。
从 Claude Code 导入供应商时,会自动加一条 Claude Desktop Official,方便随时切回去。
CC Switch 写入的是 Claude Desktop 的 3P 配置目录:
macOS:
~/Library/Application Support/Claude/claude_desktop_config.json
~/Library/Application Support/Claude-3p/claude_desktop_config.json
~/Library/Application Support/Claude-3p/configLibrary/_meta.json
~/Library/Application Support/Claude-3p/configLibrary/00000000-0000-4000-8000-000000157210.jsonWindows:
%LOCALAPPDATA%\Claude\claude_desktop_config.json
%LOCALAPPDATA%\Claude-3p\claude_desktop_config.json
%LOCALAPPDATA%\Claude-3p\configLibrary\_meta.json
%LOCALAPPDATA%\Claude-3p\configLibrary\00000000-0000-4000-8000-000000157210.json配置文件由 CC Switch 自动维护,不建议手动改。如果出现配置不一致,重新启用一次当前供应商一般就能修好。
CC Switch 的 Claude Desktop 面板本质上就是把原本只对 CLI 工具开放的供应商管理能力搬到了桌面端。对于已经在 CC Switch 里配置了一堆供应商的用户来说,从 Claude Code 一键导入是最快的路径。
直连模式省心,模型映射模式灵活。如果主力用 Claude 系列模型,直连就够了;如果想在 Claude Desktop 里用 Kimi、DeepSeek 等模型,模型映射模式配合本地路由就能搞定。
2026-04-29 14:55:00
在 AI 编程工具的世界里,Claude Code 无疑是当前最强大的选择之一。然而,随着各大云服务商纷纷推出自己的大语言模型 API,如何方便地在不同供应商之间切换,成为了一个实际的需求。今天就给大家介绍两款工具:cc switch 和 cc desktop switch,帮助你快速切换 Claude Code 的模型供应商。
项目地址:
- cc switch: farion1231/cc-switch (54.9k ⭐)
- cc desktop switch: lonr-6/cc-desktop-switch
cc switch 是一款跨平台的桌面应用,专门用于管理 Claude Code、Codex、Gemini CLI、OpenCode 和 OpenClaw 这五款主流 AI 编程 CLI 工具的供应商配置。
# 通过 Homebrew 安装(推荐)
brew tap farion1231/ccswitch
brew install --cask cc-switch
# 更新
brew upgrade --cask cc-switch或者从 Releases 页面下载 CC-Switch-v{version}-macOS.dmg。
从 Releases 页面下载:
CC-Switch-v{version}-Windows.msi 安装版CC-Switch-v{version}-Windows-Portable.zip 便携版# Arch Linux
paru -S cc-switch-bin
# 或从 Releases 下载 deb/rpm/AppImagecc desktop switch 是一款专注于 Claude Desktop 官方桌面客户端 的轻量级配置工具。它和 cc switch 的定位不同:cc switch 主要面向 CLI 用户,而 cc desktop switch 专注于桌面版 Claude Desktop。
注意:只关闭聊天窗口通常不够,请在任务栏托盘里退出 Claude,或在任务管理器里确认没有残留的 Claude 进程。
笔者使用 cc switch 已经有一段时间了,整体体验非常不错。以下是我的一些使用感受:
cc switch 和 cc desktop switch 为 Claude Code 用户提供了便捷的供应商管理方案。两者的定位略有不同:
无论你是需要测试不同模型的效果,还是想要找到性价比最高的供应商,这些工具都能满足你的需求。如果你正在使用 Claude Code,不妨试试这些工具,相信它们会给你带来不错的体验。
如果你对 AI 编程工具感兴趣,也可以看看我之前的文章:Neovim 入门指南系列,里面有很多关于编辑器配置和 AI 集成的相关内容。
2025-12-08 09:24:46
如何脱离 xcode 开发 iOS 是很多人在探索的方案。毕竟 xcode 编辑体验实在是太差了。
这里说的是脱离 xcode,而不是脱离 macOS。
这是今天要安利的工具 SweetPad。SweetPad 是 vscode 上的一个插件,插件可以实现在 vscode 中进行自动补全、调试、编译和运行、格式化、测试等功能。常见的开发场景中基本可以脱离 xcode 来使用。