2021-12-20 15:33:00

21fall 申请季格外不同,因为 2020 年 1 月全世界爆发疫情以后,校园关闭,留学生滞留国内上网课。加上中美博弈,10043 总统令,相互关闭总领馆,停止办理所有非移民签证,增加 travel ban NIE(National Interest Exceptions) 限制,使得中国学生赴美留学变得难上加难。虽然国内很快控制住疫情,但是美国疫情曲线居高不下,使得准备赴美留学的国内家长十分担心。在这种特殊的后疫情时代下,留学申请有哪些困难呢?笔者完整的经历了一遭,这篇文章来详细聊聊。
笔者留学的目的以及起源在 2019 年年终总结里面详述了,每个人情况不同,并且充满主观因素,不在本篇文章里讨论了。关于 TOEFL 和 GRE 备考相关的事情写在 2020 年年终总结里了,本篇也不赘述了。本篇文章假设你已经下定决心要去美国读 CS Master 且已准备好 TOEFL & GRE 成绩,针对申请全过程,笔者所见所闻所想,与君分享心得与“收获”。如果读者打算今年申请,那么请静下心来耐心读完,一个过来人的踩坑经历一定会让你收获“颇丰”。

由于 10043 总统令的限制,七子和北邮限制签证,所以不少优秀的学子挤到欧陆学校了。欧陆有不少好学校,除去名气很大的牛剑,瑞士,德国都有顶尖的 CS 高校。具体排名可以见 QS World University Rankings。
关于排行榜,有 2 个权威排行榜,一个是 Qs,一个是 USNews。在 Qs 榜单上,英国大学排名偏高,在 USNews 榜单上,美国大学排名偏高。
论排名,英美大学在 TOP10 上不分伯仲。但是再综合考虑毕业后就业环境,美国在 CS 这方面还是更胜一筹,因为有纽约和硅谷。回到择校上,七子和北邮可以选择欧陆,加拿大,日本,香港,新加坡。笔者对全球的大学基本都有了解,总结了下面这个表格:
| 明显优点 | 明显缺点 | |
|---|---|---|
| 美国 | GPA 不区分 985/211/双非 | 花销最大 |
| 英国 | 项目一般只有一年,花销小 | GPA 区分 985/211/双非,看重本科出身 |
| 加拿大 | CS TOP 100 的学校少,UoT 一枝独秀 | |
| 日本 | 除去 TOEFL/IELTS,还需要考 N1 | |
| 欧陆 | 除去 TOEFL/IELTS,还需要考小语种考试 | |
| 香港 | GPA 区分 985/211/双非,看重本科出身 | |
| 新加坡 | CS 就业环境普通 | |
| 澳洲 | CS 就业环境普通 |
如果上面明显缺点命中了你的缺点,建议仔细斟酌。例如语言天赋不强的人,还要去日本或者欧陆留学,2 门外语考试很折腾人;资金不充裕建议谨慎考虑美国,美国开销是最大的;如果你是双非出身,建议谨慎考虑英国和香港。
以笔者为例,笔者是非 985,所以谨慎考虑英国,香港,或者不考虑。因为在英国填写网申系统时,GPA 有区别:如果是 985 名校出身,GPA 80 分 OK,如果是 211 出身,GPA 85 分 OK,如果是双非出身,可能 GPA 95 分也不 OK。因为非名校会被放进单独的 pool 中。非名校想在英国翻身的机会很少,除去异常优秀的。笔者语言天赋一般,学英语都花了很多时间,所以直接排除日本和欧陆。笔者也很看重 CS 就业环境,所以也排除澳洲和新加坡。这样排除下来,最终的选择应该是美国和加拿大。美国的就业环境比加拿大更好,所以笔者更倾向美国。
不过笔者最终还是投了一所英国大学,一所新加坡大学,一所加拿大大学和 14 所美国大学。可能你会好奇,为什么明知申不上还要头铁往上冲?笔者是亲身实践以后发现上述规律的。如果时间能倒流,一定不会头铁往上冲。
英国/美国/新加坡/澳洲/加拿大 CS Master 又可分为 2 种类型,Courser-base 和 Research-based。Courser-base 偏就业向(但不是绝对),Research-based 偏可读 PhD 向(但也不是绝对)。如果读者对 Research 感兴趣,笔者建议可以直接申 PhD,保险起见的话,MS/PhD Research 一起申请。Research-based 的名称都是 Master of Science in Computer Science with thesis,只有这一种情况,即 MS 开头的。
笔者全部项目都是 Courser-base 的,在 Courser-base 中又可以细分为 Terminal 和非 Terminal 的。Terminal 代表终止,这个项目 100% 不能读 PhD,或者说这个项目读完对申 PhD 无帮助。例如:Master of Computer Science、Master of Engineering、Masters Program in Computer Science。更详细的 MSC@UCI, MSC@RICE, MPCS@UChicago, Meng EECS@UCB, Meng CS@Cornell Tech, MSE@CMU SCS。非 Terminal 的一般是 Master of Science in Computer Science without thesis,即缩写是 MS 开头的,中文翻译是理学硕士。这一类的项目是可以读 PhD 的,或者第一年结束后可以申本校的 PhD。
如果是找工方向,还需要注意项目中是否包含实习。如果有实习期,学校会在暑假给你 CPT,你便可以去实习。有些项目无实习,假期可能上课,例如 MSE@CMU SCS,假期上课,不给 CPT。无 CPT 的项目也能在美国找到工作,毕业后 90 天内找到工作即可开始使用 OPT。有 CPT 的项目无非是多了一次找工上岸的机会,因为 CPT 实习期间,表现良好,大概率可以拿到 return offer。如果你想在美国找工作留下来,选择一个带 CPT 实习的项目是刚需。看到此处,你应该对选哪个国家的大学,选哪种类型的 master,是否读 PhD,以及是否需要实习,心知肚明了。
如果你认识笔者,笔者什么背景你也了解。如果不了解笔者背景,那也不用了解了。笔者背景很差,双非出身,TOEFL 98+,GRE 320+3,GPA 3.82/4.0,Major 3.9/4.0。三维成绩不出众,可能中等偏下?
如果你的本科背景非常好,例如,清北 TOP2 出身,或者南京大学,上海交通大学,浙江大学,复旦大学出身,那么恭喜你,地球上大部分大学你都可以闭着眼睛申请,横着任性申。
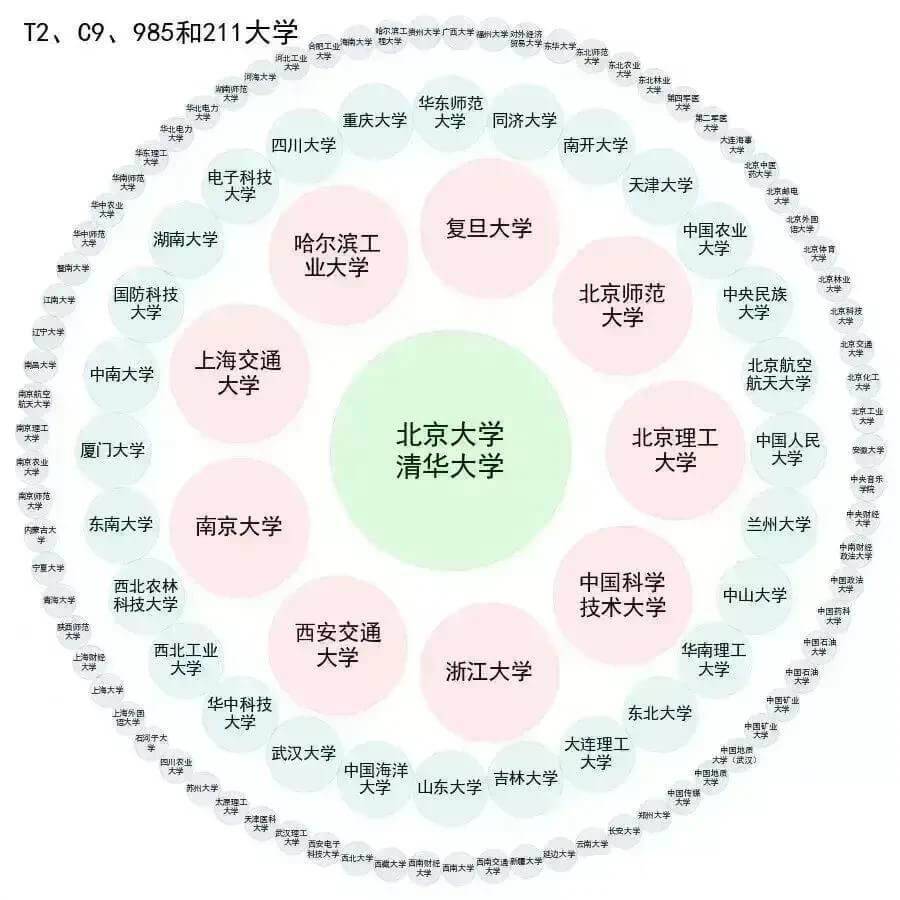
如果你的学校在上图中,英美都可以申。如果本科学校不在上图中,建议别考虑英国,因为你的出身不好。上图是陆本的排名。如果你是海本出身,那比陆本天生高人一档。举个例子,例如 UCR 不如清北,但是在申请美国 master 时,却更受招生老师的青睐。一是因为本科接受了全英文的课程教育,二是海本的 pool 优先级高于陆本的 pool。本科是 UCR 的申请者申请 UCLA,UCB 比本科是清北的申请者申请 UCLA,UCB 容易一些。再比如 Stanford,MIT,Harvard 在陆本中招生,只招清北 + 华五,有时候甚至华五都不招。但是 Stanford,MIT,Harvard 招很多海本的学生,即使学校综合排名落后于清北:
海本 > 清北 > NJU + ZJU + SJTU >> 其他华五 + 部分计算机特色学校(如北邮,华科)> 211 > 其他双非
如果你还在大学,本科背景也可以提升。可以考虑 Transfer,大一大二在国内读,大三大四 Transfer 到美本 TOP50 的学校去。本科毕业拿到美本的学历,对申请 Master 来说,提升了不止一个档了,性价比很高。大三大四在美国读书大概花费 100W RMB 左右。这条路拿到 TOP20 Master 学位总共需要 2 年,花费 200W RMB 左右。
如果你已经毕业,如果你家庭条件有很多钱资助你读书,可以考虑读美国的社区大学。相当于重新再读一个本科。美国社区大学大三也可以转学,再转到美本 TOP50 大学去。一般走这条路的人,都会选择读加州的社区大学,然后转学转到加州系的大学中的任一所,大四毕业以后即为人上人。这条路时间和金钱花费都很大,重读一个本科需要花费 4 年光阴,4 年在美国的花费也至少在 200W RMB 左右。200W 仅仅是开始,这刚刚拿到学士学位,再申 Master 读 1-2 年大概还需要 100-150W。这条路拿到 TOP20 Master 学位总共需要 6 年,花费 300-350W RMB 左右。

GPA 作为三维成绩中重要一环,重要性不必多说。有些学校尤其看着 GPA,例如 USC,UoT,它们根据申请者的 GPA 高低从高往低排序,然后按照优先级从上往下发 offer。如果你还在大一,大二或者大三,请一定规划好时间,GPA 争取越高越好。如果本科学校允许刷 GPA,可以考虑大三修完所有课程,大四重选大一大二 GPA 低的课,重修刷 GPA。
有些学校要求学信网官方认证成绩单,有些学校要求网申阶段就快递成绩单原件。所以这些材料请提前准备好。去学位网上认证成绩单,翻译件也附带弄一份,具体操作认证完以后,付费再买一份英文版的即可。要求学信网认证成绩单的学校,例如 WUSTL,会要求你通过学信网给他们发送本科的材料,认证后的学位证书(中英文)+认证后的成绩单(中英文)。要求寄成绩单原件的学校,例如 UMich,NYU,需要你去本科学校联系老师盖好教务处的印章,用学校的信封封好,再封口处再次盖章,从学校寄出。多次盖章+学校寄出目的是为了保证中途没有启封并篡改。
关于 GPA 还有一件你必须知道的事。美国有一个 WES 教育机构,它专门做 GPA 认证的。经过它认证以后的 GPA,大概率比学校成绩单上的高。因为他们不认可国内的政治相关的课程,例如《马克思主义哲学原理》、《中国近现代史纲要》、《思想道德与法律基础》、《毛泽东思想和中国特色社会主义理论体系概论》,还有国内的体育与健康课。他们在重新计算 GPA 的时候,不会计算它们。这样算出来的 GPA 会被大学成绩单上的更高一些。所以能提交 WES 认证成绩单的学校,尽量提交 WES 认证,变相提高了自己的 GPA。虽然支持 WES 认证成绩单的学校越来越少,但是还存在。例如 CMU 有好几个项目都还支持 WES 认证。USC,NYU 不支持,他们只接收大学成绩单上原始 GPA。

语言成绩不必多说,三维中的重中之重。不管你是自学,报班,一定请尽快考到想要的分数。因为 GT 分数的延后,导致申请全程过程拖沓就很不值得了。笔者英语也不厉害,学习无捷径。每个人的方法也不同。大多数看到这篇文章的读者语言分可能早已拿到了,所以这篇文章不浪费篇幅重点分析语言学习方面的经验了。感兴趣的读者可以翻一翻笔者 2019 年和 2020 年的年终总结。

软背景包含的内容比较多,暑研,顶会期刊论文,学科竞赛(ACM,CTF,MCM/ICM 等等),交换生,FLAAGTM 多段实习,其他全球奖项(Apple Scholarship 等等)
FLAAGTM = Facebook, LinkedIn, Amazon, Apple, Google, Twitter, Microsoft
关于软背景的提升,是八仙过海,各显神通。实力强劲的申请者是三维成绩顶尖,软背景也拉满:多次顶尖名校 MIT, Stanford, CMU, UCB 暑研,顶会论文若干篇,越多越好。学科竞赛金牌全部拿满,顶尖名校 Stanford,MIT,Harvard 交换生,FLAAGTM 多段实习经历。由于每个人精力有限,能力有限,尽自己所能争取拿到全世界含金量最高的奖项或者荣誉吧。
关于暑研,笔者想单独说明一下。暑研属于“奇兵”,虽然不是决定性因素,但是常常有出奇制胜的奇效。在笔者看来,暑研的主要目的并非是研究出成果,更多的是向名校的 Professor 展示自己的过程。在这一批暑研的学生中,如何让自己脱颖而出,出类拔萃,可能更“关键”。如果你足够优秀,暑研期间可以完成 PhD 的套磁,可以争取拿到 Professor 的 Strong Recommend 推荐信。有了这封推荐信,等秋季网申系统开放,第一时间申请该校,推荐信这一项能拉开同类竞争者很大差距。
最后请读者注意,如果三维成绩已成“定局”,GPA 刷不动了,GT 成绩也到瓶颈了,无法突破 110+/330+,那么请多花点时间提升软背景吧。Master 申请并非只看三维成绩,录取是评价综合实力的结果。硬背景既然定型了,那么软背景多努力努力吧~笔者三维成绩可谓“稀烂”,靠一些马马虎虎的工作经历拉“满”了软背景,最终也被 CMU 录取了。

CV 如实写即可。突出自己多方面的实力,学历,交换生,实习,暑研,顶会论文,竞赛奖项,等等软背景。
PS 文书需要根据每个学校的要求来写。不同学校不同项目,不同项目下还分不同 track,如何根据自身的特点去切合项目的要求,是写文书最需要考虑的问题。文书中一般会写自己的亮点经历,why school,why program。文书中 why school部分最能考验学生对这所学校是否了解。这涉及的是方方面面的,例如是否了解校园文化,是否了解各个导师研究课题的方向,是否了解哪些感兴趣的 lab 和 research group,是否了解学校在当地的名声与社会价值,等等。这些深层次的内容有些在学校的主页上,有些在学校的介绍视频中,有些在校园采访中。如果有心观看收集的话,自己也能找到一部分,这部分还是非常非常非常花时间的。笔者在了解各个学校,各个项目,各个学校内各个导师的研究偏好,花了特别多的时间,前前后后加起来总共有 2 周时间。
部分项目除了写 PS 以外,还要求 Video Essay / Video Interview,还有 Diversity Essay。这些部分也同样很重要。第一次录 Video Essay 比较迷茫,不知道录哪些内容。自己身上大部分的亮点在 CV 和 PS 中已经体现了。Essay 中又不允许重复。Diversity Essay 也很头疼,Diversity 算美国文化独有基因。你说你学术能力强,上十篇顶会学术论文,很独特;GPA/TOEFL/GRE 分数很高,很独特。这些都不是 Diversity。Diversity Essay 同样不能重复 CV 和 PS 中的内容,并且要求写 1000 words。这部分要根据学校的“基因”来写,有的学校服务社会,那么你过去经历中是否有社区服务相关的内容,如果有,可以写上去。有的学校引领当地的科技,那么你的过去是否存在体现自身 leadership 的案例,如果有,可以写上去。总的来说,Diversity Essay 还是比较难写。
最后是推荐信,推荐信基本要求 3 封。比较合适的组合是 2 封学术教授,1 封实习 leader。3 封推荐信尽量都要拿到强推信。如果有暑研,尽量找那所学校的教授帮你写推荐信,申请这所学校的时候,这封推荐信会占优势。学术教授尽量选择学术论文影响力很大的老师,如果校内有和你想要申请学校的教授联合研究发文的教授,优先选这个教授帮忙写推荐信。实习/工作 的 mentor/leader 推荐信同样的道理,优先选择海外知名的,如果没有,尽量选国内知名的大厂。
申请学校的教授强推 > 与申请学校招生老师或者教授有合作的教授强推 > 海外学术界知名教授 > 海外工业界知名 leader > 国内学术界知名教授 > 国内工业界知名 leader > 其他
推荐信这一块对于陆本的学生来说算“优势”,提前和关系好的教授打好招呼,给的推荐信都是强推。对于海本的学生来说,这部分有坑!海外不少教授嘴巴上说强烈推荐,有些是客套话,最终给的推荐信可能是平推甚至是毒推。海外很多教授比较耿直,有啥写啥。如果把你缺点曝光的比较多,可能就是一封毒推了。当然大部分教授都挺好,笔者这里只是想让大家留个心眼,堤防毒推。
陆本的学生还有一点需要注意的是,“防作弊”。这个案例是笔者在地里看到的。今年很多学校针对推荐信这块增加了反欺诈监测。例如,申请者包办 3 名推荐人,替他们帮自己写推荐信。推荐信的网页上会记录此次的 IP,上传文件的本地路径甚至主机名,提交时间。根据这 3 者可以判定推荐信是否是同一台机器上传。如果 3 封推荐信全部都由一台机器上传完成,甚至是同一时刻或者很短时间内上传完成,那么可以断定这名申请者自己包办了所有推荐信。正常的话根本不可能出现这种情况,正常流程应该是 3 台机器主机名都不同,上传时间之间相隔无规律,IP 也不同。除了这种上传时间和上传机器有“防作弊”检查,pdf 和 world 软件也会有检查。例如,申请者在自己的电脑上一手包办了 3 名推荐人的推荐信,在自己电脑上用 world 或者 pdf 编写的。在 mac 电脑或者 windows 电脑上使用 Microsoft office world 365,需要激活。一旦激活登录了邮箱账号以后,编辑过的 world 会在文件信息里面写入“来源”,“作者”,这两个信息。如果学校检查上传 world 或者 pdf 的文件信息,发现三个推荐信来自同一个人,基本可以断定是同一个人写的。正常情况三个推荐信不同电脑上生成的 world 和 pdf 文件信息里面的 “作者” 应该是不一样的。
笔者今年申请了 UoT,在面试环节,有专门针对推荐信的问答。有同学被招生老师问到:“从系统上看,你的这 3 封推荐信都在同一台电脑上上传的,请你解释为什么?”。很明显,招生老师怀疑推荐信的真实性,怀疑可能是该学生一手包办的。面试现场被问到这类问题特别紧张,气氛也特别尴尬。经地里同学自述,他回答说“因为老师很忙,我抱着电脑去办公室找他,催着他在我电脑上完成的”。这个答案看上去就不太好。笔者将这个看到的真实案例分享给大家,读者看完,一定要谨记申请材料的真实性,到底该怎么做,你也应该明白了。

一般美国 TOP50 的 CS 院校,三维中 TOEFL 线是 100 左右,GRE 线是 320-325 左右,GPA 3.5+。三维成绩决定了选校 Level,成绩越高越好。笔者成绩很一般,又有自己的梦校,选校范围很大,从 TOP 1 - TOP 70 都选了。分了 4 个档,彩票(TOP 10),冲刺(TOP 10-20),主申(TOP 30 左右),保底(TOP 40-70)。地里有人把美国 CS Master 申请难度排了一个序:
| Program | |
|---|---|
| tier 0 | MSCS@Standford, MSCS@MIT, MSCS@CMU, MSCS@UCB, MSCS@Princeton |
| tier 1 | Meng@UCB, MSCS@UCLA, MSCS@UT Austin, Meng@Cornell Tech, MSCS@Wisconsin Madison, MSCS@Harvard |
| tier 1.5 | MSCS@UIUC, MSCS@GaTech, MSCS@UPenn, MSCS@UM Ann Arbor |
| tier 2 | MSCS@Columbia, MSCS@UCSD, MSCSE(COC)@GaTech, MSCS@Brown, MSCS@UMich, MSCS@Duke, MSCS@Dartmouth, MSCS@Yale, MSCS@Purdue, MSCS@Washington |
| tier 3 | MCS@Rice, MSCS28@USC, MSCS@NYU, MSCS@NWU, MSCS@UCD, MCS@UCI, MSCS@JHU, MPCS@UChicago, MSCS@Virginia, MSCS@UCSB, MSCS@Stony Brook, MSCS@Virginia Tech |
tier 0 是最难申请的。北美 4 大 CS 强校,CMU,MIT,Stanford,UC. Berkeley 实力是最顶级的,MSCS 真的很难申请。Princeton 为何与四大同在 tier 0 里?因为这个项目对口语要求很高,口语 25- 基本都拒了。学术背景要求也很高,据地里统计,这个项目近 2 年陆本没有几个人被录取。
tier 0-3 涵盖了美国 CS Master TOP40 的学校。从笔者录取结果来看,笔者的水平只够 tier3 和一些保底校。笔者今年买的 3 张梦幻彩票是,MSCS@CMU,MCDS@CMU,MSCS@Gatech,都被拒了。这个天梯往上爬确实不容易,每爬一层都不容易。大家可以根据自身的实力往上爬。
针对 EE,ECE,文科专业转 CS 的同学,一定要重点考虑转专业友好的项目,例如 MPCS@UChicago, CS Align@NEU, CS37@USC。这些项目是专门为转专业同学开设的。
关于拿 2 个 CS Master 学位的问题。如果你已经拿到了一个 CS Master,再次申请 CS Master,会遇到一个问题,招生老师需要你解释为何还要拿一个 Master 学位。目前笔者在 LinkedIn 上也没有见过拿了 2 个 CS Master 的大佬。笔者不负责任的揣测一下招生老师的心理:可能会优先把机会留给没有 CS Master 的申请者。
至于拿多个 Master 学位的问题与本文无关了。笔者也可以简单提一提。通常读完 CS Master 以后,OPT 3 年会抽签 H1B。如果没有抽中呢?又想留在美国,怎么办呢?继续再读一个 Master 或者申 PhD。如果 PhD 申请不到,就继续读一个 Master。通常可以选择和专业相关的,比如 CS 可以选择 DS。也可以选择和专业不相关的,比如再读一个 Music,Laws。还有一类 Master 几乎是花钱买 CPT。这类 Master 入学就有 CPT 可以用,也俗称 “day 1 CPT”,入学即可实习。实习期间就可以抽 H1B。每周到校几次即可。反正你有钱,让你苟在美国的方式还挺多的。题外话到此为止,言归正传。
填好网申材料以后,一定请认真检查每个 section,避免出现低级错误。有些学校的 PS 要求不在项目主页里,在网申系统里。所以尽快注册好账号,看好他们的要求(比如字体大小,行间距,字数等等),给自己合理安排时间。
这个阶段比较关键。一定要安排好 DDL 和投递策略。每个学校的投递窗口不同,有的是 rolling 的,有的是 2 轮。网申投递策略十分影响最终结果!学校第一轮普遍招人比较多,最想去的项目或者很有把握的项目都要赶第一轮投递。额外再加几所保底校也第一轮投递。笔者在 21fall 的申请中吃了亏。NEU 的 MSCS 在第一轮中选拔中,GPA 3.5/TOEFL 95/GRE 315 被录取了。笔者三维比这个高,按理来说录取稳了,但是没有录取,劝转 COE 了,转完以后果然录了。而且当时 MSCS@NEU 也非常奇怪,状态变更成 under review 的当天,同时 Rej 了。笔者一度怀疑招生老师并没有看材料,直接拒了。后来经过地里多方验证,这种当天 review 当天秒拒的行为很大程度是那一轮 rolling 招满了。笔者投 MSCS@NEU 是 2 月 3 号,Recommend Letter 是 2 月 10 号 Complete 的,2 月 13 号变成 under review,当天 Rej。NEU 第一轮投递时间是 2020 年 11 月。笔者的经历告诉你,如果你想申 NEU MSCS,建议网申一开启就把它投了。即使是保底,也先保住再说。由此可见,投递策略影响投递轮次,进而影响是否能拿到 offer。
第二轮可以投一些把握没有那么大的彩票校和少量主申校。当然,如果你语言成绩 9 月前刷好了,9 月全力写每个学校的文书,10 月把所有学校都投第一轮,也是非常不错的策略。
另外网申提交之前,请多多注意申请费 waive 的问题。有些学校申请了一个项目可以再送一个项目,即免除一个项目的 waive。NEU 和 USC 都有 waive 的选项。NEU 某些学院的项目之间可以 waive 申请费的。具体情况请看当年招生说明。USC 多个 CS 项目之间,最多可以 waive 一个项目。笔者比较傻,当时虽然知道可以 waive,但是缴费的时候 3 个项目全部交钱了。正确的操作应该是先提交一个项目,然后联系学院给一个优惠码,这样再提交第二个的时候,用优惠码 waive 掉申请费。然后再提交第三个项目并付费。USC 申请 3 个项目,实际上只需要花 2 份的申请费。希望作为后来人的读者,看到这里能汲取笔者的教训,少花一笔申请费。
不少项目有面试环节。意味着申请者在申请季期间不仅要赶 PS 文书,还需同时准备面试。笔者今年申请的项目中有好几个都有面试:MEng CS@Cornell, MSCS@WUSTL, MSE@CMU, MITS@CMU, MSCS@Columbia, MScAC@UoT。面试分为几种类型,一种是 Skype 语音面试,一种是 Kira 约面,一种是 Zoom 面对面,还有一种 Coding Test。Coding Test 类似 LeetCode,1 个小时 4 道题,写完代码自己测试,但无 OJ 评判对错,提交代码后不可更改。最终成绩根据完成时长,跑过 test case 组数共同决定。语音或视频面试的问题多种多样,简单的问题会问 why school,考察你对学校的了解程度,喜爱程度是否强烈。难一点的会根据 CV 问工作/实习经历,暑研经历,交换生经历,科研经历。更难一点的会问技术,例如问你了解哪些设计模式,每个设计模式分别适用于哪些场景。本科是否学习过算法课程,学习过哪些算法。是否学习过线性代数,概率论,如果学过,请讲讲矩阵的秩,逆矩阵,基变换等概念,贝叶斯定理是什么,数学期望,泊松分部,马尔可夫链的概念等等。数据结构中红黑树是如何旋转调整节点的……问技术或者数学方面的问题,笔者觉得最难的地方是如何用英语表达出来,而且能让面试官听懂。笔者被问到什么是桥接模式,桥接模式的定义是什么,以及哪些地方会用到桥接模式。用中文能完美解释,换成英文就很“坎坷”了。
这块和平时看纯英文的技术书看少了有关系。如果日常阅读技术文章是英文,耳濡目染,技术名词肯定都会了。面试回答问题时,遇到不知道如何描述的地方,会换种方式描述。但是这种方法不如一个精准的单词来的专业。有可能你说了一堆,但是面试官提示点出了关键的一个单词,你会豁然开朗,“对对对,我想说的就是这个”。对于想在技术面试中出类拔萃的同学应该知道怎么做了吧?日常阅读技术文章请接触大量英文。
一般发 offer 的时间在美国圣诞节之后,也就是第二年的 1 月中下旬以后。1 月下旬这波 offer 对应 11 月 15 号至 11 月 30 号期间投递的申请。大批量的 offer 集中在 2 月底,3 月初。接到 offer 以后请先确定好回复的日期,在这个日期前必须做决定,否则 offer 过期。接 offer 之后有些学校还有 deposit 占位费,有些学校占位费非常高,比如 NEU $750,Columbia $4800,NYU $500。占位费是拉高申请者反悔跳车去其他学校的门槛。如果你接了 offer,后期又反悔,对学校来说是非常渣男的行为。学校为了让申请者慎重做决定,增加高额占位费,而且也算给自身增加收入。例如接了 Columbia 的 offer,但是交完占位费一个月后你又收到了 Stanford 的 offer,于是你跳车去了 Stanford。学校增加了占位费的门槛,使得你跳车走了,学校也能白白赚走了你 $4800。当然,疫情期间有些学校因为想吸引更多的学生入学,取消了占位费。希望大家双方都相互友善吧,申请者不要欺负这种不收占位费的学校,随意撕票。学校也不要海王,死活不出结果,让申请者无限期的等待。
一般 offer 的 ddl 从 2 周到 2 个月不等。收到 offer 以后请尽快多了解一些这个项目的坑点,取舍它是否最适合自己。在多个 offer 中动态找到最适合自己的项目。瞻前顾后的焦虑会让人心态爆炸。请记住,世上没有最完美的项目,只有最适合自己的项目。如果不是 MSCS@Stanford 的 offer,其他项目基本都会有取舍。学校排名,地理位置,天气气候,课程设置,就业数据,校友人脉,教授研究方向等等因素都要考虑。
确定下最终接哪所学校的 offer 以后,便要开始办理 I-20 材料。这个材料包括核对个人身份信息,财产证明,美本本科学生身份转换等等。对于陆本学生来说,主要是财产证明。学校会给我项目花费预算,需要你去银行开出大于这个预算的财产证明。I-20 材料非常重要,只有拿到了 I-20 才能开始办理美签。美签面签申请上需要填写 I-20 Number。不同学校办理速度不同,尽快提交材料,I-20 能早日到手。
以笔者 21fall 来说,笔者接的 CMU offer,办理 I-20 在提交材料以后还需要 4-6 周。其他学校,UIUC,NYU,Rice,WUSTL,Tufts,UTD 这些学校在申请者提交好 I-20 材料以后的一周内,都能下发 I-20。所以一定请尽早办好财产证明,尽早提交 I-20 申请所需材料,笔者建议,所有学校的网申结束以后,便可以开始准备自己的财产证明了,一般 16 个月的项目准备 70-90W 一定够用了。这样 offer 一来,确定好最终去哪所学校以后,当日便可提交财产证明材料,参加 I-20 排队。笔者收到 offer 以后才开始准备的 I-20,又花了一周。最终比我早一周提交材料的同学,比笔者早 10 天收到 I-20。笔者等了 7 周多的时间,接近 2 个月。因为中间还遇到了学校的纪念日放假了。所以尽早准备 I-20 的财产证明材料才是最正确的选择。尽早拿到 I-20 以后,办理面签都主动很多。
关于财产证明 funding 来源的问题,如果写 self-funding,真的是“大坑”。如果有重来一次的机会,笔者一定不写 self-funding,写 parental sponsorship。笔者一开始觉得写什么都无所谓,于是把钱都转到了自己名下的卡里,并且全部资金都办理了冻结手续。提交 I-20 以后,学校审核以后不通过,理由是“self-funding 需要提供全额的财产证明,需要补充材料”。I-20 申请材料上写的是需要提交第一年所有花费(学费+生活费+租费所有费用)的财产证明即可。但是这里如果是 self-funding,需要提供 2 年全额的所有花费(学费+生活费+租费所有费用),这个规定在学校的网站上并没有写,是隐藏规定!如果写了,笔者也不会选择 self-funding!选择了 self-funding 带来的后果是:
这 2 条都很“要命”。第一条,如果你的存款不多,double 的财产证明可能会让你有点吃不消,150W 或者更多的财产证明对于普通家庭来说,一口气拿出来非常不容易,就算有这么一笔钱,也不太可能放在银行活期账户里,也会分散在各个投资理财,基金股票的账户中。(当然也有身价上十亿的家庭,150W 现金直接放在家里作为零花钱,这种人除外)从各种分散的账户中取钱提款,来回也需要花费几天的时间。
第二条,对于 CMU 审核 I-20 材料强行卡 6 周的学校来说,补充一次材料意味着你的 I-20 材料批下来的时间更长。重新提交材料以后,学校还要一周时间审核你的补充材料。最终材料审批下来的时间需要 7 周半,接近 2 个月 8 周的时间了。综上原因,如果你非要选择 self-funding,请一定在第一次提交材料时提前准备足够多的存款证明,不要中间来回折腾!
关于应届毕业大学生,正常的应该写 parental sponsorship,如果写 self-funding 反而 F-1 面签的时候会被拒,面签官 OV 问你,“你刚刚毕业,这 150W 现金哪里来的?”,也许你可以很好的解释(“这是我买彩票中大奖”,“这是我大学创业赚的第一桶金”,“这是我炒股票基金和电子货币赚来的”),但是如果你在新加坡面签,直接 Rej,如果在国内面签,可能被 Check 资金来源。所以应届毕业大学生请别犹豫,务必写 parental sponsorship。至于工作党,写哪个都可以,但是需要注意 一旦写了 self-funding 需要提供整个项目全额的财产证明。
这是去美帝读书前的最后一步,拿到学校发给你的 I-20 材料以后,在美国使馆注册好自己的账号并填写 DS-160 以后,便可以预约 F-1 非移民面签了。需要准备的材料笔者整理了一下,如下:
| 序号 | 所需材料 | 注意事项 |
|---|---|---|
| 1 | 签证照片 | 请至正规照相馆拍摄,电子版尺寸为 51*51、白底,露出双耳,同时洗两张面签时携带 |
| 2 | DS-160 确认页 | 请填写中文表格发送至 后期顾问邮箱 |
| 3 | 护照原件 | 本人需要签字 |
| 4 | 户口本原件 | 如申请人的户口与父母不在一个户口本上,则两个户口本都要提供 |
| 5 | 签证预约确认信及签证费 1008 人民币 | 可使用借记卡在线支付,或学生本人携带护照和预约编号在中信银行柜台缴纳,保留好收据 |
| 6 | 200 美金 SEVIS 费收据 | 提供双币信用卡信息,交费单据须在线打印,并保留 |
| 7 | 录取通知书 | 如学校没有邮寄通知书原件,可使用打印版 |
| 8 | I-20 表原件 | 需要学生本人签名 |
| 9 | 英语考试证明原件 | IELTS/TOEFL/GRE/GMAT等成绩单(可在网上打印),若已报名还未考试,可以网上打印报名信息 |
| 10 | 在读证明原件/学生证 | 适用于在读学生 |
| 11 | 毕业证/学位证原件 | 适用于毕业学生 |
| 12 | 成绩单原件 | 中英文原件 |
| 13 | 个人简历和学习计划 | 英文 |
| 14 | 担保人收入证明(如父母都在职则需要提供两人的) | 收入证明模板另行发送至学生邮箱;打印在有单位抬头的信纸上,盖公章或财务章。父母双方的年薪建议在 20 万人民币以上。或依据自己单位的规定和格式开具,内容要包括:姓名、职务、任期,年总收入及组成部分、证明人等。 |
| 15 | 存款证明原件 | 建议 40 万人民币以上,与存单相符,有效期或冻结期需覆盖签证日期 |
| 16 | 房产证明原件 | 仍在还贷款的房产证不要提供;有多处房产可提供多个证明 |
| 17 | 存单或存折原件 | 存期不限,总金额应为通知书或 I-20 上显示的一年的总费用,建议 40 万人民币以上,越多越好 |
| 18 | 利息单原件 | 所提供存单如有转存记录或即将转存,请保留原来的取款利息单和原存单复印件,并提供 |
| 19 | 车产证明 | 行驶证复印件、购车发票原件 |
| 20 | 名片 | 如有,可提供,注意核对名片上职务、电话、地址与收入证明是否一致 |
| 21 | 房屋出租合同 | 房产证原件、合同原件、收据(如房屋租赁收入占家庭总收入较大比例) |
| 22 | 全家福 | 证明申请人和担保人之间关系的辅助材料;清晰生活照即可 |
| 23 | 其它材料 | 其它任何你认为对证明学习能力、国内紧密联系、社会地位有所帮助的文件。 |
| 若担保人拥有个人公司,还须提供以下资料 | ||
| 24 | 营业执照 | 如申请人或担保人是公司法人 |
| 25 | 验资报告 | 如占有股份,需要提供 |
| 26 | 承包/合作合同 | 如果公司经营模式是挂靠或其他形式,需要提供 |
| 27 | 股东证明/分红证明 | 若有,并且占家庭收入较大比例可提供 |
| 28 | 税单 | 近2年如有大额税单,可提供 |

成功拿到 F-1 签证后,去美国之前可以把房子在网上租好,如果合租 2b2b,提前找好室友。如果需要买车,也可以开始预订了。一般学校对即将到校的国际生会有一些要求,比如疫苗方面的,体检方面的。按照各个学校的要求办好手续即可。一般大学的 Orientation 在 8 月 15 日 - 25 日期间。所以最好 8 月上旬到达美国,稍微适应几天,买点日常用品,便要开始 Orientation 了。如果首次前往美国,F-1 签证只能在 I-20 表上注明的入学日期前 30 天内入境。
自 2020 年 1 月武汉爆发疫情以后,全国 TOEFL / GRE 线下考场关闭。直到 2020 年 7 月才恢复。笔者是 8 月才抢到超偏远地区的稀有考位,真的太难了。9 月和 10 月在中国偏远城市来回往返赶考线下 TOEFL 和 GRE 考试。所幸在 11 月“结束”了战斗。其实笔者最终分数也不高,本来还打算再考 4 次,刷刷分。因各种赶 DDL,压缩了不少时间,又多考了 2 次,分数都不高,最后 2 次没有继续考了,取消考试。建议看到这里的读者能在 9 月前解决完 TOEFL 和 GRE 两门考试,分数达到 105+ 和 325+。笔者语言分数出分太拖沓了,姑且不能怪疫情影响,只能怪自己英语实力垃圾,如果自己实力强劲,9 月第一场线下考试就应该出分了。那么从网申阶段开始,聊聊后疫情时代下留学申请有哪些变化。
全球疫情好转是导致 2021 年留学申请数量暴增 50% 的主因:2021年,我国实现了国内疫情的全面控制,多日实现全国零增情况,每日新增基本为外来输入病例。国内安全舒适的自由环境给众多学者造成了全球安全的暂时性假象,这也重新点燃了许多人的出国留学梦。
侥幸心理导致 2021 年留学申请数量暴增 50% 的诱因:国际留学生学费是国外各大高校经费的主要来源之一。因此,2021 年世界各大高校逐渐放宽留学生入学政策来吸引国际留学生,哈佛、麻省、斯坦福等美国知名高校宣布不再强制要求提交 SAT、ACT、GRE 等标化考试成绩(入学必须考试)。除此之外,很多人存在 2021 年留学申请竞争不大,进入世界名校几率增加的侥幸心理。对于今年的申请学生而言,爬藤会变得更困难。这就导致申请人数暴增,院校不得不推迟录取时间。
20fall 这一届的留学生因为疫情没有出国,今年 21fall 他们继续申请,导致申请人数增加;20fall 由于手握一个 offer,再次申请 21fall 没有任何包袱,申请不上更好的学校,继续读当前的学校,如果能申请上更好的学校,21fall 即入学更好的学校。所以会出现手握 20fall offer 的学生继续申请 21fall 更好的项目,吃着碗里,看着锅里的情况。两届挤一届导致战况异常惨烈。

宾夕法尼亚大学申请人数达到 55992 人,比上年增加了 34%!但学校并不打算扩招,这将导致录取率直降。

普林斯顿大学的申请人数增加了 15%,哈佛大学收到了超过 57,000 份申请,增长了 42%,申请人数超出新高。纽约大学 NYU 更是创下了人数超十万这样惊人的本科申请量,其中 22000 来自于国际学生,较去年增加了 22%!这是纽约大学连续 14 年来创纪录的申请数量,在此期间,申请数量增长了一倍以上!


不过申请人数最高的还要数 UCLA,总申请人数达到 249855 人,比去年增加了 16.1%,国际生申请率增高了 10%。面对申请人数的暴增,负责招生的工作量也随之增多。哈佛、耶鲁、哥大、布朗、宾大、康奈尔、普林斯顿等八大藤校不得不将录取结果推迟至 4 月 6 日,斯坦福推迟至 4 月 9 日。

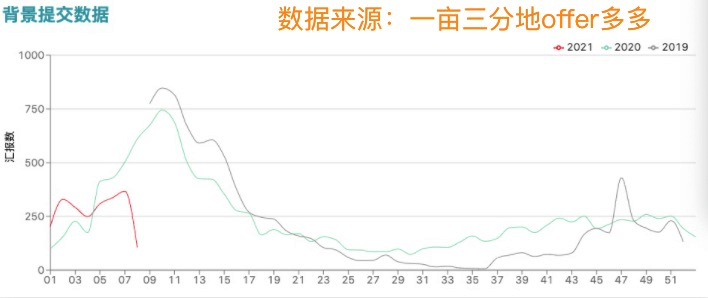
这还只是本科申请人数的变化,研究生申请人数增长可以参考一亩三分地的数据:
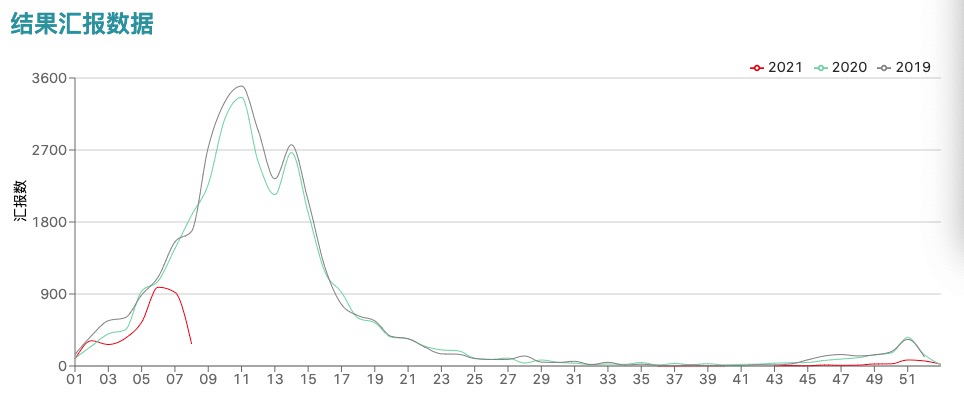
同样的情况在英国也有出现。根据英国大学与学院入学服务机构(UCAS)公布的数据,截止 2021 年 1 月 15 日,全球共有 568330 人递交了英国本科入学申请,来自欧盟以外的申请人数达到创纪录的 73080 人,比 2019 年增加 14.7%,其中来自中国的申请人数增加了 33.8%。

申请人数的上涨意味着录取率降低,竞争压力变大。一项调查结果显示,2020 年秋季的国际生入学人数下降了 16%,其中有近 4 万名国际学生在 2020 年秋季暂停入学,并将入学日期推迟到未来。美国研究生院理事会的调查也发现,尽管 2020 年秋季入学较 2019 年申请总人数增加了 3%,但因为疫情和旅行禁令影响,研究生注册人数下降了 43%,博士下降了 26%。这意味着国际生空缺急需弥补。
较之名校,国际生注册人数降低对其他大学而言是一次巨大的挑战。没了学生,学校丧失部分经济来源,因此相较于竞争激烈的藤校,普通院校可能会进一步扩招。
内卷严重,国内就业压力增加是导致 2021 年留学申请数量暴增 50% 的次因:伴随 2020 年大量海外青椒回国,国内就业压竞争力骤增,内卷严重,出现了国内高校应届博士毕业生只能做博后的境况,这也导致了大量应届毕业生选择了出国再造的现象。
内卷究竟有多卷呢?笔者举 2 个印象非常深刻的真实例子:
A 同学本科毕业于 UIUC CS,GPA 4.0/4.0 满绩点,TOEFL waive,GRE 339/340。顶会论文若干。FLAANG 实习。这三维成绩,软背景,以及海本 CS 顶尖院校,应该是 offer 收割机本机了。但是却“滑铁卢”了。A 同学申请 CMU MSCS,被拒。实在想不通今年被 CMU SCS MSCS 录取的究竟是什么神仙?
B 同学本科毕业于 CMU CS,GPA 3.9/4.0,TOEFL 115,GRE 330。软背景未知。申请 CMU MSCS 被拒。本校申本校都被拒。今年到底是多么的内卷???已经卷上天了。
因为疫情,美国大学校园关闭,所有大学都变成了"昂兰大学"(Online University) ,上课用 Zoom,招生老师也在家办公。在家办公带来的影响是效率不高。如果你很着急联系招生办,例如关联实体成绩单与网申系统的 Application ID。大概率你打电话是没人接的。因为电话打到学校,而老师在家办公。你无奈之下写邮件联系招生办的老师,但是老师回复邮件也很慢。一周 5 天都不理你。于是第二周继续写邮件催老师。第三周老师突然回复邮件,模板式的回复,“不要催!现在是申请高峰期,招生办已经满负荷工作中了。”笔者此时已无力挣扎,只能“佛系等待”,一个月以后,终于关联上了。有一说一,这个效率如果放在中国的公共服务体系里,一定会被人投诉。但是毕竟人家是美帝的工作习惯,你也无法抱怨,一周只工作 5 天,周末铁定不加班,工作日晚上到点就下班,也不清楚疫情之前他们效率是怎么样的。(有时候真的很想有 DING 一下,夺命连环 Call。当然这只能是想想,如果把招生老师惹烦了,谁催就拒谁。招生老师就是爷,得供着。)
吐槽归吐槽,标题上“不高”也是打了引号。理性的思考这个现象,背后也有它的道理。首先美国大学审核申请人材料,有他们一套很严格的审核流程。招生老师严格按照这个流程来办事,一环又一环,步骤非常严谨。再加上申请人数暴增也是事实,在家办公的影响,公布录取榜单的日期往后延迟 1 个月也可以理解的。
本篇文章起笔于 2021 年 4 月,中国大陆美国使馆并未开放。读者看见这篇文章的时候可能中国大陆使馆已经开放了。笔者犹豫之下,还是决定保留这段,毕竟冲坡办美签是 20fall 和 21fall 这辈子都难忘的一段经历。
由于疫情的原因,国内使馆停止办美签业务。加上美国 NIE 规定限制,禁止入境美国之前 14 天入境过中国的旅客。那么去第三国办美签 + 洗白成为了刚需。20fall + 21fall 至少有 10W 留学生要去新加坡办签证。(变相繁荣了新加坡旅游业)




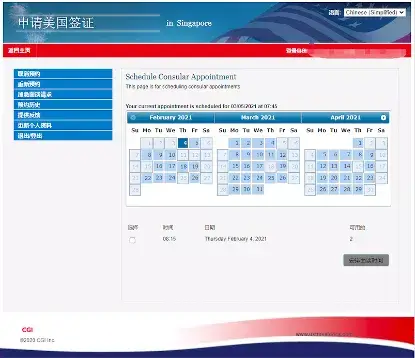


美国的 14 天旅游禁令依然生效,所以中国留学生前往美国还是需要在第三国停留 14 天以上才可以入境美国。
政策的变化很容易打乱一个人原有的安排。由于疫情和中美关系的影响,留学签证上的政策真的是时刻在变。笔者来盘点近几个月来的变化。
2 月焦急等待。2021 年 2 月 11 号是除夕,在此之前的几天,笔者收到了 Cornell 的拒信。春节期间又接到了 NEU 和 CMU 的拒信。3 连拒产生了辍学警告。那段时间每天早上一起床要刷新邮箱,在地里看录取结果。中午午饭后刷新邮箱,晚上睡前刷新邮箱。网上流传了一个新名词,“焚刷匠”,指的是每天心急如焚,疯狂刷新邮件的人。这个词描述这个月的我太合适不过了。
3 月小激动。陆陆续续 CMU 开始放榜,笔者连续收到了 2 个 CMU offer 了。此时心态平静了很多,开始准备找新工作了。计划今年在国内干到年底,赚点钱,然后 22spring 去美国本土上课。如果秋季疫情不能好,考虑在国内上网课。
4 月焦急等待。CMU 突然宣布 offer 不能 defer 了。如果 9 月不能按时到校, offer 自动作废。这个政策一出来,扯到了不少申请人的神经。立即提交 I-20 材料,做好随时飞新加坡的打算。由于 CMU 的政策,导致接下来几个月的工作性质必须是远程的。这也打断了我去字节跳动入职的计划了。没有 CMU 这个政策,笔者 100% 入职字节跳动了。吃不到字节跳动国内的豪华食堂了,戴不了字节的网红工牌做人上人了。这个梦想只能去美帝 Tiktok 实现了。
5 月继续焦急等待。CMU 的 I-20 材料非常慢,需要等待 4-6 周,按照这个时间线,要 6 月才能拿到。5 月因为政策变更,中国留学生赴美解开了 NIE 豁免。周边不少订了新加坡机票的伙伴们纷纷觉得操蛋。5 月 4 号,中国使馆北京,上海,广州,沈阳开始处理 F-1 留学签证。再一次给这一届的留学生上了一课。本来已经打算好去新加坡的,新加坡旅行签,航空豁免,Airbnb 租房,电话卡,机票全部办理完了,突然国内开放签证了。还有不少在新加坡已经被 check 的同学哭晕在厕所。更有甚者,冲动至极的孩子,I-20 还没有到手,美签 CGI 就先注册到了新加坡,填好 DS-160 并缴费。无脑冲坡的下场是损失了这 1000 RMB。此时大批留学生开始转移美签 CGI 至国内。相关留学签证群,新加坡签证群那几天全部爆炸,短短一个小时不看微信群,就能累积 2000 条消息了。笔者也是无脑冲坡的一员,无奈之下也被迫转移 CGI。给使馆疯狂打电话。
经过 2 天煎熬的打电话,终于把 CGI 转回到 China mainland 了。国内上海的电话超时会自动断掉。大概 60 分钟无人接听自动会断,等待提示音友好,静音略带电流声。北京的电话不会断,可以无限等待,直到有人接听,等待提示音友好,正常电话嘟嘟声。新加坡大使馆也不会断,可以“无限等待”,直到有人接听,等待提示音不友好,是赛马的声音。本来等待期间就焦虑,再配赛马声音,很搞心态。笔者没有测试过新加坡能否无限等待,笔者等了 30 分钟自动断了,因为话费打没了,电话停机。新加坡电话属于国际长途,打通以后就开始扣费,即使无人接听,等待期间也扣钱,因为你打通了这个系统。笔者一开始不知道扣费规则,于是付费听了 30 分钟赛马声,一分钟一块钱,真的贵。笔者最终打通了美国使馆的电话,语言选择英文。中间有播报很多英文,有些可能听不懂,不过没有关系,讲的全是美签政策相关的东西,听不太懂也不所谓。当提示你按数字键选择时,依次 1-2-2-2-5 转人工(注意不是一次按完,分 5 次输出,电话提示音让你输入的时候再输入)。等待 10-20 分钟后,有人接听电话,"Could please help me to transfer my CGI from Singapore to China mainland?",“Sure, Of course.”。之后会让你报出护照号,名字以及字母拼写,生日等验证信息。大约 3 分钟便操作完成。
笔者的一签被拒签了。请了 2 天假从上海飞到北京安家楼,本以为可以好运,但是结果却恰恰相反。订的酒店很便宜,就在北京美国大使馆旁边。前一天晚上飞机落地后,淋着暴雨入住了酒店。

北京美国大使馆真的很大,像一个超大的四合院。这是在外面看的样子。内部不准带手机,所以没有照片能展示给大家。6 月 17 号是笔者面签的日子。前一天暴雨,结果第二天早上就天晴了。还以为是好运呢。早上在酒店吃完早餐,坐电梯下楼,电梯里面都是学生,手上夹着文件夹。一看就知道是来面签的学生。我跟随着人群,来到了美领馆。上图是美领馆的后面,实际签证要围着这个建筑转一圈,走到它的正门。正门那里排队的学生一圈又一圈。由于 2020 年的疫情,20 fall 的学生都没有办法获得签证,在国内上了一年的网课。如今中国本土签证开放,算是释放了他们压抑许久的心情。我是预约的早上 7:45 面签。7:30 到使馆了,门口的人已经有 1000 多个学生了。排队是蛇形的,而且还绕了 3 大圈蛇形。20 届 + 21 届的学生对签证的需求量实在太大了。北京使馆也非常争气,火力全开。2 层楼总共 48 个窗口全部开放学生签证服务。进大使馆之前需要把随身的水瓶,雨伞,电子设备都存到对面的存包处。(存包处需要收费,如果有家长陪同,可以省下存包的钱)进大使馆只能带自己的面签材料。进门有安检,皮带上有金属物也会被查。进去以后第一道关是验 I-20 文件和护照信息。检查完以后继续排队,收集指纹,双手十个指头都需要按指纹。收集指纹结束,就到第二关,排队等待面签。现在有场控,安排你到哪个窗口去面签,自己无法选择。如果你发现你旁边窗口一直在发拒信,而场控又安排你到那个窗口,只能自求多福,欲哭无泪。我被安排到了一楼的一个靠墙边的窗口,面签官是亚裔男。由于是学生签证,所以全程必须用英文回答,检测你是否具有去美国读书的资格。面签官问了我很多问题。我推测我被挂的原因是,他问我留学资金是谁赞助的。我回答说我自己。然后他又问我工作几年了。我说快五年了。之后又草草问了一下问题。这里我可能就已经挂了。工作 5 年,有工作能力,并且攒了一大笔钱,还携带家属。移民倾向太多于强烈了!直接拒签!当前这些拒签理由都是我猜想的。拒签不会告诉我们理由。于是给了我下图的这个白单子就出来了。

拒签理由是 214b。说我无法证明放弃在美国之外有无法放弃的居住条件。国内缺少约束力:职业,工作,学校,家庭及社会关系。拿了这个白纸以后,整个人都懵了。瞬间不知道怎么办。留学之路就此断绝了?走出使馆,阳光很大很炙热,但是我的内心却下起了倾盆大雨雨。回到酒店清理行李,然后拖着行李到了首都机场。这一路都不知道是怎么走过去了。脑袋一片空白,没了记忆,已经没了灵魂,肉体拖着到了机场。

碰巧的是,今天还遇到了神舟十二号载人飞船发射,北京时间 2021 年 6 月 17 日。飞行乘组由航天员聂海胜、刘伯明和汤洪波三人组成。由于神十二的发射,首都机场实行空中管制。所有的航空线路停止客运飞机飞行。早上 11 点的飞机。一直等到下午 5 点才起飞。这一天是全国欢庆神州十二号成功发射的日子。但是我一个人一点都高兴不起来。坐在机场黑暗的小角落,心里默默流泪。
笔者由于一签的失败。回到上海开始反思二签怎么办。已经快到了 7 月了。距离开学只剩 8 周的时间了。在地里看了很多被拒签的帖子,和我情况类似的比较少。我也一直找不到好的突破点。只要想办法破除掉“缺少约束力”这个条件,二签才可以继续签。因为你再次申请面签,系统中会让你填写,这次申请和上次申请有哪些不同的地方。如果你把上次的材料原封不动的再提交上去,二签直接拒绝你。
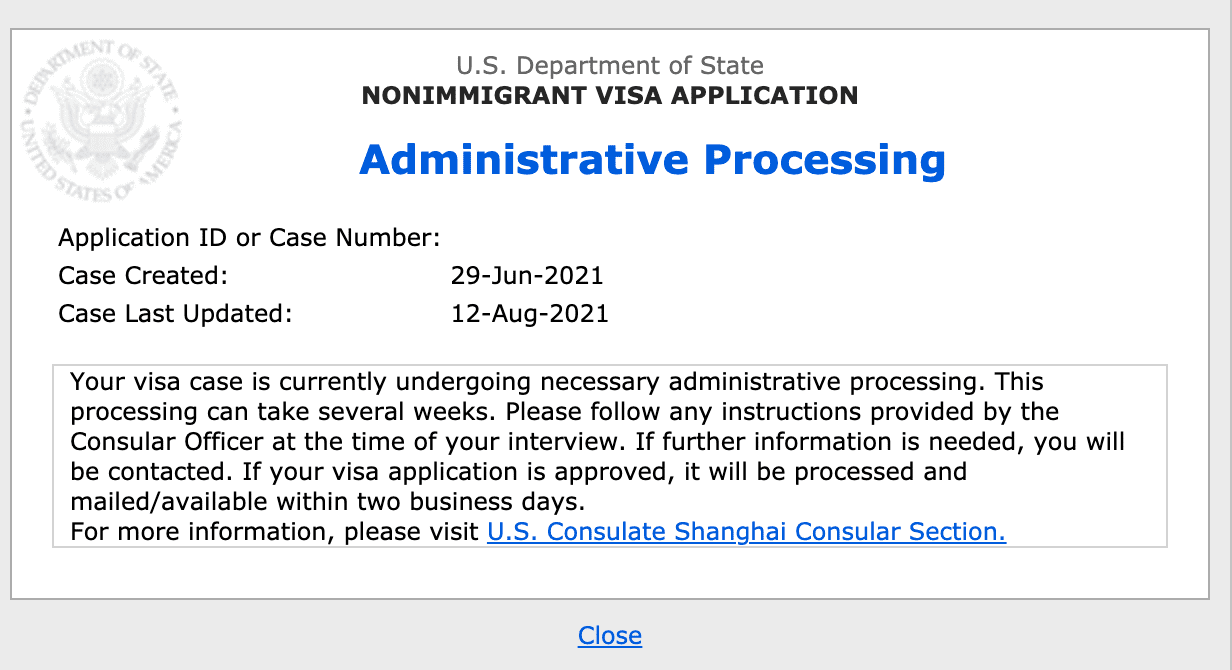
这次二签我没有携签,没有带我妹子一起去。打算一个人去签,让我妹子作为我在国内的约束力。留学存款我也改成是父母提供。还好我还留有 4 个月前的银行转账记录。这一点破除我携带大量个人资金准备移民的倾向。另外一个约束力是独生子+房产。说明上也写明自己读完书立即回国。(好像每个人都会这么写😂)一签战败安家楼,二签再战梅龙镇。上海的使馆地点在梅陇镇。签证那天我妹子陪着我一起到了使馆楼下。她帮我拿了包包,省了存包钱。流程和在北京使馆是完全一样的。面签排队的时候,我一直在观察旁边几个窗口的出签率。我这个队伍前面 2 个人都被 check 了。一个生物科学的女生和历史学的男生。轮到我面签了。先简短了问了几个个人信息的问题。然后面签官就让我等等。他在浏览我上次面签被拒签的理由。浏览了有 5 分多钟。看来上个面签官写了很多关于我的“坏话”啊。等待的时间真的很煎熬。我差点以为我还没面就要挂。这次的面签官是美国人。他看完我的“坏话”以后,就开始面试我了。问题全是针对上一个面签官写的我的坏话的问题。我小心翼翼的回答着。问了我为什么居住在上海却跑到北京去签证?为什么上次是 2 个人,这次却是一个人来面签?资金怎么证明不是我自己的,而是父母提供的?前前后后盘问了整整 1 个小时。我回答的口干舌燥。最后给我的结果是一张黄色的纸,check!让我回去等待,不需要补材料。我看我又要被拒签了。当场心态就崩了。我从面签窗口走出来,排在我后面的都没人了。因为我面了太长时间,场控把排在我后面的人都安排到其他窗口了。我拿着黄色单子下了楼。找到我的妹子。妹子非常焦急,问我为什么面了这么久?我约的面签是 7:30 分的。当我面完出来已经 9:30 了。她从我的脸色中看到了我不好的结果。check 这个结果其实是非常差的。如果当场再次被拒,那么我还可以继续约三签。现在 7 月了。被 check,check 需要等 8 周才能出结果。如果 8 周以后我被拒,那我已经没了三签的机会了。那个时候已经开学了。笔者能否去美帝读书全部压在了这次二签结果之上了。如果挂了,可能也没有笔者这篇经验分享了。笔者 6 月 29 日二签被 Check。直到 8 月 12 日才 Administrative Processing。

运气比较好的是 8 月 13 日紧接着 Issued 了。等我拿到签证护照的时候已经是 8 月 18 日了。那一周紧急的和一些好友告别,下周一 23 号就飞广州 - 首尔 - 旧金山了。如果读者也有在办理美签签证的话,我能给的建议是,祝好运!如果真的被拒签,请耐心,多签几次,还是有机会能过的。
在做飞机离开祖国之前,需要到出入境海关办理国际健康证明书。俗称,黄本本和红本本。

因为 2020 年疫情搅乱了全世界的格局,大家对 COVID-19 疫苗接种异常敏感。不接种疫苗,或者无核酸检测阴性证明都无法上飞机。上海海关入出境体检实在太难约了!笔者 7 月底想着约 8 月的体检。根本约不上,全部都满了。后来在群里了解才得知,其他同学早在 4 月就提前约好了。比我提前 3 个月。难怪我抢不到号!所以建议要留学的同学,这个体检一定要早点预约!!不然就可能约不到了。笔者看到上海约不到,就去周边城市体检。先看了南京苏州,不巧的是,突然南京突发疫情。我去南京体检完可能就无法回到上海了。于是我又看杭州的出入境管理中心。成功约到了杭州的出入境体检。体检分 2 部分。一部分是基础检查,另外一部分是打疫苗。疫苗是学校要求打的,比如打流脑疫苗,水痘疫苗等等。每个学校不同,打的疫苗也不同。有些疫苗在国内还没有,因为这种病在中国就不存在,只存在于美国。所以有些疫苗需要入境美国以后再打。当然也可以选择全部都在入境美国以后再打。笔者在国内体检完,也在国内打了学校要求的疫苗。
如果你想省钱,建议在入境美国以后再打学校要求打的疫苗。因为每个学校的医保可以全额报销疫苗的这部分开销。在国内打疫苗全部自费。
新冠疫苗中国打和美国打,都可以。有不少学生会担心,如果中国打了 2 针疫苗。到了美国再打美国的疫苗,会冲突么?笔者已经接种完美国辉瑞的 2 针疫苗。也接种完中国的 2 针疫苗。目前一切正常。笔者在国内打的是科兴疫苗,第一针是 4 月 10 号打的,第二针是 5 月 15 号。隔了半年以后,10 月底在加州打了辉瑞第一针,11 月 29 继续打了第二针。目前四针都打完了,身体一切正常。至于还有同学犹豫打不打国内的疫苗,是否能入境美国以后立即接种美国的新冠疫苗?笔者给的答案是,建议先打国内的疫苗。因为在跨国转机过程中,有很多感染的风险。打上疫苗以后,给自己加一层保障。
拔牙这件事也很重要。需要拔智齿的最好也在国内拔掉。在美国拔牙要预约,拔牙周期很长,也很花钱。笔者有 2 颗智齿没有拔掉。拔智齿需要用到切骨刀,这个工具在全上海只有一个医院才有,需要预约。拔完还需要 3 周回复,并且这 3 周内不能打其他疫苗。笔者想起来拔智齿这件事有点晚。8 月才想起来。那么我要么选择拔智齿,不打学校要求打的疫苗。要么选择打学校要求打的疫苗,不拔智齿。笔者选择了后者。因为拔智齿也许 3 周恢复不好,临近开学还是不折腾了。从这件事情也说明,拔牙要尽早规划,3,4 月等 offer 的时候就去把牙齿改拔的拔掉吧。
如果有近视眼的同学,建议在国内配一副眼镜。在美国配眼镜需要先验光,再配眼镜。整个流程很长。还是乖乖的在国内配好一副新眼镜带来备用吧。
核酸检测这个不用说,飞机起来前 2 天预约好核酸检测。如果中间需要中转其他国家,主要看好每个国家的防疫政策。有的国家只允许过境 72 小时,但是不准入关。这种情况下,换飞机只能直挂,不能入关换成飞机。这些细节都要自己看清楚。
飞机起飞没什么好说的。需要注意的是行李里面的物品。不要带美国海关违禁的物品,仔细查查药品是否是处方药。很多处方药都不允许带入美国境内。最后在入境美国之前需要填写入境单,如下图。


眼尖的读者会发现其中有英国,加拿大和新加坡的学校。确实,笔者今年 21fall 混申了。UoE 爱丁堡大学,我的一个托福老师毕业于这里,强烈我推荐申请,为了情面,我不得不申。UoT 多伦多大学,一个与我 20 年没有相见的发小在此工作。说来很巧,申请季突然联系上了,为了这份感情,我不得不申。NUS 新加坡国立大学,支持 go local,可以在武汉校区上课,如果美国疫情无法收拾,彻底无法出国,NUS 算最最最最终兜底的方案,可以呆在武汉校区上网课。
以上这些学校的申请费加起来挺贵的,平均一个项目是 $90,额外的可能还有 WES 认证,$30,每个项目 TOEFL 送分是 $20,GRE 送分 $27。平均一个项目是 $90+20+27=$137,笔者总共 23 个项目,光申请费就大约花费 $3151。
21fall 申请季也有不少遗憾,有 4 个项目被拒,笔者一直耿耿于怀。MSCS@NEU KCCS 如果 10 月底或者 11 月网申一开放,赶第一轮 rolling 立即就投,应该能被录取,这个项目没拿到 offer 算是今年申请季的一个“事故”。MSCS@NYU Tandon 是笔者想了很久的项目,今年 bar 卷上天了,实在无奈。MSCS@UCSD CSE 也是笔者想了很久的项目,做梦都在想是否能被录取,可惜最后还是被拒。MScAC@UoT 今年 GPA 的 bar 太高了,GPA < 3.9 的一律拒,唯有叹息。如果能重来的话,笔者可能还想试试这些项目 MCS@UCI,MSWE@UCI,MSCS@NYU Courant,MCS@TAMU,MSCS@Duke,MSE@JHU,MSCS@NWU,MSCS@Stony Brook University,MENG@UCLA,MENG@UCBerkley(不过这些可能都会被拒,纯属浪费申请费了,项目也不用申请太多,能被梦校录取即可)。
最后晒一晒 TOP50 的学校 offer 作为今年 21fall 申请季的结局吧。CMU 的 2 个 offer 是正式 offer,其他几个由于要交“巨额”占位费,或者不打算去的,最终 offer 都 decline 了。关于下面的 offer 都是 PDF 版截图截出来的,笔者有几点想说:











最后这段是额外加的。因为在地里看到一个关于出国留学的讨论:
我周围还真的有满足第二种情况的人。硕士毕业直接落户上海,工作 3-5 年后,硕3-硕5,在上海全额买了一套房产。真的很厉害。有读者可能疑问,一定要全额买么?北上广的房价太高,全额买必须靠父母。地里的讨论其实也包括贷款买房。但是如果你在北京或上海买房以后,再出国读书,读书期间不能打工,每月无收入进账,每个月的房贷只能靠之前自己的积蓄或者父母支撑,再加上美国每月房租和吃喝的开销。总开销不小。能支撑起这种开销的人或者家庭,在国内已经能算人上人了。
至于我,对号入座,是情况三,我就是 loser。
GitHub Repo:Halfrost-Field
Follow: halfrost · GitHub
2020-12-31 15:57:00

考虑到本系列文章有部分新的读者,所以关于本系列文章名字的起源就不再赘述了,见这里《"星霜荏苒"名字诞生记》
注意这篇年终总结是 2020 年的,并非是 2021 年的。当你看到这篇文章的时候,可能到了 2021 年年底了。
2020 年一定是属于人类历史上最具有历史事件的一年。这一年发生了全球严重的公共卫生事件。武汉作为风暴的中心,也是舆论的中心。各种阴谋论鳞次栉比。好在在共产党的领导下,大概 3 个多月就使得武汉原有的确诊病例动态清零了。也因为这 3 个月的封城,武汉的经济受到“重创”。父母的餐馆也受到毁灭性的打击,关门倒闭了。家中经济也因此受到重创。
在今年 1 月 23 号,钟南山爷爷宣布新冠病毒人传人以后,我就退了高铁票没有回家。虽然人在上海,但是基本心还是牵挂着武汉。新闻 app 每隔几个小时的疫情情况推送,时刻都牵扯着我的心。今天这里新增十几例,明天那里新增十几例,弄得人胆战心惊。还记得我去药店买口罩,大雨天大家排了很长很长的队伍,每人每日限购 2 个 N95 口罩。疫情刚刚爆发的那段时间,口罩就如同命一样,不带口罩完全不敢出门。而且那个时候口罩还非常短缺,每天在家数着口罩过日子。口罩快没有了需要赶紧出门,走几条街去排队买口罩。网友们在网上发着暖心的漫画,暂时缓解着紧张情绪。

上图是全国的美食都来看望生病的热干面了。武汉每年 4 月是武汉大学看樱花🌸的季节。因为这次疫情的封城,大多数人都不能来看樱花了。感谢医务工作者们的大无畏精神,拯救了武汉这座城。当疫情过去之时就是请你们每个人来武汉看樱花之日。

另外一个比较深刻的是,中国人再次验证了基建狂魔的称号。仅仅用几天时间就将雷神山,火神山两个医院建立起来了。

其实火神和雷神的名字是有来源的。楚文化传说中的湖北乃古楚之地,而楚国人被认为是火神祝融的后代,祝融(帝喾)则是黄帝的子孙。人的肺部五行属金,火克金。 而荼毒人类肺部的新型冠状病毒惧怕高温,火神正好能驱瘟神,于是“火神山”之名应运而生。
至于雷神山,也是对应着中国民俗文化的传说:雷神是惩罚罪恶之神。凡有违背人伦法理且犯下不可饶恕罪责者,则将遭受五雷轰顶而毙亡。这便是“雷神山”一名的来历。今天的中国,举国坚定信心、同舟共济、科学防治、精准施策,一场防控阻击新型冠状病毒的人民战争正在取得胜利,此刻有火神山和雷神山的“加盟”,人们的精神力量更加充分!
由中建三局牵头,武汉建工、武汉市政、汉阳市政等 3 家企业参建的武汉蔡甸火神山医院,将用于集中收治新型肺炎患者,被称作武汉“小汤山医院”,在 2 月 3 日前建成。除夕夜,火神山医院施工现场灯火通明,各种机械开足马力,这是一场攻坚战,建设者争分夺秒,力争早日完工。网友们纷纷开启云监工模式。5000 多万网友在家里看着火神山和雷神山施工。

网友们还将这些工地上的车分别取了各自有爱的名字。吊车是“送高宗”,带钩子的是“小红”,挖掘机是“蓝忘机”,货车是“红牛哥哥”,叉车是“叉酱”,水泥搅拌机是“呕泥酱”,还有“多尔衮”,“白居易”,“摄政王”,“光武帝”,“黄太急”,“吴三桂”,“小小黄”,“小绿”。感谢网友们风趣幽默的名字,短暂治愈了我紧张的神经。
最终,武汉这座英雄的城市,还是顺利挺过了难关!剩下的亲人离去的伤痛,经济带来的创伤,都交给时间去愈合吧。

经过 2020 年这次疫情,让我的人生轨迹也遭到了不可逆的“打击”,很多事情都回不到过去了,也不可能回到过去了。我在 6 月拿完年终奖以后,选择了辞职,去干一些自己立即想做的事情。离职了以后也没干什么惊天动地的事情,就全世界到处转转,放松放松。(这部分的故事就不细聊了。因为是疫情期间,聊旅行的事情有点违反中国防疫精神—— 非必要不旅行。)金钱确实很重要,但是如果和时间比起来,显得没那么重要了。读者可能有人不赞同我这观点,没关系,毕竟每个人的经历不尽相同,对一些事情的认识也不同。疫情也让我对以下一些“人生哲理”有了更深的认识:

从 2019 年开始,一直到 2020 年 12 月,这期间周围有无数的朋友跳槽换工作,国内外大厂,大大小小什么公司的都有。换了好公司以后,朋友就会开始在朋友圈发新公司的招聘,宣传各种福利,下面评论清一色的酸柠檬🍋。他们也会私聊我或者在群里 @ 我,问我怎么还不换工作,什么时候看机会。我每次都谦虚的回答,“我技术这么菜,面不上贵司啊”,“我这么垃圾,贵司看不上我啊~”。实际上我只是想掩盖一下我小小的梦想。有不少猎头找我要我看机会,年前 1 月跳槽季,年后 2,3 月跳槽季,财年结束 5 月跳槽季,秋季 9,10 月跳槽季,年底 11,12 月跳槽季。一年下来只有 4,7,8 这三个月电话会少一点。有猎头删我好友的,有骂我傻逼的,组织架构调整了还不离职。有骂我技术垃圾的,两年 P6 这辈子你没救了。你们说的每一句话,我都看在眼里的。我也在心里无数次提醒自己,“你就是一个傻逼,为了这个留学的目标真的值得么?执着的大傻逼!”。“我的技术确实菜,前端,客户端,后端都只懂皮毛,至今啥都不精通。”
别人微信里的猎头应该都是这样的画风:“你好厉害啊,你的技术实力肯定能面上阿里巴巴的 P13/百度 T11/腾讯 18 级/字节 5-3,来试试吧,我已经帮你投简历了”,而我微信里的猎头的画风截然相反:“大傻逼,还不跳槽,你今年再不跳槽,这辈子你就废了!!你已经废了~”(一点都没夸张,你们别说不可能,只是你们没遇到),然后我转身想解释,他已经把我删了。 我们互不相识,一上来没聊几句,我的人生怎么就废了???我一直在心里默默精心规划着我的未来,5 年规划,10 年规划,就因为不跳槽,就废啦???也有“好心”猎头帮我规划的,“今年咱们跳到字节,明年咱们再跳一下腾讯,后年咱们再跳一下百度,只需3 年,你的职业就到达一定高度了!”。这个规划和我内心的规划有差距,我说“我有我自己的规划,今年暂时不跳槽”,猎头就会问,“你的规划是什么?”,我说保密。猎头就炸了,一顿狂喷我虚伪,“技术太垃圾跳不动也就算了,偏偏找个理由说不跳槽,我对你这么真诚,你这个人怎么这么虚伪??你人品有问题啊,垃圾~”,我内心一顿委屈。怎么还骂人了?10 分钟以后平复的情绪以后,想给他解释解释原因,对方已经把我删除了。2020 年我已经被好多“脾气有点暴躁”的猎头删好友了,我也被他们莫名的贴上了各种标签,“傻逼”,“没智商”,“人品差”,“虚伪”,“没规划”,“技术垃圾”,“这人废了”……看着他们说的这些话,我真的非常窝火,他们说的没一句是正确的。由于已经被删好友,所以我也没有解释的权利和机会了。这一次次的被人骂,都在我心里默默打气,“我要好好奋斗!今天我是你们眼里的大傻逼,臭垃圾,被你们唾弃瞧不起。明天我要成为其他猎头眼里的香饽饽,暖宝宝,让你们后悔来不及”。就这样,一口气,支撑了我一整年。
一开始我和一些身边的朋友说过我在学英语。慢慢的他们也忘记了。经常会有人问我,“博客怎么不更新了?”“最近在忙什么?”。我如果如实回答,答案就是“最近在研究天文学和地理”,“最近忙着备考托福”。一些人又会开始问了,“学天文和地理干嘛?”,“你考托福干嘛?要出国?要留学?”。这个时候我再回答什么,都会导致后面的对话异常尴尬。同事如果知道了,会偷偷私下传播,“霜神要准备出国了,他肯定要离职了,这个季度的 C 就给他吧,反正他要滚蛋了。”。如果 leader 知道了,oneone 的时候,估计大概率要我背 3.25 。猎头知道了,应该也不会再帮我推荐好机会了。刚开始准备托福的前几周,我恨不得让群友都知道我去学英语了,欢迎一起交流。但是我想通说出去的后果以后,我就闭嘴了。从那以后,朋友,同事,猎头问我,“最近忙啥”,“后面职业规划是啥”,“什么时候跳槽”,类似的问题,我都打马虎眼,“啊?哈。呀?哦。。哈哈哈。。”看到这里可能有读者问了。你为什么要瞒着全世界?你说出自己的留学规划也不是丢人的事情啊。那我反问一句,你跳槽前会让同事和 leader 知道么?肯定不会啊,他们和你利益相关,很有可能你 offer 没拿到,他们就知道了,接下来在你还没有找到下家的时候就把你开除了。这个时候你只能欲哭无泪了。在国内,上班看开源库的源码实现都会被人怀疑要跳槽,仔细询问业务逻辑就会有人怀疑你要跑路。更何况你在公司看技术书,看技术博客,学习,那肯定是跳槽实锤了。为什么自己的计划和打算要和怀疑你的同事一一述说呢?为什么要给自己徒增烦恼?留学和跳槽类似,并且还需要再瞒住朋友和猎头,因为你有可能还需要他们帮你内推。如果你都交代了,他们可能就不帮你内推了。可能又会有读者问,你都要留学了,为什么还在意找工作内推的事情?这就和你们不了解考研和留学有关,既然说到这里,那我就一口气说透吧。不管是考研还是留学,知道最终是否被录取的时间都是在第二年的春天,考研复试公布最终录取名单的时间是 4 月,留学发放 offer 的时间是 2-4 月。考研是每年的 12 月,留学申请的 deadline 一般都在 12-1 月,考研考完试,留学申请完,到知道最终是否被录取之间的这段时间,你是不是还要继续工作?你不用工作,就在家里玩,啃老?那你是有钱人家的孩子。我是穷人家的孩子,每个月还有房贷,信用卡,花呗各种账单等我去还款。考研 12 月考完,第二年 1 月到 9 月入学前,这有 8 个月的时间,肯定要继续工作赚钱啊。留学申请 1 月结束,到 8 月入学,中间也有 7 个月的时间,也要继续努力工作赚钱。而且你也不知道你能不能申请到如意的学校。万一没人要你呢?你还是要继续工作赚钱。有人说 7 个月也要赚钱?这 7 个月可以赚小 50W 啊,可以抵掉留学第一年的学费,不香么?50W 说不要就不要了?如果你说出你的留学意愿以后,同事,leader,朋友,猎头全部都知道了,试想你该如何继续找工作?我的朋友圈有一点广,就算下一家的 HR 不知道, 但是能瞒得过几天呢?业界一传播,几天以后全世界就都知道了,HR 知道了会怎么想?“都要留学了,还来我这里蹭?试用期就开除他”。别笑,人心隔把刀,我不能保证别人不这么想。但是我能保证我不说。我只要不说,就能杜绝所有可能发生的坏情况。所以这也就是为什么 2021 年了,你才看到我的 2019 年的年终总结。2019 年我开始准备托福,申请留学阶段是在 2020 年冬季。我提前把 2019 年的年终总结发布出来,大家一看我在准备托福考试,全天下人都会怀疑我要出国了,我有口也狡辩不清了。在拿到最终 offer 之前,我肯定什么都不能说,而且中美关系恶化,我就算拿到了美国大学的 offer,美签能不能顺利下签也是一个头疼的时候。我当时就下定决心,等我踏上美国国土的那一刻,我再向大家公布这一切,2019 年和 2020 年的年终总结都发布出来。以上就是我隐身 2 年的原因。我对我保守的结果非常满意。我的所有目标基本完成,无人干扰。
另外,我个人是保守性格,在结果未 100% 确定的时候,我都不想透露过程。如果明年 (2021 年) 1 月在我投递完留学申请以后,我就开始找新工作了。到 4 月出结果期间,我一直会努力工作,当做什么都没发生。如果 4 月拿到好结果,那就 6 月份提离职。如果没有拿到好结果,也可以继续再干着。试想,在你准备托福考试的时候就全天下的宣传,“老子要出国留学了!”,然后等到你申请结束,什么 offer 也没有的时候,是多么的尴尬?嘴巴上天天喊着很高调的人大多数都没成功,沉默不语低头做事的人大多数都成功了。这是一个极度看重结果的社会,没有优秀的结果,谁会关注你的过程?知乎上你说你 1 天托福考到 118 分,会有大批人来围观。如果你说你花了 10 年把托福考到 100 分,肯定没人关注,你的经历是 total 失败的经历,毫无参考价值。你我都是不同人眼中的工具人,他人想从你这里学到成功的经验。在这个成王败寇,连第二名都会被遗忘的年代,无结果的努力最终只是感动了自己。我的性格就是这样,考虑周全,低调的准备完所有考试,然后拿到最好的结果以后,再来出来分享结果,丢出这一波王炸。综上,所以从 2019 年我就开始闭嘴了。大家也都不知道我忙啥去了。周围朋友跳槽的跳槽,删我好友的删我好友。我低头拿着工资,赚着奖金,拿着最好的 offer,最后还无缝对接去美国读书,难道不香么?没有任何人能破坏,也不会给机会让别人破坏我精心埋藏呵护的“完美”计划。这应该就是“闷声赚大钱”的真谛吧?(手动 @大左)。
Don’t tell anybody what your next move is. Just do it and shock them. And after shocking them, stay silent and plan your next move. And make it happen. Just keep shocking. Keep Enjoying. Keep Repeating it.
今年也许还是有很多人不明白我为什么突然要离职,突然中断自己的“光明”的职业生涯,选择留学。下这个决定的心路历程在 2019 年已经想清楚了。去年就确定了走这条路了。但是走这条路的目的没有和读者们说的很明白。那么在这里,我发自内心的给出答案:
实现职业目标
满足自己的好奇心,想看看全世界最顶级的工程师平时工作是怎么样的?
自我发展
体验全新的异国文化或生活方式
获得更高的教学质量
获得一次冒险经历
结交新朋友或扩大专业社交圈
学习一门新语言(非编程语言)
世界那么大,生而为人,多出去看看外面的世界。为自己真正想要的生活和幸福奋斗吧。当你扩大了自己的格局以后,你真的会发现,优秀的人真的很多,自己渺小如一粒沙。你真的会发现望尘莫及的事情很多,你需要一直不断努力。你会发现生活不止与眼前,You only live once.
2019 年 8 月就开始准备托福考试了。很不幸的是,到年底也没有准备好。裸考了一次才 80 分。分数很不理想。于是今年继续准备托福刷分。
今年笔者一直在准备托福和 GRE 两个考试。但是因为疫情,线下考场全部关闭,直到 8 月才开放。中间这 7 个月一直都没有考试。原以为 1,2 月复习好托福就可以考试。哪知道突发疫情,线下考场关闭。一转眼就晃到了 8 月。家里人一直督促我提前复习好托福。等考场一开放立即“秒杀”考试。但是笔者还是懒,deadline 还是第一生产力。没有具体考试日期的约束,复习效率一直不高。一般大家考前一周的复习效率是最高的。因为知道一周后自己要上考场了,临时抱佛脚也是最认真的。笔者直到 8 月 15 号才约到第二次托福考试。考完这次托福考试以后便开始了 GRE 的复习备考。
实不相瞒,感觉 2020 年过的太快了。一转眼就过去了。每天看着全球各地这里那里的疫情播报,一年四季都带着口罩。什么事都没有干,一年就过去了。
关于 GRE 考试的复习备考。笔者没有太多的成功经验分享。笔者最终的分数也没有刷到 325 分。一般托福考到 100 分左右。GRE 裸考就有 315 分了。当然这个分数是完全不够的。GRE 对我来说最难的题目就是 Verbal 填空题了。这道题对词汇量的要求太高了。有很多 GRE 的单词是从小到大一直背单词的我们,一点都没见过的单词。因为这个考试的目的是用来考英语为母语的人的。而托福考试是用来考非英语为母语的人的。GRE 的阅读和托福阅读有一部分是相似的。GRE 数学要好好刷几套模拟题。不然应用题会坑死你,里面有很多隐藏条件如果看不出来,那么那道题必错。GRE 数学中还要注意一点,有些题如果给的条件不够,不能自己脑补条件。比如没有告诉男女比例是 1:1,那么涉及到男女比例相关的题目的时候,应该大胆的选择“此题无解”。此题无解这个选项非常具有迷惑性。因为你不知道是因为你的原因导致这道题解不出来,还是因为题目条件缺失导致。由于笔者专业对 GRE 写作要求不太高,3 分或者 3.5 分都可以接受。所以笔者 GRE 写作没有投入太多的时间。用托福写作的实力去写,马马虎虎就 3 分。所以 GRE 总的来说,想考高分,数学要尽量满分。填空要尽量拿高分。GRE 满分 340 分。数学 170,剩下的语文也是 170 分。语文想拿到 160 分以上就非常难了。一般能上 150 分的话,那 325 就很有戏了。GRE 的成败就在语文的 Verbal 上了。
GRE 和托福考试相同点是,都会加试 section。考试者不知道哪个是加试的 section,加试的 section 不算分,由于不知道哪个是加试,所以每个 section 依旧要认真对待。GRE 和托福考试不同点是,GRE 的考试难度会根据考试者做题情况,动态变化。例如考生第一个 section 做的特别差,那么第二个 section 就会变得很简单。但是每道题的分数也动态的变少了。在这种情况下,即使整个 section 全对,分数依旧不是 170 分。只有在 hard 模式下全对,分数才能是 170 分满分。如果考生第一个 section 状态特别好,做了全对。那么第二个 section 会变难。当你明显感觉到难度变难了,那么恭喜你,你开启了高分困难模式。虽然你做对的几率变小了。但是如果蒙对一题的分值也变多了。
笔者很幸运,被加试的是数学。数学比较简单。笔者最终得分是 169 分,还是被扣了一分。(知乎上说 GRE 数学做不到满分💯就不是中国人,😭我不是中国人)
GRE 的单词只能靠自己多背了。《要你命 3000》这个单词书先背个 5 遍。不然上考场肯定一脸懵,基本全靠蒙了。这本书背 5 遍以下是裸泳,10 遍是比基尼,15-20 遍才是上岸。

数学也有少量要背的单词。笔者背的是考满分 GRE 单词 app。数学必备只有 360 词。背完这些完全够用了。笔者把它们 GRE 的单词也刷了一遍。正序,逆序都刷了。app 上刷单词的好处是走到哪里都可以刷,比书本方便很多。等公交车,排队等地铁,中午吃饭排队等等碎片时间,只要拿出手机就可以刷几遍。删掉娱乐 app 和游戏 app 以后,刷单词的时间真的非常多。
最后,记单词这个体力+脑力活,需要每天都接受折磨。如果中断一两天,可能需要一周才能捡起来之前连续累积的记忆力。

关于 GRE 备考。作为过来人,我可以说几句关于心态上的鼓励的话,我也是这样走过来的。相信后来人也有可能遇到相同的问题。
备考 GRE 也是非常痛苦的一件事情。GREer 的苦就是你付出之后,你可能在一个为止的时间段当中,你看不到回报。但是成功和失败之间就是你是否能够挺过这段路。无数留学申请的孩子,都走过了这段路。很多人可能复习了好几个月,上考场之后还是发现没有一点进步,心态濒临崩溃,这些都是正常的。这个时候仿佛置身在一个黑暗的隧道中,没有一点光亮,非常委屈,非常孤独,甚至绝望。有时候还想放弃。但是请你记住,这段路跪着走完,它会带给你人生中最为宝贵的财富,这笔财富称之为,成长。这段路当你真正走到尽头的时候,走出黑暗的隧道,当阳光洒到你脸上的时候,你的嘴角才能扬起留学考试胜利,才有的那份骄傲。那一刻你会对自己说,留学无悔,青春不朽!
至于笔者留学申请的结果,今年的年终总结里面无法告知,明年 4,5 月才会出结果。明年的年终总结就总结一下整个留学季申请的种种吧。
笔者的职业生涯的第一个 5 年结束了,全部是在上海奋斗的时光。按照我的规划,未来的 5 年是在全球奋斗的时光。将会解锁全球的“工作与学习的地方”。关于第二个 5 年规划,是继续读 PhD 呢?还是工作以后再申一个 MBA 呢?清华大学苏世民学院,UIUC MBA 项目等等看上去都是不错的选择。也有可能抵挡不住金钱的诱惑,先致富,财富自由以后继续旅居全球。笔者先不立 flag 了,还是等实现了以后再公布。
最后,老规矩,依旧是一些“只言片语”的感受分享一下作为年终总结的结尾吧。
好了,2020 年的【星霜荏苒】就到这里了。如有任何异议或者想讨论的地方,欢迎和我交流。

2020 年 7 月 1 日,于武汉 Wuhan。借用小福君的一幅插画,祝福全世界的人们都能富贵永驻,金刚护体,百毒不侵,天下太平。
GitHub Repo:Halfrost-Field
Follow: halfrost · GitHub
2020-06-30 16:05:00

已经 0202 年了,大厂面试手撸算法题已经是标配。第一轮就遇到手撸 LRU / LFU 的几率还是挺大的。LeetCode 上146. LRU Cache 和 460. LFU Cache,LRU 是 Medium 难度,LFU 是 Hard 难度,面试官眼里认为这 2 个问题是最最最基础的。这篇文章就来聊聊面试中 LRU / LFU 的青铜与王者。
缓存淘汰算法不仅仅只有 LRU / LFU 这两种,还有很多种,TLRU (Time aware least recently used),PLRU (Pseudo-LRU),SLRU (Segmented LRU),LFRU (Least frequent recently used),LFUDA (LFU with dynamic aging),LIRS (Low inter-reference recency set),ARC (Adaptive Replacement Cache),FIFO (First In First Out),MRU (Most recently used),LIFO (Last in first out),FILO (First in last out),CAR (Clock with adaptive replacement) 等等。感兴趣的同学可以把这每一种都用代码实现一遍。
面试官可能就直接拿出 LeetCode 上这 2 道题让你来做的。在笔者拿出标准答案之前,先简单介绍一下 LRU 和 LFU 的概念。
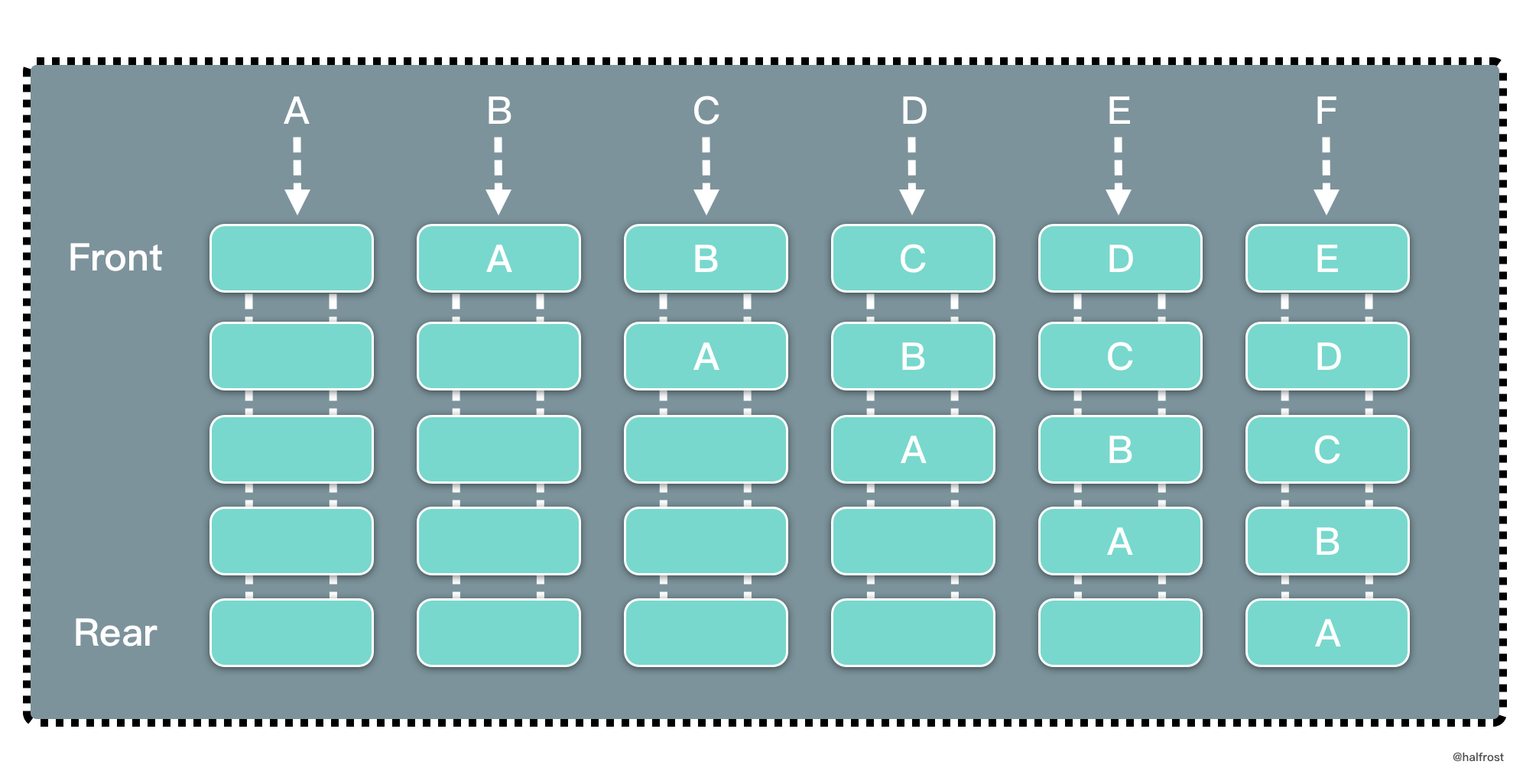
LRU 是 Least Recently Used 的缩写,即最近最少使用,是一种常用的页面置换算法,选择最近最久未使用的页面予以淘汰。如上图,要插入 F 的时候,此时需要淘汰掉原来的一个页面。
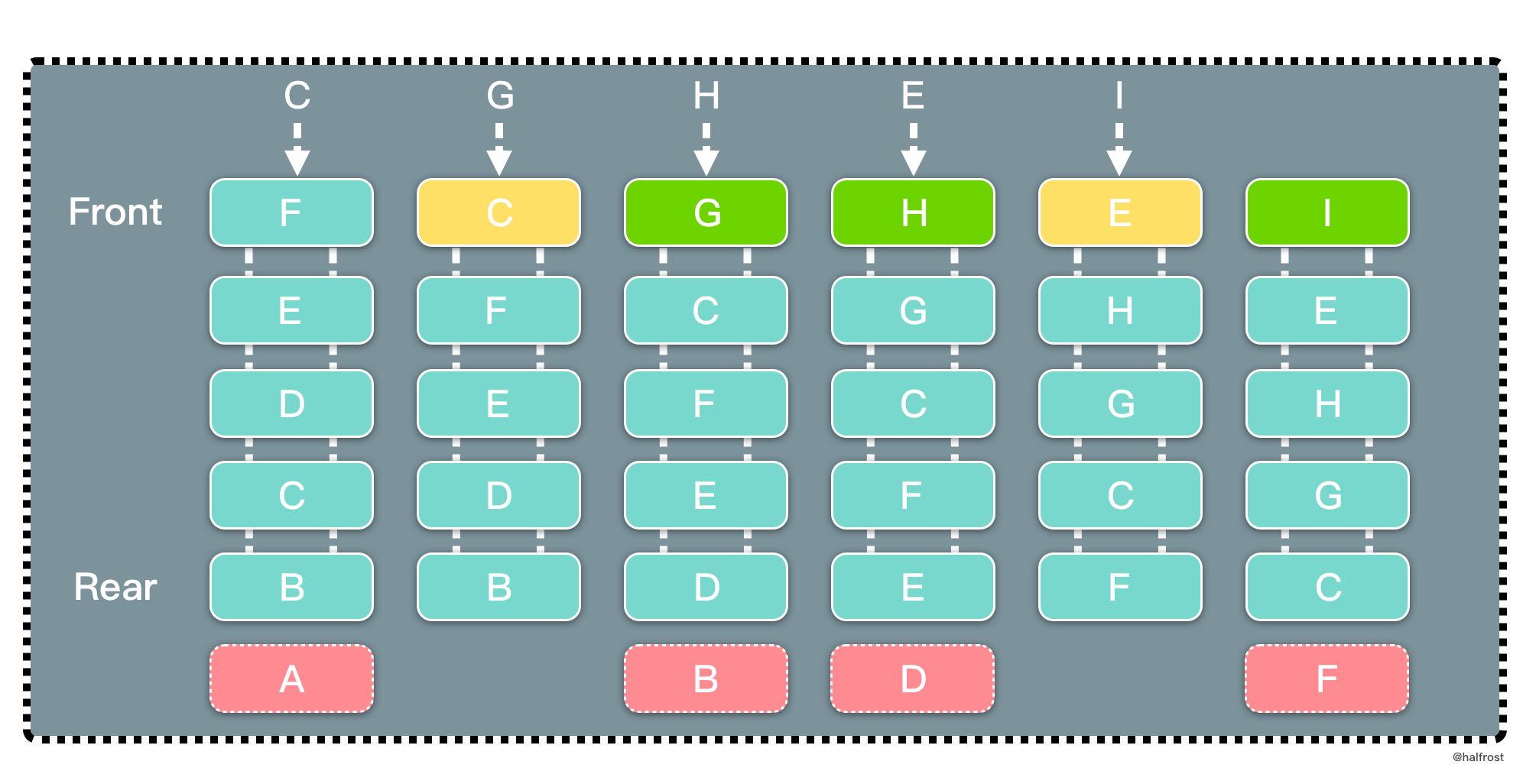
根据 LRU 的策略,每次都淘汰最近最久未使用的页面,所以先淘汰 A 页面。再插入 C 的时候,发现缓存中有 C 页面,这个时候需要把 C 页面放到首位,因为它被使用了。以此类推,插入 G 页面,G 页面是新页面,不在缓存中,所以淘汰掉 B 页面。插入 H 页面,H 页面是新页面,不在缓存中,所以淘汰掉 D 页面。插入 E 的时候,发现缓存中有 E 页面,这个时候需要把 E 页面放到首位。插入 I 页面,I 页面是新页面,不在缓存中,所以淘汰掉 F 页面。
可以发现,LRU 更新和插入新页面都发生在链表首,删除页面都发生在链表尾。
LRU 要求查询尽量高效,O(1) 内查询。那肯定选用 map 查询。修改,删除也要尽量 O(1) 完成。搜寻常见的数据结构,链表,栈,队列,树,图。树和图排除,栈和队列无法任意查询中间的元素,也排除。所以选用链表来实现。但是如果选用单链表,删除这个结点,需要 O(n) 遍历一遍找到前驱结点。所以选用双向链表,在删除的时候也能 O(1) 完成。
由于 Go 的 container 包中的 list 底层实现是双向链表,所以可以直接复用这个数据结构。定义 LRUCache 的数据结构如下:
import "container/list"
type LRUCache struct {
Cap int
Keys map[int]*list.Element
List *list.List
}
type pair struct {
K, V int
}
func Constructor(capacity int) LRUCache {
return LRUCache{
Cap: capacity,
Keys: make(map[int]*list.Element),
List: list.New(),
}
}
这里需要解释 2 个问题,list 中的值存的是什么?pair 这个结构体有什么用?
type Element struct {
// Next and previous pointers in the doubly-linked list of elements.
// To simplify the implementation, internally a list l is implemented
// as a ring, such that &l.root is both the next element of the last
// list element (l.Back()) and the previous element of the first list
// element (l.Front()).
next, prev *Element
// The list to which this element belongs.
list *List
// The value stored with this element.
Value interface{}
}
在 container/list 中,这个双向链表的每个结点的类型是 Element。Element 中存了 4 个值,前驱和后继结点,双向链表的头结点,value 值。这里的 value 是 interface 类型。笔者在这个 value 里面存了 pair 这个结构体。这就解释了 list 里面存的是什么数据。
为什么要存 pair 呢?单单指存 v 不行么,为什么还要存一份 key ?原因是在 LRUCache 执行删除操作的时候,需要维护 2 个数据结构,一个是 map,一个是双向链表。在双向链表中删除淘汰出去的 value,在 map 中删除淘汰出去 value 对应的 key。如果在双向链表的 value 中不存储 key,那么再删除 map 中的 key 的时候有点麻烦。如果硬要实现,需要先获取到双向链表这个结点 Element 的地址。然后遍历 map,在 map 中找到存有这个 Element 元素地址对应的 key,再删除。这样做时间复杂度是 O(n),做不到 O(1)。所以双向链表中的 Value 需要存储这个 pair。
LRUCache 的 Get 操作很简单,在 map 中直接读取双向链表的结点。如果 map 中存在,将它移动到双向链表的表头,并返回它的 value 值,如果 map 中不存在,返回 -1。
func (c *LRUCache) Get(key int) int {
if el, ok := c.Keys[key]; ok {
c.List.MoveToFront(el)
return el.Value.(pair).V
}
return -1
}
LRUCache 的 Put 操作也不难。先查询 map 中是否存在 key,如果存在,更新它的 value,并且把该结点移到双向链表的表头。如果 map 中不存在,新建这个结点加入到双向链表和 map 中。最后别忘记还需要维护双向链表的 cap,如果超过 cap,需要淘汰最后一个结点,双向链表中删除这个结点,map 中删掉这个结点对应的 key。
func (c *LRUCache) Put(key int, value int) {
if el, ok := c.Keys[key]; ok {
el.Value = pair{K: key, V: value}
c.List.MoveToFront(el)
} else {
el := c.List.PushFront(pair{K: key, V: value})
c.Keys[key] = el
}
if c.List.Len() > c.Cap {
el := c.List.Back()
c.List.Remove(el)
delete(c.Keys, el.Value.(pair).K)
}
}
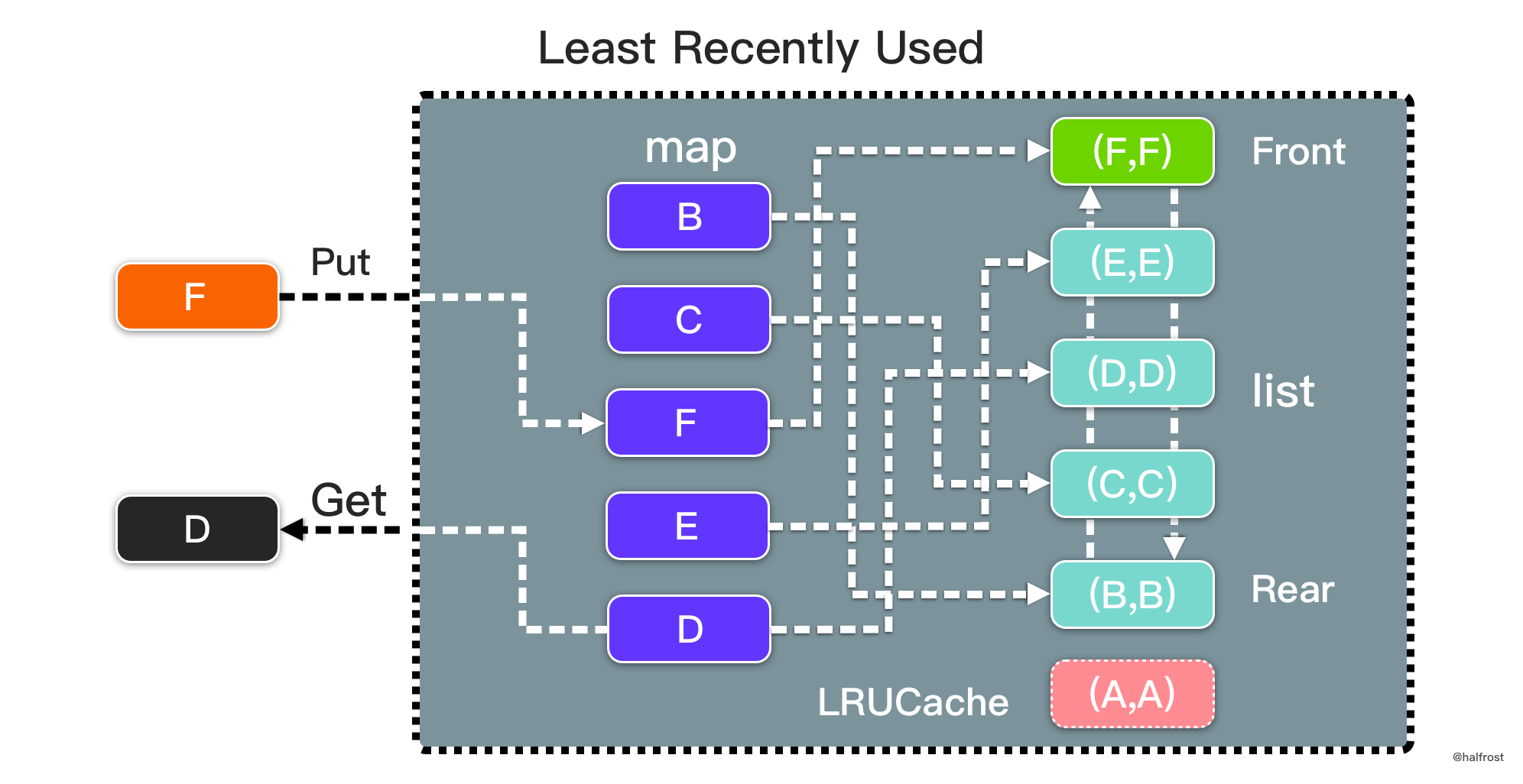
总结,LRU 是由一个 map 和一个双向链表组成的数据结构。map 中 key 对应的 value 是双向链表的结点。双向链表中存储 key-value 的 pair。双向链表表首更新缓存,表尾淘汰缓存。如下图:
提交代码以后,成功通过所有测试用例。
LFU 是 Least Frequently Used 的缩写,即最不经常最少使用,也是一种常用的页面置换算法,选择访问计数器最小的页面予以淘汰。如下图,缓存中每个页面带一个访问计数器。
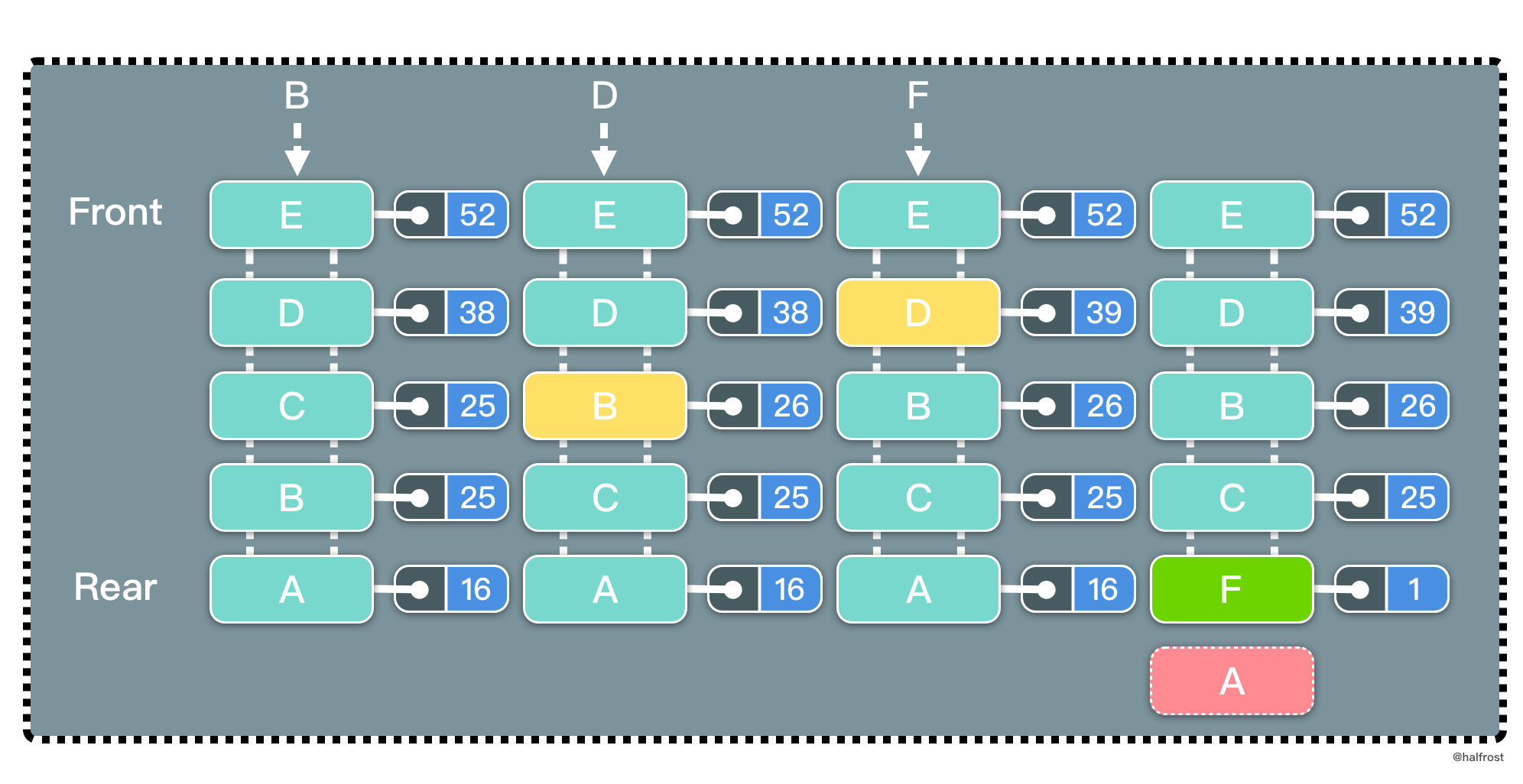
根据 LFU 的策略,每访问一次都要更新访问计数器。当插入 B 的时候,发现缓存中有 B,所以增加访问计数器的计数,并把 B 移动到访问计数器从大到小排序的地方。再插入 D,同理先更新计数器,再移动到它排序以后的位置。当插入 F 的时候,缓存中不存在 F,所以淘汰计数器最小的页面的页面,所以淘汰 A 页面。此时 F 排在最下面,计数为 1。
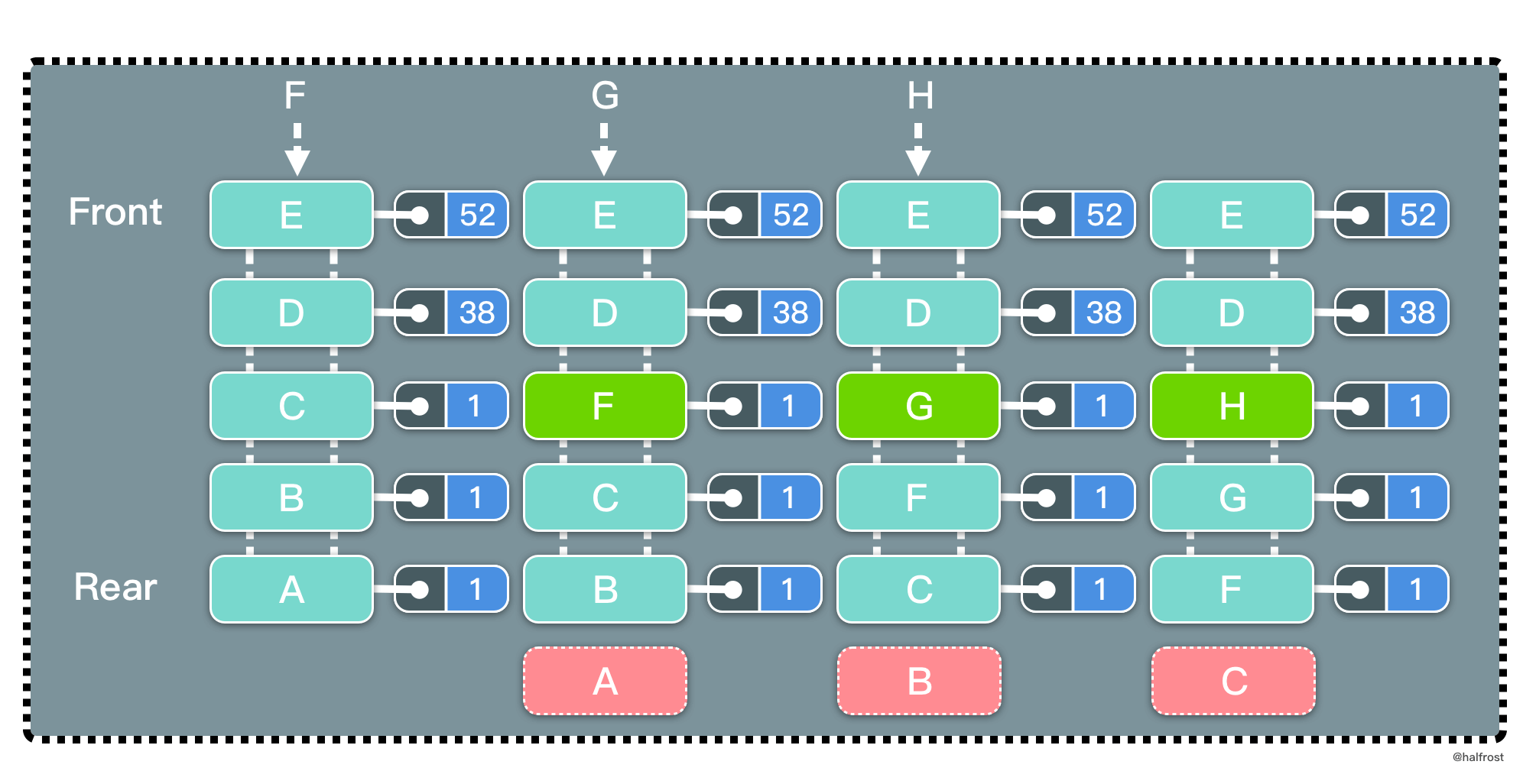
这里有一个比 LRU 特别的地方。如果淘汰的页面访问次数有多个相同的访问次数,选择最靠尾部的。如上图中,A、B、C 三者的访问次数相同,都是 1 次。要插入 F,F 不在缓存中,此时要淘汰 A 页面。F 是新插入的页面,访问次数为 1,排在 C 的前面。也就是说相同的访问次数,按照新旧顺序排列,淘汰掉最旧的页面。这一点是和 LRU 最大的不同的地方。
可以发现,LFU 更新和插入新页面可以发生在链表中任意位置,删除页面都发生在表尾。
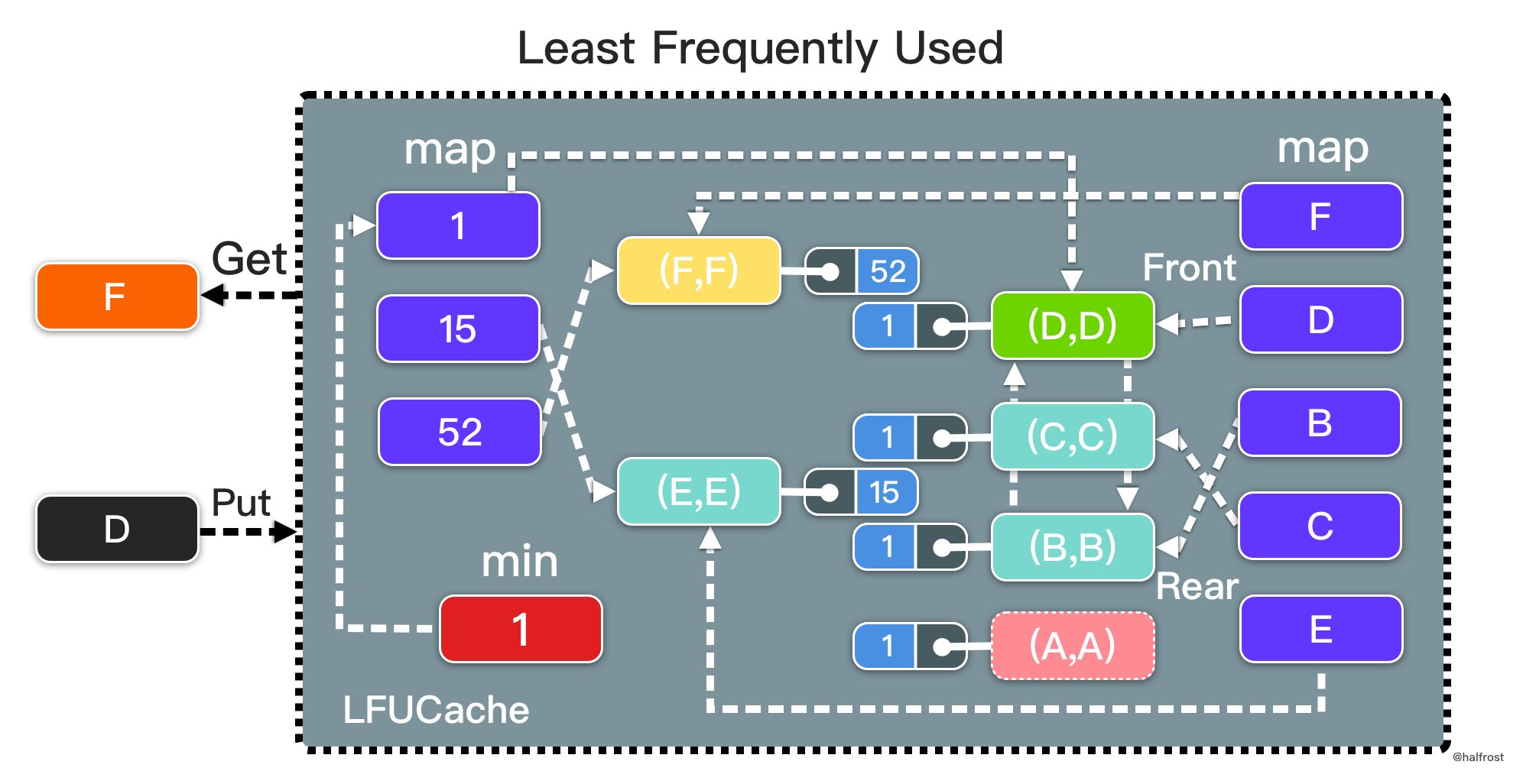
LFU 同样要求查询尽量高效,O(1) 内查询。依旧选用 map 查询。修改和删除也需要 O(1) 完成,依旧选用双向链表,继续复用 container 包中的 list 数据结构。LFU 需要记录访问次数,所以每个结点除了存储 key,value,需要再多存储 frequency 访问次数。
还有 1 个问题需要考虑,一个是如何按频次排序?相同频次,按照先后顺序排序。如果你开始考虑排序算法的话,思考方向就偏离最佳答案了。排序至少 O(nlogn)。重新回看 LFU 的工作原理,会发现它只关心最小频次。其他频次之间的顺序并不关心。所以不需要排序。用一个 min 变量保存最小频次,淘汰时读取这个最小值能找到要删除的结点。相同频次按照先后顺序排列,这个需求还是用双向链表实现,双向链表插入的顺序体现了结点的先后顺序。相同频次对应一个双向链表,可能有多个相同频次,所以可能有多个双向链表。用一个 map 维护访问频次和双向链表的对应关系。删除最小频次时,通过 min 找到最小频次,然后再这个 map 中找到这个频次对应的双向链表,在双向链表中找到最旧的那个结点删除。这就解决了 LFU 删除操作。
LFU 的更新操作和 LRU 类似,也需要用一个 map 保存 key 和双向链表结点的映射关系。这个双向链表结点中存储的是 key-value-frequency 三个元素的元组。这样通过结点中的 key 和 frequency 可以反过来删除 map 中的 key。
定义 LFUCache 的数据结构如下:
import "container/list"
type LFUCache struct {
nodes map[int]*list.Element
lists map[int]*list.List
capacity int
min int
}
type node struct {
key int
value int
frequency int
}
func Constructor(capacity int) LFUCache {
return LFUCache{nodes: make(map[int]*list.Element),
lists: make(map[int]*list.List),
capacity: capacity,
min: 0,
}
}
LFUCache 的 Get 操作涉及更新 frequency 值和 2 个 map。在 nodes map 中通过 key 获取到结点信息。在 lists 删除结点当前 frequency 结点。删完以后 frequency ++。新的 frequency 如果在 lists 中存在,添加到双向链表表首,如果不存在,需要新建一个双向链表并把当前结点加到表首。再更新双向链表结点作为 value 的 map。最后更新 min 值,判断老的 frequency 对应的双向链表中是否已经为空,如果空了,min++。
func (this *LFUCache) Get(key int) int {
value, ok := this.nodes[key]
if !ok {
return -1
}
currentNode := value.Value.(*node)
this.lists[currentNode.frequency].Remove(value)
currentNode.frequency++
if _, ok := this.lists[currentNode.frequency]; !ok {
this.lists[currentNode.frequency] = list.New()
}
newList := this.lists[currentNode.frequency]
newNode := newList.PushFront(currentNode)
this.nodes[key] = newNode
if currentNode.frequency-1 == this.min && this.lists[currentNode.frequency-1].Len() == 0 {
this.min++
}
return currentNode.value
}
LFU 的 Put 操作逻辑稍微多一点。先在 nodes map 中查询 key 是否存在,如果存在,获取这个结点,更新它的 value 值,然后手动调用一次 Get 操作,因为下面的更新逻辑和 Get 操作一致。如果 map 中不存在,接下来进行插入或者删除操作。判断 capacity 是否装满,如果装满,执行删除操作。在 min 对应的双向链表中删除表尾的结点,对应的也要删除 nodes map 中的键值。
由于新插入的页面访问次数一定为 1,所以 min 此时置为 1。新建结点,插入到 2 个 map 中。
func (this *LFUCache) Put(key int, value int) {
if this.capacity == 0 {
return
}
// 如果存在,更新访问次数
if currentValue, ok := this.nodes[key]; ok {
currentNode := currentValue.Value.(*node)
currentNode.value = value
this.Get(key)
return
}
// 如果不存在且缓存满了,需要删除
if this.capacity == len(this.nodes) {
currentList := this.lists[this.min]
backNode := currentList.Back()
delete(this.nodes, backNode.Value.(*node).key)
currentList.Remove(backNode)
}
// 新建结点,插入到 2 个 map 中
this.min = 1
currentNode := &node{
key: key,
value: value,
frequency: 1,
}
if _, ok := this.lists[1]; !ok {
this.lists[1] = list.New()
}
newList := this.lists[1]
newNode := newList.PushFront(currentNode)
this.nodes[key] = newNode
}
总结,LFU 是由两个 map 和一个 min 指针组成的数据结构。一个 map 中 key 存的是访问次数,对应的 value 是一个个的双向链表,此处双向链表的作用是在相同频次的情况下,淘汰表尾最旧的那个页面。另一个 map 中 key 对应的 value 是双向链表的结点,结点中比 LRU 多存储了一个访问次数的值,即结点中存储 key-value-frequency 的元组。此处双向链表的作用和 LRU 是类似的,可以根据 map 中的 key 更新双向链表结点中的 value 和 frequency 的值,也可以根据双向链表结点中的 key 和 frequency 反向更新 map 中的对应关系。如下图:
提交代码以后,成功通过所有测试用例。
面试中如果给出了上面青铜的答案,可能会被追问,“还有没有其他解法?” 虽然目前青铜的答案已经是最优解了,但是面试官还想考察多解。
先考虑 LRU。数据结构上想不到其他解法了,但从打败的百分比上,看似还有常数的优化空间。笔者反复思考,觉得可能导致运行时间变长的地方是在 interface{} 类型推断,其他地方已无优化的空间。手写一个双向链表提交试试,代码如下:
type LRUCache struct {
head, tail *Node
keys map[int]*Node
capacity int
}
type Node struct {
key, val int
prev, next *Node
}
func ConstructorLRU(capacity int) LRUCache {
return LRUCache{keys: make(map[int]*Node), capacity: capacity}
}
func (this *LRUCache) Get(key int) int {
if node, ok := this.keys[key]; ok {
this.Remove(node)
this.Add(node)
return node.val
}
return -1
}
func (this *LRUCache) Put(key int, value int) {
if node, ok := this.keys[key]; ok {
node.val = value
this.Remove(node)
this.Add(node)
return
} else {
node = &Node{key: key, val: value}
this.keys[key] = node
this.Add(node)
}
if len(this.keys) > this.capacity {
delete(this.keys, this.tail.key)
this.Remove(this.tail)
}
}
func (this *LRUCache) Add(node *Node) {
node.prev = nil
node.next = this.head
if this.head != nil {
this.head.prev = node
}
this.head = node
if this.tail == nil {
this.tail = node
this.tail.next = nil
}
}
func (this *LRUCache) Remove(node *Node) {
if node == this.head {
this.head = node.next
if node.next != nil {
node.next.prev = nil
}
node.next = nil
return
}
if node == this.tail {
this.tail = node.prev
node.prev.next = nil
node.prev = nil
return
}
node.prev.next = node.next
node.next.prev = node.prev
}
提交以后还真的 100% 了。
上述代码实现的 LRU 本质并没有优化,只是换了一个写法,没有用 container 包而已。
LFU 的另外一个思路是利用 Index Priority Queue 这个数据结构。别被名字吓到,Index Priority Queue = map + Priority Queue,仅此而已。
利用 Priority Queue 维护一个最小堆,堆顶是访问次数最小的元素。map 中的 value 存储的是优先队列中结点。
import "container/heap"
type LFUCache struct {
capacity int
pq PriorityQueue
hash map[int]*Item
counter int
}
func Constructor(capacity int) LFUCache {
lfu := LFUCache{
pq: PriorityQueue{},
hash: make(map[int]*Item, capacity),
capacity: capacity,
}
return lfu
}
Get 和 Put 操作要尽量的快,有 2 个问题需要解决。当访问次数相同时,如何删除掉最久的元素?当元素的访问次数发生变化时,如何快速调整堆?为了解决这 2 个问题,定义如下的数据结构:
// An Item is something we manage in a priority queue.
type Item struct {
value int // The value of the item; arbitrary.
key int
frequency int // The priority of the item in the queue.
count int // use for evicting the oldest element
// The index is needed by update and is maintained by the heap.Interface methods.
index int // The index of the item in the heap.
}
堆中的结点存储这 5 个值。count 值用来决定哪个是最老的元素,类似一个操作时间戳。index 值用来 re-heapify 调整堆的。接下来实现 PriorityQueue 的方法。
// A PriorityQueue implements heap.Interface and holds Items.
type PriorityQueue []*Item
func (pq PriorityQueue) Len() int { return len(pq) }
func (pq PriorityQueue) Less(i, j int) bool {
// We want Pop to give us the highest, not lowest, priority so we use greater than here.
if pq[i].frequency == pq[j].frequency {
return pq[i].count < pq[j].count
}
return pq[i].frequency < pq[j].frequency
}
func (pq PriorityQueue) Swap(i, j int) {
pq[i], pq[j] = pq[j], pq[i]
pq[i].index = i
pq[j].index = j
}
func (pq *PriorityQueue) Push(x interface{}) {
n := len(*pq)
item := x.(*Item)
item.index = n
*pq = append(*pq, item)
}
func (pq *PriorityQueue) Pop() interface{} {
old := *pq
n := len(old)
item := old[n-1]
old[n-1] = nil // avoid memory leak
item.index = -1 // for safety
*pq = old[0 : n-1]
return item
}
// update modifies the priority and value of an Item in the queue.
func (pq *PriorityQueue) update(item *Item, value int, frequency int, count int) {
item.value = value
item.count = count
item.frequency = frequency
heap.Fix(pq, item.index)
}
在 Less() 方法中,frequency 从小到大排序,frequency 相同的,按 count 从小到大排序。按照优先队列建堆规则,可以得到,frequency 最小的在堆顶,相同的 frequency,count 最小的越靠近堆顶。
在 Swap() 方法中,记得要更新 index 值。在 Push() 方法中,插入时队列的长度即是该元素的 index 值,此处也要记得更新 index 值。update() 方法调用 Fix() 函数。Fix() 函数比先 Remove() 再 Push() 一个新的值,花销要小。所以此处调用 Fix() 函数,这个操作的时间复杂度是 O(log n)。
这样就维护了最小 Index Priority Queue。Get 操作非常简单:
func (this *LFUCache) Get(key int) int {
if this.capacity == 0 {
return -1
}
if item, ok := this.hash[key]; ok {
this.counter++
this.pq.update(item, item.value, item.frequency+1, this.counter)
return item.value
}
return -1
}
在 hashmap 中查询 key,如果存在,counter 时间戳累加,调用 Priority Queue 的 update 方法,调整堆。
func (this *LFUCache) Put(key int, value int) {
if this.capacity == 0 {
return
}
this.counter++
// 如果存在,增加 frequency,再调整堆
if item, ok := this.hash[key]; ok {
this.pq.update(item, value, item.frequency+1, this.counter)
return
}
// 如果不存在且缓存满了,需要删除。在 hashmap 和 pq 中删除。
if len(this.pq) == this.capacity {
item := heap.Pop(&this.pq).(*Item)
delete(this.hash, item.key)
}
// 新建结点,在 hashmap 和 pq 中添加。
item := &Item{
value: value,
key: key,
count: this.counter,
}
heap.Push(&this.pq, item)
this.hash[key] = item
}
用最小堆实现的 LFU,Put 时间复杂度是 O(capacity),Get 时间复杂度是 O(capacity),不及 2 个 map 实现的版本。巧的是最小堆的版本居然打败了 100%。
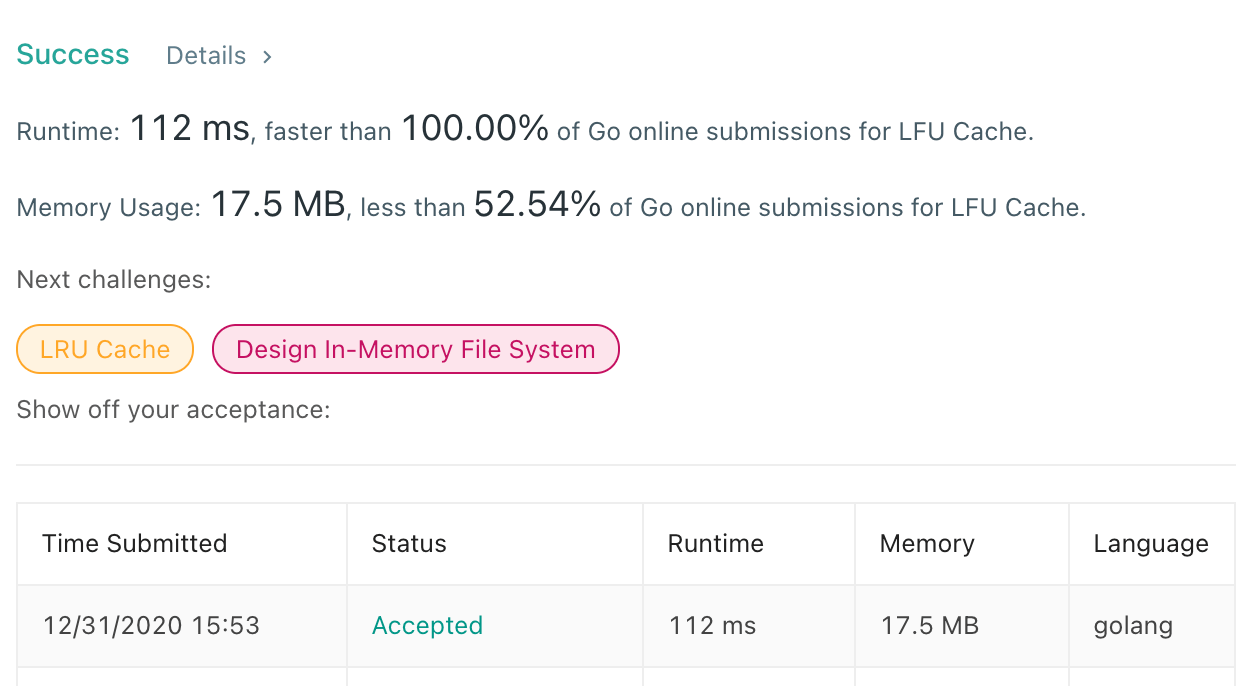
提交以后,LRU 和 LFU 都打败了 100%。上述代码都封装好了,完整代码在 LeetCode-Go 中,讲解也更新到了 《LeetCode Cookbook》第三章的第三节 LRUCache和第四节 LFUCache中。LRU 的最优解是 map + 双向链表,LFU 的最优解是 2 个 map + 多个双向链表。其实热身刚刚结束,接下来才是本文的重点。
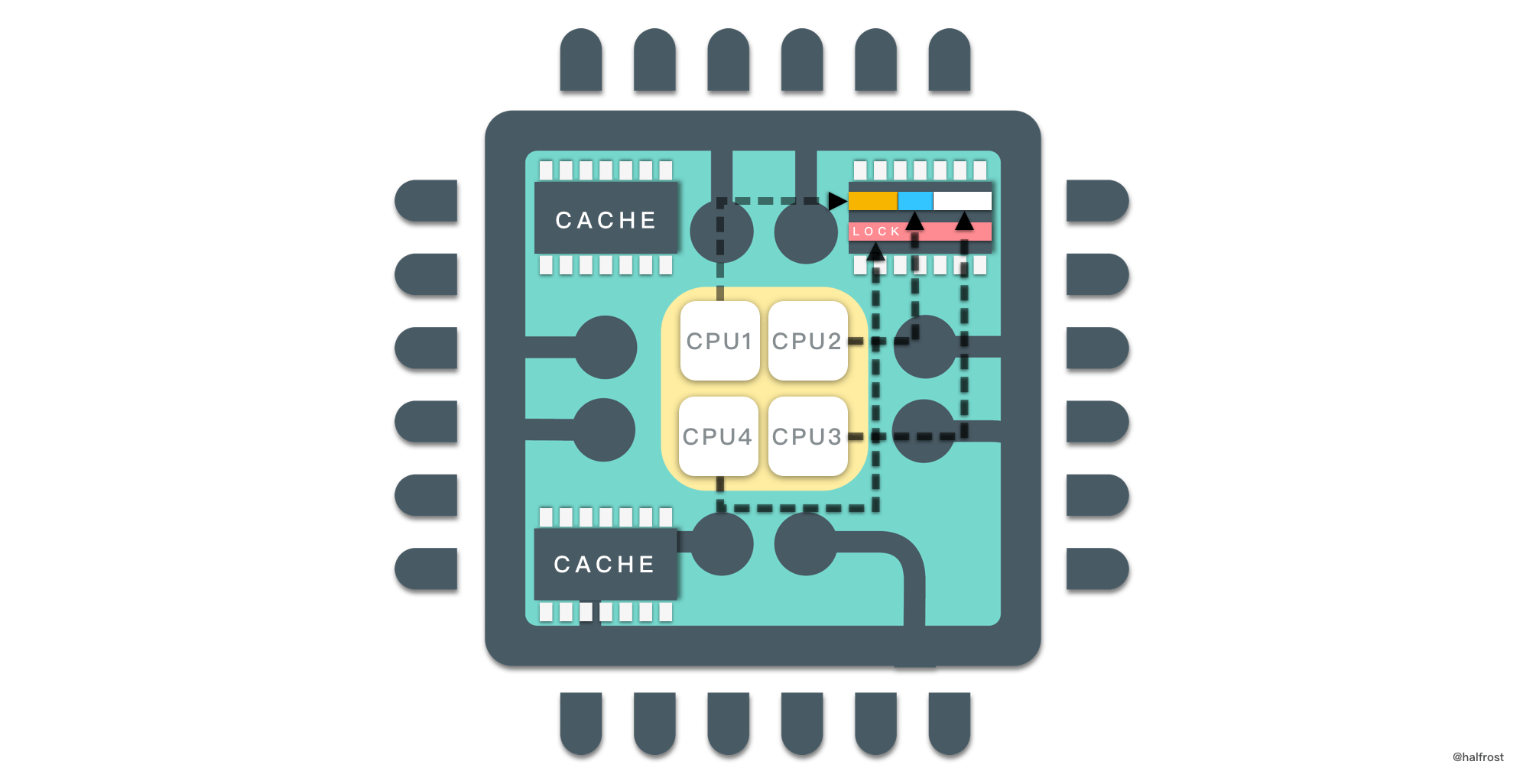
在面试者回答出黄金级的问题了以后,面试官可能会继续追问一个更高级的问题。“如何实现一个高并发且线程安全的 LRU 呢?”。遇到这个问题,上文讨论的代码模板就失效了。要想做到高并发,需要考虑 2 点,第一点内存分配与回收 GC 一定要快,最好是 Zero GC 开销,第二点执行操作耗时最少。详细的,由于要做到高并发,瞬间的 TPS 可能会很大,所以要最快的分配内存,开辟新的内存空间。垃圾回收也不能慢,否则内存会暴涨。针对 LRU / LFU 这个问题,执行的操作是 get 和 set,耗时需要最少。耗时高了,系统吞吐率会受到严重影响,TPS 上不去了。再者,在高并发的场景中,一定会保证线程安全。这里就需要用到锁。最简单的选用读写锁。以下举例以 LRUCache 为例。LFUCache 原理类似。(以下代码先给出改造新增的部分,最后再给出完整版)
type LRUCache struct {
sync.RWMutex
}
func (c *LRUCache) Get(key int) int {
c.RLock()
defer c.RUnlock()
……
}
func (c *LRUCache) Put(key int, value int) {
c.Lock()
defer c.Unlock()
……
}
上述代码虽然能保证线程安全,但是并发量并不高。因为在 Put 操作中,写锁会阻碍读锁,这里会锁住。接下来的优化思路很清晰,拆分大锁,让写锁尽可能的少阻碍读锁。一句话就是将锁颗粒化。
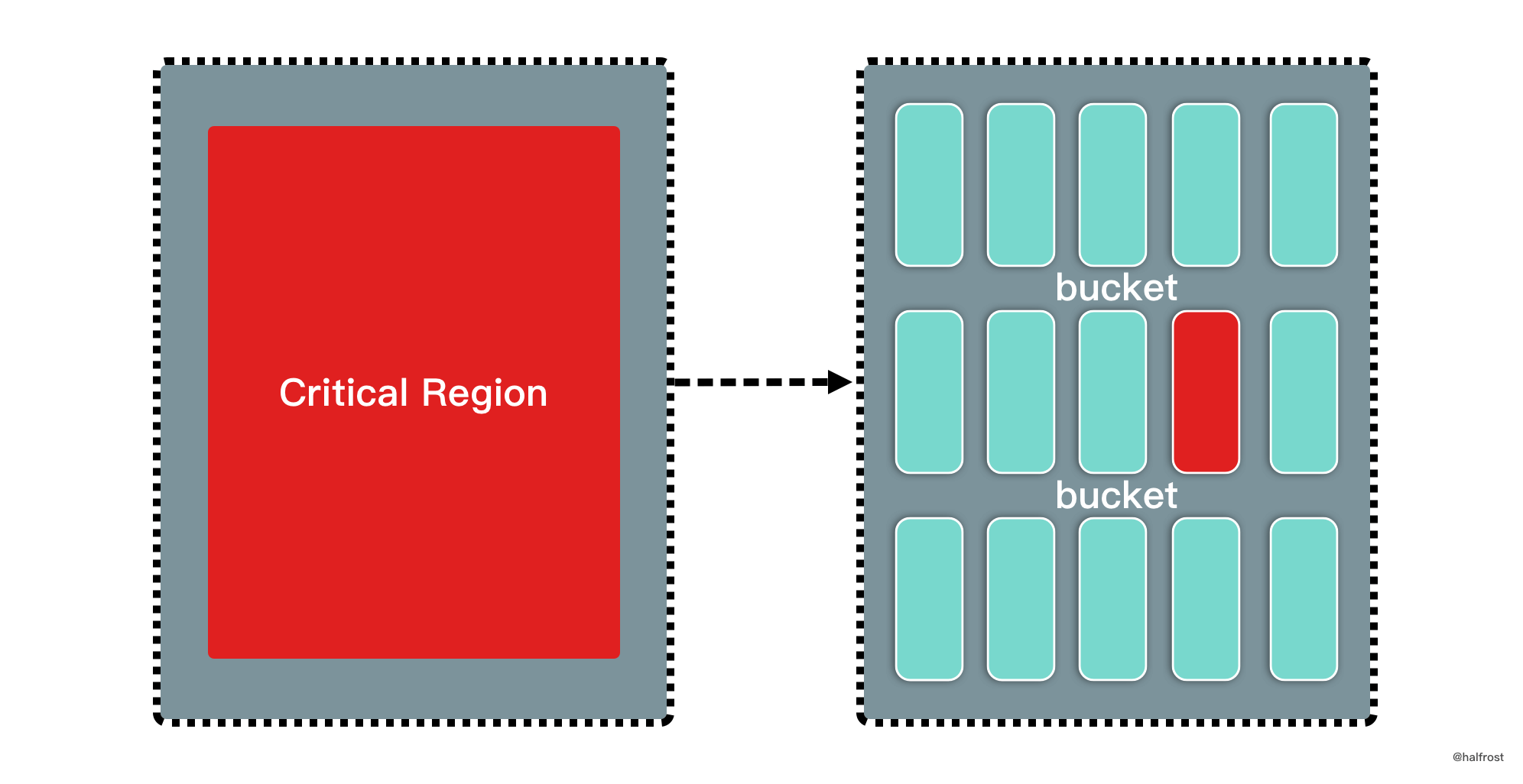
如上图,将一个大的临界区拆分成一个个小的临界区。代码如下:
type LRUCache struct {
sync.RWMutex
shards map[int]*LRUCacheShard
}
type LRUCacheShard struct {
Cap int
Keys map[int]*list.Element
List *list.List
sync.RWMutex
}
func (c *LRUCache) Get(key int) int {
shard, ok := c.GetShard(key, false)
if ok == false {
return -1
}
shard.RLock()
defer shard.RUnlock()
……
}
func (c *LRUCache) Put(key int, value int) {
shard, _ := c.GetShard(key, true)
shard.Lock()
defer shard.Unlock()
……
}
func (c *LRUCache) GetShard(key int, create bool) (shard *LRUCacheShard, ok bool) {
hasher := sha1.New()
hasher.Write([]byte(key))
shardKey := fmt.Sprintf("%x", hasher.Sum(nil))[0:2]
c.lock.RLock()
shard, ok = c.shards[shardKey]
c.lock.RUnlock()
if ok || !create {
return
}
//only time we need to write lock
c.lock.Lock()
defer c.lock.Unlock()
//check again in case the group was created in this short time
shard, ok = c.shards[shardKey]
if ok {
return
}
shard = &LRUCacheShard{
Keys: make(map[int]*list.Element),
List: list.New(),
}
c.shards[shardKey] = shard
ok = true
return
}
通过上述的改造,利用哈希把原来的 LRUCache 分为了 256 个分片(2^8)。并且写锁锁住只发生在分片不存在的时候。一旦分片被创建了,之后都是读锁。这里依旧是小瓶颈,继续优化,消除掉这里的写锁。优化代码很简单,在创建的时候创建所有分片。
func New(capacity int) LRUCache {
shards := make(map[string]*LRUCacheShard, 256)
for i := 0; i < 256; i++ {
shards[fmt.Sprintf("%02x", i)] = &LRUCacheShard{
Cap: capacity,
Keys: make(map[int]*list.Element),
List: list.New(),
}
}
return LRUCache{
shards: shards,
}
}
func (c *LRUCache) Get(key int) int {
shard := c.GetShard(key)
shard.RLock()
defer shard.RUnlock()
……
}
func (c *LRUCache) Put(key int, value int) {
shard := c.GetShard(key)
shard.Lock()
defer shard.Unlock()
……
}
func (c *LRUCache) GetShard(key int) (shard *LRUCacheShard) {
hasher := sha1.New()
hasher.Write([]byte(key))
shardKey := fmt.Sprintf("%x", hasher.Sum(nil))[0:2]
return c.shards[shardKey]
}
到这里,大的临界区已经被拆分成细颗粒度了。在细粒度的锁内部,还包含双链表结点的操作,对结点的操作涉及到锁竞争。成熟的缓存系统如 memcached,使用的是全局的 LRU 链表锁,而 Redis 是单线程的所以不需要考虑并发的问题。回到 LRU,每个 Get 操作需要读取 key 值对应的 value,需要读锁。与此同时,Get 操作也涉及到移动最近最常使用的结点,需要写锁。Set 操作只涉及写锁。需要注意的一点,Get 和 Set 先后执行顺序非常关键。例如,先 get 一个不存在的 key,返回 nil,再 set 这个 key。如果先 set 这个 key,再 get 这个key,返回的就是不是 nil,而是对应的 value。所以在保证锁安全(不发生死锁)的情况下,还需要保证每个操作时序的正确性。能同时满足这 2 个条件的非带缓冲的 channel 莫属。先来看看消费 channel 通道里面数据的处理逻辑:
func (c *CLRUCache) doMove(el *list.Element) bool {
if el.Value.(Pair).cmd == MoveToFront {
c.list.MoveToFront(el)
return false
}
newel := c.list.PushFront(el.Value.(Pair))
c.bucket(el.Value.(Pair).key).update(el.Value.(Pair).key, newel)
return true
}
还值得一提的是,get 和 set 的写操作有 2 种类型,一种是 MoveToFront,另外一种是当结点不存在的时候,需要先创建一个新的结点,并移动到头部。这个操作即 PushFront。笔者这里在结点中加入了 cmd 标识,默认值是 MoveToFront。
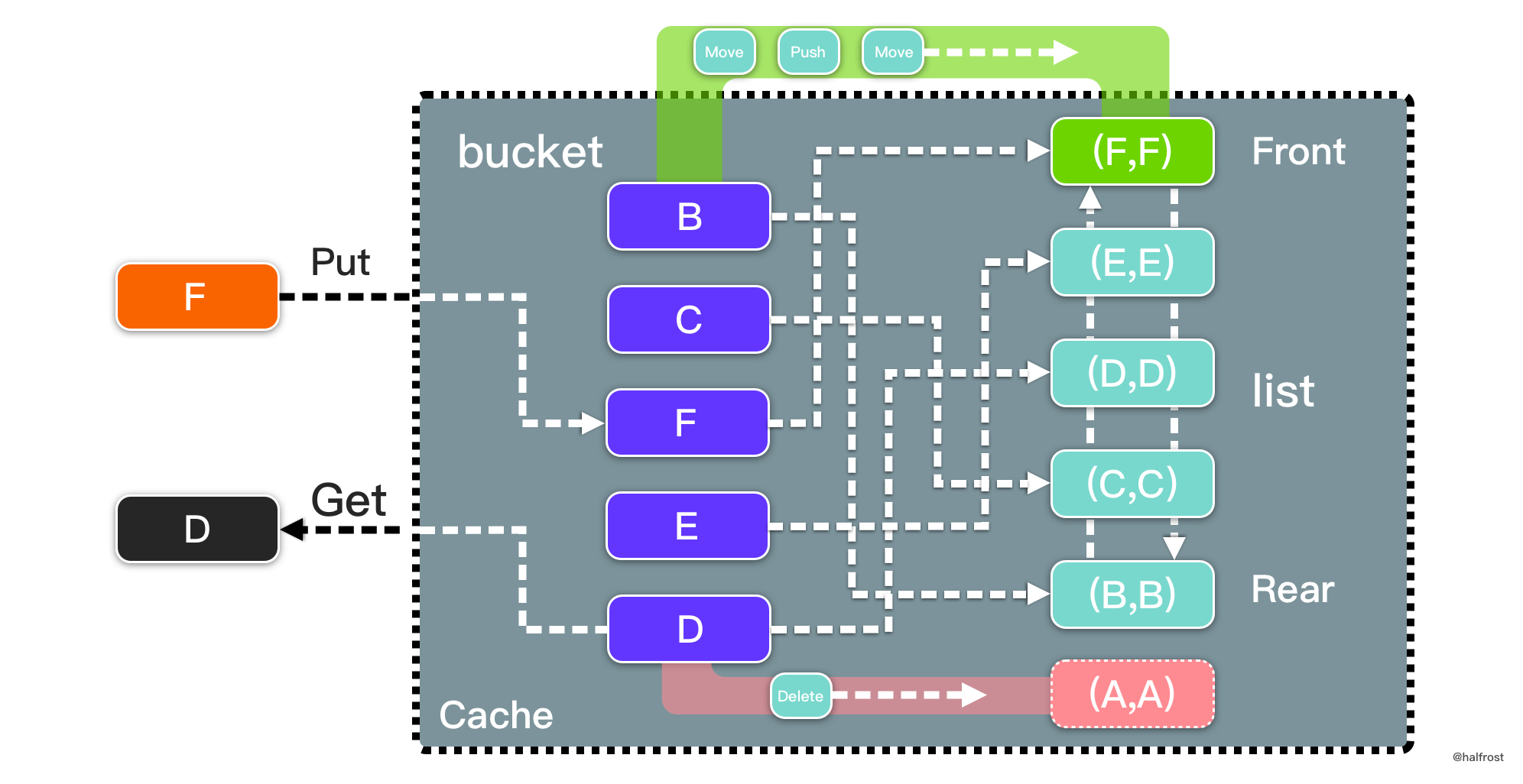
目前为止,下一步的优化思路确定使用带缓冲的 channel 了。用几个呢?答案是用 2 个。除去上面讨论的写入操作,还要管理 remove 操作。由于 LRU 逻辑的特殊性,它保证了移动结点和移除结点一定分开在双链表两端。也就是说在双链表两边同时操作,相互不影响。双链表的临界区范围可以进一步的缩小,可以缩小到结点级。最终方案就定下来了。用 2 个带缓冲的 channel,分别处理移动结点和删除结点,这两个 channel 可以在同一个协程中一起处理,互不影响。
func (c *CLRUCache) worker() {
defer close(c.control)
for {
select {
case el, ok := <-c.movePairs:
if ok == false {
goto clean
}
if c.doMove(el) && c.list.Len() > c.cap {
el := c.list.Back()
c.list.Remove(el)
c.bucket(el.Value.(Pair).key).delete(el.Value.(Pair).key)
}
case el := <-c.deletePairs:
c.list.Remove(el)
case control := <-c.control:
switch msg := control.(type) {
case clear:
for _, bucket := range c.buckets {
bucket.clear()
}
c.list = list.New()
msg.done <- struct{}{}
}
}
}
clean:
for {
select {
case el := <-c.deletePairs:
c.list.Remove(el)
default:
close(c.deletePairs)
return
}
}
}
最终完整的代码放在这里了。最后简单的跑一下 Benchmark 看看性能如何。
以下性能测试部分是面试结束后,笔者测试的。面试时写完代码,并没有当场 Benchmark。
go test -bench BenchmarkGetAndPut1 -run none -benchmem -cpuprofile cpuprofile.out -memprofile memprofile.out -cpu=8goos: darwin
goarch: amd64
pkg: github.com/halfrost/LeetCode-Go/template
BenchmarkGetAndPut1-8 368578 2474 ns/op 530 B/op 14 allocs/op
PASS
ok github.com/halfrost/LeetCode-Go/template 1.022s
BenchmarkGetAndPut2 只是简单的全局加锁,会有死锁的情况。可以看到方案一的性能还行,368578 次循环平均出来的结果,平均一次 Get/Set 需要 2474 ns,那么 TPS 大约是 300K/s,可以满足一般高并发的需求。
最后看看这个版本下的 CPU 消耗情况,符合预期:
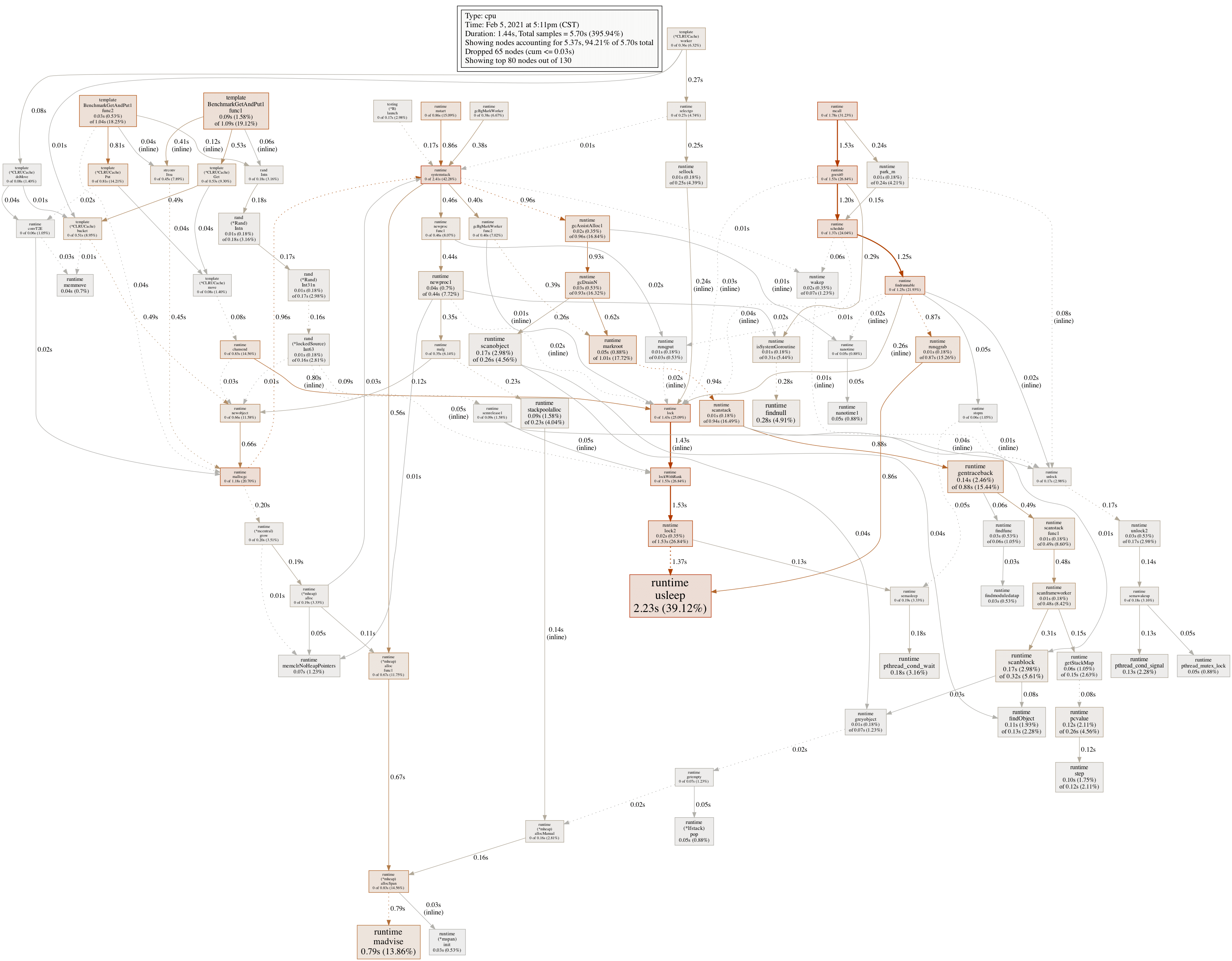
内存分配情况,也符合预期:
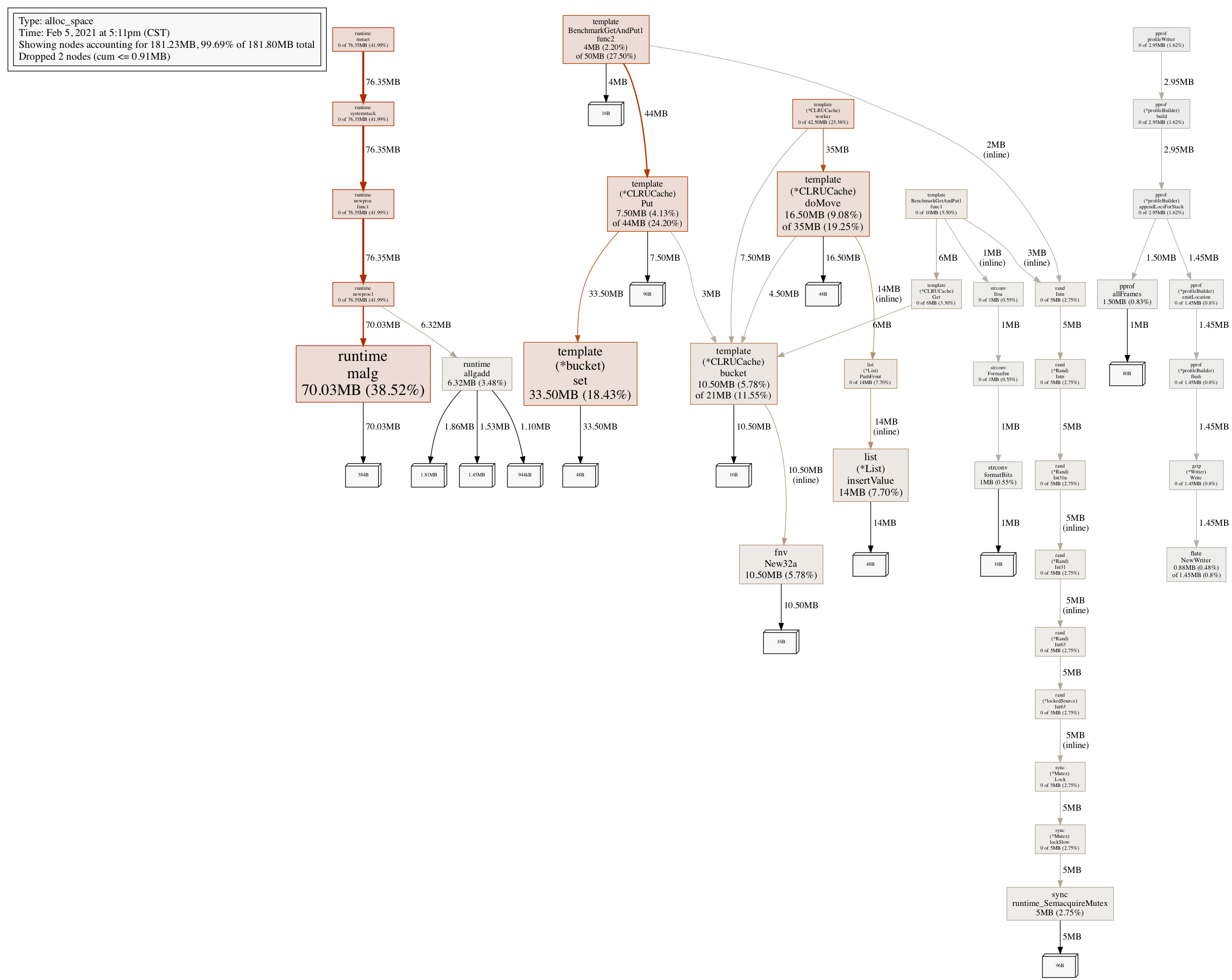
至此,你已经是王者了。
这里是附加题部分。面试官问到这里就和 LRU/LFU 直接关系不大了,更多的考察的是如何设计一个高并发的 Cache。笔者之所以在这篇文章最后提一笔,是想给读者扩展思维。面试官会针对你给出的高并发版的 LRU 继续问,“你觉得你写的这个版本缺点在哪里?和真正的 Cache 比,还有哪些欠缺?”
在上一节“最强王者”中,粗略的实现了一个高并发的 LRU。但是这个方案还不是最完美的。当高并发高到一个临界值的时候,即 Get 请求的速度达到 Go 内存回收速度的几百倍,几万倍的时候。bucket 分片被清空,试图访问该分片中的 key 的 goroutine 开始分配内存,而先前的内存仍未完全释放,从而导致内存使用量激增和 OOM 崩溃。所以这种方法的性能不能随内核数量很好地扩展。
另外这种粗略的方式是以缓存数目作为 Cap 的,没有考虑每个 value 的大小。以缓存数目作为基准,是没法限制住内存大小的。如果高负载的业务,设置大的 Cap,极端的讲,每个 value 都非常大,几十个 MB,整体内存消耗可能上百 GB。如果是低负载的业务,设置很小的 Cap,极端情况,每个 value 特别小。总内存大小可能在 1KB。这样看,内存上限和下限浮动太大了,无法折中限制。
欠缺的分为 2 部分,一部分是功能性,一部分是性能。功能性方面欠缺 TTL,持久化。TTL 是过期时间,到时间需要删除 key。持久化是将缓存中的数据保存至文件中,或者启动的时候从文件中读取。
性能方面欠缺的是高效的 hash 算法,高命中率,内存限制,可伸缩性。
高效的 hash 算法指的是类似 AES Hash,针对 CPU 是否支持 AES 指令集进行了判断,当 CPU 支持 AES 指令集的时候,它会选用 AES Hash 算法。一些高效的 hash 算法用汇编语言实现的。
高命中率方面,可以参考 BP-Wrapper: A System Framework Making Any
Replacement Algorithms (Almost) Lock Contention Free 这篇论文,在这篇论文里面提出了 2 种方式:prefetching 和 batching。简单说一下 batching 的方式。在等待临界区之前,先填满 ring buffer。如该论文所述,借用 ring buffer 这种方式,几乎没有开销,从而大大降低了竞争。实现 ring buffer 可以考虑使用 sync.Pool 而不是其他的数据结构(切片,带区互斥锁等),原因是性能优势主要是由于线程本地存储的内部使用,而其他的数据结构没有这相关的 API。
内存限制。无限大的缓存实际上是不可能的。高速缓存必须有大小限制。如何制定一套高效的淘汰的策略就变的很关键。LRU 这个淘汰策略好么?针对不同的使用场景,LRU 并不是最好的,有些场景下 LFU 更加适合。这里有一篇论文 TinyLFU: A Highly Efficient Cache Admission Policy,这篇论文中讨论了一种高效缓存准入策略。TinyLFU 是一种与淘汰无关的准入策略,目的是在以很少的内存开销来提高命中率。主要思想是仅在新的 key 的估计值高于正要被逐出的 key 的估计值时才允许进入 Cache。当缓存达到容量时,每个新的 key 都应替换缓存中存在的一个或多个密钥。并且,传入 key 的估值应该比被淘汰出去的 key 估值高。否则新的 key 禁止进入缓存中。这样做也为了保证高命中率。
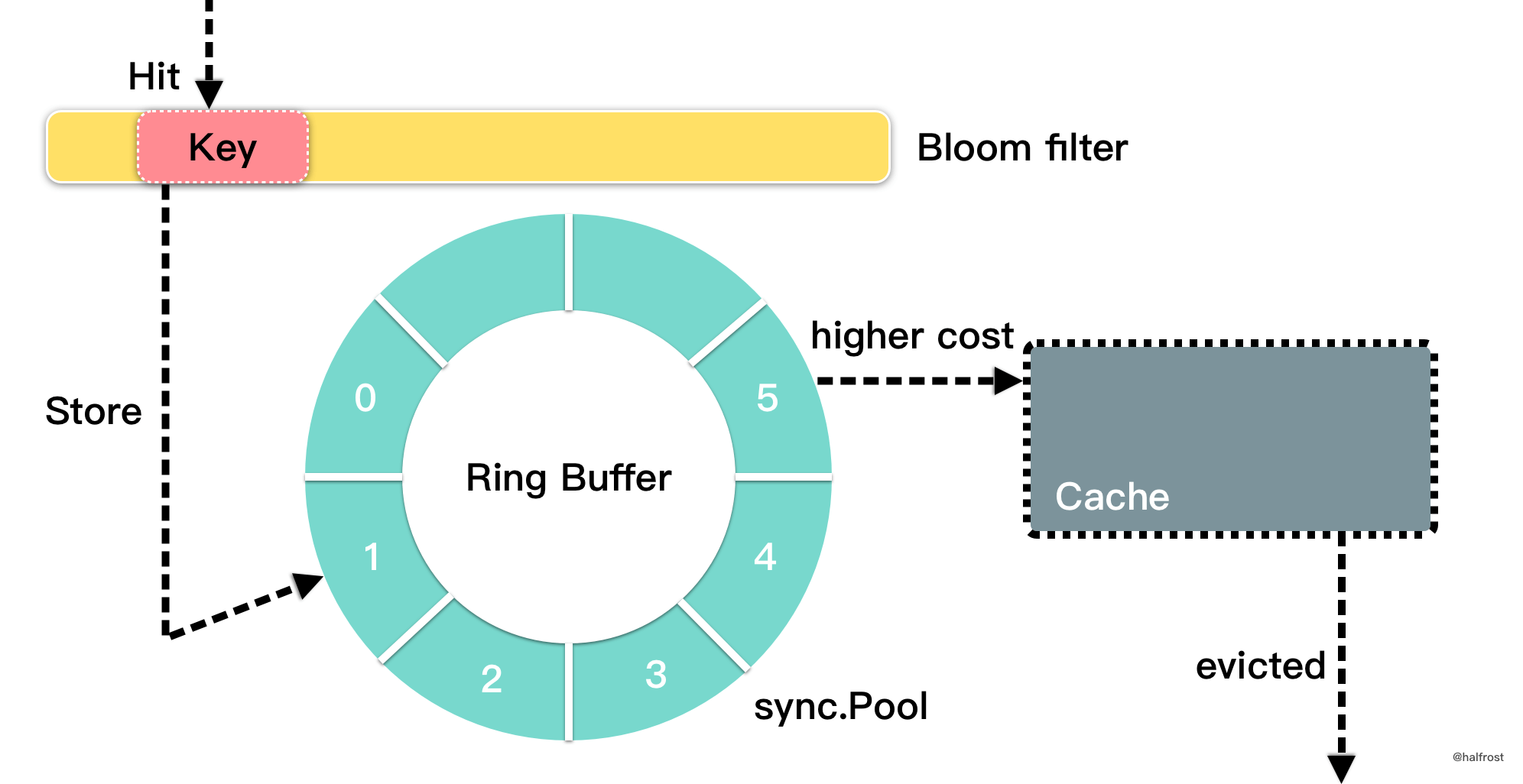
在将新 key 放入 TinyLFU 中之前,还可以使用 bloom 过滤器首先检查该密钥是否之前已被查看过。仅当 key 在布隆过滤器中已经存在时,才将其插入 TinyLFU。这是为了避免长时间不被看到的长尾键污染 TinyLFU。
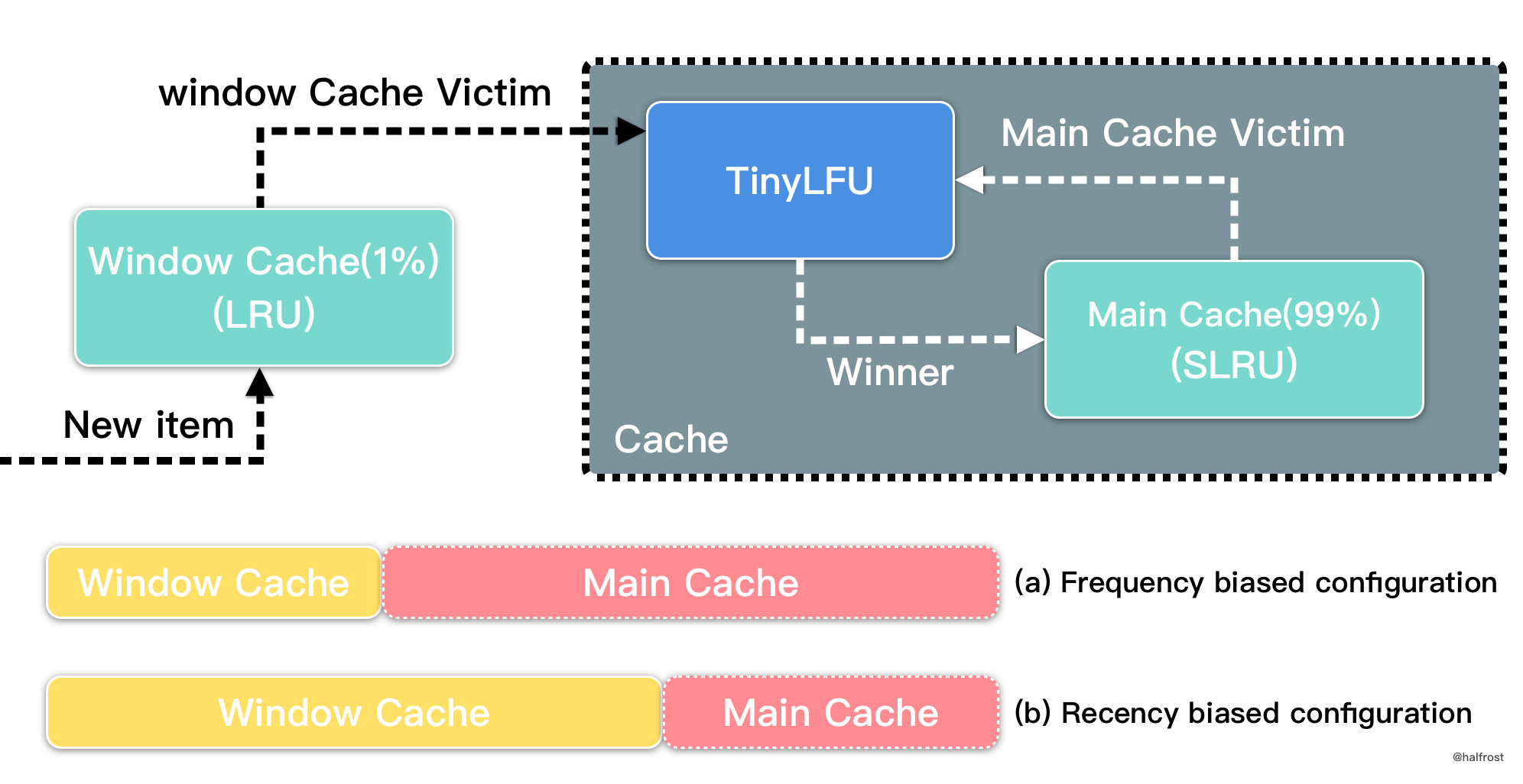
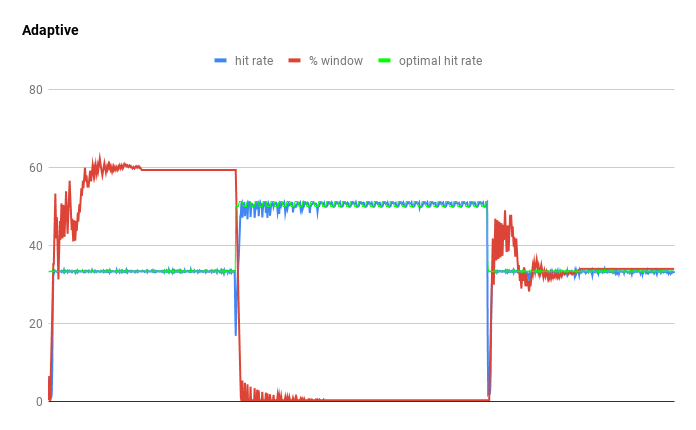
关于到底选择 LRU 还是 LFU 还是 LRU + LFU ,这个话题比较大,展开讨论又可以写好几篇新文章了。感兴趣的读者可以看看这篇论文,Adaptive Software Cache Management ,从标题上看,自适应的软件缓存管理,就能看出它在探讨了这个问题。论文的基本思想是在主缓存段之前放置一个 LRU “窗口”,并使用爬山技术自适应地调整窗口大小以最大化命中率。A high performance caching library for Java 8 — Caffeine 已经取得了很好的效果。
可伸缩性方面,选择合适的缓存大小,可以避免 False Sharing,在多核系统中,其中不同的原子计数器(每个8字节)位于同一高速缓存行(通常为64字节)中。对这些计数器之一进行的任何更新都会导致其他计数器被标记为无效。这将强制为拥有该高速缓存的所有其他核心重新加载高速缓存,从而在高速缓存行上创建写争用。为了实现可伸缩性,应该确保每个原子计数器完全占用完整的缓存行。因此,每个内核都在不同的缓存行上工作。
最后看看 Go 实现的几个开源 Cache 库。关于这些 Cache 的源码分析,本篇文章就不展开了。(有时间可能会单独再开一篇文章详解)。感兴趣的读者可以自己查阅源码。
bigcache,BigCache 根据 key 的哈希将数据分为 shards。每个分片都包含一个映射和一个 ring buffer。每当设置新元素时,它都会将该元素追加到相应分片的 ring buffer 中,并且缓冲区中的偏移量将存储在 map 中。如果同一元素被 Set 多次,则缓冲区中的先前条目将标记为无效。如果缓冲区太小,则将其扩展直到达到最大容量。每个 map 中的 key 都是一个 uint32 hash,其值是一个 uint32 指针,指向该值与元数据信息一起存储的缓冲区中的偏移量。如果存在哈希冲突,则 BigCache 会忽略前一个键并将当前键存储到映射中。预先分配较少,较大的缓冲区并使用 map[uint32]uint32 是避免承担 GC 扫描成本的好方法。
freecache,FreeCache 通过减少指针数量避免了 GC 开销。 无论其中存储了多少条目,都只有 512 个指针。通过 key 的哈希值将数据集分割为 256 个段。将新 key 添加到高速缓存时,将使用 key 哈希值的低八位来标识段 ID。每个段只有两个指针,一个是存储 key 和 value 的 ring buffer,另一个是用于查找条目的索引 slice。数据附加到 ring buffer 中,偏移量存储到排序 slice 中。如果 ring buffer 没有足够的空间,则使用修改后的 LRU 策略从 ring buffer 的开头开始,在该段中淘汰 key。如果条目的最后访问时间小于段的平均访问时间,则从 ring buffer 中删除该条目。要在 Get 的高速缓存中查找条目,请在相应插槽 slot 中的排序数组中执行二进制搜索。此外还有一个加速的优化,使用 key 的哈希的 LSB 9-16 选择一个插槽 slot。将数据划分为多个插槽 slot 有助于减少在缓存中查找键时的搜索空间。每个段都有自己的锁,因此它支持高并发访问。
groupCache,groupcache 是一个分布式的缓存和缓存填充库,在许多情况下可以替代 memcached。在许多情况下甚至可以用来替代内存缓存节点池。groupcache 实现原理和本文在上一章节中实现的方式是一摸一样的。
fastcache,fastcache 并没有缓存过期的概念。仅在高速缓存大小溢出时才从高速缓存中淘汰 key 值。key 的截止期限可以存储在该值内,以实现缓存过期。fastcache 缓存由许多 buckets 组成,每个 buckets 都有自己的锁。这有助于扩展多核 CPU 的性能,因为多个 CPU 可以同时访问不同的 buckets。每个 buckets 均由一个 hash(key)->(key,value)的映射和 64KB 大小的字节 slice(块)组成,这些字节 slice 存储已编码的(key,value)。每个 buckets 仅包含 chunksCount 个指针。例如,64GB 缓存将包含大约 1M 指针,而大小相似的 map[string][]byte 将包含 1B指针,用于小的 key 和 value。这样做可以节约巨大的 GC 开销。与每个 bucket 中的单个 chunk 相比,64KB 大小的 chunk 块减少了内存碎片和总内存使用量。如果可能,将大 chunk 块分配在堆外。这样做可以减少了总内存使用量,因为 GC 无需要 GOGC 调整即可以更频繁地收集未使用的内存。
ristretto,ristretto 拥有非常优秀的缓存命中率。淘汰策略采用简单的 LFU,性能与 LRU 相当,并且在搜索和数据库跟踪上具有更好的性能。存入策略采用 TinyLFU 策略,它几乎没有内存开销(每个计数器 12 位)。淘汰策略根据代价值判断,任何代价值大的 key 都可以淘汰多个代价值较小的 key(代价值可以是自定义的衡量标准)。
以下是这几个库的性能曲线图:
在一小时内对 CODASYL 数据库的引用:

在商业站点上运行的数据库服务器,该服务器在商业数据库之上运行 ERP 应用程序:

循环访问模式:

大型商业搜索引擎响应各种 Web 搜索请求而启动的磁盘读取访问:

吞吐量:



BP-Wrapper: A System Framework Making Any
Replacement Algorithms (Almost) Lock Contention Free
Adaptive Software Cache Management
TinyLFU: A Highly Efficient Cache Admission Policy
LIRS: An Efficient Low Inter-reference Recency Set Replacement Policy to Improve Buffer Cache Performance
ARC: A Self-Tuning, Low Overhead Replacement Cache
2019-12-31 13:20:00

考虑到本系列文章有部分新的读者,所以关于本系列文章名字的起源就不再赘述了,见这里《"星霜荏苒"名字诞生记》
当你看到这篇年终总结的时候,距离我上一篇年终总结整整过去了 500 多天。你一定很好奇这 500 天我干了哪些事情,为什么这篇文章的标题叫这个名字?
为了解释文章标题,就要先解释 10 个词语。笔者将学生等级从高到低排序是:
| 等级 | 名词 | 解释 |
|---|---|---|
| 1 | 学魔 | 对学习走火入魔,癫狂状态,不做题会死掉。 |
| 2 | 学霸 | 隐匿在人间有头脑的高智商人物,社交范围广泛,融合契合度高,琴棋书画样样精通,高端大气上档次。 |
| 3 | 学神(学帝、学仙、学圣) | 高大帅气,青春靓丽,不食人间烟火,天天游走在高难度的练习册当中却依然风华正茂。 |
| 4 | 学痞 | 他们上课睡觉,下课玩闹,但他们的成绩仍然很好。 |
| 5 | 学婊 | 每天都在玩,几乎不学习,每场考试结束后第一时间宣布自己要挂科了。但是考试成绩出来后,门门都拿第一。 |
| 6 | 学民 | 智商均衡,膜拜学霸,却瞧不起学渣等人物。他们只有一个信念,总有一天超越学霸,因此艰苦奋斗。 |
| 7 | 学弱 | 他们因为没日没夜地熬油点灯,已经身体虚弱,不堪重负。 |
| 8 | 学渣(学灰) | 智商处于半疯癫状态,兢兢业业,刻苦学习,却总是不得志。 |
| 9 | 学残 | 智商处于全疯癫状态。他们已经被学习折磨得痛苦不堪,没有人样。 |
| 10 | 学沫 | 智商不够用,却也不是很努力,每天在混着日子。总是觉得能够不劳而获。 |
| 11 | 学水 | 已经不能用智商与努力来评判他们了,他们已经自甘堕落,自暴自弃好多年。 |
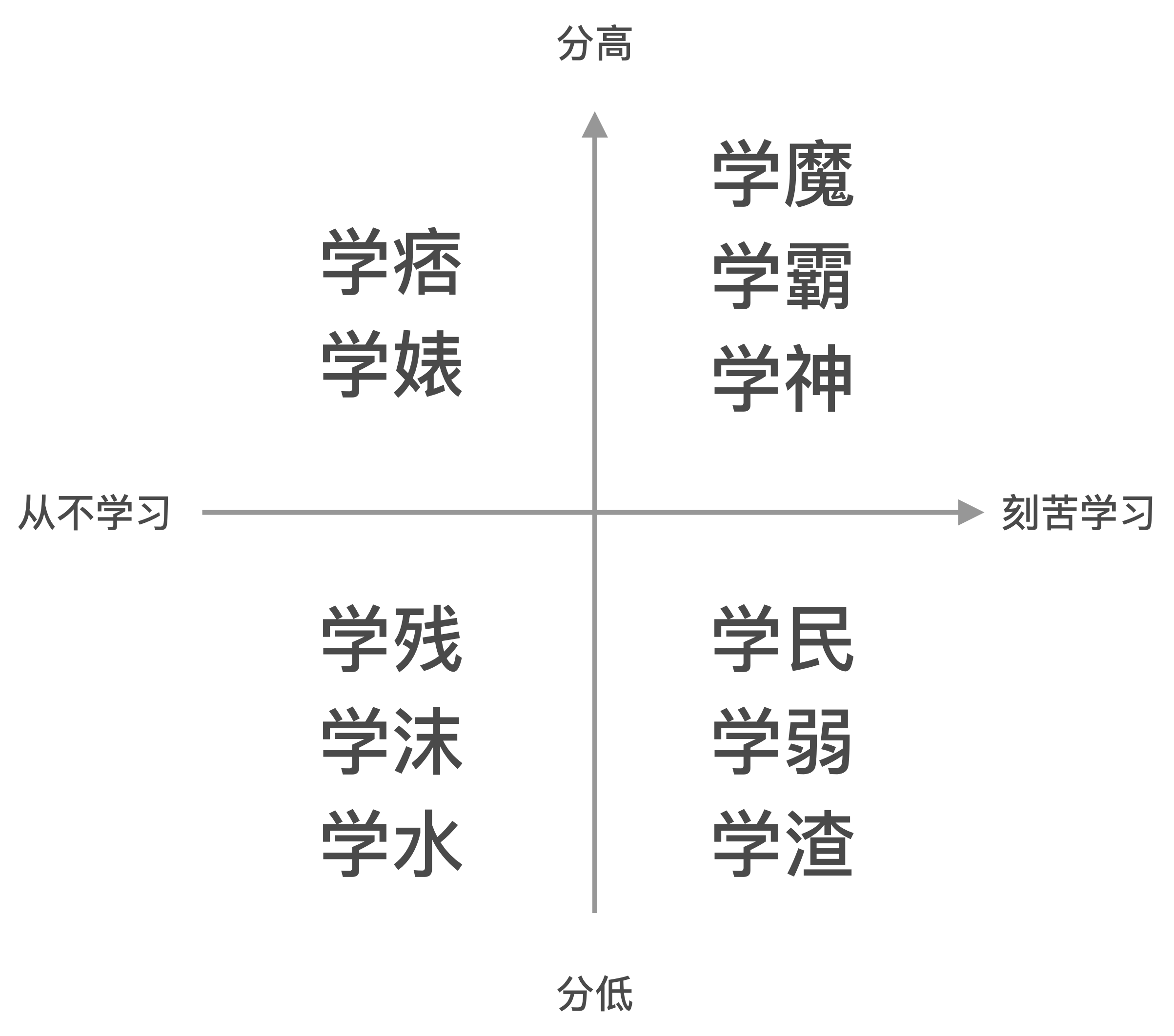
笔者这一年和学魔,学霸一起学习,经过多次考试的锤炼,最终认定自己是学民。有时候人与人之间学习能力的差距,你不得不认。笔者给自己的定义是,认真学习但也非刻苦的程度。分数不低但也不是高分。
好了,至此我关于标题的解释都述说完了。接下来聊聊今年学习和生活中遇到的一些所见所想。还有读者好奇的我这一年在忙什么。本文都会一一讲清。至于每个人对自己的人生都有自己的选择,笔者的选择不一定对。在强者面前,我的选择可能就如小丑表演一般,滑稽而可笑。那本文就献丑了。
今年组里一个大佬离职了。于是我有机会带领 5-6 名工程师一起向前冲。当真正 owner 一个超大项目以后才能感受到皇冠的重。各种事情都需要亲力亲为的开会,沟通,拿决策。每个组都有各自的利益,会议桌上各自都怀着自己的目的,所有人都想要自己的利益最大化。如果是因为我的“谈判”失误,导致影响到了组里全年的绩效,我会非常自责。不过结果来看,马马虎虎。我们吃掉了好几个组的业务。回收了他们部分 KPI 绩效,也成功拿到了他们的机器资源。接下来打算分享几件个人觉得比较成功的案例:
(这部分的分享本来有 3000 字左右,但是由于读者看到这篇文章的时候,已经是过去快 2 年的事情了,有旧事重提“炫耀”的嫌疑,加上笔者后来也从这家公司离职了。故笔者把这段删除了。)
去欧洲旅行,遇到德国人讲英语,我实在不习惯他们的口音,基本都听不懂。双方无法交流。特别尴尬。但是这次我还自己给自己找理由,毕竟是有德国口音,听不懂也正常。回国以后我也忘记了这段尴尬。
去澳洲旅行,遇到意大利人说英语,能听懂他说什么,但是当对方笑起来的时候,我并不明白他的笑点梗在哪里。这一次我又安慰自己,文化差异导致我们无法交流。回国以后我有意识的去了解了一下当地的风俗文化,不过一段时间以后,我又忘记了这段“痛”。
去迪拜旅行,和中东人聊天零星听得懂,但是自己说话对方听不懂,冲沙项目中有一个人英语可以和对方交流,于是她成为了团队的中心。我心里暗暗记住,我也要成为队伍的中心,这次经历彻底击碎我的底线。学习英语迫在眉睫。回国以后便开始制定学习计划。不然下次旅行还会被英语卡。
职业生涯如果以 5 年为界限,笔者即将到达第一个 5 年了。那么第一个 5 年做了哪些成就呢?这 5 年我对我交出的答卷并不满意。兜兜转转把客户端,前端,后端都摸了一遍。如果 5 年都专注一个领域,可能早就可以升到某个领域的技术专家了。既然开局稀烂了,那第二个 5 年必须做出一点改变,“扭转乾坤”。
在中国改革开放的大环境下,中国的市场涌入了大量的外企,给市场注入了很多新的思想。在这个地球村的时代,全球旅行不再是梦想。我已经打破了旅游的地理限制,我已经走遍了 30 多个国家,5 大洲遍布了我的足迹。接下来我在考虑,我能否打破工作上的地理限制呢?比如我能否在全球任意一个国家,通过我的本领找到一份能赚钱养活自己的工作?语言是必须优先解决的。工作中沟通交流必不可少。在我脑海中这个想法还没有成型的时候,突然某一天看到脉脉上双非本科毕业生晒 Google 的工作日常。确认过信息真实性以后,我也有了去硅谷打拼几年的想法,我要打破工作上的地理限制。我不是 985 毕业,但是依旧有自己的梦想。自己实力很菜,去不了 Google,去一个 startup 应该还可以。于是我萌生了去海外工作的想法。但是此时这个想法不是很强烈,还在徘徊中。
慢慢的,我又经历了一些事情:

人是一个社会属性的生物,他的一些决定是参考了社会因素的。例如,家长们在一起聊天,A 家长对你爸妈说,“你看你们家的孩子这么没出息,你们怎么教育的?”,或者“你看我们家孩子,年薪 5000 多W,你们家孩子年薪才 10W,干一年顶你们家孩子干 500 年。”一般这些话爸妈听了,脸面上通常会一笑而过,也许不会和你说。但是这话要是自己听到了,肯定不是滋味。由于自己的不努力,或者不够成功,导致了自己的父母在外面被其他家长“踩”。凡是有上进心的人,一定会采取一些“绝地反击”的措施吧。“我是全村的希望”,这句话看上去那么的骄傲,背后其实反映了一种自豪,一种努力,不愧对父母的养育,自己的成功,自己的出类拔萃,也让父母在别人面前出人头地。当然不少父母也是低调的,自己孩子多么成功也不会在外人面前吹。但至少,这个孩子的成功没有给其他家长“踩”自己爸妈的机会!

我通常在同行面前都会说自己是菜鸟。久而久之,大家觉得我带坏了一些风气,装弱。有些人也会觉得我是谦虚。我的花名是,霜菜,提交系统的时候,我赋予了这个花名一个含义,菜的含义是,谦逊为人,低调做事,山外有山,人外有人。读书读的越多,就会发现身边的同学都是优秀且不带优越感的人,他们明亮不刺眼,自信又懂得收敛,让你仰慕的同时又能给你能量。仔细反思,我觉得自己也许根上并不是谦虚,更多的可能是自卑。大学毕业以后,我因为不是 985 的学历,被某些独角兽公司扔简历到了垃圾桶,没有给面试机会;因为不是 985 的学历,被牛人鄙视是垃圾。考研报考了 985 学校,也因为种种原因最终失败。社会一次次的实打实的挫败着我,985 已然成为了我心头上一道深深的伤疤。这道伤什么时候会揭掉,我不知道,这道沟壑什么时候会翻篇,我也不知道,我唯一明白的是,我俯下身子,在地上爬,不想让大家看见我破损不堪的心灵,既然是垃圾了,还有什么资格平起平坐或者高人一等?
我遇到了一个 985 大佬来自学历的“鄙视”,我仔细反省以后,我觉得必须证明一下自己,打败内心不自信的“心魔”。这个心魔算是我职业生涯第一个 5 年最后的一个大 boss,也是职业生涯第二个 5 年的第一个 boss,所以我下定决心必须过了这一关。想证明自己不输于 985 学生,想证明自己的实力,需要从某些方面来证明。正好那段时间看见了一段话,“看程序员是否勤奋就看他的英语好不好,智商高不高就看他算法好不好”。那么我就觉得在这 2 方面上证明自己的实力。心里默默下定决心:等我下次面试,我一定也要去面“鄙视”我的那位 985 大佬所在的厂,当我作为他的同事,职级还要和他平起平坐。希望到了那个时候,他能不鄙视我非 985 的学历。人活着有时候就是为了一口气,你若不认输,不服输,不愿意承认自己是 loser,不愿当学渣,那就用行动证明给嘲笑过你的人看,去证明你也有“过人之处”~我就想用成绩来证明给天下人看,“虽然我不是学霸,但是我决不是学渣!”,我想撕掉心灵上学渣的这块疤。
以上就是我从迪拜回来到 7 月份这期间的一些心路历程。从萌生去海外工作的想法,到自我反省,自我认知,最后到下定决心证明自己。所以从 7 月开始,我决定开始了英语雅思和托福的备考。从今年 3 月 18 日开始,我开始刷 LeetCode。英语 + 算法两手抓。
在英语备考期间也有来自各个大厂大佬的面试邀请,有来自滴滴,腾讯,头条,阿里巴巴,百度,拼多多,美团等等大厂的面试邀请。(此处对 @孙源 大佬说声对不起🙏🏻,邀请了我好几次,我都没有说明原因,有些话当时实在不方便说出来,现在如果你看到这里,还请谅解我啊)也有来自大厂 HR 的面试邀请。我在这里和你们说一声对不起了,当时回复你们的都是“我有我自己的安排,对不起”。其实我是想去海外大厂干一段时间,多成长成长,和世界上最优秀的工程师切磋切磋,再以最好的状态入职大厂。看到这里,就是我一直隐藏着的答案。
此处也需要 @子奇 和 @萧玉,这两个大佬也邀请我面试很久了。我一直委婉拒绝,可能由于和你们太熟了,导致我没法去你们那入职。🙏🏻还请 2 位大佬原谅我的当初的拒绝。还有 @阿里云大佬,@淘敏,@闲鱼大佬,@宗心的面试邀请,我实在非常不好意思。还有很多大佬也私信邀请过我,此处没法一一@,如果你们看到这里了,就请原谅小弟我吧。有不少人说我走了一步错棋,因为没有加入你们的团队。在此我也一并说声抱歉吧,小弟不加入只因为我觉得我还不配加入你们,你们都非常优秀,我还太菜了。人生还长,当我修炼好自己以后,未来再加入你们的机会很多!

在提升英语的期间,也有太多的“诱惑”,有来自猎头的“嘲讽”:大概 19 年 7 月的时候,有一个猎头加我,说我工作快 5 年了,还没有到 P7,技术有点垃圾 ,在阿里也呆了 2 年了,可以出去看看机会。我当时心里好“憋屈”,我当时就想证明一下自己的实力。不过有“心魔”的我,当时也只能忍了,宛拒了,“我的技术实力还不行,面不上头条,我还需要在这里再磨炼几年”。朋友圈也有来自旅友的美景照片,有来自日本旅友的旅行邀请,有来自欧洲旅友的旅行邀请。有来自美洲朋友的旅行邀请。在没有战胜我内心心魔的时候,实在没心思去玩,但是每天刷到美景照片,心里实在痒痒。于是,我还是选择关闭朋友圈,减少诱惑。但是又发现旅游群里面还有诱惑,于是屏蔽群消息,又发现还会有一些私聊的诱惑,最终选择关闭微信了。这和某学习 app 每日推送说的一样。“微信不必每条都看,但是单词不能一日不背”。(不过好像不用微信,对生活好像影响不太大,工作中重要的消息都在钉钉上,和家人聊天都用的 iMessage,逢年过节上微信和朋友问候一下,发发红包送祝福)
我一度删掉了微信好几个月,屏蔽了所有外部消息。这也是为什么好多人发我消息,我都没回复的原因。并不是因为忙,并不是因为不想回,而是因为我没用微信了。微信上诱惑太多,加上我自己心理调节能力弱,我直接断舍离。微信群里经常会有人晒百万高薪,晒千万跑车,晒万亿豪宅,看了以后要么自己会酸柠檬,要么就恨自己有多没出息。多多少少心理上会有一些波动。这些心理波动对备考时期没有任何好处,至少对我来说。删掉微信以后,我每天只想我自己的事情。心理上至少做到了不以物喜不以己悲的境界。(每个人备考状态和自我调节能力不同,我的心路历程也许不能复制,只是写出来给大家参考,也可以当做是“笑料”,给大家笑笑。)
人需要沉淀,需要“静养”,弹簧的姿态压的越低,之后弹的越高。有些人说我是一个很自律的人。不过恰恰相反,我自己认为我是一个不太自律的人。一个大师和说了三个字,解决我不自律的问题,“戒,定,慧”。让我戒掉一些东西,节约时间,心定下来,产生一些学习的定力,最终会产生智慧。在群里聊天我会很不自律呢。群友的问题我看着就想回答。也可能工作 5 分钟,聊天 3 小时😂🙏所以我决定克制一下。
就这样,我朝着去海外工作的目标狂奔着。

在准备学英语之前,我去某英语培训机构裸测了一次雅思水平,居然才 5.5 分。扎心的是,老师还安慰我,“你快工作 5 年了,可能平时用英语不多吧,来上我们的课,带你提高英语水平”。我平时工作上每天打代码都是英语啊,这心里落差把我打至谷底。现在回头想想,这个英语培训机构给我的评分是真实的么?会不会故意打低分,“骗”我报班的套路?毕竟我没有参加过一次真实的雅思考试。再后来我就报班了。报了托福的培训班。😂由于雅思裸测 5.5 分,老师在课上叫我五分选手,(难道四舍五入不应该叫我六分选手么?)我经过一年的努力,我已经成功变成了八分选手。为了自嘲自己的超低水准以及提醒自己记住这段痛苦奋斗的日子,我现在仍然自称自己是五分选手。(这也是公众号名字的来源)
也因为雅思考的分数不高,使得我“怒转”复习备考托福。托福的口语是人机对话。你面对的是没有感情的机器,它不会因为你说错而产生尴尬气氛。雅思是人人对话,和真人对话时间,你说的如果对方听不懂,那会非常的尴尬。而且雅思听力里面也有我不擅长的听数字,填空等等题目形式。

这时候我也发现,一步出国工作可能有点难,可以分为两步走。先在国内的外企工作一段时间,再转去外国本土工作。国内的有名气的外企有 FLAG,开始投简历咯。我开始刷题,准备英文简历,冲击外企。现实给我泼了很大一身凉水。收到了 HR 给我的反馈,“同学,对不起,这个岗位你的学历背景差了一点,我们的候选人目前都是清北交复的硕士博士。希望未来你还有机会加入我们,谢谢”。我不会在这里公开这是哪家企业,面试岗位不是 leader 岗,只是高级 SDE 岗位而已。我接到这个回复以后,脑袋飞速运转,“可能是我的技术实力不行,用学历差了这个理由婉拒我”“有可能真的是学历不定,看 HR 的语气,要招硕士起步的人才”。不管是哪个原因,我的世界都乌云密布。既然先在国内外企工作一段时间再办签证去海外的这条路已经不通了。那么只剩下通过留学这条路去海外了。到此时,笔者才确定了留学的这条路了。
今年 7 月 13 号,滑滑鸡即将前往 CMU 读 Master 了。我和瓜神一起和他吃了自助餐,送他去美国。餐桌上他向我传授了托福裸考 108 分的经验。这次吃饭是经典的“西瓜霜”聚餐。滑滑鸡的名字中带有“西”的同音字,瓜神就是“瓜”,而我的名字中带有“霜”。餐桌上我也许下了诺言,2020 年会去美国找滑滑鸡一起吃饭。如果有缘的话,更希望能成为 CMU 校友。希望我能早日兑现男人的承诺。


很多人发现我从 2019 年就开始刷 LeetCode,其中有一小部分人怀疑我要跳槽,我的同事起初也怀疑过我要离职,但是看到我刷了半年以后都没动静,也就慢慢相信我刷题是因为爱。这一小部分人猜对了真相,不过我笑而不语。同事也都不明真相,真实情况是因为我没有通过面试,为了“掩盖”这个事实,我干脆一不做二不休继续刷。刷满一年以后,我就没有日日不间断了。现在我还隔三差五的刷 LeetCode 真的是用爱发电。刷算法是热爱,刷到世界充满爱!
我写书也是受到了 @欧长坤 大佬的影响,他的两本经典开源书令我收获颇丰。于是我也想写点开源书,回馈社区或者单纯分享知识。由于今年全年我都在复习英语和刷 LeetCode,于是决定写这两本书。

这两个本书我都放在 github 上迭代更新。至于什么时候会印制成纸质实体书,还不确定。众所周知我目前还是一个 gopher,所以这两本书的网站必然要用 hugo 搭建。第一本书我用的是 wowchemy 主题,第二本书我用的是 hugo-book 自定义主题。项目代码也都开源在 github 上了。
写开源书(让我姑且称它为书)真的非常花时间,书和一篇博客不同,博客的目录只是单篇文章的主线,但是书的目录就不同了,它是整个知识体系的主线。笔者时常写到某篇文章的时候,突然想到另外一篇文章有问题,又去调整前面写的好几篇文章。为了每天能记住 200-300 个单词,我选择每天早上 6 点早起,先把 LeetCode 每日一题写完,然后把解题思路,代码,测试文件 push 到 github。如果快的话,6 点 30 分左右都能搞完。接下来吃早餐,7 点到 9 点是刷托福 TPO 和背单词的时间。我会把阅读的文章翻译一遍,记录和分析错题,精听听力文章等等。做完练习再把心得和方法等等内容 push 到 github。9 点半左右出门去公司上班。
常看 O’Reilly 动物书的同学一看这个封面就知道是向他们致敬。确实是这个目的。O’Reilly 的封面动物都是稀缺动物,并且画风都是黑白素描风。第一本书的封面上的动物是 Coyote。经常听托福听力的同学一看到这个单词就会觉得特别亲切了。之所以选这个动物作为封面也是这个原因。Coyote 在托福听力生物类中出现的频率比较高。既然此书是动物书,又和托福有关,那么选 Coyote 是理所应当了。
Coyote 翻译过来是土狼,或者郊狼。郊狼(学名:Canis latrans),也叫草原狼、丛林狼、北美小狼,是犬科犬属的一种,与狼是近亲。郊狼产于北美大陆的广大地区,北起阿拉斯加、南到巴拿马。欧洲探险家最初是在美国西南部发现这种动物。郊狼一般单独猎食,偶尔也会组成小型的群体。平均寿命为 6-10 年。郊狼在其大小、颜色和头部形状都十分相似濒危的红狼。 其英文 coyote 一词来自中美洲阿兹特克等部族所用的纳瓦特尔语单词 coyōtl,后经西班牙语传入到英语。
第二本 LeetCode 这本书的封面动物是孔雀。孔雀开屏的意义是希望大家刷完 LeetCode 以后,提高了自身的算法能力,在人生的舞台上开出自己的“屏”。全书配色也都是绿色,因为这是 AC 的颜色。
这两本书我会一直保持更新,直到我的托福考到一个理想的分数,LeetCode 刷到 500 题。当满足这两个条件的时候,便是你看到书的时刻了。
当你在读这篇文章的时候,第二本书应该已经开源了,所有代码都在 github repo 中,并且也是 public 的。但是第一本书可能难产了。并非笔者不想开源分享,而是笔者的托福分数没有考到满分。有一天去知乎上看了一眼,个个都是托福 120 分满分选手。我这种英语垃圾选手还是低调的找个地缝藏起来了。所以笔者这辈子都不打算开源第一本书了。
既然第一本书不打算公开了。那在这里放一些它的截图吧。记录一下今年我的一些努力时光。下图是 github private repo。
接下来几张图是用 wowchemy 主题做的这本书配套的网站。


实话说,备战托福对我来说,是比较花时间的。我妹子全程目睹了我“无比艰难”的备考过程,尤其是在职那段时间,备考太艰难了,加班到半夜到家以后还要开始读英语,睡觉都是听着 TPO 睡的。那段时间我还经常被公司安排 on call,很多次都有离职的冲动,换一个闲一点的公司。(最后还是咬牙坚持把一年干完,拿完年终奖走人了。)我妹子也从来不鼓励我,反而她一直都在劝我放弃,(这难道是反向操作的鼓励?),她经常说:“你看看人家滑滑鸡,不到 6 个月解决 GT 2 门,还都是高分,你呢?6 个月 GT 还没考到人家分数的 80%,还努力啥?坚持啥?”,我确实有过放弃的念头,但是一看我的学托福学雅思的时间投入,我就不能放弃了。走路都走一半了,这个时候放弃,过去的好几千小时岂不是白费了?大家都说,凡事要享受过程,不要在乎结果。“功利”的我偏偏非常在意结果,人一辈子的时间是短暂的,投入产出比不高的事情,优先级可以降低。于是我这个垃圾靠着不能放弃宝贵时间的前期投入,一直咬牙坚持。
开始我还不承认我是学渣,我觉得自己还算努力,算学弱应该不为过(学弱:学习很努力,但是分数很低)。经过几次 GT 考试的摧残以后,我自觉的把自己的身段从学弱放回了学渣。在我妹子眼里,滑滑鸡就是100%准学霸。这点我也心服口服。在被托福和 GRE 考试无情摧残了 4 个月以上时间的我,每次看到滑滑鸡的朋友圈,或者和他微信聊天,我内心真的充满了对学霸的敬佩。(如果有不服气的,可以立即报考托福和 GRE,3 个月内能达到托福 110+,GRE 330+ 都是学霸。)滑滑鸡这种学霸型,自己高分杀 G 砍 T,期间还有额外精力去实习赚钱,刷 GPA,四线操作切换自如。不仅无开销,还赚了几十万。有时候我一个人在家备考的下午,我就会翻翻自己的留学时间线和花销记录小本本,我和他的差距已经不是学渣和学霸这两级的差距,我觉得说我们相差四级都不为过😭这可能就是双非大学毕业的学渣中的学渣和顶级 985 毕业的学霸中的学霸的巨大差距吧。在托福和 GRE 这两门考试上,我是输的心服口服,我被虐的体无完肤,毫无脾气。
大家也都别参考我,我英语太垃圾,学习能力也很差。在职的时候公司加班比较忙,每天下班以后还要刷 LeetCode,写博客,写书,背 500 个托福单词,刷托福 TPO,背 GRE 单词,刷 GRE 题目。我实在是 hold 不住了。如果每天都要完成这些任务,每天我的睡眠时间只有一个小时。最后决定托福 + GRE + LeetCode 是每天必须完成,写博客和写书放在周末完成。由于在职复习和学习进度有点慢,所以我到今年年底也没有提交申请学校的申请。
虽然我的托福没有考到满分,但是依旧可以有一些经验可以和读者分享。
托福考试是一种能力的测试,不是想办法出难题刁题(TPO只遇到过一次)为难大家。同时,考试也没有大家想象的那么难,我和考友的交流发现,考试改革以后,容错率仍然是挺高的。所以大家在对待考试的时候,不要对它产生惧怕心理,要藐视它,相信自己的付出一定能得到相应的分数。同时,是考试就有应试的技巧,无论是报课程,大家的攻略,还是每个人自己复习时候的心得,都是大家找到考试诀窍的方法。一定要对托福考试有一种熟悉感,一种我知道你想出什么题目,你在哪里出题的熟悉感,预判出题者的预判。这需要复习的时候有一颗热诚的心,要像对待女孩子一样了解她,学会去预判她的想法,做她希望你的事,而不是浪费精力做无关的事,或者作死。所以请大家复习的时候要有安排,有技巧,把精力放在最容易有效果的地方,多拿一分是一分。
托福考试分四个科目,读听说写四个方向,其实每一个方向都有一个共同的基础,那就是词汇。词汇不过关,100 分就是虚无缥缈的幻想。所以第一个月一定要沉下心来好好背单词。单词就用 KMF 词汇 app 和默默背单词,我是工作党,利用闲暇时光,目标是一天 300 个单词,白天争取在午休和吃饭的时候背好,不求背了就永远不忘,因为你会要背 3-4 遍。背单词其实是一种加速的过程,到后面几遍的时候,可能需要背的单词量也就一半不到,所以不用担心。
而听力是从 80 分到 100 分的最终助力,其实除了阅读,每个科目都和听力息息相关,每门课都要拿到高分,那需要能够精准的反映出听力的信息。我首考 74,我觉得很大的原因,除了第一次考试紧张和一些突发意外,最重要的就是没有重视听力,没有做好仔细听的心理准备,到时口语和写作综合题没有踩到所有的得分点,因此,大家一定要心理上要重视听力,考试的时候提醒自己保持听力注意力。无时无刻保持警惕感,去找到出题的点。
我背单词都是用零碎时间背的,例如,上下班等车,坐地铁,午饭后散步,晚饭后闲逛。这些零碎时间都可以用来背单词。背单词不要一个单词记 5 分钟。正确的做法应该是多重复。一个单词看 20 秒就过,一天多重复 3-4 次。重复次数越多记的越牢。试想,情景一,一个陌生人和你打个招呼聊天 10 分钟,一年以后你还能记住他么?情景二,一个陌生人和你打招呼,每天都聊 1 秒钟,连续 365 天天天和你相见,一年以后你还能记住他么?很明显,每天都重复一定会让你记住他。以下是我的单词 app 的刷词记录:
上图是笔者重新更新的截图。到 2019 年年底,连续打卡天数只有 190 天左右。笔者先用考满分单词 app 刷完所有托福词汇,并开启第二遍刷单词,差不多 10 月份的时候,开始用小站单词 app 开始刷它。当我把小站 app 所有单词都刷完一遍,我又开始用默默背单词了。如果你问我哪个 app 最好用?这个问题我其实回答不上来。因为我所有都用过,记忆单词有累加效果,并非某单一 app 促使我记住所有单词。其实这些单词 app 都差不多的。建议读者都试试,找一个适合自己的,刷起来吧。
托福备考最好能速战速决,拖的时间越长,备考效率也不高。一般以 3-4 个月为周期最佳。
这个阶段是一个准备期,就是背单词,每天争取 300 个词。背单词的同时,可以开始做阅读 TPO 了,一天一套的练习。
除了写作和口语综合题以外,所有科目都要每天分配一定的时间去完成每日目标,单词继续 300 一天,阅读一天一个 TPO,听力一天一个 TPO,口语独立一天一题。这段时间是最痛苦的时间,因为程序员工作比较忙,大家一般都 23 点左右,如果加班,到家就 1-2 点了。所以睡前一定要合理安排好工作生活与学习。每天看着时间流逝,还是很抓狂的,但是大家一定要坚持下来,而对于学生党,这些工作量应该是很轻松能完成的。
全题型都需要冲刺的阶段,重点可能会放到口语综合题和写作上面,一天的时间单词继续 250 一天,阅读一天一个 TPO,听力一天一个 TPO,口语独立一天一题,口语综合题争取一天一套(我的实际情况是考前大概做了 30 套口语),写作两天一套(考前做了 5 套)。至于每天的具体时间安排,因人而异,我可以说说我的周末安排。
上午无论几点起床,一套阅读一套听力的 TPO 的模考和错题回顾。
下午午休,醒来后一套写作。
睡前完成口语 TPO 一套。
其中找时间穿插背一背单词和背一下语料(口语和写作通用)。
有人觉得一天需要做两套 TPO,我觉得很难实现,毕竟做错题还要检查为什么错,基本上一天一套 TPO 差不多了,何况 TPO 资源有限,不能浪费,必须做一套反思一套。接下来单独说说 4 科的复习方法。
阅读是拿分重点,词汇是基础,所以单词一定要背几遍。
复习的时候,学会去找同义转换,要相信考试的时候,绝大多数题目还是在做原文的同义转换,快速定位关键词 KEYWORD,将原文和题目选项对照,所有题都做排除法,基本能保证很高的分数。我有两次考试,最后三题剩的时间都不多,最后分数 28,一方面说明同义转换的正确定,也说明了考试的容错率。
每篇 TPO 阅读做完以后可以写一写反思。错题错在哪里了。然后精读一下文章,把长难句和不懂的单词查一查。笔者大概精读了 30 篇左右。考前 TPO 阅读都做完,因为有可能出现阅读题目变成听力题目,所以 TPO 刷完,最后问题不大。


听力是从 80 分到 100 分最重要的助力。听力题是有容错率的。拿我的考试经验看,每次到时会遇到七八题需要思考一下二选一,两次考试分数都是 23 分,比自己预想的要高。听力复习最重要的是多听。
听力不是一个个单词听,每句话都有自己的主谓宾,考试考点无非就是考察主语或者宾语你有没有听到,少量题目是对整体或者段落的态度理解。
每天一套 TPO,加考后精听,精听是边听边思考上面的两个要点,一遍通过。靠前两周,做到 1.2 倍速度做题没问题,复习平均分基本就是考试分数。做题的时候,坚持到底,不要因为一句或者一段没听清楚就放弃,很多情况下,听力题目在不理解听力素材的条件下也能回答。但是要做到有连续听六题的忍耐力和注意力。TPO 题目现在有可能成为你阅读的题目,所以大家一定要做完。
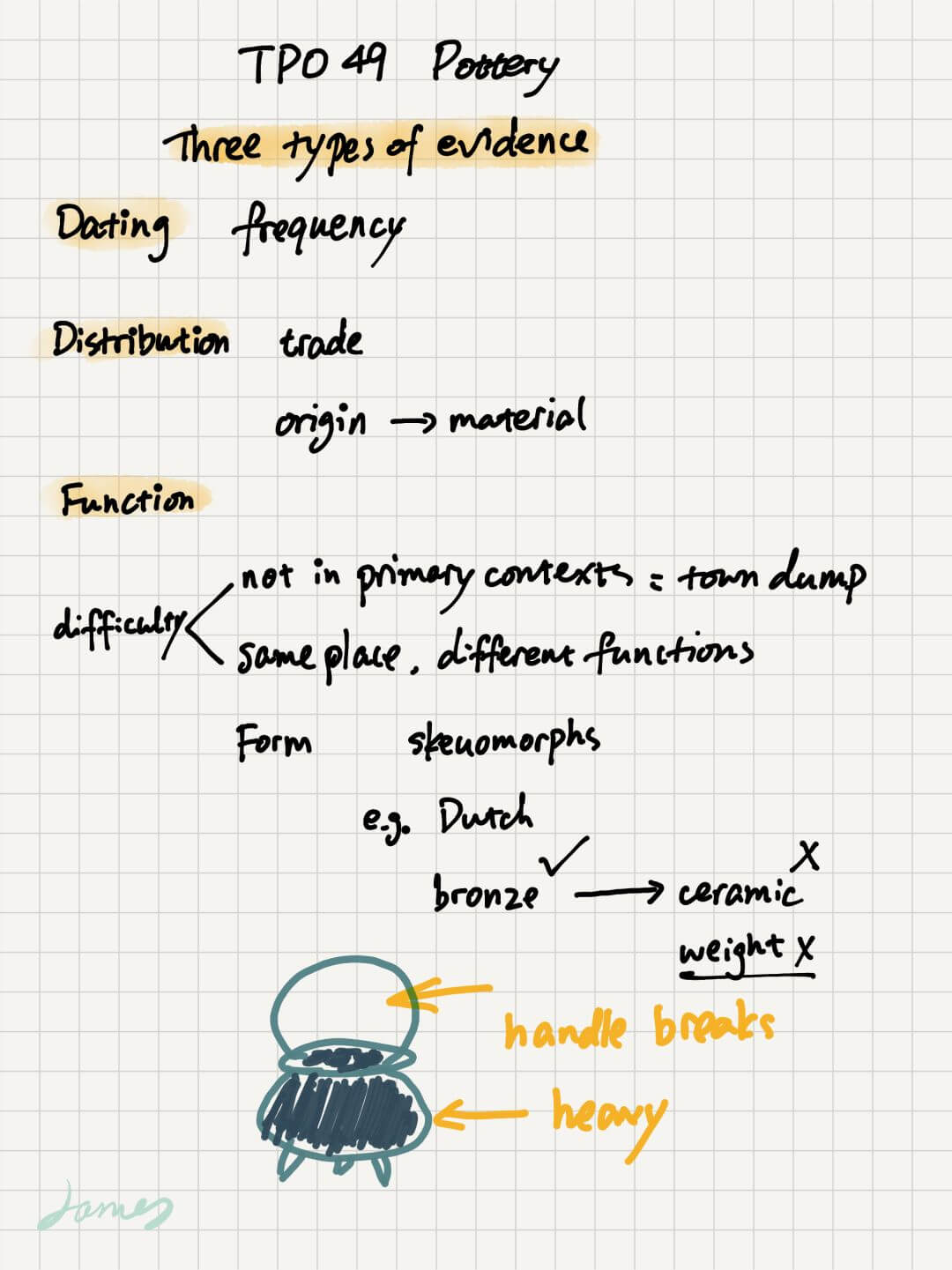
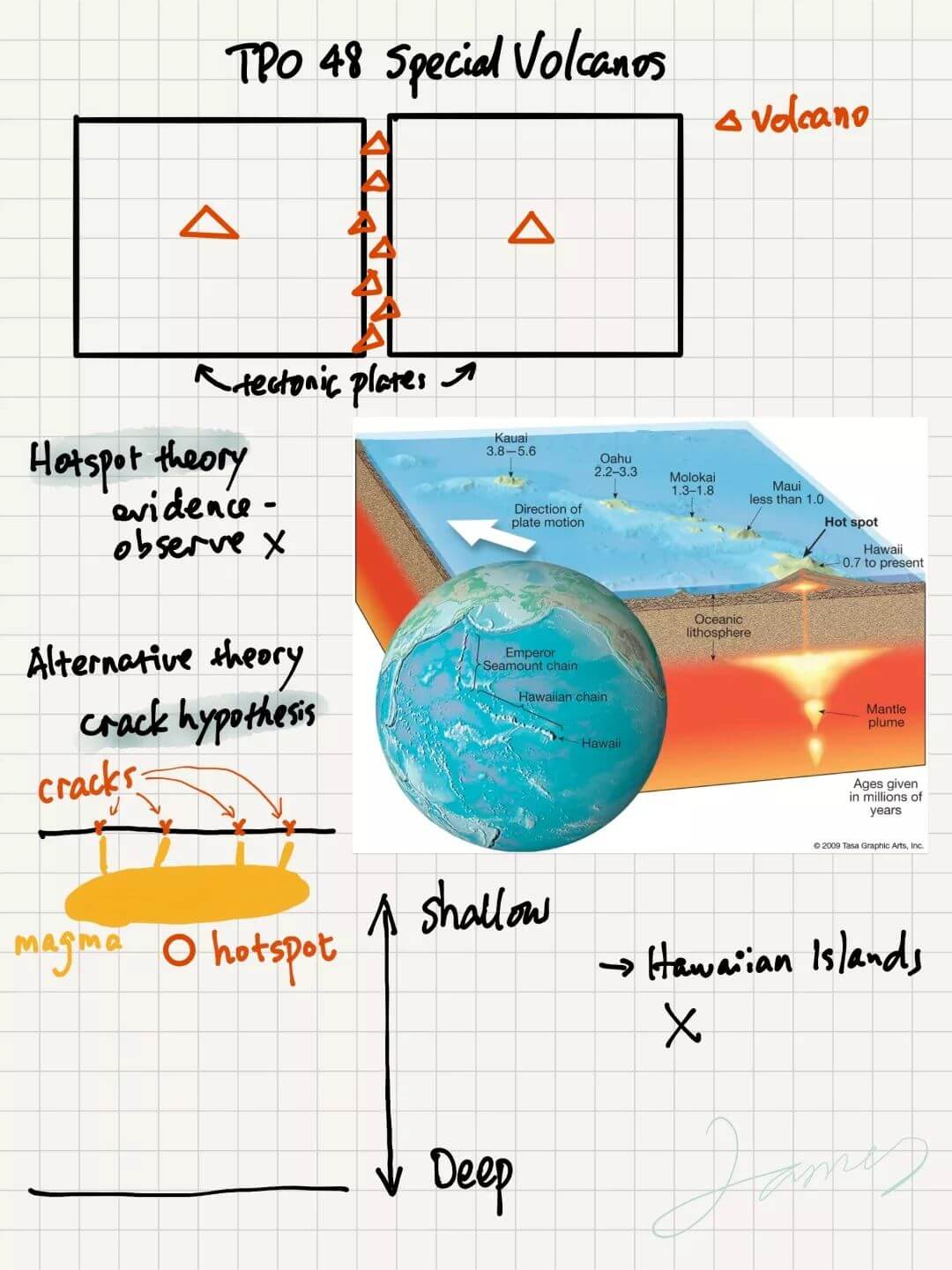
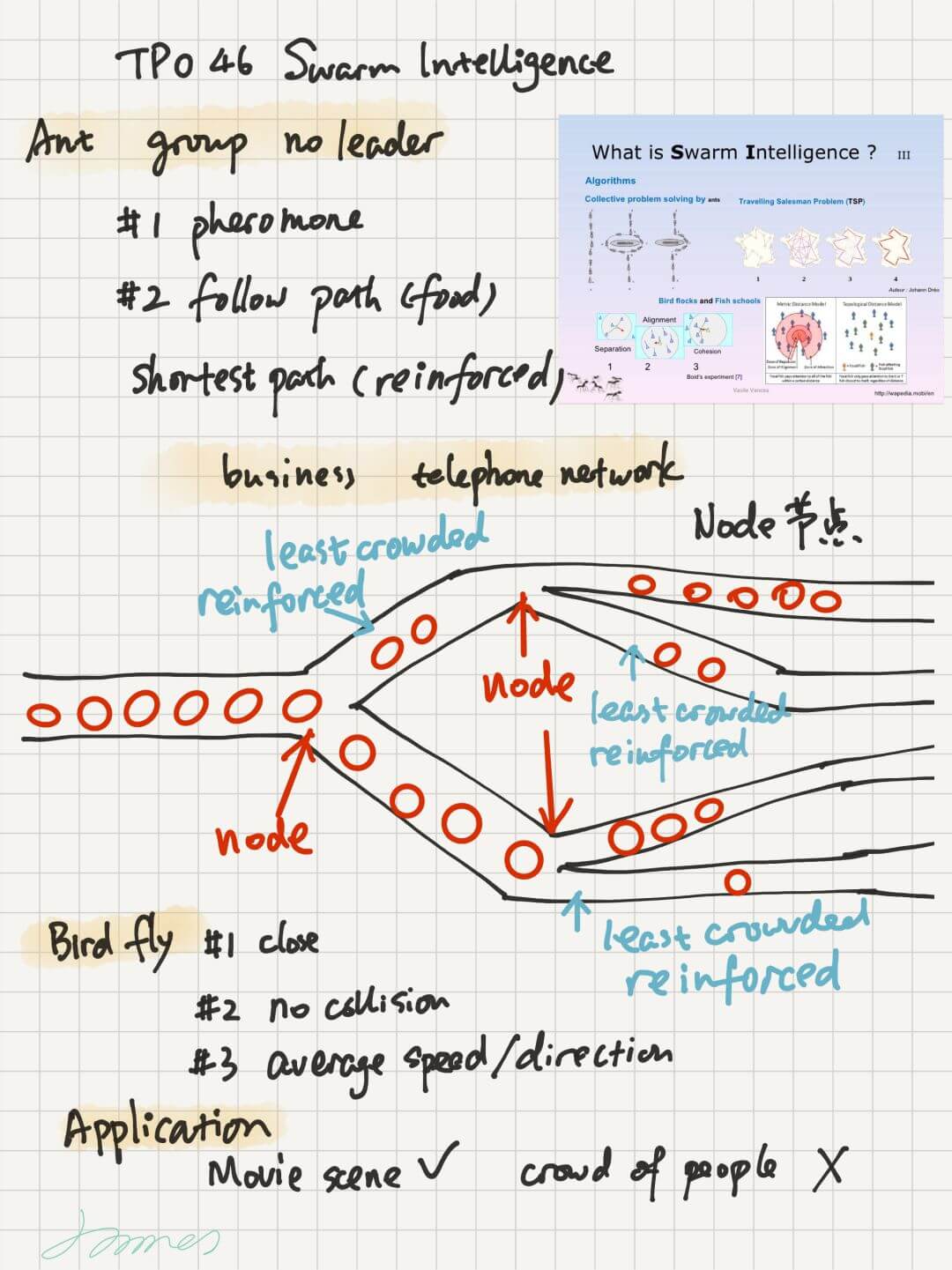
关于笔记,我的历程是一文章五六个词,到一文章记得密密麻麻,到最后考试前一文章不超过 10 个词,其实最重要的内容是记下文章观点和逻辑。关键词,术语,不重要。考前听力 TPO 都做完,问题不大。分享几个听力的笔记。有些同学不做笔记也可以拿到高分,所以笔记并不是必须的,因人而异。
考前一个月时间准备口语。如果你的口语真的说的不溜,可以考虑报个口语班,多练练,我只能说,语料是真的好用,2 个月的考试,独立口语会命中相似的语料。班上对每种题型的理解也比较清晰,也提供了答题需要注意的结构和模版,挺好用。
具体复习的时候,口语只能靠自己多说了,而且要厚着脸皮说,因为考试的时候,自信心非常重要,你身边可能有比你说的不好的,可能说得和老外一样好,这时候你如果心态疲软,会出现答题问题,越说越不自信,越说声音越小,越说语言越枯燥。
独立口语就是语料的积累,我为自己准备了多种语料,能面对交流,文化,科技,环保等内容的时候,有话可说。同时积累逻辑词,因果关系,递进关系,转折关系每种关系准备两三个词,通过结构和语料,共同搭建起自己一分钟的语言轰炸。考试的时候,保证自己能说完整完一个观点,包含态度,原因,举例,反方,总结。
综合口语更重要的其实是听力,能把考点都记下来。所以这种题型相对简单,考题结构也比较稳定,比听力题简单点。最后通过模版或者自己准备的逻辑词把重要考点说出来就可以。
关于发音练习,笔者这里推荐一个免费课程,lisa美语音标发音教程中文字幕(4.0高级技巧)
写作我也不知道要不要建议大家准备模版,因为我第一次用了模版是 21,第二次没用模版是 24。当然,这也是因为我综合写作听力有一定专门的训练,所以可能是综合写作分数往上提升。
有模版,写起来会比较简单,字数,高级词汇也会有一点。
不用模版,也不是不行,因为考试最重要的是看你的大逻辑和提供的论点是否切题,是否符合你的态度。
另一个关于打字数度,我可以给大家一个参考,独立写作 380 字,综合写作 220 字,分数也是能拿到 24 了。有些大神就 600 起步的,最猛的有打到 700 字的,(这手速要多快?)我真的很佩服,他们拿 30 分合理。
关于拼写,我感觉这个对分数影响是很大的,考前要做到不超过 5 个拼写错误。平时不要用带拼写检查的软件练习写作!语料同口语一起准备,考前两周,做到两天一套 TPO,保证自己写作评分能在 4 分稳定,问题不大。写在最后,首考的同学要做好心理建设工作,因为真实考试和模考是会有不同的。听力有时会出现英式英语,口语第一题会有一种突然开始的感觉。
最后,复习到今年年底,笔者身边很多同学说自己撑不住了,是的,这确实是备考托福的过程中,最难熬的一段时光,就像在一条,狭窄的隧道中,前面只有一丝光亮。而后面,漆黑一片,早已没有了退路。放弃是不可能了。但想拼却又觉得就那点光亮,值得么?你会觉得别人都是在阳光下奔跑,十足的胜算,你的拼搏,都变得卑微,于是你开始犹豫,你每天也在看书,但是却没有了对于美好未来的一丝憧憬,你只是在想这段路,早点结束吧。“放我出去”,是你唯一的期待。但是你却忘了,这世界上没有人是容易的。哪有什么阳光下的奔跑,都是在这条隧道中,艰难前行。未来有一天,那些所谓成功的人,回忆走过的路时,他们一定会提到,当年他们也在一条隧道里,艰难地拼搏。你才突然想起,这个地方我也去过啊,狭路相逢勇者胜,不要妄自菲薄,未来成功投射到当下,只会是一丝光亮,每个人都一样,没有阳光明媚,只有微光一点,但你的努力,本就光芒万丈,你忘记了,这一路走来,不是未来给了你希望,而是你一直在给自己力量,你要去拥抱的,不是什么狗屁成功,成功就是一个贱人,他只会依附于强大的人,你要去遇见的是那个更好的自己,那个绝不服输,决不放弃的更强大的自己。其实,你看到的那一点光亮,也是那个自己给你的,不要让在隧道尽头等着你的那个自己失望,因为你要是放弃了,她就等不到你了,而成功这个小人,也会离她而去,拼搏吧!燃烧吧!去看见,去遇见,去拥抱,然后有一天你带着成功一起讲述,你就是从隧道里寻着一束光,找到她的。然后终有一天,你可以笑着去讲述那些曾经让你哭的瞬间。💪

相比 2018 年去了 5 个国家来说,今年大幅减少了。利用五一假期去了迪拜,本来十一打算去美国常青藤学校看看,但是由于笔者托福备考进度慢了,所以十一没有出去,旅行的时间都用来上复习托福考试了。这是 2018 年年终总结里面写的新年愿望,现在看看,只完成了一部分,以后还是少立 flag,计划赶不上变化,脸疼。
2019 年的梦想是去迪拜完成 15000 米跳伞,去沙漠坐骆驼。2019 年旅行计划主要就是迪拜,欧洲和美国,去德法意瑞,看看欧洲列强们如今过的还好么;去美国体验体验常青藤学校浓厚的学术氛围;去迪拜看看白袍们有多么奢侈的生活,捡一捡丢在马路边的“垃圾”,兰博基尼,住一住七星级酒店。
一切源于年初的时候,我在世界地图上选择了 9 处比较浪漫的地方作为今年女友 18 岁的生日礼物,打算 2-3 年内完成这 9 处的打卡。我是一个不懂浪漫的穷人家的孩子,送不起房子,送不起车,只能送回忆了。既然作为 18 岁生日的礼物,那主题就叫 “勇敢者的游戏”吧。
最终定下来是去迪拜,完成棕榈岛 15000 米跳伞和沙迦沙漠深处冲沙。强烈推荐跳伞项目,真的太好玩了。笔者跳伞的长视频发在 @ halfrost 抖音号上了,欢迎读者去观看。关于迪拜的酒店,强烈推荐全世界唯一的七星级酒店帆船酒店 Burj Al Arab,和六星级酒店亚特兰蒂斯 Atlantis The Palm,当然还推荐全世界唯一的八星级酒店,只不过不在迪拜,在阿布扎比,阿布扎比皇宫酒店(Emirates Palace)。下面 2 张图分别是亚特兰蒂斯和帆船酒店。


可能有读者会问上面两个图的拍摄角度为什么这么特殊。笔者是在直升机上拍的。在亚特兰蒂斯酒店旁边有一个直升机场,可以买一张票,笔者买的是 25 分钟的票,直升机会带你飞到市中心转一圈再飞回来。沿途会经过帆船酒店,黄金相框,世界岛,哈利法塔,所有经典景观都会让你从上空看一遍。最后围绕棕榈岛半圈,回到亚特兰蒂斯旁边的停机坪。
迪拜的亚特兰蒂斯酒店可以去玩它的水上公园。是免费的。它的水上公园真的非常好玩。住在亚特兰蒂斯的话,旁边也没有什么小店可以吃饭,吃喝都在酒店里面了。(住亚特兰蒂斯的人还考虑消费么?花钱就是快乐)亚特兰蒂斯里面很多自助餐厅,至于价位嘛,消费上不封顶。带多少钱都能在这里挥霍完。笔者非常“省吃俭用”的在这里住了几天。
帆船酒店就不用说了。纯金的马桶,每晚 13-20W 的高级套房,爱马仕香皂。一切都是奢华的顶配。出门可以预约劳斯莱斯幻影。帆船酒店的房间里面的私人管家服务周到,只要你有钱,不太过分的要求都能尽量满足。比如你想把 F1 赛车运到帆船酒店的顶楼直升机停机坪,玩漂移,都是可以的。(并非玩笑,是真的可以)
比帆船酒店还要再高一星级的皇宫酒店,笔者没有体验,只去吃了自助餐。皇宫酒店在阿布扎比,它的内部不一定有帆船酒店奢华,但是它的社会地位比帆船酒店高。它本来是专门招待各国顶级领导人的。当领导人来访问的时候,是不开放给普通游客的。如果你不住在皇宫酒店,还是可以单独约这里的自助餐的。自助餐全部都是米其林星级厨师纯手工制作。所以中午吃一个自助餐,吃 2-3 小时是很正常的。
迪拜其他的打卡地有,民俗村,运河,博物馆,黄金相框等等。

上图是迪拜的民俗村,是迪拜最老的当地人住的地方。房间上面那些横着的柱子和风洞,是用来调节房间温度的,是一个天然空调。

上图是黄金相框,个人觉得还是在直升机上看这个相框更有感觉。站在它的面前,你能看到相框里面的景色就只有天空了。
迪拜的朱美拉清真寺(Jumeirah Mosque)是不得不提的打卡地。笔者是五一去玩的,正好遇到斋戒期。去清真寺一定要符合宗教的服装要求,男女服装都有要求。男士和女士需穿着保守、宽松、不透明的衣服,最好选择长袖 (腕长),长裙子 (脚踝长度) 或裤子,进入清真寺前,有一个商店可以租这些衣服。


清真寺建筑群的内外墙壁用来自希腊和马其顿的汉白玉包裹而成,内部装饰金碧辉煌,错综复杂的雕刻和壁画令人赞叹!雪白的大理石圆顶及墙面,在阳光下隐隐发亮,清真寺前湛蓝的一池清水,不禁被这片圣洁之地所吸引。黄金柱头,简洁的柱子底座,大有彩色图腾花纹的柱身,加上具有标志性的拱形洞口,整个色调的把握,把阿拉伯文化淋漓尽致演绎到建筑之中,整个清真寺就是一个奢华艺术品!在这里,你还可以亲眼目睹世界上最大的大理石马赛克装饰和纯手工地毯,给你前所未有的视觉震撼。上两张图只有你亲临现场,才能被彻底的震撼到。相关的视频也记录在笔者的抖音里面了。

上图是在直升机上拍的棕榈岛,这个就不用说了,世人都知道。还有一个没有完工的世界岛,是另外一个人造岛。笔者在直升机上没有拍到,当飞行员解说到世界岛了,我看了半天才意识到哪里是世界岛,最终错过拍照了。
最后一个打卡地就是世界最高的塔,哈利法塔。可以去 128 层的观光层往下看风景,有迪拜城市的全貌。笔者建议下午 3-4 点去,这样可以一直呆到 6 点日落的时候,和心爱的人在世界之巅一起看日落。值得一提的是哈利法塔的电梯也是世界最快的。笔者拍摄了它上升的速度,非常震撼,视频都在抖音号上。

其他的活动就是消费活动咯。The Dubai Mall 肯定是必去的。它由 10 到 15 个 Mall 中 Mall 组成,一共将有大约 1200 个商店,有 16000 个停车位。此外,它还将有世界最大的水族馆,最大的黄金市场,奥运比赛规模的冰场,6 层楼高的巨幅屏幕影院,探险公园,沙漠喷泉等等。
迪拜购物中心单独占地 500 万平方英尺(约 46 万 5000 平方米),相当于 56 个足球场的面积,连同其所有辅助设施、附属建筑在内、总共占地 900 万平方英尺(约 83 万 6000 平方米),这些数据都刷新了世界纪录,超过了加拿大埃德蒙多市的得西埃商业中心和美国明尼苏达州布卢明顿市的美国购物中心。也许你对这些数字没有感受,那笔者这样描述吧。从早上商场开门,一直逛到晚上商场关门,逛整整一天,只能逛完其中一层,连续逛一周才能把整个购物中心逛完。
迪拜的茶余饭后的娱乐活动非常匮乏,没有中国的棋牌,麻将,广场舞等等活动。女性唯一的娱乐活动就是逛商场,消费。所以 The Dubai Mall 拥有全世界最新款的 LV 包包,拥有全世界最新款和最贵的奢侈品。只有这样才能满足迪拜女性饭后的娱乐需求。(这段不是开玩笑,说的是真实的)所以当你在购物中心看见一个白袍领着他的老婆们一顿买买买,一口气买 16 个 LV,4 辆劳斯莱斯的时候,别认为是人家败家,其实人家是在娱乐呢。(4 个老婆,每个老婆一辆劳斯莱斯,一年四季,每个季节都要一个 LV 包包。所以需要 16 个 LV,4 辆劳斯莱斯)在迪拜允许一夫多妻,但是必须对每个老婆都公平对待,你的爱要平均分给每个人。
好了,今年的旅行就说到这里了,大多数迪拜的旅行视频都在 @halfrost 的抖音号上。读者有空感兴趣的话可以去看看。希望明年笔者的托福和 GRE 可以考到满意的分数。考完了想去南美或者冰岛转一转。(立 flag 要打脸)
一位大佬朋友圈写道:看程序员是否勤奋就看他的英语好不好,智商高不高就看他算法好不好。这句话我当时看到了很触动,默默的记在了心底。2019 年一年我就只做了 2 件事情,刷算法,学英语。我现在还不敢说我是优秀的程序员,但是我至少努力过。不辜负时光,无愧于自己。以上就是你们想要的答案,这就是我 2019 年的年终总结,里面揭秘了 98% 的人都不了解的事情。很多猎头迷惑的内容也都在里面了。感谢周围亲戚朋友的这 2 年的关心。这篇总结不是原子弹💥别太惊讶。
回过头来看,好像也没有做出什么牛逼的事情。就是下了一步小棋,布了一个小局。也不是什么传奇经历,无非是奋斗路上立 flag,达到 flag,再立 flag 的一滴滴汗水罢了。过去 2 年,我一直隐身于网络,也没人知道我立的这些 flag。大家的年终总结都是对自己今年 flag 完成度的复盘,而我没有勇气去直面被人嘲笑的梦想,如果最终梦想没有实现,flag 无非就是人们饭后的谈资,打肿我脸的笑柄。这也是近 2 年都没有看到我的年终总结公开出来的原因。最终的梦想总算完成了,也是时候可以把年终总结公开出来了,给关心我的读者和朋友一些交代了。(本文写于 2019 年年末,最后这一段修改于 2021年 3 月)
最后一些“只言片语”的感受分享一下作为年终总结的结尾吧。
好了,2019 年的【星霜荏苒】就到这里了。如有任何异议或者想讨论的地方,欢迎和我交流。

2019 年 5 月 5 日,于迪拜 Dubai
GitHub Repo:Halfrost-Field
Follow: halfrost · GitHub
2019-10-20 10:30:00

作为 Go 并发原语的第一篇文章,一定绕不开 Go 的并发哲学。从 Tony Hoare 写的 Communicating Sequential Processes 这篇文章说起,这篇经典论文算是 Go 语言并发原语的根基。
CSP 的全程是 Communicating Sequential Processes,直译,通信顺序进程。这一概念起源自 1978 年 ACM 期刊中 Charles Antony Richard Hoare 写的经典同名论文。感兴趣的读者可以看 Reference 中的第一个链接看原文。在这篇文章中,Hoare 在文中用 CSP 来描述通信顺序进程能力,姑且认为这是一个虚构的编程语言。该语言描述了并发过程之间的交互作用。从历史上看,软件的进步主要依靠硬件的改进,这些改进可以使 CPU 更快,内存更大。Hoare 认识到,想通过硬件提高使得代码运行速度快 10 倍,需要付出 10 倍以上的机器资源。这并没有从根本改善问题。
尽管并发相对于传统的顺序编程具有许多优势,但由于其会出错的性质,它未能获得广泛的欢迎。Hoare 借助 CSP 引入了一种精确的理论,可以在数学上保证程序摆脱并发的常见问题。Hoare 在他的 Learning CSP(这是计算机科学中引用第三多的神书!)一书中,使用“进程微积分”来表明可以处理死锁和不确定性,就像它们是普通进程中的最终事件一样。进程微积分是一种对并发系统进行数学化建模的方式,并且提供了代数法则来进行这些系统的变换来分析它们的不同属性,并发和效率。
为了防止数据被多线程破坏,Hoare 提出了临界区的概念。进程进入临界区后可以获得对共享数据的访问。在进入临界区之前,所有其他的进程必须验证和更新这一共享变量的值。退出临界区时,进程必须再次验证所有进程具有相同的值。
保持数据完整性的另一种技术是通过使用互斥信号量或互斥量。互斥锁是信号量的特定子类,它仅允许一个进程一次访问该变量。信号量是一个受限制的访问变量,它是防止并发中竞争的经典解决方案。其他尝试访问该互斥锁的进程将被阻止,并且必须等待直到当前进程释放该互斥锁。释放互斥锁后,只有一个等待的进程可以访问该变量,所有其他进程继续等待。
1970年代初期,Hoare 基于互斥量的概念开发了一种称为监视器的概念。根据 IBM 编写的 Java 编程语言 CSP 教程:
“A monitor is a body of code whose access is guarded by a mutex. Any process wishing to execute this code must acquire the associated mutex at the top of the code block and release it at the bottom. Because only one thread can own a mutex at a given time, this effectively ensures that only the owing thread can execute a monitor block of code.”
monitor 可以帮助防止数据被破坏和线程死锁。在 CSP 论文中为了说明清楚进程之间的通信,Hoare 利用 ?和 !号代表了输入和输出。!代表发送输入到一个进程,?号代表读取一个进程的输出。每个指令需要指定具体是一个输出变量(从一个进程中读取一个变量的情况),还是目的地(将输入发送到一个进程的情况)。一个进程的输出应该直接流向另一个进程的输入。

上图是从 CSP 文章中截图的一些例子,Hoare 简单的举了下面这个例子:
[c:character; west?c ~ east!c]
上述代码的意思是读取 west 输出的所有字符,然后把它们一个个的输出到 east 中。这个过程不断的重复,直到 west 终止。从描述上看,这一特性完完全全是 channel 的雏形。
文章的最后,回到了经典的哲学家问题。
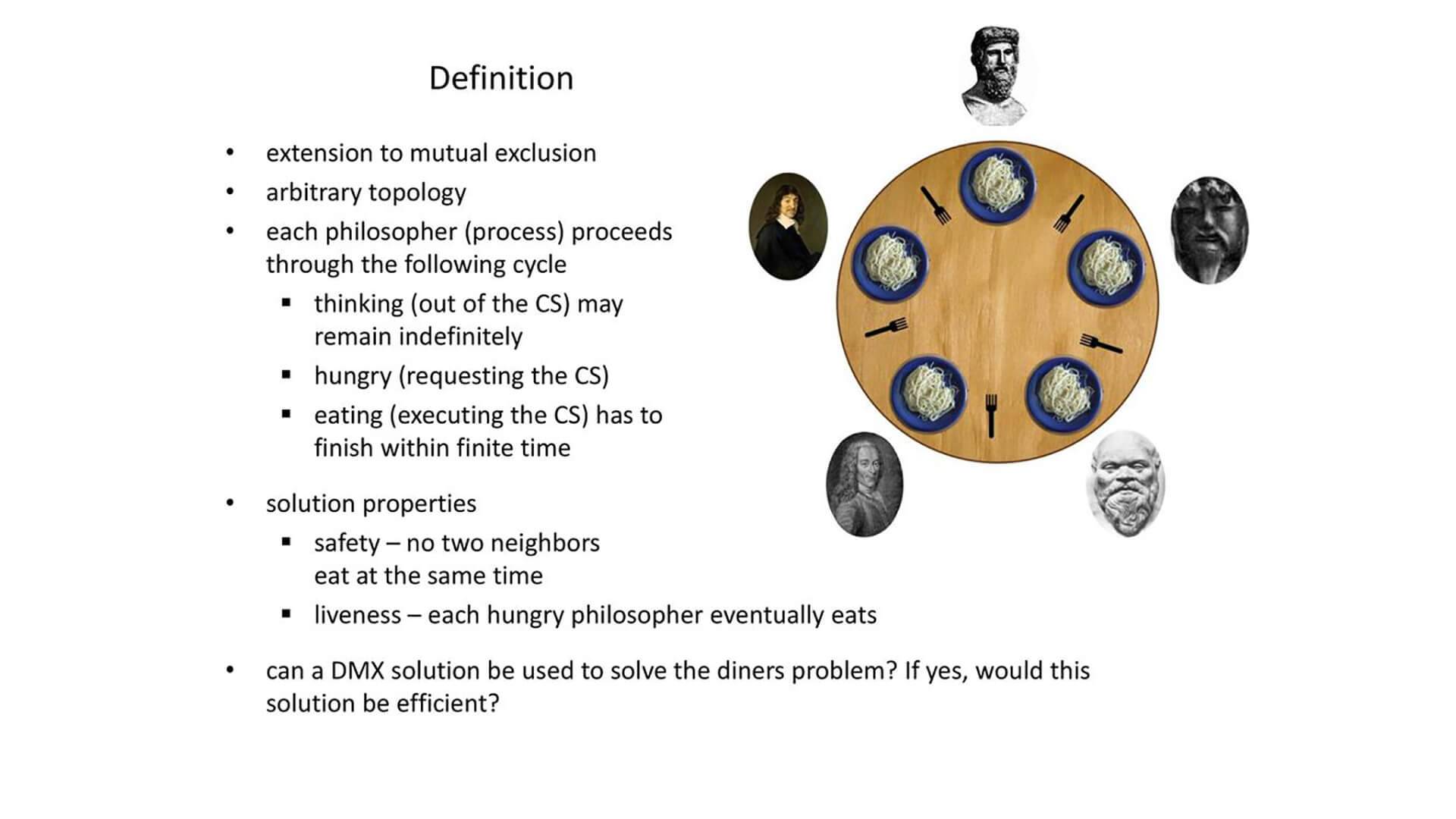
在哲学家问题中,Hoare 将 philosopher 的行为描述如下:
PHIL = *[... during ith lifetime ... --->,
THINK;
room!enter( );
fork(0!pickup( ); fork((/+ 1) rood 5)!pickup( );
EAT;
fork(i)!putdown( ); fork((/+ 1) mod 5)!putdown( );
room!exit( )
]
每个叉子由坐在两边的哲学家使用或者放下:
FORK =
*[phil(0?pickup( )--* phil(0?putdown( )
0phil((i - 1)rood 5)?pickup( ) --* phil((/- l) raod 5)?putdown( )
]
整个哲学家在房间中的行为可以描述为:
ROOM = occupancy:integer; occupancy .--- 0;
,[(i:0..4)phil(0?enter ( ) --* occupancy .--- occupancy + l
11(i:0..4)phil(0?exit ( ) --~ occupancy .--- occupancy - l
]
决定如何向等待的进程分配资源的任务称为调度。Hoare 将调度分为两个事件:
那么这个哲学家问题可以转换成 PHIL 和 FORK 这两个组件并发的过程:
[room::ROOM I [fork( i:0..4)::FORK I Iphil( i:0..4)::PHIL].
从请求到授予资源的时间就是等待时间。在 CSP 中,有几种技术可以防止无限的等待时间。
在确定性程序中,如果环境恒定,结果将是相同的。 由于并发基于非确定性,因此环境不会影响程序。给定所选的路径,程序则可以运行几次并收到不同的结果。为了确保并发程序的准确性,程序员必须能够在整体水平上考虑其程序的执行。
但是,尽管 Hoare 引入了正式的方法,但仍然缺少任何验证正确程序的证明方法。CSP 只能发现已知问题,而不能发现未知问题。虽然基于 CSP 的商业应用程序(例如ConAn)可以检测到错误的存在,但是不能检测没有错误的情况,(无法验证正确性)。尽管 CSP 为我们提供了编写可以避免常见并发错误的程序的工具,但是正确程序的证明仍然是 CSP 中尚未解决的领域。
CSP 在生物学和化学领域具有巨大的潜力,可以对自然界中的复杂系统进行建模。 由于该行业面临许多现存的逻辑问题,因此尚未在行业中广泛使用。在关于 CSP 开发 25 周年的会议上,Hoare 指出,尽管有许多由 Microsoft 资助的研究项目,但比尔·盖茨(Bill Gates)忽略了 Microsoft 何时能够将 CSP 的研究成果商业化的问题。
Hoare 提醒他的听众,动态过程领域仍然需要更多的研究。当前,计算机科学界陷入了顺序思维的范式。随着 Hoare 建立正式的并发方法的基础,科学界已做好准备成为并行编程的下一个革命。
在 Go 语言发布之前,很少有语言从底层为并发原语提供支持。大多数语言还是支持共享和内存访问同步到 CSP 的消息传递方法。Go 语言算是最早将 CSP 原则纳入其核心的语言之一。内存访问同步的方式并不是不好,只是在高并发的场景下有时候难以正确的使用,特别是在超大型,巨型的程序中。基于此,并发能力被认为是 Go 语言天生优势之一。追其根本,还是因为 Go 基于 CSP 创造出来的一系列易读,方便编写的并发原语。
Go 语言除了 CSP 并发原语以外,还支持通过内存访问同步。sync 与其他包中的结构体与方法可以让开发者创建 WaitGroup,互斥锁和读写锁,cond,once,sync.Pool。在 Go 语言的官方 FAQ 中,描述了如何选择这些并发原语:
为了尊重 mutex,sync 包实现了 mutex,但是我们希望 Go 语言的编程风格将会激励人们尝试更高等级的技巧。尤其是考虑构建你的程序,以便一次只有一个 goroutine 负责某个特定的数据。
不要通过共享内存进行通信。建议,通过通信来共享内存。(Do not communicate by sharing memory; instead, share memory by communicating)这是 Go 语言并发的哲学座右铭。相对于使用 sync.Mutex 这样的并发原语。虽然大多数锁的问题可以通过 channel 或者传统的锁两种方式之一解决,但是 Go 语言核心团队更加推荐使用 CSP 的方式。
关于如何选择并发原语的问题,本文作为第一篇文章必然需要解释清楚。Go 中的并发原语主要分为 2 大类,一个是 sync 包里面的,另一个是 channel。sync 包里面主要是 WaitGroup,互斥锁和读写锁,cond,once,sync.Pool 这一类。在 2 种情况下推荐使用 sync 包:
关于保护某个结构内部的状态和完整性。例如 Go 源码中如下代码:
var sum struct {
sync.Mutex
i int
}
//export Add
func Add(x int) {
defer func() {
recover()
}()
sum.Lock()
sum.i += x
sum.Unlock()
var p *int
*p = 2
}
sum 这个结构体不想将内部的变量暴露在结构体之外,所以使用 sync.Mutex 来保护线程安全。
相对于 sync 包,channel 也有 2 种情况:
输出数据给其他使用方的目的是转移数据的使用权。并发安全的实质是保证同时只有一个并发上下文拥有数据的所有权。channel 可以很方便的将数据所有权转给其他使用方。另一个优势是组合型。如果使用 sync 里面的锁,想实现组合多个逻辑并且保证并发安全,是比较困难的。但是使用 channel + select 实现组合逻辑实在太方便了。以上就是 CSP 的基本概念和何时选择 channel 的时机。下一章从 channel 基本数据结构开始详细分析 channel 底层源码实现。
以下代码基于 Go 1.16
channel 的底层源码和相关实现在 src/runtime/chan.go 中。
type hchan struct {
qcount uint // 队列中所有数据总数
dataqsiz uint // 环形队列的 size
buf unsafe.Pointer // 指向 dataqsiz 长度的数组
elemsize uint16 // 元素大小
closed uint32
elemtype *_type // 元素类型
sendx uint // 已发送的元素在环形队列中的位置
recvx uint // 已接收的元素在环形队列中的位置
recvq waitq // 接收者的等待队列
sendq waitq // 发送者的等待队列
lock mutex
}
lock 锁保护 hchan 中的所有字段,以及此通道上被阻塞的 sudogs 中的多个字段。持有 lock 的时候,禁止更改另一个 G 的状态(特别是不要使 G 状态变成ready),因为这会因为堆栈 shrinking 而发生死锁。
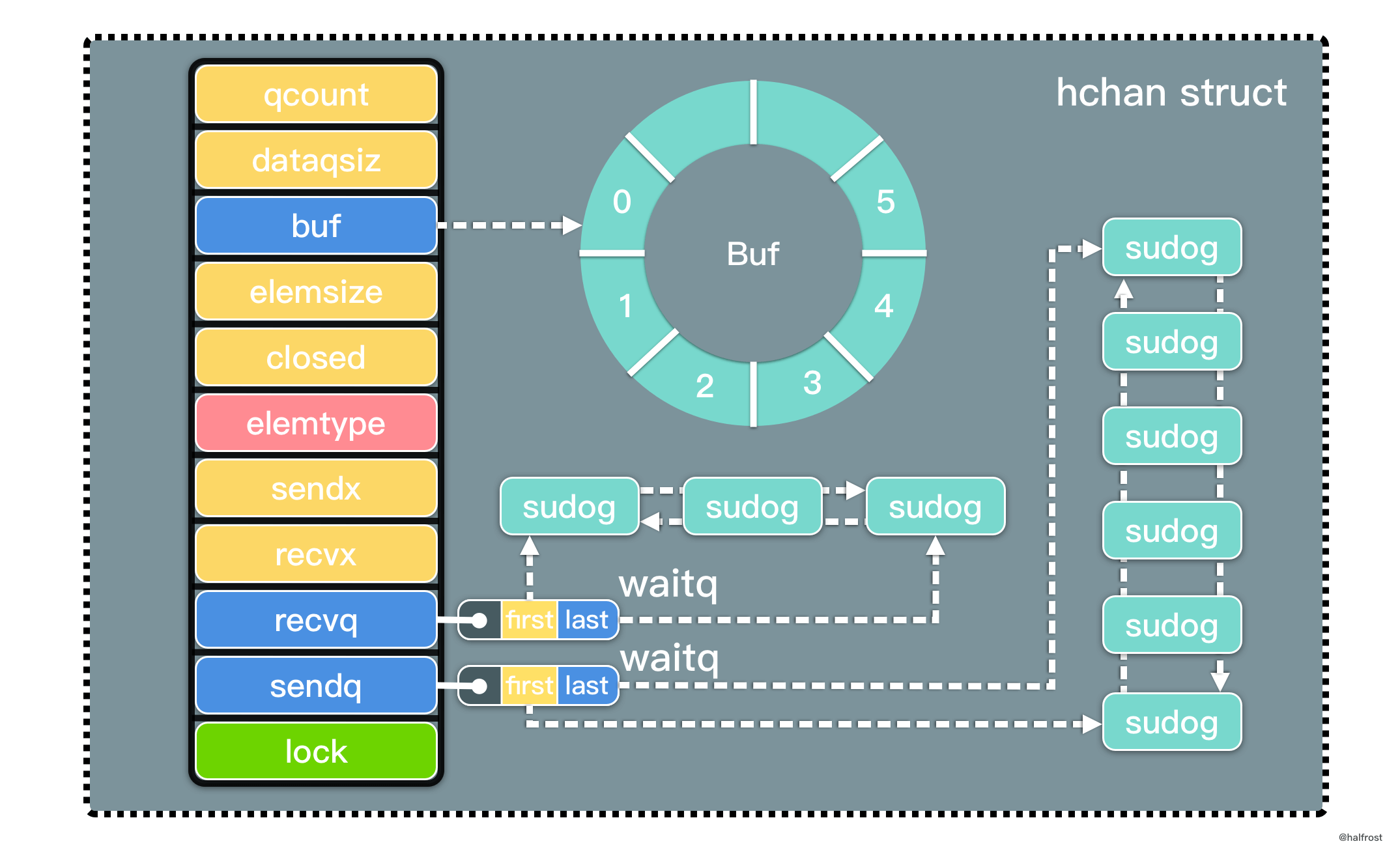
recvq 和 sendq 是等待队列,waitq 是一个双向链表:
type waitq struct {
first *sudog
last *sudog
}
channel 最核心的数据结构是 sudog。sudog 代表了一个在等待队列中的 g。sudog 是 Go 中非常重要的数据结构,因为 g 与同步对象关系是多对多的。一个 g 可以出现在许多等待队列上,因此一个 g 可能有很多sudog。并且多个 g 可能正在等待同一个同步对象,因此一个对象可能有许多 sudog。sudog 是从特殊池中分配出来的。使用 acquireSudog 和 releaseSudog 分配和释放它们。
type sudog struct {
g *g
next *sudog
prev *sudog
elem unsafe.Pointer // 指向数据 (可能指向栈)
acquiretime int64
releasetime int64
ticket uint32
isSelect bool
success bool
parent *sudog // semaRoot 二叉树
waitlink *sudog // g.waiting 列表或者 semaRoot
waittail *sudog // semaRoot
c *hchan // channel
}
sudog 中所有字段都受 hchan.lock 保护。acquiretime、releasetime、ticket 这三个字段永远不会被同时访问。对 channel 来说,waitlink 只由 g 使用。对 semaphores 来说,只有在持有 semaRoot 锁的时候才能访问这三个字段。isSelect 表示 g 是否被选择,g.selectDone 必须进行 CAS 才能在被唤醒的竞争中胜出。success 表示 channel c 上的通信是否成功。如果 goroutine 在 channel c 上传了一个值而被唤醒,则为 true;如果因为 c 关闭而被唤醒,则为 false。
创建 channel 常见代码:
ch := make(chan int)
编译器编译上述代码,在检查 ir 节点时,根据节点 op 不同类型,进行不同的检查,如下源码:
func walkExpr1(n ir.Node, init *ir.Nodes) ir.Node {
switch n.Op() {
default:
ir.Dump("walk", n)
base.Fatalf("walkExpr: switch 1 unknown op %+v", n.Op())
panic("unreachable")
case ir.OMAKECHAN:
n := n.(*ir.MakeExpr)
return walkMakeChan(n, init)
......
}
编译器会检查每一种类型,walkExpr1() 的实现就是一个 switch-case,函数末尾没有 return,因为每一个 case 都会 return 或者返回 panic。这样做是为了与存在类型断言的情况中返回的内容做区分。walk 具体处理 OMAKECHAN 类型节点的逻辑如下:
func walkMakeChan(n *ir.MakeExpr, init *ir.Nodes) ir.Node {
size := n.Len
fnname := "makechan64"
argtype := types.Types[types.TINT64]
if size.Type().IsKind(types.TIDEAL) || size.Type().Size() <= types.Types[types.TUINT].Size() {
fnname = "makechan"
argtype = types.Types[types.TINT]
}
return mkcall1(chanfn(fnname, 1, n.Type()), n.Type(), init, reflectdata.TypePtr(n.Type()), typecheck.Conv(size, argtype))
}
上述代码默认调用 makechan64() 函数。类型检查时如果 TIDEAL 大小在 int 范围内。将 TUINT 或 TUINTPTR 转换为 TINT 时出现大小溢出的情况,将在运行时在 makechan 中进行检查。如果在 make 函数中传入的 channel size 大小在 int 范围内,推荐使用 makechan()。因为 makechan() 在 32 位的平台上更快,用的内存更少。
makechan64() 和 makechan() 函数方法原型如下:
func makechan64(chanType *byte, size int64) (hchan chan any)
func makechan(chanType *byte, size int) (hchan chan any)
makechan64() 方法只是判断一下传入的入参 size 是否还在 int 范围之内:
func makechan64(t *chantype, size int64) *hchan {
if int64(int(size)) != size {
panic(plainError("makechan: size out of range"))
}
return makechan(t, int(size))
}
创建 channel 的主要实现在 makechan() 函数中:
func makechan(t *chantype, size int) *hchan {
elem := t.elem
// 编译器检查数据项大小不能超过 64KB
if elem.size >= 1<<16 {
throw("makechan: invalid channel element type")
}
// 检查对齐是否正确
if hchanSize%maxAlign != 0 || elem.align > maxAlign {
throw("makechan: bad alignment")
}
// 缓冲区大小检查,判断是否溢出
mem, overflow := math.MulUintptr(elem.size, uintptr(size))
if overflow || mem > maxAlloc-hchanSize || size < 0 {
panic(plainError("makechan: size out of range"))
}
var c *hchan
switch {
case mem == 0:
// 队列或者元素大小为 zero 时
c = (*hchan)(mallocgc(hchanSize, nil, true))
// Race 竞争检查利用这个地址来进行同步操作
c.buf = c.raceaddr()
case elem.ptrdata == 0:
// 元素不包含指针时。一次分配 hchan 和 buf 的内存。
c = (*hchan)(mallocgc(hchanSize+mem, nil, true))
c.buf = add(unsafe.Pointer(c), hchanSize)
default:
// 元素包含指针时
c = new(hchan)
c.buf = mallocgc(mem, elem, true)
}
// 设置属性
c.elemsize = uint16(elem.size)
c.elemtype = elem
c.dataqsiz = uint(size)
lockInit(&c.lock, lockRankHchan)
if debugChan {
print("makechan: chan=", c, "; elemsize=", elem.size, "; dataqsiz=", size, "\n")
}
return c
}
上面这段 makechan() 代码主要目的是生成 *hchan 对象。重点关注 switch-case 中的 3 种情况:
完成第一步的内存分配之后,再就是 hchan 数据结构其他字段的初始化和 lock 的初始化。值得说明的一点是,当存储在 buf 中的元素不包含指针时,Hchan 中也不包含 GC 关心的指针。buf 指向一段相同元素类型的内存,elemtype 固定不变。SudoG 是从它们自己的线程中引用的,因此垃圾回收的时候无法回收它们。受到垃圾回收器的限制,指针类型的缓冲 buf 需要单独分配内存。官方在这里加了一个 TODO,垃圾回收的时候这段代码逻辑需要重新考虑。
就是因为 channel 的创建全部调用的 mallocgc(),在堆上开辟的内存空间,channel 本身会被 GC 自动回收。有了这一性质,所以才有了下文关闭 channel 中优雅关闭的方法。
向 channel 中发送数据常见代码:
ch <- 1
编译器编译上述代码,在检查 ir 节点时,根据节点 op 不同类型,进行不同的检查,如下源码:
func walkExpr1(n ir.Node, init *ir.Nodes) ir.Node {
switch n.Op() {
default:
ir.Dump("walk", n)
base.Fatalf("walkExpr: switch 1 unknown op %+v", n.Op())
panic("unreachable")
case ir.OSEND:
n := n.(*ir.SendStmt)
return walkSend(n, init)
......
}
walkExpr1() 函数在创建 channel 提到了,这里不再赘述。操作类型是 OSEND,对应调用 walkSend() 函数:
func walkSend(n *ir.SendStmt, init *ir.Nodes) ir.Node {
n1 := n.Value
n1 = typecheck.AssignConv(n1, n.Chan.Type().Elem(), "chan send")
n1 = walkExpr(n1, init)
n1 = typecheck.NodAddr(n1)
return mkcall1(chanfn("chansend1", 2, n.Chan.Type()), nil, init, n.Chan, n1)
}
// entry point for c <- x from compiled code
//go:nosplit
func chansend1(c *hchan, elem unsafe.Pointer) {
chansend(c, elem, true, getcallerpc())
}
walkSend() 函数中主要逻辑调用了 chansend1(),而 chansend1() 只是 chansend() 的“外壳”。所以 channel 发送数据的核心实现在 chansend() 中。根据 channel 的阻塞和唤醒,又可以分为 2 部分逻辑代码。接下来笔者讲 chansend() 代码拆成 4 部分详细分析。
chansend() 函数一开始先进行异常检查:
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
// 判断 channel 是否为 nil
if c == nil {
if !block {
return false
}
gopark(nil, nil, waitReasonChanSendNilChan, traceEvGoStop, 2)
throw("unreachable")
}
if debugChan {
print("chansend: chan=", c, "\n")
}
if raceenabled {
racereadpc(c.raceaddr(), callerpc, funcPC(chansend))
}
// 简易快速的检查
if !block && c.closed == 0 && full(c) {
return false
}
......
}
chansend() 一上来对 channel 进行检查,如果被 GC 回收了会变为 nil。朝一个为 nil 的 channel 发送数据会发生阻塞。gopark 会引发以 waitReasonChanSendNilChan 为原因的休眠,并抛出 unreachable 的 fatal error。当 channel 不为 nil,再开始检查在没有获取锁的情况下会导致发送失败的非阻塞操作。
当 channel 不为 nil,并且 channel 没有 close 时,还需要检查此时 channel 是否做好发送的准备,即判断 full(c)
func full(c *hchan) bool {
if c.dataqsiz == 0 {
// 假设指针读取是近似原子性的
return c.recvq.first == nil
}
// 假设读取 uint 是近似原子性的
return c.qcount == c.dataqsiz
}
full() 方法作用是判断在 channel 上发送是否会阻塞(即通道已满)。它读取单个字节大小的可变状态(recvq.first 和 qcount),尽管答案可能在一瞬间是 true,但在调用函数收到返回值时,正确的结果可能发生了更改。值得注意的是 dataqsiz 字段,它在创建完 channel 以后是不可变的,因此它可以安全的在任意时刻读取。
回到 chansend() 异常检查中。一个已经 close 的 channel 是不可能从“准备发送”的状态变为“未准备好发送”的状态。所以在检查完 channel 是否 close 以后,就算 channel close 了,也不影响此处检查的结果。可能有读者疑惑,“能不能把检查顺序倒一倒?先检查是否 full(),再检查是否 close?”。这样倒过来确实能保证检查 full() 的时候,channel 没有 close。但是这种做法也没有实质性的改变。channel 依旧可以在检查完 close 以后再关闭。其实我们依赖的是 chanrecv() 和 closechan() 这两个方法在锁释放后,它们更新这个线程 c.close 和 full() 的结果视图。
channel 异常状态检查以后,接下来的代码是发送的逻辑。
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
......
lock(&c.lock)
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("send on closed channel"))
}
if sg := c.recvq.dequeue(); sg != nil {
send(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true
}
......
}
在发送之前,先上锁,保证线程安全。并再一次检查 channel 是否关闭。如果关闭则抛出 panic。加锁成功并且 channel 未关闭,开始发送。如果有正在阻塞等待的接收方,通过 dequeue() 取出头部第一个非空的 sudog,调用 send() 函数:
func send(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {
if sg.elem != nil {
sendDirect(c.elemtype, sg, ep)
sg.elem = nil
}
gp := sg.g
unlockf()
gp.param = unsafe.Pointer(sg)
sg.success = true
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
goready(gp, skip+1)
}
send() 函数主要完成了 2 件事:
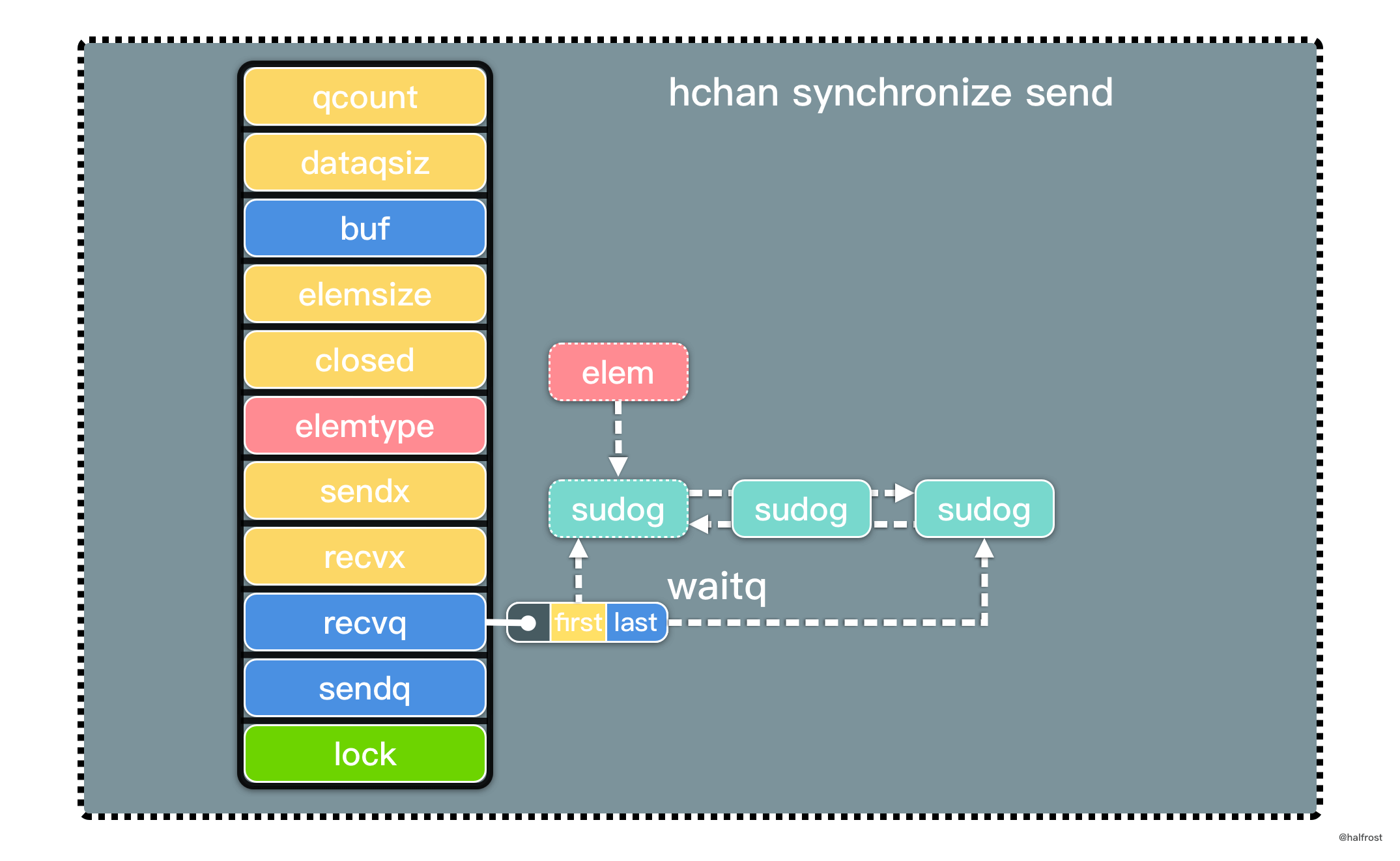
这里重点说说 goready() 的实现。理解了它的源码,就能明白为什么往 channel 中发送数据并非立即可以从接收方获取到。
func goready(gp *g, traceskip int) {
systemstack(func() {
ready(gp, traceskip, true)
})
}
func ready(gp *g, traceskip int, next bool) {
......
casgstatus(gp, _Gwaiting, _Grunnable)
runqput(_g_.m.p.ptr(), gp, next)
wakep()
releasem(mp)
}
在 runqput() 函数的作用是把 g 绑定到本地可运行的队列中。此处 next 传入的是 true,将 g 插入到 runnext 插槽中,等待下次调度便立即运行。因为这一点导致了虽然 goroutine 保证了线程安全,但是在读取数据方面比数组慢了几百纳秒。
| Read | Channel | Slice |
|---|---|---|
| Time | x * 100 * nanosecond | 0 |
| Thread safe | Yes | No |
所以在写测试用例的某些时候,需要考虑到这个微弱的延迟,可以适当加 sleep()。再比如刷 LeetCode 题目的时候,并非无脑使用 goroutine 就能带来 runtime 的提升,例如 509. Fibonacci Number,感兴趣的同学可以用 goroutine 来写一写这道题,笔者这里实现了goroutine 解法,性能方面完全不如数组的解法。
如果初始化 channel 时创建的带缓冲区的异步 Channel,当接收者队列为空时,这是会进入到异步发送逻辑:
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
......
if c.qcount < c.dataqsiz {
qp := chanbuf(c, c.sendx)
if raceenabled {
racenotify(c, c.sendx, nil)
}
typedmemmove(c.elemtype, qp, ep)
c.sendx++
if c.sendx == c.dataqsiz {
c.sendx = 0
}
c.qcount++
unlock(&c.lock)
return true
}
......
}
如果 qcount 还没有满,则调用 chanbuf() 获取 sendx 索引的元素指针值。调用 typedmemmove() 方法将发送的值拷贝到缓冲区 buf 中。拷贝完成,需要维护 sendx 索引下标值和 qcount 个数。这里将 buf 缓冲区设计成环形的,索引值如果到了队尾,下一个位置重新回到队头。
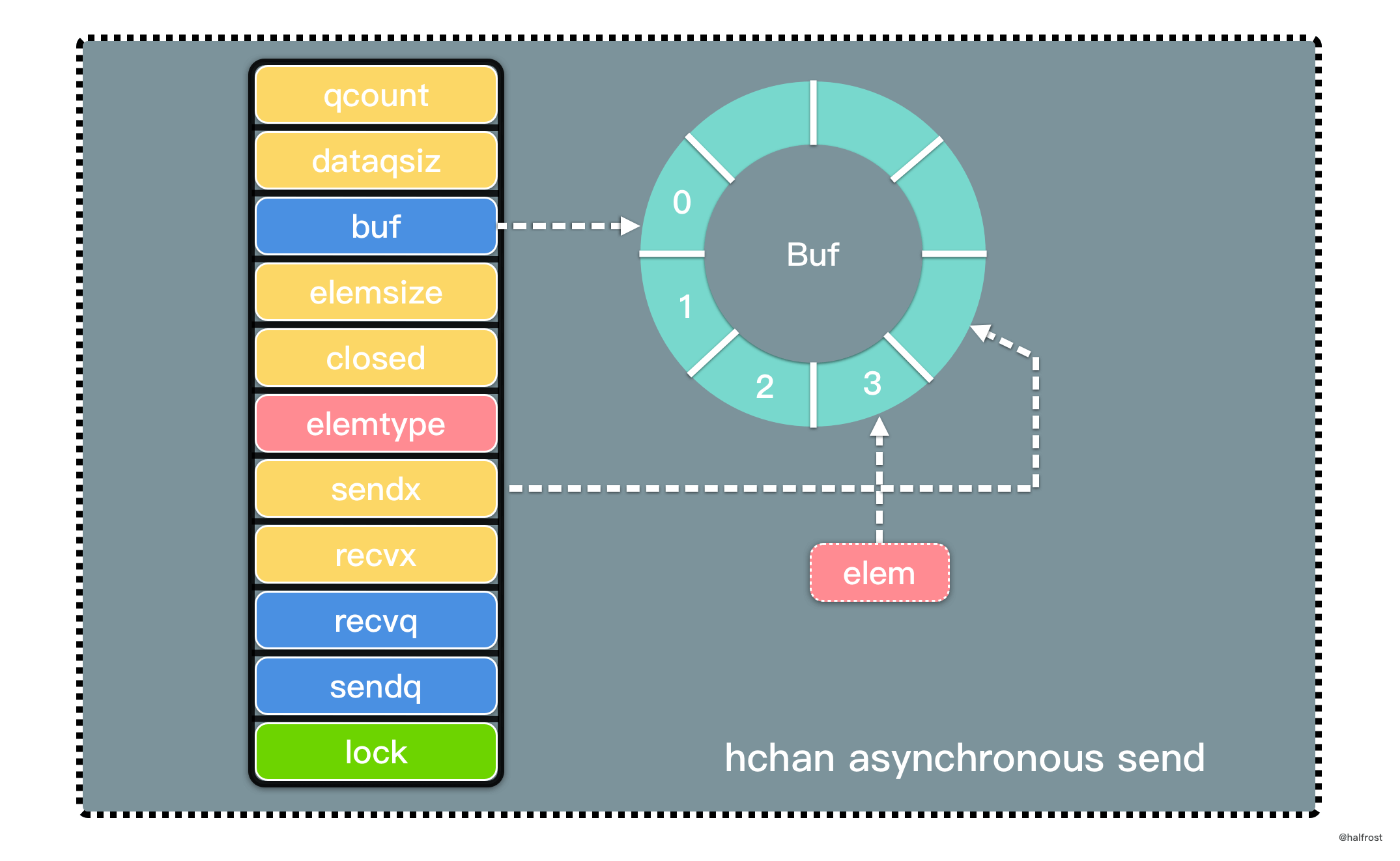
至此,两种直接发送的逻辑分析完了,接下来是发送时 channel 阻塞的情况。
当 channel 处于打开状态,但是没有接收者,并且没有 buf 缓冲队列或者 buf 队列已满,这时 channel 会进入阻塞发送。
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
......
if !block {
unlock(&c.lock)
return false
}
gp := getg()
mysg := acquireSudog()
mysg.releasetime = 0
if t0 != 0 {
mysg.releasetime = -1
}
mysg.elem = ep
mysg.waitlink = nil
mysg.g = gp
mysg.isSelect = false
mysg.c = c
gp.waiting = mysg
gp.param = nil
c.sendq.enqueue(mysg)
atomic.Store8(&gp.parkingOnChan, 1)
gopark(chanparkcommit, unsafe.Pointer(&c.lock), waitReasonChanSend, traceEvGoBlockSend, 2)
KeepAlive(ep)
......
}
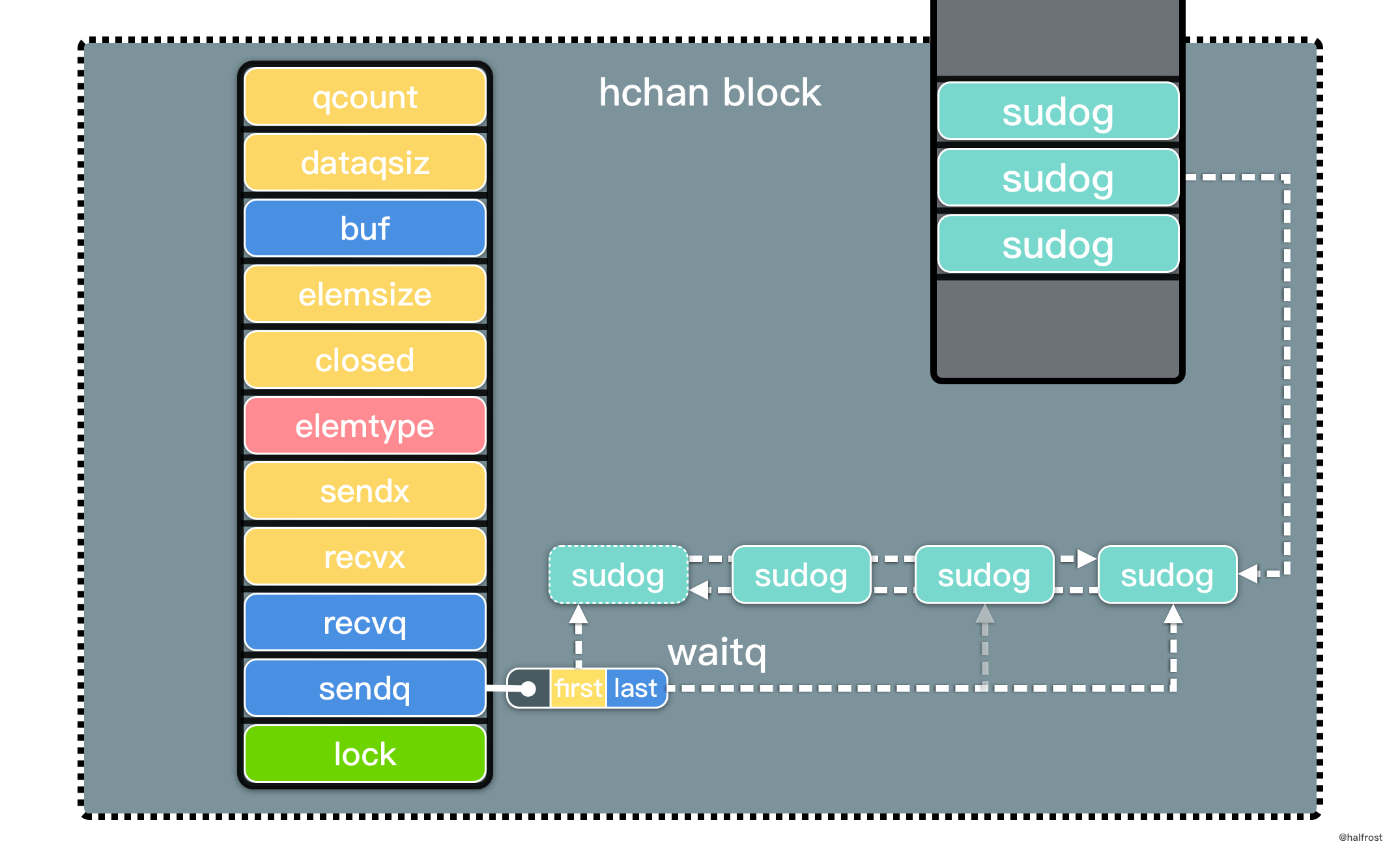
这里提一下 sudog 的二级缓存复用体系。在 acquireSudog() 方法中:
func acquireSudog() *sudog {
mp := acquirem()
pp := mp.p.ptr()
// 如果本地缓存为空
if len(pp.sudogcache) == 0 {
lock(&sched.sudoglock)
// 首先尝试将全局中央缓存存一部分到本地
for len(pp.sudogcache) < cap(pp.sudogcache)/2 && sched.sudogcache != nil {
s := sched.sudogcache
sched.sudogcache = s.next
s.next = nil
pp.sudogcache = append(pp.sudogcache, s)
}
unlock(&sched.sudoglock)
// 如果全局中央缓存是空的,则 allocate 一个新的
if len(pp.sudogcache) == 0 {
pp.sudogcache = append(pp.sudogcache, new(sudog))
}
}
// 从尾部提取,并调整本地缓存
n := len(pp.sudogcache)
s := pp.sudogcache[n-1]
pp.sudogcache[n-1] = nil
pp.sudogcache = pp.sudogcache[:n-1]
if s.elem != nil {
throw("acquireSudog: found s.elem != nil in cache")
}
releasem(mp)
return s
}
上述代码涉及到 2 个新的重要的结构体,由于这 2 个结构体特别复杂,暂时此处只展示和 acquireSudog() 有关的部分:
type p struct {
......
sudogcache []*sudog
sudogbuf [128]*sudog
......
}
type schedt struct {
......
sudoglock mutex
sudogcache *sudog
......
}
sched.sudogcache 是全局中央缓存,可以认为它是“一级缓存”,它会在 GC 垃圾回收执行 clearpools 被清理。p.sudogcache 可以认为它是“二级缓存”,是本地缓存不会被 GC 清理掉。
chansend 最后的代码逻辑是当 goroutine 唤醒以后,解除阻塞的状态:
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
......
if mysg != gp.waiting {
throw("G waiting list is corrupted")
}
gp.waiting = nil
gp.activeStackChans = false
closed := !mysg.success
gp.param = nil
if mysg.releasetime > 0 {
blockevent(mysg.releasetime-t0, 2)
}
mysg.c = nil
releaseSudog(mysg)
if closed {
if c.closed == 0 {
throw("chansend: spurious wakeup")
}
panic(plainError("send on closed channel"))
}
return true
}
sudog 算是对 g 的一种封装,里面包含了 g,要发送的数据以及相关的状态。goroutine 被唤醒后会完成 channel 的阻塞数据发送。发送完最后进行基本的参数检查,解除 channel 的绑定并释放 sudog。
func releaseSudog(s *sudog) {
if s.elem != nil {
throw("runtime: sudog with non-nil elem")
}
if s.isSelect {
throw("runtime: sudog with non-false isSelect")
}
if s.next != nil {
throw("runtime: sudog with non-nil next")
}
if s.prev != nil {
throw("runtime: sudog with non-nil prev")
}
if s.waitlink != nil {
throw("runtime: sudog with non-nil waitlink")
}
if s.c != nil {
throw("runtime: sudog with non-nil c")
}
gp := getg()
if gp.param != nil {
throw("runtime: releaseSudog with non-nil gp.param")
}
// 防止 rescheduling 到了其他的 P
mp := acquirem()
pp := mp.p.ptr()
// 如果本地缓存已满
if len(pp.sudogcache) == cap(pp.sudogcache) {
// 转移一半本地缓存到全局中央缓存中
var first, last *sudog
for len(pp.sudogcache) > cap(pp.sudogcache)/2 {
n := len(pp.sudogcache)
p := pp.sudogcache[n-1]
pp.sudogcache[n-1] = nil
pp.sudogcache = pp.sudogcache[:n-1]
if first == nil {
first = p
} else {
last.next = p
}
last = p
}
lock(&sched.sudoglock)
// 将提取的链表挂载到全局中央缓存中
last.next = sched.sudogcache
sched.sudogcache = first
unlock(&sched.sudoglock)
}
pp.sudogcache = append(pp.sudogcache, s)
releasem(mp)
}
releaseSudog() 虽然释放了 sudog 的内存,但是它会被 p.sudogcache 这个“二级缓存”缓存起来。
chansend() 函数最后返回 true 表示成功向 Channel 发送了数据。
关于 channel 发送的源码实现已经分析完了,针对 channel 各个状态做一个小结。
| Channel Status | Result | |
|---|---|---|
| Write | nil | 阻塞 |
| Write | 打开但填满 | 阻塞 |
| Write | 打开但未满 | 成功写入值 |
| Write | 关闭 | panic |
| Write | 只读 | Compile Error |
channel 发送过程中包含 2 次有关 goroutine 调度过程:
goready()将 g 插入 runnext 插槽中,状态从 Gwaiting 或者 Gscanwaiting 改变成 Grunnable,等待下次调度便立即运行。gopark() 将 g 阻塞,让出 cpu 的使用权。需要强调的是,通道并不提供跨 goroutine 的数据访问保护机制。如果通过通道传输数据的一份副本,那么每个 goroutine 都持有一份副本,各自对自己的副本做修改是安全的。当传输的是指向数据的指针时,如果读和写是由不同的 goroutine 完成的,那么每个 goroutine 依旧需要额外的同步操作。
从 channel 中接收数据常见代码:
tmp := <-ch
tmp, ok := <-ch
先看等号左边赋值一个值的情况,编译器编译上述代码,在检查 ir 节点时,根据节点 op 不同类型,进行不同的检查,如下源码:
// walkAssign walks an OAS (AssignExpr) or OASOP (AssignOpExpr) node.
func walkAssign(init *ir.Nodes, n ir.Node) ir.Node {
......
switch as.Y.Op() {
default:
as.Y = walkExpr(as.Y, init)
case ir.ORECV:
// x = <-c; as.Left is x, as.Right.Left is c.
// order.stmt made sure x is addressable.
recv := as.Y.(*ir.UnaryExpr)
recv.X = walkExpr(recv.X, init)
n1 := typecheck.NodAddr(as.X)
r := recv.X // the channel
return mkcall1(chanfn("chanrecv1", 2, r.Type()), nil, init, r, n1)
......
}
as 是入参 ir 节点强制转化成 AssignStmt 类型。AssignStmt 这个类型是赋值的一个说明:
type AssignStmt struct {
miniStmt
X Node
Def bool
Y Node
}
Y 是等号右边的值,它是 Node 类型,里面包含 op 类型。walkAssign 是检查赋值语句,如果 Y.Op() 是 ir.ORECV 类型,说明是 channel 接收的过程。调用 chanrecv1() 函数。as.X 是赋值语句左边的元素,它是接收 channel 中的值,所以它必须是可寻址的。
当从 channel 中读取数据等号左边是 2 个值的时候,编译器在 walkExpr1 中检查这个赋值语句:
func walkExpr1(n ir.Node, init *ir.Nodes) ir.Node {
switch n.Op() {
default:
ir.Dump("walk", n)
base.Fatalf("walkExpr: switch 1 unknown op %+v", n.Op())
panic("unreachable")
......
case ir.OAS2RECV:
n := n.(*ir.AssignListStmt)
return walkAssignRecv(init, n)
......
}
n.Op() 是 ir.OAS2RECV 类型,将 n 强转成 AssignListStmt 类型:
type AssignListStmt struct {
miniStmt
Lhs Nodes
Def bool
Rhs Nodes
}
AssignListStmt 和 AssignStmt 作用一样,只是 AssignListStmt 表示等号两边赋值语句不再是一个对象,而是多个。回到 walkExpr1() 中,如果是 ir.OAS2RECV 类型,调用 walkAssignRecv() 继续检查。
func walkAssignRecv(init *ir.Nodes, n *ir.AssignListStmt) ir.Node {
init.Append(ir.TakeInit(n)...)
r := n.Rhs[0].(*ir.UnaryExpr) // recv
walkExprListSafe(n.Lhs, init)
r.X = walkExpr(r.X, init)
var n1 ir.Node
if ir.IsBlank(n.Lhs[0]) {
n1 = typecheck.NodNil()
} else {
n1 = typecheck.NodAddr(n.Lhs[0])
}
fn := chanfn("chanrecv2", 2, r.X.Type())
ok := n.Lhs[1]
call := mkcall1(fn, types.Types[types.TBOOL], init, r.X, n1)
return typecheck.Stmt(ir.NewAssignStmt(base.Pos, ok, call))
}
Lhs[0] 是实际接收 channel 值的对象,Lhs[1] 是赋值语句左边第二个 bool 值。赋值语句右边由于只有一个 channel,所以这里 Rhs 也只用到了 Rhs[0]。
//go:nosplit
func chanrecv1(c *hchan, elem unsafe.Pointer) {
chanrecv(c, elem, true)
}
//go:nosplit
func chanrecv2(c *hchan, elem unsafe.Pointer) (received bool) {
_, received = chanrecv(c, elem, true)
return
}
综合上述的分析,2 种不同的 channel 接收方式会转换成 runtime.chanrecv1 和 runtime.chanrecv2 两种不同函数的调用,但是最终核心逻辑还是在 runtime.chanrecv 中。
chanrecv() 函数一开始先进行异常检查:
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
if debugChan {
print("chanrecv: chan=", c, "\n")
}
if c == nil {
if !block {
return
}
gopark(nil, nil, waitReasonChanReceiveNilChan, traceEvGoStop, 2)
throw("unreachable")
}
// 简易快速的检查
if !block && empty(c) {
if atomic.Load(&c.closed) == 0 {
return
}
if empty(c) {
// channel 不可逆的关闭了且为空
if raceenabled {
raceacquire(c.raceaddr())
}
if ep != nil {
typedmemclr(c.elemtype, ep)
}
return true, false
}
}
chanrecv() 一上来对 channel 进行检查,如果被 GC 回收了会变为 nil。从一个为 nil 的 channel 中接收数据会发生阻塞。gopark 会引发以 waitReasonChanReceiveNilChan 为原因的休眠,并抛出 unreachable 的 fatal error。当 channel 不为 nil,再开始检查在没有获取锁的情况下会导致接收失败的非阻塞操作。
这里进行的简易快速的检查,检查中状态不能发生变化。这一点和 chansend() 函数有区别。在 chansend() 简易快速的检查中,改变顺序对检查结果无太大影响,但是此处如果检查过程中状态发生变化,如果发生了 racing,检查结果会出现完全相反的错误的结果。例如以下这种情况:channel 在第一个和第二个 if 检查时是打开的且非空,于是在第二个 if 里面 return。但是 return 的瞬间, channel 关闭且空。这样判断出来认为 channel 是打开的且非空。明显是错误的结果,实际上 channel 是关闭且空的。同理检查是否为空的时候也会发生状态反转。为了防止错误的检查结果,c.closed 和 empty() 都必须使用原子检查。
func empty(c *hchan) bool {
// c.dataqsiz 是不可变的
if c.dataqsiz == 0 {
return atomic.Loadp(unsafe.Pointer(&c.sendq.first)) == nil
}
return atomic.Loaduint(&c.qcount) == 0
}
这里总共检查了 2 次 empty(),因为第一次检查时, channel 可能还没有关闭,但是第二次检查的时候关闭了,在 2 次检查之间可能有待接收的数据到达了。所以需要 2 次 empty() 检查。
不过就算按照上述源码检查,细心的读者可能还会举出一个反例,例如,关闭一个已经阻塞的同步的 channel,最开始的 !block && empty(c) 为 false,会跳过这个检查。这种情况不能算在正常 chanrecv() 里面。上述是不获取锁的情况检查会接收失败的情况。接下来在获取锁的情况下再次检查一遍异常情况。
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
......
lock(&c.lock)
if c.closed != 0 && c.qcount == 0 {
if raceenabled {
raceacquire(c.raceaddr())
}
unlock(&c.lock)
if ep != nil {
typedmemclr(c.elemtype, ep)
}
return true, false
}
......
如果 channel 已经关闭且不存在缓存数据了,则清理 ep 指针中的数据并返回。这里也是从已经关闭的 channel 中读数据,读出来的是该类型零值的原因。
同 chansend 逻辑类似,检查完异常情况,紧接着是同步接收。
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
......
if sg := c.sendq.dequeue(); sg != nil {
recv(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true, true
}
......
在 channel 的发送队列中找到了等待发送的 goroutine。取出队头等待的 goroutine。如果缓冲区的大小为 0,则直接从发送方接收值。否则,对应缓冲区满的情况,从队列的头部接收数据,发送者的值添加到队列的末尾(此时队列已满,因此两者都映射到缓冲区中的同一个下标)。同步接收的核心逻辑见下面 recv() 函数:
func recv(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {
if c.dataqsiz == 0 {
if raceenabled {
racesync(c, sg)
}
if ep != nil {
// 从 sender 里面拷贝数据
recvDirect(c.elemtype, sg, ep)
}
} else {
// 这里对应 buf 满的情况
qp := chanbuf(c, c.recvx)
if raceenabled {
racenotify(c, c.recvx, nil)
racenotify(c, c.recvx, sg)
}
// 将数据从 buf 中拷贝到接收者内存地址中
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
// 将数据从 sender 中拷贝到 buf 中
typedmemmove(c.elemtype, qp, sg.elem)
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
c.sendx = c.recvx // c.sendx = (c.sendx+1) % c.dataqsiz
}
sg.elem = nil
gp := sg.g
unlockf()
gp.param = unsafe.Pointer(sg)
sg.success = true
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
goready(gp, skip+1)
}
需要注意的是由于有发送者在等待,所以如果存在缓冲区,那么缓冲区一定是满的。这个情况对应发送阶段阻塞发送的情况,如果缓冲区还有空位,发送的数据直接放入缓冲区,只有当缓冲区满了,才会打包成 sudog,插入到 sendq 队列中等待调度。注意理解这一情况。
接收时主要分为 2 种情况,有缓冲且 buf 满和无缓冲的情况:
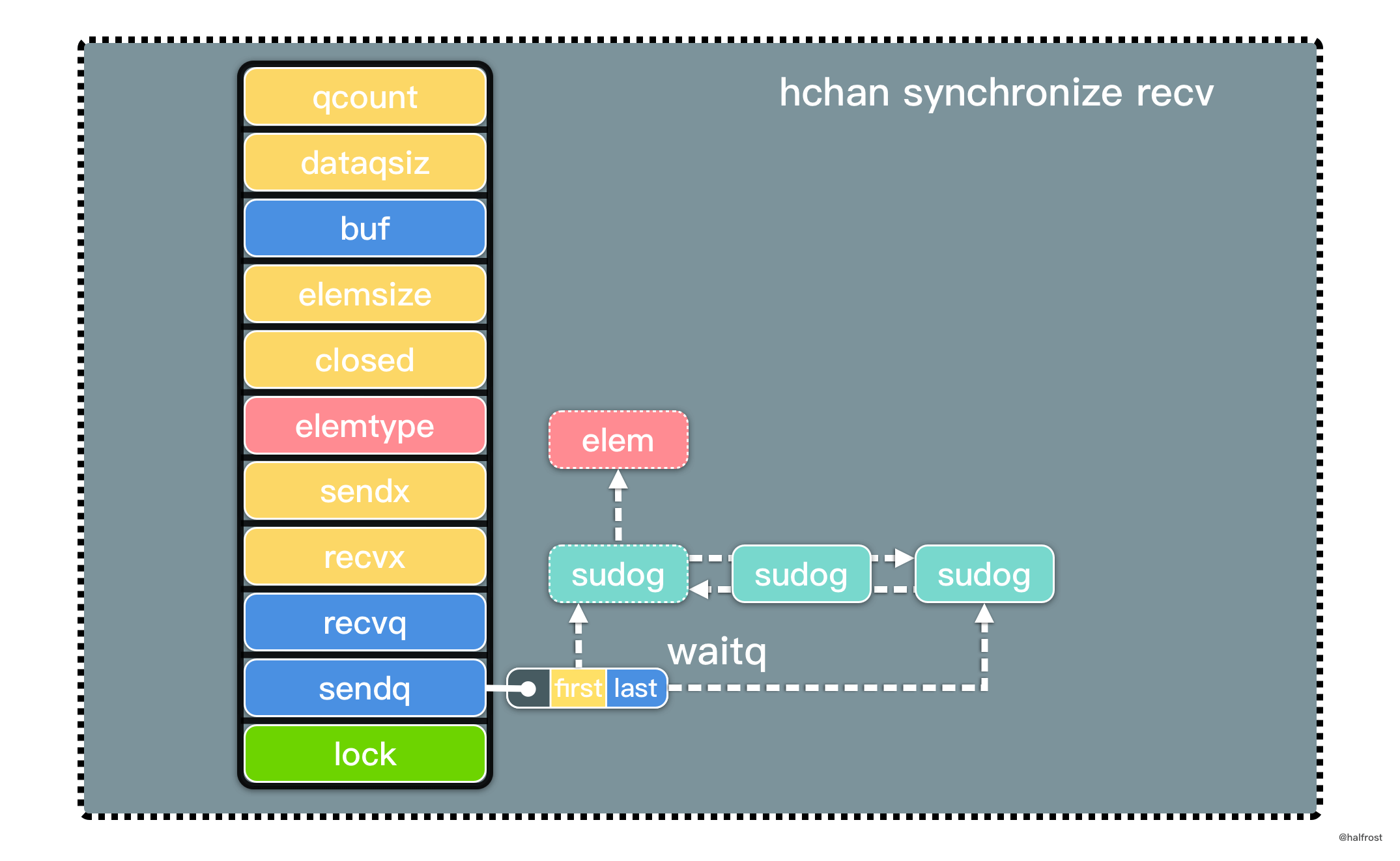
有缓冲并且 buf 满。有 2 次 copy 操作,先将队列中 recvx 索引下标的数据拷贝到接收方的内存地址,再将发送队列头的数据拷贝到缓冲区中,释放一个 sudog 阻塞的 goroutine。
有缓冲且 buf 满的情况需要注意,取数据从缓冲队列头取出,发送的数据放在队列尾部,由于 buf 装满,取出的 recvx 指针和发送的 sendx 指针指向相同的下标。
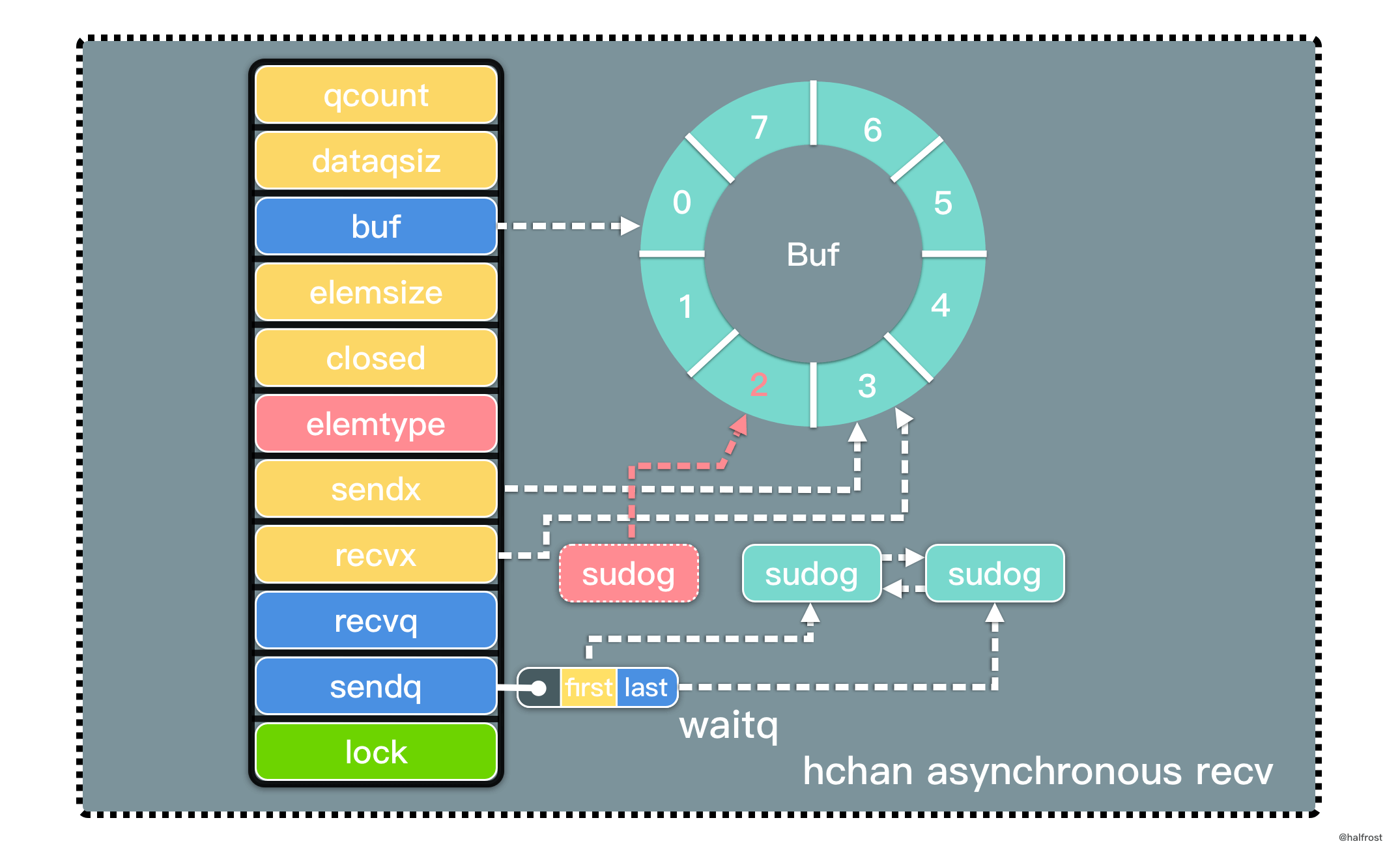
最后调用 goready() 将等待接收的阻塞 goroutine 的状态从 Gwaiting 或者 Gscanwaiting 改变成 Grunnable。下一轮调度时会唤醒这个发送的 goroutine。这部分逻辑和同步发送中一致,关于 goready() 底层实现的代码不在赘述。
如果 Channel 的缓冲区中包含一些数据时,从 Channel 中接收数据会直接从缓冲区中 recvx 的索引位置中取出数据进行处理:
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
......
if c.qcount > 0 {
// 直接从队列中接收
qp := chanbuf(c, c.recvx)
if raceenabled {
racenotify(c, c.recvx, nil)
}
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
typedmemclr(c.elemtype, qp)
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
c.qcount--
unlock(&c.lock)
return true, true
}
if !block {
unlock(&c.lock)
return false, false
}
......
上述代码比较简单,如果接收数据的内存地址 ep 不为空,则调用 runtime.typedmemmove() 将缓冲区内的数据拷贝到内存中,并通过 typedmemclr() 清除队列中的数据。
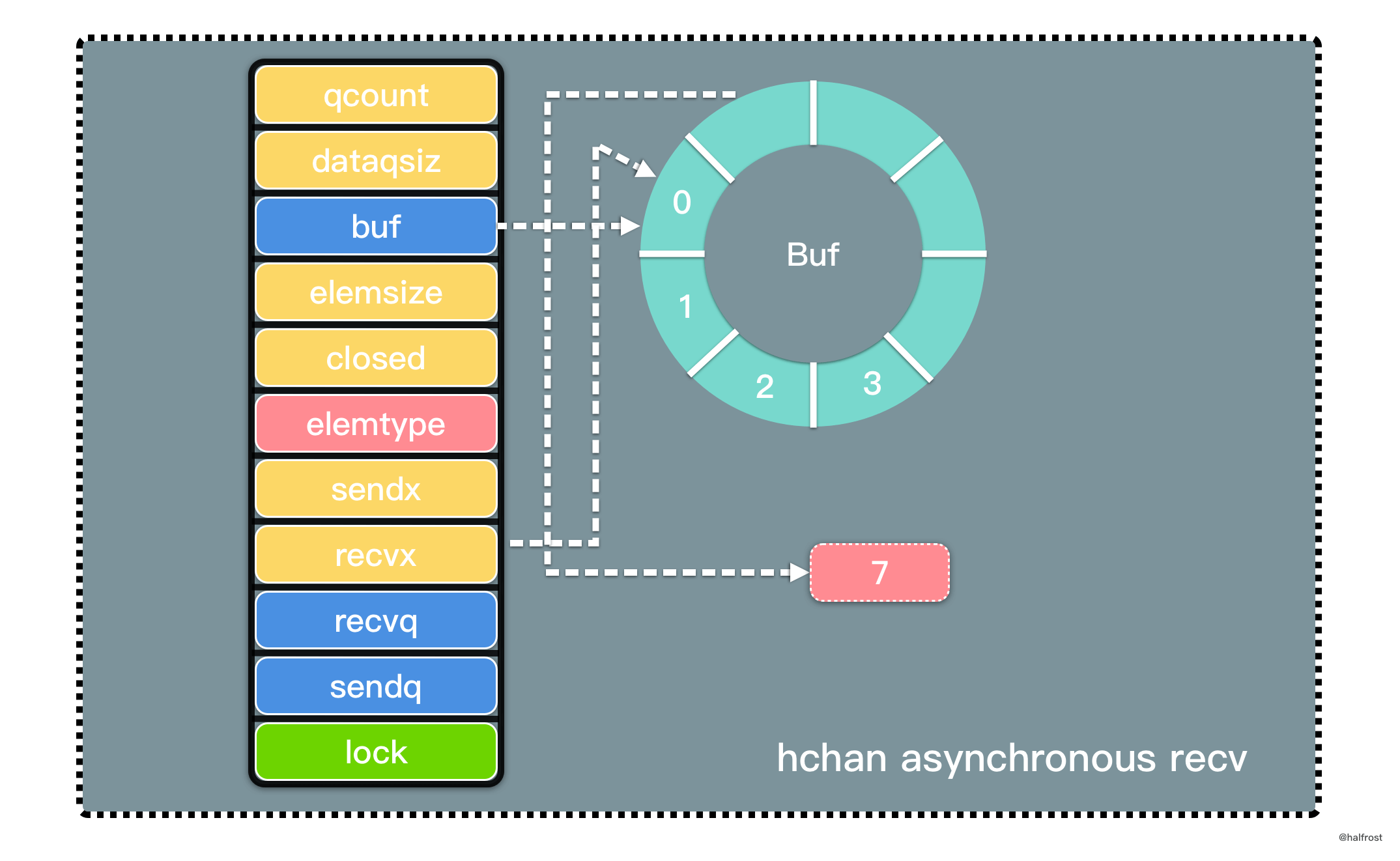
维护 recvx 下标,如果移动到了环形队列的队尾,下标需要回到队头。最后减少 qcount 计数器并释放持有 Channel 的锁。
如果 channel 发送队列上没有待发送的 goroutine,并且缓冲区也没有数据时,将会进入到最后一个阶段阻塞接收:
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
......
gp := getg()
mysg := acquireSudog()
mysg.releasetime = 0
if t0 != 0 {
mysg.releasetime = -1
}
mysg.elem = ep
mysg.waitlink = nil
gp.waiting = mysg
mysg.g = gp
mysg.isSelect = false
mysg.c = c
gp.param = nil
c.recvq.enqueue(mysg)
atomic.Store8(&gp.parkingOnChan, 1)
gopark(chanparkcommit, unsafe.Pointer(&c.lock), waitReasonChanReceive, traceEvGoBlockRecv, 2)
......
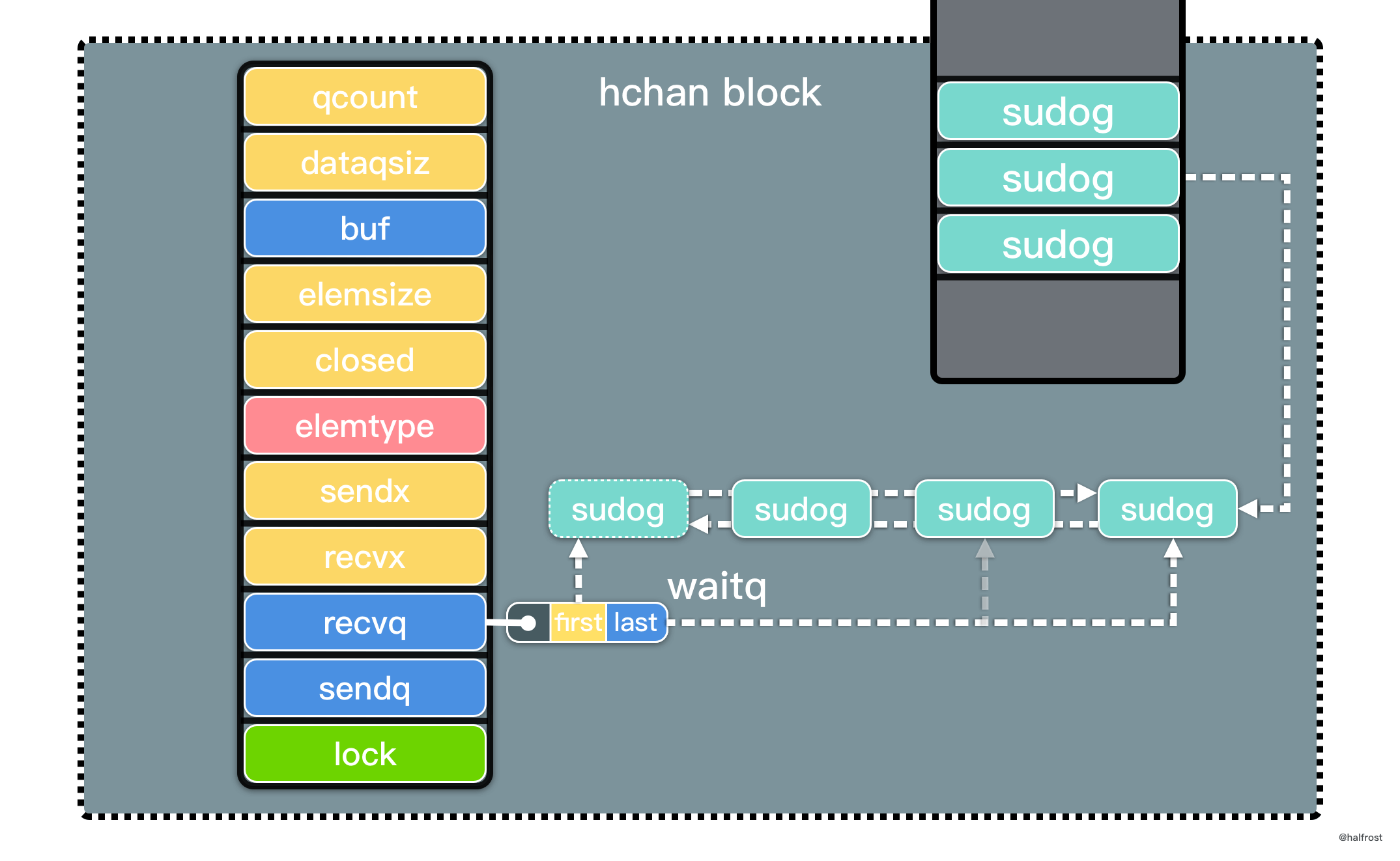
上面这段代码与 chansend() 中阻塞发送几乎完全一致,区别在于最后一步没有 KeepAlive(ep)。
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
......
// 被唤醒
if mysg != gp.waiting {
throw("G waiting list is corrupted")
}
gp.waiting = nil
gp.activeStackChans = false
if mysg.releasetime > 0 {
blockevent(mysg.releasetime-t0, 2)
}
success := mysg.success
gp.param = nil
mysg.c = nil
releaseSudog(mysg)
return true, success
}
goroutine 被唤醒后会完成 channel 的阻塞数据接收。接收完最后进行基本的参数检查,解除 channel 的绑定并释放 sudog。
关于 channel 接收的源码实现已经分析完了,针对 channel 各个状态做一个小结。
| Channel status | Result | |
|---|---|---|
| Read | nil | 阻塞 |
| Read | 打开且非空 | 读取到值 |
| Read | 打开但为空 | 阻塞 |
| Read | 关闭 | <默认值>, false |
| Read | 只读 | Compile Error |
chanrecv 的返回值有几种情况:
tmp, ok := <-ch
| Channel status | Selected | Received |
|---|---|---|
| nil | false | false |
| 打开且非空 | true | true |
| 打开但为空 | false | false |
| 关闭且返回值是零值 | true | false |
received 值会传递给读取 channel 外部的 bool 值 ok,selected 值不会被外部使用。
channel 接收过程中包含 2 次有关 goroutine 调度过程:
关于 channel 常见代码:
close(ch)
编译器会将其转换为 runtime.closechan() 方法。
func closechan(c *hchan) {
if c == nil {
panic(plainError("close of nil channel"))
}
lock(&c.lock)
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("close of closed channel"))
}
if raceenabled {
callerpc := getcallerpc()
racewritepc(c.raceaddr(), callerpc, funcPC(closechan))
racerelease(c.raceaddr())
}
c.closed = 1
......
}
关闭一个 channel 有 2 点需要注意,当 Channel 是一个 nil 空指针或者关闭一个已经关闭的 channel 时,Go 语言运行时都会直接 panic。上述 2 种情况都不存在时,标记 channel 状态为 close。
关闭 channel 的主要工作是释放所有的 readers 和 writers。
func closechan(c *hchan) {
......
var glist gList
for {
sg := c.recvq.dequeue()
if sg == nil {
break
}
if sg.elem != nil {
typedmemclr(c.elemtype, sg.elem)
sg.elem = nil
}
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
gp := sg.g
gp.param = unsafe.Pointer(sg)
sg.success = false
if raceenabled {
raceacquireg(gp, c.raceaddr())
}
glist.push(gp)
}
......
}
上述代码是回收接收者的 sudog。将所有的接收者 readers 的 sudog 等待队列(recvq)加入到待清除队列 glist 中。注意这里是先回收接收者。就算从一个 close 的 channel 中读取值,不会发生 panic,顶多读到一个默认零值。
func closechan(c *hchan) {
......
for {
sg := c.sendq.dequeue()
if sg == nil {
break
}
sg.elem = nil
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
gp := sg.g
gp.param = unsafe.Pointer(sg)
sg.success = false
if raceenabled {
raceacquireg(gp, c.raceaddr())
}
glist.push(gp)
}
unlock(&c.lock)
......
}
再回收发送者 writers。回收步骤和回收接收者是完全一致的,将发送者的等待队列 sendq 中的 sudog 放入待清除队列 glist 中。注意这里可能会产生 panic。在第四章发送数据中分析过,往一个 close 的 channel 中发送数据,会产生 panic,这里不再赘述。
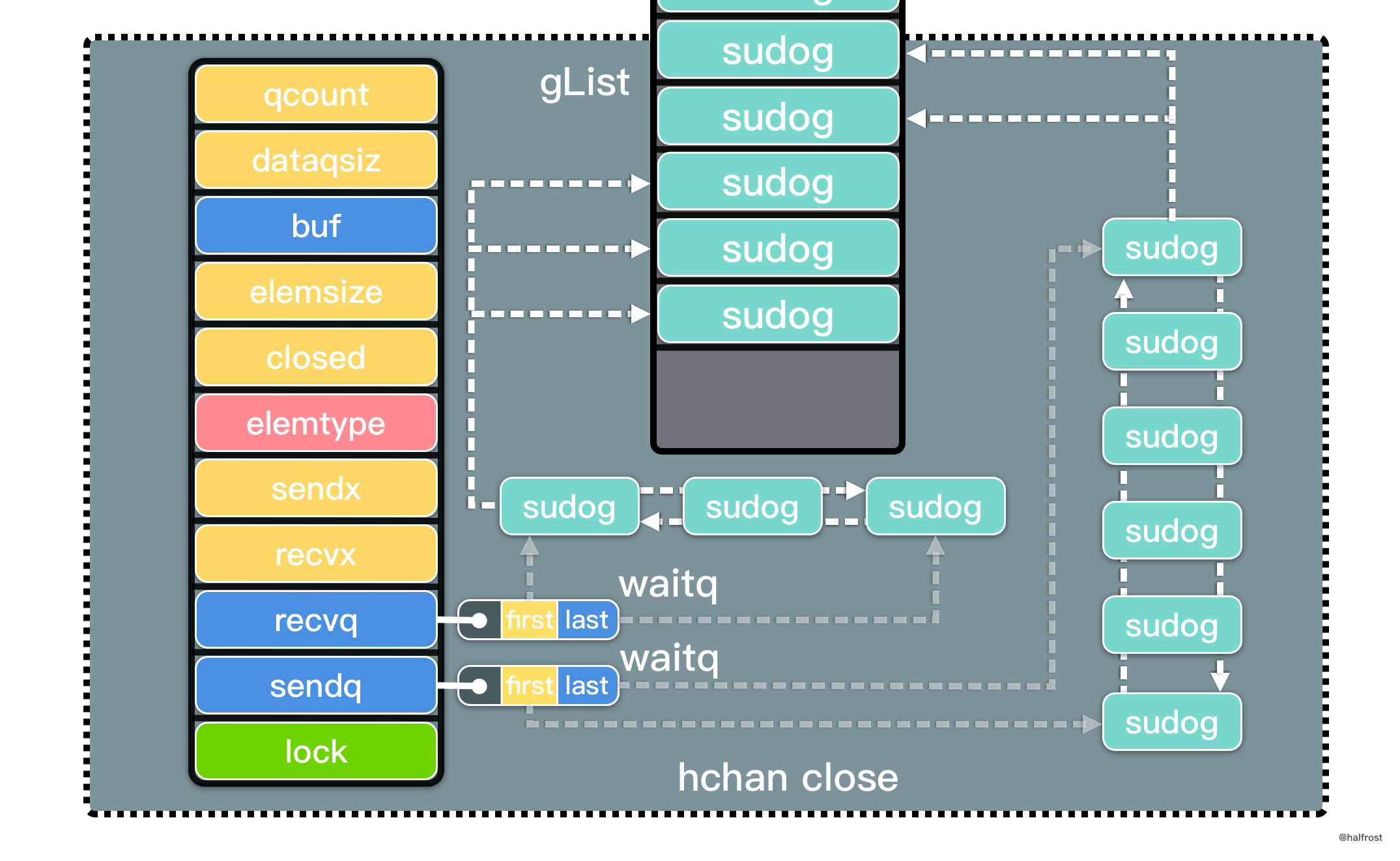
最后一步更改 goroutine 的状态。
func closechan(c *hchan) {
......
for !glist.empty() {
gp := glist.pop()
gp.schedlink = 0
goready(gp, 3)
}
......
}
最后会为所有被阻塞的 goroutine 调用 goready 触发调度。将所有 glist 中的 goroutine 状态从 _Gwaiting 设置为 _Grunnable 状态,等待调度器的调度。
“Channel 有几种优雅的关闭方法?” 这种问题常常出现在面试题中,究其原因是因为 Channel 创建容易,但是关闭“不易”:
| Channel Status | Result | |
|---|---|---|
| close | nil | panic |
| close | 打开且非空 | 关闭 Channel;读取成功,直到 Channel 耗尽数据,然后读取产生值的默认值 |
| close | 打开但为空 | 关闭 Channel;读到生产者的默认值 |
| close | 关闭 | panic |
| close | 只读 | Compile Error |
那究竟什么时候关闭 Channel 呢?由上面三个“不易”,可以浓缩为 2 点:
解释一下这 2 个问题。第一个问题,消费者不知道 Channel 何时该关闭。如果关闭了已经关闭的 Channel 会导致 panic。而且分布式应用通常有多个消费者,每个消费者的行为一致,这么多消费者都尝试关闭 Channel 必然会导致 panic。第二个问题,如果有多个生产者往 Channel 内写入数据,这些生产者的行为逻辑也都一致,如果其中一个生产者关闭了 Channel,其他的生产者还在往里写,这个时候会 panic。所以为了防止 panic,必须解决上面这 2 个问题。
关闭 Channel 的方式就 2 种:
Context 的方式在本篇文章不详细展开,详细的可以查看笔者 Context 的那篇文章。本节聊聊 done channel 的做法。假设有多个生产者,有多个消费者。在生产者和消费者之间增加一个额外的辅助控制 channel,用来传递关闭信号。
type session struct {
done chan struct{}
doneOnce sync.Once
data chan int
}
func (sess *session) Serve() {
go sess.loopRead()
sess.loopWrite()
}
func (sess *session) loopRead() {
defer func() {
if err := recover(); err != nil {
sess.doneOnce.Do(func() { close(sess.done) })
}
}()
var err error
for {
select {
case <-sess.done:
return
default:
}
if err == io.ErrUnexpectedEOF || err == io.EOF {
goto failed
}
}
failed:
sess.doneOnce.Do(func() { close(sess.done) })
}
func (sess *session) loopWrite() {
defer func() {
if err := recover(); err != nil {
sess.doneOnce.Do(func() { close(sess.done) })
}
}()
var err error
for {
select {
case <-sess.done:
return
case sess.data <- rand.Intn(100):
}
if err != nil {
goto done
}
}
done:
if err != nil {
log("sess: loop write failed: %v, %s", err, sess)
}
}
func (sess *session) ForceClose() {
sess.doneOnce.Do(func() { close(sess.done) })
}
消费者侧发送关闭 done channel,由于消费者有多个,如果每一个都关闭 done channel,会导致 panic。所以这里用 doneOnce.Do() 保证只会关闭 done channel 一次。这解决了第一个问题。生产者收到 done channel 的信号以后自动退出。多个生产者退出时间不同,但是最终肯定都会退出。当生产者全部退出以后,data channel 最终没有引用,会被 gc 回收。这也解决了第二个问题,生产者不会去关闭 data channel,防止出现 panic。
总结一下 done channel 的做法:消费者利用辅助的 done channel 发送信号,并先开始退出协程。生产者接收到 done channel 的信号,也开始退出协程。最终 data channel 无人持有,被 gc 回收关闭。
Reference:
ACM Communicating sequential processes
Stanford project about csp
2019-10-13 15:12:00

在计算机学中,反射式编程 reflective programming 或反射 reflection,是指计算机程序在运行时 runtime 可以访问、检测和修改它本身状态或行为的一种能力。用比喻来说,反射就是程序在运行的时候能够“观察”并且修改自己的行为。
Wikipedia: In computer science, reflective programming or reflection is the ability of a process to examine, introspect, and modify its own structure and behavior.
“反射”和“内省”(type introspection)在概念上有区别。内省(或称“自省”)机制仅指程序在运行时对自身信息(称为元数据)的检测;反射机制不仅包括要能在运行时对程序自身信息进行检测,还要求程序能进一步根据这些信息改变程序状态或结构。所以反射的概念范畴要大于内省。
在类型检测严格的面向对象的编程语言如 Java 中,一般需要在编译期间对程序中需要调用的对象的具体类型、接口(interface)、字段(fields)和方法的合法性进行检查。反射技术则允许将对需要调用的对象的消息检查工作从编译期间推迟到运行期间再现场执行。这样一来,可以在编译期间先不明确目标对象的接口(interface)名称、字段(fields),即对象的成员变量、可用方法,然后在运行根据目标对象自身的消息决定如何处理。它还允许根据判断结果进行实例化新对象和相关方法的调用。
反射主要用途就是使给定的程序,动态地适应不同的运行情况。利用面向对象建模中的多态(多态性)也可以简化编写分别适用于多种不同情形的功能代码,但是反射可以解决多态(多态性)并不适用的更普遍情形,从而更大程度地避免硬编码(即把代码的细节“写死”,缺乏灵活性)的代码风格。
反射也是元编程的一个关键策略。
最常见的代码如下:
import "reflect"
func main() {
// Without reflection
f := Foo{}
f.Hello()
// With reflection
fT := reflect.TypeOf(Foo{})
fV := reflect.New(fT)
m := fV.MethodByName("Hello")
if m.IsValid() {
m.Call(nil)
}
}
反射看似代码更加复杂,但是能实现的功能更加灵活了。究竟什么时候用反射?最佳实践是什么?这篇文章好好讨论一下。
在上一篇 Go interface 中,可以了解到普通对象在内存中的存在形式,一个变量值得我们关注的无非是两部分,一个是类型,一个是它存的值。变量的类型决定了底层 tpye 是什么,支持哪些方法集。值无非就是读和写。去内存里面哪里读,把 0101 写到内存的哪里,都是由类型决定的。这一点在解析不同 Json 数据结构的时候深有体会,如果数据类型用错了,解析出来得到的变量的值是乱码。Go 提供反射的功能,是为了支持在运行时动态访问变量的类型和值。
在运行时想要动态访问类型的值,必然应用程序存储了所有用到的类型信息。"reflect" 库提供了一套供开发者使用的访问接口。Go 中反射的基础是接口和类型,Go 很巧妙的借助了对象到接口的转换时使用的数据结构,先将对象传递给内部的空接口,即将类型转换成空接口 emptyInterface(数据结构同 eface 一致)。然后反射再基于这个 emptyInterface 来访问和操作实例对象的值和类型。
那么笔者就从数据结构开始梳理 Go 是如何实现反射的。在 reflect 包中,有一个描述类型公共信息的通用数据结构 rtype。从源码的注释上看,它和 interface 里面的 _type 是同一个数据结构。它们俩只是因为包隔离,加上为了避免循环引用,所以在这边又复制了一遍。
// rtype is the common implementation of most values.
// It is embedded in other struct types.
//
// rtype must be kept in sync with ../runtime/type.go:/^type._type.
type rtype struct {
size uintptr // 类型占用内存大小
ptrdata uintptr // 包含所有指针的内存前缀大小
hash uint32 // 类型 hash
tflag tflag // 标记位,主要用于反射
align uint8 // 对齐字节信息
fieldAlign uint8 // 当前结构字段的对齐字节数
kind uint8 // 基础类型枚举值
equal func(unsafe.Pointer, unsafe.Pointer) bool // 比较两个形参对应对象的类型是否相等
gcdata *byte // GC 类型的数据
str nameOff // 类型名称字符串在二进制文件段中的偏移量
ptrToThis typeOff // 类型元信息指针在二进制文件段中的偏移量
}
相同的,所有类型的元信息也都复制了一遍:
type arraytype struct {
typ _type
elem *_type
slice *_type
len uintptr
}
type chantype struct {
typ _type
elem *_type
dir uintptr
}
所有基础类型都不再赘述,详情可见上一篇《深入研究 Go interface 底层实现》。下面来看看 Type interface 究竟涵盖了哪些有用的方法:
以下这些方法是通用方法,可以适用于任何类型。
// Type 是 Go 类型的表示。
//
// 并非所有方法都适用于所有类型。
// 在调用 kind 具体方法之前,先使用 Kind 方法找出类型的种类。因为调用一个方法如果类型不匹配会导致 panic
//
// Type 类型值是可以比较的,比如用 == 操作符。所以它可以用做 map 的 key
// 如果两个 Type 值代表相同的类型,那么它们一定是相等的。
type Type interface {
// Align 返回该类型在内存中分配时,以字节数为单位的字节数
Align() int
// FieldAlign 返回该类型在结构中作为字段使用时,以字节数为单位的字节数
FieldAlign() int
// Method 这个方法返回类型方法集中的第 i 个方法。
// 如果 i 不在[0, NumMethod()]范围内,就会 panic。
// 对于一个非接口类型 T 或 *T,返回的 Method 的 Type 和 Func。
// fields 字段描述一个函数,它的第一个参数是接收方,而且只有导出的方法可以访问。
// 对于一个接口类型,返回的 Method 的 Type 字段给出的是方法签名,没有接收者,Func字段为nil。
// 方法是按字典序顺序排列的。
Method(int) Method
// MethodByName 返回类型中带有该名称的方法。
// 方法集和一个表示是否找到该方法的布尔值。
// 对于一个非接口类型 T 或 *T,返回的 Method 的 Type 和 Func。
// fields 字段描述一个函数,其第一个参数是接收方。
// 对于一个接口类型,返回的 Method 的 Type 字段给出的是方法签名,没有接收者,Func字段为nil。
MethodByName(string) (Method, bool)
// NumMethod 返回使用 Method 可以访问的方法数量。
// 请注意,NumMethod 只在接口类型的调用的时候,会对未导出方法进行计数。
NumMethod() int
// 对于定义的类型,Name 返回其包中的类型名称。
// 对于其他(非定义的)类型,它返回空字符串。
Name() string
// PkgPath 返回一个定义类型的包的路径,也就是导入路径,导入路径是唯一标识包的类型,如 "encoding/base64"。
// 如果类型是预先声明的(string, error)或者没有定义(*T, struct{}, []int,或 A,其中 A 是一个非定义类型的别名),包的路径将是空字符串。
PkgPath() string
// Size 返回存储给定类型的值所需的字节数。它类似于 unsafe.Sizeof.
Size() uintptr
// String 返回该类型的字符串表示。
// 字符串表示法可以使用缩短的包名。
// (例如,使用 base64 而不是 "encoding/base64")并且它并不能保证类型之间是唯一的。如果是为了测试类型标识,应该直接比较类型 Type。
String() string
// Kind 返回该类型的具体种类。
Kind() Kind
// Implements 表示该类型是否实现了接口类型 u。
Implements(u Type) bool
// AssignableTo 表示该类型的值是否可以分配给类型 u。
AssignableTo(u Type) bool
// ConvertibleTo 表示该类型的值是否可转换为 u 类型。
ConvertibleTo(u Type) bool
// Comparable 表示该类型的值是否具有可比性。
Comparable() bool
}
以下这些方法是某些类型专有的方法,如果类型不匹配会发生 panic。在不确定类型之前最好先调用 Kind() 方法确定具体类型再调用类型的专有方法。
| Kind | Methods applicable |
|---|---|
| Int* | Bits |
| Uint* | Bits |
| Float* | Bits |
| Complex* | Bits |
| Array | Elem, Len |
| Chan | ChanDir, Elem |
| Func | In, NumIn, Out, NumOut, IsVariadic |
| Map | Key, Elem |
| Ptr | Elem |
| Slice | Elem |
| Struct | Field, FieldByIndex, FieldByName,FieldByNameFunc, NumField |
对专有方法的说明如下:
type Type interface {
// Bits 以 bits 为单位返回类型的大小。
// 如果类型的 Kind 不属于:sized 或者 unsized Int, Uint, Float, 或者 Complex,会 panic。
//大小不一的Int、Uint、Float或Complex类型。
Bits() int
// ChanDir 返回一个通道类型的方向。
// 如果类型的 Kind 不是 Chan,会 panic。
ChanDir() ChanDir
// IsVariadic 表示一个函数类型的最终输入参数是否为一个 "..." 可变参数。如果是,t.In(t.NumIn() - 1) 返回参数的隐式实际类型 []T.
// 更具体的,如果 t 代表 func(x int, y ... float64),那么:
// t.NumIn() == 2
// t.In(0)是 "int" 的 reflect.Type 反射类型。
// t.In(1)是 "[]float64" 的 reflect.Type 反射类型。
// t.IsVariadic() == true
// 如果类型的 Kind 不是 Func.IsVariadic,IsVariadic 会 panic
IsVariadic() bool
// Elem 返回一个 type 的元素类型。
// 如果类型的 Kind 不是 Array、Chan、Map、Ptr 或 Slice,就会 panic
Elem() Type
// Field 返回一个结构类型的第 i 个字段。
// 如果类型的 Kind 不是 Struct,就会 panic。
// 如果 i 不在 [0, NumField()] 范围内,也会 panic。
Field(i int) StructField
// FieldByIndex 返回索引序列对应的嵌套字段。它相当于对每一个 index 调用 Field。
// 如果类型的 Kind 不是 Struct,就会 panic。
FieldByIndex(index []int) StructField
// FieldByName 返回给定名称的结构字段和一个表示是否找到该字段的布尔值。
FieldByName(name string) (StructField, bool)
// FieldByNameFunc 返回一个能满足 match 函数的带有名称的 field 字段。布尔值表示是否找到。
// FieldByNameFunc 先在自己的结构体的字段里面查找,然后在任何嵌入结构中的字段中查找,按广度第一顺序搜索。最终停止在含有一个或多个能满足 match 函数的结构体中。如果在该深度上满足条件的有多个字段,这些字段相互取消,并且 FieldByNameFunc 返回没有匹配。
// 这种行为反映了 Go 在包含嵌入式字段的结构的情况下对名称查找的处理方式
FieldByNameFunc(match func(string) bool) (StructField, bool)
// In 返回函数类型的第 i 个输入参数的类型。
// 如果类型的 Kind 不是 Func 类型会 panic。
// 如果 i 不在 [0, NumIn()) 的范围内,会 panic。
In(i int) Type
// Key 返回一个 map 类型的 key 类型。
// 如果类型的 Kind 不是 Map,会 panic。
Key() Type
// Len 返回一个数组类型的长度。
// 如果类型的 Kind 不是 Array,会 panic。
Len() int
// NumField 返回一个结构类型的字段数目。
// 如果类型的 Kind 不是 Struct,会 panic。
NumField() int
// NumIn 返回一个函数类型的输入参数数。
// 如果类型的 Kind 不是Func.NumIn(),会 panic。
NumIn() int
// NumOut 返回一个函数类型的输出参数数。
// 如果类型的 Kind 不是 Func.NumOut(),会 panic。
NumOut() int
// Out 返回一个函数类型的第 i 个输出参数的类型。
// 如果类型的类型不是 Func.Out,会 panic。
// 如果 i 不在 [0, NumOut()) 的范围内,会 panic。
Out(i int) Type
common() *rtype
uncommon() *uncommonType
}
在 reflect 包中,并非所有的方法都适用于所有类型的值。具体的限制在方法说明注释里面有写。在调用特定种类的方法之前,最好使用 Kind 方法找出 Value 的种类。和 reflect.Type 一样,调用类型不匹配的方法会导致 panic。需要特殊说明的是 zero Value,zero Value 代表没有值。它的 IsValid() 方法返回 false,Kind() 方法返回 Invalid,String() 方法返回 “
一个 Value 可以由多个 goroutine 并发使用,前提是底层的 Go 值可以同时用于等效的直接操作。 要比较两个 Value,请比较 Interface 相关方法的结果。 在两个 Value 上使用 ==,并不会比较它们表示的底层的值。
reflect 包里的 Value 很简单,数据结构如下:
type Value struct {
// typ 包含由值表示的值的类型。
typ *rtype
// 指向值的指针,如果设置了 flagIndir,则是指向数据的指针。只有当设置了 flagIndir 或 typ.pointers()为 true 时有效。
ptr unsafe.Pointer
// flag 保存有关该值的元数据。最低位是标志位:
// - flagStickyRO: 通过未导出的未嵌入字段获取,因此为只读
// - flagEmbedRO: 通过未导出的嵌入式字段获取,因此为只读
// - flagIndir: val保存指向数据的指针
// - flagAddr: v.CanAddr 为 true (表示 flagIndir)
// - flagMethod: v 是方法值。
// 接下来的 5 个 bits 给出 Value 的 Kind 种类,除了方法 values 以外,它会重复 typ.Kind()。其余 23 位以上给出方法 values 的方法编号。如果 flag.kind()!= Func,代码可以假定 flagMethod 没有设置。如果 ifaceIndir(typ),代码可以假定设置了 flagIndir。
flag
}
一个方法的 Value 表示一个相关方法的调用,就像一些方法接收者 r 调用 r.Read。typ + val + flag bits 位描述了接收者r,但是 Kind 标记位表示 Func(方法是函数),并且该标志的高位给出 r 的类型的方法集中的方法编号。
这一章以 reflect.TypeOf() 和 reflect.ValueOf() 这两个基本的方法为例,看看底层源码究竟是怎么实现的。源码面前一切皆无秘密。
在 reflect 包中有一个重要的方法 TypeOf(),利用这个方法可以获得一个 Type 的 interface。通过 Type interface 可以获取对象的类型信息。
// TypeOf() 方法返回的 i 这个动态类型的 Type。如果 i 是一个 nil interface value, TypeOf 返回 nil.
func TypeOf(i interface{}) Type {
eface := *(*emptyInterface)(unsafe.Pointer(&i))
return toType(eface.typ)
}
func toType(t *rtype) Type {
if t == nil {
return nil
}
return t
}
上述方法实现非常简单,就是将形参转换成 Type interface。TypeOf() 方法第一行有一个强制类型转换,把 unsafe.Pointer 转换成了 emptyInterface。emptyInterface 数据结构如下:
// emptyInterface is the header for an interface{} value.
type emptyInterface struct {
typ *rtype
word unsafe.Pointer
}
从上面数据结构可以看出,emptyInterface 其实就是 reflect 版的 eface,数据结构完全一致,所以此处强制类型转换没有问题。关于 eface 更详细的讲解见上一篇 interface 底层分析的文章。另外 TypeOf() 方法设计成返回 interface 而不是返回 rtype 类型的数据结构是有讲究的。一是设计者不希望调用者拿到 rtype 滥用。毕竟类型信息这些都是只读的,在运行时被任意篡改太不安全了。二是设计者将调用者的需求的所有需求用 interface 这一层屏蔽了,Type interface 下层可以对应很多种类型,利用这个接口统一抽象成一层。
值得说明的一点是 TypeOf() 入参,入参类型是 i interface{},可以是 2 种类型,一种是 interface 变量,另外一种是具体的类型变量。如果 i 是具体的类型变量,TypeOf() 返回的具体类型信息;如果 i 是 interface 变量,并且绑定了具体类型对象实例,返回的是 i 绑定具体类型的动态类型信息;如果 i 没有绑定任何具体的类型对象实例,返回的是接口自身的静态类型信息。例如下面这段代码:
import (
"fmt"
"reflect"
)
func main() {
ifa := new(Person)
var ifb Person = Student{name: "halfrost"}
// 未绑定具体变量的接口类型
fmt.Println(reflect.TypeOf(ifa).Elem().Name())
fmt.Println(reflect.TypeOf(ifa).Elem().Kind().String())
// 绑定具体变量的接口类型
fmt.Println(reflect.TypeOf(ifb).Name())
fmt.Println(reflect.TypeOf(ifb).Kind().String())
}
在第一组输出中,reflect.TypeOf() 入参未绑定具体变量的接口类型,所以返回的是接口类型本身 Person。对应的 Kind 是 interface。在第二组输出中,reflect.TypeOf() 入参绑定了具体变量的接口类型,所以返回的是绑定的具体类型 Student。对应的 Kind 是 struct。
Person
interface
Student
struct
toType() 方法中只是单独判断了一次是否为 nil。因为在 gc 中,唯一关心的是 nil 的 *rtype 必须转换成 nil Type。但是在 gccgo 中,这个函数需要确保同一类型的多个 *rtype 合并成单个 Type。
ValueOf() 方法返回一个新的 Value,根据 interface i 这个入参的具体值进行初始化。ValueOf(nil) 返回零值。
func ValueOf(i interface{}) Value {
if i == nil {
return Value{}
}
escapes(i)
return unpackEface(i)
}
ValueOf() 的所有逻辑只在 escapes() 和 unpackEface() 这两个方法上。先来看 escapes() 的实现。这个方法目前注释还是 TODO 的状态,从名字上我们可以知道,它是为了防止变量逃逸,把 Value 的内容存到栈上。目前所有的内容还是存在堆中。放在堆中也有好处,具体好处可以见 chanrecv/mapassign 中,这里不细致展开。escapes() 源码实现如下:
func escapes(x interface{}) {
if dummy.b {
dummy.x = x
}
}
var dummy struct {
b bool
x interface{}
}
dummy 变量就是一个虚拟标注,标记入参 x 逃逸了。这样标记是为了防止反射代码写的过于高级,以至于编译器跟不上了。ValueOf() 的主要逻辑在 unpackEface() 方法中:
func ifaceIndir(t *rtype) bool {
return t.kind&kindDirectIface == 0
}
func unpackEface(i interface{}) Value {
e := (*emptyInterface)(unsafe.Pointer(&i))
// NOTE: don't read e.word until we know whether it is really a pointer or not.
t := e.typ
if t == nil {
return Value{}
}
f := flag(t.Kind())
if ifaceIndir(t) {
f |= flagIndir
}
return Value{t, e.word, f}
}
ifaceIndir() 这个方法只是利用位运算取出特征标记位,表示 t 是否间接存储在 一个 interface value 中。unpackEface() 从名字上能看出它的目的,将 emptyInterface 转换成 Value。实现分为 3 步,先将入参 interface 强转成 emptyInterface,然后判断 emptyInterface.typ 是否为空,如果不为空才能读取 emptyInterface.word。最后拼装 Value 数据结构中的三个字段,*rtype,unsafe.Pointer,flag。
著名的 《The laws of Reflection》 这篇文章里面归纳了反射的三定律。
// ValueOf returns a new Value initialized to the concrete value
// stored in the interface i. ValueOf(nil) returns the zero Value.
func ValueOf(i interface{}) Value {
if i == nil {
return Value{}
}
// TODO: Maybe allow contents of a Value to live on the stack.
// For now we make the contents always escape to the heap. It
// makes life easier in a few places (see chanrecv/mapassign
// comment below).
escapes(i)
return unpackEface(i)
}
// TypeOf returns the reflection Type that represents the dynamic type of i.
// If i is a nil interface value, TypeOf returns nil.
func TypeOf(i interface{}) Type {
eface := *(*emptyInterface)(unsafe.Pointer(&i))
return toType(eface.typ)
}
从 reflect.Value 数据结构可知,它包含了类型和值的信息,所以将 Value 转换成实例对象很容易。
// Interface returns v's current value as an interface{}.
// It is equivalent to:
// var i interface{} = (v's underlying value)
// It panics if the Value was obtained by accessing
// unexported struct fields.
func (v Value) Interface() (i interface{}) {
return valueInterface(v, true)
}
// Int returns v's underlying value, as an int64.
// It panics if v's Kind is not Int, Int8, Int16, Int32, or Int64.
func (v Value) Int() int64 {
k := v.kind()
p := v.ptr
switch k {
case Int:
return int64(*(*int)(p))
case Int8:
return int64(*(*int8)(p))
case Int16:
return int64(*(*int16)(p))
case Int32:
return int64(*(*int32)(p))
case Int64:
return *(*int64)(p)
}
panic(&ValueError{"reflect.Value.Int", v.kind()})
}
// Uint returns v's underlying value, as a uint64.
// It panics if v's Kind is not Uint, Uintptr, Uint8, Uint16, Uint32, or Uint64.
func (v Value) Uint() uint64 {
k := v.kind()
p := v.ptr
switch k {
case Uint:
return uint64(*(*uint)(p))
case Uint8:
return uint64(*(*uint8)(p))
case Uint16:
return uint64(*(*uint16)(p))
case Uint32:
return uint64(*(*uint32)(p))
case Uint64:
return *(*uint64)(p)
case Uintptr:
return uint64(*(*uintptr)(p))
}
panic(&ValueError{"reflect.Value.Uint", v.kind()})
}
// Bool returns v's underlying value.
// It panics if v's kind is not Bool.
func (v Value) Bool() bool {
v.mustBe(Bool)
return *(*bool)(v.ptr)
}
// Float returns v's underlying value, as a float64.
// It panics if v's Kind is not Float32 or Float64
func (v Value) Float() float64 {
k := v.kind()
switch k {
case Float32:
return float64(*(*float32)(v.ptr))
case Float64:
return *(*float64)(v.ptr)
}
panic(&ValueError{"reflect.Value.Float", v.kind()})
}
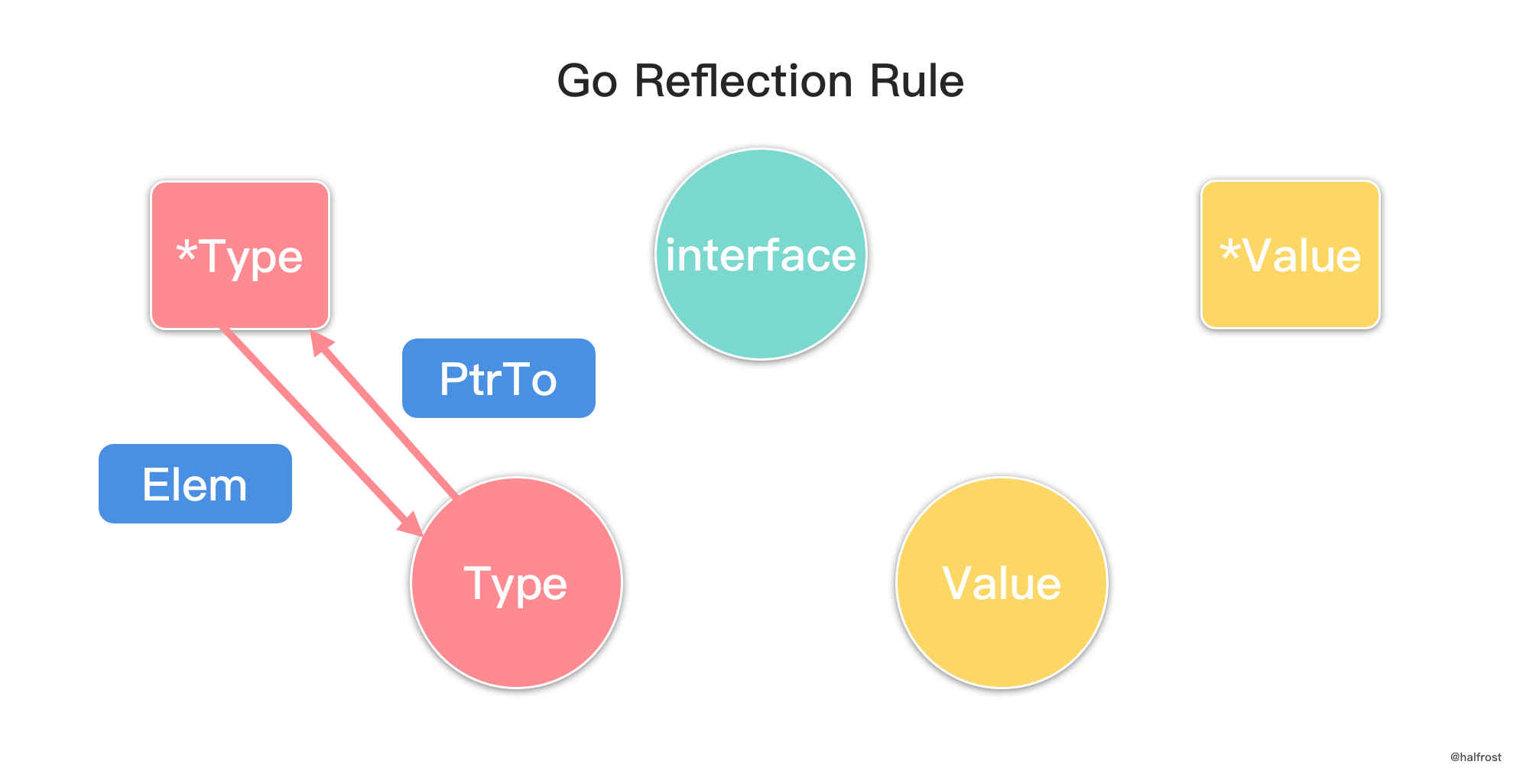
// Elem returns element type of array a.
func (a *Array) Elem() Type { return a.elem }
// Elem returns the element type of slice s.
func (s *Slice) Elem() Type { return s.elem }
// Elem returns the element type for the given pointer p.
func (p *Pointer) Elem() Type { return p.base }
// Elem returns the element type of map m.
func (m *Map) Elem() Type { return m.elem }
// Elem returns the element type of channel c.
func (c *Chan) Elem() Type { return c.elem }
// PtrTo returns the pointer type with element t.
// For example, if t represents type Foo, PtrTo(t) represents *Foo.
func PtrTo(t Type) Type {
return t.(*rtype).ptrTo()
}
针对反射三定律的这个第三条,还需要特殊说明的是:Value 值的可修改性是什么意思。举例:
func main() {
var x float64 = 3.4
v := reflect.ValueOf(x)
v.SetFloat(7.1) // Error: will panic.
}
如上面这段代码,运行以后会崩溃,崩溃信息是 panic: reflect: reflect.Value.SetFloat using unaddressable value,为什么这里 SetFloat() 会 panic 呢?这里给的提示信息是使用了不可寻址的 Value。在上述代码中,调用 reflect.ValueOf 传进去的是一个值类型的变量,获得的 Value 其实是完全的值拷贝,这个 Value 是不能被修改的。如果传进去是一个指针,获得的 Value 是一个指针副本,但是这个指针指向的地址的对象是可以改变的。将上述代码改成这样:
func main() {
var x float64 = 3.4
p := reflect.ValueOf(&x)
fmt.Println("type of p:", p.Type())
fmt.Println("settability of p:", p.CanSet())
v := p.Elem()
v.SetFloat(7.1)
fmt.Println(v.Interface()) // 7.1
fmt.Println(x) // 7.1
}
在调用 reflect.ValueOf() 方法的时候传入一个指针,这样就不会崩溃了。输出符合逻辑:
type of p: *float64
settability of p: false
7.1
7.1
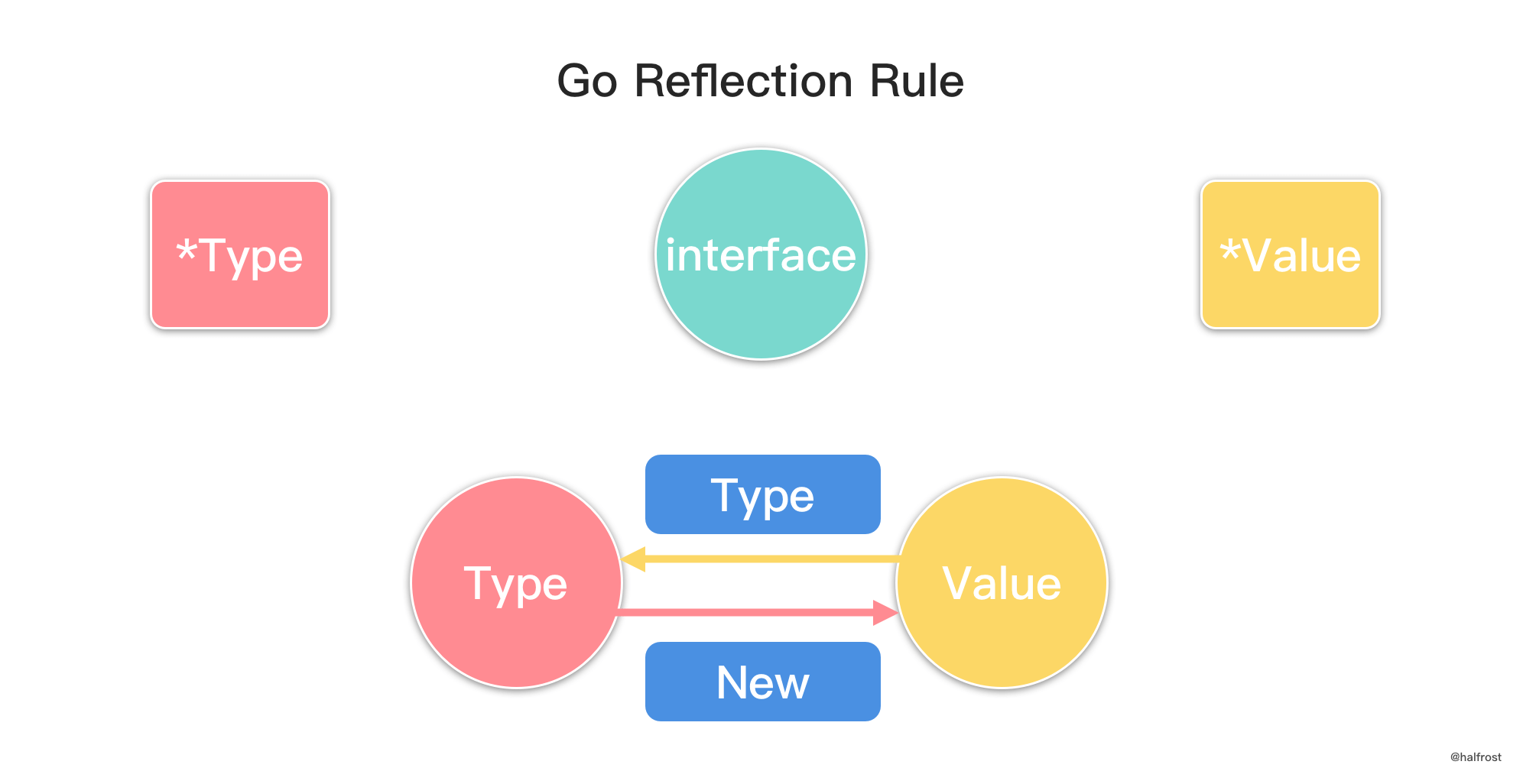
// New returns a Value representing a pointer to a new zero value
// for the specified type. That is, the returned Value's Type is PtrTo(typ).
func New(typ Type) Value {
if typ == nil {
panic("reflect: New(nil)")
}
t := typ.(*rtype)
ptr := unsafe_New(t)
fl := flag(Ptr)
return Value{t.ptrTo(), ptr, fl}
}
// MakeMap creates a new map with the specified type.
func MakeMap(typ Type) Value {
return MakeMapWithSize(typ, 0)
}
// Zero returns a Value representing the zero value for the specified type.
// The result is different from the zero value of the Value struct,
// which represents no value at all.
// For example, Zero(TypeOf(42)) returns a Value with Kind Int and value 0.
// The returned value is neither addressable nor settable.
func Zero(typ Type) Value {
if typ == nil {
panic("reflect: Zero(nil)")
}
t := typ.(*rtype)
fl := flag(t.Kind())
if ifaceIndir(t) {
var p unsafe.Pointer
if t.size <= maxZero {
p = unsafe.Pointer(&zeroVal[0])
} else {
p = unsafe_New(t)
}
return Value{t, p, fl | flagIndir}
}
return Value{t, nil, fl}
}
// Type returns v's type.
func (v Value) Type() Type {
f := v.flag
if f == 0 {
panic(&ValueError{"reflect.Value.Type", Invalid})
}
if f&flagMethod == 0 {
// Easy case
return v.typ
}
// Method value.
// v.typ describes the receiver, not the method type.
i := int(v.flag) >> flagMethodShift
if v.typ.Kind() == Interface {
// Method on interface.
tt := (*interfaceType)(unsafe.Pointer(v.typ))
if uint(i) >= uint(len(tt.methods)) {
panic("reflect: internal error: invalid method index")
}
m := &tt.methods[i]
return v.typ.typeOff(m.typ)
}
// Method on concrete type.
ms := v.typ.exportedMethods()
if uint(i) >= uint(len(ms)) {
panic("reflect: internal error: invalid method index")
}
m := ms[i]
return v.typ.typeOff(m.mtyp)
}
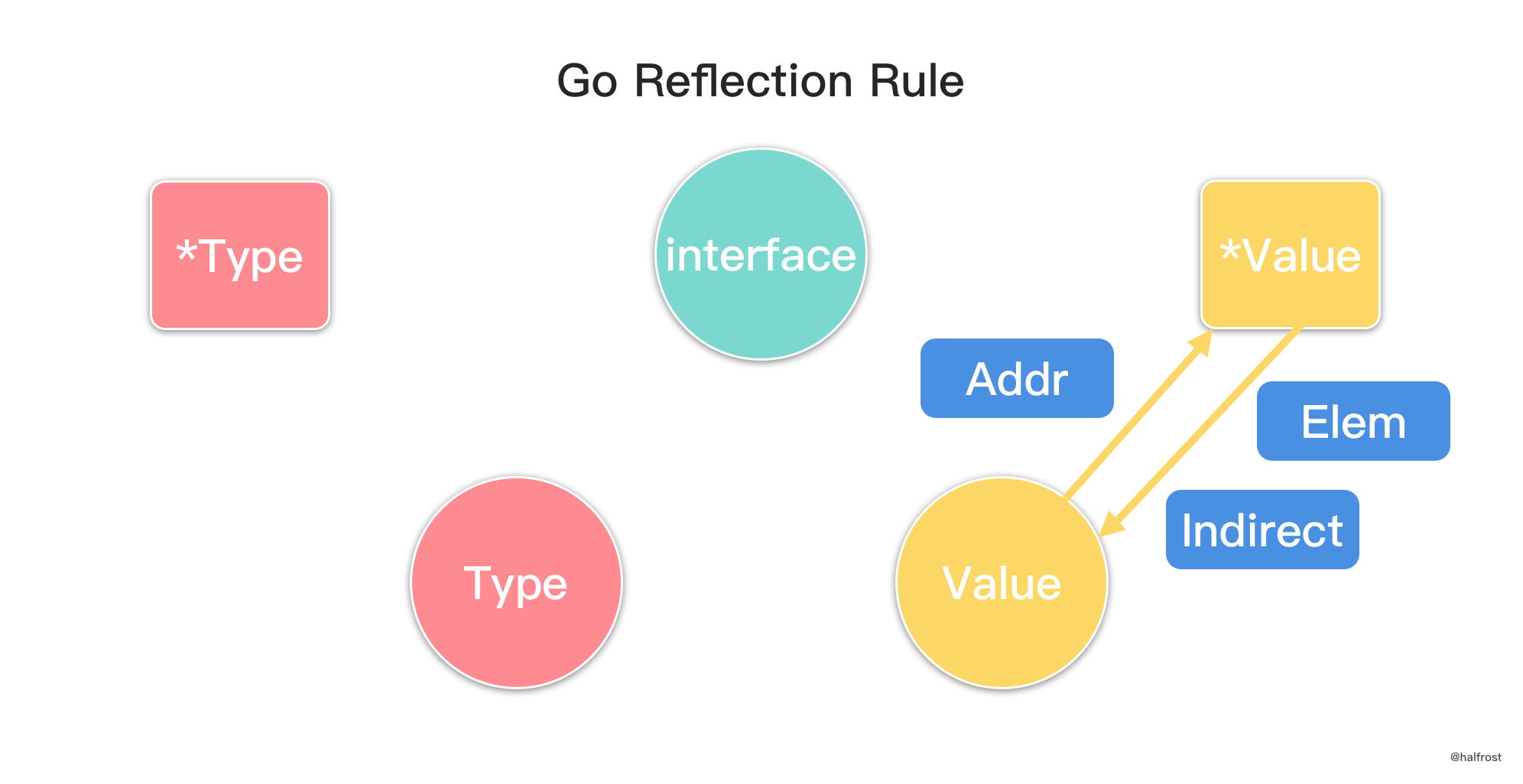
// Indirect returns the value that v points to.
// If v is a nil pointer, Indirect returns a zero Value.
// If v is not a pointer, Indirect returns v.
func Indirect(v Value) Value {
if v.Kind() != Ptr {
return v
}
return v.Elem()
}
// Elem returns the value that the interface v contains
// or that the pointer v points to.
// It panics if v's Kind is not Interface or Ptr.
// It returns the zero Value if v is nil.
func (v Value) Elem() Value {
k := v.kind()
switch k {
case Interface:
var eface interface{}
if v.typ.NumMethod() == 0 {
eface = *(*interface{})(v.ptr)
} else {
eface = (interface{})(*(*interface {
M()
})(v.ptr))
}
x := unpackEface(eface)
if x.flag != 0 {
x.flag |= v.flag.ro()
}
return x
case Ptr:
ptr := v.ptr
if v.flag&flagIndir != 0 {
ptr = *(*unsafe.Pointer)(ptr)
}
// The returned value's address is v's value.
if ptr == nil {
return Value{}
}
tt := (*ptrType)(unsafe.Pointer(v.typ))
typ := tt.elem
fl := v.flag&flagRO | flagIndir | flagAddr
fl |= flag(typ.Kind())
return Value{typ, ptr, fl}
}
panic(&ValueError{"reflectlite.Value.Elem", v.kind()})
}
从源码实现中可以看到,入参是指针或者是 interface 会影响输出的结果。
// Addr returns a pointer value representing the address of v.
// It panics if CanAddr() returns false.
// Addr is typically used to obtain a pointer to a struct field
// or slice element in order to call a method that requires a
// pointer receiver.
func (v Value) Addr() Value {
if v.flag&flagAddr == 0 {
panic("reflect.Value.Addr of unaddressable value")
}
// Preserve flagRO instead of using v.flag.ro() so that
// v.Addr().Elem() is equivalent to v (#32772)
fl := v.flag & flagRO
return Value{v.typ.ptrTo(), v.ptr, fl | flag(Ptr)}
}
这一章通过反射三定律引出了反射对象,Type、Vale 三者的关系。笔者将其之间的关系扩展成了上图。在上图中除了 Tpye 和 interface 是单向的,其余的转换都是双向的。可能有读者有疑问,Type 真的就不能转换成 interface 了么?这里谈的是通过一个方法单次是无法转换的。在上篇 interface 文章中,我们知道 interface 包含类型和值两部分,Type 只有类型部分,确实值的部分,所以和 interface 是不能互转的。那如果就是想通过 Type 得到 interface 怎么办呢?仔细看上图,可以先通过 New() 方法得到 Value,再调用 interface() 方法得到 interface。借助 interface 和 Value 互转的性质,可以得到由 Type 生成 interface 的目的。
最后聊聊在 Go 中使用反射的优缺点和最佳实践。
通过深入学习反射的特性和技巧,缺点可以尽量避免,但这需要非常多的时间和经验的积累。