2026-07-09 16:55:50
路由器管理后台,未必只能是单调的灰白界面。
luci-theme-cyberpunk 是一款为 OpenWrt LuCI 打造的深色主题。它以赛博朋克 HUD 为设计语言,将电青、玫红和状态绿融入导航、表单、表格、弹窗与系统状态,让每天都要打开的管理界面拥有更鲜明的个性,同时保留 LuCI 熟悉的操作方式。
如果你正在搭建一台OpenWrt软路由、家庭网关或旁路由,希望它不仅稳定实用,也能在视觉上更符合自己的桌面风格,那么这个主题值得一试。
主题登录页采用深色 HUD 背景与专属 Cyberpunk 标识。高对比度的电青线条和玫红点缀带来明确的视觉焦点,又没有让装饰元素盖过登录操作本身。
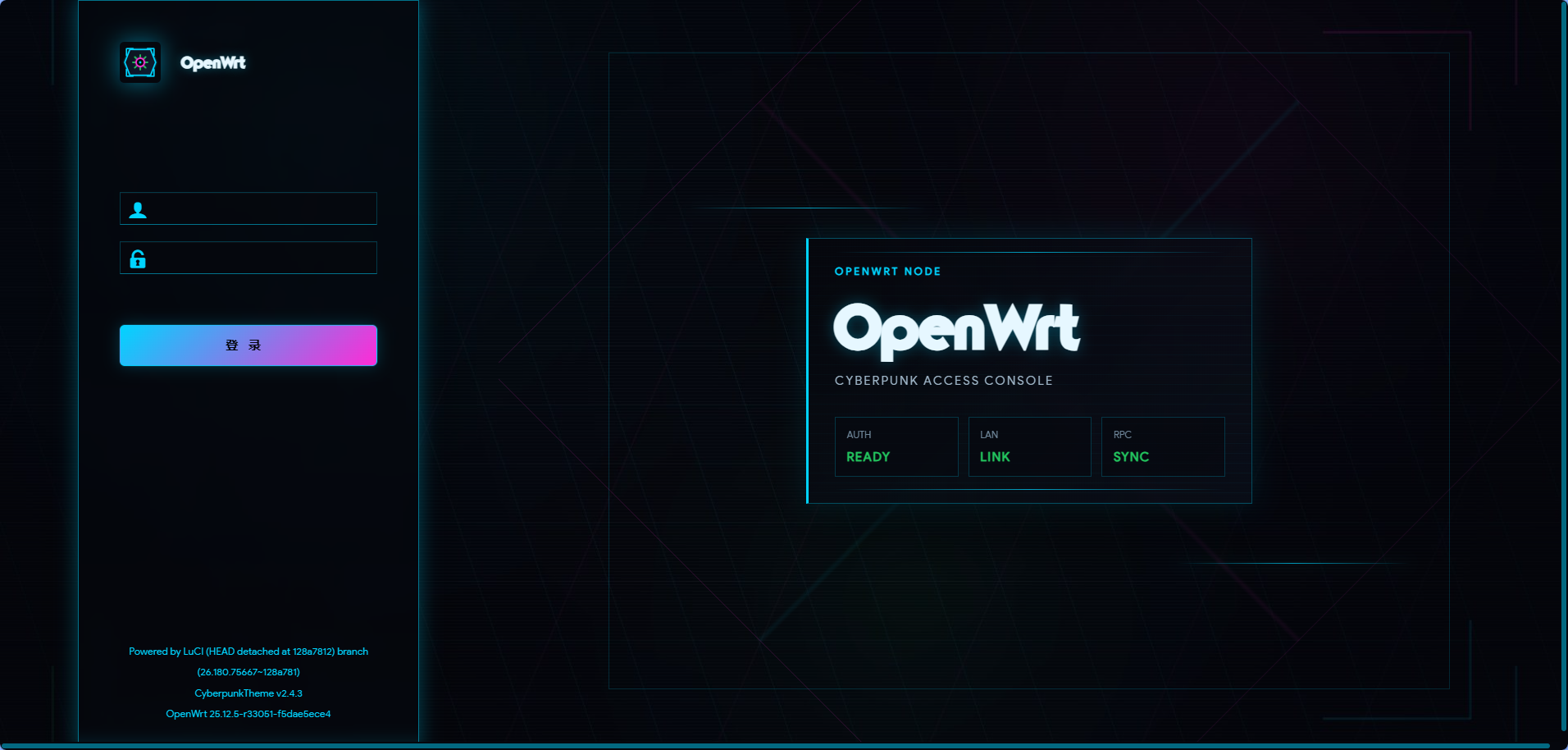
进入 LuCI 后,主题会将同一套视觉语言延伸至状态总览、顶部导航、侧边菜单、信息卡片和数据表格。熟悉的功能仍在原来的位置,但整个控制台获得了更完整、更统一的深色观感。
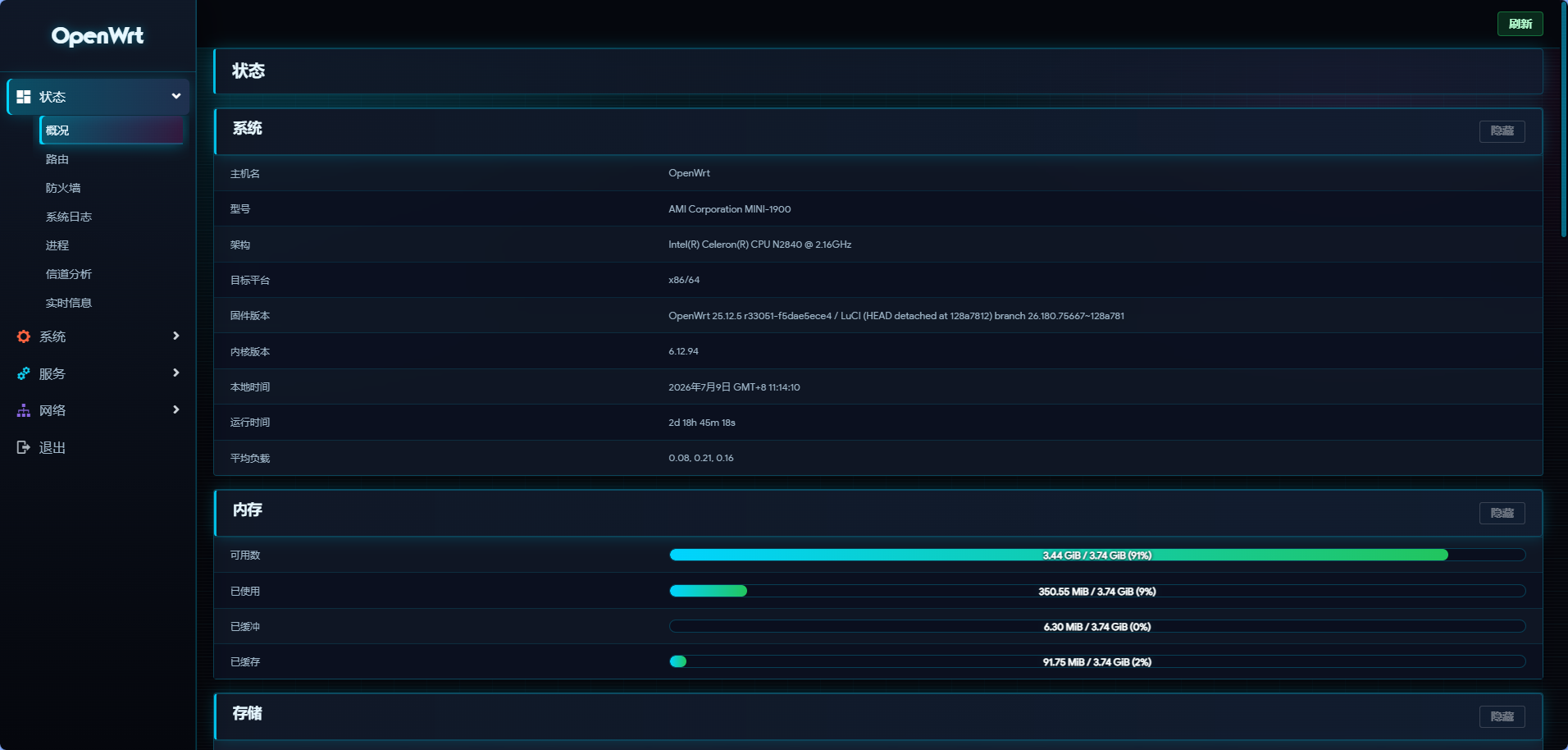
luci-theme-cyberpunk 并非简单叠加一张壁纸,而是一套独立的 LuCI 主题包。当前版本已经覆盖:
整体采用深色优先配色。电青用于主要交互与结构强调,玫红负责视觉点缀,绿色用于状态提示。三种颜色共同构成赛博朋克氛围,同时让不同类型的信息更容易区分。
路由器后台并不只会在电脑上打开。临时查看设备状态、调整无线设置或者重启服务时,手机往往更加方便。
luci-theme-cyberpunk 针对响应式界面进行了适配。在较窄的屏幕上,登录区域、导航和内容布局会随可用空间调整,尽量保持信息清晰与操作顺手。
| 移动端登录页 | 移动端状态页 |
|---|---|
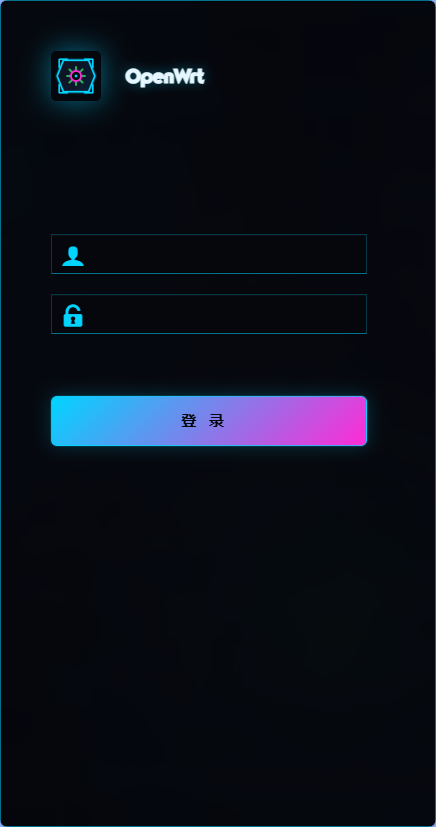 |
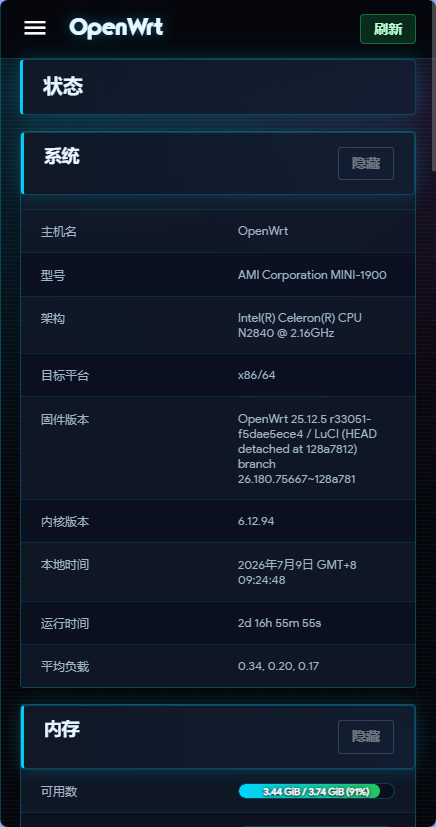 |
无论是在桌面浏览器中管理整套网络,还是用手机快速检查状态,都可以获得一致的视觉体验。
对于开发者和喜欢折腾 OpenWrt 的用户,这个主题也保持了清晰的项目结构:
luci-theme-cyberpunk;themes/cyberpunk;/luci-static/cyberpunk;menu-cyberpunk;cyberpunk;luci.cyberpunk_wallpaper。主题资源与配置均使用独立命名空间,便于在 OpenWrt buildroot 中作为普通 LuCI 软件包构建和维护。
前往 GitHub Releases 下载与你的 OpenWrt 版本匹配的软件包,然后将文件上传到设备并通过终端安装。
opkg install luci-theme-cyberpunk-*.apk由于签名密钥问题,需要允许安装未受信任的本地 APK 软件包:
apk add --allow-untrusted luci-theme-cyberpunk-*.apk安装完成后,进入 LuCI 的主题设置页面,选择 Cyberpunk 并保存即可。
安装前请确认软件包与设备架构和系统版本匹配。建议保留一个可用的 SSH 会话,以便在界面配置异常时进行检查或恢复。
如果你维护自己的 OpenWrt 固件,可以将 luci-theme-cyberpunk 放入 OpenWrt buildroot 的 package feed,并按普通 LuCI 软件包进行编译:
make package/luci-theme-cyberpunk/compile V=s一款好的主题不应改变工具的核心用途,而应让信息更清楚、操作更愉快,也让设备真正带有使用者自己的风格。
luci-theme-cyberpunk 保留了 LuCI 的功能与操作逻辑,并用克制的 HUD 设计重新组织视觉体验。从登录路由器的第一屏,到每天查看的系统状态,它都在提醒你:网络基础设施也可以拥有属于自己的美学。
现在,让你的 OpenWrt 控制台进入赛博空间。
2026-06-18 15:46:47
Artitalk v3 的数据存储、账号登录和内容操作都依赖 LeanCloud。但 LeanCloud 即将停止服务,这意味着仍在使用 Artitalk v3 的站点将无法继续正常读取和写入数据。
与此同时,原项目 ArtitalkJS/Artitalk 已经不再更新,无法等待上游提供新的后端方案。
因此,我在原项目的基础上继续维护 Artitalk,并完成了这次 v4 更新。
Artitalk 仍然是那个可以嵌入博客的轻量级“说说”组件。发布动态、Markdown/HTML 渲染、图片和视频内容、评论、登录与删除等主要功能都得到了保留。不过,从 v4 开始,Artitalk 不再需要 LeanCloud 的 appId 和 appKey,而是通过一个由用户自行部署的 Vercel 服务端运行。
Artitalk v4 采用以下结构:
博客页面中的 Artitalk ↓Vercel Serverless API ↓Neon Postgres前端不再直接操作数据库,而是将登录、查询、发布、编辑、删除和评论请求发送到 Vercel 服务端。服务端负责访问 Neon Postgres,并将结果转换成前端能够识别的数据格式。
这套方案有几个直接的变化:
ALLOW_ORIGIN 限制允许访问接口的博客域名;serverURL。新的前端配置如下:
<script src="https://unpkg.com/@hclonely/artitalk"></script><div id="artitalk_main"></div><script>new Artitalk({ backend: 'vercel', serverURL: 'https://your-vercel-app.vercel.app'})</script>其中,serverURL 是部署后的 Vercel 项目地址,不是 Neon 数据库连接字符串。
架构迁移最重要的问题不是部署新服务,而是如何带走旧数据。
Artitalk v4 提供了专门的 LeanCloud 数据迁移入口。用户可以从 LeanCloud 控制台导出旧应用数据,然后上传以下两个文件:
shuoshuo.0.jsonl:已经发布的说说;atComment.0.jsonl:说说下的评论。迁移程序会将数据写入 Neon,并尽量保留原有的 objectId、createdAt、updatedAt 和其他业务字段。这样不仅可以保留历史发布时间,也可以继续维持评论与说说之间的关联。
LeanCloud _User 中的账号和密码不会迁移。v4 会根据 Vercel 环境变量重新创建管理员账户,这样可以避免继续依赖旧平台的用户系统。
从 v3 升级到 v4,主要需要完成以下步骤:
shuoshuo 和 atComment 数据;appId、appKey 配置替换为 serverURL;迁移完成并验证无误前,请不要删除 LeanCloud 应用,也不要删除原始导出文件。保留旧环境可以在新服务出现配置问题时快速回滚。
Artitalk v4 尽量保持了原有组件的使用体验,但其运行基础已经发生变化。
以前,Artitalk 是一个直接依赖 LeanCloud 的前端组件;现在,它由前端组件、Vercel 服务端和 Neon 数据库共同组成。用户需要多完成一次部署,却也因此获得了更清晰的配置边界和更独立的数据存储方案。
这次迁移首先解决的是 LeanCloud 即将停止服务带来的生存问题,也让这个已经停止更新的项目能够继续使用和维护。未来即使需要更换数据库或部署平台,前端也不必再次跟随底层服务进行大规模重写。
如果你仍在使用 Artitalk v3,建议先备份 LeanCloud 数据,再按照迁移文档完成升级:
2026-06-15 20:11:24
在前端页面里,长列表渲染是一个很常见的性能问题。数据量不大时,直接 map 生成 HTML 再一次性插入 DOM 通常没有明显问题;但当列表变长、模板渲染逻辑变复杂、图片和元信息较多时,这种同步渲染方式就容易占满主线程,导致页面切换、滚动和点击出现明显卡顿。
本文记录一次对 hexo-bilibili-bangumi 追番页面分页渲染的优化:把原本一次性同步完成的模板渲染,改成在浏览器空闲帧中分批执行,从而降低单帧压力,让页面先保持可交互。
追番页面会先渲染每个分类前 10 条数据,剩余数据通过 bangumis.json 异步加载。旧实现大致是这样的:
const html = { wantWatch: data.wantWatch.slice(10).map((item) => renderItem(item)).join('\n'), watching: data.watching.slice(10).map((item) => renderItem(item)).join('\n'), watched: data.watched.slice(10).map((item) => renderItem(item)).join('\n')};document.querySelectorAll('#bangumi-item1>.bangumi-pagination')[0].insertAdjacentHTML('beforeBegin', html.wantWatch);document.querySelectorAll('#bangumi-item2>.bangumi-pagination')[0].insertAdjacentHTML('beforeBegin', html.watching);document.querySelectorAll('#bangumi-item3>.bangumi-pagination')[0].insertAdjacentHTML('beforeBegin', html.watched);这段代码的问题不在于写法复杂,而在于它把三类数据的模板渲染集中在一个任务里完成。浏览器主线程在执行这段 JavaScript 时,不能同时处理用户输入、样式计算、布局和绘制。如果数据量增加,单次任务耗时变长,就会出现掉帧和交互延迟。
对于博客页面来说,用户最直接的感受不是“渲染总耗时是多少”,而是“页面是不是能立刻响应”。因此优化目标不是把所有 HTML 更快地一次性生成出来,而是把大任务拆小,让浏览器有机会在任务之间处理渲染和输入。
浏览器页面的 JavaScript、样式计算、布局、绘制和用户输入处理大多运行在主线程上。如果一个 JavaScript 任务长时间不结束,浏览器就没有机会进入下一帧,也就无法及时响应滚动、点击和视觉更新。
分时函数的核心思想是:
浏览器提供了 requestIdleCallback,它会在主线程空闲时执行回调。回调参数里的 deadline.timeRemaining() 可以告诉我们当前空闲周期大概还剩多少时间。利用这个信息,可以把长列表渲染拆成多批。
不过 requestIdleCallback 并不是所有环境都支持,因此实现时还需要准备一个降级方案:如果浏览器不支持,就使用 setTimeout 延后执行。这样虽然不能精确感知空闲时间,但仍然可以避免在一个同步任务中渲染全部内容。
这次优化拆成三步。
先封装一个 runWhenIdle,优先使用 requestIdleCallback,否则退化到 setTimeout:
function runWhenIdle(callback) { if (typeof requestIdleCallback === 'function') { requestIdleCallback(callback); return; } setTimeout(() => { callback({ timeRemaining: () => 0 }); }, 16);}这里的降级实现给了一个 timeRemaining() 为 0 的 deadline。后面的批处理逻辑会保证即使没有剩余时间,每一轮也至少处理一条数据,避免任务永远无法推进。
原来每条数据都直接调用 pug.render。如果运行时支持 pug.compile,可以先把模板编译成渲染函数,然后每条数据复用这个函数:
function createBangumiPageRenderer() { if (hexoBilibiliBangumiOptions.pug && typeof hexoBilibiliBangumiOptions.pug.compile === 'function') { const render = hexoBilibiliBangumiOptions.pug.compile(hexoBilibiliBangumiOptions.pugTemplate); return function hexoBilibiliBangumiRenderPage(item) { return render({ item, ...hexoBilibiliBangumiOptions.pugOptions }); }; } return function hexoBilibiliBangumiRenderPage(item) { return hexoBilibiliBangumiOptions.pug.render(hexoBilibiliBangumiOptions.pugTemplate, { item, ...hexoBilibiliBangumiOptions.pugOptions }); };}这一步不是分时渲染的必要条件,但它能减少每条数据的重复开销。长列表优化通常要同时关注两个方向:减少总计算量,以及避免单次计算阻塞太久。
核心批处理逻辑如下:
function renderItemsInIdle(items, renderPage, onComplete) { const html = []; let index = 0; function renderBatch(deadline) { let renderedInFrame = false; while (index < items.length && (!renderedInFrame || deadline.timeRemaining() > 0)) { html.push(renderPage(items[index])); index++; renderedInFrame = true; } if (index < items.length) { runWhenIdle(renderBatch); return; } onComplete(html.join('\n')); } runWhenIdle(renderBatch);}这里有一个细节:循环条件不是简单的 deadline.timeRemaining() > 0,而是:
!renderedInFrame || deadline.timeRemaining() > 0这样可以保证每个空闲回调至少渲染一条数据。否则在降级方案里 timeRemaining() 一直是 0,任务就会被不断重新调度,却不会真正处理任何条目。
最后,把三个分类组织成任务队列,按顺序分批渲染并插入到对应分页按钮之前:
function renderTasksInIdle(tasks) { const renderPage = createBangumiPageRenderer(); let taskIndex = 0; function runNextTask() { if (taskIndex >= tasks.length) return; const task = tasks[taskIndex]; taskIndex++; renderItemsInIdle(task.items, renderPage, (html) => { document.querySelectorAll(task.selector)[0].insertAdjacentHTML('beforeBegin', html); runNextTask(); }); } runNextTask();}调用时只需要传入数据和目标选择器:
renderTasksInIdle([ { items: data.wantWatch.slice(10), selector: '#bangumi-item1>.bangumi-pagination' }, { items: data.watching.slice(10), selector: '#bangumi-item2>.bangumi-pagination' }, { items: data.watched.slice(10), selector: '#bangumi-item3>.bangumi-pagination' }]);优化前,bangumis.json 加载完成后,页面会立刻同步执行三类列表的模板渲染。数据越多,单次任务越长,用户越容易感受到卡顿。
优化后,渲染被拆分到多个空闲帧中执行:
requestIdleCallback 的浏览器可以根据真实空闲时间动态多渲染几条;不支持时也能通过 setTimeout 分批推进。这种优化不会让所有内容“瞬间完成”,但会改善用户感知性能。对用户来说,页面能先响应、逐步补齐内容,通常比等待一个长任务全部执行完更自然。
分时渲染适合以下情况:
如果是后台管理系统里的超大表格,虚拟列表可能是更彻底的方案;如果是博客、文章页、追番页这类静态内容为主的场景,分时渲染的改动更小,收益也比较直接。
分时渲染不是银弹,实现时需要注意几个边界:
requestIdleCallback 适合低优先级任务,不适合用户点击后必须立即完成的关键反馈。这次优化的关键不是换一个更复杂的框架,而是把“同步做完所有事”的思路改成“浏览器空闲时分批做”。对长列表、模板渲染和博客插件这类场景来说,分时函数是一个成本低、侵入小、效果明确的优化手段。
最终实现保留了原有数据结构和 DOM 插入位置,只替换了渲染调度方式:数据仍然来自 bangumis.json,模板仍然使用 Pug,展示结果保持一致,但渲染过程对主线程更友好。
2026-05-21 11:11:19
一个简单的服务,可以生成包含 IP 地址、地理位置、天气、系统信息等数据的签名图片。
直接访问签名图片:
https://你的域名/signature支持通过查询参数自定义图片尺寸:
https://你的域名/signature?width=1000 # 指定宽度,高度会按比例缩放https://你的域名/signature?height=600 # 指定高度,宽度会按比例缩放默认尺寸为 752x423 像素。建议只指定宽度或高度其中之一,另一个尺寸会自动按原始比例计算,如果同时指定宽度和高度,则根据高度计算。
<!-- 默认尺寸 --><img src="https://你的域名/signature" alt="IP签名档" /><!-- 自定义尺寸 --><img src="https://你的域名/signature?width=1000" alt="IP签名档" />克隆仓库:
git clone https://github.com/HCLonely/ipSignature.gitcd ipSignature安装依赖:
npm install配置环境变量:
# 复制环境变量示例文件cp .env.example .env.production# 然后编辑 .env.production 文件,修改相关配置# 至少需要配置以下变量之一:# - IPINFO_TOKEN(ipinfo.io的API令牌)# - NSMAO_TOKEN(nsmao的API令牌)## 以及:# - OPENWEATHER_API_KEY(OpenWeatherMap的API密钥)编译代码:
npm run build启动服务:
npm startFork 本仓库到你的 GitHub 账号
在 Vercel 中导入项目:
配置环境变量:
在项目设置中找到 “Environment Variables”
添加以下环境变量:
# IP地理位置服务令牌 (至少需要配置其中一个)IPINFO_TOKEN=your_ipinfo_token_hereNSMAO_TOKEN=your_nsmao_token_here# OpenWeatherMap API密钥OPENWEATHER_API_KEY=your_openweather_api_key_here# 背景图片URL (可选,仅支持 jpg, jpeg, png, gif 格式)BACKGROUND_IMAGE_URL=https://example.com/background.jpg# 生产环境标识NODE_ENV=production部署:
.vercel.app 域名创建 .env 文件并配置以下环境变量:
| 变量名 | 必需 | 默认值 | 说明 |
|---|---|---|---|
| IPINFO_TOKEN | 是* | - | ipinfo.io 的 API 令牌,用于获取访问者的地理位置信息 |
| NSMAO_TOKEN | 是* | - | nsmao.com 的 API 令牌(备选),用于获取访问者的地理位置信息 |
| OPENWEATHER_API_KEY | 是 | - | OpenWeatherMap 的 API 密钥,用于获取天气信息 |
| BACKGROUND_IMAGE_URL | 否 | - | 背景图片URL,仅支持 jpg, jpeg, png, gif 格式 |
| PORT | 否 | 3000 | 服务器端口 |
| DEBUG | 否 | false | 调试模式,设置为 true 时显示详细错误信息 |
| NODE_ENV | 否 | development | 运行环境,生产环境请设置为 production |
IPINFO_TOKEN 和 NSMAO_TOKEN 至少需要配置其中一个
本项目使用了以下第三方 API 服务:
| 参数 | 简写 | 说明 |
|---|---|---|
| –public-ip | -p | 使用公网 IP(当检测到本地 IP 时) |
2025-06-05 14:57:09
厌倦了大型图像编辑软件对电脑性能的压榨?担心在线工具泄露敏感设计?让你的树莓派不在吃灰!只需一台树莓派,你就能拥有完全私有的、功能媲美 Photoshop 的在线编辑利器——Photopea!通过部署Docker项目 photopea,我们将把强大的图像处理能力装进小小的树莓派里。
所需设备:
Docker 让部署变得异常简单。如果你的树莓派还没安装 Docker,请先安装:https://docs.docker.com/engine/install/
# 运行 Photopea 容器 (将内部 8887 端口映射到树莓派的 8080 端口)sudo docker run -d --name ps-online --restart always -p 8080:8887 ramuses/photopea:latesthttp://localhost:8080
:8080,例如:http://192.168.1.100:8080
File > Save As PSD (或导出其他格式) 保存到本地设备的习惯。2024-03-05 11:22:49
Node.js 从v18.16.0,v19.7.0版本开始原生支持了打包为可执行文件(Single executable applications), 常用的打包工具pkg也因此不在更新,下面介绍一下我在使用 NodeJs Single executable applications功能时的一些经验和问题。
因为目前该功能只能将单个 js 文件封装为可执行文件,所以我们要借助打包工具(如 webpack, rollup 等)将 js 项目大包围一个 js 文件。由于 wenpack 的配置过于繁杂,这里介绍使用 rollup 工具进行打包。
安装 rollup: npm install --global rollup;
在项目根目录新建rollup.config.js文件,内容如下(根据项目内容进行调整):
const commonjs = require('@rollup/plugin-commonjs'); // commonjs支持,使用es模块可不使用此插件,安装:npm install @rollup/plugin-commonjs -Dconst { nodeResolve } = require('@rollup/plugin-node-resolve');const json = require('@rollup/plugin-json'); // 将静态json文件作为模块导入,按需安装,安装:npm install @rollup/plugin-json -Dconst { string } = require('rollup-plugin-string'); // 将静态文件文本作为模块导入,按需安装,安装:npm install @rollup/plugin-json -Dconst terser = require('@rollup/plugin-terser');// 压缩打包后的文件大小,按需安装,安装:npm install @rollup/plugin-json -Dmodule.exports = { input: 'dist/main.js', // 项目入口文件 output: { dir: 'output', // 输出文件目录 format: 'cjs' // 输出文件格式 }, plugins: [terser({ format: { comments: false } }), nodeResolve({ preferBuiltins: true, exportConditions: ['node'] }), commonjs(), json(), string({ include: ['**/*.html', '**/*.yml'] })]};打包项目:rollup -c。
在项目根目录新建your-project-config.json文件,内容如下(根据项目需求进行调整,官方说明):
{ "main": "output/main.js", // 打包后的项目入口文件 "output": "your-project.blob", "disableExperimentalSEAWarning": true, "useCodeCache": true, "disableExperimentalSEAWarning": true, // 禁用Nodejs的试验性更能警告 "useSnapshot": false, // 使用快照 "useCodeCache": true // 使用代码缓存}封装文件:
node --experimental-sea-config your-project-config.jsonnode -e "require('fs').copyFileSync(process.execPath, 'your-project.exe')"npx postject your-project.exe NODE_SEA_BLOB your-project.blob --sentinel-fuse NODE_SEA_FUSE_fce680ab2cc467b6e072b8b5df1996b2node --experimental-sea-config your-project-config.jsoncp $(command -v node) your-projectnpx postject your-project.exe NODE_SEA_BLOB your-project.blob --sentinel-fuse NODE_SEA_FUSE_fce680ab2cc467b6e072b8b5df1996b2等待封装完成。