2026-05-23 03:51:00
As we say repeatedly on its homepage, Pika is designed to help you focus on writing, not tinkering with your blog design. To that end Pika purposely doesn’t support complex liquid templating or other such code customization. However, today I thought I’d share how crazy powerful custom CSS can be in some circumstances where you want to augment Pika.
Pika has a “Scroll to top” button floating in the bottom right of the Dashboard. Some people have asked if they can have this on their own blog. This may or may not be a feature we build right into Pika one day, but in the meantime, you can get close to a full implementation yourself in Pika. Here’s how:
First, head to Pika’s Settings, scroll down to Site footer and add this to the bottom of the site footer editor: ↑ — This is an up arrow that is linking to #top, which will now be on every page of your Pika site.
After saving that, head to Settings > Theme, scroll down to Additional options and check “Add custom CSS”. In the resulting code editor that appears, let’s add some CSS that targets that specific link, and designs it as a floating button:
.user-site-footer a[href="#top"] {
/* Float this in the bottom right of the page */
position: fixed;
bottom: var(--space-S);
right: var(--space-S);
z-index: 1;
/* Centered styling */
display: grid;
place-content: center;
/* Button styling with built-in Pika style variables */
background-color: var(--color-primary);
border-radius: var(--radius-round);
color: var(--color-txt-on-primary);
font-family: var(--font-family);
font-size: var(--font-L);
height: var(--space-XL);
width: var(--space-XL);
text-decoration: none;
}Depending on if you have other custom CSS, you might need to add !important to any of the style lines above.
That’s it! Now you have a floating back to top button on your Pika blog, designed to look like other buttons on your site. But if you want to go the extra mile, here’s how you would make it so the back to top button only shows up after scrolling a bit (since it’s not so useful when you’re already at the top of the page):
.user-site-footer a[href="#top"] {
/* Float this in the bottom right of the page */
position: fixed;
bottom: var(--space-S);
right: var(--space-S);
z-index: 1;
/* Centered styling */
display: grid;
place-content: center;
/* Button styling with built-in Pika style variables */
background-color: var(--color-primary);
border-radius: var(--radius-round);
color: var(--color-txt-on-primary);
font-family: var(--font-family);
font-size: var(--font-L);
height: var(--space-XL);
width: var(--space-XL);
text-decoration: none;
/* Hide it until a little bit of page scroll */
transition: 200ms;
opacity: 0;
pointer-events: none;
}
.scrolled-a-bit .user-site-footer a[href="#top"] {
opacity: 1;
pointer-events: all;
}Feel free to make this button your own, like adding a box-shadow (since it’s floating), or making it a rounded square, or whatever you’d like. If you’re really clever, you could probably get the button to say “Scroll to top” when you hover on it, though that would take quite a bit more HTML and CSS — but it’s possible! I leave that as an exercise for you.
2026-03-24 23:33:00
Did you know that we, Good Enough, make a little website called Album Whale where you can make beautiful lists of albums to share with your friends, the world, or just yourself? It’s true! We haven’t made an update there in quite some time (it’s pretty good enough as-is), but I was inspired this week.
Adding an album to a list previously required you to first grab an album share link from a music service of your choice (e.g. Spotify, Apple Music, Bandcamp, etc). This has always been a bit cumbersome.
I’m excited to share you can now just search for an album right away in Album Whale! Like this:

No need to first go somewhere else, you can jump right to Album Whale when you want to save an album to a list. I’ve found this really made my private “To Try” list more useful.
Behind-the-scenes we’re using MusicFetch, which supports most of the big music services. We aren’t sure, but there may be some albums that aren’t found via search? If so you can still paste in a link as you always could.
2026-01-21 01:31:00
If you follow Building Pika Out Loud, you would have heard that this year Good Enough is dogfooding and we spent the last few weeks finally moving over our site and this blog to Pika.
Today we’re announcing two more moves to Pika: our Guestbook and Newsletter — peep ‘em if you haven’t yet! 🙏
Our little thermal printer is now offline, but you can still view all the wonderful drawings we’ve received there over the years. Going forward, our official Guestbook is now the digital one here on Pika.
You can and should leave us a little drawing, or a little note, if you’d like (would you please?).
We had previously been hosting this on Substack, mostly because it was a convenient option when we started. Now that Pika has a Newsletter feature, we’re going to use it, and perhaps try to send those out slightly more regularly than we have been (no promises).
If you were subscribed to “A Good Enough Newsletter” before, we’ve imported you to the new one and you don’t have to do anything. We’ll probably send one more “We’ve moved!” newsletter from Substack, but here on out they’ll come from Pika.
2026-01-13 00:42:00
At the end of 2023, we built and launched Letterbird, a stupid simple free contact form for the web. We use it for all our own products (Pika example), and thousands of you are also using it for your own internet email forms. Thank you!
We feel pretty good that we could deliver software that does one thing good enough to be called #done and walk away, and in fact, we’ve barely touched Letterbird since launch. However, a backlog of improvement ideas has been growing, and with our team’s renewed focus, it was a good time to look at that list.
Leveling up is cool, so considering we went years without an update, we’re calling this Letterbird 2.0, why not:
We feel strongly that dark mode is a required accessibility feature for many readers, and so Letterbird (and all our other products) have always supported dark mode out-of-the-box. However, it was not customizable — you were stuck with a black form.
No longer! Now you can fully customize your form, including the shadowed-box container, in both light and dark mode:
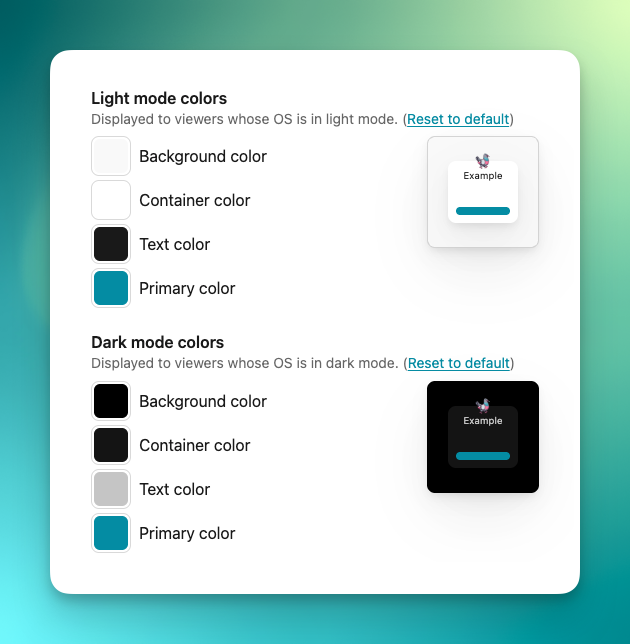
This is especially useful when your form is embedded and you want to match the colors of the site.
This one is particularly exciting: Pro subscribers can now add extra fields to their contact form!
You’ll still have the typical email-specific fields for “Name”, “Email”, “Subject” (optional), and “Body”, but you can now also add up to 10 extra fields for any other information you want to collect. Custom fields can either be a text input, radio options (select one), or checkbox options (select multiple), and answers will be at the bottom of the email you receive.
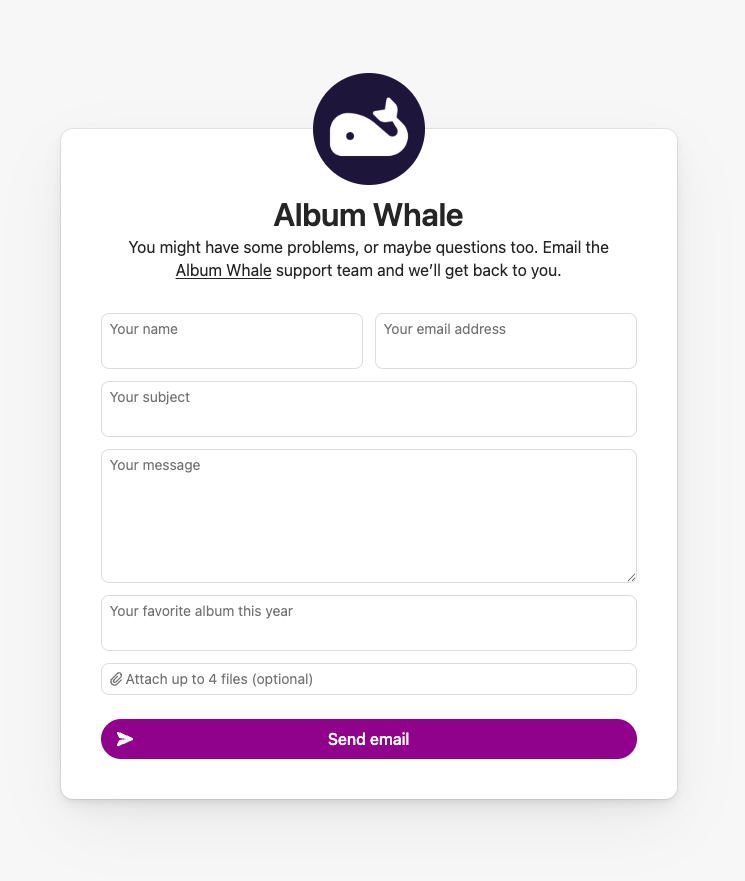
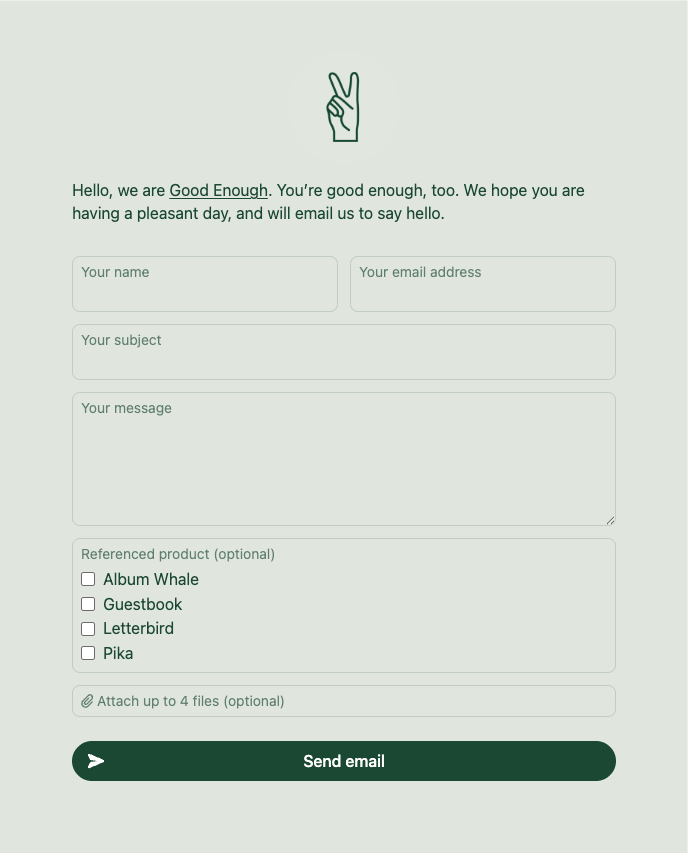
Maybe you want to require all emailers to tell you their “Favorite album this year” (like we are doing for Album Whale), or maybe you want to know if their email falls into a specific category, which you can then use to properly label in your inbox (like we are doing for our general form). This can be just for fun, or an extremely useful productivity tool.
We’d love to see what custom fields you use in your Letterbird!
From the beginning, Letterbird was designed with a shadowed-box container for the form. This was a simple solution to make sure the form was still readable as users changed the background color or embedded the form on another website. Over time we’ve learned that this shadow style doesn’t always jive with other website designs.
Now Pro subscribers can also choose to eschew that shadowed-box container and go with a flatter style, which should better fit in when embedded into just about any type of website. This works in tandem with full color customization in both light and dark mode.
As you can see in the screenshot above, we’re using this style for our own contact form on this very site.
Every email you get through your Letterbird contact form includes a small gray-text footer explaining that this message is from your contact form and who you’ll be replying to. It’s useful, but it’s included in the quoted-reply part of your reply email and some users would prefer to turn this off.
Pro subscribers can now turn it off!
Letterbird lets you translate all your form labels to another language, but customizing your confirmation message was previously locked behind a Pro subscription. We’ve removed this from being Pro-only to make sure we’re allowing full form translation for all.
We’ve updated the attachments field (a Pro-only feature) to be a more visual and better user experience. It’s easier to see which files have been attached, how big the file is, and remove errant files that accidentally got attached.
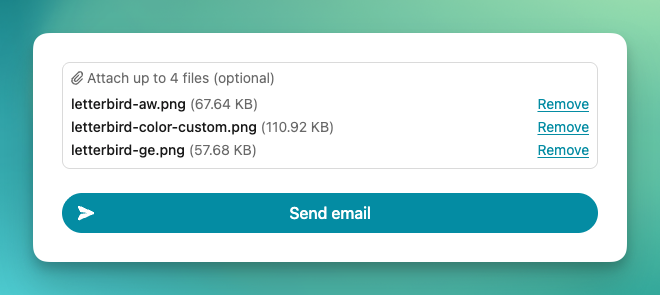
We’re now doing a better job auto-focusing the right input on page load, and resizing the “Body” part of the form as people type into it.
We’re also now doing an even better job protecting your inbox from spam and bots.
Letterbird is still a stupid simple free contact form on the web. These changes not only make the out-of-the-box version even better, but add much more useful functionality to a Pro subscription.
To celebrate, we’re running a promotion between now and the end of February: Enter code HAPPY2026 for 25% off your first year of Pro!
We’re going to call Letterbird #done again, for now, but if there’s any other features you’d really like to see, we’d really like to hear about them!
2026-01-10 01:41:39
Continuous integration is a great thing, and having tests and security checks run before every deploy is also a great thing. But if you’re a developer who has been shipping production code for more than a week, you definitely understand how much it can all feel like a house of cards that tumbles down nearly every day.
The Good Enough suite of products have been using GitHub Actions to make sure our automated test suites run before each deployment. The (mostly free) servers GitHub offers are predictably slow, with the Pika test suite generally taking close to ten minutes to run. (To that you say, “Delete most of your system tests!” Alas, due to Pika’s lovely editor, we unfortunately have to maintain quite a few system tests for the service.) Even when upgrading, and paying for, a higher-strength GitHub Action server we were seeing runs approaching eight minutes for Pika.
That’s already no fun, but even worse is the fact that our system tests were a bit flaky in the GitHub Actions environment. We eventually got the hint that running system tests in parallel just isn’t possible, but even running them one test at a time would lead to odd failures in part because of how slow things move in the Actions environment. So imagine the cycle of trying to deploy a Pika update and needing to run continuous integration two, three, or four times. Frustration!
There is. Hopefully. With the arrival of Rails 8.1 came the option to set up local CI. As a team of two wanting to move a little more quickly and with a little less frustration, this seems like a perfect fit. Here’s how I’ve set it up for Pika…
ci.rb:
# Run using bin/ci
CI.run do
step "Setup", "bin/setup --skip-server"
step "Security: Gem audit", "bin/bundler-audit"
step "Security: Brakeman code analysis", "bin/brakeman --quiet --no-pager --exit-on-warn --exit-on-error --confidence-level 2"
step "Security: Importmap vulnerability audit", "bin/importmap audit"
step "Tests: Rails", "bin/rails test"
step "Tests: System", "bin/rails test:system"
step "Tests: Seeds", "env RAILS_ENV=test bin/rails db:seed:replant"
# Set a green GitHub commit status to unblock PR merge.
# Requires the `gh` CLI and `gh extension install basecamp/gh-signoff`.
if success?
step "Signoff: All systems go. Ready for merge and deploy.", "gh signoff"
else
failure "Signoff: CI failed. Do not merge or deploy.", "Fix the issues and try again."
end
endIn order for the importmap vulnerability audit to run successfully, I needed to update our gemfile with openssl:
group :development, :test do
gem "openssl"
endHere’s an excerpt of Pika’s application_system_test_case.rb:
ENV["PARALLEL_WORKERS"] ||= "1" # System tests seem less flakey when not run in parallel
require "test_helper"
class ApplicationSystemTestCase < ActionDispatch::SystemTestCase
browser_options = Selenium::WebDriver::Chrome::Options.new.tap do |opts|
opts.add_argument("--window-size=1200,800")
opts.add_argument("--disable-extensions")
# Disable non-foreground tabs from getting a lower process priority
opts.add_argument("--disable-renderer-backgrounding")
# Normally, Chrome will treat a 'foreground' tab instead as backgrounded if the surrounding
# window is occluded (aka visually covered) by another window. This flag disables that.
opts.add_argument("--disable-backgrounding-occluded-windows")
# Suppress all permission prompts by automatically denying them.
opts.add_argument("--deny-permission-prompts")
opts.add_argument("--enable-automation")
end
Capybara.register_driver :chrome_headless do |app|
browser_options.add_argument("--headless")
Capybara::Selenium::Driver.new(app, browser: :chrome, options: browser_options)
end
Capybara.register_driver :chrome do |app|
Capybara::Selenium::Driver.new(app, browser: :chrome, options: browser_options)
end
if ENV["SYSTEM_TESTS_BROWSER"]
driven_by :chrome, screen_size: [ 1200, 1000 ]
else
driven_by :chrome_headless, screen_size: [ 1200, 1000 ]
end
endPrerequisites to run local CI:
brew install gh
gh auth login
gh extension install basecamp/gh-signoff
Run: gh signoff install
This installs the GitHub command-line interface, installs the signoff extension for GitHub command-line, and turns on the signoff requirement in your repo.
Here’s the process:
Get all your changes pushed to a branch and make a PR
Make sure your local environment doesn’t have any lingering file changes or CI will fail
Run bin/ci
Running our Pika CI locally completes in under three minutes. That’s a big improvement! Upon successful completion of local CI, signoff will land on your branch, and you can merge and push to main.
If you ever need to move quickly, say in an emergency situation:
> gh signoff create -f
> git pushSince Lettini and I are both super-duper admins in our GitHub account, we needed one more update to protect us from willy-nilly pushing to main. I had to update a setting on GitHub in each repository. I clicked on Do not allow bypassing the above settings in repo > branches > Branch protection rules > main > edit:

In an ideal world, hands-off CI is a really great thing. It will take a bit for these steps to become muscle memory. I hope they do! System tests are still notoriously flaky, but running tests only in our local environments means we shouldn’t have to account for both general flakiness and super-slow-test-running flakiness.
GitHub has a useful feature called Dependabot, which can apply security updates to your dependencies and create a pull request that’s often ready to merge. Sometimes we’ve just clicked that merge button in the past, feeling confident because our test suite had already run in GitHub Actions. Now we’ll have to pull down those branches to go through a local CI and signoff step in order to merge things.
If local CI doesn’t end up fitting us, I’ve also discovered there are faster, GitHub-Action-based alternatives for automating CI, such as Blacksmith. These services also have historically been cheaper than increasing server power at GitHub, though recent policy changes at GitHub have changed that math.
I’d be remiss if I didn’t thank 37signals for opening up their Fizzy repository. This helped me to really streamline our application_system_test_case.rb, which had become a Frankenstein’s monster of a thing as I troubleshot system test issues over the years.
2025-11-25 08:00:00
Hello reader, Matthew here. For those of you who’ve been on this journey with us since the early days, you might know the story of Good Enough’s inception. It was started by Shawn and Barry as a modest effort to realize some fun product ideas, with the lofty goal of seeing if we could make the web a little more interesting while making at least enough money to cover costs. They put together a small team (that’s when I joined), and we set out on a stormy year of prototyping and building and bad ideas.
Fast forward to today, and after much trial-and-error, a zine, a printer experiment, and many illustrations that became stickers, we’re thankful to have found some modest product successes in Jelly and Pika. What we’ve learned along the way is that, to properly care for all our products as they continue to grow, more individual focus is needed.
Internally, our team has been mostly split up for a while now, as different team members gravitated to different products. Starting next week, we’ll be making it more official and reorganizing Good Enough into separate entities:
James will continue operating Jelly outside of Good Enough.
Barry and I (Matthew) will continue operating Pika, along with Letterbird, Album Whale, and other Good Enough services not named Yay.Boo and Ponder.
Shawn and Patrick will be moving on from Good Enough and back into the real world with an exciting brick-and-mortar project in New Jersey (we wish them all the luck!).
If you use any of our products and have interacted with us via support, you probably notice that the names above are exactly who you thought of when you thought of the given product. Not much is changing in that sense, and we’re excited and motivated to continue working on them. This reorganization simply enables us to grow the products we love in a more sustainable way. (Case in point: I’ve recently been working on new features for Letterbird! Stay tuned.)
In fact, you probably wouldn’t even notice this reorganization if we didn’t say anything. The only customer-facing change here is that there’ll be a newly formed entity named on our invoices and receipts and throughout our policies: We Are Good Enough LLC.
To keep up with the latest news for Jelly, please be sure to follow the Jelly Changelog. All other Good Enough news will continue to flow through the places you’ve become accustomed to as a Good Enough follower (see the links at the bottom of this page). If you have questions, email us.
And from all of us, thank you for being on this journey with us as we enter the next chapter!