July 2026
Understanding is the new bottleneck
This is a written version of a talk I gave at the AI Engineer conference in July 2026, also shared as a tweet thread.

Hot take: I think it's still important to understand the code that our agents write!
In this talk I'll explain why that's the case, and show some ideas for how to efficiently understand code. Alright, let's dive in.
Agents are writing more and more code for us, and we all know it's getting harder to keep up.
But the good news is: there are many ways to understand code! Reading diffs line by line is not the only way.

Most of this talk will be about techniques I have found helpful to understand systems my agents are building:
- Code explainer docs
- Quizzes to check my understanding
- Micro-worlds that I can play with to understand the system
But first we have to ask a more basic question…
Why understand?

Why? Why understand?
Aren't we supposed to be taking ourselves out of the loop now, and letting the agents loop themselves? As the agents get smarter, doesn't it become less important for us to be in the details?
I think many people — even those who are pro-understanding — have a slightly incorrect answer to this question!
One possible answer: we understand to verify. We check the agent's work, we see if it's correct.
Correct can mean many things: does it match the spec, is it well architected… but it's fundamentally a thumbs-up / thumbs-down question.
Here's the thing: the agents are getting better and better at verifying their own work. And this is good! I like it when my agent doesn't make mistakes.
But hmm. Where does that leave us humans?
That's where another answer comes in: we can understand to participate.
You can learn what the agent is doing to make sure you can be an active participant in the creative process. Here's why this matters…
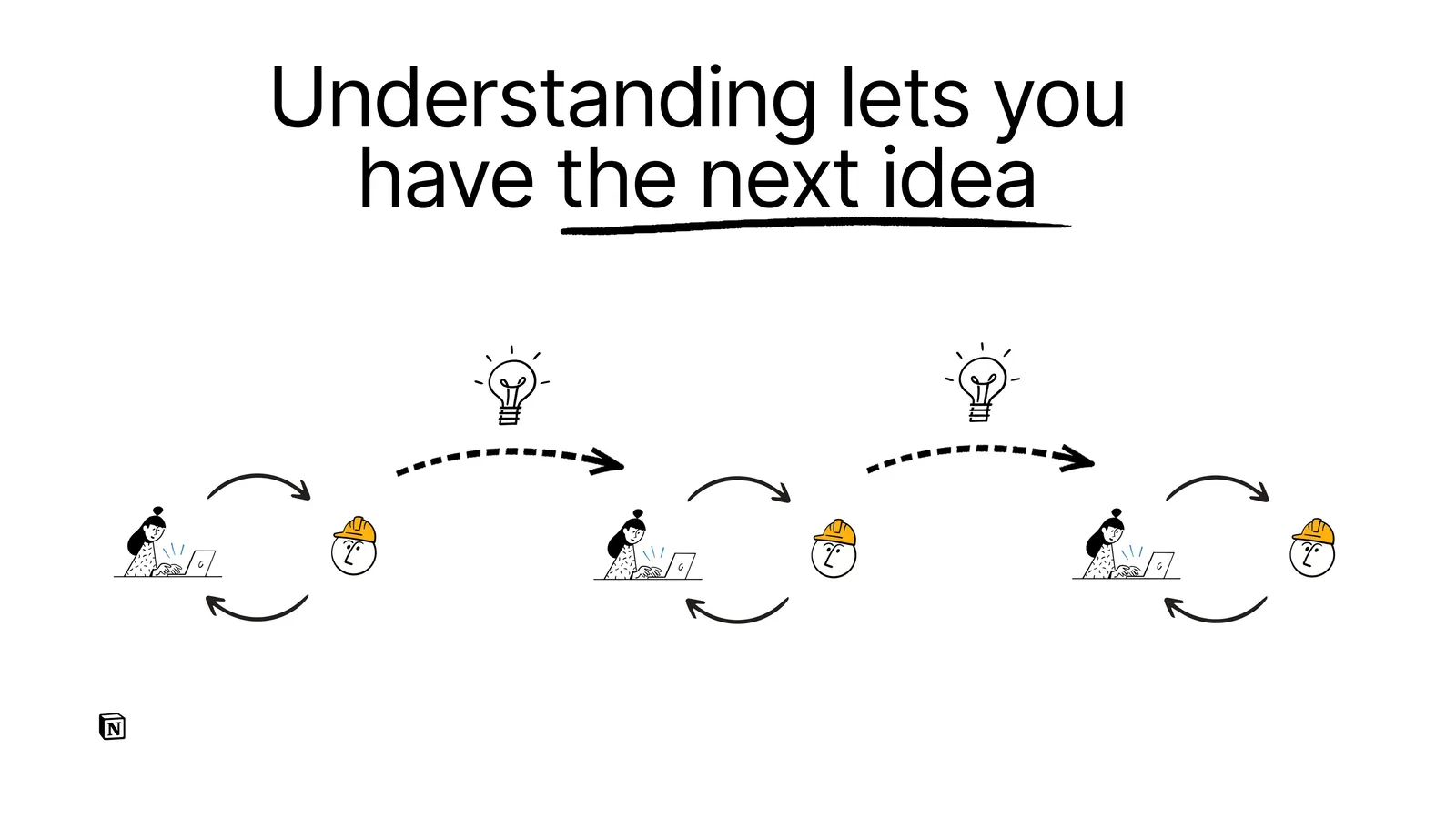
It's never just one loop! A project is many, many loops with the agent.
And the understanding you have of the system is part of your ability to come up with the next idea to evolve it.
You need a rich set of concepts in your mind to think creatively and fluently about how to move something forward. If you're lacking that fluency, your ability to participate in the project is meaningfully limited.

By the way, this relates closely to the idea of cognitive debt, popularized by Margaret Storey and Simon Willison.
It's like tech debt: you can get away with not understanding what's going on in the short term, but it'll bite you eventually.

OK, so fine, understanding matters.
But this raises the next question: how? How do we build this human understanding when we're working with AI and moving fast?
Well, turns out this is not the first time anyone has ever thought about how to communicate understanding. I think we can look to education as an inspiration. Can we steal the best ideas ever invented for education and apply them to this problem?
Technique 1: Explanations

Today I want to share three techniques that show how we can attempt this.
First: explanations. What makes a good explanation?
Whenever an agent finishes some work, it's an opportunity for an explanation — an artifact.
Most naively, we can read a code diff: the raw material that changed.
But what if we ask:
What would the best explanation be? If you had a team — human or AI — that really sweat the details of explaining something well to you, how would that feel?
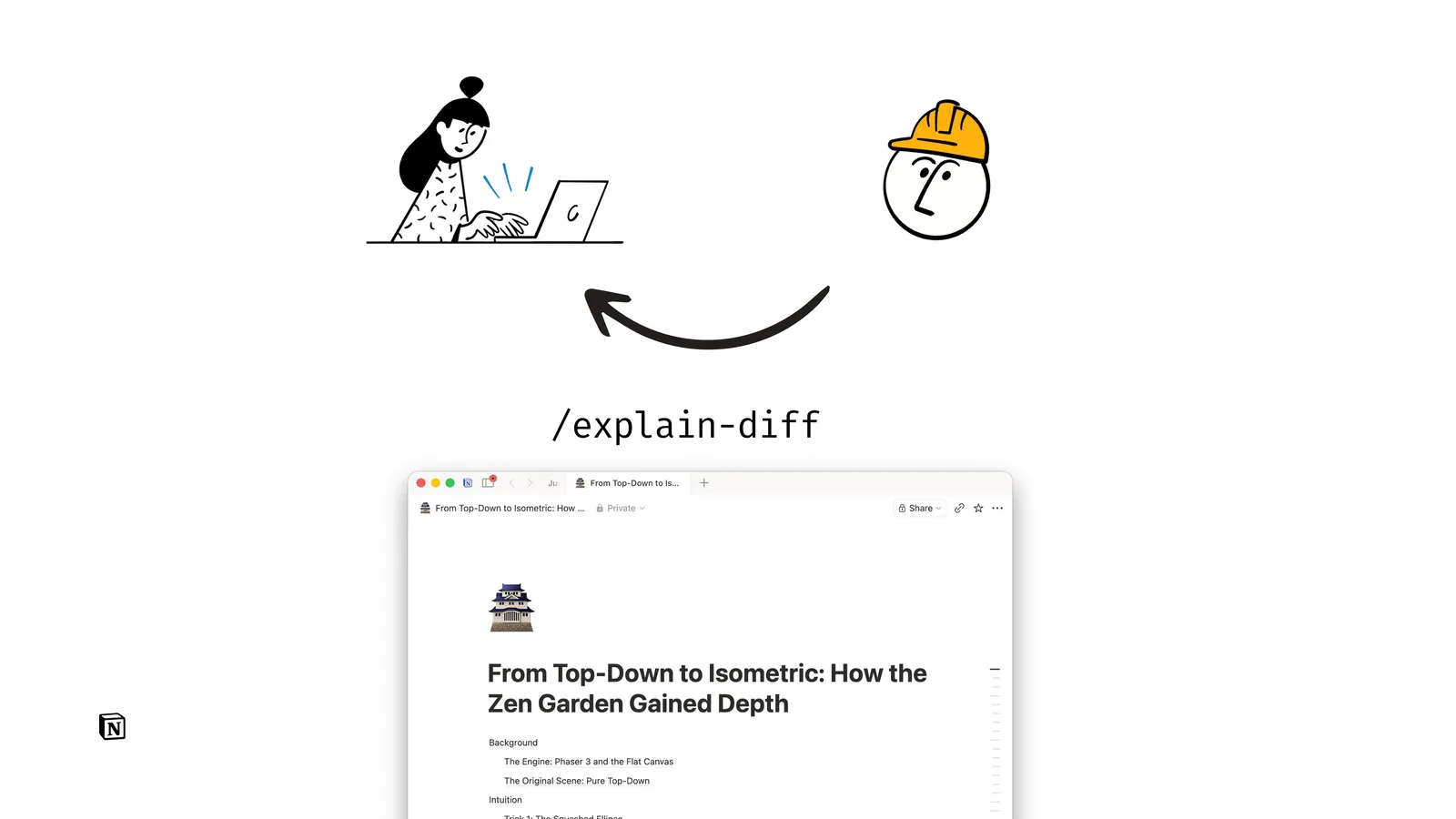
Here's one answer. I made a skill called /explain-diff, which I use every day and many coworkers have found valuable.
It outputs thoughtfully structured code explainers as HTML, markdown, or Notion docs. Notion is a good place for collaborating on and discussing these explainers as a team. (Disclaimer: I work at Notion so I'm biased.)
Let's see what's in one of these explainers, using an example of editing the perspective of a video game.
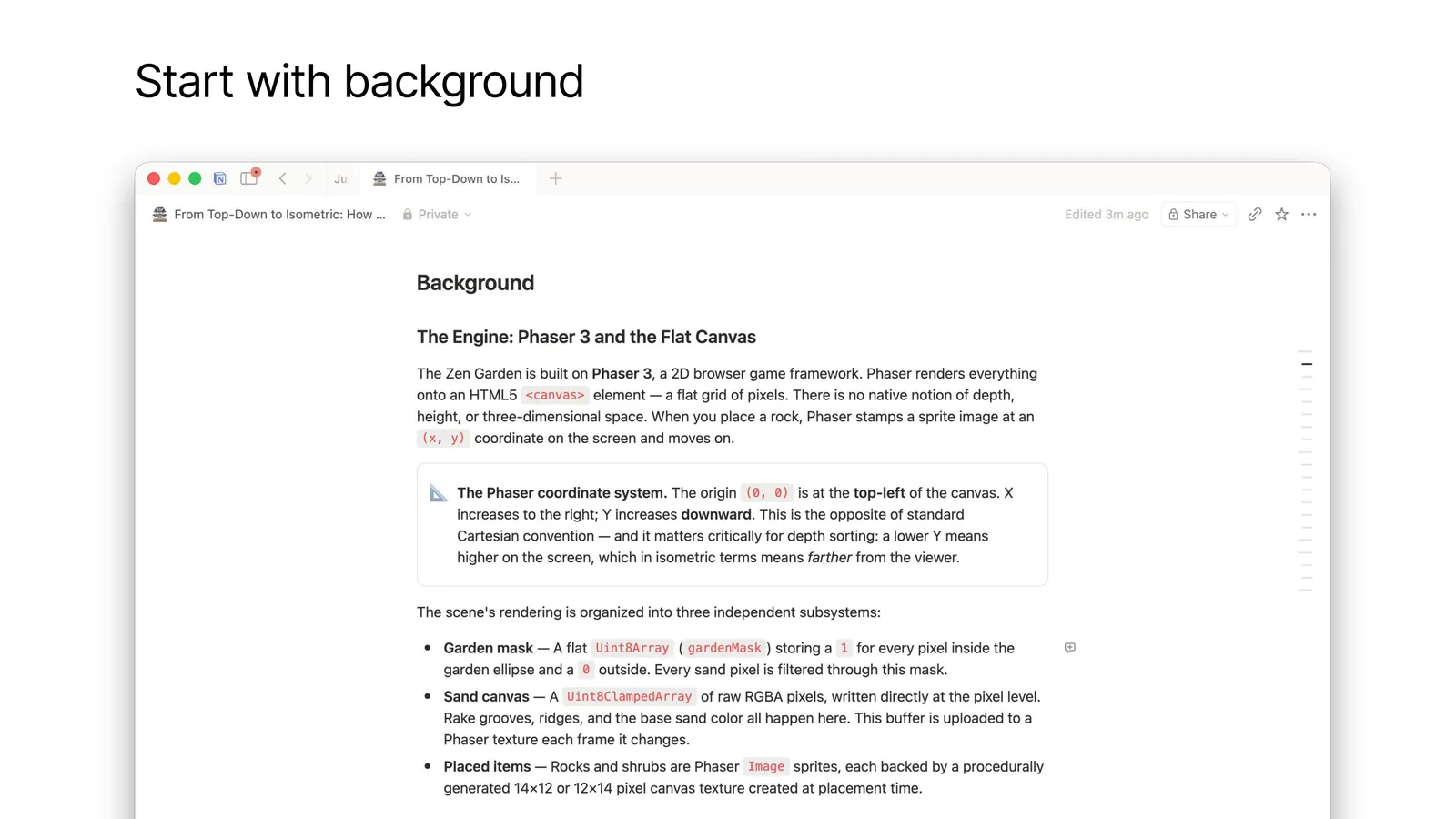
First principle: teach me background info!
Before we even get to what changed, help me understand what was already there. In this case, teach me about the game engine.
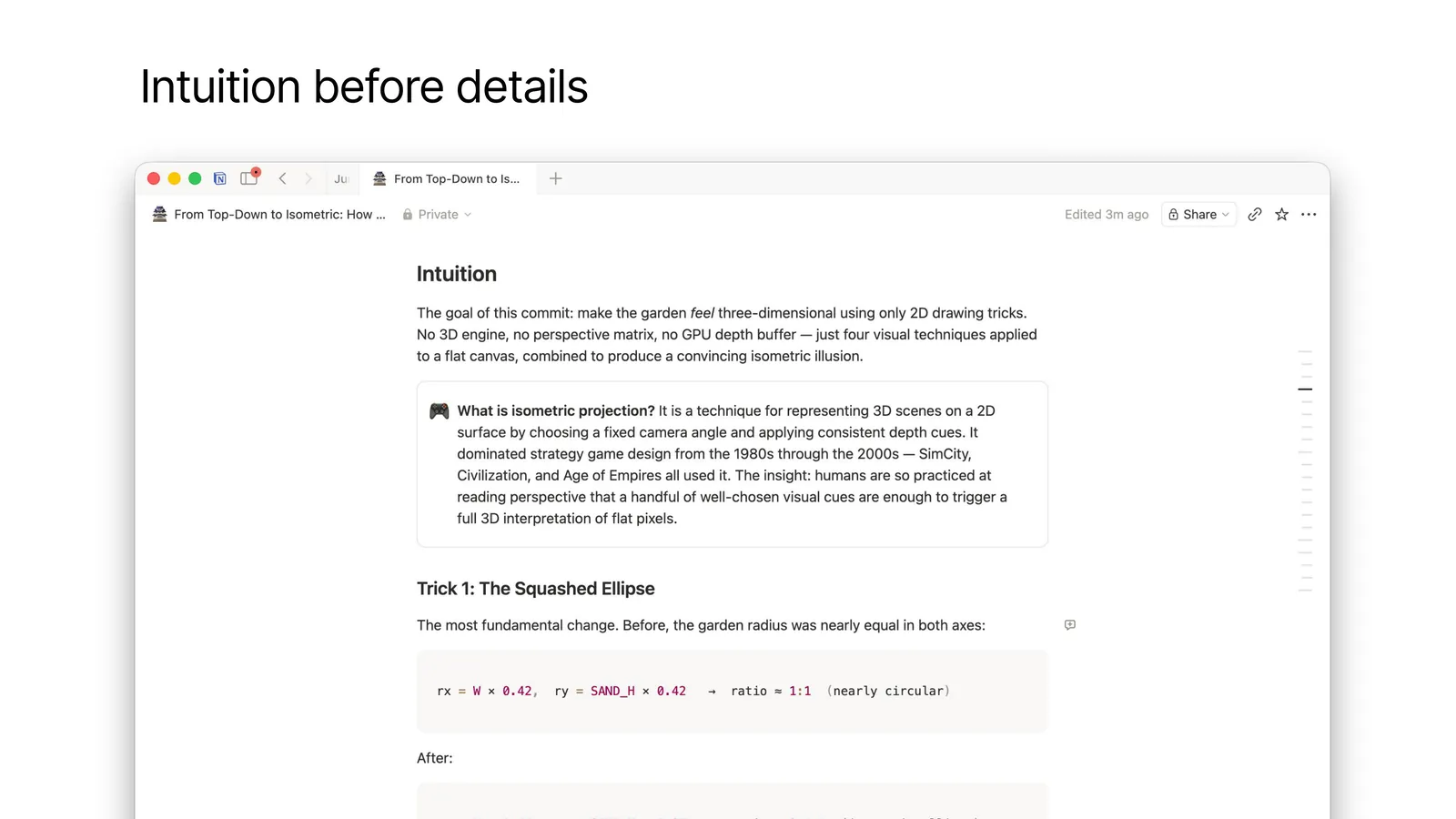
Second principle: intuition before details.
Before any code, it states the goal — “make the garden feel three-dimensional with 2D drawing tricks” — and explains related concepts, like what isometric projection is.
All of this builds my intuition for the essence of the change. It's catching me up as the human so I can be an equal participant in understanding.
You can also build intuition with interactive figures.
Here I'm understanding the isometric perspective by dragging rocks around the garden and watching their coordinates move.
(This is using a new feature Notion just shipped: you can now embed interactive HTML inside pages.)
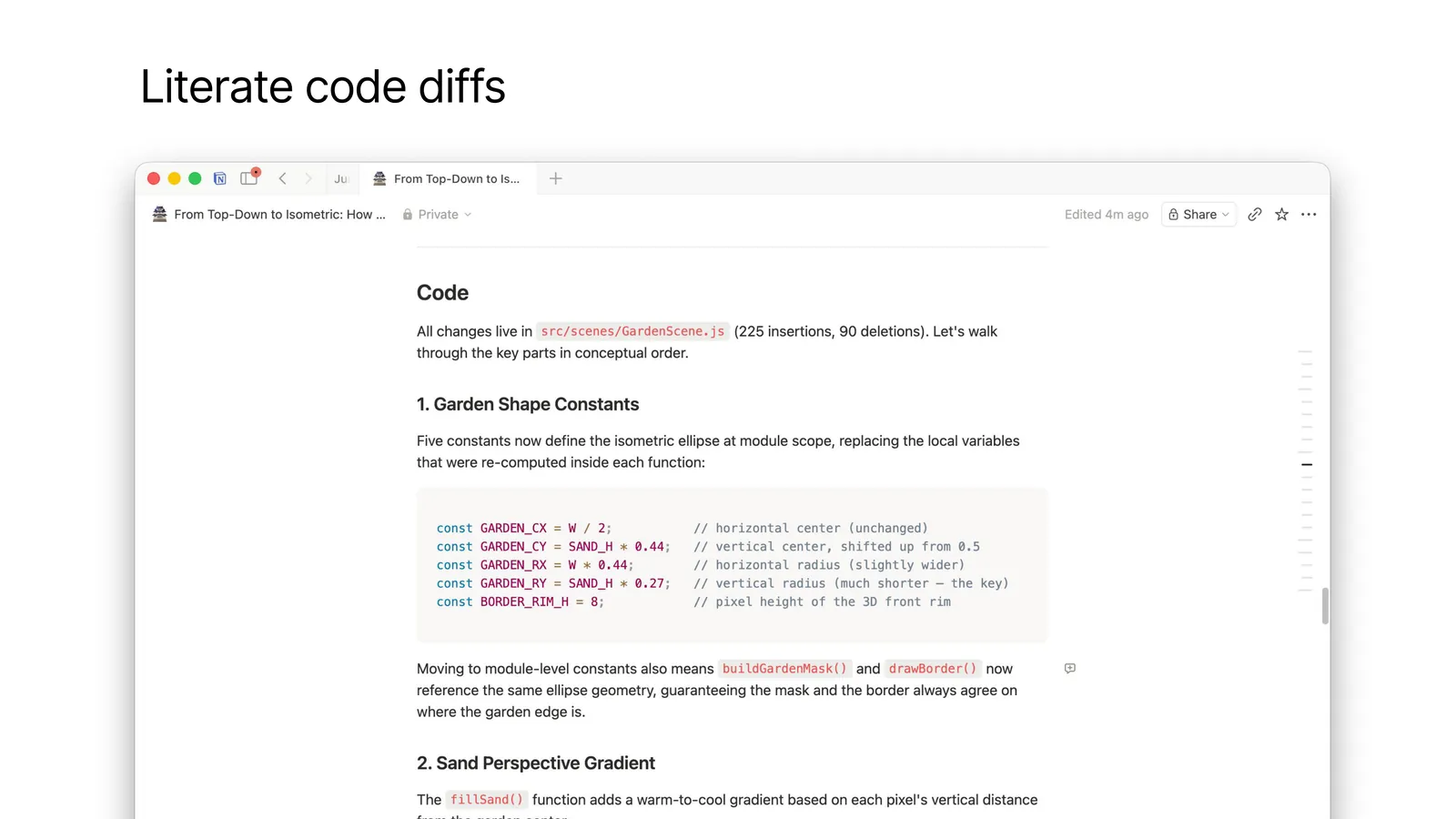
We finally get to the code. But a typical diff is a pile of files edited in alphabetical order with no explanation.
A “literate diff” as I call it is structured as prose — walking through the changes in a sensible order, with surrounding explanation and embedded code snippets. Faster to review than a raw diff.

The end result of all of this is a nice explainer packet. I still read the code diff but I always read this first.
Sometimes I'll print these out and take them to the café — less distracting.
It's beautifully ironic: AI turns an interactive activity into a static paper report I can focus on deeply :)

There's only one problem: reading is hard work 😅
As Andy Matuschak says: “books don't work”! It's too easy to fool yourself into thinking you did the reading when you really didn't retain or understand.
How do we fix this? I took inspiration from Andy and Michael Nielsen's work on embedding spaced repetition quizzes in essays.
I do something similar with my code explainers now. At the bottom of an explainer there's an interactive quiz — five questions about the change — and I try to answer them.
My rule: I won't send code to others until I can pass the quiz, and I do the same when reviewing others' code.
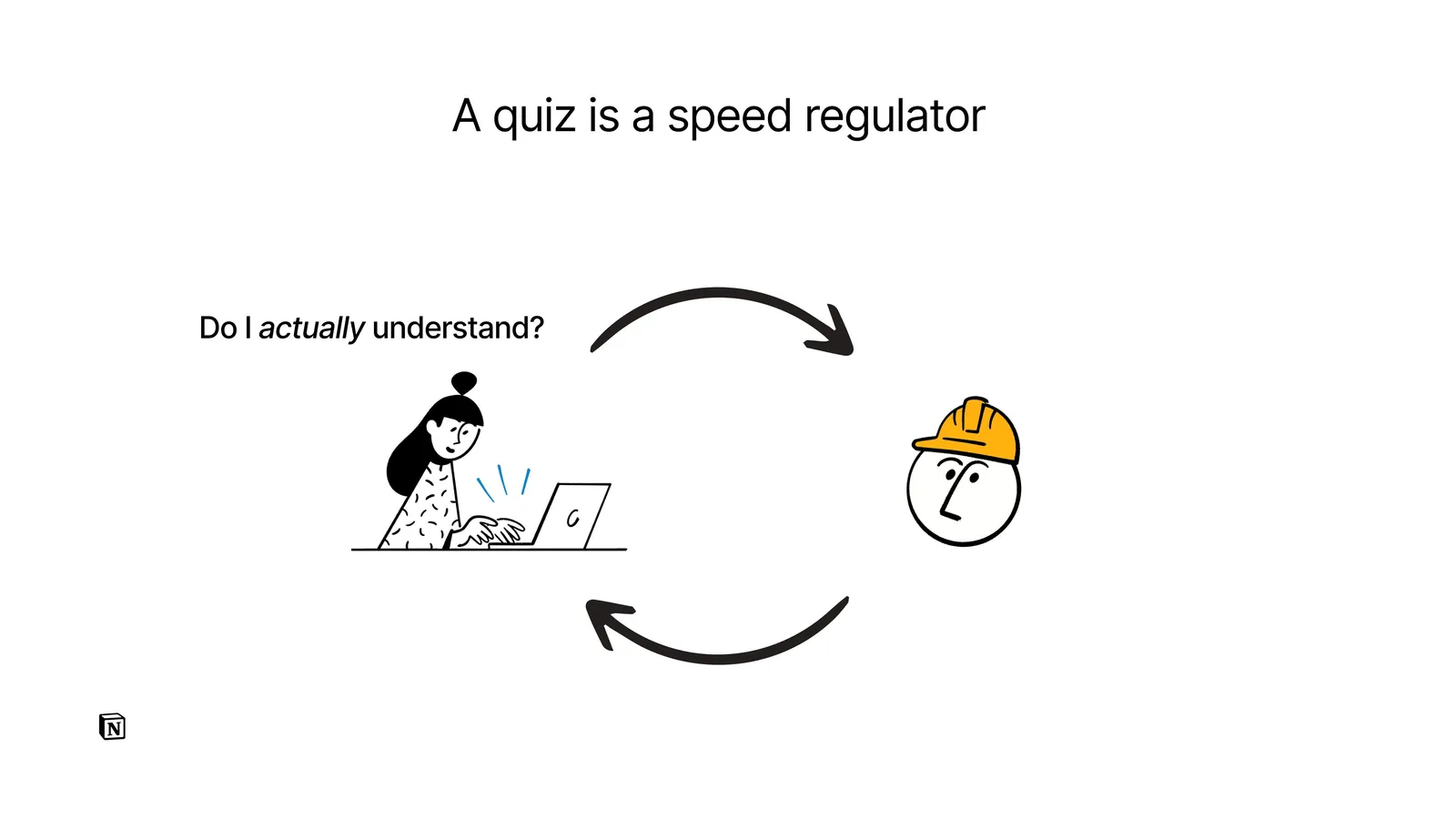
A quiz is a speed regulator. Working with AI, it's easy for the loop to run faster than the speed of human understanding.
The quiz is a counterbalancing force: I mechanically ask “do I actually understand?” so that I can remain a full creative participant.

OK, so that's explain-diff. Here's the skill if you want it: two variants that output either HTML or a Notion page.
Technique 2: Micro-worlds

Next idea: micro-worlds. This one's inspired by the visionary educator Seymour Papert.

Papert had this beautiful idea he called living in Mathland: if you want to learn math, live in Mathland — just like if you want to learn French, you go live in France. Could we build an environment where children learn math naturally, as a consequence of their curiosity?
So how do we apply that to code? Can we make worlds you inhabit and naturally intuit how the system works and how it's changing?
Last year I was coding a Prolog interpreter and struggling to intuit what was happening inside.
I worked with an agent to build this debugger, which let me step through the execution of my logic language — scrub through time, see what's on the stack and which rules are evaluated at each step. I could even leave comments for myself (“nice, we correctly applied that rule”).
There's a big difference between making a tool for me to debug and letting the agent debug — doing it myself is how I develop understanding along the way.
Another example. I was migrating my personal website from one framework to another, and Claude wrote a script that did it. But it was very hard to review: I wasn't familiar with the new framework, and all I could say was “I guess that looks about right.”
So I asked Claude to make me a video game — a command center where I do the port myself, step by step, watching the visible effects and the file tree evolve. It produced a UI where I click buttons to run the port step by step, with my old site and new site running side by side.
In this command center I watched the new site come to life incrementally. That left me with a similar understanding to doing it by hand — but much faster, because the whole experience was laid out for me.

The point here is that agents can write bits of code that help us humans understand other code.
This is a big deal!
Technique 3: Shared spaces

Alright, last technique: shared spaces. So far this has all been about understanding solo… but when you're working on a team, you need to understand together.

When you and someone else hold the same mental model, you can communicate efficiently. You have a shared vocabulary that evokes the same images, so you can jam and riff and have creative conversations. Without those shared structures, those conversations are much harder.
I'm really excited about creating shared environments where teams build that understanding together. It's kinda what Notion is all about too.
Recently in Notion we've been shipping tons of new features for humans and agents to work together, so your whole team develops a shared understanding instead of each working in a silo.
One tiny example: you can now run Claude and Cursor agents in Notion. I do a lot of my coding that way now.
And when those agents make a technical plan in Notion, it's in a collaborative page by default, so I can comment on it with my team and discuss immediately. Thinking together, not alone!
The point was always to augment

Alright, let's wrap up. Today we've covered some techniques that were about understanding code… but actually I think this is a much bigger issue.
It's still important for humans to understand how things work in general! Not just to verify, but to participate.
And surprise surprise, this is not a new idea. It harkens back to the very origins of our field of computing…

50 years ago Alan Kay envisioned that computers could be a new medium, better than the book, for teaching people — especially kids — how to think about the world.
In this picture, it might look like these kids are watching YouTube on an iPad, but they're not. They're playing an interactive game and editing the code as they play it to get a better understanding of physics. This was 50 years ago!!

And now hopefully you understand this meme.
The point was always to augment, not just automate.
It's beautiful that AI now makes creating simulations so accessible… Having AI teach us is one of the greatest possibilities computing has ever opened up.

This makes me very optimistic about the future!
If we build the right tools, we can now understand the world better than we ever could before. We don't have to merely take ourselves out of the loop, we can get deeper in the loop too. It's up to us.
FIN
Related reads
If you enjoyed this talk, you might like these other posts I've written about human-AI collaboration:
- Enough AI copilots! We need AI HUDs — "anyone serious about designing for AI should consider non-copilot form factors that more directly extend the human mind..."
- AI-generated tools can make programming more fun — "Instead, I used AI to build a custom debugger UI… which made it more fun for me to do the coding myself..."
- Code like a surgeon — "identify and delegate the secondary grunt work tasks, so you can focus on the main thing that matters."


