2026-07-31 23:53:51
我没有什么乡愁,胃也是,就算不辣也有很多好吃的。只是那些听起来辣,看起来也辣的东西,吃起来竟然不辣,令我震惊,故作此文。
来济南的第一天,到了酒店之后还有些晕,毕竟刚下飞机就又在车上坐了接近一个小时,不想出门,于是选择点外卖。纠结过后,看上一家麻辣香锅,习惯性地点了微辣,打开饭盒品尝,没有辣味。第二天,我不服,我就想吃有辣味的麻辣香锅,于是点了中辣,打开饭盒品尝,仍然没有辣味。几天后我仍对此耿耿于怀,于是点了最辣的麻辣香锅,打开饭盒品尝…… 这在重庆应该叫作微微辣吧?
虽然不辣,但第二天却拉肚子了,而且是那种吃了辣之后伴随着灼烧感的拉(我是不是应该在文章开头标注这篇文章不适合吃饭时阅读?但真的有人会一边吃饭一边读东西吗?)。真是神奇,原来辣度和能让人拉肚子的程度是分开的吗?
一星期过去,我已经习惯了济南餐馆里标注了辣味的食物实际上并没有辣味这个事实,于是毫无戒备地点了一份中辣的重庆鸡公煲…… 被辣出了感动的泪水。之后又去吃海底捞,点了海底捞双料真香锅,很香很辣很正宗。就这样,我对济南的信心又回来了。然后我站起身,路过好几张桌子…… 不是,你们为什么用开水烫火锅?愤恨中想要告诫对方,吃火锅要是没有小孩,点鸳鸯锅是会被开除重庆户籍的,点清水锅更是要被诛九族。愤恨之余想起来,哎呀,自己是自闭症来着,不敢和人讲话。(想起来的不应该是你不在重庆这个事实吗?!)
周末就这么过去了,到了周一,在公司楼下吃饺子。蘸料区有醋、酱油、耗油和辣椒,最佳的配比当然是 0 份醋、0 份酱油、0 份耗油和 10 倍的辣椒。可惜,这个辣椒恐怕当饮料喝也没有辣味。我把饺子在蘸碟里搅来搅去,让它沾满辣椒油,入口之后,没有辣味,不过挺香的。
所以,在济南,香辣等于香,麻辣等于麻,甜辣等于甜。原来这就是合并同类项啊!嗯?等等,难道说应该叫奥卡姆剃刀?你究竟在谈数学还是哲学?!不是在谈吃饭吗?
好啦好啦,玩笑结束,我知道部分地区的饮食文化更推崇品尝食材本身的味道而不是搭配调料,或者就算加调料也更偏好酱香而不是辣味。不过我依旧有一个疑问:那不辣的麻辣香锅和不辣的红油水饺究竟有什么受众呢?
总所周知红烧牛肉面对于一部分人来说其实是辣的,麻辣香锅想必同理。
—— HPCesia
啊,原来是这样吗?我确实一直不太喜欢红烧牛肉面,因为味道平平淡淡,毫无特色,据说一些不能吃辣的人会觉得红烧牛肉面太辣呢。所以,真正的问题是:那红烧牛肉面究竟有什么受众?
以后出门吃饭要随身携带老干妈。等着我把超意兴的把子肉涂满辣子吧。
回到正题上来。人们常说辣是痛觉而不是味觉,事实也的确如此。
辣是化学物质(譬如辣椒素、姜酮等)刺激细胞,在大脑中形成了类似于灼烧的微量刺激的感觉,不是由味蕾所感受到的味觉,而是疼痛。
—— 辣 - 维基百科
据说人体在受到能忍受的疼痛时,会释放内啡肽(endorphin)。这种快乐激素的化学结构和作用类似止痛药吗啡(morphine),但因为在人体内分泌,所以叫作内源性吗啡(endogenous morphine),英语单词缩合之后变成 endorphin。为了缓解疼痛,所以产生止痛物质,继而使疼痛本身带来了快感——无论是辣椒素的灼烧感还是…… 别的什么…… 奇怪的东西。
吃辣带来的快感很大程度上是因疼痛带来的内啡肽造成的,那么不辣的「辣味」食物呢?对于已经能够耐受相当程度的辣的川渝人来说,刺激感较弱的辣貌似并不能带来足够的内啡肽分泌,即便如此,沾了辣油的食物和不沾辣油的食物仍然有区别。
我想这是因为辣往往伴随着其他的风味出现,我们可以从火锅底料的配方看出些许端倪。诚然,火锅底料大部分都是油和辣椒(毫不夸张地讲,熬火锅底料的锅里一眼看去就只有辣椒,而且还是那种铁桶一样大的锅……),但仍有不少其他佐料。我简单搜索之后,发现了一种牛油火锅底料的 专利信息 ,以下是摘要,可以用作参考:
本发明公开了一种牛油火锅底料配方,以牛油、郫县豆瓣、白酒、醪糟、糍粑辣椒、生姜、大蒜、花椒、豆豉、冰糖、辣椒面、大葱为主料,以白蔻、草果、丁香、砂仁、孜然、桂皮、甘草、栀子、老蔻、甘松、陈皮、香茅草、八角、香叶、千里香、小茴香、香草为香料,该发明口味浓郁厚重,可以满足食客对火锅口味的需求,并适合在潮湿阴冷地区或者冬季食用。
所以,除了辣椒和油之外,口味浓郁的辣味食物往往还带有不少香料的风味。我想那些不够辣的辣椒油吃起来还有些滋味的原因也是如此。
作为对比,有一种很直接的辣,或许被称作「工业辣」,基本没有什么香味,只有并不愉悦的痛感(我猜成分可能是很纯的辣椒素)。去一些食品安全状况存疑的餐馆用餐时偶尔会有这种辣的体验,吃火鸡面也会有。是的,我觉得火鸡面太辣了,而且辣得很没有品味。YouTube 上有一个频道做的一系列节目貌似很有名,叫作 Hot Ones ,节目大概是请一些明星一边吃辣度不同的鸡翅,一边回答问题。尽管我没有尝试过视频里出现过的那种辣酱,但印象中那种食物也很「工业」,而且貌似就是被设计来给人「体验」的,故意把辣度拉得很夸张。
人们好像很喜欢看别人被辣得说不出话,展现出某种人皆有之的弱点,或是反过来,故意吃辣度很高的食物,来证明自己的承受能力很强。等等,我刚刚是不是写过「没小孩在,点鸳鸯锅会被开除重庆户籍」?原来我也被拉进这场无聊的游戏里了啊,真是可怕。
我想起之前树老师在《 真男人为什么应该练翘臀? 》里批评过网上那些信口开河说自己每天早上起来都能做一百个俯卧撑的男人。那些男人大多数(或许是全部)都在撒谎,因为现实中肌肉力量远超常人的美军陆战队退役大哥,做连续不间断标准俯卧撑,连续最多只能做七十多个。说自己早上爬起来就能做一百个的,要么是在撒谎,要么是动作不标准,要么是分组做的(分组是很好的练习方式,但要放到网上显摆的话,谁知道你组间休息多长,每组多少个?)。
我印象中大多数人的俯卧撑姿势都有问题,却从没反思过动作问题,哪怕不标准也要算进去。事实上刚健身的人,连续不间断做十个标准俯卧撑就已经很难了,刚开始更是只能推墙或者做跪姿俯卧撑。我不知道这种愚蠢的雄竞和男性身体焦虑从何而来,但似乎在小学体育课上就有显现。学不高身不正的体育老师用成人的标准(而且是有健身基础的成人标准)傲慢地要求小孩子做标准的连续俯卧撑,仿佛做不了才是不正常的,而且完全忽视个体的身体情况差异。于是大家都开始无知地卷了起来,无知是说大家以为把手臂弯一弯就算俯卧撑,能弯二十下是正常的,而上肢力量更弱的人,可以跪着做(我印象非常深刻,我小学体育课上的跪姿俯卧撑也不是标准的跪姿,反而更像瑜伽动作里的猫牛式);卷是说所有人都开始以一个不存在的人为标准,这个人能连着做几十个俯卧撑不喘气,每天只吃水煮菜,早上起来会洗冷水澡…… 树老师说那些即便骗人也要说自己能做 100 个俯卧撑,并且说男人都能做 100 个这种话给别人制造焦虑、让自己看起来很「男人」的男人,实际上在供奉某个不存在的「赛博关公」。我想说,在互联网之前,这种供奉就已经持续很久了。
加缪在他的自传体小说《第一个人》里用两个词描述他的外婆——无知且严厉。她会非常自信地用歪理教育孩子,严厉不是为了做正确的事,而是为了让孩子顺应她无知的头脑所能认知到的规律。这类人还很好面子,加缪写道,他小时候很不喜欢去电影院,因为那时候的无声电影要看字幕,她的外婆不认字,要外孙读字幕,却还要在开始前大声说「我今天没戴眼镜,你给我读字幕」,只为了不让人发现她是文盲。结果是,这个可怜的小男孩一边被旁边恼怒的观众责骂太吵,一边因为念得太慢被外婆催促,有好几次都被赶出了电影院,而男孩又因为浪费了家里的钱继续感到自责。
这类人不少见,有可能许多人的父母长辈都是如此。被无知且严厉的养育者带大的孩子,若不能通过读书或社交自救,恐怕就会成为焦虑和不存在的标准的奴隶,而他们也会继续想办法大声说一些谎话,来证明自己不是文盲、弱鸡和不能吃辣的人,也不知道是证明给谁看。
不识字也可以有智慧,苏格拉底甚至反对书写,认为那会让人们放弃记忆;识字的人也不见得能品味文学和阅读哲学,甚至不能读懂别人写的字,不能用文字去做有意义的事情。「弱鸡」仅仅是缺少力量,并不是没有勇气;只有力量却不懂得克制使用力量的人,并不具有美德。不辣也有很多美食;仅仅是提高辣度,而忽略了风味,把吃辣当作某种游戏,那实在是有些不尊重食物。
就这样,我得去看看什么样的辣椒酱比较便携了。
2026-07-28 00:03:22
我在自己的时间里一直坚持手写代码,但工作时难免与 Agents 打交道。一方面是公司推崇这种工具,另一方面是如果我不用的话,我就没办法按时交付工作。无论如何,有一类代码我在任何情况下都是自己设计和自己手写的,那就是接口定义。
我要讨论的不是 RESTful API,也不是 gRPC 的 Protobuf,我说的是 interface 类型。不同语言中的 interface 都略有不同,但一般都是一系列抽象方法(函数)的集合。抽象方法是说这个方法没有被实现,仅仅定义了函数名、形参数量和类型,也就是函数签名。
interface 一般用在面向对象编程中,实现 interface 就是定义一个类或命名空间,在其中实现 interface 定义的所有函数。在 Java 中,实现接口需要显式声明,例如 class ConcreteWriter implements Writer。在 Go 中,实现接口是隐式的,只要某个结构体的方法包含了某个接口定义的所有方法,就视作实现了这个接口。
动态类型语言中也有 interface,不过较少使用,我想原因是 interface 就是为静态类型系统服务的。实现了接口的某个对象可被视作同一个类型,而架构设计中的一个原则是:依赖关系应该向越来越抽象的方向流动,即抽象的不该依赖具体的、具体的应当依赖抽象的。原因在于,具体的软件本身是易变的(关于易变性带来的复杂性,可以阅读《
什么是工程问题?
》),如果抽象的业务逻辑依赖具体的部分,那么具体实现改变之后,业务逻辑也要频繁改变,这显然是不合理的。软件工程的一个重要问题就是把变更控制在软件的一小部分当中,interface 可以做到。
假设我们要编写的软件需要启动一个浏览器实例做某个操作,比起直接在主业务逻辑中添加寻找 Chrome 二进制文件的路径、管理生命周期、发送请求和解析响应体的逻辑,把这部分操作隔离开来是最好的。一般的做法是这样:
func doBusinessLogic() {
// ...
url := parseFromUserInput(input)
chrome := NewChromeInstance()
chrome.Start()
defer chrome.Close()
page := chrome.GetPage(url)
// ...
}
实际上这也不是最好的做法,如果我们某天决定不用 Chrome,改用 Firefox,那怎么办?我们要修改这个文件里的依赖引入,把 NewChromeInstance() 改成 NewFirefoxInstance(),假设 Firefox 没有 Close() 方法,用的是 Stop() 这个名字,也要修改。更何况,不同的浏览器可能还有不同的注意事项,需要额外增删代码。
你可能想用适配器设计模式(Adapter Pattern),但既然都要写新的类定义了,为什么不直接写成接口呢?
type Browser interface {
Start()
Stop()
GetPage(url string) PageResult
}
修改前面的 doBusinessLogic 函数,不要直接使用 Chrome 或者 Firefox,而是依赖这个抽象接口。
func doBusinessLogic(browser Browser) {
// ...
url := parseFromUserInput(input)
browser.Start()
defer browser.Close()
page := browser.GetPage(url)
// ...
}
抽象的就是稳定的,Browser 大概率在未来仍然只会有启动、停止和获取页面这三个方法,即便我们替换了背后的具体实现,业务逻辑也不需要做任何改变,只要 Chrome、Firefox 和未来所有的浏览器类实现了上述三个方法,并且符合里氏替换原则。
具体怎么做呢,假设我们在 main.go 里初始化环境、读取配置文件、启动必要的服务,也包括业务逻辑。你发现我在 doBusinessLogic() 的函数签名里加了一个形参吗?我们只需要在入口文件里初始化浏览器,然后把浏览器传给 doBusinessLogic()。
func main() {
firefox := NewFirefoxInstance()
doBusinessLogic(firefox)
}
func main() {
chrome := NewChromeInstance()
doBusinessLogic(chrome)
}
至于 NewFirefoxInstance() 和 NewChromeInstance(),这两个函数里面可能封装了完全不同的初始化逻辑。有可能 Firefox 这边使用 Selenium 和 WebDriver 打开了一个受控制的浏览器实例,而 Chrome 这边用 chromedp 启动了资源占用更低的无头浏览器。要把什么样的具体实现喂给业务逻辑都没关系,只要实现了 Browser 接口,就能通过类型检查。
而 Start()、Stop() 和 GetPage() 封装什么样的代码都没有问题,它可以老老实实地在本地分配内存、维护上下文、启动并管理一个浏览器进程的生命周期,然后与它通信。
type Chrome struct {}
func (c *chrome) Start() {
// 分配内存
// 以无头模式启动 Chrome
// 保留进程 ID
// ...
}
func (c *chrome) Stop() {
// 杀死进程
// 回收资源
}
func (c *chrome) GetPage(url string) PageResult {
// 与进程建立连接
// chrome.Navigate(url)
// 等待页面渲染完成
// 返回页面结果
}
还能有什么方法呢?我们可以偷偷把 Start() 改为与某个远程服务器建立连接,用 Stop() 断开连接,而 GetPage() 则是向该服务器发送 HTTP 请求并解析响应体,然后封装成 PageResult 类型的结果返回,就把它命名为 RemoteBrowser 吧。显然,无论具体实现如何,RemoteBrowser 的确实现了 Browser 接口,可以直接扔进 doBusinessLogic() 函数里。
如此一来,我们的业务逻辑就在完全没有感知的情况下与另一个外部服务进行 HTTP 通信了。可见无论是网络通信、本地进程内部通信还是普通的函数调用,都只是技术细节,可以随时替换。
那外部服务器要怎么设计?会不会很麻烦?不会,我们不是已经把 Chrome 的具体实现写好了吗?假设我们刚才的代码全都放在 internal/browser 包里,只需要创建 cmd/server 包,让这个包依赖 internal/browser,复用 Chrome 的代码,再实现 HTTP 层的通信就好了。这些全都可以写在一个代码库里,只需要单独编译 cmd/server,把它部署到另一台机器上就好了。毕竟这是 Go,几分钟就可以编译好二进制文件,几行命令就可以把这个二进制文件传送到远程服务器上运行。
我们还可以再加上一层抽象,看看下面这个 BrowserCluster 接口。
type BrowserCluster interface {
Add(browser Browser)
Delegate(url string) PageResult
}
Delegate() 的意思是委托,它的形参和返回值与 Browser.GetPage() 一模一样。我设想的是,Delegate() 函数遍历 BrowserCluster 保存的所有浏览器实例,找出当前第一个空闲的浏览器,把任务委派给它,也就是调用它的 GetPage() 方法。
显然我们需要类似 Browser.IsAvailable() 的函数检查浏览器是否可用,我们要动手改 Browser 接口的定义吗?
不,修改 Browser 接口意味着之前所有实现了这个接口的结构体,无论 Chrome 还是 Firefox,都无法再通过类型检查(因为它们不再是 Browser 了,缺少 IsAvailable() 方法)。此时可以用到组合复用原则,也就是再写一个接口。
type BrowserResource interface {
IsAvailable() bool
}
BrowserCluster 的具体实现可以依赖 BrowserResource 的抽象接口,如果需要的话,Chrome 和 Firefox 可以选择性地实现这个接口,也就是添加 IsAvailable() 方法。我们来实现 BrowserCluster 试试看。假设这个浏览器集群不限值类型,只要是浏览器都可以放进去,那就命名为 AnyBrowserCluster 好了。
type AnyBrowserCluster struct {
browsers []Browser
}
func (a *AnyBrowserCluster) Add(browser Browser) {
a.browsers = append(a.browsers, browser)
}
func (a *AnyBrowserCluster) Delegate(url string) PageResult {
for _, browser := range a.browsers {
if resource, ok := browser.(BrowserResource); ok {
if resource.IsAvailable() {
return browser.GetPage(url)
}
}
}
return PageResult{}
}
AnyBrowserCluster 没有使用浏览器的 Start() 和 Stop() 方法,光从接口隔离原则(ISP)的角度来看,这段代码不太合格,因为我们不该依赖自己不使用的代码。我们只使用了 Browser 的 GetPage() 接口,更好的隔离是把 Browser 拆成 Starter、Stopper 和 PageGetter 三个接口,让 AnyBrowserCluster 只依赖 PageGetter 和 BrowserResource,因为我们只用到了 PageGetter.GetPage() 和 BrowserResource.IsAvailable() 方法。
不过,那样就有些复杂了,而且代码读起来也不那么顺畅。无论怎么说,stopper.Stop() 看起来都有点过于抽象了(双重意义上的),设计不可能同时遵循所有的设计原则。况且,我们很有可能需要在 AnyBrowserCluster 中管理浏览器的生命周期,比方说添加浏览器之后、或者在浏览器第一次被委派任务时,启动浏览器;在 AnyBrowserCluster 自身被摧毁时,遍历 browsers 调用它们的 Stop() 方法。上面仅仅是简化版的代码。
回到业务逻辑,把 Browser 换成 BrowserCluster。
func doBusinessLogic(cluster BrowserCluster) {
// ...
url := parseFromUserInput(input)
page := cluster.Delegate(url)
// ...
}
再回到入口函数,让我们创建几个浏览器实例,放进集群里,然后把集群交给业务逻辑。
func main() {
cluster := NewAnyBrowserCluster()
cluster.Add(NewFirefoxInstance())
cluster.Add(NewChromeInstance())
cluster.Add(NewRemoteBrowser("https://imabrowser.dev:8081"))
cluster.Add(NewRemoteBrowser("https://imabrowser.dev:8084"))
cluster.Add(NewRemoteBrowser("https://imabrowser.dev:8082"))
doBusinessLogic(cluster)
}
Voilà!这下业务逻辑就毫无感知地把资源消耗较大的任务委派给了当前空闲的浏览器,这个浏览器可能跑在本地,也可能跑在远程服务器上;可能是 Firefox 也可能是 Chrome,还可以是未来任何要添加到 cluster 当中的 Browser 实现。业务逻辑不知道自己用的是什么类型的集群,集群也不知道自己用的是什么类型的浏览器,它们仅仅是调用自己所依赖的接口实现的方法而已。任何一个环节需要改动,只需要修改那一部分的代码就好,变更不会扩散。
其实我们完全可以用 AnyBrowserCluster 实现 Browser,毕竟 GetPage() 和 Delegate() 的形参和返回值一模一样。那样的话,doBusinessLogic() 就完全不用修改,业务逻辑仍然以为自己用的是普通浏览器,只有入口函数知道它喂给业务逻辑的实际上是个浏览器集群。
几乎任何具体实现都可以稍作修改,或者加上一个包装层来实现某接口,把它接到任何适配接口的地方。总之,接口让静态类型语言变得非常灵活,如果没有 interface,我可能完全不想离开动态类型语言的怀抱!
最后,
接口越大,抽象越弱
。如果你在用 Go 写代码,记得写小接口,不要跟 Java 程序员学坏了!
2026-07-27 08:10:59
连续九十周坚持在每周一的早晨或下午发表一篇刊物,大概算得上是自律吧,不过写周刊于我并不是苦修,而是温和的自我管理。我每周都会接收大量的信息,我不想让它们光滑地从我的大脑皮层上掠过,至少应该留下点痕迹。 发刊词 里写的周期性总结之类的话,对如今的我早就不成立了(另外,两年前的我竟然把 ChatGPT 聊天记录贴在文章里吗?真是可怕……)。
周刊的格式和写作方式常常改变,这些改变不是精益求精,而是为了适应生活节奏的改变。比方说前段时间我想要和社交媒体保持距离,于是「切片」栏目的内容就多了起来,记录了我原本会发在联邦宇宙上的文字。如今过上了每周上五天班,每天工作七小时的生活,周刊的写作方式大概也需要调整,毕竟上班摸鱼的时候没办法直接把发现的有意思的东西塞进周刊草稿里。各方面的压力少了很多,每天除了工作、读书、思考吃什么、惦记什么时候再去吃一次麦当劳比较合适之外,脑子里还多了不少游离、不成文、碎片的想法,这大概就是闲暇吧。
总之,周刊格式已改,变动不大,我懒得说明,还请读者自己发现。

Paramore
我曾在 第 76 期周刊 分享过《All We Know Is Falling》这张专辑,这是 Paramore 的第一张专辑,也是我最喜欢的一张(可能有先入为主的原因在,我总觉得他们从第一张专辑以后就一直在走下坡路)。
周日的时候我发现这张专辑和我同一年诞生,并且当天(7 月 26 日)正好是这张专辑的二十一岁生日。也算是奇妙的缘分。我一直很喜欢这张专辑,最近上下班的路上也时常打开来听。
无论是什么样的痛苦,或许只要吼出来就会好的。

请稍等,阿努比斯正在称量你灵魂的重量。
📻
近年来全球的生育率都在降低,这一部分原因是如今人们不再需要靠多生来保证有足够的后代存活(在以前,儿童死亡是常事),另一方面,许多地方生育率下降的拐点,都与智能手机的普及时间吻合(所谓智能手机的普及,是以 iPhone 的销售、基站的建设和某地区应用商店下载量上涨的时间节点为依据)。
除了相关性,因果性当然也能分析。调查发现许多人仍然向往传统的家庭结构,独身主义者和丁克人群没有显著增加,只不过不少这些向往结婚生子的人往往一直单身。一种视角是,可能并不是人们不愿意生了,而是愿意生的人找不到伴侣,无法踏入婚姻,更不能养育子女。对此,普遍的解释是现在经济不景气,大家都很疲惫,没有金钱、时间和经历去婚恋和生育。相关研究提供了另一种解释:智能设备的普及使得人们不再出门社交,屏幕就能为不少人提供足够的与人接触的需求,如此一来,遇见合适伴侣的概率就变小了。还有一层原因是社交媒体激起了两性矛盾,对此我不予置评。
研究中具有一定现实意义的是,提供生育补贴、在公共层面鼓励生育并不能解决生育率低的问题,因为婚后生育子女的家庭并没有显著减少(甚至是略微增加的),减少的是真正开启婚姻的人。不过我想这也不能简单地怪罪给智能手机和互联网。
顺带一提,我现在住的地方,楼下就有一个「生育主题公园」,公园里尽是些「适龄婚育」「尊重生育」「执子之手,与子偕老」之类的话,我每天经过的斑马线上也写着生育标语,还有各种爱心图案,好像年轻人看到这些东西就会被催眠,然后性欲大发没羞没躁地生育起来似的。市政府就把钱花在这种地方吗?这座城市真的没有让我对他的印象变好。
📻
主播肥杰提出了一些他在交友方面的拧巴,另一位主播惠子则给出了一些指导建议。尽管我跟肥杰是很不同的人,但他的一些纠结和别扭我也能感同身受。比方说,他在跟朋友聊到要去他新家玩之后的不久,就想要主动提出去他家玩,甚至想好了非常合适的暖房礼物,但就在他准备出门买礼物的时候,他脑袋里的另一个声音泼了他一盆冷水:你竟然主动要求去别人家玩,不觉得冒昧吗?
而现实是,这个朋友以前也很喜欢有人去他家玩,并且没有任何迹象表明他会排斥这一举动。他表示他在摇人出来玩的时候也会有类似的顾虑,他担心自己组织的活动「不够有含金量」。这也困扰我也都有过,结果就是,由于我自己提前让恐惧和不安说服了自己不去主动社交,导致朋友以为我不乐意和他交往。包括面对面时生怕给别人留下不好印象的焦虑,其实也会外化,体现在神情和小动作上,会让对方也觉得不舒服,进而留下「跟这个人在一起玩有些尴尬」的印象。
所以重点是自信和别乱想,对吧?感觉需要艰苦的练习呢。

一般人在搞清楚它是巴西利斯克还是鸡蛇之前就逃走了,只有真正狂热的爱好者才会为这种要么把你毒死要么把你石化的生物着迷。
📜
Codeberg 在这周四发文宣布了服务条款的变更,主要涉及两点有关 LLM(大语言模型)的政策。其实几个月前就有 Codeberg 成员公布本次会议的相关议程,当时我也在 联邦宇宙 发帖搬运过消息,如今总算是看到结果了。简单的版本是:Codeberg 不会用用户数据和代码训练 AI 和大语言模型;Codeberg 不再欢迎大部分由 LLM 生成、为 LLM 而写、消耗了过多资源却没有多少用户和社群的项目。
在此之前需要交代的背景是,Codeberg 由 Codeberg e.V. 这个非盈利组织运营,不是商业实体。他们的钱是靠捐赠和成员缴纳的会费得来的,这些取之于民的资金当然要用之于民,不是随便给人滥用的。Codeberg 的使命是为自由开源软件提供基础设施,并不是替代 GitHub 等商业代码托管平台,因此,Codeberg 相当重视开源协议,以非自由协议授权或保留版权的项目不该托管在 Codeberg 上。明确这些背景之后,接下来的各种理由就很合理了。
博客文章中提到的理由与我在《 我(不)想让 AI 帮我做 》一文中写过的有不少重叠,大致总结如下:
git clone 就好了,但为了获取训练数据的爬虫非要把网站上所有的网页都爬一遍,给服务器带来巨大压力的同时损害了其他用户的体验。我可以担保,Codeberg 在升级反爬措施之前的时常出现服务下线的问题,现在仍然不好过。相比禁止加密货币项目的决定,Codeberg 在禁止 LLM 这方面做得其实相当谨慎,同时也坚定了立场。1他们考虑到了一些人已经拥抱 LLM 作为自己工作流的一部分,也有相对一部分人只把特定的部分工作交给 LLM,所以从目前的表述来看,只有符合以下条件的项目和人是一定被禁止的:
那些有活跃社群、很多维护者的项目,在 LLM 出现之前就有很长开发历史的项目,以及那些在不知情的情况下合并了 LLM 贡献的项目,并不受影响。不过值得一提的是,那些不太能找到社群的个人的小项目,即便不是 LLM 写的,实际上也不该托管到 Codeberg 上,只不过只要资源消耗不太高,Codeberg 可以容忍。
我留意到这些表述中还有一条空白:那些使用了 LLM 技术辅助编程,但大体上由人设计和实现的项目,并没有被明文禁止,但也不存在于 Codeberg 明文允许的范畴中。这不难理解,Codeberg 在整体上是排斥 LLM 的,但如今越来越多的开发者离不开 LLM(顺带一提,这周某天我公司账号的 Token 没了,我在工位听取一片惨叫,好像大家都没法工作了),完全禁止并不现实,但又不能表明他们接受带有部分 LLM 生成代码的项目,所以就留白了——我想是这样。
对于本身就不在乎自由软件运动的人,我想也不会来到 Codeberg(不排除有一部分仅仅因为 GitHub 变得越来越难用,就来到 Codeberg 避难的人)。对于在乎自由和开源软件的人,我想当下最严重的问题是 LLM 对自由开源软件的「协议清洗」,人们现在可以毫无法律负担地随意使用开源项目里的代码了,这难道不可怕吗?我们离开源协议完全失去意义还有多远?此外,如果你排斥 GitHub,在考虑 Codeberg 之前,请先思考自己的项目是否是能够找到活跃社群的自由软件项目,请让我和其他众多自由软件热爱者捐的钱用到真正应该发挥作用的地方。我也在准备将自己的一些小项目从 Codeberg 上迁离。
☕
当然,不是说要踏出门,用 SSH 的方式就好了。打开终端输入这段命令:
ssh late.sh
就可以进入 late.sh,基于终端的娱乐大厅,可以和其他人聊天,也可以操作字符小人用 Vim 键位(h j k l)四处走动。如果安装它们提供的二进制文件的话,还可以在 late.sh 上听广播、播放音乐、在聊天框里粘贴图片等等。我试了试,很酷,有点像 10 年代的页游,可以在同一个服务器的同一个场景里见到其他在线的玩家。
使用 ssh 也挺方便的,只要有 SSH Key,就不需要管账号密码和用户验证的事儿了。只不过你可能要先 ssh-keygen 生成一对密钥。
不是卢梭写的那本。还有,我懒得找插图了,你想象一个男人的背影吧。
取快递之后刚被小象超市的推销员追到楼上,等我下单买了东西领了赠品才走,几分钟后打开电脑就看到 Taxodium 上的《 小象超市鮮啤簡評 》,这是什么概率?
虽然说我刚搬家确实需要那些东西,价格也合适,但到我家来看着我选商品未免有点太没边界感了吧!
明明空调就在旁边,但还是微微冒汗,原因大概是房间太大,而空调的风刚好从我旁边掠过。或许不该在客厅摆书桌的,但也没别的地方了……
上班用 Windows,下班用 Mac,我的键位已经完全混乱了。
这是一篇废稿,我怎么也复现不了当时脑子里的想法了,或许我根本没有什么正经想法。
Common Lisp 文档 把
t称作 The Truth Constant,或许可以译作「真理常量」。尽管t只是逻辑真值,但代表「真理」的这层含义无疑让它变得富有哲学隐喻意味。所以,真理与非真理是纯粹的二元关系吗?存不存在一个中间状态,或者如薛定谔的猫一样的叠加状态。一个陈述可不可以既是真理也不是真理,或者同时是真理和非真理?真理的竞争条件
竞争条件(Race condition)是错译,这里的 condition 并非条件。同 The Human Condition 不应该被译作《人的条件》一样,condition 在此语境下的含义是状况、境况、状态。再比方说,《小丑》电影里的主角无法控制大笑,他不得不递给旁人一个卡片解释情况,如果我没记错的话,卡片上写的是他有一种 Medical condition,这显然不是「医疗条件」的意思。
说回正题,竞争状态(也叫竞争冒险、竞争危害)指的是系统依赖于不受控制的事件出现的顺序。设想这样的情境,老师在家长群里收款并让付款后的家长接龙,收款的数额不定,每个家长都可能支付不一样的金额。老师为了方便,让付款后的家长直接根据上一个家长发布的金额计算出当前的总金额,比如家长甲支付了 200 元,上一个家长乙支付后的总总额为 1200 元,那么家长甲就应该接龙数字 1400 元。
这就是一个竞争状态,即有出现并发问题的隐患。如果所有家长都一个接一个地接龙数字,那么一切安好,但一旦有家长同时付费并计算金额,总金额就极有可能与实际金额不一致。
家长丙:
读取当前的总金额:1400 元
加上自己刚刚支付的 300 元,得到 1700 的总金额
在群里接龙 1700 元
家长丁:
读取当前的总金额 1400 元
加上自己刚刚支付的 100 元,得到 1500 的总金额
在群里接龙 1500 元
我们假设丙先发送接龙信息,那么最新一条的总金额记录就是丁发送的 1500 元。然而,无论谁先发送,总金额都是错误的,他们计算时都没有把对方的金额累加到总金额里,正确的总金额是 1400 + 300 + 100 = 1800 元。如果老师不注意,就可能漏掉好几百的金额数据。
好了,现在我们知道了什么是竞争状态,来做个思想实验吧。假设有一个真理变量存储在系统中,有一群哲学家想要决定这个变量的值是什么。为了方便,我们以古典哲学中的世界本原问题为例,这个变量的名字就叫作
arche(世界本原)。古希腊第一个提出本体论问题的是泰勒丝,他给出的答案是:世界的本原是水。所以他将arche赋值为"water"。接下来留基伯和德谟克利特也开始读写这个变量,他们将
arche赋值为"atom"(原子),阿那克西美尼和第欧根尼写入"air"(气),赫拉克利特写入"fire"(火),恩培多克勒总结了前人论点,提出世界本源是四元素,所以他写入一个元组("earth","water","fire","air")。我们就假设他们用的语言是 Python,元组是不可变的。显然,每次写入都会导致前一个人的内容被覆盖,真理变量最后只会有一个值。那么问题是,如果变量不会保存过往的值,那恩培多克勒是怎么总结前人观点的呢?在我们这个假象的系统里,他只能看到在他之前写入个一个值,比如他可能只能看到
"fire",如果没有见到最初的"water"和后来的"air",他怎么能总结出四元素呢?我知道我知道,如果纯粹从编程和软件工程的角度来看,这个问题有很多成熟的解决方案,比方说 可持久化数据结构 和面向对象设计模式中的 备忘录模式 。不过,我想要还原这样的场景:人类的集体意识一次只能关注一件事、一种理论、一个热点事件、一种印象。
我到底在写些什么啊!
这又是一篇废稿。
人造语言服务于创造者,其实自然语言也是一样,不过自然语言服务于历史长河中所有使用并在使用中改变了这门语言的人,是某个地域的人类的集体意识的体现——这可不就是文化吗?我一直强调自然语言的历史和发展过程,是因为时间造就了语言的很多部分。如果没有历史,就没有词源学,
也就没有极客死亡计划上《 猫头鹰化石 》这个系列了。如果某一门语言在诞生之初就要形成完整体系,那创造者必然要考虑方方面面、力求完美,要是自然语言也是这样,那如今世界的格局应该是这样的:极简主义者们创造出文法和词汇类似文言,但由类似拉丁字母的文字写就的,极其简练高效的语言;一些人可能喜爱音韵学,并认为语言应该完全开发和调动人类的喉腔,就有可能创造出与法语、意大利语和西班牙语类似的,由大舌音和小舌音以及各种其他人难以学习的音素组成的语言;内敛不多言的人可能不在乎发音,转而去关注书写,可能把象形文字发挥到了极致,开始用 Emoji 在互联网上交流。语言界可谓是百家争鸣,大家都自由地选择自己认可的语言阵营,并将其背后的哲学当作真理——没错,就跟程序员和编程语言的关系差不多。
这只是节选,更长的草稿被我扔进 罐子 里了。
你说我要是频繁地在博客写《 如何用电车难题理解 Git 》《 如何用宝可梦属性玩石头剪刀布? 》这种东西,还动不动就把周刊格式改了,塞一堆没人看得懂的东西,会不会把读者创死?
没事,我向来创死人不偿命,阅读我的博客是需要勇气的。
瞧瞧你都读到这里来了,真的很无所畏惧哦!
2026-07-25 19:02:28
读者早上好,中午好,下午好,晚上好,本人上了五天班之后终于在周末开始发疯了(其实没那么难受,工作待遇挺好的,我只是想发疯),所以我们今天来玩石头剪刀布。
因为我想看的《星期三》《人生切割术》和《同乐者》都还没出新剧集,而《瑞克与莫蒂》在周一才更新,所以我从头到尾刷了七遍《老友记》(当然是从我第一次看这部剧到现在的时间累计的),《生活大爆炸》次之,大概有三四遍吧。回顾已经看过的电视剧集会给人一种安全感,貌似有相关研究,但鉴于这篇文章我是来发疯的,所以就不扯心理学了,免得搬起石头砸自己的脚。
在《生活大爆炸》里,Sheldon 说剪刀石头布不足以做出有意义的区分,而且在熟悉的人之间,人们更容易打成平手。所以,他提议用剪刀、石头、布、蜥蜴、史波克1代替简单的石头剪刀布,规则是这样的:
——出自第二季第八集 片段
如果你没看懂这个规则,没关系,我也没看懂,下面是图示:
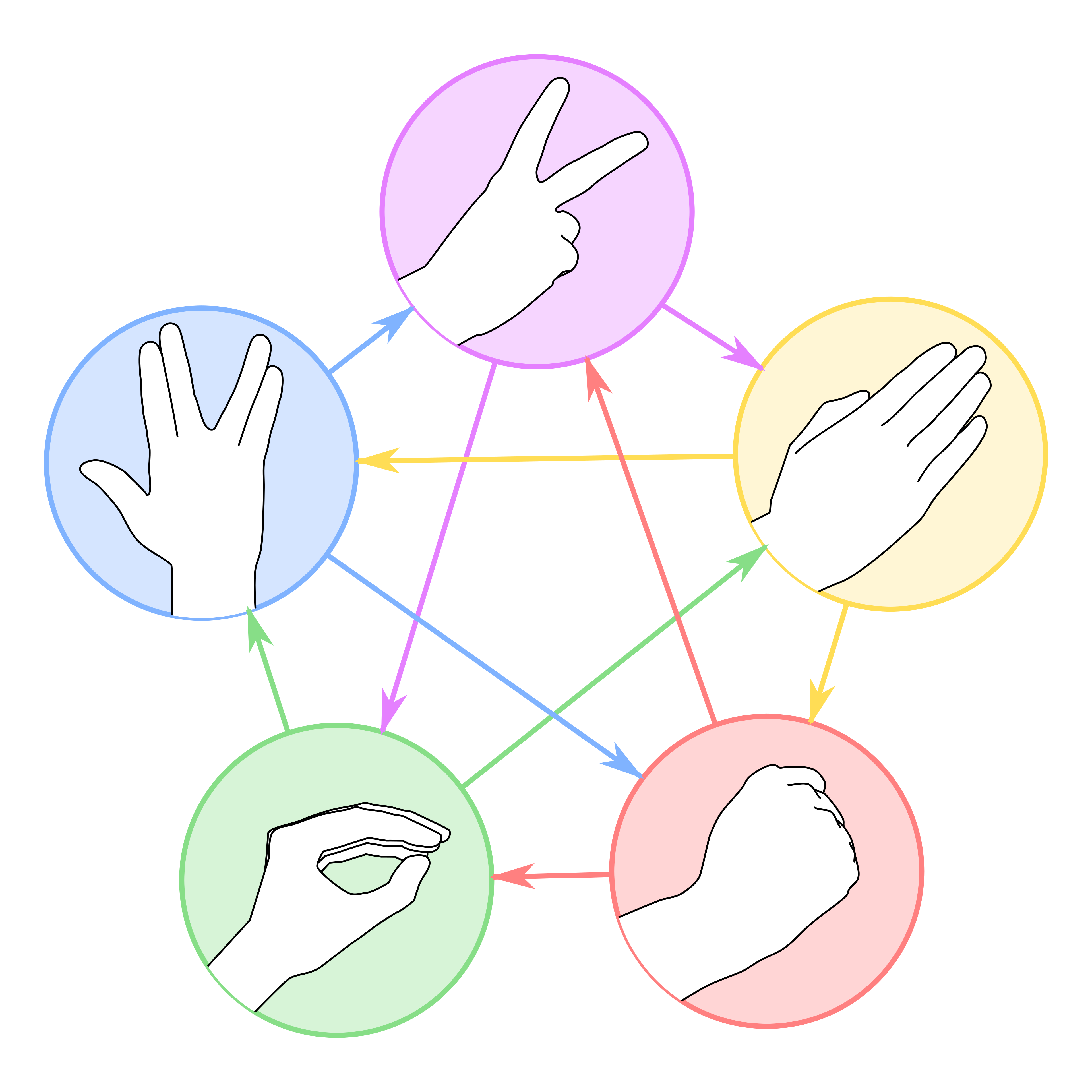
这个游戏也出现在《去月球》系列游戏里的某段对话里,具体出自哪部游戏,我已经忘记了。
尽管是情景喜剧里的笑料,但这个改良版本的石头剪刀布,通过引入两个新的出招选择,巧妙地改变了石头剪刀布的环状结构。仔细观察,上图中每个出招都有两个弱点和两个克制对象。如果忽略上图的箭头,把这张图看成是五阶完全图,每个结点都有四的度;如果看成有向图,则每个结点有两个入度和两个出度,由于出度和入度相等,所以这是张五阶平衡有向图。
你以为我要通过图论得出什么结论吗?我都说了我是来发疯的,我只是想炫耀一下我的图论知识。有一说一,石头、剪刀、布、蜥蜴、史波克还是太简单了,这个图里连自环都没有(意思是说一个结点有指向自身的一条边),两个节点之间最多只有一条边,也没有权重。想看看真正复杂的游戏吗?
Behold. The Pokemon type chart! 2
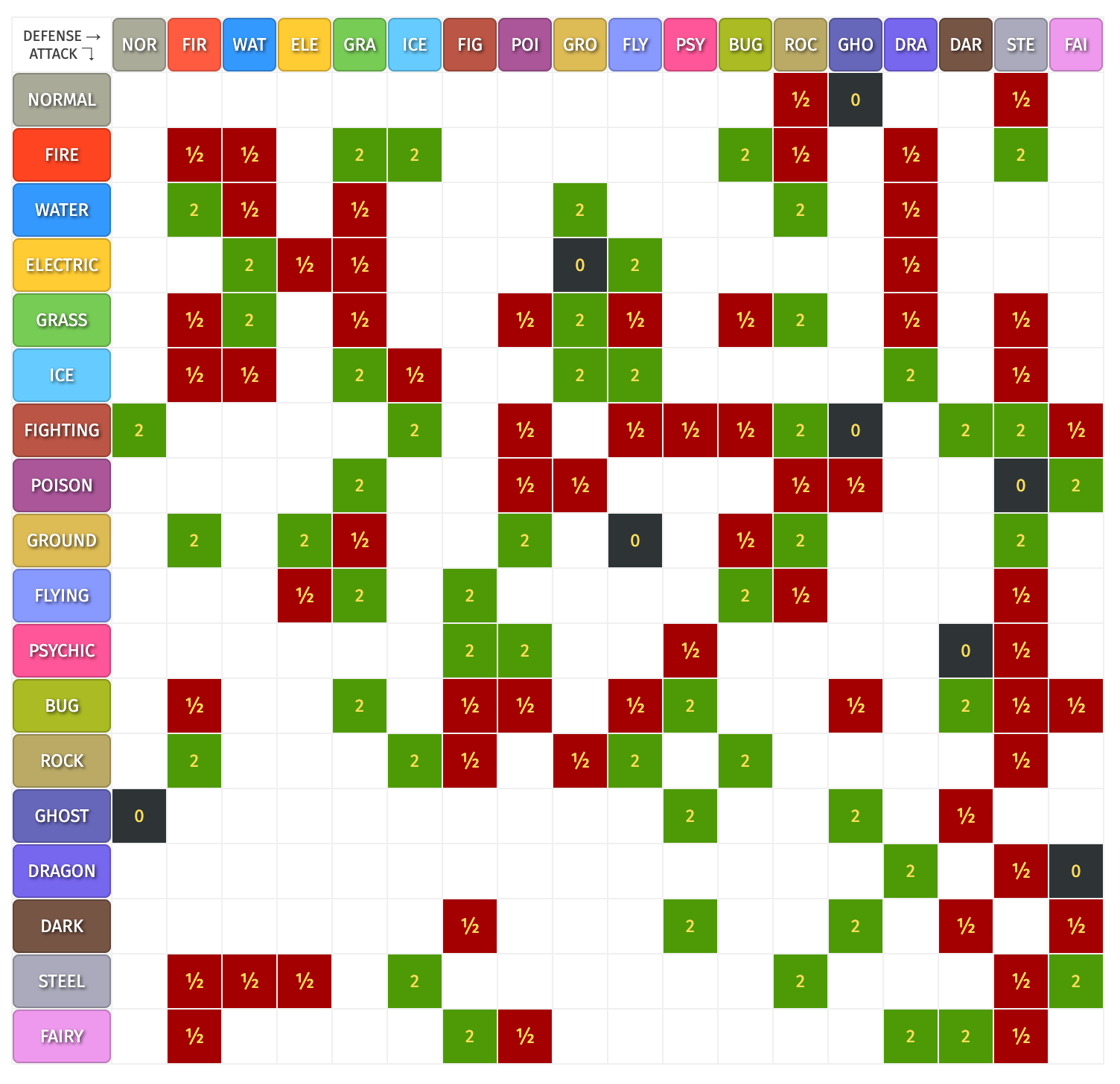
表格的左侧代表进攻方,上方代表防御方(受击方),每个表项代表攻击倍率。可以先看第一行,一般系(NORMAL)作为攻击方时,对岩石系(ROCK)和钢系(STEEL)造成 ½ 倍率的伤害,对幽灵系(GHOST)造成 0 倍率的伤害。
不难理解,宝可梦属性相克表实际上是个带权有向图的邻接矩阵,其中权重代表的是攻击方对防御方造成的伤害倍率,空白的格子其实应该是 1。我们可以把图画出来…… 噢等等,看样子还是算了吧。
一般而言,攻击方对防御方造成 2 倍伤害被称作「克制」,比如火系克制草系;造成 0.5 倍伤害则被称作「抵抗」,比如水系抵抗自身;造成 0 倍伤害叫作「无效」,比如幽灵系对一般系无效。如果要用宝可梦属性玩剪刀石头布,就要考虑倍率问题。直觉上,由于火系克制草系,那么出「火」的玩家应该能立刻打败出「草」的玩家,那么「火」对「电」呢?倍率为 1 的情况下怎么判定?如果假设玩家有 2 的生命值,而两次出「火」就能打败两次都出「电」的玩家,那只要不是低概率出现的「无效」,所有玩家都能在两回合内战胜彼此,游戏就没有太多意义了。
等等,好像也说不定?你等我写个程序模拟一下。
先定义 type-list,用 Clojure 的关键词类型列出所有的属性。
(def type-list [:NORMAL
:FIGHTING
:POISON
:FLYING
:GROUND
:ROCK
:BUG
:GHOST
:STEEL
:FIRE
:WATER
:GRASS
:ELECTRIC
:PSYCHIC
:ICE
:DRAGON
:DARK
:FAIRY])
然后写两个简单的小函数,方便获取属性在表中的索引,或者用索引获得属性名称,这就很像枚举类型了。
(defn type-index [type-name]
(.indexOf type-list type-name))
(type-index :BUG) ;; => 6
(defn type-name [type-index]
(get type-list type-index))
(type-name 2) ;; => POISON
接下来录入所有的属性相克关系,不必惊慌,可以直接复制属性相克表,粘贴到代码中变成一个二级数组,也就是矩阵的结构,然后运行 Vim 的 :%s/.../... 命令替换掉 × 之类的字符,就得到了一张干净的邻接矩阵。哦对了,Clojure 里 1/2 是不合法的,应该写成 (/ 1 2),这里批量替换为 0.5 就好。
(def type-effects [[1 1 1 1 1 0.5 1 0 0.5 1 1 1 1 1 1 1 1 1]
[2 1 0.5 0.5 1 2 0.5 0 2 1 1 1 1 0.5 2 1 2 0.5]
[1 2 1 1 1 0.5 2 1 0.5 1 1 2 0.5 1 1 1 1 1]
[1 1 1 0.5 0.5 0.5 1 0.5 0 1 1 2 1 1 1 1 1 2]
[1 1 0 2 1 2 0.5 1 2 2 1 0.5 2 1 1 1 1 1]
[1 0.5 2 1 0.5 1 2 1 0.5 2 1 1 1 1 2 1 1 1]
[1 0.5 0.5 0.5 1 1 1 0.5 0.5 0.5 1 2 1 2 1 1 2 0.5]
[0 1 1 1 1 1 1 2 1 1 1 1 1 2 1 1 0.5 1]
[1 1 1 1 1 2 1 1 0.5 0.5 0.5 1 0.5 1 2 1 1 2]
[1 1 1 1 1 0.5 2 1 2 0.5 0.5 2 1 1 2 0.5 1 1]
[1 1 1 1 2 2 1 1 1 2 0.5 0.5 1 1 1 0.5 1 1]
[1 1 0.5 0.5 2 2 0.5 1 0.5 0.5 2 0.5 1 1 1 0.5 1 1]
[1 1 2 1 0 1 1 1 1 1 2 0.5 0.5 1 1 0.5 1 1]
[1 2 1 2 1 1 1 1 0.5 1 1 1 1 0.5 1 1 0 1]
[1 1 2 1 2 1 1 1 0.5 0.5 0.5 2 1 1 0.5 2 1 1]
[1 1 1 1 1 1 1 1 0.5 1 1 1 1 1 1 2 1 0]
[1 0.5 1 1 1 1 1 2 1 1 1 1 1 2 1 1 0.5 0.5]
[1 2 1 0.5 1 1 1 1 0.5 0.5 1 1 1 1 1 2 2 1]])
数据结构清晰之后,写获取攻击效果的函数就很简单了。
(defn get-attack-effect [attack defense]
(let [atk-index (type-index attack)
dfs-index (type-index defense)]
(-> type-effects (get atk-index) (get dfs-index))))
(get-attack-effect :WATER :WATER)
;; => 0.5
(get-attack-effect :WATER :FIRE)
;; => 2
(get-attack-effect :DRAGON :FAIRY)
;; => 0
一切就绪,就可以开始跑模拟了。先来模拟玩家出招,写一个 play 函数。
(defn play []
(type-name (rand-int 18)))
(play)
;; => 随机输出一种属性名
写一个循环,模拟两人对战,有人生命值小于等于 0 时结束并返回结果。每位玩家的初始生命值为 2,每次出招玩家都会受到对方的攻击,攻击伤害等于 1 乘攻击倍率。结算时以生命值受到攻击伤害最小的玩家为赢家,比方说结束时 A 生命值为 0,而 B 生命值为 -0.5,那么 A 胜利。如果生命值相同,则打成平手。
(defn play-til-death []
(loop [round 1
p1 2
p2 2]
(if (or (<= p1 0) (<= p2 0))
;; one down, print result
(let [winner (if (= p1 p2) 0
(if (> p1 p2) 1 2))]
(if (= winner 0)
(println "It's a tie.")
(println (str "Player " winner " wins in " (- round 1) " rounds")))
{:round (- round 1) :winner winner})
;; still going
(let [p1-move (play)
p2-move (play)
p1-to-p2 (get-attack-effect p1-move p2-move)
p2-to-p1 (get-attack-effect p2-move p1-move)]
(println round)
(println "Player 1 deals " p1-to-p2 " damage to player 2 by playing " p1-move)
(println "Player 2 deals " p2-to-p1 " damage to player 1 by playing " p2-move)
(println)
(recur (inc round)
(- p1 p2-to-p1)
(- p2 p1-to-p2))))))
要看看这个游戏是否可行,我们再写一个循环,进行 N 次游戏收集样本。
(defn play-n-times [n]
(loop [counter 0
total-rounds 0
p1-wins 0
p2-wins 0
ties 0]
(if (>= counter n)
;; print statistics
(do
(println "Counter: " counter)
(println "Average round: " (float (/ total-rounds counter)))
(println "Player 1 wins: " p1-wins (percentage p1-wins counter))
(println "Player 2 wins: " p2-wins (percentage p2-wins counter))
(println "Ties: " ties (percentage ties counter)))
;; still going
(let [result (play-til-death)]
(recur (inc counter)
(+ total-rounds (:round result))
(inc-if (= (:winner result) 1) p1-wins)
(inc-if (= (:winner result) 2) p2-wins)
(inc-if (= (:winner result) 0) ties))))))
运行一万次试试。
(play-n-times 10000)
;; Counter: 10000
;; Average round: 1.7555
;; Player 1 wins: 3690 36.89999878406525%
;; Player 2 wins: 3597 35.96999943256378%
;; Ties: 2713 27.129998803138733%
结果是,这个游戏一般需要一到两轮结束(两轮的次数更多,查看记录也偶尔有三轮的情况),两名玩家赢的次数没有显著差异(合理,从算法来看,出招顺序并不影响游戏结果),整体而言,这个游戏有 27.13% 左右的概率打成平手。
这是完全随机的情况,但毕竟玩家出手时有 18 种选择,即便彼此熟悉也很难摸清楚对方的出招规律(至少没有石头剪刀布那样简单)。看起来并不会出现我们一开始以为的游戏无意义的情况,至少在双人游戏中,每个人有大约 35% 的概率会赢,35% 的概率会输,接近 30% 的概率会打成平手,某种程度上还挺公平的。Voilà!现在你可以用宝可梦属性玩石头剪刀布了。
等等,宝可梦属性和剪刀石头布,以及剪刀、石头、布、蜥蜴、史波克的主要区别在于,属性相克关系带有权重,其次,每个属性在图中的出度和入度并不相等,也就是说宝可梦相克关系图并不是个平衡图。不平衡就导致了,必然有一些属性更容易获胜,另一些更容易失败。
修改一下现有的代码,让 1 号玩家固定出招某个属性,让 2 号玩家保持随机,再运行几次测试,来看看哪个属性更容易胜利。顺便把所有打印语句都注释掉。
(defn play-til-death
([] (play-til-death nil))
([p1-fixed-move]
(loop [round 1
p1 2
p2 2]
(if (or (<= p1 0) (<= p2 0))
;; one down, print result
(let [winner (if (= p1 p2) 0
(if (> p1 p2) 1 2))]
#_(if (= winner 0)
(println "It's a tie.")
(println (str "Player " winner " wins in " (- round 1) " rounds")))
{:round (- round 1) :winner winner})
;; still going
(let [p1-move (or p1-fixed-move (play))
p2-move (play)
p1-to-p2 (get-attack-effect p1-move p2-move)
p2-to-p1 (get-attack-effect p2-move p1-move)]
#_(println round)
#_(println "Player 1 deals " p1-to-p2 " damage to player 2 by playing " p1-move)
#_(println "Player 2 deals " p2-to-p1 " damage to player 1 by playing " p2-move)
#_(println)
(recur (inc round)
(- p1 p2-to-p1)
(- p2 p1-to-p2)))))))
play-n-times 函数也做了类似的修改,此处略去。接下来我们还要写一个函数,遍历 type-list,用每种类型跑 10000 次游戏模拟看看情况。
(defn play-all-types [each-times]
(map #(play-n-times each-times %) type-list))
;; 由于直接在 REPL 里运行,所以 map 不需要包裹在 doall 里
;; 严格来说这里应该返回惰性序列,但让我们忽略这一点
(play-all-types 10000)
运行结果如下。
[Type] :NORMAL
Counter: 10000
Average round: 2.0486
Player 1 wins: 0 0.0%
Player 2 wins: 3270 32.69999921321869%
Ties: 6730 67.29999780654907%
[Type] :FIGHTING
Counter: 10000
Average round: 1.6251
Player 1 wins: 4326 43.25999915599823%
Player 2 wins: 3846 38.46000134944916%
Ties: 1828 18.279999494552612%
[Type] :POISON
Counter: 10000
Average round: 1.6658
Player 1 wins: 3507 35.06999909877777%
Player 2 wins: 3387 33.8699996471405%
Ties: 3106 31.060001254081726%
[Type] :FLYING
Counter: 10000
Average round: 1.9019
Player 1 wins: 3425 34.25000011920929%
Player 2 wins: 4129 41.29000008106232%
Ties: 2446 24.459999799728394%
[Type] :GROUND
Counter: 10000
Average round: 1.5627
Player 1 wins: 4301 43.00999939441681%
Player 2 wins: 3671 36.71000003814697%
Ties: 2028 20.28000056743622%
[Type] :ROCK
Counter: 10000
Average round: 1.4984
Player 1 wins: 4321 43.209999799728394%
Player 2 wins: 4209 42.089998722076416%
Ties: 1470 14.699999988079071%
[Type] :BUG
Counter: 10000
Average round: 1.7554
Player 1 wins: 3434 34.34000015258789%
Player 2 wins: 5200 51.99999809265137%
Ties: 1366 13.660000264644623%
[Type] :GHOST
Counter: 10000
Average round: 1.925
Player 1 wins: 3821 38.2099986076355%
Player 2 wins: 1058 10.580000281333923%
Ties: 5121 51.20999813079834%
[Type] :STEEL
Counter: 10000
Average round: 1.8247
Player 1 wins: 6063 60.62999963760376%
Player 2 wins: 3512 35.120001435279846%
Ties: 425 4.250000044703484%
[Type] :FIRE
Counter: 10000
Average round: 1.6792
Player 1 wins: 4340 43.39999854564667%
Player 2 wins: 3451 34.50999855995178%
Ties: 2209 22.08999991416931%
[Type] :WATER
Counter: 10000
Average round: 1.8075
Player 1 wins: 4428 44.279998540878296%
Player 2 wins: 2704 27.039998769760132%
Ties: 2868 28.679999709129333%
[Type] :GRASS
Counter: 10000
Average round: 1.6325
Player 1 wins: 3129 31.290000677108765%
Player 2 wins: 5516 55.15999794006348%
Ties: 1355 13.54999989271164%
[Type] :ELECTRIC
Counter: 10000
Average round: 1.94
Player 1 wins: 2933 29.330000281333923%
Player 2 wins: 2765 27.649998664855957%
Ties: 4302 43.02000105381012%
[Type] :PSYCHIC
Counter: 10000
Average round: 1.8052
Player 1 wins: 1953 19.529999792575836%
Player 2 wins: 3796 37.95999884605408%
Ties: 4251 42.50999987125397%
[Type] :ICE
Counter: 10000
Average round: 1.5982
Player 1 wins: 3594 35.94000041484833%
Player 2 wins: 4214 42.14000105857849%
Ties: 2192 21.9200000166893%
[Type] :DRAGON
Counter: 10000
Average round: 1.8582
Player 1 wins: 3171 31.709998846054077%
Player 2 wins: 2732 27.320000529289246%
Ties: 4097 40.97000062465668%
[Type] :DARK
Counter: 10000
Average round: 1.8063
Player 1 wins: 1976 19.760000705718994%
Player 2 wins: 2933 29.330000281333923%
Ties: 5091 50.91000199317932%
[Type] :FAIRY
Counter: 10000
Average round: 1.7287
Player 1 wins: 3559 35.589998960494995%
Player 2 wins: 2667 26.669999957084656%
Ties: 3774 37.74000108242035%
结果很有趣,宝可梦版本的石头剪刀布,每种出招的获胜概率都不同。非常特殊的是一般系,一直出一般系的话,在一万次的样本中,一次都没有获胜,但对手获胜的概率也被略微拉低了,增加了平手的概率。不难理解,在《宝可梦》游戏里,一般系就是非常抗打,除了格斗系没有别的弱点的属性,不过缺点是它的进攻能力很弱,不克制任何别的属性,甚至对幽灵系无效。反过来对一般系同样无效的幽灵系也非常有趣,只出幽灵系的话,平局的概率会被拉到一半,并且会让对手很难获胜(只有 10% 左右),自己则可以获得接近 40% 的胜利率。岩石系也很有趣,它提高了双方的获胜概率,并且大差不差,但是它让平局率降低到了 15% 以下。
明显弱势,很容易输掉比赛的属性不少。虫属性会让对手在一半的情况下赢得比赛;飞行系会让对手在 41% 的情况下获胜;草属性让对手获胜的概率是最高的,超过了 55%;超能力系的获胜率不到 20%,恶属性也是。具有优势,更容易获胜的属性有水属性、火属性、钢属性、幽灵属性(不过幽灵属性很容易平局)、地面属性和格斗属性,其中钢属性是最容易获胜的,可能是因为它的进攻能力和抗性都不错。
不过,《宝可梦》游戏中的对战和这个简单的石头剪刀布小游戏还有很大不同,就算只看属性克制方面,宝可梦自身的属性和攻击属性是分开的,而且自身属性还可能有双属性,一些属性抵抗还受到特性影响,比如具有干燥皮肤特性的宝可梦在受到水属性攻击时会回血,但是会变得弱火。抗性最好的宝可梦应该是麻麻鳗鱼王,它是纯电属性,只有地面系的弱点,但飘浮特性使得它可以无视地面系攻击,也就是没有弱点。
如果要考虑这些的话,这个游戏就会变得太复杂,而且,我的发疯时间也到了,现在我要去做饭吃了。
2026-07-25 11:27:21
据我对自己过去的总结,以及对比我更晚进入软件领域的人的观察,我发现新来者更容易陷入对技术问题的纠结,工程问题则被忽略了。我并不是说技术问题不如工程问题重要,我仅仅是指出,有不少人并不区分这两类问题,工程问题甚至不在他们的认知范围内,更别提去思考它了。本文我想来总结我对这两类问题的认识,并试图总结一些方法论。我也不是专家,所以肯定会有疏漏和错误,还请不吝赐教。
——Frederick Brooks《No Silver Bullet》
技术的定义或许更接近科学原则和科学事实,比方说,Go 语言中有缓冲的 channel 会在缓冲区满的时候阻塞试图向其中写入新数据的协程1。倘若这个表述变成「需要严格控制并发的场合,应该使用带缓冲的 channel」,那么我们就更接近工程的范畴了,但这依旧更像是技术细节。如果说的是「尽管协程很轻量,但这个项目里每个协程的任务都占用 100MB,而每个实例运行在 1C1G 的服务器上,再加上操作系统和程序本身占用的内存,应该用带缓冲的 channel 把并发数控制在 8 以下」,这显然就是工程问题了,尽管依旧是局部的细节。
如此看来,技术和工程的区别之一可能是接地气与否,也就是该问题是否涉及真实的软件需求、限制和外部环境。我们再来考量一下「工程化」这个词。过去人们常谈「前端工程化」这个问题,如今有不少人痛骂越来越臃肿的 Web,怒吼「 手写 HTML 难道他妈的不就是个网站了吗? 」。前端的过度工程当然是个问题,但后者的愤怒也有失公正。主流的前端库 React ,尽管我不太喜欢,但它在刚推出时的确解决了不少问题。组件(Components)在 HTML 之上增加了一层抽象,很好地包装并隔离了大型 Web 应用的复杂度。手写 HTML 当然能用,但用老三件套手写 Facebook 的用户界面实在强人所难——团队不方便分工,太多的细节都被挤在一起,所有人都有可能不小心碰到别人的代码。如果一个 HTML 页面冗长得不可理喻,要修改根本无从下手,这就使得工程无法进行下去。我从来不觉得 React 等前端库的出现是「技术进步」,它们只是「工程优化」。
真正的问题是,某些网站根本不能算得上是 Web 应用,竟然也要用一大堆 NPM 依赖写 SPA,这反而是对工程问题没有思考导致的——由于没有明确问题的规模(以及考虑未来是否有可能扩大规模),甚至根本没有考虑规模问题,就使用流行的、过度抽象的前端框架,消耗过多的计算资源。在过度抽象和极端简化的两边,都能观察到对工程考量的缺失。
接地气要考虑的东西其实很多,而技术问题顶多关乎设计和实现。我不得不说,尽管我很讨厌 Java 这门语言,但在具体工程中使用 Java 有明显优势:会 Java 的人实在是太多了,招人和组建团队非常容易;同时,遇到问题也更容易搜索到已有的解决方案;生态更成熟,JVM 也是很稳定的运行环境。当然也不能只看好处,选用 Java 的代价就是:JVM 启动需要时间,如果需要频繁停启,就会成为瓶颈;Java 的语法很啰唆,不仅如此,语言本身也有诸多限制,不够灵活,需要编写和维护的代码量很多,结构复杂,详见《
从 CLOS 审视 Java 面向对象编程
》;会被 Eltrac 嘲讽;Java 的内存占用不小,尤其是线程本身的体积,在高并发场景下表现远不如 Go 语言。如果服务跑起来就很少停止,不排斥 Java 的语法并能使用清晰的分层设计,业务逻辑大部分都是增删改查,并不消耗多少资源,那选择 Java 就是合理的,没必要花钱雇佣熟悉其他技术栈的软件工程师。
很丑陋,不是吗?没办法,现实世界就是丑陋的。我在以前很容易陷入某种精神洁癖(或许现在也是),我不允许丑陋的东西出现在我构造的软件中,二进制文件就一定比 .jar 好,Lambda 表达式就一定比函数指针好,一切都应该语义化,以至于我总是在思考软件本身,而不是软件应该要解决的问题。同样的精神洁癖也出现在年轻的作家当中:
当我在二十多岁开始写作时,我认为文学的目的是改变现实的样貌,剥离其物质层面的东西,无论如何都不应该写人们所经历过的事情。比如,那时我认为我的家庭环境和我父母作为咖啡杂货店店主的职业,以及我所居住的平民街区的生活,都是“低于文学”的。
——安妮·埃尔诺《写作是把刀》
软件不能是纯粹的软件(至少那些要写出来给人用的不是),就像文学很难是纯粹的文学(文学总是和社会现实、历史环境、哲学思想和真实的人的情感纠缠在一起,没有办法把人的事情剥离得只剩文字)。有很多人试图把软件变得不像软件,把文学变得不像文学,但另一个极端也同样值得批评。
接地气其实是面对真实业务场景的权衡取舍,对此,图灵奖得主 Frederick Brooks 在上世纪八十年代就写文探讨过。《 No Silver Bullet 》在软件工程领域也算是经典之作了。银弹(Silver bullet)源自欧洲民间神话,在很多故事里,用银制成的子弹是对付狼人、吸血鬼和女巫等超自然生物的唯一手段2,如今用于指代应对复杂问题的简单且万能的答案。《No Silver Bullet》说的是:开发软件没有简单且万能的解决方案。
(一种尖细、刻意、做作的声音)“现在‘AI’时代不一样了,什么都能用‘AI’写!”“上 K8S 就好了,用 Kafka 就好了!”“我必须要用 Vue / React / Hono / Ember.js / Modern.js / HTMX 写这个网站!”“你他妈就不能用纯 HTML?你看我这他妈不是个网站吗?”“你他妈的就不能用 Go 写吗?”“我们要燃烧几百美元的 Token 把这个能跑的玩意儿用 Rust 重写一遍!”
等一下,让我再确认一遍…… 嗯,没错,Brooks 的那篇论文是 1986 年发的,那个时候 Taylor Swift 还没有出生。现在…… 是的,我没记错,已经是 2026 年了,而 Taylor Swift 已经发了十五张专辑……
吸气四秒,屏息七秒,吐气八秒。
呼,我们继续。
Brooks 在文中引用了亚里士多德在《物理学》3中提出的偶然性(accidents)和自发性(essence)4两个概念,这篇论文的副标题就叫作 Essence and Accidents of Software Engineering(软件工程的自发性和偶然性)。他认为软件工程无银弹的事实是由软件的内在属性决定的,这种内在属性源于软件的本质:一种抽象的概念构造。
I believe the hard part of building software to be the specification, design, and testing of this conceptual construct, not the labor of representing it and testing the fidelity of the representation. We still make syntax errors, to be sure; but they are fuzz compared to the conceptual errors in most systems.
If this is true, building software will always be hard. There is. inherently no silver bullet.
我相信构建软件的难点在于为这种概念构造制定规格、设计和测试,而不是将它表示出来并测试这种表示是否准确所需的劳动。
如果这是真的,构建软件永远都会很难。软件在本质上,就是没有银弹。
在 Brooks 眼中,软件工程的自发性问题无法得到解决,这些问题主要有四个:
以上是软件内在的自发性问题,而那些偶然性问题,据 Brooks 称,已经被解决了。高级编程语言屏蔽了底层细节,消除了低级的复杂性;分时系统极大减少了软件的编译和执行时间,总的来说是缩短了系统响应时间;统一的编程环境使得人们可以一起使用、集成和复用相同的软件库6。这些解决方案我们已经习以为常,不觉得是问题,以至于我们看到新问题的新解决方案时,以为他们是银弹,而实际上它们仅仅针对偶然性问题。
近乎每次考古计算机软件领域的论文时,都会忍不住再次引用安德烈·纪德:一切被言说之物都已经被说过了,而人们会忘记,所以一切都必须再次言说。Brooks 在接下来的一章里讨论了「银弹的希望」(Hopes for the silver),其中涉及人工智能、专家系统和自动化编程。上世纪人们对 Artificial Intelligence 这个词的印象和现在当然完全不同,此处的 AI 有两种定义,而 Brooks 采用的是第一种定义「使用计算机解决在以往只有人类智能才能解决的问题」,第二种定义的 AI 被它称作「专家系统」,也就是启发式的基于规则的计算机程序,本质上是通过观察现实中专家的行为方式在总结并抽象成的一套规则集。那个时候神经网络算法其实已经出现了,也被应用到了计算机中,但大模型还没有影子,所以文中没有提及。不过他的一些建议放在如今的 LLM 辅助编程背景下,也依然成立。
Brooks 没能想象能自己设计软件并自己写代码的编程智能体(Coding agents)的出现,但文中的「专家系统」和「自动化编程」,若是组合起来,就和如今的 Agents 很相似了。专家系统是对软件设计和完整工程进行总结后,用于给软件开发给出指导建议的系统;自动化编程则顾名思义,即输入软件规格的描述,然后从已有的代码库中选择使用,加速开发。如果把专家系统的输出直接喂给自动化编程系统,我们就得到了如今会自己做计划、写 ToDo,然后写代码实现,甚至还会自己做测试和验证的编程智能体,尽管结构上很不一样。
对于专家系统,或者说 LLM 给建议和制定设计方案的功能,在 Brooks 看来也不是银弹。他写道,这种系统可以帮助没有经验的程序员积累经验,分发好的软件开发实践。他认为开发这种系统的前提是要有这样的专家存在,而从如今 LLM 训练的方式来看,激进的爬虫从互联网各个角落扒拉下来的内容很难说得上是可靠的。我们也知道 LLM 生成的代码不一定是最佳实践。即便是理想中的,能够给出最佳建议的专家系统,帮助也非常有限。
对于自动化编程,Brooks 表示在 40 年前(换算到现代,应该有 80 年了)人们就开始想象能够自动编程的系统,对此,他引用了 David Parnas(另一位软件工程领域的先锋人物)的话:
In short, automatic programming always has been a euphemism for programming with a higher-level language than was presently available to the programmer.
简单来说,自动化编程一直是对用比程序员如今可以用到的语言更高层次的语言编程的委婉语。
Brooks 给“自动化”打了引号,因为编程不可能是自动化的。哪怕是如今的 LLM 编程,程序员也需要用自然语言(或许是软件领域里抽象层次最高的一种语言)输入指令。只要程序员还需要思考和输入,就不可能解放双手。软件的内在属性(一种概念构造)就意味着开发软件永远不可能不思考和描述。
If, as I believe, the conceptual components of the task are now taking most of the time, then no amount of activity on the task components that are merely the expression of the concepts can give large productivity gains.
只要任务的概念部分是眼下最消耗时间的(我也这么相信),那么无论在仅仅是表达这种概念的部分上费多少时间精力,都不能产生巨大的生产力提升。
也就是说,无论在写代码上费多少心思,都无法影响软件在需求和设计阶段所耗费的时间,而这些时间才是真正的瓶颈。在真实软件开发中,人们可能花费数日甚至数周敲定一个所有人都挑不出毛病的方案,即便他们使用了 LLM 辅助设计。如果软件有明确的客户,那么在与客户的沟通上会出现更复杂的问题,LLM 对此唯一有用的帮助,就是快速生成原型产品(Prototype)并多次迭代,以确认用户的需求,或者验证技术方案的可行性。
Brooks 认为为数不多有可能直击软件工程的自发性问题的东西有几个:
前面三条或多或少成为了行业共识,但最后一条是最重要的。
A little retrospection shows that although many fine, useful software systems have been designed by committees and built by multipart projects, those software systems that have excited passionate fans are those which are the products of one or a few designing minds, great designers. Consider Unix, APL, Pascal, Modula, the Smalltalk interface, even Fortran; and contrast with Cobol, PL/I, Algol, MVS/370, and MS-DOS.
稍微回顾历史就能发现,尽管许多良好、有用的软件系统是由委员会设计并由多部分项目构建的,但那些令富有激情的粉丝为之激动的软件,是一位或几位懂设计的头脑的产物,那些优秀的设计师。想想 Unix、APL、Pascal、Modula、Smalltalk 接口,甚至 Fortran;反例是 Cobol、PL/I、Algol、MVS/370 和 MS-DOS。7
段落的最后出现了一些如今人们已经不熟悉的概念,或许现代的版本是这样的:想想 Linux、Lisp、Go、Rust、WebAssembly,甚至 Python;反例是 Java、JavaScript、PowerShell 和 Windows。
Brooks 认为软件工程领域能做的最重要的事情,就是培育更多优秀的设计师,从目前的大学教育和行业现状来看,大概没人把他的话当回事儿。
软件工程的自发性问题或许与工程问题相关,而技术细节仅仅是偶然性问题。当人们在不断迭代技术方案时,他们就能同时体会到软件的复杂性、遵从性、易变性和不可见性——必须花很多时间描述系统的设计,并在沟通交流中确认彼此的意思,因为软件系统很复杂;必须考虑到外部的硬件限制和使用场景,保证某项技术的选用是合理的,因为软件需要遵从外部环境;技术方案要考虑到后续软件变更的难易程度,以及可扩缩性(scalability),因为软件一定是易变的;架构层次图、时序图和数据流图都很难描述清楚软件的实际结构,UML 仅仅是作为沟通工具存在,因为软件在本质上是不可见的。这些软件工程的自发性问题(或者说本质问题)都是工程问题。
在设计阶段不会考虑或者很少考虑的具体实现和技术细节,往往都是偶然性问题,找到现成的解决方案很容易,就算没有,也可以花时间找到解决方案(而之后遇到相同的问题时,还可以复用这个方案)。比方说,一个并发系统有多个线程执行数据库写入操作,频繁等待锁使得 CPU 的利用率下降。这看起来是工程问题,但实际上只是容易解决的技术细节,引入一个专门的线程用来写入数据,其他线程把写入操作放进消息队列就好,只有一个写者就不用等待锁了。这些技术细节往往不需要在设计阶段被考虑,几乎不会影响整体项目的进展。
前些日子和朋友闲聊,他看到有人用 “AI” “一句话”生成了完整的游戏,他感到非常震撼。我其实有很多想要细讲的,但想着还是不要破坏轻松的氛围,所以就把这些思考写进博客里。我想说,LLM 编程并没有解决工程问题和自发性问题。软件的复杂性并没有被消除,只是不再被 Vibe-coders 关心。软件的易变性依旧存在,而容易改变不代表改变起来很容易,倘若设计者本人都不理解软件的复杂性(数据结构、模块划分和各个局部的设计细节),那变更时只会塞满 LLM 的上下文、消耗更多的 Token,直到那一整块奇形怪状的软件结构已经没办法被他的 “AI” 理解。
在 LLM 之前,编写游戏程序早就不是难事。游戏的难点一直是玩法设计和所有软件都要考虑的架构设计。就像 Parnas 说的,“自动化”编程仅仅是用更高层次的语言编程而已,在不能用自然语言编程的年代,高级编程语言和游戏引擎也达成了某种“自动化”。事实是,谁都写得出来,但不是谁都写得下去。想想《僵尸毁灭工程》这个历经十五年还处在 Beta 阶段的游戏吧。
React 写起来并不难,任何编程基础到位的人,都能在不借助 LLM 的情况下写一个简易的虚拟 DOM 引擎,但不是所有人都能统筹大量的开源贡献、与开发团队紧密沟通、收集用户反馈,并且维护一个代码库十三年。好的软件应该是被长期维护的,而这意味着在软件的整个生命周期里,软件工程师都要与复杂性、遵从性、易变性和不可见性作对。无论用手写还是用 LLM 写,扔下一段能跑的代码并为自己感到骄傲,实际上相当幼稚。这段代码再有用,也只是解决了偶然性问题,搞清除了某个技术细节,对工程和软件的自发性问题做出的贡献微乎其微。
我在《 我(不)想让 AI 帮我做 》一文中简略地提及过几类程序员的差别:一类只想要完成和交付他被分配的任务,如果能减少工作量,用什么工具都行;另一类更富有热情,但比起写代码,他们更喜欢创造的感觉,不写代码也能获得成就感;最后一类是我所属的一类,喜欢写代码,理解软件的复杂性本身就是一种智识锻炼和享受。
让我们忽略第一类,他们大多只想谋得生计,对软件工程本身的兴趣不大。后两类尽管有差异,但在某一点上殊途同归:我们都觉得创造软件令人愉悦,只不过一边更在意结果,另一边重视过程和体验。在这层意义上,用一个周末 Vibe code 了一个给自己用的 RSS 阅读器并为自己感到骄傲的开发者,和用几个晚上手写写出了一个已经有更成熟解决方案的软件或算法并为自己感到骄傲的开发者,创造的价值都为 0。后者可能有值得称赞的点,比方说他没有使用大量昂贵的计算资源,也没有给 “AI” 公司花钱,促使他们去消耗更多的土地资源、矿物资源、电力和水资源建造数据中心、把硬件价格炒得没人买得起,而且他完全理解他的软件,要整合到其他系统里就相对容易。可我们不能比烂,事实就是,两者都没有为整个软件生态做出任何贡献。
我不是说没有贡献就是坏的。总所周知,程序员十分热衷于重复造轮子,尽管共识与之矛盾。所有人都需要娱乐,编写软件对我们提到的两类人而言的确是很好的娱乐。如果要把娱乐的体验和经验应用在真实的软件开发中,就要三思后而行了。Vibe code 的确很快,但若是不理解软件的结构,要维护起来就很困难,所以不能在没有任何设计的情况下用几句提示词编写软件,更不能完全不读代码;重复造轮子的确很爽,反复重构和优化代码结构也很爽,但在实际工程中,若是有现成且合适的方案却不用,在影响项目继续推进的情况下过早优化,也不明智。
在我的观察中,有不少程序员是完全无法与彼此沟通的。一个在谈论他的私人项目中使用的新鲜技术,另一个则思考这种技术在实际工程中会遇到的问题;一个在思考某个项目更适合用哪个模型开发,另一个在思考使用什么样的架构和设计模式;一个试图说服对方用 Rust,另一个试图解释自己的团队里没人会 Rust,还有一个半路杀过来让他用 LLM 写 Rust…… 为了更好地沟通和相互理解,也为了更清晰地认识软件工程本身,必须要区分工程问题和技术问题,区分自发性问题和偶然性问题,区分娱乐与职责。
当然,这最多也只能是一种自律罢了。
协程指代 goroutine,是用户态的、轻量级、装载到系统线程上的并发单元。 ↩︎
这里的 Physics 译作物理学可能不够准确,读者只需明白这是个形而上学概念就好。我印象中物理学这个译名貌似是个错译,又或者是误会,我没深究。 ↩︎
「随机的」原文为 arbitary,这个词其实很难翻译成中文,它对应的中文翻译还有「武断的」「偶然的」「随心所欲的」。我对 arbitary 的理解是:如果某个现象没有更深层次的解释,没有理由地存在着,换成别的东西似乎也合理,不一定非得是它,那它就是 arbitary 的。 ↩︎
顺带一提,Brooks 在这里举的例子是 Unix 和 Interlisp,后者是围绕 Lisp 语言构建的编程环境。 ↩︎
我貌似还没有见过不批评微软的优秀软件工程师。 ↩︎
2026-07-20 07:59:10
上班的生活,貌似没有那么糟糕?兴许是因为作为刚入职的实习生,我的工作强度并不高吧。总之,本周我在忙入职和租房的事情,事件之间的空隙也有些喘息和四处游走的时间,生活还不错。
不过我的文化体力还没能恢复,本周打开了加缪的《第一个人》,没怎么读得进去。也写了一两篇文,但都成了废稿,其中一篇的题目叫作《The Only Truth Is Binary》,其实也就名字很酷而已。希望下周能恢复平衡。

Daft Punk
我听说这张专辑的方式很奇妙:我得知我最喜欢的 Taylor Swift 专辑《Red》曾与格莱美年度专辑失之交臂,当时 Taylor 听到主持人故意拖长了 Ra- 这个音节,短暂地激动了几秒钟,实际上当年的得主是 Daft Punk 的《Random Access Memories》。
最近在 Taxodium 的博客再次看到了这张专辑,于是找来听了听,还不错,不过可能更适合还没有被「电音梗」荼毒的人群聆听。要是听一半冒出来的想法是「手机电量满了」,这边建议卸载短视频软件。
喜欢《Giorgio by Moroder》《Touch》和《Get Lucky》。
📻
来自树记者的报道,我很高兴终于在《独树不成林》里听到有关年龄验证的隐私和审查问题了,之前的相关单集都只讨论了「禁止青少年使用社交媒体」这件事情本身有没有用、是否必要、有无隐患等等。这期播客更深入地分析了社交媒体禁令支持者和反对者各自的立场和观点。支持者关心青少年的心理健康(尽管我仍不相信社交媒体使用和儿童心理健康有强相关性,我仍然相信比起禁止儿童使用社交媒体,更应在家庭和社会层面为儿童提供更具吸引力的课外活动),而反对者担忧实施年龄验证的互联网会逐步演变为「一切都需要出示证件才能访问的互联网」,担心政府会借机扩大审查范围。
针对反对者的担忧,乔纳森·海特(《焦虑的一代》的作者,正是这本书在两年内引发了如此巨大的政治反应)表示他要的不是「基于内容的审查」,而是「基于设计的审查」,他反对的是纵容大科技公司对儿童肆无忌惮地使用具有成瘾性的技术。大脑尚未完全发育的儿童面对庞大的技术团队、行为分析和成瘾性设计,并不能进行平等的自由选择。乔纳森·海特反对的是儿童创建账号,也就是禁止儿童与平台建立契约,禁止企业追踪和分析儿童的一举一动。他表示先要有这样的法律制度,科技才会为了满足法律需求而开发技术手段——事实确实如此,我在 第 88 期周刊 分享了谷歌为年龄验证开发的零知识证明库,就是不知道立法者是否真的会花心思了解和采用这种技术。
这样一来,我对乔纳森·海特的观点就有了更多的理解了。不过我很好奇,他是否清楚追踪和分析用户行为并不需要创建账号,浏览器指纹技术可以通过用户的 IP 地址、屏幕尺寸、是否使用夜间模式、浏览器 User-Agent 信息等生成独特的用户指纹进行追踪,网站甚至能通过更阴险的手段跨设备追踪。试着不登录账户使用 YouTube 一段时间,你会发现谷歌能记住你的偏好和行为,除非使用抗指纹的浏览器和插件。不登录的用户,依然能被算法操纵。他的逻辑依旧很难站住脚。
Mother-fucking website
的精神后继之一,暴躁作者劝说开发者,Go 是无聊且可靠的开发语言,不仅不需要框架也能开发,语言本身还不容易让人写出复杂的抽象和难以理解和维护的代码。Go 的编译器自带各种工具链,gofmt 只有一种代码风格,不需要配置 Prettify 也不会因为每个人的代码格式不同而污染 git diff;go test 就可以运行所有测试了,加上对应的 Flag 还能运行覆盖率测试和 Benchmark;go mod 和整个依赖管理系统都安全得感人,go.sum 还提供密码学保护。Go 项目不会有 node_modules 这样的黑洞目录,更不会时不时就出现 NPM 那样的供应链攻击。
我特别喜欢这句话:
Your security team will weep with gratitude.
你的安全团队会留下感动的泪水。
最重要的是,Go 程序可以直接编译成二进制文件。要部署服务,只需要指定操作系统和处理器架构,然后用 SSH 复制到服务器上执行,最多再写一个很短的 systemd 单元文件。
Your Go binary doesn’t care. It compiled and it runs, and it’ll still run in five years on hardware that doesn’t exist yet. Your framework? Deprecated by Christmas, and the maintainer will write a Medium post about burnout.
你的 Go 二进制文件才不在乎。它编译之后就能运行,五年后还能运行在现在还不存在的硬件上。你的框架?圣诞节的时候就被弃用了,维护者会写一篇 Medium 文章说他力竭了。
你不需要去尝试这周刚出的新 JavaScript 框架,也不需要把现有的代码重写成 Rust(说真的,为什么这么多人都在用 Rust 重写,甚至燃烧美元让 LLM 重写出安全性未知的软件?),Go 足够无聊也足够好。我尤其喜欢 gofmt,Clojure 也有类似的 cljfmt 但不如 Go 标准化,人人都用一样的格式化工具真的会让 Git 历史干净很多。
在我看来,Go 作为一门无聊的语言,非常适合工程应用,有望完全替代 Java(说真的,Java 本就不是为 Web 开发而生的,Spring 框架在运行时用反射获取路由的操作真的有点幽默,跟内存不要钱、性能不重要似的)。对于那些需要长久维护的系统,用 Go 不会出问题。Go 的入门门槛也非常低,只要有编程基础,读完文档就能在当天下午立马开始写 Go 代码。当然,不无聊的语言也不是不能用,Clojure 作为非常有趣的语言也在部分领域有实际的工程应用(但作为 Lisp 的一员,普及度可想而知)。如果是写个人项目或玩具软件,用什么技术都不错,开心就好。
📜
看标题以为是用 Go 语言代替 JavaScript 做交互式网页,结果是在浏览器内嵌入异步的 Go 语言解释器,不过也算是有趣的实践。
在浏览器中运行 Go 代码的常见做法是把 Go 程序编译成 WebAssembly,Go 的编译器原生支持这个操作,只需要在环境变量中指定 GOOS=js GOARCH=wasm。作者在试错之后发现这种做法并不符合他的需求,它要求这段程序异步运行在隔离的 V81 环境中,而 GOOS=js 假设程序运行在普通的浏览器环境中,有兼容性问题。正确的做法是指定 GOOS=wasip1,将 Go 程序编译成
WASI
(WebAssembly System Interface),这个开放标准规范化了 WebAssembly 的系统 API,运行在 V8 环境中不会有上述问题。
之后就很简单了,读取用户输入后用 Yaegi (用 Go 编写的 Go 语言解释器)执行字符串中的 Go 语言代码并返回结果,把这段程序编译成 WASI,嵌入到浏览器中,就能够在网页中运行用户输入的 Go 语言代码了。
文章内容对当下的我没什么用处,但的确是很有意思的实践。WebAssembly 真是神奇的东西,这下几乎所有的现代编程语言都有了共通的编译产物,WASI 统一了 API 之后也方便用不同语言的程序进行交互,总之很有趣。
📄
Minecraft 的快照版本更新也能冲向 Hacker News 榜二吗?这游戏在黑客圈子里还是真是受欢迎啊。简单了解了一下,迁移到 SDL3 大概是给 Minecraft 带来了一些性能提升,也顺带修复了一些 Bug。当然也引入了新的 Bug,比如现在在 Wayland 上打开全屏模式会导致游戏崩溃,不过毕竟是快照版本,正式版发布的时候肯定会修复的。
不过真要解决性能瓶颈的话,能不能把 Java 换掉? 要不你们也用 Agent 把 Minecraft 用 Rust 重写一遍?(你要不听听你在说什么?)
《瑞克与莫蒂》第九季第八集,Rick 早上起来合上的那本书是海德格尔的《存在与时间》。书本封面给了两次特写,但弹幕没有人发现,你站人均文化素养可见一斑。 上次在影视作品里发现认识的书本,是《同乐者》里 Carol 和 Zosia 一起享受生活的那段,Carol 拿的书是《
黑暗的左手
》。
然后…… 时间女神 Jessica 就回来上课啦?所以之前一直没出现是故意的还是偶然?
飞到济南啦,落地之后的感受是:好平…… 为什么道路旁边一座山也没有?第二印象是:我的麻辣香锅为什么没有辣味?!
入职前去公司楼下和附近的商场逛了逛,恍惚之间觉得自己并没有离家很远,大概全国的商场都大差不差吧,只不过在 MUJI 闲逛的时候,店员不会像重庆的店员那样一直跟我说欢迎光临,商场里面也听不见熟悉的重庆方言。不过戴上耳机就好了,我以前不是一直戴耳机吗?
酒店其实挺差的,也就值八九十块一天的价格吧。洗衣房里堆了各种杂物,在房间里面能听到走廊上的各种声音,晚上空调响个不停,还好我无论在哪里睡觉都会戴耳塞和眼罩,这么说我的环境适应力还挺强的。
早上起来收到一封垃圾邮件,大概是面向网站主的,爬了我网站上所有的邮箱地址一起发送,搞笑的是联邦宇宙用户名和 XMPP 用户名也被当作邮箱地址发送了,显示在收件人里。另外这个服务商真有点没边界感,发送邮件里直接把登录密码和用户名给我了,在我不知情的情况下用我的信息创建了账户吗?
本来还想挂一下他们,但看到他们的产品连 UI 都丑得令人发指,就算了,想必会自己垮掉的。
事实证明租房和各种生活攻略都不能看小红书,除非是做旅行攻略之类的,幸存者偏差过于严重了。小红书上所有人都在说济南全是黑中介,但我今天临时找的中介倒是非常专业和认真负责,一直在帮我筛选,和房东商量租期和租金。大概不要在稀奇古怪的角落找中介就不会有问题。
另外,这是第二次看房子看一半,发现中介和我是同专业的…… 学计算机的学长学姐们为什么这么多去当房产中介了?
看房子腿快走断了……
上班第一天,进门时非常局促,一个人也不认识,找了最近的一个同事问运维坐哪儿,因为要找他安排设备和工位。后来发现他也是实习生。运维当时应该是在忙,就给我指了下位置,我以为他只是让我临时坐一下,所以就焦虑地原地刷起手机来了……
十多分钟后他把相关文档发给我,等了一会儿才过来,当他把电脑打开的时候我才发现用户名已经是我的名字了。草,所以我等于是刚来上班就坐工位上刷了十几分钟手机吗?
其实刚进门的时候还转身进了厕所缓缓…… 真的,不要让 ASD 一个人应对这种场合啊!
电脑竟然是 RoG,有 64 GB 内存,机箱甚至还带 RGB 灯带,显示器目测是 27 寸吧。除了键盘卡卡的,准备换自己的机械键盘之外,配置有些过于高端了。这真的是给实习生用的吗?老板大气……
团建,依旧不认识人(是的,入职第二天就赶上团建了,而且还是周五团建),于是闷头干饭。路上被同事误认成其他同事的家属,以为是谁带了个弟弟过来。
至少认识了一些人,最后躺在酒店房间里和前辈打牌,学会了斗地主。真是收获满满啊。
交房后花两百多块钱在美团上找了家政,预订了六个小时的深度清洁,回来验收的时候发现各个角落还有明显的灰尘,貌似也就收拾了厨房、擦了玻璃和地板。其实只过了三个小时阿姨就打电话说做完了,走的时候还念叨着已经超时了,由于当时出门在外干别的事情,再加上阿姨口音太重实在听不清楚,人走了之后我才反应过来。
所以实际上是沟通问题,阿姨以为只用做三个小时。这也从侧面反映了这家公司的办事流程不够专业。我消费的时候,服务描述明明写得明明白白,阿姨那边的信息却是不对等的,真是令人不省心。事情太多我实在没心思跟商家拉扯。果然最后还是要自己收尾吗?
后来发现京东和盒马也有保洁服务,不知道会不会靠谱一些…… 不过我也就交房的时候叫保洁,平常我是很喜欢自己做清洁的。
住惯了带密码锁的房子,交房后拿到钥匙就开始焦虑起来。不想花钱换密码锁(主要是不想社交,换锁的话要和房东商量),又担心自己丢三落四弄丢钥匙,于是连夜下单了 AirTag…… 我知道,性价比很低的选择,但确实好用。
拿到手的第一天就用上了,钥匙揣兜里,收拾床铺的时候滑倒了被子下面。能播放音效找起来确实很方便。
分享刚才看到的双关笑话,试图缓和气氛:

如果硬要翻译,我觉得可以译作:“磕到了。”2
这下气氛可算是冷下来了。