2026-04-21 00:21:23
I was originally going to write a long articulate post for each of the below, with lots of fancy graphic, charts, and detailed analysis. Then realized it is too much work. Instead, here is some human idea slop & random thoughts. Enjoy!
OAI and Anthropic are now at 0.1% of US GDP each. What % of GDP is AI revenue in 2030?
US GDP is roughly $30T. OpenAI and Anthropic are both rumored to be currently in the ball park of $30B of revenue run rate, or at 0.1% of overall GDP each. Through in clouds and other services and AI has grown from roughly zero to 0.25%-0.5% of US GDP in just a few years. If Anthropic and OpenAI hit $100B of revenue by EOY as many think they might, roughly 1% of GDP run rate will be from AI by end of 2026. This is insanely fast.
What % of GDP will AI be in 2030? 2035? How does the US economic base impact the slowing of AI impact? How much of the productivity gains ends up missing from GDP a la the missing productivity impact of the internet in the 2000s or IT in the 1980s and 1990s?
(Aside - If the impact of AI is mismeasured perhaps the wrong regulatory policies get implemented as a reaction as well - as AI gets blamed for only the bad (job losses) and not the good (new types of jobs, impact to education, healthcare…). Maybe the real ASI/Turing test is the ability to measure real world US GDP and productivity gains? :)
The AI research community just had a distributed IPO
When a company goes public many of the early employees may find themselves suddenly enriched. This may change behavior - people get distracted buying homes, chasing status or spouses, partying, or doing societal side quests. This does not apply to everyone, but a subset of people experience this.
Meta aggressively paying for talent changed the AI research talent market as the main labs had to match or provide large compensations increases to their researchers. Arguably, the AI research community just underwent the cross-company equivalent of an IPO as a cross section of the big labs & big tech. Somewhere between 50 to a few hundred people across all AI labs were granted huge sums of money as a reaction to Meta bidding on the best regarded researchers driving up everyones salaries.
Just like a traditional IPO, a subset of the members of that community are shifting some aspects of focus and lifestyle, checking out or getting distracted, while others stay the course. In general the AI community is very mission aligned around building AGI or focusing on AI for science.
Either way, an interesting new phenomenon has quietly occurred in Silicon where, instead of a company going public, a very specific slice of people effectively did. The top AI researchers became post-economic all at once. (Maybe the closest prior analogues is the early crypto HODLRs?).
Compute ceiling = artificial asymptote on near term model capabilities? Does this just re-enforce an oligopoly market for now?
We have seen amazing progress in model capabilities in the last few years. This has been reflected in the flowering of use cases + revenue for the main labs and app companies built on top.
At the same time, the labs are increasingly compute limited as one extrapolates out both training scale planned as well as future inference needs. Compute build outs seem at least in part to be limited by memory from Hynix, Samsung, Micron et al at least for the next 2 years as a build out cycle occurs for manufacturing for these companies.
This means that rather than a single lab buying well ahead, or being able to use all the compute it wants, all the big labs are effectively and increasingly in a compute constrained world. This constraint may end up creating an artificial short-term asymptote on AI model progress. While people will undoubtedly get more efficiency out of the compute they have, this artificial compute constraint may mean no one lab is able to break significantly ahead until 2028 at the soonest - re-enforcing an oligopoly market for LLMs. We may also see the labs “accordion” between allocating compute and human resources to apps vs models and back again. Similarly, the depreciation cycles on chips and systems will be different then everyone expected and the lifetime of silicon will be extended due to lack of sufficient new supply.
The counter to this is algorithmic or other breakthroughs, if contained within a single lab (vs leaking at an SF holiday party attended by researchers) could turbocharge a single company to dominance, particularly if coding takes off and there is some form of ongoing self improvement loops by AI building future AI leading into liftoff. If we do end up with a hard compute constrained environment breakaway liftoff may wait for 2028. Of course, it is also possible we are compute constrained for years post 2028 due to excess demand. Exciting to watch what happens.
Compute (tokens) is the new currency
Compute (or could be stated as tokens) is a new unit of denomination for economic value in silicon valley. Token budget impacts things like
a. What can you accomplish as an engineer
b. Your spend and potential revenue as a company
c. Your business model.
Some companies are effectively inference providers disguised as tools. Neoclouds are the clearest form of this, but things like Cursor similarly are providing cheap inference as a core part of their product offerings and effectively subsidizing compute, which has been a smart user acquisition and usage model. Who doesnt love extra tokens?
Things have gotten to the point where Allbirds (shoe company) just raised a convert to build a GPU farm. Will they be to AI what Microstrategy is to crypto?
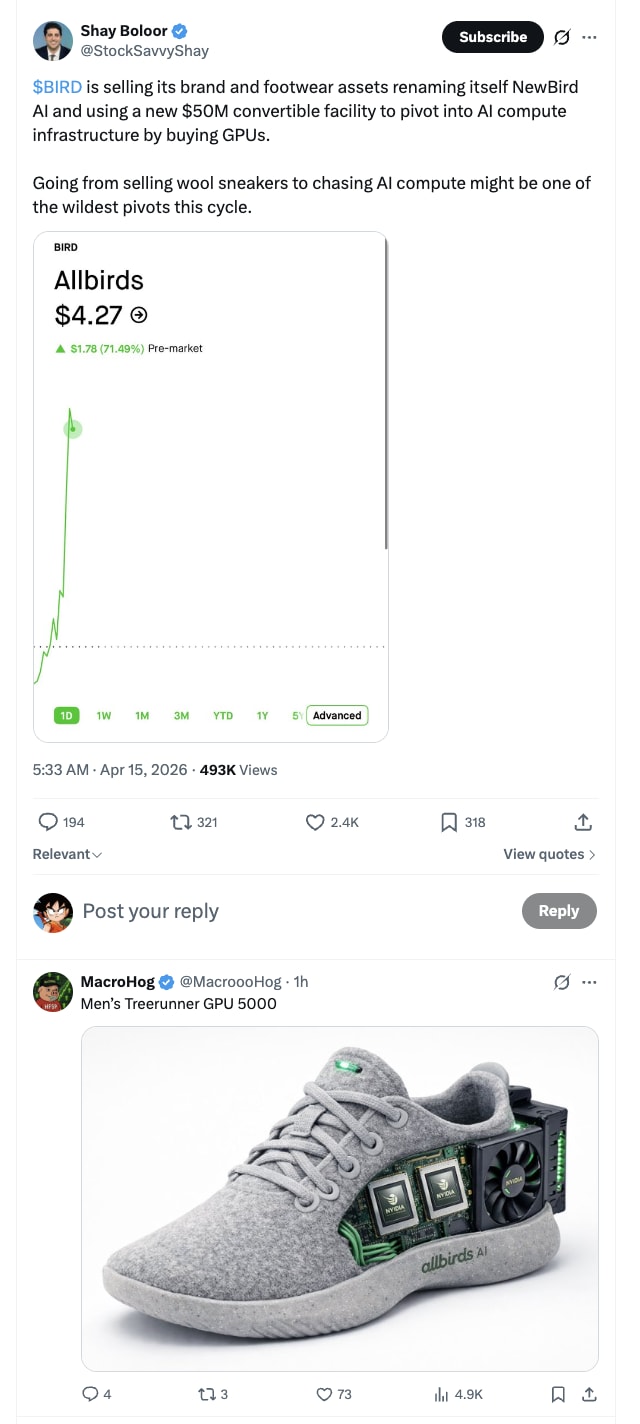
Hidden layoffs & the developing world
Most of the “layoffs due to AI” announced so far are probably just companies that overhired during the COVID zero interest rate environment slimming back down. Saying “look how good we are at AI we need fewer people” sounds much better then “we way overhired and are fixing it a few years too late”.
That said, AI is having a real impact in multiple areas such as customer support. Companies that are shrinking teams due to AI are actually cutting outsourcing firms first - so they headcount is not directly on their balance sheet but paid for as a service. This means countries like India and the Philippines may be the most impacted soonest in terms of employment and AI as they house many of these outsourced services organizations.
It also means some developing countries may lose their services ladder to upgrading their economy and work. If AI takes many of the outsourced services jobs first, employment in these economies will need to shift elsewhere. An interesting question is whether this shifts human migration patterns?
Employee headcount is going to flatten for lots of companies and then shrink
Multiple later stage CEOs told me that rather then do big layoffs due to AI, they will just stop growing. So if revenue at the company is growing 30%, 50%, or 100%, headcount may be flat or slightly down as they allow attrition to shrink staff. Existing headcount will become more productive, and companies may start swapping in fewer better people. This may medium term inflate the salaries of the very best people who can leverage AI immensely. Expect hiring to continue in sales, some engineering for growing companies, but maybe not as much elsewhere.
Some companies are starting to ask what is the right ratio of token budget vs salaries in their org? Unclear what the right timeline for this metric is.
True startups (e.g. a 5 person team) in the short run should continue to scale up headcount like in the olden days as they hit product/market fit but just with more leverage per person. So the “flat company” is going to be more of a later stage or public company phenomenon for growing companies in the next 2-4 years. Low growth companies of course should shrink.
This may have implications for HR/software companies. See also:
The Slop Age could be the golden era of AI x humanity
We are likely in the golden era of AI + humanity. Before the last few years, AI was inaccessible, not very generalizable, and could only do specific tasks. In the future, AI may become superhuman at most tasks and take over a lot of work some people find fun. Today, AI creates useful slop at volume, which means humans are still needed to desloppify the slop, but the slop provides real leverage on time and jobs, which means it is fun to be working right now. If AI displaces people eventually or does more interesting work, this golden moment may fade or change. Is the Slop Age the golden era of humanity + AI?
(One could of course argue that we were in the midst of a human slop era before the AI slop era - in other words the era of huge amounts of human created sloppy content on the internet as it grew to billions of web pages, but not billions of new human insights. Does the slop era end with AGI, or when AGI cleans up all the prior waves of human slop?)
AI will eat closed loops first
AI will first automate away the things that are easier to form a closed loop learning system on. This is why code and AI research may be accelerated and then displaced quickly - you can have testable closed loop systems so machines can learn and iterate quickly. The tighter the closed loop, the faster the AI can learn. You can make a 2x2 of jobs by how closed loop they can be made, versus their economic value, and see where AI may impact labor fastest. Fast time to closed loop + high economic value = fastest AI impact (hence software engineering).
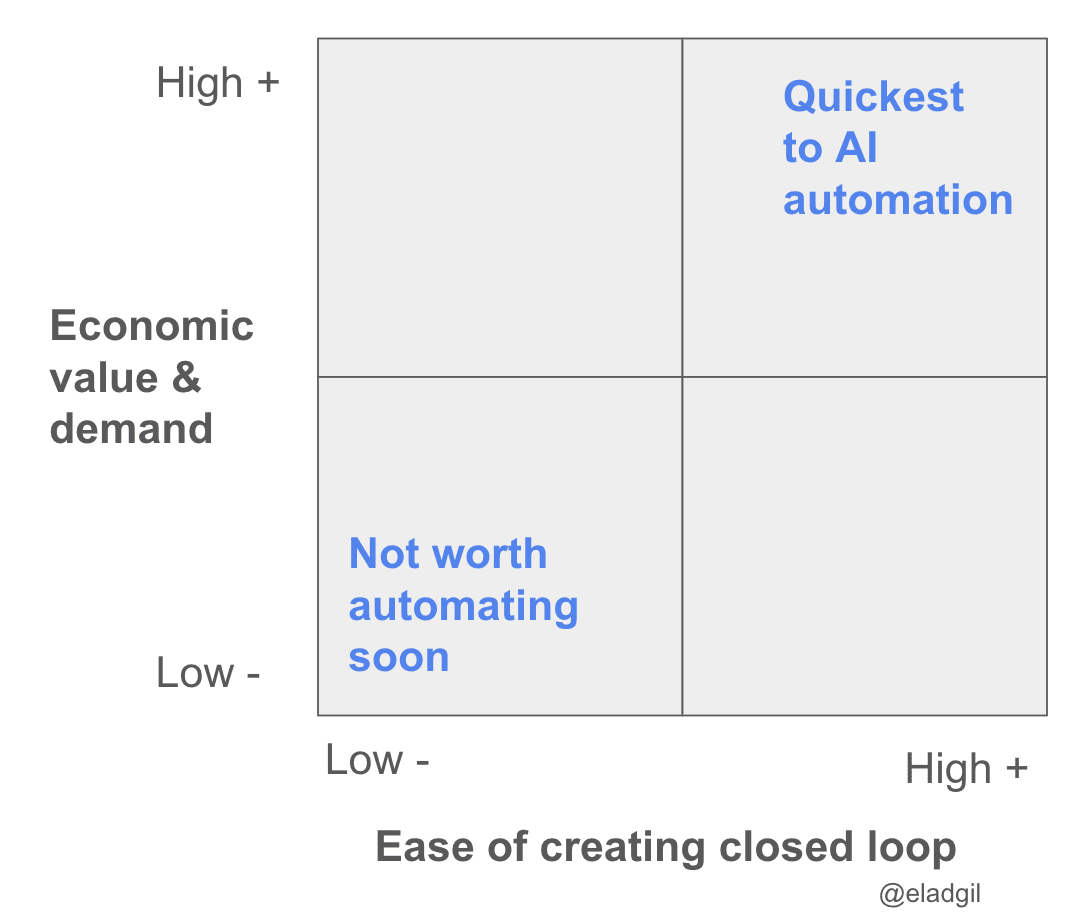
Code is interesting in that there is probably 10-100X the demand for great software developers as there is supply today (hence coding tools doing so well in market). The AI engineer of the future will be managing and orchestrating large numbers of agents to build things (systems and product thinking) vs writing a lot of code themselves (the auto-complete tab era).
An interesting question is what jobs or tasks will be made more closed loop next? Where is AI most embeddable and teachable?
Relatedly, data collection & labelling in every field will continue to grow.
Artisanal engineers vs utility engineers and AI
Deep artisanal “my code is my craft” and “I love creating bespoke things” engineers decreasingly happy in world of AI. Systems thinkers and product thinkers engineers happiest. Many people are a mix of both.
The Harness
If you look at the use of AI coding tools, the harness (and broader product surface area eg UX, workflow, etc) seems to be increasingly sticky in the short term. It is not just the model you use, but the environment, prompting, etc you build around it that helps impact your choice. Brand also matters more then many people think. At some point, either one coding model breaks very far ahead, or they stay neck in neck. How important is the harness/workflow long term for defensibility for coding or enterprise applications?
Products tend to not be sticky until they suddenly are very sticky.
There will be variability in where future forms of harnesses matter vs not. What is the sales AI harness? The AI architect harness? This leaves room for some startups to thrive.
Selling work, not software. Units of labor as the product
AI is about selling units of labor online (and eventually in the atomic world via robotics), not displacing software. While Zendesk was selling seats to customer support reps, Decagon and Sierra sell customer support agentic work output and labor.
AI grows tech TAMs dramatically.
Most AI companies should consider exiting in the next 12-18 months
In the Internet era of 1995-2001, roughly 2000 or so companies went public. Of these only a dozen or two survived. Similarly in the AI era, most companies, including those that are ramping revenue today, will see the market, competition, and adoption, turn on them.
Founders running successful AI companies should all take a cold hard look at exiting in the next 12-18 months, which may be a value maximizing moment for outcomes. A handful of companies should absolutely not exit (eg OpenAI, Anthropic) but many should if they can while everything is on the upswing.
This is all of course counterbalanced by enormous growing demand for AI services of all types. While the tide is rising, many companies will seem to be unstoppable and durable - whether they are or not in the long run remains to be seen.
Anti-AI regulation & violence will both increase
AI has had very little real world impact to eg job displacement so far. However, some AI pundits and some leaders have been quite vocal and doomer-esque to the point where a strong anti-AI narrative is emerging in both politics (Maine just banned new data centers although this also ties into energy, jobs, and NIMBYism) and amongst violence-centric activists (see recent attack on Sam Altman). Expect this to increase dramatically. It would be great if more leaders in AI continue to emphasize the optimistic side of what is coming in public rhetoric and political lobbying. In general, the AI field would benefit from its leaders continue to work actively on reigning in the doom and gloom.
Other
Any other random thoughts to consider? Ping me on X.
Thanks to Aravind Srinivas of Perplexity, Scott Wu of Cognition, Adam d’Angelo of Quora/Poe, and others for comments.
My book: High Growth Handbook. Amazon. Online.
Markets:
Firesides & Podcasts
Startup life
Co-Founders
Raising Money
2026-04-17 06:05:55
Analysis below from Shreyan Jain. All data pulled on Dec 31st of the year, so “2025” means Dec 31 2025 / Jan 1 2026 in terms of market caps.
In the past two years, we’ve seen a post-ZIRP market correction, the rapid breakout of frontier AI labs like OpenAI and Anthropic, and ongoing punditry on an “AI bubble.” Analysis suggests that San Francisco Bay Area has emerged as an AI super cluster, with 91% of global AI private market cap residing in a 1 hour radius.
Analysis from previous years can be found here: 2019, 2020, 2021, and 2023.
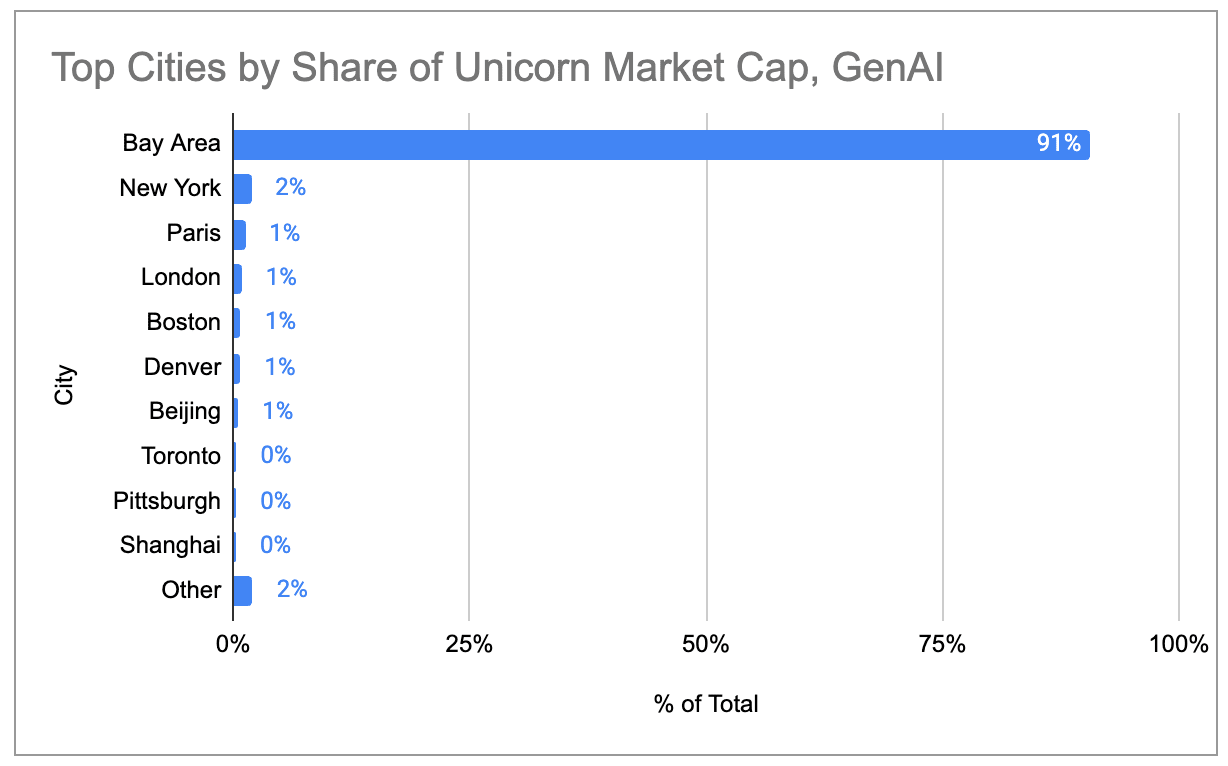
Generative AI is creating a super-cluster in the SF Bay Area. The Bay Area now accounts for ~39% of global unicorn market cap, more than 4x higher than any other city and up from ~29% 1 year ago. Among just generative AI unicorns, the Bay Area accounts for ~91% of global market cap.
Majority of unicorns are in the US: The US added almost $1.2T of unicorn market cap in the past year and now has a ~65% share of global market cap. Europe has surpassed China in terms of global market cap share, but is still at just ~10%.
Recent unicorns are even more concentrated in the US / Bay Area. The US has 83% share of total market cap across companies that became unicorns in 2023 or later, compared to 60% across companies that became unicorns in 2022 or earlier. Similarly, the Bay Area’s share is 63% in the 2023-2025 cohort vs 33% in the 2022-or-earlier cohort.
New unicorn creation has slowed down: Just ~300 new unicorns were minted between 2022 and 2025, compared to more than 900 in the three years prior.
But existing unicorns are more valuable than ever before. While the total # of unicorns grew by just 6% YoY, the total market cap of those unicorns grew by 33% in the same time period. As a result, the average per-unicorn market cap is at its highest level in the past 6 years.
Valuation growth is mainly being fueled by growth of gen AI companies: Gen AI unicorns from 2025 grew their valuation by an average of ~$2.2B YoY, compared to ~$0.4B for non-AI unicorns. Overall, gen AI has more than 10x-ed its share of total unicorn market cap from 2% to 22% between 2024 and 2026. This means the Bay Area should become even more of a concentrated hub for unicorn market cap creation going forward.
Unicorn hubs tend to consolidate around specific industries: 6 of the top 10 unicorns in the Bay Area are gen AI companies, while 7 of the top 10 unicorns in New York are fintech/crypto companies. 3 of the top 5 unicorns in LA – SpaceX, Anduril, and Relativity – are defense/space (accounting for 83% of LA’s total market cap), and another 4 of its top 10 are consumer.
All raw data was taken from CB Insights and can be found here. Some caveats:
Private funding rounds can take a while to be reflected in public datasets, and therefore there may be cases where unicorn valuations are stale. For example, the dataset does not reflect the latest funding rounds for companies like Anduril, Stripe, and SpaceX.
Unicorn market cap is at best a rough, backwards-looking proxy for startup activity within ecosystems, and there are undoubtedly errors in mapping specific companies to corresponding valuations, cities, industries, etc. That said, we believe the data provides a directionally correct view of major year-over-year trends.
Unicorn market cap has never been more geographically concentrated than it is today. The US alone accounts for 65% of all unicorn market cap, up from 58% a year ago and 44% in 2020. The US share is ~4x as much as China, which has the second highest share.
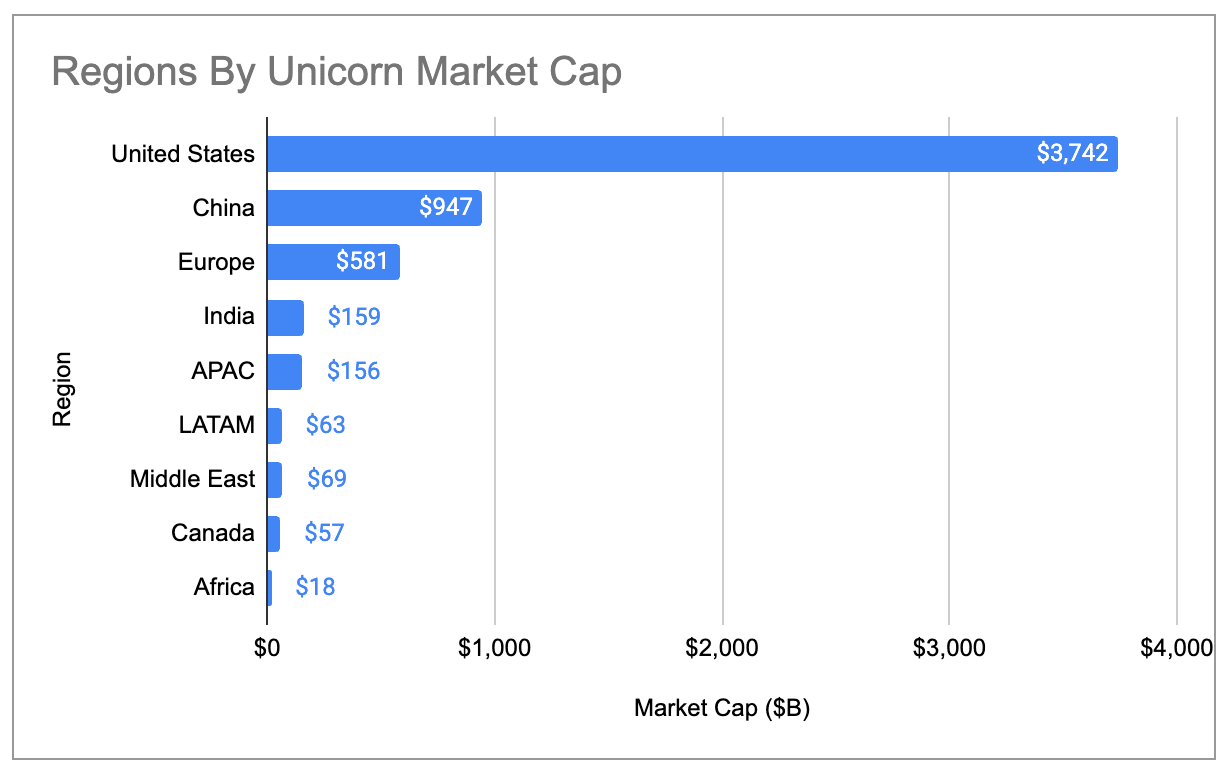
The Bay Area similarly has 4x more unicorn market cap than any other city, growing its share of global market cap from 29% in 2024 to 39% today:
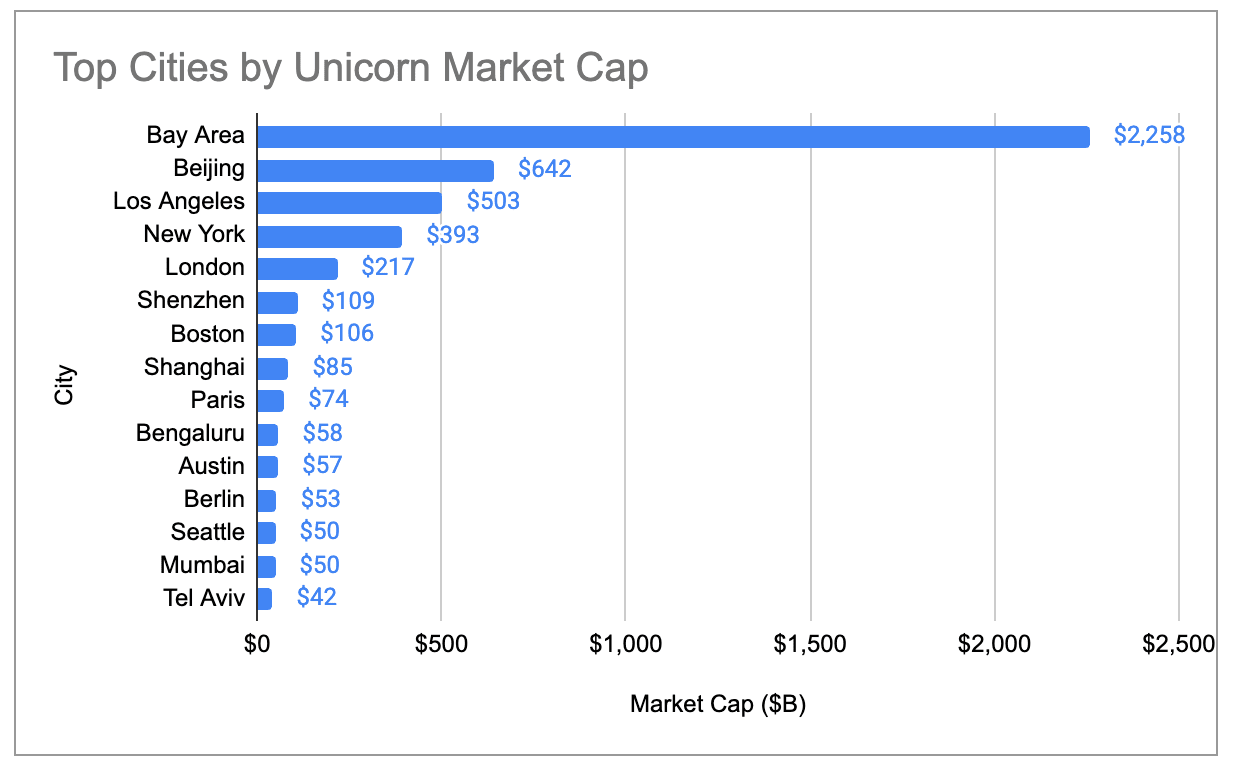
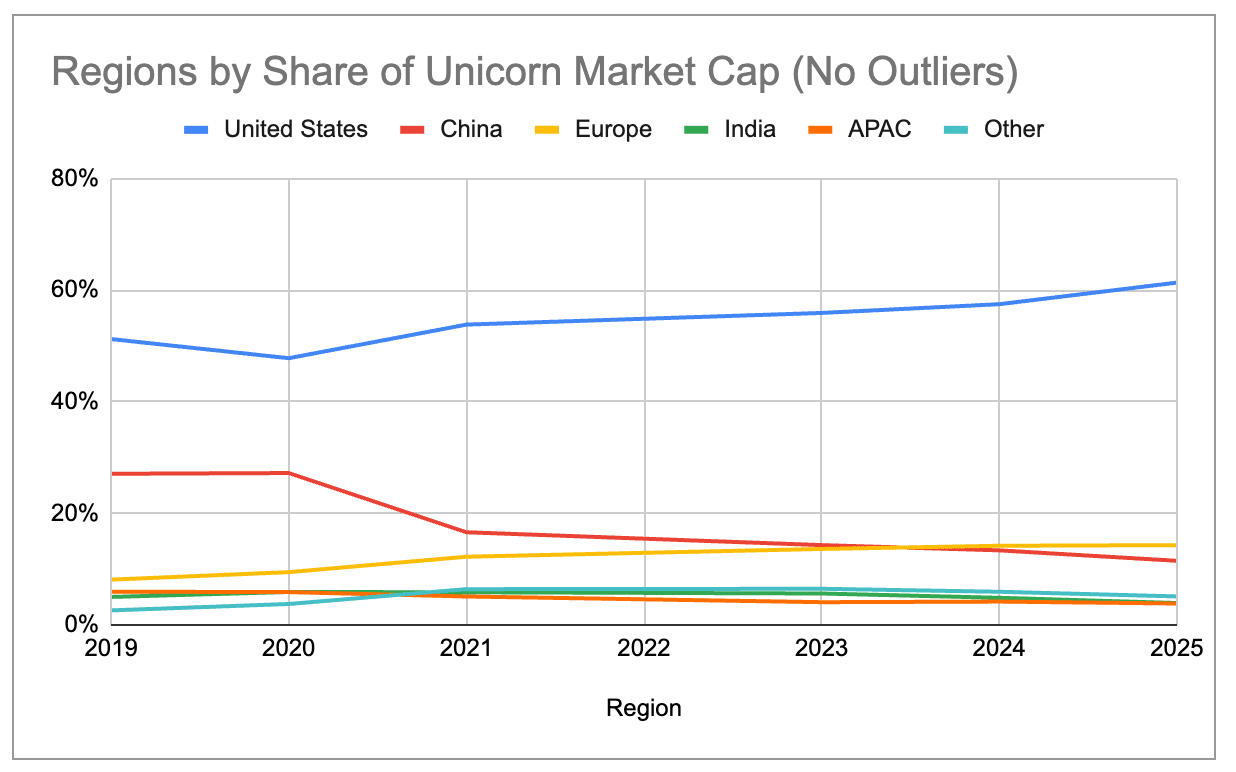
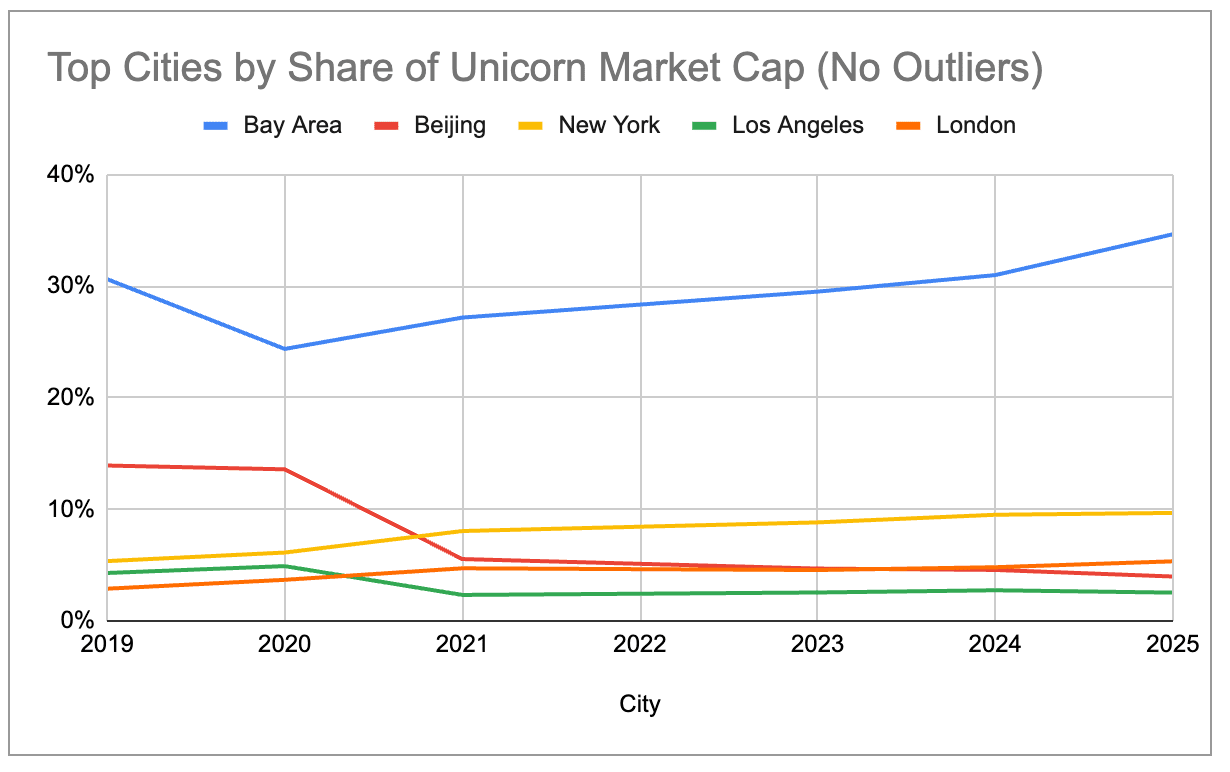
Even after filtering out the three big outliers that make up a disproportionate share of their ecosystem’s market cap – OpenAI ($500B), SpaceX ($400B), and ByteDance ($300B) – we can see that the big ecosystems are becoming progressively more concentrated since 2019. The US has been steadily increasing its share, while China has been steadily declining. Europe has surpassed China in terms of total unicorn market cap as of 2024, while New York and London have now overtaken Beijing.
If we restrict our attention to the 97 unicorns that primarily sell products/services related to generative AI, the Bay Area is even more of a concentrated “super-cluster.” The Bay Area is home to 91% of all gen AI unicorn market cap; no other city is above 2%.
Aggregate gen AI unicorn market cap is growing exponentially, with almost all of the gains coming from the US broadly and the Bay Area specifically.
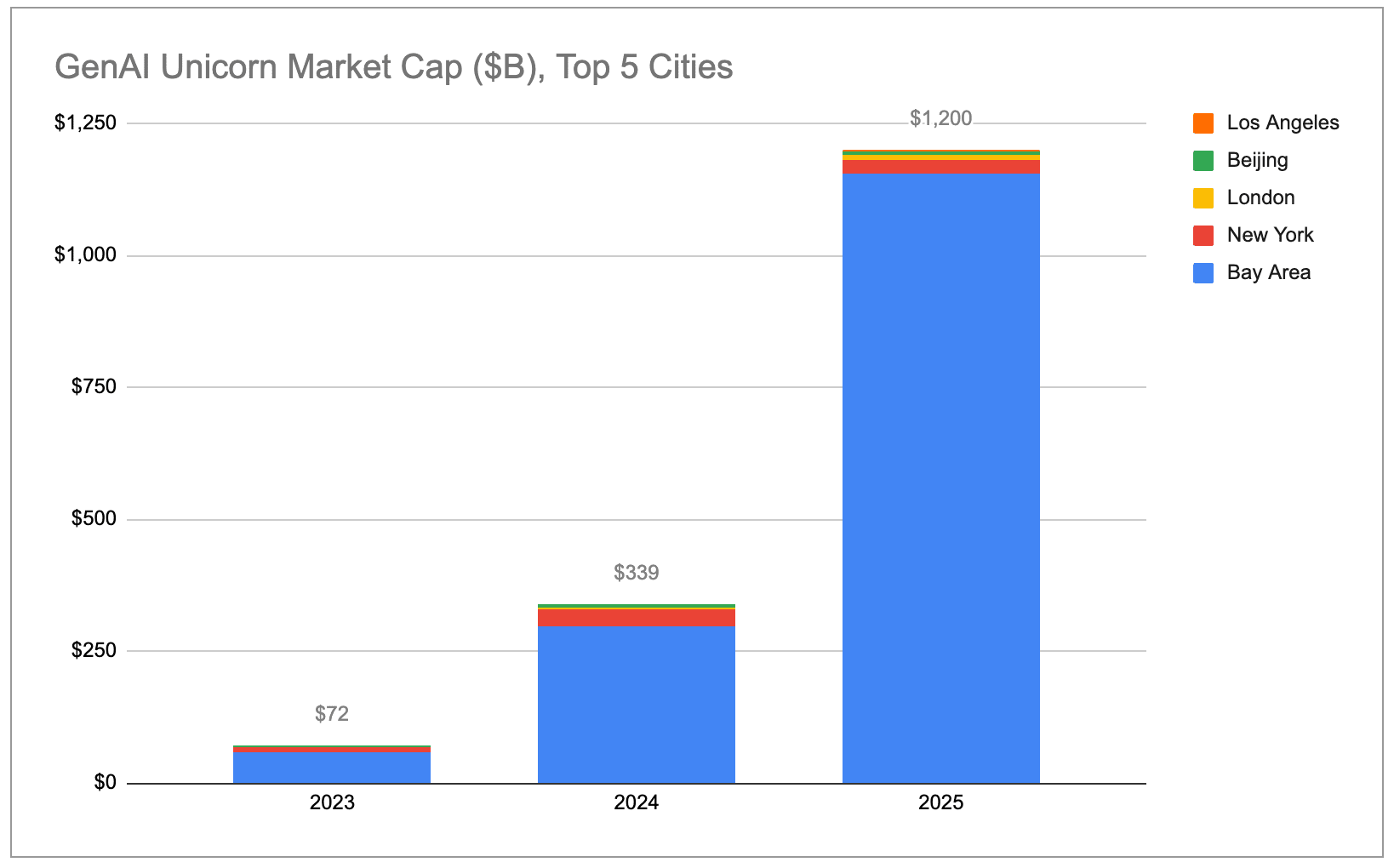
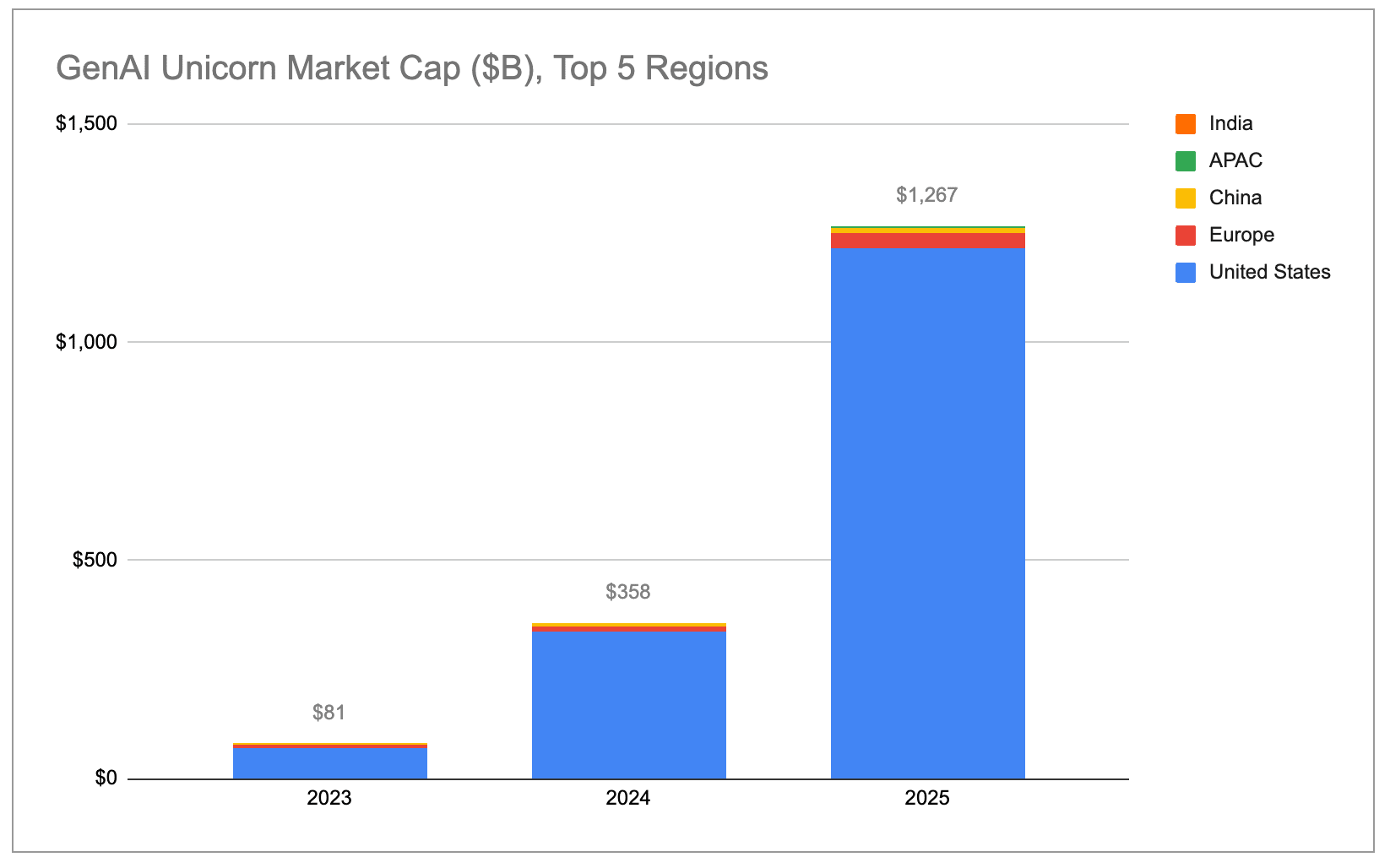
Gen AI unicorns are also growing their valuations much faster than non-AI unicorns. The 48 gen AI companies that were unicorns throughout all of 2025 grew their aggregate market cap by a total of $778B over that period. This was more than the cumulative increase across the remaining 1,100+ non-AI unicorns combined! Even if we filter out OpenAI (which added ~$343B in market cap) and Anthropic (which added ~$334B), gen AI unicorns grew their valuations by an average of ~$2.2B YoY, or 5x as much as the ~$0.44B in market cap the average non-AI unicorn added over the same period.

As a result, on a relative basis gen AI companies have grown from being 2% of all unicorn market cap in 2023 to 22% today. If this trend holds up, the Bay Area should continue to meaningfully expand its share of overall unicorn market cap due to its effective monopoly on top AI companies and talent.
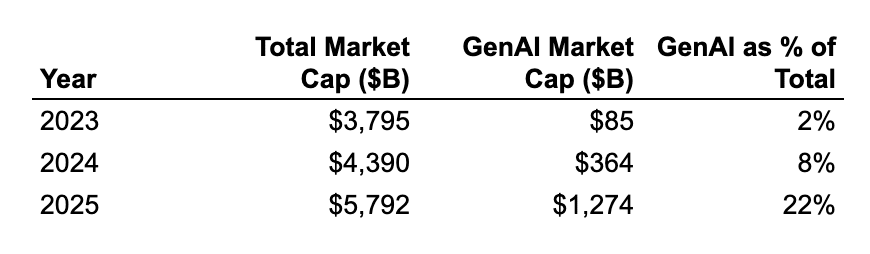
(Note: We categorized only those companies which earn the majority of their revenue directly from generative AI adoption as “gen AI” for the purposes of this exercise. You can see the list of companies here. Note that we included some chip/hardware companies like Cerebras and TensTorrent and some infrastructure companies like Coreweave and Crusoe, but we did not include data/infrastructure companies that support AI/ML workloads more broadly such as Databricks, or robotics/defense companies that use AI/ML for autonomy such as Anduril.)
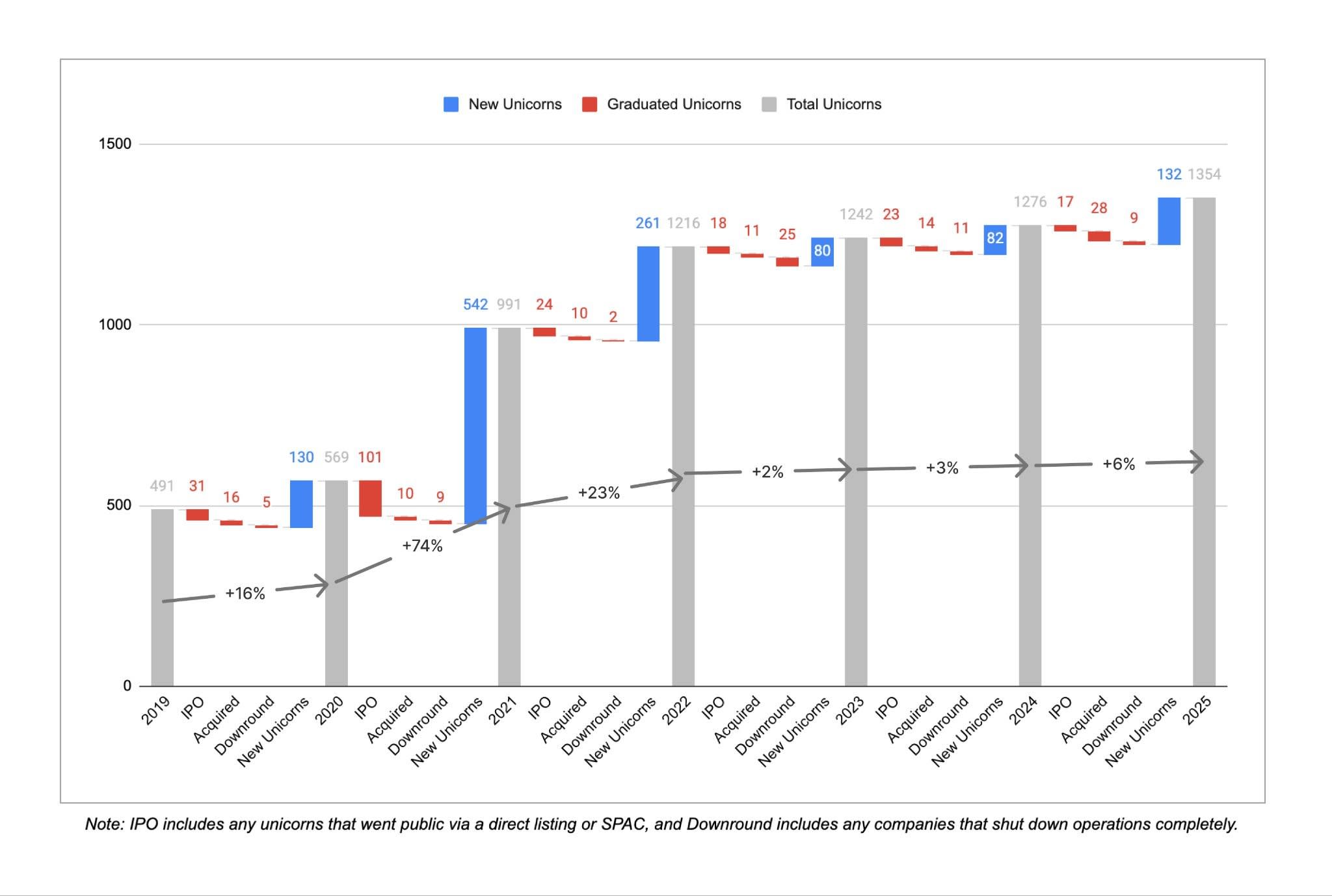
After 3 straight years of sustained growth, the rate of new unicorn creation slowed down considerably in the last 3 years. Between Dec 2019 and Dec 2022, more than ~300 companies earned unicorn status for the first time on average each year. That number fell to just ~100 new unicorns per year between Dec 2022 and Dec 2025, although 2025 saw a bit of a rebound compared to the 2 years prior. There were also 45 cases of companies losing unicorn status due to downrounds/shutdowns in the past 3 years compared to just 16 in the 3 years prior, signaling an ongoing reset from the 2021/2022 ZIRP-era days of inflated valuations.
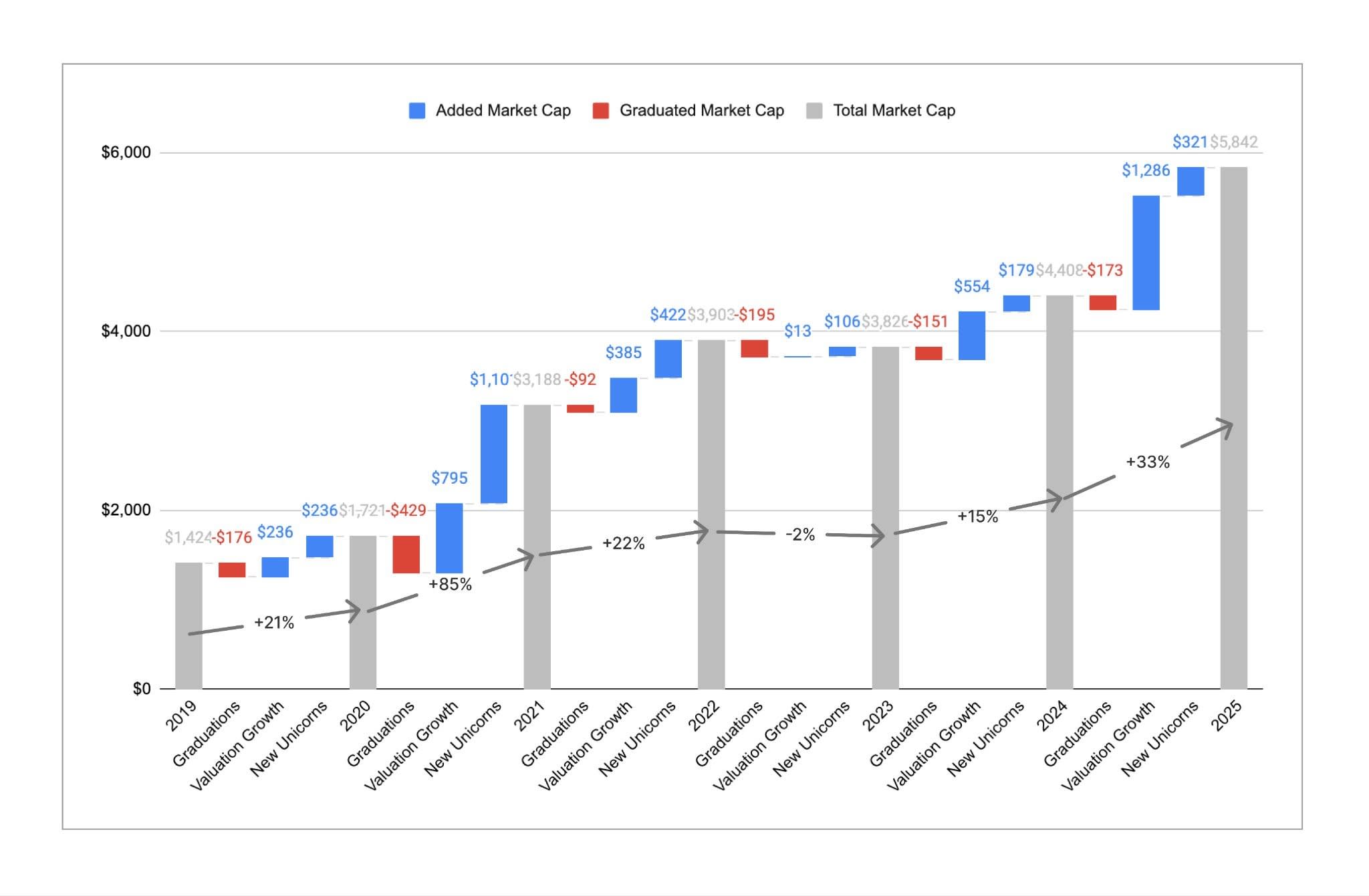
Although the number of unicorns has stayed roughly flat, the aggregate market cap of those unicorns has grown quite significantly. Total market cap across all unicorns increased by 33% in the past year, from ~$4.4T to ~$5.8T. This was a big rebound from the 2 years prior, and in particular relative to 2023 when aggregate market cap actually shrunk YoY. While market cap growth has historically been driven more by new companies becoming unicorns than by existing unicorns growing their valuation, most (~80%) of the market cap creation in 2025 was due to existing unicorns growing their valuation. As a result, the average per-unicorn market cap has increased from ~$3B to ~$4.4B, the highest mark we’ve seen in the 6 years we’ve done this analysis. While it’s harder to become a unicorn, those companies that do pass the $1B mark are on average more valuable and faster-growing than previous years.
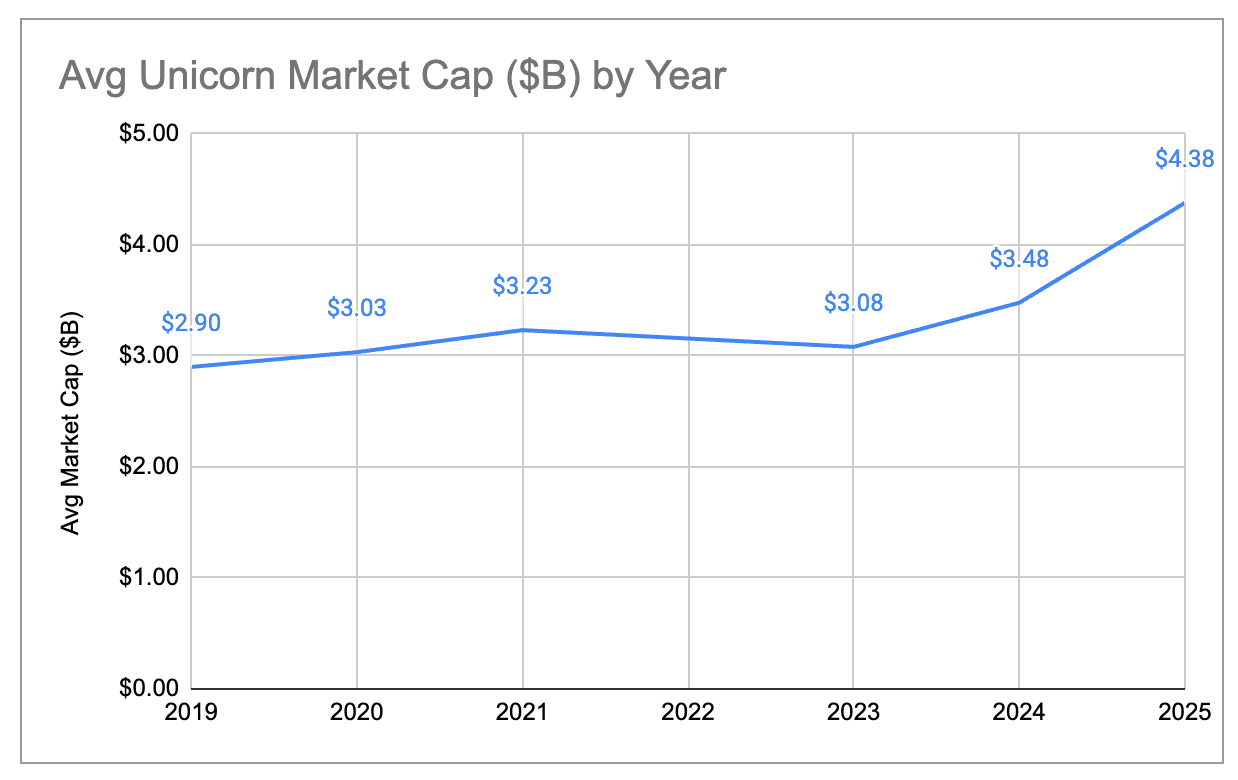
One way to offset the effect of inflated valuations is to look only at those companies that became unicorns after the end of ZIRP. Here is what the distribution of unicorn market cap looks like for companies that became unicorns prior to 2023 vs after 2023:
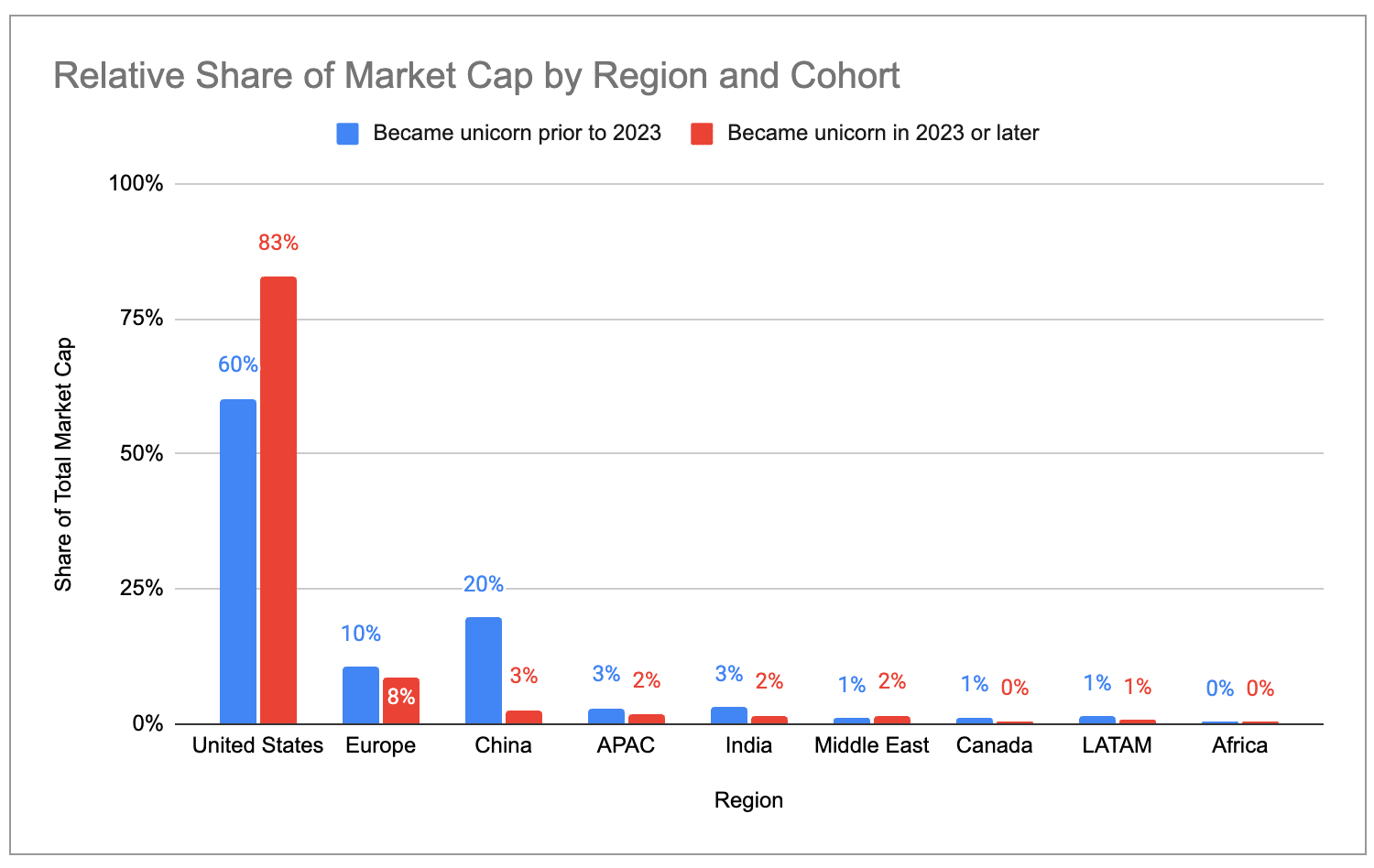
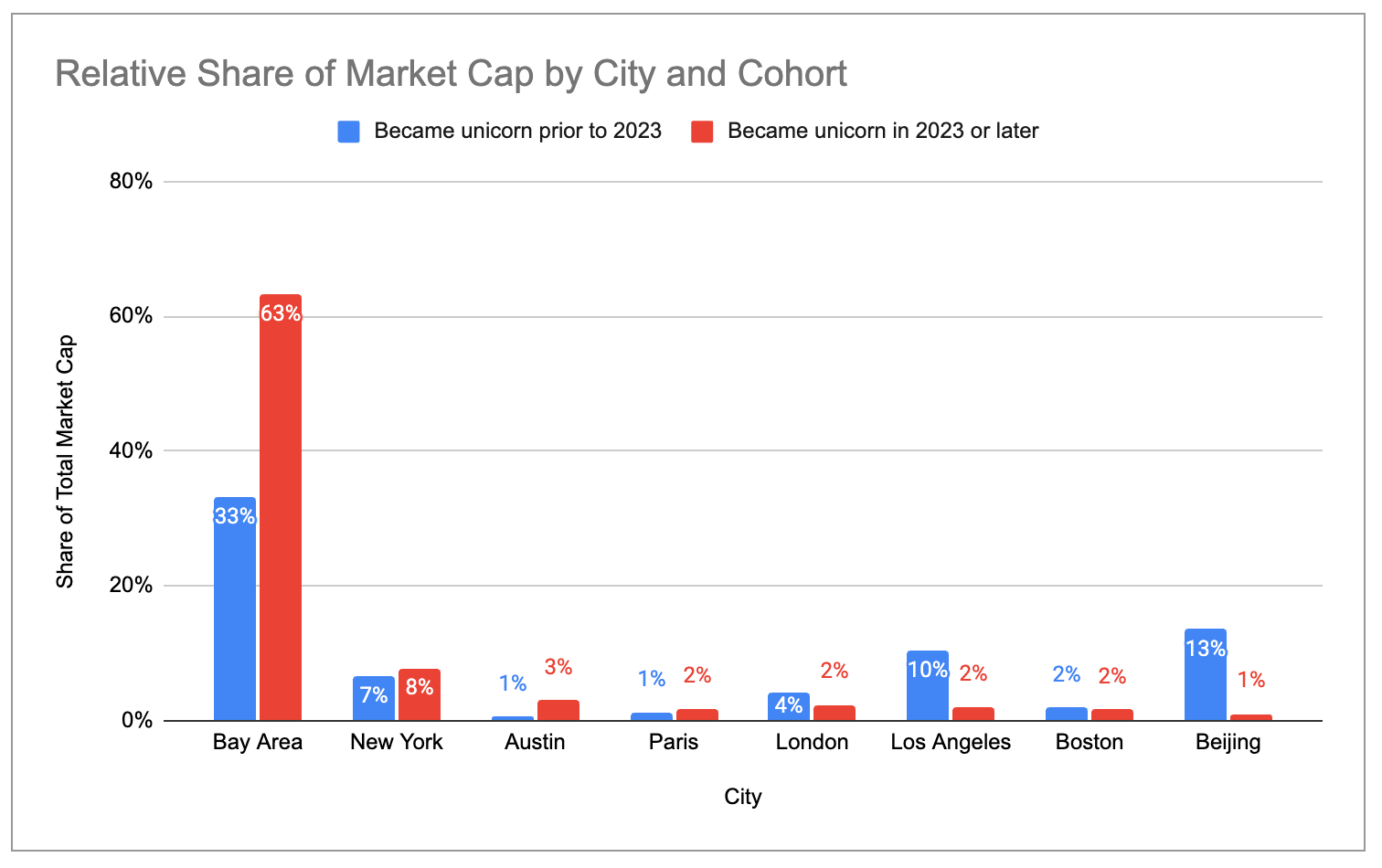
Recent unicorns tend to cluster more in the US and less in Europe and China. The Bay Area has 63% of market cap across all net-new unicorns minted since 2023, compared to 33% of market cap across older unicorns.
Roughly 60% of the nearly 1,000 companies that were unicorns as of December 2021 have kept their unicorn status without raising any new round. These “stale” unicorns raised enough capital to survive for the past 4 years, but haven’t been able to grow beyond their ZIRP-era valuation. Collectively, the stale unicorns from 2021 account for ~$1.4T of present day unicorn market cap, nearly 25% of the global total.
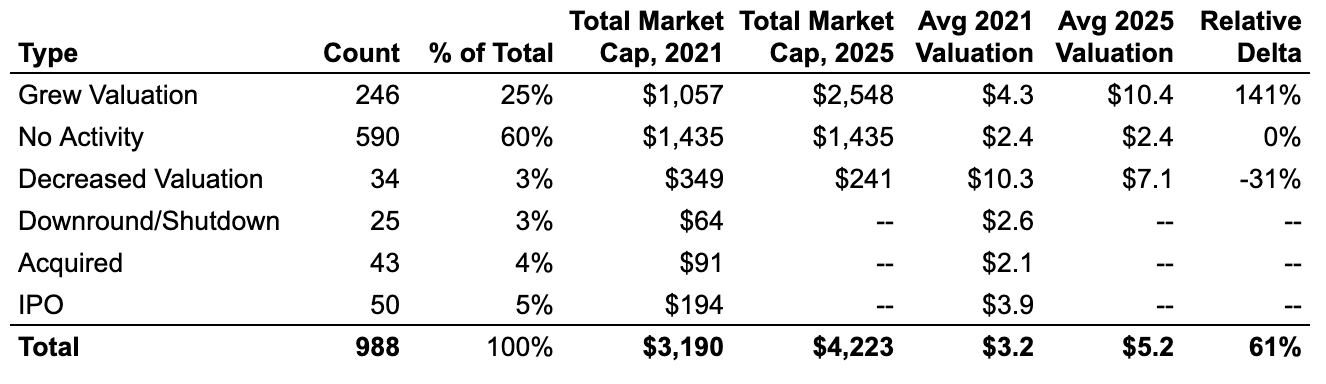
Both the US broadly and the Bay Area specifically have a much higher share of “fresh” unicorns (i.e. unicorns from 2021 that have raised new rounds since) than of stale unicorns. By comparison, Europe, India, LATAM and New York have higher concentrations of stale unicorns than of fresh ones.
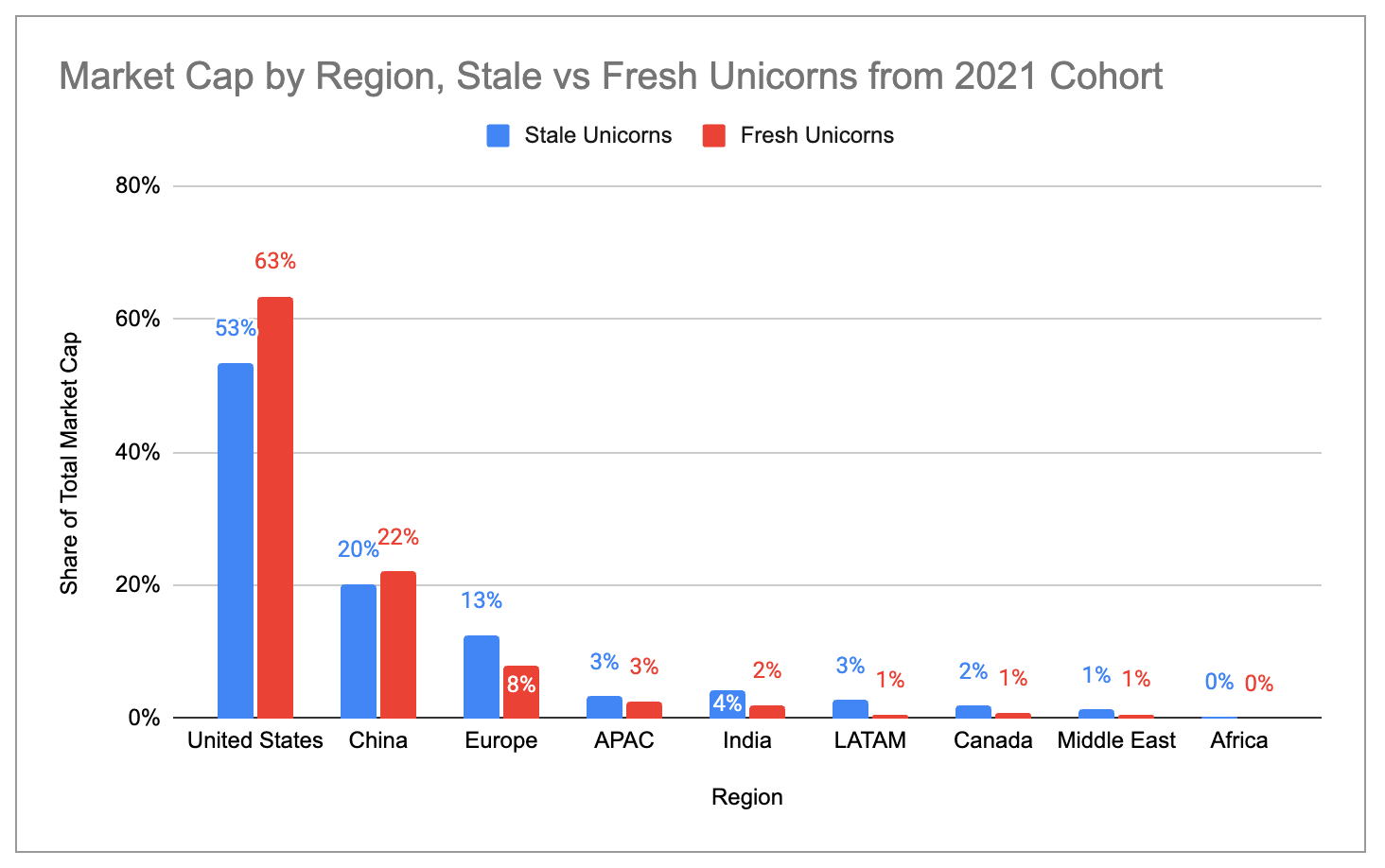
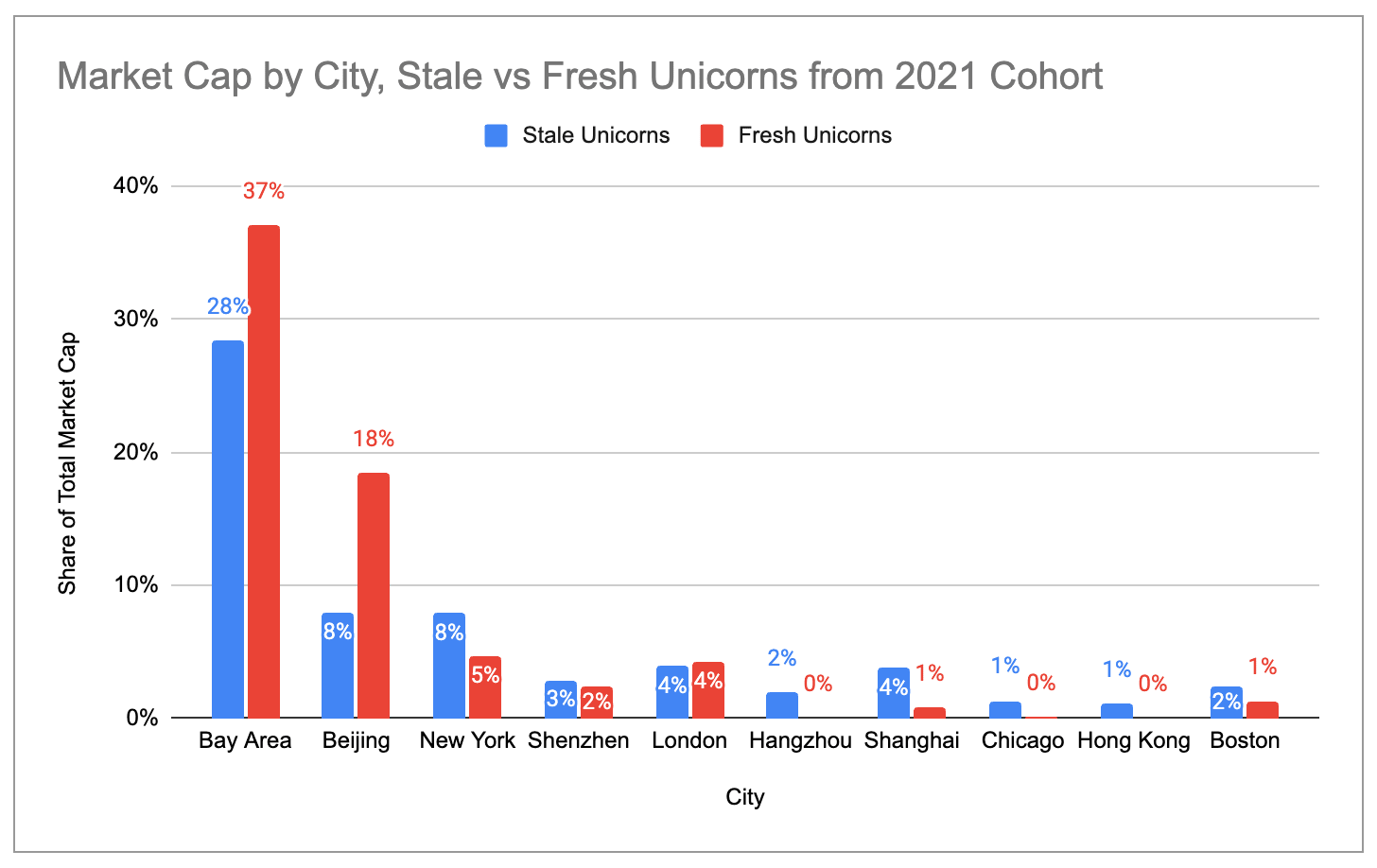
Within the US, four industry-towns combine to make up ~76% of all unicorns and ~87% of all unicorn market cap: the Bay Area, New York, Los Angeles, and Boston. Among these, the Bay Area is clearly the biggest hub, with more than 2x as many unicorns and more than 4x as much market cap as second-place New York/Los Angeles.
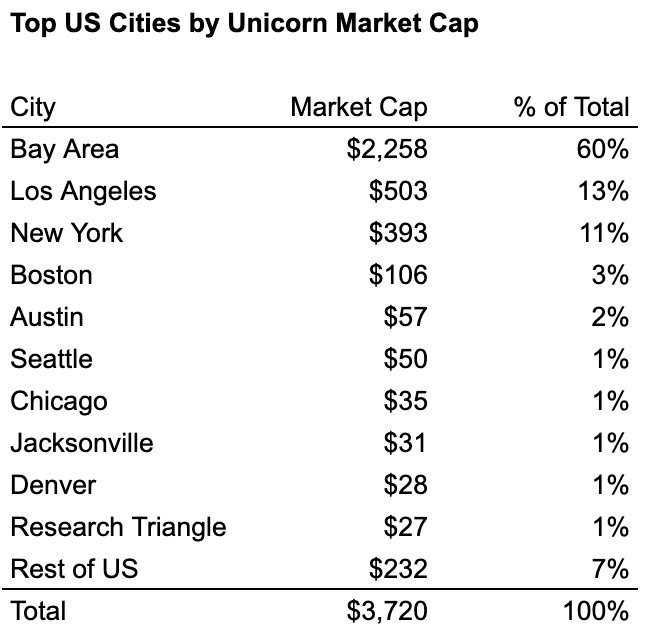
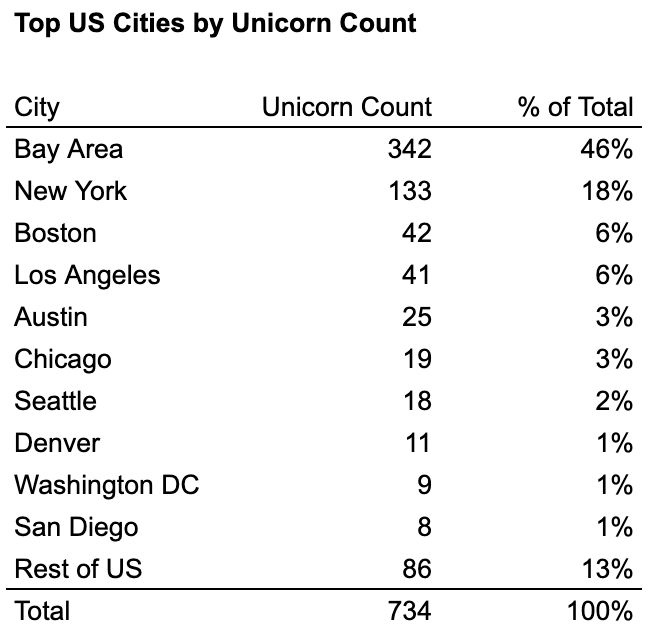
If we look at the 10 most valuable unicorns in the main US hubs, we can see that industry-towns tend to consolidate around specific industries to various extents:
The Bay Area is a gen AI cluster (6 of top 10)
New York is a fintech/crypto cluster (7 of top 10)
LA is a defense/space (3 of top 6) and consumer (4 of top 10) cluster
Boston is a bit more balanced but relatively speaking more of a biotech/healthcare cluster (3 of top 10)
2025-07-23 00:47:51
AI markets have evolved significantly over the last 4 years. When GPT-3 came out and scaling laws were openly discussed in the AI literature, it seemed clear that you could extrapolate the rate of progress from GPT-2 to GPT-3 onwards through GPT-4, 5 etc and realize a revolution was going to happen.
4 years ago, I started looking for Generative AI companies to back or help start given this curve. I ended up leading or participating in early rounds in companies like Harvey, Perplexity, Character.AI, BrainTrust, and others. At the time it was clear to just “back all the best people working on all the biggest problems” because very few people were actually starting generative AI companies. OpenAI seemed to be the only clear foundation model company (with Anthropic pre-launch and promising, Llama non-existent, and Google clearly someone who could (and would eventually) aggressively innovate but was stymied at the time by its own internal processes).
As more people outside of the core AI community woke up to this opportunity, or researchers and engineers from the main labs left to start new companies in AI, the world of AI became murkier. I used to say that the more I learn about AI, the less I knew about AI – because it was unclear in many early markets who the likely winners would be and the underlying models and tech were changing so fast. For example in 2022, it was clear code / AI driven software engineering was going to be important, but it was unclear who the winners would be (for example Cursor was not launched until 2023, Codium launched Windsurf in GA about 9 months ago, and Cognition launched Devin in limited release a bit over a year ago).
We have now entered an era where the first set of AI markets have solidified and a likely set of winners have emerged. This does not mean others won’t show up over time to compete in these markets or that current leaders won’t get acquired or eventually die (just as Stripe launched over a decade after PayPal and 4 or so years after Braintree, and Facebook launched a few years after Friendster and Myspace). We will also see a new set of markets crystalize in the coming few years and these markets today seem quite uncertain.
There are many types of foundation models including large language models (LLMs), as well as models for voice, images, video, music, chemistry, biology, materials, physics and other areas. Foundation models are often driven by scale (of data, compute, certain types of post training and feedback, etc). Scale means capital, so to win in the LLM market you need high availability of capital now entering the many billions.
In the LLM market, a core set of companies have clearly emerged as the ongoing players of the future. They are often partnered with hyperscalers (Amazon with Anthropic, Google GCP with Gemini, Microsoft Azure with OpenAI and its own efforts) as these companies have an economic incentive (cloud spend on AI via AI adoption) to fund these companies that is independent of whether these companies are good investments or not (they often are). Revenue ramps for foundation model companies are rumored to be in the $0 to many $billions range in just 3 or so years, while cloud spend on “AI” has been reported to have reached a few billion per quarter for some of the main clouds.
The core players in the LLM world are now Anthropic, Google, Meta (via Llama), Microsoft, Mistral, OpenAI, X.AI. Three or four of these companies are the clear winners on various benchmarks and most broadly adopted by developers and enterprise, and are also driving most of the spend in the industry. There are newer entrants like SSI and Thinking Machine Labs driven by brilliant AI researchers, which may either come up with innovative approaches or raise ongoing money to compete, or end up in a few years as acquisitions for companies wishing to enter the market or double down on talent.

In parallel, Chinese companies have launched new open source efforts such as Deepseek, Alibaba Qwen, and more recently Kimi, that perform well on benchmarks. There is a lot to say on Chinese open source LLMs, that might be best covered in a separate post.
In the future, it is unlikely that many new core LLM companies will get started due to capital moats, barring some new breakthrough that somehow doesn’t spread quickly.
Other foundation model markets are still lacking the clear winner or winners although promising companies exist in multiple segments.
Code is one of the earliest and clearest large-scale applications of generative AI and LLMs. For example, Github copilot was launched in October 2021 and was already well adopted and useful despite more limited functionality and fidelity of its day. Code has all sorts of properties that make it especially amendable to generative AI approaches. Revenue ramps in code are rumored to be in the $0 to $50 up to $500M in the first 2 years of some of the players live product lifetime – an insanely fast pace.
Like foundation model companies, the core likely winners in code are evident, with a handful of companies seeming to be interesting over time. Large incumbents may still enter the coding market, and products to date do not seem especially sticky but moats tend to come with time. However, this handful of companies will play an important role in the next few years of code barring the unexpected and includes Anthropic’s Claude Code, Cognition / Windsurf, Cursor, Google / Windsurf, Microsoft/Github, OpenAI, potentially startups like Magic or Poolside, and then vibe coding companies like Lovable, Replit, and others. Intriguingly, both Figma and Canva have launched vibe coding tools and one can imagine lots more coming.
A number of questions continue to exist for code (and other markets) including agentic vs IDE-based work flows and their eventual overlap (they will undoubtedly converge), as well as the degree to which the foundation model companies will integrate or subsume more of the coding companies functionality directly given both large economic value, as well as code being a bootstrap path to AGI / SI. These core questions will drive who the final winners in code will be.
The core players in core legal markets have solidified with Harvey (both law firms and enterprise) and CaseText as the current leaders. Other startups working in either overlapping (Legora) or new areas (Crosby) are starting to emerge. EvenUp moved in the post AI era into personal injury and related areas, while Eve and Supio are focused on plaintiff work flows. We are still very early in full workflow automation but startups like Harvey and EvenUp have started to take core legal workflows and build systems to complete the work start from finish. With the centrality of legal, companies like Harvey may be able to naturally integrate into other professional services workflows over time
Given the breadth of legal across vertical areas (patents, contracts, etc.) and type (law firms, enterprise, SMB, consumer) there may be new legal areas yet to explore.
Physician tools and scribing is another area with a clear set of main players that markets have consolidated against include Abridge, Ambience, Commure / Athelas, and Nuance (Microsoft). Some international players have also emerged in this area and may either end up as stand alone, or consolidated into the main players.
The key next step for these players is to expand products into other areas of the healthcare stack.
The customer experience market in the US appears to have consolidated in the short term into a few core startup players – Decagon and Sierra, while incumbents like Intercom, Zendesk and others work to add and cross-sell generative AI capabilities. Other startups of interest include Forethought, Maven, Parahelp, Wonderful, and others. Like many of the markets above, customer experience has the characteristic that generative AI is displacing or augmenting humans strongly with agentic work, versus another seat-based workflow tool.
We are starting to see the shift from selling seats, to selling units of cognition. This is an underdiscussed aspect of AI companies in general.
Reasoning model advancements and agentic infrastructure products will only accelerate this shift.
Players focused here include Google, OpenAI (chatGPT), Perplexity, and Meta. Perplexity is notably the main startup in this market, while most of the other players are incumbents. This may end up being true for other consumer and prosumer markets as well, although there is a lot of room for new consumer use cases.
Perplexity and the other players are moving quickly into the agentic future (see section below), both through tools like Deep Research, but also more recently via entry into the browser market. For example, Perplexity’s Comet browser already incorporates agentic actions for shopping on the web and other actions.
3 years ago it was clear foundation models / LLMs, code, healthcare, customer service and other areas would be important AI markets, but it was much less clear who would win or be important. Today the market leaders that are likely to play a short term role are clear (although as mentioned often new startups or incumbents launching products can still join later in the game).
The next set of markets that seem highly interesting and tractable to generative AI include, but are not limited to the below. I and my team are highly interested in investing behind companies in these areas:
Accounting. People are both building software here and in some cases doing rollups.
Compliance. Lots of different forms of compliance. Pharma compliance is one example with early players like Blue Note Health.
Financial tools. Tools to help financial analysts or others. There are a number of great teams and early companies working in this area.
Sales tooling and agents. Lots to do here – from AI agents doing SDR work to tools to augment enterprise sales.
Security. An enormous number of potential applications here, particularly in areas of high service utilization or large team complexity. There will separately emerge security companies focused on AI-end points, agents, or foundation model usage that could lead to data leaks or other exploits.
Other markets TBD. Lots to do!
What have I missed? Let me know on X.com or directly.
There are a set of exciting companies in each of these areas, and which of them will pull ahead or win will likely crystalize in the coming months or quarters. In some cases models may not yet be good enough to address these markets well, in others a broader workflow tool or better GTM approach needs to be developed. In some cases it might just be a matter of time – it takes time to fully understand a customer, build against their needs, and see product-market pull and fit.
I (and my team) am actively looking to invest in all these areas – so please ping if working on it. :)
For the “new” market segments above, one core question is what has been preventing market crystalization?
Part of it for some markets is the models need to advance in reasoning or fidelity. For example, legal workflows did not work on GPT 3.5 but with GPT4 really took off and Harvey benefited from this plus custom model work. Similarly, coding tools like Cursor benefited from Claude 3.5 (launched June 2024) and were just not as useful until the models used crossed some tipping point of fidelity. Building early against customers pre-model fidelity allows you to capture market share once the models get better.
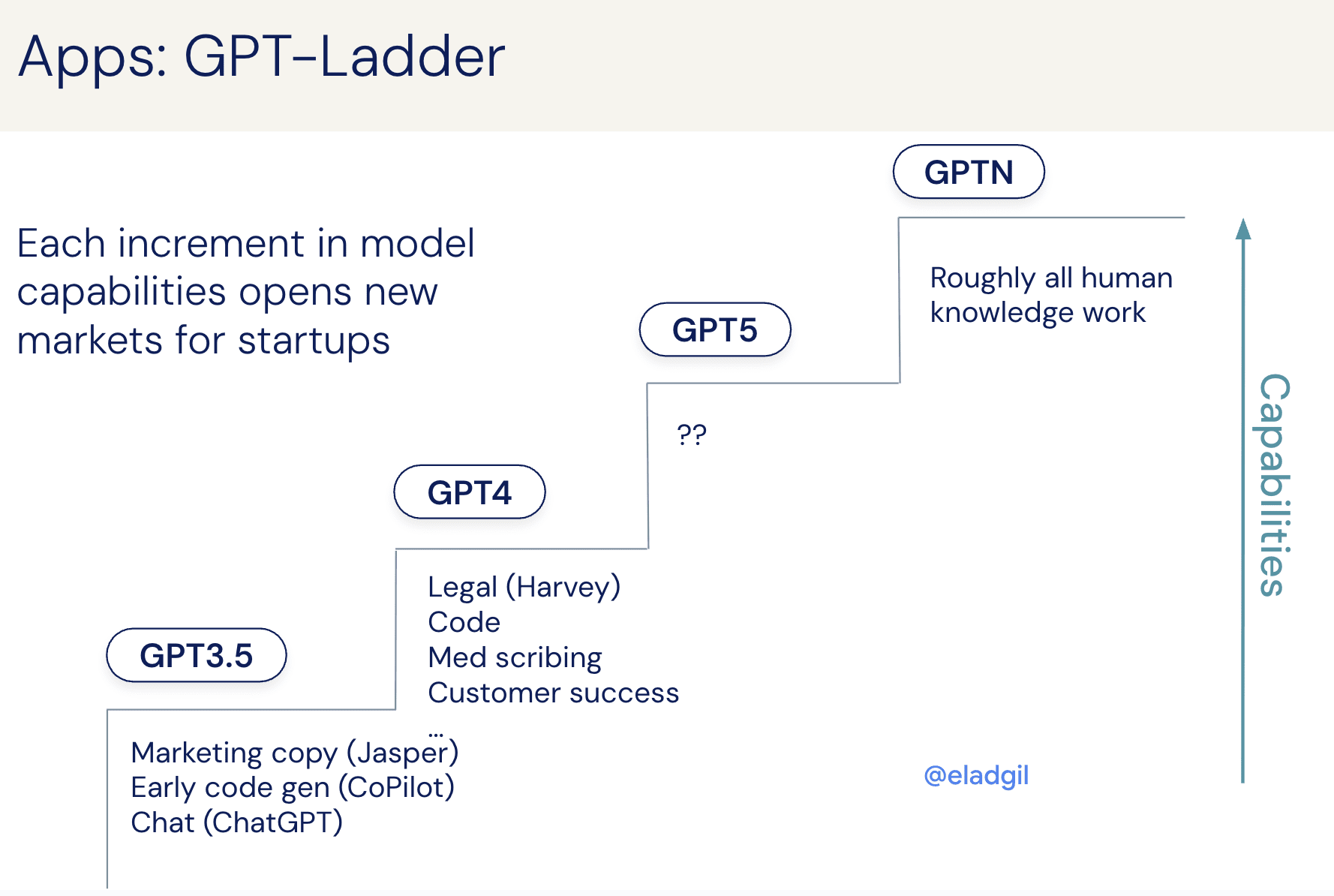
This leads to the concept of the GPT Ladder - at a certain level of GPT (or Claude, or Gemini, or Grok, or Llama) release, specific new markets will open up. For example, GPT-5 (or Claude X, or Gemini Y) should support an entirely new market that simply was not tractable technologically in the absence of the model.
Beyond models, other things that may prevent adoption of generative AI in a market may include:
Go-to-market, buying behavior & competition.
Startups may be getting go-to-market wrong (selling to the wrong customers in the wrong way)
There may be too much incumbent lock in (or ability to counter startups quickly with worse product or cross sell against an existing UI or workflow owned by the incumbent).
Buyers in the market may just be slow to move and adopt and will get there over time.
Teams. Perhaps the right team has not shown up yet, or the founders are new to the market and will take a bit of time to learn and iterate what customers need.
Time to build. It takes time to build and ship useful products. Sometimes activity in a market is just too nascent and in 6-12 months a big enough product footprint will exist for winner(s) to emerge.
One big ongoing shift is moving from pure tooling “AI chat” to agentic workflows. Agents are AI software that do actions on your behalf. It is the difference between looking up information about travel to Spain on Google, and having Google spawn an AI agent that goes and books the travel for you and takes actions on your behalf. Coding tools like Devin and customer service tools like Decagon/Sierra seem the earliest B2B adopters of agentic workflows, while informational tools like chatGPT, Gemini, and Perplexity are adding agents to do deep research for their users.
As reasoning models and agents proliferate, new infrastructure to support agentic deployment & workflows is accelerating. A number of startups are working on agentic frameworks or infrastructure, while consulting or large-scale deployment firms are also adding agents to their roster of tools to deploy in enterprises.
We are starting to see the shift from selling seats, to selling units of cognition or human equivalent labor.
I have been talking about, and investing in, generative AI driven roll ups for 3 years or so. From the earliest days of generative AI it was clear that this new form of scaled transformer-based AI was very good at human knowledge work – which is much of the white collar services economy. In AI driven roll ups, buying a company versus just selling them software can lead to outsized faster adoption and economics than just selling software.
Often, adoption of AI is not a technology problem – it is an organization, process, and people issue. Can you rework an entire organization or its way of doing things around the AI tooling? This is often a much harder problem than just the AI tooling itself and requires owning the actual company to be able to rework organizational processes on a short enough time frame to matter (at least for a startup – incumbents often take a long time).
I have funded 2 AI driven buyouts to date and am excited to back more- reach out if you are working in this area!
In another post, I talk about “market ending moves” – what big strategic play can you do (M&A? Enormous capital scale and investment? Other?) can you do to just win first place in a market.
As markets consolidate, the strategic moves to just win a market become clear. This will likely lead to various forms of M&A, partnership, channel lock in, or other strategies as the handful of players per market consolidate down into one or a small handful.
We should see a lot of consolidation and M&A coming quite soon due to the ability to win a market by combining the two main startup leaders (often hard to negotiate but worth doing) or incumbent/startup pairs (distribution + tech = winning).
Very exciting times are ahead.
AI markets are now the clearest they have been in a few years. The leaders in a given segment are clear for many of the earlier generative AI markets like Code and Legal, while new markets are ripe for disruption. Exciting times ahead.
My book: High Growth Handbook. Amazon. Online.
Markets:
Firesides & Podcasts
Startup life
Co-Founders
Raising Money
2025-05-21 07:01:19
The biopharma ecosystem is set up for a limited number of "indication" or disease areas to be worked on. Part of this is industry structure (many biotech firms are incubated by VC firms to flip into biopharma company roadmaps for M&A), part is intellectual snobbery (“cosmetics of aging - yuck! I want to do Alzheimers”) and part of this is regulatory. A lot of important and commercially viable pre-existing biology that can be translated into real world applications is thus ignored. Here are some things I wish there were more startups working on[1,2,3].
Given how important fertility is, it is shocking how few companies are working in the area. Two main thrusts of fertility that are interesting:
Allowing any adult to have children with anyone else. There is strong scientific results out of Japan in mice, in which many cell types can be converted into stem cells, and then differentiated into either sperm or egg cells. The human version of this means (roughly) anyone could have kids with anyone else. Gay couples could have kids with each other (one person would have their cells expanded into sperm, the others eggs), as long as they had a surrogate (see for example this paper from Hayashi’s group in Japan about mice produced via this technique using two fathers). Women of any age could have children. It is a huge unlock societally. Some reviews. Popular version. See also.
Expanding usable egg populations in women. Girls are born with 1 to 2 million oocytes (egg cells) and by puberty end up with ~300,000. Only a small number of these ever mature into the eggs that can be harvested for IVF or used for natural pregnancies. Methods to expand and mature egg cells seem dramatically under developed. See for example.
There is clear data that aging is a genetically manipulatable and drugable phenotype. Given the size and important of the prize (e.g. adding 100+ years of productive health life to each person) it is a surprisingly empty field with at most a half dozen or so legitimate companies working on it (including eg BioAge and NewLimit - I am an investor in both).

Neurosensory aging. As you age you lose aspects of hearing and site. For example, the muscle holding the lens of the eye weakens in part leading to blurrier vision and the need for reading glasses for people in their 40s. This seems drugable. Ditto loss of hearing in aging adults. This example of reversing aging in mouse age dependent glaucoma models is intruiging (much simpler approaches then this seem like to work).
Cosmetic aging. Cosmetic use of Botox is roughly at $1.6 billion per year. People are literally injecting a bacterial toxin into their skin. Imagine anti-aging drugs that actually rejuvenate aspects of aging? Examples:
Skin aging and wrinkles. There is enormous demand for things that will reverse or stop skin aging, as seen via botox, face lifts, face fillers, and basic cosmetics.
Balding. Hair loss is age dependent. Some treatments like Minoxidal or Propecia can halt or partially reverse it. Why aren’t there drugs that restore hair completely?
Grey hair. As you age you lose melanin cell production in/around hair follicles. This leads to greying hair. A lot of the biology has been worked out. Why are there not more active efforts to reverse this?
Tooth regrowth. Many species like sharks can regrow teeth indefinitely, while humans naturally produce a second set of teeth during childhood. Why cant we just regrow a tooth with a bad cavity versus do extensive dental work? Genes like USAG-1 may allow for tooth regrowth in certain animal models, and other approaches and factors exist.
Often the best way to run a clinical trial or discover drugs rapidly is to have an easily interrogatable biomarker that is a proxy for a biological effect. For example, we measure lipid levels as a proxy for certain types of heart health (and people are trying to develop new biomarkers for cardiac health). For most diseases, we do not have any form of biomarker from blood, saliva, or anywhere else that would be easy to track and use to expedite drug discovery. Given all the data we could theoretically generate per person, and all the ML/AI algorithms and approaches, it is a bit shocking that biomarkers are in such a primitive state.
Novel biomarkers. Develop novel biomarkers for disease states as a way to expedite drug development and study disease course. This may not be great as a stand alone company, unless some of the biomarkers are good replacements for less comfortable procedures. For example, Exact Biosciences is a $10 billion market cap company, as its product lets you do a biomarker test of your poop for colon cancer risk versus the less comfortable colonoscopy. One could imagine many more of these sorts of tests.
Smell / volatile molecules. Dogs can smell if people have certain types of cancer. This means some biomarker(s) of cancer is emitted into the air and detectable by a dog nose. Why don’t we have similar sensors built? One example in this direction to screen lung cancer.
There are a wide variety of other things that may impact human health that go ignored - for example air pollution levels and cognitive function - that may have broader societal value. Those may be subject of a future post.
[1] There are one off companies in each area. In some cases good ones, in other cases the translational biotech market seems to not have any legitimate players.
[2] References included are not the canonical or key papers in many cases - rather just wanted to show evidence these things are possible. Full scientific citing would take a lot of time and I am a bit overloaded.
[3] I am generally not investing in much biotech for the last few years. However, if there was an incredibly compelling team taking a smart approach in this area I would be interested.
My book: High Growth Handbook. Amazon. Online.
Markets:
Firesides & Podcasts
Startup life
Co-Founders
Raising Money
2025-04-09 02:26:50
Every once and a while, there is a move that end questions and competition for startups in a market. A single move can effectively win the market, or “end the market”.
Market ending moves may include:
Merging with your main competitor to remove pricing pressure and options from buyers. The merger between X.com and Paypal in the 1990s consolidated the main payment providers on the internet at the time. Uber and Lyft are rumored to have almost merged at the height of their competition in the 2010s. The rumor is Uber walked from this deal, but then went on to merge its subsidiaries with the major player in multiple international markets to increase leverage of the combined player in the market (China, Russia, etc). Private to private mergers, when companies are still young, are much easier to get past regulators than public/private buys. There are other dynamics to contend with however around ownership, leadership, and ego[1]
Buying a key supplier (of unique data, a bespoke sensor or component, etc) to starve others of a key input to products, prioritize yourself for volume, or get a cost advantage
Key distribution deal. IBM distributing Microsoft’s early O/S, or Yahoo! distributing Google were two “king making” moves in an industry.
Destroy a competitors cash cow. Sometimes your incumbent competitor will have a legacy cash cow business the funds everything else. Offering a free or cheap version of this, or changing business models to destroy their cash flow can be quite effective. This is part of the concern for Google in search/ads relative to some genAI products[2].
Capital. Sometimes you can raise an enormous sum to buy distribution or saturate a network effect market. Tiktok notoriously bought traffic early on at large scale, and Google invested billions in early search distribution. One could argue the current SOTA LLM models are reasonably locked into an oligopoly market due to ability to raise billions or tends of billions of dollars for the next giant model.
Other moves. Lots of other things can be done as well.
When you are thinking about market ending moves, be creative! You can brainstorm literally any scenario. Can you convince a large public company to spin out a key subsidiary to merge with you? Can you put aside ego with your main competitor to combine forces and stop competing for everything? Think broadly. Even if doesn’t happen, this often sparks key thinking on M&A, partnerships, and key hires that you may not have considered otherwise.
Notes
[1] Private to private mergers are notoriously hard between fierce competitors. Usually three topics come up - (a) relative ownership post merger, and (b) who is in charge (c) hard feelings between founders if one felt the other copied them, trash talked them, or the like.
[2] I think Google is most likely to transition just fine (ie survivable vs existential), but many worry this will be an issue
My book: High Growth Handbook. Amazon. Online.
Markets:
Firesides & Podcasts
Startup life
Co-Founders
Raising Money
2025-02-06 02:22:06
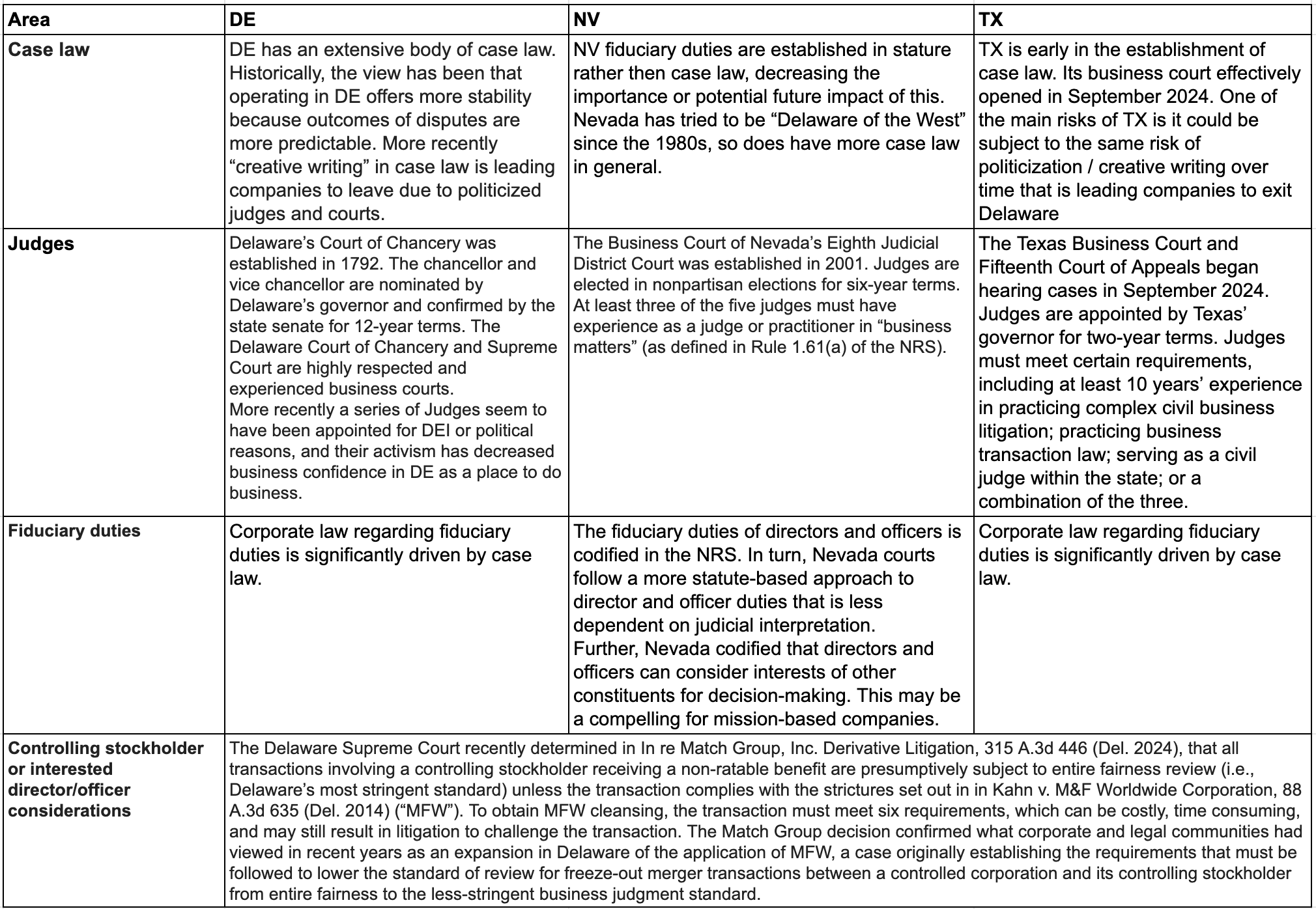
Delaware, with a population of less than 1 million people, is home to over 1.8 million business entities, including more than 60% of Fortune 500 companies. The state was traditionally viewed as having a business-friendly legal structure and specialized business court system (the Court of Chancery) which made it a preferred incorporation destination.
Businesses seek environments with clear legal frameworks and precedent, low judicial activism, and a business friendly environment. If the environment feels more arbitrary, litigious, or politicized in nature, it can harm the ability for a business to serve its customers and to function. If given a choice, business may avoid or leave these jurisdictions.
Recently, Delaware has had a series of lawsuits, “creative writing” in case law and politicized judges that has been changing the perception of the state as a stable place for companies to legally base their businesses. Companies like SpaceX, Tesla, Dropbox, and others have either left, or disclosed plans to move their incorporation from the state of DE. The primary states companies are considering for the move include Montana, Wyoming, Nevada, and Texas, with most eventually moving to either Nevada or Texas.
This post breaks down some of the pros and cons of Nevada, Texas, and Delaware as well as discusses high level process to leave the state. TradeDesk published a good primer as well.
While many companies have physically moved their headquarters from California to other states (Palantir, Oracle, SpaceX, to name a few) most CA-based companies have left their incorporation in Delaware. This is starting to shift as more companies consider moving Incorporation to Nevada or Texas.
Part of the concern in Delaware is, as a WSJ opinion piece recently put it, “the likelihood of expensive, meritless or value-destroying litigation leads public companies in Delaware to avoid deals they would otherwise make.” The other part is a few more extreme Delaware activist judges who apply “creative writing” to interpreting the law. The most famous example of this is a court invalidating Elon Musk's board and then subsequently a shareholder-approved compensation package. This ruling was viewed as political activism by many versus following any form of legal framework. Tesla subsequently reincorporated to Texas with 84% non-controller shareholder support.
However, there are other recent examples beyond Tesla. These include:
Trade Desk - Delaware court required special committee approval for controller transactions that were fully disclosed at IPO and had operated without challenge for years
Activision - Delaware court invalidated merger approval process on technical grounds despite 98% shareholder approval and no evidence of harm
Moelis & Company - Delaware court invalidated long-standing stockholder agreements between the company and its founder that were disclosed in IPO; required legislative fix
TripAdvisor - Delaware court ruled that merely reincorporating to Nevada required special committee approval and minority shareholder vote because reducing litigation exposure was deemed a "non-ratable benefit" to the controller
Three articles on why companies are leaving Delaware.
Most analysis of which state to incorporate in to collapses down to a choice between Delaware, Nevada and Texas. You can find a full analysis from Ben Potter & Team at Latham here (they have kindly open sourced a quick analysis they did for me and my team):
In general, Delaware has been historically seen to be stronger on:
Historical development & predictability of corporate law (although judicial activism is impacting this)
Experience of judiciary (specialized corporate law judges)
Office of the Secretary of State (ease of set up and doing business)
While Nevada and Texas have been better on:
Litigation risk
Business judgment rules
Takeover defenses
Director and Officer indemnification & exculpation
Expenses of doing business
Between NV and TX, there seem to be slight tradeoffs between each state enumerated below. One plus for NV is that fiduciary duties are established in statute rather than case law (Delaware and Texas being in the case law camp), so theoretically Texas could be subject to the same risk of politicization / creative writing over time that is leading companies to exit Delaware. The hope is that Nevada’s statute-based approach will offer more predictability, which was historically the draw for Delaware. However there are obvious benefits to Texas as well, leading companies like Tesla and SpaceX to decide to move there.
Companies that have left, or announced, plans to leave Delaware for:
Nevada: Dropbox, TripAdvisor, Neuralink, Pershing Square, and others
Texas: SpaceX, Tesla, and others
Tradeoffs to consider in terms of where to incorporate include case law, judges, fiduciary duties and other interests, as well as expense and cost. See also a write up from TradeDesk.
Full analysis from Ben Potter & Team at Latham here:
On the margin it seems a few more companies are choosing Nevada over Texas, although obviously SpaceX and Tesla are giant companies who decided to move to Texas. Anecdotally it seems like more corporate entities have moved to Nevada, while more market cap has moved to Texas.
The other tradeoff faced by companies is the cost of doing business in each state. Expenses seem possible lower in Nevada or Texas versus Delaware when comparing the following:

If you are just incorporating a company now, it is worth considering Nevada or Texas up front versus dealing with it later.
If you are a private company, moving to Nevada or Texas is straightforward. It will probably take a few months start to finish, but with most of the lift done by lawyers and accountants working in the background and not require much of your time as CEO. This process is known as domestication or conversion, depending on the state.
You will have to do a shareholder vote and/or board approval, initiate a conversion/domestication filing in both DE and NV/TX, obtain formation/articles of incorporation and pay a filing fee. You lawyers will then draft new bylaws compliant with new target state laws, revise or update any stock certificates, etc. Finally you may get a new EIN, file final returns in DE and initiate in the new state, and update contracts, employee benefits etc. There may be some industries with special licensing, permitting, or professional accreditation needs, but these tend to be manageable. It is basically a bunch of paperwork, but not too onerous.
If you are a public company seeking to leave Delaware, the most important thing to focus on is proper process. Process is impossible to fix after the fact, and Delaware prefers companies not leave (it is a major source of state revenue). Adhering to good process up front allows you to avoid Delaware court action or unnecessary litigation. This was an issue for TripAdvisor as it tried to leave the state for Nevada.
For a public company, the first step is to create a special committee of independent directors to start and hold the conversation on where to domicile the company. The committee needs to take a broad view of the potential move and re-incorportation and whether it benefits all shareholders (and not just the controller and/or directors of the company - which is what happened in the TripAdvisor case). Things that benefit all shareholders may include lowering costs of doing business, decreased litigation risk, or related. Everything needs to be cleanly documented and kept objective.
If you have 50% of more voting control of your company, you can initiate the move via board approval & written consent. If not, you will likely need to go down the full shareholder vote route. This opens up the potential for more complexity not only in terms of e.g. proxy filings, but also increased potential rejection by minority shareholders. This will not block the move entirely but will increase litigation risk quite a bit.
TradeDesk has a good write up on some aspects of this.
Given recent activism in Delaware courts, there are two types of companies most likely to leave the state and convert to Nevada or Texas entities. This includes founder-controlled companies that want more leeway and protection in how they operate, and politically exposed companies. Political exposure may include who the owner is (Elon Musk for example), what is the nature of the business, and its perception as politically relevant to be made an example out of. Undoubtedly this will be a minority of companies (right now >60% of the Fortune 500 are in Delaware). Just as a subset of companies has been trickling their headquarters out of California due to its high tax rates, extra regulatory burdens, and poor governance (see Palantir, Oracle, HP, Tesla, and others), one could expect an increasing flow of companies moving their incorporation out of Delaware over time in parallel.
The hope, of course, is that Delaware is able to correct some of the issues it has had in the recent past in order to maintain its position as the default for company incorporation. In the meantime, more companies are actively considering a move.
My book: High Growth Handbook. Amazon. Online.
Markets:
Firesides & Podcasts
Startup life
Co-Founders
Raising Money