2026-07-29 13:00:00
chezmoi 是一个用 [[Go]] 编写的开源 dotfiles 管理工具,帮助开发者在多台机器上统一管理个人配置文件(如 ~/.gitconfig、~/.zshrc、~/.vimrc 等)。
发音为 /ʃeɪ mwa/ (shay-moi),是法语”在我家”的意思,名称寓意让每台机器都拥有”家的感觉”。
区别于 [[GNU Stow]] 这类基于符号链接的工具,chezmoi 将配置文件复制到目标位置(而非创建 symlink),并通过 Go 模板语言实现机器之间的差异化配置,同时内置密钥管理和加密能力。
传统 dotfiles 管理方式(直接用 git 仓库 + symlink)有几个痛点:
一是密钥安全问题。git 不适合存储密码、API 密钥等敏感内容,一旦误提交到公开仓库就可能立即造成泄露。
二是多机差异问题。工作机和个人机的 git 邮箱不同、macOS 和 Linux 的配置路径不同,维护多套配置文件繁琐。
三是跨平台问题。[[GNU Stow]] 仅支持 Unix 系统,且依赖 symlink,在 Windows 上无法正常工作。
chezmoi 通过模板化、加密和声明式管理解决了上述问题。
模板化配置是 chezmoi 的核心能力。基于 [[Go]] 标准库的 text/template,同一份配置文件可以根据主机名、操作系统、环境变量等条件动态渲染出不同内容。例如:
[user]
name =
email = [email protected]@gmail.com
加密与密钥管理方面,chezmoi 原生支持 age、gpg、git-crypt 和 transcrypt 对文件加密,也支持从 1Password、Bitwarden、Vault、KeePassXC 等密码管理器中动态读取密钥,敏感内容永远不会以明文形式出现在 git 仓库中。
差异化忽略支持对不同机器忽略不同文件,例如 VPN 配置只在工作机上管理,而不出现在个人机上。
脚本执行支持在 apply 时运行安装脚本,并通过 onchange_ 前缀实现”只在配置变更时重新执行”,避免每次 apply 都重跑 Homebrew 安装等耗时操作。
干运行与 diff 模式支持 chezmoi diff 查看将要应用的变更,chezmoi apply --dry-run 模拟执行,对新机器上线特别有用。
chezmoi 维护一个”源目录”(默认在 ~/.local/share/chezmoi),其中的文件名通过前缀约定来描述意图:
dot_ 前缀:对应目标路径中的 .,例如 dot_zshrc → ~/.zshrc
private_ 前缀:文件应设置为仅所有者可读(权限 0600)executable_ 前缀:文件应具有可执行权限encrypted_ 前缀:文件内容已加密存储once_ 前缀:脚本只执行一次onchange_ 前缀:脚本在内容变更时才重新执行执行 chezmoi apply 时,chezmoi 读取源目录中的文件,渲染模板,解密加密文件,最后将结果写入 Home 目录对应位置。
一行命令安装并初始化(将 GITHUB_USERNAME 替换为你的 GitHub 用户名):
sh -c "$(curl -fsLS chezmoi.io/get)" -- init --apply GITHUB_USERNAME
macOS 用 Homebrew 安装:
brew install chezmoi
Linux 各发行版也可通过包管理器安装,或直接下载二进制文件。
初始化一个新的 chezmoi 配置(不从 git 仓库拉取):
chezmoi init
添加一个文件到 chezmoi 管理:
chezmoi add ~/.zshrc
chezmoi add ~/.gitconfig
进入 chezmoi 源目录(方便直接编辑):
chezmoi cd
查看将要应用的变更:
chezmoi diff
将源目录中的配置应用到 Home 目录:
chezmoi apply
从 git 仓库拉取最新配置并应用:
chezmoi update
编辑某个已托管的文件后直接应用:
chezmoi edit ~/.zshrc --apply
| 特性 | chezmoi | [[GNU Stow]] | YADM |
|---|---|---|---|
| 实现方式 | 文件复制 + 模板 | 符号链接 | git 包装器 |
| 模板支持 | 内置 Go 模板 | 无 | 依赖外部工具(已停维) |
| 密钥管理 | 内置多种加密 | 无 | 有限 |
| 多 OS 支持 | 优秀 | 需手动处理 | 基础 |
| Windows 支持 | 支持 | 不支持 | 不支持 |
| 停止使用成本 | 低(文件即原文件) | 需删除 symlink | 低 |
| 学习曲线 | 中等 | 极低 | 低 |
与 [[dotbot]] 相比,chezmoi 的模板能力更强,密钥管理更完善,但 dotbot 的 YAML 配置风格对习惯声明式配置的用户更直观。
同时使用多台机器(工作机、家用机、云服务器)的开发者最能受益于 chezmoi。
配置文件中含有敏感信息(API 密钥、私有地址等)需要安全管理的场景,chezmoi 的加密集成是最佳选择。
在 macOS、Linux 乃至 Windows 跨平台工作的开发者,可以用同一套源文件生成各平台的差异化配置。
对于想要在新机器上实现”一键还原工作环境”的工程师,chezmoi 配合 Homebrew Bundle 或 Nix 可以做到完整的环境复现。
优势方面,chezmoi 文档详细、社区活跃,内置功能几乎涵盖所有 dotfiles 管理场景,且单一二进制无外部依赖。由于使用文件复制而非 symlink,随时停止使用都不需要额外清理工作。
挑战方面,源目录中的文件名加了 dot_ 等前缀,与实际路径不完全对应,初期会有一定认知成本。对于只管理少量配置文件、无跨机需求的用户,chezmoi 的功能可能显得过重,简单的 git bare repo 方式或许更合适。
chezmoi 是目前功能最完整、维护最积极的 dotfiles 管理工具之一,尤其适合有跨设备、跨平台需求或需要在配置中处理敏感信息的开发者。从 [[dotbot]] 或 [[GNU Stow]] 迁移到 chezmoi 有一定学习成本,但长期来看模板化和密钥管理带来的收益十分显著。
2026-07-07 13:00:00

前几天例行 brew upgrade 之后,[[Syncthing]] 其中的某一个高频使用的同步文件夹就一直卡在 Preparing to Sync 状态,进度条纹丝不动,CPU 占用却莫名升高。我最初以为是网络问题或者对端设备没启动,结果检查一遍发现所有的其他 Syncthing 节点都正常,就是本机 macOS 这端不动弹。这个状态持续了将近一个小时,才让我意识到不对劲,开始认真排查。
Syncthing 是一款开源的点对点文件同步工具,不依赖任何中心服务器,数据直接在你自己的设备之间流转。我用它同步多台设备上的工作目录和重要文件,已经稳定运行了6,7年,这次升级前一切都好好的。
这次触发问题的,是 [[Homebrew]] 将 Syncthing 从 1.x 版本升级到了 2.x 版本。Syncthing 2.0 是一次幅度相当大的版本跨越,包含了几项可能让用户措手不及的破坏性变更(breaking changes)。
Syncthing 2.0 最核心的变化是将底层的索引数据库引擎从 Google 的 [[LevelDB]] 切换到了 SQLite。Syncthing 用这个数据库存储所有文件的元数据、校验值和同步状态,这个库一旦发生格式变更,就意味着首次启动时必须完成一次完整的数据格式迁移。
官方文档对此的表述是:”数据库后端已从 LevelDB 切换到 SQLite。首次启动时会进行一次迁移,对于较大的数据集这个过程可能需要较长时间。”对于文件数量众多的用户,这个迁移甚至可以持续数小时乃至整夜。而在迁移完成之前,Syncthing 对所有文件夹展示的状态正是 “Preparing to Sync”——它在准备,只是用户看不到进度。
问题在于,通过 brew services start syncthing 作为系统服务运行时,Syncthing 的控制台输出被完全隐藏。用户打开 Web UI 只能看到一个没有进度提示的状态标签,却无从判断迁移是否还在进行、还是真的卡死了。这种信息缺失,是让人以为出了大问题的直接原因。
在采取任何激进操作之前,先确认 Syncthing 到底是真的卡住了,还是还在默默工作。
停止 Homebrew 服务,改为手动从终端启动 Syncthing,这样就能实时看到日志输出:
brew services stop syncthing
syncthing
观察终端输出。以下这类日志都属于正常现象,说明 Syncthing 仍在工作中,不需要干预:
INF GC was interrupted due to exceeding time limit (processed=3 runtime=5m34s folder=default fdb=folder.0001-xxx.db table=blocks)
INF Completed initial scan (folder.label="Default Folder" folder.id=default folder.type=sendreceive)
第一行是 SQLite 数据库在做垃圾回收(GC),运行超过时间限制后被中断,这是 Syncthing 2.0 新引入的行为,中断不代表出错,GC 会在后续继续执行。第二行是初始扫描完成的确认,出现这行后文件夹就会脱离 “Preparing to Sync” 状态。
反之,如果日志几分钟内没有任何新内容,或者出现了 “database disk image is malformed” 这样的错误,才需要进行下一步处理。
如果手动运行后看到迁移活动,最好的做法就是什么都不做,等它跑完。文件越多,等待时间越长。根据社区反馈,拥有十几万文件的用户,迁移时间可能超过两个小时。迁移完成后,Syncthing 会自动恢复正常同步,之后再用 brew services start syncthing 挂回后台服务即可。
如果迁移确实卡死,或者日志中出现了数据库损坏相关的错误,就需要删除旧的索引数据库,让 Syncthing 从零开始重新扫描。
首先,找到 Syncthing 的数据目录:
# macOS 上默认路径
ls ~/Library/Application\ Support/Syncthing/
Syncthing 2.0 的 SQLite 索引数据库位于 index-v2/ 目录下,每个同步文件夹对应一个独立的 .db 文件(如 folder.0001-abcd1234.db),以及配套的 .db-shm 和 .db-wal 文件。如果迁移卡死或数据库损坏,可以删除整个 index-v2/ 目录让 Syncthing 重建:
brew services stop syncthing
rm -rf ~/Library/Application\ Support/Syncthing/index-v2/
如果你仍有旧版 LevelDB 格式的 index-v0.14.0.db 残留(升级异常时可能存在),也可以一并清理:
rm -rf ~/Library/Application\ Support/Syncthing/index-v0.14.0.db
删除后重新启动 Syncthing,它会从头对所有文件夹执行完整扫描。文件本身不会丢失,只是 Syncthing 需要重新建立对所有文件的认知,这个过程同样需要一些时间,但通常比数据库迁移要快得多。
如果问题只是同步状态不一致,而数据库本身没有损坏,可以尝试使用 --reset-deltas 参数启动 Syncthing,让它重置增量同步状态:
brew services stop syncthing
syncthing --reset-deltas
这个方法比删除整个数据库要温和,只清除增量同步的记录,不会触发全量重扫,适合作为第一道修复手段。
如果只有某一两个文件夹卡住,其他文件夹正常,可以通过 Syncthing 的 REST API 只重置问题文件夹的索引,避免影响已经工作正常的文件夹。
先在 Web UI 的设置里找到你的 API Key,然后执行:
# 重置特定文件夹(将 your-folder-id 替换为实际的文件夹 ID)
curl -X POST -H "X-API-Key: your-api-key" \
"http://127.0.0.1:8384/rest/system/reset?folder=your-folder-id"
如果不带 folder 参数,则会重置所有文件夹的数据库,效果等同于方案二。
如果以上方案都不奏效,可以做一次干净的重装。这个方法对 macOS + Homebrew 环境效果最好:
brew services stop syncthing
brew uninstall syncthing
brew install syncthing
重装完成后,先从终端手动启动一次,观察迁移日志,确认迁移正常完成后再切换回服务模式:
syncthing
# 等待迁移完成,Ctrl+C 退出
brew services start syncthing
除了数据库迁移,Syncthing 2.0 还有一些其他变化值得留意。日志格式改为结构化日志,旧的 --verbose 和 --logflags 命令行参数已被移除,改用 --log-level 参数控制日志级别。如果你的 Syncthing Web UI 不是绑定在默认的 127.0.0.1:8384,需要注意升级机制存在一个已知 bug,它硬编码了默认地址,非默认配置下可能导致自动升级失败。
另外,Syncthing 2.0 不再为部分平台提供预编译二进制文件,包括 DragonFlyBSD、Illumos、Linux on PowerPC64、NetBSD 和部分 OpenBSD 架构,这些平台的用户需要自行从源码编译。
这次 Syncthing 升级卡住的经历,再次提醒我在做系统级工具的大版本升级之前,最好先读一读 release notes。Syncthing 2.0 将 LevelDB 换成 SQLite 是一次从根基上的重构,好处是数据库更易于维护和调试,坏处是首次启动的迁移成本对数据量大的用户来说相当可观。
如果你遇到了同样的问题,按照本文的顺序依次尝试,大概率能在方案一或方案二这里就解决。关键是不要慌,不要在迁移过程中强行重启或删除数据,那样才是真的会造成问题。耐心等一等,或者删掉旧索引让它重建,[[Syncthing]] 本身的可靠性依然值得信任。
2026-07-03 13:00:00
最近有朋友来问我 Git 分支和发布流程相关的问题,聊着聊着我发现,分支管理这块我自己算是比较熟悉,平时用起来也有一套固定的习惯,但当话题转到 release 发布流程的时候,我反倒得停下来想一想。
因为发布这件事,在不同的团队里真的有截然不同的管理方式。有的团队一天上线十几次,有的团队一个月才发一个大版本;有的靠一条流水线全自动,有的还保留着人工审批的关卡;有的发布的是后端服务,回滚一次只要几分钟,有的发布的是手机 App,版本一旦进了用户手机,想收回来就没那么容易了。
同样是把代码送到用户面前,路径可以差得非常远。这次朋友的提问正好戳中了这个我一直觉得值得梳理却没动笔的话题,于是就有了这篇文章。

很多人刚开始用 Git 的时候,会把分支理解成一个简单的代码备份工具。我要做一个新功能,就从 main 拉一条分支;我要试验一个想法,也拉一条分支。这个理解没有错,但只看到了分支的第一层作用。
真正到了团队协作和生产发布里,分支管理解决的不是代码备份问题,而是代码流向问题。也就是说,哪一批代码可以进入测试环境,哪一批代码可以进入生产环境,哪一个 commit 对应当前线上版本,出了问题应该从哪里修,修完之后又应该合回哪里。
如果没有清晰的分支规则,团队很容易进入一种混乱状态:功能还没测完就被带到生产,线上 hotfix 修完忘了合回开发分支,测试环境和生产环境跑的代码说不清楚,发布时大家只能在群里反复确认“现在到底该发哪个 commit”。这种混乱短期看只是沟通成本,长期看就是事故来源。
所以我更愿意把分支管理看成发布系统的一部分,而不是单纯的 Git 使用技巧。分支只是表面,背后真正要设计的是从需求开发、代码合并、测试验证、版本标记、部署上线到回滚修复的完整链路。
常见的分支模型大致可以分成 Git Flow、GitHub Flow、GitLab Flow 和主干开发。它们没有绝对好坏,只有适不适合你的产品形态、团队规模和发布频率。
[[Git Flow]] 是 Vincent Driessen 在 2010 年提出的模型,也是很多人接触的第一套正规分支规范。它定义了两条长期分支和三类临时分支。两条长期分支是 main 或者 master,以及 develop。main 永远对应生产环境上正在跑的代码,develop 是所有开发工作汇集的集成分支。三类临时分支分别是 feature、release 和 hotfix。
它的工作方式是这样的:每开发一个新功能,从 develop 拉出一条 feature 分支,做完之后合并回 develop。当 develop 上积累了足够一次发布的功能,就从 develop 拉出一条 release 分支,在这条分支上只做测试和 bug 修复,不再加新功能。release 稳定之后,同时合并进 main 和 develop,在 main 上打一个版本 tag,发布上线。如果线上出了紧急 bug,从 main 拉一条 hotfix 分支,修完后同样合并回 main 和 develop。
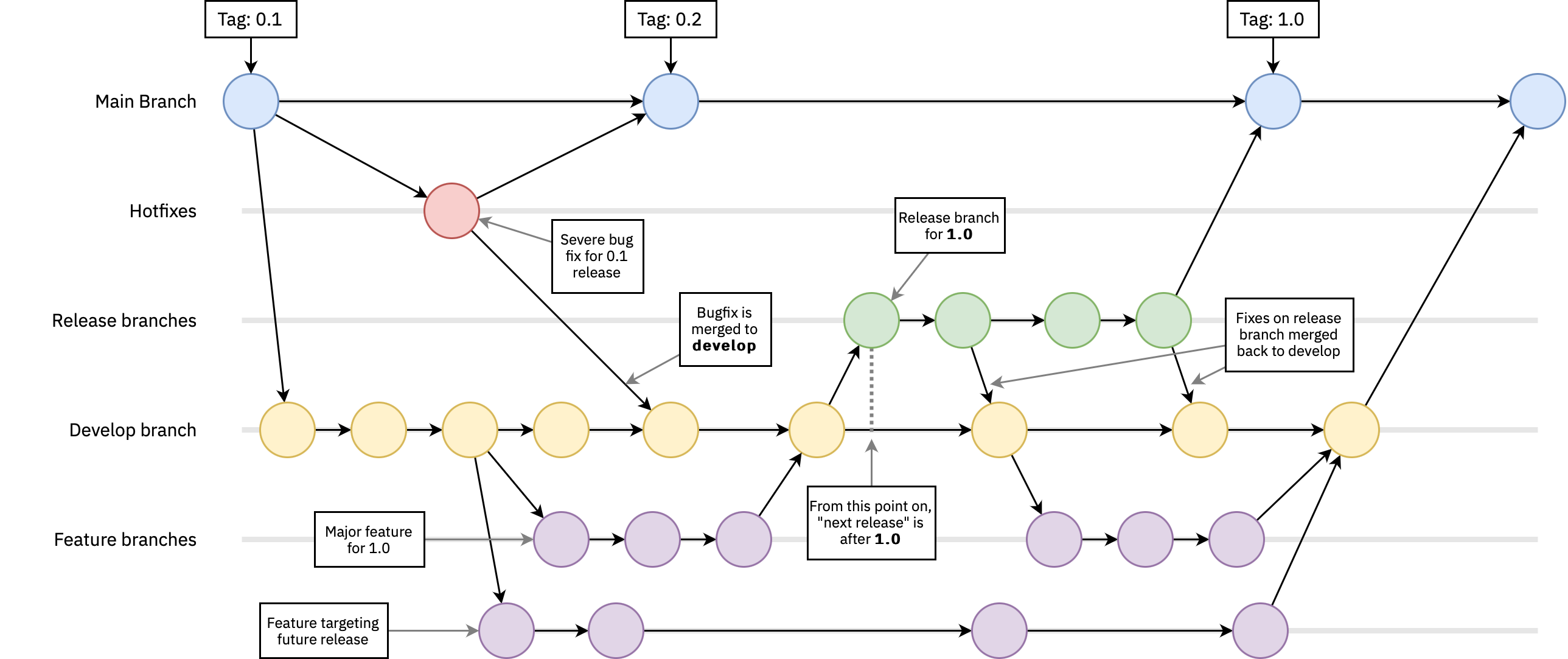
Git Flow 的优点是职责极其清晰,每条分支都有明确的语义,特别适合那种有明确版本概念、需要同时维护多个版本、发布周期比较长的软件,比如安装包类桌面应用、企业客户私有化部署产品、需要给客户提供长期支持版本的产品。
但它的缺点也很突出:太重了。两条长期分支加上频繁的双向合并,会让整个流程变得繁琐。对于现在这种追求持续交付、一天上线好几次的 Web 应用来说,Git Flow 往往是过度设计,反而拖慢节奏。
如果说 Git Flow 是重型装甲,[[GitHub Flow]] 就是轻装上阵。它只有一条长期分支 main,规则简单到一句话就能说完:main 永远是可部署的,任何改动都从 main 拉一条描述清晰的短分支,做完后开 PR,CI 通过、代码 review 通过,就合并回 main。
GitHub Flow 的核心假设是 main 分支始终保持健康,任何时刻都能拿去上线。它天然契合持续部署,你合并即上线,不存在攒一批功能再发布的概念。对于小团队、独立开发者、Web 服务、内部工具来说,这套流程非常高效。
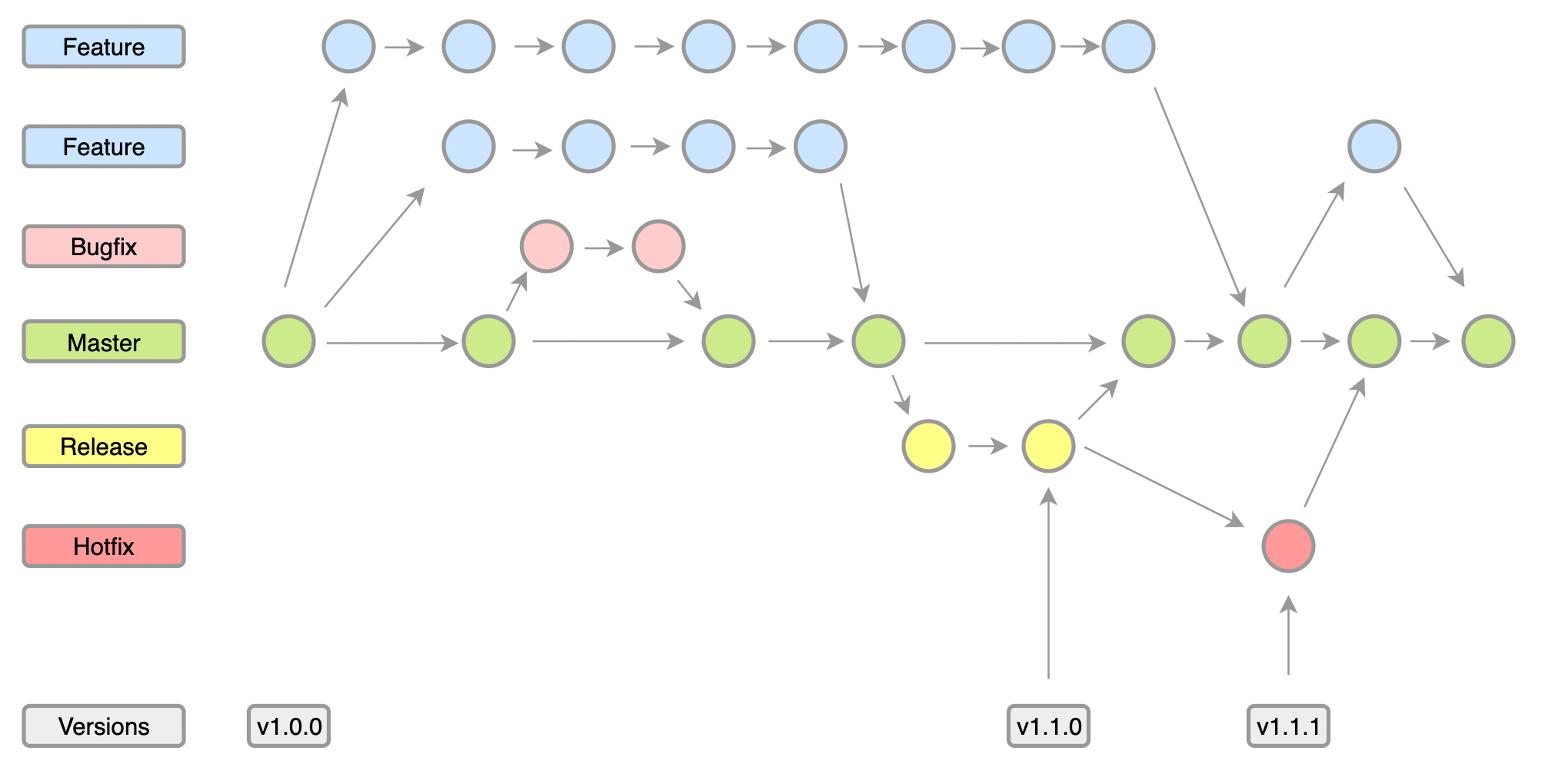
但它也有前提:自动化测试要足够可靠,review 要认真,部署流水线要成熟。否则“main 可部署”就只是一句口号。同时它缺少显式的环境概念,没有区分测试环境和生产环境的分支。如果你的发布必须经过多个环境层层验证,纯 GitHub Flow 就会显得有点薄。
[[GitLab Flow]] 可以看成是 GitHub Flow 的增强版,它在保持简单的基础上补上了环境和版本的概念。
一种常见做法是引入环境分支,比如除了 main,再加上 pre-production 和 production 分支。代码永远从上游流向下游:先合并到 main,main 部署到测试环境验证通过后,再把 main 合并到 pre-production,最后合并到 production 上线。这样每个环境对应一条分支,你随时能看到每个环境上跑的是哪一批代码。
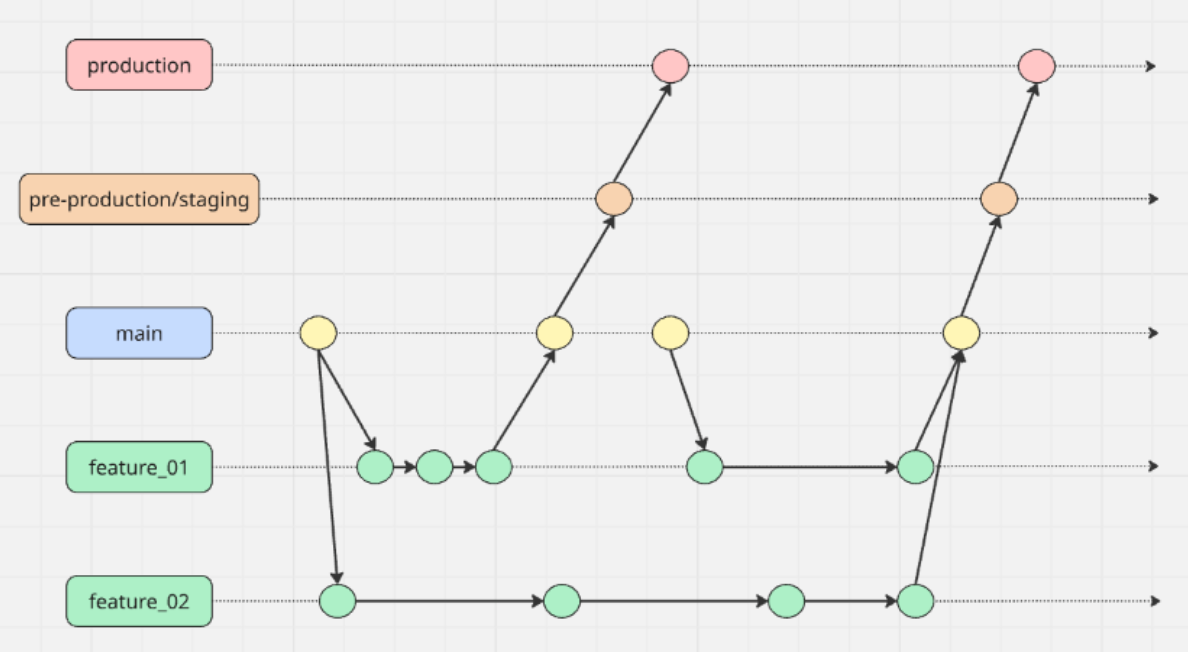
另一种做法是用 release 分支来支持版本发布。当你需要维护 2.3、2.4 这样的多个稳定版本时,为每个版本维护一条 release 分支,修复只从 main 往 release 分支 cherry-pick,保证 bug 修复的流向永远是从上游到下游,避免修了新版本忘了修老版本。
GitLab Flow 的价值在于它在简单和严谨之间找到了一个平衡点,既没有 Git Flow 那么繁琐,又比 GitHub Flow 多了对多环境、多版本的支持。
[[Trunk-Based Development]] 主干开发是近几年在大厂和高频交付团队里越来越流行的模型,它的理念有点反直觉:尽量不要有长期存在的分支。所有人都直接往主干,也就是 main 上频繁提交。即使要开分支,也应该是那种活不过一两天的极短生命周期分支,做完立刻合并。
这套做法要解决的核心问题是合并地狱。当分支存在的时间越长,它和主干的差异就越大,最后合并的时候冲突就越可怕。主干开发通过强制每个人频繁地把小改动合进主干,让分支永远不会偏离太远,冲突自然就小了。
那没做完的功能怎么办?答案是特性开关。代码合进去了,但入口用 feature flag 关着,直到功能完整、测试通过再打开。Google、Meta 这种超大规模团队用的都是主干开发的思路。
它的门槛是四种模型里最高的。你需要极其完善的自动化测试、成熟的特性开关基础设施、稳定的监控告警,以及团队对小步提交纪律的高度自觉。但一旦这些条件具备,主干开发能带来最快的集成速度和最少的合并痛苦,是持续交付的理想形态。
讲完分支模型,必须把它和环境部署对应起来,否则分支就是悬空的。一个典型的部署链路会有这么几个环境:开发环境、测试环境、预发布环境、生产环境。分支模型的作用,就是规定代码怎么从一个环境流到下一个环境,也规定每个环境应该接受什么成熟度的代码。
我一般会把环境分成四层来看。
开发环境(dev)是给开发者快速验证的地方,它对应的通常不是某一条固定分支,而是 feature 分支、个人分支,或者 main 上最新的开发构建。这个环境的目标是快,不是稳。开发环境可以频繁部署,可以被打断,可以连 mock 服务,也可以连一套临时数据库。管理上要注意两点:第一,不要让开发环境承担验收职责;第二,开发环境的数据和配置必须和生产隔离,不能因为图方便就直接连生产依赖。
测试环境(test)是给 QA、产品和团队做集成验证的地方,它通常对应 main、develop,或者专门的 integration 分支。小团队使用 GitHub Flow 时,我更建议 main 合并后自动部署到测试环境;如果团队还保留 develop 分支,那 develop 就应该是测试环境的事实来源。测试环境要比开发环境稳定,不能随便把半成品功能推进去影响别人验证。如果有多个功能并行开发,最好通过 feature flag 控制入口,而不是让测试环境在多个大分支之间来回切。
预发布环境,也就是 staging 或 pre-production,应该尽量模拟生产。它对应的代码通常是 release 分支、待发布 tag,或者某个已经通过测试环境验证的 commit。预发布环境的重点不是发现普通功能 bug,而是验证发布本身:配置是否正确,数据库迁移是否可执行,缓存、队列、定时任务、第三方回调、权限和网络策略是否和生产一致。我的建议是,预发布环境不要跟着每次 main 合并自动更新,而应该由 release candidate 触发部署,这样它代表的是“下一次准备上线的版本”。
生产环境只应该部署已经确认可发布的版本。它对应的可以是 production 分支,也可以是不可变的 Git tag、GitHub Release、镜像 digest 或者某个明确的 commit。我更偏向用 tag 或镜像 digest 标记生产,而不是长期维护一条 production 分支。因为生产环境最重要的是可追溯:你必须能回答现在生产跑的是哪个 commit、哪个构建产物、哪一组配置,以及它是通过哪一次流水线发布出去的。
如果把它们放成一条代码流,大致是这样:feature 分支先进入开发环境,合并到 main 或 develop 后进入测试环境,从 main 切 release 分支或创建 release candidate 后进入预发布环境,最后通过 tag、release 或审批流水线进入生产环境。这个过程里,代码只能向前流动,不能因为生产出了问题就直接在生产分支上手改,也不能把预发布环境里的临时补丁忘在角落里。
环境和分支的对应有两种常见做法。一种是环境即分支,像 GitLab Flow 那样,每个环境对应一条分支,例如 develop 对应测试环境,pre-production 对应预发布环境,production 对应生产环境。合并到哪条分支就部署到哪个环境。这种方式直观,适合流程需要强控制、团队成员对环境概念还不熟的阶段。
另一种是环境即版本,也就是环境不由分支定义,而由 tag、commit、release 或镜像 digest 定义。main 始终是唯一主线,测试环境自动跟随 main,预发布环境部署某个 release candidate,生产环境部署某个不可变 tag。这更符合主干开发和现代 [[GitOps]] 的理念,也更容易做到“同一份构建产物经过测试、预发布、生产逐级推进”。
我更倾向于第二种。因为环境分支看起来直观,但时间一长很容易变成环境分叉:staging 有一些改动,production 有另一些改动,最后谁也说不清哪个才是事实来源。用 commit、tag、镜像 digest 来描述环境状态,通常更干净,也更容易审计。
这里的关键在于自动化。你不应该让人去手动 build、手动上传文件、手动重启服务,这些都应该由 [[CI/CD]] 流水线在代码合并、创建 release candidate 或打 tag 的时候自动完成。手动操作是错误的温床,一次手滑就可能把测试环境配置带到生产。
如果你的产品有 iOS、Android、桌面客户端、浏览器插件,或者 Electron 这类需要安装到用户设备上的客户端,那么发布流程就不能只按后端服务的思路来设计。
后端发布失败,大多数时候可以马上回滚。客户端发布失败,问题就复杂得多。用户已经下载的 App 不会自动消失,应用商店审核需要时间,不同用户升级节奏不一致,还有一部分用户可能永远停留在旧版本。所以客户端版本管理的核心,不只是“把代码发出去”,而是“在多个客户端版本长期共存的情况下保持系统可用”。
客户端发版通常要同时管理两个版本号。一个是给用户看的 version name,比如 2.4.1;另一个是给商店和系统识别的 build number 或 version code,它必须单调递增。Git tag 通常对应 version name,而每一次提交给 TestFlight、Google Play、企业分发平台或者自动更新服务的构建,都应该有唯一的 build number,并能追溯到具体 commit。
客户端发布还要有更长的冻结窗口。进入 release candidate 阶段后,最好从 main 或 develop 拉出 release 分支,只允许修复阻断发布的问题,不再混入新功能。测试通过后,用同一份产物进入灰度、审核和正式发布。这里我特别强调“同一份产物”,不要测试包是一份,正式包又重新 build 一份。重新 build 就意味着重新引入不确定性。
客户端灰度也和后端不同。后端灰度通常是按流量切分,客户端灰度通常是按用户升级比例切分,比如先给百分之一用户,再扩大到百分之五、百分之二十,最后全量。灰度期间要盯住崩溃率、启动耗时、关键接口错误率、支付或登录等核心漏斗。如果指标异常,第一反应不是继续扩大比例,而是暂停发布、下架新版本或者提高服务端开关的保护力度。
最容易被忽略的是客户端和后端 API 的兼容关系。后端接口不能假设所有客户端都已经升级,客户端也不能假设服务端永远保持旧行为。比较稳妥的做法是后端先兼容新旧协议,客户端再逐步升级,等旧版本占比足够低之后,再清理旧字段和旧接口。对关键功能来说,服务端 feature flag、最低支持版本、强制升级弹窗、降级配置都应该提前设计好,而不是事故发生后再临时补。
所以客户端发布更适合“版本分支加灰度开关”的模式。分支负责冻结代码,tag 负责标记发布版本,build number 负责区分构建产物,远程配置和 feature flag 负责控制功能是否真正对用户开放。
后端服务发布看起来比客户端轻,因为它通常可以随时部署、随时回滚。但也正因为后端离数据、流量和依赖系统更近,它的部署流程不能只停留在“把代码 merge 到 main”。
一个比较健康的后端发布链路应该是这样的:代码合并后触发 CI,跑单元测试、集成测试、静态检查和安全扫描;通过后构建不可变制品,比如 Docker image,并把 commit hash、版本号、构建时间写入镜像标签或元数据;然后部署到测试环境跑 smoke test;确认通过后,再通过人工批准或自动策略进入生产部署。
后端部署方式常见有 rolling update、blue-green deployment 和 canary release。rolling update 是逐批替换实例,简单直接;blue-green 是准备两套完整环境,流量从旧环境切到新环境,回滚时再切回去;canary 是先让少量真实流量进入新版本,观察指标稳定后再扩大比例。小服务用 rolling update 足够,核心链路或高风险改动更适合 canary 或 blue-green。
后端部署里最容易出事故的不是代码本身,而是数据库变更。应用可以回滚,数据库 schema 一旦改坏就很麻烦。所以数据库迁移要遵循向前兼容的思路。比如先新增字段但不删除旧字段,代码同时兼容新旧字段,等新版本稳定并确认旧代码不再访问后,再做清理。这通常被称为 expand and contract 模式。
配置和密钥也要从部署流程里单独拎出来。代码制品应该是不可变的,同一个镜像可以部署到 staging,也可以部署到 production,差异来自环境变量、配置中心和密钥管理,而不是重新编译一份“生产专用包”。如果每个环境都重新 build,一方面难以追溯,另一方面也很难保证测试过的东西就是上线的东西。
上线之后,发布流程还没有结束。后端服务必须有健康检查、日志、指标、链路追踪和告警。发布完成后至少要观察错误率、延迟、CPU、内存、队列积压、数据库连接数和核心业务指标。一个成熟的流水线不只是负责 deploy,也应该负责在关键指标异常时自动停止扩容、暂停灰度,甚至触发回滚。
所以后端服务的分支策略可以很轻,但部署策略不能轻。Git 分支回答的是“哪段代码可以发布”,部署系统回答的是“这段代码如何安全地进入生产流量”。这两个问题必须放在一起看。
分支和部署之间还缺一个连接点,就是版本号。[[语义化版本]] 是目前最通用的约定,格式是主版本号、次版本号、修订号,比如 2.4.1。主版本号在有不兼容的 API 变动时加一,次版本号在新增向下兼容的功能时加一,修订号在做向下兼容的 bug 修复时加一。这套约定的好处是,别人光看版本号变化就能大致判断这次升级的风险有多大。
在 Git 里,版本通过 tag 来固化。每次正式发布,你都应该在对应的 commit 上打一个带版本号的 tag,比如 v2.4.1。tag 是不可变的锚点,它让你在任何时候都能精确地回到某个已发布版本的代码状态。当线上出问题需要回滚时,你不是慌乱地去找哪个 commit,而是直接回到上一个 tag。
我强烈建议把打 tag 这个动作和发布流程绑定。很多团队会配置成打 tag 自动触发生产部署,或者创建 GitHub Release 后触发发布流水线。这样 tag 既是版本标记,又是发布触发器,一举两得。
配合 tag,维护一份清晰的 changelog 也很重要。每个版本发布时,记录下这个版本包含哪些新功能、修了哪些 bug、有没有破坏性变更、是否需要数据库迁移、客户端最低兼容版本是多少。这份记录既是给用户看的,也是给未来的自己看的。当半年后你想知道某个行为是从哪个版本开始变的,changelog 就是最快的答案。
线上救火是每个团队都躲不掉的场景,而热修复流程恰恰最能检验你的分支策略是否健全。
糟糕的做法是,发现线上 bug 后,直接在开发分支上改,改完把开发分支上一堆没测完的东西一起推上线,结果旧 bug 没解决又带出新 bug。正确的做法是,热修复必须基于当前生产环境正在运行的那个版本,也就是从 main 分支、生产 tag 或 release 分支拉出一条独立的 hotfix 分支。
在这条 hotfix 分支上,你只做和这个 bug 相关的最小改动,不夹带任何其他东西。修复完成、测试通过后,合并回 main 并立即部署上线,同时打一个修订号加一的新 tag。
这里有一个容易被忽略的关键步骤:热修复的改动必须同步回开发主线。在 Git Flow 里是合回 develop,在主干开发里就是确保 main 已经包含这次修复。如果客户端还有 release 分支,也要把修复 cherry-pick 回对应的发布分支。否则下次正常发布的时候,这个 bug 会因为开发分支上没有这个修复而重新出现,这种回归 bug 特别隐蔽也特别让人抓狂。
客户端热修复还要多考虑一层:如果新版已经进入应用商店审核或者已经部分灰度,修复版本可能需要重新提审,这中间有时间差。所以客户端关键功能一定要能通过远程配置关闭,后端也要保留对旧客户端的兜底兼容。不要把所有希望都寄托在“赶紧发一个新包”上。
热修复流程的本质,是在紧急情况下依然保持隔离的纪律。越是着急,越容易图省事直接乱改,而这恰恰是把小事故变成大事故的根源。把热修复流程规范化,甚至写成脚本或者文档贴在显眼处,能在关键时刻救你一命。
讲了这么多模型和流程,落到实处,我想给几条具体的、不同场景下的建议。
如果你是个小团队或者独立开发者,做的是 Web 应用或者服务,别犹豫,直接用 GitHub Flow。一条 main 分支,功能分支开 PR 合并,配好 CI 自动测试和部署。不要一上来就套 Git Flow 那套复杂规范,你会被繁琐的流程拖垮,而且大概率用不上它的多版本维护能力。等团队和复杂度真的涨上来了,再考虑往 GitLab Flow 演进,加上环境分支或发布分支。
如果你做的是有明确版本概念、需要给客户提供长期支持、或者要同时维护多个大版本的软件,那 Git Flow 或者 GitLab Flow 的 release 分支模式是合适的。它的繁琐在这种场景下是必要的代价,因为你需要清楚地知道每个客户、每个环境、每个版本分别停在哪里。
如果你做的是客户端产品,我会建议保留 release 分支。main 可以保持快速迭代,但每次准备发版时从 main 切出 release 分支,进入代码冻结、测试、灰度和正式发布。发布后 tag 固化版本,后续只允许 hotfix 进入这条 release 分支。这样既不影响主线继续开发,也能保证客户端版本稳定。
如果你做的是后端服务,我会建议把精力更多放在流水线和部署策略上。分支可以简单,但要确保构建产物不可变、部署可追踪、数据库迁移可回滚或至少可兼容、灰度可观察、异常可快速止血。后端的安全感不是来自很多分支,而是来自自动化测试、监控告警和可重复的部署流程。
无论用哪种模型,有几条纪律是通用的。保持 main 分支永远可部署,这是底线。功能分支要小而短命,一个分支只做一件事,尽快合并,别让它在角落里存活好几周。所有合并都要走 PR、CI 和 review,不要绕过流程直接 push。每次发布都要有 tag、changelog 和可追溯的构建产物。热修复一定要从生产版本出发,并且修完之后合回主线。
分支管理没有银弹。Git Flow、GitHub Flow、GitLab Flow、主干开发,本质上都是在不同约束下对同一个问题的回答:如何让多人协作的代码,以尽量低风险、可追踪、可回滚的方式进入用户手里。
如果只看代码仓库,很多流程都显得差不多。但一旦把客户端版本发布、后端服务部署、数据库迁移、灰度策略、应用商店审核、线上监控这些因素放进来,你就会发现发布系统其实是一个整体。分支只是入口,真正决定稳定性的,是从 commit 到用户之间的每一道闸门。
我现在看一个团队的工程成熟度,已经不太会只问“你们用什么分支模型”。我更关心的是:main 是否随时可部署,发布是否有明确版本锚点,客户端和后端是否互相兼容,数据库变更是否可控,灰度指标是否有人看,出问题时是否能在几分钟内知道该回滚哪个版本。
能把这些问题回答清楚,分支模型反而只是一个自然结果。流程不是为了显得专业,而是为了在真正出问题的时候,让团队不用靠记忆和运气救火。
2026-07-03 13:00:00
过去一年里软件的开发方式发生了一个我自己都没料到的转变。以前写代码是工程师对着编辑器敲,现在更多时候是同时开着好几个 [[Claude Code]]、[[Codex]] 之类的编码 Agent,让它们各自去完成一个任务,工程师只负责在中间调度、审阅、拍板。这种”我带一队 Agent 干活”的模式效率确实高,但很快就撞上了一堆现实的麻烦:几个 Agent 都在同一个仓库里改文件,分支互相污染;终端窗口开了一大排,切来切去分不清哪个是哪个;改完还得一个个去看 diff、跑测试、开 PR。工具还是那套为单人设计的 IDE,可我干活的方式早就不是单人了。
直到最近我发现了 [[Orca]] 这个东西,才第一次感觉到有款工具是真的照着”人加一群 Agent”这个新范式来设计的。它来自 onorca.dev,官方给自己的定位是 Agent Development Environment,简称 ADE。这篇文章就聊聊它到底是什么、解决了什么问题、有哪些让我觉得对路的特性,以及怎么装来用。

Orca 官方有一句话把它的立场讲得很清楚:IDE 是为你设计的,ADE 是为你和你的 Agent 一起设计的。这句话初听有点像营销辞令,但你真正被前面那些麻烦折磨过之后,就会明白它戳中的是一个实实在在的空档。
传统 [[IDE]] 的每一个交互假设都建立在”一个人在写代码”上:一个工作区、一个当前分支、一个焦点文件、一个终端。可当你手里有五个 Agent 各自在忙的时候,这套假设全线崩溃。你需要的是五个互不干扰的隔离环境、五个可以同时观察的工作面、以及一套能让你快速在它们之间切换和汇总的界面。Orca 干的事,就是把 IDE 里那些为单人优化的部分,重新按照”多 Agent 并行”的思路组织了一遍,同时把终端、文件编辑器、浏览器、Git 工具这些原本散落在各处的东西,统统收进了一个应用里。
它背后是 stablyai 团队,拿了 [[Y Combinator]] 的投资,整个产品以 MIT 协议开源,代码托管在 GitHub 上。对我来说,一个还在高速迭代、又完全开源免费的开发工具,天然就少了很多顾虑,这也是我愿意认真投入时间去试它的一个前提。
如果只让我记住 Orca 的一个设计,那一定是它把 [[git worktree]] 当成了并行工作的基本单位。
熟悉 Git 的人都知道 worktree 这个特性:它允许你从同一个仓库里检出多个工作目录,每个目录停在不同的分支上,彼此完全独立。Orca 把这个能力做成了产品的地基,每一个任务、每一个 Agent,都跑在自己专属的 worktree 里。这意味着 Agent A 在重构模块、Agent B 在写测试、Agent C 在改文档,它们同时动手却谁也不会踩到谁,因为它们物理上就工作在不同的目录、不同的分支上。用官方的说法,就是不用再 stash、不用再手忙脚乱地切分支。
这一招看似简单,实际用起来的爽感却很难被替代。我以前手动维护多个 worktree 时,最烦的就是记不清哪个目录对应哪个任务,终端 cd 来 cd 去很容易搞错。Orca 把这层管理彻底接管了,每个 worktree 有清晰的名字、独立的终端、独立的编辑器状态,我只需要关心任务本身,底层那套 Git 的杂活它替我料理干净了。对于同时驱动多个 Agent 的工作流来说,这种隔离不是锦上添花,而是让并行真正可用的前提。
隔离只是地基,Orca 在上面还堆了不少让多 Agent 协作真正顺手的东西,我挑几个印象最深的讲。
它几乎不挑 Agent。官方宣称支持 25 种以上预配置的 CLI Agent,[[Claude Code]]、[[Codex]]、Cursor、[[GitHub Copilot]]、Grok、Gemini、OpenCode、Goose、Cline 这些主流的都在列,而且它的原则是任何 CLI 形态的 Agent 都能接进来。这一点对我很重要,因为我并不想被绑死在某一家 Agent 上,不同任务我会想用不同的模型和工具,Orca 这种不站队的态度让它更像一个中立的指挥台,而不是某个 Agent 的专属外壳。
它给每个 worktree 配了一个真正的浏览器。这不是内嵌一个网页控件那么简单,而是每个工作区都跑着一个独立的 Chromium 窗口,官方把它叫做 Design Mode。你在做前端时,可以直接在这个浏览器里点选某个界面元素,把对应的 HTML、CSS 甚至截图打包发回给 Agent,让它照着改。这等于在人、浏览器、Agent 之间搭了一条极短的反馈回路,我试过让 Agent 调整一个页面样式,指着浏览器里的元素说”就这块,边距太大”,比在聊天框里用文字描述半天精确得多。
它把代码审阅这件事做到了 Agent 时代该有的样子。Orca 内置了 [[VS Code]] 那套编辑器体验,更关键的是它的 diff 审阅:你可以在 Agent 改动的任意一行上写 Markdown 评论,把这些评论攒成一批,然后一键发回给 Agent 让它据此修改。这个循环解决了我一直以来的一个痛点,就是审阅 AI 的改动时脑子里冒出一堆意见,却没有一个顺手的地方把它们结构化地喂回去。除此之外,检查 CI、解决冲突、开 PR 全都能在应用内完成,甚至可以直接浏览 PR、Issue 和 [[Linear]] 的看板,创建 Issue、审批 PR,整个过程不需要在浏览器和编辑器之间反复横跳。
它还有一个我特别欣赏的设计,就是 Orca 本身是可以被脚本驱动的。它提供了一个叫 Orca CLI 的命令行接口,你可以在任何 shell 里用命令去操作一个正在运行的 Orca 编辑器,创建和检查 worktree、驱动 Agent 的终端、打开文件和 diff、甚至自动化那个内置浏览器。它的浏览器支持像 orca snapshot、orca click、orca fill 这样的脚本命令,操作的还是你正在交互的那个浏览器、那些标签页。这里最妙的一层是,既然 Orca 能被 CLI 驱动,那 Agent 自己也可以通过 CLI 来驱动 Orca,于是你就有了让 Agent 编排 Agent 的可能性。配合它对定时自动化、worktree 检查点、以及 skills 注册表加 [[MCP]] 的支持,这套东西的想象空间一下就被打开了。
对于那些跑在别处的任务,它支持 SSH worktree。你可以让 Agent 在远程机器上干活,比如需要长时间构建的服务器或者带 GPU 的机器,Orca 提供了自动重连、端口转发、密码短语缓存这些贴心的细节,让远程和本地的体验尽量接近。而当我人不在电脑前时,它还有一个移动端伴侣应用,值得单独提一句它的隐私设计:手机端是个纯粹的瘦客户端,代码、shell、Agent 全都还跑在你的桌面上,手机上什么都不运行,只是个观察窗口。配对走的是端到端加密,桌面生成一次性密钥对、显示二维码,手机扫一下之后两端之间的所有流量都用这对密钥封起来。这种把安全边界想清楚的做法,让我对把它接进日常工作流放心了不少。
最后是那些体现工程品味的细节。它的终端用 WebGL 渲染,据说灵感来自 [[Ghostty]],支持无限分屏,而且重启后连回滚缓冲都能恢复。整个界面的组织方式是分屏面板,你可以把 Agent、终端、浏览器、diff、文件按照任务的形状自由地拼进一个个分屏里。也就是说,如果一个任务需要一个 Agent 加两个终端加一个浏览器,你就照着这个形状把界面铺开,而不是被工具的固定布局绑住。
安装很直接,去官网 onorca.dev 就能下载。桌面端覆盖了 macOS 的 Apple Silicon 和 Intel 两种芯片、Windows 以及 Linux 的 AppImage,移动端有 iOS 和 Android。如果你和我一样喜欢用包管理器,macOS 上可以直接用 Homebrew 装:
brew install --cask stablyai/orca/orca
Arch Linux 用户则可以从 AUR 安装。它整个是开源的,源码就在 github.com/stablyai/orca ,想深入了解实现或者提 issue 都很方便。
我的上手建议是,别一上来就想着五个 Agent 齐飞,先从两个 worktree 开始感受隔离带来的清爽。挑两个互不相关的小任务,各开一个 worktree,各派一个 Agent,你会立刻体会到那种”它们在各自的世界里忙、我在上帝视角看着”的踏实感。等这套心智模型建立起来,再逐步增加并行度,同时去摸索它的 diff 标注和 PR 流程,把审阅这个环节也纳入进来。真正想榨干它价值的话,最后一定要去玩玩 Orca CLI,试着写个脚本去驱动一个 worktree,那一刻你会意识到 Orca 不只是个界面,而是一个可编程的 Agent 编排平台。
聊了这么多,我也得说清楚它的适用边界,免得你带着错误的期待去用。
如果你已经在用 AI 编码 Agent,而且经常不止开一个,那 Orca 几乎是为你现在的痛点量身准备的,它解决的正是并行、隔离、审阅、编排这一整条链路上的摩擦。如果你是那种喜欢把工具用到极致、乐于写脚本做自动化的人,那它的 CLI 和 MCP 支持会给你巨大的折腾空间。但反过来,如果你目前还是老老实实一个人一行行写代码,偶尔才让 AI 补全一下,那 Orca 对你可能就有点重了,一个功能完整的传统 IDE 反而更贴合你的节奏。说到底,Orca 的价值密度和你的并行度是正相关的,你手里的 Agent 越多,它替你省下的心力就越可观。
我目前升级到了最新的稳定版本 v1.4.128,但是在 Agent 中渲染中文的时候还是感觉有虚化问题,调整了字体,也让 AI 尝试解决了一下问题,还是没有解决方案。
下面的截图,左侧是 Orca,右侧是 [[Muxy]],可以明显看到字体渲染差别。

Orca 是基于 Electron 构建,应用占用的内存相对较大,体积也较大,在使用流畅程度上也能体验到稍微的延迟。
Orca 的手机应用并非可以独立运行,它必须依赖桌面端在线。如果网络不稳定或者笔记本睡眠,手机端就会失去连接。
远程 worktree 功能需要在远程机器上安装 Orca 自带的 agent ,如果是自己的 VPS ,那当然没问题,但是如果是安全审查严格的企业,可能会存在安全性问题。
回头看这大半年,最大的变化其实不是我用了哪个更强的模型,而是我组织工作的方式变了。当写代码从”我做”变成”我调度一群 Agent 做”,我需要的工具也就从一个更好的编辑器,变成了一个更好的指挥台。Orca 打动我的地方,正是它没有假装这个转变不存在,而是老老实实地围绕”人加一群 Agent”重新想了一遍开发环境该长什么样,然后用 worktree 隔离、可脚本化的 CLI、内建的浏览器和 PR 流程,把这个想法落成了一个真能用的产品。
对我个人而言,最大的收获是它帮我把一个模糊的直觉具体化了:并行运行 Agent 不是简单地多开几个窗口,而是需要一整套隔离、观察、审阅、编排的基础设施来支撑,缺了这套底座,并行度一上去就会乱成一团。Orca 让我看清了这套底座的形状。它还很年轻,功能几乎每天都在更新,未来会长成什么样谁也说不准,但它所代表的这个方向,也就是从 IDE 走向 ADE,我是真心相信会是接下来相当长一段时间里开发工具演进的主线。如果你也已经在带着 Agent 一起干活,我强烈建议你去装一个免费开源的 Orca,用两个 worktree 认真跑一跑,感受一下什么叫真正为 Agent 时代设计的开发环境。
2026-07-01 13:00:00
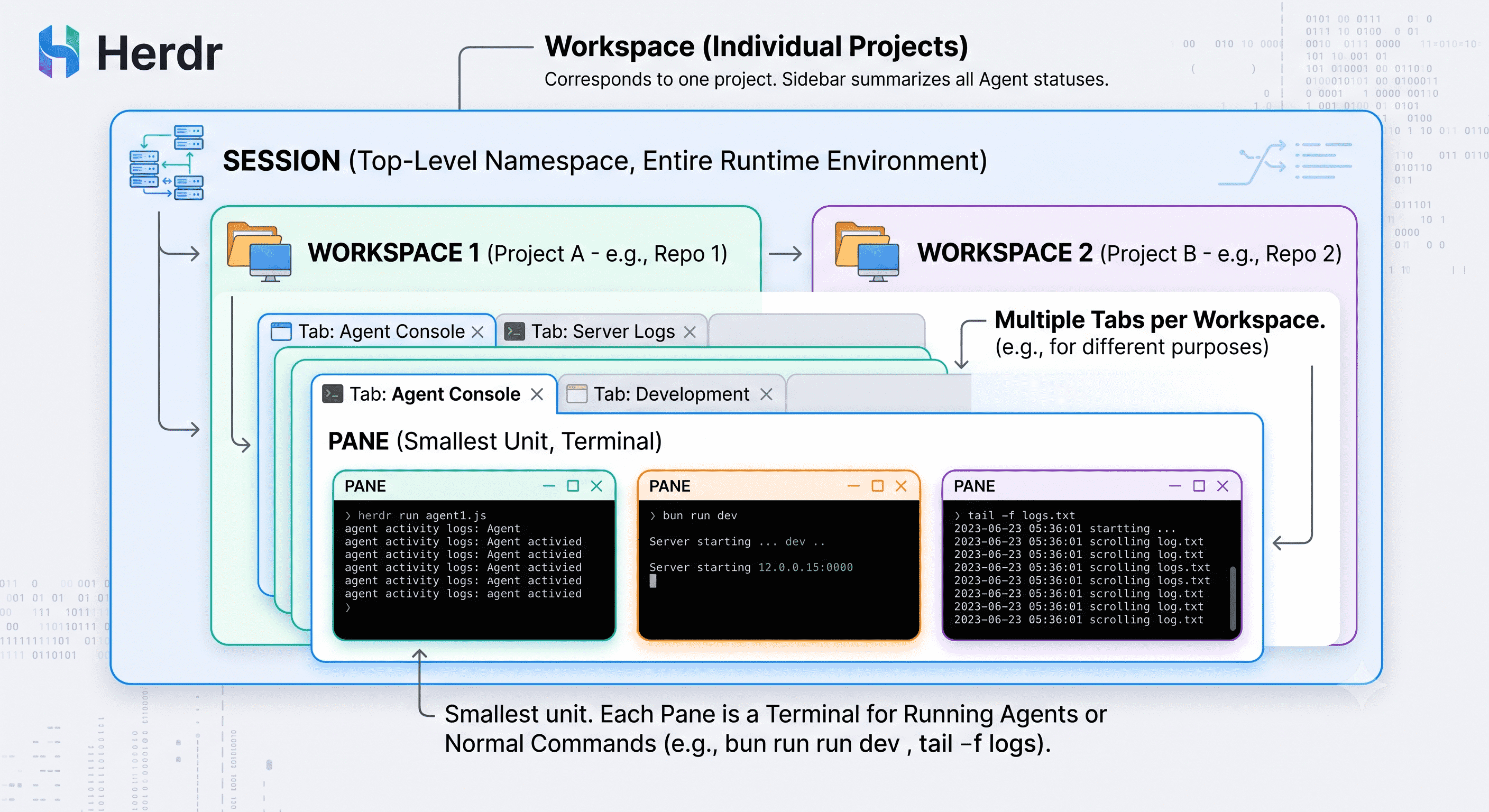
Herdr 是一个运行在终端里的 AI 编码 agent 多路复用器(agent multiplexer)。官方用一句话概括它的定位:Herdr 之于编码 agent,就像 [[tmux]] 之于终端。它运行在你的 agent 运行的地方——本地机器、服务器,或任何可以 ssh 进去的环境,让你在一个终端里同时观察和操作多个正在工作的 agent。
随着 [[Claude Code]]、[[Codex]]、[[OpenCode]] 这类终端原生的编码 agent 流行起来,开发者常常会同时跑好几个 agent 处理不同的任务或仓库。问题随之而来:哪个 agent 在干活,哪个卡住了在等你确认,哪个已经做完了?Herdr 解决的就是这个“一群 agent 的可见性与编排”问题,把整个“herd”(畜群,这里指你养的一群 agent)收拢进一个终端。
Herdr 使用 [[Rust]] 编写,是开源项目,在 GitHub 上托管于 ogulcancelik/herdr。它强调 mouse-first(鼠标优先)和 agent-aware(感知 agent 状态),并且不依赖 Electron,是真正的终端原生工具。
| Bilibili | YouTube |
Herdr 的核心价值在于把多个 agent 的状态可视化并集中控制。
Herdr 用一套层级化的概念来组织工作空间:
bun run dev、tail -f、python3 -m http.server)。这套模型对用过 tmux 或 [[Zellij]] 的人来说很熟悉,但 Herdr 在其上叠加了对 agent 状态的语义理解。
Herdr 在 Linux 和 macOS 上提供稳定版,Windows 目前是 preview beta(仅供预览)。
脚本安装(Linux/macOS):
curl -fsSL https://herdr.dev/install.sh | sh
此外还支持 Homebrew 与 [[Nix]] flake 安装。Windows 预览版通过 PowerShell:
irm https://herdr.dev/install.ps1 | iex
默认键位前缀沿用 tmux 的习惯 ctrl+b,例如 prefix+v / prefix+c 用于切分 pane,prefix+q 等。对完全没接触过多路复用器的用户,Herdr 主打鼠标优先:可以点击 pane、拖拽边框、通过右键菜单切分和切换,不需要先背快捷键。
配置文件位于 ~/.config/herdr/config.toml,可以自定义键位、主题、侧边栏行为、通知与滚动缓冲等。
Herdr 有三种输入模式,快捷键的含义取决于当前所在模式:
ctrl+b 后触发,执行单次 Herdr 命令默认前缀键为 ctrl+b,可在 ~/.config/herdr/config.toml 中自定义。
| 快捷键 | 功能 |
|---|---|
prefix+v |
向右垂直分屏 |
prefix+minus |
向下水平分屏 |
prefix+h/j/k/l |
在 Pane 间移动(左/下/上/右) |
prefix+shift+h/j/k/l |
交换相邻 Pane |
prefix+z |
放大/还原当前 Pane |
prefix+x |
关闭当前 Pane |
prefix+r |
进入调整大小模式 |
prefix+[ |
进入复制模式 |
| 快捷键 | 功能 |
|---|---|
prefix+c |
新建 Tab |
prefix+n |
切换到下一个 Tab |
prefix+p |
切换到上一个 Tab |
prefix+1..9 |
直接跳转到对应编号的 Tab |
prefix+T |
重命名当前 Tab |
prefix+X |
关闭当前 Tab |
| 快捷键 | 功能 |
|---|---|
prefix+N |
新建 Workspace |
prefix+W |
重命名 Workspace |
prefix+D |
关闭 Workspace |
prefix+w |
打开 Workspace 导航 |
prefix+g |
跳转选择器(快速跳到任意 Pane) |
prefix+b |
切换侧边栏显示/隐藏 |
prefix+q |
Detach 会话(后台继续运行) |
prefix+? |
查看所有快捷键帮助 |
不需要按前缀键,直接触发:
| 快捷键 | 功能 |
|---|---|
ctrl+alt+h/j/k/l |
聚焦左/下/上/右 Pane |
ctrl+alt+[ |
切换到上一个 Tab |
ctrl+alt+] |
切换到下一个 Tab |
ctrl+alt+c |
新建 Tab |
ctrl+alt+d |
垂直分屏 |
ctrl+alt+shift+d |
水平分屏 |
ctrl+alt+z |
放大/还原当前 Pane |
ctrl+p |
打开命令面板 |
ctrl+k |
搜索 |
进入复制模式(prefix+[)后的操作:
| 按键 | 功能 |
|---|---|
h/j/k/l、w/b/e、{/}
|
移动光标 |
v 或 Space
|
开始选择 |
y 或 Enter
|
复制选中内容 |
q 或 Esc
|
退出复制模式 |
| 快捷键 | 功能 |
|---|---|
Esc |
中断当前操作 |
shift+tab |
循环切换权限模式(permission mode) |
Herdr 一个有意思的设计是它本身对 agent 友好。它附带一个 skill 文件 SKILL.md,安装时会写入 agent 的指令目录(例如 [[Claude Code]] 的 ~/.claude/skills/herdr/SKILL.md,Codex 的 ~/.codex/AGENTS.md),这样 agent 在 pane 内部就能原生地理解并执行 Herdr 命令。
官方甚至建议让 agent 自己来完成 onboarding,把下面这段提示丢给正在运行的 agent 即可:
Help me understand and set up Herdr. Read https://herdr.dev/agent-guide.md first, then walk me through it step by step.
Herdr 还提供 CLI 与本地 socket API,允许脚本、工具和 agent 通过编程方式控制 Herdr,实现自动化编排。
Herdr 支持本地可执行的工作流插件(plugin),通过 manifest 定义 action 和 event hook 来扩展功能。社区可以通过 GitHub 分享插件并打 tag,待官方 marketplace 上线后被收录。主题方面内置了对 catppuccin、tokyo night 等流行配色的支持。
Herdr 官方提供了与同类工具的对比,核心差异在于“终端原生”与“感知 agent 状态”两点:
简单说,如果你需要的是“在终端里同时盯住一群编码 agent,谁卡住了立刻去救”,Herdr 的定位最贴合;如果只是单纯需要终端分屏与会话保持,tmux/Zellij 已经够用。
2026-06-30 13:00:00
最近在给自己的 AI 编程工作流加入 [[Headroom]] 上下文压缩工具时,遇到了一个需要特别注意的配置问题。相信有不少人和我一样,为了降低成本或者改善访问体验,已经在 [[Claude Code]] 或 [[Codex]] 里配置了第三方 API 代理,比如一些第三方聚合平台或者自建的转发服务。这时候想再套上一层 Headroom 做 Token 压缩,就需要特别注意配置细节,不然两层代理会打架。
先简单说一下背景。使用 Claude Code 或 Codex 的时候,默认走的是 Anthropic 或 OpenAI 的官方 API。但很多人会出于各种原因选择第三方代理服务:账单更透明、支持多种模型统一路由、某些地区访问更稳定,或者是公司统一管控 API 调用。配置方法很简单,只需要设置一个环境变量:
export ANTHROPIC_BASE_URL="https://your-third-party-proxy.com"
export ANTHROPIC_API_KEY="your-key"
Claude Code 启动后会把所有请求发到这个地址,就像在用官方 API 一样,体验没有任何差别。
Headroom 是一个开源的 AI Agent 上下文压缩层,它在把内容发给大模型之前先进行压缩,去掉冗余信息,只保留关键内容。官方数据显示能节省 60%~95% 的 Token,对日志、JSON 这类结构化数据效果尤其明显。我之前写过一篇详细介绍,感兴趣可以看看利用 Headroom 压缩上下文减少 Token 消耗。
Headroom 的常见使用方式有几种,其中最简单的是 CLI 包装模式:
headroom wrap claude
或者启动一个独立的本地代理:
headroom proxy --port 8787
这两种方式的本质都一样:Headroom 在本地起一个服务,拦截 Claude Code 发出的请求,压缩之后再转发给真正的 API 端点。
问题就出在这里。当你已经配置了第三方 BASE URL,同时又想加入 Headroom 时,完整链路应该是这样的:
Claude Code → Headroom(本地)→ 第三方代理 → 模型服务商
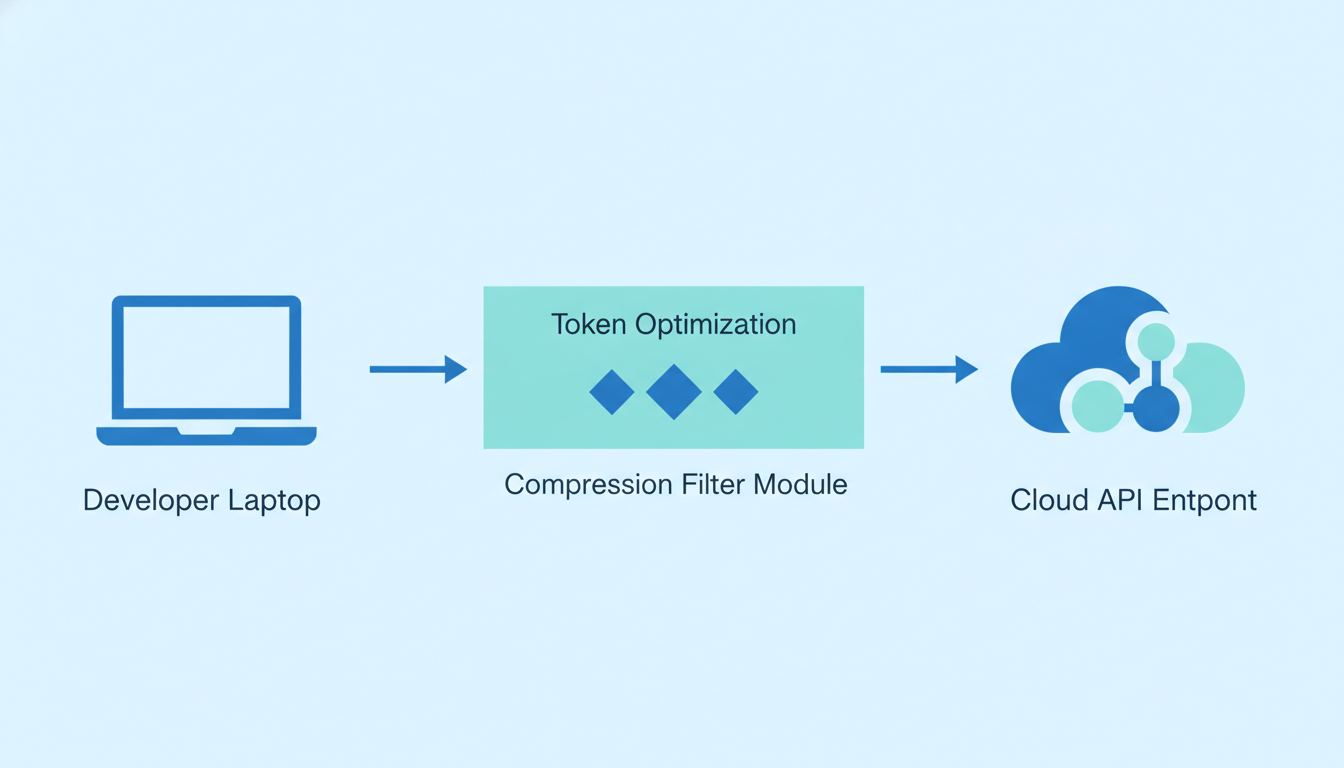
但如果你只是简单地运行 headroom wrap claude 或者 headroom proxy,Headroom 默认会把压缩后的请求发给 Anthropic 的官方 API,而不是你的第三方代理。这样一来,要么请求失败(Key 不匹配),要么绕过了你原本精心配置的代理链路。
解决方案是额外设置一个环境变量 ANTHROPIC_TARGET_API_URL,把它指向你的第三方代理地址,告诉 Headroom 压缩完之后把请求发到哪里:
export ANTHROPIC_TARGET_API_URL="https://your-third-party-proxy.com"
export ANTHROPIC_API_KEY="your-key"
然后再启动 Headroom:
headroom wrap claude
# 或者
headroom proxy --port 8787
Headroom 启动时会自动把 ANTHROPIC_BASE_URL 设置成它自己的本地端口(比如 http://localhost:8787),而 ANTHROPIC_TARGET_API_URL 才是 Headroom 压缩完之后真正转发的目标地址。
这两个变量各司其职,不能搞混:
ANTHROPIC_BASE_URL:Claude Code 连接的入口,Headroom 会自动管理这个值,指向自己的本地端口ANTHROPIC_TARGET_API_URL:Headroom 把压缩后的请求转发到哪里,也就是你的第三方代理或官方 API在实际配置过程中,有几个细节需要特别留意。
第一个是环境变量覆盖问题。如果你在 .zshrc 或 .bashrc 里已经设置了 ANTHROPIC_BASE_URL 指向第三方代理,那么 Headroom 启动时会用自己的本地端口覆盖掉这个值。这是预期行为,Headroom 必须让 Claude Code 先把请求发给自己才能拦截。所以建议不要在 shell profile 里硬编码 ANTHROPIC_BASE_URL,而是只设置 ANTHROPIC_TARGET_API_URL,让 Headroom 动态管理入口地址:
# 在 .zshrc 中推荐的配置
export ANTHROPIC_TARGET_API_URL="https://your-third-party-proxy.com"
export ANTHROPIC_API_KEY="your-key"
# 不要设置 ANTHROPIC_BASE_URL,Headroom 会自动管理
第二个是验证配置是否生效。Headroom 的代理模式提供了一个本地 Dashboard,启动后可以访问 http://localhost:8787/dashboard 查看实时的请求拦截和压缩统计。如果看到有流量进来、Token 节省数字在增长,说明链路是通的。也可以用命令行快速查看累计数据:
headroom stats
如果 Dashboard 显示请求为 0,或者 Claude Code 直接报连接错误,优先检查 ANTHROPIC_TARGET_API_URL 是否设置正确,以及 Headroom 进程是否还在运行。
第三个是 headroom wrap 和 headroom proxy 的选择。headroom wrap claude 会直接包装 Claude Code 的进程,两者生命周期绑定,退出 Claude Code 时 Headroom 也会退出,适合临时使用或者快速测试。headroom proxy --port 8787 是独立的后台服务,适合长期运行,而且如果你同时使用 [[Cursor]]、[[Aider]] 等多个工具,代理模式更方便,只需要把它们的 BASE URL 都指向 http://localhost:8787 就能共享同一个压缩层。
第四个是 Headroom 未运行时的回退情况。如果 Headroom 进程意外退出,而 ANTHROPIC_BASE_URL 还停留在 http://localhost:8787,Claude Code 就会连接失败。这也是上面那条建议”不要在 shell profile 里硬编码 ANTHROPIC_BASE_URL“的原因——让 Headroom 在启动时动态设置它,退出后这个变量的值在新的 shell session 里不会保留。
第五个是关于 Codex 的情况。[[Codex]] CLI 使用的是 OpenAI 格式的 API,对应的环境变量是 OPENAI_BASE_URL 和 OPENAI_API_KEY。Headroom 对 OpenAI 协议同样支持代理模式,配置思路完全相同,只是变量名不同 OPENAI_TARGET_API_URL 。具体映射关系以 Headroom 当前版本的文档为准,因为不同版本可能略有差异。
给 Claude Code 接入 Headroom 的核心概念其实并不复杂:两层代理串联,各自负责不同的工作。Headroom 负责压缩 Token,第三方代理负责转发到模型服务。配置的关键就是把两层 URL 分开设置,用 ANTHROPIC_TARGET_API_URL 告诉 Headroom 压缩完之后把请求发往何处,而不是让它去覆盖你已有的第三方代理配置。这个细节文档里没有特别突出,实际踩坑之后才会发现。实际用下来,在代码搜索、日志分析这类工具密集型任务中,Token 消耗确实能明显减少,长对话的质量也更稳定,值得折腾一下。