2026-07-31 23:53:49
A great deal of the discussion of the so-called benefits or problems with AI comes down to the theoretical jobs that are (or are not) lost as a result of things LLMs can (or cannot do), or the equally theoretical productivity benefits that’ll come from using LLMs in place of (or in conjunction with) humans.
Anthropic’s Economic Index and OpenAI’s Economic Research Exchange are marketing operations that exist to propagate the (wrongheaded) belief that LLMs are either leading or will soon lead to massive economic or productivity shifts, even though little or no actual evidence exists to show that this is the case, other than the occasional story about LLMs make people worse or slower at their jobs or single lines in studies that are used (incorrectly) to prove that “AI is making it harder to find a job for young people.” In fact, Anthropic’s Head of Economics recently said there was “no material increase in the unemployment rate to date.”
These conversations materially detract from the actual harms or effects of AI, and exist only to make you scared that AI will take your job. They do not have any vested interest in expressing the actual economic effects of AI, which are, at this point, a simmering cauldron of different speculative bets on whether or not LLMs — a definitively niche technology — will create or become general-purpose software (per Roger MacNamee) that scales into the next Google Search, iPhone, or Microsoft 365.
As I’ve argued again and again, the AI industry’s revenues are, outside of Anthropic and OpenAI, incredibly small. Even in Exponential View’s deliberately-pro-industry analysis, there’s only around $110 billion in trailing twelve-month revenues across the entire industry, including OpenAI and Anthropic’s cloud spend.
For those counting at home, that’s $12 billion less than the $122 billion OpenAI raised in March, and a full $145 billion less than all AI startups raised combined in the first quarter of 2026.
Anthropic and OpenAI want you to talk about the theoretical so that you don’t focus on the tangible — their hundreds of billions of dollars’ worth of commitments, said commitments effects on the remaining performance obligations of hyperscalers and chip manufacturers, and the sheer scale of venture capital’s investment in AI, which (as I’ve argued in the past) largely allows for massive on-paper gains with little or no hope of liquidity.
To put this bluntly, I believe the entire conversation around AI’s theoretical relationship to jobs to be masturbatory and a conscious attempt to avoid having a messy conversation about the scale of the actions taken based on the flimsily-founded promises of AI labs and hyperscalers.
Today’s piece will dig into the true scale of the money needed to make AI make sense, by which I mean how much OpenAI and Anthropic will need to meet their commitments, how much money hyperscalers will need to pay off their investments, venture capital’s true exposure to the AI bubble, and what will have to go right for the bubble not to be, well, a bubble.
I’ll also make the case that the longer the bubble continues to inflate, the harder the basic economic puzzle of AI becomes to solve, as creating and deploying infrastructure becomes vastly more expensive — meaning that in order to achieve profitability, hyperscalers and neoclouds need to charge significantly more for compute than before, and the only two real potential customers are ones that cannot pay for it.
This will be a more more-pointed newsletter than usual, focusing on hard numbers and harder truths.
Let’s get it on.
2026-07-29 00:29:37
If you liked this piece, you should subscribe to my premium newsletter. It’s $70 a year, or $7 a month, and in return you get a weekly newsletter that’s usually anywhere from 5,000 to 18,000 words, including vast, detailed analyses of NVIDIA, Anthropic and OpenAI’s finances, and the AI bubble writ large. My Hater's Guides To the SaaSpocalypse, Private Credit and Private Equity are essential to understanding our current financial system, and my guide to how OpenAI Kills Oracle pairs nicely with my Hater's Guide To Oracle, as well as the Hater’s Guide To Oracle (Part 2).
Subscribing to premium is both great value and makes it possible to write these large, deeply-researched free pieces every week.
Soundtrack: Queens of the Stone Age — Infinity
Two years ago, NVIDIA CEO Jensen Huang said that “the more you buy, the more you save,” referring to its new (at the time) Blackwell GPUs that would “reduce LLM inference operating cost and energy by up to 25x.” Two years later, those supposed gains have been pared back to 10x, based on case studies with private inference providers that do not share their margins and are most-decidedly not profitable, and absolutely nobody seems to mind that NVIDIA overstated the gains on Blackwell (in a vacuum, in specific circumstances) by 150%, partly because these numbers are utterly meaningless, and partly because the media in most cases ardently refuses to criticize this company.
Blackwell being “10x better” than Hopper does not appear to have made any AI startups profitable (or even more profitable), it does not appear to have lowered anyone’s costs in a way that we can measure using dollars and cents, and as a result, I feel very little when I’m told that Vera Rubin provides “up to 10x more tokens per megawatt,” especially as that was with DeepSeek R-1, a year-and-a-half-old open source model.
Nevertheless, all of this is immaterial to the larger problem that none of this appears to have resulted in anything tangible other than horrendously-overstuffed balance sheets and spuriously-puffed stock prices.
Hyperscalers will have sunk over $1.3 trillion dollars into generative AI by the end of 2026, and have plans to spend a trillion dollars more next year. On a very rational level, nothing that large language models (LLMs) have done, do or will do in the future can or will ever bring in the more than $2 trillion (or more) in brand new revenue that will be required to make any of this worth it.
To be more specific, between March 2022 and July 2026, Meta, Google, Amazon, and Microsoft added over $850 billion in property, plant, and equipment (PP&E), nearly tripling their PP&E from $498 billion or so, and in a period where they spent over $1 trillion in capital expenditures.
In that same four year period, none of them have disclosed their actual revenues from AI or AI-related services, and, as of their latest quarters, capital expenditures now represent 24.4% of Amazon’s, 33.7% of Meta’s, 37.3% of Microsoft’s, and an astonishing 43.4% of Google’s revenue, a number that’s steadily increased over the last three years.
They’ve also added over $307 billion in on-balance sheet debt, leaving them with a total of $557 billion, doubled from $250 billion or so in March 2022. I mention on-balance sheet because Nikkei reports that Meta, Google, Amazon and Microsoft have over $1.35 trillion in off-balance sheet debt — either data centers/GPUs yet to be delivered, or debt raised via SPVs that shift the actual “ownership” of them over to another party as a means of making them look less-indebted than they really are.
To be clear, it’s totally fine accountancy-wise to not include leases or commitments yet-to-commence, but it’s very important to know how big an anvil hyperscalers are conjuring above their heads. Google, for example, has $811 billion in contracted future spending commitments as of its latest quarter, increasing by a dramatic $661 billion ($478 billion or so in the latest quarter) in the last 6 months, and Meta has over $237 billion in non-cancellable contractual commitments.
Over $167 billion of that on-balance sheet debt has been raised in bonds across Google, Meta, and Amazon, with its $25 billion bond sale from July receiving (per Bloomberg) a cool reception, with “demand [settling] at 1.6 times the deal’s size…[and to] put that in perspective, US high-grade corporate deals have seen orders average around four times their size this year.”
For some further perspective, per Freedom Broker’s Saken Ismailov, there was around $100 billion of demand for $20bn of Google’s three to fourty-year-long bonds (5x) and around £9.5 billion of demand for its £1 billion 100-year bond sale (9.5x).
As of last week, Google’s century bond has already lost 10% of its value.
This is a problem, as all four are certain to become repeat visitors to the bond markets. Herman Chan of Bloomberg Intelligence estimates that hyperscalers will need to raise $1.5 trillion in investment-grade debt in the next five years just to keep up with their trillions in estimated capital expenditures.
To make matters worse, hyperscaler bonds are, to quote Bloomberg, “...underperforming on almost every metric,” and are “in the red on average,” though that includes Oracle, whose credit just got downgraded to a single rung above junk by S&P Global.
Sidenote: As an aside, whenever you hear bonds are measured in something called “spreads,” it’s how much more an investor would expect to get paid above the current US treasury bond rate in “basis points,” with 100bps referring to 1%.
The thing is, when treasury rates go up, bond prices go down, even though you’re still getting paid on the coupon (the yield, IE: the money it pays regularly) and the payoff at the end of the bond’s life. As a result, spreads exist to tell you how much more or less it pays than an equivalent US treasury bond, or a similar ultra-low-risk government bond.
Bonds are also generally raised in tranches, in different currencies, at different lengths, which makes their prices less useful than you’d think. Furthermore, bonds can be resold to third-parties, and often for cheaper than the original purchase price — which is something that would happen if people started to get worried about the company not being able to pay back its debts.
Let’s give you a (hypothetical) example. US Treasuries are 5%, and a hyperscaler raises $10 billion in bonds at 6.5%.
The “spread” here would be 150bps — which suggests that investors think they’re mostly safe. In general, 150-300bps is worth keeping an eye on, 300bps+ is worrying, and 700bps+ is a company that the market is concerned about repayment. For example, a high-credit company's bonds would have an average OAS of 20-80bps, or an investment grade (like Amazon at 118bps) would have between 80-150bps.
And, well, then there's the rest.
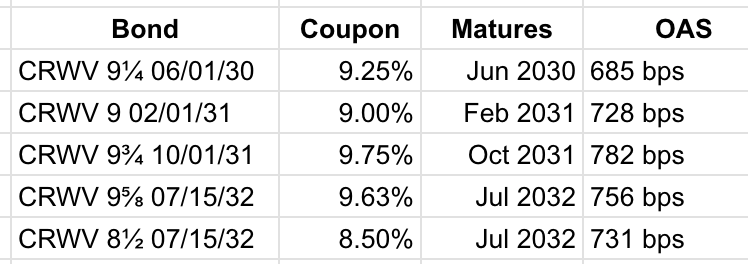
For example, CoreWeave’s $1.25 billion in bonds raised in June 2026 currently sit at an option-adjusted spread of 756bps, despite being issued somewhere around 540bps on the day of issuance. Put another way, bondholders have dumped the shit out of them in the last month and have material concerns that CoreWeave won’t pay. To make matters worse, the average for its bond/credit rating (Ba3) is 200-400bps, meaning the market is really, really concerned about whether CoreWeave pays its bondholders.
All of this is a way of telling, in realtime, how much riskier a bond might be than the rock-solid guarantee of the US government (or whatever currency it was raised in). When I say “option-adjusted spread,” that’s a forward-looking model that strips out things like if a company can recall (IE: buy back a bond early) a bond to give you a generalized spread that tells you how the market feels about a particular bond.
Things can muddle a little bit depending on the company, or should I say one company in particular.
EDITOR'S NOTE: To be clear, this is an edit to the piece, because I wanted to clarify some stuff and the article I previously linked got things wrong.
Also, thank you to eagle-eyed premium subscriber Clayton for noticing!
So, SpaceX's "investment-grade" bonds (issued in late June) are rated BBB - the lowest level possible - and have an average OAS of around 270bps, with the widest spread sitting at 346 (for its 30-year dated bond). I previously linked to a piece that said it was "trading like junk," and I was completely right in that assessment, but didn't give you, the reader, the juice to understand why.
As of writing, the average spread of Bloomberg's Corporate High Yield Index - which, to be clear, is made up of junk bonds in most cases many rating levels lower than SpaceX - is around 282bps. In other words, Musk's "investment-grade" bonds are trading like junk!
As complex as all of this sounds, it’s all pretty simple: hyperscalers have borrowed a bunch of money to fund AI, to the point that it’s pushing them into cash-flow negative territory, and every time they raise more money, bondholders become more worried about them paying it back, especially given that both Amazon and Google have now gone cash-flow negative as of their latest quarters.
Or, put more-simply, the more they raise, the more it costs.
Then there’s the other, more-obvious problem — the more they buy, the more they spend.
As I wrote in the Hater’s Guide To The Memory Crisis, the sheer scale of Microsoft, Google, Meta and Amazon’s spend on AI data centers has led to a massive supply chain crisis and price-gouging from the triopoly of Micron, SK Hynix and Samsung, with Micron alone bumping prices for DRAM by 60% in its last quarter, shooting up the price of every single kind of RAM possible, at a rate increased by the amount of GPUs and servers that hyperscalers buy.
To give you a sense of how memory hungry AI is, single 72-GPU GB300 NVL72 AI server has over 20 terabytes of high-bandwidth memory (used almost exclusively in GPUs and other AI chips), and 17 terabytes of the LPDDR5X RAM used in mobile devices, and a gigawatt data center has thousands of those NVL72 servers (or something similar). Moreover, that high-bandwidth memory that AI GPUs use requires more wafer space during manufacturing — further reducing the amount of manufacturing capacity for other kinds of memory.
This naturally creates a vicious cycle. The more AI servers that hyperscalers buy, the more demand they create for RAM and high-bandwidth memory, which increases the price of RAM and HBM, which makes the AI servers more expensive, which means hyperscalers need more money, and because AI has yet to provide meaningful improvements in revenue or cashflow, they’re forced to raise more debt.
The more they raise that debt, the more expensive that debt becomes, and the more of that debt they use, the more of it they need, because the more they spend, the more the stuff they’re buying costs, which means they need more debt.
And, to be clear, I’m talking about some of the best-capitalized companies in the world with some of the best credit in the world. Things get magnitudes harder and more expensive for a neocloud like CoreWeave (or a counterparty), or a data center SPV, or anyone that isn’t backstopped by a hyperscaler, like Google’s backstop of Cipher Mining’s data center for Anthropic.
Are you beginning to see the problem yet?
You can dance around making whatever noises you want about future GPUs or cadres of data centers magically giving somebody the margins you crave, but it appears that using AI only seems to be getting more expensive for hyperscalers, the companies that rent the GPUs, and basically anyone running a business using AI models.
Spare me your anecdata! Every AI startup is unprofitable, and every time somebody describes an AI company “getting profitable” it’s during some mythology-adjacent rain dance about mythical 90% gross margins on inference, or, in the case of the data center providers, after they’ve amortized billions (or tens of billions) of dollars’ worth of GPUs.
The problem is that the longer this goes on, the more expensive it gets, and the more extreme the payoff has to be. A trillion dollars of capex and the near-entire capitulation of the media and finance class cannot be justified by “some incremental improvements somewhere that nobody can really understand and an incredibly unprofitable way to let people write software that sometimes is faster but never in a way anyone can capture.”
Every wibbly-wobbly, fan fiction-adjacent analyst note or Twitter screed claiming that we’re in some sort of CPU or GPU supercycle never seems to reconcile with the reality that money doesn’t really seem to come out the other end when you buy something from NVIDIA unless you’re Anthropic or OpenAI. Data center operators have yet to show substantive proof of a sustainable business model renting out GPUs, let alone profits that would justify taking on billions in debt, and the payoff date seems to exist somewhere between “fuck knows” and “never.”
Take CoreWeave, the perennially debt-raising no IT loads refused neocloud, which has raised over $23 billion in the past two years with bond spreads that communicate a near-existential anxiety about the future of the company. Their previously-mentioned $1.25 billion bond raise — raised a little over a month ago — is now trading over 200bps higher than issuance when it was already at a 9.625% yield, which genuinely brings into question how future debt raises will go considering it’s guiding $31 billion to $35 billion in capex for a year and still has yet to build most of the capacity it needs to fulfil its massive backlog.
In fact, CoreWeave’s bond spreads look like a dog’s arsehole after eating a Thanksgiving turkey:
And because it hasn’t built it yet, that means it hasn’t bought all the stuff, and the longer it takes to buy the stuff, the more expensive it’ll get.
That’s also before you consider talent shortages, transformer shortages, electrical grade steel shortages, and generator shortages, which means you’re paying more money for the same thing (or less), likely having to accept whatever quality of material or talent you can get, all while battling to secure power as local authorities begin forcing data center builders to pay their fair share. This just happened in the Midwest, with local regulators in Port Washington, Wisconsin demanding Oracle puts up a $7 billion guarantee (costing it $100 million a year) to protect taxpayers if the power behind its Stargate data center doesn’t get built, largely due to that S&P credit downgrade…associated with it building so many data centers for OpenAI.
Nobody seems to want to discuss that every data center we’re describing is 2 to 3 years in the future, and the market is becoming increasingly impatient and showing signs of non-compliance with the greater AI narrative. The theoretical payoff for anyone buying a GPU in the last 12 months is that sometime in the year 2030 you will, in theory, make somewhere between 30% and 40% gross margins, assuming that you have had near-constant utilization of your GPU infrastructure from an industry where effectively every customer is either an unprofitable AI lab or a hyperscaler trying to keep their theoretical future compute off their balance sheet.
How does any of this work? Has anyone worked that out yet? Because it isn’t working right now, the only reason that any of you think it’s working is because CoreWeave (which lost $740 million last quarter) and Nebius ($399 million in revenue, $8.45 billion in debt) haven’t had trouble raising debt.
Be real with me: do any of you seriously believe CoreWeave exists in 2030?
Remember: its largest customer is OpenAI, either through Microsoft (70% of its revenue), Google (for OpenAI), or its own payments that are paid net 360.
In fact, why stop there — do you think OpenAI will be around in 2030?
I’m not asking these questions to be a dick or because I’m a hater, but more out of a genuine sense of curiosity. Over the weekend, the Wall Street Journal reported that NVIDIA was in talks with OpenAI to guarantee $250 billion in financing for a 10GW data center (allegedly) being built by SoftBank affiliate SB Energy, by which I mean NVIDIA would guarantee the compute payments (as it has with CoreWeave and Lambda but at a much bigger scale) so that SB Energy can raise debt to buy the chips from NVIDIA to rent to OpenAI:
Nvidia’s backing would allow the data-center developer, which is owned by Japanese billionaire Masayoshi Son’s investment firm SoftBank, to raise debt at more favorable terms than it could if OpenAI had no financial backer, since OpenAI has no investment-grade credit rating as an unprofitable private company. The AI company has been in advanced talks to lease the site for several weeks, people familiar with the matter said.
What’s even crazier is that the $250 billion guarantee would only cover lease payments and construction costs, and, per The Journal, NVIDIA is also discussing a deal to finance the $350 billion in GPUs to go inside it. It is unclear how that would happen, who would fund it, how it would get funded, or really anything about the deal.
This is the final boss of circular financing. SoftBank, which owns over $100 billion (on paper) in OpenAI stock, is using its affiliate SB Energy (which OpenAI and SoftBank invested in in May) to raise debt to build a 10GW data center — likely costing more than $500 billion in chips and construction — by getting a backstop from NVIDIA (which invested $30 billion in OpenAI and cited it as a material indirect customer in its 10K), which will also make upwards of $350 billion in revenue from the deal.
If/when this deal closes, SoftBank (which owns more than 15% of SB Energy) will use the contract signed with OpenAI as a way to take SB Energy public, giving both it and OpenAI a massive equity gain, all while feeding revenue from one investment to another investment, at least in theory.
Will any of this happen? God no. SB Energy is a confusing and murky business. SoftBank sold 85% of its shares to Toyota to form a company called Terras Energy in 2023, and it’s unclear if the new SB Energy has anything to do with the old one. Even if it did, neither company named SB Energy has ever actually built a data center, and to my knowledge, nobody has gotten close to building a 10GW data center.
Then there’s the problem of the debt itself. It’s unlikely that SB Energy raises all this money at once, which means that it’s going to fall into the same problem as hyperscalers are facing — that the more debt that AI data centers raise, the more expensive it becomes to raise debt for AI data centers.
That, and the debt markets are already showing their distaste. Back in May, SB Energy (via an SPV called SE Cosmos LLC) raised $999 million in 144A bonds (private debt sold exclusively to qualified institutional buyers) rated BB- (junk) by Fitch and BB+ by S&P Global to buy a former 3M campus and turn it into a 70MW data center, and it only got that with a guaranty from SoftBank Group.
Since issuance, its (option-adjusted) spread has grown from 351bps to 536bps, and that’s for a relatively low amount of debt for a relatively-straightforward data center.
Sidenote: It’s also unclear how that project gets built. Based on TD Cowen estimates, a 70MW data center would cost about $3 billion including chips and construction. The data center, per S&P Global, will be leased to “Silver Bands 3,” a company that, based on the existence of two SoftBank subsidiaries called Silver Bands 4 and 6, appears to be a subsidiary of SoftBank that is renting a data center from a subsidiary of SoftBank.
None of this appears to matter to ratings agencies.
Even with the cast-iron guarantee of mag7 findom NVIDIA, it’s hard to see how SB Energy pulls together what will likely be a succession of different $10 billion debt deals of the course of several years, especially given the above-discussed curdling of the AI data center debt markets.
I also think it’s fairly likely somewhere between nothing and very little happens as a result here, even if NVIDIA offers its backstop.
Per The Journal, phase one of the project is due to be finished sometime in 2028 and have around 800MW of power — and I must be clear that while this doesn’t seem like very much in the grand scheme of things, OpenAI’s Stargate Abilene, a 1.2GW data center that broke ground in July 2024, has energized and monetized no more than three out of eight buildings for a total of 309MW of critical IT load, or about 401MW of active power. Even if the data center has broken ground (which I don’t believe it has), it’ll be extremely difficult to meet that timeline, and at a rate of 800MW every two years, it’ll be more than a decade before it opens.
Sidenote: Hey, this kinda reminds me of something! Back in 1998, Lucent Technologies signed its largest deal ever — a $2 billion “equipment and finance agreement” — with telecommunications company Winstar, which promised to bring in “$100 million in new business over the next five years” and build a giant wireless broadband network, along with expanding Winstar’s optical networking. In practical terms, Lucent would lend money to Winstar to hand back to Lucent to buy stuff from Lucent.
In 2001, Winstar would file for bankruptcy and sue Lucent for $10 billion in damages after it failed to give it $90 million in promised funding so it could keep up with debt that was, at least in part, also owed to Lucent. Lucent was eventually forced to pay back $188 million in loans and later pay $300 million in restitution.
NVIDIA has been smart enough to not be the actual bank of last resort, choosing instead to do equity investments and give backstops. Nevertheless, the consequences might be the same. When Winstar collapsed, losses and impairments totalled 15 cents per share in Q2 2001, per The Register.
Forgive me if I feel a little dismissive, but it’s a little hard to take any of this seriously! This theoretical data center with theoretical funding built by a SoftBank affiliate to rent GPU capacity to a SoftBank investment with the backstop of an OpenAI investor that stands to make hundreds of billions of dollars is equal parts ridiculous and fantastical.
Oracle is burning its company to the ground to build data centers for OpenAI in pursuit of a $300 billion, five-year-long compute deal that was meant to begin in June 2026 and currently has 5.6% of the 7.1GW of capacity it needs to make that revenue, even with Larry Ellison throwing every dollar he has (in addition to tens of billions of debt and laying off 21,000 people) and pulling every favor imaginable.
Though it’s kind of a straggler in the cloud space, Oracle still has a ton of experience in building data centers, and if it can’t get these done within a reasonable timeframe, I struggle to see how SB Energy — a company that has, as a reminder, never built a data center before — is meant to build the largest data center campus in history, assuming it can raise the money, which it will have a great deal of trouble doing.
In any case, I won’t be surprised if a “deal” is signed, and if some sort of debt financing takes place, but it’s going to be tough for SoftBank and its various tendrils to raise the $30 billion or more for Vera Rubin chips, let alone the $14 billion for construction.
To be clear, I also don’t think this deal has very much to do with OpenAI or generative AI. SoftBank wants SB Energy to lock up the deal so that it can push it to go public and unlock some much-needed liquidity. NVIDIA wants to lock up (theoretical) hundreds of billions of dollars of revenue, and doesn’t really care if the data center gets built as long as CFO Colette Kress can find a way to book the GPU sales as revenue.
This is all a very, very bad sign for the AI industry at large. If there were real, diverse, meaningful and consistent long-term demand for generative AI or NVIDIA GPUs, NVIDIA wouldn’t have to create the world’s first circular financing within a circular financing, or need to take money from one of two different massive companies with either junk or junk-adjacent credit putting their futures in jeopardy to pay it.
Oh, right, there’s also the other problem: how the fuck will OpenAI pay for this capacity? If we, based on my estimate of $75 billion a year across the 7.1GW of Stargate data centers, assume that OpenAI would pay around $10.5 billion a gigawatt of capacity, that’s $105 billion a year in compute costs just for SoftBank, or a little less than half of the $122 billion OpenAI will have raised this year, with $60 billion of that coming from NVIDIA and SoftBank.
Nobody has an answer here! Every time one of these insane theoretical deals is announced it’s discussed like building gigawatts or raising hundreds of billions of dollars is both easy and effectively already done. It doesn’t matter that NVIDIA claimed it was investing $100 billion in OpenAI last year to build 10GW of data centers in a deal that never happened (despite CNBC claiming the first $10 billion would close within a month of the announcement!), or that OpenAI can’t afford it, or that OpenAI has been part of no less than three different announced-then-never-completed deals. The media has been fully trained to simply accept whatever slop NVIDIA shovels down their throats, and to avoid discussing messy things like “how this happens” because that wouldn’t be considered objective.
Allow me to be subjective for a second: this deal is bullshit. AI data centers are taking 18-to-36 months to build, and capacity is clearly coming online at such a slow rate that it’s hard to understand why people are still buying more GPUs, other than the fact that once they stop everybody has to admit that it was all kind of a huge waste of money. The media remains ill-prepared for this moment, because of (to quote Ed Elson) a cult-like worship of the wealthy, where the assumption is always that they’ll work it out, and anything they say that doesn’t work out is just a result of the complexity of businesses.
Yet this is actually a very, very simple situation. NVIDIA needs to keep sustained and ever-growing demand for its GPUs, and the only way that it can keep doing that is either by creating and constantly funding neoclouds (who, to quote CEO Jensen Huang, would not exist if NVIDIA didn’t support them), creating massive circular deals focused on OpenAI, or relying on hyperscalers that have run out of hypergrowth ideas and thus must keep building data centers to avoid admitting that to the markets.
You’ll notice that nobody other than hyperscalers, Anthropic, and OpenAI seem to be demanding gigawatts’ worth of compute, and that’s because outside of the AI labs and those supporting them there’s less than a fifteenth of the demand necessary to support the 190GW of planned data center capacity.
As a result, the only way that NVIDIA can continue beating and raising each earnings season is to manufacture these massive deals, all to avoid discussing the blatantly obvious truth that diverse demand does not exist. Why else would it have over $30 billion in commitments to rent back its own GPUs?
Sidenote: While Thinking Machines theoretically might “deploy” a gigawatt of Vera Rubin-powered capacity at some point, it only appears to be doing so because NVIDIA invested in it, and as ever, nobody has ever asked questions like “how?” or “where?” or “with what money?” because, at 360KW of IT load per NVL72 rack, assuming a PUE of 1.3, that’s 2136 VR200 NVL72s at $7.8 million a piece, or $16.66 billion in chips alone for a company that’s only raised $2 billion. Nothing is happening here. No data centers announced, no plans to do anything, just put the story in the bag and pump the stock! Don’t think! Only growth matters!
While NVIDIA continues to sell remarkable amounts of GPUs, it does so to an increasingly less-diverse customer base — 54% of its revenue and 64% of its accounts receivable (IE: orders shipped, revenues booked, but money not received) come from three customers. While its new (as of its latest quarter) “ACIE” (AI clouds, industrial & enterprise) segment might feign a little variety, this includes basically any SPV or VIE or neocloud that NVIDIA itself has helped prop up.
NVIDIA’s revenues are, for the most part, propped up by FOMO rather than any real relationship to revenues, productivity, or reality, much like the rest of the semiconductor companies profiting off of AI. Every move it makes is to further propagate the sense that if you don’t buy GPUs and build AI data centers that you’ll be permanently left behind — which is why it plans to invest $5 billion in mysterious AI startup Safe Superintelligence, a company with no products or plans other than to rent NVIDIA GPUs from someone at some point.
Outside of those building the infrastructure, the only people making a profit (or really much money at all) are the bankers and private credit funds underwriting data center debt, the ratings agencies getting paid to rate that debt, and any VC that’s been lucky enough to get paid out across the (very) few acquisitions of the AI bubble so far.
Otherwise, basically every layer of the AI industry exists to be exploited by the layer above it. AI startups and enterprise customers pay Anthropic and OpenAI on a per-million token rate (losing money in the process) so that Anthropic and OpenAI can rent GPUs from hyperscalers (losing tens of billions of dollars a year) so that hyperscalers can buy a trillion or more dollars’ worth of GPUs (putting them in such a hole that they’ll never, ever be able to make the money back).
It’s all deeply unsustainable, vile and wasteful, and only made possible in a lax regulatory environment, a captured tech and business ecosystem, and an economy dominated by growth-at-all-costs thinking.
As I’ve hinted at previously, AI needs to become something altogether more successful, powerful and financially viable than it is today, and that “something” grows ever-larger with every new massive data center deal and funding round and egregious statement from Clammy Sam Altman.
Hyperscalers will, by the end of the year, have sunk over $1.5 trillion in capital expenditures and equity investments into Large Language Models that have yet to provide good enough revenues to actually disclose.
Their actual AI products — outside of providing compute to Anthropic and OpenAI — are mediocre also-rans that range from embarrassing to actively harmful, deeply unremarkable simulacrums of whatever OpenAI or Anthropic’s product du jour might be, the latest of which are the (deeply embarrassing) attempts by Microsoft and Meta to make their own OpenClaw products. While people might use Google AI overviews by accident or accidentally click the Gemini icon when they’re using Google Docs, the actual outcomes of Google’s various LLMs are unexceptional, much like every hyperscaler product.
The only really successful product — GitHub Copilot — only grew to a few million paying users because it subsidized their usage, allowing them to burn more than 25 times their monthly subscription fee, leading to user revolts when they were inevitably switched to token-based billing.
Do not confuse “some revenue coming out of these products” with any kind of success. Microsoft, Google, and Amazon have tens of thousands of salespeople whose job is to harass their customers into buying AI add-ons, on top of simply changing their product categories to force AI services into regular subscriptions as an attempt to claim that they have “AI revenue.” The fact that none of these companies are willing to disclose their actual quarterly revenues for AI is a sign that they’re bad, and the fact that effectively no journalist bothers to include this in their writeups of their earnings from the last few years is a disgrace to the profession that fails the general public.
The problem that hyperscalers face is that they can’t really stop spending on AI, because once they do so, they’ll suddenly start getting graded on their AI investments. As long as we’re in a “capex buildout phase” of indeterminate length with data centers that take two to three years to come online, Microsoft, Google, Microsoft, and Meta can perpetually kick the can by spending tens of billions of dollars on capex, or at least they’ve been allowed to because their current businesses have kept growing.
There’re a few problems with this approach:
As mentioned previously, the payoff here would have to be in the trillions of dollars of new revenue, in a way that was virtually impossible to deny. Incremental revenue growth or improvement of current profit lines are insufficient justification of the current spend, let alone the future trillion-plus (and yet-to-be-unannounced) in capex or the trillion-plus in ongoing commitments.
What could possibly make any of this worth it? None of the hyperscalers have created a single new product line or service that actually matters, nor do they have any unique IP or technology that could turn into one.
AI boosters and paint-eaters continue to claim that the growth we’re seeing now is from investments in AI, but if that’s the case, that means that the current hyperscaler business lines are in such severe decline that they basically stopped growing in 2022, which is most assuredly not the case.
Sidenote: That being said, I do have one revelation for you: based on my reporting on OpenAI’s audited financials, we know that OpenAI spent $17.2 billion on Microsoft Azure in a calendar year where Microsoft had $120.4 billion in revenue in the Intelligent Cloud segment, growing 26% year-over-year (from $95.5 billion in CY2024).
This means that OpenAI’s revenue represents 69% of Microsoft’s year-over-year cloud growth for calendar year 2025, and without it, Intelligent Cloud would’ve only grown 8% year-over-year.
That’s pretty fucking bad!
And please, spare me your warbling about whatever “ad growth” you think Meta is getting from AI. This is the metaverse all over again, except larger, more annoying, and more dangerous to its balance sheet. The fact that we are even debating whether AI is helping these companies and that nobody can just show me the actual numbers to prove me wrong are the signs that something is very, very wrong in a way that’s unlikely to change.
It’s also unlikely to change with another trillion dollars’ worth of capital expenditures.
More capex means more space for Anthropic and OpenAI to spend their venture capital funds on Azure, AWS, and Google Cloud. Even if margins were to remain stable and both AI labs stay alive for the next five years, the revenue growth would still be overshadowed by capital expenditures that represent 100%, 118% and 181% of cloud revenues as of their last quarters.
It don’t take no math genius to say that this does not seem to be working out in a way that makes more dollars than it costs, and I can find no compelling evidence that another three years of data center construction magically turns this all on its head.
Yet the moment they stop spending capex (by which I mean dropping it significantly — below $15 billion, I’d say), the AI bubble pops. Any capital expenditure pullback will be an impossible-to-ignore sign that what they’ve built is sufficient, which will get hyperscalers a short-term stock bump before facing three much-uglier questions:
And there’re really no compelling answers, because, as I discussed in the Rot-Com Bubble, we haven’t had a new Google Search, iPhone, or Microsoft 365 in decades, and without one, hyperscalers don’t have a hypergrowth future.
Their only hope would be if AI itself becomes far more than it currently is, and yes, that includes Anthropic and OpenAI.
People are going to be very mad at me for saying this, but when you strip away the media hype and the investment rounds, the actual things that generative AI can do are, at best, kind of cool and for the most part awkward and mediocre.
The ability to generate code in a mindless and expensive way that sometimes works and may or may not make developers an indeterminate level of more-productive is not a business model, a point made more obvious by the fact that Anthropic and OpenAI allow users to burn $8000 to $14,000 a month for $200.
I know somebody is going to read this and oink that “they have 70% gross margins” or some such bullshit, but none of you have any proof other than something your dad’s friend’s dog’s aunt’s proctologist’s friend heard in a Discord chatroom. However “useful” AI coding tools may be — and it’s genuinely hard to tell! — is immaterial to the larger point that they’re very, very, very expensive to use, that most of those costs are either hidden from the user or subsidized by employers, and that despite all the fucking noise, they are yet to substantively replace or even enhance human beings outside of the loudest and most annoying people on Twitter.
And I think people genuinely underestimate how harmful the vacuousness of AI’s benefits has become.
Per Nik Suresh’s excellent “AI Mania Is Eviscerating Global Decision-Making”:
Unfortunately, we live in a dark timeline. All of the AI projects we have observed as a team are failing. Every single one – we have seen 0% success in a year and a half, not only amongst projects we have been asked to participate in, but even within projects that we have observed in passing while doing totally unrelated work. Even if you grant that AI tooling accelerates specific workloads, the method and scale of the current investments is senseless. Frequently the failure is not related to AI itself, but rather that companies are terminally bad at running software projects effectively, and as I have remarked previously, AI projects are subject to all the failure modes of normal projects plus you can get everything right and then still fail because of the method's novelty. Very few companies are so good at shipping software that they can afford the extra risk profile.
Suresh, a decorated consultant and software engineer who wrote one of the best pieces on AI of all time, tells the story of an economy dominated by people buying and selling AI for symbolic reasons entirely disconnected from actual productivity, with in some cases one’s sufficient devotion to using or supporting AI’s (imaginary) productivity benefits being essential to surviving in many modern businesses.
In every sufficiently large business we have observed (say, with 500+ employees), we have noted that continued advancement, and increasingly continued employment, has started to require repeated professions of belief in the transformative power of AI for said business. I am not talking about providing ideas about how to use AI in the business – I mean religious profession, declarations of faith. Overwhelmingly these statements are made by non-technicians, though it is not uncommon for technicians to emit deranged statements to curry favour.
There have been several occasions where I have seen someone, apropos of nothing, blurt out almost word-for-word “AI is changing everything”, only to concede moments later that their organisation does not currently use LLMs for anything, and indeed, that they cannot name a single thing that has changed other than they get some use out of ChatGPT (frequently the free-tier). In one extreme case, I have seen an executive confess that they had never even used ChatGPT or any AI tool in their life, immediately after producing a technical strategy for an organisation with $2B+ in revenue which was entirely centered around AI.
This is an alarming situation caused by a few things:
Suresh’s piece is both fantastic and vile, telling the story of people “AI-washing” their work, “...meaning that even when they can perfectly competently execute on their jobs to the satisfaction of their management teams, said managers are unhappy if [they didn’t use AI],” of organizations firing top performers because they achieved said performance without using AI, of a global intelligence crisis where executives lie and say they love AI and are 100x more productive with AI because if they don’t, their customers and their customers’ customers will be offended.
LLMs are capable of doing a convincing-enough demo of functional-adjacent software that they can convince basically any CEO that they can do basically anything. As I wrote in Revenge of the Business Idiot, the media and the markets are so used to coddling and celebrating the dull, brainless and mediocre executive class that it was inevitable a technology would grow not based on its actual efficacies but what it represented to the managerial sect, and what it could represent to their stupid friends.
The problem is that there’s only so far you can take something based on everybody pretending it’s magical or its convenience as a symbol of executive power. Outside of coding, AI really has no fundamental use cases beyond being slightly better at interpreting search queries, brainstorming, and searching documents.
Sidenote: The only truly useful use case I’ve found is on the Bloomberg Terminal’s ASKB feature, which takes natural language and turns it into BQL code to make requests of Bloomberg’s datasets. It’s genuinely useful! It’s also something I imagine that could be done with any number of different LLMs.
No amount of anecdotal “I used it for this one thing and it was useful” changes the amount of money that AI requires to exist, plugs the gaping holes in Anthropic and OpenAI’s cashflows, or fixes any of the economic problems with data centers I’ve already discussed.
LLMs are economically and practically unsuited to the tasks they’ve promised to solve, and no amount of extra capital expenditures or venture capital dollars will magically fix that.
If you think that’s an outlandish take, one that only a “hater” or “AI doomer” could make, allow me to refer you to this note from ratings agency Fitch, which warned that a lot of debt is going to AI capex, and the usefulness of AI (and, by extension, that capex) remains a big hanging question mark, which presents a massive risk to lenders, and by extension, the global economy:
The scale of the AI investment boom and the accelerated global technology cycle has been a significant driver of US equity market valuations and corporate bond issuance over the past year. The effects on real economic indicators are profound. The 18% yoy rise in IT capital investment directly added 1.4pp to 1Q26 GDP growth. The wealth effect from AI-related investor optimism and equity market gains has also been a meaningful support for US consumer spending growth, which has been broadly slowing.
That said, the medium- and long-term potential of the underlying technology is highly uncertain, as with previous tech cycles. The combination of revenue uncertainty and the extent to which capital markets and economies have become intertwined with AI have created a vulnerability for credit in the event of a re-evaluation of long-run returns potential. Very short-term spikes in market volatility for individual equities and tech-heavy stock indices have already occurred, but a larger, more protracted correction could have wider market, macro and credit effects depending on its scale, duration and contagion.
Anyway, I want you to imagine you wake up tomorrow, and nobody is talking about AI in the news. AI-related stocks aren’t dominating the market. Nobody on Twitter is discussing AI. Nobody you know or talk to is talking about AI. Nobody you know is using it, nobody you know has even heard of it.
Would you still be as excited? Would you feel the pressure to use it? Would any of this make any sense if there wasn’t someone threatening your job or scaring you in the media every day? Would any of this seem rational?
AI, as it stands, is an exercise in kayfabe — a thing people are taking seriously because the rich and powerful are saying they have to and a media ecosystem built to celebrate them says that you need to.
And the fundamental issue, to paraphrase Roger McNamee on CNBC, is that they’re trying to make a niche tool a general-purpose technology.
The trillion-plus dollars in capex and venture investment is an attempt to turn Large Language Models that generate and summarize things into something that can do anything, because the people at the top of both the organizations building and buying AI services don’t actually do real jobs and thus can’t understand that the vast majority of tasks are neither generative nor replaceable with a median version of their outputs.
Every layer of GPU (and CPU) intensive agentic bullshit is a tacit admission that LLMs are not a tool with any of the features of “artificial intelligence” anyone has dreamed of. Their greatest innovation is their symbolic ability to scare and compel people to change who they are or how they treat others as a patronage to the tech industry, or a general fealty to the powerful.
And I fear everything will end in tears, all because those with the responsibility to tell the truth or stand in the way of grifters both opened the doors and sung their praises, attacking and othering skeptics who wanted to avoid what I fear is now an inevitably painful future.
If you liked this piece, you should subscribe to my premium newsletter. It’s $70 a year, or $7 a month, and in return you get a weekly newsletter that’s usually anywhere from 10,000 to 18,000 words, including vast, detailed analyses of the biggest events and companies in the AI bubble.
2026-07-25 00:56:52
Good morning premium subscribers! As ever, please ping me at [email protected] if you have any questions.
Oracle has one of the strongest mythologies in the tech industry. Ask a regular person and they’ll tell you that it’s “incredibly profitable” and “growing fast,” that it’s “unstoppable,” and that Larry Ellison has the mandate of heaven with regard to the continual sales of software and hardware related to databases and AI.
And those people are completely and utterly wrong.
The original title of this article was “Is Oracle Dying?” because I assume, when I took a deeper look, that there’d be some sort of debate, some sort of bull case for a decades-old quasi-hyperscaler run by one of the more nakedly-evil CEOs in the history of tech. I assumed — incorrectly, I might add — that Oracle as a business was doing fine other than the ridiculous commitments it made to support the whims of Sam Altman and OpenAI via deals that I believed (and still believe) will kill Oracle.
Except it turns out that Oracle has already been on a death spiral for the best part of a decade (if not longer) and has only survived this long by screwing its customers, taking on masses of debt, and — most importantly — more than $85 billion in acquisitions over the last 23 years. Pretty much every major product line outside of databases is a hodge-podge of other people’s innovation stapled together with a legendary contempt for the customer. These acquisitions (and continual price increases) are the only thing keeping the reaper from Oracle’s door other than margin-destroying GPUs.
And that’s why Oracle’s revenue looks like this:
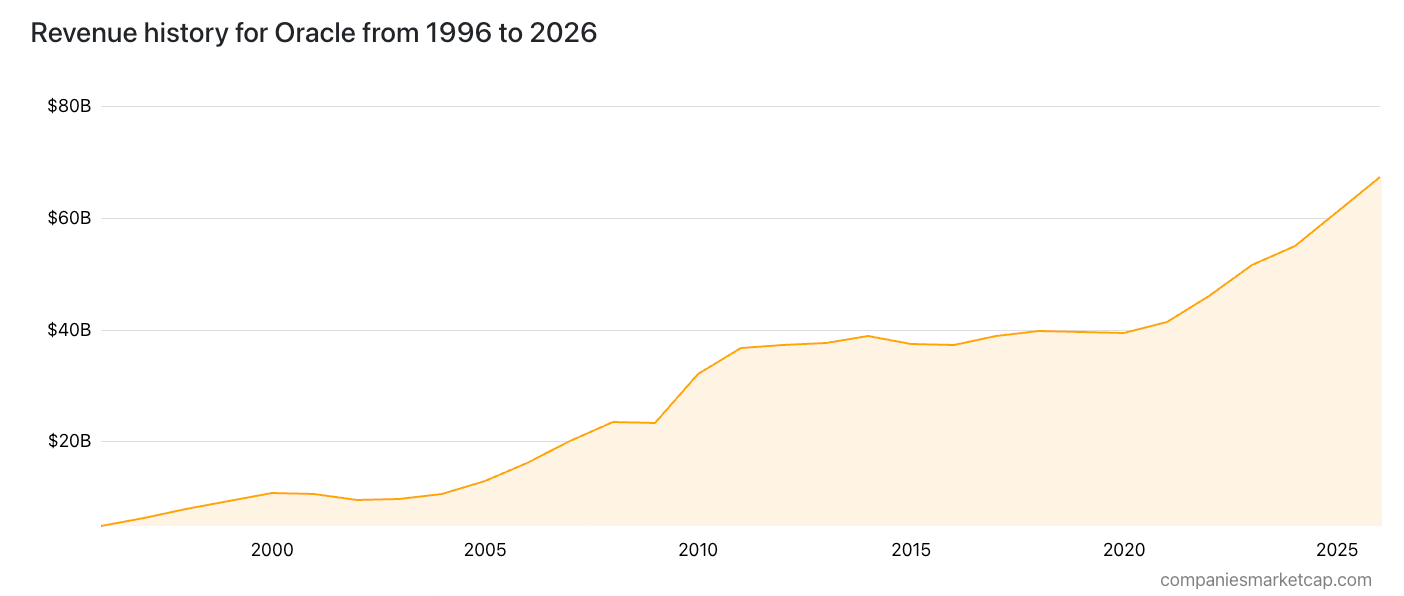
After April 2009’s $5.7 billion acquisition of Sun Microsystems, Oracle’s revenues barely kept pace with inflation until December 2021’s $28.3 billion acquisition of Cerner allowed it to create Oracle Health, adding about $6 billion in annual revenue that had 40% lower margins (about 21.7%) than Oracle’s other businesses, though Oracle immediately started closing offices and brutal layoffs to try and bring them up.
And as I mentioned above, Oracle’s other plan was to sink a little over $99 billion in capital expenditures since the middle of calendar year 2020 into AI GPUs.
Anyway, let’s see what that’s done to margins-OH MY GOD!
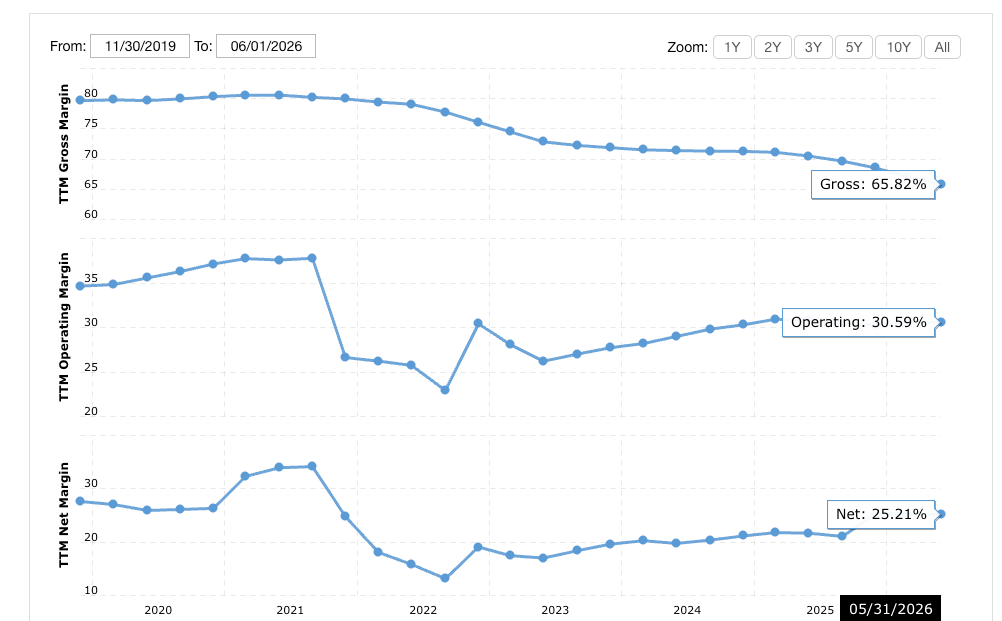
Oracle is a decades-long mission to keep reapplying lipstick to a pig. Billions of dollars of acquisitions have, for the most part, only succeeded in keeping the company’s revenue growth from going negative, and as noted by forensic accountant Howard M. Schilit, this is one of the most well-documented cases of accounting shenanigans being used to cover up that a business is in decline.
Today’s newsletter is a sequel to the Hater’s Guide To Oracle, where I told the sordid tale of how Larry Ellison grew a massive, lucrative business out of a database business that one reporter once told me was a “law firm with a database company attached,” an Enterprise Resource Planning (ERP) product that competes with SAP to create the most-annoying way to run a large company, and a business built around licensing Java that exists mostly to email people and say “you need to pay us for Java or we’ll sue you.”
Then, as I’ve mentioned, there’s Oracle’s cloud infrastructure business, a decade-old also-ran that was meant to compete with Microsoft Azure and Amazon Web Services, but only managed to catch up following the advent of AI GPUs and a movement where all it took to party was buying billions of GPUs and saying “gosh darn, we love AI.”
I originally started drafting this as a much tamer piece where I’d ask whether Oracle was dying, but as my editor and I started digging into the research, it became obvious that not only is Oracle dying, it’s been dying for years, kept alive through decades of acquisitions and a desperate and dangerous commitment to generative AI.
And AI, I believe, will be what eventually kills Oracle dead.
In the past, all Oracle had to do to survive was buy somebody else’s company and replace its flagging revenues with theirs, turning the screws on their customers and laying off as many people as necessary to balance the books. While chaotic and decaying, Oracle’s empire has kept above water by never overextending itself, always keeping a positive free cashflow, and generally avoiding buying into industry hype cycles outside of whatever SaaS vehicle might potentially plug the gap in its earnings.
Yet with AI, Oracle broke its long-standing trend of letting someone else figure out the innovation, choosing instead to build its own cloud infrastructure, spending more in capex in its last fiscal year ($55.6 billion) than it did in the previous nine years combined ($50.4 billion), tripling its debt from $56.91 billion in FY2017 to $167.4 billion in FY2026, a year that ended with its free cashflow sitting at negative $23.69 billion.
For comparison, Oracle has had positive free cashflow every single year since 2001, including the Great Financial Crisis and COVID.
Oracle has doomed itself with its commitment to the AI bubble. It has committed to building 7.1GW of data center capacity for one company — OpenAI — as part of a $300 billion, five-year-long contract that requires it to build an impossible amount of capacity in an impossible period of time for a client that could never afford the $70 billion or more in annual costs to make any of it worth it.
Today I am going to talk trash on what I consider to be one of the single-worst companies in the tech industry that’s survived only through financial engineering and never, ever overextending itself.
With revenue plateauing and customers in revolt, Oracle’s future already looked murky, but with the power of AI — and $95 billion in FY2027 capex — it’s becoming increasingly clear that this may be Larry Ellison’s last dance with Silicon Valley.
This is the Hater’s Guide To Oracle Part 2, or AIpoaclypse Now.
2026-07-23 00:08:51
Thanks for reading this week’s free Where’s Your Ed At newsletter. Friday’s premium newsletter will ask the simple question: Is Oracle dying?
It’s been one year since I launched the premium newsletter, and I’ve decided to extend the discount on annual subscriptions. Between now and 12AM ET, July 26, you can get a permanent annual rate of just $60— a $10 discount on the usual price of $70 — for life. Click here for the offer.
In addition to getting access to the entire back catalog of premium posts, you’ll also receive one additional post each week — usually anywhere between 10,000 and 20,000 words — covering the most pressing topics in the AI bubble — the best value in tech analysis. Highlights include the Hater's Guide To The Memory Crisis, a guide to how AI made everything more expensive, How OpenAI Kills Oracle (which pairs nicely with the Hater's Guide To Oracle), The Hater's Guide To NVIDIA, The Hater's Guides To Private Credit and Private Equity, and how the entire AI Compute Demand Story Is A Lie.
Soundtrack: Dillinger Escape Plan — Black Bubblegum (2007)
In The Big Short, Mark Baum shook with anger as a CDO manager told him that the market for insuring mortgage bonds was about 20 times larger than the mortgage bond market, realizing in real-time that speculation driven by greed and hype had set up a massive systemic weakness under everybody’s noses.
To get specific, Baum (played by Steve Carell) is giving a short, dramatic summary of a much greater problem — that there were trillions of dollars of synthetic collateralized debt obligations (effectively bets on whether somebody else’s bucket of mortgages (well, mortgage bonds) will actually pay up) that allowed multiple people to bet on the same mortgages again and again, meaning that once said mortgages went belly-up, the carnage would be widespread and hard to contain.
This became even more chaotic when it became clear that the same mortgage bonds were attached to many different CDOs — one study found that 5500 different mortgage bonds had been placed or referenced in CDOs over 36,000 times. A mortgage bond (or mortgage-backed security) is a slice of a pool of payments from thousands of mortgages, with each slice sold off to different buyers at different levels of seniority, the most-senior ones getting paid first and taking losses last.
In the end, the only thing you really need to know is that financial institutions built CDOs that threw together bonds in ever-more complex and dangerous ways, selling synthetic CDOs to bet on the outcomes, with different CDOs having different bonds covering the same pools of mortgages — bonds that were routinely rated by agencies at a higher grade than they should’ve been. When IMF Chief Economist Raghuram Rajan attempted to warn the financial services industry at the Kansas City Fed’s 2005 Jackson Hole symposium about the instability of the system, former US Treasury Secretary (and close friend of Jeffrey Epstein) Larry Summers referred to his concerns as “misguided.”
Meanwhile, the industry was handing out awards. On July 1, 2005 Lehman Brothers would receive one of Euromoney’s “Awards For Excellence,” where it was named the “Credits Derivatives House Of The Year.” Euromoney also referred to Lehman, a financial institution that was leveraged 25.3x in 2005, as “one of the more conservative credit derivatives houses.” It added that the company, which routinely overvalued its CDOs, was being able to take on the heavy burden of synthetic CDOs because it “...understands the arbitrage-driven economics of cash CDOs, the way that loan deliverable credit default swaps track the loan markets, how high-yield CDS trade (like bonds), and so on.”
Three years later on January 1, 2008 — nine-and-a-half months before its collapse — Risk Magazine would name Lehman Brothers’ “Point” risk management system as its “In-House System of the Year,” saying it “...stood out for the breadth of its coverage and depth and quality of its functionality.”
All of this started because of a flood of overseas money in the early 2000s buying up U.S. Treasuries as a result of a “global savings glut” — a fancy way of saying that there was too much money floating around — pushing yields down, leaving investors with far fewer places to get those all-important yields.
Low interest rates in the early 2000s (a direct response to the collapse of the dot com bubble) dropped mortgage rates to “generationally low” levels, and financial institutions realized they had an opportunity, as government policies had allowed them to loosen underwriting standards at exactly the time that foreign investors were desperate for places to park their money — mortgage-backed securities, and their associated derivatives. More mortgages meant more mortgage-backed securities, so banks made it incredibly easy to get a mortgage, to the point that in 2006, 20% of all new mortgages were subprime.
You’re probably wondering why nobody feared they’d get burned by this endless stack of different interconnected debts, and that’s because they’d “spread all that risk out” across credit default swaps with insurers, not realizing that insurers could and would become insolvent if everybody tried to make a claim at once.
This was all avoidable, and there were many warnings, and just as many people lining up to protect the grift. In June 2005, Larry Kudlow would say that housing bears were “wrong again,” dismissing those concerned with increasing default rates as “bubbleheads” that “don’t do their homework.” In September 2006, financier Michael Milken would refer to CDOs in the Wall Street Journal as a “financial innovation” that “helped to spread risk and create tens of millions of jobs by freeing up investment capital for growing businesses,” saying that they would “increase prosperity by multiplying the value of human capital, social capital and real assets.”
In other words, the argument was that the “financial innovation” of ever-expanding financial speculation was good for the economy because it created more money out of thin air, with the “risk” spread out somewhere, in a way that you shouldn’t think about because everything is going to be fine. Everybody would keep building houses forever, the numbers would only ever keep increasing, every new house would add a new mortgage to a new mortgage-backed security, and the line would only ever go up.
To put it all very simply, the great financial crisis was caused by inflated demand for housing caused by a mixture of historically-low interest rates and banks incentivizing bad habits as a means of increasing the value of speculative assets. In the end, “mortgage-backed securities” stopped existing as ways to invest in large swaths of mortgage payments, and more as high-risk financial vehicles that promised to be an infinite money glitch where nobody could lose because there would always be more demand for mortgages and, by extension, collateralized debt obligations made up of mortgage-backed securities.
It all broke because eventually those speculative assets had to interact with the real world, by which I mean mortgage defaults began to spike starting in 2005 with the expiration of teaser rates and multiple fed rate hikes throughout 2006 making adjustable-rate mortgages creep upwards. As mortgages collapsed, CDOs — and their connected synthetic CDOs — collapsed with them, crushed by the weight of the consequences of offering so many people so many mortgages under volatile and unrealistic terms, and assuming that nothing bad would ever happen because nothing bad had happened yet.
And, fundamentally, the great financial crisis was caused by massive speculation based on demand that was, in and of itself, an illusion created by the financial institution itself to justify further investment.
Say, that kinda reminds me of something!
I realize that the comparison between an AI data center and a CDO might seem a little ridiculous, but they’re actually remarkably similar. I’m going to generalize here, because each of these deals has weird little unique terms that make them, well, more dangerous.
Put simply, every time somebody builds a data center, they form a completely separate entity that owns the chips, owns the debt, and, in many cases, owns most of the risk. These SPVs only pay out to their creditors in the event that customer revenue flows in, which means that they are dependent both on the speed of construction of said data centers and their customers’ ability to pay.
CoreWeave is the main offender in the SPV no IT loads refused cash-dump, with a different SPV for each of its Direct Draw Term Loans (DDTLs), most of them non-recourse, meaning that if their customers fail to pay, investors get screwed to varying degrees based on their seniority in the debt, and CoreWeave’s assets can’t be pursued in court, though it is on the hook for the payments on the debt.
For example, CoreWeave’s $8.5 billion DDTL 4.0 loan was raised using its contract with Meta and the underlying data center assets as collateral with funding coming from banks like MUFG, Deutsche Bank, and US Bank, with funds being deposited into an SPV called CoreWeave Compute Acquisition Co VIII LLC, with another filing showing that the funding would be used to lease space from Applied Digital in Ellendale, North Dakota and fill it full of GPUs and provided to an “investment-grade customer” that Wells Fargo believes is Meta.
Similarly, CoreWeave raised its $2.6 billion DDTL 3.0 loan last year to “accelerate delivery of services from OpenAI,” funding two different SPVs called CoreWeave Compute Acquisition Co. V and VII, LLC. that, in turn, signed a deal to provide compute to OpenAI through the main CoreWeave entity. The deal also features a “cash trap” that means that if either CoreWeave screws up (IE: doesn’t deliver the compute) and OpenAI can quit or OpenAI doesn’t pay for three months, the SPV stops feeding any money to CoreWeave until the situation is cured, and if OpenAI (or someone else) doesn’t start paying, things start to break, as the deal has a contract realization ratio of .85x,.
To be clear, “non-recourse” does not mean “CoreWeave gets off scot free if these SPVs collapse,” just that creditors can jump on the SPV’s assets first and cannot immediately go after CoreWeave’s assets, though because each of these deals is guaranteed by the parent company (CoreWeave itself), it will eventually be forced to make them whole.
You can probably guess how that goes badly.
The nature of these SPVs makes it difficult to quantify the exact scale of data center debt, but Bloomberg estimates that there’s over $500 billion in outstanding AI data center debt, with (per Garima Kapoor of Elara Securities Research) at least $200 billion of it held by private credit, making up roughly 8% of outstanding private credit loans.
That being said, the number is likely much higher. Nikkei Asia reported this week that Meta, Google, Amazon, Microsoft and Oracle have accrued around $1.65 trillion in outstanding debt in the last five years, with an additional hundreds of billions of dollars’ worth of “off balance sheet” debt, meaning that the corporate structure allows the company to not include it as part of its liabilities.
For example, BlackRock is currently raising $12 billion to build a data center for Meta, which in practical terms means BlackRock has invested in and is raising debt for a holding company called “Project Sopaipilla Holdings,” of which it owns 80% and Meta owns 20%. This holding company will then buy NVIDIA GPUs and pay construction firms to build the data center, and Meta’s (theoretical) payments will be used to pay down the debt.
Despite the fact that Meta will (theoretically) own and operate as the exclusive tenant of this data center, the actual debt — $12 billion or more! — won’t appear on its balance sheet, much like its $27 billion Hyperion Data Center that belongs to an SPV called Beignet Investor LLC which is 80% owned by Blue Owl, 20% owned by Meta, and funded using bond sales to PIMCO and BlackRock.
The problem with these SPV-based deals is that they allow companies to, at least on a balance sheet basis, hide the scale of their debts. Meta’s long term debt sits, as of its latest quarter, at around $58.7 billion. It’s as if the $39 billion in debt for gigawatts’ worth of AI data centers doesn’t exist out of the payments it’ll eventually have to make.
This is all legal, worrying, and yes, a little bit Enron.
Per Amanda Iacone of Bloomberg:
Enron Corp. exploited US accounting rules to hide from investors and lenders hundreds of millions in debt it had bundled into off-balance sheet entities — obligations that contributed to one of the biggest corporate collapses in US history.
Alphabet Inc. and Meta Platforms Inc. each have turned to vehicles known as variable interest entities (VIEs) as part of the financing mix needed to construct data centers and related energy infrastructure.
Meta, the parent of Facebook, last year formed a joint venture, a VIE, to build a Louisiana data center through a partnership with Blue Owl Capital. The social media titan’s maximum exposure for the venture is $46 billion, according to its filings with the Securities and Exchange Commission. The company announced last week that it would expand its planned campus and is expected to spend as much as $250 billion on the project, Bloomberg News has reported.
To be clear, a Variable Interest Entity is a type of SPV where you have control over the entity, and you must consolidate it into your balance sheet…unless you are not considered the “primary beneficiary,” which Meta argues isn’t the case despite being the primary tenant and reason that Hyperion is being built. Per Bloomberg:
Meta determined it shouldn’t bring billions in debt from the Louisiana project onto its own balance sheet because it isn’t responsible for finding tenants to replace or join it at the nearly 4,000-acre campus — a critical job that impacts the entity’s economic performance, the social media company said in its most recent quarterly SEC filing. Meta said its role is limited to construction management, along with administrative and property management services.
Auditor Ernst & Young raised a “red flag” (per the WSJ) about this arrangement, flagging it as a “critical audit matter,” adding that it “...was especially challenging due to the significant judgment required in determining the activities that most significantly affect the VIE’s economic performance.” Nevertheless, it was approved, it happened, and everything is fine and normal.
This is why Google backstopped Fluidstack and Cipher Mining’s 300MW data center and another for TeraWulf. Both will, eventually, operate as data centers that Google will lease to provide compute to Anthropic, booking revenue for doing so, acting as the sole tenant and the entire reason that the debt was raised, yet because Fluidstack and TeraWulf and Cipher Mining are the actual entities involved, nothing shows up on Google’s balance sheet.
What’s also important to note is that none of the money going into these SPVs counts as capital expenditures. For example, across the space of five quarters (Q1 2025 through Q1 2026), Meta spent around $88.6 billion in capital expenditures, but that doesn’t include any of the debt or purchases of GPUs or anything else done in its name as part of the Hyperion SPV, despite it having (per its own fillings) $45.95 billion of exposure.
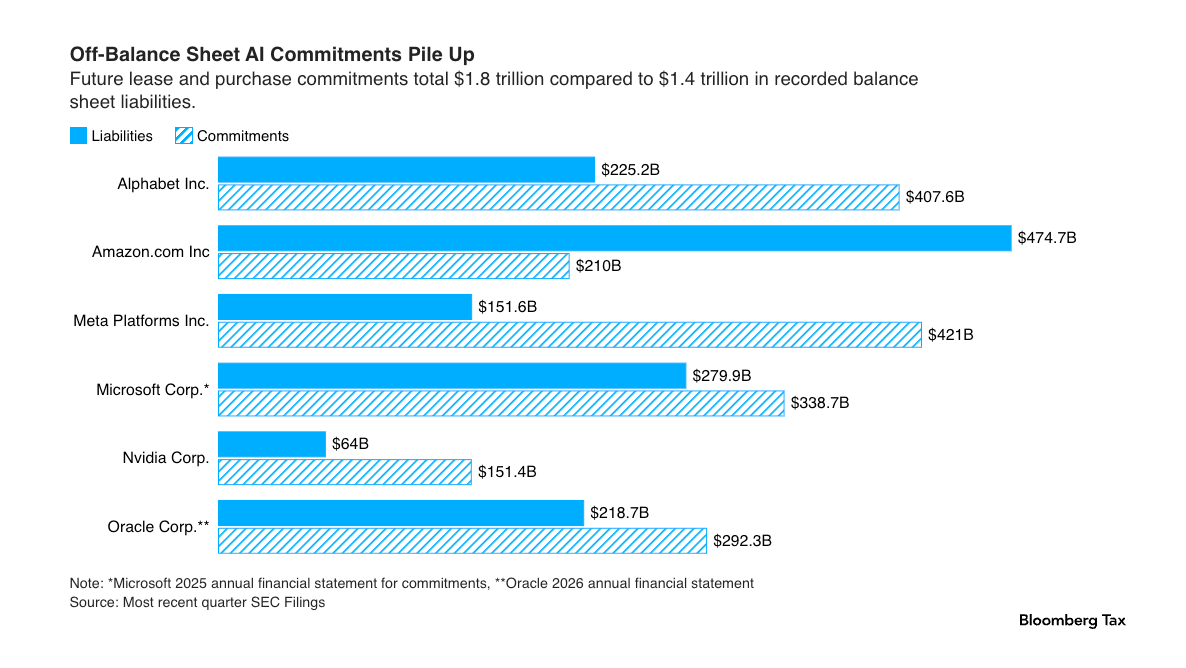
To be clear, even “on balance sheet” obligations are off-balance-sheet until the leases begin. Bloomberg has a truly horrifying chart that illustrates its scale:
Much like the Great Financial Crisis, nobody has seen any of these data center SPVs (or the greater data center bubble) as a problem yet because
I want to be very blunt about something: we do not, at this point, have a firm hand on exactly how much demand there is for AI compute, and evidence suggests that it’s much, much smaller than we’ve been led to believe.
I estimate that 70% or more of Microsoft, Google and Amazon’s compute capacity is taken up by OpenAI and Anthropic, and in my analysis of non-hyperscale compute providers, I struggled to find any customer other than them that was spending more than $50 million a year on compute.
That’s because real, diverse demand does not exist for AI compute, as evidenced by the fact that the same four or five companies are the only ones interested in renting it at scale.
Sidenote: Furthermore, any demand for compute that exists currently is inflated by the effective subsidization of paying subscribers to ChatGPT and Claude, who can burn tens of thousands of dollars worth of tokens while only paying $200-a-month.
For example, on July 1, Bloomberg reported that Meta (mere months after Zuckerberg said that “selling capacity was on the table if it overbuilt”) was creating a cloud business to rent out its AI GPU capacity. A mere two weeks later, the New York Times reported that it was in talks to rent capacity to Anthropic.
While one might argue that Meta is taking advantage of a wealthy buyer, one has to ask: if there was such insatiable demand for compute, why wouldn’t it want to sell it to a diverse set of customers who would likely pay a much higher rate than a years-long contract?
It’s because those customers do not exist at a scale that would actually make it worthwhile! If they did, we’d see massive bursts of remaining performance obligations from neoclouds like Nebius, IREN and CoreWeave that were unrelated to new contracts they’ve signed with either hyperscalers, OpenAI or Anthropic. Companies like Lightning, Runpod, and Lambda would have billions in revenue. Instead, Runpod has $120 million in ARR, $500 million in ‘annualized’ revenue, and Lambda had $114 million in revenue as of the second quarter of 2025, with a little less than half of that coming from Microsoft and Amazon.
While the counter-argument is that these companies are all GPU-constrained, and that demand is simply waiting in the wings…except surely that would mean that these companies also had massive remaining performance obligations?
To be clear, the point I’m making is not that there’s no demand, just that the vast majority of that demand is coming from either Anthropic and OpenAI — two companies that cannot afford to pay for it long-term — and hyperscalers, who are mostly buying compute on behalf of OpenAI and Anthropic.
And I’m not sure that people are taking me seriously when I say that AI compute demand does not exist at the scale that it needs to, will likely never reach that scale, and data center construction is a debt-funded asset bubble with ruinous consequences.
So, let’s set some table stakes.
Per my own analysis, NVIDIA’s predicted $1 trillion in Blackwell and Vera Rubin GPU sales (by the end of 2027) represents around 40GW of data center capacity, which will, assuming a PUE of 1.35, result in around 30GW of usable capacity. At a cost of around $12 million a megawatt, that works out to around $435 billion in global annual compute revenue to make these data centers necessary.
Right now, there appears to be roughly $100 billion or so in annual compute spend, with OpenAI representing around $50 billion (per their statements in the Musk trial), and Anthropic likely spending similar amounts. Microsoft and NVIDIA represent a combined 65% of CoreWeave’s $2.08 billion in (latest) quarterly revenue, with the rest likely taken up by OpenAI. IREN, another neocloud, recently announced it was targeting a year-end cloud ARR of “over $4 billion,” or around $333 million a month, with a customer base that includes, unsurprisingly, Microsoft and NVIDIA, as well as companies like Perplexity, Figure AI, and Together AI that are unlikely to be spending more than $50 million apiece given their funding status and revenues.
Sidenote: It’s important to note that spend isn’t necessarily the same as utilization. Much of the compute spend comes in the form of long-term contracts, where the price-per-hour for a GPU is (naturally) lower than it would be if it was rented to deal with a momentary spike in utilization. The vast majority of AI compute spend comes in the form of these long-term contracts.
Another concerning anti-demand signal is the fact that NVIDIA has committed to $30 billion in multi-year cloud compute agreements, spending $6 billion or more a year through 2028 to rent back its GPUs, including a $6.3 billion backstop for CoreWeave that explicitly states that NVIDIA is “is obligated to purchase the residual unsold capacity” through April 2032, suggesting that there would be residual capacity that had gone unsold to the tune of billions of dollars.
Oh, and NVIDIA owns 9.3% of Nebius too. It’s also invested in IREN, CoreWeave and has both invested in and rented capacity from Lambda.
If you’re wondering why these deals keep getting signed — as mentioned previously — it’s because a financial guarantee from NVIDIA is sufficient collateral for a bank to lend money to these companies to buy more GPUs.
I imagine a conversation in the Big Short 2 might go a little like this scene.
HUANG: So there’re these companies I invest in that, at least in theory, build data centers using my AI GPUs, but I need them to buy more GPUs, so I sign a contract saying that I’ll rent the GPUs back from them in the future. Because NVIDIA has such a strong balance sheet, these companies can raise billions of dollars to buy my GPUs just because I promised to rent them in the future, and the best part is all the risk is held by the companies and the investors. When I need more money, I just sign another contract, they raise more debt, I sell more GPUs.
BAUM: So — just so I have this clearly — you, the guy who makes the GPUs, invest in companies that exist pretty much to buy GPUs from you and rent them to customers. Except you’re the customer too, and a big one.
HUANG: That’s right. We call them neoclouds. S&P just revised CoreWeave’s outlook to positive.
BAUM: That’s fucking crazy.
HUANG: It’s not crazy — it’s awesome.
Those Meta and Microsoft neocloud deals exist explicitly to lower their capex and debt — by which I mean that if Nebius or IREN takes on the billions in debt to buy all of those GPUs, Microsoft and Meta only have to worry about the ongoing leases, assuming that construction is ever complete. These deals also regularly include a clause that allows them to be terminated in the event that delivery milestones are not met, as is the case with Microsoft’s $17.4 billion deal with Nebius.
This means that hyperscalers take on effectively no risk, and investors are left holding the bag. For example, Nebius’ recent $775 million debt facility is “backed by contracted cashflows and deployed GPU infrastructure,” meaning that if things fall apart, the only entity that can be sued would be a company that explicitly exists to buy NVIDIA GPUs and rent them.
To be abundantly clear, the vast majority of the AI data center compute revenue is contingent on the continued ability of two unprofitable, unsustainable AI companies’ to raise tens or hundreds of billions of dollars a year. This is not an overstatement, this is not hyperbole, it is the quite literal situation we’re stuck in.
Putting aside whether data centers are profitable or not (they aren’t), if the demand does not exist at this remarkable scale, the vast majority of AI data centers and their associated SPVs will collapse.
If we take February’s Sightline Climate report at its word, there is 190GW of data center capacity in planning, or 140GW of IT load if we take a 1.35 PUE, for a total of $1.68 Trillion. If we assume — and I’m being nice! — that there’s $120 billion in annual compute demand, and take into account that tens of billions of dollars’ worth of data centers have been announced since, this means that there’s over 15 times more data centers being planned than the demand that actually exists, and 70% to 90% of that demand is from Anthropic and OpenAI’s unprofitable services.
The hunger for speculation has vastly outpaced the actual demand for AI compute, much like it did in the great financial crisis, and for many of the same reasons. Back in May, JP Morgan’s Karen Ward brought up the global savings glut that I mentioned in the intro as part of a discussion of what she calls a “global savings grab”:
In short, a number of Asian countries were either scarred from years of financial crisis and balance-of-payments turmoil in the 1990s, or seeking to depress their currencies to focus on export-driven growth. This created a glut of savings that travelled abroad, with US government bonds top of the wish list.
[US Fed Chair] Bernanke highlighted that this was acting as both a blessing and curse for the US. It provided the US Treasury secretary with abundant cheap financing and so too for American households and businesses. But this cheap capital was too tempting, running the risk of overspend and bubbles in the US. Within a few years, this warning proved correct.
Well, good thing that the world is different now, right?
That wasn’t the end of the savings glut story, however. Stage two happened when key parts of Europe shifted from being net spenders to net savers after the Eurozone sovereign crisis.
The global savings glut got bigger, as did the investment flows into the US, one of the few areas of the world still happy to spend and grow. At the end of 2025, America had a negative net international investment position — the difference between US-owned foreign assets and foreign-owned US assets — of $27tn.
However, we are now transitioning to what could be termed a global savings grab. Governments and companies around the world want to spend more. In doing so, they are competing to offer the most attractive opportunities to the world’s savers.
The difference between a savings glut and savings grab is that there’s incredible demand for cash rather than an excess of capital to invest, at a time when banks (and private credit funds) have tons of cash but are pulling back from investing in software and healthcare companies due to AI-related risk… and investing in AI data centers, which they consider to be the “cheat code” — high-yield, low-risk investments in infrastructure that have “guaranteed” customers.
It’s a perfect storm that mixes dangerously with the $400 billion or so in private infrastructure funds waiting to deploy, much of which is funded by pension and insurance funds (as I covered in the Hater’s Guide To Private Credit) drawn to private credit — get this! — because they needed new things to invest in after the Great Financial Crisis made yields difficult to find because banks were restricted from making the same kind of reckless bets that caused the global financial system to implode.
Are you beginning to work out why I’m a little concerned? How about the fact that the amount of dry powder within these retail-focused financial institutions is shrinking — suggesting that more and more cash is being deployed, or withdrawn as a result of diminishing confidence within households.
Anyway, much of the assumption of how “safe” investments in AI data centers comes down to three ideas:
Financial institutions have built entire models based on logic that borders on childish.
The “proof” that it’s worth investing in data centers mostly comes down to seeing that hyperscalers are spending a lot of money on them, and that OpenAI and Anthropic have lots of demand for compute.
They have also mistaken the ability for hyperscalers to keep funding data centers out of cashflow as a sign that all data centers are a good investment, when what’s actually happening is that they’ve run out of hypergrowth ideas and had so much free cash sloshing about that they were able to spend a trillion dollars in four years. Hyperscaler demand for NVIDIA chips has been so significant that it made it look like NVIDIA had an insane amount of demand, which in turn created a degree of FOMO and speculation, with everybody assuming that because hyperscalers were getting rich (they weren’t, they have never disclosed their AI revenues, but people just assume they wouldn’t do this without making a profit) that they too would get rich by buying GPUs and building data centers.
NVIDIA has been a big part of creating this fake demand story with its investments in — and backstop contracts with — CoreWeave, Lambda, IREN, and Nebius. Much like people assume hyperscalers wouldn’t make a huge, trillion-dollar mistake, they also assume that NVIDIA wouldn’t invest in companies that weren’t going to see incredible demand, somehow ignoring the very obvious point that NVIDIA doesn’t give a shit about any neoclouds outside of their ability to generate more GPU sales.
This is where the media and analysts could’ve done their jobs, but because none of the neoclouds have done yet, it’s totally fine that CoreWeave is sat on $30 billion in debt, most of it impossible to pay if any client drops out of a contract, because, much like the great financial crisis, nothing bad had happened yet, by which I mean that clients leave their invoices unpaid, and CoreWeave finds itself in financial distress.
NVIDIA’s naked self-dealing and circular financing are only made possible with a completely captured tech and business media. While mildly-concerned stories have run for the last year or so about the “massive circular financing under the AI bubble,” none of them treat the situation as anything else other than a curiosity.
I cannot adequately express my contempt for those that have hand-waved the danger of this bubble, or tried to minimize the risk created by the overbuild of AI data centers.
Much like a subprime mortgage, AI data center debt is being poorly-underwritten, virtually-uncollateralized and issued to projects that have extremely low likelihoods of repayment, all based on flimsy information and hype-driven mania.
Their collapse is inevitable because their ongoing payments are made out of customer revenue that is, in the vast majority of cases, entirely theoretical or contingent on payments from unprofitable and unsustainable AI companies.
What differs this from the subprime mortgage crisis is that the systemic risks aren’t driven by derivatives or complex financials but by the sheer scale of costs to build an AI data center, a catastrophic misunderstanding of the AI industry itself and the dangerous lending standards of private credit. When every single debt deal is over $500 million and usually numbering in the billions, we don’t need a vast web of different contracts to create a systemic risk, just clusters of projects that either fail to keep up with their SPVs’ debt or bonds that go unpaid by destitute or defunct data center developers.
Also, please remember that it didn’t take massive losses to begin the great financial crisis — just hard hits to a few load-bearing pillars of the industry. Lehman Brothers suffered two sequential quarters of losses ($2.8bn in Q2 CY2008 and $3.9bn in Q3 CY2028) before it entered liquidation. Those losses weren’t what killed it, but rather, what those losses did to the broader market — as well as the perception of Lehman with potential saviors.
Similarly, Bear Sterns failed after two hedge funds under its umbrella collapsed. While the monetary losses from these funds weren’t insignificant, they were something that, if everything else was fine, Bear Sterns could recover from them. Sadly, they occurred at a time when the market was spooked, and Bear was spectacularly over-leveraged, meaning that marginal losses would have a disproportionate impact on its balance sheet.
For AI, those “hard hits” to the “load bearing pillars of the industry” means a large amount of capacity flooding the market at once — such as that caused by the failure of a major compute customer, most likely OpenAI — or the slow arrival of new capacity that can’t find revenue to pay for it. Perhaps we get both.
While the data center debt market might be much smaller than the trillions of dollars of (at least theoretical) securities that broke the back of the financial markets (I estimate somewhere between $500 billion and $750 billion), the risk — the actual underlying financing — is spread across the entire financial system, with every major bank and financial institution and the vast majority of asset management firms having billions or tens of billions of dollars’ worth of debt tied up in an impossible situation.
The scenario I’m talking about is one where the vast majority of AI data centers go unused, and because the vast majority of data centers are paid out of customer revenues, 80% or more of the funds invested in AI data center debt will be lost. None of this is written to be alarmist or hyperbolic, and represents a rational position when compared to the fact that we have over 15 times the amount of data center capacity than we need, and there is little compelling evidence that there’s more than a few billion dollars in total demand.
Sidenote: If anything, I consider it a radical and actively deranged position to believe that there is demand for all this compute, and find it distressing that nobody else is making any substantive attempt to measure the actual demand for AI compute, or have any kind of meaningful discussion of what “we overbuilt capacity” means.
This all makes me feel a little crazy. I’ve looked! I think I’ve looked harder than anyone else has! I’ve tracked down as many sources as I can of the actual amounts that people are paying to rent AI GPUs. The demand isn’t even remotely there!
I even found a bizarre mid-2025 presentation from the owner of the land that Stargate Abilene is built on top of that prices the 1.2GW of capacity at around $10 billion a year. I imagine nobody wants to talk about this because it suggests that, at scale, AI compute only sells for about $8.3 billion a gigawatt annually, which makes the whole “data centers cost $100 billion a gigawatt” mathematics a little hard to reconcile with.
I need everybody to realize that the overbuild has real consequences, and that there’s no post-bubble economy to replace this one, because it’ll be just as expensive to run these things in 2030 as it is today.
This will mean that effectively every single financial institution in the world will have to write off or mark down hundreds of millions or billions of dollars’ worth of loans — and when they go to sell the underlying assets, they’ll be dumping aging hopper and Blackwell GPUs into a market saturated with them, meaning that the salvage price they get — assuming they get one at all — will be negligible.
This is the data center equivalent of subprime loans defaulting, except instead of hundreds of thousands of loans being the trigger, all it takes is ten or fifteen of them to send the industry into a panic.
It’s easy to dismiss this entirely as “rich people problems,” but AI data centers are increasingly funded — both directly and through private credit — using pension and insurance funds that rely on these (theoretical) payments for future yield to pay out premiums.
I’ll give you some examples.
The other problem with the “private” part of private credit is that we don’t really know how much data center exposure pension and insurance funds and the insurance/retirement funds of asset managers actually have. What we do know is that private credit is sinking hundreds of billions of dollars of people’s retirements and insurance premiums into deals based on obfuscated valuations and questionable underwriting standards.
For an example of how lax those standards are, here’s a quote from The Information about Blue Owl’s due diligence on Stargate Abilene, emphasis mine:
Blue Owl’s willingness to make fast decisions has made it a favored partner for the developers racing to produce giant data centers. It took just 15 minutes for Blue Owl executives to agree to invest up to $10 billion in future projects alongside real estate firm Primary Digital Infrastructure during their first in-person meeting two years ago, said Primary chief investment officer Bill Stein. Later, Stein introduced Lipschultz to developer Crusoe, which led to Blue Owl investing in the Abilene data center.
To make matters worse, Moody’s estimated a few months ago that banks had around $1.4 trillion in exposure to private credit, with $300 billion of that exposure held by big banks.
And because neither banks nor private credit funds nor asset managers are forced to keep any level of reserves, all it takes is a few bad apples — a few billion of data center deals — to go pear-shaped for there to be a cataclysmic unwinding of the AI trade.
So, the reason that nobody is really worrying about this situation is that we’re still waiting for the vast majority of data centers funded so far to complete construction. Once that happens, the assumption is that either A) the client in question will start paying or, more likely, B) that the data center provider will simply expect said customer to appear.
Eventually, these data centers (which are taking 18-36 months to complete) will start turning on, which will require them to start having paying customers at a scale that the market can’t actually support. While subprime mortgage defaults were a kind of slow, ugly boil, it’s much more likely that the collapse of the subprime data center bubble will happen in fits and starts as capacity comes online and, assuming Anthropic and OpenAI don’t swoop in, goes unused.
Sidenote: The most frustrating part of working out when this all collapses is the deliberate obfuscation by just about every party of the current state of data center construction. Sightline said in February that there were only 5GW of data centers due in 2026 actually under construction, but that number dramatically increased when you added 2027 and 2028 — 7.6GW and 2.1GW for those years respectively — which doesn’t actually line up with the amount of GPUs sold by NVIDIA (around 4GW to 5GW a year), or any attempt to line it up the publicly-announced data centers.
This is a problem of information asymmetry I’ll get to shortly.
I think we’ll see a few rescue missions to try and keep the con alive. Hyperscalers will do everything they can, scooping up capacity anywhere they see it, to avoid the perception that AI data centers will go unused.
You see, hyperscalers are currently in their own confidence game as a result of their ruinous expenditures creating the illusion of demand. Microsoft, Google, Meta and Amazon are stuck in a terrible situation where building more capacity will cost them tens of billions of dollars, but stopping building capacity will be an immediate signal that they’ve overbuilt capacity, sending anxiety-strewn shockwaves through the industry and killing data center debt issuance.
Yet what also might kill issuance is the market itself. Per Bloomberg, AI data center debt has “hit a wall,” with 80% of data center securities issued since early 2025 quoted at a wider spread than issuance, meaning that investors are valuing them as worth less than when they were initially issued. If the market continues to sour on AI data center debt, it will eventually become difficult to impossible for hyperscalers to keep issuing bonds, leaving them with only equity sales (like Google’s $85bn stock sale) that are equal parts limited and desperate.
Any decline in appetite for AI bonds will be immediately obvious, given the scale in borrowing, with (per Goldman Sachs) AI-related bonds accounting for nearly one-quarter of all US-investment grade debt issuance.
NVIDIA’s continual circular funding of neoclouds and anyone who wants to buy NVIDIA GPUs continues only as a marketing function, and an attempt to conjure up the illusion of insatiable demand for AI compute. These deals are acts of desperation themselves, and tacit admissions that without NVIDIA, none of these neoclouds would exist — though, to be clear, Jensen Huang has quite literally said this on camera.
This, in my view, represents another troubling parallel between the AI bubble and the subprime mortgage crisis. In the early 2000s, loose lending standards — combined with the securitization of mortgages, which allowed lenders to offload their risk to third-parties — made it possible for people who shouldn’t have been able to obtain a mortgage to buy a home, albeit often at worse terms than so-called “prime” borrowers.
As I outlined in Coreweave Is A Time Bomb, Coreweave has been able to borrow tens of billions of dollars, despite having a business that is fundamentally reliant on a single customer — OpenAI — and on terms that would make a mafioso loan shark pause and say “hold on, that’s a bit harsh.”
In a sane world, Coreweave should not have been able to borrow as much as it did — and the same applies to the countless other debt-laden neoclouds that are, for the most part, cookie-cutter versions of Coreweave. These are the subprime homebuyers of the AI bubble, and the backstops and freebies offered by NVIDIA (and the other hyperscalers) has allowed said companies to raise more debt, without actually changing the fundamentals of these companies that made them so inherently risky to begin with.
Another obvious trigger is the insolvency of OpenAI or Anthropic, who have $1.1 trillion in compute commitments across Microsoft, Google, Amazon and Oracle, and, more dangerously, another $50 billion across Cerebras and CoreWeave.
In fact, maybe insolvency is going too far. CoreWeave’s own master service agreement with OpenAI will breach investor covenants if OpenAI fails to pay for three months straight, and with OpenAI delaying its IPO to 2027, it’s going to either need to raise more money or not pay its bills.
In any case, the sheer scale of AI data centers coming online massively outpaces the demand for AI compute, and to be clear, the AI bubble doesn’t have to burst for the subprime data center crisis to begin, because all it takes is for the revenue to not exist to pay for the compute.
As the vast majority of AI data center debt is project financing funded by compute revenues, the cutesy and half-assed retort of “even if it’s an overbuild, it’ll be alright” doesn’t really matter very much. The second a debt-backed data center is built, it must immediately produce revenue, because otherwise creditors will be left unpaid.
While the sheer scale of who those unpaid creditors might be is hard to quantify, what we can quantify is that the risk of the subprime data center crisis is everywhere — your bank, your community, your pension fund, your insurance company, everyone has, on some level, some exposure to the bubble.
For me to be wrong, there will have to be dramatic amounts of AI compute demand — hundreds of billions’ worth — within the next 3 years, at a time when there’s little more than $120 billion, with 80% or more of that coming from two companies that can only afford it because they have near-infinite sums of venture capital behind them.
Oh, and for some context, the entire global software market is estimated to be around $779 billion in 2026. It’s unclear where that money will come from, and nobody seems to want to talk about it.
The AI bubble is, like the great financial crisis, a product of information asymmetry — companies intentionally obfuscating how much revenue they have, how much data center capacity they have, how much revenue that capacity generates, how much demand they have for their services, and how many real dollars actually flow from the AI industry outside of investments in semiconductors.
And much like the great financial crisis, modern tech and business journalism routinely defaulted on its responsibility to demand this information, or to present a lack of information as suspicious, choosing instead to fill in the gaps and assume that whatever bullshit a rich person peddles is the truth. While many media outlets — as they did in 2007 — are now trying to somewhat quantify the risks, most business publications continue to celebrate every time NVIDIA sinks billions of dollars into a neocloud that exists only as a means of selling more GPUs, act as if AI’s continued growth is a certainty, and bring up financials only as a hesitant warning about an otherwise-solvent and successful industry.
Similarly, entire research groups — regularly quoted by the media — exist to inflate the bubble further. Exponential View’s speciously-sourced and questionably-founded research paper on AI revenues was used by Bloomberg and multiple other media outlets as a means of saying that “AI had started to pay off” because “the quarterly revenues were now outpacing depreciation,” a completely nonsensical statement that compared revenues from the entire AI industry (unspecified and undefined, by the way) with the depreciation of GPU hardware by hyperscalers.
It’s hard to see this as anything other than some tech and business journalists having a vested interest in seeing the AI industry win, which means, by proxy, that some writers will be fundamentally responsible for what follows when the bubble bursts. This is not a deliberately hyperbolic statement (and, lest I be accused of tarring the media and analysis industry with the same broad brush, there are many exceptions, and many good reporters calling bullshit where justified), but it seems as though there is a concerted effort to support industry narratives that I find repulsive.
What’s most horrifying is that OpenAI and Anthropic don’t even have to die for this all to end horribly. For one company to be able to afford even $200 billion a year in AI-related operating expenses is ludicrous.
Microsoft, a company that makes about $318 billion a year in revenue, has about $169 billion of operating expenses a year, and that includes the cost of running OpenAI’s compute. The idea that we’re going to have multiple Microsofts-worth of opex entirely focused on AI compute in the next four years is absolutely fucking ridiculous, yet it’s one of the most commonly-held beliefs in the tech industry.
As I hope I’ve made clear, I believe the vast majority of AI data centers are the AI bubble’s subprime loans, and will collapse when they face the cold, harsh reality of “someone actually paying money for AI compute,” much like subprime mortgages collapsed when teaser rates ended and homeowners were forced to pay their actual bills.
This is an inevitability — and something that’s very obvious when you sit down and actually try and work out how much capacity there is versus how much people are actually paying for AI compute. The fact that I, a random guy, albeit with a (recently-acquired) Bloomberg Terminal, am the one to say this is a sign that the media is not trying hard enough to protect consumers.
Every time that the media has accepted a spurious announcement or a questionable run rate or a circular deal or the outright refusal of hyperscalers to disclose their AI revenues, they help inflate the AI bubble and endanger the futures of millions of people, especially those tied up in a stock market increasingly-dominated by NVIDIA and other tech stocks.
Unlike the great financial crisis, the calamity to follow will be easily-traced to a complete failure of anybody to measure or demand measurements of the actual demand for AI services and AI compute.
There will be attempts to claim it was too complex or multi-faceted to pry apart, and those attempts will likely be made by media outlets that failed their readers, viewers, listeners, and the general public.
Bubbles can only inflate in an information-poor — and information-deprived — environment.
They inflate much faster and more-dangerously when that information is poisoned by marketing spiel and misinformation peddled by those who are meant to tell people the truth.
If you liked this piece, you should subscribe to my premium newsletter. It’s $70 a year, or $7 a month, and in return you get a weekly newsletter that’s usually anywhere from 10,000 to 18,000 words, including vast, detailed analyses of the biggest events and companies in the AI bubble.
As a reminder, if you sign up between now and 12AM ET, July 26, you’ll get $10 off a subscription. Click here for the offer.
2026-07-16 00:55:56
Thanks for reading this week’s free Where’s Your Ed At newsletter. As I said last week, I’m taking the rest of this week off, so there won’t be a premium on Friday. That said, if you aren’t already a member, now’s a great time to subscribe.
To celebrate the one year anniversary of the premium newsletter, I’m offering a sale on one-year subscriptions. Between now and midnight July 22, you can get a permanent annual rate of just $60— a $10 discount on the usual price of $70 - for life. Click here for the offer.
In addition to getting access to the entire back catalog of premium posts, you’ll also receive one additional post each week — usually anywhere between 10,000 and 20,000 words — covering the most pressing topics in the AI bubble - the best value in tech analysis. Highlights include last week's Hater's Guide To The Memory Crisis - a guide to how AI made everything more expensive - How OpenAI Kills Oracle (which pairs nicely with the Hater's Guide To Oracle), The Hater's Guide To NVIDIA, The Hater's Guides To Private Credit and Private Equity, and how the entire AI Compute Demand Story Is A Lie.
Today’s piece is one of the largest free newsletters I’ve ever written, and pulls together the last six months of my work.
And it all starts with a question: how much do you trust Sam Altman? The stock market and (to some extent) the global economy rests on your answer.
You see, OpenAI has become one of the largest liabilities in recent economic history. You can argue that OpenAI’s no longer the focal point of the AI bubble — you can talk all you want about open source models or Anthropic or any number of other elements — but without OpenAI, the AI industry doesn’t exist, and the justification for trillions of dollars of capex evaporates.
The AI bubble isn’t a result of any actual return on investment — whether that be in purely monetary terms, like revenue or profitability , productivity gains, or anything tangible or measurable. Rather, it’s an episode of cult-like psychosis that infected the brains of some of the most powerful and wealthy individuals and institutions, where the powerful mythology of a company inspired — and been used to inspire — the greatest capital misallocation in history.
As much as this’ll piss some people off, I fully believe that the only reason this has kept going so long is that OpenAI has yet to collapse. Its failure would be a watershed moment — the Lehman Brothers of the AI bubble, and an event that would define the end of one epoch, the start of another, and that would shake the afflicted out of that psychosis. Absent this wake-up call, NVIDIA has continued to sell GPUs, the coffers of the semiconductor industry have continued to swell, and more and more spending commitments have been made.
Look. OpenAI intends to burn over $852 billion by the end of 2030. It accounts for $748 billion of the remaining performance obligations of Microsoft, Amazon, and Oracle, on top of at least another $70 billion of RPOs across Cerebras, CoreWeave, Nebius, IREN, Lambda, and Nscale (per Kakashii), and plans to spend indeterminate billions’-worth of Broadcom “Jalapeno” chips. It intends to spend $50 billion or more on compute this year, which I estimate is more than 50% of all global AI compute spend (with OpenAI taking up 50%+ of all AI compute infrastructure).
OpenAI can only afford to pay that as a result of its latest (assuming it fully closes) $122 billion funding round, of which it has received at least $50 billion, with $20 billion from SoftBank (of $30 billion, with the third tranche due October 1, 2026). NVIDIA mentioned in its latest quarterly earnings report that it “estimate[d] that one AI research and deployment company contributed to a meaningful amount of [its] revenue by purchasing cloud services from [its] customers in the first quarter of fiscal year 2027,” referring, of course, to OpenAI.
OpenAI is the reason anyone cares about AI. In March 2019 (per JustDario), NVIDIA bought a company called Mellanox that made the high-speed networking tech necessary to create AI GPU clusters, and four months after that, Microsoft invested a billion dollars in OpenAI and started buying AI GPUs and building AI infrastructure for it. By March 2020, NVIDIA would ship its A100 GPU, and in May 2020, Microsoft would announce it had built a supercomputer just for OpenAI with “more than 285,000 CPU cores [and] 10,000 GPUs.”
The launch of ChatGPT in November 2022 came at the perfect time for a tech industry that had run out of ideas and was flirting with a prolonged depression. The IPO market had collapsed, interest hikes killed the Zero Interest Free era dead, pandemic era overhiring began to unwind with some of the worst layoffs in the history of the industry, global venture funding dwindled after historic overinvestment in 2021, and tech stocks took a massive beating.
For the first time, the tech industry was forced to cut its cloth in accordance with its means — something which it has historically been loath to do. Big tech was unpopular, both with investors and the general public. The excesses of the past decade — combined with the growing frustration with, for lack of a better word, “tech exceptionalism,” where it believed that the rules which governed the rest of the world didn’t apply to Silicon Valley — had tested the patience of both regulators and lawmakers. And, in the absence of “one more thing” — a big, splashy, game-changing product category — it no longer had an excuse for its prodigal spending, or its regular breaking of the rules, both written and unwritten, that govern society.
The existence of OpenAI justified an era of mania and opulence. Hyperscalers, bereft of new hypergrowth ideas, were able to point at the fact that ChatGPT had “the fastest growing userbase of all time” and the Microsoft “supercomputer” that built it and tell their investors that if they didn’t invest, they’d be left behind, with Amazon, Meta, and Google announcing their own nebulous “supercomputers” in 2023.
By the end of 2023, NVIDIA had sold 500,000 A100 GPUs, and the only reason it did so was because of ChatGPT’s rapid growth. Sam Altman’s brief ouster only sought to inflate the AI bubble by adding a layer of dull palace intrigue to a tech industry bereft of whimsy or character — and helped further entrench Microsoft’s role as the paternalistic benefactor of OpenAI, which made sure that Altman returned to the helm.
To be clear, when I say “rapid growth,” I mean that OpenAI hit 100 million weekly active users by the end of 2023 and had about $108 million in monthly revenue. Microsoft would invest $10 billion more that year, with the majority of that funding coming in the form of credits to be used on Microsoft Azure.
OpenAI is also the reason that Anthropic exists — not just because multiple founders came from the company, but because both Google and Amazon both agreed to give it a total of $6 billion in 2023 as a means of “competing” with Microsoft’s new obsession, which allowed both to justify spending further hundreds of billions of dollars “to make sure they didn’t miss out on AI.”
When you remove the term “AI” from the equation, this all seems a little ludicrous. $16 billion in equity investment on top of what was, by the end of 2023, over $150 billion in capital expenditures, all of which was pretty much justified by the fact that a single website had been very popular.
And the only reason either of these companies were able to grow was because of hyperscalers bankrolling their entire infrastructure.
In the fourth quarter of 2023, global venture capital funding had dropped to its lowest levels since the third quarter of 2016, with American startups taking up $183.6 billion of the year’s investments. Venture capital alone couldn’t have — and wouldn’t have — actually backed OpenAI or Anthropic at the scale that was necessary to build their infrastructure, nor would there have been any of the hunger from hyperscalers or those providing debt for data centers without hyperscalers inflating both of these companies, almost entirely because of the success of OpenAI.
Remove OpenAI from the years 2020 through 2024 and the AI bubble wouldn’t have inflated at all. No other major AI companies showed any sign of life — not those peddled by hyperscalers, funded by venture capitalists, or those launched by other tech firms.
The only reason that any hyperscaler AI efforts have any revenue — and outside OpenAI and Anthropic it’s pretty meager! — is because they knew they could just sit there and keep saying “AI is the future” until their customers eventually gave in and tried it…largely because everybody was talking about ChatGPT.
Anthropic was considered an also-ran until early 2025, and only continued to get funded because people wanted to invest in the next OpenAI, and Anthropic’s initial funding rounds and infrastructure buildout were only justified in terms of competing with OpenAI.
Those $178.5 billion in US-based data center debt deals in 2025? Pretty much entirely justified by the growth of OpenAI and its rapacious hunger for compute, because outside of OpenAI (and eventually Anthropic), nobody else was using massive clusters of tens of thousands of GPUs, nor does a market for compute at that scale appeared to have popped up in the months and years since.
The largest consumers of compute remain Microsoft (for OpenAI), Google (for Anthropic), Amazon (for OpenAI and Anthropic), CoreWeave (for OpenAI and Anthropic), Meta (which is copying what the other hyperscalers are doing), and Oracle (for OpenAI). Otherwise, there’s very little evidence — and boy, have I looked — that there’s more than a few billion in demand for AI compute, and that’s being generous.
All of those investments — both in AI startups and data centers — existed to fund either the next OpenAI or become the next OpenAI’s landlord.
The assumption — because nobody ever thinks things through — was that because one OpenAI existed, many OpenAIs would bloom. That because one large customer of compute existed, the template had been built for future compute-intensive startups…and, again, because nobody ever thinks about anything, nobody ever stopped to realize that the reason there isn’t another OpenAI is because OpenAI and Anthropic are financial psy-ops by the largest software companies in the world.
The grim truth is that you can’t venture fund an AI lab. While OpenAI and Anthropic have raised nearly $300 billion in the last few years, their actual infrastructure costs — the GPUs and the data centers to power their services — were entirely funded by hyperscalers, likely costing another $250 billion in the process, given that Microsoft has said it spent $100 billion on its OpenAI relationship as of early 2026.
Yet the real cost wasn’t just financial, but the experience and industrial know-how to actually execute on a massive infrastructure bailout. Other than Google, Microsoft, and Amazon, nobody else has the scale or experience to build the kind of AI clusters that OpenAI (and eventually Anthropic) needed.
We know that for a couple of reasons. First, because prior to 2023, there were few — if any — companies actually building AI computing clusters at the kind of scale demanded by OpenAI or Anthropic. The closest thing that one could point to were crypto-mining firms, and it’s telling that many of the neoclouds today (most famously Coreweave) started life running warehouses full of ASICs to mine Bitcoin and Ethereum.
Second, because, based on conversations with people in the data center industry, the whole Overton window of what is considered to be a “big” facility has shifted. Previously, a 50MW data center would have been considered a significant (even noteworthy) development. These were the exception, and not the rule, with most data centers being vastly more modest affairs. The only companies which had any experience building at that scale were, for the most part, hyperscalers.
By treating OpenAI as a “venture backed startup,” hyperscalers created the illusion that this was the next type of big company that would in turn create the next great demand center in cloud computing, except the only reason that these companies existed was because of the hyperscalers themselves willing them into existence, funding them with incredible sums, and allowing them to burn as much money as they’d like.
This is why the idea that OpenAI will continue to grow infinitely is central to the mythology of the AI bubble. The existence of one OpenAI allows others to — no matter how illogical — imagine the existence of more OpenAIs, which in turn means that those OpenAIs will need just as much compute as OpenAI.
The dimwitted investor who believes this tripe can justify it through any number of different buy-side analysts or captured members of the media that talk about the “insatiable demand for compute,” pointing to capacity constraints (caused by slow data center construction and — hah! — OpenAI and Anthropic taking up much of the world’s compute) and increasing GPU prices as proof that actually, there’s tons of demand, all without ever really thinking too hard.
The greatest trick that hyperscalers played was never backing down. By sinking more than a trillion dollars into AI capex without ever showing a single dollar of profit, they justified literally anyone investing in AI data centers under the logic that “the largest companies in the world couldn’t be wrong,” even if the reason they were doing so was to expand capacity for OpenAI and Anthropic, who the hyperscalers themselves incubated.
It is fundamentally illogical and insane for hyperscalers to have spent so much money on AI infrastructure, and the reason that few people will say so is because it was, until recently, considered radical to suggest that this was a waste of money, almost entirely because of the existence and continued growth of OpenAI.
Sidenote: while I realize Anthropic has taken up a lot of attention and grown rapidly in the last year, it’s only been able to do so A) because of the mythology of OpenAI and B) because it too was incubated and allowed to run at a massive loss too.
Whatever utility you may or may not get out of LLMs is irrelevant because it has not, for the most part, been what actually underpins data center investment. While accelerating gains in code generation (itself something that could have only happened without vast subsidies) might have helped grow Anthropic, the vast majority of data center capex has been built chasing the dragon of what AI could be rather than any connection to the revenues or economics of the companies at large — outside, of course, their compute spend.
This is the underlying greed that has driven this wasteful, reckless and destructive era — the belief that there will be another OpenAI and, as I’ve said, the chance to become the next OpenAI’s landlord. And because the media and analysts very rarely have original ideas, everybody justified (and justifies) the waste through the same tired mantras, saying it was “just like Uber (nope!)” or “just like Amazon Web Services (between 2003 and 2015, Amazon spent $29.7 billion on capex, normalized for inflation).”
And like any great investment bubble, the more money that piled in, the greater the fear of missing out, the more dollars that can be justified in turn, and the more-complex and deranged the mythology becomes, which is why you have noted venture capitalists claiming that AI labs have “90%+ inference margins,” a completely unproven statement that AI boosters cling to and repeat often enough that it’s taken as gospel, likely to avoid thinking about the fact that you can burn $14,000 in tokens on a $200-a-month ChatGPT subscription.
This kind of mythology only grows in an environment deliberately deprived of good information. The fact that we’re four years into this horrible bubble and still don’t have consistently-held consensus around the actual costs of large language models is a testament to an industry-wide effort to suppress them.
OpenAI, Anthropic, Microsoft, Google, and Amazon have done everything in their power — based on discussions with sources familiar with their infrastructure — to obfuscate the actual underlying costs of their operations, and Silicon Valley, an industry of alleged free thinkers and individuals, is more than willing to accept whatever convenient myths might sustain their dreams.
And in the end, they all became useful idiots for hyperscalers. Their obsessive attachment to OpenAI — and by extension Anthropic — seems like a decision made under the auspices of “democratizing powerful AI,” all as effectively every dollar flows to either Microsoft, Google, Amazon, or Oracle, who in turn feed that money to NVIDIA or Broadcom, who in turn feeds that money to TSMC, SK Hynix, Samsung, or Micron.
Invest in an AI startup? They’re gonna be paying one of the AI labs, who will in turn pay a hyperscaler. Invest in an AI infrastructure company? That money will flow to NVIDIA, and then upstream to semiconductor companies. In the end, whether they die or get acquired (as none of them are going public), all of the value will end up in the hands of one of the hyperscalers who created this imaginary era, then helped inflate it into something very, very dangerous.
Yet the problem is that this industry cannot, under any circumstances, survive without OpenAI.
When people discuss OpenAI’s potential collapse, they act with pure cowardice either saying “it won’t be that bad” or say something vague about it “being too big to fail.”
If OpenAI — the company with the most money and the most infrastructure and the most attention and the most talent in AI — collapses, it will likely do so after AI data center debt and venture capital funding has been almost entirely exhausted.
You see, Goldman Sachs’ Jeffrey Papai recently noted that it will be “very difficult” to replicate the hundreds of billions of dollars that hyperscalers have raised in the last four years — $244 billion in 2026 alone if you include NVIDIA and SpaceX — which is a problem considering that they can no longer fund their data center capex using their cashflows as of Q3 2026.
And to be clear, hyperscaler capex doesn’t have to stop for NVIDIA to stumble. It just has to slow down meaningfully enough that Jensen Huang can no longer give investors 60%+ year-over-year revenue bumps, because the AI bubble is built on vibes, and it can only survive so long as those vibes don’t become sour.
Yes, yes, I realize there are other customers, but the vast majority of NVIDIA’s demand comes from hyperscalers, who are (for the most part) either building out their operations for OpenAI and Anthropic or simply copying what the other hyperscalers are doing (see: Meta and SpaceX).
Once hyperscalers stop spending money, banks that are afraid of “choking” on data center debt will see that a vast amount of capital is leaving the market and underwrite (or not, as the case may be) deals as such.
This will mean, at some point, that both OpenAI and Anthropic will be walking around with their hands out saying “money please!” at precisely the moment that everybody will be cutting back. While NVIDIA might get a little desperate and throw some extra cash their way, if revenues start collapsing, so too will its interest in further inflating the bubble as investors begin to ask whether any of this was real or one large circular financing scam.
While this is absolutely a problem for Anthropic — especially after its $35 billion debt deal with Broadcom — it’s much, much worse for OpenAI, which has (as mentioned) made $748 billion in compute commitments to some of the largest and well-lawyered companies in the world. OpenAI’s continued marketing efforts involve constantly refreshing rate limits around the launches of its most-expensive models, giving away millions of dollars of tokens to startups, and generally running the “grow as fast as possible and work out a business later” model into the ground at speed, all fueled and funded by Clammy Sammy Altman’s nasty habit of overpromising and underdelivering.
Clamuel’s biggest mistake was leaving the pearly gates of the hyperscalers and dancing with the mortals of Oracle, Cerebras, and CoreWeave. While Microsoft or Amazon might be willing to extend payment terms as a means of saving face and prolonging the inevitable, Oracle — a law firm with a software company attached — is more than capable of loud and aggressive litigation under any contractual breach.
Then there’s the fact that Apple is suing OpenAI after poaching multiple engineers for its hardware efforts and allegedly both coaching and coercing them into stealing trade secrets, which is all but certain to destroy any chance of OpenAI releasing a device in the next few years…and potentially the company itself. These are extremely serious allegations, with Apple also accusing OpenAI of trying to coerce trusted partners into revealing manufacturing techniques for iPhones — the kind of thing that can (and will) lead to brutal discovery and potentially criminal charges.
OpenAI also, as I’ve mentioned, needs to keep growing to keep up with those bills, and at some point will run out of real dollars to pay people, likely at exactly the time that it’s hardest to find more of them. While there might be billions of dollars left to be raised, to pay any of its bills, OpenAI needs tens of billions of dollars multiple times a year. Based on my own reporting on its audited financials from 2024 and 2025, OpenAI will need to raise funding at least three more times in the next decade.
To make matters worse, its free users have become a massive liability. While The Information reported that OpenAI expected to generate $2.4 billion in ad revenue in 2026, and $102 billion in 2030, it turns out that reality is a little harsher, with analyst eMarketer projects that the entire AI chatbot ad industry combined will only make $1 billion this year, with the entire market making $5.41 billion by 2030.
This means that the 900 million weekly active users of ChatGPT will remain a massive drain on the company’s finances, with only 5% or so of them opting to pay, and a projected 80% of its $20-a-month users expected to churn in 2026.
At some point, OpenAI will simply run out of money. It’s nearly exhausted every available source of capital, and now that it’s likely delaying its IPO to 2027 — largely in part because it couldn’t list at a $1 trillion valuation — it will have to raise again, potentially at a down-round valuation or at a modest increase which will, in turn, make it much more difficult for investors to see a return in an IPO.
Investors will likely ask questions like “why couldn’t you go public?” and “what is it that bankers didn’t like?” as Sam Altman looks at them like this:

You see, OpenAI is awesome at selling mythology and hype, but crumbles the second that its numbers have to face the cold, harsh light of day.
While it’s been able to skate by in situations like Altman’s ouster and its conversion to a for-profit, these were strictly legal situations that could be dealt with by lawyers and cheered on by the press. OpenAI has never faced a problem like “not being able to pay its bills” or “breaching a contract with a major company,” and I think these are an inevitability in its future.
Sidenote: Yes, yes, you’re going to say “buhhh, bailout (nope!),” but even if Trump were to funnel another $42 billion to OpenAI, it wouldn’t cover a year’s worth of compute in 2027, the year that I imagine the Hellmouth opens and swallows it whole. If your argument is that OpenAI is going to get nationalized or “the military funds it indefinitely,” you are catastrophizing as a means of pretending you have control over the future in a way that feels intellectually satisfying, all without any of the messy work of interacting with the horrors of reality.
In the end, OpenAI’s collapse will be a dramatic narration of the boring, horrifying economics of the AI bubble.
Let me explain:
The AI bubble is inflated based on hype and hopium rather than tangible proof or substantial revenues driven to anyone outside of the semiconductor industry, and without NVIDIA’s massive returns, I don’t think anybody would’ve taken it seriously past 2024. Any and all achievements of the AI industry are a direct result of market psychosis, a broken media ecosystem, and a trillion dollars that could’ve been sunk into literally anything else, and must be evaluated as such.
The double-edge sword of a mythology-inflated bubble is that it’s much harder to sustain when said mythology dies. The AI bubble was able to grow to such a horrendous size because the markets and the media were willing to accept basically anything that Sam Altman or the greater AI industry said.
By waving away any economic problems as growing pains and dismiss those who would scrutinize it as haters or cynics, reporters and analysts provided investors with the justification to invest again and again in these companies without them ever having to make a real business, which means that, well…they don’t have real businesses, which is a problem when you need to actually pay somebody money that wasn’t given to you by a venture capitalist.
This will leave the AI industry short-changed in its most-desperate times.
The media is important for many, many reasons, but one of the biggest ones is that scrutiny is what keeps capital in check, for the benefit of humanity and at times the companies themselves. By choosing to pull their punches, ignore glaring economic problems and accept every projection with blind faith, the media empowers grifting and suffocates good businesses as a result, encouraging bad behavior and helping them raise unbelievable amounts of money at ridiculous valuations without worrying about having to make a good business. In some cases, the media even encourages them to do so, saying that “all startups lose money at first” instead of thinking about things for a fucking second.
When companies know they won’t face that scrutiny, they engineer themselves as such, putting off ever finding a real business model in favor of whatever will make them buzzy enough to get coverage and raise funding as a result. In a vacuum of skepticism, bubbles inflate, monsters get rich, and regular people always get left holding the bag. As a result, if companies ever bother to become a real business, they only do so at the very last minute, endangering anyone who has backed them and every counterparty in the event they’re incorrect.
When OpenAI dies, it will be after a prolonged period of desperate reorganization and attempts to appeal to investors and the media that it can, in fact, become a real business. These attempts — price increases, price cuts, selling off IP, nebulous circular deals, and so on — will all fail, and by the end, Sam Altman will have run through every single trick imaginable to keep the party going.
And when those fail, what do you think Perplexity does? How about Harvey? Cursor got the last chopper out of ‘Nam with the SpaceX acquisition (assuming it actually happens), but what, exactly, is Cognition, or Glean, or Sierra, or really any AI startup meant to say to compel investors to believe in them once OpenAI dies? That they’re different? That they’re gonna work it out after the company that got given basically everything it needed failed?
The entire AI industry’s sales pitch is that OpenAI opened the world’s eyes to the power of AI, and that giving the AI industry as much money as possible would end in economic abundance the likes of which we’ve never seen. Instead, we’ve got two AI labs that both lose billions of dollars, and the latest model from one of them randomly deletes people’s stuff.
It’s not like any of this was sold on actual ROI or real businesses or returns or productivity or any actual measurable thing other than physical infrastructure erected in its honor.
There are simply no compelling stories about the AI industry that can be told in the present tense. Everything is always based on the theoretical multiplicative power of just waiting a few more years, which becomes much harder to believe if the company with the Mandate of Heaven gets sent to Cocytus.
This will have massive downstream effects on basically everything and everyone connected to the AI industry. You won’t be able to raise money for a startup to spend money on compute, nor will you be able to convince somebody that your LLM wrapper will change the world, nor will you be able to justify a massive valuation. Venture capitalists fancy themselves as brave soldiers of the economy, but are really cowardly lemmings that will sprint for cover the second that things get rough.
I also keep hearing from people that Anthropic is magically safe from the AI bubble’s clutches, or insulated from its rotten economics. The amount of pure mythology and misinformation I read about this company on Twitter is genuinely offensive, and the fact that journalists have categorically failed to push back against it is proof that too few people give a shit about anything other than which boot they get to lick next.
Anthropic faces the same economic realities as OpenAI. It burns billions of dollars on training, it hides inference costs in sales and marketing, and the only real differences are that it focused more on coding and made fewer ridiculous infrastructure commitments…right up until this year, when it committed $200 billion in compute and hardware commitments to Google, raised $35 billion in debt from Apollo to buy Google TPUs, signed a $15 billion a year compute deal with SpaceX, and agreed to a 20-year-long, $19 billion lease with TeraWulf.
Much like OpenAI, Anthropic is also doing way, way too much. There’s Claude for Life Sciences, Claude for Legal, Claude for Small Business, Claude Design, and even, for whatever reason, reports that Anthropic intends to develop its own drugs — and instead of saying “hey man, what the fuck are you doing?” the media falls over itself to repeat and celebrate every single one as if they’re all viable or useful products. Anthropic is as messy, disorderly and unfocused as OpenAI, but has done a better job of convincing people that it’s somehow “ethical” as it fucks over its partners and farts out 200 new products a month.
This is a company that lacks focus or vision other than “more” and “bigger.” The only thing that differentiates OpenAI from Anthropic at this point is the nebulous promises of “AI code” and Dario Amodei’s Doom Trolling and safety theater.
The fact that the majority of the media made no efforts to push back against its shenanigan-rich “profitability” narrative is why we’re in this fucking mess.
Anthropic is an AI lab just like OpenAI. It uses GPUs, TPUs and Trainium chips. It trains models in much the same way to do much the same things, and builds quasi-functional plugins on top of them, just like OpenAI does. It makes big compute commitments, it had its infrastructure built out for it by hyperscalers, its CEO is annoying and beloved by cretins, and its value is largely determined by 1000 people on “X The Everything App” experiencing varying levels of AI psychosis.
Attempts to claim otherwise are tacit admissions that OpenAI is unsustainable.
Please note that when I say “victims,” I don’t always mean “people you should feel sorry for.” In some cases I’ll be talking about real people who are facing the horrible consequences of the OpenAI bubble bursting, and for whom you should feel a degree of sympathy, and in others, I’m referring to various Patagonia gargoyles’ financial woes. I assume you’ll be able to differentiate between them.
My last premium newsletter was the massive Hater’s Guide To The Memory Crisis, or the twisted tale of how three companies — Samsung, SK Hynix and Micron — have diverted meaningful amounts of manufacturing supply away from making the RAM you find in laptops and smartphones toward making the high-bandwidth memory that powers GPUs, jacking up the price of consumer electronics in the process.
To explain:
An AI data center is full of servers, which are in turn full of (for the most part) NVIDIA GPUs. Each NVIDIA GB300 has two B300 GPUs, the two of which have 576GB of High Bandwidth Memory (HBM, or HBM3e to be specific), and a CPU, which has 480GB of lower-power LPDDR5X RAM (the kind usually used in cellphones and other mobile devices). These systems tend to be sold in an NVL72 rack with 18 compute trays, bringing us to 36 GB300s, for a total of 20.7 terabytes of HBM and 17 terabytes of LPDDR5X RAM, and that’s before you get to the RAM associated with the high-speed networking gear and other associated components.
Because HBM takes up more space on a wafer — the slice of semiconductor material that is etched using photolithography (read: molten tin) and then cut into separate dies (individual chips) — and generally has much higher margins (the actual product its more expensive to make, but thanks to the triopoly of Samsung, SK Hynix and Micron, they can charge whatever they like, predominantly to NVIDIA), memory manufacturers are dedicating more space on their manufacturing lines to it than to regular consumer RAM, which allows (thanks to said triopoly) said manufacturers to charge effectively whatever they want for consumer RAM.
To simplify, the AI GPUs in AI data centers require hundreds of gigabytes of high-bandwidth memory, the CPUs attached to them require the same RAM as your smartphone, and the companies making all of this RAM are making huge profits by jacking up the price because of supply chain constraints that they themselves have created. That’s why Micron had 84.9% gross margins in the last quarter. The RAM triopoly controls more than 90% of the world’s memory, and can set prices at whatever rate they want.
These three companies were all fined over $100 million by the Department of justice back in 2002 for price-fixing, with Micron avoiding the fine by turning in its co-conspirators. Five years later in 2007, a Supreme Court judgment and resulting precedent (Bell Atlantic V. Twombly) drastically raised the bar for not simply winning an antitrust case, but even getting one to trial:
The Twombly Test/Rule was designed to raise the bar to civil legislation, so that defendants aren’t forced to comply with discovery in frivolous cases, which can be incredibly expensive.
While this seems reasonable at first glance, it makes it significantly harder to litigate any kind of antitrust action, because the market signals — whether they be pricing, or difficulties in new competitors bringing their products to market — tend to be the starting pistol on any action. The damning evidence — loose-lipped executives talking about their nefarious plans — tends to be something that shows up once the trial has progressed to the discovery stages.
This precedent would kill a 2019 class action case against SK Hynix, Samsung and Micron that alleged they had colluded to tighten the supply of the world’s DRAM, because despite statements from company representatives made at public events, their collective participation in certain industry groups, and observable pricing trends, the precedent set by Twombly meant that the plaintiffs required more than circumstantial evidence to bring something to trial.
Anyway, the reason I bring this up is that while I am not accusing Samsung, SK Hynix, and Micron of price-fixing, a recent lawsuit is accusing them of exactly that:
The suit claims the alleged anti-consumer behavior started in 2022, when the companies began shifting production from SDRAM to HBM — something that, at that point, they made “no economic sense” except as a means to hike prices.
“This plan has thus far succeeded, as consumer purchasers of conventional DRAM and devices incorporating it have paid supracompetitive prices and have otherwise suffered the impacts of a distorted market crippled by the behavior of DRAM oligopolists,” the filing states.
So, what does this have to do with OpenAI?
Well, back on October 1, 2025, OpenAI, Samsung and SK Hynix announced a “strategic partnership” that would involve OpenAI buying 900,000 wafers of DRAM a month (around 40% of the world’s supply at the time) for Stargate data centers — something that never actually happened (it was a memorandum of understanding, and OpenAI also had nowhere to put them), but both SK Hynix and Samsung’s stocks immediately rallied, and Samsung happened to hike prices by 60% a month later, which could be a coincidence, or could have been the company saying “yeah, wow, we’re gonna run out of RAM I guess, better buy now at whatever price we have it!”
Another clue that this might not all have been above board was that Samsung was reportedly doing another deal with OpenAI in March 2026, “...to supply up to 800 million gigabits (Gb) of 12-layer HBM4 chips to OpenAI in the second half of this year” per Reuters, for use with Broadcom’s custom “Jalapeno” chip. Though it’s hard to calculate exactly how much that would be wafer-wise, from what I understand we’re talking in terms of less than 100,000 wafers total after OpenAI, Samsung, and SK Hynix said they’d be taking up 900,000 a month.
Regardless of whether OpenAI ever takes a single wafer of silicon, these deals existed to put the squeeze on any company that uses memory in their products — including NVIDIA, AMD and Broadcom — which in turn led to the most aggressive price increases in the history of consumer electronics. As I said last Friday:
The net result is pretty simple: every single consumer electronic of any kind is getting more expensive. Valve’s Steam Machine console debuted at a 30% higher price point than planned, Apple hiked the prices of its MacBooks and iPads and will likely have to do the same for its next iPhone. Nintendo, Microsoft and Sony increased the cost of their consoles, and the PS5 and Xbox Series now cost more today than they did when they first retailed, almost six years ago.
And yes, OpenAI is responsible, both in its naked collusion with memory manufacturers to push an announcement that never resulted in anything other than price increases and its siren song that made every dimwit with debt desperate to build AI data centers.
Every single consumer suffers as a result. RAM is in everything, and it’s unclear when new manufacturing capacity will actually come online, as fabs are expensive and complex construction efforts and require tons of specialist talent, raw materials, permitting, land and power. SK Hynix Chairman Chey Tae-won said in March that the memory shortage would last until 2030, and he may be right, as a Bank of America report just said that SK Hynix may only be able to add a sixth of its planned capacity by 2028.
This means that the price of consumer electronics will be inflated for the foreseeable future, even if the AI bubble bursts. While capex pullbacks will eventually happen and by extension eventually lead to supply constraints easing, Micron, Samsung, and SK Hynix had sold out their entire 2026 supply by the second week of January, and noted that they’d only be able to handle 60% of “medium-term” customer memory orders, which suggests to me that 2027 might be even worse, with a subtle clue being that SK Hynix CEO Kwak Noh-jung recently told Reuters that 2027 would be “the worst year in the industry’s history from a supply perspective.”
While the memory triopoly has every incentive to make things seem bleak to drum up business and sustain their margins, behind the scenes reports suggest they’re turning the screws on everybody.
Speaking with Steve Burke of GamersNexus for my podcast Better Offline (out next week!), I learned that consumer electronics companies have told him in private that they’ve never seen anything like this — and that the average purchasing experience for buying RAM now involves being told a price that you either accept or never get to do business with the RAM companies again.
This is a graphic example of companies with massive amounts of leverage using it to fuck over both their customers and their customers’ customers.
Who gave them that leverage? The AI industry and Sam fucking Altman.
Hey, remember when I just said that (it seems, but I cannot confirm that) OpenAI helped SK Hynix and Samsung manufacture a supply chain crisis last year using a phoney announcement for a project that would never happen?
That happened three other fucking times in the same three week period, and modern journalism doesn’t seem to give much of a shit!
Let’s review what happened, per my year-ending Enshittifinancial Crisis newsletter:
All four of these companies’ stocks rallied on deals that land somewhere between misleading and fictional, with basically anyone who invested in them being underwater within two months, though all three have recovered thanks to similarly-questionable announcements and deals made by companies with the sole intention of boosting their stocks.
Sidenote: I didn’t even bring up what happened with the entirely-fictional $500 billion “Stargate” Project with Oracle and OpenAI, because I’d write another 200,000 words about how everyone who helped pump it should feel ashamed of themselves.
The same goes for every single analyst who reacted to Oracle’s OpenAI-driven remaining performance obligations like a horny teenager seeing his first boob. The capacity never existed, this deal will never happen, and you all know it and are either hopelessly ignorant or craven beyond words.
Why else would Sam Altman go on CNBC with NVIDIA CEO Jensen Huang on the day of an announcement of a project that was only ever a letter of understanding? Why else would Sam Altman jump on TV with Bob Iger to talk about a Disney deal that clearly never went anywhere?
Spare me any explanations around the “fast-paced dealmaking of AI” or “how deals are complex.” CNBC reported the day after the NVIDIA deal was announced that the first $10 billion tranche would “close within a month or once the transaction had finalized” via a source! It’s blatantly obvious that the intention was to create the appearance that a deal existed that never actually existed at all!
The AI trade is the natural endpoint of an increasingly-enshittified stock market where many analysts and journalists exist only to repeat narratives to influence stock prices. Outside of semiconductors, the AI trade has never, ever been about the actual underlying economics or the actual economic potential of Large Language Models, but projecting shadows on the wall to resemble something that looks like the next generation of technology.
That’s because the AI trade is entirely symbolic and driven by stock prices. When NVIDIA and the rest of the Magnificent Seven (sans Apple) does well, AI is the greatest thing on Earth. When the Magnificent Seven stumbles, everybody worries that they might be overspending on AI. The AI trade exists only to manipulate stock prices through spurious news and smoke signals on social media, and to drag gullible retail investors (who account for 20% of US equity trading volumes, the highest it’s been since 2021) and the rest of the market away from caring about things like “fundamentals” or “reality” toward whatever keys are currently jingling.
My evidence is fairly simple: Google, Meta, Microsoft, and Amazon don’t actually tell you their AI revenues, other than when Microsoft and Amazon have chosen to define it in terms of undefined “run rates.” And why would they? Reporters have been saying that their AI bets have paid off for years without the companies ever having to show it paying off other than their stocks running.
Here’s another example: CoreWeave, a time bomb/AI compute company that only really exists as a revenue source for NVIDIA (per Jensen Huang, if [NVIDIA] didn’t help CoreWeave exist, they would not exist”) by signing contracts with companies for unbuilt capacity that it then takes to banks and uses to raise more money to buy GPUs. NVIDIA knows that analysts and reporters don’t give a shit about the blatant self-dealing and circular financing, all because these deals help the stock price go up, which apparently is the only metric that modern journalism evaluates. That’s why when NVIDIA invested $2 billion in CoreWeave in January 2026 — a warning sign that the company had liquidity problems! — led to endless positive coverage after “the stock popped on the news,” per CNBC.
That’s because the AI trade exists only to extract value and con investors. It is not a trade related to the actual fundamentals of whether AI works or not, whether AI actually makes anyone money, or really anything about AI at all outside of whether mentioning AI or an AI-related company makes a stock number go up or down.
I’ll be blunt: modern journalism has failed the retail investor and directly helped the wallet inspector regulate the stock market. By empowering Sam Altman and the rest of the AI industry’s deliberate attempts to obfuscate the actual economics of generative AI and setting the terms of AI’s success as “how stocks are doing and whether the companies are growing in general,” they have defaulted on their responsibility to the general public and helped the already-rich get richer.
None of this would be possible if business journalism actually saw themselves as having a responsibility to give their audience good information. While one could argue that if you had blindly invested in the AI trade you might have made money, the ability to make money in the AI trade was directly driven by modern journalism’s inability or unwillingness to push back on any corporate narrative. Every major outlet ran a story on every one of the deals I mentioned, and not a single one seemed remotely upset or deterred by the fact they were misled, and in turn misled their audience.
And yes, investment funds can be just as easily manipulated as a retail investor, and will follow whatever trend seems likely to make them money, even if said trend is utterly disconnected from any fundamentals. Tech analysts help do so by creating vast models that give a veneer of respectability, even if their projections mostly amount to “number will always go up in the future.”
This is why Musk was able to dump SpaceX on the public markets. Why SK Hynix chose to list on the NASDAQ. When the entire world is captured by a childlike belief that “AI is good and will be the biggest thing ever,” you empower grifting and swindling at scale.
Well, that and underwriters like Goldman Sachs are so nakedly crooked that they’ll say they expect SpaceX’s AI revenue to grow 100x by 2030. Fuck off!
Yet the memory boom/bust/crisis is where the media has failed investors the most — a final insult before everything collapses.
You see (to quote myself), what makes this particular memory crisis so distinctly dangerous is that it isn’t a result of consumer demand so much as it is capital expenditures from very large companies making bets that don’t connect with reality.
Microsoft, Google, Amazon, and Meta aren’t spending $765 billion in capex in 2026 because of rapid demand by consumers for AI services, but a desperation caused by a lack of hypergrowth ideas, circular financing with Anthropic and OpenAI, and a vague concern that if they stop spending that the other guy will do something as a result.
Anyone blathering on about a “memory supercycle” is intentionally obfuscating where that revenue and demand is coming from — high-bandwidth memory attached to AI GPUs, meaning that this boom cycle only exists as a symptom of a greater hype cycle, meaning that when companies stop buying GPUs, the demand for that (briefly) high-margin high-bandwidth memory goes with it.
To give you some context, a chart from ComputerBase.de showed that high-bandwidth memory demand grew from 681 million gigabits of HBM in 2022 to 29.3 billion gigabits on 2026 — a 40x increase over the course of four years that suggests that once GPU-related capital expenditures stop, high-bandwidth memory demand will effectively disappear.
As I mentioned previously, this isn’t even me being a hater. Hyperscalers are now joining the rest of the world in having to raise debt to buy more GPUs, which means that at some point they aren’t going to be able to afford to buy as much, which will in turn mean that NVIDIA — which accounts for around 65% of all HBM purchasing — won’t need as much.
I have not read a single fucking article that mentions that this is a possibility! Every article about the memory industry right now is about supply constraints and the increasing cost of memory, but none of them warn investors or the general public about what will happen when capex slows, and certainly not the many, many articles in major business publications about SK Hynix, Samsung and Micron’s revenues. In fact, Reuters said that SK Hynix’s “scarcity premium looks built to last.”
The cynical (and boring) response here is that “the market can stay irrational longer than you can stay solvent,” but saying that distracts from the larger point of how said irrationality was manufactured by the media.
Sidenote: There’s plenty of evidence that AI has a pathetic effect on revenues. For example, it took Salesforce three years to get to $1 billion in AI ARR (read: $83 million a month for a company with revenues of $40 billion+ a year), a pathetic amount that should have had people running for the hills…except journalists were saying its AI bet had “paid off” months beforehand. It would be easy — and responsible! — to call this out.
I am not sure what the majority of the media sees as its purpose or responsibility to its readers, so I will speak plainly: the responsibility is to tell them the cold, hard truth, rather than going along with whatever hype cycle is happening out of fear of being wrong or missing out. Skepticism is not doomerism! Being critical is not being negative! These companies are some of the largest and richest enterprises in the world — they should be scrutinized!
And no, scrutiny is not publishing everything they say and then making a vague comment about “whether or not that bet will pay off.” Too often, journalism conflates objectivity with passivity, seeing critiques as “negative” or “biased” when, in fact, repeating everything that corporations say to their benefits is about as biased as it gets.
In the end, the victims are anybody who doesn’t exit the AI trade in time.
Sidenote: It seems increasingly likely that “anybody” will be retail investors, with Citadel Securities noting earlier this week that “retail remains the strongest structural buyer of US equities,” and that it hasn’t seen a single day in the month of July where retail investors were net sellers of stocks, rather than buyers.
Things are similarly bleak in South Korea — where retail investors aren’t just some of the biggest buyers of equities, but they’re doing so on margin.
By the way, there’s no Hell hot enough, by the way, for the people that will read this and smugly say “heh, well, I made money,” or who point to anyone’s returns as evidence that the AI trade is anything other than manufactured consent. The fact that anyone made money on this trade is a sign that the stock market is inherently manipulated to benefit the wealthy at the cost of the many — and when the bubble bursts, the people that will suffer will have suffered because of the media’s participation by helping Sam Altman and the rest of the AI industry obfuscate and twist reality to pump stocks.
Which leads us neatly to our next victim!
In my Hater’s Guide To SoftBank, I told the story of CEO Masayoshi Son, a degenerate gambler who has steered his company through boom and bust cycles only through the grace of whatever God he believes in and sheer luck.
SoftBank Group — the holding company, and not to be confused with Softbank Corp, which runs a bunch of telcos and media companies in Japan — makes money only through either investing in or buying companies, then taking them public or selling them to someone else, and otherwise needs debt for liquidity.
Masayoshi Son makes terrible bet after terrible bet, but his luck always seems to work out for him. His $20 million stake in Alibaba turned into $50 billion at IPO. He bought a 70% stake in Sprint that turned into a 24% holding in T-Mobile. In the early 2000s, Softbank took a 23% stake in Betfair that eventually became part of the $17.7 billion Flutter Entertainment. And then there’s its most-recent and arguably most-impressive (after Alibaba at least) investment, ARM, which it acquired for $32 billion in 2016 and then took it public in 2023 at a valuation of $54.5 billion, and currently sits at around a $300 billion market cap.
Sidenote: SoftBank Group is “valued” based on the “net asset value” of its holdings (which you can see here), and whenever you’ve seen it have “losses,” that’s because the underlying value of its assets (many of which are privately-held companies as part of its disastrous Vision Funds 1 and 2) is what gives it is “returns.”
This is why SoftBank was able to book a yearly gain of $46 billion for its Vision Fund 2 thanks to its investments in OpenAI, despite losses from DiDi Global, Coupang, and Klarna.
Yet his problem has always been his dalliances with whimsical white boys. SoftBank sunk $1.5 billion into dodgy financial services firm Greensill Capital before its collapse, and in the aftermath, it was revealed that Masayoshi Son and CEO Lex Greensill talked on the phone every day, to the point that (per Greensill himself) SoftBank managers felt “threatened” by Greensill’s relationship with Son. It only took Masayoshi Son 28 minutes of conversation with WeWork’s Adam Neumann before he drew up the terms for a $4.4 billion investment on his iPad and signing the deal in the back of a cab, with Son saying that “the last person he felt this with was [Alibaba CEO] Jack Ma.”
And no white boy has ever been more whimsical than Sam Altman.
In 2019, Altman turned down $10 billion from Masayoshi Son (which, ironically, would’ve been an incredible investment at the time), going instead with $1 billion (and full infrastructure support) from Microsoft, and I believe this moment drove Son into a level of madness that will potentially wreck the company.
You see, up until fairly recently, SoftBank had been dragged down by the declining value of its atrocious investments via its two venture capital funds — Vision Fund 1 and 2, the latter of which was self-funded and has mostly gone toward funding OpenAI. Up until recently, SoftBank had quarter after quarter of losses as investment after investment saw its NAV drop because, well, they were overvalued and SoftBank never should’ve invested in them in the first place.
To survive, SoftBank moved into “defense mode” in 2020, slowing investments and selling the vast majority of its Alibaba stock by April 2023, with the ARM IPO and billions of dollars of bond sales helping slow the bleed.
Yet Masayoshi Son knew he was destined for greater things, as he told CNBC in June 2024:
“SoftBank was founded for what purpose? For what purpose was Masa Son born? It may sound strange, but I think I was born to realize ASI. I am super serious about it,” Son said.
OpenAI — and the larger AI trade — had given Masayoshi Son a certain kind of greed-driven mania, where he believed that AI would make SoftBank (as he said recently) “the goose that laid golden eggs,” an eternal money-printer that ostensibly started with the biggest cash-burning machine in history.
Altman, like Neumann, like Greensill, told Masayoshi Son exactly what he wanted to hear: that this would be the biggest thing ever, and that Son would capture all of the value both through his investment in OpenAI and further investments in data centers and other AI infrastructure.
And so began his most vulgar investment yet — OpenAI, sinking $2 billion into the company from Vision Fund 2 in November 2024 — only for Altman to turn around and demand he fund $30 billion of a $40 billion round that would get announced four months later in March 2025.
Masayoshi Son was an emphatic “yes,” except for one little problem: he didn’t have the money, and could only afford the first $7.5 billion (due in April 2025) by taking out a $15 billion, year-long bridge loan, with the rest of it going toward his eventual purchase of Ampere computing.
To fund the remaining $22.5 billion, SoftBank was forced to take out further margin loans on its ARM stock, and sell large chunks of its T-Mobile stock, as well as its entire $5.83 billion stake in NVIDIA.
Yet as soon as the check cleared, Sam Altman was blowing up his phone demanding more money as part of a $110 billion funding round in February 2026 (that eventually became $122 billion in late March).
Masayoshi Son was once again an emphatic yes, except by this point he’d exhausted basically every useful thing left in his coffers outside of around $118 billion in ARM shares that make up around 40% of SoftBank’s net asset value, meaning that selling or using further ARM shares as collateral would directly tank its value — both through the obvious “they have less of a valuable thing” and sales/collateralization of further ARM shares affecting its share price.
So, what did Masayoshi Son do? More debt, baby! More risky debt! You can always refinance it, right?
To pay for its share of OpenAI’s 2026 funding round, SoftBank took out a $40 billion bridge loan (maturing in March 2027), bringing its investment in the company to over $40 billion, with its payments to $10 billion tranches of OpenAI funding due in April, July and October 2026.
A few months later, it tried to raise a $10 billion margin loan using its entire OpenAI investment as collateral, cut the amount it was raising to $6 billion, and when banks remained hesitant to give it the money anyway offered to “guarantee repayment of the loan to address lender concerns,” effectively backing the loan with its own balance sheet (called a recourse loan) because, despite being worth over $100 billion on paper, its lenders had doubts that its OpenAI stake was actually worth that much.
If you’re wondering why it didn’t simply take out more debt, it’s because (as a result of its continuing investments in OpenAI) S&P Global revised SoftBank’s outlook to negative, emphasis theirs:
The liquidity of SoftBank Group's investment portfolio will worsen because OpenAI now accounts for a bigger share of it. OpenAI Group PBC is a privately held U.S.-based AI research and development startup company. SoftBank Group's additional investment amount will be $30 billion (about ¥4.5 trillion).
The creditworthiness of the company's investment assets will also likely deteriorate. We see OpenAI as one of its investments with the weakest credit quality. The company's investments in AI, including OpenAI, mostly involve fledgling startups and private companies that we believe are exposed to significant AI innovation risk and fierce competition.
This has had a knock-on effect on the rating of the telecoms-focused Softbank Corp (as a reminder, Softbank Group is the holding company that owns stock in other companies, Softbank Corp is the energy/telecoms company that actually makes stuff), which is now rated BBB, or the lowest-possible rung of investment-grade financing in the S&P system.
To make matters worse, if SoftBank continues to hold a loan-to-value ratio of above 30% for much longer, it runs the risk of its debt getting downgraded even further, which would slam the door shut on its ability to raise money via bonds, which is…well, basically how SoftBank has functioned for the last 10 or 20 years.
And this is all happening as Japan is determinedly inching away from the era of persistently low interest rates — making debt far more expensive to service.
SoftBank needs OpenAI to IPO so that it can turn that on-paper gain into actual liquid stocks that can be dumped into the market or used for real-life margin loans. SoftBank has jettisoned the vast majority of its heaviest-weight investments, leaving it largely dependent on the continued value of ARM’s stock to keep its seat at the table, and if OpenAI can’t go public, it’ll end up sitting on illiquid stock in a company that will see its value tank as a result.
Yet even if OpenAI does go public, any attempts to get a margin loan will likely be dangerous, as I bet that it will be one of the single-most shorted and volatile stocks in history, which will also be a problem for SoftBank’s underlying net-asset value, which will ebb and flow based on whatever bullshit Altman cooks up every three months.
Masayoshi Son is both a victim of the manufactured consent of the AI trade and an enabler of its worst excesses, empowering and enriching Sam Altman at a time when any kind of financial prudence might have curbed OpenAI’s greed or killed it before it caused further damage.
SoftBank tanking will fuck over anyone invested in the Japanese stock market, where it currently sits as the third-largest company by market cap behind KIOXIA (a memory company booming thanks to the AI trade) and Mitsubishi UFJ Financial (a bank with heavy ties to the AI industry and data center infrastructure). While I severely doubt it’ll die — it’s likely MUFJ and SMBC Bank would extend whatever credit necessary to keep the doors open — OpenAI and the greater AI trade has become a load-bearing toothpick holding up the trillion-ton ass of the world’s most well-funded gambler.
For SoftBank to survive in its current form, OpenAI must go public, become a thriving and profitable business, and have its stock price stay elevated for the foreseeable future. Additionally, ARM must also retain or exceed its current stock price.
Hey, while we’re on the subject of “companies betting the entire future on OpenAI that recently got downgraded by S&P Global…”
Hey! You in the back! Stop laughing! Stop laughing at Larry Ellison! He’s now only the world’s 8th-most-richest guy!
Just kidding, fuck Larry Ellison. What I’m about to tell you might make you laugh, probably because it’s really funny.
Oracle is currently spending over $340 billion to build out over 7.1GW of data center capacity for OpenAI, as part of its $300 billion, five-year-long cloud compute contract that began, at least in theory, on June 1, 2026 at the beginning of its Fiscal Year 2027, though much of the capacity is yet to be built. To fund the buildout, Oracle has had to raise over $50 billion via stock sales and debt, spent $55.7 billion in its last fiscal year, and expects to spend at least $90 billion more in FY2027.
As a result of that, S&P Global downgraded Oracle’s credit rating to BBB/A-2, the literal lowest level before it’ll become junk-grade, meaning that one more downgrade (though it would have to be from two ratings agencies) from here would risk Oracle becoming a “fallen angel,” with investment funds (that can’t hold junk grade debt) having to jettison its debt from indexes, as happened to Ford in March 2020, leading to over $35 billion in debt being dumped and its borrowing costs skyrocketing to between 8.5% and 9.625% when it raised in April 2020. For some context, Ford reported an average interest rate of 5.2% on its long term debt in its 2019 annual report.
You’ll never guess why S&P Global downgraded Oracle! And, once again, the emphasis is theirs:
OpenAI remains a key credit risk. We estimate that OpenAI makes up roughly half of the $638 billion in RPO. OpenAI’s ability to meet its contractual obligations and raise external financing will be contingent upon AI tailwinds continuing and its models being market leaders. If OpenAI were unable to pay Oracle, we believe Oracle could be left with massive data center leases that it might be unable to exit or have to re-lease to new tenants under less-favorable terms. As a proxy for OpenAI’s future prospects, we’re tracking OpenAI’s financial commitments to data center operators and chip makers to gauge its overall financial exposure and its market share among enterprise and consumers.
That’s a load-bearing if, brother!
Anyway, you know who else is trying to warn you about Oracle’s exposure to OpenAI?
Oracle! Per Bloomberg:
Oracle has a new warning for investors: All of the spending on data centers might not pay off.
The disclosures were part of the company’s annual financial report, where Oracle detailed plans to spend big on AI infrastructure for customers like OpenAI. And it noted all of the ways that expensive bet could blow up. Construction of data centers may end up costing more or taking longer than expected, Oracle warned. This could happen due to supply chain hiccups, government restrictions on data center development, or the failure of third parties to complete projects on schedule.
And once the sites are done, major customers might not pay their bills, or opt not to renew their contracts, Oracle said. In this case, the company could be stuck with some very expensive assets, which it “may be unable to re-lease, repurpose or assign such capacity on acceptable terms, if at all.”
As a reminder, the only way that OpenAI will be able to afford to pay its $300 billion cloud compute contract with Oracle will be if it continues to hit revenue projections (per The Information) that have it making $113 billion in 2028, $184 billion in 2029, and $284 billion in 2030, a year when it will magically become profitable, and no, I don’t know how that happens:
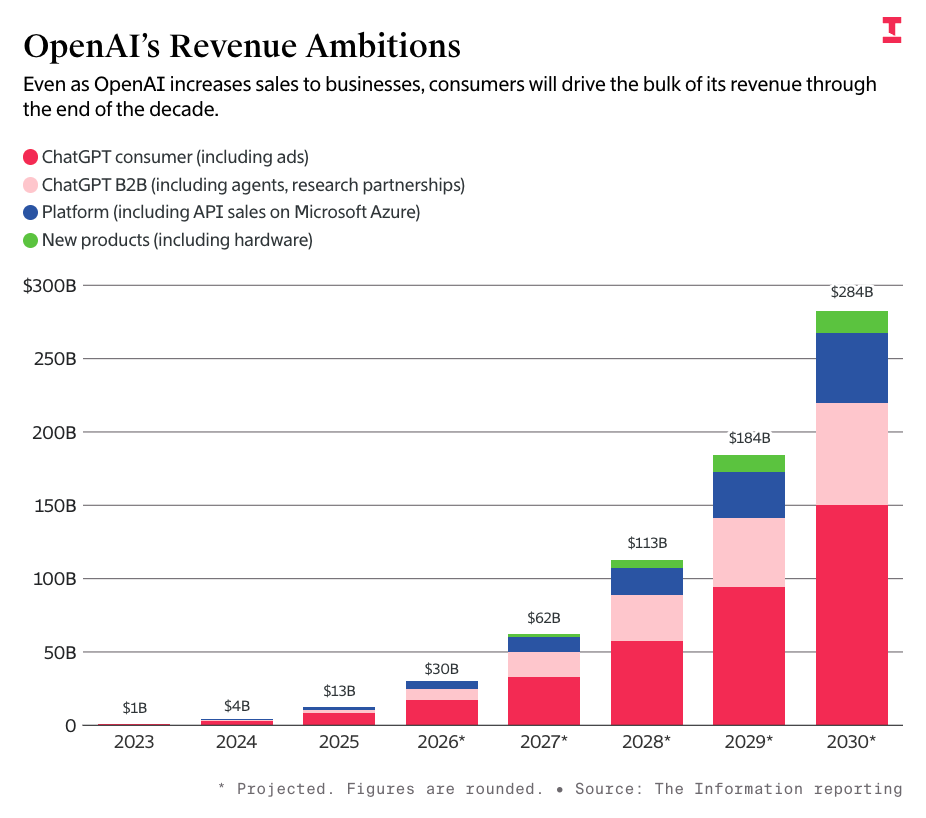
Based on my own analysis, assuming that Oracle can successfully build capacity for OpenAI to pay for (a load-bearing assumption), it would have to pay around $75 billion to rent that 7.1GW of capacity. Stargate Abilene, an 8-building, 1.2GW project that broke ground in July 2024, has (per sources familiar with the matter) only built and operationalized three buildings, despite the project having meant to be fully operational by the end of 2025 (per landowner Lancium), or energized by the middle of 2026, it isn’t really clear, and I can’t get a straight answer from anyone about whether the power even exists on site to turn any of it on.
Anyway, for Oracle to make all the rest of that money, it will have to build five more Stargate Abilenes. If you’re wondering how that’s going, Stargate Shackelford only broke ground in December 2025, Stargate Wisconsin appeared to have a single steam beam in March, Stargate Michigan only got its first steel beams two months ago, and Stargate New Mexico is still waiting for permitting to begin construction.
Based on Lancium’s presentation and discussions with sources familiar, Oracle will pull in somewhere in the region of $10 billion in annual revenue from the (assuming it’s ever done), completely-finished 824MW of critical IT infrastructure at Stargate Abilene. It is unclear how Oracle hopes to be paid even a fraction of its $300 billion compute deal, because in its current state, its annual revenue from Stargate projects currently sits in the region of a maximum $5 billion a year, or less than a tenth of its FY2026 capex.
For the most part, Oracle has funded the various Stargate data centers with project financing, meaning that a nebulous SPV will be responsible in the event it defaults on any of these contracts…until Stargate Michigan, which only closed when Oracle agreed to guarantee the $14 billion in bonds raised.
All of this revenue — both theoretical and otherwise — sits in Oracle’s “Cloud” segment, the only part of the business that’s actually growing, as the rest of its business has either been declining or plateauing for about a decade.
In any case, for Oracle to actually get paid its $300 billion, it will have to build upwards of 6GW of data center capacity…in a year and a half? This deal is meant to be worth in the higher range of tens of billions of dollars in annual revenue by FY2028, which begins on June 1 2027! Stargate is horribly, impossibly delayed, to a level that makes me wonder if anybody other than perhaps Anissa Gardizy has bothered to think about Stargate for even a fucking second.
Anyway, Oracle’s entire future rides on this deal. While Oracle Cloud Infrastructure continues to grow, its future growth (and remaining performance obligations) almost entirely hinge on both its ability to build the largest infrastructure project of all time and for OpenAI to continue raising funding for an indefinite amount of time. The rest of that growth comes from Meta and xAI, both of whom are only really “doing AI” because everybody else is.
This puts Oracle in a very, very compromising position on multiple different levels.
Generative AI is the only reason that Wall Street started liking Oracle again as its other business plateaued, even as it burned billions of dollars on capital expenditures and cut its gross margins by a little under 15% since 2022, with the vast majority of that value coming from its revenue from OpenAI and what’s actually active at Stargate Abilene.
Much like the rest of the AI trade, everything about Oracle’s future is sold on potential rather than anybody thinking about reality or things like “whether Oracle can actually build the data centers” or “how Oracle makes any of that revenue if the data centers aren’t built” or “how OpenAI affords to pay for the compute if the data centers get built.”
As Oracle said in its own disclosures, if OpenAI can’t pay, “Oracle could be left with massive data center leases that it might be unable to exit or have to re-lease to new tenants under less-favorable terms,” and there isn’t a single company on Earth who can or would pay for such a large amount of compute, nor is there the aggregate demand to justify it.
Sidenote: No, Anthropic can’t afford it either, and Sundar Pichai would unhinge his jaw and swallow Oracle whole rather than see it move off of its TPU infrastructure.
While its many government contracts and national security significance make it unlikely that Oracle would be allowed to die, the collapse of its only growth segment will likely spell dark times for a company that’s already laid off 21,000 people as a means of funding its AI buildout.
The double-edged sword of the AI trade’s childlike attachment to stock valuations poses an egregious threat to Larry Ellison himself.
Hey — HEY! I said no laughing! Stop it!
This is all very serious! This is a serious situation! You’re laughing about the potential downfall of a guy who once wrote a letter to the New York Times attacking HP for firing former CEO Mark Hurd for repeatedly making sexual advances toward a reality star using HP’s finances!
Sorry, my mistake, you should keep laughing, even the prospect of what I’m about to tell you is hilarious.
As I said in my piece about how OpenAI Kills Oracle:
[The collapse of Stargate and OpenAI would be] a very bad thing for Larry Ellison, who holds around 40% of Oracle’s shares and receives a dividend of around $2.3 billion a year as a result, especially as he’s backed the $111 billion Paramount-Warner Brothers Discovery merger deal with $45.7 billion of that as an equity commitment from the Ellison Trust (the Ellison family investment arm which holds his Oracle shares) with Larry himself guaranteeing the amount, with $24 billion of those funds likely coming from the Middle East.
This leaves the Ellison family with around $12 billion left to fund the deal. Depending on how liquid the trust is, it could foreseeably fund that in cash, but if Ellison is a little light, he might have to take out further margin loans on his Oracle stock.
Yes, I used the word “further.” Ellison has already pledged 346 million shares of his Oracle stock — or around $61.5 billion — “to secure certain personal indebtedness, including various lines of credit,” meaning “many big, beautiful loans against his Oracle shares.” which IFR estimated back in September (when Oracle’s stock price was much higher) could allow him to secure as much as $21.4 billion in debt at a (they say “conservative”) loan-to-value ratio of 20%, and that’s assuming the banks weren’t particularly generous.
One of the consistent themes of this piece is that much of the “value” of AI is hot air — by which I mean whatever people are willing to pay for a stock that’s continually inflated by specious media-driven hype.
Ellison’s wealth is driven by both his share of Oracle’s ongoing yearly dividend, his Oracle shares, and his ability to offer said shares as margin loans, which makes him vulnerable to even a symbolic collapse of OpenAI, which is why it had to tweet in February that “the NVIDIA-OpenAI deal has zero impact on its financial relationship with OpenAI” to calm those dumping the stock.
To be clear, Ellison has around 1.16 billion Oracle shares, leaving him with around 810 million or so left, allowing him to pledge them as further collateral rather than having to either dump them on the market or dip into his reserves of about $10 billion in cash and $15 billion in Tesla stock, with Ellison historically never selling more than about $4.7 billion in stock.
We don’t know the exact scale of terms of his personal loans, but do know that he’s got a shit-ton of them, and that his entire fortune rests on the idea that he never has to sell Oracle stock. That becomes a problem if things drag on with the Warner Bros deal, as he’s also guaranteed $40 billion from the Ellison Trust, effectively barring him from selling or using those shares until the deal clears (and the money from the Middle East arrives to fund the deal).
The amount of shares that Ellison has committed has oscillated on a year-by-year basis, sitting at 305 million in both 2018 and 2019, rising to 317 million in both 2020 and 2021, dropping to its lowest level in 2024 (217 million) before bumping back up to 346 million in 2025. While the board theoretically keeps an eye on his loans and what he’s pledging, he holds 40% of Oracle’s stock and the undying loyalty of veterans like former CEO Safra Catz and co-CEOs Clay Magouyrk and Mike Sicilia.
To get specific about how the Paramount/Warner Bros deal breaks down, $24 billion will be covered by funds from the Middle East (primarily sovereign wealth funds), with Ellison providing $22 billion and bank debt funding the rest.
If the deal doesn’t close by September 30, the Ellisons have to pay around $650 million a quarter in fees.
If it does, Ellison will likely either have to liquidate his Tesla stock, hand over cash, or take out further margin loans on his Oracle stock to fund it. Those would likely increase the amount of shares he’d have to commit somewhere between 150 million and 300 million (at a loan-to-value of 25% to 50%) at whatever price Oracle is currently trading at.
Though it’s hard to tell exactly, the number to look for with Oracle is “below $70.”
Once that happens, Ellison will likely have to proffer more Oracle stock to keep up with his margin calls, which will severely limit his ability to take out further margin loans using his Oracle stock. He will have to renegotiate loans, and if he’s managed to buy Paramount, he’ll be sitting on the stock of a company with $80 billion in debt and constantly loses money, which will be far less-appetizing to potential lenders who are aware that the rest of Ellison’s money is tied up in the plummeting hopes of Oracle.
Things could get much darker if Oracle plunges below $50, as at that point the encumbrances of his various enterprises and his own margin loans could become too much to avoid having to liquidate Oracle stock. If that happens, it creates a vicious cycle that will potentially involve selling off Paramount, dumping further Oracle shares, or even trying to engineer a firesale for the company.
Sidenote: While it’s true that Oracle’s software is economically important — its database systems and ERP platforms power a bunch of big businesses and government organizations — I don’t believe that any external intervention (whether that be an external investor chucking it some cash, or some form of bailout) would be able to stop the pain that’s coming to it.
Simply put, the bets it made are too big — and, economically important Oracle’s software might be, there’s no reason that said software couldn’t continue development under the stead of another company.
All of this was entirely avoidable if he had never met Sam Altman, and never gave in to the temptation of the AI trade.
When the OpenAI Bubble — and OpenAI itself — bursts, many will attempt to eulogize the situation in terms of how we could’ve possibly known this would happen, and I want to be clear that I’m going to be reading and commenting on as many of them as I can find.
I believe that once OpenAI collapses it’ll have a violent, punishing effect on the entire stock market, a precursor to a much greater drawdown as everybody accepts that the AI bubble has burst.
This view is shared by the Bank of England governor Andrew Bailey, who warned that the bursting of the AI bubble would have an effect on the UK economy, even though the UK economy — and the UK financial system — isn’t nearly as exposed to it as that of the United States, and would have significant enough effects to change British monetary policy, specifically, interest rates.
And I continue to stand by my belief that this company will die, though I can’t say when it’ll happen. The promises that Sam Altman has made at the scale that he’s made them are equal parts ridiculous and dangerous, leaving any counterparty somewhere between burned or destitute as a result.
There is no compelling story for any AI company once OpenAI dies. Other AI labs will suddenly have to explain how they avoid the same economical pitfalls while still showing the same aggressive growth projections promised by Sam Altman, and half-measures will no longer be acceptable. Their ability to secure credit — or even venture funding — will be met with impossible-to-answer questions about sustainability and profitability.
Any startup connected to its models will suffer because it’ll be clear that any AI lab is a financial black hole, and it’ll become obvious that basically every AI startup is an unprofitable LLM wrapper. That should be obvious now, but nobody bothers to look.
Any AI infrastructure company will have to pivot aggressively to open source models if they haven’t already, and realize that much of the demand for AI services came from brainless curiosity driven by the AI trade and market hype. CoreWeave, IREN, and the many circular-financed neoclouds will, much like AI labs, find themselves unable to secure funding, as the first question will be “how do you know your customers won’t die?”
NVIDIA just won’t be able to justify selling as many GPUs, as it has repeatedly cited OpenAI (albeit without saying its name) as a proxy driver of sales via counterparties including Microsoft and Amazon.
It’ll be a permanent blemish on a startup ecosystem that helped so many people become rich based on fictional or fanciful promises and projections, enabled and funded by venture capitalists that didn’t force founders to make stable or sustainable companies because it “always worked out before.”
And I genuinely think this will create an accountability crisis in the media.
I speak with readers and listeners every single day that are horrified about how many half-truths and outright lies are published and used as a means of propping up the AI bubble and the larger tech industry. The term “AI” has grown from a kind of technology to a cudgel wielded by the powerful to threaten and terrorize workers, all based on the outcomes from Large Language Models that simply do not do what their progenitors have promised and do not produce ROI or productivity benefits that are in any way measurable.
The OpenAI Bubble inflated not because Sam Altman is a super-genius, but because he’s very, very good at telling people what they want to hear. He’ll give members of the media convincing-enough projections, said with the confidence (or necessary fear) necessary to sway the vast amounts of reporters who are excited to follow the next big hype cycle (or, put another way, are scared to miss out on it).
Altman knows the exact signifiers to use and the minimum viable product necessary to “prove” OpenAI’s worth — however many hundreds of millions of weekly active users, annualized run rates, gigawatts of data centers, vague promises of “abundance” and “intelligence too cheap to meter” that never actually resemble a tangible thing — that work to con reporters and investors who don’t want to think about anything but growth.
He’s also really, really good at playing on people’s greed, be it promising Satya Nadella he can build the next generation of cloud compute cash, Larry Ellison that he can make OCI bigger than Azure, and Masayoshi Son that he can birth a goose that lays golden, AI-labeled eggs.
Altman realized early on that the only way to sell AI was to talk about it in the future tense in a mixture of threats and promises, always subtly suggesting that those who follow the OpenAI gospel will be saved from the permanent underclass.
And that same con worked on the minds of Silicon Valley founders who feel sore that they’ve yet to become an early employee of the next Apple, Google, Amazon or Microsoft, selling the dream of endless wealth under the auspices of “accelerationism” that really means “growth at all costs, usually billed to somebody else.” He and his acolytes have created a palpable mania in the Valley, convincing people that not using his software is a guarantee that they’ll be poverty-stricken imbeciles, and I think he’s fully aware of the fact that Silicon Valley is a dense monoculture that LARPs as a free thinker’s paradise.
In the end, Altman is unlikely to suffer, at least anywhere near as much as those he’s misled or helped mislead. The scale of losses that the stock market may face scare me to the point I’m almost hoping I’m wrong, with the markets heavily dependent on eternal growth of the AI trade, as without NVIDIA selling more GPUs every quarter, it’s unlikely that anybody is going to be excited to invest in tech past the year 2028.
All of this could’ve been stopped if those responsible for scrutinizing the powerful actually did their jobs, and spent more time doing that than critiquing the critics and repeating the promises of craven liars and billionaire scumbags. There were signs from the earliest days that this was all unsustainable, and the only reason it got this big was because the media and the markets fell behind a specious AI trade, empowering and enabling venture capitalists and hyperscalers to sink hundreds of billions of dollars into a doomed industry.
Whatever the AI industry achieves by the end of this farce will pale in comparison to the massive harms it has caused and will cause as a result, and for us to avoid this happening again, we need a fundamental reimagining of how the powerful are covered, how much effort is made to pry apart their plans, and accountability for those who either failed to stop them or actively assisted them.
If I sound salty, it’s because I am worried about the regular people caught up in this madness — the tens of thousands of people that have suffered AI-washed layoffs, the hundreds of millions of people that invest in a global stock market dependent on the AI trade (for a taster, see what’s happened in Korea when the KOSPI dropped earlier in the week, forcing hundreds of thousands of retail investors to face margin calls), those whose retirements and pensions and insurance annuities are tied up in private credit funds invested in AI data centers, and anyone of any kind who built their life around any promise made by Sam Altman and those that followed him.
I challenge those who are glibly dismissive of everything I say — who look for any smidgen of proof to dismiss hard numbers or clear economic issues — to truly think about the consequences of what I’ve written, and take the risk of the OpenAI Bubble seriously. Tech companies are not your friends, venture capitalists are not your saviors, Sam Altman doesn’t care if you live or die, and the AI industry — and Silicon Valley — will dump you the second that you stop being useful as an acolyte or booster.
I love technology, and credit it with making me a success and the person I’ve become, as well as connecting me to many people I love dearly. I believe that tech should be something that empowers, protects and enriches the human experience, something that’s sustainable and reliable and replicable and stable and makes human beings the same as a result.
The tech industry as it stands shows nothing but contempt for the user. Every tech product is somewhere between broken and buggy. The people that write about tech write for the companies far more than they write for those that pay them. Venture capitalists fund companies that they think they can sell to other companies or take public, which in turn means they fund things that are only attractive to people on Twitter or other venture capitalists. Big tech is unregulated, unrestrained, and works entirely to either enrich or fuck over shareholders depending on the day, and because the finance media has little interest in pushing back, they’ll continue to do so to the detriment of the markets and the retail investor.
Everything comes back to a distinct selfishness and lack of responsibility across basically every part of the tech industry. The fact that AI has grown this large is a symptom that Silicon Valley needs to be restrained — that it can and will release dangerous, unreliable, unpredictable and unstable products at scale with little regard for the consequences, in part because it knows the media will celebrate it doing so if it can show user or revenue growth.
OpenAI is the company the tech industry deserves — a directionless company of questionable worth that grew in a vacuum of responsibility that exploits greed and ignorance at scale.
And the tech industry will deserve exactly what it gets for coddling Sam Altman, and letting his empire grow this large.
If you liked this piece, you should subscribe to my premium newsletter. It’s $70 a year, or $7 a month, and in return you get a weekly newsletter that’s usually anywhere from 10,000 to 18,000 words, including vast, detailed analyses of the biggest events and companies in the AI bubble.
As a reminder, if you sign up between now and XX July, you’ll get $10 off a subscription.
2026-07-11 01:51:30
Hi premium readers! I’ll be taking a week off of the premium next week — July 17 — to have some well-earned rest. This will mark only the second time I’ve missed a premium piece since I started this newsletter in June 2025, and I hope you’ll forgive me for the (short) break.
Don’t worry. Today’s piece is also an absolute banger.
Everything’s more expensive, and it’s all AI’s fault.
It really is that simple.
An AI data center is full of servers, which are in turn full of (for the most part) NVIDIA GPUs. Each NVIDIA GB300 has two B300 GPUs, the two of which have 576GB of High Bandwidth Memory (HBM, or HBM3e to be specific), and a CPU, which has 480GB of lower-power LPDDR5X RAM (the kind usually used in cellphones and other mobile devices). These systems tend to be sold in an NVL72 rack with 18 compute trays, bringing us to 36 GB300s, for a total of 20.7 terabytes of HBM and 17 terabytes of LPDDR5X RAM, and that’s before you get to the RAM associated with the high-speed networking gear and other associated components.
Analyst estimates have the cost of the high bandwidth memory of a single NVL72 GB300 at around $15.27 per gigabyte, for a total of around $316,000 of HBM, and while I can’t seem to find a stable source for pricing around LPDDR5X, I think a fair estimate is around $4 per gigabyte based on this piece, so around $68,000 worth per NVL72 rack.
At around 150kW of power draw per NVL72, a 1GW data center (with 740MW of critical IT load) would have around 4,933 NVL7s racks — for a total of $1.894 billion in HBM and LPDDR5X costs, or around $2.559 million of HBM and LPDDR5X RAM per megawatt of IT load.
Oh, and each of these NVL72s can hold as much as a petabyte of expensive solid state storage, costing an additional tens of thousands of dollars.
Because HBM takes up more space on a wafer — the slice of semiconductor material that is etched using photolithography (read: molten tin) and then cut into separate dies (individual chips) — and generally has much higher margins (thanks to the triopoly of Samsung, SK Hynix and Micron), memory manufacturers are dedicating more space on their manufacturing lines to it than to regular consumer RAM, which allows (thanks to said triopoly) said manufacturers to charge effectively whatever they want for consumer RAM.
And thanks to AI — to quote Tom’s Hardware and Counterpoint Research — NVIDIA is buying that LPDDR5X RAM at the scale of an Apple or a Samsung:
"The bigger risk on the horizon is with advanced memory as Nvidia's recent pivot to LPDDR means it is a customer on the scale of a major smartphone maker — a seismic shift for the supply chain which can’t easily absorb this scale of demand," said MS Hwang, research director at Counterpoint Research.
The net result is pretty simple: every single consumer electronic of any kind is getting more expensive. Valve’s Steam Machine console debuted at a 30% higher price point than planned, Apple hiked the prices of its MacBooks and iPads and will likely have to do the same for its next iPhone. Nintendo, Microsoft and Sony increased the cost of their consoles, and the PS5 and Xbox Series now cost more today than they did when they first retailed, almost six years ago.
On the Android front, Samsung has bumped the price of its Galaxy smartphones, and manufacturers in this space (which tends to have smaller margins than those enjoyed by Apple) are likely to limit the number of new devices shipping with 16GB of RAM, as well as re-introduce models with 4GB of RAM .
Meanwhile, memory manufacturers are having record quarters, with Micron’s revenue quadrupling year-over-year in Q3 2026 and its gross margin improving by ten percent (from 74.9% to 84.9%) quarter-over-quarter, and Samsung’s profits growing from $38 billion to $59 billion quarter-over-quarter thanks to the spiralling cost of revenue caused by…well…the companies setting the price of memory at whatever they’d like.
This is a problem caused by the fact that these three companies — SK Hynix, Micron and Samsung — produce more than 90% of the world’s RAM, which is why there’s a price fixing lawsuit against them, per Polygon:
The class action lawsuit filed by 14 individuals and three businesses accuses Samsung, SK Hynix, and Micron of conspiring to fix prices and supply of DDR3 and DDR4 RAM, resulting in higher costs. “This lawsuit seeks to recover for—and stop—concerted anticompetitive behavior by three oligopolists in the market for dynamic random access memory, more commonly called DRAM,” the opening line of the suit reads.
The suit says that the firms have “fixed supply and prices for DRAM, engaging in conduct that makes no economic sense absent collusion and that has driven up the price of conventional DRAM (sometimes called commodity DRAM) approximately 700% in a four-year period.”
To be clear, HBM is more expensive to make than regular RAM, and takes up significantly more space (about 4x more) on the wafer, but because of the incredible demand for AI servers, Samsung, SK Hynix, and Micron can charge effectively whatever they want for it, much like they are for the regular RAM that’s in short supply. The same is becoming increasingly true for the solid state storage that these companies (and others like Sandisk) sell too.
Now, you may think it’s a little rich to suggest that memory manufacturers are colluding to rig their prices, perhaps a little judgmental, and you’d be wrong because they’ve done it before. Quoting Polygon again:
The lawsuit points out that between 1998 and 2002, these same three companies, Samsung, Hynix (the predecessor of SK Hynix), and Micron, took part in a criminal conspiracy to fix the prices of DRAM sold to major American computer companies. After the Department of Justice prosecuted the case, Samsung pleaded guilty and paid a $300 million fine, Hynix pleaded guilty and paid $185 million, and Micron avoided a fine by reporting the conspiracy and cooperating. As a result, several Samsung executives went to prison. The trio of companies was also investigated by the Chinese government during a RAM price spike between 2016 and 2018.
To be clear, I am not saying — nor can I prove — that there is any kind of price-fixing or collusion going on. Nevertheless, there are three companies that effectively make all the world’s RAM, all raising prices at the same time, all seeing record profits, all riding high at a time when everybody else is suffering as a direct result.
The Wall Street Journal put it best:
We are witnessing an enormous transfer of cash from the providers of AI—and, perhaps one day, AI users—to the memory-chip makers. Profit shifts of this scale are rare events, and investors should be paying attention to where the money’s coming from, where it’s being spent and how long it will keep flowing.
In the quarter ending May 28, Micron increased prices for DRAM chips more than 60% on the previous three months, while increasing shipments by a low single-digit percentage, it said this week. Prices for NAND flash memory, also used in data centers, jumped more than 80%.
What makes this particular memory crisis so distinctly dangerous is that it isn’t a result of consumer demand so much as it is capital expenditures from very large companies making bets that don’t connect with reality.
Microsoft, Google, Amazon, and Meta aren’t spending $765 billion in capex in 2026 because of rapid demand by consumers for AI services, but a desperation caused by a lack of hypergrowth ideas, circular financing with Anthropic and OpenAI, and a vague concern that if they stop spending that the other guy will do something as a result.
As I discussed earlier in the week, nobody can make a compelling case for building more data centers other than “we must do so, because of AI.” Nobody is having trouble accessing ChatGPT, Claude or another major AI service because of a lack of compute, outside of Anthropic and OpenAI’s continual rapacious hunger for more compute that doesn’t ever seem to involve them turning away business. While price increases generally help moderate demand for goods or services, none of that matters when you have four companies willing to spend a trillion dollars a year on the off chance that they might get something out of it.
As a result, Micron, Samsung, and SK Hynix can charge effectively as much as they want, and NVIDIA and others building black holes for AI capex can then pass those costs onto Microsoft, Google, Amazon, and Meta, who have given themselves a blank check to build whatever it is that they think will come out of the large language model era.
Put another way, the capex spend of four of the largest companies of the world — all of whom are now funding their capex using debt — has now led to the single-largest increase in the price of consumer electronics in history, for the most part thanks to one company, NVIDIA, becoming the largest purchaser of HBM in the world because those four companies are buying so many GPUs.
To give you an idea of how bad that is, NVIDIA takes up roughly 65% of all high bandwidth memory, with the other 35% (mostly) going to specialist ASICs from Google and Amazon, and AMD’s Instinct line of AI GPUs.
This is a unique — and uniquely dangerous — bubble, because demand isn’t based on actual revenues or events happening outside of those in the imaginations of Sundar Pichai, Mark Zuckerberg, Andy Jassy and Satya Nadella. They didn’t start buying these GPUs because consumers demanded them. In fact, they did so without really checking whether consumers gave a shit, which is why I’m so worried about what comes next.
Only 23% of total DRAM wafers are taken up by HBM, but it’s accounting for a remarkable chunk of revenues, at least for SK Hynix, where it took up 40% of all DRAM sales back in Q3 2025, the most-recent number I can get.
While I can’t find definitive numbers from Samsung or Micron, the situation is bad no matter which way you spin it. Either they’re increasingly-relying on HBM as a revenue driver to the point it’s crowding out the revenue from their other DRAM businesses (making them dependent on GPU and ASIC revenue), or their revenues are spiking because they’re able to crank up the cost of DRAM.
This is setting everybody up for a dramatic and painful collapse, largely based on the strange nature of how memory is built and sold, unless cooler heads prevail and capex doesn’t accelerate based on hopium.
What happens when hyperscalers reduce their capex, or when banks stop issuing data center debt? NVIDIA stops needing all that HBM, which means any and all capex dedicated to expanding manufacturing infrastructure to produce more HBM — which is not particularly valuable outside of AI GPUs — will have been built to capture demand that doesn’t exist. While that capacity could be re-engineered to make useful DRAM with mass appeal, doing so will also drag down the profits of every memory manufacturer in the process, creating a supply glut the likes of which we’ve never seen in history.
The memory industry has gambled its financial future on the idea that there’s near-infinite amounts of capital available for data center capex, adjusting its supply chains and fabs to focus on scooping up demand that’s increasingly only made possible by the availability of debt. Microsoft, Google, Amazon and Meta have turned NVIDIA into a single point of failure for the entire tech industry, creating a painful present for consumers and a brutal future for suppliers, all because they decided to spend more than a trillion dollars on a dead end industry.
The longer it takes for hyperscaler capex to retract, the more expensive everything becomes. The more GPUs that get sold, the more capacity that gets put toward high bandwidth memory, and the more that Micron, SK Hynix and Samsung can charge for it, which makes it more expensive to buy AI GPUs, which increases the amount that hyperscalers are spending on AI capex for effectively the same amount of gear. The longer that hyperscalers sustain this pace, the larger the return needs to be, and at this point, none of them have disclosed their AI revenues, which heavily suggests there’s yet to be a dollar of profit.
Yet the more they commit, the more committed they have to be. Pulling back at this point will prove to the markets that they’ve committed to too much capacity. Yet not pulling back means that hyperscalers will continue to turn their free cash flows negative in pursuit of an indeterminate goal. It’s a vicious cycle made worse by the fact that every spin of the capex wheel increases the price of just about every consumer electronic in the world, creating a market-wide inflation for what amounts to a speculative asset bubble.
And If even one hyperscaler cuts their capex, the cartel-like memory industry is in for a nightmare scenario, one larger and uglier than any they’ve ever faced.
In the end, it all comes down to whose problem this high bandwidth memory becomes. Will SK Hynix, Samsung, and Micron have already built the RAM and face waves of cancellations, resulting in a bunch of fallow inventory it can’t use or sell? Or will they already have shipped it off to NVIDIA and ASIC builders, only for it to sit in warehouses waiting for the day it can finally be melted down?
Who will end up holding the bag? The cartel of horrible fab-gargoyles, Jensen Huang’s Wallet Inspection Firm, one of the four simpleton hyperscalers, Broadcom, or one of the Taiwanese ODMs?
Just to be clear: everybody loses, unless the AI bubble continues in perpetuity.
This is the Hater’s Guide To The Memory Crisis — and the terrible tale of the boom-and-bust memory industry.