2026-03-28 12:25:00
《HITMAN》杀手三部曲,一直是我很喜欢的游戏。
特别是新杀手第一部(HITMAN 6),是少数支持 macOS 端的游戏。当年捧着 MacBook Pro 刚上大学的我,除了日常写代码外,电脑上能玩的游戏也就 HITMAN 和 Minecraft。后来又蹭室友的 Windows 台式机玩了 HITMAN 2,2021 年那会在宿舍熬夜玩新出的 HITMAN 3(现在应该叫做 HITMAN WoA)。疫情期间在家更是高强度追每个月的 ET(行踪不定的目标),对着 B 站上的攻略视频一步步打。我记得最走火入魔的时候,我在宿舍看到室友,都有种想绕后拿纤维绳按下 Q 的冲动。🤣
三部作品加起来,我的总游戏时长应该已经超过了 200 小时。但 HITMAN 的地图就那么几张,完成主线目标的暗杀后,就会开始想探索地图里的机遇与成就,甚至想去卡 Bug 突破空气墙,看看图外面的景色。之前在室友的 Windows 电脑上,我从网上随便找个 HITMAN 修改器,就能实现无限子弹、无限生命的功能,然后开始无双屠城。
回到游戏生态贫瘠的 Mac 上,我发现全网居然没人做 HITMAN macOS 版外挂!我在自己的 Mac 上只能老老实实地打任务,时间久了挺没意思的。
然而自己又是逆向苦手,IDA 启动后只会按 F5,一旦遇到反编译失败或者没符号表,我就不知所措了。
好在时代变了,现在我们有 AI 了!不需要再古法看汇编了!本文我将介绍自己是怎样用 Claude Code + Claude Opus 4.6 硬生生将 macOS 上的 HITMAN 外挂给 Vibe 出来的。也算是全网首发了吧,嘻嘻。
先从最简单的功能开始,我想先实现“无限子弹”的功能。在正式开始 Vibe 之前,我脑补了下大概有两种做法:Patch 游戏源文件或者进程注入。
macOS 上安装的 App 都是预先带有签名的,任何对 Binary 的 Patch 修改都需要重新签名才能运行。我觉得这种修改游戏本体的做法,让我的游戏程序“变脏”了,我本能地觉得抵触。况且如果我想玩纯净的原版,我还得将 Patch 还原并再次签名。那可太麻烦了。
第二种做法就是进程注入,注入游戏的运行时,修改内存。原理类似以前手机上的八门神器。但 macOS 下默认会开启系统完整性保护(SIP),限制了不能对任意进程进行注入。我也不想为了玩个游戏还专门重启电脑关 SIP。跟大模型讨论了下,提到可以使用 codesign 看下应用的签名信息,说不定应用本身就放开了口子。
codesign -dv --entitlements :- HITMAN
结果还真有意外的惊喜!HITMAN 几乎向我们完全敞开,大模型给的结论是:可以注入,而且非常容易 (Very Easy)。
allow-dyld-environment-variables
allow-unsigned-executable-memory
disable-library-validation
<key>com.apple.security.cs.allow-dyld-environment-variables</key>
<true/>
<key>com.apple.security.cs.allow-unsigned-executable-memory</key>
<true/>
<key>com.apple.security.cs.disable-library-validation</key>
<true/>
讲道理我到现在都没搞明白为什么 HITMAN 的应用签名是这样的,可能是为了开发过程中方便调试?
我让大模型 Vibe 了一个输出 Hello World + 基址的 dylib,然后用 DYLD_INSERT_LIBRARIES 环境变量带上 dylib 启动游戏,在游戏终端能看到输出了我们的注入信息!

有坑注意!
由于我使用是 M1 Pro 芯片的 Mac,但是 HITMAN 游戏是 Rosetta 转译后跑得 x86 架构程序。因此需要交叉编译 dylib 为 x86 架构。
这顺风开局让我信心满满。我决定先自己用 Cheat Engine 手动找到子弹数量的内存地址,然后发给大模型让它帮我 Vibe 一个锁定内存数值的东西就行了。
macOS 上的 Cheat Engine 并不好用,我换成了 Bit Slicer,但操作和原理都是一样的。先在内存中搜索游戏当前的子弹数值,然后开一枪,再搜索变动后的子弹数值,两次搜索结果 Diff 一下,就得出了存储子弹数量的内存地址。再将这块内存冻结住,不让数值变化,就实现了开枪但子弹不减少的无限子弹功能!
想法很美好,但当我真在游戏中实践时,我确实找到了那个内存地址,并设置冻结了,但我发现那只是展示子弹数量的游戏 UI 文本组件。我开枪后,UI 上显示的子弹数量确实不变,但武器的实际子弹是减少了的,多开几枪后还是会没弹药。那个存储武器实际子弹数的内存我死活搜不到,最后一顿瞎改,游戏画面甚至开始鬼畜了!

后来让大模型接手分析才知道,游戏的人物血量、子弹数等会使用 FNV-1 哈希做完整性校验,一旦校验不通过,就会设置 g_iCheatingDetected 这个变量,进而触发游戏的反作弊机制。当 g_iCheatingDetected 变量被破坏后,主循环每帧会用破坏后的值算出一个垃圾指针,对随机内存进行读写。随机读写到了相机的内存数据,就会导致画面开始缩放抖动。
狡猾,实在是太狡猾了!
这下我不知道怎么办了,只能大模型启动。
首先安装 ida-pro-mcp ,然后将 HITMAN 的 Binary 拖到 IDA 打开,IDA 中点击 「Edit」- 「Plugins」- 「MCP」,下方终端输出 Streamable HTTP: http://127.0.0.1:13337/mcp 即说明 MCP 服务已启动。
再在 Claude Code 里使用 /mcp 命令配置好 IDA MCP,能正确获取到 MCP 服务提供的 Tools 即可。可以先提问:
我正在用 IDA Pro 打开了什么项目?
让大模型主动调 MCP 看下是否配置正常。
后续直接:
我想做一个无限子弹的外挂,但是不知道怎样修改内存,请分析 HITMAN 游戏的子弹判定逻辑,并设计应该怎么做。
一开始大模型想着去处理那个 FNV-1 哈希的校验,然后又想去 NOP 掉扣弹的逻辑,但都走不通。最后是将 vtable 里的SetBulletsInMagazine(设置弹药数)和 GetBulletsInMagazine(获取弹药数)两个函数指针进行替换,把 Set 替换为 Get,这样每次游戏调用 Set 减少弹药时,实际执行的是 Get 读取弹药,从而使得弹药数不会改变。
第一版在游戏启动时就会注入,进入游戏就自动有无限子弹的功能了,我想 Claude 再帮忙改成按下 F1 热键才启动这个功能,同时要像 Windows 上的修改器一样,开启了功能要有提示。(F1 键其实是与游戏按键冲突的,不过问题不大,都可以 Vibe 都可以改)
我寻思这应该要用 osascript 推个系统通知的弹窗吧?没想到 Claude 实际也是这么做的,哈哈!
还有个小插曲:当时由于是深夜,我的设备自动开启了睡眠模式,导致弹窗没显示出来,我一开始还没反应过来是为啥。🤣
无限子弹完成后,我还想实现“隐身”功能,即在游戏中执行非法动作或进入非法区域时,NPC 不会产生警觉。Claude 直接逆出来了 ZActorManager::UpdateSensors 函数里的 12 个传感器(视觉、听觉、尸体发现、伪装检测等),对应着游戏内 NPC 的反应动作。UpdateSensors 函数会有一个条件分支,判断是否更新传感器,这里直接将 jnz(条件跳转)改为 jmp(无条件跳转),一次性跳过所有传感器的更新,就不会触发 NPC 的动作了。
但实际调试时,我发现击杀目标完成任务后,撤离出口并不会显示。原因是 LockdownManager::UpdateEvacuationZones 更新撤离出口的逻辑也在这里面,这里的逻辑要单独处理。
需要注意的是,如果游戏中的 NPC 已经锁定你,并进入了对你开枪的状态,这时 AI 隐身就没有用了。之前在 Windows 上用的修改器也会这样。
游戏里自带了一个 g_GodMode 上帝模式的全局变量,我猜测是用在实时渲染的过场动画中,角色会暂时处于无敌状态。当这个变量被设置为非零时,所有扣血逻辑都会被跳过并恢复满血。因此无敌模式其实是最好做的了,直接将这个变量改为 1 即可。
这应该是我最想要的特色功能。☺️
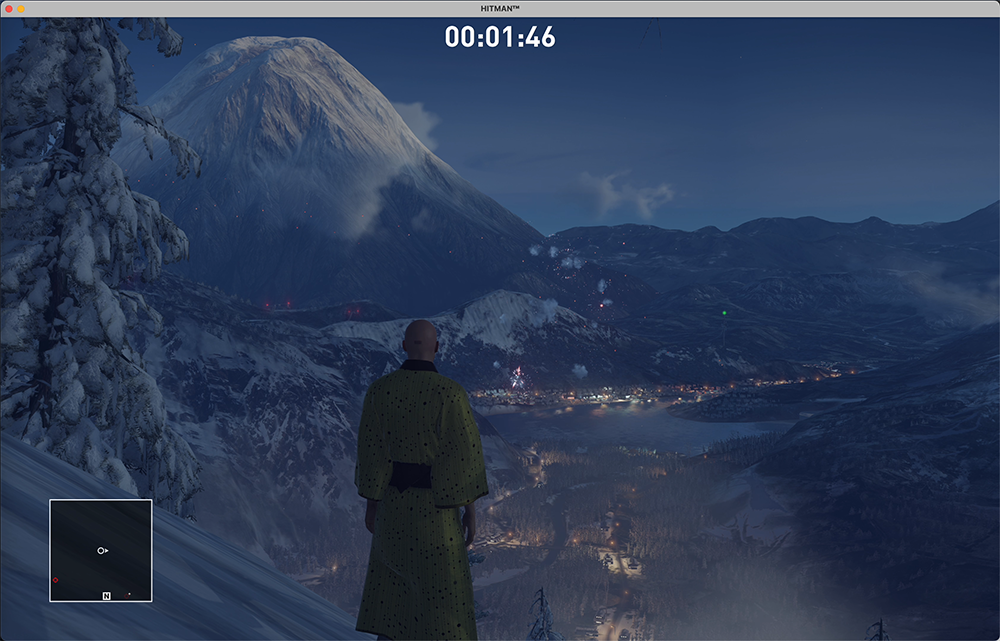
游戏中有很多墙边、柱子可以攀爬悬挂,有些悬挂点是在地图边缘或者高楼边,正常的操作是只能按 G 解除悬挂翻回室内。但我想在这个时候能强制切换到正常行走模式,这样就可以走到地图外进行探索。(例如北海道下山、萨比恩撒上房下海等)
游戏的移动系统有优先级机制,ZHM5MovementLocomotion(行走)优先级最高。其 WantControl 方法决定是否要接管控制权。将函数前 3 字节替换为 mov al, 1; ret,使其无条件返回 true,强制从任何移动状态(悬挂/攀爬/翻越)回到正常行走即可。
附上一张北海道下山的图,这是我在整个 HITMAN 游戏中最喜欢的地图!风景很美,我很喜欢。
我一开始是想要一键在背包里刷出游戏中所有物品的功能。然而 Claude 拒绝了这个需求,它说这个的难度比之前的高好几个数量级,我还得去找出游戏中所有物品的 GUID。
那好,退一步,我让 Claude 直接扫描当前整张地图里已存在物品的 GUID,再将其全部放到我的背包里。这样也能拾取到一些有意思的道具。Claude 的实现方式如下:
ZHitman5::Instance() 获取玩家实例指针。g_pWorldInventorySingleton 的获取整个地图的实体列表。QueryInterfacePtr() 查询 IItem 接口。(过滤非物品实体)ZHitman5::PickupItemDirect() 拾取。相当于是隔空拾取了地图中所有存在的物品,因此只能执行一次,东西被捡到背包里,原位置的物品就没了。但在实际使用中,我发现地图中会有少量 1-2 个物品可以无限次刷新,重复执行后还可以捡这俩东西。
这个项目我在两个月前就已经有了想法。最初是用 Gemini 3 Pro + Roo Code 来指导我用 Bit Slicer 实现无限子弹的 Demo,但效果并不理想,模型幻觉比较严重。Gemini 费了好大劲才发现 FNV-1 哈希校验机制,然后就开始胡言乱语了。
Claude Opus 4.6 发布后,我切换了模型又重新跑了遍,Claude Opus 4.6 能根据我发给它的 Bit Slicer 软件截图,结合 IDA MCP 直接算出当下地址空间随机化后的基址,进而算出我需要修改的 vtable 里的 SetBulletsInMagazine 函数的位置,帮我在 Bit Slicer 里完成了最初的 PoC。当时我还自己验算了一遍,发现完全一致!属实是被震惊到了。
关于这个项目的源码,我想了下还是不公开放出来,不然又要被发律师函了。(为什么是又呢?😝
如果你想获得源码的话,可以成为我的 GitHub Sponsor 解锁。🤗 不过我想上文都已经说得这么细致了,你把文章复制给 Claude Code,它也能给你 Vibe 出来。
收工。我们下一个目标见。
2026-02-02 23:10:00
一年多以前,我还对普通人炒股这种事嗤之以鼻。我觉得那就是庄家做局坑人割韭菜的玩意,钱进了股市注定会血本无归。
每当我看到身边有去炒股的人,我都会有种莫名的优越感,觉得自己才是保持清醒看透本质的聪明人。就像《创世纪》里霍景良的经典台词:“每天九点钟坐车上班,每个月也就挣那一万几千,省吃俭用玩股票,妄想一朝发财,他们根本就不知道真正的大赢家是什么人。”

同时我还极度厌恶风险,大部分的资产都集中在低风险的理财产品中(如微众银行的活期+ Plus,工资到手又上交公司了属于是)。这类产品基本不会有回撤,最多就是因为市场动荡某天收益为 0 而已。但这偶尔的收益为 0 也会让我感觉自己亏了钱,然后开始内耗。🤣
事情的转机发生在 2024 年末,受 KM 上同事的推荐,我去读了《金钱心理学》这本书。这本书主要想传达的是储蓄和复利的力量。书中虽然强调要控制风险并坚持足够长的时间,让复利发挥奇效,但并没有否定充满风险的股市,反倒是用巴菲特的例子来说明了价值投资的重要性。
这本书极大地改变了我对股市的看法,我觉得可以拿出储蓄里的一点小钱,去长期投资一些优质标的,来博取更高的收益。
2025 年的春节,我提前几天回了深圳,赶在过年放假前的工作日,去香港办了卡。具体可以看我小红书的这篇笔记。当时开了汇丰银行和众安银行两家的卡。众安是全程线上办理,上传了出入境记录后,很快就开通了。汇丰则是因为名字重名的问题,无法当场下卡,只能回去等实体卡和密码函的信件寄到家里。
最后果然不出意外的出意外了,后续我一直没能收到汇丰的信件。但因为众安银行的账户已经可以用来入金了,也就一直没管这事。去年 6 月想起来了,打电话让汇丰补发信件,又是过了好久,卡和密码总算寄到了。然而使用 App 激活时又提示出错了,最后还是去年 10 月国庆假期时,抽了一天时间去香港线下激活。但汇丰的卡也不是一点用处没有,我之前 HackerOne 是用 Wise 来收漏洞赏金的,后面改成众安银行的卡,提示打款被拒绝,再次改成绑定汇丰银行的卡,就能成功收款了。
回到正题,在办理了银行卡,并开通了长桥证券账号后,从零开始的美股冒险就此开始了!我将按时间顺序来梳理我过去 2025 年的操作与感悟。
开头叠甲
我没有任何系统性的金融知识,完全是小白水平从零开始。对股票的认知就是低点买,高点卖,然后就能赚钱。所以后面的很多观点可能并不成熟,甚至有的观点是因为幸存者偏差,不构成任何投资建议。
在关注美股以前,我曾听闻过苹果成为美股首家市值突破 2 万亿美元的上市公司的新闻,后续苹果又是首家市值突破 3 万亿美元的公司。因此想先买点苹果 AAPL 练练手。瞄准苹果开盘后的一个低点,“豪掷” 700 美元买了 3 股 AAPL。
可能是还在“新手保护期”吧,还真让我买在了当天的低点,没过多久就开始涨了,收盘时涨了 2 个点。
之后苹果连涨了好几天,直到 2 月 21 日开始回调下跌。虽然只是小跌了 0.11%,但我还是有样学样地卖出了 1 股。(手续费都 2 美元了🤣)
我在苹果这里尝到了甜头,单纯地认为股票只要找准合适的下跌时间,买入,然后等待上涨就行了。
市场很快就给我上了一课。
买入苹果的第二天,我又将目光瞄准了 TSLA 特斯拉。
我发现特斯拉在前一天 2 月 11 日下跌了 6 个点,便觉得它还会继续下跌。直接买了 20 股的 2 倍做空特斯拉。当时我觉得自己会做空股票可太帅了!别人买涨,我买跌,我就是叛逆,这太帅了!我就是大空头索罗斯!
结果就是,特斯拉在 2 月 12 日、13 日两天都在上涨,第二天甚至涨了 5.77%,填补了之前的下跌。我开始慌了,以为等后面正股跌回来就好了。这时有小伙伴告诉我,2 倍做空这种加杠杆的行为,是会有“磨损”的。
“磨损”是很简单的数学原理。我记得有这么一个笑话:给你的工资先涨薪 10% 再降薪 10%,与先降薪 10% 再涨 10%,到手都是亏了的。
因为 1 * 1.1 * 0.9 = 0.99,而乘法满足交换律,所以前后相同的乘数,不管是先涨后跌还是先跌后涨,最后的总数都是减少的。而杠杆又放大了这个比例,这就是 “磨损”。2 倍做空亏损后,正股需要超过之前的跌幅,才能开始回本。
第一次意识到还有这种风险,我吓得果断选择了全部清仓。前后亏损了 60 多美元。这次教训之后,我就不太敢做空了。甚至一段时间内都没再碰过特斯拉的股票。当然,站在上帝视角回看,后面发生的事情我们都知道了—— 2025 年 3 月,特朗普发动关税战,美股股灾。如果我的 2 倍做空特斯拉能拿到 3 月,确实能狠狠赚一笔。
可惜,没有如果。
在特斯拉这里栽了跟头后,我又去关注了下英伟达 NVDA,买入了 5 股。这次因为持有的是正股,我也就不那么慌了,想着一直拿着就好,跌了就补补仓。
然而我对“补仓”这一行为,也没有概念。
我以 141.40 的价格买入了 5 股英伟达,买入的 8 分钟后,股价跌了 1 美元,为 140.40。 然后我就想:股票下跌,是时候该加仓了! 以 140.40 的价格马上买了 2 股。过了 40 分钟,又跌了 1 美元到 139.00,我又买了 3 股!过两天发现跌了 2 美元到 137.00,我又买了 3 股。4 个小时后跌了 3 美元,我又补了 1 股。
当时的我对于涨跌的幅度以及每次下单时券商收取的手续费完全没有概念,看到股价跌了一点就补,导致总体成本也没降下去,白白损失了手续费。后来跟我爸聊起这事,他才纠正我,让我在英伟达每次跌幅超过 10 美元时,才选择加仓,后续涨了 10 美元时,就卖出。
我按照爸爸的建议,在 3 月 3 日英伟达距离我上次买入价跌了 10 美元时,以 112.80 的价格买入 10 股英伟达。
然而 3 月特朗普发动关税战,对我国征收高达 145% 的离谱关税。面对英伟达股票连续几天的下跌,在 3 月 11 日的时候我终于忍不住了,选择购买英伟达 2 倍做空 NVD 来进行对冲,降低亏损。是的,我又开始加杠杆做空了。好巧不巧,英伟达从那天开始上涨修复了!最终给我成功搞成了不管英伟达股票上涨还是下跌,我两头都挨打的局面。😅
在买入 NVD 的 4 个小时后又匆匆卖出了,又亏损了 60 多美元。
好消息是,10 美元买入卖出的策略初见成效。
在英伟达上涨了 8 美元,我卖出了 10 股。后面跌了 10 美元,我又以 110 美元的价格接了回来。跌到 100 美元时,又继续补仓。后续涨到 111、120、130 时再分批卖出。这波操作稳稳的降低了我的持仓成本,实打实赚到了钱。
现在回头来看,我愿称之为“反向马丁策略”。“马丁策略”也就是倍投策略,即赌博时每次翻倍下注,赢一次就能回本且赚钱。马丁策略的问题在于,每输一次,下次需要押注的金额呈指数上涨,除非资金量无限,否则多输几次很快就破产了。
而我跌 10 块买入,涨 10 块卖出的方法,实际上是相反的。我算了下,在英伟达股价 110 美元的时候,它跌 10 块我买 10 股,哪怕它跌到 0 元,我要付出的本金就是:((100 + 10) * 10 / 2) * 10 = 5500 美元。这个金额是确定的,哪怕英伟达破产退市股价为 0,我也只投入了 5500 美元。如果真有那一天,那显卡估计也不值钱了,我可以白菜价买 RTX 5090,想想也不亏。
英伟达涨了,我赚钱;英伟达跌了,我可以低价买卡。正反都是我赢,好!
经历了这次股灾之后,我总是会想:“我经历过 86 块钱的英伟达,所以已经没有什么好害怕的了。”
4 月除了继续在英伟达上微操之外,我还铤而走险去买了 NVD 和 UVIX。
4 月 17 日盘前,在公司吃完饭时,我看到新闻说老黄突然来北京谈合作了。没多想就买了 10 股 2 倍做空 NVDA。开盘后英伟达居然真的下跌了,两倍做空涨了 3 美元后我寻思差不多了,赶紧卖出,小赚一点点。
4 月 29 日睡觉前,我看到消息说特朗普将于美国时间 4 月 29 日发表百日施政讲话。我寻思特朗普这次肯定又会口无遮拦乱说话,怕不是又要带崩股市。所以睡前买了 20 股 2 倍做多恐慌指数期货 UVIX。第二天晚上去找 C 老板吃饭时,发现股价真的开始下跌了,UVIX 涨直接了 15%!我在开盘后的高点迅速卖出,小赚了一笔。但事后再看,还好当晚赶紧卖出了,从那之后 UVIX 就一直在下跌,如果没卖就彻底被套住了!
以上两次操作虽然都赚钱了,但我很清楚这些都是靠运气赚到的,所谓的看消息面只是我的一厢情愿。 技巧一点没有,只是被我蒙对了。
5 月份上半月沉迷 MyGo 和 AveMujica,下半月去东京玩了一圈,美股基本没什么操作。
时间来到 6 月,稳定币发行公司 Circle 于 6 月 5 日在纽交所上市,发行价为每股 31 美元。说实话,我对币圈一直是比较抵触的,在我的认知里,普通人玩币迟早有一天会爆仓完蛋。而我又不知道稳定币到底是个什么玩意,觉得应该也是币圈的东西,最好不碰为妙。
但 Circle CRCL 上市第一天,股价上涨 140+% 来到了 80 多美元。我试探性地挂了 79 元买入 10 股的单,快收盘时成交了。第二天睡醒一看,夜盘直接涨到了 89 块,我赶紧选择卖出,一晚上就赚了 100 美元。
当天开盘后 CRCL 股价一度冲上了 120 美元,后面甚至连涨一周多,最高点股价接近 300 美元。但是我对于这次踏空并不后悔,稳定币完全是我认知以外的东西,我并不清楚它的来龙去脉和运作原理,能赚到钱纯属跟对了风口。对于自己看不懂的东西,我坚定地选择不去碰为好。
说来也是有意思,CRCL 从 7 月之后就一直下跌,期间虽然有小的修复,但整体趋势还是向下的。最近比特币价格一直下跌,CRCL 的股价一度跌到了 62 块。现在回看,庆幸还好当时跑了,并且再也没碰过。
我怀疑散户因为这次 CRCL 上市的涨幅,对后面上市的知名公司,都有了迷之信心。对,我要说的就是被称为 2025 年最受关注的科技股 IPO:Figma FIG。Figma 作为平面 UI 设计的绝对独角兽,还曾拒绝了 Adobe 的收购,我估计很多人会将 Figma 的上市看做下一个 Circle。
Figma 上市当天确实上涨了超过 300%,很多人觉得它会像 Circle 那样连涨 7 天,所以纷纷高位进场。谁曾想 Figma 在第 4 天就破发了。往后更是一路下跌,发财报也不亮眼。我当时也在想要不要买点试试,最后因为价格太高没买成,还好还好。
由于我在 Circle、英伟达、特斯拉、CloudFlare 上数次投机成功,赚了点钱。我开始有点飘了,7 月时买入了小盘股 Destiny Tech 100 DXYZ,长达 3 个月的噩梦就此开始了。
Destiny XYZ 并不是一家常规的科技公司,它是一家资产管理公司。Destiny Tech 100 是一个包含 100 家待上市的顶级科技公司的投资组合。DXYZ 持有这些未上市公司的股票,包装为投资组合,目的是让普通人也能参与私募市场的投资。投资组合中占比最大的就是 SpaceX,因此 DXYZ 常被当做 SpaceX 或者私人航天火箭相关的标的进行投资。
我以 35.25 的价格买入了 DXYZ,随后的两个月内它基本一直在下跌,很少有涨的时候。SpaceX 星舰的发射也屡屡受挫,消息面上也带不动股价的上涨。我很难再重复之前在英伟达上的操作,来不断买入卖出降低成本。到 9 月底的时候,它的股价已经跌到了 25 美元左右。
一开始我还只是嘴上抱怨咋买了这么个垃圾股票,后来逐渐发展成了自己吓自己。我开始在推特上搜索网友关于 DXYZ 的评论,有人说他市盈率过高,有人说这就是一个把股东当 ATM 的骗钱玩意。我发现这股票没有期权,无法做空、往期财报刚好赶在行情好的时候发布、创始人的上一家公司经营的也不好。我还找到了创始人的 Linkedin 和 GitHub,发现他的 GitHub 比脸还干净。
这些消息让我逐渐对 DXYZ 丧失信心,时间来到 9 月底,我决定想办法赶紧回本然后跑路。
经过很多天的观察,我发现 DXYZ 这种成交量很少的小盘股,虽然每天盘中都是在下跌。但每天北京时间早上八九点,夜盘开始时,总会出现几个比当前股价高 2-3%涨幅的买入单。我也不知道这是哪来的大冤种,每到夜盘就花高价买入。后续有人跟我说是做市商,我寻思这做市商人还挺好,说不定我能趁机将成本降下去。
我的计划是这样的:DXYZ 每次盘中快收盘时,往往是股价最低点,这时候使用券商融资大笔买入 100 股,等到夜盘涨了 2-3% 的时候顺势卖出。每天不断这样操作,既没有融资的利息,又可以不断降低成本。我在 9 月底连着 3 天都这样操作,每天都盯盘盯的很晚,心里总是不踏实,每晚睡觉做梦都是 DXYZ 涨了或者跌了。在后来长桥的年度总结里,我有天打开 App 看了上百次 DXYZ。
我连着 3 天都成功盘后低价买入,夜盘高价卖出。甚至有一天的夜盘,要是我再晚 5 分钟卖出,股价还能涨更高,那个时候恰好就能解套了。但我忽略了一件事,虽然我每天 100 股的买入卖出,确实赚了钱,但我原来持有的 30 股 DXYZ,却一直没有动,那 30 股还是随着每天股价的下跌而亏钱,一来一回,我的总成本并没有降低多少。我一开始就应该卖出那 30 股的!
意识到这一点的时候,已经是第 4 天了,这天不出意外翻车了。DXYZ 并没有按我设想中的那样在夜盘有个上涨,我一直等到了当天开盘也没有出现。开盘后,股价还是照常下跌,此时我手握 160 股的 DXYZ,稍微的一点跌幅,亏损都会被放大很多。我直接慌了,最后以 22.70 的价格将手上的 DXYZ 股票全部卖出。
至此,我在 DXYZ 上亏了有 170 美元左右。但我心中的石头落地了,我终于可以睡个好觉了。
那是 9 月的最后一天,DXYZ 在我卖出后还在不断下跌,此时我的心里只有劫后余生的庆幸。
但这还并不是故事的结尾,经历了长达数月的下跌后,在我清仓后的第二天,10 月 1 日,DXYZ 暴涨 31.78%!
没有任何理由,没有任何新闻,它就是涨了,在我卖出后涨了。
如果我当时能再多坚持 24 小时不卖出,等到第二天开盘时,我就能狠狠地赚上一笔了。
这件事之后,我再也不碰小盘股了。
经历了 DXYZ 之后,我开始转向保守型投资了。后面买了美股七姐妹 ETF $MAGS 和纳斯达克指数 ETF $QTOP。这些标的跟着大盘走,收益虽然低,但稳定且可控。
在年初刚开始时,长桥有一个买期权送卡券的活动。这是我唯一一次碰期权,象征性地买了 2 张还有 14 天到期的英特尔 INTC Put 看跌期权,过了几天涨了 0.01 元后卖出,赚了 2 美元。但是算上手续费后,整体其实是亏的。这导致在我 App 的盈亏分析排行榜中,有个几块钱的英特尔的亏损,让人看着不爽。我寻思可以买点英特尔正股,随便赚一点把这个亏损的数给填上。
我在 10 月底英特尔大涨 5% 后的第二天回调开始建仓,成本 41.77,挺高的。后续英特尔持续下跌,但我认为这支股票已经和美国政府的利益捆绑在一起了,可以说像是波音公司一样,是美国的亲儿子,后面特朗普随便发表点暴论,立刻就能涨回来。
后续连着跌了几天,我在 38.32 时又补了点。然而 11 月底时,由于美国政府停摆 + 降息预期下降,科技股在那段时间都有不同程度的下跌。这其实是绝佳的抄底时刻,可惜我在前面的补仓中已经打光了子弹,手头还握着 MAGS 和 QTOP,实在没有闲钱加仓。因为不确定这波下跌周期会持续多久,也不敢冒然去融资。只能静静等待。
当然英特尔也算争气,11 月 28 日传出英特尔成为苹果供应商的消息,大涨 10%。(英特尔:嘿嘿,又要到饭了)12 月 2 日又大涨 8%,创年内新高。我看赚得也差不多了,分批全卖掉了。好巧不巧卖掉之后英特尔就开始下跌了,但我也没选择继续接回来,英特尔好几次大涨都是因为传出又与某某公司合作的消息,要到饭了所以股价涨了,我认为长期来看这很不健康。
虽然之后 1 月英特尔破新高涨到了 54 元,你可以理解为我又踏空了,但跟 Circle 一样,我只想赚自己认知内该赚的钱。
值得一提的是,我前几次都在赌英伟达的财报,每次财报发布前买一点,然而每次财报发布后都是下跌的行情,过了一阵子才涨回来。因此英伟达 11 月份的财报我决定不赌了,肯定又是下跌的剧情,等跌的差不多了我再来抄底!
然而财报发布后的当晚开盘,英伟达股价居然没有下跌。我以为是自己的判断出了问题,说不定英伟达这次财报跟之前都不一样,这次是要涨了呢?我赶紧以 194.80 的价格开始建仓,谁知到了盘中后半夜,英伟达急速下跌,当天直接跌了将近 8%!老黄都站出来表示不理解,英伟达保持了这么好的增长业绩,为什么市场还不买账?
是啊,我也疑惑,为什么市场还不买账?但没办法,既然被套住了,那就只能想办法解决了。我继续按照 3 月的策略,在盘后跌到 180.20 时补了一点降低下成本。之后就是长达一个多月的横盘,但我不急,我坚信英伟达会涨回来的。我之前买 DXYZ 都被套了 3 个月,就算被英伟达套 3 个月又有什么可怕的呢?
等到 1 月 6 日,英伟达开盘股价站上 192 时,我知道时间来了,卖出了 180.20 时加仓的部分。横盘了一个多月的英伟达,这天快收盘时果不其然地又跌回去了,我又在低价给接回来了。做了一个还算完美的 T。
现在我的英伟达持仓成本已经降到 186 左右了,但我不甘心就这样卖掉。因为浪费了快两个月的时间成本,我很想等到它重回 200 时再卖。
1 月的某天中午,我在公司午休刚睡醒。看到台积电发布了财报,财报内容远超预期。我立刻融资买入,当天晚上开盘后台积电 TSM 涨了将近 7 个点。我在开盘后的第一个高点全部卖出。完美的一次日内融空手套白狼。
1 月 29 日,我看特斯拉跌了 3 个点,从开盘 437 美元最低跌到了将近 415 美元,盘中慢慢又涨回去了。按照我对特斯拉这种“妖股”的理解,它每次大幅下跌后,第二天都会快速修复,可能这就是马斯克信徒的力量吧。我抱着试一试的想法,挂了个 416 元的单。第二天一觉醒来后发现居然成交了!当天晚上果然上涨了 5 个点,由于时间已经临近周五,再加上我这次又是靠融资买入的,害怕周末夜长梦多,万一特朗普又发疯说了什么话,周一大跌就完蛋了。索性周五在高点卖了,又是小赚一笔,成功把特斯拉的持仓成本降低到了 400 以下。
我爸后来叮嘱我,让我不要再去碰融资融券这些东西。用自己的钱,做确定的买卖,最多也只是全部亏光,融资则是亏完后还倒欠别人的钱。我也开始有意识的去改正,由于大盘最近一直不是很景气,我清仓了手上的 QTOP,准备多留些子弹去布局其它标的。
这是我从零开始炒美股的第一年,最终也是获得了将近 30% 的年收益率。
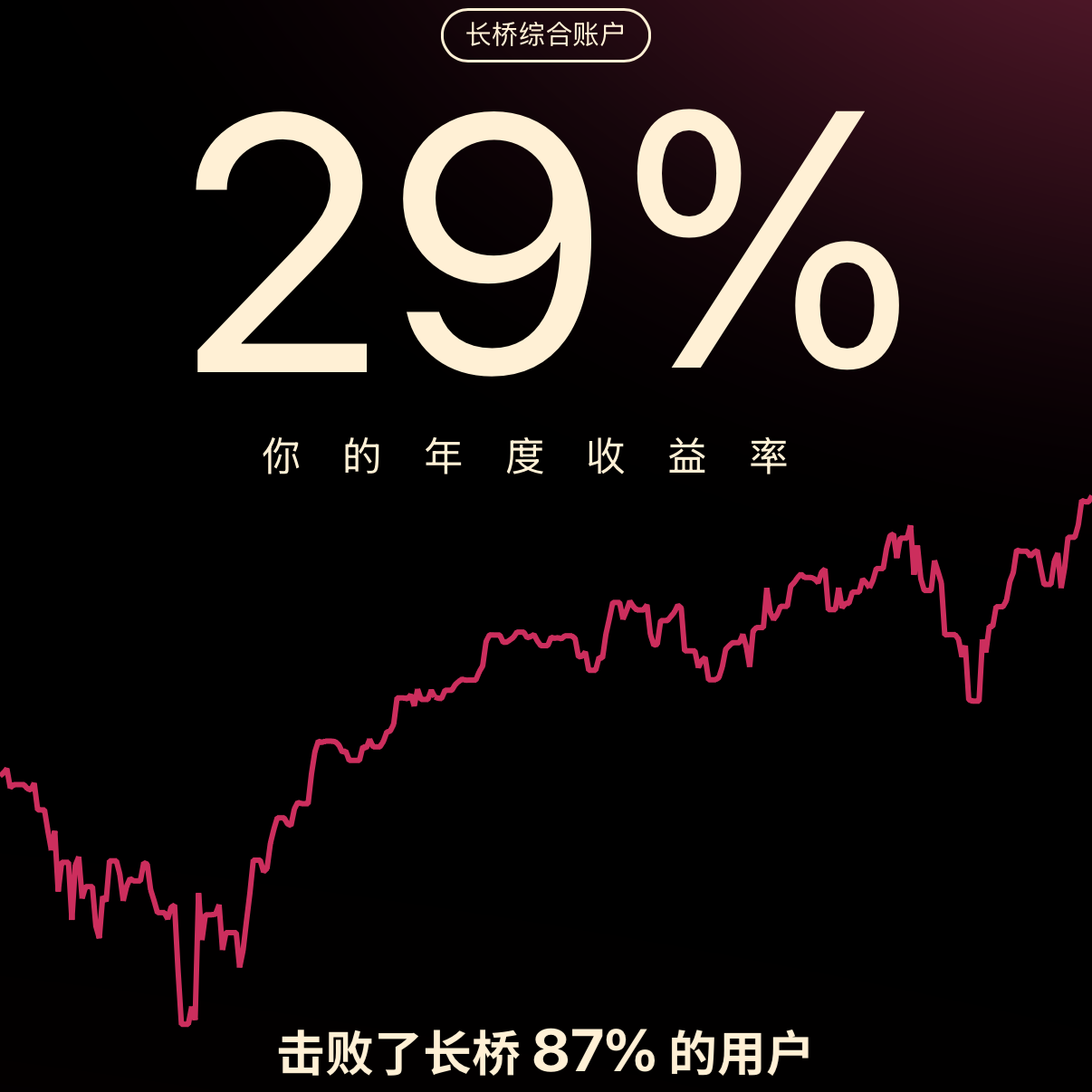
期间有过像 CRCL 这样的靠运气大赚,也有像 DXYZ 这样的靠认知大亏。赚钱的时候我会沾沾自喜,觉得跑赢纳指也不是什么难事嘛。亏钱的时候,我才意识到巴菲特能在半个世纪的时间里,穿越周期并保持冷静是多么厉害。3 月的时候传出了巴菲特卖出苹果的消息,当时我跟很多人一样,觉得是这老头跟不上时代犯糊涂了,后面随之而来的股灾让我说不出话了。
美股也让我被动去关注很多地缘政治信息、国际新闻、财经常识等。我开始知道美联储是啥,降息意味着什么,鲍威尔的 Good Afternoon 段子,ETF 是什么……
美股破产四巨头:期权、小盘股、中概、做空。
在未来的日子里,我要时刻提醒自己,不要去碰期权。买卖期权在我看来就是赌博,期权就是资本重点收割的对象。同时我的脑子也理解不来那些复杂的期权策略,这里面的钱不该我赚。
近半年来,网上关于使用大模型炒股的项目和比赛层出不穷。我也曾尝试过从零 Vibe Coding 一个大模型炒股程序,但最终还是弃坑了。一方面是觉得大模型炒股这件事并不靠谱;另一方面,我想把炒股当做一个闲暇时间的兴趣爱好,就像有的人喜欢钓鱼一样。他们并不会用机器或者 AI 去替代人工钓鱼这件事,因为个人的实际参与,才是这件事真正有意义的地方。我希望自己去关注,去按自己的思考下单买卖,大模型最多给我提供资讯方面的情报,它不应该替我执行决策。
最后再打个广告,本文中的可交互股票图表组件,使用的是我编写的 Hugo 股票图表插件 hugo-trading-chart。实现思路很简单,先从长桥的 API 抓取历史 K 线,再使用 TradingView 开源的 Lightweight Charts 组件绘制图表。数据抓取的部分是手写的,其余的前端全是 Vibe 出来的🤣,欢迎 Star~
2025-10-06 21:13:12
十年前的午后,我在b站刷到了一个视频, 视频介绍了如何在 OpenShift 平台上搭建 WordPress 博客。
很多年后,我才意识到那是一个多么生机勃勃的时代:Docker、K8s、Vue 才刚起步,字节才刚开始融资,AS3 还没凉,自然语言对话服务还是谷歌 DialogFlow,微软小冰,IBM Waston。
可惜我找不到那个视频了,估计是被删了吧。但好在我跟着视频一步步搭建的博客,陪我记录了这十年。
我在 9 月 28 日凌晨发了这条朋友圈。原本是想等到 10 月 4 日再写些东西叙叙旧,奈何一想到 10 周年就心潮澎湃,就提前开始“预热”了。😂
此刻,我正坐在同样的沙发上,同样面朝阳台,写下这段文字,和十年前一样。
你可以结合 文章归档 页面,和我一起回忆我的“黑历史”。
我很少有能一直坚持下来的事情,很多 Side Project 都是轰轰烈烈开个头,三分钟热度一过,就再也不管了。写博客最初的动力源于 WordPress 后台给了我种打扮 QQ 空间的感觉,我可以换好看的主题,装一堆插件。但它比 QQ 空间的可定制程度更高,我可以通过自己的域名访问,可以在页面底部加自己的 Copyright 版权信息,一切都是自己的东西。
在按自己的想法装扮完页面后,我想着得写点东西挂上去充数。那会儿我刚上高中,身上的“中二”气息还没褪去,再加上高中开局不利,考试成绩接连爆炸,所以写了些很丧又很幼稚的文章。现在看来真是黑历史。到了 2016 年的高二,我因为接触 WordPress 而开始学习 PHP 语言,但那时同样很难找到东西写,便把自己发的 QQ 空间说说转载到博客来,这样“滥竽充数”也就成为一篇文章了。文章大多很短,有些还很意识流,我已经看不懂当时的自己想表达什么了。
2016 年下半年,我关注了「差评」公众号,在那之后的文章,会不自觉地去模仿差评公众号文章的标题和文笔。并且都是先发表在个人公众号,再顺带转载到博客。到了 2017 年,我终于是能写点正经技术文章了,我分享了如何给 WordPress 全站开启 CDN、写 C# 时踩得坑、用 CodeIgniter 框架写得小项目、用 PHP 写得微博爬虫…… 直到这里,我才算真正产出了能帮助别人文章。
2018 年高考结束后的暑假,我分享了自己开发的微信小程序的前后端实现,如何实现树莓派的内网穿透,初识 Jenkins 等。上了大学后,大学的自由让我能自主规划去学很多新东西,博客文章也是一篇接着一篇。从 CTF 到 Docker、PHP Swoole、PHP 内核(虽然只开了头)、CI/CD、Serverless 函数计算、Redis、Vue,再到现在混饭吃用的 Go。我在那时开了 Apicon 这个坑,把我学到的这些东西融入到了这个项目里,就当是自娱自乐。
时间来到 2020 年的疫情,那年我主要是在开发 CTF 平台 Cardinal,博客文章记录了我运营这个开源项目的感受,技术上和心理上的都有,虽然都比较“稚嫩”。2020 年下半年,我将重心投入到了在 ForkAI 的工作中,博客更新频率大不如从前。我在工作中接触到了 Macaron 框架和依赖注入,还被安利了《黑客与画家》这本书,我也总结了篇读书小记。
2021 年我开了很多坑,比如 EggMD 协作文档、Elaina 代码运行器、mebeats 小米手环心率采集、asoul.video 视频站等。每个项目都有可以分享的内容,都是一篇独立的文章。(虽然很多项目后来我就没维护过了)
这里我想重点表扬下 《Your Soul, Your Beats! —— 小米手环实时心率采集》 这篇文章,这是所有文章中访问量最多的一篇,直到文章发布 4 年后的现在,每天都还有人阅读。抛开文章内容的实用性不谈,更重要的是这篇文章详细描述了我当时一步步解决问题的思路和方法技巧。 我首先使用软件检测电脑蓝牙,再逐步扩展到编写代码操作蓝牙;在遇到依赖库年久失修无法使用的情况时,我又是如何成功找到还在维护且可用的库;最后照应前文一步步的软件操作,将功能编写为代码。直到今天,我都认为这篇文章写得真的真的很好!
2022-2023 年,又是 allin 工作的一年,文章产出更是大幅减少。这段时间的工作内容主要集中在 Kubernetes 集群,所以抽空写得文章都是些集群相关的骚操作。
2024 年中,我入职了鹅厂。工作强度相比前几年小了很多,我有更多的时间去思考,去动手做一些新东西。刚入职的那一个月,几乎每个周末都能写一个新项目出来。(虽然很多都还没开源) 我开发了 Sayrud,它现在也被我用来搭建博客的评论后端。我基于 Traefik ForwardAuth 开发了自己的集群统一认证 ikD,现在我服务器集群对外暴露的所有服务,都已经接入了;甚至该 Side Project 还被我成功引入到了公司团队内,稍作修改后作为团队成员登录各服务的统一认证。😄 之后又自己实现了个大模型套壳站,这段关于大模型应用的开发经验也被我用在了公司的项目中。我发现 2024 年后,我在闲暇时间自己研究的事情——无论是开发的 Side Project,还是在自己的 Kubernetes 集群或者腾讯云运维中积累的知识,在未来的某一天都能反哺到我的工作中。颇有种我提前预判了我的工作,提前就给做完了的感觉。(叠甲:这并不是说我之后就开始摸鱼了,当然是在追求更加精益求精 😛)我很喜欢无心插柳柳成荫的意外收获,希望这样的日子能永远永远地继续下去。
我是一个很在意他人看法的人,不止是他人对我口头评价的看法,也体现在比如 Twitter 粉丝,博客文章评论量这些事情上。我会因为 GitHub Follower 数 -1 或者博客一直没人评论而烦恼,会因为日常工作中他人对我态度不友好而内耗一整天,即使这很有可能是我听错了或者想多了。我时常会在睡前突然想起白天尴尬的事情,然后在床上缩成一团。我会评判自己白天是不是哪句话说得不对,给别人留下了不好的印象。我时常会将自己的成就归结于百年难遇的运气爆棚,进而陷入自我怀疑,会有种不配得感。
反过来也是同样,我对收到来自别人的反馈或者肯定可以兴奋地睡不着觉。之前很长一段时间没有维护过 NekoBox,偶然收到了来自用户的打赏和鼓励,那天晚上就跟打了鸡血一样写新功能肝到凌晨三四点。在工作中也同样,一旦收到了正反馈,我就会感觉这是自我价值得到了实现,自愿加班到 11 点后,开始抱怨为什么空调关了只能被迫下班。
能让我坚持将一件事情做下去的动力有两个。一个是我能从中持续得到反馈,让我觉得自己的所作所为是被看见了的。另一个是我能“吃自己的狗粮”,我自己也会作为用户,会去不断使用我所创造的东西。 NekoBox 是前者,ikD 是后者。
站在十年这个时间点,我觉得得立个 Flag 做点什么。我在年初注册了 nekobase.com 这个域名,并备了案。我想开个新坑,将我博客中用到的服务组件作为 SaaS 开放出来,供大家使用(例如评论后端、代码运行器服务等),顺带继续拓宽技术栈,去做些“更高级的 CRUD”。我也不知道这个服务会不会有人来用,但至少我自己的博客会迁移过去,能 dogfooding 的话,就不会半路弃坑吧。(应该吧)
我不知道下个十年的自己会身在何处,但当下,我发自内心地十分满意现在的工作和生活,希望这样的日子能永远永远地继续下去。
2025-09-13 23:12:57
NekoBox 匿名提问箱于 2020 年 3 月上线以来,至今已有五位数的注册用户并产生了六位数的提问。
这个数据大大的出乎了我的意料,要知道 NekoBox 从未对外公开宣传过,纯靠用户间口口相传。我很喜欢这种无心插柳柳成荫的事情,自己默默做得事情能够被看见,对我来说是很幸福的事。
说来惭愧,一直以来我都是“放养式”运营,每次只有自己手头的工作不忙了,才会登录上兔小巢看一下用户的反馈,然后将一些恶性 Bug 或实现起来简单的需求给做了。很感谢使用 NekoBox 的各位能包容我的懒惰,依旧不离不弃。🧎🏻
本文记录了近期 NekoBox 迁移与重构时踩过得坑,以及我对 NekoBox 的定位与后续展望。技术向的内容会有些多,不感兴趣可以直接跳到文末。
NekoBox 最开始是我 2020 年花三天时间写出来的,作为一个小玩具部署在我的国内服务器上,并且使用我个人的备案域名。网站可以使用任意的邮箱注册,并不需要用户输入手机号并验证实名,这其实是不符合我国《互联网信息服务管理办法》的。
但当时抱有一定的侥幸心理,想着提问和回答都接了云服务商的文本内容审核 API,违规评论都会被拦截,再加上自己也没对外宣传这个站,应该不会有问题。
但这在无形中给我埋下了一个大雷。
2023 年 2 月 23 日上午 11 点左右,我在家接到了网信办的电话,对方说有人在 NekoBox 发布违法言论,我作为站长,需要配合调查。当时我吓坏了,马上光速注销备案 + 关站,并认真配合警察叔叔的工作。
最后好在我没有利用 NekoBox 进行盈利,且我事先也接了相关文本审核的功能,在配合工作提供了相关材料后,这件事便告一段落了。还好没留下什么案底,已经是万幸了。
事后复盘发现,那名用户使用谐音和表情符号绕过了文本内容审核功能。这让我意识到机器审核 API 也会有严重的漏报,但一方面因为成本原因又无法做到每条信息都接人工审核服务。
互联网不是法外之地!
这件事给我的打击挺大的,我最初的想法是将网站代码开源出来,大家能够一起共建,可惜 GitHub 上一直没有多少贡献者,还被炸弹人给爆破了。原先的国内网站下线后,我收到了很多用户的反馈,纷纷询问站点怎么无法访问了,甚至还有一位网友因为 NekoBox 了解到了我的技术博客,受到触动也开始尝试建站写博客。能成为他人的光真的是很开心的事。
因此后续 NekoBox 便迁移到了境外服务器,并且没再使用备案域名了 —— 正如 v2ex、Go 语言中文网等站点那样。希望它能在广袤互联网的一角,继续安静地存在下去。
抒情的话聊完了,该聊点技术了。
NekoBox 部署在境外的 2C2G 轻量服务器上,由于配置的原因,只能使用 Docker Swarm 进行粗糙的服务编排调度。每次需要更新线上版本时,都是 GitHub Actions 通过 SSH 连上服务器,再执行 docker service update 命令。
我想将 NekoBox 接入现有的 K3s 集群,使用 GitOps 实现更好的版本管理和平滑更新。我的 K3s Master 节点位于腾讯云上海区域,经测试发现腾讯云东京区域的线路比中国香港区域好些,因此买了台 2C4G 的境外东京区域的机器,作为 NekoBox 新的部署机器。
关于如何跨地域甚至是跨云组件 K3s 集群,这篇文章介绍的很详细:《基于K3S和zerotier-planet实现跨云搭建K8S集群》
首先使用 ZeroTier 将不同可用区的机器加入到同一 ZeroTier 网络中,这样在 K3s 看来它们就在同一内网里了。

节点均开启 IPv4 Forwarding 后,修改 Master 节点 /etc/systemd/system/k3s.service 中的 K3s 参数,显示指定 node-ip 为节点在 ZeroTier 中的 IP,并设置使用 ZeroTier 的网卡:
ExecStart=/usr/local/bin/k3s \
server --node-ip 10.243.xxx.xxx --flannel-iface ztcxxxxxxx --flannel-backend=host-gw \
同理,修改 Worker 节点 /etc/systemd/system/k3s-agent.service 的 K3s 参数:
ExecStart=/usr/local/bin/k3s \
agent --node-ip 10.243.xxx.xxx --flannel-iface ztcxxxxxxx \
重启各节点上的 K3s 服务,Lens 连上 Master 节点能在 Worker 节点启动 Node Shell 并访问 Worker 上的 Pod 日志,Worker 节点能请求到其他节点上的 Service,说明就配置成功啦~
我们再给 NekoBox 的节点加个 region=jp 的污点,防止集群里的其它服务被调度过来。
后续还推荐装上 goldpinger,它会建一个 Daemon Sets,在每个节点上放一个 Pod 来监测节点间的连接状态。
官方仓库里虽然提供了 Helm Charts,但比较敷衍,可扩展性差,建议是自己把有用的部分扒出来直接 GitOps 写 YAML 创建资源。官方仓库里还提供了 Grafana Dashboard 定义,导入 Grafana 后可以很直观的看到节点之间的连接延迟:
2020 年写 NekoBox 那会,我还很菜(虽然现在也很菜),数据库只会用 MySQL。
尝试过 Postgres 后发现真香,就想着把 NekoBox 从 MySQL 迁移到 Postgres。但 NekoBox 在线上跑着,随时会有用户访问,发布新的提问和回答往数据库插入新的数据,此举无疑是在边开飞机边换引擎。
社区的 pgloader 是一个很好用的 Postgres 数据迁移工具,但它只支持全量迁移,并不支持增量同步。换句话说我需要先给线上的 NekoBox 停机防止有新的数据写入,迁移数据,再将后端数据库配置改到新的库上。受限于老的 2C2G 服务器的性能,我需要对 pgloader 进行限速,停机迁移全量数据的时间可能会很长。
如果要实现不停机迁移,则需要在完成全量迁移后,再将全量迁移这段时间内的增量数据,也同步到新库中。在调研了市面上几个数据库同步产品后,最后我选择使用阿里云 DTS 来完成。(这里不得不吐槽下我司,腾讯云的 DTS 产品只支持 MySQL 系之间的数据同步,不支持异构数据库,还得加强呀!)
将服务器添加为阿里云数据库网关 DG 节点后,即可在 DTS 控制台选择使用数据库网关接入非阿里云的源库与目标库,配置完后启动任务即可。
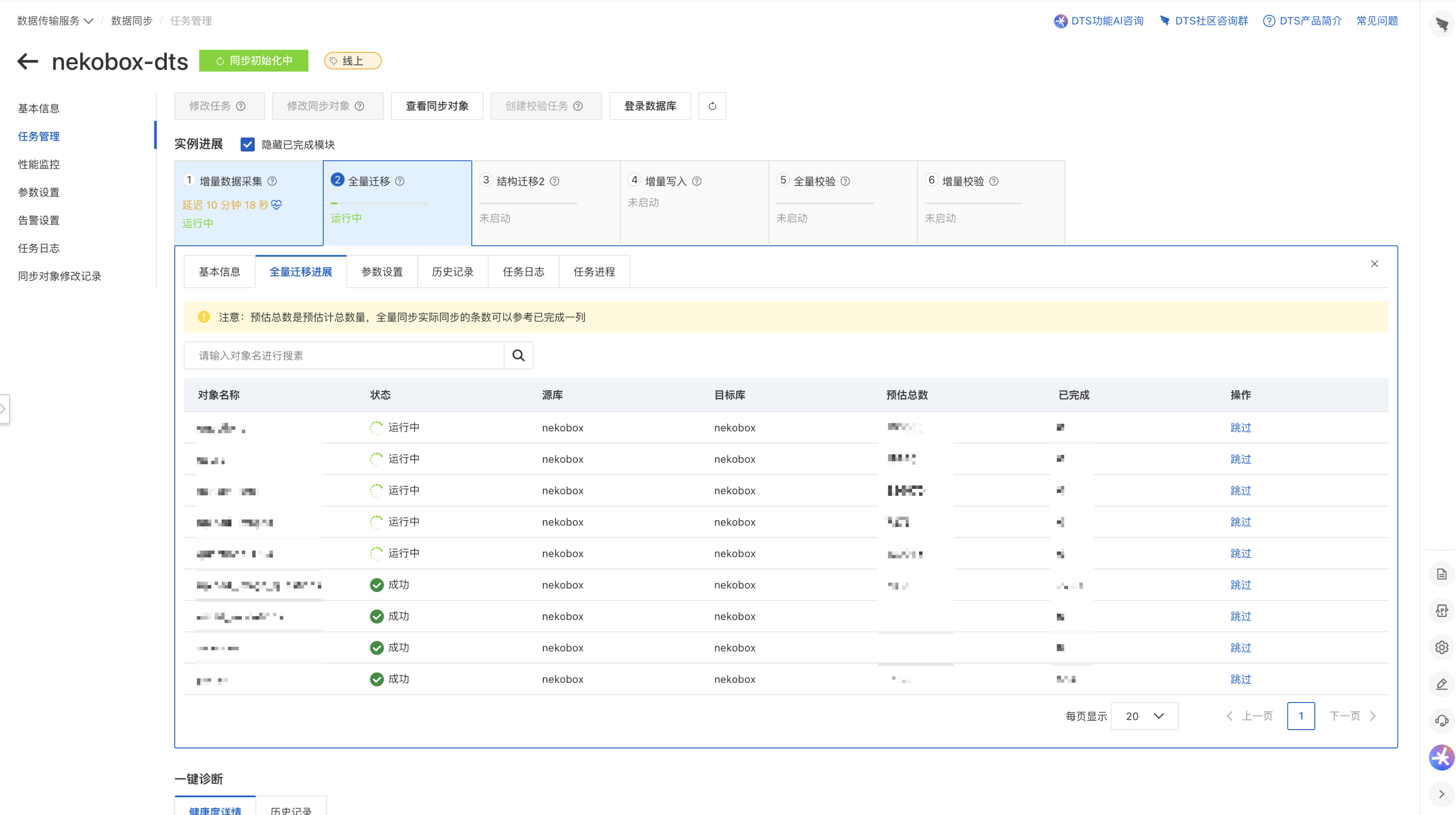
等全量迁移完了就会开始一直跑增量写入任务了,此时可以在线上写一些数据,来检查数据同步的情况。
但是阿里云在让我失望这件事上从来没有让我失望过。
我发现阿里云 DTS 居然把 MySQL tinyint(2) 类型迁移成了 Postgres smallint 类型,而非 bool 类型!这导致 GORM 在 AutoMigrate 时直接报错了!这一点在 pgloader 中专门有一条 tinyint-to-boolean 规则进行适配:
As MySQL lacks a proper boolean type, tinyint is often used to implement that. This function transforms 0 to ‘false’ and anything else to ’true’.
提工单问了客服,客服只会照本宣科给我发产品文档链接…… 我要的是怎样解决问题,不是你告诉我产品该怎么用。
更抽象的是,阿里云 DTS 怕不是根本没什么人用,产品文档中记录的“库表列名单个映射”功能,前端的树形组件下拉是有 Bug 的,如果直接全选了整个库,则无法再细化各表的字段映射配置。
这导致不看文档,用户自己是不会知道还有这功能的。但这个字段映射也只是配置目标字段的名称,并不能修改映射类型。
我的解决办法是在迁移完后,观测到线上流量低后,关闭 DTS 同步,线上服务停机,Postgres 数据库执行 SQL 修改字段类型。
ALTER TABLE "nekobox"."questions"
ALTER COLUMN is_private TYPE BOOLEAN
USING CASE
WHEN is_private = 0 THEN FALSE
ELSE TRUE
END;
ALTER TABLE "nekobox"."censor_logs"
ALTER COLUMN pass TYPE BOOLEAN
USING CASE
WHEN pass = 0 THEN FALSE
ELSE TRUE
END;
修改类型的 SQL 执行的很快,就当我以为已经全部搞定的时候,我发现阿里云 DTS 这垃圾东西居然不会迁移 Postgres 自增序列! 这意味着每一张表的ID 字段都不会自增并自动赋值,插入数据就会报错说 ID 字段为 NULL。
没办法,赶紧执行 SQL 手动加序列……
-- 1. 查看当前最大 ID(先确认数据)
SELECT MAX(id) FROM "nekobox".users;
-- 2. 创建序列并设置起始值(假设最大 id 是 1000)
CREATE SEQUENCE "nekobox".users_id_seq START WITH 1001;
-- 3. 将序列绑定到 id 列
ALTER TABLE "nekobox".users
ALTER COLUMN id SET DEFAULT nextval('nekobox.users_id_seq');
-- 4. 将序列的所有权给表(表删除时序列也删除)
ALTER SEQUENCE "nekobox".users_id_seq OWNED BY "nekobox".users.id;
还得是阿里云,能整出这种狠活来,真牛!😅
如果再给我一次机会,我会选择自己写一个工具,先记录 MySQL 数据库 BinlogID 或 GTID,然后调用 pgloader 进行全量数据迁移,再从记录的 BinlogID/GTID 处开始增量同步添加数据。
现在 NekoBox 已经迁移到了 Postgres,凌晨 3:30 开始迁移,4:00 完成。线上运行了一天 Trace 里没看到有报错,感觉是没问题了。
NekoBox 的前端使用 UIKit 组件库。这个组件库的风格我十分喜欢,扁平简单,美中不足的是它真的就只是一个 CSS + 一点点 JavaScript 的组件库。社区里有人开发了 vuikit 组件来将其接入 Vue 生态,但这个项目的最后一次 commit 已经是五年前了,并且还未适配 Vue3。
因此 NekoBox 的前端一直是以服务端渲染的形式呈现,稍微复杂一点的交互或者异步加载,则会使用 Alpine.js 实现。渐渐的,我发现它已经无法支撑起后续复杂的前端需求了。我写前端的经常会想:“这些响应式交互,Vue 来了可以全秒了。”
我开始尝试将 UIKit 的 CSS 引入 Vue3 项目中,发现它比我想象中的好用。由于 UIKit 大部分情况下只是在原生 HTML 标签上加上了 CSS 样式,因此我大可不必像 vuikit 那样将按钮、文本框之类的封装为 Vue 组件,直接在原生 HTML 标签用 class 指定样式即可。页面也比我想象中的少很多,因此只花了一个周末的时间就完成了 80% 的前端 Vue3 + 后端 RESTful API 的重构工作。
前后端分离后,由于后端部署在境外,请求 API 难免会慢一些。这里我用了 vue-loading-skeleton 来给页面加载时加上骨架屏,防止页面未加载完时布局塌陷。这个组件做得还行,可以自动识别插槽里的元素自适应调整加载的骨架元素大小。
新版的前端我不敢直接全量上线,想先小部分用户测试下。最简单的办法是将前端部署在例如 next.n3ko.cc 这样的子域下,但会导致后续主站全量上线时,子域的链接还得做重定向兼容。
复杂一点的话,在集群里搭个 Istio 服务网格来实现细粒度的流量转发,但看了下机器的配置,还是算了…… 最后简单粗暴的在 Cloudflare 上配置了回源规则:当请求 Cookies 里带 next-beta=1 时,则将请求转发到源站新版前端的端口上。后续在线上加个按钮,点一下就给 Set-Cookie 即可切换到新版前端,去掉 Cookie 就切回来。
我有问过自己,NekoBox 对我而言意味着什么?
我并不指望靠着它能够发家致富,我认为 NekoBox 是一块让我实践产品运营的“试验田”。参加工作以来,我基本没有做过对性能和服务可用性有很强要求的东西,更没有什么 To C 的经验。这既是好事,好在我不用随时 on call;也是坏事,坏在我没有那些项目经验和教训。
因此我想借 NekoBox 这个用户量还算不少的平台,亲身去实践开发和运营一个产品,去踩那些前人踩过的坑,去体验边开飞机边换引擎的惊险。因此 NekoBox 的项目经历其实也一直被写在我的简历里,作为一个还算成功的 Side Project 被我拿来跟面试官吹逼。😂
对于 NekoBox 的用户,很感谢他们能包容我的“放养式”运营,更是感谢那些还会不定期支付宝打赏的朋友们。我仅通过兔小巢这个渠道接收用户的反馈,并没有尝试组建 QQ 群之类的方式,是因为我认为每个人的圈子不同,年龄和性格也不同,求同存异会比较困难。我也很害怕跟别人起纷争或者冲突,所以还是继续维持现状吧。
关于之后的更新计划嘛,等新版前端稳定后,我想先完善一下基建方面,例如 Tracing 由 Uptrace 切到更专业的腾讯云 APM,完善项目的开发和部署文档,之后就可以开始做用户反馈中提到的暗色主题、多语言、表情评价,甚至是聊天等功能。先把 flag 立了,后面慢慢填坑哈哈哈。
2025-03-30 23:12:57
我在 2021 年时就开始用 GitHub Copilot 写代码了,2022 年 12 月初刷推特时看到了 ChatGPT,立刻注册了个号玩了下。大模型的这波风口我看到的很早,但却没有做什么行动。那个时候的自己感觉不管做什么起步都已经晚了,套壳站已经满天飞了,OpenAI 的 API Key 也被人卖的差不多了,已经没有什么新的玩法了。
今年过年的时候 DeepSeek 火了,我才惊讶地发现,几年过去了, 豆包、混元、千问虽然在业内打得不可开交,但还是有太多的人至今没有接触过这些大模型应用。我在推特上看到个喷子,喷 DeepSeek 的点居然是问今天天气怎么样,它回答不出来。很多人对这种对话式 AI 的概念还停留在 10 年前的 Siri 等手机语音助手上。换句话说,下沉市场还是一片蓝海。
刚好之前看到腾讯混元大模型的最低配模型 hunyuan-lite 居然是免费的!那我们不如也来试试当一回二道贩子,尝试自己做一个大模型套壳站,会不会有人用我不知道,但开发的过程一定很有意思。
排除掉写了一万遍的用户注册登录和一堆 CRUD,我对以下功能的实现原理很感兴趣:
SSE 代理:怎样将腾讯云大模型的 SSE 和自己的对话接口接起来?
SSE 断点续传:对话生成过程中如果页面刷新了,重新进入时怎样继续生成当前回答?(⚠️ 实践后发现这是最难实现的功能,边缘情况很多)
怎样生成对话标题?
每次对话的 Token 如何计算?单次对话的 Token 数如何限制?
开始逐个分析上述功能之前,我们先来看看社区做得怎么样了。我按 stars 排序随便挑了几个感兴趣的项目,简单读了下他们的代码后,我信心大增哈哈哈。🤣
这应该是大家最初自建套壳站时使用的了,使用 TypeScript 编写。功能中规中矩,我发现了两个有意思的点:
// https://github.com/ChatGPTNextWeb/NextChat/blob/48469bd8ca4b29d40db0ade61b57f9be6f601e01/app/client/api.ts#L197-L201
.concat([
{
from: "human",
value:
"Share from [NextChat]: https://github.com/Yidadaa/ChatGPT-Next-Web",
},
]);
// 敬告二开开发者们,为了开源大模型的发展,请不要修改上述消息,此消息用于后续数据清洗使用
// Please do not modify this message
NextChat 在生成公开的对外分享链接时,会在对话最后加上 Share from [NextChat] 的标识。目的是为了后续训练大模型时,能够分辨出哪些是人工产生的数据,哪些是以往的大模型生成的,进而清洗过滤掉大模型生成的内容。
细想一下还挺意思的,“2022 年” 像是一道屏障一样,将互联网上的文字内容隔开来了。2022 年以后的内容,读起来就得留个心眼了,凡是看到 “综上所述” “总的来说” 这些字眼,难免会怀疑是否是用 AI 生成的。它像是泄露的核废水一样,随着时间的推移逐渐蔓延并浸染整片知识的海洋。
// https://github.com/ChatGPTNextWeb/NextChat/blob/48469bd8ca4b29d40db0ade61b57f9be6f601e01/app/locales/cn.ts#L626-L632
Prompt: {
History: (content: string) => "这是历史聊天总结作为前情提要:" + content,
Topic:
"使用四到五个字直接返回这句话的简要主题,不要解释、不要标点、不要语气词、不要多余文本,不要加粗,如果没有主题,请直接返回“闲聊”",
Summarize:
"简要总结一下对话内容,用作后续的上下文提示 prompt,控制在 200 字以内",
},
NextChat 的这段代码解答了上面的问题 3 —— 对话标题是使用一段简短的 Prompt + 一个较小的模型生成的。转而一想,这里其实可能存在 Prompt 注入,只是没什么危害罢了。
open-webui 的前端做出了高仿 OpenAI 的风格。使用 Python Web 异步库 starlette 返回 SteamingResponse 来代理 SSE 接口。它也实现了对话标题生成的功能,Prompt 上比 NextChat 长很多,并且要求以 JSON 格式返回。
我担心的点是,标题生成本身用的就是小模型,这么长的 Prompt 以及限定 JSON 格式输出,对小模型而言会不会不稳定。🤔
至于并发限流、以及对话的 Token 吞吐量限制,open-webui 写了一个路由中间件解决,这里就不再赘述了。
因为我使用 Go 来编写后端,所以找了个 Stars 数很多的 Go 项目。作者应该是 PHP 转 Go 没多久,或者说是刚学编程没多久,这代码质量真的不敢恭维。
好好的 SSE 不用,画蛇添足用了 WebSocket,可从头至尾就没有需要客户端发送消息的场景。甚至这项目背后还接了个 xxl-job。😅 他能获得这么多 stars 只是因为把支付那块也给做完了,小白可以即开即用拿去做套壳。但从代码的可维护性和整洁度上来说,真是一团糟。我都想做个《鉴定网络奇葩代码》短视频了。
这个故事告诉我们,技术好不好不重要,能把事情做完最重要。
同样是 Go 项目,这个国外老哥写得代码就好多了。他使用了 langchaingo 来构造拼接对话。说实话我内心觉得这些库用起来挺花里胡哨的,又是什么模板,什么占位符,什么对话链,但最终做的事还是在拼字符串,拼出一个 Prompt 发给大模型。😁
老哥使用了 langchaingo 自带的 summarization 来做对话总结,本质上也是 langchaingo 内置了一段 Prompt。
而关于问题 4,如何计算 Token 数量,由于这个项目支持的模型都是 OpenAI 家的,因此直接使用的 OpenAI 开源的 tiktoken 来进行计算(国会听证会警告)。tiktoken 有 Go 封装的开源实现:github.com/pkoukk/tiktoken-go。
其余的一些项目我有点看不下去了,不如直接开写吧!
回忆一下,我们是怎样用豆包或元宝的,在页面左侧有一个对话列表,点开对话后可以看到我们发送的和 AI 回复的消息。因此需要创建 Chat (对话)和 Message (消息)两张表。
Chat 对话表| 字段名 | 类型 | 说明 |
|---|---|---|
ID |
int64 |
生成的自增 ID |
UserUID |
string |
用户 UID,用来对应这个对话属于哪个用户 |
Title |
string |
对话标题,后面由大模型总结生成 |
CreatedAt |
time.Time |
对话创建时间 |
Message 消息表| 字段名 | 类型 | 说明 |
|---|---|---|
ID |
int64 |
生成的自增 ID |
ChatID |
int64 |
Chat 对话表 ID,表示这条消息属于哪个对话 |
ParentID |
int64 |
父消息的 ID |
ChildrenIDs |
pq.Int64Array |
当前消息所有子消息的 ID 集合 |
Role |
MessageRole |
这条消息是谁发的,user / assistant |
Content |
string |
消息正文 |
Model |
string |
对话使用的模型,目前还没做多模型切换,先预留 |
TokenCount |
int64 |
为消息正文的 Token 数 |
CreatedAt |
time.Time |
对话创建时间 |
有坑注意!
这里的 ID 均使用 Snowflake 算法生成,Snowflake 生成的是 19 位数字,这在 Go int64 下没问题,但在前端 JavaScript 下会丢失最后 4 位的精度。即 1906281281029672960 在前端会变成 1906281281029673000。
我用了一个简单粗暴且不靠谱的 HACK,将数字除以 1000,去除后三位。
消息表中的 ParentID 和 ChildrenIDs 字段,用于记录父子消息关系。就像豆包可以点击重新生成,进而再生成一条回复。
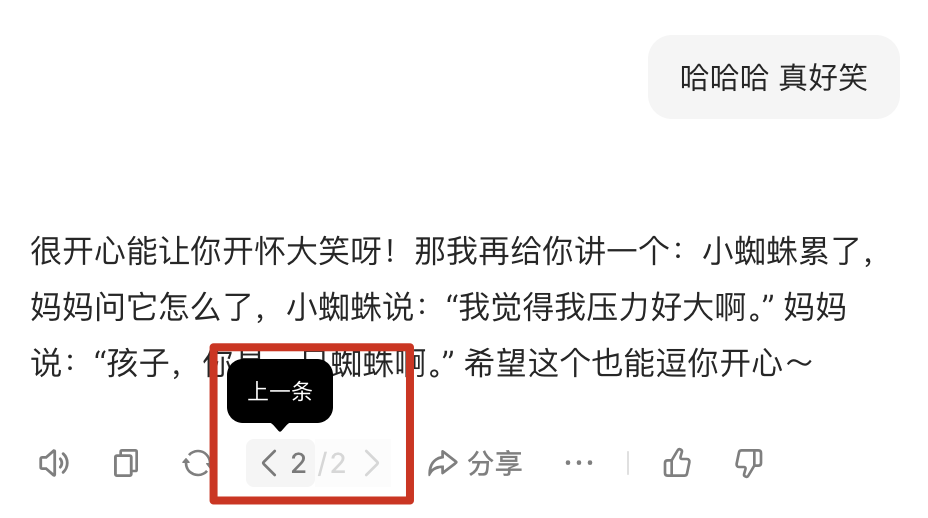
更复杂的像 ChatGPT,可以点击上文任意一条消息,新建一个分支重新生成对话。为了实现这样的效果,我们在创建一条新的消息记录时,需要 ParentID 指定它的父消息,并更新它父消息的 ChildrenIDs 字段,这俩包在一个数据库事务里做就行。
在需要构造大模型接口 JSON messages 参数时,只需从最后一条消息开始,沿着 ParentID 依次向上遍历,一直到 ParentID 为 0,即可拿到当前对话分支的消息列表。 前端实现像上图中豆包的“上一条”“下一条”翻页的效果,也只需取 ChildrenIDs 构造翻页即可。
这里再补充一些小细节,我发现腾讯元宝的消息 ID 使用 <对话ID>_<自增索引的格式> 表示,如 <对话ID>_1 <对话ID>_2 等,这从设计上使得元宝的对话只能是线性的。 用户只能重新生成最新一轮对话的消息,且不能在历史对话中重新生成创建分支。
关于 SSE 的简单介绍,可以去阅读我五年前写得 《聊聊 EventStream 服务器端推送》 这篇文章。大模型活了之后每个月都会有人在 Google 上搜 EventStream 搜到这篇。
腾讯云官方的 Go SDK 调用混元大模型时,客户端可以使用 SendOctetStream 方法,接收流式响应,此时 response 中返回的是 channel 类型的 SSEvent。我们可以先对混元大模型做简单的函数封装,从 SDK 的 channel 中提出大模型对话返回的 Content 正文,再打到函数返回值的 channel 中,精简后的代码如下:
func (h *Hunyuan) TextCompletions(ctx context.Context, input TextCompletionsInput) (chan string, error) {
// ...
eventsCh := response.BaseSSEResponse.Events // 腾讯云 SDK 输出
go func() {
for event := range eventsCh {
if event.Err != nil {
logrus.WithContext(ctx).WithError(event.Err).Error("Failed to get event")
break
}
eventData := event.Data
var respParams hunyuan.ChatCompletionsResponseParams
if err := json.Unmarshal(eventData, &respParams); err != nil {
logrus.WithContext(ctx).WithError(err).Error("Failed to unmarshal event data")
continue
}
if len(respParams.Choices) == 0 {
break
}
choice := respParams.Choices[0] // 默认取第一个结果,貌似我从没见过会有第二个
outputChan <- *choice.Delta.Content // 打到函数返回值的 channel 里
}
close(outputChan)
}()
// ...
}
我这里直接默认选第一个 Choices ,将 Content 正文放到 channel 里。JSON 反序列化那块,硬要扣的话也可以改用 sonic。
具体到对话接口的设计上,与那些自用的套壳站不同,我们是要给第三方用户使用的,在接口的入参上不能像那些自用站一样每次都将整个对话完整的 messages 发给后端处理,应该尽可能缩减用户前端可控的参数范围。前端只能传入对话 ID、父消息 ID、提问消息正文;历史消息链的拼接和 messages 参数的构造全都应该在后端完成。
对话接口先响应 Content-Type: text/event-stream 头,然后发送一条类型 event:metadata 的消息告诉前端当前对话 ID 和消息 ID,之后就从大模型的 channel 里读消息,写入 ResponseWriter 即可。
大模型接口返回的是逐 Token 生成的内容,这里其实又有一个抉择,SSE 的每条消息,是返回当下完整的消息内容,还是返回新增的 Token 内容呢?
// 返回当下完整的内容
{"v":"你好,很"}
{"v":"你好,很高兴认识你"}
// 返回新增内容
{"v":"你好,很"}
{"v":"高兴"}
{"v":"认识你"}
现在大家都是选择后者。我担心的点是如果选择后者,前端拼接字符串时会不会有概率乱掉。我在不断测试豆包的时候遇到过一次,但这也是极端情况,实际后端文本是正常的,刷新一下就好了。因此我也随大流选择了返回每次新增的内容。😁

由于我前端处理 SSE 使用的是 eventsource-client 这个库,它在传入对话接口的 URL 后,就只能处理 SSE 格式的响应了。因此这个对话接口的报错,也只能以写入单条 SSE 消息的形式返回,使用 event: error 来区分。
在对话生成结束后,需要判断当前是否为新对话,是的话则需要再调用大模型,让其生成对话标题。生成的对话标题入库存储,同时 SSE 发送一条 event: title 类型的消息,通知前端更新页面上的对话标题。
我这里的 Prompt 写得比较粗糙,你可以根据上文中提到的 NextChat 和 open-webui 的 Prompt 自己再改改。以及是将提问内容放在单独的 user 消息中,还是直接拼在 System Prompt 中,这里也可以再钻研下。
if isNewChat {
// Summarize the conversation title from LLM in a new conversation.
summaryOutput, err := llmChat.TextCompletions(ctx.Request().Context(), llm.TextCompletionsInput{
Messages: []*llm.TextCompletionsMessage{
{Role: "system", Content: "请根据给出的提问内容,总结生成一个不超过 10 个字的对话标题,尽可能是陈述句,仅输出对话标题,不要有任何其他的内容。"},
{Role: "user", Content: "提问内容:`" + content + "`"},
},
SSE: false,
})
if err != nil {
logrus.WithContext(ctx.Request().Context()).WithError(err).Error("Failed to get text completions of summary title")
} else {
for title := range summaryOutput {
if err := db.Chats.Update(ctx.Request().Context(), chat.ID, db.UpdateChatOptions{Title: title}); err != nil {
logrus.WithContext(ctx.Request().Context()).WithError(err).Error("Failed to update chat title")
}
// Set the title to the SSE response if the context is not canceled.
_ = ctx.SSEResponse("title", title)
}
}
}
混元大模型本身提供了 GetTokenCount 接口用于计算消息中的 Token 数,20 QPS 的限制还不收费,足够我们使用了。
从处理流程上来说,用户发起提问时,调用 GetTokenCount 计算提问的 Token 数;回答生成完毕后,计算并更新回答所消耗的 Token 数。为未来可能要做的 Token 付费功能铺垫。进一步,如果还要做不同套餐的上下文长度的限制,提问的长度在开始提问的时就进行判断,而对于大模型回答的长度,则是在调大模型接口时使用 max_tokens 参数限制。
然而混元的 SDK 好像不能指定这个参数,只有走 OpenAI 兼容接口调用时才支持。

我画了一张流程图来梳理目前的整个过程,带 🚀 小火箭图标的意味着这一步可以开个 goroutine 异步进行。如果上述流程没问题,那就请做紧抓稳了,我们后面要引入 SSE 断点续传功能了。
这是一个各家大厂都支持的功能,但网上好像还没人讨论应该如何实现,我在相关的大模型套壳开源项目中也没有看到。
具体来说就是,在用户提问后,前端调用了上述对话接口,页面开始逐字打出大模型的回答。就在这时用户突然刷新了页面,或者在新的浏览器标签页中打开了网页,页面上应该要接着之前的回答继续生成完。我称之为“SSE 断点续传”。
我们拆解一下这个需求,最终的效果应该是:
在前文中,我们直接将大模型的 Channel 和当前请求的 Response Channel 接在一起,一旦 SSE 请求被中断,HTTP 请求的 Context Cancel 后,会连带着混元大模型 SDK 生成请求的 Context 一起停止。因此,我们第一步应该是将大模型生成请求独立到一个 goroutine 中进行,且 Context 与外部 HTTP Context 隔离。
不管是刷新还是新开多个浏览器页面,都要能获取到之前已生成的回答内容,那么生成的内容就得找个地方存下来。这个“存下来”还不是持久化存储,因为回答生成完毕后,就会入库存到 Messages 表的 Content 字段中。我们要的是一个性能好的临时存储,它最好还自带过期功能,还支持多个浏览器接收的这种消息订阅分发模式,这里很容易能想到用 Redis。
Redis 关于消息订阅的功能有 PubSub 和 Stream。前者用于实现消息的发送与广播,但消息不会被持久化,发完就忘了;后者引入了消费组的概念,不同的消费组有单独的 position 来消费历史消息,甚至还支持 ACK 机制。那么结果就很明确了,我最终选择了 Redis Stream 来实现这个功能。
大模型生成请求在单独的 goroutine 中进行,生成的内容打到 Redis Stream 中,Stream 的 Key 使用 chat:message-stream:<message_id> 表示。每一个前端的 SSE 请求,都是从 chat:message-stream:<message_id> 中从头开始(游标为 0)间接读取消息并返回。
那么前端在进入页面后,又该如何知道当前对话还在生成中呢?我在每次调用大模型生成时都会在 Redis 里设置一个 Key,生成结束后删除。
set chat:conversation-status:<chatID> <messageID> 5*time.Minute
前端获取对话基本信息的 HTTP API,会通过查看这个 Key 是否存在来判断当前对话是否正在生成。如果正在生成,就直接调对话接口,发送空提问消息来开启 SSE 开始拉取回答消息。
这个 chat:conversation-status:<chatID> 我还设置了 5 分钟的过期时间用于兜底,如果因为意外后端重启了,对话不至于一直卡在生成中的状态。
在对话结束后,chat:conversation-status:<chatID> chat:message-stream:<message_id> 这两个 Key 都会被删除,这里会存在一个 race 的极端情况:那就是前端通过 conversation-status 得知对话正在生成,这个时刻之后刚好对话生成结束,前端启动 SSE 后发现 message-stream 被删了,这样就拉不到历史消息了。因此我在删除 conversation-status 后延迟了 5 秒再删除 message-stream 。
// Delete the conversation status in redis.
if err := redis.Get().Del(ctx, conversationStatusFlagKey).Err(); err != nil {
logrus.WithContext(ctx).WithError(err).WithField("key", conversationStatusFlagKey).Error("Failed to delete redis key")
}
time.Sleep(5 * time.Second)
// Delete the redis stream after the chat message completion is done.
if err := redis.Get().Del(ctx, messageStreamKey).Err(); err != nil {
logrus.WithContext(ctx).WithError(err).WithField("stream", messageStreamKey).Error("Failed to delete redis stream")
}
以上,我们就实现了 SSE 消息的断点续传了。但还有一个问题:用户点击前端的「停止」按钮后,我们要能够停掉 goroutine 里正在跑的大模型请求,确保生成的消息内容就停在当下。这里我单独加了个 POST /stop 接口,前端调用后会将 chat:conversation-status:<chatID> 从 Redis 中直接删掉。大模型生成的 goroutine 里再开一个 goroutine 来循环查看这个 Key 是否存在,如果不存在了,就直接关掉大模型请求的 Context:
// Scan for `conversationStatusFlagKey`
// If the conversation status is not set, which means the conversation is stopped by the user.
go func() {
for {
select {
case <-ctx.Done():
return
case <-llmCtx.Done():
return
default:
_, err := redis.Get().Get(ctx, conversationStatusFlagKey).Result()
if errors.Is(err, redispkg.Nil) {
llmCancel()
return
}
time.Sleep(1 * time.Second)
}
}
}()
至此,我们就完成了上述 SSE 断点续传的 4 个需求,属实不容易,这里的设计我斟酌思考了很久。我也不知道大厂们是怎么做的,如果你有更好的设计或者想法,欢迎留言和我讨论。
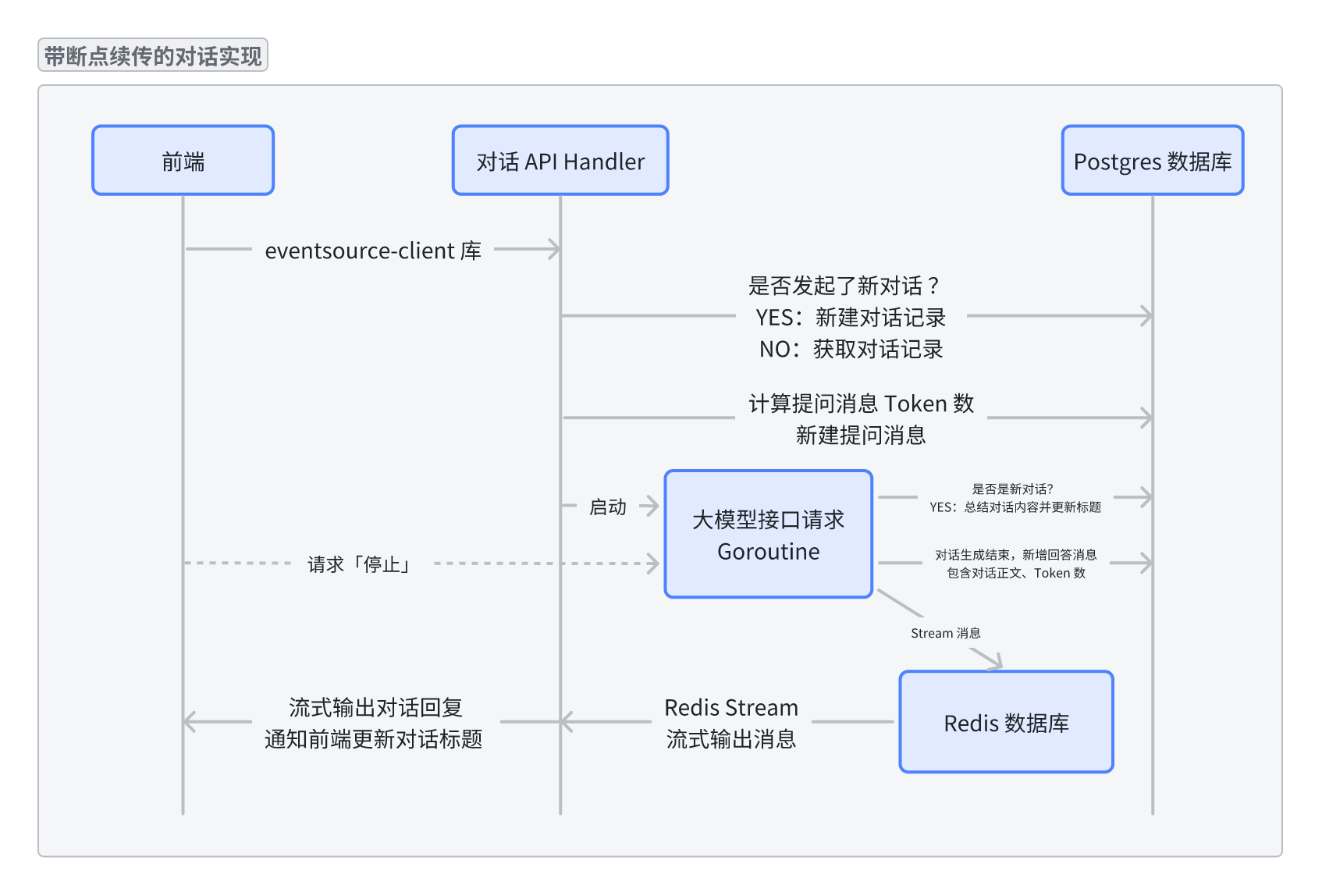
具体落实到代码上会复杂些,因为还有更新对话标题、计算 Token 等流程,很多步骤又是可以异步进行的,但互相之间又会用不同的 Context 来同步状态,然后 goroutine 中还有一堆的 defer ,这块的代码我打算后续梳理下流程好好美化下,现在只是停留在可用的状态。
整个开发过程中,我时常会去看豆包和元宝是怎么做的,参考他们的设计是怎样的(期间要不停地抓包和翻压缩后的 JS 文件),也和大家分享下。
豆包的实现比较复杂,用户发送的消息在浏览器本地的 IndexDB 会存一份。当用户开启新对话提问后,由于这时新对话还没发送到后端,前端会给这个对话和消息生成一个本地的 Local ID。带着 Local ID 将请求发给后端。但正如我前面提到的,Local ID 这种由用户本地生成的数据,后端不应该给予过多的信任,因而对话 Local ID 仅被用在第一次后端生成对话 ID 前,当后端生成并返回了对话 ID 后,后续都用该对话 ID 进行查询;消息 ID 也是同理。最后接口参数会传 本地/后端 的 对话/消息 ID 共 4 个参数,但后端会优先使用后端生成的 ID。我对着这个接口排列组合测了多种情况,发现豆包都能很好的 handle 住。
由于豆包会把消息在本地存一份,因此在页面刷新后,它是知道上次 SSE 断在哪里的。观察豆包的 SSE 返回消息,它的 JSON 中有一个自增的 event_id 游标字段,断点续传时会带上这个 event_id,SSE 接口就只会返回在这之后的消息。这样做是为了省一点传输的流量吗(?
相对而言元宝就大道至简很多。除了我们上面提到的,元宝使用 <对话ID>_<自增索引的格式> 格式的消息 ID 记录线性的消息记录。关于断点续传,元宝是拿着对话 ID + 消息 ID 请求 /continue 接口,后端 SSE 返回全部历史消息和正在生成的消息。但如果再重放 /continue 接口请求,会直接 hang 住,可能这是个 Bug 吧。
我之前总结过 BAT 三家大厂的 AI 组件库建设情况:
| 公司 | 组件库 | 评价 |
|---|---|---|
| 字节跳动 | Semi Design | 豆包同款,Semi Design 还支持搭配 Tailwind CSS 使用。缺点是只支持 React,很难受。然后开发团队还说提供了接口,社区可以自己实现 Vue 版本。呃呃,社区实现了,但又没完全实现,居然还要在 Vue 里写 JSX。😅 |
| 阿里巴巴(蚂蚁) | Ant DesIgn X | 打开官网给我浏览器卡得半死。相比其它家有欢迎栏、提示集这类独特组件。还没深入使用过。 |
| 腾讯 | TDesign | 我司这个有点一言难尽。元宝前端虽然用了 TDesign 但 AI 对话那块看起来是自己写的。组件库提供的 ChatInput 占得空间太大了,样式还不好调,我在司内的项目是拿 TDesign 的 Input 组件自己撸了一个。(以上仅代表个人观点,我爱公司😘)
|
因此前端的部分我选择了 Semi Design 组件库,因为我感觉它是真的经历了 Dogfooding 做出来的,实打实的豆包同款前端。我在写的时候前端想去仿豆包的风格,然后发现现成的组件库实现不了同样的样式,便去翻豆包的前端,惊讶地发现我踩的坑他居然都踩过一遍了! 我按照豆包前端强行加 CSS style 和 class 之后,真就搞好了。
这也是我写得第一个 React 项目,不出意外地踩了 StrictMode 下请求会发两次用来检查副作用的坑。🤣 这个过程跟我刚开始写 Vue 一样,一开始是很痛苦的,但写着写着突然就顿悟了,发现 React 把各种东西和功能定义成组件嵌套包起来的设计,还真有点妙。我也理解为什么 Vue 能火了,这俩入门难度确实不一样。
我的大模型套壳站现已部署至线上:TakoChat - https://tako.chat

Tako(たこ)是日文章鱼🐙的意思。起这个名字只是我单纯觉得微软 Teams 下的章鱼动态 Emoji 很可爱。背后接的是免费版的混元大模型,所以你可以注册体验下,只是目前的功能还很基础。(不清楚阿里云那边短信验证码备案的问题是否解决了,可能会遇到部分运营商收不到短信验证码的问题,可以换不同运营商的号试试)
你可以看到左侧有「实验室」一栏,我是打算在这里动手做做像 MCP 和 Agent 这样的小玩意。(先把坑开了,填不填再说。
呼~ 总算把这篇写完了。我还挺自我感动的,没蹭热度,仅仅只是分享一些自己总结的心得体会,比那些营销号不知道高到哪里去了。
至此,周末也要结束了,明天又可以上班继续修 bug 了 🤤
文章头图来自 @极道寂 PixivID: 69237248
2025-01-17 23:01:23
一直想要有一个平台,能够发些碎碎念之类,记录一下在食堂吃到的新菜式,或者分享一下有意思的事情。如果在 QQ 空间动态发,未免有些扰民了;如果在 Telegram 发,因为网络问题不是很方便;在知识星球发,很不幸我的知识星球账号莫名其妙地被停用了。
之前刷推特时偶然发现了 memos 这个项目,定位是一个 Self-hosted 的笔记应用,但看页面很像是一个精简版的 Twitter。memos 的功能很简单,令我感到惊讶的是,它的 Repo 居然有 36000+ 的 Stars 数,确实厉害。
碰巧 memos 也是用 Go 写,功能又这么简单,我便抽空阅读了下它的源码,也还算是小有收获,用这篇文章分享下我的心得体会。文中提到的内容可能你很早以前就知道了,还请多多包涵。
本文使用 commit edc3f1d 的代码进行演示。
语义化版本(Semantic Versioning)在 Go 里面应该是用得很多了。几年前参加 GopherChina 的时候,就有人专门分享了这个。
memos 在 server/version/version.go 下记录了当前的版本号,并为使用 golang.org/x/mod/semver 实现了排序逻辑。值得注意的是,这里的版本号会被用于在数据库迁移(migration)中。每一个版本的数据库迁移 SQL 文件会被放置在以版本号命名的文件夹中,当执行数据库迁移时,会将这些版本号文件名进行排序,并与当前的版本号进行对比,从而选择要执行的迁移脚本。
memos 支持 MySQL、Postgres、SQLite 三种数据库。遇到这种需要支持多种数据库的场景,我们往往会使用 ORM,就算对 ORM 存在的副作用不信任,也会选择 SQL 查询构造器(SQL Query Builder)的库来辅助我们构造 SQL。但 memos 不知道在坚持什么,硬生生地对着三套数据库后端写了三套代码!他甚至只用 database/sql 和对应数据库的 Driver!他甚至手写 SQL!他甚至还各种拼 SQL 查询条件的字段!
各位可以体会下 store/db/mysql/activity.go#L23-L27
fields := []string{"`creator_id`", "`type`", "`level`", "`payload`"}
placeholder := []string{"?", "?", "?", "?"}
args := []any{create.CreatorID, create.Type.String(), create.Level.String(), payloadString}
stmt := "INSERT INTO `activity` (" + strings.Join(fields, ", ") + ") VALUES (" + strings.Join(placeholder, ", ") + ")"
这段 INSERT 真就硬生生地拼字段,硬生生的写死预编译占位符。
当然,有人提了 issue 问为什么不用 ORM,并且推荐了 sqlc 和 sqlbuilders 两个库。作者的回复是前者 looks a little weird (?),后者 pretty much the same as the existing way,综上所属作者认为保持现状啥也不改!😅
FYI:https://github.com/usememos/memos/issues/2517
memos 项目中对 gRPC 的写法可谓是教科书级别的。我也算是对着它的代码入门了下 gRPC。说来惭愧,我以前除了拿 Protobuf 写过 Hello World 的 demo,就没有更深入的应用了。
Buf 是一个用来辅助使用 Protobuf 的工具。它相当于为 Protobuf 实现了“包管理”的功能,你可以使用 buf.yaml 来定义需要引用的第三方 Proto,还可以配置 Lint 之类的规则。运行 buf generate 后便会自动去帮我们完成运行 protoc-gen-go 等一切操作。memos 中就使用到了 Buf,可以在 proto/buf.yaml 找到。Buf 还会生成一个 buf.lock 文件,也就是包管理中常见的签名文件。
我们可以观察到 Buf 的 dep 依赖形如 buf.build/googleapis/googleapis 这样的 URL,访问便可跳转到 Buf Schema Registry 上对应 Package 的页面。
感觉用 Buf 来处理 Protobuf,操作简便,逼格一下就上去了,学到了。
memos 的 /proto 目录下,store 目录与数据库的表结构对应,为每张表对应的实例的 proto 定义。api/v1 目录中则是 service 的定义,这里则对应了 Web API 的路由。
service AuthService {
// GetAuthStatus returns the current auth status of the user.
rpc GetAuthStatus(GetAuthStatusRequest) returns (User) {
option (google.api.http) = {post: "/api/v1/auth/status"};
}
// SignIn signs in the user with the given username and password.
rpc SignIn(SignInRequest) returns (User) {
option (google.api.http) = {post: "/api/v1/auth/signin"};
}
// SignInWithSSO signs in the user with the given SSO code.
rpc SignInWithSSO(SignInWithSSORequest) returns (User) {
option (google.api.http) = {post: "/api/v1/auth/signin/sso"};
}
// SignUp signs up the user with the given username and password.
rpc SignUp(SignUpRequest) returns (User) {
option (google.api.http) = {post: "/api/v1/auth/signup"};
}
// SignOut signs out the user.
rpc SignOut(SignOutRequest) returns (google.protobuf.Empty) {
option (google.api.http) = {post: "/api/v1/auth/signout"};
}
}
例如上述代码,service 中的每个 rpc 可以看作与一个 API 相对应。
例如 GetAuthStatusRequest 这些是在下面定义的 message ,相当于是接口的入参表单,returns 指定了返回值。没有返回值的接口则使用了 google.protobuf.Empty 。
option 指定了 HTTP 下的请求路由和请求方法。
对于动态路由,感觉会有些复杂:
rpc GetMemo(GetMemoRequest) returns (Memo) {
option (google.api.http) = {get: "/api/v1/{name=memos/*}"};
option (google.api.method_signature) = "name";
}
rpc UpdateMemo(UpdateMemoRequest) returns (Memo) {
option (google.api.http) = {
patch: "/api/v1/{memo.name=memos/*}"
body: "memo"
};
option (google.api.method_signature) = "memo,update_mask";
}
第一个 GetMemo 中,限制了路由的必须要匹配到 /api/v1/memos/* ,后面的 method_signature 指定了必须要传 name 参数。
第二个 UpdateMemo 中,限制了路由必须匹配 /api/v1/memos/* 。大括号里有个很怪的 memo.name=,因为 proto 里参数都是在 rpc 的入参传入的(即 UpdateMemoRequest ),只是我们在通过 HTTP API 访问时才有 Path、Header、Query、Body 这些传参的方式。因此在 rpc 的定义里,路由中通配符的值来自于 UpdateMemoRequest 中的 memo.name 。而后面的 method_signature 指定了 memo 和 update_mask 为必须要传的参数。
Service 的具体实现上,其实跟正常写 HTTP 接口差不多,Service 结构体实现对应 interface 里定义的方法即可。我注意到方法的错误处理,使用的是 google.golang.org/grpc/status 构造的 error,状态码也是 grpc 包里自带的。
func (s *APIV1Service) GetMemo(ctx context.Context, request *v1pb.GetMemoRequest) (*v1pb.Memo, error) {
...
return nil, status.Errorf(codes.PermissionDenied, "permission denied")
}
codes 包里定义了 17 种状态码,我开始还怀疑就这么点状态码类型真的能给所有的错误分类吗?事实证明还真可以。像 RESTful API 里常常表示的 403 没权限、404 不存在、400 格式不对、5xx 服务寄了 等状态,都可以找到状态码进行对应。
var strToCode = map[string]Code{
`"OK"`: OK,
`"CANCELLED"`:/* [sic] */ Canceled,
`"UNKNOWN"`: Unknown,
`"INVALID_ARGUMENT"`: InvalidArgument,
`"DEADLINE_EXCEEDED"`: DeadlineExceeded,
`"NOT_FOUND"`: NotFound,
`"ALREADY_EXISTS"`: AlreadyExists,
`"PERMISSION_DENIED"`: PermissionDenied,
`"RESOURCE_EXHAUSTED"`: ResourceExhausted,
`"FAILED_PRECONDITION"`: FailedPrecondition,
`"ABORTED"`: Aborted,
`"OUT_OF_RANGE"`: OutOfRange,
`"UNIMPLEMENTED"`: Unimplemented,
`"INTERNAL"`: Internal,
`"UNAVAILABLE"`: Unavailable,
`"DATA_LOSS"`: DataLoss,
`"UNAUTHENTICATED"`: Unauthenticated,
}
memos 的 server/server.go 文件定义了 HTTP 服务。它的 HTTP 服务使用 echo 框架。
重点看下面的代码:
grpcServer := grpc.NewServer(
// Override the maximum receiving message size to math.MaxInt32 for uploading large resources.
grpc.MaxRecvMsgSize(math.MaxInt32),
grpc.ChainUnaryInterceptor(
apiv1.NewLoggerInterceptor().LoggerInterceptor,
grpcrecovery.UnaryServerInterceptor(),
apiv1.NewGRPCAuthInterceptor(store, secret).AuthenticationInterceptor,
))
s.grpcServer = grpcServer
apiV1Service := apiv1.NewAPIV1Service(s.Secret, profile, store, grpcServer)
// Register gRPC gateway as api v1.
if err := apiV1Service.RegisterGateway(ctx, echoServer); err != nil {
return nil, errors.Wrap(err, "failed to register gRPC gateway")
}
这里首先声明了一个 gRPC Server,并加了些常见的 Recover 中间件、Logger 拦截器、ACL 鉴权拦截器等。
后面的 NewAPIV1Service 创建每一块接口的 ServiceServer。跟进去可以看到,它会向上述定义的 gRPC Server 注册所支持的服务。这些注册服务的 v1pb.RegisterXXXServiceServer 就是用 proto 文件自动生成的了。
func NewAPIV1Service(secret string, profile *profile.Profile, store *store.Store, grpcServer *grpc.Server) *APIV1Service {
grpc.EnableTracing = true
apiv1Service := &APIV1Service{
Secret: secret,
Profile: profile,
Store: store,
grpcServer: grpcServer,
}
v1pb.RegisterWorkspaceServiceServer(grpcServer, apiv1Service)
v1pb.RegisterWorkspaceSettingServiceServer(grpcServer, apiv1Service)
v1pb.RegisterAuthServiceServer(grpcServer, apiv1Service)
v1pb.RegisterUserServiceServer(grpcServer, apiv1Service)
v1pb.RegisterMemoServiceServer(grpcServer, apiv1Service)
v1pb.RegisterResourceServiceServer(grpcServer, apiv1Service)
v1pb.RegisterInboxServiceServer(grpcServer, apiv1Service)
v1pb.RegisterActivityServiceServer(grpcServer, apiv1Service)
v1pb.RegisterWebhookServiceServer(grpcServer, apiv1Service)
v1pb.RegisterMarkdownServiceServer(grpcServer, apiv1Service)
v1pb.RegisterIdentityProviderServiceServer(grpcServer, apiv1Service)
reflection.Register(grpcServer)
return apiv1Service
}
最后的 reflection.Register(grpcServer) 用于注册 gRPC 的反射功能,让客户端在运行时能动态获取 gRPC 服务的相关信息,如服务列表、方法列表、方法的输入输出参数类型等,而不需要事先知道服务的具体定义。
向 gRPC Server 注册完服务后,下面是将 Echo 框架启动的 HTTP Server 作为 Gateway,以实现通过 HTTP 的方式来访问 gRPC Service。(echoServer 就是 echo.New() 出来的实例)
// Register gRPC gateway as api v1.
if err := apiV1Service.RegisterGateway(ctx, echoServer); err != nil {
return nil, errors.Wrap(err, "failed to register gRPC gateway")
}
跟进去看定义。这里居然新建了一个 gRPC 的客户端!
runtime.NewServeMux() 是 grpc-gateway 下的包,用于返回一个 HTTP Mux,后续就可以交给任意的 Go HTTP 框架去调用。下面自动生成的 v1pb.RegisterXXXServiceHandler 这些路由 Handler,就是来自于上文 proto 文件里的 google.api.http 注解。
最后将这个 HTTP Mux 包起来交给 echo 框架的 handler,放在了 /api/v1/* 路由下。这样我们就实现了 RESTful 风格的 API。
// RegisterGateway registers the gRPC-Gateway with the given Echo instance.
func (s *APIV1Service) RegisterGateway(ctx context.Context, echoServer *echo.Echo) error {
conn, err := grpc.NewClient(
fmt.Sprintf("%s:%d", s.Profile.Addr, s.Profile.Port),
grpc.WithTransportCredentials(insecure.NewCredentials()),
grpc.WithDefaultCallOptions(grpc.MaxCallRecvMsgSize(math.MaxInt32)),
)
if err != nil {
return err
}
gwMux := runtime.NewServeMux()
if err := v1pb.RegisterWorkspaceServiceHandler(ctx, gwMux, conn); err != nil {
return err
}
// ...
if err := v1pb.RegisterIdentityProviderServiceHandler(ctx, gwMux, conn); err != nil {
return err
}
gwGroup := echoServer.Group("")
gwGroup.Use(middleware.CORS())
handler := echo.WrapHandler(gwMux)
gwGroup.Any("/api/v1/*", handler)
gwGroup.Any("/file/*", handler)
// GRPC web proxy.
options := []grpcweb.Option{
grpcweb.WithCorsForRegisteredEndpointsOnly(false),
grpcweb.WithOriginFunc(func(_ string) bool {
return true
}),
}
wrappedGrpc := grpcweb.WrapServer(s.grpcServer, options...)
echoServer.Any("/memos.api.v1.*", echo.WrapHandler(wrappedGrpc))
return nil
}
下面还声明了一个 gRPC Web Proxy,这个是用 HTTP 的方式来调 gRPC。使用的 grpcweb 包,调用接口传参并不是用的 Query 或者 Body,而是 protobuf 将参数序列化后再发送那套。跟走纯 TCP 相比,仅仅只是这里走的是 HTTP 请求而已。换句话说,就是让浏览器能跟 gRPC Server 通信了。
而浏览器中调用会有同源跨域的问题,所以可以看到这里的 grpcweb.Option 也是逐重解决 CORS 和 Origin。
希望看到这里你没被绕晕。你会发现,memos 其实是用 HTTP 实现了两套服务:RESTful API 和 gRPC Server API。这两套背后的业务逻辑都是一样的,且都是使用 HTTP 协议,不同点在于路由和传参的方式不一样。
有个比较抽象的小细节不知道你发现了没有,gRPC Server -> gRPC Server API 只需要用 grpcweb 包一下就行了,但 RESTful API 需要再本地建一个 gRPC Client,然后这个 Client 自己请求本地的 Server。整条链路是 HTTP Mux -> Handler Func -> gRPC Client -> gRPC Server。而这个 gRPC Client 监听的端口,居然与对外的 HTTP 服务的端口是一样的!
换句话说,就是 gRPC Server 和 echo HTTP Server 复用了同一个端口。
这里是使用了 github.com/soheilhy/cmux 这个库来实现。这个库支持定义 Matcher 条件,哪个匹配上了就走哪个的 Serve。
像 gRPC Server 在通过 HTTP 调用时,通过 Body 发送 Protobuf 报文,Content-Type 为 application/grpc;而 RESTful API 则是常规的 HTTP 请求,除了 PATCH 方法外都会命中。
muxServer := cmux.New(listener)
go func() {
grpcListener := muxServer.MatchWithWriters(cmux.HTTP2MatchHeaderFieldSendSettings("content-type", "application/grpc"))
if err := s.grpcServer.Serve(grpcListener); err != nil {
slog.Error("failed to serve gRPC", "error", err)
}
}()
go func() {
httpListener := muxServer.Match(cmux.HTTP1Fast(http.MethodPatch))
s.echoServer.Listener = httpListener
if err := s.echoServer.Start(address); err != nil {
slog.Error("failed to start echo server", "error", err)
}
}()
go func() {
if err := muxServer.Serve(); err != nil {
slog.Error("mux server listen error", "error", err)
}
}()
这里对 gRPC 的操作属实妙哉!端口复用的操作更是一绝。想起我之前有个 Side Project,既需要跑对外的 Web Server 后端,又需要跑对内的 API Server 后端,当时的做法是监听两个不同端口,现在想来可以用 cmux 来实现端口复用了。
那么请问,上述这种教科书级别的 Protobuf 和 gRPC 的用法,是来自于哪里的呢?
我观察到 memos 的作者居然也给 Bytebase 提交过代码,好家伙,老熟人啊。同时,我在 Bytebase 的仓库里,找到了 #3751 这个 PR。(万恶之源)
在 2022 年 12 月(好像就是 DevJoy 结束后一个月),Bytebase 仓库引入了第一个 proto 文件。从此便一发不可收拾,原先的 Web API 全都变成了 gRPC Server 的写法,同时也开始使用 Buf 来管理 proto 文件。memos 的作者作为后面加入 Bytebase 的员工,也是将 Bytebase 对于 gRPC 的最佳实践,用在了他的 Side Project,也就是 memos 中。
我想大概是这么个故事情节吧。😁
memos 内部自行实现了三个很基础的定时任务。为什么说很基础呢,因为就是使用 time.NewTicker 来做的。每个定时任务的 Runner 都会实现 Run() 和 RunOnce() 两个方法,这里可能可以定义成一个接口?
func (r *Runner) Run(ctx context.Context) {
ticker := time.NewTicker(runnerInterval)
defer ticker.Stop()
for {
select {
case <-ticker.C:
r.RunOnce(ctx)
case <-ctx.Done():
return
}
}
}
三个定时任务分别是 s3presign version memopreperty 。
s3presign 每 12 个小时遍历一波数据库中存储的上传到 S3 的资源,将临时 URL 有效期不到一天的资源,重新调用 S3 SDK 中的 PreSign 签一个五天的临时 URL。memos 在数据库中存储图片等资源的临时 URL,感觉是为了防止私有笔记中的资源 URL 泄露。使用 PreSign URL 后,即使将公开笔记转为私有,之前的链接在五天后也就过期了。
version 每 8 个小时请求 memos 自己的 API 获取当前 memos 的最新版本。判断版本落后并且数据库中之前还没有过版本更新提醒的话,就新增一条 Activity 记录,并将该 Activity 加到管理员账号的 Inbox 收件箱中。让管理员收到版本更新的消息。
其中 GetLatestVersion 获取最新版本的函数,解析请求体这里,感觉可以进一步精简成一行。
BEFORE
buf := &bytes.Buffer{}
_, err = buf.ReadFrom(response.Body)
if err != nil {
return "", errors.Wrap(err, "fail to read response body")
}
version := ""
if err = json.Unmarshal(buf.Bytes(), &version); err != nil {
return "", errors.Wrap(err, "fail to unmarshal get version response")
}
AFTER
json.NewDecoder(response.Body).Decode(&version)
memopreperty 每 12 小时遍历一遍所有 Payload 为空的 memos 笔记,从它的内容中解析出 Tag、链接、代码块等属性,保存到 memos 的 Property 中。这个函数在创建、修改、更新 MemoTag 时都会调用。额外加到定时任务中出发,应该是为了兜底。
对于用户每一篇文本笔记,memos 都会使用 github.com/usememos/gomark 库来做结构化的解析。将文本内容解析成不同类型的 Go 结构体块,以实现将 Markdown 格式转纯文本、笔记 Tag 提取等功能。
这里简单拆解一下这个包的结构和原理,本质上又是把文本进行词法分析转换为 Tokens,构建 AST 抽象语法树,然后通过遍历 AST 实现上述提到的功能。gomark 好就好在他功能简单但全面,很适合像我这种从没学过编译原理的菜鸡。
parser/tokenizer/tokenizers.go 中定义了各种 Token 的类型,如下划线、星号、井号、空格、换行等,基本上就是在 Markdown 中含有语义成分的字符,都会作为一个 Token 类型。正文内容分为 Number 数字和 Text 文本两种 Token 类型。
Tokenize(text string) []*Token 函数就是很标准的传入 text 字符串,挨个字符 switch-case,然后转换为 Token 结构体添加到切片中。
var prevToken *Token
if len(tokens) > 0 {
prevToken = tokens[len(tokens)-1]
}
isNumber := c >= '0' && c <= '9'
if prevToken != nil {
if (prevToken.Type == Text && !isNumber) || (prevToken.Type == Number && isNumber) {
prevToken.Value += string(c)
continue
}
}
if isNumber {
tokens = append(tokens, NewToken(Number, string(c)))
} else {
tokens = append(tokens, NewToken(Text, string(c)))
}
对于不在上述 Markdown 语义中的字符,则判断是否为数字 0-9,如果是的话说明是一个 Number 数字 Token,同时还需要看下上一个 Token 是不是也是数字,如果是的话他俩就是挨一起的,共同组成了一个 Number Token。Text 文本 Token 也是一样的逻辑,将挨着的文本字符统一为一个 Text Token。
Token 拆分完后,就开始构建 AST 了。
ast 目录下有 inline.go 和 block.go 两个文件。前者定义了单个节点类型,如普通的文本节点、加粗、斜体、链接、井号标签等;后者定义了多个普通节点组成的集合节点,如段落、代码块、标题、有序无需列表、复选框等。
parser/parser.go 里定义的 ParseXXX 函数将第一步的 []*tokenizer.Token 解析成 []ast.Node 。
nodes := []ast.Node{}
for len(tokens) > 0 {
for _, blockParser := range blockParsers {
node, size := blockParser.Match(tokens)
if node != nil && size != 0 {
// Consume matched tokens.
tokens = tokens[size:]
nodes = append(nodes, node)
break
}
}
}
本质上也还是将 Tokens 丢给所有的 BlockParser 在 for 循环里过一遍, BlockParser 接口实现 Match() 方法,不同的 Node 会一次性读取不同数量的 Tokens,判断格式是否满足 Node 的要求,来确定这些 Tokens 是否组成了这个 Node。Match 上了则会返回生成的 Node 和匹配上的 Tokens 长度,截去这个 Node 匹配的 Tokens,剩下的 Tokens 继续轮一遍所有的 BlockParser。
var defaultInlineParsers = []InlineParser{
NewEscapingCharacterParser(),
NewHTMLElementParser(),
NewBoldItalicParser(),
NewImageParser(),
...
NewReferencedContentParser(),
NewTagParser(),
NewStrikethroughParser(),
NewLineBreakParser(),
NewTextParser(),
}
值得注意的是,这些 BlockParser 的顺序应该是有讲究的。像最普通的、最容易匹配上的 Text 纯文本类型,应该放在最后。当前面所有的 Parser 都没匹配上时,才说明这个 Token 是文本类型的 Node。如果把 TextParser 放最前面,那估计所有的 Tokens 都会被匹配成文本 Node。
将 Tokens 转换为 AST 上的 Nodes 后,最后还有个 mergeListItemNodes 函数,是用来特殊处理 List 列表节点的。如在列表的最后加上换行符,判断列表项是要拆成两个列表节点还是添加到末尾。
renderer 目录则是遍历上述 AST 中的节点,来将 AST 转换成 HTML 或者 String 纯文本。这里就很简单了,不同的节点调不同的函数 WriteString 即可。
综上,gomark 就完成了将 Markdown 格式文本,解析转换成 HTML 或 String 纯文本的工作。
最后再说些自己发现的小细节吧,就不单独分一块了。
随着 Go Embed 功能加入后,我很喜欢将 Vue 编译后的前端打包进 Go Binary 中。往往是会在 web 或者 frontend 前端代码路径下,保留放编译产物的 dist 目录,在里面放个 gitkeep 文件啥的。
memos 的做法是放置了一个 frontend/dist/index.html 文件:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Memos</title>
</head>
<body>
No embeddable frontend found.
</body>
</html>
直接在 Body 中写明了前端嵌入文件不存在。这样既可以通过编译,如若用户访问时,前端真没有被打包进来,在 index.html 也会有一个错误提示,比我只放一个不会被读到的 gitkeep 好些。
memos 使用 JWT Token 鉴权。因此需要解析通过 Authorization 头传进来的形如 Bearer xxxx 内容。问题是用户可能在 Bearer 和 Token 之间传入不定数量的空格,甚至在 Bearer 前或者 xxx 后也会有空格。
要是我的话,可能就先 strings.TrimSpace ,再 strings.Split 按空格分隔,然后再取判断长度,取第一个元素和最后一个元素,即为 Bearer 和 Token。memos 里直接使用了 strings.Fields 包来做到这一点,直接解决了上述可能存在的问题。后面要做的仅仅只有判断切片长度是否为 2 即可。
以上便是我之前阅读 memos 源码的一些心得体会。由于时间关系,我并没有很仔细的去阅读每一个文件的每一行代码,也没去审是否有潜在的安全漏洞。memos 的前端是使用 React 编写的,由于我平时不怎么写 React,所以前端这块也只是粗略的翻了翻。
memos 还是有很多可圈可点之处的,学到很多。貌似作者其它的开源项目也都有使用 memos 这种黑白动物风格的 Logo,相当于是一套统一的品牌。我对 AI 生成产品 Logo 这方面也挺感兴趣的,因为自己实在设计不来一个好看的 Logo…… 之后这块可以多研究下。