2026-07-05 23:45:00
今年第一次在周末踏出家门,来看阿 Paul 的画展。
这个美术馆离我其实很近,但是加班和下雨,整整两个多月,在临近闭展的最后一周才过来。
踏进美术馆的那一刻,脑海里就自动响起 BGM :
这是谁的路,难为你讨好
今天带著问号,投入你怀抱
回到了 1997 年前后《回家》、《大时代》、《旧历》那个时期的 Beyond ,我自己应该是在 05 年后才接触到这几张专辑,很耐听,现在每天上班写代码的时候也是会循环播放。
为什么是这个时期,因为一直觉得这个时期的 Beyond 作品,特别特别具有阿 Paul 的个人风格。
昨天其实也是大暴雨,但今天很好,只是阴天,看展的人不多,刚好可以安安静静待很久。
很多画都能在以前的歌曲里找到影子:《岁月无声》、《狂人山庄》,《黑夜迷墙》(黑色迷墙)。有一张很特殊的《谁命我名字》,也是同名歌曲,一首为流浪动物发声的歌。
类似的创作还有写给白芳礼老人的《一路好走》,探访西北地区后写的《孩子》,和饥荒有关的《同根》,不过暂时没有对应的画作。
《同根》也是我去年新创作的文身之一,就纹在我的肩膀上。
回想十年前第一个文身的最初想法也是想直接用阿 Paul 的九纹龙图案,但后来打消了这个念头,经过反复重构,用了自己的琴进行设计,坚持原创才是更符合 Beyond 精神。
画展里特别喜欢一副黑粉配色的画作,但是本次没有售卖,买了一副和猫有关的,很期待!

我买的那副,等到货了再晒出来~
2026-04-14 01:30:00
很早之前就对 Oxc 这个项目一直保持关注,看到前段时间开始进入 1.x 版本,一直想弄一套配置,这几天终于有时间搞一下。
不过目前阶段 OXLint 还是无法完整替代 ESLint ,只能是以 OXLint 为主, ESLint 为辅,但是两者可以完美结合,对项目来说,仍然可以以一套 Lint 方案去解决代码问题, OXFmt 倒是可以完美代替 Prettier 原生规则,只是部分插件仍然需要取舍,例如 Markdown 的盘古之白格式化,我只能暂时舍弃。
由于需要两套 Lint 同时工作,所以这个配置包还没有正式定名为 oxc-config ,暂时只称之为 Integration ,一个集成方案或者说是一套工作流。
这是我在 GitHub 上发布的一个开源项目。如果它对你有帮助,欢迎前往 bassist 点一个 Star。
@bassist/oxc-integration 是一个 Oxc 优先的工作流包,适合希望现在就用上带类型提示的 oxlint.config.ts 与 oxfmt.config.ts,同时在 Oxc 能力尚未完全覆盖时保留 ESLint 兜底能力的项目。
通常只需要四步:
oxlint.config.ts(参考:Oxlint 快速开始)oxfmt.config.ts(参考:Oxfmt 快速开始)eslint.config.js(参考:ESLint Fallback 快速开始)npm i -D oxlint oxfmt @bassist/oxc-integration如果你的项目需要 ESLint fallback,请再安装对应框架所需的 ESLint 生态依赖。
oxlint / eslint 的 CLI 检查结果,与编辑器里的实时诊断并不是同一件事。
如果你希望在编码过程中就获得 Oxc 的实时 lint 提示,还需要额外安装对应的编辑器插件。否则就可能出现“执行 lint 命令时能查出错误,但编辑器里没有任何 提示”的情况。
oxc.oxc-vscode 扩展官方文档: https://oxc.rs/docs/guide/usage/linter/editors.html
Oxc 的编辑器扩展会通过项目本地的 oxlint --lsp 工作,因此也请确保项目的
devDependencies 里已经安装了 oxlint。
如果你使用 VS Code 或 Cursor,也可以在项目里补一个
.vscode/settings.json,让保存时修复和类型感知检查更完整:
{
"editor.codeActionsOnSave": {
"source.fixAll.eslint": "always",
"source.fixAll.oxc": "always"
},
"oxc.typeAware": true
}source.fixAll.oxc 用于通过 oxc.oxc-vscode 扩展启用 Oxc 的保存时自动修复oxc.typeAware: true 可以在 TypeScript 项目里提供类型感知诊断eslint.config.js 作为 fallback layer,建议继续保留 source.fixAll.eslint
@bassist/eslint-config
@bassist/oxc-integration
@bassist/oxc-config 的过渡形态@bassist/oxc-integration 采用 Oxc-first workflow:
oxlint 是主 Lintereslint 是兜底 Linter,用来补齐 Oxc 还没完全覆盖的规则oxfmt 是主 Formatter这也是为什么某些项目现在仍然会同时保留 oxlint.config.ts 和 eslint.config.js。
它们不再是两个并列的主配置文件,而是:
oxlint.config.ts:主 Lint 配置eslint.config.js:兜底 Lint 配置在这些 fallback presets 内部,会自动接入 eslint-plugin-oxlint,用于关闭那些已经由 Oxlint 覆盖的 ESLint 重叠规则。
如果 Oxc 已经足够覆盖你的项目,可以只使用 oxlint.config.ts。
如果项目仍然依赖框架或生态特定的 ESLint 能力,则再补一个 eslint.config.js。
通常可以这样理解:
base / node:很多场景只用 Oxlint 就够了react:大多数情况下可以 Oxc 优先,但很多项目仍建议保留 ESLint fallbackvue:默认建议保留 ESLint fallbacknext:默认建议保留 ESLint fallbacktailwindcss:优先使用 oxlintPresets.tailwindcss() 通过 Oxc JS plugin lint;如果项目仍需要 ESLint 专属覆盖,再补 ESLint fallbackvitest:如果你需要更完整的测试规则,建议保留 ESLint fallback当前 @bassist/oxc-integration 已内建这些 ESLint fallback presets:
javascripttypescriptjsximportsjsoncmarkdownreacttailwindcssvuenextvitest当前暂不纳入这个 Oxc-first 工作流范围的内容:
lint-md这些能力后续可以单独作为内容层工作流再设计。
| 项目类型 | oxlint.config.ts |
eslint.config.js |
oxfmt.config.ts |
|---|---|---|---|
| Base TS/JS | 必需 | 可选 | 必需 |
| Node | 必需 | 可选 | 必需 |
| React | 必需 | 推荐 | 必需 |
| Vue | 必需 | 推荐 | 必需 |
| Next | 必需 | 推荐 | 必需 |
// oxlint.config.ts
import { defineOxlintConfig, oxlintPresets } from '@bassist/oxc-integration'
export default defineOxlintConfig(oxlintPresets.base())// oxlint.config.ts
import { defineOxlintConfig, oxlintPresets } from '@bassist/oxc-integration'
export default defineOxlintConfig(oxlintPresets.react(), oxlintPresets.vitest())// oxlint.config.ts
import { defineOxlintConfig, oxlintPresets } from '@bassist/oxc-integration'
export default defineOxlintConfig(oxlintPresets.vue(), oxlintPresets.vitest())如果你需要官方 oxlint 类型,请直接从 oxlint 包导入,而不是从本包导入。
oxlintPresets.base() 并不是空壳,它已经内置了这个包约定的 Oxc 基线配置。
当前内建默认值包括:
typescript、oxc
correctness: errorsuspicious: errorpedantic: warnstyle: offtypescript/no-explicit-any: off然后更高层的 presets 会在这份基线上继续扩展:
oxlintPresets.node() 会补充 Node 运行时环境oxlintPresets.react() 会补充 react、react-perf、jsx-a11y
oxlintPresets.tailwindcss() 会通过 Oxlint JS plugins 加载 eslint-plugin-better-tailwindcss
oxlintPresets.vue() 会补充 vue
oxlintPresets.vitest() 会补充 vitest
建议先使用内建默认值,再把项目特有的差异作为额外配置传入。
// oxlint.config.ts
import { defineOxlintConfig, oxlintPresets } from '@bassist/oxc-integration'
export default defineOxlintConfig(oxlintPresets.react(), {
rules: {
'no-console': 'warn',
},
ignorePatterns: ['fixtures/**'],
})可以把 presets 理解成默认基线,把额外传入的对象理解成项目级扩展层。
// oxlint.config.ts
import { defineOxlintConfig, oxlintPresets } from '@bassist/oxc-integration'
export default defineOxlintConfig(
oxlintPresets.react(),
oxlintPresets.tailwindcss({
entryPoint: './src/styles.css',
}),
)Tailwind preset 会通过 Oxlint JS plugins 使用 eslint-plugin-better-tailwindcss,让 Tailwind CSS v3 和 v4 项目共用同一套 class linting 规则。
// eslint.config.js
import { defineEslintConfig, eslintPresets } from '@bassist/oxc-integration'
export default defineEslintConfig(
eslintPresets.imports(),
eslintPresets.react(),
eslintPresets.tailwindcss(),
eslintPresets.vitest(),
)如果是 Vue 项目,把 react() 换成 vue() 即可。
如果是 Next 项目,请使用 next()。
只有项目真的在使用 Tailwind CSS 时,才需要再加上 tailwindcss()。
// eslint.config.js
import { defineEslintConfig, eslintPresets } from '@bassist/oxc-integration'
export default defineEslintConfig(eslintPresets.markdown())如果你只想为 Markdown 文件开启独立的 lint 行为,而不希望把它并入
lint-md 或基于 Prettier 的内容工作流,可以使用 markdown()。
建议优先使用带类型提示的 oxfmt.config.ts,这样配置结构会与官方 formatter API 保持一致。
// oxfmt.config.ts
import { defineConfig } from 'oxfmt'
import { oxfmtConfig } from '@bassist/oxc-integration'
export default defineConfig(oxfmtConfig)如果你想覆盖默认值:
// oxfmt.config.ts
import { defineConfig } from 'oxfmt'
import { getOxfmtConfig } from '@bassist/oxc-integration'
export default defineConfig(
getOxfmtConfig({
semi: true,
}),
)oxfmt . 会自动发现 oxfmt.config.ts,所以通常不需要额外显式传入配置路径。
如果你需要官方 formatter 类型,请直接从 oxfmt 包导入,而不是从本包导入。
{
"scripts": {
"lint": "oxlint .",
"lint:eslint": "eslint .",
"lint:full": "npm run lint && npm run lint:eslint",
"format": "oxfmt ."
}
}推荐用法:
base / node 项目先从 lint 开始vue、next、以及较复杂的 react 项目默认建议使用 lint:full
2026-02-24 17:05:02
这个春节假期对 vue-picture-cropper 这个包进行了一次改版,主要想解决一些工程设计上的老问题,例如 #49 、 #45 这些 issue 提到的问题。
虽然是个 Breaking Change ,但对用户来说迁移成本不大,并且有了一些更灵活的用法(例如组合式函数),我自己则在重写源码时积累了一些思考点,在这篇文章里分享一下。
本文说明 vue-picture-cropper 从 v0.x 升级到 v1.x 时,在打包方式、样式加载和实例管理上的设计取舍与原因。
在谈 1.x 的设计之前,有必要先回顾一下 0.x 的初衷。
0.x 的第一个版本发布于 2020 年 11 月。当时 Vue 3.x 刚刚发布,整体生态尚处于早期阶段,许多常用库还未完成适配,工程实践也尚未完全稳定。这导致当时的 Vue 3 业务项目很容易因为生态不足而延误工期。
因此,这个包最初并不是面向通用场景的组件库,而是一个为业务项目快速适配的个人小工具。那个时候我的设计目标非常明确:
因此在 0.x 中选择将 cropperjs 内置打包,用户只需安装一个包即可使用。
这个处理方式从当时的设计目标来看,是合理的取舍 —— 它优先解决了 “可用性” 和 “便捷性” 的问题,而不是工程边界与依赖模型的完备性。
但这几年随着项目逐步被更多场景使用,工程规模扩大、依赖关系复杂化,这种早期的便捷型设计也逐渐暴露出局限性。
1.x 的调整,并不是对 0.x 的否定,而是在使用场景变化之后的一次架构升级。
虽然 Cropper.js 主分支已经切换到 2.x,但 v1 与 v2 在架构和使用方式上存在显著差异:
| 对比维度 | 1.x 特点 | 2.x 特点 |
|---|---|---|
| 架构 | 传统单体 JavaScript 库,所有 API 通过构造函数和配置项提供 | 基于 Web Components(自定义元素)重构,将不同能力拆分成可组合的元素(如 <cropper-image>、<cropper-selection>),表达方式更偏 “原生 DOM 组件化” |
| API 与使用模式 | 以配置项/方法为主,适合 Vue 或纯 JS 组件封装 | 一部分 API 通过 DOM 事件、属性和自定义元素组合替代原配置项,如 viewMode、dragMode 等迁移到不同元素的属性/事件 |
| 生态兼容性和迁移成本 | API 形态对 Vue 封装友好,稳定且迁移成本低 | Web Components 架构现代,但与 Vue 响应式和生命周期体系存在适配成本,需要额外桥接层 |
| 成熟度与稳定性 | 已长期稳定维护,用户基础大,语义明确 | 引入现代架构思路,但升级仍需用户适配 API 和行为,版本替换不够直接 |
基于以上差异,选择 v1 的工程考量如下:
因此,本库依然选择依赖 Cropper.js 1.x ,而非 2.x ,以保证成熟稳定、可维护和生态兼容性。
如果希望使用 Cropper.js 2.x 的现代 Web Components 架构,建议直接使用 Cropper.js 原生库,而非本库的 Vue 封装层。
从 1.x 开始,本库仅以 ESM(ES Modules)形式发布,不再提供 CommonJS (CJS) 或 IIFE 构建版本。
背景与原因:
绝大多数 Vue 3 项目都基于 Vite 或其他现代打包工具,这些环境原生支持 ESM。提供 CJS 或 IIFE 构建在这些场景下意义不大,同时增加维护成本。
通过 CDN 分发 IIFE 构建的场景在实践中非常少见,本库统计和社区反馈均显示几乎无人使用。继续提供会增加打包体积和测试负担,但对用户价值有限。
移除 CJS/IIFE 后,库的构建流程更简单,TypeScript 类型和模块导出更一致,也避免了 CJS 下 default + named export 的潜在混乱问题。
如果你的项目依赖 CJS / IIFE,请迁移到支持 ESM 的环境,例如使用 Vite、Nuxt 或现代 Webpack 版本。
在 0.x 中,Cropper.js 作为内部依赖被打包进 vue-picture-cropper 的产物中,用户只需安装一个包即可使用:
# 0.x 时的安装方式
npm i vue-picture-cropper而在 1.x ,Cropper.js 不再被打包进本库的 Bundle ,需要由使用方在项目中显式安装并锁定 Cropper.js 1.x:
# 1.x 需要这么安装
npm i vue-picture-cropper cropperjs@^1虽然 0.x 看起来方便,但在工程项目里存在这样的问题:
cropperjs 被打包进 vue-picture-cropper ,如果用户项目中也单独使用了 cropperjs ,或其他库也依赖 cropperjs ,就可能出现:多份 cropperjs 、多个实例冲突、工程产物体积变大
简单来说,0.x 是 “内置运行时依赖的封装组件” ,而 1.x 是 “对等依赖(peer dependency)模式下的 Vue 适配层” 。
这样做带来的好处,体现在在运行时层面是:
体现在工程层面是:
注:“幽灵依赖(phantom dependency)”指代码运行时依赖某个包,但该包未在当前项目的 package.json 中显式声明。这种情况通常源于 Node.js 的模块解析机制能够访问 node_modules 中的任意已安装包,从而导致依赖关系在项目层面不可见。
和 v0.x 不同,从 1.x 开始不再自动注入样式。
在 v0.x 中,样式会被打包为字符串,并在组件加载时动态创建 <style> 标签插入到页面中,例如:
// v0.x 时的源代码设计
import { loadRes } from '@bassist/utils'
import cropperStyle from 'cropperjs/dist/cropper.css?inline'
import vpcStyle from './style.css?inline'
loadRes({
type: 'style',
id: 'cropperjs',
resource: cropperStyle,
})
loadRes({
type: 'style',
id: 'vue-picture-cropper',
resource: vpcStyle,
})从 1.x 开始,需要主动在项目的入口文件导入组件样式:
// 此处是业务项目,需要主动导入 Cropper.js 样式和 VuePictureCropper 样式
import 'cropperjs/dist/cropper.css'
import 'vue-picture-cropper/style.css'为什么移除自动注入?
自动注入样式在早期虽然方便,但也带来一些问题:
改为显式导入后:
在 1.x ,样式加载更透明、可控、可维护,符合现代前端工程化最佳实践。
在 v0.x 版本中,cropper 实例是通过模块级变量管理的:
// 0.x 源码设计
export let cropper: CropperInstance | null
// 使用 0.x 业务
import VuePictureCropper, { cropper } from 'vue-picture-cropper'这种设计带来了一些限制:
因此 1.x 完全重构了实例管理方式:
每个 VuePictureCropper 组件拥有自己的状态,不再依赖模块级变量,保证实例相互独立。
开发者可以安全地调用 getDataURL、getBlob、getFile 等方法,无需担心覆盖或冲突。
在同一页面中同时存在多个裁剪框,各实例互不干扰,操作逻辑更清晰、可复用性更高。
如果希望在纯逻辑中使用裁剪能力,而不依赖模板 ref,可以使用 1.x 提供的组合式函数 useCropper,直接获得与实例绑定的控制器,实现逻辑层面的复用和集中管理。
总的来说,1.x 在 Bundle、样式和实例三方面做了统一取舍:依赖与样式由使用方显式管理,实例与组件一一对应。这样既便于构建与 SSR,又支持多实例与逻辑复用。
虽然是一个 Breaking Change ,但 1.x 的 VuePictureCropper 组件 Props 仍然保持和 0.x 一致,主要有以下不同点:
2025-12-31 23:31:00
2025 年过得真是快,感觉比以往都要快。
梳理了这一年的变化,还是先从开源说起吧,今年在 GitHub 上的活跃度,勉强保持了打卡式活跃……

搞错了,这是黄村地铁站的 Commit ……

哈哈哈哈哈拍摄于 2025-12-30 晚上下班后,估计有人看到我在那拍,毕竟那是个人来人往的换乘站,还是在人最多的拐弯处,大家都在赶路,就我突然站在那对着墙拍照!
我的活跃在这里,截图还是生成自 GitHub Contributions ,用了好几年了这个工具。

活跃度断崖式下降,有效的新开源工具 0 ,新项目 0 。
因为 AI 辅助编程的发力,从三月份开通 Cursor Pro 开始,加上后面交叉使用的 GPT 、 Claude 、Gemini …… ,几乎全年都在 Vibe Coding ,日常已经转为一名 Prompt 工程师……

AI 发力带来的好处就是提高了生产力,解放了劳动力;带来的副作用就是好像一瞬间失去了想做点什么的动力,好像什么都能用 AI 搞,好像什么都没必要分享了,都是问一下 AI 就行。
所以今年一直只是在私有仓库里尝试一些乱七八糟的东西,或者写点私有笔记,真正拿来搞点什么东西分享到开元社区的,没有,下次一定!
在去年 2024 的年终总结 里提到公司的主力项目今年要 Release ,做到了,包括相关的硬件产品也推出了几个比较基础的型号,市场反馈和用户反馈还可以,这一年的付出还是得到了肯定。
年底公司也组织了一次团建,那天上午还开了个总结会,然后分组讨论讨论讨论着被我们产品妹子推上去讲了两句,留了张年度照片(就是旁边玩手机这个人……),哈哈哈哈我就不露脸了,露个文身看得出是我就行。

前面说到在开源一点都没产出,不过在公司里产出还算可以吧,AI 解放了双手,有更多的时间去思考和沉淀,留下了几十篇技术文档,完成的需求功能也不算少,几乎每个版本都有自己实现的东西,做的东西有人用,不论是开源还是公司产品,这一点都是成就感满满的!

总的来说工作方面我对自己也是挺满意的,有一些成果算是超出我自己的预期,虽然也依然有一些属于我自己的能力欠缺以及业务痛点还需要解决。
这一年公司也入职了很多技术超级无敌强的大佬,性格也都很好,很务实很沉稳,能一起共事真是十分荣幸,新的一年公司产品线也还会继续壮大,应该也是继续很忙,下一年的总结应该会更好。
另外,还有了一件很有纪念意义的工作服,设计灵感来自我们的系统界面,笑死,以后写 BUG 小心点,不然穿出去被人追着打...


这一年依然选择了宅了一年,哪也没去玩,不过翻阅过去一年的朋友圈,也是有一些有意思的事情发生。
简单摘录一点,也不放太多哈哈哈哈,不然就是流水账了!
六月份终于把三年前就想纹的图案构思了出来,两株麦穗,源自广州的别名 “穗城” 和她的 “五羊衔谷” 传说,从我的贝斯两侧缓缓伸出,绕肩而上,同根生长。
这个图案名为《同根》,其实也是我最喜欢的吉他手黄贯中的一张专辑名称,同根 也是这张专辑的同名主打歌曲,歌曲的创作与饥荒和互助有关,这个文身的出处也是。
另外对于我来说,还有另外一层意义,广州这座城市在我年龄还是个位数的时候,浓厚的历史沉淀就对我有着精神上的吸引,长大后在这里读书再到出社会独立,又从物质上帮我扎下了根,直到现在依然喜欢这座城市。


全部文身可以在 文身专栏 找到,这里记载了每个文身的意义。
四月份那会想重新设计博客首页,给博客找了好久 Hero 区域的素材搭配,最终敲定的方案又回到 “最好的素材就在身边” 的原则,用自己的第一个文身。
如今也快过去一年了,还是特别喜欢,越看越喜欢,包括我的手机壁纸也一直是这个文身。

重新设计博客的时候,也顺带设计了我的文身专栏,第一次这么正式向大家介绍我的文身和它们背后的故事,以及合作了十年的纹身师!
再贴下传送门:文身专栏 。

一对一轻量级资助了个山区小女生一点点费用,竟然收到教育局寄来的小朋友手写贺卡,看到这个涂改液,小时候自己涂改作业的事情回忆起来真美好!云养女儿的感觉!


虽然这两年明显感觉到发量在变少,但还好还没全秃,而且有时候起床后蓬松感还不错!
要是哪天快秃了,我就去搞个脏辫,脏辫玩够了就剃光头去!

原来真有人随机到 888 的咖啡订单号码,是谁?是我!

去年的总结《本色十年》回忆了十年来的一些工作与生活变化,包括转岗的坚持等一些心路历程。
如今在 2025 年往前看十年,其实 2015 年也是挺有意义的一年,那一年鼓起勇气入职了网易,度过了对我人生十分重要的五年,后来离职的时候还写了一篇《让摇滚的声音响彻整个夜晚》记录我在网易五年里的工作与生活,都是特别美好的回忆!
接下来是 2026 年了,也开始踏上了我文身十年,以及养猫十年的时间点,回头看过去,人生的每一步不在于是否都能踩对,但如果能留下一些有意思的事情,每次往回看十年前,依然能开心,这辈子也就值了。
回到最开始,之所以先说开源和 AI ,就是想说我这一年在工作之外其实是有点缺少目标感,说白了就是迷茫。
尽管也学了不少新东西,在工作上也用得游刃有余,但就是总觉得没什么很垂直方向的沉淀,大部分时间都在创造当前的价值优先,缺少一点可持续发展的安全感。
特别是负责了一个很需要专业知识的项目也有一年多了,虽然目前也运行的还行,有吐槽,但不算多,但始终还是处于赶需求赶需求的状态,大部分问题和实现都懂,但在这个领域还是缺少更多的专业知识学习和实际探索,时间不够用。
上一个 OKR 周期在向老板复盘汇报的时候我也说,我始终不敢说这个项目是我在负责,因为我觉得还没有做到我自己很满意的程度,没脸公开啊哈哈,只能做一个默默维护的神秘客。
前两年的总结没有定下什么目标,今年希望能安排好自己的时间去钻研下,最好也仍然能沉淀一些自己的经验记录。
另外也减少点有的没的时间浪费,新东西层出不穷,倒也没必要到处尝试,今年就是一个浪费时间的例子,笑死。
2025-10-08 23:42:03
从 2019.08.01 重新开始写日记,到今天居然坚持了 6 年了,一开始是记录在一款云笔记 App 上,直到四个月前陆陆续续把数据迁移到自己家里的 NAS ,把数据爬回来才发现居然接近 8 GB …… 一直觉得好像都是文字为主,没想到也配了不少图片,重新看的时候生活还挺丰富多彩的哈哈哈!
这里的日记就很纯粹的记录生活,不是什么读书笔记、技术笔记等等,那一类的记录对我来说都属于生活之外的事情,冷冰冰没有个人感情,生活日记记录了我每一段生活的喜怒哀乐,还有各种胡思乱想,闲着无聊的时候翻一翻,能够回顾自己过往的生活和成长,别有一番乐趣。
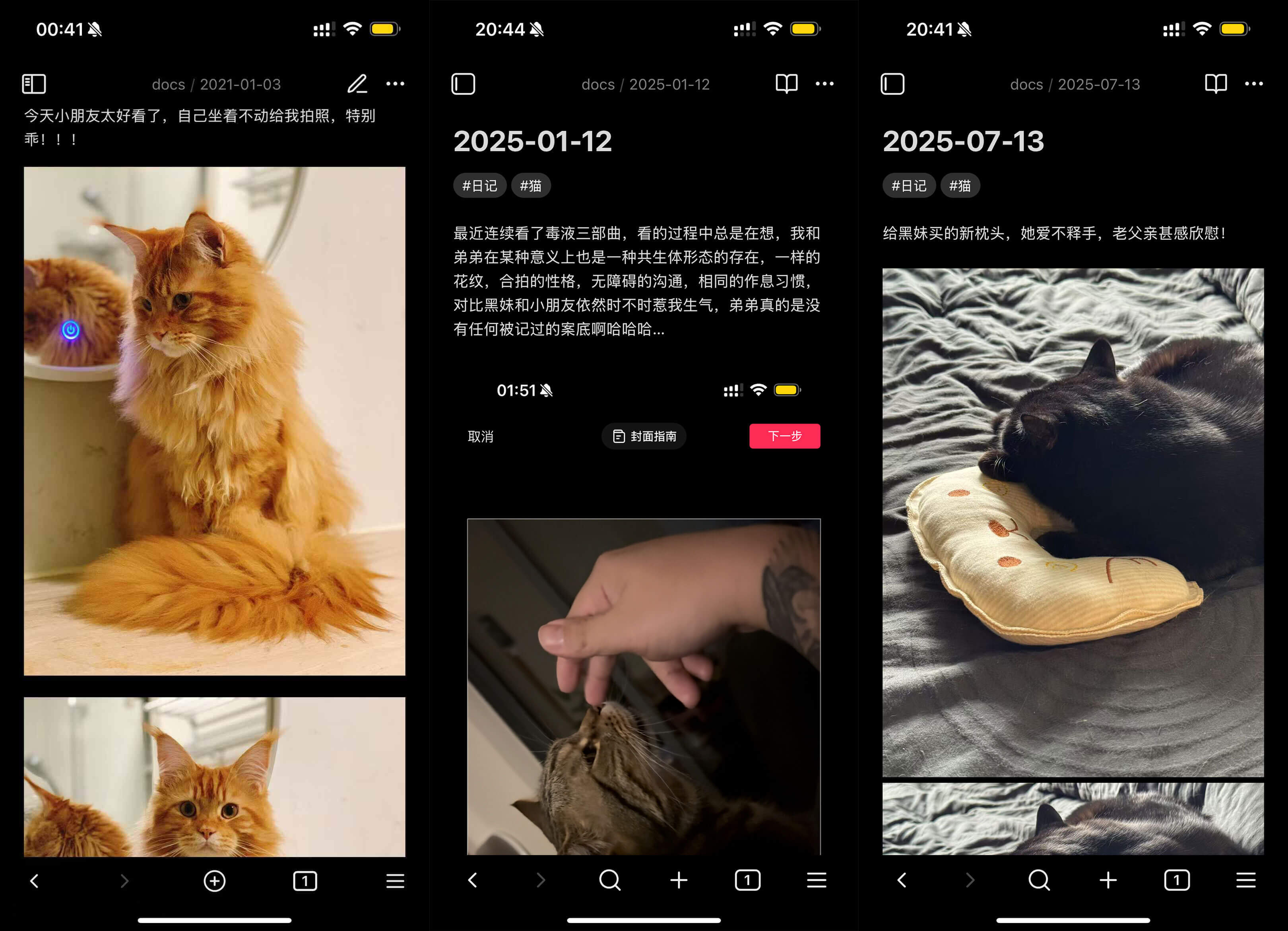
2019 年重新开始写日记那会,我当时的需求主要是晚上睡觉前用手机记录当天的日记,并且有网页版或者桌面客户端可以平时在电脑上看一看稍微管理一下就足够,但那个时候还没什么特别流行的跨平台笔记方案,而且大部分流行的笔记 App 都是广告很多。
加上当时还没有开始接触 NAS ,也没有选择自建存储的想法,后面选择了一款界面比较清爽、自我感觉用户体量比较小的 App(猜的…… ),由于那家公司本职不是做这个笔记 App 产品,所以对 App 利益相关的运营干涉不是太多,所以 “清爽的体验” 一用就这么用了五年多。
但随着长时间深入使用,这也变成了我不想用它的原因,由于 App 不够被重视,以至于多年未维护更新,产生的 BUG 也没有修复,一度让我自己想抽空做一个客户端自己用(根据它的 BUG 表现推测是比较老版本的 React Native 做的)。
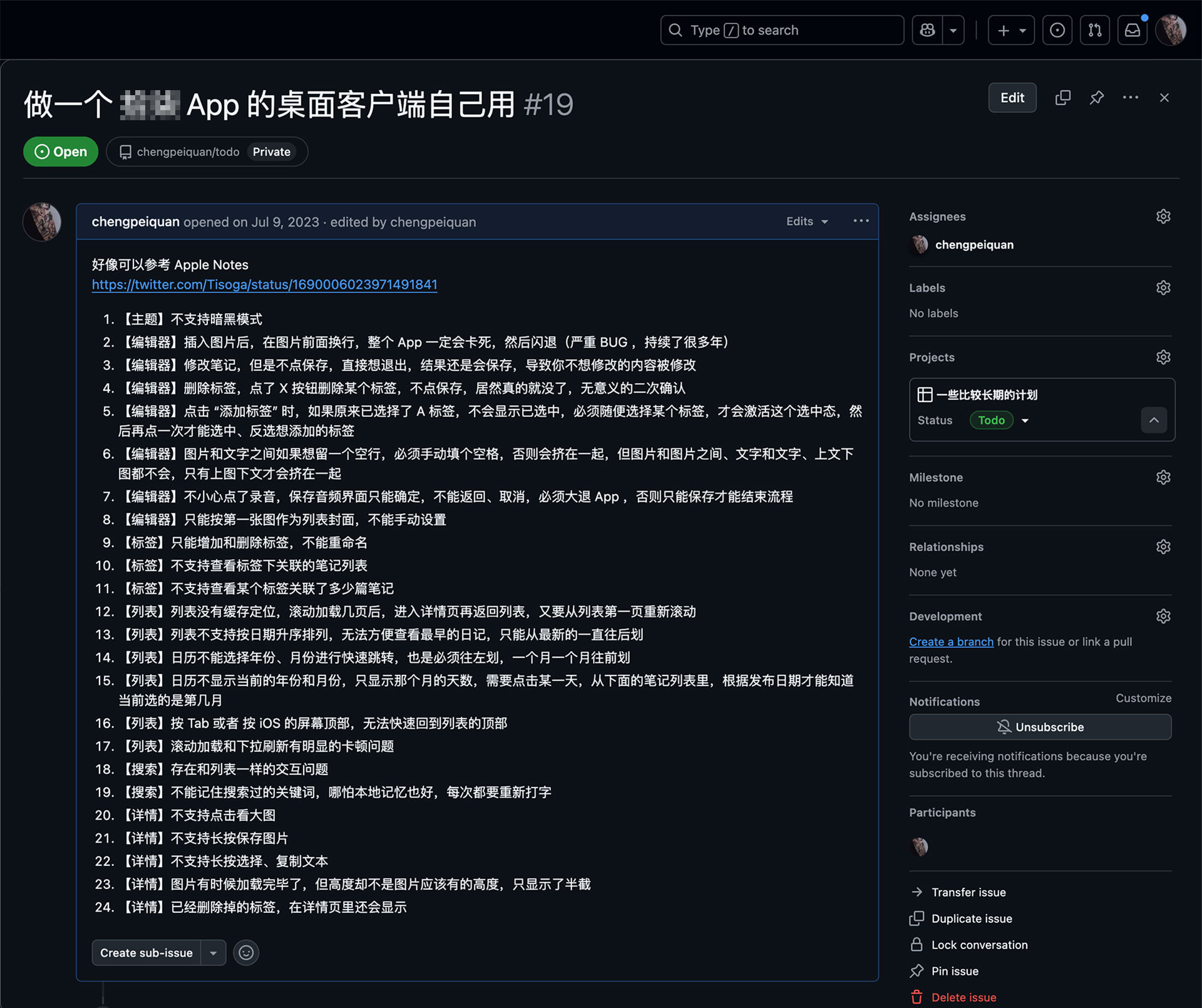
不过由于工作太忙, “做一个情怀客户端自己用” 这个事情也就一直放着,可以看到我是 23 年开的 Project ,直到现在都没动哈哈哈。
不过拖延症有拖延症的好处,因为这几年陆陆续续听到 Obsidian 、 Logseq 、 Joplin 、 Notion ,以及国产的为知笔记、思源笔记,以及语雀、飞书文档这一类不太纯笔记但也提供了很优秀的笔记功能的产品,有这么多现成的,干嘛还自己搞呢?
而且在开 Project 的那段时间,也开始玩起了 NAS (详见 我的第一台 NAS 一文),玩熟悉之后,用 NAS 来存储这些相对敏感的数据,应该说是最好的选择了。
有了数据迁移的想法,先梳理看看自己都需要些啥功能。
在现阶段,用 NAS 作为数据存储是已经确定的事情,剩下的不确定因素主要还是客户端方案的选择。
| 需求点 | 说明 |
|---|---|
| 私有化部署 | 考虑到自己当前的需求主要是个人日记,偏隐私,我选择将数据存放到我的 NAS 上 |
| 多平台客户端 | 我自己主要设备是需要有 iOS App 和 macOS App (或者 Web ) |
| 客户端响应快 | 不论是启动速度,还是搜索速度,因为写了 6 年,几千篇笔记,速度方面还是有要求的 |
| 交互体验好 | 想换掉之前的方案就是因为体验太差了,至少不能再有我上面提到的那些问题 |
| 界面颜值高 | 我当时选那个 App 的原因就是清爽,虽然没有暗模式,但亮模式的 UI 很像 Shadcn UI |
| 多端同步 | 最重要的功能,可以直接与我的 NAS 进行数据传输 |
支持私有部署的 “单机笔记” 方面,主流的就是 Obsidian 、 Logseq 、 Joplin 、为知笔记、思源笔记 这几款。
基于社区评价、私有化部署的内存占用( NAS 比较重视)、客户端颜值等维度对比后,就剩下 Obsidian 和 Logseq 两者, Logseq 是比 Obsidian 要晚一点推出的产品,所以它具备了 OB 的一些优点,同时还具有双向链接、块引用等更现代化的功能。
不过社区普遍认为 Logseq 在处理大量笔记时性能稍弱一些,而它基于大纲的组织方式,对我目前以 “日记” 为主的使用场景来说略显复杂。
未来如果要记录其他类型的内容,我可能会选择 Logseq 来做区分,但目前还是选了更为经典的 Obsidian 。
接下来讲讲我目前确定下来的具体架构和配置。
经过前面的方案对比之后,我的笔记方案整体架构非常简单。
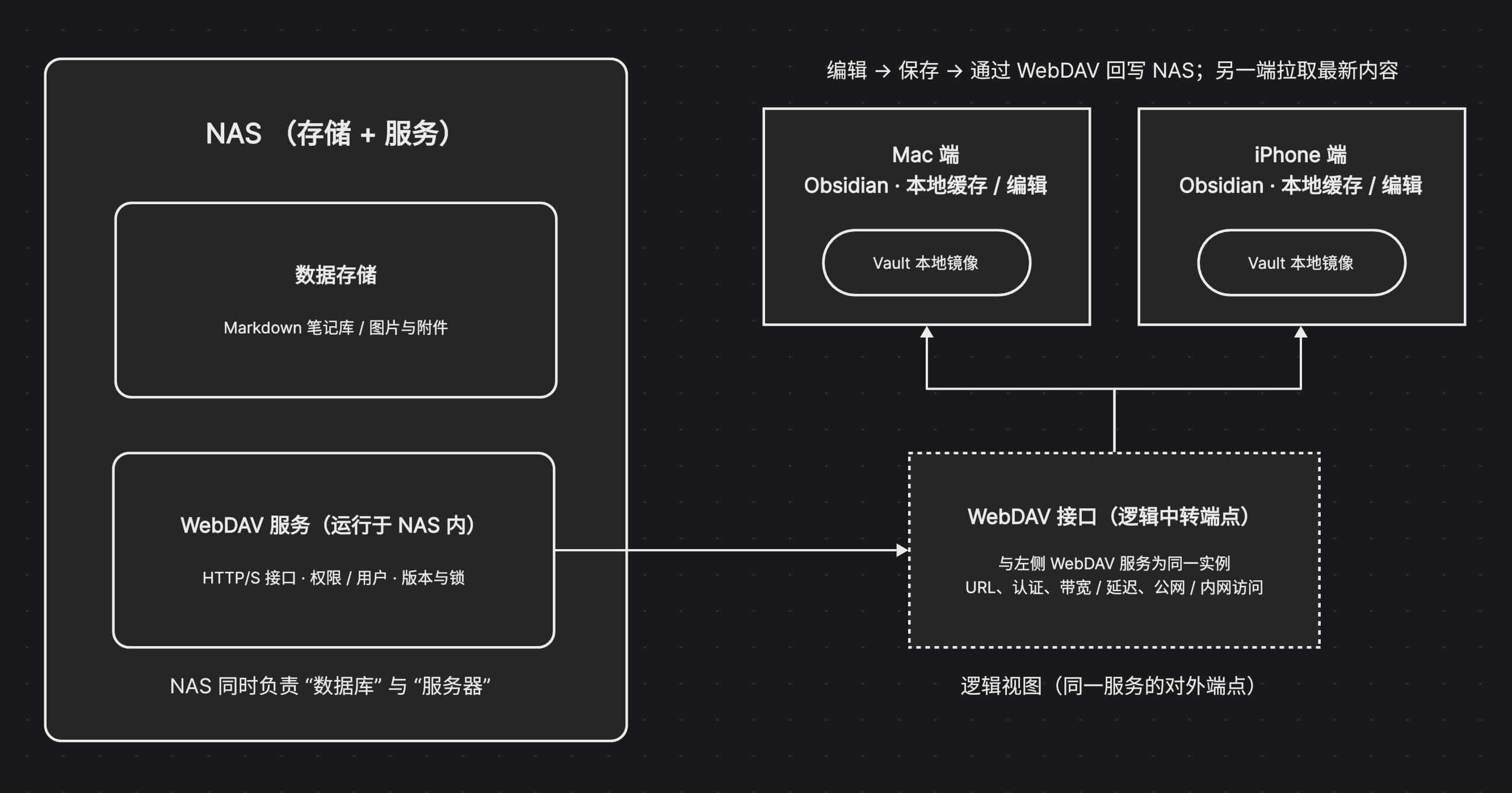
在同步方案的选择上,基于 NAS ,就毫无悬念选 WebDAV 了:
不过 Obsidian 也有其他的同步方案,这里也顺便记录下查过的方案对比,供参考:
| 方案 | 优点 | 缺点 |
|---|---|---|
| Obsidian Sync | 官方方案,稳定可靠 | 需要订阅,最低 $4 / 月,并且限制 1 GB 上限,单个文件不能超过 5 MB |
| iCloud Drive | 苹果生态无缝集成,有基础的免费容量 | 真正用起来的话需要订阅,最低 ¥6 / 月可以达到 50 GB ,否则只有 5 GB 可用,另外注意这些方便服务仅限苹果设备 |
| 网盘 | 主流云盘,稳定,有基础的免费容量 | 免费版速度慢,容量小,也是需要订阅提升体验,但依然有容量限制、文件大小限制 |
| Git 同步 | 免费,版本控制强大,文本 Diff 对比速度快 | 配置复杂,不适合非技术用户;仅对纯文本友好,不适合托管图片、视频多的笔记内容 |
| WebDAV (NAS) | 服务免费,内置服务开箱即用,局域网速度超快 | 需要 NAS 设备(一次性硬件投入) |
在这里还要提及一个特别的同步方案,那就是飞牛同步,支持 Windows 和 macOS 平台。
飞牛同步的优势在于:
可以在官网下载 飞牛同步客户端 。

不过目前飞牛同步还只有 PC 版本,还没有移动端版本支持。对于我这种需要在 iPhone 上记录日记的场景,WebDAV 方案配合 Obsidian App 是更合适的选择。
但如果你的主要使用场景是桌面端同步文件(不限于 Obsidian ),或者希望有更简单的配置流程,飞牛同步也是一个值得考虑的选择。
先说说目前方案的使用体验吧,如果你觉得这套方式也适合自己,再继续往下看配置部分。
我之前用的那个笔记 App 不支持导出数据,所以我是通过 DevTools 查看它的 API 请求过程,写了个爬虫把笔记内容爬了回来。
对方的 API 返回的是 HTML ,因此本地又编写了一个 HTML 转 Markdown 的工具进行格式转换(推荐 Remark 系列工具包)。
笔记中的图片原本也是远程 URL ,我在爬取时一并下载到本地,并按日期文件夹归档,再将笔记里的引用路径改成相对路径指向本地图片,当然这些工作也是用脚本处理的。
具体细节这里就不展开了,前端同学对这种流程应该不陌生,而且爬虫这东西也不太方便公开细说。
写这篇博客时,我已经迁移到 Obsidian + 飞牛 NAS 四个月了,总体体验可以说是非常满意:
优点:
需要注意的点:
接下来讲讲怎么围绕 NAS 这个数据中心实现多端同步,主要以飞牛 NAS 端,以及 Obsidian 桌面客户端,先把流程跑通了,在 Obsidian App 的设置也是一样的。
下面的配置步骤都是以 Web 端的操作为例,在飞牛的 App 操作也是类似,按顺序操作即可,需要注意的是,请使用管理员账号 登录飞牛 NAS ,而不要使用普通账号,很多操作需要管理员才可以设置。
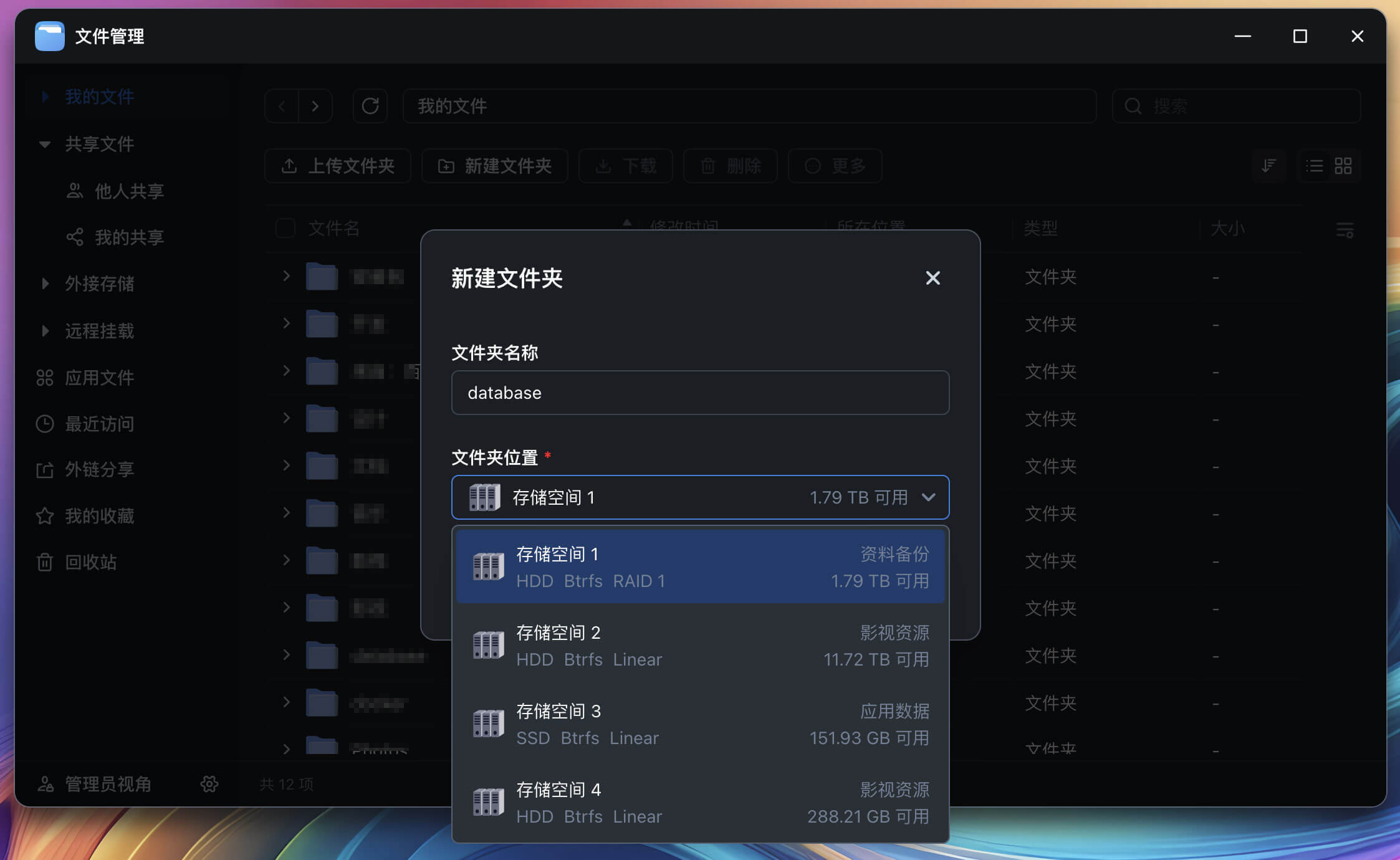
建议在 “文件管理” 中创建一个专门的文件夹,作为数据的存储根目录,比如 database ,这样其他类似的数据托管都可以存档在该文件夹里。
真正存放数据的地方,可以根据需要再建一层目录,例如我的日记是放在 database 的 diary 下。
重要数据建议存放在一个有数据保护的存储空间下,预算不高的话可以像我一样,用两块 2TB 的硬盘创建一个 RAID 1 。
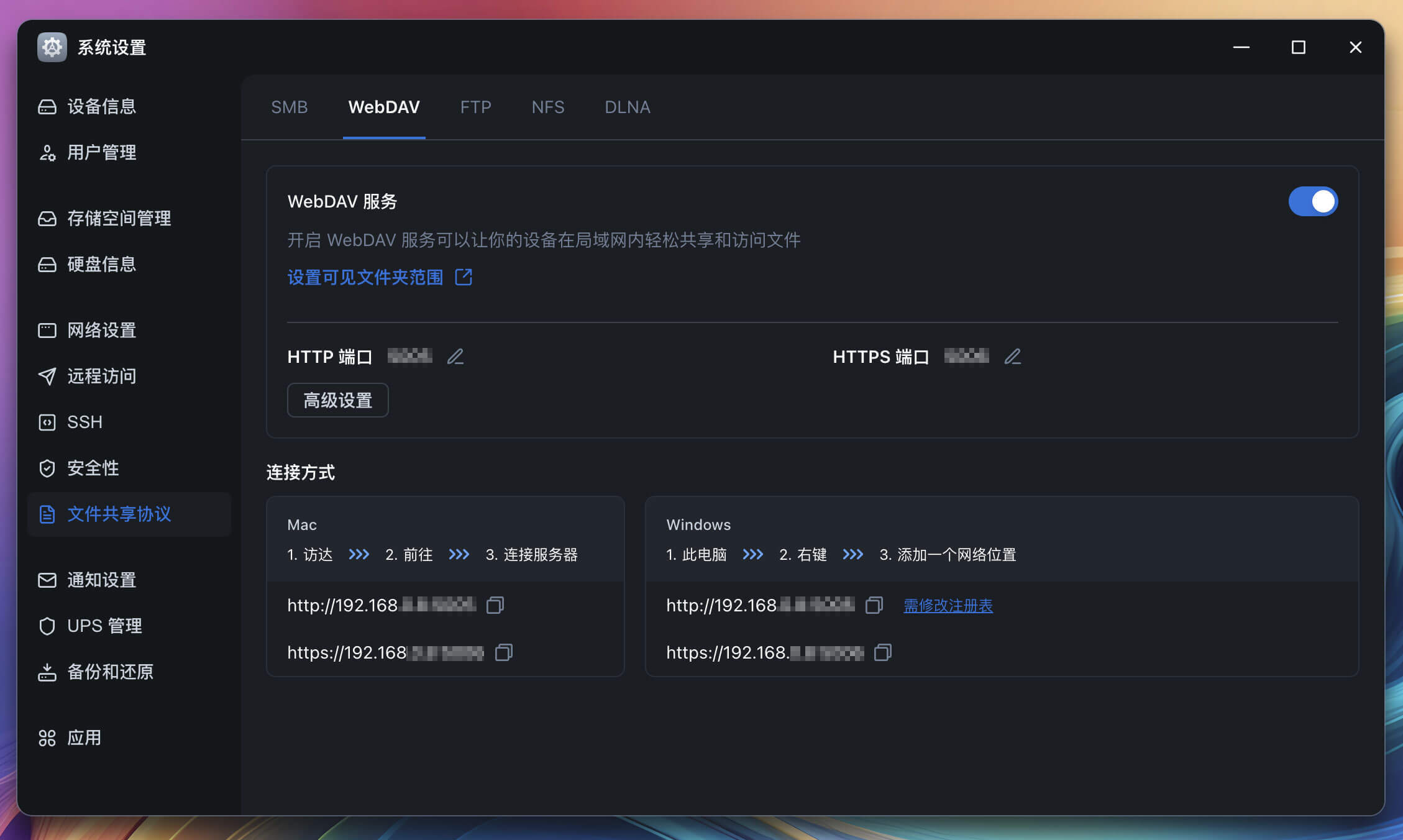
飞牛 NAS 自带 WebDAV 服务,访问 “系统设置 → 文件共享协议 → WebDAV ” ,启用服务。默认的 HTTP 端口号 5005 / HTTPS 端口号 5006 可以直接使用,也可以自行修改。
再点击 WebDAV 界面上的 “设置可见文件夹范围” ,设置允许通过 WebDAV 访问的目录范围,根据自己的需要去限制范围,记得包含刚才的数据文件夹就行。
在 NAS 的 WebDAV 配置界面上,可以看到自己的访问地址是
http://{你的 NAS 内网 IP}:{端口号}/http://{你的 NAS 域名}:{端口号}/注意,使用 HTTP 或 HTTPS 时,两者的端口号是不一样的
如果需要使用域名访问 WebDAV ,可以在 “系统设置 → 远程访问” 管理 FN Connect 账号,或者在 DDNS 配置域名,具体在这里不过多介绍,飞牛的界面操作还是很清晰的。
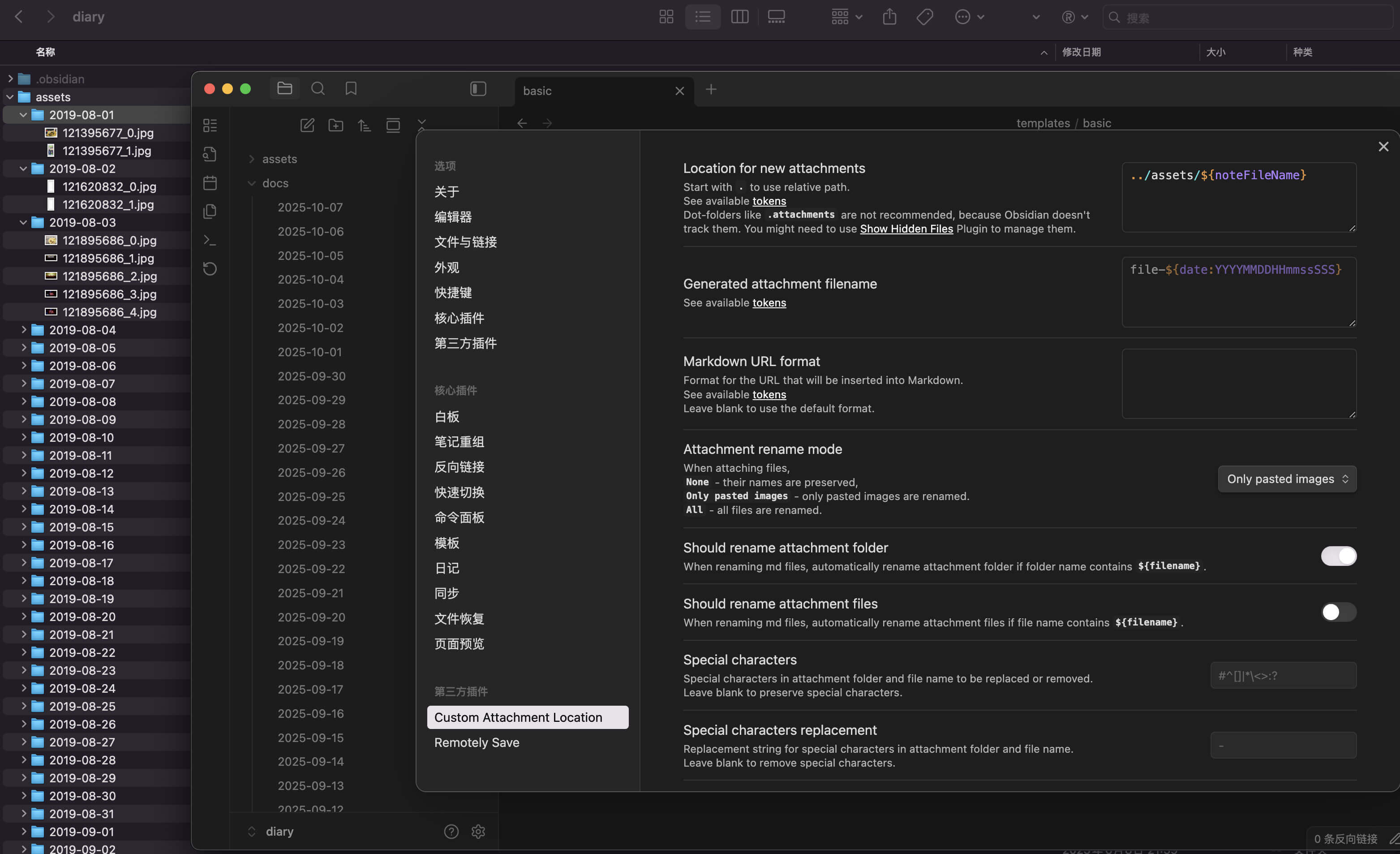
在 Obsidian 中,根据最流行的免费同步方案,使用了 Remotely Save ,另外为了统一处理 Markdown 的内嵌文件路径(图片、视频等)的存放位置,我同时使用了 Custom Attachment Location 插件。
启动 Obsidian 后会引导创建一个笔记仓库,其实就是在电脑里选择一个文件夹存档这些笔记,所选的文件夹对于这个仓库来说也是一个根目录的概念。
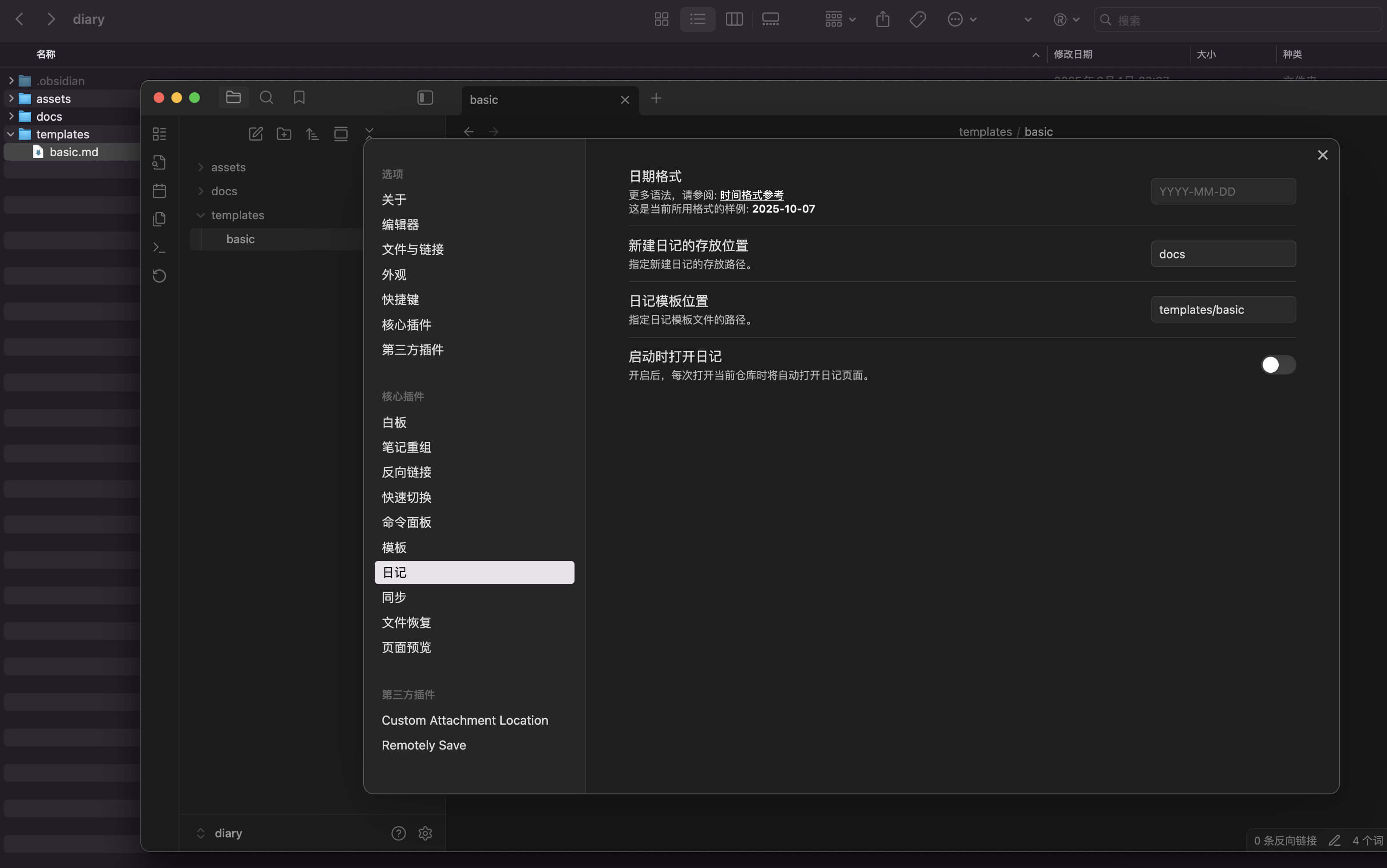
如果和我一样是用来写日记的,或者是想类似日记一样在同一个文件夹里存档笔记,并且有自己的固定笔记模板,那么可以在 “日记” 设置一些存档规则,例如我选择了将所有日记都归类到 docs 文件夹,而日记模板则归类在 template 文件夹下(模版需要具体到某一个文件的路径)。
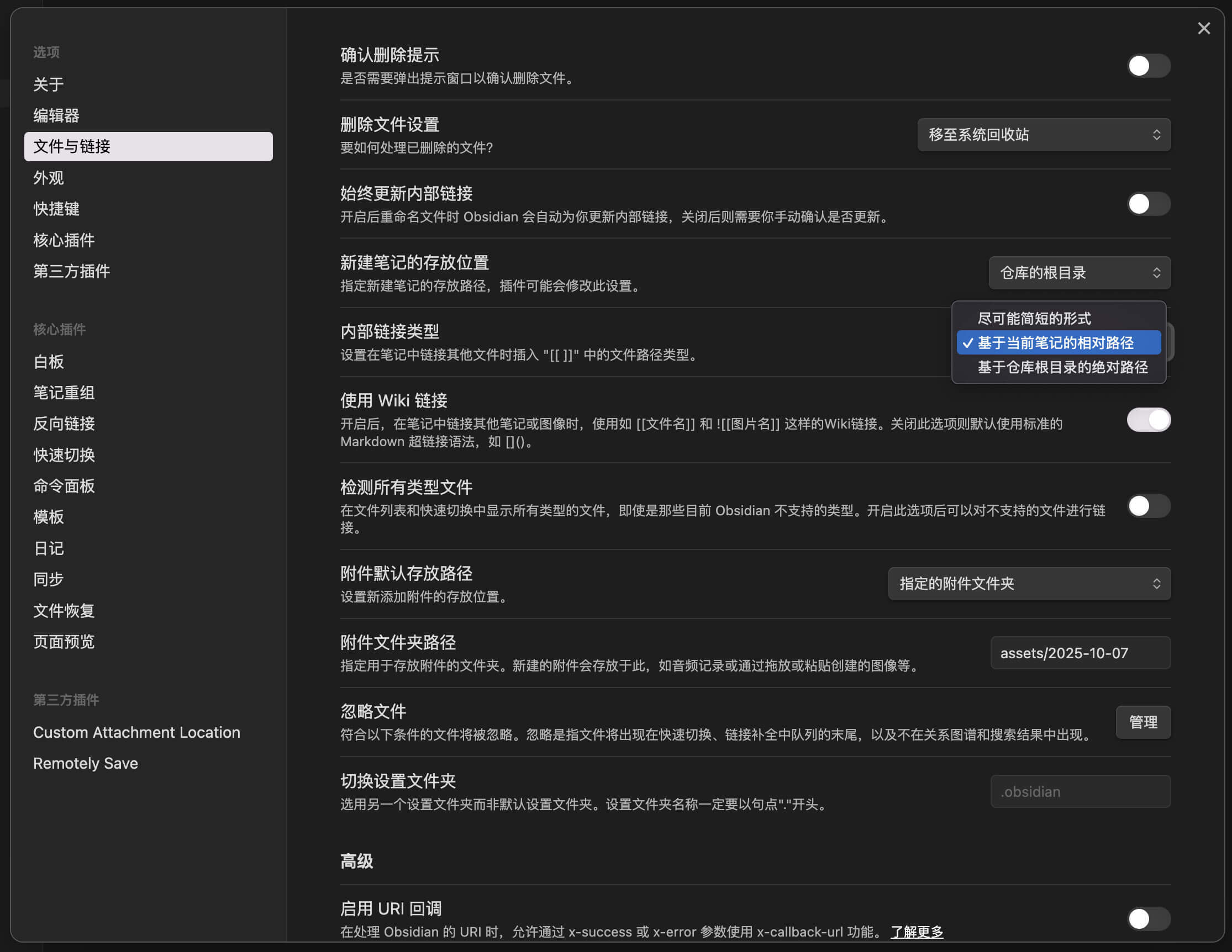
Obsidian 对 Markdown 的链接和图片引用默认是它自己的语法,为了以后兼容其他客户端,建议这里也改成 “基于当前笔记的相对路径” 。
插件好像都是从 GitHub 安装的,所以需要确保所处的网络环境可以顺利打开 GitHub 。
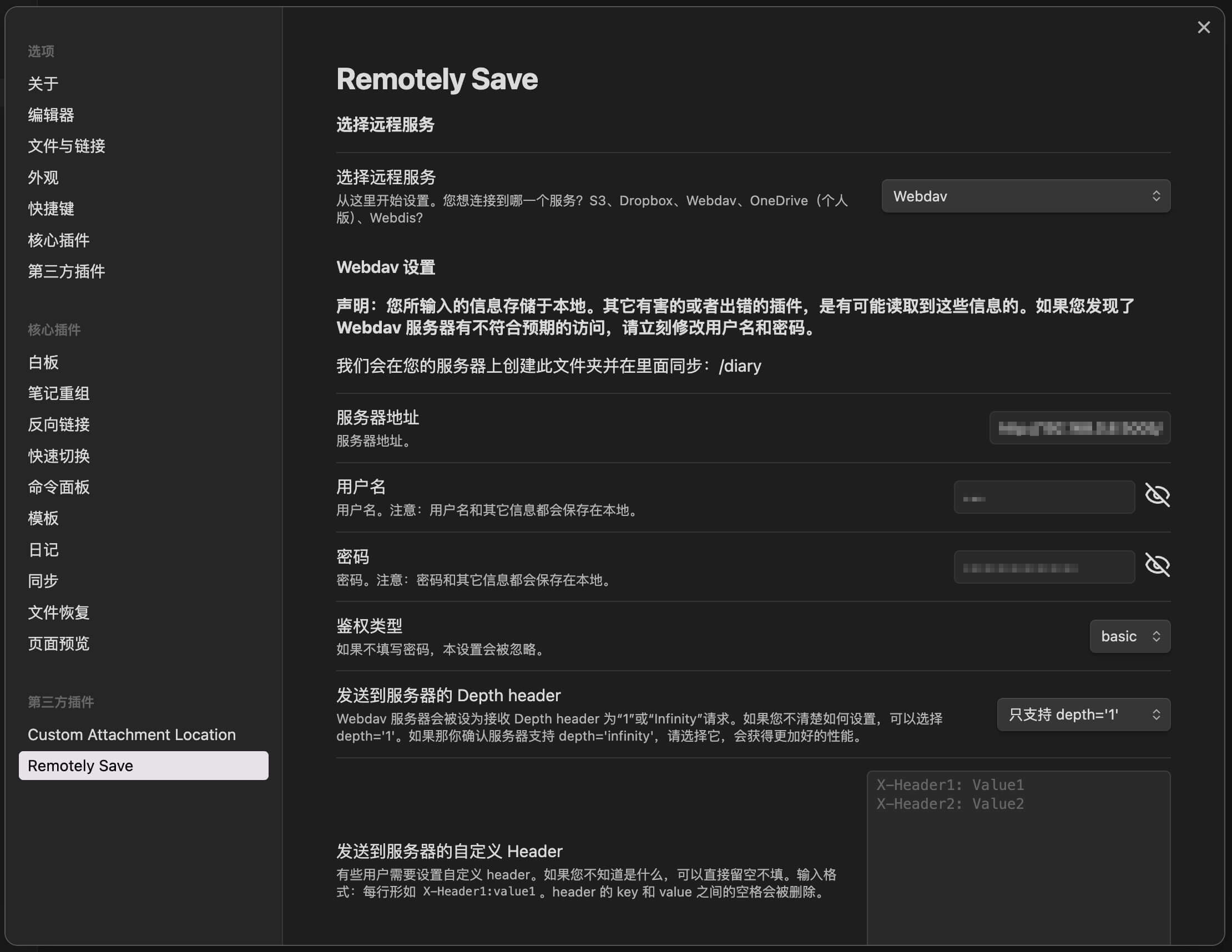
Remotely Save (必要)和 Custom Attachment Location(可选)同步插件是核心插件,使用的是 Remotely Save ,这里有几项需要设置:
| 设置项 | 如何设置 |
|---|---|
| 远程服务 | 选择 WebDAV |
| 服务器地址 | 从飞牛 NAS 复制 WebDAV 的访问地址,拼接数据库文件夹路径,例如 http://192.168.8.8:5005/database
|
| 用户名 | 飞牛 NAS 里,这个 database 文件夹的归属账号的用户名 |
| 密码 | 飞牛 NAS 里,这个 database 文件夹的归属账号的密码 |
| 并行度 | 由于我只使用局域网同步,所以我开到了最大,目前可以设置 20
|
其他的就根据实际需要调整,或者保持默认就可以了。
辅助插件目前只用了一个附件管理的 Custom Attachment Location ,从前面的仓库与日记设置可以看到我还有一个 assets 文件夹,这是因为我每天的日记除了文字,还带有不少图片,有时候还会贴视频,如果没有合理归档这些附件,混在一起就太难维护了。
| 设置项 | 如何设置 |
|---|---|
| Location for new attachments | 我配置了 Location for new attachments 为 ../assets/${noteFileName} ,这样每一篇日记的附件都会归档到 assets 文件夹下的 “笔记文件名” 文件夹里 |
| Should rename attachment folder | 如果笔记对应的 Markdown 文件修改了命名,它会监听并重命名这个附件文件夹,虽然我几乎不改,但一旦修改,这个功能确实挺省事的 |
其他选项可以根据自己需要修改,例如图片自动重命名的一些功能。
我的常用移动设备是 iPhone ,所以直接在 App Store 搜索 Obsidian 即可找到客户端下载,也可以在官网找到其他端的下载。
安装好 App 后,在 iPhone 或其他设备上重复上述步骤进行配置。
日常写笔记时,我的习惯是只在一端更新,写完后同步回 NAS ,下次在另一台设备启动 Obsidian 时,插件会自动比对版本,从 NAS 拉取最新数据,实现双向同步,这种方式在实际使用中没有出现文件冲突,整体体验非常稳定。
从 2019 年开始在第三方 App 上写日记,到现在用 Obsidian + 飞牛 NAS 搭建私有笔记系统,这 6 年的数据迁移总算告一段落。
这套方案在技术上并不复杂,但在内容管理理念上是一次很大的升级:
经过几个月使用,无论是多端同步、搜索速度还是文件安全,都比以往的云笔记方案更可靠,如果你也希望让笔记系统更可控、更长期可维护,这套组合值得一试。
2025-03-14 00:35:02
ESLint v9.0.0 是 ESLint 的一个主要版本,它有几个重大变化,其中最大的变化是其配置文件和插件生态系统的使用,可以通过官方网站的 迁移到 v9.x 文档了解如何迁移。
这里有一个关于 ESLint V9 的扁平化配置的 npm 包,内置了一些个人常用的 ESLint 配置,这也是我在 GitHub 上发布的一个开源项目。如果它对您有帮助,请 给它一个 Star !
一款现代化的扁平 ESLint 配置,适用于 ESLint v9 和 v10 ,由 @chengpeiquan 精心打造。
使用此 ESLint 配置仅需三步:
settings.json 启用自动 Lint(参考:🛠 VS Code 配置)这个快速指南可以作为入门辅助,避免遗漏关键步骤 🚀 。
使用常用的包管理器安装该包:
npm install -D eslint @bassist/eslint-config注意: 支持 ESLint 9.x 和 10.x,并且需要 TypeScript 版本 >= 5.0.0。
如果使用的是 pnpm,建议在项目根目录添加 .npmrc 文件,并包含以下配置,以更顺利地处理 peer 依赖:
shamefully-hoist=true
auto-install-peers=true如果仍在使用 ESLint v8,请参考旧版(已不再维护)包:@bassist/eslint。
在项目根目录创建 eslint.config.js 文件:
// eslint.config.js
import { imports, typescript } from '@bassist/eslint-config'
// 导出一个包含多个配置对象的数组
export default [...imports, ...typescript]然后在 package.json 中添加 "type": "module" :
{
"type": "module",
"scripts": {
"lint": "eslint src",
"lint:inspector": "npx @eslint/config-inspector"
}
}运行 npm run lint 以检查代码,或运行 npm run lint:inspector 在 http://localhost:7777 查看可视化的 ESLint 配置。
Bun 可以直接加载
eslint.config.ts。如果你通过 Node.js 运行 ESLint,建议改用eslint.config.mjs,或者按照 ESLint 文档完成额外的设置。
# pnpm 工作流
pnpm lint如果希望 ESLint 直接检查 JSON 系列文件,可以使用 jsonc 预设:
// eslint.config.js
import { jsonc } from '@bassist/eslint-config'
export default [...jsonc]jsonc 的默认行为:
.json、.jsonc、.json5
jsonc/sort-keys)package.json,让包清单 key 排序继续交给格式化流程处理如果你在 VS Code 里通过 ESLint 扩展做校验,并且手动设置了
eslint.validate,记得把 json 和 jsonc 也加进去。
如果需要,也可以在项目里覆盖默认行为:
import { jsonc } from '@bassist/eslint-config'
export default [
...jsonc,
{
files: ['**/*.json', '**/*.jsonc', '**/*.json5'],
rules: {
'jsonc/sort-keys': 'off',
},
},
]为了增强类型安全性,可以使用 defineFlatConfig:
// @ts-check
import { defineFlatConfig, imports, vue } from '@bassist/eslint-config'
export default defineFlatConfig([
...imports,
...vue,
// 添加更多自定义配置
{
// 为每个配置提供名称,以便在运行 `npm run lint:inspector` 时,
// 可以在可视化工具中清晰展示
name: 'my-custom-rule/vue',
rules: {
// 例如:默认情况下,该规则是 `off`
'vue/component-tags-order': 'error',
},
ignores: ['examples'],
},
])在 VS Code 工作区的 settings.json 添加以下配置,以启用自动 Lint 修复:
{
"editor.formatOnSave": true,
"editor.codeActionsOnSave": {
"source.fixAll.eslint": "always",
"source.fixAll.prettier": "always"
},
"editor.defaultFormatter": "esbenp.prettier-vscode",
"eslint.useFlatConfig": true,
"eslint.format.enable": true,
"eslint.validate": [
"javascript",
"javascriptreact",
"typescript",
"typescriptreact",
"json",
"jsonc"
],
"prettier.configPath": "./.prettierrc.js"
}关于 prettier.configPath 请查看 格式化工具 部分。
定义 ESLint 配置,可选支持 Prettier 和 Tailwind CSS。
API 类型声明:
/**
* 定义 ESLint 配置,可选支持 Prettier 集成。
*
* @param configs 基础 ESLint 配置数组。
* @param options - 配置选项。
* @returns 最终的 ESLint 配置数组。
*/
declare const defineFlatConfig: (
configs: FlatESLintConfig[],
options?: DefineFlatConfigOptions,
) => FlatESLintConfig[]选项类型声明:
interface DefineFlatConfigOptions {
/**
* 指定用于加载 `.prettierrc` 配置的工作目录。
*
* 配置文件应为 JSON 格式。
*
* @default process.cwd()
*/
cwd?: string
/**
* 如果 `prettierEnabled` 设为 `false`,则所有与 Prettier 相关的规则和配置都将被忽略, 即使提供了
* `prettierRules` 也不会生效。
*
* @default true
*/
prettierEnabled?: boolean
/**
* 默认情况下,会从当前工作目录读取 `.prettierrc`,并且 `.prettierrc` 文件必须是 JSON 格式。
*
* 如果配置文件不是 JSON 格式,或者使用了不同的文件名,可以将其转换为 JSON 规则后传入。
*
* 读取自定义配置后,会与默认的 ESLint 规则合并。
*
* @see https://prettier.io/docs/configuration.html
*/
prettierRules?: PartialPrettierExtendedOptions
/**
* Tailwind CSS 规则默认启用。如果它们影响了项目,可以通过该选项禁用。
*
* @default true
*/
tailwindcssEnabled?: boolean
/**
* 如果需要覆盖 Tailwind CSS 配置,可以传入相应的选项。
*
* 如果想要合并配置,可以导入 `defaultTailwindcssSettings`,手动合并后再传入。
*
* 如果传入空对象 `{}`,则会使用默认设置。
*
* @see https://github.com/schoero/eslint-plugin-better-tailwindcss
*/
tailwindcssSettings?: TailwindcssSettings
}createGetConfigNameFactory 是一个灵活的工具函数,用于生成 ESLint 配置命名工具。它可以快速拼接配置名称,确保命名空间一致,并便于组织和管理复杂的规则集。
API 类型声明:
/**
* 一个灵活的工具函数,用于生成 ESLint 配置命名工具。 它可以快速拼接配置名称,确保命名空间一致,并便于组织和管理复杂的规则集。
*
* @param prefix - 表示配置名称前缀的字符串。
* @returns 一个函数,该函数会将提供的名称片段与指定的前缀拼接在一起。
*/
declare const createGetConfigNameFactory: (
prefix: string,
) => (...names: string[]) => string使用示例:
import {
createGetConfigNameFactory,
defineFlatConfig,
} from '@bassist/eslint-config'
const getConfigName = createGetConfigNameFactory('my-prefix')
export default defineFlatConfig([
{
name: getConfigName('ignore'), // --> `my-prefix/ignore`
ignores: ['**/dist/**', '**/.build/**', '**/CHANGELOG.md'],
},
])为什么要使用它?
这个工具在构建可复用的 ESLint 配置或维护复杂项目的规则集时尤其有用。
这些是一些常用的配置,如果有额外需求,欢迎提交 PR!
格式化规则默认启用,不会单独导出。如需自定义配置,请通过 defineFlatConfig API 的 options 传入。
.prettierrc 和 .prettierignore 的内容,并添加到 ESLint 规则中。options.prettierRules 将完整配置传递进来优先作为 ESLint 规则使用eslint-plugin-better-tailwindcss,让 Tailwind CSS v3 和 v4 项目共用同一套 class linting。options.tailwindcssSettings 传递。--ext CLI 选项已被移除 (#16991) 。详细更新内容请参考 CHANGELOG 。