2026-03-14 11:53:00
最近我想看一场时长 5 个多小时的日语演唱会录像,但这份录像没有可用字幕,我又不懂日语,没有字幕MC部分根本听不懂。
于是我想到可以用本地语音转录生成字幕。调研后我发现了 McCloudS/subgen 这个项目,发现它已经把“本地自动转录”这件事做得很完整,并且可以用jellyfin集成实现视频加入和播放时自动生成字幕。
在实际体验中,我进一步希望它能覆盖“转录后翻译”的需求,于是决定在原项目基础上做一层轻量扩展,把翻译功能补齐到同一条工作流中。
因此,我在原仓库上创建了一个fork https://github.com/ddadaal/subgen-translate ,实现了:
uv run launcher.py -f "D:\Movies\movie.mp4" -t transcribe
uv run launcher.py --srt "D:\Movies\movie.subgen.medium.jpn.srt" --srt-to zh
uv管理环境、subgen.env.local来编写本地配置等我的实际环境是一个典型的家庭局域网多机协作场景:
在 Subgen 与 Jellyfin 集成时,有一个关键前提:Subgen 看到的媒体文件路径,必须与 Jellyfin 看到的路径完全一致。为了实现这一点,我
这样,Jellyfin 仍然负责媒体管理与播放触发,GPU 机器负责高耗时的转录与翻译,实现了“存储在 NAS、计算在 GPU 机器”的分工。
flowchart LR
subgraph LAN[家庭局域网]
subgraph NASHost[老 Windows 笔记本(NAS)]
Jellyfin[Jellyfin 服务]
Disk[外接硬盘盒 / 媒体库]
end
subgraph GPUHost[GPU 机器]
Subgen[Subgen 服务]
Model[Whisper + TranslateGemma]
end
Client[局域网播放器/客户端]
end
Disk -->|媒体文件路径| Jellyfin
Disk -.同盘符映射.-> Subgen
Client -->|播放/新增媒体| Jellyfin
Jellyfin -->|Webhook 事件| Subgen
Subgen -->|转录/翻译| Model
Model -->|生成字幕(双语/纯译文)| Disk
Jellyfin -->|读取字幕并展示| Client配置情况:
vad功能,其他参数可让AI来调整。# subgen.env.local
SUBGEN_KWARGS={'vad': True}faster-whisper支持多种模型( https://deepwiki.com/SYSTRAN/faster-whisper#supported-model-variants ),但是不同模型的使用体验有较大区别:
medium:在 i5-1135G7 上用CPU大约可以做到 1s/s(每 1 秒处理 1 秒原视频),台式机RTX 5070 Ti 6s/s (每秒处理约6秒原视频),速度可以接受large-v3:模型大小 3G,在台式机 RTX 5070 Ti 上最快可达 9s/s,和medium差不多,因为瓶颈在CPU上large-v3-turbo:模型体积和 medium 差不多,都是约 1.5G;但在我的环境里只能正常处理视频开头,后面基本识别不出文字,估计也和调参有关,而且既然large-v3也这么快了,直接用large-v3就好distil-large-v3:只支持识别英文faster-whisper只支持CUDA 12,不支持最新的CUDA 13translategemma-4b-it和默认参数在RTX 5070 Ti上推理一次2.3s,速度勉强可以接受。但是考虑到字幕的每一行一般较短,将多个字幕合并后同时推理效率更高,所以提供了批量翻译的功能,每一次推理翻译多行,需要根据README中的描述以及本地硬件的情况调整相关参数2026-03-06 18:50:00
实在不太放心把 nanobot 这类可以直接操作本地电脑的程序直接装在操作系统上,所以我选择把 nanobot 放在容器里运行。但是nanobot很多有意义的工作又需要和宿主机上的环境(例如浏览器)交互,而浏览器上很多网站需要我们先去登录才可以正常使用,这就需要一个既可以由 nanobot操作、也可以由我们自己的操作的浏览器
经过一番查找,终于找一个不影响 nanobot 本身的方法,操作是在部署 nanobot的 docker-compose.yaml 目录下再创建一个 docker-compose.override.yaml,内容如下:
services:
chromium-vnc-cdp:
image: linuxserver/chromium:latest
container_name: chromium-vnc-cdp
ports:
- "3000:3000" # Web 界面
shm_size: "2gb"
environment:
- PUID=1000
- PGID=1000
- TZ=Asia/Shanghai
- CHROME_CLI=--remote-debugging-address=127.0.0.1 --remote-debugging-port=9222
chromium-cdp-proxy:
image: alpine/socat
container_name: chromium-cdp-proxy
restart: unless-stopped
network_mode: "service:chromium-vnc-cdp"
command: "TCP-LISTEN:19222,fork,bind=0.0.0.0,reuseaddr TCP:localhost:9222"启动后,给 nanobot 一条明确指令:
之后都使用
chromium-vnc-cdp:19222这个 CDP 端口操作浏览器。
chromium-vnc-cdp 的职责是提供浏览器本体和 Web 访问界面(3000 端口),这样我们可以直接使用localhost:3000访问这个浏览器。
chromium-cdp-proxy 的职责是把 Chromium 容器里只监听 127.0.0.1:9222 的 CDP 端口,转发成同网络命名空间下可访问的入口。实际上这两个容器在同一个网络中,所以需要换个端口监听,这里选择了19222,其他任何端口都可以。
这里有一个关键限制:根据 pyppeteer 相关讨论中的实践结论,--remote-debugging-address=0.0.0.0 往往需要和 --remote-debugging-port、--headless 一起使用;但一旦使用 --headless,就无法达到“实时查看浏览器界面”的目标。
来源:https://github.com/pyppeteer/pyppeteer/pull/379#issuecomment-2072215518
因此我不走“浏览器直接对外暴露 CDP”的路线,而是保留有界面的 Chromium,再通过独立的 socat proxy 容器做端口转发。
这样拆分有三个好处:
socat 单独做代理,不需要改 Chromium 镜像或启动脚本。chromium-vnc-cdp:19222),配置简单且稳定。这套配置完成后:
3000 端口看到浏览器 Web 界面。2026-02-02 20:34:00
之前写过一篇关于HP战99 Ultra(搭载AMD AI Max+ 395)的使用体验,今天聊聊这台笔记本在AI推理场景下的表现。作为这台机器宣传的主要场景,AI推理的实际使用情况却优点一言难尽。
| 配置 | 详情 |
|---|---|
| CPU | AMD Ryzen AI Max+ 395 16C32T Zen5 |
| 内存 | 64G LPDDR5 8000MT 4通道可划分显存 |
| 显卡 | Radeon 8060S 40CU RDNA3.5 |
| 显存 | 可在BIOS里将几个固定挡位的内存分配给显存 |
在深入分析数据之前,需要理解几个重要概念:
重要区别:AI Max+ 395使用可划分显存架构,需要静态分配部分内存给GPU使用;而统一内存无需显式分配,灵活性更高。
为了方便,以及因为我至今没能在WSL下成功运行rocminfo也就没办法跑vllm等主流推理引擎方案(就离谱),本次测试均在Windows下使用LM Studio运行。
这是个MoE模型,总参数量30B激活3B的规模,主要测试Q4_K_M量化的情况。在这个量化等级下,在模型大小为18.13GB。
以下的给出Prompt为:
编写一个科技公司的官网的HTML
另外值得一提的是,LM Studio中对AMD显卡有两种Runtime:Vulkan和ROCm。我本以为两种Runtime不会有什么很大的区别,但是实际测试下来却axm并非如此。
在16K上下文下:
| 专用显存 | 512M | 32G |
|---|---|---|
| 显存占用 | 20.8G | 21.3G |
| Vulkan速度、总数(token/s) | 17.26 (6970) | 42.89 (6107) |
| Vulkan 首token (s) | 0.8 | 0.8 |
| ROCm速度、总数(token/s) | 15.28 (5262) | 14.42 (6351) |
| ROCm 首token (s) | 0.04 | 0.34 |
Vulkan在32G专用显存下的速度实在是过于逆天,于是我重新跑了数次,结果均非常接近。后面我们还能拿到如此让人匪夷所思的成绩。
16K的上下文只能说勉强够用。既然还有这么多显存可用,不妨试试更多的长度上下文。根据LM Studio估计,不同长度上下文的显存使用估计值:
看起来MoE模型的一大好处就是可以把上下文拉大!于是我选择GLM 4.7 Flash最大支持的长上下文 198K下,虽然LM Studio的估计显存占用也仅有22.3G,但是512M专用显存的无法正常加载:
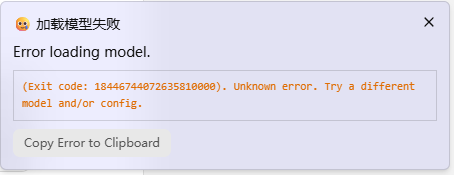
只有在32G下可以正常使用,在Vulkan下获得了**37.28 token/s(7857 token,首token 0.15s)**的成绩。
同时我还测试了Q6_K的量化模型,在16K上下文、32G专用显存下:
再次看到了不知道该说是Vulkan逆天还是ROCm的成绩!ROCm作为AMD官方的方案,居然被Vulkan拉开了如此大的差距。
在不开启思考的情况下,10 token/s的速度还是可以应付日常使用的。
稠密模型的情况就不一样了。这一部分我选择了Qwen 3 VL 32B来测试。
这是个支持图像输入的模型,于是我去stackoverflow上截了如下这一张图,
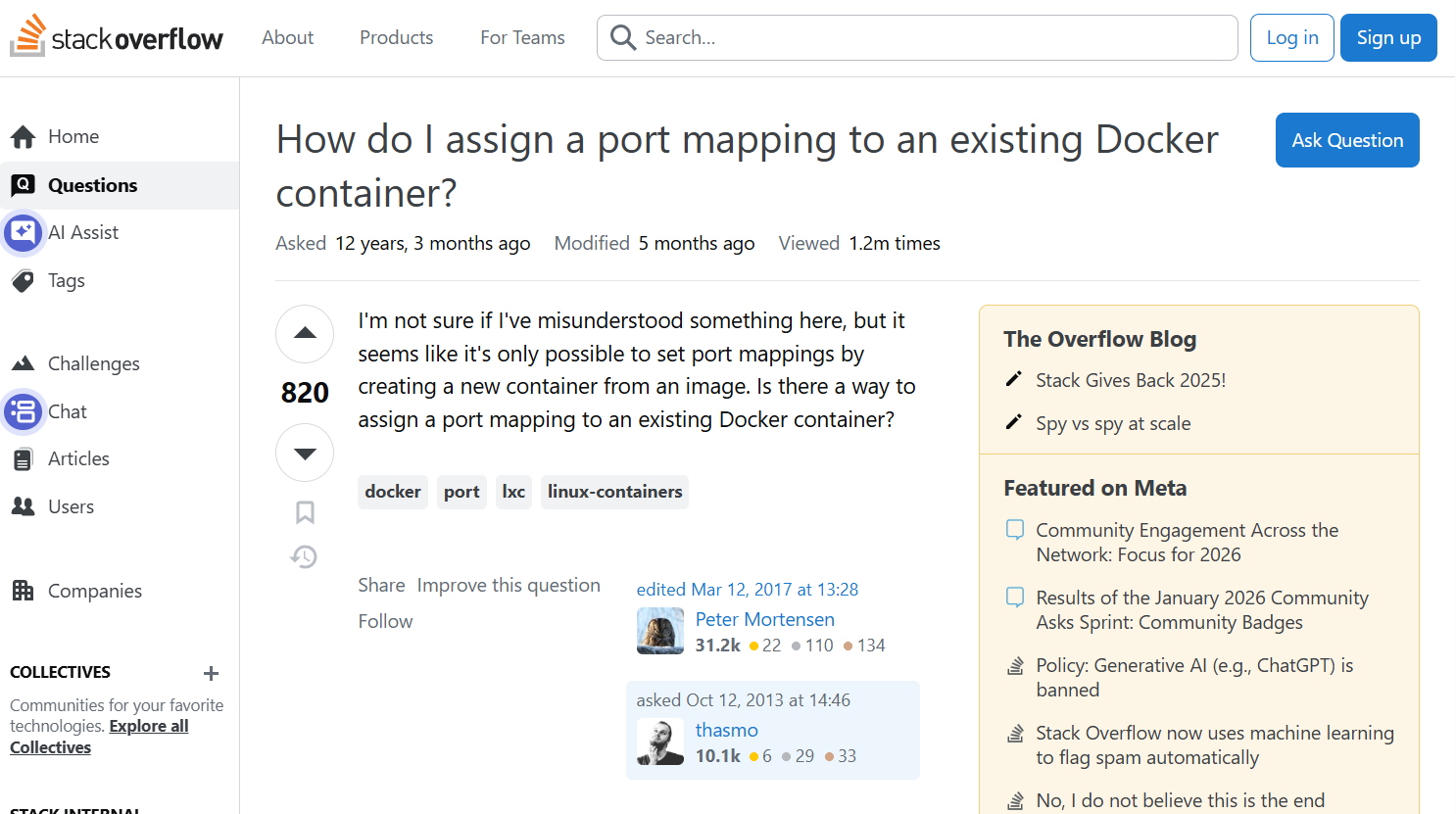
并给出prompt:
使用html和css重现这个HTML页面
以下为结果:
| 专用显存 | 512M 16K | 512M 24K | 32G 16K |
|---|---|---|---|
| 显存占用 | 25.8G | 28.3G | 27.5G |
| Vulkan速度、总数(token/s) | 3.74 (4059) | 3.51 (3676) | 9.41 (6801) |
| Vulkan 首token (s) | 36.67 | 39.29 | 18.32 |
| ROCm速度、总数(token/s) | 4.15 (3723) | 3.10 (3713) | 9.42 (4198) |
| ROCm 首token (s) | 24.59 | 26.56 | 9.46s |
可以看到,在24K上下文已经到32G显存的极限了(28G)。但不管有没有独立显存,这个推理速度用起来已经是比较难受的级别了。
395的另一个宣传点是可以将75%的内存划给显存,在64G的型号上,BIOS中最高可以将48G的内存划给显存。
听起来很美?48G显存甚至可以高量化跑32B模型了!
Qwen 3 VL 32B的Q6_K量化模型大小为28.08G,在32G显存下可以加载,但是推理的时候因为显存不够了,速度比可以完全在显存中的Q4版本慢很多。经过测试,Q5_K_M是最大的32G显存可以充分的量化规格。
而这时候你想到,48G显存岂不是就可以接近这个问题了?
可是事实却是:16G的系统内存不仅使得正常的系统操作会开始缓慢甚至卡顿,甚至模型都无法正常加载!而我已经LM Studio中有三个选项和显存和内存全部调整为不给内存太多压力了:
395的主要的宣传口号,就是内存可以当作显存用。这话当然不假,BIOS里确实可以将内存划分给显存,但是,它和我们预期的共享内存完全是两码事:
那,如果我们不划分显存,直接把内存当显存用呢?其实现在的推理框架都支持把内存当显存用,但是以下两个问题让用内存当显存的方案下的推理速度惨不忍睹:
理论上来说,395的内存和显存均为同一款芯片,问题1不存在,但实际上问题2的问题仍然无法避免:即使是在同一块芯片上,显存仍然不能直接用内存部分的部分,内存和显存之间拷贝仍然非常频繁。
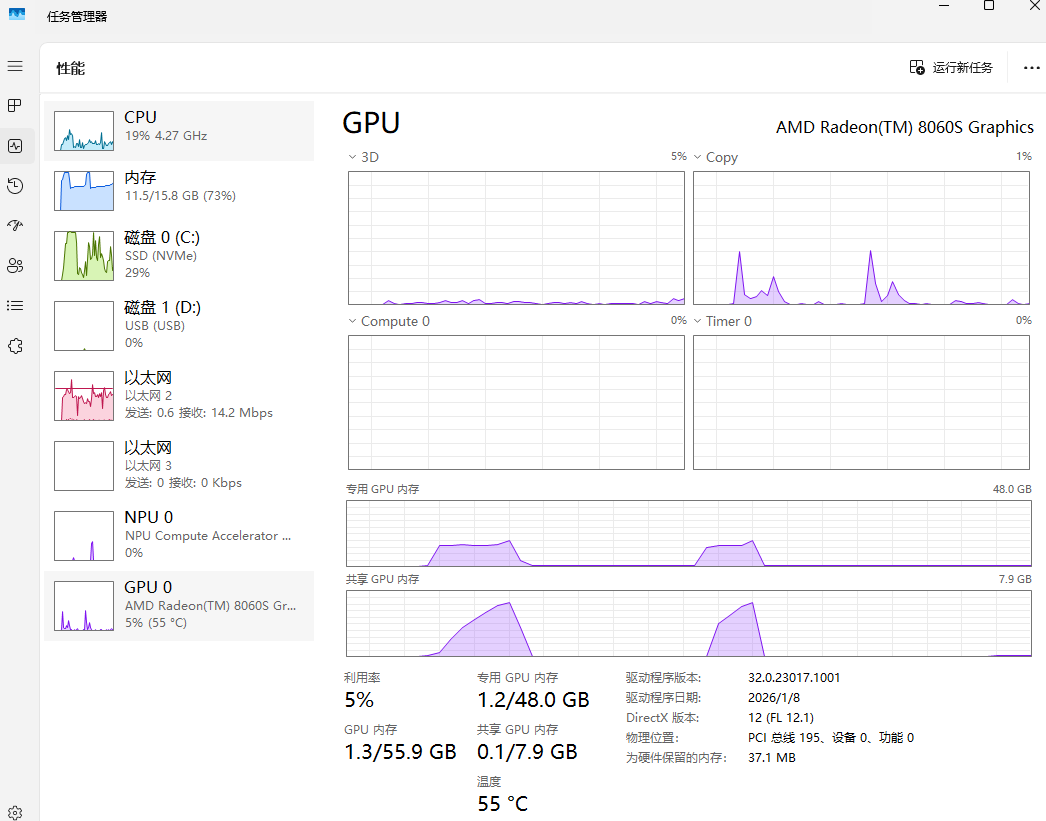
以下为使用512M专用显存(上)和32G专用显存(下)使用Vulkan运行GLM 4.7 Flash Q4_K_M时的任务管理器的图片,可以看出,512M的专用显存下GPU利用率只有70%左右,而32G下可以到达90%以上。而右上角的Copy也可以看出512M专用显存下显存一直在进行复制的操作。
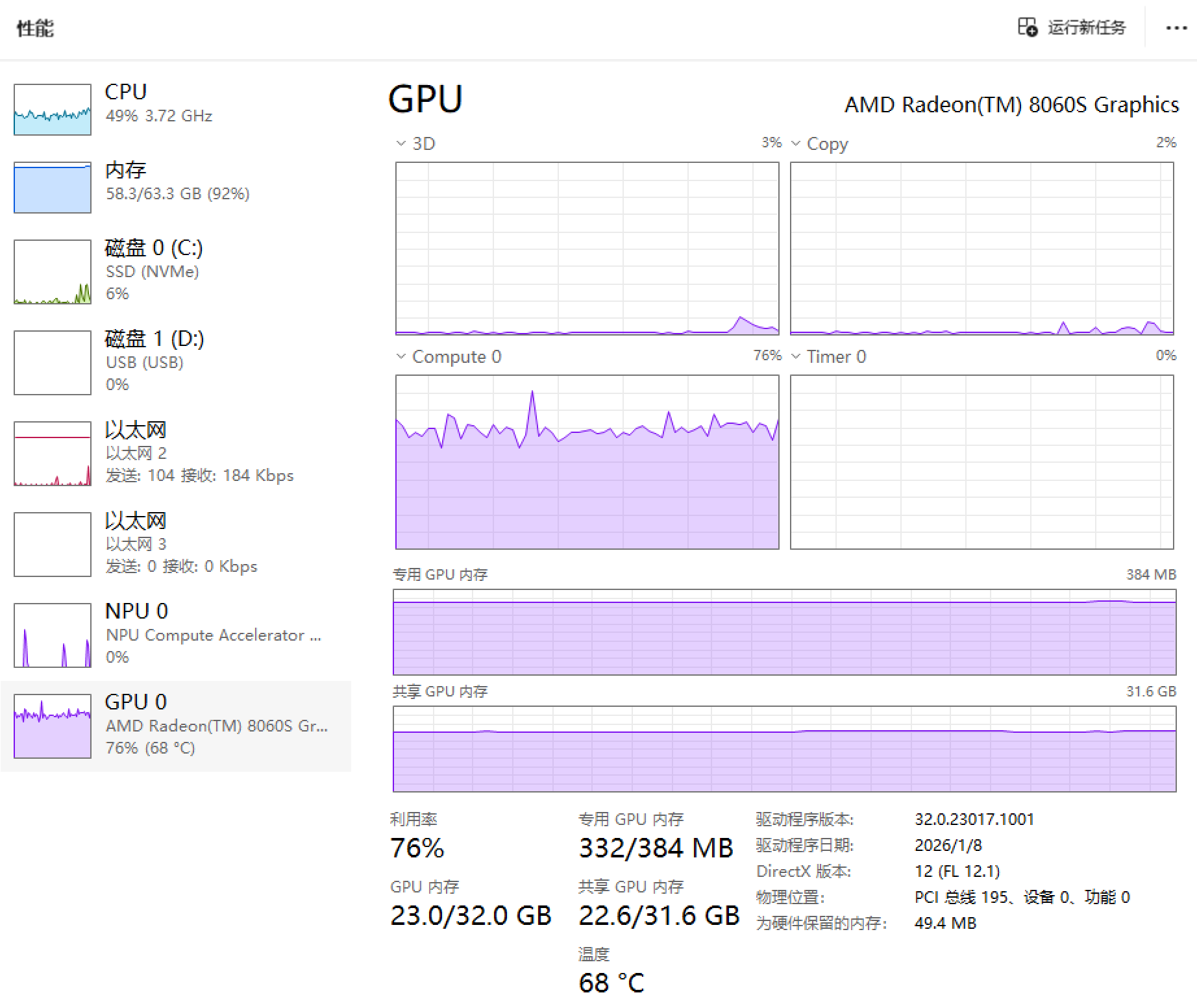
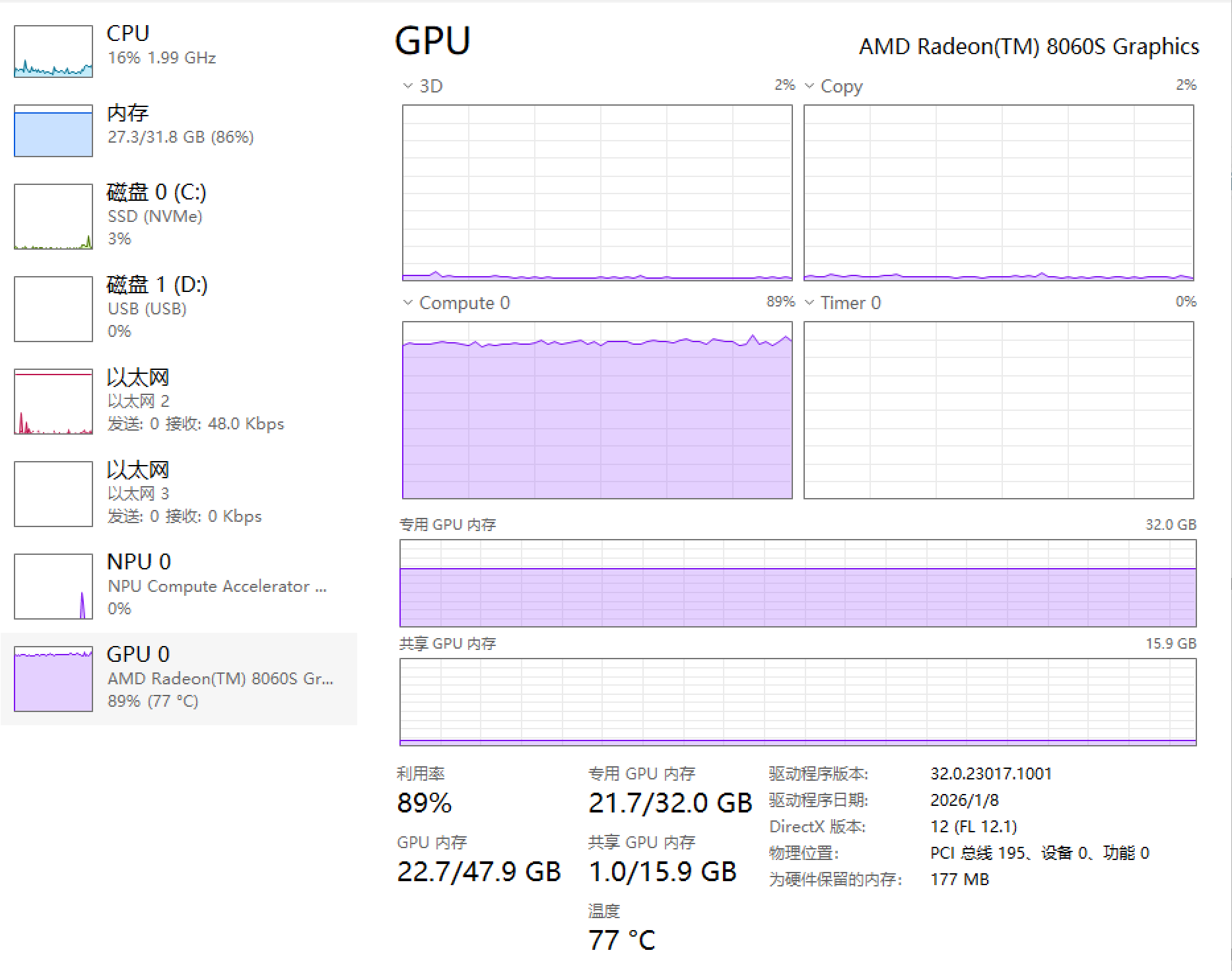
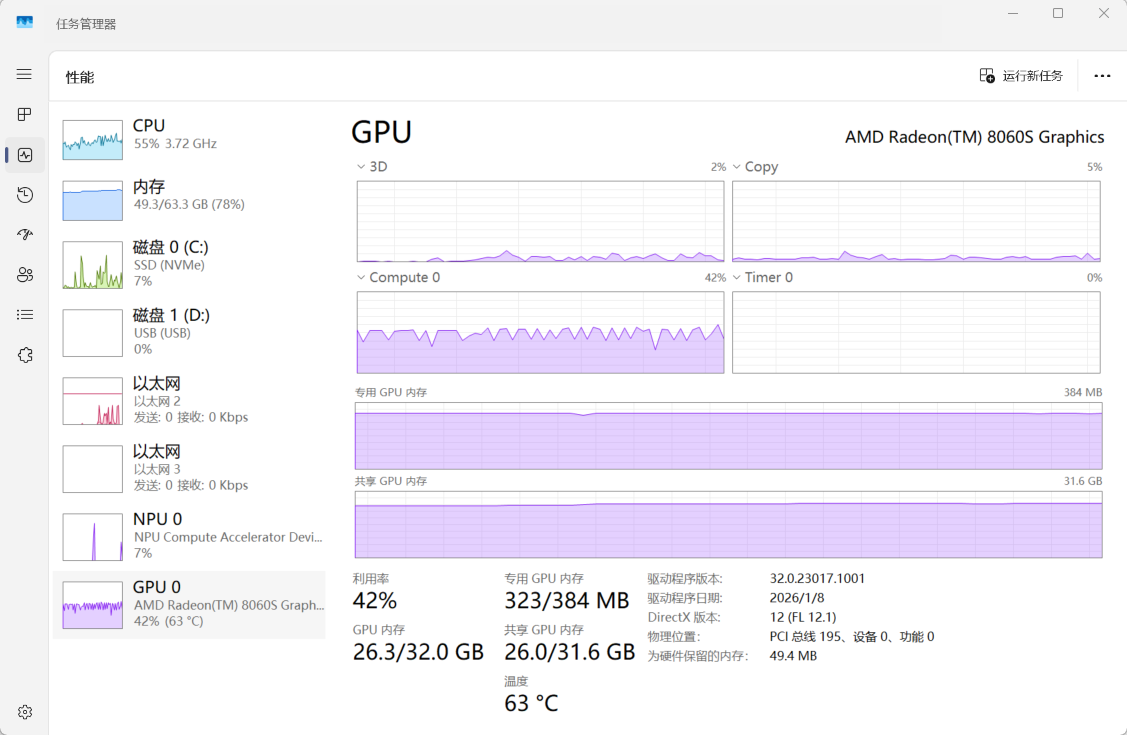
同一现象也出现在512M专用显存下运行Qwen 3 VL 32B Q4_K_M的情况,GPU利用率更是只有50%,而Copy图中也能一直看到复制的过程,而整个过程中CPU也在(艰难地)参与运算。而CPU参与计算在笔记本场景下有抢功耗的问题,更影响了GPU的性能发挥。
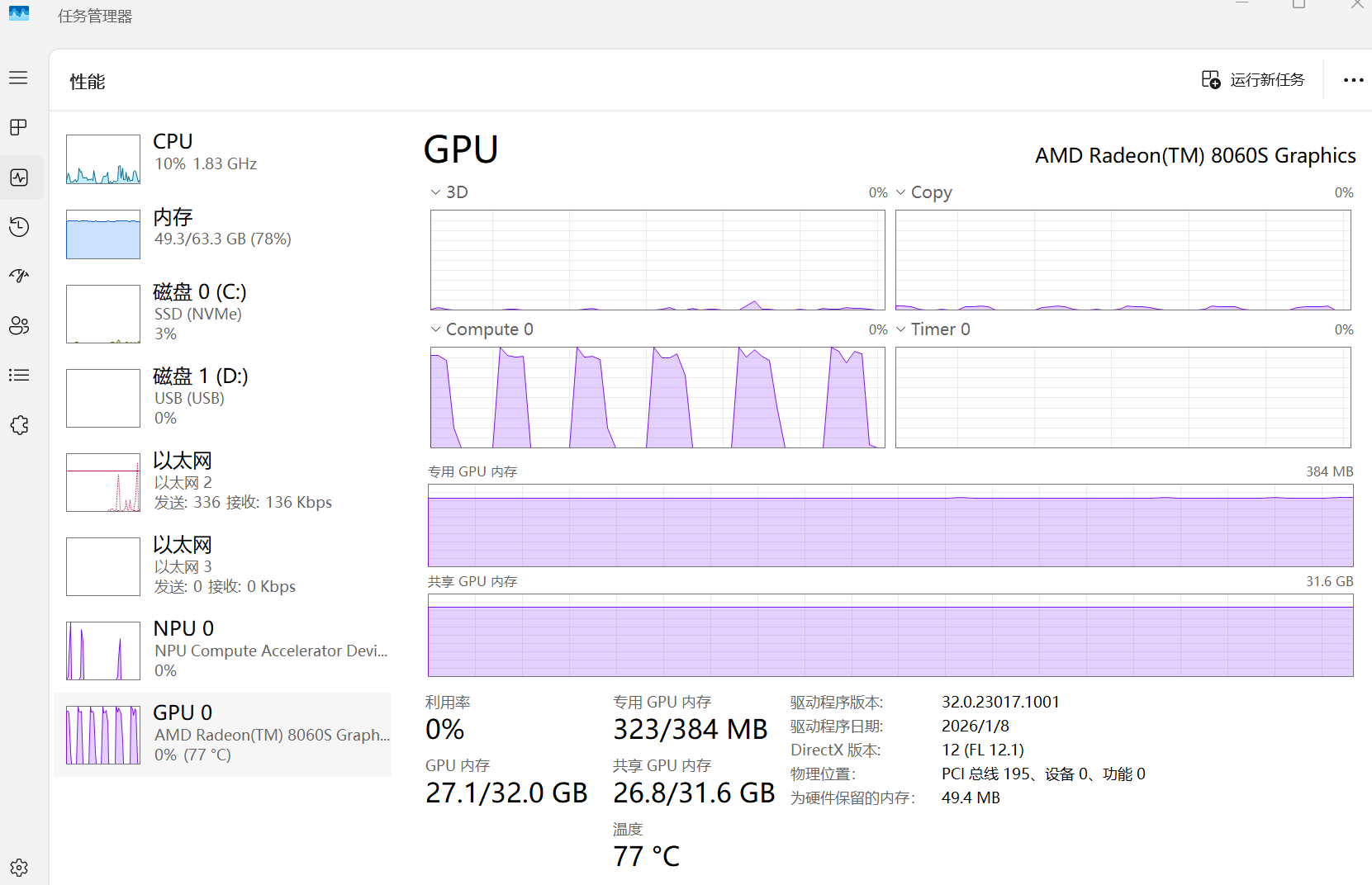
更进一步地,如果把上下文拉到24K,进一步加大显存的需求量,在512M专用显存下情况更加恶化了:GPU有接近一半的时间都闲着。要知道,这个时候显存需求甚至才26G!
我用两个字总结395的优点:能用
可是这台笔记本形态、64G的总内存的设备却有点尴尬:
所以395确实非常适合小主机场景:
pytorch)甚至小主机的价格也比笔记本形态的设备(64G 19999)便宜太多(128G普遍15000,希望还没开始涨)。在这个内存价格疯涨的年代,能以这个价格有一台可以跑大模型的机器已经很不容易了。
2025-12-31 15:30:00
对我来说,2025年的前半年和后半年是完全不同的。
主动告别了一个熟悉的工作,做出一个必定会做出的选择,期望能回到一个熟悉的工作状态,在一个全新的起点重新开始,却开始不停接受充满未知、充满了混乱的挑战。
不知道什么时候,我开始认为离开微软是一个艰难、遗憾、但是又一定会发生的事情。
一方面,在公司两年来,虽然绩效都是拉满,但是所做的、所参与的所有项目都胎死腹中,而新的被分配的AI有关的项目怎么看都很不靠谱,很难推动;年初,校招进微软,待了十余年的直接manager从公司离职;身边同事的升职空间和奖金肉眼可见的越来越小;而每个季度都能传出裁员的消息,和身边同事讨论的都是裁员、relocate、大礼包。
另一方面,可能是所有初进社会人的共同点,总是对现状不满,总是还有着自己的想法,想着换一个环境可能会更能实现自己的理想。
想着早晚会做,不如现在就做。于是我在我第一份工作的第23个月,在2025年正好过了一半的日子,我终于决定主动踏出这一步。

可能最黑色幽默的是,我那在之前从不停歇的裁员潮中稳如磐石的组,在我离开三个月后,被全部裁员。也就是说,这一次,我是否主动选择,对结果并没有什么变化,反而主动让我与20多W的赔偿金失之交臂。
新的工作,其实也没有那么新:“不新”体现在我回到了研究生期间的、由我从第一行开始从零开始的项目,并且一直以兼职的身份在参与。而“新”则是工作内容的新。从兼职到全职,从一个“局外人”到一个“局内人”,看似相同的工作,看似可以回到研究生期间以及兼职期间的更积极主动的工作状态,但其实是进入一个全新的、未知的、不停地尝试和否定的循环。
俗话说,所有软件项目到后面都会变成屎山。更别提一个一开始就是没有好好设计,作为一个玩物开始的项目了。
四年可以发生很多事情:项目从开源到闭源,连带着很多设计都需要跟着改变;所使用的框架和技术从无到有,群雄争霸到逐渐稳定;项目功能逐渐增多,需求越来越复杂,发展目标越来越不清晰……在这么大的变化下,事情总是会朝着阻力最小的方向发展。而ToG项目的本质,就决定了大部分工作都是纯业务的,甚至于还会专门花精力做一些不可复制的、临时性的工作。看起来这些工作很没有价值?可是以业务的眼光看,这些工作才是有价值的。

说到底,只有需求才能定义什么是该做的,什么是不该做的。客户关心的才值得投入精力和人力,而客户不关心的,投入一分一毫的资源都有可能是对时间、精力的挥霍。
既然项目的技术本身没什么可做的,于是我将目光投入了一些其他让我不舒服的点。从流程完善到繁琐的大公司到小公司,当然有极大的不适应。其中,信息分散是让我最头疼的:
于是在来了公司之后的两个月中,我尝试整理流程和推动文档化办公,例如
这些措施有的顺利落地,有的难产;有的受到欢迎,但大部分推动起来困难重重:
这些问题说到底,和上一段一样,哪些真的是问题?
如果所有成员都已经习惯了工作生活都用微信,微信里聊工作是最方便的方案,即使微信每发一封文件都要复制一份,发到最后自己都不知道哪份是最后的方案;所有人本来就坐在一起,已经习惯了有问题就现场聊天,让留文档反而是负担,即使第二天就忘了第一天聊了什么。
如果想解决的问题本来就不被认为是问题,那解决方案自然也毫无意义。
如果让你指出你所在公司存在的不合理的地方,你能提出多少条?我相信大多数人都能提出很多,并会对公司对这些问题熟视无睹充满了不满以及无奈。
但是当我屁股反转,真正做到“老板”的位置上后才发现,不是所有问题都可以被解决的。很多你认为存在的问题,实际上并不是问题;很多你根本没有意识到的问题,反而已经在暗处默默地影响工作效率、氛围和情绪;很多你认为你解决了问题,实际上反而让情况更糟。比解决问题更重要的是发现问题,评估问题,以及在采取措施后观察效果。而这些工作将会没有标准流程,没有标准方案,甚至于没有反馈,只能通过从各个渠道收集大量信息和反馈,分析信息,小步快跑地去做出对应的调整。
这半年来,我自认为发现了无数的问题,也尝试了一些措施去“解决”无数的问题。但是回头看来,有什么问题是被解决了,我到底提供了什么价值,又给各个同事添加了多少麻烦?我没有答案,也不知道如何回答。
这半年不得不体验了北京和长沙的双城生活,每两周在北京和长沙之间切换一次base地。
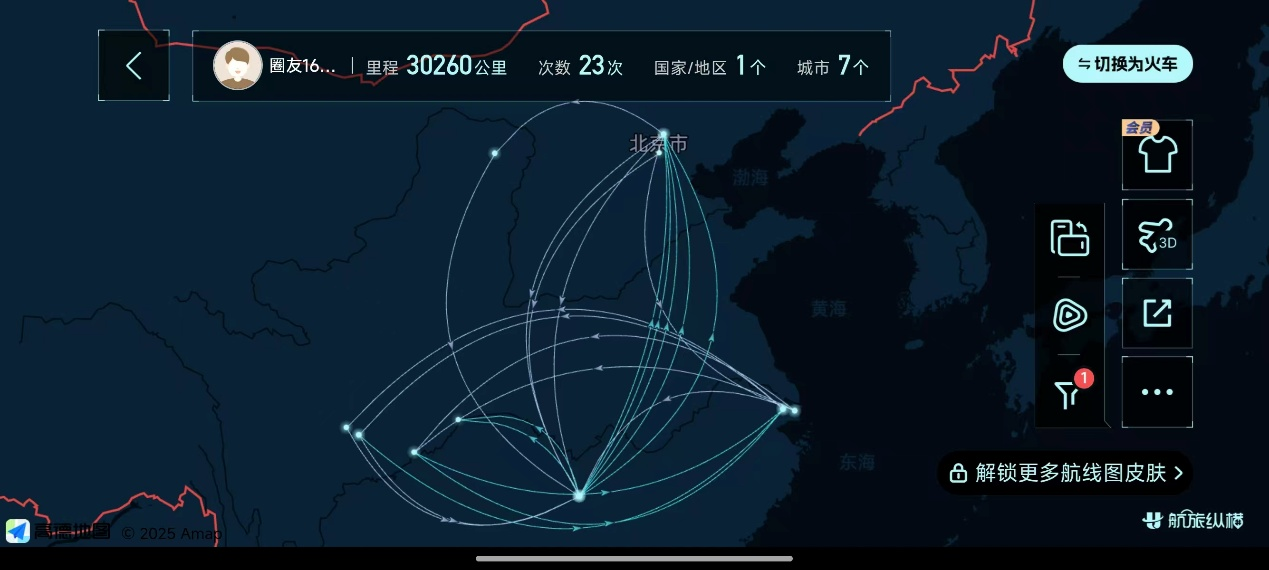
这种生活的前期是新鲜的。北京虽然租房贵,但是多亏有朋友的帮衬,能够免费在西城住上租金过万的、房龄10年左右的电梯房,体验一下全国最核心的城区的生活体验(事实证明北京市中心真不适合年轻人);长沙租房便宜,即使是工作地旁边的公寓也只有1000多,可以体验到通勤走路10分钟的生活。而两地之间的飞机通勤还让我第一次获得了航空公司的常旅客卡,加上信用卡的福利,基本可以实现休息室自由。
但是这种新鲜感只是短期的,短暂的体验之后,迎来的是缺乏归属感。
大家都说租房是一种临时生活,我个人持部分肯定的态度。我目前没有对大件的需求较少,即使有,租房并不会阻止我采购升降桌、人体工学椅这类的大件,大不了,叫个搬家公司就搬走了。可是两地通勤让我彻彻底底体验到了这个感受。
由于有两个居住地,两地的生活设施都不完整。台式机在北京,于是在长沙时只能用工作笔记本应付平时的休闲,没有显示器,小小的笔记本屏幕也完全无法获得一个较好的娱乐休闲的体验;衣服也分布在两地,在11月初两地各自入冬后,由于厚被子还在北京,在长沙10多度的时候仅有薄被子,凌晨3点被冻醒不得不开启空调才能继续入睡;两周时间说长不长说短不短,每次切换工作地的时候都要考虑各类要带走的衣物和生活,然后将宝贵的周末的至少6个小时浪费在路途中。什么都是临时的,什么都是够用就好,不常用的东西就不买。在长沙公寓的桌子和椅子都是海鲜市场的二手货;之前每周做2-3顿饭,现在甚至连厨具都没有采购;甚至于当被要求提供常住地时,都要考虑下写哪个位置。
这种临时的感觉也让我没有任何爱好和社交的欲望。这几年几部乐队的动画让我想重拾小时候的电子琴爱好,但是由于居住环境的不稳定性,不敢买任何大件,而开放琴行一般都是钢琴,和电子琴在对手的能力的要求、可以演奏的音乐的类型有比较大的区别(换句话说就是我菜,弹不了钢琴),并且无论是在北京还是长沙,琴行离居住地都有很远的距离。社交层面,在北京的时候,现在还可以找到之前的朋友;而在长沙的休息日,每天睡眠最多7小时的我,可以在装有万恶之源平板架的床上躺14个小时,在不躺的那10个小时中无比后悔又浪费了一天。
世界上有不少人过着或者已经习惯了这种不定的生活,但是经过半年的尝试,我还是不能说我已经习惯这样的生活方式。
这是一个混乱的一年。公司变了,工作内容变了,生活地点变了,生活状态变了。
是变好还是变坏了?在这一次的变化是主动选择的,是我一定会做出的选择,之后呢?了解了现状,做出这么尝试,而之后应该获取什么样的信息,做出什么样的改变?
这一年我还没休过一天假期。很幸运能在这个一年的最后一周,稍微告别一下这充满挑战的工作,和老朋友去之前从未去过的东北体验寒风和冰雪,时隔一年再次体验滑雪,然后被滑雪劝退。

在旅途中和朋友聊到五年后的职业发展情况,然而这毕业两年半的经历,让我不敢再奢谈这么久远的未来。
2025-07-26 09:14:00
最近有一次换笔记本的机会,因为之后需要频繁旅行,于是选择了14寸的笔记本作为主力机;考虑到平时开发经常需要占用大量内存,32G的内存不够用,需要64G。而现在轻薄本里提供64G选项的,主流的选择只有可以自己加内存的ThinkPad T14p,但是T14p的CPU和GPU性能都在轻薄本中中规中矩,且被11代酷睿折磨了5年的我,现在已经变成了十足的I黑😅。而AMD只有Max+系列的设备有搭载64G及以上内存的产品,且当前只有华硕幻X和战99Ultra(在国外称ZBook Ultra G1a)这两款。前者平板形态虽然非常帅,但是在非桌面场景下使用体验较差,所以最终选择了后者。主要配置如下:
| 配置 | 配置 |
|---|---|
| CPU | AMD Ryzen AI Max+ 395 16C32T Zen5 |
| 内存 | 64G LPDDR5 8000MT 4通道 |
| 硬盘 | SK Hynix PC801 2TB PCIe 4 |
| 显卡 | Radeon 8060S 40CU RDNA3.5 |
| 显示器 | 2880x1800 144Hz OLED带触屏 |
| 重量 | ~1.6kg |
| 电池 | 74Wh |
16核32线程的Zen5加40CU的RDNA 3.5居然能装在14寸的笔记本上,在这颗处理器真正面世之前简直是不可想象的。虽然用脚趾头想都知道这么小尺寸的笔记本不可能可以发挥这颗处理器的全部性能,但是,规模大了,提高多少功耗就能提高多少性能,而实测下来这台笔记本的功耗在14寸的笔记本中也不低,所以在所有同样的尺寸和功耗等级的笔记本中,这颗CPU的性能应该也是最强的。而四通道内存甚至在MSDT平台上花多少钱都体验不到。
由于价格原因,大多数人应该没有机会能用到这样的笔记本,网上也少有这款设备真实的使用体验的评测。到现在也算用了这个处理器的笔记本3周了,可以说说体验。

买这台笔记本就是为了性能。这台笔记本的性能确实很强。
插电的状态下CPU-Z可以跑760/12300左右。这段时间内CPU功耗最高80W,虽然不能一直持续,但是长时间跑仍然可以稳定70W。14寸笔记本能稳定70W的据我所知还是比较少的,再加上这个CPU恐怖的规模,基本可以确定这颗CPU的性能应该就是这个尺寸笔记本的顶尖了。
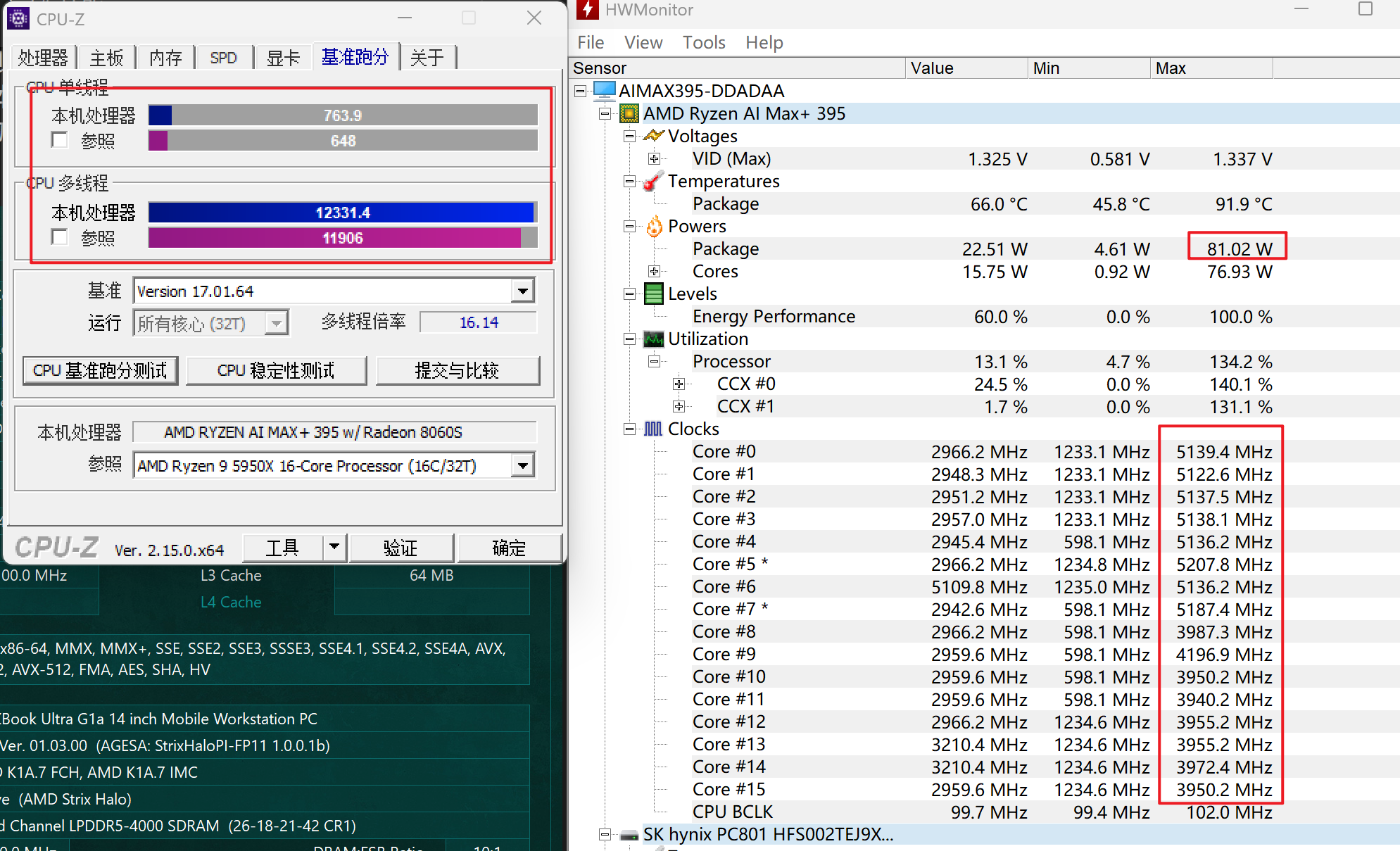
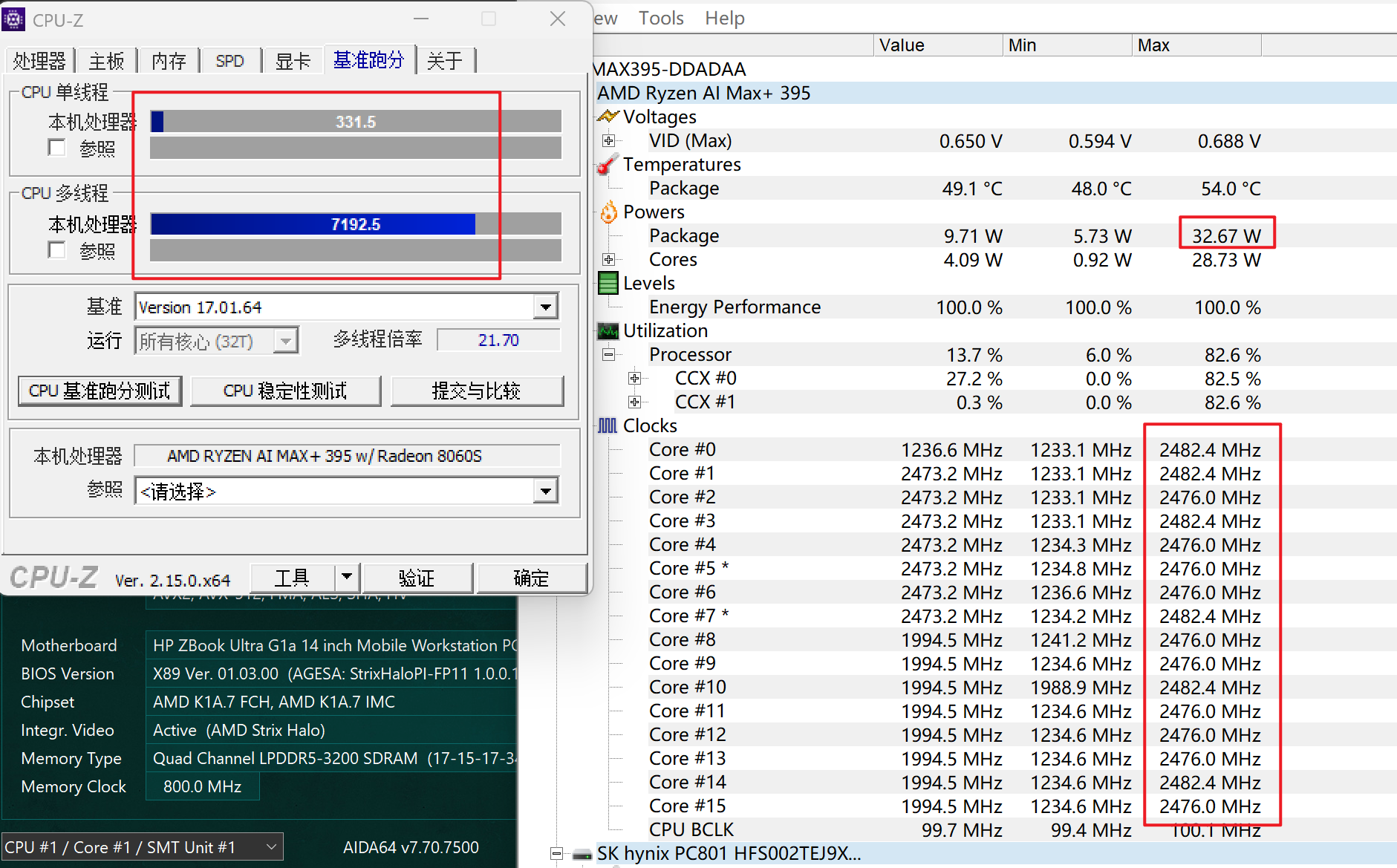
离电状态下CPU-Z的结果是326/6892,正常功耗在35W,长时间功耗在25W左右,这个功耗在离电状态下也比较正常,并且可以看出,CPU在低功耗下倾向于重点使用一个CCD,这也是控制功耗的一个做法。

打游戏的话,最近只玩了三角洲,大战场下2880*1800分辨率超高画质有100帧左右。
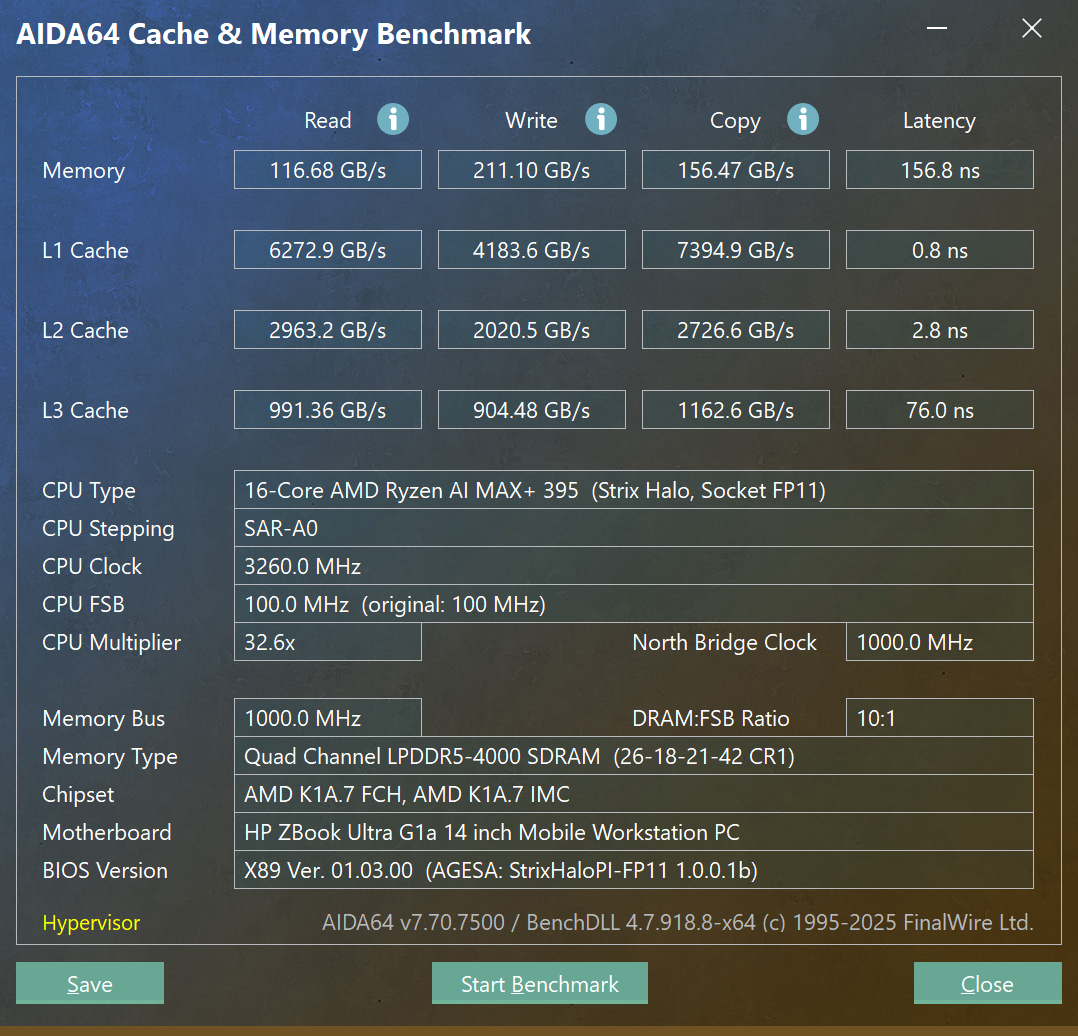
内存性能测试结果这里也放一下。考虑到是LPDDR5内存,延迟较高,但是读写性能确实体现出了4通道内存的水平。
影响笔记本续航的因素有很多,并且随着驱动的更新,结果也会变化,这里只说一下我这段时间的使用情况。在正常的主要使用微信和浏览器的办公场景下,CPU基本上在6-15W范围波动,整机功耗12-20W。由于电池是74Wh,所以整机续航在5小时左右。

这个续航表现只能说中规中矩。主要原因我认为还是空载功耗仍然太高。上面这个图里,虽然核心只占了1.41W,但是整个CPU居然消耗了7.75W,和Lunar Lake以及苹果M系列处理器的1W以下的外围功耗比起来,这个功耗实在是过于离谱了。
万万没想到,这台电脑的充电情况比我遇到过的所有设备都要复杂。
首先,这台电脑的充电器是C口的,没有问题。但是,这台电脑并不支持最常见的PD 65W充电! 插入PD 65W充电器后直接不充电,而不是像一些联想笔记本一样慢速充电。
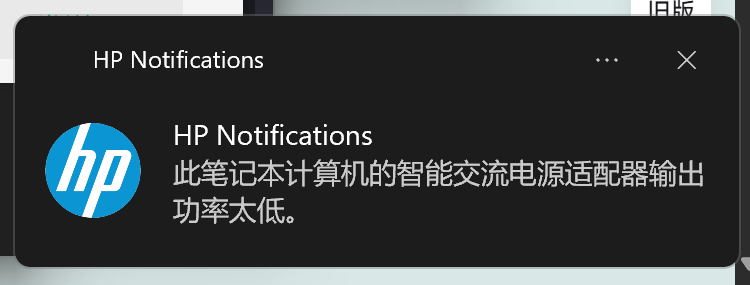
研究后发现,这台设备的包装盒上明确写着仅支持100W以上的PD充电器。
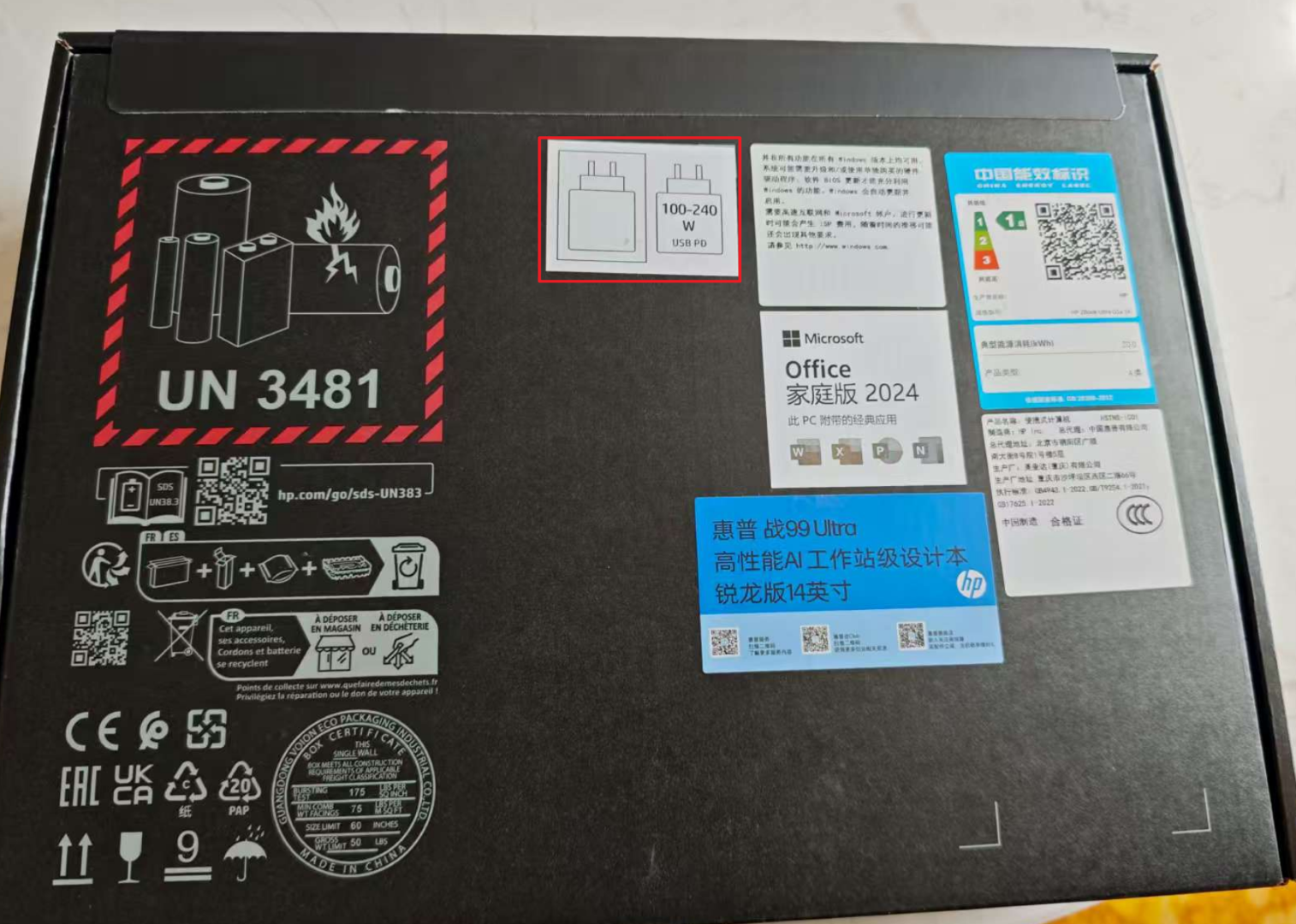
但是具体测试下来,设备支持联想T34WD-40(京东)上的96W Type-C供电,但是系统会提示低功耗充电器,且CPU功耗被限制在了45W。在这个功耗限制下,CPU-Z全核最高频率2.8Ghz,跑分9500左右,比未限制状态下的12300低了22%,还是下降得比较严重的。并且,现在市面上,除了DELL有两款支持PD 140W给笔记本供电的显示器外,其他显示器都最高只支持90W。所以一线通,这个我本来已经习以为常的办公解决方案,现在也不得不放弃了,在工作时必须再插一个充电器,不过也还好,只是多一根充电器线的事。

设备自带的充电器是支持PD 140W的大板砖,除了重,没什么问题。

从上可以看到,其支持28V 5A也就是PD标准的140W的充电器。了解了一下,目前市面上真正在使用PD标准进行高功率充电器笔记本,似乎也就只有MBP一家了。没想到苹果的充电在手机上扭扭捏捏,好不容易搞个C口还和很多iPhone 15出现之前的老C口设备存在兼容问题,反而在笔记本上如何激进地拥抱标准。
可能是覆盖的产品太少,支持这个标准的充电器并不多,并且同样是声称支持MBP和这个标准的充电器,在这台电脑上仍然存在兼容性问题。
酷态科的15号充电器是140W充电器里价格最便宜的(179不带线),支持小米快充,也声称支持MBP,但是实际使用中并不兼容这台电脑,插入电脑后,系统充电图标显示一下,HP的软件弹出如下的提示并且系统稍微卡一下,然后马上断开,以此循环。为了验证是不是线的问题,我还快速购入了酷态科的支持240W的6A线,但是问题依旧。
没有办法,只能换了Anker的充电器。虽然Anker的产品相比起来都更贵,但是考虑到Anker牌子和销量更大,兼容性应该更好,于是花更高的价格(279)购入了Anker的支持140W的充电器。而这个充电器配上自带的电源线一切正常,没有任何问题,但是要是配上之前提到的酷态科的充电线也会有时候会弹出上面的提示并且系统会卡一下(因为电池供电会影响处理器和其他硬件的设置)。
这个充电器带一个屏幕,可以实时显示系统使用的功耗。在CPU-Z跑分、CPU功耗在70W左右时候,整机功耗为120W+,100W的PD确实不能发挥整台机器的所有能力。

搭载这块CPU的设备的宣传材料都是本地跑AI大模型。内存和显存共享芯片确实是一个大卖点。

具体来说,这个电脑支持在BIOS里将固定量的内存分配给显存。这样分配给显存的内存就不可以再作为系统的内存使用了。这个功能似乎很多AMD核显本都有。
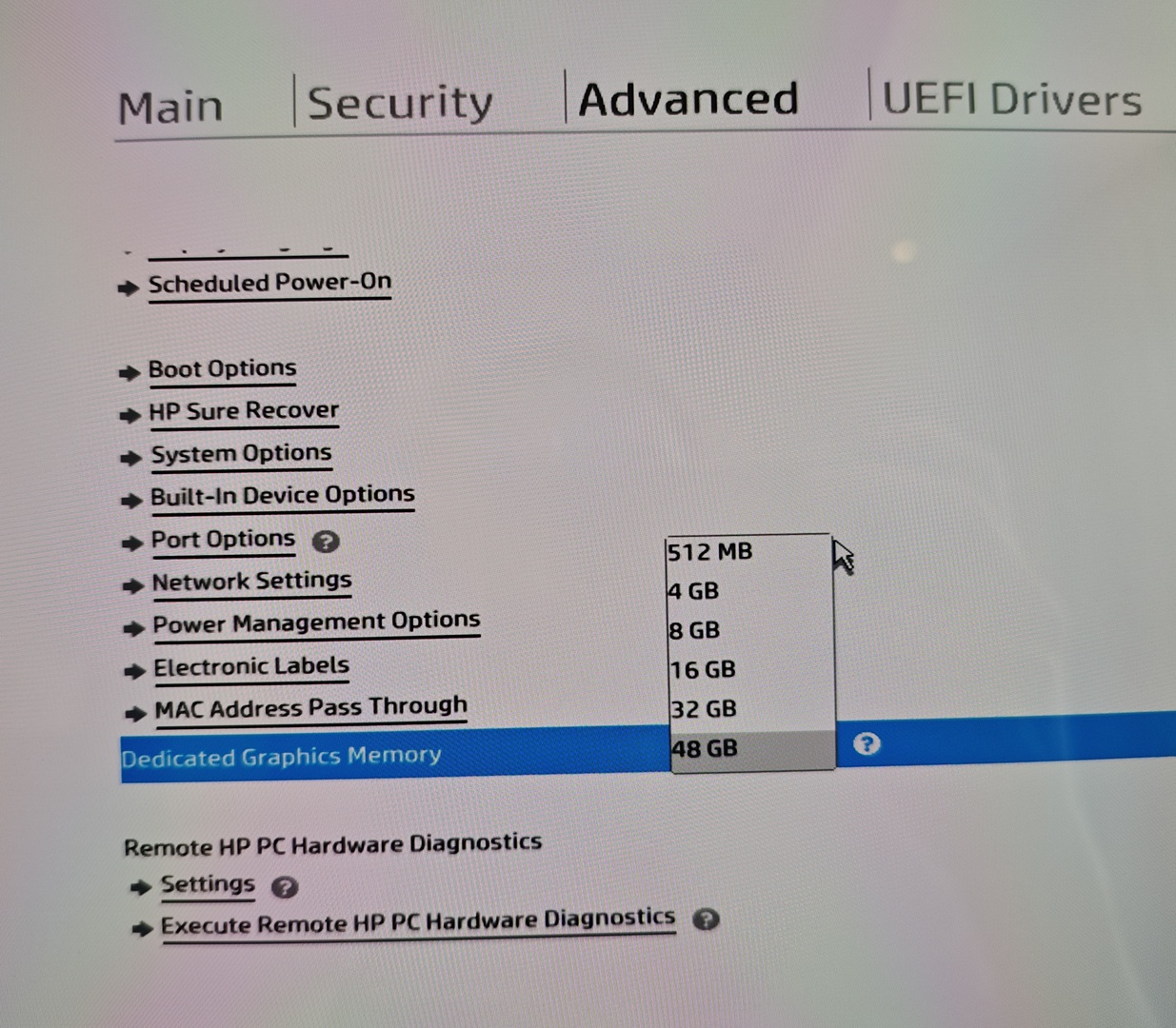
如上图所示,我的64G版本,可以手动选择将512MB、4GB、8GB、16GB、32GB或48GB的内存分配给显存。如果分配8G,于是日常就只有55G的内存可用了。
但是,这个分配量只是GPU独享的,剩下的内存是真正的共享内存,GPU同样可以支配。根据之前看到的一份材料,GPU可以动态支配剩下的其中一半的容量。也就是说,如果给GPU独享分配8G,那么GPU实际能用的是8 + (64-8)/2 = 35.5 GB。其实对于大多数使用情况来说也完全够用了。
考虑到AMD羸弱的AI生态,我买这台电脑的唯一考虑其实是变态的CPU性能和大内存,所以我没有必要给GPU分配独享的存储,于是最后就选择了512MB给独显独享。这样配置下来,GPU实际上最大也可以用32GB左右的显存,打打游戏也够用了。
这台设备的模具及外围配置同样一般。一句话总结:CPU以外就是个6000块左右设备的水平。
厚度和重量:最厚处18.5mm,重量1.6kg左右,和MBP一个水平,和轻薄不沾边(考虑到我之前的笔记本是980g的Yoga Carbon,这落差就更大了)
屏幕:一块2880x1800 144Hz的OLED屏幕,但是最高亮度只有400nit,且是镜面屏、触控层存在网格纹,甚至似乎还是PWM调光。
触控板:大小、滑动和按键手感还可以,但是并非压感触控
键盘:中规中矩的笔记本键盘,和ThinkPad等不可比。
另外还有一些小问题,例如

综上,虽然这台笔记本性能很强,但是我还是不推荐这台笔记本给绝大多数人。
这种小众机器看着非常诱人,但是价格昂贵,和外围设备兼容性存疑,并且遇到问题(例如充电器)都无法在网上找到解决方案,厂商的后续支持(例如驱动更新等)也一定会比较有限。只有像我这样什么都要的且愿意折腾的,才可以建议试试这台机器😊。
这台机器在史无前例地在14寸的机器下提供了16C32T CPU+64G/128G四通道内存的配置。虽然表现很亮眼,但是最终市场上设备种类少,价格贵,销量也低,后续AMD还会不会出下一代呢?
2025-03-08 08:47:00
最近在一个项目中,我遇到了一个使用Node.js编写的请求转发服务的性能瓶颈问题。这个服务的主要工作看似非常简单:获取用户的请求,将请求体(body)转发到后端的服务器,然后将服务器的响应原样返回给客户端。
然而,在进行压力测试时,我们发现当并发请求达到约2000时,系统表现出了明显的性能问题:
大家都说Node.js的IO性能并不算差。这个现象引发了我的思考: 是什么限制了Node.js在这种场景下的性能表现? 一个看似简单的请求转发工作,为何无法充分利用多核资源?
带着这些疑问,我决定对Node.js代理服务的基准性能进行一次深入研究。我想了解在没有任何特殊优化的情况下,一个标准的Express服务究竟能够处理多少并发请求。这将帮助我确定问题是否出在Node.js本身的并发处理能力上,并在之后遇到类似性能问题或技术选项的时候,对Node本身所能达到的极限能力有个心理预期。
为了进行这项研究,我采取了以下步骤:
编写两个简单的项目:
使用wrk作为性能测试工具,这是一个常用的HTTP基准测试工具,能够产生大量并发连接来测试服务器性能
在相同硬件条件下,测试不同并发级别下的性能表现,包括:
这个项目是一个简单的Express服务器,它接收POST请求,并返回一个模拟的AI响应。
为了模拟真实响应,这个服务器返回结果前可能会延迟一段时间。我同样会测试延迟不同的时间会对代理服务的性能表现的影响。
代理服务同样使用Express实现,它的核心功能是:
这个服务保持了最小化的实现,没有添加额外的错误处理、负载均衡或缓存等优化措施,以便我能够测试Node.js的基准性能。
测试运行于WSL2,CPU为5900X 12C24T @ 4.5 Ghz,Node版本22.14.0。
使用6个线程和不同的连接数,超时时间设置为5s,使用wrk对两个服务分别进行压力测试。其中,运行在5001端口的是模拟后端服务,5000是代理服务。
| Server | Connections | Requests/sec | Avg Latency | Max Latency | Total Requests | Timeouts | Timeout % | Total Errors | Error % |
|---|---|---|---|---|---|---|---|---|---|
| 5001 | 50 | 9776.19 | 6.03ms | 291.00ms | 97839 | 0 | 0.00% | 0 | 0.00% |
| 5001 | 100 | 9294.12 | 12.84ms | 537.33ms | 93006 | 0 | 0.00% | 0 | 0.00% |
| 5001 | 150 | 9322.45 | 31.57ms | 1.31s | 93276 | 0 | 0.00% | 0 | 0.00% |
| 5001 | 200 | 8688.89 | 63.29ms | 2.14s | 86951 | 0 | 0.00% | 0 | 0.00% |
| 5001 | 500 | 8769.33 | 163.54ms | 4.99s | 87741 | 121 | 0.14% | 121 | 0.14% |
| 5001 | 1000 | 8200.58 | 98.60ms | 4.96s | 82284 | 67 | 0.08% | 67 | 0.08% |
| 5001 | 2000 | 8808.86 | 102.43ms | 4.95s | 88480 | 54 | 0.06% | 54 | 0.06% |
| 5001 | 5000 | 7769.21 | 248.05ms | 314.09ms | 78333 | 25 | 0.03% | 1134 | 1.45% |
| 5001 | 10000 | 7531.77 | 453.61ms | 592.39ms | 76076 | 13 | 0.02% | 6176 | 8.12% |
| 5001 | 20000 | 6601.98 | 414.19ms | 582.31ms | 66423 | 15 | 0.02% | 15917 | 23.96% |
| 5000 | 50 | 2673.49 | 74.76ms | 2.34s | 26763 | 0 | 0.00% | 0 | 0.00% |
| 5000 | 100 | 2884.08 | 40.05ms | 909.96ms | 28860 | 0 | 0.00% | 0 | 0.00% |
| 5000 | 150 | 2729.84 | 94.20ms | 2.16s | 27322 | 0 | 0.00% | 0 | 0.00% |
| 5000 | 200 | 2586.36 | 176.31ms | 3.61s | 25887 | 0 | 0.00% | 0 | 0.00% |
| 5000 | 500 | 2375.25 | 192.97ms | 4.96s | 23767 | 70 | 0.29% | 70 | 0.29% |
| 5000 | 1000 | 2454.10 | 139.51ms | 5.00s | 24629 | 90 | 0.37% | 90 | 0.37% |
| 5000 | 2000 | 2449.30 | 326.00ms | 4.85s | 24597 | 33 | 0.13% | 33 | 0.13% |
| 5000 | 5000 | 1786.15 | 326.11ms | 5.00s | 18038 | 476 | 2.64% | 1768 | 9.80% |
| 5000 | 10000 | 2016.64 | 78.55ms | 3.78s | 20313 | 10 | 0.05% | 6306 | 31.04% |
| 5000 | 20000 | 1398.34 | 3.40ms | 639.14ms | 14072 | 0 | 0.00% | 16275 | 115.66% |
数据比较多,值得关注的结论如下:
对于后端服务:
对于代理服务:
在所有实验中,我还记录了CPU各个核心的使用率,下面是测试后端、2000个连接数时其中一秒的CPU使用率,可以看到,只有一个核心(2)很忙,其他核心没有被充分利用。其他所有数据都具有类似的情况。
10:51:38 AM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
10:51:39 AM all 5.93 0.00 1.52 0.00 0.00 4.97 0.00 0.00 0.00 87.58
10:51:39 AM 0 1.75 0.00 0.88 0.00 0.00 11.40 0.00 0.00 0.00 85.96
10:51:39 AM 1 0.00 0.00 1.00 0.00 0.00 1.00 0.00 0.00 0.00 98.00
10:51:39 AM 2 84.00 0.00 6.00 0.00 0.00 0.00 0.00 0.00 0.00 10.00
10:51:39 AM 3 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
10:51:39 AM 4 11.00 0.00 3.00 0.00 0.00 0.00 0.00 0.00 0.00 86.00
10:51:39 AM 5 18.18 0.00 3.03 0.00 0.00 0.00 0.00 0.00 0.00 78.79
10:51:39 AM 6 1.00 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 98.00
10:51:39 AM 7 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
10:51:39 AM 8 4.00 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 95.00
10:51:39 AM 9 2.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 98.00
10:51:39 AM 10 2.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 98.00
10:51:39 AM 11 0.00 0.00 1.98 0.00 0.00 0.00 0.00 0.00 0.00 98.02
10:51:39 AM 12 3.96 0.00 4.95 0.00 0.00 0.00 0.00 0.00 0.00 91.09
10:51:39 AM 13 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
10:51:39 AM 14 4.50 0.00 3.60 0.00 0.00 10.81 0.00 0.00 0.00 81.08
10:51:39 AM 15 0.00 0.00 0.00 0.00 0.00 2.04 0.00 0.00 0.00 97.96
10:51:39 AM 16 2.65 0.00 0.88 0.00 0.00 15.93 0.00 0.00 0.00 80.53
10:51:39 AM 17 0.92 0.00 1.83 0.00 0.00 12.84 0.00 0.00 0.00 84.40
10:51:39 AM 18 2.44 0.00 4.07 0.00 0.00 19.51 0.00 0.00 0.00 73.98
10:51:39 AM 19 0.00 0.00 2.75 0.00 0.00 13.76 0.00 0.00 0.00 83.49
10:51:39 AM 20 4.63 0.00 0.00 0.00 0.00 11.11 0.00 0.00 0.00 84.26
10:51:39 AM 21 2.73 0.00 0.00 0.00 0.00 11.82 0.00 0.00 0.00 85.45
10:51:39 AM 22 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
10:51:39 AM 23 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
在上述实验中,后端服务收到请求就直接返回。但是实际上后端服务可能需要一定时间处理。打印日志也是Node服务常见的实践。这两个场景到底对资源消耗有多大呢?
为了更直观地对比不同场景下的性能表现,多设计两个场景
console.log)我整理了以下对比表格,重点关注平均延迟(Avg Latency)、超时率(Timeout %)和错误率(Error %)这三个关键指标:
| 连接数 | 服务器 | 直接返回-延迟 | 延迟-延迟 | 输出日志-延迟 | 直接返回-超时率 | 延迟-超时率 | 输出日志-超时率 | 直接返回-错误率 | 延迟-错误率 | 输出日志-错误率 |
|---|---|---|---|---|---|---|---|---|---|---|
| 50 | 后端 | 6.03ms | 503.92ms | 9.17ms | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% |
| 500 | 后端 | 163.54ms | 506.11ms | 132.43ms | 0.14% | 0.00% | 0.13% | 0.14% | 0.00% | 0.13% |
| 2000 | 后端 | 102.43ms | 533.43ms | 105.53ms | 0.06% | 0.00% | 0.08% | 0.06% | 0.00% | 0.15% |
| 5000 | 后端 | 248.05ms | 529.92ms | 358.23ms | 0.03% | 0.00% | 0.05% | 1.45% | 7.73% | 2.23% |
| 10000 | 后端 | 453.61ms | 607.15ms | 641.06ms | 0.02% | 0.00% | 0.00% | 8.12% | 9.89% | 12.64% |
| 20000 | 后端 | 414.19ms | 610.10ms | 375.80ms | 0.02% | 0.00% | 0.00% | 23.96% | 30.43% | 35.20% |
| 50 | 代理 | 74.76ms | 519.05ms | 54.27ms | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% |
| 500 | 代理 | 192.97ms | 717.28ms | 208.93ms | 0.29% | 0.00% | 0.29% | 0.29% | 0.00% | 0.29% |
| 2000 | 代理 | 326.00ms | 726.51ms | 417.52ms | 0.13% | 2.03% | 0.21% | 0.13% | 2.03% | 0.21% |
| 5000 | 代理 | 326.11ms | 892.77ms | 434.87ms | 2.64% | 1.35% | 2.87% | 9.80% | 13.92% | 10.33% |
| 10000 | 代理 | 78.55ms | 788.52ms | 89.68ms | 0.05% | 2.90% | 0.01% | 31.04% | 36.76% | 36.39% |
| 20000 | 代理 | 3.40ms | 777.70ms | 94.90ms | 0.00% | 0.00% | 0.00% | 115.66% | 232.21% | 107.78% |
从这个对比表格中,我们可以得出几个重要观察:
延迟500ms的影响:当后端服务增加500ms延迟后,整体延迟有增加,连接数越多,平均延迟增加越少,但是增加的延迟仍然会使得错误率增加
超时情况分析:在大多数连接数下,超时率都相对较低;但在代理服务的中等连接数(2000-5000)场景下,超时率明显上升,特别是在延迟返回的测试中,显示出代理服务在处理较长延迟请求时的瓶颈
日志输出的影响:与直接返回相比,增加日志输出确实会增加延迟,但影响不是特别显著。在低并发情况下(50-500连接),日志对后端服务的影响较小;但在高并发时(10000+连接),日志输出会明显增加系统负担
错误率增长点:无论哪种场景,代理服务的错误率普遍高于后端服务,且在5000连接数左右开始出现明显的错误率上升
极端高并发下的异常:在20000连接的极端情况下,所有配置都表现出较高的错误率,但代理服务的延迟反而下降,这可能是因为大量请求被直接拒绝,导致成功请求的平均延迟降低
为了对比,我又准备了用Go使用标准库net/http编写的相同功能的两个程序,并在后端500ms延迟、不打log的情况下,测出go的成绩如下(未列出的连接数并未发生错误):
| Server | Connections | Requests/sec | Avg Latency | Max Latency | Total Requests | Timeouts | Timeout % | Total Errors | Error % |
|---|---|---|---|---|---|---|---|---|---|
| 5001 | 5000 | 7310.92 | 501.39ms | 516.91ms | 73728 | 0 | 0.00% | 902 | 1.22% |
| 5001 | 10000 | 7060.75 | 501.72ms | 517.20ms | 71154 | 0 | 0.00% | 5900 | 8.29% |
| 5001 | 20000 | 6493.01 | 501.33ms | 512.36ms | 65536 | 0 | 0.00% | 15902 | 24.26% |
| 5000 | 5000 | 5910.59 | 636.54ms | 3.46s | 59611 | 0 | 0.00% | 903 | 1.51% |
| 5000 | 10000 | 5441.54 | 657.59ms | 1.25s | 54953 | 0 | 0.00% | 5900 | 10.74% |
| 5000 | 20000 | 4857.47 | 663.12ms | 2.11s | 48912 | 0 | 0.00% | 15902 | 32.51% |
二者的差距还是在预期的,go从来没有发生过超时,整体延迟、错误率数据也比node好很多。如在5000个连接下,代理程序出现1.51%的错误,node版本出现9.08%的错误,差距在6倍左右。但是需要注意的是,go可以利用全部CPU核心,而node的js线程只能利用一个核心,如果启动多个node并进行负载均衡,最终结果不一定有很大的差别。
通过这些简单数据,我们发现
要想解决这个问题,在代码中做出一定的优化,例如减少日志打印、简化Node中的逻辑等,也会有一定的效果。如果优化代码的效果不佳,唯一的办法是运行多个node进程,可以考虑的方法主要是启动多个node服务并增加负载均衡,或者使用node cluster让node可以启动多个worker process。
本实验中的代码和结果均在 https://github.com/ddadaal/node-express-concurrency-baseline-test 中可用。
整个测试项目、测试脚本甚至本篇文章基本都是直接使用Copilot + Claude 3.7 Sonnet模型生成的,不得不说,让AI生成大框架、自己再来完善细节的做法确实能提高不少效率。这种实验的大多数工作实际上是框架代码,代码本身逻辑简单,但是需要使用大量API、编写繁琐的测试逻辑、数据分析以及做表,手写非常耗费精力,让AI来做这些繁琐的工作实在是再合适不过了。写文章也可以让AI帮忙做,我之前写篇文章至少需要花一整天,这一次居然一个上午就搞定了。
哦,上面这一句话不是AI写的😀