2026-03-30 14:55:00

—— 在对话框以外,大模型又能发挥什么作用呢?
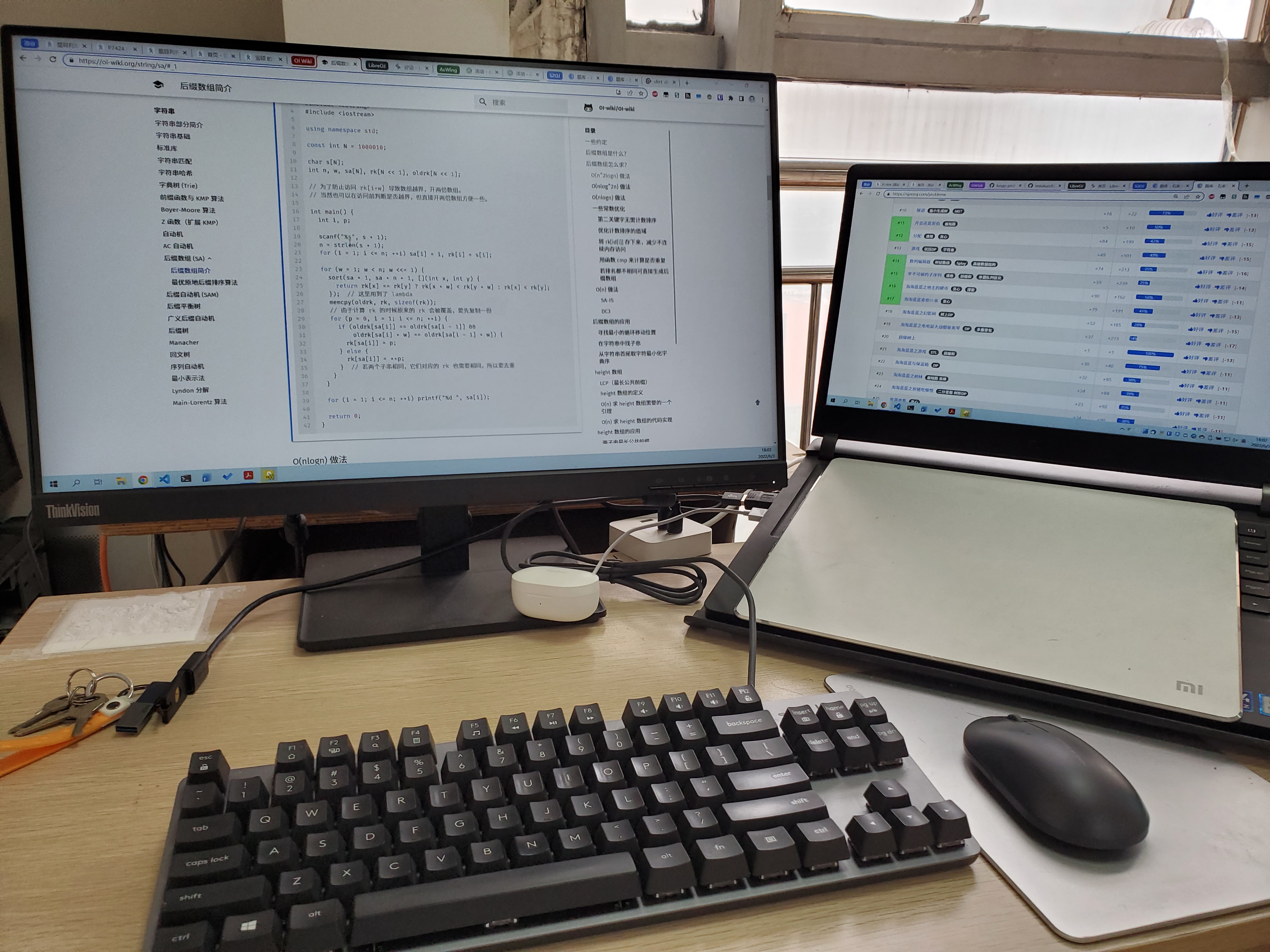
在编写新版福 uu 后端代码的过程中,我们已经实现了从教务系统上读取调课信息并应用、展示到课程表上的能力。但这个调课的展示仅限于教师录入好的单次调课,对于教务处发布的全校性假日调课通知则并没有去做解析和展示的逻辑。
究其原因,是教务处发出的调课通知都长下面这个样子:
1、10 月 1 日(星期三)至 10 月 8 日(星期三)放假,共 8 天,全校本科生课程(含通识教育选修课)停课。
2、9 月 28 日(星期日)补上 10 月 7 日(星期二)的课,10 月 11 日(星期六)补上 10 月 8 号(星期三)的课,原 9 月 28 日和 10 月 11 日的课程停课。
这种自然语言格式的描述难以被代码解析。短短几行字背后,隐含着十余条调课规则 —— 哪些日期的课取消了?哪些日期的课被挪到了另一天?原来那一天的课又怎么办?
在过去,这些调课信息需要用户自行阅读通知、对照课表、在脑中完成推理,这极大地增加了用户的心智负担,同时也增加了同学们在补课的日子出现意外旷课的可能性。
但是 LLM 的出现,使这种任务有了可能的解决方案,我们可以利用其强大的自然语言理解能力来从中提取结构化的调课信息,从而直接给用户展示时间调整后的课程表,极大地提升用户体验。为了实现这个目标,我们需要对 LLM 进行工程化的封装,使其能够具备像传统解析函数一样的表征,从而优雅地接入到现有的业务流程中。
在介绍我们的新方法以前,有必要先解释一下为什么这类通知不能用正则表达式或者规则引擎来解析。
首先是格式不固定。每次调课通知都可能由不同的老师起草,措辞、结构、标点习惯都各不相同。有时候会说「补上……的课」,有时候会说「调至……上课」,有时候会直接用「顺延」「提前」这样的表达。这导致了通知的格式不可能完全一致。
其次是语义嵌套复杂,单条规则背后往往隐藏着多个子规则。上面例子中的第二条,实际上包含了下面的几条逻辑:9 月 28 日原有课程停课;9 月 28 日按 10 月 7 日课表上课;10 月 11 日原有课程停课;10 月 11 日按 10 月 8 日课表上课。
如果用纯代码形式的规则引擎实现的话,会由于一种种边界情况的出现而越写越复杂,导致维护成本会随着边界情况的积累呈指数级增长。正因如此,LLM 的强大语言理解能力就能够派上用场了。
很多人对大模型的第一印象就是一个对话界面 —— 你问它答。但在福 uu 的这个场景中,我们需要的是一种完全不同的方案,输入一段教务处的通知,在合适的提示词引导下让其能够准确地输出一组结构化的调课规则。
在传统的业务流程中,要从某段数据中解析出一些结构化的数据,几乎都是编写一个函数来封装好解析能力。对于调用方而言,函数完全是一个黑盒,只需要按照约定的方式传参、返回结果,至于内部实现究竟如何是不需要关心的。
既然这样的话,我们完全可以把 LLM 调用封装成一个函数来实现一些功能,我们称其为「LLM Function」。没有多轮对话,没有用户交互,甚至没有前端界面。大模型在这里扮演的角色,更像是一个和传统的正则表达式、规则引擎等处于同一个生态位的解析引擎。但和传统的解析引擎相对比,利用大模型解析可以充分地理解自然语言,泛化性更强,不需要囿于固定的、一定能被代码描述的格式。
这种函数仍然具有可测试、可替换的特性,并不会对后续的开发维护流程产生什么特别的影响。
具体的实现请参阅仓库 renbaoshuo/llmfunc。
把一次 LLM 调用看作一个普通函数 f(T) → R。
定义 Function[T, R] 接收类型为 T 的业务输入,返回类型为 R 的业务输出。调用者完全不需要关心中间经历了消息组装、模型推理、工具调用、响应解析这些细节,只需要 fn.Run(ctx, &input) 就能拿到强类型的结果。
核心是一个泛型结构体:
// Function defines an LLM-backed function.
//
// - T is the input type (must implement FunctionInputFormatter interface).
// - R is the output type.
type Function[T any, R any] struct {
client *Client
output OutputHandler[T, R]
config *FunctionConfig
}它会完成下面三件事:
T 转换为 LLM 的 ChatCompletionMessage 列表;output 函数转换为类型安全的 R。其中,T 是业务输入类型,相当于函数参数,R 是业务输出类型,相当于函数返回值。对于二者的具体处理,可以参见下面的介绍。
框架在设计的时候没有强制要求输入必须是某种固定格式,而是通过 FunctionInputFormatter 接口做了一层解耦。
type FunctionInput struct {
Messages []openai.ChatCompletionMessage `json:"messages"`
}
type FunctionInputFormatter interface {
FunctionInput() *FunctionInput
}任何业务类型 T,只要实现了 FunctionInput() 方法,就能产出一个 FunctionInput 告诉框架「如何把我自己转换成 LLM 能理解的消息列表」。这样每种业务场景可以自行决定 prompt 的构造方式,比如一个「信息提取」和一个「翻译请求」可以有完全不同的消息组装逻辑,但都能被同一个 Function 框架驱动。
为什么不直接让
T就是FunctionInput?因为那样会迫使所有业务逻辑直接面对
openai.ChatCompletionMessage这种底层结构,业务语义就被淹没了。
之后在调用的时候,用实现好的接口生成构造向 LLM 发送请求使用的 FunctionInput 结构体。
if formatter, hasFormatter := any(*in).(FunctionInputFormatter); hasFormatter {
input = formatter.FunctionInput()
ok = true
}这里的 any(*in) 是为了强制使用值类型实现 FunctionInput 的 formatter,避免值和指针混写的情况发生。
对于 LLM 输出的解析,框架允许调用方在创建 Function 时自定义符合 OutputHandler[T, R] 解析器,也提供了 BypassOutput 与 UnmarshalOutput 两种内置解析器。
BypassOutput() 直接返回一个包含 LLM 的原始输出字符串的结构体作为函数返回值;UnmarshalOutput[T any, R any]() 则将输出反序列化为一个类型为 R 的结构体来作为函数返回值。在创建 Function 时给定的输出解析器,会在每次调用函数的时候被用来解析 LLM 的输出。
一般情况下,UnmarshalOutput 会配合 Structured Output 一起使用。如果启用了 Structured Output(前提是模型支持),那么则会使用以下代码自动生成提供给模型的 Output Schema:
if config.structuredOutput {
schema, err := jsonschema.GenerateSchemaForType(*new(R))
if err != nil {
panic(err)
}
OutputSchema(schema).Apply(config)
}这段代码在 NewFunction 构造阶段执行,做了这几件事:
new(R) 创建一个 R 类型的零值实例;jsonschema.GenerateSchemaForType 通过反射从这个零值中提取出完整的 JSON Schema;schema 存入 config。在生成 schema 的流程中,如果出现 error 只可能是 R 的类型定义本身有问题(比如包含了不可序列化的字段),这属于开发期就能暴露的 bug,所以直接 panic 是很合理的。
然后在 Run 阶段:
req.ResponseFormat = &openai.ChatCompletionResponseFormat{
Type: openai.ChatCompletionResponseFormatTypeJSONSchema,
JSONSchema: &openai.ChatCompletionResponseFormatJSONSchema{
Name: f.config.name,
Description: f.config.description,
Schema: f.config.outputSchema,
Strict: true,
},
}把 schema 注入到 OpenAI API 的请求中,强制 LLM 按照这个 schema 输出 JSON。
这里值得展开说说 Structured Output 对于这类业务场景的重要性。在没有 Structured Output 的时候,常见的做法是在 Prompt 里写上「请以 JSON 格式输出」,然后在代码里用正则或者字符串处理去提取 JSON 块。这种方式很脆弱 —— 模型可能会在 JSON 前后加上解释性的文字,可能会使用 Markdown 代码块,也可能因为输出截断导致 JSON 不完整。有了 Structured Output,模型在解码阶段就被约束在 schema 定义的范围内,输出的合法性由模型服务本身来保证,客户端代码可以直接 Unmarshal 而无需任何前处理。
总结一下,这样设计的好处是,在整个过程中,你只需要定义一个 Go struct,框架自动保证 LLM 输出能被安全地反序列化回这个 struct。
注:如果模型支持 Tool Calling 但不支持 Structured Output 的话,可以通过劫持 instruction 强制要求模型调用 callback tool 的方式来实现结构化的输出,但这样子会对 Prompt 造成污染,因此还是尽量使用 Structured Output 为佳。
FunctionConfig 通过经典的 Functional Options 模式暴露配置项:
llmfunc.Name("auto_adjust_course") // 函数名称
llmfunc.Description("解析调课通知") // 函数描述
llmfunc.Instruction("你是一名调课通知解析助手...") // System Prompt
llmfunc.Model("deepseek-ai/DeepSeek-V3.2") // 模型选择
llmfunc.Temperature(0.2) // 温度参数
llmfunc.StructuredOutput(true) // 启用结构化输出每个选项都是一个实现了 Option[*FunctionConfig] 接口的值,通过 Apply 方法修改配置。这种模式的好处是 API 简洁、可扩展 —— 未来增加新的参数只需要加一个新函数,不需要修改已有代码。
在调课解析这个场景中,Temperature 设置为较低值(如 0.2)是一个有意为之的选择。调课通知的解析是一个事实提取任务,而非创意生成任务。我们希望模型的输出是稳定且确定的,而不是在多次调用之间产生差异。低 Temperature 使模型更倾向于选择概率最高的 token,从而让同一份通知的解析结果具有良好的幂等性。
输入类型 AutoAdjustCourseInput 包含通知的标题和正文两个字段,并实现了 FunctionInputFormatter 接口,将二者拼接为一条 User Message:
type AutoAdjustCourseInput struct {
Title string `json:"title" description:"通知标题"`
Content string `json:"content" description:"通知内容"`
}
func (i AutoAdjustCourseInput) FunctionInput() *llmfunc.FunctionInput {
return &llmfunc.FunctionInput{
Messages: []openai.ChatCompletionMessage{
{
Role: openai.ChatMessageRoleUser,
Content: fmt.Sprintf("#%s\n\n%s", i.Title, i.Content),
},
},
}
}输出类型的设计刻意保持简洁。每条调课记录只需要两个字段:from_date 表示原本上课的日期;to_date 表示调整后的实际上课日期,若课程取消则留空。不需要额外的字段,取消和换课的语义完全由 to_date 是否为空来区分。这样子可以让模型不在多个字段之间做复杂的联动判断,让模型专注于主要任务,以提升其准确度。
type AutoAdjustCourseItem struct {
FromDate string `json:"from_date" description:"调整前课程本应上课的日期,格式为 YYYY-MM-DD"`
ToDate string `json:"to_date" description:"调整后的实际上课日期,格式为 YYYY-MM-DD,如果课程取消则留空"`
}
type AutoAdjustCourseOutput struct {
Items []AutoAdjustCourseItem `json:"items"`
}其中 description 会生成到 schema 中来帮助模型理解输出格式。具体支持的结构体标签可以查看 jsonschema 库中 reflectSchemaObject 的实现作为参考。
System Prompt 的质量直接决定了解析效果的上限。特别是对于「A 日补上 B 日的课,原 A 日课程停课」类型的表述,它们实际上各自对应着两条独立的记录,需要在 Prompt 中将这个隐含的拆分逻辑显式地写出来,避免模型不知道怎么处理这种情况而产生错误。
我们实际使用的 System Prompt 是由两部分组成的:
你是一名调课通知解析助手,负责从调课通知的标题和内容中提取调课信息。调课信息包括调整前的日期和调整后的日期(如果当日课程取消则留空)。
请根据以下要求提取信息:
1. 输入的通知中可能包含多条调课信息,请提取所有的调课信息。
2. 日期格式为 YYYY-MM-DD。
3. 对于通知中提到放假的日期,如果没有提到其对应的补课日期则表示课程取消,产生一条调课信息,调整前的日期是放假的日期,调整后的日期留空。
4. 如果通知中提到日期X补上日期Y的课,则原来应该在日期X上课的课程取消,产生两条调课信息:一条是日期X的课程取消(调整后的日期留空),另一条是日期Y的课程调整(调整前的日期是X,调整后的日期是Y)。
5. 输出的结果应该是一个包含多个调课信息的列表,每条调课信息包含调整前的日期和调整后的日期(如果当日课程取消则留空)。
6. 如果无法提取到有效的调课信息,请返回一个空列表。
【示例输入】
# 关于2026年元旦放假课程调整的通知
各学院,各教学单位:
根据党政办有关2026年元旦放假通知的精神,现将放假期间的课程调整如下:
1、1月1日(周四)至1月3日(周六)放假,共3天,全校本科生课程(含通识教育选修课)停课。
2、1月4日(周日)补上1月2日(周五)的课,原1月4日的课程停课。
3、因停课受影响的教学内容,请任课老师自行调整安排。
请各学院、教学单位及时通知相关师生。
教务处
2025年12月29日
【解析结果】
第一条信息提示1月1日到1月3日放假,停课,得到一个1月1日、1月2日、1月3日均取消的记录列表;
第二条信息提示1月4日补上1月2日的课,原1月4日的课程停课,得到一个1月4日取消的记录,将1月2日的取消记录改为调整到1月4日。
综上,得到如示例输出所示的结果。
【示例输出】
[
{
"from_date": "2026-01-01",
"to_date": ""
},
{
"from_date": "2026-01-02",
"to_date": "2026-01-04"
},
{
"from_date": "2026-01-03",
"to_date": ""
},
{
"from_date": "2026-01-04",
"to_date": ""
}
]Prompt 中附带了一个完整的示例,以元旦放假通知为输入,逐步推导出最终的 items 列表。这种 few-shot 风格的引导,可以让模型在面对真实通知时直接按照以往的思路进行推理,极大地提升了推理过程的确定性。
项目在 pkg/ai/function.go 中二次封装了一个薄薄的 NewFunction 函数,统一从配置中读取 API Key 和 Endpoint,避免在每个 LLM Function 里重复做一些获取配置的 dirty work。
func NewFunction[T any, R any](
handler llmfunc.OutputHandler[T, R],
opts ...llmfunc.Option[*llmfunc.FunctionConfig],
) *llmfunc.Function[T, R] {
client := llmfunc.NewClient(config.AI.Key, config.AI.Endpoint)
return llmfunc.NewFunction[T, R](client, handler, opts...)
}基于这个构造函数,AutoAdjustCourse 函数的完整实现如下:
func AutoAdjustCourse(ctx context.Context, input AutoAdjustCourseInput) (*AutoAdjustCourseOutput, error) {
f := NewFunction(
llmfunc.UnmarshalOutput[AutoAdjustCourseInput, AutoAdjustCourseOutput](),
llmfunc.Name("auto_adjust_course"),
llmfunc.Description("解析调课通知提取调课信息"),
llmfunc.Instruction(AutoAdjustCourseInstruction),
llmfunc.StructuredOutput(true),
llmfunc.Model("deepseek-ai/DeepSeek-V3.2"),
llmfunc.Temperature(0.2),
)
output, err := f.Run(ctx, &input)
if err != nil {
return nil, fmt.Errorf("failed to run auto adjust course function: %w", err)
}
return output, nil
}对于调用方而言,AutoAdjustCourse 和任何普通的解析函数没有任何区别,传入标题和正文,拿回结构化的 items 列表。多么优雅!
AutoAdjustCourse 被接入在通知同步的定时任务里。系统在 cmd/common/main.go 中配置了一个定期爬取教务处通知的定时任务 syncNoticeTask,每次抓取到新通知时,会异步地触发调课解析流程:
go func(notice *jwch.NoticeInfo) {
ctx := context.Background()
if err := commonSvc.NewCommonService(ctx, clientSet, taskQueue).ProcessAutoAdjustCourseNotice(notice); err != nil {
logger.Errorf("ProcessAutoAdjustCourseNotice failed, title=%s url=%s err=%v", notice.Title, notice.URL, err)
}
}(row)ProcessAutoAdjustCourseNotice 在内部处理时,首先按标题过滤,跳过标题中不包含「课程调整」的通知,如果需要处理,则拉取通知详情页的完整正文,然后解析规则:
// 获取通知内容
detail, err := jwch.NewStudent().GetNoticeDetail(&jwch.NoticeDetailReq{
WbTreeId: info.WbTreeId,
WbNewsId: info.WbNewsId,
})
// 调用 LLM 从通知标题和正文中提取结构化的课程调整条目
result, err := ai.AutoAdjustCourse(s.ctx, ai.AutoAdjustCourseInput{
Title: info.Title,
Content: content,
})拿到 items 列表后,后续处理完全回归到确定性的代码逻辑 —— 将每条记录的日期字符串映射到所在学期,并计算出对应的周次和星期,最终构造出 model.AutoAdjustCourse 准备存入数据库:
// 根据 from_date 查找所属学期
term, found := utils.FindTermByDate(calendar.Terms, fromDate)
// 计算 from_date 在该学期中对应的周次和星期几
fromWeek, fromWeekday, err := utils.GetWeekdayByDate(term.StartDate, item.FromDate)
// 构造最终数据
adjustCourse := &model.AutoAdjustCourse{
Year: year,
FromDate: item.FromDate,
ToDate: toDate,
Term: term.Term,
FromWeek: int64(fromWeek),
ToWeek: toWeekPtr,
FromWeekday: int64(fromWeekday),
ToWeekday: toWeekdayPtr,
Enabled: false, // 默认禁用,等待人工审核后再启用
}所有记录写入完成后,统一刷新涉及学期的缓存,确保后续的课表查询能立即感知到新的调课记录。
调课记录写入数据库并启用之后,在学生请求课表时,系统在拿到原始课程数据后,紧接着读取当前学期所有已启用的调课记录,并通过 getAdjustRules 生成匹配的调课规则,生成最终应用到课程上的 CourseAdjustRule 列表:
autoAdjustCourses, err := s.GetAutoAdjustCourseList(req.Term)
for _, c := range courses {
adjustRules := getAdjustRules(c.ScheduleRules, autoAdjustCourses)
c.ScheduleRules = jwch.ApplyAdjustRules(
jwch.ApplyAdjustRules(c.ScheduleRules, c.AdjustRules),
adjustRules,
)
}注意这里有两层 ApplyAdjustRules,第一层应用的是教师在教务系统中录入的单次调课(jwch 库解析出来的 c.AdjustRules),第二层才是我们新增的全校性假期调课(前面生成的 adjustRules)。
getAdjustRules 的核心逻辑是对于每条调课记录,遍历该课程的所有排课规则,找出「周次和星期与调课记录的 from_week / from_weekday 匹配」的那些排课,为其生成一条 CourseAdjustRule。这里就正好和前面的日期到周次和星期几的转换遥相呼应,通过预处理减少了在后续阶段的计算量。详细代码请参见 internal/course/service/get_course_list.go,这里就不再单独贴出来了。
在 GetCourseList 的实现里,有一个特别的设计 —— 数据库和缓存存储的课表内容是不一样的。
// 写入数据库存储
originalCourses := pack.BuildCourse(courses)
s.taskQueue.Add(fmt.Sprintf("putCourse:%s", stuId), taskqueue.QueueTask{Execute: func() error {
return s.putCourseToDatabase(stuId, req.Term, originalCourses)
}})
// ... 应用调课规则 ...
// 写入缓存存储
s.taskQueue.Add(courseKey, taskqueue.QueueTask{Execute: func() error {
return cache.SetSliceCache(s.cache, s.ctx, courseKey, courses,
constants.CourseTermsKeyExpire, "Course.SetCourseCache")
}})数据库存储原始数据是为了保留重新计算的能力。调课规则是随时可能变化的 —— 管理员可能启用新规则,也可能修改或禁用已有规则。如果数据库里存的是某个时间点的处理结果,那么每次规则变更后都需要遍历所有用户的历史数据重新修改并写入,代价极高。而存储原始课表,规则变更后只需要让缓存失效,下次访问时自然会用最新的规则重新计算并回写缓存,做到了数据和规则的解耦。
缓存存储调课后的数据是为了让 hot path 足够快。对于活跃用户而言,每次打开 App 查看课表都应该是毫秒级响应。如果缓存里存的是原始数据,那么每次命中缓存后还要再走一遍调课信息的匹配逻辑,而调课信息通常是不会频繁变化的,导致白白增加计算开销。所以把已经处理好的结果直接放进缓存,命中时直接返回即可。
以文章开头的国庆调课通知为例,来完整地走一遍我们设计的流程。
教务处通知发出后,syncNoticeTask 在下一个同步周期抓取到到新通知后,发现标题中含「课程调整」的关键词,随即在后台异步拉取通知正文并调用 AutoAdjustCourse 解析,解析后得到的结构化输出如下:
{
"items": [
{ "from_date": "2025-10-01", "to_date": "" },
{ "from_date": "2025-10-02", "to_date": "" },
{ "from_date": "2025-10-03", "to_date": "" },
{ "from_date": "2025-10-04", "to_date": "" },
{ "from_date": "2025-10-05", "to_date": "" },
{ "from_date": "2025-10-06", "to_date": "" },
{ "from_date": "2025-10-07", "to_date": "2025-09-28" },
{ "from_date": "2025-10-08", "to_date": "2025-10-11" },
{ "from_date": "2025-09-28", "to_date": "" },
{ "from_date": "2025-10-11", "to_date": "" }
]
}这 10 条记录会先以未启用的状态存进数据库里,等待管理员审核后启用。启用后,所有查询该学期课表的请求都会经过 getAdjustRules 匹配,将受影响的那几节课从课表里移除,或者把它们调整到对应的补课日。用户打开 App,看到的已经是一张应用了全部调课规则的最终课表,不需要再对照通知自行推算。
整个过程对用户完全无感,LLM 解析发生在后台,与用户请求课表的链路没有任何交集;从用户视角来看,这和以往的课表体验没有任何不同,只是课表变「聪明」了。
回顾整个流程,LLM 只做了它最擅长的那一件事 —— 自然语言理解,把教务处的通知翻译成结构化的课程调整信息列表。之后的日期到周次的换算、学期的归属判断、与每门课排课规则的匹配、缓存的刷新,全部由确定性的代码完成。两种技术各司其职,边界清晰。
这种架构在工程上带来了一个令人满意的性质:整个系统没有任何一个环节是只有 LLM 能做但却又无法被验证的黑盒。AI 层的输出可以被单元测试固定下来验证,业务层的每一条分支都可以通过 mock 独立覆盖,规则应用层是没有副作用的纯函数,数据库存储的是原始事实而非中间结论。把 LLM 当作函数来使用,意味着它必须接受和普通函数一样的工程约束 —— 可测试、可替换、职责单一 —— 而这些约束反过来也让整个系统的可靠性有了更坚实的保证。
这次实践中由 LLM 承担的部分,从代码量上看并不大,甚至可以说很小。但它完成的是在此之前我们一直没有好办法处理的格式不固定的自然语言通知的解析。这类通知隐含着复杂语义嵌套的调课逻辑,纯靠代码很难完成解析。过去这些信息只能靠用户自己去查询记录、专门留意,而现在这件事由我们的系统替用户完成了。
这次实践虽然由 LLM 实现的部分并不是很大,但它让我们看到了大模型并不只是聊天窗口里那个无所不知的助手,它同样可以是系统架构图上一个朴素而可靠的函数节点,能够和普通的代码有机结合。
相关代码:
本文所述业务接入部分的实现,是和正在参与西二在线 Go 组考核、福州大学 2025 级软件工程专业的吴佳伟同学一同完成的,在此表示感谢。感谢王智壹同学审阅本文并给出修改建议。
2025-08-05 23:18:52

最近在实习的时候,遇到了一些需求,需要自己去实现 CSS 的解析、(伪)渲染流程。以之为契机,我学习了一下编译相关的知识,其中的第一环就是 Lexer。
本文中的代码均使用 Go 实现,成果已经作为 Go 库 go.baoshuo.dev/csslexer 发布。
建议在阅读本文前对 CSS 标准内容有一定理解。
词法分析(lexical analysis)是计算机科学中将字符序列转换为记号(token,也有译为标记或词元)序列的过程。进行词法分析的程序或者函数叫作词法分析器(lexical analyzer,简称 lexer),也叫扫描器(scanner)。词法分析器一般以函数的形式存在,供语法分析器调用。
——维基百科
词法分析是编译中的第一个步骤。它读入组成源码的字符流,并将他们组织成一个个的词素(lexeme)。有了词素以后,识别并标注它的类型,就可以生成一个 <token-name, attribute-value> 形式的词法单元(token)。这个单元会被传送给下一个步骤 —— 语法分析 —— 进行后续的处理。
在进行词法分析之前,首先要设定好到底有多少种 token 类型,然后再确定每个 token 类型的判断条件和解析方式。
由 CSS Syntax Module Level 3 中的 4. Tokenization 一节可以得到 CSS 的 token 有以下几种类型:
<ident-token>
<function-token>
<at-keyword-token>
<hash-token>
<string-token>
<bad-string-token>
<url-token>
<bad-url-token>
<delim-token>
<number-token>
<percentage-token>
<dimension-token>
<whitespace-token>
<CDO-token>
<CDC-token>
<colon-token>
<semicolon-token>
<comma-token>
<[-token>
<]-token>
<(-token>
<)-token>
<{-token>
<}-token>为了解析方便,我们又在标准的 token 类型外拓展了几个 token 类型,得到了下面的 token 表:
<ident-token> IdentToken
<function-token> FunctionToken foo()
<at-keyword-token> AtKeywordToken @foo
<hash-token> HashToken #foo
<string-token> StringToken
<bad-string-token> BadStringToken
<url-token> UrlToken url()
<bad-url-token> BadUrlToken
<delim-token> DelimiterToken
<number-token> NumberToken 3
<percentage-token> PercentageToken 3%
<dimension-token> DimensionToken 3em
<whitespace-token> WhitespaceToken
<CDO-token> CDOToken <!--
<CDC-token> CDCToken -->
<colon-token> ColonToken :
<semicolon-token> SemicolonToken ;
<comma-token> CommaToken ,
<(-token> LeftParenthesisToken (
<)-token> RightParenthesisToken )
<[-token> LeftBracketToken [
<]-token> RightBracketToken ]
<{-token> LeftBraceToken {
<}-token> RightBraceToken }
<EOF-token> EOFToken
CommentToken /* ... */
IncludeMatchToken ~=
DashMatchToken |=
PrefixMatchToken ^=
SuffixMatchToken $=
SubstringMatchToken *=
ColumnToken ||
UnicodeRangeToken于是乎,我们就有了词法分析的期望目标产物 —— 由这 33 种类型的 token 组成的 token 流。
工欲善其事,必先利其器。
在实现真正的词法分析流程以前,我们需要编写一套输入流来辅助我们完成读入的操作。
首先,我们给出输入流的定义:
// Input represents a stream of runes read from a source.
type Input struct {
runes []rune // The runes in the input stream.
pos int // The current position in the input stream.
start int // The start position of the current token being read.
err error // Any error encountered while reading the input.
}这个结构封装了对一个 rune 切片的访问,并维护了当前扫描的位置(pos)和当前正在扫描的 token 的起始位置(start)。
需要注意的是,我们使用 rune 而不是 byte 来存储内容,这样做的原因是为了便于处理代码中包含的 Emoji 等 Unicode 字符。
为了使用方便,这个输入流可以从 string、[]rune、[]byte 和 io.Reader 初始化。实现细节可以查看仓库中的 input.go,各个函数签名如下:
NewInput(input string) *InputNewInputRunes(runes []rune) *InputNewInputBytes(input []byte) *InputNewInputReader(r io.Reader) *Input接下来,我们需要设计一系列合理的方法,使得这个输入流的使用能够在满足我们的实际需求的同时,还保持简洁的风格。
在 4.2 节的一系列定义中,通过观察不难发现,在解析过程中会不断地出现 consume 和 reconsume 的操作,也就是说,在输入流的末尾会不断地进行 pop_back 和 push_back 的操作。那么我们可以将这些操作转化为「预读」和「后移指针」的操作,以此来减少频繁在流末尾进行的弹出和插入操作。
于是,我们就有了以下两个方法:
func (z *Input) Peek(n int) rune
预读输入流中 pos+n 位置的字符。
func (z *Input) Move(n int)
将当前输入流的指针后移 n 位。
经过阅读规范以后,不难发现一个 token 可以由几个不同类别的字符序列组成,比如 16px 就是一个 16 (number sequence) 和一个 px (ident sequence) 共同组成的 dimension-token。所以我们在解析一个 token 的时候可能会调用多个解析函数,那么就需要在 token 级别做一个固定的输出模式。
于是,我们定义 func (z *Input) Shift() []rune 来弹出当前 token,并更新 Input 实例中的 start 值,以开始下一 token 的解析。
不过后续在解析 url-token 的时候遇到了需要读取当前已经 consume 的内容的情况,于是将 Shift 方法拆分成了 Current 和 Shift 两个不同的方法,以便使用。
除此以外,在解析的时候还有需要在满足某一特定条件下一直 consume 的能力需求,因此又设计了较为通用的 func (z *Input) MoveWhilePredicate(pred func(rune) bool) 方法,来实现这一能力。
加上错误处理逻辑以后,整个 Input 的方法如下:
func (z *Input) PeekErr(pos int) error
func (z *Input) Err() error
func (z *Input) Peek(n int) rune
func (z *Input) Move(n int)
func (z *Input) Current() []rune
func (z *Input) Shift() []rune
func (z *Input) MoveWhilePredicate(pred func(rune) bool)接下来,我们就可以正式开始 lexer 的编写了。
其实 Lexer 的方法框架设计就相对简单了,下面直接给出定义:
type Lexer struct {
r *Input // The input stream of runes to be lexed.
}
func (l *Lexer) Err() error
func (l *Lexer) Next() (TokenType, []rune)在 Next 方法中有一个巨大的 switch-case 语句,这里面包含了 4.3.1. Consume a token 中所描述的所有在 token 开始时的情形。我们将会根据一个 token 开始的几个字符(小于等于 3 个)来确定这个 token 的后续部分应该如何解析。
开始解析 token 的时候一定是在文件流的开头或者上一个 token 刚刚解析完毕的时候,那么此时我们只需要根据对应规则判断 token 类型即可。
首先预读 1 个字符,记为 next,然后对这个字符进行分类讨论。
EOF:直接返回 EOF-token。
\t, \n, \r, \f, :根据标准需要将此字符及后续的所有 whitespace 组合成一个 whitespace-token。
/:如果是 /* 则一直读取到 */ 或者 EOF 作为 comment-token。
' (单引号), "(双引号):遇到这两种引号,会调用字符串解析函数 consumeStringToken()。该函数会持续读取字符,直到遇到与之匹配的结束引号。在此过程中,它会处理转义字符(如 \")。如果在中途遇到换行符或文件末尾,则会生成一个 bad-string-token,否则生成一个 string-token。
0 ~ 9 的数字字符:如果以数字开头,确定无疑是数字类型,调用数字解析函数 consumeNumericToken()。
(, ), [, ], {, }:生成对应的括号字符。function-token 或者 url-token 的情况会在处理 ident-like 的时候另行考虑。
+, .:这两个字符,再加上 -,都比较特殊。不过 - 需要包含一些额外的判断,因此归属于另外一条规则处理。
nextCharsAreNumber() 判断后续字符是否能构成一个合法的数字(例如 +1.5, .5)。consumeNumericToken() 将其完整解析为一个 numeric-token。+ 和 . 会被当作 delimiter-token。-:除了像 + 一样判断是否有可能进入数字的处理逻辑以外,还需要考虑作为 --> (CDC-token) 和 ident-like 的情况。如果都不是才会被当做 delimiter-token。
if l.nextCharsAreNumber() {
return l.consumeNumericToken()
}
if l.r.Peek(1) == '-' && l.r.Peek(2) == '>' {
l.r.Move(3) // consume "-->"
return CDCToken, l.r.Shift()
}
if l.nextCharsAreIdentifier() {
return l.consumeIdentLikeToken()
}
l.r.Move(1)
return DelimiterToken, l.r.Shift()<:如果能构成 <!--,解析为一个 CDO-token,否则解析为 delimiter-token。
*, ^, $, |, ~: 这些是属性选择器中的匹配符。
=,则会组合成一个专有 token:*= → substring-match-token^= → prefix-match-token$= → suffix-match-token~= → include-match-token|= → dash-match-token|,如果能够组成 ||,则会成为 column-token。@:如果后续的字符能够组成一个 identifier,那么解析为 at-keyword-token,否则解析为 delimiter-token。
, (逗号):直接生成 comma-token。
: (冒号):直接生成 colon-token。
; (分号):直接生成 semicolon-token。
u 或 U:这是一个特殊前缀。如果其后是 + 紧跟着十六进制数字或 ? (例如 U+26 或 u+A?),则调用 consumeUnicodeRangeToken() 解析为一个 urange-token。否则,按标识符处理。
u+a 既是一个合法的 unicode-range,也是一个合法的 selector,需要根据上下文来判定。1 <= c <= 31, !, %, &, =, >, ?, `, 127:解析为 delimiter-token。
其余字符:尝试解析为 ident-like。
整个流程在 lexer.go 的 24-198 行,由于篇幅原因此处就不贴完整代码了。
为了方便,我们为几种逻辑复杂 / 需要重用的 token 解析逻辑进行了封装,产生了如下函数:
%,consume 掉这个 %,产生一个 percentage-token;// https://www.w3.org/TR/2021/CRD-css-syntax-3-20211224/#consume-numeric-token
func (l *Lexer) consumeNumericToken() (TokenType, []rune) {
l.consumeNumber()
if l.nextCharsAreIdentifier() {
l.consumeName()
return DimensionToken, l.r.Shift()
} else if l.r.Peek(0) == '%' {
l.r.Move(1) // consume '%'
return PercentageToken, l.r.Shift()
}
return NumberToken, l.r.Shift()
}U+0000FF,+ 后面可以跟 1 ~ 6 个 16 进制数字;U+0000??,+ 后面先跟 16 进制数字再跟 ?(通配符),总数不超过 6 个;U+0001-0002,- 两侧可以有 1 ~ 6 个 16 进制数字。// https://www.w3.org/TR/2021/CRD-css-syntax-3-20211224/#urange
func (l *Lexer) consumeUnicodeRangeToken() (TokenType, []rune) {
// range start
start_length_remaining := 6
for next := l.r.Peek(0); start_length_remaining > 0 && next != EOF && isASCIIHexDigit(next); next = l.r.Peek(0) {
l.r.Move(1) // consume the hex digit
start_length_remaining--
}
if start_length_remaining > 0 && l.r.Peek(0) == '?' { // wildcard range
for start_length_remaining > 0 && l.r.Peek(0) == '?' {
l.r.Move(1) // consume the '?'
start_length_remaining--
}
} else if l.r.Peek(0) == '-' && isASCIIHexDigit(l.r.Peek(1)) { // range end
l.r.Move(1) // consume the '-'
end_length_remaining := 6
for next := l.r.Peek(0); end_length_remaining > 0 && next != EOF && isASCIIHexDigit(next); next = l.r.Peek(0) {
l.r.Move(1) // consume the hex digit
end_length_remaining--
}
}
return UnicodeRangeToken, l.r.Shift()
}// https://www.w3.org/TR/2021/CRD-css-syntax-3-20211224/#consume-ident-like-token
func (l *Lexer) consumeIdentLikeToken() (TokenType, []rune) {
l.consumeName()
if l.r.Peek(0) == '(' {
l.r.Move(1) // consume the opening parenthesis
if equalIgnoringASCIICase(l.r.Current(), urlRunes) {
// The spec is slightly different so as to avoid dropping whitespace
// tokens, but they wouldn't be used and this is easier.
l.consumeWhitespace()
next := l.r.Peek(0)
if next != '"' && next != '\'' {
return l.consumeURLToken()
}
}
return FunctionToken, l.r.Shift()
}
return IdentToken, l.r.Shift()
}注意这里的实现其实会在含转义的 URL-token 上出现问题,后续通过修改 consumeName 函数的实现,通过返回值判断解决了此问题。
// https://www.w3.org/TR/2021/CRD-css-syntax-3-20211224/#consume-string-token
func (l *Lexer) consumeStringToken() (TokenType, []rune) {
until := l.r.Peek(0) // the opening quote, already checked valid by the caller
l.r.Move(1)
for {
next := l.r.Peek(0)
if next == until {
l.r.Move(1)
return StringToken, l.r.Shift()
}
if next == EOF {
return StringToken, l.r.Shift()
}
if isCSSNewline(next) {
return BadStringToken, l.r.Shift()
}
if next == '\\' {
next_next := l.r.Peek(1)
if next_next == EOF {
l.r.Move(1) // consume the backslash
continue
}
if isCSSNewline(next_next) {
l.r.Move(1)
l.consumeSingleWhitespace()
} else if twoCharsAreValidEscape(next, next_next) {
l.r.Move(1) // consume the backslash
l.consumeEscape()
} else {
l.r.Move(1)
}
} else {
l.r.Move(1) // consume the current rune
}
}
}consumeIdentLikeToken() 中我们把 URL 的前导空格全部 consume 掉了,但如果遇到使用引号包裹的 URL 时,这段空格理应单独作为一个 whitespace-token,不过无伤大雅,这样解析也可以,不影响后续的 parse 流程。// https://www.w3.org/TR/2021/CRD-css-syntax-3-20211224/#consume-url-token
func (l *Lexer) consumeURLToken() (TokenType, []rune) {
for {
next := l.r.Peek(0)
if next == ')' {
l.r.Move(1)
return UrlToken, l.r.Shift()
}
if next == EOF {
return UrlToken, l.r.Shift()
}
if isHTMLWhitespace(next) {
l.consumeWhitespace()
next_next := l.r.Peek(0)
if next_next == ')' {
l.r.Move(1) // consume the closing parenthesis
return UrlToken, l.r.Shift()
}
if next_next == EOF {
return UrlToken, l.r.Shift()
}
// If the next character is not a closing parenthesis, there's an error and we should mark it as a bad URL token.
break
}
if next == '"' || next == '\'' || isNonPrintableCodePoint(next) {
l.r.Move(1) // consume the invalid character
break
}
if next == '\\' {
if twoCharsAreValidEscape(next, l.r.Peek(1)) {
l.r.Move(1) // consume the backslash
l.consumeEscape()
continue
} else {
break
}
}
l.r.Move(1) // consume the current rune
}
l.consumeBadUrlRemnants()
return BadUrlToken, l.r.Shift()
}一共有以下几个片段解析的函数:
consumeUntilCommentEnd():一直读取到注释结束。
// https://www.w3.org/TR/2021/CRD-css-syntax-3-20211224/#consume-comment
func (l *Lexer) consumeUntilCommentEnd() {
for {
next := l.r.Peek(0)
if next == EOF {
break
}
if next == '*' && l.r.Peek(1) == '/' {
l.r.Move(2) // consume '*/'
return
}
l.r.Move(1) // consume the current rune
}
}consumeEscape():解析一个转义字符。
// https://www.w3.org/TR/2021/CRD-css-syntax-3-20211224/#consume-escaped-code-point
func (l *Lexer) consumeEscape() rune {
var res rune = 0
next := l.r.Peek(0)
if isASCIIHexDigit(next) {
l.r.Move(1)
res = hexDigitToValue(next)
for i := 1; i < 6; i++ {
c := l.r.Peek(0)
if isASCIIHexDigit(c) {
l.r.Move(1)
res = res*16 + hexDigitToValue(c)
} else {
break
}
}
if !isValidCodePoint(res) {
res = '\uFFFD' // U+FFFD REPLACEMENT CHARACTER
}
// If the next input code point is whitespace, consume it as well.
l.consumeSingleWhitespace()
} else if next != EOF {
l.r.Move(1) // consume the escape character
res = next
} else {
res = '\uFFFD' // U+FFFD REPLACEMENT CHARACTER for EOF
}
return res
}consumeName():读取一个 name。
// https://www.w3.org/TR/2021/CRD-css-syntax-3-20211224/#consume-name
func (l *Lexer) consumeName() {
for {
next := l.r.Peek(0)
if isNameCodePoint(next) {
l.r.Move(1)
} else if twoCharsAreValidEscape(next, l.r.Peek(1)) {
l.r.Move(1) // consume the backslash
l.consumeEscape()
} else {
break
}
}
}consumeNumber():读取一个数字。需要特别注意对科学计数法的处理,以及与调用侧配合正确解析 .7 +.7 等 case。
// https://www.w3.org/TR/2021/CRD-css-syntax-3-20211224/#consume-number
func (l *Lexer) consumeNumber() {
next := l.r.Peek(0)
// If the next rune is '+' or '-', consume it as part of the number.
if next == '+' || next == '-' {
l.r.Move(1)
}
// consume the integer part of the number
l.r.MoveWhilePredicate(isASCIIDigit)
// float
next = l.r.Peek(0)
if next == '.' && isASCIIDigit(l.r.Peek(1)) {
l.r.Move(1) // consume the '.'
l.r.MoveWhilePredicate(isASCIIDigit)
}
// scientific notation
next = l.r.Peek(0)
if next == 'e' || next == 'E' {
next_next := l.r.Peek(1)
if isASCIIDigit(next_next) {
l.r.Move(1) // consume 'e' or 'E'
l.r.MoveWhilePredicate(isASCIIDigit)
} else if (next_next == '+' || next_next == '-') && isASCIIDigit(l.r.Peek(2)) {
l.r.Move(2) // consume 'e' or 'E' and the sign
l.r.MoveWhilePredicate(isASCIIDigit)
}
}
}consumeSingleWhitespace():读取一个空格。
func (l *Lexer) consumeSingleWhitespace() {
next := l.r.Peek(0)
if next == '\r' && l.r.Peek(1) == '\n' {
l.r.Move(2) // consume CRLF
} else if isHTMLWhitespace(next) {
l.r.Move(1) // consume the whitespace character
}
}consumeWhitespace():读取多个空格。
func (l *Lexer) consumeWhitespace() {
for {
next := l.r.Peek(0)
if isHTMLWhitespace(next) {
l.consumeSingleWhitespace()
} else if next == EOF {
return
} else {
break
}
}
}consumeBadUrlRemnants():读取 bad-url-token 的剩余部分。
// https://www.w3.org/TR/2021/CRD-css-syntax-3-20211224/#consume-the-remnants-of-a-bad-url
func (l *Lexer) consumeBadUrlRemnants() {
for {
next := l.r.Peek(0)
if next == ')' {
l.r.Move(1)
return
}
if next == EOF {
return
}
if twoCharsAreValidEscape(next, l.r.Peek(1)) {
l.r.Move(1) // consume the backslash
l.consumeEscape()
continue
}
l.r.Move(1)
}
}对于 identifier,我们根据以下标准判断接下来的字符是否可能开始一个 identifier 的序列:
- 开始的 identifier(再走一遍上面两点的识别流程,同时注意 -- 的情况)。// https://www.w3.org/TR/2021/CRD-css-syntax-3-20211224/#would-start-an-identifier
func (l *Lexer) nextCharsAreIdentifier() bool {
first := l.r.Peek(0)
if isNameStartCodePoint(first) {
return true
}
second := l.r.Peek(1)
if twoCharsAreValidEscape(first, second) {
return true
}
if first == '-' {
return isNameStartCodePoint(second) || second == '-' ||
twoCharsAreValidEscape(second, l.r.Peek(2))
}
return false
}对于 number,当符合以下条件的时候可以开始一个 number 的序列:
// https://www.w3.org/TR/2021/CRD-css-syntax-3-20211224/#starts-with-a-number
func (l *Lexer) nextCharsAreNumber() bool {
first := l.r.Peek(0)
if isASCIIDigit(first) {
return true
}
second := l.r.Peek(1)
if first == '+' || first == '-' {
if isASCIIDigit(second) {
return true
}
if second == '.' {
third := l.r.Peek(2)
if isASCIIDigit(third) {
return true
}
}
}
if first == '.' {
return isASCIIDigit(second)
}
return false
}让我们来总结一下 lexer 工作流程:在 lexer 读取到某个 token 的起始点的时候,lexer 预读起始的几个字符,然后辨别 token 的类型。对于大致分类好的 token,根据其更具体的特征预读并消耗掉对应的字符,直到这个 token 结束。
大致的类型辨别是通过 Next() 函数中的那个巨大的 switch-case 语句来完成的。而对于精细的 token 类型的判断,则是 case 中的语句和 consume_token.go 定义的一系列函数来共同完成的。至于 token 内部的字符段的解析,则是 consume.go 中的一系列函数完成的。由此组合,整个 token 的解析过程得以良好运转。
除了文中提到的相关方法以外,在 util.go 中还有一系列的工具函数:
func isASCII(c rune) boolfunc isASCIIAlpha(c rune) boolfunc isASCIIDigit(c rune) boolfunc isASCIIHexDigit(c rune) boolfunc isCSSNewline(c rune) boolfunc isNameStartCodePoint(r rune) boolfunc isNameCodePoint(r rune) boolfunc isNonPrintableCodePoint(r rune) boolfunc twoCharsAreValidEscape(first, second rune) boolfunc isHTMLSpecialWhitespace(c rune) boolfunc isHTMLWhitespace(c rune) bool这些函数的作用可以很容易地由它们的名字得知,故此处不再赘述。
为了验证 lexer 的实现正确性,我们引入了 romainmenke/css-tokenizer-tests 的测试用例来对 lexer 进行测试。具体的测试流程可以参考 lexer_test.go 中的实现。
根据测试结果来看,出现的问题主要集中在与转义字符相关的处理,对于大部分情况已经能够正常解析。截止编写本文之时,测试通过率为 96.53% (167/173),个人认为已经处于可用水平。
文中所述的 lexer 的具体实现已经开源在 renbaoshuo/go-css-lexer,欢迎大家 Star!
搓这个 lexer 花了半个周末的时间,修修补补又消耗了一些时间。也算是在工作之余充实自己的大脑了。后续还可能会针对预读相关的内存访问进行优化(不知道读者有没有发现最多会预读三个字符),以提升处理效率。
文章题图由 Gemini 2.5 Pro Imagen 生成。
2025-01-28 22:57:30

即使是沉重的过去,也要接受它再继续向前迈进。
2024 年就这样过去了。上半年发生的一系列事情对我仿佛一场梦一样,而下半年我才回到真实的生活中。
前一阵子有读者来询问我的近况,同时进行了一个博客更新的催。其实我有写几篇草稿,不过中途废弃了一些,另一些还没有完成,所以一整年都没有产出。这篇总结中也会截取弃稿中一些完成度比较高的部分分享给各位读者。
备战高考是我今年上半年的主旋律。从 2023 年 5 月 4 日正式回班,到 2024 年 6 月 6 日(高考前一天),刚好经历了整整四百天。
从起初的三百余分,到高考的 615 分,我实现了在旁人看来几乎不可能的飞跃。我没有任何理由不为我自己的巨大进步而感到自豪。我在刚出考场时的估分恰好就是 615 分,这么准确的估分我觉得也可以吹很久了。总的来说,我用自己的实力与汗水,狠狠地打了某些幻想看我过不了本科线的笑话的 “学生” “老师” 和 “家长” 的脸。
在实在学不下去的时候,由于没有任何的娱乐设施,我只能通过写文章来做一些与学习无关的事情。受精神状态影响,这些文章的行文思路可能不是很正常,表达的情感也会比较激烈,还望各位读者海涵。
在一些比较特殊的日子里,我会用日记的形式来记录近况。《从零开始的异世界文化课生活》是一篇日记选集,笔者从中再次截取了一部分比较有代表性的内容。
竞赛机房的灯熄灭了。我心中的火,也骤然灭了。笃行楼陷入了黑暗之中。我踩着黑暗,一步步地走向楼下。这段熟悉地不能再熟悉的路,我已经走了许多年。
在昏暗的夜色中,教学楼的灯光确实格外璀璨,无数学子正在其中奋笔疾书,追逐属于他们的梦想。可惜这梦想并不属于我,我的梦想已然破灭。
我背着书包,走向了教学楼,再也没有回头……

▲ 从存真楼旧竞赛机房向远处望去。摄于 2022 年 6 月。

▲ 从实验楼五楼向下望去。摄于 2022 年 2 月。
很多人都说竞赛生们个个智商超群,学习能力异于常人,可我却不这么认为。站在聚光灯下的人终究是那一小部分,从总体上来看,大部分人还是陪跑的选手。很不幸,我就在陪跑之列。竞赛招生时,教练们口中的「半个月逆袭登顶」的神话也不是人人都能书写的。
我终究还是要独自面对这冰冷残酷的现实。
回到班后,我发现教室内甚至已经没有了我的座位 —— 只有花名册上的名字证明着我属于这个班。甚至考试的时候都不会给我分配考场。我确实成为了一个透明人。一张张陌生的面孔,一个个陌生的名字,一阵阵陌生的声音…… 我虽然回到了我自己的班级,但却没有得到任何归属感。
虽然学习是一名高中生的本职工作,但是我仍然要指出,我并不喜欢囿于应试教育的牢笼之中。每天机械地刷题、考试,于宿舍、食堂和教室三点一线间往返,并非我所向往的生活。我希望我能够将青春的火焰燃烧在我所热爱的事业上,而不是在一摞摞试卷中消磨殆尽。
一次次的模拟考试,每次我的名字都会出现在成绩单的末尾。在一个几乎人人都能上 600 分的班级里面,我三四百分的成绩显得格外突兀。
相比于大多数同学们的包容,数任班主任和年级主任都有想过把我从省理科实验班里面给踢出去。好在到最后也没有成功。能够留在这个班里,算是不幸中的万幸。他们可否想过:如果我真的离开了这个班级,那我该怎么重新适应一个新的环境,该怎么重新接纳一批新老师的讲课风格,又该怎么与一批新的同学相处?我猜,他们并没有想过。

▲ 高三时的教室。摄于暑假放假后,此时同学们都已把自己的书本搬回了家,准备接下来的线上学习。
高考前一百天左右,我的座位被固定了下来。
我坐在教室的倒数第二排,靠窗户的位置。有句话叫「后排靠窗,主角故乡」,希望能够在我身上应验。
另外,靠后的位置更有利于我自由发挥 —— 毕竟我的进度和班里面其他人的进度还是不太一样的,所以课上内容不能全听。
坐在这里学累了能够转向窗外看风景也是一件美事啊~
我站在天台上,冷风直吹着我的脸庞。向下望去,大地突然显得十分亲切,仿佛在等待着我的造访。独处一会,我最终还是选择从楼梯走下去。我不知道我是在逃避什么,还是在寻找什么。我只知道,我不能就这样放弃。

▲ 黄昏时的天台外景。我是从忘记锁门的维修通道溜上去的,那段时间学校在烫房顶。
此文写于高考期间。节选中删去了一些琐碎的细节部分。
四百天很长,能让我从一名小白变成一名可以安稳面对高考的成熟学生。四百天也很短,回班的日子仿佛还是昨天。
明天就要高考了,而我还坐在这里写文章。心里是不是该有愧疚感呢?我不知道。不过我觉得再继续临时抱佛脚也只能够让自己乱了阵脚罢了。
尽人事,听天命。还有那不能缺席的:高考加油!
高考第一天。
上午的语文考试只能说是正常发挥,没有什么特别的感觉。因为还有四科考试,所以也没有和别人对答案。
下午的数学考试是题型改革后的第一次高考。前面的选择填空感觉还好,第一道大题是解三角形,也比较常规。但是到了第二道大题,炸裂的就来了 —— 圆锥曲线放到第二题考,打了个措手不及。要知道,我对自己的定位是丢弃掉导数和圆锥曲线这两类大题的。但是放到第二道大题的位置,理论上不应该不拿这分。所以我只能硬着头皮做了下去,结果没做出来。接下来的几道大题也并不顺利,一道做完的都没有(好像其他同学也差不多)。不过十九题做了两问,在同学们里面算做得比较多的了。
晚上由于大家的数学都很稀碎,班里面基本上没有多少动笔的声音,许多人都在发呆。班主任老师见状紧急开会平复大家的心情,以免影响次日的考试。
(对答案后补充:选择和填空加起来应该只扣了两分。第十九题写了的两问全部正确。感觉能 120+ 了)
(出分后补充:真的考了 120 分欸)
高考第二天。
上午的物理答题意外地顺利,除了第一道大题卡了三分钟和本来就没想着做的最后一道大题以外,其他的题目都莫名其妙地顺利。出了考场以后我甚至跟老师自信地说能上 90 分(出分后补充:没上,只考了 72 分)。于是立马兴奋了起来,昨天数学带来的阴霾一扫而空。
下午的英语考试感觉自己彻底进入了状态。答完卷子以后发现还剩四五十分钟,遂捂住之前的答案再做了一遍。做完后发现有三处不一样的。仔细检查后修改了其中的两处。出考场后告知任课老师这个情况的时候她还安慰我,让我不要慌,这个是正常现象。(出分后补充:考了 137 分)
晚上又看了看化学。生物明天考完化学再看。
化学好难。不是说一年比一年简单的吗?怎么今年考完化竞生都落泪了。抱着老师哭的都出来了……
考生物的时候,我的笔速愈发加快,花了不到一个小时就做完了。然后就是等待高考结束了。这个时候的我已经没有丝毫检查的欲望了,只想快点结束这该死的考试回家睡大觉。
出考场,大概估了一下,应该能考 615 分左右吧,就会这些了。

▲ 高考结束后家委会送来的小蛋糕。
就这样吧。
在近一个星期紧张刺激的志愿填报过后,我根据自己的成绩、结合目标院校层次,筛选出了 96 个志愿 —— 卡着志愿填报的上限 —— 作为我的最终填报志愿。
根据我的期望,最终录取志愿会落在 40 ~ 60 序号的志愿上。等到录取的那天,面对迟迟没有动静的河北省教育考试院系统,我转向了各个大学的招生办的录取查询系统进行查询,最终在第 45 号志愿所对应的福州大学的查询系统上查询到自己被录取到了计算机科学与技术专业。
不久后(但是依然是焦急的等待),我就收到了录取通知书:

▲ 福州大学录取通知书外封套。从福州发出到石家庄签收全程只花了十几个小时。
虽然我知道,在这个人均 985 的时代,一张 211 的文凭已经不算什么了。但是我仍为我能通过自己的努力考上一所好学校而感到自豪。
8 月 30 日,我从石家庄启程,经由南京转机,最后抵达了福建福州,准备开始我的大学生活。
24 年的下半年可以说是非常顺畅的:
此外,我还加入了福州大学西二在线工作室(校计算机协会),遇到了一群有着相同爱好的好朋友们。

下面是日常随拍分享时间:

▲ 福州大学铜盘校区教学楼。摄于 2024 年 9 月 5 日。


▲ 福州福山郊野公园。

▲ 福州西湖公园。

▲ 落日。

▲ 从鼓山上俯瞰福州城。摄于 2024 年 12 月 20 日。

▲ 从鼓山上夜瞰福州城。摄于 2024 年 12 月 20 日。

▲ 贵安欢乐世界一角。摄于 2024 年 12 月 31 日。
在大学生活之余,我还完成了我中学时的一个愿望 —— 考取业余无线电台操作证,成为一名 HAM。
若要了解更多信息,请访问网址:https://baoshuo.ren/bd3rnw/
过去的 2024 年总体上来说还是比较顺利的。不过上了大学以后各种事情明显变多了,搞得年终总结都拖了好久😂。
最后,祝大家新的一年里身体健康,万事如意!
2024-01-01 13:10:00

2023 年就这样在恍恍惚惚间过去了,在这一年中发生了许多事情,就让我挑一些大家可能感兴趣的事情来讲讲吧。
如我在《我的 OI 生涯 —— 一名退役竞赛生的回忆录》中所述,我在竞赛失利后,已经选择了回归文化课道路。在回班以后,不时有好友、读者向我私信或者邮件询问我的近况。由于寄宿制学校放假时间极短,未能一一详尽回答,所以我将在此介绍一下我的近况,以回应各位热心读者的关切。
首先先给大家看点好笑的:

截止到现在,我在回班以后主要分为了以下几个阶段:
随着时间的推移,我从最开始几个月的 “听天书” 到现在已经逐渐适应了班内的学习节奏。虽然由于高一高二的长时间停课导致现在的成绩不太理想,但我相信通过一轮复习,我的知识水平会得到很大的提升。虽然今后还有一段很艰苦的道路要走,但我坚信只要努力就能克服路途上的艰难险阻,到达成功的彼岸。
暂时还没想好。考哪算哪,不强求。
暂时不考虑。原因有三:
高考之日未到,现在谈复读与否其实有点早。我个人以及我家长的意见都倾向于不复读。
复读,意味着又要承受一年高三的巨大压力,这对于一个人的身体和心理都是一个巨大的挑战,而我的身体较为羸弱,恐怕很难再扛得住一年这样的压力。除此之外,复读还使我在一条我不喜欢的且充满不确定性的道路上多耗费了整整一年的光阴,这样做真的值得吗?我不太好回答这个问题。
在强基计划公布以后,除非取得国家级的奖项,否则竞赛对高考已经没有了什么实质性的帮助,省一等奖最多也就给三四十分的优惠,所以最后还得看文化课的水平到底如何。
我学竞赛并无太多功利因素,更多的是怀揣着一份对计算机的热爱,这也是支撑着我度过这四年有余的竞赛生涯的最关键因素。此外,我也没见过几个一心为了功利还能取得好成绩的竞赛生。毕竟竞赛的学习过程并不轻松,且其对文化课的影响常常是显著的,所以从功利的角度来看,学习竞赛显然是不划算的。
不过,如果再给我一次机会,我还会选择学习竞赛。正如我在《我的 OI 生涯 —— 一名退役竞赛生的回忆录》中所述,竞赛带给我的并不仅仅是那几张薄薄的证书,更多的是思维方式的蜕变,这将在我今后的人生中产生深远影响。
高一的时候一定要打牢文化课基础,不然等到省选前有你紧张到哭的时候。我就是一个很好的反面教材,高一停课停早了导致文化课约等于没学,结果最后几场比赛前就非常害怕退役回去学文化课,于是就整夜整夜的失眠。
动漫于我的意义并不只是看个 “动画”,一段精彩的作画、一段感人的故事、一段轻松的日常,都能以其积极向上的乐观主义精神,将我从低谷中拉出来,使我能够更加乐观地面对今后的人生道路。






▲ 我宿舍内悬挂的《莉可丽丝》海报



▲ 故地重游(参见:USTC Hackergame 2021 旅行照片)

▲ 燕山大学


▲ 二南随拍
由于学业因素,在过去的一年里我用来写代码的时间大大减少。不出意外的话,在高考结束以前我都会保持这种低频活动状态。
对整体布局进行了一些重新设计。此外我还计划将其迁移至 Next.js 13 App Router,但尚未完工。
在新的一年里,我会继续冲刺高考,争取考一所好大学。同时也在此感谢读者们对我的关心,不过由于我长期住校,故评论、邮件等可能不会及时回复,敬请谅解。
最后,祝大家新的一年里身体健康,万事如意!
2023-05-28 11:31:46

在某些情况下,我们会遇到需要将网页打印出来的需求。但是,直接打印网页的效果往往不尽如人意,因为网页的排版和打印的排版是不同的。本文将介绍如何创建一个在打印时具有出色的质量和可读性的网页。
@media print 媒体查询经常编写 CSS 的读者应该对 @media 媒体查询是比较熟悉的了。这个语句在创建响应式网页时是非常有用的,经常被大家用来调整不同屏幕宽度的设备间的样式。而 @media print 媒体查询则是专门用来调整打印时的样式的。
@media print 媒体查询的语法如下:
@media print {
/* 在这里定义打印时应用的样式 */
body {
font-size: 12pt;
}
.header,
.footer {
display: none;
}
/* 更多样式规则... */
}这些样式只会在打印时应用,而不会在屏幕上显示。了解了 @media print 媒体查询的基本语法后,我们就可以开始创建打印友好型的网页了。
在打印时,页面上的一些与正文无关的元素需要被隐藏掉。
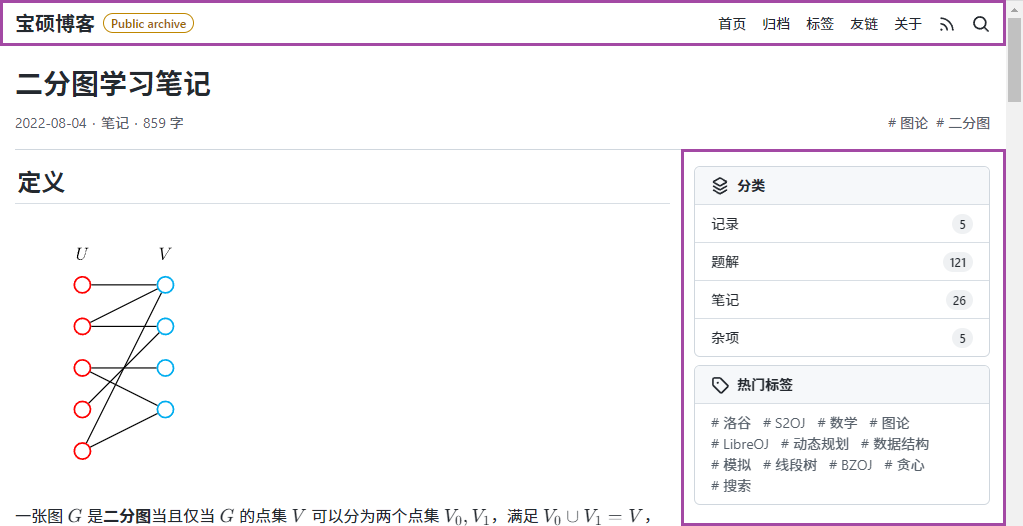
比如在《二分图学习笔记》页面中(本文在后续部分中将会一直以本页面作为示例),顶部的导航栏以及右侧的侧边栏与正文信息并没有什么关联,因此可以在打印输出中隐去。
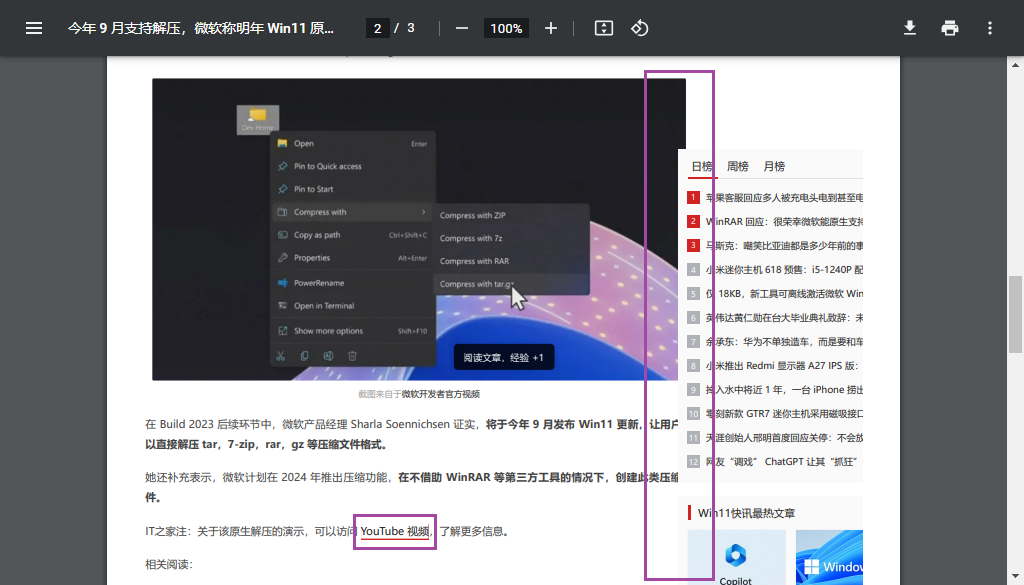
▲ IT 之家某篇文章的打印版截图。
从这张截图中可以看出这个页面似乎并没有对打印机进行适配,并且侧边栏还遮挡到了正文中的文字。不过由于笔者并没有找到更好的遮挡示例,因此只能给出这么一个有点勉强的例子 —— 侧边栏按照上一节中的建议是应该要被隐藏掉的。
对于这种情况,需要在设计、编写页面布局的时候下功夫,以避免遮挡到正文。
除了文字被遮挡的问题,截图下部的超链接在纸质媒介上显然是不能被点击的。
以此处的超链接为例,可以通过特殊处理来在纸上显示出链接的实际指向 URL:
@media print {
a:not([href^='#'])::after {
content: ' (' attr(href) ')';
font-size: 80%;
color: var(--color-fg-muted);
}
}效果如图:

除此之外,如果需要,还要对字体及其大小进行一些调整。

笔者认为在相当一部分情况下,使用衬线字体在打印后的观感要比使用非衬线字体时好很多。(PS:在此对通篇使用微软雅黑出试卷的老师表示强烈谴责)
有时网页上会包含一些音频、视频等多媒体内容,这些内容在纸质媒介上与超链接类似,无法与读者交互。
此时可以考虑提供一些替代文本来对其内容进行描述,并提供指向相关资源的链接、二维码等辅助工具来帮助读者获取多媒体资源中的信息。
在网络世界中,我们的常用单位诸如像素(px)、百分比(%)、相对大小(em、rem) 等。然而在现实世界中,我们常用的单位则为物理单位,如厘米(cm)、点(pt)等。这导致了在打印输出时需要额外注意单位制相关的问题。虽然现代浏览器对这些问题的处理已经比较优秀了,但在部分情况下仍然会导致页面排版布局出现错乱。
经常写 CSS 的读者应该对 CSS 中的样式优先级不陌生了。笔者建议在编写 CSS 时将打印相关样式置于靠下的位置以免产生冲突,同时也可以适当地使用 !important 来强制覆盖一些样式。
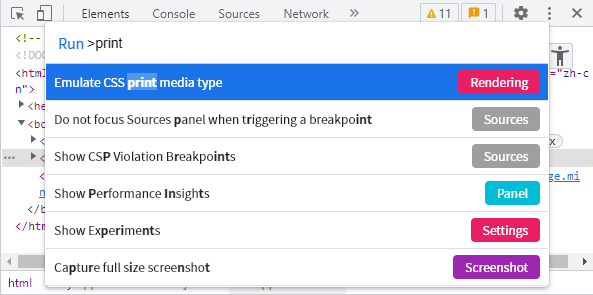
可以使用 DevTools 来模拟打印环境进行调试(按 Ctrl + Shift + P 组合键唤出菜单;对于中文版浏览器,请搜索「打印」关键字)。
感兴趣的读者可以访问 oi.baoshuo.ren/bi-graph 并尝试打印该页面。
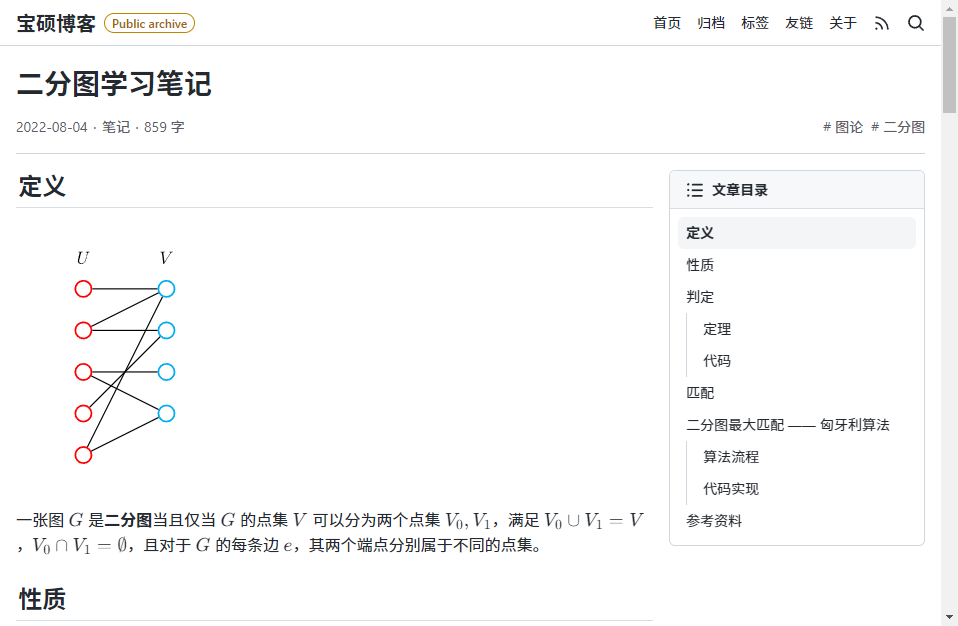
▲ 原网页
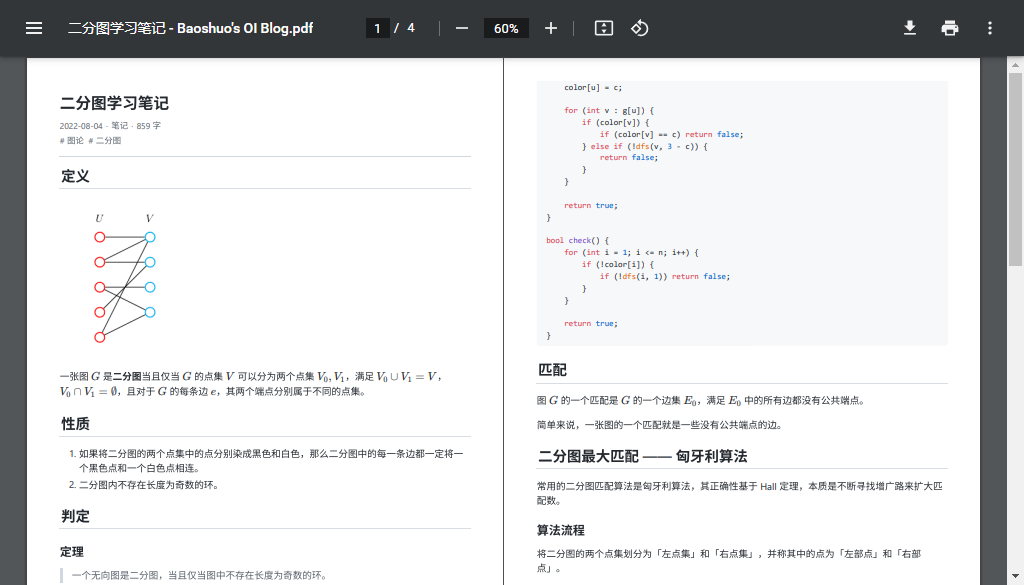
▲ 打印效果(预览)
2023-04-02 17:33:44

在经历了四年半的不算短也不算长的时光后,我的 OI 生涯画上了一个并不算圆满的句号。
是的,我退役了。
写回忆录的本质是自己给自己整理遗容。
—— 郑渊洁《舒克和贝塔历险记》
谨以此文纪念我与 OI 一同逝去的青春。
我第一次接触信息学竞赛时在初一上学期(2018 年)。当时学校与旁边的高中部合作开设了「信息贯通」课程,使得我在信息老师的帮助下了解到了信息学竞赛这个东西。这便是一切的开端了。
在学 OI 之前,我已经具有了一定的 Python 基础,并且还掌握了一些网页开发相关技能。不过这些东西和 OI 并没有什么关系,如果硬要说有的话,那么这些东西对我的帮助就是使得我的 C++ 语法入门过程并没有那么痛苦,促使了我留下来继续深入学习 OI 知识。
我对计算机有着与众不同的兴趣 —— 别的同龄人用电脑基本上都是打游戏,而我用电脑则是折腾软硬件、写写代码等等。在接触 OI 之后,我找到了有着相同兴趣的一群小伙伴,我们可以在一起交流很多计算机相关的东西 —— 大多是算法相关的内容 —— 我们都为代码可以实现的无限可能性着迷。这让我对 OI 的喜爱更甚 —— 又能学知识,还能结交好友。

▲ 初中开设的「信息贯通」课程正在授课。来源于学校微信公众号。本人跟随高中部学习,因此不在照片中。
不过与此同时,我在班级里并不是很合群,因为我不打游戏。当时流行的游戏叫做《王者荣耀》,同学们周末都会废寝忘食的去玩它,然后在返校后的课余时间交流上周末打游戏的心得,以及规划下次放假的游戏时间。而我因为对游戏没有兴趣,所以很难插上话。这使得我与班级的主体渐行渐远,转而更加亲近我们这个小圈子,在这个圈子里我能获得更多的认同感和归属感。
我初中的 OI 生涯到初三下学期(2021 年)告一段落。初三下学期是一段比较痛苦的日子 —— 我需要补习文化课,来应对即将到来的中考。我和我在学习 OI 时认识的邻班的好伙伴赵泽峰同学一起互帮互助(其实还是我向他取经比较多),共同学习。那段时间几乎每天我们两个都是最后回宿舍睡觉的人。最后的结果很令人振奋,我们都考上了我们理想的高中 —— 石家庄二中实验学校,也就是前文中提到的高中部,这所重点高中有着专业的教练团队和竞赛培养体系,是学习竞赛的好去处。

▲ 二南日落。本人在 2022 年 6 月摄于石家庄二中实验学校存真楼上。
进入高中后,我有更多的时间学习 OI,但相应地,学习文化课的时间减少了。我最初被分入了竞赛班,但我的成绩排在很靠后的位置,这是因为我不仅文化课考不了高分,而且不能兼顾竞赛和文化课的学习。这招来了文化课老师的不满 —— 学竞赛不拿金牌最后还得学文化课,而且文化课成绩太差会拉低班级平均分,这显然是他们所不想看到的。好在我高一下学期被编入了另外一个省理科实验班,这个班的班主任是上一届带竞赛班的班主任(我先前在竞赛班时班主任从没有接触过竞赛生),所以相比之下高一下学期时来自文化课班的压力要减轻许多。
高一下学期的期中考试结束后,我停课了。这给了我充足的时间去研究一些较为困难的知识点,这对我来说是一大收获。
▲ 我在存真楼上旧信息中心 NOI 教室 3 中的机位。由本人在 2022 年 6 月拍摄。
然后我就进入了高二,每天都被模拟赛压得喘不过气来。当时基本上每天的规划都是上午模拟赛,下午改题,晚上隔三岔五的还会有南校自己办的「基础模拟赛」—— 专练第一、二题难度,防止挂分(虽然该挂的还得挂)。
直到快要退役的时候,才能真正体会到往届学长们的痛楚。我送走了好几届学长,这次终于要成为了被送走的那一批。CSP-S 2022 拿了个一等,全省二十多名,这应该就是我能够达到的最好的成绩了吧。NOIP 2022 被取消了,没有考成。春季赛和省选又给我强行续了几个月的命,但于事无补。

▲ 我在 CSP-S 2022 中获得的获奖证书。
我的 OI 之旅到这里就结束了。退役之后特别喜欢学长们常说的一句话:菜是原罪。如果我的实力能够再强一些的话,我肯定不用担心退役这件事情。但即使最终的结局必然是退役,我也无悔竞赛。
在学习竞赛的过程中,我收获了许多宝贵的经验和知识。其中最重要的收获之一就是我的思维方式进行了深刻的转变。
竞赛知识点的数量很大,并且通常都比较深入、复杂、抽象。这要求我们必须具备良好的理科思维和创新思维,能够将问题进行深入研究,并将其与实际问题相结合,产生新的想法和解决方案,从而在比赛中熟练运用它们。
OI 中所涉及的知识非常广泛,仅在《NOI 大纲》中列出的知识点就已经能够涉及到好几摞半人高的书堆了。此外,在日常训练的过程中还需要接触到各类国内外的在线资料,这同时需要良好的外语水平。等等。
对我而言,在学习 OI 之余,我还略微了解了一些软件工程相关的知识,写了一些小玩具出来。
我结识了许多友好的同学,他们都非常优秀。在竞赛学习的过程中,我们经常会相互帮助,互相学习。这种友好的关系使得我们的竞赛旅途更加愉快。
俗话说得好,「人外有人,天外有天」。在学习竞赛的过程中,我时常有机会接触到并认识来自全国乃至全世界的优秀选手。
比自己更强的选手不一定只是对手,更可以成为我们的老师和榜样。从他们身上可以学习到很多独特的思维方式和优秀的解题方法,而这些在自己日常独自训练时是很难接触到的。所以要学会欣赏和学习优秀选手的思路和方法,并从中受益、成长。只有这样,我们才能不断提高自己的水平,成为更好的自己。
对于大部分人,竞赛和文化课是不可兼顾的。既然要抽出时间来学习竞赛,那么就必须压缩一些干其他的事情的时间,比如学习文化课。这会导致文化课的学习效果受到影响,然后成绩就不可避免地下滑了。
考试成绩下降之后,班主任和任课老师们自然会有意见。竞赛不是一条捷径,我们学校每年只有那么几个人能够进入省队并在国赛中取得奖牌,其他人则会慢慢地被淘汰下来,这是不可避免的。老师们自然希望我们的文化课成绩要好一些,所以会鼓动甚至要求我们放弃学习竞赛,毕竟相比之下,竞赛的容错率和回报率太低了。
那么如何在竞赛和文化课之间取得一个较好的平衡就成了一个棘手的问题,这个问题各路人马争论至今也没有一个定论,我觉得以后也不会有一个定论,毕竟人和人是不一样的。
在春季赛后,我休息了半天便准备考虑回归文化课学习的事宜。
我先回班找到了各科的任课老师们,向她们说明了我的实际情况。她们表示理解,希望我能够尽快找回状态,回归文化课的学习,因为我已经落下了很多课程的学习进度。
一些能听懂的科目自然也是要回班听一听的,网课讲得显然不如老师好。不能听懂的科目就只能自己看书听网课,一轮复习再回班跟了。
刚退役的时候还是很失落的,也不能专注到文化课的学习上,不过经过后来的慢慢调整,现在情况有转好的迹象。再慢慢观察吧。
不论结果如何,我能坚持学习竞赛到今天,都少不了来自家长、教练和同学们的鼓励与支持。
我想感谢我的父母,没有他们的支持和鼓励,我不可能坚持到今天。
我想感谢我的教练任亮老师和聂文彬老师,没有他们的指导和帮助,我不可能取得今天的成绩(虽然并不是很出类拔萃)。
我想感谢我的同学们,没有他们的陪伴和帮助,我不可能从竞赛学习中收获如此多的东西。
虽然退役了,但是我应该还会经常回来 OI 圈子看一看,没准还会参加一些比赛呢。
一切皆有可能,接下来的日子里,我会继续努力,不断提高自己的水平,成为更好的自己。
竞赛不是火,却能点亮一生。
这是石家庄二中实验学校旧信息中心旁的信息学竞赛教室墙外贴的一句话。
这句话的意思是,学习竞赛虽然不会像火焰燃烧那样为当下带来光明与温暖,但是它能够在一个人的一生中产生持久的影响。竞赛可以激发人的竞争精神,并培养毅力和耐力等品质。这些优点不仅在竞赛过程中得到锻炼,而且会伴随一个人的一生,对其产生长远、积极的影响。
上初中时第一次看到这句话时,我便对其留下了深刻的印象。随着时间的推移以及心境的不同,每次看到这句话,我都会对其有不同的理解。直到我的 OI 之旅走到尽头之时,我才明白了这句话之中的深意。
在退役之前的一个晚上,我走出实验楼的机房,向旁边的教学楼望了过去。灯火通明的教学楼与人烟稀少的实验楼形成了鲜明的对比 —— 这使得我莫名地产生了一种怅然若失的感觉 —— 我的竞赛之旅即将结束,我将要离开这个我已经熟悉的环境,去面对一个陌生的未来。
我想起了小时候读过的一首诗歌中的内容:
也许多少年后在某个地方,
我将轻声叹息把往事回顾,
一片树林里分出两条路,
而我选择了人迹更少的一条,
因此走出了这迥异的旅途。
– The Road Not Taken, Robert Frost.
我选择了竞赛,一个小众的发展方向,而这个选择决定了我今后的人生道路。竞赛决不是捷径,它只是另一种艰辛的生活方式。我不知道未来的路会怎么走,但我知道,我会一直一步一步脚踏实地地走下去。即使不再参加与竞赛相关的活动,竞赛带给我的思维方式也将伴我一生。
【心态乐观】
有人说,“生命中,我们都接到不同的剧本。平淡或浓烈,欢笑或眼泪,我们总要演好,直至落幕。”
心态好,一切都好。积极乐观的心态,是幸福生活的钥匙。
不管发生什么事,记得告诉自己,一切都会过去,好事自会发生。
—— 摘抄:人民日报夜读《善待自己,过张弛有度的生活》,2023 年 02 月 25 日。
大家都说,高考是千军万马过独木桥,不容易。
可是又有几个「大家」知道,竞赛是一个人摸黑走路,盲人骑瞎马,半夜临深池?
在无数个孤独清冷的深夜,无数次羡慕已经安然入梦的同学们。
我们都是行走在镜面边缘的人。
低下头看到的,是半个迷茫的自己,和半个不见底的深渊。
到哪里,会不会跌倒,是到终点还是滑进深渊,都不知道。
唯一确定的是,自己只有一个人。
—— 《行走在镜面的边缘》
得到与失去,只有时间会去评判;成功与失败,只有历史能去仲裁。
我不会永远成功,正如我不会永远失败一样。
—— 洪骥《……》
本文为原创文章,未经许可禁止任何形式的复制、摘抄与转载。