2026-07-08 18:18:00
强化学习 POMDP 闭环:智能体→动作→状态→观测→智能体
当前三种“世界模型”的定义是以上闭环过程的三种投影
以上三种分类的底层逻辑,是看“世界模型”的输出处于 POMDP 闭环的哪个环节;渲染器将动作作为输入并产生观测,而规划器则将观测作为输入并产生动作,模拟器将根据观测和动作,更新状态
当前三种类型的“世界模型”的现状(2026-06)
模拟器的领域难点
建立统一的世界模型
本小节内容主要参考自 《A Functional Taxonomy of World Models》
三种类型的“世界模型”虽然输入和输出的形式差异较大,但其本质都在于尝试理解世界的运作方式,包括几何、动物、动力学等信息,因此也可以看作是三位一体的。
画虎画皮难画骨
知人知面不知心
“读懂世界的心”的难点
人类与 AI 的进化之道
千万次画皮,终得皮中骨;亿万次识人,自辩人世心。
论文扩展阅读:
2026-07-01 11:06:00
仅搜集收录了部分个人感兴趣的文章,并进行简单记录
2026-04-27 文章链接
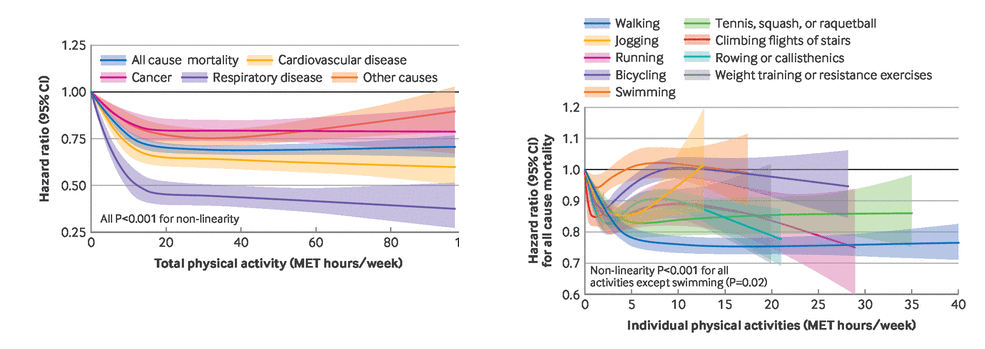
研究人员分析了两项大型长期研究的数据:护士健康研究(121700 名女性参与者)和健康专业人员随访研究(51529 名男性参与者)。这些研究对参与者进行了 30 多年的跟踪,每两年通过问卷收集一次参与者生活方式、健康史和运动习惯的定期更新信息
活动类型:步行、慢跑、跑步、骑行(包括固定健身器材骑行)、泳池游泳、划船或徒手体操、网球以及壁球或短柄墙球;后续补充了力量训练或抗阻训练;瑜伽、拉伸和塑形等低强度运动;修剪草坪这类高强度体力活;维修和园艺等中等强度户外作业;以及挖掘、劈砍等重体力户外作业;还有每天爬楼层数
代谢当量(MET)评分,
主要结论:
2026-04-29 文章链接
一项涵盖 51 项研究、逾 22.7 万名参与者的荟萃分析显示,2D: 4D(食指与无名指) 手指长度比值与性倾向显著相关。研究发现,女同性恋者的比值较低,表现出更典型的男性特征;男同性恋者的比值则较高,表现出更典型的女性特征。这些发现支持了产前雄激素和雌激素水平共同影响手指发育与性倾向形成的假说。
2026-04-22 文章链接
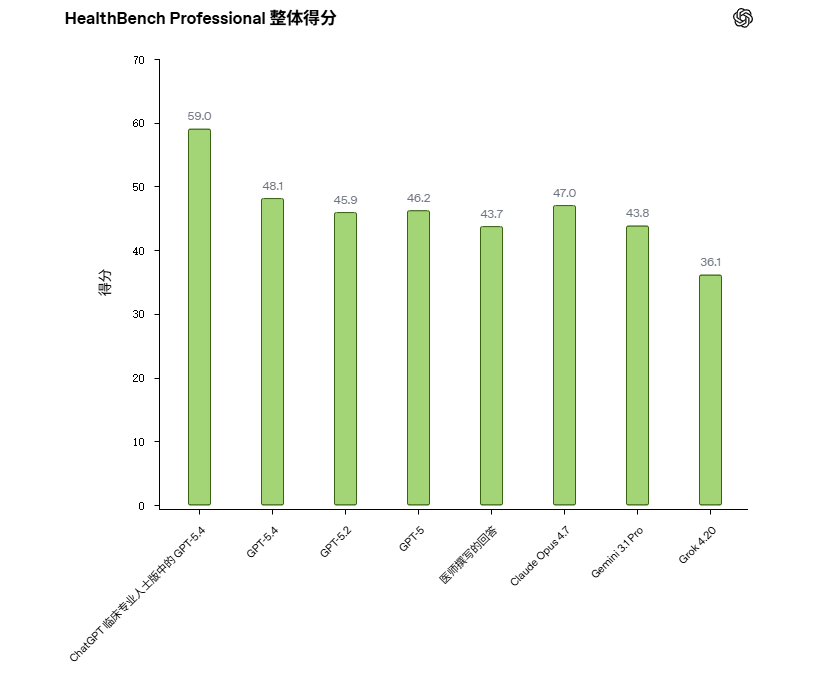
根据美国医学会 (AMA) 2026 年的一项调查,医师对 AI 的使用率现已达到历史新高:72% 的医师报告他们在临床实践中使用 AI,而去年这一比例仅为 48%
HealthBench Professiona 是针对真实临床专业人士对话任务的开放基准测试,涵盖了诊疗咨询、文书撰写与记录,以及医学研究这三个用例,是对 HealthBench 更广泛的医疗对话评估体系的进一步补充
2026-05-30 文章链接
《飞利浦未来健康指数》调研
2026-06-18 文章链接
实验设计:来自法国各地的112,395名志愿者。参与者每六个月报告他们在三天内的所有饮食和饮水情况;研究人员随后对这些食品和饮料中的成分进行了详细评估,包括防腐添加剂。参与者的健康状况被监测平均七到八年,以确定他们是否发展为高血压或心血管疾病
核心结论:
2026-05-06 文章链接
数据说明:
核心结论:
2025-03-24 文章链接
数据说明:
核心结论:
2026-01-16 文章链接
数据说明:
核心结论:
2025-12-17 文章链接
数据说明:
核心结论:
2025-09-29 文章链接
数据说明:
核心结论:
2024-09-13 文章链接
数据说明:
核心结论:
2024-11-08 文章链接
数据说明:
核心结论:
2026-06-16 文章链接
2026-06-25 22:52:00
本文主要围绕三个重要章节来展开
早期基础(1940s-1970s)
A*路径寻找算法逐渐普及,行为树(Behavior Trees)在游戏引擎中广泛使用
初显风采(1990s-2000s):
伴随硬件性能和深度学习的突破,AI 逐渐在大多数游戏领域呈现出超越人类极限的性能表现
突破极限(2010s-2019s)
2020s 之后,人类进入生成式 AI 时代,文本/语音/视频/3D 模型生成技术成熟\工具普及
2025s ~ 2027s,人类进入 Agentic AI 时代,自主代理、多代理协同系统成熟,可靠执行复杂多步任务、工具调用与长期规划成为标配,工作流自动化与个性化数字伙伴大规模落地
NPC 与动态行为/对话
程序化内容生成 (PCG)
《无人深空》No Man’s Sky 式扩展,通过多年、完全免费的大型版本更新,持续、根本性地将一个游戏从最初的状态,重塑并扩展成另一个更宏大游戏的过程;2016 年由于玩家期待过高和游戏内容贫乏而遭遇严重口碑危机,之后通过 8 年 25 个大版本的免费更新实现口碑逆转和游戏重塑
追光(光线追踪):一种模拟真实光影的高级画质技术,利用算法来模拟真实世界中的光线的物理特点,实现更清晰的倒影,玻璃反光更透彻、镜头感更加真实 DLSS(动态帧数补偿):借助独立显卡和 AI 提升帧率、降低延迟并增强画质
开发效率提速
新型实验模式
成本的降低和效率的提升,有助于更多游戏涌现,更多个性化商业模式的留存
顶尖 AI 公司布局
生成式AI在游戏领域的市场规模预计将达到约17.9亿美元,并且保持高复合年均增长率
传统游戏厂商跟进:
国内典型案例:
当 AI 队友理解指令、配合节奏并反馈时,它学到的不仅是战术,而是对人类价值和目标的理解
遗留问题:
展望思考
关键:游戏是 AI 的理想训练场,可作为微缩世界进行试错学习
虚拟与现实的边缘逐渐模糊
2027s~?(预测)
参考:
Wkipedia - Artificial intelligence in video games
硅谷 101 - 为何顶尖 AI 公司都盯上游戏?
2026-06-22 15:13:00
重症肺炎的定义
重症肺炎的分类:
重症社区获得性肺炎 SCAP 的诊断标准(IDSA/ATS 2007)
IDSA/ATS 诊断标准解读:(1)PaO₂/FiO₂ ≤250:即使无休克,也提示严重低氧 (2)多肺叶浸润:人类肺有 5 叶,影像学累及2个或以上肺叶,提示病变广泛 (3)意识障碍:反映脑灌注不足,是严重感染的标志
在 IDSA/ATS 2007 的基础上,中华医学会呼吸病学分会制定了《中国成人社区获得性肺炎诊断和治疗指南(2016 年版)》,并对重症肺炎重新进行了界定
《儿童社区获得性肺炎管理指南(2024 修订)》指出当肺炎出现以下 10 条标准中任一条指标即为重症:(1)一般反应差;(2)拒食或脱水征;(3)意识障碍;(4)呼吸频率明显增快(婴儿≥70 次 /min,大龄儿童≥50 次 /min);(5)发绀;(6)呼吸困难;(7)氧饱和度≤0.92(海平面)或 <0.90(高原);(8)肺浸润范围为多肺叶性或单侧肺≥2/3 受累;(9)胸腔积液;(10)肺外并发症
CRB-65 评分
英国胸科协会改良肺炎评分 CURB-65 评分
症状与体征预警:
实验室指标预警(治疗 72 小时后仍无改善)
影像学进展预警:
高危因素:
建模方法:
临床稳定标准:
参考
2026-06-11 22:46:00
每每打开手机,消息、文章、视频裹挟着海量数据铺面而来,思绪都仿佛变得纷飞而迟钝
看得多了,很容易让人忘记这场景应是相当壮观的,牛顿看到了都可能得直呼上帝
数据背后,诸多互联网公司仗着先发优势圈地自足,还在周围盖起了层叠的护城河
原本生机勃勃的大江大河在各大资本的切割下,变成了小湖小溪
幸得最近几年雨水很充足,所以那些小湖小溪倒也显得有几分热闹
只是生态似乎脆弱了些,川流显得污浊了些,大鱼也因为没了生存空间见不得踪影
现实似乎总是这样,无情中带着几分让人埋怨不起来却又平不下心气的合理
刚刚乱七八糟的的东西想到了太多,但一时半会儿似乎也不说清楚
索性思绪收拢一下,再次回归本文的主题:突破信息茧房与主动式学习
大多数人在面对海量信息时应该都会有很强的无力感。当面对三扇门的时候,有的人可能会稍微思索一二再选择打开,有的人也可能会仔细斟酌,寻找对自己来说最合适的一扇门;但是当面对三百万扇,乃至三百亿扇门的时候,人们可能就会直接随便打开一扇门,因为他们潜意识里已经意识到:选不过来啊,人类是有极限的
很有意思的是,几乎没有一扇门的背后存在致命的东西,只不过有很多门为了吸引你进去而放了很多有趣的东西,不排除可能存在的甜蜜的毒药哈。现状就是,我们总是疲于奔波,打开一扇扇门,停下来思考的时间少了
所以我想在本文中思考总结一些方法来避免自己陷入这种面对海量信息的无力感与焦虑
(1)掌握更多的信息搜索/获取渠道
(2)快速筛选高质量的信息与知识
此处“信息与知识”的范围不涉及 新闻/资讯/娱乐/八卦/ 类高频信源
(3)灵活利用 AI 来实现知识的萃取
(1)从不同角度把握思考与实践的脉络与层次感
(2)组装不同的学习模式,用生活惯性来打破惰性
(3)信息/知识网络的自我更新与成长,无声的断舍离
一篇文章收藏超过半年不打开,就说明这篇文章评分不高,也对你不重要
其他相关阅读:20240420 用 RSS 实现信息流整合
2026-06-08 14:14:00
本文主要参考:Anthropic - When AI builds itself
RSI(recursive self-improvement,递归自我改进):人工智能系统自主完成设计、测试、训练下一代人工智能的完整流程,形成智能的螺旋式上升,人类不再扮演关键角色。
人工智能模型的进化速度正在加速
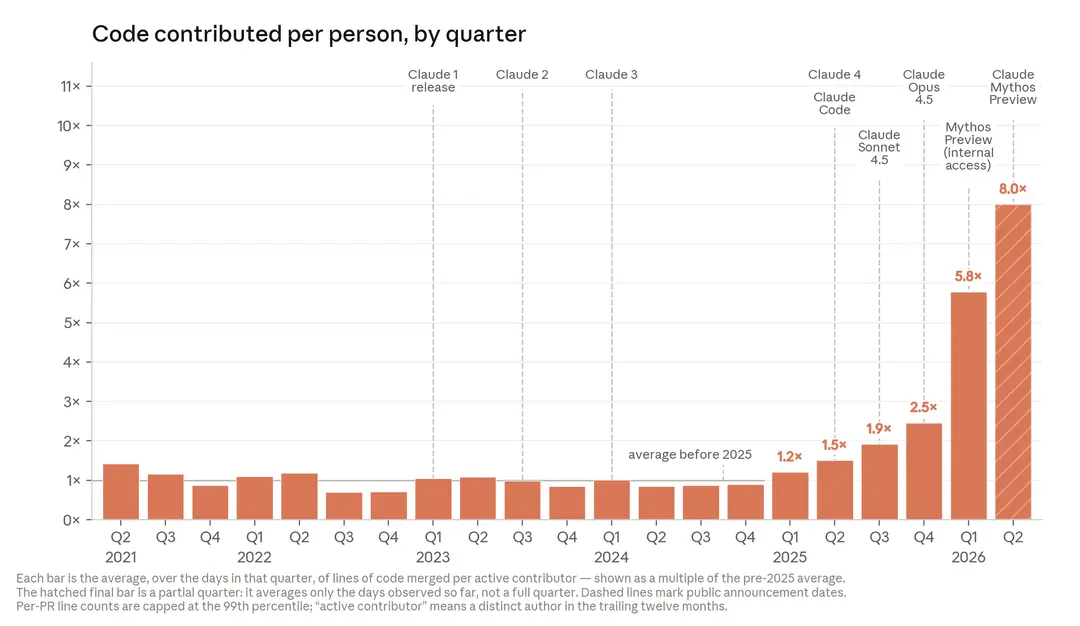
人类有了想法,模型能够比以前快一个数量级地实现、测试和评估这些想法
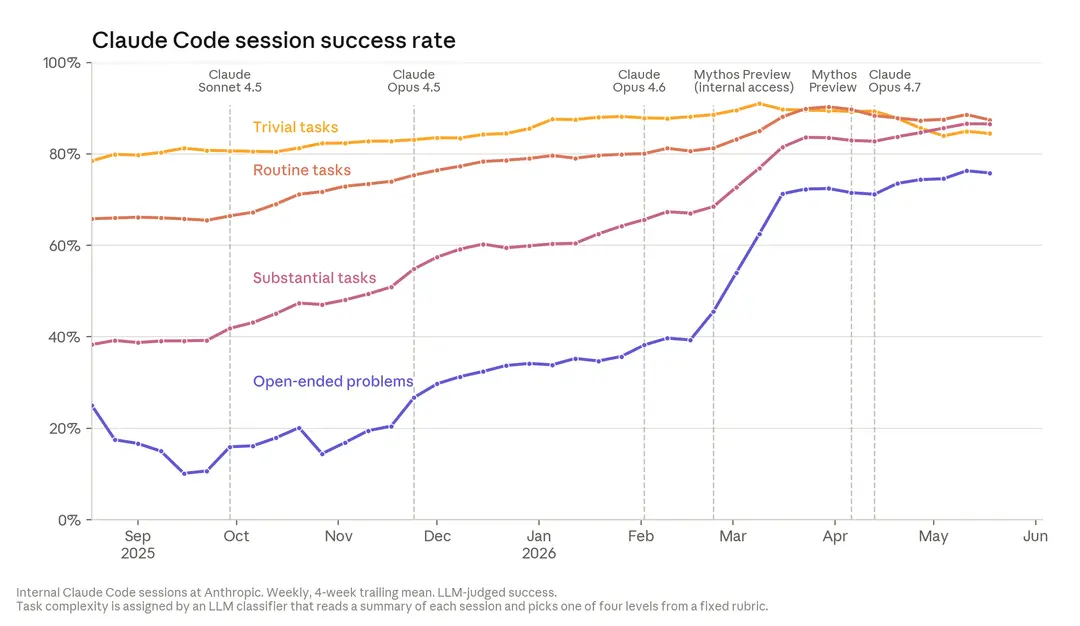
Claude 在不同难度任务中随时间的成功率变化趋势:
2025 年 11 月的最佳模型(Opus 4.5)有 51%的概率胜过人类的判断
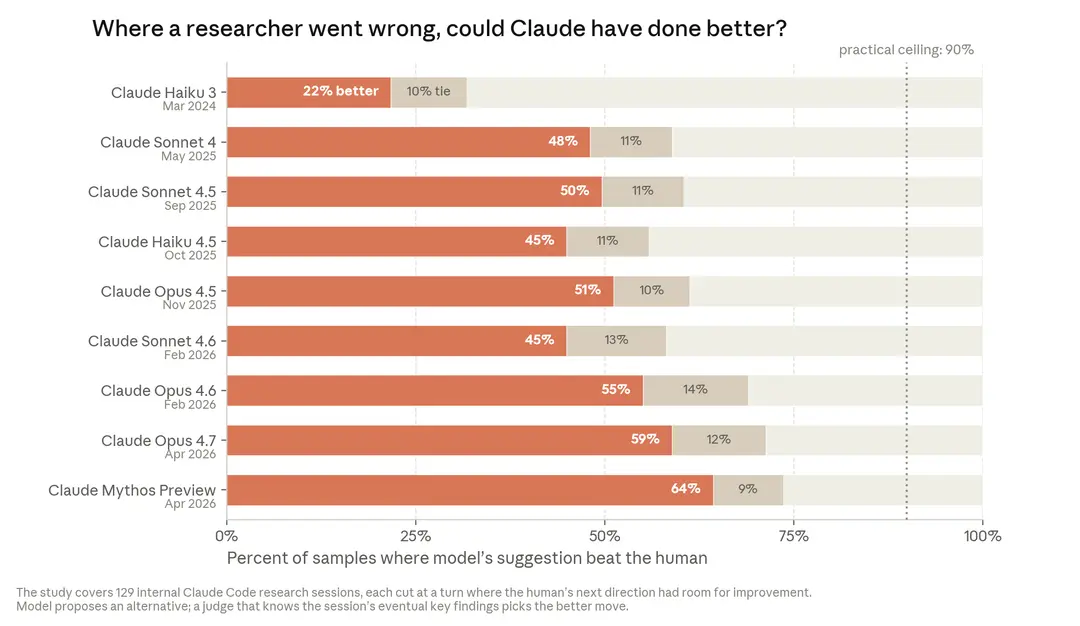
当前人类的比较优势,仍在于看到更大的图景,思考超越眼前任务的局限;具体来说,人类的比较优势领域在于研究的品味和判断,包括选择哪些问题重要,哪些结果值得信任,以及何时方法是死胡同
人工智能的 RSI 雏形
人工智能的 RSI 展望
以人类劳动力为核心的经济驱动将被彻底改变,无法预测未来社会组织和市场运作方式
人类的选择与应对