2026-03-06 06:30:00
Openclaw不用过多赘述, 是一个可以运行在 NAS 上的自动化工作流平台,类似于自托管版的 n8n,支持通过可视化的节点连接各类服务和 API,实现数据的自动抓取、处理与推送。
本文旨在提供一个借助 Openclaw 来对 Garmin Connect 上的运动/睡眠数据进行简要分析的workflow,并通过定时任务设计了一个向导每日发送出来。当然目前这仅仅算的上一个demo, 由于不懂得一些指标的重要性, 目前只是简单让其结合睡眠和运动指标来进行一些建议.
网上有很多教程, 这里我简要说一下我在部署时候遇到的一些网上可能没有的问题/思路. 首先就是隔离, 我并不打算直接在本地环境运行Openclaw, 这几天在网上看到了不少Openclaw导致的安全问题, 因此我的选择就是在Docker中运行, 将其他用到内容映射到容器中.
我的服务器系统是飞牛OS, 因此有可视化的Docker, 但直接下载现成的Openclaw后遇到了gateway无限重启的问题, 于是我最后选择去加装了一个1Panel, 通过1Panel里面的一键安装来部署Openclaw.
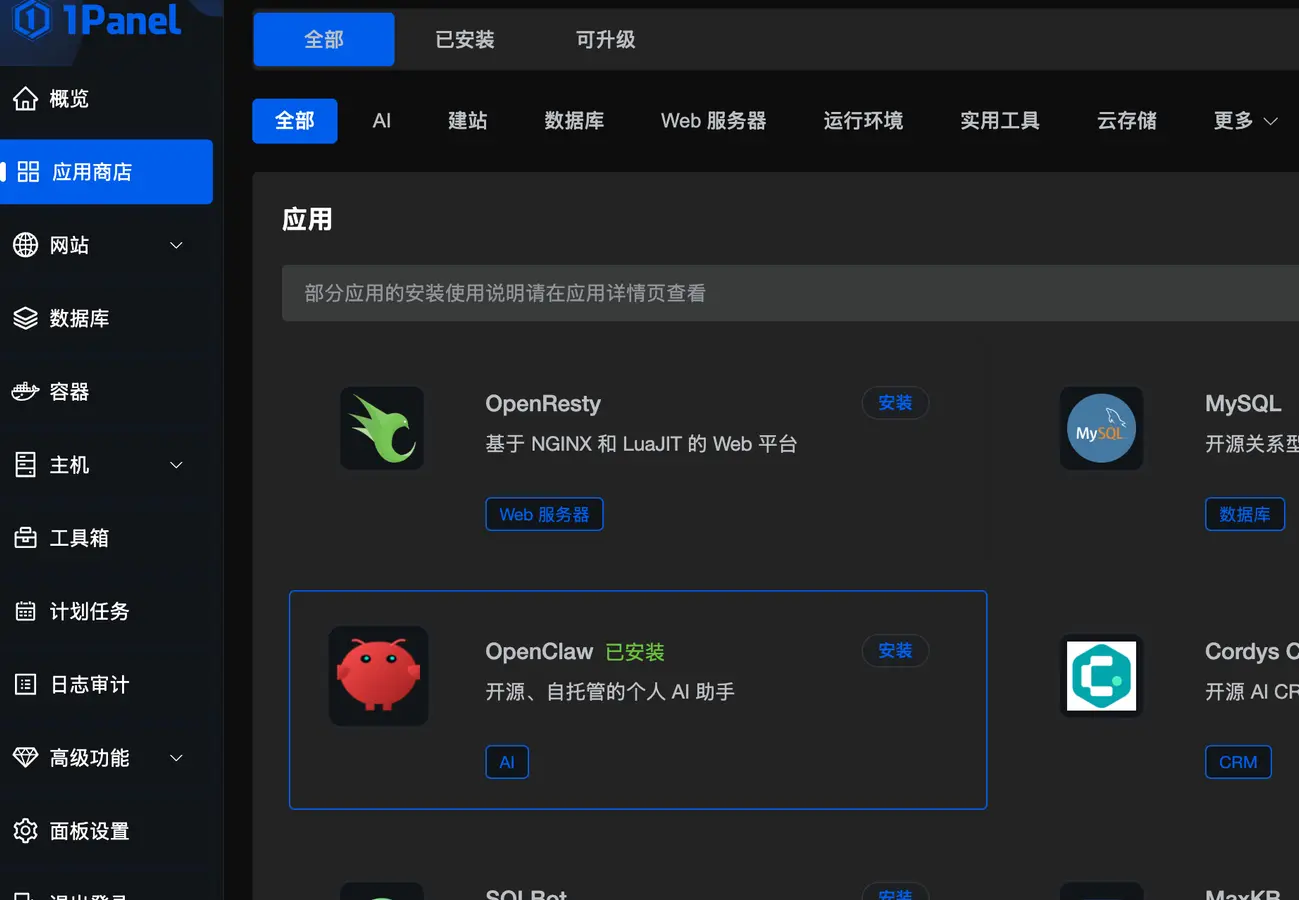
部署/启动后均没有什么问题, 启动后需要从json文件拿到token输入到面板中来进行双向验证. 我使用的API是Gemini 2.5 Flash(上一年年末的时候Google的学生优惠可以免费使用一年的Google AI Pro, 现在活动已经没有了), 额度目前很够用.
消息发送我选择了Discord, 毕竟人在北美没有网络方面的烦恼, 日常使用Discord居多. 这一系列设置下来也没有任何问题, 都是在openclaw.json中进行设置的. 目前为止openclaw已可以正常运行.
这里我本人试图偷懒, 于是和openclaw发生了如下对话:
 可以看到openclaw并没有权限使用我的账号密码, 也没有权限进行进一步的操作. 我不知道是不是我的用法不正确, 但ta也的确劝住了我不要进一步对ta下方权限. 于是我的实现思路就变成了用第三方的包来请求garmin官方, 在拿到我的数据后进行本地化存储, 由于实现设置过容器存储映射, openclaw则可以直接读取本地文件进行分析.
可以看到openclaw并没有权限使用我的账号密码, 也没有权限进行进一步的操作. 我不知道是不是我的用法不正确, 但ta也的确劝住了我不要进一步对ta下方权限. 于是我的实现思路就变成了用第三方的包来请求garmin官方, 在拿到我的数据后进行本地化存储, 由于实现设置过容器存储映射, openclaw则可以直接读取本地文件进行分析.
之前我搓了一个Astro网页, 用到了garmin-connect, 来统计我进行过的运动, 之前没有NAS, 所以放在了Github上用Action来运行, 后来token到期了懒得更新, 就放在那里了. 这次也用到了garmin-connect, 由于启用心电图必须要开启Oauth2, 这里需要注意一下登录凭证的处理.(vibe coding时候可以提供这一细节来让AI解决).
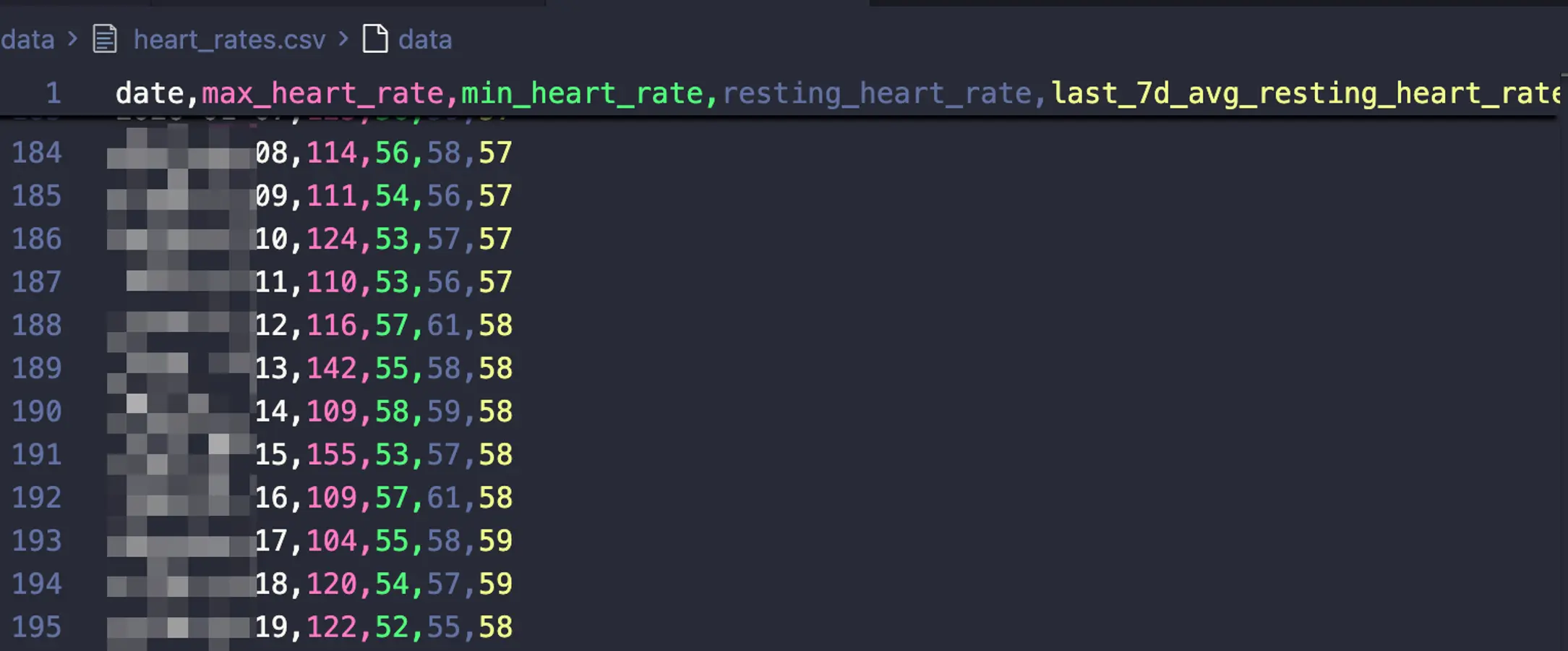
爬取到的数据是JSON, 但因为我只有一个手表, 很多行都是无效的, 因此需要格式化一下数据, 我选择了用csv进行存储, 这样看起来更直观.
扯一句题外话, 前段时间有篇论文专门研究了AI的成瘾性[^1], 说白了和老虎机是一个原理——你发出这段文字并期待AI为你生成更好的结果, 就像在赌博一样, 我遇到的80%的身边人(cs学生)对于prompt都是无所谓, 可以沟通就行, 但Openclaw不行, ta像一张白纸, 但凡没有了约束就会出现问题. 我任务一个具有大量规范性需求的prompt可以降低AI的成瘾性, 因为你在发出这个prompt的时候你就知道你大概率能得到你想要的答案了.
这是关于我的自动任务的prompt, 我深知不够完美, 但这目前是我尝试openclaw进行的一次努力:
1.我需要你阅读/home/node/.openclaw/daily的这3个csv文件.
2.基于我当天进行的运动, 心率, 以及前几天的睡眠质量, 来对我的睡眠时间进行建议.
3.如果最近没有运动数据, 不用声明运动数据缺失.
4.参照下面回答模板回答.
回答模板:
数据洞察:[一段话综述最近的睡眠/运动]
近日睡眠:[最近3天的睡眠细节]
综合建议:[对今日睡眠的规划]
额外补充:
每日理想起床时间为8AM~9AM;
基于睡眠情况和睡眠时间对sleep_need_feedback这一列数据进行解读并输出, 不要输出其原始数据.
如果运行出现错误请输出错误日志;
但似乎是由于我开启了隔离, 每次的输出依旧差别很大,以及sleep_need_feedback还是有一些问题, 需要进一步研究.

总而言之Openclaw对我来说还是一个工具, 目前来看还是一个使用频率远不如cursor等强目的性LLM的弱工具, 不过我期待后续钻研的新用法.
[^1]: The Dark Addiction Patterns of Current AI Chatbot Interfaces, ACM CHI 2025.
2026-02-26 01:02:00
Webmention 是一种用于网站之间“相互通知”的开放协议。简单说,当你引用别人时,对方可以自动收到通知,并在自己网站上显示你的引用。科普就这么多, 你如果有兴趣可以在网络上找到很多相关的内容.
这段时间又开始在网络上随机游走, 在V站的VXNA发现了很多不错的博客, 在極客死亡計劃下面发现了1年前我在Benji博客下面见到的WebMention. 趁着这段时间没有任何的ddl, 于是打算实施一下.
由于现在各类LLM过于强大, 我也成为了cursor的拥护者, 因此难以逐步提供信息, 但考虑到我的语言表达能力并没有在人类中属于出类拔萃的程度, 我想这或许是好事, 具体的方式如下:
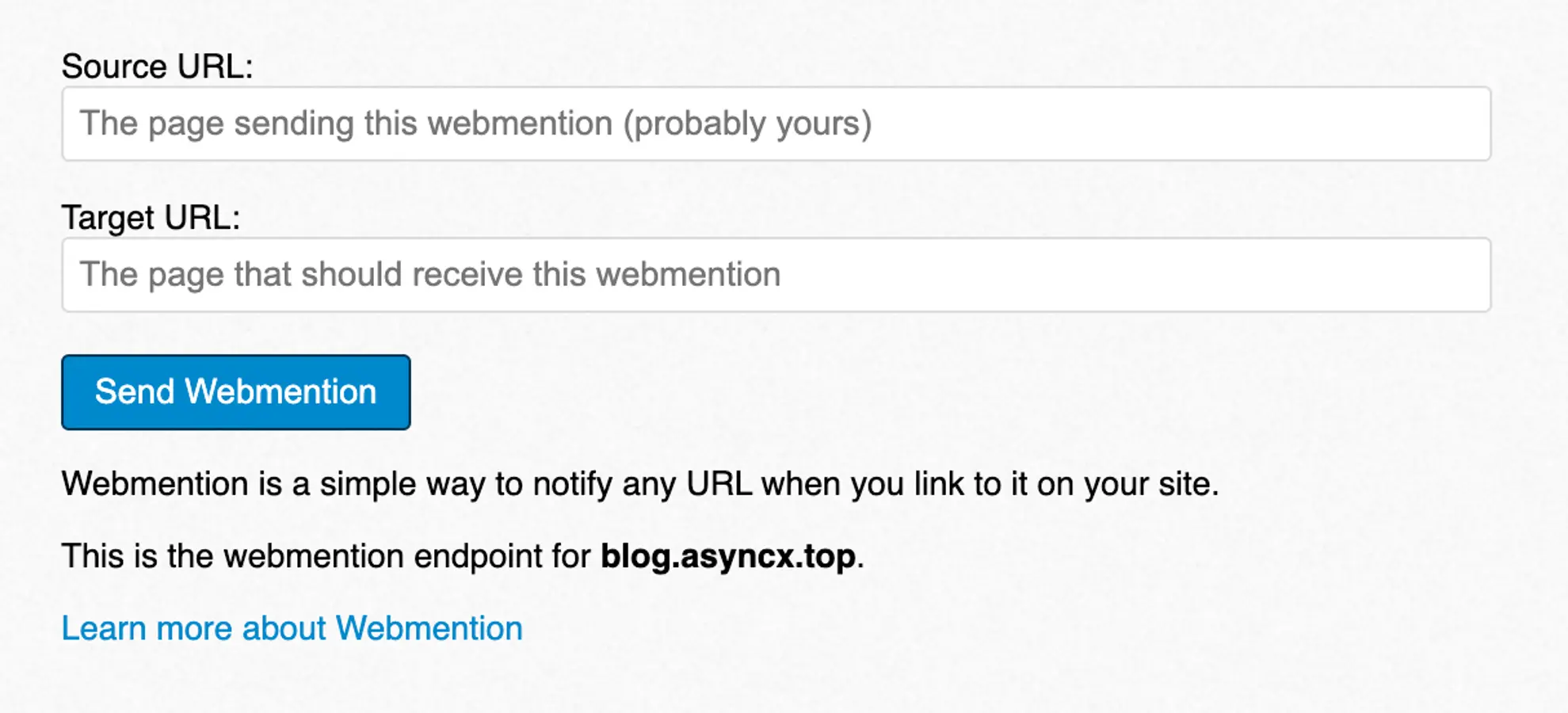
SITE_URL + 当前路径 生成标准目标地址,作为Webmention 的 target。https://webmention.io/api/mentions.jf2?target=当前文章URL发送请求,从 webmention.io 拉取所有指向该文章的 Webmention 数据接下来是你在实施前需要做的准备:
注册webmention.io并验证, 验证的方法因人而异, 我使用了github, 目的是双向确认网页属于你. 
进入Sites->Get Setup Code, 添加这行code到你网页的header中, 接下来就是在前端进行webmention的GET和渲染了, 就和上述的实施方式一致.
在实际场景中, 例如我所使用的Astro, 会根据自己的设置在访问的网页url后加上一个/, 以及在对webmention.io发送当前文章的url的时候会携带一个.html. 传过去的url和别人复制的url/本地的url等url不一致, 也会导致webmention无法正常显示, 因此值得注意.
我的主要目的是展示在Mastodon上的互动, 但Mastodon本身并不具备webmention的相关功能, 因此需要引入一个额外的工具Bridgy, 用来拉取所有在联邦宇宙中产生的互动, 并递交给webmention.io.
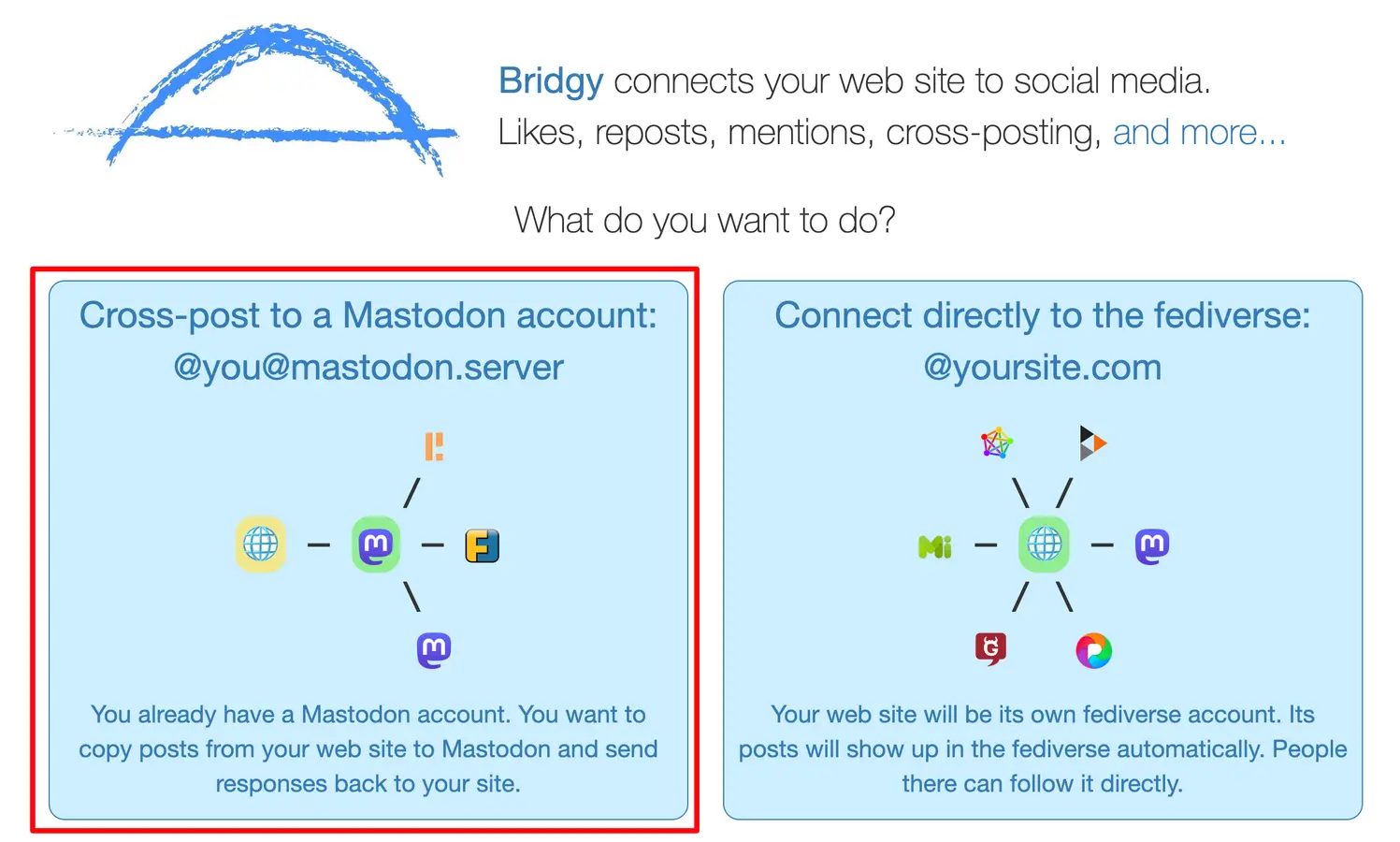 下面是我的后台展示, 你可以清晰看到各种访问成功和异常(Sent即为发送webmention成功, 你可以通过点击刷新按钮左侧的时间来查看当前条目的日志, 从而进一步确定问题所在):
下面是我的后台展示, 你可以清晰看到各种访问成功和异常(Sent即为发送webmention成功, 你可以通过点击刷新按钮左侧的时间来查看当前条目的日志, 从而进一步确定问题所在):
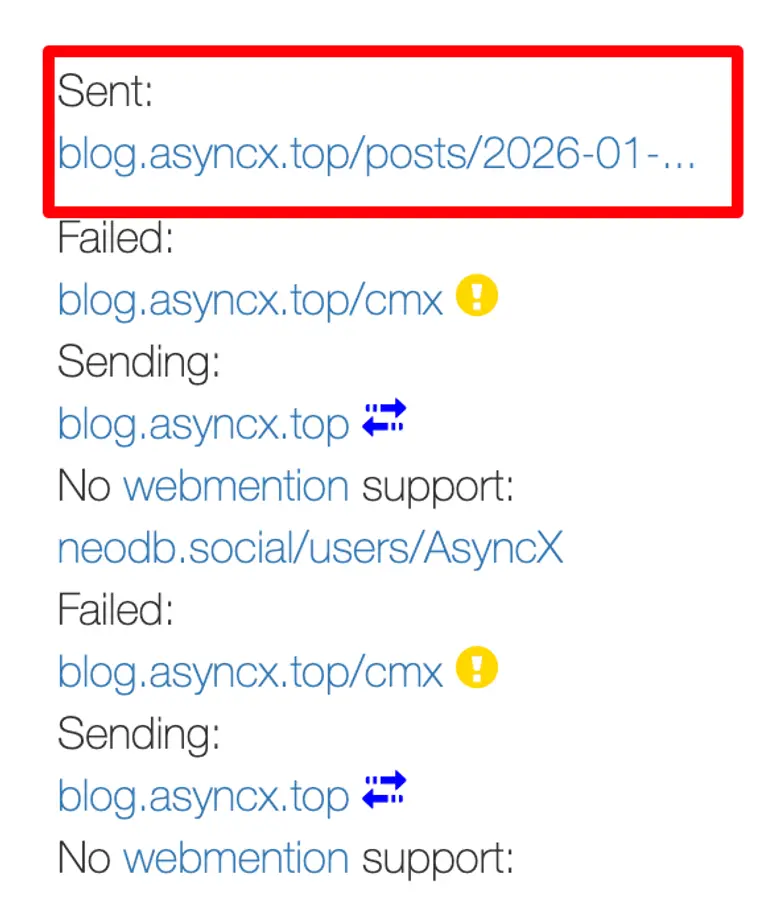
考虑到一些网络友邻没有在webmention.io进行链接提交, 这也意味着没有办法进行双向的信息展示, 即我作为A的文章被B引用了, 但B的博客没有办法告诉A我引用了你的文章, 因此我额外添加了一个手动提交的button. 当B在文章中提及了我的这篇博文, 那么ta可以在我这里手动提交表单给webmention.io, 进而收录.
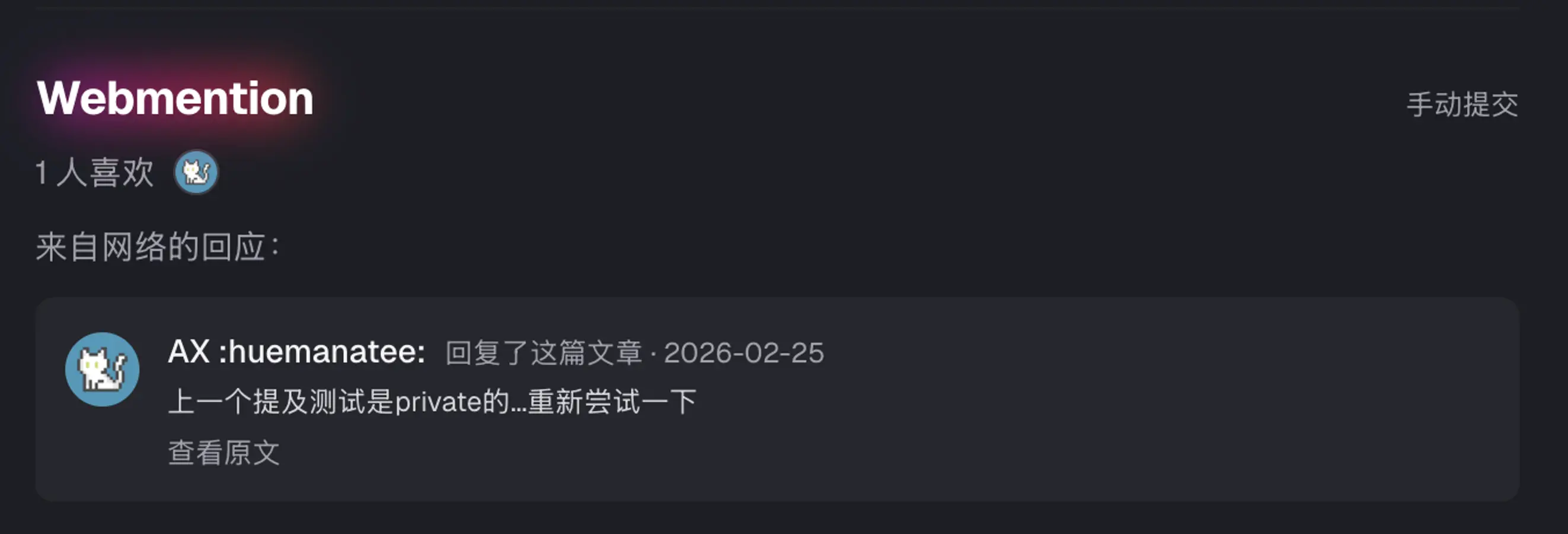
下面则是我简单设计的webmention的展示, 兼顾了日夜模式/分离了点赞和回复
2026-01-29 05:01:00
前些天写小结的时候在github的feed页看到我写博文的仓库又多了一个star. 点进用户主页, 发现这位网友也有自己的blog, 本着回访的目的点了进去, 好家伙, 直接套用了我的主题, 当然我并非斥责抵制这一行为, 但这位网友似乎直接用ai生成了readme.md, 其中声明了这个主题是heavily inspired by a web, 这个web页是一个以极简高度出名的blog template, 并不是我的主题, 也不是我二次开发前的miniblog.
这件事中, 令我生气的地方在于这个网友似乎不屑于修改ai定义的readme, 抑或是他觉得这无关紧要, 在他博文的字里行间, 我闻到了一种刻意装出来地看破一切地清高, 然而他却把网络上的自留地完全交给了ai.
鉴于这种情况, 以及在最近添加了未完成博文的的过滤, 我已不能将我的所有博文放在public的仓库中, 于是决定将GitHub repo修改为private, 但主题依然欢迎大家在遵循 CC BY-NC-SA 4.0的前提下使用, 本文发布时, 我已调整了主题页面的详情.
时至今日亲手用上cursor才意识到之前用的别的工具有多么笨拙, 下面是拼图逻辑的实现(by cursor): 实现思路本质上是 DOM 重写:
此外, 我之前写了一个组件用来显示图片的文字信息, 为了在拼图上能有更好的效果, 我又让cursor生成了一个动画:
(() => {
if (window.__imgAltOverlayInstalled) return;
window.__imgAltOverlayInstalled = true;
const trimAlt = (s) => (typeof s === "string" ? s.trim() : "");
const install = (root = document) => {
// 仅拼图图片:在 item 上挂 data-alt(不改 DOM 结构)
const items = root.querySelectorAll("article[data-pagefind-body] .image-mosaic-item");
items.forEach((item) => {
const img = item.querySelector("img");
if (!img) return;
const alt = trimAlt(img.getAttribute("alt"));
if (!alt) {
item.removeAttribute("data-alt");
return;
}
item.dataset.alt = alt;
});
};
// 注意:文章页有“图片拼图”脚本会依赖原始 DOM 结构(p/figure 里直接是 img)。
// 这里稍微延后执行,避免先 wrap 破坏拼图的容器识别逻辑。
const run = () => {
setTimeout(() => install(document), 160);
};
if (document.readyState === "loading") {
document.addEventListener("DOMContentLoaded", run);
} else {
run();
}
document.addEventListener("astro:page-load", run);
document.addEventListener("astro:after-swap", run);
})();
效果是这样的:

2026-01-29 00:01:00
距上次写完月度小结已经过了很久, 心路历程是这样的:"快期末了, 考完试再写", "考完试大家计划出去旅游, 旅游完再写", "没旅游成, 太冷了, 等最近发生一些有意思的事情了再写"...久而久之, 这篇11月月度小结就变成了冬季季度小结. 今天痛定思痛决定翻看一下相册, 将最近发生的鸡毛蒜皮小事记录下来.
依旧是学业部分, 迎来了我的最后一个学期, 我现在的状态就是标题, Confused. 对前路, 对未来. 上一学期的课程完美通过, 受益匪浅, 最后一个学期, 我选择了Computer Vision和Big Data Analysis这2门课, 选择前者是对ML方面的拓展, 后者是一个好过的课(因为我本科的实习和毕业设计和这门课很类似).
至于Confused, 则是因为我直到现在为止还是处于焦虑状态, 觉得自己一事无成, 到现在都还没有决定好之后找工作的方向. 因为政策改革, 现在申请PGWP(加拿大留学生的开放式毕业工签)需要CLB7的语言成绩, 我打算在加拿大考出来, 等到毕业后先回国休息几个月, 进而在国内一边申请PGWP一边做两手准备, 国内和加拿大同时找工作.
我不清楚我这样的选择是否正确, 但学业压力真真切切的让我的身体和心理产生了一些情况------从我来这里读Master到现在还没回去过, 我认为回去可以有效的缓解身心问题, 顺便拔掉最后一颗烦人的阻生智齿.
今年蒙特利尔的冬天格外的冷, 前两天的体感温度甚至达到了-49℃, 家里的供暖也是在全功率运行, 实在是太干了, 一个加湿器只能让湿度到20%, 于是:


前些天去朋友家里聚餐, 本来说好我不做饭最后帮忙打扫卫生, 说着说着就炸了个小酥肉, 第一次做, 很美味, 之后会更新食谱, 等回去做给家人吃.


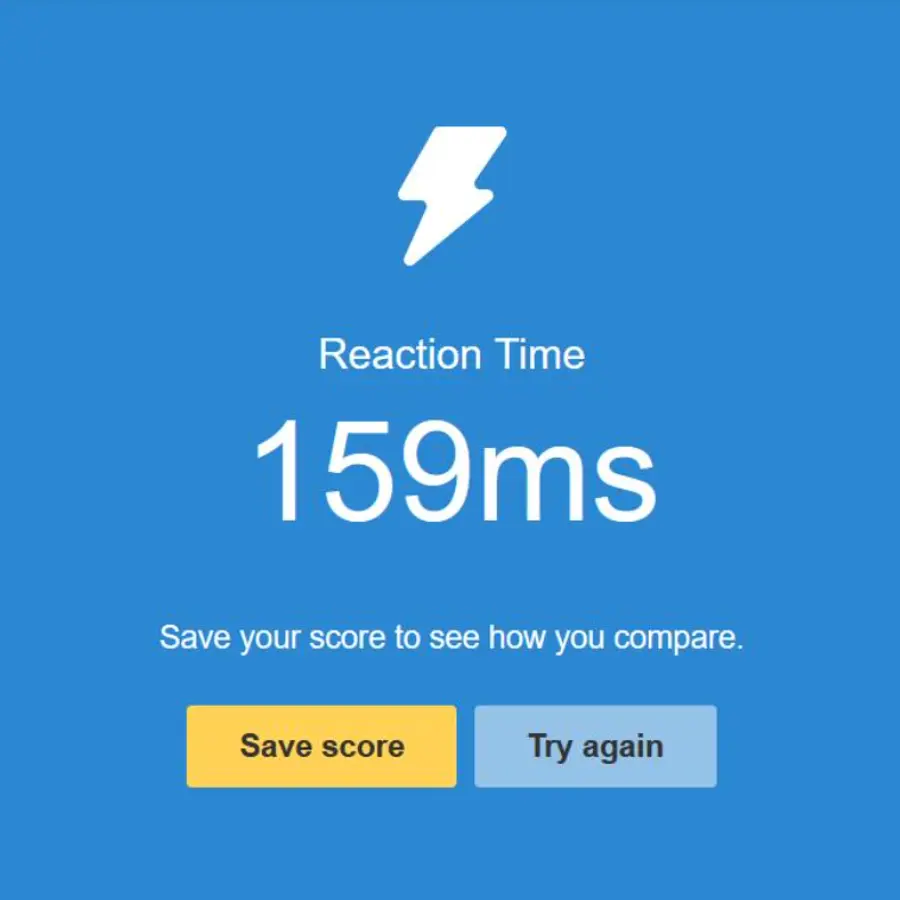
用了1年3个月的鼠标(ROG龙鳞Ace)中道崩殂了, 本来打算上网买微动修一下的, 但是这边4$4个的微动+25$的运费让我无福消受, 打算带回国再自己修, 于是购入了一个Razer Viper v3pro, 此外顺手测了一下自己的反应速度, 嗯, 我还很年轻.

最后是烧饼, 家里老人回国前手把手教我, 我纪录到了食谱中, 也是非常成功.
食谱url: https://lib.asyncx.top/02-diet/sesame-seed-cake

一些零碎的图片:







虽然一直没有更新blog, 但是因为要做饭要翻食谱, 还是经常打开Obsidian看笔记的, 跳转到博客后又发现了一些视觉问题, 于是:


++movie/56qwhB3eQxdzWP1kh6SZgo++
++movie/3kKxQBRSQcUI7ad7Y58fIM++
++movie/0mJVzyC1JCtgQzEyS4P99k++
++tv/0gxWeOgJIDF5qSEtTSc0Om++
++tv/4QwLGwPDmlU2QTJdN48z8A++
++tv/2C3YziJ5fZ9uy6dXtWFI9D++
++tv/78m0c31HHnzNTVSsFw6qnX++
++tv/2JZidKGEhSbEO9EFcQ1e6G++
++game/1BUuAewL1tD5JUZ50wCA3U++
++game/2KT0KJiapTFNIy3AWjbrrs++
++game/7Vj6wdeXgXfeJssjAoW9VI++
2025-10-31 05:10:00
本月也是一如既往的忙碌, 算法课也是迎来了期中考, 得益于朋友发的往届真题, 让考试思路变得有迹可循. 其中有道复杂度为O(n)下进行轮询子数组之和比较的伪码题难倒了很多同学, 好在我做出来了, 但坏消息是其他的题没时间写.....应该能达到Average.....此外的另一门课, 由于期中考试发生在罢工期间, 幸运的取消了:).
为什么本文的标题为行之有效, 1是因为这次考试的复习历程让我觉得复习到了老师考试的关键点, 2则是因为本月也开始上法语班了, 但由于大学课程时间的问题我无法出席, 最后不得以协商进入waitlist, 不过这3周的课程也让我受益匪浅, 最快入门一个0基础知识的方法, 就是有人督促和解惑.
 得闲之余也和朋友们去了Omega Parc野生动物园(实际上算是鹿园), 园区游览是开车进行的, 大概3小时的车程, 期间有可以下车休息的区域. 游览完后感慨被骗了.
得闲之余也和朋友们去了Omega Parc野生动物园(实际上算是鹿园), 园区游览是开车进行的, 大概3小时的车程, 期间有可以下车休息的区域. 游览完后感慨被骗了.
之所以说实际算是鹿园, 是因为到处都是鹿, 还拦路抢吃萝卜. 根据官网的宣传, 园中有各种各样的野生动物和鸟类, 但开车游览时候除了鹿, 牛等这些动物, 其余的动物都是被关在一片栅栏里的, 仅供游览, 无法互动.


++movie/4OE3wVlg1ujFfhIBTT9kxl++
++movie/6bCOihfoK7tVGElGl3HbqY++
++movie/5NAjaDqAgZeZ3ZzzPAkYEW++
++book/57CULf86zMrnoz5Ld7motM++
++game/3BiwZGaz35mNYnLkkc0SQv++
2025-10-07 09:09:00
这篇月小结拖更蛮久, 原因在于最近的生活实在是充实, 时值枫叶季, 去了一趟Mont-Tremblant,赏枫, 打算整理照片后在下个月度小结发布. 学期开学1月有余, 课业压力让我又想起了刚出国的日子... 本学期的高压课程是算法, 其次是计算机网络. 这2门课对我来说都是弱项.
算法课程细致入微, 课上课下学起来都颇费功夫. 计网截止到上周讲的还都接触过, 例如DNS解析之类的, 这周开始的可靠数据传输RDT还需要下一番功夫.
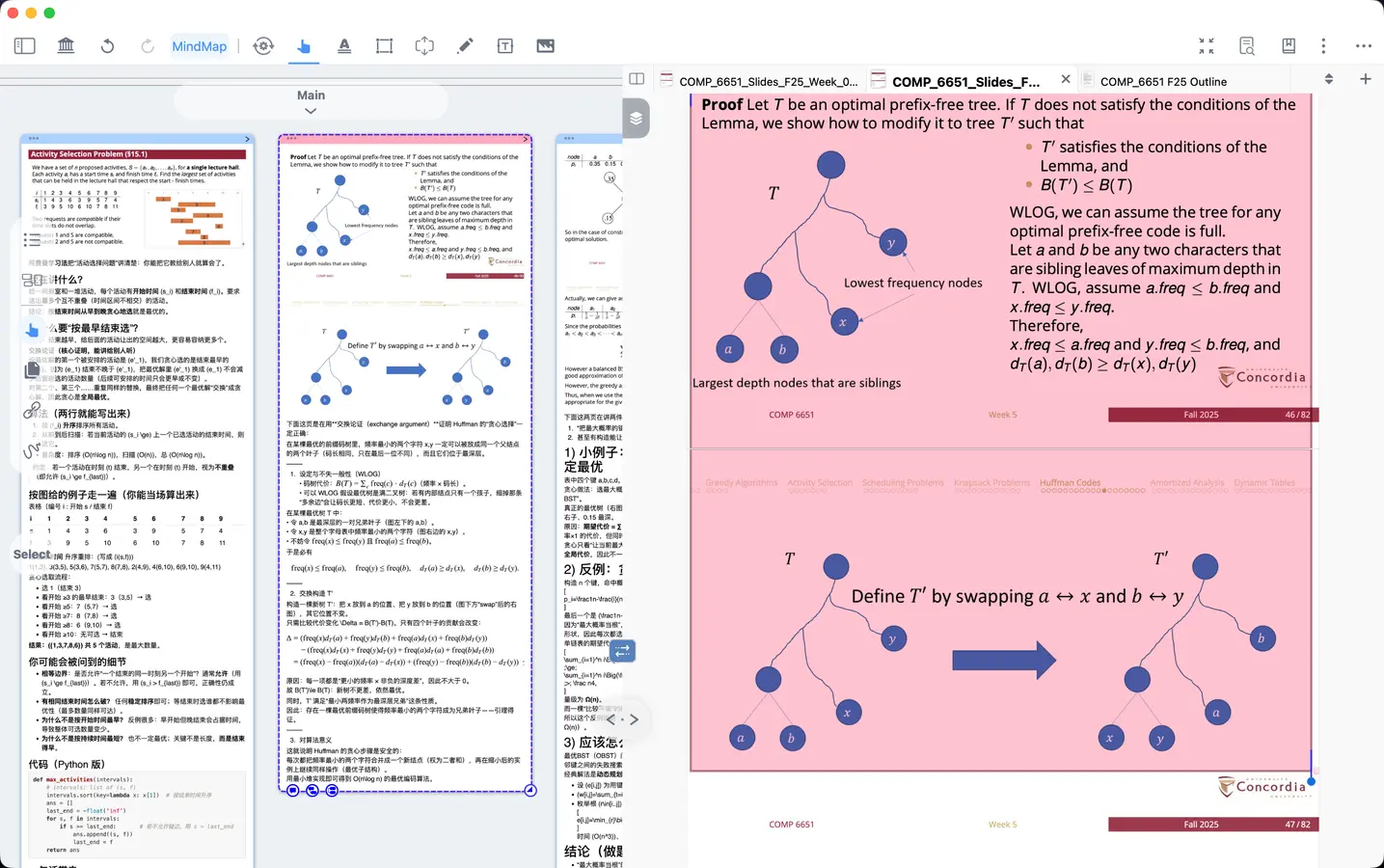
在这里不得不重提一下, 一台NAS真的优化了我的很多场景, 文件夹同步/动下载影视/外网的照片访问等功能对我来说真的很有用, 缺点也有, 外网访问摄制的视频时遇到了速度不够的问题, 接下来打算琢磨一下把视频自动备份到google drive/dropbox方便访问.
之前因为罢工和找了不靠谱的第三方集运, 我从国内寄过来的衣物和键盘丢了, 迫不得已在小红书上收了一个键盘, 这个老哥最近又在出硬盘, 我就花了55$买入了一个1T的990pro.
这2年在家里用的最多的耳机是女朋友送的水月雨Aria2, 因为我使用时间过长, 遇到了金属网老化/耳机腔体严重掉漆的情况. 金属网联系售后是10块/5对, 但是腐蚀掉漆问题无能为力, 清掉腐蚀的地方后偶尔会有一点漏电. 看到Bestbuy的棱镜2打折, 就火速购入了. 耳罩式耳机的确对耳朵更友好, 但使用下来音质的确没有有线强, 不过强在有无线和有麦克风, 偶尔和国内外朋友打游戏, 剪视频看视频还是很舒服的.
不出意料的话就要出意外了, 这里讲一下在使用这个耳机的时候遇到的断连问题, 以方便有读者通过关键词搜索到此文:
++tv/1e1nw4EEXVAwE0bSImEp9y++
++tv/5SFon8PVjPuAIIaKziZToO++
++movie/7haEvPPYBSLlekzDwj8m2i++
++book/6uMu8bCA886NcGxZVd9lAz++
++game/1EZcXj3398L8TKZ4ELPIkW++
++game/2vyzNrQ3s0lDx11arqfZm1++
