2026-07-18 00:15:53

404 Media is turning three years old! We've come a long way with your support, so let's hang out.
We're throwing TWO separate events to celebrate: A live taping of the podcast and a special night of talks on Sept. 3, and a big open-bar party on Sept. 4. Subscribers at the Supporter level get free and discounted access to both events!
Check your membership status or become a paid supporter of our work here.
On Thursday, Sept. 3, meet us at WNYC's Greene Space for 404 MEDIA LIVE! We'll discuss what we've accomplished in the past year, and what's next for our independent, human-made journalism. We'll also welcome a few very special friends to the stage: Matthew Gault joins us for a chat about AI datacenter resistance, and The Abstract's Becky Ferreira hits us with the coolest science to come out this year so far.
Supporters get 50% off their ticket to 404 MEDIA LIVE! Don't forget to check your membership status here and subscribe as a paying member for access to 50% off a full price in-person ticket.
Can't make it in person in NYC? Join us on the livestream! Grab an access ticket, donate what you're able, and watch for the link we'll send to your inbox before the event.
The next night, join us for a bash to celebrate our three year anniversary at Threes Brewing Gowanus. Have a beer, wine or seltz on us, plus light bites throughout the night. Buying a ticket to 404 MEDIA LIVE! gets you 50% off a ticket to the afterparty Friday night. Supporters get in to the party FREE!
All of us—Sam, Emanuel, Jason, and Joseph—will be there to celebrate 404 Media growing another year. We love these parties because it's a chance to connect with the people who make all of this possible: you, our subscribers.
Thank you for all the fun you've helped us have this year.
We can't wait to celebrate with you this year.
Questions? Email [email protected]

2026-07-18 00:07:19

This is Behind the Blog, where we share our behind-the-scenes thoughts about how a few of our top stories of the week came together. This week, we discuss AI music, slop bowls, and the endless quest for optimization.
EMANUEL: We’ve used Behind the Blog a few times at this point to pull the curtain on our story selection process. Usually, we do this when we explain the reasoning behind the decision to write a story we already published, but today I want to talk about a story I didn’t write (yet).
For the past few months I’ve been looking at a new and strange type of AI generated nonconsensual image on X.
2026-07-17 23:35:37
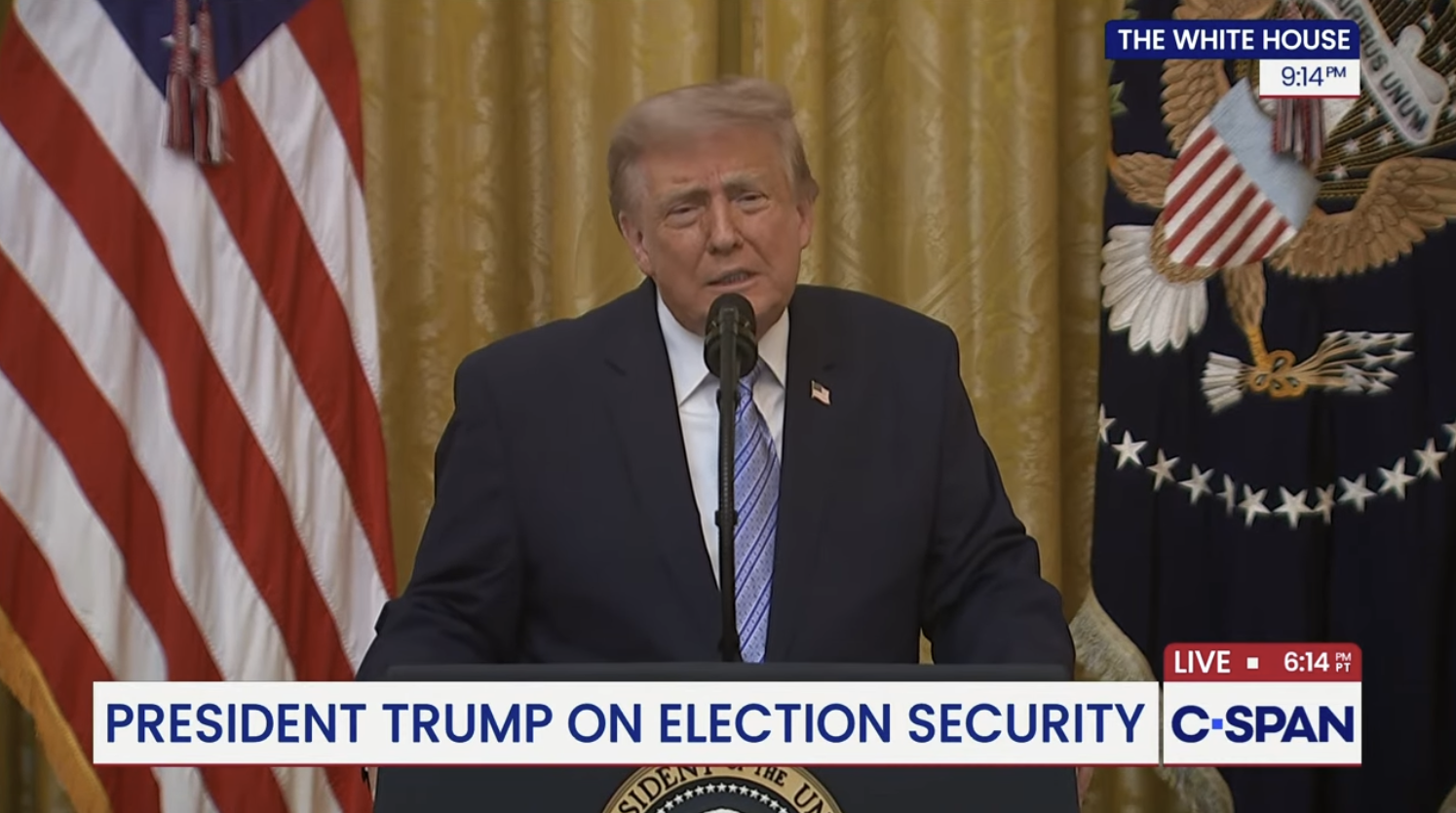
The Department of Homeland Security (DHS) plans to pay data broker giant Thomson Reuters $125 million for access to its databases of personal data — which includes peoples’ names, addresses, Social Security numbers, ethnicity, social media posts, and geolocation information — to help Immigration and Customs Enforcement (ICE) investigate what it describes as “voters fraud” and immigration fraud, according to procurement documents reviewed by 404 Media. The document says Thomson Reuters is able to let ICE continuously monitor millions of people and entities of interest.
The news comes after President Trump held a conspiracy-laden and unhinged press conference about election security on Thursday, setting the stage for potentially undermining the legitimacy of the upcoming midterm elections. It also follows ICE fatally shooting 2 people in a week.
“Due to ICE’s re-prioritized mission, there is need for this data to be readily accessible to support the presidential mandate of the identification of Voters Fraud, Immigration Fraud and National Security,” the procurement document reads. “This data specifically validates and verifies school, benefit, immigration and other eligibility requirements.”
Thomson Reuters is most well known for running the Reuters news agency, but the company is also a massive data broker and sells access to that data to companies and governments. Its data product, called CLEAR, promises to “Accelerate investigations confidently through a vast collection of public and proprietary records,” according to Thomson Reuters’ website.
Thomson Reuters lists some of the data sources that feed into CLEAR, and 404 Media has obtained an internal list. It includes credit header data, which is the personal information someone provides to a financial institution to open a credit card like their address, which goes to the credit bureaus and then transferred to Thomson Reuters. The procurement document also says it includes social media, property records, geolocation information, license plate data, and more.
The planned sale is specifically with Thomson Reuters Special Services (TRSS), a subsidiary which often handles Thomson Reuters’ government contracts. The document says TRSS offers embedded data scientists to clients who are cleared up to a Top Secret/SCI [Sensitive Compartmented Information] level. The plan is to pay the company $25 million a year over the next five years, totaling $125 million.
Parts of DHS have previously accessed CLEAR data, and 404 Media has reported on internal ICE documents which say it is integrated with Palantir’s tool for finding neighborhoods to raid. But the new document stresses that ICE has such a high need for this data, that it is planning to spend more than a hundred million dollars on another form of access to it.


Screenshots of the document.
“The importance of TRSS owning the proprietary data makes it essential for quality control to ICE. The access to that data after it is passed through another vendor serving as the prime contractor is included as part of ICE’s current contract, the data support request that ICE has in the past years for CLEAR data is significant, this year it has multiplied based on the urgency to identify Unaccompanied minors and individual involved in any type of fraud of government funds,” it continues.
“Access to the same volume of data that is owned by TRSS through other companies that offer the services will sustain in [sic] additional cost to ICE because of the transactional fees they will incur in obtaining the data,” it adds.
The document says that TRSS is the only company able to offer access to the data in “batch.” Another section reads, “TRSS is the only contractor able to provide ICE with a continuous monitoring and alert service for millions of individuals and entities of interest, this is essential for national security purposes.”
In a previous statement to 404 Media about ICE’s earlier access to CLEAR data, Thomson Reuters said, “It’s inaccurate to connect CLEAR to ICE and its deportation and enforcement operations.” When 404 Media contacted the company on Thursday and sent the new procurement document which describes ICE wanting the data for voter fraud and immigration fraud enforcement, the company provided a new statement: “We prohibit the use of CLEAR for the purpose of identifying and locating noncriminal immigrants or undocumented individuals with the intention of deportation solely on the basis of the individual’s immigration status. We take this restriction seriously, and we enforce it.”
“We continue to work with our customers to provide technology and services that support investigations into areas of national security and public safety, such as child exploitation, human trafficking, narcotics and weapons trafficking, and fraud/financial crime,” the statement added. The company also said, “Immigration status is not a search field in CLEAR.”
Thomson Reuters previously fired a longstanding employee after they spoke out about the company selling data products to ICE. 404 Media previously reported ICE invited staff to demos of a license plate reader app from Motorola that can be enhanced by CLEAR data.
Emma Pullman, head of shareholder engagement and responsible investment for the B.C. General Employees’ Union (BCGEU), which is a minority shareholder in Thomson Reuters, said, “Thomson Reuters has given shareholders, employees, and the media inconsistent and shifting accounts of the nature of its ICE contracts. TRSS latest ICE contract is the first to include voter fraud that we are aware of, and we intend to press the company, alongside other investors, for clarity on this contract.”
Update: This piece has been updated to include comment from Emma Pullman.
2026-07-17 02:00:10

Astronomers have detected an atmosphere around a rocky exoplanet in the habitable zone of its star for the first time in history, signalling a major breakthrough in the search for alien life, according to a study published on Thursday in Science.
The planet, known as LHS 1140-b, is about 5.6 times more massive than Earth and orbits a small dwarf star about 48 light years from our solar system. While scientists have discovered atmospheres around many giant gas planets in our galaxy—and even a few rocky exoplanets outside the habitable zone—the new detection of helium in the skies of LHS 1140-b marks the first direct evidence that a habitable-zone rocky world can host an atmosphere, which is a critical factor for assessing their potential to support life.
“For rockier Earth-like planets, it has been a huge challenge in the field to detect any atmospheres at all,” said Collin Cherubim, a NASA Hubble Fellow at the University of Chicago, in a call with 404 Media. “This has been a huge question in the field that so much time and energy has been devoted to answering.”
The new discovery “is really the first claim ever of any rocky exoplanet atmosphere in the habitable zone that could potentially have liquid water and really support life,” added Cherubim, who conducted the research while he was a PhD student at Harvard University. “That's what sets it apart and makes it really exciting.”
Scientists have previously inferred that some rocky exoplanets in the habitable zone might have atmospheres based on indirect evidence, such as measurements that show that their day and night temperatures are more moderate than expected, which could be explained either by an atmosphere, or other planet-wide effects. However, spotting an atmosphere around these rocky worlds is tricky because they tend to be so small compared to their stars, which is a challenge for precision observations.
Cherubim came at the problem with a new approach: He first developed theoretical models of rocky exoplanets that focused on mass fractionation, a process by which lighter molecules and atoms in the atmosphere escape into space, while heavier ones are left behind. These simulations predicted a new type of planet with thick skies closer to the surface, and a thinner upper atmosphere that allows helium to escape to space.
“Hydrogen is the lightest element and it's the easiest to blow off into space,” Cherubim explained. “My model was predicting that if your planet is in this sweet spot where you're blowing enough hydrogen away, but not too much that you're dragging helium, which is a bit heavier, along with it, then you can actually create a helium-dominated atmosphere over time.”
“This is a newly-predicted class of planets, which should have very unique chemistry,” he added.
Cherubim realized that this escaping helium might be detectable from Earth, and that the LHS 1140 system would be a prime candidate to test out the hypothesis. To that end, the team observed LHS 1140-b and another planet in the system, LHS 1140-c, over the course of 2024 and 2025 with the Warm Infrared Echelle (WINERED) Spectrograph on the Magellan Observatory in Chile.
The 2024 results revealed a strong signal of helium at LHS 1140-b, but no detection in 2025, which may mean that the helium escape varies over time. The team predicts that the planet has probably had its atmosphere for billions of years. The other planet, LHS 1140-c, did not show any signs of an atmosphere, which was also expected based on its orbit and characteristics.
The momentous discovery proves that atmospheres can exist around rocky worlds, including around dwarf stars, which are far more common than more massive stars like the Sun. Cherubim and his colleagues think it’s quite likely that LHS 1140-b has large amounts of liquid water on its surface, another key ingredient for life as we know it on Earth.
“When we think about habitability, we think about three high-level things,” Cherubim said. “We think the planet needs to be rocky for the most part. It can't be a gas-rich thing where the surface is molten, or like Jupiter where it's just all gas. It's got to be the right temperature to support surface liquid water, at least for Earth-like life, and it needs an atmosphere to hold that water in and to shield the surface from radiation.”
“With this discovery, we now know LHS 1140-b has all three of those things, which is really exciting,” he added. “And it just happens to be a very nearby system to Earth, so it's very accessible.”
Whether alien life exists on LHS 1140-b remains an open question, but scientists have already been looking for signs of life, known as biosignatures, in its skies using the Hubble Space Telescope and the James Webb Space Telescope. So far, the search hasn’t turned up any obvious signs of life, but future efforts may be able to peer at this world in more detail.
“I think this is the best place to be looking for biosignatures,” Cherubim concluded. “We're really excited to see what comes out of that.”
2026-07-16 21:56:48

Police departments around the country have used Flock cameras at least hundreds of times to search for specific people, not cars, using searches such as “heavy-set male with a black and white hat,” “person on skateboard,” and “person wearing orange vest and construction hat,” according to data reviewed by 404 Media. Sometimes searches reference a target’s race or signs of their political affiliation.
The searches highlight that while most people associate Flock cameras with scanning license plates and tracking vehicles, some of the cameras are also capable of following the movements of particular people or groups of people. Flock’s nationwide network of cameras lets police officers in one state search for a vehicle across many other states at once; the people searches do a similar thing, typically on a smaller scale, sometimes querying many hundreds of cameras at once. These are called “FreeForm” searches, and allow cops to use Flock’s system as though they would use a search engine, with Flock’s AI and image recognition interpreting what footage and which people are relevant to a police officer’s search.
2026-07-15 23:58:34

We start this week with Jason’s story about the ChatGPT flyer pandemic. They’re everywhere! Thank you to the readers and listeners who sent in their own examples. After the break, Sam tells us how Waymo snitched on kids and drove them to a group of waiting cops. In the subscribers-only section, Joseph explains why he bought a $3,000 suit that electrocutes your muscles. Yep.
Listen to the weekly podcast on Apple Podcasts, Spotify, or YouTube. Become a paid subscriber for access to this episode's bonus content and to power our journalism. If you become a paid subscriber, check your inbox for an email from our podcast host Transistor for a link to the subscribers-only version! You can also add that subscribers feed to your podcast app of choice and never miss an episode that way. The email should also contain the subscribers-only unlisted YouTube link for the extended video version too. It will also be in the show notes in your podcast player.