2023-05-08 17:52:06
 这两天技术圈里热议的一件事就是Amazon的流媒体平台Prime Video在2023年3月22日发布了一篇技术博客《规模化Prime Video的音视频监控服务,成本降低90%》,副标题:“从分布式微服务架构到单体应用程序的转变有助于实现更高的规模、弹性和降低成本”,有人把这篇文章在五一期间转到了reddit 和 hacker news 上,在Reddit上热议。这种话题与业内推崇的微服务架构形成了鲜明的对比。从“微服务架构”转“单体架构”,还是Amazon干的,这个话题足够劲爆。然后DHH在刚喷完Typescript后继续发文《即便是亚马逊也无法理解Servless或微服务》,继续抨击微服务架构,于是,瞬间引爆技术圈,登上技术圈热搜。
这两天技术圈里热议的一件事就是Amazon的流媒体平台Prime Video在2023年3月22日发布了一篇技术博客《规模化Prime Video的音视频监控服务,成本降低90%》,副标题:“从分布式微服务架构到单体应用程序的转变有助于实现更高的规模、弹性和降低成本”,有人把这篇文章在五一期间转到了reddit 和 hacker news 上,在Reddit上热议。这种话题与业内推崇的微服务架构形成了鲜明的对比。从“微服务架构”转“单体架构”,还是Amazon干的,这个话题足够劲爆。然后DHH在刚喷完Typescript后继续发文《即便是亚马逊也无法理解Servless或微服务》,继续抨击微服务架构,于是,瞬间引爆技术圈,登上技术圈热搜。
今天上午有好几个朋友在微信里转了三篇文章给我,如下所示:
看看这些标题就知道这些文章要的是流量而不是好好写篇文章。看到第二篇,你还真当 Prime Video 就是 Amazon 的全部么?然后,再看看这些文章后面的跟风评论,我觉得有 80%的人只看标题,而且是连原文都不看的。所以,我想我得写篇文章了……
要认清这个问题首先是要认认真真读一读原文,Amazon Prime Video 技术团队的这篇文章并不难读,也没有太多的技术细节,但核心意思如下:
1)这个系统是一个监控系统,用于监控数据千条用户的点播视频流。主要是监控整个视频流运作的质量和效果(比如:视频损坏或是音频不同步等问题),这个监控主要是处理视频帧,所以,他们有一个微服务主要是用来把视频拆分成帧,并临时存在 S3 上,就是下图中的 Media Conversion 服务。
2)为了快速搭建系统,Prime Video团队使用了Serverless 架构,也就是著名的 AWS Lambda 和 AWS Step Functions。前置 Lambda 用来做用户请求的网关,Step Function 用来做监控(探测器),有问题后,就发 SNS 上,Step Function 从 S3 获取 Media Conversion 的数据,然后把运行结果再汇总给一个后置的 Lambda ,并存在 S3 上。
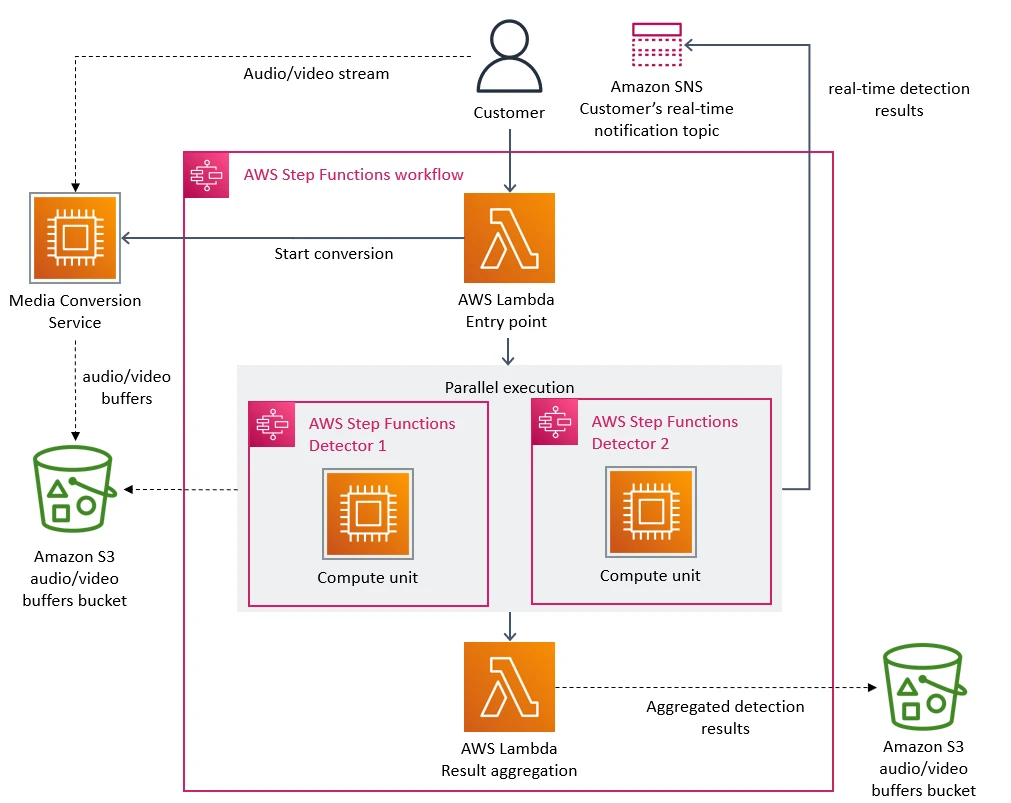
整个架构看上去非常简单 ,一点也不复杂,而且使用了 Serverless 的架构,一点服务器的影子都看不见。实话实说,这样的开发不香吗?我觉得很香啊,方便快捷,完全不理那些无聊的基础设施,直接把代码转成服务,然后用 AWS 的 Lamda + Step Function + SNS + S3 分分钟就搭出一个有模有样的监控系统了,哪里不好了?!
但是他们遇到了一个比较大的问题,就是 AWS Step Function 的伸缩问题,从文章中我看到了两个问题(注意前方高能):
注意,这里有两个关键点:1)帐户对 Step Function 有限制,2)Step Function 太贵了用不起。
然后,Prime Video 的团队开始解决问题,下面是解决的手段:
1) 把 Media Conversion 和 Step Function 全部写在一个程序里,Media Conversion 跟 Step Function 里的东西通过内存通信,不再走S3了。结果汇总到一个线程中,然后写到 S3.
2)把上面这个单体架构进行分布式部署,还是用之前的 AWS Lambda 来做入门调度。
EC2 的水平扩展没有限制,而且你想买多少 CPU/MEM 的机器由你说了算,而这些视频转码,监控分析的功能感觉就不复杂,本来就应该写在一起,这么做不更香吗?当然更香,比前面的 Serverless 的确更香,因为如下的几个原因:
好了,原文解读完了,你有自己的独立思考了吗?下面是我的独立思考,供你参考:
1)AWS 的 Serverless 也好, 微服务也好,单体也好,在合适的场景也都很香。这就跟汽车一样,跑车,货车,越野车各有各的场景,你用跑车拉货,还是用货车泡妞都不是一个很好的决定。
2)这篇文章中的这个例子中的业务太过简单了,本来就是一两个服务就可以干完的事。就是一个转码加分析的事,要分开的话,就两个微服务就好了(一个转码一个分析),做成流式的。如果不想分,合在一起也没问题了,这个粒度是微服务没毛病。微服务的划分有好些原则,我这里只罗列几个比较重要的原则:
3)Prime Video 遇到的问题不是技术问题,而是 AWS Step Function 处理能力不足,而且收费还很贵的问题。这个是 AWS 的产品问题,不是技术问题。或者说,这个是Prime Video滥用了Step Function的问题(本来这种大量的数据分析处理就不适合Step Function)。所以,大家不要用一个产品问题来得到微服务架构有问题的结论,这个没有因果关系。试问,如果 Step Funciton 可以无限扩展,性能也很好,而且白菜价,那么 Prime Video 团队还会有动力改成单体吗?他们不会反过来吹爆 Serverless 吗?
4)Prime Video 跟 AWS 是两个独立核算的公司,就像 Amazon 的电商和 AWS 一样,也是两个公司。Amazon 的电商和 AWS 对服务化或是微服务架构的理解和运维,我个人认为这个世界上再也找不到另外一家公司了,包括 Google 或 Microsoft。你有空可以看看本站以前的这篇文章《Steve Yegg对Amazon和Google平台的吐槽》你会了解的更多。
5)Prime Video 这个案例本质上是“下云”,下了 AWS Serverless 的云。云上的成本就是高,一个是费用问题,另一个是被锁定的问题。Prime Video 团队应该很庆幸这个监控系统并不复杂,重写起来也很快,所以,可以很快使用一个更传统的“服务化”+“云计算”的分布式架构,不然,就得像 DHH 那样咬牙下云——《Why We’re Leaving the Cloud》(他们的 SRE 的这篇博文 Our Cloud Spend in 2022说明了下云的困难和节约了多少成本)
最后让我做个我自己的广告。我在过去几年的创业中,帮助了很多公司解决了这些 分布式,微服务,云原生以及云计算成本的问题,如果你也有类似问题。欢迎,跟我联系:[email protected]
另外,我们今年发布了一个平台 MegaEase Cloud, 就是想让用户在不失去云计算体验的同时,通过自建高可用基础架构的方式来获得更低的成本(至少降 50%的云计算成本)。目前可以降低成本的方式:
欢迎大家试用。
如何访问
注:这两个区完全独立,帐号不互通。因为网络的不可抗力,千万不要跨区使用。
产品演示
介绍文章
(全文完)
(转载本站文章请注明作者和出处 酷 壳 – CoolShell ,请勿用于任何商业用途)
2023-02-12 00:31:16
 两个月前,我试着想用 ChatGPT 帮我写篇文章《eBPF 介绍》,结果错误百出,导致我又要从头改一遍,从那天我觉得 ChatGPT 生成的内容完全不靠谱,所以,从那天开始我说我不会再用 ChatGPT 来写文章(这篇文章不是由 ChatGPT 生成),因为,在试过一段时间后,我对 ChatGTP 有基于如下的认识:
两个月前,我试着想用 ChatGPT 帮我写篇文章《eBPF 介绍》,结果错误百出,导致我又要从头改一遍,从那天我觉得 ChatGPT 生成的内容完全不靠谱,所以,从那天开始我说我不会再用 ChatGPT 来写文章(这篇文章不是由 ChatGPT 生成),因为,在试过一段时间后,我对 ChatGTP 有基于如下的认识:

所以,基于上面这两个点认识,以发展的眼光来看问题,我觉得 ChatGPT 这类的 AI 可以成为一个小助理,他的确可以干掉那些初级的脑力工作者,但是,还干不掉专业的人士,这个我估计未来也很难,不过,这也很帅了,因为大量普通的工作的确也很让人费时间和精力,但是有个前提条件——就是ChatGPT所产生的内容必需是真实可靠的,没有这个前提条件的话,那就什么用也没有了。
今天,我想从另外一个角度来谈谈 ChatGPT,尤其是我在Youtube上看完了微软的发布会《Introducing your copilot for the web: AI-powered Bing and Microsoft Edge 》,才真正意识到Google 的市值为什么会掉了1000亿美元,是的,谷歌的搜索引擎的霸主位置受到了前所未有的挑战……
我们先来分析一下搜索引擎解决了什么样的用户问题,在我看来搜索引擎解决了如下的问题:
基本上就是上面这几个,搜索引擎在上面这几件事上作的很好,但是,还是有一些东西搜索引擎做的并不好,如:
好了,我们知道,ChatGPT 这类的技术主要是用来根据用户的需求来按一定的套路来“生成内容”的,只是其中的内容并不怎么可靠,那么,如果把搜索引擎里靠谱的内容交给 ChatGPT 呢?那么,这会是一个多么强大的搜索引擎啊,完全就是下一代的搜索引擎,上面的那些问题完全都可以解决了:
一旦 ChatGPT 利用上了搜索引擎内容准确和靠谱的优势,那么,ChatGPT 的能力就完全被释放出来了,所以,带 ChatGPT 的搜索引擎,就是真正的“如虎添翼”!
因此,微软的 Bing + ChatGPT,成为了 Google 有史以来最大的挑战者,我感觉——所有跟信息或是文字处理相关的软件应用和服务,都会因为 ChatGPT 而且全部重新洗一次牌的,这应该会是新一轮的技术革命……Copilot 一定会成为下一代软件和应用的标配!
(全文完)
(转载本站文章请注明作者和出处 酷 壳 – CoolShell ,请勿用于任何商业用途)
2023-02-03 15:46:13
 这两天在网络上又有一个东西火了,Twitter 的创始人 @jack 新的社交 iOS App Damus 上苹果商店(第二天就因为违反中国法律在中国区下架了),这个软件是一个去中心化的 Twitter,使用到的是 nostr – Notes and Other Stuff Transmitted by Relays 的协议(协议简介,协议细节),协议简介中有很大的篇幅是在批评Twitter和其相类似的中心化的产品,如:Mastodon 和 Secure Scuttlebutt 。我顺着去看了一下这个协议,发现这个协议真是非常的简单,简单到几句话就可以讲清楚了。
这两天在网络上又有一个东西火了,Twitter 的创始人 @jack 新的社交 iOS App Damus 上苹果商店(第二天就因为违反中国法律在中国区下架了),这个软件是一个去中心化的 Twitter,使用到的是 nostr – Notes and Other Stuff Transmitted by Relays 的协议(协议简介,协议细节),协议简介中有很大的篇幅是在批评Twitter和其相类似的中心化的产品,如:Mastodon 和 Secure Scuttlebutt 。我顺着去看了一下这个协议,发现这个协议真是非常的简单,简单到几句话就可以讲清楚了。
EVENT。发出事件,可以扩展出很多很多的动作来,比如:发信息,删信息,迁移信息,建 Channel ……扩展性很好。REQ。用于请求事件和订阅更新。收到REQ消息后,relay 会查询其内部数据库并返回与过滤器匹配的事件,然后存储该过滤器,并将其接收的所有未来事件再次发送到同一websocket,直到websocket关闭。CLOSE。用于停止被 REQ 请求的订阅。EVENT。用于发送客户端请求的事件。NOTICE。用于向客户端发送人类可读的错误消息或其他信息EVENT 下面是几个常用的基本事件:
0: set_metadata:比如,用户名,用户头像,用户简介等这样的信息。1: text_note:用户要发的信息内容2: recommend_server:用户想要推荐给关注者的Relay的URL(例如wss://somerelay.com)那么,这个协议是如何对抗网络审查的?
嗯,听起来很简单,整个网络是构建在一种 “社区式”的松散结构,完全可能会出现若干个 relay zone。这种架构就像是互联网的架构,没有中心化,比如 DNS服务器和Email服务器一样,只要你愿意,你完全可以发展出自己圈子里的“私服”。
其实,电子邮件是很难被封禁和审查的。我记得2003年中国非典的时候,我当时在北京,当时的卫生部部长说已经控制住了,才12个人感染,当局也在控制舆论和删除互联网上所有的真实信息。但是,大家都在用电子邮件传播信息,当时基本没有什么社交软件,大家分享信息都是通过邮件,尤其是外企工作的圈子,当时每天都要收很多的非典的群发邮件,大家还都是用公司的邮件服务器发……这种松散的,点对点的架构,让审查是基本不可能的。其实,我觉得 nostr 就是另外一个变种或是升级版的 email 的形式。
但是问题来了,如果不能删号封人的话,那么如何对抗那些制造Spam,骗子或是反人类的信息呢?nostr目前的解决方案是通过比特币闪电网络。比如有些客户端实现了如果对方没有follow 你,如果给他发私信,需要支付一点点btc ,或是relay要求你给btc才给你发信息(注:我不认为这是一个好的方法,因为:1)因为少数的坏人让大多数正常人也要跟着付出成本,这是个糟糕的治理方式,2)不鼓励那些生产内容的人,那么平台就没有任何价值了)。
不过,我觉得也有可以有下面的这些思路:
总之,还是有相应的方法的,但是一定没有完美解,email对抗了这么多年,你还是可以收到大量的垃圾邮件和钓鱼邮件,所以,我觉得 nostr 也不可能做到……
最后,我们要明白的是,无论你用什么方法,审查是肯定需要的,所以,我觉得要完全干掉审查,最终的结果就是一个到处都垃圾内容的地方!
我理解的审查不应该是为权力或是个体服务的,而是为大众和人民服务的,所以,审查必然是要有一个开放和共同决策的流程,而不是独断的。
这点可以参考开源软件基金会的运作模式。
注意下面几点
如果审查是在这个框架下运作的话,虽然不完美,但至少会在一种公允的基础下运作,是透明公开的,也是集体决策的。
开源软件社区是一个很成功的示范,所以,我觉得只有技术而没有一个良性的可持续运作的社区,是不可能解决问题的,干净整齐的环境是一定要有人打扫和整理的。

(全文完)
(转载本站文章请注明作者和出处 酷 壳 – CoolShell ,请勿用于任何商业用途)
2022-12-13 15:39:39
 写一篇与技术无关的文章,供大家参考。我住北京朝阳,从上周三开始我家一家三口陆续发烧生病,自测抗原后,都是阳性。好消息是,这个奥密克戎跟一般的病毒性感冒差不多,没什么可怕的,不过,整个过程除了发病之外还有一些别的因为感染带出来的事,大家也需要知晓,以准备好,以免造成生活的不便,更好的照顾好自己和家人。
写一篇与技术无关的文章,供大家参考。我住北京朝阳,从上周三开始我家一家三口陆续发烧生病,自测抗原后,都是阳性。好消息是,这个奥密克戎跟一般的病毒性感冒差不多,没什么可怕的,不过,整个过程除了发病之外还有一些别的因为感染带出来的事,大家也需要知晓,以准备好,以免造成生活的不便,更好的照顾好自己和家人。
我先说一下整个过程(我会不断更新这个过程,直到转阴)。说明一下,我孩子老婆都打过三针国产疫苗,孩子是科兴,老婆是北京生物,我完全没有打。
先是我家孩子(12 岁)。上周三(12 月 7 日),孩子早上起来就说头疼,一测体温,38 度 5,就停止上网课,老实休息了,我们并没给孩子吃什么药,到了晚上,孩子的体温到了 39.4,嗓子疼,我老婆用酒精给孩子物理降温(注:事实上最好别用酒精,因为会被皮肤吸收导致副作用),成功降到了 38.2 左右。周四(12 月 8 日),孩子的体温在 38.2 一天,我老婆给孩子吃了莲花清瘟,被我制止了,本来想上退烧药的,但是我想体温也不算高,能不吃就不吃,于是就让孩子冲了个复方感冒冲剂(其实里面含对乙酰氨基酚,后面会说)。周五(12 月 9 日),孩子不停地出汗,到下午体温正常了,然后咳嗽,鼻涕就来了,感冒症状来了,但精神不好,体虚无力。周末休息两天就基本没事了,也转阴了。
接下来就到我了。
周五那天感觉嗓子有点异样,我没怎么在意,周六(12 月 10)就开始发烧了,傍晚 18 点左右,我是手脚冰冷,还有点打冷颤,头晕,嗓子干燥,我就钻被子里了,在半睡不睡的状态下到了 20 点左右,我浑身发烫,我老婆过来给我一量体温,39.8,说要不要也抹点酒精?我想,北京这个季节,物理降温不就上阳台上站一会就好了吗?当然,我就是把窗开了个口,把室温降到 20 度左右,然后,短袖短裤呆了一会就感到清醒了一些。这个时候,我觉得再来碗热汤就好了,我喝不习惯生姜红糖水,又腥又甜,我就自己整了一小锅西红柿蛋花汤,为了让我更能出汗,并适合我的重口味,我又加了点辣椒,一小锅热汤下肚,汗出的不亦乐乎,体温降低到38.4度,我觉的不用再吃药了,当然,嗓子也疼了。但是我舒服了很多,最后还看了下摩洛哥是怎么把C罗送回家的比赛。
周日(12 月 11)是我最难受的一天,全天体温在 38.2左右,从早上就没有精神,吃完早点后,从 10 点一直睡到下午 15 点(因为嗓子疼,所以睡的也不安宁,各种难受), 这天我一会儿就出次汗,但是体温降不下来,始终在 38.2,然后我在犹豫是不是吃布洛芬,但是我感觉体温也不是很高,布洛芬这种药能不吃不不吃。然后,睡前喝了一袋感冒冲剂。周日这天,我婆也发烧,38.5,她全身疼痛,包括嗓子。这一天,我们在家啥也干不了,全家都在床上躲着,只有孩子还能动,所以,有些事只能让孩子去干了,我们也只点外卖了。
周一(12 月 12 日)我早上起来,38.5,开完周会后,看很多人说泰诺有用,然后翻了一下家,居然没找到,算,还是冲两包感冒冲剂得了(后来才知道,中成药里也都是掺了对乙酰氨基酚,看来中医对自己都没什么信心),于是整个下午就在出汗了,我一整天都没有什么食欲,到了下午 17 点左右,体温正常了 36.7,但是晚上又到了 37 度,开始咳痰,轻微流鼻涕,不过感觉没什么事了。而我老婆的烧居然退了,她说她应该好了。

周二(12 月 13 日)我早上起床后, 体温还是在 37.2 度,我的嗓子干燥微疼,头也不疼就是头晕,所以,今天睡了两次,一次是中午12 点半到下午 14点半,一次是 16:40 到 19:10,两次都出汗了,而且第二觉睡地太爽了,感觉是这两天睡过最高质量高的觉,而且嗓子不干了也好了,体温正常了 36.8,但是感冒症状出来了,接下来几天休息一下应该就好了。我孩子应该感冒也没有精神,所以一天来也是醒醒睡睡。而我老婆又开始发烧了,还带这样的,跳跃性发烧…… 更不好的是她嗓子已经疼到说不出话,也咽不下东西了,今天她也是床上躺了一天……
周三(12月14日)我今天已经不发烧了,就是频率不高的咳嗽,轻微鼻塞,不过,还是要休息,喝水。我老婆体温还是低烧中,嗓子疼痛好了些,感觉正在恢复中……
整个过程,对我和我孩子来说,不难受,感觉就是发3天烧睡3天,再休息 3 天的样子,嗓子干燥微疼,比以前的病毒性感冒好多了,以前的病毒性感冒导致的嗓子疼我是连咽口水都咽不下去。但是对于我老婆就不一样了,她先是浑身疼痛,嗓子干燥,到现在嗓子疼如刀割,说不出话。这个事可能也因人而异。
继续更新,自我阳性以来半个月了,从 12 月 14 日退烧后,我就一直处在感冒和低频咳嗽中,直到12 月 27 日才发现不咳嗽也不感冒了,但是说话还是有一点鼻音,估计还要 5-7 天就可以完全恢复了。

能物理降温就不要吃药来降(应该避免使用酒精擦拭,因为有副作用,用水或冰就可以了),降到 38.5 以下,就可以自己抗了。如果物理降温不奏效,就要吃布洛芬和泰诺(林),这两种药非常有帮助,但是你应该在药店里买不到了,所以,你可以买中成药或复方药,反正里面的中药没有用,而几乎所有的中成药里都被加入了“对乙酰氨基酚”,算是“间接”或“复方”泰诺(林)了。但是,不要多服,不然,药量叠加,会导致你肝肾中毒。参看《这些所谓“中成药”,关键原料是对乙酰氨基酚,服用小心叠加过量》
下面文字节选自“默沙东诊疗手册”
最有效和最广泛使用的退热药为对乙酰氨基酚和非甾体抗炎药 (NSAID),如阿司匹林、布洛芬和萘普生。
通常,人们可能采取以下方式之一:
每6小时650毫克对乙酰氨基酚(1天内不超过4000毫克)
每6小时200到400毫克布洛芬
因为许多非处方感冒药或流感制剂含有对乙酰氨基酚,人们一定要注意不要在同一时间服用对乙酰氨基酚和一种或多种这些制剂。
只有当温度达到106°F (41.1°C)左右或更高时,才需要采取其它降温措施(如用温水喷雾和降温毯降温)。避免使用酒精擦拭,因为酒精可被皮肤吸收,可能产生有害效果。
有血液感染或生命体征异常(例如,血压低、脉搏和呼吸速度加快)的人需入院。
另外,一定要多喝水,热水最好。多喝水的原因是:1)布洛芬、对乙酰氨基酚(扑热息痛)等退烧药会让人加速出汗,会导致脱水。2)布洛芬等退烧药主要在肝脏代谢,60%~90%经肾脏随尿排出。多喝水,可加速药物排出体外,减少退烧药对肝肾的损伤。3)排汗和排尿都会帮身体带走一些热量。
具体喝多少水因人而异,一般在2.5升到4升间,主要看你上厕所的频率。我因为前三天都在出汗,所以怎么喝水都不怎么上厕所,这两天我大概一天喝4升左右。总之,发烧吃退烧药更要多喝水。
另外,如果全家都病倒了,那生活就有点不方便了,所以,你得做好一些准备:
1)事先订好桶装水,18L 的那种,让人可以给家里送水,发烧期间用水很快的。
2)生活上的事要做好全家病倒的准备,做饭只能整方便的做的或是速食的了,家里存点牛奶,面包,麦片,火腿肠,水果什么的,保证营养。再不行就点外卖,我家已经点了三天的外卖。还让孩子当个配送员跑腿到菜市场和超市开着视频买东西……
3)还是要提前备药,我是准备用药的时候,发现家里只找到了布洛芬和感冒冲剂,因为我有高血脂,我还要吃瑞舒伐他汀钙片,结果发现我周边 5 公里的药店基本全都休业了,估计店员都阳了。
4)有老人的,要照顾好。有呼吸困难的,一定要送急诊。
根据知乎上的这个通过搜索引擎的测算,第一波的结束大约会在明年春节前结束。最后祝大家好运。
(全文完)
(转载本站文章请注明作者和出处 酷 壳 – CoolShell ,请勿用于任何商业用途)
2022-12-10 10:38:51
 很早前就想写一篇关于eBPF的文章,但是迟迟没有动手,这两天有点时间,所以就来写一篇,这文章主要还是简单的介绍eBPF 是用来干什么的,并通过几个示例来介绍是怎么玩的,这个技术非常非常之强,Linux 操作系统的观测性实在是太强大了,并在 BCC 加持下变得一览无余。这个技术不是一般的运维人员或是系统管理员可以驾驭的,这个还是要有底层系统知识并有一定开发能力的技术人员才能驾驭的了的。我在这篇文章的最后给了个彩蛋。
很早前就想写一篇关于eBPF的文章,但是迟迟没有动手,这两天有点时间,所以就来写一篇,这文章主要还是简单的介绍eBPF 是用来干什么的,并通过几个示例来介绍是怎么玩的,这个技术非常非常之强,Linux 操作系统的观测性实在是太强大了,并在 BCC 加持下变得一览无余。这个技术不是一般的运维人员或是系统管理员可以驾驭的,这个还是要有底层系统知识并有一定开发能力的技术人员才能驾驭的了的。我在这篇文章的最后给了个彩蛋。
eBPF(extened Berkeley Packet Filter)是一种内核技术,它允许开发人员在不修改内核代码的情况下运行特定的功能。eBPF 的概念源自于 Berkeley Packet Filter(BPF),后者是由贝尔实验室开发的一种网络过滤器,可以捕获和过滤网络数据包。
出于对更好的 Linux 跟踪工具的需求,eBPF 从 dtrace中汲取灵感,dtrace 是一种主要用于 Solaris 和 BSD 操作系统的动态跟踪工具。与 dtrace 不同,Linux 无法全面了解正在运行的系统,因为它仅限于系统调用、库调用和函数的特定框架。在Berkeley Packet Filter (BPF)(一种使用内核 VM 编写打包过滤代码的工具)的基础上,一小群工程师开始扩展 BPF 后端以提供与 dtrace 类似的功能集。 eBPF 诞生了。2014 年随 Linux 3.18 首次限量发布,充分利用 eBPF 至少需要 Linux 4.4 以上版本。
eBPF 比起传统的 BPF 来说,传统的 BPF 只能用于网络过滤,而 eBPF 则可以用于更多的应用场景,包括网络监控、安全过滤和性能分析等。另外,eBPF 允许常规用户空间应用程序将要在 Linux 内核中执行的逻辑打包为字节码,当某些事件(称为挂钩)发生时,内核会调用 eBPF 程序。此类挂钩的示例包括系统调用、网络事件等。用于编写和调试 eBPF 程序的最流行的工具链称为 BPF 编译器集合 (BCC),它基于 LLVM 和 CLang。
eBPF 有一些类似的工具。例如,SystemTap 是一种开源工具,可以帮助用户收集 Linux 内核的运行时数据。它通过动态加载内核模块来实现这一功能,类似于 eBPF。另外,DTrace 是一种动态跟踪和分析工具,可以用于收集系统的运行时数据,类似于 eBPF 和 SystemTap。[1]
以下是一个简单的比较表格,可以帮助您更好地了解 eBPF、SystemTap 和 DTrace 这三种工具的不同之处:[1]
| 工具 | eBPF | SystemTap | DTrace |
|---|---|---|---|
| 定位 | 内核技术,可用于多种应用场景 | 内核模块 | 动态跟踪和分析工具 |
| 工作原理 | 动态加载和执行无损编译过的代码 | 动态加载内核模块 | 动态插接分析器,通过 probe 获取数据并进行分析 |
| 常见用途 | 网络监控、安全过滤、性能分析等 | 系统性能分析、故障诊断等 | 系统性能分析、故障诊断等 |
| 优点 | 灵活、安全、可用于多种应用场景 | 功能强大、可视化界面 | 功能强大、高性能、支持多种编程语言 |
| 缺点 | 学习曲线高,安全性依赖于编译器的正确性 | 学习曲线高,安全性依赖于内核模块的正确性 | 配置复杂,对系统性能影响较大 |
对比表格[1]
从上表可以看出,eBPF、SystemTap 和 DTrace 都是非常强大的工具,可以用于收集和分析系统的运行情况。[1]
eBPF 是一种非常灵活和强大的内核技术,可以用于多种应用场景。下面是 eBPF 的一些常见用途:[1]
[1]
[1]
[1]
[1]
总之,eBPF 的常见用途非常广泛,可以用于网络监控、安全过滤、性能分析和虚拟化等多种应用场景。[1]
eBPF 的工作原理主要分为三个步骤:加载、编译和执行。
eBPF 需要在内核中运行。这通常是由用户态的应用程序完成的,它会通过系统调用来加载 eBPF 程序。在加载过程中,内核会将 eBPF 程序的代码复制到内核空间。
eBPF 程序需要经过编译和执行。这通常是由Clang/LLVM的编译器完成,然后形成字节码后,将用户态的字节码装载进内核,Verifier会对要注入内核的程序进行一些内核安全机制的检查,这是为了确保 eBPF 程序不会破坏内核的稳定性和安全性。在检查过程中,内核会对 eBPF 程序的代码进行分析,以确保它不会进行恶意操作,如系统调用、内存访问等。如果 eBPF 程序通过了内核安全机制的检查,它就可以在内核中正常运行了,其会通过通过一个JIT编译步骤将程序的通用字节码转换为机器特定指令集,以优化程序的执行速度。
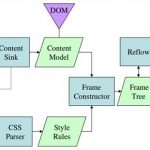
下图是其架构图。
/filters:no_upscale()/articles/gentle-linux-ebpf-introduction/en/resources/47image005-1619704397592.jpg)
(图片来自:https://www.infoq.com/articles/gentle-linux-ebpf-introduction/)
在内核中运行时,eBPF 程序通常会挂载到一个内核钩子(hook)上,以便在特定的事件发生时被执行。例如,
最后 eBPF Maps,允许eBPF程序在调用之间保持状态,以便进行相关的数据统计,并与用户空间的应用程序共享数据。一个eBPF映射基本上是一个键值存储,其中的值通常被视为任意数据的二进制块。它们是通过带有BPF_MAP_CREATE参数的bpf_cmd系统调用来创建的,和Linux世界中的其他东西一样,它们是通过文件描述符来寻址。与地图的交互是通过查找/更新/删除系统调用进行的
总之,eBPF 的工作原理是通过动态加载、执行和检查无损编译过的代码来实现的。[1]
eBPF 可以用于对内核的性能进行分析。下面是一个基于 eBPF 的性能分析的 step-by-step 示例:
第一步:准备工作:首先,需要确保内核已经支持 eBPF 功能。这通常需要在内核配置文件中启用 eBPF 相关的选项,并重新编译内核。检查是否支持 eBPF,你可以用这两个命令查看 ls /sys/fs/bpf 和 lsmod | grep bpf
第二步:写 eBPF 程序:接下来,需要编写 eBPF 程序,用于收集内核的性能指标。eBPF 程序的语言可以选择 C 或者 Python,它需要通过特定的接口访问内核的数据结构,并将收集到的数据保存到指定的位置。
下面是一个Python 示例(其实还是C语言,用python来加载一段C程序到Linux内核)
#!/usr/bin/python3
from bcc import BPF
from time import sleep
# 定义 eBPF 程序
bpf_text = """
#include <uapi/linux/ptrace.h>
BPF_HASH(stats, u32);
int count(struct pt_regs *ctx) {
u32 key = 0;
u64 *val, zero=0;
val = stats.lookup_or_init(&key, &zero);
(*val)++;
return 0;
}
"""
# 编译 eBPF 程序
b = BPF(text=bpf_text, cflags=["-Wno-macro-redefined"])
# 加载 eBPF 程序
b.attach_kprobe(event="tcp_sendmsg", fn_name="count")
name = {
0: "tcp_sendmsg"
}
# 输出统计结果
while True:
try:
#print("Total packets: %d" % b["stats"][0].value)
for k, v in b["stats"].items():
print("{}: {}".format(name[k.value], v.value))
sleep(1)
except KeyboardInterrupt:
exit()
这个 eBPF 程序的功能是统计网络中传输的数据包数量。它通过定义一个 BPF_HASH 数据结构来保存统计结果(eBPF Maps),并通过捕获 tcp_sendmsg 事件来实现实时统计。最后,它通过每秒输出一次统计结果来展示数据。这个 eBPF 程序只是一个简单的示例,实际应用中可能需要进行更复杂的统计和分析。
第三步:运行 eBPF 程序:接下来,需要使用 eBPF 编译器将 eBPF 程序编译成内核可执行的格式(这个在上面的Python程序里你可以看到——Python引入了一个bcc的包,然后用这个包,把那段 C语言的程序编译成字节码加载在内核中并把某个函数 attach 到某个事件上)。这个过程可以使用 BPF Compiler Collection(BCC)工具来完成。BCC 工具可以通过命令行的方式将 eBPF 程序编译成内核可执行的格式,并将其加载到内核中。
下面是运行上面的 Python3 程序的步骤:
sudo apt install python3-bpfcc
注:在Python3下请不要使用 pip3 install bcc (参看:这里)
如果你是 Ubuntu 20.10 以上的版本,最好通过源码安装(否则程序会有编译问题),参看:这里:
apt purge bpfcc-tools libbpfcc python3-bpfcc wget https://github.com/iovisor/bcc/releases/download/v0.25.0/bcc-src-with-submodule.tar.gz tar xf bcc-src-with-submodule.tar.gz cd bcc/ apt install -y python-is-python3 apt install -y bison build-essential cmake flex git libedit-dev libllvm11 llvm-11-dev libclang-11-dev zlib1g-dev libelf-dev libfl-dev python3-distutils apt install -y checkinstall mkdir build cd build/ cmake -DCMAKE_INSTALL_PREFIX=/usr -DPYTHON_CMD=python3 .. make checkinstall
接下来,需要将上面的 Python 程序保存到本地,例如保存到文件 netstat.py。运行程序:最后,可以通过执行以下命令来运行 Python 程序:
$ chmod +x ./netstat.py $ sudo ./netstat.py tcp_sendmsg: 29 tcp_sendmsg: 216 tcp_sendmsg: 277 tcp_sendmsg: 379 tcp_sendmsg: 419 tcp_sendmsg: 468 tcp_sendmsg: 574 tcp_sendmsg: 645 tcp_sendmsg: 29
程序开始运行后,会在控制台输出网络数据包的统计信息。可以通过按 Ctrl+C 组合键来结束程序的运行。
下面我们再看一个比较复杂的示例,这个示例会计算TCP的发包时间(示例参考于Github上 这个issue里的程序):
#!/usr/bin/python3
from bcc import BPF
import time
# 定义 eBPF 程序
bpf_text = """
#include <uapi/linux/ptrace.h>
#include <net/sock.h>
#include <net/inet_sock.h>
#include <bcc/proto.h>
struct packet_t {
u64 ts, size;
u32 pid;
u32 saddr, daddr;
u16 sport, dport;
};
BPF_HASH(packets, u64, struct packet_t);
int on_send(struct pt_regs *ctx, struct sock *sk, struct msghdr *msg, size_t size)
{
u64 id = bpf_get_current_pid_tgid();
u32 pid = id;
// 记录数据包的时间戳和信息
struct packet_t pkt = {}; // 结构体一定要初始化,可以使用下面的方法
//__builtin_memset(&pkt, 0, sizeof(pkt));
pkt.ts = bpf_ktime_get_ns();
pkt.size = size;
pkt.pid = pid;
pkt.saddr = sk->__sk_common.skc_rcv_saddr;
pkt.daddr = sk->__sk_common.skc_daddr;
struct inet_sock *sockp = (struct inet_sock *)sk;
pkt.sport = sockp->inet_sport;
pkt.dport = sk->__sk_common.skc_dport;
packets.update(&id, &pkt);
return 0;
}
int on_recv(struct pt_regs *ctx, struct sock *sk)
{
u64 id = bpf_get_current_pid_tgid();
u32 pid = id;
// 获取数据包的时间戳和编号
struct packet_t *pkt = packets.lookup(&id);
if (!pkt) {
return 0;
}
// 计算传输时间
u64 delta = bpf_ktime_get_ns() - pkt->ts;
// 统计结果
bpf_trace_printk("tcp_time: %llu.%llums, size: %llu\\n",
delta/1000, delta%1000%100, pkt->size);
// 删除统计结果
packets.delete(&id);
return 0;
}
"""
# 编译 eBPF 程序
b = BPF(text=bpf_text, cflags=["-Wno-macro-redefined"])
# 注册 eBPF 程序
b.attach_kprobe(event="tcp_sendmsg", fn_name="on_send")
b.attach_kprobe(event="tcp_v4_do_rcv", fn_name="on_recv")
# 输出统计信息
print("Tracing TCP latency... Hit Ctrl-C to end.")
while True:
try:
(task, pid, cpu, flags, ts, msg) = b.trace_fields()
print("%-18.9f %-16s %-6d %s" % (ts, task, pid, msg))
except KeyboardInterrupt:
exit()
上面这个程序通过捕获每个数据包的时间戳来统计传输时间。在捕获 tcp_sendmsg 事件时,记录数据包的发送时间;在捕获 tcp_v4_do_rcv 事件时,记录数据包的接收时间;最后,通过比较两个时间戳来计算传输时间。
从上面的两个程序我们可以看到,eBPF 的一个编程的基本方法,这样的在Python里向内核的某些事件挂载一段 “C语言” 的方式就是 eBPF 的编程方式。实话实说,这样的代码很不好写,而且有很多非常诡异的东西,一般人是很难驾驭的(上面的代码我也不是很容易都能写通的,把 Google 都用了个底儿掉,读了很多晦涩的文档……)好在这样的代码已经有人写了,我们不必再写了,在 Github 上的 bcc 库下的 tools 目录有很多……
BCC(BPF Compiler Collection)是一套开源的工具集,可以在 Linux 系统中使用 BPF(Berkeley Packet Filter)程序进行系统级性能分析和监测。BCC 包含了许多实用工具,如:
下面这张图你可能见过多次了,你可以看看他可以干多少事,内核里发生什么事一览无余。

一些经典的文章和书籍关于 eBPF 包括:
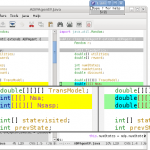
最后来到彩蛋环节。因为最近 ChatGPT 很火,于是,我想通过 ChatGPT 来帮助我书写这篇文章,一开始我让ChatGPT 帮我列提纲,并根据提纲生成文章内容,并查找相关的资料,非常之顺利,包括生成的代码,我以为我们以很快地完成这篇文章。
但是,到了代码生成的时候,我发现,ChatGPT 生成的代码的思路和方法都是对的,但是是比较老的,而且是跑不起来的,出现了好些低级错误,如:使用了未声明的变量,没有引用完整的C语言的头文件,没有正确地初始化变量,错误地获取数据,类型没有匹配……等等,在程序调试上,挖了很多的坑,C语言本来就不好搞,挖的很多运行时的坑很难察觉,所以,耗费了我大量的时间来排除各种各样的问题,其中有环境上的问题,还有代码上的问题,这些问题即便是通过 Google 也不容易找到解决方案,我找到的解决方案都放在文章中了,尤其是第二个示例,让我调试了3个多小时,读了很多 bcc 上的issue和相关的晦涩的手册和文档,才让程序跑通。
到了文章收关的阶段,我让ChatGPT 给我几个延伸阅读,也是很好的,但是没有给出链接,于是我只得人肉 Google 了一下,然后让我吃惊的是,好多ChatGPT给出来的文章是根本不存在的,完全是它伪造的。我连让它干了两次都是这样,这个让我惊掉大牙。这让我开始怀疑它之前生成的内容,于是,我不得我返回仔细Review我的文章,尤其是“介绍”、“用途”和“工作原理”这三个章节,基本都是ChatGPT生成的,在Review完后,我发现了ChatGPT 给我生造了一个叫 “无损编译器”的术语,这个术语简直了,于是我开始重写我的文章。我把一些段落重写了,有一些没有,保留下来的我都标记上了 [1],大家读的时候要小心阅读。
最后,我的结论是,ChatGPT只是一个不成熟的玩具,只能回答一些没有价值的日常聊天的问题,要说能取代Google,我觉得不可能,因为Google会基于基本的事实,而ChatGPT会基于内容生成的算法,在造假方面称得上是高手,可以列为电信诈骗的范畴了,我以后不会再使用ChatGPT生成文章内容或是作我的帮手了。StackOverflow把其ban了真是不能太赞了!
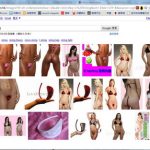
附件一:ChatGPT的造假载图和样本
|
|
|
ChatGPT 生成的样本一
ChatGPT 生成的样本二
附件二:发明的术语:无损编译器
|
|
|
(全文完)
(转载本站文章请注明作者和出处 酷 壳 – CoolShell ,请勿用于任何商业用途)
2022-10-14 12:20:38
 这两天跟 Cali 和 Rather 做了一个线上的 Podcast – Ep.5 一起聊聊团队协同。主要是从 IM 工具扩展开来聊了一下团队的协同和相应的工具,但是聊天不是深度思考,有一些东西我没有讲透讲好,所以,我需要把我更多更完整更结构化的想法形成文字。(注:聊天聊地比较详细,本文只是想表达我的主要想法)
这两天跟 Cali 和 Rather 做了一个线上的 Podcast – Ep.5 一起聊聊团队协同。主要是从 IM 工具扩展开来聊了一下团队的协同和相应的工具,但是聊天不是深度思考,有一些东西我没有讲透讲好,所以,我需要把我更多更完整更结构化的想法形成文字。(注:聊天聊地比较详细,本文只是想表达我的主要想法)
国内企业级在线交流工具主要有:企业微信、钉钉、飞书,国外的则是:Slack、Discord这两大IM工具,你会发现,他们有很多不一样的东西,其中有两个最大的不同,一个是企业管理,一个是企业文化。
Slack/Discrod 主要是通过建 Channel ,而国内的IM则主要是拉群。你可能会说,这不是一样的吗?其实是不一样的,很明显,Channel 的属性是相对持久的,而群的属性则是临时的,前者是可以是部门,可以是团队,可以是项目,可以是产品,可以是某种长期存在的职能(如:技术分享),而拉群则是相对来说临时起意的,有时候,同样的人群能被重复地拉出好几次,因为之前临时起意的事做完了,所以群就被人所遗忘了,后面再有事就再来。很明显,Channel 这种方式明显是有管理的属性的,而拉群则是没有管理的。
所以,在国内这种作坊式,野蛮粗放式的管理风格下,他们需要的就是想起一出是一出的 IM 工具,所以,拉群就是他们的工作习惯,因为没有科学的管理,所以没有章法,所以,他们不需要把工作内的信息结构化的工具。而国外则不然,国外的管理是精细化的,国外的公司还在重度使用 Email 的通讯方式,而 Email 是天生会给一个主题时行归类,而且 Email 天生不是碎片信息,所以,国外的 IM 需要跟 Email 竞争,因为像 Email 那样给邮件分类,把信息聚合在一个主题下的方式就能在 IM 上找到相关的影子。Channel 就是一个信息分类,相当于邮件分类,Slack 的 回复区和 Discord 的子区就像是把同一个主题信息时行聚合的功能。这明显是懂管理的人做的,而国内的拉群一看就是不懂管理的人干的,或者说是就是满足这些不懂管理的人的需求的。
团队协作和团队工作最大的基石是信任,如果有了信任,没有工具都会很爽,如果没有信任,什么工具都没用。信任是一种企业文化,这种文化不仅包括同级间的,还包括上下级间的。但是,因为国内的管理跟不上,所以,就导致了各种不信任的文化,而需要在这里不信任的文化中进行协同工作,国内的 IM 软件就会开发出如下在国外的 IM 中完全没有的功能:
而国外的 IM 则是,发出的信息可以修改/删除,没有已读标准,也不会监控员工。这种时候,我总是会对工作在这种不信任文化中人感到可怜……如果大家需要靠逼迫的方式把对方拉来跟我一起协作,我们还工作个什么劲啊。
所以,我们可以看到,畸形的企业管理和企业文化下,就会导致畸形的协同工具。最令人感到悲哀的是,有好多同学还觉得国内的钉钉非常之好,殊不知,你之所以感觉好用,是因为你所在的环境是如此的不堪。你看,人到了不同的环境就会有不同的认识,所以,找一个好一些的环境对一个人的成长有多重要。
给一些新入行的人的建议就是,一个环境对一个人的认知会有非常大的影响,找一个好的环境是非常重要,如果不知道什么 环境是好的,那就先从不使用钉钉为工作协同软件的公司开始吧……
我们从上面可以得到,协同的前提条件是你需要有一个基于信任的企业文化,还需要有有结构化思维的科学的管理思维。没有这两个东西,给你的团队再多的工具都不可能有真正好有协同的,大家就是装模作样罢了。
假设我们的管理和文化都没有问题,那下面我们来谈谈协同工具的事。
我个人觉得 IM 这种工具包括会议都不是一种好的协同工具,因为这些工具都无法把信息做到真正的结构化和准确化,用 IM 或是开会上的信息大多都是碎片化严重,而且没有经过深度思考或是准备的,基本都是即兴出来的东西,不靠谱的概率非常大。
找人交流和开会不是有个话题就好的,还需要一个可以讨论的“议案”。在 Amazon 里开会,会前,组织方会把要讨论的方案打印出来给大家看,这个方案是深思过的,是验证过的,是有数据和证据或是引用支撑的,会议开始后,10 -15分钟是没有人说话的,大家都在看文档,然后就开始直接讨论或发表意见,支持还是不支持,还是有条件支持……会议效率就会很高。
但是这个议案其实是可以由大家一起来完成的,所以,连打印或是开会都不需要。试想一下,使用像 Google Doc 这样的协同文档工具,把大家拉到同一个文档里直接创作,不香吗?我在前段时间,在公网上组织大家来帮我完成一个《非常时期的囤货手册》,这篇文章的形成有数百个网友的加持,而我就是在做一个主编的工作,这种工作是 IM 工具无法完成的事。与之类似的协同工具还有大家一起写代码的 Github,大家一起做设计的 Figma……这样创作类的协同工具非常多。另外,好多这些工具都能实时展示别人的创作过程,这个简直是太爽了,你可以通过观看他人创作过程,学习到很多他人的思路和想法,这个在没有协同工具的时代是很难想像的。
好的协同工具是可以互相促进互相激励的,就像一个足球队一样,当你看到你的队友在勇敢地争抢,拼命地奔跑,你也会被感染到的。
所以,好的协同就是能够跟一帮志同道合,有共同目标,有想法,有能力的人一起做个什么事。所以,在我心中我最喜欢的协同工具从来都是创作类的,不是管理类的,更不是聊天类的。管理和聊天的协同软件会让你产生一种有产出的假象,但其实不同,这种工具无论做的有多好,都是支持性的工具,不是产出类的工具,不会提升生产力的。
另外,在创作类的协同工具上如果有一些智能小帮手,如:Github 发布的 Copilot。那简直是让人爽翻天了,所以,真正能提升生产力的工具都是在内容上帮得到你的。
我其实并不喜欢今天所有的 IM 工具,因为我觉得信息不是结构化的,信息是有因果关系和上下文的,是结构化的,是多维度的,不是今天这种线性的方式,我们想像一下“脑图”或是知识图,或是 wikipedia 的网关的关联,我们可能就能想像得到一个更好的 IM 应该是什么 样的……
协同工作的想像空间实在是太大了,我觉得所有的桌面端的软件都会被协作版的重写,虽然,这种协作软件需要有网络的加持,但是协作软件的魅力和诱惑力实在的太大了,让人无法不从……
未来的企业,那些管理类的工具一定会被边缘化的,聊天类的会被打成一个通知中心,而创作类的会大放异彩,让大家直接在要干的事上进行沟通、交互和分享。
(全文完)
(转载本站文章请注明作者和出处 酷 壳 – CoolShell ,请勿用于任何商业用途)