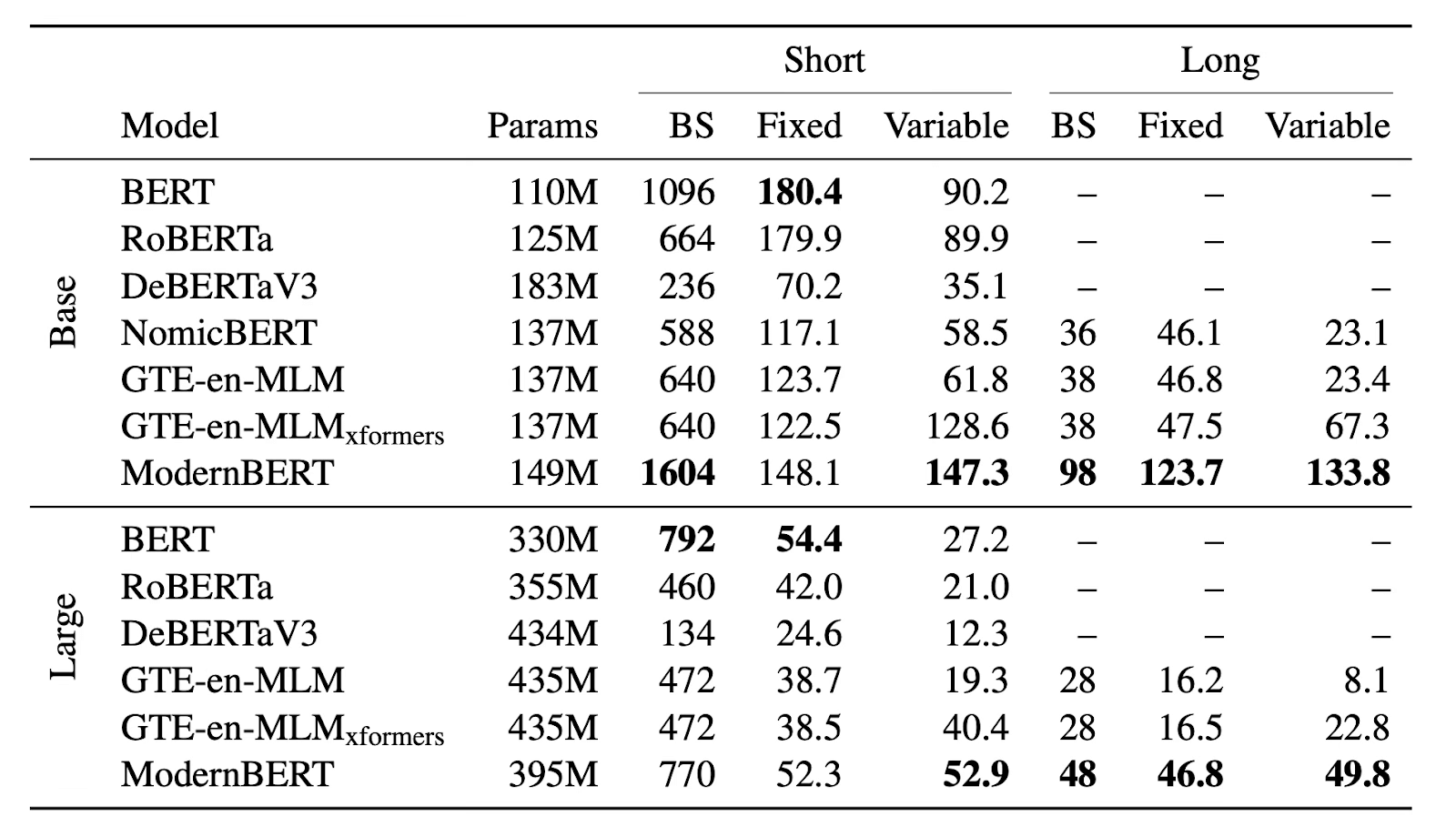
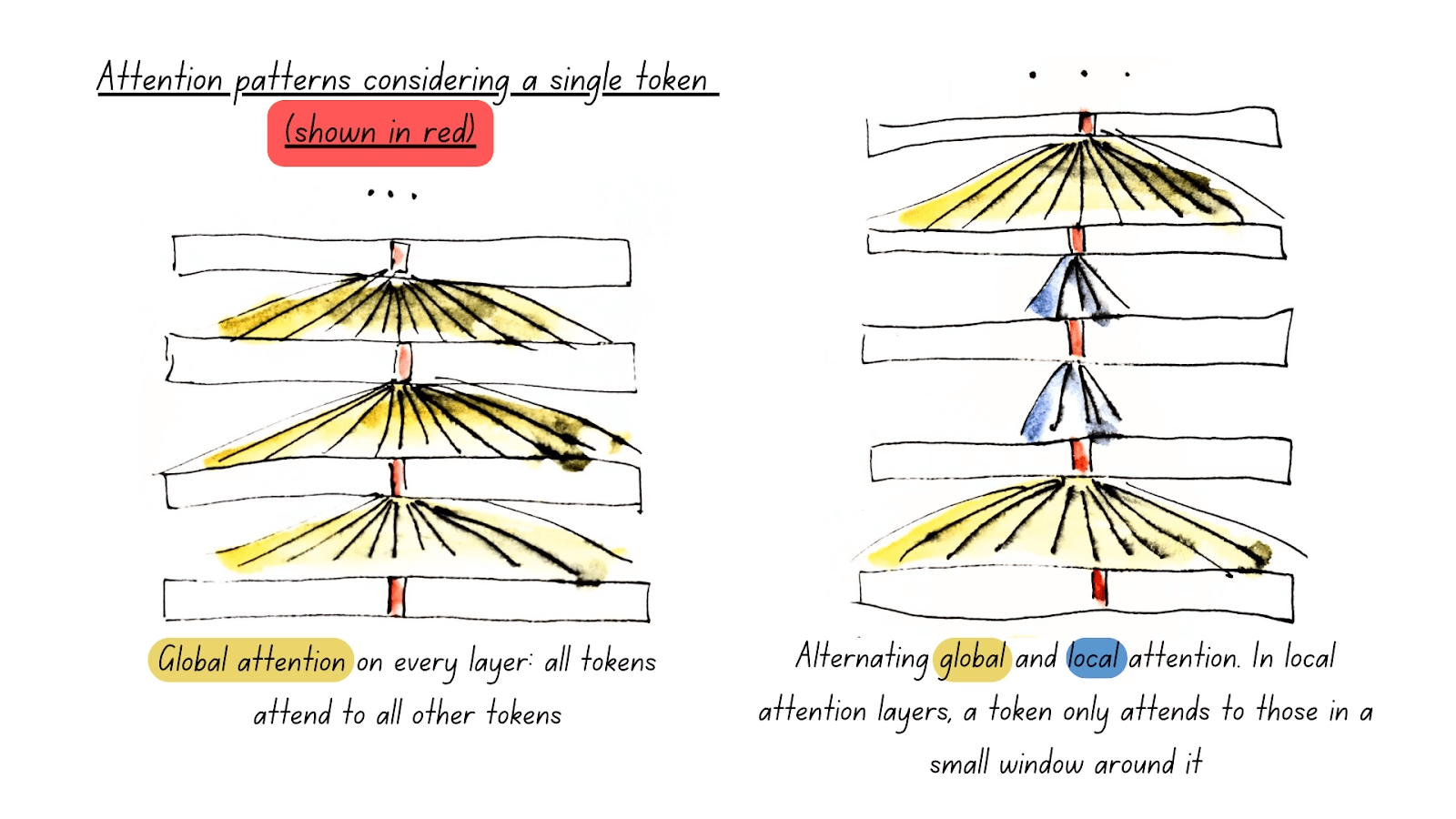



Click to see data preprocessing
import pandas as pd
import numpy as np
# Create sample data
np.random.seed(42)
data = pd.DataFrame({
'id': range(1000),
'value': np.random.normal(0, 1, 1000),
'category': np.random.choice(['A', 'B', 'C'], 1000)
})
# Preprocessing steps
data['value_normalized'] = (data['value'] - data['value'].mean()) / data['value'].std()
data['value_binned'] = pd.qcut(data['value'], q=5, labels=['Q1', 'Q2', 'Q3', 'Q4', 'Q5'])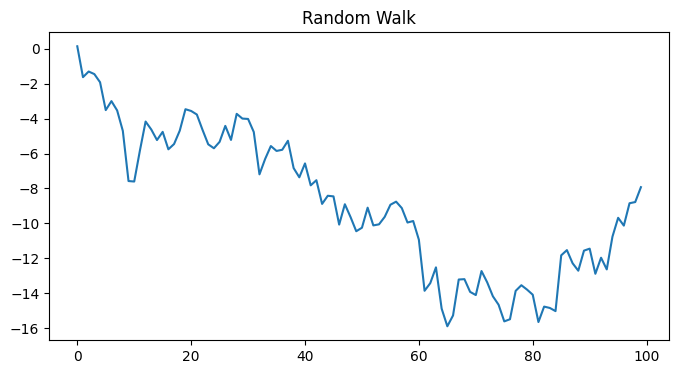
{kind=link}