2025-12-28 13:07:10
这里记录值得分享的生信相关内容,每半月发布。
本杂志开源(GitHub: openbiox/weekly),欢迎提交 issue,投稿或推荐生信相关内容。

本周话题:有了AI,还有必要学习生物信息吗?
这篇文章通过汇集多个主流AI模型的观点,共同论证了在AI时代学习生物信息学的必要性。核心结论认为,AI不会取代生物信息学,而是作为强大的工具,改变了学习的重点:从业者需要从重复性的“代码搬运”和“跑流程”中解放出来,转而更深入地掌握生物学知识、统计学原理,并培养利用AI定义科学问题、设计分析策略及解释复杂结果的高阶能力。
1、Cell Discovery | 泛黑色素瘤的生物学和治疗的蛋白基因组学研究
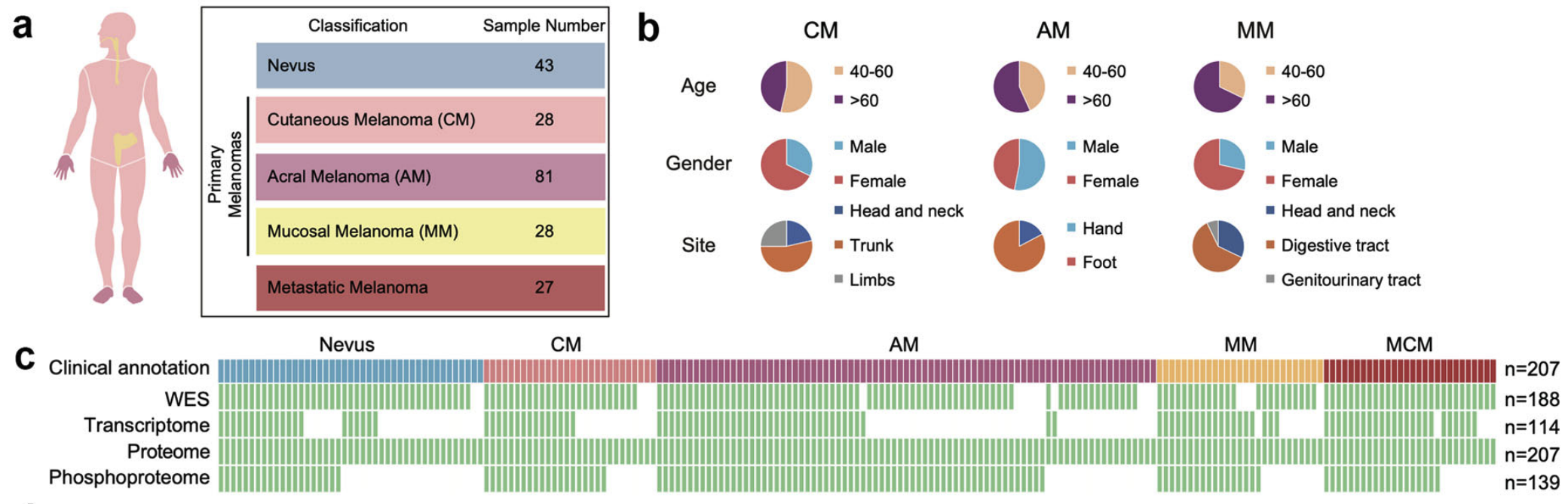
复旦大学丁琛团队等通过对包含肢端、皮肤、黏膜等亚型的207例中国黑色素瘤患者队列进行多组学整合分析,系统描绘了其蛋白基因组图谱。研究揭示了与不良预后相关的SBS7a突变特征及PRKDC基因扩增通过激活叶酸代谢促进肿瘤增殖的机制,并建立了与预后相关的蛋白质组分子分型及免疫分型,为黑色素瘤尤其是亚洲高发亚型的精准治疗提供了新的潜在靶点和分型依据。
2、Nat Mach Intell | 清华大学自动化系闾海荣等发表精准病理诊断AI基础模型,可实现对胶质瘤多种分类任务的准确诊断
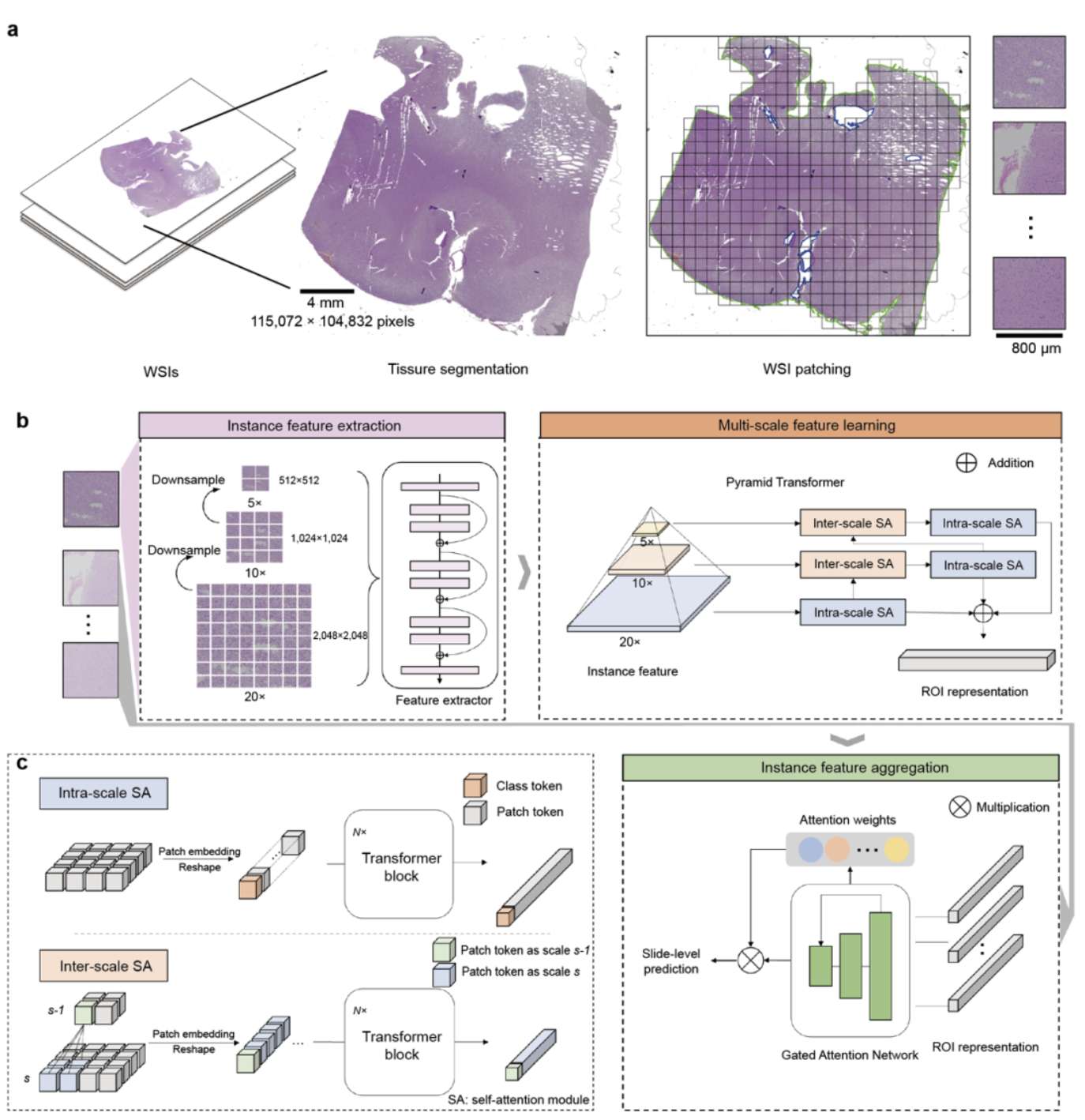
清华大学等研究团队提出了一种名为ROAM的弱监督计算病理学AI基础模型。该模型通过采用大尺寸组织图像块作为分析单元,并利用金字塔Transformer架构系统学习尺度内及尺度间的相关性特征,从而高效提取百亿像素级全切片病理图像的多尺度视觉表征。ROAM在胶质瘤的肿瘤检测、亚型分类、分级和分子特征(如IDH突变)预测等多种诊断任务上实现了临床级的高性能与良好泛化能力,其提供的可视化依据不仅能辅助病理医生提升诊断准确性,还有助于发现与分子特征相关的形态学标志物。
3、Nat Genet | 基于WGS数据绘制癌症进展过程中ecDNA扩增图谱,揭示抗癌新靶点
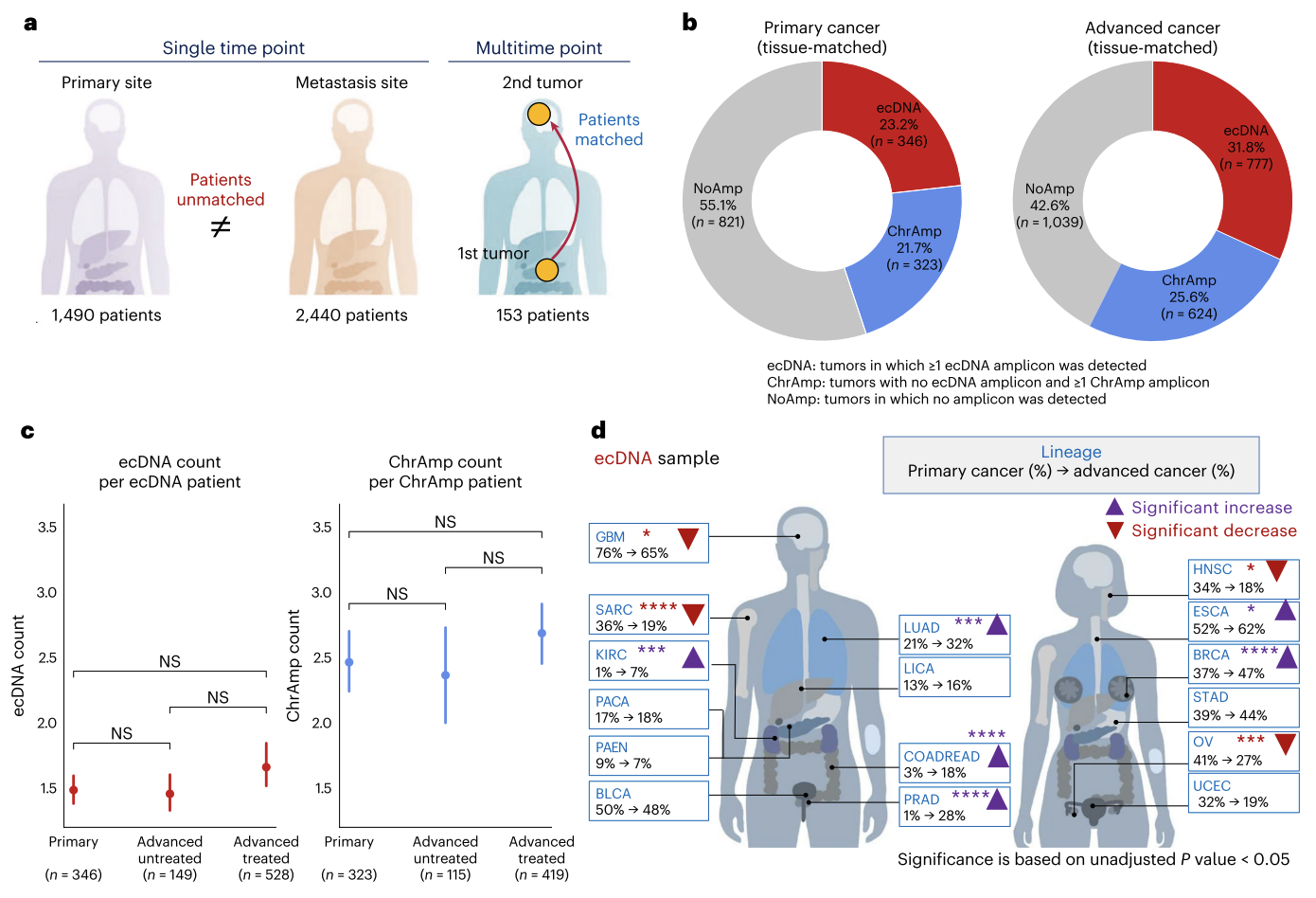
耶鲁大学医学院等研究团队通过对8060个涵盖新诊断原发性、未经治疗转移性及经治疗肿瘤的全基因组测序数据进行统一分析,系统绘制了癌症进展中染色体外DNA(ecDNA)的扩增图谱。研究发现,与早期肿瘤相比,未经治疗的转移瘤和接受过治疗的晚期肿瘤中ecDNA的出现频率显著升高,其中微管蛋白抑制剂治疗与ecDNA增加的相关性最强。研究还揭示,在肿瘤进展过程中,ecDNA相较于染色体扩增(ChrAmp)更有可能被克隆选择所保留,且其更易积累局部高突变事件。这些发现确立了ecDNA作为癌症进展的关键驱动因素和潜在治疗靶点。
20世纪70年代,克努森提出“二次突变假说”解释视网膜母细胞瘤的成因。80年代中期,麻省眼耳医院的萨德·德里亚医生通过建立肿瘤样本库并利用DNA探针技术,在肿瘤细胞中定位到第13号染色体上的关键缺失片段。随后,他与怀特黑德研究所的史蒂夫·弗兰德合作,于1986年在《自然》杂志上正式确认了该基因——即视网膜母细胞瘤易感基因(Rb)。这一发现不仅揭示了该儿童眼癌的遗传机制,更首次鉴定出一个具有广泛意义的抑癌基因,其功能失活被证明与多种成人癌症(如肺癌、乳腺癌)的发生密切相关,为理解细胞周期失控和肿瘤发生奠定了基石。
数据驱动的研究范式(如GWAS)作为传统假设驱动范式的必要补充,其产出的优质数据具有“长尾效应”,能随时间持续产生价值。当前真正的“浪费”在于数据共享机制的不足,导致大量数据被封闭,未能像TCGA等项目那样通过开放共享激发巨大的科研倍增效应。因此,提高数据整合与开放水平,才是释放测序数据价值、对科研资源负责的关键。
6、利用MCP在Cursor中访问Obsidian数据进行交互
通过安装Node.js、MCP-Obsidian连接器并进行相应配置,实现了让AI助手(如Copilot)读取和搜索Obsidian笔记的功能。
7、Sniffnet
一款可以跨平台使用的、可以便捷监控网络流量的应用程序。
8、legendry
ggh4x是一个专注于扩展和增强ggplot2中“引导元素”(guides,如坐标轴、图例、颜色条)的R语言扩展包。它通过重新实现现有引导元素来提供更强大的自定义功能(如灵活调整刻度位置、格式和分面参数),并引入了全新的引导元素类型(如针对二元变量或嵌套刻度的图例),旨在帮助用户,特别是在处理具有复杂分层结构或多维度的生物信息学数据时,创建信息更丰富、展示更精确的统计图形。
该工具实现了自动化工作流:每日抓取arXiv上的新论文,使用人工智能模型对其生成摘要,并将结果部署到GitHub Pages上完成可视化呈现。
10、Cell Host & Microbe | 人体肠道微生物蛋白质结构组数据库
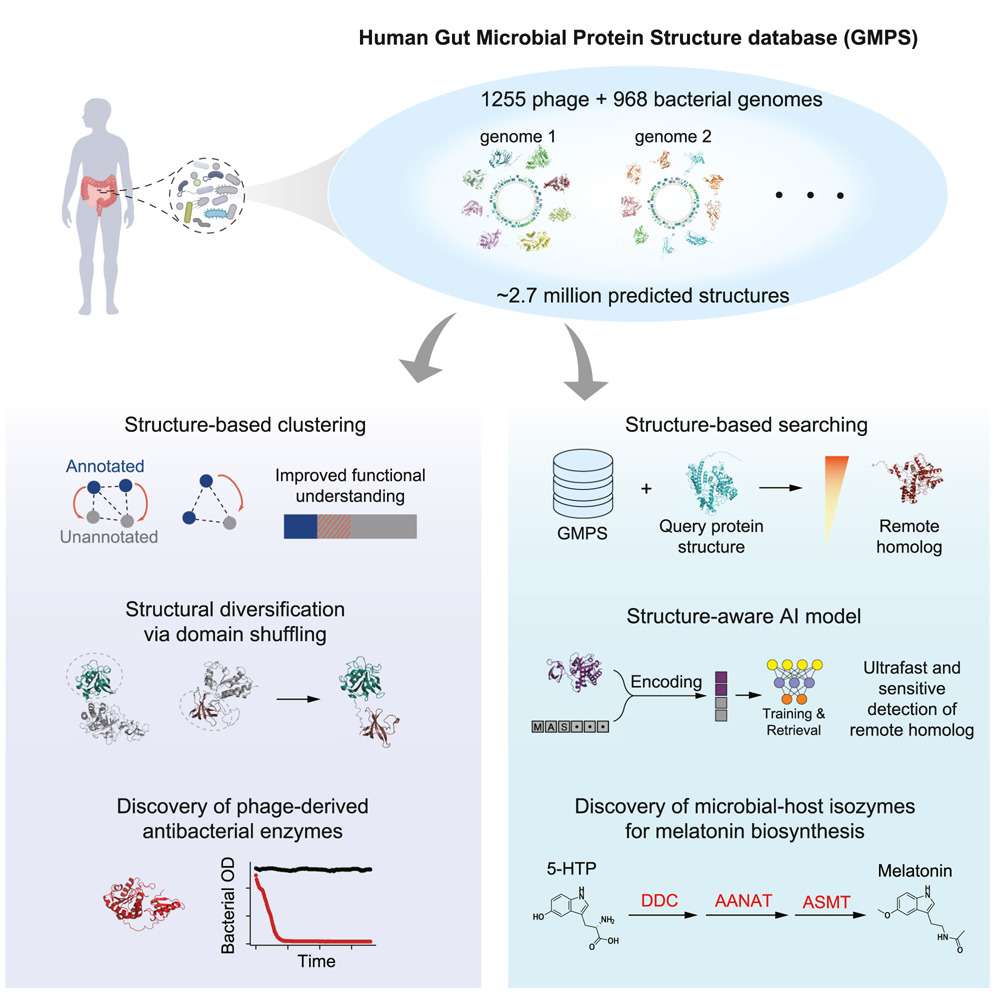
该研究建立了人体肠道微生物的蛋白质结构组数据库和结构检索方法,显著提高了对噬菌体蛋白、菌源宿主同工酶等功能暗物质的预测能力。基于这一方法,研究团队成功验证了肠道致病菌的噬菌体裂解酶,并首次揭示了肠道细菌的褪黑素合成途径。
11、Advanced Science | 多物种单细胞AI数据库

中国科学院计算机网络信息中心与动物研究所等团队联合发布了scCompass数据库。该数据库整合了覆盖人类、小鼠等13个物种、超过1亿个高质量单细胞的转录组数据,旨在为生命科学领域的大模型研发和基础生物学研究提供高标准、一站式的数据底座与服务。
「Openbiox 生信周刊」运维小队:
这个周刊每周日发布,同步更新在微信公众号「生信协作组」(elegant-r)上。
微信搜索“生信协作组”或者扫描二维码,即可订阅。
 (完)
(完)
2025-12-14 19:38:19
这里记录值得分享的生信相关内容,每半月发布。
本杂志开源(GitHub: openbiox/weekly),欢迎提交 issue,投稿或推荐生信相关内容。

许多数据驱动研究面临的核心问题并非分析工具不足,而是样本量受限导致效应被夸大、结果难以重复。在这一背景下,单纯追求更大样本并不总是可行或必要。通过在研究设计阶段优化样本构成、控制混杂因素并采用合适的统计模型,可以在有限样本条件下提高结果的稳健性与可重复性。这使得实验设计本身成为确保研究结论可靠性的关键环节。
1、Cell | 刘光慧团队破译运动抗衰密码,确定首个“运动模拟物”——甜菜碱,开拓科学抗衰新路径
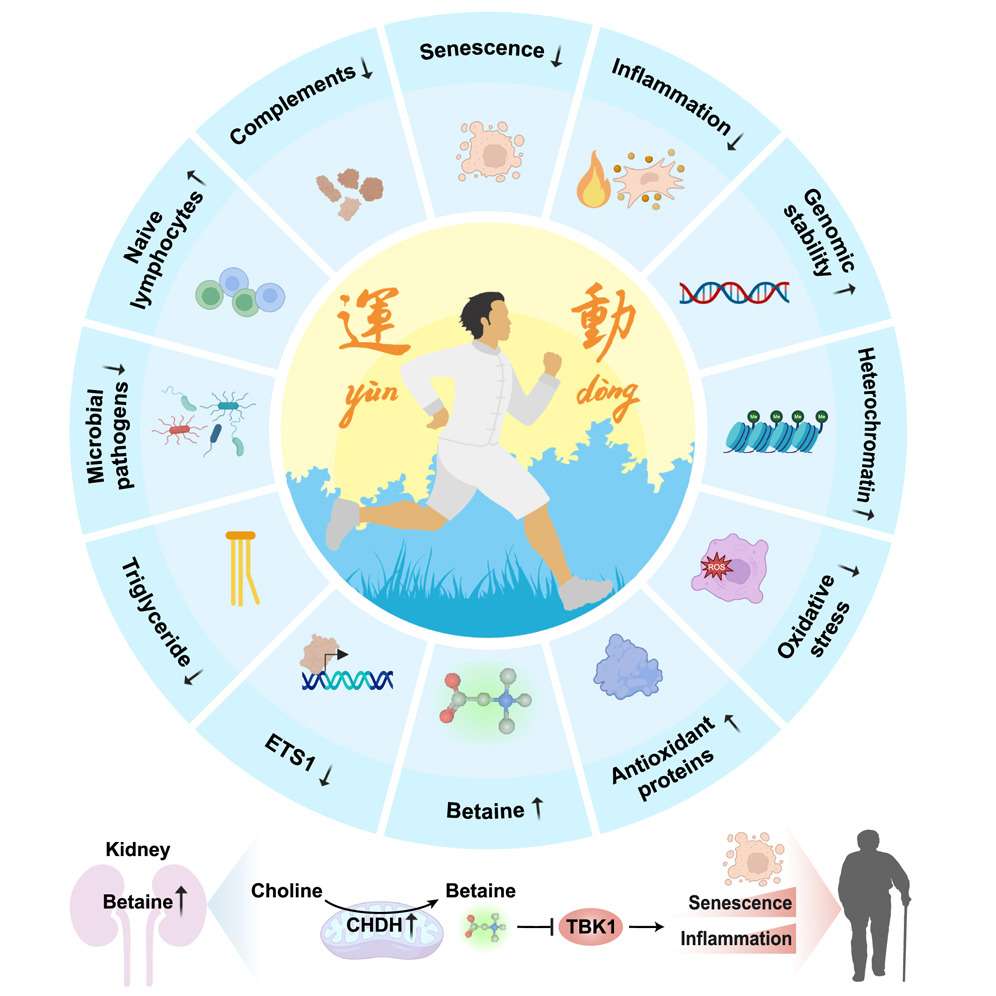
该研究系统性地剖析了运动重塑人体生理、延缓衰老的关键分子枢纽。“运动模拟物”甜菜碱不仅能精准模拟运动的抗炎与衰老保护效应,还能规避运动相关损伤风险,为老年群体开辟新型健康增益策略。
2、Nat Methods | MassQL规范了代谢组数据分析,帮助研究者更好的解读代谢组数据,寻找未发现的代谢物
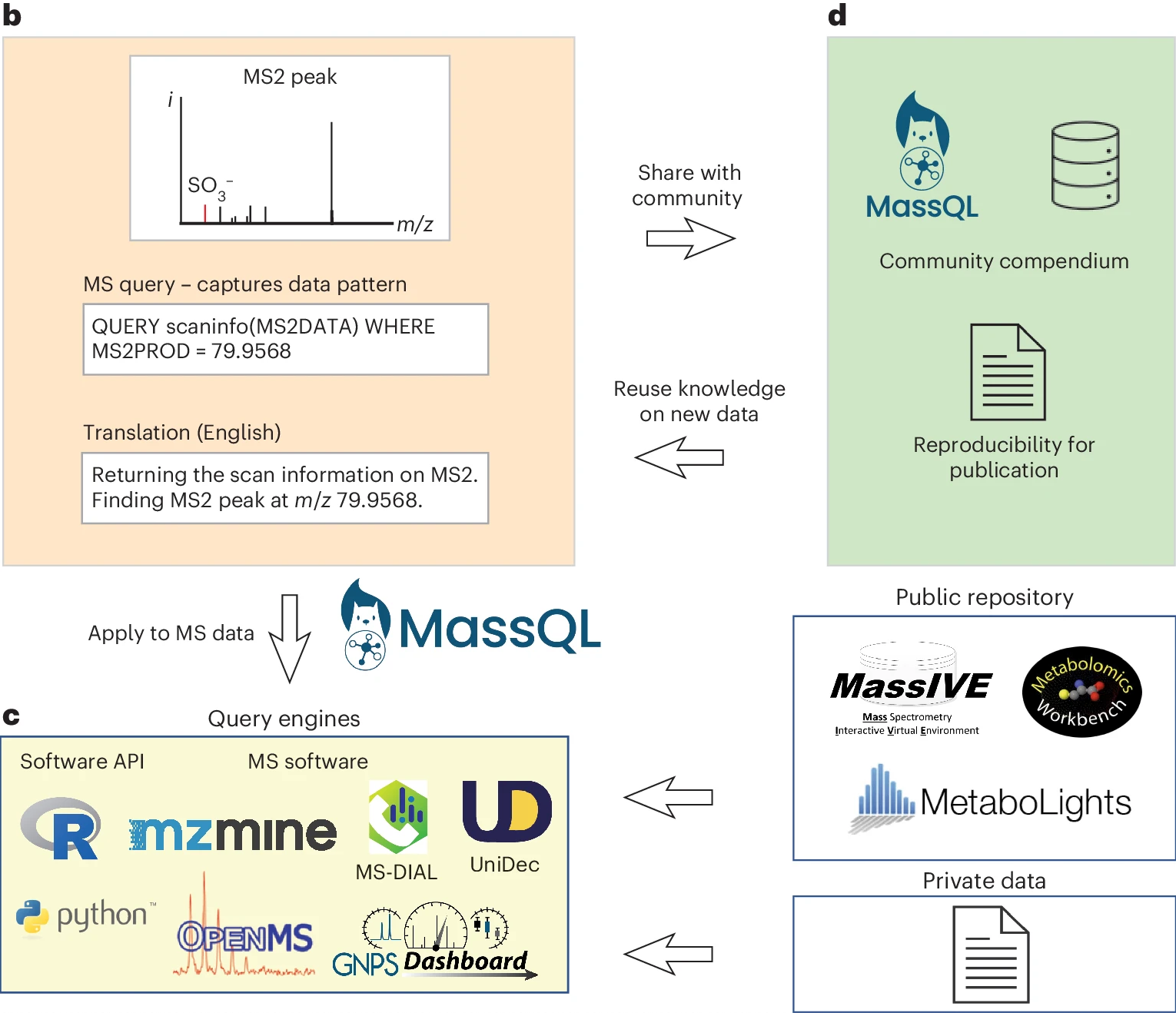
该研究提出了一种通用的质谱查询语言——Mass Spectrometry Query Language (MassQL),旨在解决当前质谱数据挖掘遗漏,脚本扩展性低和可重复性不足的问题。MassQL 提供了一个可表达、可复用的查询语言体系,用于识别并挖掘质谱数据中的特征模式,包括母离子峰、同位素模式、碎片特征等。它使科学家能够以统一的方式高效检索公共质谱数据库中的信息,促进跨研究领域的再分析与新发现。
3、Genome Biol | 基于单细胞和批量转录组学扩展人类蛋白编码基因的全基因组表达图谱,涉及所有主要组织和器官
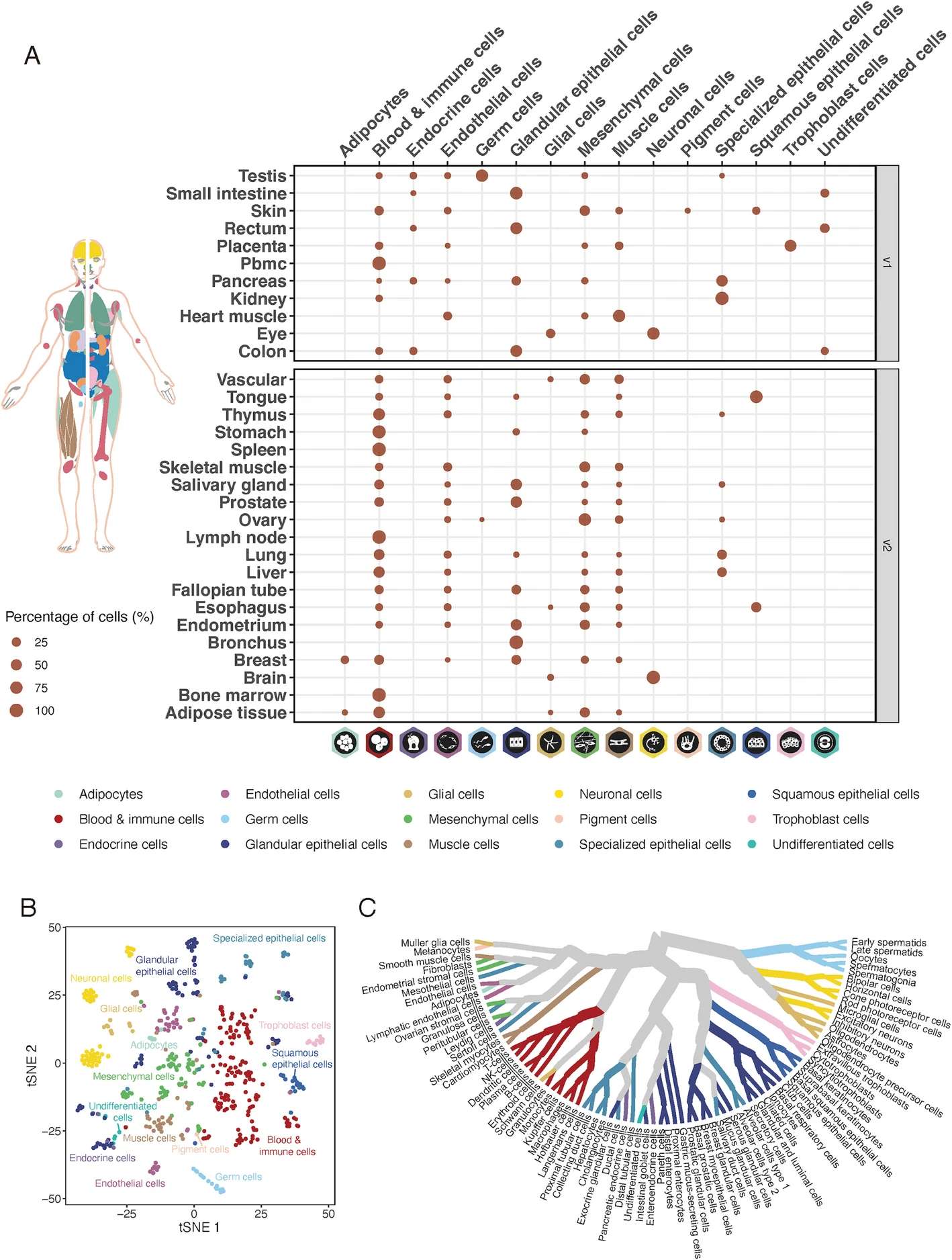
研究团队利用单细胞转录组测序和批量转录组测序,扩展了涉及所有主要人体组织和器官中蛋白质编码基因的全基因组资源。所有结果都可以在更新的开放获取人类蛋白质图谱(HPA)的单细胞类型部分获得,该部分新增了17种新组织和37种新细胞类型,拓宽了对细胞多样性和复杂转录组学的了解,为探索这些组织和细胞类型中所有蛋白质编码基因的单细胞类型数据提供了公开工具。
4、英国政府启动OpenBind,构建全球最大蛋白小分子交互数据库,重塑AI药物研发

本文介绍了英国政府启动的 OpenBind 计划,旨在构建全球最大规模的蛋白-小分子相互作用数据库,为 AI 药物研发提供高质量数据基础,推动 AI 制药进入系统化、规模化发展的新阶段。
本文系统梳理了机器学习因果推断中治疗异质性分析的 R 与 Python 工具体系,对比了两大生态在方法框架、代表性工具、应用场景与部署能力上的差异,并结合医疗健康等实际案例分析其优势与局限,为不同研究与应用场景下的工具选择提供参考。
6、R包HPAanalyze:从 HPA 自动化批量下载数据并进行探索性分析
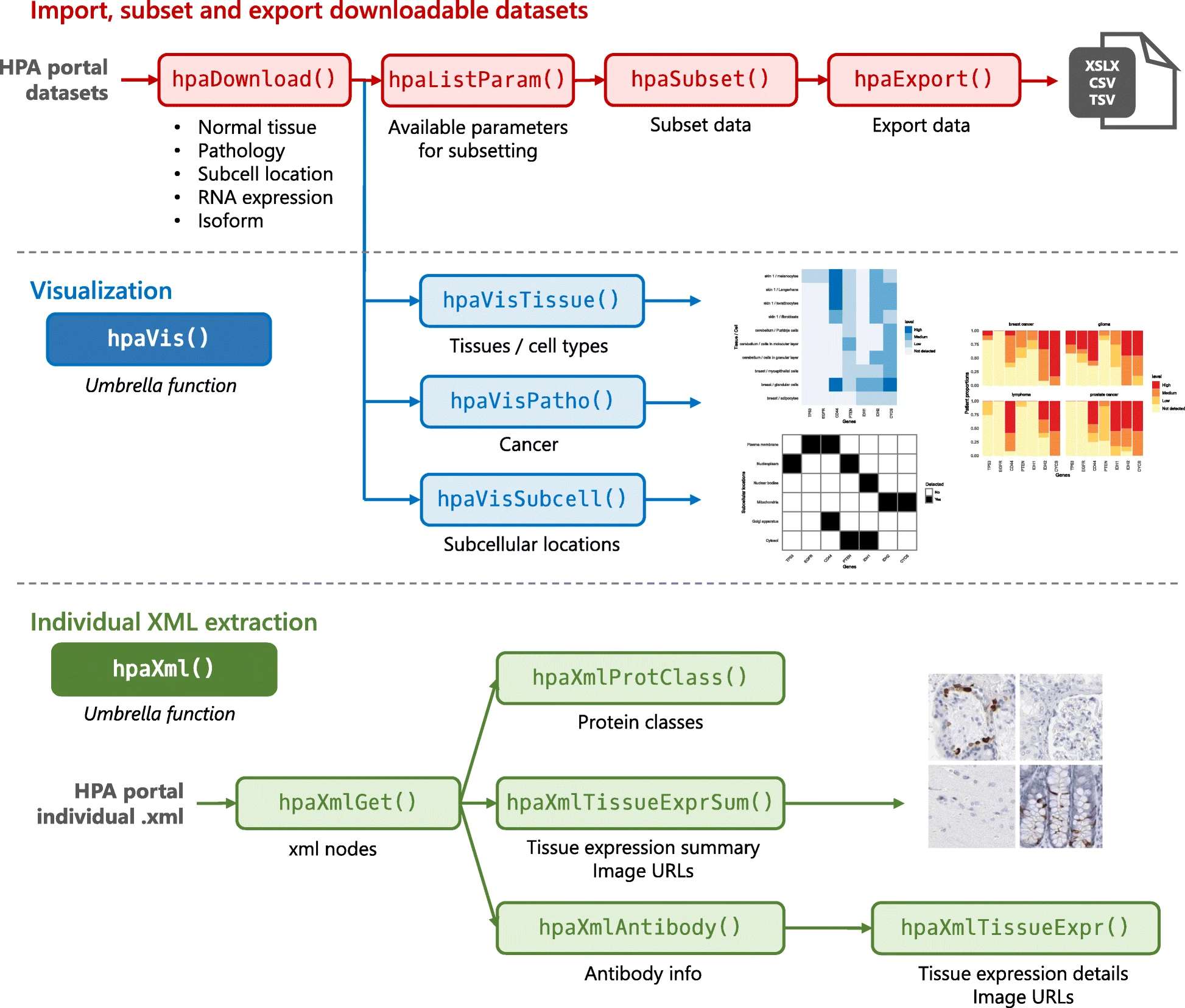
本文介绍了R包HPAanalyze,该包用于从Human Protein Atlas(HPA)数据库中下载、解析与可视化蛋白表达数据,并结合 EGFR 示例展示了其在蛋白类别、组织表达、抗体信息及免疫组化图像获取中的实际应用。
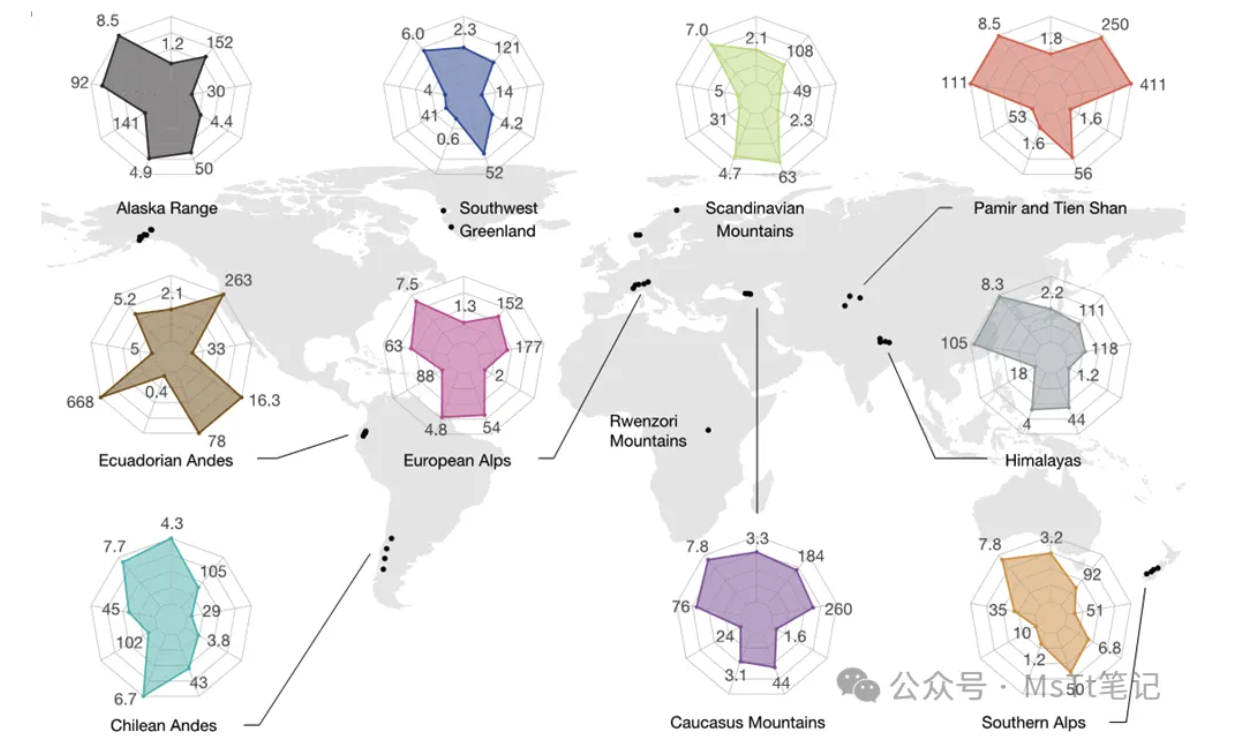
本文介绍了如何在 R 中复现多边形雷达图、分面雷达图以及带外圈注释的雷达图,结合顶级期刊实例,总结了雷达图标注、分面与布局等常见复现技巧。
8、Sceptic:面向时序单细胞测序与成像数据的伪时间分析新工具
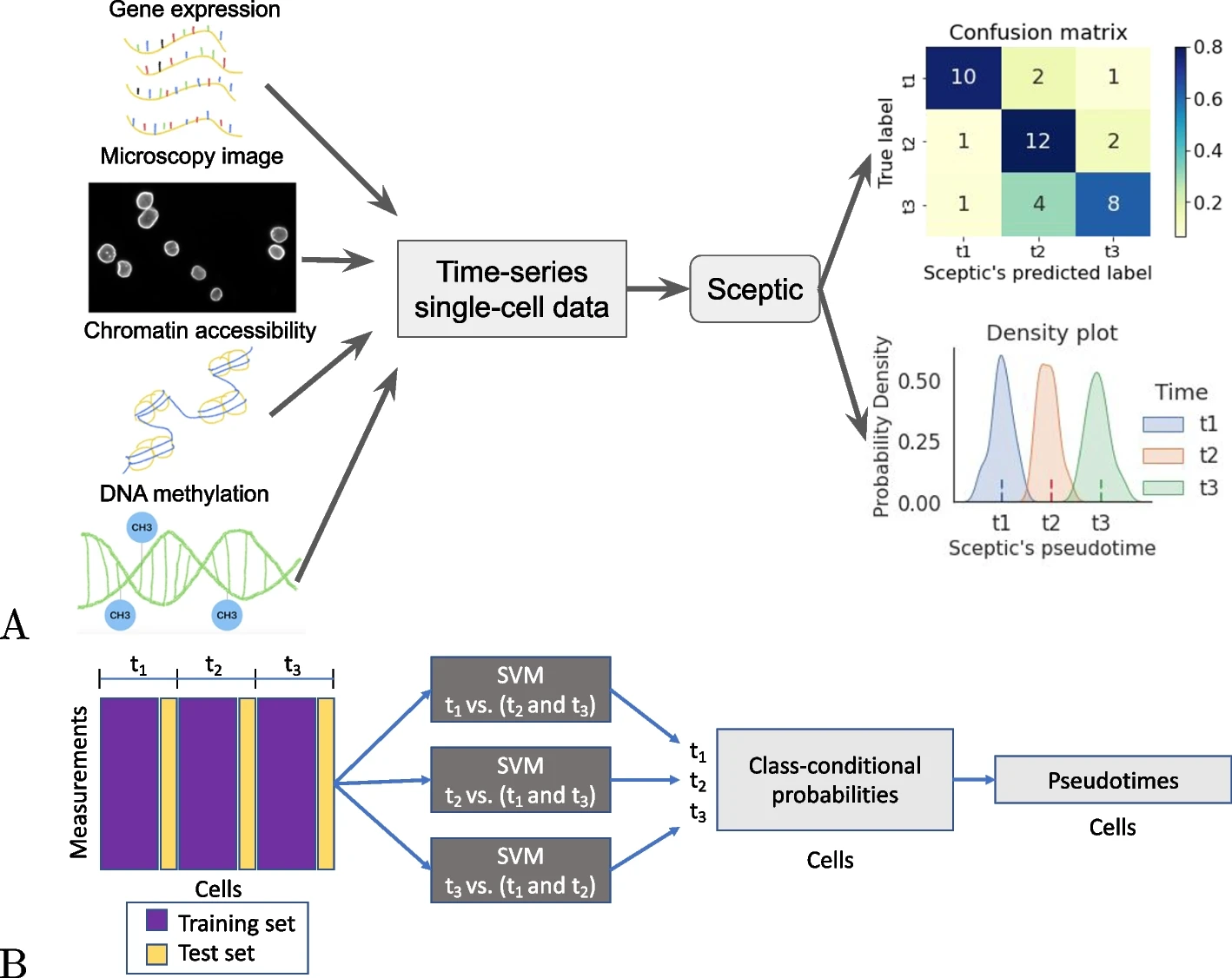
Sceptic 是一种基于支持向量机(SVM)的有监督伪时间分析方法,可用于时间序列的 scRNA-seq、scATAC-seq 及单核显微图像数据,在多模态单细胞数据中表现出较高的时间推断准确性。
9、 mLLMCelltype: 利用多个大语言模型共识进行单细胞RNA测序细胞类型注释的Python框架

mLLMCelltype 是一个创新的Python框架,用于单细胞RNA测序 (scRNA-seq) 数据的细胞类型自动注释。该工具通过多个大语言模型的迭代共识方法,显著提高注释准确性并提供可靠的不确定性量化指标。
10、盘点“低成本实现分子动力学模拟”的Web工具或本地工具
iMODS、ProDy、WebNMA 和 CABS-flex 2.0 等工具提供了基于 NMA 与弹性网络模型的蛋白构象变化与柔性分析方案,能够在无需高性能计算资源的情况下实现对蛋白动力学特征的快速探索。
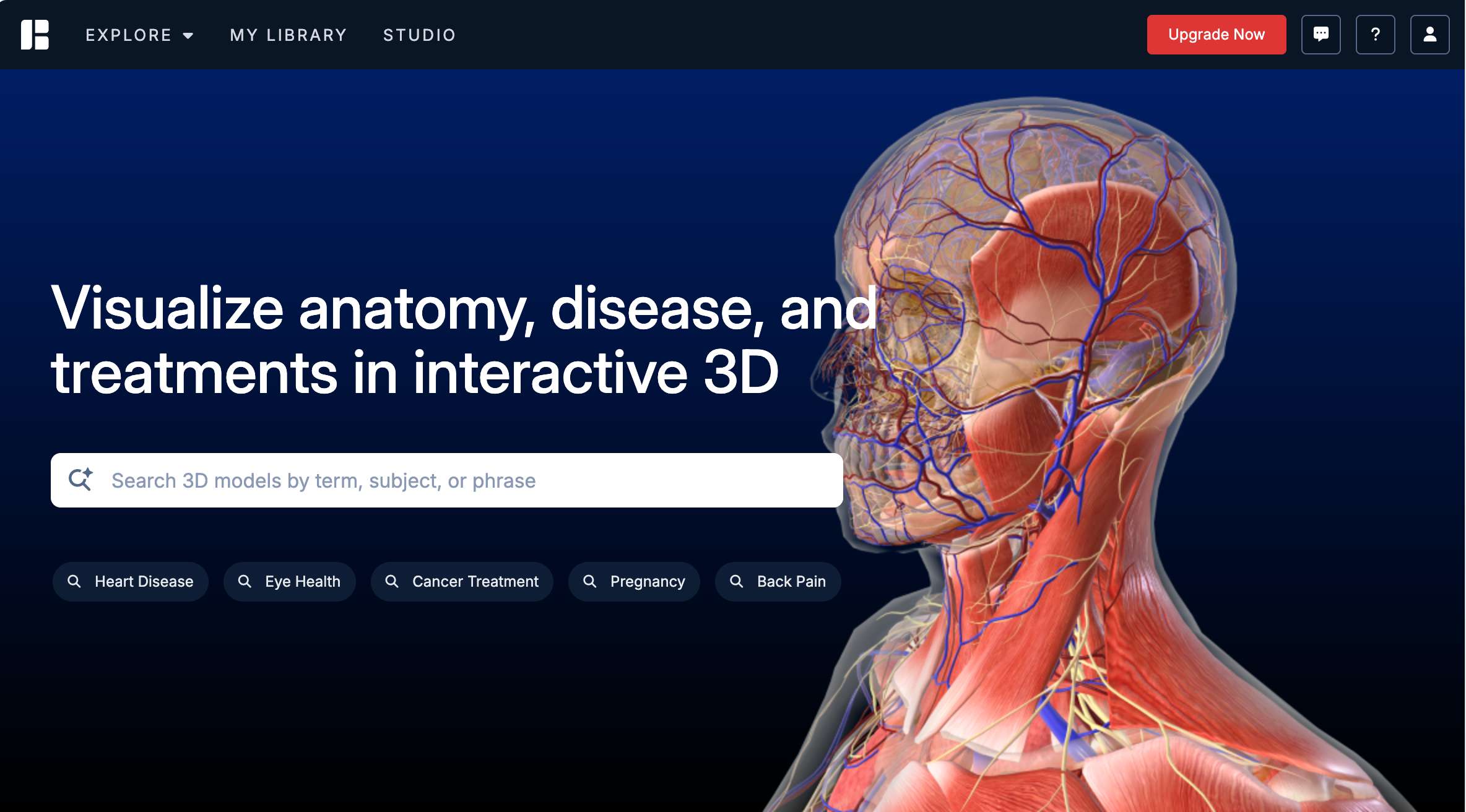
BioDigital Human平台相当于一个精确的数字医学人体虚拟地图。主要内容包括8000多个解剖结构3D模型动画和视频,600多个3D健康状态、疾病状态和治疗模型,以及一个用于创建特定视图和模型的工具包Human Studio。可帮助用户以直观的方式理解和掌握解剖学、病理学以及治疗学的相关知识。
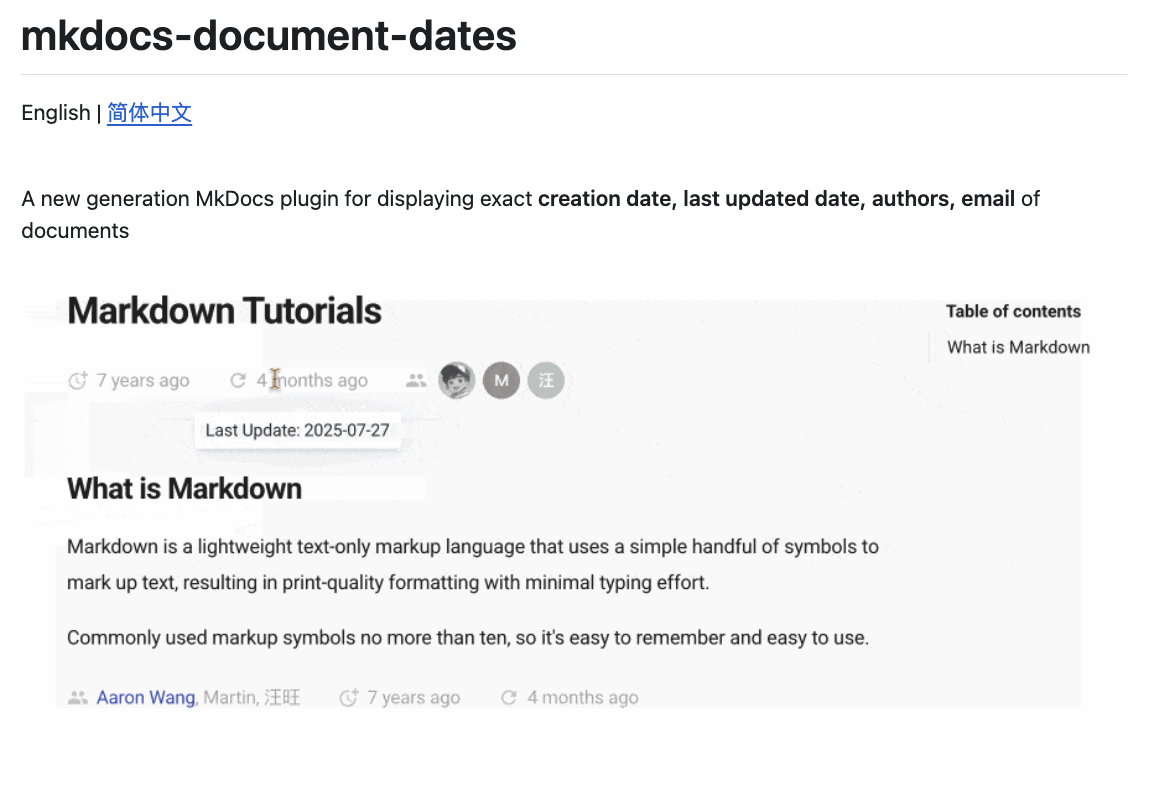
新一代用于显示文档确切创建日期、最后更新日期、作者、头像、邮箱等信息的 MkDocs 插件。
13、Enseqlopedia
Enseqlopedia 是一个面向 NGS 领域研究者与技术人员的综合性社区资源平台,整合了博客、用户地图和协作式 wiki,用于交流测序技术、实验经验与实践知识。
「Openbiox 生信周刊」运维小队:
- @ShixiangWang(王诗翔)
- @kkjtmac(阚科佳)
- @NiEntropy(赵启祥)
- @He-Kai-fly(何凯)
- @JnanZhang(张佳楠)
- @Tomcxf(陈啸枫)
- @wangdepin(王德品)
- @kongjianyang(空间阳)
- @donghongyu2020(董弘禹)
- @DrRobinLuo(罗鹏)
- @Wangcy-rachel(王春阳)
- @zoe3251(舒晨阳)
- @yanbin85(严彬)
- @MadDERt(王章宇)
- @yepu03(孙裕钧)
这个周刊每周日发布,同步更新在微信公众号「生信协作组」(elegant-r)上。
微信搜索“生信协作组”或者扫描二维码,即可订阅。

(完)
2025-12-10 11:32:42
这里记录值得分享的生信相关内容,每半月发布。
本杂志开源(GitHub: openbiox/weekly),欢迎提交 issue,投稿或推荐生信相关内容。

探究肿瘤组织样本在分子尺度上的空间分布的技术正在推动癌症研究的革命,但是庞杂的技术让人感到困扰.
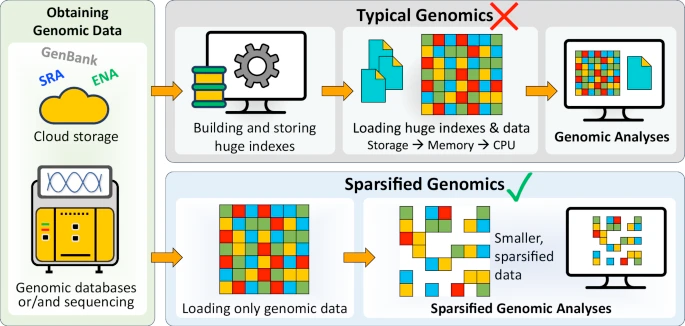
随着基因组测序数据呈指数级增长,现有的计算发放在寻找相似的基因组序列上显得力不从心。为了解决这个问题,文章提出稀疏基因组学的概念,其通过排除基因组序列中的大量碱基,生成更短、更稀疏的序列,从而减少计算负载和内存占用。这种方法能够加速基因组分析,能在保持高准确性的前提下,显著减少存储空间的需求。 - 论文链接:https://doi.org/10.1038/s41467-024-55762-1
2、iMetaOmics | 同济/上海交大-开发支持群体分组分析的宏基因组测序综合分析软件

该软件是一个针对宏基因组鸟枪法测序的综合分析软件,同时包含了群体分组分析。它包括14个模块,拥有超过50个功能,与现有的17种宏基因组鸟枪法测序(whole-metagenome shotgun sequencing,WMGS)工具相比,因其全面性而脱颖而出。OUTPOST为多组实验设计和基于荟萃分析的生物标志物鉴定引入了创新方法。 - 论文链接:https://onlinelibrary.wiley.com/doi/abs/10.1002/imo2.29
3、Nature Genetics | 整合分析揭示三维基因组与DNA、RNA和表观遗传改变之间在转移性前列腺癌中的相互作用!
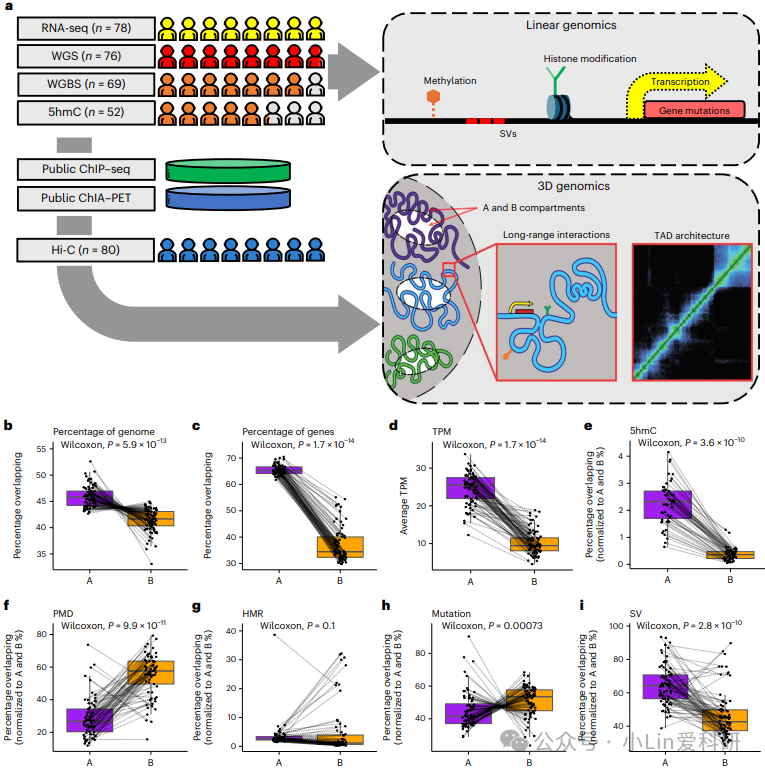
该研究通过深度 WGS、WGBS、RNA-seq等多种全基因组方法对 80 例 mCRPC 活检样本进行了分析,并揭示了癌症中常见的基因组、表观基因组和转录组改变与基因组三维拓扑结构之间的相互作用。 - 论文链接:https://doi.org/10.1038/s41588-024-01826-3
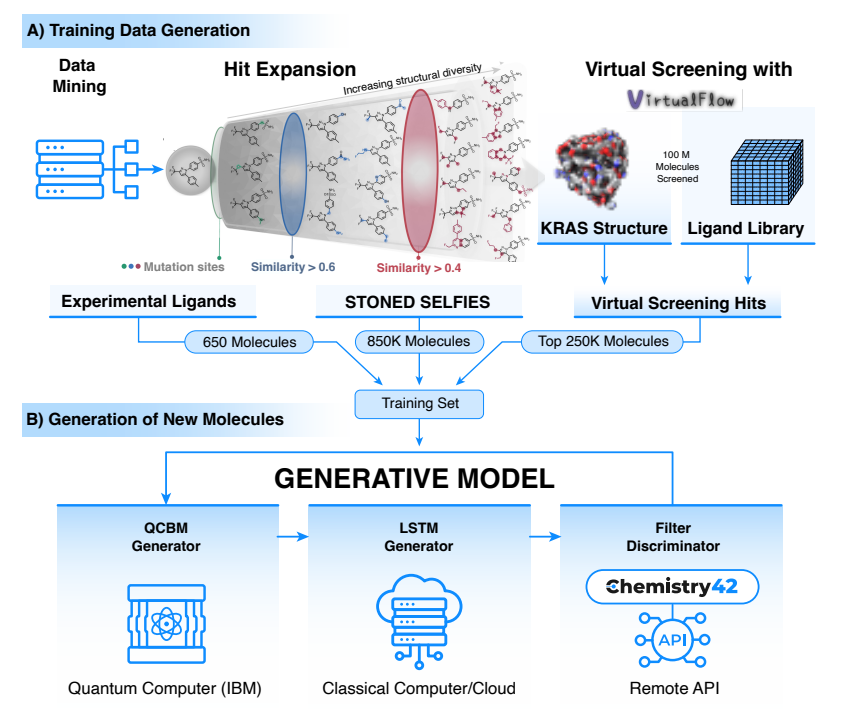
2025年1月22日发表在Nature Biotechnology杂志上的一项研究中,英矽智能与来自多伦多大学、圣裘德儿童研究医院等机构的科学家们将量子计算模型与经典计算模型和生成式人工智能相结合,通过对庞大数据集的训练、生成和筛选,探索更广泛的化学可能性,发现了靶向“不可成药”癌症驱动蛋白KRAS 的新颖分子。该研究首次展示了量子计算和人工智能在变革药物发现流程方面的潜力。 - 论文链接:https://www.nature.com/articles/s41587-024-02526-3
5、有偿论文“捉虫”:发现已发表论文中的错误可获得奖励 |《自然》职场

关于科学界的自我纠错能力,Malte Elson直言:”我们目前处理错误的方式是无效的。”ERROR项目是一个旨在系统性检测并纠正已发表心理学论文中错误的计划,通过向评审员支付报酬来检查高影响力论文的代码、统计分析和引用错误,并向提供数据和配合的作者提供补偿。项目优先选择高引用论文以扩大影响,并希望建立一种可推广的模式。目前面临作者参与度低、数据获取困难和寻找合格评审员等挑战,团队正寻求扩展至其他学科(如人工智能和医学),并呼吁研究资助机构为错误评审提供资源支持,认为系统性审查能提高科研经费的效益。

几乎所有人在数据分析中都关心一个问题,即样本量最低要多少。2020年发表在《PLOS ONE》的一篇题为《A solution to minimum sample size for regressions》的文章论述了在一般线性回归和meta 回归中,最低样本量应该是多少,模型结果就既能反映数据的实际格局,又具有较高的可重复性。
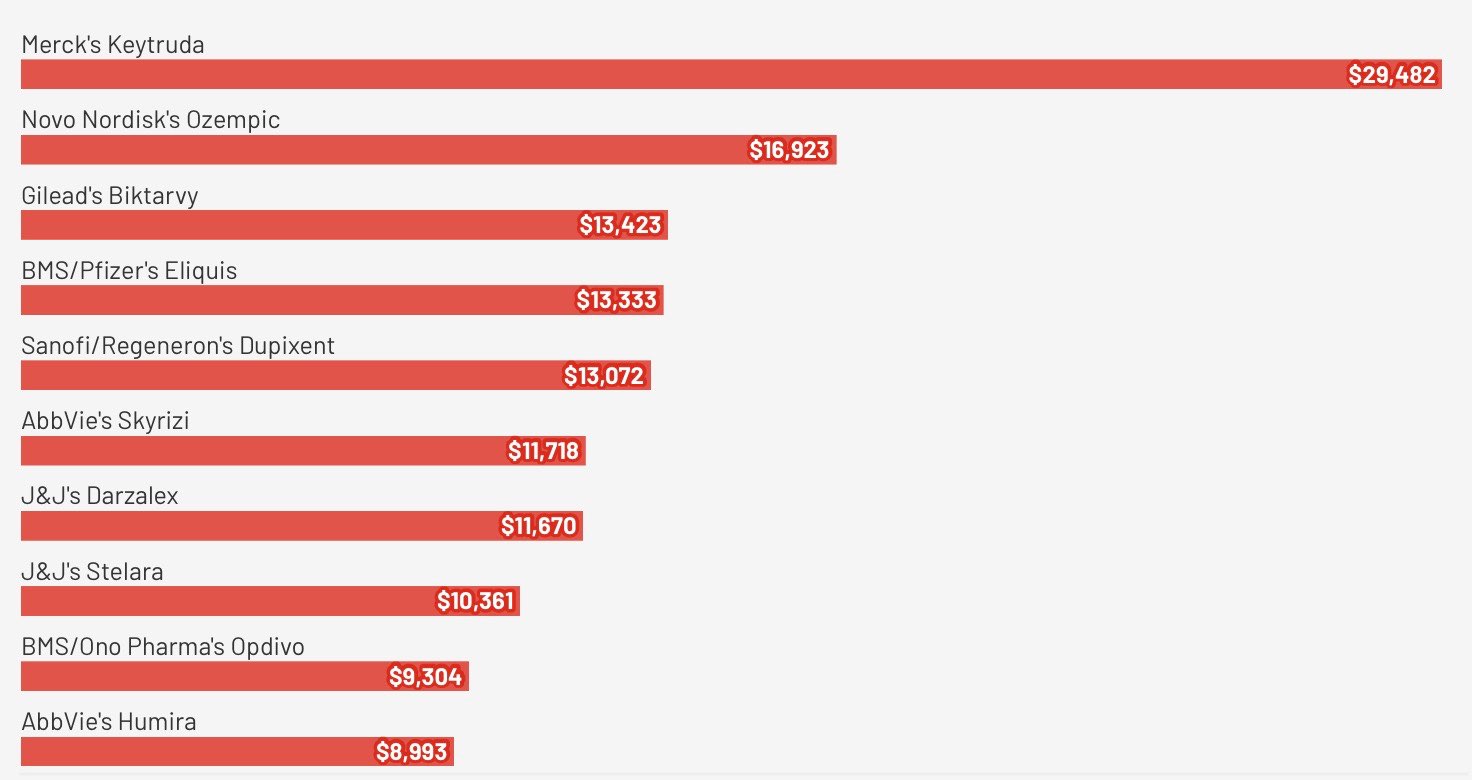
BioSpace盘点了2024年销售额最高的10大医药产品。
Docker Image Puller 是一个方便的工具,用于从 Docker 仓库拉取镜像,支持国内镜像源加速和多架构支持。该工具采用 MIT 许可证,开放源代码,方便用户根据需要进行定制和扩展。

AigcPanel 是一个简单易用的一站式AI数字人系统,小白也可使用。 支持视频合成、声音合成、声音克隆,简化本地模型管理、一键导入和使用AI模型。
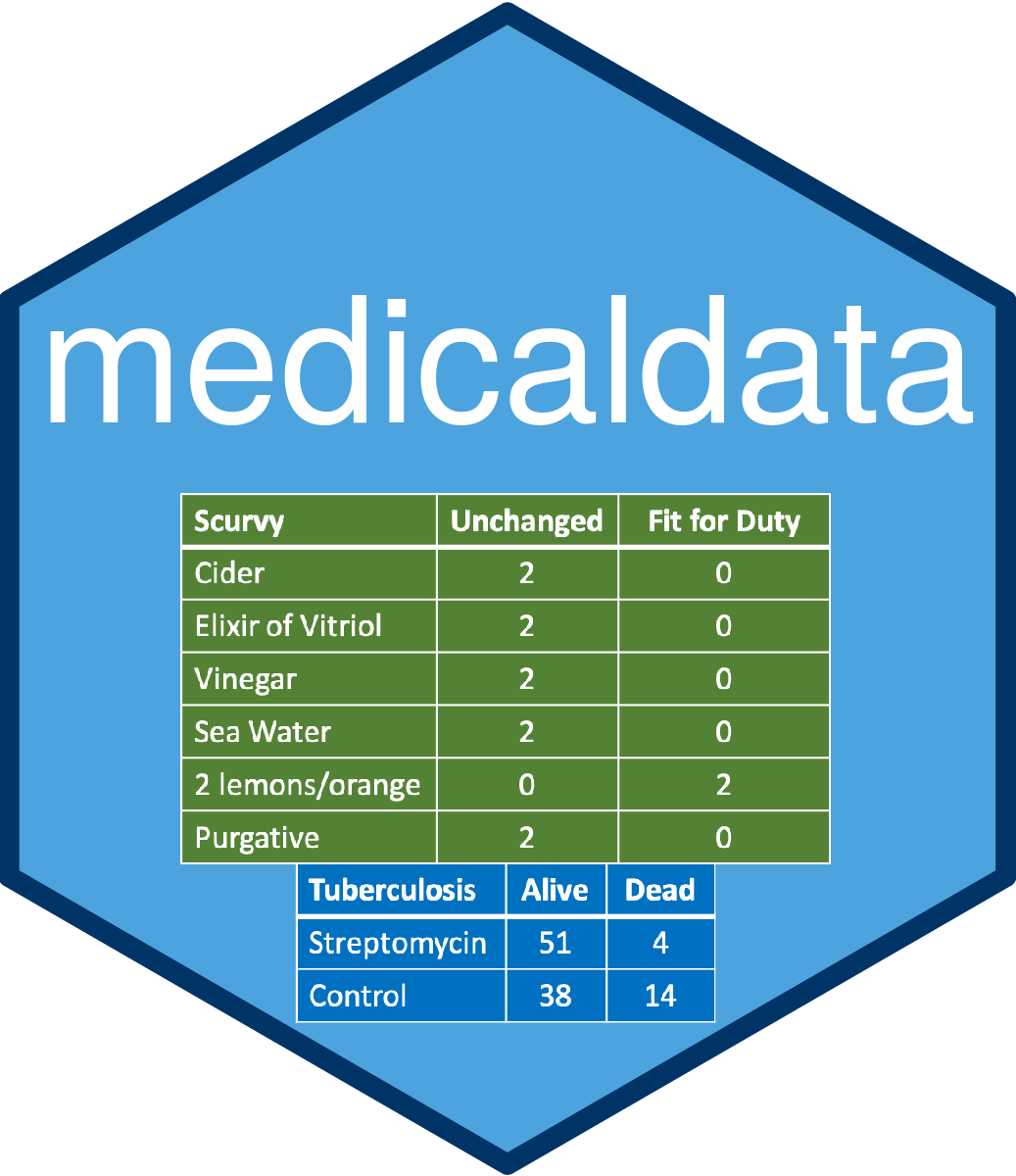
MedicalData是一个专为医学领域打造的数据练习题库,包含15个医学数据集,从几百年前的坏血病研究到最新的新冠检测数据,覆盖经典案例与现代临床试验。其核心目标是帮助医生、护士、药师、医学生等从业者,通过R语言实践可重复研究。
11、硬核基础科研系列汇总
推文汇总了细胞与分子生物学,分子克隆,qPCR等基础的科研知识。
国家生物信息中心 是我国生物信息领域的核心平台,致力于推动生物大数据的统一汇交、集中存储与安全共享,为科学研究和成果转化提供坚实支撑。
「Openbiox 生信周刊」运维小队: - @ShixiangWang(王诗翔) - @kkjtmac(阚科佳) - @NiEntropy(赵启祥) - @He-Kai-fly(何凯) - @JnanZhang(张佳楠) - @Tomcxf(陈啸枫) - @wangdepin(王德品) - @kongjianyang(空间阳) - @donghongyu2020(董弘禹) - @DrRobinLuo(罗鹏) - @Wangcy-rachel(王春阳) - @zoe3251(舒晨阳) - @yanbin85 (严彬) - @MadDERt(王章宇)
这个周刊每周日发布,同步更新在微信公众号「生信协作组」(elegant-r)上。
微信搜索“生信协作组”或者扫描二维码,即可订阅。
(完)
2025-11-16 17:00:55
这里记录值得分享的生信相关内容,每半月发布。
本杂志开源(GitHub: openbiox/weekly),欢迎提交 issue,投稿或推荐生信相关内容。

单细胞基因表达数据(如scRNA-seq数据)虽然噪声较高,但仍包含足够的基因型信息,使得通过eQTL关联预测基因型并跨数据集链接到个体成为可能,从而带来此前被低估的隐私泄露风险。
1、Science | 单细胞染色质开放性“提纯”肿瘤“调控程序”
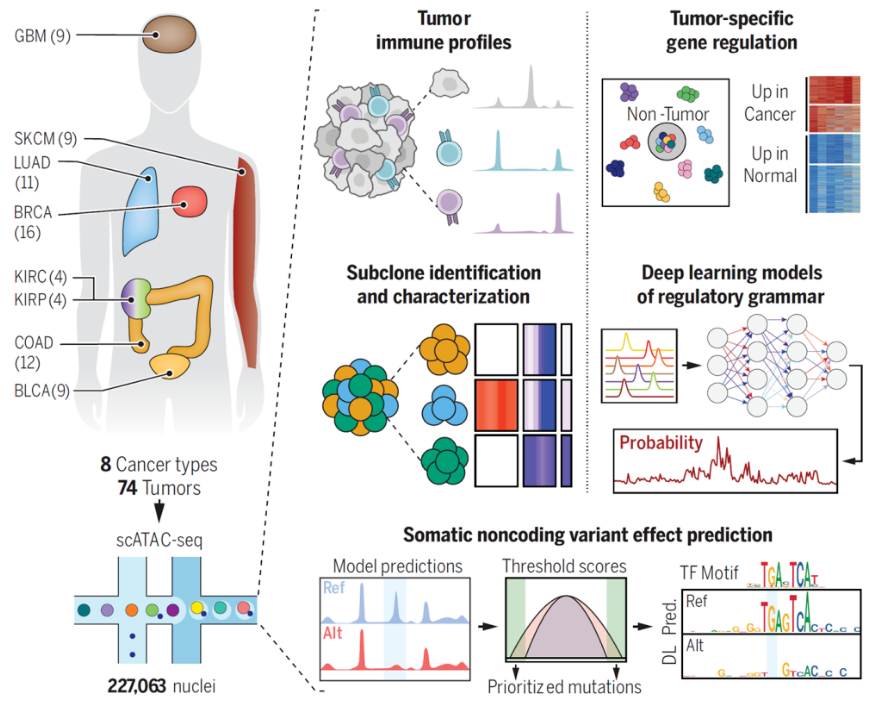
该研究利用TCGA样本构建了跨8种癌症、22.7万细胞核的单细胞染色质可及性图谱,区分出癌细胞与微环境细胞,并训练可解释深度学习模型,揭示癌症特异性调控语法、亚克隆差异及非编码突变对染色质可及性的功能性影响,为解析人类原发癌恶性表型的分子程序提供新资源。 - 论文链接:https://www.science.org/doi/10.1126/science.adk9217
2、Bioinformatics | Pangene:李恒开发泛基因图谱构建工具——探索群体基因组时代研究新方向
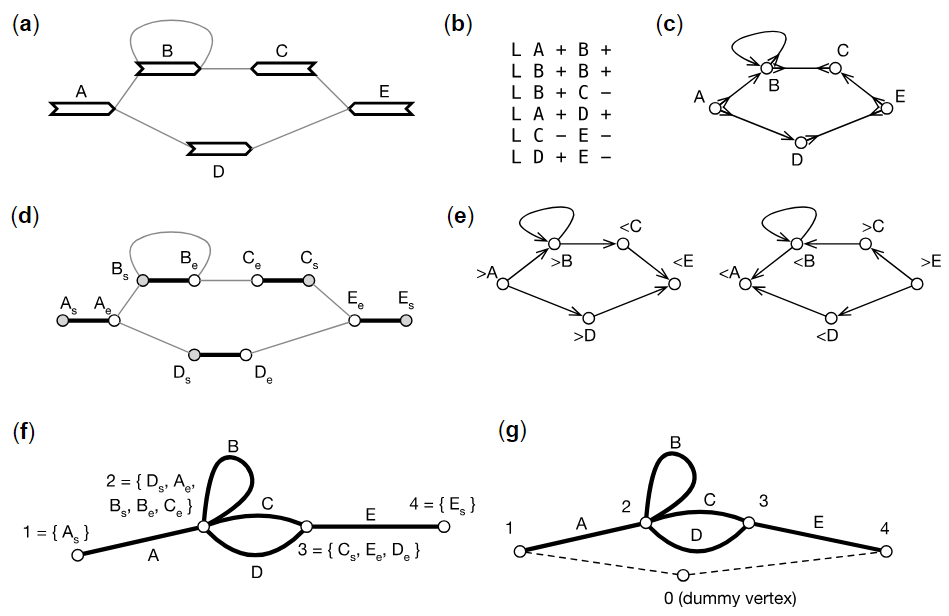
该研究开发了全新工具 Pangene,它能够基于单倍型群体基因组学数据,一站式解析并可视化基因结构变异,把所有变异整合成一张“全景图”,精准呈现整个类群的遗传多样性。 - 论文链接:https://academic.oup.com/bioinformatics/article/40/7/btae456/7718494#476450906
3、上科大团队带来“双子座”模型,AI筛选药物如何实现“集百家之长”? | 上海国际计算生物学创新大赛
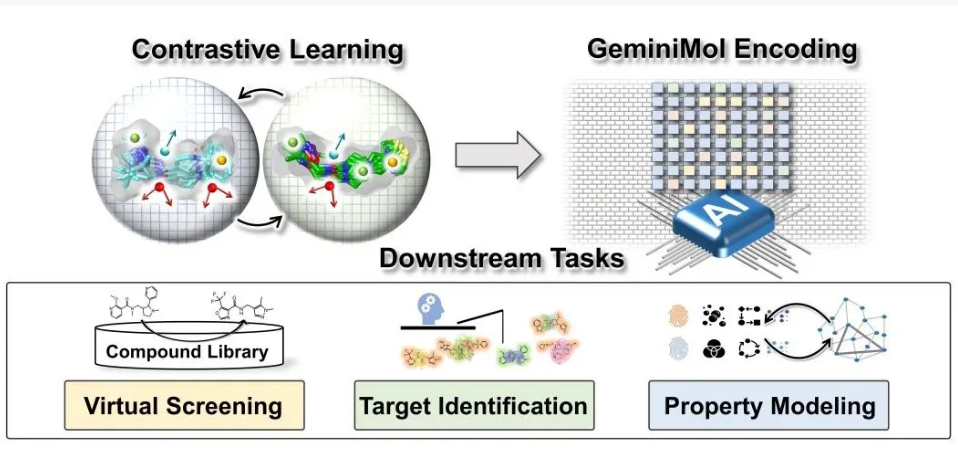
上科大GeminiMol团队凭“双子座”AI模型在上海国际计算生物学创新大赛夺冠,该模型首次大规模整合小分子动态构象空间与对比学习,1小时筛完1800万化合物,可集多活性分子之长生成新结构,在难啃的NMDA受体赛道验证普适性,为AI药物设计提供新思路。 - 论文链接:https://advanced.onlinelibrary.wiley.com/doi/full/10.1002/advs.202403998
4、50年的前沿研究:Nucleic Acids Research(NAR)
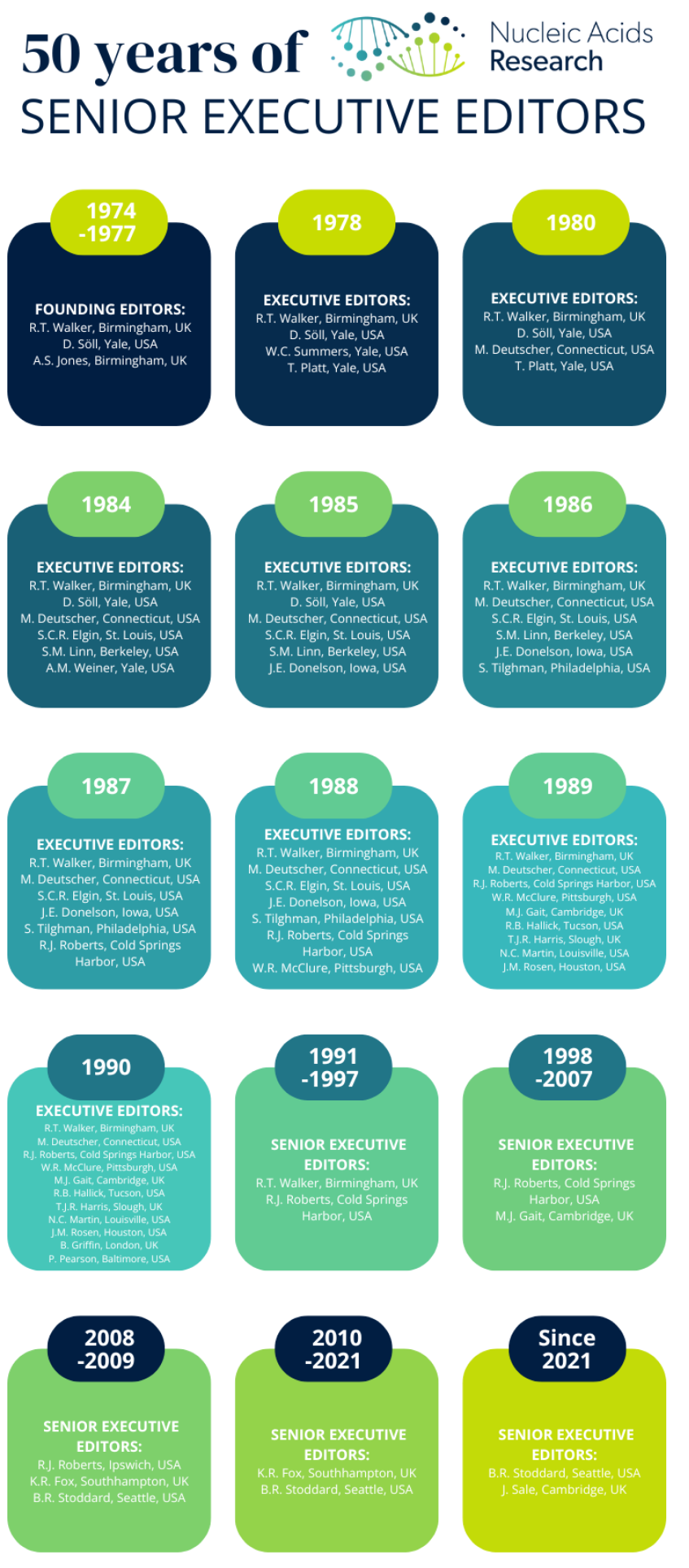
1974年,伯明翰大学的 Richard T. Walker、A. Stanley Jones 与耶鲁大学的 Dieter Söll 三位远见编辑创办 Nucleic Acids Research,旨在打破学科壁垒、汇聚核酸及相关领域的研究成果;半个世纪后,NAR 已成长为生命科学顶级期刊,持续引领并见证学科创新。
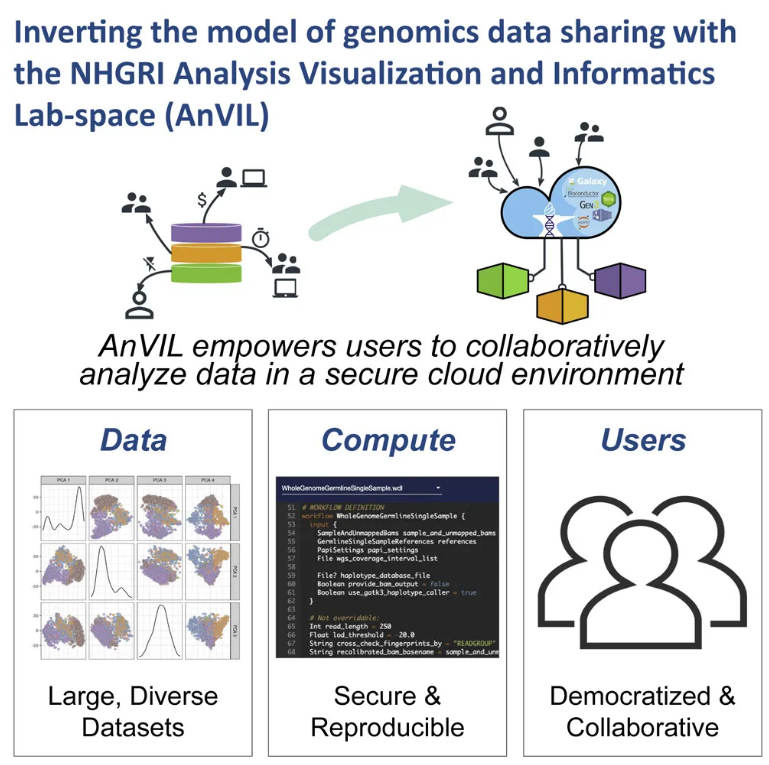
AnVIL是NHGRI打造的联合云平台,通过 Terra、Galaxy 等组件把 PB 级基因组数据、分析工具与弹性算力集中在同一安全空间,让研究者无需搬运数据即可在线协作完成人口规模分析,从而颠覆传统共享模式,加速科学发现。
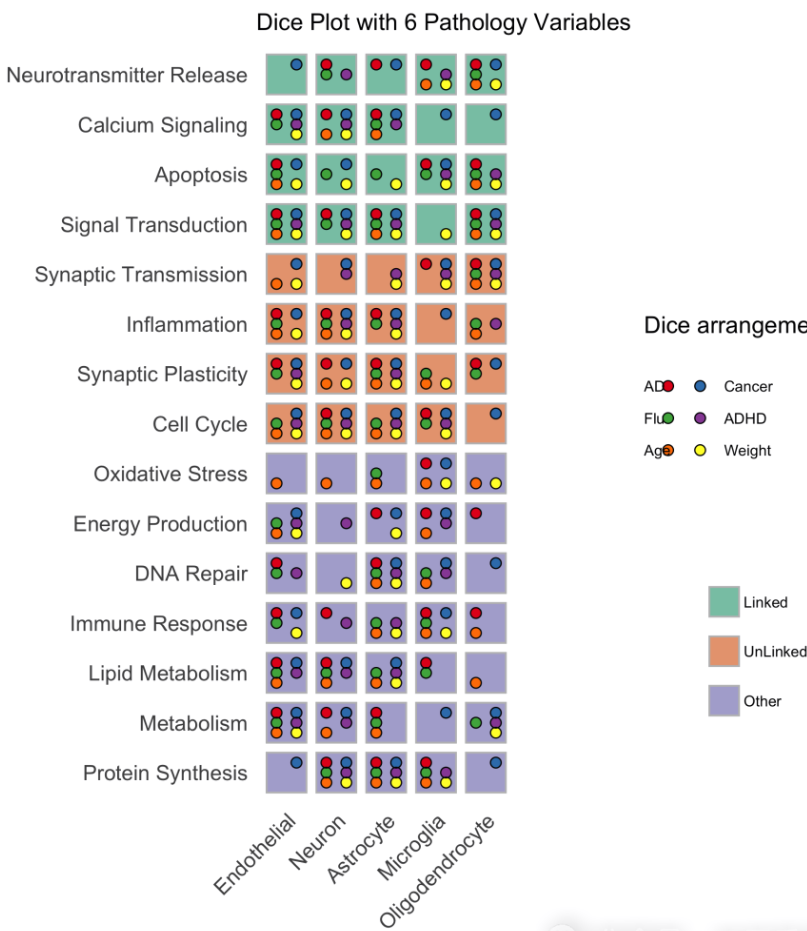
diceplot包允许为包含两个以上分类变量和额外连续变量的数据集创建可视化图表(骰子图)。该工具对于探索复杂的分类数据及其与连续变量之间的关系特别有用。
7、PanDepth | 用于快速有效的基因组覆盖率计算工具
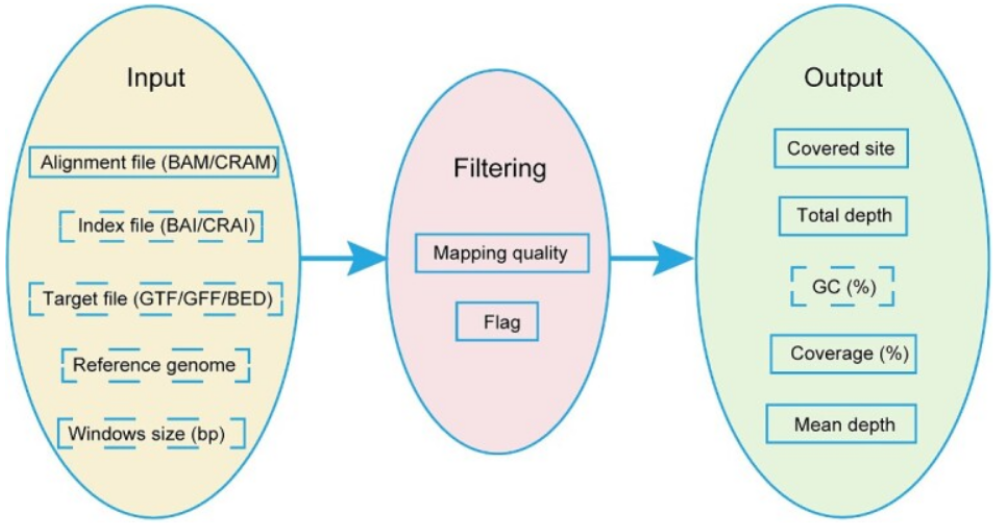
支持排序或未排序的 BAM 和 CRAM 格式对齐文件,并接受 GTF、GFF 和 BED 格式或特定窗口大小的配置文件。
8、citadel
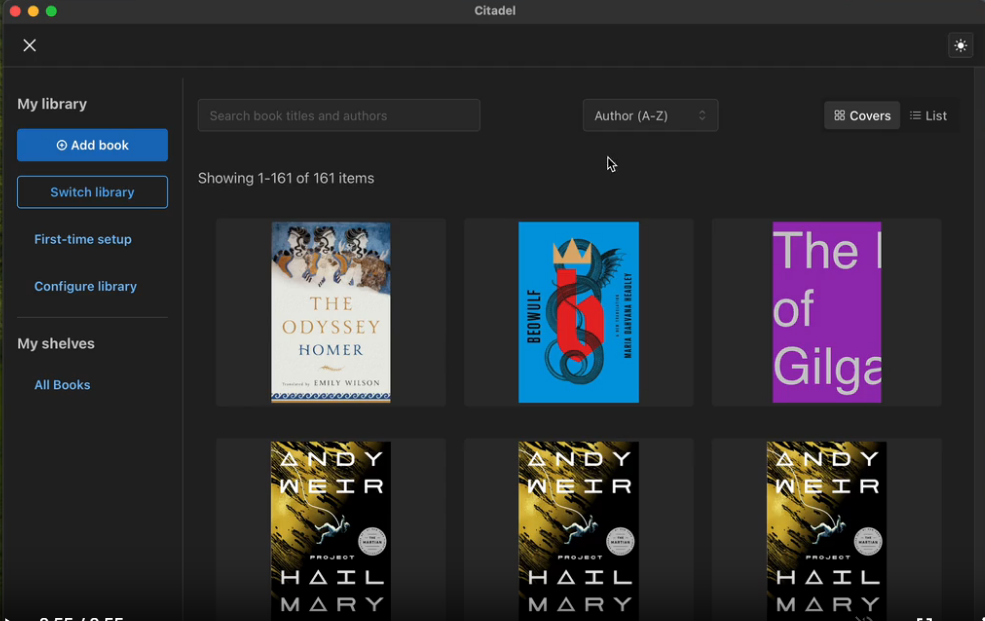
一个可以轻松实现管理电子书库的工具。

一款利用AI技术提高图片质量的软件。
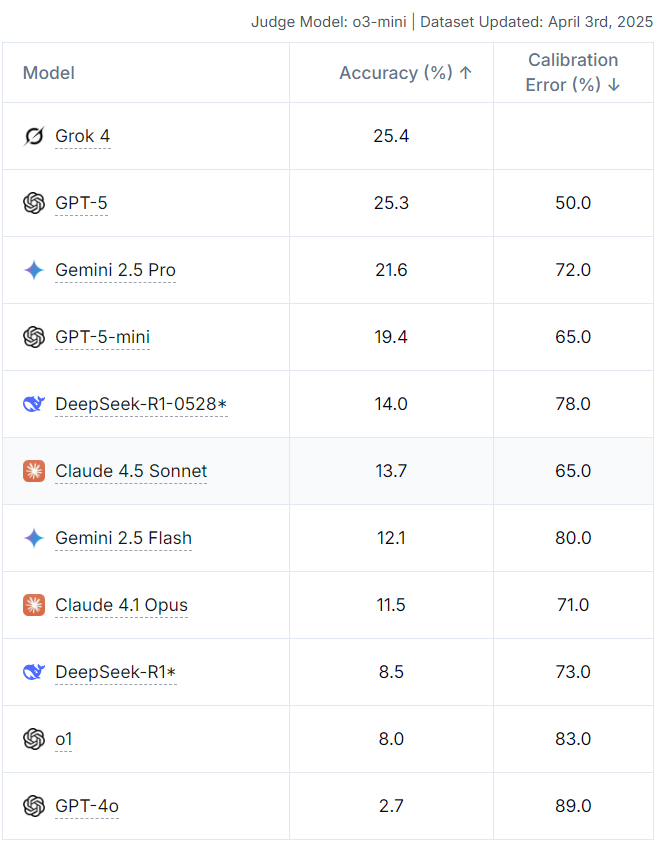
Humanity’s Last Exam 由全球 50 国、500 余家机构的近千名专家联合打造,汇集 2500 道横跨百门学科的高阶难题,对主流大语言模型进行闭卷测试,为评估通用智能进展提供全新硬核基准。

「Openbiox 生信周刊」运维小队: - @ShixiangWang(王诗翔) - @kkjtmac(阚科佳) - @NiEntropy(赵启祥) - @He-Kai-fly(何凯) - @JnanZhang(张佳楠) - @Tomcxf(陈啸枫) - @wangdepin(王德品) - @kongjianyang(空间阳) - @donghongyu2020(董弘禹) - @DrRobinLuo(罗鹏) - @Wangcy-rachel(王春阳) - @zoe3251(舒晨阳) - @yanbin85 (严彬) - @MadDERt(王章宇)
这个周刊每周日发布,同步更新在微信公众号「生信协作组」(elegant-r)上。
微信搜索“生信协作组”或者扫描二维码,即可订阅。
(完)
2025-11-02 12:16:54
这里记录值得分享的生信相关内容,每半月发布。
本杂志开源(GitHub: openbiox/weekly),欢迎提交 issue,投稿或推荐生信相关内容。
科研人员太多单打独斗,无法集中优势资源,优化配置。而如华为这般大型企业,通过各方资源整合,在科技、成果、经济等方面都走在了前列。换个角度来讲,也许,是科研人员更需要有组织科研,来完整的实现科研价值,成为可以站上庆功宴的人。
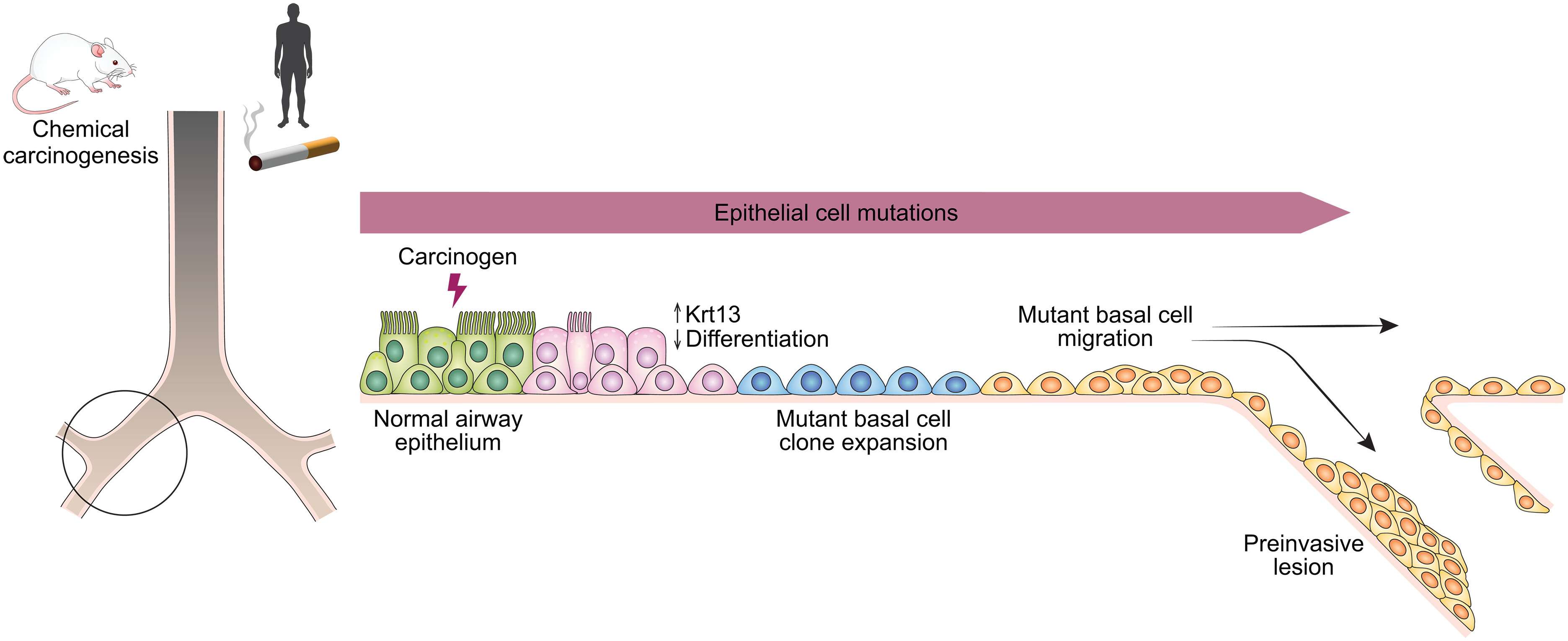
基底细胞是气道上皮的主要组成部分,且其标志物如KRT5和p63在LUSC中广泛表达,因此被认为可能是LUSC的起源细胞。研究发现,致癌物暴露导致肺基底细胞发生异常的克隆扩增和迁移,少数高度突变的克隆在支气管区域主导并形成癌前病变。通过多点测序,验证了这些病变之间的克隆相关性,揭示了基底细胞克隆动态和命运转变是肺部“癌变场域效应”的关键驱动因素。
2、Cell |李汉杰团队利用单细胞测序技术发现与体型大小相关的免疫细胞:外周小胶质细胞
该研究通过跨物种、高时空分辨率的单细胞转录组测序技术,结合多组学分析手段,首次在外周神经系统中发现了一群与中枢神经系统小胶质细胞具有相同分子特征、且与物种体型大小相关的小胶质细胞,并将其命名为PNS microglia。
3、ChatNT:首个支持DNA/RNA/蛋白的生物ChatGPT来了!
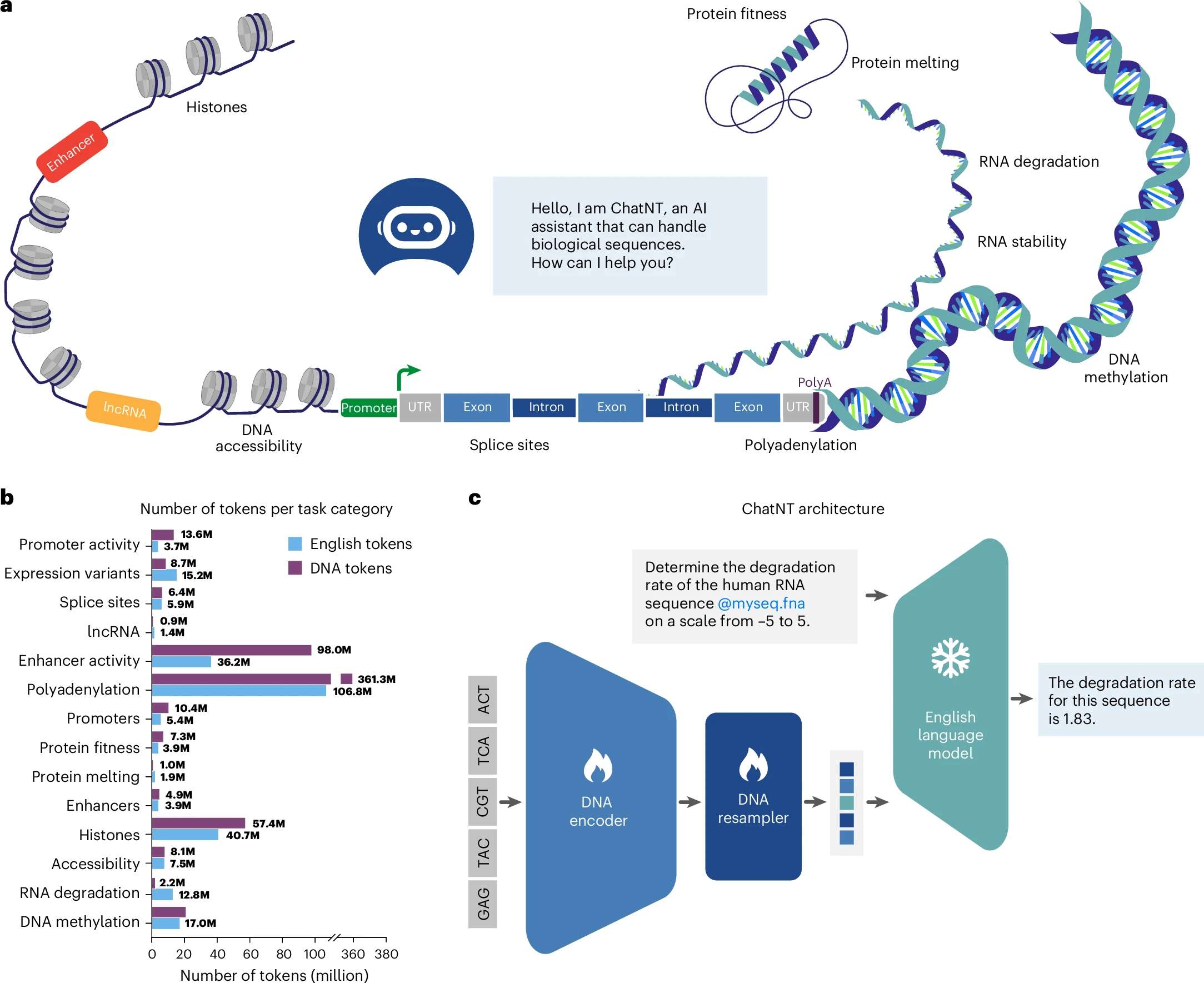
该研究介绍了由InstaDeep和BioNTech联合推出的全新生物AI助手——ChatNT。ChatNT 让生物序列第一次“说人话”,也让科研人员第一次不写代码就能高效提问基因组。它是生物界的 ChatGPT,正在开启通用生物智能助手的新时代。

本文希望围绕“Transformer到底是解决什么问题的”这个角度,阐述NLP发展以来遇到的关键问题和解法,通过这些问题引出Transformer实现原理,帮助初学者理解。
5、基因选择压力分析 | Ka/Ks, Dn/Ds 大规模计算,更快更准!
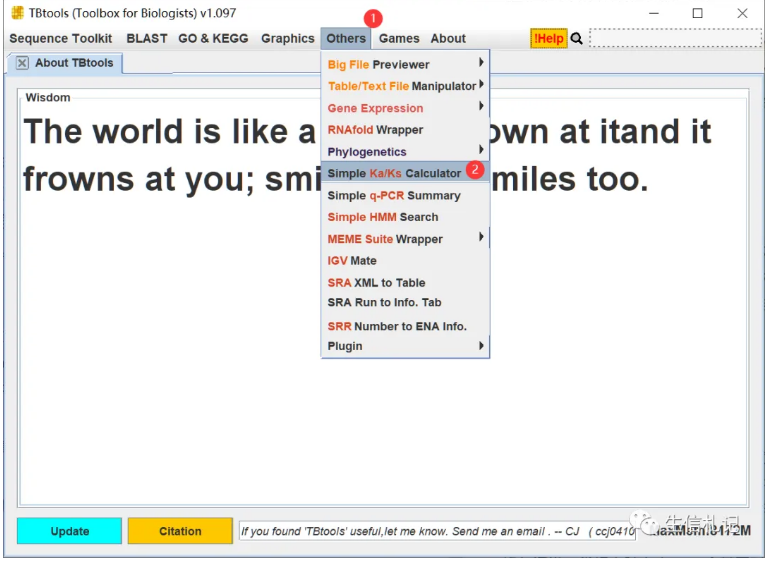
本文介绍了TBtools软件中基因对Ka/Ks计算功能的高效实现方案。与传统Emboss Needle程序或常见的MUSCLE调用方案相比,TBtools通过自研算法实现了速度的百倍提升,将万对基因的计算从数小时缩短至一分钟内,并在速度与准确性上取得了最佳平衡。
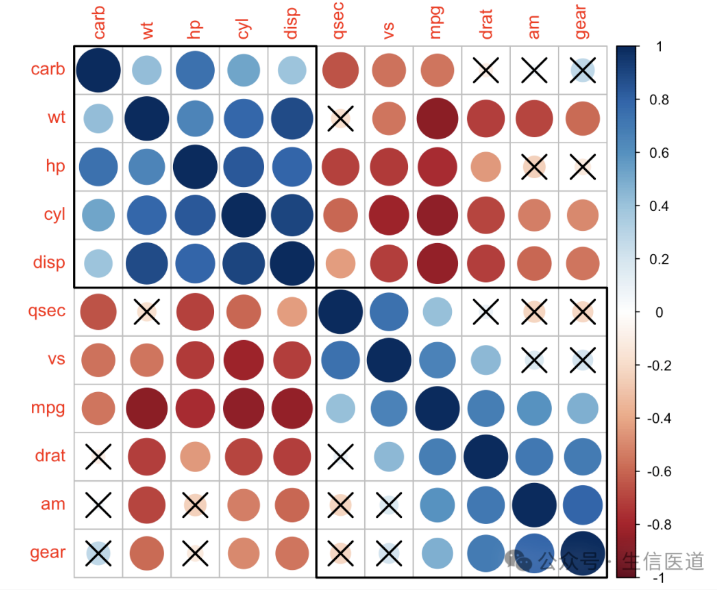
本文介绍了R包corrplot,其提供了多种相关矩阵可视化方法,支持显著性检测、矩阵重排序以及置信区间展示,适用于生物信息数据的探索性分析。
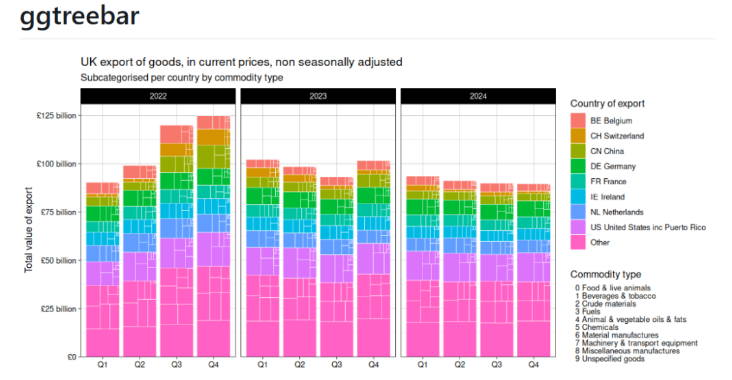
本文介绍了用于绘制条形图的R包ggtreebar的基本用法,提供了一种简洁有效的方式来展示数据的层次结构。
8、三维太复杂?FlatProt上线:用二维“展平”蛋白质结构,精准比对一目了然!
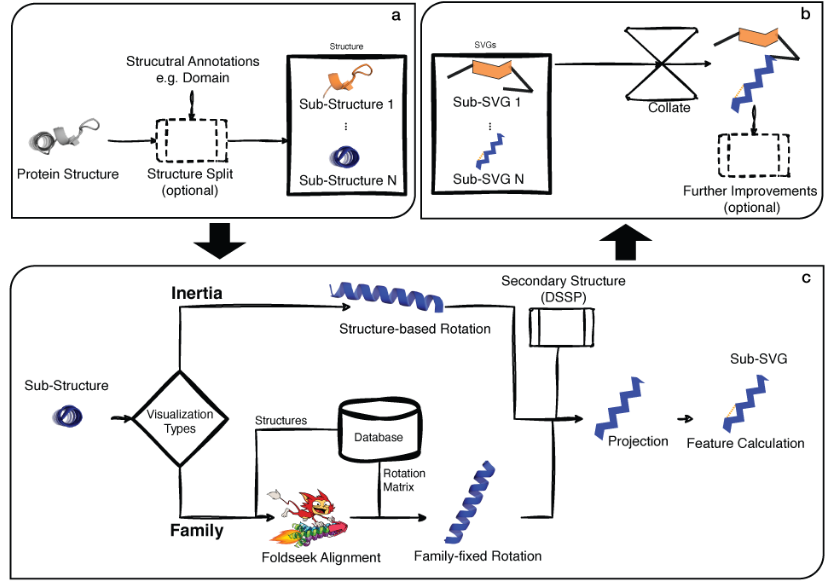
FlatProt是一款用于将蛋白质三维结构转化为标准化二维图形的开源工具。它通过快速的结构对齐和简化,可帮助科研人员高效地进行蛋白家族的结构比对与保守性分析,支持快速生成高质量SVG图形,适用于AlphaFold结果分析、结构域演化研究等多种场景。
- 工具链接:https://github.com/t03i/FlatProt
- 文章链接:https://www.biorxiv.org/content/10.1101/2025.04.22.650077v1.full.pdf
9、告别 LaTeX 排版烦恼:TeXtidote,你的智能代码矫正写作伙伴!
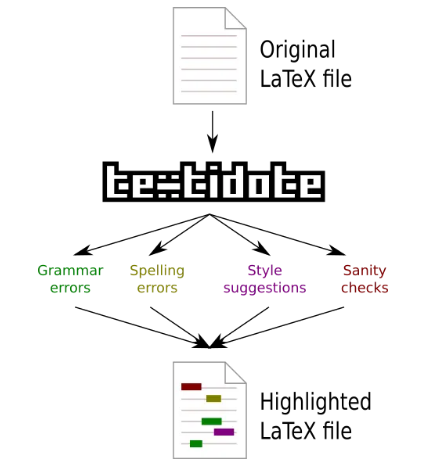
TeXtidote 是一款专为 LaTeX 文档设计的智能校对工具,能精准进行拼写、语法检查,并支持 LaTeX 特有的内容,如图表引用和标题规范。它通过命令行运行,支持多种输出格式,帮助用户高效提升文档质量,简化写作过程。 - 工具链接:https://github.com/sylvainhalle/textidote
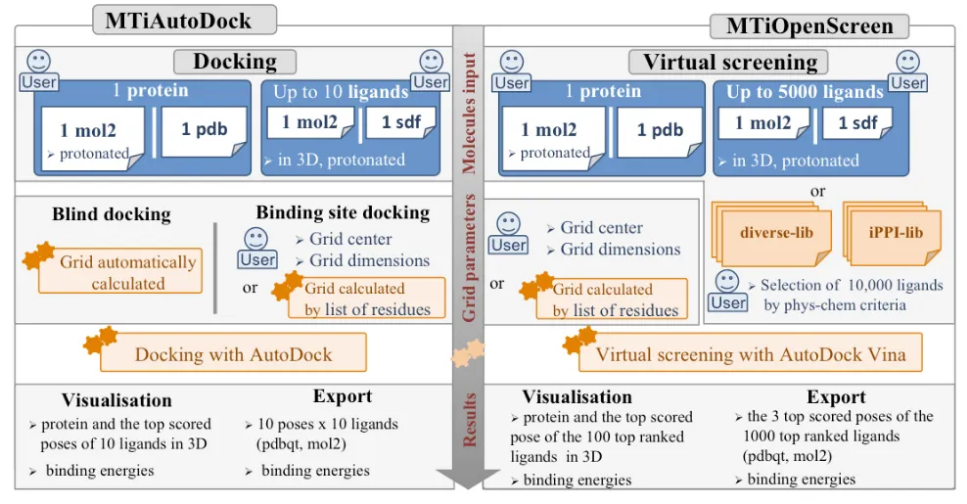
MTiOpenScreen 是一个在线虚拟筛选平台,提供基于 AutoDock 和 AutoDock Vina 的两大核心服务:MTiAutoDock(小分子对接)和 MTiOpenScreen(化学库虚拟筛选)。它支持用户上传自己的分子库或选择预定义的药物库,支持最多 5000 个分子的筛选。

一个专为ggplot2扩展开发者提供的资源库,包含插件介绍、开发文档和最佳实践等。
12、NODESCHOOL
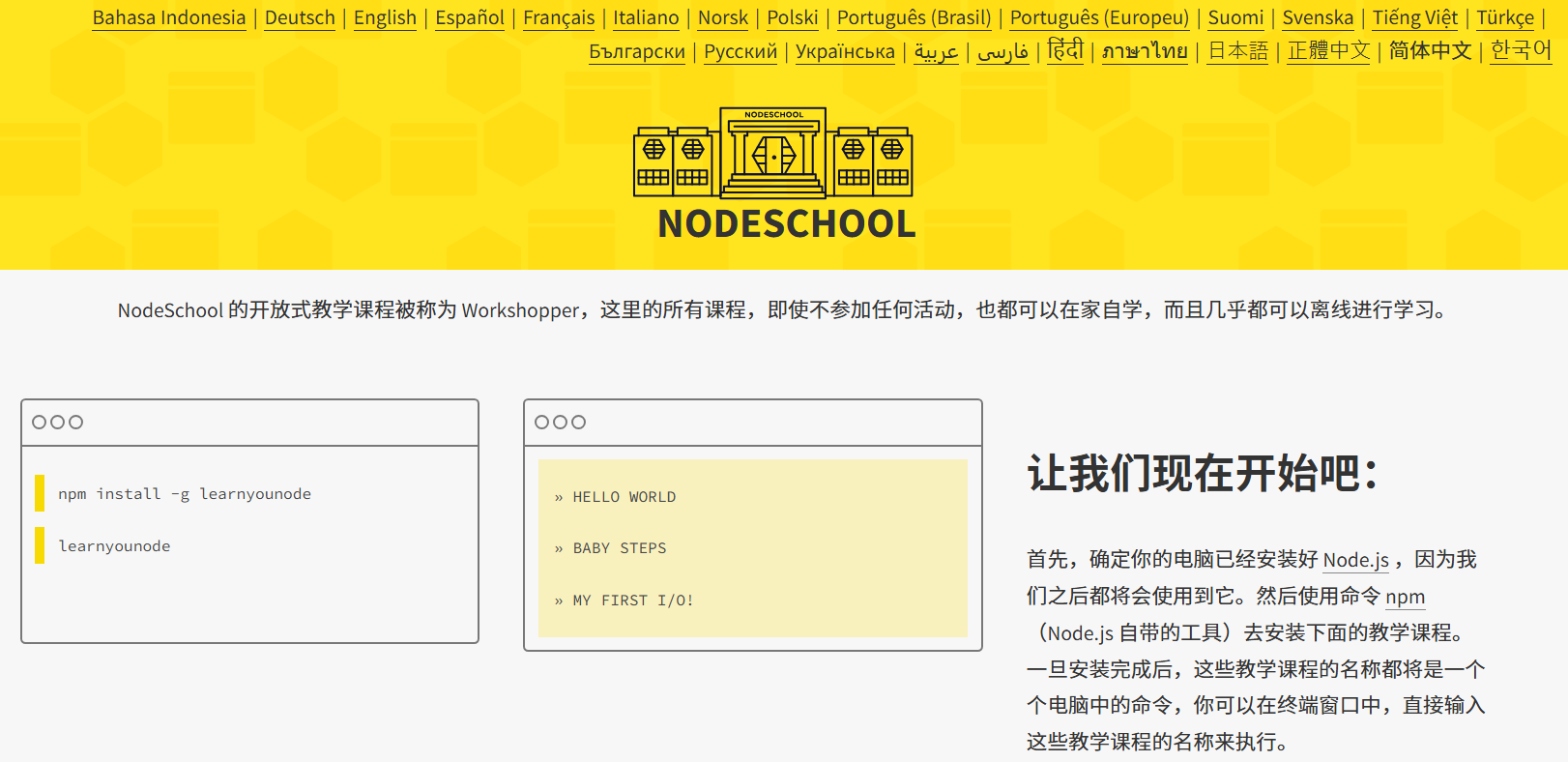
一个基于Node.js的开放式技术学习平台。它提供了一系列交互式命令行教程作为核心学习资源。这些资源覆盖了从JavaScript、Node.js基础到Git、npm、Electron等全栈开发的系统化课程,所有课程均可通过npm命令免费安装并支持离线学习。
「Openbiox 生信周刊」运维小队:
- @ShixiangWang(王诗翔)
- @kkjtmac(阚科佳)
- @NiEntropy(赵启祥)
- @He-Kai-fly(何凯)
- @JnanZhang(张佳楠)
- @Tomcxf(陈啸枫)
- @wangdepin(王德品)
- @kongjianyang(空间阳)
- @donghongyu2020(董弘禹)
- @DrRobinLuo(罗鹏)
- @Wangcy-rachel(王春阳)
- @zoe3251(舒晨阳)
- @yanbin85(严彬)
- @MadDERt(王章宇)
这个周刊每周日发布,同步更新在微信公众号「生信协作组」(elegant-r)上。
微信搜索“生信协作组”或者扫描二维码,即可订阅。
(完)
2025-10-19 11:52:08
这里记录值得分享的生信相关内容,每半月发布。
本杂志开源(GitHub: openbiox/weekly),欢迎提交 issue,投稿或推荐生信相关内容。
Source: Mitalipov Laboratory
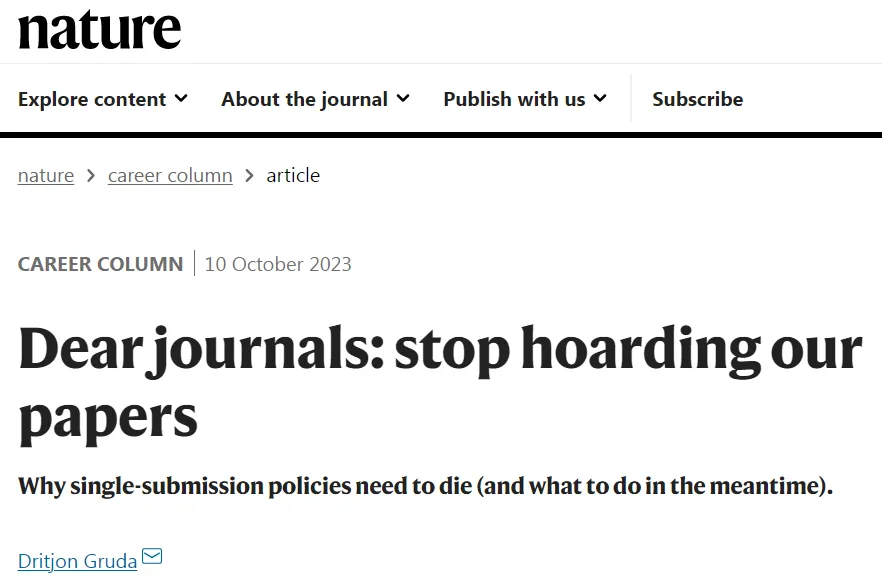
“一稿多投”一直被认为是不端的行为,但这个“规矩”是在纸质时代信息沟通不畅的情况下制定的,近年来有关取消这一观念的声音已振聋发聩!
国际顶级期刊Nature 职业专栏(Nature Career Column)发表文章指出禁止“一稿多投”不仅延误了科研工作的进程,还阻碍了科学信息的快速传播,学术期刊不应利用这项不合理的政策囤积投稿,“是时候废除‘一稿多投’禁令了。”
@ShixiangWang:AI和互联网极快地加速了学术工作的宣发,传统的机制越来越无法适用当前快节奏的时代。其实从数学/AI等普遍以预印本发表早有端倪,现在越来越多预印本的使用也会更快地加速这个过程。
1、Science丨破解FOXA1突变“双重人格”,前列腺癌治疗需“分型而治”
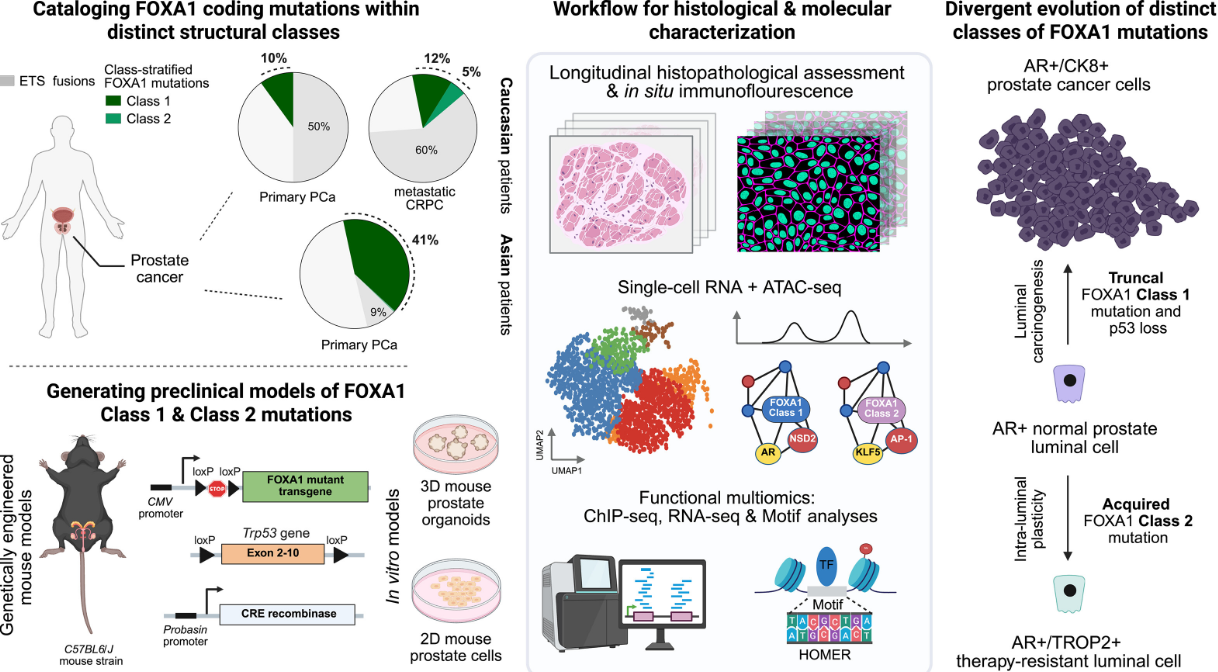
该研究首次系统性地揭示了FOXA1基因的两类功能性突变如何分别驱动前列腺癌的两种“恶性进化路径”,为前列腺癌的异质性提供了机制解释,并为基于突变分类的个体化治疗奠定基础。
2、Nature | 三发:斯坦福张元豪等揭秘癌症中的ecDNA,影响较既往认知更大、遗传方式突破基本定律
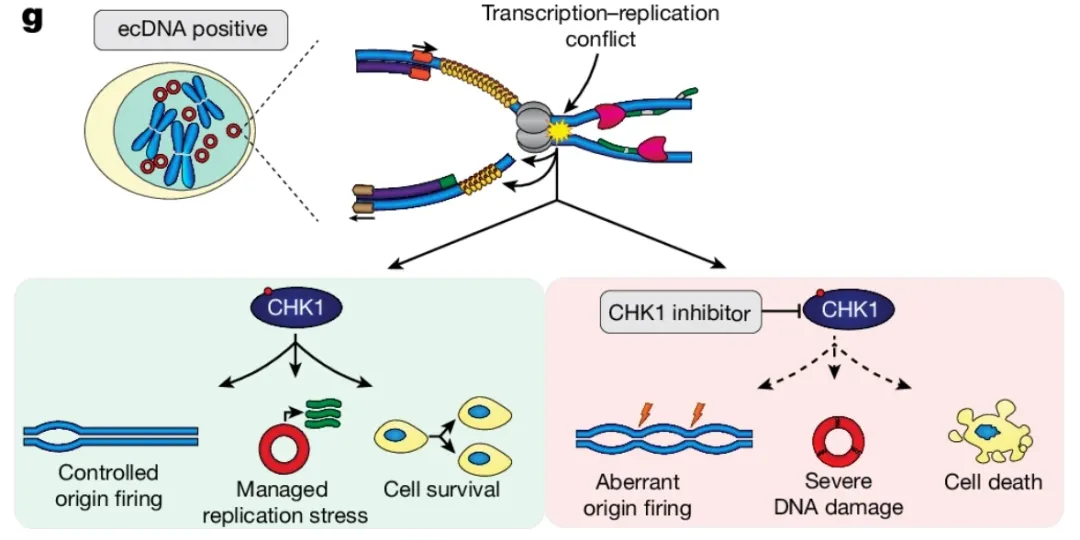
发表在《自然》杂志上的三篇论文指出,染色体外DNA(ecDNA)在多癌种中有广泛分布、流行率较既往认知高得多;在分裂过程中,多个ecDNA聚集形成ecDNA中心,以保证能连接在一起发挥作用的ecDNA在细胞分裂时被分配到同一个子细胞中继续发挥作用;ecDNA由于大量转录,会出现内源性DNA损伤,故很可能含有ecDNA的癌细胞高度依赖多复制应激调节机制以避免DNA损伤水平过高。作者认为ecDNA癌细胞通过检查点激酶1(CHK1)来管理DNA损伤,CHK1抑制剂很有可能触发ecDNA癌细胞死亡。实验结果表明在FGFR2扩增的SNU16胃癌异种移植模型中,CHK1抑制剂BBI-2779联合FGFR抑制剂infigratinib能有效避免耐药性的产生。
文章链接:
Bailey, C., Pich, O., Thol, K. et al. Origins and impact of extrachromosomal DNA. Nature 635, 193–200 (2024). https://www.nature.com/articles/s41586-024-08107-3
Hung, K.L., Jones, M.G., Wong, I.TL. et al. Coordinated inheritance of extrachromosomal DNAs in cancer cells.Nature 635, 201–209 (2024). https://www.nature.com/articles/s41586-024-07861-8
Tang, J., Weiser, N.E., Wang, G. et al. Enhancing transcription–replication conflict targets ecDNA-positive cancers. Nature 635, 210–218 (2024). https://www.nature.com/articles/s41586-024-07802-5
3、Nature medicine | 基于区块链的临床和遗传数据共享框架助力精准医学应用
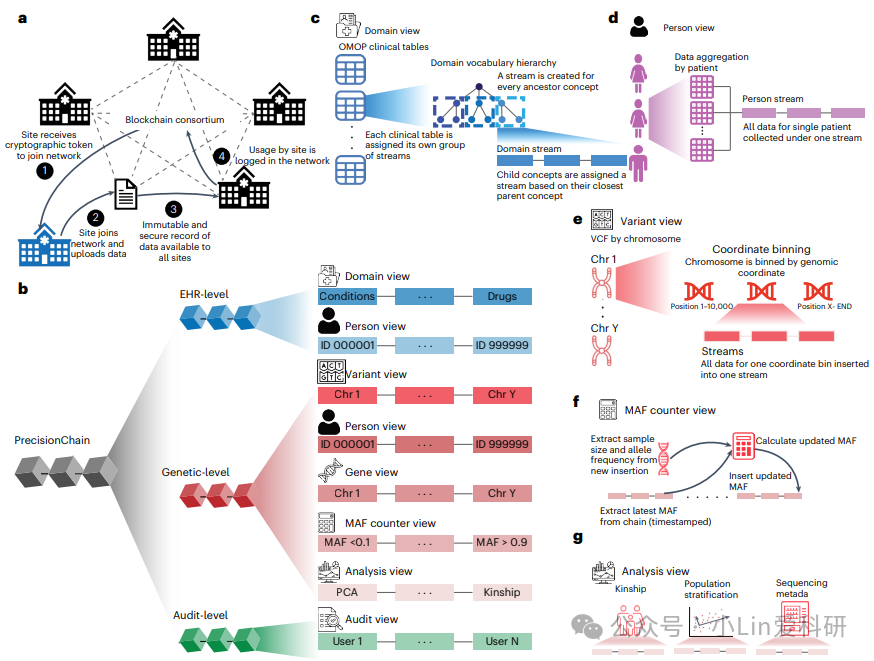
精准医学旨在根据患者的遗传、生理和环境特征,为其提供个性化的医疗方案。实现这一目标的关键在于整合临床和组学数据,以深入理解遗传背景下的临床观察结果。然而,现有的数据共享系统面临诸多挑战,例如不同数据类型的整合、互操作性、安全性以及数据所有权等问题。区块链技术具有安全、不可篡改和去中心化的特性,为解决这些挑战提供了潜在的解决方案。
基于这个概念,研究人员开发一个基于区块链技术的去中心化数据共享平台(PrecisionChain),以统一临床和遗传数据的存储、检索和分析,促进精准医学应用。PrecisionChain 提供了一个安全、可扩展的去中心化框架,用于整合临床和遗传数据,促进精准医学应用。该平台能够高效索引多模态数据、支持多模态查询和分析,并有效解决区块链技术面临的挑战。
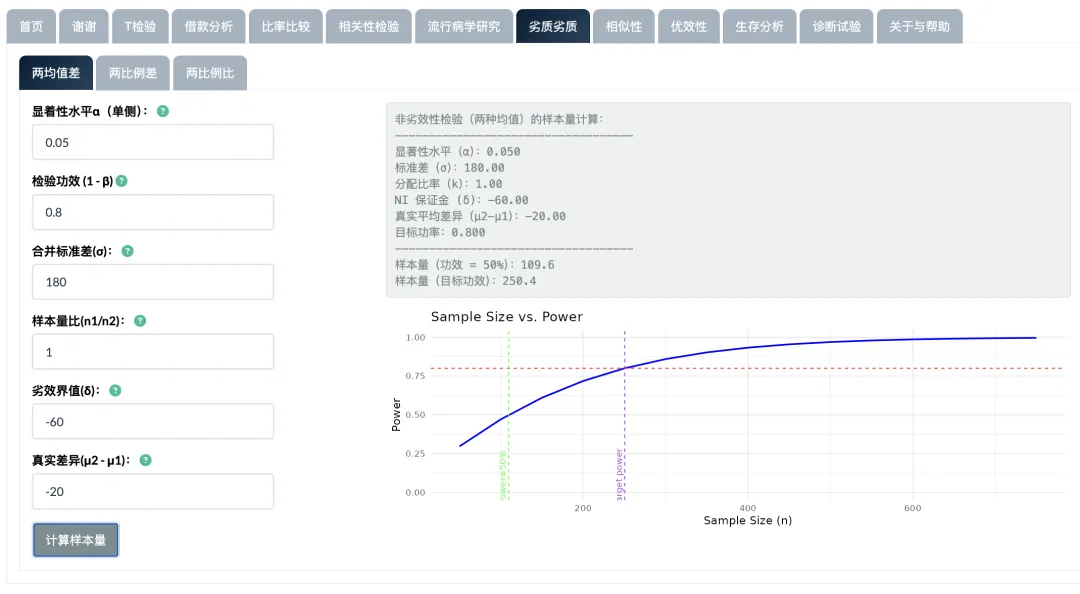
本文介绍了统计学中通过非劣效性检验(Non-Inferiority)以及等效性检验(Equivalence)进行样本估计的原理方法,并提供相关案例。
5、ggdendroplot:在R语言中使用ggplot2绘制定制树状图
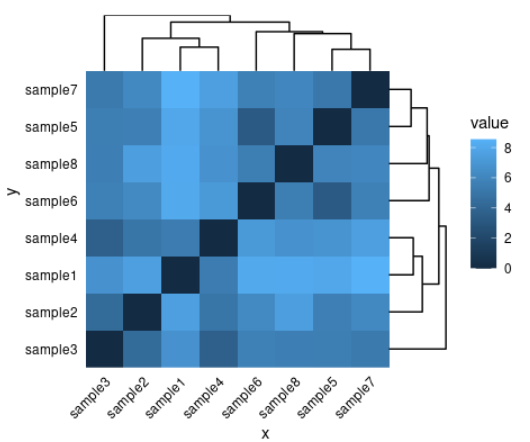
ggdendroplot可在 ggplot2中绘制高度可修改的树状图。树状图可以轻松修改并添加到现有的 ggplot 对象中。
Git 是现代软件开发过程中必不可少的版本控制工具。良好的 Commit Message 可以帮助开发人员更好地了解代码的历史、原因以及改动的目的。本文将介绍为什么要编写高质量的 Commit Message,如何编写有效的 Commit Message,以及有哪些工具可以帮助我们编写好的 Commit Message。

该推文从9层境界帮助读者深层次理解EM算法,解释了EM算法的重要性。
8、AI大模型工具 | scBERT:对scRNA-seq数据进行细胞注释
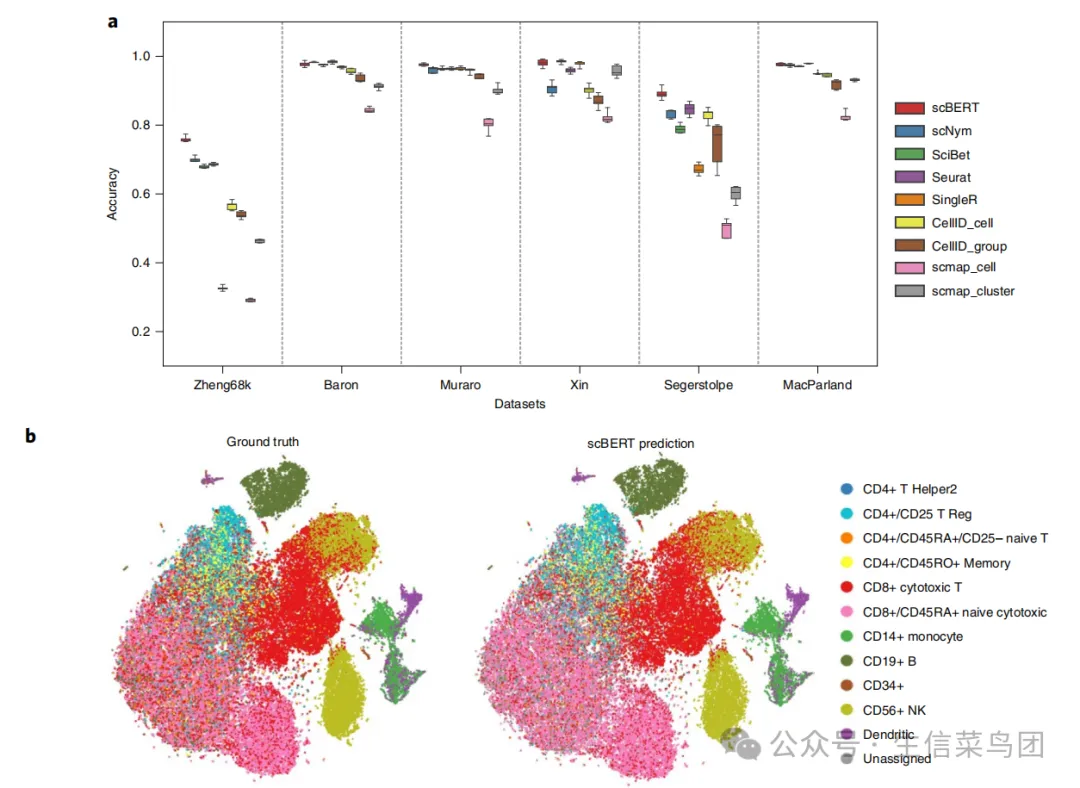
目前单细胞类型注释方法大概可以分为三类:使用marker基因注释、基于相关性的方法注释,以及通过监督分类注释。其中最后一种是遵循机器学习中的经典范式,即识别基因表达谱中的模式,然后将标签从标记数据集转移到未标记数据集。由于模型容量有限,大多数方法需要在将数据输入分类器之前进行高度可变基因(highly variable gene,HVG)选择和降维。然而HVG在不同批次和数据集中存在差异,降维可能会丢失高维信息以及基因水平的独立可解释性。HVG选择和降维的参数设置未能达成共识,造成性能评估的人为偏差。容易忽略稀有细胞类型关键基因以及基因之间相互作用信息。
为此,研究人员开发了scBERT模型,用于scRNA-seq数据的细胞注释。通过预训练和微调范式,验证了在大规模未标记scRNA-seq数据上应用自监督学习的能力,以提高模型的泛化能力和克服批次效应。广泛的基准测试表明,scBERT能够提供稳健且准确的细胞类型注释,并具有基因水平的可解释性。
10、genomepy | 一行命令下载最新基因组(FASTA)和注释(GTF/GFF)

genomepy 是一个功能强大的 Python 工具,旨在简化和自动化基因组数据的查找、下载、管理和预处理流程,让您能更专注于核心的生物学问题。
安装:
conda install -c conda-forge -c bioconda 'genomepy>=0.15'
11、硬核生物信息学系列汇总
「观科研」公众号生信相关推文汇总,涉及R语言、Bulk RNA测序、单细胞RNA测序、代谢组学等。
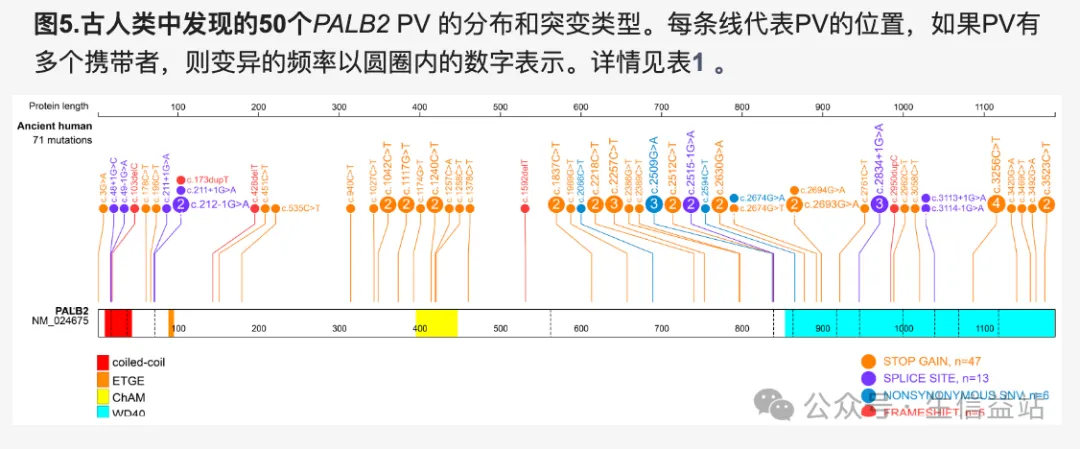
棒棒图常用于展示位点突变情况,本文介绍了10个相关的工具。
「Openbiox 生信周刊」运维小队:
@ShixiangWang(王诗翔)@kkjtmac(阚科佳)@NiEntropy(赵启祥)@He-Kai-fly(何凯)@JnanZhang(张佳楠)@Tomcxf(陈啸枫)@wangdepin(王德品)@kongjianyang(空间阳)@donghongyu2020(董弘禹)@DrRobinLuo(罗鹏)@Wangcy-rachel - 王春阳@zoe3251 - 舒晨阳@yanbin85 - 严彬@MadDERt - 王章宇这个周刊每周日发布,同步更新在微信公众号「生信协作组」(elegant-r)上。
微信搜索“生信协作组”或者扫描二维码,即可订阅。

(完)